A Survey of Large Language Models in Medicine: Progress, Application, and Challenge
周鸿渐,刘丰林,谷博阳,邹新宇,黄锦发,
ABSTRACT
摘要
Large language models (LLMs), such as ChatGPT, have received substantial attention due to their capabilities for understanding and generating human language. While there has been a burgeoning trend in research focusing on the employment of LLMs in supporting different medical tasks (e.g., enhancing clinical diagnostics and providing medical education), a comprehensive review of these efforts, particularly their development, practical applications, and outcomes in medicine, remains scarce. Therefore, this review aims to provide a detailed overview of the development and deployment of LLMs in medicine, including the challenges and opportunities they face. In terms of development, we provide a detailed introduction to the principles of existing medical LLMs, including their basic model structures, number of parameters, and sources and scales of data used for model development. It serves as a guide for practitioners in developing medical LLMs tailored to their specific needs. In terms of deployment, we offer a comparison of the performance of different LLMs across various medical tasks, and further compare them with state-of-the-art lightweight models, aiming to provide a clear understanding of the distinct advantages and limitations of LLMs in medicine. Overall, in this review, we address the following study questions: 1) What are the practices for developing medical LLMs? 2) How to measure the medical task performance of LLMs in a medical setting? 3) How have medical LLMs been employed in real-world practice? 4) What challenges arise from the use of medical LLMs? and 5) How to more effectively develop and deploy medical LLMs? By answering these questions, this review aims to provide insights into the opportunities and challenges of LLMs in medicine and serve as a practical resource for constructing effective medical LLMs. We also maintain a regularly updated list of practical guides on medical LLMs at:
大语言模型 (LLM/Large Language Model) ,如 ChatGPT,因其理解和生成人类语言的能力而受到广泛关注。尽管当前研究趋势聚焦于利用大语言模型支持各类医疗任务 (例如提升临床诊断和提供医学教育) ,但针对这些工作的系统性综述,尤其是其在医学领域的发展、实际应用及成果的全面分析仍较为匮乏。因此,本文旨在详细概述大语言模型在医学中的开发与部署,包括其面临的挑战与机遇。在开发层面,我们详细介绍了现有医疗大语言模型的原理,包括其基础模型结构、参数量级以及模型开发所用的数据来源与规模,为开发者构建符合特定需求的医疗大语言模型提供指南。在部署层面,我们对比了不同大语言模型在各类医疗任务中的表现,并进一步将其与最先进的轻量级模型进行对比,以明晰大语言模型在医学领域的独特优势与局限。总体而言,本文围绕以下研究问题展开:1) 医疗大语言模型的开发实践有哪些?2) 如何衡量大语言模型在医疗场景中的任务表现?3) 医疗大语言模型如何应用于真实世界实践?4) 使用医疗大语言模型会引发哪些挑战?5) 如何更有效地开发与部署医疗大语言模型?通过回答这些问题,本文旨在揭示大语言模型在医学领域的机遇与挑战,并为构建高效医疗大语言模型提供实用参考。我们还在以下地址持续更新医疗大语言模型的实践指南列表:
https://github.com/AI-in-Health/MedLLMsPracticalGuide
BOX: Key points
BOX: 关键点
Figure 1. An overview of the practical guides for medical large language models.
图 1: 医疗大语言模型实用指南概览
1 Introduction
1 引言
The recently emerged general large language models (LLMs)1,2, such as $\mathrm{PaLM}^{3}$ , LLaMA4,5, GPT-series6,7, and ChatGLM8,9, have advanced the state-of-the-art in various natural language processing (NLP) tasks, including text generation, text summarization, and question answering. Inspired by these successes, several endeavors have been made to adapt general LLMs to the medicine domain, leading to the emergence of medical LLMs10,11. For example, based on $\mathrm{PaLM}^{3}$ and GPT $.4^{7}$ , MedPaLM $2^{11}$ and Med Prompt 12 have respectively achieved a competitive accuracy of 86.5 and 90.2 compared to human experts $(87.0^{13})$ ) in the United States Medical Licensing Examination (USMLE)14. In particular, based on publicly available general LLMs (e.g. LLaMA4,5), a wide range of medical LLMs, including Chat Doctor 15, MedAl paca 16, PMC-LLaMA13, BenTsao17, and Clinical Camel18, have been introduced. As a result, medical LLMs have gained growing research interests in assisting medical professionals to improve patient care 19,20.
最近出现的通用大语言模型 (LLM)[1,2],如 $\mathrm{PaLM}^{3}$、LLaMA[4,5]、GPT系列[6,7] 和 ChatGLM[8,9],在文本生成、文本摘要和问答等多种自然语言处理 (NLP) 任务中取得了最先进的成果。受这些成功的启发,人们开始尝试将通用大语言模型应用于医学领域,从而催生了医学大语言模型[10,11]。例如,基于 $\mathrm{PaLM}^{3}$ 和 GPT $.4^{7}$ 的 MedPaLM $2^{11}$ 和 Med Prompt[12] 在美国医师执照考试 (USMLE)[14] 中分别达到了 86.5 和 90.2 的准确率,与人类专家 $(87.0^{13})$ 的表现相当。特别是基于公开可用的通用大语言模型 (如 LLaMA[4,5]),一系列医学大语言模型相继问世,包括 Chat Doctor[15]、MedAlpaca[16]、PMC-LLaMA[13]、BenTsao[17] 和 Clinical Camel[18]。因此,医学大语言模型在辅助医疗专业人员改善患者护理方面引起了越来越多的研究兴趣[19,20]。
Although existing medical LLMs have achieved promising results, there are some key issues in their development and application that need to be addressed. First, many of these models primarily focus on medical dialogue and medical questionanswering tasks, but their practical utility in clinical practice is often overlooked 19. Recent research and reviews 19,21,22 have begun to explore the potential of medical LLMs in different clinical scenarios, including Electronic Health Records (EHRs)23, discharge summary generation 20, health education 24, and care planning 11. However, they primarily focus on presenting clinical applications of LLMs, especially online commercial LLMs like ChatGPT (including GPT-3.5 and GPT $4^{7}$ ), without providing practical guidelines for the development of medical LLMs. Besides, they mainly perform case studies to conduct the human evaluation on a small number of samples, thus lacking evaluation datasets for assessing model performance in clinical scenarios. Second, most existing medical LLMs report their performances mainly on answering medical questions, neglecting other biomedical domains, such as medical language understanding and generation. These research gaps motivate this review which offers a comprehensive review of the development of LLMs and their applications in medicine. We aim to cover topics on existing medical LLMs, various medical tasks, clinical applications, and arising challenges.
尽管现有的医疗大语言模型已取得显著成果,但其开发与应用仍存在若干关键问题亟待解决。首先,许多模型主要聚焦于医疗对话和问答任务,却常忽视其在临床实践中的实际效用[19]。近期研究与综述[19,21,22]开始探索医疗大语言模型在电子健康档案(EHRs)[23]、出院小结生成[20]、健康教育[24]和护理计划[11]等临床场景的潜力,但主要侧重于展示大语言模型(尤其是ChatGPT等在线商业模型,包括GPT-3.5和GPT-4[7])的临床应用,未提供医疗大语言模型开发的实用指南。此外,这些研究多通过小样本案例进行人工评估,缺乏评估临床场景模型性能的数据集。其次,现有医疗大语言模型主要报告医学问答性能,忽视了医学语言理解与生成等其他生物医学领域。这些研究空白促使本文全面综述大语言模型发展及其医学应用,涵盖现有医疗大语言模型、多样化医疗任务、临床应用及新兴挑战等主题。
As shown in Figure 1, this review seeks to answer the following questions. Section 2: What are LLMs? How can medical LLMs be effectively built? Section 3: How are the current medical LLMs evaluated? What capabilities do medical LLMs offer beyond traditional models? Section 4: How should medical LLMs be applied in clinical settings? Section 5: What challenges should be addressed when implementing medical LLMs in clinical practice? Section 6: How can we optimize the construction of medical LLMs to enhance their applicability in clinical settings, ultimately contributing to medicine and creating a positive societal impact?
如图 1 所示,本综述旨在回答以下问题。
第 2 节:什么是大语言模型 (LLM)?如何有效构建医学大语言模型?
第 3 节:当前医学大语言模型如何评估?相比传统模型,医学大语言模型具备哪些额外能力?
第 4 节:医学大语言模型应如何应用于临床场景?
第 5 节:在临床实践中部署医学大语言模型需解决哪些挑战?
第 6 节:如何优化医学大语言模型的构建以提升其临床适用性,最终推动医学发展并创造积极社会影响?
For the first question, we analyze the foundational principles underpinning current medical LLMs, providing detailed descriptions of their architecture, parameter scales, and the datasets used during their development. This exposition aims to serve as a valuable resource for researchers and clinicians designing medical LLMs tailored to specific requirements, such as computational constraints, data privacy concerns, and the integration of local knowledge bases. For the second question, we evaluate the performance of medical LLMs across ten biomedical NLP tasks, encompassing both disc rim i native and generative tasks. This comparative analysis elucidates how these models outperform traditional AI approaches, offering insights into the specific capabilities that render LLMs effective in clinical environments. The third question, the practical deployment of medical LLMs in clinical settings, is explored through the development of guidelines tailored for seven distinct clinical application scenarios. This section outlines practical implementations, emphasizing specific functionalities of medical LLMs that are leveraged in each scenario. The fourth question emphasizes addressing the challenges associated with the clinical deployment of medical LLMs, such as the risk of generating factually inaccurate yet plausible outputs (hallucination), and the ethical, legal, and safety implications. Citing recent studies, we argue for a comprehensive evaluation framework that assesses the trustworthiness of medical LLMs to ensure their responsible and effective utilization in healthcare. For the last question, we propose future research directions to advance the medical LLMs field. This includes fostering interdisciplinary collaboration between AI specialists and medical professionals, advocating for a ’doctor-in-the-loop’ approach, and emphasizing human-centered design principles.
针对第一个问题,我们分析了当前医疗大语言模型的基础原理,详细阐述了其架构、参数规模及开发过程中使用的数据集。这一阐述旨在为研究人员和临床医生设计符合特定需求(如计算资源限制、数据隐私问题及本地知识库整合)的医疗大语言模型提供宝贵参考。
第二个问题中,我们评估了医疗大语言模型在十项生物医学自然语言处理任务中的表现,涵盖判别式与生成式任务。通过对比分析,阐明了这些模型如何超越传统AI方法,并揭示了使其在临床环境中表现优异的具体能力。
第三个问题聚焦医疗大语言模型在临床场景的实际部署,通过制定七种不同临床应用场景的专属指南展开探讨。该部分概述了具体实施方案,重点突出各场景中医疗大语言模型所调用的特定功能。
第四个问题着重探讨医疗大语言模型临床部署面临的挑战,例如生成事实错误但看似合理输出(幻觉)的风险,以及伦理、法律与安全隐患。援引最新研究,我们主张建立综合评估框架以检验医疗大语言模型的可信度,确保其在医疗领域负责任且高效的应用。
最后关于未来研究方向,我们提出推动医疗大语言模型领域发展的多项建议:促进AI专家与医疗从业者的跨学科合作,倡导"医生参与闭环"方法,并强调以人为本的设计原则。
By establishing robust training data, benchmarks, metrics, and deployment strategies through co-development efforts, we aim to accelerate the responsible and efficacious integration of medical LLMs into clinical practice. This study therefore seeks to stimulate continued research and development in this interdisciplinary field, with the objective of realizing the profound potential of medical LLMs in enhancing clinical practice and advancing medical science for the betterment of society.
通过共同开发建立强大的训练数据、基准、指标和部署策略,我们旨在加速医疗大语言模型(LLM)在临床实践中的负责任且有效的整合。因此,本研究旨在促进这一跨学科领域的持续研发,以实现医疗大语言模型在改善临床实践和推动医学进步方面的深远潜力,从而造福社会。
BOX 1: Background of Large Language Models (LLMs)
BOX 1: 大语言模型 (LLM) 背景
The impressive performance of LLMs can be attributed to Transformer-based language models, large-scale pre-training, and scaling laws.
大语言模型的卓越性能可归功于基于Transformer的语言模型、大规模预训练和缩放定律。
Language Models A language model 25,26,27 is a probabilistic model that models the joint probability distribution of tokens (meaningful units of text, such as words or subwords or morphemes) in a sequence, i.e., the probabilities of how words and phrases are used in sequences. Therefore, it can predict the likelihood of a sequence of tokens given the previous tokens, which can be used to predict the next token in a sequence or to generate new sequences.
语言模型
语言模型 [25,26,27] 是一种概率模型,用于建模序列中 token (文本的有意义单元,如单词、子词或语素) 的联合概率分布,即单词和短语在序列中的使用概率。因此,它能够根据先前的 token 预测序列中 token 的可能性,从而用于预测序列中的下一个 token 或生成新序列。
The Transformer architecture The recurrent neural network (RNN) 28,26 has been widely used for language modeling by processing tokens sequentially and maintaining a vector named hidden state that encodes the context of previous tokens. Nonetheless, sequential processing makes it unsuitable for parallel training and limits its ability to capture long-range dependencies, making it computationally expensive and hindering its learning ability for long sequences. The strength of the Transformer 29 lies in its fully attentive mechanism, which relies exclusively on the attention mechanism and eliminates the need for recurrence. When processing each token, the attention mechanism computes a weighted sum of the other input tokens, where the weights are determined by the relevance between each input token and the current token. It allows the model to adaptively focus on different parts of the sequence to effectively learn the joint probability distribution of tokens. Therefore, Transformer not only enables efficient modeling of long-text but also allows highly paralleled training 30, thus reducing training costs. They make the Transformer highly scalable, and therefore it is efficient to obtain LLMs through the large-scale pre-training strategy.
Transformer架构
循环神经网络(RNN) [28,26] 通过按顺序处理token并维护一个名为隐藏状态的向量(用于编码先前token的上下文)而被广泛用于语言建模。然而,顺序处理使其不适合并行训练,并限制了其捕获长距离依赖关系的能力,导致计算成本高昂且阻碍其对长序列的学习能力。Transformer [29] 的优势在于其完全基于注意力机制的全注意力机制,无需循环结构。在处理每个token时,注意力机制会计算其他输入token的加权和,其中权重由每个输入token与当前token的相关性决定。这使得模型能够自适应地关注序列的不同部分,从而有效学习token的联合概率分布。因此,Transformer不仅能高效建模长文本,还支持高度并行化训练 [30],从而降低训练成本。这些特性使Transformer具备高度可扩展性,因此能通过大规模预训练策略高效获得大语言模型。
Large-scale Pre-training The LLMs are trained on massive corpora of unlabeled texts (e.g., Common Crawl, Wiki, and Books) to learn rich linguistic knowledge and language patterns. The common training objectives are masked language modeling (MLM) and next token prediction (NTP). In MLM, a portion of the input text is masked, and the model is tasked with predicting the masked text based on the remaining unmasked context, encouraging the model to capture the semantic and syntactic relationships between tokens 30; NTP is another common training objective, where the model is required to predict the next token in a sequence given the previous tokens. It helps the model to predict the next token 6.
大规模预训练
大语言模型 (LLM) 通过海量无标注文本 (如 Common Crawl、Wiki 和 Books 等) 训练,以学习丰富的语言知识和语言模式。常见的训练目标包括掩码语言建模 (MLM) 和下一词元预测 (NTP)。在 MLM 中,输入文本的部分内容被掩码,模型需要根据未掩码的上下文预测被掩码的文本,从而促使模型学习词元 (Token) 之间的语义和句法关系 [30];NTP 是另一种常见训练目标,要求模型根据已生成的词元序列预测下一个词元,这种机制能有效提升模型的连续文本生成能力 [6]。
Scaling Laws LLMs are the scaled-up versions of Transformer architecture 29 with increased numbers of Transformer layers, model parameters, and volume of pre-training data. The “scaling laws” 31,32 predict how much improvement can be expected in a model’s performance as its size increases (in terms of parameters, layers, data, or the amount of training computed). The scaling laws proposed by OpenAI 31 show that to achieve optimal model performance, the budget allocation for model size should be larger than the data.
大语言模型的扩展规律
大语言模型是Transformer架构[29]的扩展版本,通过增加Transformer层数、模型参数和预训练数据量来实现。扩展规律[31,32]预测了随着模型规模(参数、层数、数据量或计算量)增大,其性能将如何提升。OpenAI[31]提出的扩展规律表明,为获得最佳模型性能,模型规模的预算分配应大于数据预算。
The scaling laws proposed by Google DeepMind 32 show that both model and data sizes should be increased in equal scales. The scaling laws guide researchers to allocate resources and anticipate the benefits of scaling models.
谷歌DeepMind提出的扩展定律[32]表明,模型规模和数据规模应当同步扩大。该定律为研究者提供了资源分配依据,并能预测模型扩展带来的收益。
General Large Language Models Existing general LLMs can be divided into three categories based on their architecture (Table 1).
通用大语言模型
现有通用大语言模型 (LLM) 根据架构可分为三类 (表 1)。
Encoder-only LLMs consisting of a stack of Transformer encoder layers, employ a bidirectional training strategy that allows them to integrate context from both the left and the right of a given token in the input sequence. This bi-directional it y enables the models to achieve a deep understanding of the input sentences 30. Therefore, encoder-only LLMs are particularly suitable for language understanding tasks (e.g., sentiment analysis document classification) where the full context of the input is essential for accurate predictions. BERT 30 and DeBERTa 33 are the representative encoder-only LLMs.
仅编码器的大语言模型由一系列Transformer编码器层组成,采用双向训练策略,使其能够整合输入序列中给定token左右两侧的上下文。这种双向性使模型能够深入理解输入句子[30]。因此,仅编码器的大语言模型特别适合语言理解任务(例如情感分析、文档分类),这些任务需要完整输入上下文以实现准确预测。BERT[30]和DeBERTa[33]是代表性的仅编码器大语言模型。
Decoder-only LLMs utilize a stack of Transformer decoder layers and are characterized by their uni-directional (left-to-right) processing of text, enabling them to generate language sequentially. This architecture is trained unidirectional ly using the next token prediction training objective to predict the next token in a sequence, given all the previous tokens. After training, the decoder-only LLMs generate sequences auto regressive ly (i.e. token-by-token). The examples are the GPT-series developed by OpenAI 6,7, the LLaMA-series developed by Meta 4,5, and the $\mathrm{Pa}\mathrm{LM}^{3}$ and Bard (Gemini) 34 developed by Google. Based on the LLaMA model, Alpaca 35 is fine-tuned with 52k self-instructed data supervision. In addition, Baichuan 36 is trained on approximately 1.2 trillion tokens that support bilingual communication in Chinese and English. These LLMs have been used successfully in language generation.
仅解码器大语言模型采用堆叠的Transformer解码器层结构,其特点是单向(从左到右)处理文本,从而实现序列化语言生成。该架构通过下一token预测训练目标进行单向训练,即根据已生成的所有token预测序列中的下一个token。训练完成后,仅解码器大语言模型以自回归方式(逐个token)生成序列。典型实例包括OpenAI开发的GPT系列[6,7]、Meta研发的LLaMA系列[4,5],以及谷歌推出的$\mathrm{Pa}\mathrm{LM}^{3}$和Bard (Gemini)[34]。基于LLaMA模型,Alpaca[35]通过5.2万条自指令数据进行监督微调。此外,百川[36]在约1.2万亿token的双语语料上训练,支持中英双语交流。这些大语言模型已在语言生成领域取得显著成功。
Encoder-decoder LLMs are designed to simultaneously process input sequences and generate output sequences. They consist of a stack of bidirectional Transformer encoder layers followed by a stack of unidirectional Transformer decoder layers. The encoder processes and understands the input sequences, while the decoder generates the output sequences 8,9,37. Representative examples of encoder-decoder LLMs include Flan-T5 38, and ChatGLM 8,9. Specifically, ChatGLM 8,9 has 6.2B parameters and is a conversational open-source LLM specially optimized for Chinese to support Chinese-English bilingual question-answering.
编码器-解码器大语言模型旨在同时处理输入序列并生成输出序列。其结构由双向Transformer编码器层堆叠与单向Transformer解码器层堆叠组成。编码器负责处理和理解输入序列,解码器则生成输出序列 [8,9,37]。典型的编码器-解码器大语言模型包括Flan-T5 [38] 和ChatGLM [8,9]。其中ChatGLM [8,9] 拥有62亿参数,是专为中文优化的开源对话大语言模型,支持中英双语问答。
Table 1. Summary of existing general (large) language models, their underlying structures, numbers of parameters, and datasets used for model training. Column “# params” shows the number of parameters, M: million, B: billion.
| Domains | Model Structures | Models | #Params | Pre-train Data Scale |
| General-domain (Large) Language Models | Encoder-only | BERT30 RoBERTa 39 DeBERTa 33 GPT-240 Vicuna41 Alpaca 35 Mistral 42 | 110M/340M 355M 1.5B 1.5B 7B/13B 7B/13B | 3.3B tokens 161GB 160GB 40GB LLaMA+70K dialogues LLaMA+52KIFT |
| Decoder-only | LLaMA 4 LLaMA-25 LLaMA-343 GPT-36 Qwen 44 PaLM3 FLAN-PaLM37 Gemini (Bard) 34 GPT-3.545 GPT-47 Claude-3 46 | 7B 7B/13B/33B/65B 7B/13B/34B/70B 8B/70B 6.7B/13B/175B 1.8B/7B/14B/72B 8B/62B/540B 540B | 1.4T tokens 2T tokens 15T tokens 300B tokens 3T tokens 780B tokens | |
| Encoder-Decoder | BART47 ChatGLM8.9 T538 FLAN-T5 37 UL248 GLM9 | 140M/400M 6.2B 11B 3B/11B 19.5B 130B | 160GB 1T tokens 1T tokens 780B tokens 1T tokens 400B tokens |
表 1: 现有通用(大)语言模型概览,包括其底层结构、参数量及训练数据集。"# params"列显示参数量,M:百万,B:十亿。
| 领域 | 模型结构 | 模型 | #Params | 预训练数据规模 |
|---|---|---|---|---|
| 通用领域(大)语言模型 | Encoder-only | BERT[30] RoBERTa[39] DeBERTa[33] GPT-2[40] Vicuna[41] Alpaca[35] Mistral[42] | 110M/340M 355M 1.5B 1.5B 7B/13B 7B/13B | 3.3B tokens 161GB 160GB 40GB LLaMA+70K dialogues LLaMA+52KIFT |
| Decoder-only | LLaMA[4] LLaMA-2[5] LLaMA-3[43] GPT-3[6] Qwen[44] PaLM[3] FLAN-PaLM[37] Gemini(Bard)[34] GPT-3.5[45] GPT-4[47] Claude-3[46] | 7B 7B/13B/33B/65B 7B/13B/34B/70B 8B/70B 6.7B/13B/175B 1.8B/7B/14B/72B 8B/62B/540B 540B | 1.4T tokens 2T tokens 15T tokens 300B tokens 3T tokens 780B tokens | |
| Encoder-Decoder | BART[47] ChatGLM[8][9] T5[38] FLAN-T5[37] UL2[48] GLM[9] | 140M/400M 6.2B 11B 3B/11B 19.5B 130B | 160GB 1T tokens 1T tokens 780B tokens 1T tokens 400B tokens |
2 The Principles of Medical Large Language Models
2 医疗大语言模型的原理
Box 1 and Table 1 briefly introduce the background of general LLMs1, e.g., GPT $4^{7}$ . Table 2 summarizes the currently available medical LLMs according to their model development. Existing medical LLMs are mainly pre-trained from scratch, fine-tuned from existing general LLMs, or directly obtained through prompting to align the general LLMs to the medical domain. Therefore, we introduce the principles of medical LLMs in terms of these three methods: pre-training, fine-tuning, and prompting. Meanwhile, we further summarize the medical LLMs according to their model architectures in Figure 2.
