Meta-Learning in Neural Networks: A Survey
神经网络中的元学习 (Meta-Learning) 综述
Timothy Hospedales , Antreas Antoniou, Paul Micaelli, and Amos Storkey
Timothy Hospedales、Antreas Antoniou、Paul Micaelli 和 Amos Storkey
Abstract—The field of meta-learning, or learning-to-learn, has seen a dramatic rise in interest in recent years. Contrary to conventional approaches to AI where tasks are solved from scratch using a fixed learning algorithm, meta-learning aims to improve the learning algorithm itself, given the experience of multiple learning episodes. This paradigm provides an opportunity to tackle many conventional challenges of deep learning, including data and computation bottlenecks, as well as generalization. This survey describes the contemporary meta-learning landscape. We first discuss definitions of meta-learning and position it with respect to related fields, such as transfer learning and hyper parameter optimization. We then propose a new taxonomy that provides a more comprehensive breakdown of the space of meta-learning methods today. We survey promising applications and successes of meta-learning such as few-shot learning and reinforcement learning. Finally, we discuss outstanding challenges and promising areas for future research.
摘要—元学习(meta-learning)或学会学习(learning-to-learn)领域近年来受到广泛关注。与传统AI方法使用固定学习算法从头开始解决任务不同,元学习旨在通过多个学习周期的经验来改进学习算法本身。这一范式为解决深度学习的诸多传统挑战提供了可能,包括数据和计算瓶颈以及泛化问题。本文综述了当代元学习的发展现状。我们首先讨论元学习的定义,并厘清其与迁移学习(transfer learning)、超参数优化(hyperparameter optimization)等相关领域的关系。随后提出一个新的分类体系,对当前元学习方法进行更全面的划分。我们综述了元学习在少样本学习(few-shot learning)和强化学习(reinforcement learning)等领域的成功应用。最后讨论了该领域面临的突出挑战和未来研究的潜在方向。
Index Terms—Meta-learning, learning-to-learn, few-shot learning, transfer learning, neural architecture search
索引术语—元学习 (Meta-learning)、学会学习 (learning-to-learn)、少样本学习 (few-shot learning)、迁移学习 (transfer learning)、神经架构搜索 (neural architecture search)
1 INTRODUCTION
1 引言
ON TEMPORARY machine learning models are typically trained from scratch for a specific task using a fixed learning algorithm designed by hand. Deep learning-based approaches specifically have seen great successes in a variety of fields [1], [2], [3]. However there are clear limitations [4]. For example, successes have largely been in areas where vast quantities of data can be collected or simulated, and where huge compute resources are available. This excludes many applications where data is intrinsically rare or expensive [5], or compute resources are unavailable [6].
当前机器学习模型通常针对特定任务从头开始训练,使用人工设计的固定学习算法。特别是基于深度学习的方法已在多个领域取得巨大成功[1]、[2]、[3],但仍存在明显局限[4]。例如,这些成功主要集中于能够收集或模拟海量数据且具备强大计算资源的领域。这使得许多数据天然稀缺或获取成本高昂[5]、计算资源匮乏[6]的应用场景被排除在外。
Meta-learning is the process of distilling the experience of multiple learning episodes – often covering a distribution of related tasks – and using this experience to improve future learning performance. This ‘learning-to-learn’ [7] can lead to a variety of benefits such as improved data and compute efficiency, and it is better aligned with human and animal learning [8], where learning strategies improve both on a lifetime and evolutionary timescales [8], [9], [10].
元学习是通过提炼多次学习经验(通常涵盖一系列相关任务)并利用这些经验来提升未来学习表现的过程。这种"学会学习" [7] 能带来多种优势,例如提高数据和计算效率,并且更贴近人类和动物的学习方式 [8],即学习策略会在个体生命周期和进化时间尺度上不断改进 [8] [9] [10]。
Historically, the success of machine learning was driven by advancing hand-engineered features [11], [12]. Deep learning realised the promise of feature representation learning [13], providing a huge improvement in performance for many tasks [1], [3] compared to prior hand-designed features. Metalearning in neural networks aims to provide the next step of integrating joint feature, model, and algorithm learning; that is, it targets replacing prior hand-designed learners with learned learning algorithms [7], [14], [15], [16].
历史上,机器学习的成功曾由人工设计特征推动[11][12]。深度学习实现了特征表示学习(representation learning)的承诺[13],相比之前手工设计的特征,它在众多任务上带来了巨大的性能提升[1][3]。神经网络中的元学习(metalearning)旨在实现联合特征、模型和算法学习的下一步整合,即用学习得到的学习算法替代原先手工设计的学习器[7][14][15][16]。
Neural network meta-learning has a long history [7], [17], [18]. However, its potential as a driver to advance the frontier of the contemporary deep learning industry has led to an explosion of recent research. In particular meta-learning has the potential to alleviate many of the main criticisms of contemporary deep learning [4], for instance by improving data efficiency, knowledge transfer and unsupervised learning. Meta-learning has proven useful both in multi-task scenarios where task-agnostic knowledge is extracted from a family of tasks and used to improve learning of new tasks from that family [7], [19]; and single-task scenarios where a single problem is solved repeatedly and improved over multiple episodes [15], [20], [21], [22]. Successful applications have been demonstrated in areas spanning few-shot image recognition [19], [23], unsupervised learning [16], data efficient [24], [25] and self-directed [26] reinforcement learning (RL), hyper parameter optimization [20], and neural architecture search (NAS) [21], [27], [28].
神经网络元学习有着悠久的历史 [7], [17], [18]。然而,其作为推动当代深度学习行业前沿发展的潜力,导致了近期研究的爆发式增长。元学习尤其有望缓解当前深度学习面临的诸多主要批评 [4],例如通过提升数据效率、知识迁移和无监督学习能力。研究证明,元学习在以下两种场景中都具有重要价值:多任务场景中从任务族提取任务无关知识并用于提升该族新任务的学习效果 [7], [19];单任务场景中通过多次迭代反复解决并优化同一问题 [15], [20], [21], [22]。其成功应用领域包括:少样本图像识别 [19], [23]、无监督学习 [16]、数据高效强化学习 (RL) [24], [25]、自主强化学习 [26]、超参数优化 [20] 以及神经架构搜索 (NAS) [21], [27], [28]。
Many perspectives on meta-learning can be found in the literature, in part because different communities use the term differently. Thrun [7] operationally defines learning-to-learn as occurring when a learner’s performance at solving tasks drawn from a given task family improves with respect to the number of tasks seen. $(c f.,$ conventional machine learning performance improves as more data from a single task is seen). This perspective [29], [30], [31] views meta-learning as a tool to manage the ‘no free lunch’ theorem [32] and improve genera liz ation by searching for the algorithm (inductive bias) that is best suited to a given problem, or problem family. However, this definition can include transfer, multi-task, featureselection, and model-ensemble learning, which are not typically considered as meta-learning today. Another usage of meta-learning [33] deals with algorithm selection based on dataset features, and becomes hard to distinguish from automated machine learning (AutoML) [34].
文献中对元学习 (meta-learning) 存在多种理解视角,部分原因是不同学术圈对该术语的使用存在差异。Thrun [7] 从操作层面将"学会学习"定义为:当学习者在解决来自特定任务族的任务时,其表现随所见任务数量的增加而提升(对比传统机器学习性能会随单任务数据量增加而提升)。该视角 [29][30][31] 将元学习视为应对"没有免费午餐"定理 [32] 的工具,通过搜索最适合特定问题或问题族的算法(归纳偏置)来提升泛化能力。但此定义可能涵盖迁移学习、多任务学习、特征选择和模型集成学习等现今通常不被视为元学习的技术。另一种元学习用法 [33] 涉及基于数据集特征的算法选择,这已与自动化机器学习 (AutoML) [34] 难以区分。
In this paper, we focus on contemporary neural-network meta-learning. We take this to mean algorithm learning as per [29], [30], but focus specifically on where this is achieved by end-to-end learning of an explicitly defined objective function (such as cross-entropy loss). Additionally we consider single-task meta-learning, and discuss a wider variety of (meta) objectives such as robustness and compute efficiency.
在本文中,我们聚焦于当代神经网络元学习(meta-learning)。根据[29]、[30]的定义,我们将其视为算法学习过程,但特别关注通过端到端学习显式定义的目标函数(如交叉熵损失)实现的方法。此外,我们探讨了单任务元学习,并讨论了更广泛的(元)目标,例如鲁棒性和计算效率。
This paper provides a unique, timely, and up-to-date survey of the rapidly growing area of neural network metalearning. In contrast, previous surveys are rather out of date and/or focus on algorithm selection for data mining [29], [33], [35], [36], AutoML [34], or particular applications of meta-learning such as few-shot learning [37] or NAS [38].
本文对快速发展的神经网络元学习领域进行了独特、及时且最新的综述。相比之下,之前的综述要么已经过时,要么侧重于数据挖掘的算法选择[29][33][35][36]、AutoML[34],或是元学习的特定应用,如少样本学习[37]或神经架构搜索(NAS)[38]。
We address both meta-learning methods and applications (Fig. 1, Table 1). We first introduce meta-learning through a high-level problem formalization that can be used to understand and position work in this area. We then provide a new taxonomy in terms of meta-representation, meta-objective and meta-optimizer. This framework provides a designspace for developing new meta learning methods and customizing them for different applications. We survey several popular and emerging application areas including few-shot, reinforcement learning, and architecture search; and position meta-learning with respect to related topics such as transfer and multi-task learning. We conclude by discussing outstanding challenges and areas for future research.
我们同时探讨了元学习方法与应用 (图 1, 表 1)。首先通过高层问题形式化来介绍元学习,该框架可用于理解和定位该领域的研究工作。随后从元表征 (meta-representation)、元目标 (meta-objective) 和元优化器 (meta-optimizer) 的角度提出新的分类体系。这一框架为开发新型元学习方法及针对不同应用场景的定制化提供了设计空间。我们调研了包括少样本学习、强化学习和架构搜索在内的多个热门新兴应用领域,并将元学习与迁移学习、多任务学习等相关主题进行对比定位。最后讨论了当前面临的挑战与未来研究方向。
2 BACKGROUND
2 背景
Meta-learning is difficult to define, having been used in various inconsistent ways, even within contemporary neuralnetwork literature. In this section, we introduce our definition and key terminology, and then position meta-learning with respect to related topics.
元学习 (Meta-learning) 的定义存在诸多分歧,即便在现代神经网络文献中也存在不一致的用法。本节将阐述我们的定义与核心术语,并厘清元学习与相关领域的关系。
Meta-learning is most commonly understood as learning to learn; the process of improving a learning algorithm over multiple learning episodes. In contrast, conventional ML improves model predictions over multiple data instances. During base learning, an inner (or lower/base) learning algorithm solves a task such as image classification [13], defined by a dataset and objective. During meta-learning, an outer (or upper/meta) algorithm updates the inner learning algorithm such that the model it learns improves an outer objective. For instance this objective could be generalization performance or learning speed of the inner algorithm.
元学习 (Meta-learning) 最普遍的理解是"学会学习",即在多个学习周期中改进学习算法的过程。相比之下,传统机器学习 (ML) 通过多个数据实例来改进模型预测。在基础学习 (base learning) 阶段,内部(或下层/基础)学习算法会解决由数据集和目标定义的任务(如图像分类 [13])。而在元学习阶段,外部(或上层/元)算法会更新内部学习算法,使其学到的模型能够优化外部目标(如内部算法的泛化性能或学习速度)。
As defined above, many conventional algorithms such as random search of hyper-parameters by cross-validation could fall within the definition of meta-learning. The salient characteristic of contemporary neural-network meta-learning is an explicitly defined meta-level objective, and end-to-end optimization of the inner algorithm with respect to this objective. Often, meta-learning is conducted on learning episodes sampled from a task family, leading to a base learning algorithm that performs well on new tasks sampled from this family. However, in a limiting case all training episodes can be sampled from a single task. In the following section, we introduce these notions more formally.
如上所述,许多传统算法(例如通过交叉验证随机搜索超参数)都可归入元学习的定义范畴。当代基于神经网络的元学习核心特征在于:明确定义元级优化目标,并针对该目标对内部算法进行端到端优化。元学习通常在从任务族采样的学习片段上进行,从而获得在该族新任务中表现优异的基础学习算法。但极限情况下,所有训练片段都可从单一任务中采样。下文将更规范地阐述这些概念。
2.1 Formalizing Meta-Learning
2.1 形式化元学习
Conventional Machine Learning. In conventional supervised machine learning, we are given a training dataset $\mathcal{D}=$ ${(x_{1},y_{1}),\dots,(x_{N},y_{N})},$ such as (input image, output label) pairs. We can train a predictive model $\hat{y}=f_{\boldsymbol{\theta}}(\boldsymbol{x})$ parameterized by $\theta_{,}$ , by solving:
传统机器学习。在传统的监督式机器学习中,我们会获得一个训练数据集 $\mathcal{D}=$ ${(x_{1},y_{1}),\dots,(x_{N},y_{N})}$,例如(输入图像,输出标签)对。我们可以通过求解以下问题来训练一个由参数 $\theta_{,}$ 参数化的预测模型 $\hat{y}=f_{\boldsymbol{\theta}}(\boldsymbol{x})$:
$$
\theta^{* }=\underset{\theta}{\arg\operatorname*{min}}~\mathcal{L}(\mathcal{D};\theta,\omega),
$$
$$
\theta^{* }=\underset{\theta}{\arg\operatorname*{min}}~\mathcal{L}(\mathcal{D};\theta,\omega),
$$
where $\mathcal{L}$ is a loss function that measures the error between true labels and those predicted by $f_{\boldsymbol\theta}(\cdot)$ . Here, $\omega$ specifies assumptions about ‘how to learn’, such as the choice of optimizer for $\theta$ or function class for $f$ . Generalization is then measured by evaluating $\mathcal{L}$ on test points with known labels.
其中 $\mathcal{L}$ 是衡量真实标签与 $f_{\boldsymbol\theta}(\cdot)$ 预测值之间误差的损失函数。此处 $\omega$ 规定了"如何学习"的假设,例如优化器对 $\theta$ 的选择或 $f$ 的函数类。泛化能力通过在有已知标签的测试点上评估 $\mathcal{L}$ 来衡量。
The conventional assumption is that this optimization is performed from scratch for every problem ${\mathcal{D}};$ and that $\omega$ is pre-specified. However, the specification of $\omega$ can drastically affect performance measures like accuracy or data efficiency. Meta-learning seeks to improve these measures by learning the learning algorithm itself, rather than assuming it is pre-specified and fixed. This is often achieved by revisiting the first assumption above, and learning from a distribution of tasks rather than from scratch. Note that while the following formalization of meta-learning takes a supervised perspective for simplicity, all the ideas generalize directly to a reinforcement learning setting as discussed in Section 5.2.
传统假设认为,这种优化是针对每个问题 ${\mathcal{D}};$ 从头开始进行的,且 $\omega$ 是预先指定的。然而,$\omega$ 的设定会显著影响准确率或数据效率等性能指标。元学习 (meta-learning) 试图通过学习算法本身来改进这些指标,而非假设算法是预先指定且固定的。这通常通过重新审视上述第一个假设来实现,即从任务分布中学习而非从零开始。需要注意的是,尽管下文对元学习的形式化描述为简化起见采用监督学习视角,但所有概念均可直接推广到强化学习场景,如第5.2节所述。
Meta-Learning: Task-Distribution View. A common view of meta-learning is to learn a general purpose learning algorithm that generalizes across tasks, and ideally enables each new task to be learned better than the last. We can evaluate the performance of $\omega$ over a task distribution $p(T).$ , where a task specifies a dataset and loss function $\mathcal{T}={\mathcal{D},\mathcal{L}}$ . At a high level, learning how to learn thus becomes
元学习:任务分布视角。元学习的一个常见视角是学习一种通用的学习算法,使其能够泛化到不同任务上,理想情况下能让每个新任务的学习效果比前一个更好。我们可以评估 $\omega$ 在任务分布 $p(T)$ 上的性能,其中任务由数据集和损失函数定义 $\mathcal{T}={\mathcal{D},\mathcal{L}}$。从高层次来看,"学习如何学习"就转化为
$$
\operatorname*{min}_ {\omega}\mathbb{E}_{\mathcal{T}\sim p(T)}\mathcal{L}(\mathcal{D}\emptyset\omega),
$$
$$
\operatorname*{min}_ {\omega}\mathbb{E}_{\mathcal{T}\sim p(T)}\mathcal{L}(\mathcal{D}\emptyset\omega),
$$
where $\mathcal{L}$ is a task specific loss. In typical machine-learning settings, we can split $\mathcal{D}=(D^{t r a i n},\dot{D}^{v\hat{a}l})$ . We then define the task specific loss to be $\mathcal{L}(\mathcal{D};\omega)=\mathcal{L}(\mathcal{D}^{v a l};\theta^{* }(\mathcal{D}^{t r a i n},\omega),\omega).$ ; where $\theta^{*}$ is the parameters of the model trained using the ‘how to learn’ meta-knowledge $\omega$ on dataset $\mathcal{D}^{t r a i n}$ .
其中 $\mathcal{L}$ 是任务特定的损失函数。在典型的机器学习设置中,我们可以将数据集划分为 $\mathcal{D}=(D^{train},\dot{D}^{v\hat{a}l})$。然后定义任务特定损失函数为 $\mathcal{L}(\mathcal{D};\omega)=\mathcal{L}(\mathcal{D}^{val};\theta^{* }(\mathcal{D}^{train},\omega),\omega)$;其中 $\theta^{*}$ 表示使用元知识 $\omega$ 在训练集 $\mathcal{D}^{train}$ 上训练得到的模型参数。
More concretely, to solve this problem in practice, we often assume a set of $M$ source tasks is sampled from $p(\mathcal{T})$ . Formally, we denote the set of $M$ source tasks used in the metatraining stage as $\mathcal{D}_ {s o u r c e}={(\mathcal{D}_ {s o u r c e}^{t r a i n},\mathcal{D}_ {s o u r c e}^{v a l})^{(i)}}_{i=1}^{M}$ eÞðiÞgiM1 where each task has both training and validation data. Often, the source train and validation datasets are respectively called support and query sets. The meta-training step of ‘learning how to learn’ can be written as:
更具体地说,为解决实践中的这一问题,我们通常假设从 $p(\mathcal{T})$ 中采样了一组 $M$ 个源任务。形式上,我们将元训练阶段使用的 $M$ 个源任务集合表示为 $\mathcal{D}_ {source}={(\mathcal{D}_ {source}^{train},\mathcal{D}_ {source}^{val})^{(i)}}_{i=1}^{M}$,其中每个任务都包含训练数据和验证数据。通常,源训练集和验证集分别被称为支持集(support set)和查询集(query set)。"学习如何学习"的元训练步骤可表述为:
$$
\omega^{* }=\underset{\omega}{\arg\operatorname*{min}}\sum_{i=1}^{M}\mathcal{L}(D_{s o u r c e}^{(i)};\omega).
$$
$$
\omega^{* }=\underset{\omega}{\arg\operatorname*{min}}\sum_{i=1}^{M}\mathcal{L}(D_{s o u r c e}^{(i)};\omega).
$$
Now we denote the set of $Q$ target tasks used in the metatesting stage as Dtarget ¼ f Dt tra a rig net; D tte as rt get i g iQ 1 where each task has both training and test data. In the meta-testing stage we use the learned meta-knowledge $\omega^{*}$ to train the base model on each previously unseen target task $i$ :
现在我们将在元测试阶段使用的 $Q$ 个目标任务集合表示为 Dtarget = { Dt tra a rig net; D tte as rt get iQ 1 },其中每个任务都包含训练数据和测试数据。在元测试阶段,我们使用学习到的元知识 $\omega^{*}$ 在每个未见过的目标任务 $i$ 上训练基础模型:
$$
\theta^{* (i)} = \underset{\theta}{\arg\min}, \mathcal{L}\left(\mathcal{D}_{\mathrm{target}}^{\mathrm{train}}(i); \theta, \omega^{*}\right).
$$
$$
\theta^{* (i)} = \underset{\theta}{\arg\min}, \mathcal{L}\left(\mathcal{D}_{\mathrm{target}}^{\mathrm{train}}(i); \theta, \omega^{*}\right).
$$
In contrast to conventional learning in Eq. (1), learning on the training set of a target task $i$ now benefits from metaknowledge $\omega^{* }$ about the algorithm to use. This could be an estimate of the initial parameters [19], or an entire learning model [39] or optimization strategy [14]. We can evaluate the accuracy of our meta-learner by the performance of ${\boldsymbol{\theta}}^{*(i)}$ on the test split of each target task Dtest ct
与传统学习方式(1)不同,在目标任务$i$的训练集上进行学习时,现在可以利用关于使用算法的元知识$\omega^{* }$。这可能是初始参数的估计[19],或是完整的学习模型[39],亦或是优化策略[14]。我们可以通过${\boldsymbol{\theta}}^{*(i)}$在每个目标任务测试集Dtest ct上的表现来评估元学习器的准确性。
This setup leads to analogies of conventional underfitting and over fitting: meta-under fitting and meta-over fitting.
