Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation
基于U-Net的循环残差卷积神经网络(R2U-Net)在医学图像分割中的应用
Abstract—Deep learning (DL) based semantic segmentation methods have been providing state-of-the-art performance in the last few years. More specifically, these techniques have been successfully applied to medical image classification, segmentation, and detection tasks. One deep learning technique, U-Net, has become one of the most popular for these applications. In this paper, we propose a Recurrent Convolutional Neural Network (RCNN) based on U-Net as well as a Recurrent Residual Convolutional Neural Network (RRCNN) based on U-Net models, which are named RU-Net and R2U-Net respectively. The proposed models utilize the power of U-Net, Residual Network, as well as RCNN. There are several advantages of these proposed architectures for segmentation tasks. First, a residual unit helps when training deep architecture. Second, feature accumulation with recurrent residual convolutional layers ensures better feature representation for segmentation tasks. Third, it allows us to design better U-Net architecture with same number of network parameters with better performance for medical image segmentation. The proposed models are tested on three benchmark datasets such as blood vessel segmentation in retina images, skin cancer segmentation, and lung lesion segmentation. The experimental results show superior performance on segmentation tasks compared to equivalent models including UNet and residual U-Net (ResU-Net).
摘要—基于深度学习(DL)的语义分割方法在过去几年中一直保持着最先进的性能。具体而言,这些技术已成功应用于医学图像分类、分割和检测任务。其中U-Net已成为这些应用中最受欢迎的深度学习技术之一。本文提出了基于U-Net的循环卷积神经网络(RCNN)以及基于U-Net的循环残差卷积神经网络(RRCNN),分别命名为RU-Net和R2U-Net。所提模型结合了U-Net、残差网络和RCNN的优势。这些新架构在分割任务中具有多重优势:首先,残差单元有助于训练深层架构;其次,通过循环残差卷积层实现特征累积,可为分割任务提供更好的特征表示;第三,在保持相同网络参数量的情况下,能设计出性能更优的U-Net架构用于医学图像分割。我们在三个基准数据集上测试了所提模型,包括视网膜血管分割、皮肤癌分割和肺部病变分割。实验结果表明,相较于U-Net和残差U-Net(ResU-Net)等同类模型,所提模型在分割任务中表现出更优越的性能。
Index Terms—Medical imaging, Semantic segmentation, Convolutional Neural Networks, U-Net, Residual U-Net, RU-Net, and R2U-Net.
索引术语—医学影像、语义分割、卷积神经网络、U-Net、残差U-Net、RU-Net和R2U-Net。
I. INTRODUCTION
I. 引言
NO WADAYS DL provides state-of-the-art performance for image classification [1], segmentation [2], detection and tracking [3], and captioning [4]. Since 2012, several Deep Convolutional Neural Network (DCNN) models have been proposed such as AlexNet [1], VGG [5], GoogleNet [6], Residual Net [7], DenseNet [8], and CapsuleNet [9][65]. A DL based approach (CNN in particular) provides state-of-the-art performance for classification and segmentation tasks for several reasons: first, activation functions resolve training problems in DL approaches. Second, dropout helps regularize the networks. Third, several efficient optimization techniques are available for training CNN models [1]. However, in most cases, models are explored and evaluated using classification tasks on very large-scale datasets like ImageNet [1], where the outputs of the classification tasks are single label or probability values. Alternatively, small architecturally variant models are used for semantic image segmentation tasks. For example, a fully-connected convolutional neural network (FCN) also provides state-of-the-art results for image segmentation tasks in computer vision [2]. Another variant of FCN was also proposed which is called SegNet [10].
如今,深度学习(DL)在图像分类[1]、分割[2]、检测与跟踪[3]以及描述生成[4]任务中提供了最先进的性能。自2012年以来,研究者们提出了多种深度卷积神经网络(DCNN)模型,如AlexNet[1]、VGG[5]、GoogleNet[6]、残差网络(Residual Net)[7]、密集连接网络(DenseNet)[8]和胶囊网络(CapsuleNet)[9][65]。基于深度学习(特别是CNN)的方法在分类和分割任务中表现出色,主要原因有三:首先,激活函数解决了深度学习中的训练难题;其次,Dropout技术能有效规范网络;第三,现有多种高效优化技术可用于训练CNN模型[1]。然而在多数情况下,这些模型是通过ImageNet[1]等超大规模数据集的分类任务进行探索和评估的,其输出仅为单一标签或概率值。另一方面,结构精简的变体模型被用于语义图像分割任务,例如全卷积神经网络(FCN)在计算机视觉图像分割领域同样取得了顶尖成果[2]。随后研究者又提出了FCN的改进版本SegNet[10]。
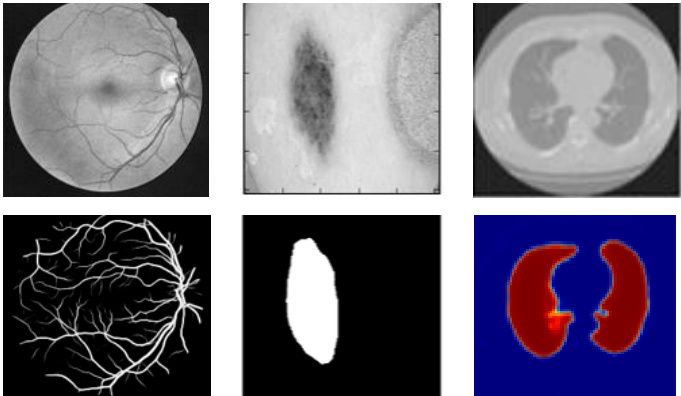
Fig. 1. Medical image segmentation: retina blood vessel segmentation in the left, skin cancer lesion segmentation, and lung segmentation in the right.
图 1: 医学图像分割:左侧为视网膜血管分割,中间为皮肤癌病灶分割,右侧为肺部分割。
Due to the great success of DCNNs in the field of computer vision, different variants of this approach are applied in different modalities of medical imaging including segmentation, classification, detection, registration, and medical information processing. The medical imaging comes from different imaging techniques such as Computer Tomography (CT), ultrasound, X-ray, and Magnetic Resonance Imaging (MRI). The goal of Computer-Aided Diagnosis (CAD) is to obtain a faster and better diagnosis to ensure better treatment of a large number of people at the same time. Additionally, efficient automatic processing without human involvement to reduce human error and also reduces overall time and cost. Due to the slow process and tedious nature of manual segmentation approaches, there is a significant demand for computer algorithms that can do segmentation quickly and accurately without human interaction. However, there are some limitations of medical image segmentation including data scarcity and class imbalance. Most of the time the large number of labels (often in the thousands) for training is not available for several reasons [11]. Labeling the dataset requires an expert in this field which is expensive, and it requires a lot of effort and time. Sometimes, different data transformation or augmentation techniques (data whitening, rotation, translation, and scaling) are applied for increasing the number of labeled samples available [12, 13, and 14]. In addition, patch based approaches are used for solving class imbalance problems. In this work, we have evaluated the proposed approaches on both patch-based and entire image-based approaches. However, to switch from the patch-based approach to the pixel-based approach that works with the entire image, we must be aware of the class imbalance problem. In the case of semantic segmentation, the image backgrounds are assigned a label and the foreground regions are assigned a target class. Therefore, the class imbalance problem is resolved without any trouble. Two advanced techniques including cross-entropy loss and dice similarity are introduced for efficient training of classification and segmentation tasks in [13, 14].
由于DCNN在计算机视觉领域的巨大成功,该方法的多种变体被应用于医学影像的不同模态中,包括分割、分类、检测、配准和医学信息处理。医学影像来自不同的成像技术,如计算机断层扫描(CT)、超声、X射线和磁共振成像(MRI)。计算机辅助诊断(CAD)的目标是获得更快、更好的诊断,以确保同时为大量患者提供更好的治疗。此外,无需人工干预的高效自动处理可以减少人为错误,并降低总体时间和成本。由于手动分割方法过程缓慢且繁琐,因此对无需人工交互即可快速准确完成分割的计算机算法需求很大。然而,医学图像分割存在一些局限性,包括数据稀缺和类别不平衡。大多数情况下,由于多种原因[11],无法获得大量(通常数以千计)用于训练的标签。标注数据集需要该领域的专家,成本高昂,且需要大量精力和时间。有时,会应用不同的数据转换或增强技术(数据白化、旋转、平移和缩放)来增加可用标记样本的数量[12、13和14]。此外,基于补丁的方法被用于解决类别不平衡问题。在这项工作中,我们评估了基于补丁和基于整幅图像的两种方法。然而,当从基于补丁的方法切换到基于像素的整幅图像处理方法时,我们必须注意类别不平衡问题。在语义分割的情况下,图像背景被分配一个标签,前景区域被分配一个目标类别。因此,类别不平衡问题可以轻松解决。[13、14]中引入了两种先进技术,包括交叉熵损失和dice相似度,用于高效训练分类和分割任务。
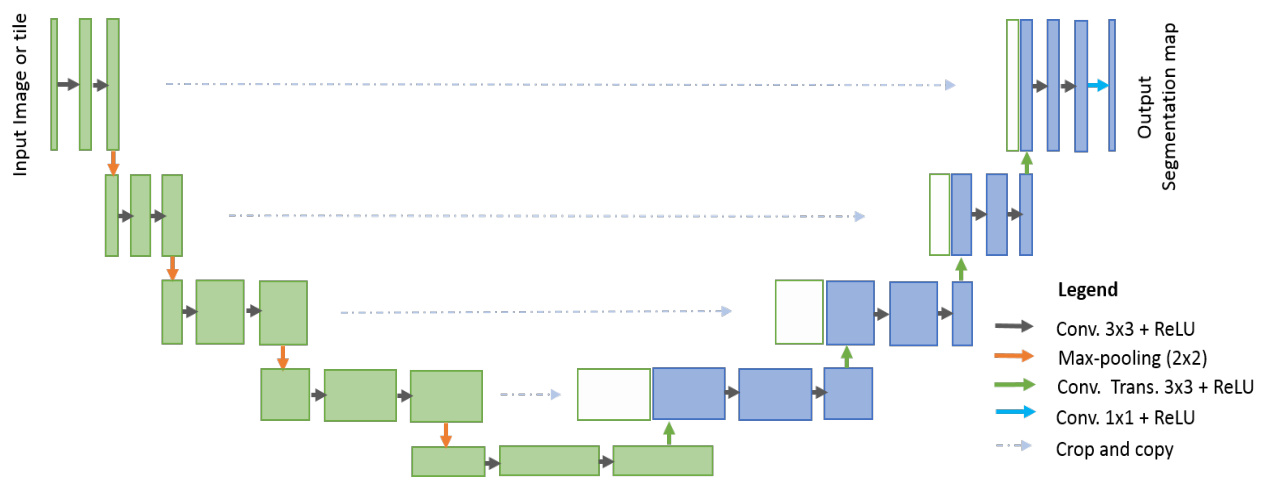
Fig. 2. U-Net architecture consisted with convolutional encoding and decoding units that take image as input and produce the segmentation feature maps with respective pixel classes.
