G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment
G-EVAL: 基于GPT-4并更好对齐人类的自然语言生成评估方法
Yang Liu Dan Iter Yichong Xu Shuohang Wang Ruochen Xu Chenguang Zhu
杨柳 丹伊特 易冲徐 硕航王 若辰徐 晨光朱
Microsoft Cognitive Services Research yaliu10, iterdan, yicxu, shuowa, ruox, chezhu @microsoft.com
微软认知服务研究 yaliu10, iterdan, yicxu, shuowa, ruox, chezhu @microsoft.com
Abstract
摘要
The quality of texts generated by natural language generation (NLG) systems is hard to measure automatically. Conventional referencebased metrics, such as BLEU and ROUGE, have been shown to have relatively low correlation with human judgments, especially for tasks that require creativity and diversity. Recent studies suggest using large language models (LLMs) as reference-free metrics for NLG evaluation, which have the benefit of being applicable to new tasks that lack human references. However, these LLM-based evaluators still have lower human correspondence than medium-size neural evaluators. In this work, we present G-EVAL, a framework of using large language models with chain-of-thoughts (CoT) and a form-filling paradigm, to assess the quality of NLG outputs. We experiment with two generation tasks, text sum mari z ation and dialogue generation. We show that G-EVAL with GPT-4 as the backbone model achieves a Spearman correlation of 0.514 with human on sum mari z ation task, outperforming all previous methods by a large margin. We also propose analysis on the behavior of LLM-based evaluators, and highlight the potential concern of LLM-based evaluators having a bias towards the LLM-generated texts. 1
自然语言生成(NLG)系统生成的文本质量难以自动衡量。传统的基于参考指标的评估方法(如BLEU和ROUGE)已被证明与人类判断相关性较低,特别是在需要创造力和多样性的任务中。近期研究表明,可将大语言模型(LLMs)作为无参考指标用于NLG评估,其优势在于适用于缺乏人工参考的新任务。然而,这些基于LLM的评估器与人类判断的吻合度仍低于中等规模的神经评估器。本研究提出G-EVAL框架,通过结合思维链(CoT)和表单填写范式,利用大语言模型评估NLG输出质量。我们在文本摘要和对话生成两个任务上进行实验,结果表明:以GPT-4为核心模型的G-EVAL在摘要任务中与人类评估的Spearman相关系数达到0.514,显著优于所有现有方法。我们还分析了基于LLM的评估器行为特征,并指出这类评估器可能对LLM生成文本存在偏好的潜在问题。[1]
1 Introduction
1 引言
Evaluating the quality of natural language generation systems is a challenging problem even when large language models can generate high-quality and diverse texts that are often indistinguishable from human-written texts (Ouyang et al., 2022). Traditional automatic metrics, such as BLEU (Papineni et al., 2002), ROUGE (Lin, 2004), and ME- TEOR (Banerjee and Lavie, 2005), are widely used for NLG evaluation, but they have been shown to have relatively low correlation with human judgments, especially for open-ended generation tasks. Moreover, these metrics require associated reference output, which is costly to collect for new tasks.
评估自然语言生成系统的质量是一个具有挑战性的问题,即使大语言模型能够生成与人类撰写文本难以区分的高质量多样化文本 (Ouyang et al., 2022)。传统自动评估指标如 BLEU (Papineni et al., 2002)、ROUGE (Lin, 2004) 和 METEOR (Banerjee and Lavie, 2005) 被广泛用于自然语言生成评估,但已证明这些指标与人类判断的相关性较低,特别是在开放式生成任务中。此外,这些指标需要关联的参考输出,而针对新任务收集这些参考数据的成本很高。
Recent studies propose directly using LLMs as reference-free NLG evaluators (Fu et al., 2023; Wang et al., 2023). The idea is to use the LLMs to score the candidate output based on its generation probability without any reference target, under the assumption that the LLMs have learned to assign higher probabilities to high-quality and fluent texts. However, the validity and reliability of using LLMs as NLG evaluators have not been systematically investigated. In addition, meta-evaluations show that these LLM-based evaluators still have lower human correspondence than medium-size neural evaluators (Zhong et al., 2022). Thus, there is a need for a more effective and reliable framework for using LLMs for NLG evaluation.
近期研究提出直接使用大语言模型作为无参考的自然语言生成评估器 (Fu et al., 2023; Wang et al., 2023)。其核心思路是利用大语言模型基于生成概率对候选输出进行评分,无需任何参考目标,前提假设是大语言模型已学会为高质量且流畅的文本赋予更高概率。然而,将大语言模型作为自然语言生成评估器的有效性和可靠性尚未得到系统验证。此外,元评估研究表明,这些基于大语言模型的评估器在人类一致性方面仍逊色于中等规模的神经评估器 (Zhong et al., 2022)。因此,亟需构建更有效可靠的大语言模型自然语言生成评估框架。
In this paper, we propose G-EVAL, a framework of using LLMs with chain-of-thoughts (CoT) (Wei et al., 2022) to evaluate the quality of generated texts in a form-filling paradigm. By only feeding the Task Introduction and the Evaluation Criteria as a prompt, we ask LLMs to generate a CoT of detailed Evaluation Steps. Then we use the prompt along with the generated CoT to evaluate the NLG outputs. The evaluator output is formatted as a form. Moreover, the probabilities of the output rating tokens can be used to refine the final metric. We conduct extensive experiments on three meta-evaluation benchmarks of two NLG tasks: text sum mari z ation and dialogue generation. The results show that G-EVAL can outperform existing NLG evaluators by a large margin in terms of correlation with human evaluations. Finally, we conduct analysis on the behavior of LLM-based evaluators, and highlight the potential issue of LLM-based evaluator having a bias towards the LLM-generated texts.
本文提出G-EVAL框架,通过结合大语言模型 (LLM) 和思维链 (CoT) (Wei et al., 2022) 技术,以表单填写范式评估生成文本质量。我们仅需输入任务介绍和评估标准作为提示,即可引导大语言模型生成包含详细评估步骤的思维链。随后将原始提示与生成的思维链结合,用于评估自然语言生成 (NLG) 输出结果。评估器输出采用表单化格式,且输出评分token的概率可用于优化最终指标。我们在文本摘要和对话生成两个NLG任务的三个元评估基准上开展大量实验,结果表明G-EVAL在人类评估相关性方面显著优于现有NLG评估方法。最后,我们分析了基于大语言模型的评估器行为,并指出其可能对LLM生成文本存在偏好的潜在问题。

Figure 1: The overall framework of G-EVAL. We first input Task Introduction and Evaluation Criteria to the LLM, and ask it to generate a CoT of detailed Evaluation Steps. Then we use the prompt along with the generated CoT to evaluate the NLG outputs in a form-filling paradigm. Finally, we use the probability-weighted summation of the output scores as the final score.
图 1: G-EVAL的整体框架。我们首先将任务介绍和评估标准输入大语言模型,要求其生成包含详细评估步骤的思维链(CoT)。随后,我们使用包含生成CoT的提示词,以填表范式评估自然语言生成(NLG)输出。最终,我们采用输出分数的概率加权求和作为最终得分。
To summarize, our main contributions in this paper are:
综上所述,本文的主要贡献包括:
2 Method
2 方法
G-EVAL is a prompt-based evaluator with three main components: 1) a prompt that contains the definition of the evaluation task and the desired evaluation criteria, 2) a chain-of-thoughts (CoT) that is a set of intermediate instructions generated by the LLM describing the detailed evaluation steps, and 3) a scoring function that calls LLM and calculates the score based on the probabilities of the return tokens.
G-EVAL是一种基于提示(prompt)的评估工具,包含三个主要组件:1) 包含评估任务定义和期望评估标准的提示;2) 思维链(chain-of-thoughts, CoT),即由大语言模型生成的一组描述详细评估步骤的中间指令;3) 评分函数,通过调用大语言模型并根据返回token的概率计算得分。
Prompt for NLG Evaluation The prompt is a natural language instruction that defines the evaluation task and the desired evaluation criteria. For example, for text sum mari z ation, the prompt can be:
自然语言生成评估提示
提示是一种自然语言指令,用于定义评估任务和期望的评估标准。例如,对于文本摘要任务,提示可以是:
You will be given one summary written for a news article. Your task is to rate the summary on one metric.
你将获得一篇新闻文章的摘要。你的任务是根据一个指标对该摘要进行评分。
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.
