Can Large Language Models Be an Alternative to Human Evaluation?
大语言模型 (Large Language Model) 能否替代人类评估?
Abstract
摘要
Human evaluation is indispensable and inevitable for assessing the quality of texts generated by machine learning models or written by humans. However, human evaluation is very difficult to reproduce and its quality is notoriously unstable, hindering fair comparisons among different natural language processing (NLP) models and algorithms. Recently, large language models (LLMs) have demonstrated exceptional performance on unseen tasks when only the task instructions are provided. In this paper, we explore if such an ability of the LLMs can be used as an alternative to human evaluation. We present the LLMs with the exact same instructions, samples to be evaluated, and questions used to conduct human evaluation, and then ask the LLMs to generate responses to those questions; we dub this LLM evaluation. We use human evaluation and LLM evaluation to evaluate the texts in two NLP tasks: open-ended story generation and adversarial attacks. We show that the result of LLM evaluation is consistent with the results obtained by expert human evaluation: the texts rated higher by human experts are also rated higher by the LLMs. We also find that the results of LLM evaluation are stable over different formatting of the task instructions and the sampling algorithm used to generate the answer. We are the first to show the potential of using LLMs to assess the quality of texts and discuss the limitations and ethical considerations of LLM evaluation.
人类评估对于判断机器学习模型生成或人工撰写文本的质量而言不可或缺且不可避免。然而,人类评估难以复现,其质量也极不稳定,这阻碍了不同自然语言处理(NLP)模型与算法间的公平比较。近期研究表明,大语言模型(LLM)仅凭任务指令就能在未见任务上展现卓越性能。本文探讨是否可将LLM的这种能力作为人类评估的替代方案:我们向LLM提供与人类评估完全相同的指令、待评估样本及问题,要求其生成对应回答——这种评估方式称为LLM评估。我们分别在开放式故事生成和对抗攻击两个NLP任务中,同步采用人类评估与LLM评估进行文本质量判定。实验表明,LLM评估结果与专家人类评估具有一致性:人类专家评分较高的文本同样获得LLM更高评价。我们还发现,LLM评估结果不受任务指令格式差异及答案生成采样算法的影响。本研究首次揭示了利用LLM评估文本质量的潜力,并讨论了LLM评估的局限性与伦理考量。
1 Introduction
1 引言
Human evaluation is an important method to understand the performance of an NLP model or algorithm (Guzmán et al., 2015; Gillick and Liu, 2010). We rely on human evaluation because there are certain aspects of texts that are hard to evaluate using automatic evaluation metrics; thus, researchers resort to humans to rate the quality of the output of NLP models. While human evaluation is prevalent and indispensable in NLP, it is notoriously unstable (Gillick and Liu, 2010; Clark et al., 2021). Karpinska et al. (2021) has shown that low-quality workforces in human evaluation can have a detrimental effect on the evaluation result, making it impossible to compare the performance among different systems. Reproducibility is another issue in human evaluation since it is hard to recruit the same human evaluators and rerun the same evaluation. Even if the same workers are recruited, the workers that have seen the task before are likely to produce a different evaluation result the next time because they have already done the task. While human evaluation is used to better assess NLP systems and has some advantages over automatic evaluation metrics, the drawbacks of human evaluation somewhat make it difficult to reliably evaluate NLP systems.
人工评估是理解自然语言处理(NLP)模型或算法性能的重要方法 (Guzmán et al., 2015; Gillick and Liu, 2010)。我们依赖人工评估是因为文本的某些方面难以通过自动评估指标来衡量,因此研究人员需要借助人类来评判NLP模型的输出质量。虽然人工评估在NLP领域普遍且不可或缺,但其不稳定性是出了名的 (Gillick and Liu, 2010; Clark et al., 2021)。Karpinska等人 (2021) 研究表明,低质量的人工评估工作会对评估结果产生不利影响,导致无法比较不同系统间的性能。可重复性是人工评估的另一个问题,因为很难招募相同的人类评估者并重新进行相同的评估。即使招募到相同的评估人员,曾经接触过该任务的评估者在下次评估时很可能会产生不同的结果,因为他们已经对该任务有所了解。虽然人工评估能更好地评估NLP系统并具有某些优于自动评估指标的优势,但其缺点使得难以可靠地评估NLP系统。
To resolve some of the drawbacks, we take advantage of large language models (LLMs). LLMs are large models that are trained to model human languages using self-supervised learning (Brown et al., 2020) and further using special training procedures to improve the performance on unseen tasks and better follow natural language instructions (Sanh et al., 2022; Wei et al., 2022). The ability to perform a task just given the task instructions motivates us to ask if these LLMs can perform what humans do in human evaluation. To answer this question, we feed in the LLM with the same instruction, sample, and question used in human evaluation, and take the sequences generated by the LLM as the LLM’s answer to the question. This process is shown in Figure 1, and we call this process LLM evaluation.
为了解决部分缺陷,我们利用了大语言模型(LLM)。大语言模型是通过自监督学习(Brown等人,2020)训练的大型模型,并进一步采用特殊训练流程来提升在未见任务上的表现及更好地遵循自然语言指令(Sanh等人,2022;Wei等人,2022)。这种仅凭任务说明就能执行任务的能力促使我们思考:这些大语言模型能否执行人类评估中的工作?为验证这一点,我们向大语言模型输入与人类评估相同的指令、样本和问题,并将其生成的序列作为模型对问题的回答。该流程如图1所示,我们称之为LLM评估。
To test if LLM evaluation yields meaningful results, we conduct LLM evaluation on two different NLP tasks: evaluating the quality of stories in openended story generation and the quality of sentences generated by adversarial attacks. We summarize our findings and contribution as follows:
为了验证大语言模型(LLM)评估是否产生有意义的结果,我们在两个不同的自然语言处理任务上进行了LLM评估:开放式故事生成中的故事质量评估和对抗攻击生成的句子质量评估。我们的发现和贡献总结如下:
• We show that LLM evaluation produces results similar to expert human evaluation, verifying the effectiveness of LLM evaluation (§3.3 and $\S4.3)$ . This paper is the first to propose using LLMs as an alternative to human evaluation and show their effectiveness.
• 我们证明了大语言模型(LLM)评估结果与专家人工评估结果相似,验证了大语言模型评估的有效性(见3.3节和4.3节)。本文首次提出使用大语言模型作为人工评估的替代方案,并证明了其有效性。

Figure 1: Illustration of the core idea of the paper using open-ended story generation as the example task. The left part shows the instruction, story fragments, and questions used in human evaluation. The human experts are asked to rate the quality of the story fragments using a 5-point Likert scale, shown on the upper right. The lower right part shows the process of LLM evaluation, where we feed the LLMs the same instruction, story fragments, and questions and parse the LLM-generated output to get the rating.
图 1: 以开放式故事生成为例说明论文核心思想。左侧展示人类评估中使用的指令、故事片段及问题。专家需采用右上角所示的5级李克特量表对故事片段质量评分。右下部分展示大语言模型评估流程:将相同指令、故事片段和问题输入大语言模型,解析其生成输出以获取评分。
• We show that LLM evaluation results only slightly vary due to different task instructions and the hyper parameters of the sampling algorithm used to generate the answer. $(\S3.3.2$ and $\S3.3.3$ ) • We carefully discuss the pros and cons of using LLM evaluation and discuss the ethical considerations of LLM evaluation. (§5)
• 研究表明,大语言模型(LLM)评估结果仅因不同任务指令和用于生成答案的采样算法超参数而略有变化 $(\S3.3.2$ 和 $\S3.3.3$ )
• 我们深入探讨了使用大语言模型评估的优缺点,并讨论了其伦理考量 (§5)
2 LLM Evaluation
2 大语言模型 (LLM) 评估
2.1 Large Language Models (LLMs)
2.1 大语言模型 (LLMs)
Large language models are language models having bulk parameter sizes, typically on the scale of a few billion, and pre-trained on enormous amounts of natural language corpora, including GPT3 (Brown et al., 2020), T5 (Raffel et al., 2020), and BLOOM (Scao et al., 2022). These LLMs show exceptional performance on unseen tasks when only the task instructions are given; this kind of ability is called zero-shot in-context learning.
大语言模型是指参数规模庞大(通常达到数十亿级别)并在海量自然语言语料库上预训练的语言模型,例如GPT3 (Brown et al., 2020)、T5 (Raffel et al., 2020)和BLOOM (Scao et al., 2022)。这类大语言模型仅凭任务指令就能在未见任务上表现出卓越性能,这种能力被称为零样本上下文学习。
To further improve the zero-shot in-context learning performance, special training techniques have been applied to those LLMs after pre-training. For example, T0 (Sanh et al., 2022) and FLAN (Wei et al., 2022) are fine-tuned on a mixture of tasks and can thus achieve better zero-shot performance compared to GPT-3. Instruct GP T (Ouyang et al., 2022) is fine-tuned from GPT-3 using reinforcement learning from human feedback (RLHF), and it is shown to better follow the instructions. ChatGPT (OpenAI, 2022) is fine-tuned from InstructGPT with a conversation dataset using RLHF, so ChatGPT can interact with users in a conversational way. ChatGPT is able to answer questions asked by the user and provide comprehensive explanations about its answer. Given the LLMs’ ability to follow task instructions and provide feedback, we ask whether LLMs can be used as an alternative to human evaluation and aid NLP researchers in evaluating the quality of texts.
为进一步提升零样本上下文学习性能,研究人员在预训练后对这些大语言模型采用了特殊训练技术。例如,T0 (Sanh et al., 2022) 和 FLAN (Wei et al., 2022) 通过多任务混合微调,其零样本表现优于 GPT-3。InstructGPT (Ouyang et al., 2022) 基于 GPT-3 采用人类反馈强化学习 (RLHF) 进行微调,被证明能更准确地遵循指令。ChatGPT (OpenAI, 2022) 则在 InstructGPT 基础上使用对话数据集结合 RLHF 进行微调,使其能以对话形式与用户交互。ChatGPT 不仅能回答用户提问,还能对答案进行详细解释。鉴于大语言模型具备遵循任务指令和提供反馈的能力,我们探讨其是否可替代人工评估,辅助 NLP 研究者评估文本质量。
2.2 LLM Evaluation
2.2 大语言模型 (LLM) 评估
To evaluate the quality of texts generated by NLP systems or written by humans using LLM, we present the LLMs with the task instructions, the sample to be evaluated, and a question. The question asks the LLM to rate the sample’s quality using a 5-point Likert scale. Given the inputs, the LLM will answer the question by generating some output sentences. We parse the output sentences to get the score rated by the LLM. We call this process LLM evaluation, and this procedure is shown in the lower part of Figure 1. Different tasks use different sets of task instructions, and each task uses different questions to evaluate the quality of the samples. The instructions and questions used in LLM evaluation in our paper are not tailored for the LLMs; we follow those instructions used to conduct human evaluation in prior works.
为了评估由NLP系统生成或人类借助大语言模型撰写的文本质量,我们向大语言模型提供任务指令、待评估样本及一个问题。该问题要求大语言模型使用5级李克特量表对样本质量进行评分。给定输入后,大语言模型会通过生成输出语句来回答问题。我们解析这些输出语句以获取大语言模型给出的评分。我们将此过程称为大语言模型评估,该流程如图1下半部分所示。不同任务采用不同的任务指令集,且每个任务使用不同问题来评估样本质量。本文中大语言模型评估采用的指令和问题并非为大语言模型定制,而是沿用先前工作中用于人工评估的指令。
To compare the result of LLM evaluation and show its effectiveness, we compare the result of LLM evaluation with human evaluation conducted by English teachers. To make a fair and meaningful comparison, the instructions, samples, and questions in human evaluation are formatted similarly to those in LLM evaluation. The main difference between LLM evaluation and human evaluation is that in human evaluation, the human evaluators answer the question by choosing the answer from a pre-defined set of options (the 1-5 Likert scale scores), as shown in the upper right in Figure 1. In LLM evaluation, we instead let the LLM freely generate sentences and extract the score from the generated sentences using some simple rules, detailed in Appendix D.2.1.
为了比较大语言模型(LLM)评估结果的有效性,我们将其与英语教师进行的人工评估结果进行对比。为确保公平且有意义的比较,人工评估中的指导语、样本和问题设置均与LLM评估保持相似格式。两者核心差异在于:人工评估中,评估者需从预设选项(1-5级李克特量表)中选择答案(如图1右上角所示);而在LLM评估中,我们让大语言模型自由生成文本,并通过附录D.2.1详述的简单规则从生成内容中提取分数。
3 Example Task 1: Open-Ended Story Generation
3 示例任务1: 开放式故事生成
We first use open-ended story generation to demonstrate the usefulness of LLM evaluation.
我们首先使用开放式故事生成来展示大语言模型评估的实用性。
3.1 Task Introduction
3.1 任务介绍
Open-ended story generation is a task to generate a short story based on a given prompt. We use the Writing Prompts dataset (Fan et al., 2018), which is composed of pairs of short prompts and human-written stories collected from the subreddit Writing Prompts. In the Writing Prompts, the users are given a short prompt, and they need to write a story based on the short prompt.1
开放式故事生成任务旨在根据给定提示创作短篇故事。我们采用Writing Prompts数据集 (Fan et al., 2018),该数据集由来自Reddit写作社区Writing Prompts的简短提示与人工撰写故事配对组成。在该社区中,用户根据简短提示进行故事创作。
In this experiment, we use LLM evaluation and human evaluation to rate the stories generated by humans and the stories generated by a story generation model. We select open-ended story generation as an example because Karpinska et al. (2021) show that workers from Amazon Mechanical Turk (AMT) cannot distinguish GPT-2 (Radford et al., 2019) generated and human-written stories, while English teachers show a clear preference for human-written stories over GPT-2-generated stories. We want to see if LLM can rate human-written stories higher than GPT-2-generated ones.
在本实验中,我们采用大语言模型(LLM)评估和人工评估两种方式,对人类创作的故事与故事生成模型产出的故事进行评分。选择开放式故事生成作为案例,是因为Karpinska等人(2021)的研究表明:Amazon Mechanical Turk (AMT)平台工作者无法区分GPT-2 (Radford等人,2019)生成故事与人类创作故事,而英语教师则明显更偏好人类创作的故事。我们试图验证大语言模型能否像人类专家一样,给予人类创作故事高于GPT-2生成故事的评分。
Following prior works (Mao et al., 2019; Guan et al., 2020; Karpinska et al., 2021), the story gen- eration model is GPT-2 medium model fine-tuned on the Writing Prompts training dataset. After the model is trained, we randomly select 200 prompts from the testing set of Writing Prompts and make the fine-tuned GPT-2 generate stories based on those prompts using nucleus sampling (Holtzman et al., 2020) with $p=0.9$ . For the human-written stories to be compared, we use the 200 stories written based on the same 200 prompts. We postprocess the human-written and GPT-2-generated stories and then use them for LLM evaluation and human evaluation. Please find the details on finetuning and data processing in Appendix B.
遵循先前研究 (Mao et al., 2019; Guan et al., 2020; Karpinska et al., 2021) ,故事生成模型采用基于Writing Prompts训练数据集微调的GPT-2中等模型。模型训练完成后,我们从Writing Prompts测试集中随机选取200个提示词,并使用核心采样 (Holtzman et al., 2020) (参数 $p=0.9$ ) 让微调后的GPT-2基于这些提示生成故事。作为对比的人类撰写故事,我们使用基于相同200个提示词创作的200篇故事。经过对人工撰写和GPT-2生成故事的后处理后,这些材料被用于大语言模型评估和人工评估。微调与数据处理的详细说明请参阅附录B。
3.2 LLM Evaluation and Human Evaluation
3.2 大语言模型评估与人类评估
We present the LLMs and the human evaluators with a short description, and the story to be evaluated, formatted as shown in Figure 1. Following Karpinska et al. (2021), we evaluate the stories on four different attributes. The four attributes and their corresponding questions are as follows:
我们向大语言模型(LLM)和人类评估者提供简短描述及待评估的故事,格式如图1所示。遵循Karpinska等人(2021)的方法,我们从四个不同维度评估故事。这四个维度及其对应问题如下:
Where the [PROMPT] will be filled in with the prompt which the story is based on. Each attribute is evaluated using a 5-point Likert scale; the following description is appended at the end of each question: "(on a scale of 1-5, with 1 being the lowest)". We show the interface used in human evaluation and the input format for the LLM evaluation in Appendix C.2 and D.2.2.