图 2: U-Net架构由卷积编码和解码单元组成,以图像作为输入并生成具有相应像素类别的分割特征图。
Furthermore, in medical image processing, global localization and context modulation is very often applied for localization tasks. Each pixel is assigned a class label with a desired boundary that is related to the contour of the target lesion in identification tasks. To define these target lesion boundaries, we must emphasize the related pixels. Landmark detection in medical imaging [15, 16] is one example of this. There were several traditional machine learning and image processing techniques available for medical image segmentation tasks before the DL revolution, including amplitude segmentation based on histogram features [17], the region based segmentation method [18], and the graph-cut approach [19]. However, semantic segmentation approaches that utilize DL have become very popular in recent years in the field of medical image segmentation, lesion detection, and localization [20]. In addition, DL based approaches are known as universal learning approaches, where a single model can be utilized efficiently in different modalities of medical imaging such as MRI, CT, and X-ray.
此外,在医学图像处理中,全局定位和上下文调制常被用于定位任务。在识别任务中,每个像素会被分配一个与目标病灶轮廓相关的类别标签及期望边界。为了定义这些目标病灶边界,我们必须强调相关像素。医学影像中的关键点检测 [15, 16] 就是其中一个例子。在深度学习 (DL) 革命之前,已有多种传统机器学习和图像处理技术可用于医学图像分割任务,包括基于直方图特征的幅度分割 [17]、基于区域的分割方法 [18] 以及图割算法 [19]。然而,近年来利用深度学习的语义分割方法在医学图像分割、病灶检测和定位领域变得非常流行 [20]。此外,基于深度学习的方法被称为通用学习方法,单个模型可高效应用于 MRI、CT 和 X 射线等不同模态的医学成像中。
According to a recent survey, DL approaches are applied to almost all modalities of medical imagining [20, 21]. Furthermore, the highest number of papers have been published on segmentation tasks in different modalities of medical imaging [20, 21]. A DCNN based brain tumor segmentation and detection method was proposed in [22].
根据最近的一项调查,深度学习 (DL) 方法已应用于几乎所有医学影像模态 [20, 21]。此外,针对不同医学影像模态的分割任务发表的论文数量最多 [20, 21]。文献 [22] 提出了一种基于深度卷积神经网络 (DCNN) 的脑肿瘤分割与检测方法。
From an architectural point of view, the CNN model for classification tasks requires an encoding unit and provides class probability as an output. In classification tasks, we have performed convolution operations with activation functions followed by sub-sampling layers which reduces the dimensionality of the feature maps. As the input samples traverse through the layers of the network, the number of feature maps increases but the dimensionality of the feature maps decreases. This is shown in the first part of the model (in green) in Fig. 2. Since, the number of feature maps increase in the deeper layers, the number of network parameters increases respectively. Eventually, the Softmax operations are applied at the end of the network to compute the probability of the target classes.
从架构角度来看,用于分类任务的CNN模型需要一个编码单元,并输出类别概率。在分类任务中,我们执行了带有激活函数的卷积运算,随后通过降采样层降低特征图的维度。随着输入样本在网络各层中传递,特征图数量增加但维度减小。如图2模型第一部分(绿色区域)所示。由于深层网络特征图数量增加,网络参数量也相应增长。最终在网络末端应用Softmax运算计算目标类别的概率。
As opposed to classification tasks, the architecture of segmentation tasks requires both convolutional encoding and decoding units. The encoding unit is used to encode input images into a larger number of maps with lower dimensionality. The decoding unit is used to perform up-convolution (deconvolution) operations to produce segmentation maps with the same dimensionality as the original input image. Therefore, the architecture for segmentation tasks generally requires almost double the number of network parameters when compared to the architecture of the classification tasks. Thus, it is important to design efficient DCNN architectures for segmentation tasks which can ensure better performance with less number of network parameters.
与分类任务不同,分割任务的架构需要同时包含卷积编码和解码单元。编码单元用于将输入图像编码为数量更多但维度更低的特征图,解码单元则通过反卷积(上采样)操作生成与原始输入图像尺寸相同的分割图。因此,分割任务的网络参数量通常达到分类任务的两倍左右。设计高效的分割任务深度卷积网络(DCNN)架构至关重要,这能在减少网络参数量的同时确保更优性能。
This research demonstrates two modified and improved segmentation models, one using recurrent convolution networks, and another using recurrent residual convolutional networks. To accomplish our goals, the proposed models are evaluated on different modalities of medical imagining as shown in Fig. 1. The contributions of this work can be summarized as follows:
本研究展示了两种改进后的分割模型,一种采用循环卷积网络 (recurrent convolution networks),另一种采用循环残差卷积网络 (recurrent residual convolutional networks)。如图 1 所示,我们在不同模态的医学影像上评估了所提模型以实现目标。本工作的贡献可总结如下:
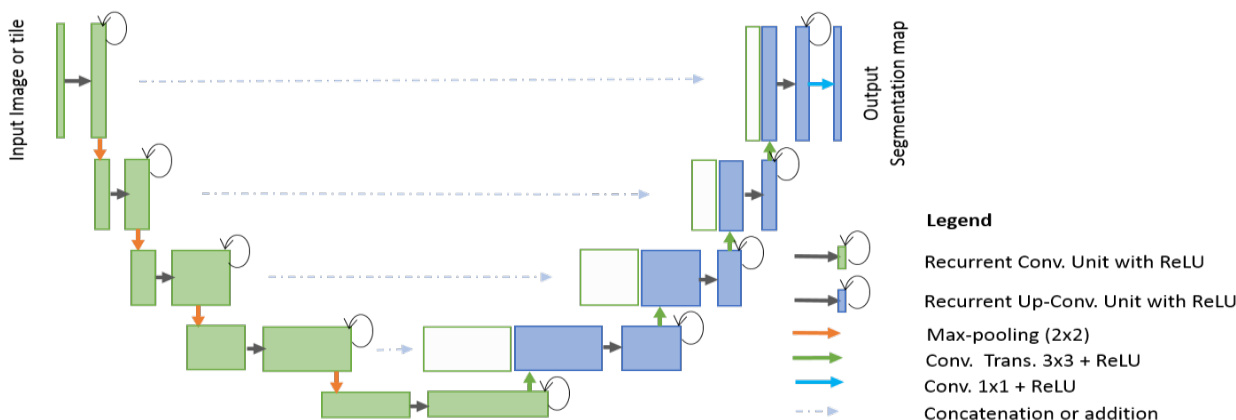
Fig. 3. RU-Net architecture with convolutional encoding and decoding units using recurrent convolutional layers (RCL) based U-Net architecture. The residual units are used with RCL for R2U-Net architecture.
图 3: 基于循环卷积层(RCL)的U-Net架构,采用卷积编码和解码单元的RU-Net结构。残差单元与RCL结合用于R2U-Net架构。
The paper is organized as follows: Section II discusses related work. The architectures of the proposed RU-Net and R2U-Net models are presented in Section III. Section IV, explains the datasets, experiments, and results. The conclusion and future direction are discussed in Section V.
本文结构如下:第II节讨论相关工作。第III节介绍提出的RU-Net和R2U-Net模型架构。第IV节阐述数据集、实验及结果。第V节讨论结论与未来方向。
II. RELATED WORK
II. 相关工作
Semantic segmentation is an active research area where DCNNs are used to classify each pixel in the image individually, which is fueled by different challenging datasets in the fields of computer vision and medical imaging [23, 24, and 25]. Before the deep learning revolution, the traditional machine learning approach mostly relied on hand engineered features that were used for classifying pixels independently. In the last few years, a lot of models have been proposed that have proved that deeper networks are better for recognition and segmentation tasks [5]. However, training very deep models is difficult due to the vanishing gradient problem, which is resolved by implementing modern activation functions such as Rectified Linear Units (ReLU) or Exponential Linear Units (ELU) [5,6]. Another solution to this problem is proposed by He et al., a deep residual model that overcomes the problem utilizing an identity mapping to facilitate the training process [26].
