Referred by Multi-Modality: A Unified Temporal Transformer for Video Object Segmentation
多模态参考的统一时序Transformer视频目标分割
Abstract
摘要
Recently, video object segmentation (VOS) referred by multimodal signals, e.g., language and audio, has evoked increasing attention in both industry and academia. It is challenging for exploring the semantic alignment within modalities and the visual correspondence across frames. However, existing methods adopt separate network architectures for different modalities, and neglect the inter-frame temporal interaction with references. In this paper, we propose MUTR, a Multimodal Unified Temporal transformer for Referring video object segmentation. With a unified framework for the first time, MUTR adopts a DETR-style transformer and is capable of segmenting video objects designated by either text or audio reference. Specifically, we introduce two strategies to fully explore the temporal relations between videos and multi-modal signals. Firstly, for low-level temporal aggregation before the transformer, we enable the multi-modal references to capture multi-scale visual cues from consecutive video frames. This effectively endows the text or audio signals with temporal knowledge and boosts the semantic alignment between modalities. Secondly, for high-level temporal interaction after the transformer, we conduct inter-frame feature communication for different object embeddings, contributing to better object-wise correspondence for tracking along the video. On Ref-YouTube-VOS and AVSBench datasets with respective text and audio references, MUTR achieves $+4.2%$ and $+8.7%$ improvements to state-of-the-art methods, demonstrating our significance for unified multi-modal VOS. Code is released at https://github.com/OpenGVLab/MUTR.
最近,基于多模态信号(如语言和音频)的视频目标分割(VOS)在工业界和学术界引起了越来越多的关注。探索模态内的语义对齐和跨帧的视觉对应关系具有挑战性。然而,现有方法针对不同模态采用独立的网络架构,忽视了参考信号与帧间的时间交互。本文提出MUTR,一种用于参考视频目标分割的多模态统一时序Transformer。MUTR首次采用统一框架,基于DETR风格的Transformer,能够分割由文本或音频参考指定的视频目标。具体而言,我们引入两种策略来充分探索视频与多模态信号之间的时序关系。首先,在Transformer之前的低层时序聚合中,我们使多模态参考能够从连续视频帧中捕获多尺度视觉线索。这有效赋予文本或音频信号时序知识,并增强模态间的语义对齐。其次,在Transformer之后的高层时序交互中,我们对不同目标嵌入进行帧间特征通信,有助于沿视频跟踪时获得更好的目标级对应关系。在分别使用文本和音频参考的Ref-YouTube-VOS和AVSBench数据集上,MUTR相比最先进方法实现了指标$+4.2%$和$+8.7%$的提升,证明了我们在统一多模态VOS中的重要性。代码发布于https://github.com/OpenGVLab/MUTR。
Introduction
引言
Multi-modal video object segmentation (VOS) aims to track and segment particular object instances across the video sequence referred by a given multi-modal signal, including referring video object segmentation (RVOS) with language reference, and audio-visual video object segmentation (AV-VOS) with audio reference. Different from the vanilla VOS (Xu et al. 2018; Yan et al. 2023) with only visual information, the multi-modal VOS is more challenging and in urgent demand, which requires a comprehensive understanding of different modalities and their temporal correspondence across frames.
多模态视频目标分割 (VOS) 旨在通过给定的多模态信号跟踪并分割视频序列中的特定目标实例,包括基于语言参考的指代视频目标分割 (RVOS) 和基于音频参考的视听视频目标分割 (AV-VOS)。与仅依赖视觉信息的传统 VOS (Xu et al. 2018; Yan et al. 2023) 不同,多模态 VOS 更具挑战性且需求迫切,需要全面理解不同模态及其跨帧的时间对应关系。
There exist two main challenges in multi-modal VOS. Firstly, it requires to not only explore the rich spatial-temporal consistency in a video, but also align the multi-modal semantics among image, language, and audio. Current approaches mainly focus on the visual-language or visual-audio modal fusion within independent frames, simply by cross-modal attention (Chen et al. 2019; Hu et al. 2020; Shi et al. 2018) or dynamic convolutions (Margffoy-Tuay et al. 2018) for feature interaction. This, however, neglects the multi-modal temporal information across frames, which is significant for consistent object segmentation and tracking along the video. Secondly, for the given references of two modalities, language and audio, existing works adopt different architecture designs and training strategies to separately tackle their modal-specific characteristics. Therefore, a powerful and unified framework for multi-modal VOS still remains an open question.
多模态视频目标分割(VOS)存在两大核心挑战。首先,该方法不仅需要挖掘视频中丰富的时空一致性,还需对齐图像、语言和音频之间的多模态语义。现有研究主要关注独立帧内的视觉-语言或视觉-音频模态融合,仅通过跨模态注意力机制(Chen et al. 2019; Hu et al. 2020; Shi et al. 2018)或动态卷积(Margffoy-Tuay et al. 2018)进行特征交互。这种做法忽略了跨帧的多模态时序信息,而该信息对于视频中目标的一致分割与跟踪至关重要。其次,针对语言和音频两种模态的给定参考,现有工作采用不同的架构设计和训练策略来分别处理其模态特性。因此,如何构建强大且统一的多模态VOS框架仍是待解难题。
To address these challenges, we propose MUTR, a Multimodal Unified Temporal transformer for Referring video object segmentation. Our approach, for the first time, presents a generic framework for both language and audio references, and enhances the interaction between temporal frames and multi-modal signals. In detail, we adopt a DETR-like (Carion et al. 2020) encoder-decoder transformer, which serves as the basic architecture to process visual information within different frames. On top of this, we introduce two attention-based modules respectively for low-level multi-modal temporal aggregation (MTA), and high-level multi-object temporal interaction (MTI). Firstly before the transformer, we utilize the encoded multi-modal references as queries to aggregate informative visual and temporal features via the MTA module. We concatenate the visual features of adjacent frames and adopt sequential attention blocks for multi-modal tokens to progressively capture temporal visual cues of different image scales. This contributes to better low-level cross-modal alignment and temporal consistency. Then, we regard the multi-modal tokens after MTA as object queries and feed them into the transformer for frame-wise decoding. After that, we apply the MTI module to conduct inter-frame object-wise interaction, and maintain a set of video-wise query representations for associating objects across frames inspired by (Heo et al. 2022). Such a module enhances the instance-level temporal communication and benefits the visual correspondence for segmenting the same object in a video. Finally, we utilize a segmentation head following previous works (Wu et al. 2022, 2021) to output the final object mask referred by multimodality input.
