Neural Extractive Sum mari z ation with Hierarchical Attentive Heterogeneous Graph Network
基于分层注意力异质图网络的神经抽取式摘要生成
Abstract
摘要
Sentence-level extractive text sum mari z ation is substantially a node classification task of network mining, adhering to the informative components and concise representations. There are lots of redundant phrases between extracted sentences, but it is difficult to model them exactly by the general supervised methods. Previous sentence encoders, especially BERT, specialize in modeling the relationship between source sentences. While, they have no ability to consider the overlaps of the target selected summary, and there are inherent dependencies among target labels of sentences. In this paper, we propose HAHSum (as shorthand for Hierarchical Attentive Heterogeneous Graph for Text Sum mari z ation), which well models different levels of information, includ- ing words and sentences, and spotlights redundancy dependencies between sentences. Our approach iterative ly refines the sentence representations with redundancy-aware graph and delivers the label dependencies by message passing. Experiments on large scale benchmark corpus (CNN/DM, NYT, and NEWSROOM) demonstrate that HAHSum yields ground-breaking performance and outperforms previous extractive summarize rs.
句子级抽取式文本摘要本质上是一种网络挖掘中的节点分类任务,需兼顾信息丰富性与表达简洁性。被抽取的句子间存在大量冗余短语,但通用监督方法难以精确建模这种现象。现有句子编码器(尤其是BERT)擅长建模源句子间关系,却无法考虑目标摘要的选句重叠问题,而句子目标标签间存在固有依赖性。本文提出HAHSum(层次化注意力异质图文本摘要的简称),该模型能有效建模词级和句级等多层次信息,并聚焦句子间的冗余依赖关系。我们的方法通过冗余感知图迭代优化句子表征,并借助消息传递机制捕捉标签依赖。在大规模基准语料(CNN/DM、NYT和NEWSROOM)上的实验表明,HAHSum实现了突破性性能,显著优于现有抽取式摘要器。
1 Introduction
1 引言
Single document extractive sum mari z ation aims to select subset sentences and assemble them as informative and concise summaries. Recent advances (Nallapati et al., 2017; Zhou et al., 2018; Liu and Lapata, 2019; Zhong et al., 2020) focus on balancing the salience and redundancy of sentences, i.e. selecting the sentences with high semantic similarity to the gold summary and resolving the redundancy between selected sentences. Taking Table
单文档抽取式摘要旨在选取部分句子并将其组合成信息丰富且简洁的摘要。最新研究进展 (Nallapati et al., 2017; Zhou et al., 2018; Liu and Lapata, 2019; Zhong et al., 2020) 聚焦于平衡句子的显著性与冗余性,即选择与黄金摘要具有高语义相似度的句子,并解决所选句子间的冗余问题。以表
Salience Label Sentence Table 1: Simplified News from Jackson County Prosecutor. Salience score is an approximate estimation derived from semantic and Label is converted from gold summary to ensure the concision and accuracy of the extracted summaries.
表 1: 杰克逊县检察官简讯。显著度分数是基于语义的近似估计,标签由黄金摘要转换而来,以确保提取摘要的简洁性和准确性。
| 句子 | 标签 | 内容 |
|---|---|---|
| sent1:0.7 | 0 | Deanna Holleranis被控谋杀 |
| sent2:0.1 | 0 | 杰克逊县检察官Jean Peters Baker今日宣布 |
| sent3:0.7 | Deanna Holleran面临交通事故指控 | |
| sent4:0.7 | 这起致命交通事故构成谋杀 | |
| sent5:0.2 | 0 | 事故导致Marianna Hernandez在9th Hardesty附近丧生 |
| 摘要: | 一名女子因致命交通事故面临谋杀指控 |
1 for example, there are five sentences in a document, and each of them is assigned one salience score and one label indicating whether this sentence should be contained in the extracted summary. Although sent1, sent3, and sent4 are assigned high salience score, just sent3 and sent4 are selected as the summary sentences (with label 1) because there are too much redundancy information between unselected sent1 and selected sent3. That is to say, whether one sentence could be selected depends on its salience and the redundancy with other selected sentences. However, it is still difficult to model the dependency exactly.
例如,一个文档中有五句话,每句话都被分配了一个显著性分数和一个标签,表明该句子是否应包含在提取的摘要中。虽然 sent1、sent3 和 sent4 被分配了较高的显著性分数,但只有 sent3 和 sent4 被选为摘要句子(标签为1),因为未选中的 sent1 与已选中的 sent3 之间存在过多冗余信息。也就是说,一个句子能否被选中取决于其显著性以及与其他已选句子的冗余程度。然而,要精确建模这种依赖关系仍然很困难。
Most of the previous approaches utilize autoregressive architecture (Narayan et al., 2018; Mendes et al., 2019; Liu and Lapata, 2019; Xu et al., 2020), which just models the unidirectional dependency between sentences, i.e., the state of the current sentence is based on previously sentence labels. These models are trained to predict the current sentence label given the ground truth labels of the previous sentences, while feeding the predicted labels of the previous sentences as input in inference phase. As we all know, the auto regressive paradigm faces error propagation and exposure bias problems (Ranzato et al., 2015). Besides, reinforcement learning is also introduced to consider the semantics of extracted summary (Narayan et al., 2018; Bae et al.,
先前的大多数方法采用自回归架构 (Narayan et al., 2018; Mendes et al., 2019; Liu and Lapata, 2019; Xu et al., 2020) ,仅建模句子间的单向依赖关系,即当前句子的状态基于先前句子的标签。这些模型在训练时基于前文句子的真实标签预测当前句子标签,而在推理阶段则以前文句子的预测标签作为输入。众所周知,自回归范式面临误差传播和曝光偏差问题 (Ranzato et al., 2015) 。此外,也有研究引入强化学习来考量提取摘要的语义 (Narayan et al., 2018; Bae et al.,
2019), which combines the maximum-likelihood cross-entropy loss with the rewards from policy gradient to directly optimize the evaluation metric for the sum mari z ation task. Recently, the popular solution is to build a sum mari z ation system with two-stage decoder. These models extract salient sentences and then rewrite (Chen and Bansal, 2018; Bae et al., 2019), compress (Lebanoff et al., 2019; Xu and Durrett, 2019; Mendes et al., 2019), or match (Zhong et al., 2020) these sentences.
2019年),该方法将最大似然交叉熵损失与策略梯度的奖励相结合,直接优化摘要任务的评估指标。近期的主流解决方案是构建两阶段解码器的摘要系统。这些模型先提取关键句子,再进行改写 (Chen and Bansal, 2018; Bae et al., 2019)、压缩 (Lebanoff et al., 2019; Xu and Durrett, 2019; Mendes et al., 2019) 或匹配 (Zhong et al., 2020) 操作。
Previous models generally use top $k$ strategy as an optimal strategy: for different documents, the number of selected sentences is constant which conflicts with the real world. For example, almost all previous approaches extract three sentences from the source articles (top-3 strategy (Zhou et al., 2018; Liu and Lapata, 2019; Zhang et al., 2019b; Xu et al., 2020)), although $40%$ documents in CNN/DM contain more or less than 3-sentences oracle summary. That’s because these approaches are difficult to measure the salience and redundancy simultaneously with error propagation. Notably, Mendes et al. (2019) introduces the length variable into the decoder and Zhong et al. (2020) can choose any number of sentences by match candidate summary in semantic space.