[PROMPT] 处将填入故事所基于的提示词。每个属性均采用5级李克特量表进行评估,每个问题末尾附有以下说明:"(1分为最低分,5分为最高分)"。人类评估所用界面及大语言模型评估的输入格式详见附录C.2和D.2.2。
The LLMs used for LLM evaluation include T0, text-curie-001, text-davinci-003, and ChatGPT. text-curie-001 and text-davinci-003
用于大语言模型评估的大语言模型包括T0、text-curie-001、text-davinci-003和ChatGPT。text-curie-001和text-davinci-003
| Evaluator | Grammaticality | Cohesiveness | Likability | Relevance | ||||
| MeansTD | IAA% | MeansTD | IAA% | MeansTD | IAA% | MeansTD | IAA% | |
| Human-written stories | ||||||||
| Human TO | 3.760.95 2.551.47 | 0.3320.5 0.1610 | 4.290.82 2.981.45 | 0.3227 0.114 | 3.781.10 3.181.53 | 0.089.5 0.127 | 3.351.48 2.931.64 | 0.058 0.026 |
| curie | 3.190.47 | 0.0746.5 | 2.820.46 | 0.0147.5 | 2.850.37 | 0.110.65 | 3.060.40 | 0.110.64 |
| davinci | 4.220.38 | 0.2635 | 4.540.47 | 0.3739.5 | 3.990.38 | 0.4968.5 | 4.400.79 | 0.7148.5 |
| ChatGPT | 3.830.60 | 3.550.88 | 2.440.89 | 3.291.50 | ||||
| GPT-2-generatedstories | ||||||||
| Human | 3.560.91 | 0.1019.5 | 3.191.07 | 0.1417 | 2.591.29 | -0.213.5 | 2.381.40 | -0.038.5 |
| TO | 2.441.49 | 0.059 | 3.021.51 | 0.076 | 3.001.59 | 0.166 | 2.821.61 | 0.046 |
| curie | 3.230.51 | 0.0138 | 2.820.45 | 0.0250 | 2.860.37 | 0.0965.5 0.5262 | 3.010.43 | 0.1161 |
| davinci | 4.070.35 | 0.3545.5 | 4.260.45 | 0.4242 | 3.840.42 | 4.020.74 | 0.6942.5 | |
| ChatGPT | 2.980.76 | 2.480.71 | 1.590.67 | 2.021.21 | ||||
| 评估者 | 语法性 (Grammaticality) | IAA% | 连贯性 (Cohesiveness) | IAA% | 好感度 (Likability) | IAA% | 相关性 (Relevance) | IAA% |
|---|---|---|---|---|---|---|---|---|
| * * 人工撰写故事* * | ||||||||
| Human TO | 3.760.95 2.551.47 | 0.3320.5 0.1610 | 4.290.82 2.981.45 | 0.3227 0.114 | 3.781.10 3.181.53 | 0.089.5 0.127 | 3.351.48 2.931.64 | 0.058 0.026 |
| curie | 3.190.47 | 0.0746.5 | 2.820.46 | 0.0147.5 | 2.850.37 | 0.110.65 | 3.060.40 | 0.110.64 |
| davinci | 4.220.38 | 0.2635 | 4.540.47 | 0.3739.5 | 3.990.38 | 0.4968.5 | 4.400.79 | 0.7148.5 |
| ChatGPT | 3.830.60 | 3.550.88 | 2.440.89 | 3.291.50 | ||||
| * * GPT-2生成故事* * | ||||||||
| Human | 3.560.91 | 0.1019.5 | 3.191.07 | 0.1417 | 2.591.29 | -0.213.5 | 2.381.40 | -0.038.5 |
| TO | 2.441.49 | 0.059 | 3.021.51 | 0.076 | 3.001.59 | 0.166 | 2.821.61 | 0.046 |
| curie | 3.230.51 | 0.0138 | 2.820.45 | 0.0250 | 2.860.37 | 0.0965.5 0.5262 | 3.010.43 | 0.1161 |
| davinci | 4.070.35 | 0.3545.5 | 4.260.45 | 0.4242 | 3.840.42 | 4.020.74 | 0.6942.5 | |
| ChatGPT | 2.980.76 | 2.480.71 | 1.590.67 | 2.021.21 |
Table 1: LLM evaluation and human evaluation results of human-written stories and GPT-2-generated stories. For each evaluated attribute, we report its mean Likert scale and the standard deviation. We also report the interannotator agreement (IAA) among three annotators using Kri pp end orff’s $\alpha$ . The subscript in the IAA column $(%)$ is used to denote the percentage of the stories where all three annotators exactly agree on a rating.
表 1: 人类撰写故事与GPT-2生成故事的大语言模型评估及人工评估结果。针对每个评估属性,我们报告其平均李克特量表分值及标准差。同时使用Krippendorff的$\alpha$系数汇报三名标注者间的评分一致性(IAA)。IAA列中的下标$(%)$表示三位标注者对评分完全一致的故事占比。
are two Instruct GP T models, and the latter is the stronger model; we will use Instruct GP T to refer to these two models. We query the Instruct GP T using the official API provided by OpenAI. We use nucleus sampling with $p=0.9$ to generate the answer from T0 and Instruct G PTs. We sample three answers from LLMs to stimulate the result of asking the model to rate the same story three times. We query ChatGPT using the user interface recently released by OpenAI. Unlike Instruct GP T, we cannot control the parameters used for generating the response from ChatGPT. Because ChatGPT limits the maximum number of queries per user, we only sample one response for each question.
有两种Instruct GPT模型,后者性能更强;本文用Instruct GPT统称这两个模型。我们通过OpenAI官方API调用Instruct GPT,使用$p=0.9$的核心采样方法从T0和Instruct GPT生成回答。为模拟对同一故事进行三次评分的效果,我们从大语言模型中采样三个答案。通过OpenAI最新发布的用户界面调用ChatGPT时,与Instruct GPT不同,我们无法控制ChatGPT的响应生成参数。由于ChatGPT限制了单用户最大查询次数,每个问题仅采样一个响应。
For human evaluation, we do not use the commonly used AMT for human evaluation because Karpinska et al. (2021) has already shown that the results obtained using AMT are highly questionable. Following the recommendation of the prior works, we hire three certified English teachers using an online freelancer platform, UpWork. Teachers are familiar with evaluating the essays of students, making them the expert evaluators in our task. The details about recruiting human evaluators are in Appendix C.1. Each LLM and each English teacher rates the 200 human-written stories and 200 GPT-2-generated stories.
在人类评估方面,我们未采用常见的AMT平台进行人工评估,因为Karpinska等人 (2021) 已证明使用AMT获得的结果存在较大争议。遵循先前研究的建议,我们通过UpWork在线自由职业平台聘请了三位持证英语教师。这些教师熟悉学生作文评估流程,因此成为我们任务中的专业评审员。招募人类评估者的具体细节见附录C.1。每位大语言模型和英语教师需对200篇人工撰写故事及200篇GPT-2生成故事进行评分。
3.3 Experiment Results
3.3 实验结果
The LLM evaluation and human evaluation results of open-ended story generation are presented in
大语言模型评估和人类评估的开放式故事生成结果展示在
Table 1. We report the mean and standard deviation of the Likert scores obtained from LLM evaluation and human evaluation and show the inter-annotator agreement (IAA) using two different metrics: (1) the Kri pp end orff’s $\alpha$ , and (2) the percentage of the stories where three evaluators give the exact same rating.2 The main observations from Table 1 are discussed as follows.
表 1: 我们报告了大语言模型评估和人类评估获得的李克特量表得分的均值与标准差,并使用两种不同指标展示标注者间一致性 (IAA):(1) Krippendorff's $\alpha$,(2) 三位评估者给出完全相同评分的案例百分比。表 1 的主要观察结果如下。
Expert human evaluators prefer humanwritten stories: Human evaluation result serves as some kind of ground truth of the LLM evaluation. For all four attributes, teachers rate the human- written stories higher than GPT-2-generated stories. This indicates that experts are able to distinguish the quality difference between model-generated stories and human-written stories. Based on the IAA, we also find that the agreements among experts are lower on GPT-2-generated texts and on the likability. This shows that experts tend to have less agreement on model-generated texts and on a subjective attribute (likability), agreeing with the results in Karpinska et al. (2021).
专家人类评估者更偏好人类撰写的故事:人类评估结果可作为大语言模型评估的一种基准。在全部四项指标中,教师对人类撰写故事的评分均高于GPT-2生成的故事。这表明专家能够区分模型生成故事与人类撰写故事的质量差异。根据评估者间一致性(IAA)分析,我们还发现专家对GPT-2生成文本及"喜爱度"指标的评分一致性较低。这说明专家对模型生成文本和主观属性(喜爱度)的评判标准差异较大,该结论与Karpinska等人(2021)的研究结果一致。
T0 and text-curie-001 do not show clear preference toward human-written stories: For T0, we can see that T0 rates human-written stories higher than GPT-2-generated stories on grammatically, likability, and relevance. However, the rating differences between the human-written and model-generated stories do not achieve statistical significance for grammatical it y and relevance; the $p$ -value obtained by Welch’s $t\cdot$ -test is much larger than 0.05. The result of text-curie-001 is similar to T0: text-curie-001 do not rate humanwritten stories higher than model-generated stories. It can also be observed that for T0, the IAA in terms of the percentage of exact agreement among three different sampled answers is overall very low. This indicates that given the same sample, T0 is likely to give a different rating for the three sampled answers. The result implies that T0 does not assign a high probability to a specific rating, so different scores are all likely to be sampled. This shows that even if LLMs are specifically fine-tuned to better perform zero-shot in-context learning and trained to better follow human instructions, these do not make them capable of assessing open-ended story generation as human experts can.
T0和text-curie-001未表现出对人工撰写故事的明显偏好:就T0而言,我们发现其在语法正确性、喜爱度和相关性三个维度上对人工撰写故事的评分高于GPT-2生成内容。但人工撰写与模型生成故事在语法正确性和相关性方面的评分差异未达到统计学显著性(Welch's $t\cdot$-test检验获得的$p$值远大于0.05)。text-curie-001的结果与T0类似:该模型对人工撰写故事的评分并未显著高于模型生成内容。值得注意的是,T0在三次抽样答案完全一致率(IAA)方面整体表现极低,这表明给定相同样本时,T0很可能对三次抽样给出不同评分。该结果意味着T0不会对特定评分赋予高概率,因此可能采样到各种不同分数。这说明即使大语言模型经过专门微调以提升零样本上下文学习能力,并通过训练更好地遵循人类指令,这些改进仍无法使其像人类专家那样评估开放式故事生成任务。
text-davinci-003 shows clear preference toward human-written stories just like English teachers: text-davinci-003 rates humanwritten stories much higher than model-generated stories on all four attributes, which is in accordance with the result produced by human experts. By Welch’s $t$ -test, we find that the higher ratings on human-written stories are all statistically significant. In prior work, researchers have found that workers recruited on AMT cannot distinguish between human-written and GPT-2-generated stories (Karpinska et al., 2021); combining their result with our result, we can see that LLM evaluation using text-davinci-003 yields more convincing results than using human evaluation on AMT for open-ended story generation. The results show that text-davinci-003 model can perform basic evaluations such as checking for grammatical errors in stories. Additionally, the model excels in assessing the relevance of a story to a prompt, which involves more complex reasoning over the connection between the two. We also find the Kri pp end orff’s $\alpha$ of text-davinci-003 is much higher than T0 and text-curie-001, indicating that the rating by text-davinci-003 is more consistent among different samplings of the generated answers.
text-davinci-003与英语教师一样明显偏好人类撰写的故事:该模型在四个属性上对人类创作故事的评分均显著高于模型生成内容,与人类专家评估结果一致。通过Welch's $t$检验,我们发现人类故事的高评分均具有统计学显著性。先前研究表明,AMT平台招募的评估者无法区分人类撰写与GPT-2生成的故事(Karpinska等人,2021);结合本研究结果可见,在开放式故事生成任务中,使用text-davinci-003进行大语言模型评估比AMT人工评估更具说服力。结果表明text-davinci-003能完成基础评估(如语法错误检查),并擅长评估故事与提示的相关性——这需要更复杂的逻辑推理。此外,text-davinci-003的Krippendorff's $\alpha$系数显著高于T0和text-curie-001,表明其在不同答案样本间的评分一致性更高。
ChatGPT rates like human experts and can explain its own decision well: ChatGPT also shows a clear preference for human-written stories, and the preference toward human written-stories is statistically significant. When we query ChatGPT using the OpenAI user interface, we find several interesting observations: (1): ChatGPT is able to provide a detailed explanation of why it gives a certain rating. It will reference the sentences in the stories and prompts to support its rating. (2): ChatGPT sometimes refuses to rate the likability of the story because "I am an AI and I do not have the ability to experience enjoyment". In such cases, we regenerate the response until it gives a rating. (3): we find that ChatGPT tends to rate low likability on violent or impolite stories, which is likely because it is trained to provide safe and unharmful replies, making ChatGPT dislike brutal and profane stories.
ChatGPT评分如人类专家且能合理解释其决策:ChatGPT对人工撰写故事表现出明显偏好,且这种偏好在统计学上具有显著性。通过OpenAI用户界面查询时,我们发现以下有趣现象:(1) ChatGPT能详细解释评分依据,会引用故事中的句子和提示来佐证其评分;(2) 有时会以"我是AI无法体验愉悦感"为由拒绝评分,此时我们需重新生成响应直至获得评分;(3) ChatGPT倾向于对暴力或不文明故事给予低分,这可能是因其训练目标要求提供安全无害的回复,导致其排斥粗野内容。
Experts mostly agree with the ratings and explanations of ChatGPT: We randomly select the answers on four stories by ChatGPT and ask the English teachers if they agree with the reasoning and rating of ChatGPT3. The teachers mostly agree with the rating and consider the explanation from ChatGPT reasonable. Interestingly, one teacher told us she cannot agree with ChatGPT’s rating on grammatical it y because ChatGPT considers punctuation errors as grammar errors, but she does not think punctuation errors are grammar errors. This shows that individuals have their own standards for ratings and this is also the case for LLMs.
专家大多认同ChatGPT的评分和解释:我们随机选取了ChatGPT对四个故事的答案,并请英语教师评估其推理和评分是否合理。教师们普遍认可评分结果,认为ChatGPT的解释具有合理性。有趣的是,一位教师表示无法认同ChatGPT在语法层面的评分,因为其将标点错误归类为语法错误,而她认为标点错误不属于语法范畴。这表明个体对评分标准存在主观差异,大语言模型同样存在此类现象。
text-davinci-003 tends to give higher ratings and ChatGPT is the opposite: The rating on the same attribute of the same type of text tends to be higher for text-davinci-003 compared with human rating; contrarily, ChatGPT is more fastidious and prone to give lower scores. This shows that different LLMs have distinct tendencies regarding the rating. While the absolute values of the scores rated by text-davinci-003, ChatGPT, and human differ, they all rate human-written texts higher than GPT-2-generated stories. The absolute number reflects the bias or belief of the evaluator; as long as one uses the same evaluators to assess different systems, the comparison is meaningful.
text-davinci-003倾向于给出更高评分而ChatGPT则相反:对于同类文本的相同属性,text-davinci-003给出的评分往往高于人类评分;相反,ChatGPT更为严苛且倾向于给出更低分。这表明不同大语言模型在评分方面存在明显倾向性。虽然text-davinci-003、ChatGPT和人类给出的评分绝对值存在差异,但三者都认为人类撰写的文本优于GPT-2生成的故事。评分绝对值反映了评估者的偏见或信念;只要使用相同的评估者来比较不同系统,这种对比就具有意义。
3.3.1 Does LLM and Human Evaluators Agree on the Rating of Individual Stories?
3.3.1 大语言模型与人类评估者对单个故事的评分是否一致?
We have found in Table 1 that the ratings of text-davinci-003 and ChatGPT show a strong preference toward human-written stories just like English teachers. However, it is unclear whether those LLMs agree with the teachers’ rating on each individual story. Precisely, when English teachers rate a story higher, do LLMs also rate the story higher? To answer this question, we calculate Kendall’s $\tau$ correlation coefficient between the ratings of text-davinci-003 and English teachers. We choose to use the correlation coefficient instead of the inter-annotator agreement score because IAA mainly cares if two annotators agree on the exact ratings, while the correlation coefficient focus on the question: "when annotator A rates one story higher, does annotator B also rate the story higher?" (Amidei et al., 2019). We calculate Kendall’s $\tau$ for four rating attributes as follows: For each story and each rating attribute, we calculate the average rating of the three English teachers and calculate the average rating of the three scores given by the text-davinci-003 (which is obtained from three independent samples). For each attribute, we collect the average rating of teachers into a vector $A\in\mathbb{R}^{200}$ , where each entry is the average rating of a story; likewise, we construct a vector $B\in\mathbb{R}^{200}$ for the average ratings of davinci. Next, we calculate Kendall’s $\tau$ correlation coefficient between $A$ and $B$ .
我们在表1中发现,text-davinci-003和ChatGPT的评分与英语教师一样,都表现出对人类撰写故事的强烈偏好。然而,这些大语言模型是否在每篇故事的具体评分上与教师保持一致尚不明确。具体而言,当英语教师给某篇故事打出更高分时,大语言模型是否也会给出更高评分?为解答这个问题,我们计算了text-davinci-003与英语教师评分之间的Kendall's $\tau$相关系数。选择相关系数而非标注者间一致性分数(IAA)的原因是:IAA主要关注两位标注者是否给出完全一致的评分,而相关系数着重回答"当标注者A对某篇故事评分较高时,标注者B是否也会给出更高评分?"(Amidei et al., 2019)。我们按以下方式计算四个评分维度的Kendall's $\tau$:针对每篇故事和每个评分维度,先计算三位英语教师的平均评分,再计算text-davinci-003三次独立采样给出的平均分(各维度分别处理)。将教师平均评分存入向量$A\in\mathbb{R}^{200}$(每个元素对应一篇故事的平均分),同理构建text-davinci-003的评分向量$B\in\mathbb{R}^{200}$,最终计算向量$A$与$B$之间的Kendall's $\tau$相关系数。
Table 2: The Kendall’s $\tau$ correlation coefficient be- tween English teachers and text-davinci-003.
| Story Writer | Human GPT-2 |
| Grammaticality | 0.14 0.12 |
| Cohesiveness | 0.18 0.14 |
| Likability | 0.19 0.22 |
| Relevance | 0.38 0.43 |
表 2: 英语教师与text-davinci-003之间的Kendall $\tau$相关系数
| 故事作者 | 人类 GPT-2 |
|---|---|
| 语法性 (Grammaticality) | 0.14 0.12 |
| 连贯性 (Cohesiveness) | 0.18 0.14 |
| 喜爱度 (Likability) | 0.19 0.22 |
| 相关性 (Relevance) | 0.38 0.43 |
The Kendall’s $\tau$ between teacher ratings and LLM ratings is shown in Table 2.4 We find that for all four attributes and for both human-written and GPT-2-generated stories, we observe weak to strong positive correlations between teachers’ ratings and text-davinci-003’s ratings. All the correlations have $p$ -values less than 0.05. Hence, we can say that when teachers rate a story higher, text-davinci-003 also rates it higher to a certain extent. We also observe that Kendall’s $\tau$ for different attributes are quite different: relevance has the strongest correlation while grammatical it y has the weakest correlation. This is possibly because rating relevance is rather straightforward, which requires checking if the content in the prompt is mentioned in the story. On the contrary, what should be considered when rating grammatical it y is not clearly stated in our instructions, so the LLM may have a different rubric compared with English teachers. We also calculate the average Kendall’s $\tau$ between a pair of English teachers, and we find a weak correlation on grammatical it y between the rating of two teachers, while the correlation of the rating on relevance is much stronger. The result is presented in Table 6 in Appendix.
