S crib Former: Transformer Makes CNN Work Better for Scribble-based Medical Image Segmentation
S crib Former: Transformer 让 CNN 在基于涂鸦的医学图像分割中表现更优
Abstract— Most recent scribble-supervised segmentation methods commonly adopt a CNN framework with an encoder-decoder architecture. Despite its multiple benefits, this framework generally can only capture small-range feature dependency for the convolutional layer with the local receptive field, which makes it difficult to learn global shape information from the limited information provided by scribble annotations. To address this issue, this paper proposes a new CNN-Transformer hybrid solution for scribble-supervised medical image segmentation called S crib Former. The proposed S crib Former model has a triplebranch structure, i.e., the hybrid of a CNN branch, a Transformer branch, and an attention-guided class activation map (ACAM) branch. Specifically, the CNN branch collaborates with the Transformer branch to fuse the local features learned from CNN with the global representations obtained from Transformer, which can effectively overcome limitations of existing scribble-supervised segmentation methods. Furthermore, the ACAM branch assists in unifying the shallow convolution features and the deep convolution features to improve model’s performance further. Extensive experiments on two public datasets and one private dataset show that our S crib Former has superior performance over the state-of-the-art scribble-supervised segmentation methods, and achieves even better results than the fullysupervised segmentation methods. The code is released at https://github.com/HUANGLIZI/S crib Former.
摘要— 当前大多数涂鸦监督的分割方法通常采用具有编码器-解码器架构的CNN框架。尽管该框架具有多重优势,但由于卷积层的局部感受野特性,通常只能捕获小范围特征依赖关系,难以从涂鸦标注提供的有限信息中学习全局形状信息。为解决这一问题,本文提出了一种新型CNN-Transformer混合解决方案ScribFormer,用于涂鸦监督的医学图像分割。所提出的ScribFormer模型采用三分支结构,即CNN分支、Transformer分支和注意力引导类激活图(ACAM)分支的混合架构。具体而言,CNN分支与Transformer分支协同工作,将CNN学习到的局部特征与Transformer获取的全局表征相融合,能有效克服现有涂鸦监督分割方法的局限性。此外,ACAM分支通过统一浅层卷积特征与深层卷积特征,进一步提升模型性能。在三个公开数据集和一个私有数据集上的大量实验表明,ScribFormer性能优于当前最先进的涂鸦监督分割方法,甚至超越了全监督分割方法的效果。代码已开源:https://github.com/HUANGLIZI/ScribFormer。
Index Terms— Transformer, Medical image segmentation, Scribble-supervised learning.
索引关键词— Transformer、医学图像分割、涂鸦监督学习。
This work was supported in part by National Natural Science Foundation of China (grant numbers 62131015, 62250710165, U23A20295), Science and Technology Commission of Shanghai Municipality (STCSM) (grant numbers 21010502600), and The Key R&D Program of Guangdong Province, China (grant numbers 2021 B 0101420006).
本研究部分由国家自然科学基金(62131015、62250710165、U23A20295)、上海市科学技术委员会(21010502600)和广东省重点研发计划项目(2021B0101420006)资助。
Zihan Li is with Xiamen University and the Department of Bio engineering, University of Washington, Seattle, WA 98195, USA.
李梓涵任职于厦门大学及美国华盛顿州西雅图市华盛顿大学生物工程系(邮编:98195)。
Yuan Zheng, Dandan Shan and Beizhan Wang are with Xiamen University, Xiamen 361005, China.
袁征、单丹丹和王北战就职于厦门大学,厦门 361005,中国。
Yuanting Zhang is with the Department of Electronic Engineering at the Chinese University of Hong Kong, Shatin, Hong Kong, China, and also Hong Kong Institute of Medical Engineering, Taipo, Hong Kong, China.
张远霆就职于中国香港沙田的香港中文大学电子工程学系,同时隶属于中国香港大埔的香港医学工程研究院。
Qingqi Hong is with Xiamen University, Xiamen 361005, China, and also Hong Kong Centre for Cerebro-cardiovascular Health Engineering, Hong Kong, China. (e-mail: hongqq@xmu.edu.cn).
洪清绮就职于厦门大学(中国厦门,361005),同时兼任香港心脑血管健康工程中心(中国香港)。(电子邮箱:hongqq@xmu.edu.cn)。
Dinggang Shen is with the School of Biomedical Engineering & State Key Laboratory of Advanced Medical Materials and Devices, Shanghai Tech University, Shanghai 201210, China, Shanghai United Imaging Intelligence Co., Ltd., Shanghai 200230, China, and also Shanghai Clinical Research and Trial Center, Shanghai, 201210, China. (e-mail: dinggang.shen@gmail.com).
丁钢(Dinggang Shen)就职于上海科技大学(Shanghai Tech University)生物医学工程学院及先进医用材料与器件国家重点实验室(上海 201210)、上海联影智能医疗科技有限公司(Shanghai United Imaging Intelligence Co., Ltd., 上海 200230),并兼任上海临床研究中心(Shanghai Clinical Research and Trial Center, 上海 201210)。(e-mail: dinggang.shen@gmail.com)
I. INTRODUCTION
I. 引言

Fig. 1. Performance comparison of segmentation results across various methods: (a) Input images, masks, and scribble annotations, (b) CNNbased fully-supervised method $(\mathsf{U N e t}++$ [1]), (c) CNN-based scribblesupervised method $(\mathsf{U N e t}++)$ ), and (d) Our proposed S crib Former.
图 1: 不同方法分割结果性能对比:(a) 输入图像、掩码及涂鸦标注,(b) 基于CNN的全监督方法 $(\mathsf{U Net}++$ [1]),(c) 基于CNN的涂鸦监督方法 $(\mathsf{U Net}++$),(d) 我们提出的Scrib Former。
D hEiEgPh lcyo npr vo olm u it iso inn gal r nees u url t asl inne ttwhoer kasu t(oCmNaNti)c hsaevge m peron td a utico end of medical images. However, their advancement is hindered by the lack of sufficiently large and fully labeled training datasets. Generally, most deep CNN methods require large-scale images with precise, dense, pixel-level annotations for model training. Unfortunately, manual annotation of medical images is a timeconsuming and expensive process that requires skilled clinical professionals. To address this challenge, recent researchers have been developing novel techniques that do not rely on fully and accurately labeled datasets. One such technique is weaklysupervised learning, which trains a model using loosely-labeled annotations such as points, scribbles, and bounding boxes for areas of interest. These approaches aim to reduce burden on clinical professionals while still achieving high-quality segmentation results. Compared to other annotation methods, such as bounding boxes and points, scribble-based learning (where masks are provided in the form of scribbles) offers greater convenience and versatility for annotating complex objects in images [2].
规则:
- 输出中文翻译部分时仅保留翻译标题,无冗余内容、不重复、不解释
- 不输出无关内容
- 保留原始段落格式及术语(如FLAC/JPEG)、公司缩写(如Microsoft/Amazon/OpenAI)
- 人名不译
- 保留文献引用格式如[20]
- 图表翻译保留原格式("图1: "/"表1: ")
- 全角括号转半角并添加间距(例 (xxx) )
- 专业术语首现标注英文(如"生成式AI (Generative AI)"),后续直接使用中文
- AI术语对照:
- Transformer -> Transformer
- Token -> Token
- LLM -> 大语言模型
- Zero-shot -> 零样本
- Few-shot -> 少样本
- AI Agent -> AI智能体
- AGI -> 通用人工智能
- Python -> Python语言
策略:
- 保留无法识别的特殊字符/公式
- HTML表格转Markdown格式
- 完整翻译为符合中文习惯的内容
最终仅返回Markdown格式译文
当前翻译内容:
深度卷积神经网络 (CNN) 在医学图像分割领域展现出卓越性能,但其发展受限于缺乏足够大规模且完全标注的训练数据集。通常,大多数深度CNN方法需要带有精确密集像素级标注的大规模图像进行模型训练。然而,医学图像的人工标注过程耗时昂贵,且需要专业临床人员参与。为应对这一挑战,近期研究者开始开发不依赖完整精确标注数据集的新技术。其中弱监督学习 (weakly-supervised learning) 通过使用松散标注(如兴趣区域的点标记、涂鸦标记和边界框)来训练模型。这些方法旨在减轻临床专业人员负担的同时保持高质量分割效果。相较于边界框和点标记等其他标注方式,基于涂鸦的学习(以涂鸦形式提供掩码)为图像中复杂对象的标注提供了更高便利性和适应性 [2]。
Existing CNN-based scribble learning models can be broadly classified into two categories according to the ways of using the limited information provided by scribble annotations. The first category focuses on learning adversarial global shape information with a conditional mask generator and a disc rim in at or [3]–[5], which generally requires extra fullyannotated masks. The second category, on the other hand, utilizes targeted training strategies or elaborated structures directly on the scribbles [6]–[8]. However, the process of scribble-supervised training may generate noisy labels that can degrade segmentation performance of trained models. As shown in Fig. 1, compared to the fully-supervised CNN (b), the scribble-supervised CNN (c) trained only on a few labeled pixels may lead to extra segmentation areas with noise. In recent years, several studies have attempted to expand scribble annotation by leveraging data enhancement strategies [9] or generating pseudo labels [10] to address the issue of noisy labels. Nevertheless, the principal obstacle of scribblebased segmentation still lies in training a segmentation model with inadequate supervision information, as a scribble is an inaccurate representation for the area of interest.
现有的基于CNN的涂鸦学习模型根据利用涂鸦标注提供的有限信息的方式,大致可分为两类。第一类侧重于通过条件掩码生成器和判别器学习对抗性全局形状信息 [3]–[5],通常需要额外全标注掩码。第二类则直接在涂鸦上采用针对性训练策略或精心设计的结构 [6]–[8]。然而,涂鸦监督训练过程可能产生噪声标签,降低训练模型的分割性能。如图1所示,相比全监督CNN(b),仅基于少量标注像素训练的涂鸦监督CNN(c)可能导致带有噪声的额外分割区域。近年来,部分研究尝试通过数据增强策略 [9] 或生成伪标签 [10] 来扩展涂鸦标注,以解决噪声标签问题。但涂鸦分割的核心障碍仍在于监督信息不足,因为涂鸦是对目标区域的粗糙表达。
Our work delves into the use of scribble annotations to efficiently train high-performance medical image segmentation models. To address the first issue of learning global shape information without the availability of fully-annotated masks, we investigate the utilization of Transformers [11] for weaklysupervised semantic segmentation (WSSS). Generally, the Vision Transformer (ViT) [12] leverages multi-head selfattention and multi-layer perce ptr on s to capture long-range semantic correlations, which are crucial for both localizing entire objects and implicitly learning global shape information through subsequent ACAM branches. However, in contrast to CNN, ViT often ignores local feature details of objects that are also important for WSSS applications. Hybrid combinations of CNN and ViT architectures have been developed [13]–[16] to take advantage of their respective strengths. In particular, we utilize a CNN branch and a Transformer branch to fuse local features and global representations interdependent ly at multiple scales, which can achieve superior performance on the segmentation task.
