Question-Answering Dense Video Events
密集视频事件问答
Abstract
摘要
Multimodal Large Language Models (MLLMs) have shown excellent performance in question-answering of single-event videos. In this paper, we present question-answering dense video events, a novel task that requires answering and grounding the dense-event questions in long videos, thus challenging MLLMs to faithfully comprehend and reason about multiple events occurring over extended time periods. To facilitate the study, we construct DeVE-QA – a dataset featuring $78K$ questions about $26K$ events on $10.6K$ long videos. We then benchmark and show that existing MLLMs excelling at single-event QA struggle to perform well in DeVE-QA. For improvement, we propose DeVi, a novel training-free MLLM approach that highlights a hierarchical captioning module, a temporal event memory module, and a self-consistency checking module to respectively detect, contextualize and memorize, and ground dense-events in long videos for question answering. Extensive experiments show that $\mathrm{DeVi}$ is superior at answering dense-event questions and grounding relevant video moments. Compared with existing MLLMs, it achieves a remarkable increase of $4.1%$ and $3.7%$ for G(round)QA accuracy on DeVE-QA and NExT-GQA respectively. Our data and code will be released.
多模态大语言模型 (MLLM) 在单事件视频问答任务中展现出卓越性能。本文提出密集事件视频问答这一新任务,要求对长视频中的密集事件问题进行回答与定位,从而挑战 MLLM 对长时间跨度的多事件进行忠实理解和推理的能力。为此,我们构建了 DeVE-QA 数据集——包含 10.6K 个长视频中 26K 个事件的 78K 个问题。基准测试表明,现有擅长单事件问答的 MLLM 在 DeVE-QA 上表现欠佳。为改进性能,我们提出无需训练的 DeVi 框架,其创新性体现在:1) 层次化描述模块;2) 时序事件记忆模块;3) 自一致性校验模块,分别用于长视频中的密集事件检测、上下文关联记忆以及问答定位。大量实验证明,DeVi 在密集事件问答及视频片段定位方面表现优异,相较现有 MLLM 在 DeVE-QA 和 NExT-GQA 的 G(round)QA 准确率分别显著提升 4.1% 和 3.7%。我们的数据与代码将开源发布。
Introduction
引言
Multimodal Large Language Models (MLLMs) (Alayrac et al. 2022; Li et al. 2023b; Maaz et al. 2023; Zhang, Li, and Bing 2023; Lin et al. 2023; Reid et al. 2024) have shown significant capability in question-answering of single-event videos ( $\mathrm{{Xu}}$ et al. 2017; Jang et al. 2017), where the videos are short in $3\sim20$ seconds and the QAs factor single global types of events, e.g. “who did what”. Yet, real-world video often comes in long format and features a complex overlay of dense events. Consider the 2-minute video taken from a motorcycle activity shown in Figure 1. A variety of questions can be asked about this video, with each pertaining to an individual event but involving different participants and durations interspersed throughout the video. The events, while being separate, are still related to each other, e.g. a motorcycle stunt performance.
多模态大语言模型 (MLLMs) (Alayrac et al. 2022; Li et al. 2023b; Maaz et al. 2023; Zhang, Li, and Bing 2023; Lin et al. 2023; Reid et al. 2024) 在单事件视频问答任务 ( $\mathrm{{Xu}}$ et al. 2017; Jang et al. 2017) 中展现出卓越能力。这类视频时长通常为 $3\sim20$ 秒,问答内容聚焦于单一全局事件类型,例如"谁做了什么"。然而现实场景中的视频往往篇幅较长,且包含密集事件的复杂叠加。以图 1 所示的摩托车活动视频为例,这段 2 分钟的视频可衍生出多种问题,每个问题都关联着视频中不同时段、涉及不同参与者的独立事件。这些事件虽相互独立,却又彼此关联(例如摩托车特技表演)。
The inherent challenge of understanding such dense video events is thus to either isolate or agglomerate, as needed, relevant video content and generate relevant event responses.
理解这类密集视频事件的固有挑战在于根据需要隔离或聚合相关视频内容,并生成相应的事件响应。

Figure 1: Example of DeVE-QA.
图 1: DeVE-QA示例。
While part of the challenge is tackled in dense-event captioning (Krishna et al. 2017) (e.g., isolation and generation), the holistic caption generation offers very limited insight of reasoning and understanding of dense video events, as MLLMs are prone to hallucination (Ma et al. 2023). Furthermore, evaluating captions is challenging, as the annotations are often subjective (Wang, Deng, and Jia 2024) and the generated captions are often in diverse language formats (Vedantam, Lawrence Zitnick, and Parikh 2015). Alternatively, video question answering inherits all the challenge for dense event understanding. It also enables deterministic evaluation by multi-choice classification (Xiao et al. 2021; Mangalam, Akshulakov, and Malik 2024; Patraucean et al. 2024). As such, we propose question-answering of dense video events, a novel task that challenges MLLMs in comprehending and reasoning the dense events occurring over long-lasting videos.
尽管密集事件描述(Krishna等人2017)已解决部分挑战(如事件隔离与生成),但整体描述生成对大语言模型理解密集视频事件的推理过程揭示有限,因其易产生幻觉(Ma等人2023)。此外,描述评估存在主观标注(Wang、Deng和Jia 2024)和语言表达多样性(Vedantam、Lawrence Zitnick和Parikh 2015)的难题。视频问答则继承了密集事件理解的全部挑战,同时通过多选分类实现确定性评估(Xiao等人2021;Mangalam、Akshulkov和Malik 2024;Patraucean等人2024)。为此,我们提出长视频密集事件问答这一新任务,旨在考察大语言模型对持续视频中密集事件的理解与推理能力。
Specifically, given a video that carries multiple events and a question about a specific event in the video, questionanswering dense video events requires MLLMs to comprehend the question to the relevant event and reason over the event to derive the correct answer. For comprehending, we require the models to localize the relevant video moments, disambiguate different video events to avoid conflicting answers, and thus substantiate the the predictions with visual evidences. The task delivers 3 particular challenges. First, each question pertains to a specific event at a specific time duration (see Figure 1). The duration varies among events, so to precisely comprehend the questions, it is imperative to capture the events spanning over different time scales. Second, the long-form videos poses a challenge in articulating the possible distant contextual events for understanding a particular questioned event. Finally, to promote faithful reasoning, a correct answer prediction necessitates correct grounding and question answering. This asks for strong capability of dense visual event understanding and conditioning, versus exploiting common-sense knowledge in LLMs.
具体而言,给定一个包含多个事件的视频和关于视频中特定事件的问题,密集视频事件问答要求多模态大语言模型能够将问题理解到相关事件,并通过事件推理得出正确答案。在理解层面,我们要求模型能够定位相关视频片段,区分不同视频事件以避免矛盾答案,从而用视觉证据支撑预测结果。该任务带来三个特殊挑战:首先,每个问题都涉及特定时间段的具体事件(见图1)。事件持续时间各不相同,因此要准确理解问题,必须捕捉跨越不同时间尺度的事件。其次,长视频在阐述可能存在的远距离上下文事件以理解特定提问事件时存在挑战。最后,为确保可信推理,正确答案预测需要正确的基础定位和问答能力。这要求强大的密集视觉事件理解与条件处理能力,而非依赖大语言模型中的常识知识。
As there is no suitable benchmark for question-answering of dense video events, we construct DeVE-QA, a Dense Video Event QA dataset featuring $78K$ questions about $26K$ events on $10.6K$ videos. DeVE-QA is constructed by curating multi-choice questions from the dense-event caption annotations of Activity Net-Caption (Krishna et al. 2017), specifically via prompting GPT-4 accompanied with rigorous manual checking and correction.
由于目前缺乏针对密集视频事件问答的合适基准,我们构建了DeVE-QA数据集。该数据集包含10.6K个视频中26K个事件的78K道多选题,其问题通过以下方式生成:基于ActivityNet-Caption (Krishna等人2017) 的密集事件标注描述,使用GPT-4生成初始问题后,再经过严格人工校验与修正。
With DeVE-QA, we first benchmark the prominent MLLMs (Wang et al. 2023; Yu et al. 2024; Momeni et al. 2023; Suris, Menon, and Vondrick 2023; Zhang et al. $2023\mathrm{a}$ ; Kim et al. 2024) that perform well in popular videoQA about single global events, but find that their performances drop significantly, especially on the DeVE-QA subsets that features denser events and longer videos. This reflects the models’ severe deficiency in understanding dense-events long videos and in faithful reasoning for question answering. For improvement, we propose a training-free MLLM approach DeVi. DeVi performs dense video-event QA by first detecting from the video multiple events and then reason over the events to achieve QA. To solve the aforementioned challenges, we incorporates three specific strategies: 1) hierarchical dense event captioning to detect the dense events at multiple temporal scales, 2) temporal event contextual izing and memorizing to capture long-term event dependency and to facilitate event-grounded QA, and 3) self-consistency checking to anchor or rectify the answers with regard to the grounded event moments.
借助DeVE-QA,我们首先对主流多模态大语言模型(Wang et al. 2023; Yu et al. 2024; Momeni et al. 2023; Suris, Menon, and Vondrick 2023; Zhang et al. $2023\mathrm{a}$; Kim et al. 2024)进行基准测试。这些模型在针对单一全局事件的流行视频问答任务中表现优异,但发现它们在DeVE-QA子集(尤其是包含密集事件和较长视频的子集)上的性能显著下降。这反映出模型在理解密集事件长视频和忠实推理回答问题方面存在严重缺陷。为改进这一问题,我们提出了一种免训练的多模态大语言模型方法DeVi。DeVi通过先检测视频中的多个事件,再基于这些事件进行推理来实现密集视频事件问答。针对上述挑战,我们整合了三种具体策略:1) 分层密集事件描述,用于在多时间尺度检测密集事件;2) 时序事件上下文记忆,用于捕捉长期事件依赖并促进基于事件的问答;3) 自一致性校验,用于锚定或修正基于事件时刻的答案。
We evaluate $\mathrm{DeVi}$ on DeVE-QA, and for better comparison, we also extend our experiments to the recent NExTGQA (Xiao et al. 2024b). We achieve accuracy increases of $4.1%$ and $6.6%$ over the state-of-the-arts (SoTAs) on DeVEQA for QA with and without grounding respectively. Also, we improve GQA accuracy on NExT-GQA by $3.7%$ . Further ablation experiments validate DeVi’s strength and its particular designs for dense-event and long-form video QA. Additionally, we share our investigation of other alternative implementations for DeVi, e.g. different MLLMs for captioners and QA models, and highlight the crucial importance of large models for success.
我们在DeVE-QA上评估了$\mathrm{DeVi}$,为了更好地比较,还将实验扩展到最新的NExTGQA (Xiao et al. 2024b)。在DeVEQA上,对于有 grounding 和无 grounding 的问答任务,我们分别比当前最优方法 (SoTAs) 提高了$4.1%$和$6.6%$的准确率。同时,在NExT-GQA上的GQA准确率提升了$3.7%$。进一步的消融实验验证了DeVi的优势及其针对密集事件和长视频问答的特殊设计。此外,我们分享了DeVi其他替代实现方案的研究,例如使用不同的大语言模型 (MLLM) 作为字幕生成器和问答模型,并强调了大型模型对成功的关键作用。
To summarize, our contributions are as follows:
总结来说,我们的贡献如下:
• We propose question answering dense video events to challenge MLLMs in comprehending and reasoning the dense events in long videos. Accordingly, we construct DeVE-QA dataset to facilitate the study. • We propose DeVi, a training-free MLLM approach that performs grounded question-answering on dense video events by highlighting three dedicated components of hi
• 我们提出密集视频事件问答任务,以挑战多模态大语言模型(MLLM)在长视频中对密集事件的理解与推理能力。为此,我们构建了DeVE-QA数据集来推动相关研究。
• 我们提出DeVi方法,这是一种无需训练的多模态大语言模型方案,通过突出三个核心组件(hi...
erarchical dense-event captioning, event contextual i zing and memorizing, and self-consistency checking. • We achieve new SoTA zero-shot results on both DeVEQA and NExT-GQA, surpassing the previous SoTAs profoundly by $4.1%$ and $3.7%$ , respectively.