语义分割是一个活跃的研究领域,其中深度卷积神经网络 (DCNNs) 被用于对图像中的每个像素进行单独分类,这一领域的发展得益于计算机视觉和医学影像领域中各种具有挑战性的数据集 [23, 24, 25]。在深度学习革命之前,传统的机器学习方法主要依赖于手工设计的特征,这些特征被用于独立分类像素。过去几年中,许多模型被提出,证明了更深的网络对于识别和分割任务更有效 [5]。然而,由于梯度消失问题,训练非常深的模型十分困难,这一问题通过实现现代激活函数如修正线性单元 (ReLU) 或指数线性单元 (ELU) 得到了解决 [5,6]。He 等人提出了另一种解决方案,即深度残差模型,该模型利用恒等映射克服了这一问题,从而简化了训练过程 [26]。
In addition, CNNs based segmentation methods based on FCN provide superior performance for natural image segmentation [2]. One of the image patch-based architectures is called Random architecture, which is very computationally intensive and contains around $134.5\mathrm{M}$ network parameters. The main drawback of this approach is that a large number of pixel overlap and the same convolutions are performed many times. The performance of FCN has improved with recurrent neural networks (RNN), which are fine-tuned on very large datasets [27]. Semantic image segmentation with DeepLab is one of the state-of-the-art performing methods [28]. SegNet consists of two parts, one is the encoding network which is a 13-layer VGG16 network [5], and the corresponding decoding network uses pixel-wise classification layers. The main contribution of this paper is the way in which the decoder upsamples its lower resolution input feature maps [10]. Later, an improved version of SegNet, which is called Bayesian SegNet was proposed in 2015 [29]. Most of these architectures are explored using computer vision applications. However, there are some deep learning models that have been proposed specifically for the medical image segmentation, as they consider data insufficiency and class imbalance problems.
此外,基于FCN的CNN分割方法在自然图像分割中表现出优越性能 [2]。其中一种基于图像块的架构称为随机架构(Random architecture),其计算量极大,包含约$134.5\mathrm{M}$个网络参数。该方法的主要缺点是存在大量像素重叠且需重复执行相同卷积运算。通过在大规模数据集上微调循环神经网络(RNN),FCN的性能得到了提升 [27]。采用DeepLab的语义图像分割是最先进的性能方法之一 [28]。SegNet由两部分组成:编码网络采用13层VGG16网络 [5],对应的解码网络则使用逐像素分类层。本文主要贡献在于解码器对低分辨率输入特征图进行上采样的方式 [10]。2015年又提出了改进版Bayesian SegNet [29]。这些架构大多应用于计算机视觉领域,但也有专门针对医学图像分割提出的深度学习模型,这类模型考虑了数据不足和类别不平衡问题。
One of the very first and most popular approaches for semantic medical image segmentation is called “U-Net” [12]. A diagram of the basic U-Net model is shown in Fig. 2. According to the structure, the network consists of two main parts: the convolutional encoding and decoding units. The basic convolution operations are performed followed by ReLU activation in both parts of the network. For down sampling in the encoding unit, $2\times2$ max-pooling operations are performed. In the decoding phase, the convolution transpose (representing up-convolution, or de-convolution) operations are performed to up-sample the feature maps. The very first version of U-Net was used to crop and copy feature maps from the encoding unit to the decoding unit. The U-Net model provides several advantages for segmentation tasks: first, this model allows for the use of global location and context at the same time. Second, it works with very few training samples and provides better performance for segmentation tasks [12]. Third, an end-to-end pipeline process the entire image in the forward pass and directly produces segmentation maps. This ensures that U-Net preserves the full context of the input images, which is a major advantage when compared to patch-based segmentation approaches [12, 14].
语义医学图像分割最早且最流行的方法之一是“U-Net”[12]。图2展示了基础U-Net模型的示意图。该网络结构由两个主要部分组成:卷积编码单元和解码单元。网络两部分均执行基础卷积运算后接ReLU激活函数。在编码单元的下采样过程中,会执行$2\times2$最大池化操作。解码阶段则通过转置卷积(代表上卷积或反卷积)操作对特征图进行上采样。U-Net最初版本采用将编码单元特征图裁剪并复制到解码单元的方式。该模型为分割任务提供三大优势:首先,可同时利用全局位置和上下文信息;其次,仅需少量训练样本即可获得优异的分割性能[12];第三,端到端流程在前向传播中处理整幅图像并直接生成分割图,确保保留输入图像的完整上下文信息,相较基于图像块的分割方法具有显著优势[12, 14]。
However, U-Net is not only limited to the applications in the domain of medical imaging, nowadays this model is massively applied for computer vision tasks as well [30, 31]. Meanwhile, different variants of U-Net models have been proposed, including a very simple variant of U-Net for CNN-based segmentation of Medical Imaging data [32]. In this model, two modifications are made to the original design of U-Net: first, a combination of multiple segmentation maps and forward feature maps are summed (element-wise) from one part of the network to the other. The feature maps are taken from different layers of encoding and decoding units and finally summation (element-wise) is performed outside of the encoding and decoding units. The authors report promising performance improvement during training with better convergence compared to U-Net, but no benefit was observed when using a summation of features during the testing phase [32]. However, this concept proved that feature summation impacts the performance of a network. The importance of skipped connections for biomedical image segmentation tasks have been empirically evaluated with U-Net and residual networks [33]. A deep contour-aware network called Deep ContourAware Networks (DCAN) was proposed in 2016, which can extract multi-level contextual features using a hierarchical architecture for accurate gland segmentation of histology images and shows very good performance for segmentation [34]. Furthermore, Nabla-Net: a deep dig-like convolutional architecture was proposed for segmentation in 2017 [35].
然而,U-Net的应用不仅限于医学影像领域,如今该模型也被广泛应用于计算机视觉任务[30, 31]。与此同时,研究者们提出了多种U-Net变体,包括一种基于CNN的医学影像数据分割的极简版U-Net[32]。该模型对原始U-Net设计进行了两处修改:首先,将多个分割图与前向特征图在网络不同部分间进行逐元素求和。这些特征图取自编码器和解码器单元的不同层级,最终在编解码单元外部执行逐元素求和。作者报告称,相比原始U-Net,该变体在训练时表现出更好的收敛性和性能提升,但在测试阶段使用特征求和并未观察到益处[32]。这一概念证实了特征求和会影响网络性能。通过U-Net和残差网络的实证研究表明,跳跃连接对生物医学图像分割任务至关重要[33]。2016年提出的深度轮廓感知网络(Deep ContourAware Networks, DCAN)采用分层架构提取多级上下文特征,在组织学图像腺体分割中表现出色[34]。此外,2017年提出的Nabla-Net采用类数字卷积结构进行分割任务[35]。
Other deep learning approaches have been proposed based on U-Net for 3D medical image segmentation tasks as well. The 3D-Unet architecture for volumetric segmentation learns from sparsely annotated volumetric images [13]. A powerful end-toend 3D medical image segmentation system based on volumetric images called V-net has been proposed, which consists of a FCN with residual connections [14]. This paper also introduces a dice loss layer [14]. Furthermore, a 3D deeply supervised approach for automated segmentation of volumetric medical images was presented in [36]. High-Res3DNet was proposed using residual networks for 3D segmentation tasks in 2016 [37]. In 2017, a CNN based brain tumor segmentation approach was proposed using a 3D-CNN model with a fully connected CRF [38]. Pancreas segmentation was proposed in [39], and Voxresnet was proposed in 2016 where a deep voxel wise residual network is used for brain segmentation. This architecture utilizes residual networks and summation of feature maps from different layers [40].
其他基于U-Net的深度学习方法也被提出用于3D医学图像分割任务。3D-Unet架构通过学习稀疏标注的体图像进行体积分割[13]。一种基于体图像的强大端到端3D医学图像分割系统V-net被提出,该系统包含带有残差连接的全卷积网络(FCN)[14]。该论文还引入了dice损失层[14]。此外,文献[36]提出了一种用于自动分割体积医学图像的3D深度监督方法。2016年提出的High-Res3DNet将残差网络用于3D分割任务[37]。2017年,一种基于CNN的脑肿瘤分割方法被提出,该方法使用带有全连接条件随机场(CRF)的3D-CNN模型[38]。文献[39]提出了胰腺分割方法,2016年提出的Voxresnet采用深度体素级残差网络进行脑部分割。该架构利用残差网络和来自不同层的特征图求和[40]。
Alternatively, we have proposed two models for semantic segmentation based on the architecture of U-Net in this paper. The proposed Recurrent Convolutional Neural Networks (RCNN) model based on U-Net is named RU-Net, which is shown in Fig. 3. Additionally, we have proposed a residual RCNN based U-Net model which is called R2U-Net. The following section provides the architectural details of both models.
