ByT5: Towards a Token-Free Future with Pre-trained Byte-to-Byte Models
ByT5: 迈向基于字节到字节预训练模型的无Token未来
Abstract
摘要
Most widely-used pre-trained language models operate on sequences of tokens corre- sponding to word or subword units. By comparison, token-free models that operate directly on raw text (bytes or characters) have many benefits: they can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with minimal modifications to process byte sequences. We characterize the trade-offs in terms of parameter count, training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level counterparts. We also demonstrate that bytelevel models are significantly more robust to noise and perform better on tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our experiments.1
大多数广泛使用的预训练语言模型处理的是对应单词或子词单元的 token 序列。相比之下,直接处理原始文本(字节或字符)的无 token (token-free) 模型具有诸多优势:它们可以开箱即用地处理任何语言的文本,对噪声更鲁棒,并且通过移除复杂且容易出错的文本预处理流程来减少技术债。由于字节或字符序列比 token 序列更长,过去关于无 token 模型的研究通常会引入新的模型架构,以分摊直接处理原始文本的成本。在本文中,我们证明标准 Transformer 架构只需极少的修改即可用于处理字节序列。我们从参数量、训练 FLOPs 和推理速度等方面权衡利弊,并证明字节级模型与 token 级模型性能相当。我们还表明,字节级模型对噪声的鲁棒性显著更强,在拼写和发音敏感的任务上表现更好。作为贡献的一部分,我们发布了一组基于 T5 架构的新预训练字节级 Transformer 模型,以及实验中使用的所有代码和数据。[1]
1 Introduction
1 引言
An important consideration when designing NLP models is the way that text is represented. One common choice is to assign a unique token ID to each word in a fixed finite vocabulary. A given piece of text is thus converted into a sequence of tokens by a tokenizer before being fed into a model for processing. An issue with using a fixed vocabulary of words is that there is no obvious way to process a piece of text that contains an out-of-vocabulary word. A standard approach is to map all unknown words to the same $<\mathrm{UNK}>$ token, but this prevents the model from distinguishing between different out-of-vocabulary words.
设计自然语言处理(NLP)模型时的一个重要考量是文本的表示方式。一种常见做法是为固定有限词汇表中的每个单词分配唯一的token ID。因此,一段给定文本在被送入模型处理前,会先通过分词器(tokenizer)转换为token序列。使用固定单词词汇表的问题是,当文本包含词汇表外的单词时,没有明确的方法进行处理。标准做法是将所有未知单词映射到同一个$<\mathrm{UNK}>$ token,但这会导致模型无法区分不同的词汇表外单词。
Subword tokenizers (Sennrich et al., 2016; Wu et al., 2016; Kudo and Richardson, 2018) present an elegant solution to the out-of-vocabulary problem. Instead of mapping each word to a single token, subword tokenizers decompose words into smaller subword units with a goal of minimizing the total length of the token sequences for a fixed vocabulary size. As an example, a subword tokenizer might tokenize the word doghouse as the pair of tokens dog and house even if doghouse is not in the subword vocabulary. This flexibility has caused subword tokenizers to become the de facto way to tokenize text over the past few years.
子词分词器 (Sennrich et al., 2016; Wu et al., 2016; Kudo and Richardson, 2018) 为词汇表外问题提供了一种优雅的解决方案。与将每个单词映射为单个token不同,子词分词器将单词分解为更小的子词单元,旨在固定词汇表大小的前提下最小化token序列的总长度。例如,子词分词器可能将单词doghouse分解为dog和house两个token,即使doghouse不在子词词汇表中。这种灵活性使得子词分词器成为过去几年文本分词的实际标准方法。
However, subword tokenizers still exhibit various undesirable behaviors. Typos, variants in spelling and capitalization, and morphological changes can all cause the token representation of a word or phrase to change completely, which can result in mis predictions. Furthermore, unknown characters (e.g. from a language that was not used when the subword vocabulary was built) are typically out-of-vocabulary for a subword model.
然而,子词分词器仍存在多种不良行为。拼写错误、大小写变体和词形变化都可能导致单词或短语的token表示完全改变,从而引发预测错误。此外,未知字符(例如来自构建子词词汇表时未使用的语言)通常会成为子词模型的未登录词。
A more natural solution that avoids the aforementioned pitfalls would be to create token-free NLP models that do not rely on a learned vocabulary to map words or subword units to tokens. Such models operate on raw text directly. We are not the first to make the case for token-free models, and a more comprehensive treatment of their various benefits can be found in recent work by Clark et al. (2021). In this work, we make use of the fact that text data is generally stored as a sequence of bytes. Thus, feeding byte sequences directly into the model enables the processing of arbitrary text sequences. This approach is well-aligned with the philosophy of end-to-end learning, which endeavors to train models to directly map from raw data to predictions. It also has a concrete benefit in terms of model size: the large vocabularies of word- or subword-level models often result in many parameters being devoted to the vocabulary matrix. In contrast, a byte-level model by definition only requires 256 embeddings. Migrating word representations out of a sparse vocabulary matrix and into dense network layers should allow models to generalize more effectively across related terms (e.g. book / books) and orthographic variations. Finally, from a practical standpoint, models with a fixed vocabulary can complicate adaptation to new languages and new terminology, whereas, by definition, tokenfree models can process any text sequence.
一种更自然的解决方案是创建无Token (token-free) 的NLP模型,这类模型不依赖学习得到的词汇表来将单词或子词单元映射为Token,从而避免了前述缺陷。此类模型直接处理原始文本。我们并非首个倡导无Token模型的研究团队,Clark等人 (2021) 近期工作对其多重优势进行了更全面的论述。本研究利用了文本数据通常以字节序列形式存储的特性,通过直接将字节序列输入模型,实现了对任意文本序列的处理。这种方法与端到端学习 (end-to-end learning) 的理念高度契合——该理念致力于训练模型直接从原始数据映射到预测结果。在模型尺寸方面也具有实际优势:词级或子词级模型的大词汇表往往导致大量参数被用于词汇矩阵,而字节级模型按定义仅需256个嵌入向量。将词表示从稀疏的词汇矩阵迁移到稠密的网络层,应能使模型在相关术语(如book/books)和拼写变体上实现更有效的泛化。最后从实践角度看,固定词汇表模型难以适配新语言和新术语,而无Token模型按定义可处理任何文本序列。
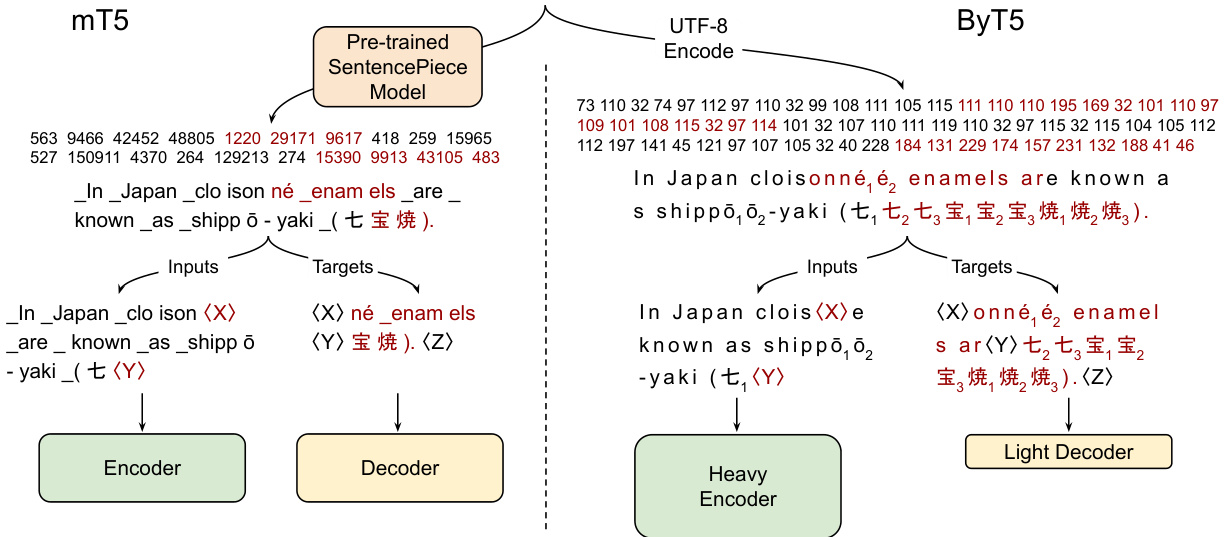
Figure 1: Pre-training example creation and network architecture of mT5 (Xue et al., 2021) vs. ByT5 (this work). mT5: Text is split into Sentence Piece tokens, spans of ${\sim}3$ tokens are masked (red), and the encoder/decoder transformer stacks have equal depth. ByT5: Text is processed as UTF-8 bytes, spans of ${\sim}20$ bytes are masked, and the encoder is $3\times$ deeper than the decoder. $\langle\mathbf{X}\rangle$ , $\langle\mathbf{Y}\rangle$ , and $\langle Z\rangle$ represent sentinel tokens.
图 1: mT5 (Xue et al., 2021) 与 ByT5 (本工作) 的预训练示例创建及网络架构对比。mT5: 文本被分割为 Sentence Piece token,约 3 个 token 的片段被掩码 (红色),编码器/解码器 Transformer 层数相同。ByT5: 文本以 UTF-8 字节处理,约 20 字节的片段被掩码,编码器深度是解码器的 3 倍。$\langle\mathbf{X}\rangle$、$\langle\mathbf{Y}\rangle$ 和 $\langle Z\rangle$ 表示哨兵 token。
The main drawback of byte-level models is that byte sequences tend to be significantly longer than token sequences. Since computational costs of machine learning models tend to scale with sequence length, much previous work on character- and bytelevel models has explored ways to process long sequences efficiently using convolutions with pooling (Zhang et al., 2015; Lee et al., 2017) or adaptive computation time (Graves, 2016).
