Large AI Models in Health Informatics: Applications, Challenges, and the Future
大语言模型在健康信息学中的应用、挑战与未来
Jianing Qiu, Lin Li, Jiankai Sun, Jiachuan Peng, Peilun Shi, Ruiyang Zhang, Yinzhao Dong, Kyle Lam, Frank P.-W. Lo, Bo Xiao, Wu Yuan, Senior Member, IEEE, Ningli Wang, Dong Xu, and Benny Lo, Senior Member, IEEE
Jianing Qiu, Lin Li, Jiankai Sun, Jiachuan Peng, Peilun Shi, Ruiyang Zhang, Yinzhao Dong, Kyle Lam, Frank P.-W. Lo, Bo Xiao, Wu Yuan (IEEE高级会员), Ningli Wang, Dong Xu, Benny Lo (IEEE高级会员)
Abstract— Large AI models, or foundation models, are models recently emerging with massive scales both parameter-wise and data-wise, the magnitudes of which can reach beyond billions. Once pretrained, large AI models demonstrate impressive performance in various down- stream tasks. A prime example is ChatGPT, whose capability has compelled people’s imagination about the farreaching influence that large AI models can have and their potential to transform different domains of our lives. In health informatics, the advent of large AI models has brought new paradigms for the design of methodologies. The scale of multi-modal data in the biomedical and health domain has been ever-expanding especially since the community embraced the era of deep learning, which provides the ground to develop, validate, and advance large AI models for breakthroughs in health-related areas. This article presents a comprehensive review of large AI models, from background to their applications. We identify seven key sectors in which large AI models are applicable and might have substantial influence, including 1) bio in formatics; 2) medical diagnosis; 3) medical imaging; 4) medical
摘要—大 AI模型(或称基础模型)是近年来涌现的参数量和数据量均达到数十亿甚至更大规模的模型。这类模型经过预训练后,在各种下游任务中展现出惊人性能,ChatGPT的卓越能力更让人们充分认识到大AI模型可能产生的深远影响及其改变生活各领域的潜力。在健康信息学领域,大AI模型为方法论设计带来了新范式。随着深度学习时代的到来,生物医学与健康领域的多模态数据规模持续扩张,这为开发、验证和推进大AI模型以实现健康领域突破提供了基础。本文系统梳理了大AI模型从背景到应用的完整脉络,重点阐述了其可能产生重大影响的七大应用领域:1) 生物信息学;2) 医学诊断;3) 医学影像;4) 医学...
Jianing Qiu is with the Department of Computing, Imperial College London, U.K., and he is also with the Department of Biomedical Engineering, The Chinese University of Hong Kong, Hong Kong SAR. He was with Precision Robotics (Hong Kong) Ltd., Hong Kong SAR (e-mail: jianing.qiu17@imperial.ac.uk).
Jianing Qiu 就职于英国伦敦帝国理工学院计算系,同时兼任中国香港特别行政区香港中文大学生物医学工程系。他曾任职于香港特别行政区精准机器人(香港)有限公司 (邮箱: jianing.qiu17@imperial.ac.uk)。
Lin Li is with the Department of Informatics, King’s College London, U.K. (e-mail: lin.3.li@kcl.ac.uk).
Lin Li 隶属于英国伦敦国王学院信息学系 (e-mail: lin.3.li@kcl.ac.uk)。
Jiankai Sun is with the School of Engineering, Stanford University, USA (e-mail: jksun@stanford.edu).
Jiankai Sun 就职于美国斯坦福大学工程学院 (e-mail: jksun@stanford.edu)。
Jiachuan Peng is with the Department of Engineering Science, University of Oxford, U.K. (e-mail: jiachuan.peng@seh.ox.ac.uk).
Jiachuan Peng 就职于英国牛津大学工程科学系 (e-mail: jiachuan.peng@seh.ox.ac.uk)。
Peilun Shi and Wu Yuan are with the Department of Biomedical Engineering, The Chinese University of Hong Kong, Hong Kong SAR (e-mails: peilunshi@cuhk.edu.hk and wyuan@cuhk.edu.hk).
Peilun Shi和Wu Yuan就职于香港中文大学生物医学工程系(电子邮件:peilunshi@cuhk.edu.hk及wyuan@cuhk.edu.hk)。
Ruiyang Zhang is with Precision Robotics (Hong Kong) Ltd., Hong Kong SAR (e-mail: r.zhang@prhk.ltd).
张瑞阳就职于精密机器人(香港)有限公司(香港特别行政区)(邮箱: r.zhang@prhk.ltd)。
Yinzhao Dong is with the Faculty of Engineering, The University of Hong Kong, Hong Kong SAR (e-mail: dongyz@connect.hku.hk).
董寅钊就职于香港特别行政区香港大学工程学院(电子邮箱:dongyz@connect.hku.hk)。
Kyle Lam is with the Department of Surgery and Cancer, Imperial College London, U.K. (e-mail: k.lam@imperial.ac.uk).
Kyle Lam 隶属于英国伦敦帝国理工学院外科与癌症系 (email: k.lam@imperial.ac.uk)。
Frank P.-W. Lo and Bo Xiao are with the Hamlyn Centre for Robotic Surgery, Imperial College London, U.K. (e-mails: po.lo15@imperial.ac.uk and b.xiao@imperial.ac.uk).
Frank P.-W. Lo和Bo Xiao就职于英国帝国理工学院哈姆林机器人手术中心 (邮箱: po.lo15@imperial.ac.uk 和 b.xiao@imperial.ac.uk)。
Ningli Wang is with Beijing Tongren Eye Center, Beijing Tongren Hospital, Capital Medical University, and also with Beijing Ophthalmology & Visual Sciences Key Laboratory, Beijing, China (e-mail: wningli@vip.163.com)
王宁利就职于首都医科大学附属北京同仁医院北京同仁眼科中心,同时任职于北京市眼科与视觉科学重点实验室(电子邮箱:wningli@vip.163.com)
Dong Xu is with the Department of Electrical Engineering and Computer Science, and the Christopher S. Bond Life Sciences Center, University of Missouri, USA (e-mail: xudong@missouri.edu).
董旭就职于美国密苏里大学电气工程与计算机科学系及Christopher S. Bond生命科学中心 (邮箱: xudong@missouri.edu)。
Benny Lo is with the Facualty of Medicine, Imperial College London, U.K., and he is also with Precision Robotics (Hong Kong) Ltd., Hong Kong SAR (e-mail: benny.lo@imperial.ac.uk).
Benny Lo 就职于英国伦敦帝国理工学院医学院,同时兼任香港特别行政区精准机器人有限公司(Precision Robotics (Hong Kong) Ltd.)(电子邮箱: benny.lo@imperial.ac.uk)。
Corresponding authors: Wu Yuan and Benny Lo informatics; 5) medical education; 6) public health; and 7) medical robotics. We examine their challenges, followed by a critical discussion about potential future directions and pitfalls of large AI models in transforming the field of health informatics.
通讯作者:Wu Yuan 和 Benny Lo 信息学;5) 医学教育;6) 公共卫生;7) 医疗机器人。我们探讨了这些领域的挑战,随后对大型 AI 模型在变革健康信息学领域的潜在未来方向和陷阱进行了批判性讨论。

Fig. 1: Number of publications related to ChatGPT and SAM in medical and health areas. Statistics were queried from Google Scholar with the keywords “Medical ChatGPT” or “Medical Segment Anything”, and the last entry was 31-th Aug. 2023. From April to August, each month, there were over 200 publications about ChatGPT in medicine and healthcare.
图 1: 医疗健康领域ChatGPT与SAM相关出版物数量统计。数据通过Google Scholar以"Medical ChatGPT"或"Medical Segment Anything"为关键词检索获得,最后更新日期为2023年8月31日。从4月到8月,每月关于ChatGPT在医学和医疗保健领域的出版物均超过200篇。
Index Terms— artificial intelligence; bioinformatics; bio medicine; deep learning; foundation model; health informatics; healthcare; medical imaging
索引术语— 人工智能;生物信息学;生物医学;深度学习;基础模型;健康信息学;医疗保健;医学影像
I. INTRODUCTION
I. 引言
HE introduction of ChatGPT [1] has triggered a new T wave of development and deployment of Large AI Models (LAMs) recently. As shown in Fig. 1, ChatGPT and the phenomenal Segment Anything Model (SAM) [2] have sparked active research in medical and health sectors since their initial launch. Although groundbreaking, the AI community has in fact started creating LAMs much earlier, and it was the seminal work introducing the Transformer model [3] back in 2017 that accelerated the creation of LAMs.
ChatGPT [1] 的推出近期引发了新一轮大语言模型 (Large AI Models, LAMs) 开发和部署的热潮。如图 1 所示,ChatGPT 和现象级模型 Segment Anything Model (SAM) [2] 自发布之初就激发了医疗健康领域的活跃研究。尽管具有突破性意义,但事实上 AI 社区更早就开始构建大语言模型,而 2017 年 Transformer 模型 [3] 这一开创性工作的提出加速了大语言模型的创建进程。
Large Al Models: Key Features and New Paradigm Shift
大语言模型 (Large Language Model):关键特性与新范式转变
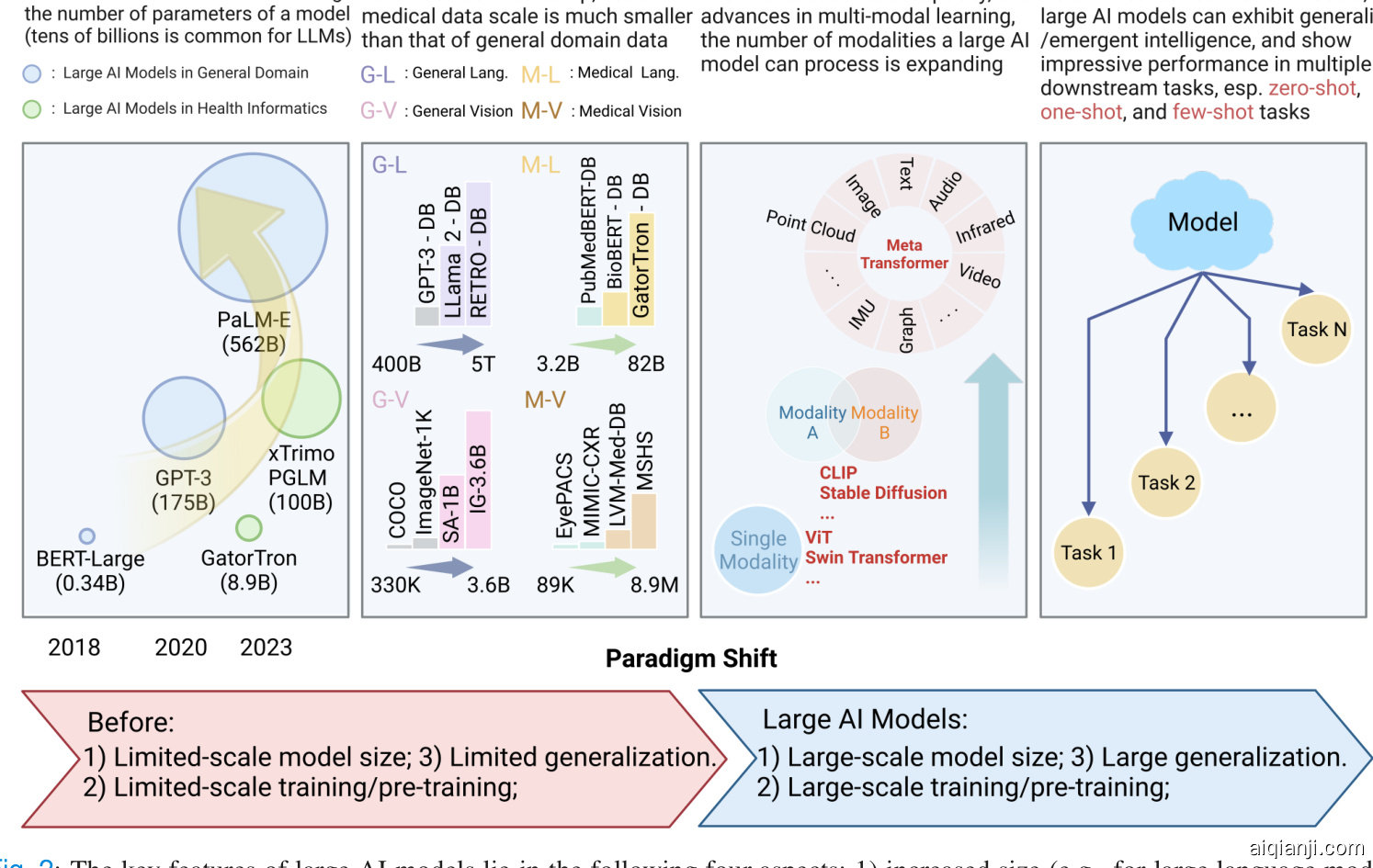
Fig. 2: The key features of large AI models lie in the following four aspects: 1) increased size (e.g., for large language models (LLMs), the number of parameters is often billions); 2) trained with large-scale data (e.g., for LLMs, the data can contain trillions of tokens; and for large vision models (LVMs), the data can contain billions of images); 3) able to process data of multiple modalities; and 4) can perform well across multiple downstream tasks, especially on zero-, one-, and few-shot tasks.
图 2: 大型AI模型的关键特征体现在以下四个方面: 1) 规模增大 (例如大语言模型的参数量通常达到数十亿级别); 2) 使用大规模数据进行训练 (例如大语言模型的训练数据可包含数万亿token, 大型视觉模型的训练数据可包含数十亿张图像); 3) 能够处理多模态数据; 4) 在多种下游任务中表现优异, 尤其在零样本、单样本和少样本任务上。
The recent advances in data science and AI algorithms have endowed LAMs with strengthened generative and reasoning capabilities, as well as generalist intelligence across multiple tasks with impressive zero- and few-shot performance, significantly distinguishing them from early deep models. For example, when asked for medical advice, ChatGPT, based on GPT-4 [4], demonstrates the capability of recalling prior conversation and being able to contextual ize the user’s past medical history before answering, showing a new level of intelligence way beyond that of a simple symptom checker [5].
数据科学与AI算法的最新进展,赋予了大语言模型 (LLM) 更强大的生成与推理能力,以及跨任务的通用智能表现,其零样本 (Zero-shot) 和少样本 (Few-shot) 性能显著区别于早期深度学习模型。例如基于GPT-4 [4] 的ChatGPT在医疗咨询场景中,能够回忆先前的对话内容,并在回答前结合用户既往病史进行情境化分析 [5],展现出远超简单症状检查工具的新型智能水平。
One notable bottleneck of developing supervised medical and clinical AI models is that they require annotated data at scale for training a well-functioning model. However, such annotations have to be conducted by domain experts, which is often expensive and time-consuming. This causes the curation of large-scale medical and clinical data with highquality annotations to be challenging. However, this may no longer be a bottleneck for LAMs, as they can leverage selfsupervision and reinforcement learning in training, relieving the annotation burden and workload of curating large-scale annotated datasets [6]. With the ever-increasing proliferation of medical Internet of things such as pervasive wearable sensors, medical and clinical history such as electronic health records (EHRs), prevalent medical imaging for diagnosis such as computed-tomography (CT) scans, the growing genomic sequence discovery, and more, the abundance of biomedical, clinical, and health data fosters the development of the next generation of AI models in the field, which are expected to have a large capacity for modeling the complexity and magnitude of health-related data, and generalize to multiple unseen scenarios to actively assist and engage in clinical and medical decision-making.
开发监督式医疗和临床AI模型的一个显著瓶颈在于,它们需要大规模标注数据来训练性能良好的模型。然而,这类标注必须由领域专家完成,通常成本高昂且耗时。这使得获取具有高质量标注的大规模医疗临床数据极具挑战性。但对于大语言模型而言,这一瓶颈可能不复存在,因为它们能利用自监督学习和强化学习进行训练,从而减轻标注负担及构建大规模标注数据集的工作量 [6]。随着可穿戴传感器等医疗物联网设备的普及、电子健康档案(EHR)等临床病史记录的积累、计算机断层扫描(CT)等诊断影像的广泛应用,以及基因组序列发现的持续增长,海量生物医学与健康数据正推动该领域新一代AI模型的发展。这些模型需具备强大能力以建模健康数据的复杂性与规模,并能泛化至多种未见场景,从而主动参与临床决策支持。
Despite the homogeneity of the model architecture (current LAMs are primarily based on Transformer [3]), LAMs inherently are strong learners of heterogeneous data due to their large capacity, unified input modeling of different modalities, and improved multi-modal learning techniques. Multimodality is common in biomedical and health settings, and the multi-modal nature of health data provides the natural and promising ground for developing and evaluating LAMs.
尽管模型架构具有同质性(当前的 LAM 主要基于 Transformer [3]),但由于其大容量、对不同模态的统一输入建模以及改进的多模态学习技术,LAM 天生就是异构数据的强大学习者。多模态在生物医学和健康领域很常见,健康数据的多模态特性为开发和评估 LAM 提供了自然而充满前景的基础。
The LAMs that this article discusses are mainly foundation models [7]. However, this article also provides a retrospective of the recent LAMs that are not necessarily considered foundational at their current stage, but are seminal in advancing the future development of LAMs in the fields of bio medicine and health informatics. Fig. 2 summarizes the key features of LAMs, and highlights the paradigm shift it is introducing, i.e., 1) large-scale model size; 2) large-scale training/pre-training; and 3) large generalization.
本文讨论的 LAMs 主要是基础模型 [7]。不过,本文也回顾了近期一些在当前阶段未必被视为基础、但对推动 LAMs 在生物医学和健康信息学领域未来发展具有开创性意义的 LAMs。图 2 总结了 LAMs 的关键特征,并强调了它带来的范式转变,即:1) 大规模模型尺寸;2) 大规模训练/预训练;3) 强泛化能力。
Albeit inspirational, LAMs still face challenges and limitations, and the rapid rise of LAMs brings new opportunities as well as potential pitfalls. This article aims to provide a comprehensive review of the recent developments of LAMs, with a particular focus on their impacts on the biomedical and health informatics communities. The remainder of this article is organized as follows: Section II describes the background of LAMs in general domains, such as natural language processing (NLP) and computer vision (CV); Section III discusses current progress and possible applications of LAMs in key sectors of health informatics; Section IV discusses challenges, limitations and risks of LAMs; Section V points out some potential future directions of advancing LAMs in health informatics, and Section VI concludes.
尽管鼓舞人心,LAMs仍面临挑战与局限,其快速发展既带来新机遇也暗藏潜在风险。本文旨在全面综述LAMs的最新进展,特别关注其对生物医学和健康信息学领域的影响。文章结构如下:第二节概述LAMs在自然语言处理(NLP)和计算机视觉(CV)等通用领域的研究背景;第三节探讨LAMs在健康信息学关键领域的当前进展与应用潜力;第四节分析LAMs面临的挑战、局限及风险;第五节指出健康信息学中推进LAMs研究的潜在发展方向;第六节总结全文。
As this field progresses very rapidly, and also due to the page limit, there are a lot of works that this paper cannot cover. It is our hope that the community can be updated with the latest advances, so we refer readers to our website 1 for the latest progress about LAMs.
由于该领域发展非常迅速,加之篇幅限制,本文无法涵盖大量相关工作。我们希望学界能持续关注最新进展,因此建议读者访问我们的网站1获取关于LAMs (Large Action Models) 的最新动态。
II. BACKGROUND OF LARGE AI MODELS
II. 大模型 (Large AI Models) 背景
The burgeoning AI community has devoted much effort to developing large AI models (LAMs) in recent years by leveraging the massive influx of data and computational resources. Based on the pre-training data modality, this article categorizes the current LAMs into three types and defines them as follows:
近年来,蓬勃发展的AI社区利用海量数据和计算资源,投入大量精力开发大AI模型(LAMs)。根据预训练数据模态,本文将现有LAMs分为三类并定义如下:
scaled up to billions; 2) data-wise, a large volume of unlabelled data are used to pre-train an LLM, and the amount can often reach millions or billions if not more; 3) paradigm-wise, LLMs are first pre-trained often with weakly- or self-supervised learning (e.g., masked language modeling [9] and next token prediction [4]), and then fine-tuned or adapted to various downstream tasks such as question answering and dialogue in which they are able to demonstrate impressive performance.
规模扩大到数十亿;2) 数据方面,大量未标注数据用于预训练大语言模型 (LLM),其数量通常可达数百万甚至数十亿;3) 范式方面,大语言模型通常首先通过弱监督或自监督学习(如掩码语言建模 [9] 和下一token预测 [4])进行预训练,然后针对问答、对话等各种下游任务进行微调或适配,在这些任务中它们能够展现出令人印象深刻的性能。
Recent advances reveal that LLMs are impressive zeroshot, one-shot, and few-shot learners. They are able to extract, summarize, translate, and generate textual information with only a few or even no prompt/fine-tuning samples [4]. Furthermore, LLMs manifest impressive reasoning capability, and this capability can be further strengthened with prompt engineering techniques such as Chain-of-Thought prompting [22].
近期研究表明,大语言模型 (LLM) 在零样本、单样本和少样本学习场景中表现卓越。仅需少量甚至无需提示/微调样本,它们就能完成文本信息的提取、摘要、翻译和生成 [4]。此外,大语言模型展现出惊人的推理能力,通过思维链提示 (Chain-of-Thought prompting) 等提示工程技术,这种能力还能进一步增强 [22]。
There was an upsurge in the number of new LLMs from 2022 onwards. Despite the general consensus that scaling up the number of parameters and the amount of data will lead to improved performance, which leads to a dominant trend of developing LLMs often with billions of parameters (e.g., LLMs such as PaLM [13] have already contained 540 billion parameters) and even trillions of data tokens (e.g., LLaMa 2 was pre-trained with 2 trillion tokens [11], and the training data of RETRO [23] had over 5 trillion tokens), there is currently no concerted agreement within the community that if this continuous growth of model and data size is optimal [10], [14], and there is also lacking a verified universal scaling law. To balance the data annotation cost and efficacy, as well as to train an LLM that can better align with human intent, researchers have commonly used reinforcement learning from human feedback (RLHF) [24] to develop LLMs that can exhibit desired behaviors. The core idea of RLHF is to use human preference datasets to train a Reward Model (RM), which can predict the reward function and be optimized by RL algorithms (e.g., Proximal Policy Optimization (PPO) [25]). The framework of RLHF has attracted much attention and become a key component of many LLMs, such as InstructGPT [19], Sparrow [26], and ChatGPT [1]. Recently, Susano Pinto et al. [27] have also investigated this reward optimization in vision tasks, which can possibly advance the development of future LVMs using RLHF.
自2022年起,新增大语言模型数量激增。尽管普遍认为扩大参数规模和数据量能提升性能(例如PaLM [13]等模型已包含5400亿参数),甚至使用数万亿数据token进行预训练(如LLaMa 2采用2万亿token [11],RETRO [23]训练数据超过5万亿token),但学界对持续增大模型和数据规模是否最优仍无共识[10][14],也缺乏经过验证的通用扩展定律。为平衡数据标注成本与效能,并训练出更符合人类意图的大语言模型,研究者普遍采用基于人类反馈的强化学习(RLHF) [24]来开发具备预期行为的模型。RLHF的核心思想是利用人类偏好数据集训练奖励模型(RM),通过强化学习算法(如近端策略优化(PPO) [25])优化奖励函数。该框架已成为InstructGPT [19]、Sparrow [26]和ChatGPT [1]等模型的关键组件。近期Susano Pinto等人[27]在视觉任务中探索了这种奖励优化机制,有望推动未来基于RLHF的视觉大模型发展。
This section provides an overview of the background of these three types of LAMs in general domains.
本节概述了这三类LAM在通用领域的背景。
A. Large Language Models
A. 大语言模型
The proposal of the Transformer architecture [3] heralds the start of developing large language models (LLMs) in the field of NLP. Since 2018, following the birth of GPT (Generative Pre-trained Transformer) [8] and BERT (Bidirectional Encoder Representations from Transformers) [9], the development of LLMs has progressed rapidly.
Transformer架构的提出[3]标志着NLP领域大语言模型(LLM)研发的开端。自2018年GPT(Generative Pre-trained Transformer)[8]和BERT(Bidirectional Encoder Representations from Transformers)[9]诞生以来,大语言模型的发展突飞猛进。
Broadly speaking, the recent LLMs [10]–[21], have the following three distinct characteristics: 1) parameter-wise, the number of learnable parameters of an LLM can be easily
广义而言,近期的大语言模型 [10]–[21] 具有以下三个显著特征:1) 参数量方面,大语言模型的可学习参数数量可轻松
B. Large Vision Models
B. 大视觉模型
In computer vision, it has been a common practice for years to first pre-train a model on a large-scale dataset and then fine-tune it on the dataset of interest (usually smaller than the one for pre-training) for improved generalization [28]. The fundamental changes driving this evolution of large models lie in the scale of pre-training datasets and models, and the pre-training methods. ImageNet-1K (1.28M images) [29] and -21K (14M images) [30] used to be canonical datasets for visual pre-training. ImageNet is manually curated for highquality labeling, but the prohibitive cost of curation severely hindered further scaling. To push the scale beyond ImageNet’s, datasets like JFT (300M [31] and 3B [32] images) and IG (3.5B [33] and 3.6B [34] images) were collected from the web with less or no curation. The quality of annotation is therefore compromised, and the accessibility of datasets become limited because of copyright issues.
在计算机视觉领域,多年来普遍采用的做法是先在大型数据集上进行模型预训练,然后在目标数据集(通常比预训练数据集小)上进行微调以提高泛化能力 [28]。推动大模型演进的根本变化在于预训练数据集和模型的规模,以及预训练方法。ImageNet-1K(128万张图像)[29] 和 -21K(1400万张图像)[30] 曾是视觉预训练的经典数据集。ImageNet 经过人工精心标注以保证高质量标签,但高昂的标注成本严重阻碍了进一步扩展。为了突破 ImageNet 的规模限制,JFT(3亿 [31] 和 30亿 [32] 张图像)和 IG(35亿 [33] 和 36亿 [34] 张图像)等数据集从网络收集而来,标注程度较低甚至未经标注。因此这些数据集标注质量有所下降,且由于版权问题导致可访问性受限。
The compromised annotation requires the pre-training paradigm to shift from supervised learning to weakly-/selfsupervised learning or unsupervised learning. The latter methods include auto regressive modeling, generative modeling and contrastive learning. Auto regressive modeling trains the model to auto regressive ly predict the next pixel conditioned on the preceding pixels [35]. Generative modeling trains the model to reconstruct the entire original image, or some target regions within it [36], from its corrupted [37] or masked [38] variants. Contrastive learning trains the model to discriminate similar and/or dissimilar data instances [39].