本文还提出了两种基于U-Net架构的语义分割模型。基于U-Net的循环卷积神经网络(RCNN)模型被命名为RU-Net,如图3所示。此外,我们还提出了一种基于残差RCNN的U-Net模型,称为R2U-Net。以下部分将详细介绍这两种模型的结构。
III. RU-NET AND R2U-NET ARCHITECTURES
III. RU-NET 与 R2U-NET 架构
Inspired by the deep residual model [7], RCNN [41], and UNet [12], we propose two models for segmentation tasks which are named RU-Net and R2U-Net. These two approaches utilize the strengths of all three recently developed deep learning models. RCNN and its variants have already shown superior performance on object recognition tasks using different benchmarks [42, 43]. The recurrent residual convolutional operations can be demonstrated mathematically according to the improved-residual networks in [43]. The operations of the Recurrent Convolutional Layers (RCL) are performed with respect to the discrete time steps that are expressed according to the RCNN [41]. Let’s consider the $x_{l}$ input sample in the $l^{t h}$ layer of the residual RCNN (RRCNN) block and a pixel located at $(i,j)$ in an input sample on the $k^{\mathrm{th}}$ feature map in the RCL. Additionally, let’s assume the output of the network $O_{i j k}^{l}(t)$ is at the time step $t.$ . The output can be expressed as follows as:
受深度残差模型 [7]、RCNN [41] 和 UNet [12] 的启发,我们提出了两种用于分割任务的模型,分别命名为 RU-Net 和 R2U-Net。这两种方法结合了近期三种深度学习模型的优势。RCNN 及其变体已在不同基准测试中展现出卓越的目标识别性能 [42, 43]。根据 [43] 中改进的残差网络,循环残差卷积操作可通过数学方式证明。循环卷积层 (RCL) 的操作基于离散时间步执行,其表达式遵循 RCNN [41] 的定义。设 $x_{l}$ 为残差 RCNN (RRCNN) 模块第 $l^{t h}$ 层的输入样本,$(i,j)$ 为 RCL 中第 $k^{\mathrm{th}}$ 个特征图上某像素位置,$O_{i j k}^{l}(t)$ 表示网络在时间步 $t$ 的输出,其表达式如下:
$$
O_{i j k}^{l}(t)=\left(w_{k}^{f}\right)^{T}*x_{l}^{f(i,j)}(t)+(w_{k}^{r})^{T}*x_{l}^{r(i,j)}(t-1)+b_{k}
$$
$$
O_{i j k}^{l}(t)=\left(w_{k}^{f}\right)^{T}*x_{l}^{f(i,j)}(t)+(w_{k}^{r})^{T}*x_{l}^{r(i,j)}(t-1)+b_{k}
$$
Here $x_{l}^{f(i,j)}(t)$ and $x_{l}^{r(i,j)}(t-1)$ are the inputs to the standard convolution layers and for the $l^{t h}{\mathrm{\tinyRCL}}$ respectively. The $w_{k}^{f}$ and $w_{k}^{r}$ values are the weights of the standard convolutional layer and the RCL of the $k^{\mathrm{th}}$ feature map respectively, and $b_{k}$ is the bias. The outputs of RCL are fed to the standard ReLU activation function $f$ and are expressed:
这里 $x_{l}^{f(i,j)}(t)$ 和 $x_{l}^{r(i,j)}(t-1)$ 分别是标准卷积层和第 $l^{t h}{\mathrm{\tinyRCL}}$ 的输入。$w_{k}^{f}$ 和 $w_{k}^{r}$ 分别是标准卷积层和第 $k^{\mathrm{th}}$ 个特征图的 RCL 权重,$b_{k}$ 是偏置项。RCL 的输出经过标准 ReLU 激活函数 $f$ 处理后表示为:
$$
\mathcal{F}(x_{l},w_{l})=f(O_{i j k}^{l}(t))=\operatorname*{max}(0,O_{i j k}^{l}(t))
$$
$$
\mathcal{F}(x_{l},w_{l})=f(O_{i j k}^{l}(t))=\operatorname*{max}(0,O_{i j k}^{l}(t))
$$
$\mathcal{F}(x_{l},w_{l})$ represents the outputs from of $l^{t h}$ layer of the RCNN unit. The output of $\mathcal{F}(x_{l},w_{l})$ is used for down-sampling and up-sampling layers in the convolutional encoding and decoding units of the RU-Net model respectively. In the case of R2U-Net, the final outputs of the RCNN unit are passed through the residual unit that is shown Fig. 4(d). Let’s consider that the output of the RRCNN-block is $x_{l+1}$ and can be calculated as follows:
$\mathcal{F}(x_{l},w_{l})$ 表示RCNN单元第$l^{t h}$层的输出。$\mathcal{F}(x_{l},w_{l})$的输出分别用于RU-Net模型卷积编码和解码单元中的下采样和上采样层。在R2U-Net中,RCNN单元的最终输出会经过如图4(d)所示的残差单元。假设RRCNN块的输出为$x_{l+1}$,其计算公式如下:
$$
x_{l+1}=x_{l}+\mathcal{F}(x_{l},w_{l})
$$
$$
x_{l+1}=x_{l}+\mathcal{F}(x_{l},w_{l})
$$
Here, $x_{l}$ represents the input samples of the RRCNN-block. The $x_{l+1}$ sample is used the input for the immediate succeeding sub-sampling or up-sampling layers in the encoding and decoding convolutional units of R2U-Net. However, the number of feature maps and the dimensions of the feature maps for the residual units are the same as in the RRCNN-block shown in Fig. 4 (d).
这里,$x_{l}$ 表示 RRCNN-block 的输入样本。$x_{l+1}$ 样本用作 R2U-Net 编码和解码卷积单元中后续子采样或上采样层的输入。然而,残差单元的特征图数量和维度与图 4 (d) 所示的 RRCNN-block 相同。
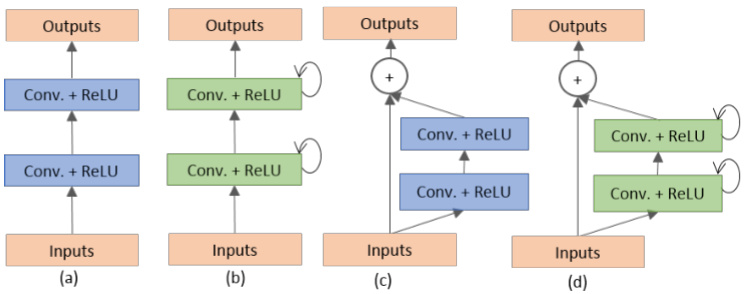
Fig. 4. Different variant of convolutional and recurrent convolutional units (a) Forward convolutional units, (b) Recurrent convolutional block (c) Residual convolutional unit, and (d) Recurrent Residual convolutional units (RRCU).
图 4: 卷积和循环卷积单元的不同变体 (a) 前向卷积单元, (b) 循环卷积块, (c) 残差卷积单元, (d) 循环残差卷积单元 (RRCU)。
The proposed deep learning models are the building blocks of the stacked convolutional units shown in Fig. 4(b) and (d).
所提出的深度学习模型是图4(b)和(d)中堆叠卷积单元的基础构建模块。
There are four different architectures evaluated in this work. First, U-Net with forward convolution layers and feature concatenation is applied as an alternative to the crop and copy method found in the primary version of U-Net [12]. The basic convolutional unit of this model is shown in Fig. 4(a). Second, U-Net with forward convolutional layers with residual connectivity is used, which is often called residual U-net (ResU-Net) and is shown in Fig. 4(c) [14]. The third architecture is U-Net with forward recurrent convolutional layers as shown in Fig. 4(b), which is named RU-Net. Finally, the last architecture is U-Net with recurrent convolution layers with residual connectivity as shown in Fig. 4(d), which is named R2U-Net. The pictorial representation of the unfolded RCL layers with respect to time-step is shown in Fig 5. Here $t=2(0\sim2)$ , refers to the recurrent convolutional operation that includes one single convolution layer followed by two subsequential recurrent convolutional layers. In this implementation, we have applied concatenation to the feature maps from the encoding unit to the decoding unit for both RUNet and R2U-Net models.
本研究评估了四种不同的架构。首先,采用带有前向卷积层和特征拼接的U-Net,作为原始版本U-Net中裁剪复制方法的替代方案[12]。该模型的基本卷积单元如图4(a)所示。其次,使用带有残差连接的前向卷积层U-Net,通常称为残差U-Net(ResU-Net),如图4(c)所示[14]。第三种架构是带有前向循环卷积层的U-Net,如图4(b)所示,命名为RU-Net。最后一种架构是带有残差连接的循环卷积层U-Net,如图4(d)所示,命名为R2U-Net。按时间步展开的RCL层图示如图5所示。这里$t=2(0\sim2)$,指的是包含一个单卷积层和两个后续循环卷积层的循环卷积操作。在本实现中,我们对RUNet和R2U-Net模型都采用了从编码单元到解码单元的特征图拼接方法。
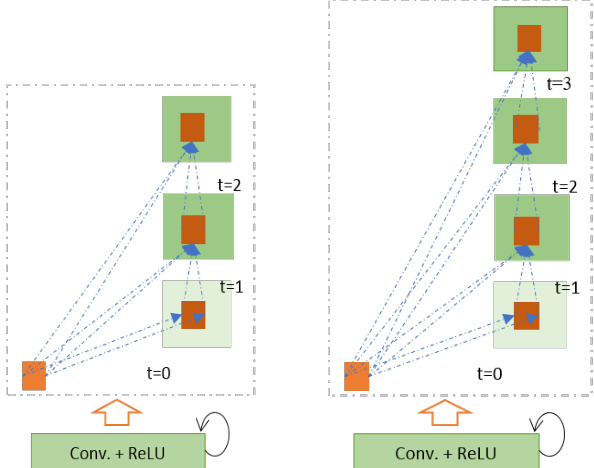
Fig. 5. Unfolded recurrent convolutional units for $t=2$ (left) and $t=3$ (right).
图 5: 展开的循环卷积单元,展示 $t=2$ (左) 和 $t=3$ (右) 的情况。
The differences between the proposed models with respect to the U-Net model are three-fold. This architecture consists of convolutional encoding and decoding units same as U-Net. However, the RCLs and RCLs with residual units are used instead of regular forward convolutional layers in both the encoding and decoding units. The residual unit with RCLs helps to develop a more efficient deeper model. Second, the efficient feature accumulation method is included in the RCL units of both proposed models. The effectiveness of feature accumulation from one part of the network to the other is shown in the CNN-based segmentation approach for medical imaging. In this model, the element-wise feature summation is performed outside of the U-Net model [32]. This model only shows the benefit during the training process in the form of better convergence. However, our proposed models show benefits for both training and testing phases due to the feature accumulation inside the model. The feature accumulation with respect to different time-steps ensures better and stronger feature representation. Thus, it helps extract very low-level features which are essential for segmentation tasks for different modalities of medical imaging (such as blood vessel segmentation). Third, we have removed the cropping and copying unit from the basic U-Net model and use only concatenation operations, resulting a much-sophisticated architecture that results in better performance.
