MAST: Multimodal Abstract ive Sum mari z ation with Trimodal Hierarchical Attention
MAST:基于三模态分层注意力的多模态抽象摘要生成
Abstract
摘要
This paper presents MAST, a new model for Multimodal Abstract ive Text Summarization that utilizes information from all three modalities – text, audio and video – in a multimodal video. Prior work on multimodal abstractive text sum mari z ation only utilized information from the text and video modalities. We examine the usefulness and challenges of deriving information from the audio modality and present a sequence-to-sequence trimodal hierarchical attention-based model that overcomes these challenges by letting the model pay more attention to the text modality. MAST outperforms the current state of the art model (video-text) by 2.51 points in terms of Content F1 score and 1.00 points in terms of Rouge-L score on the How2 dataset for multimodal language understanding.
本文提出MAST,一种新型多模态抽象文本摘要模型,该模型综合利用视频中文本、音频和视觉三种模态的信息。此前多模态抽象文本摘要研究仅利用文本和视觉模态信息。我们探究了从音频模态提取信息的价值与挑战,并提出基于层级注意力机制的序列到序列三模态模型,通过增强模型对文本模态的关注度来解决这些挑战。在How2多模态语言理解数据集上,MAST以内容F1值2.51分和Rouge-L值1.00分的优势超越当前最佳(视频-文本)模型。
1 Introduction
1 引言
In recent years, there has been a dramatic rise in information access through videos, facilitated by a proportional increase in the number of videosharing platforms. This has led to an enormous amount of information accessible to help with our day-to-day activities. The accompanying transcripts or the automatic speech-to-text transcripts for these videos present the same information in the textual modality. However, all this information is often lengthy and sometimes incomprehensible because of verbosity. These limitations in user experience and information access are improved upon by the recent advancements in the field of multimodal text sum mari z ation.
近年来,随着视频分享平台数量的激增,通过视频获取信息的方式呈现爆发式增长。这使得海量信息得以帮助我们完成日常活动。这些视频附带的文字记录或自动语音转文字记录以文本形式呈现相同内容。然而,由于内容冗长,这些信息往往篇幅巨大且有时难以理解。多模态文本摘要 (multimodal text summarization) 领域的最新进展正逐步改善这些用户体验和信息获取方面的局限。
Multimodal text sum mari z ation is the task of condensing this information from the interacting modalities into an output summary. This generated output summary may be unimodal or multimodal (Zhu et al., 2018). The textual summary may, in turn, be extractive or abstract ive. The task of extractive multimodal text sum mari z ation involves selection and concatenation of the most important sentences in the input text without altering the sentences or their sequence in any way. Li et al. (2017) made the selection of these important sentences using visual and acoustic cues from the corresponding visual and auditory modalities. On the other hand, the task of abstract ive multimodal text sum mari z ation involves identification of the theme of the input data and the generation of words based on the deeper understanding of the material. This is a tougher problem to solve which has been alleviated with the advancements in the abstract ive text sum mari z ation techniques – Rush et al. (2015), See et al. (2017) and Liu and Lapata (2019). Sanabria et al. (2018) introduced the How2 dataset for large-scale multimodal language understanding, and Palaskar et al. (2019) were able to produce state of the art results for multimodal abstract ive text sum mari z ation on the dataset. They utilized a sequence-to-sequence hierarchical attention based technique (Libovicky and Helcl, 2017) for combining textual and image features to produce the textual summary from the multimodal input. Moreover, they used speech for generating the speech-to-text transcriptions using pre-trained speech recognizer s, however it did not supplement the other modalities.
