Foundation models for generalist medical artificial intelligence
通用医疗人工智能的基础模型
https://doi.org/10.1038/s41586-023-05881-4
https://doi.org/10.1038/s41586-023-05881-4
Received: 3 November 2022
收稿日期:2022年11月3日
Accepted: 22 February 2023
录用日期:2023年2月22日
Published online: 12 April 2023 Check for updates
在线发表:2023年4月12日 检查更新
Michael Moor1,6, Oishi Banerjee2,6, Zahra Shakeri Hossein Abad3, Harlan M. Krumholz4, Jure Leskovec1, Eric J. Topol5,7 ✉ & Pranav Rajpurkar2,7 ✉
Michael Moor1,6, Oishi Banerjee2,6, Zahra Shakeri Hossein Abad3, Harlan M. Krumholz4, Jure Leskovec1, Eric J. Topol5,7 ✉ & Pranav Rajpurkar2,7 ✉
The exceptionally rapid development of highly flexible, reusable artificial intelligence (AI) models is likely to usher in newfound capabilities in medicine. We propose a new paradigm for medical AI, which we refer to as generalist medical AI (GMAI). GMAI models will be capable of carrying out a diverse set of tasks using very little or no task-specific labelled data. Built through self-supervision on large, diverse datasets, GMAI will flexibly interpret different combinations of medical modalities, including data from imaging, electronic health records, laboratory results, genomics, graphs or medical text. Models will in turn produce expressive outputs such as free-text explanations, spoken recommendations or image annotations that demonstrate advanced medical reasoning abilities. Here we identify a set of high-impact potential applications for GMAI and lay out specific technical capabilities and training datasets necessary to enable them. We expect that GMAI-enabled applications will challenge current strategies for regulating and validating AI devices for medicine and will shift practices associated with the collection of large medical datasets.
高度灵活、可复用的人工智能(AI)模型的异常快速发展,很可能为医学领域带来前所未有的能力。我们提出了一种新型医疗AI范式,称之为通用医疗AI(GMAI)。GMAI模型能够仅使用极少甚至无需特定任务的标注数据,就能执行多样化任务。通过在海量多样化数据集上进行自监督训练构建的GMAI,可灵活解读包括影像、电子健康档案、实验室结果、基因组学、图表及医疗文本等不同医疗模态数据的组合。这些模型将生成具有表现力的输出,如展现高级医学推理能力的自由文本解释、语音建议或图像标注。本文我们明确了GMAI一系列高影响力潜在应用场景,并详细阐述了实现这些应用所需的具体技术能力与训练数据集。我们预计,GMAI赋能的应用将挑战当前医疗AI设备的监管验证策略,并改变大规模医疗数据收集的实践方式。
Foundation models—the latest generation of AI models—are trained on massive, diverse datasets and can be applied to numerous downstream tasks1. Individual models can now achieve state-of-the-art performance on a wide variety of problems, ranging from answering questions about texts to describing images and playing video games . This versatility represents a stark change from the previous generation of AI models, which were designed to solve specific tasks, one at a time.
基础模型(Foundation models)——最新一代AI模型——经过海量多样化数据集训练,可应用于众多下游任务[1]。单个模型如今能在各类问题上实现最先进性能,涵盖文本问答、图像描述到电子游戏对战等领域。这种多功能性标志着与上一代AI模型的显著差异,后者仅能针对单一特定任务进行设计。
Driven by growing datasets, increases in model size and advances in model architectures, foundation models offer previously unseen abilities. For example, in 2020 the language model GPT-3 unlocked a new capability: in-context learning, through which the model carried out entirely new tasks that it had never explicitly been trained for, simply by learning from text explanations (or ‘prompts’) containing a few examples5. Additionally, many recent foundation models are able to take in and output combinations of different data modalities 4,6. For example, the recent Gato model can chat, caption images, play video games and control a robot arm and has thus been described as a generalist agent2. As certain capabilities emerge only in the largest models, it remains challenging to predict what even larger models will be able to accomplish 7.
在数据集不断增长、模型规模扩大以及模型架构进步的推动下,基础模型 (foundation model) 展现出前所未有的能力。例如,2020年语言模型GPT-3解锁了新能力:上下文学习 (in-context learning),该模型仅需通过包含少量示例的文本说明(或称"提示")进行学习,就能完成从未接受过专门训练的全新任务[5]。此外,许多最新基础模型能够处理并输出不同数据模态的组合[4,6]。例如,近期Gato模型既能聊天、为图像配文、玩电子游戏,又能控制机械臂,因此被称为通用智能体 (generalist agent)[2]。由于某些能力仅在最大规模的模型中显现,预测更庞大模型将实现哪些功能仍具挑战性[7]。
Although there have been early efforts to develop medical foundation models8–11, this shift has not yet widely permeated medical AI, owing to the difficulty of accessing large, diverse medical datasets, the complexity of the medical domain and the recency of this development. Instead, medical AI models are largely still developed with a task-specific approach to model development. For instance, a chest X-ray interpretation model may be trained on a dataset in which every image has been explicitly labelled as positive or negative for pneumonia, probably requiring substantial annotation effort. This model would only detect pneumonia and would not be able to carry out the complete diagnostic exercise of writing a comprehensive radiology report. This narrow, task-specific approach produces inflexible models, limited to carrying out tasks predefined by the training dataset and its labels. In current practice, such models typically cannot adapt to other tasks (or even to different data distributions for the same task) without being retrained on another dataset. Of the more than 500 AI models for clinical medicine that have received approval by the Food and Drug Administration, most have been approved for only 1 or 2 narrow tasks12.
尽管早期已有开发医疗基础模型 (foundation model) [8-11] 的努力,但由于获取大规模多样化医疗数据集的困难、医疗领域的复杂性以及这一发展的新近性,这种转变尚未在医疗AI领域广泛渗透。目前,医疗AI模型仍主要采用任务特定的开发方式。例如,一个胸部X光判读模型可能在每个图像都明确标注为肺炎阳性或阴性的数据集上训练,这通常需要大量标注工作。该模型仅能检测肺炎,无法完成撰写完整放射学报告的全面诊断工作。这种狭隘的任务特定方法产生的模型缺乏灵活性,仅限于执行训练数据集及其标签预定义的任务。在当前实践中,此类模型通常无法适应其他任务(甚至同一任务的不同数据分布),除非在另一数据集上重新训练。在美国食品药品监督管理局批准的500多个临床医学AI模型中,大多数仅获批执行1到2项狭窄任务[12]。
Here we outline how recent advances in foundation model research can disrupt this task-specific paradigm. These include the rise of multimodal architectures 13 and self-supervised learning techniques 14 that dispense with explicit labels (for example, language modelling 15 and contrastive learning16), as well as the advent of in-context learning capabilities 5.
在此我们概述基础模型 (foundation model) 研究的最新进展如何颠覆这种任务特定范式。这些进展包括:无需显式标签的多模态架构 [13] 和自监督学习技术 [14](例如语言建模 [15] 和对比学习 [16])的兴起,以及上下文学习能力 [5] 的出现。
These advances will instead enable the development of GMAI, a class of advanced medical foundation models. ‘Generalist’ implies that they will be widely used across medical applications, largely replacing task-specific models.
这些进步将推动通用医疗人工智能 (GMAI) 的发展,这是一类先进的医疗基础模型。"通用"意味着它们将在医疗应用中广泛使用,很大程度上取代特定任务的模型。
Inspired directly by foundation models outside medicine, we identify three key capabilities that distinguish GMAI models from conventional medical AI models (Fig. 1). First, adapting a GMAI model to a new task will be as easy as describing the task in plain English (or another language). Models will be able to solve previously unseen problems simply by having new tasks explained to them (dynamic task specification), without needing to be retrained3,5. Second, GMAI models can accept inputs and produce outputs using varying combinations of data modalities (for example, can take in images, text, laboratory results or any combination thereof). This flexible interactivity contrasts with the constraints of more rigid multimodal models, which always use predefined sets of modalities as input and output (for example, must always take in images, text and laboratory results together). Third, GMAI models will formally represent medical knowledge, allowing them to reason through previously unseen tasks and use medically accurate language to explain their outputs.
