Factor iz able Net: An Efficient Subgraph-based Framework for Scene Graph Generation
可分解网络:一种基于子图的高效场景图生成框架
Abstract. Generating scene graph to describe the object interactions inside an image gains increasing interests these years. However, most of the previous methods use complicated structures with slow inference speed or rely on the external data, which limits the usage of the model in real-life scenarios. To improve the efficiency of scene graph generation, we propose a subgraph-based connection graph to concisely represent the scene graph during the inference. A bottom-up clustering method is first used to factorize the entire graph into subgraphs, where each subgraph contains several objects and a subset of their relationships. By replacing the numerous relationship representations of the scene graph with fewer subgraph and object features, the computation in the intermediate stage is significantly reduced. In addition, spatial information is maintained by the subgraph features, which is leveraged by our proposed Spatial-weighted Message Passing (SMP) structure and Spatial-sensitive Relation Inference (SRI) module to facilitate the relationship recognition. On the recent Visual Relationship Detection and Visual Genome datasets, our method outperforms the state-of-the-art method in both accuracy and speed. Code has been made publicly available $^6$ .
摘要。近年来,生成描述图像内物体交互关系的场景图(scene graph)受到越来越多的关注。然而,现有方法大多采用推理速度缓慢的复杂结构或依赖外部数据,限制了模型在实际场景中的应用。为提高场景图生成效率,我们提出一种基于子图的连接图(subgraph-based connection graph),在推理过程中简洁地表示场景图。首先采用自底向上的聚类方法将整个图分解为多个子图,每个子图包含若干物体及其部分关系。通过用更少的子图和物体特征替代场景图中大量的关系表示,中间阶段的计算量显著降低。此外,子图特征保留了空间信息,我们提出的空间加权消息传递(Spatial-weighted Message Passing, SMP)结构和空间敏感关系推理(Spatial-sensitive Relation Inference, SRI)模块利用这些信息来提升关系识别效果。在最新的视觉关系检测(Visual Relationship Detection)和视觉基因组(Visual Genome)数据集上,我们的方法在准确率和速度方面均优于现有最优方法。代码已开源$^6$。
Keywords: Visual Relationship Detection · Scene Graph Generation · Scene Understanding · Object Interactions · Language and Vision
关键词:视觉关系检测 · 场景图生成 · 场景理解 · 物体交互 · 语言与视觉
1 Introduction
1 引言
Inferring the relations of the objects in images has drawn recent attentions in computer vision community on top of accurate object detection [6, 28, 34, 35, 37, 58, 64]. Scene graph, as an abstraction of the objects and their pair-wise relationships, contains higher-level knowledge for scene understanding. Because of the structured description and enlarged semantic space of scene graphs, efficient scene graph generation will contribute to the downstream applications such as image retrieval [26, 45] and visual question answering [33, 38].
推断图像中物体间的关系在计算机视觉领域引起了广泛关注,其基础是精准的物体检测 [6, 28, 34, 35, 37, 58, 64]。场景图 (scene graph) 作为物体及其成对关系的抽象表示,蕴含了更高层次的场景理解知识。由于场景图的结构化描述和扩展的语义空间,高效的场景图生成将助力下游应用,例如图像检索 [26, 45] 和视觉问答 [33, 38]。
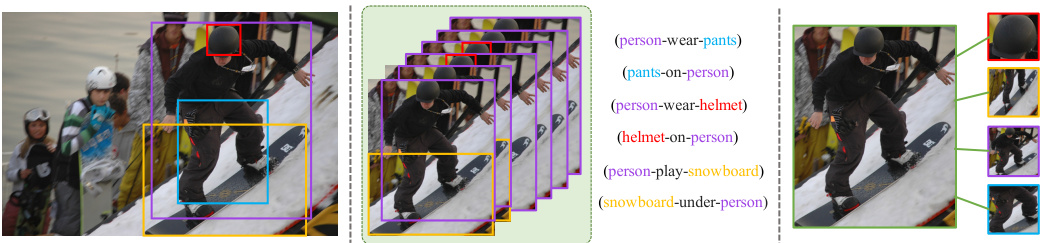
Fig. 1: Left: Selected objects ; Middle: Relationships (subject-predicate-object triplets) are represented by phrase features in previous works [6,28,34,35,37,58, 64]; Right: replacing the phrases with a concise subgraph representation, where relationships can be restored with subgraph features (green) and corresponding subject and object.
图 1: 左: 选定对象; 中: 在先前工作中[6,28,34,35,37,58,64], 关系(主谓宾三元组)由短语特征表示; 右: 用简洁的子图表示替换短语, 其中关系可通过子图特征(绿色)及对应的主语和宾语还原。
Currently, there are two approaches to generate scene graphs. The first approach adopts the two-stage pipeline, which detects the objects first and then recognizes their pair-wise relationships [6, 36, 37, 58, 62]. The other approach is to jointly infer the objects and their relationships [34,35,58] based on the object region proposals. To generate a complete scene graph, both approaches should group the objects or object proposals into pairs and use the features of their union area (denoted as phrase feature), as the basic representation for predicate inference. Thus, the number of phrase features determines how fast the model performs. However, due to the number of combinations growing quadratically with that of objects, the problem will quickly get intractable as the number of objects grows. Employing fewer objects [35, 58] or filtering the pairs with some simple criteria [6,34] could be a solution. But both sacrifice (the upper bound of) the model performance. As the most time-consuming part is the manipulations on the phrase feature, finding a more concise intermediate representation of the scene graph should be the key to solve the problem.
目前,生成场景图有两种方法。第一种采用两阶段流程,先检测物体再识别它们的成对关系 [6, 36, 37, 58, 62]。另一种方法基于物体区域提议,联合推断物体及其关系 [34,35,58]。要生成完整的场景图,两种方法都需将物体或物体提议分组配对,并使用它们的联合区域特征(称为短语特征)作为谓词推理的基本表示。因此,短语特征的数量决定了模型的执行速度。然而,由于组合数量随物体数量呈二次方增长,随着物体数量增加,问题会迅速变得难以处理。减少物体数量 [35, 58] 或用简单标准过滤配对 [6,34] 可能是解决方案,但二者都会牺牲模型性能(的上限)。由于最耗时的部分是对短语特征的操作,找到更简洁的场景图中间表示应是解决问题的关键。
We observe that multiple phrase features can refer to some highly-overlapped regions, as shown by an example in Fig. 1. Prior to constructing different subjectobject⟩ pairs, these features are of similar representations as they correspond to the same overlapped regions. Thus, a natural idea is to construct a shared represent ation for the phrase features of similar regions in the early stage. Then the shared representation is refined to learn a general representation of the are by passing the message from the connected objects. In the final stage, we can extract the required information from this shared representation to predict object relations by combining with different ⟨subject-object⟩ parirs. Based on this observation, we propose a subgraph-based scene graph generation approach, where the object pairs referring to the similar interacting regions are clustered into a subgraph and share the phrase representation (termed as subgraph features). In this pipeline, all the feature refining processes are done on the shared subgraph features. This design significantly reduces the number of the phrase features in the intermediate stage and speed up the model both in training and inference.
我们注意到,多个短语特征可能指向高度重叠的区域,如图1所示。在构建不同的〈主体-客体〉对之前,这些特征具有相似的表示,因为它们对应相同的重叠区域。因此,一个自然的想法是在早期阶段为相似区域的短语特征构建共享表示。随后,通过传递来自连接客体的信息,对共享表示进行细化,以学习该区域的通用表示。在最后阶段,我们可以从这一共享表示中提取所需信息,并结合不同的〈主体-客体〉对来预测客体关系。基于这一观察,我们提出了一种基于子图的场景图生成方法,其中指向相似交互区域的客体对被聚类到一个子图中,并共享短语表示(称为子图特征)。在这一流程中,所有特征细化过程都在共享的子图特征上完成。该设计显著减少了中间阶段的短语特征数量,并加速了模型在训练和推理时的速度。
As different objects correspond to different parts of the shared subgraph regions, maintaining the spatial structure of the subgraph feature explicitly retains such connections and helps the subgraph features integrate more spatial information into the representations of the region. Therefore, 2-D feature maps are adopted to represent the subgraph features. And a spatial-weighted message passing (SMP) structure is introduced to employ the spatial correspondence between the objects and the subgraph region. Moreover, spatial information has been shown to be valuable in predicate recognition [6,36,62]. To leverage the such information, the Spatial-sensitive Relation Inference (SRI) module is designed. It fuses object feature pairs and subgraph features for the final relationship inference. Different from the previous works, which use object coordinates or the mask to extract the spatial features, our SRI could learn to extract the embedded spatial feature directly from the subgraph feature maps.