多模态文本摘要任务旨在从交互模态中浓缩信息生成输出摘要。生成的摘要可能是单模态或多模态的 (Zhu et al., 2018)。文本摘要又可分为抽取式和生成式。抽取式多模态文本摘要任务需要在不改变句子或其顺序的前提下,从输入文本中选择并拼接最重要的句子。Li et al. (2017) 通过视觉和听觉模态中的视觉与声学线索来筛选重要句子。而生成式多模态文本摘要任务则需要识别输入数据的主题,并基于对材料的深入理解生成词汇。这是一个更复杂的难题,但随着生成式文本摘要技术的进步得以缓解——如 Rush et al. (2015)、See et al. (2017) 以及 Liu 和 Lapata (2019) 的研究。Sanabria et al. (2018) 提出了用于大规模多模态语言理解的 How2 数据集,Palaskar et al. (2019) 则在该数据集上实现了多模态生成式文本摘要的顶尖成果。他们采用基于序列到序列分层注意力的技术 (Libovicky and Helcl, 2017) 来融合文本与图像特征,从而从多模态输入中生成文本摘要。此外,他们使用预训练语音识别器生成语音转文字记录,但该模态并未对其他模态形成补充。
Though the previous work in abstract ive multimodal text sum mari z ation has been promising, it has not yet been able to capture the effects of combining the audio features. Our work improves upon this shortcoming by examining the benefits and challenges of introducing the audio modality as part of our solution. We hypothesize that the audio modality can impart additional useful information for the text sum mari z ation task by letting the model pay more attention to words that are spoken with a certain tone or level of emphasis. Through our experiments, we were able to prove that not all modalities contribute equally to the output. We found a higher contribution of text, followed by video and then by audio. This formed the motivation for our MAST model, which places higher importance on text input while generating the output summary. MAST is able to produce a more illustrative summary of the original text (see Table 1) and achieves state of the art results.
尽管先前在抽象多模态文本摘要 (abstractive multimodal text summarization) 领域的研究取得了进展,但尚未能充分捕捉结合音频特征的效果。我们的工作通过探索引入音频模态作为解决方案一部分的优势与挑战,改进了这一不足。我们假设音频模态能为文本摘要任务提供额外有用信息,使模型更关注以特定语调或强调程度说出的词语。实验证明,并非所有模态对输出的贡献均等:文本贡献最高,其次是视频,最后是音频。这促使我们开发了MAST模型,该模型在生成摘要时更重视文本输入。MAST能生成更具阐释性的原文摘要(见表1),并取得了最先进的成果。
Table 1: Comparison of outputs by using different modality configurations for a test video example. Frequently occurring words are highlighted in red, which are easier for a simpler model to predict but do not contribute much in terms of useful content. The summary generated by the MAST model contains more content words as compared to the baselines.
表 1: 针对测试视频示例使用不同模态配置的输出对比。高频词以红色高亮显示,这些词汇更容易被简单模型预测但对有效内容贡献不大。与基线模型相比,MAST模型生成的摘要包含更多实义词。
| 原始文本: 现在我们来谈谈如何用蛆饵装钩。通常你会用它来钓泛鱼类。这不是广为人知的常见技巧,但在某些日子,它可能成为钓到鱼和空手而归的关键。你只需选用更大的蛆虫(可能更适合这种大钩),将钩子直接穿过蛆体。像这样的大钩,我可能会挂上十条蛆,把整只钩排满。这更适合钓泛鱼类,比如鲈鱼和太阳鱼等小型鱼。但如果你有这类蛆虫、面包虫,或是 |
| 文本仅: 冰钓用于冰钓。在这个免费钓鱼视频中向经验丰富的渔民学习钓鱼课程。 |
| MAST模型: 蛆虫适合钓鲈鱼。了解更多 |
In summary, our primary contributions are:
总之,我们的主要贡献包括:
2 Methodology
2 方法论
In this section we describe (1) the dataset used, (2) the modalities, and (3) our MAST model’s architec
在本节中,我们将介绍:(1) 使用的数据集,(2) 模态类型,以及 (3) 我们的 MAST 模型架构
ture. The code for our model is available online1.
我们的模型代码已在线发布1。
2.1 Dataset
2.1 数据集
We use the 300h version of the How2 dataset (Sanabria et al., 2018) of open-domain videos. The dataset consists of about 300 hours of short instructional videos spanning different domains such as cooking, sports, indoor/outdoor activities, music, and more. A human-generated transcript accompanies each video, and a 2 to 3 sentence summary is available for every video, written to generate interest in a potential viewer. The 300h version is used instead of the 2000h version because the audio modality information is only available for the 300h subset.
我们使用How2数据集的300小时版本(Sanabria等人,2018),这是一个开放领域的视频数据集。该数据集包含约300小时的简短教学视频,涵盖烹饪、体育、室内/室外活动、音乐等多个领域。每段视频都附有人工生成的文字记录,并为每段视频提供了2到3句的摘要,旨在激发潜在观众的兴趣。选择300小时版本而非2000小时版本,是因为音频模态信息仅适用于300小时的子集。
The dataset is divided into the training, validation and test sets. The training set consists of 13,168 videos totaling 298.2 hours. The validation set consists of 150 videos totaling 3.2 hours, and the test set consists of 175 videos totaling 3.7 hours. A more detailed description of the dataset has been given by Sanabria et al. (2018). For our experiments, we took 12,798 videos for the training set, 520 videos for the validation set and 127 videos for the test set.