请确保仔细阅读并理解这些说明。请在审阅时保持此文档打开,并根据需要参考。
The prompt should also contain customized evaluation criteria for different NLG tasks and, such as coherence, conciseness, or grammar. For example, for evaluating coherence in text sum mari z ation, we add the following content to the prompt:
提示词还应包含针对不同自然语言生成(NLG)任务定制的评估标准,例如连贯性、简洁性或语法。例如,为评估文本摘要的连贯性,我们在提示词中添加以下内容:
Evaluation Criteria:
评估标准:
Coherence (1-5) - the collective quality of all sentences. We align this dimension with the DUC quality question of structure and coherence whereby ”the summary should be well-structured and well-organized. The summary should not just be a heap of related information, but should build from sentence to sentence to a coherent body of information about a topic.”
连贯性 (1-5) - 所有句子的整体质量。我们将此维度与DUC质量评估中的结构与连贯性问题对齐,即"摘要应具备良好的结构和组织性。摘要不应只是相关信息的堆砌,而应通过句子间的递进关系,构建出关于主题的连贯信息体。"
Auto Chain-of-Thoughts for NLG Evaluation The chain-of-thoughts (CoT) is a sequence of intermediate representations that are generated by the LLM during the text generation process. For evaluation tasks, some criteria need a more detailed evaluation instruction beyond the simple definition, and it is time-consuming to manually design such evaluation steps for each task. We find that LLM can generate such evaluation steps by itself. The CoT can provide more context and guidance for the LLM to evaluate the generated text, and can also help to explain the evaluation process and results. For example, for evaluating coherence in text summarization, we add a line of “Evaluation Steps:” to the prompt and let LLM to generate the following CoT automatically:
自动思维链(Chain-of-Thoughts)用于自然语言生成评估
思维链(CoT)是大语言模型在文本生成过程中产生的一系列中间表征。对于评估任务而言,某些标准需要比简单定义更详细的评估指导,而针对每个任务手动设计这类评估步骤非常耗时。我们发现大语言模型可以自主生成此类评估步骤。思维链能为大语言模型评估生成文本提供更多上下文和指导,同时有助于解释评估过程与结果。例如在评估文本摘要连贯性时,我们在提示词中添加"评估步骤:"行,让大语言模型自动生成如下思维链:
- Read the news article carefully and identify the main topic and key points. 2. Read the summary and compare it to the news article. Check if the summary covers the main topic and key points of the news article, and if it presents them in a clear and logical order. 3. Assign a score for coherence on a scale of 1 to 5, where 1 is the lowest and 5 is the highest based on the Evaluation Criteria.
- 仔细阅读新闻文章,确定主要话题和关键点。
- 阅读摘要并与新闻文章对比。检查摘要是否涵盖新闻文章的主要话题和关键点,以及是否以清晰、逻辑的顺序呈现。
- 根据评估标准,在1到5的范围内为连贯性打分,其中1为最低,5为最高。
Scoring Function The scoring function calls the LLM with the designed prompt, auto CoT, the input context and the target text that needs to be evaluated. Unlike GPTScore (Fu et al., 2023) which uses the conditional probability of generating the target text as an evaluation metric, G-EVAL directly performs the evaluation task with a form-filling paradigm. For example, for evaluating coherence in text sum mari z ation, we concatenate the prompt, the CoT, the news article, and the summary, and then call the LLM to output a score from 1 to 5 for each evaluation aspect, based on the defined criteria.
评分函数
评分函数通过设计的提示(prompt)、自动思维链(auto CoT)、输入上下文以及需要评估的目标文本来调用大语言模型(LLM)。与GPTScore (Fu et al., 2023)使用生成目标文本的条件概率作为评估指标不同,G-EVAL直接采用表单填充范式执行评估任务。例如,在评估文本摘要的连贯性时,我们将提示、思维链(CoT)、新闻文章和摘要拼接起来,然后调用大语言模型根据定义的标准为每个评估维度输出1到5的分数。
However, we notice this direct scoring function has two issues:
然而,我们注意到这种直接评分函数存在两个问题:
To address these issues, we propose using the probabilities of output tokens from LLMs to normalize the scores and take their weighted summation as the final results. Formally, given a set of scores (like from 1 to 5) predefined in the prompt $S={s_ {1},s_ {2},...,s_ {n}}$ , the probability of each score $p(s_ {i})$ is calculated by the LLM, and the final score is:
为了解决这些问题,我们提出利用大语言模型(LLM)输出token的概率对分数进行归一化,并采用加权求和作为最终结果。具体而言,给定提示中预定义的一组分数(如1到5分) $S={s_ {1},s_ {2},...,s_ {n}}$ ,通过大语言模型计算每个分数 $p(s_ {i})$ 的概率,最终得分为:
$$
s c o r e=\sum_ {i=1}^{n}p(s_ {i})\times s_ {i}
$$
$$
s c o r e=\sum_ {i=1}^{n}p(s_ {i})\times s_ {i}
$$
This method obtains more fine-grained, continuous scores that better reflect the quality and diversity of the generated texts.
该方法获得更细粒度、连续的分数,能更好地反映生成文本的质量和多样性。
3 Experiments
3 实验
Following Zhong et al. (2022), we meta-evaluate our evaluator on three benchmarks, SummEval, Topical-Chat and QAGS, of two NLG tasks, summarization and dialogue response generation.
根据Zhong等人(2022)的研究,我们在SummEval、Topical-Chat和QAGS三个基准上对评估器进行了元评估,涵盖摘要和对话响应生成两个自然语言生成任务。
3.1 Implementation Details
3.1 实现细节
We use OpenAI’s GPT family as our LLMs, including GPT-3.5 (text-davinci-003) and GPT-4. For GPT-3.5, we set decoding temperature to 0 to increase the model’s determinism. For GPT-4, as it does not support the output of token probabilities, we set ‘ $n=20$ $),t e m p e r a t u r e=1,t o p_ {-}p=1^{\prime}$ to sample 20 times to estimate the token probabilities. We use G-EVAL-4 to indicate G-EVAL with GPT-4 as the backbone model, and G-EVAL-3.5 to indicate G-EVAL with GPT-3.5 as the backbone model. Example prompts for each task are provided in the Appendix.
我们采用OpenAI的GPT系列作为大语言模型,包括GPT-3.5(text-davinci-003)和GPT-4。对于GPT-3.5,我们将解码温度设置为0以增强模型确定性。GPT-4由于不支持输出token概率,我们设置'$n=20$), temperature=1, top_ p=1'进行20次采样以估算token概率。使用G-EVAL-4表示以GPT-4为骨干模型的G-EVAL,G-EVAL-3.5表示以GPT-3.5为骨干模型的G-EVAL。各任务示例提示详见附录。
| Metrics | Coherence | Consistency | Fluency | Relevance | AVG | |||||
| p | T | p | T | p T | p T | p | T | |||
| ROUGE-1 | 0.167 | 0.126 | 0.160 | 0.130 | 0.115 | 0.094 | 0.326 | 0.252 | 0.192 | 0.150 |
| ROUGE-2 | 0.184 | 0.139 | 0.187 | 0.155 | 0.159 | 0.128 | 0.290 | 0.219 | 0.205 | 0.161 |
| ROUGE-L | 0.128 | 0.099 | 0.115 | 0.092 | 0.105 | 0.084 | 0.311 | 0.237 | 0.165 | 0.128 |
| BERTScore | 0.284 | 0.211 | 0.110 | 0.090 | 0.193 | 0.158 | 0.312 | 0.243 | 0.225 | 0.175 |
| MOVERSscore | 0.159 | 0.118 | 0.157 | 0.127 | 0.129 | 0.105 | 0.318 | 0.244 | 0.191 | 0.148 |
| BARTScore | 0.448 | 0.342 | 0.382 | 0.315 | 0.356 | 0.292 | 0.356 | 0.273 | 0.385 | 0.305 |
| UniEval | 0.575 | 0.442 | 0.446 | 0.371 | 0.449 | 0.371 | 0.426 | 0.325 | 0.474 | 0.377 |
| GPTScore | 0.434 | 一 | 0.449 | 一 | 0.403 | 一 | 0.381 | 一 | 0.417 | 一 |
| G-EVAL-3.5 | 0.440 | 0.335 | 0.386 | 0.318 | 0.424 | 0.347 | 0.385 | 0.293 | 0.401 | 0.320 |
| - Probs | 0.359 | 0.313 | 0.361 | 0.344 | 0.339 | 0.323 | 0.327 | 0.288 | 0.346 | 0.317 |
| G-EVAL-4 | 0.582 | 0.457 | 0.507 | 0.425 | 0.455 | 0.378 | 0.547 | 0.433 | 0.514 | 0.418 |
| - Probs | 0.560 | 0.472 | 0.501 | 0.459 | 0.438 | 0.408 | 0.511 | 0.444 | 0.502 | 0.446 |
| - CoT | 0.564 | 0.454 | 0.493 | 0.413 | 0.403 | 0.334 | 0.538 | 0.427 | 0.500 | 0.407 |
Table 1: Summary-level Spearman $(\rho)$ and Kendall-Tau $(\tau)$ correlations of different metrics on SummEval benchmark. G-EVAL without probabilities (italicized) should not be considered as a fair comparison to other metrics on $\tau$ , as it leads to many ties in the scores. This results in a higher Kendall-Tau correlation, but it does not fairly reflect the true evaluation ability. More details are in Section 4.