由于不同对象对应于共享子图区域的不同部分,显式保持子图特征的空间结构能够保留此类关联,并帮助子图特征将更多空间信息整合到区域表征中。因此,本文采用二维特征图表示子图特征,并引入空间加权消息传递 (SMP) 结构来利用对象与子图区域间的空间对应关系。此外,已有研究表明空间信息在谓词识别中具有重要价值 [6,36,62]。为利用此类信息,我们设计了空间敏感关系推理 (SRI) 模块,通过融合对象特征对和子图特征进行最终关系推断。与先前使用对象坐标或掩码提取空间特征的方法不同,我们的 SRI 可直接从子图特征图中学习提取嵌入式空间特征。
To summarize, we propose an efficient sub-graph based scene graph generation approach with following novelties: First, a bottom-up clustering method is proposed to factorize the image into subgraphs. By sharing the region representations within the subgraph, our method could significantly reduce the redundant computation and accelerate the inference speed. In addition, fewer representations allow us to use 2-D feature map to maintain the spatial information for subgraph regions. Second, a spatial weighted message passing (SMP) structure is proposed to pass message between object feature vectors and sub-graph feature maps. Third, a Spatial-sensitive Relation Inference (SRI) module is proposed to use the features from subject, object and subgraph representations for recognizing the relationship between objects. Experiments on Visual Relationship Detection [37] and Visual Genome [28] show our method outperforms the stateof-the-art method with significantly faster inference speed. Code has been made publicly available to facilitate further research.
总结来说,我们提出了一种基于子图的高效场景图生成方法,具有以下创新点:首先,提出了一种自下而上的聚类方法将图像分解为子图。通过在子图内共享区域表征,我们的方法能显著减少冗余计算并加速推理速度。此外,更少的表征允许我们使用二维特征图来保持子图区域的空间信息。其次,提出了一种空间加权消息传递 (SMP) 结构,用于在物体特征向量和子图特征图之间传递消息。第三,提出了空间敏感关系推理 (SRI) 模块,利用主语、宾语和子图表征的特征来识别物体间的关系。在Visual Relationship Detection [37]和Visual Genome [28]上的实验表明,我们的方法在显著提升推理速度的同时,性能优于当前最优方法。代码已开源以促进进一步研究。
2 Related Work
2 相关工作
Visual Relationship has been investigated by numerous studies in the last decade. In the early stage, most of the works targeted on using specific types of visual relations, such as spatial relations [5, 10, 14, 20, 26, 30] and actions (i.e. interactions between objects) [1, 9, 11, 16, 19, 46, 47, 50, 56, 57, 60]. In most of these studies, hand-crafted features were used in relationships or phrases detection and detection works and these works were mostly supposed to leveraging other tasks, such as object recognition [4,12,13,31,32,44,51,53,55], image classification and retrieval [17, 39], scene understanding and generation [2, 3, 18, 23, 24, 61, 65], as well as text grounding [27, 43, 49]. However, in this paper, we focus on the higher-performed method dedicated to generic visual relationship detection task which is essentially different from works in the early stage.
视觉关系在过去十年中已被众多研究探讨。早期大多数工作集中于利用特定类型的视觉关系,如空间关系 [5, 10, 14, 20, 26, 30] 和动作 (即物体间的交互) [1, 9, 11, 16, 19, 46, 47, 50, 56, 57, 60]。这些研究大多采用手工特征进行关系或短语检测,并主要用于辅助其他任务,如物体识别 [4, 12, 13, 31, 32, 44, 51, 53, 55]、图像分类与检索 [17, 39]、场景理解与生成 [2, 3, 18, 23, 24, 61, 65] 以及文本定位 [27, 43, 49]。然而,本文专注于针对通用视觉关系检测任务的高性能方法,这与早期工作存在本质差异。
In recent years, new methods are developed specifically for detecting visual relationships. An important series of methods [7,8,52] consider the visual phrase as an integrated whole, i.e. considering each distinct combination of object categories and relationship predicates as a distinct class. Such methods will become intractable when the number of such combinations becomes very large.
近年来,专门用于检测视觉关系的新方法不断涌现。一个重要系列方法 [7,8,52] 将视觉短语视为整体,即将物体类别与关系谓词的每种独特组合视为独立类别。当此类组合数量激增时,这些方法将变得难以处理。
As an alternative paradigm, considering relationship predicates and object categories separately becomes more popular in recent works [36,41,63,64]. Generic visual relationship detection was first introduced as a visual task by Lu et al. in [37]. In this work, objects are detected first, and then the predicates between object pairs are recognized, where word embeddings of the object categories are employed as language prior for predicate recognition. Dai et al. proposed DR-Net to exploit the statistical dependencies between objects and their rela tion ships for this task [6]. In this work, a CRF-like optimization process is adopted to refine the posterior probabilities iterative ly [6]. Yu et al. presented a Linguistic Knowledge Distillation pipeline to employ the annotations and external corpus (i.e. wikipedia), where strong correlations between predicate and ⟨subject-object⟩ pairs are learned to regularize the training and provide extra cues for inference [62]. Plummer et al. designed a large collection of handcrafted linguistic and visual cues for visual relationship detection and constructed a pipeline to learn the weights for combining them [42]. Li et al. used the message passing structure among subject, object and predicate branches to model their dependencies [34].
作为一种替代范式,将关系谓词和对象类别分开考虑的方法在近年研究中日益流行[36,41,63,64]。Lu等人在[37]中首次将通用视觉关系检测引入为视觉任务,该工作先检测对象,再识别对象对之间的谓词,其中对象类别的词嵌入被用作谓词识别的语言先验。Dai等人提出DR-Net来利用对象及其关系的统计依赖性完成该任务[6],该工作采用类似CRF的优化过程迭代细化后验概率[6]。Yu等人提出语言知识蒸馏框架,通过标注数据和外部语料(如维基百科)学习谓词与⟨主体-客体⟩对间的强相关性,从而规范训练并为推理提供额外线索[62]。Plummer等人设计大量手工构建的语言和视觉特征用于视觉关系检测,并建立管道学习这些特征的组合权重[42]。Li等人通过在主体、客体和谓词分支间建立消息传递结构来建模其依赖关系[34]。
The most related works are the methods proposed by Xu et al. [58] and Li et al. [35], both of which jointly detect the objects and recognize their rela tion ships. In [58], the scene graph was constructed by refining the object and predicate features jointly in an iterative way. In [35], region caption was introduced as a higher-semantic-level task for scene graph generation, so the objects, pair-wise relationships and region captions help the model learn representations from three different semantic levels. Our method differs in two aspects: (1) We propose a more concise graph to represent the connections between objects instead of enumerating every possible pair, which significantly reduces the computation complexity and allows us to use more object proposals; (2) Our model could learn to leverage the spatial information embedded in the subgraph feature maps to boost the relationship recognition. Experiments show that the proposed framework performs substantially better and faster in all different task settings.
最相关的工作是Xu等人[58]和Li等人[35]提出的方法,二者都通过联合检测物体并识别其关系来构建场景图。在[58]中,场景图是通过以迭代方式联合优化物体和谓词特征构建的。在[35]中,区域描述被引入作为场景图生成的更高语义级别任务,因此物体、成对关系和区域描述帮助模型从三个不同语义级别学习表征。我们的方法在两方面有所不同:(1) 我们提出用更简洁的图来表示物体间的连接,而非枚举所有可能组合,这显著降低了计算复杂度并允许使用更多物体提议;(2) 我们的模型能学习利用嵌入在子图特征图中的空间信息来提升关系识别能力。实验表明,所提框架在所有不同任务设置中都表现出显著更优且更快的性能。
3 Framework of the Factor iz able Network
3 可因子化网络框架
The overview of our proposed Factor iz able Network (F-Net) is shown in Figure 2. Detailed introductions to different components will be given in the following sections.
