MASS-EDITING MEMORY IN A TRANSFORMER
在Transformer中批量编辑记忆
Kevin Meng1,2 Arnab Sen Sharma2 Alex Andonian1 Yonatan Belinkov† 3 David Bau2 1MIT CSAIL 2 Northeastern University 3Technion – IIT
Kevin Meng1,2 Arnab Sen Sharma2 Alex Andonian1 Yonatan Belinkov† 3 David Bau2 1MIT CSAIL 2东北大学 3以色列理工学院
ABSTRACT
摘要
Recent work has shown exciting promise in updating large language models with new memories, so as to replace obsolete information or add specialized knowledge. However, this line of work is predominantly limited to updating single associations. We develop MEMIT, a method for directly updating a language model with many memories, demonstrating experimentally that it can scale up to thousands of associations for GPT-J (6B) and GPT-NeoX (20B), exceeding prior work by orders of magnitude. Our code and data are at memit.baulab.info.
近期研究在更新大语言模型记忆方面展现出令人振奋的潜力,旨在替换过时信息或添加专业知识。然而这类工作目前主要局限于更新单一关联。我们开发了MEMIT方法,可直接为语言模型批量更新记忆,实验证明该方法能在GPT-J (6B)和GPT-NeoX (20B)模型上实现数千条关联的更新,规模超越前人工作数个量级。代码与数据详见memit.baulab.info。
1 INTRODUCTION
1 引言
How many memories can we add to a deep network by directly editing its weights?
通过直接编辑权重,我们能为深度网络增添多少记忆?
Although large auto regressive language models (Radford et al., 2019; Brown et al., 2020; Wang & Komatsu zak i, 2021; Black et al., 2022) are capable of recalling an impressive array of common facts such as “Tim Cook is the CEO of Apple” or “Polaris is in the constellation Ursa Minor” (Petroni et al., 2020; Brown et al., 2020), even very large models are known to lack more specialized knowledge, and they may recall obsolete information if not updated periodically (Lazaridou et al., 2021; Agarwal & Nenkova, 2022; Liska et al., 2022). The ability to maintain fresh and customizable information is desirable in many application domains, such as question answering, knowledge search, and content generation. For example, we might want to keep search models updated with breaking news and recently-generated user feedback. In other situations, authors or companies may wish to customize models with specific knowledge about their creative work or products. Because re-training a large model can be prohibitive (Patterson et al., 2021) we seek methods that can update knowledge directly.
虽然大型自回归语言模型 (Radford et al., 2019; Brown et al., 2020; Wang & Komatsuzaki, 2021; Black et al., 2022) 能够回忆大量常见事实,例如"Tim Cook是苹果公司CEO"或"北极星位于小熊座" (Petroni et al., 2020; Brown et al., 2020),但即使是超大规模模型也已知缺乏更专业的知识,且若未定期更新可能会回忆过时信息 (Lazaridou et al., 2021; Agarwal & Nenkova, 2022; Liska et al., 2022)。保持信息新鲜度和可定制性的能力在问答系统、知识搜索和内容生成等众多应用领域都至关重要。例如,我们可能希望让搜索模型持续更新突发新闻和最新用户反馈。在其他场景中,作者或企业可能希望用特定创作或产品知识来定制模型。由于重新训练大模型成本过高 (Patterson et al., 2021),我们寻求能够直接更新知识的方法。
To that end, several knowledge-editing methods have been proposed to insert new memories directly into specific model parameters. The approaches include constrained fine-tuning (Zhu et al., 2020), hyper network knowledge editing (De Cao et al., 2021; Hase et al., 2021; Mitchell et al., 2021; 2022), and rank-one model editing (Meng et al., 2022). However, this body of work is typically limited to updating at most a few dozen facts; a recent study evaluates on a maximum of 75 (Mitchell et al., 2022) whereas others primarily focus on single-edit cases. In practical settings, we may wish to update a model with hundreds or thousands of facts simultaneously, but a naive sequential application of current state-of-the-art knowledge-editing methods fails to scale up (Section 5.2).
为此,研究者们提出了多种知识编辑方法,用于将新记忆直接植入特定模型参数。这些方法包括约束微调 (Zhu et al., 2020) 、超网络知识编辑 (De Cao et al., 2021; Hase et al., 2021; Mitchell et al., 2021; 2022) 以及秩一模型编辑 (Meng et al., 2022) 。然而,这类工作通常仅限于更新最多几十条事实:近期研究最多评估了75条 (Mitchell et al., 2022) ,而其他研究主要关注单次编辑场景。在实际应用中,我们可能希望同时更新模型数百或数千条事实,但简单地顺序应用当前最先进的知识编辑方法无法实现规模化扩展 (第5.2节) 。
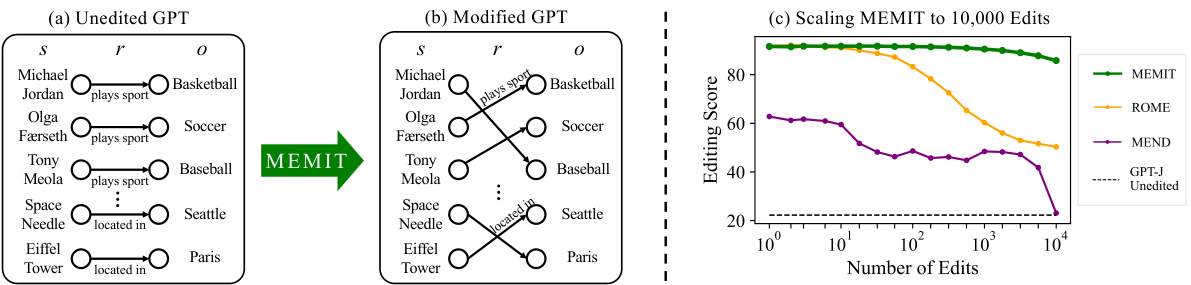
Figure 1: MEMIT is capable of updating thousands of memories at once. (a) Language models can be viewed as knowledge bases containing memorized tuples $(s,r,o)$ , each connecting some subject $s$ to an object $o$ via a relation $r$ , e.g., ( $s=$ Michael Jordan, $r=$ plays sport, $o=$ basketball). (b) MEMIT modifies transformer weights to edit memories, e.g., “Michael Jordan now plays the sport baseball,” while (c) maintaining generalization, specificity, and fluency at scales beyond other methods. As Section 5.2.2 details, editing score is the harmonic mean of efficacy, generalization, and specificity metrics.
图 1: MEMIT能够一次性更新数千条记忆。(a) 语言模型可视为包含记忆元组$(s,r,o)$的知识库,每个元组通过关系$r$将主体$s$与客体$o$关联,例如($s=$Michael Jordan,$r=$plays sport,$o=$basketball)。(b) MEMIT通过修改Transformer权重来编辑记忆,例如"Michael Jordan now plays the sport baseball",同时(c)在规模上保持泛化性、特异性和流畅性优于其他方法。如第5.2.2节所述,编辑分数是效力、泛化性和特异性指标的调和平均值。
We propose MEMIT, a scalable multi-layer update algorithm that uses explicitly calculated parameter updates to insert new memories. Inspired by the ROME direct editing method (Meng et al., 2022), MEMIT targets the weights of transformer modules that we determine to be causal mediators of factual knowledge recall. Experiments on GPT-J (6B parameters; Wang & Komatsu zak i 2021) and GPT-NeoX (20B; Black et al. 2022) demonstrate that MEMIT can scale and successfully store thousands of memories in bulk. We analyze model behavior when inserting true facts, counter factual s, 27 specific relations, and different mixed sets of memories. In each setting, we measure robustness in terms of generalization, specificity, and fluency while comparing the scaling of MEMIT to rank-one, hyper network, and fine-tuning baselines.
我们提出MEMIT,这是一种可扩展的多层更新算法,通过显式计算参数更新来插入新记忆。受ROME直接编辑方法(Meng等,2022)的启发,MEMIT针对Transformer模块中我们确定为事实知识回忆因果介质的权重进行修改。在GPT-J(60亿参数;Wang & Komatsuzaki 2021)和GPT-NeoX(200亿;Black等 2022)上的实验表明,MEMIT能够扩展并成功批量存储数千条记忆。我们分析了插入真实事实、反事实、27种特定关系以及不同混合记忆集时的模型行为。在每种设置中,我们从泛化性、特异性和流畅性三个维度测量鲁棒性,同时将MEMIT与秩一法、超网络和微调基线进行扩展性对比。
2 RELATED WORK
2 相关工作
Scalable knowledge bases. The representation of world knowledge is a core problem in artificial intelligence (Richens, 1956; Minsky, 1974), classically tackled by constructing knowledge bases of real-world concepts. Pioneering hand-curated efforts (Lenat, 1995; Miller, 1995) have been followed by web-powered knowledge graphs (Auer et al., 2007; Bollacker et al., 2007; Suchanek et al., 2007; Havasi et al., 2007; Carlson et al., 2010; Dong et al., 2014; Vrandecic & Krotzsch, 2014; Bosselut et al., 2019) that extract knowledge from large-scale sources. Structured knowledge bases can be precisely queried, measured, and updated (Davis et al., 1993), but they are limited by sparse coverage of uncatalogued knowledge, such as commonsense facts (Weikum, 2021).
可扩展知识库。世界知识的表示是人工智能领域的核心问题 (Richens, 1956; Minsky, 1974),传统方法通过构建现实世界概念的知识库来解决。继早期人工编纂的知识库 (Lenat, 1995; Miller, 1995) 之后,出现了基于网络的知识图谱 (Auer et al., 2007; Bollacker et al., 2007; Suchanek et al., 2007; Havasi et al., 2007; Carlson et al., 2010; Dong et al., 2014; Vrandecic & Krotzsch, 2014; Bosselut et al., 2019),这些知识图谱从大规模数据源中提取知识。结构化知识库可以进行精确查询、度量和更新 (Davis et al., 1993),但其局限性在于对未编目知识(如常识性事实)的覆盖不足 (Weikum, 2021)。
Language models as knowledge bases. Since LLMs can answer natural-language queries about real-world facts, it has been proposed that they could be used directly as knowledge bases (Petroni et al., 2019; Roberts et al., 2020; Jiang et al., 2020; Shin et al., 2020). However, LLM knowledge is only implicit; responses are sensitive to specific phrasings of the prompt (Elazar et al., 2021; Petroni et al., 2020), and it remains difficult to catalog, add, or update knowledge (AlKhamissi et al., 2022). Nevertheless, LLMs are promising because they scale well and are un constrained by a fixed schema (Safavi & Koutra, 2021). In this paper, we take on the update problem, asking how the implicit knowledge encoded within model parameters can be mass-edited.
语言模型作为知识库。由于大语言模型能够回答关于现实世界事实的自然语言查询,有人提出可以直接将其用作知识库 (Petroni et al., 2019; Roberts et al., 2020; Jiang et al., 2020; Shin et al., 2020)。然而,大语言模型的知识仅具有隐式特性:其响应易受提示词具体表述的影响 (Elazar et al., 2021; Petroni et al., 2020),且知识的编目、添加或更新仍存在困难 (AlKhamissi et al., 2022)。尽管如此,大语言模型仍具潜力,因其具备良好的扩展性且不受固定模式约束 (Safavi & Koutra, 2021)。本文聚焦知识更新问题,探讨如何对编码在模型参数中的隐式知识进行批量编辑。
Hyper network knowledge editors. Several meta-learning methods have been proposed to edit knowledge in a model. Sinitsin et al. (2019) proposes a training objective to produce models amenable to editing by gradient descent. De Cao et al. (2021) proposes a Knowledge Editor (KE) hyper network that edits a standard model by predicting updates conditioned on new factual statements. In a study of KE, Hase et al. (2021) find that it fails to scale beyond a few edits, and they scale an improved objective to 10 beliefs. MEND (Mitchell et al., 2021) also adopts meta-learning, inferring weight updates from the gradient of the inserted fact. To scale their method, Mitchell et al. (2022) proposes SERAC, a system that routes rewritten facts through a different set of parameters while keeping the original weights unmodified; they demonstrate scaling up to 75 edits. Rather than meta-learning, our method employs direct parameter updates based on an explicitly computed mapping.
超网络知识编辑器。已有多种元学习方法被提出用于编辑模型中的知识。Sinitsin等人(2019)提出了一种训练目标,使模型能够通过梯度下降进行编辑。De Cao等人(2021)提出了一种知识编辑器(KE)超网络,通过基于新事实陈述预测更新来编辑标准模型。Hase等人(2021)在对KE的研究中发现,该方法难以扩展到少量编辑之外,他们将改进后的目标扩展到10个信念。MEND(Mitchell等人,2021)也采用元学习,从插入事实的梯度推断权重更新。为了扩展其方法,Mitchell等人(2022)提出了SERAC系统,该系统通过不同的参数集路由重写事实,同时保持原始权重不变;他们展示了扩展到75次编辑的能力。与元学习不同,我们的方法基于显式计算映射直接进行参数更新。
Direct model editing. Our work most directly builds upon efforts to localize and understand the internal mechanisms within LLMs (Elhage et al., 2021; Dar et al., 2022). Based on observations from Geva et al. (2021; 2022) that transformer MLP layers serve as key–value memories, we narrow our focus to them. We then employ causal mediation analysis (Pearl, 2001; Vig et al., 2020; Meng et al., 2022), which implicates a specific range of layers in recalling factual knowledge. Previously, Dai et al. (2022) and Yao et al. (2022) have proposed editing methods that alter sparse sets of neurons, but we adopt the classical view of a linear layer as an associative memory (Anderson, 1972; Kohonen, 1972). Our method is closely related to Meng et al. (2022), which also updates GPT as an explicit associative memory. Unlike the single-edit approach taken in that work, we modify a sequence of layers and develop a way for thousands of modifications to be performed simultaneously.