表 1: 不同指标在SummEval基准上的摘要级Spearman $(\rho)$ 和Kendall-Tau $(\tau)$ 相关性汇总。未使用概率的G-EVAL(斜体)不应被视为在 $\tau$ 上与其他指标的公平比较,因为它会导致大量分数并列。这会带来更高的Kendall-Tau相关性,但并不能公平反映真实的评估能力。更多细节见第4节。
| 指标 | 连贯性 | 一致性 | 流畅性 | 相关性 | 平均 |
|---|---|---|---|---|---|
| p | T | p | T | p | |
| ROUGE-1 | 0.167 | 0.126 | 0.160 | 0.130 | 0.115 |
| ROUGE-2 | 0.184 | 0.139 | 0.187 | 0.155 | 0.159 |
| ROUGE-L | 0.128 | 0.099 | 0.115 | 0.092 | 0.105 |
| BERTScore | 0.284 | 0.211 | 0.110 | 0.090 | 0.193 |
| MOVERSscore | 0.159 | 0.118 | 0.157 | 0.127 | 0.129 |
| BARTScore | 0.448 | 0.342 | 0.382 | 0.315 | 0.356 |
| UniEval | 0.575 | 0.442 | 0.446 | 0.371 | 0.449 |
| GPTScore | 0.434 | - | 0.449 | - | 0.403 |
| G-EVAL-3.5 | 0.440 | 0.335 | 0.386 | 0.318 | 0.424 |
| - Probs | 0.359 | 0.313 | 0.361 | 0.344 | 0.339 |
| G-EVAL-4 | 0.582 | 0.457 | 0.507 | 0.425 | 0.455 |
| - Probs | 0.560 | 0.472 | 0.501 | 0.459 | 0.438 |
| - CoT | 0.564 | 0.454 | 0.493 | 0.413 | 0.403 |
3.2 Benchmarks
3.2 基准测试
We adopt three meta-evaluation benchmarks to measure the correlation between G-EVAL and human judgments.
我们采用三个元评估基准来衡量G-EVAL与人类判断之间的相关性。
SummEval (Fabbri et al., 2021) is a benchmark that compares different evaluation methods for sum mari z ation. It gives human ratings for four aspects of each summary: fluency, coherence, consistency and relevance. It is built on the CNN/DailyMail dataset (Hermann et al., 2015)
SummEval (Fabbri等人,2021) 是一个用于比较不同摘要评估方法的基准测试。它为每个摘要的四个方面提供人工评分:流畅性、连贯性、一致性和相关性。该基准基于CNN/DailyMail数据集 (Hermann等人,2015)构建。
Topical-Chat (Mehri and Eskenazi, 2020) is a testbed for meta-evaluating different evaluators on dialogue response generation systems that use knowledge. We follow (Zhong et al., 2022) to use its human ratings on four aspects: naturalness, coherence, engaging ness and grounded ness.
Topical-Chat (Mehri and Eskenazi, 2020) 是一个用于元评估不同评估者在基于知识的对话响应生成系统上表现的测试平台。我们遵循 (Zhong et al., 2022) 的方法,采用其人类评分涉及的四个维度:自然度、连贯性、吸引力和知识关联性。
QAGS (Wang et al., 2020) is a benchmark for evaluating hallucinations in the sum mari z ation task. It aims to measure the consistency dimension of summaries on two different sum mari z ation datasets.
QAGS (Wang et al., 2020) 是一个用于评估摘要任务中幻觉现象的基准测试。它旨在衡量两个不同摘要数据集上摘要内容的一致性维度。
3.3 Baselines
3.3 基线方法
We evaluate G-EVAL against various evaluators that achieved state-of-the-art performance.
我们针对当前性能最优的各种评估器对G-EVAL进行了评估。
BERTScore (Zhang et al., 2019) measures the similarity between two texts based on the contextualized embedding from BERT (Devlin et al., 2019).
BERTScore (Zhang et al., 2019) 通过BERT (Devlin et al., 2019) 的上下文嵌入来衡量两段文本的相似度。
MoverScore (Zhao et al., 2019) improves BERTScore by adding soft alignments and new aggregation methods to obtain a more robust similarity measure.
MoverScore (Zhao et al., 2019) 通过引入软对齐和新聚合方法改进了 BERTScore,从而获得更稳健的相似性度量。
BARTScore (Yuan et al., 2021) is a unified evaluator which evaluate with the average likelihood of the pretrained encoder-decoder model, BART (Lewis et al., 2020). It can predict different scores depending on the formats of source and target.
BARTScore (Yuan等人, 2021) 是一个统一的评估器,通过预训练的编码器-解码器模型 BART (Lewis等人, 2020) 的平均似然进行评估。根据源文本和目标文本的不同格式,它可以预测不同的分数。
FactCC and QAGS (Kryscinski et al., 2020; Wang et al., 2020) are two evaluators that measure the factual consistency of generated summaries. FactCC is a BERT-based classifier that predicts whether a summary is consistent with the source document. QAGS is a question-answering based evaluator that generates questions from the summary and checks if the answers can be found in the source document.
FactCC和QAGS (Kryscinski等人,2020;Wang等人,2020) 是两种用于评估生成摘要事实一致性的工具。FactCC是一种基于BERT的分类器,用于预测摘要是否与源文档一致。QAGS是一种基于问答的评估器,它从摘要中生成问题并检查答案是否能在源文档中找到。
USR (Mehri and Eskenazi, 2020) is evaluator that assess dialogue response generation from different perspectives. It has several versions that assign different scores to each target response.
USR (Mehri和Eskenazi, 2020) 是一个从不同角度评估对话响应生成的评估器。它有多个版本,每个版本为目标响应分配不同的分数。
UniEval (Zhong et al., 2022) is a unified evaluator that can evaluate different aspects of text generation as QA tasks. It uses a pretrained T5 model (Raffel et al., 2020) to encode the evaluation task, source and target texts as questions and answers, and then computes the QA score as the evaluation score. It can also handle different evaluation tasks by changing the question format.
UniEval (Zhong et al., 2022) 是一个统一的评估器,能够以问答任务形式评估文本生成的不同方面。它使用预训练的T5模型 (Raffel et al., 2020) 将评估任务、源文本和目标文本编码为问题和答案,随后通过计算问答得分作为评估分数。通过改变问题格式,该评估器还能处理不同的评估任务。
GPTScore (Fu et al., 2023) is a new framework that evaluates texts with generative pre-training models like GPT-3. It assumes that a generative pre-training model will assign a higher probability of high-quality generated text following a given instruction and context. Unlike G-EVAL, GPTScore formulates the evaluation task as a conditional generation problem instead of a form-filling problem.
GPTScore (Fu et al., 2023) 是一种利用生成式预训练模型(如GPT-3)评估文本的新框架。该框架假设生成式预训练模型会对遵循给定指令和上下文的高质量生成文本赋予更高概率。与G-EVAL不同,GPTScore将评估任务构建为条件生成问题而非表格填写问题。
3.4 Results for Sum mari z ation
3.4 总结性结果
We adopt the same approach as Zhong et al. (2022) to evaluate different sum mari z ation metrics using summary-level Spearman and Kendall-Tau correlation. The first part of Table 1 shows the results of metrics that compare the semantic similarity between the model output and the reference text. These metrics perform poorly on most dimensions. The second part shows the results of metrics that use neural networks to learn from human ratings of summary quality. These metrics have much higher correlations than the similarity-based metrics, suggesting that they are more reliable for summarization evaluation.