受损的标注要求预训练范式从监督学习转向弱监督/自监督学习或无监督学习。后者的方法包括自回归建模、生成式建模和对比学习。自回归建模训练模型基于前面的像素自回归地预测下一个像素[35]。生成式建模训练模型从其损坏的[37]或掩码的[38]变体中重建整个原始图像或其中的某些目标区域[36]。对比学习训练模型区分相似和/或不相似的数据实例[39]。
Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs) are two major architectural families of LVMs. For vision transformers, pioneering works ViT [40] and iGPT [35] transferred the transformer architectures from NLP to CV with minimal modification, but the resulting architectures incur high computational complexity, which is quadratic to the image size. Later, works like TNT [41] and Swin Transformer [42] were proposed to better adapt transformers to visual data. Recently, ViT-G/14 [32], SwinV2-G [43] and ViT-22B [44] substantially scaled the vision transformers up using a bag of training tricks to achieve state-of-the-art (SOTA) accuracy on various benchmarks. While ViTs may seem to gain more momentum than CNNs in developing LVMs, to improve CNNs, the latest works such as ConvNeXt [45] and Intern Image [46] redesigned CNN architecture with inspirations from ViTs and achieved SOTA accuracy on ImageNet. This refutes the previous statement that CNNs are inferior to ViTs. Apart from the above, recent works like CoAtNet [47] and ConViT [48] merge CNNs and ViTs to form new hybrid architectures. Note that ViT-22B is the largest vision model to date, whose scale is significantly larger than that (1.08B) of the current art of CNNs (Intern Image) but is still much behind that of the contemporary LLMs.
视觉Transformer (ViT) 和卷积神经网络 (CNN) 是LVM的两大主流架构体系。在视觉Transformer领域,开创性工作ViT [40] 和iGPT [35] 以最小修改将Transformer架构从NLP迁移至CV领域,但由此产生的架构存在计算复杂度高的问题(与图像尺寸呈平方关系)。随后,TNT [41] 和Swin Transformer [42] 等研究对Transformer进行视觉数据适配优化。近期,ViT-G/14 [32]、SwinV2-G [43] 和ViT-22B [44] 通过系列训练技巧大幅扩展视觉Transformer规模,在多项基准测试中达到最先进 (SOTA) 精度。虽然ViT在LVM发展中看似比CNN更具势头,但ConvNeXt [45] 和Intern Image [46] 等最新研究通过借鉴ViT思想重构CNN架构,在ImageNet上同样实现了SOTA精度,这反驳了先前"CNN逊于ViT"的论断。此外,CoAtNet [47] 和ConViT [48] 等近期工作通过融合CNN与ViT形成新型混合架构。值得注意的是,ViT-22B是目前规模最大的视觉模型,其参数量(220亿)远超当前CNN最高水平(Intern Image的10.8亿),但仍远落后于同期大语言模型的规模。
Architecturally speaking, LVMs are largely-scaled-up variants of their base architectures. How they are scaled up can significantly impact the final performance. Simply increasing the depth by repeating layers vertically may be suboptimal [49], so a line of studies [46], [50], [51] investigate the rules for effective scaling. Furthermore, scaling the model size up is usually combined with larger-scale pre-training [49], [52] and efficient parallelism [53] for improved performance.
从架构角度来看,LVM(大规模视觉模型)本质上是其基础架构的放大版本。模型扩展方式会显著影响最终性能。简单地通过垂直堆叠层来增加深度可能并非最优方案 [49],因此一系列研究 [46][50][51] 探索了高效扩展的规律。此外,扩大模型规模通常需要结合更大规模的预训练 [49][52] 和高效并行技术 [53] 来提升性能。
LVMs also transform other fundamental computer vision tasks beyond classification. The latest breakthrough in segmentation task is SAM [2]. SAM is built with a ViT-H image encoder (632M), a prompt encoder and a transformer-based mask decoder that predicts object masks from the output of the above two encoders. Prompts can be points or bounding boxes in images or text. SAM demonstrates a remarkable zero-shot generalization ability to segment unseen objects and images. Furthermore, to train SAM, a largest segmentation dataset to date, SA-1B, with over 1B masks is constructed.
LVMs 也在分类之外的其他基础计算机视觉任务中带来变革。分割任务的最新突破是 SAM [2]。SAM 由 ViT-H 图像编码器 (632M)、提示编码器和基于 Transformer 的掩码解码器构成,该解码器根据前两个编码器的输出预测物体掩码。提示可以是图像中的点、边界框或文本。SAM 展现出卓越的零样本泛化能力,能够分割未见过的物体和图像。此外,为训练 SAM,研究团队构建了迄今为止最大的分割数据集 SA-1B,包含超过 10 亿个掩码。
C. Large Multi-modal Models
C. 大语言多模态模型
This section describes large multi-modal models (LMMs). While the primary focus is on one type of LMMs: large visionlanguage models (LVLMs), multi-modality beyond vision and language is also summarized in the end.
本节介绍大型多模态模型 (LMM)。虽然主要关注一种特定类型的大型视觉语言模型 (LVLM),但文末也总结了超越视觉与语言的多模态研究。
Training LVLMs like CLIP [54] requires more than hundreds of millions of image-text pairs. Such large amount of data was often closed source [54]–[56]. Until recently, LAION-5B [57] was created with 5.85B data samples, matching the size of the largest private dataset while being available to the public.
训练如CLIP [54]这样的大视觉语言模型(LVLM)需要超过数亿的图文对。如此庞大的数据通常都是闭源的[54]–[56]。直到最近,LAION-5B [57]才公开了5.85亿数据样本,其规模与最大的私有数据集相当。
LVLMs usually adopt a dual-stream architecture: input text and image are processed separately by their respective encoders to extract features. For representation learning, the features from different modalities are then aligned through contrastive learning [54]–[56] or fused into a unified representation through another encoder on the top of all extracted features [58]–[62]. Typically, the entire model, including unimodal encoder and multi-modal encoder if have, is pre-trained on the aforementioned large-scale image-text datasets, and fine-tuned on the downstream tasks or to carry out zeroshot tasks without fine-tuning. The pre-training objectives can be multi-modal tasks only or with unimodal tasks (see Section II-B). Common multi-modal pre-training tasks contain image-text contrastive learning [54]–[56], image-text matching [58], [61], [63], autoregressive modeling [59], [62], masked modeling [58], image-grounded text generation [61], [63], etc. Recent studies suggest that scaling the unimodal encoders up [60], [64] and pre-training with multiple objectives across uniand multi-modalities [61], [63] can substantially benefit multimodal representation learning.
LVLM通常采用双流架构:输入文本和图像分别由各自的编码器处理以提取特征。在表征学习阶段,不同模态的特征通过对比学习[54]–[56]进行对齐,或通过在所有提取特征顶部叠加的另一编码器融合为统一表征[58]–[62]。典型流程包括:整个模型(含单模态编码器及可能存在的多模态编码器)先在所述大规模图文数据集上预训练,再在下游任务微调或直接执行零样本任务。预训练目标可仅包含多模态任务,也可联合单模态任务(参见第II-B节)。常见多模态预训练任务包括图文对比学习[54]–[56]、图文匹配[58][61][63]、自回归建模[59][62]、掩码建模[58]、基于图像的文本生成[61][63]等。最新研究表明,扩大单模态编码器规模[60][64]及跨单/多模态的多目标预训练[61][63]能显著提升多模态表征学习效果。
Recently, LVLMs made a major breakthrough in text-toimage generation. There are generally two classes of methods for such a task: auto regressive model [65]–[67] and diffusion model [67]–[70]. Auto regressive model, like introduced in Section II-B, first concatenates the tokens (returned by some encoders) of text and images together and then learns a model to predict the next item in the sequence. In contrast, diffusion model first perturbs an image with random noise progressively until the image becomes complete noise (forward diffusion process) and then learns a model to gradually denoise the completely noisy image to restore the original image (reverse diffusion process) [71]. Text description is first encoded by a separate encoder and then integrated into the reverse diffusion process as the input to the model so that the image generation can be conditioned on the text prompt. It is common to reuse those pre-defined LLM and LVM architectures and/or their pre-trained parameters as the aforementioned encoders. The scale of these encoders and the generator can significantly impact the quality of generation and the ability of language understanding [66], [70].
最近,大语言视觉模型 (LVLM) 在文生图领域取得重大突破。这类任务通常采用两类方法:自回归模型 [65][66][67] 和扩散模型 [67][68][69][70]。如第 II-B 节所述,自回归模型首先将文本和图像的 token (由编码器生成) 拼接在一起,然后训练模型预测序列中的下一项。相比之下,扩散模型先通过逐步添加随机噪声破坏图像 (前向扩散过程),再训练模型对完全噪声化的图像逐步去噪以重建原图 (逆向扩散过程) [71]。文本描述会先经过独立编码器处理,再作为条件输入融入逆向扩散过程,从而实现基于文本提示的图像生成。通常,这些预定义的大语言模型和视觉模型架构及其预训练参数会被复用为前述编码器。编码器和生成器的规模会显著影响生成质量与语言理解能力 [66][70]。
The paradigm of bridging language and vision modalities can be beyond learning, e.g., using LLM to instruct other LVMs to perform vision-language tasks [72]. Beyond vision and language, recent development in LMMs seeks to unify more modalities under one single framework, e.g., ImageBind [73] combines six whereas Meta-Transformer [74] unifies twelve modalities.
连接语言与视觉模态的范式可以超越单纯的学习,例如利用大语言模型指导其他视觉语言模型 (LVMs) 执行视觉语言任务 [72]。除视觉和语言外,近期多模态大模型 (LMMs) 的发展致力于在单一框架下统一更多模态,例如 ImageBind [73] 整合了六种模态,而 Meta-Transformer [74] 则统一了十二种模态。
III. APPLICATIONS OF LARGE AI MODELS IN HEALTH INFORMATICS
III. 大语言模型在健康信息学中的应用
In this section, we identify seven key sectors in which LAMs will have substantial influence and bring a new paradigm for tackling the problems and challenges in health informatics. The seven key sectors include 1) bioinformatics; 2) medical diagnosis; 3) medical imaging; 4) medical informatics; 5) medical education; 6) public health; and 7) medical robotics. Table I compares current LAMs with previous SOTA methods in these seven sectors.
在本节中,我们确定了七个关键领域,LAMs将在这些领域产生重大影响,并为解决健康信息学中的问题和挑战带来新范式。这七个关键领域包括:1) 生物信息学;2) 医疗诊断;3) 医学影像;4) 医学信息学;5) 医学教育;6) 公共卫生;7) 医疗机器人。表 I 比较了当前LAMs与这些领域中先前SOTA方法的差异。
A. Bioinformatics
A. 生物信息学
Molecular biology studies the roles of biological macromolecules (e.g., DNA, RNA, protein) in life processes and describes various life activities and phenomena including the structure, function, and synthesis of molecules. Although many experimental attempts have been made on this topic over decades [75]–[77], they are still of high cost, long experiment cycle, and high production difficulty. For example, the number of experimentally determined protein structures stored in the protein data bank (PDB) hardly rivals the number of protein sequences that have been generated. Efficient and accurate computational methods are therefore needed and can be used to accelerate the protein structure determination process. Due to the huge number of parameters and learning capacity, LAMs endow us with prospects to approach such a Herculean task. Especially, LLMs’ outstanding representation learning ability has been employed to implicitly model the biological properties hidden in large-scale unlabeled data including RNA and protein sequences.
分子生物学研究生物大分子(如DNA、RNA、蛋白质)在生命过程中的作用,描述包括分子结构、功能及合成在内的各种生命活动与现象。尽管数十年来已有大量实验研究[75]-[77],但这些方法仍存在成本高、实验周期长、制备难度大等问题。例如,蛋白质数据库(PDB)中实验确定的蛋白质结构数量远不及已测序的蛋白质序列数量。因此需要高效准确的计算方法来加速蛋白质结构测定流程。由于参数量巨大且具备强大学习能力,大语言模型为我们应对这一艰巨任务提供了可能。特别是大语言模型卓越的表征学习能力,已被用于隐式建模RNA和蛋白质序列等大规模未标注数据中隐藏的生物学特性。
When it comes to the field of protein, starting from amino acid sequences, we can analyze the spatial structure of proteins and furthermore understand their functions, and mutual interactions. AlphaFold2 [78] pioneered leveraging the attention-based Transformer model [3] to predict protein structures. Specifically, they treated structure prediction as a 3D graph inference problem, where the network’s inputs are pairwise features between residues, available templates, and multi-sequence alignment (MSA) embeddings. Especially, embeddings extracted from MSA can infer the evolutionary information between aligned sequences. Evoformer and structure modules were proposed to update the input representation and predict the final 3D structure, the whole process of which was recycled several times. Meanwhile, despite being trained on single-protein chains, AlphaFold2 exhibits the ability to predict multimers. To further enable multimeric inputs for training, DeepMind proposed AlphaFold-Multimer [79], achieving impressive performance, especially in he te rome ric protein complexes structure prediction. Specifically, positional encoding was improved to encode chains, and multi-chain MSAs were paired based on species annotations and target sequence similarity.
在蛋白质研究领域,从氨基酸序列出发,我们可以分析蛋白质的空间结构,进而理解其功能与相互作用。AlphaFold2 [78] 率先采用基于注意力机制的Transformer模型 [3] 来预测蛋白质结构。具体而言,该研究将结构预测视为三维图推理问题,网络输入包括残基间的成对特征、可用模板以及多序列比对(MSA)嵌入。特别地,从MSA提取的嵌入能够推断比对序列间的进化信息。研究提出了Evoformer和结构模块来更新输入表示并预测最终三维结构,整个过程会循环多次。尽管训练数据仅包含单蛋白链,AlphaFold2仍展现出预测多聚体的能力。为了支持多聚体输入的训练,DeepMind提出了AlphaFold-Multimer [79],在异源多聚体蛋白复合物结构预测中表现尤为突出。具体改进包括:采用链编码的位置编码方案,并根据物种注释与目标序列相似性对多链MSA进行配对。
In spite of the groundbreaking endeavors aforementioned works have contributed, to achieving optimal prediction, they still heavily rely on MSAs and templates searched from genetic and structure databases, which is time-consuming. Analogous to mining semantic information in natural language, researchers managed to explore co-evolution information in protein sequences in a self-supervised manner by employing large-scale protein language models (PLMs), which learn the global relation and long-range dependencies of unaligned and unlabelled protein sequences. ProGen (1.2B) [80] utilized a conditional language model to provide controllable generation of protein sequences. By inputting desired tags (e.g., function, organism), ProGen can generate corresponding proteins such as enzymes with good functional activity. Elnaggar et al. [81] devised ProtT5-XXL (11B) which was first trained on BFD [82] and then fine-tuned on UniRef50 [83] to predict the secondary structure. ESMfold [84] scaled the number of model parameters up to 15B and observed a significant prediction improvement over AlphaFold2 (0.68 vs 0.38 for TM-score on CASP14) with considerably faster inference speed when MSAs and templates are unavailable. Similarly, from only the primary sequence input, OmegaFold [85] can outperform MSA-based methods [78], [86], especially when predicting orphan proteins that are characterized by the paucity of homologous structure. xTrimoPGLM [87] proposed a unified pre-training strategy that integrates the protein understanding and generation by optimizing masked language modelling and general language modelling concurrently and achieved remarkable performance over 13 diverse protein tasks with its 100B parameters. For instance, for GB1 fitness prediction in protein function task, xTrimoPGLM outperforms the previous SOTA method: Ankh [88], with an $11%$ performance increase. Moreover, for antibody structure prediction, xTrimoPGLM outperformed AlphaFold2 (TM-score: 0.951) and achieved SOTA performance (TM-score: 0.961) with significantly faster inference speed. We underscore that in the presence of MSA, although the performance of PLMs is hardly on par with Alphfold2, PLMs can make predictions several orders of magnitude faster, which speeds up the process of related applications such as drug discovery. In addition, because PLMs implicitly understand the deep information implied in protein sequences, they are promising to predict mutations in protein structures and their potential impact to help guide the design of next-generation vaccines.