• 我们实现了分层密集事件描述、事件情境化与记忆以及自一致性检查。
• 在DeVEQA和NExT-GQA上取得了新的零样本(Zero-shot)最优结果(SoTA),分别以4.1%和3.7%的显著优势超越先前最优水平。
Related Works
相关工作
Dense Event Video Understanding Dense video event understanding has primarily focused on captioning (Krishna et al. 2017; Wang et al. 2018; Lin et al. 2022; Yang et al. 2023). However, optimizing for holistic sentence generation often results in over-fitting (Chen, Li, and $\mathrm{Hu}2020)$ and object hallucination (Rohrbach et al. 2018). MLLMs on the other hand, have shown strong capabilities for visual description (Li et al. 2023a; Liu et al. 2024; Maaz et al. 2023; Li et al. 2023b; Lin et al. 2023; Ren et al. 2023; Xu et al. 2024). Yet, the subjective caption annotations and the subeffective sentence-matching metrics (e.g., BLEU (Papineni et al. 2002) and CIDEr (Vedantam, Lawrence Zitnick, and Parikh 2015)) make it challenging to evaluate these models, especially from a zero-shot perspective. Our work proposes to use question-answering as an alternative to evaluate the understanding and reasoning of dense video events.
密集事件视频理解
密集视频事件理解主要集中于视频描述生成 (Krishna et al. 2017; Wang et al. 2018; Lin et al. 2022; Yang et al. 2023) 。然而,针对整体句子生成的优化往往会导致过拟合 (Chen, Li, and $\mathrm{Hu}2020)$ 和物体幻觉 (Rohrbach et al. 2018) 。另一方面,大语言模型 (MLLM) 已展现出强大的视觉描述能力 (Li et al. 2023a; Liu et al. 2024; Maaz et al. 2023; Li et al. 2023b; Lin et al. 2023; Ren et al. 2023; Xu et al. 2024) 。但主观的描述标注和低效的句子匹配指标 (如 BLEU (Papineni et al. 2002) 和 CIDEr (Vedantam, Lawrence Zitnick, and Parikh 2015)) 使得评估这些模型具有挑战性,尤其是从零样本的角度。我们的研究提出使用问答作为替代方案,以评估对密集视频事件的理解和推理能力。
Video Question Answering VideoQA works are center on single event videos; this is reflected in the popular benchmarks, such as TGIF-QA (Jang et al. 2017), MSRVTT-QA and MSVD-QA (Xu et al. 2017), Act it iv it y Net-QA (Yu et al. 2019) and iVQA (Yang et al. 2021), and related techniques (Dai et al. 2023; Maaz et al. 2023; Zhang et al. 2023b; Wang et al. 2023; Li, Wang, and Jia 2023). The video clips in these benchmarks tend to be short or the questions are related to global events spanning the entire clips. NExT-QA (Xiao et al. 2021) advances somewhat by addressing multiple action relations in relatively longer clips. The videos, however, focus on daily life actions and lack complexity in multievent understanding. We also note that some techniques claim for event VideoQA (Yin et al. 2023; Liu, Li, and Lin 2023; Bai, Wang, and Chen 2024) but the events essentially refer to actions alone or single global event of short video. Compared with these works, our work shapes itself by studying multi-event comprehending and reasoning across long videos, where an event refers to a complete combination of subjects, actions, objects, time, etc (Krishna et al. 2017).
视频问答
VideoQA研究主要围绕单一事件视频展开,这体现在主流基准数据集如TGIF-QA (Jang et al. 2017)、MSRVTT-QA和MSVD-QA (Xu et al. 2017)、ActivityNet-QA (Yu et al. 2019)和iVQA (Yang et al. 2021),以及相关技术(Dai et al. 2023; Maaz et al. 2023; Zhang et al. 2023b; Wang et al. 2023; Li, Wang, and Jia 2023)中。这些基准数据集的视频片段通常较短,或问题仅涉及贯穿整个片段的全局事件。NExT-QA (Xiao et al. 2021)通过处理较长片段中的多重动作关系取得一定进展,但其视频仍聚焦日常生活动作,缺乏多事件理解的复杂性。值得注意的是,部分技术声称研究事件VideoQA (Yin et al. 2023; Liu, Li, and Lin 2023; Bai, Wang, and Chen 2024),但这些事件本质上仅指单一动作或短视频的全局事件。相较之下,我们的工作通过研究长视频中的多事件理解与推理形成特色,其中事件指代主体、动作、对象、时间等要素的完整组合(Krishna et al. 2017)。
MLLMs for VideoQA Most existing Video-LLMs are designed for short-video understanding (Xiao et al. 2024a). This includes the instruction-tuned models such as VideoChatGPT (Maaz et al. 2023), Video-LLaMA (Zhang, Li, and Bing 2023), Video-LLaVA (Lin et al. 2023), VideoChat (Li et al. 2023b,c) and PLLaVA (Xu et al. 2024), and targetfinetuned models like SeViLA (Yu et al. 2024) and LLaMAVQA (Ko et al. 2023). The short input $_{4\sim32}$ frames) restricts these models from handling long videos. Trainingfree approaches, such as ViperGPT (Suris, Menon, and Vondrick 2023) and LLoVi (Zhang et al. 2023a), handle long videos by traversing or dense-captioning the video. Traversal approaches cannot agglomerate multiple events interspersed at different times for joint reasoning. Therefore, we follow the Caption-then-QA pipeline of LLoVi (Zhang et al. 2023a). Yet, we incorporate dedicated modules for enhanced dense-event capturing and event-grounded QA.
用于视频问答的多模态大语言模型
现有大多数视频大语言模型(Video-LLM)主要针对短视频理解设计(Xiao et al. 2024a),包括指令调优模型如VideoChatGPT(Maaz et al. 2023)、Video-LLaMA(Zhang, Li, and Bing 2023)、Video-LLaVA(Lin et al. 2023)、VideoChat(Li et al. 2023b,c)和PLLaVA(Xu et al. 2024),以及目标微调模型如SeViLA(Yu et al. 2024)和LLaMAVQA(Ko et al. 2023)。这些模型受限于短输入(4~32帧)而无法处理长视频。免训练方法如ViperGPT(Suris, Menon, and Vondrick 2023)和LLoVi(Zhang et al. 2023a)通过视频遍历或密集描述来处理长视频,但遍历方法无法聚合分散在不同时段的多个事件进行联合推理。因此我们沿用LLoVi(Zhang et al. 2023a)的"描述-再问答"流程,同时引入专用模块来增强密集事件捕捉和基于事件的问答能力。

Figure 2: DeVE-QA construction pipeline.
图 2: DeVE-QA构建流程。
Table 1: Statistics of DeVE-QA. Ratio (S./V.): Average length of segments w.r.t. the entire video.
表 1: DeVE-QA 数据集统计。比例 (S./V.): 片段平均长度占整段视频的比率。
| 分割集 | 视频数 | 问题数 | 平均问题长度 | 片段时长(秒) | 视频时长(秒) | 比例 (S./V.) |
|---|---|---|---|---|---|---|
| 训练集 | 7,179 | 53,361 | 10.70 | 38.68 | 127.32 | 0.32 |
| 测试集 | 3,464 | 24,963 | 10.71 | 40.98 | 125.03 | 0.34 |
DeVE-QA Dataset
DeVE-QA 数据集
We follow dense-event captioning (Krishna et al. 2017) to define an event as a completed description of a person’s (or a group’s) specific behavior within a specific time, e.g., “A man is playing the piano at [10.2s, $34.5s J^{5}$ . Therefore, we curate our dataset DeVE-QA from Activity Net-Captions.
我们遵循密集事件描述 (Krishna et al. 2017) 的定义,将事件描述为一个人在特定时间内 (或一组人) 的特定行为的完整描述,例如 "一个男人正在弹钢琴 [10.2s, $34.5s J^{5}$"。因此,我们从 Activity Net-Captions 中筛选出 DeVE-QA 数据集。
Dataset Construction Given dense event captions, we derive question-answer sets by prompting GPT-4 (OpenAI 2024a) followed by human checking and corrections. Specifically, the construction process has three major stages (see Figure 2). In the first stage, we prompt GPT-4 to generate different types of question-answer pairs (QAs) corresponding to each individual event using videos with clear and long event descriptions captions (i.e., no pronouns and longer than 10 words). This encourages understanding the event from multiple different aspects, e.g. with an implicit pattern of ”who did what at where and when, why and how” implied from generation prompts. In the second stage, we retrieve distractor answers to form multiple choices for each question to facilitate deterministic evaluation. The distractor answers are from the answers of top-similar questions. Additionally, we incorporate approaches to maximally limit potential bias from the candidate answers, such as adding distractor answers related to different events in the same video. Then we also perform QA filtration to remove meaningless questions and also analyze the key activities inside the videos. The third stage is manual checking and correction to ensure the QA quality. We specially correct for 1) wrong QA pairs, 2) redundant questions, and 3) potential correct distractor answers. Finally, we obtain around 78k questions. We present an example in Figure 1. Other details along with the QAs are attached in Supplementary.
数据集构建
给定密集的事件描述,我们通过提示 GPT-4 (OpenAI 2024a) 生成问答集,并经过人工检查和修正。具体而言,构建过程分为三个阶段 (见图 2)。第一阶段,我们使用事件描述清晰且较长(即不含代词且超过 10 个单词)的视频,提示 GPT-4 为每个独立事件生成不同类型的问答对 (QAs),以鼓励从多个不同角度理解事件,例如通过生成提示中隐含的“谁在何时何地做了什么、为什么以及如何做”的模式。第二阶段,我们检索干扰答案,为每个问题形成多项选择,以便进行确定性评估。干扰答案来自相似度最高问题的答案。此外,我们采用多种方法尽可能限制候选答案中的潜在偏差,例如添加与同一视频中不同事件相关的干扰答案。随后,我们还进行问答过滤以剔除无意义的问题,并分析视频中的关键活动。第三阶段是人工检查和修正,以确保问答质量。我们特别修正了以下问题:1) 错误的问答对,2) 冗余问题,以及 3) 潜在的正确答案干扰项。最终,我们获得了约 78k 个问题。图 1 展示了一个示例,其他细节及问答对见补充材料。
Statistics and Analysis DeVE-QA is the first benchmark dataset that support question-answering of dense events in long videos. Table 1 shows detailed statistics of our $\mathrm{DeVE}\cdot$ - QAdataset. It comprises $10.6\mathrm{k}$ $7.2\mathrm{k}$ training $/3.5\mathrm{k}$ testing) videos and $78.3\mathrm{k}$ $(53.3\mathrm{k}$ training $/~25\mathrm{{k}}$ testing) questions. The average video length is 127s, with also many videos (more than 580) ranging from 4 to 10 minutes, The average number of questions per video is 7.5, and the average number of events per video is 2.6 (vs. 1 for most other benchmarks). A comparison between this two suggests that an average of 2.5 questions are posed about an individual event. Figure 3(a) shows the distribution of question types; questions are not only about “what is done” but also go beyond that to infer “how” and “why” questions to target a more comprehensive understanding of events. Note that the “when” questions are hidden in the requirement on temporal grounding. Also, we limit the number of “who” and “where” questions to keep them in a low percentage of the dataset, as they can be well-answered without the need for video-level understanding (Xu et al. 2017; Lei et al. 2018). Other analyses are presented in Supplementary.