字节级模型的主要缺点在于字节序列往往比token序列长得多。由于机器学习模型的计算成本通常随序列长度增加而上升,先前关于字符级和字节级模型的研究大多通过带池化的卷积 (Zhang et al., 2015; Lee et al., 2017) 或自适应计算时间 (Graves, 2016) 来探索高效处理长序列的方法。
In this work, we take a simpler approach and show that the Transformer architecture can be straightforwardly adapted to process byte sequences without a dramatically unfavorable increase in computational cost. We focus on the T5 framework (Raffel et al., 2020), where all textbased NLP problems are cast to a text-to-text format. This approach makes it simple to tackle an
在本工作中,我们采用了一种更简单的方法,证明Transformer架构可以直接适配处理字节序列,而不会导致计算成本的大幅增加。我们基于T5框架 (Raffel et al., 2020) 展开研究,该框架将所有基于文本的NLP问题都转换为文本到文本的格式。这种方法使得处理...
NLP task by generating a sequence of bytes conditioned on some input bytes. Our proposed ByT5 architecture is described in section 3. The design stays fairly close to mT5 (the multilingual variant of T5 introduced by Xue et al. (2021)), with the differences illustrated in fig. 1. Through extensive experiments on a diverse set of English and multilingual tasks (presented in section 4), we show that ByT5 is competitive with a subword-level baseline, despite being pre-trained on $4\times$ less text. We also confirm in section 5 that byte-level models are more robust to corruptions of the input text. Throughout, we characterize the trade-offs of our design decisions in terms of computational cost and parameter count, discussed in more detail in sections 6 and 7. The end result is a set of pre-trained ByT5 models that we release alongside this paper.
通过生成基于输入字节序列的字节序列来完成NLP任务。第3节将介绍我们提出的ByT5架构,其设计基本沿用了Xue等人(2021)提出的多语言T5变体(mT5),具体差异如图1所示。在第4节展示的各类英语及多语言任务实验中,尽管预训练文本量减少了$4\times$,ByT5仍能媲美子词级别的基线模型。第5节进一步验证了字节级模型对输入文本损坏具有更强鲁棒性。全文通过第6、7节的详细讨论,从计算成本和参数量角度阐明了设计决策的权衡取舍。最终我们发布了一组预训练的ByT5模型作为本文的配套成果。
2 Related Work
2 相关工作
The early neural language models of Sutskever et al. (2011) and Graves (2013) operated directly on character sequences. This precedent led many to use character-level language modeling as a benchmark to evaluate neural architectures (Kalchbrenner et al., 2016; Chung et al., 2017; Ha et al., 2017; Zilly et al., 2017; Melis et al., 2018; Al-Rfou et al., 2019). Choe et al. (2019) showed byte language models can match the perplexity of word-level models when given the same parameter budget. How- ever, standard practice in real-world scenarios has remained to use word- or subword-level models.
Sutskever等人(2011)和Graves(2013)的早期神经语言模型直接作用于字符序列。这一先例促使许多人将字符级语言建模作为评估神经架构的基准(Kalchbrenner等人,2016; Chung等人,2017; Ha等人,2017; Zilly等人,2017; Melis等人,2018; Al-Rfou等人,2019)。Choe等人(2019)表明,在给定相同参数预算的情况下,字节语言模型可以达到与词级模型相当的困惑度。然而,在实际应用中的标准做法仍然是使用词级或子词级模型。
A number of character-aware architectures have been proposed that make use of character-level features but still rely on a tokenizer to identify word boundaries. These approaches include ELMo (Peters et al., 2018), Character BERT (El Boukkouri et al., 2020) and many others (Ling et al., 2015; Chung et al., 2016; Kim et al., 2016; Józefowicz et al., 2016; Wang et al., 2020; Wei et al., 2021). Separately, some work has endeavored to ameliorate issues with token iz ation, for example by adapting vocabularies to new languages (Garcia et al., 2021) or randomly choosing different subword segmentations to improve robustness in low-resource and out-of-domain settings (Kudo, 2018). These methods do not meet our goal of simplifying the NLP pipeline by removing text preprocessing.
已有多种利用字符级特征但仍依赖分词器识别词边界的字符感知架构被提出。这些方法包括ELMo (Peters et al., 2018)、Character BERT (El Boukkouri et al., 2020) 以及许多其他工作 (Ling et al., 2015; Chung et al., 2016; Kim et al., 2016; Józefowicz et al., 2016; Wang et al., 2020; Wei et al., 2021)。另一方面,部分研究致力于改善分词问题,例如通过调整词汇表以适应新语言 (Garcia et al., 2021),或随机选择不同子词分割方案来提升低资源和领域外场景的鲁棒性 (Kudo, 2018)。这些方法均未实现我们通过消除文本预处理来简化NLP流程的目标。
There have been a few recent efforts to develop general-purpose token-free pre-trained language models for transfer learning.2 Akbik et al. (2018) show strong results on sequence labeling with character-level pre-training and release models covering four languages. More recently, Clark et al. (2021) develop CANINE, which shows gains over multilingual BERT by working with characters instead of word-piece tokens, though the “CANINE-S” model still uses a tokenizer during pre-training to define targets for the masked language modeling task. Our work differs from these in that (i) we train encoder-decoder models that extend to generative tasks, (ii) our models work directly with UTF-8 bytes, and (iii) we explore the effect of model scale, training models beyond 10 billion parameters.
最近有若干研究致力于开发通用无token预训练语言模型用于迁移学习。Akbik等人(2018)展示了字符级预训练在序列标注任务上的优异表现,并发布了覆盖四种语言的预训练模型。Clark等人(2021)最新提出的CANINE模型通过直接处理字符而非word-piece token,在多语言BERT基础上实现了性能提升,不过其"CANINE-S"模型在预训练阶段仍需要使用tokenizer来定义掩码语言建模任务的目标。我们的工作与这些研究的区别在于:(i) 我们训练的是可扩展至生成任务的编码器-解码器架构;(ii) 模型直接处理UTF-8字节流;(iii) 我们探索了模型规模效应,训练了参数量超过100亿的大模型。
3 ByT5 Design
3 ByT5 设计
Our goal in designing ByT5 is to take an existing token-based model and perform the minimal set of modifications to make it token-free, thereby limiting experimental confounds. We base ByT5 on the recent mT5 model (Xue et al., 2021), which was trained on mC4 (a large corpus of unlabeled multilingual text data) and achieved state-of-the-art on many community benchmarks. We release ByT5 in five sizes analogous to T5 and mT5 (Small, Base, Large, XL, XXL). We aim for ByT5 to cover the same use cases as mT5: it is a general-purpose pre-trained text-to-text model covering $100+$ languages. We expect ByT5 will be particular useful for tasks operating on short-to-medium length text sequences (a few sentences or less), as these will incur less slowdown in fine-tuning and inference.
我们设计ByT5的目标是对现有基于token的模型进行最小化修改,使其实现无token化,从而减少实验干扰。该模型基于最新的mT5模型(Xue等人,2021),后者在mC4(一个大规模多语言无标注文本数据集)上训练,并在多个社区基准测试中达到最先进水平。我们发布了与T5和mT5对应的五种规模版本(Small、Base、Large、XL、XXL)。ByT5旨在覆盖与mT5相同的应用场景:这是一个通用型预训练文本生成模型,支持100多种语言。我们预计ByT5将特别适用于处理短到中等长度文本序列(几个句子以内)的任务,因为这类任务在微调和推理时的速度下降较少。
3.1 Changes from mT5
3.1 与mT5的差异
Compared to mT5, we make the following key changes in designing ByT5. First and foremost, we dispense with the Sentence Piece (Kudo and Richardson, 2018) vocabulary and feed UTF-8 bytes directly into the model without any text preprocessing. The bytes are embedded to the model hidden size using a vocabulary of 256 possible byte values. An additional 3 IDs are reserved for special tokens: padding, end-of-sentence, and an unused $<\mathrm{UNK}>$ token that we include only for convention.
与mT5相比,我们在设计ByT5时做出了以下关键改动。首先,我们摒弃了Sentence Piece (Kudo and Richardson, 2018)词汇表,直接将UTF-8字节输入模型而不进行任何文本预处理。这些字节通过包含256种可能字节值的词汇表嵌入到模型的隐藏层大小中。另外保留了3个ID用于特殊token:填充符、句尾符以及一个仅出于惯例保留的未使用$<\mathrm{UNK}>$ token。
Second, we modify the pre-training task. mT5 uses the “span corruption” pre-training objective first proposed by Raffel et al. (2020) where spans of tokens in unlabeled text data are replaced with a single “sentinel” ID and the model must fill in the missing spans. Rather than adding 100 new tokens for the sentinels, we find it sufficient to reuse the final 100 byte IDs. While mT5 uses an average span length of 3 subword tokens, we find that masking longer byte-spans is valuable. Specifically, we set our mean mask span length to 20 bytes, and show ablations of this value in section 6.
其次,我们调整了预训练任务。mT5采用Raffel等人 (2020) 提出的"span corruption"预训练目标,即在未标注文本数据中用单个"哨兵"ID替换token片段,模型需预测缺失片段。我们发现复用最后的100个字节ID作为哨兵即可,无需新增100个token。mT5的平均掩码片段长度为3个子词token,而我们发现掩码更长的字节片段效果更好:具体将平均掩码长度设为20字节,并在第6节对该值进行消融实验。
Third, we find that ByT5 performs best when we decouple the depth of the encoder and decoder stacks. While T5 and mT5 used “balanced” architectures, we find byte-level models benefit significantly from a “heavier” encoder. Specifically, we set our encoder depth to 3 times that of the decoder. Intuitively, this heavier encoder makes the model more similar to encoder-only models like BERT. By decreasing decoder capacity, one might expect quality to deteriorate on tasks like sum mari z ation that require generation of fluent text. However, we find this is not the case, with heavy-encoder byte models performing better on both classification and generation tasks. We ablate the effect of encoder/decoder balance in section 6.
第三,我们发现当解耦编码器和解码器堆栈的深度时,ByT5表现最佳。虽然T5和mT5采用"平衡"架构,但字节级模型明显受益于"更重"的编码器。具体而言,我们将编码器深度设置为解码器的3倍。直观上,这种更重的编码器使模型更接近BERT等纯编码器模型。通过降低解码器容量,人们可能预期在需要生成流畅文本的任务(如摘要)上质量会下降。然而,我们发现情况并非如此,具有重型编码器的字节模型在分类和生成任务上都表现更好。我们将在第6节分析编码器/解码器平衡的影响。
As not all byte sequences are legal according to the UTF-8 standard, we drop any illegal bytes in the model’s output3 (though we never observed our models predicting illegal byte sequences in practice). Apart from the above changes, we follow mT5 in all settings. Like mT5, we set our sequence length to 1024 (bytes rather than tokens), and train for 1 million steps over batches of $2^{20}$ tokens.