我们采用与Zhong等人 (2022) 相同的方法,使用摘要级别的Spearman和Kendall-Tau相关性来评估不同的摘要指标。表1的第一部分展示了比较模型输出与参考文本之间语义相似度的指标结果,这些指标在大多数维度上表现不佳。第二部分展示了使用神经网络从人工摘要质量评分中学习的指标结果,这些指标比基于相似度的指标具有更高的相关性,表明它们对于摘要评估更为可靠。
In the last part of Table 1 which corresponds to GPT-based evaluators, GPTScore also uses GPTs for evaluating sum mari z ation texts, but relies on GPT’s conditional probabilities of the given target. G-EVAL substantially surpasses all previous state-of-the-art evaluators on the SummEval benchmark. G-EVAL-4 achieved much higher human correspondence compared with G-EVAL-3.5 on both Spearman and Kendall-Tau correlation, which indicates that the larger model size of GPT-4 is beneficial for sum mari z ation evaluation. G-EVAL also outperforms GPTScore on several dimension, demonstrating the effectiveness of the simple formfilling paradigm.
表1的最后部分是关于基于GPT的评估器,GPTScore同样使用GPT来评估摘要文本,但依赖于GPT对给定目标的条件概率。G-EVAL在SummEval基准测试中显著超越了所有之前的先进评估器。G-EVAL-4在Spearman和Kendall-Tau相关性上相比G-EVAL-3.5获得了更高的人类一致性,这表明GPT-4更大的模型规模有利于摘要评估。G-EVAL在多个维度上也优于GPTScore,证明了简单填表范式的有效性。
3.5 Results for Dialogue Generation
3.5 对话生成结果
We use the Topical-chat benchmark from Mehri and Eskenazi (2020) to measure how well different evaluators agree with human ratings on the quality of dialogue responses. We calculate the Pearson and Spearman correlation for each turn of the dialogue. Table 2 shows that similaritybased metrics have good agreement with humans on how engaging and grounded the responses are, but not on the other aspects. With respect to the learning-based evaluators, before G-EVAL, UniEval predicts scores that are most consistent with human judgments across all aspects.
我们采用Mehri和Eskenazi (2020)提出的Topical-chat基准,来衡量不同评估器与人类在对话响应质量评分上的一致性程度。通过计算对话每一轮的皮尔逊(Pearson)和斯皮尔曼(Spearman)相关系数。表2显示,基于相似度的指标在响应吸引力和事实依据性方面与人类评价高度一致,但在其他维度表现欠佳。在学习型评估器中,在G-EVAL出现之前,UniEval在所有维度上预测的分数与人类判断最为一致。
As shown in the last part, G-EVAL also substantially surpasses all previous state-of-the-art evaluator on the Topical-Chat benchmark. Notably, the G-EVAL-3.5 can achieve similar results with G-EVAL-4. This indicates that this benchmark is relatively easy for the G-EVAL model.
如最后部分所示,G-EVAL在Topical-Chat基准测试中也显著超越了之前所有的最先进评估器。值得注意的是,G-EVAL-3.5能够取得与G-EVAL-4相似的结果。这表明该基准测试对G-EVAL模型来说相对容易。
3.6 Results on Hallucinations
3.6 幻觉相关实验结果
Advanced NLG models often produce text that does not match the context input (Cao et al., 2018), and recent studies find even powerful LLMs also suffer from the problem of hallucination. This motivates recent research to design evaluators for measuring the consistency aspect in summarization (Kryscinski et al., 2020; Wang et al., 2020; Cao et al., 2020; Durmus et al., 2020). We test the QAGS meta-evaluation benchmark, which includes two different sum mari z ation datasets: CNN/DailyMail and XSum (Narayan et al., 2018) Table 3 shows that BARTScore performs well on the more extractive subset (QAGS-CNN), but has low correlation on the more abstract ive subset (QAGS-Xsum). UniEval has good correlation on both subsets of the data.
先进的自然语言生成(NLG)模型经常产生与上下文输入不匹配的文本(Cao et al., 2018),最新研究发现即使强大的大语言模型也存在幻觉问题。这促使近期研究开始设计评估指标来衡量摘要任务中的一致性(Kryscinski et al., 2020; Wang et al., 2020; Cao et al., 2020; Durmus et al., 2020)。我们在QAGS元评估基准上进行了测试,该基准包含两个不同的摘要数据集:CNN/DailyMail和XSum(Narayan et al., 2018)。表3显示BARTScore在更具抽取性的子集(QAGS-CNN)上表现良好,但在更抽象的摘要子集(QAGS-Xsum)上相关性较低。UniEval在两个数据子集上都表现出良好的相关性。
On average, G-EVAL-4 outperforms all state-ofthe-art evaluators on QAGS, with a large margin on QAGS-Xsum. G-EVAL-3.5, on the other hand, failed to perform well on this benchmark, which indicates that the consistency aspect is sensitive to the LLM’s capacity. This result is consistent with Table 1.
平均而言,G-EVAL-4在QAGS上优于所有最先进的评估器,在QAGS-Xsum上优势显著。而G-EVAL-3.5在该基准测试中表现不佳,表明一致性方面对大语言模型的能力较为敏感。该结果与表1一致。
4 Analysis
4 分析
Will G-EVAL prefer LLM-based outputs? One concern about using LLM as an evaluator is that it may prefer the outputs generated by the LLM itself, rather than the high-quality human-written texts. To investigate this issue, we conduct an experiment on the sum mari z ation task, where we compare the evaluation scores of the LLM-generated and the human-written summaries. We use the dataset collected in Zhang et al. (2023), where they first ask freelance writers to write high-quality summaries for news articles, and then ask annotators to compare human-written summaries and LLMgenerated summaries (using GPT-3.5, text-davinci
G-EVAL会更偏好基于大语言模型的输出吗?
关于使用大语言模型作为评估器的一个担忧是,它可能更倾向于选择由大语言模型自身生成的输出,而非高质量的人工撰写文本。为了研究这一问题,我们在摘要生成任务中进行了实验,比较了大语言模型生成摘要与人工撰写摘要的评估分数。我们使用了Zhang等人(2023)收集的数据集,其中他们首先请自由撰稿人为新闻文章撰写高质量摘要,然后让标注者比较人工撰写摘要与大语言模型生成摘要(使用GPT-3.5,text-davinci)。
| Metrics | Naturalness | Coherence | Engagingness | Groundedness | AVG | |||
| r | p | r p | r | p | r 0.310 | p | r p | |
| ROUGE-L | 0.176 | 0.146 0.193 | 0.203 | 0.295 | 0.300 | 0.327 | 0.243 | 0.244 |
| BLEU-4 | 0.180 0.175 | 0.131 | 0.235 | 0.232 | 0.316 0.213 | 0.310 | 0.189 | 0.259 |
| METEOR BERTScore | 0.212 | 0.191 0.250 | 0.302 | 0.367 | 0.439 | 0.333 0.391 | 0.290 | 0.331 |
| 0.226 | 0.209 0.214 | 0.233 | 0.317 | 0.335 | 0.291 0.317 | 0.262 | 0.273 | |
| USR | 0.337 | 0.325 0.416 | 0.377 | 0.456 | 0.465 | 0.222 | 0.447 0.358 | 0.403 |
| UniEval | 0.455 0.330 | 0.602 | 0.455 | 0.573 | 0.430 | 0.577 0.453 | 0.552 | 0.417 |
| G-EVAL-3.5 | 0.532 0.539 | 0.519 | 0.544 | 0.660 | 0.691 | 0.586 | 0.567 0.574 | 0.585 |
| G-EVAL-4 | 0.549 0.565 | 0.594 | 0.605 | 0.627 | 0.631 | 0.531 0.551 | 0.575 | 0.588 |
Table 2: Turn-level Spearman $(\rho)$ and Kendall-Tau $(\tau)$ correlations of different metrics on Topical-Chat benchmark.
| 指标 | 自然度 | 连贯性 | 吸引力 | 真实性 | 平均 | |||
|---|---|---|---|---|---|---|---|---|
| r | p | r p | r | p | r 0.310 | p | r p | |
| ROUGE-L | 0.176 | 0.146 0.193 | 0.203 | 0.295 | 0.300 | 0.327 | 0.243 | 0.244 |
| BLEU-4 | 0.180 0.175 | 0.131 | 0.235 | 0.232 | 0.316 0.213 | 0.310 | 0.189 | 0.259 |
| METEOR BERTScore | 0.212 | 0.191 0.250 | 0.302 | 0.367 | 0.439 | 0.333 0.391 | 0.290 | 0.331 |
| 0.226 | 0.209 0.214 | 0.233 | 0.317 | 0.335 | 0.291 0.317 | 0.262 | 0.273 | |
| USR | 0.337 | 0.325 0.416 | 0.377 | 0.456 | 0.465 | 0.222 | 0.447 0.358 | 0.403 |
| UniEval | 0.455 0.330 | 0.602 | 0.455 | 0.573 | 0.430 | 0.577 0.453 | 0.552 | 0.417 |
| G-EVAL-3.5 | 0.532 0.539 | 0.519 | 0.544 | 0.660 | 0.691 | 0.586 | 0.567 0.574 | 0.585 |
| G-EVAL-4 | 0.549 0.565 | 0.594 | 0.605 | 0.627 | 0.631 | 0.531 0.551 | 0.575 | 0.588 |
表 2: Topical-Chat基准上不同指标的回合级Spearman $(\rho)$ 和Kendall-Tau $(\tau)$ 相关性。
003).