统计与分析
DeVE-QA是首个支持长视频中密集事件问答的基准数据集。表1展示了我们$\mathrm{DeVE}\cdot$-QA数据集的详细统计信息。该数据集包含$10.6\mathrm{k}$个视频($7.2\mathrm{k}$个训练/$3.5\mathrm{k}$个测试)和$78.3\mathrm{k}$个问题($53.3\mathrm{k}$个训练/$25\mathrm{k}$个测试)。视频平均时长为127秒,其中超过580个视频时长在4至10分钟之间。每段视频平均包含7.5个问题和2.6个事件(其他基准数据集多为1个事件),这表明每个事件平均对应2.5个问题。
图3(a)展示了问题类型的分布情况:问题不仅涉及"做了什么",还包括推断"如何"和"为什么",以实现对事件更全面的理解。需注意"何时"类问题隐含在时序定位要求中。此外,我们限制了"谁"和"哪里"类问题的数量(Xu et al. 2017; Lei et al. 2018),因其无需视频级理解即可回答,这类问题在数据集中占比较低。其他分析详见补充材料。
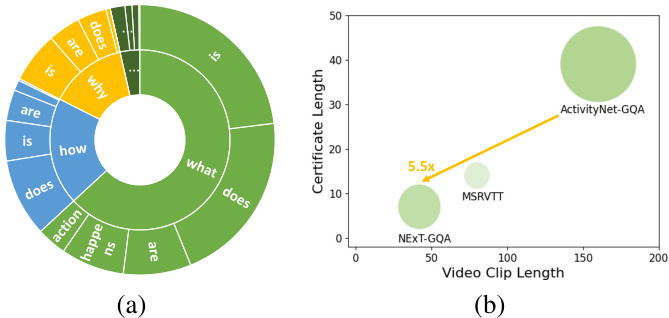
Figure $3\colon\mathrm{DeVE{-}Q A}$ analysis. (a) Questions based on first two words.(b) Certificate length of VideoQA datasets.
图 3: DeVE-QA 分析。(a) 基于前两个单词的问题。(b) VideoQA数据集的证书长度。
Table 2: Dataset comparison. D.E.: dense event.
表 2: 数据集对比。D.E.: 密集事件。
| 数据集 | D.E. | 视频时长(s) | #QAS | 片段长度(s) |
|---|---|---|---|---|
| MSRVTT-QA (Xu et al. 2017) | 15 | 243K | ||
| MSVD-QA (Xu et al. 2017) | 10 | 50K | ||
| TGIF-QA (Jang et al. 2017) | 3 | 139K | ||
| ActivityNet-QA (Yu et al. 2019) | 118 | 58K | ||
| NExT-QA (Xiao et al. 2021) | x | 44 | 52K | |
| TVQA (Lei et al. 2018) | 76 | 152K | 11.2 | |
| NExT-GQA (Xiao et al. 2024b) | x | 42 | 43K | 7.0 |
| DeVE-QA (ours) | 127 | 78K | 39.4 |
Comparison with Existing Benchmarks Table 2 compares DeVE-QA with existing VideoQA datasets. First and foremost, DeVE-QA targets at dense event and long-form VideoQA and enables temporal grounding evaluation. These requirement stands out from all existing datasets which focus on global video event (e.g., all datasets in the 1st block except for NExT-QA) and short videos (e.g., the top3 datasets listed in Table 2). Compared with other temporal grounding datasets such as TVQA (Lei et al. 2018) and NExT-GQA (Xiao et al. 2024b), DeVE-QA has longer videos and segments, shaping its challenge for event-level QA. For example, Figure 3(b) shows that the temporal certificate length (average length of video segments needed to answer a question (Mangalam, Akshulakov, and Malik 2024)) of DeVE-QA is $5.5\times$ that of NExT-GQA (Xiao et al.
与现有基准对比
表2比较了DeVE-QA与现有VideoQA数据集的特点。首先,DeVE-QA专注于密集事件和长视频问答,支持时序定位评估。这一特性使其显著区别于现有所有关注全局视频事件(例如第一栏除NExT-QA外的所有数据集)和短视频(如表2列出的前三个数据集)的数据集。与TVQA (Lei et al. 2018) 和NExT-GQA (Xiao et al. 2024b) 等其他时序定位数据集相比,DeVE-QA的视频和片段更长,这为事件级问答带来了挑战。例如,图3(b)显示DeVE-QA的时间凭证长度(回答问题所需的视频片段平均长度 (Mangalam, Akshulakov, and Malik 2024))是NExT-GQA (Xiao et al.) 的$5.5\times$。
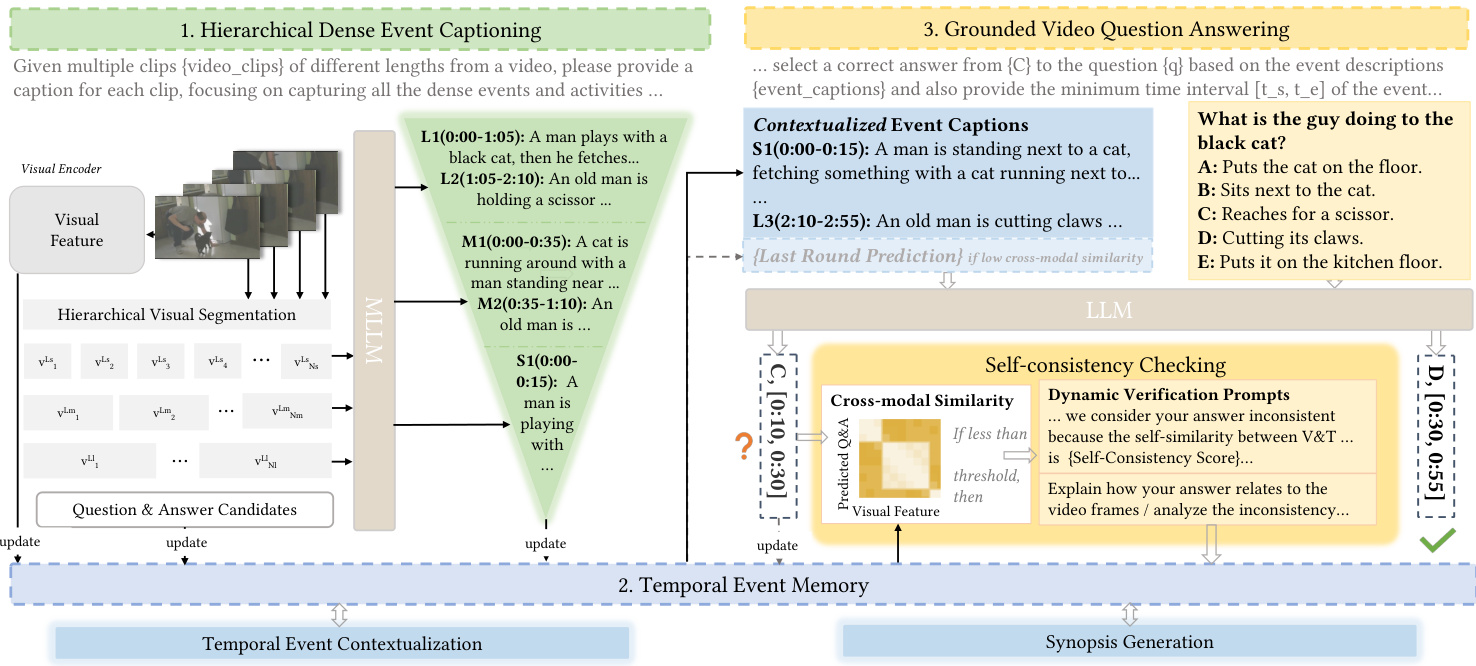
Figure 4: DeVi pipeline: (1) Hierarchical dense event video segmenting and captioning, (2) contextual i zing and memorizing events in temporal event memory, and (3) event-grounded video question answering with self-consistency checking.
图 4: DeVi流程: (1) 分层密集事件视频分割与描述生成, (2) 在时序事件记忆中进行事件上下文关联与记忆, (3) 基于事件的视频问答与自一致性校验。
2024b). In addition, TVQA pays attention to simple visual recognition of “what is” in TV shows. Its temporal grounding are biased to localizing the subtitles invoked in the QAs.
2024b)。此外,TVQA专注于电视剧中"是什么"的简单视觉识别,其时序定位偏向于定位问答中引用的字幕。
DeVi Solution
DeVi解决方案
Overview
概述
Formally, given a $T$ -second video $v$ containing a collection of events $E={e_{1},e_{2},\cdot\cdot\cdot,e_{n}}$ , a question $q$ along with candidate answer set $C={c_{1},\cdots,c_{5}}$ , dense video-event QA is to predict a correct answer $\hat{c}\in C$ and the relevant event moment $\hat{t}={t_{s},t_{e}}$ where $t_{s}\le t_{e}\le T$ . Our solution is conceptually as follows:
形式上,给定一段 $T$ 秒的视频 $v$ 包含事件集合 $E={e_{1},e_{2},\cdot\cdot\cdot,e_{n}}$,一个问题 $q$ 及候选答案集 $C={c_{1},\cdots,c_{5}}$,密集视频事件问答的任务是预测正确答案 $\hat{c}\in C$ 和相关事件时刻 $\hat{t}={t_{s},t_{e}}$,其中 $t_{s}\le t_{e}\le T$。我们的解决方案概念如下:
$$
\hat{c},\hat{t}=\psi(c,t|E,q,C)\phi(E|v),
$$
$$
\hat{c},\hat{t}=\psi(c,t|E,q,C)\phi(E|v),
$$
where $\phi$ and $\psi$ denote the models for dense event detection and event-conditioned QA respectively. Note that the time stamps $t$ come along with the detected events $E$ .
其中 $\phi$ 和 $\psi$ 分别表示密集事件检测和事件条件问答的模型。注意时间戳 $t$ 会随检测到的事件 $E$ 一同输出。
we realize the objective defined in Eqn. (1) as follows. First, to achieve dense video event detection $\phi(E|v)$ , we incorporate a hierarchical dense captioning mechanism into MLLMs to detect the video events at multiple different time scales. Then, we design a temporal event memory module that captures the long-term event dependency to contextual ize s and also memorize the individually detected video events $E$ . Finally, to achieve event-grounded QA $\psi(c,t|E,q,C)$ , we read from the memory the contextual i zed events $E$ , and feed it to LLMs along with the QAs (question $q$ and candidate answers $C$ ) to determine the correct answers and the corresponding event moments. In this process, we highlight a self-consistency checking mechanism to ensure the right answer for the right event. An overview of our solution is illustrated in Figure 4.
我们通过以下方式实现公式 (1) 中定义的目标。首先,为实现密集视频事件检测 $\phi(E|v)$ ,我们在多模态大语言模型 (MLLM) 中引入分层密集描述机制,以多时间尺度检测视频事件。接着,我们设计了时序事件记忆模块,该模块既能捕获长期事件依赖关系以构建上下文,又能单独记忆检测到的视频事件 $E$ 。最后,为实现基于事件的问答 $\psi(c,t|E,q,C)$ ,我们从记忆模块读取上下文事件 $E$ ,并将其与问答数据(问题 $q$ 和候选答案 $C$ )共同输入大语言模型,以确定正确答案及对应事件时刻。在此过程中,我们特别强调自一致性校验机制,确保答案与事件的正确匹配。解决方案概览如图 4 所示。
Hierarchical Dense Event Captioning
层次化密集事件描述
Temporal Event Memory
时序事件记忆
The above events are independently detected by focusing on individual local video segments. The lack of contextual information often results in inaccurate or incomplete event captions. While the hierarchical captioning strategy helps alleviate the issue, it cannot model the long-term temporal event dependency. For example, in the video shown in Figure 1, we may have captured the event of “a man enters the field” at the beginning and “a biker is performing” at the middle of the video. However, we cannot answer questions such as why the man enter the field and who (man or woman)
上述事件是通过聚焦于单个局部视频片段独立检测的。缺乏上下文信息往往导致事件描述不准确或不完整。虽然分层描述策略有助于缓解该问题,但无法建模长期时间事件依赖关系。例如,在图1所示的视频中,我们可能在开头捕捉到"一名男子进入场地"的事件,在视频中间捕捉到"骑自行车的人正在表演"的事件。但我们无法回答诸如该男子为何进入场地、以及谁(男子或女子)等问题
the biker is based on the individual event captions. By capturing temporal dependency, we aim to modify the events to be “a man enters the field for biking performance” and “a male biker is performing” to facilitate QA.