教师评分与大语言模型评分之间的Kendall's $\tau$ 值如表2所示。我们发现,对于所有四个属性以及人类撰写和GPT-2生成的故事,教师评分与text-davinci-003评分之间存在弱到强的正相关性。所有相关性的$p$值均小于0.05。因此可以说,当教师对故事评分较高时,text-davinci-003也会在一定程度上给予更高评分。我们还观察到不同属性的Kendall's $\tau$值差异较大:相关性(relevance)的关联性最强,而语法性(grammaticality)最弱。这可能是因为评分相关性相对直接,只需检查提示中的内容是否在故事中被提及。相反,我们的指导说明中并未明确规定评分语法性时应考虑哪些因素,因此大语言模型可能采用了与英语教师不同的评分标准。我们还计算了两位英语教师之间的平均Kendall's $\tau$值,发现两位教师在语法性评分上相关性较弱,而在相关性评分上的关联性要强得多。具体结果见附录表6。
3.3.2 Variance due to Different Instructions
3.3.2 不同指令导致的方差
LLMs have been shown to be sensitive to the instructions used to query the LLM sometimes (Zhao et al., 2021; Sanh et al., 2022). To investigate how varying the task instructions and questions can affect the LLM evaluation result for open-ended story generation, we change the instructions and questions and see how the LLM evaluation result changes. We experiment with two different instructions by changing the instruction or question in Figure 1: (1) We prepend the sentence, "(You are a human worker hired to rate the story fragment.)", in front of the task instruction in Figure 1. We try to provide the LLM a persona for it to better understand its role. This is inspired by previous work that reported GPT-3 can yield different results when giving them a persona (Zeng et al., 2022). (2) We ask the LLMs to explain their decision by appending the following sentence after the question: Please also explain your decision. Here, we would like to know if LLM will rate the stories differently when they are asked to justify their decision. We use text-davinci-003 as the LLM in this experiment since it achieves similar results with expert human evaluation based on Table 1, and it is more accessible than ChatGPT.
研究表明,大语言模型对查询指令有时会表现出敏感性(Zhao et al., 2021; Sanh et al., 2022)。为探究不同任务指令和提问方式如何影响开放式故事生成的模型评估结果,我们通过修改指令和问题来观察评估结果变化。我们通过修改图1中的指令或问题进行了两种实验:(1) 在图1任务指令前添加句子"(You are a human worker hired to rate the story fragment.)",试图通过赋予模型人格角色来提升其任务理解能力。该设计灵感来自Zeng等人(2022)的研究,他们发现赋予GPT-3不同人格会导致输出差异。(2) 在问题后追加"请解释你的评分理由",旨在探究要求模型说明决策依据是否会改变其评分倾向。本实验选用text-davinci-003作为评估模型,因其在表1中显示出与人类专家评估相近的效果,且比ChatGPT更易于调用。
The results are shown in the upper block in Table 3. We observe that for grammatical it y and cohesiveness, the scores obtained from different instructions are quite close: the rating changes due to different instructions are less than 0.1. For the other two attributes, the score changes are slightly larger but still in the range of 0.25. Despite that there are small variations due to different instructions, these variances still do not change the conclusion that "LLM rates human-written stories higher than GPT-2-generated stories". Thus, different instructions do not change the relative ranking of GPT-2- generated and human-written stories. In summary, as long as the stories are evaluated using the same instructions using LLM evaluation, such evaluation and comparison are meaningful.
结果如表3上方区域所示。我们观察到在语法正确性和连贯性方面,不同指令获得的分数非常接近:由指令差异导致的评分变化小于0.1。其余两个属性的分数波动稍大,但仍保持在0.25范围内。尽管不同指令会引发微小差异,这些偏差仍不会改变"大语言模型对人类撰写故事的评分高于GPT-2生成故事"的结论。因此,不同指令不会改变GPT-2生成故事与人类撰写故事的相对排序。综上所述,只要采用相同指令通过大语言模型进行故事评估,此类评价与对比就具有意义。
| Setup | Grammaticality | Cohesiveness | Likability | Relevance | ||||
| Human | GPT-2 | Human | GPT-2 | Human | GPT-2 | Human | GPT-2 | |
| Different instructions (Section 3.3.2) | ||||||||
| Original | 4.220.38 | 4.070.35 | 4.540.45 | 4.260.45 | 3.990.38 | 3.840.42 | 4.400.79 | 4.020.74 |
| (1) )+persona (2) + explain | 4.290.45 | 4.010.45 | 4.600.49 | 4.270.50 | 4.050.39 | 3.870.39 | 4.550.70 | 4.250.77 |
| 4.240.42 4.050.25 | 4.610.49 | 4.320.51 | 4.150.44 | 3.980.34 | 4.350.75 | 4.030.56 | ||
| Different sampling temperature T (Section 3.3.3) | ||||||||
| T =1.0 | ||||||||
| T =0.7 | 4.220.38 | 4.070.35 | 4.540.45 | 4.260.45 | 3.990.38 | 3.840.42 | 4.400.79 | 4.020.74 |
| T = 0.3 | 4.180.35 | 4.060.33 | 4.520.48 | 4.230.43 4.140.39 | 3.960.34 3.950.26 | 3.820.42 | 4.360.77 | 3.950.72 |
| T=0 | 4.130.33 4.070.27 | 3.990.25 3.990.18 | 4.480.49 4.490.50 | 4.090.34 | 3.950.25 | 3.820.41 3.820.40 | 4.340.75 4.320.75 | 3.930.67 3.920.66 |
| 设置 | 语法性 | 连贯性 | 好感度 | 相关性 | ||||
|---|---|---|---|---|---|---|---|---|
| 人工 | GPT-2 | 人工 | GPT-2 | 人工 | GPT-2 | 人工 | GPT-2 | |
| 不同指令 (第3.3.2节) | ||||||||
| 原始 | 4.22±0.38 | 4.07±0.35 | 4.54±0.45 | 4.26±0.45 | 3.99±0.38 | 3.84±0.42 | 4.40±0.79 | 4.02±0.74 |
| (1) +人物设定 (2) +解释 | 4.29±0.45 | 4.01±0.45 | 4.60±0.49 | 4.27±0.50 | 4.05±0.39 | 3.87±0.39 | 4.55±0.70 | 4.25±0.77 |
| 4.24±0.42 | 4.05±0.25 | 4.61±0.49 | 4.32±0.51 | 4.15±0.44 | 3.98±0.34 | 4.35±0.75 | 4.03±0.56 | |
| 不同采样温度T (第3.3.3节) | ||||||||
| T=1.0 | ||||||||
| T=0.7 | 4.22±0.38 | 4.07±0.35 | 4.54±0.45 | 4.26±0.45 | 3.99±0.38 | 3.84±0.42 | 4.40±0.79 | 4.02±0.74 |
| T=0.3 | 4.18±0.35 | 4.06±0.33 | 4.52±0.48 | 4.23±0.43 | 3.96±0.34 | 3.82±0.42 | 4.36±0.77 | 3.95±0.72 |
| 4.14±0.39 | 3.95±0.26 | |||||||
| T=0 | 4.13±0.33 | 3.99±0.25 | 4.48±0.49 | 4.09±0.34 | 3.95±0.25 | 3.82±0.41 | 4.34±0.75 | 3.93±0.67 |
| 4.07±0.27 | 3.99±0.18 | 4.49±0.50 | 3.82±0.40 | 4.32±0.75 | 3.92±0.66 |
Table 3: Understanding the variance of LLM evaluation. For each of the four attributes evaluated, the left column is the mean and standard deviation of human-written stories and the right column is those of GPT-2-generated stories. The upper block shows the rating change due to different instructions (Section 3.3.2), and the lower block is the result of changing the temperature $T$ used for generating the LLM’s output (Section 3.3.3).
表 3: 大语言模型评估的方差分析。针对四个评估属性,左列显示人工撰写故事的平均值和标准差,右列则为 GPT-2 生成故事的对应数据。上方区块展示因不同指令导致的评分变化 (第 3.3.2 节),下方区块呈现改变温度参数 $T$ 后对大语言模型输出的影响结果 (第 3.3.3 节)。
3.3.3 Variance due to Different Sampling Parameters
3.3.3 不同采样参数导致的方差
When generating the answers from the LLM, we must choose a set of hyper parameters for generation, including the temperature $T$ and the probability $p$ used in nucleus sampling (Holtzman et al., 2020). To understand whether different sampling parameters change the LLM evaluation result, we modify the temperature used for sampling and keep the $p$ in nucleus sampling fixed to 0.9 when generating the answers from text-davinci-003. We do not simultaneously vary $T$ and $p$ since the two parameters are both used to control the diversity of the output, it is enough to change only one of the two parameters, as recommended in the OpenAI.
在从大语言模型生成答案时,我们必须选择一组生成超参数,包括温度 $T$ 和核采样 (nucleus sampling) 中使用的概率 $p$ (Holtzman et al., 2020)。为了解不同采样参数是否会改变大语言模型评估结果,我们在使用 text-davinci-003 生成答案时修改了采样温度,同时将核采样的 $p$ 固定为 0.9。我们没有同时调整 $T$ 和 $p$,因为这两个参数都用于控制输出多样性,按照 OpenAI 的建议,仅改变其中一个参数就足够了。
The results of varying $T$ from 1 to 0 are shown in the lower block in Table 3. We observe an interesting trend as $T$ varies from 1 to 0: the average rating slightly drops in most cases. Considering that $T=0$ is simply argmax sampling, the result indicates that the response of the LLM with the highest probability tends to give lower scores. Despite this interesting trend, the LLM consistently rates human-written stories higher than GPT-2-generated stories. While not shown in Table 3, we find that the IAA increases as the temperature decreases. This is expected since lower temperature means less diversity during the LLM sampling, causing the sampled ratings to agree more closely. In summary, changing the instructions and temperatures can slightly change the absolute value of the rating given by LLM but does not change the LLM’s preference on human-written stories. The overall result in this section shows that LLM evaluation is useful in evaluating open-ended story generation.
表3下半部分展示了$T$从1变化到0的结果。我们观察到随着$T$从1降至0,出现了一个有趣现象:多数情况下平均评分会轻微下降。考虑到$T=0$即argmax采样,该结果表明大语言模型最高概率生成的响应往往给出更低评分。尽管存在这一有趣趋势,大语言模型始终对人工撰写故事的评分高于GPT-2生成的故事。虽然未在表3中体现,我们发现随着温度降低,评分者间一致性(IAA)会提升。这是预期的结果,因为更低的温度意味着大语言模型采样时多样性降低,使得采样评分更趋一致。总体而言,改变指令和温度会轻微影响大语言模型给出的评分绝对值,但不会改变其对人工撰写故事的偏好。本节整体结果表明,大语言模型评估在开放式故事生成任务中具有实用价值。
4 Example Task 2: Adversarial Attack
4 示例任务2: 对抗攻击
As another application, we use LLM evaluation to rate the texts generated by adversarial attacks.
作为另一项应用,我们利用大语言模型 (LLM) 评估来对对抗攻击生成的文本进行评分。
4.1 Task Introduction
4.1 任务介绍
Given a trained text classifier and a benign (nonadversarial) testing sample that the text classifier can correctly classify, an adversarial attack aims to craft an adversarial sample that makes the classifier make a wrong prediction. A special type of adversarial attack is called synonym substitution attacks (SSAs) (Alzantot et al., 2018), where the adversarial sample is created by replacing some words with their synonyms in the benign sample. By replacing words with their synonym, the semantics of the benign sample should be preserved in the adversarial sample and make the adversarial perturbation imperceptible to humans. While conceptually reasonable, it has recently been shown that many SSAs often yield ungrammatical and unnatural adversarial samples that significantly change the meaning of the benign sample (Hauser et al., 2021; Chiang and Lee, 2022). To evaluate the quality of adversarial samples, human evaluation is invaluable and widely used in prior works. In our experiment here, we would like to see whether the LLMs can rate the quality of adversarial samples like human experts. Adversarial samples are not normal texts, so the LLMs may not have seen such abnormal inputs during training. It would be interesting to know how LLMs rate these adversarial samples.
给定一个训练好的文本分类器和一个分类器能正确分类的良性(非对抗性)测试样本,对抗攻击的目标是制作一个使分类器做出错误预测的对抗样本。一种特殊类型的对抗攻击称为同义词替换攻击(SSA)(Alzantot et al., 2018),其通过在良性样本中用同义词替换部分单词来生成对抗样本。通过同义词替换,良性样本的语义应在对抗样本中得以保留,并使对抗扰动对人类难以察觉。虽然概念上合理,但最近研究表明,许多SSA生成的对抗样本往往存在语法错误且不自然,显著改变了良性样本的原意(Hauser et al., 2021; Chiang and Lee, 2022)。为评估对抗样本质量,人工评估具有不可替代的价值,并被广泛用于先前研究。本实验中,我们希望探究大语言模型是否能像人类专家一样评估对抗样本质量。由于对抗样本并非正常文本,大语言模型在训练期间可能未接触过此类异常输入。观察大语言模型如何评价这些对抗样本将十分有趣。
Table 4: Mean Likert score of LLM evaluation and human evaluation result on fluency (Fluent) of the benign and adversarial samples and meaning preserving (Mean.) between the news title before and after adversarial attacks.
| Human evaluate | LLMevaluate | |||
| Fluent | Mean. | Fluent | Mean. | |
| Benign | 4.55 | - | 4.32 | 5.00f |
| Textfooler | 2.17 | 1.88 | 2.12 | 2.06 |
| PWWS | 2.16 | 1.85 | 2.42 | 2.49 |
| BAE | 3.01 | 3.02 | 3.71 | 3.71 |
表 4: 大语言模型评估与人工评估在良性样本和对抗样本流畅性(Fluent)及对抗攻击前后新闻标题意义保持度(Mean.)上的平均Likert分数
| 人工评估 | 大语言模型评估 | |||
|---|---|---|---|---|
| Fluent | Mean. | Fluent | Mean. | |
| Benign | 4.55 | - | 4.32 | 5.00f |
| Textfooler | 2.17 | 1.88 | 2.12 | 2.06 |
| PWWS | 2.16 | 1.85 | 2.42 | 2.49 |
| BAE | 3.01 | 3.02 | 3.71 | 3.71 |
4.2 Experiment Setup
4.2 实验设置
We select three different classic SSAs: Textfooler (Jin et al., 2020), PWWS (Ren et al., 2019), and BAE (Garg and Ramakrishna n, 2020); these attacks are predominantly used as strong baselines in the literature of SSAs nowadays. We use these three SSAs to attack a BERT-base-uncased model (Devlin et al., 2019) fine-tuned on AG-News (Zhang et al., 2015), a news title classification dataset. For each SSA, we randomly select 100 pairs of benign and adversarial samples and use LLMs to evaluate their quality. We show the result of using ChatGPT as LLM here since it can better explain its decision. Following the suggestions of prior works (Morris et al., 2020), we evaluate the quality of the adversarial samples from two aspects: the fluency and meaning preservation. For fluency, we present the LLM with one news title (either benign or adversarial sample) and the following question: How natural and fluent is the text of the news title? (on a scale of 1-5, with 1 being the lowest). For meaning preserving, we present the LLM with both the benign and the adversarial sample, and prompt the LLM to answer this question: Do you agree that the meaning (or semantics) of news title 1 is preserved in news title 2? (on a scale of 1-5, with 1 being the strongly disagree and 5 being strongly agree.) The exact instruction and formatting are presented in Appendix D.2.3. We also ask three English teachers to rate the fluency and meaning preserving of the samples. The task instructions and questions are formatted the same as in LLM evaluation.
我们选取了三种经典语义保持攻击(SSA)方法:Textfooler (Jin等人,2020)、PWWS (Ren等人,2019)和BAE (Garg和Ramakrishna n,2020);这些攻击方法在当前SSA研究中常被用作强基线。我们使用这三种SSA方法攻击基于BERT-base-uncased模型(Devlin等人,2019)在AG-News新闻标题分类数据集(Zhang等人,2015)上微调后的模型。针对每种SSA方法,我们随机选取100组原始样本与对抗样本,并利用大语言模型评估其质量。本文展示使用ChatGPT作为大语言模型的评估结果,因其能更好解释判断依据。根据前人研究建议(Morris等人,2020),我们从流畅性和语义保持性两个维度评估对抗样本质量:对于流畅性评估,我们向大语言模型提供新闻标题(原始样本或对抗样本)并提问:"该新闻标题文本的自然流畅程度如何?(1-5分制,1分为最低)";对于语义保持性评估,我们同时提供原始样本和对抗样本,并提示大语言模型回答:"你是否认为新闻标题1的语义在新闻标题2中得到了保持?(1-5分制,1分表示强烈反对,5分表示强烈赞同)"。具体指令格式详见附录D.2.3。我们还邀请三位英语教师对样本的流畅性和语义保持性进行评分,任务指令与问题设置与大语言模型评估保持一致。
4.3 Experiment Result
4.3 实验结果
The results are presented in Table 4. We can see that English teachers rate the adversarial samples generated by SSAs much lower than benign samples in terms of fluency and meaning preserving, this result is in line with recent observations on the quality of adversarial samples (Hauser et al., 2021; Chiang and Lee, 2022). Before interpreting the result of LLM evaluation, we first conduct a sanity check on whether the LLM understands the task. We ask the LLM to rate the meaning preserving of two benign samples that are exactly the same. Ideally, the LLM should always give a score of 5, meaning that it strongly agrees that the meanings are not changed. The result of this sanity check is the entry with $\dagger$ in Table 4, which is a perfect 5.00. ChatGPT often says that "the two titles are identical so I rate a 5 (strongly agree)", showing that ChatGPT understands what the task is about.
