The COT COLLECTION: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning
COT COLLECTION:通过思维链微调提升大语言模型的零样本和少样本学习能力
Abstract
摘要
Language models (LMs) with less than 100B parameters are known to perform poorly on chain-of-thought (CoT) reasoning in contrast to large LMs when solving unseen tasks. In this work, we aim to equip smaller LMs with the step-by-step reasoning capability by instruction tuning with CoT rationales. In order to achieve this goal, we first introduce a new instructiontuning dataset called the COT COLLECTION, which augments the existing Flan Collection (including only 9 CoT tasks) with additional 1.84 million rationales across 1,060 tasks. We show that CoT fine-tuning Flan-T5 (3B & 11B) with COT COLLECTION enables smaller LMs to have better CoT capabilities on unseen tasks. On the BIG-Bench-Hard (BBH) benchmark, we report an average improvement of $+4.34%$ (Flan-T5 3B) and $+2.60%$ (Flan-T5 11B), in terms of zero-shot task accuracy. Furthermore, we show that instruction tuning with COT COLLECTION allows LMs to possess stronger fewshot learning capabilities on 4 domain-specific tasks, resulting in an improvement of $+2.24%$ (Flan-T5 3B) and $+2.37%$ (Flan-T5 11B), even outperforming ChatGPT utilizing demonstrations until the max length by a $+13.98%$ margin. Our code, the COT COLLECTION data, and model checkpoints are publicly available 1.
参数少于100B的语言模型(LM)在解决未见任务时,其思维链(CoT)推理能力明显逊色于大语言模型。本研究旨在通过CoT原理的指令微调,为小型LM赋予逐步推理能力。为此,我们首先引入了名为COT COLLECTION的新指令微调数据集,该数据集在原有Flan Collection(仅含9个CoT任务)基础上,新增了覆盖1,060个任务的184万条推理原理。实验表明,使用COT COLLECTION对Flan-T5(3B和11B)进行CoT微调后,小型LM在未见任务上展现出更强的CoT能力。在BIG-Bench-Hard(BBH)基准测试中,Flan-T5 3B和11B的零样本任务准确率分别平均提升$+4.34%$和$+2.60%$。此外,采用COT COLLECTION进行指令微调的模型在4个特定领域任务上表现出更强的少样本学习能力,Flan-T5 3B和11B分别提升$+2.24%$和$+2.37%$,甚至以$+13.98%$的优势超越了使用最大长度演示的ChatGPT。我们的代码、COT COLLECTION数据及模型检查点已公开1。
1 Introduction
1 引言
Language models (LMs) pre-trained on massive text corpora can adapt to downstream tasks in both zero-shot and few-shot learning settings by incorporating task instructions and demonstrations (Brown et al., 2020; Wei et al., 2021; Sanh et al., 2021; Mishra et al., 2022; Wang et al., 2022b; Iyer et al., 2022; Liu et al., 2022b; Chung et al., 2022; Long- pre et al., 2023; Ye et al., 2023). One approach that has been particularly effective in enabling LMs to excel at a multitude of tasks is Chain-of-Thought (CoT) prompting, making LMs generate a rationale to derive its final prediction in a sequential manner (Wei et al., 2022b; Kojima et al., 2022; Zhou et al., 2022; Zhang et al., 2022; Yao et al., 2023).
在大规模文本语料库上预训练的语言模型 (language model, LM) 可以通过融入任务指令和示例, 在零样本 (zero-shot) 和少样本 (few-shot) 学习场景中适应下游任务 [Brown et al., 2020; Wei et al., 2021; Sanh et al., 2021; Mishra et al., 2022; Wang et al., 2022b; Iyer et al., 2022; Liu et al., 2022b; Chung et al., 2022; Longpre et al., 2023; Ye et al., 2023]。其中, 思维链 (Chain-of-Thought, CoT) 提示法被证明能显著提升语言模型处理多任务的能力, 该方法使模型通过逐步生成推理过程来得出最终预测 [Wei et al., 2022b; Kojima et al., 2022; Zhou et al., 2022; Zhang et al., 2022; Yao et al., 2023]。
While CoT prompting works effectively for large LMs with more than 100 billion parameters, it does not necessarily confer the same benefits to smaller LMs (Tay et al., 2022; Suzgun et al., 2022; Wei et al., 2022a; Chung et al., 2022). The requirement of a large number of parameters consequently results in significant computational cost and accessibility issues (Kaplan et al., 2020; Min et al., 2022; Liu et al., 2022b; Mhlanga, 2023; Li et al., 2023).
虽然思维链 (CoT) 提示对参数量超过千亿的大语言模型效果显著,但它未必能为较小规模的模型带来同等优势 (Tay et al., 2022; Suzgun et al., 2022; Wei et al., 2022a; Chung et al., 2022)。这种对海量参数的需求进而导致了高昂的计算成本和可及性问题 (Kaplan et al., 2020; Min et al., 2022; Liu et al., 2022b; Mhlanga, 2023; Li et al., 2023)。
Recent work has focused on empowering relatively smaller LMs to effectively solve novel tasks as well, primarily through fine-tuning with rationales (denoted as CoT fine-tuning) and applying CoT prompting on a single target task (Shridhar et al., 2022; Ho et al., 2022; Fu et al., 2023). How- ever, solving a single task does not adequately address the issue of generalization to a broad range of unseen tasks. While Chung et al. (2022) leverage 9 publicly available CoT tasks during instruction tuning to solve multiple unseen tasks, the imbalanced ratio compared to 1,827 tasks used for direct finetuning results in poor CoT results across smaller LMs (Longpre et al., 2023). In general, the community still lacks a comprehensive strategy to fully leverage CoT prompting to solve multiple unseen novel tasks in the context of smaller LMs.
近期研究主要关注如何通过基于原理的微调(称为CoT微调)和在单一目标任务上应用CoT提示(Shridhar等人,2022;Ho等人,2022;Fu等人,2023),使相对较小的大语言模型也能有效解决新任务。然而,解决单一任务并不能充分应对广泛未见任务的泛化问题。尽管Chung等人(2022)在指令微调中利用了9个公开可用的CoT任务来解决多个未见任务,但与直接微调所用的1,827个任务相比,这种不平衡的比例导致较小的大语言模型的CoT效果较差(Longpre等人,2023)。总体而言,学界仍缺乏一个全面策略,以在较小的大语言模型背景下充分利用CoT提示来解决多个未见新任务。
To bridge this gap, we present the COT COLLECTION, an instruction tuning dataset that augments 1.84 million rationales from the FLAN Collection (Longpre et al., 2023) across 1,060 tasks. We fine-tune Flan-T5 (3B & 11B) using COT COLLECTION and denote the resulting model as CoTT5. We perform extensive comparisons of CoT-T5 and Flan-T5 under two main scenarios: (1) zeroshot learning and (2) few-shot learning.
为弥补这一差距,我们提出了COT COLLECTION,这是一个指令微调数据集,在1,060个任务中扩展了来自FLAN Collection (Longpre et al., 2023) 的184万条原理。我们使用COT COLLECTION对Flan-T5 (3B & 11B) 进行微调,并将所得模型命名为CoTT5。我们在两种主要场景下对CoT-T5和Flan-T5进行了广泛比较:(1) 零样本学习 (zero-shot learning) 和 (2) 少样本学习 (few-shot learning)。
In the zero-shot learning setting, CoT-T5 (3B & 11B) outperforms Flan-T5 (3B & 11B) by $+4.34%$ and $+2.60%$ on average accuracy across 27 datasets from the Big Bench Hard (BBH) benchmark (Suzgun et al., 2022) when evaluated with CoT prompting. During ablation experiments, we show that CoT fine-tuning T0 (3B) (Sanh et al., 2021) on a subset of the CoT Collection, specifically 163 training tasks used in T0, shows a performance increase of $+8.65%$ on average accuracy across 11 datasets from the P3 Evaluation benchmark. Moreover, we translate 80K instances of COT COLLECTION into 5 different languages (French, Japanese, Korean, Russian, Chinese) and observe that CoT fine-tuning mT0 (3B) (Mu en nigh off et al., 2022) on each language results in $2\mathrm{x}\sim10\mathrm{x}$ performance improvement on average accuracy across all 5 languages from the MGSM benchmark (Shi et al., 2022).
在零样本学习设置中,CoT-T5(3B和11B)在使用思维链提示(CoT prompting)评估时,在Big Bench Hard(BBH)基准测试(Suzgun等人,2022)的27个数据集上平均准确率分别比Flan-T5(3B和11B)高出$+4.34%$和$+2.60%$。在消融实验中,我们发现对T0(3B)(Sanh等人,2021)在思维链集合(CoT Collection)的子集(特别是T0中使用的163个训练任务)上进行微调后,在P3评估基准的11个数据集上平均准确率提升了$+8.65%$。此外,我们将思维链集合中的80K个实例翻译成5种不同语言(法语、日语、韩语、俄语、中文),并观察到对mT0(3B)(Muennighoff等人,2022)在每种语言上进行微调后,在MGSM基准测试(Shi等人,2022)的所有5种语言上平均准确率提升了$2\mathrm{x}\sim10\mathrm{x}$。
In the few-shot learning setting, where LMs must adapt to new tasks with a minimal number of instances, CoT-T5 (3B & 11B) exhibits a $+2.24%$ and $+2.37%$ improvement on average compared to using Flan-T5 (3B & 11B) as the base model on 4 different domain-specific tasks2. Moreover, it demonstrates $+13.98%$ and $+8.11%$ improvement over ChatGPT (OpenAI, 2022) and Claude (Anthropic, 2023) that leverages ICL with demonstrations up to the maximum input length.
在少样本学习场景下,当大语言模型需要以极少量样本适应新任务时,基于Flan-T5 (3B & 11B)的CoT-T5 (3B & 11B)在4个不同领域任务上平均实现了$+2.24%$和$+2.37%$的性能提升。此外,相较于采用最大输入长度演示样本的ChatGPT (OpenAI, 2022)和Claude (Anthropic, 2023),其性能优势分别达到$+13.98%$和$+8.11%$。
Our contributions are summarized as follows:
我们的贡献总结如下:
• We introduce COT COLLECTION, a new instruction dataset that includes 1.84 million rationales across 1,060 tasks that could be used for applying CoT fine-tuning to LMs. • With COT COLLECTION, we fine-tune Flan- T5, denoted as CoT-T5, which shows a nontrivial boost in zero-shot and few-shot learning capabilities with CoT Prompting. • For ablations, we show that CoT fine-tuning could improve the CoT capabilities of LMs in low-compute settings by using a subset of COT COLLECTION and training on (1) smaller number of tasks (T0 setting; 163 tasks) and (2) smaller amount of instances in 5 different languages (French, Japanese, Korean, Russian, Chinese; 80K instances).
• 我们推出COT COLLECTION,这是一个包含1060个任务中184万条推理链的新指令数据集,可用于对大语言模型进行思维链 (CoT) 微调。
• 基于COT COLLECTION,我们对Flan-T5进行微调得到CoT-T5模型,该模型在使用思维链提示时,零样本和少样本学习能力均有显著提升。
• 消融实验表明:在低算力环境下,通过使用COT COLLECTION子集(1)减少任务量(T0设定,163个任务)或(2)缩减5种语言(法语、日语、韩语、俄语、中文)的实例规模(8万条),仍能提升大语言模型的思维链能力。
2 Related Works
2 相关工作
2.1 Chain-of-Thought (CoT) Prompting
2.1 思维链 (Chain-of-Thought, CoT) 提示
Wei et al. (2022b) propose Chain of Thought (CoT) Prompting, a technique that triggers the model to generate a rationale before the answer. By generating a rationale, large LMs show improved reasoning abilities when solving challenging tasks. Kojima et al. (2022) show that by appending the phrase ‘Let’s think step by step’, large LMs could perform CoT prompting in a zero-shot setting. Different work propose variants of CoT prompting such as automatically composing CoT demonstrations (Zhang et al., 2022) and performing a finegrained search through multiple rationale candidates with a tree search algorithm (Yao et al., 2023). While large LMs could solve novel tasks with CoT Prompting, Chung et al. (2022) and Longpre et al. (2023) show that this effectiveness does not necessarily hold for smaller LMs. In this work, we aim to equip smaller LMs with the same capabilities by instruction tuning on large amount of rationales.
Wei等人 (2022b) 提出了思维链 (Chain of Thought, CoT) 提示技术,该方法通过触发模型在生成答案前先产生推理过程。实验表明,生成推理步骤能显著提升大语言模型解决复杂任务时的推理能力。Kojima等人 (2022) 发现只需追加"让我们逐步思考"的提示语,大语言模型就能实现零样本场景下的思维链推理。后续研究提出了多种改进方案,包括自动构建思维链演示样本 (Zhang等人, 2022) ,以及通过树搜索算法在多候选推理路径中进行细粒度筛选 (Yao等人, 2023) 。尽管大语言模型能通过思维链提示解决新任务,但Chung等人 (2022) 和Longpre等人 (2023) 的研究表明,较小规模语言模型未必具备同等能力。本研究旨在通过海量推理步骤的指令微调,使较小规模语言模型获得 comparable 的推理能力。
2.2 Improving Zero-shot Generalization
2.2 提升零样本 (Zero-shot) 泛化能力
Previous work show that instruction tuning enables generalization to multiple unseen tasks (Wei et al., 2021; Sanh et al., 2021; Aribandi et al., 2021; Ouyang et al., 2022; Wang et al., 2022b; Xu et al., 2022). Different work propose to improve instruction tuning by enabling cross-lingual generaliza- tion (Mu en nigh off et al., 2022), improving label generalization capability (Ye et al., 2022), and training modular, expert LMs (Jang et al., 2023). Meanwhile, a line of work shows that CoT fine-tuning could improve the reasoning abilities of LMs on a single-seen task (Zelikman et al., 2022; Shridhar et al., 2022; Ho et al., 2022; Fu et al., 2023). As a follow-up study, we CoT fine-tune on 1,060 instruction tasks and observe a significant improvement in terms of zero-shot generalization on multiple tasks.
先前研究表明,指令微调 (instruction tuning) 能够实现模型在未见任务上的泛化能力 (Wei et al., 2021; Sanh et al., 2021; Aribandi et al., 2021; Ouyang et al., 2022; Wang et al., 2022b; Xu et al., 2022)。不同研究团队通过提升跨语言泛化能力 (Muennighoff et al., 2022)、改进标签泛化能力 (Ye et al., 2022) 以及训练模块化专家大语言模型 (Jang et al., 2023) 来优化指令微调。同时,一系列研究表明,思维链 (CoT) 微调可以提升大语言模型在单一已知任务上的推理能力 (Zelikman et al., 2022; Shridhar et al., 2022; Ho et al., 2022; Fu et al., 2023)。作为后续研究,我们在1,060个指令任务上进行思维链微调,观察到模型在多项任务上的零样本泛化能力显著提升。
2.3 Improving Few-Shot Learning
2.3 改进少样本学习
For adapting LMs to new tasks with a few instances, recent work propose advanced parameter efficient fine-tuning (PEFT) methods, where a small number of trainable parameters are added (Hu et al., 2021; Lester et al., 2021; Liu et al., 2021, 2022b; Asai et al., 2022; Liu et al., 2022c). In this work, we show that a simple recipe of (1) applying LoRA (Hu et al., 2021) to a LM capable of per- forming CoT reasoning and (2) CoT fine-tuning on a target task results in strong few-shot performance.
为了让大语言模型能够用少量样本适应新任务,近期研究提出了先进的参数高效微调 (parameter efficient fine-tuning, PEFT) 方法,即仅添加少量可训练参数 (Hu et al., 2021; Lester et al., 2021; Liu et al., 2021, 2022b; Asai et al., 2022; Liu et al., 2022c)。本文证明,只需采用以下简单策略:(1) 对具备思维链 (CoT) 推理能力的大语言模型应用LoRA技术 (Hu et al., 2021),(2) 在目标任务上进行思维链微调,即可实现强大的少样本性能。
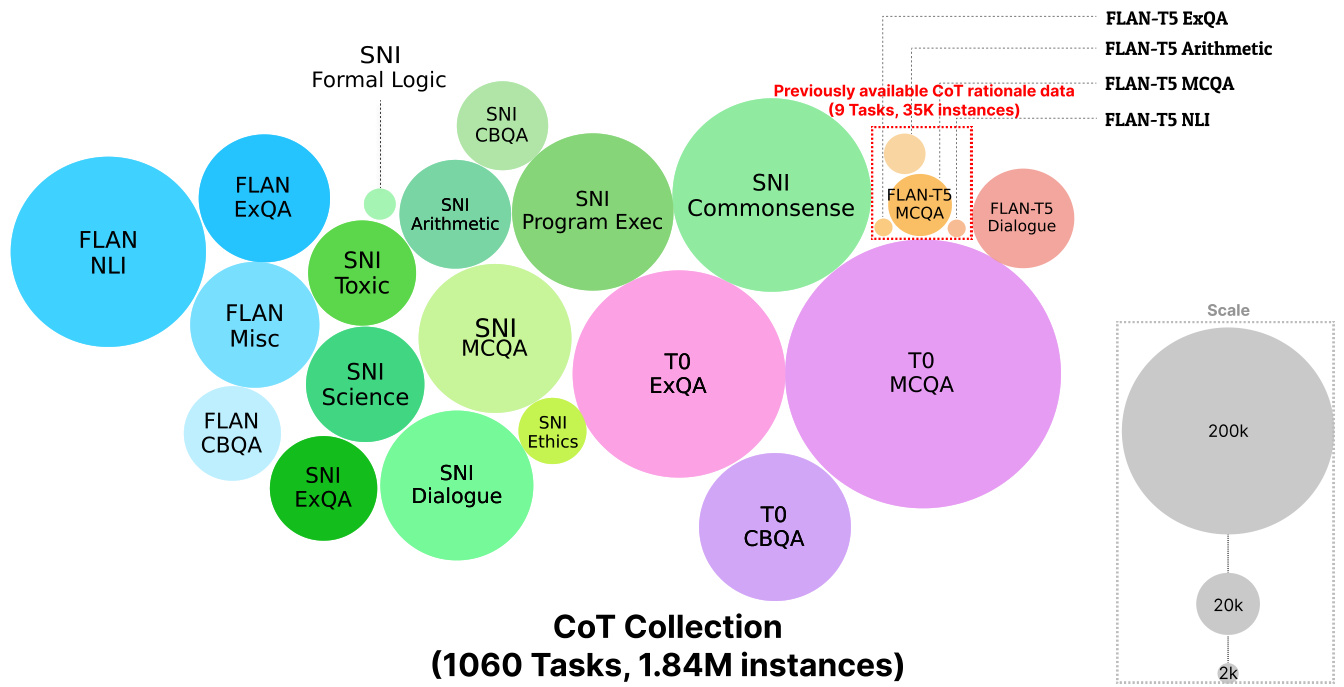
Figure 1: An illustration of the overall task group and dataset source of where we obtained the instances to augment the rationales in COT COLLECTION. Compared to the 9 datasets that provide publicly available rationales (included within ‘Flan-T5 ExQA’, ‘Flan-T5 Arithmetic’, ‘Flan-T5 MCQA’, ‘Flan-T5 NLI’ from the red box), we generate ${\sim}51.29$ times more rationales (1.84 million rationales) and ${\sim}117.78$ times more task variants (1,060 tasks).