骑行者是基于单个事件描述的。通过捕捉时间依赖性,我们的目标是将事件修改为"一名男子进入场地进行自行车表演"和"一名男性骑行者正在表演",以便于问答。
Thus, to capture the long-term event dependency, we design an event memory module to contextual ize the event captions while also cache the original visual and event represent at ions. To be specific, we achieve this by prompting LLMs (e.g., GPT-4o (OpenAI 2024b)) to refine each caption in a way like “... given a set of event captions ${\mathrm{E}}$ and a question ${{\bf q}}$ of a video, you are required to refine each caption by incorporating contextual information from all the other captions and question via analyzing the overall narratives, identifying relevant context and incorporate context with coherence...”. We also curate examples to perform incontext-learning for LLMs before the actual generation. Additionally, we prompt GPT-4o to articulate all events into a synopsis $e_{y}$ which serves as a global event for the entire video. Consequently, we obtain $E^{\prime}={E_{s}^{'},E_{m}^{'},E_{l}^{'},e_{y}}$ , in which the events at each level are enhanced with long-range temporal dependency. More details are in Supplementary.
因此,为捕捉长期事件依赖关系,我们设计了事件记忆模块,用于对事件描述进行情境化处理,同时缓存原始视觉和事件表征。具体而言,我们通过提示大语言模型(如 GPT-4o (OpenAI 2024b))以下列方式优化每个描述:"...给定一组事件描述 ${\mathrm{E}}$ 和视频问题 ${{\bf q}}$,你需要通过分析整体叙事、识别相关上下文并保持连贯性地整合上下文信息,来优化每个描述..."。在实际生成前,我们还精选示例供大语言模型进行上下文学习。此外,我们提示 GPT-4o 将所有事件表述为概要 $e_{y}$,作为整个视频的全局事件。最终我们获得 $E^{\prime}={E_{s}^{'},E_{m}^{'},E_{l}^{'},e_{y}}$,其中每个层级的事件都通过长程时间依赖关系得到增强。更多细节见补充材料。
Generally, by transferring the video into different representations (visual features, hierarchical captions and synopsis), this module links the contextual events from longranged time periods to aid in answering questions and grounding results about specific events.
通常,通过将视频转换为不同的表示形式(视觉特征、分层字幕和概要),该模块将来自长时间段的上下文事件联系起来,以帮助回答有关特定事件的问题并提供基础结果。
Event-Grounded QA
事件驱动的问答
Intuitively, we can read the events $E^{\prime}$ from the event memory and feed it to LLMs (e.g., GPT-4o) along with the QAs to accomplish answer prediction and moment localization. This can be achieved by prompting like “... select a correct answer from ${C}$ to the question ${q}$ based on the events ${E}$ and also output the time span $[t_{s},t_{e}]$ of the event that carries the correct answer ...”. This method is straightforward but we find that the performance is not as good as expected. There is a large discrepancy where the LLM often gives the correct answer but with wrong time span or vice-versa. For improvement, we establish a mechanism to check for consistency between a predicted answer and the corresponding time span.
直观上,我们可以从事件记忆中读取事件 $E^{\prime}$ 并将其与大语言模型(例如 GPT-4o)及问答对一起输入,以完成答案预测和时间定位。这可以通过类似“...根据事件 ${E}$ 从选项 ${C}$ 中选择问题 ${q}$ 的正确答案,并输出承载正确答案的事件时间跨度 $[t_{s},t_{e}]$ ...”的提示来实现。这种方法虽然直接,但我们发现其性能不如预期。存在一个明显的差异:大语言模型经常给出正确答案但对应错误的时间跨度,反之亦然。为了改进这一点,我们建立了一种机制来检查预测答案与对应时间跨度之间的一致性。
We evaluate consistency based on the cosine similarity $R$ between the answer $a$ and the video content within time span $[t_{s},t_{e}]$ :
我们基于答案 $a$ 与时间跨度 $[t_{s},t_{e}]$ 内视频内容的余弦相似度 $R$ 来评估一致性:
$$
R_{v a}=c o s(f_{v},f_{a})=\frac{f_{v}\cdot f_{a}}{||f_{v}||||f_{a}||},
$$
$$
R_{v a}=c o s(f_{v},f_{a})=\frac{f_{v}\cdot f_{a}}{||f_{v}||||f_{a}||},
$$
where $f_{a}$ and $f_{v}$ are encodings of the answer text and video segment using CLIP (Radford et al. 2021). Predictions with low consistency (i.e., small $R_{v a}$ ) will be feedbacked to LLM for adjusting its predictions. This processes will iterate multiple times before getting the predictions with consistency that is higher than a threshold $\sigma$ or reaching the predefined maximal iteration number $\delta$ . More details are presented in the Supplementary.
其中 $f_{a}$ 和 $f_{v}$ 分别是答案文本和视频片段通过 CLIP (Radford et al. 2021) 编码后的表示。一致性较低的预测 (即 $R_{va}$ 值较小) 将被反馈给大语言模型以调整其预测结果。该过程会迭代多次,直到获得高于阈值 $\sigma$ 的一致性预测或达到预设的最大迭代次数 $\delta$。更多细节详见补充材料。
Table 3: Zero-shot VideoQA results on DeVE-QA. Only LLaMA-Adapter $\mathrm{(f/t)}$ is fune-tuned.
表 3: DeVE-QA 上的零样本视频问答结果。仅 LLaMA-Adapter $\mathrm{(f/t)}$ 进行了微调。
| 模型 | Acc@QA | 模型 | Acc@QA |
|---|---|---|---|
| Video-LLaMA | 41.2 | Videochat2 | 58.7 |
| InternVideo | 48.3 | SeViLA | 61.2 |
| VFC | 49.5 | GPT-40 | 62.6 |
| ViperGPT | 55.1 | PLLaVA13B | 63.7 |
| Video-LLaVA | 56.2 | LLoVi | 63.8 |
| LLaMA-adapter(f/t) | 58.3 | IG-VLM | 64.2 |
| DeVi (ours) | 70.8 |
Table 4: Grounded VideoQA results on DeVE-QA. *: pretrained on video-language grounding datasets.
| 模型 | mIoP | IoP@0.5 | mIoU | IoU@0.5 | Acc@QA | Acc@GQA |
|---|---|---|---|---|---|---|
| 弱监督 | ||||||
| FrozenBiLM(NG+) | 21.2 | 18.2 | 8.50 | 6.2 | 61.6 | 14.5 |
| TempCLIP | 24.6 | 24.8 | 12.5 | 9.1 | 58.9 | 14.9 |
| SeViLA* | 25.8 | 19.9 | 21.2 | 11.5 | 62.7 | 16.1 |
| 零样本 | ||||||
| LLoVi | 27.5 | 27.0 | 17.9 | 12.9 | 63.9 | 22.8 |
| DeVi (ours) | 33.8 | 32.2 | 20.7 | 17.4 | 70.9 | 26.9 |
表 4: DeVE-QA 上的视频问答定位结果。*: 在视频-语言定位数据集上预训练。
Experiments Configuration and Evaluation
实验配置与评估
Our experiments are conducted on the test set of DeVEQA. Additionally, we extend our experiments to NExTGQA (Xiao et al. 2024b). NExT-GQA supports research for grounded QA about multiple actions though not for event grounding. It contains 990 videos and 5,553 questions for testing. For hierarchical event captioning, the number of hierarchies $H$ is set to 3, and the segment lengths $L_{s}$ , $L_{m}$ and $L_{h}$ are set to ${10\mathrm{s},35\mathrm{s},65\mathrm{s}}$ for DeVE-QA and ${5\mathrm{s},$ 15s, $45\mathrm{s}}$ for NExT-GQA, respectively. For self-consistency checking, the similarity threshold $\sigma$ is set to 0.6 by implementation analysis in Table 5(d), and the maximal iteration number $\delta$ is set to 2 for efficiency. The thresholds are empirically determined according to the QA accuracy. For evaluation, we follow NExT-GQA (Xiao et al. 2024b) to report QA accuracy Acc $\ @\mathrm{QA}$ , grounding quality Intersection over Prediction (IoP) and Intersection over Union (IoU), as well as grounded QA accuracy Acc $@$ GQA, all in percentages $(%)$ .
我们的实验在DeVEQA测试集上进行。此外,我们还将实验扩展到NExT-GQA (Xiao et al. 2024b)。NExT-GQA支持针对多动作的基于视觉的问答研究(但不支持事件定位),包含990个测试视频和5,553个问题。在层次化事件描述任务中,层级数$H$设为3,片段长度$L_{s}$、$L_{m}$和$L_{h}$分别设置为${10\mathrm{s},35\mathrm{s},65\mathrm{s}}$(DeVE-QA)和${5\mathrm{s},15\mathrm{s},45\mathrm{s}}$(NExT-GQA)。自洽性检查的相似度阈值$\sigma$通过表5(d)的实现分析设为0.6,最大迭代次数$\delta$出于效率考虑设为2。所有阈值均根据问答准确率进行经验性设定。评估指标方面,我们沿用NExT-GQA (Xiao et al. 2024b)的报告方式:问答准确率Acc$\ @\mathrm{QA}$、定位质量预测交并比(IoP)和联合交并比(IoU),以及基于视觉的问答准确率Acc$@$GQA,结果均以百分比$(%)$表示。
Performance Analysis
性能分析
We first adapt the prominent MLLMs (e.g., Video-LLaMA (Zhang, Li, and Bing 2023), Intern Video (Wang et al. 2023), VFC (Momeni et al. 2023), etc) that perform well on “single event” QA to DeVE-QA and compare them with DeVi. The models (except for LLaMA-Adapter (Zhang et al. 2023b)) are directly prompted for zero-shot VideoQA. We specify the adaptation in Supplementary. Most of these methods do not perform grounding, so we compare $\operatorname{Acc}@\operatorname{QA}$ .
我们首先将表现突出的多模态大语言模型(如Video-LLaMA (Zhang, Li, and Bing 2023)、Intern Video (Wang et al. 2023)、VFC (Momeni et al. 2023)等)适配到DeVE-QA任务中,这些模型在“单一事件”问答任务上表现良好,并与DeVi进行比较。除LLaMA-Adapter (Zhang et al. 2023b)外,其他模型均采用零样本视频问答直接提示。具体适配方法详见补充材料。由于大多数方法不执行定位任务,因此我们比较$\operatorname{Acc}@\operatorname{QA}$指标。
Table 3 shows that DeVi, with an accuracy of $70.8%$ , outperforms the second-best model IG-VLM (Kim et al. 2024) significantly by $6.6%$ . Moreover, DeVi surpasses a native use of GPT-4o (feed multiple video frames and prompt GPT4o for question answering) remarkably by $8.2%$ and a naive
表 3 显示,DeVi 以 $70.8%$ 的准确率显著优于第二名模型 IG-VLM (Kim et al. 2024) $6.6%$ 。此外,DeVi 比直接使用 GPT-4o (输入多帧视频并提示 GPT4o 进行问答) 的准确率高出 $8.2%$ ,且明显优于简单...
Table 5: Grounded VideoQA results on NExT-GQA. *: pretrained on video-language grounding datasets.
表 5: NExT-GQA上的视频问答定位结果。*: 在视频-语言定位数据集上预训练。
| 模型 | mloP | IoP@0.5 | mIoU | IoU@0.5 | Acc@QA | Acc@GQA |
|---|---|---|---|---|---|---|
| 弱监督 | ||||||
| TempCLIP | 25.7 | 25.5 | 12.6 | 8.9 | 60.2 | 15.9 |
| FrozenBiLM(NG+) | 24.2 | 23.7 | 9.5 | 6.1 | 70.8 | 17.5 |
| SeViLA* | 29.5 | 22.9 | 21.7 | 13.8 | 68.1 | 16.6 |
| 零样本 | ||||||
| LLoVi | 37.3 | 36.9 | 20.0 | 15.3 | 66.8 | 24.3 |
| DeVi | 39.3 | 37.9 | 22.3 | 17.4 | 71.6 | 28.0 |
| 模型 | Acc@QA | Acc@GQA |
|---|---|---|
| DeVi | 70.8 | 26.9 |
| 无分层密集描述 (w/o Hierarchical Dense Captioning) | 66.9 | 23.3 |
| 无时序上下文建模 (w/o Temporal Contextualizing) | 68.8 | 25.3 |
| 无一致性校验 (w/o Consistency Checking) | 66.3 | 21.7 |
Table 6: Major model ablation on DeVE-QA. We ablate the components by removing one at a time.