尽管上述研究取得了突破性进展,但为了实现最优预测,它们仍严重依赖从遗传和结构数据库中搜索的多序列比对(MSA)和模板,这一过程耗时较长。类似于挖掘自然语言中的语义信息,研究者尝试通过大规模蛋白质语言模型(PLM)以自监督方式探索蛋白质序列中的共进化信息,这类模型能够从未对齐且无标注的蛋白质序列中学习全局关系和长程依赖性。ProGen(1.2B)[80]采用条件语言模型实现可控的蛋白质序列生成,通过输入目标标签(如功能、生物体),可生成具有良好功能活性的酶等对应蛋白质。Elnaggar等人[81]开发的ProtT5-XXL(11B)先在BFD[82]上预训练,再于UniRef50[83]上微调以预测二级结构。ESMfold[84]将模型参数量扩展至150亿,在无MSA和模板时,其预测性能显著超越AlphaFold2(CASP14测试集TM-score:0.68 vs 0.38),且推理速度大幅提升。同样仅凭一级序列输入,OmegaFold[85]能超越基于MSA的方法[78][86],尤其在预测缺乏同源结构的孤儿蛋白时表现突出。xTrimoPGLM[87]提出统一预训练策略,通过同步优化掩码语言建模和通用语言建模实现蛋白质理解与生成的融合,其1000亿参数模型在13项蛋白质任务中表现卓越。例如在蛋白质功能任务的GB1适应性预测中,xTrimoPGLM以11%的性能提升超越此前SOTA方法Ankh[88]。此外在抗体结构预测中,其TM-score达0.961,优于AlphaFold2(0.951)且推理速度更快。我们强调,虽然存在MSA时PLM性能仍难与AlphaFold2比肩,但其预测速度可快数个数量级,能加速药物发现等应用进程。由于PLM能隐式理解蛋白质序列的深层信息,它们有望预测蛋白质结构突变及其潜在影响,从而指导下一代疫苗设计。
In the context of RNA structure prediction, the number of non redundant 3D RNA structures stored in PDB is significantly less than that of protein structures, which hinders the accurate and general iz able prediction of RNA structure from sequence information using deep learning. To mitigate the severe un availability of labeled RNA data, Chen et al. [89] proposed the RNA foundation model (RNA-FM), which learns evolutionary information implicitly from 23 million unlabeled ncRNA sequences [90] by recovering masked nucleotide tokens, to facilitate multiple downstream tasks including RNA secondary structure prediction and 3D closeness prediction. Especially, for secondary structure prediction, RNAFM achieves $3-5%$ performance increase among three metrics (i.e., Precision, Recall, and F1-score), compared to UFold [91] which utilizes U-Net as the backbone. Furthermore, based on RNA-FM, Shen et al. [92] pioneered predicting 3D RNA structure directly.
在RNA结构预测领域,PDB数据库中存储的非冗余RNA三维结构数量远少于蛋白质结构,这阻碍了利用深度学习从序列信息中实现准确且可泛化的RNA结构预测。为缓解标记RNA数据的严重不足,Chen等人[89]提出了RNA基础模型(RNA-FM),该模型通过恢复被遮蔽的核苷酸token,从2300万条未标记的非编码RNA序列[90]中隐式学习进化信息,以促进包括RNA二级结构预测和三维紧密度预测在内的多项下游任务。特别是在二级结构预测方面,与采用U-Net架构的UFold[91]相比,RNA-FM在三个指标(即精确率、召回率和F1值)上实现了3-5%的性能提升。此外,Shen等人[92]基于RNA-FM开创了直接预测RNA三维结构的方法。
Undoubtedly, these models are seminal and have reduced the time and cost of molecule structure prediction by a
毫无疑问,这些模型具有开创性意义,大幅降低了分子结构预测的时间和成本。
TABLE I: Comparison between state-of-the-art LAMs (second row) and prior arts (first row) in typical tasks of seven biomedical and health sectors. “−” denotes not applicable. “N/R” denotes not released in the original literature. For zero-shot medical segmentation task, we tested the off-the-shelf Mask RCNN model to compare with SAM.
表 1: 当前最优LAM(第二行)与现有技术(第一行)在七个生物医学和健康领域典型任务中的对比。"-"表示不适用。"N/R"表示原始文献未发布。对于零样本医学分割任务,我们测试了现成的Mask RCNN模型以与SAM进行对比。
| Sector | Task | Model Name | Model Type | Model Size | (Pre-)training Dataset | Evaluation Dataset | Evaluation Metric | Performance | OA |
| Bioinformatics | MSA-free Protein Sequence Prediction | Alphafold2 | 93M | ProteinData Bank | CASP14 | TM Score | 0.38 | ||
| ESMfold | LLM | 15B | UniRef | 0.68 | |||||
| RNA Structure Prediction | UFold | 8.64 M | RNAStralign, bpRNA-TRO | Archivell600 | 90.5% F1 Score | ||||
| RNA-FM | LLM | N/R | RNAcentral | 94.1% | |||||
| GB1Fitness Prediction | Ankh | 450M | FLIPDatabase | FLIPDatabase | 0.85 Spearman | ||||
| xTrimoPGLM | LLM | 100B | FLIPDatabase | Score 0.96 | × | ||||
| Medical Diagnosis | Electrocardiogram- based Diagnosis | EfficientNet-B4 | 19 M | ImageNet | Morningside Hospital Data | AUROC | 0.92&0.77 | ||
| HeartBEiT | LVM 86M | 8.5MECGs | 0.93&0.80 | × | |||||
| Medical lmaging | Zero-Shot Medical Segmentation | Mask RCNN | 44 M | COCO | ISIC 2018 Dice Challenge | 39.7% | |||
| SAM | LVM >636M | SA-1B | 73.0% | ||||||
| Medical Segmentation | nnU-Net | 60M | Total- Segmentator TotalSegmentator | Dice | 86.8% | ||||
| STU-Net | LVM | 1.4 B | Total- Segmentator | 90.1% | |||||
| Medical Informatics | Medical Question Answering | PubMedBERT | LLM | 110 M | PubMed | MedQA | 38.1% Accuracy | ||
| Med PaLM 2 | LLM | N/R | N/R | 86.5% × | |||||
| Clinical Concept Extraction | BioBERT | LLM | 345 M | 18 B words | F1Score | 87.8% | |||
| GatorTron-Large | LLM | 8.9B | 2018 n2c2 90 B words | 90.0% | |||||
| Medical Education | United StatesMedical Licensing Examination | GPT-3.5 | LLM | 175B | N/R Sample Exam | Accuracy | 58.8% | × | |
| GPT-4 | LMM N/R | N/R | 86.7% | × | |||||
| PublicHealth | Global Weather Forecast | Operational IFS | ERA5 (5-day Z500) | RMSE | 333.7 | × | |||
| Pangu-Weather | LVM 256M | ERA5 | 296.7 | ||||||
| Medical Robotics | Endoscopic Video Analysis | VCL | 14.4 M | 5 MEndo. Frames PolypDiag & | F1 score& Dice & F1 score | 87.6%& 69.1% & 78.1% | |||
| Endo-FM | LVM | 5 M Endo. 121 M | CVC-12k& KUMC Frames | 90.7%&73.9% &84.1% |
| 领域 | 任务 | 模型名称 | 模型类型 | 模型规模 | (预)训练数据集 | 评估数据集 | 评估指标 | 性能 | OA |
|---|---|---|---|---|---|---|---|---|---|
| 生物信息学 | 无需多序列比对的蛋白质序列预测 | Alphafold2 | 93M | ProteinData Bank | CASP14 | TM Score | 0.38 | ||
| ESMfold | 大语言模型 | 15B | UniRef | 0.68 | |||||
| RNA结构预测 | UFold | 8.64 M | RNAStralign, bpRNA-TRO | Archivell600 | 90.5% F1 Score | ||||
| RNA-FM | 大语言模型 | N/R | RNAcentral | 94.1% | |||||
| GB1适应性预测 | Ankh | 450M | FLIPDatabase | FLIPDatabase | 0.85 Spearman | ||||
| xTrimoPGLM | 大语言模型 | 100B | FLIPDatabase | Score 0.96 | × | ||||
| 医学诊断 | 基于心电图诊断 | EfficientNet-B4 | 19 M | ImageNet | Morningside Hospital Data | AUROC | 0.92&0.77 | ||
| HeartBEiT | LVM 86M | 8.5MECGs | 0.93&0.80 | × | |||||
| 医学影像 | 零样本医学分割 | Mask RCNN | 44 M | COCO | ISIC 2018 Dice Challenge | 39.7% | |||
| SAM | LVM >636M | SA-1B | 73.0% | ||||||
| 医学分割 | nnU-Net | 60M | Total-Segmentator TotalSegmentator | Dice | 86.8% | ||||
| STU-Net | LVM | 1.4 B | Total-Segmentator | 90.1% | |||||
| 医学信息学 | 医学问答 | PubMedBERT | 大语言模型 | 110 M | PubMed | MedQA | 38.1% Accuracy | ||
| Med PaLM 2 | 大语言模型 | N/R | N/R | 86.5% × | |||||
| 临床概念提取 | BioBERT | 大语言模型 | 345 M | 18 B words | F1Score | 87.8% | |||
| GatorTron-Large | 大语言模型 | 8.9B | 2018 n2c2 90 B words | 90.0% | |||||
| 医学教育 | 美国医师执照考试 | GPT-3.5 | 大语言模型 | 175B | N/R Sample Exam | Accuracy | 58.8% | × | |
| GPT-4 | LMM N/R | N/R | 86.7% | × | |||||
| 公共卫生 | 全球天气预报 | Operational IFS | ERA5 (5-day Z500) | RMSE | 333.7 | × | |||
| Pangu-Weather | LVM 256M | ERA5 | 296.7 | ||||||
| 医疗机器人 | 内窥镜视频分析 | VCL | 14.4 M | 5 MEndo. Frames PolypDiag & | F1 score& Dice & F1 score | 87.6%& 69.1% & 78.1% | |||
| Endo-FM | LVM | 5 M Endo. 121 M | CVC-12k& KUMC Frames | 90.7%&73.9% &84.1% |
large margin. Thereby, this raises the question of whether LAMs can completely replace experimental methods such as Cryo-EM [75]. We deem that it still falls short from that point. Specifically, the advance of LAMs builds upon big data and large model capacity, which means they are still data-driven, and hence their ability to predict unseen types of data could sometimes be problematic. For instance, [93] stated that AlphaFold can barely handle missense mutation on protein structure due to the lack of a corresponding dataset. Furthermore, how we can assess the quality of model prediction for unknown protein structures remains unclear. In turn, these unverified protein structures cannot be applied to, for example, drug discovery. Therefore, protocols and metrics need to be established to assess their quality and potential impacts. There are mutual and complementary benefits between LAMs and conventional experimental techniques. LAMs can be re-designed to predict the process of protein folding and reveal their mutual interactions so as to facilitate experimental methods. On the other hand, experimental information, such as some physical properties of molecules, can be leveraged by LAMs to further improve prediction performance, especially when dealing with rare data (e.g., orphan protein).
大差距。因此,这引发了一个问题:LAMs是否能完全取代诸如冷冻电镜 (Cryo-EM) [75] 等实验方法。我们认为目前仍无法达到这一点。具体而言,LAMs的进步建立在海量数据和大模型容量的基础上,这意味着它们仍是数据驱动的,因此其预测未见数据类型的能力有时可能存在问题。例如,[93] 指出,由于缺乏相应数据集,AlphaFold几乎无法处理蛋白质结构的错义突变。此外,如何评估模型对未知蛋白质结构的预测质量仍不明确。反过来,这些未经验证的蛋白质结构也无法应用于药物发现等领域。因此,需要建立协议和指标来评估其质量及潜在影响。LAMs与传统实验技术存在相互补充的优势。LAMs可被重新设计以预测蛋白质折叠过程并揭示其相互作用,从而辅助实验方法。另一方面,LAMs可利用实验信息(如分子的某些物理特性)进一步提升预测性能,尤其是在处理罕见数据(如孤儿蛋白)时。
B. Medical Diagnosis
B. 医疗诊断
As research has been carried out to improve the safety and strengthen the factual grounding of LAMs, it is foreseeable that LAMs will play a significant role in medical diagnosis and decision-making.
随着研究不断推进以提高大语言模型 (LAM) 的安全性和事实依据性,可以预见 LAM 将在医疗诊断和决策领域发挥重要作用。
CheXzero [94], a zero-shot chest X-ray classifier, has demonstrated radiologist-level performance in classifying multiple path o logie s which it never saw in its self-supervised learning process. Recently, ChatCAD [95], a framework that integrates multiple diagnostic networks with ChatGPT, demonstrated a potential use case for applying LLMs in computeraided diagnosis (CAD) for medical images. By stratifying the decision-making process with specialized medical networks, and followed by an iteration of prompts based on the outcomes of those networks as the queries to an LLM for medical recommendations, the workflow of ChatCAD offers an insight into the integration of the LLMs that were pre-trained using a massive corpus, with the upstream specialized diagnostic networks for supporting medical diagnosis and decision-making. Its follow-up work ChatCAD $^+$ [96], shows improved quality of generating diagnostic reports with the incorporation of a retrieval system. Using external knowledge and information retrieval can potentially enable the resulting diagnostics more factually-grounded, and such a design has also been favoured and implemented in the ChatDoctor model [97]. By leveraging a linear transformation layer to align two medical LAMs, XrayGPT [98], a conversational chest X-ray diagnostic tool, shows decent accuracy in responding to diagnostic summary. While most LLMs are based on English, researchers have also managed to fine-tune LLaMa [10], an LLM, with Chinese medical knowledge, and the resulting model shows improved medical expertise in Chinese [99].
CheXzero [94] 是一种零样本胸部X光分类器,在其自监督学习过程中从未见过的多种病理分类任务中展现了与放射科医生相当的性能。最近,ChatCAD [95] 这一整合了多个诊断网络与ChatGPT的框架,展示了将大语言模型应用于医学影像计算机辅助诊断(CAD)的潜在用例。通过采用专业医疗网络分层决策流程,并基于这些网络的输出结果迭代生成提示词作为大语言模型的医学建议查询,ChatCAD的工作流程为整合海量文本预训练的大语言模型与上游专业诊断网络提供了创新思路,以支持医疗诊断和决策制定。其后续研究ChatCAD$^+$[96]通过引入检索系统,提升了诊断报告生成质量。利用外部知识和信息检索可使诊断结果更具事实依据,这一设计理念也在ChatDoctor模型[97]中得到应用。XrayGPT[98]作为胸部X光对话式诊断工具,通过线性变换层对齐两个医疗大语言模型,在诊断摘要响应中表现出良好准确性。尽管多数大语言模型基于英语开发,研究人员仍成功将LLaMa[10]模型适配中文医疗知识,最终模型展现出更强的中文医疗专业能力[99]。
Apart from chest X-ray diagnostics and medical question answering, LAMs have also been applied to other diagnostic scenarios. HeartBEiT [100], a foundation model pre-trained using 8.5 million electrocardiograms (ECGs), shows that largescale ECG pre-training could produce accurate cardiac diagnosis and improved explain ability of the diagnostic outcome, and the amount of annotated data for downstream fine-tuning could be reduced. Medical LAMs may also potentially produce a more reliable forecast of treatment outcomes and the future development of diseases using their strong reasoning capability. For example, Li et al. [101] proposed BEHRT, which is able to predict the most likely disease of a patient in his/her next visit by learning from a large archive of EHRs. Rasmy et al. [102] proposed Med-BERT, which is able to predict the heart failure of diabetic patients.
除了胸部X光诊断和医疗问答,LAMs还被应用于其他诊断场景。HeartBEiT [100] 是一个基于850万份心电图(ECG)预训练的基础模型,研究表明大规模ECG预训练能够实现准确的心脏诊断,并提升诊断结果的可解释性,同时减少下游微调所需的标注数据量。医疗LAMs凭借其强大的推理能力,还可能更可靠地预测治疗结果和疾病发展进程。例如Li等人[101]提出的BEHRT能够通过学习大量电子健康记录(EHRs)预测患者下次就诊时最可能患的疾病。Rasmy等人[102]提出的Med-BERT则可以预测糖尿病患者的心力衰竭风险。
With the ubiquity of internet, medical LAMs can also offer remote diagnosis and medical consultation for people at home, providing people in need with more flexibility. We also envision that future diagnosis of complex diseases may also be conducted or assisted by a panel of clinical LAMs.
随着互联网的普及,医疗大语言模型还能为居家患者提供远程诊断和医疗咨询,为有需求的人群提供更灵活的服务。我们预见未来复杂疾病的诊断也可能由一组临床大语言模型主导或辅助完成。
C. Medical Imaging
C. 医学影像
The adoption of medical imaging and vision techniques has vastly influenced the process of diagnosis and treatment of a patient. The wide use of medical imaging, such as CT and MRI, has produced a vast amount of multi-modal, multisource, and multi-organ medical vision data to accelerate the development of medical vision LAMs.
医学影像与视觉技术的应用极大地影响了患者的诊疗过程。CT和MRI等医学影像的广泛使用产生了大量多模态、多源、多器官的医学视觉数据,推动着医学视觉大语言模型的发展。
The recent success of SAM [2] has drawn much attention within the medical imaging community. SAM has been extensively examined in medical imaging, especially on its zero-shot segmentation ability. While research revealed that for certain medical imaging modalities and targets, the zeroshot performance of SAM is impressive (e.g., on endoscopic and der mos co pic images, as these are essentially RGB images, which are the same type as that of SAM’s pre-training images), for imaging modalities that are medicine-specific such as MRI and OCT (optical coherence tomograpy), SAM often fails to segment targets in a zero-shot way [103], mainly because the topology and presentation of a target in those imaging modalities are much different from what SAM has seen during pre-training. Nevertheless, after adaptation and fine-tuning, the medical segmentation accuracy of SAM can surpass current SOTA with a clear margin [104], showing the potential of extending versatility of general LVMs to medical imaging with parameter-efficient adaptation. Apart from zero-shot segmentation, MedCLIP [105] was proposed, a contrastive learning framework for decoupled medical images and text, which demonstrated impressive zero-shot medical image classification accuracy. In particular, it yielded over $80%$ accuracy in detecting Covid-19 infection in a zero-shot setting. The recent PLIP model [106], built using image-text pairs curated from medical Twitter, enables both image-based and text-based pathology image retrieval, as well as enhanced zeroshot pathology image classification compared to CLIP [54].
SAM [2] 近期的成功在医学影像领域引起了广泛关注。SAM 在医学影像中得到了广泛测试,尤其是其零样本分割能力。研究表明,对于某些医学影像模态和目标,SAM 的零样本表现令人印象深刻(例如在内窥镜和皮肤镜图像上,因为这些本质上都是 RGB 图像,与 SAM 预训练图像类型相同),但对于医学特有的成像模态(如 MRI 和 OCT(光学相干断层扫描)),SAM 往往无法以零样本方式分割目标 [103],主要是因为这些成像模态中目标的拓扑结构和表现形式与 SAM 预训练所见差异较大。然而,经过适配和微调后,SAM 的医学分割精度能显著超越当前 SOTA [104],展现了通过参数高效适配将通用 LVMs 的泛化能力扩展到医学影像的潜力。除零样本分割外,MedCLIP [105] 提出了一种针对解耦医学图像和文本的对比学习框架,在零样本医学图像分类中表现出色。特别是在零样本设置下检测 Covid-19 感染时,其准确率超过 $80%$。最新提出的 PLIP 模型 [106] 利用医学 Twitter 整理的图文对构建,支持基于图像和文本的病理图像检索,并在零样本病理图像分类上较 CLIP [54] 有所提升。
Many medical imaging modalities are 3-dimensional (3D), and thus developing 3D medical LVMs are crucial. Med3D [107], a heterogeneous 3D framework that enables pre-training on multi-domain medical vision datasets, shows strong generalization capabilities in downstream tasks, such as lung segmentation and pulmonary nodule classification.
许多医学成像模式都是三维(3D)的,因此开发3D医学大语言模型至关重要。Med3D [107]是一个异构3D框架,能够在多领域医学视觉数据集上进行预训练,在下游任务(如肺部分割和肺结节分类)中展现出强大的泛化能力。
With the success of generative LAMs such as Stable Diffusion [68] in the general domain, which can generate realistic high-fidelity images with text descriptions, Chambon et al. [108] recently fine-tuned Stable Diffusion on medical data to generate synthetic chest X-ray images based on clinical descriptions. The encouraging generative capability of Stable Diffusion in the medical domain may inspire more future research on using generative LAMs to augment medical data that are conventionally hard to obtain, and expensive to annotate.
随着Stable Diffusion [68]等生成式大语言模型在通用领域的成功(能够根据文本描述生成逼真的高保真图像),Chambon等人[108]最近在医疗数据上对Stable Diffusion进行了微调,以基于临床描述生成合成胸部X光图像。Stable Diffusion在医疗领域展现出的鼓舞人心的生成能力,可能会激发更多未来研究,探索如何利用生成式大语言模型来增强传统上难以获取且标注成本高昂的医疗数据。
Nevertheless, some compromises are also evident in medical vision LAMs. For example, the currently common practice of training LVMs and LMMs often limits the size of the medical images to shorten the training time and reduce the computational costs. The reduced size inevitably causes information loss, e.g., some small lesions that are critical for accurate recognition might be removed in a compressed down sampled medical image, whereas doctors could examine the original high-resolution image and spot these early-stage tumors. This may cause performance discrepancies between current medical vision LAMs and well-trained doctors. In addition, although research has shown that increasing medical LAM size and data size could improve medical domain performance of the model, e.g., STU-Net [109], a medical segmentation model with 1.4 billion parameters, the best practice of model-data scaling is yet to be conclusive in medical imaging and vision.
然而,医疗视觉LAMs也存在明显妥协。例如,当前训练LVMs和LMMs的常见做法往往缩小医学图像尺寸以缩短训练时间并降低计算成本。这种尺寸缩减不可避免地导致信息丢失——某些对精准识别至关重要的微小病灶可能在压缩降采样后的医学图像中被剔除,而医生却能通过原始高分辨率图像发现这些早期肿瘤。这可能导致当前医疗视觉LAMs与训练有素的医生之间存在性能差异。此外,尽管研究表明扩大医疗LAM规模和数据量可提升模型在医疗领域的表现(如拥有14亿参数的医学分割模型STU-Net [109]),但在医学影像与视觉领域,模型-数据规模化的最佳实践尚未形成定论。
D. Medical Informatics
D. 医学信息学
In medical informatics, it has been a topic of long-standing interest to leverage large-scale medical information and signals to create AI models that can recognize, summarize, and generate medical and clinical content.
在医学信息学领域,如何利用大规模医疗信息和信号来创建能够识别、总结及生成医学临床内容的AI模型,一直是一个备受关注的长期课题。
Over the past few years, with advances in the development of LLMs [9], [13], [110], and the abundance of EHRs as well as public medical text outlets such as PubMed [111], [112], research has been carried out to design and propose Biomedical LLMs. Since the introduction of BioBERT [113], a seminal Biomedical LLM which outperformed previous SOTA methods on various biomedical text mining tasks such as biomedical named entity recognition, many different Biomedical LLMs that stem from their general LLM counterparts have been proposed, including Clinic alBERT [114], BioMegatron [115], BioMe d RoBERTa [116], Med-BERT [117], Bio- ELECTRA [118], PubMedBERT [119], Bio Link BERT [120], BioGPT [121], and Med-PaLM [122].
过去几年,随着大语言模型(LLM) [9][13][110]的发展进步,以及电子健康记录(EHR)和PubMed [111][112]等公共医学文本资源的丰富,研究人员开始致力于设计和提出生物医学大语言模型。自开创性的BioBERT [113]问世以来——这个生物医学大语言模型在生物医学命名实体识别等多项生物医学文本挖掘任务上超越了之前的SOTA方法——许多源自通用大语言模型的生物医学变体相继被提出,包括ClinicalBERT [114]、BioMegatron [115]、BioMed-RoBERTa [116]、Med-BERT [117]、BioELECTRA [118]、PubMedBERT [119]、BioLinkBERT [120]、BioGPT [121]和Med-PaLM [122]。
The recent GatorTron [123] model (8.9 billion parameters) pre-trained with de-identified clinical text (82 billion words) revealed that scaling up the size of clinical LLMs leads to improvements on different medical language tasks, and the improvements are more substantial for complex ones, such as medical question answering and inference. Previously, the PubMedBERT work [119] also suggested that pre-training an LLM with biomedical corpora from scratch can lead to better results than continually training an LLM that has been pre-trained on the general-domain corpora. While training large number of parameters may seem daunting, parameterefficient adaptation techniques such as low-rank adaptation (LoRA) [124] have enabled researchers to efficiently adapt a 13 billion LLaMa model to produce decent US Medical Licensing Exam (USMLE) answers, and the performance of a collection of such fine-tuned models, called MedAlpaca [125] also reveals that increasing model size and quality of data can improve model’s medical domain expertise. As LLMs start to show emergent abilities [126] with their size scaled up increasingly, Agrawal et al. [127] revealed that recent LLMs such as Instruct GP T [19] and GPT-3 [110] can well extract clinical information in a few-shot setting despite being not explicitly trained for the clinical domain. Med-PaLM [122], a Biomedical LLM with 540 billion parameters generated by applying instruction prompt tuning on Flan-PaLM [12] (which exhibited SOTA accuracy on MultiMedQA [122]), demonstrated the ability to answer consumer medical questions that are comparable to the performance of clinicians. Its followup work, Med-PaLM 2 [128], further strengthens medical reasoning, and as shown in Table I, it has reached an accuracy of $86.5%$ on the MedQA benchmark. As prompt engineering has become a key technique for investigating and improving LLMs, Liévin et al. [129] have also applied various prompt engineering on the GPT-3.5 series such as Instruct GP T [19] to understand their abilities on medical question answering, and their results suggested that increasing Chain-of-Thoughts (CoTs) [22] per question can deliver better, more interpret able medical question responses.