图 1: 展示COT COLLECTION中用于增强原理的实例来源及整体任务组构成示意图。与提供公开原理的9个数据集(红色框内的"Flan-T5 ExQA"、"Flan-T5 Arithmetic"、"Flan-T5 MCQA"、"Flan-T5 NLI")相比,我们生成的原理数量多出${\sim}51.29$倍(184万条原理),任务变体数量多出${\sim}117.78$倍(1060个任务)。
3 The COT COLLECTION
3 COT 合集
Despite its effectiveness for CoT fine-tuning, rationale data still remains scarce. To the best of our knowledge, recent work mostly rely on 9 publicly available NLP datasets3 for fine-tuning with rationales (Zelikman et al., 2022; Shridhar et al., 2022; Chung et al., 2022; Ho et al., 2022; Longpre et al., 2023; Fu et al., 2023). This is due to the difficulty in gathering human-authored rationales (Kim et al., 2023). To this end, we create COT COLLECTION, an instruction-tuning dataset that includes $1.84\mathrm{mil}$ - lion rationales augmented across 1,060 tasks4. In this section, we explain the datasets we select to augment into rationales and how we perform the overall augmentation process.
尽管思维链 (CoT) 微调效果显著,但推理数据仍然稀缺。据我们所知,近期研究大多依赖9个公开NLP数据集3进行带推理的微调 (Zelikman et al., 2022; Shridhar et al., 2022; Chung et al., 2022; Ho et al., 2022; Longpre et al., 2023; Fu et al., 2023),这主要源于人工撰写推理的困难性 (Kim et al., 2023)。为此,我们构建了COT COLLECTION指令微调数据集,包含跨1,060个任务4增强的184万条推理数据。本节将阐述所选的数据集及其增强为推理的整体流程。
Broad Overview Given an input $X~=~[I,z]$ composed of an instruction $I$ , and an instance $z$ along with the answer $y$ , we obtain a rationale $r$ by applying in-context learning (ICL) with a large LM. Note that this differs from previous works which focused on generating new instances $z$ using large LMs (West et al., 2022; Liu et al., 2022a; Kim et al., 2022; Honovich et al., 2022; Wang et al., 2022a; Taori et al., 2023; Chiang et al., 2023) while we extend it to generating new rationales $r$ .
概要概览
给定一个由指令 $I$、实例 $z$ 和答案 $y$ 组成的输入 $X~=~[I,z]$,我们通过在大语言模型上应用上下文学习 (ICL) 来获得推理过程 $r$。需要注意的是,这与之前的工作不同,之前的工作主要关注使用大语言模型生成新实例 $z$ (West et al., 2022; Liu et al., 2022a; Kim et al., 2022; Honovich et al., 2022; Wang et al., 2022a; Taori et al., 2023; Chiang et al., 2023),而我们将这一方法扩展到了生成新的推理过程 $r$。
Source Dataset Selection As a source dataset to extract rationales, we choose the Flan Collection (Longpre et al., 2023), consisting of 1,836 di- verse NLP tasks from P3 (Sanh et al., 2021), SuperNatural Instructions (Wang et al., 2022b), Flan (Wei et al., 2021), and some additional dialogue & code datasets. We choose 1,060 tasks, narrowing our focus following the criteria as follows:
源数据集选择
作为提取原理的源数据集,我们选择了Flan Collection (Longpre等人,2023),该集合包含来自P3 (Sanh等人,2021)、SuperNatural Instructions (Wang等人,2022b)、Flan (Wei等人,2021)的1,836个多样化NLP任务,以及一些额外的对话和代码数据集。我们筛选出1,060个任务,并依据以下标准缩小研究范围:
• Generation tasks with long outputs are excluded since the total token length of appending $r$ and $y$ exceeds the maximum output token length (512 tokens) during training. • Datasets that are not publicly available such as DeepMind Coding Contents and Dr Repair (Yasunaga and Liang, 2020) are excluded. • Datasets where the input and output do not correspond to each other in the hugging face datasets (Lhoest et al., 2021) are excluded. • When a dataset appears in common across different sources, we prioritize using the task from P3 first, followed by SNI, and Flan. • During preliminary experiments, we find that for tasks such as sentiment analysis, sentence completion, co reference resolution, and word disambiguation, rationales generated by large LMs are very short and uninformative. We exclude these tasks to prevent negative transfer during multitask learning (Aribandi et al., 2021; Jang et al., 2023).
- 排除了输出较长的生成任务,因为在训练过程中追加 $r$ 和 $y$ 的总 token 长度超过了最大输出 token 长度 (512 tokens)。
- 排除了非公开可用的数据集,例如 DeepMind Coding Contents 和 Dr Repair (Yasunaga and Liang, 2020)。
- 排除了在 Hugging Face 数据集中输入与输出不对应的数据集 (Lhoest et al., 2021)。
- 当同一数据集出现在不同来源时,我们优先使用 P3 的任务,其次是 SNI 和 Flan。
- 在初步实验中,我们发现对于情感分析、句子补全、共指消解和词义消歧等任务,大语言模型生成的原理非常简短且信息量不足。为避免多任务学习中的负迁移 (Aribandi et al., 2021; Jang et al., 2023),我们排除了这些任务。
Creating Demonstrations for ICL We first create prompts to apply in-context learning (ICL) with large LMs for augmenting the instances in the selected tasks with rationales. Preparing demonstrations $\mathcal{D}^{t}$ for each task $t$ is the most straightforward, but it becomes infeasible to prepare demonstrations for each task as the number of tasks gets larger. Instead, we assign each task $t$ to $T_{k}$ , a family of tasks that shares a similar task format such as multiple choice QA, closed book QA, and dialogue generation. Each family of tasks share $\mathcal{D}^{T_{k}}$ , which consists of $6\sim8$ demonstrations. These $6\sim8$ demonstrations for each task group $T_{k}$ is manually created by 3 of the authors in this paper. Specifically, given 136 instances sampled from Flan Collection, two annotators are assigned to write a rationale, and the other third annotator conducts an $\mathbf{A}/\mathbf{B}$ testing between the two options. We manually create $\mathcal{D}^{T_{k}}$ across $k~=~26$ task groups. We include the prompts for all of the different task groups in Appendix D.
为ICL创建演示样本
我们首先创建提示(prompt),用于在大语言模型(LLM)中应用上下文学习(ICL),通过添加推理过程来增强选定任务中的实例。为每个任务$t$准备演示样本$\mathcal{D}^{t}$是最直接的方法,但随着任务数量增加,为每个任务单独准备样本变得不可行。因此,我们将每个任务$t$分配到$T_{k}$(共享相似任务格式的任务族,例如多选题QA、闭卷QA和对话生成)。每个任务族共享由$6\sim8$个演示样本组成的$\mathcal{D}^{T_{k}}$。这些样本由本文三位作者手动创建:从Flan Collection采样的136个实例中,两位标注者撰写推理过程,第三位标注者对两个选项进行$\mathbf{A}/\mathbf{B}$测试。我们手动创建了覆盖$k~=~26$个任务组的$\mathcal{D}^{T_{k}}$,所有任务组的提示模板详见附录D。
Rationale Augmentation We use the OpenAI $\mathrm{Codex^{5}}$ to augment rationales. Formally, given $(X_{i}^{t},y_{i}^{t})$ , the $i^{t h}$ instance of a task $t$ , the goal is to generate corresponding rationale $r_{i}^{t}$ . Note that during preliminary experiments, we found that ordering the label in front of the rationale within the demonstration $\mathcal{D}^{T_{k}}$ was crucial to generate good quality rationales. We conjecture this is because ordering the label in front of the rationale loosens the need for the large LM to solve the underlying task and only focus on generating a rationale. However, we also found that in some tasks such as arithmetic reasoning, large LMs fail to generate good-quality rationales. To mitigate this issue, we apply filtering to the augmented rationales. We provide the criteria used for the filtering phase and
原理增强
我们使用OpenAI的$\mathrm{Codex^{5}}$来增强原理。形式上,给定任务$t$的第$i^{t h}$个实例$(X_{i}^{t},y_{i}^{t})$,目标是生成对应的原理$r_{i}^{t}$。需要注意的是,在初步实验中,我们发现将标签放在演示$\mathcal{D}^{T_{k}}$中的原理之前,对于生成高质量的原理至关重要。我们推测这是因为将标签放在原理前面,降低了大语言模型解决底层任务的需求,使其仅专注于生成原理。然而,我们也发现,在某些任务(如算术推理)中,大语言模型无法生成高质量的原理。为了缓解这一问题,我们对增强后的原理进行了过滤。我们提供了过滤阶段使用的标准以及
[Example 1]
[示例 1]

Figure 2: MCQA Prompt used to augment rationales from P3 dataset. Through ICL, the large LM generates a rationale that is conditioned on the ground-truth label.
图 2: 用于增强P3数据集原理的MCQA提示模板。通过少样本学习(ICL) ,大语言模型基于正确答案标签生成相应原理说明。
the filtered cases at Appendix B. Also, we include analysis of the diversity and quality of COT COLLECTION compared to the existing 9 CoT tasks and human-authored rationales in Appendix A.
附录B中筛选的案例。此外,我们在附录A中分析了COT COLLECTION与现有9个CoT任务及人工编写原理在多样性和质量上的对比。
4 Experiments
4 实验
For our main experiments, we use Flan-T5 (Chung et al., 2022) as our base model, and obtain CoTT5 by CoT fine-tuning on the COT COLLECTION. Formally, given $X_{i}^{t}$ , the goal of CoT fine-tuning is to sequentially generate the rationale $r_{i}^{t}$ and answer $y_{i}^{t}$ . To indicate that $r_{i}^{t}$ should be generated before $y_{i}^{t}$ , the trigger phrase ‘Let’s think step by step’ is added during both training and evaluation. We mostly follow the details for training and evaluation from Chung et al. (2022), and provide additional details in Appendix C. In this section, we show how training on COT COLLECTION enhances zeroshot generalization capabilities (Section 4.2) and few-shot adaptation capabilities (Section 4.3).
在我们的主要实验中,我们使用Flan-T5 (Chung et al., 2022)作为基础模型,并通过在COT COLLECTION上进行思维链(CoT)微调获得CoTT5。形式化地,给定$X_{i}^{t}$,CoT微调的目标是顺序生成推理过程$r_{i}^{t}$和答案$y_{i}^{t}$。为了表明$r_{i}^{t}$应在$y_{i}^{t}$之前生成,在训练和评估阶段都添加了触发短语"Let's think step by step"。我们基本遵循Chung et al. (2022)中的训练和评估细节,并在附录C中提供了更多细节。本节将展示在COT COLLECTION上的训练如何增强零样本泛化能力(第4.2节)和少样本适应能力(第4.3节)。
4.1 Evaluation
4.1 评估
We evaluate under two different evaluation methods: Direct Evaluation and CoT Evaluation. For Direct Evaluation on classification tasks, we follow previous works using verbalize rs, choosing the option with the highest probability through comparison of logit values (Schick and Schütze, 2021;
我们在两种不同的评估方法下进行评估:直接评估 (Direct Evaluation) 和思维链评估 (CoT Evaluation)。对于分类任务的直接评估,我们遵循先前使用言语化器 (verbalizer) 的工作,通过比较 logit 值选择概率最高的选项 (Schick and Schütze, 2021;
Sanh et al., 2021; Ye et al., 2022; Jang et al., 2023), and measure the accuracy. For generation tasks, we directly compare the LM’s prediction with the answer and measure the EM score.
Sanh等人, 2021; Ye等人, 2022; Jang等人, 2023), 并测量准确性。对于生成任务, 我们直接将大语言模型的预测与答案进行比较, 并测量EM分数。
When evaluating with CoT Evaluation, smaller LMs including Flan-T5 often do not generate any rationales even with the trigger phrase ‘Let’s think step by step’. Therefore, we adopt a hard constraint of requiring the LM to generate $r_{i}^{t}$ with at least a minimum length of 8 tokens. In classification tasks, we divide into two steps where the LM first generates $r_{i}^{t}$ , and then verbalize rs are applied with a indicator phrase ‘[ANSWER]’ inserted between $r_{i}^{t}$ and the possible options. For generation tasks, we extract the output coming after the indicator phrase. Accuracy metric is used for classification tasks while EM metric is used for generation tasks.
在使用思维链(CoT)评估时,包括Flan-T5在内的小型大语言模型即使使用触发短语"Let's think step by step"也经常无法生成任何推理过程。因此,我们采用硬性约束,要求大语言模型生成的$r_{i}^{t}$至少包含8个token的最小长度。在分类任务中,我们分为两个步骤:首先让大语言模型生成$r_{i}^{t}$,然后在$r_{i}^{t}$和可能选项之间插入指示短语"[ANSWER]"来应用语言化表达。对于生成任务,我们提取指示短语后的输出内容。分类任务使用准确率(Accuracy)作为评估指标,而生成任务则采用精确匹配(EM)指标。
4.2 Zero-shot Generalization
4.2 零样本 (Zero-shot) 泛化
In this subsection, we show how training with COT COLLECTION could effectively improve the LM’s ability to solve unseen tasks. We have three difference experimental set-ups, testing different aspects: Setup #1: training on the entire 1060 tasks in COT COLLECTION and evaluating the reasoning capabilities of LMs with the Bigbench Hard (BBH) benchmark (Suzgun et al., 2022), Setup #2: training only on 163 tasks that T0 (Sanh et al., 2021) used for training (a subset of the COT COLLECTION), and evaluating the linguistic capabilities of LMs with the P3 evaluation benchmark (Sanh et al., 2021), and Setup #3: training with a translated, subset version of COT COLLECTION for each five different languages and evaluating how LMs could perform CoT reasoning in multilingual settings using the MGSM benchmark (Shi et al., 2022).
在本小节中,我们将展示如何通过COT COLLECTION训练有效提升大语言模型解决未知任务的能力。我们设计了三种不同的实验设置以测试不同方面:
设置#1:在COT COLLECTION全部1060个任务上训练,并使用Bigbench Hard (BBH)基准测试(Suzgun et al., 2022)评估大语言模型的推理能力;
设置#2:仅在T0 (Sanh et al., 2021)训练使用的163个任务(COT COLLECTION子集)上训练,通过P3评估基准(Sanh et al., 2021)测试大语言模型的语言能力;
设置#3:使用COT COLLECTION翻译后的五语言子集进行训练,并基于MGSM基准(Shi et al., 2022)评估大语言模型在多语言场景下的思维链推理表现。
Setup #1: CoT Fine-tuning with 1060 CoT Tasks We first perform experiments with our main model, CoT-T5, by training Flan-T5 on the entire COT COLLECTION and evaluate on the BBH benchmark (Suzgun et al., 2022). In addition to evaluating Flan-T5, we compare the performances of different baselines such as (1) T5-LM (Raffel et al., 2020): the original base model of Flan-T5, (2) T0 (Sanh et al., 2021): an instruction-tuned LM trained with P3 instruction dataset, (3) TkInstruct (Wang et al., 2022b): an instruction-tuned LM trained with SNI instruction dataset, and (4) GPT-3 (Brown et al., 2020): a pre-trained LLM with 175B parameters. For ablation purposes, we also train T5-LM with COT COLLECTION (denoted as ${}^{5}\mathrm{T}5+\mathrm{CoT}$ FT’). Note that FLAN Collection includes 15 million instances, hence ${\sim}8$ times larger compared to our COT COLLECTION.
实验设置1:基于1060项CoT任务进行微调
我们首先在完整COT COLLECTION数据集上对Flan-T5进行训练,并在BBH基准测试(Suzgun et al., 2022)中评估主要模型CoT-T5的表现。除Flan-T5外,我们还对比了以下基线模型:(1) T5-LM (Raffel et al., 2020):Flan-T5的原始基础模型;(2) T0 (Sanh et al., 2021):基于P3指令数据集微调的指令调优模型;(3) TkInstruct (Wang et al., 2022b):基于SNI指令数据集微调的指令调优模型;(4) GPT-3 (Brown et al., 2020):拥有1750亿参数的预训练大语言模型。为进行消融实验,我们同时使用COT COLLECTION训练了T5-LM (记为${}^{5}\mathrm{T}5+\mathrm{CoT}$ FT')。需注意FLAN Collection包含1500万实例,规模约为COT COLLECTION的${\sim}8$倍。
Table 1: Evaluation performance on all the 27 unseen datasets from BBH benchmark, including generation tasks. All evaluations are held in a zero-shot setting. The best comparable performances are bolded and second best underlined.
| 方法 | CoT | Direct | 总平均 |
|---|---|---|---|
| T5-LM-3B | 26.68 | 26.96 | 26.82 |
| TO-3B | 26.64 | 27.45 | 27.05 |
| TK-INSTRUCT-3B | 29.86 | 29.90 | 29.88 |
| TK-INSTRUCT-11B | 33.60 | 30.71 | 32.16 |
| T0-11B | 31.83 | 33.57 | 32.70 |
| FLAN-T5-3B | 34.06 | 37.14 | 35.60 |
| GPT-3(175B) | 38.30 | 33.60 | 38.30 |
| FLAN-T5-11B | 38.57 | 40.99 | 39.78 |
| T5-3B+CoTFT | 37.95 | 35.52 | 36.74 |
| CoT-T5-3B | 38.40 | 36.18 | 37.29 |
| T5-11B+CoT FT | 40.02 | 38.76 | 39.54 |
| CoT-T5-11B | 42.20 | 42.56 | 42.38 |
表 1: 在BBH基准测试的27个未见数据集(包括生成任务)上的评估性能。所有评估均在零样本设置下进行。最佳可比性能加粗显示,次佳性能加下划线标注。
The results on BBH benchmark are shown across Table 1 and Table 2. In Table 1, CoT-T5 (3B & 11B) achieves a $+4.34%$ and $+2.60%$ improvement over Flan-T5 (3B & 11B) with CoT Evaluation. Surprisingly, while CoT-T5-3B CoT performance improves $+4.34%$ with the cost of $0.96%$ degradation in Direct Evalution, CoT-T5-11B’s Direct Evaluation performance even improves, resulting in a $+2.57%$ total average improvement. Since COT COLLECTION only includes instances augmented with rationales, these results show that CoT fine-tuning could improve the LM’s capabilities regardless of the evaluation method. Also, T5-3B $+\mathrm{CoT}$ FT and $\ensuremath{\mathrm{T}}5\ensuremath{-}11\ensuremath{\mathrm{B}}+\ensuremath{\mathrm{CoT}}.$ FT outperforms FLAN-T5-3B and FLAN-T5-11B by a $+1.45%$ and $+3.89%$ margin, respectively, when evaluated with CoT evaluation. Moreover, $\mathrm{T}5{-}3\mathbf{B}+\mathrm{CoT}$ FINE-TUNING outperforms ${\sim}4$ times larger models such as T0-11B and Tk-Instruct-11B in both Direct and CoT Evaluation. The overall results indicate that (1) CoT fine-tuning on a diverse number of tasks enables smaller LMs to outperform larger LMs and (2) training with FLAN Collection and CoT Collection provides complementary improvements to LMs under different evaluation methods; CoT-T5 obtains good results across both evaluation methods by training on both datasets.