直接模型编辑。我们的工作最直接建立在定位和理解大语言模型内部机制的研究基础上 (Elhage et al., 2021; Dar et al., 2022)。基于Geva等人 (2021; 2022) 关于Transformer的MLP层作为键值存储的观察,我们将研究范围缩小到这些层。随后采用因果中介分析 (Pearl, 2001; Vig et al., 2020; Meng et al., 2022),该方法揭示了特定层范围在事实知识回忆中的作用。此前,Dai等人 (2022) 和Yao等人 (2022) 提出了修改稀疏神经元集的编辑方法,但我们采用线性层作为关联记忆的经典观点 (Anderson, 1972; Kohonen, 1972)。我们的方法与Meng等人 (2022) 密切相关,后者也将GPT更新为显式关联记忆。不同于该研究的单次编辑方法,我们修改了一系列层,并开发了同时执行数千次修改的技术。
3 PRELIMINARIES: LANGUAGE MODELING AND MEMORY EDITING
3 基础知识:语言建模与记忆编辑
The goal of MEMIT is to modify factual associations stored in the parameters of an auto regressive LLM. Such models generate text by iterative ly sampling from a conditional token distribution
MEMIT的目标是修改自回归大语言模型参数中存储的事实关联。这类模型通过从条件token分布中迭代采样来生成文本。
$\mathbb{P}\left[x_{[t]}\mid x_{[1]},\ldots,x_{[E]}\right]$ parameterized by a $D$ -layer transformer decoder, $G$ (Vaswani et al., 2017):
$\mathbb{P}\left[x_{[t]}\mid x_{[1]},\ldots,x_{[E]}\right]$ 由 $D$ 层 Transformer 解码器 $G$ 参数化 (Vaswani et al., 2017):
$$
\begin{array}{r}{\mathbb{P}\left[x_{[t]}|x_{[1]},\ldots,x_{[E]}\right]\triangleq G([x_{[1]},\ldots,x_{[E]}])=\operatorname{softmax}\left(W_{y}h_{[E]}^{D}\right),}\end{array}
$$
$$
\begin{array}{r}{\mathbb{P}\left[x_{[t]}|x_{[1]},\ldots,x_{[E]}\right]\triangleq G([x_{[1]},\ldots,x_{[E]}])=\operatorname{softmax}\left(W_{y}h_{[E]}^{D}\right),}\end{array}
$$
where $h_{[E]}^{D}$ is the transformer’s hidden state representation at the final layer $D$ and ending token $E$ . This state is computed using the following recursive relation:
其中 $h_{[E]}^{D}$ 是Transformer在最终层 $D$ 和结束token $E$ 处的隐藏状态表示。该状态通过以下递归关系计算:
$$
\begin{array}{r l}&{{\boldsymbol{h}}_ {[t]}^{l}(\boldsymbol{x})={\boldsymbol{h}}_ {[t]}^{l-1}(\boldsymbol{x})+a_{[t]}^{l}(\boldsymbol{x})+m_{[t]}^{l}(\boldsymbol{x})}\ &{\quad\mathrm{where~}a^{l}=\mathrm{attn}^{l}\left({\boldsymbol{h}}_ {[1]}^{l-1},{\boldsymbol{h}}_ {[2]}^{l-1},\dots,{\boldsymbol{h}}_ {[t]}^{l-1}\right)}\ &{\quad m_{[t]}^{l}={\boldsymbol{W}}_ {o u t}^{l}\sigma\left({\boldsymbol{W}}_ {i n}^{l}\gamma\left({\boldsymbol{h}}_{[t]}^{l-1}\right)\right),}\end{array}
$$
$$
\begin{array}{r l}&{{\boldsymbol{h}}_ {[t]}^{l}(\boldsymbol{x})={\boldsymbol{h}}_ {[t]}^{l-1}(\boldsymbol{x})+a_{[t]}^{l}(\boldsymbol{x})+m_{[t]}^{l}(\boldsymbol{x})}\ &{\quad\mathrm{where~}a^{l}=\mathrm{attn}^{l}\left({\boldsymbol{h}}_ {[1]}^{l-1},{\boldsymbol{h}}_ {[2]}^{l-1},\dots,{\boldsymbol{h}}_ {[t]}^{l-1}\right)}\ &{\quad m_{[t]}^{l}={\boldsymbol{W}}_ {o u t}^{l}\sigma\left({\boldsymbol{W}}_ {i n}^{l}\gamma\left({\boldsymbol{h}}_{[t]}^{l-1}\right)\right),}\end{array}
$$
$h_{[t]}^{0}(x)$ is the embedding of token $x_{[t]}$ , and $\gamma$ is layernorm. Note that we have written attention and MLPs in parallel as done in Black et al. (2021) and Wang & Komatsu zak i (2021).
$h_{[t]}^{0}(x)$ 是 token $x_{[t]}$ 的嵌入向量,$\gamma$ 是层归一化 (layernorm)。注意,我们按照 Black 等人 (2021) 以及 Wang 和 Komatsuzaki (2021) 的方式将注意力机制和 MLP 并行处理。
Large language models have been observed to contain many memorized facts (Petroni et al., 2020; Brown et al., 2020; Jiang et al., 2020; Chowdhery et al., 2022). In this paper, we study facts of the form (subject $s$ , relation $r$ , object $o$ ), e.g., $s=$ Michael Jordan, $r=$ plays sport, $o=$ basketball). A generator $G$ can recall a memory for $(s_{i},r_{i},*)$ if we form a natural language prompt $p_{i}=p(s_{i},r_{i})$ such as “Michael Jordan plays the sport of” and predict the next token(s) representing $o_{i}$ . Our goal is to edit many memories at once. We formally define a list of edit requests as:
研究发现大语言模型中存储了大量事实性知识 (Petroni et al., 2020; Brown et al., 2020; Jiang et al., 2020; Chowdhery et al., 2022)。本文研究形式为 (主体 $s$ , 关系 $r$ , 客体 $o$ ) 的三元组事实,例如 $s=$ Michael Jordan, $r=$ 从事运动, $o=$ 篮球)。当构建自然语言提示 $p_{i}=p(s_{i},r_{i})$ 如"Michael Jordan从事的运动是"时,生成器 $G$ 若能预测表示 $o_{i}$ 的后续token,则视为成功调用了 $(s_{i},r_{i},*)$ 的记忆。我们的目标是实现批量记忆编辑,将编辑请求列表形式化定义为:
$$
\mathcal{E}={(s_{i},r_{i},o_{i})|i}\mathrm{ s.t. }\vec{\beta}i,j.\left(s_{i}=s_{j}\right)\wedge(r_{i}=r_{j})\wedge(o_{i}\neq o_{j}).
$$
$$
\mathcal{E}={(s_{i},r_{i},o_{i})|i}\mathrm{ s.t. }\vec{\beta}i,j.\left(s_{i}=s_{j}\right)\wedge(r_{i}=r_{j})\wedge(o_{i}\neq o_{j}).
$$
The logical constraint ensures that there are no conflicting requests. For example, we can edit Michael Jordan to play $o_{i}=$ “baseball”, but then we exclude associating him with professional soccer.
逻辑约束确保不存在冲突的请求。例如,我们可以将Michael Jordan编辑为参与 $o_{i}=$ "棒球(baseball)",但这样就排除了他与职业足球的关联。
What does it mean to edit a memory well? At a superficial level, a memory can be considered edited after the model assigns a higher probability to the statement “Michael Jordan plays the sport of baseball” than to the original prediction (basketball); we say that such an update is effective. Yet it is important to also view the question in terms of generalization, specificity, and fluency:
如何才算编辑好一段记忆?从表面上看,当模型对"Michael Jordan从事棒球运动"这一陈述赋予的概率高于原始预测(篮球)时,即可认为记忆已被编辑;我们称这种更新是有效的。但更重要的是从泛化性、特异性和流畅性三个维度来审视这个问题:
• To test for generalization, we can rephrase the question: “What is Michael Jordan’s sport? What sport does he play professionally?” If the modification of $G$ is superficial and overfitted to the specific memorized prompt, such predictions will fail to recall the edited memory, “baseball.” • Conversely, to test for specificity, we can ask about similar subjects for which memories should not change: “What sport does Kobe Bryant play? What does Magic Johnson play?” These tests will fail if the updated $G$ indiscriminately regurgitates “baseball” for subjects that were not edited. • When making changes to a model, we must also monitor fluency. If the updated model generates disfluent text such as “baseball baseball baseball baseball,” we should count that as a failure.
• 为测试泛化性,我们可以改写问题:"迈克尔·乔丹从事什么运动?他以什么运动为职业?"如果对$G$的修改是表面化的,并且过度拟合了特定的记忆提示,这类预测将无法回忆起被编辑的记忆"棒球"。
• 相反地,为测试特异性,我们可以询问不应改变记忆的相似主体:"科比·布莱恩特从事什么运动?魔术师约翰逊从事什么运动?"如果更新后的$G$不加区分地对未经编辑的主体重复输出"棒球",这些测试就会失败。
• 修改模型时,我们还必须监控流畅性。如果更新后的模型生成诸如"棒球棒球棒球棒球"之类不流畅的文本,应将其视为失败案例。
4 METHOD
4 方法
MEMIT inserts memories by updating transformer mechanisms that have recently been elucidated using causal mediation analysis (Meng et al., 2022). In GPT-2 XL, we found that there is a sequence of critical MLP layers $\mathcal{R}$ that mediate factual association recall at the last subject token $S$ (Figure 2). MEMIT operates by (i) calculating the vector associations we want the critical layers to remember, then (ii) storing a portion of the desired memories in each layer $l\in\mathcal R$ .
MEMIT通过更新最近通过因果中介分析 (Meng et al., 2022) 阐明的Transformer机制来插入记忆。在GPT-2 XL中,我们发现存在一系列关键MLP层 $\mathcal{R}$ ,它们在最后一个主体token $S$ 处中介事实关联回忆 (图 2)。MEMIT的操作方式是:(i) 计算我们希望关键层记住的向量关联,然后 (ii) 将部分所需记忆存储在每个层 $l\in\mathcal R$ 中。
Throughout this paper, our focus will be on states representing the last subject token $S$ of prompt $p_{i}$ , so we shall abbreviate $h_{i}^{l}=h_{[S]}^{l}(p_{i})$ . Similarly, $m_{i}^{l}$ and $a_{i}^{l}$ denote $m_{[S]}^{l}(p_{i})$ and $a_{[S]}^{l}(p_{i})$ .
在本文中,我们将重点关注表示提示 $p_{i}$ 最后一个主题token $S$ 的状态,因此我们将简写为 $h_{i}^{l}=h_{[S]}^{l}(p_{i})$ 。类似地,$m_{i}^{l}$ 和 $a_{i}^{l}$ 分别表示 $m_{[S]}^{l}(p_{i})$ 和 $a_{[S]}^{l}(p_{i})$ 。
4.1 IDENTIFYING THE CRITICAL PATH OF MLP LAYERS
4.1 识别 MLP 层的关键路径
Figure 3 shows the results of applying causal tracing to the larger GPT-J (6B) model; for implementation details, see Appendix A. We measure the average indirect causal effect of each $h_{i}^{l}$ on a sample of memory prompts $p_{i}$ , with either the Attention or MLP modules for token $S$ disabled. The results confirm that GPT-J has a concentration of mediating states $h_{i}^{l}$ ; moreover, they highlight a mediating causal role for a range of MLP modules, which can be seen as a large gap between the effect of single states (purple bars in Figure 3) and the effects with MLP severed (green bars); this gap diminishes after layer 8. Unlike Meng et al. (2022) who use this test to identify a single edit layer, we select the whole range of critical MLP layers $l\in\mathcal R$ . For GPT-J, we have $\mathcal{R}={3,\bar{4},5,6,7,\dot{8}}$ .
图 3: 展示了在更大的 GPT-J (6B) 模型上应用因果追踪的结果,具体实现细节参见附录 A。我们测量了每个 $h_{i}^{l}$ 对记忆提示样本 $p_{i}$ 的平均间接因果效应,其中 Token $S$ 的注意力模块或 MLP 模块被禁用。结果证实 GPT-J 具有中介状态 $h_{i}^{l}$ 的集中性;此外,它们突显了一系列 MLP 模块的中介因果作用,这可以看作是单状态效应(图 3 中的紫色条)与 MLP 切断效应(绿色条)之间的巨大差距,该差距在第 8 层后减小。与 Meng 等人 (2022) 使用此测试识别单个编辑层不同,我们选择了关键 MLP 层 $l\in\mathcal R$ 的整个范围。对于 GPT-J,我们有 $\mathcal{R}={3,\bar{4},5,6,7,\dot{8}}$。
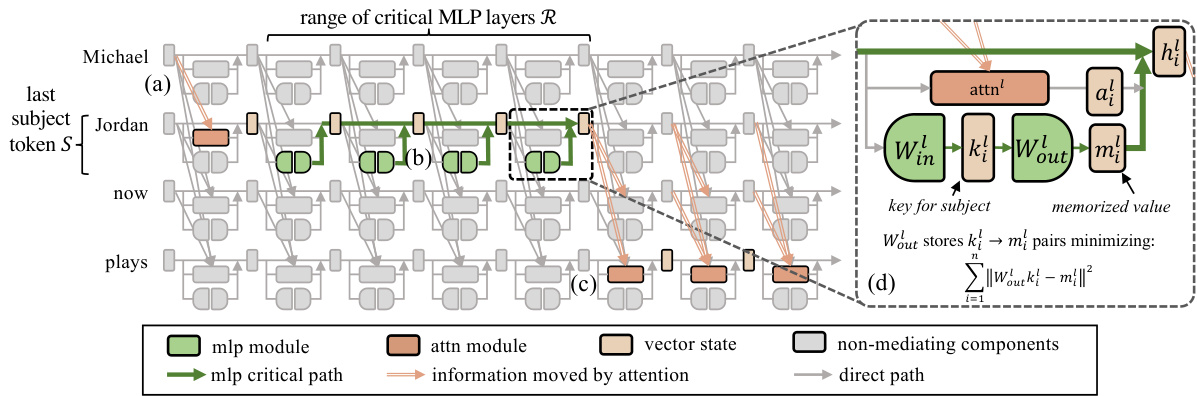
Figure 2: MEMIT modifies transformer parameters on the critical path of MLP-mediated factual recall. We edit stored associations based on observed patterns of causal mediation: (a) first, the early-layer attention modules gather subject names into vector representations at the last subject token $S$ . (b) Then MLPs at layers $l\in\mathcal R$ read these encodings and add memories to the residual stream. (c) Those hidden states are read by attention to produce the output. (d) MEMIT edits memories by storing vector associations in the critical MLPs.
图 2: MEMIT通过修改MLP介导的事实回忆关键路径上的Transformer参数实现编辑。我们基于观察到的因果中介模式修改存储关联:(a) 首先,浅层注意力模块将主语名称汇集到最后一个主语token $S$ 的向量表示中。(b) 随后位于层 $l\in\mathcal R$ 的MLP读取这些编码,并向残差流添加记忆。(c) 这些隐藏状态被注意力模块读取以生成输出。(d) MEMIT通过在关键MLP中存储向量关联来实现记忆编辑。
Given that a range of MLPs play a joint mediating role in recalling facts, we ask: what is the role of one MLP in storing a memory? Each token state in a transformer is part of the residual stream that all attention and MLP modules read from and write to (Elhage et al., 2021). Unrolling Eqn. 2 for $h_{i}^{L^{-}}=h_{[S]}^{L}(p_{i})$ :
鉴于多个MLP在事实回忆中共同发挥中介作用,我们提出疑问:单个MLP在记忆存储中扮演什么角色?Transformer中的每个Token状态都是残差流的一部分,所有注意力模块和MLP模块都从中读取并写入 (Elhage et al., 2021) 。展开公式2中的 $h_{i}^{L^{-}}=h_{[S]}^{L}(p_{i})$ 可得:
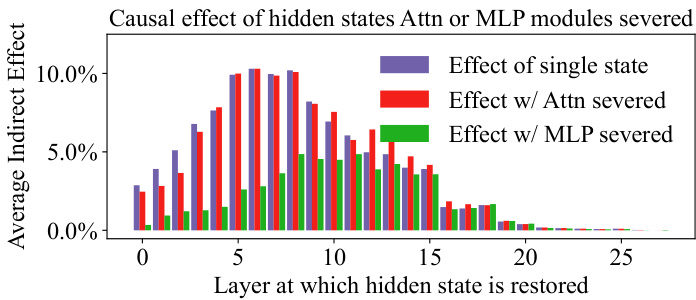
Figure 3: A critical mediating role for mid-layer MLPs.
