DCSAU-Net: A Deeper and More Compact Split-Attention U-Net for Medical Image Segmentation
DCSAU-Net: 用于医学图像分割的更深更紧凑的分割注意力U-Net
A R T I C L E I N F O
文章信息
A B S T R A C T
摘要
Keywords: Medical image segmentation Multi-scale fusion attention Depthwise separable convolution Computer-aided diagnosis
关键词: 医学图像分割 多尺度融合注意力 深度可分离卷积 计算机辅助诊断
Deep learning architecture with convolutional neural network (CNN) achieves outstanding success in the field of computer vision. Where U-Net, an encoder-decoder architecture structured by CNN, makes a great breakthrough in biomedical image segmentation and has been applied in a wide range of practical scenarios. However, the equal design of every down sampling layer in the encoder part and simply stacked convolutions do not allow U-Net to extract sufficient information of features from different depths. The increasing complexity of medical images brings new challenges to the existing methods. In this paper, we propose a deeper and more compact split-attention u-shape network (DCSAU-Net), which efficiently utilises low-level and high-level semantic information based on two novel frameworks: primary feature conservation and compact split-attention block. We evaluate the proposed model on CVC-ClinicDB, 2018 Data Science Bowl, ISIC-2018 and SegPC-2021 datasets. As a result, DCSAU-Net displays better performance than other state-of-the-art (SOTA) methods in terms of the mean Intersection over Union (mIoU) and F1-socre. More significantly, the proposed model demonstrates excellent segmentation performance on challenging images. The code for our work and more technical details can be found at https://github.com/xq141839/DCSAU-Net.
采用卷积神经网络 (CNN) 的深度学习架构在计算机视觉领域取得了卓越成就。其中基于CNN构建的编码器-解码器结构U-Net,在生物医学图像分割领域实现重大突破,并广泛应用于实际场景。然而,U-Net编码器部分各下采样层的均等设计及简单的卷积堆叠结构,使其难以充分提取不同深度的特征信息。随着医学图像复杂度的提升,现有方法面临新的挑战。本文提出更深层、更紧凑的分裂注意力U型网络 (DCSAU-Net),通过两个创新框架——基础特征保留机制和紧凑分裂注意力模块,实现了对低层级与高层级语义信息的高效利用。我们在CVC-ClinicDB、2018 Data Science Bowl、ISIC-2018和SegPC-2021数据集上评估模型性能,结果表明DCSAU-Net在平均交并比 (mIoU) 和F1分数指标上均优于其他前沿方法。尤为重要的是,该模型在复杂图像上展现出优异的分割性能。相关工作代码及技术细节详见 https://github.com/xq141839/DCSAU-Net。
1. Introduction
1. 引言
Common types of cancer such as colon cancer, multiple myeloma and melanoma, are still one of the major causes of human suffering and death globally. Medical image analysis plays an essential role in terms of diagnosing and treating these diseases [1]. For example, numerous cells in a microscopy image are able to illustrate the stage of diseases, assist in discriminating tumour types, support in insight of cellular and molecular genetic mechanisms, and present valuable information to many other applications, such as cancer and chronic obstructive pulmonary disease [2]. Traditionally, medical images are analysed by pathologists manually. In other words, the result of diagnosis is usually dominated by on the experience of medical experts, which can be timeconsuming, subjective, and error-prone [3]. Computer-aided diagnosis (CAD) has received significant attention from both pathological researchers and clinical practice, which is mainly depend on the result of medical image segmentation [4]. Different from classification and detection tasks, the target of biomedical image segmentation is to separate the specified object from the background in an image, which is able to provide patients with more detailed disease analysis [5]. Existing classic segmentation algorithms are based on edge detection, threshold ing, morphology, distances between two objects and pixel energy, such as Otsu threshold ing [6], Snake [7] and Fuzzy algorithms [8]. Each algorithm has its own parameters to accommodate different requirements. However, these algorithms often show limited performance on the generalization of complex datasets [9]. The segmentation performance of these methods is also affected by image acquisition quality. For example, some pathological images may be blurred or contain noises. Other situations could have negative influences too, including uneven illumination, low image contrast between foreground and background, and complex tissue background [10]. Therefore, it is essential to construct a powerful and generic model which can achieve adequate robustness on challenging images and works for different biomedical applications.
常见癌症类型如结肠癌、多发性骨髓瘤和黑色素瘤,仍是全球人类痛苦与死亡的主要原因之一。医学影像分析在这些疾病的诊断与治疗中发挥着关键作用 [1]。例如,显微图像中的大量细胞能够展示疾病发展阶段、辅助鉴别肿瘤类型、帮助理解细胞与分子遗传机制,并为癌症和慢性阻塞性肺病等其他重要应用提供有价值的信息 [2]。传统上,医学影像由病理学家手动分析,这意味着诊断结果往往取决于医学专家的经验,这种方式耗时、主观且易出错 [3]。计算机辅助诊断 (CAD) 因其主要依赖医学图像分割结果,已受到病理学研究和临床实践的高度关注 [4]。与分类和检测任务不同,生物医学图像分割的目标是从图像背景中分离特定对象,从而为患者提供更精细的疾病分析 [5]。现有经典分割算法基于边缘检测、阈值化、形态学、对象间距离和像素能量等方法,例如大津阈值法 (Otsu thresholding) [6]、Snake算法 [7] 和模糊算法 [8]。每种算法都有适应不同需求的参数,但这些算法在复杂数据集上的泛化性能往往有限 [9]。这些方法的分割性能还受图像采集质量影响,例如部分病理图像可能存在模糊或噪声。其他影响因素包括光照不均、前景与背景对比度低以及复杂的组织背景 [10]。因此,构建一个强大通用的模型至关重要,该模型需在具有挑战性的图像上保持足够鲁棒性,并能适用于不同生物医学应用场景。
CNN-based encoder-decoder architectures have outperformed traditional image processing methods in various medical image segmentation tasks [11]. The success of these models is largely due to the skip connection strategy that incorporates the low-level semantic information with highlevel semantic information to generate the final mask [12]. However, many improved architectures only focus on optimising algorithms in terms of in-depth feature extraction, which ignores the loss of high-resolution information in the header of the encoder. The sufficient feature maps extracted from this layer is able to help to compensate for the spatial information lost during the pooling operations [13].
基于CNN的编码器-解码器架构在各种医学图像分割任务中表现优于传统图像处理方法[11]。这些模型成功的关键在于采用了跳跃连接策略,将低层语义信息与高层语义信息结合以生成最终掩码[12]。然而,许多改进架构仅专注于深度特征提取方面的算法优化,忽略了编码器头部高分辨率信息的丢失。从该层提取的充分特征图有助于补偿池化操作期间丢失的空间信息[13]。
In this paper, we propose a novel encoder-decoder architecture for medical image segmentation, called DCSAU-Net. In the encoder part, our model first adopts a novel primary feature conservation (PFC) strategy that reduces the number of parameters, amount of computation and integrates the long-range spatial information of the network in the shadow layer. The rich primary feature obtained from this layer will be delivered to our novel constructed module: compact splitattention (CSA) block. The CSA module strengthens the feature representation of different channels using multi-path attention structure. Each path contains a different number of convolutions so that the CSA module can output mixed feature maps with different receptive field scales. Both new frameworks are designed with residual style in order to alleviate gradient vanishing problem with increasing layers. For the decoder, encoded features in every down sampling layer are concatenated with corresponding upsampled features by skip connection. we apply the same CSA block to complete efficient feature extraction from the combined features. The proposed DCSAU-Net is easy to train without any extra support samples (eg. Initial is ed mask or edge). The main contributions of this work can be summarized as follows:
本文提出了一种名为DCSAU-Net的新型编码器-解码器架构用于医学图像分割。在编码器部分,我们的模型首先采用了一种新颖的主特征保留 (PFC) 策略,该策略减少了参数量、计算量,并在浅层网络整合了长程空间信息。从该层获取的丰富主特征将被传递至我们新构建的模块:紧凑型拆分注意力 (CSA) 块。CSA模块通过多路径注意力结构强化了不同通道的特征表征,每条路径包含不同数量的卷积层,使该模块能输出具有不同感受野尺度的混合特征图。两个新框架均采用残差结构设计以缓解随着层数增加导致的梯度消失问题。在解码器部分,每个下采样层的编码特征通过跳跃连接与对应的上采样特征进行拼接,我们应用相同的CSA模块从合并特征中完成高效特征提取。所提出的DCSAU-Net无需任何额外支撑样本(如初始掩码或边缘)即可轻松训练。本工作的主要贡献可归纳如下:
2. Related Work
2. 相关工作
2.1. Medical Image Segmentation
2.1. 医学图像分割
Deep learning methods based on Convolutional Neural Network (CNN) have indicated outstanding performance in medical image segmentation. U-Net, proposed by Ronneberg et al. [19], is comprised of two components: encoder and decoder. Upsampling operators are added in the decoder, which is used to recover the resolution of input images. Also, features extracted from the encoder are combined with upsampled results to achieve precise local is ation. U-Net shows a favourable segmentation performance in different kinds of medical images. Inspired by this architecture, Zhou et al. [20] presented a nested U-Net (Unet $^{++}$ ) for medical image segmentation. To reduce the semantic information loss of feature fusion between encoder and decoder, a series of nested and skip pathways are added to the model. Huang et al. [21] designed another full-scale skip connection method that combines low-resolution information and high-resolution information in different scales. Jha et al. [22] constructed a DoubleU-Net network that organise two U-Net architectures sequentially. In the encoder part, Atrous Spatial Pyramid Pooling (ASPP) is constructed at the end of each downsample layer to obtain contextual information. The evaluation result demonstrates that DoubleU-Net performs well in polyp, lesion boundary and nuclei segmentation. The gradient vanishing issue has been discovered when trying to converge deeper networks. To address this problem, He et al. [23] introduced a deep residual architecture (ResNet) that had been widely applied in different segmentation networks. For medical image segmentation, Jha et al. [24] constructed an advanced u-shape architecture for polyp segmentation, called ResUNe $^{++}$ . This model involves residual style, squeeze and excitation module, ASPP, and attention mechanism.
