Masked Vision and Language Pre-training with Unimodal and Multimodal Contrastive Losses for Medical Visual Question Answering
基于单模态与多模态对比损失的掩码视觉语言预训练在医学视觉问答中的应用
Abstract. Medical visual question answering (VQA) is a challenging task that requires answering clinical questions of a given medical image, by taking consider of both visual and language information. However, due to the small scale of training data for medical VQA, pre-training fine-tuning paradigms have been a commonly used solution to improve model generalization performance. In this paper, we present a novel self-supervised approach that learns unimodal and multimodal feature representations of input images and text using medical image caption datasets, by leveraging both unimodal and multimodal contrastive losses, along with masked language modeling and image text matching as pretraining objectives. The pre-trained model is then transferred to downstream medical VQA tasks. The proposed approach achieves state-of-the-art (SOTA) performance on three publicly available medical VQA datasets with significant accuracy improvements of $2.2%$ , $14.7%$ , and $1.7%$ respectively. Besides, we conduct a comprehensive analysis to validate the effectiveness of different components of the approach and study different pre-training settings. Our codes and models are available at https://github.com/peng fei li HE U/MUMC.
摘要。医学视觉问答 (VQA) 是一项具有挑战性的任务,需要通过综合考虑视觉和语言信息来回答给定医学图像的临床问题。然而,由于医学 VQA 训练数据规模较小,预训练微调范式已成为提升模型泛化性能的常用解决方案。本文提出了一种新颖的自监督方法,利用医学图像描述数据集,通过单模态和多模态对比损失以及掩码语言建模和图文匹配作为预训练目标,学习输入图像和文本的单模态及多模态特征表示。预训练模型随后迁移至下游医学 VQA 任务。所提方法在三个公开医学 VQA 数据集上实现了最先进 (SOTA) 性能,准确率分别显著提升 $2.2%$、$14.7%$ 和 $1.7%$。此外,我们通过全面分析验证了方法各组成部分的有效性,并研究了不同预训练设置。代码和模型发布于 https://github.com/peng fei li HE U/MUMC。
Keywords: Medical Visual Question Answering, Masked Vision Language Pre-training, Unimodal and Multimodal Contrastive Losses
关键词: 医疗视觉问答 (Medical Visual Question Answering), 掩码视觉语言预训练 (Masked Vision Language Pre-training), 单模态与多模态对比损失 (Unimodal and Multimodal Contrastive Losses)
1 Introduction
1 引言
Medical VQA is a specialized domain of VQA that aims to generate answers to natural language questions about medical images. It is very challenging to train deep learning based medical VQA models from scratch, since the medical VQA datasets available for research are relatively small in scale. Many existing works are proposed to leverage pre-trained visual encoders with external datasets to solve downstream medical VQA tasks, such as utilizing denoising auto encoders [1] and meta-models [2]. These methods mainly transfer feature encoders that are separately pre-trained on unimodal (image or text) tasks.
医学VQA是VQA的一个专门领域,旨在生成关于医学图像的自然语言问题的答案。由于可用于研究的医学VQA数据集规模相对较小,从头开始训练基于深度学习的医学VQA模型非常具有挑战性。许多现有工作提出利用预训练的视觉编码器和外部数据集来解决下游医学VQA任务,例如利用去噪自动编码器 [1] 和元模型 [2]。这些方法主要迁移在单模态(图像或文本)任务上单独预训练的特征编码器。
Unlike unimodal pre training approaches, both image and text feature presentations can be enhanced by learning through the visual and language interactions, given relatively richer resources of medical image caption datasets [3-5]. Liu et al. followed the work of MOCO [19] that trained teacher model for visual encoder via contrastive loss of different image views (by data augmentations) to improve the generalization of medical VQA [6]. Eslami et al. utilized CLIP [7] for visual model initialization, and learned cross-modality representations from medical image-text pairs by maximizing the cosine similarity between the extracted features of medical images and their corresponding captions [8]. Cong et al. devised an innovative framework, which featured a semantic focusing module to emphasize image regions that were pertinent to the caption and a progressive cross-modality comprehension module that iterative ly enhanced the comprehension of the correlation between the image and caption [9]. Chen et al. proposed a medical vision language pre-training approach that used both masked image modelling and masked language modelling to jointly learn representations of medical images and their corresponding descriptions [10]. However, to the best of our knowledge, there have been no existing methods that explore learning both unimodal and multimodal features at the pre-training stage for downstream medical VQA tasks.