图 3: 中间层 MLP 的关键中介作用。
$$
h_{i}^{L}=h_{i}^{0}+\sum_{l=1}^{L}a_{i}^{l}+\sum_{l=1}^{L}m_{i}^{l}.
$$
$$
h_{i}^{L}=h_{i}^{0}+\sum_{l=1}^{L}a_{i}^{l}+\sum_{l=1}^{L}m_{i}^{l}.
$$
Eqn. 6 highlights that each individual
式 6 强调每个个体
MLP contributes by adding to the memory at $h_{i}^{L}$ (Figure 2b), which is later read by last-token attention modules (Figure 2c). Therefore, when writing new memories into $G$ , we can spread the desired changes across all the critical layers $m_{i}^{l}$ for $l\in\mathcal R$ .
MLP通过向$h_{i}^{L}$处的记忆添加内容做出贡献 (图 2b),这些内容随后会被最后token注意力模块读取 (图 2c)。因此,当向$G$写入新记忆时,我们可以将所需的变化扩散到所有关键层$m_{i}^{l}$,其中$l\in\mathcal R$。
4.2 BATCH UPDATE FOR A SINGLE LINEAR ASSOCIATIVE MEMORY
4.2 单一线性联想记忆的批量更新
In each individual layer $l$ , we wish to store a large batch of $u\gg1$ memories. This section derives an optimal single-layer update that minimizes the squared error of memorized associations, assuming that the layer contains previously-stored memories that should be preserved. We denote $W_{0}\triangleq W_{o u t}^{l}$ (Eqn. 4, Figure 2) and analyze it as a linear associative memory (Kohonen, 1972; Anderson, 1972) that associates a set of input keys $k_{i}\triangleq k_{i}^{l}$ (encoding subjects) to corresponding memory values $m_{i}\triangleq m_{i}^{l}$ (encoding memorized properties) with minimal squared error:
在每一层$l$中,我们希望存储大批量$u\gg1$的记忆。本节推导出在假设该层包含需要保留的先前存储记忆的情况下,能最小化记忆关联平方误差的最优单层更新。我们将$W_{0}\triangleq W_{o u t}^{l}$(公式4,图2)表示为一个线性联想记忆(Kohonen, 1972; Anderson, 1972),它以最小平方误差将一组输入键$k_{i}\triangleq k_{i}^{l}$(编码主体)与对应的记忆值$m_{i}\triangleq m_{i}^{l}$(编码记忆属性)相关联:
$$
W_{0}\triangleq\underset{\hat{W}}{\operatorname{argmin}}\sum_{i=1}^{n}\left|\hat{W}k_{i}-m_{i}\right|^{2}.
$$
$$
W_{0}\triangleq\underset{\hat{W}}{\operatorname{argmin}}\sum_{i=1}^{n}\left|\hat{W}k_{i}-m_{i}\right|^{2}.
$$
If we stack keys and memories as matrices $K_{0}=[k_{1}\mid k_{2}\mid\cdots\mid k_{n}]$ and $M_{0}=[m_{1}\mid m_{2}\mid\cdots\mid m_{n}]$ , then Eqn. 7 can be optimized by solving the normal equation (Strang, 1993, Chapter 4):
如果将键和记忆堆叠为矩阵 $K_{0}=[k_{1}\mid k_{2}\mid\cdots\mid k_{n}]$ 和 $M_{0}=[m_{1}\mid m_{2}\mid\cdots\mid m_{n}]$ ,那么通过求解正规方程 (Strang, 1993, Chapter 4) 可以优化公式 7:
$$
W_{0}K_{0}K_{0}^{T}=M_{0}K_{0}^{T}.
$$
$$
W_{0}K_{0}K_{0}^{T}=M_{0}K_{0}^{T}.
$$
Suppose that pre-training sets a transformer MLP’s weights to the optimal solution $W_{0}$ as defined in Eqn. 8. Our goal is to update $W_{0}$ with some small change $\Delta$ that produces a new matrix $W_{1}$ with
假设预训练将 Transformer MLP 的权重设置为公式 8 中定义的最优解 $W_{0}$。我们的目标是用一个小的变化 $\Delta$ 来更新 $W_{0}$,从而生成一个新的矩阵 $W_{1}$。
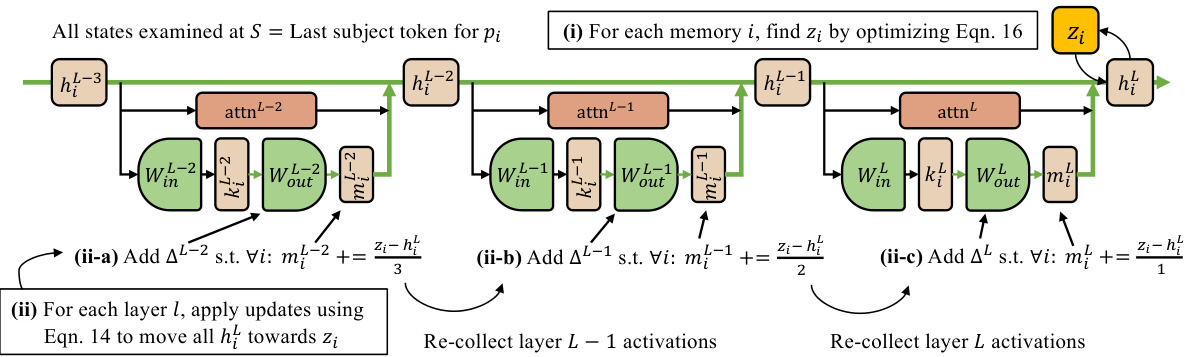
Figure 4: The MEMIT update. We first (i) replace $h_{i}^{l}$ with the vector $z_{i}$ and optimize Eqn. 16 so that it conveys the new memory. Then, after all $z_{i}$ are calculated we (ii) iterative ly insert a fraction of the residuals for all $z_{i}$ over the range of critical MLP modules, executing each layer’s update by applying Eqn. 14. Because changing one layer will affect activation s of downstream modules, we recollect activation s after each iteration.
图 4: MEMIT更新过程。我们首先(i)用向量$z_{i}$替换$h_{i}^{l}$并优化公式16,使其传递新记忆。随后在所有$z_{i}$计算完成后,(ii)我们在关键MLP模块范围内迭代插入各$z_{i}$的部分残差,通过应用公式14执行每层更新。由于单层修改会影响下游模块的激活值,我们在每次迭代后重新收集激活值。
a set of additional associations. Unlike Meng et al. (2022), we cannot solve our problem with a constraint that adds only a single new association, so we define an expanded objective:
一组额外关联。与Meng等人(2022)不同,我们无法通过仅添加单个新关联的约束条件来解决该问题,因此定义了一个扩展目标:
$$
W_{1}\triangleq\underset{\hat{W}}{\operatorname{argmin}}\left(\sum_{i=1}^{n}\left|{\hat{W}}k_{i}-m_{i}\right|^{2}+\sum_{i=n+1}^{n+u}\left|{\hat{W}}k_{i}-m_{i}\right|^{2}\right).
$$
$$
W_{1}\triangleq\underset{\hat{W}}{\operatorname{argmin}}\left(\sum_{i=1}^{n}\left|{\hat{W}}k_{i}-m_{i}\right|^{2}+\sum_{i=n+1}^{n+u}\left|{\hat{W}}k_{i}-m_{i}\right|^{2}\right).
$$
We can solve Eqn. 9 by again applying the normal equation, now written in block form:
我们可以通过再次应用正规方程来求解方程9,现在以分块形式表示:
$$
W_{1}\left[K_{0}\quad K_{1}\right]\left[K_{0}\quad K_{1}\right]^{T}=\left[M_{0}\quad M_{1}\right]\left[K_{0}\quad K_{1}\right]^{T}
$$
$$
W_{1}\left[K_{0}\quad K_{1}\right]\left[K_{0}\quad K_{1}\right]^{T}=\left[M_{0}\quad M_{1}\right]\left[K_{0}\quad K_{1}\right]^{T}
$$
$$
\begin{array}{r l}{\mathrm{{1}d s t o. }}&{{}(W_{0}+\Delta)(K_{0}K_{0}^{T}+K_{1}K_{1}^{T})=M_{0}K_{0}^{T}+M_{1}K_{1}^{T}}\end{array}
$$
$$
\begin{array}{r l}{\mathrm{{1}d s t o. }}&{{}(W_{0}+\Delta)(K_{0}K_{0}^{T}+K_{1}K_{1}^{T})=M_{0}K_{0}^{T}+M_{1}K_{1}^{T}}\end{array}
$$
$$
W_{0}K_{0}K_{0}^{T}+W_{0}K_{1}K_{1}^{T}+\Delta K_{0}K_{0}^{T}+\Delta K_{1}K_{1}^{T}=M_{0}K_{0}^{T}+M_{1}K_{1}^{T}
$$
$$
W_{0}K_{0}K_{0}^{T}+W_{0}K_{1}K_{1}^{T}+\Delta K_{0}K_{0}^{T}+\Delta K_{1}K_{1}^{T}=M_{0}K_{0}^{T}+M_{1}K_{1}^{T}
$$
$$
\mathrm{ing Eqn. 8 from Eqn.~12:}\quad\Delta(K_{0}K_{0}^{T}+K_{1}K_{1}^{T})=M_{1}K_{1}^{T}-W_{0}K_{1}K_{1}^{T}.
$$
$$
\mathrm{由式 8 减式 12 得:}\quad\Delta(K_{0}K_{0}^{T}+K_{1}K_{1}^{T})=M_{1}K_{1}^{T}-W_{0}K_{1}K_{1}^{T}.
$$
A succinct solution can be written by defining two additional quantities: $C_{0}\triangleq K_{0}K_{0}^{T}$ , a constant proportional to the uncentered covariance of the pre-existing keys, and $R\triangleq M_{1}-W_{0}K_{1}$ , the residual error of the new associations when evaluated on old weights $W_{0}$ . Then Eqn. 13 can be simplified as:
通过定义两个额外的量可以写出简洁的解法:$C_{0}\triangleq K_{0}K_{0}^{T}$(与已有键(key)的非中心化协方差成比例的常量),以及$R\triangleq M_{1}-W_{0}K_{1}$(用旧权重$W_{0}$评估新关联时的残差)。于是式(13)可简化为:
$$
\Delta=R K_{1}^{T}(C_{0}+K_{1}K_{1}^{T})^{-1}.
$$
$$
\Delta=R K_{1}^{T}(C_{0}+K_{1}K_{1}^{T})^{-1}.
$$
Since pre training is opaque, we do not have access to $K_{0}$ or $M_{0}$ . Fortunately, computing Eqn. 14 only requires an aggregate statistic $C_{0}$ over the previously stored keys. We assume that the set of previously memorized keys can be modeled as a random sample of inputs, so that we can compute
由于预训练过程不透明,我们无法获取$K_{0}$或$M_{0}$。幸运的是,计算方程14仅需基于先前存储密钥的聚合统计量$C_{0}$。我们假设先前记忆的密钥集合可建模为输入数据的随机样本,从而能够进行计算。
$$
C_{0}=\lambda\cdot\mathbb{E}_{k}\left[k k^{T}\right]
$$
$$
C_{0}=\lambda\cdot\mathbb{E}_{k}\left[k k^{T}\right]
$$
by estimating $\mathbb{E}_{k}\left[k k^{T}\right]$ , an uncentered covariance statistic collected using an empirical sample of vector inputs to the lay er. We must also select $\lambda$ , a hyper parameter that balances the weighting of new v.s. old associations; a typical value is $\lambda=1.5\times\bar{1}0^{4}$ .
通过估计 $\mathbb{E}_{k}\left[k k^{T}\right]$ ,即使用该层向量输入的实证样本收集的非中心化协方差统计量。我们还需选择超参数 $\lambda$ ,用于平衡新旧关联的权重;典型值为 $\lambda=1.5\times\bar{1}0^{4}$ 。
4.3 UPDATING MULTIPLE LAYERS
4.3 更新多层结构
We now define the overall update algorithm (Figure 4). Inspired by the observation that robustness is improved when parameter change magnitudes are minimized (Zhu et al., 2020), we spread updates evenly over the range of mediating layers $\mathcal{R}$ . We define a target layer $L\triangleq\operatorname*{max}(\mathcal{R})$ at the end of the mediating layers, at which the new memories should be fully represented. Then, for each edit $(s_{i},r_{i},o_{i})\in\mathbf{\bar{\mathcal{E}}}$ , we (i) compute a hidden vector $z_{i}$ to replace $h_{i}^{L}$ such that adding $\delta_{i}\triangleq z_{i}-h_{i}^{L}$ to the hidden state at layer $L$ and token $T$ will completely convey the new memory. Finally, one layer at a time, we (ii) modify the MLP at layer $l$ , so that it contributes an approximately-equal portion of the change $\delta_{i}$ for each memory $i$ .
我们现在定义整体更新算法(图4)。受参数变化幅度最小时鲁棒性会提升这一观察的启发(Zhu et al., 2020),我们将更新均匀分布在中间层范围$\mathcal{R}$上。我们在中间层末端定义目标层$L\triangleq\operatorname*{max}(\mathcal{R})$,新记忆应在此层完全呈现。然后,对于每个编辑$(s_{i},r_{i},o_{i})\in\mathbf{\bar{\mathcal{E}}}$,我们(i)计算隐藏向量$z_{i}$以替换$h_{i}^{L}$,使得在层$L$和token$T$处向隐藏状态添加$\delta_{i}\triangleq z_{i}-h_{i}^{L}$将完整传递新记忆。最后,我们逐层(ii)修改层$l$的MLP,使其为每个记忆$i$贡献近似等量的变化$\delta_{i}$。
(i) Computing $z_{i}$ . For the $i$ th memory, we first compute a vector $z_{i}$ that would encode the association $(s_{i},r_{i},o_{i})$ if it were to replace $h_{i}^{L}$ at layer $L$ at token $S$ . We find $z_{i}=h_{i}^{L}+\delta_{i}$ by optimizing the residual vector $\delta_{i}$ using gradient descent:
(i) 计算 $z_{i}$。对于第 $i$ 个记忆单元,我们首先计算向量 $z_{i}$,该向量将编码关联 $(s_{i},r_{i},o_{i})$,前提是它要在第 $L$ 层的 token $S$ 处替换 $h_{i}^{L}$。我们通过梯度下降优化残差向量 $\delta_{i}$,得到 $z_{i}=h_{i}^{L}+\delta_{i}$:
$$
z_{i}=h_{i}^{L}+\underset{\delta_{i}}{\mathrm{argmin}}\frac{1}{P}\sum_{j=1}^{P}-\log\mathbb{P}_ {G(h_{i}^{L}+=\delta_{i})}\left[o_{i}\mid x_{j}\oplus p(s_{i},r_{i})\right].
$$
$$
z_{i}=h_{i}^{L}+\underset{\delta_{i}}{\mathrm{argmin}}\frac{1}{P}\sum_{j=1}^{P}-\log\mathbb{P}_ {G(h_{i}^{L}+=\delta_{i})}\left[o_{i}\mid x_{j}\oplus p(s_{i},r_{i})\right].
$$
In words, we optimize $\delta_{i}$ to maximize the model’s prediction of the desired object $o_{i}$ , given a set of factual prompts ${x_{j}\oplus p(s_{i},r_{i})}$ that concatenate random prefixes $x_{j}$ to a templated prompt to aid generalization across contexts. $\acute{G}(h_{i}^{L}+=\delta_{i})$ indicates that we modify the transformer execution by substituting the modified hidden state $z_{i}$ for $\dot{h}_{i}^{L}$ ; this is called “hooking” in popular ML libraries.