我们的工作深入探讨了如何利用涂鸦标注高效训练高性能医学图像分割模型。针对缺乏全标注掩膜时学习全局形状信息的首要问题,我们研究了Transformer[11]在弱监督语义分割(WSSS)中的应用。Vision Transformer(ViT)[12]通常通过多头自注意力机制和多层感知器捕获长程语义关联,这对定位完整目标及通过后续ACAM分支隐式学习全局形状信息至关重要。但与CNN相比,ViT往往会忽略对WSSS应用同样重要的目标局部特征细节。目前已有研究[13]–[16]开发了CNN与ViT架构的混合组合以发挥各自优势。我们特别采用CNN分支和Transformer分支在多尺度上相互依赖地融合局部特征与全局表征,从而在分割任务中实现更优性能。
To address the second issue of expanding scribble annotations for WSSS, class activation maps (CAMs) [17], [18] are often used to generate initial seeds for localization. However, the pseudo labels generated from CAMs for training a WSSS model have an issue of partial activation, which generally tends to highlight the most disc rim i native part of an object instead of the entire object area [19], [20]. Recent work [14] has pointed out that the reason may be the intrinsic characteristic of CNNs, i.e., the local receptive field only captures small-range feature dependencies. Although various methods have been proposed to identify an activation area aligned with the entire object region [19], [20], little work has directly addressed the local receptive field deficiencies of the CNN when applied to WSSS. Motivated by these observations, we incorporate an attention-guided class activation map (ACAM) branch into the network. In the ACAM branch, instead of implementing traditional CAMs that generally only highlight the most disc rim i native part, attentionguided CAMs restore activation regions missed in various encoding layers during the encoding process. This approach can achieve the reactivation of mixed features and focuses on the whole object. Moreover, ACAMs-consistency is employed to penalize inconsistent feature maps from different convolution layers, in which the low-level ACAMs are regularized by the high-level ACAM generated from feature of last CNN
为解决弱监督语义分割(WSSS)中扩展涂鸦标注的第二个问题,通常使用类别激活图(CAMs) [17][18]来生成定位初始种子。然而,基于CAMs生成的伪标签存在部分激活问题,往往仅突出物体最具判别性的局部区域而非完整物体范围[19][20]。近期研究[14]指出这可能是CNN固有特性所致,即局部感受野仅能捕获小范围特征依赖关系。虽然已有多种方法试图识别与完整物体区域对齐的激活区域[19][20],但鲜有研究直接解决CNN应用于WSSS时的局部感受野缺陷。基于这些观察,我们在网络中引入了注意力引导的类别激活图(ACAM)分支。该分支通过注意力引导的CAMs,在编码过程中恢复各编码层遗漏的激活区域,而非传统CAMs仅突出最具判别性局部的做法。该方法可实现混合特征的再激活,并聚焦于完整物体。此外,采用ACAMs一致性约束来惩罚不同卷积层产生的特征图不一致性,其中低层ACAMs受到由末层CNN特征生成的高层ACAM的规整化约束。
Transformer branch layer.
Transformer分支层。
In this paper, we propose a novel weakly-supervised model for scribble-supervised medical image segmentation, named S crib Former, which consists of a triple-branch network, i.e., the hybrid CNN and Transformer branches, along with an attentionguided class activation map (ACAM) branch. Specifically, in the hybrid CNN and Transformer branches, the global representations and the local features are mixed to enhance each other. Fig. 1 shows two examples of segmentation results generated by different models. It can be observed that the famous CNN-based UNet model could fail in the scribble supervision-based segmentation, which generates several invalid prediction results in background regions (Fig. 1 (c)). On the contrary, our S crib Former model can overcome this problem and generate much more satisfactory results (Fig. 1 (d)) based on the proposed triple-branch architecture. The hybrid architecture can leverage detailed high-resolution spatial information from CNN features and also the global context encoded by Transformers, which is of great help for scribblesupervised medical image segmentation.
本文提出了一种新型弱监督涂鸦标注医学图像分割模型Scrib Former,该模型由三重分支网络构成:混合CNN与Transformer分支以及注意力引导类激活图(ACAM)分支。具体而言,在混合CNN与Transformer分支中,全局表征与局部特征相互融合增强。图1展示了不同模型生成的分割结果示例,可见著名的基于CNN的UNet模型在涂鸦监督分割中可能出现失效,在背景区域产生无效预测结果(图1(c))。相比之下,我们提出的Scrib Former模型基于三重分支架构能够克服这一问题,生成更理想的分割结果(图1(d))。这种混合架构既能利用CNN特征中的高分辨率空间细节信息,又能结合Transformer编码的全局上下文,对涂鸦监督医学图像分割具有重要价值。
The contributions of this paper are summarized as follows:
本文的贡献总结如下:
II. RELATED WORKS
II. 相关工作
A. Trans fomer s for Medical Image Segmentation
A. 医学图像分割中的Transformer
Medical image segmentation plays a crucial role in many fields, such as brain segmentation [21], [22], registration [23], and disease diagnosis [24]. A new paradigm for medical image segmentation has evolved thanks to the success of Vision Transformer (ViT) [12] in many computer vision fields. Generally, the Transformer-based models for medical image segmentation can be classified into two types: 1) ViT as the main encoder and 2) ViT as an additional encoder [25]. In the first type, the global attention-based ViT is utilized as the main encoder and connected to the CNNs-based decoder modules, such as the works presented in [26]–[31]. The second model type utilizes Transformers as the secondary encoder after the main encoder CNN. There are several representative works following this widely-adopted structure, including TransUNet [32], TransUNet+ $^{\cdot+}$ [33], CoTr [34], SegTrans [35], TransBTS [36], and so on. In the hybrid models, ViT and CNN encoders are combined to take the medical image as input, and then the embedded features are fused to connect to the decoder. This multi-branch structure provides the benefits of simultaneously learning global and local information, which has been utilized in several ViT-based architectures, such as Cross Teaching [37]. Although the Transformer-based models have demonstrated tremendous success in medical image segmentation, most of them are based on fully-supervised or semi-supervised learning, which generally requires a large amount of fully-annotated training data. To the best of our knowledge, the Transformerbased techniques have not been explored for scribble-supervised medical image segmentation.
医学图像分割在诸多领域扮演着关键角色,例如脑区分割 [21]、[22]、配准 [23] 和疾病诊断 [24]。随着 Vision Transformer (ViT) [12] 在计算机视觉领域的成功,医学图像分割的新范式逐渐形成。基于 Transformer 的医学图像分割模型通常可分为两类:1) 以 ViT 作为主编码器;2) 将 ViT 作为辅助编码器 [25]。第一类模型采用基于全局注意力的 ViT 作为主编码器,并与基于 CNN 的解码器模块连接,如 [26]–[31] 中提出的工作。第二类模型在 CNN 主编码器后接 Transformer 作为辅助编码器,采用这种主流结构的代表性工作包括 TransUNet [32]、TransUNet+$^{\cdot+}$[33]、CoTr [34]、SegTrans [35]、TransBTS [36] 等。在混合模型中,ViT 和 CNN 编码器共同接收医学图像输入,随后融合嵌入特征并连接至解码器。这种多分支结构能同时学习全局与局部信息,已被应用于 Cross Teaching [37] 等基于 ViT 的架构中。尽管 Transformer 模型在医学图像分割中取得显著成功,但现有方法大多基于全监督或半监督学习,通常需要大量全标注训练数据。据我们所知,基于 Transformer 的技术尚未在涂鸦监督 (scribble-supervised) 的医学图像分割中得到探索。

Fig. 2. Overview of our proposed S crib Former. The framework consists of the hybrid CNN-Transformer encoders, the CNN decoder, the Transformer decoder, and the attention-guided class activation map (ACAM) branch. Both the CNN prediction yCNN and the Transformer prediction $y T r a n s$ are compared separately with the scribble annotations and the dynamically mixed pseudo label. Furthermore, the ACAM branch compares multi-scale ACAMs with ACAM-consistency.
图 2: 我们提出的Scrib Former框架概览。该框架包含混合CNN-Transformer编码器、CNN解码器、Transformer解码器以及注意力引导的类别激活图(ACAM)分支。CNN预测结果yCNN和Transformer预测结果$y Trans$会分别与涂鸦标注及动态混合伪标签进行对比。此外,ACAM分支会通过ACAM一致性对比多尺度ACAMs。
B. Scribble-supervised Image Segmentation
B. 涂鸦监督的图像分割
To reduce the cost of training a learning model using fully annotated datasets without performance compromise, scribble-supervised learning is widely used in solving various vision tasks, including object detection [38]–[40] and semantic segmentation [41]–[43]. Scribble-based supervision has recently emerged as a promising medical image segmentation technique. Ji et al. [44] proposed a scribble-based hierarchical weakly supervised learning model for brain tumor segmentation, combining two weak labels for model training, i.e., scribbles on whole tumor and healthy brain tissue, and global labels for the presence of each substructure. In the meantime, several research works focus on scribble-supervised segmentation without requiring extra annotated masks. Can et al. [45] investigated training strategies to learn parameters of a pixel-wise segmentation network from scribble annotations alone, where a dataset relabeling mechanism was introduced using the dense conditional random field (CRF) during the process of training. Luo et al. [10] proposed a scribble-supervised segmentation model via training a dual-branch network with dynamically mixed pseudo labels supervision (DMPLS). Recently, Cyclemix [9] was proposed for scribble learning-based medical image segmentation, which generated mixed images and regularized the model by cycle consistency. Generally, none of these methods have exploited global information of the image for the medical image segmentation problem. We believe the hidden global information in the dataset learned by Transformers could be useful for enhancing the performance of segmentation.
为降低使用全标注数据集训练学习模型的成本而不影响性能,涂鸦监督学习被广泛应用于解决各类视觉任务,包括目标检测 [38]–[40] 和语义分割 [41]–[43]。近年来,基于涂鸦的监督已成为一种有前景的医学图像分割技术。Ji 等人 [44] 提出了一种基于涂鸦的分层弱监督学习模型用于脑肿瘤分割,结合了两种弱标签进行模型训练:全肿瘤和健康脑组织的涂鸦标注,以及各子结构存在的全局标签。同时,多项研究聚焦于无需额外标注掩膜的涂鸦监督分割方法。Can 等人 [45] 探索了仅通过涂鸦标注学习像素级分割网络参数的训练策略,在训练过程中引入基于密集条件随机场 (CRF) 的数据集重标注机制。Luo 等人 [10] 提出通过动态混合伪标签监督 (DMPLS) 训练双分支网络的涂鸦监督分割模型。近期,Cyclemix [9] 被提出用于基于涂鸦学习的医学图像分割,该方法通过生成混合图像并利用循环一致性约束模型。总体而言,这些方法均未充分利用图像的全局信息来解决医学图像分割问题。我们认为 Transformer 学习到的数据集中隐含的全局信息有助于提升分割性能。
III. METHOD A. Overview of S crib Former
III. 方法
A. S crib Former 概述
A schematic view of the framework of our proposed S crib Former is presented in Fig. 2. The framework consists of a triple-branch network, i.e., the hybrid CNN and Transformer branches, along with an attention-guided class activation map (ACAM) branch. For scribble-supervised learning, the leveraging dataset $D={(x,s){n}}{n=1}^{N}$ consists of images $x$ and scribble annotations $s$ , where a scribble contains a set of pixels of strokes representing a certain category or unknown label. First, the CNN branch collaborates with the Transformer branch to fuse the local features learned from CNN with the global representations obtained from Transformers, and generates dual segmentation outputs, i.e., $y_{c n n}$ and $y T r a n s$ , which are then compared with the scribble annotations by applying partial cross-entropy loss. Then, both outputs are compared with the hard pseudo labels generated by mixing two predictions dynamically for pseudo-supervised learning. Furthermore, the process of extracting ACAMs from the CNN branch and verifying the application consisting of ACAMs enables the shallow convolution layer to learn the pixels affected by the deep one. Specifically, since the deep convolutional layer can effectively amalgamate the advantages of both CNN and Transformer, it encompasses more advanced local details as well as global contextual information. When computing the ACAMs-consistency loss, shallow features are utilized to narrow the gap with the deep features, enabling the shallow features to learn semantic information akin to that present in the deep features. This approach effectively addresses the issue of local activation s.