表 6: DeVE-QA 主要模型消融实验。我们通过逐一移除组件进行消融。
dense-caption based QA method LLoVi (Zhang et al. 2023a) by $7.0%$ . We also find that all other end-to-end MLLMs such as Video-LLaMA, Video-LLaVA and VideoChat2 perform worse than $\mathrm{DeVi}$ by $10%\sim30%$ . The results demonstrate that DeVi has made significant optimization s over general MLLMs on the challenges posed by performing questionanswering on dense video events.
基于密集描述的视频问答方法LLoVi (Zhang et al. 2023a) 的性能比$\mathrm{DeVi}$低$7.0%$。我们还发现其他端到端多模态大语言模型(如Video-LLaMA、Video-LLaVA和VideoChat2)的表现比$\mathrm{DeVi}$差$10%\sim30%$。结果表明,在面对密集视频事件问答挑战时,DeVi相比通用多模态大语言模型实现了显著优化。
Table 4 presents grounded QA accuracy, comparing with methods from (Xiao et al. 2024b). DeVi surpasses state-ofthe-art zero-shot method LLoVi by $4.1%$ on $\operatorname{Acc}@\operatorname{GQA}$ . Furthermore, improvements come from both better QA $(+7.0%$ Acc@QA) and better grounding $(+5.2%\mathrm{IoP}@0.5)$ . This differs from the previous methods, where improvements are primarily from either better grounding or better QA alone (also see Table 5 on NExT-GQA).
表 4 展示了基于事实的问答准确率,并与 (Xiao et al. 2024b) 的方法进行了对比。DeVi 在 $\operatorname{Acc}@\operatorname{GQA}$ 上以 $4.1%$ 的优势超越了当前最先进的零样本方法 LLoVi。此外,改进来自更优的问答性能 $(+7.0%$ Acc@QA) 和更精准的定位能力 $(+5.2%\mathrm{IoP}@0.5)$。这与之前的方法形成鲜明对比——那些方法的提升通常仅源于单一维度的优化 (另见 NExT-GQA 的表 5)。
Table 5 shows that DeVi consistently achieves superior performance on NExT-GQA, outperforming the second-best method LLoVi by $3.7%$ . The results demonstrate $\mathrm{DeVi}$ ’s superiority in multi-action video understanding aside from dense-event video understanding.
表 5: 显示 DeVi 在 NExT-GQA 上持续取得更优性能,以 $3.7%$ 的优势超越次优方法 LLoVi。结果表明 $\mathrm{DeVi}$ 不仅在密集事件视频理解方面,在多动作视频理解领域同样具有优势。
Ablation Study
消融实验
We first conduct an ablation to the 3 major designs in DeVi on DeVE-QA. Table 6 shows that all three components significantly contribute to DeVi’s success. Specifically, by substituting the hierarchical event captioning with a normal dense video captioning used in LLoVi (Zhang et al. 2023a), the results in Table 6 show that both QA and GQA accuracy decline remarkable by $3.9%$ and $3.6%$ . Moreover, the ablation comparison in Table 7 demonstrate that without hierarchical event captioning strategy, DeVi ’s performance on dense events drops apparently (e.g., $-4.4%$ on QA) compared to single and double events (e.g., - $-1.6%$ and $-3.4%$ on QA). We speculate that this demonstrate its ability of capturing specific information from different scales in multiple and complicated events. Then, we remove the temporal event contextual iz ation module. The results again degrade by $2.0%$ on QA and $1.6%$ on GQA. This is understandable as contextual i zed captions are rectified with potential mis
我们首先在DeVE-QA上对DeVi的三大设计进行消融实验。表6显示这三个组件都对DeVi的成功有显著贡献。具体而言,当用LLoVi (Zhang et al. 2023a)中使用的常规密集视频描述替代分层事件描述时,表6结果显示QA和GQA准确率分别显著下降$3.9%$和$3.6%$。此外,表7的消融对比表明,与单事件和双事件相比(如QA分别下降$-1.6%$和$-3.4%),缺乏分层事件描述策略会使DeVi在密集事件上的性能明显下降(如QA下降$-4.4%$)。我们推测这表明其具备从多尺度复杂事件中捕捉特定信息的能力。接着,我们移除了时序事件上下文模块,结果QA和GQA准确率再次分别下降$2.0%$和$1.6%$。这可以理解,因为上下文描述能修正潜在的误...
| 指标 | 模型 | 事件密度-单事件 | 事件密度-双事件 | 事件密度-密集事件 | 事件密度-总计 |
|---|---|---|---|---|---|
| Acc@QA | FrozenBiLM(NG+) | 62.1 | 61.8 | 59.2 | 61.6 |
| SeViLA | 63.3 | 62.9 | 61.7 | 62.7 | |
| LLoVi | 65.2 | 65.8 | 61.2 | 63.9 | |
| DeVi(w/oHDC) DeVi | 66.2 67.8 | 65.5 68.9 | 67.1 71.5 | 66.9 70.8 | |
| Acc@GQA | FrozenBiLM(NG+) | 15.1 | 15.0 | 13.9 | 14.5 |
| SeViLA | 15.9 | 16.1 | 16.2 | 16.1 | |
| LLoVi | 24.1 | 22.6 | 21.1 | 22.8 | |
| DeVi(w/oHDC) | 23.5 | 23.3 | 24.2 | 23.3 | |
| DeVi | 25.5 | 26.4 | 28.2 | 26.9 |
Table 7: Results w.r.t. different event densities. Single/Double/Dense-Event: 1/2/more than 2 main event(s) is/are present in the related videos. 200 videos are selected for each event-density level, respectively. HDC: Hierarchical dense captioning.
表 7: 不同事件密度下的结果。单事件/双事件/密集事件: 相关视频中存在1/2/超过2个主要事件。每个事件密度级别分别选取200个视频。HDC: 分层密集描述 (Hierarchical dense captioning)。
Table 8: Results w.r.t. different video lengths. Short/Medium/Long: videos that are 0-60/60-120/more than 120 seconds. 200 videos are selected for each event-density level, respectively. TC: Temporal Contextual i zing.
| 指标 | 模型 | 视频长度-短 | 视频长度-中 | 视频长度-长 | 总计 |
|---|---|---|---|---|---|
| Acc@QA | SeViLA | 64.2 | 62.4 | 60.6 | 62.7 |
| LLoVi | 66.0 | 64.1 | 62.8 | 63.9 | |
| DeViw/oTC | 68.9 | 68.8 | 68.8 | 68.8 | |
| DeVi | 70.1 | 70.8 | 71.7 | 70.8 | |
| Acc@GQA | SeViLA | 18.4 | 16.2 | 14.9 | 16.1 |
| LLoVi | 24.7 | 22.4 | 21.1 | 22.8 | |
| DeViw/oTC | 25.4 | 25.5 | 25.2 | 25.3 | |
| DeVi | 25.5 | 26.8 | 27.5 | 26.9 |
表 8: 不同视频长度的结果。短/中/长: 0-60/60-120/超过120秒的视频。每个事件密度级别分别选取200个视频。TC: 时序上下文建模。
understanding and in completion that might arise from isolation captioning. Moreover, the ablation results (e.g., $-2.3%$ on long video GQA -1.1% on short video GQA ) in Table 8 also justify its ability on longer videos. Finally, we remove the self-consistency checking module and apply an intuitive way to prompt LLMs for final predictions. We find that the QA and especially GQA accuracy degenerate significantly by $5.2%$ , suggesting that a large amount of answers only ”guess” the answer and provide irrelevant video segments. Naturally, these answers could not be found and corrected without self-consistency checking process.
理解以及因孤立描述可能产生的完成问题。此外,表8中的消融实验结果(例如长视频GQA下降2.3% vs. 短视频GQA下降1.1%)也验证了其对较长视频的处理能力。最后,我们移除了自一致性检查模块,并采用直观方式提示大语言模型进行最终预测。发现QA(尤其是GQA)准确率显著下降5.2%,表明大量答案仅通过"猜测"给出,并提供了无关视频片段。显然,若缺乏自一致性检查流程,这些错误答案将无法被识别和修正。
To better illustrate the advantage of DeVi, we present an example on DeVE-QA in Figure 6. The comparison of QA and grounding results between different models demonstrate the efficacy of $\mathrm{DeVi}$ , as well as our design with selfconsistency checking (in temporal grounding) and hierarchical dense captioning (in dense event QA). Specifically, self-consistency checking is effective in correcting wrongly grounded segments. Hierarchical dense captioning is helpful for event-grounded QA. Temporal contextual i zing helps improve QA and grounding as well.
为了更好地说明DeVi的优势,我们在图6中展示了一个DeVE-QA的示例。不同模型在问答和定位结果上的对比证明了$\mathrm{DeVi}$的有效性,以及我们在时间定位中设计的自一致性检查机制和密集事件问答中的分层密集描述方案。具体而言,自一致性检查能有效修正错误定位的片段,分层密集描述有助于基于事件的问答任务,时序上下文建模也同时提升了问答和定位性能。
To better dissect the models’ behavior in answering questions about videos with different event density and lengths, we conduct additional evaluation on video subsets with different event numbers and lengths in Table 7 and 8, respectively. Table 7 delivers an interesting finding: The accuracy of existing MLLMs decreases with the increase of event density, whereas DeVi’s accuracy increases. This clearly demonstrates DeVi’s strength in coping with dense-event videos. Also, we analyze performance with different length of videos to better justify DeVi’s long-range temporal ability, as shown in Table 8. Apparently, DeVi increases its performance when videos become longer, while other baseline models decreases visibly. This unequivocally shows DeVi’s proficiency in handling lengthy videos. Additionally, the results in Table 7 and 8 highlight the importance of hierarchical dense event captioning and temporal event contextual izing for handing dense events and long videos respectively.
为了更好地剖析模型在回答关于不同事件密度和长度视频问题时的行为,我们分别在表7和表8中对不同事件数量和长度的视频子集进行了额外评估。表7揭示了一个有趣的现象:现有MLLM的准确率随事件密度增加而下降,而DeVi的准确率却随之上升。这清晰地证明了DeVi在处理高事件密度视频时的优势。同时,如表8所示,我们还分析了不同视频长度下的性能表现,以进一步验证DeVi的长时程时序能力。显然,当视频变长时,DeVi的性能有所提升,而其他基线模型则明显下降。这无疑表明了DeVi在处理长视频方面的熟练程度。此外,表7和表8的结果分别凸显了分层密集事件描述和时间事件上下文化对于处理密集事件和长视频的重要性。
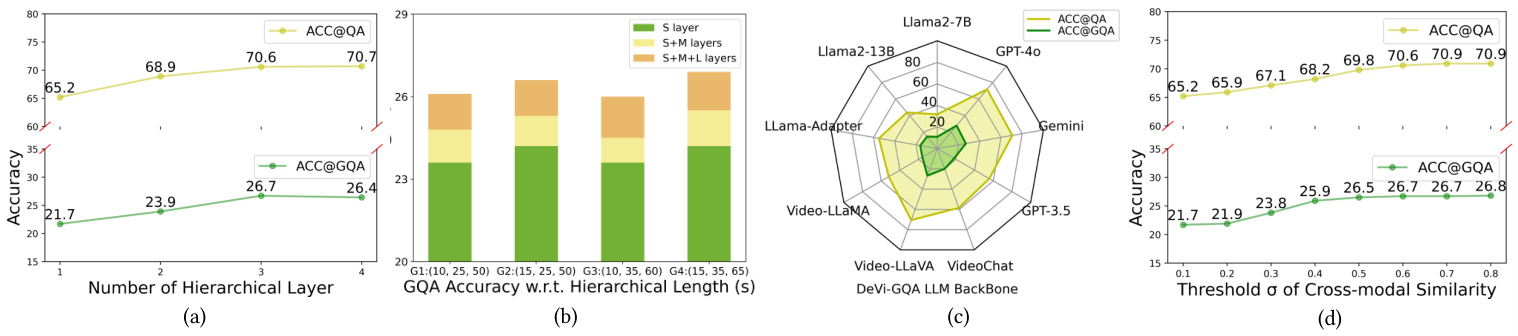
Figure 5: Analysis of $\mathrm{DeVi}$ . (a) Hierarchy layers analysis. (b) Video hierarchical segment length analysis. (c) MLLM reasoning backbone analysis on DeVE-QA. (d) QA and GQA accuracy w.r.t. cross-modal similarity threshold $\sigma$ .