为解决这些挑战,我们提出了MUTR(多模态统一时序Transformer),用于视频目标参照分割。该方法首次提出了一个同时适用于语言和音频参照的通用框架,并增强了时序帧与多模态信号之间的交互。具体而言,我们采用类似DETR(Carion等人,2020)的编码器-解码器Transformer作为基础架构来处理不同帧的视觉信息。在此基础上,我们引入了两个基于注意力的模块:分别用于低层次的多模态时序聚合(MTA)和高层次的多目标时序交互(MTI)。
首先在Transformer之前,我们利用编码后的多模态参照作为查询,通过MTA模块聚合具有信息量的视觉和时序特征。我们将相邻帧的视觉特征拼接起来,并采用序列注意力块处理多模态Token,逐步捕获不同图像尺度的时序视觉线索。这有助于实现更好的低层次跨模态对齐和时序一致性。然后,我们将MTA处理后的多模态Token视为目标查询,并将其输入Transformer进行逐帧解码。之后,我们应用MTI模块进行帧间目标级交互,并维护一组视频级查询表示(受Heo等人2022年工作启发)以实现跨帧目标关联。该模块增强了实例级的时序通信,有利于分割视频中同一目标的视觉对应关系。最后,我们沿用先前工作(Wu等人2022、2021)的分割头,输出由多模态输入参照的最终目标掩码。
To evaluate our effectiveness, we conduct extensive experiments on several popular benchmarks for multi-modal VOS. RVOS with language reference (Ref-YouTube-VOS (Seo, Lee, and Han 2020) and Ref-DAVIS 2017 (Khoreva, Rohrbach, and Schiele 2019)), and one benchmark for AVVOS with audio reference (AVSBench (Zhou et al. 2022)). On Ref-YouTube-VOS (Seo, Lee, and Han 2020) and RefDAVIS 2017 (Khoreva, Rohrbach, and Schiele 2019) with language references, MUTR surpasses the state-of-the-art method Refer From er (Wu et al. 2022) by $+4.2%$ and $+4.1%$ scores, respectively. On AV-VOS (Zhou et al. 2022) with audio references, we also outperform Baseline (Zhou et al. 2022) by $+8.7%$ score.
为评估我们的有效性,我们在多个流行的多模态视频目标分割(VOS)基准上进行了广泛实验:包括带语言参考的RVOS(Ref-YouTube-VOS (Seo, Lee和Han 2020)和Ref-DAVIS 2017 (Khoreva, Rohrbach和Schiele 2019)),以及一个带音频参考的AVVOS基准(AVSBench (Zhou等 2022))。在Ref-YouTube-VOS (Seo, Lee和Han 2020)和Ref-DAVIS 2017 (Khoreva, Rohrbach和Schiele 2019)语言参考基准上,MUTR分别以$+4.2%$和$+4.1%$的分数超越了当前最优方法ReferFormer (Wu等 2022)。在带音频参考的AV-VOS (Zhou等 2022)基准上,我们同样以$+8.7%$的分数超越了基线方法(Zhou等 2022)。
Overall, our contributions are summarized as follows:
总体而言,我们的贡献可概括如下:
• For the first time, we present a unified transformer architecture, MUTR, to tackle video object segmentation referred by multi-modal inputs, i.e., language and audio. • To better align the temporal information with multi-modal signals, we propose two attention-based modules, MTA and MTI, respectively for low-level multi-scale aggregation and high-level multi-object interaction, achieving superior cross-modal understanding in a video. • On benchmarks of two modalities, our approach both achieves state-of-the-art results, e.g., $+4.2%$ and $+4.1%$ for Ref-YouTube-VOS and Ref-DAVIS 2017, $+8.7%$ for AV-VOS. This fully indicates the significance and generalization ability of MUTR.
• 我们首次提出了一种统一的Transformer架构MUTR,用于处理由多模态输入(即语言和音频)引用的视频对象分割任务。
• 为了更好地将时序信息与多模态信号对齐,我们提出了两个基于注意力的模块MTA和MTI,分别用于低层级多尺度聚合和高层级多对象交互,从而在视频中实现卓越的跨模态理解。
• 在两种模态的基准测试中,我们的方法均取得了最先进的结果,例如在Ref-YouTube-VOS和Ref-DAVIS 2017上分别提升 指标 $+4.2%$ 和 $+4.1%$,在AV-VOS上提升 指标 $+8.7%$。这充分证明了MUTR的重要性和泛化能力。
Related Work
相关工作
Referring video object segmentation (R-VOS). R-VOS introduces the language expression for target object tracking and segmentation, following the trend of vision-language learning (Zhang et al. 2022, 2023b; Zhu et al. 2023; Fang et al. 2023). Existing R-VOS methods can be broadly classified into three categories. One of the most straightforward ideas is to apply referring image segmentation methods (Ding et al. 2021; Yang et al. 2022; Wang et al. 2022) independently to video frames, such as RefVOS (Bellver et al. 2020). Obviously, it disregards the temporal information, which makes it difficult to process common video challenges like object disappearance in reproduction. Another approach involves propagating the target mask detected from key frame and selecting the object to be segmented based on a visual grounding model (Kamath et al. 2021; Luo et al. 2020). Although it applies the temporal information to some extent, its complex multi-stage training approach is not desirable. The recent work MTTR (Botach, Z helton oz hsk ii, and Baskin 2022) and Refer Former (Wu et al. 2022) have employed query-based mechanisms. Nevertheless, they are end-to-end frameworks, they perform R-VOS task utilizing image-level segmentation. Con stra st ly, our unified framework fully explores video-level visual-attended language information for low-level temporal aggregation.
参考视频目标分割 (R-VOS)。R-VOS 引入了用于目标对象跟踪和分割的语言表达,顺应了视觉-语言学习的发展趋势 (Zhang et al. 2022, 2023b; Zhu et al. 2023; Fang et al. 2023)。现有 R-VOS 方法大致可分为三类。最直观的思路是将参考图像分割方法 (Ding et al. 2021; Yang et al. 2022; Wang et al. 2022) 独立应用于视频帧,如 RefVOS (Bellver et al. 2020)。显然,这种方法忽略了时序信息,难以处理目标再现时消失等常见视频挑战。另一种方法是通过传播关键帧检测到的目标掩膜,并基于视觉定位模型 (Kamath et al. 2021; Luo et al. 2020) 选择待分割对象。虽然该方法在一定程度上利用了时序信息,但其复杂的多阶段训练方式并不理想。近期工作 MTTR (Botach, Z helton oz hsk ii, and Baskin 2022) 和 Refer Former (Wu et al. 2022) 采用了基于查询的机制。尽管它们是端到端框架,但仍使用图像级分割执行 R-VOS 任务。相比之下,我们的统一框架充分挖掘了视频级视觉关注的语言信息,用于低层时序聚合。
Audio-visual video object segmentation (AV-VOS). Inspired by recent multi-modality efforts (Zhang et al. 2023a; Gao et al. 2023; Lin et al. 2023; Wang et al. 2023; Guo et al. 2023; Han et al. 2023b,a), AV-VOS is proposed for predicting pixel-level individual positions based on a given sound signal. There is little previous work on audio-visual video object segmentation. Until recently (Zhou et al. 2022) proposed the audio-visual video object segmentation dataset. Different from it, (Mo and Tian 2023) is based on the recent visual foundation model Segment Anything Model (Kirillov et al. 2023; Zhang et al. 2023c) to achieve audio-visual segmentation. However, all of them lack the temporal alignment between multi-modal information.