数据集被划分为训练集、验证集和测试集。训练集包含13,168个视频,总计298.2小时;验证集包含150个视频,总计3.2小时;测试集包含175个视频,总计3.7小时。Sanabria等人 (2018) 对该数据集进行了更详细的描述。在我们的实验中,训练集使用了12,798个视频,验证集520个,测试集127个。
2.2 Modalities
2.2 模态
We use the following three inputs corresponding to the three different modalities used:
我们使用以下三种输入,分别对应三种不同的模态:
• Audio: We use the concatenation of 40- dimensional Kaldi (Povey et al., 2011) filter bank features from 16kHz raw audio using a time window of $25\mathrm{ms}$ with 10ms frame shift and the 3-dimensional pitch features extracted from the dataset to obtain the final sequence of 43-dimensional audio features. • Text: We use the transcripts corresponding to each video. All texts are normalized and lower-cased. • Video: We use a 2048-dimensional feature vector per group of 16 frames, which is extracted from the videos using a ResNeXt-101 3D CNN trained to recognize 400 different actions (Hara et al., 2018). This results in a sequence of feature vectors per video.
• 音频:我们使用Kaldi (Povey等人,2011) 从16kHz原始音频中提取的40维滤波器组特征,采用25ms时间窗口和10ms帧移,并与数据集中提取的3维音高特征拼接,最终得到43维音频特征序列。
• 文本:我们使用与每个视频对应的转录文本。所有文本均经过标准化处理并转为小写。
• 视频:我们使用ResNeXt-101 3D CNN (Hara等人,2018) 从视频中提取的每16帧一组2048维特征向量,该模型训练用于识别400种不同动作。最终每个视频生成一个特征向量序列。
2.3 Multimodal Abstract ive Sum mari z ation with Trimodal Hierarchical Attention
2.3 基于三模态层次化注意力的多模态摘要生成
Figure 1 shows the architecture of our Multimodal Abstract ive Sum mari z ation with Trimodal Hierarchical Attention (MAST) model. The model consists of three components - Modality Encoders, Trimodal Hierarchical Attention Layer and the Trimodal Decoder.
图 1: 展示了我们的多模态抽象摘要模型MAST (Multimodal Abstractive Summarization with Trimodal Hierarchical Attention) 的架构。该模型包含三个组件 - 模态编码器 (Modality Encoders) 、三模态分层注意力层 (Trimodal Hierarchical Attention Layer) 和三模态解码器 (Trimodal Decoder) 。
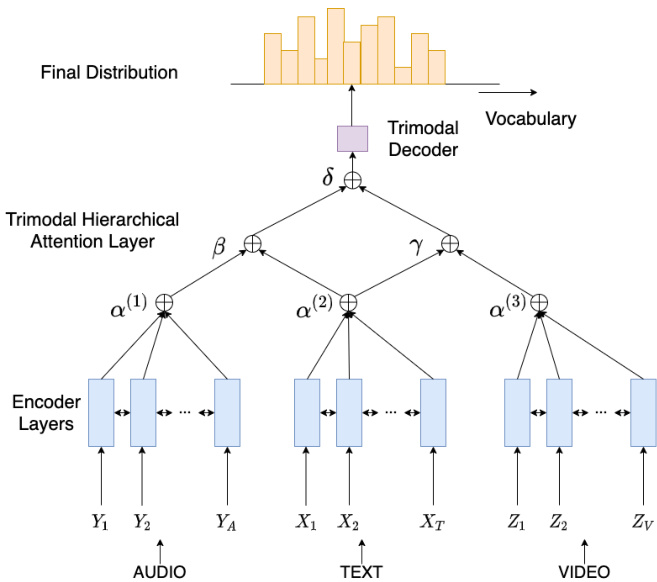
Figure 1: Multimodal Abstract ive Sum mari z ation with Trimodal Hierarchical Attention (MAST) architecture: MAST is a sequence to sequence model that uses information from all three modalities – audio, text and video. The modality information is encoded using Modality Encoders, followed by a Trimodal Hierarchical Attention Layer, which combines this information using a three-level hierarchical attention approach. It attends to two pairs of modalities $(\delta)$ (Audio-Text and VideoText) followed by the modality in each pair ( $\beta$ and $\gamma$ ), followed by the individual features within each modality $(\alpha)$ . The decoder utilizes this combination of modalities to generate the output over the vocabulary.
