Chain-of-Action: Faithful and Multimodal Question Answering through Large Language Models
基于大语言模型的可靠多模态问答
Abstract
摘要
We present a Chain-of-Action (CoA) framework for multimodal and retrieval-augmented QuestionAnswering (QA). Compared to the literature, CoA overcomes two major challenges of current QA applications: (i) unfaithful hallucination that is inconsistent with real-time or domain facts and (ii) weak reasoning performance over compositional information. Our key contribution is a novel reasoning-retrieval mechanism that decomposes a complex question into a reasoning chain via systematic prompting and pre-designed actions. Methodological ly, we propose three types of domain-adaptable ‘Plug-and-Play’ actions for retrieving real-time information from heterogeneous sources. We also propose a multi-reference faith score (MRFS) to verify and resolve conflicts in the answers. Empirically, we exploit both public benchmarks and a Web3 case study to demonstrate the capability of CoA over other methods.
我们提出了一种用于多模态和检索增强问答 (QA) 的行动链 (Chain-of-Action, CoA) 框架。与现有研究相比,CoA 克服了当前 QA 应用的两大挑战:(i) 与实时或领域事实不符的虚假幻觉 (hallucination);(ii) 对组合信息推理能力较弱。我们的核心贡献是一种新颖的推理-检索机制,通过系统提示和预设计动作将复杂问题分解为推理链。在方法论上,我们提出了三种可适应不同领域的"即插即用"动作,用于从异构源检索实时信息。此外,我们还提出多参考可信度评分 (multi-reference faith score, MRFS) 来验证和解决答案中的冲突。实证方面,我们通过公共基准测试和 Web3 案例研究证明了 CoA 相对于其他方法的优势。
1. Introduction
1. 引言
This work proposes a new reasoning-retrieval framework to enhance the quality of Large Language Models (LLMs) question answering without additional training and querying costs. As exemplified in Figure 1, this work overcomes two major drawbacks in applying LLMs to answer complex questions: (i) unfaithful generation, where the response may not align with real-time or domain-specific facts (e.g. failing to localize relevant facts in Figure 1(b)), and (ii) weak reasoning, where LLMs struggle to aggregate heterogeneous information sources, resolve their conflicts, adequately reason over the information to provide useful, tailored responses (such as the failure of the stopped analysis in Figure 1(c) despite having successfully localized relevant search results).
本研究提出了一种新的推理-检索框架,旨在不增加额外训练和查询成本的情况下提升大语言模型(LLM)的问答质量。如图1所示,该工作解决了LLM在回答复杂问题时存在的两大缺陷:(i) 不可靠生成——响应内容可能与实时或领域事实不符(例如图1(b)中未能定位相关事实);(ii) 薄弱推理——LLM难以整合异构信息源、解决信息冲突,并基于信息进行充分推理以提供有用的定制化响应(如图1(c)所示,尽管成功定位了相关搜索结果,却仍出现分析中断的失败案例)。
To enhance faithfulness and multi-step reasoning, previous approaches such as chain-of-thought based work (Wang et al., 2022; Saparov & He, 2022; Yao et al., 2023a) en- courage LLMs to think step-by-step to break down complex questions. However, only pushing models to continue thinking may not be ideal. Models are expected to learn to pause to verify results and decide if they need more information before continuing to generate. Recent work, thereby, explores integrating information retrieval (Yao et al., 2022; Xu et al., 2023; Li et al., 2023b) into the reasoning chain. However, we argue that seeking external information is not only retrieval, but should manifest as configurable ‘Plugand-Play’ actions: querying web text, encoding domain knowledge, analyzing tabular and numerical data, etc. The key challenge of such heterogeneous multimodal data is to automatically decide when to cease generation to solicit information, what types of external sources to leverage, and how to cross-validate conflicting insights.
为提升可信度与多步推理能力,先前基于思维链的研究 (Wang et al., 2022; Saparov & He, 2022; Yao et al., 2023a) 鼓励大语言模型通过逐步思考分解复杂问题。然而,仅推动模型持续思考可能并非最优解。模型需要学会暂停以验证结果,并判断是否需要更多信息后再继续生成。近期研究开始探索将信息检索 (Yao et al., 2022; Xu et al., 2023; Li et al., 2023b) 融入推理链,但我们认为外部信息获取不应仅限于检索,而应表现为可配置的"即插即用"操作:查询网络文本、编码领域知识、分析表格与数值数据等。此类异构多模态数据的关键挑战在于自动决策何时停止生成以获取信息、应利用哪些类型的外部源,以及如何交叉验证冲突观点。
To that end, we propose a new universal framework Chainof-Action (CoA) equipping LLMs to pro actively initiate information-seeking actions. We design three ‘Plug-andPlay’ actions in this paper: (i) web-querying to extract real-time information as discrete text tokens, (ii) knowledgeencoding to embed domain-specific knowledge concepts as continuous vectors, and (iii) data-analyzing for accessing and interpreting numeric tabular sources. A key advantage of this framework is the extensibility to diverse modalities, e.g., images in the future. Beyond adapting across data modalities, new actions can be introduced to handle emerging domains or data processing techniques.
为此,我们提出了一种新的通用框架 Chainof-Action (CoA),使大语言模型能够主动发起信息搜索行为。本文设计了三种"即插即用"式行为:(i) 网络查询,将实时信息提取为离散的文本token;(ii) 知识编码,将领域特定知识概念嵌入为连续向量;(iii) 数据分析,用于访问和解释数字表格数据源。该框架的一个关键优势是可扩展至多种模态,例如未来的图像处理。除了跨数据模态的适配外,还可以引入新行为来处理新兴领域或数据处理技术。
In detail, as illustrated in Figure 2, the CoA framework first inject the question and action descriptions into the predesigned prompting template through in-context learning. Then LLMs construct an action chains (ACs), where each action node represents a sub-question, a missing-data flag indicating the need for additional information, and an initial answer. After that, we perform action execution and monitoring to address retrieval demands in three steps: (i) retrieving related information, (ii) verifying conflict between the initial answer and the retrieved information, and (iii) inferring missing content with retrieved information when necessary. To verify information conflicts, we design a verification module utilizing our multi-reference faith score (MRFS). If the LLM-generated answer confidence is below a certain threshold, the corresponding action incorporates the retrieved information for answer correction. In this way, LLMs can effectively generate the final answer that is sound and externally-grounded.
具体来说,如图2所示,CoA框架首先通过上下文学习将问题和动作描述注入预设的提示模板。随后,大语言模型构建动作链(ACs),其中每个动作节点代表一个子问题、标识需要额外信息的缺失数据标志以及初始答案。接着,我们通过三个步骤执行动作并监控检索需求:(i)检索相关信息,(ii)验证初始答案与检索信息之间的冲突,(iii)必要时利用检索信息推断缺失内容。为验证信息冲突,我们设计了基于多参考可信度评分(MRFS)的验证模块。若大语言模型生成答案的置信度低于特定阈值,相应动作会整合检索信息进行答案修正。通过这种方式,大语言模型能有效生成合理且基于外部依据的最终答案。
We show the example outputs in Figure 1, where the outputs exhibit significant improvement. A key feature of CoA is automatically solicit external information that forms as tokens, vectors, or numbers for integration into model reasoning. Rather than hard-coding their connections, actions are designed as dataset-agnostic modules that LLMs invoke selectively.
我们在图 1 中展示了输出示例,这些输出显示出显著改进。CoA 的一个关键特性是自动获取外部信息,这些信息以 token、向量或数字形式存在,并整合到模型推理中。动作被设计为与大语言模型选择性调用的数据集无关模块,而非硬编码它们的连接。
The significant improvement of CoA is not only showed in experiments on multiple QA datasets, but also is validated from the notable success of the real-world deployment. Upon integration into a Web3 QA application, key metrics including active users and positive feedback volumes increased remarkably within a few months. This performance highlights CoA’s effectiveness in real-world applications.
CoA的显著改进不仅体现在多个问答数据集上的实验结果,还通过实际部署取得的显著成功得到了验证。集成到Web3问答应用后,包括活跃用户数量和正面反馈量在内的关键指标在几个月内显著提升。这一表现凸显了CoA在实际应用中的高效性。
In summary, our main contributions are as follows:
总之,我们的主要贡献如下:
• We present CoA, which integrates a novel reasoningretrieval mechanism to decompose complex questions into reasoning chains of configurable actions via systematic prompting. It can retrieve heterogeneous multimodal information and reduce information conflicts. • We propose three types of ‘Plug-and-Play’ domainadaptable actions to address retrievals for real-time information, domain knowledge, and tabular data. The actions are flexible to incorporate additional sources. • We propose a novel metric, the multi-reference faith score (MRFS), to identify and resolve conflicts between retrieved information and LLM-generated answers, enhancing answer reliability. • Our experimental results demonstrate that our framework surpasses existing methods in public benchmarks.
• 我们提出CoA框架,通过系统性提示将复杂问题分解为可配置动作的推理链,整合了创新的推理-检索机制。该机制能检索异构多模态信息并减少信息冲突。
• 我们设计了三类"即插即用"的领域自适应动作,分别用于实时信息、领域知识和表格数据的检索。这些动作可灵活集成其他数据源。
• 我们提出新指标多参考可信度分数(MRFS),用于识别和解决检索信息与大语言模型生成答案间的冲突,提升答案可靠性。
• 实验结果表明,我们的框架在公开基准测试中优于现有方法。
• Additionally, a real-world application in our Web3 QA product has shown significant user engagement and positive feedback, validating the CoA framework’s effectiveness and practicality in real-world scenarios.
