Enhancing Retinal Vascular Structure Segmentation in Images With a Novel Design Two-Path Interactive Fusion Module Model
基于新型双路径交互融合模块模型的视网膜血管结构图像分割增强方法
Abstract
摘要
Precision in identifying and differentiating micro and macro blood vessels in the retina is crucial for the diagnosis of retinal diseases, although it poses a significant challenge. Current auto encoding-based segmentation approaches encounter limitations as they are constrained by the encoder and undergo a reduction in resolution during the encoding stage. The inability to recover lost information in the decoding phase further impedes these approaches. Consequently, their capacity to extract the retinal micro vascular structure is restricted. To address this issue, we introduce Swin-Res-Net, a specialized module designed to enhance the precision of retinal vessel segmentation. Swin-Res-Net utilizes the Swin transformer which uses shifted windows with displacement for partitioning, to reduce network complexity and accelerate model convergence. Additionally, the model incorporates interactive fusion with a functional module in the Res2Net architecture. The Res2Net leverages multi-scale techniques to enlarge the receptive field of the convolutional kernel, enabling the extraction of additional semantic information from the image. This combination creates a new module that enhances the localization and separation of micro vessels in the retina. To improve the efficiency of processing vascular information, we've added a module to eliminate redundant information between the encoding and decoding steps.
准确识别和区分视网膜中的微血管与大血管对于视网膜疾病的诊断至关重要,但这仍是一项重大挑战。当前基于自动编码的分割方法存在局限性,因为它们受限于编码器,且在编码阶段会降低分辨率。解码阶段无法恢复丢失的信息进一步阻碍了这些方法的效果,从而限制了它们提取视网膜微血管结构的能力。为解决这一问题,我们提出了Swin-Res-Net,这是一个专为提升视网膜血管分割精度而设计的模块。Swin-Res-Net采用Swin transformer(使用位移窗口进行分区)来降低网络复杂度并加速模型收敛。此外,该模型在Res2Net架构中集成了功能模块的交互融合。Res2Net利用多尺度技术扩大卷积核的感受野,从而能够从图像中提取更多语义信息。这种组合形成了一个新模块,可增强视网膜微血管的定位和分离能力。为提高血管信息处理的效率,我们还添加了一个模块来消除编码和解码步骤之间的冗余信息。
Our proposed architecture produces outstanding results, either meeting or surpassing those of other published models. The AUC reflects significant enhancements, achieving values of 0.9956, 0.9931, and 0.9946 in pixel-wise segmentation of retinal vessels across three widely utilized datasets: CHASE-DB1, DRIVE, and STARE, respectively. Moreover, Swin-Res-Net outperforms alternative architectures, demonstrating superior performance in both IOU and F1 measure metrics.
我们提出的架构产生了出色的结果,达到或超越了其他已发表模型的性能。AUC值反映了显著提升,在三个广泛使用的数据集(CHASE-DB1、DRIVE和STARE)上分别实现了0.9956、0.9931和0.9946的视网膜血管像素级分割效果。此外,Swin-Res-Net在IOU和F1指标上均优于其他架构,展现出更卓越的性能。
Keywords: Retinal Vessel Segmentation, Swin-Transformer, Res2net, Fusion block, Medical Imaging, Ophthalmology, Fundus image
关键词: 视网膜血管分割, Swin-Transformer, Res2net, 融合模块, 医学影像, 眼科学, 眼底图像
1. Introduction
1. 引言
Retinal examinations can diagnose many retinal conditions, such as diabetic ret in opa thy, epiretinal membrane, macular edema, and cytomegalovirus retinitis. Retinal vascular disorders, which attack the retinal blood vessels, are typically connected to other diseases such as atherosclerosis, hypertension or changes in the circulatory area [1, 2], and the precise segment of retinal blood vessels and the identification of the playful space of retinal area disorders are needed to determine their pertinent diagnosis.
视网膜检查可以诊断多种视网膜疾病,如糖尿病视网膜病变 (diabetic retinopathy) 、视网膜前膜 (epiretinal membrane) 、黄斑水肿 (macular edema) 和巨细胞病毒性视网膜炎 (cytomegalovirus retinitis) 。视网膜血管疾病主要侵袭视网膜血管,通常与动脉粥样硬化 (atherosclerosis) 、高血压 (hypertension) 或循环区域变化等疾病相关 [1, 2] ,其准确诊断需依赖视网膜血管的精确分段及病变区域活动空间的识别。
In recent years, retinal vessel segment methods have been proposed based on the methods of image processing and machine learning [3-6]. In particular, although the detection performance of the vessel appears to be generally improved, it is difficult to obtain pixelaccurate segmentation in some cases because of factors such as insufficient illumination of the image and periodic noise, likely resulting in a large number of false positives [3].
近年来,基于图像处理和机器学习的方法提出了多种视网膜血管分割技术 [3-6]。尽管血管检测性能总体上有所提升,但由于图像光照不足、周期性噪声等因素,某些情况下仍难以实现像素级精确分割,可能导致大量误报 [3]。
Early research on vessel segmentation primarily focused on techniques using hand-crafted features [7, 8], filter-based models [9], and statistical models [10]. By improving border gradients, eliminating irrelevant background information, and filtering picture noise, these techniques aim to simplify the segmentation problem to a mathematical optimization problem with a predetermined solution. The advancements of data-driven methodologies and technology in computers have made deep learning an important field of research and application in medical image analysis. Deep learning has been extensively studied for its remarkable representational learning capabilities [11], consistently outperforming traditional data segmentation approaches.
早期关于血管分割的研究主要集中在使用手工特征 [7, 8]、基于滤波器的模型 [9] 和统计模型 [10] 的技术上。这些技术通过改善边界梯度、消除无关背景信息以及过滤图像噪声,旨在将分割问题简化为具有预定解的数学优化问题。随着数据驱动方法和计算机技术的进步,深度学习已成为医学图像分析领域的重要研究和应用方向。凭借其卓越的表征学习能力 [11],深度学习被广泛研究,并持续超越传统的数据分割方法。
From 2012 to 2020, convolutional neural networks (CNNs) dominated the integration of medical imaging with deep learning. CNNs extract shallow and deep visual features layer by layer by using multiple convolutional layers, pooling layers, and fully connected layers at the bottleneck. For medical image segmentation, models like Deeplab-v3 [12] have not been widely adopted due to the complexity of the models and the features of medical images. Currently, the basic model for deep learning-based medical image segmentation is the U-Net model [13] proposed in 2015. Future advancements in this field are based on its symmetric encoder and decoder structure.