图 1: 基于三模态分层注意力机制的多模态抽象摘要 (MAST) 架构:MAST 是一种序列到序列模型,利用音频、文本和视频三种模态的信息。模态信息通过模态编码器进行编码,随后经过三模态分层注意力层,该层采用三级分层注意力机制整合信息。首先关注两对模态组合 $(\delta)$ (音频-文本和视频-文本),其次关注每对模态中的单个模态 $(\beta$ 和 $\gamma)$,最后关注各模态内部特征 $(\alpha)$。解码器利用这种多模态组合在词汇表上生成输出。
2.3.1 Modality Encoders
2.3.1 模态编码器
The text is embedded with an embedding layer and encoded using a bidirectional GRU encoder. The audio and video features are encoded using bidirectional LSTM encoders. This gives us the individual output encoding corresponding to all modalities at each encoder timestep. The tokens $t_{i}^{(k)}$ corresponding to modality $k$ are encoded using the corresponding modality encoders and produce a sequence of hidden states $h_{i}^{(k)}$ for each encoder time step $(i)$ .
文本通过嵌入层进行嵌入,并使用双向GRU编码器进行编码。音频和视频特征则通过双向LSTM编码器进行编码。这使我们在每个编码器时间步获得所有模态对应的独立输出编码。模态$k$对应的token $t_{i}^{(k)}$通过相应的模态编码器进行编码,并为每个编码器时间步$(i)$生成一系列隐藏状态$h_{i}^{(k)}$。
2.3.2 Trimodal Hierarchical Attention Layer
2.3.2 三模态分层注意力层
Where $s_{i}$ is the decoder hidden state at $i$ -th decoder timestep, h(j $h_{j}^{(k)}$ is the encoder hidden state at $j$ -th encoder timestep, $N_{k}$ is the number of encoder timesteps for the $k$ -th modality and ei(jk) is attention energy corresponding to them. $W_{a}$ and $U_{a}$ are trainable projection matrices, $v_{a}$ is a weight vector and $b_{a t t}$ is the bias term.
其中 $s_{i}$ 是解码器在第 $i$ 个时间步的隐藏状态,$h_{j}^{(k)}$ 是编码器在第 $j$ 个时间步的隐藏状态,$N_{k}$ 是第 $k$ 种模态的编码器时间步数,$e_{i}(j k)$ 是它们对应的注意力能量。$W_{a}$ 和 $U_{a}$ 是可训练的投影矩阵,$v_{a}$ 是权重向量,$b_{a t t}$ 是偏置项。
We now look at two different strategies of combining information from the modalities. The first is a simple extension of the hierarchical attention combination. The second is the strategy used in MAST, which combines modalities using three levels of hierarchical attention.
我们现在来看两种结合多模态信息的不同策略。第一种是层次化注意力组合的简单扩展。第二种是MAST中采用的策略,它通过三层层次化注意力来融合多模态信息。
- TrimodalH2: To obtain our first baseline model (TrimodalH2), with 2 level attention hierarchy, the context vectors for all three modalities are combined using a second layer of attention mechanism and its context vector is computed separately by using hierarchical attention combination as in Libovicky and Helcl (2017):
- TrimodalH2: 为了获得我们的第一个基线模型 (TrimodalH2) ,采用2级注意力层级结构,所有三种模态的上下文向量通过第二层注意力机制进行组合,并按照 Libovicky 和 Helcl (2017) 提出的分层注意力组合方式分别计算其上下文向量:
$$
\begin{array}{c}{{e_{i}^{(k)}=v_{b}^{T}\mathrm{tanh}(W_{b}s_{i}+U_{b}^{(k)}c_{i}^{(k)})}}\ {{\eta_{i}^{(k)}=\mathrm{softmax}(e_{i}^{(k)})}}\ {{c_{i}=\displaystyle\sum_{k\in{\mathrm{audio},\mathrm{text},\mathrm{video}}}}}\end{array}
$$
$$
\begin{array}{c}{{e_{i}^{(k)}=v_{b}^{T}\mathrm{tanh}(W_{b}s_{i}+U_{b}^{(k)}c_{i}^{(k)})}}\ {{\eta_{i}^{(k)}=\mathrm{softmax}(e_{i}^{(k)})}}\ {{c_{i}=\displaystyle\sum_{k\in{\mathrm{audio},\mathrm{text},\mathrm{video}}}}}\end{array}
$$
where $\eta^{(k)}$ is the hierarchical attention distribution over the modalities, $c_{i}^{(k)}$ is the context vector of the $k$ -th modality encoder, $v_{b}$ and $W_{b}$ are shared parameters across modalities, and U b( $U_{b}^{(k)}$ and U c(k) are modality-specific projection matrices.