BBH基准测试结果如表1和表2所示。在表1中,CoT-T5 (3B & 11B) 通过CoT评估相比Flan-T5 (3B & 11B) 分别实现了$+4.34%$和$+2.60%$的提升。值得注意的是,虽然CoT-T5-3B的CoT性能提升$+4.34%$的同时导致直接评估下降$0.96%$,但CoT-T5-11B的直接评估性能反而有所提升,最终实现$+2.57%$的总平均改进。由于COT COLLECTION仅包含增强推理链的实例,这些结果表明无论采用何种评估方法,CoT微调都能提升语言模型的能力。此外,T5-3B $+\mathrm{CoT}$ FT和$\ensuremath{\mathrm{T}}5\ensuremath{-}11\ensuremath{\mathrm{B}}+\ensuremath{\mathrm{CoT}}$ FT在CoT评估下分别以$+1.45%$和$+3.89%$的优势超越FLAN-T5-3B和FLAN-T5-11B。更重要的是,$\mathrm{T}5{-}3\mathbf{B}+\mathrm{CoT}$微调模型在直接评估和CoT评估中均优于T0-11B和Tk-Instruct-11B等约4倍规模的模型。整体结果表明:(1) 在多任务上进行CoT微调可使较小语言模型超越较大模型;(2) FLAN Collection与CoT Collection训练能为不同评估方法下的语言模型提供互补性改进——通过联合训练这两个数据集,CoT-T5在两种评估方法下均取得良好表现。
In Table 2, CoT-T5-11B obtains same or better results on 15 out of 23 tasks when evaluated with Direct evaluation, and 17 out of 23 tasks when evaluated with CoT Evaluation compared to Flan
在表2中,与Flan相比,CoT-T5-11B采用直接评估 (Direct evaluation) 时在23个任务中的15个上取得相同或更好的结果,采用思维链评估 (CoT Evaluation) 时则在23个任务中的17个上表现更优。
Table 2: Evaluation performance on 23 unseen classification datasets from BBH benchmark. Scores of Vicuna, ChatGPT, Codex (teacher model of COT-T5), GPT-4 are obtained from Chung et al. (2022) and Mukherjee et al. (2023). Evaluations are held in a zero-shot setting. The best comparable performances are bolded and second best underlined among the open-sourced LMs.
表 2: BBH基准测试中23个未见分类数据集的评估表现。Vicuna、ChatGPT、Codex (COT-T5的教师模型) 和GPT-4的分数来自Chung等人 (2022) 和Mukherjee等人 (2023) 。评估在零样本设置下进行。开源大语言模型中最佳表现加粗显示,次佳表现加下划线。
| Task | CoT-T5-11B CoT | CoT-T5-11B Direct | FLAN-T5-11B CoT | FLAN-T5-11B Direct | VICUNA-13B Direct | CHATGPT Direct | CODEX Direct | GPT-4 Direct |
|---|---|---|---|---|---|---|---|---|
| BOOLEANEXPRESSIONS | 65.6 | 59.2 | 51.6 | 56.8 | 40.8 | 82.8 | 88.4 | 77.6 |
| CAUSALJUDGMENT | 60.4 | 60.2 | 58.3 | 61.0 | 42.2 | 57.2 | 63.6 | 59.9 |
| DATE UNDERSTANDING | 52.0 | 51.0 | 46.8 | 54.8 | 10.0 | 42.8 | 63.6 | 74.8 |
| DISAMBIGUATION QA | 63.4 | 68.2 | 63.2 | 67.2 | 18.4 | 57.2 | 67.2 | 69.2 |
| FORMAL FALLACIES | 51.2 | 55.2 | 54.4 | 55.2 | 47.2 | 53.6 | 52.4 | 64.4 |
| GEOMETRIC SHAPES | 22.0 | 10.4 | 12.4 | 21.2 | 3.6 | 25.6 | 32.0 | 40.8 |
| HYPERBATON | 65.2 | 64.2 | 55.2 | 70.8 | 44.0 | 69.2 | 60.4 | 62.8 |
| LOGICAL DEDUCTION (5) | 48.2 | 54.4 | 51.2 | 53.6 | 4.8 | 38.8 | 32.4 | 66.8 |
| LOGICAL DEDUCTION (7) | 52.4 | 60.6 | 57.6 | 60.0 | 1.2 | 39.6 | 26.0 | 66.0 |
| LOGICAL DEDUCTION (3) | 55.4 | 75.0 | 66.4 | 74.4 | 16.8 | 60.4 | 52.8 | 94.0 |
| MOVIE RECOMMENDATION | 44.6 | 52.8 | 32.4 | 36.4 | 43.4 | 55.4 | 84.8 | 79.5 |
| NAVIGATE | 59.0 | 60.0 | 60.8 | 61.6 | 46.4 | 55.6 | 50.4 | 68.8 |
| PENGUINS IN A TABLE | 39.1 | 41.8 | 41.8 | 41.8 | 15.1 | 45.9 | 66.4 | 76.7 |
| REASONING COLORED OBJ. | 32.6 | 33.2 | 22.8 | 23.2 | 12.0 | 47.6 | 67.6 | 84.8 |
| RUIN NAMES | 42.8 | 41.6 | 31.6 | 34.4 | 15.7 | 56.0 | 75.2 | 89.1 |
| SALIENT TRANS ERR. | 43.8 | 49.2 | 35.6 | 49.2 | 2.0 | 40.8 | 62.0 | 62.4 |
| SNARKS | 67.7 | 66.2 | 59.5 | 70.2 | 28.1 | 59.0 | 61.2 | 87.6 |
| SPORTS UNDERSTANDING | 64.8 | 66.4 | 56.0 | 60.0 | 48.4 | 79.6 | 72.8 | 84.4 |
| TEMPORAL SEQUENCES | 27.4 | 28.8 | 24.4 | 28.8 | 16.0 | 35.6 | 77.6 | 98.0 |
| TRACKING SHUFF OBJ.(5) | 20.0 | 13.2 | 19.6 | 15.2 | 9.2 | 18.4 | 20.4 | 25.2 |
| TRACKING SHUFF OBJ.(7) | 18.4 | 9.6 | 13.2 | 12.0 | 5.6 | 15.2 | 14.4 | 25.2 |
| TRACKING SHUFF OBJ.(3) | 41.8 | 31.2 | 28.8 | 24.4 | 23.2 | 31.6 | 37.6 | 42.4 |
| WEB OF LIES | 57.0 | 51.6 | 52.8 | 50.0 | 41.2 | 56.0 | 51.6 | 49.6 |
| AVERAGE | 47.60 | 48.00 | 43.32 | 47.05 | 23.30 | 48.90 | 52.80 | 67.40 |
Table 3: Evaluation performance on 11 different unseen P3 dataset (Sanh et al., 2021) categorized into 4 task categories. We report the direct performance of the baselines since they were not CoT fine-tuned on instruction data. The best comparable performances are bolded and second best underlined. We exclude Flan-T5 and CoT-T5 since they were trained on the unseen tasks (tasks from FLAN and SNI overlap with the P3 Eval datasets), breaking unseen task assumption.
| 方法 | 自然语言推理 | 句子补全 | 指代消解 | 词义消歧 | 总平均 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RTE | CB | AN.R1 | AN.R2 | AN.R3 | COPA | Hellasw. | StoryC. | Winogr. | WSC | WiC | ||
| T5-3B (Raffel et al., 2020) | 53.03 | 34.34 | 32.89 | 33.76 | 33.82 | 54.88 | 27.00 | 48.16 | 50.64 | 54.09 | 50.30 | 42.99 |
| TO-3B (Sanh et al., 2021) | 60.61 | 48.81 | 35.10 | 33.27 | 33.52 | 75.13 | 27.18 | 84.91 | 50.91 | 65.00 | 51.27 | 51.43 |
| ROE-3B (Jang et al., 2023) | 64.01 | 43.57 | 35.49 | 34.64 | 31.22 | 79.25 | 34.60 | 86.33 | 61.60 | 62.21 | 52.97 | 53.48 |
| KIC-770M (Pan et al., 2022) | 74.00 | 67.90 | 36.30 | 35.00 | 37.60 | 85.30 | 29.60 | 94.40 | 55.30 | 65.40 | 52.40 | 57.56 |
| FLIPPED-3B (Ye et al., 2022) | 71.05 | 57.74 | 39.99 | 37.05 | 37.73 | 89.88 | 41.64 | 95.88 | 58.56 | 58.37 | 50.42 | 58.03 |
| GPT-3 (175B) (Brown et al., 2020) | 63.50 | 46.40 | 34.60 | 35.40 | 34.50 | 91.00 | 78.90 | 83.20 | 70.20 | 65.40 | 45.92 | 59.00 |
| TO-11B (Sanh et al., 2021) | 80.83 | 70.12 | 43.56 | 38.68 | 41.26 | 90.02 | 33.58 | 92.40 | 59.94 | 61.45 | 56.58 | 60.76 |
| T5-3B+CoTFT-EVALW/DIRECT | 69.96 | 58.69 | 37.58 | 36.00 | 37.44 | 84.59 | 40.92 | 90.47 | 55.40 | 64.33 | 51.53 | 56.99 |
| TO-3B+CoTFT-EVALW/DIRECT | 80.79 | 65.00 | 39.49 | 35.13 | 38.58 | 88.27 | 41.04 | 92.13 | 56.40 | 65.96 | 53.60 | 59.67 |
| T5-3B+CoTFT-EVALW/CoT | 80.61 | 69.17 | 40.24 | 36.67 | 40.13 | 90.10 | 41.08 | 93.00 | 56.47 | 55.10 | 56.73 | 59.94 |
| TO-3B+CoTFT-EVALW/CoT | 80.25 | 72.62 | 41.71 | 37.22 | 41.89 | 90.88 | 39.50 | 94.47 | 57.47 | 50.58 | 54.27 | 60.08 |
表 3: 在11个未见过的P3数据集 (Sanh et al., 2021) 上的评估性能, 分为4个任务类别。我们报告了基线的直接性能, 因为它们未在指令数据上进行思维链微调。最佳可比性能加粗显示, 次佳性能加下划线。我们排除了Flan-T5和CoT-T5, 因为它们是在未见任务上训练的 (FLAN和SNI的任务与P3评估数据集存在重叠), 这违背了未见任务假设。
T5-11B. Interestingly, Vicuna (Chiang et al., 2023), a LM trained on long-form dialogues between users and GPT models, perform much worse compared to both CoT-T5 and Flan-T5. We conjecture that training on instruction datasets from existing academic benchmarks consisting CoT Collection and Flan Collection is more effective in enabling LMs to solve reasoning tasks compared to chat LMs.
T5-11B。有趣的是,Vicuna (Chiang et al., 2023) 这个基于用户与GPT模型长对话训练的大语言模型,表现远逊于CoT-T5和Flan-T5。我们推测,相比聊天型大语言模型,使用包含CoT Collection和Flan Collection的现有学术基准指令数据集进行训练,能更有效地提升大语言模型解决推理任务的能力。
Setup #2: CoT Fine-tuning with 163 CoT Tasks (T0 Setup) To examine whether the effect of CoT fine-tuning is dependent on large number of tasks and instances, we use the P3 training subset from the COT COLLECTION consisted of 644K instances from 163 tasks, and apply CoT finetuning to T0 (3B) (Sanh et al., 2021) and T5-LM (3B) (Raffel et al., 2020). Note that T0 is trained with 12M instances, hence ${\sim}18.63$ times larger. Then, we evaluate on the P3 evaluation benchmark which consists of 11 different NLP datasets. In addition to the baselines from the previous section (T5-LM, T0, and GPT-3), we also include LMs that are trained on the same T0 setup for comparison such as, (1) RoE (Jang et al., 2023): a modular expert LM that retrieves different expert models depending on the unseen task, (2) KiC (Pan et al., 2022): a retrieval-augmented model that is instruction-tuned to retrieve knowledge from a KB memory, and (3) Flipped (Ye et al., 2022): an instruction-tuned model that is trained to generate the instruction in order to resolve the LM overfitting to the output label as baseline models.
设置 #2: 使用163个思维链任务进行微调 (T0设置)
为验证思维链微调效果是否依赖于大量任务和实例,我们采用COT COLLECTION中的P3训练子集(包含来自163个任务的644K实例),对T0(3B) [Sanh等人,2021]和T5-LM(3B) [Raffel等人,2020]进行思维链微调。需注意T0使用12M实例训练,规模约为${\sim}18.63$倍。随后在包含11个不同NLP数据集的P3评估基准上进行测试。除上一节的基线模型(T5-LM、T0和GPT-3)外,我们还纳入采用相同T0设置训练的对比模型:(1) RoE [Jang等人,2023]:根据未见任务检索不同专家模型的模块化专家大语言模型;(2) KiC [Pan等人,2022]:通过指令调优从知识库内存检索知识的检索增强模型;(3) Flipped [Ye等人,2022]:通过生成指令来解决大语言模型输出标签过拟合问题的指令调优模型。
The results are shown in Table 3. Surprisingly, $\mathrm{T}5{-}3\mathbf{B}+\mathrm{CoT}\mathbf{F}$ T outperforms T0-3B by a $+8.24%$ margin when evaluated with CoT Evaluation, while using ${\sim}18.63$ times less instances. This supports that CoT fine-tuning is data efficient, being effective even with less number of instances and tasks. Moreover, $\mathrm{T}0{-}3\mathbf{B}+\mathrm{CoT}$ FT improves T0-3B by $+8.65%$ on average accuracy. When compared with T0-11B with ${\sim}4$ times more number of parameters, it achieves better performance at sentence completion, and word sense disambiguation (WSD) tasks, and obtains similar performances at natural language inference and co reference resolution tasks.
结果如表 3 所示。令人惊讶的是,在使用 CoT 评估时,$\mathrm{T}5{-}3\mathbf{B}+\mathrm{CoT}\mathbf{F}$ 的表现比 T0-3B 高出 $+8.24%$,而使用的实例数量却减少了 ${\sim}18.63$ 倍。这表明 CoT 微调具有数据高效性,即使在实例和任务数量较少的情况下也能有效工作。此外,$\mathrm{T}0{-}3\mathbf{B}+\mathrm{CoT}$ FT 将 T0-3B 的平均准确率提高了 $+8.65%$。与参数数量多出 ${\sim}4$ 倍的 T0-11B 相比,它在句子补全和词义消歧 (WSD) 任务上表现更好,在自然语言推理和共指消解任务上表现相近。
Setup #3: Multilingual Adaptation with CoT Fine-tuning In previous work, Shi et al. (2022) proposed MGSM, a multilingual reasoning benchmark composed of 10 different languages. In this subsection, we conduct a toy experiment to examine whether CoT fine-tuning could enable LMs to reason step-by-step in multilingual settings as well, using a subset of 5 languages (Korean, Russian, French, Chineses, Japanese) from MGSM.
设置 #3: 采用思维链微调的多语言适应
在之前的工作中,Shi等人 (2022) 提出了MGSM,这是一个由10种不同语言组成的多语言推理基准。在本小节中,我们进行了一个小规模实验,以检验思维链微调是否也能使大语言模型在多语言环境下进行逐步推理,实验中使用了MGSM中的5种语言子集 (韩语、俄语、法语、汉语、日语)。
In Table 4, current smaller LMs can be divided into three categories: (1) Flan-T5, a LM that is CoT fine-tuned with mostly English instruction data, (2) MT5 (Xue et al., 2021), a LM pretrained on diverse languages, but isn’t instruction tuned or CoT finetuned, (3) MT0 (Mu en nigh off et al., 2022), a LM that is instruction-tuned on diverse languages, but isn’t CoT fine-tuned. In relatively underrepresented languages such as Korean, Japanese, and Chinese, all three LMs get close to zero accuracy.
在表4中,当前较小规模的大语言模型可分为三类:(1) Flan-T5,一个主要使用英语指令数据进行思维链(CoT)微调的大语言模型;(2) MT5 (Xue et al., 2021),一个在多语言上预训练但未进行指令调优或CoT微调的大语言模型;(3) MT0 (Muennighoff et al., 2022),一个在多语言上进行指令调优但未进行CoT微调的大语言模型。在韩语、日语和汉语等相对资源不足的语言中,这三种大语言模型的准确率都接近于零。
A natural question arises whether training a multilingual LM that could reason step-by-step on different languages is viable. As a preliminary research, we examine whether CoT Fine-tuning on a single language with a small amount of CoT data could enable LMs to avoid achieving near zero score such as Korean, Chinese and Japanese subsets of MGSM. Since there is no publicly available multilingual instruction dataset, we translate 60K $\sim80\mathrm{K}$ instances from COT COLLECTION for each 5 languages using ChatGPT (OpenAI, 2022), and CoT fine-tune mT5 and mT0 on each of them.