2012年至2020年期间,卷积神经网络 (CNNs) 主导了医学影像与深度学习的结合。CNNs通过多个卷积层、池化层和瓶颈处的全连接层逐层提取浅层和深层视觉特征。在医学图像分割领域,由于模型复杂性和医学影像特性,诸如Deeplab-v3 [12] 等模型并未被广泛采用。当前基于深度学习的医学图像分割基础模型仍是2015年提出的U-Net模型 [13],该领域的未来进展都基于其对称编码器-解码器结构。
Although CNNs have good feature extraction ability, their inherent inductive bias property limits their attention to local image features, hindering further model performance improvement. Some works have introduced CNN-based network attention mechanisms, such as Compression Excitation Networks [14] and Axial DeepLab [15]. However, these studies have not significantly addressed the natural deficiencies of CNNs.
尽管CNN具有良好的特征提取能力,但其固有的归纳偏置特性限制了其对局部图像特征的关注,阻碍了模型性能的进一步提升。部分研究引入了基于CNN的网络注意力机制,例如压缩激励网络 [14] 和轴向DeepLab [15]。然而,这些研究并未显著改善CNN的天然缺陷。
The Deep Self-Attention Network (Transformer), first proposed in the article “Attention is All You Need” [16], originally used in natural language processing, has become the cornerstone of large-scale models such as GPT-3. The Transformer's ability to model longdistance correlations and focus on the global properties of input information makes it ideal for areas such as language translation. Since 2020, researchers have explored applying Transformers to computer vision with significant progress. Google's ViT [17], Facebook's DeiT [18], and Microsoft Research Asia's Swin Transformer [19] are excellent examples. Swin Transformer has been widely used in various computer vision tasks, including medical image segmentation [19-21], showing its potential to match or exceed CNN performance, opening new avenues for computer vision development.
深度自注意力网络 (Transformer) 最初在论文《Attention is All You Need》[16]中提出,原用于自然语言处理,现已成为GPT-3等大规模模型的基石。Transformer能够建模长距离关联并聚焦输入信息的全局特性,使其成为语言翻译等领域的理想选择。2020年以来,研究者开始探索将Transformer应用于计算机视觉并取得重大进展。Google的ViT [17]、Facebook的DeiT [18]和微软亚洲研究院的Swin Transformer [19]都是典型案例。Swin Transformer已广泛应用于医学图像分割[19-21]等计算机视觉任务,展现出媲美甚至超越CNN的潜力,为计算机视觉发展开辟了新路径。
In this paper, we propose a novel model that integrates the Swin Transformer into U-Net, improving the network's capacity to capture long-distance dependencies and model global information. This addresses the limitations of convolutional networks, which predominantly focus on local details, resulting in a more precise segmentation of small vessels. In theory, increasing network depth should improve performance. In practice, deeper networks pose challenges for training optimization algorithms, leading to increased training errors. To address issues like gradient vanishing, our model utilizes Res2net, ensuring that training efficiency is maintained even with a deeper network. This novel technique uses multi-scale approaches to increase the convolutional kernel's receptive field, which enables the extraction of more semantic information from the image. Additionally, our model includes a mechanism to remove redundant information between the encoder and decoder, enhancing overall model efficiency.
本文提出了一种将Swin Transformer集成到U-Net中的新模型,增强了网络捕捉长距离依赖关系和建模全局信息的能力。这解决了卷积网络主要关注局部细节的局限性,从而实现了对小血管更精确的分割。理论上,增加网络深度应能提升性能。但在实践中,更深的网络会给训练优化算法带来挑战,导致训练误差增加。为解决梯度消失等问题,我们的模型采用Res2net,确保即使网络更深也能保持训练效率。这项新技术通过多尺度方法增大了卷积核的感受野,从而能从图像中提取更多语义信息。此外,我们的模型还包含一种机制,用于消除编码器与解码器之间的冗余信息,从而提升整体模型效率。
2. Methodology
2. 方法
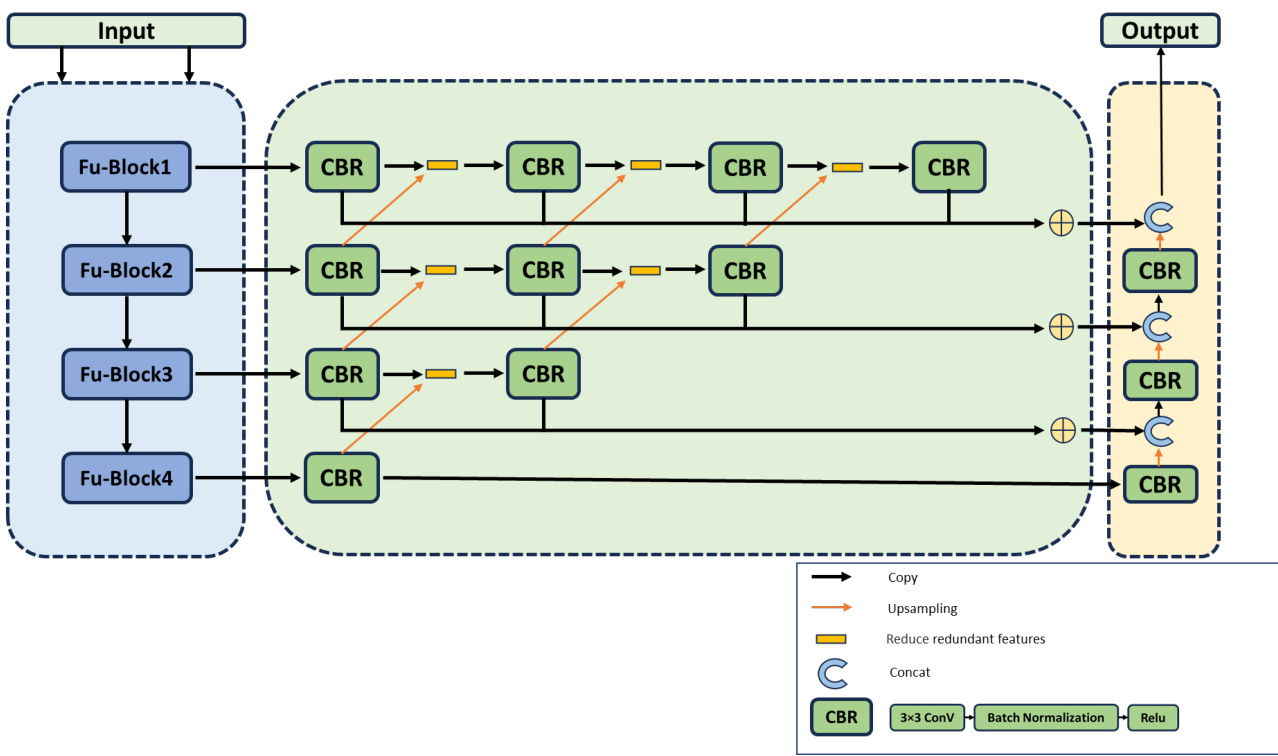
Figure 1: Architecture of the model structure. It consists of three parts: a feature extraction encoder (light blue), a redundant information reduction module (light green) and a decoder (light orange).