框 1 和表 1 简要介绍了通用大语言模型 (LLM) 的背景,例如 GPT-4 [7]。表 2 根据模型开发方式总结了当前可用的医疗大语言模型。现有医疗大语言模型主要通过从头预训练、基于现有通用大语言模型微调,或直接通过提示 (prompting) 使通用大语言模型适配医疗领域获得。因此,我们从预训练、微调和提示这三个方法层面介绍医疗大语言模型的原理。同时,我们在图 2 中进一步根据模型架构对医疗大语言模型进行了分类。
Table 2. Summary of existing medical-domain LLMs, in terms of their model development, the number of parameters (# params), the scale of pre-training/fine-tuning data, and the data source. M: million, B: billion.
| Domains | Model Development Models | # Params | Data Scale | Data Source | |
| BioBERT49 PubMedBERT52 | 110M 110M/340M | 18B tokens | PubMed 50+PMC 51 | ||
| 3.2B tokens | PubMed 50+PMC 51 | ||||
| SciBERT53 | 110M | 3.17B tokens | Literature 54 | ||
| NYUTron55 | 110M | 7.25M notes, 4.1B tokens | NYU Notes 5s | ||
| ClinicalBERT56 | 110M | 112k clinical notes | MIMIC-II157 | ||
| BioM-ELECTRA58 | 110M/335M | PubMed 50 | |||
| BioMed-RoBERTa59 | 125M | 7.55B tokens | S20RC6 | ||
| BioLinkBERT61 | 110M/340M | 21GB | PubMed 50 | ||
| BlueBERT 6263.64 | 110M/340M | >4.5B tokens | PubMed 50+MIMIC-III57 | ||
| SciFive 65 | 220M/770M | PubMed 50+PMC 51 | |||
| ClinicalT566 | 220M/770M | 2M clinical notes | MIMIC-III57 | ||
| 330M | 255M articles | PubMed 50 | |||
| Medical-domain LLMs (Sec. 2) | MedCPT67 DRAGON6S | 360M | 6GB | BookCorpus 69 | |
| BioGPT70 | 1.5B | 15M articles | PubMed 50 | ||
| BioMedLM71 | 2.7B | 110GB | Pile 2 | ||
| OphGLM73 | 6.2B | 20k dialogues | MedDialog 74 | ||
| GatorTron 23 | 8.9B | >82Btokens+6B tokens | EHRs23+PubMed 50 | ||
| 2.5B tokens+0.5B tokens | Wiki+MIMIC-II7 | ||||
| GatorTronGPT 75 DoctorGLM 76 | 5B/20B 6.2B | 277B tokens | EHRs 75 CMD.77 | ||
| BianQue 78 | 6.2B | 323MB dialogues 2.4M dialogues | BianQueCorpus 7s | ||
| ClinicaIGPT79 | 96k EHRs + 100k dialogues | MD-EHR 79+MedDialog 74 | |||
| Qilin-Med 80 | 7B | 192 medical QA | VariousMedQA14 | ||
| ChatDoctor 's | 7B 7B | 3GB | ChiMed 80 | ||
| BenTsao 17 | 7B | 110k dialogues 8k instructions | HealthCareMagic \$1+iCliniq2 CMeKG-8K83 | ||
| HuatuoGPT&4 | 7B | 226k instructions&dialogues | Hybrid SFT&4 | ||
| Baize-healthcare&5 | 7B | 101K dialogues | Quora+MedQuAD&6 | ||
| BioMedGPT87 MedAlpaca16 | 10B | S2ORC60 | |||
| 7B/13B | >26B tokens 160k medical QA | Medical Meadow 16 | |||
| 7B/13B | MedInstruct-52k88 | ||||
| AlpaCare 8 | 13B | 52k instructions | |||
| Zhongjing 89 PMC-LLaMA 13 | 70k dialogues | CMtMedQA89 | |||
| Fine-tuning (Sec.2.2) CPLLM9 | 13B | 79.2B tokens | Books+Literature 60+MedC-I13 | ||
| 13B | 109k EHRs | eICU-CRD9+MIMIC-IV92 | |||
| Med42 93 | 7B/70B | 250M tokens | PubMed + MedQA14 + OpenOrca | ||
| MEDITRON 94.95 | 7B/70B | 48.1B tokens | PubMed 50+Guidelines 94 | ||
| OpenBioLLM% | 8B/70B | ||||
| MedLlama3-v20 97 | 8B/70B | ||||
| Clinical Camel 18 13B/70B | 70k dialogues+100k articles 4k medical QA | ShareGPT98+PubMed 50 MedQA14 | |||
| MedPaLM-2 11 340B | 193k medical QA | MultiMedQA 11 | |||
| Med-Flamingo 99 | 600k pairs | Multimodal Textbook+PMC-OA99 VQA-RAD100+PathVQA101 | |||
| LLaVA-Med 102 | 660k pairs | PMC-15M 102+VQA-RAD 100 SLAKE103+PathVQA101 | |||
| MAIRA-1 104 | 337k pairs | MIMIC-CXR105 | |||
| RadFM 106 | 32M pairs | MedMD 106 MedQA-R&RS 108++MultiMedQA11 | |||
| Med-Gemin 107.10s | +MIMIC-I157+MultiMedBench109 | ||||
| CodeX110 | GPT-3.5 / LLaMA-2 Chain-of-Thought (CoT 111 | ||||
| Prompting (Sec.2.3) | DeID-GPTI12 | ChatGPT / GPT-4 | Chain-of-Thought (CoT) I1 | ||
| ChatCADI13 Dr. Knows I14 | ChatGPT | In-Context Learning (ICL) ICL | UMLS 115 | ||
| MedPaLM10 | ChatGPT PaLM (540B) | CoT & ICL | MultiMedQA11 | ||
| MedPrompt 12 | GPT-4 | CoT & ICL 1 | |||
| Retrieval-Augmented Generation (RAG)PubMed+Guidelines 17UpToDate 1+Dyname1 | |||||
| QA-RAG 120 | Chat-Orthopedist I16 | ChatGPT | |||
| Almanac 21 | ChatGPT | RAG | FDA QA 120 | ||
| ChatGPT | RAG & CoT | Clinical QA 121 | |||
| Oncology-GPT-4 93 | GPT-4 | RAG & ICL | Oncology Guidelines from ASCO and ESMO |
表 2: 现有医疗领域大语言模型总结,涵盖模型开发、参数量 (# params)、预训练/微调数据规模及数据来源。M: 百万,B: 十亿。
| 领域 | 模型开发模型 | # 参数量 | 数据规模 | 数据来源 | |
|---|---|---|---|---|---|
| BioBERT49 PubMedBERT52 | 110M 110M/340M | 18B tokens | PubMed 50+PMC 51 | ||
| 3.2B tokens | PubMed 50+PMC 51 | ||||
| SciBERT53 | 110M | 3.17B tokens | Literature 54 | ||
| NYUTron55 | 110M | 7.25M notes, 4.1B tokens | NYU Notes 55 | ||
| ClinicalBERT56 | 110M | 112k clinical notes | MIMIC-III57 | ||
| BioM-ELECTRA58 | 110M/335M | PubMed 50 | |||
| BioMed-RoBERTa59 | 125M | 7.55B tokens | S2ORC60 | ||
| BioLinkBERT61 | 110M/340M | 21GB | PubMed 50 | ||
| BlueBERT62-64 | 110M/340M | >4.5B tokens | PubMed 50+MIMIC-III57 | ||
| SciFive65 | 220M/770M | PubMed 50+PMC 51 | |||
| ClinicalT566 | 220M/770M | 2M clinical notes | MIMIC-III57 | ||
| 330M | 255M articles | PubMed 50 | |||
| 医疗领域大语言模型 (第2节) | MedCPT67 DRAGON68 | 360M | 6GB | BookCorpus69 | |
| BioGPT70 | 1.5B | 15M articles | PubMed 50 | ||
| BioMedLM71 | 2.7B | 110GB | Pile72 | ||
| OphGLM73 | 6.2B | 20k dialogues | MedDialog74 | ||
| GatorTron23 | 8.9B | >82B tokens+6B tokens | EHRs23+PubMed 50 | ||
| 2.5B tokens+0.5B tokens | Wiki+MIMIC-III57 | ||||
| GatorTronGPT75 DoctorGLM76 | 5B/20B 6.2B | 277B tokens | EHRs75 CMD77 | ||
| BianQue78 | 6.2B | 323MB dialogues 2.4M dialogues | BianQueCorpus78 | ||
| ClinicalGPT79 | 96k EHRs + 100k dialogues | MD-EHR79+MedDialog74 | |||
| Qilin-Med80 | 7B | 192 medical QA | VariousMedQA14 | ||
| ChatDoctor81 | 7B 7B | 3GB | ChiMed80 | ||
| BenTsao17 | 7B | 110k dialogues 8k instructions | HealthCareMagic81+iCliniq82 CMeKG-8K83 | ||
| HuatuoGPT84 | 7B | 226k instructions&dialogues | Hybrid SFT84 | ||
| Baize-healthcare85 | 7B | 101K dialogues | Quora+MedQuAD86 | ||
| BioMedGPT87 MedAlpaca16 | 10B | S2ORC60 | |||
| 7B/13B | >26B tokens 160k medical QA | Medical Meadow16 | |||
| 7B/13B | MedInstruct-52k88 | ||||
| AlpaCare88 | 13B | 52k instructions | |||
| Zhongjing89 PMC-LLaMA13 | 70k dialogues | CMTMedQA89 | |||
| 微调 (第2.2节) CPLLM90 | 13B | 79.2B tokens | Books+Literature60+MedC-I13 | ||
| 13B | 109k EHRs | eICU-CRD90+MIMIC-IV92 | |||
| Med4293 | 7B/70B | 250M tokens | PubMed + MedQA14 + OpenOrca | ||
| MEDITRON94-95 | 7B/70B | 48.1B tokens | PubMed50+Guidelines94 | ||
| OpenBioLLM96 | 8B/70B | ||||
| MedLlama3-v2097 | 8B/70B | ||||
| Clinical Camel18 | 13B/70B | 70k dialogues+100k articles 4k medical QA | ShareGPT98+PubMed50 MedQA14 | ||
| MedPaLM-211 | 340B | 193k medical QA | MultiMedQA11 | ||
| Med-Flamingo99 | 600k pairs | Multimodal Textbook+PMC-OA99 VQA-RAD100+PathVQA101 | |||
| LLaVA-Med102 | 660k pairs | PMC-15M102+VQA-RAD100 SLAKE103+PathVQA101 | |||
| MAIRA-1104 | 337k pairs | MIMIC-CXR105 | |||
| RadFM106 | 32M pairs | MedMD106 MedQA-R&RS108++MultiMedQA11 | |||
| Med-Gemini107-109 | +MIMIC-III57+MultiMedBench109 | ||||
| CodeX110 | GPT-3.5/LLaMA-2 Chain-of-Thought (CoT)111 | ||||
| 提示 (第2.3节) | DeID-GPT112 | ChatGPT/GPT-4 | Chain-of-Thought (CoT)112 | ||
| ChatCAD113 Dr. Knows114 | ChatGPT | In-Context Learning (ICL) | UMLS115 | ||
| MedPaLM10 | ChatGPT PaLM (540B) | CoT & ICL | MultiMedQA11 | ||
| MedPrompt12 | GPT-4 | CoT & ICL12 | |||
| Retrieval-Augmented Generation (RAG) PubMed+Guidelines17 UpToDate119+Dynamed119 | |||||
| QA-RAG120 | Chat-Orthopedist116 | ChatGPT | |||
| Almanac121 | ChatGPT | RAG | FDA QA120 | ||
| ChatGPT | RAG & CoT | Clinical QA121 | |||
| Oncology-GPT-493 | GPT-4 | RAG & ICL | Oncology Guidelines from ASCO and ESMO |
2.1 Pre-training
2.1 预训练
Pre-training typically involves training an LLM on a large corpus of medical texts, including both structured and unstructured text, to learn the rich medical knowledge. The corpus may include $\mathrm{EHRs}^{75}$ , clinical notes 23, and medical literature 56. In particular, PubMed50, MIMIC-III clinical notes57, and PubMed Central (PMC) literature 51, are three widely used medical corpora for medical LLM pre-training. A single corpus or a combination of corpora may be used for pre-training. For example, PubMed BERT 52 and Clinic alBERT are pre-trained on PubMed and MIMIC-III, respectively. In contrast, BlueBERT62 combines both corpora for pre-training; BioBERT49 is pre-trained on both PubMed and PMC. The University of Florida (UF) Health EHRs are further introduced in pre-training Gator Tron 23 and Gator Tron GP T 75. MEDITRON94 is pre-trained on Clinical Practice Guidelines (CPGs). The CPGs are used to guide healthcare practitioners and patients in making evidence-based decisions about diagnosis, treatment, and management.
预训练通常包括在大规模医学文本语料库上训练大语言模型(LLM),涵盖结构化与非结构化文本,以学习丰富的医学知识。语料库可能包含电子健康记录(EHRs)[75]、临床记录[23]和医学文献[56]。其中PubMed[50]、MIMIC-III临床记录[57]和PubMed Central(PMC)文献[51]是三种广泛用于医学大语言模型预训练的语料库。预训练可采用单一语料库或组合语料库,例如PubMed BERT[52]和ClinicalBERT分别在PubMed和MIMIC-III上预训练,而BlueBERT[62]则结合了这两个语料库;BioBERT[49]同时在PubMed和PMC上预训练。佛罗里达大学(UF)健康电子健康记录进一步用于GatorTron[23]和GatorTronGPT[75]的预训练。MEDITRON[94]基于临床实践指南(CPGs)进行预训练,这些指南用于辅助医疗从业者和患者做出基于证据的诊断、治疗和管理决策。
To meet the needs of the medical domain, pre-training medical LLMs typically involve refining the following commonly used training objectives in general LLMs: masked language modeling, next sentence prediction, and next token prediction (Please see Box 1 for an introduction of these three pre-training objectives). For example. BERT-series models (e.g., BioBERT 49, PubMed BERT 52, Clinic alBERT 56, and Gator Tron 23) mainly adopt the masked language modeling and the next sentence prediction for pre-training; GPT-series models (e.g., BioGPT70, and Gator Tron GP T 75) mainly adopt the next token prediction for pre-training. It is worth mentioning that BERT-like Medical LLMs (e.g., BioBERT49, PubMed BERT 52, Clinical BERT56) are originally derived from the general domain BERT or RoBERTa models. To clarify the differences between different models, in our Table 2, we only show the data source used to further construct medical LLMs. In particular, a more recent work122 provides a systematic review of existing clinical text datasets for LLMs. After pre-training, medical LLMs can learn rich medical knowledge that can be leveraged to achieve strong performance on different medical tasks.
为满足医疗领域需求,预训练医疗大语言模型通常会对通用大语言模型中以下三种常用训练目标进行改进:掩码语言建模 (masked language modeling)、下一句预测 (next sentence prediction) 和下一词元预测 (next token prediction) (详见框1对这三种预训练目标的介绍)。例如,BERT系列模型(如BioBERT [49]、PubMed BERT [52]、ClinicalBERT [56]和GatorTron [23])主要采用掩码语言建模和下一句预测进行预训练;GPT系列模型(如BioGPT [70]和GatorTronGPT [75])则主要采用下一词元预测进行预训练。值得注意的是,类BERT医疗大语言模型(如BioBERT [49]、PubMed BERT [52]、ClinicalBERT [56])最初源自通用领域的BERT或RoBERTa模型。为明确不同模型间的差异,我们在表2中仅展示用于构建医疗大语言模型的数据来源。近期一项研究[122]系统综述了现有面向大语言模型的临床文本数据集。通过预训练,医疗大语言模型可学习丰富的医学知识,从而在不同医疗任务中实现优异性能。
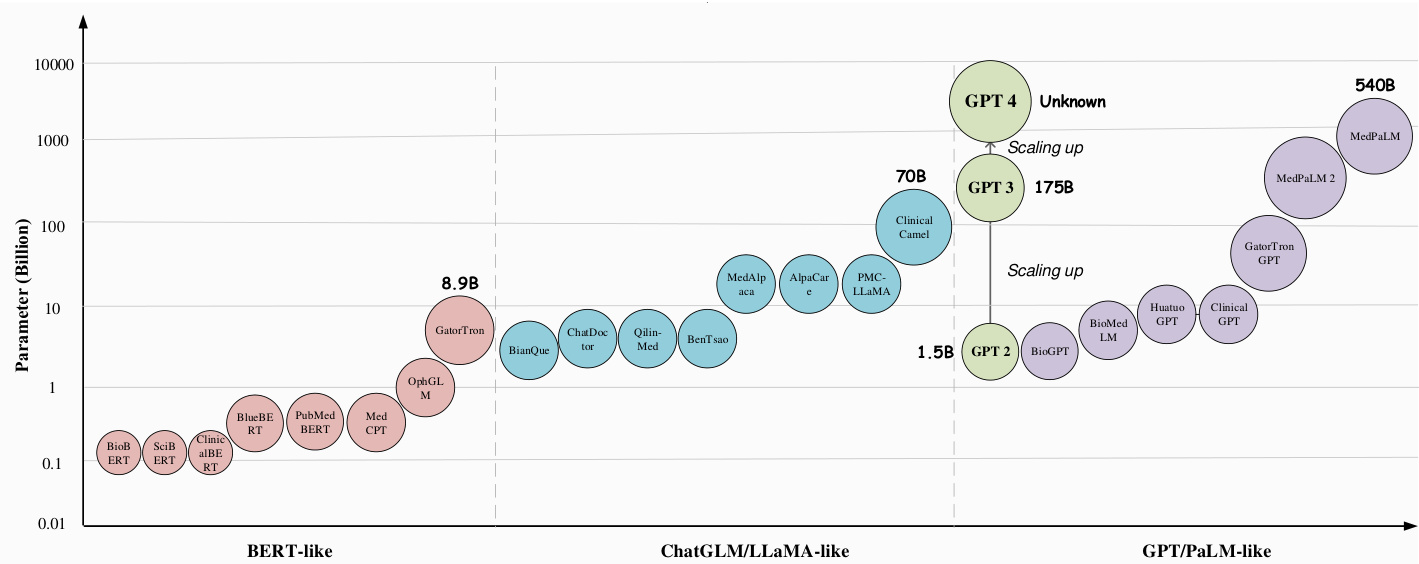
Figure 2. We adopt the data from Table 2 to demonstrate the development of model sizes for medical large language models in different model architectures, i.e., BERT-like, ChatGLM/LLaMA-like, and GPT/PaLM-like.
图 2: 我们采用表 2 中的数据来展示不同模型架构(即类 BERT、类 ChatGLM/LLaMA 和类 GPT/PaLM)下医疗大语言模型的规模发展情况。
2.2 Fine-tuning
2.2 微调
It is high-cost and time-consuming to train a medical LLM from scratch, due to its requirement of substantial (e.g., several days or even weeks) computational power and manual labor. One solution is to fine-tune the general LLMs with medical data, and researchers have proposed different fine-tuning methods11,16,18 for learning domain-specific medical knowledge and obtaining medical LLMs. Current fine-tuning methods include Supervised Fine-Tuning (SFT), Instruction Fine-Tuning (IFT), and Parameter-Efficient Fine-Tuning (PEFT). The resulting fine-tuned medical LLMs are summarized in Table 2. SFT can serve as continued pre-training to fine-tune general LLMs on existing (usually unlabeled) medical corpora. IFT focuses on fine-tuning general LLMs on instruction-based medical data containing additional (usually human-constructed) instructions.
从头训练一个医疗大语言模型成本高昂且耗时,因为这需要大量(例如数天甚至数周)的计算资源和人力投入。一种解决方案是利用医疗数据对通用大语言模型进行微调,研究人员已提出了多种微调方法[11,16,18]来学习特定领域的医学知识并获得医疗大语言模型。当前的微调方法包括监督微调(Supervised Fine-Tuning, SFT)、指令微调(Instruction Fine-Tuning, IFT)和参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)。表2总结了通过这些方法得到的医疗大语言模型。SFT可作为持续预训练方法,在现有(通常未标注的)医疗语料库上微调通用大语言模型。IFT则侧重于在包含额外(通常由人工构建的)指令的医疗数据上对通用大语言模型进行微调。
Supervised Fine-Tuning (SFT) aims to leverage high-quality medical corpus, which can be physician-patient conversations 15, medical question-answering 16, and knowledge graphs 80,17. The constructed SFT data serves as a continuation of the pre-training data to further pre-train the general LLMs with the same training objectives, e.g., next token prediction. SFT provides an additional pre-training phase that allows the general LLMs to learn rich medical knowledge and align with the medical domain, thus transforming them into specialized medical LLMs.
监督微调 (Supervised Fine-Tuning, SFT) 旨在利用高质量医学语料,包括医患对话 [15]、医学问答 [16] 和知识图谱 [80,17]。构建的 SFT 数据作为预训练数据的延续,以相同训练目标(如下一个token预测)对通用大语言模型进行进一步预训练。SFT 提供了一个额外的预训练阶段,使通用大语言模型能够学习丰富的医学知识并与医学领域对齐,从而将其转化为专业医学大语言模型。
The diversity of SFT enables the development of diverse medical LLMs by training on different types of medical corpus. For example, Doctor GL M 76 and Chat Doctor 15 are obtained by fine-tuning the general LLMs ChatGLM8,9 and LLaMA4 on the physician-patient dialogue data, respectively. MedAl paca 16 based on the general LLM Alpaca35 is fine-tuned using over 160,000 medical QA pairs sourced from diverse medical corpora. Clinical camel 18 combines physician-patient conversations, clinical literature, and medical QA pairs to refine the LLaMA-2 model5. In particular, Qilin-Med80 and Zhong jing 89 are obtained by incorporating the knowledge graph to perform fine-tuning on the Baichuan36 and LLaMA4, respectively.
SFT (Supervised Fine-Tuning) 的多样性使得通过训练不同类型的医学语料库来开发多样化的医疗大语言模型成为可能。例如,Doctor GLM [76] 和 Chat Doctor [15] 分别通过对通用大语言模型 ChatGLM [8,9] 和 LLaMA [4] 在医患对话数据上进行微调获得。基于通用大语言模型 Alpaca [35] 的 MedAlpaca [16] 使用了来自不同医学语料库的超过 16 万条医学问答对进行微调。Clinical Camel [18] 结合了医患对话、临床文献和医学问答对来优化 LLaMA-2 模型 [5]。特别地,Qilin-Med [80] 和 Zhongjing [89] 通过整合知识图谱分别对 Baichuan [36] 和 LLaMA [4] 进行微调获得。
In summary, existing studies have demonstrated the efficacy of SFT in adapting general LLMs to the medical domain. They show that SFT improves not only the model’s capability for understanding and generating medical text, but also its ability to provide accurate clinical decision support 123.
总之,现有研究已证明监督微调(SFT)能有效将通用大语言模型适配到医疗领域。研究表明,SFT不仅能提升模型对医学文本的理解与生成能力,还可增强其提供准确临床决策支持的能力[123]。
Instruction Fine-Tuning (IFT) constructs instruction-based training datasets 124,123,1, which typically comprise instructioninput-output triples, e.g., instruction-question-answer. The primary goal of IFT is to enhance the model’s ability to follow various human/task instructions, align their outputs with the medical domain, and thereby produce a specialized medical LLM.
指令微调 (Instruction Fine-Tuning, IFT) 通过构建基于指令的训练数据集 [124,123,1] 来实现,这些数据集通常包含指令-输入-输出的三元组,例如指令-问题-答案。IFT 的主要目标是提升模型遵循各类人类/任务指令的能力,使其输出与医疗领域对齐,从而生成一个专业化的医疗大语言模型。
Thus, the main difference between SFT and IFT is that the former focuses primarily on injecting medical knowledge into a general LLM through continued pre-training, thus improving its ability to understand the medical text and accurately predict the next token. In contrast, IFT aims to improve the model’s instruction following ability and adjust its outputs to match the given instructions, rather than accurately predicting the next token as in $\mathrm{SFT}^{124}$ . As a result, SFT emphasizes the quantity of training data, while IFT emphasizes their quality and diversity. Since IFT and SFT are both capable of improving model performance, there have been some recent works89,80,88 attempting to combine them for obtaining robust medical LLMs.