所提模型与U-Net模型的差异主要体现在三个方面。该架构与U-Net同样包含卷积编码和解码单元,但在编码和解码单元中使用RCL(循环卷积层)及带残差单元的RCL替代常规前向卷积层。带RCL的残差单元有助于构建更高效的深层模型。其次,两个提案模型均在RCL单元中采用了高效特征累积方法。基于CNN的医学影像分割方法已证明网络不同部分间特征累积的有效性[32],该模型在U-Net外部进行逐元素特征求和,仅以更好收敛性的形式体现在训练过程中。而我们的提案模型由于在内部实现特征累积,在训练和测试阶段均显现优势。不同时间步的特征累积确保了更优、更强的特征表征能力,因此能有效提取对多模态医学影像分割(如血管分割)至关重要的底层特征。第三,我们移除了基础U-Net中的裁剪复制单元,仅保留拼接操作,从而形成更精密的架构以获得更优性能。
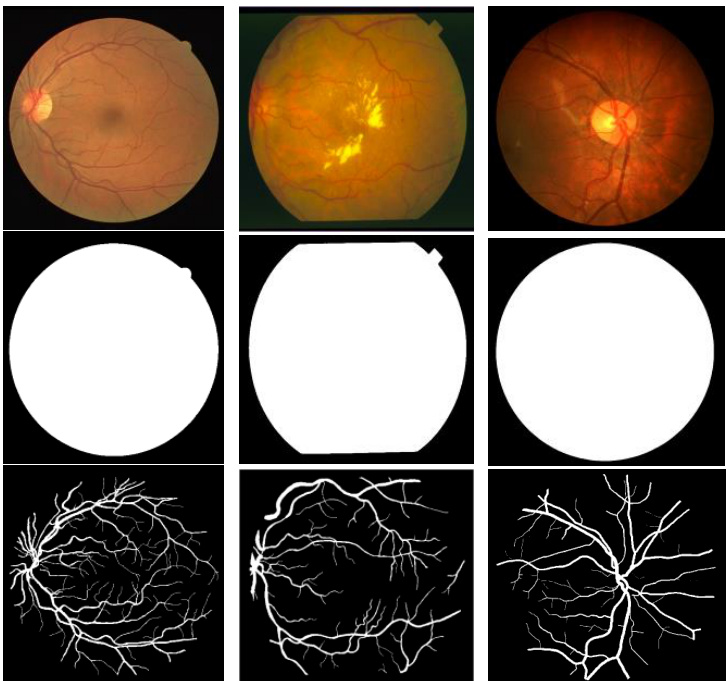
Fig. 6. Example images from training dataset: left column from DRIVE dataset, middle column from STARE dataset and right column from CHASE-DB1 dataset. The first row shows the original images, second row shows fields of view (FOV), and third row shows the target outputs.
图 6: 训练数据集示例图像:左列来自DRIVE数据集,中间列来自STARE数据集,右列来自CHASE-DB1数据集。第一行显示原始图像,第二行显示视场 (FOV) ,第三行显示目标输出。
There are several advantages of using the proposed architectures when compared with U-Net. The first is the efficiency in terms of the number of network parameters. The proposed RU-Net, and R2U-Net architectures are designed to have the same number of network parameters when compared to U-Net and ResU-Net, and RU-Net and R2U-Net show better performance on segmentation tasks. The recurrent and residual operations do not increase the number of network parameters. However, they do have a significant impact on training and testing performance. This is shown through empirical evidence with a set of experiments in the following sections [43]. This approach is also general iz able, as it easily be applied deep learning models based on SegNet [10], 3D-UNet [13], and VNet [14] with improved performance for segmentation tasks.
与U-Net相比,所提出的架构具有多项优势。首先是网络参数数量方面的效率。所提出的RU-Net和R2U-Net架构在设计时保持与U-Net和ResU-Net相同的参数数量,但在分割任务中表现出更优性能。循环和残差操作不会增加网络参数总量,却能显著提升训练和测试性能。后续章节的实验数据 [43] 证实了这一点。该方案还具备通用性,可轻松移植至基于SegNet [10]、3D-UNet [13] 和VNet [14] 的深度学习模型,从而提升分割任务表现。
IV. EXPERIMENTAL SETUP AND RESULTS
IV. 实验设置与结果
To demonstrate the performance of the RU-Net and R2U-Net models, we have tested them on three different medical imaging datasets. These include blood vessel segmentation s from retina images (DRIVE, STARE, and CHASE_DB1 shown in Fig. 6), skin cancer lesion segmentation, and lung segmentation from 2D images. For this implementation, the Keras, and TensorFlow frameworks are used on a single GPU machine with 56G of RAM and an NIVIDIA GEFORCE GTX-980 Ti.
为了展示RU-Net和R2U-Net模型的性能,我们在三个不同的医学影像数据集上进行了测试。这些数据集包括视网膜图像中的血管分割(如图6所示的DRIVE、STARE和CHASE_DB1)、皮肤癌病变分割以及2D图像中的肺部分割。本次实现使用了Keras和TensorFlow框架,运行在配备56G内存和NVIDIA GEFORCE GTX-980 Ti单GPU的机器上。
A. Database Summary
A. 数据库概述
1) Blood Vessel Segmentation
1) 血管分割
We have experimented on three different popular datasets for retina blood vessel segmentation including DRIVE, STARE, and CHASH_DB1. The DRIVE dataset is consisted of 40 color retinal images in total, in which 20 samples are used for training and remaining 20 samples are used for testing. The size of each original image is $565\times584$ pixels [44]. To develop a square dataset, the images are cropped to only contain the data from columns 9 through 574, which then makes each image $565\times565$ pixels. In this implementation, we considered 190,000 randomly selected patches from 20 of the images in the DRIVE dataset, where 171,000 patches are used for training, and the remaining 19,000 patches used for validation. The size of each patch is $48\times48$ for all three datasets shown in Fig. 7. The second dataset, STARE, contains 20 color images, and each image has a size of $700\times605$ pixels [45, 46]. Due to the smaller number of samples, two approaches are applied very often for training and testing on this dataset. First, training sometimes performed with randomly selected samples from all 20 images [53].
我们在三个不同的视网膜血管分割常用数据集上进行了实验,包括DRIVE、STARE和CHASH_DB1。DRIVE数据集共包含40张彩色视网膜图像,其中20个样本用于训练,剩余20个样本用于测试。每张原始图像的尺寸为$565\times584$像素[44]。为构建方形数据集,图像被裁剪为仅保留第9至574列的数据,使每张图像变为$565\times565$像素。本实验中,我们从DRIVE数据集的20张图像中随机选取了190,000个图像块,其中171,000块用于训练,剩余19,000块用于验证。如图7所示,三个数据集的每个图像块尺寸均为$48\times48$。第二个数据集STARE包含20张彩色图像,每张图像尺寸为$700\times605$像素[45,46]。由于样本量较小,该数据集常采用两种训练测试方法:第一种是从全部20张图像中随机选取样本进行训练[53]。

Fig. 7. Example patches in the left and corresponding outputs of patches are shown in the right.
图 7: 左侧展示示例补丁,右侧为对应补丁的输出结果。
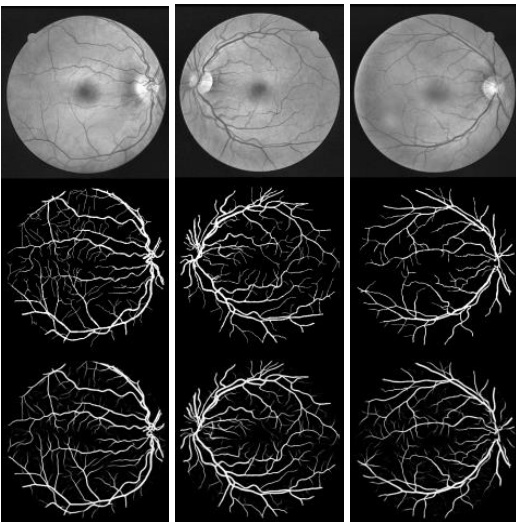
Fig. 8. Experimental outputs for DRIVE dataset using R2UNet: first row shows input image in gray scale, second row show ground truth, and third row shows the experimental outputs.
图 8: 使用R2UNet在DRIVE数据集上的实验结果:第一行显示灰度输入图像,第二行显示真实标注,第三行显示实验输出结果。
Another approach is the “leave-one-out” method, in which each image is tested, and training is conducted on the remaining 19 samples [47]. Therefore, there is no overlap between training and testing samples. In this implementation, we used the “leaveone-out” approach for STARE dataset. The CHASH_DB1 dataset contains 28 color retina images and the size of each image is $999\times960$ pixels [48]. The images in this dataset were collected from both left and right eyes of 14 school children. The dataset is divided into two sets where samples are selected randomly. A 20-sample set is used for training and the remaining 8 samples are used for testing.
另一种方法是“留一法”(leave-one-out),即对每张图像进行测试,并在剩余的19个样本上进行训练[47]。因此,训练样本和测试样本之间没有重叠。在本实现中,我们对STARE数据集采用了“留一法”。CHASH_DB1数据集包含28张彩色视网膜图像,每张图像尺寸为$999\times960$像素[48]。该数据集的图像采集自14名学童的左右眼。数据集被随机分为两组:20个样本用于训练,其余8个样本用于测试。
As the dimensionality of the input data larger than the entire DRIVE dataset, we have considered 250,000 patches in total from 20 images for both STARE and CHASE_DB1. In this case 225,000 patches are used for training and the remaining 25,000 patches are used for validation. Since the binary FOV (which is shown in second row in Fig. 6) is not available for the STARE and CHASE_DB1 datasets, we generated FOV masks using a similar technique to the one described in [47]. One advantage of the patch-based approach is that the patches give the network access to local information about the pixels, which has impact on overall prediction. Furthermore, it ensures that the classes of the input data are balanced. The input patches are randomly sampled over an entire image, which also includes the outside region of the FOV.
由于输入数据的维度大于整个DRIVE数据集,我们从STARE和CHASE_DB1的20张图像中总共考虑了250,000个图像块。其中225,000个图像块用于训练,剩余的25,000个用于验证。由于STARE和CHASE_DB1数据集没有二值FOV (如图6第二行所示),我们采用了与[47]类似的技术生成FOV掩模。基于图像块的方法有一个优势:这些图像块能让网络获取像素的局部信息,从而影响整体预测。此外,该方法还能确保输入数据的类别均衡。输入图像块是在整张图像上随机采样的,也包括FOV以外的区域。
2) Skin Cancer Segmentation
2) 皮肤癌分割
This dataset is taken from the Kaggle competition on skin lesion segmentation that occurred in 2017 [49]. This dataset contains 2000 samples in total. It consists of 1250 training samples, 150 validation samples, and 600 testing samples. The original size of each sample was $700\times900$ , which was rescaled to $256\times256$ for this implementation. The training samples include the original images, as well as corresponding target binary images containing cancer or non-cancer lesions. The target pixels are represented with a value of either 255 or 0 for the pixels outside of the target lesion.