图 1: 模型结构架构。它由三部分组成:特征提取编码器 (浅蓝色)、冗余信息缩减模块 (浅绿色) 和解码器 (浅橙色)。
2.1 Overall of the model
2.1 模型概述
The model proposed in this paper is based on the U-Net neural network architecture. The traditional U-Net structure follows a U-shaped design, consisting of three key components: an encoder, a decoder, and connections. As illustrated in Figure 1, the encoder of our proposed model comprises four groups of Fu_Block modules, utilizing convolution and down sampling techniques to extract context information from the feature map. In contrast, the decoder includes three groups of CBR modules and up-sampling modules to restore the resolution of the feature map. The CBR module consists of a $3\times3$ convolution layer, a batch normalization layer, and a ReLU activation layer. Finally, to ensure effective communication between the encoder and decoder levels, a redundant information reduction module is employed. This module is crucial because multiple convolutions may cause the feature map to lose spatial information. This is in contrast to the U-Net model, where there is no module for reducing redundant information, in order to easily affect the combination of the context-rich feature map from the encoder with the feature map from the decoder and at the same time inhibit excess transfer of information to the decoder, thus increasing the efficiency of the model.
本文提出的模型基于U-Net神经网络架构。传统U-Net结构采用U型设计,由三个关键组件构成:编码器、解码器和连接层。如图1所示,我们提出的模型编码器包含四组Fu_Block模块,利用卷积和下采样技术从特征图中提取上下文信息。而解码器则包含三组CBR模块和上采样模块,用于恢复特征图的分辨率。CBR模块由$3\times3$卷积层、批归一化层和ReLU激活层组成。最后,为确保编码器与解码器层级间的有效通信,采用了冗余信息削减模块。该模块至关重要,因为多重卷积可能导致特征图丢失空间信息。这与U-Net模型形成对比——后者没有冗余信息削减模块,以便更容易地将编码器富含上下文的特征图与解码器特征图结合,同时抑制信息向解码器的过量传输,从而提升模型效率。
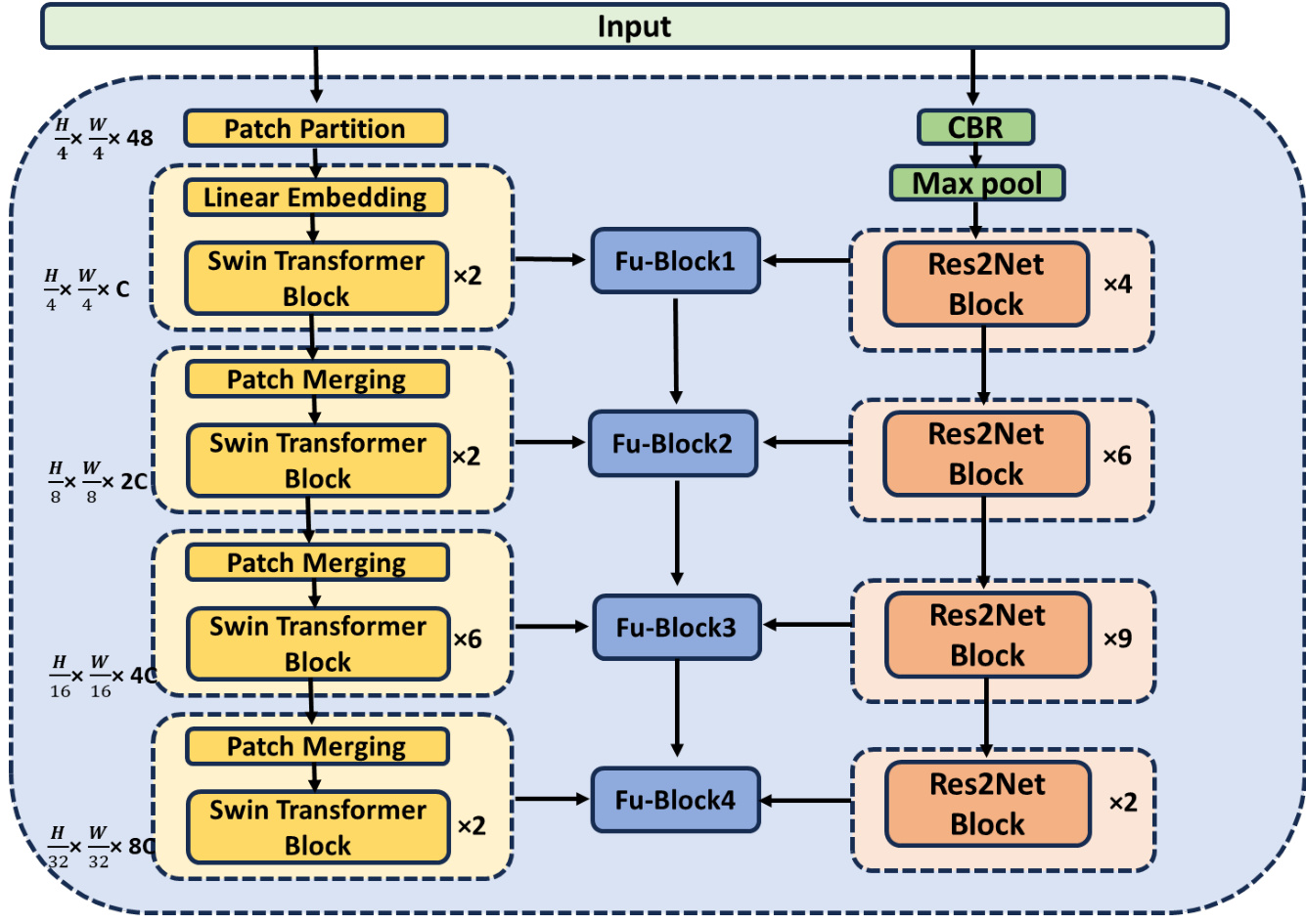
Figure 2: Feature extraction encoder
图 2: 特征提取编码器
2.2 Encoder
2.2 编码器
Figure 2 illustrates the detailed structure of the feature extraction encoder. The preprocessed image gets into the Swin Transformer method and the Residual Block method in the encoder. On the other hand, in both paths of the four-layer, the output of each layer has been made by the two methods. Thereafter, the two layers are converged, and the fusions sent to the redundant information reduction module.