由于并非所有字节序列都符合UTF-8标准,我们会丢弃模型输出中的非法字节3(尽管实践中从未观察到模型预测出非法字节序列)。除上述调整外,所有设置均遵循mT5方案。与mT5相同,我们将序列长度设为1024(以字节而非token为单位),并在每批$2^{20}$个token的数据上训练100万步。
| mT5 | ByT5 | |||||
|---|---|---|---|---|---|---|
| 型号 | 参数量 | 词表维度 dmodel/dff | 编码/解码层数 | 词表占比 | dmodel/dff | 编码/解码层数 |
| Small300M | 85% | 512/1024 | 8/8 | 0.3% | 1472/3584 | 12/4 |
| Base | 582M 66% | 768/2048 | 12/12 | 0.1% | 1536/3968 | 18/6 |
| Large 1.23B | 42% | 1024/2816 | 24/24 | 0.06% | 1536/3840 | 36/12 |
| XL 3.74B | 27% | 2048/5120 | 24/24 | 0.04% | 2560/6720 | 36/12 |
| XXL 12.9B | 16% | 4096/10240 | 24/24 | 0.02%4672/12352 | 36/12 |
Table 1: Comparison of mT5 and ByT5 architectures. For a given named size (e.g. “Large”), the total numbers of parameters and layers are fixed. “Vocab” shows the percentage of vocabulary-related parameters, counting both the input embedding matrix and the decoder softmax layer. ByT5 moves these parameters out of the vocabulary and into the transformer layers, as well as shifting to a 3:1 ratio of encoder to decoder layers.
表 1: mT5与ByT5架构对比。对于给定命名尺寸(如"Large"),参数总量和层数固定。"Vocab"显示词表相关参数占比(包含输入嵌入矩阵和解码器softmax层)。ByT5将这些参数从词表转移至Transformer层,并将编码器与解码器层数比例调整为3:1。
3.2 Comparing the Models
3.2 模型对比
Our goal in this paper is to show that straight forward modifications to the Transformer architecture can allow for byte-level processing while incurring reasonable trade-offs in terms of cost. Characterizing these trade-offs requires a clear definition of what is meant by “cost”, since there are many axes along which it is possible to measure a model’s size and computational requirements.
本文的目标是证明,通过对Transformer架构进行直接修改,可以在成本方面做出合理权衡的同时实现字节级处理。要明确这些权衡关系,首先需要清晰定义"成本"的含义,因为衡量模型规模和计算需求的维度有很多。
Models that use a word or subword vocabulary typically include a vocabulary matrix that stores a vector representation of each token in the vocabulary. They also include an analogous matrix in the output softmax layer. For large vocabularies (e.g. those in multilingual models), these matrices can make up a substantial proportion of the model’s parameters. For example, the vocabulary and softmax output matrices in the mT5-Base model amount to 256 million parameters, or about $66%$ of the total parameter count. Switching to a byte-level model allows allocating these parameters elsewhere in the model, e.g. by adding layers or making existing layers “wider”. To compensate for reduction in total parameter count due to changing from a token-based to token-free model, we adjust our ByT5 model hidden size $(\mathrm{d}{\mathrm{model}})$ and feed-forward dimensionality $(\mathrm{d_{ff}})$ to be parameter-matched with mT5, while maintaining a ratio of roughly 2.5 between $\mathrm{d_{ff}}$ and $\mathrm{d}_{\mathrm{model}}$ , as recommended by Kaplan et al. (2020). Table 1 shows the resulting model architectures across all five model sizes.
使用单词或子词词汇表的模型通常包含一个词汇矩阵,用于存储词汇表中每个token的向量表示。它们还在输出softmax层中包含一个类似的矩阵。对于大型词汇表(例如多语言模型中的词汇表),这些矩阵可能占据模型参数的很大比例。例如,mT5-Base模型中的词汇表和softmax输出矩阵共有2.56亿个参数,约占总参数量的66%。改用字节级模型可以将这些参数分配到模型的其他部分,例如通过增加层数或扩展现有层的宽度。为了弥补从基于token的模型转变为无token模型导致的总参数减少,我们调整了ByT5模型的隐藏大小$(\mathrm{d}{\mathrm{model}})$和前馈维度$(\mathrm{d_{ff}})$,使其与mT5参数匹配,同时按照Kaplan等人(2020)的建议,保持$\mathrm{d_{ff}}$与$\mathrm{d}_{\mathrm{model}}$之间大约2.5的比例。表1展示了所有五种模型尺寸的最终架构。
Separately, as previously mentioned, changing from word or subword sequences to byte sequences will increase the (tokenized) sequence length of a given piece of text. The self-attention mechanism at the core of the ubiquitous Transformer architecture (Vaswani et al., 2017) has a quadratic time and space complexity in the sequence length, so byte sequences can result in a significantly higher computational cost. While recurrent neural networks and modified attention mechanisms (Tay et al., 2020) can claim a better computational complexity in the sequence length, the cost nevertheless always scales up as sequences get longer.
另外,如前所述,从单词或子词序列改为字节序列会增加给定文本的(token化后的)序列长度。作为无处不在的Transformer架构 (Vaswani et al., 2017) 核心的自注意力机制,其时间和空间复杂度与序列长度呈平方关系,因此字节序列可能导致显著更高的计算成本。虽然循环神经网络和改进的注意力机制 (Tay et al., 2020) 在序列长度上具有更好的计算复杂度,但随着序列变长,计算成本始终会上升。
Thus far, we have been discussing easy-tomeasure quantities like the parameter count and FLOPs. However, not all FLOPs are equal, and the real-world cost of a particular model will also depend on the hardware it is run on. One important distinction is to identify operations that can be easily parallel i zed (e.g. the encoder’s fullyparallel iz able processing) and those that cannot (e.g. auto regressive sampling in the decoder during inference). For byte-level encoder-decoder models, if the decoder is particularly large, autoregressive sampling can become comparatively expensive thanks to the increased length of byte sequences. Relatedly, mapping an input token to its corresponding vector representation in the vocabulary matrix is essentially “free” in terms of FLOPs since it can be implemented by addressing a particular row in memory. Therefore, reallocating parameters from the vocabulary matrix to the rest of the model will typically result in a model that requires more FLOPs to process a given input sequence (see section 7 for detailed comparison).
至此,我们一直在讨论易于衡量的指标,如参数量和FLOPs (浮点运算次数)。然而,并非所有FLOPs都是等价的,实际运行成本还取决于硬件设备。关键区别在于区分可并行化操作(如编码器的全并行处理)与不可并行化操作(如推理时解码器的自回归采样)。对于字节级编码器-解码器模型,若解码器规模过大,由于字节序列长度增加,自回归采样的相对成本会显著上升。值得注意的是,将输入token映射到词表矩阵中的对应向量表示在FLOPs层面基本"零成本",因为这只需寻址内存中的特定行即可实现。因此,若将参数从词表矩阵重新分配到模型其他部分,通常会导致处理相同输入序列需要更多FLOPs(详见第7节对比分析)。
Finally, we note that another important metric is data efficiency, i.e. how much data is required for the model to reach a good solution. For NLP problems, this can be measured either in terms of the number of tokens or the amount of raw text seen during training. Specifically, a byte-level model trained on the same number of tokens as a word- or subword-level model will have been trained on less text data. In Figure 2, we show the compression rates of mT5 Sentence Piece tokenization, measured as the ratio of UTF-8 bytes to tokens in each language split of the mC4 corpus used in pre-training. This ratio ranges from 2.5 (Maltese) to 9.0 (Khmer). When considering the mC4 corpus as a whole, sampled according to the mT5 pre-training mixing ratios, we have an overall compression rate of 4.1 bytes per Sentence Piece token. On the one hand, this $4\times$ lengthening could be seen as an advantage for ByT5: with longer sequences, the model gets more compute to spend encoding a given piece of text. On the other hand, given a fixed input sequence length and number of training steps, the model will be exposed to roughly $4\times$ less actual text during pre-training.
最后,我们注意到另一个重要指标是数据效率,即模型需要多少数据才能达到良好的解决方案。对于自然语言处理(NLP)问题,可以通过训练期间处理的token数量或原始文本量来衡量。具体而言,与词级或子词级模型相比,在相同token数量下训练的字节级模型接触的文本数据更少。在图2中,我们展示了mT5 Sentence Piece分词方案的压缩率,该指标通过预训练所用mC4语料库各语言分片中UTF-8字节数与token数的比值计算得出。该比值范围从2.5(马耳他语)到9.0(高棉语)。若按mT5预训练混合比例对整个mC4语料库进行采样,整体压缩率为每个Sentence Piece token对应4.1字节。一方面,这种$4\times$的序列延长可视为ByT5的优势:更长的序列使模型能分配更多计算资源来编码给定文本。另一方面,在固定输入序列长度和训练步数的情况下,模型在预训练期间接触的实际文本量将减少约$4\times$。
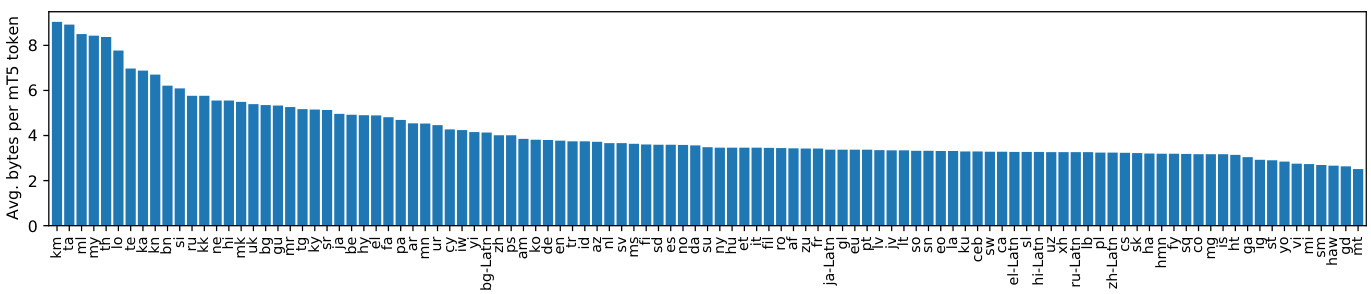
Figure 2: Per-language compression rates of the mT5 Sentence Piece vocabulary, measured over the mC4 pre-training corpus. For each language, we measure the ratio of UTF-8 bytes to tokens over all $\mathrm{mC4}$ data in that language.