视听视频对象分割 (AV-VOS)。受近期多模态研究 (Zhang et al. 2023a; Gao et al. 2023; Lin et al. 2023; Wang et al. 2023; Guo et al. 2023; Han et al. 2023b,a) 的启发,AV-VOS 旨在根据给定声音信号预测像素级的个体位置。此前关于视听视频对象分割的研究较少。直到近期 (Zhou et al. 2022) 提出了视听视频对象分割数据集。与之不同的是,(Mo and Tian 2023) 基于最新的视觉基础模型 Segment Anything Model (Kirillov et al. 2023; Zhang et al. 2023c) 实现视听分割。然而,这些方法都缺乏多模态信息间的时间对齐。
Method
方法
In this section, we illustrate the details of our MUTR for multi-modal video object segmentation. We first describe the overall pipeline in Section . Then, in Section and Section , we respectively elaborate on the proposed designs of the multiscale temporal aggregation module (MTA), and multi-object temporal interaction module (MTI).
在本节中,我们将详细阐述用于多模态视频对象分割的MUTR方法。首先在第节中介绍整体流程,随后分别在第节和第节中详细说明所提出的多尺度时序聚合模块(MTA)和多对象时序交互模块(MTI)的设计方案。
Overall Pipeline
总体流程
The overall pipeline of MUTR is shown in Figure 1. We adopt a DETR-based (Carion et al. 2020) transformer as our basic architecture, including a visual backbone, a visual encoder and a decoder, on top of which, two modules MTA and MTI are proposed for temporal multi-modal interaction. In this section, we successively introduce the pipeline of MUTR for video object segmentation.
MUTR的整体流程如图1所示。我们采用基于DETR (Carion等人 2020) 的Transformer作为基础架构,包含视觉主干网络、视觉编码器和解码器,在此基础上提出了MTA和MTI两个模块用于时序多模态交互。本节将依次介绍MUTR在视频目标分割任务中的处理流程。
Feature Backbone. Given an input video-text/audio pair, we first sample $T$ frames from the video clip, and utilize the visual backbone and a pre-trained text/audio backbone to extract the image and multi-modal features. Specifically, we utilize ResNet (He et al. 2016) or Swin Transformer (Liu et al. 2021) as the visual backbone, and obtain the multiscale visual features of the $2^{n d},3^{r d},4^{t h}$ stages. Concurrently, for the text reference, we employ an off-the-shelf language model, RoBERTa (Liu et al. 2019), to encode the linguistic embedding tokens. For the audio reference, we first process it as a spec tr ogram transform via a short-time Fourier Transform and then feed it into a pre-trained VGGish (Hershey et al. 2017) model. After the text/audio encoding, a linear projection layer is adopted to align the multi-modal feature dimension with the visual features. Note that, following previous work (Wu et al. 2022), we adopt an early fusion module in the visual backbone to inject preliminary text/audio knowledge into visual features.
特征主干网络。给定输入的视频-文本/音频对,我们首先从视频片段中采样 $T$ 帧,并利用视觉主干网络和预训练的文本/音频主干网络提取图像和多模态特征。具体而言,我们采用 ResNet (He et al. 2016) 或 Swin Transformer (Liu et al. 2021) 作为视觉主干网络,获取 $2^{nd},3^{rd},4^{th}$ 阶段的多尺度视觉特征。同时,对于文本参考,我们使用现成的语言模型 RoBERTa (Liu et al. 2019) 对语言嵌入 token 进行编码。对于音频参考,我们首先通过短时傅里叶变换将其处理为频谱图,然后输入预训练的 VGGish (Hershey et al. 2017) 模型。完成文本/音频编码后,采用线性投影层将多模态特征维度与视觉特征对齐。需要注意的是,遵循先前工作 (Wu et al. 2022),我们在视觉主干网络中采用早期融合模块,将初步的文本/音频知识注入视觉特征。
MTA Module. On top of feature extraction, we feed the visual and text/audio features into the multi-scale temporal aggregation module (MTA). We concatenate the visual features of adjacent frames, and adopt cascaded cross-attention blocks to enhance the multi-scale and multi-modal feature fusion, which is specifically described in Section .
MTA模块。在特征提取的基础上,我们将视觉和文本/音频特征输入多尺度时序聚合模块(MTA)。通过连接相邻帧的视觉特征,并采用级联交叉注意力块来增强多尺度、多模态特征融合,具体实现细节详见章节。
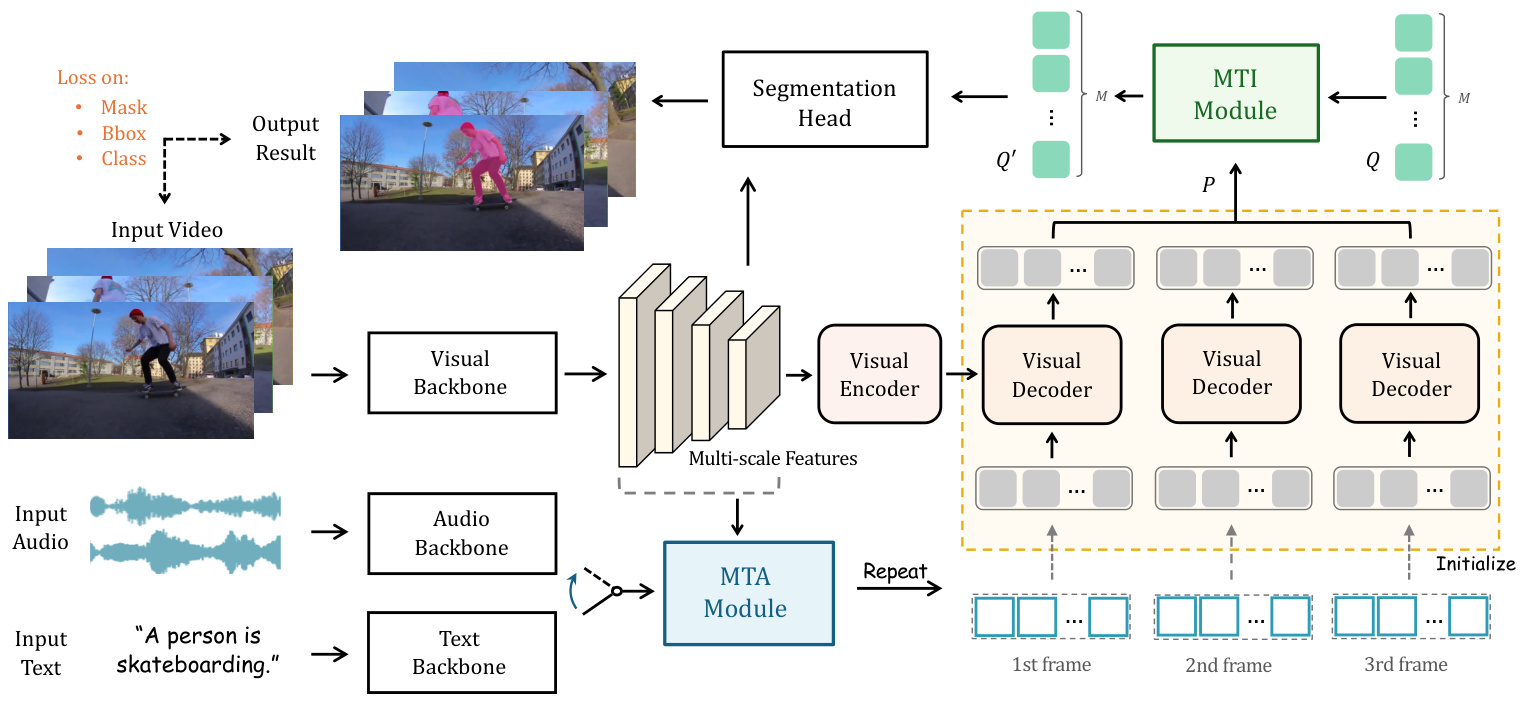
Figure 1: The Overall Pipeline of MUTR for referring video object segmentation. We present a unified transformer architecture to tackle video object segmentation referred by multi-modal inputs. We propose MTA module and MTI module for low-level multi-scale aggregation and high-level multi-object interaction, respectively.