003)。
The dataset can be divided in three categories: 1) human-written summaries that are rated higher than GPT-3.5 summaries by human judges, 2) human-written summaries that are rated lower than GPT-3.5 summaries by human judges, and 3) human-written summaries and GPT-3.5 summaries are rated equally good by human judges. We use GEVAL-4 to evaluate the summaries in each category, and compare the averaged scores. 2
该数据集可分为三类:1) 人工撰写的摘要,其评分高于GPT-3.5生成的摘要;2) 人工撰写的摘要,其评分低于GPT-3.5生成的摘要;3) 人工撰写与GPT-3.5生成的摘要获得同等评分。我们使用GEVAL-4评估每类摘要,并比较平均得分。
The results are shown in Figure 2. We can see that, G-EVAL-4 assigns higher scores to humanwritten summaries when human judges also prefer human-written summaries, and assigns lower scores when human judges prefer GPT-3.5 summaries. However, G-EVAL-4 always gives higher scores to GPT-3.5 summaries than human-written summaries, even when human judges prefer humanwritten summaries. We propose two potential reasons for this phenomenon:
结果如图 2 所示。我们可以看到,当人类评判者更倾向于人工撰写的摘要时,G-EVAL-4 会给人工撰写的摘要打更高的分数;而当人类评判者更喜欢 GPT-3.5 生成的摘要时,G-EVAL-4 则会打较低的分数。然而,即便在人类评判者更青睐人工摘要的情况下,G-EVAL-4 始终给予 GPT-3.5 生成的摘要比人工摘要更高的评分。针对这一现象,我们提出两种可能的原因:
- NLG outputs from high-quality systems are in natural difficult to evaluate. The authors of the original paper found that inter-annotator agreement on judging human-written and LLM-generated summaries is very low, with Kri pp end orff’s alpha at 0.07.
- 高质量系统生成的NLG输出自然难以评估。原论文作者发现,在评判人工撰写和大语言模型生成的摘要时,标注者间一致性极低,Krippendorff's alpha系数仅为0.07。
- G-EVAL may have a bias towards the LLMgenerated summaries because the model could share the same concept of evaluation criteria during generation and evaluation.
- G-EVAL可能对大语言模型生成的摘要存在偏好,因为该模型在生成和评估过程中可能共享相同的评价标准概念。
Our work should be considered as a preliminary study on this issue, and more research is needed to fully understand the behavior of LLM-based evaluators to reduce its inherent bias towards LLMgenerated text. We highlight this concern in the context that LLM-based evaluators may lead to self-reinforcement of LLMs if the evaluation score is used as a reward signal for further tuning. And this could result in the over-fitting of the LLMs to their own evaluation criteria, rather than the true evaluation criteria of the NLG tasks.
我们的工作应被视为对该问题的初步研究,需要更多研究来充分理解基于大语言模型的评估器行为,以减少其对LLM生成文本的固有偏见。我们强调这一担忧的背景是:若将评估分数作为进一步调优的奖励信号,基于大语言模型的评估器可能导致模型自我强化。这可能导致大语言模型过度拟合其自身评估标准,而非自然语言生成任务的真实评估标准。
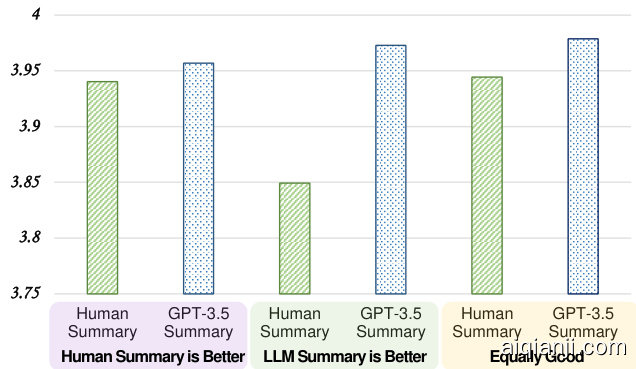
Figure 2: Averaged G-EVAL-4’s scores for humanwritten summaries and GPT-3.5 summaries, divided by human judges’ preference.
图 2: 人工撰写摘要与GPT-3.5生成摘要的G-EVAL-4平均得分 (按人类评委偏好分组)
The Effect of Chain-of-Thoughts We compare the performance of G-EVAL with and without chain-of-thoughts (CoT) on the SummEval benchmark. Table 1 shows that G-EVAL-4 with CoT has higher correlation than G-EVAL-4 without CoT on all dimensions, especially for fluency. This suggests that CoT can provide more context and guidance for the LLM to evaluate the generated text, and can also help to explain the evaluation process and results.
思维链效果对比
我们在SummEval基准上比较了G-EVAL使用思维链(CoT)与不使用思维链的性能差异。表1显示,在所有维度上,采用CoT的G-EVAL-4比未采用CoT的版本具有更高的相关性,尤其在流畅度方面表现突出。这表明思维链能为大语言模型评估生成文本时提供更多上下文和指导,同时有助于解释评估过程及结果。
The Effect of Probability Normalization We compare the performance of G-EVAL with and without probability normalization on the SummEval benchmark. Table 1 shows that, on KendallTau correlation, G-EVAL-4 with probabilities is inferior to G-EVAL-4 without probabilities on SummEval. We believe this is related to the calculation of Kendall-Tau correlation, which is based on the number of concordant and discordant pairs. Direct scoring without probabilities can lead to many ties, which are not counted as either concordant or discordant. This may result in a higher Kendall-Tau correlation, but it does not reflect the model’s true capacity of evaluating the generated texts. On the other hand, probability normalization can obtain more fine-grained, continuous scores that better capture the subtle difference between generated texts. This is reflected by the higher Spearman correlation of G-EVAL-4 with probabilities, which is based on the rank order of the scores.
概率归一化的效果
我们在SummEval基准上比较了G-EVAL在使用和不使用概率归一化时的性能。表1显示,在KendallTau相关性方面,带概率的G-EVAL-4在SummEval上表现不如不带概率的G-EVAL-4。我们认为这与Kendall-Tau相关性的计算方式有关,该计算基于一致对和不一致对的数量。不采用概率的直接评分会导致大量平局,这些平局既不被计入一致对也不被计入不一致对。这可能导致更高的Kendall-Tau相关性,但并不能反映模型评估生成文本的真实能力。另一方面,概率归一化可以获得更细粒度、连续的分数,从而更好地捕捉生成文本之间的细微差异。这一点体现在带概率的G-EVAL-4具有更高的Spearman相关性上,该相关性基于分数的排名顺序。
| Metrics | QAGS-CNN | QAGS-XSUM | Average | |||||
| r | p | T r | p | T | r | p | T | |
| ROUGE-2 | 0.459 | 0.418 | 0.333 | 0.097 0.083 | 0.068 | 0.278 | 0.250 | 0.200 |
| ROUGE-L | 0.357 | 0.324 | 0.254 | 0.024 -0.011 | -0.009 | 0.190 | 0.156 | 0.122 |
| BERTScore | 0.576 | 0.505 | 0.399 | 0.024 0.008 | 0.006 | 0.300 | 0.256 | 0.202 |
| MoverScore | 0.414 | 0.347 | 0.271 | 0.054 0.044 | 0.036 | 0.234 | 0.195 | 0.153 |
| FactCC | 0.416 | 0.484 | 0.376 | 0.297 0.259 | 0.212 | 0.356 | 0.371 | 0.294 |
| QAGS | 0.545 | - | 0.175 - | 0.375 | ||||
| BARTScore | 0.735 | 0.680 | 0.557 | 0.184 0.159 | 0.130 | 0.459 | 0.420 | 0.343 |
| CTC | 0.619 | 0.564 | 0.450 | 0.309 0.295 | 0.242 | 0.464 | 0.430 | 0.346 |
| UniEval | 0.682 | 0.662 | 0.532 | 0.461 0.488 | 0.399 | 0.571 | 0.575 | 0.465 |
| G-EVAL-3.5 | 0.477 | 0.516 | 0.410 | 0.211 0.406 | 0.343 | 0.344 | 0.461 | 0.377 |
| G-EVAL-4 | 0.631 | 0.685 | 0.591 | 0.558 0.537 | 0.472 | 0.599 | 0.611 | 0.525 |
Table 3: Pearson $(r)$ , Spearman $(\rho)$ and Kendall-Tau $(\tau)$ correlations of different metrics on QAGS benchmark.