图 2: mT5 Sentence Piece词表在各语言上的压缩率,基于mC4预训练语料库测量。对于每种语言,我们计算该语言所有mC4数据中UTF-8字节数与Token数的比值。
With these factors in mind, we choose to focus on the following measures of efficiency in our experiments: parameter count, inference time, and pre-training efficiency. Parameter count is a simple and easy-to-measure quantity that directly relates to the amount of memory required to use a model. Inference time is a real-world measurement of the model’s computational cost that represents a “worst-case” measurement for byte-level models given the potential additional cost of auto regressive sampling. Finally, pre-training efficiency allows us to measure whether byte-level models can learn a good solution after seeing less pre-training data.
考虑到这些因素,我们选择在实验中重点关注以下效率指标:参数量 (parameter count)、推理时间 (inference time) 和预训练效率 (pre-training efficiency)。参数量是一个简单易测的指标,直接关联模型运行所需的内存大小。推理时间是对模型计算成本的现实测量,对于字节级模型而言,由于自回归采样可能带来的额外开销,该指标代表"最坏情况"下的测量结果。最后,预训练效率能帮助我们衡量字节级模型在接触较少预训练数据后能否学习到良好的解决方案。
4 Core Results
4 核心结果
In this section, we compare ByT5 against mT5 on a wide range of tasks. We show that ByT5 is competitive with mT5 on standard English and multilingual NLP benchmarks and outperforms mT5 at small model sizes. Additionally, ByT5 excels on free-form generation tasks and word-level tasks.
在本节中,我们将ByT5与mT5在多种任务上进行比较。结果表明,ByT5在标准英语及多语言NLP基准测试中与mT5表现相当,并在小模型规模下优于mT5。此外,ByT5在自由格式生成任务和词级任务中表现尤为突出。
For each downstream task, we fine-tune mT5 and ByT5 models for 262,144 steps, using a constant learning rate of 0.001 and a dropout rate of 0.1.4 We use a batch size of $2^{17}$ tokens by default, but increased this to $2^{20}$ for several tasks with larger training sets (GLUE, SuperGLUE, XNLI, TweetQA), and decreased to $2^{16}$ for the Dakshina task. In all cases, we select the best model checkpoint based on validation set performance.
对于每项下游任务,我们以262,144步微调mT5和ByT5模型,采用0.001的恒定学习率和0.1的丢弃率。默认使用$2^{17}$ token的批量大小,但对于训练集较大的任务(GLUE、SuperGLUE、XNLI、TweetQA)会增至$2^{20}$,对Dakshina任务则降至$2^{16}$。所有情况下,我们都根据验证集表现选择最佳模型检查点。
4.1 English Classification Tasks
4.1 英语分类任务
On the widely-adopted GLUE (Wang et al., 2019b) and SuperGLUE (Wang et al., 2019a) text classification benchmarks, we find ByT5 beats mT5 at the Small and Base sizes, but mT5 has the advantage at larger sizes, as shown in table 2. The strong performance of ByT5 at smaller sizes likely stems from the large increase in dense parameters over mT5. While the overall models are parameter-matched, most of the mT5 Small and Base parameters are “locked” in vocab-related matrices and are only accessed when a particular token is present. We suspect that replacing these with “dense” parameters activated across all examples encourages more efficient parameter usage and sharing.
在广泛采用的 GLUE (Wang et al., 2019b) 和 SuperGLUE (Wang et al., 2019a) 文本分类基准测试中,我们发现 ByT5 在 Small 和 Base 规模上优于 mT5,但 mT5 在更大规模时具有优势,如 表 2 所示。ByT5 在较小规模上的强劲表现可能源于其密集参数相比 mT5 的大幅增加。虽然整体模型的参数量相匹配,但 mT5 Small 和 Base 的大部分参数被"锁定"在与词汇表相关的矩阵中,仅在特定 token 出现时才会被访问。我们推测,用"密集"参数替换这些参数(这些参数在所有样本中都会被激活)可以促进更高效的参数使用和共享。
Table 2: mT5 and ByT5 performance on GLUE and SuperGLUE. For each benchmark, we fine-tune a single model on a mixture of all tasks, select the best checkpoint per task based on validation set performance, and report average validation set scores over all tasks.
表 2: mT5 和 ByT5 在 GLUE 和 SuperGLUE 上的性能表现。对于每个基准测试,我们在所有任务的混合数据上微调单个模型,根据验证集表现选择每个任务的最佳检查点,并报告所有任务的平均验证集分数。
| GLUE | SuperGLUE | |||
|---|---|---|---|---|
| mT5 | ByT5 | mT5 | ByT5 | |
| Small | 75.6 | 80.5 | 60.2 | 67.8 |
| Base | 83.0 | 85.3 | 72.5 | 74.0 |
| Large | 87.6 | 87.0 | 81.9 | 80.4 |
| TX | 88.7 | 87.9 | 84.7 | 83.2 |
| XXL | 90.7 | 90.1 | 89.2 | 88.6 |
4.2 English Generation Tasks
4.2 英语生成任务
We also compare ByT5 with mT5 on three English generative tasks. XSum (Narayan et al., 2018) is an abstract ive sum mari z ation task requiring models to summarize a news article in a single sentence. For better comparison to recent work, we adopt the version of the task defined in the GEM benchmark (Gehrmann et al., 2021). TweetQA (Xiong et al., 2019) is an abstract ive question-answering task built from tweets mentioned in news articles. This tests understanding of the “messy” and informal language of social media. Finally, DROP (Dua et al., 2019) is a challenging reading comprehension task that requires numerical reasoning.
我们还在三项英文生成任务上对比了ByT5和mT5的表现。XSum (Narayan et al., 2018) 是一个抽象摘要生成任务,要求模型用单句话概括新闻文章。为便于与近期研究对比,我们采用了GEM基准 (Gehrmann et al., 2021) 中定义的该任务版本。TweetQA (Xiong et al., 2019) 是基于新闻提及推文构建的抽象问答任务,用于测试模型对社交媒体"混乱"非正式语言的理解能力。DROP (Dua et al., 2019) 则是需要数值推理能力的挑战性阅读理解任务。
Table 3 shows that ByT5 outperforms mT5 on
表 3: 显示 ByT5 在性能上优于 mT5
| 模型 | GEM-XSum (BLEU) | TweetQA (BLEU-1) | DROP (F1/EM) | |||
|---|---|---|---|---|---|---|
| mT5 | ByT5 | mT5 | ByT5 | mT5 | ByT5 | |
| Small | 6.9 | 9.1 | 54.4 | 65.7 | 40.0/38.4 | 66.6/65.1 |
| Base | 8.4 | 11.1 | 61.3 | 68.7 | 47.2/45.6 | 72.6/71.2 |
| Large | 10.1 | 11.5 | 67.9 | 70.0 | 58.7/57.3 | 74.4/73.0 |
| TX | 11.9 | 12.4 | 68.8 | 70.6 | 62.7/61.1 | 68.7/67.2 |
| IXX | 14.3 | 15.3 | 70.8 | 72.0 | 71.2/69.6 | 80.0/78.5 |
Table 3: mT5 vs. ByT5 on three English generation tasks, reporting the best score on the validation set.
表 3: mT5 与 ByT5 在三个英语生成任务上的对比 (验证集最高分)
each generative task across all model sizes. On GEM-XSum, ByT5 comes close (15.3 vs. 17.0) to the best score reported by Gehrmann et al. (2021), a PEGASUS model (Zhang et al., 2020) pre-trained specifically for sum mari z ation. On TweetQA, ByT5 outperforms (72.0 vs. 67.3) the BERT baseline of Xiong et al. (2019). On DROP, ByT5 comes close (EM 78.5 vs. 84.1) to the best result from Chen et al. (2020), a QDGAT (RoBERTa) model with a specialized numeric reasoning module.
在所有模型规模下的每个生成任务中,ByT5在GEM-XSum上的表现接近(15.3 vs. 17.0)Gehrmann等人(2021)报告的最佳成绩,该成绩由专门为摘要任务预训练的PEGASUS模型(Zhang等人,2020)取得。在TweetQA上,ByT5的表现(72.0 vs. 67.3)优于Xiong等人(2019)的BERT基线。在DROP上,ByT5接近(EM 78.5 vs. 84.1)Chen等人(2020)的最佳结果,后者是带有专门数值推理模块的QDGAT(RoBERTa)模型。
4.3 Cross-lingual Benchmarks
4.3 跨语言基准测试
Changes to vocabulary and token iz ation are likely to affect different languages in different ways. To test the effects of moving to byte-level modeling on cross-lingual understanding, we compare parameter-matched ByT5 and mT5 models on tasks from the popular XTREME benchmark suite (Hu et al., 2020). Specifically we evaluate on the same six tasks as Xue et al. (2021). These consist of two classification tasks: XNLI (Conneau et al., 2018) and PAWS-X (Yang et al., 2019), three extractive QA tasks: XQuAD (Artetxe et al., 2020), MLQA (Lewis et al., 2020) and TyDiQA (Clark et al., 2020), and one structured prediction task: WikiAnn NER (Pan et al., 2017).
词汇和标记化(Tokenization)的变化可能对不同语言产生不同影响。为测试转向字节级建模对跨语言理解的影响,我们在XTREME基准测试套件(Hu et al., 2020)的任务上比较了参数匹配的ByT5和mT5模型。具体而言,我们采用与Xue et al. (2021)相同的六项任务进行评估:两项分类任务——XNLI (Conneau et al., 2018)和PAWS-X (Yang et al., 2019);三项抽取式问答任务——XQuAD (Artetxe et al., 2020)、MLQA (Lewis et al., 2020)和TyDiQA (Clark et al., 2020);以及一项结构化预测任务——WikiAnn命名实体识别(Pan et al., 2017)。
Table 4 shows that ByT5 is quite competitive overall. On the most realistic in-language setting, where some gold training data is available in all languages, ByT5 surpasses the previous state-of-art mT5 on all tasks and model sizes. On the translatetrain setting, ByT5 beats mT5 at smaller sizes, but the results are mixed at larger sizes. We report zeroshot results for completeness, but emphasize that this setting is less aligned with practical applications, as machine translation is widely available.5
表 4 显示 ByT5 整体表现相当出色。在最贴近实际的多语言场景中 (即所有语言都提供部分标注训练数据时),ByT5 在所有任务和模型规模上都超越了此前最先进的 mT5。在翻译训练 (translatetrain) 设定下,ByT5 在较小模型规模上优于 mT5,但在较大模型规模上结果存在波动。出于完整性我们汇报了零样本 (zero-shot) 结果,但需要强调该设定与实际应用场景契合度较低,因为机器翻译技术已广泛普及。5
We explore per-language breakdowns on two tasks to see how different languages are affected by the switch to byte-level processing. One might expect languages with rich inflectional morphology (e.g. Turkish) to benefit most from the move away from a fixed vocabulary. We were also curious to see if any patterns emerged regarding language family (e.g. Romance vs. Slavic), written script (e.g. Latin vs. non-Latin), character set size, or data availability (high vs. low resource).