其中 $\eta^{(k)}$ 是模态上的分层注意力分布,$c_{i}^{(k)}$ 是第 $k$ 个模态编码器的上下文向量,$v_{b}$ 和 $W_{b}$ 是跨模态共享参数,$U_{b}^{(k)}$ 和 $U_{c}^{(k)}$ 是模态特定的投影矩阵。
- MAST: To obtain our MAST model, the context vectors for audio-text and text-video are combined using a second layer of hierarchical attention mechanisms ( $\beta$ and $\gamma$ ) and their context vectors are computed separately. These context-vectors are then combined using the third hierarchical attention mechanism $(\delta)$ .
- MAST: 为获得MAST模型,音频-文本和文本-视频的上下文向量通过第二层分层注意力机制($\beta$和$\gamma$)进行组合,并分别计算它们的上下文向量。随后,这些上下文向量通过第三层分层注意力机制$(\delta)$进行融合。
$$
e_{i}^{(k)}=v_{d}^{T}\mathrm{tanh}(W_{d}s_{i}+U_{d}^{(k)}c_{i}^{(k)})
$$
$$
e_{i}^{(k)}=v_{d}^{T}\mathrm{tanh}(W_{d}s_{i}+U_{d}^{(k)}c_{i}^{(k)})
$$
$$
\beta_{i}^{(k)}=\mathrm{softmax}(e_{i}^{(k)})
$$
$$
\beta_{i}^{(k)}=\mathrm{softmax}(e_{i}^{(k)})
$$
$$
d_{i}^{(1)}=\sum_{k\in{\mathrm{audio},\mathrm{text}}}\beta_{i}^{(k)}U_{e}^{(k)}c_{i}^{(k)}
$$
$$
d_{i}^{(1)}=\sum_{k\in{\mathrm{audio},\mathrm{text}}}\beta_{i}^{(k)}U_{e}^{(k)}c_{i}^{(k)}
$$
2. Video-Text:
2. 视频-文本:
$$
\begin{array}{c}{{e_{i}^{(k)}=v_{f}^{T}\mathrm{tanh}(W_{f}s_{i}+U_{f}^{(k)}c_{i}^{(k)})}}\ {{\gamma_{i}^{(k)}=\mathrm{softmax}(e_{i}^{(k)})}}\ {{d_{i}^{(2)}=\displaystyle\sum_{k\in{\mathrm{video,text}}}\gamma_{i}^{(k)}U_{g}^{(k)}c_{i}^{(k)}}}\end{array}
$$
$$
\begin{array}{c}{{e_{i}^{(k)}=v_{f}^{T}\mathrm{tanh}(W_{f}s_{i}+U_{f}^{(k)}c_{i}^{(k)})}}\ {{\gamma_{i}^{(k)}=\mathrm{softmax}(e_{i}^{(k)})}}\ {{d_{i}^{(2)}=\displaystyle\sum_{k\in{\mathrm{video,text}}}\gamma_{i}^{(k)}U_{g}^{(k)}c_{i}^{(k)}}}\end{array}
$$
where $d_{i}^{(l)}$ , $l\in$ {audio-text, video-text} is the context vector obtained for the corresponding pair-wise modality combination.
其中 $d_{i}^{(l)}$ ( $l\in$ {audio-text, video-text} ) 是对应成对模态组合获得的上下文向量。
Finally, these audio-text and video-text context vectors are combined using the third and final attention layer $(\delta)$ . With this trimodal hierarchical atten- tion architecture, we combine the textual modality twice with the other two modalities in a pair-wise manner, and this allows the model to pay more attention to the textual modality while incorporating the benefits of the other two modalities.