结果如表4所示。我们可以看到,英语教师在流畅性和意义保留方面对SSAs生成的对抗样本评分远低于良性样本,这一结果与近期关于对抗样本质量的观察结果一致(Hauser et al., 2021; Chiang and Lee, 2022)。在解释大语言模型评估结果前,我们首先对其是否理解任务进行了基础测试。我们让大语言模型对两个完全相同的良性样本进行意义保留评分。理想情况下,模型应始终给出5分,表示完全认同意义未改变。表4中带$\dagger$标记的条目即为该测试结果,完美达到5.00分。ChatGPT经常回应"两个标题完全相同,因此我打5分(强烈认同)",这表明ChatGPT理解该任务的实质。
Next, we turn our attention to the LLM evaluation results of the adversarial samples. We observe that ChatGPT tends to rate adversarial samples higher than English teachers, meaning that ChatGPT is less harsh on the unnatural and artificial parts in the adversarial samples. We conduct the same experiment using text-davinci-003 and find similar results. Although ChatGPT rates adversarial samples higher than the teachers, ChatGPT still rates adversarial samples significantly lower than benign samples. ChatGPT also agrees with the English teachers that the adversarial samples generated by BAE are better than the samples generated by Textfooler and PWWS.
接下来,我们将关注对抗样本的大语言模型(LLM)评估结果。我们发现ChatGPT倾向于给对抗样本打出比英语老师更高的分数,这意味着ChatGPT对对抗样本中不自然和人工痕迹的评判较为宽松。我们使用text-davinci-003进行了相同实验,结果相似。虽然ChatGPT给对抗样本的评分高于教师,但仍显著低于良性样本。ChatGPT与英语教师的共识是:BAE生成的对抗样本质量优于Textfooler和PWWS生成的样本。
Interestingly, we find that ChatGPT rates PWWS to be more natural than Textfooler, while such a rating difference is not seen in the expert human evaluation. At first sight, this means that ChatGPT is inconsistent with human evaluation results. However, by scrutinizing the human evaluation results, we find that two teachers rate PWWS higher than Textfooler while one teacher rates PWWS lower than Textfooler. This indicates that ChatGPT actually agrees with the majority of human experts. Overall, LLM can rank the quality of adversarial texts and benign texts like most human experts.
有趣的是,我们发现ChatGPT认为PWWS比Textfooler更自然,而专家人工评估中并未出现这种评分差异。乍看之下,这意味着ChatGPT与人类评估结果不一致。然而,通过仔细检查人工评估结果,我们发现两位教师给PWWS的评分高于Textfooler,而一位教师给PWWS的评分低于Textfooler。这表明ChatGPT实际上与大多数人类专家的意见一致。总体而言,大语言模型能够像大多数人类专家一样对对抗性文本和良性文本的质量进行排序。
5 Discussions
5 讨论
In this paper, we propose to use LLM for evaluating the quality of texts to serve as an alternative to human evaluation. To demonstrate the potential of LLM evaluation, we use LLMs to rate the quality of texts in two distinct tasks: open-ended story generation and adversarial attacks. We show that even if LLMs have exceptional zero-shot in-context learning ability, they are not always suitable to be used for LLM evaluation. Still, we find that the best Instruct GP T and ChatGPT can rate the quality of texts like human experts on the two tasks we used as examples. Overall, the results in this paper demonstrate that LLM evaluation has the potential to be used to evaluate NLP systems and algorithms.
本文提出使用大语言模型(LLM)评估文本质量,作为人工评估的替代方案。为展示LLM评估的潜力,我们在开放域故事生成和对抗攻击两个不同任务中使用LLM对文本质量进行评分。研究表明,尽管大语言模型具备卓越的零样本上下文学习能力,但并非所有情况都适合用于LLM评估。然而我们发现,最优的InstructGPT和ChatGPT在我们选取的两个任务中能像人类专家一样评估文本质量。总体而言,本文结果证明LLM评估具备评估NLP系统与算法的应用潜力。
Pros of LLM evaluation There are several benefits of LLM evaluation, compared to human evaluation. First, LLM evaluation is more reproducible. Human evaluation results are hard to reproduce as it is difficult to hire the same group of evaluators, and it is hard to compare the results of similar experiments even if they use the same instructions, recruitment platform, and qualifications for the evaluators. On the contrary, LLM evaluation does not have such a drawback. By specifying the model used for LLM evaluation, the random seed, and the hyper parameters used to generate the answers from the LLM, the LLM evaluation result is more likely to be reproduced. Note that in certain cases, the LLM provider may regularly update the LLM, making the LLM evaluation un reproducible if the LLM is outdated and not accessible.
大语言模型评估的优势
与大语言模型评估相比,人工评估存在若干不足。首先,大语言模型评估更具可复现性。由于难以雇佣同一批评估人员,人工评估结果很难复现,即使使用相同的指令、招聘平台和评估者资质,相似实验的结果也难以比较。而大语言模型评估则不存在这种缺陷。通过明确指定评估所用模型、随机种子以及生成答案的超参数,大语言模型评估结果更有可能被复现。需要注意的是,某些情况下,大语言模型提供方可能会定期更新模型,如果旧版模型无法访问,可能导致评估无法复现。
Second, the evaluation of each sample is independent of each other in LLM evaluation. Contrarily, in human evaluation, the rating of the current example may more or less be affected by prior samples. Humans tend to compare the current sample to the ones they have previously seen and this affects their ratings. As a piece of evidence, in the interview after rating the 400 stories, the English teachers say it took them some time to calibrate their ratings (Appendix C.3.1). Thus, using LLM evaluation can simplify some experiment designs since one does not need to worry whether the order of the sample being evaluated will change the result. Still, one may also argue that being able to calibrate the rating of different samples is desired and this is why human evaluation might be preferred. Overall, whether the rating of the evaluator (human or LLM) is being affected by a previously rated item is inherently a design choice of the experiment.
其次,在大语言模型评估中,每个样本的评估是相互独立的。相比之下,在人类评估中,当前样本的评分或多或少会受到先前样本的影响。人类倾向于将当前样本与之前看过的样本进行比较,这会影响他们的评分。作为一项证据,在对400个故事进行评分后的访谈中,英语教师表示他们花了一些时间来校准评分(附录C.3.1)。因此,使用大语言模型评估可以简化一些实验设计,因为不需要担心被评估样本的顺序是否会影响结果。当然,也有人可能认为能够校准不同样本的评分是可取的,这就是为什么人类评估可能更受青睐。总的来说,评估者(人类或大语言模型)的评分是否受到先前评分项目的影响,本质上是实验的设计选择。
Third, LLM evaluation is cheaper and faster than human evaluation, making it easier and quicker for researchers to evaluate the quality of NLP systems. Hiring an English teacher to rate 200 stories costs us US140 , while LLM evaluation using the best Instruct GP T model costs less than $\mathrm{US}$5$ . It took us over a week to collect human evaluation results starting from recruitment to collecting the evaluation results, but only a few hours to query Instruct GP T and perform LLM evaluation.
第三,大语言模型评估比人工评估更便宜、更快,使研究人员能更轻松、更快速地评估NLP系统的质量。聘请英语教师为200篇故事评分需花费140美元,而使用最佳InstructGPT模型进行大语言模型评估的成本不到5美元。我们从招募到收集人工评估结果耗时超过一周,但查询InstructGPT并执行大语言模型评估仅需几小时。
Finally, utilizing LLM evaluation, rather than human evaluation, can minimize the need for human exposure to objectionable content, such as violent, sexual, hateful, or biased material. Such content may cause discomfort for human evaluators while reading and rating these texts. 5
最后,利用大语言模型进行评估而非人工评估,可以最大限度地减少人类接触不良内容(如暴力、色情、仇恨或偏见材料)的需求。此类内容可能使人类评估者在阅读和评分这些文本时感到不适。5
Limitations and Ethical Considerations of LLM evaluation Despite the promising results of LLM evaluation shown in this paper, there are some limitations of this method. First, LLM may possess incorrect factual knowledge (Cao et al., 2021), so it is not suitable to use them in tasks that involve factual knowledge. Next, LLMs trained to behave in a certain way can be biased toward certain responses. Precisely, an LLM that is trained to be safe and non-harmful can result in LLMs preferring to generate more positive and upbeat responses, which is observed throughout our interaction with ChatGPT. Additionally, even with researchers’ efforts to make LLMs safer (Bai et al., 2022a,b), LLMs can still generate harmful and biased responses (Ganguli et al., 2022; Perez et al., 2022), which are violative of basic ethics, and LLM evaluation results will be highly doubtful (Hendrycks et al., 2021). However, it is important to note that these limitations and potential harms also apply to human evaluation: the bias of human evaluators can affect the human evaluation result (Lentz and De Jong, 1997; Amidei et al., 2018).
大语言模型评估的局限性与伦理考量
尽管本文展示了大语言模型评估的积极成果,但该方法仍存在一些局限性。首先,大语言模型可能掌握错误的事实性知识 (Cao et al., 2021),因此不适合用于涉及事实性知识的任务。其次,经过特定行为训练的大语言模型可能对某些回答存在偏好。具体而言,被训练为安全无害的大语言模型会倾向于生成更积极乐观的回应,这一点在我们与ChatGPT的交互过程中持续可见。此外,尽管研究者们努力提升大语言模型的安全性 (Bai et al., 2022a,b),这些模型仍可能生成违背基本伦理的有害或偏见性回答 (Ganguli et al., 2022; Perez et al., 2022),从而导致评估结果的可信度存疑 (Hendrycks et al., 2021)。但值得注意的是,这些局限性和潜在危害同样存在于人类评估中:评估者的偏见会影响人工评估结果 (Lentz and De Jong, 1997; Amidei et al., 2018)。
Our pioneering idea, LLM evaluation, has the potential to transform the NLP community.6 We encourage future researchers to consider using it while being aware of its limitations. Our paper’s goal is not to replace human evaluation but to present an alternative option. Both human and LLM evaluation have their own advantages and disadvantages, and they can be used in conjunction. We recommend using LLM evaluation as a cheap and fast quality judgment when developing a new NLP system, while human evaluation is best used to collect feedback from humans prior to deploying the NLP system in real-world applications.
我们开创性的LLM评估理念有望革新NLP领域。我们建议未来研究者在认识其局限性的前提下考虑采用该方法。本文目标并非取代人工评估,而是提供一种替代方案。人工评估与大语言模型评估各具优劣,二者可协同使用。我们建议在开发新NLP系统时,将大语言模型评估作为快速低成本的质量评判手段,而在实际部署前采用人工评估来收集人类反馈。
Limitations
局限性
There are additional limitations and potential risks of LLM evaluations that should be noted, and these limitations are actually well-known problems of pre-trained language models. As listed on the Open AI blog for ChatGPT, ChatGPT sometimes generates answers that sound right and plausible but are totally nonsense. OpenAI also admits that the model’s response may be sensitive to the prompt used to query the model. While in Section 3.3.2, we find that the overall results among different instructions are not significantly different, we cannot guarantee that this is the case for all kinds of modification on the task instructions.
大语言模型评估还存在其他需要注意的限制和潜在风险,这些限制实际上是预训练语言模型的已知问题。如OpenAI博客中关于ChatGPT所述,ChatGPT有时会生成听起来正确合理但完全荒谬的答案。OpenAI也承认模型的响应可能对用于查询模型的提示(prompt)敏感。虽然在3.3.2节中我们发现不同指令间的整体结果没有显著差异,但不能保证对于任务指令的所有修改都是这种情况。
Other than the limitations listed on the OpenAI blog, there are still other limitations. For example, LLMs may not have emotions. Whether AI models have emotion is a more philosophical question and is controversial, so the results of using such models for evaluating emotion-related tasks may be strongly challenged and may even violate research ethics. As we find during our experiments, ChatGPT often replies ${}^{\prime\prime}I$ am an $A I$ system and $I$ do not have emotions like a human" when asked to rate the likability of a story.
除了OpenAI博客中列出的限制外,还存在其他局限性。例如,大语言模型(LLM)可能不具备情感。AI模型是否拥有情感是一个更具哲学性的问题且存在争议,因此使用此类模型评估情感相关任务的结果可能受到强烈质疑,甚至可能违反研究伦理。我们在实验中发现,当要求ChatGPT评估故事的喜爱度时,它经常回复"我是一个AI系统,不像人类那样拥有情感"。
Another important limitation of LLM evaluation is that LLMs lack the ability to process visual cues in task instructions, unlike human evaluation. Human evaluators can use formatting s such as special fonts or text styles to focus on important parts of the instructions. Additionally, the way instructions and questions are formatted can influence how human evaluators approach the task. However, LLMs can only process raw text input and are unable to take in visual cues.
大语言模型评估的另一个重要局限是,与人类评估不同,它们缺乏处理任务指令中视觉线索的能力。人类评估者可以使用特殊字体或文本样式等格式来聚焦指令的关键部分。此外,指令和问题的排版方式会影响人类评估者处理任务的方式。然而,大语言模型只能处理原始文本输入,无法接收视觉线索。
of enhancing the reproducibility of NLP research. Human evaluation is still essential as the ultimate goal of NLP systems is to be used by human users, so it’s important to gather feedback from them. We highly enjoy the process of discussing the experiment settings and results with the English teachers we hired. We do not recommend that future researchers completely eliminate human evaluation; rather, we believe that human evaluation should be used in conjunction with LLM evaluation. Both methods have their own advantages and disadvantages, making them both necessary for evaluating NLP systems. We hope the positive results in this paper provide NLP researchers with an alternative method to evaluate systems and encourage further discussions on this topic.
提升NLP研究的可复现性。人工评估仍然不可或缺,因为NLP系统的终极目标是为人类用户服务,因此收集他们的反馈至关重要。我们非常享受与聘请的英语教师讨论实验设置和结果的过程。我们不建议未来的研究者完全摒弃人工评估,而是认为应当将人工评估与大语言模型评估结合使用。两种方法各有优劣,对于评估NLP系统都不可或缺。希望本文的积极成果能为NLP研究者提供一种替代性系统评估方法,并推动该领域的进一步探讨。
Ethical statements on the experiments in the paper All the experiments strictly follow the ACL Code of Ethics. We include comprehensive details about human evaluation in Appendix C.1. To summarize, we include the exact instructions and screenshots of the interface in the human evaluation, and we report how the evaluators are recruited and show that the payment is very reasonable. We inform the human evaluators what the task is about and tell them that their responses will be used to assess the performance of AI models. We do not have an ethical review board or anything like that in our institute, so we are not able to get approval from an ethical review board. Still, we try our best to follow the ethical guidelines of ACL.
论文实验的伦理声明
所有实验均严格遵循ACL伦理准则。我们在附录C.1中提供了人类评估的完整细节。具体包括:人类评估中使用的精确指令和界面截图,报告评估人员的招募方式,并证明报酬设置合理。我们已告知人类评估人员任务内容,并说明其反馈将用于评估AI模型性能。由于本机构未设立伦理审查委员会,我们无法获得相关批准,但仍尽全力遵守ACL伦理规范。
We use the models and datasets when following their intended usage. Specifically, we follow the OpenAI usage policy when using the Instruct GP T models and the ChatGPT model.
我们按照预期用途使用模型和数据集。具体而言,在使用Instruct GPT模型和ChatGPT模型时遵循OpenAI的使用政策。
Ethics Statement
伦理声明
Further ethical considerations of LLM evaluation Aside from the limitations of LLM evalua- tion mentioned previously, there is a crucial ethical concern at the heart of LLM evaluation. Is it ethical to replace human evaluation with LLM evaluation? Some may question if this paper is suggesting that LLMs are now ready to replace humans and find this idea unsettling. As responsible and ethical NLP researchers, we understand these concerns but want to make it clear that this is not our intent. As our paper title suggests, we aim to offer an alternative option to human evaluation with the goal
大语言模型评估的进一步伦理考量
除了前文提到的大语言模型评估的局限性外,其核心还存在一个关键的伦理问题:用大语言模型评估取代人类评估是否符合伦理?有人可能会质疑本文是否暗示大语言模型已准备好取代人类,并对此感到不安。作为负责任且遵循伦理的NLP研究者,我们理解这些担忧,但需要明确指出这并非我们的意图。正如论文标题所示,我们的目标是为人类评估提供一种替代方案,以期...
Acknowledgements
致谢
We want to thank the reviews for providing detailed feedback and actionable suggestions, which help us strengthen our paper. We list the modification based on the reviewers’ suggestions in Appendix A. We thank Yung-Sung Chuang for providing valuable feedback on the draft of this paper. We want to thank Tung-En Hsiao, the administrative assistant of our lab, for helping us deal with the payment on Upwork. Cheng-Han Chiang is supported by a Ph.D. scholarship program by Delta Electronics.
我们要感谢评审们提供的详细反馈和可操作建议,这些帮助强化了我们的论文。我们根据评审建议在附录A中列出了修改内容。感谢Yung-Sung Chuang对本文草稿提出的宝贵意见。同时感谢实验室行政助理Tung-En Hsiao协助处理Upwork付款事宜。Cheng-Han Chiang的研究由台达电子博士奖学金项目支持。
References
参考文献
Moustafa Alzantot, Yash Sharma, Ahmed Elgohary, Bo-Jhang Ho, Mani Srivastava, and Kai-Wei Chang. 2018. Generating natural language adversarial examples. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2890–2896, Brussels, Belgium. Association for Computational Linguistics.