这种设置导致了与传统欠拟合和过拟合的类比:元欠拟合和元过拟合。
In particular, meta-over fitting is an issue whereby the metaknowledge learned on the source tasks does not generalize to the target tasks. It is relatively common, especially in the case where only a small number of source tasks are available. It can be seen as learning an inductive bias $\omega$ that constrains the hypothesis space of $\theta$ too tightly around solutions to the source tasks.
特别是元过拟合问题,即源任务中学到的元知识无法泛化到目标任务。这种情况相对常见,尤其是在仅有少量源任务可用时。可以将其视为学习了一个归纳偏置 $\omega$,该偏置将 $\theta$ 的假设空间过于紧密地约束在源任务的解周围。
Meta-Learning: Bilevel Optimization View. The previous discussion outlines the common flow of meta-learning in a multiple task scenario, but does not specify how to solve the meta-training step in Eq. (3). This is commonly done by casting the meta-training step as a bilevel optimization problem. While this picture is most accurate for the optimizer-based methods (see Section 3.1), it is helpful to visualize the mechanics of meta-learning more generally. Bilevel optimization [40] refers to a hierarchical optimization prob $1\mathrm{em},$ where one optimization contains another optimization as a constraint [20], [41]. Using this notation, meta-training can be formalised as follows:
元学习:双层优化视角。前文概述了多任务场景下元学习的通用流程,但未明确如何求解公式(3)中的元训练步骤。通常,这通过将元训练步骤转化为双层优化问题来实现。虽然该框架最适用于基于优化器的方法(见第3.1节),但它有助于更直观地理解元学习的运作机制。双层优化[40]指具有层级结构的优化问题,其中一个优化问题将另一个优化问题作为约束条件[20][41]。采用此表述,元训练可形式化如下:
$$
\omega^{* } = \underset{\omega}{\arg\min} \sum_{i=1}^{M} \mathcal{L}^{\mathrm{meta}}\left(\mathcal{D}_{\mathrm{source}}^{\mathrm{val}}; \theta^{*(i)}(\omega), \omega\right)
$$
$$
\omega^{* } = \underset{\omega}{\arg\min} \sum_{i=1}^{M} \mathcal{L}^{\mathrm{meta}}\left(\mathcal{D}_{\mathrm{source}}^{\mathrm{val}}; \theta^{*(i)}(\omega), \omega\right)
$$
$$
\mathrm{s.t.}\qquad{\theta^{* }}^{(i)}(\omega)=\underset{\theta}{\arg\operatorname*{min}}{\mathcal{L}}^{t a s k}(\mathcal{D}_{s o u r c e}^{t r a i n}{(i)};\theta,\omega),
$$
$$
\mathrm{s.t.}\qquad{\theta^{* }}^{(i)}(\omega)=\underset{\theta}{\arg\operatorname*{min}}{\mathcal{L}}^{t a s k}(\mathcal{D}_{s o u r c e}^{t r a i n}{(i)};\theta,\omega),
$$
where $\mathcal{L}^{m e t a}$ and $\mathcal{L}^{t a s k}$ refer to the outer and inner objectives respectively, such as cross entropy in the case of classification; and we have dropped explicit dependence of $\omega$ on $\mathcal{D}$ for brevity. Note the leader-follower asymmetry between the outer and inner levels: the inner optimization Eq. (6) is conditional on the learning strategy $\omega$ defined by the outer level, but it cannot change $\omega$ during its training.
其中 $\mathcal{L}^{m e t a}$ 和 $\mathcal{L}^{t a s k}$ 分别指代外部目标和内部目标 (例如分类任务中的交叉熵) ;为简洁起见,我们省略了 $\omega$ 对 $\mathcal{D}$ 的显式依赖。需注意内外层级间的领导者-追随者不对称性:内部优化方程 (6) 受外部层级定义的学习策略 $\omega$ 制约,但其训练过程中无法改变 $\omega$。
Here $\omega$ could indicate an initial condition in non-convex optimization [19] or a hyper-parameter such as regular iz ation strength [20]. Section 4.1 discusses the space of choices for $\omega$ in detail. The outer level optimization trains $\omega$ to produce models $\theta^{*(i)}(\omega)$ that perform well on their validation sets after training. Section 4.2 discusses how to optimize $\omega$ . Note that $\mathcal{L}^{m e t a}$ and $\mathcal{L}^{t a s k}$ are distinctly denoted, because they can be different functions. For example, $\omega$ can define the inner task loss $\mathcal{L}_{\omega}^{t a s k}$ (see Section 4.1, [25], [42]); and as explored in Section 4.3, $\mathcal{L}^{m e t a}$ can measure different quantities such as validation performance, learning speed or robustness.
这里 $\omega$ 可以表示非凸优化中的初始条件 [19] ,或是正则化强度等超参数 [20] 。第4.1节将详细讨论 $\omega$ 的选择空间。外层优化通过训练 $\omega$ 来生成模型 $\theta^{*(i)}(\omega)$ ,这些模型在训练后能在验证集上表现良好。第4.2节将探讨如何优化 $\omega$ 。需要注意的是 $\mathcal{L}^{meta}$ 和 $\mathcal{L}^{task}$ 被明确区分标注,因为它们可以是不同的函数。例如 $\omega$ 可以定义内部任务损失 $\mathcal{L}_{\omega}^{task}$ (参见第4.1节 [25] [42] );如第4.3节所述, $\mathcal{L}^{meta}$ 可以衡量验证性能、学习速度或鲁棒性等不同指标。
Finally, we note that the above formalization of meta-training uses the notion of a distribution over tasks. While common in the meta-learning literature, it is not a necessary condition for meta-learning. More formally, if we are given a single train and test dataset $\left.M=Q=1\right.$ ), we can split the training set to get validation data such that $\mathcal{D}_ {s o u r c e}\overset{\cdot}{=}(\mathcal{D}_ {s o u r c e}^{t r a i n},\mathcal{D}_ {s o u r c e}^{v a l})$ for meta-training, and for meta-testing we can use $\mathcal{D}_ {t a r g e t}=$ $(\mathcal{D}_ {s o u r c e}^{t r a i n}\cup\mathcal{D}_ {s o u r c e}^{v a l},\mathcal{D}_{t a r g e t}^{t e s t})$ . We still learn $\omega$ over several episodes, and different train-val splits are usually used during meta-training.
最后,我们注意到上述元训练的形式化使用了任务分布的概念。虽然在元学习文献中很常见,但这并不是元学习的必要条件。更正式地说,如果给定单个训练和测试数据集 $\left.M=Q=1\right.$),我们可以拆分训练集以获得验证数据,使得 $\mathcal{D}_ {s o u r c e}\overset{\cdot}{=}(\mathcal{D}_ {s o u r c e}^{t r a i n},\mathcal{D}_ {s o u r c e}^{v a l})$ 用于元训练,而对于元测试,我们可以使用 $\mathcal{D}_ {t a r g e t}=$ $(\mathcal{D}_ {s o u r c e}^{t r a i n}\cup\mathcal{D}_ {s o u r c e}^{v a l},\mathcal{D}_{t a r g e t}^{t e s t})$。我们仍然通过多个回合学习 $\omega$,并且在元训练期间通常会使用不同的训练-验证拆分。
Meta-Learning: Feed-Forward Model View. As we will see, there are a number of meta-learning approaches that synthesize models in a feed-forward manner, rather than via an explicit iterative optimization as in Eqs. 5-6 above. While they vary in their degree of complexity, it can be instructive to understand this family of approaches by instant i a ting the abstract objective in Eq. (2) to define a toy example for meta-training linear regression [43].
元学习:前馈模型视角。我们将看到,有多种元学习方法以前馈方式合成模型,而非通过上述公式5-6中的显式迭代优化。尽管这些方法在复杂度上存在差异,但通过实例化公式(2)中的抽象目标来定义线性回归[43]的元训练示例,有助于理解这类方法体系。
$$
\operatorname*{min}_ {\omega}\mathbb{E}_ {{T}\sim p(T)(\mathcal{D}^{t r},\mathcal{D}^{v a l})\in{T}}\quad\sum_{({\boldsymbol x},{\boldsymbol y})\in\mathcal{D}^{v a l}}\left[({\boldsymbol x}^{T}\mathbf{g}_{\omega}(\mathcal{D}^{t r})-{\boldsymbol y})^{2}\right].
$$
$$
\operatorname*{min}_ {\omega}\mathbb{E}_ {{T}\sim p(T)(\mathcal{D}^{t r},\mathcal{D}^{v a l})\in{T}}\quad\sum_{({\boldsymbol x},{\boldsymbol y})\in\mathcal{D}^{v a l}}\left[({\boldsymbol x}^{T}\mathbf{g}_{\omega}(\mathcal{D}^{t r})-{\boldsymbol y})^{2}\right].
$$
Here we meta-train by optimizing over a distribution of tasks. For each task a train and validation set is drawn. The train set $\mathcal{D}^{t r}$ is embedded [44] into a vector $\mathbf{g}_ {\omega}$ which defines the linear regression weights to predict examples $\mathbf{x}$ from the validation set. Optimizing Eq. (7) ‘learns to learn’ by training the function $\mathbf{g}_ {\omega}$ to map a training set to a weight vector. Thus $\mathbf{g}_ {\omega}$ should provide a good solution for novel meta-test tasks $\mathcal{T}^{t e}$ drawn from $p(\mathcal{T})$ . Methods in this family vary in the complexity of the predictive model g used, and how the support set is embedded [44] (e.g., by pooling, CNN or RNN). These models are also known as amortized [45] because the cost of learning a new task is reduced to a feedforward operation through $\mathbf{g}_{\omega}(\cdot),$ , with iterative optimization already paid for during meta-training of $\omega$ .
我们通过优化任务分布进行元训练。对于每个任务,都会抽取训练集和验证集。训练集 $\mathcal{D}^{t r}$ 被嵌入 [44] 成向量 $\mathbf{g}_ {\omega}$ ,该向量定义了从验证集预测样本 $\mathbf{x}$ 的线性回归权重。通过优化方程 (7) ,训练函数 $\mathbf{g}_ {\omega}$ 将训练集映射到权重向量,从而实现"学会学习"。因此, $\mathbf{g}_ {\omega}$ 应当为从 $p(\mathcal{T})$ 中抽取的新元测试任务 $\mathcal{T}^{t e}$ 提供良好的解决方案。这类方法的不同之处在于使用的预测模型 g 的复杂度,以及支持集如何被嵌入 [44] (例如通过池化、CNN 或 RNN)。这些模型也被称为摊销模型 [45] ,因为学习新任务的成本被降低为通过 $\mathbf{g}_{\omega}(\cdot)$ 的前向传播操作,而迭代优化的代价已在 $\omega$ 的元训练阶段支付。
2.2 Historical Context of Meta-Learning
2.2 元学习的历史背景
Meta-learning and learning-to-learn first appear in the literature in 1987[17]. J. Schmid huber introduced a family of methods that can learn how to learn, using self-referential learning. Self-referential learning involves training neural networks that can receive as inputs their own weights and predict updates for said weights. Schmid huber proposed to learn the model itself using evolutionary algorithms.
元学习 (Meta-learning) 和学习如何学习 (learning-to-learn) 的概念最早出现在1987年的文献中[17]。J. Schmidhuber提出了一系列能够学习如何学习的方法,这些方法利用了自指学习 (self-referential learning)。自指学习通过训练神经网络来接收自身权重作为输入,并预测这些权重的更新。Schmidhuber建议使用进化算法 (evolutionary algorithms) 来学习模型本身。
Meta-learning was subsequently extended to multiple areas. Bengio et al.[46], [47] proposed to meta-learn biologically plausible learning rules. Schmid huber et al.continued to explore self-referential systems and meta-learning [48], [49]. S. Thrun et al. took care to more clearly define the term learning to learn in [7] and introduced initial theoretical justifications and practical implementations. Proposals for training meta-learning systems using gradient descent and back propagation were first made in 1991 [50] followed by more extensions in 2001 [51], [52], with [29] giving an overview of the literature at that time. Meta-learning was used in the context of reinforcement learning in 1995 [53], followed by various extensions [54], [55].
元学习随后被扩展到多个领域。Bengio等人[46]、[47]提出通过元学习实现生物学上合理的学习规则。Schmidhuber等人继续探索自指系统和元学习[48]、[49]。S. Thrun等人在[7]中更清晰地定义了"学会学习"这一术语,并提出了初步的理论依据和实践实现。1991年首次提出使用梯度下降和反向传播训练元学习系统的方法[50],随后在2001年进行了更多扩展[51]、[52],[29]对当时的文献进行了综述。1995年元学习被应用于强化学习领域[53],之后出现了各种扩展研究[54]、[55]。
2.3 Related Fields
2.3 相关领域
Here we position meta-learning against related areas whose relation to meta-learning is often a source of confusion.
在此,我们将元学习(meta-learning)与相关领域进行对比,这些领域与元学习的关系常常令人困惑。
Transfer Learning (TL). TL [35], [56] uses past experience from a source task to improve learning (speed, data efficiency, accuracy) on a target task. TL refers both to this problem area and family of solutions, most commonly parameter transfer plus optional fine tuning [57] (although there are numerous other approaches [35]).
迁移学习 (TL)。TL [35][56] 利用源任务 (source task) 的经验来提升目标任务 (target task) 的学习效果(速度、数据效率、准确性)。该术语既指这一研究领域,也涵盖解决方案族,最常见的是参数迁移加可选微调 (fine tuning) [57](尽管还存在许多其他方法 [35])。
In contrast, meta-learning refers to a paradigm that can be used to improve TL as well as other problems. In TL the prior is extracted by vanilla learning on the source task without the use of a meta-objective. In meta-learning, the corresponding prior would be defined by an outer optimization that evaluates the benefit of the prior when learn a new task, as illustrated by MAML [19]. More generally, meta-learning deals with a much wider range of meta-represent at ions than solely model parameters (Section 4.1).
相比之下,元学习 (meta-learning) 是一种可用于改进迁移学习 (TL) 及其他问题的范式。在迁移学习中,先验知识是通过对源任务的常规学习提取的,而不使用元目标。而在元学习中,对应的先验知识由外部优化定义,该优化评估先验知识在学习新任务时的效用,如 MAML [19] 所示。更广泛地说,元学习处理的元表示范围远不止模型参数 (第 4.1 节)。
Domain Adaptation (DA) and Domain Generalization (DG). Domain-shift refers to the situation where source and target problems share the same objective, but the input distribution of the target task is shifted with respect to the source task [35], [58], reducing model performance. DA is a variant of transfer learning that attempts to alleviate this issue by adapting the source-trained model using sparse or unlabeled data from the target. DG refers to methods to train a source model to be robust to such domain-shift without further adaptation. Many knowledge transfer methods have been studied [35], [58] to boost target domain performance. However, as for ${\mathrm{TL}},$ vanilla DA and DG don’t use a meta-objective to optimize ‘how to learn’ across domains. Meanwhile, meta-learning methods can be used to perform both DA [59] and DG [42] (see Section 5.8).
域适应 (Domain Adaptation, DA) 和域泛化 (Domain Generalization, DG)。域偏移 (domain-shift) 指源任务与目标任务目标相同但输入分布发生变化的情况 [35][58],这会降低模型性能。DA 是迁移学习的一种变体,通过利用目标域的稀疏或无标注数据来调整源域训练模型以缓解该问题。DG 则指不进行额外适配就能使源模型对域偏移具有鲁棒性的训练方法。目前已研究出多种提升目标域性能的知识迁移方法 [35][58]。但与 ${\mathrm{TL}}$ 类似,传统 DA 和 DG 并未使用元目标来优化跨域"如何学习"。同时,元学习方法可同时实现 DA [59] 和 DG [42](参见第 5.8 节)。
Continual Learning (CL). Continual or lifelong learning [60], [61] refers to the ability to learn on a sequence of tasks drawn from a potentially non-stationary distribution, and in particular seek to do so while accelerating learning new tasks and without forgetting old tasks. Similarly to metalearning, a task distribution is considered, and the goal is partly to accelerate learning of a target task. However most continual learning methodologies are not meta-learning methodologies since this meta objective is not solved for explicitly. Nevertheless, meta-learning provides a potential framework to advance continual learning, and a few recent studies have begun to do so by developing meta-objectives that encode continual learning performance [62], [63], [64].
持续学习 (CL)。持续或终身学习 [60][61] 指的是从潜在非平稳分布中抽取的任务序列上进行学习的能力,尤其致力于在加速学习新任务的同时不遗忘旧任务。与元学习类似,该方法考虑任务分布,其目标部分在于加速目标任务的学习。然而大多数持续学习方法并非元学习方法,因为这一元目标并未被显式求解。尽管如此,元学习为推进持续学习提供了潜在框架,近期一些研究已开始通过开发编码持续学习性能的元目标来实现这一点 [62][63][64]。
Multi-Task Learning (MTL) Aims to jointly learn several related tasks, to benefit from regular iz ation due to parameter sharing and the diversity of the resulting shared representation [65], [66], as well as compute/memory savings. Like TL, DA, and CL, conventional MTL is a single-level optimization without a meta-objective. Furthermore, the goal of MTL is to solve a fixed number of known tasks, whereas the point of meta-learning is often to solve unseen future tasks. Nonetheless, meta-learning can be brought in to benefit ${\mathrm{MTL}},$ e.g., by learning the relatedness between tasks [67], or how to prioritise among multiple tasks [68].
多任务学习 (MTL) 旨在通过联合学习多个相关任务,从参数共享带来的正则化效应和最终共享表征的多样性中受益 [65], [66],同时节省计算/内存资源。与迁移学习 (TL)、领域自适应 (DA) 和持续学习 (CL) 类似,传统多任务学习是单层优化过程,不包含元目标。此外,多任务学习的目标是解决固定数量的已知任务,而元学习的重点通常是解决未知的未来任务。尽管如此,元学习仍可被引入以优化 ${\mathrm{MTL}}$,例如通过学习任务间关联性 [67],或确定多任务优先级策略 [68]。
Hyper parameter Optimization (HO) is within the remit of meta-learning, in that hyper parameters like learning rate or regular iz ation strength describe ‘how to learn’. Here we include HO tasks that define a meta objective that is trained end-to-end with neural networks, such as gradient-based hyper parameter learning [67], [69] and neural architecture search [21]. But we exclude other approaches like random search [70] and Bayesian Hyper parameter Optimization [71], which are rarely considered to be meta-learning.
超参数优化 (Hyper parameter Optimization, HO) 属于元学习范畴,因为学习率或正则化强度等超参数定义了"如何学习"。本文涵盖通过神经网络端到端训练定义元目标的HO任务,例如基于梯度的超参数学习 [67][69] 和神经架构搜索 [21]。但排除了随机搜索 [70] 和贝叶斯超参数优化 [71] 等方法,这些通常不被视为元学习。
Hierarchical Bayesian Models (HBM) involve Bayesian learning of parameters $\theta$ under a prior $p(\theta\vert\omega)$ . The prior is written as a conditional density on some other variable $\omega$ which has its own prior $p(\omega)$ . Hierarchical Bayesian models feature strongly as models for grouped data ${\mathcal{D}}={{\mathcal{D}}_ {i}|i=1,2,\ldots,{\mathit{M}}},$ where each group $i$ has its own $\theta_{i}$ . The full model is $\left|\prod_{i=1}^{M}p(\mathcal{D}_ {i}\right|$ $\theta_{i})p(\theta_{i}|\omega)]p(\omega)$ . The levels of hierarchy can be increased further; in particular $\omega$ can itself be parameterized, and hence $p(\omega)$ can be learnt. Learning is usually full-pipeline, but using some form of Bayesian marginal is ation to compute the posterior over $\omega$ : $\begin{array}{r}{P(\omega|\mathcal{\bar{D}})\sim p(\omega)\prod_{i=1}^{M}\int d\theta_{i}p(\mathcal{D}_ {i}|\theta_{i})p(\dot{\theta}_{i}|\omega)}\end{array}$ . The ease of doing the marginal is a tio n depends on the model: in some (e.g., Latent Dirichlet Allocation [72]) the marginal is ation is exact due to the choice of conjugate exponential models, in others (see e.g., [73]), a stochastic variation al approach is used to calculate an approximate posterior, from which a lower bound to the marginal likelihood is computed.