最后,这些音频-文本和视频-文本上下文向量通过第三个也是最后一个注意力层 $(\delta)$ 进行组合。借助这种三模态分层注意力架构,我们以两两配对的方式将文本模态与其他两种模态进行了两次结合,这使得模型在融入其他两种模态优势的同时,能够更加关注文本模态。
$$
e_{i}^{(l)}=v_{h}^{T}\mathrm{tanh}(W_{g}s_{i}+U_{h}^{(l)}d_{i}^{(l)})
$$
$$
e_{i}^{(l)}=v_{h}^{T}\mathrm{tanh}(W_{g}s_{i}+U_{h}^{(l)}d_{i}^{(l)})
$$
$$
\delta_{i}^{(l)}=\mathrm{softmax}(e_{i}^{(l)})
$$
$$
\delta_{i}^{(l)}=\mathrm{softmax}(e_{i}^{(l)})
$$
$$
c_{i}^{f}=\sum\delta_{i}^{(l)}U_{m}^{(l)}d_{i}^{(l)}
$$
$$
c_{i}^{f}=\sum\delta_{i}^{(l)}U_{m}^{(l)}d_{i}^{(l)}
$$
where $c_{i}^{f}$ is the final context vector at $i$ -th decoder timestep.
其中 $c_{i}^{f}$ 是第 $i$ 个解码器时间步的最终上下文向量。
2.3.3 Trimodal Decoder
2.3.3 三模态解码器
We use a GRU-based conditional decoder (Firat and Cho, 2016) to generate the final vocabulary distribution at each timestep. At each timestep, the decoder has the aggregate information from all the modalities. The trimodal decoder focuses on the modality combination, followed by the individual modality, then focuses on the particular information inside that modality. Finally, it uses this information along with information from previous timesteps, which is passed on to two linear layers to generate the next word from the vocabulary.
我们采用基于GRU的条件解码器 (Firat and Cho, 2016) 在每个时间步生成最终的词汇分布。解码器在每个时间步都聚合了来自所有模态的信息。三模态解码器首先关注模态组合,其次是单个模态,最后聚焦于该模态内的特定信息。最终,解码器将这些信息与先前时间步的信息结合,传递给两个线性层以生成词汇表中的下一个词。
3 Experiments
3 实验
We train Trimodal Hierarchical Attention (MAST) and TrimodalH2 models on the 300h version of the
我们在300小时版本的语料上训练了Trimodal Hierarchical Attention (MAST)和TrimodalH2模型
How2 dataset, using all three modalities. We also train Hierarchical Attention models considering Audio-Text and Video-Text modalities, as well as simple Seq2Seq models with attention for each modality individually as baselines. As observed by Palaskar et al. (2019), the Pointer Generator model (See et al., 2017) does not perform as well as Seq2Seq models on this dataset, hence we do not use that as a baseline in our experiments. We consider another transformer-based baseline for the text modality, BertSumAbs (Liu and Lapata, 2019).
How2数据集,使用全部三种模态。我们还训练了考虑音频-文本和视频-文本模态的分层注意力模型,以及针对每种模态单独使用带注意力的简单Seq2Seq模型作为基线。如Palaskar等人 (2019) 所观察到的,指针生成器模型 (See等人, 2017) 在该数据集上表现不如Seq2Seq模型,因此我们未将其作为实验基线。针对文本模态,我们考虑了另一种基于Transformer的基线模型BertSumAbs (Liu和Lapata, 2019)。
For all our experiments (except for the BerSumAbs baseline), we use the nmtpytorch toolkit (Caglayan et al., 2017). The source and the target vocabulary consists of 49,329 words on which we train our word embeddings. We use the NLL loss and the Adam optimizer (Kingma and Ba, 2014) with learning rate 0.0004 and trained the models for 50 epochs. We generate our summaries using beam search with a beam size of 5, and then evaluate them using the ROUGE metric (Lin, 2004) and the Content F1 metric (Palaskar et al., 2019).
在我们所有的实验中(除BerSumAbs基线外), 我们使用了nmtpytorch工具包(Caglayan et al., 2017)。源语言和目标语言的词汇表包含49,329个单词, 我们在此基础上训练词嵌入。我们使用负对数似然(NLL)损失函数和Adam优化器(Kingma and Ba, 2014), 学习率设为0.0004, 模型训练50个epoch。我们使用束搜索(beam size=5)生成摘要, 然后使用ROUGE指标(Lin, 2004)和Content F1指标(Palaskar et al., 2019)进行评估。
In our experiments, the text is embedded with an embedding layer of size 256 and then encoded using a bidirectional GRU encoder (Cho et al., 2014) with a hidden layer of size 128, which gives us a 256-dimensional output encoding corresponding to the text at each timestep. The audio and video frames are encoded using bidirectional LSTM encoders (Hochreiter and Schmid huber, 1997) with a hidden layer of size 128, which gives a 256- dimensional output encoding corresponding to the audio and video features at each timestep. Finally, the GRU-based conditional decoder uses a hidden layer of size 128 followed by two linear layers which transform the decoder output to generate the final output vocabulary distribution.