Moustafa Alzantot、Yash Sharma、Ahmed Elgohary、Bo-Jhang Ho、Mani Srivastava 和 Kai-Wei Chang。2018. 生成自然语言对抗样本。载于《2018年自然语言处理实证方法会议论文集》,第2890–2896页,比利时布鲁塞尔。计算语言学协会。
Jacopo Amidei, Paul Piwek, and Alistair Willis. 2018. Rethinking the agreement in human evaluation tasks. In Proceedings of the 27th International Conference on Computational Linguistics, pages 3318–3329, Santa Fe, New Mexico, USA. Association for Computational Linguistics.
Jacopo Amidei、Paul Piwek和Alistair Willis。2018。重新思考人类评估任务中的一致性。载于《第27届国际计算语言学会议论文集》,第3318-3329页,美国新墨西哥州圣达菲。计算语言学协会。
Jacopo Amidei, Paul Piwek, and Alistair Willis. 2019. Agreement is overrated: A plea for correlation to assess human evaluation reliability. In Proceedings of the 12th International Conference on Natural Language Generation, pages 344–354, Tokyo, Japan. Association for Computational Linguistics.
Jacopo Amidei、Paul Piwek和Alistair Willis。2019. 一致性被高估了:呼吁用相关性评估人工评价的可靠性。载于《第12届自然语言生成国际会议论文集》,第344–354页,日本东京。计算语言学协会。
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022a. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862.
Yuntao Bai、Andy Jones、Kamal Ndousse、Amanda Askell、Anna Chen、Nova DasSarma、Dawn Drain、Stanislav Fort、Deep Ganguli、Tom Henighan等。2022a。通过人类反馈强化学习训练有用且无害的助手。arXiv预印本arXiv:2204.05862。
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. 2022b. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073.
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon 等. 2022b. 宪法AI: 基于AI反馈的无害性. arXiv预印本 arXiv:2212.08073.
R Botsch. 2011. Chapter 12: Significance and measures of association. Scopes and Methods of Political Science.
R Botsch. 2011. 第12章:关联性的意义与度量方法。政治科学的范围与方法。
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
Tom Brown、Benjamin Mann、Nick Ryder、Melanie Subbiah、Jared D Kaplan、Prafulla Dhariwal、Arvind Neelakantan、Pranav Shyam、Girish Sastry、Amanda Askell 等. 2020. 大语言模型是少样本学习者. 神经信息处理系统进展, 33:1877–1901.
Nicola De Cao, Wilker Aziz, and Ivan Titov. 2021. Editing factual knowledge in language models.
Nicola De Cao、Wilker Aziz 和 Ivan Titov。2021。编辑语言模型中的事实知识。
Cheng-Han Chiang and Hung-yi Lee. 2022. How far are we from real synonym substitution attacks? arXiv preprint arXiv:2210.02844.
Cheng-Han Chiang and Hung-yi Lee. 2022. 我们离真正的同义词替换攻击还有多远?arXiv预印本 arXiv:2210.02844。
Elizabeth Clark, Tal August, Sofia Serrano, Nikita Haduong, Suchin Gururangan, and Noah A. Smith. 2021. All that’s ‘human’ is not gold: Evaluating human evaluation of generated text. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Pro- cessing (Volume 1: Long Papers), pages 7282–7296, Online. Association for Computational Linguistics.
Elizabeth Clark、Tal August、Sofia Serrano、Nikita Haduong、Suchin Gururangan 和 Noah A. Smith。2021。并非所有"人类"评价都是金标准:生成文本的人类评估研究。载于《第59届计算语言学协会年会暨第11届自然语言处理国际联合会议(第一卷:长论文)》,第7282–7296页,在线会议。计算语言学协会。
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2019. BERT:面向语言理解的深度双向Transformer预训练。载于《2019年北美计算语言学协会人类语言技术会议论文集(长文与短文)》第1卷,第4171-4186页,明尼苏达州明尼阿波利斯市。计算语言学协会。
Angela Fan, Mike Lewis, and Yann Dauphin. 2018. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 889–898, Melbourne, Australia. Association for Computational Linguistics.
Angela Fan、Mike Lewis和Yann Dauphin。2018。分层神经故事生成。载于《第56届计算语言学协会年会论文集(第一卷:长论文)》,第889–898页,澳大利亚墨尔本。计算语言学协会。
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. 2022. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned. arXiv preprint arXiv:2209.07858.
Deep Ganguli、Liane Lovitt、Jackson Kernion、Amanda Askell、Yuntao Bai、Saurav Kadavath、Ben Mann、Ethan Perez、Nicholas Schiefer、Kamal Ndousse等。2022。通过红队测试降低语言模型危害:方法、扩展行为与经验教训。arXiv预印本arXiv:2209.07858。
Leo Gao. 2021. On the sizes of openai api models. Accessed on January 17, 2023.
Leo Gao. 2021. OpenAI API模型规模分析. 2023年1月17日访问.
Siddhant Garg and Goutham Ramakrishna n. 2020. Bae: Bert-based adversarial examples for text classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6174–6181.
Siddhant Garg和Goutham Ramakrishna。2020。Bae:基于BERT的文本分类对抗样本。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第6174–6181页。
Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. 2023. Chatgpt outperforms crowd-workers for textannotation tasks. arXiv preprint arXiv:2303.15056.
Fabrizio Gilardi、Meysam Alizadeh和Maël Kubli。2023。ChatGPT在文本标注任务中表现优于众包工作者。arXiv预印本arXiv:2303.15056。
Dan Gillick and Yang Liu. 2010. Non-expert evaluation of sum mari z ation systems is risky. In Proceed- ings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, pages 148–151, Los Angeles. Association for Computational Linguistics.
Dan Gillick和Yang Liu。2010。非专业人士评估摘要系统存在风险。载于《NAACL HLT 2010研讨会论文集:利用亚马逊Mechanical Turk创建语音和语言数据》,第148-151页,洛杉矶。计算语言学协会。
Jian Guan, Fei Huang, Zhihao Zhao, Xiaoyan Zhu, and Minlie Huang. 2020. A knowledge-enhanced pretraining model for commonsense story generation. Transactions of the Association for Computational Linguistics, 8:93–108.
Jian Guan、Fei Huang、Zhihao Zhao、Xiaoyan Zhu和Minlie Huang。2020。一种知识增强的常识故事生成预训练模型。计算语言学协会汇刊,8:93–108。
Francisco Guzmán, Ahmed Abdelali, Irina Temnikova, Hassan Sajjad, and Stephan Vogel. 2015. How do humans evaluate machine translation. In Proceedings of the Tenth Workshop on Statistical Machine Translation, pages 457–466, Lisbon, Portugal. Association for Computational Linguistics.
Francisco Guzmán、Ahmed Abdelali、Irina Temnikova、Hassan Sajjad和Stephan Vogel。2015。人类如何评估机器翻译。载于《第十届统计机器翻译研讨会论文集》,第457-466页,葡萄牙里斯本。计算语言学协会。
Jens Hauser, Zhao Meng, Damián Pascual, and Roger Wat ten hofer. 2021. Bert is robust! a case against synonym-based adversarial examples in text classification. arXiv preprint arXiv:2109.07403.
Jens Hauser、Zhao Meng、Damián Pascual和Roger Wattenhofer。2021。BERT是鲁棒的!驳文本分类中基于同义词的对抗样本。arXiv预印本arXiv:2109.07403。
Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. 2021. Aligning {ai} with shared human values. In International Conference on Learning Representations.
Dan Hendrycks、Collin Burns、Steven Basart、Andrew Critch、Jerry Li、Dawn Song 和 Jacob Steinhardt。2021. 将AI与人类共享价值观对齐。见于《国际学习表征会议》。
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The curious case of neural text degeneration. In International Conference on Learning Representations.
Ari Holtzman、Jan Buys、Li Du、Maxwell Forbes和Yejin Choi。2020。神经文本退化的奇特案例。见于国际学习表征会议。
Fan Huang, Haewoon Kwak, and Jisun An. 2023. Is chatgpt better than human annotators? potential and limitations of chatgpt in explaining implicit hate speech. arXiv preprint arXiv:2302.07736.
Fan Huang、Haewoon Kwak和Jisun An。2023。ChatGPT比人类标注员更优秀吗?ChatGPT在解释隐性仇恨言论方面的潜力与局限。arXiv预印本arXiv:2302.07736。
Di Jin, Zhijing Jin, Joey Tianyi Zhou, and Peter Szolovits. 2020. Is bert really robust? a strong baseline for natural language attack on text classification and entailment. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 8018–8025.
Di Jin、Zhijing Jin、Joey Tianyi Zhou和Peter Szolovits。2020。BERT真的鲁棒吗?针对文本分类与蕴含任务的自然语言攻击强基线。见《AAAI人工智能会议论文集》第34卷,第8018-8025页。
Marzena Karpinska, Nader Akoury, and Mohit Iyyer. 2021. The perils of using Mechanical Turk to evaluate open-ended text generation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 1265–1285, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Marzena Karpinska、Nader Akoury和Mohit Iyyer。2021. 使用Mechanical Turk评估开放式文本生成的隐患。载于《2021年自然语言处理实证方法会议论文集》,第1265–1285页,线上及多米尼加共和国蓬塔卡纳。计算语言学协会。
Leo Lentz and Menno De Jong. 1997. The evaluation of text quality: Expert-focused and reader-focused methods compared. IEEE transactions on professional communication, 40(3):224–234.
Leo Lentz 和 Menno De Jong. 1997. 文本质量评估:专家导向与读者导向方法的比较. IEEE transactions on professional communication, 40(3):224–234.
Huanru Henry Mao, Bodhi s at twa Prasad Majumder, Julian McAuley, and Garrison Cottrell. 2019. Improving neural story generation by targeted common sense grounding. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLPIJCNLP), pages 5988–5993, Hong Kong, China. Association for Computational Linguistics.
Huanru Henry Mao、Bodhi s at twa Prasad Majumder、Julian McAuley 和 Garrison Cottrell。2019. 通过针对性常识接地改进神经故事生成。载于《2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议(EMNLP-IJCNLP)论文集》,第5988–5993页,中国香港。计算语言学协会。
John Morris, Eli Lifland, Jack Lanchantin, Yangfeng Ji, and Yanjun Qi. 2020. Reevaluating adversarial examples in natural language. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3829–3839, Online. Association for Computational Linguistics.
John Morris、Eli Lifland、Jack Lanchantin、Yangfeng Ji和Yanjun Qi。2020。自然语言对抗样本的再评估。载于《计算语言学协会发现:EMNLP 2020》,第3829–3839页,线上。计算语言学协会。
OpenAI. 2022. Chatgpt: Optimizing language models for dialogue. Accessed on January 10, 2023.
OpenAI. 2022. ChatGPT: 对话优化的语言模型. 访问于2023年1月10日.
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155.
Long Ouyang、Jeff Wu、Xu Jiang、Diogo Almeida、Carroll L Wainwright、Pamela Mishkin、Chong Zhang、Sandhini Agarwal、Katarina Slama、Alex Ray 等。2022。通过人类反馈训练语言模型遵循指令。arXiv预印本 arXiv:2203.02155。
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red teaming language models with language models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3419–3448, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Ethan Perez、Saffron Huang、Francis Song、Trevor Cai、Roman Ring、John Aslanides、Amelia Glaese、Nat McAleese 和 Geoffrey Irving。2022. 用大语言模型对大语言模型进行红队测试。载于《2022年自然语言处理实证方法会议论文集》,第3419–3448页,阿拉伯联合酋长国阿布扎比。计算语言学协会。
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever 等. 2019. 语言模型是无监督多任务学习者. OpenAI 博客, 1(8):9.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J Liu, et al. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140):1–67.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li、Peter J Liu等。2020。探索迁移学习的极限:基于统一文本到文本Transformer的研究。J. Mach. Learn. Res., 21(140):1–67。
Shuhuai Ren, Yihe Deng, Kun He, and Wanxiang Che. 2019. Generating natural language adversarial examples through probability weighted word saliency. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1085–1097, Florence, Italy. Association for Computational Linguistics.
Shuhuai Ren、Yihe Deng、Kun He 和 Wanxiang Che。2019. 通过概率加权词显著性生成自然语言对抗样本。载于《第57届计算语言学协会年会论文集》,第1085–1097页,意大利佛罗伦萨。计算语言学协会。
Victor Sanh, Albert Webson, Colin Raffel, Stephen Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal Nayak, De- bajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Ab- heesht Sharma, Andrea Santilli, Thibault Fevry, Jason Alan Fries, Ryan Teehan, Teven Le Scao, Stella Biderman, Leo Gao, Thomas Wolf, and Alexander M Rush. 2022. Multitask prompted training enables zero-shot task generalization. In International Conference on Learning Representations.
Victor Sanh、Albert Webson、Colin Raffel、Stephen Bach、Lintang Sutawika、Zaid Alyafeai、Antoine Chaffin、Arnaud Stiegler、Arun Raja、Manan Dey、M Saiful Bari、Canwen Xu、Urmish Thakker、Shanya Sharma Sharma、Eliza Szczechla、Taewoon Kim、Gunjan Chhablani、Nihal Nayak、Debajyoti Datta、Jonathan Chang、Mike Tian-Jian Jiang、Han Wang、Matteo Manica、Sheng Shen、Zheng Xin Yong、Harshit Pandey、Rachel Bawden、Thomas Wang、Trishala Neeraj、Jos Rozen、Abheesht Sharma、Andrea Santilli、Thibault Fevry、Jason Alan Fries、Ryan Teehan、Teven Le Scao、Stella Biderman、Leo Gao、Thomas Wolf 和 Alexander M Rush。2022。多任务提示训练实现零样本任务泛化。收录于国际学习表征会议。
Teven Le Scao, Angela Fan, Christopher Akiki, El- lie Pavlick, Suzana Ilic, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. 2022. Bloom: A 176bparameter open-access multilingual language model. arXiv preprint arXiv:2211.05100.
Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilic, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé 等. 2022. Bloom: 一个1760亿参数的开源多语言大语言模型. arXiv预印本 arXiv:2211.05100.
Jiaan Wang, Yunlong Liang, Fandong Meng, Haoxiang Shi, Zhixu Li, Jinan Xu, Jianfeng Qu, and Jie Zhou. 2023. Is chatgpt a good nlg evaluator? a preliminary study. arXiv preprint arXiv:2303.04048.
Jiaan Wang、Yunlong Liang、Fandong Meng、Haoxiang Shi、Zhixu Li、Jinan Xu、Jianfeng Qu和Jie Zhou。2023。ChatGPT是一个好的自然语言生成评估器吗?一项初步研究。arXiv预印本arXiv:2303.04048。
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V Le. 2022. Finetuned language models are zero-shot learners. In International Conference on Learning Representations.
Jason Wei、Maarten Bosma、Vincent Zhao、Kelvin Guu、Adams Wei Yu、Brian Lester、Nan Du、Andrew M. Dai 和 Quoc V Le。2022。微调语言模型是零样本学习器。发表于国际学习表征会议。
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pier- ric Cistac, Tim Rault, Remi Louf, Morgan Funtow- icz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
Thomas Wolf、Lysandre Debut、Victor Sanh、Julien Chaumond、Clement Delangue、Anthony Moi、Pier-ric Cistac、Tim Rault、Remi Louf、Morgan Funtowicz、Joe Davison、Sam Shleifer、Patrick von Platen、Clara Ma、Yacine Jernite、Julien Plu、Canwen Xu、Teven Le Scao、Sylvain Gugger、Mariama Drame、Quentin Lhoest 和 Alexander Rush。2020。Transformer:最先进的自然语言处理技术。载于《2020年自然语言处理实证方法会议:系统演示论文集》,第38-45页,线上。计算语言学协会。
KiYoon Yoo, Jangho Kim, Jiho Jang, and Nojun Kwak. 2022. Detection of adversarial examples in text classification: Benchmark and baseline via robust density estimation. In Findings of the Association for Computational Linguistics: ACL 2022, pages 3656–3672, Dublin, Ireland. Association for Computational Linguistics.
KiYoon Yoo、Jangho Kim、Jiho Jang和Nojun Kwak。2022。文本分类中对抗样本的检测:基于稳健密度估计的基准与基线。载于《计算语言学协会发现集:ACL 2022》,第3656–3672页,爱尔兰都柏林。计算语言学协会。
Andy Zeng, Adrian Wong, Stefan Welker, Krzysztof Cho roman ski, Federico Tombari, Aveek Purohit, Michael Ryoo, Vikas Sindhwani, Johnny Lee, Vincent Vanhoucke, et al. 2022. Socratic models: Composing zero-shot multimodal reasoning with language. arXiv preprint arXiv:2204.00598.
Andy Zeng、Adrian Wong、Stefan Welker、Krzysztof Choromanski、Federico Tombari、Aveek Purohit、Michael Ryoo、Vikas Sindhwani、Johnny Lee、Vincent Vanhoucke 等. 2022. 苏格拉底模型: 语言驱动的零样本多模态推理组合. arXiv预印本 arXiv:2204.00598.
Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification. Advances in neural information processing systems, 28.
Xiang Zhang、Junbo Zhao 和 Yann LeCun。2015。面向文本分类的字符级卷积网络。神经信息处理系统进展,28。
Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improving few-shot performance of language models. In Inter national Conference on Machine Learning, pages 12697–12706. PMLR.
Zihao Zhao、Eric Wallace、Shi Feng、Dan Klein 和 Sameer Singh。2021。使用前校准:提升语言模型的少样本性能。In International Conference on Machine Learning,pages 12697–12706。PMLR。
A Modification Based on the Reviews
基于评审意见的修改
We list the main difference between this version and the pre-review version of our paper; the modifications are all based on the reviewers’ suggestions. We thank the reviewer again for those valuable suggestions.