基于卷积神经网络 (CNN) 的深度学习方法在医学图像分割中表现出卓越性能。Ronneberg等人[19]提出的U-Net由编码器和解码器两部分组成。解码器中添加了上采样算子用于恢复输入图像分辨率,同时将编码器提取的特征与上采样结果结合以实现精确定位。U-Net在各类医学图像中均展现出优异的分割性能。受此架构启发,Zhou等人[20]提出了一种嵌套U-Net (Unet$^{++}$) 用于医学图像分割。为减少编解码器间特征融合的语义信息损失,该模型添加了一系列嵌套跳跃路径。Huang等人[21]设计了另一种全尺度跳跃连接方法,将不同尺度的低分辨率信息与高分辨率信息相结合。Jha等人[22]构建了DoubleU-Net网络,该网络将两个U-Net架构顺序连接。在编码器部分,每个下采样层末端都构建了空洞空间金字塔池化 (ASPP) 以获取上下文信息。评估结果表明DoubleU-Net在息肉、病灶边界和细胞核分割中表现优异。
当尝试收敛更深层网络时会出现梯度消失问题。为解决该问题,He等人[23]提出的深度残差架构 (ResNet) 已被广泛应用于各类分割网络。针对医学图像分割,Jha等人[24]构建了用于息肉分割的进阶U型架构ResUNe$^{++}$。该模型融合了残差结构、压缩激励模块、ASPP及注意力机制。
2.2. Attention Mechanisms
2.2. 注意力机制
In previous years, the attention mechanism has rapidly appeared in computer vision. SENet [25], one of channel attention, has been widely applied in medical image segmentation [26, 27]. It uses a squeeze module, with global average pooling, to collect global spatial information, and an excitation module to obtain the relationship between each channel in feature maps. Spatial attention can be referred to as an adaptive spatial location selection mechanism. For instance, Oktay et al. [28] introduced an attention U-Net using a novel bottom-up attention gate, which can precisely focus on a specific region that highlights useful features without extra computational costs and model parameters. Furthermore, Transformers [29] have received lot of attention recently because its success in natural language processing (NLP). Dosovitskiy et al. [30] developed a vision transformer (ViT) architecture for computer vision tasks and indicated comparable performance to CNN. Also, a series of ungraded ViT has been in a wider range of fields. Xu et al. [31] proposed LeViT-UNet to collect distant spatial information from features. In addition, Transformers have demonstrated strong performance when incorporated with CNN. Chen et al. [32], provided a novel TransUNet that selects CNN as the first half of the encoder to obtain image patches and uses the Transformer model to extract the global contexts. The final mixed feature in the decoder can achieve more accurate localisation.
近年来,注意力机制在计算机视觉领域迅速兴起。通道注意力机制的代表SENet [25] 已广泛应用于医学图像分割 [26, 27],其通过压缩模块(采用全局平均池化)收集全局空间信息,再通过激励模块获取特征图中各通道间的关系。空间注意力可视为自适应空间位置选择机制,例如Oktay等人 [28] 提出的注意力U-Net采用新型自底向上注意力门控,无需额外计算成本和模型参数即可精准聚焦于凸显有效特征的特定区域。此外,Transformer [29] 因在自然语言处理(NLP)领域的成功而备受关注,Dosovitskiy等人 [30] 提出的视觉Transformer(ViT)架构在计算机视觉任务中展现出与CNN相当的性能,一系列改进ViT模型也拓展至更广泛领域。Xu等人 [31] 提出的LeViT-UNet可从特征中捕获远距离空间信息。值得注意的是,当与CNN结合时Transformer展现出强劲性能:Chen等人 [32] 提出的TransUNet以CNN作为编码器前半段获取图像块,利用Transformer模型提取全局上下文,最终在解码器融合的特征能实现更精准的定位。
2.3. Depthwise Separable Convolution
2.3. 深度可分离卷积 (Depthwise Separable Convolution)
Depthwise separable convolution is an efficient neural nework architecture proposed by Howard et al. [33]. Each convolution filter in this architecture is responsible for one input channel. Compared with a standard convolution, depthwise convolution not only can achieve the same effects but also costs fewer number of parameters and computations. However, it only extracts features of every input channel. To combine the information between the channels and create new feature maps, a 1x1 convolution, called pointwise convolution, follows a depthwise convolution. The final MobileNets model was established and considered as a new backbone in deep learning. In the image classification task, Chollet [34] used depthwise separable convolution to construct an Xception model that outperformed previous SOTA methods and showed lower complexity. However, Sandler et al. [35] observed that depthwise convolution performs poorly in the low-channel feature maps. To tackle aforementioned issues, they proposed a new Mobile Ne tV 2 model that adds a 1x1 convolution in front of the depthwise convolution in order to increase the dimension of features in advance. Compared with MobileNets, Mobile Ne tV 2 does not raise the number of parameters but decreases the degradation of performance. In medical image segmentation, Qi et al. [36] introduced an Xnet model for 3D brain stroke lesion segmentation. A novel feature similarity module (FSM) was created to capture distance spatial information in feature maps using depthwise separable convolution. The experiment results demonstrate the X-net model costs only half the number of parameters of other SOTA models to achieve higher performance.
深度可分离卷积 (depthwise separable convolution) 是由Howard等人[33]提出的一种高效神经网络架构。该架构中每个卷积滤波器仅负责一个输入通道。与标准卷积相比,深度卷积 (depthwise convolution) 不仅能达到相同效果,还能减少参数量和计算量。但其仅能提取各输入通道的特征。为了融合通道间信息并生成新特征图,在深度卷积后会接一个被称为逐点卷积 (pointwise convolution) 的1x1卷积。最终建立的MobileNets模型被视为深度学习中的新骨干网络。在图像分类任务中,Chollet[34]使用深度可分离卷积构建了Xception模型,其性能超越先前SOTA方法且复杂度更低。然而Sandler等人[35]发现深度卷积在低通道特征图中表现不佳。针对该问题,他们提出了MobileNetV2模型,通过在深度卷积前增加1x1卷积来预先提升特征维度。相比MobileNets,MobileNetV2未增加参数量却降低了性能退化。在医学图像分割领域,Qi等人[36]提出了用于3D脑卒中病灶分割的Xnet模型,通过深度可分离卷积构建新型特征相似性模块 (FSM) 来捕捉特征图中的距离空间信息。实验表明Xnet模型仅需其他SOTA模型一半参数量即可实现更高性能。
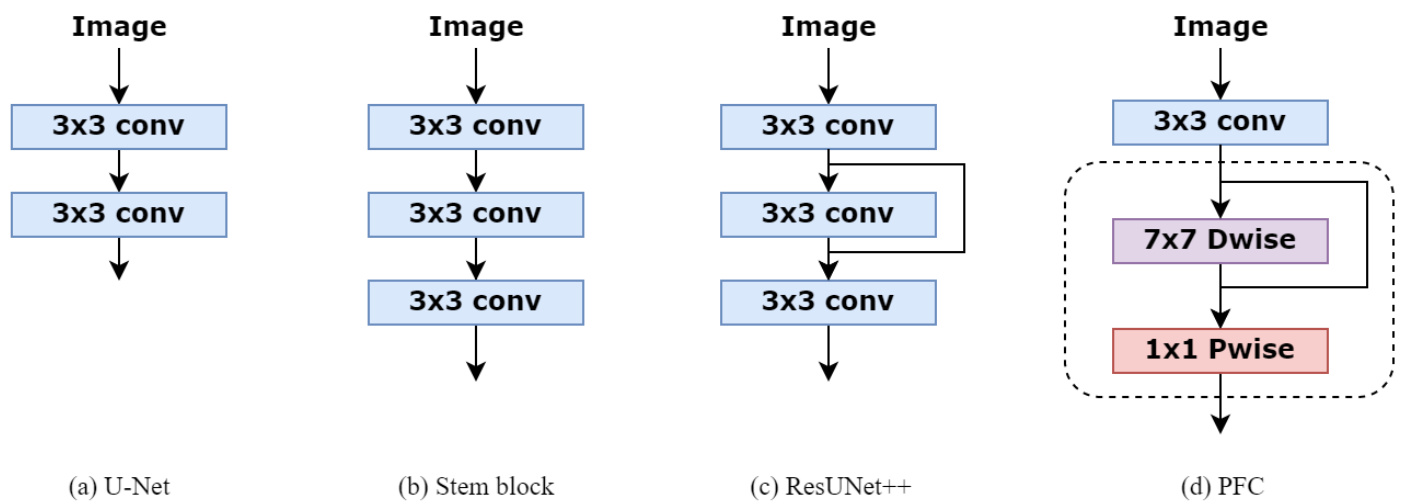
Figure 1: Comparing our PFC strategy with U-Net [19], Stem block [37] and ResUNet $^{++}$ [24] designs used to extract the low-level semantic information from the input images.