图 2: 展示了我们提出的Scrib Former框架示意图。该框架由三分支网络组成,即混合CNN与Transformer分支,以及注意力引导的类别激活图(ACAM)分支。对于涂鸦监督学习,所用数据集$D={(x,s){n}}{n=1}^{N}$包含图像$x$和涂鸦标注$s$,其中涂鸦由代表特定类别或未知标签的笔画像素集合构成。首先,CNN分支与Transformer分支协作,将CNN学到的局部特征与Transformer获得的全局表征相融合,生成双重分割输出$y_{cnn}$和$yTrans$,随后通过应用部分交叉熵损失与涂鸦标注进行对比。接着,这两个输出会与动态混合两种预测生成的硬伪标签进行对比,用于伪监督学习。此外,从CNN分支提取ACAM并验证其组成应用的过程,使得浅层卷积层能够学习受深层影响的像素。具体而言,由于深层卷积层能有效融合CNN与Transformer的优势,它既包含更高级的局部细节,也涵盖全局上下文信息。在计算ACAM一致性损失时,利用浅层特征来缩小与深层特征的差距,使浅层特征能学习到类似深层特征中的语义信息。该方法有效解决了局部激活问题。
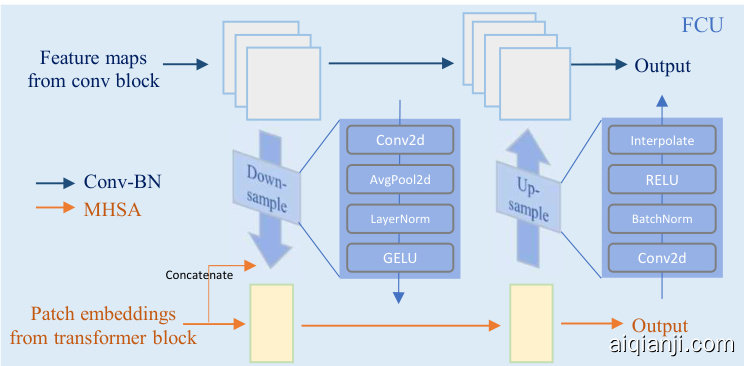
Fig. 3. Schematic illustration of FCU (Feature Coupling Units). Due to inconsistency of feature dimensions of CNN and Transformers, feature maps from convolution blocks and patch embeddings from Transformer blocks are fused in the down-sample and up-sample blocks after the channel and spatial alignments.
图 3: FCU (Feature Coupling Units) 结构示意图。由于 CNN 和 Transformer 的特征维度不一致,卷积块的特征图与 Transformer 块的补丁嵌入 (patch embeddings) 需经过通道对齐和空间对齐后,在下采样和上采样模块中进行融合。
In comparison to previous CNN-Transformer hybrid networks, such as TransUNet [32], Cotr [34], and Conformer [14], our proposed S crib Former not only applies scribble data to the CNN-Trans hybrid network, but also takes the unique characteristics of scribble data into account. Previous networks, such as Conformer [14], include encoders and decoders as part of the CNN-Trans structure. Our S crib Former, on the other hand, only integrates the CNN-Trans structure between encoders. In the decoders, the CNN feature and the Transformer feature are distinguished, which allows us to concentrate on similarities between CNN-Trans as a hybrid network while also considering differences in the decoders. This is especially important for the scribble-supervised model lacking supervision signals in scribble annotations (compared to full annotations), which often results in mis-segmentation. Our goal is to ensure both CNN and Transformer branches to focus on different parts of image as much as possible for robust segmentation results.
与之前的CNN-Transformer混合网络(如TransUNet [32]、Cotr [34]和Conformer [14])相比,我们提出的Scrib Former不仅将涂鸦数据应用于CNN-Trans混合网络,还考虑了涂鸦数据的独特特性。之前的网络(如Conformer [14])将编码器和解码器作为CNN-Trans结构的一部分。而我们的Scrib Former仅在编码器之间整合了CNN-Trans结构。在解码器中,CNN特征和Transformer特征被区分开来,这使得我们能够专注于CNN-Trans作为混合网络的相似性,同时考虑解码器中的差异。这对于涂鸦监督模型尤为重要,因为涂鸦标注中缺乏监督信号(与完整标注相比),通常会导致分割错误。我们的目标是确保CNN和Transformer分支尽可能关注图像的不同部分,以获得稳健的分割结果。
B. Hybrid CNN-Transformer Encoders
B. 混合 CNN-Transformer 编码器
The encoder of the CNN branch adopts a feature pyramid structure. As the stage of the CNN encoder increases, the resolution of the feature map decreases, while the number of channels increases. Each convolution block contains multiple bottlenecks from ResNet, including a down-projection convolution, spatial convolution, and upper-projection convolution. The down-projection convolution reduces spatial dimensions of input data by emphasizing crucial information through convolution and max pooling. The spatial convolution extracts features by detecting patterns and correlations among adjacent pixels, enabling the network to capture local features and learn spatial hierarchies. The upper-projection convolution increases the size of feature maps using de convolution, while preserving spatial relationships of the learned features. The CNN branch can continuously provide local feature details to the Transformer branch. Unlike the CNN branch, the Transformer branch concerns global representation, which contains the same number of Transformer blocks as the convolution blocks in the CNN branch. The projection layer compresses the feature map generated by the stem module into patch embeddings. Each Transformer block comprises a multi-head self-attention (MHSA) module and an MLP block, where LayerNorm follows before each layer and also residual connection is used in each layer.
CNN分支的编码器采用特征金字塔结构。随着CNN编码器阶段的增加,特征图的分辨率降低,而通道数增加。每个卷积块包含来自ResNet的多个瓶颈结构,包括下投影卷积、空间卷积和上投影卷积。下投影卷积通过卷积和最大池化强调关键信息,从而降低输入数据的空间维度。空间卷积通过检测相邻像素间的模式和相关性来提取特征,使网络能够捕获局部特征并学习空间层级。上投影卷积使用反卷积增大特征图尺寸,同时保留学习特征的空间关系。CNN分支可持续向Transformer分支提供局部特征细节。与CNN分支不同,Transformer分支关注全局表征,其包含的Transformer块数量与CNN分支中的卷积块相同。投影层将stem模块生成的特征图压缩为patch嵌入。每个Transformer块由多头自注意力(MHSA)模块和MLP块组成,其中每层前都采用LayerNorm并应用残差连接。
The FCU (Feature Coupling Units) shown in Fig. 3 is introduced to integrate the CNN branch and the Transformer branch for feature fusion. Specifically, the CNN feature map collected from the local convolutional operator and Transformer patch embedding, aggregated with the global self-attention mechanism, is aligned and added. This alignment ensures that convolutional and Transformer features share the same feature space, preventing issues arising from dimensional disparities. The aligned features are combined through addition, effectively merging locally-captured patterns from the CNN with global contextual relationships from the Transformer. This feature fusion enhances the model’s ability to recognize intricate patterns and contextual relationships within the data, achieving effective feature sharing between the two components. Each Transformer block takes the output of the FCU and adds it to the token embeddings from the previous Transformer block. This process is the same for each CNN block, combining features from dual branches. The down sampling process is implemented using Conv2D and AvgPool2D. The Conv features initially traverse a Conv2D layer, followed by an AvgPool2D layer, a layer normalization layer, and a GELU activation layer. Subsequently, they are concatenated with the transformer features from the preceding layer, finalizing the alignment process. Upsampling is executed using both Conv2D and interpolation techniques. Specifically, the transformer features undergo a sequence of processing, including a Conv2D layer, a batch normalization layer, and a RELU activation layer. The resultant transformer features are then harmonized with the convolutional features via an interpolation operation.
图 3 所示的 FCU (Feature Coupling Units) 用于整合 CNN 分支和 Transformer 分支以实现特征融合。具体而言,将从局部卷积算子收集的 CNN 特征图与通过全局自注意力机制聚合的 Transformer 块嵌入进行对齐并相加。这种对齐确保卷积特征和 Transformer 特征共享相同的特征空间,避免因维度差异导致的问题。对齐后的特征通过加法结合,有效融合了 CNN 捕获的局部模式与 Transformer 提取的全局上下文关系。这种特征融合增强了模型识别数据中复杂模式和上下文关系的能力,实现了两个组件之间的有效特征共享。每个 Transformer 块接收 FCU 的输出,并将其与前一 Transformer 块的 Token 嵌入相加。每个 CNN 块也采用相同流程进行双分支特征组合。下采样过程通过 Conv2D 和 AvgPool2D 实现:卷积特征先经过 Conv2D 层,再通过 AvgPool2D 层、层归一化层和 GELU 激活层,随后与来自前一层的 Transformer 特征拼接完成对齐。上采样则同时采用 Conv2D 和插值技术:Transformer 特征依次经过 Conv2D 层、批归一化层和 RELU 激活层处理,最终通过插值操作与卷积特征进行协调。

Fig. 4. Schematic illustration of attention-guided class activation maps (ACAM) branch.
图 4: 注意力引导的类别激活图 (ACAM) 分支示意图。
C. Decoders and ACAM Branch
C. 解码器和 ACAM 分支
- Decoders: The structure of the CNN decoder is similar to UNet. The output of each CNN decoder layer is concatenated with the feature map from the last convolutional layer of the corresponding encoder stage. The stem module also contains three convolutional blocks to extract the features required by the decoder. However, unlike UNet decoder, our Transformer decoder upsamples global representation since the resolution of embedding in each Transformer encoder layer is same.
- 解码器:CNN解码器的结构与UNet类似。每个CNN解码器层的输出会与对应编码器阶段最后一个卷积层的特征图拼接。主干模块还包含三个卷积块,用于提取解码器所需的特征。但与UNet解码器不同,我们的Transformer解码器会对全局表征进行上采样,因为每个Transformer编码器层中的嵌入分辨率是相同的。
- ACAM Branch: As shown in Fig. 4, the ACAM branch is designed to identify the most relevant regions on which the training network should concentrate. Compared to traditional CAMs, our attention-guided CAMs are more compatible with semantic segmentation models. The images are inputted into Conv Embedding, initiating the process. The attentionguided CAMs are generated by combining channel attention modulation and spatial attention modulation, which can extract minor features and model the channel-spatial relationship. Specifically, the sensitivity of the features is modeled by the spatial average pooling and the convolutional layer. The Gaussian modulation function in channel attention modulation leverages the distribution of the Gaussian function, which amplifies weights near the mean. This mechanism enhances the importance of regions associated with main features. Furthermore, spatial attention modulation is employed to collect spatial inter dependency of the features through the channel average pooling and the convolutional layer, which helps increase the minor activation s. The parameterized representation of the modulation function is : $\begin{array}{r}{f\left(\dot{A}\right)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(A^{\star}-\mu)^{2}}{2\sigma^{2}}}}\end{array}$ √21πσ e− 2−σ2 , where attention values $A$ are obtained through spatial/channel downsampling.
- ACAM分支:如图4所示,ACAM分支旨在识别训练网络应关注的最相关区域。与传统CAM相比,我们的注意力引导CAM更适配语义分割模型。图像输入Conv Embedding后启动处理流程,通过结合通道注意力调制和空间注意力调制生成注意力引导CAM,可提取细微特征并建模通道-空间关系。具体而言,特征敏感度通过空间平均池化和卷积层建模。通道注意力调制中的高斯调制函数利用高斯分布特性,放大均值附近权重,该机制能增强主要特征相关区域的重要性。此外,空间注意力调制通过通道平均池化和卷积层收集特征的空间互依赖性,有助于提升细微激活。调制函数的参数化表示为:$\begin{array}{r}{f\left(\dot{A}\right)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(A^{\star}-\mu)^{2}}{2\sigma^{2}}}}\end{array}$ √21πσ e− 2−σ2 ,其中注意力值 $A$ 通过空间/通道下采样获得。
The attention-guided CAMs (ACAMs) are inspired by attention modulation modules (AMMs) [46], but there are some differences between these two modules. AMMs are connected between convolution stages, while ACAMs are generated for the extra ACAM branch. Moreover, AMMs are generated from local features and optimized for local features, whereas the modulations of ACAMs are generated from the mixture of local features and global representations and are employed to optimize CAMs. By incorporating ACAMs, our model leverages strengths of the CNN and Transformer branches and refines feature localization with a distinctive blend of channel and spatial attention modulation. This integration significantly elevates the model’s capacity to grasp intricate feature interconnections and extract valuable insights from vital regions, facilitating precise segmentation.