因此,SFT (Supervised Fine-Tuning) 与 IFT (Instruction Fine-Tuning) 的主要区别在于:前者主要通过持续预训练将医学知识注入通用大语言模型,从而提升其理解医学文本和准确预测下一个Token的能力;而后者旨在提升模型的指令跟随能力,调整输出以匹配给定指令,而非像 $\mathrm{SFT}^{124}$ 那样精确预测下一个Token。因此,SFT更注重训练数据量,而IFT更注重数据质量与多样性。由于IFT和SFT均能提升模型性能,近期已有研究 [89,80,88] 尝试将二者结合以获得更稳健的医学大语言模型。
In other words, to enhance the performance of LLMs through IFT, it is essential to ensure that the training data for IFT are of high quality and encompass a wide range of medical instructions and medical scenarios. To this end, MedPaLM $2^{11}$ invited qualified medical professionals to develop the instruction data for fine-tuning the general PaLM. BenTsao17 and ChatGLMMed125 constructed the knowledge-based instruction data from the knowledge graph. Zhong jing 89 further incorporated the multi-turn dialogue as the instruction data to perform IFT. MedAl paca 16 simultaneously incorporated the medical dialogues and medical QA pairs for instruction fine-tuning.
换句话说,要通过指令微调(IFT)提升大语言模型(LLM)的性能,关键在于确保训练数据质量高且覆盖广泛的医疗指令和场景。为此,MedPaLM $2^{11}$ 邀请了专业医疗人员开发用于微调通用PaLM的指令数据。BenTsao17和ChatGLMMed125从知识图谱构建了基于知识的指令数据。Zhong jing 89进一步将多轮对话纳入指令数据进行微调。MedAl paca 16则同时整合了医疗对话和医疗问答对进行指令微调。
Recent advancements in multimodal LLMs have expanded the capabilities of LLMs to process complex and multimodal medical data. Notable examples include Med-Flamingo99, LLaVA-Med102, and Med-Gemini108. Med-Flamingo99 undergoes IFT on medical image-text data, learning to identify abnormalities and generate diagnostic reports. LLaVA-Med’s102 two-stage IFT process involves aligning medical concepts across visual and textual modalities, followed by fine-tuning the model on diverse medical instructions. Med-Gemini’s108 IFT utilizes a curated dataset of medical instructions and multimodal data, enabling it to comprehend complex medical concepts, procedures, and diagnostic reasoning. Meanwhile, MAIRA-1104 and RadFM106 are two multimodal LLMs specifically designed for radiology applications. MAIRA-1104 employs IFT on a dataset of radiology instructions and corresponding medical images, enabling it to analyze radiological images and generate accurate diagnostic reports. RadFM106, on the other hand, leverages a pre-training approach on a large corpus of radiology-specific image-text data, followed by instruction fine-tuning on a diverse set of radiology instructions. These models’ multimodal IFT approaches enable them to bridge the gap between visual and textual medical information, perform a wide range of medical tasks accurately, and generate context-aware responses to complex medical queries.
多模态大语言模型的最新进展拓展了大语言模型处理复杂多模态医疗数据的能力。代表性成果包括Med-Flamingo99、LLaVA-Med102和Med-Gemini108。Med-Flamingo99通过医疗图文数据的指令微调(IFT),学习识别异常并生成诊断报告。LLaVA-Med102采用两阶段指令微调流程:先对齐视觉与文本模态的医疗概念,再针对多样化医疗指令进行模型微调。Med-Gemini108的指令微调使用精选医疗指令和多模态数据集,使其能理解复杂医疗概念、操作流程和诊断推理。与此同时,MAIRA-1104和RadFM106是专为放射学应用设计的两种多模态大语言模型。MAIRA-1104在放射学指令及对应医学影像数据集上进行指令微调,可分析放射影像并生成精准诊断报告。RadFM106则采用预训练方法处理大规模放射学专用图文数据,再通过多样化放射学指令进行微调。这些模型的多模态指令微调方法能弥合视觉与文本医疗信息的鸿沟,精准执行各类医疗任务,并对复杂医疗查询生成情境感知的响应。
Parameter-Efficient Fine-Tuning (PEFT) aims to substantially reduce computational and memory requirements for fine-tuning general LLMs. The main idea is to keep most of the parameters in pre-trained LLMs unchanged, by fine-tuning only the smallest subset of parameters (or additional parameters) in these LLMs. Commonly used PEFT techniques include Low-Rank Adaptation (LoRA)126, Prefix Tuning127, and Adapter Tuning128,129.
参数高效微调 (PEFT) 旨在大幅降低通用大语言模型微调所需的计算和内存资源。其核心思想是保持预训练大语言模型的大部分参数不变,仅对这些模型中最小的参数子集 (或额外参数) 进行微调。常用的 PEFT 技术包括低秩自适应 (LoRA) [126]、前缀调优 [127] 以及适配器调优 [128,129]。
In contrast to fine-tuning full-rank weight matrices, 1) LoRA preserves the parameters of the original LLMs and only adds trainable low-rank matrices into the self-attention module of each Transformer layer126. Therefore, LoRA can substantially reduce the number of trainable parameters and improve the efficiency of fine-tuning, while still enabling the fine-tuned LLM to capture effectively the characteristics of the tasks. 2) Prefix Tuning takes a different approach from LoRA by adding a small set of continuous task-specific vectors (i.e. “prefixes”) to the input of each Transformer layer 127,1. These prefixes serve as the additional context to guide the generation of the model without changing the original pre-trained parameter weights. 3) Adapter Tuning involves introducing small neural network modules, known as adapters, into each Transformer layer of the pre-trained LLMs130. These adapters are fine-tuned while keeping the original model parameters frozen130, thus allowing for flexible and efficient fine-tuning. The number of trainable parameters introduced by adapters is relatively small, yet they enable the LLMs to adapt to clinical scenarios or tasks effectively.
与微调全秩权重矩阵不同,1) LoRA保留了原始大语言模型的参数,仅在每个Transformer层的自注意力模块中添加可训练的低秩矩阵[126]。因此,LoRA能显著减少可训练参数量并提升微调效率,同时仍使微调后的大语言模型有效捕捉任务特征。2) Prefix Tuning采用与LoRA不同的方法,通过在每个Transformer层的输入中添加一组小型连续任务特定向量(即"前缀")[127,1]。这些前缀作为额外上下文引导模型生成,且不改变原始预训练参数权重。3) Adapter Tuning通过在预训练大语言模型的每个Transformer层中插入称为适配器的小型神经网络模块实现[130]。这些适配器在保持原始模型参数冻结的情况下进行微调[130],从而实现灵活高效的微调。适配器引入的可训练参数量相对较少,却能使大语言模型有效适应临床场景或任务。
In general, PEFT is valuable for developing LLMs that meet unique needs in specific (e.g., medical) domains, due to its ability to reduce computational demands while maintaining the model performance. For example, medical LLMs Doctor GL M 76, MedAl paca 16, Baize-Healthcare 85, Zhong jing 89, CPLLM90, and Clinical Camel18 adopted the LoRA126 to perform parameter-efficient fine-tuning to efficiently align the general LLMs to the medical domain.
通常来说,参数高效微调 (PEFT) 对于开发满足特定领域 (如医疗) 独特需求的大语言模型具有重要价值,因为它能在保持模型性能的同时降低计算需求。例如,医疗领域的大语言模型 Doctor GL M [76]、MedAl paca [16]、Baize-Healthcare [85]、Zhong jing [89]、CPLLM [90] 和 Clinical Camel [18] 采用 LoRA [126] 进行参数高效微调,从而高效地将通用大语言模型适配到医疗领域。
2.3 Prompting
2.3 提示工程
Fine-tuning considerably reduces computational costs compared to pre-training, but it requires further model training and collections of high-quality datasets for fine-tuning, thus still consuming some computational resources and manual labor. In contrast, the “prompting” methods efficiently align general LLMs (e.g., $\mathrm{PaLM}^{3}.$ ) to the medical domain (e.g., MedPaLM10), without training any model parameters. Popular prompting methods include In-Context Learning (ICL), Chain-of-Thought (CoT) prompting, Prompt Tuning, and Retrieval-Augmented Generation (RAG).
微调相比预训练大幅降低了计算成本,但仍需进行额外的模型训练和收集高质量微调数据集,因此仍需消耗部分计算资源和人力。相比之下,"提示"(prompting)方法能高效地将通用大语言模型(如$\mathrm{PaLM}^{3}$)适配到医疗领域(如MedPaLM10),而无需训练任何模型参数。常见的提示方法包括上下文学习(ICL)、思维链(CoT)提示、提示调优(Prompt Tuning)和检索增强生成(RAG)。
In-Context Learning (ICL) aims to directly give instructions to prompt the LLM to perform a task efficiently. In general, the ICL consists of four process: task understanding, context learning, knowledge reasoning, and answer generation. First, the model must understand the specific requirements and goals of the task. Second, the model learns to understand the contextual information related to the task with argument context. Then, use the model’s internal knowledge and reasoning capabilities to understand the patterns and logic in the example. Finally, the model generates the task-related answers. The advantage of ICL is that it does not require a large amount of labeled data for fine-tuning. Based on the type and number of input examples, ICL can be divided into three categories 131. 1) One-shot Prompting: Only one example and task description are allowed to be entered. 2) Few-shot Prompting: Allows the input of multiple instances and task descriptions. 3) Zero-shot Prompting: Only task descriptions are allowed to be entered. ICL presents the LLMs making task predictions based on contexts augmented with a few examples and task demonstrations. It allows the LLMs to learn from these examples or demonstrations to accurately perform the task and follow the given examples to give corresponding answers6. Therefore, ICL allows LLMs to accurately understand and respond to medical queries. For example, MedPaLM10 substantially improves the task performance by providing the general LLM, PaLM3, with a small number of task examples such as medical QA pairs.
上下文学习 (ICL) 旨在直接通过指令提示大语言模型高效执行任务。通常,ICL包含四个流程:任务理解、上下文学习、知识推理和答案生成。首先,模型必须理解任务的具体要求和目标。其次,模型通过论证上下文学习理解与任务相关的上下文信息。接着,利用模型内部知识和推理能力理解示例中的模式和逻辑。最后,模型生成与任务相关的答案。ICL的优势在于不需要大量标注数据进行微调。根据输入示例的类型和数量,ICL可分为三类 [131]:
- 单样本提示 (One-shot Prompting):仅允许输入一个示例和任务描述。
- 少样本提示 (Few-shot Prompting):允许输入多个实例和任务描述。
- 零样本提示 (Zero-shot Prompting):仅允许输入任务描述。
ICL通过少量示例和任务演示增强上下文,使大语言模型能够基于上下文进行任务预测。它让大语言模型从这些示例或演示中学习,从而准确执行任务并按照给定示例生成相应答案 [6]。因此,ICL使大语言模型能够准确理解和响应医学查询。例如,MedPaLM [10] 通过为通用大语言模型 PaLM [3] 提供少量任务示例(如医学问答对),显著提升了任务性能。
Chain-of-Thought (CoT) Prompting further improves the accuracy and logic of model output, compared with In-Context Learning. Specifically, through prompting words, CoT aims to prompt the model to generate intermediate steps or paths of reasoning when dealing with downstream (complex) problems 111. Moreover, CoT can be combined with few-shot prompting by giving reasoning examples, thus enabling medical LLMs to give reasoning processes when generating responses. For tasks involving complex reasoning, such as medical QA, CoT has been shown to effectively improve model performance 10,11. Medical LLMs, such as DeID-GPT112, MedPaLM10, and Med Prompt 12, use CoT prompting to assist them in simulating a diagnostic thought process, thus providing more transparent and interpret able predictions or diagnoses. In particular, Med Prompt 12 directly prompts a general LLM, GPT $.4^{7}$ , to outperform the fine-tuned medical LLMs on medical QA without training any model parameters.
思维链 (Chain-of-Thought, CoT) 提示相较于上下文学习能进一步提升模型输出的准确性和逻辑性。具体而言,CoT通过提示词引导模型在处理下游(复杂)问题时生成中间推理步骤或路径[111]。此外,CoT可与少样本提示相结合,通过提供推理示例使医疗大语言模型在生成回答时展现推理过程。对于涉及复杂推理的任务(如医疗问答),研究证明CoT能有效提升模型性能[10,11]。DeID-GPT[112]、MedPaLM[10]和Med Prompt[12]等医疗大语言模型采用CoT提示来模拟诊断思维过程,从而提供更透明、可解释的预测或诊断。值得注意的是,Med Prompt[12]直接提示通用大语言模型GPT-4[7],无需训练任何模型参数即可在医疗问答任务上超越微调后的医疗大语言模型。
Prompt Tuning aims to improve the model performance by employing both prompting and fine-tuning techniques 132,129. The prompt tuning method introduces learnable prompts, i.e. trainable continuous vectors, which can be optimized or adjusted during the fine-tuning process to better adapt to different medical scenarios and tasks. Therefore, they provide a more flexible way of prompting LLMs than the “prompting alone” methods that use discrete and fixed prompts, as described above. In contrast to traditional fine-tuning methods that train all model parameters, prompt tuning only tunes a very small set of parameters associated with the prompts themselves, instead of extensively training the model parameters. Thus, prompt tuning effectively and accurately responds to medical problems12, with minimal incurring computational cost.
提示调优 (Prompt Tuning) 通过结合提示和微调技术来提升模型性能 [132,129]。该方法引入可学习的提示 (即可训练的连续向量),这些提示在微调过程中可被优化调整,从而更好地适应不同医疗场景和任务。相较于前文所述仅使用离散固定提示的"纯提示"方法,提示调优为大语言模型提供了更灵活的提示方式。与传统微调需要训练所有模型参数不同,提示调优仅调整与提示本身相关的极少量参数,而非大规模训练模型参数。因此,该方法能以最低计算成本精准高效地应对医疗问题 [12]。
Existing medical LLMs that employ the prompting techniques are listed in Table 2. Recently, MedPaLM10 and MedPaLM $2^{11}$ propose to combine all the above prompting methods, resulting in Instruction Prompt Tuning, to achieve strong performances on various medical question-answering datasets. In particular, using the MedQA dataset for the US Medical Licensing Examination (USMLE), MedPaLM $2^{11}$ achieves a competitive overall accuracy of $86.5%$ compared to human experts $(87.0%)$ , surpassing previous state-of-the-art method MedPaLM10 by a large margin $(19%)$ .
现有采用提示技术的医疗大语言模型列于表2。近期,MedPaLM10和MedPaLM $2^{11}$ 提出整合上述所有提示方法,形成指令提示调优(Instruction Prompt Tuning),在多项医疗问答数据集上取得优异表现。特别在针对美国医师执照考试(USMLE)的MedQA数据集上,MedPaLM $2^{11}$ 以86.5%的综合准确率逼近人类专家水平(87.0%),较此前最优方法MedPaLM10大幅提升19%。
Retrieval-Augmented Generation (RAG) enhances the performance of LLMs by integrating external knowledge into the generation process. In detail, RAG can be used to minimize LLM’s hallucinations, obscure reasoning processes, and reliance on outdated information by incorporating external database knowledge 133. RAG consists of three main components: retrieval, augmentation, and generation. The retrieval component employs various indexing strategies and input query processing techniques to search and top-ranked relevant information from an external knowledge base. The retrieved external data is then augmented into the LLM’s prompt, providing additional context and grounding for the generated response. By directly updating the external knowledge base, RAG mitigates the risk of catastrophic forgetting associated with model weight modifications, making it particularly suitable for domains with low error tolerance and rapidly evolving information, such as the medical field. In contrast to traditional fine-tuning methods, RAG enables the timely incorporation of new medical information without compromising the model’s previously acquired knowledge, ensuring the generated outputs remain accurate and up-to-date in the face of evolving medical challenges. Most recently, researchers proposed the first benchmark MIRAGE134 based on medical information RAG, including 7,663 questions from five medical QA datasets, which has been established to both steer research and facilitate the practical deployment of medical RAG systems
检索增强生成 (Retrieval-Augmented Generation, RAG) 通过将外部知识整合到生成过程中来提升大语言模型的性能。具体而言,RAG 可通过融合外部数据库知识来最小化大语言模型的幻觉、模糊推理过程以及对过时信息的依赖 [133]。RAG 包含三个主要组件:检索、增强和生成。检索组件采用多种索引策略和输入查询处理技术,从外部知识库中搜索并排名相关度最高的信息。随后,检索到的外部数据会被增强到大语言模型的提示中,为生成响应提供额外上下文和依据。通过直接更新外部知识库,RAG 降低了因模型权重修改导致的灾难性遗忘风险,使其特别适用于低错误容忍度且信息快速更新的领域(如医疗领域)。与传统微调方法相比,RAG 能够在不损害模型已获取知识的前提下及时整合新医疗信息,确保生成内容在面对不断演变的医疗挑战时保持准确性和时效性。最新研究中,学者们提出了首个基于医疗信息 RAG 的基准测试 MIRAGE[134],该基准包含来自五个医疗问答数据集的 7,663 个问题,旨在引导研究方向并推动医疗 RAG 系统的实际部署。
In RAG, retrieval can be achieved by calculating the similarity between the embeddings of the question and document chunks, where the semantic representation capability of embedding models plays a key role. Recent research has introduced prominent embedding models such as AngIE135, Voyage136, and BGE137. In addition to embedding, the retrieval process can be optimized via various strategies such as adaptive retrieval, recursive retrieval, and iterative retrieval 138,139,140. Several recent works have demonstrated the effectiveness of RAG in medical and pharmaceutical domains. Almanac121 is a large language framework augmented with retrieval capabilities for medical guidelines and treatment recommendations, surpassing the performance of ChatGPT on clinical scenario evaluations, particularly in terms of completeness and safety. Another work QA-RAG120 employs RAG with LLM for pharmaceutical regulatory tasks, where the model searches for relevant guideline documents and provides answers based on the retrieved guidelines. Chat-Orthopedist 116, a retrieval-augmented LLM, assists adolescent idiopathic scoliosis (AIS) patients and their families in preparing for meaningful discussions with clinicians by providing accurate and comprehensible responses to patient inquiries, leveraging AIS domain knowledge.
在RAG (Retrieval-Augmented Generation) 中,检索可以通过计算问题与文档块的嵌入 (embedding) 相似度实现,其中嵌入模型的语义表示能力起关键作用。近期研究推出了AngIE135、Voyage136和BGE137等代表性嵌入模型。除嵌入技术外,检索过程还可通过自适应检索、递归检索和迭代检索等策略进行优化[138,139,140]。多项最新研究验证了RAG在医疗医药领域的有效性:Almanac121是具备医学指南与治疗方案检索能力的大语言框架,在临床场景评估中(尤其是完整性与安全性维度)超越ChatGPT表现;QA-RAG120将RAG与大语言模型结合用于药品监管任务,通过检索相关指导文件并基于内容生成回答;Chat-Orthopedist116作为检索增强型大语言模型,利用青少年特发性脊柱侧凸 (AIS) 领域知识,为患者及家属提供准确易懂的答复,帮助其与临床医生开展有效沟通。
2.4 Discussion
2.4 讨论
This section discusses the principles of medical LLMs, including three types of methods for building models: pre-training, fine-tuning, and prompting. To meet the needs of practical medical applications, users can choose proper medical LLMs according to the magnitude of their own computing resources. Companies or institutes with massive computing resources can either pre-train an application-level medical LLM from scratch or fine-tune existing open-source general LLM models (e.g., LLaMA43) using large-scale medical data. The results in existing literature (e.g., MedPaLM-211, MedAl paca 16 and Clinical Camel18) have shown that fine-tuning general LLMs on medical data122 can boost their performance of medical tasks. For example, Clinical Camel18, which is fine-tuned on the LLaMA-2-70B5 model, even outperforms GPT-418. However, for small enterprises or individuals with certain computing resources, combining with the understanding of medical tasks and a reasonable combination of ICL, prompting engineering, and RAG, to prompt black-box LLMs may also achieve strong results. For example, Med Prompt 12 stimulates the commercial LLM GPT $4^{7}$ through an appropriate combination of prompt strategies to achieve comparable or even better results than fine-tuned medical LLMs (e.g., MedPaLM $2^{11}$ ) and human experts, suggesting that a mix of prompting strategies is an efficient and green solution in the medical domain rather than fine-tuning.
本节探讨医疗大语言模型的构建原理,包括预训练 (pre-training)、微调 (fine-tuning) 和提示工程 (prompting) 三类方法。为满足实际医疗应用需求,用户可根据自身计算资源规模选择合适的医疗大语言模型。拥有海量计算资源的公司或机构既可从零开始预训练应用级医疗大语言模型,也可基于现有开源通用大语言模型(如LLaMA43)通过大规模医疗数据进行微调。现有研究成果(如MedPaLM-211、MedAlpaca16和Clinical Camel18)表明,对通用大语言模型进行医疗数据122微调能显著提升其医疗任务表现。例如基于LLaMA-2-70B5微调的Clinical Camel18甚至超越了GPT-418。而对于具备一定计算资源的中小企业或个人,结合对医疗任务的理解,合理运用上下文学习 (ICL)、提示工程和检索增强生成 (RAG) 来驱动黑盒大语言模型,同样能取得优异效果。例如Med Prompt12通过提示策略的巧妙组合激发商用大语言模型GPT-47,其表现可媲美甚至超越微调医疗大语言模型(如MedPaLM211)和人类专家,这提示在医疗领域混合提示策略是比微调更高效环保的解决方案。
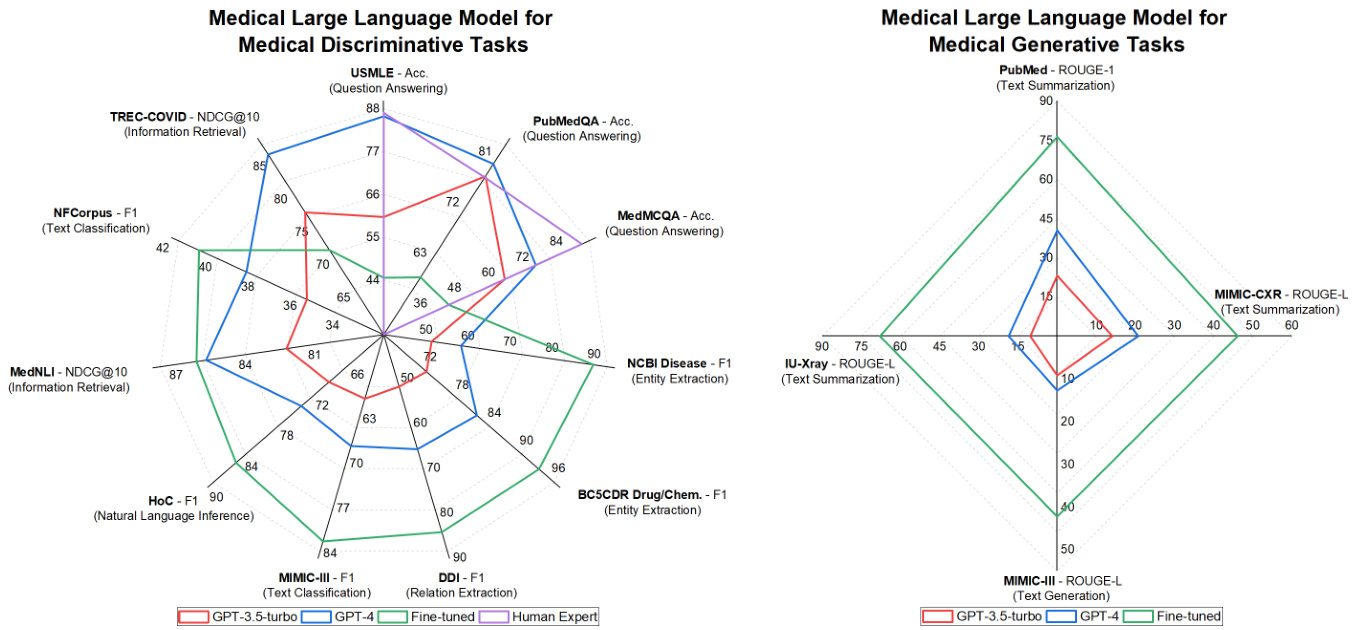
Figure 3. Performance (Dataset-Metric (Task)) comparison between the GPT-3.5 turbo, GPT-4, state-of-the-art task-specific lightweight models (Fine-tuned), and human experts, on seven medical tasks across eleven datasets. All data presented in our Figures originates from published and peer-reviewed literature. Please refer to the supplementary material for the detailed data.