我们通过两项任务的分语言细分来探究不同语言在切换至字节级处理时的表现差异。理论上,形态变化丰富的语言(如土耳其语)应能从突破固定词表限制中获益最多。同时,我们也关注语言谱系(如罗曼语族与斯拉夫语族)、文字系统(如拉丁字母与非拉丁文字)、字符集规模及数据可用性(高资源与低资源)是否呈现特定规律。
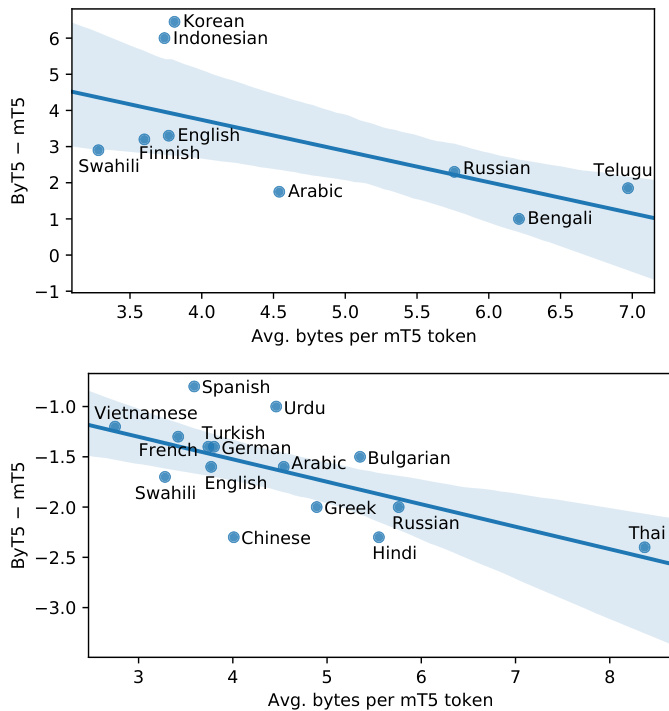
Figure 3: Per-language performance gaps between ByT5-Large and mT5-Large, as a function of each language’s “compression rate”. Top: TyDiQA-GoldP gap. Bottom: XNLI zero-shot gap.
图 3: ByT5-Large 与 mT5-Large 在不同语言间的性能差距,以各语言的"压缩率"为函数。上图: TyDiQA-GoldP 差距。下图: XNLI 零样本差距。
Figure 3 shows the per-language gaps between ByT5-Large and mT5-Large on TyDiQA-GoldP and XNLI zero-shot. One notable trend is that the gap is fairly stable across languages. For example, ByT5 is better in each language on TyDiQAGoldP, while mT5 is consistently better on XNLI. Comparing across languages, we observe that languages with a higher Sentence Piece token compression rate (e.g. Thai and Telugu) tend to favor mT5, whereas those with a lower compression rate (e.g. Indonesian and Vietnamese) tend to favor ByT5. We did not observe any robust trends regarding morphological complexity, language family, script, character set size, or data availability.
图 3: 展示了ByT5-Large和mT5-Large在TyDiQA-GoldP和XNLI零样本任务上的各语言表现差距。一个显著趋势是这种跨语言差距相对稳定。例如,ByT5在TyDiQA-GoldP的每种语言中都表现更好,而mT5在XNLI上持续占优。跨语言比较发现,Sentence Piece token压缩率较高的语言(如泰语和泰卢固语)往往更适合mT5,而压缩率较低的语言(如印尼语和越南语)则更适配ByT5。我们未在形态复杂度、语系、文字系统、字符集规模或数据可用性方面观察到显著规律。
4.4 Word-Level Tasks
4.4 词级任务
Given its direct access to the “raw” text signal, we expect ByT5 to be well-suited to tasks that are sensitive to the spelling or pronunciation of text. In this section we test this hypothesis on three wordlevel benchmarks: (i) transliteration, (ii) graphemeto-phoneme, and (iii) morphological inflection.
由于ByT5能直接处理"原始"文本信号,我们预期它在对文本拼写或发音敏感的任务中表现优异。本节通过三个单词级基准测试验证这一假设:(i) 音译转换,(ii) 字形到音素转换,以及(iii) 形态屈折变化。
Table 4: ByT5 and mT5 performance on a subset of XTREME tasks. Our evaluation setup follows Xue et al. (2021). For QA tasks we report F1 / EM scores.
| Small | Base | Large | XL | XXL | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| mT5 | ByT5 | mT5 | ByT5 | mT5 | ByT5 | mT5 | ByT5 | mT5 | ByT5 | |
| 同语言多任务 (模型在所有目标语言的黄金数据上微调) | ||||||||||
| WikiAnnNER | 86.4 | 90.6 | 88.2 | 91.6 | 89.7 | 91.8 | 91.3 | 92.6 | 92.2 | 93.7 |
| TyDiQA-GoldP | 75.9/64.8 | 82.6/73.6 | 81.7/71.2 | 86.4/78.0 | 85.3/75.3 | 87.7/79.2 | 87.6/78.4 | 88.0/79.3 | 88.7/79.5 | 89.4/81.4 |
| 翻译训练 (模型在英语数据及所有目标语言的翻译数据上微调) | ||||||||||
| 76.6 | 82.8 | 85.3 | 85.0 | 87.1 | ||||||
| XNLI PAWS-X | 75.3 | 88.6 | 80.5 90.5 | 79.9 89.8 | 84.4 91.3 | 90.6 | 91.0 | 90.5 | 91.5 | 85.7 91.7 |
| XQuAD | 87.7 71.3/55.7 | 74.0/59.9 | 77.6/62.2 | 78.5/64.6 | 81.3/66.5 | 81.4/67.4 | 82.7/68.1 | 83.7/69.5 | 85.2/71.3 | 84.1/70.2 |
| MLQA | 56.6/38.8 | 67.5/49.9 | 69.7/51.0 | 71.9/54.1 | 74.0/55.0 | 74.4/56.1 | 75.1/56.6 | 75.9/57.7 | 76.9/58.3 | 76.9/58.8 |
| TyDiQA-GoldP | 49.8/35.6 | 64.2/50.6 | 66.4/51.0 | 75.6/61.7 | 75.8/60.2 | 80.1/66.4 | 80.1/65.0 | 81.5/67.6 | 83.3/69.4 | 83.2/69.6 |
| 跨语言零样本迁移 (模型仅在英语数据上微调) | ||||||||||
| XNLI | 67.5 | 69.1 | 75.4 | 75.4 | 81.1 | 79.7 | 82.9 | 82.2 | 85.0 | 83.7 |
| PAWS-X | 82.4 | 84.0 | 86.4 | 86.3 | 88.9 | 87.4 | 89.6 | 88.6 | 90.0 | 90.1 |
| WikiAnnNER | 50.5 | 57.6 | 55.7 | 62.0 | 58.5 | 62.9 | 65.5 | 61.6 | 69.2 | 67.7 |
表 4: ByT5 和 mT5 在 XTREME 任务子集上的表现。我们的评估设置遵循 Xue et al. (2021)。对于问答任务,我们报告 F1/EM 分数。
Table 5: mT5 vs. ByT5 on three word-level tasks. Dakshina metrics are reported on the development set to be comparable with Roark et al. (2020). SIGMORPHON metrics are reported on the test sets.
表 5: mT5 与 ByT5 在三个词级任务上的对比。Dakshina 指标在开发集上报告以便与 Roark et al. (2020) 具有可比性。SIGMORPHON 指标在测试集上报告。
| Dakshina | SIGMORPHON2020 | |
|---|---|---|
| 音译 CER (↑) | 字形到音素 WER R(↓)/PER (↓) | |
| 模型 | mT5 | ByT5 |
| Small | 20.7 | 9.8 |
| Base | 19.2 | 9.9 |
| Large | 18.1 | 10.5 |
| XL | 17.3 | 10.6 |
| XXL | 16.6 | 9.6 |
For transliteration, we use the Dakshina benchmark (Roark et al., 2020), which covers 12 South Asian languages that are traditionally written with Brahmic or Perso-Arabic scripts but may also be written using Latin characters in informal contexts. The single-word transliteration task asks a model to “translate” a word from Latin script to native script and measures character error rate. The remaining tasks are SIGMORPHON 2020 shared tasks. Multilingual grapheme-to-phoneme conversion (Gorman et al., 2020) covers 15 languages and requires mapping a word to its pronunciation as phonemes (e.g. $c a t\rightarrow/\mathrm{kxt}/\zeta$ . Typo logically diverse morphological inflection (Vylomova et al., 2020) covers 90 languages and requires generating a specific inflection of a word (e.g. $e a t+\mathrm{PAST}\rightarrow a t e,$ .
对于音译任务,我们采用Dakshina基准测试 (Roark et al., 2020),该测试涵盖12种南亚语言。这些语言传统上使用婆罗米或波斯-阿拉伯文字书写,但在非正式场合也可能使用拉丁字符。单词语音转换任务要求模型将拉丁字符单词"翻译"为原生文字,并测量字符错误率。其余任务来自SIGMORPHON 2020共享任务:多语言字形到音素转换 (Gorman et al., 2020) 涵盖15种语言,要求将单词映射为其音素发音(例如 $c a t\rightarrow/\mathrm{kxt}/\zeta$);类型学多样的形态屈折变化 (Vylomova et al., 2020) 涵盖90种语言,要求生成单词的特定屈折形式(例如 $e a t+\mathrm{PAST}\rightarrow a t e,$)。
We fine-tune mT5 and ByT5 models for each task. For simplicity, we train one multilingual model per task, with a prefix indicating the language in question. Table 5 shows that ByT5 outperforms mT5 by large margins across the board.6 While it is unsurprising that “characteraware” models should excel on tasks around wordinternal phenonema, we wish to highlight that these core NLP tasks have often been overlooked in evaluating general-purpose NLP models.