图 1: MUTR 用于参考视频对象分割的整体流程。我们提出了一种统一的 Transformer 架构来处理由多模态输入参考的视频对象分割。我们分别提出了 MTA 模块和 MTI 模块用于低层级的多尺度聚合和高层级的多对象交互。
Visual Encoder-decoder Transformer. The basic transformer consists of a visual encoder and a visual decoder, which processes the video in a frame-independent manner to focus on the feature fusion within a single frame. In detail, the visual encoder adopts vanilla self-attention blocks to encode the multi-scale visual features. The visual decoder regards the encoded visual features as the key and value, and the output references from the MTA module as learnable object queries for decoding. Unlike the randomly initialized queries in traditional DETR (Carion et al. 2020), ours are input-conditioned ones obtained via MTA module, which contains video-level multi-modal prior knowledge. With the visual decoder, the object queries gain rich instance information, which provides effective cues for the final segmentation process.
视觉编码器-解码器 Transformer。基础 Transformer 由视觉编码器和视觉解码器组成,以帧独立方式处理视频以聚焦单帧内的特征融合。具体而言,视觉编码器采用标准自注意力块 (vanilla self-attention blocks) 编码多尺度视觉特征。视觉解码器将编码后的视觉特征作为键 (key) 和值 (value),并将来自 MTA 模块的输出参考作为可学习对象查询 (object queries) 进行解码。与传统 DETR (Carion et al. 2020) 中随机初始化的查询不同,我们的查询是通过 MTA 模块获得的输入条件式查询,包含视频级多模态先验知识。通过视觉解码器,对象查询获得丰富的实例信息,为最终分割过程提供有效线索。
MTI Module. After the visual transformer, a multi-object temporal interaction (MTI) module is proposed for objectwise interaction, which is described in Section . In detail, we utilize an MTI encoder to communicate temporal features of the same object in different views. Then an MTI decoder is proposed to grasp information into a set of video-wise query representations for associating objects across frames, inspired by (Heo et al. 2022).
MTI模块。在视觉Transformer之后,我们提出了一个用于对象间交互的多目标时序交互(MTI)模块,具体描述见章节。具体而言,我们利用MTI编码器在不同视角间传递同一对象的时序特征。随后受(Heo et al. 2022)启发,提出MTI解码器将这些信息汇聚为一组视频级查询表征,用于跨帧关联对象。
Multi-scale Temporal Aggregation
多尺度时间聚合
To boost both the multi-modal and multi-frame feature fusion, we introduce Multi-scale Temporal Aggregation module for low-level temporal aggregation. The proposed MTA module generates a set of object queries that contain multi-modal knowledge for subsequent transformer decoding.
为了增强多模态和多帧特征融合,我们引入了多尺度时序聚合(Multi-scale Temporal Aggregation,MTA)模块进行低层级时序聚合。该MTA模块生成一组包含多模态知识的对象查询(object queries),用于后续Transformer解码。
Multi-scale Temporal Transform. As shown in Figure 2, the MTA module take the text/audio features $F_{r}$ , and multiscale visual features as input, i.e., the extracted features of $2^{n d},3^{r d},4^{t h}$ stages from the visual backbone. We first utilize linear projection layers on the multi-scale features to transform them into the same dimension. Specifically, we separately utilize $1\times1$ convolution layers on the $2^{{\dot{n}}d},3^{r d}$ , $\dot{4}^{t h}$ scale features, and an additional $3\times3$ convolution layer on the $4^{t h}$ stage features to obtain the $5^{t h}$ scale features. We denote the projected features as ${F_{v j}^{i}}$ , where $2\leq i\leq5$ , $1\leq$ $j\leq T$ represent the stage number and frame number. After
多尺度时间变换。如图 2 所示,MTA 模块以文本/音频特征 $F_{r}$ 和多尺度视觉特征作为输入,即从视觉骨干网络提取的 $2^{n d},3^{r d},4^{t h}$ 阶段特征。我们首先在多尺度特征上使用线性投影层将其转换为相同维度。具体而言,我们分别在 $2^{{\dot{n}}d},3^{r d}$ 和 $\dot{4}^{t h}$ 尺度特征上使用 $1\times1$ 卷积层,并在 $4^{t h}$ 阶段特征上额外使用 $3\times3$ 卷积层以获得 $5^{t h}$ 尺度特征。我们将投影后的特征表示为 ${F_{v j}^{i}}$ ,其中 $2\leq i\leq5$ , $1\leq$ $j\leq T$ 分别表示阶段编号和帧编号。
Multi-scale Temporal Aggregation
多尺度时间聚合
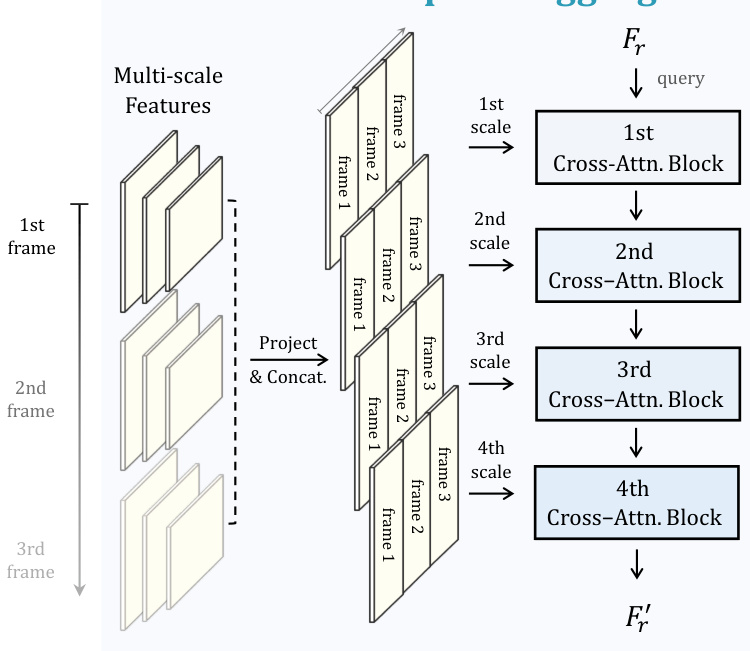
Figure 2: Multi-scale Temporal Aggregation. For low-level multimodal temporal aggregation, we propose MTA module for interframe interaction, which generates tokens with multi-modal knowledge as the input queries for transformer decoding.