图 3: GPT-3.5 turbo、GPT-4、当前最优任务专用轻量级模型(微调版)与人类专家在7项医疗任务11个数据集上的性能(数据集-指标(任务))对比。图中所有数据均来自已发表的同行评审文献,详细数据请参阅补充材料。
3 Medical Tasks
3 医疗任务
In this section, we will introduce two popular types of medical machine learning tasks: generative and disc rim i native tasks, including ten representative tasks that further build up clinical applications. Figure 3 illustrates the performance comparisons between different LLMs. For clarity, we will only cover a general discussion of those tasks. The detailed definition of the task and the performance comparisons can be found in our supplementary material.
在本节中,我们将介绍两类流行的医疗机器学习任务:生成式 (generative) 与判别式 (discriminative) 任务,包括支撑临床应用的十项代表性任务。图 3 展示了不同大语言模型间的性能对比。为简明起见,我们仅对这些任务进行概述性讨论,具体任务定义与性能对比可参阅补充材料。
3.1 Disc rim i native Tasks
3.1 判别式任务
Disc rim i native tasks are for categorizing or differentiating data into specific classes or categories based on given input data. They involve making distinctions between different types of data, often to categorize, classify, or extract relevant information from structured text or unstructured text. The representative tasks include Question Answering, Entity Extraction, Relation Extraction, Text Classification, Natural Language Inference, Semantic Textual Similarity, and Information Retrieval.
判别式任务旨在根据给定的输入数据,将数据分类或区分为特定的类别。这类任务涉及对不同类型的数据进行区分,通常用于对结构化文本或非结构化文本进行分类、归类或提取相关信息。代表性任务包括问答、实体抽取、关系抽取、文本分类、自然语言推理、语义文本相似度以及信息检索。
The typical input for disc rim i native tasks can be medical questions, clinical notes, medical documents, research papers, and patient EHRs. The output can be labels, categories, extracted entities, relationships, or answers to specific questions, which are often structured and categorized information derived from the input text. In existing LLMs, the disc rim i native tasks are widely studied and used to make predictions and extract information from input text.
判别式任务的典型输入可以是医学问题、临床记录、医疗文档、研究论文和患者电子健康档案(EHR)。输出可以是标签、类别、提取的实体、关系或特定问题的答案,这些通常是从输入文本中提取的结构化和分类信息。在现有的大语言模型中,判别式任务被广泛研究并用于从输入文本中做出预测和提取信息。
For example, based on medical knowledge, medical literature, or patient EHRs, the medical question answering (QA) task can provide precise answers to clinical questions, such as symptoms, treatment options, and drug interactions. This can help clinicians make more efficient and accurate diagnoses 10,11,19. Entity extraction can automatically identify and categorize critical information (i.e. entities) such as symptoms, medications, diseases, diagnoses, and lab results from patient EHRs, thus assisting in organizing and managing patient data. The following entity linking task aims to link the identified entities in a structured knowledge base or a standardized terminology system, e.g., SNOMED CT141, UMLS115, or ICD codes142. This task is critical in clinical decision support or management systems, for better diagnosis, treatment planning, and patient care.
例如,基于医学知识、医学文献或患者电子健康记录(EHR),医疗问答(QA)任务可以为临床问题(如症状、治疗方案和药物相互作用)提供精确答案,帮助临床医生做出更高效、准确的诊断[10,11,19]。实体提取能自动从患者EHR中识别并分类关键信息(即实体),如症状、药物、疾病、诊断和实验室结果,从而协助组织和管理患者数据。随后的实体链接任务旨在将识别出的实体关联到结构化知识库或标准化术语系统(如SNOMED CT[141]、UMLS[115]或ICD代码[142]),该任务对临床决策支持或管理系统至关重要,可优化诊断、治疗计划和患者护理。
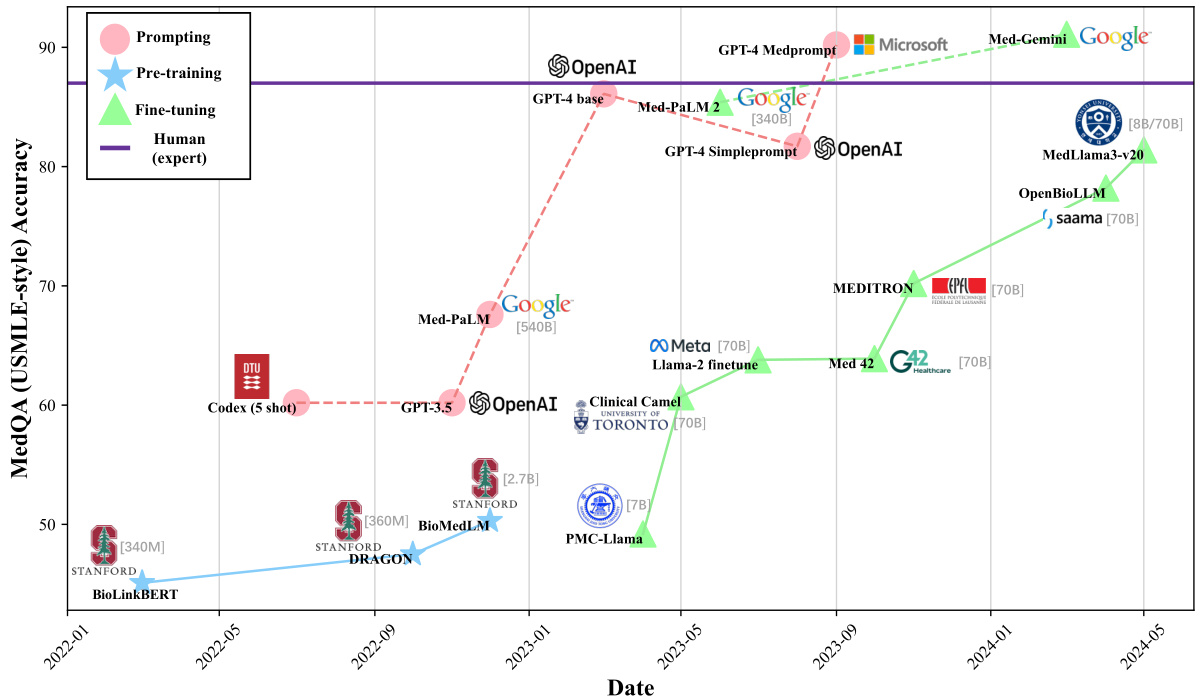
Figure 4. We demonstrate the development of medical large language models over time in different model development types through the scores of the United States Medical Licensing Examination (USMLE) from the MedQA dataset. Solid and dashed lines represent open-source and closed-source models, respectively.
图 4: 我们通过MedQA数据集中美国医师执照考试(USMLE)的分数,展示了不同模型开发类型下医疗大语言模型随时间的发展情况。实线和虚线分别代表开源和闭源模型。
3.2 Generative Tasks
3.2 生成式任务
Different from disc rim i native tasks that focus on understanding and categorizing the input text, generative tasks require a model to accurately generate fluent and appropriate new text based on given inputs. These tasks include medical text sum mari z ation 143,144, medical text generation 70, and medical text simplification 145.
与专注于理解和分类输入文本的判别式任务不同,生成式任务要求模型根据给定输入准确生成流畅且恰当的新文本。这些任务包括医学文本摘要[143,144]、医学文本生成[70]以及医学文本简化[145]。
For medical text sum mari z ation, the input and output are typically long and detailed medical text (e.g., “Findings” in radiology reports), and a concise summarized text (e.g., the “Impression” in radiology reports). Such text contains important medical information that enables clinicians and patients to efficiently capture the key points without going through the entire text. It can also help medical professionals to draft clinical notes by summarizing patient information or medical histories.
对于医疗文本摘要任务,输入和输出通常是长篇详尽的医疗文本(例如放射报告中的"检查所见"部分)与简洁的总结文本(如放射报告中的"印象"部分)。这类文本包含关键医疗信息,能让临床医生和患者无需阅读全文即可高效掌握要点。它还能通过汇总患者信息或病史,帮助医疗专业人员撰写临床记录。
In medical text generation, e.g., discharge instruction generation 146, the input can be medical conditions, symptoms, patient demographics, or even a set of medical notes or test results. The output can be a diagnosis recommendation of a medical condition, personalized instructional information, or health advice for the patient to manage their condition outside the hospital.
在医疗文本生成领域,例如出院指导生成[146],输入可以是医疗状况、症状、患者人口统计数据,甚至是一组医疗记录或检测结果。输出可以是对某种医疗状况的诊断建议、个性化指导信息,或是患者在医院外管理自身健康状况的健康建议。
Medical text simplification 145 aims to generate a simplified version of the complex medical text by, for example, clarifying and explaining medical terms. Different from text sum mari z ation, which concentrates on giving shortened text while maintaining most of the original text meanings, text simplification focuses more on the readability part. In particular, complicated or opaque words will be replaced; complex syntactic structures will be improved; and rare concepts will be explained 38. Thus, one example application is to generate easy-to-understand educational materials for patients from complex medical texts. It is useful for making medical information accessible to a general audience, without altering the essential meaning of the texts.
医学文本简化旨在通过澄清和解释医学术语等方式,生成复杂医学文本的简化版本。与文本摘要(专注于缩短文本同时保留原意)不同,文本简化更注重可读性提升:替换复杂晦涩的词汇、优化冗长句式结构、解释生僻概念[38]。典型应用场景包括将专业医学文献转化为患者易懂的教育材料,在不改变核心含义的前提下,帮助普通大众理解医疗信息。
3.3 Performance Comparisons
3.3 性能对比
Figure 3 shows that some existing general LLMs (e.g., GPT-3.5-turbo and GPT $4^{7}$ ) have achieved strong performance on existing medical machine learning tasks. This is most noticeable for the QA task where GPT-4 (shown in the blue line in Figure 3) consistently outperforms existing task-specific fine-tuned models and is even comparable to human experts (shown in the purple line). The QA datasets of evaluation include MedQA (USMLE)14, PubMed QA 147, and MedMCQA148. To better understand the QA performance of existing medical LLMs, in Figure 4, we further demonstrate the QA performance of medical LLMs on the MedQA dataset over time in different model development types. It also clearly shows that current works, e.g., Med Prompt 12 and Med-Gemini107,108, have successfully proposed several prompting and fine-tuning methods to enable LLMs to outperform human experts.
图 3 显示,现有的一些通用大语言模型(例如 GPT-3.5-turbo 和 GPT $4^{7}$)在现有医疗机器学习任务中已展现出强劲性能。这一现象在问答任务中最为显著,GPT-4(图 3 蓝线所示)持续超越现有针对特定任务微调的模型,甚至可与人类专家水平(紫线所示)比肩。评估使用的问答数据集包括 MedQA (USMLE) [14]、PubMed QA [147] 和 MedMCQA [148]。为深入理解现有医疗大语言模型的问答性能,图 4 进一步展示了不同模型开发类型下医疗大语言模型在 MedQA 数据集上随时间变化的问答表现。该图也清晰表明,当前研究工作(如 Med Prompt [12] 和 Med-Gemini [107,108])已成功提出多种提示与微调方法,使大语言模型性能超越人类专家。
However, on the non-QA disc rim i native tasks and generative tasks, as shown in Figure 3, the existing general LLMs perform worse than the task-specific fine-tuned models. For example, for the non-QA disc rim i native tasks, the state-of-the-art task-specific fine-tuned model BioBERT49 achieves an F1 score of 89.36, substantially exceeding the F1 score of 56.73 by
然而,在非问答判别任务和生成任务上,如图 3 所示,现有的通用大语言模型表现不如针对特定任务微调的模型。例如,在非问答判别任务中,最先进的针对特定任务微调模型 BioBERT49 的 F1 分数达到 89.36,大幅超过通用大语言模型的 56.73 分。
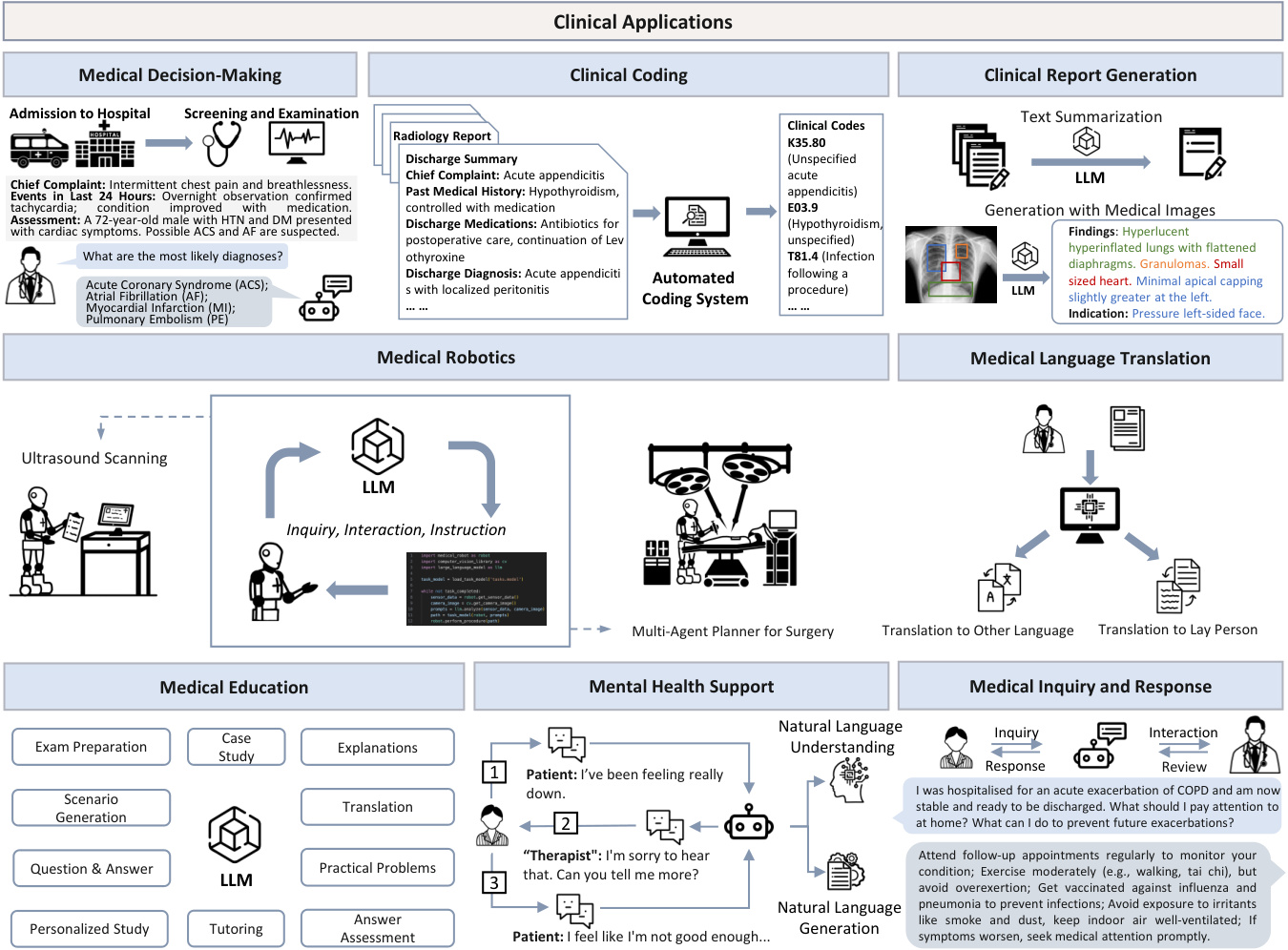
Figure 5. Integrated overview of potential applications 114,150,151,152,153 of large language models in medicine.
图 5: 大语言模型在医学领域的潜在应用 [114,150,151,152,153] 综合概览。
GPT-4, on the entity extraction task using the NCBI disease dataset149. For the generative tasks, we can see that the strong LLM GPT-4 clearly under performs task-specific lightweight models on all datasets. We hypothesize that the reason for the strong QA capability of the current general LLMs is that the QA task is close-ended; i.e. the correct answer is already provided by multiple candidates. In contrast, most non-QA tasks are open-ended where the model has to predict the correct answer from a large pool of possible candidates, or even without any candidates provided.
GPT-4在NCBI疾病数据集149上的实体抽取任务表现。对于生成式任务,我们可以发现强大的大语言模型GPT-4在所有数据集上都明显逊于特定任务的轻量级模型。我们推测当前通用大语言模型在问答任务上表现优异的原因在于:问答任务属于封闭式任务(即正确答案已包含在给定的候选选项中)。相比之下,大多数非问答任务都是开放式的,模型需要从大量潜在候选答案中预测正确答案,有时甚至没有任何候选选项可供参考。
Overall, the comparison proves that the current general LLMs have a strong question-answering capability, however, the capability on other tasks still needs to be improved. In detail, current LLMs are comparable to state-of-the-art models and human experts on the exam-style close-ended QA task with provided answer options. However, real-world open clinical practice usually involves answering open-ended questions without pre-set options and diverges far from the structured nature of exam-taking. The poor performance of LLMs in other non-QA tasks without options indicates a considerable need for advancement before LLMs can be integrated into the actual clinical decision-making process without answer options. Therefore, we advocate that the evaluation of medical LLMs should be extended to a broad range of tasks including non-QA tasks, instead of being limited mainly to medical QA tasks. Hereafter, we will discuss specific clinical applications of LLMs, followed by their challenges and future directions.
总体而言,对比结果表明当前通用大语言模型具备强大的问答能力,但在其他任务上的表现仍有待提升。具体而言,在提供备选答案的封闭式考试类问答任务中,现有大语言模型的表现可与最先进模型及人类专家比肩。然而,真实临床实践通常需要回答无预设选项的开放式问题,这与结构化考试场景存在显著差异。大语言模型在无备选答案的非问答类任务中表现欠佳,表明其距离实际临床决策应用仍有较大提升空间。因此,我们主张医学大语言模型的评估应拓展至包含非问答类任务的广泛范畴,而非主要局限于医疗问答任务。下文将探讨大语言模型的具体临床应用场景,继而分析其面临的挑战与未来发展方向。
4 Clinical Applications
4 临床应用
Currently, most of existing medical LLMs are still in the research and development stage, with limited application and validation in real-world clinical scenarios. However, some initial attempts and explorations have begun to emerge. Researchers are also exploring the integration of large language models into clinical decision support systems to provide evidence-based recommendations and references 155,55,154. Additionally, some research teams are developing tools based on large language models to assist in clinical trial recruitment by analyzing electronic health records to identify eligible participants 156. Some healthcare institutions are experimenting with using LLMs for clinical coding and formatting to improve efficiency and accuracy in medical billing and reimbursement 161,162,163. Researchers are investigating the use of LLMs for clinical report generation, aiming to automate the process of creating coherent and accurate medical reports based on patient data113,104,106. LLMs are being integrated into medical robotics to enhance decision-making, collaboration, and diagnostic capabilities, improving surgical precision and efficiency 167,169,170. In the realm of medical language translation, efforts are being made to utilize LLMs to translate medical information into multiple languages for foreign patients 171,174,175 and to simplify complex medical terminology for lay people176,177, enhancing patient understanding and communication. In the field of medical education, LLMs are being considered as tools to enhance learning experiences by providing personalized content, answering questions, and offering interactive educational materials 178,108. Certain organizations are testing the use of chatbots or virtual assistants to provide mental health support, aiming to increase the accessibility of mental health services 179,180,181. Furthermore, researchers are developing LLM-based systems for medical inquiry and response, aiming to provide accurate and timely answers to patients’ questions, triage inquiries, and assist healthcare professionals in addressing common concerns 189,190,191.
目前,大多数现有医疗大语言模型仍处于研发阶段,在实际临床场景中的应用和验证有限。但已开始出现一些初步尝试和探索。研究人员正在探索将大语言模型整合到临床决策支持系统中,以提供循证建议和参考[155,55,154]。此外,部分研究团队正在开发基于大语言模型的工具,通过分析电子健康记录来协助临床试验招募符合条件的受试者[156]。一些医疗机构正在尝试使用大语言模型进行临床编码和格式化,以提高医疗账单和报销的效率和准确性[161,162,163]。研究人员正在研究利用大语言模型生成临床报告,旨在基于患者数据自动创建连贯准确的医疗报告[113,104,106]。大语言模型正被整合到医疗机器人中,以增强决策、协作和诊断能力,提高手术精度和效率[167,169,170]。在医疗语言翻译领域,研究人员正尝试利用大语言模型为外国患者将医疗信息翻译成多种语言[171,174,175],并为普通民众简化复杂医学术语[176,177],从而提升患者理解和沟通效果。在医学教育领域,大语言模型被视为可通过提供个性化内容、答疑和交互式教学材料来增强学习体验的工具[178,108]。某些组织正在测试使用聊天机器人或虚拟助手提供心理健康支持,旨在提高心理健康服务的可及性[179,180,181]。此外,研究人员正在开发基于大语言模型的医疗问询应答系统,旨在为患者问题提供准确及时的答案、分诊查询,并协助医疗专业人员处理常见问题[189,190,191]。
Table 3. Summary of existing medical LLMs tailored to various clinical applications, in terms of their architecture, model development, the number of parameters, the scale of PT/FT data, and the data source. M: million, B: billion. PT: pre-training. FT: fine-tuning. ICL: in-context learning. CoT: chain-of-thought prompting. RAG: retrieval-augmented generation. This information provides guidelines on how to select and build models. We further provide the evaluation information (i.e., task and performance) to show how current works evaluate their models.
