PeFoMed: Parameter Efficient Fine-tuning of Multimodal Large Language Models for Medical Imaging
面向医学影像的多模态大语言模型参数高效微调
ABSTRACT
摘要
Multimodal large language models (MLLMs) represent an evolutionary expansion in the capabilities of traditional large language models, enabling them to tackle challenges that surpass the scope of purely text-based applications. It leverages the knowledge previously encoded within these language models, thereby enhancing their applicability and functionality in the reign of multimodal contexts. Recent works investigate the adaptation of MLLMs as a universal solution to address medical multi-modal problems as a generative task. In this paper, we propose a parameter efficient framework for fine-tuning MLLMs, specifically validated on medical visual question answering (Med-VQA) and medical report generation (MRG) tasks, using public benchmark datasets. We also introduce an evaluation metric using the 5-point Likert scale and its weighted average value to measure the quality of the generated reports for MRG tasks, where the scale ratings are labelled by both humans manually and the GPT-4 model. We further assess the consistency of performance metrics across traditional measures, GPT-4, and human ratings for both VQA and MRG tasks. The results indicate that semantic similarity assessments using GPT-4 align closely with human annotators and provide greater stability, yet they reveal a discrepancy when compared to conventional lexical similarity measurements. This questions the reliability of lexical similarity metrics for evaluating the performance of generative models in Med-VQA and report generation tasks. Besides, our finetuned model significantly outperforms GPT-4v. This indicates that without additional fine-tuning, multi-modal models like GPT-4v do not perform effectively on medical imaging tasks. The code will be available here: https://github.com/jinlHe/PeFoMed.
多模态大语言模型 (MLLM) 是对传统大语言模型能力的进化扩展,使其能够应对超越纯文本应用范围的挑战。它利用先前编码在这些语言模型中的知识,从而增强其在多模态领域的适用性和功能性。近期研究探索将MLLM作为通用解决方案,以生成式任务形式处理医学多模态问题。本文提出一种参数高效的MLLM微调框架,在医学视觉问答 (Med-VQA) 和医学报告生成 (MRG) 任务上使用公开基准数据集进行验证。我们还引入基于5级李克特量表及其加权平均值的评估指标,用于衡量MRG任务生成报告的质量,其中量表评分由人工标注和GPT-4模型共同完成。我们进一步评估了VQA和MRG任务在传统指标、GPT-4评分与人工评分之间的一致性。结果表明,使用GPT-4进行的语义相似性评估与人工标注高度吻合且稳定性更优,但与传统词汇相似性测量存在差异。这对词汇相似性指标在评估Med-VQA和报告生成任务中生成模型性能的可靠性提出了质疑。此外,我们的微调模型显著优于GPT-4v,这表明如GPT-4v等多模态模型未经额外微调时,在医学影像任务上表现不佳。代码将发布于:https://github.com/jinlHe/PeFoMed。
CCS CONCEPTS
CCS概念
• Computing methodologies $\rightarrow$ Artificial intelligence; Computer vision.
• 计算方法 $\rightarrow$ 人工智能 (Artificial Intelligence);计算机视觉 (Computer Vision)。
KEYWORDS
关键词
Multimodal Large Language Model, Medical Visual Question Answering, Medical Report Generation, Generative Model, Parameter Efficient Fine-tuning
多模态大语言模型 (Multimodal Large Language Model)、医学视觉问答 (Medical Visual Question Answering)、医学报告生成 (Medical Report Generation)、生成式模型 (Generative Model)、参数高效微调 (Parameter Efficient Fine-tuning)
1 INTRODUCTION
1 引言
Medical multimodal tasks involve the integration of both computer vision (CV) and natural language processing (NLP) techniques to analyze data from multiple modalities (i.e. image and text) to answer clinical-related questions as medical visual question answering (Med-VQA) tasks or generate textual reports from radiological images. Various deep learning models primarily approach medical multimodal tasks using dedicated models for each task, for example using classification models for VQA [4, 5, 7, 33, 35, 40] that categorize the image-text representation into a predefined set of answers, and auto-regressive models for generating image reports [2, 39, 52].
医学多模态任务涉及计算机视觉 (CV) 和自然语言处理 (NLP) 技术的融合,通过分析多模态数据(如图像和文本)来回答临床相关问题(如医学视觉问答 (Med-VQA) 任务)或从放射学图像生成文本报告。各类深度学习模型主要通过为每项任务设计专用模型来处理医学多模态任务,例如使用分类模型处理VQA [4,5,7,33,35,40](将图文表征归类至预定义答案集),以及使用自回归模型生成影像报告 [2,39,52]。
Recently, an alternative solution is treating medical multimodal tasks as generative tasks by using language models as decoders [51], which provides a universal framework to tackle medical multimodal problems. There has been emerging research that uses Large Language Models (LLMs) [42, 44, 49, 50] for generating free-form text as answers on Med-VQA tasks, [54] using proper prompting techniques. This type of models, namely Multimodal Large Language Models (MLLMs) have been actively studied and the early attempts, such as Med-Flamingo [19] and LLaVA-Med [10] have shown the performance on various medical multimodal tasks.
最近,一种替代方案是将医学多模态任务视为生成式任务,通过使用语言模型作为解码器 [51],这为解决医学多模态问题提供了一个通用框架。已有研究开始利用大语言模型 (LLM) [42, 44, 49, 50] 在医学视觉问答 (Med-VQA) 任务中生成自由文本作为答案 [54],并采用了适当的提示技术。这类模型,即多模态大语言模型 (MLLM),正被积极研究,早期尝试如 Med-Flamingo [19] 和 LLaVA-Med [10] 已在多种医学多模态任务中展现出性能。
However, directly training MLLMs from scratch for solving medical multimodal tasks requires numerous computational resources and large-scale annotated data. In response to these challenges, we propose a novel framework that uses Parameter-Efficient Finetuning (PEFT) techniques on MLLM foundation models for MedVQA and medical report generation (MRG) tasks, namely the PeFoMed model. We utilize the pre-trained weights of a general domain LLM and ViT[25], which have been adeptly trained on diverse datasets, and fine-tune them with medical image-caption pairs and downstream Med-VQA and medical reports datasets. In training, the vision encoder and LLM are frozen, and only the vision projection layer and the low-rank adaptation layer (LoRA) [13] are updated, which results in a minimal footprint of trainable parameters. Specific prompting templates are designed for the above fine-tuning process.
然而,直接从头训练多模态大语言模型(MLLM)来解决医学多模态任务需要大量计算资源和大规模标注数据。针对这些挑战,我们提出了一种新颖框架,在MLLM基础模型上采用参数高效微调(PEFT)技术来处理医学视觉问答(MedVQA)和医疗报告生成(MRG)任务,即PeFoMed模型。我们利用通用领域大语言模型和ViT[25]的预训练权重(这些模型已在多样化数据集上经过充分训练),并通过医学图像-标题对及下游Med-VQA与医疗报告数据集进行微调。训练过程中冻结视觉编码器和大语言模型,仅更新视觉投影层和低秩适应层(LoRA)[13],从而实现可训练参数的最小化占用。针对上述微调过程设计了特定提示模板。
Furthermore, metrics based on lexical similarity, such as BLEU, often fall short of capturing semantic similarity between generated text and ground truth. In generative tasks like VQA and report generation, we utilize the GPT-4 model to assess the semantic similarity of generated answers or reports and compare it with human evaluations to examine consistency. For report generation, where the text can be lengthy, we employ a 5-point Likert scale to gauge the overall quality and coherence. This approach investigates the potential of GPT-4 as an accurate evaluation tool for large datasets, with carefully designed prompting templates.
此外,基于词汇相似度的指标(如BLEU)往往难以捕捉生成文本与真实文本之间的语义相似性。在视觉问答(VQA)和报告生成等生成式任务中,我们利用GPT-4模型评估生成答案或报告的语义相似度,并与人工评估结果进行一致性对比。针对篇幅较长的报告生成任务,我们采用5级李克特量表(Likert scale)来衡量整体质量与连贯性。该方法通过精心设计的提示模板,探索了GPT-4作为海量数据集精准评估工具的潜力。
The contributions of this work can be summarized as follows:
本工作的贡献可总结如下:
2 RELATED WORKS
2 相关工作
2.1 Medical Multimodal Large Language Model
2.1 医疗多模态大语言模型
Large language foundation models, such as GPT-3 [48], PaLM [8], and LLaMA [50] have demonstrated superior performance across a diverse range of medical-related NLP tasks. Previous works like ChatDoctor [26], Doctorglm [15] and Huatuo [14], have yielded promising results in various medical NLP tasks. One step ahead, the latest works have leveraged both vision and language foundation models to resolve multimodal tasks in the medical domain aligns with this paradigm. Early attempts to address multimodal (i.e. vision and language) problems, like Visual Med-Alpaca [11], that converts images to intermediate text prompts, combine with the question texts and feed them into the LLM for predicting answers. This type of method may be constrained by the pre-trained image caption model and fail to capture detailed information from images.
大语言基础模型,如 GPT-3 [48]、PaLM [8] 和 LLaMA [50],已在多种医学相关 NLP 任务中展现出卓越性能。ChatDoctor [26]、Doctorglm [15] 和 Huatuo [14] 等先前工作在各种医学 NLP 任务中取得了令人鼓舞的成果。更进一步,最新研究同时利用视觉和语言基础模型解决医学领域的多模态任务,符合这一范式。早期解决多模态(即视觉与语言)问题的尝试,如 Visual Med-Alpaca [11],将图像转换为中间文本提示,与问题文本结合后输入大语言模型以预测答案。此类方法可能受限于预训练的图像描述模型,无法从图像中捕捉细节信息。
Alternatively, recent work integrates vision embeddings into language models as visual prompts to enhance text generation. LLM-CXR [21] applied a pre-trained VQ-GAN [20] to tokenize images and generate visual and language tokens in an auto regressive manner, and fine-tuned the entire LLM with these tokens. Another intuitive solution is to explicitly model the projection of image embedding space to LLM space that can produce LLM-aligned image embeddings [23]. Similarly, LLaVA-Med [10] fine-tuned the projection layer and the entire LM on the GPT-4 generated instruction- tuning and downstream biomedical datasets.