图 5: $\mathrm{DeVi}$ 分析。(a) 层次结构分析。(b) 视频分层片段长度分析。(c) DeVE-QA上的MLLM推理主干分析。(d) QA和GQA准确率与跨模态相似度阈值 $\sigma$ 的关系。
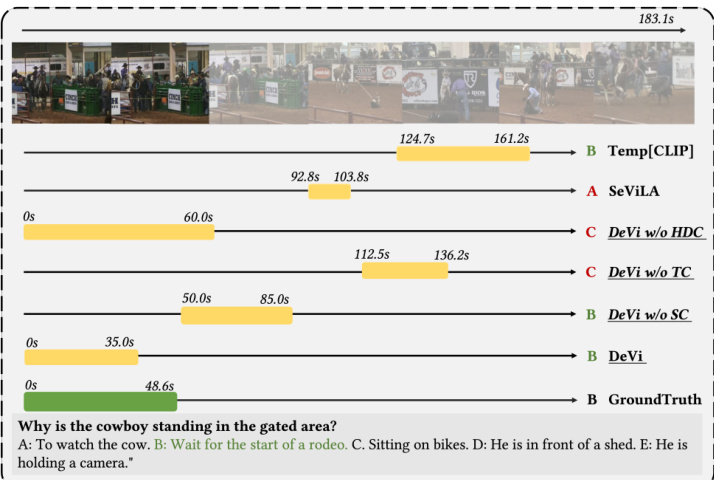
Figure 6: Prediction visualization on DeVE-QA. Baseline models like SeViLA and Temp[CLIP] tend to answer the question without truly grounding it to related video segments. Hierarchical Dense Captioning (HDC) is useful to improve QA. Temporal Contextual i zing (TC) helps improve GQA. Self-consistency checking (SC) is effective in correcting wrongly grounded segments.
图 6: DeVE-QA 预测可视化。SeViLA 和 Temp[CLIP] 等基线模型倾向于直接回答问题而非真正关联到相关视频片段。分层密集描述 (HDC) 有助于提升问答效果。时序上下文建模 (TC) 能改进图问答题 (GQA) 。自洽性校验 (SC) 可有效修正错误关联的片段。
Implementation Investigation
实现调研
Dense Video Event Captioner Table 9 shows that a substitution of Video-LLaVA with VideoBLIP deteriorates the accuracy by near $4%$ and $7%$ for QA with and without grounding respectively. We speculate that apart from the larger size of Video-LLaVA, its unified mapping mechanism for visual and textual features allows for better visual context understanding. Plus, its comprehensive pre training strategy brings robustness for analyzing different domain videos, thus resulting in more accurate caption generation.
密集视频事件描述器
表 9 显示,将 Video-LLaVA 替换为 VideoBLIP 后,带定位和不带定位的问答准确率分别下降了近 $4%$ 和 $7%$。我们推测,除了 Video-LLaVA 的模型规模更大外,其视觉与文本特征的统一映射机制有助于更好地理解视觉上下文。此外,其全面的预训练策略为分析不同领域视频带来了鲁棒性,从而生成更准确的描述。
Table 9: Captioner ablation.
表 9: 字幕生成模型消融实验。
| 字幕模型 | Acc@QA | Acc@GQA |
|---|---|---|
| VideoBLIP | 62.1 | 22.0 |
| VideoBLIPwHDC | 64.2 | 23.9 |
| Video-LLaVA | 68.9 | 25.6 |
| Video-LLaVA wHDC | 70.8 | 26.9 |
Then we further analyze the influence of hierarchy level and segmentation length on DeVE-QA. As depicted in Figure 5(a), the results peak at 3 hierarchy layers; the hyperparameters are finalized to be 15s, 35s, and 65s with experiments. Additionally, we observe from Figure 5(b) that increasing segment length brings better GQA accuracy (G2 & G3), indicating that it is influenced by the nature of datasets (overall duration, timestamps, etc.).
接着我们进一步分析层次级别和分段长度对DeVE-QA的影响。如图5(a)所示,结果在3个层次时达到峰值;通过实验最终确定超参数为15秒、35秒和65秒。此外,从图5(b)中我们观察到,增加分段长度会带来更好的GQA准确率(G2和G3),这表明它受数据集特性(总时长、时间戳等)的影响。
LLM Backbone Figure 5(c) shows that GPT-4o achieves the best performance $70.8%$ for QA and $26.9%$ for GQA), followed by Gemini $(69.3%)$ and Video-LLaVA $(64.8%)$ . These results again suggest that stronger LLMs (e.g., GPT4o) are key to success, as indicated by the remarkable margins in both GQA and QA accuracy between GPT-4o and other alternatives. We also observe that the GQA accuracy improves when increasing LLM size of the same model (e.g., from $10.9%$ of LLama2-7B to $4.6%$ of LLama2-13B). We speculate that larger model is more adept at understanding nuanced relationships within the video content and this further demonstrates our choice of large models.
大语言模型主干
图5(c)显示GPT-4o在问答(QA)任务上取得最佳性能(70.8%),在图形问答(GQA)任务上达到26.9%,其次是Gemini(69.3%)和Video-LLaVA(64.8%)。这些结果再次表明,更强的大语言模型(如GPT-4o)是成功关键,其在GQA和QA准确率上与其他方案存在显著差距。我们还发现,当增大同系列模型的参数规模时(如从LLama2-7B的10.9%提升至LLama2-13B的4.6%),GQA准确率会相应提高。我们推测更大规模的模型更擅长理解视频内容中的细微关联,这进一步验证了我们选用大模型的合理性。
Conclusion
结论
In this paper, we proposed to study question answering on dense video events to challenge the MLLMs from three aspects of dense-event captioning, long-form video understanding, and faithful multimodal reasoning by grounding. We constructed the DeVE-QA dataset with manual efforts and proposed DeVi model. DeVi is a training-free MLLM approach that solves the aforementioned challenges by a set of tailored practices, including hierarchical dense event captioning, temporal event contextual i zing and memoring, and trustworthy QA with self-consistency checking. Our extensive experiments demonstrate the effectiveness and superiority of DeVi in performing QA in the context of dense video events. We also share some implementation alternatives and highlight the power of larger MLLMs for our success. With these efforts, we hope this work provides a solid foundation for QA research on dense video events.
本文提出通过密集事件视频问答任务,从密集事件描述、长视频理解和基于定位的可靠多模态推理三个维度挑战大语言模型。我们人工构建了DeVE-QA数据集并提出了DeVi模型。DeVi是一种免训练的大语言模型方案,通过分层密集事件描述、时序事件上下文记忆以及自一致性检验的可信问答等定制化方法解决上述挑战。大量实验表明DeVi在密集视频事件问答场景中具有显著优势和有效性。我们还探讨了不同实现方案的对比,并验证了更大规模大语言模型的关键作用。希望这项工作能为密集视频事件问答研究奠定坚实基础。
References Alayrac, J.-B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Has- son, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. 2022. Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems, 35: 23716–23736. Bai, Z.; Wang, R.; and Chen, X. 2024. Glance and focus: Memory prompting for multi-event video question answering. Advances in Neural Information Processing Systems, 36. Chen, H.; Li, J.; and Hu, X. 2020. Delving deeper into the decoder for video captioning. In ECAI 2020, 1079–1086. IOS Press.Dai, W.; Li, J.; Li, D.; Tiong, A. M. H.; Zhao, J.; Wang, W.; Li, B.; Fung, P.; and Hoi, S. 2023. Instruct BLIP: towards general-purpose vision-language models with instruction tuning. In Proceedings of the 37th International Conference on Neural Information Processing Systems, 49250– 49267. Jang, Y.; Song, Y.; Yu, Y.; Kim, Y.; and Kim, G. 2017. Tgifqa: Toward spatio-temporal reasoning in visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2758–2766. Johnson, J.; Karpathy, A.; and Fei-Fei, L. 2016. Densecap: Fully convolutional localization networks for dense captioning. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4565–4574. Kim, W.; Choi, C.; Lee, W.; and Rhee, W. 2024. An image grid can be worth a video: Zero-shot video question answering using a vlm. arXiv preprint arXiv:2403.18406. Ko, D.; Lee, J. S.; Kang, W.; Roh, B.; and Kim, H. J. 2023. Large language models are temporal and causal reasoners for video question answering. arXiv preprint arXiv:2310.15747. Krishna, R.; Hata, K.; Ren, F.; Fei-Fei, L.; and Car-los Niebles, J. 2017. Dense-captioning events in videos. In Proceedings of the IEEE international conference on computer vision, 706–715. Lei, J.; Yu, L.; Bansal, M.; and Berg, T. L. 2018. Tvqa: Localized, compositional video question answering. arXiv preprint arXiv:1809.01696. Li, J.; Li, D.; Savarese, S.; and Hoi, S. 2023a. Blip-2: Boots trapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, 19730–19742. PMLR. Li, K.; He, Y.; Wang, Y.; Li, Y.; Wang, W.; Luo, P.; Wang,Y.; Wang, L.; and Qiao, Y. 2023b. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355.
参考文献
Alayrac, J.-B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; 等. 2022. Flamingo: 一种用于少样本学习的视觉语言模型. 《神经信息处理系统进展》, 35: 23716–23736.
Bai, Z.; Wang, R.; 和 Chen, X. 2024. 一瞥与聚焦: 多事件视频问答的记忆提示机制. 《神经信息处理系统进展》, 36.
Chen, H.; Li, J.; 和 Hu, X. 2020. 深入解码器探索视频描述生成. 《ECAI 2020》, 1079–1086. IOS Press.
Dai, W.; Li, J.; Li, D.; Tiong, A. M. H.; Zhao, J.; Wang, W.; Li, B.; Fung, P.; 和 Hoi, S. 2023. Instruct BLIP: 通过指令微调构建通用视觉语言模型. 《第37届国际神经信息处理系统会议论文集》, 49250–49267.
Jang, Y.; Song, Y.; Yu, Y.; Kim, Y.; 和 Kim, G. 2017. TGIF-QA: 视觉问答中的时空推理研究. 《IEEE计算机视觉与模式识别会议论文集》, 2758–2766.
Johnson, J.; Karpathy, A.; 和 Fei-Fei, L. 2016. DenseCap: 全卷积定位网络实现密集描述生成. 《IEEE计算机视觉与模式识别会议论文集》, 4565–4574.
Kim, W.; Choi, C.; Lee, W.; 和 Rhee, W. 2024. 图像网格可替代视频: 基于视觉语言模型的零样本视频问答. arXiv预印本 arXiv:2403.18406.
Ko, D.; Lee, J. S.; Kang, W.; Roh, B.; 和 Kim, H. J. 2023. 大语言模型作为视频问答的时间与因果推理器. arXiv预印本 arXiv:2310.15747.
Krishna, R.; Hata, K.; Ren, F.; Fei-Fei, L.; 和 Carlos Niebles, J. 2017. 视频事件密集描述生成. 《IEEE国际计算机视觉会议论文集》, 706–715.