| Application | Model | Architecture | Model Development # Params | Data Scale | Data Source | Evaluation (Task: Score) | |
| Medical Decision-Making (Sec. 4) | Dr. Knows 114 | GPT-3.5 | ICL | 154B | 5820 notes | MIMIC-II 7+IN-HOUSE 114 | Diagnosis Summarization: 30.72 ROUGE-L |
| DDx PaLM-2 154 | PaLM-2 | FT &ICL | 340B | MultiMedQA I+MIMIC-III57 | Differential Diagnosis: 0.591 top-10 Accuracy Readmission Prediction: 0.799 AUC | ||
| NYUTron 55 | BERT | PT &FT | 110M | 7.25M notes, 4.1B tokens NYU Notes 55 | In-hospital Mortality Prediction: 0.949 AUC Comorbidity Index Prediction: 0.894 AUC Length of Stay Prediction: 0.787 AUC Insurance Denial Prediction: 0.872 AUC | ||
| Foresight 155 | GPT-2 | PT & FT | 1.5B | 35M notes | King's College Hospital, MIMIC-III South London and Maudsley Hospital | Next Biomedical Concept Forecast: 0.913 F1 | |
| GPT-4 | 184 patients | 2016 SIGIR 157,2021& 2022 TREC 158 | Ranking Clinical Trials: 0.733 P@ 10, 0.817 NDCG@ 10 Excluding clinical trials: 0.775 AUROC | ||||
| Clinical Coding (Sec. 4) | PLM-ICD 159 | RoBERTa | FT | 355M | 70,539 notes | MIMIC-II160+MIMIC-III57 | ICD Code Prediction: 0.926 AUC, 0.104 F1 |
| DRG-LLaMA 161 | LLaMA-7B | FT | 7B | 25k pairs | MIMIC-IV 105 | Diagnosis-related Group Prediction: 0.327 F1 | |
| ChatICD 162 | ChatGPT | ICL | 10k pairs | MIMIC-III57 | ICD Code Prediction: 0.920 AUC,0.681 F1 | ||
| LLM-codex 163 | ChatGPT+LSTM ICL | MIMIC-III57 | ICD Code Prediction: 0.834 AUC, 0.468 F1 | ||||
| Clinical Report Generation (Sec. 4.3) | ImpressionGPT 164 | ChatGPT | ICL & RAG | 110M | 184k reports | MIMIC-CXR 105+IU X-ray 165 | Report Summarization: 47.93 ROUGE-L |
| RadAdapt 166 | T5 | FT | 223M, 738M 80k reports | MIMIC-II1\$7 | Report Summarization: 36.8 ROUGE-L | ||
| ChatCAD I13 | GPT-3 | ICL | 175B | 300 reports | MIMIC-CXR105 | Report Generation: 0.605 F1 | |
| MAIRA-1 104 | ViT+Vicuna-7B | FT | 8B | 337k pairs | MIMIC-CXR105 | Report Generation: 28.9 ROUGE-L | |
| RadFM 106 | ViT+LLaMA-13B PT& FT | 14B | 32M pairs | MedMD 106 | Report Generation: 18.22 ROUGE-L | ||
| Medical Robotics (Sec. 4.4) | SuFIA 167 | GPT-4 | ICL | 4 tasks | ORBIT-Surgical 168 | Surgical Tasks: 100 Success Rate | |
| UltrasoundGPT 169 | GPT-4 | ICL | 522 tasks | Task Completion: 80 Success Rate | |||
| Robotic X-ray 170 | GPT-4 | ICL | X-ray Surgery: 7.6/10 Human Rating | ||||
| Medical Language Translation (Sec. 4.5) | Medical mT5 171 | T5 | PT | 738M, 3B | 4.5B pairs | PubMed 0 +EMEA 172 ClinicalTrials 173, etc. | (Multi-Task) Sequence Labeling: 0.767 F1 Augment Mining 0.733 F1 |
| Apollo 174 | Qwen | PT & FT | 1.8B-7B | 2.5B pairs | ApolloCorpora 174 | QA: 0.588 Accuracy | |
| BiMedix 175 | Mistral | FT | 13B | 1.3M pairs | BiMed1.3M 175 | Question Answering: 0.654 Accuracy | |
| Biomed-sum 176 | BART | FT | 406M | 27k papers | BioCiteDB 176 | Abstractive Summarization: 32.33 ROUGE-L | |
| RALL 177 | BART | FT & RAG | 406M | 63k pairs | CELLS 176 | Lay Language Generation: N/A | |
| Medical Education (Sec. 4.6) | ChatGPT178 | GPT-3.5/GPT-4 | ICL | Curriculum Generation, Learning Planning | |||
| Med-Gemini 108 | Gemini | FT & CoT | MedQA-R/RS I08+MultiMedQA 11 MIMIC-II57+MultiMedBench 109 | Text-based QA: 0.911 Accuracy Multimodal QA: 0.935 Accuracy | |||
| Mental Health Support (Sec. 4.7) | PsyChat 179 | ChatGLM | FT | 6B | 350k pairs | Xingling 179+Smilechat 179 | Text Generation: 27.6 ROUGE-L |
| ChatCounselor 180 | Vicuna | FT | 7B | 8k instructions | Psych8K 180 Dreaddit 182+DepSeverity 18+SDCNL184 | Question Answering: Evaluated by ChatGPT | |
| Mental-LLM 181 | Alpaca, FLAN-T5 FT & ICL | 7B, 11B | 31k pairs | CSSRS-Suicide 185+Red-Sam 186 Twt-60Users 187+SAD188 | Mental Health Prediction: 0.741 Accuracy | ||
| Medical Inquiry and Response (Sec. 4.8) | AMIE 189 | PaLM2 | FT | 340B | >2M pairs | MedQA 14+MultiMedBench 109 MIMIC-II157+real-world diaglogue 189 | Diagnostic Accuracy: 0.920 Top-10 Accuracy Inquiry Capability: 4.62/5 (ChatGPT) |
| Healthcare Copilot 190 | ChatGPT | ICL | MedDialog 1900 | Conversational Fluency: 4.06/5 (ChatGPT) Response Accuracy: 4.56/5 (ChatGPT) Response Safety: 3.88/5 (ChatGPT) | |||
| Conversational Diagnosis 191 GPT-4/LLaMA | ICL | 40k pairs | MIMIC-IV 92 | Disease Screening: 0.770 Top-10 Hit Rate Differential Diagnosis: 0.910 Accuracy | |||
表 3. 针对不同临床应用定制的现有医疗大语言模型汇总,包括架构、模型开发、参数量、预训练/微调数据规模及数据来源。M:百万,B:十亿。PT:预训练。FT:微调。ICL:上下文学习。CoT:思维链提示。RAG:检索增强生成。该信息为模型选择和构建提供指导。我们进一步提供评估信息(即任务和性能)以展示当前工作如何评估其模型。
| 应用领域 | 模型 | 架构 | 模型开发 | 参数量 | 数据规模 | 数据来源 | 评估(任务:得分) |
|---|---|---|---|---|---|---|---|
| 医疗决策(第4节) | Dr. Knows 114 | GPT-3.5 | ICL | 154B | 5820份病历 | MIMIC-II 7+内部数据114 | 诊断摘要:30.72 ROUGE-L |
| DDx PaLM-2 154 | PaLM-2 | FT & ICL | 340B | - | MultiMedQA I+MIMIC-III57 | 鉴别诊断:0.591 top-10准确率 再入院预测:0.799 AUC | |
| NYUTron 55 | BERT | PT & FT | 110M | 725万份病历,41亿token | NYU病历55 | 院内死亡率预测:0.949 AUC 合并症指数预测:0.894 AUC 住院时长预测:0.787 AUC 保险拒赔预测:0.872 AUC | |
| Foresight 155 | GPT-2 | PT & FT | 1.5B | 3500万份病历 | 国王学院医院,MIMIC-III 南伦敦和莫兹利医院 | 下一生物医学概念预测:0.913 F1 | |
| GPT-4 | - | - | 184名患者 | 2016 SIGIR 157, 2021&2022 TREC 158 | 临床试验排序:0.733 P@10, 0.817 NDCG@10 排除临床试验:0.775 AUROC | ||
| 临床编码(第4节) | PLM-ICD 159 | RoBERTa | FT | 355M | 70,539份病历 | MIMIC-II160+MIMIC-III57 | ICD编码预测:0.926 AUC, 0.104 F1 |
| DRG-LLaMA 161 | LLaMA-7B | FT | 7B | 25k对 | MIMIC-IV 105 | 诊断相关组预测:0.327 F1 | |
| ChatICD 162 | ChatGPT | ICL | - | 10k对 | MIMIC-III57 | ICD编码预测:0.920 AUC, 0.681 F1 | |
| LLM-codex 163 | ChatGPT+LSTM | ICL | - | - | MIMIC-III57 | ICD编码预测:0.834 AUC, 0.468 F1 | |
| 临床报告生成(第4.3节) | ImpressionGPT 164 | ChatGPT | ICL & RAG | 110M | 184k份报告 | MIMIC-CXR 105+IU X-ray 165 | 报告摘要:47.93 ROUGE-L |
| RadAdapt 166 | T5 | FT | 223M, 738M | 80k份报告 | MIMIC-II17 | 报告摘要:36.8 ROUGE-L | |
| ChatCAD I13 | GPT-3 | ICL | 175B | 300份报告 | MIMIC-CXR105 | 报告生成:0.605 F1 | |
| MAIRA-1 104 | ViT+Vicuna-7B | FT | 8B | 337k对 | MIMIC-CXR105 | 报告生成:28.9 ROUGE-L | |
| RadFM 106 | ViT+LLaMA-13B | PT & FT | 14B | 3200万对 | MedMD 106 | 报告生成:18.22 ROUGE-L | |
| 医疗机器人(第4.4节) | SuFIA 167 | GPT-4 | ICL | - | 4项任务 | ORBIT-Surgical 168 | 手术任务:100%成功率 |
| UltrasoundGPT 169 | GPT-4 | ICL | - | 522项任务 | - | 任务完成:80%成功率 | |
| Robotic X-ray 170 | GPT-4 | ICL | - | - | - | X光手术:7.6/10人工评分 | |
| 医学语言翻译(第4.5节) | Medical mT5 171 | T5 | PT | 738M, 3B | 45亿对 | PubMed 0+EMEA 172 ClinicalTrials 173等 | (多任务)序列标注:0.767 F1 增强挖掘:0.733 F1 |
| Apollo 174 | Qwen | PT & FT | 1.8B-7B | 25亿对 | ApolloCorpora 174 | 问答:0.588准确率 | |
| BiMedix 175 | Mistral | FT | 13B | 130万对 | BiMed1.3M 175 | 问答:0.654准确率 | |
| Biomed-sum 176 | BART | FT | 406M | 27k篇论文 | BioCiteDB 176 | 摘要生成:32.33 ROUGE-L | |
| RALL 177 | BART | FT & RAG | 406M | 63k对 | CELLS 176 | 通俗语言生成:N/A | |
| 医学教育(第4.6节) | ChatGPT178 | GPT-3.5/GPT-4 | ICL | - | - | - | 课程生成,学习规划 |
| Med-Gemini 108 | Gemini | FT & CoT | - | - | MedQA-R/RS I08+MultiMedQA 11 MIMIC-II57+MultiMedBench 109 | 文本问答:0.911准确率 多模态问答:0.935准确率 | |
| 心理健康支持(第4.7节) | PsyChat 179 | ChatGLM | FT | 6B | 350k对 | 星聆179+微笑聊天179 | 文本生成:27.6 ROUGE-L |
| ChatCounselor 180 | Vicuna | FT | 7B | 8k指令 | Psych8K 180 Dreaddit 182+DepSeverity 18+SDCNL184 | 问答:由ChatGPT评估 | |
| Mental-LLM 181 | Alpaca, FLAN-T5 | FT & ICL | 7B, 11B | 31k对 | CSSRS-Suicide 185+Red-Sam 186 Twt-60Users 187+SAD188 | 心理健康预测:0.741准确率 | |
| 医疗问诊与应答(第4.8节) | AMIE 189 | PaLM2 | FT | 340B | >200万对 | MedQA 14+MultiMedBench 109 MIMIC-II157+真实世界对话189 | 诊断准确率:0.920 top-10准确率 问诊能力:4.62/5(ChatGPT评分) |
| Healthcare Copilot 190 | ChatGPT | ICL | - | - | MedDialog 1900 | 对话流畅度:4.06/5(ChatGPT评分) 应答准确率:4.56/5(ChatGPT评分) 应答安全性:3.88/5(ChatGPT评分) | |
| Conversational Diagnosis 191 | GPT-4/LLaMA | ICL | - | 40k对 | MIMIC-IV 92 | 疾病筛查:0.770 top-10命中率 鉴别诊断:0.910准确率 |
To this end, as shown in Figure 5, we will introduce the clinical applications of LLMs in this section. Each subsection contains a specific application and discusses how LLMs perform this task. Table 3 summarizes the guidelines on how to select, build, and evaluate medical LLMs for various clinical applications. Although there are currently no large-scale clinical trials specifically targeting these models, researchers are actively evaluating their effectiveness and safety in various healthcare settings. As research progresses and evidence accumulates, it is expected that the application of these large language models in clinical practice will gradually expand, subject to rigorous validation processes and ethical reviews.
为此,如图 5 所示,我们将在本节介绍大语言模型 (LLM) 的临床应用。每个小节包含一个具体应用,并讨论大语言模型如何执行该任务。表 3 总结了针对不同临床应用如何选择、构建和评估医疗大语言模型的指导原则。尽管目前尚未有针对这些模型的大规模临床试验,但研究人员正在积极评估其在各类医疗场景中的有效性与安全性。随着研究进展和证据积累,预计这些大语言模型在临床实践中的应用将逐步扩展,但需经过严格的验证流程和伦理审查。
4.1 Medical Decision-Making
4.1 医疗决策
Medical decision-making, including diagnosis, prognosis, treatment suggestion, risk prediction, clinical trial matching, etc., heavily relies on the synthesis and interpretation of vast amounts of information from various sources, such as patient medical histories, clinical data, and the latest medical literature. The advent of LLMs has opened up new opportunities for enhancing these critical processes in healthcare. These advanced models can rapidly process and comprehend massive volumes of medical data, literature, and legal guidelines, potentially aiding healthcare professionals in making more informed and legally sound decisions across a wide range of clinical scenarios 192,19. For instance, in medical diagnosis, LLMs can assist practitioners in analyzing objective medical data from tests and self-described subjective symptoms to conclude the most likely health problem occurring in the patient192. Similarly, LLMs can support treatment planning by providing personalized recommendations based on the latest clinical evidence and patient-specific factors 19. Furthermore, LLMs can contribute to prognosis and risk prediction by identifying patterns and risk factors from large-scale patient data, enabling more accurate and timely interventions 55. By leveraging the power of LLMs, healthcare professionals can enhance their decision-making capabilities across the spectrum of clinical tasks, leading to improved patient outcomes and more efficient healthcare delivery.
医疗决策(包括诊断、预后、治疗建议、风险预测、临床试验匹配等)高度依赖于对患者病史、临床数据和最新医学文献等多源海量信息的综合解析。大语言模型(LLM)的出现为提升这些关键医疗流程创造了新机遇。这些先进模型能快速处理并理解大量医疗数据、文献和法律指南,帮助医疗从业者在广泛临床场景中做出更明智且合规的决策 [192,19]。例如在医学诊断中,LLM可协助从业者分析检测报告的客观医疗数据与患者自述的主观症状,从而推断最可能的健康问题 [192];在治疗规划中,LLM能根据最新临床证据和患者个体特征提供个性化建议 [19];此外,LLM还能通过从大规模患者数据中识别模式和风险因素,提升预后与风险预测的准确性,实现更精准及时的干预 [55]。借助LLM的能力,医疗从业者能全面提升各类临床任务的决策水平,最终改善患者疗效并优化医疗服务效率。
Guideline To create an effective LLM-based medical decision-making system, practitioners should begin with a robust LLM and enhance it with specialized medical knowledge. This section outlines key strategies and examples of successful implementations in this field. Dr. Knows114 demonstrates the efficacy of integrating knowledge graphs from the Unified Medical Language System (UMLS)115 to improve diagnosis prediction and provide treatment suggestions. This approach involves fine-tuning T5 models193 with extracted diagnoses as prompts and employing zero-shot prompting for LLMs like ChatGPT. Alternatively, models like DDx PaLM-2154 showcase the potential of fine-tuning LLMs (such as Google’s PaLM-2) with extensive medical datasets. This approach enables interactive diagnosis assistance, supporting clinicians in identifying potential diagnoses for better medical decision-making. NYUTron55 is pretrained and fine-tuned on various NYU hospitals and is capable of three clinical tasks (in-patient mortality prediction, co morbidity index prediction, and read mission prediction) and two operational tasks (insurance claim denial prediction and inpatient LOS prediction). Foresight 155, is another model which trained on UK hospital patient data and can be used for forecasting the risk of disorders, differential diagnoses, suggest substances (e.g., to do with medicines, allergies, or poisonings) to be used, etc. For clinical trial matching, TrialGPT 156 presents a novel GPT-4-based framework that accurately predicts criterion-level eligibility with faithful explanations, reducing screening time for human experts. Evaluating LLM-based medical diagnosis systems requires task-specific approaches. For general diagnostic accuracy, metrics like AUC, precision, recall, and F1 score are used with annotated datasets 154,155,156. Some works evaluate the diagnostics with free-text using ROUGE score and CUI F-score114. Crucially, all evaluations must include expert clinician review to ensure clinical relevance and potential real-world impact.
指南
要创建一个基于大语言模型(LLM)的有效医疗决策系统,实践者应从强大的大语言模型入手,并通过专业医学知识进行增强。本节概述了该领域的关键策略和成功实施案例。
Dr. Knows114展示了整合统一医学语言系统(UMLS)115的知识图谱在改善诊断预测和提供治疗建议方面的有效性。该方法涉及使用提取的诊断作为提示对T5模型193进行微调,并对ChatGPT等大语言模型采用零样本提示。
另一种方法如DDx PaLM-2154展示了通过大量医学数据集对大语言模型(如Google的PaLM-2)进行微调的潜力。这种方法支持交互式诊断辅助,帮助临床医生识别潜在诊断以优化医疗决策。
NYUTron55在纽约大学多家医院进行了预训练和微调,能够执行三项临床任务(住院患者死亡率预测、共病指数预测和再入院预测)以及两项运营任务(保险拒赔预测和住院时长预测)。
Foresight155是另一个基于英国医院患者数据训练的模型,可用于预测疾病风险、鉴别诊断,并建议相关物质(如药物、过敏或中毒)的使用等。
在临床试验匹配方面,TrialGPT156提出了一种基于GPT-4的新框架,能够准确预测标准级资格并提供可靠解释,从而减少人类专家的筛选时间。
评估基于大语言模型的医疗诊断系统需要采用任务特定的方法。对于一般诊断准确性,可使用AUC、精确率、召回率和F1分数等指标结合标注数据集154,155,156进行评估。部分研究通过ROUGE分数和CUI F-score114对自由文本的诊断进行评估。
关键的是,所有评估必须包括临床专家的审查,以确保临床相关性和潜在的实际影响。
Discussion One distinct limitation of using LLMs as the sole tool for medical diagnosis is the heavy reliance on subjective text inputs from the patient. Since LLMs are text-based, they lack the inherent capability to analyze medical diagnostic imagery. Given that objective medical diagnoses frequently depend on visual images, LLMs are often unable to directly conduct diagnostic assessments as they lack concrete visual evidence to support disease diagnosis 194. However, they can help with diagnosis as a logical reasoning tool for improving accuracy in other vision-based models. One such example is ChatCAD113, where images are first fed into an existing computer-aided diagnosis (CAD) model to obtain tensor outputs. These outputs are translated into natural language, which is subsequently fed into ChatCAD to summarize results and formulate diagnoses. ChatCAD achieves a recall score of 0.781, substantially higher than that (0.382) of the state-of-the-art task-specific model. Nevertheless, all the aforementioned methods of implementing LLMs cannot directly process images; instead, they either rely on transforming images into text beforehand or rely on an external separate vision encoder to embed images.
讨论
将大语言模型(LLM)作为医疗诊断唯一工具的显著局限性在于高度依赖患者的主观文本输入。由于大语言模型基于文本,其本质上缺乏分析医学诊断影像的能力。鉴于客观医学诊断往往依赖于视觉图像,大语言模型通常无法直接进行诊断评估,因为它们缺乏支持疾病诊断的具体视觉证据[194]。不过,它们可以作为逻辑推理工具协助诊断,以提高其他基于视觉模型的准确性。ChatCAD[113]就是一个例子:图像首先输入现有的计算机辅助诊断(CAD)模型获取张量输出,这些输出被转化为自然语言后输入ChatCAD,由其汇总结果并形成诊断。ChatCAD的召回率达到0.781,显著高于当前最优任务专用模型的0.382。然而,上述所有大语言模型实现方法都无法直接处理图像,它们要么依赖预先将图像转化为文本,要么依赖外部独立视觉编码器来嵌入图像。
4.2 Clinical Coding
4.2 临床编码
Clinical coding, such as the International Classification of Diseases $\mathrm{(ICD)}^{142}$ , medication coding, and procedure coding, plays a crucial role in healthcare by standardizing diagnostic, procedural, and treatment information. These codes are essential for tracking health metrics, treatment outcomes, billing, and reimbursement processes. However, the manual entry of these codes is time-consuming and prone to errors. Large language models (LLMs) have shown promise in automating the clinical coding process by extracting relevant medical terms from clinical notes and assigning corresponding codes, including ICD codes159,161,162,163, medication codes (e.g., National Drug Code195 or $\mathrm{RxNorm^{196}}$ ), and procedure codes (e.g., Current Procedural Terminology 197). By leveraging the vast medical knowledge and natural language understanding capabilities of LLMs, healthcare professionals can benefit from reduced workload and improved accuracy in clinical coding.
临床编码,如国际疾病分类 $\mathrm{(ICD)}^{142}$ 、药物编码和操作编码,通过标准化诊断、操作和治疗信息,在医疗保健领域发挥着关键作用。这些编码对于追踪健康指标、治疗结果、计费和报销流程至关重要。然而,人工录入这些编码既耗时又容易出错。大语言模型 (LLMs) 在自动化临床编码流程中展现出潜力,能够从临床记录中提取相关医学术语并分配对应编码,包括ICD编码[159,161,162,163]、药物编码(如国家药品编码[195]或 $\mathrm{RxNorm^{196}}$)以及操作编码(如现行操作术语[197])。借助大语言模型庞大的医学知识和自然语言理解能力,医疗专业人员可以减少工作量并提高临床编码的准确性。
Guideline When developing LLM-based applications for ICD coding, several notable examples can serve as guidance and inspiration, especially in automating the process of ICD coding. PLM-ICD159 is an example of an LLM-based approach that builds upon the RoBERTa model39, fine-tuning it specifically for ICD coding. It utilizes a domain-specific base model with medicine-specific knowledge to enhance its ability to understand medical terms and achieves strong performance on 70,539 notes from the MIMIC-II and MIMIC-III datasets57. Other LLM-based approaches for ICD coding include DRG-LLaMA161, which leverages the LLaMA model and applies parameter-efficient fine-tuning techniques, such as LoRA, to adapt the model to this task. ChatICD162 and LLM-codex163 both utilize the ChatGPT model with prompts for ICD coding, with LLM-codex163 taking a step further by training an LSTM model on top of the ChatGPT responses, demonstrating its strong performance.
指南
在开发基于大语言模型(LLM)的ICD编码应用时,以下几个典型案例可作为参考和灵感来源,特别是在ICD编码自动化方面。PLM-ICD159是基于RoBERTa模型39构建的LLM方案范例,通过针对性微调使其专精于ICD编码任务。该方案采用具备医学专业知识的领域基础模型,强化医学术语理解能力,并在MIMIC-II和MIMIC-III数据集57的70,539份病历记录上展现出优异性能。其他基于LLM的ICD编码方案包括:采用LLaMA模型并应用LoRA等参数高效微调技术的DRG-LLaMA161;运用ChatGPT模型结合提示工程的ChatICD162与LLM-codex163——后者更进一步在ChatGPT输出结果上训练LSTM模型,展现出强劲性能。
ICD coding is typically formulated as a multi-label classification task, with most work in this area utilizing the MIMIC-III dataset for training and evaluation. Models are assessed based on their F1 score, AUC, and Precision $\ @\mathbf{k}$ , considering either the top k most frequent labels or the full label set. The development of LLMs for ICD coding has the potential to reduce the manual effort required from healthcare professionals, improve the accuracy and consistency of coded data, and facilitate more efficient billing and reimbursement processes.
ICD编码通常被表述为多标签分类任务,该领域大多数研究使用MIMIC-III数据集进行训练和评估。模型评估指标包括F1分数、AUC和Precision $\ @\mathbf{k}$,考察范围可以是前k个高频标签或完整标签集。开发用于ICD编码的大语言模型有望减少医疗专业人员的手动工作量,提高编码数据的准确性和一致性,并优化计费与报销流程效率。
Discussion One challenge while deploying LLMs for clinical coding is the potential biases and hallucinations. In particular, traditional multi-label classification models can easily constrain their outputs to a predefined list of (usually ${>}1000$ ) candidate codes through a classification neural network. In contrast, generative LLMs can suffer from major hallucinations while the input text is lengthy. As a result, the LLM may assign an code that is not in the candidate list or a non-existent clinical code to the input text. It leads to confusion when interpreting medical records 23 and is, therefore, crucial to establish a proactive mechanism to detect and rectify errors before they enter patient EHRs.
讨论
在临床编码中部署大语言模型(LLM)时面临的一个挑战是潜在的偏见和幻觉问题。特别是,传统的多标签分类模型可以通过分类神经网络轻松将其输出限制在预定义的候选代码列表(通常超过1000个)内。相比之下,生成式大语言模型在输入文本较长时可能会出现严重幻觉。这可能导致模型为输入文本分配一个不在候选列表中的代码,或生成一个不存在的临床代码。这种情况会造成医疗记录解读混乱[23],因此建立主动机制在错误进入患者电子健康档案(EHR)前进行检测和纠正是至关重要的。
Currently, the majority of research on LLMs for clinical coding focuses on ICD coding due to its widespread use and the availability of large-scale datasets, such as MIMIC-III, which provide ample training data for model development and evaluation. However, there is a growing need for LLMs that can be applied to other types of clinical coding, such as medication and procedure coding. These coding systems are equally important for accurately capturing patient information, facilitating billing and reimbursement processes, and supporting clinical decision-making. Expanding the capabilities of LLMs to encompass medication and procedure coding would greatly enhance the efficiency and accuracy of the clinical coding process. By leveraging the vast knowledge and natural language understanding capabilities of LLMs, healthcare professionals could benefit from automated coding systems that accurately extract medication and procedure information from clinical notes, reducing the time and effort required for manual coding.