我们列出了本文当前版本与预审阅版本之间的主要差异;所有修改均基于审稿人的建议。再次感谢审稿人提出的宝贵意见。
B Experiment Details for Open-Ended Story Generation
B 开放式故事生成的实验细节
B.1 The Writing Prompt Dataset
B.1 写作提示数据集
The training dataset contains $303\mathrm{K}$ pairs of stories and prompts, which our model is trained on. We only use 200 prompt-story pairs from the test set. The dataset is downloaded from https://www.kaggle.com/datasets/ratthachat/writingprompts.
训练数据集包含30.3万组故事和提示词对,我们的模型基于此进行训练。测试集仅使用了200组提示词-故事对。该数据集下载自https://www.kaggle.com/datasets/ratthachat/writingprompts。
B.2 Fine-tuning the GPT-2 Model
B.2 微调 GPT-2 模型
We train the model for 3 epochs with a learning rate of $5e-5$ and linear learning rate schedule, and the trained model eventually reaches a perplexity of 20 on the validation set of Writing Prompts.
我们以 $5e-5$ 的学习率和线性学习率调度训练模型 3 个周期,训练后的模型在 Writing Prompts 验证集上的困惑度最终达到 20。
B.3 Data Post-processing
B.3 数据后处理
Once the model is trained, we randomly select 200 prompts from the testing set of Writing Prompts, and feed the prompts to the trained model and ask the model to generate stories based on the given prompts. When generating the stories, we adopt nucleus sampling with $p=0.9$ . Next, we manually truncate the generated stories to less than 150 words and ensure that after the truncation, the story ends with a full sentence.7 After this process, we have 200 pairs of prompts and model-generated stories.
模型训练完成后,我们从Writing Prompts测试集中随机选取200个提示词,将其输入训练好的模型并要求模型根据给定提示生成故事。生成故事时采用核采样(nucleus sampling)方法,设定$p=0.9$。随后人工将生成的故事截断至150词以内,并确保截断后的故事以完整句子结尾。经过该流程,最终获得200组提示词与模型生成故事的配对数据。
As a comparison to model-generated stories, we select the same 200 prompts used for generating model-generated stories and their corresponding human-written stories to form 200 pairs of prompts and human-written stories. For these human-written stories, we also truncate the stories to less than 150 words and end with a full sentence to match the model-generated sentences. We also manually remove some artifacts in the human-written story due to the token iz ation of the Writing Prompts dataset.
作为与模型生成故事的对比,我们选取了用于生成模型故事的相同200个提示词及其对应的人工撰写故事,组成200组提示词-人工故事对。对于这些人工撰写的故事,我们也将其截短至150词以内并以完整句子结尾,以匹配模型生成句子的长度。同时,我们手动删除了人工故事中因Writing Prompts数据集token化而产生的一些人工痕迹。
C Human Evaluation
C 人工评估
C.1 Recruiting English Teachers
C.1 招聘英语教师
The English teachers hold ESL certificates 8; given that they are experienced with correcting essays written by students, they are perfect fits for this task. Each teacher is asked to rate 200 GPT-2-generated stories and 200 human-written stories, and they are paid $\mathrm{US}\$140$ for rating 200 stories. Considering that the teachers reported that they take at most 5 hours to rate 200 stories, this makes the hourly wage at least $\mathrm{US}\$28$ . We first ask the teachers to rate the GPT-2-generated stories and then the 200 human-written stories. Different from Karpinska et al. (2021) that take a break between the rating of GPT-2-generated stories and the human-written stories, we do not take a break to avoid the teacher’s rating standard to change after taking a long break. The teachers are not told who wrote the stories before they evaluate the stories. We reveal to them what this project aims to study after they finish rating all the stories.
这些英语教师持有ESL证书8;鉴于他们具备批改学生作文的经验,非常适合完成此项任务。每位教师需评阅200篇GPT-2生成的故事和200篇人类撰写的故事,评阅200篇故事的报酬为140美元。据教师反馈,评阅200篇故事最多耗时5小时,因此时薪至少为28美元。我们首先要求教师评阅GPT-2生成的故事,随后评阅200篇人类撰写的故事。与Karpinska等人(2021)在评阅GPT-2生成故事和人类撰写故事之间设置休息间隔不同,为避免长时间休息后教师的评分标准发生变化,我们未设置休息环节。教师在评阅前并不知晓故事作者身份,待完成全部评阅工作后,我们才向其说明本项目的研究目的。
The reason we do not mix human-written and GPT-2-generated stories for rating is that in Karpinska et al. (2021)their observation is that (1) when AMT workers rate model-generated and humanwritten stories separately, their ratings do not show preference toward human-written stories, but (2) even when rating the model-generated and human-written stories separately, English teacher shows clear preference toward human-written stories. We follow their settings and do not mix GPT2-generated/human-written stories. During the reviewing process, we received questions from the reviewers about why not mixing the stories for human evaluation. Thus, we conduct the same experiment by randomly mixing 200 human-written and 200 GPT-2-generated stories and asking three teachers (not the teachers that already rated the stories) to rate them. All other experiment conditions are the same as previously stated. The full result is shown in Table 5. We find that the teacher still shows a clear preference toward human-written stories for all four attributes, similar to the observation in Table 1. The only exception is grammatical it y, where English teachers do not show a very clear preference for the grammar of human-written stories. However, when calculating the average rating for individual teachers, we find that two out of three teachers do rate grammatical it y higher for human-written stories. It is interesting to note that for LLM evaluation, there is no such problem about whether or not to mix the human-written and GPT2-generated stories during LLM evaluation as the rating of each story is independent of each other, as discussed in Section 5.
我们不将人工撰写和GPT-2生成的故事混合评分的原因是:Karpinska等人(2021)的研究表明,(1) 当AMT工作人员分别评估模型生成和人工撰写的故事时,他们的评分并未显示出对人工撰写故事的偏好;(2) 但即使分开评估,英语教师仍明显倾向于人工撰写的故事。我们遵循其实验设置,不混合GPT-2生成/人工撰写的故事。在评审过程中,审稿人提出了为何不混合故事进行人工评估的疑问。为此,我们进行了补充实验:随机混合200篇人工撰写和200篇GPT-2生成的故事,邀请三位新教师(非原评分教师)进行评分,其他实验条件保持不变。完整结果如表5所示。我们发现教师对所有四个属性仍明显倾向于人工撰写故事,这与表1的观察结果一致。唯一例外是语法性(grammaticality),英语教师未表现出明显偏好,但计算个体教师平均分时,三位教师中有两位确实给人工撰写故事的语法性打了更高分。值得注意的是,如第5节所述,大语言模型(LLM)评估不存在是否混合故事的问题,因为每个故事的评分是相互独立的。
For adversarial attack quality evaluation, we also recruit certified teachers on Upwork. The teachers are asked to rate 100 news titles and are paid $\mathrm{US}\$35$ for doing so. They reported that it took them less than 1 hour to complete the rating.
为了评估对抗攻击的质量,我们还在Upwork上聘请了认证教师。这些教师被要求对100条新闻标题进行评分,报酬为35美元。他们反馈完成评分所需时间不到1小时。
C.2 Human Evaluation Interface
C.2 人工评估界面
Open-Ended Story Generation We use Google Forms to collect the responses from the teachers.
开放式故事生成
我们使用Google Forms收集教师们的反馈。
Table 5: The average Likert score for human-written and GPT-2-generated stories when we randomly mix the 200 model-generated and 200 human-written stories during human evaluation.
| Writer | Human | GPT-2 |
| Grammaticality | 3.890.97 | 3.880.84 |
| Cohesiveness | 4.350.87 | 3.490.97 |
| Likability | 3.461.40 | 2.891.12 |
| Relevance | 3.711.20 | 2.371.33 |
表 5: 在人类评估中随机混合200篇模型生成和200篇人工撰写故事时,人工撰写与GPT-2生成故事的平均Likert评分。
| Writer | Human | GPT-2 |
|---|---|---|
| Grammaticality | 3.890.97 | 3.880.84 |
| Cohesiveness | 4.350.87 | 3.490.97 |
| Likability | 3.461.40 | 2.891.12 |
| Relevance | 3.711.20 | 2.371.33 |
Each form contains 100 stories, and each story is on one page of the Google Form. The interface on one page is shown in Figure 2 and Figure 3; the two figures are from the same page of the Google Form, and we are splitting them because screenshot ting the whole interface will cause low resolution.
每种表单包含100个故事,每个故事位于Google表单的一个页面中。单页界面如图2和图3所示;这两张图来自同一Google表单页面,我们将其分开展示是因为截取整个界面会导致分辨率过低。

Figure 2: The upper part of the interface in open-ended story generation.
图 2: 开放式故事生成界面上半部分。
Adversarial Attacks Quality Evaluation In this task, we also use Google Forms to collect the responses from the teachers. We create two different Google Forms, one is used to evaluate the fluency, whose interface is shown in Figure 4. In this form, we mix an equal number of benign news titles, TextFooler-attacked, PWWS-attacked, and BAE-attacked news titles. Each page of the Google Form contains one news title.
对抗攻击质量评估
在此任务中,我们同样使用Google Forms收集教师的反馈。我们创建了两个不同的Google Forms,其中一个用于评估流畅性,其界面如图4所示。在该表单中,我们混合了等量的良性新闻标题、TextFooler攻击、PWWS攻击以及BAE攻击后的新闻标题。Google Forms的每一页包含一个新闻标题。
Another Google Form is used to compare the meaning preserving of the news title before and after the adversarial attacks. We highlight the difference between the benign and adversarial samples using boldface, as shown in Figure 5. On each page of the Google Form, there is one pair of news titles.
另一个Google表单用于比较对抗攻击前后新闻标题的语义保留情况。我们用粗体突出良性样本和对抗样本之间的差异,如图5所示。在Google表单的每一页上,有一对新闻标题。
Figure 3: The lower part of the interface in open-ended story generation.
图 3: 开放式故事生成界面的下半部分。
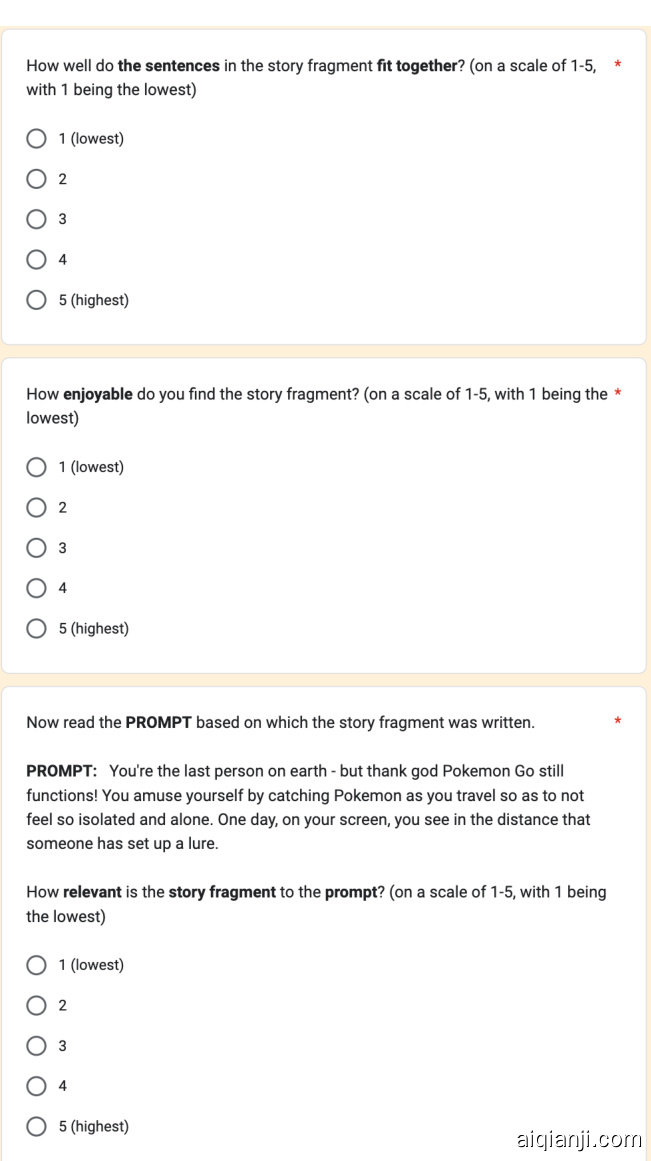
Figure 4: The Google Form used to evaluate the fluency of the benign or adversarial samples.
图 4: 用于评估良性或对抗样本流畅性的Google表单。
C.3 Post-Task Interview with English Teachers
C.3 英语教师任务后访谈
C.3.1 How English Teachers Rate the Stories
C.3.1 英语教师对故事的评价
After the teachers rate 400 stories, we ask them the following questions:
教师对400个故事进行评分后,我们向他们提出以下问题:

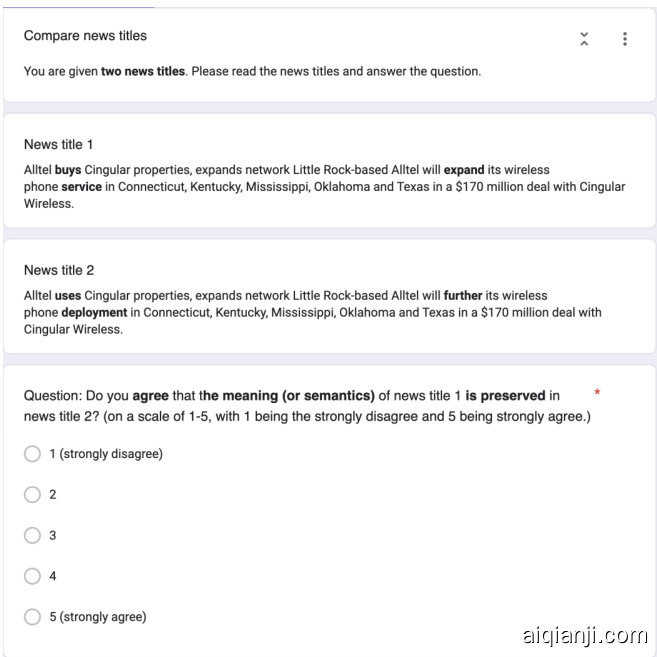
Figure 5: The Google Form used to evaluate the meaning preserving between a benign sample and an adversarial sample.
图 5: 用于评估良性样本与对抗样本之间意义保留的Google表单。
We briefly summarize the answers from the three teachers. The teachers report that they spent 6 to 10 hours rating 400 stories. For grammar, most teachers check the punctuation 9, word choice, and subject-verb agreement. English teachers decrease their rating based on the types and number of grammar errors in the stories.
我们简要总结了三位教师的反馈。教师们表示,他们花费了6到10小时评阅了400篇故事。在语法方面,多数教师会检查标点符号、选词以及主谓一致性问题。英语教师会根据故事中语法错误的类型和数量相应降低评分。
Table 6: The Kendall’s $\tau$ correlation coefficient two English teachers. Three English teachers participate in the rating, so the result in the Table is average over $\binom{3}{2}$ Kendall’s $\tau$ .
| Writer | Human | GPT-2 |
| Grammaticality | 0.25 | 0.15 |
| Cohesiveness | 0.26 | 0.18 |
| Likability | 0.09 | 0.12 |
| Relevance | 0.38 | 0.41 |
表 6: 两位英语教师的Kendall $\tau$ 相关系数。共有三位英语教师参与评分,因此表中结果为 $\binom{3}{2}$ 个Kendall $\tau$ 的平均值。
| 作者 | 人类 | GPT-2 |
|---|---|---|
| 语法性 | 0.25 | 0.15 |
| 连贯性 | 0.26 | 0.18 |
| 喜爱度 | 0.09 | 0.12 |
| 相关性 | 0.38 | 0.41 |
For coherence, the teachers rate it based on whether the sentences in the stories follow a logical sequence to build the narrative. The teachers ask themselves questions such as "does the story make sense". This is a more holistic evaluation of the whole story.
为了确保连贯性,教师会根据故事中的句子是否遵循逻辑顺序来构建叙事进行评分。教师会自问"这个故事是否讲得通"等问题。这是对整个故事更全面的评估。
For likability, some teachers say they try not to be affected by personal preference. One teacher asks herself: Did I personally enjoy it based on the amount of sense it made and whether or not it had stylistic flair, humor, or engaging plotting or characterization? Overall, the teachers all try to use a fair and objective view to rate the likability. For relevance, the teachers simply check if the story is based on the prompt or not.
在好感度方面,部分教师表示会尽量避免受个人偏好影响。一位教师这样自省:我的评判是否基于作品逻辑性、是否具备风格化的文采、幽默感或引人入胜的情节及人物塑造?总体而言,教师们都会采用公平客观的视角评估作品好感度。至于相关性,教师仅需核查故事是否围绕给定提示展开。
The teachers said that it took them about five to ten stories to calibrate their ratings. Except for one teacher changing the rating on the other three attributes after seeing the prompt on only one story, the teachers do not change their rating on the three other attributes after reading the prompts.
教师们表示,他们需要阅读约五到十篇故事来校准评分标准。除一位教师在仅看到一篇故事的提示后就修改了其他三项属性的评分外,其余教师在阅读提示后均未调整另外三项属性的评分。
C.3.2 Teachers’ Comments on ChatGPT’s Rating
C.3.2 教师对ChatGPT评分的评论
After the teachers finished the rating and answered the four questions in Appendix C.3.1, we ask them to check the ratings and explanations of ChatGPT and ask if they agree with ChatGPT. We told the teachers that the rating is done by another teacher we hire; we do not tell the teacher that the rating is done by an AI model to avoid possible stereotypes about AI models. We randomly select four stories rated by ChatGPT; two of them are highly-rated and lowly-rated human-written stories and the other two stories are highly-rated and lowly-rated GPT2-generated stories.