一个自然的问题是,训练一个能在不同语言上逐步推理的多语言大语言模型是否可行。作为初步研究,我们探讨了在单一语言上使用少量思维链 (CoT) 数据进行微调,是否能让大语言模型避免在MGSM的韩语、汉语和日语子集等测试中接近零分的情况。由于目前没有公开的多语言指令数据集,我们使用ChatGPT (OpenAI, 2022) 将COT COLLECTION中的6万$\sim80\mathrm{K}$条实例分别翻译成5种语言,并对mT5和mT0模型进行了各语言的思维链微调。
The results are shown in Table 4. Across all the 5 different languages, CoT fine-tuning brings
结果如表 4 所示。在全部 5 种不同语言中,CoT (Chain-of-Thought) 微调带来了
| 方法 | ko | ru | fr | zh | ja |
|---|---|---|---|---|---|
| FLAN-T5-3B | 0.0 | 2.8 | 7.2 | 0.0 | 0.0 |
| FLAN-T5-11B | 0.0 | 5.2 | 13.2 | 0.0 | 0.0 |
| MT5-3.7B | 0.0 | 1.2 | 2.0 | 0.8 | 0.8 |
| MT0-3.7B | 0.0 | 4.8 | 7.2 | 1.6 | 2.4 |
| GPT-3 3(175B) | 0.0 | 4.4 | 10.8 | 6.8 | 0.8 |
| MT5-3.7B+CoTFT | 3.2 | 6.8 | 9.6 | 6.0 | 7.6 |
| MT0-3.7B+CoTFT | 7.6 | 10.4 | 15.6 | 11.2 | 11.0 |
Table 4: Evaluation performance on MGSM benchmark (Shi et al., 2022) across 5 languages (Korean, Russian, French, Chinese, Japanese, respectively). All evaluations are held in a zero-shot setting with CoT Evaluation except GPT-3 using a 6-Shot prompt for ICL. The best comparable performances are bolded and second best underlined. Note that $\mathrm{^{4}M T}5\mathrm{-}3.7\mathrm{B}+$ COT FT’ and $\mathrm{^{\circ}M T0-}3.7\mathrm{B}+\mathrm{CoT}$ FT’ are trained on a single language instead of multiple languages as mT5 and mT0.
表 4: MGSM基准测试(Shi et al., 2022)在5种语言(韩语、俄语、法语、汉语、日语)上的评估性能。除GPT-3使用6样本提示进行ICL外,所有评估均在零样本设置下使用思维链(CoT)评估进行。最佳性能加粗显示,次佳性能加下划线标注。注意 $\mathrm{^{4}M T}5\mathrm{-}3.7\mathrm{B}+$ CoT FT 和 $\mathrm{^{\circ}M T0-}3.7\mathrm{B}+\mathrm{CoT}$ FT 是在单一语言而非多语言(如mT5和mT0)上训练的。
about non-trivial gains in performance. Even for relatively low-resource languages such as Korean Japanese, and Chinese, CoT fine-tuning on the specific language allows the underlying LM to perform mathematical reasoning in the target language, which are considered very difficult (Shi et al., 2022). Considering that only a very small number of instances were used for language-specific adaptation $(60\mathrm{k}{-}80\mathrm{k})$ , CoT fine-tuning shows potential for efficient language adaptation.
在性能上取得显著提升。即使对于韩语、日语和中文等资源相对较少的语言,针对特定语言进行思维链 (CoT) 微调也能使底层大语言模型在目标语言中执行数学推理任务(这类任务通常被认为极具挑战性 [Shi et al., 2022])。值得注意的是,仅需极少量语种适配样本 $(60\mathrm{k}{-}80\mathrm{k})$ 即可实现这一目标,这表明CoT微调在高效语言适配方面具有潜力。
However, it is noteworthy that we limited our setting to training/evaluating on a single target language, without exploring the cross-lingual transfer of CoT capabilities among varied languages. The chief objective of this experimentation was to ascertain if introducing a minimal volume of CoT data could facilitate effective adaptation to the target language, specifically when addressing reasoning challenges. Up to date, no hypothesis has suggested that training with CoT in various languages could enable cross-lingual transfer of CoT abilities among different languages. We identify this as a promising avenue for future exploration.
然而值得注意的是,我们的实验设置仅限于在单一目标语言上进行训练/评估,并未探索思维链 (CoT) 能力在不同语言间的跨语言迁移。本实验的主要目的是验证:当处理推理任务时,引入少量思维链数据是否有助于有效适应目标语言。迄今为止,尚无假设表明用多种语言的思维链数据进行训练可以实现不同语言间思维链能力的跨语言迁移。我们认为这是一个值得未来探索的研究方向。
4.3 Few-shot Generalization
4.3 少样本 (Few-shot) 泛化
In this subsection, we show how CoT-T5 performs in a few-shot adaptation setting where a limited number of instances from the target task can be used for training, which is sometimes more likely in real-world scenarios.
在本小节中,我们将展示CoT-T5在少样本适应(few-shot adaptation)设置下的表现,该设置允许使用目标任务的有限实例进行训练,这在实际场景中更为常见。
Dataset Setup We choose 4 domain-specific datasets from legal and medical domains including LEDGAR (Tuggener et al., 2020), Case Hold (Zheng et al., 2021), MedNLI (Romanov and Shivade, 2018), and PubMedQA (Jin et al., 2019). To simulate a few-shot setting, we randomly sample 64 instances from the train split of each dataset.
数据集设置
我们从法律和医疗领域选择了4个特定领域数据集,包括LEDGAR (Tuggener et al., 2020)、Case Hold (Zheng et al., 2021)、MedNLI (Romanov and Shivade, 2018) 和 PubMedQA (Jin et al., 2019)。为模拟少样本设置,我们从每个数据集的训练集中随机抽取64个实例。
Table 5: Evaluation performance on 4 domain-specific datasets. FT. denotes Fine-tuning, COT FT. denotes CoT fine-tuning, and COT PT. denotes CoT Prompting. The best comparable performances are bolded and second best underlined. For a few-shot adaptation, we use 64 randomly sampled instances from each dataset.
表 5: 在4个特定领域数据集上的评估性能。FT. 表示微调 (Fine-tuning),COT FT. 表示思维链微调 (CoT fine-tuning),COT PT. 表示思维链提示 (CoT Prompting)。最佳性能加粗显示,次佳性能加下划线。对于少样本适应,我们从每个数据集中随机抽取64个样本。
| 方法 | #训练参数量 | Ledgar | Case Hold | MedNLI | PubmedQA | 总平均 |
|---|---|---|---|---|---|---|
| Flan-T5-3B+全参数微调 | 2.8B | 52.60 | 61.40 | 66.82 | 66.28 | 61.78 |
| Flan-T5-3B+全参数思维链微调 | 2.8B | 53.60 | 58.80 | 65.89 | 65.89 | 61.05 |
| CoT-T5-3B + 全参数思维链微调 (Ours) | 2.8B | 51.90 | 60.60 | 67.16 | 68.12 | 61.95 |
| Flan-T5-3B + LoRA微调 | 2.35M | 53.20 | 58.80 | 61.60 | 67.18 | 60.19 |
| Flan-T5-3B+LoRA思维链微调 | 2.35M | 51.20 | 61.60 | 62.59 | 66.06 | 60.36 |
| CoT-T5-3B + LoRA思维链微调 (Ours) | 2.35M | 54.80 | 63.60 | 68.00 | 69.66 | 64.02 |
| Flan-T5-11B + LoRA微调 | 4.72M | 55.30 | 64.90 | 75.91 | 70.25 | 66.59 |
| Flan-T5-11B+LoRA思维链微调 | 4.72M | 52.10 | 65.50 | 71.63 | 71.60 | 65.21 |
| CoT-T5-11B + LoRA思维链微调 (Ours) | 4.72M | 56.10 | 68.30 | 78.02 | 73.42 | 68.96 |
| Claude (Anthropic, 2023) + 上下文学习 | 0 | 55.70 | 57.20 | 75.94 | 54.58 | 60.85 |
| Claude (Anthropic,2023)+ 思维链提示 | 0 | 34.80 | 43.60 | 76.51 | 52.06 | 51.74 |
| ChatGPT (OpenAI, 2022) + 上下文学习 | 0 | 51.70 | 32.10 | 70.53 | 65.59 | 54.98 |
| ChatGPT (OpenAI, 2022) + 思维链提示 | 0 | 51.00 | 18.90 | 63.71 | 25.22 | 39.70 |
We report the average accuracy across 3 runs with different random seeds. We augment rationales for the 64 training instances using the procedure described in Section 3 for the rationale augmentation phase, utilizing the MCQA prompt from P3 dataset. In an applied setting, practitioners could obtain rationales written by human experts.
我们报告了使用不同随机种子进行3次运行的平均准确率。在理由增强阶段,我们采用P3数据集中的MCQA提示,按照第3节描述的程序对64个训练实例的理由进行了增强。在实际应用中,从业者可以获取由人类专家撰写的理由。
Training Setup We compare Flan-T5 & CoT-T5, across 3B and 11B scale and explore 4 different approaches for few-shot adaptation: (1) regular finetuning, (2) CoT fine-tuning, (3) LoRA fine-tuning, and (4) LoRA CoT fine-tuning. When applying Lora, we use a rank of 4 and train for 1K steps following Liu et al. (2022b). This results in training 2.35M parameters for 3B scale models and 4.72M parameters for 11B scale models. Also, we include Claude (Anthropic, 2023) and ChatGPT (OpenAI, 2022) as ICL baselines by appending demonstrations up to maximum context length6. Specifically, For CoT prompting, the demonstrations are sampled among 64 augmented rationales are used.
训练设置
我们比较了Flan-T5和CoT-T5在3B和11B规模下的表现,并探索了四种少样本适应方法:(1) 常规微调,(2) 思维链微调,(3) LoRA微调,(4) LoRA思维链微调。应用LoRA时,我们采用秩为4的配置,并按照Liu等人(2022b)的方法训练1000步。这使得3B规模模型训练参数达235万,11B规模模型达472万。同时,我们将Claude(Anthropic, 2023)和ChatGPT(OpenAI, 2022)作为上下文学习基线,通过添加示例直至最大上下文长度6。具体而言,对于思维链提示,从64个增强推理样本中选取演示案例。
Effect of LoRA The experimental results are shown in Table 5. Overall, CoT fine-tuning CoTT5 integrated with LoRA obtains the best results overall. Surprisingly for Flan-T5, applying full fine-tuning obtains better performance compared to its counterpart using LoRA fine-tuning. However, when using CoT-T5, LoRA achieves higher performance compared to full fine-tuning. We conjecture this to be the case because introducing only a few parameters enables CoT-T5 to maintain the CoT ability acquired during CoT fine-tuning.
LoRA的影响
实验结果如表5所示。总体而言,集成LoRA的CoT微调CoTT5取得了最佳效果。令人惊讶的是,对于Flan-T5,相比使用LoRA微调的版本,全参数微调表现更优。但在使用CoT-T5时,LoRA的性能反而超越了全参数微调。我们推测这是因为仅引入少量参数能使CoT-T5保持其在CoT微调阶段获得的思维链(CoT)能力。
Fine-tuning vs. CoT Fine-tuning While CoT fine-tuning obtains similar or lower performance compared to regular fine-tuning in Flan-T5, CoTT5 achieves higher performance with CoT finetuning compared to Flan-T5 regular fine-tuning. This results in CoT-T5 in combination with CoT fine-tuning showing the best performance in fewshot adaptation setting.
微调 vs. 思维链 (CoT) 微调
虽然 Flan-T5 的思维链微调相比常规微调取得了相似或更低的性能,但 CoT-T5 通过思维链微调实现了比 Flan-T5 常规微调更高的性能。这使得结合思维链微调的 CoT-T5 在少样本适应场景中表现出最佳性能。
Fine-tuning vs. ICL Lastly, fine-tuning methods obtain overall better results compared to ICL methods utilizing much larger, proprietary LLMs. We conjecture this to be the case due to the long input length of legal and medical datasets, making appending all available demonstrations (64) impossible. While increasing the context length could serve as a temporary solution, it would still mean that the inference time will increase quadratically in proportion to the input length, which makes ICL computationally expensive.
微调 vs 上下文学习
最后,与使用规模更大、专有大语言模型的上下文学习方法相比,微调方法总体上能获得更好的结果。我们推测这是由于法律和医疗数据集的输入长度较长,导致无法附加所有可用示例(64个)。虽然增加上下文长度可以作为一种临时解决方案,但这仍意味着推理时间将随输入长度呈二次方增长,使得上下文学习在计算上成本高昂。
5 Analysis of of CoT Fine-tuning
5 CoT微调分析
In this section, we conduct experiments to address the following two research questions:
在本节中,我们通过实验来解答以下两个研究问题:
• For practitioners, is it more effective to augment CoT rationales across diverse tasks or more instances with a fixed number of tasks? During CoT fine-tuning, does the LM maintain its performance on in-domain tasks without any catastrophic forgetting?
• 对于从业者而言,在多样化任务中增强思维链(CoT)推理更有效,还是在固定任务数量下增加更多实例更有效?在进行思维链微调时,大语言模型能否保持其在领域内任务上的性能而不出现灾难性遗忘?
5.1 Scaling the number of tasks & instances
5.1 扩展任务和实例数量
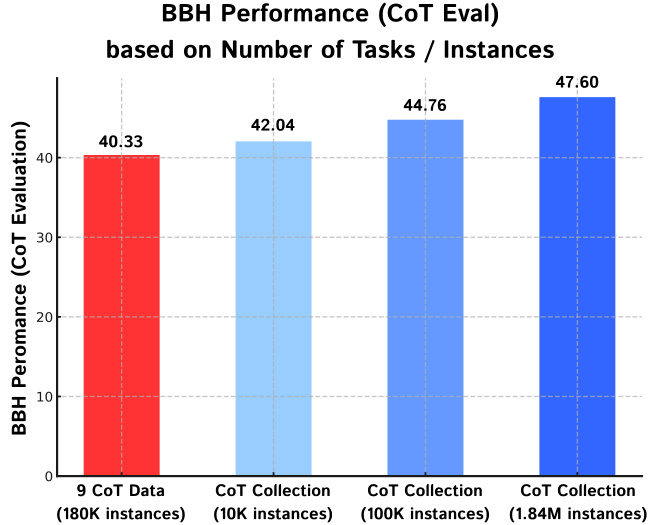
In our main experiments, we used a large number of instances (1.84M) across a large number of tasks (1,060) to apply CoT fine-tuning. A natural question arises: “Is it more effective to increase the number of tasks or the number of instances?” To address this question, we conduct an experiment of randomly sampling a small number of instances within the COT COLLECTION and comparing the BBH performance with (1) a baseline that is only CoT fine-tuned with the existing $9\mathrm{CoT}$ tasks and (2) COT-T5 that fully utilizes all the 1.84M instances. Specifically, we sample 10K, 100K instances within the COT COLLECTION and for the 9 CoT tasks, we fully use all the 180K instances. As COT-T5, we use Flan-T5 as our base model and use the same training configuration and evaluation setting (CoT Eval) during our experiments.
在我们的主要实验中,我们使用了大量任务(1,060个)中的大量实例(1.84M)来进行CoT微调。一个自然的问题是:"增加任务数量还是增加实例数量更有效?"为了回答这个问题,我们进行了一项实验:在COT COLLECTION中随机抽取少量实例,并将其BBH性能与(1)仅使用现有$9\mathrm{CoT}$任务进行CoT微调的基线、(2)充分利用所有1.84M实例的COT-T5进行对比。具体而言,我们在COT COLLECTION中抽取了10K和100K实例,而对于9个CoT任务,我们完全使用了所有180K实例。作为COT-T5,我们使用Flan-T5作为基础模型,并在实验过程中采用相同的训练配置和评估设置(CoT Eval)。
The results are shown in Figure 3, where surprisingly, only using 10K instances across 1,060 tasks obtains better performance compared to using 180K instances across 9 tasks. This shows that maintaining a wide range of tasks is more crucial compared to increasing the number of instances.
结果如图 3 所示,令人惊讶的是,仅在 1,060 个任务中使用 10K 样本的表现优于在 9 个任务中使用 180K 样本。这表明保持任务多样性比增加样本数量更为关键。
5.2 In-domain Task Accuracy of CoT-T5
5.2 CoT-T5的领域内任务准确率
It is well known that LMs that are fine-tuned on a wide range of tasks suffer from catastrophic forgetting (Chen et al., 2020; Jang et al., 2021, 2023), a phenomenon where an LM improves its performance on newly learned tasks while the performance on previously learned tasks diminishes.
众所周知,在广泛任务上进行微调的大语言模型会遭遇灾难性遗忘 (catastrophic forgetting) (Chen et al., 2020; Jang et al., 2021, 2023),即模型在新学习任务上性能提升的同时,先前已掌握任务的性能却出现下降。
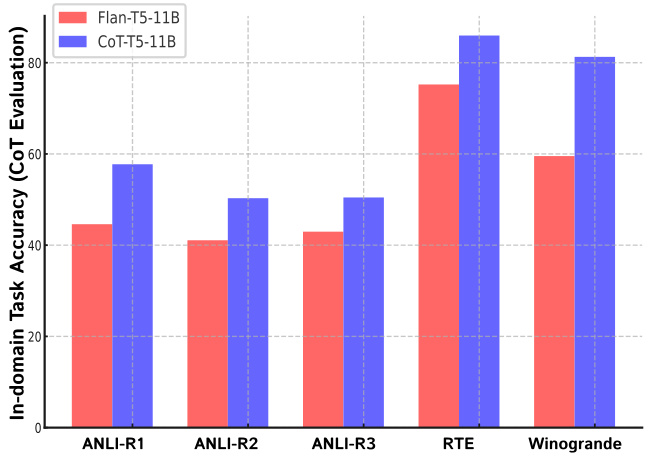
Figure 3: Scaling plot of increasing the number of instances within the COT COLLECTION compared to using the existing 9 CoT datasets. Even with less number of instances, maintaining a wider range of tasks is crucial to improve the CoT abilities of an underlying LLM. In-domain Task Accuracy (CoT Eval) Figure 4: In-domain task accuracy with CoT evaluation. CoT Fine-tuning with the COT COLLECTION also improves accuracy on in-domain tasks as well.
图 3: COT COLLECTION 增加实例数量与使用现有 9 个 CoT 数据集的扩展对比图。即使实例数量较少,保持更广泛的任务范围对于提升底层大语言模型的 CoT 能力至关重要。
图 4: 采用 CoT 评估的领域内任务准确率。使用 COT COLLECTION 进行 CoT 微调也能提高领域内任务的准确率。
While COT-T5 uses the same tasks as its base model (Flan-T5), we also check whether CoT finetuning on a wide range of tasks could possibly harm performance. For this purpose, we use the test set of 5 tasks within the COT COLLECTION, namely ANLI-R1, ANLI-R2, ANLI-R3, RTE, and Winogrande. Note that this differs with the Setup #2 in the main experiments in that we use different base models ( $\mathbf{\nabla}^{\prime}\mathbf{T}()\nu s$ Flan-T5), and the tasks are already used for CoT fine-tuning.
虽然COT-T5使用了与其基础模型(Flan-T5)相同的任务,但我们还检查了在广泛任务上进行思维链(CoT)微调是否会损害性能。为此,我们使用了COT COLLECTION中的5个任务的测试集,即ANLI-R1、ANLI-R2、ANLI-R3、RTE和Winogrande。请注意,这与主要实验中的设置#2不同,因为我们使用了不同的基础模型( $\mathbf{\nabla}^{\prime}\mathbf{T}()\nu s$ vs Flan-T5),且这些任务已用于CoT微调。
Results are shown in Figure 4, where COT-T5 consistently improves in-domain accuracy on the learned tasks as well. However, we conjecture that this is because we used the exact same task that Flan-T5 used to CoT fine-tuned COT-T5. Adding additional tasks that were not used to train Flan-T5 and COT-T5 could show different results, and we leave additional exploration of catastrophic forgetting during CoT fine-tuning to future work.
结果如图 4 所示,其中 COT-T5 在已学习任务上的领域内准确率也持续提升。然而,我们推测这是因为我们使用了与 Flan-T5 完全相同的任务对 COT-T5 进行思维链 (CoT) 微调。若加入未用于训练 Flan-T5 和 COT-T5 的其他任务,可能会呈现不同结果。关于思维链微调过程中的灾难性遗忘问题,我们留待未来工作中进一步探索。
6 Conclusion
6 结论
In this work, we show that augmenting rationales from an instruction tuning data using LLMs (Open AI Codex), and CoT fine-tuning could improve the reasoning capabilities of smaller LMs. Specifically, we construct COT COLLECTION, a largescale instruction-tuning dataset with 1.84M CoT rationales extracted across 1,060 NLP tasks. With our dataset, we CoT fine-tune Flan-T5 and obtain CoT-T5, which shows better zero-shot generalization performance and serves as a better base model when training with few number of instances. We hope COT COLLECTION could be beneficial in the development of future strategies for advancing the capabilities of LMs with CoT fine-tuning.
在本研究中,我们展示了利用大语言模型(OpenAI Codex)增强指令调优数据中的推理依据(rationales),并通过思维链(CoT)微调提升较小规模语言模型的推理能力。具体而言,我们构建了COT COLLECTION数据集——一个包含184万条跨1,060项NLP任务的思维链推理依据的大规模指令调优数据集。基于该数据集,我们对Flan-T5进行思维链微调得到CoT-T5模型,该模型展现出更优的零样本泛化性能,并在少样本训练时成为更优的基础模型。我们希望COT COLLECTION能助力未来通过思维链微调提升语言模型能力的策略开发。
Limitations
局限性
References
参考文献
Recently, there has been a lot of focus on distilling the ability to engage in dialogues with longform outputs in the context of instruction following (Taori et al., 2023; Chiang et al., 2023). Since our model COT-T5 is not trained to engage in dialogues with long-form responses from LLMs, it does not necessarily possess the ability to be applied in chat applications. In contrast, our work focuses on improving the zero-shot and few-shot capabilities by training on academic benchmarks (COT COLLECTION, Flan Collection), where LMs trained with chat data lack on. Utilizing both longform chat data from LLMs along with instruction data from academic tasks has been addressed in future work (Wang et al., 2023). Moreover, various applications have been introduced by using the FEEDBACK COLLECTION to train advanced chat models 7.
近期,指令跟随场景下长文本对话能力的提炼受到广泛关注 (Taori et al., 2023; Chiang et al., 2023)。由于我们的模型COT-T5未针对大语言模型的长文本对话进行训练,其未必具备应用于聊天场景的能力。相比之下,我们的工作聚焦于通过学术基准数据集 (COT COLLECTION, Flan Collection) 训练来提升零样本和少样本能力——这正是基于聊天数据训练的语言模型所欠缺的。如何结合大语言模型的长文本聊天数据与学术任务的指令数据,已有研究将其列为未来工作方向 (Wang et al., 2023)。此外,利用FEEDBACK COLLECTION训练高级聊天模型已催生多种应用7。
Also, since COT-T5 uses Flan-T5 as a base model, it doesn’t have the ability to perform stepby-step reasoning in diverse languages. Exploring how to efficiently and effectively train on CoT data from multiple languages is also a promising and important line of future work. While Shi et al. (2022) has shown that large LMs with more than 100B parameters have the ability to write CoT in different languages, our results show that smaller LMs show nearly zero accuracy when solving math problems in different languages. While CoT finetuning somehow shows slight improvement, a more comprehensive strategy of integrating the ability to write CoT in diverse language would hold crucial.
此外,由于COT-T5以Flan-T5为基础模型,它不具备用多种语言进行逐步推理的能力。探索如何高效地从多语言CoT数据中进行训练,也是一个有前景且重要的未来研究方向。虽然Shi等人 (2022) 表明参数量超过1000亿的大语言模型具备用不同语言编写CoT的能力,但我们的结果显示,较小规模语言模型在解决不同语言的数学问题时准确率几乎为零。尽管CoT微调显示出轻微改进,但整合多语言CoT编写能力的更全面策略将至关重要。
In terms of reproducibility, it is extremely concerning that proprietary LLMs shut down such as the example of the Codex, the LLM we used for rationale augmentation. We provide additional analysis on how different LLMs could be used for this process in Appendix A. Also, there is room of improvement regarding the quality of our dataset by using more powerful LLMs such as GPT-4 and better prompting techniques such as Tree of Thoughts (ToT) (Yao et al., 2023). This was examined by later work in Mukherjee et al. (2023) which used GPT-4 to augment 5 million rationales and Yue et al. (2023) which mixed Chain-of-Thoughts and Program of Thoughts (PoT) during fine-tuning. Using rationales extracted using Tree of Thoughts (Yao et al., 2023) could also be explored in future work.
在可复现性方面,像我们用于原理增强的Codex这样的专有大语言模型停止服务的情况令人极度担忧。我们在附录A中提供了关于如何用不同大语言模型完成这一过程的额外分析。此外,通过使用更强大的大语言模型(如GPT-4)和更好的提示技术(如思维树(ToT) (Yao et al., 2023),我们的数据集质量仍有提升空间。这一点在后续研究中得到了验证:Mukherjee et al. (2023) 使用GPT-4增强了500万条原理,Yue et al. (2023) 在微调阶段混合使用了思维链和程序思维(PoT)。未来工作中还可以探索使用思维树(Yao et al., 2023)提取的原理。
Shourya Aggarwal, Divyanshu Mandowara, Vishwajeet Agrawal, Dinesh Khandelwal, Parag Singla, and Dinesh Garg. 2021. Explanations for commonsense qa: New dataset and models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3050–3065.
Shourya Aggarwal、Divyanshu Mandowara、Vishwajeet Agrawal、Dinesh Khandelwal、Parag Singla和Dinesh Garg。2021。常识问答的解释:新数据集与模型。载于《第59届计算语言学协会年会暨第11届自然语言处理国际联合会议(第一卷:长论文)》,第3050–3065页。
Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Ha- jishirzi. 2019. Mathqa: Towards interpret able math word problem solving with operation-based formalisms. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2357–2367.
Aida Amini、Saadia Gabriel、Shanchuan Lin、Rik Koncel-Kedziorski、Yejin Choi和Hannaneh Hajishirzi。2019. MathQA: 基于运算形式化的可解释数学应用题求解方法。载于《2019年北美计算语言学协会人类语言技术会议论文集》第1卷(长文与短文),第2357–2367页。
Anthropic. 2023. Claude. https: //www.anthropic.com/index/ introducing-claude.
Anthropic. 2023. Claude. https: //www.anthropic.com/index/ introducing-claude.
Vamsi Aribandi, Yi Tay, Tal Schuster, Jinfeng Rao, Huaixiu Steven Zheng, Sanket Vaibhav Mehta, Honglei Zhuang, Vinh Q Tran, Dara Bahri, Jianmo Ni, et al. 2021. Ext5: Towards extreme multi- task scaling for transfer learning. arXiv preprint arXiv:2111.10952.
Vamsi Aribandi、Yi Tay、Tal Schuster、Jinfeng Rao、Huaixiu Steven Zheng、Sanket Vaibhav Mehta、Honglei Zhuang、Vinh Q Tran、Dara Bahri、Jianmo Ni等。2021。Ext5:面向迁移学习的极端多任务扩展。arXiv预印本arXiv:2111.10952。
Akari Asai, Mohammad reza Salehi, Matthew E Peters, and Hannaneh Hajishirzi. 2022. Attention al mixtures of soft prompt tuning for parameter-efficient multi-task knowledge sharing. arXiv preprint arXiv:2205.11961.
Akari Asai、Mohammad reza Salehi、Matthew E Peters和Hannaneh Hajishirzi。2022。基于注意力混合软提示调参的高效多任务知识共享方法。arXiv预印本arXiv:2205.11961。
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
Tom Brown、Benjamin Mann、Nick Ryder、Melanie Subbiah、Jared D Kaplan、Prafulla Dhariwal、Arvind Neelakantan、Pranav Shyam、Girish Sastry、Amanda Askell 等. 2020. 大语言模型是少样本学习者. 神经信息处理系统进展, 33:1877–1901.
Oana-Maria Camburu, Tim Rock t s chel, Thomas L ukasiewicz, and Phil Blunsom. 2018. e-snli: Natural language inference with natural language explanations. Advances in Neural Information Processing Systems, 31.
Oana-Maria Camburu、Tim Rocktäschel、Thomas Lukasiewicz 和 Phil Blunsom。2018. e-SNLI:带自然语言解释的自然语言推理。神经信息处理系统进展,31。
Sanyuan Chen, Yutai Hou, Yiming Cui, Wanxiang Che, Ting Liu, and Xiangzhan Yu. 2020. Recall and learn: Fine-tuning deep pretrained language models with less forgetting. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7870–7881.
Sanyuan Chen、Yutai Hou、Yiming Cui、Wanxiang Che、Ting Liu和Xiangzhan Yu。2020。记忆与学习:减少遗忘的深度预训练语言模型微调。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第7870–7881页。
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An opensource chatbot impressing gpt-4 with $90%*$ chatgpt quality.
Wei-Lin Chiang、Zhuohan Li、Zi Lin、Ying Sheng、Zhanghao Wu、Hao Zhang、Lianmin Zheng、Siyuan Zhuang、Yonghao Zhuang、Joseph E. Gonzalez、Ion Stoica 和 Eric P. Xing。2023。Vicuna:一款以90% ChatGPT质量惊艳GPT-4的开源聊天机器人。
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2022. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
Hyung Won Chung、Le Hou、Shayne Longpre、Barret Zoph、Yi Tay、William Fedus、Eric Li、Xuezhi Wang、Mostafa Dehghani、Siddhartha Brahma 等. 2022. 规模化指令微调语言模型. arXiv预印本 arXiv:2210.11416.
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
Karl Cobbe、Vineet Kosaraju、Mohammad Bavarian、Jacob Hilton、Reiichiro Nakano、Christopher Hesse 和 John Schulman。2021. 训练验证器解决数学应用题。arXiv预印本 arXiv:2110.14168。
Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, and Tushar Khot. 2023. Specializing smaller language models towards multi-step reasoning. arXiv preprint arXiv:2301.12726.
Yao Fu、Hao Peng、Litu Ou、Ashish Sabharwal 和 Tushar Khot。2023。面向多步推理的小型语言模型专业化研究。arXiv预印本 arXiv:2301.12726。
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. 2021. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics, 9:346– 361.
Mor Geva、Daniel Khashabi、Elad Segal、Tushar Khot、Dan Roth 和 Jonathan Berant。2021。亚里士多德使用过笔记本电脑吗?一个蕴含隐式推理策略的问答基准。《计算语言学协会汇刊》9:346–361。
Olga Golovneva, Moya Chen, Spencer Poff, Martin Corredor, Luke Z ett le moyer, Maryam Fazel-Zarandi, and Asli Cel i kyi l maz. 2022. Roscoe: A suite of metrics for scoring step-by-step reasoning. arXiv preprint arXiv:2212.07919.
Olga Golovneva、Moya Chen、Spencer Poff、Martin Corredor、Luke Zettlemoyer、Maryam Fazel-Zarandi和Asli Celikyilmaz。2022。Roscoe: 一套用于评估逐步推理的指标集。arXiv预印本arXiv:2212.07919。
Google. 2023. Bard. blog.google/technology/ai/ bard-google-ai-search-updates/.
Google. 2023. Bard. https://blog.google/technology/ai/bard-google-ai-search-updates/.
Namgyu Ho, Laura Schmid, and Se-Young Yun. 2022. Large language models are reasoning teachers. arXiv preprint arXiv:2212.10071.
Namgyu Ho、Laura Schmid 和 Se-Young Yun。2022。大语言模型 (Large Language Model) 是推理导师。arXiv 预印本 arXiv:2212.10071。
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2019. The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751.
Ari Holtzman、Jan Buys、Li Du、Maxwell Forbes 和 Yejin Choi。2019。神经文本退化的奇特案例。arXiv预印本 arXiv:1904.09751。
Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. 2022. Unnatural instructions: Tuning language models with (almost) no human labor. arXiv preprint arXiv:2212.09689.
Or Honovich、Thomas Scialom、Omer Levy 和 Timo Schick. 2022. 非自然指令: 以(几乎)无需人工的方式调优语言模型. arXiv预印本 arXiv:2212.09689.
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
Edward J Hu、Yelong Shen、Phillip Wallis、Zeyuan Allen-Zhu、Yuanzhi Li、Shean Wang、Lu Wang 和 Weizhu Chen。2021。LoRA: 大语言模型的低秩适配。arXiv预印本 arXiv:2106.09685。
Srinivasan Iyer, Xi Victoria Lin, Ramakanth Pasunuru, Todor Mihaylov, Dániel Simig, Ping Yu, Kurt Shuster, Tianlu Wang, Qing Liu, Punit Singh Koura, et al. 2022. Opt-iml: Scaling language model instruction meta learning through the lens of generalization. arXiv preprint arXiv:2212.12017.
Srinivasan Iyer、Xi Victoria Lin、Ramakanth Pasunuru、Todor Mihaylov、Dániel Simig、Ping Yu、Kurt Shuster、Tianlu Wang、Qing Liu、Punit Singh Koura等。2022。Opt-IML:通过泛化视角扩展语言模型指令元学习。arXiv预印本 arXiv:2212.12017。
Joel Jang, Seonghyeon Ye, Sohee Yang, Joongbo Shin, Janghoon Han, Gyeonghun Kim, Stanley Jungkyu Choi, and Minjoon Seo. 2021. Towards continual knowledge learning of language models. arXiv preprint arXiv:2110.03215.
Joel Jang、Seonghyeon Ye、Sohee Yang、Joongbo Shin、Janghoon Han、Gyeonghun Kim、Stanley Jungkyu Choi 和 Minjoon Seo。2021。语言模型的持续知识学习探索。arXiv预印本 arXiv:2110.03215。
Joel Jang, Seungone Kim, Seonghyeon Ye, Doyoung Kim, Lajanugen Logeswaran, Moontae Lee, Kyung- jae Lee, and Minjoon Seo. 2023. Exploring the benefits of training expert language models over instruction tuning. arXiv preprint arXiv:2302.03202.
Joel Jang、Seungone Kim、Seonghyeon Ye、Doyoung Kim、Lajanugen Logeswaran、Moontae Lee、Kyung-jae Lee 和 Minjoon Seo。2023。探索专家语言模型训练相较于指令调优的优势。arXiv预印本 arXiv:2302.03202。
Quentin Lhoest, Albert Villanova del Moral, Yacine Jernite, Abhishek Thakur, Patrick von Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, et al. 2021. Datasets: A community library for natural language processing. arXiv preprint arXiv:2109.02846.
Quentin Lhoest、Albert Villanova del Moral、Yacine Jernite、Abhishek Thakur、Patrick von Platen、Suraj Patil、Julien Chaumond、Mariama Drame、Julien Plu、Lewis Tunstall 等。2021. Datasets: 自然语言处理的社区库。arXiv预印本 arXiv:2109.02846。
Haoran Li, Dadi Guo, Wei Fan, Mingshi Xu, and Yangqiu Song. 2023. Multi-step jail breaking privacy attacks on chatgpt. arXiv preprint arXiv:2304.05197.
Haoran Li、Dadi Guo、Wei Fan、Mingshi Xu 和 Yangqiu Song。2023。针对 ChatGPT 的多步越狱隐私攻击。arXiv 预印本 arXiv:2304.05197。
Alisa Liu, Swabha S way am dip ta, Noah A Smith, and Yejin Choi. 2022a. Wanli: Worker and ai collabora- tion for natural language inference dataset creation. arXiv preprint arXiv:2201.05955.
Alisa Liu、Swabha Swayamdipta、Noah A Smith 和 Yejin Choi. 2022a. Wanli: 工人与AI协作创建自然语言推理数据集. arXiv预印本 arXiv:2201.05955.
Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin A Raffel. 2022b. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. Advances in Neural Information Processing Systems, 35:1950–1965.
Haokun Liu、Derek Tam、Mohammed Muqeeth、Jay Mohta、Tenghao Huang、Mohit Bansal 和 Colin A Raffel。2022b。少样本参数高效微调优于且成本低于上下文学习。《神经信息处理系统进展》,35:1950–1965。
Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. 2022c. P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 61–68.