Lei, J.; Yu, L.; Bansal, M.; 和 Berg, T. L. 2018. TVQA: 局部化组合式视频问答. arXiv预印本 arXiv:1809.01696.
Li, J.; Li, D.; Savarese, S.; 和 Hoi, S. 2023a. BLIP-2: 冻结图像编码器与大语言模型引导的语言-图像预训练. 《国际机器学习会议》, 19730–19742. PMLR.
Li, K.; He, Y.; Wang, Y.; Li, Y.; Wang, W.; Luo, P.; Wang, Y.; Wang, L.; 和 Qiao, Y. 2023b. VideoChat: 以对话为中心的视频理解框架. arXiv预印本 arXiv:2305.06355.
Appendix A: DeVE-QA Dataset Construction
附录 A: DeVE-QA 数据集构建
Activity Net-Captions dataset (Krishna et al. 2017) is the data source of DeVE-QA. It contains $20\mathrm{k\Omega}$ videos amounting to 849 hours with $100\mathrm{k\Omega}$ descriptions, each with it’s unique start and end timestamps. On average, the captions for each video describe $94.6%$ of the entire video content (Johnson, Karpathy, and Fei-Fei 2016), demonstrating that each caption annotation could cover the corresponding major events within the video. Furthermore, $10%$ of the temporal descriptions overlap with each other, showing that the events cover simultaneous events. By selecting Activity Net-Captions as our data source, we first conduct raw data filtering with filter criteria that 1) the descriptions should be more than 10 words, and 2) captions for each video cover at least $95%$ of the video. Then we perform random sampling over all the Activity Net-Captions to get the final subset of 10,643 videos and 26,111 captions.
Activity Net-Captions数据集 (Krishna et al. 2017) 是DeVE-QA的数据来源。该数据集包含 $20\mathrm{k\Omega}$ 个视频,总计849小时时长,附带 $100\mathrm{k\Omega}$ 条描述文本,每条描述都有独立的起止时间戳。平均而言,每个视频的字幕覆盖了 $94.6%$ 的视频内容 (Johnson, Karpathy, and Fei-Fei 2016),表明每条标注都能涵盖视频中的主要事件。此外, $10%$ 的时间描述存在相互重叠,说明事件标注覆盖了同步发生的场景。我们选择Activity Net-Captions作为数据源后,首先执行原始数据过滤,筛选标准为:1) 描述文本需超过10个单词,2) 每个视频的字幕覆盖率至少达到 $95%$ 。随后对所有Activity Net-Captions数据进行随机采样,最终获得包含10,643个视频和26,111条字幕的子集。
Automatic QA Generation
自动问答生成
During the generation process, we first perform automated QA generation with dense event captions by prompting GPT-4.0. Specifically, we feed 26,111 event captions of Activity Net-Captions into GPT-4.0, and prompt it to generate multiple (maximal 3 to limit the cost) different questionanswer pairs pertaining to different aspects of a particular event caption.
在生成过程中,我们首先通过提示 GPT-4.0 对密集事件描述进行自动化问答生成。具体而言,我们将 Activity Net-Captions 的 26,111 条事件描述输入 GPT-4.0,并提示其为每条特定事件描述生成最多 3 组(以控制成本)涉及不同方面的问题-答案对。
During the QA generation process, we also perform analysis on one-shot vs. n-shot prompting strategy. To be specific, one-shot strategy prompts once for all $\mathbf{N}$ captions It is cost-efficient by sending less tokens to GPT-4. However, the generated questions appear to be of low quality and are often similar to each other. Alternatively, n-shot strategy separately prompts for each caption. It is relatively costinefficient compared to one-shot because of the attached prompt, but it significantly improves the generated QA quality. We speculate that N-shot prompting is able to utilize more tailored and content-specific information from each caption for generating questions. Moreover, it is likely that the one-shot prompting generate questions by using the information from all N captions simultaneously, despite these captions being originally intended to be separate entities. quality because it allows for more tailored and contextspecific questions for each caption, reducing redundancy and enhancing the diversity and relevance of the generated questions. Considering the quality, we eventually opt for the n-shot prompting strategy.
在QA生成过程中,我们还分析了一样本(one-shot)与多样本(n-shot)提示策略。具体而言,一样本策略对所有$\mathbf{N}$条字幕仅提示一次,通过向GPT-4发送更少的token实现成本效益。但生成的问题质量较低且往往雷同。而多样本策略则对每条字幕单独提示,虽然因附加提示导致成本效率相对较低,但显著提升了生成QA的质量。我们推测多样本提示能利用每条字幕中更具针对性和内容特异性的信息来生成问题。此外,一样本提示可能同时利用所有N条字幕的信息生成问题,尽管这些字幕本应是独立实体。多样本策略通过为每条字幕生成更定制化、上下文相关的问题,减少了冗余并增强了问题的多样性和相关性。基于质量考量,我们最终选择了多样本提示策略。
Distractor Answers Retrieval
干扰项答案检索
After the QA generation process, question and corresponding correct answers are obtained. To curate the distractor answers and form multiple choices, we incorporate the following steps: For each question, we first retrieve its Top-10 similar questions and use their correct answers as candidate wrong answers. In particular, the Top-10 similar questions is obtained by the similarity of first 3 words which indicate both the question types and the subject of activities. To ensure hard negatives, we additionally filter for videoirrelevant candidate answers. Specifically, for each question
在问答生成过程后,我们获得了问题及其对应的正确答案。为了整理干扰项答案并形成多项选择题,我们采用了以下步骤:针对每个问题,首先检索其前10个相似问题,并将这些问题的正确答案作为候选错误答案。具体而言,前10个相似问题是通过问题前3个单词的相似度获得的,这些单词既表明了问题类型,也反映了活动主题。为确保干扰项的难度,我们还额外筛选了与视频无关的候选答案。具体来说,针对每个问题
You are a good question generator. I need your help in generating question-answer pairs pertaining to the visual event descriptions. Below are the examples:
你是一个优秀的问题生成器。我需要你帮助生成与视觉事件描述相关的问题-答案对。示例如下:
• Given description: An elderly man is playing the piano in front of a crowd. Good generated Question-Answer (QA) pairs can be: Q: What is the elderly man doing in front of a crowd? A: Playing the piano. Q: Why is a crowd in front of an elderly man? A: Watch him playing the piano. Q: How did the elderly man attract the crowd? A: Playing the piano. • Given description: A woman walks to the piano and briefly talks to the elderly man. Good QAs can be: Q: Why did the woman walk to the piano? A: Talks to the elderly man. Q: What does the woman do before talking to the elderly man? A: Walk to the piano. Q: What does the woman do after walking to the piano? A: Talks to the elderly man. Please generate up to 3 QA pairs for each description, and limit the generated questions to a maximal 22 words while the answers to a maximal 6 words. I hope your questions feature different causal and temporal reasoning keywords such as ’why’ and ’how’, ’before’ and ’after’. Different questions should be diverse and be related to different aspects of the described events. Also, make sure the answer is correct according to the description. ... Please label each question in sequence. Here are the descriptions: descriptions .
• 给定描述:一位老人在人群前弹钢琴。可生成的良好问答对 (QA) 如下:
Q1: 老人在人群前做什么?
A1: 弹钢琴。
Q2: 为什么人群聚集在老人面前?
A2: 看他弹钢琴。
Q3: 老人如何吸引人群?
A3: 弹钢琴。
• 给定描述:一位女士走向钢琴并简短地与老人交谈。良好的问答对如下:
Q1: 女士为何走向钢琴?
A1: 与老人交谈。
Q2: 女士在与老人交谈前做了什么?
A2: 走向钢琴。
Q3: 女士走向钢琴后做了什么?
A3: 与老人交谈。
请为每个描述生成最多3组问答对,并将问题限制在最多22个单词,答案限制在最多6个单词。希望您的问题包含不同的因果和时间推理关键词,如“为什么”“如何”“之前”“之后”。不同问题应多样化,并涉及描述事件的不同方面。同时确保答案与描述一致。……请按顺序标注每个问题。以下是描述内容:descriptions。
Table 10: Prompt for question generation.
表 10: 问题生成的提示词。
and its corresponding temporal segment, we sample video frames that are outside this temporal segment (covering its left or right parts) and use them to further retrieve the candidate answers by calculating the cross-modal similarity between frames and other related QA pairs. Finally, we select two such candidate answers that are relevant to the video but not the target segment, thus encouraging temporal grounding to answer the questions. To further encourage spatial reasoning, we include one candidate answer that is related to the segment but is wrong regarding the question. Finally, we randomly select one candidate answer from the Top-K answer list to form 5 options including the correct answer for each question. Note that for all questions, the correct answers are randomly but evenly inserted into the 5 options. Then we also perform QA filtration to remove meaningless questions and also analyze the key activities inside the videos.
及其对应的时间段,我们采样该时间段之外的视频帧(覆盖其左右部分),并通过计算这些帧与其他相关问答对之间的跨模态相似性,进一步检索候选答案。最后,我们选择两个与视频相关但与目标时间段无关的候选答案,从而促使时间定位来回答问题。为进一步鼓励空间推理,我们加入一个与时间段相关但针对问题错误的候选答案。最终,我们从Top-K答案列表中随机选取一个候选答案,形成包含正确答案在内的5个选项。注意所有问题的正确答案均被随机但均匀地插入这5个选项中。随后我们还进行了问答过滤以剔除无意义问题,并分析了视频中的关键活动。
Manual QA Checking and Curation
手动质量检查与审核
As all QAs are automatically generated, manual curation process is necessary to ensure the quality of questions and effective s ness of the candidate answers. As such, we perform manual checking and correction following the requirements: 1) All 4 distractor answers should not be potential correct answers. 2) The distract answers should logically answer the given question, do not overlap each other, and be closely related to the video content. We particularly emphasize on checking potential correct distractor answers that might lead to confusing and controversial results. The checking process involves 35 volunteers with 267 hours spent, and around $74%$ QA pairs are modified. Figure 7 shows some manual curation examples of overlap answers, potential correct distractor answers and logically irrelevant answers.
由于所有问答对均为自动生成,需通过人工审核流程确保问题质量及候选答案的有效性。我们按以下要求进行人工校验与修正:1) 4个干扰项均不得成为潜在正确答案;2) 干扰项需逻辑对应问题、彼此不重叠且与视频内容紧密相关。我们重点核查可能引发混淆或争议的潜在正确干扰项。审核过程动员35名志愿者,耗时267小时,约74%的问答对被修改。图7展示了重叠答案、潜在正确干扰项及逻辑无关答案的人工审核案例。

Figure 7: Manual curation examples.
图 7: 人工整理示例。
DeVE-QA Examples
DeVE-QA 示例
Figure 10 shows some examples in DeVE-QA.
图 10: DeVE-QA中的一些示例。
Appendix B:DeVi Design and Analysis Hierarchical Dense Event Captioning
附录 B: DeVi 设计与分析层次化密集事件描述
The dense events within videos often intertwine and vary in duration, posing a challenge for machines to accurately segment them for captioning. We propose the hierarchical dense event captioning approach to gain comprehensive under standing of events over different time scales. Specifically, our DeVi first samples video in three hierarchical lengthlevels (e.g., 15s, 35, and 65s for DeVE-QA) sequentially with no overlaps, then 5/7/13 frames are sampled uniformly from each video segments and sent to Video-LLaVA (Lin et al. 2023) to produce segment captions with designed prompt for different length-level of video segments to captures different level of event information. Full prompts are shown in Table 11.
视频中的密集事件往往相互交织且持续时间不一,这给机器准确分割并生成字幕带来了挑战。我们提出分层密集事件描述方法,以全面理解不同时间尺度的事件。具体而言,我们的DeVi首先在三个分层时长级别(例如DeVE-QA数据集中采用15秒、35秒和65秒)无重叠地顺序采样视频,随后从每个视频片段中分别均匀抽取5/7/13帧输入Video-LLaVA (Lin et al. 2023),通过为不同时长视频片段设计的提示词生成片段描述,从而捕获不同层级的事件信息。完整提示词见表11。
Temporal Event Memory
时序事件记忆
We design the temporal event memory that contextual ize s event captions while also storing the original visual and event representations to capture long-term dependencies between events. To be specific, the hierarchical video event (a) Word clouds for frequent words in answers of the training subset.