我们用语言描述就是:通过优化 $\delta_{i}$ 来最大化模型对目标对象 $o_{i}$ 的预测概率,其中输入是一组事实提示 ${x_{j}\oplus p(s_{i},r_{i})}$ ——这些提示将随机前缀 $x_{j}$ 与模板化提示拼接,以提升跨上下文的泛化能力。 $\acute{G}(h_{i}^{L}+=\delta_{i})$ 表示我们通过用修改后的隐藏状态 $z_{i}$ 替换 $\dot{h}_{i}^{L}$ 来改变 Transformer 的执行过程,这种操作在主流机器学习库中被称为"hooking"。
(ii) Spreading $z_{i}-h_{i}^{L}$ over layers. We seek delta matrices $\Delta^{l}$ such that:
(ii) 将 $z_{i}-h_{i}^{L}$ 分散到各层。我们需要找到增量矩阵 $\Delta^{l}$ 使得:
$$
\begin{array}{r l}&{\mathrm{ting}\hat{W}_ {o u t}^{l}:=W_{o u t}^{l}+\Delta^{l}\mathrm{ for all }l\in\mathcal{R}\mathrm{ optimizes }\displaystyle\operatorname*{min}_ {{\Delta^{l}}}\sum_{i}\Big|z_{i}-\hat{h}_ {i}^{L}\Big|^{2},}\ &{\mathrm{where}\hat{h}_ {i}^{L}=h_{i}^{0}+\displaystyle\sum_{l=1}^{L}a_{i}^{l}+\displaystyle\sum_{l=1}^{L}\hat{W}_ {o u t}^{l}\sigma\left(W_{i n}^{l}\gamma\left(h_{t}^{l-1}\right)\right).}\end{array}
$$
$$
\begin{array}{r l}&{\mathrm{令}\hat{W}_ {o u t}^{l}:=W_{o u t}^{l}+\Delta^{l}\mathrm{ 对所有 }l\in\mathcal{R}\mathrm{ 优化 }\displaystyle\operatorname*{min}_ {{\Delta^{l}}}\sum_{i}\Big|z_{i}-\hat{h}_ {i}^{L}\Big|^{2},}\ &{\mathrm{其中}\hat{h}_ {i}^{L}=h_{i}^{0}+\displaystyle\sum_{l=1}^{L}a_{i}^{l}+\displaystyle\sum_{l=1}^{L}\hat{W}_ {o u t}^{l}\sigma\left(W_{i n}^{l}\gamma\left(h_{t}^{l-1}\right)\right).}\end{array}
$$
Because edits to any layer will influence all following layers’ activation s, we calculate $\Delta^{l}$ iterative ly in ascending layer order (Figure 4ii-a,b,c). To compute each individual $\Delta^{l}$ , we need the corresponding keys $K^{l}=\mathbf{\overline{{[}}\it{k_{1}^{l}\mathrm{ \overline{{ }}{ | \cdot \cdot \cdot | } }}}k_{n}^{l}\mathbf{\bar{\Psi}}]$ and memories $M^{l}=[\dot{m}_ {1}^{l}\mid\cdots\mid m_{n}^{l}]$ to insert using Eqn. 14. Each key $k_{i}^{\check{l}}$ is computed as the input to $W_{o u t}^{l}$ at each layer $l$ (Figure 2d):
由于对任何层的编辑都会影响后续所有层的激活,我们按升序层序迭代计算 $\Delta^{l}$ (图 4ii-a,b,c)。为计算每个独立的 $\Delta^{l}$,需要对应的键 $K^{l}=\mathbf{\overline{{[}}\it{k_{1}^{l}\mathrm{ \overline{{ }}{ | \cdot \cdot \cdot | } }}}k_{n}^{l}\mathbf{\bar{\Psi}}]$ 和记忆 $M^{l}=[\dot{m}_ {1}^{l}\mid\cdots\mid m_{n}^{l}]$ 以便通过公式14进行插入。每个键 $k_{i}^{\check{l}}$ 的计算方式是作为每层 $l$ 中 $W_{o u t}^{l}$ 的输入(图 2d):
$$
k_{i}^{l}=\frac{1}{P}\sum_{j=1}^{P}k(x_{j}+s_{i}),\mathrm{ where }k(x)=\sigma\left(W_{i n}^{l}\gamma\left(h_{i}^{l-1}(x)\right)\right).
$$
$$
k_{i}^{l}=\frac{1}{P}\sum_{j=1}^{P}k(x_{j}+s_{i}),\mathrm{ where }k(x)=\sigma\left(W_{i n}^{l}\gamma\left(h_{i}^{l-1}(x)\right)\right).
$$
$m_{i}^{l}$ is then computed as the sum of its current value and a fraction of the remaining top-level residual:
$m_{i}^{l}$ 的计算方式为其当前值加上剩余顶层残差的一部分:
where the denominator of $r_{i}$ spreads the residual out evenly. Algorithm 1 summarizes MEMIT, and additional implementation details are offered in Appendix B.
其中$r_{i}$的分母将残差均匀分布。算法1总结了MEMIT方法,附录B提供了更多实现细节。
Algorithm 1: The MEMIT Algorithm
算法 1: MEMIT算法
| Data: Requested edits & = {(s, r, o)}, generator G, layers to edit S, covariances Cl Result:Modified generator containing edits from & | ||
| for Si,ri,O E & do I/ Compute target % vectors for every memory i | ||
| optimize 8 ←argmins: ∑§=1 - log PG(h +=8a) [o | x, p(si, ri)] (Eqn. 16) | ||
| i←h+ | ||
| 4end sforl∈Rdo | // Perform update: spread changes over layers | |
| h ← h-1 + a + m (Eqn. 2) for si,ri,O E & do | // Run layer I with updated weights | |
| 8 | k←k =∑=1 k(xj + si) (Eqn. 19) | |
| // Distribute residual over remaining layers | ||
| 10 | end | |
| 11 | Kl ←[k,,k] | |
| 12 | R←[r..r] | |
| 13 | △ ← RlKlT (Cl + Kl KiT)-1 (Eqn. 14) | |
| 14 | Wl ←Wl + △ | // Update layer I MLP weights in model |
| 15 end | ||
数据:请求编辑集 & = {(s, r, o)},生成器 G,待编辑层 S,协方差 Cl
结果:包含 & 编辑的修改后生成器
对于 Si,ri,O ∈ & 执行
// 为每个记忆 i 计算目标向量
优化 δ ← argminδ ∑i=1 -log PG(h+δai) [o | x, p(si, ri)] (公式 16)
i←h+
4结束
对于 l∈R 执行
// 执行更新:将变化传播到各层
h ← hl-1 + al + ml (公式 2)
对于 si,ri,O ∈ & 执行
// 使用更新后的权重运行第 l 层
8
k←k =∑j=1 k(xj + si) (公式 19)
// 将残差分配到剩余层
10
结束
11
Kl ←[k1,...,k]
12
R←[r1..r]
13
△ ← RlKlT (Cl + Kl KlT)-1 (公式 14)
14
Wl ←Wl + △
// 更新模型中第 l 层 MLP 权重
15 结束
5 EXPERIMENTS
5 实验
5.1 MODELS AND BASELINES
5.1 模型与基线
We run experiments on two auto regressive LLMs: GPT-J (6B) and GPT-NeoX (20B). For baselines, we first compare with a naive fine-tuning approach that uses weight decay to prevent forgetfulness (FT-W). Next, we experiment with MEND, a hyper network-based model editing approach that edits multiple facts at the same time (Mitchell et al., 2021). Finally, we run a sequential version of ROME (Meng et al., 2022): a direct model editing method that iterative ly updates one fact at a time. The recent SERAC model editor (Mitchell et al., 2022) does not yet have public code, so we cannot compare with it at this time. See Appendix B for implementation details.
我们在两个自回归大语言模型上进行了实验:GPT-J (6B) 和 GPT-NeoX (20B)。作为基线方法,首先与采用权重衰减防止遗忘的简单微调方法 (FT-W) 进行比较。接着测试了基于超网络的模型编辑方法 MEND (Mitchell et al., 2021),该方法可同时编辑多个事实。最后运行了 ROME (Meng et al., 2022) 的序列版本:这种直接模型编辑方法每次迭代更新一个事实。近期提出的 SERAC 模型编辑器 (Mitchell et al., 2022) 尚未公开代码,因此暂时无法进行比较。具体实现细节参见附录 B。
5.2 MEMIT SCALING
5.2 MEMIT 扩展
5.2.1 EDITING 10K MEMORIES IN ZSRE
5.2.1 在ZSRE中编辑10K记忆
We first test MEMIT on zsRE (Levy et al., 2017), a question-answering task from which we extract 10,000 real-world facts; zsRE tests MEMIT’s ability to add correct information. Because zsRE does not contain generation tasks, we evaluate solely on prediction-based metrics. Efficacy
我们首先在zsRE (Levy et al., 2017) 上测试MEMIT,这是一个问答任务,从中我们提取了10,000个真实世界的事实;zsRE测试了MEMIT添加正确信息的能力。由于zsRE不包含生成任务,我们仅基于预测指标进行评估。有效性
Table 1: 10,000 zsRE Edits on GPT-J (6B).
| Editor | Score↑ | Efficacy ↑ | Paraphrase ↑ | Specificity↑ |
| GPT-J | 26.4 | 26.4 (±0.6) | 25.8 (±0.5) | 27.0 (±0.5) |
| FT-W | 42.1 | 69.6 (±0.6) | 64.8 (±0.6) | 24.1 (±0.5) |
| MEND | 20.0 | 19.4 (±0.5) | 18.6 (±0.5) | 22.4 (±0.5) |
| ROME | 2.6 | 21.0 (±0.7) | 19.6 (±0.7) | 0.9 (±0.1) |
| MEMIT | 50.7 | 96.7 (±0.3) | 89.7 (±0.5) | 26.6 (±0.5) |
表 1: GPT-J (6B) 上的 10,000 次 zsRE 编辑
| Editor | Score↑ | Efficacy ↑ | Paraphrase ↑ | Specificity↑ |
|---|---|---|---|---|
| GPT-J | 26.4 | 26.4 (±0.6) | 25.8 (±0.5) | 27.0 (±0.5) |
| FT-W | 42.1 | 69.6 (±0.6) | 64.8 (±0.6) | 24.1 (±0.5) |
| MEND | 20.0 | 19.4 (±0.5) | 18.6 (±0.5) | 22.4 (±0.5) |
| ROME | 2.6 | 21.0 (±0.7) | 19.6 (±0.7) | 0.9 (±0.1) |
| MEMIT | 50.7 | 96.7 (±0.3) | 89.7 (±0.5) | 26.6 (±0.5) |
measures the proportion of cases where $o$ is the argmax generation given $p(s,r)$ , Paraphrase is the same metric but applied on paraphrases, Specificity is the model’s argmax accuracy on a randomly-sampled unrelated fact that should not have changed, and Score is the harmonic mean of the three aforementioned scores; Appendix C contains formal definitions. As Table 1 shows, MEMIT performs best at 10,000 edits; most memories are recalled with generalization and minimal bleedover. Interestingly, simple fine-tuning FT-W performs better than the baseline knowledge editing methods MEND and ROME at this scale, likely because its objective is applied only once.
衡量在给定 $p(s,r)$ 时 $o$ 作为 argmax 生成结果的比例,Paraphrase 是相同指标但应用于改写文本,Specificity 是模型在随机采样的无关事实上不应发生变化的 argmax 准确率,Score 是上述三个分数的调和平均数;附录 C 包含正式定义。如表 1 所示,MEMIT 在 10,000 次编辑时表现最佳,大多数记忆都能被召回且具有泛化性和最小的干扰。有趣的是,在这个规模下,简单的微调方法 FT-W 优于基线知识编辑方法 MEND 和 ROME,这可能是因为其目标函数仅应用一次。
5.2.2 COUNTER FACT SCALING CURVES
5.2.2 反事实缩放曲线
Next, we test MEMIT’s ability to add counter factual information using COUNTER FACT, a collection of 21,919 factual statements (Meng et al. (2022), Appendix C). We first filter conflicts by removing facts that violate the logical condition in Eqn. 5 (i.e., multiple edits modify the same $(s,r)$ prefix to different objects). For each problem size $n\in{1,2,3,6,10,18,32$ , $56,100,178,3\mathrm{i}\mathrm{i}\overline{{6}},562,1000,1778,316\dot{2},5623,10000}^{1},$ , $n$ counter factual s are inserted.
接下来,我们测试MEMIT通过COUNTER FACT数据集(包含21,919条反事实陈述[Meng et al. (2022), 附录C])添加反事实信息的能力。首先通过移除违反公式5逻辑条件(即多个编辑将相同$(s,r)$前缀修改为不同对象)的事实来过滤冲突。针对每个问题规模$n\in{1,2,3,6,10,18,32$, $56,100,178,3\mathrm{i}\mathrm{i}\overline{{6}},562,1000,1778,316\dot{2},5623,10000}^{1}$,插入$n$条反事实陈述。
Following Meng et al. (2022), we report several metrics designed to test editing desiderata. Efficacy Success $\mathbf{\mu}(\mathbf{ES})$ evaluates editing success and is the proportion of cases for which the new object $o_{i}$ ’s probability is greater than the probability of the true real-world object $o_{i}^{c}$ :2 $\mathbb{E}_ {i}\left[\mathbb{P}_ {G}\left[o_{i}\mid p(s_{i},\bar{r}_ {i})\right]>\mathbb{P}_ {G}\left[o_{i}^{c}\mid\bar{p}(s_{i},r_{i})\right]\right]$ . Paraphrase Success (PS) is a generalization measure defined similarly, except $G$ is prompted with rephrasing s of the original statement. For testing specificity, Neighborhood Success (NS) is defined similarly, but we check the probability $G$ assigns to the correct answer $o_{i}^{c}$ (instead of $o_{i}$ ), given prompts about distinct but semantically-related subjects (instead of $s_{i}$ ). Editing Score (S) aggregates metrics by taking the harmonic mean of ES, PS, NS.
遵循 Meng 等人 (2022) 的方法,我们报告了几种用于测试编辑需求的指标。效能成功率 (Efficacy Success, μ(ES)) 评估编辑成功情况,计算新对象 $o_{i}$ 的概率高于真实世界对象 $o_{i}^{c}$ 概率的案例比例:2 $\mathbb{E}_ {i}\left[\mathbb{P}_ {G}\left[o_{i}\mid p(s_{i},\bar{r}_ {i})\right]>\mathbb{P}_ {G}\left[o_{i}^{c}\mid\bar{p}(s_{i},r_{i})\right]\right]$。改写成功率 (Paraphrase Success, PS)) 是类似定义的泛化度量,区别在于用原始语句的改写版本提示 $G$。为测试特异性,邻域成功率 (Neighborhood Success, NS)) 采用类似定义,但检查 $G$ 在给定与不同但语义相关主题 (而非 $s_{i}$) 的提示时,对正确答案 $o_{i}^{c}$ (而非 $o_{i}$) 赋予的概率。编辑分数 (Editing Score, S)) 通过取 ES、PS、NS 的调和平均值来聚合指标。
We are also interested in measuring generation quality of the updated model. First, we check that $G$ ’s generations are semantically consistent with the new object using a Reference Score (RS), which is collected by generating text about $s$ and checking its TF-IDF similarity with a reference Wikipedia text about $o$ . To test for fluency degradation due to excessive repetition, we measure Generation Entropy (GE), computed as the weighted sum of the entropy of bi- and tri-gram $n$ -gram distributions of the generated text. See Appendix C for further details on metrics.