图 1: 对比我们的PFC策略与U-Net [19]、Stem block [37]和ResUNet$^{++}$[24]用于从输入图像中提取低层语义信息的设计方案。
3. Method
3. 方法
3.1. Primary Feature Conservation
3.1. 主要特征保留
For most of medical image segmentation networks, the co volution s used in the first down sampling block operation is to extract low-level semantic information from images. The U-Net architecture [19] in Fig.1 (a) has been widely used in different models [22, 28]. The stem block [37] in Fig.1 (b) is usually designed to obtain the same receptive field as $7\mathrm{x}7$ convolution and reduce the number of parameters. The first feature scale down sampling layer in ${\tt R e s U N e t++}$ [24] adds skip connection strategy to mitigate the potential impact of the gradient vanish, which is shown in Fig.1 (c). Although stacking more convolutional blocks can extend the receptive field of neural network, the number of parameters and the amount of computation will increase rapidly. The stability of the model may be destroyed. Also, recent research suggests that the valid receptive field will decrease to some extent when the number of stacked $3{\times}3$ convolutions keep increasing [38]. To address this issue, we introduce a new primary feature conservation (PFC) strategy in the first down sampling block, which is provided in Fig.1 (d). The main refinement of our module adopts depthwise separable convolution, consisting of $7\mathrm{x}7$ depthwise convolution followed by 1x1 pointwise convolution. As depthwise separable convolution decreases the costs of computation and the number of parameters compared to the standard convolution [33], we have the opportunity to apply large kernel sizes for the depthwise convolution in order to merge distant spatial information and preserve primary features as much as possible in the low-level semantic layer. The 1x1 pointwise convolution is used to combine channel information. Also, 3x3 convolution is added to the head of this module for downsampling the input image and raising the channel because depthwise separable convolution shows degradation of performance on low-dimensional features [35]. Every convolution is followed by a ReLU activation and BatchNorm. To avoid gradient vanish, PFC block is constructed with residual style. To this end, our proposed PFC module can improve the performance without increasing the number of parameters and computational costs. In addition, the reason for using depthwise convolution with $7\mathrm{x}7$ kernel size will be explained in section 5.
大多数医学图像分割网络的首个下采样块操作采用卷积提取图像的低级语义信息。图1(a)中的U-Net架构[19]已被广泛应用于多种模型[22,28]。图1(b)中的stem block[37]通常设计为获得与$7\mathrm{x}7$卷积相同的感受野并减少参数量。${\tt R e s U N e t++}$[24]的首个特征尺度下采样层通过添加跳跃连接策略缓解梯度消失的潜在影响,如图1(c)所示。虽然堆叠更多卷积块能扩展神经网络感受野,但参数量和计算量会急剧增加,可能破坏模型稳定性。近期研究还表明,当$3{\times}3$卷积堆叠层数持续增加时,有效感受野会一定程度缩小[38]。为解决该问题,我们在首个下采样块引入新的初级特征保留(PFC)策略,如图1(d)所示。该模块主要采用深度可分离卷积,包含$7\mathrm{x}7$深度卷积与1x1逐点卷积。由于深度可分离卷积相比标准卷积能降低计算成本和参数量[33],我们得以采用大核深度卷积来融合远距离空间信息,最大限度保留低级语义层的初级特征。1x1逐点卷积用于整合通道信息。模块头部还添加3x3卷积进行图像下采样和通道提升,因深度可分离卷积在低维特征上存在性能退化问题[35]。所有卷积后接ReLU激活和BatchNorm。为规避梯度消失,PFC块采用残差结构。最终提出的PFC模块能在不增加参数量和计算成本的前提下提升性能。第5节将阐述采用$7\mathrm{x}7$核深度卷积的具体原因。
3.2. Compact Split-Attention block
3.2. 紧凑型分割注意力 (Compact Split-Attention) 模块
The VGGNet [39] and typical residual structures [23] have been applied in many previous semantic segmentation networks, such as DoubleUnet [22] and ResUnet [40]. However, convolutional layers in VGGNet are stacked directly, which means every feature layer has a comparatively constant receptive field [41]. In medical image segmentation, different lesions may have different sizes. Sufficient representation of multi-scale features is beneficial for the model to perceive data features. Recently various models learning the representation via cross-channel features have been proposed, such as ResNeSt [42]. Inspired by these methods, we develop a new compact split-attention (CSA) architecture.
VGGNet [39] 和典型的残差结构 [23] 已被应用于许多先前的语义分割网络中,例如 DoubleUnet [22] 和 ResUnet [40]。然而,VGGNet 中的卷积层是直接堆叠的,这意味着每个特征层都具有相对固定的感受野 [41]。在医学图像分割中,不同的病灶可能具有不同的大小。充分表示多尺度特征有助于模型感知数据特征。最近,提出了多种通过学习跨通道特征来学习表示的方法,例如 ResNeSt [42]。受这些方法的启发,我们开发了一种新的紧凑型分割注意力 (CSA) 架构。
An overview of CSA block is illustrated in Fig. 2. The ResNeSt utilises a large channel-split groups for feature extraction, which is more efficient for general computer vision tasks with the adequate data and costs massive parameters. Furthermore, each group of this model adopts the same convolutional operations that receive an equal receptive field size. To optimise the structure and make it more suitable for medical image segmentation, our proposed block maintains two feature groups $N=2,$ ) to reduce the number of parameters the entire network. These two groups split from the input features will be fed into different transformations $F_{i}$ . Both two groups involve one $1\times1$ convolution followed by one $3{\times}3$ convolution. To improve the representation across channels, the output feature maps of the other group $(F_{2})$ will combine with the result of the first group $(F_{1})$ and go through another $3{\times}3$ convolution, which can receive semantic information from both split groups and expand the receptive field of the network. Therefore, CSA block presents a stronger ability to extract both global and local information from feature maps. Mathematically, the fusion feature maps can be defined as:
CSA模块的概览如图2所示。ResNeSt采用大通道分割组进行特征提取,在数据充足的情况下能更高效地完成通用计算机视觉任务,但需要大量参数。此外,该模型的每个组采用相同的卷积操作,接收相同的感受野大小。为优化结构并使其更适合医学图像分割,我们提出的模块保留了两个特征组 $N=2$ 以减少整个网络的参数量。从输入特征分割出的这两组将馈入不同的变换 $F_{i}$ 。两组均包含一个 $1\times1$ 卷积和一个 $3{\times}3$ 卷积。为提升跨通道表征能力,另一组 $(F_{2})$ 的输出特征图将与第一组 $(F_{1})$ 的结果结合,并通过另一个 $3{\times}3$ 卷积,从而获取来自两个分割组的语义信息并扩展网络的感受野。因此,CSA模块展现出更强的从特征图中提取全局和局部信息的能力。数学上,融合特征图可定义为:
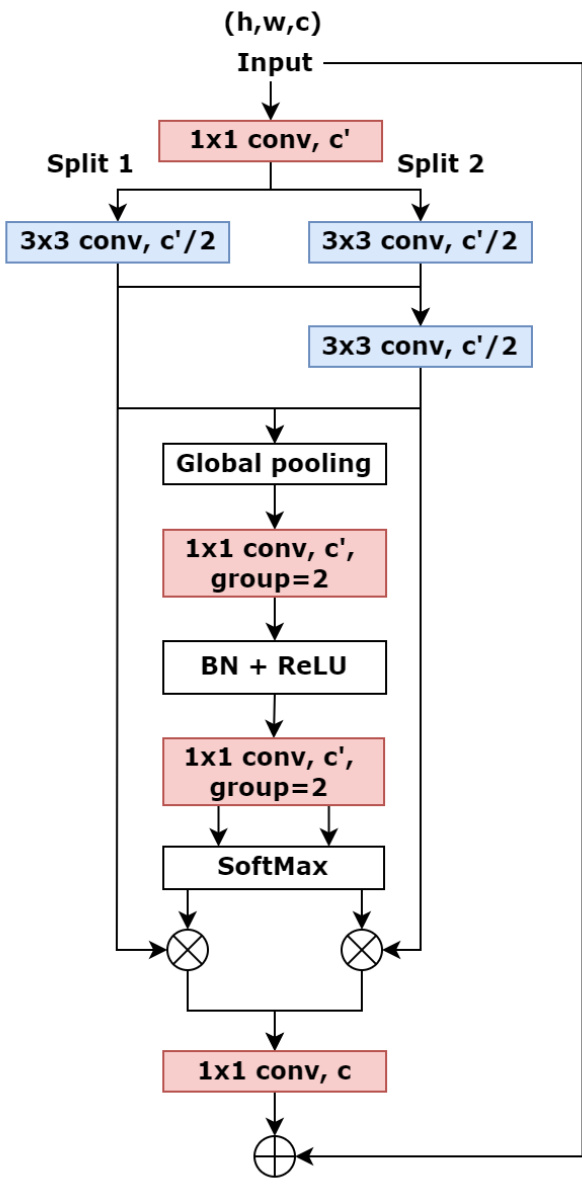
Figure 2: The framework of CSA block
图 2: CSA模块框架
$$
\hat{U}=\sum_{i=1}^{N}F_{i}(X_{i}),\hat{U}\in R^{H\times W\times C}
$$
$$
\hat{U}=\sum_{i=1}^{N}F_{i}(X_{i}),\hat{U}\in R^{H\times W\times C}
$$
Where H, W and C are the scales of output feature maps. The channel-wise statistics generated by global average pooling collect global spatial information, which is produced by compressing transformation output through spatial dimensions and the $c$ -th component calculated by:
其中H、W和C表示输出特征图的尺度。通过全局平均池化生成的通道级统计信息汇聚了全局空间信息,该信息是通过压缩空间维度上的变换输出产生的,其第$c$个分量计算公式为:
$$
S_{c}=\frac{1}{H\times W}\sum_{\alpha=1}^{H}\sum_{\beta=1}^{W}\hat{U}_{c}\left(\alpha,\beta\right),~S\in R^{C}
$$
$$
S_{c}=\frac{1}{H\times W}\sum_{\alpha=1}^{H}\sum_{\beta=1}^{W}\hat{U}_{c}\left(\alpha,\beta\right),~S\in R^{C}
$$
The channel-wise soft attention is used for aggregating a weighted fusion represented by cardinal group representation, where a split weighted combination can catch crucial information in feature maps. Then the $c$ -th channel of feature maps is calculated as:
通道级软注意力 (channel-wise soft attention) 用于聚合以基数群表示 (cardinal group representation) 的加权融合,其中分割加权组合能捕捉特征图中的关键信息。随后特征图的第 $c$ 个通道计算公式为:
$$
V_{c}=\sum_{i=1}^{N}a_{i}\left(c\right)F_{i}(X_{i})
$$
$$
V_{c}=\sum_{i=1}^{N}a_{i}\left(c\right)F_{i}(X_{i})
$$
Where $a_{i}$ is a (soft) assignment weight designed by:
其中 $a_{i}$ 是由以下公式设计的 (软) 分配权重:
$$
a_{i}\left(c\right)=\frac{e x p(\mathcal{G}{i}^{c}(S))}{\sum_{j=1}^{N}e x p(\mathcal{G}_{j}^{c}(S))}
$$
$$
a_{i}\left(c\right)=\frac{e x p(\mathcal{G}{i}^{c}(S))}{\sum_{j=1}^{N}e x p(\mathcal{G}_{j}^{c}(S))}
$$
Here $\mathcal{G}_{i}^{c}$ indicates the weight of global spatial information $S$ to the $c$ -th channel and is quantified using two 1x1 convolutions with BatchNorm and ReLU activation. As a result, the full CSA block is designed with a standard residual architecture that the output $Y$ is calculated using a skip connection: $Y=V+X$ , when the shape of output feature maps is the same as the input feature maps. Otherwise, an extra transformation $T$ will be applied on the skip connection to obtain the same shape. For instance, $T$ can be convolution with a stride or mix of convolution and pooling.
这里 $\mathcal{G}_{i}^{c}$ 表示全局空间信息 $S$ 对第 $c$ 个通道的权重,并通过两个带有批归一化 (BatchNorm) 和 ReLU 激活的 1x1 卷积进行量化。因此,完整的 CSA (Channel-Spatial Attention) 模块采用标准的残差结构设计,当输出特征图的形状与输入特征图相同时,输出 $Y$ 通过跳跃连接计算得出: $Y=V+X$ 。若形状不同,则会在跳跃连接上应用额外的变换 $T$ 以匹配形状。例如, $T$ 可以是带步长的卷积或卷积与池化的组合。
3.3. DCSAU-Net Architecture
3.3. DCSAU-Net 架构
For medical image segmentation, we establish a novel model using the proposed PFC strategy and CSA block following the encoder-decoder architecture, which is referred to as DCSAU-Net, and shown in Fig. 3. The encoder of DCSAU-Net first uses PFC strategy to extract low-level semantic information from the input images. The depthwise separable convolution with a large $7\mathrm{x}7$ kernel size is able to broaden the receptive field of the network and preserve primary features without increasing the number of parameters. The CSA block applies multi-path feature groups with a different number of convolutions and the attention mechanism, which incorporates channel information across different receptive field scales and highlights meaningful semantic features. Each of block is followed by a $2\times2$ max pooling with stride 2 for performing a down sampling operation. Every decoder sub-network starts with an upsampling operator to recover the original size of the input image step by step. The skip connections are used to concatenate these feature maps with the feature maps from the corresponding encoder layer, which mixes low-level and high-level semantic information to generate a precise mask. The skip connections are followed by CSA blocks to alleviate the gradient vanishing problem and capture efficient features. Finally, a $1\times1$ convolution succeeded by a sigmoid or softmax layer is used to output the binary or multi-class segmentation mask.
在医学图像分割领域,我们基于编码器-解码器架构,采用提出的PFC策略和CSA模块构建了一个新型模型,命名为DCSAU-Net,如图3所示。DCSAU-Net的编码器首先运用PFC策略从输入图像中提取低层次语义信息。采用大尺寸$7\mathrm{x}7$核的深度可分离卷积能在不增加参数量的前提下扩大网络感受野并保留主要特征。CSA模块通过多路径特征组(包含不同卷积数量)结合注意力机制,整合跨不同感受野尺度的通道信息,并突出有意义的语义特征。每个模块后接步长为2的$2\times2$最大池化进行下采样操作。解码器子网络均以逐步恢复输入图像原始尺寸的上采样算子起始,通过跳跃连接将特征图与对应编码器层的特征图拼接,融合低层次与高层次语义信息以生成精确掩码。跳跃连接后接CSA模块以缓解梯度消失问题并捕获有效特征。最终采用$1\times1$卷积接Sigmoid或Softmax层输出二值或多类别分割掩码。
4. Experiments and Results
4. 实验与结果
4.1. Datasets
4.1. 数据集
To evaluate the effectiveness of DCSAU-Net, we test it on four publicly available medical image datasets.
为了评估DCSAU-Net的有效性,我们在四个公开可用的医学影像数据集上进行了测试。
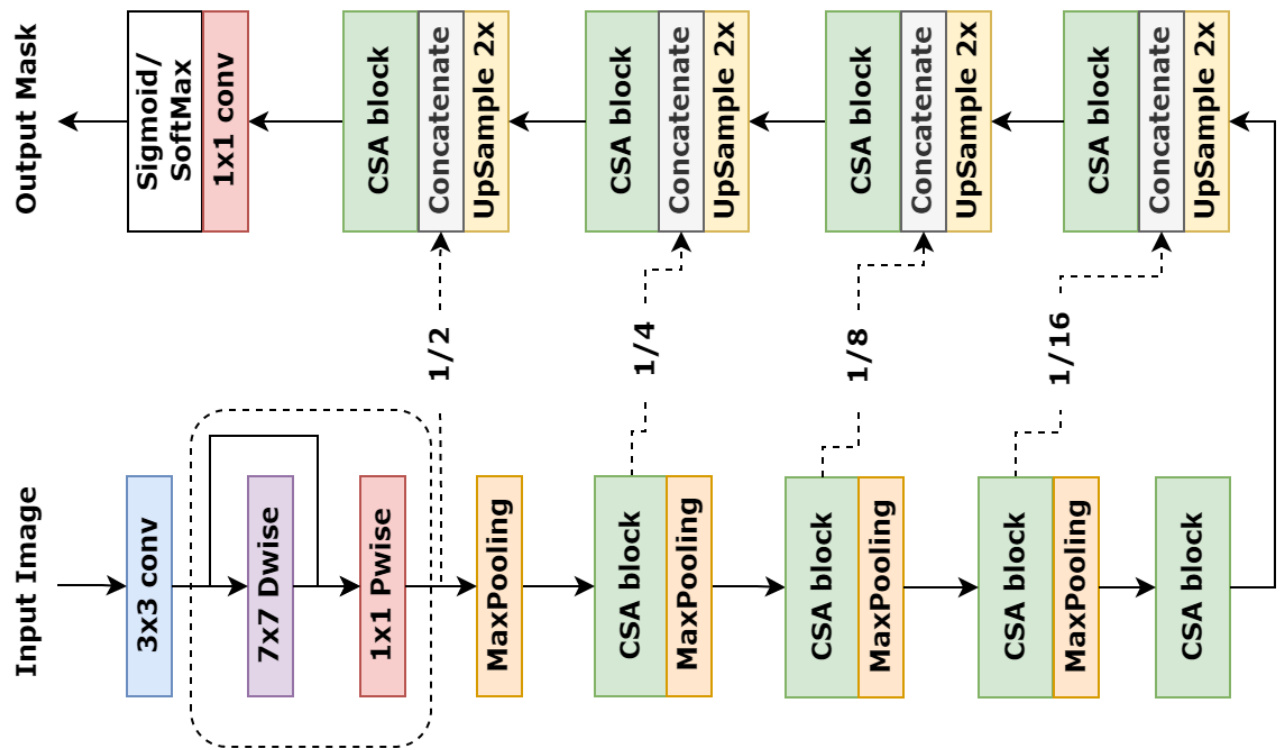
Figure 3: The presentation of DCSAU-Net with PFC strategy and CSA block
图 3: 采用PFC策略和CSA模块的DCSAU-Net结构展示
More details about data split are presented in Table 1. All of these datasets are related to clinic diagnosis. Therefore, their segmentation result can be significant for patients.
关于数据拆分的更多细节见表1。所有这些数据集都与临床诊断相关,因此它们的分类结果对患者具有重要意义。
Table 1 Details of the medical segmentation datasets used in our experiments.
表 1: 本实验所用医学分割数据集详情。
| 数据集 | 图像数量 | 输入尺寸 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|---|---|
| CVC-ClinicDB | 612 | 384×288 | 441 | 110 | 61 |
| 2018 DataScience Bowl | 670 | 可变 | 483 | 120 | 67 |
| ISIC2018 | 2594 | 可变 | 1868 | 467 | 259 |
| SegPC 2021 | 498 | 可变 | 360 | 89 | 49 |
4.2. Evaluation Metrics
4.2. 评估指标
Mean intersection over union (mIoU), Accuracy, Recall, Precision and F1-score are standard metrics for medical image segmentation, where mIoU is a common metric used in competitions to compare the performance between each of models. For the more exhaustive comparison between the performance of DCSAU-Net and other popular models, we calculate each of these metrics in our experiment.
平均交并比 (mIoU)、准确率、召回率、精确率和F1分数是医学图像分割的标准评估指标,其中mIoU是竞赛中用于比较各模型性能的常用指标。为了更全面地对比DCSAU-Net与其他流行模型的性能表现,我们在实验中计算了上述所有指标。
4.3. Data Augmentation
4.3. 数据增强
Medical image datasets usually have a limited number of samples to be available in the training phase due to obtaining and annotating images is expensive and time-consuming [43]. Therefore, the model is prone to over fitting. To mitigate this issue, data augmentation methods are generally used in the training stage to extend the diversity of samples and enhance the model generalisation. In our experiment, we randomly apply horizontal flip, rotation and cutout with the probability of 0.25 to the training set of each dataset.
医学图像数据集在训练阶段通常样本数量有限,因为获取和标注图像既昂贵又耗时 [43]。因此,模型容易出现过拟合。为了缓解这一问题,训练阶段通常会采用数据增强方法,以扩展样本多样性并提升模型泛化能力。在我们的实验中,我们对每个数据集的训练集随机应用水平翻转、旋转和随机擦除 (cutout),概率均为0.25。
4.4. Implementation Details
4.4. 实现细节
All experiments are implemented using PyTorch 1.10.0 framework on a single NVIDIA V100 Tensor Core GPU, 8-core CPU and 16GB RAM. We use a common segmentation loss function, Dice loss, and an Adam optimizer with a learning rate of 1e-4 to train all models. The number of batch sizes and epochs are set to 16 and 200 respectively. During training, we resize the images to $256\times256$ for CVCClinicDB and 2018 Data Science Bowl datasets. For ISIC2018 and SegPC-2021 datasets, the input images are resized to $512\times512$ . Also, we apply Reduce LR On Plateau to optimise the learning rate. All experiments on four datasets are conducted on the same train, validation, and test datasets. In addition, we train other SOTA models with default parameters, meanwhile, a pretrained ViT model is loaded when training the TransUNet and LeViT-UNet. The rest of models are trained from scratch.
所有实验均在配备NVIDIA V100 Tensor Core GPU、8核CPU和16GB内存的单机上使用PyTorch 1.10.0框架实现。我们采用通用的分割损失函数Dice loss和学习率为1e-4的Adam优化器训练所有模型,批次大小和训练周期分别设为16和200。训练过程中,CVCClinicDB和2018 Data Science Bowl数据集的图像被调整为$256\times256$分辨率,ISIC2018与SegPC-2021数据集则调整为$512\times512$。同时采用Reduce LR On Plateau策略动态优化学习率。四个数据集的实验均使用相同的训练集、验证集和测试集。此外,其他SOTA模型均采用默认参数训练,其中TransUNet和LeViT-UNet加载了预训练的ViT模型,其余模型均从头开始训练。
4.5. Results
4.5. 结果
In this section, we present quantitative results on four different biomedical image datasets and compare our proposed architecture with other SOTA methods.
在本节中,我们展示了四个不同生物医学图像数据集的定量结果,并将提出的架构与其他SOTA方法进行了比较。
4.5.1. Comparison on CVC-ClinicDB Dataset
4.5.1. CVC-ClinicDB数据集对比
The quantitative results on CVC-ClinicDB dataset are shown in Table 2. For medical image segmentation task, the performance of network on mIoU and F1-score metrics usually receives more attention. From Table 2, DCSAU-Net achieves a F1-score of 0.916 and a mIoU of 0.861, which outperforms DoubleU-Net by $2.0%$ in terms of F1-score and $2.5%$ in mIoU. Particularly, our proposed model provides a significant improvement over the two recent transformerbased architectures, where the mIoU of DCSAU-Net is $6.2%$ and $10.7%$ higher than TransUNet and LeViT-UNet, and the F1-score of DCSAU-Net is $4.9%$ and $8.8%$ higher than these two models respectively.
CVC-ClinicDB数据集的定量结果如表2所示。对于医学图像分割任务,网络在mIoU和F1-score指标上的表现通常更受关注。从表2可以看出,DCSAU-Net实现了0.916的F1-score和0.861的mIoU,在F1-score上比DoubleU-Net高出$2.0%$,在mIoU上高出$2.5%$。特别是,我们提出的模型相比最近两种基于Transformer的架构有显著提升,DCSAU-Net的mIoU分别比TransUNet和LeViT-UNet高出$6.2%$和$10.7%$,F1-score分别高出$4.9%$和$8.8%$。
Table 2 Results on the CVC-ClinicDB
表 2 CVC-ClinicDB 数据集上的结果
| 方法 | 准确率 | 精确率 | 召回率 | F1分数 | mloU |
|---|---|---|---|---|---|
| U-Net [19] | 0.984±0.0190.882±0.1950.893±0.1760.872±0.1890.809±0.213 | ||||
| Unet++[20] | 0.984±0.022 | 0.919±0.1390.859±0.197 | 0.876±0.184 | 0.811±0.196 | |
| Attention-UNet[28] | 0.986±0.016 | 0.904±0.170 | 0.901±0.185 | 0.895±0.1680.835±0.179 | |
| ResUNet++ [24] | 0.982±0.021 | 0.870±0.191 | 0.853±0.213 | 0.854±0.196 | 0.781±0.213 |
| R2U-Net [44] | 0.978±0.028 | 0.880±0.185 | 0.847±0.223 | 0.841±0.205 | 0.765±0.224 |
| DoubleU-Net[22] | 0.986±0.017 | 0.892±0.179 | 0.912±0.197 | 0.896±0.173 | 0.836±0.196 |
| UNet3+ [21] | 0.984±0.022 | 0.907±0.152 | 0.885±0.155 | 0.892±0.171 | 0.827±0.191 |
| TransUNet [32] | 0.982±0.209 | 90.876±0.1990.873±0.191 | 0.867±0.188 | 0.799±0.201 | |
| LeViT-UNet[45] | 0.980±0.0230.849±0.2410 | 0.826±0.232 | 0.828±0.233 | 30.754±0.244 | |
| DCSAU-Net | 0.990±0.0150.917±0.1480.920±0.1430.916±0.1410.861±0.156 |
4.5.2. Comparison on SegPC-2021 Dataset
4.5.2. SegPC-2021数据集对比
For medical image analysis, some of medical images may have multi-class objects that need to be segmented out. To satisfy this demand, we evaluate all models on $\mathrm{SegPC}\boldsymbol{-}2021$ dataset with two different kinds of cells. The quantitative results are provided in Table 3. Compared with other SOTA models, DCSAU-Net displays the best performance in all defined metrics. Specifically, our proposed method produces a mIoU score of 0.8048 with a more significant rise of $3.6%$ over Une $^{++}$ and $2.8%$ in F1-score compared to the DoubleUNet architecture.
在医学图像分析领域,部分医学图像可能包含需要分割的多类目标。为满足这一需求,我们在包含两种细胞的$\mathrm{SegPC}\boldsymbol{-}2021$数据集上评估了所有模型。定量结果如表3所示。与其他SOTA模型相比,DCSAU-Net在所有定义指标中均展现出最佳性能。具体而言,我们提出的方法取得了0.8048的mIoU分数,较U-Net$^{++}$有3.6%的显著提升,在F1分数上比DoubleUNet架构高出2.8%。
Table 3 Results on the $\mathsf{S e g P C2021}$ (Multiple Myeloma Plasma Cells Segmentation challenge)
表 3: $\mathsf{S e g P C2021}$ (多发性骨髓瘤浆细胞分割挑战赛) 结果
| 方法 | 准确率 | 精确度 | 召回率 | F1分数 | mIoU |
|---|---|---|---|---|---|
| U-Net [19] | 0.939±0.053 | 30.842±0.1420.879±0.118 | - | - | 30.855±0.1190.766±0.148 |
| Unet++[20] | 0.942±0.058 | 0.855±0.142 | 0.876±0.141 | 0.857±0.127 | 0.770±0.163 |
| Attention-UNet[28] | 0.940±0.048 | - | 0.845±0.143 | 0.866±0.125 | 0.849±0.117 |
| ResUNet++[24] | 0.934±0.051 | 0.838±0.118 | 0.858±0.101 | 0.840±0.086 | 0.736±0.121 |
| R2U-Net [44] | 0.933±0.056 | 0.852±0.122 | 0.831±0.136 | 0.834±0.112 | 0.744±0.128 |
| DoubleU-Net[22] | 0.937±0.052 | 0.833±0.120 | 0.896±0.084 | 0.858±0.089 | 0.763±0.130 |
| UNet3+ [21] | 0.939±0.051 | 0.848±0.119 | 0.866±0.078 | 0.852±0.083 | 0.766±0.131 |
| TransUNet [32] | 0.939±0.047 | 0.822±0.130 | 0.869±0.121 | 0.838±0.113 | 0.741±0.146 |
| LeViT-UNet[45] | 0.939±0.049 | 0.850±0.120 | 0.837±0.115 | 0.837±0.101 | 0.738±0.137 |
| DCSAU-Net | - | - | - | 0.950±0.0450.871±0.113 0.910±0.0670.886±0.0780.806±0.121 | - |
4.5.3. Comparison on 2018 Data Science Bowl Dataset
4.5.3. 2018数据科学碗数据集对比
Nuclei segmentation plays an important role in the biomedical image analysis. We use an open-access dataset from 2018 Data Science Bowl challenge to evaluate the performance of DSAU-Net and other SOTA networks. A comparison between each model is presented in Table 4 The results demonstrate that DCSAU-Net achieves a F1-score of 0.914 which is $1.9%$ higher than TransUNet and mIoU of 0.850, which is $2.5%$ higher than $\mathrm{UNet3+}$ . Overall, our proposed model demonstrates the highest score in the most of evaluation metrics, including precision and accuracy.
细胞核分割在生物医学图像分析中扮演着重要角色。我们采用2018年Data Science Bowl挑战赛的公开数据集评估DSAU-Net及其他SOTA网络的性能。各模型对比结果如 表4 所示:DCSAU-Net的F1分数达到0.914 (比TransUNet高 $1.9%$ ),mIoU为0.850 (较 $\mathrm{UNet3+}$ 提升 $2.5%$ )。总体而言,我们提出的模型在多数评估指标(包括精确度和准确率)上均取得最高分值。
Table 4 Results on the 2018 Data Science Bowl
表 4: 2018 Data Science Bowl 结果
| 方法 | 准确率 (Accuracy) | 精确率 (Precision) | 召回率 (Recall) | F1分数 (F1-score) | mloU |
|---|---|---|---|---|---|
| U-Net [19] | 0.955±0.047 | 0.872±0.105 | - | - | - |
| Unet++ [20] | 0.955±0.047 | 0.874±0.122 | 0.918±0.141 | 0.886±0.132 | 0.814±0.150 |
| Attention-UNet [28] | 0.953±0.046 | 0.870±0.151 | 0.918±0.136 | 0.887±0.134 | 0.816±0.152 |
| ResUNet++ [24] | 0.954±0.048 | 0.900±0.120 | 0.903±0.104 | 0.894±0.104 | 0.822±0.138 |
| R2U-Net [44] | 0.956±0.047 | 0.884±0.135 | 0.911±0.140 | 0.891±0.135 | 0.822±0.156 |
| DoubleU-Net [22] | 0.955±0.045 | 0.876±0.111 | 0.927±0.131 | 0.889±0.133 | 0.817±0.150 |
| UNet3+ [21] | 0.957±0.044 | 0.889±0.149 | 0.909±0.135 | 0.893±0.133 | 0.825±0.150 |
| TransUNet [32] | 0.954±0.047 | 0.900±0.101 | 0.906±0.121 | 0.895±0.099 | 0.821±0.136 |
| LeViT-UNet [45] | 0.953±0.049 | 0.889±0.150 | 0.888±0.147 | 0.882±0.136 | 0.808±0.157 |
| DCSAU-Net | - | - | - | - | - |
4.5.4. Comparison on ISIC-2018 Dataset
4.5.4. ISIC-2018数据集上的对比
Table 5 shows the quantitative results on ISIC-2018 dataset for the lesion boundary segmentation task. mIoU is an official evaluation metric for the challenge. According to Table 4, DCSAU-Net has an increase of $2.4%$ over LeViT-UNet in this metric, and $1.8%$ over ${\mathrm{UNet}}3+{\mathrm{\Omega}}$ in F1-score. Within the rest of metrics, our model achieves a recall of 0.922 and an accuracy of 0.960, which is better than other baseline methods. Also, a high recall score is more favourable in clinic applications [46].
表 5 展示了 ISIC-2018 数据集上病灶边界分割任务的定量结果。mIoU 是该挑战赛的官方评估指标。根据表 4,DCSAU-Net 在该指标上比 LeViT-UNet 提高了 $2.4%$,在 F1-score 上比 ${\mathrm{UNet}}3+{\mathrm{\Omega}}$ 提高了 $1.8%$。在其他指标中,我们的模型实现了 0.922 的召回率和 0.960 的准确率,优于其他基线方法。此外,高召回率在临床应用中更受青睐 [46]。
Table 5 Results on the ISIC 2018 (Skin Lesion Segmentation challenge)
表 5 ISIC 2018 (皮肤病变分割挑战赛) 结果
| 方法 | 准确率 | 精确度 | 召回率 | F1分数 | mloU |
|---|---|---|---|---|---|
| U-Net [19] | 0.952±0.0790.883±0.1520.906±0.1800.874±0.1580.802±0.182 | ||||
| Unet++ [20] | 0.954±0.077 | 0.899±0.136 | 0.906±0.155 | 0.883±0.138 | 0.812±0.171 |
| Attention-UNet [28] | 0.954±0.078 | 0.915±0.140 | 0.890±0.171 | 0.883±0.149 | 0.814±0.180 |
| ResUNet++ [24] | 0.954±0.082 | 0.905±0.139 | 0.889±0.183 | 0.879±0.153 | 0.810±0.181 |
| R2U-Net [44] | 0.945±0.078 | 0.834±0.189 | 0.912±0.163 | 0.848±0.160 | 0.762±0.189 |
| DoubleU-Net [22] | 0.953±0.092 | 0.903±0.149 | 0.897±0.186 | 0.879±0.167 | 0.813±0.191 |
| UNet3+ [21] | 0.956±0.068 | 0.889±0.151 | 0.916±0.130 | 0.886±0.132 | 0.816±0.165 |
| TransUNet [32] | 0.945±0.085 | 0.847±0.186 | 0.898±0.185 | 0.849±0.178 | 0.770±0.203 |
| LeViT-U [45] | 0.954±0.089 | 0.896±0.152 | 0.908±0.176 | 0.883±0.161 | 0.817±0.185 |
| DCSAU-Net | 0.960±0.0750.917±0.1270.922±0.1390.904±0.1280.841±0.158 |
4.6. Ablation Study
4.6. 消融实验
In this section, we conduct an extensional ablation study on the DCSAU-Net. The number of parameters, floating point operations (FLOPs) and frames per second (FPS) are calculated to investigate the effectiveness of each module in more detail. Table 6 provides the ablation results of four configurations on all four datasets.
在本节中,我们对DCSAU-Net进行了扩展消融实验。通过计算参数量、浮点运算次数(FLOPs)和每秒帧率(FPS)来更详细地研究各模块的有效性。表6展示了四种配置在全部四个数据集上的消融结果。
Table 6 Detailed ablation study of the DCSAU-Net architecture.
表 6: DCSAU-Net架构的详细消融研究
| 数据集 | 方法 | 准确率 | 精确度 | 召回率 | F1分数 | mloU | 参数量 | FLOPs | FPS |
|---|---|---|---|---|---|---|---|---|---|
| CVC-ClinicDB | U-Net [19] | 0.984±0.019 | 0.882±0.195 | 0.893±0.176 | 0.872±0.189 | 0.809±0.213 | 13.40M | 31.11 | 109.95 |
| U-Net + PFC | 0.987±0.014 | 0.901±0.191 | 0.885±0.214 | 0.881±0.211 | 0.828±0.216 | 13.37M | 29.70 | 103.49 | |
| U-Net + CSA | 0.987±0.015 | 0.890±0.211 | 0.903±0.179 | 0.890±0.193 | 0.840±0.204 | 2.62M | 8.33 | 44.26 | |
| U-Net + PFC + CSA (ours) | 0.990±0.015 | 0.917±0.148 | 0.920±0.143 | 0.916±0.141 | 0.861±0.156 | 2.60M | 6.91 | 43.37 | |
| SegPC-2021 | U-Net [19] | 0.939±0.053 | 0.842±0.142 | 0.879±0.118 | 0.855±0.119 | 0.766±0.148 | 13.40M | 124.58 | 48.46 |
| U-Net + PFC | 0.946±0.046 | 0.866±0.123 | 0.874±0.086 | 0.864±0.085 | 0.780±0.144 | 13.37M | 119.79 | 47.63 | |
| U-Net + CSA | 0.946±0.046 | 0.855±0.135 | 0.896±0.071 | 0.870±0.080 | 0.781±0.146 | 2.62M | 33.35 | 33.22 | |
| U-Net + PFC + CSA (ours) | 0.950±0.045 | 0.871±0.113 | 0.910±0.067 | 0.886±0.078 | 0.806±0.121 | 2.60M | 27.66 | 32.08 | |
| 2018Data | U-Net [19] | 0.955±0.047 | 0.872±0.105 | 0.920±0.111 | 0.887±0.090 | 0.808±0.126 | 13.40M | 31.11 | 125.30 |
| U-Net + PFC | 0.955±0.046 | 0.905±0.105 | 0.910±0.096 | 0.901±0.084 | 0.830±0.123 | 13.37M | 29.70 | 117.09 | |
| U-Net + CSA | 0.957±0.045 | 0.903±0.105 | 0.925±0.090 | 0.908±0.082 | 0.839±0.122 | 2.62M | 8.33 | 43.87 | |
| U-Net + PFC + CSA (ours) | 0.959±0.045 | 0.914±0.098 | 0.924±0.077 | 0.914±0.077 | 0.850±0.114 | 2.60M | 6.91 | 43.42 | |
| ISIC-2018 | U-Net [19] | 0.952±0.079 | 0.883±0.152 | 0.906±0.180 | 0.874±0.158 | 0.802±0.182 | 13.40M | 31.11 | 115.85 |
| U-Net + PFC | 0.955±0.076 | 0.915±0.129 | 0.901±0.148 | 0.890±0.128 | 0.821±0.161 | 13.37M | 29.70 | 113.36 | |
| U-Net + CSA | 0.955±0.078 | 0.915±0.123 | 0.909±0.140 | 0.893±0.127 | 0.830±0.160 | 2.62M | 8.33 | 43.19 | |
| U-Net + PFC + CSA (ours) | 0.960±0.075 | 0.917±0.127 | 0.922±0.139 | 0.904±0.128 | 0.841±0.158 | 2.60M | 6.91 | 41.91 |
Table 7 An investigation of different kernel size in the PFC block of the DCSAU-Net architecture.
表 7: DCSAU-Net 架构中 PFC 块不同卷积核尺寸的对比研究
| 数据集 | 卷积核尺寸 | 准确率 | 精确率 | 召回率 | F1分数 | mloU | 参数量 | FLOPs | FPS |
|---|---|---|---|---|---|---|---|---|---|
| CVC-ClinicDB | 3x3 | 0.989±0.014 | 0.892±0.196 | 0.922±0.176 | 0.903±0.188 | 0.857±0.194 | 2.58M | 6.24 | 43.02 |
| 5x5 | 0.987±0.010 | 0.898±0.172 | 0.916±0.136 | 0.904±0.159 | 0.858±0.174 | 2.59M | 6.50 | 42.89 | |
| 7x7 | 0.990±0.015 | 0.917±0.148 | 0.920±0.143 | 0.916±0.141 | 0.861±0.156 | 2.60M | 6.91 | 43.37 | |
| 9x9 | 0.988±0.017 | 0.908±0.160 | 0.902±0.180 | 0.894±0.177 | 0.841±0.198 | 2.61M | 7.44 | 43.39 | |
| SegPC-2021 | 3x3 | 0.946±0.058 | 0.866±0.118 | 0.882±0.091 | 0.869±0.075 | 0.790±0.145 | 2.58M | 39.42 | 32.09 |
| 5x5 | 0.948±0.048 | 0.863±0.122 | 0.901±0.070 | 0.877±0.080 | 0.800±0.131 | 2.59M | 40.49 | 32.02 | |
| 7x7 | 0.950±0.045 | 0.871±0.113 | 0.910±0.067 | 0.886±0.078 | 0.806±0.121 | 2.60M | 42.10 | 32.08 | |
| 9x9 | 0.946±0.050 | 0.851±0.134 | 0.896±0.078 | 0.868±0.104 | 0.786±0.153 | 2.61M | 44.25 | 31.45 | |
| 2018Data Science Bowl | 3x3 | 0.958±0.045 | 0.911±0.101 | 0.920±0.076 | 0.911±0.077 | 0.845±0.115 | 2.58M | 6.24 | 43.31 |
| 5x5 | 0.958±0.044 | 0.915±0.096 | 0.918±0.077 | 0.912±0.077 | 0.847±0.114 | 2.59M | 6.50 | 43.12 | |
| 7x7 | 0.959±0.045 | 0.914±0.098 | 0.924±0.077 | 0.914±0.077 | 0.850±0.114 | 2.60M | 6.91 | 43.42 | |
| 9×9 | 0.957±0.045 | 0.908±0.106 | 0.921±0.083 | 0.908±0.081 | 0.841±0.119 | 2.61M | 7.44 | 43.08 | |
| ISIC-2018 | 3x3 | 0.958±0.080 | 0.921±0.112 | 0.904±0.171 | 0.893±0.144 | 0.829±0.173 | 2.58M | 6.24 | 42.17 |
| 5x5 | 0.959±0.077 | 0.919±0.127 | 0.913±0.149 | 0.898±0.139 | 0.836±0.165 | 2.59M | 6.50 | 42.12 | |
| 7x7 | 0.960±0.075 | 0.917±0.127 | 0.922±0.139 | 0.904±0.128 | 0.841±0.158 | 2.60M | 6.91 | 41.91 | |
| 9x9 | 0.958±0.080 | 0.922±0.117 | 0.903±0.164 | 0.893±0.146 | 0.830±0.172 | 2.61M | 7.44 | 42.63 |
4.6.1. Significance of PFC Strategy
4.6.1. PFC策略的重要性
The PFC Strategy is an essential part of the proposed DCSAU-Net model. It uses residual depthwise separable architecture with a large kernel size to enrich low-level semantic information in the initial down sampling block and help to generate a more accurate segmentation mask. We compare the network configurations: U-Net and $\mathrm{U-Net}+\mathrm{\Omega}$ PFC to evaluate the efficiency of the PFC strategy. From the mIoU metric in Table 6, PFC shows an improvement of $1.9%$ on the CVC-ClinicDB dataset, $1.4%$ improvement on the $\mathrm{SegPC}\boldsymbol{-}2021$ , $2.2%$ improvement on the 2018 Data Science Bowl dataset and $1.9%$ improvement on the ISIC 2018 dataset. Thus, it can be concluded that the PFC strategy enhances the performance of the original U-Net.
PFC策略是所提出的DCSAU-Net模型的重要组成部分。它采用大核尺寸的残差深度可分离架构,在初始下采样块中丰富低级语义信息,并帮助生成更准确的分割掩码。我们比较了网络配置:U-Net和$\mathrm{U-Net}+\mathrm{\Omega}$ PFC,以评估PFC策略的效率。从表6中的mIoU指标来看,PFC在CVC-ClinicDB数据集上提升了$1.9%$,在$\mathrm{SegPC}\boldsymbol{-}2021$数据集上提升了$1.4%$,在2018 Data Science Bowl数据集上提升了$2.2%$,在ISIC 2018数据集上提升了$1.9%$。因此可以得出结论,PFC策略提升了原始U-Net的性能。
4.6.2. Effectiveness of CSA Block
4.6.2. CSA模块的有效性
The DCSAU-Net model uses the CSA block to combine multi-scale feature maps, which can perceive different sizes of lesions in medical images. The effectiveness of CSA block can be evaluated by comparing the configurations: U-Net and $\mathrm{U-Net}+\mathrm{CSA}$ in Table 6. On the mIoU, the CSA block achieves an improvement of $3.1%$ on the CVC-ClinicDB dataset, $1.5%$ improvement on the SegPC-2021, $3.1%$ improvement on the 2018 Data Science Bowl dataset and $2.8%$ improvement on the ISIC 2018 dataset. Therefore, we can argue that the CSA block performs better than the U-Net model and has a more significant impact than the PFC strategy. By taking advantage of both modules, the DCSAU-Net model (U-Net $+\mathrm{PFC}+\mathrm{CSA})$ can further improve the F1-score by $0.6%$ to $3.5%$ and the mIoU by $1.1%$ to $3.3%$ compared to the U-Net with a single PFC or CSA module.
DCSAU-Net模型采用CSA模块融合多尺度特征图,能够感知医学图像中不同尺寸的病灶。通过对比表6中U-Net和$\mathrm{U-Net}+\mathrm{CSA}$的配置可评估CSA模块的有效性。在mIoU指标上,CSA模块在CVC-ClinicDB数据集上提升$3.1%$,在SegPC-2021数据集上提升$1.5%$,在2018 Data Science Bowl数据集上提升$3.1%$,在ISIC 2018数据集上提升$2.8%$。因此可以证明,CSA模块性能优于U-Net模型,且比PFC策略影响更显著。通过联合使用这两个模块,DCSAU-Net模型(U-Net $+\mathrm{PFC}+\mathrm{CSA})$相比仅采用单个PFC或CSA模块的U-Net,F1分数可进一步提升$0.6%$至$3.5%$,mIoU提升$1.1%$至$3.3%$。
5. Discussion
5. 讨论
Semantic segmentation has been widely witnessed in the field of medical image analysis. Many deep learning models construct encoder-decoder architectures and fuse low-level to high-level semantic information through skip connection. These methods usually select the U-Net [19] block as the header of the encoder to extract low-level semantic information, which probably misses some momentous features in images. Our approach adopts the depthwise separable convolutions with a larger kernel size to build a novel PFC strategy that retains these primary features as much as possible. In addition, we explore the impact of depthwise convolution with different number of kernel sizes on the performance, which is presented in Table 7. From the experiment results, we can observe that the DCSAU-Net model is able to achieve a similar performance when using 3x3, 5x5 and $7\mathrm{x}7$ kernel sizes. In practical scenarios, people probably select a small kernel size to reduce the number of parameters and computation costs. However, to display the best performance of our proposed architecture in the study, we use a 7x7 kernel size to train the model. Based on the efficiency of depthwise separable convolution, adding more such layers may improve the information capture capability of the PFC module in the low-level semantic layer, which is worth exploring in future work. We next establish the CSA block that not only enhances the connectivity across different channels but also strengthens the feature representation in different scales with the attention mechanism and completes the multi-scale combination in the end. The effectiveness of both modules has been shown in Table 6 and proved by the ablation study. Although U-Net performs a shorter inference time than the DCSAU-Net model, our approach uses a tiny number of parameters in the equal output feature channels and also expends acceptable inference time, which is more suitable for deployment on machines with limited memory.
语义分割在医学图像分析领域得到了广泛应用。许多深度学习模型通过构建编码器-解码器架构,利用跳跃连接融合低层到高层的语义信息。这些方法通常选择U-Net [19]模块作为编码器头部来提取低层语义信息,但可能会遗漏图像中的某些重要特征。我们采用大核深度可分离卷积构建了新颖的PFC策略,尽可能保留这些关键特征。此外,我们探究了不同卷积核尺寸对性能的影响,如表7所示。实验结果表明,DCSAU-Net模型在使用3x3、5x5和$7\mathrm{x}7$卷积核时能获得相近的性能。实际应用中通常会选择较小核尺寸以减少参数量和计算成本,但为展示本研究提出的最佳架构性能,我们采用7x7核尺寸进行训练。基于深度可分离卷积的高效性,增加此类层数可能提升PFC模块在低层语义特征的信息捕获能力,这值得未来研究探索。我们进一步构建的CSA模块不仅增强了跨通道连接性,还通过注意力机制强化了多尺度特征表示,最终完成多尺度特征融合。表6和消融实验证明了这两个模块的有效性。虽然U-Net推理时间短于DCSAU-Net,但我们的方法在相同输出特征通道下参数量极少,且推理时间在可接受范围内,更适用于内存受限的设备部署。

Figure 4: Qualitative comparison results between DCSAU-Net and other SOTA models on challenging images of four different medical segmentation datasets.
图 4: DCSAU-Net与其他SOTA模型在四种不同医学分割数据集挑战性图像上的定性对比结果。

Figure 5: Results of the first 20 epochs on the test dataset of four medical image segmentation tasks.
图 5: 四个医学图像分割任务测试数据集上前20个epoch的结果。
To further demonstrate that there is a significant improvement of the DCSAU-Net model for the medical image segmentation task, we visualise some of segmentation results using all models on challenging images, which is provided in Fig. 4. From the qualitative results, the segmentation mask generated by our proposed model is able to capture more proper foreground information from low-quality images, such as incomplete staining or obscurity, compared to other SOTA methods. Although the segmentation result of DCSAU-Net is not completely correct, this imperfect mask with more shape information has the possibility to be fixed using image post-processing algorithms, such as applying conditional random fields. In our experiments, we train all models based on a standard dice loss function. We compared the convergence speed of each model on all four datasets, which is shown in Fig 5. It can be observed that our proposed model converges noticeably faster than other SOTA methods in the first 20 epochs, which means the DCSAUNet model is able to reach reliable performance by training fewer epochs. Furthermore, Using other advanced methods in training, such as deep supervision or combined loss functions, may show higher performance in medical image segmentation. Therefore, DCSAU-Net shows its robustness and superior performance on various medical segmentation tasks and we believe it can be used as a new SOTA model for medical image segmentation.
为了进一步证明DCSAU-Net模型在医学图像分割任务中的显著改进,我们在图4中展示了所有模型在具有挑战性图像上的部分分割结果可视化。从定性结果来看,与其他SOTA方法相比,我们提出的模型生成的分割掩模能够从低质量图像(如染色不完整或模糊)中捕获更准确的前景信息。尽管DCSAU-Net的分割结果并非完全正确,但这种包含更多形状信息的非完美掩模有可能通过图像后处理算法(如应用条件随机场)进行修正。在实验中,我们基于标准dice损失函数训练所有模型。图5展示了各模型在四个数据集上的收敛速度对比,可以观察到在前20个epoch中,我们提出的模型收敛速度明显快于其他SOTA方法,这意味着DCSAUNet模型能够通过更少的训练周期达到可靠性能。此外,在训练中使用其他先进方法(如深度监督或组合损失函数)可能会在医学图像分割中展现更高性能。因此,DCSAU-Net在各种医学分割任务中展现出其鲁棒性和卓越性能,我们相信它可以作为医学图像分割的新SOTA模型。
6. Conclusion
6. 结论
In this paper, we propose a novel encoder-decoder architecture for medical image segmentation, called DCSAU-Net. The presented model is comprised of the PFC strategy and the CSA block. The former enhances the ability to preserve primary features from images. The latter splits the input feature maps into two feature groups. Each group contains a different number of convolutions and highlights meaningful features using the attention mechanism. Therefore, the CSA block can combine feature maps in the different receptive fields. We evaluate our model on four different medical image segmentation datasets. The results show that the DCSAU-Net architecture achieves higher scores than other SOTA models in the F1-score and mIoU metrics. Especially, our model performs better on the multi-class segmentation task and complex images. In the future, we will focus on optimising the DCSAU-Net architecture to improve its performance and make it suitable for more medical image segmentation tasks.
本文提出了一种新型的医学图像分割编解码架构DCSAU-Net。该模型由PFC策略和CSA模块组成:前者增强了从图像中保留主要特征的能力,后者将输入特征图分为两组特征(每组包含不同数量的卷积层),并通过注意力机制突出有意义特征。因此,CSA模块能够融合不同感受野的特征图。我们在四个医学图像分割数据集上评估模型,结果显示DCSAU-Net在F1-score和mIoU指标上均优于其他SOTA模型,尤其在多类别分割任务和复杂图像处理中表现突出。未来工作将重点优化DCSAU-Net架构以提升性能,并拓展其适用场景。