分层贝叶斯模型 (HBM) 在先验 $p(\theta\vert\omega)$ 下对参数 $\theta$ 进行贝叶斯学习。该先验被表示为另一个变量 $\omega$ 的条件密度,而 $\omega$ 本身也有其先验 $p(\omega)$。分层贝叶斯模型特别适用于分组数据 ${\mathcal{D}}={{\mathcal{D}}_ {i}|i=1,2,\ldots,{\mathit{M}}},$ 的建模,其中每组 $i$ 都有其专属的 $\theta_{i}$。完整模型为 $\left|\prod_{i=1}^{M}p(\mathcal{D}_ {i}\right|$ $\theta_{i})p(\theta_{i}|\omega)]p(\omega)$。层级可以进一步增加,特别是 $\omega$ 本身也可以被参数化,因此 $p(\omega)$ 也可以被学习。学习通常是全流程的,但会使用某种形式的贝叶斯边缘化来计算 $\omega$ 的后验分布: $\begin{array}{r}{P(\omega|\mathcal{\bar{D}})\sim p(\omega)\prod_{i=1}^{M}\int d\theta_{i}p(\mathcal{D}_ {i}|\theta_{i})p(\dot{\theta}_{i}|\omega)}\end{array}$。边缘化的难易程度取决于模型:在某些情况下(例如潜在狄利克雷分配 [72]),由于选择了共轭指数模型,边缘化是精确的;而在其他情况下(参见 [73]),则使用随机变分方法来计算近似后验,并从中计算边缘似然的下界。
Bayesian hierarchical models provide a valuable viewpoint for meta-learning, by providing a modeling rather than an algorithmic framework for understanding the metalearning process. In practice, prior work in HBMs has typically focused on learning simple tractable models $\theta$ while most meta-learning work considers complex inner-loop learning processes, involving many iterations. Nonetheless, some meta-learning methods like MAML [19] can be understood through the lens of HBMs [74].
贝叶斯分层模型 (Bayesian hierarchical models) 为元学习提供了有价值的视角,它通过建模而非算法框架来理解元学习过程。实践中,先前关于 HBM 的研究通常侧重于学习简单易处理的模型 $\theta$,而大多数元学习工作则考虑复杂的内部循环学习过程,涉及多次迭代。尽管如此,像 MAML [19] 这样的元学习方法可以通过 HBM 的视角来理解 [74]。
AutoML. AutoML [33], [34] is a rather broad umbrella for approaches aiming to automate parts of the machine learning process that are typically manual, such as data preparation, algorithm selection, hyper-parameter tuning, and architecture search. AutoML often makes use of numerous heuristics outside the scope of meta-learning as defined here, and focuses on tasks such as data cleaning that are less central to metalearning. However, AutoML sometimes makes use of end-toend optimization of a meta-objective, so meta-learning can be seen as a specialization of AutoML.
AutoML。AutoML [33][34] 是一个涵盖范围较广的领域,旨在将机器学习过程中通常需要手动完成的部分自动化,例如数据准备、算法选择、超参数调优和架构搜索。AutoML 经常使用许多超出本文定义的元学习 (meta-learning) 范畴的启发式方法,并专注于数据清洗等对元学习不那么核心的任务。然而,AutoML 有时会利用元目标的端到端优化,因此元学习可以被视为 AutoML 的一个特例。
3 TAXONOMY
3 分类体系
3.1 Previous Taxonomies
3.1 现有分类体系
Previous [75], [76] categorizations of meta-learning methods have tended to produce a three-way taxonomy across optimization-based methods, model-based (or black box) methods, and metric-based (or non-parametric) methods.
先前 [75]、[76] 对元学习方法的分类倾向于将其划分为三类:基于优化的方法、基于模型(或黑盒)的方法,以及基于度量(或非参数)的方法。
Optimization. Optimization-based methods include those where the inner-level task (Eq. (6)) is literally solved as an optimization problem, and focuses on extracting meta-knowledge $\omega$ required to improve optimization performance. A famous example is MAML [19], which aims to learn the initialization $\omega=\theta_{0},$ such that a small number of inner steps produces a classifier that performs well on validation data. This is also performed by gradient descent, differentiating through the updates of the base model. More elaborate alternatives also learn step sizes [77], [78] or train recurrent networks to predict steps from gradients [14], [15], [79]. Meta-optimization by gradient over long inner optimization s leads to several compute and memory challenges which are discussed in Section 6. A unified view of gradient-based meta learning expressing many existing methods as special cases of a generalized inner loop meta-learning framework has been proposed [80].
优化。基于优化的方法包括那些将内层任务(式(6))作为优化问题直接求解的方法,其核心在于提取能提升优化性能的元知识$\omega$。典型代表是MAML [19],该方法通过学习初始化参数$\omega=\theta_{0}$,使得少量内层迭代即可生成在验证数据上表现良好的分类器。该过程同样通过梯度下降实现,需对基础模型的参数更新进行微分。更复杂的变体还包括学习步长[77][78],或训练循环神经网络根据梯度预测步长[14][15][79]。长周期内层优化产生的梯度元优化会引发计算与内存方面的挑战,第6节将对此展开讨论。近期研究[80]提出了基于梯度的元学习统一框架,将多种现有方法表述为广义内循环元学习框架的特例。
Black Box/Model-Based. In model-based (or black-box) methods the inner learning step (Eq. (6), Eq. (4)) is wrapped up in the feed-forward pass of a single model, as illustrated in Eq. (7). The model embeds the current dataset $\mathcal{D}$ into activation state, with predictions for test data being made based on this state. Typical architectures include recurrent networks [14], [51], convolutional networks [39] or hypernetworks [81], [82] that embed training instances and labels of a given task to define a predictor for test samples. In this case all the inner-level learning is contained in the activation states of the model and is entirely feed-forward. Outer-level learning is performed with $\omega$ containing the CNN, RNN or hyper network parameters. The outer and inner-level optimizations are tightly coupled as $\omega$ and $\mathcal{D}$ directly specify $\theta$ .
黑盒/基于模型。在基于模型(或黑盒)方法中,内部学习步骤(式(6)、式(4))被封装在单个模型的前向传播过程中,如式(7)所示。该模型将当前数据集$\mathcal{D}$嵌入激活状态,并基于此状态对测试数据进行预测。典型架构包括循环网络[14][51]、卷积网络[39]或超网络[81][82],它们通过嵌入给定任务的训练实例和标签来定义测试样本的预测器。此时所有内部学习都包含在模型的激活状态中,且完全通过前向传播完成。外部学习通过$\omega$(包含CNN、RNN或超网络参数)实现。由于$\omega$和$\mathcal{D}$直接决定了$\theta$,外层与内层优化过程紧密耦合。
Memory-augmented neural networks [83] use an explicit storage buffer and can be seen as a model-based algorithm [84], [85]. Compared to optimization-based approaches, these enjoy simpler optimization without requiring second-order gradients. However, it has been observed that model-based approaches are usually less able to generalize to out-of-distribution tasks than optimization-based methods [86]. Furthermore, while they are often very good at data efficient few-shot learning, they have been criticised for being asymptotically weaker [86] as they struggle to embed a large training set into a rich base model.
记忆增强神经网络 [83] 使用显式存储缓冲区,可视为基于模型的算法 [84], [85]。与基于优化的方法相比,这类方法优化过程更简单,无需二阶梯度。但研究表明,基于模型的方法在分布外任务上的泛化能力通常弱于基于优化的方法 [86]。此外,尽管这类方法在数据高效的少样本学习方面表现优异,但其渐近性能较弱 [86],因为难以将大规模训练集嵌入到强大的基础模型中。
Metric-Learning. Metric-learning or non-parametric algorithms are thus far largely restricted to the popular but specific few-shot application of meta-learning (Section 5.1.1). The idea is to perform non-parametric ‘learning’ at the inner (task) level by simply comparing validation points with training points and predicting the label of matching training points. In chronological order, this has been achieved with siamese [87], matching [88], prototypical [23], relation [89], and graph [90] neural networks. Here outer-level learning corresponds to metric learning (finding a feature extractor $\omega$ that represents the data suitably for comparison). As before $\omega$ is learned on source tasks, and used for target tasks.
度量学习 (Metric-Learning)。度量学习或非参数算法目前主要局限于元学习中流行但特定的少样本应用 (第5.1.1节)。其核心思想是通过简单比较验证点与训练点,并预测匹配训练点的标签,在内部(任务)层面执行非参数"学习"。按时间顺序,这一目标已通过孪生网络 [87]、匹配网络 [88]、原型网络 [23]、关系网络 [89] 和图神经网络 [90] 实现。此处的外部学习对应度量学习(寻找能恰当表示数据以进行比较的特征提取器 $\omega$)。与之前相同,$\omega$ 在源任务上学习,并用于目标任务。
Discussion. The common breakdown reviewed above does not expose all facets of interest and is insufficient to understand the connections between the wide variety of meta-learning frameworks available today. For this reason, we propose a new taxonomy in the following section.
讨论。上述常见分类并未涵盖所有关注维度,也不足以理解当前各类元学习框架之间的联系。为此,我们将在下一节提出新的分类体系。
3.2 Proposed Taxonomy
3.2 提出的分类法
We introduce a new breakdown along three independent axes. For each axis we provide a taxonomy that reflects the current meta-learning landscape.
我们提出了一种沿三个独立维度展开的新分类方法。针对每个维度,我们提供了反映当前元学习(meta-learning)研究现状的分类体系。
Meta-Representation $(^{\prime\prime}W h a t?^{\prime\prime})$ . The first axis is the choice of meta-knowledge $\omega$ to meta-learn. This could be anything from initial model parameters [19] to readable code in the case of program induction [91].
元表示 $(^{\prime\prime}W h a t?^{\prime\prime})$。第一个轴是选择要元学习的元知识 $\omega$,这可以是初始模型参数 [19],也可以是程序归纳情况下的可读代码 [91]。
Meta-Optimizer $(^{\prime\prime}H o w?^{\prime\prime})$ . The second axis is the choice of optimizer to use for the outer level during meta-training (see Eq. (5)). The outer-level optimizer for $\omega$ can take a variety of forms from gradient-descent [19], to reinforcement learning [91] and evolutionary search [25].
元优化器 $(^{\prime\prime}H o w?^{\prime\prime})$。第二个轴是在元训练期间用于外层优化的优化器选择(见公式(5))。针对 $\omega$ 的外层优化器可以采用多种形式,包括梯度下降[19]、强化学习[91]和进化搜索[25]。
Meta-Objective $(^{\prime\prime}W h y?^{\prime\prime})$ . The third axis is the goal of meta-learning which is determined by choice of meta-objective $\mathcal{L}^{m e t a}$ (Eq. (5)), task distribution $p(\mathcal{T})$ , and data-flow between the two levels. Together these can customize metalearning for different purposes such as sample efficient fewshot learning [19], [39], fast many-shot optimization [91], [92], robustness to domain-shift [42], [93], label noise [94], and adversarial attack [95].
元目标 $(^{\prime\prime}W h y?^{\prime\prime})$。第三条轴是元学习的目标,由元目标 $\mathcal{L}^{m e t a}$ (公式(5))、任务分布 $p(\mathcal{T})$ 以及两个层级间的数据流共同决定。这些要素可以针对不同目的定制元学习,例如样本高效的少样本学习 [19][39]、快速多样本优化 [91][92]、对领域偏移的鲁棒性 [42][93]、标签噪声 [94] 以及对抗攻击 [95]。
Together these axes provide a design-space for metalearning methods that can orient the development of new algorithms and customization for particular applications. Note that the base model representation $\theta$ isn’t included in this taxonomy, since it is determined and optimized in a way that is specific to the application at hand.
这些维度共同构成了元学习方法的设计空间,能够指导新算法的开发并为特定应用进行定制。需要注意的是,基础模型表示 $\theta$ 并未包含在此分类体系中,因为它是根据具体应用需求以特定方式确定和优化的。
4 SURVEY: METHODOLOGIES
4 调研:方法论
In this section we break down existing literature according to our proposed new methodological taxonomy.
在本节中,我们根据提出的新方法分类体系对现有文献进行梳理。
4.1 Meta-Representation
4.1 元表征 (Meta-Representation)
Meta-learning methods make different choices about what meta-knowledge v should be, i.e., which aspects of the learning strategy should be learned; and (by exclusion) which aspects should be considered fixed.
元学习方法对元知识v的选择各不相同,即学习策略的哪些方面应该被学习;以及(通过排除)哪些方面应被视为固定。
Parameter Initialization. Here $\omega$ corresponds to the initial parameters of a neural network to be used in the inner optimization, with MAML being the most popular example [19], [96], [97]. A good initialization is just a few gradient steps away from a solution to any task $\tau$ drawn from $p(T).$ , and can help to learn without over fitting in few-shot learning. A key challenge with this approach is that the outer optimization needs to solve for as many parameters as the inner optimization (potentially hundreds of millions in large CNNs). This leads to a line of work on isolating a subset of parameters to meta-learn, for example by subspace [76], [98], by layer [81], [98], [99], or by separating out scale and shift [100]. Another concern is whether a single initial condition is sufficient to provide fast learning for a wide range of potential tasks, or if one is limited to narrow distributions $p(\mathcal{T})$ . This has led to variants that model mixtures over multiple initial conditions [98], [101], [102].
参数初始化。这里 $\omega$ 对应用于内部优化的神经网络初始参数,其中MAML [19], [96], [97] 是最著名的例子。良好的初始化只需少量梯度步就能适应从 $p(T)$ 采样的任何任务 $\tau$ 的解决方案,并有助于在少样本学习中避免过拟合。该方法的关键挑战在于,外部优化需要求解与内部优化相同数量的参数(大型CNN中可能高达数亿)。这催生了一系列关于隔离元学习参数子集的研究,例如通过子空间 [76], [98]、分层 [81], [98], [99] 或分离缩放平移参数 [100]。另一个关注点是单一初始条件是否能针对广泛任务提供快速学习能力,还是仅适用于狭窄分布 $p(\mathcal{T})$。这促使了基于多初始条件混合建模的变体方法 [98], [101], [102]。
Optimizer. The above parameter-centric methods usually rely on existing optimizers such as SGD with momentum or Adam [103] to refine the initialization when given some new task. Instead, optimizer-centric approaches [14], [15], [79], [92] focus on learning the inner optimizer by training a function that takes as input optimization states such as $\theta$ and $\nabla_{\boldsymbol{\theta}}\mathcal{L}^{t a s k}$ and produces the optimization step for each base learning iteration. The trainable component $\omega$ can span simple hyper-parameters such as a fixed step size [77], [78] to more sophisticated pre-conditioning matrices [104], [105]. Ultimately $\omega$ can be used to define a full gradient-based optimizer through a complex non-linear transformation of the input gradient and other metadata [14], [15], [91], [92]. The parameters to learn here can be few if the optimizer is applied coordinate-wise across weights [15]. The initialization-centric and optimizer-centric methods can be merged by learning them jointly, namely having the former learn the initial condition for the latter [14], [77]. Optimizer learning methods have both been applied to for few-shot learning [14] and to accelerate and improve many-shot learning [15], [91], [92]. Finally, one can also meta-learn zeroth-order optimizers [106] that only require evaluations of $\mathcal{L}^{t a s k}$ rather than optimizer states such as gradients. These have been shown [106] to be competitive with conventional Bayesian Optimization [71] alternatives.
优化器。上述以参数为中心的方法通常依赖现有优化器(如带动量的SGD或Adam [103])在给定新任务时优化初始化。而以优化器为中心的方法 [14], [15], [79], [92] 则专注于通过学习一个函数来训练内部优化器,该函数以优化状态(如$\theta$和$\nabla_{\boldsymbol{\theta}}\mathcal{L}^{t a s k}$)为输入,并为每个基础学习迭代生成优化步骤。可训练组件$\omega$的范围可以从简单的超参数(如固定步长 [77], [78])到更复杂的预条件矩阵 [104], [105]。最终,$\omega$可用于通过对输入梯度和其他元数据进行复杂的非线性变换来定义完整的基于梯度的优化器 [14], [15], [91], [92]。如果优化器在权重上逐坐标应用,则学习的参数可能较少 [15]。以初始化为中心的方法和以优化器为中心的方法可以通过联合学习来合并,即让前者为后者学习初始条件 [14], [77]。优化器学习方法已应用于少样本学习 [14] 以及加速和改进多样本学习 [15], [91], [92]。最后,还可以元学习零阶优化器 [106],这些优化器仅需要评估$\mathcal{L}^{t a s k}$,而不需要梯度等优化状态。研究表明 [106],这些方法与传统的贝叶斯优化 [71] 替代方案具有竞争力。
Feed-Forward Models (FFMs. aka, Black-Box, Amortized). Another family of models trains learners $\omega$ that provide a feed-forward mapping directly from the support set to the parameters required to classify test instances, i.e., $\theta=$ $\bar{g}_{\omega}(\mathcal{D}^{t r a i n})$ – rather than relying on a gradient-based iterative optimization of $\theta$ . These correspond to black-box modelbased learning in the conventional taxonomy (Section 3.1) and span from classic [107] to recent approaches such as CNAPs [108] that provide strong performance on challenging cross-domain few-shot benchmarks [109].
前馈模型 (FFMs, 又称黑盒模型/摊销模型). 这类模型通过训练学习器 $\omega$ 直接建立从支持集到测试样本分类参数的前馈映射, 即 $\theta=\bar{g}_{\omega}(\mathcal{D}^{t r a i n})$ , 而非依赖基于梯度的 $\theta$ 迭代优化. 该范式对应传统分类体系中的黑盒模型学习 (第3.1节), 涵盖从经典方法 [107] 到CNAPs [108] 等新近方案, 后者在跨域少样本基准测试 [109] 中展现出卓越性能.
These methods have connections to Hyper networks [110] which generate the weights of another neural network conditioned on some embedding – and are often used for compression or multi-task learning. Here $\omega$ is the hyper network and it synthesis es $\theta$ given the source dataset in a feed-forward pass [98], [111]. Embedding the support set is often achieved by recurrent networks [51], [112], [113] convolution [39], or set embeddings [45], [108]. Research here often studies architectures for param a teri zing the classifier by the task-embedding network: (i) Which parameters should be globally shared across all tasks, versus synthesized per task by the hyper network (e.g., share the feature extractor and synthesize the classifier [81], [114]), and (ii) How to parameterize the hyper network so as to limit the number of parameters required in $\omega$ (e.g., via synthesizing only lightweight adapter layers in the feature extractor [108], or class-wise classifier weight synthesis [45]).
这些方法与超网络[110]有关联,后者基于某些嵌入生成另一个神经网络的权重,常用于压缩或多任务学习。其中$\omega$代表超网络,它通过前向传播[98][111]根据源数据集合成$\theta$。支持集的嵌入通常通过循环网络[51][112][113]、卷积[39]或集合嵌入[45][108]实现。该领域研究主要聚焦于通过任务嵌入网络参数化分类器的架构:(i) 哪些参数应在所有任务间全局共享,而哪些应由超网络按任务合成(例如共享特征提取器并合成分类器[81][114]);(ii) 如何参数化超网络以限制$\omega$所需的参数量(例如仅合成特征提取器中的轻量适配层[108],或按类别合成分类器权重[45])。
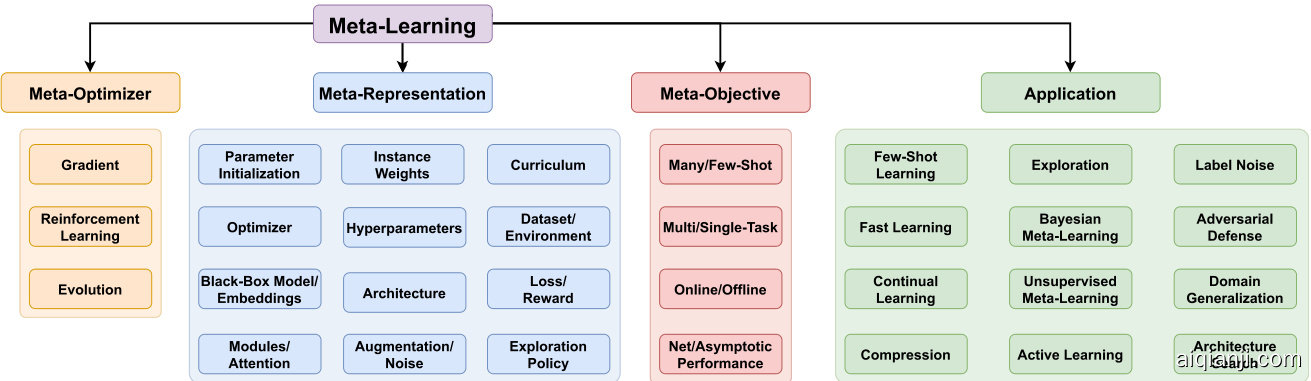
Fig. 1. Overview of the meta-learning landscape including algorithm design (meta-optimizer, meta-representation, meta-objective), and applications.
图 1: 元学习领域的概览,包括算法设计(元优化器、元表示、元目标)和应用。
Some FFMs can also be understood elegantly in terms of amortized inference in probabilistic models [45], [107], making predictions for test data $x$ as:
一些FFM也可以通过概率模型中的摊销推断 (amortized inference) 来优雅地理解 [45], [107], 对测试数据 $x$ 的预测如下:
$$
q_{\omega}(y|x,\mathcal{D}^{t r})=\int p(y|x,\theta)q_{\omega}(\theta|\mathcal{D}^{t r})d\theta,
$$
$$
q_{\omega}(y|x,\mathcal{D}^{t r})=\int p(y|x,\theta)q_{\omega}(\theta|\mathcal{D}^{t r})d\theta,
$$
where the meta-representation $\omega$ is a network $q_{\omega}(\cdot)$ that approximates the intractable Bayesian inference for parameters $\theta$ that solve the task with training data $\mathcal{D}^{t r}$ , and the integral may be computed exactly [107], or approximated by sampling [45] or point estimate [108]. The model $\omega$ is then trained to minimise validation loss over a distribution of training tasks cf. Eq. (7).
元表示 $\omega$ 是一个网络 $q_{\omega}(\cdot)$ ,它近似于对参数 $\theta$ 的难解贝叶斯推断,这些参数通过训练数据 $\mathcal{D}^{t r}$ 解决任务,而积分可以精确计算 [107],或通过采样 [45] 或点估计 [108] 近似。然后训练模型 $\omega$ 以最小化训练任务分布上的验证损失,参见式 (7)。
Finally, memory-augmented neural networks, with the ability to remember old data and assimilate new data quickly, typically fall in the FFM category as well [84], [85].
最后,具备记忆旧数据和快速吸收新数据能力的内存增强神经网络 (memory-augmented neural networks) 通常也属于 FFM 类别 [84], [85]。
Embedding Functions (Metric Learning). Here the meta-optimization process learns an embedding network $\omega$ that transforms raw inputs into a representation suitable for recognition by simple similarity comparison between query and support instances [23], [81], [88], [114] (e.g., with cosine similarity or euclidean distance). These methods are classified as metric learning in the conventional taxonomy (Section 3.1) but can also be seen as a special case of the feed-forward black-box models above. This can easily be seen for methods that produce logits based on the inner product of the embeddings of support and query images $x_{s}$ and $x_{q},$ namely $g_{\omega}^{T}(x_{q})\bar{g_{\omega}}(x_{s})$ [81], [114]. Here the support image generates ‘weights’ to interpret the query example, making it a special case of a FFM where the ‘hyper network’ generates a linear classifier for the query set. Vanilla methods in this family have been further enhanced by making the embedding task-conditional [99], [115], learning a more elaborate comparison metric [89], [90], or combining with gradient-based meta-learning to train other hyper-parameters such as stochastic regularize rs [116].
嵌入函数(度量学习)。这里的元优化过程学习一个嵌入网络$\omega$,将原始输入转换为适合通过查询和支持实例之间的简单相似性比较(如余弦相似度或欧几里得距离)进行识别的表示[23], [81], [88], [114]。这些方法在传统分类中被归类为度量学习(第3.1节),但也可以看作是前馈黑盒模型的一个特例。对于那些基于支持图像和查询图像的嵌入内积生成logits的方法(即$g_{\omega}^{T}(x_{q})\bar{g_{\omega}}(x_{s})$[81], [114]),这一点很容易理解。在这里,支持图像生成“权重”来解释查询示例,使其成为FFM(前馈模型)的一个特例,其中“超网络”为查询集生成一个线性分类器。该领域的原始方法通过使嵌入任务条件化[99], [115]、学习更精细的比较度量[89], [90],或与基于梯度的元学习相结合以训练其他超参数(如随机正则化器[116])得到了进一步改进。
Losses and Auxiliary Tasks. These approaches learn the inner task-loss $\mathcal{L}_{\omega}^{t a s k}$ for the base model (in contrast to $\mathcal{L}^{m e t a}$ , which is fixed). Loss-learning approaches typically define a function that inputs relevant quantities (e.g., predictions, labels, or model parameters) and outputs a scalar to be treated as a loss by the inner (task) optimizer. This can lead to a learned loss that is easier to optimize (less local minima) than standard alternatives [22], [25], [117], provides faster learning with improved generalization [43], [118], [119], [120], robustness to label noise [121], or whose minima corresponds to a model more robust to domain shift [42]. Loss learning methods have also been used to learn from unlabeled instances [99], [122], or to learn task as a differentiable approximation to a true nondifferentiable $\mathcal{L}^{m e t a}$ of interest such as area under precision recall curve [123].
损失函数与辅助任务。这类方法学习基础模型的内在任务损失 $\mathcal{L}_{\omega}^{t a s k}$ (区别于固定的元损失 $\mathcal{L}^{m e t a}$ )。损失学习方法通常定义一个函数,其输入相关量(如预测值、标签或模型参数)并输出一个标量,作为内部(任务)优化器的损失值。由此习得的损失函数可能比标准替代方案更易优化(局部极小值更少) [22][25][117],能实现更快学习并提升泛化能力 [43][118][119][120],对标签噪声具有鲁棒性 [121],或使其极小值对应的模型对领域偏移更具适应性 [42]。损失学习方法还被用于从未标注样本中学习 [99][122],或将任务学习作为真实不可微元损失 $\mathcal{L}^{m e t a}$ (如精确率-召回率曲线下面积 [123])的可微近似。
Loss learning also arises in generalizations of selfsupervised [124] or auxiliary task [125] learning. In these problems unsupervised predictive tasks (such as colourising pixels in vision [124], or simply changing pixels in RL [125]) are defined and optimized with the aim of improving the representation for the main task. In this case the best auxiliary task (loss) to use can be hard to predict in advance, so meta-learning can be used to select among several auxiliary losses according to their impact on improving main task learning. I.e., $\omega$ is a per-auxiliary task weight [68]. More generally, one can meta-learn an auxiliary task generator that annotates examples with auxiliary labels [126].
损失学习也出现在自监督[124]或辅助任务[125]学习的泛化中。在这些问题中,定义了无监督预测任务(例如视觉中的像素着色[124],或简单地改变强化学习中的像素[125]),并通过优化这些任务来改进主任务的表示。在这种情况下,最佳辅助任务(损失)可能难以提前预测,因此可以使用元学习根据多个辅助损失对改进主任务学习的影响进行选择。即,$\omega$是每个辅助任务的权重[68]。更一般地,可以元学习一个辅助任务生成器,用辅助标签标注样本[126]。
Architectures. Architecture discovery has always been an important area in neural networks [38], [127], and one that is not amenable to simple exhaustive search. Meta-Learning can be used to automate this very expensive process by learning architectures. Early attempts used evolutionary algorithms to learn the topology of LSTM cells [128], while later approaches leveraged RL to generate descriptions for good CNN architectures [28]. Evolutionary Algorithms [27] can learn blocks within architectures modelled as graphs which could mutate by editing their graph. Gradient-based architecture representations have also been visited in the form of DARTS [21] where the forward pass during training consists in a softmax across the outputs of all possible layers in a given block, which are weighted by coefficients to be meta learned (i.e., $\omega$ ). During meta-test, the architecture is disc ret i zed by only keeping the layers corresponding to the highest coefficients. Recent efforts to improve DARTS have focused on more efficient different i able approximations [129], robust if ying the disc ret iz ation step [130], learning easy to adapt initialization s [131], or architecture priors [132]. See Section 5.3 for more details.
架构。架构发现一直是神经网络领域的重要研究方向[38][127],且无法通过简单穷举搜索实现。元学习(Meta-Learning)可通过学习架构来自动化这一高成本过程。早期尝试使用进化算法学习LSTM单元的拓扑结构[128],后续方法则利用强化学习(RL)生成优质CNN架构描述[28]。进化算法[27]可学习以图结构建模的架构模块,这些模块能通过编辑图结构实现变异。基于梯度的架构表示方法也以DARTS[21]形式出现,其训练阶段前向传播采用给定模块中所有可能层级输出的softmax加权(权重系数由元学习确定,即$\omega$)。在元测试阶段,通过仅保留最高系数对应层级来实现架构离散化。近期DARTS改进工作聚焦于:更高效的可微分近似[129]、鲁棒化离散步骤[130]、学习易适应的初始化参数[131]或架构先验[132]。详见第5.3节。
Attention Modules. have been used as comparator s in metric-based meta-learners [133], to prevent catastrophic forgetting in few-shot continual learning [134] and to summarize the distribution of text classification tasks [135].
注意力模块 (Attention Modules) 已被用作基于度量的元学习中的比较器 [133],用于防止少样本持续学习中的灾难性遗忘 [134],以及总结文本分类任务的分布 [135]。
Modules. Modular meta-learning [136], [137] assumes that the task agnostic knowledge $\omega$ defines a set of modules, which are re-composed in a task specific manner defined by $\theta$ in order to solve each encountered task. These strategies can be seen as meta-learning generalizations of the typical structural approaches to knowledge sharing that are well studied in multi-task and transfer learning [66], [138], and may ultimately underpin compositional learning [139].
模块化元学习 [136][137] 假设任务无关知识 $\omega$ 定义了一组模块,这些模块按照 $\theta$ 定义的任务特定方式重新组合以解决每个遇到的任务。这些策略可视为多任务和迁移学习 [66][138] 中典型知识共享结构方法的元学习泛化,并可能最终支撑组合式学习 [139]。
Hyper-Parameters. Here $\omega$ represents hyper parameters of the base learner such as regular iz ation strength [20], [69], perparameter regular iz ation [93], task-relatedness in multi-task learning [67], or sparsity strength in data cleansing [67]. Hyper parameters such as step size [69], [77], [78] can be seen as part of the optimizer, leading to an overlap between hyperparameter and optimizer learning categories.
超参数 (Hyper-Parameters)。这里 $\omega$ 表示基础学习器的超参数,例如正则化强度 (regularization strength) [20][69]、逐参数正则化 (perparameter regularization) [93]、多任务学习中的任务相关性 (task-relatedness) [67] 或数据清洗中的稀疏强度 (sparsity strength) [67]。步长 (step size) [69][77][78] 等超参数可视为优化器的一部分,这导致超参数学习和优化器学习类别之间存在重叠。
Data Augmentation and Noise. In supervised learning it is common to improve generalization by synthesizing more training data through label-preserving transformations on the existing data [13]. The data augmentation operation is wrapped up in the inner problem (Eq. (6)), and is conventionally hand-designed. However, when $\omega$ defines the data augmentation strategy, it can be learned by the outer optimization in Eq. (5) in order to maximize validation performance [140]. Since augmentation operations are often non-differentiable, this requires reinforcement learning [140], discrete gradientestimators [141], or evolutionary [142] methods. Recent attempts use meta-gradient to learn mixing proportions in mixup-based augmentation [143]. For stochastic neural networks that exploit noise internally [116], $\omega$ can define a learnable noise distribution.
数据增强与噪声。在监督学习中,通常通过对现有数据进行标签保留变换来合成更多训练数据以提升泛化能力[13]。数据增强操作被封装在内部问题(式(6))中,传统上采用人工设计方式。但当$\omega$定义数据增强策略时,可通过式(5)的外部优化进行学习,以最大化验证性能[140]。由于增强操作通常不可微分,这需要强化学习[140]、离散梯度估计器[141]或进化方法[142]。最新研究尝试利用元梯度学习基于mixup增强的混合比例[143]。对于内部利用噪声的随机神经网络[116],$\omega$可定义可学习的噪声分布。
Minibatch Selection, Instance Weights, and Curriculum Learning. When the base algorithm is minibatch-based stochastic gradient descent, a design parameter of the learning strategy is the batch selection process. Various hand-designed methods [144] exist to improve on randomly-sampled mini batches. Meta-learning approaches can define $\omega$ as an instance selection probability [145] or neural network that picks instances [146] for inclusion in a minibatch. Related to mini-batch selection policies are methods that learn or infer per-instance loss weights for each sample in the training set [147], [148]. For example defining a base loss as $\begin{array}{r}{\mathcal{L}=\sum_{i}\omega_{i}\ell(f(x_{i}),y_{i})}\end{array}$ . This can be used to learn under label-noise by discounting noisy samples [147], [148], discount outliers [67], or correct for class imbalance [147].
小批量选择、实例权重与课程学习。当基础算法采用基于小批量的随机梯度下降时,学习策略的一个设计参数是批次选择过程。现有多种人工设计方法[144]可改进随机采样的小批量。元学习方法可将$\omega$定义为实例选择概率[145]或选择实例的神经网络[146],用于构建小批量。与小批量选择策略相关的是那些学习或推断训练集中每个样本的逐实例损失权重的方法[147][148],例如将基础损失定义为$\begin{array}{r}{\mathcal{L}=\sum_{i}\omega_{i}\ell(f(x_{i}),y_{i})}\end{array}$。该方法可通过降低噪声样本权重[147][148]、排除异常值[67]或校正类别不平衡[147]来实现带标签噪声的学习。
More generally, the curriculum [149] refers to sequences of data or concepts to learn that produce better performance than learning items in a random order. For instance by focusing on instances of the right difficulty while rejecting too hard or too easy (already learned) instances. Instead of defining a curriculum by hand [150], meta-learning can automate the process and select examples of the right difficulty by defining a teaching policy as the meta-knowledge and training it to optimize the student’s progress [146], [151].
更广泛地说,课程学习 [149] 指的是通过学习数据或概念的顺序,从而比随机顺序学习获得更好的性能。例如,通过专注于难度适中的实例,同时排除过难或过易(已掌握)的实例。与手动定义课程 [150] 不同,元学习可以自动化这一过程,通过将教学策略定义为元知识并训练它以优化学生的学习进度 [146] [151],从而选择难度合适的示例。
Datasets, Labels and Environments. Another meta-representation is the support dataset itself. This departs from our initial formalization of meta-learning which considers the source datasets to be fixed (Section 2.1, Eqs. (2) and (3)). However, it can be easily understood in the bilevel view of Eqs. (5) and (6). If the validation set in the upper optimization is real and fixed, and a train set in the lower optimization is para mate rize d by $\omega,$ the training dataset can be tuned by meta-learning to optimize validation performance.
数据集、标签与环境。另一种元表示形式是支撑数据集本身。这与我们最初对元学习的形式化定义不同(第2.1节,公式(2)和(3)),后者假设源数据集是固定的。但在公式(5)和(6)的双层优化视角下很容易理解:若上层优化的验证集真实且固定,而下层优化的训练集通过参数$\omega$进行参数化,则可通过元学习调整训练数据集以优化验证性能。
In dataset distillation [152], [153], [154], the support images themselves are learned such that a few steps on them allows for good generalization on real query images. This can be used to summarize large datasets into a handful of images, which is useful for replay in continual learning where streaming datasets cannot be stored.
在数据集蒸馏 [152], [153], [154] 中,支持图像本身是通过学习得到的,使得在其上进行少量步骤就能在真实查询图像上实现良好的泛化。这种方法可用于将大型数据集概括为少量图像,对于持续学习中无法存储流式数据集的回放场景非常有用。
Rather than learning input images $x$ for fixed labels $y,$ one can also learn the input labels $y$ for fixed images $x$ . This can be used in distilling core sets [155] as in dataset distillation; or semi-supervised learning, for example to directly learn the unlabeled set’s labels to optimize validation set performance [156], [157].
与其学习固定标签 $y$ 对应的输入图像 $x$,也可以学习固定图像 $x$ 对应的输入标签 $y$。这种方法可用于提炼核心集 [155],如数据集蒸馏;或用于半监督学习,例如直接学习未标注集的标签以优化验证集性能 [156] [157]。
In the case of sim2real learning [158] in computer vision or reinforcement learning, one uses an environment simulator to generate data for training. In this case, as detailed in Section 5.10, one can also train the graphics engine [159] or simulator [160] so as to optimize the real-data (validation) performance of the downstream model after training on data generated by that environment simulator.
在计算机视觉或强化学习中的模拟到真实学习(sim2real learning) [158]场景下,研究者会使用环境模拟器生成训练数据。如第5.10节所述,这种情况下还可以通过训练图形引擎 [159] 或模拟器 [160] 来优化下游模型在使用该环境模拟器生成的数据训练后,在真实数据(验证集)上的表现。
Discussion: Trans duct ive Representations and Methods. Most of the representations $\omega$ discussed above are parameter vectors of functions that process or generate data. However a few represent at ions mentioned are trans duct ive in the sense that the $\omega$ literally corresponds to data points [152], labels [156], or perinstance weights [67], [148]. Therefore the number of parameters in $\omega$ to meta-learn scales as the size of the dataset. While the success of these methods is a testament to the capabilities of contemporary meta-learning [154], this property may ultimately limit their s cal ability.
讨论:直推式表示与方法。上述讨论的大多数表示 $\omega$ 都是处理或生成数据的函数参数向量。然而,也有少数提到的表示是直推式的,即 $\omega$ 直接对应于数据点 [152]、标签 [156] 或逐实例权重 [67][148]。因此,元学习所需的 $\omega$ 参数数量会随数据集规模增长。虽然这些方法的成功证明了当代元学习的能力 [154],但这一特性可能最终会限制其可扩展性。
Distinct from a trans duct ive representation are methods that are trans duct ive in the sense that they operate on the query instances as well as support instances [99], [126].
不同于传导式表示的是那些在查询实例和支持实例上操作的传导式方法 [99], [126]。
Discussion: Interpret able Symbolic Representations. A crosscutting distinction that can be made across many of the metarepresentations discussed above is between un interpret able (sub-symbolic) and human interpret able (symbolic) representations. Sub-symbolic representations, such as when $\omega$ parameterizes a neural network [15], are more common and make up the majority of studies cited above. However, meta-learning with symbolic representations is also possible, where $\omega$ represents human readable symbolic functions such as optimization program code [91]. Rather than neural loss functions [42], one can train symbolic losses $\omega$ that are defined by an expression analogous to cross-entropy [119], [121]. One can also metalearn new symbolic activation s [161] that outperform standards such as ReLU. As these meta-representations are nonsmooth, the meta-objective is non-differentiable and is harder to optimize (see Section 4.2). So the upper optimization for $\omega$ typically uses RL [91] or evolutionary algorithms [119]. However, symbolic representations may have an advantage [91], [119], [161] in their ability to generalize across task families. I. e., to span wider distributions $p(\mathcal{T})$ with a single $\omega$ during meta-training, or to have the learned $\omega$ generalize to an out of distribution task during meta-testing (see Section 6).
讨论:可解释的符号化表征。上述讨论的多种元表征之间存在一个贯穿性区别,即不可解释(亚符号)与人类可解释(符号化)表征之分。亚符号表征(例如当$\omega$参数化神经网络时[15])更为常见,构成了前文引用的大部分研究。然而,采用符号化表征进行元学习同样可行,此时$\omega$代表人类可读的符号化函数(如优化程序代码[91])。相较于神经损失函数[42],可以训练由类似交叉熵的表达式定义的符号化损失$\omega$[119][121]。还能通过元学习获得优于ReLU等标准的新型符号化激活函数[161]。由于这些元表征不具备平滑性,元目标函数不可微分且更难优化(见4.2节),因此对$\omega$的上层优化通常采用强化学习[91]或进化算法[119]。但符号化表征在跨任务族泛化能力方面可能具有优势[91][119][161],即在元训练期间用单个$\omega$覆盖更广的分布$p(\mathcal{T})$,或使学习到的$\omega$在元测试时泛化至分布外任务(见第6节)。
Discussion: Amortization. One way to relate some of the representations discussed is in terms of the degree of learning amortization entailed [45]. That is, how much task-specific optimization is performed during meta-testing versus how much learning is amortized during meta-training. Training from scratch, or conventional fine-tuning [57] perform full task-specific optimization at meta-testing, with no amortization. MAML [19] provides limited amortization by fitting an initial condition, to enable learning a new task by few-step fine-tuning. Pure FFMs [23], [88], [108] are fully amortized, with no task-specific optimization, and thus enable the fastest learning of new tasks. Meanwhile some hybrid approaches [98], [99], [109], [162] implement semiamortized learning by drawing on both feed-forward and optimization-based meta-learning in a single framework.
讨论:摊销。将所讨论的部分表征联系起来的一种方式是通过学习摊销的程度 [45]。也就是说,在元测试期间执行了多少特定任务的优化,与在元训练期间摊销了多少学习。从头开始训练或传统的微调 [57] 在元测试时执行完整的特定任务优化,没有摊销。MAML [19] 通过拟合初始条件提供有限的摊销,以实现通过少量步骤的微调来学习新任务。纯FFM [23]、[88]、[108] 是完全摊销的,没有特定任务的优化,因此能够最快地学习新任务。同时,一些混合方法 [98]、[99]、[109]、[162] 通过在单一框架中结合前馈和基于优化的元学习来实现半摊销学习。
4.2 Meta-Optimizer
4.2 元优化器
Given a choice of which facet of the learning strategy to optimize, the next axis of meta-learner design is actual outer (meta) optimization strategy to use for training $\omega$ .
给定选择优化学习策略的哪个方面后,元学习器设计的下一个轴是用于训练$\omega$的实际外部(元)优化策略。
Gradient. A large family of methods use gradient descent on the meta parameters $\omega$ [14], [19], [42], [67]. This requires computing derivatives $d\mathcal{L}^{m e t a}/d\omega$ of the outer objective, which are typically connected via the chain rule to the model parameter $\theta,$ , $d{\mathcal{L}}^{m e t a}/d\omega=(d{\mathcal{L}}^{m e t a}/d\theta)(d\theta/d\omega)$ . These methods are potentially the most efficient as they exploit analytical gradients of $\omega$ . However key challenges include: (i) Efficiently differentiating through many steps of inner optimization, for example through careful design of differentiation algorithms [20], [69], [190] and implicit different i ation [154], [163], [191], and dealing tractably with the required second-order gradients [192]. (ii) Reducing the inevitable gradient degradation problems whose severity increases with the number of inner loop optimization steps. (iii) Calculating gradients when the base learner, $\omega,$ or $\mathcal{L}^{\mathit{\hat{t}a s k}}$ include discrete or other non-differentiable operations.
梯度。一大类方法在元参数 $\omega$ 上使用梯度下降 [14], [19], [42], [67]。这需要计算外部目标的导数 $d\mathcal{L}^{m e t a}/d\omega$,这些导数通常通过链式法则与模型参数 $\theta$ 相关联,即 $d{\mathcal{L}}^{m e t a}/d\omega=(d{\mathcal{L}}^{m e t a}/d\theta)(d\theta/d\omega)$。这些方法可能是最高效的,因为它们利用了 $\omega$ 的解析梯度。然而,关键挑战包括:(i) 高效地通过内部优化的多步进行微分,例如通过精心设计微分算法 [20], [69], [190] 和隐式微分 [154], [163], [191],并有效处理所需的二阶梯度 [192]。(ii) 减少不可避免的梯度退化问题,其严重性随着内部循环优化步骤的增加而增加。(iii) 当基础学习器 $\omega$ 或 $\mathcal{L}^{\mathit{\hat{t}a s k}}$ 包含离散或其他不可微操作时计算梯度。
Reinforcement Learning. When the base learner includes non-differentiable steps [140], or the meta-objective $\mathcal{L}^{m e t a}$ is itself non-differentiable [123], many methods [24] resort to RL to optimize the outer objective Eq. (5). This estimates the gradient $\nabla_{\omega}\mathcal{L}^{m e t a},$ typically using the policy gradient theorem. However, alleviating the requirement for different i ability in this way is typically extremely costly. Highvariance policy-gradient estimates for $\nabla_{\omega}\dot{\mathcal{L}}^{m e t a}$ mean that many outer-level optimization steps are required to converge, and each of these steps are themselves costly due to wrapping task-model optimization within them.
强化学习。当基础学习器包含不可微步骤 [140],或元目标 $\mathcal{L}^{meta}$ 本身不可微 [123] 时,许多方法 [24] 采用强化学习 (RL) 来优化外部目标方程 (5)。这通常利用策略梯度定理来估计梯度 $\nabla_{\omega}\mathcal{L}^{meta}$。然而,以这种方式缓解可微性要求通常代价极高。针对 $\nabla_{\omega}\dot{\mathcal{L}}^{meta}$ 的高方差策略梯度估计意味着需要大量外部优化步骤才能收敛,而由于每个步骤都包含任务模型优化,这些步骤本身的计算成本也很高。
Evolution. Another approach for optimizing the metaobjective are evolutionary algorithms (EA) [17], [127], [193]. Many evolutionary algorithms have strong connections to reinforcement learning algorithms [194]. However, their performance does not depend on the length and reward sparsity of the inner optimization as for RL.
进化。另一种优化元目标的方法是进化算法 (EA) [17], [127], [193]。许多进化算法与强化学习算法有紧密联系 [194],但其性能不像强化学习那样依赖于内部优化的长度和奖励稀疏性。
EAs are attractive for several reasons [193]: (i) They can optimize any base model and meta-objective with no differentiability constraint. (ii) Not relying on back propagation avoids both gradient degradation issues and the cost of high-order gradient computation of conventional gradient-based methods. (iii) They are highly parallel iz able for s cal ability. (iv) By maintaining a diverse population of solutions, they can avoid local minima that plague gradient-based methods [127]. However, they have a number of disadvantages: (i) The population size required increases rapidly with the number of parameters to learn. (ii) They can be sensitive to the mutation strategy and may require careful hyper parameter optimization. (iii) Their fitting ability is generally inferior to gradient-based methods, especially for large models such as CNNs.
进化算法 (EA) 具有以下优势[193]:(i) 能够优化任何基础模型和元目标,且不受可微性约束。(ii) 不依赖反向传播,既避免了梯度退化问题,又规避了传统基于梯度方法的高阶梯度计算成本。(iii) 具备高度并行化能力,可扩展性强。(iv) 通过维持多样化的解决方案种群,能够规避基于梯度方法常陷入的局部极小值问题[127]。但其也存在若干不足:(i) 所需种群规模会随待学习参数数量急剧增加。(ii) 对变异策略敏感,可能需要进行细致的超参数优化。(iii) 拟合能力通常逊于基于梯度的方法,特别是对于CNN等大型模型。
EAs are relatively more commonly applied in RL applications [25], [169] (where models are typically smaller, and inner optimization s are long and non-differentiable). However they have also been applied to learn learning rules [195], optimizers [196], architectures [27], [127] and data augmentation strategies [142] in supervised learning. They are also particularly important in learning human interpretable symbolic meta-representations [119].
进化算法 (EAs) 在强化学习应用中相对更为常见 [25], [169] (这类场景通常模型较小,且内部优化过程长且不可微分)。但它们也被用于监督学习中学习学习规则 [195]、优化器 [196]、架构 [27], [127] 以及数据增强策略 [142]。在习得人类可解释的符号化元表征 [119] 方面,进化算法也尤为重要。
Discussion. These three optimizers are also all used in conventional learning. However meta-learning comparatively more often resorts to RL and Evolution, e.g., as $\bar{\mathcal{L}}^{m e t a}$ is often non-differentiable with respect to representation $\omega$ .
讨论。这三种优化器在传统学习中也都有应用。然而元学习相对更常采用强化学习 (RL) 和进化算法,例如当 $\bar{\mathcal{L}}^{m e t a}$ 关于表示 $\omega$ 通常不可微时。
4.3 Meta-Objective and Episode Design
4.3 元目标与回合设计
The final component is to define the meta-learning goal through choice of meta-objective $\mathcal{L}^{m e t a},$ , and associated data flow between inner loop episodes and outer optimization s. Most methods define a meta-objective using a performance metric computed on a validation set, after updating the task model with $\omega$ . This is in line with classic validation set approaches to hyper parameter and model selection. However, within this framework, there are several design options:
最终组件是通过选择元目标 $\mathcal{L}^{meta}$ 来定义元学习目标,以及内部循环事件与外部优化之间的关联数据流。大多数方法使用在验证集上计算的性能指标来定义元目标,这是在用 $\omega$ 更新任务模型之后进行的。这与经典的超参数和模型选择的验证集方法一致。然而,在这一框架内,存在几种设计选项:
Many versus Few-Shot Episode Design. According to whether the goal is improving few- or many-shot performance, inner loop learning episodes may be defined with many [67], [91], [92] or few- [14], [19] examples per-task.
多样本与少样本情节设计。根据目标是提升少样本还是多样本性能,内循环学习情节可以定义为每个任务包含多个 [67], [91], [92] 或少量 [14], [19] 样本。
Fast Adaptation versus Asymptotic Performance. When validation loss is computed at the end of the inner learning episode, meta-training encourages better final performance of the base task. When it is computed as the sum of the validation loss after each inner optimization step, then meta-train- ing also encourages faster learning in the base task [78], [91], [92]. Most RL applications also use this latter setting.
快速适应与渐进性能。当在内部学习阶段结束时计算验证损失时,元训练会提升基础任务的最终性能。若将验证损失计算为每个内部优化步骤后的损失总和,则元训练还会促进基础任务中的更快学习 [78], [91], [92]。大多数强化学习应用也采用后一种设置。
Multi versus Single-Task When the goal is to tune the learner to better solve any task drawn from a given family, then inner loop learning episodes correspond to a randomly drawn task from $p(\mathcal{T})$ [19], [23], [42]. When the goal is to tune the learner to simply solve one specific task better, then the inner loop learning episodes all draw data from the same underlying task [15], [67], [173], [180], [181], [197].
多任务与单任务
当目标是调整学习器以更好地解决从给定任务族中抽取的任何任务时,内循环学习阶段对应于从 $p(\mathcal{T})$ 中随机抽取的任务 [19], [23], [42]。当目标是调整学习器以仅更好地解决一个特定任务时,内循环学习阶段均从同一底层任务中抽取数据 [15], [67], [173], [180], [181], [197]。
It is worth noting that these two meta-objectives tend to have different assumptions and value propositions. The multi-task objective obviously requires a task family $p(\mathcal{T})$ to work with, which single-task does not. Meanwhile for multi-task, the data and compute cost of meta-training can be amortized by potentially boosting the performance of multiple target tasks during meta-test; but single-task – without the new tasks for amortization – needs to improve the final solution or asymptotic performance of the current task, or meta-learn fast enough to be online.
值得注意的是,这两个元目标往往具有不同的假设和价值主张。多任务目标显然需要一个任务族 $p(\mathcal{T})$ 来支撑,而单任务则不需要。与此同时,对于多任务而言,元训练的数据和计算成本可以通过在元测试阶段提升多个目标任务的表现来分摊;但单任务由于没有新任务用于分摊成本,必须提升当前任务的最终解或渐近性能,或者实现足够快的元学习以支持在线应用。
Online versus Offline. While the classic meta-learning pipeline defines the meta-optimization as an outer-loop of the inner base learner [15], [19], some studies have attempted to preform meta-optimization online within a single base learning episode [42], [180], [197], [198]. In this case the base model $\theta$ and learner $\omega$ co-evolve during a single episode. Since there is now no set of source tasks to amortize over, meta-learning needs to be fast compared to base model learning in order to benefit sample or compute efficiency.
在线与离线。传统元学习流程将元优化定义为内部基础学习器的外循环 [15], [19], 而部分研究尝试在单个基础学习周期内在线执行元优化 [42], [180], [197], [198]。此时基础模型 $\theta$ 和学习器 $\omega$ 会在单个周期内协同演化。由于缺乏可分摊成本的源任务集,元学习必须比基础模型学习更快,才能提升样本或计算效率。
TABLE 1 Research Papers According to Our Taxonomy
| Meta-Representation | Meta-Optimizer | ||
| Gradient | RL | Evolution | |
| Initial Condition | MAML [19], [162]. MetaOptNet [163]. [76], [85], [99], [164] | [9]19]]9]99]9] | ES-MAML [168]. [169] |
| Optimizer | GD2 []]]]][]]] | PSD [78]. [90] | |
| Hyperparam | HyperRep [20], HyperOpt [66], LHML [68] | MetaTrace [171]. [172] | [169] [173] |
| Feed-Forward model | SNAIL [38], CNAP [107]. [44], [83], [174], [175] [176]-[178] | PEARL [110].[23], [112] | |
| Metric | MatchingNets [87], ProtoNets [22], RelationNets [88]. [89] | ||
| Loss/Reward | MetaReg [92]. [41] [120] | MetaCritic[117].[122] [179] [120] | EPG [24]. [119] [173] |
| Architecture | DARTS [21]. [130] | [27] | [26] |
| Exploration Policy | MetaCuriosity[25].[180]-[184] | ||
| Dataset/Environment | Data Distillation [151].[152] [155] | Learn to Sim [158] | [159] |
| InstanceWeights | MetaWeightNet[146].MentorNet[150].[147] | ||
| Data Augmentation/Noise | MetaDropout[185].[140] [115]. | AutoAugment [139]. | [141] |
| Modules | [135], [136] | ||
| AnnotationPolicy | [186], [187] | [188] | |
We use color to indicate salient meta-objective or application goal. We focus on the main goal of each paper for simplicity. The color code is: sample efficiency (red), learning speed (green), asymptotic performance (purple), cross-domain (blue).
表 1 根据我们分类法的研究论文
| 元表示 | 元优化器 |
|---|---|
| 梯度 | |
| 初始条件 | MAML [19], [162], MetaOptNet [163], [76], [85], [99], [164] |
| 优化器 | GD2 []]]]][]]] |
| 超参数 | HyperRep [20], HyperOpt [66], LHML [68] |
| 前馈模型 | SNAIL [38], CNAP [107], [44], [83], [174], [175], [176]-[178] |
| 度量 | MatchingNets [87], ProtoNets [22], RelationNets [88], [89] |
| 损失/奖励 | MetaReg [92], [41], [120] |
| 架构 | DARTS [21], [130] |
| 探索策略 | |
| 数据集/环境 | Data Distillation [151], [152], [155] |
| 实例权重 | MetaWeightNet [146], MentorNet [150], [147] |
| 数据增强/噪声 | MetaDropout [185], [140], [115] |
| 模块 | [135], [136] |
| 标注策略 | [186], [187] |
我们使用颜色来突出元目标或应用目标。为简化起见,我们关注每篇论文的主要目标。颜色代码为:样本效率(红色)、学习速度(绿色)、渐进性能(紫色)、跨领域(蓝色)。
Other Episode Design Factors. Other operators can be inserted into the episode generation pipeline to customize meta-learning for particular applications. For example one can simulate domain-shift between training and validation to meta-optimize for good performance under domain-shift [42], [59], [93]; simulate network compression such as quantization [199] between training and validation to meta-optimize for network compress i bil it y; provide noisy labels during meta-training to optimize for label-noise robustness [94], or generate an adversarial validation set to meta-optimize for adversarial defense [95]. These opportunities are explored in more detail in the following section.
其他情节设计因素。可以在情节生成流程中插入其他算子,针对特定应用定制元学习。例如:可以模拟训练与验证间的域偏移 (domain-shift) 来元优化域偏移下的性能 [42][59][93];模拟网络压缩 (如量化 [199]) 来元优化网络可压缩性;在元训练阶段提供噪声标签以优化标签噪声鲁棒性 [94];或生成对抗性验证集来元优化对抗防御能力 [95]。下一节将更详细探讨这些可能性。
5 APPLICATIONS
5 应用
In this section we briefly review the ways in which metalearning has been exploited in computer vision, reinforcement learning, architecture search, and so on.
本节我们简要回顾元学习在计算机视觉、强化学习、架构搜索等领域的应用方式。
5.1 Computer Vision and Graphics
5.1 计算机视觉与图形学
Computer vision is a major consumer domain of meta-learning techniques, notably due to its impact on few-shot learning, which holds promise to deal with the challenge posed by the long-tail of concepts to recognise in vision.
计算机视觉是元学习技术的主要应用领域,尤其体现在其对少样本学习的显著影响上,这为解决视觉识别中长尾概念带来的挑战提供了可能。
5.1.1 Few-Shot Learning Methods
5.1.1 少样本 (Few-Shot) 学习方法
Few-shot learning (FSL) is extremely challenging, especially for large neural networks [1], [13], where data volume is often the dominant factor in performance [200], and training large models with small datasets leads to over fitting or nonconvergence. Meta-learning-based approaches are increasingly able to train powerful CNNs on small datasets in many vision problems. We provide a non-exhaustive representative summary as follows.
少样本学习 (Few-shot learning, FSL) 极具挑战性,尤其对于大型神经网络 [1][13] 而言,数据量往往是性能的主导因素 [200],使用小数据集训练大模型会导致过拟合或不收敛。基于元学习的方法在众多视觉问题上越来越能够利用小数据集训练强大的CNN模型。我们提供以下非详尽代表性总结:
Classification. The most common application of meta-learning is few-shot multi-class image recognition, where the inner and outer loss functions are typically the cross entropy over training and validation data respectively [14], [23], [75], [77], [78], [88], [90], [98], [99], [102], [105], [201], [202], [203], [204]. Optimizer-centric [19], black-box [39], [81] and metric learning [88], [89], [90] models have all been considered.
分类。元学习最常见的应用是少样本多类图像识别,其中内部和外部损失函数通常分别是训练数据和验证数据的交叉熵 [14], [23], [75], [77], [78], [88], [90], [98], [99], [102], [105], [201], [202], [203], [204]。以优化器为中心 [19]、黑盒 [39], [81] 以及度量学习 [88], [89], [90] 模型都已被研究过。
This line of work has led to a steady improvement in performance compared to early methods [19], [87], [88]. However, performance is still far behind that of fully supervised methods, so there is more work to be done. Current research issues include improving cross-domain generalization [116], recognition within the joint label space defined by metatrain and meta-test classes [82], and incremental addition of new few-shot classes [134], [175].
与早期方法[19]、[87]、[88]相比,这一系列研究实现了性能的持续提升。然而,其表现仍远落后于全监督方法,因此仍需进一步探索。当前研究重点包括:提升跨域泛化能力[116]、在元训练与元测试类联合定义的标签空间内进行识别[82],以及逐步新增少样本类别[134]、[175]。
Object Detection. Building on progress in few-shot classification, few-shot object detection [175], [205] has been demonstrated, often using feed-forward hyper networkbased approaches to embed support set images and synthesize final layer classification weights in the base model.
目标检测。基于少样本分类的进展,少样本目标检测 [175]、[205] 已被实现,通常采用基于前馈超网络的方法来嵌入支持集图像,并在基础模型中合成最终层分类权重。
Landmark Prediction. aims to locate a skeleton of key points within an image, such as such as joints of a human or robot. This is typically formulated as an image-conditional regression. For example, a MAML-based model was shown to work for human pose estimation [206], modular-metalearning was successfully applied to robotics [136], while a hyper network-based model was applied to few-shot clothes fitting for novel fashion items [175].
地标预测 (Landmark Prediction)。旨在定位图像中关键点的骨架结构,例如人体或机器人的关节。该任务通常被建模为图像条件回归问题。例如,基于MAML的模型被证明适用于人体姿态估计 [206],模块化元学习成功应用于机器人领域 [136],而基于超网络的模型则被用于少样本服装适配新时尚单品 [175]。
Few-Shot Object Segmentation. is important due to the cost of obtaining pixel-wise labeled images. Hyper networkbased meta-learners have been applied in the one-shot regime [207], and performance was later improved by adapting prototypical networks [208]. Other models tackle cases where segmentation has low density [209].
少样本物体分割。由于获取像素级标注图像的成本较高,这一任务具有重要意义。基于超网络的元学习方法已被应用于单样本场景[207],随后通过改进原型网络[208]进一步提升了性能。其他模型则针对分割密度较低的情况进行了优化[209]。
Actions. Beyond still images, meta-learning has been applied to few-shot action recognition [210], [211] and prediction [212] using both FFM [210] and optimization-based [211], [212] approaches.
动作。除了静态图像,元学习还被应用于少样本动作识别 [210]、[211] 和预测 [212],采用了基于 FFM [210] 和基于优化 [211]、[212] 的方法。
Image and Video Generation. In [45] an amortized probabilistic meta-learner is used to generate multiple views of an object from just a single image, generative query networks [213] render scenes from novel views, and talking faces are generated from little data by learning the initialization of an adversarial model for quick adaptation [214]. In video domain, [215] meta-learns a weight generator that synthesizes videos given few example images as cues. Meta-learning has also accelerated style transfer by learning a FFM to solve the corresponding optimization problem [216].
图像与视频生成。在[45]中,采用摊销概率元学习器从单张图像生成物体的多视角视图,生成式查询网络[213]实现了新视角下的场景渲染,而通过学习对抗模型的初始化实现快速适配,仅需少量数据即可生成会说话的人脸[214]。在视频领域,[215]通过元学习权重生成器,以少量示例图像为线索合成视频。元学习还通过训练FFM解决相应优化问题,加速了风格迁移[216]。
Generative Models and Density Estimation. Density estimators capable of generating images typically require many parameters, and as such overfit in the few-shot regime. Gradient-based meta-learning of PixelCNN generators was shown to enable their few-shot learning [217].
生成式模型与密度估计。能够生成图像的密度估计器通常需要大量参数,因此在少样本场景下容易过拟合。基于梯度的元学习方法已被证明能实现PixelCNN生成器的少样本学习[217]。
5.1.2 Few-Shot Learning Benchmarks
5.1.2 少样本 (Few-Shot) 学习基准
Progress in AI and machine learning is often measured, and spurred, by well designed benchmarks [218]. Conventional ML benchmarks define a task and dataset for which a model should generalize from seen to unseen instances. In metalearning, benchmark design is more complex, since we are often dealing with a learner that should generalize from seen to unseen tasks. Benchmark design thus needs to define families of tasks from which meta-training and meta-testing tasks can be drawn. Established FSL benchmarks include mini Image Net [14], [88], Tiered-ImageNet [219], SlimageNet [220], Omniglot [88] and Meta-Dataset [109].
人工智能和机器学习的进展通常通过精心设计的基准测试来衡量和推动[218]。传统机器学习基准测试定义了模型应从已见实例推广到未见实例的任务和数据集。而在元学习(meta learning)中,基准设计更为复杂,因为我们通常需要处理一个应从已见任务推广到未见任务的学习者。因此,基准设计需要定义能从中抽取元训练和元测试任务的任务族。已建立的少样本学习(FSL)基准包括mini ImageNet[14][88]、Tiered-ImageNet[219]、SlimageNet[220]、Omniglot[88]和Meta-Dataset[109]。
Dataset Diversity, Bias and Generalization. The standard benchmarks provide tasks for training and evaluation, but suffer from a lack of diversity (narrow $p(T))$ ; performance on these benchmarks are not reflective of performance on real-world few shot tasks. For example, switching between kinds of animal photos in mini Image Net is not a strong test of generalization. Ideally bechmarks would span more diverse categories and types of images (satellite, medical, agricultural, underwater, etc), and even test domain-shifts between meta-train and meta-test tasks.
数据集多样性、偏差与泛化性。标准基准测试提供了训练和评估任务,但存在多样性不足(狭窄的$p(T)$)问题;这些基准上的表现并不能反映真实世界少样本任务中的性能。例如,在mini Image Net中切换不同种类的动物照片并不能有效检验泛化能力。理想情况下,基准测试应覆盖更广泛的图像类别和类型(卫星影像、医学影像、农业影像、水下影像等),甚至需要测试元训练任务与元测试任务之间的领域偏移。
There is work still to be done here as, even in the manyshot setting, fitting a deep model to a very wide distribution of data is itself non-trivial [221], as is generalizing to out-ofsample data [42], [93]. Similarly, the performance of metalearners often drops drastically when introducing a domain shift between the source and target task distributions [114]. This motivates the recent Meta-Dataset [109] and CVPR cross-domain few-shot challenge [222]. Meta-Dataset aggregates a number of individual recognition benchmarks to provide a wider distribution of tasks $p(\mathcal{T})$ to evaluate the ability to fit a wide task distribution and generalize across domain-shift. Meanwhile, [222] challenges methods to generalize from the everyday ImageNet images to medical, satellite and agricultural images. Recent work has begun to try and address these issues by meta-training for domain-shift robustness as well as sample efficiency [116]. Generalization issues also arise in applying models to data from under-represented countries [223].
这里仍有工作要做,因为即使在多样本设置下,将深度模型拟合到非常广泛的数据分布本身就不简单 [221],同样地,泛化到样本外数据 [42]、[93] 也是如此。类似地,当源任务和目标任务分布之间存在领域偏移时,元学习器的性能通常会急剧下降 [114]。这促使了最近的元数据集 (Meta-Dataset) [109] 和 CVPR 跨领域少样本挑战赛 [222] 的出现。元数据集汇集了多个独立的识别基准,以提供更广泛的任务分布 $p(\mathcal{T})$,用于评估模型适应广泛任务分布和跨领域偏移泛化的能力。与此同时,[222] 挑战方法从日常的 ImageNet 图像泛化到医学、卫星和农业图像。最近的研究开始尝试通过元训练来解决领域偏移鲁棒性和样本效率问题 [116]。在将模型应用于代表性不足国家的数据时,也会出现泛化问题 [223]。
5.2 Meta Reinforcement Learning and Robotics
5.2 元强化学习与机器人学
Reinforcement learning is typically concerned with learning control policies that enable an agent to obtain high reward after performing a sequential action task within an environment. RL typically suffers from extreme sample inefficiency due to sparse rewards, the need for exploration, and the high-variance [224] of optimization algorithms. However, applications often naturally entail task families which metalearning can exploit – for example locomoting-to or reaching-to different positions [185], navigating within different environments [39], traversing different terrains [64], driving different cars [184], competing with different competitor agents [62], and dealing with different handicaps such as failures in individual robot limbs [64]. Thus RL provides a fertile application area in which meta-learning on task distributions has had significant successes in improving sample efficiency over standard RL algorithms. One can intuitively understand the efficacy of these methods. For instance meta-knowledge of a maze layout is transferable for all tasks that require navigating within the maze.
强化学习通常关注于学习控制策略,使智能体在环境中执行序列动作任务后获得高奖励。由于稀疏奖励、探索需求以及优化算法的高方差性 [224],RL通常面临样本效率极低的问题。然而,应用场景往往天然包含任务族,这正是元学习可以利用的——例如移动到不同位置 [185]、在不同环境中导航 [39]、穿越不同地形 [64]、驾驶不同车辆 [184]、与不同竞争智能体对抗 [62],以及应对诸如机器人肢体故障等不同障碍 [64]。因此,RL成为元学习在任务分布上显著提升样本效率的肥沃应用领域,其效果优于标准RL算法。这些方法的有效性可直观理解:例如迷宫布局的元知识可迁移至所有需在迷宫中导航的任务。
Problem Setup. Meta-RL uses essentially the same problem setup outlined in Section 2.1, but in the setting of sequential decision making within Markov decision processes (MDPs). A conventional RL problem is defined by an MDP $\mathcal{M},$ in which policy $\pi_{\theta}$ chooses actions $a_{t}$ based on states $s_{t}$ and obtains rewards $r_{t}$ . The policy is trained to maximize the expected cumulative return $\begin{array}{r}{\check{R}_ {\tau}=\sum_{t}^{T}\gamma^{t}r_{t}}\end{array}$ of an episode $\tau\sim\mathcal{M}$ ; $\tau=(s_{0},a_{0},\ldots,s_{T},a_{T},r_{T})$ aft er $T$ timesteps, $\theta^{* }=\arg\operatorname*{max}_{\theta}E_{\tau\sim\mathcal{M},\pi_{\theta}}[R_{\tau}]$ . Meta $\cdot{\mathrm{RL}},$ usually assumes a distribution over MDPs $p(\mathcal{M})$ , analogous to the distribution over tasks in Section 2.1. Some aspect of the learning pro- cess for policy $\theta$ is then para mate rize d by meta-knowledge $\omega,$ for example the initial condition [19], or surrogate reward/ loss function [22], [25]. Then the goal of Meta-RL is to train the meta-representation $\omega$ so as to maximize the expected return of learning within the MDP distribution $p(\mathcal{M})$ :
问题设定。元强化学习 (Meta-RL) 基本沿用了第2.1节所述的问题框架,但将其置于马尔可夫决策过程 (MDP) 的序列决策场景中。传统强化学习问题由MDP $\mathcal{M}$ 定义,其中策略 $\pi_{\theta}$ 根据状态 $s_{t}$ 选择动作 $a_{t}$ 并获取奖励 $r_{t}$。该策略通过训练来最大化回合 $\tau\sim\mathcal{M}$ 的期望累计回报 $\begin{array}{r}{\check{R}_ {\tau}=\sum_{t}^{T}\gamma^{t}r_{t}}\end{array}$;在 $T$ 个时间步后得到 $\tau=(s_{0},a_{0},\ldots,s_{T},a_{T},r_{T})$,最优参数为 $\theta^{* }=\arg\operatorname*{max}_ {\theta}E_{\tau\sim\mathcal{M},\pi_{\theta}}[R_{\tau}]$。元强化学习通常假设存在MDP分布 $p(\mathcal{M})$,这与第2.1节中的任务分布概念类似。策略 $\theta$ 的学习过程中某些方面会被元知识 $\omega$ 参数化,例如初始条件 [19] 或代理奖励/损失函数 [22][25]。因此元强化学习的目标是训练元表示 $\omega$,以最大化MDP分布 $p(\mathcal{M})$ 内的学习期望回报:
$$
\omega^{\ast}=\arg\operatorname*{max}_ {\omega}\mathbb{E}_ {\mathcal{M}\sim p(\mathcal{M})}\mathbb{E}_ {\tau\sim\mathcal{M},\pi_{\theta^{\ast}}}[R_{\tau}].
$$
$$
\omega^{\ast}=\arg\operatorname*{max}_ {\omega}\mathbb{E}_ {\mathcal{M}\sim p(\mathcal{M})}\mathbb{E}_ {\tau\sim\mathcal{M},\pi_{\theta^{\ast}}}[R_{\tau}].
$$
This is the RL version of the meta-training problem in Eq. (2), and solutions are similarly based on bi-level optimization (e.g., [19], cf: Eqs 5-6), or feed-forward approaches (e.g., [39], cf: Eq. (7)). Finally, once trained, the meta-learner $\omega^{*}$ can also be deployed to rapidly learn in a new MDP $\mathcal{M}\sim$ $p(\mathcal{M})$ analogously to the meta-test step in Eq. (4).
这是元训练问题在强化学习(RL)中的版本,其解决方案同样基于双层优化(例如[19],参见公式5-6)或前馈方法(例如[39],参见公式7)。最终,经过训练的元学习器$\omega^{*}$可以像公式(4)中的元测试步骤一样,快速部署到新MDP $\mathcal{M}\sim$ $p(\mathcal{M})$中进行学习。
5.2.1 Methods
5.2.1 方法
Several previously discussed meta-representations have been explored in RL including learning the initial conditions [19], [170], hyper parameters [170], [174], step directions [77] and step sizes [172]. These enable gradient-based learning of a neural policy with fewer environmental interactions and training fast convolutional [39] or recurrent [24], [113] blackbox models to synthesize a policy by embedding the enviroment experience. Recent work has developed improved meta-optimization algorithms [167], [168], [169] for these tasks, and provided theoretical guarantees for meta-RL [225].
先前讨论的几种元表示方法已在强化学习(RL)中得到探索,包括学习初始条件[19][170]、超参数[170][174]、步进方向[77]和步长[172]。这些方法通过嵌入环境经验,能够以较少的环境交互实现基于梯度的神经策略学习,并快速训练卷积[39]或循环[24][113]黑盒模型来合成策略。近期研究针对这些任务开发了改进的元优化算法[167][168][169],并为元强化学习[225]提供了理论保证。
Exploration. A meta-representation rather unique to RL is the exploration policy. RL is complicated by the fact that the data distribution is not fixed, but varies according to the agent’s actions. Furthermore, sparse rewards may mean that an agent must take many actions before achieving a reward that can be used to guide learning. As such, how to explore and acquire data for learning is a crucial factor in any RL algorithm. Traditionally exploration is based on sampling random actions [226], or hand-crafted heuristics [227]. Several meta-RL studies have instead explicitly treated exploration strategy or curiosity function as metaknowledge $\omega$ ; and modeled their acquisition as a metalearning problem [26], [183], [184], [228] – leading to sample efficiency improvements by ‘learning how to explore’.
探索。强化学习中一个相当独特的元表征是探索策略。强化学习的复杂性在于数据分布并非固定不变,而是会随着智能体的行为发生变化。此外,稀疏奖励意味着智能体可能需要执行大量动作才能获得可用于指导学习的奖励信号。因此,如何探索并获取学习数据是任何强化学习算法的关键因素。传统探索方法基于随机动作采样 [226] 或人工设计的启发式规则 [227]。而多项元强化学习研究则明确将探索策略或好奇心函数视为元知识 $\omega$,并将其获取过程建模为元学习问题 [26][183][184][228] —— 通过"学习如何探索"实现了样本效率的提升。
Optimization. RL is a difficult optimization problem where the learned policy is usually far from optimal, even on ‘training set’ episodes. This means that, in contrast to meta ${\cdot}S\mathrm{L},$ meta-RL methods are more commonly deployed to increase asymptotic performance [25], [174], [180] as well as sample-efficiency, and can lead to significantly better solutions overall. The meta-objective of many meta-RL frameworks is the net return of the agent over a full episode, and thus both sample efficient and asymptotically performant learning are rewarded. Optimization difficulty also means that there has been relatively more work on learning losses (or rewards) [22], [120], [180], [229] which an RL agent should optimize instead of – or in addition to – the conventional sparse reward objective. Such learned losses may be easier to optimize (denser, smoother) compared to the true target [25], [229]. This also links to exploration as reward learning and can be considered to instantiate meta-learning of learning intrinsic motivation [181].
优化。强化学习 (RL) 是一个困难的优化问题,即使是在"训练集"情节上,学习到的策略通常也远非最优。这意味着,与元 ${\cdot}S\mathrm{L}$ 不同,元强化学习方法更常用于提升渐近性能 [25][174][180] 和样本效率,并能带来整体上明显更好的解决方案。许多元强化学习框架的元目标是智能体在整个情节中的净回报,因此样本高效和渐近性能良好的学习都会得到奖励。优化难度也意味着,关于学习损失函数(或奖励)[22][120][180][229] 的研究相对较多,这些损失函数是强化学习智能体应该优化的目标,可以替代或补充传统的稀疏奖励目标。与真实目标相比,这类学习到的损失函数可能更容易优化(更密集、更平滑)[25][229]。这也与探索即奖励学习相关联,可视为对学习内在动机的元学习的具体实现 [181]。
Online Meta-RL A significant fraction of meta-RL studies addressed the single-task setting, where the meta-knowledge such as loss [22], [180], reward [174], [181], hyperparameters [172], [173], or exploration strategy [182] are trained online together with the base policy while learning a single task. These methods thus do not require task families and provide a direct improvement to their respective base learners’ performance.
在线元强化学习
相当一部分元强化学习研究针对单任务场景,其中损失函数 [22][180]、奖励函数 [174][181]、超参数 [172][173] 或探索策略 [182] 等元知识会与基础策略同步在线训练。这类方法无需预设任务族,可直接提升基础学习器的性能。
On- versus Off-Policy Meta-RL. A major dichotomy in conventional RL is between on-policy and off-policy learning such as PPO [226] versus SAC [230]. Off-policy methods are usually significantly more sample efficient. However, off-policy methods have been harder to extend to meta-RL, leading to more meta-RL methods being built on on-policy RL methods, thus limiting the absolute performance of meta-RL. Early work in off-policy meta-RL methods has led to strong results [22], [111], [166], [229]. Off-policy learning also improves the efficiency of the meta-train stage [111], which can be expensive in meta-RL. It also provides new opportunities to accelerate meta-testing by replay buffer sample from meta-training [166].
在线与离线策略元强化学习。传统强化学习中的一个主要区分是在线策略学习(如PPO [226])与离线策略学习(如SAC [230])。离线策略方法通常样本效率显著更高。然而,离线策略方法较难扩展到元强化学习,导致更多元强化学习方法基于在线策略强化学习构建,从而限制了元强化学习的绝对性能。早期关于离线策略元强化学习方法的研究已取得显著成果 [22], [111], [166], [229]。离线策略学习还提高了元训练阶段的效率 [111],这在元强化学习中可能成本高昂。此外,它还提供了通过元训练回放缓冲区样本来加速元测试的新机会 [166]。
Other Trends and Challenges. [64] is noteworthy in demonstrating successful meta-RL on a real-world physical robot. Knowledge transfer in robotics is often best studied compositionally [231]. E.g., walking, navigating and object pick/place may be subroutines for a room cleaning robot. However, developing meta-learners with effective compositional knowledge transfer is an open question, with modular meta-learning [137] being an option. Unsupervised meta-RL variants aim to perform meta-training without manually specified rewards [232], or adapt at meta-testing to a changed environment but without new rewards [233]. Continual adaptation provides an agent with the ability to adapt to a sequence of tasks within one meta-test episode [62], [63], [64], similar to continual learning. Finally, meta-learning has also been applied to imitation [112] and inverse RL [234].
其他趋势与挑战。[64] 的研究值得关注,它成功在真实物理机器人上实现了元强化学习 (meta-RL)。机器人领域的知识迁移通常最适合通过组合方式进行研究 [231],例如行走、导航和物体抓取/放置可能是房间清洁机器人的子程序。然而,开发具有有效组合知识迁移能力的元学习器仍是一个开放性问题,模块化元学习 [137] 是一种可能的解决方案。无监督元强化学习变体旨在无需手动指定奖励的情况下进行元训练 [232],或在元测试阶段适应环境变化但无需新奖励 [233]。持续适应使智能体能够在一个元测试周期内适应一系列任务 [62][63][64],这与持续学习类似。最后,元学习还被应用于模仿学习 [112] 和逆向强化学习 [234]。
5.2.2 Benchmarks
5.2.2 基准测试
Meta-learning benchmarks for RL typically define a family to solve in order to train and evaluate an agent that learns how to learn. These can be tasks (reward functions) to achieve, or domains (distinct environments or MDPs).
强化学习的元学习基准通常定义一系列待解决的问题,用于训练和评估具备"学会学习"能力的智能体。这些基准可能包含需要达成的任务(奖励函数)或不同领域(独立环境或马尔可夫决策过程)。
Discrete Control RL. An early meta-RL benchmark for vision-actuated control is the arcade learning environment (ALE) [235], which defines a set of classic Atari games split into meta-training and meta-testing. The protocol here is to evaluate return after a fixed number of timesteps in the metatest environment. A challenge is the great diversity (wide $p(T))$ across games, which makes successful meta-training hard and leads to limited benefit from knowledge transfer [235]. Another benchmark [236] is based on splitting Sonichedgehog levels into meta-train/meta-test. The task distribution here is narrower and beneficial meta-learning is relatively easier to achieve. Cobbe et al.[237] proposed two purpose designed video games for benchmarking meta-RL. CoinRun game [237] provides $2^{32}$ procedurally generated levels of varying difficulty and visual appearance. They show that some 10,000 levels of meta-train experience are required to generalize reliably to new levels. CoinRun is primarily designed to test direct generalization rather than fast adaptation, and can be seen as providing a distribution over MDP environments to test generalization rather than over tasks to test adaptation. To better test fast learning in a wider task distribution, ProcGen [237] provides a set of 16 procedurally generated games including CoinRun.
离散控制强化学习。早期基于视觉驱动的元强化学习基准测试是街机学习环境(ALE) [235],该环境定义了一组经典Atari游戏,划分为元训练和元测试集。此处的评估协议是在元测试环境中固定时间步长后计算回报。挑战在于游戏间存在巨大差异性(宽泛的$p(T)$),这使得成功的元训练变得困难,并导致知识迁移收益有限[235]。另一基准测试[236]基于将《索尼克》游戏关卡划分为元训练/元测试集。该任务分布范围较窄,实现有益的元学习相对更容易。Cobbe等人[237]提出了两款专门设计的视频游戏用于元强化学习基准测试。CoinRun游戏[237]提供$2^{32}$个程序生成的不同难度和视觉表现的关卡。研究表明需要约10,000个元训练关卡才能可靠泛化至新关卡。CoinRun主要设计用于测试直接泛化能力而非快速适应能力,可视为通过MDP环境分布来测试泛化性能而非通过任务分布测试适应性能。为更好测试广泛任务分布中的快速学习能力,ProcGen[237]提供了包含CoinRun在内的16款程序生成游戏。
Continuous Control RL. While common benchmarks such as gym [238] have greatly benefited RL research, there is less consensus on meta-RL benchmarks, making existing work hard to compare. Most continuous control meta-RL studies have proposed home-brewed benchmarks that are low dimensional parametric variants of particular tasks such as navigating to various locations or velocities [19], [111], or traversing different terrains [64]. Several multi-MDP benchmarks [239], [240] have recently been proposed but these primarily test generalization across different environmental perturbations rather than different tasks. The Meta-World benchmark [241] provides a suite of 50 continuous control tasks with state-based actuation, varying from simple parametric variants such as lever-pulling and door-opening. This benchmark should enable more comparable evaluation, and investigation of generalization within and across task distributions. The meta-world evaluation [241] suggests that existing meta-RL methods struggle to generalize over wide task distributions and meta-train/meta-test shifts. This may be due to our meta-RL models being too weak and/ or benchmarks being too small, in terms of number and coverage tasks, for effective learning-to-learn. Another recent benchmark suitable for meta-RL is PHYRE [242] which provides a set of 50 vision-based physics task templates which can be solved with simple actions but are likely to require modelbased reasoning to address efficiently. These also provide within and cross-template generalization tests.
连续控制强化学习。虽然诸如gym [238]这样的常见基准极大地推动了强化学习研究,但在元强化学习基准上缺乏共识,使得现有工作难以比较。大多数连续控制元强化学习研究提出了自制的基准,这些基准是特定任务的低维参数化变体,例如导航到不同位置或速度 [19]、[111],或穿越不同地形 [64]。最近提出了几个多马尔可夫决策过程基准 [239]、[240],但这些主要测试不同环境扰动下的泛化能力,而非不同任务间的泛化。Meta-World基准 [241] 提供了一套50个基于状态驱动的连续控制任务,涵盖从简单的参数化变体(如杠杆拉动和开门)到复杂任务。该基准应能实现更具可比性的评估,并研究任务分布内及跨任务分布的泛化能力。Meta-World评估 [241] 表明,现有元强化学习方法在广泛任务分布和元训练/元测试偏移下的泛化能力不足。这可能是由于我们的元强化学习模型过于薄弱,和/或基准在任务数量和覆盖范围上过小,无法有效支持"学会学习"。另一个适合元强化学习的最新基准是PHYRE [242],它提供了50个基于视觉的物理任务模板,这些任务可通过简单动作解决,但可能需要基于模型的推理才能高效处理。这些基准同样提供了模板内和跨模板的泛化测试。
Discussion. One complication of vision-actuated meta-RL is disentangling visual generalization (as in computer vision) with fast learning of control strategies more generally. For example CoinRun [237] evaluation showed large benefit from standard vision techniques such as batch norm suggesting that perception is a major bottleneck.
讨论。视觉驱动的元强化学习的一个复杂之处在于,如何将视觉泛化(如计算机视觉中)与更通用的控制策略快速学习分离开来。例如,CoinRun [237] 的评估显示,批量归一化等标准视觉技术带来了巨大收益,这表明感知是一个主要瓶颈。
5.3 Neural Architecture Search (NAS)
5.3 神经架构搜索 (NAS)
Architecture search [21], [27], [28], [38], [127] can be seen as a kind of hyper parameter optimization where v specifies the architecture of a neural network. The inner optimization trains networks with the specified architecture, and the outer optimization searches for architectures with good validation performance. NAS methods have been analysed [38] according to ‘search space’, ‘search strategy’, and ‘performance esti- mation strategy’. These correspond to the hypothesis space for $\omega_{\cdot}$ , the meta-optimization strategy, and the meta-objective. NAS is particularly challenging because: (i) Fully evaluating the inner loop is expensive since it requires training a manyshot neural network to completion. This leads to approximations such as sub-sampling the train set, early termination of the inner loop, and interleaved descent on both $\omega$ and $\theta$ [21] as in online meta-learning. (ii.) The search space is hard to define, and optimize. This is because most search spaces are broad, and the space of architectures is not trivially differentiable. This leads to reliance on cell-level search [21], [28] constrain- ing the search space, RL [28], discrete gradient estimators [129] and evolution [27], [127].
架构搜索 [21]、[27]、[28]、[38]、[127] 可视为一种超参数优化,其中v指定了神经网络的架构。内部优化负责训练具有指定架构的网络,而外部优化则搜索具有良好验证性能的架构。已有研究 [38] 从"搜索空间"、"搜索策略"和"性能评估策略"三个维度对NAS方法进行了分析,这些维度分别对应$\omega_{\cdot}$的假设空间、元优化策略和元目标。NAS的挑战性主要体现在:(i) 完全评估内部循环成本高昂,因为需要完整训练一个多轮次神经网络。这催生了训练集子采样、内部循环提前终止、以及$\omega$和$\theta$交替下降 [21] 等近似方法,类似在线元学习。(ii) 搜索空间难以定义和优化,因为大多数搜索空间过于宽泛,且架构空间不具备简单的可微性。这导致研究者依赖单元级搜索 [21]、[28] 来约束搜索空间,并采用强化学习 [28]、离散梯度估计器 [129] 和进化算法 [27]、[127]。
Topical Issues. While NAS itself can be seen as an instance of hyper-parameter or hypothesis-class metalearning, it can also interact with meta-learning in other forms. Since NAS is costly, a topical issue is whether discovered architectures can generalize to new problems [243]. Meta-training across multiple datasets may lead to improved cross-task generalization of architectures [132]. Finally, one can also define NAS meta-objectives to train an architecture suitable for few-shot learning [244]. Similarly to fast-adapting initial condition meta-learning approaches such as MAML [19], one can train good initial architectures [131] or architecture priors [132] that are easy to adapt towards specific tasks.
热点问题。虽然神经网络架构搜索(NAS)本身可视为超参数或假设类元学习的一个实例,但它也能以其他形式与元学习产生交互。由于NAS成本高昂,一个核心议题是已发现的架构能否泛化至新问题[243]。跨数据集元训练可能提升架构的跨任务泛化能力[132]。此外,也可通过定义NAS元目标来训练适用于少样本学习的架构[244]。类似于MAML[19]等快速适应初始条件的元学习方法,我们能够训练出易于适应特定任务的优质初始架构[131]或架构先验[132]。
Benchmarks NAS is often evaluated on CIFAR-10, but it is costly to perform and results are hard to reproduce due to confounding factors such as tuning of hyper parameters. To support reproducible and accessible research, the NASbenches [245] provide pre-computed performance measures for a large number of network architectures.
基准测试
NAS通常基于CIFAR-10进行评估,但由于超参数调优等混杂因素,执行成本高昂且结果难以复现。为支持可复现和可访问的研究,NASbenches [245] 提供了大量网络架构的预计算性能指标。
5.4 Hyper-Parameter Optimization
5.4 超参数优化
Meta-learning address hyper parameter optimization when considering $\omega$ to specify hyper parameters, such as regularization strength or learning rate. There are two main settings: we can learn hyper parameters that improve training over a distribution of tasks, just a single task. The former case is usually relevant in few-shot applications, especially in optimization based methods. For instance, MAML can be improved by learning a learning rate per layer per step [78]. The case where we wish to learn hyper parameters for a single task is usually more relevant for many-shot applications [69], [154], where some validation data can be extracted from the training dataset, as discussed in Section 2.1. Endto-end gradient-based meta-learning has already demonstrated promising s cal ability to millions of parameters (as demonstrated by MAML [19] and Dataset Distillation [152], [154], for example) in contrast to the classic approaches (such cross-validation by grid or random [70] search, or Bayesian Optimization [71]) which are typically only successful with dozens of hyper-parameters.
元学习在处理超参数优化问题时,将$\omega$视为指定超参数(如正则化强度或学习率)的变量。主要存在两种设定:我们可以学习能提升跨任务分布训练效果的通用超参数,或是针对单一任务的专用超参数。前者通常适用于少样本场景,特别是在基于优化的方法中。例如,通过为每层每步学习独立的学习率可改进MAML [78]。而针对单一任务的超参数学习更常见于多样本应用场景 [69][154],如第2.1节所述,此时可从训练数据集中划分验证数据。与传统方法(如网格/随机搜索的交叉验证 [70] 或贝叶斯优化 [71])通常仅能处理数十个超参数相比,基于端到端梯度的元学习方法已展现出处理百万级参数的可扩展性优势(如MAML [19] 和数据集蒸馏 [152][154] 所证明)。
5.5 Bayesian Meta-Learning
5.5 贝叶斯元学习
Bayesian meta-learning approaches formalize meta-learning via Bayesian hierarchical modelling, and use Bayesian inference for learning rather than direct optimization of parameters. In the meta-learning context, Bayesian learning is typically intractable, and so approximations such as stochastic variation al inference or sampling are used.
贝叶斯元学习方法通过贝叶斯分层建模对元学习进行形式化,并采用贝叶斯推理进行学习而非直接优化参数。在元学习场景中,贝叶斯学习通常难以处理,因此需采用随机变分推断或采样等近似方法。
Bayesian meta-learning importantly provides uncertainty measures for the $\omega$ parameters, and hence measures of prediction uncertainty which can be important for safety critical applications, exploration in ${\mathrm{RL}},$ and active learning.
贝叶斯元学习 (Bayesian meta-learning) 的重要优势在于能为$\omega$参数提供不确定性度量,从而获得预测不确定性指标。这对安全关键型应用、${\mathrm{RL}}$中的探索以及主动学习 (active learning) 具有重要意义。
A number of authors have explored Bayesian approaches to meta-learning complex neural network models with competitive results. For example, extending variation al auto encoders to model task variables explicitly [73]. Neural Processes [176] define a feed-forward Bayesian meta-learner inspired by Gaussian Processes but implemented with neural networks. Deep kernel learning is also an active research area that has been adapted to the meta-learning setting [246], and is often coupled with Gaussian Processes [247]. In [74] gradient based meta-learning is recast into a hierarchical empirical Bayes inference problem (i.e., prior learning), which models uncertainty in task-specific parameters $\theta$ . Bayesian MAML [248] improves on this model by using a Bayesian ensemble approach that allows non-Gaussian posteriors over $\theta,$ , and later work removes the need for costly ensembles [45], [249]. In Probabilistic MAML [96], it is the uncertainty in the metaknowledge $\omega$ that is modelled, while a MAP estimate is used for $\theta$ . Increasingly, these Bayesian methods are shown to tackle ambiguous tasks, active learning and RL problems.
多位研究者探索了贝叶斯方法在元学习复杂神经网络模型中的应用,并取得了具有竞争力的成果。例如,通过扩展变分自编码器 (variational autoencoder) 来显式建模任务变量 [73]。神经过程 (Neural Processes) [176] 提出了一种受高斯过程 (Gaussian Process) 启发、但用神经网络实现的前馈贝叶斯元学习器。深度核学习 (deep kernel learning) 也是一个活跃的研究领域,已被应用于元学习场景 [246],并常与高斯过程结合使用 [247]。文献 [74] 将基于梯度的元学习重新表述为分层经验贝叶斯推断问题(即先验学习),该方法对任务特定参数 $\theta$ 的不确定性进行建模。贝叶斯 MAML (Bayesian MAML) [248] 通过采用支持 $\theta$ 非高斯后验分布的贝叶斯集成方法改进了该模型,后续研究则消除了对高成本集成方案的需求 [45][249]。概率化 MAML (Probabilistic MAML) [96] 专注于元知识 $\omega$ 的不确定性建模,而对 $\theta$ 采用最大后验概率 (MAP) 估计。这些贝叶斯方法在解决模糊任务、主动学习和强化学习问题方面正展现出日益强大的能力。
Separate from the above, meta-learning has also been proposed to aid the Bayesian inference process itself, as in [250] where the authors adapt a Bayesian sampler to provide efficient adaptive sampling methods.
除上述内容外,元学习 (meta-learning) 也被提出用于辅助贝叶斯推断 (Bayesian inference) 过程本身,例如 [250] 中作者通过调整贝叶斯采样器来实现高效的自适应采样方法。
5.6 Unsupervised and Semi-Supervised Meta-Learning
5.6 无监督与半监督元学习
There are several distinct ways in which unsupervised learning can interact with meta-learning, depending on whether unsupervised learning in performed in the inner loop or outer loop, and during meta-train versus meta-test.
根据无监督学习是在内循环还是外循环中进行,以及在元训练阶段还是元测试阶段执行,无监督学习与元学习的交互方式存在几种明显不同的形式。
Unsupervised Learning of a Supervised Learner. The aim here is to learn a supervised learning algorithm (e.g., via MAML [19] style initial condition for supervised fine-tuning), but do so without the requirement of a large set of source tasks for meta-training [251], [252], [253]. To this end, synthetic source tasks are constructed without supervision via clustering or class-preserving data augmentation, and used to define the meta-objective for meta-training.
无监督学习监督学习器。其目标是学习一种监督学习算法(例如通过MAML [19]风格的监督微调初始条件实现),但无需依赖大量元训练源任务 [251], [252], [253]。为此,通过聚类或类保持数据增强无监督地构建合成源任务,并用于定义元训练的元目标。
Supervised Learning of an Unsupervised Learner. This family of methods aims to meta-train an unsupervised learner. For example, by training the unsupervised algorithm such that it works well for downstream supervised learning tasks. One can train unsupervised learning rules [16] or losses [99], [122] such that downstream supervised learning performance is optimized – after re-using the unsupervised representation for a supervised task [16], or adapting based on unlabeled data [99], [122]. Alternatively, when unsupervised tasks such as clustering exist in a family, rather than in isolation, then learning-to-learn of ‘how-to-cluster’ on several source tasks can provide better performance on new clustering tasks in the family [177], [178], [179], [254], [255]. The methods in this group that make use of feed-forward models are often known as amortized clustering [178], [179], because they amortize the typically iterative computation of clustering algorithms into the cost of training a single inference model, which subsequently performs clustering using a single feed-froward pass. Overall, these methods help to deal with the ill-defined ness of the unsupervised learning problem by transforming it into a problem with a clear supervised (meta) objective.
无监督学习器的监督学习。这类方法旨在对无监督学习器进行元训练。例如,通过训练无监督算法使其在下游监督学习任务中表现良好。可以训练无监督学习规则[16]或损失函数[99][122],从而优化下游监督学习性能——在将无监督表征重用于监督任务后[16],或基于未标记数据进行调整[99][122]。另一种情况是,当聚类等无监督任务存在于一个系列中而非孤立存在时,通过在多个源任务上学习"如何聚类"的元学习,能够在该系列的新聚类任务中获得更好性能[177][178][179][254][255]。该组方法中使用前馈模型的通常被称为摊销聚类[178][179],因为它们将聚类算法典型的迭代计算成本分摊到训练单个推理模型的代价中,随后通过单次前馈传递执行聚类。总体而言,这些方法通过将无监督学习问题转化为具有明确监督(元)目标的问题,帮助应对无监督学习问题定义不明确的困境。
Semi-Supervised Learning (SSL). This family of methods aim to train a base-learner capable of performing well on validation data after learning from a mixture of labeled and unlabeled training examples. In the few-shot regime, approaches include SSL extensions of metric-learners [219], and meta-learning measures of confidence [256] or instance weights [157] to ensure that reliably labeled instances are used in self-training. In the many-shot regime, approaches include direct trans duct ive training of labels [156] , or training a teacher network to generate labels for a student [257].
半监督学习 (SSL)。这类方法旨在通过混合使用标注和未标注的训练样本,训练出能在验证数据上表现良好的基础学习器。在少样本场景下,相关方法包括度量学习的SSL扩展[219],以及通过元学习衡量置信度[256]或实例权重[157]来确保自训练中使用可靠标注的样本。多样本场景下的方法则包括直接转导式标签训练[156],或训练教师网络为学生网络生成标签[257]。
5.7 Continual, Online and Adaptive Learning
5.7 持续学习、在线学习与自适应学习
Continual Learning. Refers to the human-like capability of learning tasks presented in sequence. Ideally this is done while exploiting forward transfer so new tasks are learned better given past experience, without forgetting previously learned tasks, and without needing to store past data [61]. Deep Neural Networks struggle to meet these criteria, especially as they tend to forget information seen in earlier tasks – a phenomenon known as catastrophic forgetting. Meta-learning can include the requirements of continual learning into a meta-objective, for example by defining a sequence of learning episodes in which the support set contains one new task, but the query set contains examples drawn from all tasks seen until now [105], [171]. Various meta-representations can be learned to improve continual learning performance, such as weight priors [134], gradient descent preconditioning matrices [105], or RNN learned optimizers [171], or feature representations [258]. A related idea is meta-training representations to support local editing updates [259] for improvement without interference.
持续学习 (Continual Learning)。指像人类一样按顺序学习任务的能力。理想情况下,这应该通过利用前向迁移 (forward transfer) 来实现——即基于过往经验更好地学习新任务,同时不遗忘先前学到的任务,且无需存储历史数据 [61]。深度神经网络难以满足这些要求,尤其容易遗忘早期任务中的信息,这种现象被称为灾难性遗忘 (catastrophic forgetting)。元学习 (meta-learning) 可以将持续学习的要求纳入元目标,例如通过定义一系列学习片段:其中支持集 (support set) 包含一个新任务,而查询集 (query set) 包含迄今为止所见所有任务的样本 [105], [171]。可以通过学习多种元表示 (meta-representation) 来提升持续学习性能,例如权重先验 (weight priors) [134]、梯度下降预处理矩阵 (gradient descent preconditioning matrices) [105]、RNN学习优化器 (RNN learned optimizers) [171] 或特征表示 (feature representations) [258]。相关思路还包括元训练表征以支持局部编辑更新 (local editing updates) [259],从而实现无干扰的改进。
Online and Adaptive Learning Also consider tasks arriving in a stream, but are concerned with the ability to effectively adapt to the current task in the stream, more than remembering the old tasks. To this end an online extension of MAML was proposed [97] to perform MAML-style metatraining online during a task sequence. Meanwhile others [62], [63], [64] consider the setting where meta-training is performed in advance on source tasks, before meta-testing adaptation capabilities on a sequence of target tasks.
在线与自适应学习
同样考虑以流式到达的任务,但更关注有效适应当前任务的能力,而非记忆旧任务。为此,[97] 提出了一种在线扩展的 MAML (Model-Agnostic Meta-Learning) 方法,在任务序列中实时执行 MAML 风格的元训练。与此同时,其他研究 [62]、[63]、[64] 探讨了先在源任务上完成元训练,再在一系列目标任务序列上测试适应能力的场景。
Benchmarks. A number of benchmarks for continual learning work quite well with standard deep learning methods. However, most cannot readily work with meta-learning approaches as their their sample generation routines do not provide a large number of explicit learning sets and an explicit evaluation sets. Some early steps were made towards defining meta-learning ready continual benchmarks in [97], [171], [258], mainly composed of Omniglot and perturbed versions of MNIST. However, most of those were simply tasks built to demonstrate a method. More explicit benchmark work can be found in [220], which is built for meta and non meta-learning approaches alike.
基准测试。许多持续学习的基准测试在标准深度学习方法中表现良好。然而,大多数基准测试难以直接适用于元学习方法,因为它们的样本生成流程无法提供大量显式学习集和评估集。在[97]、[171]、[258]中已初步定义了适用于元学习的持续学习基准,主要包括Omniglot和MNIST的扰动版本,但这些基准多用于方法演示。更明确的基准测试工作可参考[220],该基准同时适用于元学习和非元学习方法。
5.8 Domain Adaptation and Domain Generalization
5.8 领域自适应与领域泛化
Domain-shift refers to the statistics of data encountered in deployment being different from those used in training. Numerous domain adaptation and generalization algorithms have been studied to address this issue in supervised, unsupervised, and semi-supervised settings [58].
域偏移 (domain-shift) 指部署时遇到的数据统计特性与训练时使用的数据不同。针对这一现象,研究者已在监督式、无监督式和半监督式场景下提出了大量域适应 (domain adaptation) 和域泛化 (domain generalization) 算法 [58]。
Domain Generalization. Domain generalization aims to train models with increased robustness to train-test domain shift [260], often by exploiting a distribution over training domains. Using a validation domain that is shifted with respect to the training domain [261], different kinds of meta-knowledge such as regularize rs [93], losses [42], and noise augmentation [116] can be (meta) learned to maximize the robustness of the learned model to train-test domain-shift.
域泛化 (Domain Generalization)。域泛化的目标是通过利用训练域上的分布,训练出对训练-测试域偏移 (train-test domain shift) 具有更强鲁棒性的模型 [260]。通常采用与训练域存在偏移的验证域 [261],通过元学习 (meta-learn) 不同类型的元知识,例如正则化器 (regularizer) [93]、损失函数 [42] 和噪声增强 (noise augmentation) [116],以最大化所学模型对训练-测试域偏移的鲁棒性。
Domain Adaptation. To improve on conventional domain adaptation[58], meta-learning can be used to define a metaobjective that optimizes the performance of a base unsupervised DA algorithm [59].
领域自适应 (Domain Adaptation)。为了改进传统领域自适应[58],元学习 (meta-learning) 可用于定义元目标 (metaobjective),以优化基础无监督DA算法的性能[59]。
Benchmarks. Popular benchmarks for DA and DG consider image recognition across multiple domains such as photo/sketch/cartoon. PACS [262] provides a good starter benchmark, with Visual Decathlon [42], [221] and MetaDataset [109] providing larger scale alternatives.
基准测试。针对领域适应(DA)和领域泛化(DG)的常用基准测试主要考量跨多领域(如照片/素描/卡通)的图像识别任务。PACS [262] 提供了优质的入门级基准,而 Visual Decathlon [42][221] 和 MetaDataset [109] 则提供了更大规模的替代方案。
5.9 Language and Speech
5.9 语言与语音
Language Modelling. Few-shot language modelling increasingly showcases the versatility of meta-learners. Early matching networks showed impressive performances on one-shot tasks such as filling in missing words [88]. Many more tasks have since been tackled, including text classification [135], neural program induction [263] and synthesis [264], English to SQL program synthesis [265], text-based relationship graph extractor [266], machine translation [267], and quickly adapting to new personas in dialogue [268].
语言建模。少样本语言建模日益展现出元学习器的多功能性。早期的匹配网络在填空等单样本任务中表现出色[88]。此后,更多任务被攻克,包括文本分类[135]、神经程序归纳[263]与合成[264]、英语到SQL程序合成[265]、基于文本的关系图提取器[266]、机器翻译[267],以及对话中快速适应新角色[268]。
Speech Recognition. Deep learning is now the dominant paradigm for state of the art automatic speech recognition (ASR). Meta-learning is beginning to be applied to address the many few-shot adaptation problems that arise within ASR including learning how to train for low-resource languages [269], cross-accent adaptation [270] and optimizing models for individual speakers [271].
语音识别。深度学习目前已成为实现最先进自动语音识别(ASR)的主流范式。元学习技术正开始被应用于解决ASR领域中的诸多少样本适应问题,包括学习如何训练低资源语言模型[269]、跨口音适应[270]以及针对个体说话人优化模型[271]。
5.10 Emerging Topics
5.10 新兴主题
Environment Learning and Sim2Real. In Sim2Real we are interested in training a model in simulation that is able to generalize to the real-world. The classic domain randomization approach simulates a wide distribution over domains/ MDPs, with the aim of training a sufficiently robust model to succeed in the real world – and has succeeded in both vision [272] and RL [158]. Nevertheless tuning the simulation distribution remains a challenge. This leads to a meta- learning setup where the inner-level optimization learns a model in simulation, the outer-level optimization $\mathcal{L}^{m e t a}$ evaluates the model’s performance in the real-world, and the meta-representation $\omega$ corresponds to the parameters of the simulation environment. This paradigm has been used in RL [160] as well as vision [159], [273]. In this case the source tasks used for meta-train tasks are not a pre-provided data distribution, but para mate rize d by omega, $\mathcal{D}_{s o u r c e}(\omega)$ . However, challenges remain in terms of costly back-propagation through a long graph of inner task learning steps; as well as minimising the number of real-world $\mathcal{L}^{m e t a}$ evaluations in the case of Sim2Real.
环境学习与仿真到现实(Sim2Real)。在Sim2Real中,我们关注于在仿真环境中训练能够泛化到现实世界的模型。经典的域随机化方法通过模拟广泛的领域/MDP分布,旨在训练出足够鲁棒的模型以在现实世界中成功——这种方法已在视觉[272]和强化学习[158]领域取得成效。然而,调整仿真分布仍具挑战性。这催生了一种元学习框架:内层优化在仿真中学习模型,外层优化$\mathcal{L}^{meta}$评估模型在现实世界的性能,而元表征$\omega$对应仿真环境的参数。该范式已应用于强化学习[160]和视觉[159][273]领域。此时用于元训练任务的源任务并非预定义的数据分布,而是由$\omega$参数化的$\mathcal{D}_{source}(\omega)$。但该框架仍面临两大挑战:一是需要反向传播贯穿长序列的内层任务学习步骤导致计算成本高昂;二是在Sim2Real场景中需最小化现实世界$\mathcal{L}^{meta}$评估次数。
Meta-Learning for Social Good. Meta-learning lends itself to challenges that arise in applications of AI for social good such as medical image classification and drug discovery, where data is often scarce. Progress in the medical domain is especially relevant given the global shortage of pathologists [274]. In [5] an LSTM is combined with a graph neural network to predict molecular behaviour (e.g., toxicity) in the one-shot data regime. In [275] MAML is adapted to weakly-supervised breast cancer detection tasks, and the order of tasks are selected according to a curriculum. MAML is also combined with denoising auto encoders to do medical visual question answering [276], while learning to weigh support samples [219] is adapted to pixel wise weighting for skin lesion segmentation tasks that have noisy labels [277].
面向社会公益的元学习
元学习适用于AI社会公益应用中的挑战,如医学图像分类和药物发现等数据稀缺场景。鉴于全球病理学家短缺[274],医疗领域的进展尤为重要。文献[5]将LSTM与图神经网络结合,在单样本数据场景下预测分子行为(如毒性)。文献[275]将MAML应用于弱监督乳腺癌检测任务,并根据课程学习策略选择任务顺序。MAML还与去噪自编码器结合用于医学视觉问答[276],而学习加权支持样本[219]的方法被改进为像素级加权,用于存在噪声标签的皮肤病变分割任务[277]。
Non-Backprop and Biologically Plausible Learners. Most meta-learning work that uses explicit (non feed-forward/ black-box) optimization for the base model is based on gradient descent by back propagation. Meta-learning can define the function class of $\omega$ so as to lead to the discovery of novel learning rules that are unsupervised [16] or biologically plausible [46], [278], [279], making use of ideas less commonly used in contemporary deep learning such as Hebbian updates [278] and neuro modulation [279].
非反向传播与生物合理学习器。大多数基于显式优化(非前馈/黑箱)的元学习方法都采用反向传播梯度下降作为基础模型。元学习可以定义$\omega$的函数类,从而发现无监督[16]或生物合理[46][278][279]的新型学习规则,这些规则利用了当代深度学习中较少使用的概念,如赫布更新[278]和神经调控[279]。
Network Compression. Contemporary CNNs require large amounts of memory that may be prohibitive on embedded devices. Thus network compression in various forms such as quantization and pruning are topical research areas [280]. Meta-learning is beginning to be applied to this objective as well, such as training gradient generator meta-networks that allow quantized networks to be trained [199], and weight generator meta-networks that allow quantized networks to be trained with gradient [281].
网络压缩。当代CNN需要大量内存,这在嵌入式设备上可能难以实现。因此,量化(quantization)和剪枝(pruning)等多种形式的网络压缩成为热门研究领域[280]。元学习也开始应用于这一目标,例如训练梯度生成器元网络(meta-network)来量化网络训练[199],以及通过权重生成器元网络实现带梯度的量化网络训练[281]。
Communications. systems are increasingly impacted by deep learning. For example by learning coding systems that surpass hand designed codes for realistic channels [282]. Few-shot meta-learning can be used to provide rapid adaptation of codes to changing channel characteristics [283].
通信系统正日益受到深度学习的深远影响。例如通过学习编码系统,在现实信道中超越人工设计的编码方案 [282]。少样本元学习可用于快速调整编码方案以适应变化的信道特性 [283]。
Active Learning (AL). Methods wrap supervised learning, and define a policy for selective data annotation – typically in the setting where annotation can be obtained sequentially. The goal of AL is to find the optimal subset of data to annotate so as to maximize performance of downstream supervised learning with the fewest annotations. AL is a well studied problem with numerous hand designed algorithms [284]. Meta-learning can map active learning algorithm design into a learning task by: (i) defining the innerlevel optimization as conventional supervised learning on the annotated dataset so far, (ii) defining $\omega$ to be a query policy that selects the best unlabeled datapoints to annotate, (iii), defining the meta-objective as validation performance after iterative learning and annotation according to the query policy, (iv) performing outer-level optimization to train the optimal annotation query policy [187], [188], [189]. However, if labels are used to train AL algorithms, they need to generalize across tasks to amortize their training cost [189].
主动学习 (Active Learning, AL)。这些方法封装了监督学习,并定义了选择性数据标注的策略——通常适用于可以顺序获取标注的场景。AL的目标是找到最优的数据子集进行标注,从而以最少的标注量最大化下游监督学习的性能。AL是一个经过充分研究的问题,拥有大量手工设计的算法 [284]。元学习可以通过以下方式将主动学习算法设计转化为学习任务:(i) 将内部优化定义为对当前已标注数据集的常规监督学习,(ii) 将 $\omega$ 定义为选择最佳未标注数据点进行标注的查询策略,(iii) 将元目标定义为根据查询策略进行迭代学习和标注后的验证性能,(iv) 执行外部优化以训练最优的标注查询策略 [187][188][189]。然而,如果使用标签来训练AL算法,则需要这些算法能够跨任务泛化,以分摊训练成本 [189]。
Learning with Label Noise. Commonly arises when large datasets are collected by web scraping or crowd-sourcing. While there are many algorithms hand-designed for this situation, recent meta-learning methods have addressed label noise. For example by trans duct iv ely learning sample-wise weighs to down-weight noisy samples [147], or learning an initial condition robust to noisy label training [94].
标签噪声学习。常见于通过网页抓取或众包收集大型数据集时。虽然针对这种情况已有许多手工设计的算法,但最近的元学习方法也开始解决标签噪声问题。例如通过转导学习样本权重来降低噪声样本的权重 [147],或学习对噪声标签训练具有鲁棒性的初始条件 [94]。
Adversarial Attacks and Defenses. Deep Neural Networks can be fooled into mis classifying a data point that should be easily recognizable, by adding a carefully crafted humaninvisible perturbation to the data [285]. Numerous attack and defense methods have been published in recent years, with defense strategies usually consisting in carefully handdesigned architectures or training algorithms. Analogous to the case in domain-shift, one can train the learning algorithm for robustness by defining a meta-loss in terms of performance under adversarial attack [95], [286].
对抗性攻击与防御。深度神经网络可能因数据中添加了精心设计的人类不可察觉的扰动,而对本应轻易识别的数据点产生误分类 [285]。近年来已发表大量攻击与防御方法,防御策略通常涉及精心设计的手动架构或训练算法。与领域偏移情况类似,可通过定义对抗攻击下表现的元损失来训练学习算法的鲁棒性 [95][286]。
Recommendation Systems. Are a mature consumer of machine learning in the commerce space. However, bootstrapping recommendations for new users with little historical interaction data, or new items for recommendation remains a challenge known as the cold-start problem. Metalearning has applied black-box models to item cold-start [287] and gradient-based methods to user cold-start [288].
推荐系统。作为机器学习在商业领域的成熟应用,其核心挑战在于冷启动问题:如何为新用户(缺乏历史交互数据)或新推荐商品生成初始推荐。元学习已通过黑盒模型解决物品冷启动[287],并采用基于梯度的方法应对用户冷启动[288]。
6 CHALLENGES AND OPEN QUESTIONS
6 挑战与开放性问题
Diverse and Multi-Modal Task Distributions The difficulty of fitting a meta-learner to a distribution of tasks $p(\mathcal{T})$ can depend on its width. Many big successes of meta-learning have been within narrow task families, while learning on diverse task distributions can challenge existing methods [109], [221], [241]. This may be partly due to conflicting gradients between tasks [289].
多样化和多模态任务分布
拟合元学习器到任务分布 $p(\mathcal{T})$ 的难度可能取决于其宽度。元学习的许多重大成功案例都局限于狭窄的任务家族,而在多样化任务分布上学习可能会挑战现有方法 [109], [221], [241]。这部分原因可能是任务间存在冲突梯度 [289]。
Many meta-learning frameworks [19] implicitly assume that the distribution over tasks $p(\mathcal{T})$ is uni-modal, and a single learning strategy $\omega$ provides a good solution for them all. However task distributions are often multi-modal; such as medical versus satellite versus everyday images in computer vision, or putting pegs in holes versus opening doors [241] in robotics. Different tasks within the distribution may require different learning strategies, which is hard to achieve with today’s methods. In vanilla multi-task learning, this phenomenon is relatively well studied with, e.g., methods that group tasks into clusters [290] or subspaces [291]. However this is only just beginning to be explored in meta-learning [292].
许多元学习框架[19]隐含假设任务分布$p(\mathcal{T})$是单模态的,且单一学习策略$\omega$就能为所有任务提供良好解决方案。然而任务分布往往呈现多模态特性,例如计算机视觉中的医疗影像、卫星图像与日常照片,或是机器人学中的插桩入孔与开门任务[241]。分布内不同任务可能需要不同的学习策略,这在现有方法中难以实现。经典多任务学习领域对此现象已有较深入研究,例如通过任务聚类[290]或子空间划分[291]等方法。但在元学习领域,相关探索才刚刚起步[292]。
Meta-Generalization. Meta-learning poses a new generalization challenge across tasks analogous to the challenge of gen- eralizing across instances in conventional machine learning. There are two sub-challenges: (i) The first is generalizing from meta-train to novel meta-test tasks drawn from $p(\mathcal{T})$ . This is exacerbated because the number of tasks available for metatraining is typically low (much less than the number of instances available in conventional supervised learning), making it difficult to generalize. One failure mode for generalization in few-shot learning has been well studied under the guise of mem or is ation [201], which occurs when each meta-training task can be solved directly without performing any task-specific adaptation based on the support set. In this case models fail to generalize in meta-testing, and specific regularize rs [201] have been proposed to prevent this kind of metaover fitting. (ii) The second challenge is generalizing to metatest tasks drawn from a different distribution than the training tasks. This is inevitable in many potential practical applications of meta-learning, for example generalizing few-shot visual learning from everyday training images of ImageNet to specialist domains such as medical images [222]. From the perspective of a learner, this is a meta-level generalization of the domain-shift problem, as observed in supervised learning. Addressing these issues through meta-generalizations of regu lari z ation, transfer learning, domain adaptation, and domain generalization are emerging directions [116]. Furthermore, we have yet to understand which kinds of meta-representations tend to generalize better under certain types of domain shifts.
元泛化。元学习提出了跨任务的泛化新挑战,类似于传统机器学习中跨实例泛化的挑战。这一挑战包含两个子问题:(i) 首先是从元训练任务泛化到从$p(\mathcal{T})$采样的新元测试任务。由于元训练可用的任务数量通常较少(远少于传统监督学习中的实例数量),这种泛化尤为困难。少样本学习中的一种泛化失败模式已被深入研究,表现为记忆化现象[201]——当每个元训练任务无需基于支持集进行任务特定适配就能直接解决时,模型在元测试中会泛化失败,为此研究者提出了特定正则化方法[201]来防止这类元过拟合。(ii) 第二个挑战是泛化到与训练任务分布不同的元测试任务。这在元学习的许多实际应用中不可避免,例如将ImageNet日常图像训练的少样本视觉学习泛化到医学图像等专业领域[222]。从学习器视角看,这是监督学习中领域偏移问题的元级表现。通过正则化、迁移学习、领域自适应和领域泛化的元级扩展来解决这些问题,正成为新兴研究方向[116]。此外,我们仍需探究哪些类型的元表征在特定领域偏移下具有更好的泛化能力。
Task Families. Many existing meta-learning frameworks, especially for few-shot learning, require task families for metatraining. While this indeed reflects lifelong human learning, in some applications data for such task families may not be available. Unsupervised meta-learning [251], [252], [253] and single-task meta-learning methods [42], [173], [180], [181], [197], could help to alleviate this requirement; as can improvements in meta-generalization discussed above.
任务族。许多现有的元学习框架,尤其是针对少样本学习的框架,需要任务族来进行元训练。虽然这确实反映了人类的终身学习过程,但在某些应用中,此类任务族的数据可能无法获取。无监督元学习 [251]、[252]、[253] 和单任务元学习方法 [42]、[173]、[180]、[181]、[197] 可能有助于缓解这一需求;上文讨论的元泛化改进也能起到类似作用。
Computation Cost & Many-Shot. A naive implementation of bilevel optimization as shown in Section 2.1 is expensive in both time (because each outer step requires several inner steps) and memory (because reverse-mode differentiation requires storing the intermediate inner states). For this reason, much of meta-learning has focused on the few-shot regime [19], where the number of inner gradient steps (aka the horizon) is small. However, there is an increasing focus on methods which seek to extend optimization-based metalearning to the many-shot regime, where long horizons are inevitable. Popular solutions include implicit differentiation of $\omega$ [154], [163], [293], forward-mode differentiation of $\omega$ [67], [69], [294], gradient preconditioning [105], evolutionary strategies [295], solving for a greedy version of $\omega$ online by alternating inner and outer steps [21], [42], [198], truncation [296], shortcuts [297] or inversion [190] of the inner optimization. Long horizon meta-learning can also be achieved by learning an initialization that minimizes the gradient descent trajectory length over task manifolds [298]. Finally, another family of approaches accelerate meta-training via closed-form solvers in the inner loop [164], [165].
计算成本与多样本。如第2.1节所示,双层优化的简单实现在时间(因为每个外部步骤需要多个内部步骤)和内存(因为反向模式微分需要存储中间内部状态)方面都很昂贵。因此,元学习大多集中在少样本领域[19],其中内部梯度步骤(即范围)的数量较少。然而,越来越多的人关注将基于优化的元学习扩展到多样本领域的方法,其中长范围是不可避免的。流行的解决方案包括$\omega$的隐式微分[154]、[163]、[293],$\omega$的前向模式微分[67]、[69]、[294],梯度预处理[105],进化策略[295],通过交替内部和外部步骤在线求解$\omega$的贪婪版本[21]、[42]、[198],内部优化的截断[296]、捷径[297]或反转[190]。长范围元学习也可以通过最小化任务流形上的梯度下降轨迹长度的初始化来实现[298]。最后,另一类方法通过内环中的闭式求解器加速元训练[164]、[165]。
Each of these strategies provides different trade-offs on the following axes: the accuracy at meta-test time, the compute and memory cost as the size of $\omega$ increases, and the computate and memory cost as the horizon gets longer. Implicit gradients scale to high-dimensional $\omega_{,}$ ; but only provide approximate gradients for it, and require the inner task loss to be a function of $\omega$ . Forward-mode differentiation is exact and doesn’t have such constraints, but scales poorly with the dimension of $\omega$ . Online methods are cheap in both memory and compute but suffer from a short-horizon bias [299] and thus have lower meta-test accuracy. The same could be said of truncation methods which are cheap but suffer from truncation bias [300]. Gradient degradation is also a challenge in the many-shot regime, and solutions include warp layers [105] or gradient averaging [69].
每种策略在以下维度上提供了不同的权衡:元测试时的准确性、随着$\omega$规模增加的计算和内存成本,以及随着时间跨度延长而增加的计算和内存成本。隐式梯度适用于高维$\omega$,但仅提供近似梯度,且要求内部任务损失必须是$\omega$的函数。前向模式微分精确且不受此类限制,但随着$\omega$维度的增加而扩展性较差。在线方法在内存和计算上都很廉价,但存在短视偏差[299],因此元测试准确性较低。截断方法同样廉价但存在截断偏差[300]。在多样本场景中,梯度退化也是一个挑战,解决方案包括warp层[105]或梯度平均[69]。
In terms of the cost of solving new tasks at the meta-test stage, FFMs have a significant advantage over optimizationbased meta-learners, which makes them appealing for applications involving deployment of learning algorithms on mobile devices such as smartphones [6], for example to achieve person alisa tion. This is especially so because the embedded device versions of contemporary deep learning software frameworks typically lack support for back propagation-based training, which FFMs do not require.
在元测试阶段解决新任务的成本方面,FFM相比基于优化的元学习方法具有显著优势,这使得它们特别适合应用于智能手机等移动设备上的学习算法部署 [6] ,例如实现个性化定制。这一点尤为重要,因为当代深度学习软件框架的嵌入式设备版本通常不支持基于反向传播的训练,而FFM并不需要这种训练方式。
7 CONCLUSION
7 结论
The field of meta-learning has seen a rapid growth in interest. This has come with some level of confusion, with regards to how it relates to neighbouring fields, what it can be applied to, and how it can be benchmarked. In this survey we have sought to clarify these issues by thoroughly surveying the area both from a methodological point of view – which we broke down into a taxonomy of metarepresentation, meta-optimizer and meta-objective; and from an application point of view. We hope that this survey will help newcomers and practitioners to orient themselves to develop and exploit in this growing field, as well as highlight opportunities for future research.
元学习领域近年来受到广泛关注。这种快速增长也带来了一定程度的困惑,包括该领域与邻近学科的关系、适用场景以及评估方法等问题。在本综述中,我们通过方法学视角(将其分解为元表征、元优化器和元目标的三元分类体系)和应用视角的系统梳理,力求澄清这些关键问题。希望本文能帮助新进入者和从业者在这个蓬勃发展的领域找准方向开展研发工作,同时指明未来研究的潜在机会。
ACKNOWLEDGMENTS
致谢
The work of Timothy Hospedales was supported in part by the Engineering and Physical Sciences Research Council of the U.K. (EPSRC) under Grant EP/S000631/1, in part by the U.K. MOD University Defence Research Collaboration (UDRC) in Signal Processing, and in part by the EPSRC under Grant EP/R026173/1.
Timothy Hospedales的工作得到了以下项目的部分支持:英国工程与物理科学研究理事会(EPSRC)资助项目EP/S000631/1、英国国防部信号处理大学国防研究合作计划(UDRC),以及EPSRC资助项目EP/R026173/1。
REFERENCES
参考文献
Timothy Hospedales is currently a professor at the University of Edinburgh, and a principal researcher with Samsung AI Research. His research interests include data efficient and robust learning-to-learn with diverse applications in vision, language, reinforcement learning, and beyond.
Timothy Hospedales 现任爱丁堡大学教授及三星人工智能研究院(Samsung AI Research)首席研究员。他的研究兴趣包括数据高效与鲁棒的学习方法(learning-to-learn),在视觉、语言、强化学习等领域有广泛应用。




Antreas Antoniou is currently working toward the PhD degree, supervised by Amos Storkey, from the University of Edinburgh. His research contributions in meta-learning and few-shot learning are commonly seen as key benchmarks in the field. His research interest includes metalearning better priors such as losses, initializations, and neural network layers, to improve fewshot and life-long learning.
Antreas Antoniou目前正在爱丁堡大学攻读博士学位,导师为Amos Storkey。他在元学习 (meta-learning) 和少样本学习领域的研究成果被广泛视为该领域的关键基准。他的研究兴趣包括改进损失函数、初始化方法和神经网络层等先验知识的元学习方法,以提升少样本学习和终身学习性能。
Paul Micaelli is currently working toward the PhD degree, supervised by Amos Storkey and Timothy Hospedales, from the University of Edinburgh. His research interests include zero-shot knowledge distillation and on meta-learning over long horizons for many-shot problems.
Paul Micaelli目前正在爱丁堡大学攻读博士学位,导师为Amos Storkey和Timothy Hospedales。他的研究方向包括零样本知识蒸馏 (zero-shot knowledge distillation) 以及针对多样本问题的长周期元学习 (meta-learning over long horizons)。
Amos Storkey is currently a professor of machine learning and AI at the School of Informatics, University of Edinburgh. He leads a research team focused on deep neural networks, Bayesian and probabilistic models, efficient inference and metalearning.
Amos Storkey 现任爱丁堡大学信息学院机器学习与人工智能教授。他领导的研究团队专注于深度神经网络、贝叶斯与概率模型、高效推理和元学习。
$\vartriangleright$ For more information on this or any other computing topic, please visit our Digital Library at www.computer.org/csdl.
$\vartriangleright$ 如需了解更多关于此话题或其他计算领域的信息,请访问我们的数字图书馆:www.computer.org/csdl。