我们针对每项任务对mT5和ByT5模型进行微调。为简化流程,每个任务训练一个多语言模型,并添加表示目标语言的前缀。表5显示,ByT5在所有任务上都大幅领先mT5。虽然"字符感知"模型在词汇内部现象相关任务中表现优异不足为奇,但需要强调的是,这些核心NLP任务在通用NLP模型评估中经常被忽视。
5 Experiments on Synthetic Noise
5 合成噪声实验
Text on modern digital platforms is noisy and exhibits complex character-level phenomena such as typos, character repetitions, and non-standard case changes (Caswell et al., 2020). Beyond these, errors can be introduced by NLP systems such as predictive input methods and automatic speech recognition. We have already seen strong ByT5 performance on the “messy” text in TweetQA. In this section, we move to even noisier text and explore model performance on inputs that have been corrupted with artificial noise of various kinds. Across a range of noising schemes, we find that ByT5 outperforms mT5, demonstrating higher robustness to noise across tasks and languages.
现代数字平台上的文本充满噪声,并表现出复杂的字符级现象,如拼写错误、字符重复和非标准的大小写变化 (Caswell et al., 2020) 。除此之外,预测输入法和自动语音识别等自然语言处理 (NLP) 系统也可能引入错误。我们已经在 TweetQA 的"混乱"文本中观察到 ByT5 的出色表现。本节我们将转向噪声更大的文本,探索模型在受到各种人工噪声干扰的输入上的性能。通过一系列噪声方案测试,我们发现 ByT5 优于 mT5,在不同任务和语言中展现出更强的抗噪鲁棒性。
We experiment with five noising schemes: (1) Drop: Each character (i.e. Unicode codepoint) has a $10%$ chance of being dropped. (2) Repetitions: Each character has a $20%$ chance of being selected for repetition. If selected, 1–3 repetitions (with equal likelihood) are appended after the original character. (3) Antspeak: Each character is capitalized and padded with spaces, so “an owl” becomes “ A N O W L ”. (4) Uppercase: Each character is converted to uppercase. (5) Random case: Each character is set to a random case (upper or lower). For the last two noise types, we restrict to languages whose scripts distinguish case.
我们测试了五种加噪方案:(1) 丢弃:每个字符(即Unicode码位)有$10%$的概率被丢弃。(2) 重复:每个字符有$20%$的概率被选中进行重复。若被选中,将在原字符后追加1-3次重复(等概率)。(3) 蚁语模式:每个字符转为大写并用空格分隔,如"an owl"变为" A N O W L "。(4) 大写:每个字符转为大写形式。(5) 随机大小写:每个字符被随机设置为大写或小写。对于后两种噪声类型,我们仅限用于区分大小写的书写体系。
Table 6: Degradation of mT5 and ByT5 under various types of noise. “Clean” shows original task performance. Subsequent rows show the delta from “clean” when adding different types of noise. Learnable noise is added in training and eval, while unseen noise only affects eval.
表 6: mT5和ByT5在不同类型噪声下的性能下降情况。"Clean"显示原始任务性能。后续行显示添加不同类型噪声时与"Clean"的差值。可学习噪声在训练和评估时添加,而未见噪声仅影响评估。
| 可学习噪声 | 未见噪声 XNLI | |||
|---|---|---|---|---|
| XNLI (准确率) | TyDiQA-GoldP (F1) | (准确率) | ||
| Clean | 模型 mT5 | 81.1 | 85.3 | 81.1 |
| ByT5 | 79.7 | 87.7 | 79.7 | |
| Drop | mT5 | -10.2 | -24.0 | -18.3 |
| ByT5 | -8.2 | -19.5 | -11.4 | |
| Repetitions | mT5 | -8.5 | -9.5 | -12.3 |
| ByT5 | -4.1 | -3.0 | -5.9 | |
| Antspeak | mT5 | -32.0 | -27.7 | -34.4 |
| ByT5 | -8.7 | -4.8 | -24.4 | |
| Uppercase | mT5 | -7.0 | -8.0 | -8.1 |
| ByT5 | -1.5 | -0.5 | -1.7 | |
| Random Case | mT5 | -25.7 | -14.3 | -19.2 |
| ByT5 | -1.5 | -0.2 | -5.9 |
We first consider the easier setting of learnable noise, where noise is applied during both fine-tuning and evaluation. We evaluate on XNLI zero-shot and TyDiQA-GoldP. For XNLI, both the premise and hypothesis are noised, and the model predicts an entailment label as usual. For TyDiQA, we add noise to the question and the context, but leave the answer unchanged. Thus, in many cases, the model needs to first locate the noisy answer, and then “undo” the noise to produce the target. We fine-tune all models for 30,000 steps following the procedure in section 4.
我们首先考虑可学习噪声的简单设定,即在微调和评估阶段都施加噪声。实验在XNLI零样本和TyDiQA-GoldP任务上进行。对于XNLI任务,前提和假设文本均被添加噪声,模型照常预测蕴含标签。在TyDiQA任务中,我们对问题和上下文添加噪声但保持答案不变,因此模型通常需要先定位带噪答案,再"消除"噪声以生成目标答案。所有模型均按照第4章节流程微调30,000步。
Table 6 shows the differing ability of ByT5 and mT5 to adapt to learnable noise. We measure the degradation of the task metric between the clean and noisy settings. We observe that mT5 degrades more in the presence of noise than ByT5, across all noise conditions. In the most extreme contrast, rANdOm CaSE (often used as an affective device on social media7) is hugely detrimental to mT5, with losses of $-25.7$ and $-14.3$ points, while ByT5 only drops by $-1.5$ and $-0.2$ points. ByT5 is also quite robust to UPPERCASE and repetitions.
表 6 展示了 ByT5 和 mT5 在适应可学习噪声方面的能力差异。我们测量了干净和噪声设置之间任务指标的下降情况。在所有噪声条件下,mT5 在噪声存在时的性能下降比 ByT5 更严重。在最极端的对比中,rANdOm CaSE (社交媒体上常用的一种情感表达手段) 对 mT5 极为不利,损失达到 $-25.7$ 和 $-14.3$ 分,而 ByT5 仅下降 $-1.5$ 和 $-0.2$ 分。ByT5 对 UPPERCASE 和重复字符也表现出较强的鲁棒性。
We also test robustness to noise that is unseen during training but injected during evaluation. This is relevant in making models more future-proof as well as more resilient to accidental or adversarial spelling mistakes (Pruthi et al., 2019; Sun et al., 2020). We evaluate only XNLI and skip TyDiQAGoldP in this setting, as it is unreasonable to expect a generative model that was fine-tuned to always copy spans from the context to spontaneously “undo” corruptions and predict novel spans. The rightmost column of table 6 shows that in this more challenging setting, ByT5 is once again more resilient to noise. While some types of unseen noise like A N T S P E A K are highly detrimental, ByT5 sees only minor degradation s for casing noise.
我们还测试了模型对训练时未见过但在评估时注入的噪声的鲁棒性。这一测试对于提升模型的前瞻适应性以及增强对意外或对抗性拼写错误的抵抗力具有重要意义 (Pruthi et al., 2019; Sun et al., 2020)。在此设置中,我们仅评估XNLI而跳过TyDiQAGoldP,因为期望一个经过微调始终从上下文中复制片段的大语言模型能够自发"修复"损坏并预测新片段是不合理的。表6最右侧列显示,在这一更具挑战性的设置中,ByT5再次展现出更强的噪声抵抗力。虽然某些未见噪声类型(如A N T S P E A K)会造成严重损害,但ByT5在大小写噪声方面仅出现轻微性能下降。
Table 7: Models used in our ablation study.
表 7: 消融研究中使用的模型
| Model | Params | Description |
|---|---|---|
| ByT5-Large | 1.23B | 基线 ByT5 模型 |
| mT5-Large | 1.23B | 基线 mT5 模型 |
| (a) ByT5-36/12-668M | 668M | 编码器: 36, 解码器: 12 |
| (b) ByT5-24/24-718M | 718M | 编码器: 24, 解码器: 24 |
| (c) ByT5-12/36-768M | 768M | 编码器: 12, 解码器: 36 |
| (d) mT5-36/12-1.18B | 1.18B | 编码器: 36, 解码器: 12 |
| (e) ByT5-Large-Span3 | 1.23B | 平均噪声跨度 3.0 |
| (f) ByT5-Large-Span40 | 1.23B | 平均噪声跨度 40.0 |
| (g) CharT5-36/12-1.23B | 1.23B | 47K 字符词汇表 |
Our findings echo the results of Durrani et al. (2019), who find that character-level models are more robust to real and synthetic noise than BPE or word-based models, across a range of morphological, syntactic and semantic tagging tasks. The more general conclusion that emerges is that token-free models are more robust to noise across many tasks.
我们的发现与Durrani等人 (2019) 的研究结果相呼应,他们发现在一系列形态、句法和语义标注任务中,字符级模型比BPE或基于单词的模型对真实和合成噪声更具鲁棒性。由此得出的更普遍结论是:无token模型在多数任务中都具有更强的抗噪性。
6 Ablation Study
6 消融研究
To better understand the importance of various design choices, we train ablation models and compare these against our baselines on three tasks: XNLI zero-shot, TyDiQA-GoldP and GEM-XSum. Our baselines and ablations are listed in table 7. The baselines are the parameter-matched ByT5-Large and mT5-Large models discussed above.
为了更好地理解各种设计选择的重要性,我们在三项任务(XNLI零样本、TyDiQA-GoldP和GEM-XSum)上训练了消融模型,并与基线进行比较。我们的基线和消融实验列于表7。基线是前文讨论过的参数匹配的ByT5-Large和mT5-Large模型。
6.1 Matched Transformer Layer Size
6.1 匹配的Transformer层尺寸
Model (a) ByT5-36/12-668M is identical to ByT5- Large except that $\mathrm{d}{\mathrm{model}}$ and $\mathrm{d_{ff}}$ are matched to mT5-Large, giving a model with 668 million parameters, ${\sim}54%$ the size of ByT5-Large and mT5-Large. As seen in table 8, this model is still competitive, and outperforms the roughly similarly sized mT5-Base by a large margin (cf. table 4).