我们还关注评估更新后模型的生成质量。首先通过参考分数(RS)验证生成器$G$的输出与新对象语义一致性,该分数通过生成关于$s$的文本并计算其与维基百科参考文本$o$的TF-IDF相似度获得。为检测过度重复导致的流畅性下降,我们计算生成熵(GE),即生成文本中二元组和三元组$n$-gram分布熵的加权和。具体指标说明详见附录C。
Figure 5 plots performance v.s. number of edits on log scale, up to 10,000 facts. ROME performs well up to $n=10$ but degrades starting at $n=32$ . Similarly, MEND performs well at $n=1$ but rapidly declines at $n=6$ , losing all efficacy before $n=1{,}000$ and, curiously, having negligible effect on the model at $n=10{,}000$ (the high specificity score is achieved by leaving the model nearly unchanged). MEMIT performs best at large $n$ . At small $n$ , ROME achieves better generalization at the cost of slightly lower specificity, which means that ROME’s edits are more robust under rephrasing s, likely due to that method’s hard equality constraint for weight updates, compared to MEMIT’s soft error minimization. Table 2 provides a direct numerical comparison at 10,000 edits on both GPT-J and GPT-NeoX. FT-W3 does well on probability-based metrics but suffers from complete generation failure, indicating significant model damage.
图 5: 绘制了性能与对数尺度上编辑数量(最多10,000条事实)的关系。ROME在 $n=10$ 时表现良好,但从 $n=32$ 开始性能下降。类似地,MEND在 $n=1$ 时表现优异,但在 $n=6$ 时迅速衰退,在 $n=1{,}000$ 前完全失效,有趣的是,在 $n=10{,}000$ 时对模型的影响微乎其微(高特异性得分是通过几乎不改变模型实现的)。MEMIT在大规模 $n$ 时表现最佳。在小规模 $n$ 时,ROME以略微降低特异性为代价实现了更好的泛化能力,这意味着ROME的编辑在句式改写下更稳健,这可能是因为该方法对权重更新采用了硬性等式约束,而MEMIT采用的是软性误差最小化。表 2: 提供了GPT-J和GPT-NeoX在10,000次编辑时的直接数值对比。FT-W3在基于概率的指标上表现良好,但出现了完全生成失败的情况,表明模型受到了严重损害。
Appendix B provides a runtime analysis of all four methods on 10,000 edits. We find that MEND is fastest, taking 98 sec. FT is second at around $29\mathrm{{min}}$ , while MEMIT and ROME are the slowest at
附录 B 提供了四种方法在 10,000 次编辑上的运行时间分析。我们发现 MEND 速度最快,耗时 98 秒。FT 次之,约为 $29\mathrm{{min}}$,而 MEMIT 和 ROME 最慢。
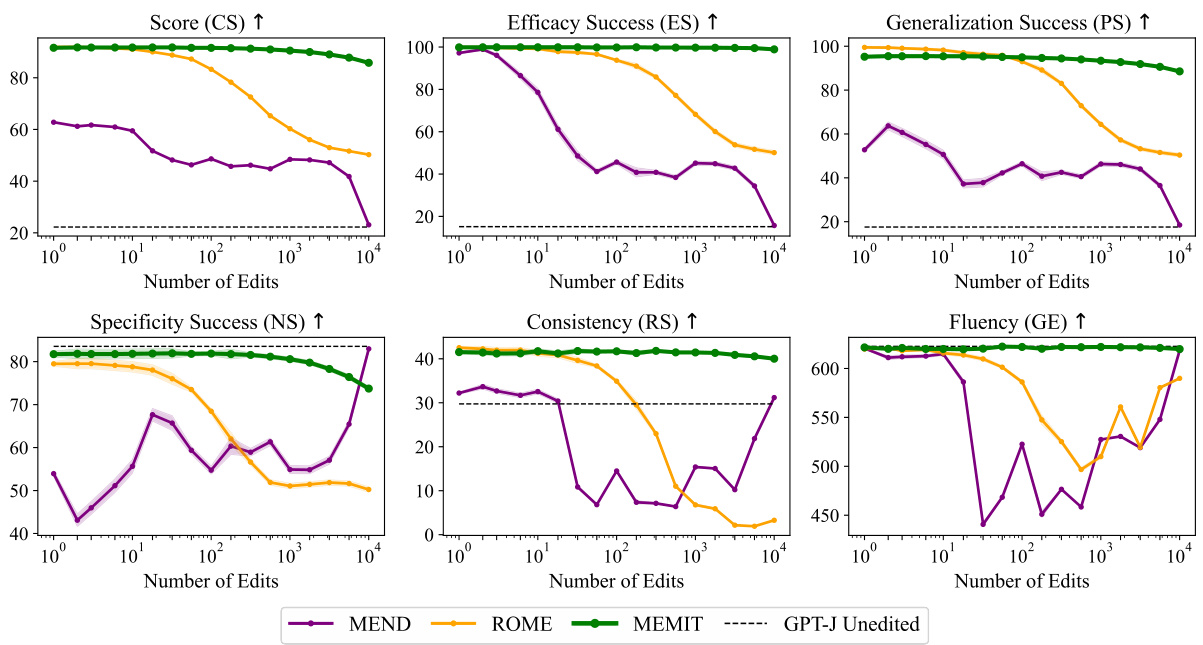
Figure 5: MEMIT scaling curves plot editing performance against problem size (log-scale). The dotted line indicates GPT-J’s pre-edit performance; specificity (NS) and fluency (GE) should stay close to the baseline. $95%$ confidence intervals are shown as areas.
图 5: MEMIT扩展曲线展示了编辑性能随问题规模(对数尺度)的变化。虚线表示GPT-J的预编辑性能;特异性(NS)和流畅度(GE)应保持接近基线水平。95%置信区间以区域形式显示。
Table 2: Numerical results on COUNTER FACT for 10,000 edits.
| Editor | Score | Efficacy | Generalization | Specificity | Fluency | Consistency |
| S↑ | ES ↑ | PS ↑ | NS ↑ | GE↑ | RS ↑ | |
| GPT-J | 22.4 | 15.2 (0.7) | 17.7 (0.6) | 83.5 (0.5) | 622.4 (0.3) | 29.4 (0.2) |
| FT-W | 67.6 | 99.4 (0.1) | 77.0 (0.7) | 46.9 (0.6) | 293.9 (2.4) | 15.9 (0.3) |
| MEND | 23.1 | 15.7 (0.7) | 18.5 (0.7) | 83.0 (0.5) | 618.4 (0.3) | 31.1 (0.2) |
| ROME | 50.3 | 50.2 (1.0) | 50.4 (0.8) | 50.2 (0.6) | 589.6 (0.5) | 3.3 (0.0) |
| MEMIT | 85.8 | 98.9 (0.2) | 88.6 (0.5) | 73.7 (0.5) | 619.9 (0.3) | 40.1 (0.2) |
| GPT-NeoX | 23.7 | 16.8 (1.9) | 18.3 (1.7) | 81.6 (1.3) | 620.4 (0.6) | 29.3 (0.5) |
| MEMIT | 82.0 | 97.2 (0.8) | 82.2 (1.6) | 70.8 (1.4) | 606.4 (1.0) | 36.9 (0.6) |
表 2: COUNTER FACT数据集上10,000次编辑的数值结果
| Editor | Score | Efficacy | Generalization | Specificity | Fluency | Consistency |
|---|---|---|---|---|---|---|
| S↑ | ES ↑ | PS ↑ | NS ↑ | GE↑ | RS ↑ | |
| GPT-J | 22.4 | 15.2 (0.7) | 17.7 (0.6) | 83.5 (0.5) | 622.4 (0.3) | 29.4 (0.2) |
| FT-W | 67.6 | 99.4 (0.1) | 77.0 (0.7) | 46.9 (0.6) | 293.9 (2.4) | 15.9 (0.3) |
| MEND | 23.1 | 15.7 (0.7) | 18.5 (0.7) | 83.0 (0.5) | 618.4 (0.3) | 31.1 (0.2) |
| ROME | 50.3 | 50.2 (1.0) | 50.4 (0.8) | 50.2 (0.6) | 589.6 (0.5) | 3.3 (0.0) |
| MEMIT | 85.8 | 98.9 (0.2) | 88.6 (0.5) | 73.7 (0.5) | 619.9 (0.3) | 40.1 (0.2) |
| GPT-NeoX | 23.7 | 16.8 (1.9) | 18.3 (1.7) | 81.6 (1.3) | 620.4 (0.6) | 29.3 (0.5) |
| MEMIT | 82.0 | 97.2 (0.8) | 82.2 (1.6) | 70.8 (1.4) | 606.4 (1.0) | 36.9 (0.6) |
$7.44\mathrm{hr}$ and $12.29\mathrm{hr}$ , respectively. While MEMIT’s execution time is high relative to MEND and FT, we note that its current implementation is naive and does not batch the independent $z_{i}$ optimization s, instead computing each one in series. These computations are actually “embarrassingly parallel” and thus could be batched.
$7.44\mathrm{hr}$ 和 $12.29\mathrm{hr}$。虽然 MEMIT 的执行时间相对于 MEND 和 FT 较高,但我们注意到其当前实现较为原始,未对独立的 $z_{i}$ 优化进行批处理,而是逐个串行计算。这些计算实际上是"高度可并行"的,因此可以进行批处理。
5.3 EDITING DIFFERENT CATEGORIES OF FACTS
5.3 编辑不同类别的事实
For insight into MEMIT’s performance on different types of facts, we pick the 27 categories from COUNTER FACT that have at least 300 cases each, and assess each algorithm’s performance on those cases. Figure 6a shows that MEMIT achieves better overall scores compared to FT and MEND in all categories. It also reveals that some relations are harder to edit compared to others; for example, each of the editing algorithms faced difficulties in changing the sport an athlete plays. Even on harder cases, MEMIT outperforms other methods by a clear margin.
为了深入了解MEMIT在不同类型事实上的表现,我们从COUNTER FACT中选取了27个类别(每个类别至少包含300个案例),并评估各算法在这些案例上的表现。图6a显示,MEMIT在所有类别中的综合得分均优于FT和MEND。同时表明某些关系比其他关系更难编辑,例如所有编辑算法在修改运动员从事的运动项目时都遇到困难。即使在较难的案例上,MEMIT仍以明显优势超越其他方法。
Model editing methods are known to occasionally suffer from a trade-off between attaining high generalization and good specificity. This trade-off is clearly visible for MEND in Figure 6b. FT consistently fails to achieve good specificity. Overall, MEMIT achieves a higher score in both dimensions, although it also exhibits a trade-off in editing some relations such as P127 (“product owned by company”) and P641 (“athlete plays sport”).
已知模型编辑方法偶尔需要在实现高泛化性和良好特异性之间进行权衡。这种权衡在图6b中MEND的表现尤为明显。FT始终难以达到良好的特异性。总体而言,MEMIT在这两个维度上都取得了更高的分数,尽管在编辑某些关系(如P127("公司拥有的产品")和P641("运动员从事的运动"))时也表现出类似的权衡。
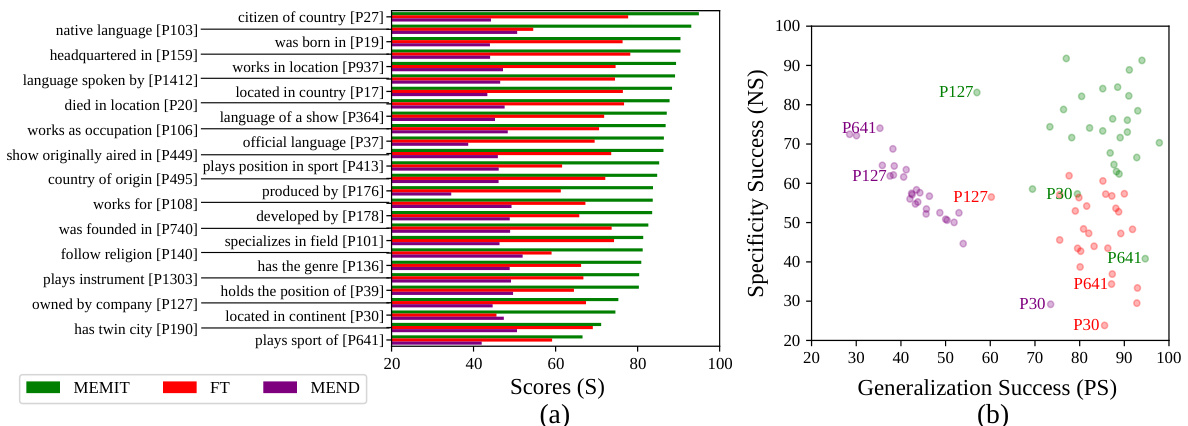
Figure 6: (a) Category-wise rewrite scores achieved by different approaches in editing 300 similar facts. (b) Category-wise specificity vs generalization scores by different approaches on 300 edits.
图 6: (a) 不同方法在编辑300条相似事实时取得的分类重写分数。(b) 不同方法在300次编辑上的分类特异性与泛化性分数对比。

Figure 7: When comparing mixes of edits, MEMIT gives consistent near-linear (near-average) performance while scaling up to 700 facts.
图 7: 在比较混合编辑时,MEMIT 在扩展到 700 个事实时仍能保持接近线性 (接近平均) 的性能。
5.4 EDITING DIFFERENT CATEGORIES OF FACTS TOGETHER
5.4 同时编辑不同类别的事实
To investigate whether the scaling of MEMIT is sensitive to differences in the diversity of the memories being edited together, we sample sets of cases $\mathcal{E}_ {m i x}$ that mix two different relations from the COUNTER FACT dataset. We consider four scenarios depicted in Figure 7, where the relations have similar or different classes of subjects or objects. In all of the four cases, MEMIT’s performance on $\mathcal{E}_{m i x}$ is close to the average of the performance of each relation without mixing. This provides support to the hypothesis that the scaling of MEMIT is neither positively nor negatively affected by the diversity of the memories being edited. Appendix D contains implementation details.
为了研究MEMIT的扩展性是否对同时编辑的记忆多样性差异敏感,我们从COUNTER FACT数据集中抽样了混合两种不同关系的案例集$\mathcal{E}_ {m i x}$。我们考虑了图7中描述的四种场景,其中关系的主体或客体类别相似或不同。在所有四种情况下,MEMIT在$\mathcal{E}_{m i x}$上的表现接近于未混合时各关系表现的平均值。这支持了以下假设:MEMIT的扩展性既不受被编辑记忆多样性的正面影响,也不受其负面影响。附录D包含实现细节。
6 DISCUSSION AND CONCLUSION
6 讨论与结论
We have developed MEMIT, a method for editing factual memories in large language models by directly manipulating specific layer parameters. Our method scales to much larger sets of edits (100x) than other approaches while maintaining excellent specificity, generalization, and fluency.