近期基于去标识化临床文本(820亿词)训练的GatorTron[123]模型(89亿参数)表明,扩大临床大语言模型规模能提升各类医疗语言任务表现,且在复杂任务(如医疗问答和推理)上提升更为显著。此前PubMedBERT[119]研究也指出,从头开始使用生物医学语料预训练大语言模型,比在通用领域预训练模型上继续训练能获得更好效果。虽然训练海量参数看似困难,但参数高效适配技术(如低秩适配LoRA[124])已帮助研究者成功将130亿参数的LLaMa模型适配生成合格美国医师执照考试(USMLE)答案,而此类微调模型集合MedAlpaca[125]的表现也证明,扩大模型规模与提升数据质量可增强模型的医疗领域专业性。
随着大语言模型规模扩大开始展现涌现能力[126],Agrawal等[127]发现GPT-3[110]和InstructGPT[19]等最新模型虽未接受临床领域专门训练,仍能在少样本设定下出色提取临床信息。通过对Flan-PaLM12进行指令提示调优生成的5400亿参数生物医学大语言模型Med-PaLM[122],展现了与临床医生水平相当的消费者医疗问题解答能力。其后续工作Med-PaLM 2[128]进一步强化了医学推理能力,如表1所示,该模型在MedQA基准测试中达到了86.5%的准确率。
随着提示工程成为研究和改进大语言模型的关键技术,Liévin等[129]也对InstructGPT[19]等GPT-3.5系列模型应用了多种提示工程,以评估其医疗问答能力。他们的结果表明,通过增加每个问题的思维链(CoTs)[22],能获得更优质、更可解释的医疗问题回答。
The impressive performance of Biomedical LLMs on medical language tasks shows their potential to be used to assist clinicians in processing, interpreting, and analyzing clinical and medical data more efficiently, and also to vastly reduce the time that clinicians have to spend on documenting EHRs. Patel and Lam [130] recently shed insight on using ChatGPT [1] to generate discharge summaries, which could potentially relieve doctors from laborious writing and improve their clinical productivity. Biomedical LLMs can also assist in the writing of prior authorizations for insurance purposes, accelerating treatment authorizations [131]. On the patient side, the zero-, one-, and few-shot learning capability of LLMs may enable them to provide personalized medical assistance based on the medical history of each individual patient. In addition, LLMs may also find them applicable in clinical trial matching. Based on candidates’ demographics and medical history, a Biomedical LLM may effectively generate eligible matching, which accelerates clinical trial recruitment and initiation.
生物医学大语言模型在医学语言任务上的出色表现,展现了其辅助临床医生更高效处理、解读和分析临床医疗数据的潜力,同时能大幅减少医生在电子健康记录(EHRs)文档工作上花费的时间。Patel和Lam [130] 近期探讨了利用ChatGPT [1]生成出院小结的可能性,这项应用有望将医生从繁重的文书工作中解放出来,提升临床工作效率。生物医学大语言模型还能协助撰写保险预授权文件,从而加快治疗授权流程 [131]。对患者而言,大语言模型的零样本、单样本和少样本学习能力,可基于个体病史提供个性化医疗辅助。此外,这类模型在临床试验匹配领域也具应用价值——通过分析受试者人口统计学特征和病史,生物医学大语言模型能高效生成合格匹配方案,加速临床试验的受试者招募与启动进程。
E. Medical Education
E. 医学教育
It is likely that future medical education will also be influenced by LAMs, as research continues to strengthen their scientific grounding and creative generation. Many LAMs, such as GPT-4 [4] and Med PaLM 2 [128], have already passed USMLE with a score of over $86%$ , demonstrating sound knowledge spectrum and reasonable capabilities in bioethics, clinical reasoning, and medical management.
未来的医学教育很可能会受到大语言模型 (LAM) 的影响,随着研究不断强化其科学基础和创造性生成能力。许多大语言模型(如 GPT-4 [4] 和 Med PaLM 2 [128])已在美国医师执照考试 (USMLE) 中获得超过 $86%$ 的分数,展现出扎实的知识谱系以及在生物伦理、临床推理和医疗管理方面的合理能力。
The generative capability of such LAMs may augment medical student learning and help them gain additional insights from AI-generated content as recently pointed out in [132]. A LAM with wide knowledge and social compliance can act as a companion learning assistant, answering medical questions promptly and explaining intricate terms and practices in simple sentences. For example, the recent GPT-4 model [4] can act as a Socratic tutor, leading a student step-by-step to find the answers by themselves, which is an important step towards practical adoption of LAMs in education as they can be steered to teach/assist students in a desired manner. The OPTICAL model proposed by Shue et al. [133] recently shows the feasibility of using LLMs to guide beginners in analyzing bioinformatics data. The sentence paraphrasing abilities of LLMs [134] such as ChatGPT may also help students with dyslexia in their learning. However, concerns about the illegitimate uses of LAMs such as plagiarism are practical and should raise awareness. A pilot study conducted by Mitchell et al. [135] proposed a zero-shot detector named DetectGPT, which is able to distinguish human-written or LLM-generated text. This attempt may lead to more research into developing reliable tools for verifying the content source and potentially countering the side effects of LAMs in education.
此类大语言模型 (LAM) 的生成能力可以增强医学生的学习效果,并帮助他们从AI生成内容中获得额外见解,正如[132]最近指出的那样。一个知识广博且符合社会规范的LAM可以充当学习伴侣助手,快速回答医学问题,并用简单的句子解释复杂的术语和实践。例如,最近的GPT-4模型[4]可以充当苏格拉底式导师,引导学生逐步自行找到答案,这是LAM在教育中实际应用的重要一步,因为它们可以被引导以期望的方式教学/辅助学生。Shue等人[133]最近提出的OPTICAL模型展示了使用大语言模型指导初学者分析生物信息学数据的可行性。像ChatGPT这样的大语言模型的句子改写能力[134]也可能帮助有阅读障碍的学生学习。然而,关于LAM非法使用(如剽窃)的担忧是现实的,应引起重视。Mitchell等人[135]进行的一项试点研究提出了一种名为DetectGPT的零样本检测器,能够区分人类书写或大语言模型生成的文本。这一尝试可能会促使更多研究开发可靠工具来验证内容来源,并可能抵消LAM在教育中的副作用。
For medical education givers, LAMs can potentially create novel teaching and exam contents, and diversify the teaching formats and their presentation. Based on the history of medical study and outcomes, LAMs may also help design personalized and precise course materials for students in need. In addition, LAMs may also help deliver remote medical education, providing engaging learning experiences and opportunities for students living in resource-poor areas or from underprivileged families. LAMs can also serve as a grading and scoring system in medical education, e.g., grading the surgical skill of a surgeon operating a surgical robot.
对于医学教育者而言,大语言模型(LAM)能创新教学与考试内容,丰富教学形式及呈现方式。基于医学学习历程与成果数据,它还能为有需求的学生定制个性化精准课程资料。此外,大语言模型可助力远程医学教育,为资源匮乏地区或弱势家庭学生提供沉浸式学习体验与机会。该系统还能作为医学教育评分工具,例如评估外科医生操作手术机器人的技能水平。
In medical and clinical training such as nurse training, one can imagine a domain-knowledgeable LAM can act as an assistant or a trainer to supervise the training. For certain frequent and tedious routine medical training courses, human trainers tend to become less productive as training keeps repeating, and the quality of training delivery also varies among different human trainers. With a wide knowledge spectrum and responsive interactions, training delivered by a LAM can potentially be more engaging and productive, and the standard of training can be maintained as equal and of high quality.
在护士培训等医疗和临床培训中,可以设想一个具备领域知识的LAM(Large Action Model)能够作为助手或培训师来监督培训过程。对于某些频繁且单调的常规医疗培训课程,人类培训师在重复培训中往往会效率下降,且不同培训师的教学质量也存在差异。凭借广泛的知识覆盖和即时响应能力,由LAM提供的培训可能更具吸引力和效率,同时能保持统一的高质量标准。
F. Public Health
F. 公共卫生
As the American epi de mio logi st Larry Brilliant said “outbreaks are inevitable, but pandemics are optional”, with the world gradually returning to normal after the Covid-19 pandemic, if there is one thing that the world has to reflect on, it is how we become prepared to prevent the next pandemic.
正如美国流行病学家 Larry Brilliant 所说"疫情暴发不可避免,但大流行可以选择",随着世界逐渐从新冠疫情中恢复正常,如果说全世界必须反思一件事,那就是我们该如何做好准备以预防下一场大流行。
Based on past public policy and interventions to contain the spread of infectious diseases and the specific current situation, LLMs may help epidemiologists and policymakers to draft targeted public policies and recommend effective interventions. LLMs and other LAMs are also likely to be used to monitor, track, forecast, and analyze the progress of new outbreaks. LAMs have been actively researched for drug discovery, e.g., the Pangu Drug model [136], and they can potentially be used for the design of vaccine and drugs to treat and save people from new outbreaks. Furthermore, another potential usage of LAMs, as pointed out in [137], can be in precision triage and diagnosis, in which they could play a pivotal role as medical care workforce might be stretched when encountering a new outbreak. An important aspect of tackling an outbreak/epidemic is to handle misinformation. The study conducted by Chen et al. [138] revealed that from 21 January 2020 to 21 March 2020, Twitter produced over 72 million Covid-19-related tweets. If unverified media information proliferates at scale, it inevitably causes complications in tackling the outbreak. Although LAMs could be double-edged swords when it comes to misinformation, with gradually complete regulations and strengthened factual grounding of LAMs, they can be used to effectively identify misinformation and tackle public health infodemic.
基于过去的公共卫生政策与干预措施以遏制传染病传播的经验及当前具体情况,大语言模型(LLM)可协助流行病学家和政策制定者起草针对性公共政策并推荐有效干预方案。大语言模型及其他多模态大模型(LAM)还可能用于监测、追踪、预测和分析新发疫情的进展。多模态大模型在药物研发领域已开展积极研究,例如盘古药物模型(Pangu Drug model) [136],未来或可用于疫苗和治疗药物的设计以应对新发疫情。此外,如文献[137]指出,多模态大模型在精准分诊与诊断方面具有应用潜力——当医疗系统面临新发疫情冲击时,这类模型能发挥关键作用。应对疫情的重要环节是处理虚假信息。Chen等人的研究[138]显示,2020年1月21日至3月21日期间,Twitter产生了超过7200万条新冠相关推文。若未经核实的媒体信息大规模传播,必将加剧疫情防控的复杂性。尽管多模态大模型在虚假信息领域可能成为双刃剑,但随着监管体系逐步完善和模型事实性基础的增强,它们将能有效识别虚假信息并应对公共卫生信息疫情。
Beyond their promising usage in preventing pandemics, LAMs are also an effective tool for solving other public health challenges, for example, providing large-scale dietary monitoring and assessment [139], [140] to tackle the growing double burden of malnutrition [141] in many low- and middle-income countries, and de mystifying and proposing new solutions for mental illnesses that are common in populations. Researchers have recently proposed ClimaX [142], a foundation model for forecasting weather and climate change. With their remarkable forecasting capability, LAMs like ClimaX and Pangu-Weather [143] can advance our understanding of climate change and provide solutions to better address the global health issues posed by climate change.
除在预防流行病方面具有广阔前景外,LAMs (Large Action Models) 还是解决其他公共卫生挑战的有效工具。例如:通过大规模饮食监测与评估 [139][140] 应对中低收入国家日益严重的营养不良双重负担问题 [141];针对人群常见心理疾病进行祛魅并提出创新解决方案。研究者近期提出的气候基础模型ClimaX [142] 及Pangu-Weather [143] 等LAMs凭借卓越的预测能力,可深化人类对气候变化的理解,并为应对气候变化引发的全球健康问题提供解决方案。
G. Medical Robotics
G. 医疗机器人
From surgical robots that allow surgeons to perform precision minimally invasive surgery, to wearable robots that assist patients with health monitoring and rehabilitation, medical robotics has seen rapid growth and advances over the past few decades. LAMs have begun to show exciting prospects in enhancing medical robotic vision, interaction, and autonomy.
从让外科医生能够进行精准微创手术的手术机器人,到协助患者进行健康监测和康复的可穿戴机器人,医疗机器人技术在过去几十年里经历了快速增长和重大进步。大语言模型 (LLM) 在增强医疗机器人的视觉、交互和自主性方面已展现出令人振奋的前景。
- Enhance Vision: The integration of LAMs into surgical robots has the potential to enhance the vision of these systems in surgery. Endo-FM [144], a foundation model with high precision for endoscopic video classification, segmentation, and detection, could be one of these LAMs to provide robotic surgery systems with enhanced vision. In addition to online vision enhancement, LAMs can also potentially improve the offline workflow analysis of robotic surgery, and more accurately and objectively predict the likelihood of complications and successful outcomes, which help surgeons better plan and execute surgeries in the future. Furthermore, with their strong generative capabilities, LAMs can be used to generate and simulate surgical procedures, allowing surgeons to practice and refine their techniques before operating on a patient with real surgical robots. Beyond surgical robots, the perception of many companion and assistive robots can also be enhanced by LAMs, e.g., enabling a companion robot to better understand a patient’s emotion through accurate recognition of facial expressions [145], and enabling an assistive robot to offer safer, more natural navigation for visually impaired people [146].