• 此外,我们的 Web3 QA 产品在实际应用中的用户参与度和积极反馈显著,验证了 CoA 框架在真实场景中的有效性和实用性。
2. Methodology
2. 方法论
As shown in Figure 2, we first introduce how to generate the action chain by LLM (Sec. 2.1). Then, the actions address multimodal retrieval demands of the chain’s nodes in three processes: (i) retrieving related information, (ii) verifying whether the LLM-generated answer is good enough or in demand of more information from retrieval, and (iii) checking if the initial answer of each node’s sub-question is missing so that we fill in missing contents with the retrieved information. Finally, we get the final answer by the LLM based on this refined and processed action chain.
如图 2 所示,我们首先介绍如何通过大语言模型生成动作链 (Sec. 2.1)。随后,这些动作通过三个流程处理链节点中的多模态检索需求:(i) 检索相关信息,(ii) 验证大语言模型生成的答案是否足够好或是否需要从检索中获取更多信息,(iii) 检查每个节点子问题的初始答案是否存在缺失,以便用检索到的信息填补缺失内容。最终,我们基于这条经过细化和处理的动作链,通过大语言模型获得最终答案。
2.1. Action Chain Generation
2.1. 动作链生成
We use in-context learning to generate an action chain by LLM. As shown in Figure 2 (a), we design a prompt template to decompose the user’s question into many subquestions, as well as the corresponding Missing Flags (MF) and guess answers shown in Figure 2 (b). Then, we assign one of the actions to solve each sub-question.
我们利用上下文学习 (in-context learning) 通过大语言模型生成动作链。如图 2 (a) 所示,我们设计了一个提示模板,将用户问题分解为多个子问题,以及对应的缺失标志 (Missing Flags, MF) 和猜测答案(如图 2 (b) 所示)。随后,我们为每个子问题分配一个解决动作。
Prompt design. We design a prompt template as shown in Figure 4 starting with "Construct an action reasoning chain for [questions]..." to prompt LLM to generate an Action Chain $A C$ not answer our question $Q$ directly.
提示设计。我们设计了一个提示模板,如图 4 所示,以"为[问题]构建一个行动推理链..."开头,提示大语言模型生成一个行动链 $A C$,而不是直接回答问题 $Q$。
$$
\begin{array}{r l}&{A C_{Q}=(\mathsf{A c t i o n}{1},\mathsf{S u b}{1},\mathsf{M F}{1},\mathsf{A}{1}),}\ &{\qquad\to(\mathsf{A c t i o n}{2},\mathsf{S u b}{2},\mathsf{M F}{2},\mathsf{A}{2}),\ldots,}\ &{\qquad\to(\mathsf{A c t i o n}{n},\mathsf{S u b}{n},\mathsf{M F}{n},\mathsf{A}_{n}).}\end{array}
$$
$$
\begin{array}{r l}&{A C_{Q}=(\mathsf{A c t i o n}{1},\mathsf{S u b}{1},\mathsf{M F}{1},\mathsf{A}{1}),}\ &{\qquad\to(\mathsf{A c t i o n}{2},\mathsf{S u b}{2},\mathsf{M F}{2},\mathsf{A}{2}),\ldots,}\ &{\qquad\to(\mathsf{A c t i o n}{n},\mathsf{S u b}{n},\mathsf{M F}{n},\mathsf{A}_{n}).}\end{array}
$$
Each action node represents four elements, including Acti $\mathsf{o n}{i}$ , the content of the sub-questions $\mathsf{S u b}{i}$ , the missing data flag ${\mathsf{M F}}{i}$ , the guess answer from LLMs $\mathsf{A}_{i}$ , where $i\in{1,\ldots,n}$ . When the inner-knowledge of LLM is enough to answer the sub-questions, LLM generates an initial answer as the value of “guess answer”. Otherwise, the value of "missing flag" becomes “True”, followed by a blank “guess answer”.
每个动作节点包含四个要素:动作 $\mathsf{o n}{i}$、子问题内容 $\mathsf{S u b}{i}$、缺失数据标志 ${\mathsf{M F}}{i}$ 以及大语言模型生成的猜测答案 $\mathsf{A}_{i}$(其中 $i\in{1,\ldots,n}$)。当大语言模型的内部知识足以回答子问题时,会生成初始答案作为"猜测答案"的值;否则,"缺失标志"值变为"True",且"猜测答案"留空。
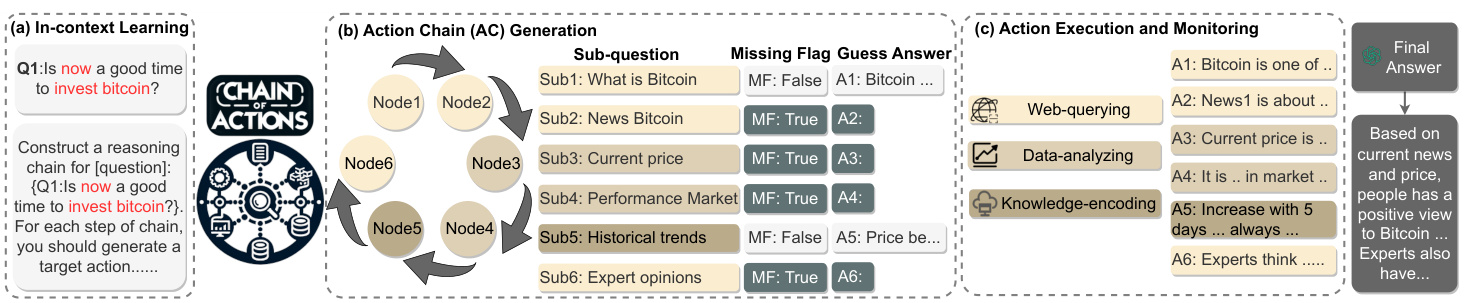
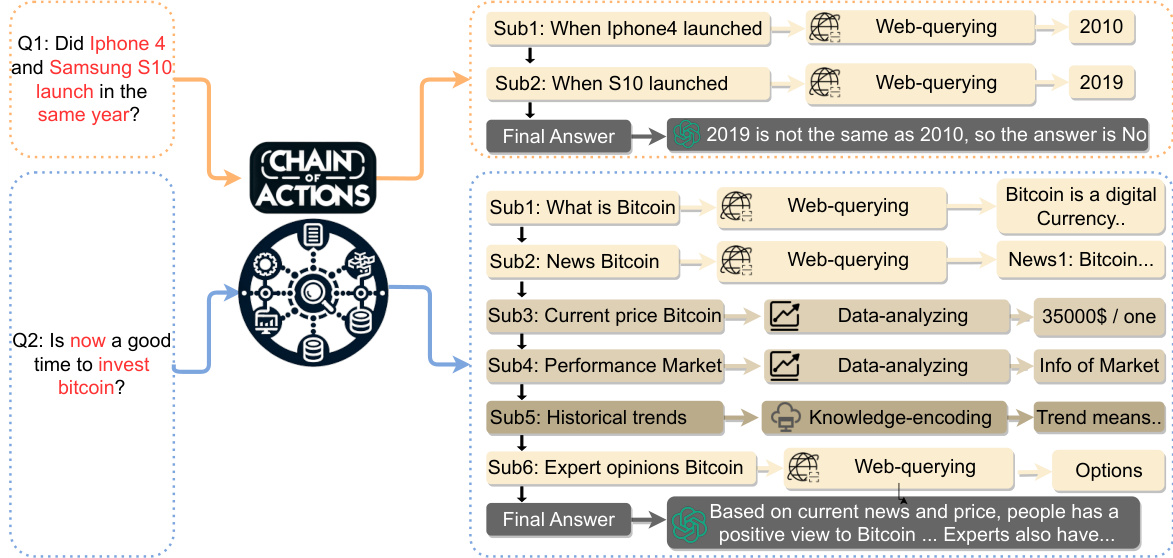
Figure 2. Overview of Chain-of-Action framework. We first use in-context learning to prompt LLM to generate the action chain. The chain has many nodes consisting of sub-questions (Sub), missing flags (MF), and LLM-generated guess answers (A). Then, the actions address multimodal retrieval demands of the nodes in three steps: (i) retrieving related information, (ii) verifying whether the LLM-generated answer needs correction by retrieval, and (iii) checking if we need to fill in missing contents with the retrieved information. Finally, we generate the final answer by the LLM based on the refined and processed action chain. Figure 3. Two samples from our Chain-of-Action Framework.
图 2: Chain-of-Action框架概览。我们首先使用上下文学习提示大语言模型生成动作链。该链条包含多个由子问题(Sub)、缺失标志(MF)和大语言模型生成的推测答案(A)组成的节点。随后,系统通过三个步骤处理节点的多模态检索需求:(i) 检索相关信息,(ii) 验证是否需要通过检索修正大语言模型生成的答案,(iii) 检查是否需要使用检索信息填补缺失内容。最终,大语言模型基于优化处理后的动作链生成最终答案。
图 3: 来自Chain-of-Action框架的两个样本案例。
2.2. Actions Implementation
2.2. 动作实现
We propose three types of actions to address multimodal retrieval demands. Each of them has three working steps: (i) Information Retrieval, (ii) Answering Verification, and (iii) Missing Detection. We first introduce the design of the three actions. Then, we describe the details of the three common steps.