另一种方法是将视觉嵌入作为视觉提示整合到语言模型中,以增强文本生成能力。LLM-CXR [21] 采用预训练的 VQ-GAN [20] 对图像进行 Token 化处理,以自回归方式生成视觉和语言 Token,并利用这些 Token 对整个大语言模型进行微调。另一种直观解决方案是显式建模图像嵌入空间到大语言模型空间的投影,从而生成与大语言模型对齐的图像嵌入 [23]。类似地,LLaVA-Med [10] 在 GPT-4 生成的指令调优数据集和下游生物医学数据集上,对投影层及整个语言模型进行了微调。
Fine-tuning the entire LLM may not always be a practical solution when computing resources are constrained, instead, parameter- efficient fine-tuning techniques offer a balanced and efficient approach to adapt large pre-trained models to specific tasks while preserving the vast knowledge these models have already acquired. There have been some works that use PEFT techniques in various multi modality use cases [1, 36]. Therefore, in our approach, we employ parameter-efficient fine-tuning methods on Med-VQA and MRG tasks, which minimizes the training costs while yielding robust results.
当计算资源受限时,对整个大语言模型进行微调可能并非总是可行的解决方案。相反,参数高效微调技术 (parameter-efficient fine-tuning) 提供了一种平衡且高效的方法,既能将大型预训练模型适配到特定任务,又能保留这些模型已习得的丰富知识。已有若干研究在多模态应用场景中采用了参数高效微调技术 [1, 36]。因此,我们在Med-VQA和MRG任务中采用了参数高效微调方法,这种方法能以最低的训练成本获得稳健的结果。
2.2 Medical Visual Question Answering
2.2 医学视觉问答 (Medical Visual Question Answering)
Med-VQA tasks can be categorized into classification tasks [4, 5, 7, 34, 35, 40] and generative tasks [10, 19, 23]. Classification-based Med-VQA predefines an answer candidate set. Although this approach can yield high performance on specific datasets, it concurrently limits the model’s capability to address open-ended questions. When integrated with LLMs, Med-VQA tasks transition to generative tasks. Li et al. explored the zero-shot setting of the GPT-4v model [43] on Med-VQA dataset, where GPT-4v is a universal model and is not tailored to specific Med-VQA data types and tasks. Its performance on both open-ended and closed-ended question types is not comparable to the existing non-generative methods. Concurrently, Med-Flamingo [19] extended from the base Flamingo framework [17], forming an in-context learning strategy with interleaved medical image-text pairs to achieve a few shot capacity for Med-VQA tasks. LLaVA-Med [10] represents the first effort to adapt multimodal instruction tuning for the biomedical domain, implementing end-to-end training to develop biomedical multimodal dialogue assistants, thereby achieving promising outcomes in medical image-text dialogue.
医学视觉问答 (Med-VQA) 任务可分为分类任务 [4, 5, 7, 34, 35, 40] 和生成式任务 [10, 19, 23]。基于分类的 Med-VQA 预定义了候选答案集,虽然这种方法在特定数据集上能取得高性能,但同时也限制了模型处理开放式问题的能力。当与大语言模型结合时,Med-VQA 任务会转变为生成式任务。Li 等人探索了 GPT-4v 模型 [43] 在 Med-VQA 数据集上的零样本表现,GPT-4v 作为通用模型并未针对特定 Med-VQA 数据类型和任务进行优化,其在开放式和封闭式问题类型上的表现均无法与现有非生成式方法相比。同期,Med-Flamingo [19] 基于 Flamingo 框架 [17] 进行扩展,通过交错排列的医学图文对构建上下文学习策略,实现了 Med-VQA 任务的少样本能力。LLaVA-Med [10] 首次将多模态指令微调应用于生物医学领域,通过端到端训练开发生物医学多模态对话助手,从而在医学图文对话中取得显著成果。
2.3 Medical Report Generation
2.3 医疗报告生成
Similar to image-captioning tasks, MRG generates text corresponding to medical images. As medical reports, the text generated by MRG is more professional than the conventional image-captioning task, and the text is relatively long and more complex. R2Gen [3] produces radiology reports through a memory-driven transformer employing relational memory to capture key information throughout the generation process. Additionally, R2Gen employs conditional layer normalization to integrate memory within the transformer’s decoder. Chen et al. [2] observed cross-modal data bias and applied cross-modal causal intervention to reduce this bias in medical reports and images, achieving notable results in medical report datasets. ITHN [52] learns disc rim i native features between images and reports by separately learning images and their hard negatives, thereby capturing fine-grained details in multimodal data. Chen et al. [39] addressed the discrepancy between medical images and text data by designing a distiller that leverages both prior and posterior knowledge to identify specific abnormalities in images and assimilate prior medical knowledge, yielding high performance in datasets such as IU-Xray.
与图像描述任务类似,医学报告生成(MRG)会生成与医学图像对应的文本。作为医学报告,MRG生成的文本比传统图像描述任务更具专业性,且文本相对较长、结构更复杂。R2Gen [3]通过采用关系记忆的Transformer生成放射学报告,利用记忆驱动机制捕捉生成过程中的关键信息。此外,R2Gen采用条件层归一化技术将记忆模块整合到Transformer解码器中。Chen等人 [2]观察到跨模态数据偏差现象,通过应用跨模态因果干预减少医学报告与图像间的偏差,在医学报告数据集中取得显著效果。ITHN [52]通过分别学习图像及其困难负样本,捕获图像与报告间的判别性特征,从而提取多模态数据中的细粒度细节。Chen等人 [39]设计了融合先验知识与后验知识的蒸馏器,通过识别图像中的特定异常并吸收先验医学知识,解决了医学图像与文本数据间的差异问题,在IU-Xray等数据集中表现出色。
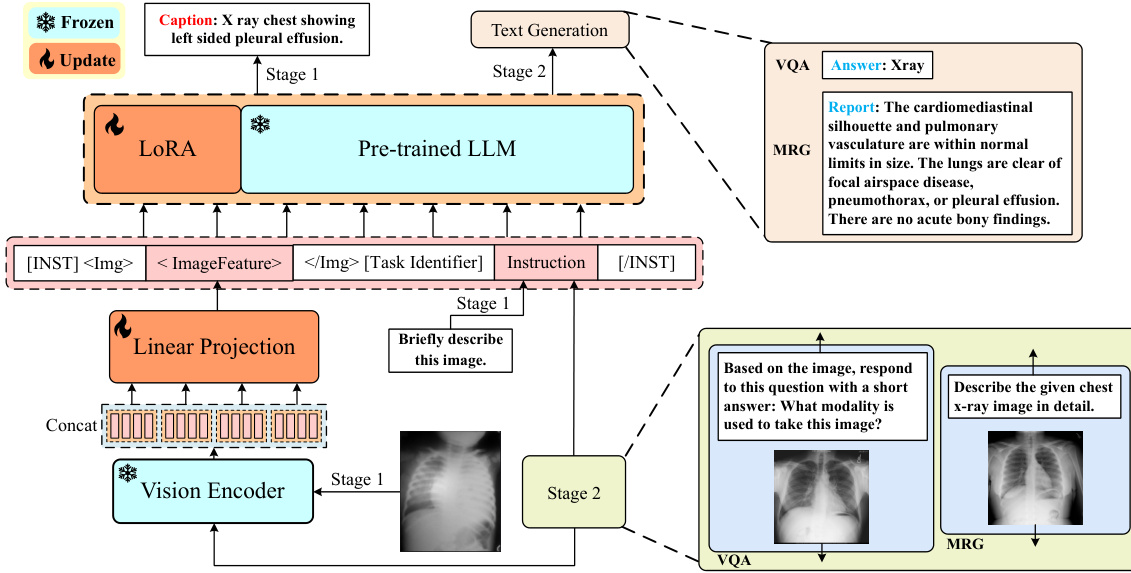
Figure 1: The architecture of the model.
图 1: 模型架构。
Furthermore, Yang et al. introduced MedXChat [53], a model utilizing LLMs for chest X-ray multimodal tasks, which demonstrated effectiveness in generating chest X-ray medical reports. However, these studies often concentrate on a single MRG task or a specific type of medical image, like chest X-rays, employing general-domain text generation metrics for evaluation. Such metrics cannot accurately represent the quality of the generated medical reports.
此外,Yang等人提出了MedXChat[53],这是一个利用大语言模型处理胸部X光多模态任务的模型,在生成胸部X光医学报告方面表现出色。然而,这些研究通常只关注单个医学报告生成任务或特定类型的医学影像(如胸部X光),并使用通用领域的文本生成指标进行评估。这类指标无法准确反映所生成医学报告的质量。
3 METHODS
3 方法
In this section, we will introduce the model architecture used in the work and the training strategy which involves two stages of fine-tuning. Subsequently, we will delineate the evaluation criteria adopted and the metrics proposed for MRG.