目前,针对大语言模型(LLM)在临床编码领域的研究主要集中在ICD编码上,这得益于其广泛应用及MIMIC-III等大规模数据集的可用性,这些数据集为模型开发和评估提供了充足的训练数据。然而,业界对适用于其他临床编码类型(如药物编码和手术编码)的大语言模型需求日益增长。这些编码系统对于准确记录患者信息、简化计费报销流程以及支持临床决策同样重要。若能将大语言模型的能力扩展到药物和手术编码领域,将显著提升临床编码流程的效率和准确性。通过利用大语言模型的海量知识库和自然语言理解能力,医疗从业者将受益于能自动从临床记录中精准提取药物及手术信息的编码系统,从而减少人工编码所需的时间和精力。
4.3 Clinical Report Generation
4.3 临床报告生成
Clinical reports, such as radiology reports, discharge summaries, and patient clinic letters, refer to standardized documentation that healthcare workers complete after each patient visit198. Therefore, clinical report generation usually involves text generation/sum mari z ation, and information retrieval. A large portion of the report is often medical diagnostic results. It is typically tedious for overworked clinicians to write clinical reports, and thus they are often incomplete or error-prone. Meanwhile, LLMs can be used intuitively as a sum mari z ation tool to help with clinical report generation. In this instance, LLMs act as an assistant tool for clinicians which helps improve efficiency and reduce potential errors in lengthy reports 164,166.
临床报告(如放射学报告、出院小结和门诊病历)是指医护人员在每次接诊后完成的标准化文档[198]。因此,临床报告生成通常涉及文本生成/摘要和信息检索,其中大部分内容往往是医学诊断结果。由于临床医生工作繁重,撰写临床报告通常繁琐耗时,导致报告常出现内容缺失或错误。与此同时,大语言模型可直观地作为摘要工具辅助临床报告生成。在此场景下,大语言模型充当临床医生的辅助工具,既能提升效率,又能减少冗长报告中潜在的差错[164][166]。
Another popular approach to generating clinical reports using LLMs involves incorporating a vision-based model to provide complementary information 113,106,104. The vision model analyzes the input medical image and generates an annotation, which serves as a direct and supplementary input to the LLM alongside additional text prompts. By leveraging the combination of visual and textual information, the LLM produces accurate and fluent reports that adhere to the specified parameters and structure.
另一种利用大语言模型生成临床报告的流行方法是结合视觉模型提供补充信息[113][106][104]。视觉模型会分析输入的医学图像并生成标注,这些标注与额外的文本提示一起作为大语言模型的直接补充输入。通过结合视觉和文本信息,大语言模型能够生成符合指定参数和结构的准确流畅报告。
Guideline When developing LLM-based applications for radiology report generation, several models can serve as guidance and inspiration, which have different focus. General medical vision-language models like Med-Gemini108, LlaVA-Med102, and Med-Flamingo99 can be serviced as foundation models for the broad medical domain including, radiology, pathology, etc., where there are also models trained specifically on radio graphs, such as ChatCAD113, MAIRA-1104, and RadFM106, have shown superior performance in specific subdomains. These models leverage the power of large language models and fine-tune them on domain-specific data to generate radiology reports that accurately capture the relevant information and findings.
指南
在开发基于大语言模型(LLM)的放射学报告生成应用时,可参考多种不同侧重点的模型。通用医学视觉-语言模型如Med-Gemini108、LlaVA-Med102和Med-Flamingo99可作为涵盖放射学、病理学等广泛医学领域的基础模型;而专门针对放射影像训练的模型如ChatCAD113、MAIRA-1104和RadFM106,则在特定子领域展现出更优性能。这些模型通过结合大语言模型的能力,并针对领域数据进行微调,从而生成准确捕捉相关信息和发现的放射学报告。
An alternative approach to radiology report generation focuses on language models that leverage textual data for report sum mari z ation. This can be achieved using either unimodal LLMs, which input a long report and generate a summary, or multimodal LLMs, which input both the long report and the related image to generate a summary. The vision-language models mentioned above can also be developed for report sum mari z ation. In terms of unimodal LLMs, Impression GP T 164 serves as an example, employing dynamic prompt generation and iterative optimization to generate concise and informative report summaries. Rad Adapt 166 systematically evaluates various language models and lightweight adaptation methods, achieving optimal performance through pre-training on clinical text and parameter-efficient fine-tuning with LoRA, while also investigating the impact of few-shot prompting.
放射学报告生成的另一种方法侧重于利用文本数据进行报告总结的语言模型。这可以通过单模态大语言模型(输入长报告并生成摘要)或多模态大语言模型(同时输入长报告和相关图像以生成摘要)实现。上述视觉语言模型也可用于报告总结任务。在单模态大语言模型方面,Impression GPT [164] 采用动态提示生成和迭代优化技术来生成简洁且信息丰富的报告摘要。Rad Adapt [166] 系统评估了多种语言模型和轻量级适配方法,通过临床文本预训练结合LoRA参数高效微调达到最优性能,同时探究了少样本提示的影响。
When evaluating the performance of LLM-based radiology report generation models, most work relies on the MIMIC-III or
在评估基于大语言模型的放射学报告生成模型性能时,大多数工作依赖于 MIMIC-III 或
MIMIC-IV datasets for training and evaluation, as they are the largest publicly available free-text electronic health records (EHRs). Common automatic evaluation metrics include lexical methods such as BLEU199, ROUGE200, and METEOR201, as well as semantic-based methods like BERT Score 202. Additionally, radiology-specific metrics such as CheXbert similarity 203, Rad Graph 204, and RadCliQ205 have been developed to better assess the quality and accuracy of the generated reports in the context of radiology.
MIMIC-IV数据集用于训练和评估,因为它们是最大的公开免费文本电子健康记录(EHRs)。常见的自动评估指标包括词汇方法如BLEU199、ROUGE200和METEOR201,以及基于语义的方法如BERT Score 202。此外,还开发了放射学专用指标如CheXbert相似度203、Rad Graph 204和RadCliQ205,以更好地评估生成报告在放射学背景下的质量和准确性。
By leveraging these existing models and evaluation metrics, researchers and developers can create LLM-based radiology report generation applications that accurately and efficiently produce high-quality reports, ultimately improving the efficiency and effectiveness of radiology workflows.
通过利用这些现有模型和评估指标,研究人员和开发者能够构建基于大语言模型的放射学报告生成应用,准确高效地生成高质量报告,最终提升放射学工作流程的效率和效果。
Discussion While LLMs have demonstrated the ability to generate clinical reports that are more comprehensive and precise than those written by human counterparts 144, they still face challenges in terms of hallucinations and literal interpretation of inputs, lacking the assumption-based perspective often employed by human doctors. Moreover, LLM-generated reports tend to be less concise compared to human-written ones. The evaluation of LLMs in this domain is particularly challenging due to the specialized nature of the content and the generative nature of the task. Current automatic evaluation methods for clinical report generation primarily focus on lexical metrics, which can lead to biased and inaccurate assessments of the contextual information present in the reports206. For instance, consider two sentences with similar meanings but different wordings: “The patient’s blood glucose level is within normal limits” and “The patient does not exhibit signs of hyperglycemia”. While both convey the absence of hyperglycemia, lexical evaluation metrics may struggle to accurately capture their semantic equivalence, as they rely on direct word-level comparisons. This discrepancy highlights the need for more sophisticated evaluation techniques that can account for the nuances and variations in expressing clinical information. Developing evaluation methods that go beyond surface-level similarities and consider the underlying medical context is crucial for ensuring the reliability and usefulness of LLMs in generating clinical reports.
讨论
尽管大语言模型(LLM)已展现出生成比人工撰写更全面、更精确的临床报告的能力[144],但仍面临幻觉问题和对输入的机械解读,缺乏人类医生常用的基于假设的视角。此外,与人工撰写的报告相比,大语言模型生成的报告往往不够简洁。由于内容的专业性和任务的生成性质,该领域对大语言模型的评估尤为困难。当前临床报告生成的自动评估方法主要依赖词汇指标,可能导致对报告中上下文信息的评估存在偏差和不准确[206]。例如,考虑两个含义相似但措辞不同的句子:"患者血糖水平在正常范围内"和"患者未表现出高血糖迹象"。虽然两者都传达了无高血糖的信息,但词汇评估指标可能难以准确捕捉它们的语义等价性,因为这些指标依赖于直接的词汇层面比较。这种差异凸显了对更复杂评估技术的需求,这些技术应能考虑临床信息表达的细微差别和变化。开发超越表面相似性、考量底层医学背景的评估方法,对于确保大语言模型生成临床报告的可靠性和实用性至关重要。
4.4 Medical Robotics
4.4 医疗机器人
Medical robotics is revolutionizing healthcare, offering precision in various aspects, such as surgical procedures and medical imaging207. Recent advancements in incorporating LLMs into medical robotics have shown promising results in enhancing the capabilities of these systems208. LLMs serve as a complementary technology to robotics, augmenting their decision-making, communication, interaction, and control abilities. For example, surgical robots assisted with LLMs enable minimally invasive procedures with increased accuracy and reduced patient recovery times169,208,209. Multi-agent planning systems designed with LLMs involve the coordination of multiple robotic units to perform collaborative tasks, enhancing surgical accuracy and efficiency 209. Additionally, in the field of ultrasound and radiology diagnostics, LLMs have been combined with domain knowledge to enable precise diagnostics and dynamic scanning strategies, improving the efficiency and quality of scans 169,170.
医疗机器人正在革新医疗保健领域,在手术操作和医学影像等各个方面提供精确性[207]。将大语言模型(LLM)整合到医疗机器人的最新进展表明,这些系统的能力得到了显著提升[208]。大语言模型作为机器人技术的补充,增强了其决策、交流、交互和控制能力。例如,由大语言模型辅助的手术机器人能够以更高精度实施微创手术,同时缩短患者恢复时间[169][208][209]。采用大语言模型设计的智能体多机协作系统,通过协调多个机器人单元执行协同任务,从而提升手术精确度和效率[209]。此外,在超声和放射诊断领域,大语言模型与领域知识相结合,实现了精确诊断和动态扫描策略,提高了扫描效率和质量[169][170]。
Guideline Integrating LLMs into medical robotics poses challenges due to healthcare complexities and real-world evaluation difficulties. Nevertheless, three innovative systems from current research exemplify the potential of LLMs in enhancing medical robotics, serving as representative examples in this emerging field. SuFIA167 showcases the integration of LLMs in robotic surgery. This system combines the advanced reasoning capabilities of LLMs, specifically GPT-4 Turbo, with perception modules to implement high-level planning and low-level control of surgical robots for sub-task execution. In the field of medical imaging, Ultrasound GP T 169 presents an innovative approach to ultrasound-guided procedures. This system equips ultrasound robots with LLMs and domain-specific knowledge, utilizing an ultrasound operation knowledge database to enable precise motion planning. Ultrasound GP T employs a dynamic scanning strategy based on prompt engineering, allowing LLMs to adjust motion planning during procedures. This system demonstrates improved ultrasound scan efficiency and quality through verbal command interpretation, contributing to advancements in non-invasive diagnostics and streamlined workflows. Another noteworthy application involves the interpretation of domain-specific language in X-ray-guided surgery170. This work introduces a minimal protocol enabling an LLM, specifically GPT-4, to control a robotic $\mathrm{X}$ -ray system, namely the Brainlab Loop-X device. This development showcases the potential of LLMs to enhance the precision and efficiency of X-ray-guided surgical procedures through improved communication between surgeons and imaging systems.
将大语言模型(LLM)整合到医疗机器人领域面临医疗系统复杂性和现实评估困难等挑战。然而当前研究中的三个创新系统展现了该技术在医疗机器人领域的潜力,成为这一新兴领域的代表性案例。
SuFIA167展示了LLM在机器人手术中的整合应用。该系统将GPT-4 Turbo等大语言模型的高级推理能力与感知模块相结合,实现了手术机器人从高层次规划到低层次控制的子任务执行。
在医学影像领域,Ultrasound GPT169提出了一种超声引导手术的创新方案。该系统通过配备LLM和领域专业知识库,利用超声操作知识数据库实现精确的运动规划。Ultrasound GPT采用基于提示工程(prompt engineering)的动态扫描策略,使LLM能够在术中实时调整运动规划。该系统通过语音指令解析显著提升了超声扫描效率和质量,推动了无创诊断和工作流程优化的发展。
另一项值得关注的应用涉及X射线引导手术中的领域专用语言解析170。该研究开发了一套精简协议,使GPT-4大语言模型能够控制Brainlab Loop-X等机器人X射线系统。这一进展通过改善外科医生与成像系统间的交互,展示了LLM提升X射线引导手术精度和效率的潜力。
Evaluating such systems clinically can be complicated. The complexity of medical procedures, ethical considerations, and patient safety concerns make it difficult to conduct comprehensive evaluations in actual healthcare environments. Consequently, most current evaluations rely heavily on simulated data and controlled laboratory settings. For instance, SuFIA and Robotic X-ray’s performance are assessed using a combination of simulated surgical scenarios and expert human evaluation 167,170. Similarly, Ultrasound GP T is tested through the assessment of task completion 169.
临床评估此类系统可能较为复杂。医疗程序的复杂性、伦理考量以及患者安全问题使得在实际医疗环境中进行全面评估变得困难。因此,当前大多数评估主要依赖模拟数据和受控实验室环境。例如,SuFIA和Robotic X-ray的性能通过模拟手术场景与专家人工评估相结合的方式进行测试[167,170]。类似地,Ultrasound GPT通过任务完成度评估进行验证[169]。
Discussion Integrating LLMs into medical robotics algorithms for route planning and motion control poses a critical challenge due to the risk of errors and biases inherent in LLMs. The complex and dynamic nature of shared human-robot workspaces may lead to LLM-powered medical robots misjudging human intentions or making inappropriate decisions, posing safety risks. Future research opportunities could explore safety features for medical robots, such as sophisticated sensing technologies and physical design constraints, which aim to minimize the occurrence and consequences of judgment errors related to LLMs in shared human-robot environments 210,211,212.
讨论
将大语言模型(LLM)整合到医疗机器人算法中以实现路径规划和运动控制,由于大语言模型固有的错误和偏见风险而构成关键挑战。人机共享工作空间的复杂动态特性可能导致基于大语言模型的医疗机器人误判人类意图或做出不当决策,从而带来安全隐患。未来研究可探索医疗机器人的安全特性,例如精密传感技术和物理设计约束(physical design constraints) ,这些技术旨在最大限度减少人机共享环境中与大语言模型相关的判断错误的发生及其后果[210,211,212]。
4.5 Medical Language Translation
4.5 医疗语言翻译
There are two main areas of medical language translation; the translation of medical terminology from one language to another 171,174,175 and the translation of medical dialogue for ease of interpretation by non-professional personnel 176,177. Both areas are important for seamless communication between different groups. It promotes accurate diagnosis, treatment planning, and medication administration, minimizing medical errors and improving patient safety. By bridging the communication gap between healthcare providers and patients, it fosters informed decision-making, shared understanding, and enhanced patient satisfaction. Moreover, it empowers non-medical personnel to actively participate in patient care, promoting patient-centered care and cultural sensitivity. Effective medical language translation is essential for providing high-quality healthcare to diverse patient populations.
医学语言翻译主要有两大领域:一是医学术语在不同语言间的转换 [171,174,175],二是将医学对话转化为便于非专业人员理解的形式 [176,177]。这两个领域对于不同群体间的无缝沟通都至关重要。它能促进精准诊断、治疗方案制定和用药管理,最大限度减少医疗差错并提升患者安全。通过弥合医患之间的沟通鸿沟,有助于形成知情决策、达成共识并提高患者满意度。此外,还能赋能非医务人员积极参与患者护理,推动以患者为中心的医疗服务和跨文化敏感度。高效的医学语言翻译对于为多样化患者群体提供优质医疗服务具有不可替代的作用。
Guideline In the development of multilingual LLMs for medical language translation, fine-tuning pre-trained models on parallel corpora of medical texts has proven to be an effective approach. By leveraging diverse datasets such as scientific articles, clinical notes, and medical glossaries, these models can capture the nuances and domain-specific meanings of medical terms across languages. Multilingual LLMs like Medical mT5171, Apollo174 and BiMediX175, which are trained on extensive medical datasets in multiple languages, can be further fine-tuned to accurately translate medical terminology between languages such as English, French, Spanish, Chinese, and Arabic. This enables seamless communication and knowledge sharing among healthcare professionals across linguistic boundaries.
指南
在开发用于医学语言翻译的多语言大语言模型时,对预训练模型在医学文本平行语料库上进行微调已被证明是一种有效方法。通过利用科学论文、临床记录和医学词典等多样化数据集,这些模型能够捕捉跨语言医学术语的细微差别和领域特定含义。诸如Medical mT5171、Apollo174和BiMediX175等多语言大语言模型,经过多语言大规模医学数据集训练后,可进一步微调以实现英语、法语、西班牙语、中文和阿拉伯语等语言间医学术语的精准翻译。这有助于跨越语言障碍,实现医疗专业人员间的无缝沟通与知识共享。
When translating medical dialogue for non-professional understanding, it is crucial to fine-tune LLMs on datasets that encompass both technical medical conversations and their corresponding lay-language explanations. This training approach allows the models to learn the mapping between complex medical jargon and more accessible language, facilitating better comprehension by patients and the general public. Techniques such as retrieval augmentation, which involves retrieving relevant lay-language explanations from external knowledge sources, can further enhance the quality and clarity of the translated dialogue 176,177. By integrating domain-specific knowledge from various sources, LLMs can generate more accurate and informative translations that cater to the needs of non-professional audiences.
在将医学对话翻译为非专业人士可理解的内容时,关键在于使用同时包含专业医学术语对话和对应通俗解释的数据集对大语言模型进行微调。这种训练方式能让模型学习复杂医学术语与通俗表达之间的映射关系,从而帮助患者和普通大众更好地理解内容。采用检索增强等技术(即从外部知识源获取相关通俗解释)可进一步提升翻译对话的质量和清晰度 [176,177]。通过整合多领域的专业知识,大语言模型能生成更准确且信息丰富的翻译结果,满足非专业受众的需求。
Evaluating the performance of multilingual LLMs in medical language translation requires a multi-faceted approach. Some of the models use multiple choice question and answering test data with the calculation of accuracy score174,175. For generative benchmark, such as sum mari z ation 176,177, quantitative metrics such as BLEU199, ROUGE200, METEOR201, and BERT Score 202 are commonly used to assess translation quality, but they should be supplemented with domain-specific evaluation criteria. For medical translations, accuracy of terminology, preservation of clinical meaning, and consistency across languages are crucial factors. Human evaluation by bilingual medical experts is essential to validate the nuanced understanding of medical concepts across languages. For patient-oriented translations, comprehension tests with lay individuals can assess the effectiveness of jargon simplification.
评估多语言大语言模型在医学翻译中的表现需要采用多维度方法。部分模型采用选择题测试数据并计算准确率得分[174,175]。对于生成式基准测试(如摘要[176,177]),通常使用BLEU[199]、ROUGE[200]、METEOR[201]和BERT Score[202]等量化指标评估翻译质量,但需辅以领域特定的评估标准。医学翻译的关键因素包括:术语准确性、临床意义保留度以及跨语言一致性。双语医学专家的人工评估对于验证跨语言医学概念的细微理解至关重要。针对患者导向的翻译,可通过非专业人士的理解测试来评估专业术语简化的有效性。
Discussion In both translation and simplification tasks, misinterpretation is a common occurrence that can have damaging consequences. In developing and deploying medical translation and simplification platforms, developers should prioritize professional datasets, such as textbooks and peer-reviewed journals for medical knowledge recall. This way, it will be less likely for misinformation from unreliable web sources to skew the output213. Another ethical consideration of using LLMs to perform medical translation is the potential for discriminatory verbiage to be inserted inadvertently into the output. Such verbiage is difficult to prevent due to the nature of the pipeline. This may cause mis communications and even have legal consequences. 214.
讨论
在翻译和简化任务中,误解是常见现象且可能造成严重后果。开发部署医疗翻译与简化平台时,开发者应优先采用专业数据集(如教科书和同行评审期刊)进行医学知识召回,从而降低不可靠网络信息导致错误输出的可能性 [213]。使用大语言模型进行医疗翻译的另一伦理风险是输出中可能无意包含歧视性措辞。由于流程特性,此类措辞难以完全规避,可能导致沟通障碍甚至法律后果 [214]。
4.6 Medical Education
4.6 医学教育
LLMs can be incorporated into the medical education system in different ways, including facilitating study through explanations, aiding in language translation, answering questions, assisting with medical exam preparation, and providing Socratic-style tutoring 215,152. Therefore, medical education could involve text generation, text simplification, semantic textual similarity, information retrieval, and etc. It has been suggested that medical education can be augmented by generating scenarios, problems, and corresponding answers by an LLM. Students will gain a richer educational experience through personalized study modules and case-based assessments, encountering a wider array of challenges and scenarios beyond those found in standard textbooks 214. LLMs can also generate feedback on student responses to practical problems, allowing students to know their areas of weakness in real time. Inherently, these will better prepare these medical students for the real world since they would have been exposed to more scenarios 216.
大语言模型可以通过多种方式融入医学教育体系,包括通过解释促进学习、辅助语言翻译、回答问题、协助备考医学考试以及提供苏格拉底式辅导 [215,152]。因此,医学教育可能涉及文本生成、文本简化、语义文本相似性、信息检索等领域。有研究表明,通过大语言模型生成场景、问题及对应答案,可以增强医学教育效果。学生将通过个性化学习模块和基于案例的评估获得更丰富的教育体验,接触到标准教材之外更广泛的挑战和场景 [214]。大语言模型还能针对学生实践问题的回答生成实时反馈,帮助学生即时了解薄弱环节。本质上,这些功能能让医学生更好地为现实世界做准备,因为他们将接触到更多样化的临床情境 [216]。
Another use of LLMs in the medical field is educating the public. Medical dialogues are often complex and difficult to understand for the average patient. LLMs can tune the textual output of prompts to use varying degrees of medical terminology for different audiences. This will make medical information easy to understand for the average person while ensuring medical professionals have access to the most precise information 214.
大语言模型在医疗领域的另一应用是公众教育。由于医学术语通常复杂难懂,普通患者难以理解医疗对话内容。大语言模型能根据受众差异,动态调整提示词输出的医学术语密度:既确保普通民众获得易于理解的医疗信息,又能为专业人员保留精准的学术表述 [214]。
Guideline Integrating LLMs into medical education can start with existing pre-trained models such as ChatGPT217, and Med-Gemini108. Instead of developing models from scratch, it is often more effective to leverage the knowledge synthesis, question answering, and content generation capabilities of these powerful models. For instance, ChatGPT178 can provide explanations and clarifications on complex medical concepts, facilitating self-study and reinforcing understanding. MedGemini 108, a multimodal model, can analyze medical images and generate detailed reports, aiding in the training of diagnostic skills. Institutions are exploring the integration of these language models into curricula, leveraging their strengths while ensuring proper oversight and ethical considerations. As this technology continues to advance, it holds promise for enhancing the efficiency and accessibility of medical education while complementing human expertise.
将大语言模型 (LLM) 整合到医学教育的指南可从现有预训练模型(如 ChatGPT217 和 Med-Gemini108)着手。相比从头开发模型,利用这些强大模型的知识综合、问答和内容生成能力往往更高效。例如,ChatGPT178 可对复杂医学概念提供解释说明,辅助自学并巩固理解;多模态模型 MedGemini108 能分析医学影像并生成详细报告,助力诊断技能训练。教育机构正探索将这些语言模型融入课程体系,在发挥其优势的同时确保适当的监管与伦理考量。随着技术持续发展,该领域有望提升医学教育的效率与可及性,同时与人类专业知识形成互补。
To evaluate the effectiveness of integrating LLMs into medical education, a combination of quantitative and qualitative methods should be employed. Current research focuses on the QA based evaluation 108. Quantitative metrics can include student performance on assessments, such as exam scores and clinical skills evaluations, comparing outcomes before and after the introduction of LLM-based tools. Qualitative methods, such as surveys and focus groups, can gather feedback from students and educators on the perceived benefits, challenges, and areas for improvement in using LLMs for learning and teaching. Additionally, longitudinal studies can track the long-term impact of LLM integration on student learning outcomes, clinical competence, and career preparedness. By employing a comprehensive evaluation framework, institutions can iterative ly refine their approach to leveraging LLMs in medical education, ensuring that these powerful tools are effectively harnessed to enhance learning while maintaining educational quality and ethical standards.