图 2: 特征提取编码器的详细结构。预处理后的图像进入编码器中的 Swin Transformer 方法和残差块 (Residual Block) 方法。另一方面,在四层的两条路径中,每一层的输出都由这两种方法生成。随后,这两层会进行融合,并将融合结果发送到冗余信息减少模块。
2.2.1 Swin Transformer path
2.2.1 Swin Transformer路径
Inspired by its remarkable achievements in segmentation tasks, we have incorporated the Swin Transformer into the U-Net architecture. With this integration, the network can recognize the long-range dependencies and therefore be capable of establishing a coherent understanding of the global context. This development effectively overcomes the limitation of the classical convolutional network, which is only programmed to process local information. Consequently, our method improves the accuracy of identifying and segmenting fine details, like small blood vessels.
受其在分割任务中的显著成就启发,我们将Swin Transformer整合到U-Net架构中。通过这种结合,网络能够识别长程依赖关系,从而建立对全局上下文的一致性理解。这一进展有效克服了经典卷积网络仅能处理局部信息的局限性。因此,我们的方法提高了识别和分割细微结构(如小血管)的准确性。
The initial step involves dividing a pre processed RGB image into non-overlapping patches using a patch splitting module. Each patch is considered a "token," with its feature represented as the concatenation of raw pixel RGB values. For our work, we use a patch size of $4\times4$ , which means the feature dimension will be $4\times4\times3=48$ . We then apply a linear embedding layer to this raw-valued feature, which projects it to an arbitrary dimension, denoted as C.
初始步骤涉及使用分块模块将预处理后的RGB图像划分为不重叠的块。每个块被视为一个"Token",其特征表示为原始像素RGB值的串联。在本研究中,我们采用$4\times4$的分块尺寸,这意味着特征维度将为$4\times4\times3=48$。随后,我们对这些原始值特征应用线性嵌入层,将其投影至任意维度(记为C)。
Subsequently, multiple Transformer blocks, incorporating customized self-attention computations and referred to as Swin Transformer blocks, are applied to these patch tokens. These Transformer blocks maintain the token count at $\mathrm{H}/4\times\mathrm{W}/4$ , forming what we term 'Stage 1.'
随后,多个结合了定制化自注意力计算的Transformer块(称为Swin Transformer块)被应用于这些patch token。这些Transformer块将token数量保持在$\mathrm{H}/4\times\mathrm{W}/4$,形成我们称之为"Stage 1"的阶段。
To generate a hierarchical representation, the reduction in the number of tokens occurs through patch merging layers as the network deepens. The first layer merges these two concatenated patch features into one by concatenating the features of each pair of $2\times2$ neighboring patches and applying a linear layer to these concatenated 4C-dimensional features. This process results in a fourfold reduction in tokens (equivalent to a $2\times2$ downsampling of resolution), while adjusting the output dimension to 2C. Following this, Swin Transformer blocks perform feature transformation while maintaining the resolution at $\mathrm{H}/8$ $\times\mathrm{ \textW/8~}$ . The procedure progresses through four phases, with notable developments occurring in 'Stage $3"$ and 'Stage 4.' Here, the resolution of the output is enhanced to $\mathrm{H}/16$ $\times\mathrm{W}/16$ and to $\mathrm{H}/32\times\mathrm{W}/32$ , respectively.
为生成层次化表征,随着网络加深,通过补丁合并层实现token数量的缩减。第一层将每对$2\times2$相邻补丁的特征拼接后,对拼接后的4C维特征应用线性层,从而将两个拼接的补丁特征合并为一个。这一过程使token数量减少四倍(相当于分辨率$2\times2$下采样),同时将输出维度调整为2C。随后,Swin Transformer块在保持$\mathrm{H}/8$$\times\mathrm{ \textW/8~}$分辨率的同时进行特征变换。该流程经历四个阶段,其中"阶段3"和"阶段4"出现显著变化:输出分辨率分别提升至$\mathrm{H}/16$$\times\mathrm{W}/16$和$\mathrm{H}/32\times\mathrm{W}/32$。
The Swin Transformer is constructed by replacing the standard multi-head self-attention (MSA) module in a Transformer block with a module based on shifted windows, while keeping other layers unchanged. As depicted in Figure 3 (a), a Swin Transformer block is basically a shifted window-based MSA module, followed by a 2-layer MLP with GELU non linearity. A LayerNorm (LN) layer is applied before each MSA module and each MLP, and a residual connection is applied after each module. The calculation process of a continuous Swin Transformer block can be expressed by a series of formulas:
Swin Transformer 是通过将 Transformer 块中的标准多头自注意力 (MSA) 模块替换为基于移位窗口的模块而构建的,同时保持其他层不变。如图 3 (a) 所示,Swin Transformer 块基本上是一个基于移位窗口的 MSA 模块,后跟一个带有 GELU 非线性的 2 层 MLP。在每个 MSA 模块和每个 MLP 之前应用 LayerNorm (LN) 层,并在每个模块之后应用残差连接。连续 Swin Transformer 块的计算过程可以用一系列公式表示:
$$
\begin{array}{r l}&{\hat{z}^{l}=W\cdot M S A(\mathrm{LN}(z^{l-1}))+z^{l-1},}\ &{z^{l}=M L P(L N(\hat{z}^{l}))+\hat{z}^{l},}\ &{\hat{z}^{l+1}=S W\cdot M S A(\mathrm{LN}(z^{l}))+z^{l},}\ &{z^{l+1}=M L P(L N(\hat{z}^{l+1}))+\hat{z}^{l+1},}\end{array}
$$
$$
\begin{array}{r l}&{\hat{z}^{l}=W\cdot M S A(\mathrm{LN}(z^{l-1}))+z^{l-1},}\ &{z^{l}=M L P(L N(\hat{z}^{l}))+\hat{z}^{l},}\ &{\hat{z}^{l+1}=S W\cdot M S A(\mathrm{LN}(z^{l}))+z^{l},}\ &{z^{l+1}=M L P(L N(\hat{z}^{l+1}))+\hat{z}^{l+1},}\end{array}
$$
Here $z^{l}$ denotes the output features of the SW-MSA module and the MLP module for block $l$ , respectively. W-MSA and SW-MSA represent window-based multi-head selfattention using regular and shifted window partitioning configurations, respectively.
这里 $z^{l}$ 分别表示第 $l$ 个块中SW-MSA模块和MLP模块的输出特征。W-MSA和SW-MSA分别代表使用常规和移位窗口分区配置的基于窗口的多头自注意力机制。
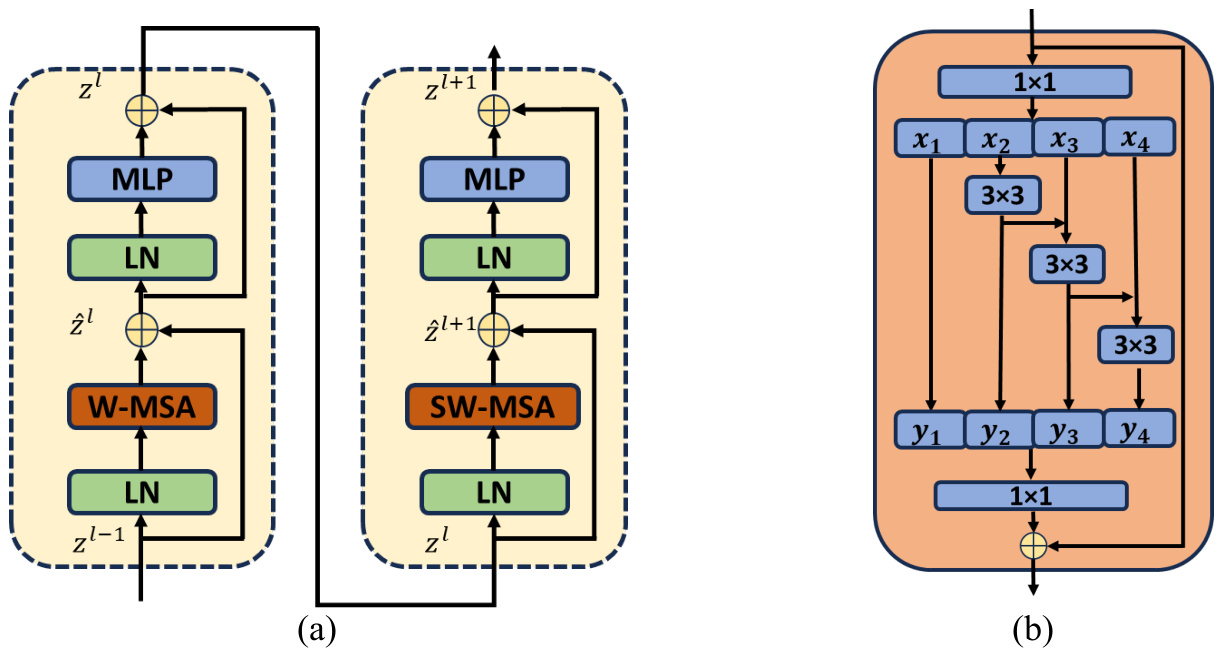
Figure 3: (a) The basic structure of consecutive Swin Transformer blocks; (b) The basic structure of residual blocks (Res2 module).
图 3: (a) 连续 Swin Transformer 块的基本结构; (b) 残差块(Res2模块)的基本结构。
2.2.2 Residual Block path
2.2.2 残差块路径
A Res2Net block has been introduced as an additional module in another path. In the segmentation of fundus image vessels, the distribution of micro-vessels is diffuse, and their size is small. Hence, there is a high probability of loss of semantic information on small objects with a number of single convolution operations that lead to the segmentation accuracy of the small objects being comparatively reduced [22]. Drawing inspiration from Res2Net, this paper introduces and incorporates the Res2Net Block into U-Net. This consists of partitioning the feature map across numerous channels, merging the adjacent feature maps, and later applying convolution in order to develop the receptive field of the network. This new method is designed to overcome obstacles in accurately segmenting small objects, focusing on improving the retrieval of semantic information within the process of segmenting vessels in fundus images.
在另一路径中引入了Res2Net模块作为附加组件。在眼底图像血管分割中,微血管分布弥散且尺寸微小。因此,经过多次单卷积操作后,小目标语义信息存在较高丢失概率,导致其分割精度相对降低[22]。受Res2Net启发,本文将该模块整合至U-Net架构:通过将特征图在多通道间划分、合并相邻特征图后实施卷积操作,从而扩展网络感受野。该创新方法旨在攻克小目标精确分割难题,重点提升眼底图像血管分割过程中的语义信息保留能力。
The process begins with the input of a pre processed RGB image into the CBR module and max pool. Subsequently, we apply Res2Net blocks 4, 6, 9, and 2 times across the four layers. Figure 3 (b) displays the configuration of the Res2Net block, beginning with the application of a $1\times1$ convolution kernel to the input feature map, followed by the division of the channel into four separate groups. While the first group is directly transmitted downward, all other groups have a $3\times3$ convolution kernel, which is used to extract features and bring about a change in the receptive field in the branch. Each group's output, fused with the feature map on the left, is applied. Group splicing and fusion are then done through a $1\times1$ convolution kernel. In the final step, the outcome is combined with the output from the residual connection branch. This approach is based on multi-scale methods that increase the receptive field of the convolutional kernel, enabling further semantic information extraction from images.
流程首先将预处理后的RGB图像输入到CBR模块和最大池化层。随后,我们在四个层级分别应用Res2Net块4次、6次、9次和2次。图3(b)展示了Res2Net块的配置:首先对输入特征图应用$1\times1$卷积核,然后将通道划分为四个独立组。第一组直接向下传输,其余各组均采用$3\times3$卷积核进行特征提取,并在分支中改变感受野。每组输出与左侧特征图融合后,通过$1\times1$卷积核进行组拼接与融合。最后一步将结果与残差连接分支的输出合并。该方法基于多尺度策略扩大卷积核感受野,从而能从图像中提取更深层的语义信息。
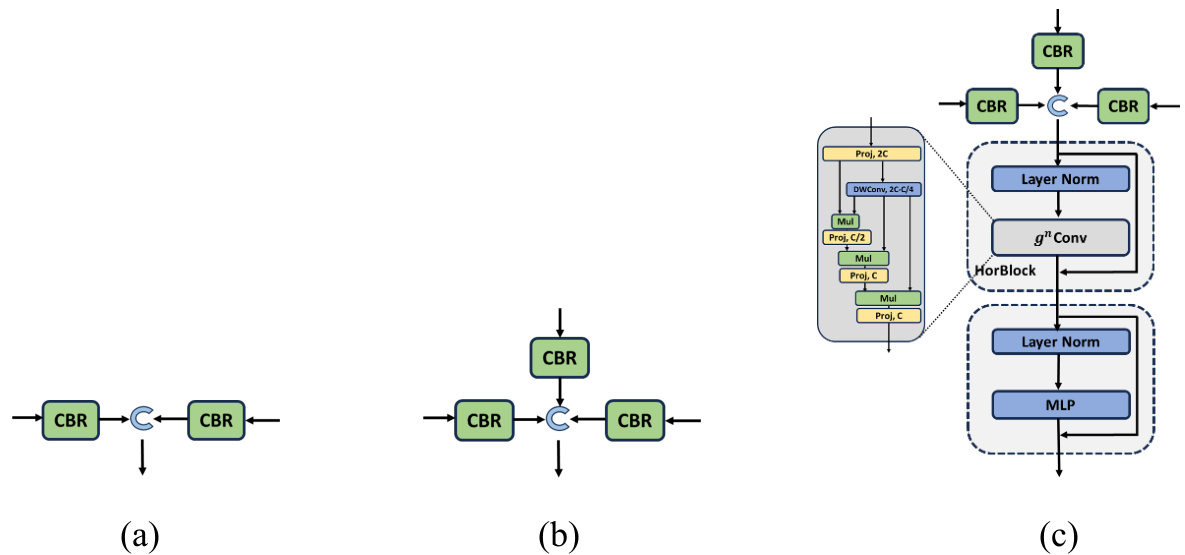
Figure 4: The basic structure of fusion blocks. (a) Fu-Block 1; (b) Fu-Block 2 and 3; (c) Fu-Block 4
图 4: 融合块的基本结构。(a) Fu-Block 1; (b) Fu-Block 2 和 3; (c) Fu-Block 4
2.2.3 Fusion of the outputs of two paths
2.2.3 双路径输出的融合
As depicted in Figure 2, the two paths are fused separately at the output of each layer. Figure 4 illustrates the structure of four Fu-Blocks, which perform CBR on each input and then utilize concatenation to connect the 1-dimensional feature matrix. Fu-Block 1 has two inputs: one from the output of the 1st layer Swin Transformer block and the other from the 1st layer Residual block. Fu-Blocks 2, 3, and 4 have three inputs, two of which are identical to those in Fu-Block 1 from the Swin Transformer Block and Residual Block, while the remaining input is copied from the preceding Fu-Block.
如图 2 所示,两条路径在每层的输出处分别进行融合。图 4 展示了四个 Fu-Block 的结构,它们对每个输入执行 CBR (Convolution-BatchNorm-ReLU) 操作后,通过拼接 (concatenation) 连接一维特征矩阵。Fu-Block 1 有两个输入:一个来自第 1 层 Swin Transformer 块的输出,另一个来自第 1 层残差块 (Residual block) 的输出。Fu-Blocks 2、3 和 4 有三个输入,其中两个与 Fu-Block 1 中来自 Swin Transformer 块和残差块的输入相同,其余输入则复制自前一个 Fu-Block。
The output of Fu-Block 4 distinguishes itself from the others through the implementation of fusion coding using a Horblock. This specialized approach is employed to capture attention and enhance fusion attention features. Notably, Horblock incorporates Recursive Gated Convolution $(g^{n}C o n v)$ , as illustrated in Figure 4 (c). In this newly designed approach, it has been intended to support the efficient, translation-e qui variant, and extendable high-order spatial interactions via a recursive architecture with the help of gated convolutions.
Fu-Block 4的输出通过采用Horblock的融合编码方式与其他模块区分开来。这一特殊方法旨在捕捉注意力并增强融合注意力特征。值得注意的是,Horblock整合了递归门控卷积 $(g^{n}C o n v)$ ,如图4(c)所示。这一新设计的方法旨在通过门控卷积的递归架构,支持高效、平移等变且可扩展的高阶空间交互。
It's important to emphasize that $g^{n}C o n v$ can seamlessly replace the spatial mixing layer in various Vision Transformers and convolution-based models. The quadratic complexity in input size related to self-attention encumbers the limit for how practically it can be efficiently used within Vision Transformers, more so in tasks like segmentation and detection, which require higher resolution for its feature maps.
需要强调的是,$g^{n}C o n v$ 可以无缝替代各种视觉Transformer和基于卷积模型中的空间混合层。自注意力机制在输入大小上的二次复杂度限制了其在视觉Transformer中的实际高效应用,尤其是在分割和检测等需要更高分辨率特征图的任务中。
2.3 Reduce redundant information module.
2.3 冗余信息消减模块
In Figure 1, the light green block represents the module to reduce the redundant information. It is responsible for providing the capacity to combine the context-rich feature map from the encoder with the feature map from the decoder. It also prevents oversupply of information to the decoder, thus making this overall model more efficient.
图1中,浅绿色模块表示用于减少冗余信息的组件。该模块负责将编码器生成的富含上下文信息的特征图与解码器的特征图进行融合,同时防止向解码器过度输送信息,从而提升整体模型效率。
Bilinear interpolation is employed as the method for upsampling, effectively enlarging the features in layer $\mathfrak{n}{+}1$ to match the spatial dimensions of layer n. After the upsampling, the module measures the absolute element-wise difference between the upsampled tensor of the current layer $\mathfrak{n}{+}1$ and the tensor of the previous layer n. This computation quantifies the absolute difference between the two feature maps, preserving the most important information and enabling copy and crop to the decoder. The functionality of the following code will depend on the characteristic and the architecture of the deep learning model to apply. The module can be expressed using the formulas provided below.
采用双线性插值作为上采样的方法,有效地将层 $\mathfrak{n}{+}1$ 中的特征放大以匹配层n的空间维度。上采样后,该模块会计算当前层 $\mathfrak{n}{+}1$ 的上采样张量与前一层的张量n之间的逐元素绝对差值。这一计算量化了两个特征图之间的绝对差异,保留了最重要的信息,并支持向解码器的复制和裁剪操作。后续代码的功能将取决于所应用深度学习模型的特性和架构。该模块可通过以下公式表示。
$$
\begin{array}{r l}&{f(x)^{1^{\prime}}=a b s(C B R(f(x)^{1})-\uparrow[C B R(f(x)^{2})])}\ &{f(x)^{1^{\prime\prime}}=a b s(C B R(f(x)^{1^{\prime}})-\uparrow[C B R(f(x)^{2^{\prime}})])}\ &{\qquad\vdots}\ &{f(x)^{2^{\prime\prime}}=a b s(C B R(f(x)^{2^{\prime}})-\uparrow[C B R(f(x)^{3^{\prime}})])}\ &{\qquad\vdots}\end{array}
$$
$$
\begin{array}{r l}&{f(x)^{1^{\prime}}=a b s(C B R(f(x)^{1})-\uparrow[C B R(f(x)^{2})])}\ &{f(x)^{1^{\prime\prime}}=a b s(C B R(f(x)^{1^{\prime}})-\uparrow[C B R(f(x)^{2^{\prime}})])}\ &{\qquad\vdots}\ &{f(x)^{2^{\prime\prime}}=a b s(C B R(f(x)^{2^{\prime}})-\uparrow[C B R(f(x)^{3^{\prime}})])}\ &{\qquad\vdots}\end{array}
$$
Where $f(x)$ is the feature map for each layer. The number of superscripts is the layer number. The prime symbol is the number of reduced redundant operations. ↑ represents the bilinear interpolation unsampling method.
其中 $f(x)$ 是每一层的特征图。上标数字表示层号。撇号表示减少的冗余操作次数。↑代表双线性插值上采样方法。
2.4 Decoder
2.4 解码器
In Figure 1, the light-yellow section represents the decoder component of our model. At Layer 4, the input undergoes a single cycle of CBR (convolution, batch normalization, and ReLU activation) before being unsampled and concatenated with the input at Layer 3. This process repeats until the final output is obtained.
在图1中,浅黄色部分代表我们模型的解码器组件。在第4层,输入经过一次CBR(卷积、批量归一化和ReLU激活)循环后,进行上采样并与第3层的输入拼接。这一过程不断重复,直至获得最终输出。
3. Experiments
3. 实验
3.1 Dataset
3.1 数据集
The DRIVE [23] dataset is a collection of 40 retinal images with segmentation annotations, obtained from a diabetic ret in opa thy screening program in the Netherlands. Seven of the images show mild early diabetic ret in opa thy, and 33 show normal ones. The retinal images were formally divided into training sets. The images are captured at a size of $565\times584$ pixels with 8 bits per color plane.
DRIVE [23] 数据集包含40张带有分割标注的视网膜图像,采集自荷兰的糖尿病视网膜病变筛查项目。其中7张图像显示轻度早期糖尿病视网膜病变,33张为正常样本。这些视网膜图像被正式划分为训练集,图像尺寸为$565\times584$像素,每色彩平面为8位深度。
The CHASE_DB1 [24] dataset, designed for retinal vascular segmentation, contains 28 color retina images of $999\times960$ pixels' resolution, taken from the left and right eyes of 14 students. All the sets of these images were manually annotated for segmentation by two independent experts, normally taking the annotations of the first expert as the ground truth. The first 20 images are meant for training, while the remaining eight are reserved for testing.
CHASE_DB1 [24] 数据集专为视网膜血管分割设计,包含28张彩色视网膜图像,分辨率为 $999\times960$ 像素,采集自14名学生的左右眼。这些图像全部由两位独立专家手动标注分割结果,通常以第一位专家的标注作为基准真值。前20张图像用于训练,其余8张保留用于测试。
The STARE [25] dataset encompasses 20 retinal fundus images, half of which exhibit pathological signs. During the iteration, 18 images are selected at a time and are considered as training samples, while the remaining set of images will be used as test samples over 10 repetitions. There was no predefined division of the data to solidify the reliability of the experimental results, hence making 10-fold cross-validation a suitable method to apply.
STARE [25] 数据集包含20张视网膜眼底图像,其中一半呈现病理特征。在迭代过程中,每次选取18张图像作为训练样本,其余图像则在10次重复中作为测试样本。实验未预先划分数据以确保结果可靠性,因此采用10折交叉验证是适用的方法。
3.2 Preprocessing
3.2 预处理
Image pre-processing was performed with the aim of increasing the data diversity and therefore making the model more robust before entering the model. (1) A random horizontal flip operation with a 0.5 probability was applied. (2) A random vertical flip with a 0.5 probability was employed. (3) Random rotations were applied to the images.
图像预处理旨在增加数据多样性,从而使模型在输入前更加鲁棒。(1) 应用了概率为0.5的随机水平翻转操作。(2) 采用了概率为0.5的随机垂直翻转。(3) 对图像进行了随机旋转。
3.3 Hyper-parameter
3.3 超参数
Hyper parameter settings used in our model training are as follows. Optimizer: Adam. Initial learning rate: $10^{-4}$ . Weight decay: $10^{-5}$ . Learning rate adjustment strategy: Cosine Annealing LR. Post-processing image threshold: 0.5. Number of training epochs: 40.
我们模型训练中使用的超参数设置如下。优化器:Adam。初始学习率:$10^{-4}$。权重衰减:$10^{-5}$。学习率调整策略:余弦退火学习率 (Cosine Annealing LR)。后处理图像阈值:0.5。训练轮次:40。
3.4 Loss function: Binary Cross-Entropy Loss (BCELoss).
3.4 损失函数:二元交叉熵损失 (Binary Cross-Entropy Loss, BCELoss)
The model employs a binary cross-entropy loss with a fixed threshold of 0.5 to determine whether a pixel belongs to a vessel or the background. The unreduced loss can be described as:
该模型采用二元交叉熵损失函数,并设定固定阈值0.5来判断像素属于血管还是背景。未缩减的损失可表示为:
$$
\begin{array}{r}{\mathcal{L}(y,\hat{y})=-\frac{1}{N}{\sum_{i=1}^{N}}[y_{i}l o g\hat{y}_{i}+(1-y_{i})l o g(1-\hat{y}_{i})]}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}(y,\hat{y})=-\frac{1}{N}{\sum_{i=1}^{N}}[y_{i}l o g\hat{y}_{i}+(1-y_{i})l o g(1-\hat{y}_{i})]}\end{array}
$$
where $y$ and $\hat{y}$ indicate ground truth and predicated of $i^{t h}$ image, $\mathrm{_N}$ is the batch size.
其中 $y$ 和 $\hat{y}$ 分别表示第 $i^{t h}$ 张图像的真实值和预测值,$\mathrm{_N}$ 为批次大小。
3.5 Quantitative Benchmarking
3.5 定量基准测试
We conducted an extensive comparative analysis, assessing our architecture alongside several high-performing models, including Unet $^{++}$ [26], CS-Net [27], Residual U-Net [28], RV-GAN [29], and FR-Unet [30]. Training and evaluation were performed using their publicly accessible source code on all three datasets.
我们进行了广泛的对比分析,将我们的架构与多个高性能模型进行了评估,包括Unet$^{++}$[26]、CS-Net[27]、Residual U-Net[28]、RV-GAN[29]和FR-Unet[30]。训练和评估均使用它们公开可获取的源代码在所有三个数据集上进行。
Subsequently, we have compared our architecture with the existing retinal vessel segmentation models and presented the results for datasets DRIVE, CHASE-DB1, and STARE in Table 1. Sensitivity, specificity, accuracy, F1-score, and area under the curve (AUC) are some of the conventional performance evaluation parameters that are calculated. We have further investigated the retinal vessel segmentation accuracy and structural similarity using intersection-over-union (IOU). These evaluations offer a comprehensive understanding of the strengths and weaknesses of each model in our comparative analysis.
随后,我们将我们的架构与现有的视网膜血管分割模型进行了比较,并在表1中展示了DRIVE、CHASE-DB1和STARE数据集的结果。敏感性、特异性、准确率、F1分数和曲线下面积(AUC)是计算得出的一些常规性能评估参数。我们还通过交并比(IOU)进一步研究了视网膜血管分割的准确性和结构相似性。这些评估为我们对比分析中每个模型的优缺点提供了全面的理解。
As observed in the tables, our model is ranked consistently with better performance compared with the existing U-Net based design and even the more recent GAN-based models. These are evidenced by the AUC, F1 score, and IOU, which are the main evaluation metrics in this task. Notably, our model improved specificity, accuracy, AUC, F1 score, and IOU values across all datasets.
从表中可以看出,与现有基于U-Net的设计乃至较新的基于GAN的模型相比,我们的模型始终表现出更优的性能排名。这一点通过AUC、F1分数和IOU等该任务主要评估指标得到印证。值得注意的是,我们的模型在所有数据集上都提升了特异性、准确率、AUC、F1分数和IOU值。
Table 1 (a): Result of vessel segmentation (CHASE_DB1)
| 方法 | 年份 | 灵敏度 | 特异性 | 准确率 | AUC | F1 | IOU |
|---|---|---|---|---|---|---|---|
| Unet++ | 2018 | 0.8357 | 0.9832 | 0.9739 | 0.9881 | 0.7898 | 0.6526 |
| CS-Net | 2020 | 0.8400 | 0.9832 | 0.9742 | 0.9881 | 0.8042 | 0.6725 |
| ResidualU-Net | 2021 | 0.8178 | 0.9822 | 0.9644 | 0.9834 | ||
| RV-GAN | 2021 | 0.8199 | 0.9806 | 0.9697 | 0.9914 | 0.8957 | |
| FR-Unet | 2022 | 0.8798 | 0.9814 | 0.9748 | 0.9913 | 0.8151 | 0.6882 |
| Swin-Res-Net | 2024 | 0.8467 | 0.9918 | 0.9813 | 0.9956 | 0.8665 | 0.7646 |
表 1(a): 血管分割结果 (CHASE_DB1)
Table 1 (b): Result of vessel segmentation (Drive dataset)
| 方法 | 年份 | 灵敏度 | 特异性 | 准确率 | AUC | F1 | IOU |
|---|---|---|---|---|---|---|---|
| Unet++ | 2018 | 0.7891 | 0.9850 | 0.9679 | 0.9825 | 0.8114 | 0.6827 |
| CS-Net | 2019 | 0.8170 | 0.9854 | 0.9632 | 0.9798 | 0.8039 | 0.7017 |
| ResidualU-Net | 2021 | 0.8062 | 0.9825 | 0.9683 | 0.9802 | ||
| RV-GAN | 2021 | 0.7927 | 0.9969 | 0.9790 | 0.9887 | 0.8690 | |
| FR-Unet | 2022 | 0.8356 | 0.9837 | 0.9705 | 0.9889 | 0.8316 | 0.7120 |
| Swin-Res-Net | 2024 | 0.8214 | 0.9872 | 0.9728 | 0.9931 | 0.8394 | 0.7234 |
表 1 (b): 血管分割结果 (Drive数据集)
Table 1 (c): Result of vessel segmentation (STARE Dataset) data and charts.
| 方法 | 年份 | 灵敏度 | 特异性 | 准确率 | AUC | F1 | IOU |
|---|---|---|---|---|---|---|---|
| Unet++ | 2018 | 0.7909 | 0.9883 | 0.9734 | 0.9884 | 0.8118 | 0.6856 |
| CS-Net | 2020 | 0.7926 | 0.9882 | 0.9735 | 0.9885 | 0.8159 | 0.6912 |
| ResidualU-Net | 2021 | 0.7930 | 0.9883 | 0.9716 | 0.9869 | ||
| RV-GAN | 2020 | 0.8356 | 0.9864 | 0.9754 | 0.9887 | 0.8323 | |
| FR-Unet | 2022 | 0.8327 | 0.9869 | 0.9752 | 0.9914 | 0.8330 | 0.7156 |
| Swin-Res-Net | 2024 | 0.8383 | 0.9892 | 0.9779 | 0.9946 | 0.8498 | 0.7389 |
表 1(c): 血管分割结果 (STARE数据集) 数据与图表。
3.6 Precision of vessel segmentation s
3.6 血管分割精度
As illustrated in Figure 5, Swin-Res-Net demonstrates a high level of accuracy in vessel segmentation compared to ground truths. The most challenging task is micro blood vessel
如图 5 所示,与真实标注相比,Swin-Res-Net 在血管分割任务中展现出极高的准确度。最具挑战性的任务是微血管分割。
segmentation. Notably, our model successfully identified and segmented micro blood vessels.
分割。值得注意的是,我们的模型成功识别并分割了微血管。

Figure 5: Swin-Res-Net segments vessel with good precision on the micro blood vessel
图 5: Swin-Res-Net 在微血管分割中展现出高精度
4. Conclusions
4. 结论
In this research paper, we introduce Swin-Res-Net, a new multiscale architecture. By integrating innovative matching loss functionality, this architecture demonstrates the ability to generate highly accurate segmentation s of vein structures while providing robust confidence values for two key performance parameters. Our architectural innovation holds significant application potential in the field of ophthalmology, particularly in analyzing degenerative retinal diseases and predicting future developments. Our future research efforts aim to extend the application of this methodology to diverse data modalities.
在本研究论文中,我们介绍了新型多尺度架构Swin-Res-Net。通过整合创新的匹配损失功能,该架构展现出生成高精度静脉结构分割的能力,同时为两个关键性能参数提供稳健的置信度值。我们的架构创新在眼科领域具有重要应用潜力,特别是在分析退行性视网膜病变及预测病情发展方面。未来研究工作将致力于将该方法扩展至多种数据模态的应用。
References
参考文献
Photographs Using a Novel Multi-scale Generative Adversarial Network," in International Conference on Medical Image Computing and Computer-Assisted Intervention, 2021. [30] W. Liu et al., "Full-Resolution Network and Dual-Threshold Iteration for Retinal Vessel and Coronary Angiograph Segmentation," IEEE Journal of Biomedical and Health Informatics, vol. 26, no. 9, pp. 4623-4634, 2022, doi: 10.1109/JBHI.2022.3188710.
利用新型多尺度生成对抗网络进行医学图像超分辨率重建》,发表于国际医学图像计算与计算机辅助干预会议,2021年。[30] W. Liu等,《基于全分辨率网络和双阈值迭代的视网膜血管与冠状动脉造影分割》,载于《IEEE生物医学与健康信息学杂志》第26卷第9期,第4623-4634页,2022年,doi: 10.1109/JBHI.2022.3188710。