与单模态预训练方法不同,在医学图像描述数据集相对丰富的资源支持下 [3-5],通过视觉与语言的交互学习可以同时增强图像和文本特征表示。Liu等人沿用了MOCO [19] 的工作,通过不同图像视图(数据增强生成)的对比损失训练视觉编码器的教师模型,以提升医学VQA的泛化能力 [6]。Eslami等人利用CLIP [7] 初始化视觉模型,并通过最大化医学图像提取特征与其对应描述文本之间的余弦相似度,从医学图文对中学习跨模态表征 [8]。Cong等人设计了一个创新框架,包含聚焦语义模块(突出与描述相关的图像区域)和渐进式跨模态理解模块(迭代增强图像与文本关联性的理解)[9]。Chen等人提出了一种医学视觉语言预训练方法,联合使用掩码图像建模和掩码语言建模来学习医学图像及其对应描述的表示 [10]。然而据我们所知,目前尚无方法在预训练阶段同时探索单模态与多模态特征学习以服务于下游医学VQA任务。
In this paper, we proposed a new self-supervised vision language pre-training (VLP) approach that applied Masked image and text modeling with Unimodal and Multimodal Contrastive losses (MUMC) in the pre-training phase for solving downstream medical VQA tasks. The model was pretrained on image caption datasets for aligning visual and text information, and transferred to downstream VQA datasets. The unimodal and multimodal contrastive losses in our work are applied to (1) align image and text features; (2) learn unimodal image encoders via momentum contrasts of different views of the same image (i.e. different views are generated by different image masks); (3) learn unimodal text encoder via momentum contrasts. We also introduced a new masked image strategy by randomly masking the patches of the image with a probability of $25%$ , which serves as a data augmentation technique to further enhance the performance of the model. Our approach outperformed existing methods and sets new benchmarks on three medical VQA datasets [11-13], with significant enhancements of $2.2%$ , $14.7%$ , and $1.7%$ respectively. Besides, we conducted an analysis to verify the effectiveness of different components and find the optimal masking probability. We also conducted a qualitative analysis on the attention maps using Grad-CAM [14] to validate whether the corresponding part of the image is attended when answering a question.
本文提出了一种新型自监督视觉语言预训练(VLP)方法,在预训练阶段采用带单模态与多模态对比损失的掩码图像文本建模(MUMC)来解决下游医疗视觉问答(VQA)任务。该模型首先在图像描述数据集上进行视觉与文本信息对齐的预训练,随后迁移至下游VQA数据集。我们提出的单模态与多模态对比损失用于:(1) 对齐图像与文本特征;(2) 通过同一图像不同视图(即不同图像掩码生成的视图)的动量对比学习单模态图像编码器;(3) 通过动量对比学习单模态文本编码器。我们还引入了一种新的掩码图像策略,以25%的概率随机遮蔽图像块,作为进一步提升模型性能的数据增强技术。本方法在三个医疗VQA数据集[11-13]上超越现有方法并创下新基准,分别显著提升2.2%、14.7%和1.7%。此外,我们通过实验分析验证了各模块的有效性并确定了最优掩码概率,同时采用Grad-CAM[14]对注意力图进行定性分析,以验证回答问题时的图像关注区域是否准确。
2 Methods
2 方法
In this section, we provide the detailed description of the proposed approach, which includes the network architectures, self-supervised pre-training objectives, and the way to fine-tune on downstream medical VQA tasks.
在本节中,我们将详细描述所提出的方法,包括网络架构、自监督预训练目标以及在下游医疗VQA任务上的微调方式。
2.1 Model Architecture
2.1 模型架构
In the pre-training phase, the network architecture comprises an image encoder, a text encoder, and a multimodal encoder, which are all based on the transformer architecture [15]. As shown in Fig. 1(a), the image encoder leverages a 12-layer Vision Transformer (ViT) [16] to extract visual features from the input images, while the text encoder employs a 6-layer transformer which is initialized by the first 6 layers of pretrained BERT [17]. The last 6 layers of BERT are utilized as the multimodal encoder and incorporated cross-attention at each layer, which fuses the visual and linguistic features to facilitate learning of multimodal interactions. The model is trained on medical image-caption pairs. An image is partitioned into patches of size $16\times16$ , and $25%$ of the patches are randomly masked. The remaining unmasked image patches are converted into a sequence of embeddings by an image encoder. The text, i.e. the image caption is tokenized into a sequence of tokens using a WordPiece [18] tokenizer and fed into the BERT-based text encoder. In addition, the special tokens, [CLS] are appended to the beginning of both the image and text sequence.