注意力引导的类激活图(ACAMs)受到注意力调制模块(AMMs) [46] 的启发,但两者存在差异。AMMs连接在卷积阶段之间,而ACAMs是为额外的ACAM分支生成的。此外,AMMs从局部特征生成并针对局部特征进行优化,而ACAMs的调制则来自局部特征和全局表征的混合,用于优化CAMs。通过整合ACAMs,我们的模型结合了CNN和Transformer分支的优势,并以通道注意力和空间注意力调制的独特组合来优化特征定位。这种集成显著提升了模型捕捉复杂特征关联的能力,并从关键区域提取有价值的信息,从而实现精确分割。
D. Mixed-supervision Learning
D. 混合监督学习
- Scribble-supervised Learning: We apply the partial crossentropy function for scribble-supervised learning, which ignores unlabeled pixels in the scribble annotation. Hence, the loss of scribble supervision $L_{s s}$ for sample $(x,s)$ is formulated as:
- 涂鸦监督学习 (Scribble-supervised Learning): 我们采用部分交叉熵函数进行涂鸦监督学习,该方法会忽略涂鸦标注中未标记的像素。因此,样本 $(x,s)$ 的涂鸦监督损失 $L_{s s}$ 可表示为:
$$
L_{s s}\left(s,y_{C N N},y_{T r a n s}\right)=\frac{L_{c e}\left(y_{C N N},s\right)+L_{c e}\left(y_{T r a n s},s\right)}{2}
$$
$$
L_{s s}\left(s,y_{C N N},y_{T r a n s}\right)=\frac{L_{c e}\left(y_{C N N},s\right)+L_{c e}\left(y_{T r a n s},s\right)}{2}
$$
where $y_{C N N}$ is the CNN branch prediction and $y T r a n s$ is the Transformer branch prediction. $L_{c e}$ is the partial cross-entropy function:
其中 $y_{C N N}$ 是 CNN 分支预测结果,$y T r a n s$ 是 Transformer 分支预测结果。$L_{c e}$ 表示部分交叉熵函数:
$$
L_{c e}(y,s)=\sum_{i\in\Omega_{l}}\sum_{k\in K}-s_{i}^{k}\log\left(y_{i}^{k}\right)
$$
$$
L_{c e}(y,s)=\sum_{i\in\Omega_{l}}\sum_{k\in K}-s_{i}^{k}\log\left(y_{i}^{k}\right)
$$
where $K$ is the set of strategies in scribble annotations, and $\Omega_{l}$ is the set of labeled pixels in scribble $s$ . $s_{i}^{k}$ and $y_{i}^{k}$ are separately the scribble element and the predicted probability of pixel $i$ belonging to class $k$ .
其中 $K$ 是涂鸦标注中的策略集合,$\Omega_{l}$ 是涂鸦 $s$ 中已标注像素的集合。$s_{i}^{k}$ 和 $y_{i}^{k}$ 分别表示像素 $i$ 属于类别 $k$ 的涂鸦元素和预测概率。
- Pseudo-supervised Learning: Based on difference of receptive fields between the CNN branch and the Transformer branch, we further explore their outputs to boost the model training. Following [10], the hard pseudo label is generated by dynamically mixing the CNN branch prediction $y_{c n n}$ and the Transformer branch prediction $y T r a n s$ , and then employed to supervise the two predictions separately. The pseudo label loss $L_{p l}$ is formulated as:
- 伪监督学习:基于CNN分支与Transformer分支感受野的差异,我们进一步探索它们的输出来促进模型训练。遵循[10]的做法,通过动态混合CNN分支预测 $y_{cnn}$ 和Transformer分支预测 $yTrans$ 生成硬伪标签,并分别用于监督这两个预测。伪标签损失 $L_{pl}$ 的公式为:
$$
L_{p l}=average(L_{d i c e}{C N N},Y),L_{d i c e}(y_{T r a n s},Y)
$$
$$
L_{p l}=average(L_{d i c e}{C N N},Y),L_{d i c e}(y_{T r a n s},Y)
$$
where $L_{d i c e}$ is the Dice function, and $Y$ is the pseudo label defined by:
其中 $L_{dice}$ 是 Dice 函数,$Y$ 是由以下公式定义的伪标签:
$$
Y=\operatorname{argmax}\left(\alpha\times y_{C N N}+\beta\times y_{T r a n s}\right),\alpha,\beta\in(0,1)
$$
$$
Y=\operatorname{argmax}\left(\alpha\times y_{C N N}+\beta\times y_{T r a n s}\right),\alpha,\beta\in(0,1)
$$
Here, $\alpha$ is dynamically generated using the random.random() function in each iteration, and $\beta$ is set as $1-\alpha$ . By permitting $\alpha$ to vary, the model seeks to discover diverse weight combinations for the branches, with the intention of finding more optimal configurations that reach a balance between the two.
这里,$\alpha$ 在每次迭代中通过 Python语言的 random.random() 函数动态生成,$\beta$ 设为 $1-\alpha$。通过允许 $\alpha$ 变化,模型试图寻找分支的不同权重组合,以期找到更优的配置,在两者之间达到平衡。
- ACAM-Consistency Learning: General consistency learning aims to ensure smooth predictions at a data level, i.e., the predictions of the same data under different transformations and perturbations should be consistent [37]. In contrast to data-level consistency, we enforce feature-level consistency through a novel ACAM-consistency evaluation model between the deep features and the shallow features at the pixel level. Additionally, this method can also introduce implicit shape constraints. The ACAM-consistency loss is formulated as:
- ACAM一致性学习:通用一致性学习旨在确保数据层面的预测平滑性,即同一数据在不同变换和扰动下的预测应保持一致 [37]。与数据层面的一致性不同,我们通过在像素级别建立深度特征与浅层特征之间的新型ACAM一致性评估模型,强制实现特征层面的一致性。此外,该方法还能引入隐式形状约束。ACAM一致性损失函数定义为:
$$
L_{a c a m}=\sum_{i}\omega_{i}\times L_{c e}\left(F(E_{i\dots4}\left(c_{i}\right),F(c_{5})\right)
$$
$$
L_{a c a m}=\sum_{i}\omega_{i}\times L_{c e}\left(F(E_{i\dots4}\left(c_{i}\right),F(c_{5})\right)
$$
It is a weighted sum of a set of cross-entropy losses $L_{c e}$ calculated based on different attention-guided CAMs $c_{i}$ from different layers $i$ of the CNN branch encoder. The convolutional embedding 1 and 2 plus the convolutional layer 1-3 are denoted as $c_{1}-c_{5}$ , respectively. By aligning different convolutional layers using the ACAM encoder $E$ , other ACAMs are expected to be similar to the ACAM of the last convolutional layer $c_{5}$ . The down-sampling layer $i$ of the ACAM encoder is represented by $E_{i}$ , and the number of encoder layers can differ based on the resolutions of ACAMs. The lower the resolution of ACAM, the fewer layers it requires for down-sampling. $E_{i\dots4}$ represents that $c_{i}$ is the input of ACAM encoder layer $i$ , and the low-level ACAM is the output from the ACAM encoder layer 4. $F$ is the ACAM filter that is set as the sigmoid function. It should be noted that each pixel of ACAM is labeled either with 1 (if concentrated by the layer) or 0 (not concentrated by the layer).
这是一个基于CNN分支编码器不同层$i$的注意力引导CAM $c_{i}$计算出的交叉熵损失$L_{ce}$的加权和。卷积嵌入1和2加上卷积层1-3分别表示为$c_{1}-c_{5}$。通过使用ACAM编码器$E$对齐不同卷积层,其他ACAM应类似于最后一层卷积层$c_{5}$的ACAM。ACAM编码器的下采样层$i$由$E_{i}$表示,编码器层数可根据ACAM的分辨率而变化。ACAM分辨率越低,下采样所需的层数越少。$E_{i\dots4}$表示$c_{i}$是ACAM编码器层$i$的输入,而低级ACAM是ACAM编码器第4层的输出。$F$是设置为sigmoid函数的ACAM滤波器。需注意,ACAM的每个像素被标记为1(若被该层聚焦)或0(未被该层聚焦)。
Finally, the training objective $L_{t o t a l}$ is formulated as:
最终,训练目标 $L_{t o t a l}$ 的公式为:
$$
\begin{array}{r c l}{L_{t o t a l}}&{=}&{\lambda_{1}\times L_{s s}+\lambda_{2}\times L_{p l}+\lambda_{3}\times L_{a c a m}}\end{array}
$$
$$
\begin{array}{r c l}{L_{t o t a l}}&{=}&{\lambda_{1}\times L_{s s}+\lambda_{2}\times L_{p l}+\lambda_{3}\times L_{a c a m}}\end{array}
$$
where $\lambda_{1},\lambda_{2}$ , and $\lambda_{3}$ are the weight factors used to balance different supervisions.
其中 $\lambda_{1}$、$\lambda_{2}$ 和 $\lambda_{3}$ 是用于平衡不同监督的权重因子。

Fig. 5. Qualitative comparison between S crib Former and other state-of-the-art methods on ACDC and MSCMRseg datasets. Subscripts $F$ and $s$ denote the segmentation models trained with fully-annotated masks or scribble annotations, respectively.
图 5: S crib Former 与其他先进方法在 ACDC 和 MSCMRseg 数据集上的定性对比。下标 $F$ 和 $s$ 分别表示使用全标注掩码或涂鸦标注训练的分割模型。
TABLE I PERFORMANCE COMPARISON OF DICE SCORE BETWEEN OUR METHOD (S CRIB FORMER) AND OTHER STATE-OF-THE-ART METHODS ON ACDC DATASET. BOLD DENOTES THE BEST PERFORMANCE AMONG ALL METHODS EXCEPT NNUNET.
表 1: 我们的方法 (ScribFormer) 与其他最先进方法在 ACDC 数据集上的 Dice 分数性能对比。加粗表示除 nnUNet 外所有方法中的最佳性能。
| 方法 | 数据 | LV | RV | MYO | Avg |
|---|---|---|---|---|---|
| 35scribbles | |||||
| UNetpce | scribbles | .624 | .537 | .526 | .562 |
| UNetem | scribbles | .789 | .761 | .788 | .779 |
| UNetcrf | scribbles | .766 | .661 | .590 | .672 |
| UNetmloss | scribbles | .873 | .812 | .833 | .839 |
| UNetustr | scribbles | .605 | .599 | .655 | .620 |
| UNetwpce | scribbles | .784 | .675 | .563 | .674 |
| scribbles | .785 | .725 | .746 | .752 | |
| scribbles | .846 | .787 | .652 | .761 | |
| Co-mixup | scribbles | .622 | .621 | .702 | .648 |
| CutMix | scribbles | .641 | .734 | .740 | .705 |
| Puzzle Mix | scribbles | .663 | .650 | .559 | .624 |
| Cutout | scribbles | .832 | .754 | .812 | .800 |
| MixUp | scribbles | .803 | .753 | .767 | .774 |
| CycleMixs | scribbles | .883 | .798 | .863 | .848 |
| ScribFormer | scribbles | .922 | .871 | .871 | .888 |
| 35scribbles + 35unpaired masks | |||||
| UNetD | mixed | .404 | .597 | .753 | .585 |
| MAAG | mixed | .879 | .817 | .752 | .816 |
| ACCL | mixed | .878 | .797 | .735 | .803 |
| PostDAE | mixed | .806 | .667 | .556 | .676 |
| 35 masks | |||||
| UNetF | masks | .892 | .830 | .789 | .837 |
| UNet F | masks | .849 | .792 | .817 | .820 |
| masks | .875 | .798 | .771 | .815 | |
| Puzzle Mix F | masks | .849 | .807 | .865 | .840 |
| CycleMixF | masks | .919 | .858 | .882 | .886 |
| nnUNet | masks | .943 | .915 | .901 | .920 |
IV. EXPERIMENTS
IV. 实验
A. Datasets
A. 数据集
- ACDC: The ACDC [47] dataset consists of cine-MRI scans from 100 patients. For each scan, manual scribble annotations of the left ventricle (LV), right ventricle (RV), and myocardium (MYO) are from [4]. The scribble annotations underwent a rigorous process conducted by experienced annotators. Following [4], [9], [48], the 100 scans are randomly separated into three sets of sizes 70, 15, and 15, respectively, for the purpose of model training, validation and testing. To compare with the state-of-the-art approaches that employ unpaired masks to learn global shape information, we split the training set into two halves, i.e., 35 training images with scribble labels and 35 masks with full annotations where the corresponding images would not be used for training. Generally, only 35 training images are used to train the baselines and our S crib Former unless otherwise specified.