图 2: 多尺度时序聚合。针对低层级多模态时序聚合,我们提出了用于帧间交互的MTA模块,该模块生成具有多模态知识的token作为Transformer解码的输入查询。
that, we concatenate the visual features of adjacent frames for each scale, formulated as
我们将每个尺度的相邻帧视觉特征进行拼接,公式表示为
$$
F_{v}^{i}=\mathrm{Concat}(F_{v1}^{i},F_{v2}^{i},..., F_{v j}^{i},~...,~F_{v T}^{i}),
$$
$$
F_{v}^{i}=\mathrm{Concat}(F_{v1}^{i},F_{v2}^{i},...,F_{v j}^{i},~...,~F_{v T}^{i}),
$$
where $2\leq i\leq5$ , $1\leq j\leq T,$ $F_{v j}^{i}$ represents the projected $j^{t h}$ frame features of $i^{t h}$ scale, and ${F_{v}^{i}}_{i=2}^{5}$ is the final transformed multi-scale visual feature. Then, the resulting multi-modal temporal features are regarded as the key and value in the following cross-attention blocks.
其中 $2\leq i\leq5$,$1\leq j\leq T$,$F_{v j}^{i}$ 表示第 $i$ 个尺度下第 $j$ 帧的投影特征,${F_{v}^{i}}_{i=2}^{5}$ 是最终转换的多尺度视觉特征。随后,生成的多模态时序特征将作为后续交叉注意力块中的键和值。
Multi-modal Cross-attention. On top of this, we adopt sequential cross-attention mechanisms for multi-modal tokens to progressively capture temporal visual cues of different image scales. We adopt four cross-attention blocks that are assigned to each scale respectively for multi-scale temporal feature extracting. In each attention block, the text/audio features serve as the query, while the multi-scale visual features serve as the key and value. We formulate it as
多模态交叉注意力。在此基础上,我们采用序列化交叉注意力机制处理多模态token,逐步捕捉不同图像尺度的时间视觉线索。我们采用四个交叉注意力模块分别对应每个尺度,用于多尺度时序特征提取。在每个注意力模块中,文本/音频特征作为查询(query),而多尺度视觉特征作为键(key)和值(value)。其公式可表示为
$$
F_{f}=\mathrm{Block}{i-1}(F_{r},F_{v}^{i},F_{v}^{i}),2\leq i\leq5,
$$
$$
F_{f}=\mathrm{Block}{i-1}(F_{r},F_{v}^{i},F_{v}^{i}),2\leq i\leq5,
$$
where Block represents the sequential cross-attention blocks in MTA module, $F_{f}$ is the output multi-modal tokens that contain the multi-modal information.
其中 Block 代表 MTA 模块中的顺序交叉注意力块,$F_{f}$ 是包含多模态信息的输出多模态 token。
After that, we simply repeat the class token of $F_{f}$ for $T\times N$ times, where $T$ is the frame number and $N$ is the query number. We adopt them as the initialized queries fed into the visual transformer for frame-wise decoding. With the MTA module, the pre-initialized input queries obtain prior multi-scale knowledge and temporal information for better multi-modal alignment during subsequent decoding.
之后,我们只需将 $F_{f}$ 的类别token重复 $T\times N$ 次,其中 $T$ 是帧数,$N$ 是查询数。我们将其作为初始化的查询输入到视觉Transformer中进行逐帧解码。通过MTA模块,预初始化的输入查询获得了先验的多尺度知识和时序信息,以便在后续解码过程中实现更好的多模态对齐。
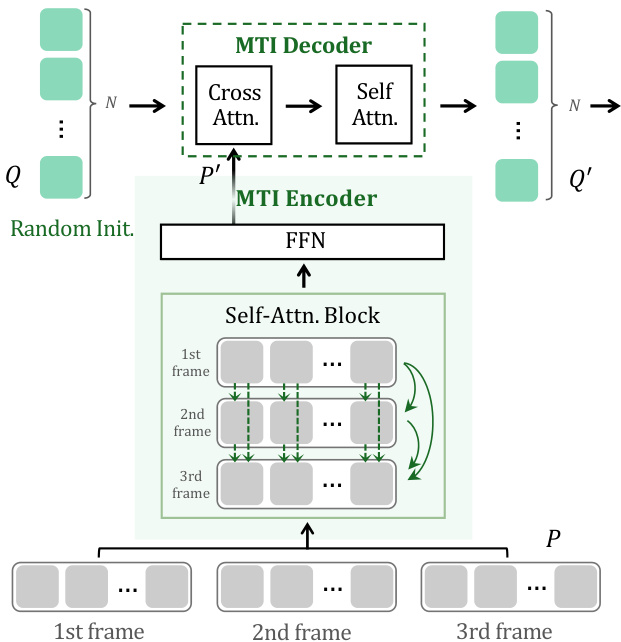
Multi-object Temporal Interaction Figure 3: Multi-object Temporal Interaction. We introduce MTI module for inter-frame object-wise interaction, and maintain a set of video-wise query representations for associating objects across frames.
图 3: 多目标时序交互。我们引入MTI模块实现帧间对象级交互,并维护一组视频级查询表征以实现跨帧目标关联。
Multi-object Temporal Interaction
多目标时序交互
As the visual transformer adopts a frame-independent manner and fails to interact information among multiple frames, we further introduce a Multi-object Temporal Interaction module to conduct inter-frame object-wise interaction. This module enhances the high-level temporal communication of objects, and benefits the visual correspondence for effective segmentation. The details of MTI are shown in Figure 3, which consists of an MTI encoder and an MTI decoder.
由于视觉Transformer采用帧独立方式且无法在多个帧之间交互信息,我们进一步引入了多目标时序交互模块(Multi-object Temporal Interaction, MTI)来实现帧间对象级交互。该模块增强了对象的高层时序通信,并有利于建立有效的视觉对应关系以实现精准分割。MTI的具体结构如图3所示,由MTI编码器和MTI解码器组成。
MTI Encoder. We obtain the object query outputs $P$ of each frame from the transformer decoder, and feed them into the MTI encoder, which contains a self-attention layer to conduct object-wise interaction across multiple frames, and a feed-forward network layer for feature transformation. To achieve more efficient implementation, we adopt shifted window-attention (Liu et al. 2021) with linear computational complexity in the self-attention layer. The process of MTI encoder is formulated as
MTI编码器。我们从Transformer解码器获取每帧的目标查询输出$P$,并将其输入到MTI编码器中。该编码器包含一个自注意力层(用于跨多帧执行目标级交互)和一个前馈网络层(用于特征转换)。为实现更高效的实现,我们在自注意力层采用线性计算复杂度的移位窗口注意力机制(shifted window-attention)[20]。MTI编码器的处理过程可表述为
$$
P^{\prime}=\mathrm{MTI}_\mathrm{Encoder}(P)
$$
$$
P^{\prime}=\mathrm{MTI}_\mathrm{Encoder}(P)
$$
where MT I Encoder denotes the MTI encoder, and $P^{\prime}$ is the outputs of MTI encoder.