我们提出的可分解网络 (F-Net) 概览如图 2 所示。不同组件的详细介绍将在后续章节中给出。
The entire process can be summarized as the following steps: (1) generate object region proposals with Region Proposal Network (RPN) [48]; (2) group the object proposals into pairs and establish the fully-connected graph, where every two objects have two directed edges to indicate their relations; (3) cluster the fully-connected graph into several subgraphs and share the subgroup features for object pairs within the subgraph, then a factorized connection graph is obtained by treating each subgraph as a node; (4) ROI pools [15, 21] the objects and subgraph features and transforms them into feature vectors and 2-D feature maps respectively; (5) jointly refine the object and subgraph features by passing message along the subgraph-based connection graph for better represent at ions; (6) recognize the object categories with object features and their relations (predicates) by fusing the subgraph features and object feature pairs.
整个过程可概括为以下步骤:(1) 使用区域提议网络(Region Proposal Network, RPN) [48]生成物体区域提议;(2) 将物体提议分组配对并建立全连接图,其中每两个物体通过两条有向边表示其关系;(3) 将全连接图聚类为若干子图,共享子图内物体对的组特征,通过将每个子图视为节点获得因子化连接图;(4) 通过ROI池化(ROI pooling) [15,21]处理物体和子图特征,分别转换为特征向量和二维特征图;(5) 基于子图连接图传递消息,联合优化物体和子图特征以获得更佳表征;(6) 通过融合子图特征与物体特征对,结合物体特征识别物体类别及其关系(谓词)。
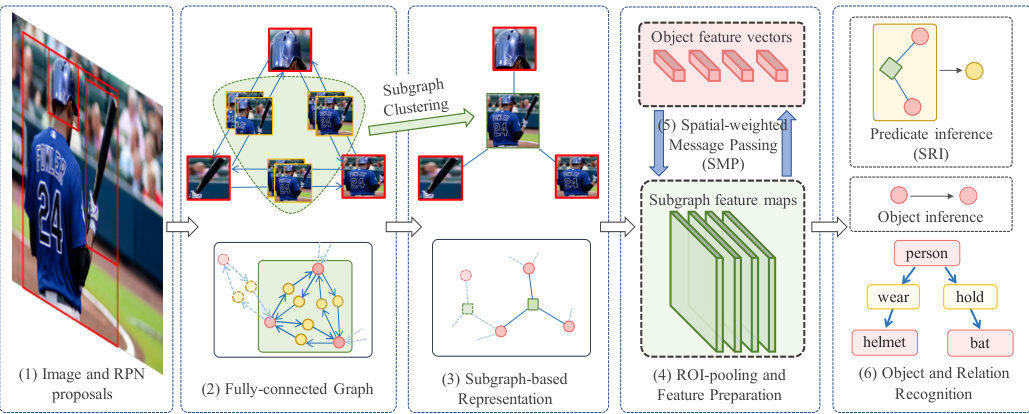
Fig. 2: Overview of our F-Net. (1) RPN is used for object region proposals, which shares the base CNN with other parts. (2) Given the region proposal, objects are grouped into pairs to build up a fully-connected graph, where every two objects are connected with two directed edges. (3) Edges which refer to similar phrase regions are merged into subgraphs, and a more concise connection graph is generated. (4) ROI-Pooling is employed to obtain the corresponding features (2-D feature maps for subgraph and feature vectors for objects). (5) Messages are passed between subgraph and object features along the factorized connection graph for feature refinement. (6) Objects are predicted from the object features and predicates are inferred based on the object features and the subgraph features. Green, red and yellow items refer to the subgraph, object and predicate respectively.
图 2: 我们的F-Net概述。(1) RPN用于生成物体区域提议,与其他部分共享基础CNN。(2) 给定区域提议后,物体被配对构建全连接图,其中每两个物体通过两条有向边连接。(3) 指向相似短语区域的边被合并为子图,生成更简洁的连接图。(4) 采用ROI-Pooling获取相应特征(子图的2-D特征图和物体的特征向量)。(5) 消息沿分解后的连接图在子图与物体特征间传递以实现特征优化。(6) 从物体特征预测物体,并基于物体特征和子图特征推断谓词。绿色、红色和黄色项分别代表子图、物体和谓词。
3.1 Object Region Proposal
3.1 目标区域提议
Region Proposal Network [48] is adopted to generate object proposals. It shares the base convolution layers with our proposed F-Net. An auxiliary convolution layer is added after the shared layers. The anchors are generated by clustering the scales and ratios of ground truth bounding boxes in the training set [35].
采用区域提议网络 (Region Proposal Network) [48] 生成目标候选框。该网络与我们提出的 F-Net 共享基础卷积层,并在共享层后添加了辅助卷积层。通过聚类训练集中真实边界框的尺度和长宽比来生成锚框 [35]。
3.2 Grouping Proposals into Fully-connected Graph
3.2 将提案分组为全连接图
As every two objects possibly have two relationships in opposite directions, we connect them with two directed edges (termed as phrases). A fully-connected graph is established, where every edge corresponds to a potential relationship (or background). Thus, $N$ object proposals will have $N(N\mathrm{-}1)$ candidate relations (yellow circles in Fig. 2 (2)). Empirically, more object proposals will bring higher recall and make it more likely to detect objects within the image and generate a more complete scene graph. However, large quantities of candidate relations may deteriorate the model inference speed. Therefore, we design an effective representations of all these relationships in the intermediate stage to adopt more object proposals.
由于每两个物体之间可能存在两种方向相反的关系,我们用两条有向边(称为短语)将它们连接起来。这样就建立了一个全连接图,其中每条边对应一种潜在关系(或背景)。因此,$N$个物体候选框会产生$N(N\mathrm{-}1)$个候选关系(图2(2)中的黄色圆圈)。经验表明,更多的物体候选框会带来更高的召回率,更有可能检测到图像中的物体并生成更完整的场景图。然而,大量候选关系可能会降低模型推理速度。因此,我们在中间阶段设计了这些关系的有效表示方式,以采用更多的物体候选框。
3.3 Factorized Connection Graph Generation
3.3 因子化连接图生成
By observing that many relations refer to overlapped regions (Fig. 1), we share the representations of the phrase region to reduce the number of the intermediate phrase representations as well as the computation cost. For any candidate relation, it corresponds to the union box of two objects (the minimum box containing the two boxes). Then we define its confidence score as the product of the scores of the two object proposals. With confidence scores and bounding box locations, non-maximum-suppression (NMS) [15] can be applied to suppress the number of the similar boxes and keep the bounding box with highest score as the representative. So these merged parts compose a subgraph and share an unified representation to describe their interactions. Consequently, we get a subgraph-based representation of the fully-connected graph: every subgraph contains several objects; every object belongs to several subgraphs; every candidate relation refers to one subgraph and two objects.
通过观察发现许多关系指向重叠区域(图1),我们共享短语区域的表示以减少中间短语表示的数量和计算成本。对于任何候选关系,它对应两个物体的联合框(包含这两个框的最小框)。然后我们将其置信度分数定义为两个物体提议得分的乘积。利用置信度分数和边界框位置,可以应用非极大值抑制(NMS)[15]来抑制相似框的数量,并保留得分最高的边界框作为代表。因此这些合并部分构成子图,并共享统一表示来描述它们的交互。最终,我们得到基于子图的完全连接图表示:每个子图包含若干物体;每个物体属于若干子图;每个候选关系指向一个子图和两个物体。
Discussion In previous work, ViP-CNN [34] proposed a triplet NMS to preprocess the relationship candidates and remove some overlapped ones. However, it may falsely discard some possible pairs because only spatial information is considered. Differently, our method just proposes a concise representation of the fully-connect graph by sharing the intermediate representation. It does not prune the edges, but represent them in a different form. Every predicate will still be predicted in the final stage. Thus, it is no harm for the model potential to generate the full graph.
讨论
在之前的工作中,ViP-CNN [34] 提出了三元组非极大值抑制 (triplet NMS) 来预处理关系候选并移除部分重叠项。然而,由于仅考虑空间信息,该方法可能会错误地丢弃某些潜在配对。与之不同,我们的方法通过共享中间表示,仅提出了一种全连接图的简洁表征形式。它不会剪枝边,而是以不同形式表征它们。每个谓词仍将在最终阶段被预测。因此,这对模型生成完整图的潜力没有损害。
3.4 ROI-Pool the Subgraph and Object Features
3.4 子图与目标特征的ROI池化
After the clustering, we have two sets of proposals: objects and subgraphs. Then ROI-pooling [15, 21] is used to generate corresponding features. Different from the prior art methods [35, 58] which use feature vectors to represent the phrase features, we adopt 2-D feature maps to maintain the spatial information within the subgraph regions. As the subgraph feature is shared by several predicate inferences, 2-D feature map can learn more general representation of the region and its inherit spatial structure can help to identify the subject/object and their relations, especially the spatial relations. We continue employing the feature vector to represent the objects. Thus, after the pooling, 2-D convolution layers and fully-connected layers are used to transform the subgraph feature and object features respectively.