在本节中,我们将介绍工作中使用的模型架构和包含两阶段微调的训练策略。随后,我们将阐述采用的评估标准以及为MRG提出的指标。
3.1 Model Architecture
3.1 模型架构
The model is composed of three parts: the vision encoder, a pretrained LLM for processing multimodal inputs and generating answers, and a single linear layer for projecting embeddings from visual encoding space to LLM space, as shown in Fig.1. A ViT type of visual backbone, EVA [25] is used to encode image tokens into visual embeddings, where the model weights are frozen during the entire fine-tuning processes. We group four consecutive tokens into one single visual embedding to effectively reduce resource consumption, by concatenating on the embedding dimension. The grouped visual tokens are then fed into the projection layer and output embeddings (of length 4096) in the LLM space. A multimodal prompt template is designed to include both visual and question information and passed to the pre-trained LLM, LLaMA2-chat(7B) [49] as the decoder for generating answers. We adopt the low-rank adaptation (LoRA) technique [13] in the LLM for efficient finetuning, where the other parts of the LLM are entirely frozen during the downstream fine-tuning. A beam search with a width of 1.
该模型由三部分组成:视觉编码器、用于处理多模态输入并生成答案的预训练大语言模型(LLM),以及将嵌入从视觉编码空间投影到LLM空间的单层线性层,如图1所示。采用ViT类型的视觉主干网络EVA [25]将图像token编码为视觉嵌入,其模型权重在整个微调过程中保持冻结。我们通过嵌入维度拼接,将四个连续token合并为单个视觉嵌入,以有效降低资源消耗。分组后的视觉token随后输入投影层,输出LLM空间中长度为4096的嵌入。设计的多模态提示模板同时包含视觉和问题信息,并传递给预训练的大语言模型LLaMA2-chat(7B) [49]作为生成答案的解码器。我们在LLM中采用低秩自适应(LoRA)技术 [13]进行高效微调,LLM其余部分在下游微调期间完全冻结。使用宽度为1的束搜索。
The multimodal prompt incorporates input images, questions and dedicated tokens for downstream tasks. In Figure 1, image features derived from linear projection are denoted as , and the corresponding questions are the text instructions. Special tokens, such as $I V Q A]$ for the Med-VQA task and [report] for the MRG task, serve as task identifiers. This forms the complete multimodal instructional template as:[INST]
[Task Identifier] Instruction [/INST].
多模态提示结合了输入图像、问题以及针对下游任务的专用token。在图1中,通过线性投影得到的图像特征表示为,对应的问题则是文本指令。特殊token(如Med-VQA任务中的$I V Q A]$和MRG任务中的[report])作为任务标识符。由此构成完整的多模态指令模板:[INST]
[Task Identifier] Instruction [/INST]。
3.2 Model Training
3.2 模型训练
We use the weights from MiniGPT-v2 [1] that are pre-trained on datasets in general domains, and further fine-tune the models using multimodal medical datasets in two stages. We adopt an efficient fine-tuning technique, LoRA [13], to only update a small part of the entire model. The details can be seen below:
我们采用MiniGPT-v2 [1]在通用领域数据集上预训练的权重,并通过两阶段使用多模态医疗数据集对模型进行微调。采用高效微调技术LoRA [13],仅更新整个模型的一小部分。具体细节如下:
Stage 1: Fine-tuning with Image Captioning. During this stage, we fine-tune the model using four medical image-caption datasets, ROCO [45], CLEF2022 [46], MEDICAT [47] and MIMICCXR [30]. These datasets consist of medical image-caption, the captions are text descriptions of the corresponding images and have a variety of lengths. We use the prompt template:
阶段1:基于图像描述的微调。在此阶段,我们使用四个医学图像-描述数据集(ROCO [45]、CLEF2022 [46]、MEDICAT [47] 和 MIMICCXR [30])对模型进行微调。这些数据集包含医学图像及其对应的文本描述,描述长度各异。我们采用提示模板:
Stage 2: Fine-tuning on VQA and Report Generation. In the second stage, the model undergoes fine-tuning on the Med-VQA and MRG datasets. Specifically, for Med-VQA, the VQA-RAD [31], SLAKE [38], and PathVQA [29] datasets are used, while the IUXray [6] dataset is utilized for the downstream MRG task. We adopt the following template, “[INST] <Image Feature ${>}{<}/i m g{>}[T a s k$ Identifier] Instruction [/INST]”, wherein [Task Identifier] is substituted with $I V Q A{\cal J}$ or [Report] according to the downstream tasks. For Med-VQA, the instruction prompt used in our experiment is: Based on the image, respond to this question with a short answer: {question}, where {question} is the question corresponding to the given medical image. The motivation for generating short answers is to validate against the annotated ground truth labels in VQA datasets where the answers are mostly short in both open-ended and closed-ended QA pairs. For MRG task, the instruction prompt is randomly selected from an instruction pool, for example: Describe the given chest $x$ -ray image in detail. Similarly, at this stage, we also keep the vision encoder and the LLM frozen while only updating the linear projection and LoRA layer in LLM.
阶段2:VQA与报告生成的微调。在第二阶段,模型在Med-VQA和MRG数据集上进行微调。具体而言,Med-VQA使用VQA-RAD [31]、SLAKE [38]和PathVQA [29]数据集,而下游MRG任务采用IUXray [6]数据集。我们采用以下模板:"[INST] <Image Feature ${>}{<}/i m g{>}[T a s k$ Identifier] Instruction [/INST]",其中[Task Identifier]根据下游任务替换为$I V Q A{\cal J}$或[Report]。对于Med-VQA,实验使用的指令提示为:基于图像,用简短答案回答此问题:{question},其中{question}是对应给定医学图像的问题。生成简短答案的动机是为了与VQA数据集中标注的真实标签(开放性和封闭性QA对的答案大多较短)进行验证。对于MRG任务,指令提示从指令池中随机选择,例如:详细描述给定的胸部$x$光图像。同样在此阶段,我们保持视觉编码器和大语言模型冻结,仅更新大语言模型中的线性投影和LoRA层。
3.3 Evaluation Metrics
3.3 评估指标
In the experiment, we notice that the generated answers and the ground truth label in the VQA task, may not exactly match on a word-by-word basis, particularly for open-ended questions. As shown in Table 1, one of the common patterns from our observations is an inclusive relationship between the ground truth and the generated answer. For example, in the first case, it is shown where the ground truth is ${}^{\prime\prime}\mathbf{x}$ -ray" and the generated answer is "chest xray". In the conventional metric, this will be falsely classified as an incorrect prediction. In the second example, the prediction, "head" is semantically equivalent to the ground truth, "pancreatic head", where the organ information is presented in the question. Besides, there are cases where the prediction and ground truth are synonyms, like ‘both’ and ‘bilateral’ when asking questions about the sides of the lung.
在实验中,我们注意到VQA任务中生成的答案与真实标签可能不会逐字匹配,尤其是开放式问题。如表1所示,我们观察到一个常见模式是真实答案与生成答案之间存在包含关系。例如第一个案例中,真实标签是${}^{\prime\prime}\mathbf{x}$-ray"而生成答案为"chest xray"。传统指标会将其错误归类为预测错误。第二个示例中,预测结果"head"与真实标签"pancreatic head"在语义上等价(问题中已包含器官信息)。此外还存在预测与标签为同义词的情况,比如询问肺部方位时出现的'both'和'bilateral'。
Table 1: Examples of model prediction on open-ended questions. Figure 2: 5-point Likert scale for semantic similarity, used to evaluate medical reports.
表 1: 开放性问题模型预测示例
图 2: 用于评估医学报告的5级Likert语义相似度量表
| 问题 | 真实答案 | 预测结果 |
|---|---|---|
| Whatkind of image is this? | x-ray | chestx-ray |
| The mass is found in which part of the pan- creas? | pancreatichead | head |
| Is the spleen present? | onpatient'sleft | yes |
| Are pleural opacities lo- cated on theleft,right,or both sides of the lung? | both | bilateral |
This issue leads to an inaccurate measurement of model performance. Therefore, we evaluate all the generated answers from our model both manually and by GPT-4, against the ground truth in our experiment. We prepare a spreadsheet that contains all the predictions (that are labelled as not correct according to the conventional metric) with their associated ground truth. Then, ten team members independently evaluate each pair and re-classify the predictions as correct if they fall into the pattern as we shown above. In our experiment, we report both the exact match accuracy, GPT-4 measurement and the more precious measurement from our human evaluation process.
这一问题导致模型性能的测量不准确。因此,我们在实验中通过人工和GPT-4两种方式,对所有模型生成的答案与真实值进行对比评估。我们准备了一份电子表格,其中包含所有预测结果(根据传统指标标记为不正确的)及其对应的真实值。随后,十名团队成员独立评估每对数据,若预测结果符合上文所述模式则重新归类为正确。实验中,我们同时报告了精确匹配准确率、GPT-4评估结果以及人工评估得出的更精确测量值。
Semantic Similarity Using GPT-4: In the evaluation of generated results in open-ended questions of VQA and descriptive reports in MRG, we note that the existing evaluation metrics, based on lexical similarity, fall short in accurately capturing the semantic similarity measurements and handling synonyms. To mitigate this issue, we explore the options of using GPT-4 as the measurement engine to evaluate the semantic similarities between the ground truth text and its generated counterparts from the proposed models, which are then validated against human-labelled data.
使用GPT-4评估语义相似性:在评估VQA开放性问题生成结果及MRG描述性报告时,我们发现现有基于词汇相似度的评估指标难以准确衡量语义相似度并处理同义词问题。为此,我们探索采用GPT-4作为测量引擎,评估基准文本与模型生成文本之间的语义相似性,并通过人工标注数据进行验证。
Particularly in MRG tasks, where the generated content is relatively lengthy, using a binary rating may not be ideal. Instead, a 5-point Likert scale for semantic similarity can provide a more fine-grained validation of the results. As shown in Figure 2, it encompasses five levels: 0, 1, 2, 3, and 4. Each level represents specific evaluation criteria, with the quality of generated reports progressively improving from level 0 (completely dissimilar) to level 4 (very similar). We calculate the weighted average score of the similarity metric (WASM), as follows:
特别是在MRG任务中,由于生成内容较长,使用二元评分可能不够理想。我们改用5级Likert量表进行语义相似度评估,能更精细地验证结果质量。如图2所示,量表分为0、1、2、3、4五个等级,每个等级对应具体的评判标准,生成报告的质量从0级(完全不相似)到4级(高度相似)逐级提升。我们通过加权平均相似度指标(WASM)进行计算,公式如下:
$$
W A S M=\frac{\sum_{i=0}^{4}(i\cdot N_{i})}{\sum_{i=0}^{4}N_{i}}
$$
$$
W A S M=\frac{\sum_{i=0}^{4}(i\cdot N_{i})}{\sum_{i=0}^{4}N_{i}}
$$
where 𝑖 denotes the ith level and $N_{i}$ denotes the number of samples in the ith level. In our experiments, this metric is assessed through both human evaluation and GPT-4 evaluation.
其中𝑖表示第i层,$N_{i}$表示第i层的样本数量。在我们的实验中,该指标通过人工评估和GPT-4评估进行衡量。
4 EXPERIMENTS AND RESULTS
4 实验与结果
4.1 Datasets
4.1 数据集
We utilized four datasets for stage 1 image-caption fine-tuning: ROCO [45], CLEF2022 [46], MEDICAT [47], and MIMIC-CXR [30]. ROCO, consisting of 87,952 radiological images and associated captions from PubMed Central, our study used only the training set.
我们使用了四个数据集进行第一阶段图像-标题微调:ROCO [45]、CLEF2022 [46]、MEDICAT [47] 和 MIMIC-CXR [30]。ROCO包含来自PubMed Central的87,952张放射学图像及相关标题,我们的研究仅使用了其训练集。
Table 2: The performance of various models on the VQA-RAD, SLAKE, and PathVQA datasets, where numbers in brackets represent standard deviations, indicating that the results come from the average of ten independent evaluations.
表 2: 各模型在VQA-RAD、SLAKE和PathVQA数据集上的性能表现,括号内数字表示标准差,表明结果来自十次独立评估的平均值。
| 方法 | 类型 | 准确率测量 | 可训练参数量 | VQA-RAD | SLAKE | PathVQA | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 开放 | 封闭 | 总体 | 开放 | 封闭 | 总体 | 开放 | 封闭 | 总体 | ||||
| MMQ [7] | Non-LLMs 精确匹配 | 28.3M | 52.0% | 72.4% | 64.3% | 11.8% | 82.1% | 47.1% | ||||
| MTL [5] | 69.8% | 79.8% | 75.8% | 80.2% | 86.1% | 82.5% | ||||||
| VQA-Adapter [40] | 2.09M | 66.1% | 82.3% | 75.8% | 79.2% | 83.7% | 81.0% | - | - | |||
| M3AE [4] | 67.2% | 83.5% | 77.0% | 80.3% | 87.8% | 83.2% | ||||||
| M2I2 [35] | 262.15M | 66.5% | 83.5% | 76.8% | 74.7% | 91.1% | 81.2% | 36.3% | 88.0% | 62.2% | ||
| MUMC [34] | 211.06M | 71.5% | 84.2% | 79.2% | 81.5% | 91.1% | 84.9% | 39.0% | 90.4% | 65.1% | ||
| ARL [28] | 362M | 67.6% | 86.8% | 79.2% | 81.9% | 91.4% | 85.6% | |||||
| LLaVA-Med(LLaVA) [10] | 61.5% | 84.2% | 75.2% | 83.1% | 85.3% | 84.0% | 38.0% | 91.2% | 64.7% | |||
| LLaVA-Med(Vicuna)[10] LLaVA-Med(Bio-CLIP) [10] | 开放:Token召回 封闭:精确匹配 | 64.4% 64.8% | 82.0% 83.1% | 75.0% 75.8% | 84.7% 87.1% | 83.2% 86.8% | 84.1% 87.0% | 38.9% 39.6% | 91.7% 91.1% | 65.3% 65.4% | ||
| GPT-4v [43] | 精确匹配 LLMs | |||||||||||
| 61.4% | ||||||||||||
| 精确匹配 | 62.6% | 87.1% 77.4% | 77.8% | 88.7% | 82.1% | 35.7% | 91.3% | 63.6% | ||||
| 人工评估 GPT-4评估 | 77.7%(3.2%) 87.6%(0.2%) 79.9%(1.2%) 87.5%(0.0%) | 83.7%(1.3%) 84.4%(0.5%) | 83.1%(0.3%) | 88.7%(0.0%) | 85.3%(0.2%) | 45.7% | 91.3% | 68.6% |
CLEF2022, offering broad coverage across medical fields, contains over 90,000 image-caption pairs. MEDICAT features over 210,000 image-caption pairs from PubMed Central. MIMIC-CXR features 377,110 radiology images and 227,835 reports from 64,588 patients. We used the official training set split.
CLEF2022涵盖广泛的医学领域,包含超过90,000个图像-标题对。MEDICAT收录了来自PubMed Central的210,000多个图像-标题对。MIMIC-CXR包含来自64,588名患者的377,110张放射影像和227,835份报告。我们使用了官方的训练集划分。
Stage 2 fine-tuning for Med-VQA utilized three datasets: VQARAD [31], SLAKE [38], and PathVQA [29]. VQA-RAD comprises 315 radiologic images with 3,515 question-answer pairs across 11 question types such as abnormality and modality, featuring 104 axial CT scans of the abdomen, 104 head scans (CT/MRI), and 107 chest radio graphs, split into 3,064 training and 451 test pairs. SLAKE, a bilingual Med-VQA dataset, provided us with the English subset containing 642 images and 7,032 pairs, divided as 4,918 for training, 1,053 for validation, and 1,061 for testing. PathVQA features 4,998 pathology images and 32,795 question-answer pairs. It includes eight question types: ’what’, ’where’, ’when’, ’how’, ’why’, ’whose’, ’which’, and ’how much’. The dataset was split into training, validation, and test sets in a 7:1:2 ratio.
Med-VQA的第二阶段微调使用了三个数据集:VQARAD [31]、SLAKE [38]和PathVQA [29]。VQA-RAD包含315张放射影像及3,515个问答对,涵盖异常性、模态等11类问题类型,其中包含104张腹部轴向CT扫描、104张头部扫描(CT/MRI)以及107张胸部X光片,划分为3,064个训练对和451个测试对。双语Med-VQA数据集SLAKE为我们提供了包含642张图像和7,032个问答对的英文子集,划分为4,918个训练对、1,053个验证对和1,061个测试对。PathVQA包含4,998张病理图像和32,795个问答对,涵盖"what"、"where"、"when"、"how"、"why"、"whose"、"which"和"how much"八类问题类型,按7:1:2比例划分为训练集、验证集和测试集。
The IU-Xray dataset was utilized for stage 2 fine-tuning in MRG. IU-Xray, a benchmark dataset from Indiana University, is widely used for MRG evaluation. It includes 7,470 chest X-ray images and 3,955 radiology reports, each associated with frontal and lateral views. The dataset was segmented into training, validation, and test sets in a 7:1:2 ratio for this study.
IU-Xray数据集被用于MRG的第二阶段微调。IU-Xray是印第安纳大学提供的基准数据集,广泛用于MRG评估。该数据集包含7,470张胸部X光图像和3,955份放射学报告,每份报告关联正位和侧位视图。本研究按7:1:2的比例将数据集划分为训练集、验证集和测试集。
4.2 Implementation Details
4.2 实现细节
All experiments were carried out using Python 3.9 on 4 NVIDIA Tesla A40 GPUs, each with 48GB of GPU memory. We initialized the model using the pre-trained weights of MiniGPT-v2. Throughout the training process, we only updated the linear projection layer and fine-tuned the LoRA layers (with a rank of 64) of the LLM.
所有实验均在配备4块NVIDIA Tesla A40 GPU(每块显存48GB)的设备上运行,使用Python语言 3.9版本。模型初始化采用MiniGPT-v2的预训练权重,训练过程中仅更新线性投影层并对大语言模型的LoRA层(秩为64)进行微调。
In both fine-tuning stages, images are set to a resolution of $448\times448$ , and the maximum text length is set to 1024. We employed AdamW [16] optimizer along with a cosine learning rate scheduler to train the model. For stage 1 fine-tuning, the learning rate was gradually decreased from an initial $1e^{-4}$ to $8e^{-5}$ , the epoch is set to
在两个微调阶段中,图像分辨率设置为$448\times448$,最大文本长度设置为1024。我们采用AdamW [16]优化器配合余弦学习率调度器来训练模型。第一阶段微调的学习率从初始$1e^{-4}$逐步降至$8e^{-5}$,训练周期设为
- In stage 2 fine-tuning, the learning rate is progressively lowered from $3e^{-5}$ to $1e^{-5}$ , and the epoch is set to 50.
- 在第二阶段微调中,学习率从 $3e^{-5}$ 逐步降低至 $1e^{-5}$,训练周期(epoch)设为50次。
4.3 Comparison with the State-of-the-Art Methods
4.3 与现有最优方法的对比
In this section, we present the results of our proposed models against the existing state-of-the-art (SOTA) models, on both MedVQA and MRG tasks.