我们提出三种类型的操作来满足多模态检索需求。每种操作都包含三个工作步骤:(i) 信息检索 (Information Retrieval),(ii) 答案验证 (Answering Verification),以及 (iii) 缺失检测 (Missing Detection)。我们首先介绍这三种操作的设计,然后详细说明这三个通用步骤的具体内容。
2.2.1. ACTIONS DESIGN
2.2.1. 动作设计
Action 1: Web-querying. Web-querying action utilizes the existing search engines (e.g., Google Search) and follows our query strategy to get the relevant content from the Internet. In detail, it first searches for the keywords of the given sub-question ${\sf S u b}{n}$ to obtain the result list. If the corresponding "Missing flag" is "True", we choose the top $\boldsymbol{\cdot}\mathbf{k}$ results and extract their contents from their page sources. Otherwise, we combine their titles T and snippets Sn of the top M pages. Then, we transfer each pair of title and snippet ${\mathsf{T}{m},\mathsf{S}\mathsf{n}{m}}$ into a 1536-dimension vector $E m b{\mathsf{T}{m}|\mathsf{S}\mathsf{n}{m}}$ by the embedding model (text-embeddingada-002 from OpenAI (OpenAI, 2023b)). Meanwhile, we also transfer the sub-question and guess answer $ {S u b {n},A{n}} $ into $E m b{\mathsf{S u b}{n}|\mathsf{A}{n}}$ . Next, we calculate the similarity between each $E m b{\mathsf{T}{m}|\mathsf{S}\mathsf{n}{m}}$ and $E m b{\mathsf{S u b}{n}|\mathsf{A}{n}}$ to filter the pages whose similarities are lower than 0.8. Then, we extract the contents of high-similarity pages and calculate the similarity between them and $E m b{\mathsf{S u b}{n}|\mathsf{A}{n}}$ to rank and get the top $\mathbf{\nabla\cdotk}$ final pages. Those contents of the $\mathbf{k}$ final pages are the final information that we retrieve by the action.
动作1:网络查询。网络查询动作利用现有搜索引擎(如Google Search)并遵循我们的查询策略从互联网获取相关内容。具体而言,它首先搜索给定子问题${\sf Sub}{n}$的关键词以获取结果列表。若对应"Missing flag"为"True",则选取前$\boldsymbol{\cdot}\mathbf{k}$个结果并从其页面源码提取内容;否则组合前M个页面的标题T与摘要Sn。接着通过OpenAI的嵌入模型(text-embedding-ada-002 (OpenAI, 2023b))将每对标题和摘要${\mathsf{T}{m},\mathsf{Sn}{m}}$转换为1536维向量$Emb{\mathsf{T}{m}|\mathsf{Sn}{m}}$,同时将子问题与猜测答案$ {Sub{n},A{n}} $转换为$Emb{\mathsf{Sub}{n}|\mathsf{A}{n}}$。随后计算每个$Emb{\mathsf{T}{m}|\mathsf{Sn}{m}}$与$Emb{\mathsf{Sub}{n}|\mathsf{A}{n}}$的相似度,过滤低于0.8的页面。对高相似度页面提取内容后,再次计算其与$Emb{\mathsf{Sub}{n}|\mathsf{A}_{n}}$的相似度进行排序,最终保留前$\mathbf{\nabla\cdot k}$个页面。这$\mathbf{k}$个页面的内容即为通过该动作检索的最终信息。
Action 2: Knowledge-encoding. Knowledge-encoding action utilizes the vector database (e.g., ChromaDB) as data storage to store the domain information and corresponding embedded vectors. For example, we collect web3 domain information from different sources (X, experts’ blogs, white papers, and trending strategies) to support our QA case study. After data collection, we split each document into many chunks based on the length. Then, we encode each chunk of content into an embedded vector and store it in our
行动2: 知识编码。知识编码操作利用向量数据库(如 ChromaDB)作为数据存储,用于存储领域信息及对应的嵌入向量。例如,我们从不同渠道(X平台、专家博客、白皮书和热门策略)收集web3领域信息来支持问答案例研究。数据收集完成后,我们根据长度将每份文档分割成多个文本块,然后将每个内容块编码为嵌入向量并存储至
Construct an action reasoning chain for this complex [Question]: “$ QUESTION $" in JSON format. For each step of the reasoning chain, choose an action from three choices: [Web-querying Engine(search real-time news or new words), Knowledge-encoding Engine (search existing domain information in local knowledge base), Data-analyzing Engine (query real-value data and calculate some results)] as the value of element "Action", and also generate a sub-question for each action to get one of [web-search keywords, needed information description, data features description] as the value of element "Sub". Also, generate an initial answer for each Sub as the value of the element "Guess answer" if you make sure it is correct. In addition, if you cannot answer some sub-questions, make the element “Missing flag” value “False”, otherwise, make it True” You need to try to generate the final answer for the [Question] by referring to the "Action"-"Sub""Guess answer"-"Missing flag" in "Chain", as the value of the element "Final answer". For example:
为该复杂[问题]构建一个动作推理链:"$问题 $",以JSON格式呈现。推理链的每一步需从三个选项中选择一个动作:[网络查询引擎(搜索实时新闻或新词)、知识编码引擎(在本地知识库中检索现有领域信息)、数据分析引擎(查询实值数据并计算结果)]作为"Action"元素的值,同时为每个动作生成一个子问题,以获取[网络搜索关键词、所需信息描述、数据特征描述]之一作为"Sub"元素的值。若确信答案正确,还需为每个"Sub"生成初始答案作为"Guess answer"元素的值。此外,若无法回答某些子问题,则将"Missing flag"元素值设为"False",否则设为"True"。最终需参考"Chain"中的"Action"-"Sub"-"Guess answer"-"Missing flag"生成[问题]的最终答案,作为"Final answer"元素的值。例如:
{"Question":"ls it good to invest in Bitcoin now? A. It is a good time. B. It is not a good time.", "Chain": [ ("Action": “Knowledge-encoding", "Sub": "what is bitcoin","Guess answer": "Bitcoin is one of the crypto currencies.", "Missing flag" : "False"), to YY..", "Missing_ flag" : "False"),
现在投资比特币是明智之举吗?A. 现在是好时机。B. 现在不是好时机。
Figure 4. Prompt to Generate Action Chain in Chain-of-Action (CoA). This template integrates the user’s question along with a description of each available action. The resulting action chain comprises elements such as actions, subs, guess answers and missing flags. This prompt not only decomposes complex questions into multiple sub-questions, guided by the features of the actions but also allows the LLM to answer certain sub-questions using its existing inner-knowledge. This process exemplifies our proposed reasoning-retrieval mechanism.
图 4: Chain-of-Action (CoA) 中生成动作链的提示模板。该模板整合了用户问题及每个可用操作的描述,生成的动作链包含操作项、子问题、推测答案和缺失标记等要素。该提示不仅能根据操作特性将复杂问题分解为多个子问题,还允许大语言模型利用其内部知识直接回答部分子问题。这一过程体现了我们提出的推理-检索机制。
vector database with its index. When we need to execute this engine to retrieve domain information, we could forward the $E m b{\mathsf{S u b}{n}|\mathsf{A}{n}}$ to compute the similarity between the input and each chunk to obtain the top-k results.
带索引的向量数据库。当需要执行该引擎检索领域信息时,可将 $E m b{\mathsf{S u b}{n}|\mathsf{A}{n}}$ 转发以计算输入与每个数据块之间的相似度,从而获取top-k结果。
Action 3: Data-analyzing. Data-analyzing action aims to retrieve the data information from some real-value data sources (e.g., market data of digital currencies). In some special situations, we could directly retrieve the relevant values from our deployed API when some sub-questions demand up-to-date or historical value data. Furthermore, we can also use LLM to compute more sophisticated features by generating Python or SQL codes to execute. It is flexible and compatible with various situations. In this paper, we only design it to retrieve the market data for the Web3 case.
行动3:数据分析。数据分析行动旨在从某些实值数据源(如数字货币市场数据)中检索数据信息。在特定情况下,当子问题需要最新或历史数值数据时,我们可以直接从部署的API中获取相关值。此外,我们还可以利用大语言模型通过生成Python语言或SQL代码来计算更复杂的特征,这种方式灵活且兼容多种场景。本文中,我们仅针对Web3案例设计其用于检索市场数据的功能。
2.2.2. ACTIONS WORKFLOW
2.2.2. 操作流程
In the action chain, the framework executes the actions workflow for each node until it finishes the whole chain, as shown in Algorithm 1.
在动作链中,该框架会为每个节点执行动作工作流,直到完成整个链条,如算法1所示。
Information Retrieval. In the information retrieval stage, we need to find the most relevant and similar contents from different knowledge/data sources. At first, we choose both sub-questions and guess the answer of each node as a query section, $Q S_{n}$ . Then, with the encoding of LLM’s embedding model1, we transfer our query $Q S_{n}={{\sf S u b}{n}|A{n}}$ into a 1536-dimension vector $E m b{Q S_{n}}$ . With this embedded vector, we can perform information retrieval and then rank the results by calculating the similarity. Finally, actions return the top-k results R QS :
信息检索。在信息检索阶段,我们需要从不同知识/数据源中找出最相关且相似的内容。首先,我们选择子问题并猜测每个节点的答案作为查询片段$QS_n$。接着,通过大语言模型的嵌入模型1编码,将查询$QS_n={{\sf Sub}_n|A_n}$转换为1536维向量$Emb{QS_n}$。利用该嵌入向量执行信息检索,并通过相似度计算对结果排序。最终,操作返回前k个结果R_QS:
$$
R_{{Q S}}=(r_{1}\mid r_{2}\mid\ldots\mid r_{k}).
$$
$$
R_{{Q S}}=(r_{1}\mid r_{2}\mid\ldots\mid r_{k}).
$$
Answering Verification. After the information retrieval, we verify the information conflicts between guess answer $A_{n}$ and retrieved facts $R_{{Q S}}$ . Inspired by the ROUGE (Lin,
回答验证。在信息检索后,我们验证猜测答案$A_{n}$与检索到的事实$R_{{Q S}}$之间的信息冲突。受ROUGE (Lin,
2004), we propose a multi-reference faith score, MRFS. To get the MRFS, we compute the pairwise faith score $S$ between a candidate summary and every reference, then take the maximum of faith scores. $S$ is a composite metric computed based on three individual components: Precision (P), Recall (Rcl), and Average Word Length (AWL) in the Candidate Summary. The mathematical representation of the score is given by:
2004年,我们提出了一种多参考可信度评分MRFS。计算MRFS时,我们首先计算候选摘要与每个参考摘要之间的成对可信度得分$S$,然后取这些可信度得分的最大值。$S$是一个基于三个独立指标组合计算的复合指标:精确率(P)、召回率(Rcl)以及候选摘要中的平均词长(AWL)。该得分的数学表达式为:
$$
\begin{array}{r}{\mathbf{S}=\alpha\times P+\beta\times R c l+\gamma\times A W L}\end{array}
$$
$$
\begin{array}{r}{\mathbf{S}=\alpha\times P+\beta\times R c l+\gamma\times A W L}\end{array}
$$
Where:
其中:
• $\alpha,\beta,\gamma$ are weights corresponding to the importance of Precision, Recall, and Average Word Length, respectively. Their values can be adjusted based on specific requirements but should sum up to 1 for normalization purposes.