| 指标 | QAGS-CNN | QAGS-XSUM | 平均值 | |||||
|---|---|---|---|---|---|---|---|---|
| r | p | T r | p | T | r | p | T | |
| ROUGE-2 | 0.459 | 0.418 | 0.333 | 0.097 | 0.083 | 0.068 | 0.278 | 0.250 |
| ROUGE-L | 0.357 | 0.324 | 0.254 | 0.024 | -0.011 | -0.009 | 0.190 | 0.156 |
| BERTScore | 0.576 | 0.505 | 0.399 | 0.024 | 0.008 | 0.006 | 0.300 | 0.256 |
| MoverScore | 0.414 | 0.347 | 0.271 | 0.054 | 0.044 | 0.036 | 0.234 | 0.195 |
| FactCC | 0.416 | 0.484 | 0.376 | 0.297 | 0.259 | 0.212 | 0.356 | 0.371 |
| QAGS | 0.545 | - | 0.175 | - | 0.375 | |||
| BARTScore | 0.735 | 0.680 | 0.557 | 0.184 | 0.159 | 0.130 | 0.459 | 0.420 |
| CTC | 0.619 | 0.564 | 0.450 | 0.309 | 0.295 | 0.242 | 0.464 | 0.430 |
| UniEval | 0.682 | 0.662 | 0.532 | 0.461 | 0.488 | 0.399 | 0.571 | 0.575 |
| G-EVAL-3.5 | 0.477 | 0.516 | 0.410 | 0.211 | 0.406 | 0.343 | 0.344 | 0.461 |
| G-EVAL-4 | 0.631 | 0.685 | 0.591 | 0.558 | 0.537 | 0.472 | 0.599 | 0.611 |
表 3: 不同指标在QAGS基准上的皮尔逊 $(r)$ 、斯皮尔曼 $(\rho)$ 和肯德尔-陶 $(\tau)$ 相关性。
The Effect of Model Size We compare the performance of G-EVAL with different model sizes on the SummEval and QAGS benchmarks. Table 1 and Table 3 show that G-EVAL-4 has higher correlation than G-EVAL-3.5 on most dimensions and datasets, except for engaging ness and grounded ness on the Topical-Chat benchmark. This demonstrates that larger model size can improve the performance of G-EVAL, especially for more challenging and complex evaluation tasks, such as consistency and relevance.
模型尺寸的影响
我们在SummEval和QAGS基准上比较了不同尺寸的G-EVAL模型性能。表1和表3显示,除Topical-Chat基准中的吸引力和基础性维度外,G-EVAL-4在大多数维度和数据集上比G-EVAL-3.5具有更高的相关性。这表明更大的模型尺寸可以提升G-EVAL的性能,尤其是对于更具挑战性和复杂性的评估任务,如一致性和相关性。
5 Related Work
5 相关工作
Ngram-based Metrics Ngram-based metrics refer to the scores for evaluating the NLG models by measuring the lexical overlap between a generated text and a reference text. BLEU (Papineni et al., 2002) is the most widely used metric for machine translation evaluation, which calculates the geometric mean of modified n-gram precision and a brevity penalty. ROUGE (Lin, 2004) is a recall-oriented metric for sum mari z ation evaluation, which measures the n-gram overlap between a generated summary and a set of reference summaries. It has been shown that more than $60%$ of recent papers on NLG only rely on ROUGE or BLEU to evaluate their systems (Kasai et al., 2021). However, these metrics fail to measure content quality (Reiter and Belz, 2009) or capture syntactic errors (Stent et al., 2005), and therefore do not reflect the reliability of NLG systems accurately.
基于Ngram的指标
基于Ngram的指标指通过衡量生成文本与参考文本之间的词汇重叠度来评估自然语言生成(NLG)模型得分的指标。BLEU (Papineni等人,2002) 是机器翻译评估中最广泛使用的指标,它计算修正后的n-gram精确度的几何平均值和简短惩罚。ROUGE (Lin,2004) 是一个面向召回率的摘要评估指标,用于衡量生成摘要与一组参考摘要之间的n-gram重叠度。研究表明,超过 $60%$ 的最新NLG论文仅依赖ROUGE或BLEU来评估其系统 (Kasai等人,2021) 。然而,这些指标无法衡量内容质量 (Reiter和Belz,2009) 或捕捉语法错误 (Stent等人,2005) ,因此不能准确反映NLG系统的可靠性。
Embedding-based Metrics Embedding-based metrics refer to the scores for evaluating the NLG models by measuring the semantic similarity between a generated text and a reference text based on the word or sentence embeddings. WMD (Kusner et al., 2015) is a metric that measures the distance between two texts based on the word embeddings. BERTScore (Zhang et al., 2019) measures the similarity between two texts based on the contextual i zed embedding from BERT (Devlin et al., 2019). MoverScore (Zhao et al., 2019) improves BERTScore by adding soft alignments and new aggregation methods to obtain a more robust similarity measure. (Clark et al., 2019) propose a metric that evaluates multi-sentence texts by computing the similarity between the generated text and the reference text based on the sentence embeddings.
基于嵌入的指标
基于嵌入的指标是指通过测量生成文本与参考文本在词或句子嵌入层面的语义相似度来评估自然语言生成(NLG)模型性能的评分体系。WMD (Kusner等人,2015) 是一种基于词嵌入测量两段文本距离的指标。BERTScore (Zhang等人,2019) 通过BERT (Devlin等人,2019) 的上下文嵌入来度量文本相似度。MoverScore (Zhao等人,2019) 通过引入软对齐和新聚合方法改进了BERTScore,从而获得更稳健的相似性度量。(Clark等人,2019) 提出了一种基于句子嵌入计算生成文本与参考文本相似度的多语句评估指标。
Task-specific Evaluators Task-specific metrics refer to the scores for evaluating the NLG models by measuring the quality of the generated texts based on the specific task requirements. For example, sum mari z ation tasks need to assess the consistency of the generated summaries (Kryscinski et al., 2020; Wang et al., 2020; Cao et al., 2020; Durmus et al., 2020), and di- alogue response generation tasks need to assess the coherence of the generated responses (Dziri et al., 2019; Ye et al., 2021). However, these metrics are not general iz able to other NLG tasks, and they are not able to measure the overall quality of the generated texts.
任务特定评估器
任务特定指标是指根据特定任务要求衡量生成文本质量以评估自然语言生成(NLG)模型的分数。例如,摘要任务需要评估生成摘要的一致性 [Kryscinski et al., 2020; Wang et al., 2020; Cao et al., 2020; Durmus et al., 2020],而对话响应生成任务需要评估生成回复的连贯性 [Dziri et al., 2019; Ye et al., 2021]。然而,这些指标无法推广到其他NLG任务,也不能衡量生成文本的整体质量。
Unified Evaluators Recently, some evaluators have been developed to assess text quality from multiple dimensions by varying the input and output contents (Yuan et al., 2021) or the model variants (Mehri and Eskenazi, 2020) they use. UniEval (Zhong et al., 2022) is a unified evaluator that can evaluate different aspects of text generation as QA tasks. By changing the question format, it can handle different evaluation tasks.
统一评估器
最近,一些评估器通过改变输入和输出内容 (Yuan et al., 2021) 或使用的模型变体 (Mehri and Eskenazi, 2020) ,从多个维度评估文本质量。UniEval (Zhong et al., 2022) 是一个统一评估器,能够以问答任务的形式评估文本生成的不同方面。通过改变问题格式,它可以处理不同的评估任务。
LLM-based Evaluators Fu et al. (2023) propose GPTScore, a new framework that evaluated texts with generative pre-training models like GPT-3. It assumes that a generative pre-training model will assign a higher probability of high-quality generated text following a given instruction and context. Wang et al. (2023) conduct a preliminary survey of using ChatGPT as a NLG evaluator. Kocmi and Federmann (2023) proposed to use GPT models for evaluating machine translation tasks.