在本节中,我们将展示所提模型在MedVQA和MRG任务上对比现有最先进(SOTA)模型的结果。
a. Medical Visual Question Answering
a. 医学视觉问答
For Med-VQA, as shown in Table 2, we compare the proposed model with the previous SOTA methods. We briefly categorized existing models based on their decoder types, including non-LLM types such as class if i ers, BERT [18], and generative LLMs. For nonLLM approaches employing class if i ers or BERT as decoders, the accuracy was computed through an exact match metric between the predicted answers and the ground truth text. On the other hand, the type of methods, like our method, used generative models that yield free-form text as answers using LLM as decoders, where the accuracy was measured differently. LLaVA-Med [10] employed token-based recall for open-ended questions, while exact-match accuracy for closed-ended ones. In our work, we applied three accuracy metrics for the generated free-form answers: exact match accuracy as in the previous works, GPT-4 similarity evaluation and human manual evaluation in order to minimize the evaluation bias.
在Med-VQA方面,如表2所示,我们将提出的模型与之前的SOTA方法进行了比较。我们根据解码器类型对现有模型进行了简要分类,包括分类器、BERT [18]等非大语言模型类型,以及生成式大语言模型。对于采用分类器或BERT作为解码器的非大语言模型方法,其准确率是通过预测答案与真实文本之间的精确匹配指标计算的。另一方面,像我们这样的方法使用生成式模型,以大语言模型作为解码器生成自由形式的文本答案,其准确率测量方式有所不同。LLaVA-Med [10]对开放式问题采用基于token的召回率,对封闭式问题则使用精确匹配准确率。在我们的工作中,我们对生成的自由形式答案应用了三种准确率指标:与之前工作相同的精确匹配准确率、GPT-4相似性评估以及人工手动评估,以尽量减少评估偏差。
On the VQA-RAD dataset, our LLM-based method was close to the performance of the dedicated VQA models, with an overall accuracy of $77.4%$ , while outperforming the existing methods on closed-ended questions $(87.1%)$ , under the same exact-match accuracy metric. For open-ended questions, our MLLM-based model achieved $62.6%$ , compared to non-LLM dedicated visual language models, such as M3AE $(67.2%)$ [4] and MUMC $(71.5%)$ [34] In comparison, the early attempt to use LLM as answer decoders by the LLaVA-Med model series [10] achieved overall accuracy of $75.8%$ , specifically, $84.2%$ for closed-ended questions and $64.8%$ for openended questions. It is important to note that LLaVA-Med measures accuracy for open-ended and closed-ended questions differently, i.e.
在VQA-RAD数据集上,我们基于大语言模型(LLM)的方法接近专用VQA模型的性能,总体准确率达到$77.4%$,同时在封闭式问题上$(87.1%)$以完全匹配准确率指标超越了现有方法。对于开放式问题,我们基于多模态大语言模型(MLLM)的模型取得了$62.6%$的准确率,而专用视觉语言模型如M3AE$(67.2%)$[4]和MUMC$(71.5%)$[34]表现更优。相比之下,LLaVA-Med模型系列[10]早期尝试将大语言模型作为答案解码器,总体准确率为$75.8%$,其中封闭式问题$84.2%$,开放式问题$64.8%$。需要注意的是,LLaVA-Med对开放式和封闭式问题的准确率测量方式不同。
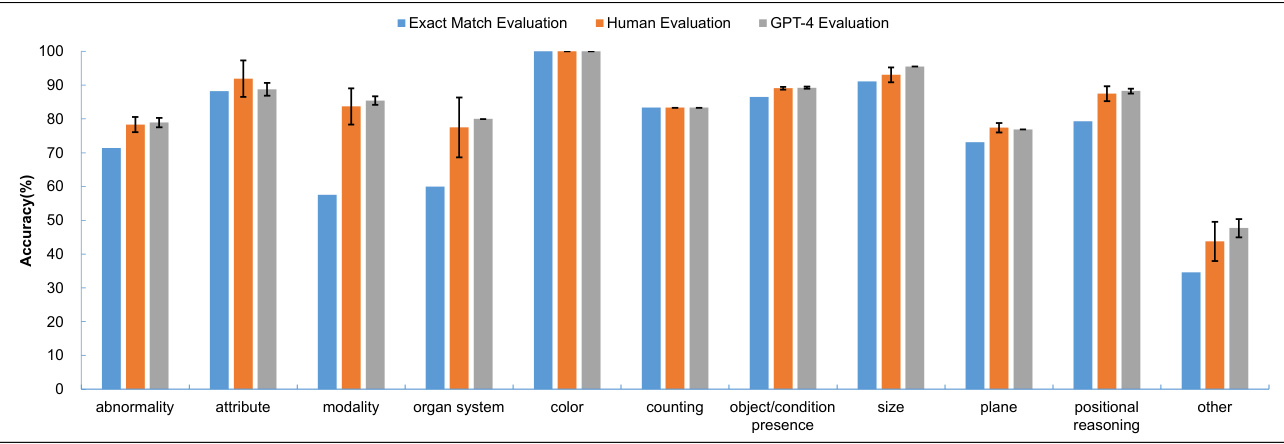
Figure 3: The accuracy of different question types on the VQA-RAD dataset by different evaluation methods.
图 3: 不同评估方法在VQA-RAD数据集上对各题型回答的准确率。
measuring token recall rate for open-ended questions, and conventional classification accuracy for closed-ended types. Furthermore, a recent study validated the capability of GPT-4v (without finetuning) on the VQA dataset, and reported an accuracy of $61.4%$ on closed-ended questions, where our model achieved $87.1%$ in comparison.
测量开放式问题的token召回率,以及封闭式问题的传统分类准确率。此外,最近一项研究验证了GPT-4v(未经微调)在VQA数据集上的能力,报告其在封闭式问题上的准确率为$61.4%$,而我们的模型达到了$87.1%$。
Table 3: The accuracy of different phrase types on the VQARAD dataset by different evaluation methods, para denotes the parameterized form phrase.
表 3: 不同评估方法在VQARAD数据集上对不同短语类型的准确率,para表示参数化形式的短语。
| 评估方法 | 短语类型 |
|---|---|
| 自由形式 | |
| 精确匹配评估 | 72.7% |
| 人工评估 | 81.5% (1.8%) |
| GPT-4评估 | 80.8% (0.6%) |
As discussed in the method section, accuracy measured using the exact-match metric may not reflect the true performance in an MLLM-based generative setup. Therefore, we cross-validated the results using both GPT-4 and human evaluation methods, which were collected from 10 human annotators, and 10 independent inferences on the GPT-4 model with different seeding choices. Table 2 presents the results, indicating that the accuracies measured by human annotators $(87.6%)$ and GPT-4 $(87.5%)$ align closely with the exact match metric $(87.1%)$ . However, a significant discrepancy is observed in open-ended questions, where using GPT-4 evaluation yields an accuracy of $79.9%$ , closely mirroring the human annotations $(77.7%)$ and surpassing the exact matches. This discrepancy raises concerns about the suitability of the exact match metric for evaluating open-ended questions and MRG tasks.
如方法部分所述,在使用精确匹配指标衡量基于多模态大语言模型 (MLLM) 的生成式设置时,其准确性可能无法反映真实性能。因此,我们采用 GPT-4 和人工评估方法对结果进行了交叉验证,其中人工评估数据来自 10 位标注员,GPT-4 评估数据则通过不同种子选择的 10 次独立推理获得。表 2 展示了验证结果:人工标注准确率 $(87.6%)$ 与 GPT-4 评估准确率 $(87.5%)$ 均与精确匹配指标 $(87.1%)$ 高度吻合。但在开放式问题中出现了显著差异,GPT-4 评估准确率达 $79.9%$ ,与人工标注结果 $(77.7%)$ 高度接近且明显优于精确匹配值。这一差异引发了关于精确匹配指标是否适用于开放式问题和多模态推理生成 (MRG) 任务评估的质疑。
We further analyzed the impacts of different evaluation methods across the pre-defined question types within the VQA-RAD dataset. Figure 3 shows the accuracy under the three distinct evaluation methods and the standard deviations for human and GPT-4 evaluations. The results suggest that accuracy measurements from human and GPT-4 evaluations are closely aligned across different question types, while GPT-4 has a consistently low variability compared to human annotators. A noticeable disparity can be seen between the results of human and GPT-4 evaluation methods and the exact match evaluation, for question types of ’abnormality’, ’modality’, and ’organ system’. Besides, regardless of the evaluation metrics, the model performed relatively well on question types, like ‘color’, ‘attribute’ and ‘size’. Questions associated with ‘abnormality’, ‘plane’ and ‘organ system’ seem to be challenging for our approach.
我们进一步分析了VQA-RAD数据集中预定义问题类型下不同评估方法的影响。图3展示了三种不同评估方法下的准确率以及人类评估与GPT-4评估的标准差。结果表明,在不同问题类型下,人类评估与GPT-4评估的准确率测量结果高度一致,而GPT-4的变异性始终低于人工标注者。对于"abnormality"、"modality"和"organ system"这三类问题,人类评估与GPT-4评估方法与精确匹配评估之间存在明显差异。此外,无论采用哪种评估指标,模型在"color"、"attribute"和"size"等问题类型上都表现较好,而与"abnormality"、"plane"和"organ system"相关的问题对我们的方法而言更具挑战性。
Table 4: The accuracy of different image organs under different evaluation methods on the VQA-RAD dataset.