聚类后,我们得到两组候选区域:物体和子图。随后采用ROI-pooling [15, 21]生成对应特征。与现有方法[35, 58]使用特征向量表示短语特征不同,我们采用二维特征图来保留子图区域的空间信息。由于子图特征被多个谓词推理共享,二维特征图能学习到更通用的区域表征,其固有的空间结构有助于识别主语/宾语及其关系(尤其是空间关系)。我们仍使用特征向量表示物体。因此池化后,分别使用二维卷积层和全连接层来转换子图特征与物体特征。
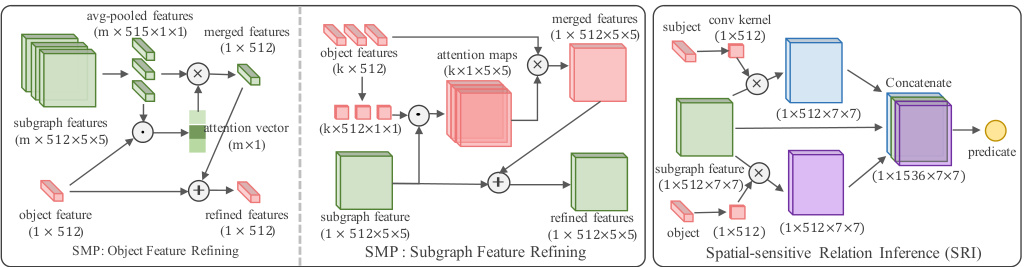
Fig. 3: Left:SMP structure for object/subgraph feature refining. Right: SRI Module for predicate recognition. Green, red and yellow refer to the subgraphs, objects and predicates respectively. $\odot$ denotes the dot product. $\bigoplus$ and $\bigotimes$ denote the element-wise sum and product.
图 3: 左: 用于对象/子图特征优化的SMP结构。右: 用于谓词识别的SRI模块。绿色、红色和黄色分别代表子图、对象和谓词。$\odot$ 表示点积。$\bigoplus$ 和 $\bigotimes$ 表示逐元素求和与乘积。
3.5 Feature Refining with Spatial-weighted Message Passing
3.5 基于空间加权消息传递的特征优化
As object and subgraph features involve different semantic levels, where objects concentrate on the details and subgraph focus on their interactions, passing message between them could help to learn better representations by leveraging their complementary information. Thus, we design a spatial weighted message passing (SMP) structure to pass message between object feature vectors and subgraph feature maps (left part of Fig. 3). Messages passing from objects to subgraphs and from subgraphs to objects are two parallel processes. $\mathbf{o_{i}}$ denotes the object feature vector and $\mathbf{S_{k}}$ denotes the subgraph feature map.
由于物体和子图特征涉及不同的语义层次(物体关注细节,子图侧重交互关系),在二者间传递消息能通过互补信息学习更好的表征。为此,我们设计了空间加权消息传递(SMP)结构,用于在物体特征向量$\mathbf{o_{i}}$和子图特征图$\mathbf{S_{k}}$之间传递消息(图3左侧)。物体到子图与子图到物体的消息传递是两个并行过程。
Pass Message From Subgraphs to Objects This process is to pass several 2-D feature maps to feature vectors. Since objects only require the general information about the subgraph regions instead of their spatial information, 2-D average pooling is directly adopted to pool the 2-D feature maps $\mathbf{S_{k}}$ into feature vectors $\mathbf{s_{k}}$ . Because each object is connected to various number of subgraphs, we need first aggregate the subgraph features and then pass them to the target object nodes. Attention [59] across the subgraphs is employed to keep the scale aggregated features invariant to the number of input subgraphs and determine the importance of different subgraphs to the object:
将子图信息传递至对象
此过程旨在将多个二维特征图转化为特征向量。由于对象仅需获取子图区域的整体信息而无需其空间位置信息,我们直接采用二维平均池化 (average pooling) 将二维特征图 $\mathbf{S_{k}}$ 池化为特征向量 $\mathbf{s_{k}}$。鉴于每个对象可能连接不同数量的子图,需先聚合子图特征再传递至目标对象节点。通过子图间的注意力机制 [59] ,既保持聚合特征的规模不受输入子图数量影响,又能判定不同子图对对象的重要性:
$$
\tilde{\mathbf{s}}{i}=\sum_{\mathbf{s}{\mathbf{k}}\in\mathbb{S}{i}}p_{i}(\mathbf{S}{k})\boldsymbol{\cdot}\mathbf{s}_{k}
$$
$$
\tilde{\mathbf{s}}{i}=\sum_{\mathbf{s}{\mathbf{k}}\in\mathbb{S}{i}}p_{i}(\mathbf{S}{k})\boldsymbol{\cdot}\mathbf{s}_{k}
$$
where $\mathbb{S}{i}$ denotes the set of subgraphs connected to object $i$ . $\tilde{\mathbf{s}}{i}$ denotes aggregated subgraph features passed to object $i$ . $\mathbf{s}{k}$ denotes the feature vector average-pooled from the 2-D feature map $\mathbf{S}{k}$ . $p_{i}(\mathbf{S}{k})$ denotes the probability that $\mathbf{s}_{k}$ is passed to the target $i$ -th object (attention vector in Fig. 3):
其中 $\mathbb{S}{i}$ 表示连接到对象 $i$ 的子图集合,$\tilde{\mathbf{s}}{i}$ 表示传递给对象 $i$ 的聚合子图特征,$\mathbf{s}{k}$ 表示从二维特征图 $\mathbf{S}{k}$ 平均池化得到的特征向量,$p_{i}(\mathbf{S}{k})$ 表示 $\mathbf{s}_{k}$ 传递给目标第 $i$ 个对象的概率 (图3中的注意力向量):
$$
p_{i}(\mathbf{S}{k})=\frac{\exp\Big(\mathbf{o}{i}\cdot\mathrm{FC}^{(a t t_{-s})}\left(\mathrm{ReLU}\left(\mathbf{s}{k}\right)\right)\Big)}{\sum_{\mathbf{S_{k}}\in\mathbb{C}{i}}\exp\left(\mathbf{o}{i}\cdot\mathrm{FC}^{(a t t_{-s})}\left(\mathrm{ReLU}\left(\mathbf{s}_{k}\right)\right)\right)}
$$
$$
p_{i}(\mathbf{S}{k})=\frac{\exp\Big(\mathbf{o}{i}\cdot\mathrm{FC}^{(a t t_{-s})}\left(\mathrm{ReLU}\left(\mathbf{s}{k}\right)\right)\Big)}{\sum_{\mathbf{S_{k}}\in\mathbb{C}{i}}\exp\left(\mathbf{o}{i}\cdot\mathrm{FC}^{(a t t_{-s})}\left(\mathrm{ReLU}\left(\mathbf{s}_{k}\right)\right)\right)}
$$
where $\mathrm{FC}^{(a t t_{-}s)}$ transforms the feature $\mathbf{s}{k}$ to the target domain of $\mathbf{o}_{i}$ . ReLU denotes the Rectified Linear Unit layer [40].
其中 $\mathrm{FC}^{(a t t_{-}s)}$ 将特征 $\mathbf{s}{k}$ 转换到 $\mathbf{o}_{i}$ 的目标域。ReLU表示修正线性单元层 [40]。
After obtaining message features, the target object feature is refined as:
获取消息特征后,目标对象特征被精炼为:
$$
\hat{\mathbf{o}}{i}=\mathbf{o}{i}+\mathrm{FC}^{\left(s\rightarrow o\right)}\left(\mathrm{ReLU}\left(\tilde{\mathbf{s}}_{i}\right)\right)
$$
$$
\hat{\mathbf{o}}{i}=\mathbf{o}{i}+\mathrm{FC}^{\left(s\rightarrow o\right)}\left(\mathrm{ReLU}\left(\tilde{\mathbf{s}}_{i}\right)\right)
$$
where $\hat{\mathbf{o}}_{i}$ denotes the refined object feature. $\mathrm{FC}^{(s\rightarrow o)}$ denotes the fully-connected layer to transform merged subgraph features to the target object domain.
其中 $\hat{\mathbf{o}}_{i}$ 表示精炼后的物体特征,$\mathrm{FC}^{(s\rightarrow o)}$ 表示将合并子图特征转换到目标物体域的全连接层。
Pass Message From Objects to Subgraphs Each subgraph connects to several objects, so this process is to pass several feature vectors to a 2-D feature map. Since different objects correspond to different regions of the subgraph features, when aggregating the object features, their weights should also depend on their locations:
将对象消息传递至子图
每个子图连接多个对象,因此这一过程是将多个特征向量传递至二维特征图。由于不同对象对应于子图特征的不同区域,在聚合对象特征时,其权重也应取决于它们的位置:
$$
\tilde{\mathbf{O}}{k}\left(x,y\right)=\sum_{\mathbf{o}{\mathbf{i}}\in\mathbb{O}{k}}\mathbf{P}{k}(\mathbf{o}{i})(x,y)\cdot\mathbf{o}_{i}
$$
$$
\tilde{\mathbf{O}}{k}\left(x,y\right)=\sum_{\mathbf{o}{\mathbf{i}}\in\mathbb{O}{k}}\mathbf{P}{k}(\mathbf{o}{i})(x,y)\cdot\mathbf{o}_{i}
$$
where $\mathbb{O}{k}$ denotes the set of objects contained in subgraph $k$ . $\dot{\mathbf O}{k}\left(x,y\right)$ denotes aggregated object features to pass to subgraph $k$ at location $(x,y)$ . $\mathbf{P}{k}(\mathbf{o}{i})(x,y)$ denotes the probability map that the object feature $\mathbf{o}_{i}$ is passed to the $k$ -th subgraph at location $(x,y)$ (corresponding to the attention maps in Fig. 3):
其中 $\mathbb{O}{k}$ 表示子图 $k$ 中包含的对象集合。$\dot{\mathbf O}{k}\left(x,y\right)$ 表示在位置 $(x,y)$ 处传递给子图 $k$ 的聚合对象特征。$\mathbf{P}{k}(\mathbf{o}{i})(x,y)$ 表示对象特征 $\mathbf{o}_{i}$ 在位置 $(x,y)$ 处传递给第 $k$ 个子图的概率图 (对应图 3 中的注意力图):
$$
\mathbf{P}{k}(\mathbf{o}{i})(x,y)=\frac{\exp\left(\mathrm{FC}^{(a t t-o)}\left(\mathrm{ReLU}\left(\mathbf{o}{i}\right)\right)\cdot\mathbf{S}{k}(x,y)\right)}{\sum_{\mathbf{S}{\mathbf{k}}\in\mathbb{C}{i}}\exp\left(\mathrm{FC}^{(a t t-o)}\left(\mathrm{ReLU}\left(\mathbf{o}{i}\right)\right)\cdot\mathbf{S}_{k}(x,y)\right)}
$$
$$
\mathbf{P}{k}(\mathbf{o}{i})(x,y)=\frac{\exp\left(\mathrm{FC}^{(a t t-o)}\left(\mathrm{ReLU}\left(\mathbf{o}{i}\right)\right)\cdot\mathbf{S}{k}(x,y)\right)}{\sum_{\mathbf{S}{\mathbf{k}}\in\mathbb{C}{i}}\exp\left(\mathrm{FC}^{(a t t-o)}\left(\mathrm{ReLU}\left(\mathbf{o}{i}\right)\right)\cdot\mathbf{S}_{k}(x,y)\right)}
$$
where $\mathrm{FC}^{(a t t.o)}$ transforms $\mathbf{o}{i}$ to the target domain of $\mathbf{S}{k}(x,y)$ . The probabilities are summed to 1 across all the objects at each location to normalize the scale of the message features. But there are no such constraints along the spatial dimensions. So different objects help to refine different parts of the subgraph features.
其中 $\mathrm{FC}^{(a t t.o)}$ 将 $\mathbf{o}{i}$ 转换到 $\mathbf{S}{k}(x,y)$ 的目标域。在每个位置上,所有对象的概率之和为1以归一化消息特征的尺度,但空间维度上不存在此类约束。因此,不同对象有助于细化子图特征的不同部分。
After the aggregation in Eq. 4, we get a feature map where the object features are aggregated with different weights at different locations. Then we can refine the subgraph features as:
在式4的聚合操作后,我们得到一个特征图,其中物体特征在不同位置以不同权重进行聚合。随后可按以下方式细化子图特征:
$$
\hat{\mathbf{S}}{k}=\mathbf{S}{k}+\mathrm{Conv}^{(o\rightarrow s)}\left(\mathrm{ReLU}\left(\tilde{\mathbf{O}}_{k}\right)\right)
$$
where $\hat{\bf S}_{i}$ denotes the refined subgraph features. $\operatorname{Conv}^{(o\to s)}$ denotes the convolution layer to transform merged object messages to the target subgraph domain. Discussion Since subgraph features embed the interactions among several objects and objects are the basic elements of subgraphs, message passing between object and subgraph features could: (1) help the object feature learn better represent at ions by considering its interactions with other objects and introduce the contextual information; (2) refine different parts of subgraph features with corresponding object features. Different from the message passing in ISGG [58] and MSDN [35], our SMP (1) passes message between “points” (object vectors) and “2-D planes” (subgraph feature maps); (2) adopts attention scheme to merge different messages in a normalized scale. Besides, several SMP modules can be stacked to enhance the representation ability of the model.
其中 $\hat{\bf S}_{i}$ 表示精炼后的子图特征。$\operatorname{Conv}^{(o\to s)}$ 表示将合并后的物体信息转换到目标子图域的卷积层。
讨论:由于子图特征嵌入了多个物体间的交互关系,而物体是子图的基本构成元素,物体与子图特征间的消息传递能够:(1) 通过考虑物体与其他物体的交互关系并引入上下文信息,帮助物体特征学习更好的表征;(2) 用对应的物体特征精炼子图特征的不同部分。与ISGG [58] 和MSDN [35] 中的消息传递不同,我们的SMP (1) 在"点"(物体向量)与"二维平面"(子图特征图)之间传递消息;(2) 采用注意力机制以归一化尺度合并不同消息。此外,可以堆叠多个SMP模块以增强模型的表征能力。
3.6 Spatial-sensitive Relation Inference
3.6 空间敏感关系推断
After the message passing, we have got refined representations of the objects $\mathbf{o}{i}$ and subgraph regions $\mathbf{S}{k}$ . Object categories can be predicted directly with the object features. Because subgraph features may refer to several object pairs, we use the subject and object features along with their corresponding subgraph feature to predict their relationship:
在消息传递之后,我们获得了物体$\mathbf{o}{i}$和子图区域$\mathbf{S}{k}$的精细化表征。物体类别可直接通过物体特征进行预测。由于子图特征可能涉及多个物体对,我们使用主语和宾语特征及其对应的子图特征来预测它们的关系:
$$
\mathbf{p}^{\langle i,k,j\rangle}=\mathbf{f}\left(\mathbf{o}{i},\mathbf{S}{k},\mathbf{o}_{j}\right)
$$
$$
\mathbf{p}^{\langle i,k,j\rangle}=\mathbf{f}\left(\mathbf{o}{i},\mathbf{S}{k},\mathbf{o}_{j}\right)
$$
As different objects correspond to different regions of subgraph features, subject and object features work as the convolution kernels to extract the visual cues of their relationship from feature map.
由于不同对象对应子图特征的不同区域,主体和客体特征作为卷积核从特征图中提取它们关系的视觉线索。
$$
\mathbf{S}{k}^{(i)}=\mathrm{FC}\left(\mathrm{ReLU}\left(\mathbf{o}{i}\right)\right)\otimes\mathrm{ReLU}\left(\mathbf{S}_{k}\right)
$$
$$
\mathbf{S}{k}^{(i)}=\mathrm{FC}\left(\mathrm{ReLU}\left(\mathbf{o}{i}\right)\right)\otimes\mathrm{ReLU}\left(\mathbf{S}_{k}\right)
$$
where S(ki) denotes the convolution result of subgraph feature map $\mathbf{S}_{k}$ with $i$ -th object as convolution kernel. $\bigotimes$ denotes the convolution operation. As learning a convolution kernel needs large quantities of parameters, Group Convolution [29] is adopted. We set group numbers as the number of channels, so the group convolution can be reformulated as element-wise product.