在我们的实验中,文本通过一个大小为256的嵌入层进行嵌入,然后使用隐藏层大小为128的双向GRU编码器 (Cho et al., 2014) 进行编码,这为我们在每个时间步生成一个256维的文本输出编码。音频和视频帧则通过隐藏层大小为128的双向LSTM编码器 (Hochreiter and Schmidhuber, 1997) 进行编码,为每个时间步的音频和视频特征生成256维的输出编码。最后,基于GRU的条件解码器使用一个大小为128的隐藏层,后接两个线性层,将解码器输出转换为最终的输出词汇分布。
To improve generalization of our model, we use two dropout layers within the Text Encoder and one dropout layer on the output of the conditional decoder, all with a probability of 0.35. We also use implicit regular iz ation by using early stopping mechanism on the validation loss with a patience of 40 epochs.
为了提高模型的泛化能力,我们在文本编码器中使用了两个dropout层,并在条件解码器输出端添加了一个dropout层,所有dropout概率均为0.35。同时采用早停机制对验证损失进行隐式正则化,耐心值设为40个epoch。
3.1 Challenges of using audio modality
3.1 音频模态的使用挑战
The first challenge comes with obtaining a good representation of the audio modality that adds value beyond the text modality for the task of text sum mari z ation. As found by Mohamed (2014), DNN acoustic models prefer features that smoothly change both in time and frequency, like the log mel-frequency spectral coefficients (MFSC), to the de correlated mel-frequency cepstral coefficients (MFCC). MFSC features make it easier for DNNs to discover linear relations as well as higher order causes of the input data, leading to better overall system performance. Hence we do not consider MFCC features in our experiments and use the filter bank features instead.
第一个挑战在于如何获取音频模态的良好表征,使其在文本摘要任务中能提供超越文本模态的价值。Mohamed (2014) 研究发现,DNN声学模型更青睐在时间和频率上平滑变化的特征(如对数梅尔频谱系数 MFSC),而非去相关的梅尔频率倒谱系数 (MFCC)。MFSC特征使DNN更容易发现输入数据的线性关系及高阶因果关系,从而提升整体系统性能。因此我们在实验中未采用MFCC特征,转而使用滤波器组特征。
The second challenge arises due to the larger number of parameters that a model needs when handling the audio information. The number of parameters in the Video-Text baseline is 16.95 million as compared to 32.08 million when we add audio. This is because of the high number of input timesteps in the audio modality encoder, which makes learning trickier and more time-consuming.
第二个挑战源于模型处理音频信息时需要更多的参数。Video-Text基线模型的参数量为1695万,而加入音频后参数量增至3208万。这是由于音频模态编码器的高输入时间步数导致的,这使得学习过程更加棘手且耗时。
To demonstrate these challenges, as an experiment, we group the audio features across input timesteps into bins with an average of 30 consecutive timesteps and train our MAST model. This makes the number of audio timesteps comparable to the number of video and text timesteps. While we observe an improvement in computational efficiency, it achieves a lower performance than the baseline Video-Text model as described in Table 2 (MAST-Binned). We also train Audio only and Audio-Text models which fail to beat the Text only baseline. We observe that the generated summaries of the Audio only model are similar and repetitive, indicating that the model failed to learn useful information relevant to the task of text sum mari z ation.
为了验证这些挑战,我们进行了一项实验:将输入时间步的音频特征按每30个连续时间步为一组进行分箱处理,并训练我们的MAST模型。这使得音频时间步数量与视频和文本时间步数量相当。虽然计算效率有所提升,但其性能低于表2所述的基准视频-文本模型(MAST-Binned)。我们还训练了纯音频和音频-文本模型,但均未能超越纯文本基准。观察到纯音频模型生成的摘要内容相似且重复,表明该模型未能学习到与文本摘要任务相关的有效信息。
4 Results and Discussion
4 结果与讨论
Table 2: Results for different configurations. MAST outperforms all baseline models in terms of ROUGE scores, and obtains a higher Content-F1 score than all baselines while obtaining a score close to the TrimodalH2 model.