其中 MT I Encoder 表示 MTI 编码器,$P^{\prime}$ 是 MTI 编码器的输出。
MTI Decoder. Based on the MTI encoder, we maintain a set of video-wise query $Q$ for associating objects across frames, which are randomly initialized. We regard the outputs from MTI encoder as the key and value, and feed them and video-wise queries $Q$ into MTI decoder for video-wise decoding. The MTI decoder consists of a cross-attention layer, a self-attention layer, and a feed-forward network layer. We
MTI解码器。基于MTI编码器,我们维护一组视频级查询$Q$用于跨帧关联对象,这些查询是随机初始化的。我们将MTI编码器的输出视为键和值,并将它们与视频级查询$Q$一起输入MTI解码器进行视频级解码。MTI解码器由交叉注意力层、自注意力层和前馈网络层组成。我们
Table 1: Performance of MUTR on Ref-YouTube-VOS and Ref-DAVIS 2017 Datasets. We report the results of MUTR and prior works on multiple backbones, where our MUTR shows the state-of-the-art performance on all datasets.
表 1: MUTR在Ref-YouTube-VOS和Ref-DAVIS 2017数据集上的性能。我们报告了MUTR和先前工作在多个骨干网络上的结果,其中我们的MUTR在所有数据集上都展示了最先进的性能。
| 方法 | 骨干网络 | Ref-YouTube-VOS | Ref-DAVIS 2017 | ||||
|---|---|---|---|---|---|---|---|
| J&F | J | F | J&F | J | F | ||
| CMSA (Ye et al. 2019) URVOS (Seo, Lee, and Han 2020) LBDT-4 (Ding et al. 2022b) YOFO (Li et al. 2022) ReferFormer (Wu et al. 2022) MUTR | ResNet-50 | 47.2 48.2 48.6 58.7 61.9 | 33.3 45.3 50.6 47.5 57.4 60.4 | 36.5 49.2 49.4 49.7 60.1 63.4 | 34.7 51.5 53.3 61.1 65.3 | 32.2 47.3 48.8 58.0 62.4 | 37.2 56.0 57.9 64.1 68.2 |
| CITD (Liang et al. 2021) ReferFormer (Wu et al. 2022) MUTR | ResNet-101 | 56.4 59.3 63.6 | 54.8 58.1 61.8 | 58.1 60.4 65.4 | 61.0 65.3 | 58.1 61.9 | 63.8 68.6 |
| ReferFormer (Wu et al. 2022) MUTR | Swin-L | 64.2 68.4 | 62.3 66.4 | 66.2 70.4 | 63.9 68.0 | 60.8 64.8 | 67.0 71.3 |
| MANet (Chen et al. 2022) ReferFormer (Wu et al. 2022) MUTR | Video-Swin-T | 55.6 62.6 64.0 | 54.8 59.9 62.2 | 56.5 63.3 65.8 | 62.8 66.5 | 60.8 63.0 | 67.0 70.0 |
| ReferFormer (Wu et al. 2022) MUTR | Video-Swin-B | 63.8 64.9 67.5 | 61.9 62.8 65.4 | 65.6 67.0 69.6 | 61.6 64.3 66.4 | 58.9 60.7 62.8 | 64.3 68.0 70.0 |
formulate them as
将它们表述为
$$
Q^{\prime}=\mathrm{MTI_Decoder}(Q,P^{\prime},P^{\prime})
$$
$$
Q^{\prime}=\mathrm{MTI_Decoder}(Q,P^{\prime},P^{\prime})
$$
where MT I Decoder represents the MTI decoder, $Q^{\prime}$ is the outputs of MTI decoder. In this way, the proposed MTI module promotes high-level temporal fusion and enhances the connection and interaction of the same objects in different frames, which further contributes to effective segmentation.
其中 MT I Decoder 表示 MTI 解码器,$Q^{\prime}$ 是 MTI 解码器的输出。通过这种方式,提出的 MTI 模块促进了高层次的时间融合,并增强了不同帧中同一对象的连接和交互,从而进一步有助于有效分割。
Joint Training for Multi-modality
多模态联合训练
As a unified VOS framework for multi-modality, MUTR has the potential to segment video objects referred by either text or audio reference. To achieve this, we conduct joint training by combining both text- and audio-referred datasets. Specifically, to balance the data amount of two modalities, the joint training data is composed of partial Ref-YouTube-VOS (Seo, Lee, and Han 2020) (text reference) and the entire AVSBench S4 (Zhou et al. 2022) (audio reference). We sample a subset of Ref-YouTube-VOS for training (10,093 clips (5 frames per clip) out of 72,920), for which we utilize only one description for videos with multiple text descriptions, and filter out half of the instances based on odd-index positions for training.
作为统一的多模态视频目标分割(VOS)框架,MUTR具备通过文本或音频指代分割视频对象的潜力。为实现这一目标,我们采用文本指代数据集Ref-YouTube-VOS (Seo, Lee和Han 2020)与音频指代数据集AVSBench S4 (Zhou等 2022)进行联合训练。具体而言,为平衡两种模态的数据量:从Ref-YouTube-VOS的72,920个视频片段(每段5帧)中采样10,093个训练片段,对含多文本描述的视频仅采用单条描述,并基于奇数索引位置过滤半数实例;同时完整采用AVSBench S4的音频指代数据进行训练。
For text or audio reference, we accordingly switch to their respective encoders for feature encoding, i.e., RoBERTa for text and VGGish for audio. Then, they share the same subsequent network modules, including the MTA, visual encoder, visual decoder, MTI, and segments head. By our proposed temporal and cross-modality interaction modules, the jointly trained MUTR can obtain superior performance on either of the two modalities.
对于文本或音频参考,我们相应地切换到各自的编码器进行特征编码,即文本使用RoBERTa,音频使用VGGish。之后,它们共享相同的后续网络模块,包括MTA、视觉编码器、视觉解码器、MTI和分段头。通过我们提出的时序和跨模态交互模块,联合训练的MUTR可以在两种模态中的任一种上获得卓越性能。
Experiments
实验
Quantitative Results
定量结果
Ref-YouTube-VOS. As shown in Table 1, MUTR outperforms the previous state-of-the-art methods by a large margin under on all datasets. On Ref-YouTube-VOS, MUTR with a lightweight backbone ResNet-50 achieves the superior performance with overall of $61.9%$ , an improvement of $+3.2%$ than the previous state-of-the-art method Refer former. By adopting a more powerful backbone SwinTransformer (Liu et al. 2021), MUTR improves the performance to $\mathcal{I}&\mathcal{F}68.4%$ , which is $+4.2%$ than the previous method Refer Former (Wu et al. 2022). Using a more strong backbone, our method has a higher percentage of improvement, which better reflects the robustness of our method on the scaled-up model size. To reflect the powerful temporal modeling capability of MUTR, we therefore adopt the video Swin transformer (Liu et al. 2022) as the backbone, which is a spatial-temporal encoder that can effectively capture the spatial and temporal cues simultaneously, to compensate for the temporal limitations of the Refer Former as discussed in (Hu et al. 2022). It can be observed that our method significantly outperforms the Refer Former, which demonstrates the effectiveness of the temporal consistency in our model.
Ref-YouTube-VOS。如表 1 所示,MUTR 在所有数据集上都大幅领先于之前的最先进方法。在 Ref-YouTube-VOS 上,采用轻量级主干网络 ResNet-50 的 MUTR 以 61.9% 的总体 取得了优异性能,比之前的最先进方法 Refer former 提升了 +3.2%。通过采用更强大的主干网络 SwinTransformer (Liu et al. 2021),MUTR 将性能提升至 $\mathcal{I}&\mathcal{F}68.4%$,比之前的方法 Refer Former (Wu et al. 2022) 高出 +4.2%。使用更强大的主干网络时,我们的方法具有更高的提升百分比,这更好地反映了我们的方法在扩大模型规模时的鲁棒性。为了体现 MUTR 强大的时序建模能力,我们采用视频 Swin transformer (Liu et al. 2022) 作为主干网络,这是一种能够同时有效捕捉空间和时序线索的时空编码器,以弥补 Refer Former 在时序方面的局限性 (Hu et al. 2022)。可以观察到,我们的方法显著优于 Refer Former,这证明了我们模型中时序一致性的有效性。
Ref-DAVIS 2017. On the Ref-DAVIS 2017, our method also achieves the best results under the same backbone setting. Since Refer Former (Wu et al. 2022) does not include the resultson Ref-DAVIS 2017, we report its results using the official pre-trained models provided by Refer Former.
Ref-DAVIS 2017。在Ref-DAVIS 2017上,我们的方法在相同主干网络设置下同样取得了最佳结果。由于Refer Former (Wu et al. 2022)未包含Ref-DAVIS 2017的结果,我们使用Refer Former官方提供的预训练模型报告其性能。
AV-VOS. Table 2 shows the performance of our MUTR on the AVSBench dataset. MUTR significantly surpasses all the previous best competitors $(\mathcal{I}&\mathcal{F}\mathbf{83.0%}$ VS $78.8%$ ; $61.6%$ VS $52.9%$ with the same ResNet-50 backbone. We also achieve a new state-of-the-art performance with Swin-L (Liu et al. 2021) backbone. By employing a stronger backbone, we observe consistent performance improvement of MUTR, indicating the strong generalization of our approach.
AV-VOS。表 2 展示了我们的 MUTR 在 AVSBench 数据集上的性能表现。MUTR 显著超越了所有先前的最佳竞争对手 (I&F 83.0% VS 78.8%;61.6% VS 52.9%),且使用相同的 ResNet-50 骨干网络。我们还采用 Swin-L (Liu et al. 2021) 骨干网络实现了新的最先进性能。通过使用更强的骨干网络,我们观察到 MUTR 的性能持续提升,这表明我们的方法具有强大的泛化能力。
Table 2: Performance of MUTR on AVSBench Dataset. MUTR surpasses the state-of-the-art method.
表 2: MUTR 在 AVSBench 数据集上的性能表现。MUTR 超越了现有最优方法。
| 方法 | Backbone | AVSBenchS4 | AVSBenchMS3 | ||||
|---|---|---|---|---|---|---|---|
| J&F | J | F | J&F | J | F | ||
| LVS (Chen et al. 2021) SST (Duke et al.2021) LGVT (Zhang et al.2021) Baseline (Zhou et al.2022) | ResNet-18 | 44.5 | 37.9 | 51.0 | 31.3 | 29.5 | 33.0 |
| ResNet-50 | 73.2 | 66.3 | 80.1 | 49.9 | 42.6 | 57.2 | |
| Swin-B | 81.1 | 74.9 | 87.3 | 50.0 | 40.7 | 59.3 | |
| ResNet-50 PvT-V2 | 78.8 83.3 | 72.8 78.7 | 84.8 87.9 | 52.9 59.3 | 47.9 54.0 | 57.8 64.5 | |
| MUTR | ResNet-50 ResNet-101 | 83.0 | 78.6 | 87.3 | 61.6 | 57.0 | 66.1 |
| PvT-V2 | 83.1 | 78.5 | 87.6 | 63.7 | 59.0 | 68.3 | |
| Swin-L | 85.1 | 80.7 | 89.5 | 67.9 | 63.7 | 72.0 | |
| Video-Swin-T | 85.7 | 81.5 | 89.8 | 69.0 | 65.0 | 73.0 | |
| Video-Swin-S | 83.0 | 78.7 79.8 | 87.2 88.3 | 64.0 67.3 | 59.2 | 68.7 | |
| Video-Swin-B | 84.1 85.7 | 81.6 | 89.7 | 68.8 | 62.7 64.0 | 71.8 73.5 |
Table 3: Performance of MUTR on Ref-YouTube-VOS by Multi-modality Joint Training.
表 3: MUTR 通过多模态联合训练在 Ref-YouTube-VOS 上的性能表现
| 方法 | J&F | J | F |
|---|---|---|---|
| ReferFormer (Wu et al. 2022) | 32.5 | 32.6 | 32.4 |
| MUTR | 39.9 | 39.4 | 40.5 |
| MUTR | 41.3 | 40.6 | 42.0 |
Table 5: Ablation Study of MTA Module.
表 5: MTA模块消融实验
| 组件 | 时序 | 块数量 | J&F | J | F |
|---|---|---|---|---|---|
| 多尺度 | 1 | 61.3 | 59.7 | 62.7 | |
| - | √ | 1 | 60.4 | 58.9 | 61.9 |
| √ | 1 | 61.9 | 60.4 | 63.4 | |
| √ | 2 | 60.7 | 59.3 | 62.2 | |
| √ | 3 | 60.4 | 59.1 | 61.7 |
Joint Training Datasets. We keep most training hyperparameters consistent with our previous text-referred video object segmentation experiments, and adopt ResNet-50 as the visual backbone. Table 3 and 4 present the performance of MUTR by joint training on Ref-YouTube-VOS and AVSBench S4, respectively. Therein, Refer Former, the ‘Baseline’, and $\mathrm{MUTR}^{*}$ are all trained exclusively on text- or audio-referred dataset, while MUTR is trained on the multimodality joint dataset. As shown, the single unified MUTR by joint training can achieve even better performance than their separate training. This indicates the effectiveness of our proposed architecture to serve as a unified framework simultaneously for text and audio input.