基于大语言模型的评估方法
Fu等人 (2023) 提出GPTScore框架,该框架利用GPT-3等生成式预训练模型评估文本质量。其核心假设是:给定指令和上下文后,优质文本在生成式预训练模型中会获得更高生成概率。Wang等人 (2023) 对ChatGPT作为自然语言生成评估器的应用进行了初步研究。Kocmi和Federmann (2023) 提出使用GPT模型评估机器翻译任务。
6 Conclusion
6 结论
In this paper, we propose G-EVAL, a framework of using LLM with chain-of-thoughts (CoT) to evaluate the quality of generated texts. We conduct extensive experiments on two NLG tasks, text summarization and dialogue generation, and show that G-EVAL can outperform state-of-the-art evaluators and achieve higher human correspondence. We also propose preliminary analysis on the behavior of LLM-based evaluators, and highlight the potential issue of LLM-based evaluator having a bias towards the LLM-generated texts. We hope our work can inspire more research on using LLMs for NLG evaluation, and also raise awareness of the potential risks and challenges of using LLMs as evaluators.
本文提出G-EVAL框架,该框架利用大语言模型(LLM)和思维链(CoT)来评估生成文本的质量。我们在文本摘要和对话生成两个自然语言生成(NLG)任务上进行了大量实验,结果表明G-EVAL能够超越现有最佳评估器,并实现更高的人类评分一致性。我们还对基于大语言模型的评估器行为进行了初步分析,指出这类评估器可能对LLM生成文本存在偏好倾向。我们希望这项工作能激发更多关于使用大语言模型进行NLG评估的研究,同时提高人们对将大语言模型作为评估工具时潜在风险和挑战的认识。
References
参考文献
Satanjeev Banerjee and Alon Lavie. 2005. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65–72.
Satanjeev Banerjee和Alon Lavie。2005。Meteor:一种自动评估机器翻译的指标,其与人工判断的相关性更高。在《机器翻译和/或摘要的内在和外在评估指标acl研讨会论文集》中,第65-72页。
Meng Cao, Yue Dong, Jiapeng Wu, and Jackie Chi Kit Cheung. 2020. Factual error correction for abstractive sum mari z ation models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6251–6258.
Meng Cao、Yue Dong、Jiapeng Wu和Jackie Chi Kit Cheung。2020。抽象摘要模型的事实错误修正。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第6251–6258页。
Ziqiang Cao, Furu Wei, Wenjie Li, and Sujian Li. 2018. Faithful to the original: Fact aware neural abstract ive sum mari z ation. In thirty-second AAAI conference on artificial intelligence.
曹自强、韦福如、李文杰和李素建。2018。忠于原文:基于事实感知的神经抽象摘要生成。在第32届AAAI人工智能大会上。
Elizabeth Clark, Asli Cel i kyi l maz, and Noah A Smith. 2019. Sentence mover’s similarity: Automatic evaluation for multi-sentence texts. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2748–2760.
Elizabeth Clark、Asli Celikyilmaz 和 Noah A Smith。2019. 句子移动相似度:多句文本的自动评估。在《第57届计算语言学协会年会论文集》中,第2748–2760页。
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171– 4186.
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2019。BERT:面向语言理解的深度双向 Transformer (Transformers) 预训练。载于《2019年北美计算语言学协会会议论文集:人类语言技术》(长篇与短篇论文)第1卷,第4171–4186页。
Esin Durmus, He He, and Mona Diab. 2020. Feqa: A question answering evaluation framework for faithfulness assessment in abstract ive sum mari z ation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5055– 5070.
Esin Durmus、He He和Mona Diab。2020。FEQA:一种用于评估摘要生成忠实度的问答框架。载于《第58届计算语言学协会年会论文集》,第5055–5070页。
Nouha Dziri, Ehsan Kamalloo, Kory Mathewson, and Osmar R Zaiane. 2019. Evaluating coherence in dialogue systems using entailment. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 3806–3812.
Nouha Dziri、Ehsan Kamalloo、Kory Mathewson 和 Osmar R Zaiane。2019. 基于蕴含评估对话系统的连贯性。载于《2019年北美计算语言学协会人类语言技术会议论文集》第1卷(长论文与短论文),第3806-3812页。
Alexander R Fabbri, Wojciech Kryscinski, Bryan Mc- Cann, Caiming Xiong, Richard Socher, and Dragomir Radev. 2021. Summeval: Re-evaluating summarization evaluation. Transactions of the Association for Computational Linguistics, 9:391–409.
Alexander R Fabbri、Wojciech Kryscinski、Bryan Mc- Cann、Caiming Xiong、Richard Socher 和 Dragomir Radev。2021。Summeval: 重新评估摘要评估。计算语言学协会汇刊,9:391–409。
Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, and Pengfei Liu. 2023. Gptscore: Evaluate as you desire. arXiv preprint arXiv:2302.04166.
Jinlan Fu、See-Kiong Ng、Zhengbao Jiang和Pengfei Liu。2023。Gptscore: 按需评估。arXiv预印本arXiv:2302.04166。
Karl Moritz Hermann, Tomas Kocisky, Edward Grefen- stette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. 2015. Teaching machines to read and comprehend. Advances in neural information processing systems, 28.
Karl Moritz Hermann、Tomas Kocisky、Edward Grefen- stette、Lasse Espeholt、Will Kay、Mustafa Suleyman 和 Phil Blunsom。2015. 教机器阅读和理解。神经信息处理系统进展,28。
Jungo Kasai, Keisuke Sakaguchi, Ronan Le Bras, Lavinia Dunagan, Jacob Morrison, Alexander R Fabbri, Yejin Choi, and Noah A Smith. 2021. Bidimensional leader boards: Generate and evaluate language hand in hand. arXiv preprint arXiv:2112.04139.
Jungo Kasai、Keisuke Sakaguchi、Ronan Le Bras、Lavinia Dunagan、Jacob Morrison、Alexander R Fabbri、Yejin Choi 和 Noah A Smith。2021. 二维排行榜:生成与评估语言模型相辅相成。arXiv预印本 arXiv:2112.04139。
Tom Kocmi and Christian Federmann. 2023. Large language models are state-of-the-art evaluators of translation quality. arXiv preprint arXiv:2302.14520.
Tom Kocmi 和 Christian Federmann. 2023. 大语言模型 (Large Language Model) 是翻译质量评估的最先进方法. arXiv 预印本 arXiv:2302.14520.
Wojciech Kryscinski, Bryan McCann, Caiming Xiong, and Richard Socher. 2020. Evaluating the factual consistency of abstract ive text sum mari z ation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9332–9346.
Wojciech Kryscinski、Bryan McCann、Caiming Xiong 和 Richard Socher。2020。评估抽象文本摘要的事实一致性。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第9332–9346页。
Matt Kusner, Yu Sun, Nicholas Kolkin, and Kilian Weinberger. 2015. From word embeddings to document distances. In International conference on machine learning, pages 957–966. PMLR.
Matt Kusner、Yu Sun、Nicholas Kolkin 和 Kilian Weinberger。2015。从词嵌入到文档距离。发表于国际机器学习会议,第957-966页。PMLR。
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghaz vi nine j ad, Abdel rahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Z ett le moyer. 2020. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pages 7871–7880. Association for Computational Linguistics.
Mike Lewis、Yinhan Liu、Naman Goyal、Marjan Ghazvininejad、Abdelrahman Mohamed、Omer Levy、Veselin Stoyanov 和 Luke Zettlemoyer。2020。BART:用于自然语言生成、翻译和理解的去噪序列到序列预训练。载于《第58届计算语言学协会年会论文集》,ACL 2020,在线,2020年7月5-10日,第7871-7880页。计算语言学协会。
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text sum mari z ation branches out, pages 74–81.
Chin-Yew Lin. 2004. ROUGE: 自动摘要评估工具包。In Text summarization branches out, pages 74-81.
Shikib Mehri and Maxine Eskenazi. 2020. Usr: An unsupervised and reference free evaluation metric for dialog generation. arXiv preprint arXiv:2005.00456.
Shikib Mehri和Maxine Eskenazi。2020。USR:一种用于对话生成的无监督与无参考评估指标。arXiv预印本arXiv:2005.00456。
Shashi Narayan, Shay B Cohen, and Mirella Lapata. 2018. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme sum mari z ation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1797–1807.
