Universal Instance Perception as Object Discovery and Retrieval
通用实例感知:作为对象发现与检索
Abstract
摘要
All instance perception tasks aim at finding certain objects specified by some queries such as category names, language expressions, and target annotations, but this complete field has been split into multiple independent subtasks. In this work, we present a universal instance perception model of the next generation, termed UNINEXT. UNINEXT reformulates diverse instance perception tasks into a unified object discovery and retrieval paradigm and can flexibly perceive different types of objects by simply changing the input prompts. This unified formulation brings the following benefits: (1) enormous data from different tasks and label vocabularies can be exploited for jointly training general instance-level representations, which is especially beneficial for tasks lacking in training data. (2) the unified model is parameter-efficient and can save redundant computation when handling multiple tasks simultaneously. UNINEXT shows superior performance on 20 challenging benchmarks from 10 instance-level tasks including classical image-level tasks (object detection and instance segmentation), vision-and-language tasks (referring expression comprehension and segmentation), and six video-level object tracking tasks. Code is available at https://github.com/MasterBin-IIAU/UNINEXT.
所有实例感知任务的目标都是通过类别名称、语言描述或目标标注等查询条件找到特定对象,但这一完整领域被分割成了多个独立子任务。本研究提出了新一代通用实例感知模型UNINEXT,该模型将多样化的实例感知任务重新定义为统一的对象发现与检索范式,仅需改变输入提示即可灵活感知不同类型的对象。这种统一范式具有以下优势:(1) 能够利用来自不同任务和标签词汇的海量数据联合训练通用实例级表征,这对训练数据匮乏的任务尤为有益;(2) 统一模型具有参数高效性,在同时处理多任务时可节省冗余计算。UNINEXT在10类实例级任务的20个挑战性基准测试中表现优异,涵盖经典图像级任务(目标检测与实例分割)、视觉语言任务(指代表达理解与分割)以及六类视频级目标追踪任务。代码已开源:https://github.com/MasterBin-IIAU/UNINEXT。
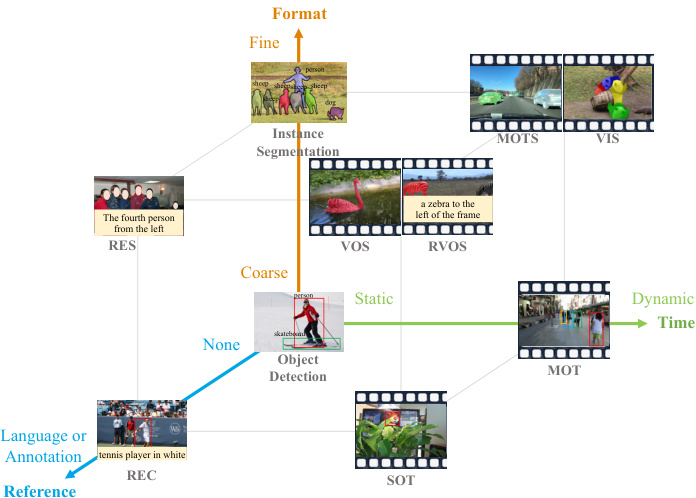
Figure 1. Task distribution on the Format-Time-Reference space. Better view on screen with zoom-in.
图 1: 任务在格式-时间-参考空间中的分布。建议放大屏幕以获得更佳视觉效果。
1. Introduction
1. 引言
videos, Multiple Object Tracking (MOT) [3, 78, 130, 133], Multi-Object Tracking and Segmentation (MOTS) [50, 98, 113], and Video Instance Segmentation (VIS) [46,105, 108, 117] require finding all object trajectories of specific categories in videos. Except for category names, some tasks provide other reference information. For example, Referring Expression Comprehension (REC) [120,126,135], Referring Expression Segmentation (RES) [121,124,126], and Referring Video Object Segmentation (R-VOS) [7, 91, 109] aim at finding objects matched with the given language expressions like “The fourth person from the left”. Besides, Single Object Tracking (SOT) [5, 54, 111] and Video Object Segmentation (VOS) [19, 82, 112] take the target annotations (boxes or masks) given in the first frame as the reference, requiring to predict the trajectories of the tracked objects in the subsequent frames. Since all the above tasks aim to perceive instances of certain properties, we refer to them collectively as instance perception.
视频中的多目标跟踪 (MOT) [3, 78, 130, 133]、多目标跟踪与分割 (MOTS) [50, 98, 113] 以及视频实例分割 (VIS) [46, 105, 108, 117] 需要找出视频中特定类别的所有目标轨迹。除了类别名称外,部分任务还提供其他参考信息。例如,指代表达理解 (REC) [120, 126, 135]、指代表达分割 (RES) [121, 124, 126] 和参考视频目标分割 (R-VOS) [7, 91, 109] 旨在定位与给定语言描述(如"左侧第四个人")匹配的目标。此外,单目标跟踪 (SOT) [5, 54, 111] 和视频目标分割 (VOS) [19, 82, 112] 以首帧标注(框或掩码)为参考,要求预测后续帧中目标的运动轨迹。由于上述任务均针对特定属性的实例感知,我们将其统称为实例感知任务。
Object-centric understanding is one of the most essential and challenging problems in computer vision. Over the years, the diversity of this field increases substantially. In this work, we mainly discuss 10 sub-tasks, distributed on the vertices of the cube shown in Figure 1. As the most fundamental tasks, object detection [8, 9, 33, 62, 86, 88, 96] and instance segmentation [6, 40, 67, 95, 102] require finding all objects of specific categories by boxes and masks respectively. Extending inputs from static images to dynamic
以物体为中心的理解是计算机视觉中最关键且最具挑战性的问题之一。多年来,该领域的多样性大幅增加。本工作中,我们主要讨论分布在图1所示立方体顶点上的10个子任务。作为最基础的任务,目标检测 [8, 9, 33, 62, 86, 88, 96] 和实例分割 [6, 40, 67, 95, 102] 分别要求通过边界框和掩码找出特定类别的所有物体。当输入从静态图像扩展到动态...
Although bringing convenience to specific applications, such diverse task definitions split the whole field into fragmented pieces. As the result, most current instance perception methods are developed for only a single or a part of sub-tasks and trained on data from specific domains. Such fragmented design philosophy brings the following drawbacks: (1) Independent designs hinder models from learning and sharing generic knowledge between different tasks and domains, causing redundant parameters. (2) The possibility of mutual collaboration between different tasks is overlooked. For example, object detection data enables models to recognize common objects, which can naturally improve the performance of REC and RES. (3) Restricted by fixed-size class if i ers, traditional object detectors are hard to jointly train on multiple datasets with different label vocabularies [39,64,93] and to dynamically change object categories to detect during inference [24, 64, 78, 85, 117, 125]. Since essentially all instance perception tasks aim at finding certain objects according to some queries, it leads to a natural question: could we design a unified model to solve all mainstream instance perception tasks once and for all?
尽管为特定应用带来了便利,但这种多样化的任务定义将整个领域分割成碎片化的部分。因此,当前大多数实例感知方法仅针对单个或部分子任务开发,并在特定领域的数据上进行训练。这种碎片化的设计理念带来了以下缺点:(1) 独立设计阻碍了模型在不同任务和领域之间学习和共享通用知识,导致参数冗余。(2) 忽视了不同任务之间相互协作的可能性。例如,目标检测数据使模型能够识别常见物体,这自然可以提高REC和RES的性能。(3) 受限于固定大小的分类器,传统目标检测器难以在具有不同标签词汇的多个数据集上联合训练[39,64,93],也难以在推理过程中动态更改要检测的物体类别[24, 64, 78, 85, 117, 125]。由于本质上所有实例感知任务都旨在根据某些查询找到特定物体,这引出一个自然的问题:我们能否设计一个统一的模型,一劳永逸地解决所有主流实例感知任务?
To answer this question, we propose UNINEXT, a universal instance perception model of the next generation. We first reorganize 10 instance perception tasks into three types according to the different input prompts: (1) category names as prompts (Object Detection, Instance Segmentation, VIS, MOT, MOTS). (2) language expressions as prompts (REC, RES, R-VOS). (3) reference annotations as prompts (SOT, VOS). Then we propose a unified prompt-guided object discovery and retrieval formulation to solve all the above tasks. Specifically, UNINEXT first discovers $N$ object proposals under the guidance of the prompts, then retrieves the final instances from the proposals according to the instance-prompt matching scores. Based on this new formulation, UNINEXT can flexibly perceive different instances by simply changing the input prompts. To deal with different prompt modalities, we adopt a prompt generation module, which consists of a reference text encoder and a reference visual encoder. Then an early fusion module is used to enhance the raw visual features of the current image and the prompt embeddings. This operation enables deep information exchange and provides highly disc rim i native representations for the later instance prediction step. Considering the flexible query-toinstance fashion, we choose a Transformer-based object detector [136] as the instance decoder. Specifically, the decoder first generates $N$ instance proposals, then the prompt is used to retrieve matched objects from these proposals. This flexible retrieval mechanism overcomes the disadvantages of traditional fixed-size class if i ers and enables joint training on data from different tasks and domains.
为回答这一问题,我们提出了新一代通用实例感知模型UNINEXT。首先根据输入提示的不同形式,将10种实例感知任务重组为三类:(1) 以类别名称为提示(目标检测、实例分割、VIS、MOT、MOTS);(2) 以语言描述为提示(REC、RES、R-VOS);(3) 以参考标注为提示(SOT、VOS)。随后提出统一的提示引导目标发现与检索框架来解决所有任务。具体而言,UNINEXT首先在提示引导下发现$N$个候选目标,再根据实例-提示匹配分数从中检索最终实例。基于这一新框架,仅需改变输入提示即可灵活感知不同实例。针对多模态提示,采用包含参考文本编码器和参考视觉编码器的提示生成模块,并通过早期融合模块增强当前图像原始视觉特征与提示嵌入。该操作实现深层信息交互,为后续实例预测步骤提供高判别性表征。考虑到灵活的查询-实例交互方式,选择基于Transformer的目标检测器[136]作为实例解码器。具体而言,解码器首先生成$N$个实例候选,再通过提示从中检索匹配目标。这种灵活检索机制克服了传统固定尺寸分类器的缺陷,支持跨任务跨领域数据的联合训练。
With the unified model architecture, UNINEXT can learn strong generic representations on massive data from various tasks and solve 10 instance-level perception tasks using a single model with the same model parameters. Extensive experiments demonstrate that UNINEXT achieves superior performance on 20 challenging benchmarks. The contributions of our work can be summarized as follows.
通过统一的模型架构,UNINEXT能够在来自各类任务的海量数据上学习强大的通用表征,并使用同一套模型参数解决10项实例级感知任务。大量实验表明,UNINEXT在20个具有挑战性的基准测试中均取得了卓越性能。我们的工作贡献可概括如下:
• We propose a unified prompt-guided formulation for universal instance perception, reuniting previously fragmented instance-level sub-tasks into a whole. • Benefiting from the flexible object discovery and retrieval paradigm, UNINEXT can train on different tasks and domains, in no need of task-specific heads. • UNINEXT achieves superior performance on 20 challenging benchmarks from 10 instance perception tasks using a single model with the same model parameters.
• 我们提出了一种统一的提示引导式通用实例感知框架,将以往分散的实例级子任务重新整合为一个整体。
• 得益于灵活的对象发现与检索范式,UNINEXT能够在不同任务和领域上进行训练,无需任务特定的输出头。
• UNINEXT使用单一模型(参数保持不变)在10类实例感知任务的20个高难度基准测试中取得了卓越性能。
2. Related Work
2. 相关工作
Instance Perception. The goals and typical methods of 10 instance perception tasks are introduced as follows.
实例感知。以下介绍10种实例感知任务的目标与典型方法。
Retrieval by Category Names. Object detection and instance segmentation aim at finding all objects of specific classes on the images in the format of boxes or masks. Early object detectors can be mainly divided into two-stage methods [8,12,88] and one-stage methods [36,63,86,96,128] according to whether to use RoI-level operations [38, 40]. Recently, Transformer-based detectors [9, 56, 136] have drawn great attention for their conceptually simple and flexible frameworks. Besides, instance segmentation approaches can also be divided into detector-based [8, 12, 40, 52, 95] and detector-free [17, 102] fashions according to whether box-level detectors are needed. Object detection and instance segmentation play critical roles and are foundations for all other instance perception tasks. For example, MOT, MOTS, and VIS extend image-level detection and segmentation to videos, requiring finding all object trajectories of specific classes in videos. Mainstream algorithms [50, 83, 106, 107, 114, 129] of MOT and MOTS follow an online ”detection-then-association” paradigm. However, due to the intrinsic difference in benchmarks of MOTS [98, 125] (high-resolution long videos) and VIS [117] (low-resolution short videos), most recent VIS methods [46, 61, 105, 108] adopt an offline fashion. This strategy performs well on relatively simple VIS2019 [117], but the performance drops drastically on challenging OVIS [85] benchmark. Recently, IDOL [110] bridges the performance gap between online fashion and its offline counterparts by disc rim i native instance embeddings, showing the potential of the online paradigm in unifying MOT, MOTS, and VIS.
按类别名称检索。目标检测和实例分割旨在以边界框或掩码形式找出图像中特定类别的所有对象。早期目标检测器根据是否使用RoI级操作[38,40]主要分为两阶段方法[8,12,88]和单阶段方法[36,63,86,96,128]。近年来,基于Transformer的检测器[9,56,136]因其概念简洁灵活的框架受到广泛关注。此外,实例分割方法根据是否需要框级检测器,也可分为基于检测器[8,12,40,52,95]和无检测器[17,102]两种范式。目标检测与实例分割具有关键作用,是所有其他实例感知任务的基础。例如MOT(多目标跟踪)、MOTS(多目标跟踪与分割)和VIS(视频实例分割)将图像级检测与分割延伸至视频领域,需找出视频中特定类别的所有对象轨迹。MOT与MOTS的主流算法[50,83,106,107,114,129]遵循在线"检测-关联"范式。但由于MOTS98,125与VIS117基准的内在差异,近期多数VIS方法[46,61,105,108]采用离线处理策略。该策略在相对简单的VIS2019[117]上表现良好,但在具有挑战性的OVIS[85]基准上性能急剧下降。最近IDOL[110]通过判别式实例嵌入缩小了在线范式与离线范式的性能差距,展现了在线范式统一MOT、MOTS和VIS的潜力。
Retrieval by Language Expressions. REC, RES, and RVOS aim at finding one specific target referred by a language expression using boxes or masks on the given images or videos. Similar to object detection, REC methods can be categorized into three paradigms: two-stage [43, 65, 68, 118], one-stage [60, 73, 119, 120], and Transformerbased [25, 48, 134] ones. Different from REC, RES approaches [11,27,34,44,47,72,124] focus more on designing diverse attention mechanisms to achieve vision-language alignment. Recently, SeqTR [135] unifies REC and RES as a point prediction problem and obtains promising results. Finally, R-VOS can be seen as a natural extension of RES from images to videos. Current state-of-the-art methods [7, 109] are Transformer-based and process the whole video in an offline fashion. However, the offline paradigm hinders the applications in the real world such as long videos and ongoing videos (e.g. autonomous driving).
基于语言表达的检索。REC、RES和RVOS旨在通过给定的图像或视频中的边界框或掩码,找到语言表达式所指的特定目标。与目标检测类似,REC方法可分为三种范式:两阶段 [43, 65, 68, 118]、单阶段 [60, 73, 119, 120] 以及基于Transformer [25, 48, 134] 的方法。与REC不同,RES方法 [11,27,34,44,47,72,124] 更侧重于设计多样化的注意力机制以实现视觉-语言对齐。近期,SeqTR [135] 将REC和RES统一为点预测问题并取得了显著效果。最后,R-VOS可视为RES从图像到视频的自然延伸。当前最先进的方法 [7, 109] 基于Transformer并以离线方式处理整段视频,但离线范式限制了其在长视频和实时视频(如自动驾驶)等现实场景中的应用。
Retrieval by Reference Annotations. SOT and VOS first specify tracked objects on the first frame of a video using boxes or masks, then require algorithms to predict the trajectories of the tracked objects in boxes or masks respectively. The core problems of these two tasks include (1) How to extract informative target features? (2) How to fuse the target information with representations of the current frame? For the first question, most SOT methods [5, 15, 53, 54, 115] encode target information by passing a template to a siamese backbone. While VOS ap- proaches [19,82,122] usually pass multiple previous frames together with corresponding mask results to a memory encoder for extracting fine-grained target information. For the second question, correlations are widely adopted by early SOT algorithms [5, 54, 116]. However, these simple linear operations may cause serious information loss. To alleviate this problem, later works [15, 20, 115, 123] resort to Transformer for more disc rim i native representations. Besides, feature fusion in VOS is almost dominated by space-time memory networks [18, 19, 82, 122].
基于参考标注的检索。单目标跟踪(SOT)和视频目标分割(VOS)首先在视频首帧通过边界框或掩码指定待跟踪目标,随后要求算法分别以边界框或掩码形式预测被跟踪目标的运动轨迹。这两项任务的核心问题包括:(1) 如何提取信息丰富的目标特征?(2) 如何将目标信息与当前帧表征进行融合?针对第一个问题,多数SOT方法[5,15,53,54,115]通过将模板输入孪生骨干网络来编码目标信息;而VOS方法[19,82,122]通常将多帧历史图像与对应掩码结果共同输入记忆编码器,以提取细粒度目标特征。对于第二个问题,早期SOT算法[5,54,116]广泛采用相关性运算,但这类简单线性操作可能导致严重信息损失。为缓解该问题,后续研究[15,20,115,123]转而采用Transformer获取更具判别性的表征。此外,VOS中的特征融合几乎被时空记忆网络[18,19,82,122]所主导。
Unified Vision Models. Recently, unified vision models [13, 17, 37, 40, 57, 71, 87, 92, 100, 114, 137] have drawn great attention and achieved significant progress due to their strong general iz ability and flexibility. Unified vision models attempt to solve multiple vision or multi-modal tasks by a single model. Existing works can be categorized into unified learning paradigms and unified model architectures.
统一视觉模型 (Unified Vision Models)。近年来,统一视觉模型 [13, 17, 37, 40, 57, 71, 87, 92, 100, 114, 137] 因其强大的泛化能力和灵活性受到广泛关注并取得显著进展。这类模型试图通过单一模型解决多种视觉或多模态任务。现有研究可分为统一学习范式 (unified learning paradigms) 和统一模型架构 (unified model architectures) 两大类。
Unified Learning Paradigms. These works [2, 37, 71, 87, 92, 100, 137] usually present a universal learning paradigm for covering as many tasks and modalities as possible. For example, MuST [37] presents a multi-task self-training approach for 6 vision tasks. INTERN [92] introduces a continuous learning scheme, showing strong generalization ability on 26 popular benchmarks. Unified-IO [71] and OFA [100] proposes a unified sequence-to-sequence framework that can handle a variety of vision, language, and multi-modal tasks. Although these works can perform many tasks, the common ali ty and inner relationship among different tasks are less explored and exploited.
统一学习范式。这些工作 [2, 37, 71, 87, 92, 100, 137] 通常提出一种通用学习范式,以覆盖尽可能多的任务和模态。例如,MuST [37] 提出了一种针对6种视觉任务的多任务自训练方法。INTERN [92] 引入了一种持续学习方案,在26个流行基准测试中展现出强大的泛化能力。Unified-IO [71] 和 OFA [100] 提出了一个统一的序列到序列框架,能够处理多种视觉、语言和多模态任务。尽管这些工作可以执行许多任务,但不同任务之间的共性和内在关联却较少被探索和利用。
Unified Model Architectures. These works [13, 17, 40, 57, 114] usually design a unified formulation or model architecture for a group of closely related tasks. For example, Mask R-CNN [40] proposes a unified network to perform object detection and instance segmentation simultaneously. Mask 2 Former [17] presents a universal architecture capable of handling panoptic, instance, and semantic segmentation. Pix2SeqV2 [13] designs a unified pixelto-sequence interface for four vision tasks, namely object detection, instance segmentation, keypoint detection, and image captioning. GLIP [57] cleverly reformulates object detection as phrase grounding by replacing classical classification with word-region alignment. This new formulation allows joint training on both detection and grounding data, showing strong transfer ability to various objectlevel recognition tasks. However, GLIP [57] supports neither prompts in other modalities such as images & annotations nor video-level tracking tasks. In terms of object tracking, Unicorn [114] proposes a unified solution for SOT, VOS, MOT, and MOTS, achieving superior performance on 8 benchmarks with the same model weights. However, it is still difficult for Unicorn to handle diverse label vocabularies [24,64,78,85,117,125] during training and inference. In this work, we propose a universal prompt-guided architecture for 10 instance perception tasks, conquering the drawbacks of GLIP [57] and Unicorn [114] simultaneously.