我们开发了MEMIT方法,通过直接操控特定层参数来实现大语言模型中的事实记忆编辑。该方法支持比其他方法更大规模的编辑量(100倍),同时保持出色的特异性、泛化性和流畅性。
Our investigation also reveals some challenges: certain relations are more difficult to edit with robust specificity, yet even on challenging cases we find that MEMIT outperforms other methods by a clear margin. The knowledge representation we study is also limited in scope to working with directional $(s,r,o)$ relations: it does not cover spatial or temporal reasoning, mathematical knowledge, linguistic knowledge, procedural knowledge, or even symmetric relations. For example, the association that “Tim Cook is CEO of Apple” must be processed separately from the opposite association that “The CEO of Apple is Tim Cook.”
我们的调查还揭示了一些挑战:某些关系难以通过稳健的特异性进行编辑,但即使在具有挑战性的案例中,我们发现MEMIT仍明显优于其他方法。我们研究的知识表示在范围上也仅限于处理定向$(s,r,o)$关系:它不涵盖空间或时间推理、数学知识、语言知识、程序性知识,甚至对称关系。例如,"Tim Cook是Apple的CEO"这一关联必须与相反的关联"Apple的CEO是Tim Cook"分开处理。
Despite these limitations, it is noteworthy that large-scale model updates can be constructed using an explicit analysis of internal computations. Our results raise a question: might interpret ability-based methods become a commonplace alternative to traditional opaque fine-tuning approaches? Our positive experience brings us optimism that further improvements to our understanding of network internals will lead to more transparent and practical ways to edit, control, and audit models.
尽管存在这些限制,值得注意的是,我们可以通过对内部计算的显式分析来构建大规模模型更新。我们的研究结果提出了一个问题:基于可解释性的方法是否会成为传统不透明微调方法的常见替代方案?我们的积极经验使我们乐观地认为,随着对网络内部机制理解的进一步深入,将催生出更透明、更实用的模型编辑、控制和审计方法。
7 ETHICAL CONSIDERATIONS
7 伦理考量
Although we test a language model’s ability to serve as a knowledge base, we do not find these models to be a reliable source of knowledge, and we caution readers that a LLM should not be used as an authoritative source of facts. Our memory-editing methods shed light on the internal mechanisms of models and potentially reduce the cost and energy needed to fix errors in a model, but the same methods might also enable a malicious actor to insert false or damaging information into a model that was not originally present in the training data.
虽然我们测试了语言模型作为知识库的能力,但我们发现这些模型并非可靠的知识来源,并提醒读者不应将大语言模型 (LLM) 作为事实的权威依据。我们的记忆编辑方法揭示了模型的内部机制,并可能降低修正模型错误的成本和能耗,但同样方法也可能被恶意行为者利用,向模型中植入训练数据原本不存在的虚假或有害信息。
8 ACKNOWLEDGEMENTS.
8 致谢
Thanks to Jaden Fiotto-Kaufmann for building the demonstration at memit.baulab.us. This project was supported by an AI Alignment grant from Open Philanthropy. YB was also supported by the Israel Science Foundation (grant No. 448/20) and an Azrieli Foundation Early Career Faculty Fellowship.
感谢 Jaden Fiotto-Kaufmann 在 memit.baulab.us 上构建演示。本项目由 Open Philanthropy 的 AI Alignment 资助支持。YB 还获得了以色列科学基金会 (资助编号 448/20) 和 Azrieli Foundation Early Career Faculty Fellowship 的支持。
9 REPRODUCIBILITY
9 可复现性
The code and data for our methods and experiments are available at memit.baulab.info.
我们的方法和实验代码及数据可在 memit.baulab.info 获取。
All experiments are run on workstations with NVIDIA A6000 GPUs. The language models are loaded using Hugging Face Transformers (Wolf et al., 2019), and PyTorch (Paszke et al., 2019) is used for executing the model editing algorithms on GPUs.
所有实验均在配备NVIDIA A6000 GPU的工作站上运行。语言模型通过Hugging Face Transformers (Wolf等人,2019) 加载,并使用PyTorch (Paszke等人,2019) 在GPU上执行模型编辑算法。
GPT-J experiments fit into one 48GB A6000, but GPT-NeoX runs require at least two: one 48GB GPU for running the model in float16, and another slightly smaller GPU for executing the editing method. Due to the size of these language models, our experiments will not run on GPUs with less memory.
GPT-J实验可在单块48GB显存的A6000上运行,但GPT-NeoX至少需要两块:一块48GB GPU以float16精度运行模型,另一块稍小显存的GPU执行编辑方法。由于这些大语言模型的规模,我们的实验无法在显存更低的GPU上运行。
REFERENCES
参考文献
Zhengbao Jiang, Frank F Xu, Jun Araki, and Graham Neubig. How can we know what language models know? Transactions of the Association for Computational Linguistics, 8:423–438, 2020.
郑宝江、Frank F Xu、Jun Araki 和 Graham Neubig。我们如何知道语言模型知道什么?计算语言学协会汇刊,8:423-438,2020。
Teuvo Kohonen. Correlation matrix memories. IEEE transactions on computers, 100(4):353–359, 1972.
Teuvo Kohonen. 相关矩阵记忆. IEEE计算机汇刊, 100(4):353–359, 1972.
Angeliki Lazaridou, Adhi Kuncoro, Elena Gri bo vs kaya, Devang Agrawal, Adam Liska, Tayfun Terzi, Mai Gimenez, Cyprien de Masson d’Autume, Tomas Kocisky, Sebastian Ruder, et al. Mind the gap: Assessing temporal generalization in neural language models. Advances in Neural Information Processing Systems, 34:29348–29363, 2021.
Angeliki Lazaridou、Adhi Kuncoro、Elena Gribovskaya、Devang Agrawal、Adam Liska、Tayfun Terzi、Mai Gimenez、Cyprien de Masson d'Autume、Tomas Kocisky、Sebastian Ruder等。《注意差距:评估神经语言模型的时间泛化能力》。载于《神经信息处理系统进展》,34卷:29348–29363页,2021年。
Douglas B Lenat. Cyc: A large-scale investment in knowledge infrastructure. Communications of the ACM, 38(11):33–38, 1995.
Douglas B Lenat. Cyc: 知识基础设施的大规模投入. Communications of the ACM, 38(11):33–38, 1995.
Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Z ett le moyer. Zero-shot relation extraction via reading comprehension. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pp. 333–342, 2017.
Omer Levy、Minjoon Seo、Eunsol Choi 和 Luke Zettlemoyer。通过阅读理解实现零样本关系抽取。见《第21届计算自然语言学习会议论文集》(CoNLL 2017),第333-342页,2017年。
Adam Liska, Tomas Kocisky, Elena Gri bo vs kaya, Tayfun Terzi, Eren Sezener, Devang Agrawal, D’Autume Cyprien De Masson, Tim Scholtes, Manzil Zaheer, Susannah Young, et al. StreamingQA: A benchmark for adaptation to new knowledge over time in question answering models. In International Conference on Machine Learning, pp. 13604–13622. PMLR, 2022.
Adam Liska、Tomas Kocisky、Elena Gribovskaya、Tayfun Terzi、Eren Sezener、Devang Agrawal、D'Autume Cyprien De Masson、Tim Scholtes、Manzil Zaheer、Susannah Young 等。StreamingQA: 问答模型随时间适应新知识的基准测试。载于《国际机器学习会议》,第13604–13622页。PMLR,2022。
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. Advances in Neural Information Processing Systems, 35, 2022.
Kevin Meng、David Bau、Alex Andonian 和 Yonatan Belinkov。定位并编辑 GPT 中的事实关联。Advances in Neural Information Processing Systems,35,2022。
George A Miller. Wordnet: a lexical database for english. Communications of the ACM, 38(11): 39–41, 1995.
George A Miller. WordNet: 一个英语词汇数据库. Communications of the ACM, 38(11): 39–41, 1995.
Marvin Minsky. A framework for representing knowledge, 1974.
Marvin Minsky. 知识表示的框架,1974。
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D. Manning. Fast model editing at scale, 2021.
Eric Mitchell、Charles Lin、Antoine Bosselut、Chelsea Finn 和 Christopher D. Manning。《大规模快速模型编辑》,2021年。
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D. Manning. Memorybased model editing at scale. In International Conference on Machine Learning, 2022.
Eric Mitchell、Charles Lin、Antoine Bosselut、Chelsea Finn 和 Christopher D. Manning。基于记忆的大规模模型编辑。收录于国际机器学习大会,2022。
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019.
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga 等. PyTorch: 一种命令式风格的高性能深度学习库. 神经信息处理系统进展, 32, 2019.
David Patterson, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. Carbon emissions and large neural network training. arXiv preprint arXiv:2104.10350, 2021.
David Patterson、Joseph Gonzalez、Quoc Le、Chen Liang、Lluis-Miquel Munguia、Daniel Rothchild、David So、Maud Texier 和 Jeff Dean。大型神经网络训练的碳排放。arXiv预印本 arXiv:2104.10350,2021。
Judea Pearl. Direct and indirect effects. In Proceedings of the Seventeenth conference on Uncertainty in artificial intelligence, pp. 411–420, 2001.
Judea Pearl. 直接与间接效应. 见: 第十七届人工智能不确定性会议论文集, 第411-420页, 2001.
Fabio Petroni, Tim Rock t s chel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. Language models as knowledge bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 2463–2473, 2019.
Fabio Petroni、Tim Rocktäschel、Sebastian Riedel、Patrick Lewis、Anton Bakhtin、Yuxiang Wu和Alexander Miller。语言模型能作为知识库吗?见《2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议论文集》(EMNLP-IJCNLP),第2463–2473页,2019年。
Fabio Petroni, Patrick Lewis, Aleksandra Piktus, Tim Rock t s chel, Yuxiang Wu, Alexander H Miller, and Sebastian Riedel. How context affects language models’ factual predictions. In Automated Knowledge Base Construction, 2020.
Fabio Petroni、Patrick Lewis、Aleksandra Piktus、Tim Rockt schel、Yuxiang Wu、Alexander H Miller和Sebastian Riedel。上下文如何影响语言模型的事实性预测。收录于《自动化知识库构建》,2020年。
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, pp. 9, 2019.
Alec Radford、Jeffrey Wu、Rewon Child、David Luan、Dario Amodei、Ilya Sutskever 等. 语言模型是无监督多任务学习者. OpenAI 博客, 第9页, 2019.
Richard H Richens. Pre programming for mechanical translation. Mechanical Translation, 3(1): 20–25, 1956.
Richard H Richens. 机械翻译的预编程. Mechanical Translation, 3(1): 20–25, 1956.
Adam Roberts, Colin Raffel, and Noam Shazeer. How much knowledge can you pack into the parameters of a language model? In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 5418–5426, 2020.
Adam Roberts、Colin Raffel 和 Noam Shazeer。语言模型的参数能承载多少知识?载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第5418–5426页,2020年。
Tara Safavi and Danai Koutra. Relational world knowledge representation in contextual language models: A review. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 1053–1067, 2021.
Tara Safavi和Danai Koutra。情境语言模型中的关系型世界知识表示:综述。载于《2021年自然语言处理实证方法会议论文集》,第1053–1067页,2021年。
Taylor Shin, Yasaman Razeghi, Robert L Logan IV, Eric Wallace, and Sameer Singh. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 4222–4235, 2020.
Taylor Shin、Yasaman Razeghi、Robert L Logan IV、Eric Wallace 和 Sameer Singh。AutoPrompt: 通过自动生成提示从语言模型中提取知识。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第4222-4235页,2020年。
Anton Sinitsin, Vsevolod Plo k hot n yuk, Dmitry Pyrkin, Sergei Popov, and Artem Babenko. Editable neural networks. In International Conference on Learning Representations, 2019.
Anton Sinitsin、Vsevolod Plokhotnyuk、Dmitry Pyrkin、Sergei Popov和Artem Babenko。可编辑神经网络。收录于国际学习表征会议,2019年。
Gilbert Strang. Introduction to linear algebra. Wellesley-Cambridge Press Wellesley, MA, 1993.
Gilbert Strang. 线性代数导论. Wellesley-Cambridge Press Wellesley, MA, 1993.
Fabian M Suchanek, Gjergji Kasneci, and Gerhard Weikum. Yago: a core of semantic knowledge. In Proceedings of the 16th international conference on World Wide Web, pp. 697–706, 2007.
Fabian M Suchanek、Gjergji Kasneci 和 Gerhard Weikum。 Yago: 语义知识核心。 在《第16届国际万维网会议论文集》中,第697-706页,2007年。
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pp. 5998–6008, 2017.
Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N Gomez、Łukasz Kaiser 和 Illia Polosukhin。Attention is all you need。载于《神经信息处理系统进展》,第5998-6008页,2017年。
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart M Shieber. Investigating gender bias in language models using causal mediation analysis. In NeurIPS, 2020.
Jesse Vig、Sebastian Gehrmann、Yonatan Belinkov、Sharon Qian、Daniel Nevo、Yaron Singer 和 Stuart M Shieber。基于因果中介分析的语言模型性别偏见研究。发表于 NeurIPS,2020。
Denny Vrandecic and Markus Krotzsch. Wikidata: a free collaborative knowledge base. Communications of the ACM, 57(10):78–85, 2014.
Denny Vrandecic 和 Markus Krotzsch. Wikidata: 一个免费的协作知识库. Communications of the ACM, 57(10):78–85, 2014.
Ben Wang and Aran Komatsu zak i. GPT-J-6B: A 6 Billion Parameter Auto regressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax, May 2021.
Ben Wang 和 Aran Komatsu zak i. GPT-J-6B: 一个 60 亿参数的自回归语言模型。https://github.com/kingoflolz/mesh-transformer-jax, 2021 年 5 月。
Gerhard Weikum. Knowledge graphs 2021: a data odyssey. Proceedings of the VLDB Endowment, 14(12):3233–3238, 2021.
Gerhard Weikum. 知识图谱2021:数据奥德赛. Proceedings of the VLDB Endowment, 14(12):3233–3238, 2021.
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Hugging face’s transformers: State-of-the-art natural language processing. arXiv preprint arXiv:1910.03771, 2019.
Thomas Wolf、Lysandre Debut、Victor Sanh、Julien Chaumond、Clement Delangue、Anthony Moi、Pierric Cistac、Tim Rault、Rémi Louf、Morgan Funtowicz等。Hugging Face的Transformers:最先进的自然语言处理。arXiv预印本arXiv:1910.03771,2019。
Yunzhi Yao, Shaohan Huang, Li Dong, Furu Wei, Huajun Chen, and Ningyu Zhang. Kformer: Knowledge injection in transformer feed-forward layers. In CCF International Conference on Natural Language Processing and Chinese Computing, pp. 131–143. Springer, 2022.
姚云志, 黄少晗, 董力, 韦福如, 陈华钧, 张宁豫. Kformer: 知识注入Transformer前馈层. 见: CCF自然语言处理与中文计算国际会议, 第131–143页. Springer出版社, 2022.