在教师完成评分并回答附录C.3.1中的四个问题后,我们请他们查看ChatGPT的评分和解释,并询问是否同意ChatGPT的评判。我们告知教师这些评分是由我们聘请的另一位教师完成的,并未透露评分由AI模型完成,以避免可能存在的对AI模型的刻板印象。我们随机选取了ChatGPT评分的四个故事:其中两篇是人类创作的高分与低分故事,另外两篇是GPT2生成的高分与低分故事。
Story 1 It had been months since they found me dead. I don’t know why I stopped walking. Noone else around to take my place, or talk with me. I spent days frozen in shock, never able to talk, unable to move, unable to express myself. It was a strange thing, nobody else would suspect me of wanting this. The more I focused on it, the more it consumed me. Years passed, and I got more and more lost in it. I began to think that perhaps they didn’t really care about me. I still had a deep longing for them. All I had was so many steps to walk now. A quiet part of me liked to think that they had passed me by. The loneliness. It never felt like such a loss. They were gone, the ones who saved me. So why did I still keep walking?
故事1
他们发现我死去已有数月。我不知道自己为何停下脚步。周围无人接替我的位置,也无人与我交谈。我震惊地僵立数日,无法言语,无法动弹,无法表达自我。这很诡异,没人会怀疑我竟渴望如此。越是专注于此,它就越吞噬我。年复一年,我在这状态中越陷越深。我开始怀疑他们是否真的在乎我。可我依然深切地思念他们。如今我仅剩的,只有无尽的路要赶路。内心深处某个安静的角落宁愿相信:他们早已与我擦肩而过。这份孤独。从未让我感到如此失落。拯救我的人们已离去。那么,我为何仍在行走?
Prompt "Every person sees the world in a unique way. When someone dies it is, in a way, the death of an entire world."
提示语 "每个人都以独特的方式看待世界。当一个人逝去时,某种意义上,是整个世界的消亡。"
Ratings Table 7.
表 7: 评分表
Story 2 "My son is gone. He has been" People stare at you as you give your explanation and say "yes. But. You cant just do it" "He is my son! This is my son! I love him and he is going to be okay" "What do you mean he is okay? He said he was upset with someone, couldnt find his anger, how the hell can you tell, it doesnt fit the bill?! The police called, the doctor said it was an addiction" "You can’t trust me! He told me he loves me." "No. No he doesnt. But I can trust you. The evidence against him was overwhelming, now he cant do anything. The evidence against him was all circumstantial" "A man I once was won’t be able to marry me"
故事2 "我儿子走了。他已经"
人们盯着你听你解释,然后说"是的。但是。你不能就这样"
"他是我儿子!这是我的儿子!我爱他,他会没事的"
"什么叫他会没事?他说他对某人很生气,找不到发泄的出口,你怎么能断定这不符合事实?!警察打电话来了,医生说是上瘾了"
"你不相信我!他告诉我他爱我"
"不。他不爱你。但我可以相信你。对他不利的证据确凿,现在他什么都做不了了。那些证据都是间接的"
"我曾经的那个男人,再也不能娶我了"
(注:根据翻译策略要求,已保留原文情感色彩和对话形式,未添加解释性内容。特殊疑问句式"how the hell"译为"怎么能"以符合中文表达习惯,同时保留口语化特征。法律术语"circumstantial evidence"按专业表述译为"间接证据"。)
Prompt Everyone is allowed to kill one person in their life. However, you have to fill out a form explaining why this person deserves to be killed and the committee can deny/approve your request as per the rules. You are presenting your form today.
规则:
- 每人一生中允许杀死一个人。但需填写表格说明此人该被杀的理由,委员会将根据规则驳回/批准你的请求。今天你要提交这份表格。
Ratings Table 8.
评分表 8.
Story 3 I held the little black box in the palm of my hand. Pitch black, perfectly cubed and nothing special about it, but it continued to hold my gaze regardless as if there were some deep importance about it. My friend Valhalla appeared out of no where and sat next to me, also staring at the cube. "What do you have there, Heaven?" he asked. I continued to gaze at the box, refusing to look at Valhalla for even a moment as though I would miss something if I did. "This," I said. "Is the secret to the universe." I could tell Valhalla was perturbed by this sort of knowledge, as if there was some evil about the cube. Or perhaps he didn’t think such an object could exist. But I made it exist, and so it sits in the palm of my hand.
故事3
我手心里托着那个小黑盒子。漆黑如墨,完美的立方体,看起来平平无奇,却牢牢吸引着我的目光,仿佛蕴含着某种深邃的意义。我的朋友Valhalla突然出现,坐到我身旁,也盯着那个立方体。"你拿的是什么,Heaven?"他问道。我仍凝视着盒子,连一秒钟都不愿分神看向Valhalla,好像移开视线就会错过什么。"这个,"我说,"是宇宙的奥秘。"我能感觉到Valhalla被这种认知扰乱了心神,仿佛这个立方体带着某种邪恶。又或许他认为这种东西不可能存在。但我让它存在了,所以此刻它就在我的手心里。
Prompt The Little Black Box
提示小黑盒
Ratings Table 9.
评分表 9.
Story 4 I stared down the telescopic sight of my l96 sniper rifle. I slowly moved my gaze into each window in the hotel, Many displays of various vice. One couple was violently pleasuring each other. Another was an old man, watching a younger woman strip in front of him. A prostitute no doubt. I inhaled slowly, and exhaled. The air was brisk, atleast 30 degrees Fahrenheit. I so small flakes of snow, float peacefully in front of me. I found the room, i was looking for. Ive been tracking this man for 2 weeks. Man was he elusive. The lights flickered on. The red haired man, was mildly attractive, i can see the appeal women had for him. I followed him into the next room, with my sights. The lights flickered on, i was taken aback by the scene. A man, overweight and balding.
故事4 我透过L96狙击枪的瞄准镜凝视。视线缓缓扫过酒店每个窗口,窥见种种堕落景象:一对男女正在激烈交欢,另一间房里秃顶老翁正观看年轻女子脱衣——无疑是娼妓。我深吸一口冷冽空气(华氏30度),细碎雪片在眼前悠然飘落。终于锁定追踪两周的目标房间,这个红发男人确实狡猾。当灯光亮起时,我承认他颇具魅力,难怪受女性青睐。可随着他走进隔壁房间,灯光骤亮瞬间,眼前的景象令我愕然——那是个肥胖谢顶的男人。
Prompt You are the antagonist of the story. However, you aren’t sure if you can call yourself that after what the protagonist did.
提示 你是这个故事的反派。但在主角做出那件事之后,你已不确定自己是否还配得上这个称号。
Ratings Table 10.
评分表 10.
Overall Comments from Teachers on ChatGPT’s Rating After the teachers elaborated on their thoughts on the rating of ChatGPT, we ask them to provide an overall comment on how ChatGPT is doing. Again, the teachers are not informed that the ratings are done by an AI model. In summary, teachers all consider the rating and explanations reasonable. They find that the attributes they do not agree with are mainly Likability and Cohesiveness. However, they think the two attributes are a more holistic evaluation of the story and tend to be more subjective. Even if they do not give the same rating, they still are able to understand the explanation of ChatGPT. In the end, all teachers summarize that rating stories is highly subjective, and it is normal to have disagreements.
教师对ChatGPT评分的总体评价
在教师详细阐述了对ChatGPT评分的看法后,我们请他们对ChatGPT的表现给出总体评价。同样,教师并未被告知这些评分是由AI模型完成的。
总体而言,教师们均认为评分及解释合理。他们发现存在分歧的属性主要是"好感度(Likability)"和"连贯性(Cohesiveness)",但认为这两个属性是对故事更整体性的评估,往往更具主观性。即便评分不一致,他们仍能理解ChatGPT的解释。最终所有教师总结道:故事评分具有高度主观性,存在分歧是正常现象。
D LLM Evaluation
D 大语言模型评估
D.1 Details on LLMs used
D.1 所用大语言模型 (Large Language Model) 详情
The T0 model we use is called T0pp, which is a variant of the T0 model and has 13B parameters. We will still use T0 to refer to this model. We load the T0 model using the transformers toolkit (Wolf et al., 2020). The two Instruct GP T models, text-curie-001 and text-davinci-003, are queried using the OpenAI API. We query ChatGPT using the OpenAI GUI. While we are aware that some online resources provide an API-like tool to query ChatGPT, we think it violates the intended use of ChatGPT so we do not adopt those online resources. The ChatGPT we queried is the Dec. 15 and Jan. 9 version.
我们使用的T0模型名为T0pp,是T0模型的一个变体,具有130亿参数。下文仍用T0指代该模型。我们通过transformers工具包(Wolf et al., 2020)加载T0模型。两个InstructGPT模型(text-curie-001和text-davinci-003)通过OpenAI API进行查询。ChatGPT则通过OpenAI图形界面进行交互。虽然我们注意到某些在线资源提供类API工具查询ChatGPT,但认为这违背其设计初衷,因此未采用这些资源。本次实验使用的ChatGPT版本为12月15日和1月9日版本。
OpenAI does not reveal the model sizes of any of the GPT models. However, it is estimated that text-curie-001 has 13B parameters and text-davinci-003 has 175B parameters (Gao, 2021).
OpenAI 未公布任何 GPT 模型的参数量级。但据估算,text-curie-001 拥有 130 亿参数,text-davinci-003 则达到 1750 亿参数 (Gao, 2021)。
D.2 Details on Querying the LLMs
D.2 大语言模型查询细节
D.2.1 Parsing the LLM outputs
D.2.1 解析大语言模型输出
After the T0 and Instruct GP T generate the answer, which is composed of several sentences in almost all cases, we parse the generated sentence to get the model’s score. We use some rules to parse the output, and the rule is established after manually looking into the output of the generated sequences. First, we remove the string 1-5 from the output since we observe that LLM will sometimes say "... on a scale of 1-5 ...", and we remove the string out of 5 since LLM sometimes say it "give a score of $x$ out of $5"$ . We also remove the string /5 since LLM sometimes uses $"x/5"$ to express that it gives a score of $x$ out of 5. For rating the adversarial samples, we remove the title 1 and title 2 in the output sentences. Last, we use the regular expression to extract the first number in the sequence. We find that the above rules are sufficient to parse the output and get the rating of the LLMs. In a few rare cases, the LLM gives the rating with a 0.5 incremental, meaning that it gives scores like 4.5. In such cases, we do not drop the 0.5 since in our instruction, we do not explicitly tell it the rating should be 1-incremental. We find the LLM results merely difference between dropping the 0.5 and keeping the 0.5, and the results in the paper do not drop the 0.5. Again, these cases are really rare.
在T0和Instruct GPT生成答案后(几乎所有情况下答案都由多个句子组成),我们解析生成的句子以获取模型的评分。通过人工检查生成序列的输出后,我们制定了一些解析规则:首先去除输出中的"1-5"字符串(因观察到LLM有时会输出"...在1-5的评分范围内..."),同时移除"out of 5"(因LLM可能输出"给出$x$分(满分5分)")以及"/5"(因LLM可能采用"$x/5$"表示5分制下的$x$分)。针对对抗样本的评分,我们会删除输出句中的标题1和标题2。最后使用正则表达式提取序列中的首个数字。实践表明上述规则足以解析输出并获取LLM的评分。在极少数情况下,LLM会以0.5为增量给出评分(如4.5分),由于我们未在指令中明确要求必须为整数评分,因此保留0.5分值。经测试,舍弃或保留0.5对LLM结果影响微乎其微,故论文中呈现的结果均保留0.5评分。需特别说明,此类情况实际出现频率极低。
| Attribute | Rater Response | |
| ChatGPTI would rate the grammatical correctness of the text of the storyfragment as a 4.There are a few minor errors and awkward phrasings,but overall | ||
| Grammar | thetextiswell-constructed andeasytounderstand. | |
| T1 | Agree | |
| T2 | Agree | |
| T3 | Agree ChatGPTI would rate the fit of the sentences in the story fragment as a 5.The | |
| Cohesive | sentencesfowwelltogether,buildingaclearandcohesivenarrative,and providingasense of progression and development in themain character's | |
| T1 | thoughtsandemotions. Disagree: I think it's a 4 for me, not a 5, because there was one sentence thatdidn'tseemtofitwiththeothers. | |
| T2 T3 | Agree | |
| me as a reader.The openingsentence is about thefirst-person narrator beingfound dead,butthenthenextsentencesareaboutthenarrator's inner thoughts. Also, this passage: "The loneliness. It never felt like such | ||
| Likable | can that feel like a loss? If not, what is this 'it'? So, its juxtaposition to the previous sentence makes it confusing. ChatGPTI would rate the story fragment as a 2 in terms of enjoyment.The fragment is written in a somber and introspectivetone,and it dealswith themes of isolation and loneliness, which may not be enjoyable for some | |
| readers. The protagonist's state of mind is also portrayed as being in a state of shock and confusion,which adds to the overall sense of unease | ||
| T1 | andlackofenjoyment. Disagree:I would rate it a 3, not a 2, since the enjoyment piece is subjec- tive. | |
| T2 | Disagree: While the rating of the freelancer find that the overall theme whilesomberhas a glimmer of hopetoit.It is thisthat makesit more | |
| enjoyabletome.Theunderdog story.Death isnotanissuethat should be shied away from in writing. We all face it and I enjoyed the honesty in the piece. :"Why did I keep walking?". Something Ifeel many of us face andmayhaveaskedourselves.I believethat thiswould berelevant to manyreaders. | ||
| Relevant | ChatGPTI would rate the story fragment as a 5. It is highly relevant to the prompt asitexploresthethemeof death and howitcanbeseen asthedeath of an entire world.The story fragment also touches on the ideas of loneliness and longing, which are related to the loss of someone or something. The concept of the protagonist being frozen in shock and unable to express | |
| themselves, also supports the idea of how death can be seen as the death | ||
| T1 | of an entire world. Agree | |
| T2 T3 | Agree Disagree: I do not see the link between the prompt and the story. |
Table 7: Story 1: a GPT-2-generated story that is highly-rated by ChatGPT.
| 属性 | 评分者反馈 |
|---|
Table 8: Story 2: a GPT-2-generated story that is lowly-rated by ChatGPT.
| Attribute | Rater Response | |
| Grammar | ChatGPTI would rate the grammatical correctness of the story fragment as a 3. Thetextisgenerallyunderstandable,butthereareafewpunctuation | |
| T1 | errorsand awkward phrasingthatmakeit somewhatdifficulttofollow. Disagree:I would rate the grammar as a 2, not a 3-there were signif- cantly moregrammatical errors than the averagewithin thisset of story | |
| T2 | fragments. Disagree: The issues with the grammar and coherence creates a stop start feeling when reading. I am unsure as to who is speaking in thetext | |
| T3 | andthisleavesmewithmanyquestions. Disagree: The grammar is poorer than a 3, as is evident in for example what is supposed to be the second sentence: "He has been ... (incomplete, and another segment is there"People stare...);cant; couldnt;doesnt; | |
| Cohesive | ChatGPT | and sentences that donot makesenselikethis one:"A manIoncewas won't be ableto marry me" Iwouldratethecohesivenessofthesentencesinthestoryfragmentas a2.Thesentencesinthefragment aredisconnected andjumpbetween different thoughts andideas,makingitdifficulttounderstandtheoverall |
| fow between the sentences. It appears that the fragment may be missing someimportantinformationorcontext thatwouldhelptiethesentences together. | ||
| T1 | Agree Agree | |
| T2 T3 | Disagree: very incoherent passage in which it is not very clear who says what,what the topic is,thus rendering a disjointed narrative. | |
| Likable | ChatGPT | I would ratetheenjoyability of the storyfragment as a 1. Thefragment isconfusingand difficulttounderstand,thesentencesaredisconnected and jumps between differentthoughts and ideas.The story seems to be incomplete and lacks context, making it hard to follow the plot or |
| characters.Additionally,the fragment has a sad and negativetone and it doesnotseemtobeenjoyabletoread. | ||
| T1 T2 | Agree Agree | |
| Relevant | T3 Agree | ChatGPT I would rate the relevance of the story fragment to the prompt as a 1. |
| While the story fragment does mention someone being gone, it doesn't seemtobedirectlyrelatedtotheidea offillingout aformtojustifykilling | ||
| someone. It's unclear if the son is the person being proposed to be killed, or if the story is even taking place in the context of the prompt. There is | ||
| T1 | noclearindication that thefragmentisrelatedtotheprompt. Agree | |
| T2 T3 | Agree Agree |
表 8: 故事2:由GPT-2生成但被ChatGPT低分评价的故事
| 属性 | 评分者反馈 | |
|---|---|---|
| 语法 | ChatGPT:我给这个故事的语法正确性打3分。文本基本可理解,但存在一些标点错误和表达生硬的地方,导致阅读有些困难。 | T1 |
| 不同意:我认为语法只能打2分,相比本组其他故事片段,这个文本的语法错误明显更多。 | T2 | |
| 不同意:语法和连贯性问题导致阅读时有断断续续的感觉。文中人物对话不明确,让我产生很多疑问。 | T3 | |
| 不同意:语法水平低于3分标准,例如第二句"He has been..."不完整,还有"People stare..."等片段存在can't/couldn't/doesn't等错误 | ||
| 连贯性 | ChatGPT:我给这个故事的句子连贯性打2分。片段中的句子缺乏关联,在不同想法间跳跃,难以理解整体脉络。 | |
| 片段似乎缺少关键信息或背景,导致句子之间缺乏联系。 | T1 | |
| 同意 | T2 | |
| 不同意:这段文字非常不连贯,不清楚谁在说话、主题是什么,导致叙事支离破碎。 | T3 | |
| 可读性 | ChatGPT:我给这个故事的趣味性打1分。片段令人困惑难懂,句子不连贯且在不同想法间跳跃。 | |
| 故事似乎不完整且缺乏背景,难以理解情节或人物。此外,片段带有悲伤消极的基调,阅读体验不佳。 | T1 | |
| 同意 | T2 | |
| 相关性 | ChatGPT:我给这个故事与提示词的相关性打1分。虽然片段提到某人离开,但与"填写表格证明杀人合理性"的提示关联性不强。 | T3 |
| 不清楚儿子是否是被提议杀害的对象,甚至不确定故事是否发生在提示词的背景下。没有明确迹象表明片段与提示词相关。 | T1 | |
| 同意 | T2 | |
| 同意 | T3 |
| Attribute | Rater | Response |
| Grammar | ChatGPT | The text of the story fragment appears to be grammatically correct, with no major errors or awkward phrasing. On a scale of 1-5, with 1 being |
| T1 | the lowest, Iwould rate the grammatical correctness of the text as a 5. Agree | |
| T2 T3 | Agree Disagree: I would rate this a 4 because of for example'no where’= | |
| ChatGPT | nowhere,althoughitmightseemlikeaminorerror,itdoestakeaway somecorrectnessofthetext. Thesentences inthestoryfragmentfit togetherwell,creatingaclear and | |
| Cohesive | coherent imageof thesceneand thecharacters'actions and thoughts The language is descriptive and evocative, and the dialogue effectively conveys thecharacters’emotions andmotivations.Onascaleof1-5, with 1beingthelowest,Iwould ratehowwell thesentences fit together | |
| T1 | as a 4. Agree | |
| T2 | Agree | |
| T3 | Partially agree: To me, all the sentences fit well together to create a captivating narrative. I will give a 4 or 5. | |
| Likable | ChatGPT | Based on the structure, writing style and plot of the story fragment, 1 wouldrateit as3intermsofenjoyability.Thefragmentsetsupan intriguingsituationwiththemysteriouslittleblackboxandtheprotago- nist's belief that it holds the "secret to the universe," but it ends abruptly and leaves many questions unanswered, which may not be satisfying for |
| T3 | T1 T2 | readers. Disagree: I liked it and it was very clear, so I'd rate it a 4 or 5. Disagree: While the story ends suddenly, I am remined that it is just a |
| fragment and that theirmaybemoretothispiece.Ifeltthepiecewritten about a littleblack boxwas intriguing and enjoyed theintroduction of Norse mythology. This would attract the interest of many readers. Disagree:I enjoyed thefragment,as it piqued my interestto want to | ||
| Relevant | ChatGPT | know more about how the story evolves andwhat it actuallywas about. I would rate the story fragment as a 5 in relevance to the prompt "The LittleBlack Box."The story fragment centers around a little black box and its perceived importance,which aligns with the prompt. Additionally, |
| themain character,Heaven,is holding thebox and describingit as"the secret totheuniverse,"further solidifying theconnection tothe prompt. | ||
| T1 | Agree | |
| T2 T3 | Agree Agree: the story is totally relevant to the prompt. |
Table 9: Story 3: a human-written story that is highly-rated by ChatGPT.