Shashi Narayan、Shay B Cohen和Mirella Lapata。2018。无需细节,只需摘要!面向极端摘要的主题感知卷积神经网络。载于《2018年自然语言处理实证方法会议论文集》,第1797-1807页。
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
Long Ouyang、Jeffrey Wu、Xu Jiang、Diogo Almeida、Carroll Wainwright、Pamela Mishkin、Chong Zhang、Sandhini Agarwal、Katarina Slama、Alex Ray 等。2022。通过人类反馈训练语言模型遵循指令。《神经信息处理系统进展》,35:27730–27744。
Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
Kishore Papineni、Salim Roukos、Todd Ward和WeiJing Zhu。2002。BLEU:一种机器翻译自动评估方法。载于《第40届计算语言学协会年会论文集》,第311-318页。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21:1– 67.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J Liu。2020。探索迁移学习的极限:基于统一文本到文本Transformer的研究。Journal of Machine Learning Research,21:1–67。
Ehud Reiter and Anja Belz. 2009. An investigation into the validity of some metrics for automatically evaluating natural language generation systems. Computational Linguistics, 35(4):529–558.
Ehud Reiter和Anja Belz. 2009. 自然语言生成系统自动评估指标有效性研究. Computational Linguistics, 35(4):529–558.
Amanda Stent, Matthew Marge, and Mohit Singhai. 2005. Evaluating evaluation methods for generation in the presence of variation. In Proceedings of the 6th international conference on Computational Linguistics and Intelligent Text Processing, pages 341–351.
Amanda Stent、Matthew Marge 和 Mohit Singhai。2005。存在变体情况下的生成评估方法评测。载于《第六届计算语言学与智能文本处理国际会议论文集》,第341-351页。
Alex Wang, Kyunghyun Cho, and Mike Lewis. 2020. Asking and answering questions to evaluate the factual consistency of summaries. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5008–5020.
Alex Wang、Kyunghyun Cho和Mike Lewis。2020。通过提问和回答问题来评估摘要的事实一致性。载于《第58届计算语言学协会年会论文集》,第5008–5020页。
Jiaan Wang, Yunlong Liang, Fandong Meng, Haoxiang Shi, Zhixu Li, Jinan Xu, Jianfeng Qu, and Jie Zhou. 2023. Is chatgpt a good nlg evaluator? a preliminary study. arXiv preprint arXiv:2303.04048.
Jiaan Wang, Yunlong Liang, Fandong Meng, Haoxiang Shi, Zhixu Li, Jinan Xu, Jianfeng Qu, and Jie Zhou. 2023. ChatGPT是否是一个好的自然语言生成评估器?一项初步研究。arXiv preprint arXiv:2303.04048.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903.
Jason Wei、Xuezhi Wang、Dale Schuurmans、Maarten Bosma、Ed Chi、Quoc Le 和 Denny Zhou。2022。思维链提示激发大语言模型推理能力。arXiv预印本 arXiv:2201.11903。
Zheng Ye, Liucun Lu, Lishan Huang, Liang Lin, and Xiaodan Liang. 2021. Towards quantifiable dialogue coherence evaluation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 2718–2729.
郑烨、卢柳存、黄立山、林亮与梁晓丹。2021。迈向可量化的对话连贯性评估。载于《第59届计算语言学协会年会暨第11届自然语言处理国际联合会议论文集(第一卷:长论文)》,第2718–2729页。
Weizhe Yuan, Graham Neubig, and Pengfei Liu. 2021. Bartscore: Evaluating generated text as text generation. Advances in Neural Information Processing Systems, 34.
Weizhe Yuan、Graham Neubig 和 Pengfei Liu。2021。Bartscore: 将生成文本评估视为文本生成任务。《神经信息处理系统进展》,34。
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675.
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, Yoav Artzi. 2019. BERTScore: 基于BERT的文本生成评估. arXiv预印本 arXiv:1904.09675.
Tianyi Zhang, Faisal Ladhak, Esin Durmus, Percy Liang, Kathleen McKeown, and Tatsunori B. Hashimoto. 2023. Benchmarking large language models for news sum mari z ation.
Tianyi Zhang、Faisal Ladhak、Esin Durmus、Percy Liang、Kathleen McKeown和Tatsunori B. Hashimoto。2023。评估大语言模型在新闻摘要任务中的表现。
Wei Zhao, Maxime Peyrard, Fei Liu, Yang Gao, Christian M Meyer, and Steffen Eger. 2019. Moverscore: Text generation evaluating with contextual i zed embeddings and earth mover distance. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 563–578.
Wei Zhao、Maxime Peyrard、Fei Liu、Yang Gao、Christian M Meyer 和 Steffen Eger。2019. Moverscore: 基于上下文嵌入和推土机距离的文本生成评估。载于《2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议论文集》(EMNLP-IJCNLP),第563-578页。
Ming Zhong, Yang Liu, Da Yin, Yuning Mao, Yizhu Jiao, Pengfei Liu, Chenguang Zhu, Heng Ji, and Jiawei Han. 2022. Towards a unified multidimensional evaluator for text generation. arXiv preprint arXiv:2210.07197.
Ming Zhong、Yang Liu、Da Yin、Yuning Mao、Yizhu Jiao、Pengfei Liu、Chenguang Zhu、Heng Ji 和 Jiawei Han。2022。迈向统一的多维文本生成评估器。arXiv预印本 arXiv:2210.07197。
A Example Prompts
示例提示
Evaluate Coherence in the Sum mari z ation Task
评估摘要任务中的连贯性
You will be given one summary written for a news article.
你将获得一篇新闻文章的摘要。
Your task is to rate the summary on one metric.
你的任务是根据一个指标对摘要进行评分。
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.
请确保仔细阅读并理解这些说明。在审阅过程中请保持本文件开启,并按需查阅。
Evaluation Criteria:
评估标准:
Coherence (1-5) - the collective quality of all sentences. We align this dimension with the DUC quality question of structure and coherence whereby ”the summary should be well-structured and well-organized. The summary should not just be a heap of related information, but should build from sentence to sentence to a coherent body of information about a topic.”
连贯性(1-5) - 所有句子的整体质量。我们将这一维度与DUC评估中的结构与连贯性问题对齐,即"摘要应具备良好的结构和组织性。摘要不应只是相关信息的堆砌,而应通过句子间的递进关系,构建出关于某个主题的连贯信息体。"
Evaluation Steps:
评估步骤:
- Read the news article carefully and identify the main topic and key points. 2. Read the summary and compare it to the news article. Check if the summary covers the main topic and key points of the news article, and if it presents them in a clear and logical order. 3. Assign a score for coherence on a scale of 1 to 5, where 1 is the lowest and 5 is the highest based on the Evaluation Criteria.
- 仔细阅读新闻文章,确定主要话题和关键点。
- 阅读摘要并与新闻文章对比。检查摘要是否涵盖新闻文章的主要话题和关键点,并以清晰、逻辑的顺序呈现。
- 根据评估标准,在1到5的范围内为连贯性打分,其中1为最低分,5为最高分。
Example: Source Text: {{Document}} Summary: {{Summary}}
示例:源文本:{{Document}} 摘要:{{Summary}}
Evaluation Form (scores ONLY): - Coherence:
评估表(仅限评分):- 连贯性:
Evaluate Engaging ness in the Dialogue Generation Task
评估对话生成任务中的吸引力
You will be given a conversation between two individuals. You will then be given one potential response for the next turn in the conversation. The response concerns an interesting fact, which will be provided as well.
你将看到两个人之间的对话。随后会给出对话下一轮的一个潜在回应。该回应涉及一个有趣的事实,该事实也将一并提供。
Your task is to rate the responses on one metric.
你的任务是根据一个指标对回答进行评分。
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.
请确保仔细阅读并理解这些说明。请在审阅时保持此文档打开,并根据需要参考。
Evaluation Crieteria:
评估标准:
Evaluation Steps:
评估步骤:
- Read the conversation, the corresponding fact and the response carefully. 2. Rate the response on a scale of 1-3 for engaging ness, according to the criteria above. 3. Provide a brief explanation for your rating, referring to specific aspects of the response and the conversation.
- 仔细阅读对话、对应的事实和回应。
- 根据上述标准,对回应的吸引力按1-3分进行评分。
- 简要说明评分理由,具体提及回应和对话的某些方面。
Evaluate Hallucinations
评估幻觉
Human Evaluation of Text Sum mari z ation Systems:
文本摘要系统的人工评估:
Factual Consistency: Does the summary untruthful or misleading facts that are not supported by the source text?
事实一致性:摘要是否包含源文本未支持的不真实或误导性事实?
Source Text: Document Summary: Summary
文档摘要:摘要
Does the summary contain factual inconsistency? Answer:
摘要是否存在事实不一致?回答: