Large language models in medicine: the potentials and pitfalls
大语言模型在医学中的应用:潜力与挑战
Jesu to fun mi A. Omiye1* , Haiwen Gui1* , Shawheen J. Rezaei1, James $\mathrm{Zou}^{2}$ , Roxana Daneshjou1,2 * These authors contributed equally as a co-first author to this manuscript 1 Department of Dermatology, Stanford University, Stanford, USA 2 Department of Biomedical Data Science, Stanford University, Stanford, USA
Jesu to fun mi A. Omiye1* , Haiwen Gui1* , Shawheen J. Rezaei1, James $\mathrm{Zou}^{2}$, Roxana Daneshjou1,2 * 这些作者作为共同第一作者对本稿件贡献均等 1 美国斯坦福大学皮肤科 2 美国斯坦福大学生物医学数据科学系
Abstract:
摘要:
Large language models (LLMs) have been applied to tasks in healthcare, ranging from medical exam questions to responding to patient questions. With increasing institutional partnerships between companies producing LLMs and healthcare systems, real world clinical application is coming closer to reality. As these models gain traction, it is essential for healthcare practitioners to understand what LLMs are, their development, their current and potential applications, and the associated pitfalls when utilized in medicine. This review and accompanying tutorial aim to give an overview of these topics to aid healthcare practitioners in understanding the rapidly changing landscape of LLMs as applied to medicine.
大语言模型 (LLM) 已应用于医疗健康领域的多项任务,从医学考试题目到回答患者问题。随着开发大语言模型的企业与医疗系统之间的机构合作日益增多,现实世界的临床应用正逐渐成为现实。随着这些模型受到关注,医疗从业者必须了解大语言模型是什么、其发展历程、当前及潜在应用,以及在医学领域中使用的相关风险。本综述及配套教程旨在概述这些主题,帮助医疗从业者理解大语言模型在医学领域中快速发展的现状。
1. Introduction:
1. 引言:
Large Language models (LLMs) have become increasingly mainstream since the launch of OpenAI's (San Francisco, USA) publicly available Chat Generative Pre-trained Transformer (ChatGPT) in November $2022^{1}$ . This milestone was quickly followed by the unveiling of similar models like Google’s Bard2, Anthropic’s Claude 3, alongside open-source variants such as Meta’s LLaMA4. LLMs are a subset of foundation models 5 (see Glossary), that are trained on massive text data, can have billions of parameters 6, and are primarily interacted with via text. Fundamentally, a language model serves as a channel that receives text queries and generates text in return . LLMs can be adapted to a wide range of language-related tasks beyond their primary training objective. Their popularity has led to increasing interest in the medical field, and they have been applied to various tasks like note-taking8, answering medical exam questions 9,10, answering patient questions 11, and generating clinical summaries8. Despite their versatility, LLM’s behaviors are poorly understood , and they have the potential to produce medically inaccurate outputs12 and amplify existing biases 13,14.
自2022年11月OpenAI(美国旧金山)发布公开可用的Chat Generative Pre-trained Transformer (ChatGPT)以来,大语言模型(LLM)逐渐成为主流。这一里程碑事件后,谷歌的Bard2、Anthropic的Claude 3等类似模型以及Meta的LLaMA4等开源变体相继问世。大语言模型是基础模型5(见术语表)的子集,通过海量文本数据训练而成,可拥有数十亿参数6,主要通过文本进行交互。本质上,语言模型是接收文本查询并生成返回文本的通道。大语言模型可适配多种超出其初始训练目标的语言相关任务,其流行度引发了医学领域日益增长的兴趣,已被应用于电子病历记录8、医学考试答题9,10、患者咨询回复11、临床摘要生成8等场景。尽管功能多样,但大语言模型的行为机制尚不明确,可能产生医学错误输出12并放大现有偏见13,14。
Evidence suggests that interest in LLMs is growing among physicians 8,15,16, and institutional partnerships are on the rise. Examples include its use in a training module for medical residents at Beth Israel Deaconess Medical Centre (Boston, USA) and a partnership with EPIC, a major electronic health records provider, to integrate GPT-4 into their services18. As these models gain traction, it is essential for physicians to understand what LLMs are, their development, existing models, their current and potential applications, and the associated pitfalls when utilized in medicine. In this review, we will give an overview of how LLMs are trained as this background is instrumental in exploring their applications and drawbacks, describe previous ways that LLMs have been applied in medicine, and discuss both the limitations and potential for LLMs in medicine. Additionally, we provide several tutorial-like use cases to allow healthcare practitioners to trial some of the capabilities of one such model, ChatGPT using GPT3.5.
证据表明,医生群体对大语言模型(LLM)的兴趣正在增长[8,15,16],机构合作也呈上升趋势。例如美国波士顿贝斯以色列女执事医疗中心将其用于住院医师培训模块,以及主要电子健康记录提供商EPIC与GPT-4达成合作将其集成至服务中[18]。随着这些模型日益普及,医生有必要了解大语言模型的本质、发展历程、现有模型、当前及潜在应用场景,以及在医疗领域使用时可能存在的隐患。本综述将概述大语言模型的训练原理(这对探索其应用与缺陷至关重要),描述大语言模型在医学领域的既有应用方式,并探讨其在医学领域的局限性与发展潜力。此外,我们还提供了若干教程式用例,帮助医疗从业者试用ChatGPT(GPT3.5版本)这类模型的部分功能。
Table of Glossary:
| Term | Definition |
| Neural networks (NN) | Systems inspired by the neuronal connections in the brain, that are capable of learning, recognizing patterns, and making predictions on tasks without explicit programming. They are the building blocks of many modern machine learning |
| (FM) | Foundation Model A large-scale NN model trained on vast data to develop broad learning capabilities which can be fine-tuned for specific tasks. An FM can be fine-tuned to generate reports, answer medical questions. |
| Generative AI | content. This can be audio, visual, or text. |
| Large Language Models (LLMs) | Artificial intelligence models trained on an enormous amount of text data. LLMs are capable of generating human-like text and learning relationships between |
| Transformer | words. A deep learning model architecture that relies on self-attention mechanisms, by |
| Architecture | differentially weighting the importance of each part of the model's input. This makes it particularly useful for language tasks. |
| Attention | This is a mechanism within the Transformer architecture that enables the differential weighing mentioned above. |
| Parameters | These are values that are learned during the training process of a model. |
| Self-supervised learning | A form of training a model where it learns from unlabeled data, but utilizes the input data as its own supervision. A popular example is predicting the next word in a sentence. |
| Tokenization | This is a pre-training process in which text is converted into smaller units which can be like a character or a word, before being fed into the model. For example. hypertension can be tokenized into the following ^hy', ‘per', ^tension'. |
| Pre-training | This is the initial phase of training a model on a large dataset before fine-tuning i on a task-specific dataset. The parameters are updated in the training process. |
| Fine-tuning | This refers to further training a pre-trained model on a specific task and adjusting the pre-existing parameters to achieve better performance for a particular task. |
| Zero-shot prompting | Using language prompts to get a model to perform specific tasks without having seen explicit examples of those tasks. |
| Few-shot prompting | In this case, the model is provided with some examples of the task, hence the name ‘few'. |
| how to perform a task, alongside labeled examples that demonstrate the training objective/desired behavior. |
术语表:
| 术语 | 定义 |
|---|---|
| 神经网络 (Neural networks, NN) | 受大脑神经元连接启发的系统,能够通过学习、识别模式并对任务进行预测,而无需显式编程。它们是许多现代机器学习的构建模块。 |
| 基础模型 (Foundation Model, FM) | 通过海量数据训练的大规模神经网络模型,具备广泛学习能力,可针对特定任务进行微调。基础模型可通过微调生成报告、回答医学问题等。 |
| 生成式 AI (Generative AI) | 能够生成音频、视觉或文本等内容的人工智能。 |
| 大语言模型 (Large Language Models, LLMs) | 基于大量文本数据训练的人工智能模型,能够生成类人文本并学习词汇间关联性。 |
| Transformer | 一种依赖自注意力机制的深度学习模型架构,通过对模型输入各部分进行差异化加权处理,使其特别适合语言任务。 |
| 架构 (Architecture) | Transformer模型的结构设计。 |
| 注意力 (Attention) | Transformer架构中的机制,实现上述差异化加权功能。 |
| 参数 (Parameters) | 模型训练过程中学习得到的数值。 |
| 自监督学习 (Self-supervised learning) | 模型从无标注数据中学习,但利用输入数据自身作为监督信号的训练方式。典型例子是预测句子中的下一个词。 |
| Token化 (Tokenization) | 将文本转换为更小单元(如字符或单词)的预处理过程。例如"hypertension"可被token化为"hy"、"per"、"tension"。 |
| 预训练 (Pre-training) | 在特定任务数据集上微调之前,先在大规模数据集上训练模型的初始阶段,此过程中会更新参数。 |
| 微调 (Fine-tuning) | 在预训练模型基础上针对特定任务进一步训练,调整已有参数以获得更好性能。 |
| 零样本提示 (Zero-shot prompting) | 使用语言提示让模型执行特定任务,而无需提供该任务的显式示例。 |
| 少样本提示 (Few-shot prompting) | 为模型提供少量任务示例(因此得名"few")以及展示训练目标/期望行为的标注示例。 |
Multi-modal LLMs
多模态大语言模型
In-Context Learning Bias (in AI)
上下文学习偏差 (in AI)
MedMCQA
MedMCQA
PubMedQA
PubMedQA
2. Architecture of LLMs
2. 大语言模型 (LLM) 的架构
LLMs rely on the 'Transformer' architecture 19,20. This architecture leverages an 'attention' mechanism which uses multi-layered neural networks to help LLMs comprehend context and learn meaning within sentences and long paragraphs 6. Akin to how a physician identifies important details of a patient's case while ignoring extraneous information, this mechanism enables LLMs to ‘learn’ important relationships between words while ignoring irrelevant information.