- 提升视觉能力:将LAMs集成到手术机器人中有望增强这些系统在手术中的视觉能力。Endo-FM [144] 作为一种高精度的内窥镜视频分类、分割和检测基础模型,可以成为这类LAMs之一,为机器人手术系统提供增强视觉。除了在线视觉增强,LAMs还可能改善机器人手术的离线工作流分析,更准确、客观地预测并发症和手术成功概率,从而帮助外科医生更好地规划和执行未来手术。此外,凭借强大的生成能力,LAMs可用于生成和模拟手术流程,让外科医生在使用真实手术机器人操作患者前进行技术练习与优化。除手术机器人外,LAMs还能增强许多陪伴和辅助机器人的感知能力,例如:通过精准识别面部表情使陪伴机器人更好地理解患者情绪 [145] ,以及让辅助机器人为视障人士提供更安全、自然的导航 [146] 。
- Improve Interaction: LAMs may significantly improve the interactive capabilities of many medical robots, by enabling them to recognize human emotions, gestures, and speech, and respond to high-level human language commands. For example, this will be easier for patients undergoing rehabilitation to communicate and engage with their robotic assistants, improving their overall recovery experience. More intelligent LAMs may also better understand human intentions and create more human-like companionship, which could improve the overall quality of care for the elderly [147]. Recently, SurgicalGPT [148], a visual question answering model for surgery, has shown great promise that future robotic surgery could become more interactive between surgeons and the surgical robots.
- 提升交互能力:LAM可通过识别人类情绪、手势和语音,并响应高级人类语言指令,显著增强医疗机器人的交互能力。例如,这将使康复患者更容易与机器人助手沟通互动,从而改善整体康复体验。更智能的LAM还能更好地理解人类意图,提供更拟人化的陪伴,有望提升老年护理的整体质量 [147]。近期,面向手术的视觉问答模型SurgicalGPT [148] 展现出巨大潜力,未来外科医生与手术机器人之间的交互可能变得更加紧密。
- Increase Autonomy: LAMs have the potential to turn robotic pipelines from the current engineer in the loop to user in the loop using high-level language commands [149], which could enable surgeons with less programming proficiency to easily adapt robotic manipulations to their target tasks. Studies have proposed to use a single LAM to conduct diverse robotic tasks, demonstrating impressive adaptability and generalization skills [150]–[156]. These advancements can potentially inspire the development of more autonomous medical robots.
- 提升自主性:语言动作模型(LAM)有望将机器人流程从当前需要工程师参与的模式转变为用户通过高级语言指令控制的模式 [149],这将使编程能力较弱的外科医生也能轻松调整机器人操作以适应目标任务。研究表明,单个LAM可执行多种机器人任务,展现出卓越的适应性和泛化能力 [150]–[156]。这些进展可能推动更自主的医疗机器人发展。
IV. CHALLENGES, LIMITATIONS, AND RISKS
IV. 挑战、局限性与风险
Despite the promising outcome of LAMs, there remain many challenges and potential risks in developing and deploying LAMs in biomedical, clinical, and healthcare applications.
尽管LAMs展现出令人期待的成果,但在生物医学、临床和医疗保健应用中开发和部署LAMs仍存在诸多挑战与潜在风险。
- Data: Most existing public datasets for health informatics are much smaller (please refer to Fig. 2 and Table $\mathrm{ I I }^{2}.$ ) than those used in general domains and thus are likely insufficient to unlock the full potential of LAMs in biomedical and health scenarios. Building large-scale high-quality medical datasets are particularly challenging because (1) curation requires domain-expertise to identify data of clinical relevance, and quality assurance is very important with health data; (2) some data modalities like MRI require special devices to collect, which is inefficient and expensive; (3) the collected data may not be allowed to publish or use for training because of consent, legal and privacy issues. Furthermore, the training strategy RLHF of some LLMs like ChatGPT requires even more intense engagement of human experts.
- 数据:现有大多数健康信息学公开数据集规模远小于通用领域所用数据(详见 图 2 和 表 $\mathrm{ I I }^{2}.$ ),可能无法充分释放大语言模型在生物医学和健康场景的潜力。构建大规模高质量医疗数据集面临特殊挑战:(1) 数据筛选需要临床相关性的领域专业知识,且健康数据的质量保证至关重要;(2) MRI等数据模态需专用设备采集,效率低且成本高;(3) 受限于知情同意、法律及隐私问题,部分采集数据可能无法公开或用于训练。此外,ChatGPT等大语言模型采用的RLHF训练策略需要更高强度的人类专家参与。
TABLE II: Large-scale datasets in biomedical and health informatics
| Dataset Name | Scale | Modality | Task | OA | |
| Bioinformatics | BigFantasticDatabase | 2.1 B protein sequences, 393 B amino acids | protein sequence | protein representation learning | |
| ObservedAntibodySpace | 558M antibodysequences | antibody sequence | antibody representation learning | ||
| RNAcentral | 34 M ncRNA sequences,22M secondary structure | ncRNA sequence, functional information | RNA representation learning | ||
| ZINC20 | 1.4 B compoundsfrom 310 catalogs from 150 companies | molecule,compound | drug discovery | ||
| Medical Diagnosis | MIMIC-CXR | 65Kpatients,containing337Kchest X-ray images and 227Kradiology reports | chest X-ray images, text | medical vision-language processing | |
| MountSinai ECG Data | 2.1 Mpatients, containing 8.5 M discrete ECGrecordings | ECG | cardiac diseaserecognition | × | |
| Google DR Dev.Dataset | 239 K unique individuals, 1.6 M fundus images | fundusimage | diabetic retinopathy grading | ||
| Medical Imaging | MedMNISTV2 | 708 K 2D medical images, 10 K 3D medical images | pathology,chest X-ray, dermatoscope,oct,fundus, ultrasound,microscope,CT | medical image classification | |
| Medical Informatics | Medical Meadow | 1.5 M data points covering a wide range of medicai language processing tasks | text | medical question answering | |
| UFHealthIDR Clinical Note Database | 290Mclinical notes,withup to82B medicalwords | text | medical language processing | × | |
| Public Health | Clinical PracticeResearch Datalink | 11.3 M patients covering data on demographics, symptoms, diagnoses,etc | longitudinal electronic healthrecord | medical language processing, diseaseprogressforecasting | Upon Approval |
| Medical Robotics | Endo-FMdatabase | 33 K endoscopic videos,with up to 5 M frames | endoscopic video | endoscopicvideoanalysis |
表 II: 生物医学与健康信息学中的大规模数据集
| 数据集名称 | 规模 | 模态 | 任务 | OA | |
|---|---|---|---|---|---|
| * * 生物信息学* * | BigFantasticDatabase | 21亿条蛋白质序列,3930亿个氨基酸 | 蛋白质序列 | 蛋白质表征学习 | |
| ObservedAntibodySpace | 5.58亿条抗体序列 | 抗体序列 | 抗体表征学习 | ||
| RNAcentral | 3400万条非编码RNA序列,2200万条二级结构 | 非编码RNA序列,功能信息 | RNA表征学习 | ||
| ZINC20 | 来自150家公司的310个目录的14亿种化合物 | 分子、化合物 | 药物发现 | ||
| * * 医学诊断* * | MIMIC-CXR | 6.5万名患者,包含33.7万张胸部X光片和22.7万份放射学报告 | 胸部X光图像,文本 | 医学视觉-语言处理 | |
| MountSinai ECG Data | 210万名患者,包含850万份离散心电图记录 | 心电图 | 心脏疾病识别 | × | |
| Google DR Dev.Dataset | 23.9万名独立个体,160万张眼底图像 | 眼底图像 | 糖尿病视网膜病变分级 | ||
| * * 医学影像* * | MedMNISTV2 | 70.8万张2D医学图像,1万张3D医学图像 | 病理、胸部X光、皮肤镜、OCT、眼底、超声、显微镜、CT | 医学图像分类 | |
| * * 医学信息学* * | Medical Meadow | 150万条数据点,涵盖广泛的医学语言处理任务 | 文本 | 医学问答 | |
| UFHealthIDR Clinical Note Database | 2.9亿份临床记录,包含高达820亿个医学词汇 | 文本 | 医学语言处理 | × | |
| * * 公共卫生* * | Clinical Practice Research Datalink | 1130万名患者,涵盖人口统计、症状、诊断等数据 | 纵向电子健康记录 | 医学语言处理,疾病进展预测 | 需批准 |
| * * 医疗机器人* * | Endo-FM database | 3.3万条内窥镜视频,包含高达500万帧 | 内窥镜视频 | 内窥镜视频分析 |
- Computation: Training, or even fine-tuning, contemporary LAMs is extremely expensive in terms of time and resource consumption, which is beyond the budget of most researchers and organizations [157]. Taking LLaMa as an example, an LLM with 65B parameters, it took about 21 days on 2048 A100 GPUs to train the model once on a dataset of 1.4T tokens [10]. Furthermore, even inference can be prohibitively costly due to the model size, making it impractical for most hospitals to deploy these LAMs locally using their computing devices at hand.
- 计算:训练乃至微调当代LAMs在时间和资源消耗方面极其昂贵,这超出了大多数研究者和组织的预算[157]。以LLaMa为例,一个拥有650亿参数的LLM,在2048块A100 GPU上对1.4T token的数据集进行一次训练需要约21天[10]。此外,由于模型规模庞大,即使是推理也可能成本过高,使得大多数医院难以利用现有计算设备在本地部署这些LAMs。
- Reliability: The reliability threshold for translation into clinical practice is significantly higher [158]. Despite the impressive performance, LLMs are still far from reliable [159] and prone to hallucinate [4], [160], i.e., generating factuallyincorrect yet plausible content which misleads users. In addition, the unsatisfactory robustness of LAMs impairs their credibility. LLMs are known to be sensitive to prompts [161]. LLMs as well as LMs for other modalities remain vulnerable to out-of-distribution and adversarial examples [159], [162]. Improving the robustness of LAMs may require even more data [163]. Therefore, caution is highly required when using LAMs in healthcare practice to alleviate the potential danger of over-reliance. In addition, LAMs, especially LLMs were trained offline, in many clinical and health scenarios, using up-to-date information is critical.
- 可靠性:转化为临床应用的可靠性门槛显著更高 [158]。尽管大语言模型表现令人印象深刻,但其可靠性仍远未达标 [159],且易产生幻觉 [4][160],即生成事实错误但看似合理的内容误导用户。此外,语言与多模态模型 (LAMs) 欠佳的鲁棒性也损害了其可信度。众所周知,大语言模型对提示词极为敏感 [161],无论是大语言模型还是其他模态的语言模型,面对分布外样本和对抗样本时仍显脆弱 [159][162]。提升语言与多模态模型的鲁棒性可能需要更海量的数据 [163]。因此在医疗实践中使用语言与多模态模型需高度谨慎,以规避过度依赖的潜在风险。另外,语言与多模态模型(尤其是大语言模型)采用离线训练模式,而许多临床和健康场景中,使用最新信息至关重要。
- Privacy: First, LAMs have been reported to have excessive capacity to memorize their training data [164], and more importantly, it is viable to extract sensitive information in the memorized data using direct prompts [164], [165]. This was later mitigated by fine-tuning LAMs to refuse to answer such prompts [166]. However, Li et al. [166] also show that this mitigation can be bypassed through tricky prompts called jail breaking. Moreover, membership inference attacks [167] could reveal if a sample is in the training set, e.g., if a patient is in a cancer dataset. It has been recently demonstrated to work even on the latest large diffusion models [168].
- 隐私:首先,据报道LAMs具有过度记忆训练数据的能力[164],更重要的是,通过直接提示可以提取记忆数据中的敏感信息[164][165]。后来通过微调LAMs使其拒绝回答此类提示来缓解这一问题[166]。然而,Li等人[166]也表明,这种缓解措施可以通过称为越狱的巧妙提示绕过。此外,成员推理攻击[167]可以揭示样本是否在训练集中,例如患者是否在癌症数据集中。最近的研究表明,即使是最新的大型扩散模型[168]也受到此类攻击影响。
Second, the information provided by users to query LLMintegrated applications may be leaked. According to the data policy of OpenAI [169], they store the data that users provide to ChatGPT or DALL-E to train their models. Unfortunately, it has been reported that the stored personal information can be leaked incidentally by a “chat history” bug [170] or deliberately by indirect prompt injection attack [171].
其次,用户用于查询大语言模型集成应用的信息可能会泄露。根据OpenAI的数据政策[169],他们会存储用户提供给ChatGPT或DALL-E的数据以训练模型。不幸的是,据报道,存储的个人信息可能因"聊天历史"漏洞[170]意外泄露,或通过间接提示注入攻击[171]被故意泄露。
- Fairness: LAMs are data-driven approaches so they could learn any bias from the training data. Unfortunately, bias widely exists in the delivery of healthcare [172] and also the data collected in this process [173]–[175]. Machine learning models trained on such data are reported to mimic human bias against race [173], gender [174], politics [176], etc. In addition to these conventional biases, LLMs present language bias as well, i.e., they perform better in particular languages like English but worse in others [177] because training data is dominated by a few languages.
- 公平性: LAM作为数据驱动方法,可能从训练数据中习得任何偏见。遗憾的是,医疗保健服务领域普遍存在偏见 [172] ,其过程收集的数据亦然 [173]–[175] 。研究表明,基于此类数据训练的机器学习模型会复现针对种族 [173] 、性别 [174] 、政治立场 [176] 等的人类偏见。除传统偏见外,大语言模型还存在语言偏见——由于训练数据以英语等少数语言为主,其在这些语言中表现优异,但在其他语言中表现欠佳 [177] 。

Fig. 3: Future directions of LAMs in health informatics
图 3: 健康信息学中LAMs的未来方向
- Toxicity: Current LAMs, even LLMs explicitly trained with alignment, do not understand and represent human ethics [178]. LLMs are reported to produce hate speech [179] that causes offensive and psychologically harmful content and even incites violence. Secondly, LAMs may endorse unethical or harmful views and behaviors [178] and motivate users to perform. Lastly, LAMs can be used intentionally to facilitate harmful activities like spreading disinformation and encouraging criminal activities. Although some countermeasures like filtering are applied, they can be circumvented by prompt injection [177].