该数据集取自2017年Kaggle皮肤病变分割竞赛[49],共包含2000个样本,其中训练集1250个、验证集150个、测试集600个。每个样本原始尺寸为$700\times900$,在本研究中被调整为$256\times256$。训练样本包含原始图像及对应的目标二值图像(标注癌症/非癌症病变区域),目标像素值为255,非病变区域像素值为0。
3) Lung Segmentation
3) 肺部分割
The Lung Nodule Analysis (LUNA) competition at the Kaggle Data Science Bowl in 2017 was held to find lung lesions in 2D and 3D CT images. The provided dataset consisted of 534 2D samples with respective label images for lung segmentation [50]. For this study, $70%$ of the images are used for training and the remaining $30%$ are used for testing. The original image size was $512\times512$ , however, we resized the images to $256\times256$ pixels in this implementation.
2017年Kaggle数据科学碗举办的肺结节分析(LUNA)竞赛旨在检测2D和3D CT图像中的肺部病变。提供的数据集包含534个2D样本及对应的肺部分割标注图像[50]。本研究中,$70%$的图像用于训练,剩余$30%$用于测试。原始图像尺寸为$512\times512$,但在本实现中我们将图像调整为$256\times256$像素。
B. Quantitative Analysis Approaches
B. 定量分析方法
For quantitative analysis of the experimental results, several performance metrics are considered, including accuracy (AC), sensitivity (SE), specificity (SP), F1-score, Dice coefficient (DC), and Jaccard similarity (JS). To do this we also use the variables True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN). The overall accuracy is calculated using Eq. (4), and sensitivity is calculated using Eq. (5).
为定量分析实验结果,我们考虑了多项性能指标,包括准确率(AC)、灵敏度(SE)、特异度(SP)、F1分数、Dice系数(DC)和Jaccard相似度(JS)。为此我们还使用了真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)等变量。总体准确率通过公式(4)计算,灵敏度通过公式(5)计算。
$$
\begin{array}{l}{{A C=\frac{T P+T N}{T P+T N+F P+F N}}}\ {{S E=\frac{T P}{T P+F N}}}\end{array}
$$
$$
\begin{array}{l}{{A C=\frac{T P+T N}{T P+T N+F P+F N}}}\ {{S E=\frac{T P}{T P+F N}}}\end{array}
$$
$$
\begin{array}{r}{S P=\frac{T N}{T N+F P}}\end{array}
$$
$$
\begin{array}{r}{S P=\frac{T N}{T N+F P}}\end{array}
$$
The DC is expressed as in Eq. (7) according to [51]. Here GT refers to the ground truth and SR refers the segmentation result.
DC 根据 [51] 由式 (7) 表示。其中 GT 指真实值 (ground truth) ,SR 指分割结果 (segmentation result) 。
$$
\begin{array}{r}{D C=2\frac{|G T\cap S R|}{|G T|+|S R|}}\end{array}
$$
$$
\begin{array}{r}{D C=2\frac{|G T\cap S R|}{|G T|+|S R|}}\end{array}
$$
The JS is represented using Eq. (8) as in [52].
JS 用式 (8) 表示,如 [52] 所述。
$$
\begin{array}{r}{J S={\frac{|G T\cap S R|}{|G T\cup S R|}}}\end{array}
$$
$$
\begin{array}{r}{J S={\frac{|G T\cap S R|}{|G T\cup S R|}}}\end{array}
$$
However, the area under curve (AUC) and the receiver operating characteristics (ROC) curve are common evaluation measures for medical image segmentation tasks. In this experiment, we utilized both analytical methods to evaluate the performance of the proposed approaches considering the mentioned criterions against existing state-of-the-art techniques.
然而,曲线下面积 (AUC) 和受试者工作特征 (ROC) 曲线是医学图像分割任务的常见评估指标。在本实验中,我们采用这两种分析方法,根据上述标准对所提方法与现有最先进技术进行性能评估。

Fig. 9. Training accuracy of the proposed models of RU-Net, and R2U-Net against ResU-Net and U-Net.
图 9: 提出的 RU-Net 和 R2U-Net 模型与 ResU-Net 和 U-Net 的训练准确率对比。
C. Results
C. 结果
1) Retina Blood Vessel Segmentation Using the DRIVE Dataset
1) 使用DRIVE数据集进行视网膜血管分割
The precise segmentation results achieved with the proposed R2U-Net model are shown in Fig. 8. Figs. 9 and 10 show the training and validation accuracy when using the DRIVE dataset. These figures show that the proposed R2U-Net and RU-Net models provide better performance during both the training and validation phase when compared to U-Net and ResU-Net.
所提出的R2U-Net模型实现的精确分割结果如图8所示。图9和图10展示了使用DRIVE数据集时的训练和验证准确率。这些图表表明,与U-Net和ResU-Net相比,提出的R2U-Net和RU-Net模型在训练和验证阶段都提供了更好的性能。

Fig. 10. Validation accuracy of the proposed models against ResU-Net and UNet.
图 10: 所提模型与ResU-Net和UNet的验证准确率对比。
- Retina blood vessel segmentation on the STARE dataset The experimental outputs of R2U-Net when using the STARE dataset are shown in Fig. 11. The training and validation accuracy for the STARE dataset is shown in Figs. 12 and 13 respectively.
- STARE数据集上的视网膜血管分割
R2U-Net在STARE数据集上的实验输出如图11所示。STARE数据集的训练和验证准确率分别如图12和图13所示。
R2U-Net shows a better performance than all other models during training. In addition, the validation accuracy in Fig. 13 demonstrates that the RU-Net and R2U-Net models provide better validation accuracy when compared to the equivalent UNet and ResU-Net models. Thus, the performance demonstrates the effectiveness of the proposed approaches for segmentation tasks.
R2U-Net在训练过程中表现出优于其他所有模型的性能。此外,图13中的验证准确率表明,与等效的UNet和ResU-Net模型相比,RU-Net和R2U-Net模型提供了更好的验证准确率。因此,这些性能表现证明了所提出方法在分割任务中的有效性。

Fig. 11. Experimental outputs of STARE dataset using R2UNet: first row shows input image after performing normalization, second row show ground truth, and third row shows the experimental outputs.
图 11: 使用R2UNet在STARE数据集上的实验结果:第一行显示归一化后的输入图像,第二行显示真实标注,第三行显示实验输出结果。

Fig. 12. Training accuracy in STARE dataset for R2U-Net, RU-Net, ResU-Net, and U-Net.
图 12: R2U-Net、RU-Net、ResU-Net和U-Net在STARE数据集上的训练准确率

Fig. 13. Validation accuracy in STARE dataset for R2U-Net, RU-Net, ResUNet, and U-Net.
图 13: R2U-Net、RU-Net、ResUNet和U-Net在STARE数据集上的验证准确率。
3) CHASE_DB1
3) CHASE_DB1
For qualitative analysis, the example outputs of R2U-Net are shown in Fig. 14. For quantitative analysis, the results are given in Table I. From the table, it can be concluded that in all cases, the proposed RU-Net and R2U-Net models show better performance in terms of AUC and accuracy. The ROC for the highest AUCs for the R2U-Net model on each of the three retina blood vessel segmentation datasets is shown in Fig. 15.
定性分析中,R2U-Net的示例输出如图14所示。定量分析结果如表1所示。从表中可以得出结论:在所有情况下,所提出的RU-Net和R2U-Net模型在AUC和准确率指标上均表现出更优性能。图15展示了R2U-Net模型在三个视网膜血管分割数据集上最高AUC对应的ROC曲线。
validation during training with a batch size of 32 and 150 epochs.
训练过程中使用批量大小为32和150个周期进行验证。
The training accuracy of the proposed models R2U-Net and RU-Net was compared with that of ResU-Net and U-Net for an end-to-end image based segmentation approach. The result is
所提模型R2U-Net和RU-Net的训练准确率与ResU-Net和U-Net在端到端基于图像的分割方法中进行了比较。结果
ABLE I. EXPERIMENTAL RESULTS OF PROPOSED APPROACHES FOR RETINA BLOOD VESSEL SEGMENTATION AND COMPARISON AGAINST OTHERTRADITIONAL AND DEEP LEARNING-BASED APPROACHES.
表 1: 视网膜血管分割方法的实验结果及与传统方法和基于深度学习方法的对比
| 数据集 | 方法 | 年份 | F1分数 | SE | SP | AC | AUC |
|---|---|---|---|---|---|---|---|
| DRIVE | Chen [53] | 2014 | 二 | 0.7252 | 0.9798 | 0.9474 | 0.9648 |
| Azzopardi [54] | 2015 | 二 | 0.7655 | 0.9704 | 0.9442 | 0.9614 | |
| Roychowdhury [55] | 2016 | 二 | 0.7250 | 0.9830 | 0.9520 | 0.9620 | |
| Liskowsk [56] | 2016 | 二 | 0.7763 | 0.9768 | 0.9495 | 0.9720 | |
| Qiaoliang Li [57] | 2016 | 0.7569 | 0.9816 | 0.9527 | 0.9738 | ||
| U-Net | 2018 | 0.8142 | 0.7537 | 0.9820 | 0.9531 | 0.9755 | |
| Residual U-Net | 2018 | 0.8149 | 0.7726 | 0.9820 | 0.9553 | 0.9779 | |
| Recurrent U-Net | 2018 | 0.8155 | 0.7751 | 0.9816 | 0.9556 | 0.9782 | |
| R2U-Net | 2018 | 0.8171 | 0.7792 | 0.9813 | 0.9556 | 0.9784 | |
| STARE | Marin et al. [58] | 2011 | 二 | 0.6940 | 0.9770 | 0.9520 | 0.9820 |
| Fraz [59] | 2012 | 二 | 0.7548 | 0.9763 | 0.9534 | 0.9768 | |
| Roychowdhury [55] | 2016 | 二 | 0.7720 | 0.9730 | 0.9510 | 0.9690 | |
| Liskowsk [56] | 2016 | 二 | 0.7867 | 0.9754 | 0.9566 | 0.9785 | |
| Qiaoliang Li [57] | 2016 | 二 | 0.7726 | 0.9844 | 0.9628 | 0.9879 | |
| U-Net | 2018 | 0.8373 | 0.8270 | 0.9842 | 0.9690 | 0.9898 | |
| Residual U-Net | 2018 | 0.8388 | 0.8203 | 0.9856 | 0.9700 | 0.9904 | |
| Recurrent U-Net | 2018 | 0.8396 | 0.8108 | 0.9871 | 0.9706 | 6066'0 | |
| CHASE_DB1 | R2U-Net | 2018 | 0.8475 | 0.8298 | 0.9862 | 0.9712 | 0.9914 |
| Fraz [59] | 2012 | 二 | 0.7224 | 0.9711 | 0.9469 | 0.9712 | |
| Fraz [60] | 2014 | 二 | 0.9524 | 0.9760 | |||
| Azzopardi [54] | 2015 | 二 | 0.7655 | 0.9704 | 0.9442 | 0.9614 | |
| Roychowdhury [55] | 2016 | 0.7201 | 0.9824 | 0.9530 | 0.9532 | ||
| Qiaoliang Li [57] | 2016 | 0.7507 | 0.9793 | 0.9581 | 0.9793 | ||
| U-Net | 2018 | 0.7783 | 0.8288 | 0.9701 | 0.9578 | 0.9772 | |
| Residual U-Net | 2018 | 0.7800 | 0.7726 | 0.9820 | 0.9553 | 0.9779 | |
| Recurrent U-Net | 2018 | 0.7810 | 0.7459 | 0.9836 | 0.9622 | ||
| R2U-Net | 2018 | 0.7928 | 0.7756 | 0.9820 | 0.9634 | 0.9815 |

Fig. 14. Qualitative analysis for CHASE_DB1 dataset. The segmentation outputs of 8 testing samples using R2U-Net. First row shows the input images, second row is ground truth, and third row shows the segmentation outputs using R2U-Net.
图 14: CHASE_DB1数据集的定性分析。使用R2U-Net对8个测试样本的分割结果。第一行显示输入图像,第二行为真实标注,第三行展示R2U-Net的分割输出。
4) Skin Cancer Lesion Segmentation
4) 皮肤癌病变分割
In this implementation, this dataset is pre processed with mean subtraction and normalized according to the standard deviation. We used the ADAM optimization technique with a learning rate of $2\times10^{-4}$ and binary cross entropy loss. In addition, we also calculated MSE error during the training and validation phase. In this case $10%$ of the samples are used for shown in Fig. 16. The validation accuracy is shown in Fig. 17. In both cases, the proposed models show better performance when compared with the equivalent U-Net and ResU-Net models. This clearly demonstrates the robustness of the proposed models in end-to-end image-based segmentation tasks.
在此实现中,该数据集经过均值减法预处理并按标准差归一化。我们采用ADAM优化技术,学习率为$2\times10^{-4}$,并使用二元交叉熵损失函数。此外,在训练和验证阶段还计算了均方误差(MSE)。本案例中$10%$的样本用于验证,如图16所示。验证准确率如图17所示。两种情况下,所提模型相比等效的U-Net和ResU-Net模型均表现出更优性能,这清晰证明了所提模型在端到端图像分割任务中的鲁棒性。

Fig. 15. AUC for retina blood vessel segmentation for the best performance achieved with R2U-Net.
图 15: R2U-Net在视网膜血管分割任务中取得最佳性能时的AUC值。

Fig. 16. Training accuracy for skin lesion segmentation.
图 16: 皮肤病变分割的训练准确率。
clearly shows the robustness of the proposed segmentation method.
明显展示了所提出的分割方法的鲁棒性。
We have compared the performance of the proposed approaches against recently published results with respect to sensitivity, specificity, accuracy, AUC, and DC. The proposed R2U-Net model provides a testing accuracy 0.9424 with a higher AUC, which is 0.9419. The average AUC for skin lesion segmentation is shown in Fig. 19. In addition, we calculated the average DC in the testing phase and achieved 0.8616, which is around $1.26%$ better than recently proposed alternatives [62]. Furthermore, the JSC and F1 scores are calculated and the R2UNet model obtains 0.9421 for JSC and 0.8920 for F1 score for skin lesion segmentation with $t{=}3$ . These results are achieved
我们比较了所提方法与近期发表成果在灵敏度、特异性、准确率、AUC和DC指标上的性能。提出的R2U-Net模型取得了0.9424的测试准确率,同时具有更高的AUC值0.9419。皮肤病变分割的平均AUC如图19所示。此外,我们在测试阶段计算的平均DC达到0.8616,比近期提出的替代方案[62]高出约$1.26%$。进一步计算JSC和F1分数时,R2UNet模型在$t{=}3$条件下进行皮肤病变分割的JSC得分为0.9421,F1分数为0.8920。这些结果表明...
TABLE II. EXPERIMENTAL RESULTS OF PROPOSED APPROACHES FOR SKIN CANCER LESION SEGMENTATION AND COMPARISON AGAINST OTHEREXISTING APPROACHES. JACCARD SIMILARITY SCORE (JSC).
表 II: 皮肤癌病灶分割方法的实验结果及与其他现有方法的对比 (Jaccard相似性评分 (JSC))
| 方法 | 年份 | SE | SP | JSC | F1分数 | AC | AUC | DC |
|---|---|---|---|---|---|---|---|---|
| Conv.classifierVGG-16 [61] | 2017 | 0.533 | 0.6130 | 0.6420 | ||||
| Conv.classifierInception-v3 [61] | 2017 | 0.760 | 0.6930 | 0.7390 | ||||
| Melanomadetection [62] | 2017 | 0.9340 | 0.8490 | |||||
| SkinLesionAnalysis [63] | 2017 | 0.8250 | 0.9750 | 0.9340 | ||||
| U-Net (t=2) | 2018 | 0.9479 | 0.9263 | 0.9314 | 0.8682 | 0.9314 | 0.9371 | 0.8476 |
| ResU-Net (t=2) | 2018 | 0.9454 | 0.9338 | 0.9367 | 0.8799 | 0.9367 | 0.9396 | 0.8567 |
| RecU-Net (t=2) | 2018 | 0.9334 | 0.9395 | 0.9380 | 0.8841 | 0.9380 | 0.9364 | 0.8592 |
| R2U-Net (t=2) | 2018 | 0.9496 | 0.9313 | 0.9372 | 0.8823 | 0.9372 | 0.9405 | 0.8608 |
| R2U-Net (t=3) | 2018 | 0.9414 | 0.9425 | 0.9421 | 0.8920 | 0.9424 | 0.9419 | 0.8616 |
The quantitative results of this experiment were compared against existing methods as shown in Table II. Some of the example outputs from the testing phase are shown in Fig. 18. The first column shows the input images, the second column shows the ground truth, the network outputs are shown in the third column, and the fourth column demonstrates the final outputs after performing post processing with a threshold of 0.5. Figure 18 shows promising segmentation results.
本实验的定量结果与现有方法进行了对比,如表 II 所示。测试阶段的部分示例如图 18 所示。第一列显示输入图像,第二列为真实标注,第三列展示网络输出,第四列呈现阈值为 0.5 的后处理最终结果。图 18 显示出具有前景的分割效果。

Fig. 17. Validation accuracy for skin lesion segmentation.
图 17: 皮肤病变分割的验证准确率。
In most cases, the target lesions are segmented accurately with almost the same shape of ground truth. However, if we observe the second and third rows in Fig. 18, it can be clearly seen that the input images contain two spots, one is a target lesion and the other bright spot which is not a target. This result is obtained even though the non-target lesion is brighter than the target lesion shown in the third row in Fig. 18. The R2UNet model still segments the desired part accurately, which with a R2U-Net model that only contains about 1.037 million (M) network parameters. Contrarily, the work presented in [61] evaluated VGG-16 and Incpetion-V3 models for skin lesion segmentation, but those networks contained around 138M and 23M network parameters respectively.
在大多数情况下,目标病灶的分割结果与真实标注几乎完全吻合。但观察图18的第二、三行可见,输入图像中存在两个光斑:一个是目标病灶,另一个亮度更高的非目标光斑(图18第三行中非目标病灶甚至比目标病灶更亮)。R2UNet模型仍能准确分割目标区域,而该模型仅包含约103.7万(M)网络参数。相比之下,[61]研究中评估的VGG-16和Inception-V3皮肤病灶分割模型分别包含约1.38亿和2300万参数。

Fig. 18. This results demonstrates qualitative assessment of the proposed R2UNet for skin cancer segmentation task with $t{=}3$ . First column is the input sample, second column is ground truth, third column shows the outputs from
图 18: 该结果展示了所提出的R2UNet在皮肤癌分割任务中的定性评估(设置$t{=}3$)。第一列为输入样本,第二列为真实标签,第三列显示来自
network, and fourth column show the final resulting after performing threshold ing with 0.5.
网络,第四列显示经过0.5阈值处理后的最终结果。
5) Lung Segmentation
5) 肺部分割
Lung segmentation is very important for analyzing lung related diseases, and can be applied to lung cancer segmentation and lung pattern classification for identifying other problems. In this experiment, the ADAM optimizer is used with a learning rate of $2\times10^{-4}$ . We used binary cross entropy loss, and also calculated MSE during training and validation. In this case $10%$ of the samples were used for validation with a batch size of 16 and 150 epochs 150. Table III shows the summary of how well the proposed models performed against equivalent U-Net and ResU-Net models. The experimental results show that the proposed models outperform the U-Net and ResU-Net models respectively. However, we also experimented with U-Net, ResU-Net, RU-Net, and R2U-Net models with following structure: $1\rightarrow16\rightarrow32\rightarrow64\rightarrow128\rightarrow64\rightarrow32\rightarrow16\rightarrow1$ . In this case we used a time-step of $t{=}3$ , which refers to one forward convolution layer followed by three subsequent recurrent convolutional layers. This network was tested on skin and lung lesion segmentation. Though the number of network parameters increase little bit with respect to the time-step in the recurrent convolution layer, further improved performance can be clearly seen in the last rows of Table II and III. Furthermore, we have evaluated both of the proposed models for patch-based modeling on retina blood vessel segmentation and end-to-end image-based methods for skin and lung lesion segmentation.
肺部分割对于分析肺部相关疾病非常重要,可应用于肺癌分割和肺部模式分类以识别其他问题。本实验使用ADAM优化器,学习率为$2\times10^{-4}$。我们采用二元交叉熵损失函数,并在训练和验证过程中计算均方误差(MSE)。其中$10%$的样本用于验证,批次大小为16,训练轮数为150。表III展示了所提模型与等效U-Net和ResU-Net模型的性能对比摘要。实验结果表明,所提模型分别优于U-Net和ResU-Net模型。此外,我们还测试了具有以下结构的U-Net、ResU-Net、RU-Net和R2U-Net模型:$1\rightarrow16\rightarrow32\rightarrow64\rightarrow128\rightarrow64\rightarrow32\rightarrow16\rightarrow1$。此时采用时间步长$t{=}3$,即一个前向卷积层后接三个循环卷积层。该网络在皮肤和肺部病变分割任务上进行了测试。虽然循环卷积层的时间步长会使网络参数数量略有增加,但表II和表III最后一行清晰显示了性能的进一步提升。此外,我们评估了所提模型在视网膜血管分割任务中的基于补丁建模方法,以及在皮肤和肺部病变分割任务中的端到端图像处理方法。
In both cases, the proposed models outperform existing statewith same number of network parameters.
在两种情况下,所提出的模型在相同网络参数数量下均优于现有最优方法。
TABLE III. EXPERIMENTAL OUTPUTS OF PROPOSED MODELS OF RU-NET AND R2U-NET FOR LUNG SEGMENTATION AND COMPARISON AGAINST RESU-NET AND U-NET MODELS.
表 III. RU-NET与R2U-NET模型在肺部分割中的实验结果及与RESU-NET、U-NET模型的对比
| 方法 | 年份 | SE | SP | JSC | F1-Score | AC | AUC |
|---|---|---|---|---|---|---|---|
| U-Net (t=2) | 2018 | 0.9696 | 0.9872 | 0.9858 | 0.9658 | 0.9828 | 0.9784 |
| ResU-Net (t=2) | 2018 | 0.9555 | 0.9945 | 0.9850 | 0.9690 | 0.9849 | 0.9750 |
| RU-Net (t=2) | 2018 | 0.9734 | 0.9866 | 0.9836 | 0.9638 | 0.9836 | 0.9800 |
| R2U-Net (t=2) | 2018 | 0.9826 | 0.9918 | 0.9897 | 0.9780 | 0.9897 | 0.9872 |
| R2U-Net (t=3) | 2018 | 0.9832 | 0.9944 | 0.9918 | 0.9823 | 0.9918 | 0.9889 |

Fig. 19. ROC-AUC for skin segmentation four models with $t{=}2$ and $t{=}3$ .
图 19: 皮肤分割四种模型在 $t{=}2$ 和 $t{=}3$ 时的 ROC-AUC 曲线。
Furthermore, many models struggle to define the class boundary properly during segmentation tasks [64]. However, if we observe the experimental outputs shown in Fig. 20, the outputs in the third column show different hit maps on the border, which can be used to define the boundary of the lung region, while the ground truth tends to have a smooth boundary.
此外,许多模型在分割任务中难以正确定义类别边界 [64]。然而,如果我们观察图 20 所示的实验输出,第三列的输出在边界上显示出不同的热力图,这些热力图可用于定义肺部区域的边界,而真实标注 (ground truth) 往往具有平滑的边界。
In addition, if we observe the input, ground truth, and output of this proposed approaches in the second row, it can be observed that the output of the proposed approaches shows better segmentation with appropriate contour. The ROC with AUCs are shown Fig. 21. The highest AUC is achieved with the proposed approach of R2U-Net with $\scriptstyle t=3$ .
此外,若观察第二行中该方法的输入、真实标注和输出结果,可以看出所提方法的输出具有更优的分割效果和恰当的轮廓。ROC曲线与AUC值如图21所示。其中最高AUC由R2U-Net在$\scriptstyle t=3$参数下的方案实现。
D. Evaluation
D. 评估
Most of the cases, the networks are evaluated for different segmentation tasks with following architectures: $1\rightarrow64\rightarrow128\rightarrow256\rightarrow512\rightarrow256\rightarrow128\rightarrow64\rightarrow1$ that require 4.2M network parameters and $1\to64\to128\to256\to512\to256$ $\rightarrow128{\rightarrow}64{\rightarrow}1$ , which require about $8.5\mathbf{M}$ network parameters of-the-art methods including ResU-Net and U-Net in terms of AUC and accuracy on all three datasets. The network architectures with different numbers of network parameters with respect to the different time-step are shown in Table IV. The processing times during the testing phase for the STARE, CHASE_DB, and DRIVE datasets were 6.42, 8.66, and 2.84 seconds per sample respectively. In addition, skin cancer segmentation and lung segmentation take 0.22 and 1.145 seconds per sample respectively.
大多数情况下,网络采用以下架构进行不同分割任务的评估:$1\rightarrow64\rightarrow128\rightarrow256\rightarrow512\rightarrow256\rightarrow128\rightarrow64\rightarrow1$ 需要420万网络参数,以及 $1\to64\to128\to256\to512\to256$ $\rightarrow128{\rightarrow}64{\rightarrow}1$ 约需850万网络参数。这些方法(包括ResU-Net和U-Net)在所有三个数据集的AUC和准确率指标上均达到当前最优水平。表IV展示了不同时间步长对应的网络参数量变化情况。测试阶段各数据集单样本处理时间分别为:STARE 6.42秒、CHASE_DB 8.66秒、DRIVE 2.84秒。此外,皮肤癌分割和肺部分割的单样本处理时间分别为0.22秒和1.145秒。
TABLE IV. ARCHITECTURE AND NUMBER OF NETWORK PARAMETERS.
表 IV: 网络架构及参数量
| t | 网络架构 (Network architectures) | 参数量 (百万) (Number of parameters (million)) |
|---|---|---|
| 2 | --9<-81<9<-<-9<- >16->1 | 0.845 |
| 3 | -<-9<-81<9<-<-9<- >16->1 | 1.037 |


Fig. 20. Qualitative assessment of R2U-Net performance on Lung segmentation dataset: first column input images, second column ground truth, and third column outputs with R2U-Net.
图 20: R2U-Net在肺部分割数据集上的定性评估结果: 第一列为输入图像, 第二列为真实标注, 第三列为R2U-Net输出结果。
E. Computational time
E. 计算时间
TABLE V. COMPUTATIONAL TIME FOR TESTING PHASE.
表 V: 测试阶段计算时间
| 数据集 | 时间(秒)/样本 |
|---|---|
| 血管分割 | |
| DRIVE | 6.42 |
| STARE | 8.66 |
| CHASE_DB1 | 2.84 |
| 皮肤癌分割 | 0.22 |
| 肺部分割 | 1.15 |
The computational time for testing per sample is shown in Table V for blood vessel segmentation for retina images, skin cancer, and lung segmentation respectively.
每样本测试的计算时间如 表 V 所示,分别对应视网膜图像血管分割、皮肤癌和肺部分割任务。

Fig. 21. ROC curve for lung segmentation four models with $t{=}2$ and $t{=}3$ .
图 21: 肺部分割的ROC曲线,对比四种模型在$t{=}2$和$t{=}3$时的表现。
V. CONCLUSION AND FUTURE WORKS
V. 结论与未来工作
In this paper, we proposed an extension of the U-Net architecture using Recurrent Convolutional Neural Networks and Recurrent Residual Convolutional Neural Networks. The proposed models are called “RU-Net” and “R2U-Net” respectively. These models were evaluated using three different applications in the field of medical imaging including retina blood vessel segmentation, skin cancer lesion segmentation, and lung segmentation. The experimental results demonstrate that the proposed RU-Net, and R2U-Net models show better performance in segmentation tasks with the same number of network parameters when compared to existing methods including the U-Net and residual U-Net (or ResU-Net) models on all three datasets. In addition, results show that these proposed models not only ensure better performance during the training but also in testing phase. In future, we would like to explore the same architecture with a novel feature fusion strategy from encoding to the decoding units.
在本文中,我们提出了一种基于循环卷积神经网络 (Recurrent Convolutional Neural Networks) 和循环残差卷积神经网络 (Recurrent Residual Convolutional Neural Networks) 的U-Net架构扩展方案。所提出的模型分别命名为"RU-Net"和"R2U-Net"。这些模型通过在医学影像领域的三个不同应用(视网膜血管分割、皮肤癌病变分割和肺部组织分割)进行评估。实验结果表明,与现有方法(包括U-Net和残差U-Net/ResU-Net模型)相比,在保持相同网络参数量的情况下,所提出的RU-Net和R2U-Net模型在所有三个数据集上都展现出更优的分割性能。此外,结果显示这些模型不仅在训练阶段表现优异,在测试阶段同样保持优势。未来,我们将探索该架构在编解码单元间采用新型特征融合策略的可行性。