其中S(ki)表示子图特征图$\mathbf{S}_{k}$以第$i$个对象为卷积核的卷积结果,$\bigotimes$表示卷积运算。由于学习卷积核需要大量参数,我们采用分组卷积(Group Convolution) [29]。将组数设置为通道数,使分组卷积可重构为逐元素乘积。
Then we concatenate S(ki) and S(kj) with the subgraph feature $\mathbf{S}_{k}$ and predict the relationship directly with a fully-connected layer:
然后我们将S(ki)和S(kj)与子图特征$\mathbf{S}_{k}$连接起来,并通过一个全连接层直接预测关系:
$$
\mathbf{p}^{\langle i,k,j\rangle}=\mathrm{FC}^{(p)}\left(\mathrm{ReLU}\left(\left[\mathbf{S}{k}^{(i)};\mathbf{S}{k};\mathbf{S}_{k}^{(j)}\right]\right)\right)
$$
$$
\mathbf{p}^{\langle i,k,j\rangle}=\mathrm{FC}^{(p)}\left(\mathrm{ReLU}\left(\left[\mathbf{S}{k}^{(i)};\mathbf{S}{k};\mathbf{S}_{k}^{(j)}\right]\right)\right)
$$
where $\mathrm{FC}^{({p})}$ denotes the fully-connected layer for predicate recognition. $[\cdot]$ denotes the concatenation.
其中 $\mathrm{FC}^{({p})}$ 表示用于谓词识别的全连接层,$[\cdot]$ 表示拼接操作。
Bottleneck Layer Directly predicting the convolution kernel leads to a lot of parameters to learn, which makes the model huge and hard to train. The number of parameters of $\mathrm{FC}^{({p})}$ equals:
瓶颈层 直接预测卷积核会导致需要学习大量参数,这使得模型庞大且难以训练。$\mathrm{FC}^{({p})}$ 的参数数量等于:
$$
\mathrm{FC}^{(p)}=C^{(p)}\times C\times W\times H
$$
$$
\mathrm{FC}^{(p)}=C^{(p)}\times C\times W\times H
$$
where $C^{(p)}$ denotes the number of predicate categories. $C$ denotes the channel size. $W$ and $H$ denote the width and height of the feature map. Inspired by the bottleneck structure in [22], we introduce an additional $1\times1$ bottleneck convolution layer prior to $\mathrm{FC}^{\left(p\right)}$ to reduce the number of channels (omitted in Fig. 3). After adding an bottleneck layer with channel size equalling to $C^{\prime}$ , the parameter size gets:
其中 $C^{(p)}$ 表示谓词类别数,$C$ 表示通道数,$W$ 和 $H$ 分别表示特征图的宽度和高度。受 [22] 中瓶颈结构的启发,我们在 $\mathrm{FC}^{\left(p\right)}$ 前引入了一个额外的 $1\times1$ 瓶颈卷积层来减少通道数 (图 3 中已省略)。当添加通道数为 $C^{\prime}$ 的瓶颈层后,参数量变为:
$$
\mathrm{Conv}^{(b o t t l e n e c k)}+\mathrm{FC}^{(p)}=C\times C^{\prime}+C^{(p)}\times C^{\prime}\times W\times H
$$
$$
\mathrm{Conv}^{(b o t t l e n e c k)}+\mathrm{FC}^{(p)}=C\times C^{\prime}+C^{(p)}\times C^{\prime}\times W\times H
$$
If we take $C^{\prime}=C/2$ , as $\mathrm{Conv}^{(b o t t l e n e c k)}$ is far less than $\mathrm{FC}^{(p)}$ , we almost half the number of parameters.
如果我们取 $C^{\prime}=C/2$ ,由于 $\mathrm{Conv}^{(b o t t l e n e c k)}$ 远小于 $\mathrm{FC}^{(p)}$ ,参数数量几乎减半。
Discussion In previous work, spatial features have been extracted from the coordinates of the bounding box or object masks [6, 36, 62]. Different from these methods, ours embeds the spatial information in the subgraph feature maps. Since $\mathrm{FC}^{\left(p\right)}$ has different weights at different locations, it could learn to decide whether to leverage the spatial feature and how to use that by itself from the training data.
讨论
在先前的工作中,空间特征通常从边界框坐标或物体掩码中提取 [6, 36, 62]。与这些方法不同,我们的方法将空间信息嵌入到子图特征图中。由于 $\mathrm{FC}^{\left(p\right)}$ 在不同位置具有不同的权重,它能够通过训练数据自行学习是否利用空间特征以及如何使用这些特征。
4 Experiments
4 实验
In this section, implementation details of our proposed method and experiment settings will be introduced. Ablation studies will be done to show the effectiveness of different modules. We also compare our F-Net with state-of-the-art methods on both accuracy and testing speed.
在本节中,我们将介绍所提方法的实现细节和实验设置。通过消融实验验证各模块的有效性,并在精度和测试速度方面将F-Net与前沿方法进行对比。
4.1 Implementation details
4.1 实现细节
Model details ImageNet pretrained VGG16 [54] is adopted to initialize the base CNN, which is shared by RPN and F-Net. ROI-align [21] is used to generated $5\times5$ object and subgraph features. Two FC layers are used to transform the pooled object features to 512-dim feature vectors. Two $3\times3$ Conv layers are used to generate 512-dim subgraph feature maps. For SRI module, we use a 256-dim bottleneck layer to reduce the model size. All the newly introduced layers are randomly initialized.
模型细节
采用ImageNet预训练的VGG16 [54]初始化基础CNN (Convolutional Neural Network),该网络由RPN (Region Proposal Network)和F-Net共享。使用ROI-align [21]生成$5\times5$的目标和子图特征。两个全连接层(FC)将池化后的目标特征转换为512维特征向量。两个$3\times3$卷积层用于生成512维子图特征图。对于SRI (Spatial Relation Inference)模块,我们使用256维瓶颈层来减小模型规模。所有新增层均采用随机初始化。
Training details During training, we fix Conv $\mathbf{\Psi}_{\perp}$ and Conv $^2$ of VGG16, and set the learning rate of the other convolution layers of VGG as 0.1 of the overall learning rate. Base learning rate is 0.01, and get multiplied by 0.1 every 3 epochs. RPN NMS threshold is set as 0.7. Subgraph clustering threshold is set as 0.5. For the training samples, 256 object proposals and 1024 predicates are sampled $50%$ foregrounds. There is no sampling for the subgraphs, so the subgraph connection maps are identical from training to testing. The RPN part is trained first, and then RPN, F-Net and base VGG part are jointly trained.
训练细节
在训练过程中,我们固定VGG16的Conv $\mathbf{\Psi}_{\perp}$ 和Conv $^2$,并将VGG其他卷积层的学习率设为整体学习率的0.1倍。基础学习率为0.01,每3个epoch乘以0.1。RPN (Region Proposal Network) 的非极大值抑制 (NMS) 阈值设为0.7。子图聚类阈值设为0.5。对于训练样本,采样256个目标提议和1024个谓词,其中 $50%$ 为前景。子图不进行采样,因此子图连接图从训练到测试保持一致。首先训练RPN部分,随后联合训练RPN、F-Net和基础VGG部分。
Inference details During testing phase, RPN NMS threshold and subgraph clustering threshold are set as 0.6 and 0.5 respectively. All the predicates (edges of fully-connected graph) will be predicted. Top-1 categories will be used as the prediction for objects and relations. Predicated relationship triplets will be sorted in the descending order based on the products of their subject, object and predicate confidence probabilities. Inspired by Li et al. in [34], triplet NMS is adopted to remove the redundant predictions if the two triplets refer to the identical relationship.