Chen Zhu, Ankit Singh Rawat, Manzil Zaheer, Srinadh B hoja napa lli, Daliang Li, Felix Yu, and Sanjiv Kumar. Modifying memories in transformer models, 2020.
Chen Zhu、Ankit Singh Rawat、Manzil Zaheer、Srinadh Bhojanapalli、Daliang Li、Felix Yu 和 Sanjiv Kumar。修改Transformer模型中的记忆,2020。
A CAUSAL TRACING
因果追踪

Figure 8: Causal Tracing (using the method of Meng et al. 2022). Each grid cell’s intensity reflects the average causal indirect effect of a hidden state on the expression of a factual association, with strong causal mediators highlighted with darker colors. We find that MLPs at the last subject token and attention modules at the last token are important. The presence of influential attention activation s at the earliest layers of the last subject token is investigated with additional path dependent experiments (Figure 3).
图 8: 因果追踪 (采用Meng等人2022年的方法)。每个网格单元的亮度反映了隐藏状态对事实关联表达的因果间接效应平均值,深色突出显示强因果中介效应。我们发现最后一个主语token处的MLP和最后一个token处的注意力模块至关重要。针对最早层最后一个主语token存在显著注意力激活的现象,我们通过路径依赖性实验进行了进一步研究 (图3)。
MEMIT begins by identifying MLP layers that are causal mediators for recall of factual associations in the model. To do so in GPT-J, we use code provided by Meng et al. (2022): beginning with a sample of 501 true statements of facts that are correctly predicted by GPT-J, we measure baseline predicted probabilities of each true fact when noise is introduced into encoding of the subject tokens to degrade the accuracy of the model. Then in Figure 8 (a) for each individual $h_{t}^{l}$ , we restore the state to the value that it would have had without injected noise, and we plot the average improvement of predicted probability. As in Meng et al. (2022), we use Gaussian noise with standard deviation $3\sigma$ ( $(\sigma^{2}$ is the empirically observed variance of embedding activation s) and plot averages for all 501 statements over 10 noise samples. For (b) and (c) we use the same procedure, except we restore runs of 10 layers of MLP outputs $\overset{\vartriangle}{{\boldsymbol{m}}_ {t}^{l}}$ and 10 layers of Attn $a_{t}^{l}$ , instead of full hidden states.
MEMIT首先识别出模型中作为事实关联回忆因果中介的MLP层。在GPT-J中,我们采用Meng等人(2022)提供的代码实现:从GPT-J能正确预测的501条真实事实陈述样本出发,当在主语token编码中引入噪声以降低模型准确率时,我们测量每条真实陈述的基线预测概率。接着在图8(a)中,针对每个单独的$h_{t}^{l}$,我们将状态恢复至未注入噪声时的原始值,并绘制预测概率的平均提升幅度。如Meng等人(2022)所述,我们使用标准差为$3\sigma$的高斯噪声(其中$(\sigma^{2}$是嵌入激活的经验观测方差),并对所有501条陈述在10个噪声样本上取平均值。对于(b)和(c),我们采用相同流程,区别在于恢复的是10层MLP输出$\overset{\vartriangle}{{\boldsymbol{m}}_ {t}^{l}}$和10层注意力$a_{t}^{l}$,而非完整隐藏状态。
These measurements confirm that GPT-J has a causal structure that is similar to the structure reported by Meng et al. (2022) in their study of GPT2-XL. Unlike with GPT-XL, a strong causal effect is observed in the earliest layers of Attention at the last subject token, which likely reflects a concentrated attention computation when GPT-J is recognizing and chunking the n-gram subject name, but the path-dependent experiment (Figure 3) suggests that Attention is not an important mediator of factual recall of memories about the subject.
这些测量结果证实,GPT-J具有与Meng等人 (2022) 在研究GPT2-XL时报告的类似因果结构。与GPT-XL不同,在最后一个主语token的Attention早期层中观察到了强烈的因果效应,这可能反映了GPT-J在识别和分块n-gram主语名称时的集中注意力计算,但路径依赖实验 (图 3) 表明,Attention并非关于主语事实记忆回忆的重要中介因素。
In the main paper, Figure 3 plots the same data as Figure 8 (a) as a bar graph, focused on only the last subject token, and it adds two additional measurements. In red bars, it repeats the measurement of causal effects of states with Attention modules at the last subject token frozen in the corrupted state, so that cannot be influenced by the state being probed, and in green bars it repeats the experiment with the MLP modules at the last subject token similarly frozen, so they cannot be influenced by the causal probe. Severing the Attention modules does not shift the curve, which suggests that Attention computations do not play a decisive mediating role in knowledge recall at the last subject token. In contrast, severing the MLP modules reveals a large gap, which suggests that, at layers where the gap is largest, the role of the MLP computation is important. We select the layers where the gap is largest as the range $\mathcal{R}$ to use for the intervention done by MEMIT.
在主论文中,图3以柱状图形式展示了与图8(a)相同的数据,但仅聚焦于最后一个主体token,并新增了两项测量指标。红色柱体重复测量了Attention模块在损坏状态下最后一个主体token被冻结时的因果效应(因此无法受探测状态影响),绿色柱体则重复了MLP模块在相同冻结条件下的实验(因此无法受因果探针影响)。切断Attention模块并未改变曲线形态,这表明Attention计算在最后一个主体token的知识召回中不起决定性中介作用。相比之下,切断MLP模块显示出显著差距,说明在差距最大的层级中,MLP计算起着关键作用。我们选择差距最大的层级范围$\mathcal{R}$作为MEMIT干预的实施区间。
B IMPLEMENTATION DETAILS
B 实现细节
B.1 FINE-TUNING WITH WEIGHT DECAY
B.1 带权重衰减的微调
Our fine-tuning baseline updates layer 21 of GPT-J, which Meng et al. (2022) found to provide the best performance in the single-edit case. Rather than using a hard $L_{\infty}$ -norm constraint, we use a soft weight decay regularize r. However, the optimal amount of regular iz ation depends strongly on the number of edits (more edits require higher-norm edits), so we tune this hyper parameter for the $n=10{,}000$ case. Figure 9 shows that $5\times1\bar{0}^{-4}$ selects for the optimal tradeoff between generalization and specificity. FT-W optimization proceeds for a maximum of 25 steps with a learning rate of $5\times1\dot{0}^{-4}$ . To prevent over fitting, early stopping is performed when the loss reaches $10^{-2}$ . Regarding runtime, FT takes 1,716.21 sec $\approx0.48\mathrm{hr}$ to execute 10,000 edits on GPT-J.
我们的微调基线更新了GPT-J的第21层,Meng等人 (2022) 研究发现该层在单次编辑情况下能提供最佳性能。我们没有采用硬性的$L_{\infty}$范数约束,而是使用了软权重衰减正则化器。然而,最佳的正则化量很大程度上取决于编辑次数(更多编辑需要更高范数的编辑),因此我们针对$n=10{,}000$的情况调整了这个超参数。图9显示$5\times10^{-4}$能在泛化性和特异性之间取得最佳平衡。FT-W优化最多进行25步,学习率为$5\times10^{-4}$。为防止过拟合,当损失达到$10^{-2}$时执行早停。在运行时间方面,FT在GPT-J上执行10,000次编辑耗时1,716.21秒$\approx0.48\mathrm{小时}$。

Figure 9: Optimizing fine-tuning weight decay on 10,000 edits. We find an evident tradeoff between generalization and specificity, opting for the value with the highest Score.
图 9: 在10,000次编辑上优化微调权重衰减 (weight decay) 。我们发现泛化性与特异性之间存在明显权衡,最终选择了得分最高的数值。
Note that we choose not to complicate the analysis by tuning FT-W on more than one layer. Table 2 demonstrates that FT-W, with just one layer, already gets near-perfect efficacy at the cost of low specificity, which indicates sufficient edit capacity.
需要注意的是,我们选择不通过调整多个层的FT-W来使分析复杂化。表2表明,仅使用单层的FT-W就能以较低特异性为代价获得近乎完美的效果,这表明其具备足够的编辑能力。
B.2 MODEL EDITING NETWORKS WITH GRADIENT DECOMPOSITION (MEND)
B.2 基于梯度分解的模型编辑网络 (MEND)
MEND makes concurrent edits by accumulating gradients from all edit examples, then passing them through the hyper network together. We use the GPT-J MEND hyper network trained by Meng et al. (2022). During inference, learning rate scale is set to the default value of 1.0. MEND is by far the fastest method, taking 98.25 seconds to execute 10,000 updates on GPT-J.
MEND通过累积所有编辑示例的梯度进行并发编辑,然后将它们一起传递给超网络。我们使用Meng等人 (2022) 训练的GPT-J MEND超网络。在推理过程中,学习率缩放系数保持默认值1.0。MEND是目前最快的方法,在GPT-J上执行10,000次更新仅需98.25秒。
B.3 RANK-ONE MODEL EDITING (ROME)
B.3 秩一模型编辑 (ROME)
The default ROME hyper parameters are available in their open source code: GPT-J updates are executed at layer 5, where optimization proceeds for 20 steps with a weight decay of 0.5, KL factor of 0.0625, and learning rate of $5\times10^{-\bar{1}}$ . ROME uses prefix sampling, resulting in 10 prefixes of length 5 and 10 prefixes of length 10. Covariance statistics are collected in fp32 on Wikitext using a sample size of 100,000. See Meng et al. (2022) for more details.
ROME的默认超参数可在其开源代码中获取:GPT-J的更新在第5层执行,优化过程进行20步,权重衰减为0.5,KL因子为0.0625,学习率为$5\times10^{-\bar{1}}$。ROME采用前缀采样,生成10个长度为5的前缀和10个长度为10的前缀。协方差统计在Wikitext上以fp32精度收集,样本量为100,000。详见Meng等人(2022)的论文[20]。
ROME takes $44,248.26\sec\approx12.29\mathrm{hr}$ for 10,000 edits on GPT-J, which works out to approximately 4 seconds per edit.
ROME在GPT-J上进行10,000次编辑耗时44,248.26秒(约12.29小时),平均每次编辑耗时约4秒。
B.4 MASS-EDITING MEMORY IN A TRANSFORMER (MEMIT)
B.4 大语言模型中记忆的大规模编辑 (MEMIT)
On GPT-J, we choose $\mathcal{R}={3,4,5,6,7,8}$ and set $\lambda$ , the covariance adjustment factor, to 15,000. Similar to ROME, covariance statistics are collected using 100,000 samples of Wikitext in $\mathtt{f p}32$ . $\delta_{i}$ optimization proceeds for 25 steps with a learning rate of $5\times10^{-1}$ . In practice, we clamp the $L_{2}$ norm of $\delta_{i}$ such that it is less than $\textstyle{\frac{3}{4}}$ of the original hidden state norm, $\left\lceil\left\lceil h_{i}^{L}\right\rceil\right\rceil$ . On GPT-NeoX, we select $\mathcal{R}={6,7,8,9,10}$ and set $\lambda^{'}=20\small{,}000$ . Covariance statistics are collected over 50,000 samples of Wikitext in $\mathtt{f p16}$ but stored in fp32. Optimization for $\delta_{i}$ proceeds for 20 steps using a learning rate of $5\times10^{-1}$ while clamping $|h_{i}^{L}|$ to $\frac{3}{10}\parallel h_{i}^{L}\parallel$ .
在GPT-J上,我们选择$\mathcal{R}={3,4,5,6,7,8}$,并将协方差调整因子$\lambda$设为15,000。与ROME类似,协方差统计使用100,000个$\mathtt{fp}32$精度的Wikitext样本进行收集。$\delta_{i}$优化进行25步,学习率为$5\times10^{-1}$。实际操作中,我们将$\delta_{i}$的$L_{2}$范数限制在原始隐藏状态范数$\left\lceil\left\lceil h_{i}^{L}\right\rceil\right\rceil$的$\textstyle{\frac{3}{4}}$以内。对于GPT-NeoX,我们选择$\mathcal{R}={6,7,8,9,10}$并设置$\lambda^{'}=20\small{,}000$。协方差统计基于50,000个$\mathtt{fp16}$精度的Wikitext样本收集,但以fp32格式存储。$\delta_{i}$优化进行20步,学习率为$5\times10^{-1}$,同时将$|h_{i}^{L}|$限制为$\frac{3}{10}\parallel h_{i}^{L}\parallel$。
In MEMIT, we have the luxury of being able to pre-compute and cache $z_{i}$ values, since they are inserted in parallel. If all such vectors are already computed, MEMIT takes $3.226.35\sec\approx0.90\mathrm{hr}$ for 10,000 updates on GPT-J, where the most computationally expensive step is inverting a large square matrix (Eqn. 14). Computing each $z_{i}$ vector is slightly less expensive than computing a ROME update; to get all $10{,}000{z}_{i}$ vectors, we need $23{,}546.65\sec\approx6.54\mathrm{hr}$ . This optimization is currently done in series, but it is actually “embarrassingly parallel,” as we can greatly reduce computation time by batching the gradient descent steps. Note that this speed-up does not apply to ROME, since each update must be done iterative ly.
在MEMIT中,由于采用并行插入方式,我们可以预先计算并缓存$z_{i}$值。若所有向量均已预先计算,GPT-J上执行10,000次更新需时$3.226.35\sec\approx0.90\mathrm{hr}$,其中计算量最大的步骤是求大型方阵的逆矩阵(公式14)。计算单个$z_{i}$向量略快于完成一次ROME更新;获取全部$10{,}000{z}_{i}$向量共需$23{,}546.65\sec\approx6.54\mathrm{hr}$。当前优化采用串行方式实现,但该过程实际上具有"天然并行性",通过批量处理梯度下降步骤可显著缩短计算时间。需注意,该加速方案不适用于ROME方法,因其每次更新必须迭代执行。
C EVALUATION METRICS
C 评估指标
C.1 FOR ZSRE
C.1 零样本关系提取 (ZSRE)
For consistency with previous works that use the zsRE task (Mitchell et al., 2021; Meng et al., 2022), we report the same three probability tests:
为与先前使用zsRE(零样本关系抽取)任务的研究工作保持一致[20][21],我们报告了相同的三项概率测试:
• Efficacy is the proportion of edits that $G$ recalls with top-1 accuracy. Note that the prompt matches exactly what the edit method sees at runtime:
• 效能 (Efficacy) 是指 $G$ 以 top-1 准确率召回编辑的比例。需注意,提示词 (prompt) 与编辑方法在运行时所见内容完全一致:
$$
\mathbb{E}_ {i}\left[o_{i}=\underset{x_{E}}{\operatorname{argmax}}\mathbb{P}_ {G}\left[x_{E}\mid p(s_{i},r_{i})\right]\right].
$$
$$
\mathbb{E}_ {i}\left[o_{i}=\underset{x_{E}}{\operatorname{argmax}}\mathbb{P}_ {G}\left[x_{E}\mid p(s_{i},r_{i})\right]\right].
$$
• Paraphrase is the accuracy on rephrasing s of the original statement:
• 复述 (Paraphrase) 是指对原始陈述进行重新表述的准确性:
$$
\mathbb{E}_ {i}\left[\mathbb{E}_ {p\in\mathrm{paraphrases}\left(s_{i},r_{i}\right)}\left[o_{i}=\underset{x_{E}}{\mathrm{argmax}}\mathbb{P}_ {G}\left[x_{E}\mid p\right]\right]\right].
$$
$$
\mathbb{E}_ {i}\left[\mathbb{E}_ {p\in\mathrm{paraphrases}\left(s_{i},r_{i}\right)}\left[o_{i}=\underset{x_{E}}{\mathrm{argmax}}\mathbb{P}_ {G}\left[x_{E}\mid p\right]\right]\right].
$$
• Specificity is the proportion of neighborhood prompts that the model gets correct. In COUNTERFACT, all such prompts have the same correct answer $o_{i}^{c}$ :
• 特异性是指模型正确回答邻域提示的比例。在COUNTERFACT中,所有此类提示的正确答案都是相同的 $o_{i}^{c}$ :
$$
\mathbb{E}_ {i}\left[\mathbb{E}_ {p\in\mathrm{neighborhoodprompts}(s_{i},r_{i})}\left[o_{i}^{c}=\underset{x_{E}}{\mathrm{argmax}}\mathbb{P}_ {G}\left[x_{E}\mid p\right]\right]\right].
$$
$$
\mathbb{E}_ {i}\left[\mathbb{E}_ {p\in\mathrm{neighborhoodprompts}(s_{i},r_{i})}\left[o_{i}^{c}=\underset{x_{E}}{\mathrm{argmax}}\mathbb{P}_ {G}\left[x_{E}\mid p\right]\right]\right].
$$
We also report an aggregated Score: the harmonic mean of Efficacy, Paraphrase, and Specificity.