Xiao Liu、Kaixuan Ji、Yicheng Fu、Weng Tam、Zhengxiao Du、Zhilin Yang和Jie Tang。2022c。P-tuning: 提示调优在规模和任务上可与微调相媲美。载于《第60届计算语言学协会年会论文集(第二卷:短论文)》,第61–68页。
Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. 2021. Gpt understands, too. arXiv preprint arXiv:2103.10385.
Xiao Liu、Yanan Zheng、Zhengxiao Du、Ming Ding、Yujie Qian、Zhilin Yang和Jie Tang。2021。GPT也懂。arXiv预印本arXiv:2103.10385。
Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. 2023. The flan collection: Designing data and methods for effective instruction tuning. arXiv preprint arXiv:2301.13688.
Shayne Longpre、Le Hou、Tu Vu、Albert Webson、Hyung Won Chung、Yi Tay、Denny Zhou、Quoc V Le、Barret Zoph、Jason Wei 等. 2023. FLAN 数据集:设计数据与方法以实现高效指令调优. arXiv 预印本 arXiv:2301.13688.
David Mhlanga. 2023. Open ai in education, the responsible and ethical use of chatgpt towards lifelong learning. Education, the Responsible and Ethical Use of ChatGPT Towards Lifelong Learning (February 11, 2023).
David Mhlanga. 2023. 教育领域的OpenAI:以负责任和合乎道德的方式使用ChatGPT促进终身学习。Education, the Responsible and Ethical Use of ChatGPT Towards Lifelong Learning (February 11, 2023).
Sewon Min, Mike Lewis, Luke Z ett le moyer, and Hannaneh Hajishirzi. 2022. Metaicl: Learning to learn in context. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2791–2809.
Sewon Min、Mike Lewis、Luke Zettlemoyer和Hannaneh Hajishirzi。2022。MetaICL:学习在上下文中学习。载于《2022年北美计算语言学协会人类语言技术会议论文集》,第2791–2809页。
Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. 2022. Cross-task generalization via natural language crowd sourcing instructions. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3470–3487.
Swaroop Mishra、Daniel Khashabi、Chitta Baral 和 Hannaneh Hajishirzi。2022. 通过自然语言众包指令实现跨任务泛化。载于《第60届计算语言学协会年会论文集(第一卷:长论文)》,第3470–3487页。
Niklas Mu en nigh off, Thomas Wang, Lintang Sutawika, Adam Roberts, Stella Biderman, Teven Le Scao, M Saiful Bari, Sheng Shen, Zheng-Xin Yong, Hailey Schoelkopf, et al. 2022. Cross lingual generalization through multitask finetuning. arXiv preprint arXiv:2211.01786.
Niklas Muennighoff、Thomas Wang、Lintang Sutawika、Adam Roberts、Stella Biderman、Teven Le Scao、M Saiful Bari、Sheng Shen、Zheng-Xin Yong、Hailey Schoelkopf等。2022。通过多任务微调实现跨语言泛化。arXiv预印本arXiv:2211.01786。
Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. 2023. Orca: Progressive learning from complex explanation traces of gpt-4. arXiv preprint arXiv:2306.02707.
Subhabrata Mukherjee、Arindam Mitra、Ganesh Jawahar、Sahaj Agarwal、Hamid Palangi 和 Ahmed Awadallah。2023。Orca: 从GPT-4的复杂解释轨迹中进行渐进式学习。arXiv预印本 arXiv:2306.02707。
Yasumasa Onoe, Michael JQ Zhang, Eunsol Choi, and Greg Durrett. 2021. Creak: A dataset for com- monsense reasoning over entity knowledge. arXiv preprint arXiv:2109.01653.
Yasumasa Onoe、Michael JQ Zhang、Eunsol Choi 和 Greg Durrett。2021. Creak: 基于实体知识的常识推理数据集。arXiv预印本 arXiv:2109.01653。
OpenAI. 2022. ChatGPT. https://openai.com/ blog/chatgpt.
OpenAI. 2022. ChatGPT. https://openai.com/blog/chatgpt.
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155.
Long Ouyang、Jeff Wu、Xu Jiang、Diogo Almeida、Carroll L Wainwright、Pamela Mishkin、Chong Zhang、Sandhini Agarwal、Katarina Slama、Alex Ray 等. 2022. 通过人类反馈训练语言模型遵循指令. arXiv预印本 arXiv:2203.02155.
Xiaoman Pan, Wenlin Yao, Hongming Zhang, Dian Yu, Dong Yu, and Jianshu Chen. 2022. Knowledge-incontext: Towards knowledgeable semi-parametric language models. arXiv preprint arXiv:2210.16433.
Xiaoman Pan, Wenlin Yao, Hongming Zhang, Dian Yu, Dong Yu, and Jianshu Chen. 2022. 上下文知识化: 构建知识丰富的半参数化语言模型. arXiv preprint arXiv:2210.16433.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J Liu, et al. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140):1–67.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li、Peter J Liu 等. 2020. 探索迁移学习的极限:基于统一文本到文本Transformer的研究. J. Mach. Learn. Res., 21(140):1–67.
Alexey Romanov and Chaitanya Shivade. 2018. Lessons from natural language inference in the clinical domain. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1586–1596.
Alexey Romanov和Chaitanya Shivade。2018。临床领域自然语言推理的经验教训。载于《2018年自然语言处理实证方法会议论文集》,第1586-1596页。
Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, et al. 2021. Multitask prompted training enables zero-shot task generalization. arXiv preprint arXiv:2110.08207.
Victor Sanh、Albert Webson、Colin Raffel、Stephen H Bach、Lintang Sutawika、Zaid Alyafeai、Antoine Chaffin、Arnaud Stiegler、Teven Le Scao、Arun Raja等。2021。多任务提示训练实现零样本任务泛化。arXiv预印本arXiv:2110.08207。
Timo Schick and Hinrich Schütze. 2021. Exploiting cloze-questions for few-shot text classification and natural language inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 255–269.
Timo Schick 和 Hinrich Schütze. 2021. 利用完形填空问题实现少样本文本分类与自然语言推理. 载于《第16届欧洲计算语言学会会议论文集: 主卷》, 第255–269页.
Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush Vosoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, et al. 2022. Language models are multilingual chain-of-thought reasoners. arXiv preprint arXiv:2210.03057.
Freda Shi、Mirac Suzgun、Markus Freitag、Xuezhi Wang、Suraj Srivats、Soroush Vosoughi、Hyung Won Chung、Yi Tay、Sebastian Ruder、Denny Zhou 等. 2022. 语言模型是多语言思维链推理器. arXiv预印本 arXiv:2210.03057.
Kumar Shridhar, Alessandro Stolfo, and Mrinmaya Sachan. 2022. Distilling multi-step reasoning capabilities of large language models into smaller models via semantic decomposition s. arXiv preprint arXiv:2212.00193.
Kumar Shridhar、Alessandro Stolfo 和 Mrinmaya Sachan。2022. 通过语义分解将大语言模型的多步推理能力蒸馏到小模型中。arXiv 预印本 arXiv:2212.00193。
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Se- bastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, et al. 2022. Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261.
Mirac Suzgun、Nathan Scales、Nathanael Schärli、Sebastian Gehrmann、Yi Tay、Hyung Won Chung、Aakanksha Chowdhery、Quoc V Le、Ed H Chi、Denny Zhou等。2022。挑战Big-Bench任务及思维链(Chain-of-Thought)能否解决它们。arXiv预印本arXiv:2210.09261。
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/ stanford alpaca.
Rohan Taori、Ishaan Gulrajani、Tianyi Zhang、Yann Dubois、Xuechen Li、Carlos Guestrin、Percy Liang 和 Tatsunori B. Hashimoto。2023。斯坦福 Alpaca:一个遵循指令的 LLaMA 模型。https://github.com/tatsu-lab/stanford_alpaca。
Yi Tay, Mostafa Dehghani, Vinh Q Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, and Donald Metzler. 2022. Unifying language learning paradigms. arXiv preprint arXiv:2205.05131.
Yi Tay、Mostafa Dehghani、Vinh Q Tran、Xavier Garcia、Dara Bahri、Tal Schuster、Huaixiu Steven Zheng、Neil Houlsby 和 Donald Metzler。2022。统一语言学习范式。arXiv预印本 arXiv:2205.05131。
Don Tuggener, Pius Von Däniken, Thomas Peetz, and Mark Cieliebak. 2020. Ledgar: a large-scale multilabel corpus for text classification of legal provisions in contracts. In Proceedings of the Twelfth Language Resources and Evaluation Conference, pages 1235– 1241.
Don Tuggener、Pius Von Däniken、Thomas Peetz和Mark Cieliebak。2020。Ledgar:一个用于合同法律条款文本分类的大规模多标签语料库。载于《第十二届语言资源与评估会议论文集》,第1235–1241页。
Cunxiang Wang, Shuailong Liang, Yue Zhang, Xiaonan Li, and Tian Gao. 2019. Does it make sense? and why? a pilot study for sense making and explanation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4020–4026.
王存祥、梁帅龙、张悦、李晓楠和高天。2019。这合理吗?为什么?关于意义构建与解释的初步研究。载于《第57届计算语言学协会年会论文集》,第4020-4026页。
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. 2022a. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
Xuezhi Wang、Jason Wei、Dale Schuurmans、Quoc Le、Ed Chi和Denny Zhou。2022a。自洽性提升大语言模型中的思维链推理。arXiv预印本arXiv:2203.11171。
Yizhong Wang, Hamish Ivison, Pradeep Dasigi, Jack Hessel, Tushar Khot, Khyathi Raghavi Chandu, David Wadden, Kelsey MacMillan, Noah A Smith, Iz Beltagy, et al. 2023. How far can camels go? exploring the state of instruction tuning on open resources. arXiv preprint arXiv:2306.04751.
Yizhong Wang、Hamish Ivison、Pradeep Dasigi、Jack Hessel、Tushar Khot、Khyathi Raghavi Chandu、David Wadden、Kelsey MacMillan、Noah A Smith、Iz Beltagy等。2023。骆驼能走多远?探索开放资源上的指令微调现状。arXiv预印本arXiv:2306.04751。
Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhana sekar an, Atharva Naik, David Stap, et al. 2022b. Super-natural instructions: Generalization via declarative instructions on $1600+$ nlp tasks. URL https://arxiv. org/abs/2204.07705.
Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, David Stap等. 2022b. 超自然指令: 通过$1600+$项NLP任务的声明式指令实现泛化. 网址 https://arxiv.org/abs/2204.07705.
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, An- drew M Dai, and Quoc V Le. 2021. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652.
Jason Wei、Maarten Bosma、Vincent Y Zhao、Kelvin Guu、Adams Wei Yu、Brian Lester、Nan Du、Andrew M Dai 和 Quoc V Le。2021. 微调语言模型是零样本学习器。arXiv预印本 arXiv:2109.01652。
Jason Wei, Yi Tay, and Quoc V Le. 2022a. Inverse scaling can become u-shaped. arXiv preprint arXiv:2211.02011.
Jason Wei、Yi Tay 和 Quoc V Le. 2022a. 逆缩放可能呈现U型曲线. arXiv预印本 arXiv:2211.02011.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. 2022b. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903.
Jason Wei、Xuezhi Wang、Dale Schuurmans、Maarten Bosma、Ed Chi、Quoc Le 和 Denny Zhou。2022b。思维链提示激发大语言模型中的推理能力。arXiv预印本 arXiv:2201.11903。
Peter West, Chandra Bhaga va tula, Jack Hessel, Jena Hwang, Liwei Jiang, Ronan Le Bras, Ximing Lu, Sean Welleck, and Yejin Choi. 2022. Symbolic knowledge distillation: from general language models to commonsense models. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4602–4625.
Peter West、Chandra Bhagavatula、Jack Hessel、Jena Hwang、Liwei Jiang、Ronan Le Bras、Ximing Lu、Sean Welleck 和 Yejin Choi。2022。符号知识蒸馏:从通用语言模型到常识模型。载于《2022年北美计算语言学协会人类语言技术会议论文集》,第4602–4625页。
Haike Xu, Zongyu Lin, Jing Zhou, Yanan Zheng, and Zhilin Yang. 2022. A universal discriminator for zero-shot generalization. arXiv preprint arXiv:2211.08099.
Haike Xu、Zongyu Lin、Jing Zhou、Yanan Zheng 和 Zhilin Yang。2022。零样本泛化的通用判别器。arXiv预印本 arXiv:2211.08099。
Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021. mt5: A massively multilingual pre-trained text-to-text transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 483–498.
Linting Xue、Noah Constant、Adam Roberts、Mihir Kale、Rami Al-Rfou、Aditya Siddhant、Aditya Barua 和 Colin Raffel。2021。MT5:一种大规模多语言预训练文本到文本Transformer。载于《2021年北美计算语言学协会人类语言技术会议论文集》,第483-498页。
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601.
Shunyu Yao、Dian Yu、Jeffrey Zhao、Izhak Shafran、Thomas L Griffiths、Yuan Cao 和 Karthik Narasimhan。2023。思维之树:利用大语言模型进行深思熟虑的问题求解。arXiv预印本 arXiv:2305.10601。
Michihiro Yasunaga and Percy Liang. 2020. Graphbased, self-supervised program repair from diagnostic feedback. In International Conference on Machine Learning, pages 10799–10808. PMLR.
Michihiro Yasunaga和Percy Liang。2020。基于图的自监督程序修复与诊断反馈。见于《国际机器学习会议》,第10799–10808页。PMLR。
Seonghyeon Ye, Hyeonbin Hwang, Sohee Yang, Hyeongu Yun, Yireun Kim, and Minjoon Seo. 2023. In-context instruction learning. arXiv preprint arXiv:2302.14691.
Seonghyeon Ye、Hyeonbin Hwang、Sohee Yang、Hyeongu Yun、Yireun Kim 和 Minjoon Seo. 2023. 上下文指令学习. arXiv预印本 arXiv:2302.14691.
Seonghyeon Ye, Doyoung Kim, Joel Jang, Joongbo Shin, and Minjoon Seo. 2022. Guess the instruction! making language models stronger zero-shot learners. arXiv preprint arXiv:2210.02969.
Seonghyeon Ye、Doyoung Kim、Joel Jang、Joongbo Shin 和 Minjoon Seo。2022。猜指令!让语言模型成为更强的零样本学习者。arXiv预印本 arXiv:2210.02969。
Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wen- hao Huang, Huan Sun, Yu Su, and Wenhu Chen. 2023. Mammoth: Building math generalist models through hybrid instruction tuning. arXiv preprint arXiv:2309.05653.
Xiang Yue、Xingwei Qu、Ge Zhang、Yao Fu、Wen-hao Huang、Huan Sun、Yu Su和Wenhu Chen。2023。Mammoth: 通过混合指令微调构建数学通用模型。arXiv预印本arXiv:2309.05653。
Eric Zelikman, Yuhuai Wu, and Noah D Goodman. 2022. Star: Boots trapping reasoning with reasoning. arXiv preprint arXiv:2203.14465.
Eric Zelikman、Yuhuai Wu 和 Noah D Goodman。2022. STAR:通过推理自举推理。arXiv预印本 arXiv:2203.14465。
Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2022. Automatic chain of thought prompting in large language models. arXiv preprint arXiv:2210.03493.
Zhuosheng Zhang, Aston Zhang, Mu Li 和 Alex Smola. 2022. 大语言模型中的自动思维链提示. arXiv预印本 arXiv:2210.03493.
Lucia Zheng, Neel Guha, Brandon R Anderson, Peter Henderson, and Daniel E Ho. 2021. When does pretraining help? assessing self-supervised learning for law and the casehold dataset of $53\mathrm{,OOO+}$ legal holdings. In Proceedings of the eighteenth international conference on artificial intelligence and law, pages 159–168.
Lucia Zheng、Neel Guha、Brandon R Anderson、Peter Henderson 和 Daniel E Ho。2021。预训练何时有效?评估法律领域的自监督学习及包含 53,000+ 条法律裁定的 CaseHold 数据集。载于《第十八届国际人工智能与法律会议论文集》,第159-168页。
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Olivier Bousquet, Quoc Le, and Ed Chi. 2022. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625.
Denny Zhou、Nathanael Schärli、Le Hou、Jason Wei、Nathan Scales、Xuezhi Wang、Dale Schuurmans、Olivier Bousquet、Quoc Le 和 Ed Chi。2022。最少到最多提示 (Least-to-most prompting) 使大语言模型具备复杂推理能力。arXiv预印本 arXiv:2205.10625。
A Analysis of COT COLLECTION
COT COLLECTION 分析
Non-cherry picked rationales within COT COLLECTION are shown in Table 8. We perform an analysis regarding the quality, diversity, and reproducibility of rationale within the COT COLLECTION.
表 8: COT COLLECTION 中未经筛选的推理过程示例。我们对 COT COLLECTION 中推理过程的质量、多样性和可复现性进行了分析。
Diversity of Rationales To take a look into the diversity of COT COLLECTION, we use Berkeley Neural Parser (Kitaev and Klein, 2018; Kitaev et al., 2019) and parse rationales. More specifically, the verb which is closest to the root of the parse tree along the noun object is extracted. We compare this with the rationales from the 9 CoT datasets used in Chung et al. (2022). As shown in Figure 5, COT COLLECTION have diverse textual formats included compared to the 9 existing CoT datasets that have a high proportion assigned to ‘answer question’ and ‘consider following’.
理性多样性
为了探究COT COLLECTION的多样性,我们使用Berkeley Neural Parser (Kitaev and Klein, 2018; Kitaev et al., 2019) 对理性进行解析。具体而言,我们提取了最靠近解析树根节点且沿名词对象的动词,并与Chung等人 (2022) 使用的9个CoT数据集中的理性进行比较。如图5所示,相较于现有9个CoT数据集中"回答问题"和"考虑以下"占比较高的情况,COT COLLECTION包含了更多样化的文本格式。
Quality of Rationales To ensure the quality of COT COLLECTION, we use ROSCOE (Golovneva et al., 2022), a suite of metrics designed to evaluate rationales under different criteria within semantic alignment, semantic similarity, logical inference, language coherence. We compare with human-authored rationales obtained during Prompt Creation in Section 3. The 13 ROSCOE scores are shown in Table 6. The results show that COT COLLECTION include CoT rationales that are faithful, less repetitive, informative, and logical even when compared to human-authored rationales. Yet, we find that machine-generated rationales tend to have higher perplexity, leading to lower language coherence scores. We conjecture this is because including diverse textual formats leads may result in relatively higher perplexity (Holtzman et al., 2019).