模型 (a) ByT5-36/12-668M 与 ByT5-Large 完全相同,只是 $\mathrm{d}{\mathrm{model}}$ 和 $\mathrm{d_{ff}}$ 与 mT5-Large 相匹配,从而得到一个拥有 6.68 亿参数的模型,其大小约为 ByT5-Large 和 mT5-Large 的 ${\sim}54%$。如表 8 所示,该模型仍然具有竞争力,并且大幅优于参数规模大致相当的 mT5-Base (参见表 4)。
Table 8: Ablation model results across three tasks.
表 8: 三项任务的消融模型结果。
| 模型 | XNLI (准确率) | TyDiQA-GoldP (F1) | GEM-XSum (BLEU) |
|---|---|---|---|
| ByT5-Large (1.23B) | 79.7 | 87.7 | 11.5 |
| mT5-Large (1.23B) | 81.1 | 85.3 | 10.1 |
| (a) ByT5-36/12-668M | 78.3 | 87.8 | 12.3 |
| (b) ByT5-24/24-718M | 75.4 | 83.0 | 7.1 |
| (c) ByT5-12/36-768M | 73.5 | 83.1 | 8.3 |
| (d) mT5-36/12-1.18B | 81.5 | 87.1 | 10.8 |
| (e) ByT5-Large-Span3 | 79.4 | 87.4 | 10.2 |
| (f) ByT5-Large-Span40 | 78.9 | 88.3 | 12.6 |
| (g) CharT5-36/12-1.23B | 79.0 | 87.6 | 11.2 |
This is evidence that the value of ByT5 does not come solely from using wider transformer layers.
这表明ByT5的价值并非仅源于使用更宽的Transformer层。
6.2 Encoder/Decoder Balance
6.2 编码器/解码器平衡
To investigate the effect of decoupling encoder and decoder depth, we train two additional ByT5 models with $\mathrm{d}{\mathrm{model}}$ and $\mathrm{d_{ff}}$ matched to mT5-Large: (b) ByT5-24/24-718M, a “balanced” model with 24/24 encoder/decoder layers, and (c) ByT5-12/36- $768\mathbf{M}$ , a “heavy decoder” model. As decoder layers have extra parameters used for decoder-encoder attention, these models are bigger than our default heavy encoder setup. Yet despite the extra parameters, these configurations under perform on all tasks, including even the generative GEM-XSum task that we might expect to benefit from a stronger decoder.
为了研究解耦编码器和解码器深度的影响,我们训练了两个额外的ByT5模型,其$\mathrm{d}{\mathrm{model}}$和$\mathrm{d_{ff}}$与mT5-Large匹配:(b) ByT5-24/24-718M,这是一个具有24/24编码器/解码器层的"平衡"模型;(c) ByT5-12/36-$768\mathbf{M}$,这是一个"重型解码器"模型。由于解码器层包含用于解码器-编码器注意力的额外参数,这些模型比我们默认的重型编码器设置更大。然而,尽管有额外的参数,这些配置在所有任务上表现不佳,甚至包括我们预期会从更强的解码器中受益的生成式GEM-XSum任务。
To test whether a heavier encoder benefits mT5 as well, we train (d) mT5-36/12-1.18B, a model with the same configuration as mT5-Large, but switching to 36/12 encoder/decoder layers. As with ByT5, we observe benefits across all three tasks. However, the gains $(+0.4,+1.8,+0.7)$ are much smaller than those of ByT5 $(+2.9,+4.8,+5.2)$ .
为了验证更重的编码器是否同样有益于mT5,我们训练了(d) mT5-36/12-1.18B,该模型与mT5-Large配置相同,但将编码器/解码器层数调整为36/12。与ByT5类似,我们在所有三项任务中都观察到了提升。然而,其增益 $(+0.4,+1.8,+0.7)$ 远小于ByT5的 $(+2.9,+4.8,+5.2)$。
We suspect a heavy encoder may be particularly important in vocabulary-free models as the encoder stack must stand in for the missing high-capacity token embedding matrix, allowing the model to learn a “soft lexicon” covering potentially millions of idiosyncratic mappings from word forms to meanings. In concurrent work, Wies et al. (2021) also observe that models with tiny vocabularies benefit from additional depth. One reason the decoder may not need as much capacity is that in inference, the decoder is run auto regressive ly, using a full forward pass for every token prediction. Given the increased resolution of byte sequences, this means ByT5 predictions will benefit from 2–9 times more passes through the decoder stack depending on the language (see fig. 2), as compared to mT5. In this light, even a shallower byte decoder may be sufficient to compete with a larger subword decoder.
我们推测,在无词汇表模型中,一个重型编码器可能尤为重要,因为编码器堆栈必须替代缺失的高容量token嵌入矩阵,使模型能够学习覆盖数百万种从词形到意义的独特映射的"软词典"。Wies等人(2021)在同期研究中也观察到,小词汇量模型会从额外深度中受益。解码器可能不需要同等容量的一个原因是:在推理过程中,解码器以自回归方式运行,每个token预测都需要完整的正向传播。考虑到字节序列的更高分辨率,这意味着ByT5预测将比mT5多经历2-9次解码器堆栈传播(具体取决于语言,见图2)。从这个角度看,即使较浅的字节解码器也可能足以与更大的子词解码器竞争。
6.3 Masked Span Length
6.3 掩码跨度长度
The T5 mean span length hyper parameter controls the average length of the masked spans used in the unsupervised pre-training objective. For T5 and mT5, this was 3 Sentence Piece tokens. For ByT5, we hypothesize that predicting such short byte-spans would be too easy of a task, as this would often just require reconstructing part of a single word (regardless of language). Our final ByT5 models use mean span length of 20 bytes, which results in more challenging reconstruction tasks. We also show ablations (e–f) with span length 3 and 40. Table 8 shows that our baseline with length 20 performs the best on the classification task XNLI, whereas length 40 performs better on TyDiQA-GoldP and GEM-XSum, both of which require generating a natural language text output.
T5的平均遮蔽跨度长度超参数控制无监督预训练目标中使用的遮蔽跨度的平均长度。对于T5和mT5,该参数为3个Sentence Piece token。对于ByT5,我们假设预测如此短的字节跨度任务会过于简单,因为这通常只需要重建单个单词的部分内容(无论何种语言)。我们最终的ByT5模型采用20字节的平均跨度长度,这会带来更具挑战性的重建任务。我们还展示了跨度长度为3和40的消融实验(e-f)。表8显示,在分类任务XNLI上,我们采用长度20的基线表现最佳,而在需要生成自然语言文本输出的TyDiQA-GoldP和GEM-XSum任务上,长度40表现更好。
6.4 Character Vocabulary
6.4 字符词汇表
A character-level vocabulary serves as an intermediate point between a large subword vocabulary and a tiny byte vocabulary. As a point of comparison, we train (g) CharT5-36/12-1.23B: a model with a vocabulary of 47,198 characters, the same encoder/decoder ratio as ByT5, and the same overall parameter count as ByT5-Large and mT5-Large. To achieve this matched parameter count, we set $\mathrm{d}{\mathrm{model}}{=}1376$ and $\mathrm{d_{ff}=3840}$ . The resulting proportion of vocab-related parameters is $11%$ (compared to $42%$ for mT5-Large and $0.06%$ for ByT5-Large). The vocabulary itself is implemented using the SentencePiece library, but with an added restriction that tokens may only represent single characters. The characters cover all those seen in a sample of 4 million documents taken from the mC4 pre-training corpus, mixing languages with the ratios used during pre-training. We use the byte-level fallback mechanism, so no character is out-of-vocabulary.
字符级词汇表(character-level vocabulary)是大型子词词汇表与微型字节词汇表之间的折中方案。作为对比基准,我们训练了(g) CharT5-36/12-1.23B模型:该模型采用47,198个字符的词汇表,编码器/解码器比例与ByT5相同,总参数量与ByT5-Large和mT5-Large持平。为实现参数匹配,我们设定$\mathrm{d}{\mathrm{model}}{=}1376$和$\mathrm{d_{ff}=3840}$,最终词汇相关参数占比为$11%$(对比mT5-Large的$42%$和ByT5-Large的$0.06%$)。该词汇表通过SentencePiece库实现,但额外限定每个token仅能代表单个字符。字符覆盖范围来自mC4预训练语料库中400万文档样本的所有字符,并保持预训练时的多语言比例。我们采用字节级回退机制,因此不存在未登录字符。
Table 8 shows that CharT5 is fairly competitive, but performs slightly worse than ByT5 on all three tasks. We suspect this may be due to two factors: (i) CharT5 reserves a capacity for rare characters, and these parameters would be better allocated in the transformer layers, and (ii) using UTF-8 bytes increases the sequence length for non-ASCII text, resulting in extra computational budget for encoding and decoding languages with non-Latin scripts.
表 8: 显示 CharT5 表现相当有竞争力,但在所有三项任务上略逊于 ByT5。我们推测这可能源于两个因素:(i) CharT5 为稀有字符预留了容量,这些参数本应更合理地分配在 Transformer 层中;(ii) 使用 UTF-8 字节会增长非 ASCII 文本的序列长度,导致对非拉丁文字的语言进行编解码时需消耗额外计算资源。
Table 9: Pre-training speed and computation of mT5 vs. ByT5. Left: Sequences per second pre-training on a TPUv3-64 device. Right: Total einsum operations for a forward pass, as logged by the T5 framework.