我们还报告了一个综合得分:效能、改写和特异性的调和平均值。
C.2 FOR COUNTER FACT
C.2 反事实条件
COUNTER FACT contains an assortment of prompts and texts for evaluating model rewrites (Figure 14). This section provides formal definitions for each COUNTER FACT metric. First, the probability tests:
COUNTER FACT包含一系列用于评估模型重写的提示和文本(图14)。本节为COUNTER FACT的每个指标提供正式定义。首先是概率测试:
• Efficacy Success (ES) is the proportion of cases where $o_{i}$ exceeds $o_{i}^{c}$ in probability. Note that the prompt matches exactly what the edit method sees at runtime:
• 疗效成功率 (Efficacy Success, ES) 是指 $o_{i}$ 在概率上超过 $o_{i}^{c}$ 的案例比例。需注意提示词 (prompt) 与编辑方法在运行时所见内容完全一致:
$$
\mathbb{E}_ {i}\left[\mathbb{P}_ {G}\left[o_{i}\mid p(s_{i},r_{i})\right]>\mathbb{P}_ {G}\left[o_{i}^{c}\mid p(s_{i},r_{i})\right]\right].
$$
$$
\mathbb{E}_ {i}\left[\mathbb{P}_ {G}\left[o_{i}\mid p(s_{i},r_{i})\right]>\mathbb{P}_ {G}\left[o_{i}^{c}\mid p(s_{i},r_{i})\right]\right].
$$
• Paraphrase Success $(\mathbf{PS})$ is the proportion of cases where $o_{i}$ exceeds $o_{i}^{c}$ in probability on rephrasing s of the original statement:
• 复述成功率 $(\mathbf{PS})$ 是指在对原始陈述进行复述时,$o_{i}$ 在概率上超过 $o_{i}^{c}$ 的情况所占比例:
$$
\begin{array}{r}{\mathbb{E}_ {i}\left[\mathbb{E}_ {p\in\mathrm{paraphrases}(s_{i},r_{i})}\left[\mathbb{P}_ {G}\left[o_{i}\mid p\right]>\mathbb{P}_ {G}\left[o_{i}^{c}\mid p\right]\right]\right].}\end{array}
$$
$$
\begin{array}{r}{\mathbb{E}_ {i}\left[\mathbb{E}_ {p\in\mathrm{paraphrases}(s_{i},r_{i})}\left[\mathbb{P}_ {G}\left[o_{i}\mid p\right]>\mathbb{P}_ {G}\left[o_{i}^{c}\mid p\right]\right]\right].}\end{array}
$$
• Neighborhood Success (NS) is the proportion of neighborhood prompts where the models assigns higher probability to the correct fact:
• 邻域成功率 (Neighborhood Success, NS) 是指模型在邻域提示中将更高概率分配给正确事实的比例:
$$
\begin{array}{r}{\mathbb{E}_ {i}\left[\mathbb{E}_ {p\in\mathrm{neighborhoodprompts}(s_{i},r_{i})}\left[\mathbb{P}_ {G}\left[o_{i} \middle| p\right]<\mathbb{P}_ {G}\left[o_{i}^{c}~\middle|~p\right]\right]\right].}\end{array}
$$
$$
\begin{array}{r}{\mathbb{E}_ {i}\left[\mathbb{E}_ {p\in\mathrm{neighborhoodprompts}(s_{i},r_{i})}\left[\mathbb{P}_ {G}\left[o_{i} \middle| p\right]<\mathbb{P}_ {G}\left[o_{i}^{c}~\middle|~p\right]\right]\right].}\end{array}
$$
• Editing Score (S), is the harmonic mean of ES, PS, and NS.
• 编辑分数 (S) 是ES、PS和NS的调和平均数。
Now, the generation tests:
生成测试:
• Reference Score (RS) measures the consistency of $G$ ’s free-form generations. To compute it, we first prompt $G$ with the subject $s$ , then compute TF-IDF vectors for both $G(s)$ and a reference Wikipedia text about $o$ ; RS is defined as their cosine similarity. Intuitively, $G(s)$ will match better with $o$ ’s reference text if it has more consistent phrasing and vocabulary.
• 参考分数 (RS) 用于衡量 $G$ 自由生成内容的一致性。计算时,我们首先用主题 $s$ 提示 $G$,然后分别计算 $G(s)$ 和关于 $o$ 的维基百科参考文本的 TF-IDF 向量;RS 定义为两者的余弦相似度。直观而言,若 $G(s)$ 的措辞和词汇更一致,其与 $o$ 参考文本的匹配度会更高。
• We also check for excessive repetition (a common failure case with model editing) using Generation Entropy (GE), which relies on the entropy of $n$ -gram distributions:
• 我们还通过生成熵 (Generation Entropy, GE) 检测过度重复 (模型编辑的常见故障案例),该方法基于 $n$-gram 分布的熵:
$$
-\left({\frac{2}{3}}\sum_{k}f_{2}(k)\log_{2}f_{2}(k)+{\frac{4}{3}}\sum_{k}f_{3}(k)\log_{2}f_{3}(k)\right).
$$
$$
-\left({\frac{2}{3}}\sum_{k}f_{2}(k)\log_{2}f_{2}(k)+{\frac{4}{3}}\sum_{k}f_{3}(k)\log_{2}f_{3}(k)\right).
$$
Here, $f_{n}(\cdot)$ is the $n$ -gram frequency distribution.
这里,$f_{n}(\cdot)$ 是 $n$-gram 频率分布。
D EDITING DIFFERENT CATEGORIES OF FACTS TOGETHER
D 同时编辑不同类别的事实
For an edit $(s,r,o)$ , $r$ associates a subject $s$ and object $o$ . Both $s$ and $o$ have their associated types $\tau(s)$ and $\tau(o)$ . For example, $r=$ “is a citizen of” is an association between a Person and Country. We say that $\tau(s_{1})$ and $s_{2}$ are diverse if $\tau(s_{1})\neq(\tau(s_{2}))$ , and similar otherwise. The definition follows similarly for objects. For any relation pair $(r_{1},r_{2})$ , we sample from COUNTER FACT a set of edits $\mathcal{E}_ {m i x}={(s,r,o)\mid r\in{r_{1},r_{2}}}$ , such that numbers of edits for each relation are equal. We compare MEMIT’s performance on the set of edits $\mathcal{E}_{m i x}$ in four pairs of relations that have different levels of diversity between them. Each relation is followed by its corresponding relation id in WikiData:
对于一个编辑 $(s,r,o)$,$r$ 关联了主语 $s$ 和宾语 $o$。$s$ 和 $o$ 都有其关联的类型 $\tau(s)$ 和 $\tau(o)$。例如,$r=$"is a citizen of"表示Person与Country之间的关联。如果 $\tau(s_{1})\neq(\tau(s_{2}))$,我们称 $\tau(s_{1})$ 和 $s_{2}$ 是多样化的,否则为相似。对象的定义同理。对于任意关系对 $(r_{1},r_{2})$,我们从COUNTER FACT中采样一组编辑 $\mathcal{E}_ {m i x}={(s,r,o)\mid r\in{r_{1},r_{2}}}$,使得每个关系的编辑数量相等。我们在四个具有不同多样性水平的关系对中比较MEMIT在编辑集 $\mathcal{E}_{m i x}$ 上的表现。每个关系后附其对应的WikiData关系ID:
Figure D depicts MEMIT rewrite performance in these four scenarios. We find that the effectiveness of $\mathcal{E}_{m i x}$ closely follows the average of the individual splits. Therefore, the presence of diversity in the edits (or lack thereof) does not tangibly influence MEMIT’s performance.
图 D 描绘了 MEMIT 在这四种场景下的改写性能。我们发现 $\mathcal{E}_{m i x}$ 的效果与各分割部分的平均值高度吻合。因此,编辑内容的多样性(或其缺失)对 MEMIT 的性能没有实质性影响。
E DEMONSTRATIONS
E 演示
This section provides two case studies, in which we apply MEMIT to mass-edit new or corrected memories into GPT-J (6B).
本节提供两个案例研究,我们将MEMIT应用于GPT-J (6B)中批量编辑新增或修正的记忆。
Knowledge freshness. On November 8th, 2022, the United States held elections for 435 congressional seats, 36 governor seats, and 35 senator seats, several of which changed hands. We applied MEMIT to incorporate the election results into GPT-J in the form of (congress person, elected from, district) and (governor/senator, elected from, state).4 The MEMIT edit attained $100%$ efficacy (ES) and $94%$ generalization (PS).
知识时效性。2022年11月8日,美国举行了435个国会席位、36个州长席位和35个参议员席位的选举,其中多个席位易主。我们使用MEMIT方法将选举结果以(国会议员,当选选区,选区编号)和(州长/参议员,当选州,州名)的形式更新到GPT-J中。该MEMIT编辑实现了100%的编辑成功率(ES)和94%的泛化能力(PS)。
Application in a specialized knowldge domain. For a second application, we used MEMIT to create a model with specialized knowledge of amateur astronomy. We scraped the names of stars that were referenced more than 100 times from WikiData and belong to one of the 18 constellations named below.
在专业知识领域的应用。作为第二个应用案例,我们使用MEMIT方法构建了一个具备业余天文学专业知识的大语言模型。我们从WikiData中抓取被引用超过100次的恒星名称,这些恒星均属于以下18个指定星座之一。
Andromeda, Aquarius, Cancer, Cassiopeia, Gemini, Hercules, Hydra, Indus, Leo, Libra, Orion, Pegasus, Perseus, Pisces, Sagittarius, Ursa Major, Ursa Minor, Virgo
仙女座、水瓶座、巨蟹座、仙后座、双子座、武仙座、长蛇座、印第安座、狮子座、天秤座、猎户座、飞马座、英仙座、双鱼座、人马座、大熊座、小熊座、室女座
We obtained 289 tuples of the form (star, belongs to, constellation). The accuracy of the unmodified GPT-J in recalling constellation of a star was only $53%$ . Post-MEMIT, accuracy increased to $86%$ .
我们获得了289组(star, belongs to, constellation)形式的三元组。未经修改的GPT-J在回忆恒星所属星座时的准确率仅为$53%$。经过MEMIT处理后,准确率提升至$86%$。

Figure 10: MEMIT’s performance while editing memories with four levels of diversity. Each data point is a mean of 10 experiments. Filled areas show $90%$ confidence intervals of the values from those experiments.
图 10: MEMIT在四种多样性水平下编辑记忆的性能表现。每个数据点是10次实验的平均值。填充区域显示这些实验值的90%置信区间。
F ABLATIONS
F 消融实验
MEMIT contains several critical design choices: it uses a (i) range of critical mid-layer (ii) MLP modules at the (iii) last subject token, with the (iv) hyper parameter $\lambda$ (Eqn. 15) to control the impact of the update. Choice (iii) was already demonstrated by Meng et al. (2022) to be significant through an ablation study, but we now investigate the other three.
MEMIT包含几个关键设计选择:它使用了(i)关键中间层范围、(ii)位于(iii)最后一个主题token处的MLP模块,并通过(iv)超参数$\lambda$(公式15)来控制更新的影响。Meng等人(2022)已通过消融研究证明选择(iii)的重要性,但我们现在将研究其他三个选项。
F.1 VARYING THE NUMBER AND LOCATION OF EDITED LAYERS
F.1 调整编辑层数量与位置
We test five total configurations of $\mathcal{R}$ , the set of critical MLP layers to be targeted during editing. Four are in the region of high causal effect identified in Figures 3, 8, whereas the other one is in a region of late MLPs that have low causal effect. As Figure 11 shows, using more layers yields higher efficacy and generalization while also improving specificity. Moreover, edits at the late-layer MLPs are considerably worse. These results confirm the importance of the causal analysis to MEMIT’s performance.
我们测试了$\mathcal{R}$的五种配置组合,即待编辑的关键MLP层集合。其中四种配置位于图3和图8所示的高因果效应区域,另一种则位于因果效应较低的后段MLP区域。如图11所示,使用更多层数能获得更高的效能和泛化性,同时提升特异性。此外,对后段MLP层的编辑效果明显较差。这些结果验证了因果分析对MEMIT性能的重要性。

Figure 11: Varying the edited MLP layers
图 11: 编辑不同MLP层效果对比
F.2 VARYING THE TARGETED MODULE: EDITING ATTENTION
F.2 调整目标模块:注意力编辑
Next, we check whether edits at either early or late-layer attention modules perform comparably to their MLP counterparts. As Figure 12 shows, attention edits perform considerably worse.
接下来,我们检查早期或晚期注意力层的编辑效果是否与对应的MLP层相当。如图12所示,注意力层的编辑效果明显较差。
F.3 VARYING THE COVARIANCE HYPER PARAMETER $\lambda$
F.3 协方差超参数 $\lambda$ 的变化
Finally, we investigate the impact of the covariance adjustment factor (denoted $\lambda$ in Eqn. 15) on performance; Figure 13 displays the results. Specificity and fluency increase monotonically with $\lambda$ , indicating that higher $\lambda$ values preserve original model behavior. However, at the same time, efficacy and generalization fall when $\lambda$ is increased. We can see that around $\approx10^{4}$ , the aggregated score reaches a maximum.
最后,我们研究了协方差调整因子(式15中的 $\lambda$)对性能的影响;图13展示了结果。特异性和流畅性随 $\lambda$ 单调递增,表明较高的 $\lambda$ 值能保持原始模型行为。然而与此同时,当 $\lambda$ 增大时,效用和泛化能力会下降。可以看到在 $\approx10^{4}$ 附近,综合得分达到最大值。

Figure 12: Varying the edited attention layers
图 12: 编辑不同注意力层

Figure 13: Varying the covariance adjustment factor $\lambda$
图 13: 调整协方差因子 $\lambda$ 的变化