表 4: VQA-RAD 数据集中不同评估方法下各图像器官的准确率。
| 评估方法 | CHEST | HEAD | ABDOMEN |
|---|---|---|---|
| ExactMatchEvaluation | 81.0% | 79.0% | 72.2% |
| HumanEvaluation | 86.4% (1.0%) | 85.4% (2.8%) | 79.4% (1.9%) |
| GPT-4Evaluation | 87.4% (0.0%) | 86.8% (1.3%) | 79.3% (0.7%) |
A similar discrepancy can be seen on different phrase types (i.e. free-form and parameterized form) in the VQA-RAD dataset. The free-form question refers to a type of question or answer format that does not adhere to a predefined structure or set of possible responses, and are usually open-ended, allowing for a wide range of natural language expressions. Parameterized form phrase uses a structured representation of a question or answer that includes placeholder s for specific parameters. For example, In the phrase, "What is the size of the [anatomical structure]?" where "[anatomical structure]" is a placeholder that can be replaced with different anatomical structures such as "heart", "lung", or "tumor" to generate specific questions like "What is the size of the heart?" As shown in Table 3, the discrepancy of exact-match and GPT-4 or human evaluation in free-form questions is much larger than the parameterized ones. As shown in Table 4, among the three organ types, the largest discrepancy between human and GPT-4 evaluations is merely $1.4%$ , with the smallest being $0.1%$ . The smallest gap with exact match evaluation reaches $5.4%$ .
在VQA-RAD数据集中,不同短语类型(即自由形式和参数化形式)也存在类似差异。自由形式问题指不遵循预定义结构或固定应答格式的开放式问题,允许使用多样化的自然语言表达。参数化形式短语采用结构化表征方式,包含特定参数的占位符。例如短语"What is the size of the [anatomical structure]?"中,"[anatomical structure]"作为占位符可替换为"心脏"、"肺"或"肿瘤"等解剖结构,生成诸如"What is the size of the heart?"的具体问题。如表3所示,自由形式问题在精确匹配与GPT-4/人工评估间的差异远大于参数化问题。如表4所示,三种器官类型中,人工评估与GPT-4的最大差异仅为$1.4%$,最小差异为$0.1%$;而与精确匹配评估的最小差距达到$5.4%$。
Similarly, we observed significant performance gaps of accuracy measurements for open-ended questions on both the SLAKE and PathVQA datasets, using GPT-4 and exact-match evaluations. On the SLAKE dataset, our model achieved an overall accuracy of $82.1%$ (with exact-match evaluation) and $85.3%$ (using GPT-4 evaluation), showcasing a competitive performance across all evaluated models. On the PathVQA dataset, the largest among the three VQA datasets, featuring a test set of 6761 samples, there is an even larger discrepancy of $10%$ for open-ended questions between the two evaluations.
同样,我们在SLAKE和PathVQA数据集上使用GPT-4和精确匹配评估时,观察到开放式问题的准确率测量存在显著性能差距。在SLAKE数据集上,我们的模型总体准确率达到$82.1%$(精确匹配评估)和$85.3%$(GPT-4评估),在所有评估模型中展现出竞争力。在三个VQA数据集中规模最大的PathVQA数据集(测试集包含6761个样本)上,两种评估方式对开放式问题的结果差异甚至达到$10%$。

Figure 4: Accuracy of different evaluation methods for different types of questions on the PathVQA dataset.
图 4: PathVQA数据集中不同类型问题采用不同评估方法的准确率。
Using GPT-4 semantic similarity evaluation, the results demonstrate a strong consistency across multiple inferences on the VQARAD and SLAKE datasets. The largest standard deviation across 10 independent runs is only $1.2%$ , compared to the results of 10 independent human annotators $(3.2%)$ for open-ended questions. On closed-ended questions, the standard deviations on GPT-4 evaluation over multiple runs between generated answers and ground truth is nearly 0 on both VQA-RAD and SLAKE datasets.
使用GPT-4语义相似度评估的结果表明,在VQARAD和SLAKE数据集上的多次推理具有很强的一致性。10次独立运行的最大标准差仅为$1.2%$,而针对开放式问题的10次独立人工标注结果标准差为$(3.2%)$。在封闭式问题上,GPT-4评估生成的答案与标准答案之间在VQA-RAD和SLAKE数据集上的多次运行标准差接近0。
Table 5: Performance of various models on the IU-Xray.
表 5: 各模型在 IU-Xray 数据集上的性能表现
| 方法 | 类型 | METEORT | ROUGE-L | CIDErT |
|---|---|---|---|---|
| PPKED [39] | Non-LLMs | 0.376 | 0.351 | |
| ITHN [52] | Non-LLMs | 0.210 | 0.495 | |
| VLCL [2] | Non-LLMs | 0.204 | 0.397 | 0.456 |
| R2Gen [3] | Non-LLMs | 0.211 | 0.377 | 0.438 |
| BiomedGPT [54] | LLMs | 0.146 | 0.302 | 0.360 |
| PeFoMed (ours) | LLMs | 0.157 | 0.286 | 0.462 |
As illustrated in Figure 4, we provide a detailed analysis of the various types of questions contained in the PathVQA dataset. For most of the closed-ended question types in this dataset, like the questions of ‘is’, ‘does’ and ‘did’, the results using GPT-4 evaluation have almost identical results with the exact-match evaluation. On the other hand, observations revealed that for more abstract question types, including ’what’, ’how’, and ’why’, the accuracy measurements using exact match evaluation significantly differ from the counterparts using GPT-4 semantic similarity evaluation. This indicates that exact match evaluation may not be sufficiently effective in assessing the performance of MLLMs on more complex open-ended question types.
如图 4 所示,我们对 PathVQA 数据集中包含的各类问题进行了详细分析。对于该数据集中大多数封闭式问题类型(如 "is"、"does" 和 "did" 类问题),使用 GPT-4 评估的结果与精确匹配评估结果几乎一致。另一方面,观察发现对于更抽象的问题类型(包括 "what"、"how" 和 "why"),使用精确匹配评估的准确率测量结果与使用 GPT-4 语义相似度评估的结果存在显著差异。这表明精确匹配评估在评估大语言模型对更复杂的开放式问题类型的性能时可能不够有效。
Besides, it is worth highlighting that with the adoption of parameterefficient fine-tuning, our model featured notably fewer trainable parameters (56.63M) in comparison to LLaVA-Med (7B parameters), which made our method a significantly more efficient framework for fine-tuning MLLMs.
此外,值得强调的是,通过采用参数高效微调 (parameter-efficient fine-tuning) ,我们的模型相比 LLaVA-Med (7B 参数) 具有显著更少的可训练参数 (56.63M) ,这使得我们的方法成为微调 MLLM 的一个显著更高效的框架。
b. Medical Report Generation
b. 医疗报告生成
As shown in Table 6, our MLLM-based model was evaluated on MRG tasks using the IU-Xray dataset. We evaluated the performance with the commonly used metrics: METEOR, ROUGE-L and CIDEr. The results show that the LLM-based models, including both our method and a recent approach, BiomedGPT [54] underperformed the existing dedicated MRG models, while our method is slightly better than BiomedGPT on METEOR and CIDEr measurements.
如表 6 所示,我们基于 MLLM 的模型在 IU-Xray 数据集上进行了 MRG 任务的评估。我们使用常用指标 METEOR、ROUGE-L 和 CIDEr 评估了性能。结果表明,基于大语言模型的方案 (包括我们的方法和近期提出的 BiomedGPT [54] ) 表现均逊于现有专用 MRG 模型,但我们的方法在 METEOR 和 CIDEr 指标上略优于 BiomedGPT。
Table 6: Semantic similarity for 100 randomly selected samples from the IU-Xray dataset, assessed through both human evaluation and GPT-4 evaluation, respectively.
表 6: 从IU-Xray数据集中随机选取的100个样本的语义相似度,分别通过人工评估和GPT-4评估得出。
| 评估方法 | 0 | 1 | 2 | 3 | WASMT | |
|---|---|---|---|---|---|---|
| 人工评估 | 7.75(5.55) | 23.38(12.81) | 21.88(5.64) | 29.13(14.73) | 17.25(11.07) | 2.24(0.42) |
| GPT-4评估 | 2.80(0.63) | 7.80(1.62) | 17.10(1.91) | 22.60(5.36) | 48.70(2.54) | 3.08(0.03) |
Evaluating the WASM using GPT-4 on the IU-Xray dataset (covering 1180 samples) to measure the similarity between generated reports and ground truth, our model achieved a WASM score of 2.79, as shown in Table 7. Nearly $90%$ of the similarity scores are within the range from 2 (moderate similar) to 4 (very similar), and $27.5%$ of the generated reports were rated as highly similar to the ground truth. Furthermore, we randomly sampled 100 samples from the IU-Xray dataset and compared the score of the 5-point Likert scale between the GPT-4 and human evaluations, as shown in Table 6. An interesting observation from the study is that human annotators tend to have more neutral opinions; approximately $75%$ of their responses fall within the 2-3 range on a 5-point scale. However, GPT-4 frequently assigned a higher similarity score of 4 in $48.7%$ of cases. Using GPT-4 evaluation results in a significantly higher WASM score of 3.08, with a standard deviation of 0.03 across 10 runs, compared to a score of 2.24 when evaluated by humans. This raises the question of whether using GPT-4 for similar measurements provides a more robust metric for MRG tasks.
在IU-Xray数据集(覆盖1180个样本)上使用GPT-4评估WASM以衡量生成报告与真实值的相似度时,我们的模型获得了2.79的WASM分数,如表7所示。近$90%$的相似度分数介于2(中等相似)到4(非常相似)之间,且$27.5%$的生成报告被评为与真实值高度相似。此外,我们从IU-Xray数据集中随机抽取100个样本,比较了GPT-4与人工评估的5级李克特量表评分,如表6所示。研究中发现一个有趣现象:人类标注者倾向给出更中立的评价,约$75%$的评分集中在2-3分区间;而GPT-4在$48.7%$的情况下给出了更高的4分相似度评分。使用GPT-4评估得到的WASM分数显著更高(3.08分,10次运行标准差0.03),而人工评估仅为2.24分。这引发了一个问题:在MRG任务中,使用GPT-4进行相似性测量是否能提供更稳健的评估指标。
Table 7: Semantic similarity evaluated by GPT-4 on the IUXray test set. Num denotes the count of samples at each level. Per indicates the percentage of samples corresponding to each level within the test set.