表 9: mT5 与 ByT5 的预训练速度与计算量对比。左: 在 TPUv3-64 设备上的每秒处理序列数。右: T5框架记录的单次前向传播总 einsum 运算量。
| sequences/sec | einsum ops ×1e12 | |||
|---|---|---|---|---|
| mT5 | ByT5 | mT5 | ByT5 | |
| Small | 1646 | 1232 (0.75x) | 87 | 98 (1.13×) |
| Base | 747 | 576 (0.77x) | 168 | 194 (1.15×) |
| Large | 306 | 232 (0.76x) | 346 | 416 (1.20×) |
| XL | 94 | 70 (0.74×) | 1000 | 1220 (1.22×) |
| XXL | 33 | 25 (0.76×) | 1660 | 2070 (1.25×) |
| Grapheme-to-Phoneme | Dakshina | |||
|---|---|---|---|---|
| mT5 | ByT5 | mT5 | ByT5 | |
| Small | 1223 | 1190 (1.0×) | 9483 | 6482 (1.5×) |
| Base | 726 | 932 (0.8×) | 7270 | 4272 (1.7×) |
| Large | 387 | 478 (0.8×) | 4243 | 2282 (1.9×) |
| XL | 280 | 310 (0.9×) | 2922 | 1263 (2.3×) |
| TXX | 150 | 146 (1.0×) | 1482 | 581 (2.6×) |
| XNLI | GEM-XSum | |||
|---|---|---|---|---|
| mT5 | ByT5 | mT5 | ByT5 | |
| Small | 8632 | 1339 (6.4×) | 750 | 202 (3.7×) |
| Base | 5157 | 687 (7.5×) | 450 | 114 (3.9×) |
| Large | 1598 | 168 (9.5×) | 315 | 51 (6.2×) |
| XL | 730 | 81 (9.0×) | 162 | 25 (6.4×) |
| TXX | 261 | 33 (8.0×) | 61 | 10 (6.3×) |
Table 10: Average inference examples per second on the test sets of word-level tasks (top) and sentence- or document-level tasks (bottom). We use a TPUv3-128 for GEM-XSum, and a TPUv3-32 elsewhere.
表 10: 在词级任务(上)和句子或文档级任务(下)测试集上的平均每秒推理示例数。GEM-XSum使用TPUv3-128,其他任务使用TPUv3-32。
7 Speed Comparisons
7 速度对比
Table 9 compares the pre-training FLOPs of ByT5 vs. mT5, as well as the pre-training speed on fixed hardware, as sequences per second with sequence length of 1024. Across all model sizes, ByT5 requires ${\sim}1.2\times$ more operations, resulting in ${\sim}0.75\times$ as many sequences per second.
表 9 对比了 ByT5 与 mT5 的预训练 FLOPs (浮点运算次数) 以及在固定硬件上的预训练速度 (以序列长度 1024 的每秒处理序列数为单位)。在所有模型规模下,ByT5 需要多消耗约 1.2 倍运算量,导致其每秒处理的序列数降至约 0.75 倍。
Table 10 compares the inference speed of ByT5 and mT5 by measuring the average number of inference predictions per second across four tasks. On word-level tasks, ByT5 is fairly competitive: on SIGMORPHON 2020 Grapheme-to-Phoneme, where targets are written using the International Phonetic Alphabet, ByT5 and mT5 have similar inference speed; on Dakshina transliteration, ByT5 is 1.5 to 2.6 times slower. On tasks with longer input sequences, the slowdown is more pronounced: on GEM-XSum8 (document sum mari z ation), ByT5 is 3.7 to 6.4 times slower than mT5, while on XNLI zero-shot classification it is 6.4 to 9.5 times slower. More generally, we observe that—as expected due to its deeper encoder and shallower decoder—ByT5 achieves more competitive inference speed (relative to mT5) on tasks with short inputs and/or long targets. In this light, XNLI represents something of a worst-case, where inputs are sentence pairs and labels are single digits ${0,1,2}$ .
表 10 通过测量四项任务中每秒的平均推理预测次数,对比了 ByT5 和 mT5 的推理速度。在词级任务上,ByT5 表现相当有竞争力:在 SIGMORPHON 2020 字形到音素转换任务(目标采用国际音标书写)中,ByT5 与 mT5 推理速度相近;在 Dakshina 转写任务中,ByT5 慢 1.5 至 2.6 倍。对于输入序列较长的任务,速度下降更为明显:在 GEM-XSum8(文档摘要)任务中,ByT5 比 mT5 慢 3.7 至 6.4 倍;在 XNLI 零样本分类任务中则慢 6.4 至 9.5 倍。总体而言,我们观察到——由于其更深的编码器和更浅的解码器结构——ByT5 在输入较短和/或目标较长的任务中能获得相对更优的推理速度(相较于 mT5)。从这个角度看,XNLI 任务代表了最不利的情况,其输入为句子对而标签仅为单个数字 ${0,1,2}$。
The time required for fine-tuning is also variable across tasks. When holding batch size constant at a fixed number of tokens, we find that ByT5 typically takes more fine-tuning steps than mT5 to reach optimal performance on a holdout set. For example, ByT5-Large took $1.2\times$ as many steps as mT5- Large to reach peak validation performance on XNLI zero-shot, $2.6\times$ as many steps for TyDiQAGoldP, and $4.5\times$ as many for GEM-XSum. This overall trend is expected, in that fewer labeled examples fit into each ByT5 fine-tuning batch. However, on tasks that strongly favor byte-level represent at ions, ByT5 reaches peak performance in fewer fine-tuning steps, suggesting that the model can generalize better from a small number of training examples. For example, ByT5-Large took $2.5\times$ fewer steps than mT5-Large to reach peak performance on Dakshina.
不同任务所需的微调时间也有所不同。在保持批次大小恒定为固定token数量的情况下,我们发现ByT5通常需要比mT5更多的微调步骤才能在保留集上达到最佳性能。例如,ByT5-Large在XNLI零样本任务上达到峰值验证性能所需的步骤是mT5-Large的$1.2\times$,在TyDiQAGoldP任务上是$2.6\times$,在GEM-XSum任务上则是$4.5\times$。这种总体趋势符合预期,因为每个ByT5微调批次能容纳的标注样本更少。然而,在强烈偏好字节级表示的任务上,ByT5能以更少的微调步骤达到峰值性能,这表明该模型能够从少量训练样本中更好地泛化。例如,ByT5-Large在Dakshina任务上达到峰值性能所需的步骤比mT5-Large少$2.5\times$。
Overall, we believe that the additional pretraining cost (roughly $+33%$ wall time) and the additional fine-tuning cost (for some tasks) is justified in non-latency-sensitive applications by the benefits of reduced system complexity, better robustness to noise, and improved task performance on many benchmarks.
总体而言,我们认为额外的预训练成本(大约增加33%的墙上时间)和某些任务所需的额外微调成本,在非延迟敏感型应用中具有合理性,这体现在降低系统复杂度、提升抗噪鲁棒性以及多项基准测试任务性能的改进上。
8 Conclusion
8 结论
In this work, we presented ByT5, a token-free variant of multilingual T5 (Xue et al., 2021) that simplifies the NLP pipeline by doing away with vocabulary building, text preprocessing and tokenization. On downstream task quality, ByT5 is competitive with parameter-matched mT5 models that rely on Sentence Piece vocabulary. Specifically, ByT5 outperforms mT5 in any of these five scenarios: (1) at model sizes under 1 billion parameters, (2) on generative tasks, (3) on multilingual tasks with in-language labels, (4) on word-level tasks sensitive to spelling and/or pronunciation, and (5) in the presence of various types of noise.
在本工作中,我们提出了ByT5——多语言T5 (Xue et al., 2021) 的无Token变体,它通过取消词汇表构建、文本预处理和Token化步骤简化了自然语言处理流程。在下游任务质量方面,ByT5与依赖Sentence Piece词表的同参数量mT5模型表现相当。具体而言,ByT5在以下五种场景中优于mT5:(1) 参数量低于10亿的模型规模,(2) 生成式任务,(3) 使用目标语言标签的多语言任务,(4) 对拼写或发音敏感的词语级任务,(5) 存在各类噪声干扰时。
While beating mT5 in many cases, ByT5 slightly under performed in certain conditions—most notably, on English classification tasks for model sizes over 1 billion parameters. In future work, it will also be important to evaluate token-free approaches on a more diverse set of tasks, especially those where character-based models have traditionally struggled. These include word similarity tasks (Hiebert et al., 2018), syntactic and semantic tagging tasks (Durrani et al., 2019), and machine translation from a non-English source into English (Shaham and Levy, 2021).
虽然ByT5在许多情况下表现优于mT5,但在某些条件下其性能略有不足——最明显的是在参数量超过10亿的英语分类任务中。未来的工作中,还需要在更多样化的任务上评估无token方法,尤其是在基于字符的模型传统上表现不佳的领域。这些任务包括词汇相似度任务 (Hiebert et al., 2018)、句法和语义标注任务 (Durrani et al., 2019),以及从非英语源语言到英语的机器翻译 (Shaham and Levy, 2021)。
Through ablations, we showed that byte-level encoder-decoder models benefit from a “heavier” encoder (decoupling encoder and decoder depth), and that the pre-training task benefits from masking longer ID sequences. We also showed that for fixed parameter count, character-level models give similar but somewhat worse results.
通过消融实验,我们发现字节级编码器-解码器模型受益于"更重"的编码器(解耦编码器和解码器深度),且预训练任务受益于掩码更长的ID序列。我们还表明,在参数数量固定的情况下,字符级模型能产生相似但稍差的结果。
Interestingly, the gains we observe with ByT5 are achieved despite the model being pre-trained on $4\times$ less text than mT5. This suggests that bytelevel models may be more data efficient learners.
有趣的是,尽管 ByT5 的预训练文本量比 mT5 少 $4\times$ ,我们仍观察到了性能提升。这表明字节级模型 (byte-level) 可能是数据效率更高的学习者。
These gains in design simplicity, task quality and data efficiency come at the cost of additional computation. Our “hands-off” approach of feeding raw UTF-8 bytes directly into the Transformer costs $+33%$ pre-training time, as well as longer inference time (up to $10\times$ slower in the worst case). As such, there is significant room for improvement. We believe techniques such as hash embeddings, local attention and down-sampling (Clark et al., 2021), as well as sparse computation (Fedus et al., 2021) can help address latency issues, removing the remaining barriers to a token-free future.
在设计简洁性、任务质量和数据效率方面取得的这些优势,是以额外计算为代价的。我们直接将原始UTF-8字节输入Transformer的"免干预"方法,导致预训练时间增加33%,推理时间也更长(最坏情况下可能慢10倍)。因此,仍有很大的改进空间。我们认为诸如哈希嵌入(hash embeddings)、局部注意力(local attention)和下采样(Clark et al., 2021)等技术,以及稀疏计算(Fedus et al., 2021)可以帮助解决延迟问题,为无token化的未来扫清剩余障碍。