受医学领域外基础模型的直接启发,我们总结出通用医疗人工智能(GMAI)模型区别于传统医疗AI模型的三大核心能力(图1)。首先,GMAI模型只需用自然语言描述新任务即可完成适配(动态任务指定),无需重新训练即可解决前所未见的问题[3,5]。其次,GMAI模型能灵活处理任意数据模态组合的输入输出(如图像、文本、实验室结果的任意组合),这与必须使用预设模态组合的刚性多模态模型形成鲜明对比。第三,GMAI模型将具备形式化医学知识表征能力,可基于医学逻辑进行推理,并使用专业术语解释输出结果。
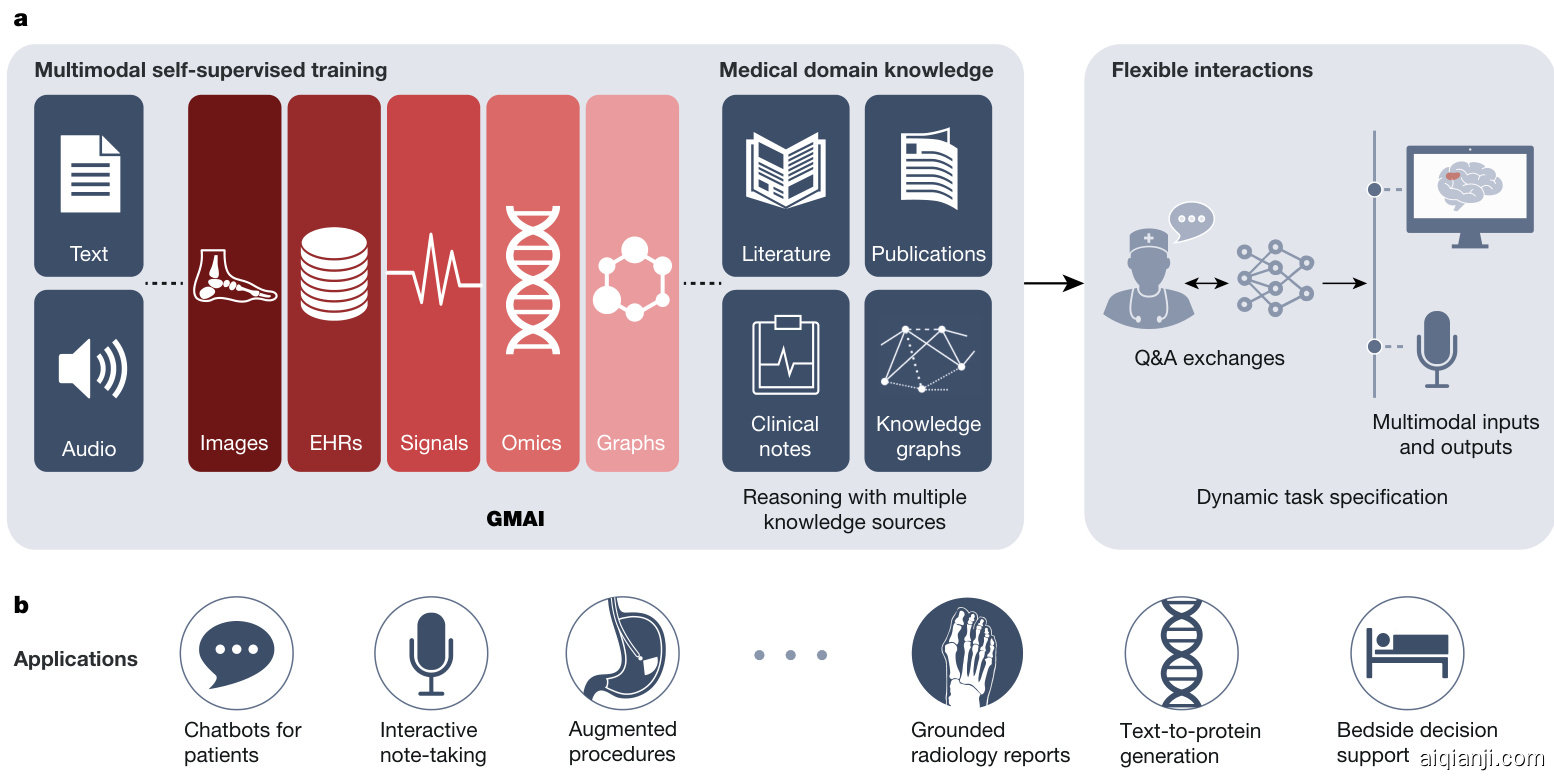
Regulations: Application approval; validation; audits; community-based challenges; analyses of biases, fairness and diversity Fig. 1 | Overview of a GMAI model pipeline. a, A GMAI model is trained on multiple medical data modalities, through techniques such as self-supervised learning. To enable flexible interactions, data modalities such as images or data from EHRs can be paired with language, either in the form of text or speech data. Next, the GMAI model needs to access various sources of medical knowledge to carry out medical reasoning tasks, unlocking a wealth of capabilities that can be used in downstream applications. The resulting GMAI model then carries
图 1: GMAI模型流程概述。a) GMAI模型通过自监督学习等技术在多种医疗数据模态上进行训练。为实现灵活交互,图像或电子健康记录(EHR)等数据模态可与语言(文本或语音数据形式)配对。接着,GMAI模型需要访问各类医学知识源以执行医疗推理任务,从而解锁可用于下游应用的丰富能力。最终形成的GMAI模型将执行...
We list concrete strategies for achieving this paradigm shift in medical AI. Furthermore, we describe a set of potentially high-impact applications that this new generation of models will enable. Finally, we point out core challenges that must be overcome for GMAI to deliver the clinical value it promises.
我们列出了实现医疗AI范式转变的具体策略。此外,我们描述了新一代模型将支持的一系列潜在高影响力应用。最后,我们指出了通用医疗人工智能(GMAI)要实现其承诺的临床价值必须克服的核心挑战。
The potential of generalist models in medical AI
通用人工智能模型在医学AI中的潜力
GMAI models promise to solve more diverse and challenging tasks than current medical AI models, even while requiring little to no labels for specific tasks. Of the three defining capabilities of GMAI, two enable flexible interactions between the GMAI model and the user: first, the ability to carry out tasks that are dynamically specified; and second, the ability to support flexible combinations of data modalities. The third capability requires that GMAI models formally represent medical domain knowledge and leverage it to carry out advanced medical reasoning. Recent foundation models already exhibit individual aspects of GMAI, by flexibly combining several modalities 2 or making it possible to dynamically specify a new task at test time5, but substantial advances are still required to build a GMAI model with all three capabilities. For example, existing models that show medical reasoning abilities (such as GPT-3 or PaLM) are not multimodal and do not yet generate reliably factual statements.
GMAI模型有望解决比当前医疗AI模型更多样化和更具挑战性的任务,甚至在特定任务中几乎不需要标注数据。GMAI的三个核心能力中有两个支持模型与用户之间的灵活交互:一是动态指定任务的能力,二是支持多模态数据灵活组合的能力。第三个能力要求GMAI模型能形式化表征医学领域知识,并利用其进行高级医学推理。近期的基础模型已展现出GMAI的部分特性,例如灵活组合多种模态[2]或在测试时动态指定新任务[5],但要构建同时具备这三种能力的GMAI模型仍需重大突破。例如,现有展现医学推理能力的模型(如GPT-3或PaLM)既非多模态,也无法稳定生成事实性陈述。
out tasks that the user can specify in real time. For this, the GMAI model can retrieve contextual information from sources such as knowledge graphs or databases, leveraging formal medical knowledge to reason about previously unseen tasks. b, The GMAI model builds the foundation for numerous applications across clinical disciplines, each requiring careful validation and regulatory assessment.
用户可以实时指定的任务。为此,GMAI模型可以从知识图谱或数据库等来源检索上下文信息,利用正式的医学知识对未见过的任务进行推理。b,GMAI模型为跨临床学科的众多应用奠定了基础,每个应用都需要经过严格的验证和监管评估。
Flexible interactions
灵活交互
GMAI offers users the ability to interact with models through custom queries, making AI insights easier for different audiences to understand and offering unprecedented flexibility across tasks and settings. In current practice, AI models typically handle a narrow set of tasks and produce a rigid, predetermined set of outputs. For example, a current model might detect a specific disease, taking in one kind of image and always outputting the likelihood of that disease. By contrast, a custom query allows users to come up with questions on the fly: “Explain the mass appearing on this head MRI scan. Is it more likely a tumour or an abscess?”. Furthermore, queries can allow users to customize the format of their outputs: “This is a follow-up MRI scan of a patient with glioblastoma. Outline any tumours in red”.
GMAI 赋予用户通过自定义查询与模型交互的能力,使不同受众更容易理解AI洞察,并在任务和场景中提供前所未有的灵活性。当前实践中,AI模型通常处理有限任务集并生成固定预设的输出。例如,现有模型可能仅能检测特定疾病,输入单一类型图像并始终输出该疾病的概率。相比之下,自定义查询允许用户即时提出问题:"解释这张头部MRI扫描中出现的肿块。是肿瘤还是脓肿的可能性更高?"此外,查询功能支持用户自定义输出格式:"这是胶质母细胞瘤患者的随访MRI扫描。用红色标出所有肿瘤轮廓"。
Custom queries will enable two key capabilities—dynamic task specification and multimodal inputs and outputs—as follows.
自定义查询将支持两项关键功能——动态任务指定和多模态输入输出——具体如下。
Dynamic task specification. Custom queries can teach AI models to solve new problems on the fly, dynamically specifying new tasks without requiring models to be retrained. For example, GMAI can answer highly specific, previously unseen questions: “Given this ultrasound, how thick is the gallbladder wall in millimetres?”. Un surprisingly, a GMAI model may struggle to complete new tasks that involve unknown concepts or path o logie s. In-context learning then allows users to teach the GMAI about a new concept with few examples: “Here are the medical histories of ten previous patients with an emerging disease, an infection with the Langya he nip a virus. How likely is it that our current patient is also infected with Langya he nip a virus?”17.
动态任务指定。自定义查询可以教会AI模型即时解决新问题,动态指定新任务而无需重新训练模型。例如,GMAI能够回答高度特定、前所未见的问题:"根据这张超声图,胆囊壁厚度是多少毫米?"。不出所料,GMAI模型可能在完成涉及未知概念或病理的新任务时遇到困难。上下文学习功能允许用户通过少量示例向GMAI教授新概念:"这是十位感染琅琊亨尼帕病毒新兴疾病患者的既往病史。我们当前患者同样感染琅琊亨尼帕病毒的可能性有多大?"[17]。
Multimodal inputs and outputs. Custom queries can allow users to include complex medical information in their questions, freely mixing modalities. For example, a clinician might include multiple images and laboratory results in their query when asking for a diagnosis. GMAI models can also flexibly incorporate different modalities into responses, such as when a user asks for both a text answer and an accompanying visualization. Following previous models such as Gato, GMAI models can combine modalities by turning each modality’s data into ‘tokens’, each representing a small unit (for example, a word in a sentence or a patch in an image) that can be combined across modalities. This blended stream of tokens can then be fed into a transformer architecture 18, allowing GMAI models to integrate a given patient’s entire history, including reports, waveform signals, laboratory results, genomic profiles and imaging studies.
多模态输入与输出。自定义查询功能允许用户在提问中整合复杂的医疗信息,自由混合多种模态。例如,临床医生在请求诊断时,可在查询中同时包含多张图像和实验室检测结果。GMAI模型也能灵活地将不同模态融入响应中,比如当用户同时要求文本回答和配套可视化图表时。借鉴Gato等先前模型,GMAI模型通过将每种模态数据转化为"token"来实现模态融合,每个token代表一个小单元(如句子中的单词或图像中的分块),这些单元可跨模态组合。这种混合token流随后被输入transformer架构[18],使GMAI模型能整合患者完整病史,包括报告、波形信号、实验室结果、基因组图谱和影像学研究。
Medical domain knowledge
医学领域知识
In stark contrast to a clinician, conventional medical AI models typically lack prior knowledge of the medical domain before they are trained for their particular tasks. Instead, they have to rely solely on statistical associations between features of the input data and the prediction target, without having contextual information (for example, about path o physiological processes). This lack of background makes it harder to train models for specific medical tasks, particularly when data for the tasks are scarce.
与传统临床医生形成鲜明对比的是,常规医疗AI模型在针对特定任务训练前通常缺乏医学领域的先验知识。它们只能完全依赖输入数据特征与预测目标之间的统计关联,而无法获取上下文信息(例如病理生理过程相关背景)。这种背景知识的缺失使得针对特定医疗任务训练模型变得更为困难,尤其在任务数据稀缺时。
GMAI models can address these shortcomings by formally representing medical knowledge. For example, structures such as knowledge graphs can allow models to reason about medical concepts and relationships between them. Furthermore, building on recent retrieval-based approaches, GMAI can retrieve relevant context from existing databases, in the form of articles, images or entire previous cases19,20.
GMAI模型能够通过形式化表示医学知识来解决这些缺陷。例如,知识图谱等结构可以让模型推理医学概念及其相互关系。此外,基于近期检索式方法的研究进展,GMAI可以从现有数据库中以文章、图像或完整历史病例[19,20]的形式检索相关上下文。
The resulting models can raise self-explanatory warnings: “This patient is likely to develop acute respiratory distress syndrome, because the patient was recently admitted with a severe thoracic trauma and because the patient’s partial pressure of oxygen in the arterial blood has steadily decreased, despite an increased inspired fraction of oxygen”.
生成的模型可以发出自解释性警告:"该患者很可能出现急性呼吸窘迫综合征,因为患者近期因严重胸部创伤入院,且尽管吸入氧浓度增加,患者的动脉血氧分压仍持续下降。"
As a GMAI model may even be asked to provide treatment recommendations, despite mostly being trained on observational data, the model’s ability to infer and leverage causal relationships between medical concepts and clinical findings will play a key role for clinical applicability 21.
由于GMAI模型可能被要求提供治疗建议,尽管其主要基于观察性数据进行训练,但该模型推断并利用医学概念与临床发现之间因果关系的能力,对临床适用性起着关键作用 [21]。
Finally, by accessing rich molecular and clinical knowledge, a GMAI model can solve tasks with limited data by drawing on knowledge of related problems, as exemplified by initial works on AI-based drug re purposing 22.
最后,通过获取丰富的分子和临床知识,GMAI模型能够借助相关问题的知识来解决数据有限的任务,基于AI的药物重定位初步研究[22]就体现了这一点。
Use cases of GMAI
GMAI的应用场景
We present six potential use cases for GMAI that target different user bases and disciplines, although our list is hardly exhaustive. Although there have already been AI efforts in these areas, we expect GMAI will enable comprehensive solutions for each problem.
我们提出了GMAI的六个潜在应用场景,针对不同的用户群体和学科领域,尽管这份清单远非详尽无遗。虽然这些领域已有AI技术的尝试,但我们预计GMAI将为每个问题提供全面的解决方案。
Grounded radiology reports. GMAI enables a new generation of versatile digital radiology assistants, supporting radiologists throughout their workflow and markedly reducing workloads. GMAI models can automatically draft radiology reports that describe both abnormalities and relevant normal findings, while also taking into account the patient’s history. These models can provide further assistance to clinicians by pairing text reports with interactive visualization s, such as by highlighting the region described by each phrase. Radiologists can also improve their understanding of cases by chatting with GMAI models: “Can you highlight any new multiple sclerosis lesions that were not present in the previous image?”.
基于实际的放射学报告。GMAI支持新一代多功能数字放射学助手,协助放射科医生完成整个工作流程,显著减少工作量。GMAI模型能自动起草放射学报告,描述异常和相关正常发现,同时考虑患者病史。这些模型还能通过将文本报告与交互式可视化配对(例如高亮每个短语描述的区域)为临床医生提供进一步帮助。放射科医生还可通过与GMAI模型对话加深对病例的理解:"能否高亮显示之前图像中未出现的多发性硬化新病灶?"
A solution needs to accurately interpret various radiology modalities, noticing even subtle abnormalities. Furthermore, it must integrate information from a patient’s history, including sources such as indications, laboratory results and previous images, when describing an image. It also needs to communicate with clinicians using multiple modalities, providing both text answers and dynamically annotated images. To do so, it must be capable of visual grounding, accurately pointing out exactly which part of an image supports any statement. Although this may be achieved through supervised learning on expert-labelled images, explain ability methods such as Grad-CAM could enable self-supervised approaches, requiring no labelled data23.