- ACDC:ACDC [47] 数据集包含100名患者的电影磁共振成像 (cine-MRI) 扫描数据。每份扫描的左心室 (LV)、右心室 (RV) 和心肌 (MYO) 涂鸦标注来自 [4],这些标注由经验丰富的标注员经过严格流程完成。遵循 [4]、[9]、[48] 的方法,100份扫描被随机分为70、15和15三组,分别用于模型训练、验证和测试。为与采用未配对掩码学习全局形状信息的先进方法对比,我们将训练集平分为两部分:35张带涂鸦标签的训练图像和35份完整标注的掩码(其对应图像不用于训练)。除非特别说明,基线模型和我们的Scrib Former仅使用这35张训练图像进行训练。
TABLE II PERFORMANCE COMPARISON OF DICE SCORE BETWEEN OUR METHOD (S CRIB FORMER) AND OTHER STATE-OF-THE-ART METHODS ON MSCMRSEG DATASET. BOLD DENOTES THE BEST PERFORMANCE AMONG ALL METHODS EXCEPT NNUNET.
表 II 我们的方法 (ScribFormer) 与其他先进方法在 MSCMRSEG 数据集上的 Dice 分数性能对比。加粗表示除 nnUNet 外所有方法中的最佳性能。
| 方法 | 数据 | LV | RV | MYO | Avg |
|---|---|---|---|---|---|
| 25scribbles | |||||
| scribbles | .494 | .583 | .057 | .378 | |
| scribbles | .497 | .506 | .472 | .492 | |
| Co-mixup | scribbles | .356 | .343 | .053 | .251 |
| scribbles | .578 | - | .761 | .654 | |
| CutMix | scribbles | .061 | .622 | .028 | .241 |
| Puzzle Mix | scribbles | - | .634 | - | - |
| Cutout | scribbles | .459 | .641 | .697 | .599 |
| MixUp | scribbles | .610 | .463 | .378 | .484 |
| CycleMixs | scribbles | .870 | .739 | .791 | .800 |
| ScribFormer | scribbles | .896 | .807 | .813 | .839 |
| 25 masks | |||||
| UNetF | masks | .850 | .721 | .738 | .770 |
| UNet+ | masks | .857 | .720 | .689 | .755 |
| F | masks | .866 | .745 | .731 | .774 |
| Puzzle MixF | masks | .867 | .742 | .759 | .789 |
| CycleMixF | masks | .864 | .785 | .781 | .810 |
| nnUNet | masks | .944 | .880 | .882 | .902 |
- MSCMRseg: The MSCMRseg [49], [50] dataset com- prises late gadolinium enhancement (LGE) MRI scans from 45 cardiomyopathy patients. Scribble annotations of LV, MYO, RV for each scan are provided by [9]. The scribble annotations were custom-designed to suit the dataset’s requirements and encompass average coverage percentages for different regions, i.e., background, RV, MYO, and LV scribbles were represented at rates of $3.4%$ , $27.7%$ , $31.3%$ , and $24.1%$ , respectively.
- MSCMRseg:MSCMRseg [49][50] 数据集包含45名心肌病患者的晚期钆增强 (LGE) MRI 扫描。每例扫描的左心室 (LV)、心肌 (MYO) 和右心室 (RV) 涂鸦标注由 [9] 提供。这些涂鸦标注根据数据集需求定制设计,涵盖不同区域的平均覆盖率:背景、RV、MYO 和 LV 涂鸦的占比分别为 $3.4%$、$27.7%$、$31.3%$ 和 $24.1%$。
TABLE III PERFORMANCE COMPARISON OF DICE SCORE BETWEEN OUR METHOD (S CRIB FORMER) AND OTHER STATE-OF-THE-ART METHODS ON HEARTUII. BOLD DENOTES THE BEST PERFORMANCE AMONG ALL METHODS EXCEPT NNUNET.
表 III HEARTUII数据集上我们的方法(SCRIB FORMER)与其他先进方法在Dice分数上的性能对比。加粗表示除nnUNet外所有方法中的最佳性能。
| 方法 | 数据 | LV | LA | RV | RA | AO | MYO | Avg |
|---|---|---|---|---|---|---|---|---|
| 53scribbles | ||||||||
| UNetpce | scribbles | .802 | .833 | .702 | .375 | .694 | .521 | .655 |
| UNetustr | scribbles | .709 | .772 | .799 | .389 | .783 | .534 | .664 |
| UNetem | scribbles | .847 | .865 | .798 | .562 | .814 | .682 | .761 |
| UNeterf | scribbles | .739 | .885 | .812 | .731 | .843 | .698 | .785 |
| scribbles | .834 | .819 | .749 | .567 | .694 | .620 | .714 | |
| CycleMixs | scribbles | .851 | .814 | .756 | .799 | .871 | .768 | .810 |
| ScribFormer | scribbles | .873 | .867 | .859 | .774 | .843 | .783 | .833 |
| 53masks | ||||||||
| UNetF | masks | .771 | .817 | .744 | .714 | .777 | .661 | .747 |
| masks | .873 | .881 | .825 | .759 | .842 | .816 | .833 | |
| nnUNet | masks | .943 | .927 | .886 | .902 | .942 | .882 | .914 |
Compared to ACDC, MSCMRseg is much smaller and more arduous to create, since LGE MRI segmentation is more complicated. Following [9], [48], we randomly divided the 45 scans into three sets: 25 for training, 5 for validation, and 15 for testing.
与ACDC相比,MSCMRseg规模更小且创建过程更为艰巨,因为LGE MRI(晚期钆增强磁共振成像)分割更为复杂。参照[9]、[48]的方法,我们将45次扫描随机分为三组:25次用于训练,5次用于验证,15次用于测试。
- HeartUII: HeartUII is a CT dataset collected by us, comprising six distinct categories: Right Atrium (RA), Right Ventricle (RV), Left Ventricle (LV), Aorta (AO), Left Atrium (LA), and Myocardium (MYO). To ensure accuracy and authenticity of scribble annotations, we sought the expertise of professionals in the relevant field. These experts utilized ITKSNAP to meticulously annotate the dataset. The annotation process was conducted similarly to the ACDC dataset. The dataset consists of a total of 80 cases, with 53 cases utilized for training, 13 for validation, and 16 for testing, respectively. Each case encompasses a range of 78 to 320 slices.
- HeartUII:HeartUII是我们收集的CT数据集,包含六个不同类别:右心房(RA)、右心室(RV)、左心室(LV)、主动脉(AO)、左心房(LA)和心肌(MYO)。为确保涂鸦标注的准确性和真实性,我们邀请了相关领域的专业人士使用ITKSNAP进行精细标注。标注流程与ACDC数据集类似。该数据集共包含80个病例,其中53例用于训练,13例用于验证,16例用于测试。每个病例包含78至320张切片。
B. Implementation Details
B. 实现细节
The model was implemented using Pytorch and trained on one NVIDIA 1080Ti 11GB GPU. We initially rescaled the intensity of each slice in the ACDC dataset, the MSCMR dataset, and the HeartUII dataset to a range of values between 0 and 1. To expand the training set, we applied random rotation, flipping, and noise to the images. The enhanced image was adjusted to $256~\times~256$ pixels before being utilized as input to the network. For the MSCMR dataset, each image was cropped or padded to the identical size of $212\times212$ pixels to enhance performance. The optimizer choice was AdamW. In a series of preliminary experiments, we observed that the model converged within 300 epochs, with diminishing returns on further training. Therefore, we trained for 300 epochs on each dataset. For learning rate and weight decay, a grid search was conducted, resulting in the optimal performance achieved at a learning rate of 0.001 and weight decay of 0.0005, respectively. Early stopping was not employed during the training process. Additionally, the total training time was hard-coded to maintain consistency across experiments. The ACAM-consistency factors $(\omega_{1},\omega_{2},\omega_{3},\omega_{4})$ were set to (0.25, 0.5, 0.75, 1). We empirically set the weights $(\lambda_{1},\lambda_{2},\lambda_{3})$ to (1, 0.5, 0.1) in Eq.(6). For all datasets, Dice Score (Dice) was used as an evaluation metric.
该模型使用Pytorch实现,并在NVIDIA 1080Ti 11GB GPU上进行训练。我们首先将ACDC数据集、MSCMR数据集和HeartUII数据集中每个切片的强度值重新缩放到0到1之间。为扩充训练集,对图像进行了随机旋转、翻转和添加噪声处理。增强后的图像被调整为$256~\times~256$像素后作为网络输入。针对MSCMR数据集,每张图像被裁剪或填充至统一的$212\times212$像素尺寸以提升性能。优化器选择AdamW。通过初步实验发现模型在300个epoch内收敛,继续训练收益递减,因此每个数据集均训练300个epoch。学习率和权重衰减经过网格搜索,最终确定最优性能对应的学习率为0.001、权重衰减为0.0005。训练过程中未采用早停机制,总训练时长固定以保证实验一致性。ACAM一致性因子$(\omega_{1},\omega_{2},\omega_{3},\omega_{4})$设为(0.25, 0.5, 0.75, 1)。式(6)中的权重$(\lambda_{1},\lambda_{2},\lambda_{3})$根据经验设为(1, 0.5, 0.1)。所有数据集均采用Dice Score (Dice)作为评估指标。
C. Comparison with State-of-the-art (SOTA) Methods
C. 与最先进 (SOTA) 方法的比较
To demonstrate the comprehensive segmentation performances of our method, the proposed S crib Former is compared with different SOTA methods.
为了展示我们方法的全面分割性能,所提出的Scrib Former与不同的SOTA方法进行了比较。
We f irst compared our approach to several state-of-the-art scribble-supervised methods, including 1) different scribblesupervised training strategies to UNet [51] as the base segmentation network architecture with only partial cross-entropy loss (pce) [6], using entropy minimization (em) regular iz ation [8], with conditional random field (crf) [52], with mumford–shah Loss (mloss) [7], transformation-consistent regular iz ation (ustr) [53], and weighted partial cross-entropy loss (wpce) [4], or utilizing uncertainty-aware self-ensembling; 2) different frameworks with same scribble-supervised training loss, i.e., using partial cross-entropy loss on different variants of $\mathrm{UNet}{p c e}$ [6], including ${\mathrm{UNet}}{p c e}^{+}$ [54], which has fewer channels in the upsampling path with transpose convolutions adjusted to match the number of classes, and ${\mathrm{UNet}}{p c e}^{++}$ [1], a classic variant incorporating nested and dense skip connections upon original UNet architecture; 3) different data augmentation strategies to ${\mathrm{UNet}}{p c e}^{+}$ [54] , including Co-mixup [55], CutMix [56], Puzzle Mix [57], Cutout [58], MixUp [59], or $\mathrm{CycleMix}{S}$ [9]. Second, we also compared our method with some adversarial learning methods, including ${\mathrm{UNet}}{D}$ [4], MAAG [4], ACCL [60], and PostDAE [61], which utilized additional unpaired segmentation masks. F inally, we investigated the upper bound using all mask annotations, i.e., fully-supervised methods such as ${\sf U N e t}{F}$ [51], ${\mathrm{UNet}}{F}^{+}$ [54], ${\mathrm{UNet}}{F}^{++}$ [1], and those applying augmentation strategies such as Puzzle $\operatorname{Mix}{F}$ [57] and $\mathbf{CycleMix}_{F}$ [9].