大语言模型依赖Transformer架构[19,20]。该架构利用"注意力"机制,通过多层神经网络帮助大语言模型理解句子和长段落中的上下文及语义[6]。类似于医生在诊断时会关注病例关键细节而忽略无关信息,该机制使大语言模型能够"学习"词语间的重要关联,同时过滤无关内容。
The training of these complex models involves billions of parameters, and has been made possible by recent advancements in computational power and model architecture 5 (Figure 1). For example, GPT-3 was trained on vast data sources and reportedly has about 175 billion parameters 21, while the open source LLaMA family of models have 7 to 70 billion parameters 4,22. The first step of LLM training, known as pre-training, is a self-supervised approach that involves training on a large corpus of unlabeled data, such as internet text, Wikipedia, Github code, social media posts, and Books Corpus 4–6. Some are also trained on proprietary datasets containing specialized texts like scientific articles4. The training objective is usually to predict the next word in a sentence, and this process is resource-intensive 23. It requires the conversion of the text into tokens before they are fed into the model24. The result of this step is a base model that is in itself simply a general language-generating model, but lacks the capacity for nuanced tasks.
这些复杂模型的训练涉及数十亿参数,得益于近年来计算能力和模型架构的进步才得以实现 [5] (图 1)。例如,GPT-3 在庞大数据源上训练完成,据称拥有约 1750 亿参数 [21],而开源 LLaMA 系列模型的参数量则在 70 亿至 700 亿之间 [4,22]。大语言模型训练的第一步称为预训练 (pre-training),这是一种自监督学习方法,通过互联网文本、维基百科、Github 代码、社交媒体帖子和书籍语料库等大量无标注数据进行训练 [4-6]。部分模型还会使用包含科学论文等专业文本的专有数据集进行训练 [4]。训练目标通常是预测句子中的下一个词,这一过程需要消耗大量资源 [23]。在将文本输入模型前,需要先将其转换为 token [24]。此阶段产生的基座模型本质上只是一个通用语言生成模型,尚不具备处理复杂任务的能力。
This base model then undergoes a second phase, known as fine-tuning24. Here, the model can be further trained on narrower datasets like medical transcripts for a healthcare application, or legal briefs for a legal assistant bot. This fine-tuning process can be augmented with a Constitutional AI approach25, which involves embedding predefined rules or principles directly into the model's architecture. Also, this phase can be enhanced with reward training 6,26, where humans score the quality of multiple model outputs, and a reinforcement learning from human feedback (RLHF) approach26, which employs a comparison-based system to optimize the model responses. This step, which is less computationally expensive, albeit
该基础模型随后进入第二阶段,即微调 (fine-tuning) [24]。在此阶段,模型可通过医疗记录等专业数据集(适用于医疗应用)或法律简报(适用于法律助手机器人)进行针对性训练。这种微调过程可通过宪法AI (Constitutional AI) 方法[25]进行增强,即将预定义规则或原则直接嵌入模型架构。该阶段还可结合奖励训练[6][26](人类对多个模型输出进行评分)以及基于人类反馈的强化学习 (RLHF) [26](采用比较系统优化模型响应)。该步骤计算成本较低,但...
human-intensive, adjusts the model to perform a specific task with controlled outputs. The fine-tuned model from this phase is what is deployed in flexible applications like a chatbot.
人力密集型,调整模型以执行特定任务并控制输出。此阶段微调后的模型可部署于聊天机器人等灵活应用中。
LLMs’ adaptability to unfamiliar tasks27 and apparent reasoning abilities 28 are captivating. However, unlocking their full potential in specialized fields like medicine requires even more specific training strategies. These strategies could include direct prompting techniques like few-shot learni ng 21,29, where a few examples of a task at test time guide the model's responses, and zero-shot learnin g 30–32, where no prior specific examples are given. More nuanced approaches such as chain-of-thought prompting 33, which encourages the model to detail its reasoning process step by step, and self-consistency prompting 34, where the model is challenged to verify the consistency of its responses, also play important roles.
大语言模型对陌生任务的适应能力[27]和显而易见的推理能力[28]令人着迷。然而,要在医学等专业领域充分发挥其潜力,还需要更具体的训练策略。这些策略可能包括少样本学习[21,29]等直接提示技术(测试时用少量任务示例指导模型响应)和零样本学习[30-32](不提供具体先验示例)。更精细的方法如思维链提示[33](鼓励模型逐步详述推理过程)和自洽性提示[34](要求模型验证其响应一致性)也发挥着重要作用。
Another promising technique is instruction prompt tuning, introduced by Lester et al.35, which provides a cost-effective solution to update the model's parameters, thereby improving performance in many downstream medical tasks. This approach offers significant benefits over the few-shot prompt approaches, particularly for clinical applications as demonstrated by Singhal et al12. Overall, these methods augment the core training processes of fine-tuned models and can enhance their alignment with medical tasks as recently shown in the Flan-PaLM model12. As these models continue to evolve, understanding their training methodologies will serve as a good foundation for discussing their current capabilities and future applications.
另一种有前景的技术是由Lester等人[35]提出的指令提示调优(instruction prompt tuning),该技术为更新模型参数提供了一种经济高效的解决方案,从而提升了许多下游医疗任务的性能。相较于少样本提示方法,这种方案展现出显著优势,Singhal等人[12]的研究尤其证明了其在临床应用中的价值。总体而言,这些方法增强了微调模型的核心训练流程,并能提升模型与医疗任务的契合度——Flan-PaLM模型[12]的最新研究已印证了这一点。随着这些模型的持续演进,理解其训练方法论将为探讨当前能力与未来应用奠定坚实基础。
Figure 1. Overview of LLM training process. LLMs ‘learn’ from more focused inputs at each stage of the training process. The first phase of this learning is pre-training, where the LLM can be trained on a mix of unlabeled data and proprietary data without any human supervision. The second phase is finetuning, where narrower datasets and human feedback are introduced as inputs to the base model. The fine-tuned model can then enter an additional phase, where humans with specialized knowledge implement prompting techniques that can transform the LLM into a model that is augmented to perform specialized tasks.