在预训练阶段,网络架构包含基于Transformer架构[15]的图像编码器、文本编码器和多模态编码器。如图1(a)所示,图像编码器采用12层Vision Transformer (ViT)[16]从输入图像中提取视觉特征,文本编码器使用由预训练BERT[17]前6层初始化的6层Transformer。BERT的最后6层作为多模态编码器,并在每层加入交叉注意力机制,融合视觉与语言特征以促进多模态交互学习。该模型通过医学图像-描述对进行训练:图像被分割为$16\times16$大小的图块,其中$25%$的图块被随机遮蔽。未遮蔽的图像图块经图像编码器转换为嵌入序列;文本描述通过WordPiece[18]分词器转换为token序列输入基于BERT的文本编码器。此外,特殊token [CLS]被添加到图像和文本序列的开头。
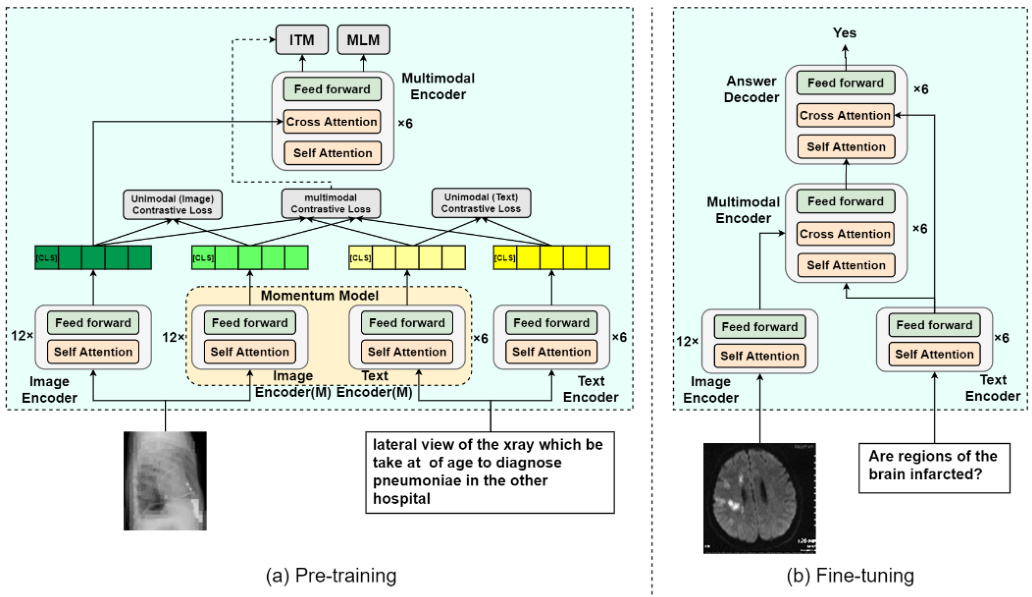
Fig. 1. Overview of the network architecture in both pre-training and fine-tuning phases.
图 1: 网络架构在预训练和微调阶段的概览。
To transfer the models trained on image caption datasets to the downstream medical VQA tasks, we utilize the weights from the pre-training stage to initialize the image encoder, text encoder and multimodal encoder, as shown in Fig. 1(b). To generate answers, we add an answering decoder with a 6-layer transformer-based decoder to the model, which receives the multimodal embeddings and output text tokens. A [CLS] token serves as the initial input token for the decoder, and a [SEP] token is appended to signify the end of the generated sequence. The downstream VQA model is fine-tuned via the masked language model (MLM) loss [17], using ground-truth answers as targets.
为了将在图像字幕数据集上训练的模型迁移到下游医疗视觉问答(VQA)任务,我们利用预训练阶段的权重来初始化图像编码器、文本编码器和多模态编码器,如图1(b)所示。为生成答案,我们在模型中添加了一个基于6层Transformer的应答解码器,该解码器接收多模态嵌入并输出文本token。[CLS] token作为解码器的初始输入token,[SEP] token用于标记生成序列的结束。下游VQA模型通过掩码语言模型(MLM)损失[17]进行微调,使用真实答案作为目标。
2.2 Unimodal and Multimodal Contrastive Losses
2.2 单模态与多模态对比损失
The proposed self-supervised objective attempts to capture the semantic discrepancy between positive and negative samples across both unimodal and multimodal domains at the same time. The unimodal contrastive loss (UCL) aims to differentiate between examples of one modality, such as images or text, in a latent space to make similar examples close. And the multimodal contrastive loss (MCL) learns the alignments between both modalities by maximizing the similarity between images and their corresponding text captions, while separating from the negative examples. In the implementation, we maintain two momentum models for image and text encoders respectively to generate different perspectives or representations of the same input sample, which serve as positive samples for contrastive learning.
提出的自监督目标旨在同时捕捉单模态和多模态领域中正负样本之间的语义差异。单模态对比损失 (UCL) 旨在潜在空间中区分一种模态(如图像或文本)的样本,使相似样本彼此靠近。而多模态对比损失 (MCL) 通过最大化图像与其对应文本描述之间的相似性,同时与负样本分离,来学习两种模态之间的对齐关系。在实现中,我们分别为图像和文本编码器维护两个动量模型,以生成同一输入样本的不同视角或表征,这些将作为对比学习的正样本。
In detail, we denote the image and caption embeddings from the unimodal image encoder and text encoder as $v_{c l s}$ and $t_{c l s}$ , which are further processed through the transformations $g_{v}$ and $g_{t}$ , to normalize and map the image and text embeddings to be lower-dimensional representations. The embeddings are inserted into a lookup table, and only the most recent 65,535 pairs of image-text embedding are stored for contrastive learning. We utilize the momentum update technique originally proposed in Mo $\mathrm{Co}$ [19], which is updated every $k$ iterations where $\mathrm{k\Omega}$ is a hyper parameter. We denote the ground-truth one-hot similarity by $y_{i2i}(V),y_{t2t}(T),y_{i2t}(V)$ , and $y_{t2i}(T)$ , where the probability of negative pairs is 0 and the probability of the positive pair is 1. The unimodal contrastive losses and multimodal contrastive losses can be defined as the cross-entropy $H$ given as follows:
具体而言,我们将单模态图像编码器和文本编码器生成的图像与标题嵌入分别表示为$v_{cls}$和$t_{cls}$,这些嵌入会通过变换$g_v$和$g_t$进行归一化处理,并映射为低维表示。嵌入被存入查找表,仅保留最近的65,535对图文嵌入用于对比学习。我们采用MoCo[19]最初提出的动量更新技术,每$k$次迭代更新一次,其中$\mathrm{k\Omega}$为超参数。真实单热相似度由$y_{i2i}(V)$、$y_{t2t}(T)$、$y_{i2t}(V)$和$y_{t2i}(T)$表示,负样本对概率为0,正样本对概率为1。单模态对比损失和多模态对比损失可定义为交叉熵$H$,公式如下:
$$
\begin{array}{r l}&{L_{u c l}=\frac{1}{2}\mathbb{E}{(V,T)D}\left[H\left(y_{i2i}(V),\frac{\exp(s(V,V_{i})/\tau)}{\sum_{n=1}^{N}\exp(s(V,V_{i})/\tau)}\right)+H\left(y_{t2t}(T),\frac{e x p\left(s(T,T_{i})/\tau\right)}{\sum_{n=1}^{N}e x p\left(s(T,T_{i})/\tau\right)}\right)\right]}\ &{L_{m c l}=\frac{1}{2}\mathbb{E}_{(V,T)D}\left[H\left(y_{i2t}(V),\frac{e x p\left(s(V,T_{i})/\tau\right)}{\sum_{n=1}^{N}e x p\left(s(V,T_{i})/\tau\right)}\right)+H\left(y_{t2i}(T),\frac{e x p\left(s(T,V_{i})/\tau\right)}{\sum_{n=1}^{N}e x p\left(s(T,V_{i})/\tau\right)}\right)\right]}\end{array}
$$
$$
\begin{array}{r l}&{L_{u c l}=\frac{1}{2}\mathbb{E}{(V,T)D}\left[H\left(y_{i2i}(V),\frac{\exp(s(V,V_{i})/\tau)}{\sum_{n=1}^{N}\exp(s(V,V_{i})/\tau)}\right)+H\left(y_{t2t}(T),\frac{e x p\left(s(T,T_{i})/\tau\right)}{\sum_{n=1}^{N}e x p\left(s(T,T_{i})/\tau\right)}\right)\right]}\ &{L_{m c l}=\frac{1}{2}\mathbb{E}_{(V,T)D}\left[H\left(y_{i2t}(V),\frac{e x p\left(s(V,T_{i})/\tau\right)}{\sum_{n=1}^{N}e x p\left(s(V,T_{i})/\tau\right)}\right)+H\left(y_{t2i}(T),\frac{e x p\left(s(T,V_{i})/\tau\right)}{\sum_{n=1}^{N}e x p\left(s(T,V_{i})/\tau\right)}\right)\right]}\end{array}
$$
where $s$ denotes cosine similarity function, $\begin{array}{r}{s(\mathrm{V},V_{i})=g_{v}(v_{c l s})^{T}g_{v}(v_{c l s}){i},s(\mathrm{T},T_{i})=}\end{array}$ $g_{t}(t_{c l s})^{T}g_{t}(t_{c l s})_{i}$ , $s(\mathsf{V},T_{i})=g_{v}(v_{c l s})^{T}g_{t}(t_{c l s})_{i}$ , $s(\mathrm{T},V_{i})=g_{t}(t_{c l s})^{T}g_{v}(v_{c l s})_{i}$ and $\tau$ is a learnable temperature parameter.
其中 $s$ 表示余弦相似度函数,$\begin{array}{r}{s(\mathrm{V},V_{i})=g_{v}(v_{c l s})^{T}g_{v}(v_{c l s}){i},s(\mathrm{T},T_{i})=}\end{array}$ $g_{t}(t_{c l s})^{T}g_{t}(t_{c l s})_{i}$,$s(\mathsf{V},T_{i})=g_{v}(v_{c l s})^{T}g_{t}(t_{c l s})_{i}$,$s(\mathrm{T},V_{i})=g_{t}(t_{c l s})^{T}g_{v}(v_{c l s})_{i}$,$\tau$ 是可学习的温度参数。
2.3 Image Text Matching
2.3 图文匹配
We adopt the image text matching (ITM) strategy similar to prior works [20, 21] as one of the training objectives, by creating a binary classification task with negative text labels randomly sampled from the same minibatch. The joint representation of the image and text are encoded by the multimodal encoder, and utilized as input to the binary classification head. The ITM task is optimized using the cross-entropy loss:
我们采用与先前工作[20, 21]类似的图像文本匹配(ITM)策略作为训练目标之一,通过从同一小批次中随机采样负样本文本来构建二分类任务。图像和文本的联合表示由多模态编码器编码,并作为二分类头的输入。ITM任务使用交叉熵损失进行优化:
$$
\mathcal{L}{i t m}=\mathbb{E}{(V,T)D}H(y_{i t m},p_{i t m}(V,T))
$$
$$
\mathcal{L}{i t m}=\mathbb{E}{(V,T)D}H(y_{i t m},p_{i t m}(V,T))
$$
the function $H(,)$ represents a cross-entropy computation, where $y_{i t m}$ denotes the ground-truth label and $p_{i t m}(V,T)$ is a function for predicting the class.
函数 $H(,)$ 表示交叉熵计算,其中 $y_{i t m}$ 代表真实标签,$p_{i t m}(V,T)$ 是用于预测类别的函数。
2.4 Masked Language Modeling
2.4 掩码语言建模 (Masked Language Modeling)
Masked Language Modeling (MLM) is another pre-trained objective in our approach, that predicts masked tokens in text based on both the visual and unmasked contextual information. For each caption text, $15%$ of tokens are randomly masked and replaced with the special token, [MASK]. Predictions of the masked tokens are conditioned on both unmasked text and image features. We minimize the cross-entropy loss for MLM:
掩码语言建模 (Masked Language Modeling, MLM) 是我们方法中的另一个预训练目标,它基于视觉和未掩码的上下文信息来预测文本中被掩码的 token。对于每个标题文本,随机掩码 $15%$ 的 token 并用特殊 token [MASK] 替换。被掩码 token 的预测依赖于未掩码文本和图像特征。我们最小化 MLM 的交叉熵损失:
$$
\mathcal{L}{m l m}=\mathbb{E}{(V,\hat{T})D}H(y_{m l m},p_{m l m}(V,\hat{T}))
$$
$$
\mathcal{L}{m l m}=\mathbb{E}{(V,\hat{T})D}H(y_{m l m},p_{m l m}(V,\hat{T}))
$$
where $H(,)$ is a cross-entropy calculation, $\hat{T}$ denotes the masked text token, $y_{m l m}$ represents the ground-truth of the masked text token and $p_{m l m}(V,\hat{T})$ is the predicted probability of a masked token.
其中 $H(,)$ 是交叉熵计算,$\hat{T}$ 表示被掩码的文本 token,$y_{m l m}$ 代表被掩码文本 token 的真实值,而 $p_{m l m}(V,\hat{T})$ 是被掩码 token 的预测概率。
2.5 Masked Image Strategy
2.5 掩码图像策略
Besides the training objectives, we introduce a masked image strategy as a data augmentation technique. In our experiment, input images are partitioned into patches which are randomly masked with a probability of $25%$ , and only the unmasked patches are passed through the network. Unlike the previous methods [10, 22], we do not utilize reconstruction loss [23], but use this only as a data augmentation method. This enables us to process more samples at each step, resulting in a more efficient pretraining of vision-language models with a similar memory footprint.
除了训练目标外,我们引入了一种掩码图像策略作为数据增强技术。在实验中,输入图像被分割成若干图像块 (patch) ,这些图像块会以 $25%$ 的概率被随机掩码,只有未被掩码的图像块会通过网络。与之前的方法 [10, 22] 不同,我们没有使用重建损失 [23] ,而是仅将其作为一种数据增强手段。这使得我们能在每一步处理更多样本,从而在内存占用相近的情况下更高效地预训练视觉-语言模型。
3 Experiments
3 实验
3.1 Datasets
3.1 数据集
Our model is pre-trained on three datasets: ROCO [3], MedICaT [4], and the Image CLEF 2022 Image Caption Dataset [5]. ROCO comprises over 80,000 imagecaption pairs. MedICaT includes over 217,000 medical images and their corresponding captions. Image CLEF 2022 is another well-known dataset that has nearly 90,000 pairs of medical images and captions.
我们的模型在三个数据集上进行了预训练:ROCO [3]、MedICaT [4] 和 Image CLEF 2022 图像描述数据集 [5]。ROCO 包含超过 80,000 对图像-描述组合。MedICaT 包含超过 217,000 张医学图像及其对应描述。Image CLEF 2022 是另一个知名数据集,包含近 90,000 对医学图像和描述。
For the downstream medical VQA task, we fine-tune and validate the model on three public medical VQA datasets: VQA-RAD [11], PathVQA [12] and SLAKE [13]. VQA-RAD has 315 radiology images with 3064 question-answer pairs, with 451 pairs used for testing. SLAKE has 14,028 pairs of samples which are further divided into $70%$ training, $15%$ validation, and $15%$ testing subsets. PathVQA is the largest dataset, containing 32,799 pairs of data that are split into training $(50%)$ , validation $(30%)$ , and test $(20%)$ sets.
在下游医疗视觉问答任务中,我们在三个公开医疗VQA数据集上对模型进行微调和验证:VQA-RAD [11]、PathVQA [12]和SLAKE [13]。VQA-RAD包含315张放射影像及3064组问答对,其中451组用于测试。SLAKE拥有14,028组样本,按70%训练集、15%验证集和15%测试集划分。PathVQA是规模最大的数据集,包含32,799组数据,划分为训练集(50%)、验证集(30%)和测试集(20%)。
There are two types of questions: closed-ended questions that have limited answer choices (e.g. "yes" or "no") and open-ended questions that VQA models are required to generate answers in free text, which are more challenging.
问题分为两类:封闭式问题,其答案选项有限(如“是”或“否”),以及开放式问题,要求视觉问答(VQA)模型生成自由文本答案,后者更具挑战性。
3.2 Implementation Details
3.2 实现细节
Our method was implemented in Python 3.8 and PyTorch 1.10. The experiments were conducted on a server with an Intel Xeon(R) Platinum 8255C and 2 NVIDIA Tesla V100 GPUs with 32GB memory each. We pre-trained our model on three medical image caption datasets for 40 epochs with a batch size of 64. AdamW [24] optimizer was used with a weight decay of 0.002 and an initial learning rate of $1e^{-4}$ , which decayed to $2e^{-5}$ by following the cosine schedule. We utilized randomly cropped images of $256\times256$ resolution as input, and also applied Rand Augment to augment more training samples [25].
我们的方法基于Python语言 3.8和PyTorch 1.10实现。实验在一台配备Intel Xeon(R) Platinum 8255C处理器和2块32GB显存的NVIDIA Tesla V100 GPU的服务器上进行。我们在三个医学影像描述数据集上以64的批次大小预训练模型40个周期,采用AdamW [24]优化器 (权重衰减系数0.002),初始学习率$1e^{-4}$按余弦调度衰减至$2e^{-5}$。输入图像经随机裁剪为$256\times256$分辨率,并采用Rand Augment [25]进行数据增强。
For downstream medical VQA tasks, we fine-tuned our model for 30 epochs with a batch size of 8. We used the AdamW optimizer with a reduced learning rate of $2e^{-5}$ , which decayed to $1e^{-8}$ . Besides, we increased image inputs from a resolution of $256\times256$ to $384\times384$ and interpolated the positional encoding following [16].
在下游医疗VQA任务中,我们以批量大小8对模型进行了30轮微调。采用AdamW优化器,初始学习率降至$2e^{-5}$,并衰减至$1e^{-8}$。此外,我们将图像输入分辨率从$256\times256$提升至$384\times384$,并参照[16]对位置编码进行了插值处理。
3.3 Comparison with the State-of-the-arts
3.3 与现有最优技术的对比
We performed a comparative evaluation of our model against the existing approaches [10, 26] on three benchmark datasets, VQA-RAD, PathVQA and SLAKE. Consistent with previous research [1, 2, 6, 8-10, 26, 27], we adopt accuracy as the performance metric. We treated VQA as a generative task by calculating similarities between the generated answers and candidate list answers, selecting the highest score as the final answer. As shown in Table 1, our approach outperformed all other methods on all the three datasets in terms of overall performance, and yielded the best accuracy for openended or closed-ended answers. On the VQA-RAD dataset [11], our method achieved an absolute margin of $2.2%$ overall over the current state-of-the-art method, M3AE, with improvements of $4.3%$ and $0.7%$ on open-ended and closed-ended answers respectively.
我们在VQA-RAD、PathVQA和SLAKE三个基准数据集上,对现有方法[10,26]进行了对比评估。与先前研究[1,2,6,8-10,26,27]一致,我们采用准确率作为性能指标。通过计算生成答案与候选列表答案的相似度,选取最高分作为最终答案,将VQA视为生成式任务。如表1所示,我们的方法在三个数据集上的整体性能均优于其他方法,并在开放式和封闭式答案上均取得最高准确率。在VQA-RAD数据集[11]上,我们的方法相较当前最优方法M3AE实现了2.2%的绝对优势提升,其中开放式和封闭式答案分别提升4.3%和0.7%。
Table 1. Comparisons with the state-of-the-art methods on the VQA-RAD, PathVQA and SLAKE test set.
On the largest dataset, PathVQA [12], our method significantly outperformed the previous state-of-the-art model, AMAM [26], by a substantial margin with improvements of $20.8%$ , $6.0%$ and $14.7%$ on the closed-ended, open-ended, and overall answers, respectively. Moreover, on the SLAKE dataset [13], the proposed approach
表 1: 在VQA-RAD、PathVQA和SLAKE测试集上与最先进方法的对比。
| Methods | VQA-RAD | PathVQA | SLAKE | ||||
|---|---|---|---|---|---|---|---|
| Open | Closed | Overall | Open | Closed | Overall | Overall | |
| MEVF [1] | 43.9 | 75.1 | 62.6 | 8.1 | 81.4 | 44.8 | 78.6 |
| MMQ [2] | 52.0 | 72.4 | 64.3 | 11.8 | 82.1 | 47.1 | |
| VQAMix[27] | 56.6 | 79.6 | 70.4 | 13.4 | 83.5 | 48.6 | |
| AMAM[26] | 63.8 | 80.3 | 73.3 | 18.2 | 84.4 | 50.4 | - |
| CPRD [6] | 61.1 | 80.4 | 72.7 | 82.1 | |||
| PubMedCLIP [8] | 60.1 | 80.0 | 72.1 | 80.1 | |||
| MTL [9] | 69.8 | 79.8 | 75.8 | 82.5 | |||
| M3AE [10] | 67.2 | 83.5 | 77.0 | - | - | - | 83.2 |
| MUMC (Ours) | 71.5 | 84.2 | 79.2 | 39.0 | 90.4 | 65.1 | 84.9 |
在最大的数据集PathVQA [12]上,我们的方法显著优于之前最先进的模型AMAM [26],在封闭式、开放式和整体答案上分别实现了$20.8%$、$6.0%$和$14.7%$的大幅提升。此外,在SLAKE数据集[13]上,所提出的方法
exhibited superior performance compared to the existing state-of-the-art model, M3AE, by a margin of $1.7%$ in terms of overall answer accuracy.
与现有最先进的模型M3AE相比,在整体回答准确率上表现出优越性能,优势达1.7%。
3.4 Ablation Study
3.4 消融实验
To further verify the effectiveness of the proposed methods in learning multimodal representations, we conducted an ablation study across all three medical VQA datasets. Table 2 shows the overall performance of the medical VQA tasks using various pre-training approaches. Compared to the baseline pre-training tasks (i.e., ${\bf M L M\Sigma+}$ ITM), integrating either UCL or MCL significantly improved the performance of the pre-trained model across all medical VQA datasets. Notably, the simultaneous use of UCL and MCL achieved a performance increase of $1.1%$ , $1.0%$ , and $0.9%$ on VQARAD, PathVQA, and SLAKE dataset, respectively.
为了进一步验证所提方法在学习多模态表征方面的有效性,我们在三个医学VQA数据集上进行了消融实验。表2展示了采用不同预训练方法时医学VQA任务的总体性能。与基线预训练任务(即 ${\bf M L M\Sigma+}$ ITM)相比,整合UCL或MCL均显著提升了预训练模型在所有医学VQA数据集上的性能。值得注意的是,同时使用UCL和MCL在VQARAD、PathVQA和SLAKE数据集上分别实现了 $1.1%$ 、 $1.0%$ 和 $0.9%$ 的性能提升。
Table 2. Ablation Study on Different Pre-training Objective Settings.
表 2: 不同预训练目标设置的消融研究。
| 训练任务 | VQA-RAD (总体) | PathVQA (总体) | SLAKE (总体) |
|---|---|---|---|
| ITM+MLM | 74.5 | 61.5 | 82.0 |
| ITM+MLM+UCL | 77.3 | 63.5 | 83.2 |
| ITM+MLM+MCL | 78.1 | 64.1 | 84.0 |
| MUMC(ITM+MLM+UCL+MCL) | 79.2 | 65.1 | 84.9 |
Furthermore, to assess the performance of the proposed masked image strategy and identify the optimal masking probability, experiments were conducted by varying the masking probabilities of input images at levels of $0%$ , $25%$ , $50%$ and $75%$ . As presented in Table 3, the results are consistent among all the three datasets. With $25%$ masking probability, the model yielded the best results, compared to no masking applied. The performance decreased if $50%$ and $75%$ masking probabilities were used.
此外,为评估所提出的掩码图像策略的性能并确定最佳掩码概率,实验通过将输入图像的掩码概率分别设置为 $0%$ 、 $25%$ 、 $50%$ 和 $75%$ 进行。如表 3 所示,三个数据集的结果表现一致。当掩码概率为 $25%$ 时,模型取得了最佳结果,优于未使用掩码的情况。若采用 $50%$ 和 $75%$ 的掩码概率,性能则会下降。
Table 3. Study of different masked image probabilities.
表 3: 不同掩码图像概率的研究
| 掩码概率 | VQA-RAD (总体) | PathVQA (总体) | SLAKE (总体) |
|---|---|---|---|
| 75% | 76.9 | 63.4 | 82.6 |
| 50% | 78.6 | 64.3 | 83.7 |
| 25% | 79.2 | 65.1 | 84.9 |
| 0% | 77.8 | 64.0 | 83.2 |
3.5 Visualization
3.5 可视化
We utilized Grad-CAM [14] to visualize the cross-attention maps between the questions and images, and analyzed the relevance of the attended image regions for generating the answers. In Fig. 2, it showed some attention maps that overlayed on the original images. For answering open-ended questions, the model accurately attended to the relevant infarct regions, as shown in Fig. 2a and Fig. 2b. In Fig. 2a, to answer the question, “Where is/are the infarct located?”, the model highlighted the areas that well covered the infarction. Interestingly, the model attended to infarct areas on both hemispheres (Fig. 2b) and generated the answer, “Bilateral”. Besides the positionrelated questions, in Fig. 2c, it showed the attention map to answer the closed form question, “Is there any region in the brain that is lesioned?”. The model successfully attended to the lesion area and provided the correct answer of “Yes”. Moreover, the model demonstrated its ability to attend to the regions of ribs to answer the countingrelated question in Fig. 2d, where the question was “Are there more than 12 ribs?”, and the model accurately outputted the answer “Yes”.
我们采用Grad-CAM [14] 可视化问题与图像间的交叉注意力图,分析关注图像区域对生成答案的相关性。如图 2 所示,部分注意力图叠加在原始图像上呈现。针对开放式问题,模型准确聚焦于相关梗死区域 (如图 2a 和图 2b) 。图 2a 中,为回答"梗死位于何处?"这一问题,模型高亮区域完整覆盖了梗死病灶。值得注意的是,模型同时关注到双侧半球的梗死区域 (图 2b) ,并生成答案"双侧"。除定位问题外,图 2c 展示了回答封闭式问题"大脑是否存在病变区域?"的注意力图,模型成功聚焦病灶区域并给出正确答案"是"。此外,图 2d 中模型展现出对肋骨区域的关注能力以回答计数问题"肋骨是否超过12根?",准确输出答案"是"。

Fig. 2. Visualization s of the image attention maps on medical VQA tasks.
图 2: 医疗VQA任务中的图像注意力热力图可视化。
4 Conclusion
4 结论
In this paper, we propose a new method to tackle the challenge of medical VQA tasks, which is pre-trained on the medical image caption datasets and then transferred to the downstream medical VQA tasks. The proposed self-supervised pre-training approach with unimodal and multimodal contrastive losses leads to significant performance improvement on three public VQA datasets. Also, using masked images as a data augmentation technique is proven to be effective for learning representations on medical visual and language tasks. As a result, our proposed method not only outperformed the state-of-the-art methods by a significant margin, but also demonstrated the potential for model interpret ability.
本文提出了一种新方法来应对医疗视觉问答(VQA)任务的挑战,该方法先在医疗图像描述数据集上进行预训练,再迁移至下游医疗VQA任务。我们提出的采用单模态和多模态对比损失的自监督预训练方法,在三个公开VQA数据集上实现了显著性能提升。同时,使用掩码图像作为数据增强技术被证明能有效学习医疗视觉与语言任务的表征。实验结果表明,我们提出的方法不仅以显著优势超越了现有最优方法,还展现了模型可解释性的潜力。