我们首先将我们的方法与几种先进的涂鸦监督方法进行了比较,包括:1) 不同的涂鸦监督训练策略,如仅使用部分交叉熵损失 (pce) [6] 的 UNet [51] 作为基础分割网络架构,结合熵最小化 (em) 正则化 [8]、条件随机场 (crf) [52]、Mumford-Shah 损失 (mloss) [7]、变换一致性正则化 (ustr) [53]、加权部分交叉熵损失 (wpce) [4],或利用不确定性感知自集成;2) 相同涂鸦监督训练损失的不同框架,即在 $\mathrm{UNet}{p c e}$ [6] 的不同变体上使用部分交叉熵损失,包括 ${\mathrm{UNet}}{p c e}^{+}$ [54](其在上采样路径中通道数较少,转置卷积调整为匹配类别数量)和 ${\mathrm{UNet}}{p c e}^{++}$ [1](在原始 UNet 架构上结合嵌套和密集跳跃连接的经典变体);3) 对 ${\mathrm{UNet}}{p c e}^{+}$ [54] 应用不同的数据增强策略,包括 Co-mixup [55]、CutMix [56]、Puzzle Mix [57]、Cutout [58]、MixUp [59] 或 $\mathrm{CycleMix}{S}$ [9]。其次,我们还与一些对抗学习方法进行了比较,包括 ${\mathrm{UNet}}{D}$ [4]、MAAG [4]、ACCL [60] 和 PostDAE [61],这些方法利用了额外的未配对分割掩码。最后,我们研究了使用所有掩码注释的上限,即全监督方法,如 ${\sf U N e t}{F}$ [51]、${\mathrm{UNet}}{F}^{+}$ [54]、${\mathrm{UNet}}{F}^{++}$ [1],以及应用增强策略的方法,如 Puzzle $\operatorname{Mix}{F}$ [57] 和 $\mathbf{CycleMix}_{F}$ [9]。
The results of the above methods on ACDC and MSCMR are reported in Table I, Table II and Table III separately, with some results obtained from [10] and [9]. In the initial section of these three tables, our S crib Former model showcases its superiority over several training strategies, model architectures, and data augmentation techniques based on UNet when it comes to scribble supervision. Notably, it outperforms the state-ofthe-art method, CycleMix, by a substantial margin of $4.0%$ $ 88.8% $ vs $84.8%$ ), $3.9%$ $83.9%$ vs $80.0%$ ), and $2.3%$ ( $83.3%$ vs $81.0%$ ) on ACDC, MSCMRseg, and HeartUII, respectively. This compelling performance differential underscores the effectiveness of incorporating Transformer global context into CNN’s local features within the framework of scribblesupervised semantic segmentation.
上述方法在ACDC和MSCMR上的结果分别报告在表I、表II和表III中,部分结果引自[10]和[9]。在这三张表格的开头部分,我们的ScribFormer模型展示了其在涂鸦监督任务上优于多种基于UNet的训练策略、模型架构和数据增强技术。值得注意的是,它在ACDC、MSCMRseg和HeartUII数据集上分别以显著优势($4.0%$ ($88.8%$ vs $84.8%$)、$3.9%$ ($83.9%$ vs $80.0%$)和$2.3%$ ($83.3%$ vs $81.0%$))超越了当前最先进的CycleMix方法。这一显著的性能差距凸显了在涂鸦监督语义分割框架中,将Transformer全局上下文融入CNN局部特征的有效性。
In the second section of Table I, the ACDC results underscore substantial performance advancements achieved by S crib Former compared to other weakly-supervised methods. Notably, ScribFormer’s Dice scores for all three categories (LV, MYO, and RV) outperform the previous best method (MAAG). Unlike approaches relying on additional unpaired masks, which are constrained in learning global shape information from a limited training image set, S crib Former overcomes this limitation. It achieves this by leveraging the ACAM branch to implicitly learn global shape information, eliminating the need for extra fully-annotated masks.
在表 I 的第二部分中,ACDC 结果突显了 ScribFormer 相比其他弱监督方法实现的显著性能提升。值得注意的是,ScribFormer 在所有三个类别 (LV、MYO 和 RV) 的 Dice 分数均优于之前的最佳方法 (MAAG)。与依赖额外未配对掩码的方法不同 (这些方法受限于从有限的训练图像集中学习全局形状信息),ScribFormer 通过利用 ACAM 分支隐式学习全局形状信息,克服了这一限制,从而无需额外全标注掩码。
In the final sections of all three tables, we conducted comparison between S crib Former and several fully-supervised learning methods, including CycleMix and nnUNet under full supervision. As observed in the tables, fully-supervised learning outperforms scribble annotations combined with additional unpaired masks. This performance difference is primarily attributed to the exclusion of images associated with masks and the absence of pixel-wise relationships. However, it’s worth noting that our S crib Former outperforms most of the fullysupervised methods (except nnUNet) at a lower annotation cost. This demonstrates the great potential of the proposed scribble-supervised model in medical image segmentation.
在三张表格的最后部分,我们对Scrib Former与几种全监督学习方法(包括CycleMix和全监督下的nnUNet)进行了对比。如表格所示,全监督学习优于涂鸦标注结合额外未配对掩码的方案。这种性能差异主要源于排除了与掩码相关的图像以及缺乏像素级关联。但值得注意的是,我们的Scrib Former以更低的标注成本超越了大多数全监督方法(nnUNet除外),这证明了所提出的涂鸦监督模型在医学图像分割领域的巨大潜力。
Fig. 5 presents segmentation results of different methods on ACDC and MSCMR. It can be observed that other scribblesupervised methods tend to generate insufficient or extra segmentation areas, especially on MSCMR, probably due to the limited image information learned from scribbles. In contrast, our method can obtain global representations from the Transformer branch, making up for the deficiency of CNN local features. The results generated by our method are closer to the ground truth, especially in terms of shape completeness than other scribble-supervised and even fully-supervised methods.
图 5: 展示了不同方法在ACDC和MSCMR上的分割结果。可以观察到,其他涂鸦监督方法往往会产生不足或多余的分割区域,尤其是在MSCMR上,这可能是由于从涂鸦中学到的图像信息有限。相比之下,我们的方法能够从Transformer分支获取全局表征,弥补了CNN局部特征的不足。我们方法生成的结果更接近真实标注,尤其在形状完整性方面优于其他涂鸦监督甚至全监督方法。
D. Comparison with Pseudo-label Generating Methods
D. 与伪标签生成方法的对比
- Comparison with UNet-based Methods: To assess the performance of S crib Former in comparison to other methods for pseudo-label generation, we adopted a UNet with only partial cross-entropy loss (pce) [6] as the foundation, enhanced in several ways: 1) $\mathrm{UNet}{r w}$ [62], utilizing pseudo-labels generated by the Random Walker method. 2) $\mathrm{UNet}_{s2l}$ [63], incorporating pseudo-labeling alongside label filtering known as Scribble 2 Label. 3) DMPLS [10], employing a dual-branch approach with dynamically mixed pseudo-label supervision. 4) TS-UNet [45], a variant of ${\mathrm{UNet}}++$ that combines the Random Walker, Dense CRF, and uncertainty estimation techniques. Table IV presents the results. It’s evident that some pseudolabel-based methods using scribble annotations can achieve reasonably good performance, with both S2L and DMPLS achieving accuracy of $80%$ or higher. However, our approach outperforms CNN-based methods by a substantial margin, underscoring the effectiveness of the CNN-Transformer synergy embedded in our network.
- 与基于UNet方法的对比:为了评估Scrib Former在伪标签生成任务中的性能表现,我们以仅采用部分交叉熵损失(pce) [6]的UNet为基础框架,并对比了以下改进方法:1) $\mathrm{UNet}{rw}$ [62]:使用随机游走(Random Walker)方法生成伪标签;2) $\mathrm{UNet}_{s2l}$ [63]:结合涂鸦转标签(Scribble 2 Label)的伪标注与标签过滤机制;3) DMPLS [10]:采用动态混合伪标签监督的双分支架构;4) TS-UNet [45]:基于${\mathrm{UNet}}++$框架,融合随机游走、稠密CRF和不确定性估计技术。表IV展示了对比结果。可见部分基于涂鸦标注的伪标签方法能取得较好性能(S2L和DMPLS准确率达$80%$以上),但我们的方法显著优于基于CNN的方案,这印证了网络中CNN-Transformer协同架构的有效性。
TABLE IV COMPARISON OF DICE SCORE WITH PSEUDO-LABEL GENERATING METHODS ON THE ACDC DATASET.
表 IV: ACDC数据集上伪标签生成方法的Dice分数对比
| 方法 | 主干网络 | 数据 | LV | RV | MYO | 平均 |
|---|---|---|---|---|---|---|
| UNetpce UNetrw UNets2l DMPLS | CNN CNN CNN CNN | 涂鸦 涂鸦 涂鸦 涂鸦 | .624 .840 .767 .875 | .537 .730 .715 .903 | .526 .802 .765 | .562 .791 .820 |
| TS-UNet SwinUNet | CNN Trans | 涂鸦 涂鸦 | .479 .872 | .408 .773 | .852 .272 .793 | .870 .386 |
| TransUNet TFCNs | CNN+Trans CNN+Trans | 涂鸦 涂鸦 | .857 .839 | .762 .713 | .807 .774 | .813 .808 .775 |
- Comparison with Transformer-based Methods: In this section, we further compared our method with Transformer-based methods in scribble-annotated medical image. Specifically, SwinUNet [64] are the volumetric medical image segmentation models utilizing pure Transformers as the encoder to capture long-range spatial dependencies. Meanwhile, TransUNet [32] and TFCNs [30] are both planar medical image segmentation models utilizing a combination of convolutional layers and Transformers. For fairness, all models were trained using the labeled pixels from the scribble data and incorporated pseudo labels generated by the Random Walker algorithm. Table IV contains the outcome of our experiments. Interestingly, the Transformer-based medical image segmentation models, which were designed with full annotation data in mind, demonstrated only average performance when applied to scribble data. In contrast, our S crib Former model excelled in this context, achieving superior performance by adeptly combining both local detailed information and global contextual understanding.
- 与基于Transformer方法的对比:本节我们进一步将所提方法与基于Transformer的涂鸦标注医学图像分割方法进行对比。具体而言,SwinUNet [64] 是采用纯Transformer作为编码器来捕获长程空间依赖关系的 volumetric 医学图像分割模型;TransUNet [32] 和 TFCNs [30] 则是结合卷积层与Transformer的平面医学图像分割模型。为确保公平性,所有模型均使用涂鸦数据中的标注像素进行训练,并整合了Random Walker算法生成的伪标签。表IV展示了实验结果:有趣的是,这些原本针对全标注数据设计的基于Transformer的医学图像分割模型,在涂鸦数据上仅表现出中等性能。相比之下,我们的Scrib Former模型通过巧妙融合局部细节信息与全局上下文理解,在此场景下展现出卓越性能优势。
E. Ablation Study
E. 消融实验
This section studies the effectiveness of different components of the proposed S crib Former, including the CNN, Transformer, and ACAM branches. Table V reports the results.
本节研究了所提出的Scrib Former中不同组件的有效性,包括CNN、Transformer和ACAM分支。表V报告了结果。
- Effectiveness of Transformer Branch: As illustrated in Table V, Model #4 exhibits a significantly better performance than Model #1 and Model #2. For Model #1, it is difficult to obtain global representations from scribble annotations by using CNN. For Model #2, the pure Transformer architecture excels in capturing global information, granting it a distinct advantage when dealing with irregular regions such as MYO during segmentation. On the other hand, the CNN branch of Model #4 provides local features to minimize incorrect predictions of unlabeled pixels within the object. Meanwhile, Transformer branch of Model #4 provides global representations that help reduce incorrect predictions of unlabeled pixels throughout the entire image, including the background.
- Transformer分支的有效性:如表 V 所示,模型 #4 的性能明显优于模型 #1 和模型 #2。对于模型 #1,使用 CNN 难以从涂鸦标注中获取全局表征。模型 #2 的纯 Transformer 架构擅长捕捉全局信息,使其在分割 MYO 等不规则区域时具有显著优势。另一方面,模型 #4 的 CNN 分支提供了局部特征,可最小化对象内未标注像素的错误预测。同时,模型 #4 的 Transformer 分支提供了全局表征,有助于减少整个图像(包括背景)中未标注像素的错误预测。
TABLE V ABLATION STUDY OF S CRIB FORMER FOR IMAGE SEGMENTATION USING DICE SCORE, INVESTIGATING DIFFERENT SETTINGS INCLUDING THE CNN BRANCH, TRANSFORMER BRANCH, AND ACAM BRANCH.
表 5: 基于Dice评分的SCRIB FORMER图像分割消融研究,包括CNN分支、Transformer分支和ACAM分支的不同设置对比
| 模型 | CNN | Transformer | ACAM | LV | RV | MYO | 平均 |
|---|---|---|---|---|---|---|---|
| #1 | ✓ | × | × | .809 | .642 | .582 | .678 |
| #2 | × | ✓ | × | .790 | .701 | .525 | .672 |
| #3 | ✓ | × | ✓ | .830 | .659 | .650 | .713 |
| #4 | ✓ | ✓ | × | .906 | .862 | .847 | .872 |
| #5 | ✓ | ✓ | ✓ | .922 | .871 | .871 | .888 |
- Effectiveness of ACAM Branch: As shown in Table V, compared to Model #1, Model #3 with the extra ACAM branch achieves better results. The same situation occurred between Model #4 and Model #5. Since the unlabeled pixels in the scribble do not participate in the training, it is difficult for the model to predict these pixels. On the contrary, ACAM can obtain the pixels with more attention by the convolution layer, which can expand the trainable pixels to the entire image. In addition, the proposed ACAM-consistency loss can train the low-level convolutional layers under the supervision of highlevel convolutional features, leading to further improvement in model performance.
- ACAM分支的有效性:如表 V 所示,与模型 #1 相比,增加 ACAM 分支的模型 #3 取得了更好的结果。模型 #4 和模型 #5 之间也出现了相同情况。由于涂鸦中未标注的像素不参与训练,模型难以预测这些像素。相反,ACAM 能通过卷积层获取更高关注度的像素,从而将可训练像素扩展到整张图像。此外,提出的 ACAM 一致性损失 (ACAM-consistency loss) 能在高层卷积特征的监督下训练低层卷积层,从而进一步提升模型性能。
- Effectiveness of Decoder: As depicted in Table VI, we conducted ablation experiments involving different decoding strategies built upon the foundation of the CNN-Transformer encoder. Specifically, we assessed the performance when employing only CNN as the decoder, solely Transformer as the decoder, and a combination of both CNN and Transformer as decoders. The results unequivocally affirm the effectiveness of our multi-branch decoder design in enhancing segmentation performance. Notably, the CNN-Transformer hybrid decoderoutperforms both individual decoders, substantiating the claim made in the second paragraph of Section III-A. In that section, we emphasize the hybrid design’s ability to focus on the shared aspects between the CNN and Transformer components while accommodating the unique characteristics of each decoder. This design consideration proves particularly vital in the context of scribble-supervised models, where robustness against missegmentation is achieved through tailored attention to various parts of the image. These results reinforce the significance of our approach in achieving superior segmentation accuracy.
- 解码器有效性:如表 VI 所示,我们在 CNN-Transformer 编码器基础上进行了不同解码策略的消融实验。具体而言,我们评估了仅使用 CNN 作为解码器、仅使用 Transformer 作为解码器以及同时使用 CNN 和 Transformer 作为解码器时的性能。结果明确证实了我们多分支解码器设计对提升分割性能的有效性。值得注意的是,CNN-Transformer 混合解码器的表现优于单一解码器,这验证了第 III-A 节第二段中的观点。在该部分中,我们强调了混合设计能够同时关注 CNN 和 Transformer 组件的共性特征,并兼顾各解码器的独特特性。这一设计考虑在涂鸦监督模型中尤为重要,通过对图像不同区域的针对性关注,实现了对错误分割的鲁棒性。这些结果进一步印证了我们方法在实现更高分割精度方面的重要意义。

Fig. 6. The comparison of Attention-guided Class Activation Maps (ACAMs) between different layers of S crib Former on the ACDC dataset.
图 6: S crib Former 在 ACDC 数据集上不同层的注意力引导类激活图 (ACAMs) 对比。
TABLE VI COMPARISON OF PERFORMANCE WITH CNN DECODER AND TRANSFORMER DECODER ON THE ACDC DATASET USING DICE SCORE.
表 VI: 在ACDC数据集上使用Dice分数比较CNN解码器和Transformer解码器的性能
| 解码器 | 数据 | LV | RV | MYO | 平均 |
|---|---|---|---|---|---|
| CNN | scribbles | .748 | .654 | .675 | .692 |
| Transformer | scribbles | .869 | .804 | .818 | .830 |
| CNN+Transformer | scribbles | .922 | .871 | .871 | .888 |
- Effectiveness of Loss Function: As shown in Table VII, to comprehensively examine the effects of various loss functions on the overall performance of our model, we systematically assess the influence of each loss function on the Dice score. Our investigations provide insights into the role of each loss function in enhancing the model’s stability and overall segmentation accuracy. Notably, the incorporation of the pseudo-label loss $(L_{p l})$ leads to the most substantial performance improvement, resulting in a notable $8.6%$ enhancement compared to methods solely utilizing the loss $(L_{s s})$ . Furthermore, the inclusion of the $L_{a c a m}$ loss helps mitigate the performance discrepancy across different categories.
- 损失函数有效性:如表 VII 所示,为全面考察不同损失函数对模型整体性能的影响,我们系统评估了各损失函数对 Dice 分数的作用。研究表明,每种损失函数对提升模型稳定性和整体分割精度具有独特贡献。其中,引入伪标签损失 $(L_{pl})$ 带来了最显著的性能提升,相较仅使用 $(L_{ss})$ 损失的方法实现了 8.6% 的显著改进。此外,加入 $L_{acam}$ 损失有效缓解了不同类别间的性能差异。
TABLE VII ABLATION STUDY ON THE LOSS FUNCTION USING DICE SCORE.
表 7: 基于Dice分数的损失函数消融研究
| Lss | Lpl | Lacam | LV | RV | MYO | Avg |
|---|---|---|---|---|---|---|
| ✓ | × | × | .822 | .747 | .771 | .780 |
| ✓ | × | ✓ | .786 | .801 | .831 | .806 |
| ✓ | ✓ | × | .907 | .854 | .837 | .866 |
| ✓ | ✓ | ✓ | .922 | .871 | .871 | .888 |
- Effectiveness of $\lambda$ and $\omega$ : To investigate the influence of $\lambda$ and $\omega$ values on model performance, we carried out a series of ablation experiments targeting these parameters. Beginning with $\lambda$ , it’s important to note that $\lambda_{1}$ should be no greater than 1. To explore its impact, we reduced $\lambda_{1}$ to 0.9 while adjusting $\lambda_{2}$ to 0.3. The findings, as presented in Table VIII, indicate that decreasing $\lambda_{1}$ and $\lambda_{2}$ results in decreased performance. This observation emphasizes the advantage of setting $\lambda_{1}$ and $\lambda_{2}$ to higher values for better performance. As for $\omega$ values, which should follow an arithmetic progression within the range [0, 1], we specifically reduced $w_{4}$ to 0.9. We then reconfigured the arithmetic progression as $(\omega_{1},\omega_{2},\omega_{3},\omega_{4})=(0.225,0.45,0.675,0.9)$ and conducted corresponding experiments. The results indicated a performance decline, as seen in Table IX, upon altering $\omega_{4}$ to smaller one. Additionally, significance tests were conducted, revealing that the obtained $\mathsf{p}$ -values for both experiments were greater than 0.05. This may be attributed to the influence of extremely small values and limited sample size in the experimental data. We acknowledge this potential impact in our method.
- $\lambda$ 和 $\omega$ 的有效性:为探究 $\lambda$ 和 $\omega$ 取值对模型性能的影响,我们针对这两个参数进行了一系列消融实验。首先关于 $\lambda$,需注意 $\lambda_{1}$ 不应大于1。为考察其影响,我们将 $\lambda_{1}$ 降至0.9,同时将 $\lambda_{2}$ 调整为0.3。如表 VIII 所示,降低 $\lambda_{1}$ 和 $\lambda_{2}$ 会导致性能下降,这说明设定较高值的 $\lambda_{1}$ 和 $\lambda_{2}$ 更有利于提升性能。对于 $\omega$ 取值(应在[0,1]范围内呈等差数列),我们特别将 $w_{4}$ 降至0.9,并重新配置等差数列为 $(\omega_{1},\omega_{2},\omega_{3},\omega_{4})=(0.225,0.45,0.675,0.9)$ 进行实验。如表 IX 所示,当 $\omega_{4}$ 取较小值时性能出现下降。此外,显著性检验显示两组实验获得的 $\mathsf{p}$ 值均大于0.05,这可能是由于实验数据中存在极小值及样本量有限的影响。我们在方法中已考虑这一潜在影响。
| 入1 | 入2 | 入3 | LV | RV | MYO | Avg |
|---|---|---|---|---|---|---|
| 1 | 0.5 | 0.1 | .922 | .871 | .871 | .888 |
| 0.9 | 0.3 | 0.1 | .917 | .866 | .871 | .885 |
TABLE VIII ABLATION STUDY ON THE $\lambda$ USING DICE SCORE.TABLE IX ABLATION STUDY ON THE $\omega$ USING DICE SCORE.
表 VIII: 基于Dice分数的$\lambda$消融实验
表 IX: 基于Dice分数的$\omega$消融实验
| W1 | W2 | W3 | W4 | LV | RV | MYO | Avg |
|---|---|---|---|---|---|---|---|
| 0.25 | 0.5 | 0.75 | 1 | .922 | .871 | .871 | .888 |
| 0.225 | 0.45 | 0.675 | 0.9 | .921 | .870 | .868 | .886 |
F. ACAMs Visualization
F. ACAMs 可视化
To explain the role of ACAM-consistency and further verify the effectiveness of Transformers, the visualization of the ACAMs in each layer is shown in Fig. 6. It can be observed that i) the ACAMs of convolution layer3 closely match the goal segmentation region of the ground truth, rather than discriminative regions, which means the introduction of Transformers can help modulate the activation maps, emphasizing global features in scribble supervision. ii) As the network goes deeper, the activation maps of the convolution layer also gradually approach the target segmentation areas. Specifically, Conv Embedding1 and Conv Embedding2 concentrate on locating high-contrast regions, which appear as low and scattered highlights on the activation map. The activation maps of the Conv Layer1 contain multiple relatively-dense tiny regions and begin to focus on the segmentation area. Conv Layer2 gets closer to the target, and the ACAMs of Conv Layer3 are extremely similar to the ground truth. The observed outcome can be ascribed to the joint effect of Transformer refinement and ACAM-consistency regular iz ation on the attention regions of the shallow ACAMs. Furthermore, when comparing ACAM with and without consistency loss, it is evident that our model maintains the capability to focus on the target region even without consistency loss. Nonetheless, certain level of confusion arises in the absence of consistency loss. This highlights the effectiveness of integrating our ACAMs with consistency loss, as it serves to further enhance the refinement of attention-guided class activation maps.