图 1: 大语言模型训练流程概览。模型在训练过程的每个阶段都会从更聚焦的输入中"学习"。第一阶段是预训练 (pre-training),大语言模型可以在无人监督的情况下,通过未标注数据和专有数据的混合进行训练。第二阶段是微调 (fine-tuning),此时会向基础模型输入更精细的数据集和人类反馈。经过微调的模型可进入附加阶段,由具备专业知识的人类通过提示工程 (prompting) 技术,将大语言模型增强为能够执行专业任务的模型。

3. Overview of current medical-LLMs
3. 当前医疗大语言模型概述
Prior to the emergence of LLMs, natural language processing challenges were tackled by more rudimentary language models like statistical language models (SLM) and neural language models $\mathrm{(NLM)}^{6}$ , which had significantly fewer parameters and trained on relatively small datasets. These predecessor models lacked the emergent capabilities of modern LLMs, such as reasoning and in-context learning. The advent of the Transformer architecture was a pivotal point, heralding the age of multifaceted LLMs we see today. Often, specialized datasets are used to evaluate an LLMs’ performance on medical tasks, typically deploying an array of QA tools like MedMCQA, PubMedQA12,36 (in Glossary), and more novel ones like Multi Med Bench 37.
在大语言模型出现之前,自然语言处理挑战通常由统计语言模型 (SLM) 和神经语言模型 $\mathrm{(NLM)}^{6}$ 等更基础的语言模型应对,这些模型参数规模显著更小,且训练数据量有限。这些早期模型缺乏现代大语言模型涌现的能力,例如推理和上下文学习。Transformer 架构的出现成为关键转折点,开启了当今多面手大语言模型的时代。通常,医学任务会使用专业数据集评估大语言模型的性能,例如 MedMCQA、PubMedQA [12,36] (术语表中有说明) 等问答工具,以及 Multi Med Bench [37] 等新型评估工具。
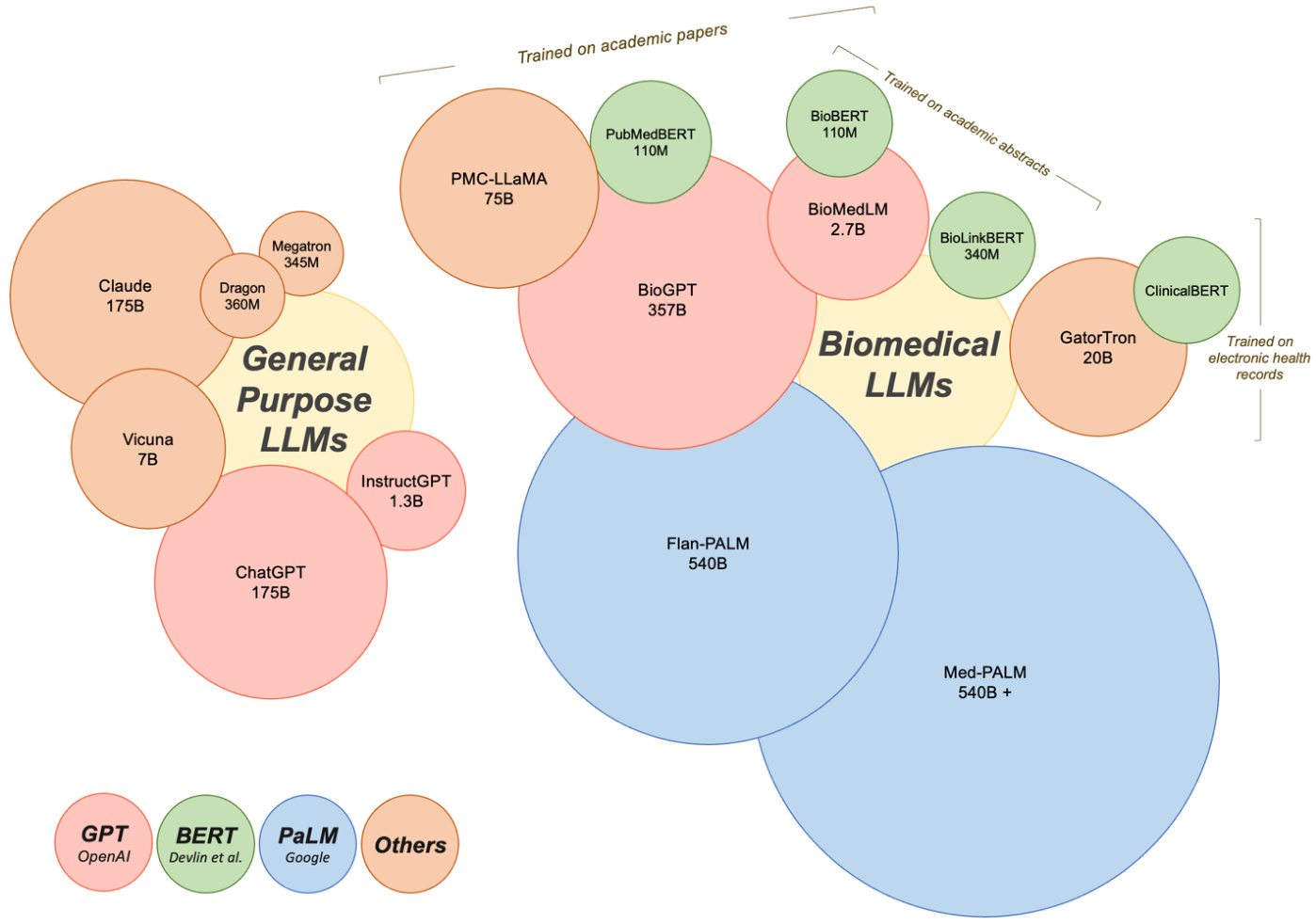
In this section, we will provide an overview of general-purpose LLMs, with a specific emphasis on those that have been applied to tasks within the medical field. Additionally, we'll delve into domain-specific LLMs, referring to models that have been either pre-trained or uniquely fine-tuned using medical literature (Figure 2).
在本节中,我们将概述通用大语言模型,并重点介绍那些已应用于医疗领域任务的模型。此外,我们还将深入探讨特定领域的大语言模型,即通过医学文献进行预训练或专门微调的模型 (图 2)。
● Generative Pre-trained Transformers (GPT): Arguably the most popular of the general Large Language Models are those that belong to the GPT lineage, largely due to their chat-facing product. Developed by OpenAI in $2018^{38}$ , the GPT series has significantly scaled in recent years, with the latest version, GPT-4, speculated to possess significantly more parameters than its predecessors. The evolution in parameters from a mere 0.12B in GPT-1 speaks to the enormous strides made in this area. GPT-4 represents a leap forward in terms of its ability to handle multimodal input such as images, text, and audio - an attribute that aligns seamlessly with the multifaceted nature of medical practice. Novel prompting techniques were introduced with the GPT models, paving the way for the popular ChatGPT product, which is based on GPT-3.5 and GPT4. ChatGPT has demonstrated its utility in various medical scenarios discussed later in this paper8,39–41. Certain studies have concentrated on evaluating the healthcare utility of ChatGPT and Instruct GP T, while others have focused on its fine-tuning for specific medical tasks. For instance, Luo et al. introduced BioGPT, a model that utilized the GPT-2 framework pre-trained on 15 million PubMed abstracts for tasks including question answering (QA), relation extraction, and document classification . Their model outperformed the state-of-the-art models across all evaluated tasks. In a similar vein, BioMedLM 2.7B (formerly known as PubMedGPT), pretrained on both PubMed abstracts and full texts42, demonstrates the continued advancements in this field. Some researchers have even leveraged GPT-4 to create multi-modal medical LLMs, reporting promising results43,44.