推理细节
在测试阶段,RPN (Region Proposal Network) 的非极大值抑制 (NMS) 阈值和子图聚类阈值分别设为0.6和0.5。所有谓词(全连接图的边)将被预测。目标与关系的预测将采用Top-1类别。预测的关系三元组会按其主语、宾语及谓词置信度概率的乘积降序排列。受[34]中Li等人的启发,若两个三元组指向同一关系,则采用三元组NMS消除冗余预测。
Table 1: Dataset statistics. VG-MSDN and VG-DR-Net are two cleansedversion of raw Visual Genome dataset. #Img denotes the number of images. #Rel denotes the number of subject-predicate-object relation pairs. #Object and #Predicate denotes the number of object and predicate categories respectively.
| Dataset | Training Set #Img | #Rel | Testing Set #Img #Rel | #Object | #Predicate |
| VRD [37] | 4,000 | 30,355 | 1,000 7,638 | 100 | 70 |
| VG-MSDN 28,35 | 46,164 | 507,296 | 10,000 111,396 | 150 | 50 |
| VG-DR-Net [6,28] | 67,086 | 798,906 | 8,995 26,499 | 399 | 24 |
表 1: 数据集统计信息。VG-MSDN和VG-DR-Net是原始Visual Genome数据集的两个清洗版本。#Img表示图像数量,#Rel表示主语-谓语-宾语关系对数量,#Object和#Predicate分别表示物体类别和谓词类别的数量。
| Dataset | Training Set #Img | #Rel | Testing Set #Img #Rel | #Object | #Predicate |
|---|---|---|---|---|---|
| VRD [37] | 4,000 | 30,355 | 1,000 7,638 | 100 | 70 |
| VG-MSDN 28,35 | 46,164 | 507,296 | 10,000 111,396 | 150 | 50 |
| VG-DR-Net [6,28] | 67,086 | 798,906 | 8,995 26,499 | 399 | 24 |
4.2 Datasets
4.2 数据集
Two datasets are employed to evaluate our method, Visual Relationship Detection (VRD) [37] and Visual Genome [28]. VRD is a small benchmark dataset where most of the existing methods are evaluated. Compared to VRD, raw Visual Genome contains too many noisy labels, so dataset cleansing should be done to make it available for model training and evaluation. For fair comparison, we adopt two cleansed-version Visual Genome used in [35] and [6] and compare with their methods on corresponding datasets. Detailed statistics of the three datasets are shown in Tab. 1.
我们采用两个数据集来评估方法:视觉关系检测(VRD) [37]和视觉基因组(Visual Genome) [28]。VRD是一个小型基准数据集,现有方法大多在此评估。与VRD相比,原始视觉基因组包含过多噪声标签,需经过数据清洗才能用于模型训练和评估。为公平对比,我们采用[35]和[6]中使用的两个清洗版视觉基因组,并在对应数据集上与其方法进行比较。三个数据集的详细统计信息如 表 1 所示。
4.3 Evaluation Metrics
4.3 评估指标
Models will be evaluated on two tasks, Visual Phrase Detection (PhrDet) and Scene Graph Generation (SGGen). Visual Phrase Detection is to detect the ⟨subject-predicate-object⟩ phrases, which is tightly connected to the Dense Captioning [25]. Scene Graph Generation is to detect the objects within the image and recognize their pair-wise relationships. Both tasks recognize the ⟨subjectpredicate-object⟩ triplets, but scene graph generation needs to localize both the subject and the object with at least 0.5 IOU (intersection over union) while visual phrase detection only requires one bounding box for the entire phrase.
模型将在两个任务上进行评估:视觉短语检测 (PhrDet) 和场景图生成 (SGGen)。视觉短语检测旨在检测⟨主语-谓语-宾语⟩短语,这与密集描述生成 (Dense Captioning) [25] 紧密相关。场景图生成则需要检测图像中的对象并识别它们之间的成对关系。两个任务都识别⟨主语-谓语-宾语⟩三元组,但场景图生成要求以至少0.5 IOU (交并比) 同时定位主语和宾语,而视觉短语检测仅需为整个短语提供一个边界框。
The testing speed of the model is also reported. Previously, only accuracy is reported in the papers. So lots of complicated structure and post-processing methods are used to enhance the Recall. As scene graph generation is getting closer to the practical applications and products, testing speed become a critical metric to evaluate the model. If not specified, testing speed is evaluated with Titan-X GPU.
模型的测试速度也被纳入报告。以往论文仅报告准确率,因此采用了大量复杂结构和后处理方法以提高召回率(Recall)。随着场景图生成技术日益接近实际应用和产品化,测试速度成为评估模型的关键指标。除非另有说明,测试速度均在Titan-X GPU环境下评测。
Table 2: Ablation studies of the proposed model. PhrDet denotes phrase detection task. SGGen denotes the scene graph generation task. SubGraph denotes whether to use Subgraph-based clustering strategy. 2-D indicates whether we use 2-D feature map or feature vector to represent subgraph features. #SMP denotes the number of the Multimodal Message Passing structures (model 1 adopts the message passing in [35]). #Boxes denotes the number of object proposals we use during the testing. SRI denotes whether the SRI module is used (baseline method is average pooling the subgraph feature maps to vectors). Speed shows the time spent for one inference forward pass (second/image).
表 2: 所提模型的消融研究。PhrDet表示短语检测任务。SGGen表示场景图生成任务。SubGraph表示是否使用基于子图的聚类策略。2-D表示我们使用2维特征图还是特征向量来表示子图特征。#SMP表示多模态消息传递结构的数量(模型1采用[35]中的消息传递)。#Boxes表示测试时使用的物体提议框数量。SRI表示是否使用SRI模块(基线方法是对子图特征图进行平均池化为向量)。Speed显示单次推理前向传播耗时(秒/图像)。
| ID | SubGraph | #SMP | 2-D SRI | #Boxes | PhrDet R@50 R@100 | SGGen R@50 R@100 | Speed | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 64 | 16.92 | 21.04 | 8.52 | 10.81 | ||
| 1 | 人 | 0 | 64 | 16.50 | 20.79 | 8.49 | 10.33 | |
| 2 | 人 | 0 | - | 200 | 18.71 | 22.77 | 9.73 | 12.02 |
| 3 | 人 | 0 | 人 | 200 | 19.09 | 22.88 | 9.90 | 12.08 |
| 4 | 1 | - | 200 | 20.48 | 25.69 | 11.62 | ||
| 5 | 1 | 人 | 人 | 200 | 22.54 | 28.31 | 12.83 | |
| 6 | 2 | √ | 200 | 22.84 | 28.57 | 13.06 | 16.47 |
4.4 Component Analysis
4.4 组件分析
In this section, we perform several experiments to evaluate the effectiveness of different components of our F-Net (Tab. 2). All the experiments are performed on VG-MSDN [35] as it is larger than VRD [37] to eliminate over fitting and contains more predicate categories than VG-DR-Net [6].
在本节中,我们通过多项实验评估F-Net各模块的有效性 (Tab. 2)。所有实验均在VG-MSDN [35]数据集上进行,因其规模大于VRD [37]可避免过拟合,且比VG-DR-Net [6]包含更多谓词类别。
Subgraph-based pipeline For the baseline model 0, every relation candidate is represented by a phrase feature vector, and the predicates are predicted based on the concatenation of subject, object and phrase features. In comparison, model 1 and 2 adopt the subgraph-based presentation of the fully-connected graph with different numbers of object proposals. By comparing model 0 and 1, we can see that subgraph-based clustering could significantly speed up the model inference because of the fewer intermediate features. However, since most of the phrase features are approximated by the subgraph features, the accuracy of model 1 is slightly lower than that of model 0. However, the disadvantage of model 1 can be easily compensated by employing more object proposal as model 2 outperforms model 0 both in speed and accuracy by a large scale. Furthermore, model 1∼6 are all faster than model 0, which proves the efficiency of our subgraph-based representations.
基于子图的流程
对于基线模型0,每个关系候选都由一个短语特征向量表示,谓语预测基于主语、宾语和短语特征的拼接。相比之下,模型1和2采用全连接图的基于子图表示,但使用了不同数量的目标提议。通过比较模型0和1可以看出,基于子图的聚类能显著加速模型推理,因为中间特征更少。然而,由于大部分短语特征被子图特征近似替代,模型1的准确率略低于模型0。但模型1的劣势可通过增加目标提议轻松弥补——模型2在速度和准确率上均大幅超越模型0。此外,模型1∼6都比模型0更快,这证明了我们基于子图表示的高效性。
2-D feature map From model 3, we start to use 2-D feature map to represent the subgraph features, which can maintain the spatial information within the subgraph regions. Compared to model 2, model 3 adopts 2-D representations of the subgraph features and use average-pooled subgraph features (concatenated with the subject and object feature) to predict the relationships. Since SRI is not used, the main difference is two $3\times3-$ conv layers are used instead of FC layer to transform the subgraph features. Since we pool the subgraph regions to $5\times5$ feature maps, which is just the perceptual field of two $3\times3$ conv layers, therefore, model 3 has less parameters to learn and the spatial structure of the feature map could serve as a regular iz ation. Therefore, compared to model 2, model 3 performs better.