联合训练数据集。我们保持大部分训练超参数与之前文本引用视频对象分割实验一致,并采用ResNet-50作为视觉主干网络。表3和表4分别展示了MUTR在Ref-YouTube-VOS和AVSBench S4联合训练上的性能表现。其中,Refer Former、"Baseline"和$\mathrm{MUTR}^{*}$均仅在文本或音频引用数据集上训练,而MUTR则在多模态联合数据集上训练。结果表明,通过联合训练的单一统一MUTR模型,其性能甚至优于单独训练的模型。这证明了我们提出的架构作为同时处理文本和音频输入的统一框架的有效性。
Table 4: Performance of MUTR on AVSBench S4 by Multimodality Joint Training.
表 4: MUTR 在 AVSBench S4 上通过多模态联合训练的性能表现。
| 方法 | J&F | J | F |
|---|---|---|---|
| Baseline e (Zhou et al. 2022) | 78.8 | 72.8 | 84.8 |
| MUTR | 79.7 | 74.5 | 84.9 |
| MUTR | 81.4 | 76.8 | 85.9 |
Table 6: Ablation Study of MTI Module.
表 6: MTI模块消融实验
| 组件 | 块数量 | J&F | J | F | |
|---|---|---|---|---|---|
| 编码器 | 解码器 | 3 | 60.3 | 58.8 | 61.9 |
| - | √ | 3 | 61.2 | 60.0 | 62.6 |
| √ | √ | 3 | 61.9 | 60.4 | 63.4 |
| √ | 2 | 61.1 | 59.5 | 62.6 | |
| √ | √ | 1 | 60.8 | 59.3 | 62.3 |
Qualitative Results
定性结果
The first two columns of Figure 4 visualize some qualitative results in comparison with Refer Former (Wu et al. 2022), which lacks inter-frame interaction in terms of temporal dimension. As demonstrated, along with multiple highly similar objects in the video, Refer Former (Wu et al. 2022) is easier to misidentifies them. In contrast, our MUTR is able to associate all the objects in temporal, which can better track and segment all targets accurately.
图 4 的前两列展示了与 Refer Former (Wu et al. 2022) 对比的部分定性结果,该方法在时间维度上缺乏帧间交互。如图所示,当视频中存在多个高度相似的物体时,Refer Former (Wu et al. 2022) 更容易出现误识别。相比之下,我们的 MUTR 能够在时间上关联所有物体,从而更准确地跟踪和分割所有目标。
The last column of Figure 4 visualizes the audio-visual result compared with Baseline (Zhou et al. 2022) on AVSBbench S4 dataset. With temporal consistency, MUTR can successfully track and segment challenging situations that are surrounded or occluded by similar instances.
图 4 最后一列展示了 MUTR 与基线方法 (Zhou et al. 2022) 在 AVSBbench S4 数据集上的视听对比结果。得益于时序一致性,MUTR 能成功追踪并分割被相似实例包围或遮挡的复杂场景。

表 7: MTA和MTI模块的消融研究。
| MTA | MTI | J&F | J | F | FPS | Parameters |
|---|---|---|---|---|---|---|
| 60.2 | 58.7 | 61.7 | 19.64 | 168.1M | ||
| √ | 60.8 | 59.3 | 62.2 | 19.53 | 176.4M | |
| √ | 61.5 | 60.1 | 63.0 | 19.44 | 169.3M | |
| √ | √ | 61.9 | 60.4 | 63.4 | 19.37 | 177.6M |
Ablation Studies
消融实验
In this section, we perform experiments to analyze the main components and hyper-parameters of MUTR. All the experiments are conducted with the ResNet-50 backbone and evaluate their impact by the Ref-YouTube-VOS performance.
在本节中,我们通过实验分析MUTR的主要组件和超参数。所有实验均采用ResNet-50主干网络,并通过Ref-YouTube-VOS性能评估其影响。
Effectiveness of Main Comp one nets. Table 7 demonstrates the effectiveness of MTA and MTI proposed in our framework. The performance will be seriously degraded from $61.9%$ to $60.2%$ by removing MTA and MTI modules. Besides, our MTA and MTI modules introduce a marginal increase in inference latency, demonstrating favorable implementation and parameter efficiency.
主要组件的有效性。表7展示了我们框架中提出的MTA和MTI模块的有效性。移除MTA和MTI模块会导致性能从$61.9%$显著下降至$60.2%$。此外,我们的MTA和MTI模块仅带来微小的推理延迟增加,展现出良好的实现和参数效率。
Ablation Study on MTA. In Table 5, if either the singlescale temporal aggregation or multi-scale aggregation at the image level are adopted, the performance of MUTR would significantly drop to $60.4%$ and $61.3%$ , respectively, which demonstrates the necessity of the MTA module. We also ablate the number of MTA blocks. As seen in Table 5, more MTA blocks cannot bring further performance improvement, since (1) not enough videos for training; (2) the embedding space of visual and reference is only 256-dimensional, which is difficult to optimize so many parameters.
MTA消融实验。在表5中,若仅采用单尺度时序聚合或图像级多尺度聚合,MUTR性能会显著下降至$60.4%$和$61.3%$,这验证了MTA模块的必要性。我们还对MTA块数量进行消融实验。如表5所示,增加MTA块数无法带来性能提升,因为:(1) 训练视频数据不足;(2) 视觉与参考的嵌入空间仅为256维,难以优化过多参数。
Ablation Study on MTI. As shown in Table 6, the performance of MUTR is improved by using more MTI blocks. A possible reason is that the larger the MTI blocks, the more sufficient temporal communication between instance-level can be performed. Moreover, using only the encoder or decoder, the performance of MUTR would both decline.
MTI消融研究。如表6所示,使用更多MTI模块能提升MUTR的性能。可能的原因是MTI模块越大,实例级之间的时序通信就越充分。此外,仅使用编码器或解码器都会导致MUTR性能下降。
Conclusion
结论
This paper proposes a MUTR, a Multi-modal Unified Temporal transformer for Referring video object segmentation. A simple yet and effective Multi-scale Temporal Aggregation (MTA) is introduced for multi-modal references to explore low-level multi-scale visual information in videolevel. Besides, the high-level Multi-object Temporal Interaction (MTI) is designed for inter-frame feature communication to achieve temporal correspondence between the instancelevel across the entire video. Aided by the MTA and MTI, our MUTR achieves new state-of-the-art performance on three RVOS/AV-VOS benchmarks compared to previous solutions. We hope the MTA and MTI will help ease the future study of multi-modal VOS and related tasks (e.g., referring video object tracking and video instance segmentation). We do not foresee negative social impact from the proposed work.
本文提出MUTR,一种用于参考视频目标分割的多模态统一时序Transformer。我们引入了一种简单而有效的多尺度时序聚合(MTA)方法,通过多模态参考探索视频中的底层多尺度视觉信息。此外,设计了高层多目标时序交互(MTI)机制,用于实现帧间特征交流,从而在整个视频中建立实例级的时序对应关系。借助MTA和MTI,我们的MUTR在三个RVOS/AV-VOS基准测试中相比现有方案取得了最先进的性能。我们希望MTA和MTI能够促进未来多模态视频目标分割及相关任务(如参考视频目标跟踪和视频实例分割)的研究。我们预计该工作不会产生负面社会影响。