● 生成式预训练Transformer (Generative Pre-trained Transformers, GPT): 目前最受欢迎的通用大语言模型当属GPT系列,这主要归功于其面向对话场景的产品。OpenAI于2018年[38]开发的GPT系列近年来规模显著扩大,最新版本GPT-4的参数规模据推测远超其前代。从GPT-1仅有的0.12B参数发展至今,该领域已取得巨大进步。GPT-4在处理图像、文本和音频等多模态输入方面实现了跨越式进步,这一特性与医疗实践的多维需求高度契合。GPT模型引入的创新提示技术为基于GPT-3.5和GPT-4的ChatGPT产品铺平了道路。如后文所述[8,39–41],ChatGPT已在多种医疗场景中展现出实用价值。部分研究聚焦评估ChatGPT和Instruct GPT的医疗应用潜力,另一些则致力于针对特定医疗任务进行微调。例如Luo等人开发的BioGPT采用GPT-2框架,基于1500万篇PubMed摘要进行预训练,在问答系统(QA)、关系抽取和文档分类等任务中表现超越所有基准模型。类似地,基于PubMed摘要与全文[42]预训练的BioMedLM 2.7B(原PubMedGPT)也展现了该领域的持续进展。更有研究者利用GPT-4构建多模态医疗大语言模型,并报告了令人鼓舞的成果[43,44]。
Bidirectional Encoder Representations from Transformers (BERT): Another prominent category of language models that warrant discussion stems from the BERT family. First introduced by Devlin and colleagues, BERT was unique due its focus on understanding sentences through bidirectional training of the model, compared to previous models that used context from one side45. For medical tasks, researchers have developed domain-specific versions of BERT tailored to scientific and clinical text. BioBERT incorporates biomedical corpus data from PubMed abstracts and PubMed Central articles during pre-training46. PubMedBERT follows a similar methodology using just PubMed abstracts 47. Clinic alBERT adapts BERT for clinical notes, trained on the large MIMIC-III dataset of electronic health records48. More recent work has
来自Transformer的双向编码器表示(BERT): 另一个值得讨论的重要语言模型类别源自BERT家族。由Devlin等人首次提出的BERT具有独特性,因为它通过模型的双向训练来理解句子,而之前的模型仅使用单侧上下文[45]。针对医学任务,研究人员开发了针对科学和临床文本的领域特定版本BERT。BioBERT在预训练阶段整合了来自PubMed摘要和PubMed Central文章的生物医学语料数据[46]。PubMedBERT采用类似方法但仅使用PubMed摘要[47]。ClinicalBERT则针对临床笔记调整了BERT模型,并在大型电子健康记录数据集MIMIC-III上进行训练[48]。最新研究还...
focused on enhancing BERT for specific applications. Bio Link BERT adds entity linking to connect biomedical concepts in text to ontologies . These extensions showcase how baseline BERT architectures can be customized for medicine. With proper tuning BERT-based LLMs have demonstrated potential to augment various medical tasks. ● Pathways Language Model (PaLM): Developed by Google, this model represents one of the largest LLMs to date. Researchers first fine-tuned PaLM for medical QA, creating the Flan $\mathrm{PaLM}^{50}$ which achieved state-of-the-art results on QA benchmarks. Building on this, the MedPaLM model was produced via instruction tuning, demonstrating strong capabilities in clinical knowledge, scientific consensus, and medical reasoning 12. This has recently been extended to create a multimodal medical LLM37. PaLM-based models underscore the utility of large foundation models fine-tuned for medicine. Beyond big tech companies, other proprietary and open source medical LLMs have emerged. Models trained from scratch on clinical corpora, such as GatorTron , have shown improved performance on certain tasks compared to general domain LLMs. Claude, developed by Anthropic, has been evaluated on medical biases and other safety issues for clinical applications 13. Active open-source projects are also contributing to the medical LLMs field. For example, PMC-LLaMA leverages the LLaMA model and incorporates biomedical papers in its pre-training 52. Other popular base models like DRAGON53, Megatron54, and Vicuna55 have enabled development of multimodal LLMs incorporating visual data43.
专注于优化BERT在特定应用中的表现。Bio Link BERT通过添加实体链接功能,将文本中的生物医学概念与本体论相关联。这些改进展示了如何针对医学领域定制基础BERT架构。经过适当调优后,基于BERT的大语言模型已展现出增强多种医疗任务的潜力。
● Pathways语言模型(PaLM):由Google开发,是迄今为止规模最大的大语言模型之一。研究人员首先对PaLM进行医学问答(medical QA)微调,创建了Flan $\mathrm{PaLM}^{50}$,该模型在问答基准测试中取得了最先进的结果。在此基础上,通过指令微调开发出MedPaLM模型,展现出在临床知识、科学共识和医学推理方面的强大能力[12]。最近该模型进一步扩展为多模态医疗大语言模型[37]。基于PaLM的模型证明了针对医学领域微调大型基础模型的价值。
除科技巨头外,其他专有和开源医疗大语言模型也相继涌现。例如基于临床语料库从头训练的GatorTron模型,在特定任务上表现优于通用领域大语言模型。Anthropic开发的Claude模型已针对临床应用中的医疗偏见等安全问题进行了评估[13]。活跃的开源项目也在推动医疗大语言模型领域发展,例如PMC-LLaMA基于LLaMA模型并整合生物医学论文进行预训练[52]。DRAGON[53]、Megatron[54]和Vicuna[55]等其他流行基础模型也支持开发整合视觉数据的多模态大语言模型[43]。
Overall, domain-specific pre-training on medical corpora produces models that excel on biomedical tasks compared to generalist LLMs (with some exceptions like GPT-4). However, fine-tuning approaches for adapting general models like BERT and GPT-3 have achieved strong results on medical tasks in a more computationally efficient manner. This is promising given the challenges of limited medical data for training.
总体而言,相比通用大语言模型(除GPT-4等少数例外),在医学语料库上进行领域特定预训练产生的模型在生物医学任务中表现更优。然而,通过微调方法(如BERT和GPT-3等通用模型)能以更高计算效率在医疗任务上取得优异成果。鉴于医疗训练数据有限的挑战,这一发现尤为鼓舞人心。
As LLMs continue to scale up with larger parameter counts, they appear likely to implicitly learn useful biological and clinical knowledge, evidenced by models like Med-PaLM demonstrating improved accuracy, calibration, and physician-like responses. While not equal to real clinical expertise, these characteristics highlight the growing potential of LLMs in medicine and healthcare.
随着大语言模型 (LLM) 参数量持续扩大,它们似乎能隐式学习有用的生物学和临床知识。Med-PaLM 等模型表现出更高的准确性、校准度及类医生响应,印证了这一点。虽然这些能力尚无法等同于真实临床经验,但这些特性凸显了大语言模型在医疗健康领域日益增长的应用潜力。
Figure 2. Current LLMs in medicine. Currently there are general purpose and biomedical LLMs used for medical tasks. While GPT by OpenAI, BERT by Devlin and colleagues, and PaLM by Google have led the development of LLMs with applications in medicine, other proprietary and open source LLMs also exist in this space. Circle sizes reflect the model size and the number of parameters used to build the models. LLMs with applications in medicine vary widely in how they were trained. BioMedLM 2.7B by GPT was trained on the corpus of PubMed articles and abstracts, for example, whereas Clinic alBERT was trained specifically on electronic health records. These differences in training and development can have important implications for how LLMs perform in certain medical scenarios.
图 2: 当前医疗领域的大语言模型。目前存在通用型和生物医学专用的大语言模型用于医疗任务。虽然OpenAI的GPT、Devlin及其同事提出的BERT以及谷歌的PaLM引领了大语言模型在医疗领域的发展,但该领域还存在其他专有和开源的大语言模型。圆圈大小反映了模型规模及构建模型所用的参数量。应用于医疗领域的大语言模型在训练方式上差异显著。例如,GPT开发的BioMedLM 2.7B基于PubMed文章和摘要语料库训练,而ClinicalBERT则专门针对电子健康记录进行训练。这些训练与开发方式的差异会显著影响大语言模型在特定医疗场景中的表现。
4. LLM in medical tasks:
4. 大语言模型 (LLM) 在医疗任务中的应用:
4.1 Overview of LLM in medicine
4.1 大语言模型 (LLM) 在医学领域的概述
Given the rapid advances in LLMs, there has already been an incredible amount of research conducted exploring the usage of LLMs in medicine, ranging from answering patient questions in cardiology 10 to serving as a support tool in tumor boards15, to aiding researchers in academia 56,57. A brief search in PubMed for “ChatGPT'' revealed 800-plus results, showing the rapid exploration and adoption of this technology.
鉴于大语言模型(LLM)的快速发展,已有大量研究探索其在医学领域的应用,范围涵盖心脏病学中的患者问题解答[10]、肿瘤会诊中的辅助工具[15],以及协助学术研究者[56,57]。在PubMed中简单检索"ChatGPT"可得到800余条结果,显示出该技术的快速探索与采纳态势。
Prior to ChatGPT, many patients have been using the internet to learn more about their health conditions 58,59. As ChatGPT surfaced, one of the first-line uses for the language model was answering patient questions. In cardiology, researchers have found that ChatGPT was able to adequately respond to prevention questions, suggesting that LLMs could help augment patient education and patient-clinician communication 10. Similarly, researchers have explored ChatGPT’s responses to common patient questions in hip replacements 11, radiology report findings60, and management of venomous snake bites61. Additionally, there has been interest in using ChatGPT to aid with translating medical texts and clinical encounters, with an objective of improving patient communication and satisfaction 62. These findings suggest a potential for bridging gaps in patient education; however, additional testing is needed to ensure fairness and accuracy.
在ChatGPT出现之前,许多患者已通过互联网了解自身健康状况[58,59]。随着ChatGPT的问世,该语言模型的首批应用场景之一便是解答患者疑问。心脏病学领域研究发现,ChatGPT能恰当回答疾病预防类问题,表明大语言模型可助力提升患者教育及医患沟通水平[10]。类似研究还探索了ChatGPT对髋关节置换术[11]、放射学报告解读[60]及毒蛇咬伤处理[61]等常见患者咨询的应答能力。另有研究关注利用ChatGPT进行医学文献翻译和临床会话转译,旨在改善患者沟通体验与满意度[62]。这些发现揭示了弥补患者教育鸿沟的潜力,但需进一步测试以确保公平性与准确性。
In addition to augmenting patient education, researchers are exploring LLM’s use as clinical workflow support tools. One study evaluated ChatGPT’s recommendations for next step management in breast cancer tumor boards, which are frequently composed of the most complex clinical cases15. Other studies explored the use of ChatGPT in responding to patient portal messages40, creating discharge summaries 41, writing operative notes63, and generating structured templates for radiology 60. While these studies suggest opportunities for mitigating the documentation burden facing physicians, rigorous real world evaluation should be completed prior to any clinical use.
除了增强患者教育外,研究人员还在探索将大语言模型(LLM)作为临床工作流支持工具的用途。一项研究评估了ChatGPT在乳腺癌肿瘤委员会中对下一步管理建议的表现(这些案例通常属于最复杂的临床病例)[15]。其他研究探讨了ChatGPT在回复患者门户消息[40]、创建出院小结[41]、撰写手术记录[63]以及生成放射学结构化模板[60]中的应用。虽然这些研究表明大语言模型有望减轻医生的文书负担,但在任何临床应用前都应完成严格的现实世界评估。
Aside from uses in clinical medicine, LLMs are being utilized in medical education and academia. Multiple researchers have explored LLM’s ability to conduct radiation oncology physics calculations 64, answer medical board questions in USMLE style9, and respond to clinical vignettes 65. The ability of this technology to adequately achieve passing scores on these medical exams raises questions on the need to revise medical curriculum and practices 66. Other programs have started exploring using LLM’s generative ability to create multiple choice questions for student exams67. In academia, there is a rise in exploring LLM’s ability to aid researchers, ranging from topic brainstorming to writing journal articles 56,68, resulting in a rising debate on the ethics and usage of LLMs in academic writing.
除了在临床医学中的应用外,大语言模型(LLM)还被用于医学教育和学术界。多位研究者探索了大语言模型执行放射肿瘤物理学计算[64]、以美国医师执照考试(USMLE)风格回答医学委员会问题[9]以及应对临床病例分析[65]的能力。该技术在这些医学考试中达到及格分数线的能力,引发了关于是否需要修订医学课程和实践的讨论[66]。其他项目已开始探索利用大语言模型的生成能力为学生考试创建选择题[67]。在学术界,越来越多研究探索大语言模型辅助研究者的能力,从主题头脑风暴到撰写期刊文章[56,68],这引发了关于学术写作中使用大语言模型的伦理与应用的持续争论。
4.2 Proposed tasks of LLM in medicine:
4.2 大语言模型 (LLM) 在医学领域的建议任务:
As evident by the abundance of work already done with LLMs, there is an ubiquitous amount of tasks that this technology can aid clinicians with, ranging from administrative tasks to gathering and enhancing medical knowledge (Table 1).
从大语言模型 (LLM) 已完成的丰富工作中可以看出,这项技术可以在从行政任务到收集和增强医学知识等众多任务中为临床医生提供帮助 (表 1)。
Table 1. Analysis of possible large language models tasks in medicine
表 1: 医学领域大语言模型潜在任务分析
| Task | Potential Pitfalls | Mitigation Strategies | |
| Administrative: Write insurance authorization letters Summarize medical notes Aid medical record documentation Create patient communication | Lack of HIPAA compliance: No publicly available model is currently HIPAA compliant, and thus PHI cannot be shared with the models. | Integrate LLMs within electronic health record systems. | |
| Augmenting knowledge: Answer diagnostic questions Answer questions about medical management Create and translate patient | Inherent bias: Pre-trained data models used for diagnostic analyses will introduce inherent bias. | Create domain-specific models that are trained on carefully curated datasets. Always include a human in the loop. | |
| Medical education: Write recommendation letters Create new exam questions and case-based scenarios Generate summaries of medical text at a student level | Lack of personalization: LLMs are generated from prior work already published, resulting in repetitive and unoriginal work. | Educate clinicians and users in using LLM tools to augment their work rather than replace. Encourage understanding how the technology works to mitigate unrealistic expectations of output. | |
| Generate research ideas and novel directions Write academic papers Write grants | Ethics: There has been an incredible amount of discussion among the scientific community on the ethics of using ChatGPT to generate scientific publications. This also raises the question of accessibility and the potential difficulties of future access to this technology. | Engage in conversation to increase accessibility of this technology to prevent widening gaps in research disparities. | |
| 任务 | 潜在风险 | 缓解策略 |
|---|---|---|
| * * 行政事务* * : | ||
| 撰写保险授权书 | ||
| 汇总医疗笔记 | ||
| 辅助病历记录 | ||
| 创建患者沟通材料 | 违反HIPAA合规性: | |
| 目前没有公开可用的模型符合HIPAA标准,因此无法与模型共享受保护健康信息(PHI)。 | 将大语言模型集成到电子健康记录系统中。 | |
| * * 知识增强* * : | ||
| 解答诊断问题 | ||
| 回答医疗管理相关问题 | ||
| 创建和翻译患者材料 | 固有偏见: | |
| 用于诊断分析的预训练数据模型会引入固有偏见。 | 构建基于精细筛选数据训练的领域专用模型。 | |
| 始终保持人工参与闭环。 | ||
| * * 医学教育* * : | ||
| 撰写推荐信 | ||
| 创建新型考题和基于案例的情景 | ||
| 生成适合学生理解的医学文本摘要 | 缺乏个性化: | |
| 大语言模型基于已发表的既往成果生成内容,导致重复且缺乏原创性。 | 教育临床医生和用户将大语言模型作为工作辅助工具而非替代品。 | |
| 鼓励理解技术原理以消除对输出结果的不切实际期望。 | ||
| * * 科研工作* * : | ||
| 产生研究创意和新方向 | ||
| 撰写学术论文 | ||
| 编写基金申请书 | 伦理问题: | |
| 科学界对使用ChatGPT生成科学出版物存在大量伦理讨论。 | ||
| 这同时引发了技术可及性问题及未来获取该技术可能面临的困难。 | 通过对话促进技术普及,防止研究差距进一步扩大。 |
5. Limitations and mitigation strategies:
- 局限性与缓解策略:
While researchers have demonstrated the feasibility of LLM’s use in medicine, there are also many limitations to these preliminary studies, emphasizing the need for future research and analysis. As discussed briefly above in Table 1, there are many potential pitfalls that clinicians using this technology need to be aware of. Key challenges posed by LLM include issues related to accuracy, bias, model inputs/outputs and privacy/ethical concerns. By understanding and addressing these limitations, researchers can foster responsible development and usage of these models to create a more equitable and trustworthy ecosystem.
虽然研究人员已经证明了大语言模型 (LLM) 在医学领域应用的可行性,但这些初步研究仍存在诸多局限性,凸显了未来研究和分析的必要性。如表 1 简要讨论的那样,临床医生在使用该技术时需要注意许多潜在陷阱。大语言模型带来的关键挑战包括准确性、偏见、模型输入/输出以及隐私/伦理问题。通过理解和解决这些局限性,研究人员可以促进这些模型负责任的开发和使用,从而建立一个更公平、更可信的生态系统。
5.1 Accuracy issues and dataset bias
5.1 准确性问题与数据集偏差
Models are only as accurate as the datasets that are used to train them, resulting in a reliance on the accuracy and completeness of the data. LLMs are trained on large datasets that have long surpassed the ability of human teams to manually quality check. This results in a model that is trained on a nebulous dataset that may further decrease user trust in these algorithms. Due to the inability to quality check the dataset, there is often overlap between the training and testing datasets, which results in over prediction of the accuracies of the models 24. Authors of GPT-3, the base model that ChatGPT was built on, reported that after training the model, they discovered some overlap in their dataset, but could not afford to retrain the model 21. In addition, frequently factual information that was used to train the models can become outdated, and it is nontrivial to retrain the model on updated information.
模型的准确性仅取决于用于训练它们的数据集,这使得模型高度依赖于数据的准确性和完整性。大语言模型(LLM)训练所使用的大型数据集早已超出人工质检的能力范围,导致模型基于边界模糊的数据集进行训练,这可能进一步降低用户对这些算法的信任度。由于无法对数据集进行质量检查,训练集和测试集之间经常存在重叠,从而导致模型准确率被高估[24]。作为ChatGPT基础模型的GPT-3研发团队曾报告称,在模型训练完成后发现数据集中存在部分重叠,但已无力承担重新训练模型的成本[21]。此外,用于训练模型的事实信息往往会过时,而基于更新后的信息重新训练模型也并非易事。
It is also important to note that ChatGPT and many of the other LLMs are not trained on specifically curated medical datasets, but rather on a broad range of inputs, ranging from news articles to literary works, that allow models to capture linguistic patterns and features. This results in poor performance in domain-specific questions, including medical applications 69.
同样值得注意的是,ChatGPT 和许多其他大语言模型并非基于专门整理的医学数据集训练,而是通过新闻文章到文学作品等广泛输入来捕捉语言模式和特征。这导致其在包括医学应用在内的领域特定问题上表现欠佳 [69]。
Aside from the source of the datasets, it is important to explore the specific characteristics of the datasets. Models frequently enhance and reinforce structural biases that are found in the training datasets. Multiple groups have exhibited that models are promoting race-based medicine practices that have long been scientifically refuted. When answering questions about eGFR calculations, multiple LLMs tried to justify race-based medicine with false assertions about Black people having different muscle mass and thus higher creatinine levels13. Others have found that LLMs associate phrases referencing people with disabilities with more negative sentiment words, and that gun violence, homelessness, and drug addiction are overrepresented in texts discussing mental illness70. In another scenario, multiple LLMs were asked to provide analgesia choices for chest pain for white patients and black patients, resulting in weaker analgesic recommendations for black patients71 .
除了数据集的来源外,探索数据集的具体特征也很重要。模型经常会增强并强化训练数据集中存在的结构性偏见。多个研究团队表明,模型正在推广基于种族的医疗实践,而这些做法早已被科学界否定。在回答关于eGFR计算的问题时,多个大语言模型试图用黑人肌肉质量不同、因此肌酐水平更高的错误断言来为基于种族的医学辩护[13]。其他研究发现,大语言模型将提及残疾人的短语与更多负面情绪词汇联系起来,并且在讨论精神疾病的文本中,枪支暴力、无家可归和药物滥用的比例过高[70]。在另一个场景中,多个大语言模型被要求为白人患者和黑人患者提供胸痛的镇痛选择,结果对黑人患者的镇痛建议较弱[71]。
A way to mitigate the accuracy and bias of these models is to train these models on domain-specific datasets. Work has been done to fine-tune LLMs in radiology, creating a system that leverages radiology reports during model creation, ultimately increasing the performance of the models for radiology-specific tasks 72. Aside from fine-tuning previously trained LLMs, there has been work done to create models from scratch using electronic health record data, coined as clinical foundation models 73. These models were shown to have better predictive performance, require less labeled data, more effectively handle multimodal data, and offer novel interfaces for human-AI interaction 73. Clinicians can also aid developers in decreasing dataset bias by working to gather more diverse datasets for these models to train on, by conducting outreach to underrepresented patient populations.
缓解这些模型准确性和偏差的一种方法是在特定领域数据集上训练这些模型。已有研究针对放射学领域对大语言模型进行微调,开发了一个在模型创建过程中利用放射学报告的系统,最终提升了模型在放射学特定任务中的性能[72]。除了对预训练的大语言模型进行微调外,还有研究尝试使用电子健康记录数据从头开始构建模型,这类模型被称为临床基础模型[73]。研究表明,这些模型具有更好的预测性能、需要更少的标注数据、能更有效地处理多模态数据,并为人类与AI交互提供了新颖的接口[73]。临床医生也可以通过接触代表性不足的患者群体来收集更多样化的数据集供模型训练,从而帮助开发者减少数据集偏差。
5.2 Weak input, poor output, and change over time
5.2 弱输入、劣质输出与时变问题
The inputs of LLMs are very fickle; very small changes in the input wording results in dramatic changes in the output. Frequently, these variations in prompt syntax often occur in ways that are un intuitive to the users 24. This causes difficulties with ensuring consistency when using LLMs in a healthcare setting.
大语言模型(LLM)的输入非常敏感,输入措辞的微小变化会导致输出结果发生巨大改变。这些提示语法的变化往往以用户难以直观理解的方式出现[24],这在医疗保健领域使用大语言模型时会导致难以确保结果一致性。
In addition to the fickle nature of inputs, models frequently generate “hallucinations”, where the model produces nonsensical and factually incorrect responses 74,75. This is exacerbated when insufficient information is provided in the prompt, a scenario that is frequently seen in healthcare. Researchers prompted LLMs to summarize documents, and found substantial amounts of hallucinations in the summaries, where the model will insert grossly inaccurate information not found in the original document inputs 76. In addition, these language models frequently utilize confident language in the output which could lead users to blindly trust LLMs outputs despite incorrect information 77.
除了输入的不稳定性外,模型还经常产生"幻觉"(hallucination),即生成毫无意义或事实错误的响应[74,75]。当提示信息不足时(医疗领域常见场景),这种现象会进一步加剧。研究人员要求大语言模型(LLM)总结文档时,发现摘要中存在大量幻觉现象——模型会插入原始文档中根本不存在的严重错误信息[76]。此外,这些语言模型常以高度确信的语气输出结果,即使用户面对错误信息,也可能盲目信任大语言模型的输出[77]。
Finally, because many LLMs take inputs as truthful, it attempts to generate an output that fits the user’s assumption, rather than offering factual corrections or clarifying prompts71. This inherently raises challenges for use cases in medicine, where researchers and clinicians may exacerbate misconceptions, worsening confirmation biases. To help mitigate some of these limitations, clinicians and researchers should be well-versed in prompt engineering to encourage accurate and sensible use of this new technology 78.
最后,由于许多大语言模型(LLM)将输入内容默认为真实信息,它们会试图生成符合用户假设的输出,而非提供事实性修正或澄清性提示[71]。这一特性在医疗应用场景中尤为棘手,研究人员和临床医生可能会因此强化错误认知,加剧确认偏误。为缓解部分局限性,临床医生和研究人员应精通提示工程(prompt engineering)技术[78],以促进这项新技术的准确合理应用。
Aside from the fickle nature of inputs and unpredictable nature of the outputs, LLMs are also evolving rapidly and un predictably over time 79. This makes it challenging to incorporate these models into larger workflows. Given the novelty of this technology, much work still remains to observe long-term trends and analyses. Utilization of this technology in healthcare should not be without careful oversight.
除了输入的不稳定性和输出的不可预测性外,大语言模型(LLM)本身也在快速且难以预测地演进[79]。这使得将这些模型整合到更大型工作流程中具有挑战性。鉴于该技术的新颖性,仍需大量工作来观察长期趋势并进行分析。在医疗保健领域应用这项技术时,必须保持审慎监管。
5.3 Privacy and ethical concerns:
5.3 隐私与伦理问题:
Frequently, personally identifiable information (PII) have been found within pre-training datasets in earlier LLMs, including phone numbers and email addresses 80. Even if the datasets are completely devoid of PII, privacy violations can occur due to inference. LLMs may make correct assumptions about a patient based on correlation al data about other people without access to private data about that particular individual. In other words, LLMs may attempt to predict the patient’s gender, race, income, or religion based on user input, ultimately violating the individual’s privacy 77. Researchers have already shown that patient-entered text, in the form of Twitter accounts, are able to accurately predict alcoholism recovery81. LLMs are text-based models that may have these abilities as well.
在早期大语言模型的预训练数据集中,经常发现包含电话号码和电子邮件地址等个人身份信息(PII) [80]。即使数据集完全不含PII,仍可能因推理过程导致隐私泄露。大语言模型可能基于与其他人的关联数据(而非特定个体的私人数据)对患者做出正确推断 [77]。换言之,大语言模型会根据用户输入尝试预测患者的性别、种族、收入或宗教信仰,最终侵犯个人隐私。研究人员已证实,通过患者发布的Twitter文本能准确预测酒精成瘾康复情况 [81]。作为基于文本的模型,大语言模型同样可能具备这些推断能力。
Aside from the above privacy issues, there are ethical concerns with LLM use in medicine. Even when assuming non-malicious users of these models, there are unfortunately opportunities for the models to generate harmful content. For example, when disclosing difficult diagnoses in medicine, there are steps in place that can help patients cope and provide support. With the rise of LLMs in medicine, patients may inadvertently be exposed to difficult topics that can cause severe emotional harm. While this problem is not unique to language models, as patients have other means to access information (E.g. Google), LLMs produce a greater risk given the conversation-like structure of these publicly-available models. Many of these models are human-enough, but frequently lack the ability for additional personalized emotional support.
除上述隐私问题外,大语言模型(LLM)在医疗领域的应用还存在伦理隐患。即便假设这些模型的用户不存在恶意意图,模型仍可能生成有害内容。例如在传达医学难诊时,现有流程会分步骤帮助患者应对并提供支持。但随着大语言模型在医疗领域的普及,患者可能意外接触到引发严重情绪伤害的敏感话题。虽然该问题并非语言模型独有(患者可通过谷歌等渠道获取信息),但由于这些公开模型采用类对话结构,其风险系数更高。多数模型已具备近似人类的交互能力,但往往无法提供个性化的情感支持。
Another ethical concern is the rising difficulty in distinguishing between LLM-generated and humanwritten text, which could result in spread of misinformation, plagiarism, and impersonation. For example, while the use of LLMs to aid clinicians in administrative tasks can help decrease document burden, this could also result in malicious use by others to generate false documents.
另一个伦理问题是越来越难以区分大语言模型生成的文本和人类撰写的文本,这可能导致错误信息传播、剽窃和身份冒充。例如,虽然使用大语言模型协助临床医生处理行政事务有助于减轻文书负担,但也可能被他人恶意利用来伪造文件。
To help mitigate these privacy and ethical concerns, regular auditing and evaluation of LLMs can help identify and address these ethical concerns. There have been calls recently in the AI research community to develop regulations for LLM use in medicine82. In addition, care must be taken in the selection of
为帮助缓解这些隐私和伦理问题,定期审计和评估大语言模型有助于识别并解决相关伦理隐患。近期AI研究界已呼吁制定医疗领域大语言模型使用规范[82]。此外,在筛选...
training datasets, especially when using medicine domain-specific datasets to ensure adequate handling of sensitive data.
训练数据集,尤其是在使用医学领域特定数据集时,需确保对敏感数据的妥善处理。
6. Tutorial with ChatGPT
6. ChatGPT 教程
In this section, we will walk through some of the use cases that highlight both the benefits and pitfalls of one LLM, OpenAI’s ChatGPT (Table 1). To complete this tutorial section, individuals will need to visit https://openai.com/ and create a free account for ChatGPT.
在本节中,我们将通过一些用例来展示 OpenAI 的 ChatGPT 这一大语言模型的优势与局限性 (表 1)。要完成本教程部分,用户需要访问 https://openai.com/ 并创建免费的 ChatGPT 账户。
6.1 Insurance authorization letters
6.1 保险授权书
We will start with creating authorization letters, which is quite common in the clinical setting. The prompt for this exercise is: “Can you write an authorization letter for Aetna insurance for a total left hip replacement procedure in a patient with osteoarthritis of the left hip? Please ensure to be accurate as this service is not typically covered by insurance.” It is important to not include personally identifiable information and protected health information when utilizing this tool. From the model output in Figure 3a, you can see that sections that require identifiable details are filled with placeholder s. You can tweak the prompts or add more details as required and see how that changes the outputs.
我们将从撰写授权信开始,这在临床环境中相当常见。本次练习的提示词是:"能否为一位左髋骨关节炎患者撰写致Aetna保险公司的全左髋关节置换术授权信?请注意准确性,因为该服务通常不在保险范围内。" 使用该工具时需注意,不得包含个人身份信息和受保护的健康信息。从图3a的模型输出可见,需要填写身份信息的段落均以占位符替代。您可根据需求调整提示词或补充细节,观察输出结果的变化。
6.2 Exploring hallucinations via basic patient handouts
6.2 通过基础患者手册探索幻觉现象
To create a basic patient handout, we use the prompt, “Create a one-page patient handout about acid reflux to be used in a physician's office. Use accessible language that is at a 5th grade level.” When we use this prompt, we get the output seen in Figure 3b. The information in this generated handout appears to be accurate. However, as mentioned before, these models can “hallucinate”; in this case, the “sources” listed on this handout do not exist. Now repeat the same prompt and look at the output, do you get the same result? As mentioned previously, these models are stochastic and do not give the exact same output (in some cases, you can change a “temperature” parameter which controls stochastic it y).
为了制作一份基础的病人手册,我们使用提示词:"创建一份关于胃酸反流的单页病人手册,供医生办公室使用。采用五年级学生能理解的通俗语言。"使用该提示后,我们得到如图3b所示的输出内容。这份生成手册中的信息看似准确,但如前所述,这些模型可能出现"幻觉"(hallucinate)——本例中手册列出的"参考文献"并不存在。现在重复相同提示并观察输出,你会得到相同结果吗?正如前文提到的,这些模型具有随机性(stochastic),不会生成完全一致的输出(某些情况下可通过调整"温度"(temperature)参数来控制随机性程度)。
6.3 Exam questions and case-based scenarios
6.3 考题与基于案例的场景
Here, we used GPT-4, the more advanced model (which is available through a paid subscription). For this scenario, we use the prompt, “Create a USMLE Step 3 question that tests the concept of digoxin side effects.” The output from this prompt is shown in Figure 3c. The output is clear and you can see the model attempts to provide an explanation for the answer. Although, in reality the NBME Step 3 questions could be more vague. Try this with different prompts on various medical concepts and evaluate what you get. Feel free to use the free ChatGPT version. You are likely to see some hallucinations here when the model tries to explain the answer. You can also ask it to use a different question style and see if it meets your expectations.
此处我们采用了更先进的GPT-4模型(需付费订阅使用)。针对该场景,我们使用提示词"创建一道测试地高辛副作用概念的USMLE第三步试题"。如图3c所示,模型输出清晰且尝试为答案提供解释。不过实际NBME第三步考题可能更为模糊。建议尝试不同医学概念的提示词并评估结果,也可使用免费版ChatGPT进行测试——当模型解释答案时很可能会出现幻觉现象。此外,可要求其采用不同题型风格,观察是否符合预期。
6.4 Honing model outputs via academic paper outlines
6.4 通过学术论文提纲优化模型输出
To use this technology to help with medical research, we use the prompt, “Create an outline for a review paper on the implications of social media in healthcare.” While the output (Figure 3d) creates a comprehensive outline for researchers to follow, we can see that the first iteration of the outline is quite generic. You can then continue to “converse” with the model to provide more details and enhancements to improve the outline and the outputs. We use the prompt “Include a literature review of prior works in the introduction”, which allows the model to hone in on creating language to aid researchers in writing their papers. Explore asking ChatGPT to provide more or less detail to create the outline for your paper.
要利用这项技术辅助医学研究,我们使用提示词:"创建一篇关于社交媒体在医疗保健领域影响的综述论文大纲"。虽然输出结果(图3d)为研究人员提供了全面的框架,但可以看出初始版本的大纲较为笼统。此时可继续与模型"对话",通过"在引言部分加入前人研究的文献综述"等提示,使模型优化表述方式来辅助论文写作。尝试要求ChatGPT增减细节来完善论文框架。
Figure 3. ChatGPT’s output to the following prompts. a) Can you write an authorization letter for Aetna insurance for a total left hip replacement procedure in a patient with osteoarthritis of the left hip? Please ensure to be accurate as this service is not typically covered by insurance b) Create a one-page patient handout about acid reflux to be used in a physician's office. Use accessible language that is at a 5th grade level. c) Create a USMLE Step 3 question that tests the concept of digoxin side effects. d) Create an outline for a review paper on the implications of social media in healthcare
图 3: ChatGPT对以下提示的输出。a) 你能为一位左髋骨关节炎患者撰写一封关于全左髋关节置换术的Aetna保险授权信吗?请确保内容准确,因为该服务通常不在保险范围内。b) 创建一份关于胃酸反流的单页患者手册,供医生办公室使用。使用相当于五年级水平的易懂语言。c) 创建一道测试地高辛副作用概念的USMLE Step 3试题。d) 创建一篇关于社交媒体在医疗保健领域影响的综述论文大纲


7. Future of LLM in medicine:
7. 大语言模型 (LLM) 在医学领域的未来:
LLMs are currently at the forefront of AI innovation in medicine, with a surge of new developments being introduced regularly. Their potential to improve care delivery and alter the practice of medicine is notable. Here we discuss future developments for LLMs in medicine could look like, drawing on both currently emerging trends and future conjectures.
大语言模型 (LLM) 目前处于医学领域 AI 创新的前沿,新进展层出不穷。它们在改善医疗服务模式和改变医学实践方面的潜力值得关注。本文将结合当前趋势与未来猜想,探讨大语言模型在医学领域的可能发展方向。
Technological Advancements: The integration of multiple data types into LLMs, referred to as multimodality, is an emerging trend83 with significant implications for healthcare 84. Initially introduced by GPT-4, this property has been further developed for medicine with a proof-of-concept generalist medical AI called Med-PaLM Multimodal (Med-PaLM M)37. Recent studies such as LLaVa-Med85, SkinGPT444, and MiniGPT $\boldsymbol{\mathrm{\nabla}}4^{43}$ provide compelling evidence for the effectiveness of multi-modal LLMs, which are poised to gain prevalence in healthcare due to the multi-faceted nature of medical data that spans text, images, audio, and genetics. Also, more advanced models with better architectures and longer context length (which enables models to maintain coherence) could lead to more accurate responses for medical tasks.
技术进步:将多种数据类型整合到大语言模型中(称为多模态)是一个新兴趋势[83],对医疗健康领域具有重大意义[84]。这一特性最初由GPT-4引入,随后通过概念验证的通用医疗AI系统Med-PaLM Multimodal (Med-PaLM M)[37]在医学领域得到进一步发展。近期研究如LLaVa-Med[85]、SkinGPT4[44]和MiniGPT $\boldsymbol{\mathrm{\nabla}}4^{43}$ 为多模态大语言模型的有效性提供了有力证据。由于医疗数据涵盖文本、图像、音频和遗传信息等多维度特性,这类模型有望在医疗领域获得广泛应用。此外,采用更优架构和更长上下文窗口(使模型能保持连贯性)的进阶模型,可能为医疗任务带来更精准的响应。
Simultaneously, progress in minimizing resource requirements for LLMs is likely to democratize access and benefit physicians in resource-limited settings, enabling them to train LLMs for their own clinical and research tasks. By extension, this could reduce racial and gender bias in model outputs as more robust models are developed. Moreover, the reduction in demand for compute resources could pave the way for institution-specific LLMs - models trained on data specific to a health institution, thereby reflecting its
与此同时,降低大语言模型(LLM)资源需求的进展可能使资源有限地区的医生也能受益,使他们能够针对自己的临床和研究任务训练大语言模型。随着更稳健模型的开发,这还可能减少模型输出中的种族和性别偏见。此外,计算资源需求的降低可能为机构专用大语言模型铺平道路——这种模型基于特定医疗机构的数据进行训练,从而反映其...
standard procedures, guidelines, and unique challenges. Such models have the potential to enhance productivity, reduce burnout, and improve patient care.
标准流程、指南和独特挑战。这类模型有望提升工作效率、减少职业倦怠并改善患者护理。
Accessibility and Equity: The creation of synthetic medical data by leveraging the generative capabilities of LLMs also offers a promising approach to address the challenges associated with the scarcity of medical research data. For example, more diverse medical data could be available for training AI models. This can lead to more inclusive and equitable medical research.
可及性与公平性:利用大语言模型 (LLM) 的生成能力创建合成医疗数据,为解决医学研究数据稀缺问题提供了新思路。例如,AI模型训练可获得更多样化的医疗数据,从而推动更具包容性和公平性的医学研究。
Regulatory Considerations: From a regulatory standpoint, it is imperative to establish standard frameworks for validating LLMs across clinical tasks, while ensuring fairness. This is particularly crucial in medicine, where inaccurate model outputs can have severe consequences and lead to patient harm. LLM governance structures need to evolve to protect patient privacy, and address issues like model transparency, fairness, and accuracy82.
监管考量:从监管角度来看,必须建立标准化框架来验证大语言模型(LLM)在临床任务中的表现,同时确保公平性。这在医学领域尤为关键,因为不准确的模型输出可能造成严重后果并危害患者。大语言模型治理结构需要不断发展,以保护患者隐私,并解决模型透明度、公平性和准确性等问题 [82]。
Future Research Directions: Research into LLM explain ability, where the model provides logical reasoning for its decision-making or question-answering process, is essential in medicine and should be prioritized. Models that can elucidate their reasoning are more likely to gain acceptance and trust from physicians. Also, standardized holistic metrics for the assessment of LLM abilities in medicine are necessary to improve widespread adoption. These metrics should be holistic and cover clinical accuracy, reasoning, bias, and fairness.
未来研究方向:在医学领域,对大语言模型可解释性的研究至关重要,应予以优先考虑。这类研究要求模型能为其决策或问答过程提供逻辑推理。能够阐明推理过程的模型更容易获得医生的认可和信任。此外,为评估医学领域大语言模型能力,需要建立标准化的整体评价指标,以促进其广泛应用。这些指标应具有全面性,涵盖临床准确性、推理能力、偏见及公平性等方面。
In summary, the future of LLMs in medicine will likely feature advancements that enhance their utility as supportive tools for healthcare workers, not replacement. These developments could play a crucial role in addressing challenges related to healthcare shortages and inefficiencies.
总之,大语言模型在医学领域的未来将主要体现在作为医护人员辅助工具的实用性提升,而非替代。这些进步可能在解决医疗资源短缺和效率低下等挑战方面发挥关键作用。
8. Conclusion
8. 结论
LLMs have risen in popularity as models become more widely available for public use. With technological advancements and spread in popularity, potential opportunities exist for application of LLMs in the medical field. Multiple tech companies have already developed models trained with the intention to perform medical tasks. There are several areas of medicine where LLMs could be employed, such as completing administrative tasks (e.g.: summarizing medical notes), augmenting clinician knowledge (e.g.: translating patient materials), medical education (e.g.: creating new exam questions), and medical research (e.g.: generating novel research ideas). Despite these opportunities, many notable challenges with LLMs remain unresolved, limiting the implementation of these models in medicine. Issues surrounding underlying biases in datasets, data quality and unpredictability of outputs, and patient privacy and ethical concerns make innovations in LLMs difficult to translate to adoption in healthcare settings in their current form. Physicians and other healthcare professionals must weigh potential opportunities with these existing limitations as they seek to incorporate LLMs into their practice of medicine.
随着大语言模型(LLM)日益向公众开放使用,其普及度迅速提升。技术进步与广泛传播为医疗领域应用大语言模型创造了潜在机遇。多家科技公司已开发出专门针对医疗任务训练的模型。大语言模型可应用于多个医疗场景,包括:完成行政工作(如:总结病历)、辅助临床知识(如:翻译患者资料)、医学教育(如:编写新型考题)以及医学研究(如:产生创新研究思路)。尽管存在这些机遇,大语言模型仍存在诸多显著挑战未解决,限制了其在医疗领域的应用。数据集固有偏见、输出结果的质量不可控与不可预测性、患者隐私及伦理问题等障碍,使得当前形态的大语言模型创新难以直接转化为医疗场景的实际应用。医师及其他医疗从业者在将大语言模型引入医疗实践时,必须权衡其潜在价值与现存局限性。