理由的质量
为确保 COT COLLECTION 的质量,我们使用 ROSCOE (Golovneva et al., 2022) —— 一套专为评估理由设计的指标,涵盖语义对齐、语义相似性、逻辑推理和语言连贯性等不同标准。我们在第 3 节的提示创建过程中获取了人工撰写的理由,并与之进行对比。13 项 ROSCOE 评分结果如表 6 所示。结果表明,即使与人工撰写的理由相比,COT COLLECTION 包含的思维链 (CoT) 理由仍然具备忠实性、低重复性、信息丰富性和逻辑性。然而,我们发现机器生成的理由往往具有更高的困惑度,从而导致语言连贯性评分较低。我们推测,这是因为包含多样化的文本格式可能导致相对较高的困惑度 (Holtzman et al., 2019)。
表 6:
Is COT COLLECTION Reproducible? Onecould doubt whether COT COLLECTION is reproducible due to the usage of OpenAI model in the process of CoT rationale augmentation 8. In this section, we test different LLMs to generate 150 rationales randomly sampled from COT COLLECTION, and compare the ROSCOE score (Golovneva et al., 2022) in order to assess the quality. We use Bard (Google, 2023), Claude (Anthropic, 2023), for comparing with OpenAI Codex. The comparison of quality is shown in Figure 6. The results show that different LLMs are able to produce high quality rationales in terms of semantic alignment and language coherence.
COT COLLECTION是否可复现?
由于在COT原理增强过程中使用了OpenAI模型,有人可能怀疑COT COLLECTION的可复现性。本节我们测试了不同的大语言模型,从COT COLLECTION中随机采样150条原理生成,并通过比较ROSCOE评分 (Golovneva et al., 2022) 来评估质量。我们使用Bard (Google, 2023)、Claude (Anthropic, 2023) 与OpenAI Codex进行对比。质量对比结果如图6所示。结果表明,不同大语言模型在语义对齐和语言连贯性方面均能生成高质量原理。
Table 6: Comparison of the quality between human-authored rationales and machine-generated rationales. 13 label-free metrics from ROSCOE (Golovneva et al., 2022) is used.
表 6: 人工撰写原理与机器生成原理的质量对比。使用了来自ROSCOE (Golovneva et al., 2022) 的13个无标签指标。
| 指标类别 | 具体指标 | 人工 | CoT Collection |
|---|---|---|---|
| 语义对齐 | faithfulness | 0.8836 | 0.8914 |
| faithfulness_ww | 0.8756 | 0.8793 | |
| repetition_word | 0.9376 | 0.9419 | |
| 语义相似性 | informativeness_step informativeness_chain | 0.9519 0.2295 | 0.9521 0.2797 |
| repetition_sent | 0.2453 | 0.2910 | |
| 逻辑推理 | discourse_representation | 0.4855 | 0.4687 |
| coherence_step_vs_step | 0.7763 | 0.7813 | |
| 语言连贯性 | perplexity_step | 0.0198 | 0.0122 |
| perplexity_chain | 0.0475 | 0.0255 | |
| perplexity_step_max | 0.0144 | 0.0088 | |
| grammar_step | 0.8883 | 0.8721 | |
| 0.8013 | |||
| grammar_step_max | 0.7724 |
B Filtering COT COLLECTION
B 过滤思维链 (COT) 收集
Filtering After generating multiple rationales, we filter to ensure high quality. We apply the following criteria to filter instances:
过滤
在生成多个原理后,我们会进行过滤以确保高质量。我们采用以下标准来筛选实例:
We further include the filtered instances in Table 9.
我们进一步将筛选后的实例纳入表9。
Also, we found that in many cases, Codex degenerates and starts writing code after the rationale. To prevent inclusion of code snippets, we apply additional filtering based on trigger tokens that abundantly appear in the start of the code. The list of trigger tokens are as follows:
此外,我们发现Codex经常在生成原理说明后开始退化并输出代码。为避免包含代码片段,我们基于高频出现在代码起始位置的触发token (trigger tokens) 进行了额外过滤,具体触发token列表如下:
sampling (Holtzman et al., 2019) with $p{=}0.8$ and no repeat n gram ${=}3$ was very effective in generating good-quality rationales.
采样 (Holtzman et al., 2019) 使用 $p{=}0.8$ 且无重复 n 元组 ${=}3$ 的策略在生成高质量推理时非常有效。
C Training and Evaluation Details of CoT-T5
C CoT-T5的训练与评估细节
Table 7: Hyper parameters used for fine-tuning CoT-T5.
表 7: 用于微调 CoT-T5 的超参数。
| Params | Model | Batch size | LR | Optimizer |
|---|---|---|---|---|
| 3B | CoT-T5-3B | 64 | 5e-5 | AdamW |
| 11B | CoT-T5-11B | 8 | 1e-4 | Adafactor |
We mostly follow the fine-tuning details of Chung et al. (2022) to train CoT-T5. The hyperparameters used for training CoT-T5 are shown in Table 7. We find 3B and 11B sized LMs converge well using different optimizers. While CoT-T5-3B tends to converge well using AdamW, CoT-T5-11B is well optimized using Adafactor. For both sizes, we train with 1 epoch using COT COLLECTION which takes 1 day (3B) and 7 days (11B) when 8 A 100 (80GB) GPUs are used. For both settings, we use a gradient accumulation step of 8.
我们主要遵循Chung等人 (2022) 的微调细节来训练CoT-T5。训练CoT-T5使用的超参数如表7所示。我们发现30亿和110亿参数规模的大语言模型使用不同优化器都能良好收敛:CoT-T5-3B倾向于使用AdamW优化器达到最佳收敛效果,而CoT-T5-11B则更适合采用Adafactor优化器。两种规模模型均使用COT COLLECTION数据集训练1个epoch,在使用8块A100 (80GB) GPU的情况下,3B模型耗时1天,11B模型耗时7天。两种配置均采用8步梯度累积策略。
For sampling training instances, we sample instances from Flan Collection (Longpre et al., 2023) by using the proportion of $23.94%$ (FLAN), $30.85%(\mathrm{P}3)$ , $7.89%$ (Existing 9 CoT datasets), $25.47%(\mathrm{SNI})$ and $11.85%$ (other dialogue & code datasets). This is done by sampling 400 instances (FLAN), 300 instances (P3), 150 instances (SNI), 4000 instances (Existing 9 CoT datasets), and 300 instances (other dialogue & code datasets), respectively. We generate 5 rationales per instance and then apply filtering, leading to the final set of COT COLLECTION, which is consisted of 1.84 million instances and rationales across 1,060 tasks.
在采样训练实例时,我们按比例从Flan Collection (Longpre et al., 2023) 中抽取样本:$23.94%$ (FLAN)、$30.85%(\mathrm{P}3)$、$7.89%$ (现有9个CoT数据集)、$25.47%(\mathrm{SNI})$ 以及 $11.85%$ (其他对话和代码数据集)。具体采样数量为:400个实例 (FLAN)、300个实例 (P3)、150个实例 (SNI)、4000个实例 (现有9个CoT数据集) 和300个实例 (其他对话和代码数据集)。每个实例生成5条推理链后经过筛选,最终构成包含184万条实例和推理链的COT COLLECTION,覆盖1060项任务。
During evaluation, we found that using nucleus
在评估过程中,我们发现使用核采样

Figure 5: The top 20 common root verbs (inner circle) and their top 4 noun objects (outer circle) within the rationales of the $9\mathrm{CoT}$ tasks used in Chung et al. (2022) (left side) and our COT COLLECTION with 1,060 tasks (right side).
图 5: Chung 等人 (2022) 研究中使用的 $9\mathrm{CoT}$ 任务(左侧)与我们包含 1,060 个任务的 CoT COLLECTION (右侧) 中,最常见的 20 个根动词(内圈)及其前 4 个名词宾语(外圈)分布。

Figure 6: Comparison of the quality of augmenting CoT rationales using different LLMs by reference-free ROSCOE scores. Semantic Alignment(SA), Semantic Similarity(SS), Logical Inference(LI), Coherence(LC).
图 6: 通过无参考ROSCOE分数比较不同大语言模型在增强思维链(CoT)推理过程时的质量表现。语义对齐(SA)、语义相似度(SS)、逻辑推理(LI)、连贯性(LC)。
Table 8: Example of rationales within COT COLLECTION including tasks such as Multiple choice QA (MCQA), Extractive QA (ExQA), Closed-book QA (CBQA), Formal Logic, Natural Language Inference (NLI), and Arithmetic.
表 8: COT COLLECTION 中包含各类任务的推理示例,例如多项选择问答 (MCQA)、抽取式问答 (ExQA)、闭卷问答 (CBQA)、形式逻辑、自然语言推理 (NLI) 和算术。
| 问题与指令 | 答案 | 推理过程 |
|---|---|---|
| 阅读以下上下文并选择最佳答案。上下文:从她五分钟后执行的三重循环中,他怀疑 | 三重循环是指飞机在空中完成三个环飞动作的机动。根据上下文可以推断 | |
| 她比夏天时更频繁地偷偷溜出去飞行 | ||
| 并想知道 George 在业余时间练习的认真程度。 | ||
| 问题:什么是三重循环? | ||
| 选项: | ||
| A. 以上都不是 | ||
| B. 飞机航线的3次往返 | ||
| C. 飞行时佩戴的3条领带 | ||
| D. 通过在空中完成3个环飞动作实现的特性 | ||
| 阅读以下段落并选择正确答案(选项为"更多"或"更少"): | ||
| 在炎热天气里,恒温动物可能通过增加体表血流量来散发更多热量。 | 通过增加体表血流量。因此可以推断血流减少意味着散热减少。由于 Sarah 注意到自己的血液没有剧烈流动 | |
| Sarah 散步后注意到 | 更少 | |
| 自己的血液没有剧烈流动。 | ||
| Sarah 可以知道因为今天是凉爽天气,与平时相比她散发的热量是更多还是更少? | ||
| 阅读并回答问题。 | ||
| 青春期发育也会影响循环和呼吸系统,因为青少年的心脏和肺在大小和容量上都会增长。 | ||
| 这些变化会增强运动能力和耐力。 | ||
| 性别差异很明显,男性往往发育出 | ||
| "更大的心脏和肺,更高的收缩压, | ||
| 更低的静息心率, | ||
| 更强的血液携氧能力, | ||
| 更强的中和肌肉运动化学产物的能力, | ||
| 更高的血红蛋白和更多红细胞:" | ||
| 哪种性别往往发育出更大的心脏和肺? | ||
| 在这个任务中,你会得到一个字符序列。 | ||
| 你需要移除字符串中的重复字符 | nXGFzHYudOiyWLZQfpw | 给定字符串中没有重复字符, |
| 如果有的话,并返回结果字符串。 | 因此结果字符串将与输入相同。 | |
| "nXnGFzHFYudOiHyWLZXQfpw" | 因此输出将是"nXGFzHYudOiyWLZQfpw"。 | |
| 在这个任务中你会得到一个数字列表 | ||
| 你应该移除列表中的所有重复项 | 给定列表是{3, 5, 1, 0, 3}。 | |
| 如果列表中每个数字都重复出现,则应返回空列表。 | {5,1,0} | 可以看到'3'在列表中出现两次。 |
| 你的列表应该像给定列表一样用括号括起来。 | 因此我们需要保留一个'3'并移除另一个。结果列表是{5, 1, 0}。 | |
| {3,5, 1, 0, 3} | ||
| 如何在车内保持手机凉爽 | ||
| 如果需要使用手机,请将其放在通风口支架上并开启空调。 | ||
| 如果需要在车内使用手机,可以购买安装在仪表板通风口上的支架。 | ||
| 打开空调以保持手机凉爽。 | ||
| 我们能得出以下结论吗? | ||
| 在车内使用时,将手机和平板电脑安装在空调通风口上保持凉爽。 | ||
| 因此"无法确定" | ||
| 选项: | ||
| -是 | ||
| - 无法确定 | ||
| - 否 | ||
| 给出问题"谁提名了 Stephen G. Breyer?"的一个可能正确答案 | Bill Clinton | Stephen G.Breyer是由Bill Clinton提名的最高法院大法官 |
| 并于1994年7月29日获得确认。 | ||
| 虽然他并非在1998或1999年被提名,但这仍然是一个有效答案 | ||
| 因为这是在那些日期之前的5年内发生的。 | ||
| 写出这个数学问题的解法:解方程291c -264c =189求c。 | STEP1.291C-264C=189 | |
| STEP2.27*C=189 |
| 问题 | 答案 | 思维链推理 |
|---|---|---|
| 给定一个数学应用题,你只能通过文本中嵌入的数字进行减法运算来回答以下问题,并仅报告最终数值答案。背景:Jake比Steven少8个桃子,多10个苹果。Steven有11个苹果和18个桃子。问题:Steven的桃子比苹果多多少个? | 7 | 解题需确定Steven拥有的苹果和桃子数量。根据文本可知:Jake的桃子数=Steven的桃子数-8,Jake的苹果数=Steven的苹果数+10。已知Steven有11个苹果和18个桃子,由此建立方程:Steven的桃子=Jake的桃子+8Steven的苹果=Jake的苹果-10合并方程得:(18+11)=(Jake的桃子+8)+(Jake的苹果-10)29=Jake的桃子+Jake的苹果-2a=29-2=27b=(18+11)-a |
| 求解方程690*c +14495=-4825中的c值。 | -28 | 计算步骤:c=b/2nd=c*2690*c + 14495 = -4825两边同时减去4825:0=6996+3*069两边同除以690:c=-14.02391304348 |
Table 9: Two representative rationale examples that are filtered with our filtering criteria. It demonstrates that not including the ground truth token within the rationale could indicate that the LLM failed to generate a consistent rationale, often leading to degeneration. This phenomenon is mostly found on math datasets.
表 9: 通过我们的过滤标准筛选出的两个代表性原理示例。这表明若原理中未包含真实答案token (ground truth token) ,可能意味着大语言模型未能生成一致的推理过程,通常会导致性能退化。该现象在数学数据集中最为常见。
D Prompts used for Rationale Augmentation
D 用于原理增强的提示词
Among the 26 demonstrations used for each family of tasks when augmenting CoT rationales, we include 4 examples, other demonstrations for task families can be seen at this link.
在增强思维链(CoT)推理的每个任务族所使用的26个演示中,我们包含了4个示例,其他任务族的演示可在此链接查看。
[Options] − beg the doctors to try again get her up and walking home − bring Skylar back
[选项]
- 恳求医生再试一次 让她站起来走回家
- 把Skylar带回来
[Answer] beg the doctors to try again
[答案] 恳请医生们再试一次
[Rationale]
[依据]
So the answer is to beg the doctors to try again.
所以答案是恳请医生们再试一次。
[Options] − No − Yes [Answer]
[选项] - 否 - 是
[答案]
No
不
[Rationale]
[原理]
Alcoholic fermentation is a process that occurs in living organisms, most commonly yeast, to convert glucose into energy. This process does not produce enough energy to power something like a bicycle.
酒精发酵是发生在活体生物(最常见的是酵母)中将葡萄糖转化为能量的过程。这一过程产生的能量不足以驱动自行车等设备。
So the answer is No.
所以答案是否定的。
What type of doctor might the person have had to see − A pae dia tricia n − A heart surgeon − a gynecologist − None of the above choices
该患者可能看过哪种医生 - 儿科医生 - 心脏外科医生 - 妇科医生 - 以上都不是
[Answer] a gynecologist
[答案] 妇科医生
[Rationale]
[依据]
The context mentions a cyst in the pelvic region and the symptoms of the cyst rupturing, including pain and fluid leakage. This suggests that the issue is related to the reproductive or urinary system. Given that the issue is related to the reproductive or urinary system, it is likely that the person would have had to see a specialist in these areas. Out of the given options, "a gynecologist" is the most likely specialist that the person would have had to see, as gynecologists specialize in female reproductive health, including issues related to the uterus, ovaries, and other reproductive organs.
文中提到盆腔区域有一个囊肿,以及囊肿破裂的症状,包括疼痛和液体渗漏。这表明问题与生殖或泌尿系统有关。鉴于问题涉及生殖或泌尿系统,此人很可能需要就诊于相关领域的专科医生。在给定的选项中,"妇科医生 (gynecologist) "是最可能的就诊对象,因为妇科医生专攻女性生殖健康,包括子宫、卵巢及其他生殖器官相关的问题。
In conclusion, based on the given context, the most likely answer is a gynecologist.
根据给定背景,最可能的答案是妇科医生。
Question:
问题:
suppose if no water is available happens, how will it affect vegetables?
假设没有可用水源,这将如何影响蔬菜?
− A: more − B: less
- A: 更多
- B: 更少
[选项] -A -B
B [依据] 播种过程需要水分,这对植物生长至关重要。水能帮助运输养分、调节温度并从土壤中吸收矿物质。若缺水,种子不会发芽,植物也无法正常生长,导致蔬菜减产。因此,缺水会造成蔬菜"减少",故答案为"B"。
[示例5]
[指令与问题]
阅读对话并回答问题。
男:我很担心我妹妹露西。
女:为什么?
男:她总觉得自己太胖。
女:真的吗?
男:不胖,但她一直不吃饭,只吃薯片喝可乐。
女:我以前也这样,这叫暴食行为,一点都不好!
男:你怎么改掉的?
女:医生让我饿了就吃,她说"吃饱为止,否则之后会吃更多",还说很多女孩因此毁了健康。
男:她建议吃什么?
女:她说"吃水果、蔬菜、肉类和谷物,规律进餐,也要运动"。
问题:对话者是什么关系?
[选项]
- 医患
- 朋友
- 兄妹
[答案]
朋友
[依据]
对话中男性(M)和女性(W)在讨论男性妹妹因身材焦虑节食的问题。女性分享自己曾有类似行为,并转述医生建议均衡饮食和运动。三个选项中:首先,女性在转述医生建议,说明她本人非医疗从业者,排除医患关系;其次,男性谈论的是自己妹妹,女性不可能是其妹妹;最后,对话内容非正式且涉及私事,最可能是朋友关系。因此答案为朋友。
[示例6]
[指令与问题]
问题:捣蛋鬼最适合在什么地方偷偷抽烟?是卫生间吗?
[选项]
- 操场
- 学校
- 酒店
- 剧院
- 便利店
[依据]
选择"学校"作为答案的原因是:
[Answer] smokers traditionally use school bathrooms
[答案] 吸烟者传统上使用学校卫生间
[Rationale]
[Rationale]
Here’s the rationale: "smokers traditionally use school bathrooms".