解决方案需要准确解读各类放射学模态(Modality),甚至能察觉细微异常。同时,在描述影像时必须整合患者病史信息,包括检查指征、实验室结果和既往影像等数据源。该系统还需支持多模态临床沟通,既能提供文本回答,又能生成动态标注图像。为此,它必须具备视觉定位(Visual Grounding)能力,能精确指出图像中支持诊断结论的具体区域。虽然可通过专家标注图像的监督学习实现,但Grad-CAM等可解释性方法或能实现无需标注数据的自监督学习[23]。
Augmented procedures. We anticipate a surgical GMAI model that can assist surgical teams with procedures: “We cannot find the intestinal rupture. Check whether we missed a view of any intestinal section in the visual feed of the last 15 minutes”. GMAI models may carry out visualization tasks, potentially annotating video streams of a procedure in real time. They may also provide information in spoken form, such as by raising alerts when steps of a procedure are skipped or by reading out relevant literature when surgeons encounter rare anatomical phenomena.
增强手术流程。我们期待一种能够协助手术团队的外科GMAI模型:"我们找不到肠道破裂处。请检查过去15分钟的视频画面中是否遗漏了任何肠段视角"。GMAI模型可执行可视化任务,实时标注手术视频流。它们还能通过语音提供信息,例如在跳过手术步骤时发出警报,或在外科医生遇到罕见解剖现象时朗读相关文献[20]。
This model can also assist with procedures outside the operating room, such as with endoscopic procedures. A model that captures topographic context and reasons with anatomical knowledge can draw conclusions about previously unseen phenomena. For instance, it could deduce that a large vascular structure appearing in a duo de nos copy may indicate an a or to duodenal fistula (that is, an abnormal connection between aorta and the small intestine), despite never having encountered one before (Fig. 2, right panel). GMAI can solve this task by first detecting the vessel, second identifying the anatomical location, and finally considering the neighbouring structures.
该模型还可协助手术室外的操作流程,例如内窥镜检查。具备地形语境理解能力并结合解剖学知识推理的模型,能够对未知现象做出判断。例如,即使从未遇到过主动脉十二指肠瘘(即主动脉与小肠间的异常连接),它也能推断出十二指肠镜检中出现的粗大血管结构可能提示该症状(图2右面板)。通用医疗人工智能(GMAI)可通过三个步骤解决该问题:先检测血管,再识别解剖位置,最后分析毗邻结构。
A solution needs to integrate vision, language and audio modalities, using a vision–audio–language model to accept spoken queries and carry out tasks using the visual feed. Vision–language models have already gained traction, and the development of models that incorporate further modalities is merely a question of time24. Approaches may build on previous work that combines language models and knowledge graphs25,26 to reason step-by-step about surgical tasks. Additionally, GMAI deployed in surgical settings will probably face unusual clinical phenomena that cannot be included during model development, owing to their rarity, a challenge known as the long tail of unseen conditions 27. Medical reasoning abilities will be crucial for both detecting previously unseen outliers and explaining them, as exemplified in Fig. 2.
解决方案需要整合视觉、语言和音频模态,使用视觉-音频-语言模型来接收语音查询并利用视觉输入执行任务。视觉-语言模型已获得广泛关注,而开发融合更多模态的模型只是时间问题 [24]。相关方法可以基于先前结合大语言模型和知识图谱 [25,26] 的工作,逐步推理外科手术任务。此外,在外科场景中部署的通用医疗人工智能 (GMAI) 可能会遇到因罕见性而无法在模型开发阶段涵盖的特殊临床现象,这一挑战被称为未预见情况的长尾问题 [27]。如图 2 所示,医疗推理能力对于检测和解释这些未见异常值至关重要。
Bedside decision support. GMAI enables a new class of bedside clinical decision support tools that expand on existing AI-based early warning systems, providing more detailed explanations as well as recommendations for future care. For example, GMAI models for bedside decision support can leverage clinical knowledge and provide free-text explanations and data summaries: “Warning: This patient is about to go into shock. Her circulation has de stabilized in the last 15 minutes . Recommended next steps: ”.
床边决策支持。GMAI能够实现一类新型床边临床决策支持工具,这类工具在现有基于AI(Artificial Intelligence)的早期预警系统基础上进行了扩展,可提供更详细的解释以及未来护理建议。例如,用于床边决策支持的GMAI模型可以整合临床知识,并生成自由文本解释和数据摘要:"警告:该患者即将进入休克状态。过去15分钟内其循环系统已出现失代偿 <数据摘要链接>。建议后续步骤:<检查清单链接>"
A solution needs to parse electronic health record (EHR) sources (for example, vital and laboratory parameters, and clinical notes) that involve multiple modalities, including text and numeric time series data. It needs to be able to summarize a patient’s current state from raw data, project potential future states of the patient and recommend treatment decisions. A solution may project how a patient’s condition will change over time, by using language modelling techniques to predict their future textual and numeric records from their previous data. Training datasets may specifically pair EHR time series data with eventual patient outcomes, which can be collected from discharge reports and ICD (International Classification of Diseases) codes. In addition, the model must be able to compare potential treatments and estimate their effects, all while adhering to therapeutic guidelines and other relevant policies. The model can acquire the necessary knowledge through clinical knowledge graphs and text sources such as academic
一种解决方案需要解析涉及多种模态的电子健康记录(EHR)数据源(例如生命体征和实验室参数、临床笔记),包括文本和数值时间序列数据。它需要能够从原始数据中总结患者的当前状态,预测患者的潜在未来状态并推荐治疗决策。该解决方案可以通过使用语言建模技术,根据患者既往数据预测其未来的文本和数值记录,从而推演患者病情随时间的变化趋势。训练数据集可以专门将EHR时间序列数据与最终患者结局(可从出院报告和ICD(国际疾病分类)代码中收集)进行配对。此外,该模型必须能够比较潜在治疗方案并评估其效果,同时遵守治疗指南和其他相关政策。模型可通过临床知识图谱和学术文献等文本来源获取必要知识。
Perspective
视角

Fig. 2 | Illustration of three potential applications of GMAI. a, GMAI could enable versatile and self-explanatory bedside decision support. b, Grounded radiology reports are equipped with clickable links for visualizing each finding. c, GMAI has the potential to classify phenomena that were never encountered before during model development. In augmented procedures, a rare outlier finding is explained with step-by-step reasoning by leveraging medical domain knowledge and topographic context. The presented example is inspired by a case report58. Image of the fistula in panel c adapted from ref. 58, CC BY 3.0.
图 2 | GMAI的三种潜在应用场景。a) GMAI可实现多功能且自解释的床边决策支持。b) 基于证据的放射学报告配备可点击链接用于可视化每个发现。c) GMAI具备对模型开发期间从未遇到过现象进行分类的潜力。在增强诊疗流程中,通过利用医学领域知识和解剖学背景,采用逐步推理方式解释罕见异常发现。展示案例受病例报告[58]启发。图c中的瘘管图像改编自参考文献[58],遵循CC BY 3.0协议。
publications, educational textbooks, international guidelines and local policies. Approaches may be inspired by REALM, a language model that answers queries by first retrieving a single relevant document and then extracting the answer from it, making it possible for users to identify the exact source of each answer20.
出版物、教育教材、国际指南和地方政策。这些方法可能受到REALM的启发,该大语言模型通过先检索单个相关文档再从文档中提取答案来响应用户查询,使用户能够准确识别每个答案的来源 [20]。
Interactive note-taking. Documentation represents an integral but labour-intensive part of clinical workflows. By monitoring electronic patient information as well as clinician–patient conversations, GMAI models will preemptively draft documents such as electronic notes and discharge reports for clinicians to merely review, edit and approve. Thus, GMAI can substantially reduce administrative overhead, allowing clinicians to spend more time with patients.
交互式笔记记录。文档工作是临床工作流程中不可或缺但劳动密集型的一部分。通过监控电子患者信息及医患对话,GMAI模型将预先起草电子病历、出院报告等文档,供临床医生仅需审阅、编辑和批准。因此,GMAI能显著减少行政负担,让临床医生有更多时间与患者相处。
A GMAI solution can draw from recent advances in speech-to-text models28, specializing techniques for medical applications. It must accurately interpret speech signals, understanding medical jargon and abbreviations. Additionally, it must contextual ize speech data with information from the EHRs (for example, diagnosis list, vital parameters and previous discharge reports) and then generate free-text notes or reports. It will be essential to obtain consent before recording any interaction with a patient. Even before such recordings are collected in large numbers, early note-taking models may already be developed by leveraging clinician–patient interaction data collected from chat applications.
GMAI解决方案可以借鉴语音转文本模型( speech-to-text models ) [28]的最新进展,并针对医疗应用进行专门优化。该系统需要准确解析语音信号,理解医学术语和缩写。此外,必须结合电子健康档案(EHRs)中的信息(如诊断清单、生命体征参数和既往出院报告)对语音数据进行情境化处理,进而生成自由文本形式的病历记录或报告。在录制任何医患互动前必须获得患者同意。即使尚未大规模采集此类录音数据,早期版本的病历记录模型仍可通过利用聊天应用程序收集的医患互动数据进行开发。
Chatbots for patients. GMAI has the potential to power new apps for patient support, providing high-quality care even outside clinical settings. For example, GMAI can build a holistic view of a patient’s condition using multiple modalities, ranging from unstructured descriptions of symptoms to continuous glucose monitor readings to patient-provided medication logs. After interpreting these heterogeneous types of data, GMAI models can interact with the patient, providing detailed advice and explanations. Importantly, GMAI enables accessible communication, providing clear, readable or audible information on the patient’s schedule. Whereas similar apps rely on clinicians to offer personalized support at present , GMAI promises to reduce or even remove the need for human expert intervention, making apps available on a larger scale. As with existing live chat applications, users could still engage with a human counsellor on request.
面向患者的聊天机器人。GMAI有望为患者支持类应用提供新动力,在临床环境之外也能提供高质量护理服务。例如,GMAI可通过多模态数据(包括非结构化的症状描述、持续血糖监测读数以及患者提供的用药记录)构建患者健康状况的全景视图。在解析这些异构数据后,GMAI模型能与患者互动,提供细致的建议与解释。值得注意的是,GMAI能实现无障碍沟通,按照患者的时间安排提供清晰可读或可听的医疗信息。当前类似应用仍需临床医生提供个性化支持,而GMAI有望减少甚至消除对人类专家介入的依赖,从而推动这类应用的大规模普及。与现有实时聊天应用类似,用户仍可根据需求选择与人工顾问沟通。
Building patient-facing chatbots with GMAI raises two special challenges. First, patient-facing models must be able to communicate clearly with non-technical audiences, using simple, clear language without sacrificing the accuracy of the content. Including patient-focused medical texts in training datasets may enable this capability. Second, these models need to work with diverse data collected by patients. Patient-provided data may represent unusual modalities; for example, patients with strict dietary requirements may submit before-and-after photos of their meals so that GMAI models can automatically monitor their food intake. Patient-collected data are also likely to be noisier compared to data from a clinical setting, as patients may be more prone to error or use less reliable devices when collecting data. Again, incorporating relevant data into training can help overcome this challenge. However, GMAI models also need to monitor their own uncertainty and take appropriate action when they do not have enough reliable data.
构建面向患者的聊天机器人时,GMAI面临两大特殊挑战。首先,面向患者的模型必须能用简单清晰的语言与非技术受众沟通,同时确保内容准确性。在训练数据集中加入以患者为中心的医学文本可能有助于实现这一能力。其次,这些模型需要处理患者提供的多样化数据。患者提交的数据可能包含非常规形式,例如有严格饮食要求的患者可能提交餐前餐后照片,使GMAI模型能自动监测其食物摄入量。与临床环境采集的数据相比,患者收集的数据通常噪声更多,因为患者在采集时更容易出错或使用可靠性较低的设备。同样,将相关数据纳入训练有助于应对这一挑战。不过,GMAI模型还需监测自身不确定性,在缺乏足够可靠数据时采取适当措施。
Text-to-protein generation. GMAI could generate protein amino acid sequences and their three-dimensional structures from textual prompts. Inspired by existing generative models of protein sequences 30, such a model could condition its generation on desired functional properties. By contrast, a biomedical ly knowledgeable GMAI model promises protein design interfaces that are as flexible and easy to use as concurrent text-to-image generative models such as Stable Diffusion or DALL-E31,32. Moreover, by unlocking in-context learning capabilities, a GMAI-based text-to-protein model may be prompted with a handful of example instructions paired with sequences to dynamically define a new generation task, such as the generation of a protein that binds with high affinity to a specified target while fulfilling additional constraints.
文本到蛋白质生成。GMAI可以根据文本提示生成蛋白质氨基酸序列及其三维结构。受现有蛋白质序列生成模型[30]的启发,这种模型可以基于所需功能特性进行条件生成。相比之下,具备生物医学知识的GMAI模型有望提供与Stable Diffusion或DALL-E[31,32]等当前文本到图像生成模型同样灵活易用的蛋白质设计界面。此外,通过解锁上下文学习能力,基于GMAI的文本到蛋白质模型可以通过少量示例指令与配对的序列动态定义新的生成任务,例如生成一种在满足额外约束条件的同时与指定靶标高亲和力结合的蛋白质。
There have already been early efforts to develop foundation models for biological sequences 33,34, including RF diffusion, which generates proteins on the basis of simple specifications (for example, a binding target)35. Building on this work, GMAI-based solution can incorporate both language and protein sequence data during training to offer a versatile text interface. A solution could also draw on recent advances in multimodal AI such as CLIP, in which models are jointly trained on paired data of different modalities 16. When creating such a training dataset, individual protein sequences must be paired with relevant text passages (for example, from the body of biological literature) that describe the properties of the proteins. Large-scale initiatives, such as UniProt, that map out protein functions for millions of proteins, will be indispensable for this effort36.
已有早期研究致力于开发面向生物序列的基础模型[33,34],例如能根据简单参数(如结合靶点)生成蛋白质的RF diffusion技术[35]。基于这些成果,采用GMAI的解决方案可在训练过程中同时整合语言和蛋白质序列数据,从而提供多功能文本交互界面。该方案还可借鉴多模态AI(如CLIP模型)的最新进展——这类模型通过不同模态的配对数据进行联合训练[16]。构建此类训练数据集时,需将单个蛋白质序列与描述其特性的相关文本段落(例如来自生物文献的内容)进行配对。UniProt等绘制数百万种蛋白质功能图谱的大规模项目,对此项工作至关重要[36]。
Opportunities and challenges of GMAI
通用人工智能的机遇与挑战
GMAI has the potential to affect medical practice by improving care and reducing clinician burnout. Here we detail the over arching advantages of GMAI models. We also describe critical challenges that must be addressed to ensure safe deployment, as GMAI models will operate in particularly high-stakes settings, compared to foundation models in other fields.
GMAI有潜力通过改善医疗服务和减少临床医生职业倦怠来影响医疗实践。在此我们详述GMAI模型的总体优势。同时我们也必须指出,与其他领域的基础模型相比,GMAI模型将在特别高风险的场景中运行,因此需要解决关键挑战以确保安全部署。
Paradigm shifts with GMAI
通用人工智能(GMAI)带来的范式转变
Control l ability. GMAI allows users to finely control the format of its outputs, making complex medical information easier to access and understand. For example, there will be GMAI models that can rephrase natural language responses on request. Similarly, GMAI-provided visualizations may be carefully tailored, such as by changing the viewpoint or labelling important features with text. Models can also potentially adjust the level of domain-specific detail in their outputs or translate them into multiple languages, communicating effectively with diverse users. Finally, GMAI’s flexibility allows it to adapt to particular regions or hospitals, following local customs and policies. Users may need formal instruction on how to query a GMAI model and to use its outputs most effectively.
可控性。GMAI允许用户精细控制其输出格式,使复杂医疗信息更易于获取和理解。例如,部分GMAI模型能根据要求重新表述自然语言回复。类似地,GMAI提供的可视化内容可进行细致定制,如调整观察视角或用文本标注关键特征。模型还能动态调节输出内容的专业细节层级,或将其翻译成多种语言,从而与不同用户高效沟通。最后,GMAI的灵活性使其能适配特定地区或医院,遵循当地惯例和政策。用户可能需要接受正式指导,以掌握如何查询GMAI模型并最有效地使用其输出结果。
Adaptability. Existing medical AI models struggle with distribution shifts, in which distributions of data shift owing to changes in technologies, procedures, settings or populations 37,38. However, GMAI can keep pace with shifts through in-context learning. For example, a hospital can teach a GMAI model to interpret X-rays from a brandnew scanner simply by providing prompts that show a small set of examples. Thus, GMAI can adapt to new distributions of data on the fly, whereas conventional medical AI models would need to be retrained on an entirely new dataset. At present, in-context learning is observed predominantly in large language models39. To ensure that GMAI can adapt to changes in context, a GMAI model backbone needs to be trained on extremely diverse data from multiple, complementary sources and modalities. For instance, to adapt to emerging variants of coronavirus disease 2019, a successful model can retrieve characteristics of past variants and update them when confronted with new context in a query. For example, a clinician might say, “Check these chest X-rays for Omicron pneumonia. Compared to the Delta variant, consider infiltrates surrounding the bronchi and blood vessels as indicative signs”40.
适应性。现有医疗AI模型难以应对数据分布偏移问题,即因技术、操作流程、环境或人群变化导致的数据分布变化[37,38]。而通用医疗AI(GMAI)可通过上下文学习实时适应这些变化。例如医院只需提供少量新扫描仪生成的X光片示例作为提示,就能教会GMAI模型解读该设备的成像结果。这种即时适应能力使GMAI能动态应对新数据分布,而传统医疗AI模型需要完全重新训练。目前上下文学习主要见于大语言模型[39]。为确保GMAI具备情境适应能力,其模型主干需通过多源异构数据进行训练。以新冠肺炎变异株为例,优秀模型应能检索历史毒株特征,并在遇到新变异株查询时更新认知。例如临床医生可提示:"检查这些X光片是否显示奥密克戎肺炎,与德尔塔毒株相比,需将支气管和血管周围浸润视为指征性表现"[40]。
Although users can manually adjust model behaviour through prompts, there may also be a role for new techniques to automatically incorporate human feedback. For example, users may be able to rate or comment on each output from a GMAI model, much as users rate outputs of ChatGPT (released by OpenAI in 2022), an AI-powered chat interface. Such feedback can then be used to improve model behaviour, following the example of Instruct GP T, a model created by using human feedback to refine GPT-3 through reinforcement learning41.
虽然用户可以通过提示词手动调整模型行为,但也可能需要新技术来自动整合人类反馈。例如,用户可以像评价 ChatGPT (OpenAI 于 2022 年发布的 AI 聊天界面) 的输出那样,对 GMAI 模型的每个输出进行评分或评论。这类反馈可用于改进模型行为,例如 Instruct GPT 就通过人类反馈结合强化学习[41]对 GPT-3 进行了优化。
Applicability. Large-scale AI models already serve as the foundation for numerous downstream applications. For instance, within months after its release, GPT-3 powered more than 300 apps across various industries 42. As a promising early example of a medical foundation model, CheXzero can be applied to detect dozens of diseases in chest X-rays without being trained on explicit labels for these diseases9. Likewise, the shift towards GMAI will drive the development and release of large-scale medical AI models with broad capabilities, which will form the basis for various downstream clinical applications. Many applications will interface with the GMAI model itself, directly using its final outputs. Others may use intermediate numeric representations, which GMAI models naturally generate in the process of producing outputs, as inputs for small specialist models that can be cheaply built for specific tasks. However, this flexible applicability can act as a double-edged sword, as any failure mode that exists in the foundation model will be propagated widely throughout the downstream applications.
适用性。大规模AI模型已成为众多下游应用的基础。例如,GPT-3发布数月内就支撑了跨行业的300多个应用[42]。作为医疗基础模型的早期范例,CheXzero无需针对特定疾病进行标注训练,即可检测胸片中的数十种病症[9]。同样,向通用医疗人工智能(GMAI)的转型将推动具备广泛能力的大规模医疗AI模型的研发与发布,这些模型将成为各类下游临床应用的基础。部分应用会直接对接GMAI模型本身,使用其最终输出结果;另一些则可能利用GMAI模型生成输出过程中产生的中间数值表征,作为针对特定任务低成本构建的小型专科模型的输入。然而这种灵活性犹如双刃剑——基础模型中存在的任何故障模式都将通过下游应用广泛传播。
Challenges of GMAI
GMAI的挑战
Validation. GMAI models will be uniquely difficult to validate, owing to their unprecedented versatility. At present, AI models are designed for specific tasks, so they need to be validated only for those predefined use cases (for example, diagnosing a particular type of cancer from a brain MRI). However, GMAI models can carry out previously unseen tasks set forth by an end user for the first time (for example, diagnosing any disease in a brain MRI), so it is categorically more challenging to anticipate all of their failure modes. Developers and regulators will be responsible for explaining how GMAI models have been tested and what use cases they have been approved for. GMAI interfaces themselves should be designed to raise ‘off-label usage’ warnings on entering uncharted territories, instead of confidently fabricating inaccurate information. More generally, GMAI’s uniquely broad capabilities require regulatory foresight, demanding that institutional and governmental policies adapt to the new paradigm, and will also reshape insurance arrangements and liability assignment.
验证。GMAI模型将因其前所未有的多功能性而面临独特的验证难题。当前AI模型专为特定任务设计,仅需针对预定义用例进行验证(例如通过脑部MRI诊断特定类型癌症)。然而,GMAI模型能首次执行终端用户提出的全新任务(例如通过脑部MRI诊断任意疾病),因此预判所有故障模式具有本质性挑战。开发者和监管机构需负责说明GMAI模型的测试方法及获批用例范围。GMAI界面设计应能在进入未知领域时触发"超范围使用"警告,而非自信地生成错误信息。更广泛而言,GMAI独特的广泛能力需要监管前瞻性,要求机构和政府政策适应新范式,并将重塑保险安排与责任划分机制。
Verification. Compared to conventional AI models, GMAI models can handle unusually complex inputs and outputs, making it more difficult for clinicians to determine their correctness. For example, conventional models may consider only an imaging study or a whole-slide image when classifying a patient’s cancer. In each case, a sole radiologist or pathologist could verify whether the model’s outputs are correct. However, a GMAI model may consider both kinds of inputs and may output an initial classification, a recommendation for treatment and a multimodal justification involving visualization s, statistical analyses and references to the literature. In this case, a multidisciplinary panel (consisting of radiologists, pathologists, on colo gist s and additional specialists) may be needed to judge the GMAI’s output. Fact-checking GMAI outputs therefore represents a serious challenge, both during validation and after models are deployed.
验证。与传统AI模型相比,GMAI模型能处理异常复杂的输入和输出,这使得临床医生更难判断其正确性。例如,传统模型在对患者癌症进行分类时可能仅考虑影像学检查或全切片图像。在这两种情况下,仅需一名放射科医师或病理学家即可验证模型输出的正确性。然而,GMAI模型可能同时考虑这两种输入,并输出初始分类、治疗建议以及包含可视化、统计分析和文献引用的多模态论证。此时,可能需要由多学科专家组(包括放射科医师、病理学家、肿瘤学家及其他专科医生)来评估GMAI的输出。因此,无论是在验证阶段还是模型部署后,对GMAI输出进行事实核查都构成重大挑战。
Creators can make it easier to verify GMAI outputs by incorporating explain ability techniques. For example, a GMAI’s outputs might include clickable links to supporting passages in the literature, allowing clinicians to more efficiently verify GMAI predictions. Other strategies for fact-checking a model’s output without human expertise have recently been proposed43. Finally, it is vitally important that GMAI models accurately express uncertainty, thereby preventing overconfident statements in the first place.
创作者可以通过融入可解释性技术,使验证GMAI输出变得更加容易。例如,GMAI的输出可能包含可点击的链接,指向文献中的支持段落,从而让临床医生更高效地验证GMAI的预测。近期还提出了其他无需人类专业知识即可核查模型输出的策略[43]。最重要的是,GMAI模型必须准确表达不确定性,从而从一开始就避免过度自信的陈述。
Social biases. Previous work has already shown that medical AI models can perpetuate biases and cause harm to marginalized populations. They can acquire biases during training, when datasets either underrepresent certain groups of patients or contain harmful correlations 44,45. These risks will probably be even more pronounced when developing GMAI. The unprecedented scale and complexity of the necessary training datasets will make it difficult to ensure that they are free of undesirable biases. Although biases already pose a challenge for conventional AI in health, they are of particular relevance for GMAI as a recent large-scale evaluation showed that social bias can increase with model scale46.
社会偏见。先前研究已证实,医疗AI模型可能延续偏见并对边缘群体造成伤害。这些偏见通常产生于训练阶段,当数据集对某些患者群体代表性不足或包含有害关联时[44,45]。开发通用医疗AI(GMAI)时,这类风险可能更为突出。由于所需训练数据集具有前所未有的规模和复杂性,确保其完全消除不良偏见将极为困难。虽然偏见已是传统医疗AI面临的挑战,但对GMAI尤为关键——近期大规模评估表明,社会偏见可能随模型规模扩大而加剧[46]。
GMAI models must be thoroughly validated to ensure that they do not under perform on particular populations such as minority groups. Furthermore, models will need to undergo continuous auditing and regulation even after deployment, as new issues will arise as models encounter new tasks and settings. Prize-endowed competitions could in centi viz e the AI community to further scrutinize GMAI models. For instance, participants might be rewarded for finding prompts that produce harmful content or expose other failure modes. Swiftly identifying and fixing biases must be an utmost priority for developers, vendors and regulators.
GMAI模型必须经过全面验证,以确保其在少数群体等特定人群上不会表现不佳。此外,即使部署后模型仍需持续接受审计和监管,因为随着模型遇到新任务和场景,新问题将不断出现。设立奖金的竞赛可以激励AI社区进一步审查GMAI模型。例如,参与者可能因发现生成有害内容或暴露其他故障模式的提示而获得奖励。快速识别并修正偏差必须是开发者、供应商和监管机构的首要任务。
Perspective
视角
Privacy. The development and use of GMAI models poses serious risks to patient privacy. GMAI models may have access to a rich set of patient characteristics, including clinical measurements and signals, molecular signatures and demographic information as well as behavioural and sensory tracking data. Furthermore, GMAI models will probably use large architectures, but larger models are more prone to memorizing training data and directly repeating it to users47. As a result, there is a serious risk that GMAI models could expose sensitive patient data in training datasets. By means of de identification and limiting the amount of information collected for individual patients, the damage caused by exposed data can be reduced.
隐私。GMAI模型的开发和使用对患者隐私构成严重风险。GMAI模型可能获取丰富的患者特征数据,包括临床测量指标、分子特征、人口统计信息以及行为与感官追踪数据。此外,GMAI模型很可能采用大型架构,但模型规模越大越容易记忆训练数据并直接向用户复述[47]。这导致GMAI模型存在暴露训练数据集中敏感患者信息的重大风险。通过去标识化处理和限制单个患者的信息采集量,可降低数据泄露造成的危害。
However, privacy concerns are not limited to training data, as deployed GMAI models may also expose data from current patients. Prompt attacks can trick models such as GPT-3 into ignoring previous instructions 48. As an example, imagine that a GMAI model has been instructed never to reveal patient information to un credential ed users. A malicious user could force the model to ignore that instruction to extract sensitive data.
然而,隐私问题不仅限于训练数据,已部署的通用医疗人工智能(GMAI)模型也可能泄露当前患者数据。提示攻击可诱使GPT-3等模型忽略先前的指令[48]。例如,假设某GMAI模型被设定禁止向未授权用户透露患者信息,恶意攻击者仍可能迫使模型违反该指令以获取敏感数据。
Scale. Recent foundation models have increased markedly in size, driving up costs associated with data collection and model training. Models of this scale require massive training datasets that, in the case of GPT-3, contain hundreds of billions of tokens and are expensive to collect. Furthermore, PaLM, a 540-billion-parameter model developed by Google, required an estimated 8.4 million hours’ worth of tensor processing unit v4 chips for training, using roughly 3,000 to 6,000 chips at a time, amounting to millions of dollars in computational costs49. Additionally, developing such large models brings a substantial environmental cost, as training each model has been estimated to generate up to hundreds of tons of ${\mathrm{CO}}_ {2}$ equivalent 50.
规模。近期的基础模型规模显著增大,推高了数据收集和模型训练的相关成本。这种规模的模型需要海量训练数据集,以GPT-3为例,其数据集包含数千亿token,采集成本高昂。此外,Google开发的5400亿参数模型PaLM训练时估计需要840万张TPU v4芯片小时,单次训练需同时使用约3000至6000张芯片,计算成本高达数百万美元[49]。开发此类大模型还会带来巨大的环境代价,据估算单个模型的训练过程可能产生数百吨二氧化碳当量排放[50]。
These costs raise the question of how large datasets and models should be. One recent study established a link between dataset size and model size, recommending 20 times more tokens than parameters for optimal performance, yet existing foundation models were successfully trained with a lower token-to-parameter ratio51. It thus remains difficult to estimate how large models and datasets must be when developing GMAI models, especially because the necessary scale depends heavily on the particular medical use case.
这些成本引发了关于数据集和模型规模应有多大的问题。最近一项研究建立了数据集大小与模型大小之间的联系,建议为了获得最佳性能,token数量应是参数数量的20倍,但现有的基础模型在较低的token与参数比例下也成功完成了训练[51]。因此,在开发GMAI模型时,仍然难以估计模型和数据集的必要规模,尤其是因为所需规模很大程度上取决于具体的医疗应用场景。
Data collection will pose a particular challenge for GMAI development, owing to the need for unprecedented amounts of medical data. Existing foundation models are typically trained on heterogeneous data obtained by crawling the web, and such general-purpose data sources can potentially be used to pretrain GMAI models (that is, carry out an initial preparatory round of training). Although these datasets do not focus on medicine, such pre training can equip GMAI models with useful capabilities. For example, by drawing on medical texts present within their training datasets, general-purpose models such as Flan-PaLM or ChatGPT can accurately answer medical questions, achieving passing scores on the United States Medical Licensing Exam10,52,53. Nevertheless, GMAI model development will probably also require massive datasets that specifically focus on the medical domain and its modalities. These datasets must be diverse, anonymized and organized in compatible formats, and procedures for collecting and sharing data will need to comply with heterogeneous policies across institutions and regions. Although gathering such large datasets will pose a substantial challenge, these data will generally not require costly expert labels, given the success of self-supervision 9,54. Additionally, multimodal self-supervision techniques can be used to train models on multiple datasets containing measurements from a few modalities each, reducing the need for large, expensive datasets that contain measurements from many modalities per patient. In other words, a model can be trained on one dataset with EHR and MRI data and a second with EHR and genomic data, without requiring a large dataset that contains EHR, MRI and genomic data, jointly. Large-scale data-sharing efforts, such as the MIMIC (Medical Information Mart for Intensive Care) database55 or the UK Biobank56, will play a critical role in GMAI, and they should be extended to underrepresented countries to create larger, richer and more inclusive training datasets.
数据收集将成为GMAI开发中的特殊挑战,因其需要前所未有的海量医疗数据。现有基础模型通常通过爬取网络获取异构数据进行训练,这类通用数据源或可用于GMAI模型的预训练(即执行初始准备性训练)。尽管这些数据集不专注于医学领域,此类预训练仍能为GMAI模型提供实用能力。例如Flan-PaLM或ChatGPT等通用模型通过调用训练数据中的医学文本,能准确回答医学问题,甚至在美国医师执照考试中达到合格分数[10,52,53]。然而,GMAI开发可能还需要专门针对医学领域及其模态的大规模数据集。这些数据集需满足多样性、匿名化及格式兼容性要求,且数据收集与共享流程需符合跨机构、跨地区的异构政策。尽管构建此类大型数据集将面临重大挑战,鉴于自监督技术的成功[9,54],这些数据通常无需昂贵的专家标注。此外,多模态自监督技术可在多个数据集上训练模型(每个数据集仅含少数模态的测量数据),从而减少对每个患者包含多模态测量的大型昂贵数据集的需求。换言之,模型可在包含电子健康记录(EHR)和MRI数据的数据集,以及包含EHR和基因组数据的另一数据集上分别训练,而无需联合包含EHR、MRI和基因组数据的大型数据集。MIMIC(重症监护医疗信息集市)数据库[55]和英国生物银行[56]等大规模数据共享项目将在GMAI发展中发挥关键作用,这些项目应扩展至代表性不足的国家,以构建更大规模、更丰富且更具包容性的训练数据集。
The size of GMAI models will also cause technical challenges. In addition to being costly to train, GMAI models can be challenging to deploy, requiring specialized, high-end hardware that may be difficult for hospitals to access. For certain use cases (for example, chatbots), GMAI models can be stored on central compute clusters maintained by organizations with deep technical expertise, as DALL-E or GPT-3 are. However, other GMAI models may need to be deployed locally in hospitals or other medical settings, removing the need for a stable network connection and keeping sensitive patient data on-site. In these cases, model size may need to be reduced through techniques such as knowledge distillation, in which large-scale models teach smaller models that can be more easily deployed under practical constraints 57.
GMAI模型的规模也会带来技术挑战。除了训练成本高昂外,GMAI模型的部署也可能面临困难,需要医院难以获取的专用高端硬件。对于某些应用场景(例如聊天机器人),GMAI模型可以存储在由具备深厚技术专长的组织维护的中央计算集群上,如DALL-E或GPT-3的部署方式。然而,其他GMAI模型可能需要在医院或其他医疗场所本地部署,这样既无需稳定网络连接,又能将敏感患者数据保留在现场。在这些情况下,可能需要通过知识蒸馏等技术来减小模型规模——该技术通过大规模模型指导更易于在实际限制条件下部署的小型模型[57]。
Conclusion
结论
Foundation models have the potential to transform healthcare. The class of advanced foundation models that we have described, GMAI, will interchangeably parse multiple data modalities, learn new tasks on the fly and leverage domain knowledge, offering opportunities across a nearly unlimited range of medical tasks. GMAI’s flexibility allows models to stay relevant in new settings and keep pace with emerging diseases and technologies without needing to be constantly retrained from scratch. GMAI-based applications will be deployed both in traditional clinical settings and on remote devices such as smartphones, and we predict that they will be useful to diverse audiences, enabling both clinician-facing and patient-facing applications.
基础模型有潜力彻底改变医疗保健领域。我们所描述的这类先进基础模型GMAI,将能无缝解析多种数据模态、实时学习新任务并利用领域知识,为近乎无限的医疗任务提供解决方案。GMAI的灵活性使模型能在新环境中保持适用性,并与新兴疾病和技术同步发展,而无需从头开始不断重新训练。基于GMAI的应用将部署在传统临床环境和智能手机等远程设备上,我们预测它们将对各类用户都有价值,既能支持面向临床医生的应用,也能开发面向患者的功能。
Despite their promise, GMAI models present unique challenges. Their extreme versatility makes them difficult to comprehensively validate, and their size can bring increased computational costs. There will be particular difficulties associated with data collection and access, as GMAI’s training datasets must be not only large but also diverse, with adequate privacy protections. We implore the AI community and clinical stakeholders to carefully consider these challenges early on, to ensure that GMAI consistently delivers clinical value. Ultimately, GMAI promises unprecedented possibilities for healthcare, supporting clinicians amid a range of essential tasks, overcoming communication barriers, making high-quality care more widely accessible, and reducing the administrative burden on clinicians to allow them to spend more time with patients.
尽管前景广阔,GMAI模型仍面临独特挑战。其极强的通用性使得全面验证变得困难,庞大的体量也会带来更高的计算成本。数据收集与获取方面存在特殊难题,因为GMAI的训练数据集不仅需要海量,还必须具备多样性并配备完善的隐私保护措施。我们呼吁AI社区和临床相关方尽早审慎考虑这些挑战,以确保GMAI能持续提供临床价值。最终,GMAI有望为医疗健康领域带来前所未有的可能性:支持临床工作者完成各类核心任务、突破沟通壁垒、扩大优质医疗服务的可及性,同时减轻临床工作者的行政负担,让他们有更多时间陪伴患者。
Acknowledgements We gratefully acknowledge I. Kohane for providing insightful comments that improved the manuscript. E.J.T. is supported by the National Institutes of Health (NIH) National Center for Advancing Translational Sciences grant UL 1 TR 001114. M.M. is supported by Defense Advanced Research Projects Agency (DARPA) N 660011924033 (MCS), NIH National Institute of Neurological Disorders and Stroke R61 NS11865, GSK and Wu Tsai Neuroscience s Institute. J.L. was supported by DARPA under Nos. HR 00112190039 (TAMI) and N 660011924033 (MCS), the Army Research Office under Nos. W911NF-16-1-0342 (MURI) and W911NF-16-1-0171 (DURIP), the National Science Foundation under Nos. OAC-1835598 (CINES), OAC-1934578 (HDR) and CCF-1918940 (Expeditions), the NIH under no. 3 U 54 HG 010426-04S1 (HuBMAP), Stanford Data Science Initiative, Wu Tsai Neuroscience s Institute, Amazon, Docomo, GSK, Hitachi, Intel, JPMorgan Chase, Juniper Networks, KDDI, NEC and Toshiba.
致谢
我们衷心感谢 I. Kohane 提供了富有洞察力的评论,从而改进了本手稿。E.J.T. 获得了美国国立卫生研究院 (NIH) 国家促进转化科学中心资助 UL 1 TR 001114 的支持。M.M. 获得了美国国防高级研究计划局 (DARPA) N 660011924033 (MCS)、NIH 国家神经疾病与中风研究所 R61 NS11865、葛兰素史克 (GSK) 和吴蔡神经科学研究所的资助。J.L. 获得了 DARPA HR 00112190039 (TAMI) 和 N 660011924033 (MCS)、陆军研究办公室 W911NF-16-1-0342 (MURI) 和 W911NF-16-1-0171 (DURIP)、美国国家科学基金会 OAC-1835598 (CINES)、OAC-1934578 (HDR) 和 CCF-1918940 (Expeditions)、NIH 3 U 54 HG 010426-04S1 (HuBMAP)、斯坦福数据科学计划、吴蔡神经科学研究所、Amazon、Docomo、GSK、Hitachi、Intel、JPMorgan Chase、Juniper Networks、KDDI、NEC 和 Toshiba 的支持。
Author contributions P.R. conceived the study. M.M., O.B., E.J.T. and P.R. designed the review article. M.M. and O.B. made substantial contributions to the synthesis and writing of the article. Z.S.H.A. and M.M. designed and implemented the illustrations. All authors provided critical feedback and substantially contributed to the revision of the manuscript.
作者贡献
P.R. 提出研究构想。M.M.、O.B.、E.J.T. 和 P.R. 共同设计了这篇综述文章。M.M. 和 O.B. 对文章的综合分析与撰写作出重大贡献。Z.S.H.A. 和 M.M. 设计并完成了图表制作。所有作者均对稿件修订提供了关键意见并作出实质性贡献。
Competing interests In the past three years, H.M.K. received expenses and/or personal fees from United Health, Element Science, Eye dent if eye, and F-Prime; is a co-founder of Refactor Health and HugoHealth; and is associated with contracts, through Yale New Haven Hospital, from the Centers for Medicare & Medicaid Services and through Yale University from the Food and Drug Administration, Johnson & Johnson, Google and Pfizer. The other authors declare no competing interests.
利益冲突
过去三年间,H.M.K. 从 United Health、Element Science、Eye dent if eye 及 F-Prime 获得差旅费及/或个人咨询费;担任 Refactor Health 与 HugoHealth 联合创始人;并通过耶鲁纽黑文医院获得美国医疗保险和医疗补助服务中心 (Centers for Medicare & Medicaid Services) 的合同,通过耶鲁大学获得美国食品药品监督管理局 (Food and Drug Administration)、强生 (Johnson & Johnson)、谷歌 (Google) 和辉瑞 (Pfizer) 的合同。其他作者声明无利益冲突。
Additional information
附加信息
Correspondence and requests for materials should be addressed to Eric J. Topol or Pranav Rajpurkar.
材料和通信请求请发送至Eric J. Topol或Pranav Rajpurkar。
Peer review information Nature thanks Arman Cohan, Joseph Ledsam and Jenna Wiens for their contribution to the peer review of this work.
同行评审信息
Nature 感谢 Arman Cohan、Joseph Ledsam 和 Jenna Wiens 对本工作的同行评审所做的贡献。
Reprints and permissions information is available at http://www.nature.com/reprints. Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
转载和许可信息可在 http://www.nature.com/reprints 获取。出版商注:Springer Nature 对已出版地图中的管辖权主张及机构从属关系保持中立。
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rights holder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Springer Nature或其许可方(如学会或其他合作伙伴)根据与作者或其他权利持有人的出版协议,拥有本文的独家权利;接受稿件版本的文章作者自存档仅受该出版协议和适用法律的条款约束。