为评估将大语言模型(LLM)整合到医学教育中的有效性,应采用定量与定性相结合的方法。当前研究主要关注基于问答(QA)的评估[108]。定量指标可包括学生在评估中的表现,如考试成绩和临床技能评估结果,比较引入基于LLM的工具前后的差异。定性方法(如问卷调查和焦点小组)可收集学生和教师对使用大语言模型进行教学与学习的感知效益、挑战及改进方向的反馈。此外,纵向研究可追踪LLM整合对学生学习成果、临床能力和职业准备的长期影响。通过采用综合评估框架,教育机构能迭代优化其在医学教育中应用大语言模型的方法,确保在保持教育质量和伦理标准的同时,有效利用这些强大工具来提升学习效果。
Discussion Potential downsides of using LLMs in medical education include the current lack of ethical training and biases in training datasets 24. These biases, if not addressed, can propagate through the generated outputs, reinforcing stereotypes and potentially leading to discrimination in medical education. The lack of explicit ethical training during LLM development may also result in the generation of content that does not align with the ethical principles and guidelines of the medical profession, such as promoting unethical practices or violating patient privacy.
讨论
在医学教育中使用大语言模型 (LLM) 的潜在缺点包括当前缺乏伦理训练以及训练数据集中的偏见 [24]。这些偏见若不加以解决,可能会通过生成内容传播,强化刻板印象并可能导致医学教育中的歧视。大语言模型开发过程中缺乏明确的伦理训练,也可能导致生成内容与医学职业的伦理原则和指南不符,例如宣扬不道德行为或侵犯患者隐私。
Furthermore, the risk of misinformation, particularly in the form of hallucinations, presents a challenge in utilizing LLMs for medical education. LLMs can generate plausible-sounding but factually incorrect information, which can mislead students and healthcare professionals if relied upon without proper verification. This can lead to the propagation of misconceptions, inappropriate treatment strategies, or misdiagnosis 218. To mitigate these risks, it is essential to establish rigorous fact-checking and validation processes and emphasize the importance of critical thinking, evidence-based practice, and the verification of information from multiple reliable sources in medical education.
此外,错误信息(特别是幻觉形式)的风险给大语言模型在医学教育中的应用带来了挑战。大语言模型可能生成听起来合理但事实错误的信息,若未经适当验证就加以采用,可能误导医学生和医疗专业人员。这会导致错误观念传播、不当治疗策略或误诊[218]。为降低这些风险,必须建立严格的事实核查与验证流程,并在医学教育中强调批判性思维、循证实践以及从多个可靠信源验证信息的重要性。
4.7 Mental Health Support
4.7 心理健康支持
Mental health support involves both diagnosis and treatment. For example, depression is treated through a variety of psychotherapies, including cognitive behavior therapy, interpersonal psychotherapy, psychodynamic therapy, etc.153. Many of these techniques are primarily dominated by patient-doctor conversations, with lengthy treatment plans that are cost-prohibitive for many. The ability of LLMs to serve as conversation partners and companions may lower the barrier to entry for patients with financial or physical constraints 219, increasing the accessibility to mental health treatments 180. There have been various research works and discussions on the effects of incorporating LLMs into the treatment plan 180,220,221.
心理健康支持包括诊断和治疗两方面。以抑郁症为例,其治疗方式涵盖多种心理疗法,如认知行为疗法、人际心理治疗、精神动力学疗法等 [153]。这些技术手段大多以医患对话为核心,但漫长的治疗周期使许多人难以承担高昂费用。大语言模型 (LLM) 作为对话伙伴和陪伴者的能力,可能为受经济或行动限制的患者降低治疗门槛 [219],提升心理健康治疗的可及性 [180]。目前已有大量研究探讨将大语言模型纳入治疗方案的成效 [180,220,221]。
The level of self-disclosure has a heavy impact on the effectiveness of mental health diagnosis and treatment. The degree of willingness to share has a direct impact on the diagnosis results and treatment plan. Studies have shown that patient willingness to discuss mental health-related topics with a robot is high 222,220. Alongside the convenience and lower financial stakes, mental health support by LLMs has the potential to be more effective than human counterparts in many scenarios.
自我披露程度对心理健康诊断和治疗效果具有重大影响。分享意愿的强弱直接影响诊断结果和治疗方案。研究表明,患者与机器人讨论心理健康相关话题的意愿较高[222,220]。除了便利性和较低的经济成本外,大语言模型(LLM)提供的心理健康支持在许多场景下可能比人类更有效。
Guideline Development and deployment of LLMs targeted at mental health support can start with an existing LLM. Instead of pre-training or fine-tuning on general medical data, it is often better to use medical question and answer data as most of the LLM’s work will be talking to the patient, which involves back-and-forth conversation in the format of question and answering 223. PsyChat179 is a client-centric LLM dialogue system that provides psychological support comprising five modules: client behavior recognition, counselor strategy selection, input packer, response generator, and response selection. Specifically, the response generator is fine-tuned with ChatGLM-6B with a vast dialogue dataset. Through both automatic and human evaluations, the system has demonstrated its effectiveness and practicality in real-life mental health support scenarios. Chat Counselor is designed to provide mental health support. It initializes from Vicuna and fine-tunes from an 8k size instruct-tuning dataset collected from real-world counseling dialogue examples 180. Psy-LLM is an LLM aimed to be an assistive mental health tool to support the workflow of professional counselors, particularly to support those who might be suffering from depression or anxiety223. Another work presents a comprehensive evaluation of prompt engineering, few-shot, and fine-tuning techniques on multiple LLMs in the mental health domain 181. The results reveal that fine-tuning on a variety of datasets can improve LLM’s capability on multiple mental-health-specific tasks across different datasets simultaneously 181. The work also releases their model Mental-Alpaca and Mental-FLAN-T5 as open-source LLMs targeted at multiple mental health prediction tasks181. Evaluating mental health-focused language models involves a multi-faceted approach that combines automated metrics and expert human assessment. Automated evaluations measure the relevance, coherence, and empathy of the generated responses using specialized metrics tailored to the mental health domain. Mental health professionals conduct human evaluations through simulated counseling sessions, assessing the clinical appropriateness and therapeutic potential of the models’ responses. Recent research has introduced various evaluation frameworks that integrate tasks such as text generation (conversational response) 223, $\mathrm{QA}^{180}$ and mental health prediction 181. Liu et al.180 prompt GPT-4 to compare Chat Counselor’s responses with other models based on specific criteria and explanations. This multi-faceted approach provides researchers with a thorough understanding of the strengths and limitations of mental health-focused language models, enabling them to refine the models and develop more effective and reliable tools for mental health support.
针对心理健康支持的大语言模型(LLM)开发与部署可从现有模型入手。相比在通用医疗数据上进行预训练或微调,更优策略是采用医疗问答数据,因为LLM主要工作是与患者进行问答式对话[223]。PsyChat[179]是以客户为中心的LLM对话系统,包含五大模块:客户行为识别、咨询师策略选择、输入打包器、响应生成器和响应选择器。其中响应生成器基于ChatGLM-6B模型,通过海量对话数据集进行微调。自动评估与人工评估均表明,该系统在实际心理健康支持场景中具有显著效果。
Chat Counselor专为心理健康支持设计,以Vicuna为基础模型,采用8k规模的真实心理咨询对话样本进行指令微调[180]。Psy-LLM则是面向专业咨询师的辅助工具,重点支持抑郁症和焦虑症患者[223]。另有研究系统评估了心理健康领域中提示工程、少样本学习及微调技术在多个LLM上的表现[181],结果表明跨数据集微调可同步提升模型在多项心理健康专项任务上的能力。该研究还开源了面向多任务的心理健康预测模型Mental-Alpaca和Mental-FLAN-T5[181]。
心理健康语言模型的评估需结合自动化指标与专家人工评估。自动化评估采用专业指标衡量生成响应的相关性、连贯性和共情能力;心理健康专家则通过模拟咨询会话评估响应的临床适用性与治疗潜力。最新研究提出了整合文本生成(对话响应)[223]、QA[180]和心理健康预测[181]的评估框架。Liu等[180]通过提示GPT-4,基于特定标准对比分析了Chat Counselor与其他模型的响应质量。这种多维评估方法能全面揭示心理健康语言模型的优势与局限,为开发更可靠的支持工具提供依据。
Discussion Two of the most critical difficulties in employing LLMs for mental health support are the lack of emotional understanding and the risk of inappropriate or harmful responses 224. LLMs, being language models, may struggle to fully grasp and respond to the complex emotional states and needs of individuals seeking mental health support. They may not be able to provide the same level of empathy and human connection that is crucial in therapeutic interactions.
讨论
在将大语言模型(LLM)应用于心理健康支持时,两个最关键的困难是缺乏情感理解能力以及存在不当或有害回复的风险[224]。作为语言模型,大语言模型可能难以完全理解并回应寻求心理健康支持者的复杂情绪状态和需求。它们无法提供治疗性互动中至关重要的共情能力与人性化连接。
Moreover, if not properly trained or controlled, LLMs may generate responses that are inappropriate, insensitive, or even harmful to individuals in vulnerable emotional states225. They may provide advice that is not grounded in evidence-based psychological practices or that goes against established mental health guidelines. Addressing these challenges requires rigorous training of LLMs in evidence-based practices, ethical considerations, and risk assessment protocols, as well as collaboration between mental health professionals and AI researchers.
此外,如果训练或控制不当,大语言模型(LLM)可能会生成不恰当、不敏感甚至对情绪脆弱个体有害的响应[225]。它们可能提供缺乏循证心理学依据的建议,或违背既定的心理健康指南。解决这些挑战需要对大语言模型进行循证实践、伦理考量和风险评估协议的严格训练,同时需要心理健康专业人士与AI研究人员的协作。
4.8 Medical Inquiry and Response
4.8 医疗问诊与应答
The rapid advancement of LLMs also opens up new possibilities for improving healthcare delivery and patient care. LLMs, trained on vast amounts of medical knowledge, have the potential to understand and generate human-like text, making them suitable for tasks such as answering patient inquiries and assisting physicians in documentation 190,226. As the demand for accessible and efficient healthcare services grows, researchers are exploring the use of medical LLMs to alleviate the burden on healthcare professionals and provide patients with reliable information and support. Therefore, medical inquiry and response could involve entity extraction, information retrieval, question answering.
大语言模型的快速发展也为改善医疗服务和患者护理开辟了新可能。经过海量医学知识训练的大语言模型能够理解并生成类人文本,使其适用于回答患者咨询、协助医生记录等任务 [190,226]。随着对便捷高效医疗服务需求的增长,研究者正探索利用医疗大语言模型来减轻医护人员负担,为患者提供可靠信息支持。因此,医疗问诊可能涉及实体提取、信息检索、问答等环节。
Guideline Large language models can be effectively integrated into medical consultation systems to provide AI-powered assistance to healthcare professionals and enhance patient care. Instead of relying solely on rule-based algorithms or limited datasets, these systems leverage the vast knowledge and reasoning capabilities of LLMs to engage in diagnostic conversations and provide personalized recommendations. For example, Healthcare Copilot190 combines dialogue, memory, and processing components to enable safe patient-LLM interactions, enhance conversations with historical data, and summarize consultations. Similarly, Google’s Articulate Medical Intelligence Explore (AMIE)189 employs a novel self-play-based simulated environment with automated feedback mechanisms, allowing the system to learn and adapt across diverse medical contexts. Another LLM-based diagnostic system191 emulates the thought processes of experienced physicians and leverages reinforcement learning techniques to assist in disease screening, initial diagnoses, and the parsing of medical guidelines. These pioneering systems showcase the potential of medical LLMs in providing high-quality, AI-powered consultations and assisting physicians in their daily practice, while emphasizing the importance of rigorous testing, ethical oversight, and collaboration between medical experts and AI researchers to ensure their safe and responsible deployment. These systems showcase the potential of medical LLMs in providing high-quality, AI-powered medical consultations and assisting physicians in their daily practice.
指南:大语言模型可有效整合到医疗咨询系统中,为医护人员提供AI驱动的辅助并提升患者护理水平。这些系统不再仅依赖基于规则的算法或有限数据集,而是利用大语言模型的海量知识和推理能力,开展诊断对话并提供个性化建议。例如,Healthcare Copilot190结合对话、记忆和处理组件,实现安全的患者-大语言模型交互,通过历史数据增强对话并生成咨询摘要。同样,谷歌的Articulate Medical Intelligence Explore (AMIE)189采用基于自我对弈的新型模拟环境与自动反馈机制,使系统能在多样化医疗场景中持续学习适应。另一项基于大语言模型的诊断系统191模拟资深医师的思维过程,运用强化学习技术辅助疾病筛查、初步诊断和医疗指南解析。这些开创性系统展示了医疗大语言模型在提供高质量AI咨询、辅助医师日常实践方面的潜力,同时强调需通过严格测试、伦理监督及医学专家与AI研究者的协作来确保安全可靠的应用部署。这些系统彰显了医疗大语言模型在提供优质AI医疗咨询、辅助医师日常工作方面的广阔前景。
Current evaluation of these systems often involves the calculation of metrics such as accuracy, precision, recall, and F1-score189 . Additionally, some studies conduct multi-dimensional assessments of the models’ performance, examining aspects such as inquiry capability, conversational fluency, response accuracy and safety using benchmarks and comparisons with human experts or well-established models like ChatGPT190. However, these metrics alone are not sufficient for a comprehensive real-world assessment. It is adviced that the evaluation of this should focus on the diagnostic accuracy, patient satisfaction, and adherence to medical guidelines 227.
当前对这些系统的评估通常涉及准确率、精确率、召回率和F1分数等指标的计算[189]。此外,一些研究通过基准测试或与人类专家及ChatGPT[190]等成熟模型的对比,从问诊能力、对话流畅度、回答准确性和安全性等多维度评估模型表现。但仅凭这些指标不足以全面评估实际应用效果,建议应重点关注诊断准确率、患者满意度和医疗指南遵循度等核心维度[227]。
Discussion However, there is still far from deploying them in the real-world healthcare system. Several challenges must be addressed before widespread deployment in real-world healthcare settings. One major concern is the potential for biased or inaccurate outputs, which could lead to improper medical advice or misdiagnosis 218. Rigorous testing and validation across diverse patient populations and medical contexts are essential to ensure the reliability and general iz ability of these systems. Additionally, the integration of medical LLMs into existing healthcare workflows and infrastructure may require substantial technical and organizational efforts. Privacy and security concerns surrounding patient data must also be carefully considered and addressed.
讨论
然而,要将其部署到现实世界的医疗系统中仍面临诸多挑战。在广泛投入实际医疗应用前,必须解决几个关键问题。首要担忧是可能存在的偏见或错误输出,这可能导致不当的医疗建议或误诊 [218]。为确保这些系统的可靠性和泛化能力,必须在多样化患者群体和医疗场景中进行严格测试与验证。此外,将医疗大语言模型整合到现有医疗工作流程和基础设施中,可能需要大量技术与组织层面的投入。围绕患者数据的隐私与安全问题也需审慎评估和处理。
Furthermore, the development and deployment of medical LLMs raise important ethical and responsible AI considerations. Ensuring transparency, explain ability, and accountability in the decision-making processes of these systems is crucial to maintaining trust and facilitating informed consent from patients 228,229. The potential impact on the doctor-patient relationship and the role of human physicians in an AI-assisted healthcare setting must also be carefully examined. Ongoing collaboration between AI researchers, healthcare professionals, ethicists, and policymakers will be necessary to establish guidelines and best practices for the responsible development and deployment of medical LLMs in real-world healthcare settings.
此外,医疗大语言模型(LLM)的开发与部署引发了重要的伦理和负责任AI议题。确保这些系统决策过程的透明度、可解释性和问责机制,对于维持患者信任并促进知情同意至关重要[228][229]。AI辅助医疗环境下对医患关系的潜在影响以及人类医生角色的转变也需要审慎评估。AI研究人员、医疗从业者、伦理学家和政策制定者需持续协作,共同制定指导方针和最佳实践,以负责任的方式推动医疗大语言模型在真实医疗场景中的开发与应用。
5 Challenges
5 大挑战
We address the challenges and discuss solutions to the adoption of LLMs in an array of medical applications.
我们探讨了大语言模型 (LLM) 在医疗应用领域落地面临的挑战及解决方案。
5.1 Hallucination
5.1 幻觉
Hallucination of LLMs refers to the phenomenon where the generated output contains inaccurate or nonfactual information. It can be categorized into intrinsic and extrinsic hallucinations 230,218. Intrinsic hallucination generates outputs logically contradicting factual information, such as wrong calculations of mathematical formulas 218. Extrinsic hallucination happens when the generated output cannot be verified, typical examples include LLMs ‘faking’ citations that do not exist or ‘dodging’ the question. When integrating LLMs into the medical domain, fluent but nonfactual LLM hallucinations can lead to the dissemination of incorrect medical information, causing misdiagnoses, inappropriate treatments, and harmful patient education. It is therefore vital to ensure the accuracy of LLM outputs in the medical domain.
大语言模型的幻觉 (Hallucination of LLMs) 是指生成内容包含不准确或非事实信息的现象。根据 [230,218] 的研究,可将其分为内在幻觉和外在幻觉两类。内在幻觉会产生与事实信息逻辑矛盾的输出,例如数学公式的错误计算 [218];外在幻觉则发生在生成内容无法被验证时,典型例子包括大语言模型伪造不存在的引用或回避问题。当将大语言模型应用于医疗领域时,流畅但非事实的模型幻觉可能导致错误医疗信息的传播,引发误诊、不当治疗及对患者的有害指导。因此,确保大语言模型在医疗领域输出的准确性至关重要。
Potential Solutions Current solutions to mitigate LLM hallucination can be categorized into training-time correction, generation-time correction, and retrieval-augmented correction. The first (i.e. training-time correction) adjusts model parameter weights, thus reducing the probability of generating hallucinated outputs. Its examples include factually consistent reinforcement learning 231 and contrastive learning 232. The second (i.e. generation-time correction) adds a ‘reasoning’ process to the LLM inference to ensure reliability, using drawing multiple samples 233 or a confidence score to identify hallucination before the final generation. The third approach (i.e. retrieval-augmented correction) utilizes external resources to mitigate hallucination, for example, using factual documents as prompts234 or chain-of-retrieval prompting technique 235.
潜在解决方案
当前缓解大语言模型(LLM)幻觉的解决方案可分为训练时校正、生成时校正和检索增强校正三类。第一类(即训练时校正)通过调整模型参数权重来降低幻觉输出的概率,代表性方法包括事实一致性强化学习[231]和对比学习[232]。第二类(即生成时校正)在LLM推理过程中加入"推理"环节以确保可靠性,例如通过多重采样[233]或置信度评分在最终生成前识别幻觉。第三类方法(即检索增强校正)利用外部资源来减轻幻觉,例如将事实文档作为提示[234]或采用检索链提示技术[235]。
5.2 Lack of Evaluation Benchmarks and Metrics
5.2 缺乏评估基准与指标
Current benchmarks and metrics often fail to evaluate LLM’s overall capabilities, especially in the medical domain. For example, MedQA (USMLE)14 and MedMCQA148 offer extensive coverage on QA tasks but fail to evaluate important LLM-specific metrics, including trustworthiness, helpfulness, explain ability, and faithfulness 206. It is therefore imperative to develop domain and LLM-specific benchmarks and metrics.
当前的基准和指标往往无法全面评估大语言模型(LLM)的能力,尤其是在医疗领域。例如,MedQA(USMLE)[14]和MedMCQA[148]虽然覆盖了广泛的问答任务,但未能评估重要的LLM专属指标,包括可信度、有用性、可解释性和忠实性[206]。因此,开发针对特定领域和LLM的基准与指标势在必行。
Potential Solutions Singhal et al.10 proposed Health Search QA consisting of commonly searched health queries, offering a more human-aligned benchmark for evaluating LLM’s capabilities in the medical domain. Benchmarks such as Truthful QA 236 and Hal uE val 237 evaluate more LLM-specific metrics, such as truthfulness, but do not cover the medical domain. Future research is necessary to meet the need for more medical and LLM-specific benchmarks and metrics than what is currently available.
潜在解决方案
Singhal等人[10]提出了Health Search QA,包含常见健康搜索查询,为评估大语言模型(LLM)在医疗领域的能力提供了更符合人类需求的基准。Truthful QA[236]和HalEval[237]等基准评估了更多LLM特有的指标(如真实性),但未覆盖医疗领域。未来研究需要满足对更多医疗专用及LLM特有基准和指标的需求,以弥补当前不足。
5.3 Domain Data Limitations
5.3 领域数据限制
Current datasets in the medical domain (Table 2) remain relatively small compared to datasets for training general-purpose LLMs (Table 1). These limited small datasets only cover a small space10 of the vase domain of medical knowledge. This results in LLMs exhibiting extraordinary performance on open benchmarks with extensive data coverage, yet falling short on real-life tasks such as differential diagnosis and personalized treatment planning 11.
当前医学领域的数据集(表 2)与训练通用大语言模型的数据集(表 1)相比仍然较小。这些有限的小型数据集仅覆盖了广阔医学知识领域中的一小部分[10]。这导致大语言模型在数据覆盖广泛的开放基准测试中表现出色,但在实际任务(如鉴别诊断和个性化治疗计划)中表现欠佳[11]。
Although the volume of medical and health data is large, most require extensive ethical, legal, and privacy procedures to be accessed. In addition, these data are often unlabeled, and solutions to leverage these data, such as human labeling and unsupervised learning 238, face challenges due to the lack of human expert resources and small margins of error.
尽管医疗健康数据体量庞大,但大多数数据需要经过复杂的伦理、法律和隐私程序才能获取。此外,这些数据通常未标注,而利用这些数据的解决方案(如人工标注和无监督学习 [238])由于缺乏医学专家资源且容错空间极小而面临挑战。
Potential Solutions Current state-of-the-art approaches 11,15 typically fine-tune the LLMs on smaller open-sourced datasets to improve their domain-specific performance. Another solution is to generate high-quality synthetic datasets using LLMs to broaden the knowledge coverage; however, it has been discovered that training on generated datasets causes models to forget 239. Future research is needed to validate the effectiveness of using synthetic data for LLMs in the medical field.
潜在解决方案
当前最先进的方法[11,15]通常在大语言模型上使用较小的开源数据集进行微调,以提高其特定领域的性能。另一种解决方案是利用大语言模型生成高质量的合成数据集以扩大知识覆盖范围;然而研究发现,在生成的数据集上训练会导致模型遗忘[239]。未来需要进一步研究验证在医学领域使用合成数据对大语言模型的有效性。
5.4 New Knowledge Adaptation
5.4 新知识适应
LLMs are trained on extensive data to learn knowledge. Once trained, it is expensive and inefficient to inject new knowledge into an LLM through re-training. However, it is sometimes necessary to update the knowledge of the LLM, for example, on a new adverse effect of a medication or a novel disease. Two problems occur during such knowledge updates. The first problem is how to make LLMs appropriately ‘forget’ the old knowledge, as it is almost impossible to remove all ‘old knowledge’ from the training data, and the discrepancy between new and old knowledge can cause unintended association and bias240. The second problem is the timeliness of the additional knowledge - how do we ensure the model is updated in real-time241? Both problems pose substantial barriers to using LLMs in medical fields, where accurate and timely updates of medical knowledge are crucial in real-world implementations.
大语言模型通过海量数据训练学习知识。一旦完成训练,通过重新训练向模型注入新知识既昂贵又低效。然而在某些情况下必须更新模型知识,例如药品新发现的副作用或新型疾病。此类知识更新会引发两个问题:首要问题是如何让大语言模型合理"遗忘"旧知识,由于几乎不可能从训练数据中彻底清除所有"旧知识",新旧知识间的差异可能导致非预期关联和偏见[240];其次是新增知识的时效性问题——如何确保模型能实时更新[241]?这两个问题对医疗领域应用大语言模型构成重大障碍,因为在实际应用中,医学知识的准确性和及时更新至关重要。
Potential Solutions Current solutions to knowledge adaptation can be categorized into model editing and retrieval-augmented generation. Model editing242 alters the knowledge of the model by modifying its parameters. However, this method does not generalize well, with their effectiveness varying across different model architectures. In contrast, retrieval-augmented generation provides external knowledge sources as prompts during model inference; for example, Lewis et al.243 enabled model knowledge updates by updating the model’s external knowledge memory.