先前模型通常采用 top $k$ 策略作为最优策略:对不同文档选取固定数量的句子,这与现实场景存在矛盾。例如,现有方法大多从源文章中抽取三句话(top-3策略 (Zhou et al., 2018; Liu and Lapata, 2019; Zhang et al., 2019b; Xu et al., 2020)),但CNN/DM数据集中 $40%$ 文档的理想摘要句子数并非3句。这是因为这些方法难以同时衡量显著性与冗余度,且存在误差传播问题。值得注意的是,Mendes et al. (2019) 在解码器中引入长度变量,Zhong et al. (2020) 则通过语义空间匹配候选摘要实现任意数量句子的选择。
In order to address above issues, we construct the source article as a hierarchical heterogeneous graph (HHG) and propose a Graph Attention Net (Velickovic et al., 2018) based model (HAHSum) to extract sentences by simultaneously balancing salience and redundancy. In HHG, both words and sentences are constructed as nodes, the relations between them are constructed as different types of edges. This hierarchical graph can be viewed as a two-level graph: word-level and sentencelevel. For word-level graph (word-word), we design an Abstract Layer to learn the semantic represent ation of each word. Then, we transduce the word-level graph into the sentence-level one, by aggregating each word to its corresponding sentence node. For sentence-level graph (sentencesentence), we design a Redundancy Layer, which firstly pre-labels each sentence and iterative ly updates the label dependencies by propagating redundancy information. The redundancy layer restricts the scale of receptive field for redundancy information, and the information passing is guided by the ground-truth labels of sentences. After obtaining the redundancy-aware sentence representations, we use a classifier to label these sentence-level nodes with a threshold. In this way, the whole framework extracts summary sentences simultaneously instead of auto regressive paradigm, taking away the top $k$ strategy.
为了解决上述问题,我们将源文章构建为分层异构图 (HHG),并提出一种基于图注意力网络 (Velickovic et al., 2018) 的模型 (HAHSum),通过同时平衡显著性和冗余性来提取句子。在 HHG 中,单词和句子都被构建为节点,它们之间的关系被构建为不同类型的边。这种分层图可以看作是一个两级图:单词级和句子级。对于单词级图 (word-word),我们设计了一个抽象层来学习每个单词的语义表示。然后,通过将每个单词聚合到其对应的句子节点,我们将单词级图转换为句子级图。对于句子级图 (sentence-sentence),我们设计了一个冗余层,该层首先对每个句子进行预标注,并通过传播冗余信息迭代更新标签依赖关系。冗余层限制了冗余信息的感受野范围,信息传递由句子的真实标签引导。在获得冗余感知的句子表示后,我们使用分类器以阈值对这些句子级节点进行标注。这样,整个框架同时提取摘要句子,而不是采用自回归范式,移除了 top $k$ 策略。
The contributions of this paper are as below: 1) We propose a hierarchical attentive heterogeneous graph based model(HAHSum) to guide the redundancy information propagating between sentences and learn redundancy-aware sentence represent ation; 2) Our architecture is able to extract flexible quantity of sentences with a threshold, instead of top $k$ strategy; 3) We evaluate HAHSum on three popular benchmarks (CNN/DM, NYT, NEWSROOM) and experimental results show that HAHSum outperforms the existing state-of-the-art approaches. Our source code will be available on Github 1.
本文的贡献如下: 1) 我们提出了一种基于分层注意力异构图(HAHSum)的模型,用于指导句子间的冗余信息传播并学习冗余感知的句子表示; 2) 我们的架构能够通过阈值提取灵活数量的句子,而非传统的top $k$策略; 3) 我们在三个主流基准数据集(CNN/DM、NYT、NEWSROOM)上评估HAHSum,实验结果表明HAHSum优于现有的最先进方法。我们的源代码将在Github 1上公开。
2 Related Work
2 相关工作
2.1 Extractive Sum mari z ation
2.1 抽取式摘要
Neural networks have achieved great success in the task of text sum mari z ation. There are two main lines of research: abstract ive and extractive. The abstract ive paradigm (Rush et al., 2015; See et al., 2017; Celikyilmaz et al., 2018; Sharma et al., 2019) focuses on generating a summary word-by-word after encoding the full document. The extractive approach (Cheng and Lapata, 2016; Zhou et al., 2018; Narayan et al., 2018) directly selects sentences from the document to assemble into a summary.
神经网络在文本摘要任务中取得了巨大成功。现有研究主要分为两大方向:生成式 (abstractive) 和抽取式 (extractive)。生成式方法 (Rush et al., 2015; See et al., 2017; Celikyilmaz et al., 2018; Sharma et al., 2019) 通过对全文编码后逐词生成摘要,而抽取式方法 (Cheng and Lapata, 2016; Zhou et al., 2018; Narayan et al., 2018) 则直接从原文中选取句子组合成摘要。
Recent research work on extractive summarization spans a large range of approaches. These work usually instantiate their encoder-decoder architecture by choosing RNN (Nallapati et al., 2017; Zhou et al., 2018), Transformer (Wang et al., 2019; Zhong et al., 2019b; Liu and Lapata, 2019; Zhang et al., 2019b) or Hierarchical GNN (Wang et al., 2020) as encoder, auto regressive (Jadhav and Rajan, 2018; Liu and Lapata, 2019) or nonauto regressive (Narayan et al., 2018; Arumae and Liu, 2018) decoders. The application of RL provides a means of summary-level scoring and brings improvement (Narayan et al., 2018; Bae et al., 2019).
近期关于抽取式摘要的研究工作涵盖了多种方法。这些工作通常通过选择RNN (Nallapati et al., 2017; Zhou et al., 2018)、Transformer (Wang et al., 2019; Zhong et al., 2019b; Liu and Lapata, 2019; Zhang et al., 2019b)或层次图神经网络 (Wang et al., 2020)作为编码器,以及自回归 (Jadhav and Rajan, 2018; Liu and Lapata, 2019)或非自回归 (Narayan et al., 2018; Arumae and Liu, 2018)解码器来实例化其编码器-解码器架构。强化学习的应用为摘要级评分提供了方法并带来了改进 (Narayan et al., 2018; Bae et al., 2019)。
2.2 Graph Neural Network for NLP
2.2 用于自然语言处理的图神经网络 (Graph Neural Network)
Recently, there is considerable amount of interest in applying GNN to NLP tasks and great success has been achieved. Fernandes et al. (2019) applied sequence GNN to model the sentences with named entity information. Yao et al. (2019) used twolayer GCN for text classification and introduced a well-designed adjacency matrix. GCN also played an important role in Chinese named entity (Ding et al., 2019). Liu et al. (2019) proposed a new contextual i zed neural network for sequence learning by leveraging various types of non-local contextual information in the form of information passing over GNN. These studies are related to our work in the sense that we explore extractive text summarization by message passing through hierarchical heterogeneous architecture.
最近,将图神经网络 (GNN) 应用于自然语言处理 (NLP) 任务引起了广泛关注,并取得了巨大成功。Fernandes 等人 (2019) 应用序列 GNN 对带有命名实体信息的句子进行建模。Yao 等人 (2019) 使用双层 GCN (Graph Convolutional Network) 进行文本分类,并引入了一个精心设计的邻接矩阵。GCN 在中文命名实体识别中也发挥了重要作用 (Ding 等人, 2019)。Liu 等人 (2019) 提出了一种新的上下文感知神经网络,通过利用 GNN 上信息传递形式的多种非局部上下文信息进行序列学习。这些研究与我们的工作相关,因为我们探索了通过层次化异构架构的消息传递进行抽取式文本摘要。
3 Methodology
3 方法论
3.1 Problem Definition
3.1 问题定义
Let ${\cal{S}}={s_{1},s_{2},...,s_{N}}$ denotes the source document sequence which contains $N$ sentences, where $s_{i}$ is the $i$ -th sentence of document. Let $T$ denotes the hand-crafted summary. Extractive sum mari z ation aims to produce summary $S^{*}=$ ${s_{1}^{*},s_{2}^{*},...,s_{M}^{*}}$ by selecting $M$ sentences from $S$ where $M\leq N$ . Labels $Y={y_{1},y_{2},...,y_{N}}$ are derived from $T$ , where $y_{i}\in{0,1}$ denotes whether sentence $s_{i}$ should be included in the extracted summary. Oracle summary is a subset of $S$ , which achieves the highest ROUGE score calculated with $T$ .