从模型3开始,我们采用二维特征图来表示子图特征,这种表示方式能保留子图区域内的空间信息。与模型2相比,模型3采用子图特征的二维表示,并使用平均池化的子图特征(与主体和客体特征拼接)来预测关系。由于未使用SRI,主要区别在于用两个$3\times3-$卷积层替代了全连接层来处理子图特征。由于我们将子图区域池化为$5\times5$特征图,这正好是两个$3\times3$卷积层的感受野范围,因此模型3需要学习的参数量更少,且特征图的空间结构能起到正则化作用。最终模型3的表现优于模型2。
Message Passing between objects and subgraphs When comparing Model 3 and 4, $2.02%{\sim}2.37%$ SGGen Recall increase is observed, which shows our proposed SMP could also help the model learn a better representation of the objects and the subgraph regions. With our proposed SMP, different parts of subgraph features can be refined by different objects, and object features can also get refined by receiving more information about their interactions with other object regions. Furthermore, when comparing model 5 and model 6, we can see that stacking more SMP modules can further improve the model performance as more complicated message paths are introduced. However, more SMP modules will deteriorate the testing speed, especially when we use feature maps to represent the subgraph features.
对象与子图间的消息传递
在比较模型3和模型4时,观察到SGGen Recall提升了$2.02%{\sim}2.37%$,这表明我们提出的SMP(结构化消息传递)能帮助模型学习更优的对象与子图区域表征。通过SMP机制,子图特征的不同部分可被不同对象细化,同时对象特征也能通过接收与其他对象区域的交互信息得到增强。此外,对比模型5和模型6可见,堆叠更多SMP模块能引入更复杂的消息路径,从而进一步提升模型性能。但更多SMP模块会降低测试速度,尤其在用特征图表示子图特征时更为明显。
Spatial-sensitive Relation Inference From Eq. 9, Fully-Connected layer is used to predict the relationships from the 2-D feature map, so every point within the map will be assigned a location-specified weight and the SRI could learn to model the hidden spatial connections. Different from previous models that employing handcrafted spatial features like axises of the subject/object proposals, our model could not only improve the recognition accuracy of explicit spatial relationships like above and below, but also learn to extract the inherit spatial connection of other relationships. Experiment results of model 4 and 5 show the improvement brought by our proposed SRI module.
空间敏感关系推断
从公式9可知,全连接层用于从二维特征图预测关系,因此图中的每个点都会被分配一个位置特定的权重,使SRI能够学习建模隐藏的空间连接。与以往采用手工空间特征(如主/客体提案轴)的模型不同,我们的模型不仅能提升显式空间关系(如上/下)的识别准确率,还能学习提取其他关系的固有空间关联。模型4和5的实验结果验证了所提SRI模块的改进效果。
4.5 Comparison with Existing Methods
4.5 与现有方法的对比
We compare our proposed F-Net with existing methods in Tab. 3. These methods can be roughly divided into two groups. One employs the two-stage pipeline, which is to detect the objects first and then recognize their relationships, including LP [37], DR-Net [6] and ILC [42]. Compared with these methods, our F-Net jointly recognizes the objects and their relationships, so the feature level connections can be leveraged for better recognition. In addition, complicated postprocessing stages introduced by these methods may reduce the inference speed and make it more difficult to implement with GPU or other high-performance hardware like FPGA. The other methods like ViP-CNN [34], ISGG [58], MSDN [35] adopt the similar pipeline to ours and propose different feature learning methods. Both ViP-CNN and ISGG used message passing to refine the object and predicate features. MSDN introduced an additional task, dense captioning, to improve scene graph generation. However, in these methods, each relationship is represented by an individual phrase feature. This leads to limited object proposals that are used to generate scene graph, as the number of relationships grows quadratically with that of the proposals. In comparison, our proposed subgraphbased pipeline significantly reduces the relationship representations by clustering them into subgraphs. Therefore, it allows us to use more object proposals to generate scene graph, and correspondingly, helps our model to perform better than these methods both in speed and accuracy.
我们在表3中将提出的F-Net与现有方法进行对比。这些方法大致可分为两类:一类采用两阶段流程(先检测物体再识别关系),包括LP [37]、DR-Net [6]和ILC [42]。相较之下,F-Net能同步识别物体及其关系,从而利用特征层面的关联提升识别效果。此外,这些方法引入的复杂后处理阶段会降低推理速度,增加GPU或FPGA等高性能硬件的实现难度。另一类方法如ViP-CNN [34]、ISGG [58]和MSDN [35]采用与我们相似的流程,但提出了不同的特征学习方案:ViP-CNN和ISGG通过消息传递优化物体与谓词特征,MSDN则引入密集描述任务来增强场景图生成。但这些方法中每个关系都需独立短语特征表示,导致可用物体提议数量受限(因为关系数量随提议数呈平方增长)。相比之下,我们提出的基于子图的流程通过聚类关系形成子图,显著减少了关系表征数量,从而能使用更多物体提议生成场景图,最终在速度和精度上均超越现有方法。
Table 3: Comparison with existing methods on visual phrase detection (PhrDet) and scene graph generation(SGGen). Speed indicates the testing time spent on one image (second/image). Benchmark dataset, VRD [37], and two cleansedversion Visual Genome [6, 28, 35] are used for fair comparison.
∗ Only consider the post-processing time given the CNN features and object detection results. ∗∗ As reported in [42], it takes about 45 minutes to test 1000 images on single K80 GPU.
表 3: 视觉短语检测(PhrDet)和场景图生成(SGGen)的现有方法对比。Speed表示单张图像测试耗时(秒/图)。基准数据集采用VRD [37]和两个清洗版Visual Genome [6, 28, 35]以确保公平比较。
| Dataset | Model | PhrDet Rec@50 | PhrDet Rec@100 | SGGen Rec@50 | SGGen Rec@100 | Speed |
|---|---|---|---|---|---|---|
| VRD [37] | LP [37] ViP-CNN [34] | 16.17 | 17.03 | 13.86 | 14.70 | 1.18* |
| 22.78 | 27.91 | 17.32 | 20.01 | 0.78 | ||
| DR-Net [6] | 19.93 | 23.45 | 17.73 | 20.88 | 2.83 | |
| ILC [42] | 16.89 | 20.70 | 15.08 | 18.37 | 2.70** | |
| Ours Full:1-SMP | 25.90 | 30.52 | 18.16 | 21.04 | 0.45 | |
| Ours Full:2-SMP | 26.03 | 30.77 | 18.32 | 21.20 | 0.55 | |
| VG-MSDN [28,35] | ISGG [58] | 15.87 | 19.45 | 8.23 | 10.88 | 1.64 |
| MSDN [35] | 19.95 | 24.93 | 10.72 | 14.22 | 3.56 | |
| Ours-Full:2-SMP | 22.84 | 28.57 | 13.06 | 16.47 | 0.55 | |
| VG-DR-Net [6,28] | DR-Net [6] | 23.95 | 27.57 | 20.79 | 23.76 | 2.83 |
| Ours-Full:2-SMP | 26.91 | 32.63 | 19.88 | 23.95 | 0.55 |
- 仅统计给定CNN特征和目标检测结果的后处理时间
** 据[42]报告,在单块K80 GPU上测试1000张图像约需45分钟
5 Conclusion
5 结论
This paper introduces an efficient scene graph generation model, Factor iz able Network (F-Net). To tackle the problem of the quadratic combinations of possible relationships, a concise subgraph-based representation of the scene graph is introduced to reduce the number of intermediate representations during the inference. 2-D feature maps are used to maintain the spatial information within the subgraph region. Correspondingly, a Spatial-weighted Message Passing structure and a Spatial-sensitive Relation Inference module are designed to make use of the inherent spatial structure of the feature maps. Experiment results show that our model is significantly faster than the previous methods with better results.
本文介绍了一种高效的场景图生成模型——可分解网络 (F-Net)。针对可能关系的二次组合问题,我们引入了一种基于子图的简洁场景图表示方法,以减少推理过程中的中间表示数量。通过使用二维特征图来保持子图区域内的空间信息,相应地设计了空间加权消息传递结构 (Spatial-weighted Message Passing) 和空间敏感关系推理模块 (Spatial-sensitive Relation Inference) 以利用特征图固有的空间结构。实验结果表明,我们的模型在取得更好结果的同时,速度显著快于现有方法。