为解释ACAM一致性(ACAM-consistency)的作用并进一步验证Transformer的有效性,图6展示了各层ACAM的可视化结果。可以观察到:i) 卷积层3的ACAM与真实标注的目标分割区域高度吻合,而非判别性区域,这表明Transformer的引入能帮助调制激活图(activation maps),在涂鸦监督中强化全局特征;ii) 随着网络深度增加,卷积层的激活图也逐渐逼近目标分割区域。具体而言,Conv Embedding1和Conv Embedding2集中于定位高对比度区域,在激活图上呈现为稀疏的低亮度高亮区;Conv Layer1的激活图包含多个相对密集的微小区域并开始关注分割区域;Conv Layer2更接近目标区域;Conv Layer3的ACAM与真实标注极为相似。这一现象可归因于Transformer细化与ACAM一致性正则化对浅层ACAM注意力区域的联合作用。此外,通过比较有无一致性损失的ACAM可见,即使不施加一致性损失,我们的模型仍保持聚焦目标区域的能力,但会出现一定程度的混淆。这凸显了将ACAM与一致性损失结合的有效性,可进一步提升注意力引导的类别激活图细化效果。
G. Data Sensitivity Study
G. 数据敏感性研究
The data sensitivity study delves into S crib Former’s performance when trained with varying numbers of scribble annotations. Table X showcases a clear trend where ScribFormer’s performance progressively improves as the number of scribble-annotated samples increases. Notably, even with just 14 training samples that include scribbles, our model achieves a respectable accuracy of $84.7%$ . This highlights S crib Former’s ability to produce satisfactory segmentation results with a relatively small amount of scribble annotations. The model’s overall performance stabilizes as it’s trained with 56 scribble annotations (which amounts to $80%$ of the total 70 scribbles). The peak performance is achieved when all 70 scribble annotations are utilized, resulting in an impressive accuracy of $89.4%$ .
数据敏感性研究深入探讨了ScribFormer在不同数量涂鸦标注下的性能表现。表X展示了明显趋势:随着涂鸦标注样本数量的增加,ScribFormer性能逐步提升。值得注意的是,即使仅使用14个含涂鸦的训练样本,我们的模型仍能达到84.7%的准确率。这凸显了ScribFormer在少量涂鸦标注下仍能产生令人满意的分割结果的能力。当使用56个涂鸦标注(占总标注量70个的80%)进行训练时,模型整体性能趋于稳定。当使用全部70个涂鸦标注时,模型达到峰值性能,获得89.4%的优异准确率。
TABLE X DATA SENSITIVITY STUDY: EVALUATING S CRIB FORMER’S PERFORMANCE WITH VARYING NUMBERS OF SCRIBBLES FOR TRAINING USING DICE SCORE.
表 X 数据敏感性研究: 评估SCRIB FORMER在不同数量涂鸦训练下的性能(使用Dice分数)
| 数据 | LV | RV | MYO | 平均 |
|---|---|---|---|---|
| 14涂鸦 | .899 | .839 | .804 | .847 |
| 28涂鸦 | .900 | .853 | .844 | .866 |
| 35涂鸦 | .922 | .871 | .871 | .888 |
| 56涂鸦 | .925 | .873 | .877 | .892 |
| 70涂鸦 | .926 | .878 | .877 | .894 |
H. Model Complexity Comparison
H. 模型复杂度对比
As illustrated in Table XI, to assess the model’s complexity, we compared the parameter count and FLOPs between the proposed S crib Former and other benchmark methods. It’s worth noting that the UNet variants, such as $\mathrm{UNet}{p c e}$ , $\mathrm{UNet}{u s t r}$ , and ${\mathrm{UNet}}_{p c e}^{++}$ , maintain equivalent parameter sizes and FLOPs to their respective UNet and ${\mathrm{UNet^{++}}}$ counterparts. Compared with the UNet variants, the parameter count of our model is relatively higher, primarily due to the inclusion of Transformer components. However, in comparison to CycleMix, our model exhibits lower computational complexity. Furthermore, we evaluated the averaged inference time per case within the
如表 XI 所示,为评估模型复杂度,我们比较了所提出的 S crib Former 与其他基准方法的参数量和 FLOPs。值得注意的是,UNet 变体如 $\mathrm{UNet}{p c e}$、$\mathrm{UNet}{u s t r}$ 和 ${\mathrm{UNet}}_{p c e}^{++}$ 保持与其对应 UNet 和 ${\mathrm{UNet^{++}}}$ 相同的参数量级和 FLOPs。与 UNet 变体相比,本模型参数量较高,主要因包含 Transformer 组件所致。但与 CycleMix 相比,本模型展现出更低计算复杂度。此外,我们还评估了每例平均推理时间在
HeartUII test set for both CycleMix and S crib Former. The results indicate that CycleMix requires 21.21 seconds per case, whereas S crib Former achieves a faster inference time at just 13.96 seconds. The observation underscores our advantage in terms of inference efficiency. And, we observe computational demands of the Transformer architecture posing a potential challenge for real-time applications. To address this concern, our ongoing efforts are focusing on optimization of S crib Former to enhance its suitability across a broader spectrum of scenarios. At the same time, experimental results also suggest that S crib Former outperforms or competes favorably with existing architectures in some benchmark tasks. These evidences add credibility to the model’s capabilities, reinforcing its potential as a reliable solution in various applications.
HeartUII测试集上CycleMix和Scrib Former的对比结果显示,CycleMix每例耗时21.21秒,而Scrib Former仅需13.96秒即可完成推理。这一发现凸显了我们在推理效率方面的优势。同时,我们注意到Transformer架构的计算需求可能对实时应用构成挑战。为解决这一问题,我们正持续优化Scrib Former以提升其在更广泛场景中的适用性。实验数据还表明,Scrib Former在部分基准任务中优于或持平现有架构。这些证据进一步验证了该模型的能力,强化了其作为多场景可靠解决方案的潜力。
TABLE XI MODEL COMPLEXITY COMPARISON BETWEEN OUR METHOD (S CRIB FORMER) AND OTHER METHODS ON THE HEARTUII DATASET.
表 11: 我们的方法 (ScribFormer) 与其他方法在 HEARTUII 数据集上的模型复杂度对比
| 方法 | 参数量(M) | 计算量(G) |
|---|---|---|
| UNet | 1.81 | 24.25 |
| UNet++ | 9.16 | 279.25 |
| CycleMix | 25.76 | 469.41 |
| ScribFormer | 50.44 | 436.67 |
TABLE XII
表 12:
| 方法 | Dice (95% CI) | p值 |
|---|---|---|
| UNetpce | .655 (.609 至 .694) | 5.380·10-9 |
| UNetustr | .664 (.621 至 .703) | 9.430·10-9 |
| UNetem | .761 (.729 至 .793) | 4.026·10-4 |
| UNetcrf | .785 (.720 至 .839) | 1.080·10-1 |
| UNet++ pce | .714 (.670 至 .757) | 1.064·10-5 |
| CycleMixs | .810 (.790 至 .831) | 1.073·10-1 |
| ScribFormer | .833 (.808 至 .854) | / |
I. Inference Statistical Evaluation
I. 推理统计评估
To conduct a thorough significance analysis, we computed $95%$ confidence intervals using the bootstrap method [65] and calculated p-values through t-test on the HeartUII testing set, as presented in Table XII. By comparing $95%$ confidence intervals and p-values, our approach exhibits significant differences compared to $\mathrm{UNet}{p c e}$ , $\mathrm{UNet}{u s t r}$ , $\mathrm{UNet}{e m}$ , and ${\mathrm{UNet}}{p c e}^{++}$ . Despite the non-significant trend in p-values for $\mathrm{UNet}{c r f}$ and $\mathrm{CycleMix}{S}$ analyzing the $95%$ confidence interval reveals a narrower range for our method compared to ${\mathrm{UNet}}{c r f}$ . This indicates lower overall variance and also suggests greater robustness in our model. Moreover, by examining the box plot of inference results in Fig. 7, our method demonstrates a higher median than $\mathbf{CycleMix}_{S}$ , indicating that our approach outperforms CycleMix $\boldsymbol{\cdot}\boldsymbol{S}$ at the average level of the testing samples.
为进行全面的显著性分析,我们采用自助法 (bootstrap) [65] 计算了95%置信区间,并在HeartUII测试集上通过t检验计算p值,如表XII所示。通过对比95%置信区间和p值,我们的方法与$\mathrm{UNet}{p c e}$、$\mathrm{UNet}{u s t r}$、$\mathrm{UNet}{e m}$以及${\mathrm{UNet}}{p c e}^{++}$均存在显著差异。尽管$\mathrm{UNet}{c r f}$和$\mathrm{CycleMix}{S}$的p值未呈现显著趋势,但分析95%置信区间可发现,相较于${\mathrm{UNet}}{c r f}$,本方法的置信区间范围更窄,表明总体方差更低,也意味着模型具有更强的鲁棒性。此外,通过观察图7中的推理结果箱线图,本方法的中位数高于$\mathbf{CycleMix}_{S}$,说明在测试样本的平均水平上,我们的方法优于CycleMix$\boldsymbol{\cdot}\boldsymbol{S}$。
V. CONCLUSION
V. 结论
In this paper, a new Transformer-CNN hybrid solution, called S crib Former, has been proposed to solve the limitations of CNN-based networks for scribble-supervised medical image segmentation. The main motivation behind S crib Former is based on our observation that attention weights from shallow Transformer blocks could capture low-level spatial feature similarities, while attention weights from deep Transformer blocks could capture high-level semantic context. Specifically, S crib Former explicitly leverages the attention weights from the Transformer branch to refine both the convolutional features and the ACAMs generated from the CNN branch. Our method, as the first Transformer-based solution in scribblesupervised medical image segmentation, is simple, efficient, and effective for generating high-quality pixel-level segmentation results. It enhances medical image analysis by reducing the need for extensive annotations, thereby minimizing manual labeling efforts and broadening the possibilities for scribblesupervised medical image segmentation. Experimental results demonstrate new SOTA performance of our S crib Former on ACDC, MSCMRseg, and HeartUII datasets. However, it should be noted that our method may yield non-significant results when compared with some SOTA methods for inference statistical evaluation. In future work, we will focus on addressing limitations of our method by further reducing its computational complexity and exploring the influence of hyper parameters more comprehensively.
本文提出了一种名为ScribbleFormer的新型Transformer-CNN混合解决方案,旨在解决基于CNN的网络在涂鸦监督医学图像分割中的局限性。ScribbleFormer的核心动机源于我们的观察:浅层Transformer块的注意力权重能捕捉低级空间特征相似性,而深层Transformer块的注意力权重可捕获高级语义上下文。具体而言,ScribbleFormer显式利用Transformer分支的注意力权重来优化CNN分支生成的卷积特征和ACAMs。作为涂鸦监督医学图像分割领域首个基于Transformer的解决方案,我们的方法简单高效,能生成高质量的像素级分割结果。该方法通过减少对大量标注的需求来增强医学图像分析,从而降低人工标注工作量,拓宽涂鸦监督医学图像分割的应用前景。实验结果表明,ScribbleFormer在ACDC、MSCMRseg和HeartUII数据集上实现了新的SOTA性能。但需注意,与部分SOTA方法进行推理统计评估时,我们的方法可能产生非显著性结果。未来工作将重点通过进一步降低计算复杂度、更全面地探索超参数影响来解决当前方法的局限性。

Fig. 7. Comparison of the inference results for each case in the test set with other SOTA methods on the HeartUII dataset.
图 7: 在HeartUII数据集上,测试集中各案例与其他SOTA方法的推理结果对比。