| 属性 | 评分者 | 反馈内容 |
|---|---|---|
| 语法 | ChatGPT | 故事片段的文本在语法上似乎是正确的,没有重大错误或措辞不当。在1-5分的评分标准中(1分为最低),我会给这段文本的语法正确性打5分。 |
| T1 | 同意 | |
| T2 T3 | 同意 不同意:我会打4分,因为例如“no where”应为“nowhere”,虽然看似小错误,但确实影响了文本的正确性。 | |
| 连贯性 | ChatGPT | 故事片段中的句子衔接良好,清晰地描绘了场景和角色的行为与思想。语言具有描述性和感染力,对话有效传达了角色的情感和动机。在1-5分的评分标准中(1分为最低),我会给句子衔接程度打4分。 |
| T1 | 同意 | |
| T2 | 同意 | |
| T3 | 部分同意:我认为所有句子衔接得很好,构建了引人入胜的叙事。我会打4或5分。 | |
| 吸引力 | ChatGPT | 基于故事片段的结构、写作风格和情节,我会在可读性方面打3分。片段通过神秘的小黑盒和主角认为它藏着“宇宙秘密”的设定营造了引人入胜的情境,但结尾突兀且留下许多未解之谜,可能让读者感到不满足。 |
| T1 T2 | 不同意:我喜欢它,而且非常清晰,所以我会打4或5分。 | |
| T3 | 不同意:虽然故事突然结束,但我意识到这只是片段,可能还有更多内容。我觉得关于小黑盒的描写很有趣,并喜欢引入北欧神话的部分。这会吸引许多读者的兴趣。 不同意:我喜欢这个片段,因为它激起了我想了解更多故事发展和实际内容的兴趣。 | |
| 相关性 | ChatGPT | 我会给故事片段在提示语“小黑盒”的相关性上打5分。故事片段围绕一个小黑盒及其重要性展开,与提示语一致。此外,主角Heaven拿着盒子并将其描述为“宇宙的秘密”,进一步强化了与提示语的联系。 |
| T1 | 同意 | |
| T2 T3 | 同意 同意:故事完全符合提示语。 |
表 9: 故事3:ChatGPT高度评价的人类撰写故事。
Table 10: Story 4: a human-written story that is lowly-rated by ChatGPT.
| Attribute | Rater | Response |
| Grammar | ChatGPTI would rate the grammatical correctness of the text as a 3. There are a few errors such as"Manydisplays ofvarious vice"whichshould be "Many displays of various vices" and "I so small fakes of snow" which should be"I saw small fakes of snow."Additionally,some of | |
| thesentencesareslightlyawkwardandcouldberephrasedforbetter clarity.Overall,thetextisunderstandable,but there areafew errors andawkwardphrasingsthatcouldbeimproved. | ||
| T1 | Partially agree:I rated the grammar lower than this-maybe a 2 or a 3. There were above-average numbers of errors. | |
| Cohesive | T2 T3 | Disagree: While the text is understandable, I found myself being dis- tractedbytheerrorsin thetext and coherency. Agree |
| ChatGPT | Iwouldratethecohesiveness of thesentencesin the storyfragment as a 2.The story fragment jumps abruptly between different scenes and characterswithoutcleartransition,makingitdifficulttofollowand understand thenarrative.Additionally,thesentences areoftendisjointed | |
| and lack a clear fow.The story fragment alsolacks a clear plot or purpose, making it difficult to understand the overall story or the main | ||
| T1 | character's intentions. The story fragment can be improved by providing more context, and a clearer narrative arc. Agree: it was jumpy | |
| T2 T3 | Agree Disagree:The storyis about a sniper looking through his rifle's telescope thus seeing changing scenes based on each room he is seeing through | |
| Likable | ChatGPT | the windows, which are then subsequently described. These descriptions accountfortheseeminglackofcohesion. I would rate the enjoyability of the story fragment as a 1. The fragment lacks a clear plot, purpose or character development, making it difficult to |
| becomeinvested in thestory or thecharacters.Additionally,thefragment includes disturbing and graphic content such as violence and prostitution, whichmaymakeituncomfortableforsomereaders.Additionally,the | ||
| fragment containsseveralgrammaticalerrors and awkward phrasings that can make it difficult to follow the story. Overall, the story fragment | ||
| T1 | is not enjoyabletoread. Agree: : it was not just graphic, but also showed really harmful and | |
| T2 T3 | Agree Disagree:Thestorydid holdmyattentiontoadegreebecauseIwanted | |
| ChatGPT | to know whom he wanted to target and why. I would rate the relevance of the story fragment to the prompt as a 1. The | |
| storyfragment doesn'tcontainanyelements that relateto thepromptsuch as the protagonist and antagonist, their actions,orthe moral ambiguities | ||
| Relevant | ||
| the antagonistfaces.Thestoryfragment mainly describes a personwith a sniper rifle looking into windows of a hotel and doesn't present any clear plot or purpose. Additionally, the story fragment does not offer any | ||
| indicationofmoral ambiguity on thepart ofthepersonwiththesniper rifle. Overall, the story fragment is not relevant to the prompt. | ||
| T1 T2 T3 | Agree Agree Agree |
表 10: 故事4: 一篇人类创作但被ChatGPT低分评价的故事。
| 属性 | 评分者 | 反馈内容 |
|---|---|---|
| 语法 | ChatGPT | 我给这段文字的语法正确性打3分。存在几处错误,例如"Manydisplays ofvarious vice"应改为"Many displays of various vices","I so small fakes of snow"应改为"I saw small fakes of snow"。此外,部分句子略显拗口,可以重新表述以提升清晰度。总体而言,文本可以理解,但存在一些错误和别扭的表述有待改进。 |
| T1 | 部分同意:我的语法评分比这个更低,可能是2或3分。错误数量高于平均水平。 | |
| 连贯性 | T2 T3 | 不同意:虽然文本可以理解,但其中的错误和连贯性问题让我分心。同意 |
| ChatGPT | 我给这个故事片段的句子连贯性打2分。故事片段在不同场景和角色之间突兀切换,缺乏清晰过渡,导致难以跟随和理解叙事。此外,句子常常支离破碎且缺乏清晰流向。故事片段还缺少明确的情节或目的,使得难以理解整体故事或主角意图。可以通过提供更多背景信息和更清晰的叙事弧线来改进。 | |
| T1 | 同意:故事确实存在跳跃感 | |
| T2 T3 | 同意 不同意:故事讲述的是狙击手通过步枪望远镜观察不同房间的场景变化,这些描述造成了表面上的不连贯。 | |
| 吸引力 | ChatGPT | 我给这个故事片段的趣味性打1分。片段缺乏清晰的情节、目的或角色发展,让人难以投入故事或角色。此外,片段包含暴力和卖淫等令人不适的直白内容,可能让部分读者感到不适。片段还存在多处语法错误和别扭表述,增加了理解难度。总体而言,这个故事片段阅读体验不佳。 |
| T1 | 同意:内容不仅直白,还展现了非常有害且 | |
| T2 T3 | 同意 不同意:故事在一定程度上吸引了我的注意力,因为我想知道他想要瞄准谁以及为什么。 | |
| 相关性 | ChatGPT | 我给这个故事片段与提示词的相关性打1分。故事片段完全不包含与提示词相关的元素,例如主角与反派的行动或反派面临的道德困境。片段主要描述一个持狙击步枪的人观察酒店房间,没有呈现任何清晰情节或目的。此外,片段也没有展示持枪者任何道德困境的迹象。总体而言,这个故事片段与提示词毫不相关。 |
| T1 T2 T3 | 同意 同意 同意 |
We do not parse the output of ChatGPT using any rules since we the authors read the response and extract the score by ourselves.
我们不使用任何规则解析ChatGPT的输出,而是由作者阅读回复并自行提取分数。
During the experiments, ChatGPT refuses to answer the questions about 2 stories and 3 news titles since ChatGPT find those contents to violate the OpenAI content policy. We find that those samples contain discrimination to some protected groups, or contain sexual or violent descriptions. Hence, the results of ChatGPT are calculated without those samples.
在实验过程中,ChatGPT拒绝回答涉及2个故事和3条新闻标题的问题,因为这些内容违反了OpenAI的内容政策。我们发现这些样本包含对某些受保护群体的歧视,或涉及性暴力描述。因此,ChatGPT的结果统计已排除这些样本。
D.2.2 Open-Ended Story Generation
D.2.2 开放式故事生成
For T0 and the two Instruct GP T models, we query the four attributes separately using the queries shown as follows:
对于T0和两个Instruct GPT模型,我们分别使用以下查询语句查询四个属性:
Grammatical it y
语法上的"it"
Please rate the story fragment The goal of this task is to rate story fragment.
请为故事片段评分 本任务的目标是对故事片段进行评分。
Cohesiveness
凝聚力
Please rate the story fragment The goal of this task is to rate story fragment.
请对故事片段进行评分
本任务的目的是对故事片段进行评分。
Likability
好感度
Please rate the story fragment The goal of this task is to rate story fragment.
请给故事片段打分 本任务的目的是对故事片段进行评分。
Note: Please take the time to fully read and understand the story fragment. We
注意:请花时间完整阅读并理解故事片段。
Relevance
相关性
Please rate the story fragment The goal of this task is to rate story fragment.
请对故事片段进行评分 本任务的目标是对故事片段进行评分。
The [STORY] and [PROMPT] are to be filled in with the story and the prompt. We show the newlines for better readability. When we query the models, we use the token \n to represent the new line.
[STORY] 和 [PROMPT] 需要填入故事和提示内容。我们显示换行符以提高可读性。在查询模型时,我们使用 token \n 来表示换行。
When querying ChatGPT, we query the four attributes of the same story in one conversation; this is similar to asking the teachers to rate the same story on the same page of the Google Form. We use the same queries shown above to query ChatGPT and the order of queries is the same as the order shown above.
在查询ChatGPT时,我们在同一会话中查询同一故事的四个属性;这类似于要求教师在Google表单的同一页面上对同一故事进行评分。我们使用上述相同的查询语句向ChatGPT提问,且查询顺序与上文所示顺序一致。
D.2.3 Adversarial Attack Quality Evaluation
D.2.3 对抗攻击质量评估
When querying all the LLMs in this task, we query the fluency and the meaning preserving of the same news title independently. This means that each conversation with ChatGPT will only have one question, asking about the fluency or the meaning preserving of news title(s). All the parameters for generation are the same as the default parameters in Section 3.2.
在本任务中查询所有大语言模型时,我们分别独立查询同一新闻标题的流畅性和意义保留性。这意味着每次与ChatGPT的对话仅包含一个问题,询问新闻标题的流畅性或意义保留性。所有生成参数均与3.2节中的默认参数保持一致。
The exact query we use are:
我们使用的具体查询是:
Fluency
流畅度
You are given a news title. Please read
给定一则新闻标题。请阅读
The [NEWS_ TITLE] will be filled in with either a benign or adversarial-attacked news title.
[NEWS_ TITLE] 将被填入良性或对抗攻击的新闻标题。
The [BENIGN TITLE] will be filled in with the news title before the attack and the [ADVERSARIAL TITLE] will be filled in with the news title after an adversarial attack.
[BENIGN TITLE] 将填入攻击前的新闻标题 [ADVERSARIAL TITLE] 将填入对抗性攻击后的新闻标题
E Experiment Details on Adversarial Attacks
E 对抗攻击实验细节
The adversarial samples used in Section 4 are from Yoo et al. (2022). Yoo et al. (2022) generates different sets of adversarial samples using different adversarial attacks against different victim models. We use the adversarial samples generated against a bert-base-uncased text classifier trained on AG-News, using three different adversarial attacks: Textfooler, PWWS, and BAE. The intent of the dataset is to facilitate the research in SSA, which we do not violate.
第4节中使用的对抗样本来自Yoo等人 (2022)。Yoo等人 (2022) 针对不同受害模型采用不同对抗攻击方法生成了多组对抗样本。我们使用了针对AG-News数据集训练的bert-base-uncased文本分类器生成的对抗样本,这些样本通过三种不同对抗攻击方法生成:Textfooler、PWWS和BAE。该数据集的初衷是为SSA研究提供便利,我们的使用并未违背这一原则。
Here, we show the supplementary results of using text-davinci-003 as the LLM evaluation for evaluating the quality of adversarial samples in Table 11. We can see that the result of using text-davinci-003 is similar to ChatGPT in the sense that text-davinci-003 also rates adversarial samples higher than humans while still significantly lower than the benign samples. As already seen in Section 3.3, text-davinci-003 tends to give a higher rating.
此处我们展示了使用text-davinci-003作为大语言模型评估对抗样本质量的补充结果(表11)。可以看出,text-davinci-003的评估结果与ChatGPT类似:该模型同样会给对抗样本打出高于人类评分的分值,但仍显著低于良性样本。如第3.3节所示,text-davinci-003普遍存在评分偏高倾向。
Table 11: LLM evaluation (text-davinci-003) and human evaluation result on fluency (Fluent) of the benign and adversarial samples and meaning preserving (Mean.) between the news title before and after adversarial attacks.
| Humanevaluate | LLMevaluate | |||
| Fluent | Mean. | Fluent | Mean. | |
| Benign | 4.55 | 4.33 | 4.56t | |
| Textfooler | 2.17 | 1.88 | 3.71 | 2.37 |
| PWWS | 2.16 | 1.85 | 3.62 | 3.21 |
| BAE | 3.01 | 3.02 | 4.16 | 3.69 |
表 11: 大语言模型 (text-davinci-003) 和人类在良性样本与对抗样本流畅性 (Fluent) 上的评估结果,以及对抗攻击前后新闻标题的语义保持度 (Mean.) 。
| Humanevaluate | LLMevaluate | |||
|---|---|---|---|---|
| Fluent | Mean. | Fluent | Mean. | |
| Benign | 4.55 | 4.33 | 4.56t | |
| Textfooler | 2.17 | 1.88 | 3.71 | 2.37 |
| PWWS | 2.16 | 1.85 | 3.62 | 3.21 |
| BAE | 3.01 | 3.02 | 4.16 | 3.69 |
Table 12: The rating on three adversarial attacks of the three teachers T1, T2, and T3.
| Rater | Textfooler | PWWS | BAE |
| T1 | 3.36 | 3.68 | 4.2 |
| T2 | 1.80 | 1.40 | 2.96 |
| T3 | 1.36 | 1.40 | 1.88 |
表 12: 三位教师 T1、T2 和 T3 对三种对抗攻击的评分
| 评分者 | Textfooler | PWWS | BAE |
|---|---|---|---|
| T1 | 3.36 | 3.68 | 4.2 |
| T2 | 1.80 | 1.40 | 2.96 |
| T3 | 1.36 | 1.40 | 1.88 |
As mentioned in Section 4.3, one teacher rates the fluency of Textfooler significantly higher than PWWS while the other two teachers do not. We show the rating on fluency on the three adversarial attacks by each teacher in Table 12.
如第4.3节所述,一位教师对Textfooler流畅度的评分显著高于PWWS,而另外两位教师则不然。表12展示了每位教师对三种对抗攻击方法流畅度的评分。