理由是: "吸烟者传统上使用学校洗手间"。
Why is the narrator so down in the dumps ? Pick the best answer from the following option
为什么叙述者如此沮丧?从以下选项中选择最佳答案
[Options]
[选项]
− A − B − − D
- A - B - - D
[Answer]
[答案]
[Rationale]
[依据]
The quote in the question mentions the narrator’s feelings about an injury and the depression that follows. The narrator says that it’s not just about being out of shape and unable to play, but rather they feel like they are missing a part of themselves. This implies that the reason for their depression is linked to their physical inability to participate in a sport or activity they enjoy. Based on the context, it can be inferred that the narrator is upset because they are hurt and unable to play ice hockey.
问题中的引述提到了叙述者对受伤及随之而来的抑郁的感受。叙述者表示,这不仅是因为身体状态不佳无法参赛,更因为他们感觉自己缺失了一部分自我。这表明其抑郁原因与无法参与喜爱的冰球运动有关。根据上下文可推断,叙述者因受伤无法打冰球而感到沮丧。
So, the answer is B.
所以,答案是 B。
Choices:
选择:
[Options] − inertia − water gravity − magnetism [Answer] magnetism
[选项]
- 惯性
- 水的重力
- 磁力
[答案] 磁力
[Rationale]
[依据]
A generator is a device that converts mechanical energy into electrical energy. This is done by using a magnetic field to induce a current in the generator’s windings. This current is then sent to an external circuit, where it can be used to power electrical devices. The generator uses magnetism to generate currents, so the answer is magnetism.
发电机是一种将机械能转化为电能的装置。它通过磁场在绕组中感应出电流来实现这一转换。随后,该电流被输送至外部电路,用于为电气设备供电。发电机利用磁力产生电流,因此答案是磁力。
[Example 9] [Instruction and Question]
[示例9] [指令与问题]
Prompts 1: Demonstration used for tasks in family of MCQA (T0)
Prompts 1: 用于MCQA (T0) 系列任务的演示
So the answer is to beg the doctors to try again.
所以答案是恳请医生们再试一次。
[opt No − Yes [Answer]
[opt No - Yes [Answer]
[Rationale]
[Rationale]
Alcoholic fermentation is a process that occurs in living organisms, most commonly yeast, to convert glucose into energy. This process does not produce enough energy to power something like a bicycle.
酒精发酵是活体生物(最常见的是酵母)将葡萄糖转化为能量的过程。该过程产生的能量不足以驱动自行车等设备。
So the answer is No.
所以答案是“否”。
− A pae dia tricia n − A heart surgeon − a gynecologist − None of the above choices
- 儿科医生
- 心脏外科医生
- 妇科医生
- 以上选项均不正确
[Answer] a gy neco log is
[答案] 一位妇科医生
[Rationale]
[原理]
The context mentions a cyst in the pelvic region and the symptoms of the cyst rupturing, including pain and fluid leakage. This suggests that the issue is related to the reproductive or urinary system. Given that the issue is related to the reproductive or urinary system, it is likely that the person would have had to see a specialist in these areas. Out of the given options, "a gynecologist" is the most likely specialist that the person would have had to see, as gynecologists specialize in female reproductive health, including issues related to the uterus, ovaries, and other reproductive organs.
文中提到盆腔区域的囊肿以及囊肿破裂的症状,包括疼痛和液体渗漏。这表明问题与生殖或泌尿系统有关。鉴于问题涉及生殖或泌尿系统,患者很可能需要就诊于这些领域的专科医生。在给定的选项中,"妇科医生"是最可能接诊的专科医师,因为妇科医生专攻女性生殖健康问题,包括子宫、卵巢及其他生殖器官相关疾病。
In conclusion, based on the given context, the most likely answer is a gynecologist.
根据给定上下文,最可能的答案是妇科医生。
[示例1] [指令与问题] Skylar已停止呼吸,但Lee仍抓着Skylar的手臂,徒劳无功。根据上下文:Lee接下来想做什么?
可能的答案:恳求医生再试一次、扶她起来走回家、让Skylar复活
[选项]
恳求医生再试一次
扶她起来走回家
让Skylar复活
[答案] 恳求医生再试一次
[分析]
情境背景是Skylar已停止呼吸,Lee仍抓着Skylar的手臂。这表明Skylar已接受医疗救治但未能生还。基于此,Lee最可能想恳求医生再次尝试救治,因为这是最合理的选择。
suppose if no water is available happens, how will it affect vegetables?
假设没有可用水源的情况发生,会对蔬菜产生什么影响?
Question:
问题:
− A: more − B: less
- A: 更多
- B: 更少
[Options]
[选项]
[Answer]
[答案]
[Rationale]
[Rationale]
The process of planting seeds requires water, which is essential for the growth of plants. Water helps transport nutrients, regulate temperature, and absorb minerals from the soil. If no water is available, the seed will not germinate and the plant will not grow properly, leading to fewer vegetables. Hence, the absence of water will result in "less" vegetables, making the answer $"\mathbf{B}"$ .
播种过程需要水,这对植物生长至关重要。水能帮助运输养分、调节温度并从土壤中吸收矿物质。如果没有水,种子将无法发芽,植物也无法正常生长,导致蔬菜产量减少。因此,缺水会导致蔬菜"减少",故答案为 $\mathbf{B}$。
M: Did she say what to eat?
M: 她说了要吃什么吗?
W: She said, "Eat fruit, vegetables, meats and grains. Have regular meals and snacks. Get exercise, too."
她说:"要吃水果、蔬菜、肉类和谷物。要规律进餐和吃零食。还要锻炼身体。"
Question: What’s the relationship between the speakers?
问题:说话者之间的关系是什么?
[Answer]
[答案]
Friends
朋友
[Rationale]
[Rationale]
The conversation between two people, a man(M) and a woman(W), is discussing the man’s sister who has a negative view of her own body and is skipping meals. The woman shares that she used to engage in similar behavior, and explains that her doctor advised her to eat a balanced diet and exercise.
两人对话中,一位男性(M)和一位女性(W)正在讨论男性对自己身材持负面看法并开始节食的妹妹。女性分享了自己过去也有类似行为,并解释医生曾建议她保持均衡饮食和适量运动。
Among the three options,
在三个选项中,
− First, since the woman is sharing her experience of what the doctor told her, it is unlikely she would be a medical professional. So the answer couldn’t be doctor and patient.
- 首先,由于这位女士是在分享医生对她所说的话,她不太可能是医疗专业人士。因此答案不可能是医生和患者。
− Second, given that the man is talking about his sister, the woman is unlikely to be the man’s sister.
- 其次,鉴于该男子正在谈论他的妹妹,这位女士不太可能是该男子的妹妹。
− Lastly, because the conversation is informal and the speakers are discussing a personal matter it is likely that the relationship between the speakers is that of friends.
- 最后,由于对话是非正式的,且双方在讨论个人事务,说话者之间的关系很可能是朋友。
Therefore, the answer is Friends.
因此,答案是Friends。
The rationale to choose ""school"" as the answer is that:
选择“学校”作为答案的理由是:
[Options]
[选项]
Not Given
未提供
[Answer] smokers traditionally use school bathrooms
[回答] 吸烟者传统上使用学校卫生间
[Rationale]
[Rationale]
Here’s the rationale: "smokers traditionally use school bathrooms"
理由是: "吸烟者传统上使用学校卫生间"
[Example 7]
[示例 7]
Why is the narrator so down in the dumps ?
为什么叙述者如此沮丧?
Pick the best answer from the following options
从以下选项中选择最佳答案
[Options]
[选项]
− A − B − C − D
− A − B − C − D
[Answer]
[答案]
[Rationale]
[原理]
The quote in the question mentions the narrator’s feelings about an injury and the depression that follows. The narrator says that it’s not just about being out of shape and unable to play, but rather they feel like they are missing a part of themselves. This implies that the reason for their depression is linked to their physical inability to participate in a sport or activity they enjoy. Based on the context, it can be inferred that the narrator is upset because they are hurt and unable to play ice hockey.
问题中的引述提到了叙述者对受伤及随之而来的抑郁情绪的感受。叙述者表示,这不仅关乎身材走样或无法参赛,更在于他们感觉自己缺失了一部分自我。这暗示其抑郁根源与无法参与喜爱的冰球运动有关。根据上下文可推断,叙述者因受伤无法打冰球而感到沮丧。
So, the answer is B.
所以,答案是 B。
[Example 8]
[示例 8]
[Instruction and Question] Q: What does the ubiquitous generator use to generate currents?
[指令与问题]
Q: 无处不在的发电机用什么来产生电流?
Choices:
选项:
− inertia − water − gravity − magnetism
- 惯性 - 水 - 重力 - 磁性
[Options] − inertia water gravity − magnetism
[选项] - 惯性 水重力 - 磁力
[Answer]
[答案]
magnetism
磁性
[Rationale]
[依据]
A generator is a device that converts mechanical energy into electrical energy. This is done by using a magnetic field to induce a current in the generator’s windings. This current is then sent to an external circuit, where it can be used to power electrical devices. The generator uses magnetism to generate currents, so the answer is magnetism.
发电机是一种将机械能转化为电能的装置。它通过磁场在发电机绕组中感应出电流来实现这一转换。随后,该电流被输送至外部电路,可用于为电气设备供电。发电机利用磁力产生电流,因此答案是磁力。
[Example 9] [Instruction and Question]
[示例9] [指令与问题]
Prompts 2: Demonstration used for tasks in family of Commonsense (SNI)
提示词 2: 用于常识推理任务(SNI)系列的演示
[Answer]
[答案]
no
无
[Rationale]
[依据]
The information given only pertains to cases seen in this particular eating disorder clinic and may not be representative of the entire population. To determine whether anorexia is becoming common in males, we would need to look at data from a larger sample size or population, as well as data from multiple sources to verify the trend. So the answer is "no"
所提供的信息仅涉及该特定饮食失调诊所的病例,可能无法代表整个人群。要判断厌食症是否在男性中变得普遍,我们需要查看更大样本量或人群的数据,以及来自多个来源的数据以验证这一趋势。因此答案为"否"
[Answer]
[答案]
He also liked swimming and cycling. He said that he wrote stories, though he had to admit that he had never got further than the first two pages. Willie meanwhile not only remained silent during these conversations but picked his berries slowly so that they might forget that he was there but he reckoned without Zach.\n\n Hypothesis: Willie was there
他还喜欢游泳和骑自行车。他说自己写故事,尽管不得不承认从未写到超过前两页。而Willie在这些谈话中不仅保持沉默,还故意放慢摘浆果的速度,好让他们忘记自己的存在,但他没把Zach算进去。
假设:Willie当时在场
[Rationale]
[Rationale]
Here’s a context and an example for natural language inference task:\nHe also liked swimming and cycling. He said that he wrote stories, though he had to admit that he had never got further than the first two pages. Willie meanwhile not only remained silent during these conversations but picked his berries slowly so that they might forget that he was there but he reckoned without Zach.\n\n Hypothesis: Willie was there
以下是自然语言推理任务的一个上下文和示例:\n他还喜欢游泳和骑自行车。他说他写故事,尽管他不得不承认自己从未写过超过前两页。与此同时,Willie不仅在这些谈话中保持沉默,还慢慢地摘他的浆果,这样他们可能会忘记他在那里,但他没有考虑到Zach。\n\n假设:Willie在那里
[Example 3]
[示例 3]
[Answer] It’s impossible to say
[答案] 这很难说
[Rationale]
[Rationale]
While the information provided in the options about Jeremy Brock suggests that he is indeed an English writer and director with a number of successful works under his belt, there is not enough information to determine whether he is actually "popular" or not. The term "popular" is subjective and can vary depending on different factors, such as time period, genre, and audience. So the answer is "It’s impossible to say".
虽然关于Jeremy Brock的选项信息表明他确实是一位英国编剧和导演,名下有多部成功作品,但现有信息不足以判断他是否真的"受欢迎"。因为"受欢迎"是一个主观概念,可能因时间、流派和受众群体等因素而异。因此答案是"It’s impossible to say"。
Today, two Biff Burger restaurants remain.\nBiff Burger came about in Clearwater Florida. OPTIONS:\n− Yes\n− It’s impossible to say\n− No\nA:
如今,仅剩两家Biff Burger餐厅仍在营业。
Biff Burger起源于佛罗里达州的克利尔沃特。
选项:
− 是
− 无法确定
− 否
A:
[Answer]
[答案]
Yes
是
[依据] 为验证"Biff Burger诞生于佛罗里达州克利尔沃特"这一说法,我们应在上下文中寻找佐证。可见"Biff Burger (Best In Fast Food)是源自佛罗里达州克利尔沃特的汉堡快餐连锁品牌"这一陈述支持待验证的主张,因此答案为"是"。
[示例5] [指令与问题] 输入假设:1950年代前的十年间,美国联邦调查局(FBI)开始公开维护其认定的十大通缉犯名单\n上下文:1950年代,美国联邦调查局在J·埃德加·胡佛局长任内开始公开维护十大通缉犯名单。下文简要回顾了将该年代置于历史背景下的FBI人物与事件,并列出了1950年代期间首次登上十大通缉名单的逃犯历史记录。\n选项:\n-是\n-无法判断\n-否\n判断正误:
[答案] 否 [依据] 上下文明确指出FBI是在1950年代胡佛局长任内建立该公开名单,并列举了该年代首次上榜的逃犯,这反驳了"名单存在于1950年代之前"的假设,因此答案为"否"。
[示例6] [指令与问题] 问:若原告主张彭罗斯设计的独特性在于其非周期性(图案几乎但不完全重复)和五重对称性(该特征当时被认为自然界不存在,但后来在某些晶体结构中被发现),能否认为"该设计没有可辨识的独有特征"?\n选项:\n-是\n-无法判断\n-否\n答:
[答案] 否 [依据] 原告明确指出设计具有使其与众不同的独特特征,这与"设计没有可辨识独有特征"的陈述直接矛盾,因此答案为"否"。
[示例7] [指令与问题] "苏联航天器的首次对接最终由1969年1月的联盟4号与联盟5号任务实现"是否包含"首次载人航天器对接发生于何时"的正确答案?
[答案] 是 [依据] 该段落描述了首次两人乘组航天器的成功对接(联盟4号与联盟5号对接时各载两名宇航员),因此该陈述包含问题的正确答案,故答案为"是"。
[示例8] [指令与问题] 输入问题:若"狐狸夜间闯入袭击鸡群,我必须看守它们"为真,能否认为"我必须看守狐狸"为真?\n选项:\n-否\n-是\n输出答案:
[答案] 否 [依据] "我必须看守狐狸"的表述未能准确反映第二句中"我必须看守它们"的情境。此处的"它们"指代狐狸,正确表述应为"我必须看守它们"而非"我必须看守狐狸",因此答案为"否"。
[示例9] [指令与问题] 问题:\n前提:穿蓝衬衫橙短裤的男子注视着穿黄衬衫蓝短裤的幼童,背景由树木构成。\n假设:幼童身后有许多树木。\n该假设是否成立?\n选项:\n-是\n-无法判断\n-否\n\n答案:
[答案] 无法判断
[Rationale]
[依据]
While it is mentioned that trees make up the backdrop, it is not specified whether there are a lot of trees or not. Additionally, the focus of the premise is on the man and child and not on the trees in the background. Hence, it is not possible to determine whether the hypothesis is true or not.
虽然提到树木构成了背景,但并未具体说明树木的数量多少。此外,前提的重点在于男子与孩子,而非背景中的树木。因此,无法判断假设是否成立。
[Example 10] [Instruction and Question]
[示例 10] [指令与问题]
Prompts 3: Demonstration used for tasks in family of NLI (FLAN)
提示 3: 用于自然语言推理 (FLAN) 系列任务的演示
| [示例1] [指令与问题] 树林中原有15棵树。今天园林工人将在树林中植树。完成后树林将有21棵树。今天园林工人种植了多少棵树? | |
| [答案] 6 [解析] | |
| 他们种植后树量变为21棵,因此必须种植了21-15=6棵树。[示例2] | |
| [指令与问题] 如果停车场原有3辆车,又驶入2辆,现在停车场共有多少辆车? | |
| [答案] 5 [解析] | |
| 停车场原有3辆车,新增2辆后总量为3+2=5辆。 | |
| [示例3] [指令与问题] Leah有32颗巧克力,她妹妹有42颗。若她们吃掉35颗,总共还剩多少颗? | |
| [答案] 39 [解析] | |
| Leah的32颗加上妹妹的42颗,原本共有32+42=74颗巧克力。吃掉35颗后剩余74-35=39颗。 | |
| [示例4] [指令与问题] Jason原有20根棒棒糖,给Denny若干后还剩12根。Jason给Denny多少根棒棒糖? | |
| [答案] 8 | |
| [解析] Jason原有20根,剩余12根说明给Denny的数量为20-12=8根。 | |
| [示例5] [指令与问题] Shawn有5个玩具,圣诞节时从父母处各获赠2个玩具。他现在有多少玩具? | |
| [答案] 9 | |
| [解析] 初始5个玩具,从母亲处获得2个后变为5+2=7个,再从父亲处获得2个,最终总量为7+2=9个玩具。 | |
| [示例6] | |
| [指令与问题] 服务器机房原有9台电脑,周一到周四每天安装5台新电脑。现在机房共有多少台电脑? | |
| [答案] 29 [解析] | |
| 4天共新增5×4=20台电脑,原有9台,因此当前总量为9+20=29台。 |
现在有9+20=29台电脑。
[示例7] [指令与问题] Michael有58个高尔夫球。周二他丢了23个高尔夫球,周三又丢了2个。周三结束时他还有多少个高尔夫球?
[答案] 33 [解析]
Michael最初有58个球。周二丢了23个后剩下58 - 23 = 35个球。周三又丢了2个后剩余35 - 2 = 33个球。
[示例8] [指令与问题]
Olivia有23美元。她以每个3美元的价格买了5个面包圈,还剩多少钱?
[答案] 8 [解析]
她以每个3美元买了5个面包圈,共花费5 * 3 = 15美元。最初有23美元,现在剩余23 - 15 = 8美元。
[示例9] [指令与问题]
Prompts 4: Demonstration used for tasks in family of Arithmetic (FLAN)
提示 4: 用于算术任务族(FLAN)的演示