统一模型架构。这些工作 [13, 17, 40, 57, 114] 通常为一组紧密相关的任务设计统一的公式或模型架构。例如,Mask R-CNN [40] 提出了一个统一网络,可同时执行目标检测和实例分割。Mask2Former [17] 提出了一种通用架构,能够处理全景分割、实例分割和语义分割。Pix2SeqV2 [13] 为四个视觉任务(即目标检测、实例分割、关键点检测和图像描述)设计了统一的像素到序列接口。GLIP [57] 通过用词区域对齐替换经典分类,巧妙地将目标检测重新表述为短语定位。这种新公式允许在检测和定位数据上进行联合训练,显示出对各种对象级识别任务的强大迁移能力。然而,GLIP [57] 不支持其他模态(如图像和标注)的提示,也不支持视频级跟踪任务。在目标跟踪方面,Unicorn [114] 提出了针对单目标跟踪 (SOT)、视频目标分割 (VOS)、多目标跟踪 (MOT) 和多目标跟踪与分割 (MOTS) 的统一解决方案,使用相同的模型权重在8个基准测试中实现了卓越性能。然而,Unicorn 在训练和推理过程中仍难以处理多样化的标签词汇 [24,64,78,85,117,125]。在这项工作中,我们提出了一种通用的提示引导架构,适用于10个实例感知任务,同时克服了 GLIP [57] 和 Unicorn [114] 的缺点。
3. Approach
3. 方法
Before introducing detailed methods, we first categorize existing instance perception tasks into three classes.
在介绍具体方法之前,我们首先将现有的实例感知任务分为三类。
• Object detection, instance segmentation, MOT, MOTS, and VIS take category names as prompts to find all instances of specific classes. • REC, RES, and R-VOS exploit an expression as the prompt to localize a certain target. • SOT and VOS use the annotation given in the first frame as the prompt for predicting the trajectories of the tracked target.
- 目标检测 (object detection)、实例分割 (instance segmentation)、多目标跟踪 (MOT)、多目标跟踪与分割 (MOTS) 和视频实例分割 (VIS) 以类别名称作为提示 (prompt) 来查找特定类别的所有实例。
- 指代表达式理解 (REC)、指代表达式分割 (RES) 和指代视频对象分割 (R-VOS) 利用表达式作为提示来定位特定目标。
- 单目标跟踪 (SOT) 和视频对象分割 (VOS) 使用第一帧中给出的标注作为提示来预测被跟踪目标的轨迹。
Essentially, all the above tasks aim to find objects specified by some prompts. This common ali ty motivates us to reformulate all instance perception tasks into a prompt-guided object discovery and retrieval problem and solve it by a unified model architecture and learning paradigm. As demonstrated in Figure 2, UNINEXT consists of three main components: (1) prompt generation (2) image-prompt feature fusion (3) object discovery and retrieval.
本质上,上述所有任务都旨在通过某些提示(prompt)查找指定对象。这一共性促使我们将所有实例感知任务重新定义为提示引导的对象发现与检索问题,并通过统一的模型架构和学习范式来解决。如图2所示,UNINEXT包含三个核心组件:(1) 提示生成 (2) 图像-提示特征融合 (3) 对象发现与检索。
3.1. Prompt Generation
3.1. 提示生成
First, a prompt generation module is adopted to transform the original diverse prompt inputs into a unified form. According to different modalities, we introduce the corresponding strategies in the next two paragraphs respectively.
首先,采用提示生成模块将原始多样化的提示输入转换为统一形式。针对不同模态,我们将在接下来的两段中分别介绍相应的策略。
To deal with language-related prompts, a language encoder [26] $\mathrm{Enc_{L}}$ is adopted. To be specific, for categoryguided tasks, we concatenate class names that appeared in the current dataset [64,85,117,125] as the language expression. Take COCO [64] as an example, the expression can be written as “person. bicycle. ... . toothbrush”. Then for both category-guided and expression-guided tasks, the language expression is passed into $\mathrm{Enc_{L}}$ , getting a prompt embedding $F_{p}\in\mathbb{R}^{L\times d}$ with a sequence length of $L$ .
为处理与语言相关的提示,我们采用了一种语言编码器 [26] $\mathrm{Enc_{L}}$。具体而言,对于类别引导的任务,我们将当前数据集中出现的类别名称 [64,85,117,125] 拼接成语言表达。以 COCO [64] 为例,该表达可写作“person. bicycle. ... . toothbrush”。随后,无论是类别引导还是表达引导的任务,语言表达都会被输入 $\mathrm{Enc_{L}}$,得到一个序列长度为 $L$ 的提示嵌入 $F_{p}\in\mathbb{R}^{L\times d}$。
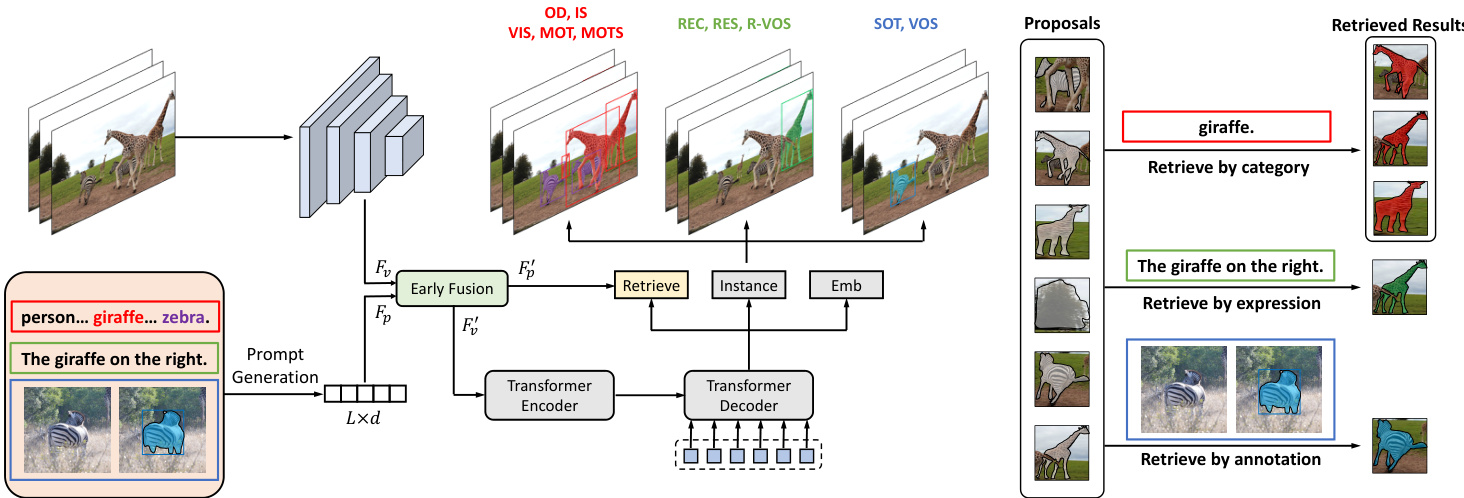
Figure 2. Framework of UNINEXT. The whole pipeline is shown on the left side. The schematic diagram of object retrieval is shown on the right side. The instance head predicts both boxes and masks of the objects. Better view in color on screen.
图 2: UNINEXT框架。左侧展示了整个流程。右侧为对象检索示意图。实例头(instance head)同时预测对象的边界框(box)和掩码(mask)。建议屏幕彩色查看效果更佳。
For the annotation-guided tasks, to extract fine-grained visual features and fully exploit the target annotations, an additional reference visual encoder $\mathrm{Enc_{V}^{r e f}}$ is introduced. Specifically, first a template with $2^{2}$ times the target box area is cropped centered on the target location on the reference frame. Then the template is resized to a fixed size of $256\times256$ . To introduce more precise target information, an extra channel named the target prior is concatenated to the template image, forming a 4-channel input. In more detail, the value of the target prior is 1 on the target region otherwise 0. Then the template image together with the target prior is passed to the reference visual encoder $\mathrm{Enc_{V}^{r e f}}$ obtaining a hierarchical feature pyramid ${\mathrm{C}{3},\mathrm{C}{4},\mathrm{C}{5},\mathrm{C}_{6}}$ . The corresponding spatial sizes are $32\times32$ , $16\times16$ , $8\times8$ , and $4\times4$ . To keep fine target information and get the prompt embedding in the same format as other tasks, a merging module is applied. Namely, all levels of features are first upsampled to $32\times32$ then added, and flattened as the final prompt embedding Fp ∈ R1024×d.