表 7: GPT-4在IUXray测试集上评估的语义相似度。Num表示每个级别的样本数量,Per表示测试集中对应每个级别的样本百分比。
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| Num | 22 | 118 | 267 | 449 | 324 |
| % | 1.9% | 10.0% | 22.6% | 38.1% | 27.5% |
| WASM↑ | 2.79 |
4.4 Ablation Study
4.4 消融研究
a. Medical Visual Question Answering
a. 医学视觉问答
We conducted an ablation study to explore the impacts of the two stage fine-tuning strategy on the VQA performance. In Table 8 and 9, they show the VQA accuracy measurements of models that (i) perform zero-shot without fine-tuning; (ii) are only fine-tuned on the image caption dataset; (iii) are only fine-tuned on the VQA dataset; and (iv) have two stage fine-tuning.
我们进行了消融实验,以探究两阶段微调策略对VQA性能的影响。在表8和表9中,展示了以下模型的VQA准确率测量结果:(i) 未经微调的零样本模型;(ii) 仅在图像描述数据集上微调的模型;(iii) 仅在VQA数据集上微调的模型;(iv) 采用两阶段微调的模型。
Tables 8 and 9(b) demonstrate that two-stage fine-tuning significantly enhances model performance across all three benchmark datasets in both exact-match and GPT-4 similarity evaluations, and second-stage fine-tuning contributes the most performance improvements. We primarily focus on the results from GPT-4 similarity evaluations, which are largely consistent with those from exactmatch evaluations. Without fine-tuning the VQA-RAD dataset, models only achieve a $40%$ overall accuracy and $26.2%$ on open-ended questions. Stage 1 fine-tuning with image captioning tasks raises overall accuracy by $11.1%$ , while Stage 2 fine-tuning on VQA tasks alone doubles performance to $79.6%$ and boosts combined overall accuracy to $84.4%$ . Similarly, without fine-tuning, the Slake dataset starts with open-ended question accuracy at $47.0%$ and overall accuracy at $52.1%$ , with modest gains from image-caption task finetuning. Direct VQA task fine-tuning substantially improves Slake’s and PathVQA’s accuracies to $83.8%$ and $64.3%$ , respectively, with overall accuracies reaching $85.3%$ for Slake and $68.6%$ for PathVQA after completing both stages, notably increasing PathVQA’s openended question accuracy by $7.2%$ .
表8和表9(b)表明,两阶段微调在所有三个基准数据集上均显著提升了模型性能,无论是精确匹配还是GPT-4相似度评估,其中第二阶段微调贡献了最主要的性能提升。我们主要关注GPT-4相似度评估结果,这些结果与精确匹配评估基本一致。未对VQA-RAD数据集进行微调时,模型总体准确率仅为40%,开放式问题准确率为26.2%。第一阶段图像描述任务微调使总体准确率提升11.1%,而仅通过第二阶段VQA任务微调就将性能翻倍至79.6%,组合总体准确率提升至84.4%。同样,未微调的Slake数据集初始开放式问题准确率为47.0%,总体准确率为52.1%,图像描述任务微调带来有限提升。直接进行VQA任务微调使Slake和PathVQA准确率分别大幅提升至83.8%和64.3%,完成两阶段微调后总体准确率分别达到85.3%(Slake)和68.6%(PathVQA),其中PathVQA开放式问题准确率显著提升7.2%。
Table 8: The ablation study under different training setups and the comparison between exact match evaluation and GPT-4 evaluation on the Slake and PathVQA datasets.
表 8: 不同训练设置下的消融研究以及在Slake和PathVQA数据集上精确匹配评估与GPT-4评估的对比。
| 评估方法 | 阶段1 | 阶段2 | Slake-开放 | Slake-封闭 | Slake-总体 | PathVQA-开放 | PathVQA-封闭 | PathVQA-总体 |
|---|---|---|---|---|---|---|---|---|
| 23.9% | 58.9% | 37.6% | 2.4% | 59.0% | 30.8% | |||
| (a) | √ | 11.6% | 50.5% | 26.9% | 1.2% | 53.3% | 27.3% | |
| 精确匹配评估 | X | √ | 77.5% | 85.3% | 80.6% | 31.2% | 90.0% | 60.7% |
| √ | √ | 77.8% | 88.7% | 82.1% | 35.7% | 91.3% | 63.6% | |
| X | 47.0%(0.5%) | 59.9%(0.0%) | 52.1%(0.3%) | 12.3% | 59.3% | 35.9% | ||
| (b) | √ | 50.0%(0.9%) | 62.5%(0.4%) | 54.9%(0.7%) | 12.1% | 53.9% | 33.1% | |
| GPT-4评估 | X | √ | 82.8%(0.3%) | 85.3%(0.0%) | 83.8%(0.2%) | 38.5% | 90.0% | 64.3% |
| √ | √ | 83.1%(0.3%) | 88.7%(0.0%) | 85.3%(0.2%) | 45.7% | 91.3% | 68.6% |
Table 9: The ablation study under different training setups and the comparison between exact match evaluation, human evaluation and GPT-4 evaluation on the VQA-RAD dataset.
表 9: VQA-RAD数据集上不同训练设置的消融研究,以及精确匹配评估、人工评估和GPT-4评估的对比。
| 评估方法 | Stage1 | Stage2 | Open | Closed | Overall |
|---|---|---|---|---|---|
| (a) | X | X | 13.4% | 48.2% | 34.4% |
| ExactMatch | X | 16.2% | 59.9% | 42.6% | |
| Evaluation | √ | 58.1% | 82.0% | 72.5% | |
| √ | √ | 62.6% | 87.1% | 77.4% | |
| X | 26.2%(1.1%) | 49.1%(0.3%) | 40.0%(0.4%) | ||
| (b) | √ | X | 37.3%(1.1%) | 60.2%(0.1%) | 51.1%(0.5%) |
| GPT-4 | X | 75.0%(0.4%) | 82.7%(0.0%) | 79.6%(0.1%) | |
| Evaluation | √ | 79.9%(1.2%) | 87.5%(0.0%) | 84.4%(0.5%) | |
| (c)F Human Evaluation | √ | 77.7%(3.2%) | 87.6%(0.2%) | 83.7%(1.3%) |
Performance declines were observed when applying stage-1 finetuning alone, which involves training with image captioning tasks. This decline was particularly noticeable in the Slake and PathVQA datasets (in Table 8), where stage-1 fine-tuning significantly reduced performance on both open-ended and closed-ended questions. Specifically, applying only stage-1 fine-tuning leads to a significant decrease in accuracy, with a $10.7%$ overall drop and a $12.3%$ reduction in open-ended question accuracy on the Slake dataset. Combining image captioning tasks with VQA tasks leads to optimal performance, outperforming the use of either task alone.
仅应用第一阶段微调(涉及图像描述任务训练)时观察到性能下降。这一现象在Slake和PathVQA数据集中尤为明显(表8),其中第一阶段微调显著降低了开放性和封闭性问题的性能表现。具体而言,单独使用第一阶段微调会导致准确率大幅下降:Slake数据集总体准确率下降10.7%,开放性问题准确率下降12.3%。将图像描述任务与视觉问答任务结合使用可获得最佳性能,其表现优于单独使用任一任务。
We observed discrepancies between the exact match and GPT-4 evaluations in the Slake dataset. Table 8 shows that after stage-1 fine-tuning, overall accuracy declined from $37.6%$ to $26.9%$ . However, using GPT-4 evaluation, open-ended and closed-ended accuracies showed an approximate increase of $3%$ . This raises concerns about the reliability of using the exact match similarity metric (where accuracy is determined by a word-by-word comparison between predicted answers and ground truths) to evaluate the performance of generative models in Med-VQA. Such a metric can result in biased and inaccurate evaluations for models that used generative LLMs as answer decoders, particularly for open-ended questions.
我们观察到Slake数据集中精确匹配与GPT-4评估之间存在差异。表8显示,经过第一阶段微调后,总体准确率从$37.6%$下降至$26.9%$。但采用GPT-4评估时,开放式和封闭式问题的准确率均呈现约$3%$的提升。这引发了对使用精确匹配相似度指标(通过逐字比对预测答案与标准答案来确定准确率)评估生成式模型在Med-VQA任务中性能可靠性的质疑。该指标可能导致对采用生成式大语言模型作为答案解码器的模型产生偏差且不准确的评估,尤其针对开放式问题。
Table 10: The ablation study under different training setups on the IU-Xray dataset.
表 10: IU-Xray数据集上不同训练设置的消融研究。
| Stage1 | Stage2 | METEOR | ROUGE-L↑ | CIDEr↑ |
|---|---|---|---|---|
| 0.059 | 0.089 | 0.007 | ||
| √ | 0.153 | 0.247 | 0.124 | |
| X | √ | 0.146 | 0.295 | 0.393 |
| √ | √ | 0.157 | 0.286 | 0.462 |
b. Medical Report Generation
b. 医疗报告生成
Since the MRG task is akin to the image captioning task used in stage-1 fine-tuning, applying only stage-1 fine-tuning can yield significant performance improvements. Table 10 shows that zeroshot testing on the IU-Xray dataset produced poor results, with METEOR, ROUGE-L, and CIDEr scores of 0.059, 0.089, and 0.007, respectively. This is primarily because models trained in general domains may not perform well on medical images. After fine-tuning with image captioning, these metrics improved to 0.152 for METEOR, 0.089 for ROUGE-L, and 0.124 for CIDEr. The model exhibited its best performance after undergoing both stages of fine-tuning, with the metrics reaching 0.157, 0.286, and 0.462.
由于MRG任务类似于阶段1微调中使用的图像描述任务,仅应用阶段1微调即可带来显著的性能提升。表10显示,在IU-Xray数据集上进行零样本测试的结果较差,METEOR、ROUGE-L和CIDEr得分分别为0.059、0.089和0.007。这主要是因为通用领域训练的模型在医学图像上表现不佳。经过图像描述微调后,这些指标分别提升至METEOR 0.152、ROUGE-L 0.089和CIDEr 0.124。该模型在完成两阶段微调后展现出最佳性能,三项指标分别达到0.157、0.286和0.462。
Table 11: The ablation study reported on semantic similarity by GPT-4 under different training setups on the IU-Xray dataset.
表 11: 在IU-Xray数据集上,GPT-4在不同训练设置下报告的语义相似性消融研究。
| Stage1 | Stage2 | 0 | 1 | 2 | 3 | 4 | WASMT |
|---|---|---|---|---|---|---|---|
| X | 1048 | 79 | 33 | 20 | 0 | 0.17 | |
| √ | X | 51 | 170 | 192 | 318 | 449 | 2.80 |
| X | √ | 39 | 125 | 193 | 447 | 376 | 2.84 |
| √ | √ | 22 | 118 | 267 | 449 | 324 | 2.79 |
Additionally, we discovered that the Weighted Average Score Metric (WASM) is sensitive to changes in accuracy measurements.
此外,我们发现加权平均分数指标 (WASM) 对精度测量的变化非常敏感。
Table 11 shows the WASM scores for each experiment setting, where the model’s WASM score without any fine-tuning stands at merely 0.17, with a total of 1127 reports receiving scores of 0 and 1. Following the first and second stage of medical image-caption fine-tuning, the WASM score improved to 2.8 and 2.84 respectively. This is consistent with the overall model performance as shown in Table 10. Moreover, fine-tuning models on tasks that resemble the downstream tasks seems to provide the greatest benefits. For instance, fine-tuning on image captioning, which is closely related to report generation, tends to enhance performance directly on MRG tasks.
表 11 展示了各实验设置的 WASM 分数。未经微调的模型 WASM 分数仅为 0.17,共有 1127 份报告得分为 0 和 1。经过第一阶段和第二阶段医学图像-描述微调后,WASM 分数分别提升至 2.8 和 2.84,这与表 10 所示的整体模型性能表现一致。此外,在与下游任务相似的任务上进行微调似乎能带来最大收益。例如,对与报告生成密切相关的图像描述任务进行微调,往往能直接提升 MRG 任务的性能。
5 CONCLUSION
5 结论
In this work, we proposed a novel parameter efficient fine-tuning framework for fine-tuning multimodal large language models for both Med-VQA and MRG tasks using a generative approach. Our research challenges the specialized models by introducing an LLMbased decoder as a universal solution for diverse downstream tasks, with minimal training footprint. Additionally, we express concerns that current metrics based on lexical similarity may produce inaccurate results. As an alternative, we suggest using GPT-4 to assess the semantic similarity between generated content and the corresponding ground truths. To validate that, for the first time in the context of medical MLLMs, we employed both human and GPT-4 evaluations alongside conventional metrics for Med-VQA and MRG tasks. The findings indicate that GPT-4 is a robust and reliable semantic similarity metric, consistent with human evaluations but with greater stability, which makes it suitable for analyzing the quality of generated outcomes in Med-VQA and MRG tasks.
在本研究中,我们提出了一种新颖的参数高效微调框架,采用生成式方法对大语言模型进行多模态微调,同时适用于医学视觉问答(Med-VQA)和医学报告生成(MRG)任务。我们的研究通过引入基于大语言模型的解码器作为通用解决方案,以极小的训练成本挑战了传统专用模型。此外,我们对当前基于词汇相似度的评估指标可能产生不准确结果表示担忧,建议采用GPT-4来衡量生成内容与真实答案之间的语义相似度。为验证该方法,我们首次在医学多模态大语言模型领域同时采用人工评估、GPT-4评估与传统指标对Med-VQA和MRG任务进行综合评价。结果表明,GPT-4是一种稳健可靠的语义相似度评估指标,其评估结果与人工判断高度一致且更具稳定性,适用于分析Med-VQA和MRG任务的生成结果质量。
6 ACKNOWLEDGMENTS
6 致谢
This work was supported by the Ministry of Education Humanities and Social Science Research Planning Fund Project under grant number 23YJAZH079 and Natural Science Foundation of Heilongjiang Province under grant number LH2021F015.
本研究得到教育部人文社会科学研究规划基金项目(23YJAZH079)和黑龙江省自然科学基金项目(LH2021F015)的资助。
REFERENCES
参考文献
A MORE QUALITATIVE RESULTS
更多定性结果
We conducted detailed experiments on the Slake dataset, as illustrated in Figure 5. Experiments were carried out on various question types within the dataset. Notably, the "KG" type questions, those requiring additional knowledge for answers, exhibited the largest discrepancy post-evaluations. Possessing substantial additional knowledge precisely characterizes medical MLLMs. As indicated in Figure 6, experiments across various image organ types revealed that "Chest media st in al" was the sole organ type yielding consistent results. This organ type is notably prevalent in the MIMIC-CXR dataset, which possesses the most extensive data used for first-stage image-caption fine-tuning. This observation further demonstrates the significant impact of stage 1 fine-tuning on downstream tasks.
我们在Slake数据集上进行了详细实验,如图5所示。针对数据集中的各类问题类型开展了实验,其中需要额外知识作答的"KG"类问题在评估后显示出最大差异。拥有丰富额外知识正是医疗多模态大语言模型(MLLM)的典型特征。如图6所示,对不同图像器官类型的实验表明,"胸部影像"是唯一结果一致的器官类型。该器官类型在MIMIC-CXR数据集中尤为常见,该数据集拥有用于第一阶段图像-文本微调的最广泛数据。这一发现进一步证明了第一阶段微调对下游任务的显著影响。

Figure 5: The accuracy of different evaluation methods for different question types on the Slake dataset.
图 5: Slake数据集上不同评估方法针对不同问题类型的准确率。

Figure 6: The accuracy of different evaluation methods for different image organ types on the Slake dataset.
图 6: 不同评估方法在Slake数据集上针对不同图像器官类型的准确率。
B GPT-4 INSTRUCTION
B GPT-4 指令
B.1 MRG Instruction
B.1 MRG指令
As shown in Figure 7, we formulated the instruction for GPT-4 evaluation in MRG, where Description i corresponds to the description for score 𝑖, Applicability i denotes the applicability of the score $i_{:}$ actual medical report refers the ground truth of the dataset, and generated report denotes the report produced by the model.
如图 7 所示,我们为 GPT-4 在 MRG 中的评估制定了指令,其中 Description i 对应分数 𝑖 的描述,Applicability i 表示分数 $i_{:}$ 的适用性,actual medical report 指数据集的真实值,generated report 表示模型生成的报告。
B.2 Med-VQA Instruction
B.2 Med-VQA 指令
The GPT-4 instruction designed by us to evaluate Med-VQA is shown in Figure 8, where question represents the question text in the VQA dataset, true answer represents the ground truth in the dataset, generated answer represents the answer generated by the model.
我们设计的用于评估Med-VQA的GPT-4指令如图8所示,其中question代表VQA数据集中的问题文本,true answer代表数据集中的标准答案,generated answer代表模型生成的答案。

Figure 7: Instruction designed for GPT-4 to evaluate MRG.
图 7: 为评估 MRG 而设计的 GPT-4 指令

Figure 8: Instruction designed for GPT-4 to evaluate MedVQA.
图 8: 为评估MedVQA设计的GPT-4指令
C MORE MRC DETAILS
C MORE MRC 详细信息
As shown in Table 12, we give a detailed description and application of MRC metric, which is adopted by human evaluation and GPT-4 evaluation.
如表 12 所示, 我们详细描述了 MRC (Machine Reading Comprehension) 指标及其应用, 该指标被用于人工评估和 GPT-4 评估。
Table 12: Detailed description and applicability of MRC metric.
表 12: MRC指标的详细说明及适用性
| 分数 | 描述 | 适用性 |
|---|---|---|
| 4 | 生成的医学报告与实际报告在意义上差异极小,确保建议完整。包含所有必要信息要素,无遗漏。 | 当评估者难以区分生成报告与实际医学报告时适用此等级。 |
| 3 | 生成的医学报告在关键要素上与实际报告高度相似,虽有微小偏差但不影响整体准确性和可理解性。尽管非必要信息可能存在可忽略的差异,但仍与真实报告的主要诊断和建议保持一致。涵盖几乎所有重要信息,极少遗漏且不影响全面理解。 | 当生成报告的整体质量接近实际报告,仅在细节上存在轻微差异时适用此标准。 |
| 2 | 生成的报告在多个关键方面与实际报告存在显著差异,但其主要内容和意图仍可识别。尽管关键信息存在差异,核心诊断和建议仍准确。部分信息要素的遗漏对报告整体可理解性影响有限。 | 当报告的基本结构与实际报告相似,但存在大量且严重的错误或遗漏时适用此等级。 |
| 1 | 生成的报告在多个关键方面与实际报告差异较大,影响报告的基本理解和使用。关键信息存在多处错误或误导性陈述。更多重要信息被遗漏,影响报告的完整性和实用性。 | 尽管报告保留了一些基本框架或内容,但存在许多错误,影响整体质量。 |
| 0 | 生成的报告与实际报告几乎无一致性,完全偏离正确信息或目的。报告中的信息与实际报告完全不符,充满错误或无关内容。缺乏作为有效医学报告的必要信息要素。 | 当报告内容与预期目标完全不一致,几乎无法识别为有效医学报告时适用。 |