- $\alpha,\beta,\gamma$ 分别代表精确率 (Precision)、召回率 (Recall) 和平均词长 (Average Word Length) 的权重系数。其数值可根据具体需求调整,但需满足归一化条件 (即三者之和为 1)。
• $_P$ (Precision) is the fraction of relevant instances among the retrieved instances. It is calculated as:
• $_P$ (Precision) 是指在检索出的实例中相关实例所占的比例。计算公式为:
$$
P={\frac{\mathrm{number of relevant items retrieved}}{\mathrm{total number of items~retrieved}}}
$$
$$
P={\frac{\mathrm{number of relevant items retrieved}}{\mathrm{total number of items~retrieved}}}
$$
• Rcl (Recall) is defined as the fraction of relevant instances that were retrieved. It is calculated as:
• Rcl (Recall) 定义为检索到的相关实例所占比例。计算公式为:
$$
R c l=\frac{\mathrm{number of relevant items retrieved}}{\mathrm{total number of relevant~items}}
$$
$$
R c l=\frac{\mathrm{number of relevant items retrieved}}{\mathrm{total number of relevant~items}}
$$
• $\pmb{A W L}$ (Average Word Length in Candidate Summary) represents the mean length of the words present in the summarized content. It is calculated as:
• $\pmb{A W L}$ (候选摘要中的平均词长) 表示摘要内容中单词的平均长度。计算公式为:
$$
A W L={\frac{\mathrm{sum}\mathrm{of}\mathrm{lengths}\mathrm{of}\mathrm{all}\mathrm{words}}{\mathrm{totalnumber}\mathrm{of}\mathrm{words}}}
$$
$$
A W L={\frac{\mathrm{sum}\mathrm{of}\mathrm{lengths}\mathrm{of}\mathrm{all}\mathrm{words}}{\mathrm{totalnumber}\mathrm{of}\mathrm{words}}}
$$
Adjusting the weights $\alpha,\beta,\gamma$ will allow for emphasizing different aspects (Precision, Recall, or Word Length) depending on the specific evaluation criteria or context.
调整权重 $\alpha,\beta,\gamma$ 可根据具体评估标准或上下文强调不同方面(精确率、召回率或词长)。
算法 1: 动作工作流描述
初始化: 动作链 (Actions Chain): AC; 问题 (Question): Q; 大语言模型 (LLM Model): M; 查询部分 (Query Section): QS; 子问题 (Sub-question): Sub; 猜测答案 (Guess Answer): A; 置信分数 (Faith Score): S; 多参考置信分数 (Multi-reference Faith Score): MRFS; 检索结果 (Retrieved Results): R; 缺失标志 (Missing Flag): MF; 输出: 最终生成答案 (Final Generated Answer).
函数 IR(Sub, A, MF):
QSn = 拼接[Subi|Ai];
R = 检索(QSn);
MRFS = argk max S(rk, Ai);
如果 MF == True 则
AC.添加(Sub, r1); //添加 Top-1 数据
结束 如果
如果 MRFS < T 则
AC.修正(Subi, rk);
结束 如果
AC.添加(Sub, r1);
结束 函数
函数 主函数(Q, M):
AC = 链式生成(Q, M);
对于 AC 中的每个 (Subi, Ai, MF) 执行
IR(Sub, A, MF);
结束 对于
最终答案生成(AC, M)
返回 "完成";
结束 函数
After getting the MRFS through:
通过以下方式获取MRFS后:
$$
M R F S=\arg_{k}\operatorname*{max}S(r_{k},A_{i}),
$$
$$
M R F S=\arg_{k}\operatorname*{max}S(r_{k},A_{i}),
$$
we setup a threshold $T$ to decide whether the answer $A_{i}$ is faithful. If MRFS is greater than $\mathrm{\DeltaT}.$ , we keep the answer; otherwise, we change the answer $A_{i}$ to reference contents.
我们设定一个阈值 $T$ 来决定答案 $A_{i}$ 是否可信。如果MRFS大于 $\mathrm{\DeltaT}$ ,则保留该答案;否则,将答案 $A_{i}$ 替换为参考内容。
Missing Detection. The last stage of each action is detecting whether the guess answer $A_{i}$ is complete. When a sub-question needs some special or real-time information, the corresponding guess answer $A_{i}$ could be incomplete with a Missing Flag $M F_{i}$ being "true". If a guess answer’s MF is "True", we inject the retrieved information into the $A_{i}$ to fill in the blank "Guess answer".
缺失检测。每个动作的最后阶段是检测猜测答案$A_{i}$是否完整。当子问题需要某些特殊或实时信息时,对应的猜测答案$A_{i}$可能不完整,此时缺失标志$M F_{i}$为"true"。若某猜测答案的MF为"True",我们会将检索到的信息注入$A_{i}$以填补空白"猜测答案"。
2.3. Final answer generation
2.3. 最终答案生成
After all actions’ executions, we propose a prompt template shown in Figure 5 to integrate all corrected answers and corresponding sub-questions of the AC. Then, it can prompt LLM to refer to the newest retrieved information and generate the final answer starting with "[Final Content]" through the corrected reasoning chain.
在所有动作执行完毕后,我们提出了如图5所示的提示模板,用于整合AC模块的所有修正答案及对应子问题。随后,该模板可引导大语言模型基于最新检索信息,通过修正后的推理链生成以"[Final Content]"开头的最终答案。
Here is the corrected reasoning chain for this complex [Question]: “(how's buying bitcoin]". Each step of the reasoning chain has [Sub-question] and [Solved Answer]. Answer the [Question]: “[how's buying bitcoin}" starting with [Final Content] through the reasoning chain.
以下是针对复杂问题“(how's buying bitcoin]”的修正推理链。推理链的每一步都包含[子问题]和[已解决答案]。通过推理链回答[问题]:“[how's buying bitcoin]”,并以[最终内容]开头。
And its price become more and more high recently [2].Also, there is a lot of news to promote Bitcoin such as...[3].Sothe answerisIt is a good time toinvest inBitcoin now, but you need to consider the risk of investing in crypto currency.
而且最近其价格越来越高[2]。此外,还有很多推动比特币的新闻,例如...[3]。所以答案是现在投资比特币是个好时机,但你需要考虑投资加密货币的风险。
Figure 5. Prompt for final answer generation in CoA. We use the processed chain to prompt LLM to reanswer the user’s question.
图 5: CoA中最终答案生成的提示。我们使用处理后的链式提示让大语言模型重新回答用户的问题。
3. Experiments
3. 实验
In this section, we initially compare the performance of our Chain-of-Action framework with recent state-of-the-art baselines across various public benchmarks, followed by an in-depth analysis of these comparisons. Subsequently, we provide a detailed analysis of our launched case study: a Question Answering (QA) application in the Web3 domain.
在本节中,我们首先将 Chain-of-Action 框架与当前最先进的基线模型在多个公开基准测试中的性能进行对比,随后深入分析这些比较结果。接着,我们对已落地的案例研究——Web3 领域的问答 (QA) 应用进行详细解析。
3.1. Experiments with Benchmarks
3.1. 基准测试实验
Datasets and Evaluation Metric. We select four classic QA tasks that include web-based QA (Web Questions $\mathrm{QA}^{2}$ (WQA)(Berant et al., 2013)), general $\mathrm{QA}^{3}$ (DATE, General Knowledge, Social QA (SoQA)), Truth $\mathrm{QA}^{2}$ (Srivastava et al., 2022), Strategy $\mathrm{QA}^{2}(\mathrm{SQA})$ (Geva et al., 2021), and Fact Checking (FEVER4 (Thorne et al., 2018)).
数据集与评估指标。我们选择了四个经典问答任务,包括基于网络的问答 (Web Questions $\mathrm{QA}^{2}$ (WQA)(Berant et al., 2013))、通用 $\mathrm{QA}^{3}$ (DATE、常识问答、社交问答 (SoQA))、真实性 $\mathrm{QA}^{2}$ (Srivastava et al., 2022)、策略性 $\mathrm{QA}^{2}(\mathrm{SQA})$ (Geva et al., 2021) 以及事实核查 (FEVER4 (Thorne et al., 2018))。
For the evaluation metric, we use cover-EM (Rosset et al., 2020) to represent whether the generated answer contains the ground truth.
在评估指标方面,我们使用 cover-EM (Rosset et al., 2020) 来衡量生成答案是否包含真实答案。
We categorize our baseline methods into two types: the first type focuses on reasoning, prompting LLM to solve complex questions (Few-shot Prompting, Chain-of-Thought (CoT) (Wei et al., 2022), Self Consistency (SC) (Wang et al., 2022), Tree of Thought (ToT) (Yao et al., 2023a), Leastto-Most (Zhou et al., 2022), and Auto-Chain-of-Thought (Auto-CoT) (Zhang et al., 2023)), and the second RetrievalAugmented-Generation (RAG) type that integrates Information Retrieval to enhance reasoning capabilities (ToolFormer (Schick et al., 2023a),Self-Ask (Press et al., 2022), React (Yao et al., 2023b), Search Chain (SeChain) (Xu et al., 2023), and DSP (Khattab et al., 2022)). We conduct a thorough functional comparison between these baseline methods and our Chain-of-Action (CoA), as presented in Table 1.
我们将基线方法分为两类:第一类侧重推理,通过提示大语言模型解决复杂问题(少样本提示 (Few-shot Prompting)、思维链 (Chain-of-Thought, CoT) [20]、自洽性 (Self Consistency, SC) [21]、思维树 (Tree of Thought, ToT) [22]、最少到最多 (Least-to-Most) [23] 和自动思维链 (Auto-Chain-of-Thought, Auto-CoT) [24]);第二类检索增强生成 (Retrieval-Augmented-Generation, RAG) 方法则融合信息检索来增强推理能力(ToolFormer [25]、自问自答 (Self-Ask) [26]、React [27]、搜索链 (Search Chain, SeChain) [28] 和 DSP [29])。我们对这些基线方法与行动链 (Chain-of-Action, CoA) 进行了全面的功能对比,如表 1 所示。
Implementation. Our experimental framework incorporates the data preprocessing techniques of Google’s Bigbench (Srivastava et al., 2022), and Auto-COT (Zhang et al.,
实现。我们的实验框架整合了Google Bigbench (Srivastava et al., 2022) 的数据预处理技术以及Auto-COT (Zhang et al.,
Table 1. The functional comparison of Chain-of-Thought baselines with our method CoA.
表 1. 思维链基线方法与我们的CoA方法功能对比
| 方法 | 少样本 | CoT | SC | ToT | Auto-CoT | Least-to-Most | ToolFormer | Self-Ask | React | DSP | SearchChain | CoA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MultistepReasoning | √ | √ | √ | √ | / | √ | ||||||
| Retrieval | √ | √ | ||||||||||
| Multimodal | 人 | |||||||||||
| Verification | √ |
Table 2. We conduct a comprehensive evaluation of accuracy for six question-answering and one fact-checking dataset. Our study involves the implementation of 11 baseline methods alongside our own Chain-of-Action (CoA) method. We assess the performance of these methods across seven tasks, considering both information retrieval and non-retrieval scenarios. The results averaged over three runs, are presented with variance values omitted $(\mathrm{all}\leq2%)$ ). Our presentation format involves bolding the best results and underlining the second-best results. Our findings highlight the superior performance of CoA, which achieved the highest accuracy in 12 out of 14 test scenarios. Notably, CoA consistently outperforms all baseline methods, even when external memory was not employed, demonstrating its robust and top-tier performance.
表 2: 我们对六个问答数据集和一个事实核查数据集进行了全面的准确性评估。研究实施了11种基线方法以及我们提出的行动链 (Chain-of-Action, CoA) 方法,在包含信息检索与非检索场景的七项任务中评估这些方法的性能。所有结果为三次运行的平均值 (方差均≤2%,故省略)。最佳结果加粗显示,次优结果加下划线标注。实验结果表明CoA在14个测试场景中有12项取得最高准确率,即使在不使用外部记忆的情况下也持续超越所有基线方法,展现出稳健的顶尖性能。
| 方法 | WebQA | DATE | GK | SocialQA | TruthQA | StrategyQA | 事实核查 FEVER |
|---|---|---|---|---|---|---|---|
| 无信息检索 | |||||||
| 零样本 (Zero-shot) | 43.0 | 43.6 | 91.0 | 73.8 | 65.9 | 66.3 | 50.0 |
| 少样本 (Few-shot) | 44.7 | 49.5 | 91.1 | 74.2 | 68.9 | 65.9 | 50.7 |
| CoT (Wei等, 2022) | 42.5 | 43.7 | 88.1 | 71.0 | 66.2 | 65.8 | 40.4 |
| SC (Wang等, 2022) | 36.5 | 50.0 | 87.5 | 60.0 | 66.7 | 70.8 | 53.3 |
| ToT (Ya0等, 2023a) | 32.3 | 47.1 | 85.1 | 68.5 | 66.6 | 43.3 | 41.2 |
| Auto-CoT (Zhang等, 2023) | 42.1 | 52.3 | 89.7 | 59.1 | 61.6 | 65.4 | 32.5 |
| 最少到最多 (Zhou等, 2022) | 44.0 | 42.1 | 80.8 | 68.1 | 59.5 | 65.8 | 43.4 |
| SeChain无IR | 50.8 | 44.7 | 75.0 | 64.9 | 54.1 | 75.6 | 39.2 |
| CoA无行动 | 64.7 | 55.3 | 91.4 | 80.2 | 63.3 | 70.6 | 54.2 |
| 信息检索交互 | |||||||
| ToolFormer (Schick等, 2023a) | 34.5 | 53.9 | 72.3 | 48.1 | 57.5 | 69.4 | 60.2 |
| Self-Ask (Press等, 2022) | 31.1 | 55.1 | 79.7 | 52.1 | 60.5 | 67.7 | 64.2 |
| React (Ya0等, 2023b) | 38.3 | / | 85.1 | 65.8 | 59.9 | 70.4 | 43.9 |
| DSP (Khattab等, 2022) | 59.4 | 48.8 | 85.1 | 68.2 | 58.4 | 72.4 | 62.2 |
| SearchChain (Xu等, 2023) | 65.3 | 51.0 | 87.6 | 69.4 | 61.7 | 77.0 | 65.9 |
| CoA | 70.7 | 57.4 | 98.6 | 83.1 | 67.3 | 79.2 | 68.9 |
| -无验证 | 66.9 | 56.8 | 95.7 | 81.5 | 65.0 | 75.2 | 65.7 |
| -无插补 | 67.4 | 56.3 | 97.1 | 82.9 | 65.8 | 76.5 | 65.3 |
2023). For generating multiple reasoning steps, we employ OpenAI’s gpt-3.5-turbo (OpenAI, 2023a) model accessed via API as our primary LLM. Additionally, to tackle the challenges in controlling response formats with black-box models like gpt-3.5-turbo, we establish an advanced evaluation pipeline utilizing GPT-4 (Bevilacqua et al., 2023).
2023年)。为生成多步推理过程,我们采用通过API调用的OpenAI gpt-3.5-turbo (OpenAI, 2023a) 模型作为核心大语言模型。针对gpt-3.5-turbo等黑盒模型在响应格式控制上的难题,我们基于GPT-4 (Bevilacqua et al., 2023) 构建了高级评估流程。
3.1.1. EXPERIMENTAL ANALYSIS
3.1.1. 实验分析
Our comprehensive evaluation, detailed in Table 2, compares the effectiveness of our CoA framework and eleven baseline methods across six question-answering datasets and one fact-checking dataset. We evaluate the framework’s performance in both information retrieval and non-retrieval scenarios, separately. The sole exception pertains to React, implemented by Langchian (Topsakal & Akinci, 2023). It exhibits an unresponsive behavior in the DATE dataset. As a result, we omit the comparison involving React within the DATE dataset. Our CoA framework demonstrates superior performance metrics in 12 of 14 test scenarios. Our method achieves a significant $3.42%$ improvement in the test tasks without information retrieval compared to the state-of-the-art baseline (Search Chain without IR), and a $6.14%$ increase in the test tasks with information retrieval over its state-of-the-art baseline (Search Chain). This is a significant outcome, as it underscores the effectiveness of our framework. It also demonstrates that CoA is well-suited for various question-answering tasks. In particular, the enhancement in performance is consistent regardless of the integration of IR. This indicates that our framework has intrinsic robustness and comprehensive understanding that is not reliant on external information.
我们在表2中详细展示了全面评估结果,对比了CoA框架与11种基线方法在六个问答数据集和一个事实核查数据集上的表现。我们分别评估了框架在信息检索和非检索场景下的性能。唯一例外是Langchian实现的React (Topsakal & Akinci, 2023),该模型在DATE数据集中出现无响应现象,因此我们排除了React在DATE数据集中的对比。CoA框架在14个测试场景中有12个表现出最优性能指标。在无信息检索的测试任务中,我们的方法比当前最优基线(无IR的Search Chain)显著提升3.42%;在含信息检索的测试任务中,比当前最优基线(Search Chain)提升6.14%。这一重要成果既验证了框架的有效性,也证明CoA能很好地适应各类问答任务。值得注意的是,无论是否集成信息检索,性能提升都保持稳定,这表明我们的框架具有不依赖外部信息的内在鲁棒性和全面理解能力。
In a further analysis detailed in Table 3, we delve into the complexity of reasoning processes in various methods. Our framework exhibits a higher average number of reasoning steps when decomposing complex questions. This metric is vital, highlighting the framework’s capability to engage in a multi-step inference process, a capability that is essential for solving intricate problems that require more than surface-level understanding. The fact that our framework outperforms others in this measure suggests that it can better understand and navigate the layers of complexity within questions, which is a testament to the sophisticated reasoning algorithms it employs.
在表3的进一步分析中,我们深入研究了各种方法的推理过程复杂度。我们的框架在分解复杂问题时展现出更高的平均推理步骤数。这一指标至关重要,凸显了该框架参与多步推理的能力——这种能力对于解决需要超越表层理解的复杂问题不可或缺。我们的框架在该指标上优于其他方法,表明其能更好地理解和驾驭问题中的多层复杂性,这印证了其所采用的先进推理算法。
Additionally, Table 6 explores the average frequency of LLM usage per question. Our framework shows a reduced frequency, reflecting the CoA framework’s efficiency in minimizing LLM usage costs. It is a vital attribute for addressing complex issues with lower expenditure. This aspect suggests that our CoA surpasses others in this respect.
此外,表6探讨了每个问题的LLM平均使用频率。我们的框架显示出更低的频率,反映了CoA框架在最小化LLM使用成本方面的效率。这是以更低支出解决复杂问题的重要特性。这一方面表明我们的CoA在这方面超越了其他方法。
Lastly, Table 4 scrutinizes the methods in terms of their susceptibility to being misled by external knowledge. This is a nuanced aspect of framework evaluation, as it speaks to the framework’s ability to discern relevant from irrelevant information, a nontrivial task in the age of information overload. Our framework emerges as the most resistant to misinformation, maintaining high accuracy even when interfacing with external data sources. This reveals not only the advanced data parsing and filtering capabilities of CoA but also its potential to mitigate the risks associated with the proliferation of false LLM-generated information.
最后,表4详细分析了这些方法在易受外部知识误导方面的表现。这是框架评估中一个微妙的方面,因为它反映了框架区分相关信息与无关信息的能力,在信息过载时代这是一项不简单的任务。我们的框架表现出最强的抗误导性,即使在与外部数据源交互时也能保持高准确度。这不仅揭示了CoA先进的数据解析和过滤能力,也展现了其在降低大语言模型生成虚假信息扩散风险方面的潜力。
In conclusion, the empirical evidence from our assessments presents a compelling case for the superiority of our framework. It excels in understanding and answering complex queries, demonstrates advanced reasoning capabilities, and exhibits resilience against the pitfalls of external misinformation. These findings position our framework as a new benchmark in the realms of question-answering and factchecking, underscoring its comprehensive superiority.
综上所述,我们的评估实证有力证明了该框架的优越性。它在理解和回答复杂查询方面表现卓越,展现出先进的推理能力,并对抗外部错误信息具有显著韧性。这些发现将该框架确立为问答与事实核查领域的新标杆,彰显其全面优势。
Table 3. We conduct a comprehensive analysis of the average number of reasoning steps to demonstrate the intricacy of test tasks. Our study takes place in a non-information retrieval context. The results, obtained through three separate runs, are displayed without including variance values $(\mathrm{all}\leq0.1%)$ ).
表 3: 我们对平均推理步骤数进行全面分析,以展示测试任务的复杂性。研究在非信息检索环境下进行,通过三次独立运行获得结果 (所有方差值均≤0.1%)。
| WQA SQA | SoQA | |
|---|---|---|
| CoT | 2.2 2.1 | 2.4 |
| SC | 2.1 | 2.1 2.8 |
| Auto-CoT | 3.2 | 2.9 3.0 |
| Least-to-Most | 1.2 | 1.2 1.8 |
| Self-Askw/oIR | 2.1 | 2.4 2.9 |
| SeChainw/oIR | 3.4 | 3.7 4.0 |
| CoAw/oActions | 3.9 | 4.1 4.6 |
Table 4. We perform a detailed analysis showing that external knowledge leads LLM astray in solving questions using baseline methods. Our study takes place in a context involving information retrieval tasks. The results, obtained through three separate runs, are displayed without including variance values (all $\leq0.4%$ ).
表 4: 我们通过详细分析表明,在使用基线方法解决问题时,外部知识会导致大语言模型偏离正确方向。本研究在涉及信息检索任务的背景下进行。通过三次独立运行获得的结果展示如下(所有方差值均≤0.4%)。
| WQA | SQA | SoQA | FEVER | |
|---|---|---|---|---|
| Self-Ask | 14.3 | 10.3 | 14.1 | 10.7 |
| React | 16.1 | 10.0 | 15.8 | 11.2 |
| DSP | 13.5 | 9.2 | 14.3 | 10.1 |
| SeChain | 7.2 | 5.3 | 9.4 | 8.5 |
| CoA | 1.9 | 2.6 | 6.1 | 3.4 |
3.2. Case Study with Web3 QA application
3.2. Web3问答应用案例研究
We also apply our framework to develop a QA application in the real-world Web3 domain. Users can ask this QA system up-to-date questions about the Web3 domain. Our system automatically decomposes the user’s question into many subquestions and solves them one by one. In the solving subquestions process, the system considers injecting knowledge from different sources, such as search engines, existing domain knowledge, and even market databases. Figure 6 illustrates our system’s website interface. Despite having a substantial user base and positive user feedback, we rely on expert evaluation to assess our case study and showcase the framework’s real-world performance.
我们还应用该框架开发了一个现实世界Web3领域的问答应用。用户可以向该系统咨询Web3领域的最新问题。我们的系统会自动将用户问题分解为若干子问题并逐一解决。在求解子问题过程中,系统会考虑注入来自不同来源的知识,包括搜索引擎、现有领域知识甚至市场数据库。图6展示了我们系统的网站界面。尽管拥有大量用户基础和积极反馈,我们仍通过专家评估来验证案例研究,展示框架在真实场景中的表现。
Expert Evaluation We design an expert evaluation to assess the quality of explanations and reasoning trajectories. Our experts rate these explanations on a 1 to 3 scale (with 3 being the best) based on several criteria:
专家评估
我们设计了专家评估来衡量解释和推理轨迹的质量。专家们根据以下几个标准对这些解释进行1到3分的评分(3分为最佳):

Figure 6. Example of a Web3 QA application interface. In our application, the agent responds to questions and retrieves relevant information for the response.
图 6: Web3问答应用界面示例。在我们的应用中,AI智能体回答问题并检索响应所需的相关信息。
• Coverage: The explanation and reasoning should cover all essential points important for the factchecking process. • Non-redundancy: The explanation and reasoning should include only relevant information necessary to understand and fact-check the claim, avoiding any unnecessary or repeated details.
• 覆盖性:解释和推理应涵盖事实核查过程中所有关键要点。
• 非冗余性:解释和推理应仅包含理解及核查主张所需的必要信息,避免任何不必要或重复的细节。
Table 5. We conduct an in-depth analysis comparing the various SOTA baselines – ‘React’ (Rt) and ‘Self-Ask’ (SA) – with our CoA method in the Web3 scenario. We evaluate performance based on coverage, non-redundancy, and readability. The results, obtained through three separate runs, are displayed without including variance values (a $11\leq0.4%)$ .
表 5: 我们在Web3场景下对多种SOTA基线方法(包括'React'(Rt)和'Self-Ask'(SA))与我们的CoA方法进行了深入对比分析。评估维度涵盖覆盖率、非冗余性和可读性。结果通过三次独立实验获得(方差值均≤0.4%),表中未显示具体方差数据。
| Rt | SA | DSP | CoA | |
|---|---|---|---|---|
| 覆盖率 | 1.5 | 1.8 | 1.7 | 2.9 |
| 非冗余性 | 2.0 | 1.9 | 2.1 | 2.3 |
| 可读性 | 2.1 | 2.1 | 2.0 | 2.7 |
| 综合得分 | 1.9 | 2.0 | 2.0 | 2.6 |
• Readability: The explanation and reasoning should be clear and easy to read.
• 可读性:解释和推理应清晰易懂。
• Overall Quality: This is a general assessment of the overall quality of the generated explanation and reasoning.
• 整体质量 (Overall Quality): 这是对生成解释和推理整体质量的综合评估。
Table 6. We perform a thorough analysis to compare the average number of interactions with LLM across four datasets. The results, obtained through three separate runs, are displayed without including variance values $(\mathrm{all}\leq0.4%)$ .
表 6: 我们对四个数据集中与大语言模型的平均交互次数进行了全面对比分析。通过三次独立运行获得的结果已展示 (所有方差值均≤0.4%) 。
| WQA | SQA | SoQA | FEVER |
|---|---|---|---|
| Self-Ask | 5.3 5.0 | 5.0 | 5.1 |
| React | 5.2 5.2 | 5.3 | 5.5 |
| SeChain | 6.4 6.7 | 6.0 | 5.6 |
| CoA | 4.0 4.0 | 4.4 | 4.2 |
We design an expert evaluation to assess the quality of explanations and reasoning trajectories. Our experts rate these explanations on a 1 to 3 scale (with 3 being the best) based on several criteria: We randomly sample the 100 questions from real users’ question history and use React, Self-Ask, and our CoA to answer these questions. Table 5 shows the averaged scores of the expert evaluation. The study reveals that CoA outperforms others in expert evaluations, demonstrating its ability to deliver responses that are both more readable and less redundant compared to baseline methods. In summary, these results demonstrate that our framework can get the best performance in the real-world scenario.
我们设计了一项专家评估来衡量解释和推理轨迹的质量。专家们根据以下标准对这些解释进行1到3分的评分(3分为最佳):我们从真实用户的历史问题中随机抽取100个问题,分别使用React、Self-Ask和我们的CoA进行回答。表5展示了专家评估的平均分数。研究表明,CoA在专家评估中表现优于其他方法,相较于基线方法能够提供更具可读性且冗余度更低的回答。综上所述,这些结果表明我们的框架在真实场景中能够取得最佳性能。
4. Related Work
4. 相关工作
We review the literature about prompting methods, agent frameworks, tool learning, and hallucination methods. Owing to page constraints, the contents of tool learning and hallucination methods are relegated to the appendix A.
我们回顾了关于提示方法、AI智能体框架、工具学习和幻觉方法的文献。由于篇幅限制,工具学习和幻觉方法的内容被移至附录A。
Prompting methods. The key to prompting is to lead LLMs’ behavior to follow the instructions. The generic way few-shot prompting (Kaplan et al., 2020) enables incontext learning, guiding LLMs to follow instructions and answer questions with only a few examples. CoT (Wei et al., 2022) and its improved prompting versions (Wang et al., 2022; Saparov & He, 2022) try to lead the LLMs to decompose a complex task into a reasoning chain and get better performance. However, they still only support the text information and can not generate the newest information, which is not included in training data.
提示方法。提示的关键在于引导大语言模型的行为遵循指令。少样本提示的通用方法 (Kaplan et al., 2020) 实现了上下文学习,仅需少量示例就能引导大语言模型遵循指令并回答问题。思维链 (CoT) (Wei et al., 2022) 及其改进的提示版本 (Wang et al., 2022; Saparov & He, 2022) 试图引导大语言模型将复杂任务分解为推理链以获得更好的性能。然而,它们仍仅支持文本信息,无法生成训练数据中未包含的最新信息。
Agent frameworks. Many frameworks aim to expand both the ability and knowledge edges of LLMs. ReAct (Yao et al., 2022) allows LLMs to interact with external tools to retrieve additional information. Self-ask (Press et al., 2022) repeatedly prompts the model to ask follow-up questions to construct the thought process through the search engine. However, these frameworks do not fully harness LLMs intrinsic knowledge to solve any inner question in the answering process. And they also do not consider the conflicts between LLM-generated content and retrieved information. Search-in-the-Chain (Xu et al., 2023) relying on the Dense Passage Retrieval (DPR) tries to verify information in the reasoning chain. However, its processing is so complex and sequential that it costs inevitable LLM usages and causes corresponding high latency. Moreover, it still cannot support multimodal data processing. While Chain-of-Knowledge (Li et al., 2023b) augments LLMs by incorporating grounding information from heterogeneous sources, it highly relies on the fine-tuning of one more LLMs to generate queries sequentially. In addition, it cannot support real-time information. Therefore, we propose a more efficient CoA framework that needs no training cost and supports realtime information. Most importantly, our CoA framework solves sub-questions parallelly, ensuring efficiency.
智能体框架。许多框架致力于扩展大语言模型的能力和知识边界。ReAct (Yao et al., 2022) 使大语言模型能够与外部工具交互以获取额外信息。Self-ask (Press et al., 2022) 通过搜索引擎反复提示模型提出后续问题来构建思维过程。然而这些框架未能充分利用大语言模型的内在知识来解决回答过程中的内部问题,也未考虑大语言模型生成内容与检索信息之间的冲突。基于稠密段落检索 (Dense Passage Retrieval, DPR) 的Search-in-the-Chain (Xu et al., 2023) 尝试验证推理链中的信息,但其处理流程过于复杂且顺序执行,导致不可避免的大语言模型使用开销和相应的高延迟,且不支持多模态数据处理。虽然Chain-of-Knowledge (Li et al., 2023b) 通过整合多源基础信息来增强大语言模型,但其高度依赖额外大语言模型的微调来顺序生成查询,且不支持实时信息。因此,我们提出了一种更高效的CoA框架,无需训练成本且支持实时信息。最重要的是,我们的CoA框架能并行解决子问题,确保效率。
5. Conclusions and Future Work
5. 结论与未来工作
We introduces the Chain-of-Action (CoA) framework, an innovative approach designed to enhance LLMs capabilities in handling complex tasks, particularly in scenarios where real-time or domain-specific information is crucial. We also propose a efficient verification module utlizing our MRFS to correct the LLM-generated answer by retrieved information. This framework addresses two primary challenges: unfaithful hallucination, where the LLM generates information inconsistent with real-world facts, and weak reasoning in complex tasks over multiple information sources.
我们介绍了行动链 (Chain-of-Action, CoA) 框架,这是一种创新方法,旨在增强大语言模型处理复杂任务的能力,尤其是在实时或特定领域信息至关重要的场景中。我们还提出了一种高效的验证模块,利用我们的 MRFS 通过检索信息来修正大语言模型生成的答案。该框架解决了两个主要挑战:不真实的幻觉(即大语言模型生成与现实世界事实不一致的信息)以及在跨多个信息源的复杂任务中推理能力薄弱的问题。
A notable application of CoA is in a Web3 Question Answering product, which demonstrates substantial success in user engagement and satisfaction. It exemplifies the framework’s potential in specialized, real-world domains.
CoA的一个显著应用是在Web3问答产品中,该产品在用户参与度和满意度方面取得了巨大成功。它展示了该框架在专业现实领域中的潜力。
Future work includes explorations on the information extraction and analysis on more data modalities, such as vision data. The ultimate goal is enhance faithfulness and multistep reasoning for real-world question answering where comprehensive analysis must sync with external data.
未来工作包括探索更多数据模态的信息提取与分析,例如视觉数据。最终目标是提升现实世界问答任务中的可信度与多步推理能力,确保综合分析结果与外部数据同步。
Broader Impact
更广泛的影响
Our research methodology can bolster comprehension and problem resolution across numerous areas, including AI research, fostering clearer and more decipherable outcomes. However, this method might simplify intricate problems too much by dividing them into distinct segments, possibly neglecting subtleties and linked components. Moreover, a strong dependence on this approach could curtail innovative problem-solving, since it promotes a sequential and orderly method, which may hinder unconventional thought processes.
我们的研究方法论能够增强对包括AI研究在内的众多领域的理解与问题解决能力,促进更清晰、更易解读的成果。然而,这种方法可能因将复杂问题分割为独立部分而过度简化,从而忽略细节和关联要素。此外,过度依赖该方法可能抑制创新性解题,因为它推崇顺序化和结构化的方式,这可能会阻碍非传统的思维过程。
References
参考文献
Supplementary Material
补充材料
A. Related Work
A. 相关工作
Tool learning. Recently, tool learning combines the strengths of specialized tools and foundation models to achieve enhanced accuracy and efficiency of problem solving (Qin et al., 2023). Toolformer (Schick et al., 2023b) tries to train models to execute APIs for solving problems. Lang2LTL (Liu et al., 2023) utilizes LLM to ground temporal navigational commands to LTL specifications. However, they mainly focus on specific tasks and domains with delicate algorithm designs. (Bubeck et al., 2023) finds that the state-of-the-art methods do not know when they should use tools and when they should simply respond based on their own parametric knowledge. (Qin et al., 2023) also finds that information conflict between Model Knowledge and Augmented Knowledge is a vital challenge to the accuracy and reliability of model generation and planning. Hence, our CoA framework is designed to teach LLMs when to request external help and when to solve tasks by themselves with decreasing information conflicts.
工具学习。近期,工具学习通过结合专用工具与基础模型的优势,实现了问题解决精度与效率的提升 (Qin et al., 2023)。Toolformer (Schick et al., 2023b) 尝试训练模型执行API来解决问题,Lang2LTL (Liu et al., 2023) 则利用大语言模型将时序导航指令映射为LTL规范。但这些方法主要针对特定任务领域,依赖精巧的算法设计。(Bubeck et al., 2023) 发现现有先进方法无法自主判断何时使用工具、何时基于自身参数化知识响应。(Qin et al., 2023) 同时指出,模型知识 (Model Knowledge) 与增强知识 (Augmented Knowledge) 间的信息冲突是影响生成与规划可靠性的关键挑战。因此,我们提出的CoA框架旨在指导大语言模型权衡外部求助与自主决策的时机,从而减少信息冲突。
Hallucination methods. Some work try to solve the hallucination problem by ensemble algorithms (Lai et al., 2024). But they are only based on training process without obtaining the real-time information. Retrieval augmentation and verification are the main approaches for mitigating hallucination (Han et al., 2024). Self-Checker (Li et al., 2023a) comprises many modules including retrieval and veracity prediction for fact-checking by prompting LLMs only. Self Check GP T (Manakul et al., 2023) is a black-box zero-resource hallucination verification scheme, which operates by comparing multiple sampled responses and measuring consistency. However, both methods need lots of interactions with LLMs to be inefficient. This drawback motives us to propose the efficient and effective verification module utilizing our MRFS to decrease the hallucination without lots of interactions with LLMs.
幻觉缓解方法。部分研究尝试通过集成算法解决幻觉问题 (Lai et al., 2024),但这些方法仅基于训练过程而无法获取实时信息。检索增强与验证是缓解幻觉的主要途径 (Han et al., 2024)。Self-Checker (Li et al., 2023a) 包含检索模块和真实性预测模块,仅通过提示大语言模型实现事实核查。Self Check GPT (Manakul et al., 2023) 是一种黑盒零资源幻觉验证方案,通过比较多个采样响应并测量一致性来运作。然而这两种方法都需要与大语言模型进行大量交互,效率低下。这一缺陷促使我们提出基于MRFS的高效验证模块,可在减少与大语言模型交互次数的同时有效降低幻觉。
B. Case Study
B. 案例研究
In this section, we compare the effectiveness of various web3 case solutions, including Chain-of-Actions, Chain-of-Thought, and the ReAct agent, in addressing complex financial questions.
在本节中,我们比较了多种Web3案例解决方案在解决复杂金融问题时的有效性,包括行动链 (Chain-of-Actions)、思维链 (Chain-of-Thought) 以及ReAct智能体。
| (a) 行动链 | (b) 思维链 | (c) ReAct智能体 |
|---|---|---|
| dYdX V4升级对DeFi生态和去中心化交易具有重大意义。以下是关键点总结:2023年10月,该平台已支持更多可交易工具...1 | 根据2022年1月最后更新的知识库,尚无具体信息 | |
| 完全去中心化:迁移至Cosmos和dYdX链..2交易量增长:V4升级后dYdX交易量显著提升...3对DeFi生态影响:通过V4升级从应用转型为应用链...4总之,dYdX V4升级不仅扩展了平台交易能力和规模,更推动了DeFi生态的整体发展与稳定。 | 理解协议:首先全面..审视动机:分析升级背后的原因..需注意重要性评估..要获取dYdX V4最新分析,应参考DeFi社区资源、文章讨论并咨询专家意见 | dYdX V4升级的意义在于强化去中心化特性,实现交易所完全去中心化,并带来交易量增长与dYdX发展机遇。 |
| (b) 思维链 | 现在是买入比特币的好时机吗? | |
| 决策依据... | (c) ReAct智能体 | |
| 代币名称:BTC | ||
| 当前价格:$42426.71 | 第一步:研究并理解比特币 | |
| 市场情绪分析 | 投资比特币前必须充分理解... | |
| 新闻情绪呈现多空交织态势... | 第二步:评估财务状况根据自身财务情况和风险承受能力决策。只投入可承受损失的资金... | 搜索结果提供了比特币现状信息,包括近期新闻和监管动态,但未明确回答是否适合买入。因此最终答案是:我无法判断当前是否适合买入比特币。 |
| 技术分析 | 加密货币可能... | |
| RSI指标当前为38.28,显示BTC尚未进入超卖区间.. | ||
| 第八步:持续跟踪随时关注加密货币市场并调整策略。 | ||
| 市场条件可能快速变化。 | ||
| 建议与交易策略 | ||
| 鉴于当前看跌指标和市场情绪,建议空头持仓... |
Figure 7. Case studies 1 and 2. Case 1 involves a question that necessitates up-to-date information. Our Chain-of-Actions (CoA) framework efficiently gathers domain knowledge about dYdX and the associated upgrade documentation from the web, subsequently synthesizing this information into a definitive answer. Conversely, the Chain-of-Thought (CoT) approach solely offers guidance on reading the white paper, lacking the capability to access real-time data. The ReAct agent, while successful in locating relevant content via search engines, offers only a broad overview, falling short of providing detailed insights. In case 2, our CoA stands out for providing real-time market price and technical analysis, offering multi-dimensional market insights through a combination of sentiment analysis and technical indicators such as RSI, along with specific trading strategy recommendations, which are invaluable for investors seeking actionable advice. In contrast, the CoT lacks integration of real-time data, focusing more on the decision-making process rather than immediate market actions, while the ReAct, despite aggregating relevant information, falls short by not offering specific guidance and failing to provide a clear conclusion.
图 7: 案例研究 1 和 2。案例 1 涉及需要最新信息的问题。我们的行动链 (CoA) 框架能高效地从网络收集关于 dYdX 及相关升级文档的领域知识,随后将这些信息综合成明确答案。相比之下,思维链 (CoT) 方法仅提供阅读白皮书的指导,缺乏获取实时数据的能力。ReAct 智能体虽然能通过搜索引擎成功定位相关内容,但只给出宽泛概述,未能提供详细见解。在案例 2 中,我们的 CoA 因提供实时市场价格和技术分析而表现突出,通过结合情绪分析和技术指标 (如 RSI) 提供多维市场洞察,并给出具体交易策略建议,这对寻求可操作建议的投资者极具价值。反观 CoT 缺乏实时数据整合,更关注决策过程而非即时市场行动;而 ReAct 尽管汇总了相关信息,却因未提供具体指导和明确结论而存在不足。

Figure 8. Case study 3 and 4. In case 3, our CoA for DOGE provides a comprehensive snapshot by analyzing current market sentiment, which is predominantly positive, and technical indicators like the RSI, which is neutral at 40.66. The recommendation takes into account both these aspects, suggesting caution due to the bearish technical indicators despite the positive sentiment, which is a nuanced approach for traders considering DOGE transactions. However, the CoT and ReAct fall short by not providing specific or updated information, offering general investment advice, and emphasizing personal research and judgment instead of actionable insights. For case 4, the Bitcoin price drop case, our CoA gives a detailed account of factors leading to the price decline, including selling pressure post-ETF approval and temporary profit-taking by investors. It presents a clear narrative of events contributing to the drop, showing a deep dive into the cause-and-effect within the market. The ReAct, on the other hand, acknowledges the lack of clear reasons for the price drop and suggests a variety of possible influences, such as market conditions and investor sentiment, highlighting the complexity and multifaceted nature of crypto currency markets but not providing a definitive explanation.
图 8: 案例研究3和4。在案例3中,我们针对DOGE的CoA通过分析当前市场情绪(以看涨为主)及RSI等技术指标(中性值40.66)提供了全面快照。该建议综合考量这两个维度,指出尽管情绪面积极,但技术指标看跌,建议交易者采取谨慎态度,为考虑DOGE交易的用户提供了细致入微的决策依据。相比之下,CoT和ReAct仅提供笼统投资建议,既未给出具体更新信息,也未提供可操作见解,而是强调个人研究与判断。在案例4的比特币价格下跌分析中,我们的CoA详细列举了导致下跌的因素,包括ETF获批后的抛压和投资者暂时获利了结行为,清晰梳理了市场因果链条。而ReAct仅承认价格下跌缺乏明确原因,罗列市场环境、投资者情绪等潜在影响因素,虽凸显加密货币市场的复杂多变性,但未能给出确定性解释。
| (a) 行动链 | (b) 思考链 | (c) ReAct智能体 |
|---|---|---|
| 为何Kinza Finance比其他借贷协议更稳定? | ||
| Kinza Finance因其多项关键差异化因素成为稳定的借贷协议: | ||
| 安全措施:Kinza Finance采用领先的安全标准,包括频繁审计、漏洞赏金计划... | 根据我2022年1月的最新知识更新,我不了解Kinza Finance的具体情况或相关进展,因此无法提供其稳定性或与其他借贷协议的比较信息。 | 根据收集的信息,Kinza Finance因其安全措施、高级安全功能、内置机制与奖励以及创新的代币经济,被认为比其他借贷协议更稳定。 |
| 经验丰富的领导团队:该平台由来自知名机构的资深团队领导... | 但一般而言,借贷协议的稳定性取决于多种因素,包括: | 它还提供竞争优势,吸引投资者和贷款人,改善财务表现并建立客户忠诚度。不过,关于Kinza Finance相比其他借贷协议稳定性的具体细节仍需进一步了解。 |
| 什么是自治世界 (Autonomous World)? | (b) 思考链 | (c) ReAct智能体 |
| (a) 行动链 "自治世界"一词指虚拟环境和游戏化的区块链网络特性。这些自治世界... | ||
| 关于自治世界需注意的要点包括:定义:自治世界指虚拟环境...特性:自治世界旨在为用户提供无与伦比的控制...解决的挑战:自治世界的概念解决了... | 具体含义取决于使用语境。不过我可以提供该术语相关的一般性解释和可能性: | 根据搜索结果,自治世界指虚拟环境的概念。此外,已有组织和公司致力于探索和推进自治世界的潜力。最终答案:自治世界 |
Figure 9. Case study 5 and 6. In case 5, our CoA for Kinza Finance highlights its stability as a lending protocol, detailing its robust security measures, experienced leadership, and strategic partnerships. This comprehensive approach emphasizes the unique strengths that contribute to Kinza’s stability and resilience in the market. On the contrary, the CoT lacks current updates on Kinza, providing only general factors that affect lending protocol stability, while the ReAct, although it gathers relevant information, only partially addresses why Kinza might be more stable, pointing to security measures and token economy without a thorough analysis. For case 6, in discussing Autonomous World, our CoA provides a clear definition and outlines the impact of such virtual environments on gaming and blockchain technology, citing features, challenges, and the potential for revolutionizing digital interaction. This detailed overview presents a forward-looking view of the integration of blockchain in gaming. However the CoT, with its last update in January 2022, does not offer a precise definition, indicating that the concept can vary widely. Similarly, the ReAct retrieves general information but lacks a focused perspective on the practical implications and future possibilities of Autonomous Worlds.
图 9: 案例研究5和6。在案例5中,我们为Kinza Finance撰写的链上分析(CoA)重点突出了其作为借贷协议的稳定性,详细阐述了其强大的安全措施、经验丰富的领导团队以及战略合作伙伴关系。这种全面分析强调了Kinza在市场中保持稳定性和韧性的独特优势。相比之下,链上推特(CoT)缺乏关于Kinza的最新动态,仅提供影响借贷协议稳定性的一般性因素;而反应式分析(ReAct)虽然收集了相关信息,但仅部分说明了Kinza可能更稳定的原因,指出了安全措施和代币经济机制,但缺乏深入分析。在案例6中,关于自治世界(Autonomous World)的讨论,我们的CoA给出了明确定义,并概述了此类虚拟环境对游戏和区块链技术的影响,列举了其特征、挑战以及革新数字交互的潜力。这一详细概述呈现了区块链与游戏融合的前瞻性视角。然而CoT的最后更新停留在2022年1月,未能提供准确定义,仅表明该概念可能存在广泛差异。同样地,ReAct检索到的是一般性信息,缺乏对自治世界实际应用及未来可能性的聚焦视角。
C. System
C. 系统
All experiments are carried out on a cluster, with the exception of the distributed compute node experiment. Each node within the cluster is equipped with 1 NVIDIA GEFORCE RTX 2080 Ti GPUs and 6 8-core Intel XEON Silver 4214 processors running at 2.20GHz. The combined RAM capacity across the cluster nodes amounts to 755GB, and the operating system employed is Ubuntu 18.04.
除分布式计算节点实验外,所有实验均在集群上完成。集群中每个节点配置如下:1块NVIDIA GEFORCE RTX 2080 Ti显卡、6颗主频2.20GHz的8核Intel XEON Silver 4214处理器。集群节点总内存容量为755GB,操作系统采用Ubuntu 18.04。
D. Hyper parameter
D. 超参数 (Hyperparameter)
In our experiment, we exclusively require the hyper parameters for LLM, with the exception of Auto-CoT. For the Auto-CoT method, we utilize the KNN model for clustering. Below, we provide a list of all the hyper parameters used in our experiments.
在我们的实验中,除了 Auto-CoT 方法外,我们仅需为大语言模型 (LLM) 配置超参数。对于 Auto-CoT 方法,我们采用 KNN 模型进行聚类。下方列出了实验涉及的所有超参数列表。
Table 7. Hyper parameter used in the task.
表 7. 任务中使用的超参数。
| 参数 | 值 |
|---|---|
| temperature | 0.0 |
| max_length | 1000 |
| top_p | 1.0 |
| n_clusters | 5 |
| retrieval_number | 3 |
| seed | 1 |