设 ${\cal{S}}={s_{1},s_{2},...,s_{N}}$ 表示包含 $N$ 个句子的源文档序列,其中 $s_{i}$ 是文档的第 $i$ 个句子。设 $T$ 表示人工撰写的摘要。抽取式摘要旨在通过从 $S$ 中选择 $M$ 个句子(其中 $M\leq N$)生成摘要 $S^{*}={s_{1}^{*},s_{2}^{*},...,s_{M}^{*}}$。标签 $Y={y_{1},y_{2},...,y_{N}}$ 由 $T$ 导出,其中 $y_{i}\in{0,1}$ 表示句子 $s_{i}$ 是否应被包含在抽取的摘要中。Oracle摘要是 $S$ 的一个子集,其与 $T$ 计算的ROUGE分数达到最高。
3.2 Graph Construction
3.2 图构建
In order to model the redundancy relation between sentences, we use a heterogeneous graph which contains multi-granularity levels of information to represent a document, as shown in Figure 1. In this graph, there are three types of nodes: named entity, word, and sentence. To reduce semantic sparsity, we replace text spans of Named Entity by anonymized tokens (e.g. [Person A], [Person B], [Date A]). Word node is the original textual item, representing word-level information. Different from Div Graph Pointer (Sun et al., 2019), which aggregates identical words into one node, we keep each word occurrence as one node to avoid the confusion of different contexts. Each Sentence node corresponds to one sentence and represents the global information of one sentence.
为了建模句子间的冗余关系,我们使用包含多粒度信息的异构图来表示文档,如图1所示。该图包含三种节点类型:命名实体、词语和句子。为降低语义稀疏性,我们将命名实体的文本片段替换为匿名化token(例如 [Person A], [Person B], [Date A])。词语节点是原始文本项,代表词级信息。与Div Graph Pointer (Sun et al., 2019) 将相同词语聚合为单一节点不同,我们保留每个词语出现实例作为独立节点以避免不同上下文的混淆。每个句子节点对应一个句子并表征该句子的全局信息。
We also define four types of edges to represent various structural information in HAHSum:
我们还定义了四种边类型来表示HAHSum中的各种结构信息:
- We connect sequential named entities and words in one sentence using directed Next edges.
- 我们使用有向Next边连接同一句子中的连续命名实体和单词。
The topological structure of graph can be represented by adjacency matrix $A$ , where the booltype element is indicating whether there is an edge between nodes. Because HAHsum contains multi-granularity levels of information, it can be divided into three subgraphs: the word-level, wordsentence, and sentence-level subgraph. So, we define three adjacency matrices: $A_{w o r d}$ is used for the word-level graph, constructed by Entity node, Word node, Next edge and Same edge. $A_{w o r d-s e n t}$ is used for the word-sentence graph, constructed by three types of nodes and In edge. $A_{s e n t}$ is used for sentence-level graph, constructed by Sentence node and Similar edge. By propagating the information from word-level to sentence-level graph, we can obtain the sentence representation and model the redundancy between sentences.
图的拓扑结构可以用邻接矩阵 $A$ 表示,其中布尔型元素表示节点间是否存在边。由于HAHsum包含多粒度信息,可划分为三个子图:词级子图、词句子图和句级子图。因此我们定义三个邻接矩阵:$A_{word}$ 用于词级图,由实体节点、词节点、Next边和Same边构成;$A_{word-sent}$ 用于词句子图,由三类节点和In边构成;$A_{sent}$ 用于句级图,由句子节点和Similar边构成。通过将信息从词级图传播至句级图,我们可以获得句子表示并建模句子间的冗余性。
Generally, the message passing over graphs can be achieved in two steps: aggregation and combination, and this process can be conducted multiple times (referred as layers or hops in GNN literature) (Tu et al., 2019). Therefore, we iterative ly update the sentence nodes representation with redundancy message passing which will be described in the following sections.
通常,图上的消息传递可以通过两个步骤实现:聚合和组合,这一过程可以进行多次(在GNN文献中称为层或跳) (Tu et al., 2019)。因此,我们通过冗余消息传递迭代更新句子节点表示,具体方法将在后续章节中描述。
3.3 Graph Attention Network
3.3 图注意力网络 (Graph Attention Network)
To represent graph structure $A$ and node content $X$ in a unified framework, we develop a variant of Graph Attention Network (GAT) (Velickovic et al., 2018). GAT is used to learn hidden representations of each node by aggregating the information from its neighbors, with the attention coefficients:
为了在图结构 $A$ 和节点内容 $X$ 的统一框架中表示它们,我们开发了一种图注意力网络 (Graph Attention Network, GAT) (Velickovic et al., 2018) 的变体。GAT 通过学习注意力系数,通过聚合来自邻居节点的信息来学习每个节点的隐藏表示:
$$
e_{i j}=\mathrm{LeakReLU}(a(W x_{i}||W x_{j}))
$$
$$
e_{i j}=\mathrm{LeakReLU}(a(W x_{i}||W x_{j}))
$$
where $W\in\mathbb{R}^{d\times d}$ is a shared linear transformation weight matrix for this layer, $||$ is the concatenation operation, and $a\in\mathbb{R}^{2d}$ is a shared attention al weight vector.
其中 $W\in\mathbb{R}^{d\times d}$ 是该层共享的线性变换权重矩阵,$||$ 是拼接操作,$a\in\mathbb{R}^{2d}$ 是共享的注意力权重向量。
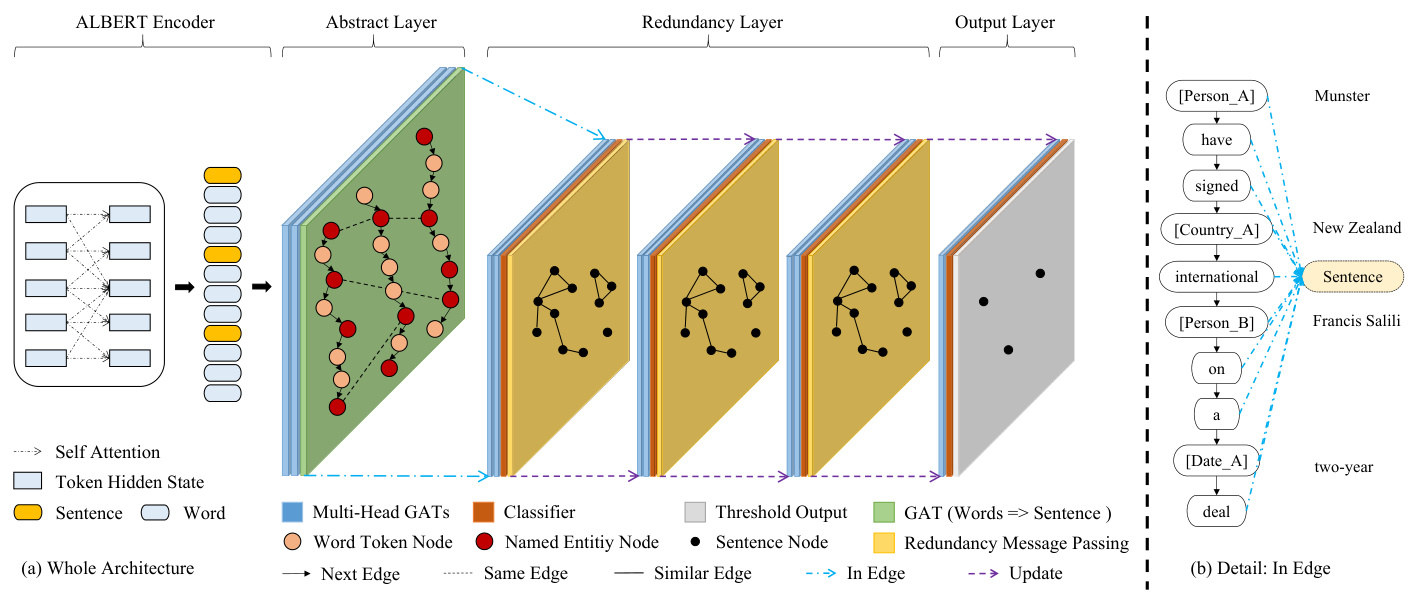
Figure 1: Overview of Hierarchical Attentive Heterogeneous Graph
图 1: 层次化注意力异构图总览
To make the attention coefficients easily comparable across different nodes, we normalize them as follows:
为了使注意力系数在不同节点之间更容易比较,我们对其进行如下归一化:
$$
\alpha_{i j}=\mathrm{softmax}(e_{i j})=\frac{\exp(e_{i j})}{\sum_{k\in\mathcal{N}_{i}}\exp(e_{i k})}
$$
$$
\alpha_{i j}=\mathrm{softmax}(e_{i j})=\frac{\exp(e_{i j})}{\sum_{k\in\mathcal{N}_{i}}\exp(e_{i k})}
$$
where $\mathcal{N}_{i}$ denotes the neighbors of node $i$ according to adjacency matrix $A$ .
其中 $\mathcal{N}_{i}$ 表示根据邻接矩阵 $A$ 得出的节点 $i$ 的邻居。
Then, the normalized attention coefficients are used to compute a linear combination of features.
然后,使用归一化的注意力系数来计算特征的线性组合。
$$
x_{i}^{\prime}=\sigma(\sum_{j\in\mathcal{N}{i}}\alpha_{i j}W x_{j})+W^{\prime}x_{i}
$$
$$
x_{i}^{\prime}=\sigma(\sum_{j\in\mathcal{N}{i}}\alpha_{i j}W x_{j})+W^{\prime}x_{i}
$$
where $W^{\prime}$ is used to distinguish the information between $x_{i}$ and its neighbors.
其中 $W^{\prime}$ 用于区分 $x_{i}$ 与其邻居之间的信息。
3.4 Message Passing
3.4 消息传递
Shown in Figure 1, HAHSum consists of ALBERT Encoder, Abstract Layer, Redundancy Layer, and Output Layer. We next introduce how the information propagates over these layers.
如图 1 所示,HAHSum 由 ALBERT 编码器 (ALBERT Encoder)、摘要层 (Abstract Layer)、冗余层 (Redundancy Layer) 和输出层 (Output Layer) 组成。接下来我们将介绍信息如何在这些层之间传播。
3.4.1 ALBERT Encoder
3.4.1 ALBERT编码器
In order to learn the contextual representation of words, we use a pre-trained ALBERT (Lan et al., 2019) for sum mari z ation and the architecture is similar to BERTSUMEXT (Liu and Lapata, 2019). The output of ALBERT encoder contains word hidden states $h^{w o r d}$ and sentence hidden states $h^{s e n t}$ . Specifically, ALBERT takes subword units as input, which means that one word may correspond to multiple hidden states. In order to accurately use these hidden states to represent each word, we apply an average pooling function to the outputs of ALBERT.
为了学习单词的上下文表示,我们使用预训练的ALBERT (Lan et al., 2019)进行摘要生成,其架构与BERTSUMEXT (Liu and Lapata, 2019)相似。ALBERT编码器的输出包含单词隐藏状态$h^{word}$和句子隐藏状态$h^{sent}$。具体而言,ALBERT以子词单元作为输入,这意味着一个单词可能对应多个隐藏状态。为了准确利用这些隐藏状态表示每个单词,我们对ALBERT的输出应用了平均池化函数。
3.4.2 Abstract Layer
3.4.2 抽象层
The abstract layer contains three GAT sublayers which are described in Section 3.3: two for wordlevel graph and one for word-sentence transduction. The first two GAT sublayers are used to learn the hidden state of each word based on its two-order neighbors inspired by Kipf and Welling[2017],
抽象层包含三个GAT子层(如第3.3节所述):两个用于词级图,一个用于词句转换。前两个GAT子层受Kipf和Welling[2017]启发,用于基于单词的二阶邻居学习每个单词的隐藏状态。
$$
\begin{array}{r}{\mathcal{W}={\tt G A T}({\tt G A T}(h^{w o r d},A_{w o r d}),A_{w o r d})}\end{array}
$$
$$
\begin{array}{r}{\mathcal{W}={\tt G A T}({\tt G A T}(h^{w o r d},A_{w o r d}),A_{w o r d})}\end{array}
$$
where $A_{w o r d}$ denotes the adjacency matrix of the word-level subgraph, and $\mathcal{W}$ denotes the hidden state of the word nodes.
其中 $A_{word}$ 表示词级子图的邻接矩阵,$\mathcal{W}$ 表示词节点的隐藏状态。
The third GAT sublayer is to learn the initial representation of each sentence node, derived from the word hidden states:
第三个GAT子层用于学习每个句子节点的初始表征,该表征源自单词隐藏状态:
$$
[\mathcal{W},{S_{a b s}}]=\mathbf{G}\mathbf{A}\mathbf{T}([\mathcal{W},h^{s e n t}],A_{w o r d-s e n t})
$$
$$
[\mathcal{W},{S_{a b s}}]=\mathbf{G}\mathbf{A}\mathbf{T}([\mathcal{W},h^{s e n t}],A_{w o r d-s e n t})
$$
where $A_{w o r d-s e n t}$ denotes the adjacency matrix of the word-sentence subgraphs, and $S_{a b s}$ (abs is for abstract) is the initial representation of sentence nodes.
其中 $A_{w o r d-s e n t}$ 表示词-句子子图的邻接矩阵,$S_{a b s}$ (abs代表abstract) 是句子节点的初始表示。
3.4.3 Redundancy Layer
3.4.3 冗余层
The BERT encoder and abstract layer specialize in modeling salience with overall context representation of sentences, while it is powerless for redun- dancy information with dependencies among target labels. So, redundancy layer aims to model the redundancy, by iterative ly updating the sentence representation with redundancy message passing, and this process is supervised by ground-truth labels.
BERT编码器和抽象层专注于通过句子的整体上下文表征来建模显著性,但对于目标标签间存在依赖关系的冗余信息却无能为力。因此,冗余层旨在通过冗余消息传递迭代更新句子表征来建模冗余,该过程由真实标签监督。
This layer only deals with sentence-level information ${\mathcal S}={h_{1},h_{2},...,h_{N}}$ and iterative ly updates it $L$ times with classification scores:
该层仅处理句子级信息 ${\mathcal S}={h_{1},h_{2},...,h_{N}}$ ,并通过分类分数对其进行 $L$ 次迭代更新:
$$
\begin{array}{r}{\widetilde{\mathcal{S}}{r e}^{l}=\mathtt{G A T}(\mathtt{G A T}(\mathcal{S}{r e}^{l},A_{s e n t}),A_{s e n t})}\ {P(y_{i}=1|\widetilde{\mathcal{S}}{r e}^{l})=\sigma(\mathrm{FFN}(\mathrm{LN}(\widetilde{h}{i}^{l}+\mathrm{MHAtt}(\widetilde{h}_{i}^{l}))))}\end{array}
$$
$$
\begin{array}{r}{\widetilde{\mathcal{S}}{r e}^{l}=\mathtt{G A T}(\mathtt{G A T}(\mathcal{S}{r e}^{l},A_{s e n t}),A_{s e n t})}\ {P(y_{i}=1|\widetilde{\mathcal{S}}{r e}^{l})=\sigma(\mathrm{FFN}(\mathrm{LN}(\widetilde{h}{i}^{l}+\mathrm{MHAtt}(\widetilde{h}_{i}^{l}))))}\end{array}
$$
where $S_{r e}^{0}=S_{a b s}$ (re is for redundancy) and we get $S_{r e}^{L}$ at the end, $W_{c},W_{r}$ are weight parameters, FFN, LN, MHAtt are feed-foreard network, layer normalization and multi-head attention layer.
其中 $S_{r e}^{0}=S_{a b s}$ (re表示冗余) 且最终得到 $S_{r e}^{L}$,$W_{c},W_{r}$ 是权重参数,FFN、LN、MHAtt 分别代表前馈网络 (feed-foreard network)、层归一化 (layer normalization) 和多头注意力层 (multi-head attention layer)。
We update $\tilde{h}{i}^{l}$ by reducing the redundancy information $g_{i}^{l}$ , which is the weighted summation of neighbors information:
我们通过减少冗余信息 $g_{i}^{l}$ 来更新 $\tilde{h}{i}^{l}$,其中 $g_{i}^{l}$ 是邻居信息的加权求和:
$$
\begin{array}{c}{\displaystyle g_{i}^{l}=\frac{1}{|\mathcal{N}{i}|}\sum_{j\in\mathcal{N}{i}}P(y_{j}=1|\widetilde{S}{r e}^{l})\widetilde{h}{j}^{l}}\ {\displaystyle}\ {h_{i}^{l+1}=W_{c}^{l}*\widetilde{h}{i}^{l}-\widetilde{h}{i}^{l T}W_{r}^{l}\operatorname{tanh}(g_{i}^{l})}\ {\displaystyle S_{r e}^{l+1}=(h_{1}^{l+1},h_{2}^{l+1},...,h_{|\mathcal{S}|}^{l+1})}\end{array}
$$
$$
\begin{array}{c}{\displaystyle g_{i}^{l}=\frac{1}{|\mathcal{N}{i}|}\sum_{j\in\mathcal{N}{i}}P(y_{j}=1|\widetilde{S}{r e}^{l})\widetilde{h}{j}^{l}}\ {\displaystyle}\ {h_{i}^{l+1}=W_{c}^{l}*\widetilde{h}{i}^{l}-\widetilde{h}{i}^{l T}W_{r}^{l}\operatorname{tanh}(g_{i}^{l})}\ {\displaystyle S_{r e}^{l+1}=(h_{1}^{l+1},h_{2}^{l+1},...,h_{|\mathcal{S}|}^{l+1})}\end{array}
$$
where $\mathcal{N}{i}$ is redundancy receptive field for node $i$ , according to $A_{s e n t}$ .
其中 $\mathcal{N}{i}$ 是根据 $A_{sent}$ 得出的节点 $i$ 的冗余感受野。
Specifically, we employ a gating mechanism (Gilmer et al., 2017) for the information update, so that: 1) to avoid GNN smoothing problem; 2) the original overall information from ALBERT is accessible for the ultimate classifier.
具体来说,我们采用门控机制 (gating mechanism) [Gilmer et al., 2017] 进行信息更新,以便:1) 避免 GNN 平滑问题;2) 最终分类器可以访问来自 ALBERT 的原始整体信息。
$$
\begin{array}{r l}&{\quad\tilde{h}{i}^{l^{\prime}}=W_{c}^{l}*\tilde{h}{i}^{l}-\tilde{h}{i}^{l T}W_{r}^{l}\operatorname{tanh}(g_{i}^{l})}\ &{\quad p_{g}^{l}=\sigma(f_{g}^{l}([\tilde{h}{i}^{l};\tilde{h}{i}^{l^{\prime}}]))}\ &{\quad h_{i}^{l+1}=\tilde{h}{i}^{l}\odot p_{g}^{l}+\tilde{h}{i}^{l^{\prime}}\odot(1-p_{g}^{l})}\end{array}
$$
$$
\begin{array}{r l}&{\quad\tilde{h}{i}^{l^{\prime}}=W_{c}^{l}*\tilde{h}{i}^{l}-\tilde{h}{i}^{l T}W_{r}^{l}\operatorname{tanh}(g_{i}^{l})}\ &{\quad p_{g}^{l}=\sigma(f_{g}^{l}([\tilde{h}{i}^{l};\tilde{h}{i}^{l^{\prime}}]))}\ &{\quad h_{i}^{l+1}=\tilde{h}{i}^{l}\odot p_{g}^{l}+\tilde{h}{i}^{l^{\prime}}\odot(1-p_{g}^{l})}\end{array}
$$
where $\odot$ denotes element-wise multiplication.
其中 $\odot$ 表示逐元素相乘。
3.5 Objective Function
3.5 目标函数
Previous approaches for modeling the salience and redundancy is auto regressive, where observations from previous time-steps are used to predict the value at current time-step:
先前用于建模显著性和冗余度的方法是自回归的,即利用先前时间步的观测值来预测当前时间步的值:
$$
P(Y|S)=\prod_{t=1}^{|S|}P(y_{t}|S,y_{1},y_{2},...,y_{t-1})
$$
$$
P(Y|S)=\prod_{t=1}^{|S|}P(y_{t}|S,y_{1},y_{2},...,y_{t-1})
$$
The auto regressive models have some disadvantages: 1) the error in inference will propagate subsequently, 2) label $y_{t}$ is generated just depend on previous sentences $y_{<t}$ rather than considering bidirectional dependency, and 3) it is difficult to decide how many sentences to extract.
自回归模型存在一些缺点:1) 推理过程中的误差会向后传播,2) 标签 $y_{t}$ 仅依赖于前文 $y_{<t}$ 生成,未考虑双向依赖关系,3) 难以确定需要提取多少句子。
Table 2: Data Statistics: CNN/Daily Mail, NYT, Newsroom
表 2: 数据统计: CNN/Daily Mail, NYT, Newsroom
| 数据集 | avg.doclength words sentences | avg.summarylength |
|---|---|---|
| CNN | 760.50 | words 45.70 sentences |
| DailyMail | 653.33 33.98 29.33 | 54.65 3.59 3.86 |
| NYT | 800.04 35.55 | 45.54 2.44 |
| Newsroom (Ext) | 605.44 28.78 | 40.95 1.90 |
Our HAHSum predicts these labels simultaneously:
我们的HAHSum模型同步预测这些标签:
$$
P(Y|S)=\prod_{t=1}^{|S|}P(y_{t}|S,S_{a b s},S_{r e})
$$
$$
P(Y|S)=\prod_{t=1}^{|S|}P(y_{t}|S,S_{a b s},S_{r e})
$$
where we extract flexible quantity of sentences with a threshold instead of top $k$ . For $L$ class if i ers in our model, we train them simultaneously with different proportions.
我们通过设定阈值而非固定选取前 $k$ 个句子来灵活提取句子数量。对于模型中的 $L$ 个类别分类器,我们以不同比例同时训练它们。
4 Experiments Setting
4 实验设置
4.1 Benchmark Datasets
4.1 基准数据集
As shown in Table 2, we employ three datasets widely-used with multiple sentences summary (CNN/DM (Hermann et al., 2015), NYT (Sandhaus, 2008), and NEWSROOM (Grusky et al., 2018)). These summaries vary with respect to the type of rewriting operations, e.g., CNN/DM and NYT prefer to the abstract ive approaches and Newsroom(Ext) is genuinely extractive. We employ the greedy method to obtain ground-truth sentence labels (Nallapati et al., 2017).
如表 2 所示,我们采用了三个广泛使用的多句子摘要数据集 (CNN/DM (Hermann et al., 2015)、NYT (Sandhaus, 2008) 和 NEWSROOM (Grusky et al., 2018))。这些摘要在改写操作类型上有所不同,例如 CNN/DM 和 NYT 倾向于抽象式方法,而 Newsroom(Ext) 则是纯抽取式的。我们采用贪心算法获取真实句子标签 (Nallapati et al., 2017)。
CNN/DailyMail: We use the standard splits for training, validation, and test (90,266/1,220/1,093 for CNN and 196,96/12,148/10,397 for DailyMail) (Liu and Lapata, 2019). Input documents are truncated to 768 BPE tokens, with anonymized entities and processed by Stanford CoreNLP.
CNN/DailyMail:我们使用标准划分进行训练、验证和测试(CNN为90,266/1,220/1,093,DailyMail为196,96/12,148/10,397)(Liu and Lapata, 2019)。输入文档被截断为768个BPE token,其中实体经过匿名化处理,并通过Stanford CoreNLP进行处理。
NYT: Following previous work (Zhang et al., 2019b; Xu and Durrett, 2019), we use 137,778, 17,222 and 17,223 samples for training, validation, and test, respectively. Input documents were truncated to 768 BPE tokens too. Note that there are different division for NYT (Durrett et al., 2016; Liu and Lapata, 2019) and several models are not evaluated on NYT officially (See et al., 2017; Mendes et al., 2019), so we re-train and evaluate them on NYT with the source code from Github.
NYT: 遵循先前工作 (Zhang et al., 2019b; Xu and Durrett, 2019), 我们分别使用137,778、17,222和17,223个样本进行训练、验证和测试。输入文档被截断为768个BPE token。需要注意的是, NYT存在不同划分方式 (Durrett et al., 2016; Liu and Lapata, 2019), 且部分模型未在NYT上官方评估 (See et al., 2017; Mendes et al., 2019), 因此我们使用Github上的源代码在NYT上重新训练并评估这些模型。
Newsroom(Ext): We employ the extractive part of Newsroom with same divisioin method (Mendes et al., 2019) for training/validation/test (331,778/36,332/36,122). Input documents are truncted to 768 BPE tokens.
Newsroom(Ext): 我们采用Newsroom的抽取部分,使用相同的划分方法 (Mendes et al., 2019) 进行训练/验证/测试集划分 (331,778/36,332/36,122)。输入文档被截断至768个BPE token。
4.2 Evaluation Metric & Parameter Settings
4.2 评估指标与参数设置
Metric: ROUGE (Lin, 2004) is the standard metric for evaluating the quality of summaries. We report the ROUGE-1, ROUGE-2, and ROUGE-L of HAHSum by ROUGE-1.5.5.pl, which calculates the overlap lexical units of extracted sentences and ground-truth.
指标:ROUGE (Lin, 2004) 是评估摘要质量的标准指标。我们通过 ROUGE-1.5.5.pl 计算 HAHSum 的 ROUGE-1、ROUGE-2 和 ROUGE-L,该工具基于提取句子与参考答案之间的词汇重叠单元进行计算。
Graph Structure: For abstract layer, we extract the named entities ([Person], [Date], [Country], [Buildings], [Monetary]) using CoreNLP, and replace them by anonymized tokens. Similar to Fernandes et al. (2019), we have tried to add dependency parse edges and they didn’t show significant benefits, owing to the facts that 1) the dependency tree is substantially a permutation sequential structure, with little advancements for original information; 2) the performance is influenced by the accuracy of the upstream annotators. We have tried the iteration steps of [1, 2, 3, 5] for updating redundancy layer, and $L=3$ is the best value in experiment result.
图结构:在抽象层,我们使用CoreNLP提取命名实体([Person]、[Date]、[Country]、[Buildings]、[Monetary])并用匿名token替换。与Fernandes等人(2019)的研究类似,我们尝试添加依存解析边但未观察到显著效果,原因在于:1) 依存树本质上是排列顺序结构,对原始信息提升有限;2) 性能受上游标注器精度影响。我们测试了[1,2,3,5]四种迭代步长更新冗余层,实验结果表明$L=3$为最优值。
Parameters: We employ pre-trained ‘albertxxlarge $\mathbf{\nabla}\cdot\mathbf{V}2^{,2}$ and reuse the implementation of $\mathrm{PreSumm}^{3}$ . We train our model (with about 400M parameters) one day for 100,000 steps on 2 GPUs(Nvidia Tesla V100, 32G) with gradient accumulation every two steps. We select the top-3 checkpoints according to the evaluation loss on validation set and report the averaged results on the test set. Adam with $\beta_{1}=0.9$ , $\beta_{2}=0.999$ is used as optimizer and learning rate schedule follows the strategies with warming-up on first 10,000 steps (Vaswani et al., 2017). The final threshold in extraction is 0.65 for CNN/DM, 0.58 for NYT and 0.64 for Newsroom, with the highest ROUGE-1 score individually. A higher threshold will be with more concise summary and the lower threshold will return more information.
参数:我们采用预训练的 'albertxxlarge $\mathbf{\nabla}\cdot\mathbf{V}2^{,2}$ 并复用 $\mathrm{PreSumm}^{3}$ 的实现。在2块GPU(Nvidia Tesla V100, 32G)上训练模型(约4亿参数)一天,共10万步,每两步进行一次梯度累积。根据验证集评估损失选择top-3检查点,并报告测试集上的平均结果。使用Adam优化器( $\beta_{1}=0.9$ , $\beta_{2}=0.999$ ),学习率调度采用前1万步预热策略(Vaswani et al., 2017)。最终提取阈值为:CNN/DM数据集0.65、NYT数据集0.58、Newsroom数据集0.64,这些阈值各自对应最高的ROUGE-1分数。阈值越高生成摘要越简洁,阈值越低保留信息越多。
4.3 Baselines
4.3 基线
Extractive Methods: Oracle is the extracted summary according to the ground-truth labels. Lead is a base method for extractive text summarization that chooses first several sentences as a summary. Summa RuNNer takes content, salience, novelty, and position of each sentence into consideration when deciding if a sentence should be included in the extractive summary. PNBERT tries to employ the unsupervised transferable knowledge. BERTSUMEXT applies pretrained BERT in text sum mari z ation and proposes a general framework for both extractive and abstractive models. MATCHSUM is a two-stage method for extract-then-match, and the first-stage is BERTSUMEXT.
抽取式方法:Oracle是根据真实标签抽取的摘要。Lead是一种抽取式文本摘要的基线方法,选择前几个句子作为摘要。Summa RuNNer在决定是否将句子纳入抽取式摘要时,会考虑内容、显著性、新颖性和句子位置。PNBERT尝试利用无监督可迁移知识。BERTSUMEXT在文本摘要中应用预训练的BERT,并提出了一个适用于抽取式和生成式模型的通用框架。MATCHSUM是一种先抽取后匹配的两阶段方法,其第一阶段采用BERTSUMEXT。
Abstract ive Methods: ABS is the normal architecture with RNN-based encoder and decoder. PGC augments the standard Seq2Seq attention al model with pointer and coverage mechanisms. Transformer ABS employs Transformer in text sum mari z ation. MASS proposes masked Seq2Seq pre-training for encoder-decoder. UniLM presents unified pre-trained language model, that can be finetuned for sum mari z ation. BART, and ProphetNet are pre-trained on large unlabeled data and perform excellent performance with Transformer architecture. PEGASUS proposes Transformerbased models with extracted gap-sentences for abstractive sum mari z ation.
摘要方法:ABS是基于RNN编码器和解码器的标准架构。PGC通过指针和覆盖机制增强了标准Seq2Seq注意力模型。Transformer ABS在文本摘要中采用了Transformer架构。MASS提出了用于编码器-解码器的掩码Seq2Seq预训练方法。UniLM展示了统一预训练语言模型,可微调用于摘要任务。BART和ProphetNet基于Transformer架构在大规模无标注数据上进行预训练,并表现出优异性能。PEGASUS提出了基于Transformer的模型,通过提取间隔句子进行生成式摘要。
Specifically, these Transformer-based approaches are divided into Base and Large versions, according to the layers of Transformer.
具体来说,这些基于Transformer的方法根据Transformer的层数分为Base版和Large版。
5 Analysis
5 分析
5.1 Rouge Scores
5.1 Rouge 得分
The experiment results on three benchmark datasets are shown in Table 3. There are ignored positions for Newsroom(Ext), which is designed for extractive approaches, eliminating the demanding of abstractive ones. It is obvious that HAHSum almost outperforms all the baselines across most of the evaluation metrics. For CNN/DM, there is little gap between the performance of extractive and abstractive architectures, particularly demonstrating the popularity and generality of this dataset. While NYT prefers to abstract ive methods, and NEWSROOM(Ext) is constructed by extracting sentences directly. For extractive approaches, HAHSum, MATCHSUM, and BERTSUMEXT are outstanding with the power of pre-trained BERT-like models. For abstract ive methods, these variants of Transformer perform extremely with deep architectures and large-scale unlabeled corpus.
三个基准数据集的实验结果如表3所示。Newsroom(Ext)存在忽略位置,该数据集专为抽取式方法设计,排除了对生成式方法的需求。显然,HAHSum在大多数评估指标上几乎优于所有基线模型。在CNN/DM数据集上,抽取式和生成式架构的性能差距很小,尤其体现了该数据集的普及性和通用性。而NYT更倾向于生成式方法,NEWSROOM(Ext)则直接通过抽取句子构建。对于抽取式方法,HAHSum、MATCHSUM和BERTSUMEXT凭借预训练BERT类模型的优势表现突出。生成式方法方面,这些Transformer变体通过深层架构和大规模无标注语料展现出卓越性能。
Table 3: Automatic Evaluation or ROUGE
表 3: 自动评估或ROUGE
| 模型 | CNN/DM | NYT | Newsroom (Ext) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| 生成式 | |||||||||
| ABS (2015) | 35.46 | 13.30 | 32.65 | 42.78 | 25.61 | 35.26 | 6.1 | 0.2 | 5.4 |
| PGC (2017) | 39.53 | 17.28 | 36.38 | 43.93 | 26.85 | 38.67 | 39.1 | 27.9 | 36.2 |
| TransformerABS (2017) | 40.21 | 17.76 | 37.09 | 45.36 | 27.34 | 39.53 | 40.3 | 28.7 | 36.5 |
| MASSLarge (2019) | 43.05 | 20.02 | 40.08 | ||||||
| UniLMLarge (2019) | 43.33 | 20.21 | 40.51 | ||||||
| BARTLarge (2019) | 44.16 | 21.28 | 40.90 | 48.73 | 29.25 | 44.48 | |||
| PEGASUSLarge (2019a) | 44.17 | 21.47 | 41.11 | ||||||
| ProphetNetLarge (2020) | 44.20 | 21.17 | 41.30 | ||||||
| 抽取式 | |||||||||
| Oracle | 55.61 | 32.84 | 51.88 | 64.22 | 44.57 | 57.27 | |||
| Lead | 40.42 | 17.62 | 36.67 | 41.80 | 22.60 | 35.00 | 53.1 | 49.0 | 52.4 |
| SummaRuNNer (2017) | 39.60 | 16.20 | 35.30 | 42.37 | 23.89 | 38.74 | 48.96 | 44.33 | 49.57 |
| Exconsumm (2019) | 41.7 | 18.6 | 37.8 | 43.18 | 24.43 | 38.92 | 68.4 | 62.9 | 67.3 |
| PNBERTBase (2019a) | 42.69 | 19.60 | 38.85 | ||||||
| BERTSUMEXTLarge (2019) | 43.85 | 20.34 | 39.90 | 48.51 | 30.27 | 44.65 | 70.85 | 67.03 | 69.61 |
| MATCHSUMBase (2020) | 44.41 | 20.86 | 40.55 | ||||||
| HAHSumLarge (Ours) | 44.68 | 21.30 | 40.75 | 49.36 | 31.41 | 44.97 | 71.31 | 68.75 | 70.83 |
HAHSum outperforms all other extractive approaches for that: 1) HAHSum achieves improvements to mitigate the redundancy bias by measuring salience and redundancy simultaneously, while this would not be possible with any framework in the auto regressive literature because salience and redundancy are treated as two different processes due to the dependency among target labels. 2) The promising results of heterogeneous sequencegraph models outperform pure sequence models. Sequence encoders with a graph component can reason about long-distance relationships in weakly structured data such as text, which requires nontrivial understanding of the input, while attentive sequential architectures prefer to calculate the relevance merely.
HAHSum在所有抽取式方法中表现最优,原因在于:1) HAHSum通过同步衡量显著性(salience)和冗余度(redundancy)来缓解冗余偏差,而自回归(auto regressive)研究中的任何框架都无法实现这一点,因为目标标签间的依赖性导致显著性和冗余度被视为两个独立过程。2) 异构序列图模型(heterogeneous sequence-graph models)的优异表现超越了纯序列模型。带有图组件的序列编码器能够推理弱结构化数据(如文本)中的长距离关系,这需要对输入内容进行深度理解,而注意力序列架构(attentive sequential architectures)往往仅计算相关性。
5.2 Ablation Studies
5.2 消融实验
Table 4: Ablation Study on CNN/DM Test Set
表 4: CNN/DM测试集消融研究
| Models | R-1 | R-2 | R-L |
|---|---|---|---|
| HAHSum | 44.68 | 21.30 | 40.75 |
| w/oAL | 44.35 | 20.98 | 40.49 |
| w/oRL | 44.49 | 21.11 | 40.58 |
| w/o ALBERT | 44.57 | 21.14 | 40.53 |
We propose several strategies to improve the performance by relieving the semantic sparsity and redundancy bias, including abstract layer(AL), the iterative redundancy layer(RL), and pre-trained ALBERT. To investigate the influence of these factors, we conduct the experiments and list the results in Table 4. Significantly, AL is more important than RL, for the reason that there are lots of meaningless named entities. Besides, RL mechanism enlarges the advantage of extraction without top $k$ strategy, for there are more than $40%$ documents in CNN/DM contains more or less than 3-sentences oracle summary. As shown in Table 6, HAHSum predicts sequence exactly with two sentences, same as the oracle summary. While BERTSUMEXT extracts top-3 sentences strictly, in spite of the inaccurateness and redundancy.
我们提出了几种策略来通过缓解语义稀疏性和冗余偏差提升性能,包括抽象层(AL)、迭代冗余层(RL)和预训练ALBERT。为研究这些因素的影响,我们进行了实验并将结果列于表4。值得注意的是,AL比RL更重要,因为存在大量无意义的命名实体。此外,RL机制在没有top $k$策略的情况下扩大了抽取优势,因为CNN/DM中超过$40%$的文档包含或多或少的3句黄金摘要。如表6所示,HAHSum精确预测出两句话的序列,与黄金摘要一致。而BERTSUMEXT严格抽取前三句,尽管存在不准确和冗余问题。
5.3 Human Evaluation for Sum mari z ation
5.3 摘要任务的人工评估
It is not enough only relying on the ROUGE evaluation for a sum mari z ation system, although the ROUGE correlates well with human judgments (Owczarzak et al., 2012). To evaluate the performance of HAHSum more accurately, we design an Amazon Mechanical Turk experiment based on ranking method. Following Cheng and Lapata (2016); Narayan et al. (2018); Zhang et al. (2019b), firstly, we randomly select 40 samples from Daily Mail test set. Then the human participants are presented with a original document and a list of corresponding summaries produced by different model systems. Participants are requested to rank these summaries (ties allowed) by taking informativeness (Can the summary capture the important information from the document) and fluency (Is the summary grammatical) into account. Each document is annotated by three different participants separately.
仅依赖ROUGE评估对摘要系统来说是不够的,尽管ROUGE与人工判断有较高相关性 (Owczarzak et al., 2012)。为更准确评估HAHSum的性能,我们基于排序方法设计了Amazon Mechanical Turk实验。参照Cheng和Lapata (2016)、Narayan等人 (2018)、Zhang等人 (2019b) 的方法,首先从Daily Mail测试集中随机选取40个样本。然后向参与者展示原始文档及不同模型系统生成的对应摘要列表,要求参与者综合考虑信息量(摘要是否能捕捉文档重要信息)和流畅度(摘要是否符合语法)对这些摘要进行排序(允许并列)。每份文档由三位不同参与者分别标注。
Table 5: Human evaluation on Daily Mail.
表 5: Daily Mail 人工评估结果
| 模型 | 1st | 2nd | 3rd | 4th | 5th | MeanR |
|---|---|---|---|---|---|---|
| SummaRuNNer | 0.14 | 0.27 | 0.24 | 0.22 | 0.13 | 2.93 |
| BERTSUMEXT | 0.20 | 0.28 | 0.31 | 0.16 | 0.05 | 2.58 |
| MATCHSUM | 0.24 | 0.36 | 0.16 | 0.15 | 0.09 | 2.49 |
| HAHSum | 0.45 | 0.34 | 0.18 | 0.03 | 0.00 | 2.24 |
| Ground-Truth | 0.70 | 0.21 | 0.05 | 0.04 | 0.00 | 1.43 |
Following the previous work, the input article and ground truth summaries are also shown to the human participants in addition to the four model summaries (Summa RuNNer, BERTSUMEXT, MATCHSUM and HAHSum). From the results shown in Table 5, we can see that HAHSum is better in relevance compared with others.
根据先前的研究,除了四种模型摘要(Summa RuNNer、BERTSUMEXT、MATCHSUM 和 HAHSum)外,输入文章和真实摘要也会展示给人类参与者。从表 5 所示的结果可以看出,HAHSum 在相关性方面优于其他模型。
5.4 Visualization
5.4 可视化
We visualize the learned embedding of word and sentence nodes in a two-dimensional space by applying the t-SNE algorithm. We randomly select 500 continuous word nodes (approximately 30 sentences in a document) and 1000 sentence nodes from BERTSUMEXT and HAHSum separately. As shown in Figure 2, for word nodes, the darkness determines it’s position in one document; while for sentence nodes, red points are the sentences with label 1, and green points are with label 0. The result shows: 1) It is amazing that sentence-level sum mari z ation constrains word representations to be shared across whole sentence, and there are obviously word clusters in BERTSUMEXT; 2) The word clusters are more distinct and meaningful in HAHSum equipped with abstract layer and GAT; 3) Intuitively, the redundancy layer has particularly strong representation power and general iz ability, for that oracle sentence nodes in HAHSum are easy to identify, without auto regressive formalism used for capturing sentence-level redundancy.
我们通过应用t-SNE算法将学习到的词节点和句子节点嵌入可视化到二维空间中。我们分别从BERTSUMEXT和HAHSum中随机选取500个连续词节点(约30个句子)和1000个句子节点。如图2所示:对于词节点,颜色深浅表示其在文档中的位置;对于句子节点,红点标记为标签1的句子,绿点标记为标签0的句子。结果表明:1) 令人惊讶的是,句子级摘要任务使词表征能在整个句子中共享,且BERTSUMEXT中存在明显的词簇;2) 配备抽象层和GAT的HAHSum中,词簇区分更明显且更具语义意义;3) 直观来看,冗余层具有特别强的表征能力和泛化能力,因为HAHSum中的关键句节点无需使用自回归形式化方法即可轻松识别。

Figure 2: T-SNE Visualization on CNN/DM Test Set
图 2: CNN/DM测试集上的T-SNE可视化
Table 6: Case Study on CNN/DM Test Set
表 6: CNN/DM测试集案例分析
| 源文档(节选):耗资10亿英镑建成的新广播大楼是BBC皇冠上的明珠,也是其自嘲讽刺节目W1A的拍摄地。(...)新广播大楼容纳了3个24小时新闻频道、9个广播网络和6000名员工。 |
| Oracle摘要:新广播大楼由女王于2013年揭幕——比原计划推迟了四年,且至少超支5500万英镑。BBC承认其耗资10亿英镑的新广播大楼"偶尔"会出现会议室不足的情况。 |
| HAHSum:新广播大楼由女王于2013年揭幕——比原计划推迟了四年,且至少超支5500万英镑。BBC承认其耗资10亿英镑的新广播大楼"偶尔"会出现会议室不足的情况。 |
| BERTSUMEXT:新广播大楼由女王于2013年揭幕——比原计划推迟了四年,且至少超支5500万英镑。另有人表示:"在街对面开会简直荒谬。" |
6 Conclusion
6 结论
In this paper, we propose hierarchical attentive heterogeneous graph, aiming to advance text summarization by measuring salience and redundancy simultaneously. Our approach model redundancy information by iterative ly update the sentence information with message passing in redundancy-aware graph. As a result, HAHSum produces more focused summaries with fewer superfluous and the performance improvements are more pronounced on more extractive datasets.
本文提出分层注意力异构图(HAHSum),旨在通过同步衡量显著性与冗余性来提升文本摘要效果。该方法在冗余感知图中通过消息传递迭代更新句子信息来建模冗余信息,从而使生成的摘要更聚焦、冗余更少,在抽取式数据集上的性能提升尤为显著。