潜在解决方案
当前的知识适应解决方案可分为模型编辑 (model editing) 和检索增强生成 (retrieval-augmented generation)。模型编辑[242]通过修改模型参数来改变其知识,但该方法泛化性较差,其效果因模型架构而异。相比之下,检索增强生成在模型推理时提供外部知识源作为提示,例如Lewis等人[243]通过更新模型的外部知识记忆来实现知识更新。
5.5 Behavior Alignment
5.5 行为对齐
Behavior alignment refers to the process of ensuring that the LLM’s behaviors align with the objectives of its task. Development efforts have been spent on aligning LLMs with general human behavior, but the behavior discrepancy between general humans and medical professionals remains challenging for adopting LLMs in the medical domain. For example, ChatGPT is well aligned with general human behavior, but their answers to medical consultations are not as concise and professional as those by human experts45. In addition, misalignment in the medical domain introduces unnecessary harm and ethical concerns 244 that lead to undesirable consequences.
行为对齐 (Behavior alignment) 是指确保大语言模型 (LLM) 行为与其任务目标保持一致的过程。当前研究主要致力于将大语言模型与普通人行为对齐,但普通人与医疗专业人员之间的行为差异仍是医疗领域应用大语言模型的主要挑战。例如,ChatGPT 能很好地对齐普通人行为,但其医疗咨询回答的简洁性和专业性仍无法与人类专家比肩 [45]。此外,医疗领域的行为失准会引发不必要的伤害和伦理问题 [244],最终导致严重后果。
Potential Solutions Current solutions include instruction fine-tuning, reinforcement learning from human feedback (RLHF)45, and prompt tuning132,129. Instruction fine-tuning124 refers to improving the performance of LLMs on specific tasks based on explicit instructions. For example, Ouyang et al.45 used it to help LLMs generate less toxic and more suitable outputs. RLHF uses human feedback to evaluate and align the outputs of LLMs. It is effective in multiple tasks, including becoming helpful chat bots 245 and decision-making agents246. Prompt tuning can also align LLMs to the expected output format. For example, Liu et al. 247 uses a prompting strategy, chain of hindsight, to enable the model to detect and correct its errors, thus aligning the generated output with human expectations.
潜在解决方案
当前的解决方案包括指令微调 (instruction fine-tuning)、基于人类反馈的强化学习 (RLHF) [45] 和提示调优 (prompt tuning) [132][129]。指令微调 [124] 指根据显式指令提升大语言模型在特定任务上的表现。例如 Ouyang 等人 [45] 通过该方法使大语言模型生成更具适宜性且降低有害性的输出。RLHF 通过人类反馈评估并校准大语言模型的输出,在多项任务中成效显著,包括构建实用聊天机器人 [245] 和决策智能体 [246]。提示调优同样能校准大语言模型至预期输出格式,例如 Liu 等人 [247] 采用 hindsight 链式提示策略,使模型具备检测并修正错误的能力,从而确保生成内容符合人类预期。
5.6 Ethical and Safety Concerns
5.6 伦理与安全问题
Concerns have been raised regarding using LLMs (e.g., ChatGPT) in the medical domain248, with a focus on ethics, accountability, and safety. For example, the scientific community has disapproved of using ChatGPT in writing biomedical research papers 228 due to ethical concerns. The accountability of using LLMs as assistants to practice medicine is challenging 123,249. Li et al. 250 and Shen et al. 229 found that prompt injection can cause the LLM to leak personally identifiable information (PII), e.g., email addresses, from its training data, which is a substantial vulnerability when implementing LLM in the medical domain.
关于在医疗领域使用大语言模型(LLM)(如ChatGPT)的担忧已经引起关注[248],主要集中在伦理、责任和安全方面。例如,科学界出于伦理考虑不赞成使用ChatGPT撰写生物医学研究论文[228]。将大语言模型作为医疗实践助手的责任认定具有挑战性[123,249]。Li等人[250]和Shen等人[229]发现,提示词注入可能导致大语言模型从其训练数据中泄露个人身份信息(PII),如电子邮件地址,这是在医疗领域实施大语言模型时的重大漏洞。
Potential Solutions With no immediate solutions available, we have nevertheless observed research efforts to understand the cause of these ethical and legal concerns. For example, Wei et al. 251 propose that PII leakage is attributed to the mismatched generalization between safety and capability objectives (i.e., the pre-training of LLMs utilizes a larger and more varied dataset compared to the dataset used for safety training, resulting in many of the model’s capabilities are not covered by safety training).
潜在解决方案
虽然目前尚无立即可行的解决方案,但我们已注意到相关研究正在努力理解这些伦理和法律问题的成因。例如,Wei等人[251]提出,个人身份信息(PII)泄露归因于安全目标与能力目标之间的泛化错配(即大语言模型的预训练使用了比安全训练数据集更庞大、更多样的数据集,导致模型的许多能力未被安全训练覆盖)。
5.7 Regulatory Challenges
5.7 监管挑战
The regulatory landscape of LLMs presents distinct challenges due to their large scale, broad applicability and varying reliability across applications. As LLMs progressively permeate the fields of medicine and healthcare, their versatility allows a single LLM family to facilitate a multitude of tasks across a broad spectrum of interest groups. This represents a substantial departure from the AI-based medical technologies of the past, which were typically tailored to meet specific medical needs and cater to particular interest groups 252,192. In addition, the recent innovations of AI-enabled personalized approaches in areas such as oncology also present challenges to the traditional one-for-all auditing process 253. This divergence and innovation necessitate regulators to develop adaptable, foresight ful frameworks to ensure the safety, ethical standards, and privacy of the new family of LLMs-powered medical technologies.
大语言模型(LLM)的监管格局因其规模庞大、适用性广泛以及在不同应用中的可靠性差异而面临独特挑战。随着大语言模型逐步渗透到医学和医疗保健领域,其多功能性使得单一LLM家族能够为广泛利益群体提供多样化任务支持。这与过去基于AI的医疗技术形成显著差异,传统技术通常针对特定医疗需求定制,服务于特定利益群体[252,192]。此外,AI赋能的个性化方法在肿瘤学等领域的最新创新,也对传统"一刀切"的审核流程提出了挑战[253]。这种差异性和创新性要求监管机构制定具有适应性和前瞻性的框架,以确保新一代LLM驱动的医疗技术在安全性、伦理标准和隐私保护方面符合要求。
Potential Solutions To address the complex regulatory challenges without hindering innovation, regulators should devise adaptive, flexible, and robust frameworks. Drawing on the insights from Mesko and Topol252, creating a dedicated regulatory category and implementing patient design to enhance decision-making for LLMs used for medical purposes can better address their unique attributes and minimize harm. Furthermore, the insights outlined by Derraz et al. 253 emphasize the importance of implementing agile regulatory frameworks that can keep pace with the fast-paced advancements in personalized applications. Researchers both inside 252,253 and outside of healthcare 254,255 have proposed innovative strategies to regulate the use of LLMs involving (i) assessing LLMs-enabled applications in real-world settings, (ii) obligations of transparency of data and algorithms, (iii) adaptive risk assessment and mitigation processes, (iv) continuous testing and refinement of audited technologies. Such proactive regulatory adaptations are crucial to maintaining high standards of safety, ethics, and trustworthiness of medical technology.
潜在解决方案
为应对复杂的监管挑战而不阻碍创新,监管机构应制定适应性、灵活且稳健的框架。借鉴Mesko和Topol[252]的观点,创建专门的监管类别并采用患者设计来优化医疗用途大语言模型(LLM)的决策,能更好地应对其独特属性并降低风险。此外,Derraz等人[253]提出的见解强调了实施敏捷监管框架的重要性,以跟上个性化应用快速发展的步伐。来自医疗领域内[252,253]和外[254,255]的研究人员提出了创新监管策略,包括:(i) 在真实场景中评估LLM赋能的应用,(ii) 数据与算法的透明度义务,(iii) 适应性风险评估与缓解流程,(iv) 对审计技术进行持续测试与优化。此类前瞻性监管调整对维持医疗技术的高安全性、伦理性和可信度至关重要。

Figure 6. Future directions of LLMs in clinical medicine in terms of both development and deployment.
图 6: 大语言模型 (LLM) 在临床医学领域未来发展和部署方向。
6 Future Directions
6 未来方向
Although LLMs have already made an impact on people’s lives through chatbots and search engines, their integration into medicine is still in the infant stage. As shown in Figure 6, numerous new avenues of medical LLMs await researchers and practitioners to explore how to better serve the general public and patients.
尽管大语言模型已通过聊天机器人和搜索引擎对人们的生活产生影响,但其在医学领域的整合仍处于起步阶段。如图6所示,医学大语言模型还有众多新途径等待研究者和从业者探索,以更好地服务大众和患者。
6.1 Introduction of New Benchmarks
6.1 新基准测试介绍
Recent studies have underscored the shortcomings of existing benchmarks in evaluating LLMs for clinical applications 256,257. Traditional benchmarks, which primarily gauge accuracy in medical question-answering, inadequately capture the full spectrum of clinical skills necessary for LLMs10. Criticisms have been leveled against the use of human-centric standardized medical exams for LLM evaluation, arguing that passing these tests does not necessarily reflect an LLM’s proficiency in the nuanced expertise required in real-world clinical settings10. In response, there is an emerging consensus on the need for more comprehensive benchmarks. These should include capabilities like sourcing from authoritative medical references, adapting to the evolving landscape of medical knowledge, and clearly communicating uncertainties 19,10. To further enhance the relevance of these benchmarks, new benchmarks should incorporate scenarios that test an LLM’s ability through simulation of real-world applications and adjust to feedback from clinicians while maintaining robustness. Additionally, considering the sensitive nature of healthcare, these benchmarks should also assess factors such as fairness, ethics, and equity, which, though crucial, pose quant if i cation challenges 10. While efforts such as the AMIE study have advanced benchmarking by utilizing real physician evaluations and comprehensive criteria rooted in actual clinical skills and communication, as reflected in the Objective Structured Clinical Examination (OSCE), there remains a pressing need for benchmarks that are adaptive, scalable and robust for other diverse and personalized applications of LLMs. The aim is to create benchmarks that more effectively mirror diverse real-world clinical scenarios, thus providing a more accurate measure of LLMs’ suitability for their applications in medicine. Future research may focus on (i) using synthetic data along with real-world data to create benchmarks that are both comprehensive and scalable, (ii) using clinical guidelines and criteria to reflect real-world values that are not normally included in traditional benchmarks, (iii) physician-in-the-loop benchmarks to evaluate the performance of LLMs leveraging their human counterparts or users.
近期研究揭示了现有基准在评估临床应用大语言模型(LLM)时的不足[256,257]。传统基准主要衡量医学问答的准确性,却未能全面捕捉大语言模型所需的临床技能[10]。针对使用以人类为中心的标准化医学考试来评估大语言模型的做法,批评指出通过这些测试并不必然反映大语言模型在真实临床环境中所需的细致专业知识水平[10]。为此,学界正形成共识:需要建立更全面的评估基准,包括从权威医学文献溯源、适应医学知识的动态发展、清晰传达不确定性等能力[19,10]。
为提升基准的相关性,新基准应纳入测试场景:通过模拟真实应用来评估大语言模型能力,在保持稳健性的同时适应临床医生的反馈。鉴于医疗领域的敏感性,这些基准还需评估公平性、伦理性和公正性等关键但难以量化的因素[10]。虽然AMIE研究等尝试通过采用真实医师评估、基于客观结构化临床考试(OSCE)的临床技能与沟通标准推进了基准建设,但仍亟需开发适应性强、可扩展且稳健的基准,以满足大语言模型在多样化、个性化医疗场景中的应用需求。
未来研究可聚焦于:(i) 结合合成数据与真实数据创建兼具全面性和可扩展性的基准;(ii) 采用临床指南和标准来反映传统基准通常忽略的现实价值;(iii) 建立"医师参与循环"基准,通过人类同行或用户来评估大语言模型表现。最终目标是建立能更有效反映多样化真实临床场景的基准,从而更准确衡量大语言模型在医疗领域的适用性。
6.2 Multimodal LLM Integrated with Time-Series, Visual, and Audio Data
6.2 融合时间序列、视觉和音频数据的多模态大语言模型
Multimodal LLMs (MLLMs), or Large Multimodal Models (LMMs), are LLM-based models designed to perform multimodal (e.g., involving both visual and textual) tasks258. While LLMs primarily address NLP tasks, MLLMs support a broader range of tasks, such as comprehending the underlying meaning of a meme and generating website codes from images. This versatility suggests promising applications of MLLMs in medicine. Several MLLM-based frameworks integrating vision and language, e.g., MedPaLM $\mathbf{M}^{259}$ , LLaVA-Med260, Visual Med-Alpaca261, Med-Flamingo 262, and Qilin-Med-VL263, have been proposed to adopt the medical image-text pairs for fine-tuning, thus enabling the medical LLMs to efficiently understand the input medical (e.g., radiology) images. A recent study264 proposes to integrate vision, audio, and language inputs for automated diagnosis in dentistry. However, there exist only very few medical LLMs that can process time series data, such as electrocardiograms $\left(\mathrm{ECGs}\right)^{265}$ and sph yg moma no meters (PPGs)266, despite such data being important for medical diagnosis and monitoring. Although early in their proposed research stages, these studies suggest that MLLMs trained at scale have the potential to effectively generalize across various domains and modalities outside of NLP tasks. However, the training of MLLMs at scale is still costly and ineffective, resulting in the size of MLLMs being much smaller than LLMs. Moving forward, future research may focus on (i) more effective processing, representation, and learning of multi-modal data and knowledge, (ii) cost-effective training of MLLMs, especially modalities that are more resource-demanding such as videos and images, (iii) collecting or accessing safely, currently unavailable, multi-modal data in medicine and healthcare.
多模态大语言模型 (MLLMs) 或称大型多模态模型 (LMMs),是基于大语言模型设计的、用于执行多模态(例如同时涉及视觉和文本)任务的模型[258]。虽然大语言模型主要处理自然语言处理任务,但多模态大语言模型支持更广泛的任务,例如理解表情包的潜在含义以及从图像生成网站代码。这种多功能性表明多模态大语言模型在医学领域具有广阔的应用前景。目前已提出多个整合视觉与语言的基于多模态大语言模型的框架,如 MedPaLM $\mathbf{M}^{259}$、LLaVA-Med[260]、Visual Med-Alpaca[261]、Med-Flamingo[262] 和 Qilin-Med-VL[263],这些框架采用医学图文对进行微调,从而使医学大语言模型能够有效理解输入的医学(如放射学)图像。近期一项研究[264]提出整合视觉、音频和语言输入用于牙科自动诊断。然而,目前仅有极少数医学大语言模型能够处理时间序列数据,例如心电图 $\left(\mathrm{ECGs}\right)^{265}$ 和光电容积脉搏波(PPGs)[266],尽管这类数据对医学诊断和监测至关重要。虽然这些研究尚处于早期阶段,但表明大规模训练的多模态大语言模型有望在自然语言处理任务之外的各领域和模态中实现有效泛化。然而,大规模训练多模态大语言模型仍然成本高昂且效率低下,导致其模型规模远小于大语言模型。未来研究可能会聚焦于:(i) 多模态数据和知识的更有效处理、表示与学习,(ii) 高性价比的多模态大语言模型训练,特别是对视频和图像等资源需求更高的模态,(iii) 安全收集或获取当前不可用的医疗健康多模态数据。
6.3 Medical Agents
6.3 医疗智能体
LLM-based agents 267,268 utilize LLMs as controllers to leverage their reasoning capabilities. By integrating LLMs with external tools and multimodal perceptions, these agents can interact with environments, learn from feedback, and acquire new skills, enabling them to solve complex tasks (e.g., software design, molecular dynamics simulation) through human-like behaviors, such as role-playing and communication 269,270.
基于大语言模型(LLM)的AI智能体 267,268 利用LLM作为控制器来发挥其推理能力。通过将LLM与外部工具和多模态感知相结合,这些智能体能够与环境互动、从反馈中学习并获取新技能,从而通过角色扮演和沟通 269,270 等类人行为来解决复杂任务(例如软件设计、分子动力学模拟)。
However, integrating these agents effectively within the medical domain remains a challenge. The medical field involves numerous roles 270 and decision-making processes, especially in disease diagnosis that often requires a series of investigations involving CT scans, ultrasounds, electrocardiograms, and blood tests. The idea of utilizing LLMs to model each of these roles, thereby creating collaborative medical agents, presents a promising direction. These agents could mimic the roles of radiologists, cardiologists, pathologists, etc., each specializing in interpreting specific types of medical data. For example, a radiologist agent could analyze CT scans, while a pathologist agent could focus on blood test results. The collaboration among these specialized agents could lead to a more holistic and accurate diagnosis. By leveraging the comprehensive knowledge base and contextual understanding capabilities of LLMs, these agents not only interpret individual medical reports but also integrate these interpretations to form a cohesive medical opinion. To enhance the integration of LLMs-based agents, future research may explore (i) a seamless data pipeline that collects data from various devices and transforms them into data format compatible with LLMs (ii) effective communication and collaboration between agents, especially in areas such as ensuring truthfulness during communication, dispute resolution between agents, and role-based data security measures, (iii) real-time decision-making such as making timely decisions using data collected from remote monitoring devices, (iv) adaptive learning such as preparing for a new pandemic or learning from unseen medical conditions.
然而,在医疗领域有效整合这些AI智能体仍面临挑战。医疗行业涉及270多种角色和决策流程,尤其在需要CT扫描、超声检查、心电监测和血液检测等一系列检查的疾病诊断场景中。利用大语言模型为每个角色建模以构建协作式医疗智能体的构想,展现出了极具前景的发展方向。这些智能体可模拟放射科医师、心脏科专家、病理学家等角色,各自专精于解析特定类型的医疗数据。例如放射科智能体能分析CT影像,而病理学智能体则专注于血液检测结果。这些专业智能体的协作有望实现更全面精准的诊断。通过发挥大语言模型的知识广度和语境理解能力,这些智能体不仅能解析单项医疗报告,还能整合各项解读形成连贯的医学意见。为加强基于大语言模型的智能体整合,未来研究可探索:(i) 构建无缝数据管道,从各类设备采集数据并转换为大语言模型兼容格式;(ii) 优化智能体间的通信协作机制,重点包括确保沟通真实性、争议解决和基于角色的数据安全措施;(iii) 实现实时决策能力,例如利用远程监测设备数据进行及时判断;(iv) 发展自适应学习能力,包括应对新型疫情或学习未知病症。
6.4 LLMs in Underrepresented Specialties
6.4 小众专业领域的大语言模型
Current LLM research in medicine has largely focused on general medicine, likely due to the greater availability of data in this area 11,249. This has resulted in the under-representation of LLM applications in specialized fields like ‘rehabilitation therapy’ or ‘sports medicine’. The latter, in particular, holds potential, given the global health challenges posed by physical inactivity. The World Health Organization identifies physical inactivity as a major risk factor for non-communicable diseases (NCDs), impacting over a quarter of the global adult population 271. Despite initiatives to incorporate physical activity (PA) into healthcare systems, implementation remains challenging, particularly in developing countries with limited PA education among healthcare providers 271. LLMs could play a pivotal role in these settings by disseminating accurate PA knowledge and aiding in the creation of personalized PA programs 272. Such applications could enhance PA levels, improving global health outcomes, especially in resource-constrained environments. To spark innovation in these underrepresented specialties, future research can focus on areas such as (i) effective data collection in underrepresented specialties, (ii) applications of LLMs in assisting with tasks of underrepresented specialties, (iii) using LLMs to help progress the research of these underrepresented specialties.
当前医学领域的大语言模型(LLM)研究主要集中于全科医学,这可能是由于该领域数据可获得性更高[11,249]。这导致"康复治疗"或"运动医学"等专业领域的大语言模型应用研究相对不足。后者尤其具有发展潜力,考虑到身体活动不足带来的全球健康挑战。世界卫生组织指出,缺乏身体活动是非传染性疾病(NCDs)的主要风险因素,影响着全球超过四分之一的成年人口[271]。尽管各国已采取举措将身体活动(PA)纳入医疗保健体系,但实施仍面临挑战,特别是在医疗从业人员身体活动教育不足的发展中国家[271]。在这些场景中,大语言模型可以通过传播准确的身体活动知识、协助制定个性化运动方案发挥关键作用[272]。此类应用有望提升身体活动水平,改善全球健康状况,特别是在资源有限的环境中。为激发这些代表性不足学科的创新,未来研究可聚焦以下方向:(i) 在冷门学科中实施有效数据收集;(ii) 探索大语言模型在辅助冷门学科任务中的应用;(iii) 利用大语言模型推动冷门学科研究进展。
6.5 Interdisciplinary Collaborations
6.5 跨学科协作
Just as interdisciplinary collaborations are crucial in safety-critical areas like nuclear energy production, collaborations between the medical and technology communities for developing medical LLMs are essential to ensure AI safety and efficacy in medicine. The medical community has primarily adopted LLMs provided by technology companies without rigorously questioning their data training, ethical protocols, or privacy protection. Medical professionals are therefore encouraged to actively participate in creating and deploying medical LLMs by providing relevant training data, defining the desired benefits of LLMs, and conducting tests in real-world scenarios to evaluate these benefits 19,21,22. Such assessments would help to determine the legal and medical risks associated with LLM use in medicine and inform strategies to mitigate LLM hallucination 273. Additionally, training ‘bilingual’ professionals—those versed in both medicine and LLM technology—is increasingly vital due to the rapid integration of LLMs in healthcare. Future research may explore (i) interdisciplinary frameworks, such as frameworks to facilitate the sharing of localized data from rural clinics, (ii) ‘bilingual education programs’ that offer training from both worlds - AI and medicine, (iii) effective in-house development methods to help hospitals and physicians ‘guard’ patient data from corporations while still being able to embrace innovation.
正如跨学科合作在核能生产等安全关键领域至关重要一样,医疗界与技术界合作开发医疗大语言模型对于确保AI在医学领域的安全性和有效性也极为重要。目前医疗界主要采用科技公司提供的大语言模型,却未严格质疑其数据训练、伦理规范或隐私保护机制。因此,我们鼓励医疗专业人员通过以下方式积极参与医疗大语言模型的创建与部署:提供相关训练数据、明确大语言模型的预期效益,并在真实医疗场景中进行测试评估 [19,21,22]。这类评估有助于确定医疗领域使用大语言模型的法律与医疗风险,并为缓解模型幻觉 (hallucination) 提供策略依据 [273]。
随着大语言模型在医疗领域的快速融合,培养同时精通医学与大语言模型技术的"双语型"专业人才显得日益重要。未来研究可重点关注:(i) 跨学科协作框架,例如促进乡村诊所本地化数据共享的机制;(ii) 融合AI与医学的"双语教育项目";(iii) 有效的内部开发方法,使医院和医生能在保护患者数据不被企业获取的同时,仍能拥抱技术创新。
References
参考文献
Acknowledgements
致谢
This work was supported in part by the Pandemic Sciences Institute at the University of Oxford; the National Institute for Health Research (NIHR) Oxford Biomedical Research Centre (BRC); an NIHR Research Professorship; a Royal Academy of Engineering Research Chair; the Well-come Trust funded VITAL project; the UK Research and Innovation (UKRI); the Engineering and Physical Sciences Research Council (EPSRC); and the InnoHK Hong Kong Centre for Cerebro-cardiovascular Engineering (COCHE).
本研究部分获得以下机构资助:牛津大学流行病科学研究所、英国国家健康研究所(NIHR)牛津生物医学研究中心(BRC)、NIHR研究教授基金、英国皇家工程研究院研究主席基金、惠康基金会资助的VITAL项目、英国研究与创新署(UKRI)、工程与物理科学研究理事会(EPSRC),以及香港InnoHK心血管工程中心(COCHE)。
Author Contributions
作者贡献
FL, ZL, JL, and DC supervised the project. FL conceived and designed the study. HZ, FL, BG, XZ, JH, and WJ conducted the literature review, performed data analysis, and drafted the manuscript. All authors contributed to the interpretation and final manuscript preparation. All authors read and approved the final manuscript.
FL、ZL、JL和DC负责项目监督。FL构思并设计了研究方案。HZ、FL、BG、XZ、JH和WJ进行了文献综述、数据分析并起草了初稿。所有作者都参与了结果解读和最终文稿的撰写工作。全体作者阅读并核准了最终稿件。
Competing Interests
竞争性利益
The authors declare no competing interests.
作者声明无竞争性利益。