- 毒性:当前的语言辅助模型(LAM),即便是经过明确对齐训练的大语言模型,也无法理解并体现人类伦理 [178]。据报道,大语言模型会产生仇恨言论 [179],这些内容具有冒犯性、会造成心理伤害,甚至煽动暴力。其次,语言辅助模型可能支持不道德或有害的观点和行为 [178],并怂恿用户实施。最后,语言辅助模型可能被蓄意利用来助长有害活动,例如传播虚假信息和鼓励犯罪行为。虽然已采取过滤等应对措施,但这些措施可能被提示词注入(prompt injection)绕过 [177]。
- Transparency: Recently, some impactful LAMs like ChatGPT and Med-PaLM 2 chose not to disclose the complete technical details, the pre-trained models, and the used data. This makes it impossible for others to independently reproduce, improve upon and audit their methods. This transparency threat for LAMs can be more serious in healthcare as many medical data is private and models built upon them are not allowed to be open sourced.
- 透明度:近期,一些具有影响力的大语言模型(如 ChatGPT 和 Med-PaLM 2)选择不公开完整技术细节、预训练模型及所用数据。这使得他人无法独立复现、改进或审计其方法。在医疗领域,这种大语言模型的透明度威胁可能更为严重,因为许多医疗数据属于隐私信息,基于这些数据构建的模型不允许开源。
- Interpret ability: LAMs inherently lack interpret ability due to their extremely dense hidden layers. Even worse, the behavior of LAMs can be meaningless [180], [181], hard to predict [182], [183] and thus mysterious. For example, DALL-E 2 generates the images of physical objects with absurd prompts (e.g., “Apoploe ve sr re a it a is” for birds) [180]; the reasoning ability of LLMs can be improved by simply adding a text of “Let’s think step by step” to prompts [182]. There has been little progress towards explaining LAMs. Chain-of-thought prompts provide one way to reveal the intermediate reasoning steps behind an output, but it remains unclear whether the generated description of reasoning reflects the model’s true internal reasoning. Alternatively, mechanistic interpret ability methods [183] reverse-engineer the computation of LAMs to illuminate the model’s internal mechanism of reasoning.
- 可解释性:由于隐藏层极度稠密,LAMs天生缺乏可解释性。更糟的是,LAMs的行为可能毫无意义 [180]、[181],难以预测 [182]、[183],因而显得神秘。例如,DALL-E 2会基于荒谬提示生成物理对象图像(如用"Apoploe ve sr re a it a is"生成鸟类)[180];大语言模型的推理能力只需在提示中添加"Let's think step by step"文本即可提升 [182]。目前对LAMs的解释研究进展甚微。思维链提示虽能揭示输出背后的中间推理步骤,但生成的推理描述是否反映模型真实内部机制仍不明确。另一种方法是机械可解释性方法 [183],通过逆向工程解析LAMs的计算过程来阐明其内部推理机制。
- Sustainability: Despite many benefits, LAMs, if abused, will negatively impact the sustainability of our society. LAMs consume lots of computation resource [10] and energy [184] and emit tons of carbon [184] in all activities in their lifecycle (from training to deployment) because of their scale. For example, as estimated by [185], training a GPT-3 model consumes 1287 MWh and emits 552 tons of $\mathrm{CO_ {2}}$ . As the paradigm moves towards LAMs in healthcare, more and more research is expected to be conducted based on LAMs, which could be environmentally unfriendly due to the cost and carbon emission if right practices [184] are not established.
- 可持续性: 尽管益处众多, 但若滥用 LAM (Large Action Model), 将对社会可持续性造成负面影响。由于其规模, LAM 在生命周期各环节 (从训练到部署) 会消耗大量计算资源 [10] 和能源 [184], 并排放大量碳足迹 [184]。例如 [185] 估算, 训练一个 GPT-3 模型需消耗 1287 兆瓦时电力并排放 552 吨 $\mathrm{CO_ {2}}$。随着医疗健康领域向 LAM 范式转型, 预计将有更多研究基于 LAM 开展, 若未建立正确实践规范 [184], 其成本和碳排放可能导致环境不友好。
- Regulation: Regulation is needed to ensure responsible LAMs especially when some of the above issues cannot be technically addressed. Particularly, data collection and usage should be governed to protect the rights of data owner such as copyright, privacy and “being forgotten” [186]. The liability of LAMs’ creators/owners for the possible harm caused by the model’s output should be clarified. LAMs should be deployed in critical healthcare services only if regulatory approval is obtained and standardized safety assessment is passed. Regulation today is much behind the development of technology for LAMs, even for more general AI. Our webpage lists some major legislation for reference if readers want to know more about AI regulation.
- 监管: 需要制定监管措施以确保负责任的大语言模型应用,特别是当某些上述问题无法通过技术手段解决时。尤其需要规范数据收集和使用,以保护数据所有者的权利,如版权、隐私和"被遗忘权" [186]。应明确大语言模型创建者/所有者对模型输出可能造成危害的责任。只有在获得监管批准并通过标准化安全评估后,大语言模型才能部署在关键医疗服务中。当前监管措施远落后于大语言模型技术的发展,甚至落后于更通用的AI技术。我们的网页列出了一些主要立法供参考,如果读者想了解更多关于AI监管的信息。
V. FUTURE DIRECTIONS
V. 未来方向
In this section, we discuss some promising directions for future work to advance LAMs in the field of biomedical and health informatics, and our discussion below is mainly focused on two aspects: capability and responsibility.
在本节中,我们讨论了一些有前景的未来研究方向,以推动生物医学和健康信息学领域的 LAMs (Large Action Models) 发展。下面的讨论主要集中在能力和责任两个方面。
A. Capability
A. 能力
The first is to develop new LAMs for health informatics with better capability. The better capability here refers to either new abilities (e.g., a versatile medical task solver) or improved existing abilities (e.g., higher diagnostic accuracy), compared to the prior paradigm. Interestingly, some emergent new abilities may be unexpected or even unknown to humans [126]. Among numerous approaches to LAMs, some are perceived by us as most promising. Scaling up the size of dataset and model are two widely recognized approaches, but how to do it efficiently is of importance and far from solved. Furthermore, pre-training with varied tasks and modalities has achieved remarkable progress towards versatility in performing downstream tasks. A huge benefit is foreseeable if diverse knowledge that exists in these varied tasks (e.g., biology, medicine, etc.) and data modalities (e.g., medical corpora, imaging, physiological signals, etc.) can be incorporated into a single foundation model as a world model [187]. This world model boosts capability by complementing the information missing in an input, e.g., offering biomedical knowledge (acquired from other tasks) for diagnosing a disease when only the symptom data is given as input. Note that this is exactly how human doctors diagnose in practice, i.e., they comprehend information from the symptoms based on their medical knowledge acquired from learning and clinical practicing, i.e., multiple other tasks and sources.
首先是开发能力更强的新型健康信息学LAM。这里的"更强能力"是指相较于现有范式,要么具备新能力(如通用医疗任务解决器),要么提升现有能力(如更高诊断准确率)。值得注意的是,某些新涌现的能力可能是人类未曾预料甚至未知的[126]。在众多LAM开发路径中,我们认为以下几种最具前景:扩大数据集规模和模型规模是两种广为人知的方法,但如何高效实现仍至关重要且远未解决。此外,通过多任务多模态预训练,在下游任务通用性方面已取得显著进展。若能将这些多样化任务(如生物学、医学等)和数据模态(如医学文本、影像、生理信号等)中蕴含的知识整合到单个基础模型中形成世界模型[187],将带来巨大收益。这种世界模型通过补全输入缺失的信息来增强能力,例如当仅输入症状数据时,能提供(从其他任务获取的)生物医学知识来辅助疾病诊断。值得注意的是,这正是人类医生的实际诊断方式——他们基于从学习和临床实践(即其他多种任务和来源)获得的医学知识来理解症状信息。
The second is to reveal the hidden capabilities of existing pre-trained LAMs. A capability is hidden if it has been already developed in a pre-trained model but just unknown to users. Discovering hidden capabilities involves nothing but probing the model. A typical example is the substantially improved reasoning ability of LLMs by simply adding a line of “Let’s think step by step” to prompts [182]. There are still many unknowns about existing LAMs as they have become increasingly complex with enormously large sets of parameters. It is unclear whether the full potential of existing LAMs has been harnessed or not. Therefore, it is worth investigating if those pre-trained LAMs possess hidden capabilities about the health informatics tasks of interest. If so, discovering these hidden capabilities provides a solution or improvement to the tasks in a nearly cost-free way as it requires no further largescale training. Prompt engineering [188] as an emerging field is an effective approach to discovering hidden capabilities.
其次是揭示现有预训练LAMs的隐藏能力。如果某项能力已在预训练模型中形成但用户尚未知晓,则可视为隐藏能力。发现隐藏能力只需对模型进行探测,典型例子是通过在提示词中添加"Let's think step by step"就能大幅提升大语言模型的推理能力[182]。由于现有LAMs参数规模极其庞大且日益复杂,仍存在许多未知特性。目前尚不清楚现有LAMs的全部潜力是否已被充分挖掘,因此值得探究这些预训练模型是否具备与目标健康信息学任务相关的隐藏能力。若存在此类能力,发现它们就能以近乎零成本的方式(无需额外大规模训练)为任务提供解决方案或改进。作为新兴领域的提示工程(prompt engineering)[188]正是发现隐藏能力的有效途径。
B. Responsibility
B. 责任
Responsible LAMs for social good is paramount [189]. We suggest two complementary strategies: development and deployment, for future work to tackle challenges in LAM reliability, fairness, transparency, and beyond. Development strategy focuses on learning responsible LAMs, while deployment strategy emphasizes using LAMs responsibly.
开发造福社会的负责任LAM至关重要[189]。我们提出两项互补策略:开发策略与部署策略,以应对未来LAM在可靠性、公平性、透明度等方面的挑战。开发策略聚焦于学习负责任的LAM,而部署策略则强调负责任地使用LAM。
Technically, responsible LAMs can be developed through two perspectives: data and algorithms. As LAMs learn bias from training data, an intuitive counter measure is thus to mitigate bias in training data. It can be done by filtering biased data [190], increasing underrepresented populations’ data, etc. Unfortunately, how to efficiently inspect large-scale datasets remains challenging. Besides, training data should encompass diverse distributions to robustify the model against the distribution shifts in the wild, and human preference to align the model with human values. Some of them like human preference must be collected from human activities, while the rest can be also generated by other algorithms like data augmentation and generative models. Once we have highquality data, algorithms like RLHF and adversarial training can be adopted to exploit these data to acquire the desired properties for responsible LAMs.
从技术和算法两个角度可以开发出负责任的LAM。由于LAM会从训练数据中学习偏见,因此一个直观的应对措施就是减少训练数据中的偏见。这可以通过过滤有偏见的数据[190]、增加代表性不足群体的数据等方式实现。遗憾的是,如何高效检查大规模数据集仍具挑战性。此外,训练数据应涵盖多样化的分布,以使模型对现实中的分布变化具有鲁棒性,并通过人类偏好使模型与人类价值观保持一致。其中像人类偏好这类数据必须从人类活动中收集,而其他数据也可以通过数据增强和生成模型等算法生成。一旦获得高质量数据,就可以采用RLHF和对抗训练等算法来利用这些数据,使LAM具备负责任的特性。
In addition to training LAMs to be responsible, it is also vital to use LAMs in a responsible way. Efforts should be made to educate the users, especially those use LAMs for critical healthcare services, about the basics and limitations of LAMs being used. Human-LAM partnership should also be researched for the effective, efficient and responsible use of LAMs, including how to query/instruct LAMs by prompt engineering and assess/adopt the responses from LAMs. Besides, a comprehensive verification framework [191] covering various desired properties for LAMs is critical for assessing how irresponsible a LAM is, which is still lacking. We encourage future work to design methods to better evaluate, verify and benchmark LAMs. Last, rules and regulations should be implemented to govern the development, deployment and use of LAMs. This is a vital measure to enforce LAMs for social good and prevent anti-social usage. Overall, building responsible LAMs calls a closer collaboration in the future among academia, industry and government.
除了训练LAMs(Large Action Models)具备责任感外,负责任地使用LAMs同样至关重要。需要努力教育用户——尤其是那些将LAMs用于关键医疗服务的用户——了解所使用LAMs的基本原理和局限性。还应研究人机协作机制,以实现高效、精准且负责任的LAMs应用,包括如何通过提示工程(prompt engineering)查询/指令LAMs,以及如何评估/采纳LAMs的响应。此外,目前仍缺乏一个覆盖LAMs各项理想属性的综合验证框架[191],这对评估LAMs的不负责任程度至关重要。我们鼓励未来研究设计更好的方法来评估、验证和基准测试LAMs。最后,应制定规则和法规来规范LAMs的开发、部署和使用。这是确保LAMs造福社会并防止反社会用途的重要措施。总体而言,构建负责任的LAMs需要学术界、产业界和政府未来更紧密的协作。
VI. CONCLUSIONS
VI. 结论
We highlight an ongoing paradigm shift within AI community, which is fostering large AI models for transforming different biomedical and health sectors. The new paradigm aims to learn a versatile foundation model on a large-scale (multi-modal) dataset covering varied data distributions and learning tasks. Boundaries between different intelligent tasks, and even between different data modalities, are being dismantled. With generalist intelligence and more unknown capabilities activated, we believe large AI models will augment, instead of replacing, medical professionals and practitioners in the future. Human-AI cooperation will become pervasive. In this regard, the development of large AI models requires even closer and more intense collaboration between domain experts, as well as gradually established regulations.
我们注意到AI领域正在经历一场范式转变,即通过培育大型AI模型来变革不同生物医学和健康领域。这一新范式旨在基于覆盖多样化数据分布和学习任务的大规模(多模态)数据集,学习通用的基础模型。不同智能任务之间、甚至不同数据模态之间的界限正在被打破。随着通用智能和更多未知能力的激活,我们相信大型AI模型未来将增强而非取代医疗专业人员。人机协作将变得无处不在。在这方面,大型AI模型的开发需要领域专家之间更紧密深入的合作,以及逐步建立的监管规范。