对于标注引导的任务,为了提取细粒度视觉特征并充分利用目标标注,额外引入了一个参考视觉编码器 $\mathrm{Enc_{V}^{r e f}}$。具体而言,首先以参考帧上的目标位置为中心,裁剪出面积为目标框 $2^{2}$ 倍的模板。然后将模板调整为固定尺寸 $256\times256$。为了引入更精确的目标信息,模板图像会拼接一个名为目标先验的额外通道,形成4通道输入。更详细地说,目标先验在目标区域上的值为1,其余区域为0。接着,模板图像与目标先验一起输入参考视觉编码器 $\mathrm{Enc_{V}^{r e f}}$,获得分层特征金字塔 ${\mathrm{C}{3},\mathrm{C}{4},\mathrm{C}{5},\mathrm{C}_{6}}$,其对应空间尺寸分别为 $32\times32$、$16\times16$、$8\times8$ 和 $4\times4$。为保留精细目标信息并使提示嵌入与其他任务格式一致,应用了合并模块:将所有层级的特征先上采样至 $32\times32$ 再相加,最后展平为最终提示嵌入 Fp ∈ R1024×d。
3.2. Image-Prompt Feature Fusion
3.2. 图像-提示特征融合
In parallel with the prompt generation, the whole current image is passed through another visual encoder $\mathrm{Enc_{V}}$ , obtaining hierarchical visual features $F_{v}$ . To enhance the original prompt embedding by the image contexts and to make the original visual features prompt-aware, an early fusion module is adopted. To be specific, first a bi-directional cross-attention module (Bi-XAtt) is used to retrieve information from different inputs, and then the retrieved representations are added to the original features. This process can be formulated as
在生成提示词的同时,当前完整图像会通过另一个视觉编码器 $\mathrm{Enc_{V}}$ 处理,获得分层视觉特征 $F_{v}$。为了通过图像上下文增强原始提示嵌入,并使原始视觉特征具备提示感知能力,我们采用了早期融合模块。具体而言,首先使用双向交叉注意力模块 (Bi-XAtt) 从不同输入中检索信息,然后将检索到的表征叠加到原始特征上。该过程可表述为
$$
\begin{array}{r l}&{F_{\mathsf{p2v}},F_{\mathsf{v2p}}=\mathsf{B i-X A t t}(F_{v},F_{p})}\ &{F_{v}^{\prime}=F_{v}+F_{\mathsf{p2v}};F_{p}^{\prime}=F_{p}+F_{\mathsf{v2p}}}\end{array}
$$
$$
\begin{array}{r l}&{F_{\mathsf{p2v}},F_{\mathsf{v2p}}=\mathsf{B i-X A t t}(F_{v},F_{p})}\ &{F_{v}^{\prime}=F_{v}+F_{\mathsf{p2v}};F_{p}^{\prime}=F_{p}+F_{\mathsf{v2p}}}\end{array}
$$
Different from GLIP [57], which adopts 6 vision-language fusion layers and 6 additional BERT layers for feature enhancement, our early fusion module is much more efficient.
与采用6层视觉-语言融合层和6个额外BERT层进行特征增强的GLIP [57]不同,我们的早期融合模块效率更高。
3.3. Object Discovery and Retrieval
3.3. 目标发现与检索
With disc rim i native visual and prompt representations, the next crucial step is to transform input features into instances for various perception tasks. UNINEXT adopts the encoder-decoder architecture proposed by Deformable DETR [136] for its flexible query-to-instance fashion. We introduce the detailed architectures as follows.
在具备判别性视觉和提示表征后,关键步骤是将输入特征转化为各类感知任务的实例。UNINEXT采用Deformable DETR [136]提出的编码器-解码器架构,因其灵活的查询到实例转换机制。具体架构如下所述。
The Transformer encoder takes hierarchical promptaware visual features as the inputs. With the help of efficient Multi-scale Deformable Self-Attention [136], target information from different scales can be fully exchanged, bringing stronger instance features for the subsequent instance decoding. Besides, as performed in two-stage Deformable DETR [136], an auxiliary prediction head is appended at the end of the encoder, generating $N$ initial reference points with the highest scores as the inputs of the decoder.
Transformer编码器以分层提示感知视觉特征作为输入。借助高效的多尺度可变形自注意力机制[136],能够充分交换来自不同尺度的目标信息,为后续实例解码提供更强的实例特征。此外,如两阶段可变形DETR[136]所示,在编码器末端添加了一个辅助预测头,生成得分最高的$N$个初始参考点作为解码器的输入。
The Transformer decoder takes the enhanced multi-scale features, $N$ reference points from the encoder, as well as $N$ object queries as the inputs. As shown in previous works [77, 105, 109, 127], object queries play a critical role in instance perception tasks. In this work, we attempt two query generation strategies: (1) static queries which do not change with images or prompts. (2) dynamic queries conditioned on the prompts. The first strategy can be easily implemented with nn.Embedding(N,d). The second one can be performed by first pooling the enhanced prompt features $F_{v}^{\prime}$ along the sequence dimension, getting a global representation, then repeating it by $N$ times. The above two meth- ods are compared in $\mathrm{Sec}4.3$ and we find that static queries usually perform better than dynamic queries. The potential reason could be that static queries contain richer information and possess better training stability than dynamic queries. With the help of the deformable attention, the object queries can efficiently retrieve prompt-aware visual features and learn strong instance embedding $F_{\mathrm{ins}}\in\mathbb{R}^{N\times d}$ .
Transformer解码器以增强的多尺度特征、编码器提供的$N$个参考点以及$N$个对象查询(object queries)作为输入。如先前研究[77, 105, 109, 127]所示,对象查询在实例感知任务中起着关键作用。本文尝试了两种查询生成策略:(1) 静态查询(static queries),即不随图像或提示变化;(2) 动态查询(dynamic queries),即基于提示生成。第一种策略可通过nn.Embedding(N,d)轻松实现,第二种策略则需先沿序列维度池化增强的提示特征$F_{v}^{\prime}$获得全局表征,再重复$N$次。在$\mathrm{Sec}4.3$中对比发现,静态查询通常优于动态查询,潜在原因可能是静态查询包含更丰富信息且训练稳定性更强。借助可变形注意力机制,对象查询能高效检索提示相关的视觉特征,学习到强实例嵌入$F_{\mathrm{ins}}\in\mathbb{R}^{N\times d}$。
At the end of the decoder, a group of prediction heads is exploited to obtain the final instance predictions. Specifically, an instance head produces both boxes and masks of the targets. Besides, an embedding head [110] is introduced for associating the current detected results with previous trajectories in MOT, MOTS, and VIS. Until now, we have mined $N$ potential instance proposals, which are represented with gray masks in Figure 2. However, not all proposals are what the prompts really refer to. Therefore, we need to further retrieve truly matched objects from these proposals according to the prompt embeddings as demonstrated in the right half of Figure 2. Specifically, given the prompt embeddings $F_{p}^{\prime}$ after early fusion, for categoryguided tasks, we take the embedding of each category name as a weight matrix $W\in\mathbb{R}^{1\times d}$ . Besides, for expressionguided and annotation-guided tasks, the weight matrix $W$ is obtained by aggregating the prompt embedding $F_{p}^{\prime}$ using global average pooling (GAP) along the sequence dimension.
在解码器末端,利用一组预测头(prediction heads)获取最终实例预测结果。具体而言,实例头(instance head)会同时生成目标框和掩码。此外,还引入了嵌入头(embedding head)[110]用于在MOT、MOTS和VIS任务中将当前检测结果与历史轨迹关联。至此,我们已挖掘出$N$个潜在实例提案(instance proposals),如图2中的灰色掩码所示。但并非所有提案都真正对应提示所指内容,因此需要根据提示嵌入(prompt embeddings)从这些提案中进一步检索真正匹配的目标,如图2右半部分所示。具体而言,给定早期融合后的提示嵌入$F_{p}^{\prime}$:对于类别引导任务,我们将每个类别名称的嵌入作为权重矩阵$W\in\mathbb{R}^{1\times d}$;对于表达式引导和标注引导任务,则通过对提示嵌入$F_{p}^{\prime}$沿序列维度进行全局平均池化(GAP)来聚合得到权重矩阵$W$。
does not have mask annotations, we introduce two auxiliary losses proposed by BoxInst [97] for training the mask branch. The loss function can be formulated as
由于没有掩码标注,我们引入了BoxInst [97]提出的两种辅助损失函数来训练掩码分支。该损失函数可表示为
$$
\mathcal{L}{\mathrm{stage1}}=\mathcal{L}{\mathrm{retrieve}}+\mathcal{L}{\mathrm{box}}+\mathcal{L}_{\mathrm{mask}}^{\mathrm{boxinst}}
$$
$$
\mathcal{L}{\mathrm{stage1}}=\mathcal{L}{\mathrm{retrieve}}+\mathcal{L}{\mathrm{box}}+\mathcal{L}_{\mathrm{mask}}^{\mathrm{boxinst}}
$$
Then based on the pretrained weights of the first stage, we finetune UNINEXT jointly on image datasets, namely COCO [64] and the mixed dataset of RefCOCO [126], Re $\mathrm{fCOCO+}$ [126], and $\mathrm{RefCOCOg}$ [81]. With manually labeled mask annotations, the traditional loss functions like Dice Loss [79] and Focal Loss [63] can be used for the mask learning. After this step, UNINEXT can achieve superior performance on object detection, instance segmentation, REC, and RES.
然后基于第一阶段的预训练权重,我们在图像数据集(即COCO [64]以及RefCOCO [126]、RefCOCO+ [126]和RefCOCOg [81]的混合数据集)上联合微调UNINEXT。通过手动标注的掩码注释,传统损失函数如Dice Loss [79]和Focal Loss [63]可用于掩码学习。经过此步骤后,UNINEXT在目标检测、实例分割、REC和RES任务上均能取得优异性能。
$$
\mathcal{L}{\mathrm{stage2}}=\mathcal{L}{\mathrm{retrieve}}+\mathcal{L}{\mathrm{box}}+\mathcal{L}_{\mathrm{mask}}
$$
$$
\mathcal{L}{\mathrm{stage2}}=\mathcal{L}{\mathrm{retrieve}}+\mathcal{L}{\mathrm{box}}+\mathcal{L}_{\mathrm{mask}}
$$
Finally, we further finetune UNINEXT on video-level datasets for various downstream object tracking tasks and benchmarks. In this stage, the model is trained on two frames randomly chosen from the original videos. Besides, to avoid the model forgetting previously learned knowledge on image-level tasks, we also transform image-level datasets to pseudo videos for joint training with other video datasets. In summary, the training data in the third stage includes pseudo videos generated from COCO [64], $\mathrm{RefCOCO/g/+}$ [81, 126, 126], SOT&VOS datasets (GOT-10K [45], LaSOT [31], TrackingNet [80], and Youtube-VOS [112]), MOT&VIS datasets (BDD100K [125], VIS19 [117], OVIS [85]), and R-VOS dataset Ref-Youtube-VOS [91]. Meanwhile, a reference visual encoder for SOT&VOS and an extra embedding head for association are introduced and optimized in this period.
最后,我们进一步在视频级数据集上对UNINEXT进行微调,以适配各种下游目标跟踪任务和基准测试。在此阶段,模型训练使用的两帧图像是从原始视频中随机选取的。此外,为防止模型遗忘先前在图像级任务中学到的知识,我们还将图像级数据集转换为伪视频,与其他视频数据集进行联合训练。总体而言,第三阶段的训练数据包括:由COCO [64]、$\mathrm{RefCOCO/g/+}$ [81, 126, 126]生成的伪视频,单目标跟踪与视频目标分割(SOT&VOS)数据集(GOT-10K [45]、LaSOT [31]、TrackingNet [80]、Youtube-VOS [112]),多目标跟踪与视频实例分割(MOT&VIS)数据集(BDD100K [125]、VIS19 [117]、OVIS [85]),以及参考视频目标分割(R-VOS)数据集Ref-Youtube-VOS [91]。同时,在此阶段还引入并优化了用于SOT&VOS任务的参考视觉编码器和一个额外的关联嵌入头。
$$
\mathcal{L}{\mathrm{stage3}}=\mathcal{L}{\mathrm{retrieve}}+\mathcal{L}{\mathrm{box}}+\mathcal{L}{\mathrm{mask}}+\mathcal{L}_{\mathrm{embed}}
$$
$$
\mathcal{L}{\mathrm{stage3}}=\mathcal{L}{\mathrm{retrieve}}+\mathcal{L}{\mathrm{box}}+\mathcal{L}{\mathrm{mask}}+\mathcal{L}_{\mathrm{embed}}
$$
Finally, the instance-prompt matching scores $S$ can be computed as the matrix multiplication of the target features and the transposed weight matrix. $S~=~F_{\mathrm{{ins}}}W^{\top}$ . Following previous work [57], the matching scores can be supervised by Focal Loss [63]. Different from previous fixed-size class if i ers [136], the proposed retrieval head selects objects by the prompt-instance matching mechanism. This flexible design enables UNINEXT to jointly train on enormous datasets with diverse label vocabularies from different tasks, learning universal instance representations.
最后,实例-提示匹配分数 $S$ 可通过目标特征与转置权重矩阵的矩阵乘法计算得出: $S~=~F_{\mathrm{{ins}}}W^{\top}$ 。借鉴先前工作 [57],匹配分数可采用Focal Loss [63] 进行监督。与以往固定尺寸分类器 [136] 不同,本文提出的检索头通过提示-实例匹配机制选择目标。这种灵活设计使UNINEXT能够联合训练来自不同任务、具有多样化标签词汇的海量数据集,从而学习通用实例表征。
3.4. Training and Inference
3.4. 训练与推理
Training. The whole training process consists of three consecutive stages: (1) general perception pre training (2) image-level joint training (3) video-level joint training.
训练。整个训练过程包含三个连续阶段:(1) 通用感知预训练 (2) 图像级联合训练 (3) 视频级联合训练。
In the first stage, we pretrain UNINEXT on the largescale object detection dataset Objects365 [93] for learning universal knowledge about objects. Since Objects365
在第一阶段,我们在大型目标检测数据集Objects365 [93]上预训练UNINEXT,以学习关于物体的通用知识。由于Objects365
Inference. For category-guided tasks, UNINEXT predicts instances of different categories and associates them with previous trajectories. The association proceeds in an online fashion and is purely based on the learned instance embedding following [83, 110]. For expression-guided and annotation-guided tasks, we directly pick the object with the highest matching score with the given prompt as the final result. Different from previous works [99, 109] restricted by the offline fashion or complex post-processing, our method is simple, online, and post-processing free.
推理。对于类别引导的任务,UNINEXT预测不同类别的实例并将其与先前的轨迹关联。关联过程以在线方式进行,完全基于[83, 110]中学习到的实例嵌入。对于表达式引导和标注引导的任务,我们直接选择与给定提示匹配分数最高的对象作为最终结果。与之前受限于离线方式或复杂后处理的工作[99, 109]不同,我们的方法简单、在线且无需后处理。
4. Experiments
4. 实验
4.1. Implementation Details
4.1. 实现细节
We attempt three different backbones, ResNet-50 [41], ConvNeXt-Large [69], and ViT-Huge [29] as the visual encoder. We adopt BERT [26] as the text encoder and its parameters are trained in the first and second training stages while being frozen in the last training stage. The Transformer encoder-decoder architecture follows [136] with 6 encoder layers and 6 decoder layers. The number of object queries $N$ is set to 900. The optimizer is AdamW [70] with weight decay of 0.05. The model is trained on 32 and 16 A100 GPUs for Objects365 pre training and other stages respectively. More details can be found in the appendix.
我们尝试了三种不同的主干网络作为视觉编码器:ResNet-50 [41]、ConvNeXt-Large [69] 和 ViT-Huge [29]。文本编码器采用 BERT [26],其参数在前两个训练阶段进行训练,在最后一个训练阶段保持冻结。Transformer 编码器-解码器架构遵循 [136],包含 6 个编码器层和 6 个解码器层。目标查询数量 $N$ 设为 900。优化器采用 AdamW [70],权重衰减为 0.05。模型分别在 32 块和 16 块 A100 GPU 上进行 Objects365 预训练和其他阶段的训练。更多细节详见附录。
Table 1. State-of-the-art comparison on object detection.
表 1: 目标检测领域最新技术对比
| 模型 | Backbone | AP | AP50 | AP75 | APs | APM | APL |
|---|---|---|---|---|---|---|---|
| FasterR-CNN[88] DETR [9] | 42.0 | 62.1 | 45.5 | 26.6 | 45.4 | 53.4 | |
| 43.3 | 63.1 | 45.9 | 22.5 | 47.3 | 61.1 | ||
| Sparse R-CNN [94] | 45.0 | 63.4 | 48.2 | 26.9 | 47.2 | 59.5 | |
| Cascade Mask-RCNN[8] | 46.3 | 64.3 | 50.5 | ||||
| Deformable-DETR[136] | 46.9 | 65.6 | 51.0 | 29.6 | 50.1 | 61.6 | |
| DN-Deformable-DETR[56] | 48.6 | 67.4 | 52.7 | 31.0 | 52.0 | 63.7 | |
| UNINEXT | 51.3 | 68.4 | 56.2 | 32.6 | 55.7 | 66.5 | |
| HTC++ [12] | 58.0 | ||||||
| DyHead[22] CascadeMaskR-CNN[8] | ConvNeXt-L | 60.3 | |||||
| UNINEXT | ConvNeXt-L | 54.8 | 73.8 | 59.8 | |||
| ViTDet-H[75] | ViT-H | 58.1 | 74.9 | 63.7 | 40.7 | 62.5 | 73.6 |
| UNINEXT | ViT-H | 58.7 60.6 | 77.5 | 66.7 | 45.1 | 64.8 | 75.3 |
Table 2. State-of-the-art comparison on instance segmentation. Methods marked with ∗ are evaluated on the val2017 split.
表 2. 实例分割的先进方法对比。标有∗的方法在val2017分割集上评估。
| 模型 | Backbone | AP | AP50 | AP75 | APs | APM | APL |
|---|---|---|---|---|---|---|---|
| CondInst[95] Cascade Mask R-CNN[8] | ResNet-50 | 38.6 38.6 | 60.2 60.0 | 41.4 41.7 | 20.6 21.7 | 41.0 40.8 | 51.1 49.6 |
| SOLOv2[104] | ResNet-50 | 38.8 | 59.9 | 41.7 | 16.5 | 41.7 | 56.2 |
| ResNet-50 | 39.7 | ||||||
| HTC[12] | ResNet-50 | 61.4 | 43.1 | 22.6 | 42.2 | 50.6 | |
| QueryInst[32] | ResNet-50 | 40.6 | 63.0 | 44.0 | 23.4 | 42.5 | 52.8 |
| UNINEXT QueryInst[32] | Swin-L | 44.9 | 67.0 | 48.9 | 26.3 | 48.5 | 59.0 |
| Mask2Former[17]* | Swin-L | 49.1 50.1 | 74.2 | 53.8 | 31.5 29.9 | 51.8 53.9 | 63.2 72.1 |
| CascadeMaskR-CNN[8] | ConvNeXt-L | 47.6 | 71.3 | 51.7 | |||
| UNINEXT | 49.6 | 73.4 | 54.3 | 30.4 | 53.6 | 65.7 | |
| ViTDet-H[75]* | 50.9 | ||||||
| ViT-H | |||||||
| UNINEXT | ViT-H | 51.8 | 76.2 | 56.7 | 33.3 | 55.9 | 67.5 |
Table 3. State-of-the-art comparison on REC.
表 3. REC 任务上的最先进方法对比
| 方法 | RefCOCO | RefCOCO+ | RefCOCOg | |||||
|---|---|---|---|---|---|---|---|---|
| val | testA | testB | val | testA | testB | val-u | test-u | |
| UNITERL[16] | 81.41 | 87.04 | 74.17 | 75.90 | 81.45 | 66.70 | 74.86 | 75.77 |
| VILLAL[35] | 82.39 | 87.48 | 74.84 | 76.17 | 81.54 | 66.84 | 76.18 | 76.71 |
| MDETR[48] | 86.75 | 89.58 | 81.41 | 79.52 | 84.09 | 70.62 | 81.64 | 80.89 |
| RefTR [58] | 85.65 | 88.73 | 81.16 | 77.55 | 82.26 | 68.99 | 79.25 | 80.01 |
| SeqTR [135] | 87.00 | 90.15 | 83.59 | 78.69 | 84.51 | 71.87 | 82.69 | 83.37 |
| UNINEXT-R50 | 89.72 | 91.52 | 86.93 | 79.76 | 85.23 | 72.78 | 83.95 | 84.31 |
| UNINEXT-L | 91.43 | 93.73 | 88.93 | 83.09 | 87.90 | 76.15 | 86.91 | 87.48 |
| UNINEXT-H | 92.64 | 94.33 | 91.46 | 85.24 | 89.63 | 79.79 | 88.73 | 89.37 |
4.2. Evaluations on 10 Tasks
4.2. 10项任务评估
We compare UNINEXT with task-specific counterparts in 20 datasets. In each benchmark, the best two results are indicated in bold and with underline. UNINEXT in all benchmarks uses the same model parameters.
我们在20个数据集中将UNINEXT与任务专用模型进行对比。每个基准测试中表现最佳的两项结果以粗体和下划线标出。所有基准测试中的UNINEXT均使用相同模型参数。
Object Detection and Instance Segmentation. We compare UNINEXT with state-of-the-art object detection and instance segmentation methods on COCO val2017 $5k$ images) and test-dev split $20k$ images) respectively. As shown in Table 1, UNINEXT surpasses state-of-theart query-based detector DN-Deformable DETR [56] by 2.7 box AP. By replacing ResNet-50 [41] with stronger ConvNeXt-Large [69] and ViT-Huge [29] backbones, UNINEXT achieves a box AP of 58.1 and 60.6, surpassing competitive rivals Cascade Mask-RCNN [8] and ViTDetH [75] by 3.3 and 1.9 respectively. Besides, the results of instance segmentation are shown in Table 2. With the same ResNet-50 backbone, UNINEXT outperforms stateof-the-art QueryInst by $4.3\mathrm{AP}$ and $6.2\mathrm{AP}_{L}$ . When using ConvNeXt-Large as the backbone, UNINEXT achieves a mask AP of 49.6, surpassing Cascade Mask R-CNN [8] by 2.0. With ViT-Huge as the backbone, UNINEXT achieves state-of-the-art mask AP of 51.8.
目标检测与实例分割。我们在COCO val2017 ($5k$ 张图像) 和 test-dev 划分集 ($20k$ 张图像) 上分别将UNINEXT与最先进的目标检测和实例分割方法进行对比。如表1所示,UNINEXT以2.7个框AP超越基于查询的最先进检测器DN-Deformable DETR [56]。通过将ResNet-50 [41] 替换为更强的ConvNeXt-Large [69] 和 ViT-Huge [29] 骨干网络,UNINEXT分别达到58.1和60.6的框AP,超越竞争对手Cascade Mask-RCNN [8] 和 ViTDetH [75] 3.3和1.9个点。此外,实例分割结果如表2所示。在相同ResNet-50骨干网络下,UNINEXT以 $4.3\mathrm{AP}$ 和 $6.2\mathrm{AP}_{L}$ 超越最先进的QueryInst。当采用ConvNeXt-Large作为骨干时,UNINEXT取得49.6的掩膜AP,超越Cascade Mask R-CNN [8] 2.0个点。使用ViT-Huge骨干时,UNINEXT以51.8的掩膜AP达到当前最优水平。
Table 4. State-of-the-art comparison on RES.
表 4. RES上的最新方法对比。
| 方法 | RefCOCO | RefCOCO+ | RefCOCOg | |||||
|---|---|---|---|---|---|---|---|---|
| val | testA | testB | val | testA | testB | val-u | test-u | |
| CMSA [124] | 58.32 | 60.61 | 55.09 | 43.76 | 47.60 | 37.89 | ||
| BRINet [44] | 60.98 | 62.99 | 59.21 | 48.17 | 52.32 | 42.11 | ||
| CMPC+ [66] | 62.47 | 65.08 | 60.82 | 50.25 | 54.04 | 43.47 | ||
| MCN [73] | 62.44 | 64.20 | 59.71 | 50.62 | 54.99 | 44.69 | 49.22 | 49.40 |
| EFN [34] | 62.76 | 65.69 | 59.67 | 51.50 | 55.24 | 43.01 | ||
| VLT [27] | 65.65 | 68.29 | 62.73 | 55.50 | 59.20 | 49.36 | 52.99 | 56.65 |
| SeqTR [135] | 71.70 | 73.31 | 69.82 | 63.04 | 66.73 | 58.97 | 64.69 | 65.74 |
| LAVT [121] | 72.73 | 75.82 | 68.79 | 62.14 | 68.38 | 55.10 | 61.24 | 62.09 |
| UNINEXT-R50 | 77.90 | 79.68 | 75.77 | 66.20 | 71.22 | 59.01 | 70.04 | 70.52 |
| UNINEXT-L | 80.32 | 82.61 | 77.76 | 70.04 | 74.91 | 62.57 | 73.41 | 73.68 |
| UNINEXT-H | 82.19 | 83.44 | 81.33 | 72.47 | 76.42 | 66.22 | 74.67 | 76.37 |
REC and RES. RefCOCO [126], $\scriptstyle{\mathrm{RefCOCO+}}$ [126], and RefCOCOg [74] are three representative benchmarks for REC and RES proposed by different institutions. Following previous literature, we adopt Precision $\ @0.5$ and overall IoU (oIoU) as the evaluation metrics for REC and RES respectively and results are rounded to two decimal places. As shown in Table 3 and Table 4, our method with ResNet-50 backbone surpasses all previous approaches on all splits. Furthermore, when using ConvNeXt-Large and ViT-Huge backbones, UNINEXT obtains new state-of-theart results, exceeding the previous best method by a large margin. Especially on RES, UNINEXT-H outperforms LAVT [121] by 10.85 on average.
REC和RES。RefCOCO [126]、RefCOCO+ [126]和RefCOCOg [74]是由不同机构提出的三个代表性REC和RES基准。遵循先前文献,我们采用Precision @0.5和整体IoU (oIoU)分别作为REC和RES的评估指标,结果保留两位小数。如表3和表4所示,我们采用ResNet-50骨干网络的方法在所有分割上都超越了之前的所有方法。此外,当使用ConvNeXt-Large和ViT-Huge骨干网络时,UNINEXT取得了新的最先进结果,大幅超越了之前的最佳方法。特别是在RES上,UNINEXT-H平均比LAVT [121]高出10.85。
SOT. We compare UNINEXT with state-of-the-art SOT methods on four large-scale benchmarks: LaSOT [31], LaSOT-ext [30], Tracking Net [80], and TNL-2K [103]. These benchmarks adopt the area under the success curve (AUC), normalized precision $(\mathbf{P}_{N o r m})$ , and precision (P) as the evaluation metrics and include 280, 150, 511, and 700 videos in the test set respectively. As shown in Table 5, UNINEXT achieves the best results in terms of AUC and P among all trackers with ResNet-50 backbone. Especially on TNL-2K, UNINEXT outperforms the second best method TransT [15] by 5.3 AUC and $5.8\mathrm{P~}$ respectively. Besides, UNINEXT with stronger backbones obtains the best AUC on all four benchmarks, exceeding Unicorn [114] with the same backbone by 3.9 on LaSOT.
单目标跟踪 (SOT)。我们在四大基准测试上将UNINEXT与最先进的SOT方法进行对比:LaSOT [31]、LaSOT-ext [30]、TrackingNet [80]和TNL-2K [103]。这些基准采用成功率曲线下面积 (AUC)、归一化精度 $(\mathbf{P}_{Norm})$ 和精度 (P)作为评估指标,测试集分别包含280、150、511和700段视频。如表5所示,UNINEXT在使用ResNet-50骨干网络的所有跟踪器中,AUC和P指标均取得最佳结果。尤其在TNL-2K数据集上,UNINEXT的AUC和P指标分别比第二名TransT [15]高出5.3和$5.8\mathrm{P~}$。此外,采用更强骨干网络的UNINEXT在所有四个基准测试中都获得了最佳AUC,在LaSOT上比使用相同骨干网络的Unicorn [114]高出3.9个点。
Table 5. State-of-the-art comparison on SOT.
表 5. SOT 上的先进方法对比
| 方法 | Backbone | LaSOT [31] | LaSOText [30] | TrackingNet [80] | TNL-2K [103] | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUC | PNorm | P | AUC | PNorm | P | AUC | PNorm | P | AUC | P | ||
| PrDiMP [23] | ResNet-50 | 59.8 57.2 | 68.8 | 60.8 | 75.8 | 81.6 | 70.4 | 47.0 | 45.9 | |||
| LTMU [21] | - | 57.2 | 41.4 | 49.9 | 47.3 | - | 48.5 | 47.3 | ||||
| TransT [15] | 64.9 | 73.8 | 69.0 | 81.4 | 86.7 | 80.3 | 50.7 | 51.7 | ||||
| KeepTrack [76] | 67.1 | 77.2 | 70.2 | 48.2 | - | - | - | - | ||||
| UNINEXT | 69.2 | 77.1 | 75.5 | 51.2 | 58.1 | 58.1 | 83.2 | 86.9 | 83.3 | 56.0 | 57.5 | |
| SimTrack [10] | 69.3 ViT-B | 78.5 | - | - | - | 82.3 | 86.5 | 54.8 | 53.8 | |||
| OSTrack[123] | 71.1 | 81.1 | 77.6 | 50.5 | 61.3 | 57.6 | 83.9 | 88.5 | 83.2 | 55.9 | ||
| SeqTrack[14] | 71.5 | 81.1 | 77.8 | 50.5 | 61.6 | 57.5 | 83.9 | 88.8 | 83.6 | 57.8 | ||
| Unicorn [114] | 68.5 | 76.6 | 74.1 | - | 83.0 | 86.4 | 82.2 | |||||
| UNINEXT | ConvNeXt-L | 72.4 | 80.7 | 78.9 | 54.4 | 61.8 | 61.4 | 85.1 | 88.2 | 84.7 | 58.1 | 60.7 |
| UNINEXT | ViT-H | 72.2 | 80.7 | 79.4 | 56.2 | 63.8 | 63.8 | 85.4 | 89.0 | 86.4 | 59.3 | 62.8 |
Table 6. State-of-the-art comparison on VOS.
表 6. VOS领域的最新方法对比
| 方法 | YT-VOS2018val[112] | DAVIS 2017 val[84] F |
|---|---|---|
| g Js sFsJuFu | J&F J | |
| STM [82] nory CFBI[122] lem STCN [19] M XMem [18] | 79.4 79.7 84.2 72.8 80.9 81.8 79.2 84.3 81.4 81.1 8 85.875.3 383.4 81.9 79.1 84.6 83.081.986.5 77.985.7 82.2 | |
| SiamMask[101] | 85.4 86.1 85.1 89.8 80.3 89.2 87.7 | 88.6 84.0 91.4 54.3 58.5 |
| 52.8 60.2 58.2 45.1 47.7 | ||
| Unicorn [114] TVOS [131] | 56.4 | |
| SiamR-CNN[99]73.2 73.5 on | 69.2 65.2 | |
| FRTM [90] | 66.2 70.6 66.1 | |
| 67.8 67.1 69.4 63.0 71.6 72.3 69.9 | ||
| 72.1 72.3 76.2 65.9 74.1 | 76.7 73.9 | 74.7 79.6 |
| UNINEXT-R50 77.0 76.8 81.0 70.8 79.4 | 74.5 71.3 | 77.6 |
| UNINEXT-L 78.1 79.1 | 77.2 | |
| 83.5 71.0 78.9 | 73.2 | |
| UNINEXT-H | 78.6 79.9 84.9 70.6 79.2 | 81.8 77.7 |
VOS. The comparisons between UNINEXT with previous semi-supervised VOS methods are demonstrated in Table 6. DAVIS-2017 [84] adopts region similarity $\mathcal{I}$ , con- tour accuracy $\mathcal{F}$ , and the averaged score as the metrics. Similarly, Youtube-VOS 2018 [112] reports $\mathcal{I}$ and $\mathcal{F}$ for both seen and unseen categories, and the averaged overall score $\mathcal{G}$ . UNINEXT achieves the best results among all non-memory-based methods, largely bridging the performance gap between non-memory-based approaches and memory-based ones. Furthermore, compared with traditional memory-based methods [19,82], UNINEXT does not rely on the intermediate mask predictions. This leads to constant memory consumption, enabling UNINEXT to handle long sequences of any length.
VOS。UNINEXT与之前半监督VOS方法的对比结果如表6所示。DAVIS-2017 [84] 采用区域相似度 $\mathcal{I}$、轮廓准确率 $\mathcal{F}$ 以及平均得分 作为评估指标。类似地,Youtube-VOS 2018 [112] 报告了可见类别和不可见类别的 $\mathcal{I}$ 和 $\mathcal{F}$ 值,以及整体平均得分 $\mathcal{G}$。UNINEXT在所有非基于记忆的方法中取得了最佳结果,大幅缩小了非基于记忆方法与基于记忆方法之间的性能差距。此外,与传统基于记忆的方法 [19,82] 相比,UNINEXT不依赖中间掩模预测,这使得其内存消耗保持恒定,能够处理任意长度的长序列。
Table 7. State-of-the-art comparison on MOT.
表 7: MOT任务的最新方法对比
| 方法 | 数据集划分 | mMOTA↑ | mIDF1↑ | MOTA↑ | IDF1↑ | ID Sw.√ |
|---|---|---|---|---|---|---|
| Yu等[125] | val | 25.9 | 44.5 | 56.9 | 66.8 | 8315 |
| QDTrack[83] | val | 36.6 | 50.8 | 63.5 | 71.5 | 6262 |
| Unicorn[114] | val | 41.2 | 54.0 | 66.6 | 71.3 | 10876 |
| UNINEXT-L | val | 41.8 | 54.9 | 64.6 | 68.7 | 9134 |
| UNINEXT-H | val | 44.2 | 56.7 | 67.1 | 69.9 | 10222 |
MOT. We compare UNINEXT with state-of-the-art MOT methods on BDD100K [125], which requires tracking 8 classes of instances in the autonomous driving scenario. Except for classical evaluation metrics Multiple-Object Tracking Accuracy (MOTA), Identity F1 Score (IDF1), and Identity Switches (IDS), BDD100K additionally introduces mMOTA, and mIDF1 to evaluate the average performance across 8 classes. As shown in Table 7, UNINEXT surpasses Unicorn [114] by 3.0 mMOTA and 2.7 mIDF1 respectively.
MOT。我们在BDD100K [125]上将UNINEXT与最先进的MOT方法进行比较,该数据集要求在自动驾驶场景中跟踪8类实例。除了经典评估指标多目标跟踪准确率(MOTA)、身份F1分数(IDF1)和身份切换次数(IDS)外,BDD100K还引入了mMOTA和mIDF1来评估8个类别的平均性能。如表7所示,UNINEXT分别以3.0 mMOTA和2.7 mIDF1的优势超越Unicorn [114]。
Table 8. State-of-the-art comparison on MOTS.
表 8. MOTS 上的最新技术对比。
| 方法 | 在线 | mMOTSA↑ | mMOTSP↑ | mIDF1↑ | ID Sw.↓ |
|---|---|---|---|---|---|
| SortIoU | 10.3 | 59.9 | 21.8 | 15951 | |
| MaskTrackRCNN[117] | 12.3 | 59.9 | 26.2 | 9116 | |
| STEm-Seg[1] | 12.2 | 58.2 | 25.4 | 8732 | |
| QDTrack-mots[83] | 22.5 | 59.6 | 40.8 | 1340 | |
| PCAN [50] | 27.4 | 66.7 | 45.1 | 876 | |
| VMT [49] | 28.7 | 67.3 | 45.7 | 825 | |
| Unicorn [114] | 29.6 | 67.7 | 44.2 | 1731 | |
| UNINEXT-L | 32.0 | 60.2 | 45.4 | 1634 | |
| UNINEXT-H | 35.7 | 68.1 | 48.5 | 1776 |
MOTS. Similar to MOT, BDD100K MOTS Chal- lenge [125] evaluates the performance on multi-class tracking by mMOTSA, mMOTSP, mIDF1, and ID Sw. This benchmark contains 37 sequences with mask annotations in the validation set. As shown in Table 8, UNINEXT achieves state-of-the-art performance, surpassing the previous best method Unicorn [114] by 6.1 mMOTSA.
MOTS。与MOT类似,BDD100K MOTS挑战赛[125]通过mMOTSA、mMOTSP、mIDF1和ID Sw指标评估多类别跟踪性能。该基准测试在验证集中包含37个带有掩码标注的序列。如表8所示,UNINEXT实现了最先进的性能,以6.1 mMOTSA的优势超越之前的最佳方法Unicorn[114]。
VIS. We compare UNINEXT against state-of-the-art VIS methods on Youtube-VIS 2019 [117] and OVIS [85] validation sets. Specifically, Youtube-VIS 2019 and OVIS have 40 and 25 object categories, containing 302 and 140 videos respectively in the validation set. Both benchmarks take AP as the main metric. As shown in Table 9, when using the same ResNet-50 backbone, UNINEXT obtains the best results on both datasets. Especially on more challenging OVIS, UNINEXT exceeds the previous best method IDOL [110] by 3.8 AP. When using stronger ViT-Huge backbone, UNINEXT achieves state-of-the-art AP of 66.9 on Youtube-VIS 2019 and 49.0 on OVIS respectively, surpassing previous methods by a large margin.
VIS。我们在Youtube-VIS 2019 [117]和OVIS [85]验证集上将UNINEXT与最先进的VIS方法进行比较。具体而言,Youtube-VIS 2019和OVIS分别包含40和25个对象类别,验证集中分别有302和140个视频。两个基准均以AP作为主要指标。如表9所示,当使用相同的ResNet-50骨干网络时,UNINEXT在两个数据集上均取得最佳结果。尤其在更具挑战性的OVIS上,UNINEXT以3.8 AP的优势超越之前的最佳方法IDOL [110]。当使用更强的ViT-Huge骨干网络时,UNINEXT在Youtube-VIS 2019和OVIS上分别达到66.9和49.0的AP,大幅超越先前方法。
R-VOS. Ref-Youtube-VOS [91] and Ref-DAVIS17 [51] are two popular R-VOS benchmarks, which are constructed by introducing language expressions for the objects in the original Youtube-VOS [112] and DAVIS17 [84] datasets. As same as semi-supervised VOS, region similarity $\mathcal{I}$ , contour accuracy $\mathcal{F}$ , and the averaged score are adopted as the metrics. As demonstrated in Table 10, UNINEXT outperforms all previous R-VOS approaches by a large margin, when using the same ResNet-50 backbone. Especially on Ref-DAVIS17, UNINEXT exceeds previous best Refer Former [109] by $5.4~\mathcal{I}&\mathcal{F}$ . Furthermore, when adopting stronger ViT-Huge backbone, UNINEXT achieves new state-of-the-art $\mathcal{I}&\mathcal{F}\mathrm{of}70.1$ on Ref-Youtube-VOS and 72.5 on Ref-DAVIS17. Besides, different from offline RefFormer, UNINEXT works in a flexible online fashion, making it applicable to ongoing videos in the real world.
R-VOS。Ref-Youtube-VOS [91] 和 Ref-DAVIS17 [51] 是两个流行的 R-VOS 基准数据集,它们通过为原始 Youtube-VOS [112] 和 DAVIS17 [84] 数据集中的对象引入语言表达而构建。与半监督 VOS 相同,区域相似度 $\mathcal{I}$、轮廓准确度 $\mathcal{F}$ 以及平均分数 被用作评估指标。如表 10 所示,在使用相同 ResNet-50 主干网络时,UNINEXT 大幅领先于所有先前的 R-VOS 方法。特别是在 Ref-DAVIS17 上,UNINEXT 以 $5.4~\mathcal{I}&\mathcal{F}$ 的优势超越了之前的最佳方法 Refer Former [109]。此外,当采用更强的 ViT-Huge 主干网络时,UNINEXT 在 Ref-Youtube-VOS 上实现了 70.1 的最新 分数,在 Ref-DAVIS17 上达到了 72.5。与离线的 RefFormer 不同,UNINEXT 以灵活的在线方式运行,使其适用于现实世界中的实时视频。
Table 9. State-of-the-art comparison on VIS.
表 9: VIS领域最新技术对比
| 方法 | 骨干网络 | 在线 | VIS2019val | OVIS val | ||||
|---|---|---|---|---|---|---|---|---|
| AP | AP50 | AP75 | AP | AP50 | AP75 | |||
| VisTR [105] MaskProp [4] | 36.2 | 59.8 | 36.9 | |||||
| 40.0 | 42.9 | |||||||
| IFC [46] | 42.8 | 65.8 | 46.8 | 13.1 | 27.8 | 11.6 | ||
| SeqFormer[108] | 47.4 | 69.8 | 51.8 | 15.1 | 31.9 | 13.8 | ||
| IDOL [110] | 49.5 | 74.0 | 52.9 | 30.2 | 51.3 | 30.0 | ||
| VITA [42] | 49.8 | 72.6 | 54.5 | 19.6 | 41.2 | 17.4 | ||
| UNINEXT | 53.0 | 75.2 | 59.1 | 34.0 | 55.5 | 35.6 | ||
| SeqFormer[108] | 59.3 | 82.1 | 66.4 | |||||
| VMT [49] | 59.7 | 66.7 | 19.8 | 39.6 | 17.2 | |||
| VITA [42] | 63.0 | 86.9 | 67.9 | |||||
| IDOL [110] | ConvNeXt-L | 64.3 | 87.5 | 71.0 | 42.6 | 65.7 | 45.2 | |
| UNINEXT | 64.3 | 87.2 | 71.7 | 41.1 | 65.8 | 42.0 | ||
| UNINEXT | ViT-H | √ | 66.9 | 87.5 | 75.1 | 49.0 | 72.5 | 52.2 |
Table 10. State-of-the-art comparison on R-VOS.
表 10. R-VOS领域最新技术对比
| 方法 | 主干网络 | Ref-Youtube-VOS | Ref-DAVIS17 | ||||
|---|---|---|---|---|---|---|---|
| J&F | J | F | J&F | J | F | ||
| CMSA [124] URVOS[91] | ResNet-50 | 36.4 | 34.8 | 38.1 | 40.2 | 36.9 | 43.5 |
| ResNet-50 | 47.2 | 45.3 | 49.2 | 51.5 | 47.3 | 56.0 | |
| YOFO[55] | ResNet-50 | 48.6 | 47.5 | 49.7 | 54.4 | 50.1 | 58.7 |
| ReferFormer[109] | ResNet-50 | 58.7 | 57.4 | 60.1 | 58.5 | 55.8 | 61.3 |
| UNINEXT | ResNet-50 | 61.2 | 59.3 | 63.0 | 63.9 | 59.6 | 68.1 |
| PMINet+CFBI [28] CITD [59] | Ensemble | 54.2 | 53.0 | 55.5 | |||
| Ensemble | 61.4 | 60.0 | 62.7 | ||||
| MTTR [7] ReferFormer[109] | Video-Swin-T | 55.3 | 54.0 | 56.6 | |||
| Video-Swin-T | 64.9 | 62.8 | 67.0 | 61.1 | 58.1 | 64.1 | |
| UNINEXT | ConvNext-L ViT-H | 66.2 | 64.0 | 68.4 | |||
| ConvNext-L ViT-H | 70.1 | 67.6 | 72.7 | 66.7 72.5 | 62.3 68.2 | 71.1 76.8 |
4.3. Ablations and Other Analysis
4.3. 消融实验及其他分析
In this section, we conduct component-wise analysis for better understanding our method. All models take ResNet-50 as the backbone. The methods are evaluated on five benchmarks (COCO [64], RefCOCO [126], Youtube-VOS [112], Ref-Youtube-VOS [91], and YoutubeVIS 2019 [117]) from five tasks (object detection, REC, VOS, R-VOS, and VIS). The results are shown in Table 11.
在本节中,我们进行了组件级分析以更好地理解我们的方法。所有模型均采用 ResNet-50 作为主干网络。这些方法在五个任务(目标检测、REC、VOS、R-VOS 和 VIS)的五个基准数据集(COCO [64]、RefCOCO [126]、Youtube-VOS [112]、Ref-Youtube-VOS [91] 和 YoutubeVIS 2019 [117])上进行了评估。结果如表 11 所示。
Fusion. To study the effect of feature fusion between visual features and prompt embeddings, we implement a variant without any early fusion. In this version, prompt embeddings do not have an influence on proposal generation but are only used in the final object retrieval process. Experiments show that early fusion has the greatest impact on VOS, the performance on VOS drops dras- tically by $21.4:\mathcal{I}&\mathcal{F}$ without feature fusion. This is mainly caused by the following reasons (1) Without the guidance of prompt embeddings, the network can hardly find rare referred targets like trees and sinks. (2) Without early fusion, the network cannot fully exploit fine mask annotations in the first frame, causing degradation of the mask quality. Besides, the removal of feature fusion also causes performance drop of $2.3:\mathrm{P}@0.5$ and 2.8 & on REC and RVOS respectively, showing the importance of early fusion in expression-guided tasks. Finally, feature fusion has minimum influence on object detection and VIS. This can be understood because both two tasks aim to find all objects as completely as possible rather than locating one specific target referred by the prompt.
融合。为了研究视觉特征与提示嵌入之间的特征融合效果,我们实现了一个不进行任何早期融合的变体版本。在该版本中,提示嵌入不会影响候选框生成,仅用于最终的目标检索过程。实验表明早期融合对视频目标分割(VOS)影响最大,在没有特征融合的情况下,VOS性能急剧下降$21.4:\mathcal{I}&\mathcal{F}$。这主要由以下原因导致:(1) 缺乏提示嵌入的引导,网络难以定位树木、水槽等罕见参照目标;(2) 缺少早期融合时,网络无法充分利用首帧精细掩码标注,导致掩码质量下降。此外,移除特征融合还会使参照表达式理解(REC)和参照视频目标分割(RVOS)性能分别下降$2.3:\mathrm{P}@0.5$和2.8&,印证了早期融合在表达式引导任务中的重要性。最后,特征融合对目标检测和视频实例分割(VIS)影响最小,这是因为二者旨在尽可能完整地找出所有目标,而非定位提示所指的特定对象。
Table 11. Ablations. The settings in our final model is underlined.
表 11: 消融实验。我们最终模型的设置已用下划线标出。
| 实验 | 方法 | OD COCO (AP) | REC RefCOCO (P@0.5) | VOS YTBVOS (J&F) | RVOS R-YTBVOS (J&F) | VIS VIS19 (AP) |
|---|---|---|---|---|---|---|
| 融合 | 早期融合 | 51.3 | 89.7 | 77.0 | 61.2 | 53.0 |
| 无融合 | 51.1 (+0.2) | 87.4 (+2.3) | 55.6 (+21.4) | 58.4 (+2.8) | 51.0 (+2.0) | |
| 查询 | 静态动态 | 51.3 | 89.7 | 77.0 | 61.2 | 53.0 |
| 51.9 (-0.6) | 89.8 (-0.1) | 77.4 (-0.4) | 61.6 (-0.4) | 50.2 (+2.8) | ||
| 模型 | 统一 | 51.3 | 89.7 | 77.0 | 61.2 | 53.0 |
| 任务专用 | 50.8 (+0.5) | 87.6 (+2.1) | 74.2 (+2.8) | 57.2 (+4.0) | 50.1 (+2.9) |
Queries. We compare two different query generation strategies: static queries by nn.Embedding(N, d) and dynamic queries conditioned on the prompt embeddings. Experiments show that dynamic queries perform slightly better than static queries on the first four tasks. However, static queries outperform dynamic ones by 2.8 AP on the VIS task, obtaining higher overall performance. A potential reason is that $N$ different object queries can encode richer inner relationship among different targets than simply copying the pooled prompt by $N$ times as queries. This is especially important for VIS because targets need to be associated according to their affinity in appearance and space.
查询。我们比较了两种不同的查询生成策略:基于nn.Embedding(N, d)的静态查询和基于提示嵌入(prompt embeddings)的动态查询。实验表明,在前四项任务中动态查询略优于静态查询,但在VIS任务中静态查询以2.8 AP的优势超越动态查询,获得了更高的整体性能。潜在原因是$N$个独立的目标查询(target queries)能编码不同目标间更丰富的内在关联,而非简单地将池化提示(pooled prompt)复制$N$次作为查询。这对VIS任务尤为重要,因为需要根据目标在外观和空间上的相似性进行关联。
Unification. We also compare two different model design philosophies, one unified model or multiple taskspecific models. Except for the unified model, we also retrain five task-specific models only on data from corresponding tasks. Experiments show that the unified model achieves significantly better performance than its taskspecific counterparts on five tasks, demonstrating the superiority of the unified formulation and joint training on all instance perception tasks. Finally, the unified model can save tons of parameters, being much more parameter-efficient.
统一化。我们还比较了两种不同的模型设计理念:单一统一模型或多个任务专用模型。除统一模型外,我们还仅使用对应任务数据重新训练了五个任务专用模型。实验表明,统一模型在五项任务上的性能显著优于任务专用模型,证明了统一建模方式及联合训练在所有实例感知任务中的优越性。最终,统一模型可节省大量参数量,具有更高的参数效率。
5. Conclusions
5. 结论
We propose UNINEXT, a universal instance perception model of the next generation. For the first time, UNINEXT unifies 10 instance perception tasks with a prompt-guided object discovery and retrieval paradigm. Extensive experiments demonstrate that UNINEXT achieves superior performance on 20 challenging benchmarks with a single model with the same model parameters. We hope that UNINEXT can serve as a solid baseline for the research of instance perception in the future.
我们提出UNINEXT,一种新一代通用实例感知模型。该模型首次通过提示引导的目标发现与检索范式,统一了10项实例感知任务。大量实验表明,UNINEXT仅用单一模型参数就在20个具有挑战性的基准测试中实现了卓越性能。我们希望UNINEXT能为未来实例感知研究提供坚实基线。
Acknowledgement. We would like to thank the reviewers for their insightful comments. The paper is supported in part by the National Key R&D Program of China under Grant No. 2018AAA0102001, 2022ZD0161000 and National Natural Science Foundation of China under grant No. 62293542, U1903215, 62022021 and the Fundamental Research Funds for the Central Universities No.DUT22ZD210.
致谢。我们要感谢审稿人富有洞察力的意见。本研究部分得到国家重点研发计划(No. 2018AAA0102001, 2022ZD0161000)、国家自然科学基金(No. 62293542, U1903215, 62022021)及中央高校基本科研业务费专项资金(No.DUT22ZD210)的资助。