我们设计了时序事件记忆模块,用于将事件描述置于上下文中,同时存储原始视觉和事件表征以捕捉事件间的长期依赖关系。具体而言,分层视频事件 (a) 训练子集答案中高频词的词云图。


(b) Word clouds for frequent words in answers of the validation subset.
(b) 验证子集答案中高频词的词云图。
Figure 8: Word cloud for frequent words in answers of the training (a) and (b) validation set.
图 8: 训练集 (a) 和验证集 (b) 答案中高频词的词云。
You are a helpful expert in dense event video analysis. Given multiple clips ${{\mathrm{video.clips}}}$ of different temporal length from a video, please provide a caption for each clip, focusing on capturing all the dense events and activities occurring within it. Your caption should succinctly describe the sequence of actions, highlighting key movements, interactions, and significant moments. Be detailed and descriptive, providing context for the viewer to understand the intensity and intricacy of the events unfolding.
你是一位精通密集事件视频分析的专家。给定视频中不同时间长度的多个片段 ${{\mathrm{video.clips}}}$ ,请为每个片段提供字幕,重点捕捉其中发生的所有密集事件和活动。字幕应简洁描述动作序列,突出关键动作、互动和重要时刻。内容需详尽且具有描述性,为观众提供理解事件强度和复杂性的背景信息。
Table 11: Prompt for hierarchical dense event captioning.
表 11: 层次化密集事件描述的提示词。
You are a highly intelligent language agent in improving the quality of video captions. Given a set of captions (each representing a different time segment of a video) and a question of a video, you are required to refine each caption by incorporating contextual information from all the other captions and question via analyzing the overall narrative, identifying relevant context and incorporate context with coherence.
你是一个擅长提升视频字幕质量的智能语言代理。给定一组字幕(每条代表视频的不同时间段)和一个视频问题,你需要通过分析整体叙述、识别相关上下文并连贯地整合信息来优化每条字幕。
Table 12: Prompt of temporal contextual iz ation.
表 12: 时序上下文提示模板
captions ${E}$ are initially updated to the temporal event memory. At the same time, we sample the original with 1 fps and the video encoder CLIP VIT-L/14 (Radford et al. 2021) are also applied to extract visual features $f_{v}$ from the original entire video and store them in the temporal event memory. The visual features will be read by the self-consistency checking module to estimate the cross-modal similarity with predicted answers.
标题${E}$最初被更新到时态事件记忆中。同时,我们以1 fps的速率对原始视频进行采样,并应用视频编码器CLIP VIT-L/14 (Radford et al. 2021) 从原始完整视频中提取视觉特征$f_{v}$,将其存储到时态事件内存中。这些视觉特征将由自一致性检查模块读取,用于评估与预测答案的跨模态相似度。
After that, we try to catch the long-term relationship between events by prompting LLMs to get enhanced video event captions ${E^{'}}$ with the entire video context. We instruct the LLM to refine each event caption using information from all other event captions and any given question, focusing on understanding the overall story and incorporating relevant details coherently. To aid the LLM, we also provide examples for in-context learning before generating captions (see Table 12). Furthermore, we also ask the LLM to create the synopsis $e_{y}$ of all videos (see Table 12) to enhance the contextual i zed event captions, which also serves as a global overview of the entire video. This expanded set of events, including the synopsis, improves the understanding of event relationships across different time scales.
之后,我们尝试通过提示大语言模型获取增强版视频事件描述 ${E^{'}}$ 来捕捉事件间的长期关联性。我们指导大语言模型利用其他所有事件描述和给定问题中的信息来优化每个事件描述,重点关注对整体故事的理解并连贯地整合相关细节。为辅助大语言模型,在生成描述前我们还提供了上下文学习示例 (见表 12)。此外,我们也要求大语言模型创建所有视频的概要 $e_{y}$ (见表 12),以增强情境化事件描述,同时作为整个视频的全局概览。这个包含概要的扩展事件集合,能提升对不同时间尺度事件关系的理解。

Figure 9: Detailed prediction visualization on DeVE-QA.
图 9: DeVE-QA数据集上的详细预测可视化。
Table 13: Prompt for Event-Grounded QA.
表 13: 事件驱动的问答提示模板。
You are a helpful expert in dense event video analysis. You have been provided with video descriptions and one multiple-choice question about the video and gave out your answer and the minimum frame(s) interval to support. However, after our professional check, we consider your answer inconsistent because the self-similarity between your previous answer {Previous Answer} and {Supportive Frames $}$ is only {Self Consistency Score}. On this premise, I want you to answer this question again: {Prompts for Event-Grounded $\mathrm{{\itQA}}$ and judge whether your answer is consistent with the previous one. If no, analyze the inconsistency in detail. If yes, explain how the answer relates to the video frames.
你是一位密集事件视频分析领域的专业助手。我们为你提供了视频描述和相关的多选题,你已给出答案及支持结论的最短帧间隔。但经专业核查发现,你先前答案 {Previous Answer} 与支持帧 {Supportive Frames} 的自洽度仅为 {Self Consistency Score},存在不一致性。现要求你重新回答该问题:{Prompts for Event-Grounded QA},并判断新答案是否与先前一致。若不一致,需详细分析矛盾点;若一致,则阐明答案与视频帧的关联依据。
Table 14: Prompt for dynamic verification.
表 14: 动态验证提示词。
Overall, the temporal event memory $M={E,E^{'},f_{v}}$ describes and links the relevant occurrence of dense events from long-ranged time periods to aid in answering questions and grounding results about specific events.
总体而言,时间事件记忆 $M={E,E^{'},f_{v}}$ 用于描述并关联长周期密集事件的相关发生情况,以辅助回答特定事件的问题并夯实结果。
Self-inconsistency in Event-Grounded QA
基于事件问答的自洽性问题
Formally as described in the main text, we evaluate the selfconsistency based on the cosine similarity $R$ between the answer $a$ and the video features within time span $[t_{s},t_{e}]$ , and compare it with threshold $\sigma$ . Then, we conduct an error analysis based on over three hundred samples from the DeVE-QAdataset. Specifically, we let volunteers to manually check the predicted GQA results together with the videos, captions, synopsis, etc. and annotate the error reason. The results show that $82%$ of errors are originated from the event-grounded QA process, while less than $10%$ are attributed to caption quality and $8%$ are from others (including synopsis, meaningless answers, etc.). These findings not only validate the effectiveness of the hierarchical dense event captioning strategy but also highlight the challenges of DE-Video QA tasks in both question answering and temporal grounding.
根据正文所述,我们通过计算答案$a$与时间跨度$[t_{s},t_{e}]$内视频特征的余弦相似度$R$来评估自一致性,并将其与阈值$\sigma$进行比较。随后,我们对DeVE-QA数据集中的300多个样本进行了错误分析。具体而言,我们让志愿者结合视频、字幕、剧情简介等材料人工检查预测的GQA结果,并标注错误原因。结果显示$82%$的错误源于基于事件的问答过程,不足$10%$归因于字幕质量,$8%$来自其他因素(包括剧情简介、无意义答案等)。这些发现不仅验证了分层稠密事件描述策略的有效性,也凸显了DE-Video QA任务在问答和时间定位两方面面临的挑战。


Figure 10: DeVE-QA examples.
图 10: DeVE-QA 示例。
Therefore, we focus on a better LMM-prompt in the last stage of event-grounded QA with the feedback from selfconsistency checking. Specifically, we craft the dynamic verification prompt as shown in Table 14. When the similarity score $R_{v t}$ is smaller than $\sigma$ , DeVi will resubmit the captions and QA pair together with this dynamic verification prompt to LLM, thus efficient in improving the relia- bility and transparency of the model’s responses. In particular, the dynamic verification prompt is designed to feedback the self-consistency checking results between the LLM’s answer prediction and the supportive video evidence from the previous round. The model is then required to re-answer the question with the given extra information. If the results from the two rounds are consistent, the model needs to elaborate on the relationship between the answer and the video segments. Otherwise, it is required to explain the reasons for the inconsistency. Through the process of justifying its answers, we speculate that the LLM could consider the underlying logic and relationships behind, which can lead to more accurate and con textually relevant responses to improve the GQA accuracy.
因此,我们基于自一致性检查的反馈,在事件驱动的问答最后阶段聚焦于优化大语言模型提示。具体而言,我们设计了如表14所示的动态验证提示。当相似度得分$R_{v t}$小于$\sigma$时,DeVi系统会将该动态验证提示连同视频描述和问答对重新提交给大语言模型,从而有效提升模型响应的可靠性与透明度。该动态验证提示的核心设计是反馈前轮次中大语言模型答案预测与视频佐证之间的自洽性检查结果,并要求模型基于额外信息重新回答问题。若两轮结果一致,模型需详细阐述答案与视频片段间的关联;若存在矛盾,则需说明不一致的原因。我们推测,通过这种答案论证过程,大语言模型能深入考量底层逻辑与关联关系,从而生成更精准且符合语境的响应,最终提升广义问答准确率。
Overall, this process helps the model identify and correct potential errors, as the model cross-checks its reasoning against the given previous prediction, ultimately enhancing its performance in the GQA task that requires complex under standing and decision-making.
总体而言,这一过程通过让模型根据先前预测交叉验证其推理,有助于识别并修正潜在错误,最终提升其在需要复杂理解与决策的GQA任务中的表现。
Further Analysis
进一步分析
Table 15: Efficiency analysis by time usage.
表 15: 时间使用效率分析
| 时间使用 (秒) | QA | GQA |
|---|---|---|
| DeVi | 1.83 | 2.12 |
| LLoVi | 1.43 | 1.68 |
Event sample. To further demonstrate the mechanism behind DeVi, we visualize an example in Figure 9. According to the example, we can find that baseline models like SeViLA and Temp[CLIP] tend to answer the question without truly grounding it to related video segments. Hierarchical Dense Captioning (HDC) helps DeVi further understand the events in different scales, Temporal Contextual izing (TC) helps improve GQA with the ability of refining or correcting the isolated captions according to related context, and Self-consistency checking (SC) is effective in correcting wrongly grounded segments.
事件样本。为了进一步展示DeVi背后的机制,我们在图9中可视化了一个示例。通过该示例可以发现,SeViLA和Temp[CLIP]等基线模型倾向于直接回答问题而非真正关联到相关视频片段。分层密集描述(HDC)帮助DeVi从不同尺度理解事件,时序上下文建模(TC)通过根据相关上下文优化或修正孤立描述来提升GQA能力,而自一致性检验(SC)能有效修正错误关联的片段。
Efficiency analysis. To evaluate the efficiency of DeVi, we also conduct experimental analysis on the time consumption of DeVi and LLoVi (experiments are performed on NVIDIA A800 GPU). Specifically, we randomly sample one thousand samples from DeVE-QA and evaluate their response time on both QA task and GQA task, and the results are shown in Table 15. We can observe that DeVi and LLoVi reaches roughly the same efficiency on both GQA and QA task, whereas DeVi cost slightly more time. We speculate that this result from the more comprehensive mechanism inside DeVi , especially the self-inconsistency checking that may leads to multiple-round reasoning. Moreover, GQA task cost more time in both model.
效率分析。为评估DeVi的效率,我们同样对DeVi和LLoVi的时间消耗进行了实验分析(实验在NVIDIA A800 GPU上进行)。具体而言,我们从DeVE-QA中随机抽取一千个样本,评估它们在QA任务和GQA任务上的响应时间,结果如表15所示。可以观察到DeVi和LLoVi在GQA和QA任务上的效率大致相当,但DeVi耗时稍多。我们推测这是由于DeVi内部更全面的机制所致,尤其是可能导致多轮推理的自不一致性检查。此外,两个模型在GQA任务上的耗时都更长。