表 2: 不同配置的结果。MAST 在 ROUGE 分数上优于所有基线模型,并且在获得接近 TrimodalH2 模型分数的同时,获得了比所有基线更高的 Content-F1 分数。
| 模型名称 | ROUGE 1 | ROUGE 2 | ROUGE L | Content F1 |
|---|---|---|---|---|
| Text Only | 46.01 | 25.16 | 39.98 | 33.45 |
| BertSumAbs | 29.68 | 11.74 | 22.58 | 31.53 |
| VideoOnly | 39.23 | 19.82 | 34.17 | 27.06 |
| AudioOnly | 29.16 | 12.36 | 28.86 | 26.65 |
| Audio-Text | 34.56 | 15.22 | 31.63 | 28.36 |
| Video-Text | 48.40 | 27.97 | 42.23 | 32.89 |
4.1 Preliminaries
4.1 预备知识
Our results are given in Table 2. To demonstrate the contribution of various modalities towards the output summary, we experiment with the three modalities taken individually as well as in combination. Text only, Video only and the Audio only are attention-based S2S models (Bahdanau et al., 2014) with their respective modality features taken as encoder inputs. To situate the efficacy of the encoderdecoder architecture for our task, we use the BertSumAbs (Liu and Lapata, 2019) as a BERT based baseline for abstract ive text sum mari z ation. AudioText and the Video-Text are S2S models with hierarchical attention layer. The Video-Text model as presented by Palaskar et al. (2019) has been compared on the 300h version instead of the 2000h version of the dataset because the audio modality is only available in the former. TrimodalH2 model, adds the audio modality in the second-level of hierarchical attention. MAST-Binned model groups the features of the audio modality for computational efficiency. These models show alternative methods for utilizing audio modality information.
我们的结果如表2所示。为验证不同模态对输出摘要的贡献,我们分别对三种模态单独及组合进行实验。"仅文本"、"仅视频"和"仅音频"都是基于注意力机制的序列到序列(S2S)模型(Bahdanau等人,2014),各自以对应模态特征作为编码器输入。为验证编码器-解码器架构在本任务中的有效性,我们使用BertSumAbs(Liu和Lapata,2019)作为基于BERT的生成式文本摘要基线。AudioText和Video-Text是带有分层注意力层的S2S模型。由于音频模态仅在前者可用,我们采用Palaskar等人(2019)提出的Video-Text模型在300小时版本数据集上进行对比(而非2000小时版本)。TrimodalH2模型在第二级分层注意力中加入了音频模态。MAST-Binned模型为提升计算效率对音频模态特征进行分组处理。这些模型展示了利用音频模态信息的替代方法。
We evaluate our models with the ROUGE metric (Lin, 2004) and the Content F1 metric (Palaskar et al., 2019). The Content F1 metric is the F1 score of the content words in the summaries based on a monolingual alignment. It is calculated using the METEOR toolkit (Denkowski and Lavie, 2011) by setting zero weight to function words $(\delta)$ , equal weights to Precision and Recall $(\alpha)$ , and no cross-over penalty $(\gamma)$ for generated words. Additionally, a set of catchphrases like the words - in, this, free, video, learn, how, tips, expert - which appear in most summaries and act like function words instead of content words are removed from the reference and hypothesis summaries as a postprocessing step. It ignores the fluency of the output, but gives an estimate of the amount of useful content words the model is able to capture in the output.
我们使用ROUGE指标 (Lin, 2004) 和Content F1指标 (Palaskar et al., 2019) 评估模型性能。Content F1指标是基于单语对齐的摘要内容词F1分数,通过METEOR工具包 (Denkowski and Lavie, 2011) 计算得出:设置功能词权重为零 $(\delta)$ ,精确率和召回率权重相等 $(\alpha)$ ,且不对生成词施加交叉惩罚 $(\gamma)$ 。后处理阶段会从参考摘要和假设摘要中移除高频短语(如in/this/free/video/learn/how/tips/expert等兼具功能词特性的常见词)。该指标虽忽略输出流畅度,但能有效衡量模型在输出中捕获有用内容词的能力。
4.2 Discussion
4.2 讨论
As observed from the scores for the Text Only model, the text modality contains the most amount of information relevant to the final summary, followed by the video and the audio modalities. The scores obtained by combining the audio-text and video-text modalities also indicate the same. The transformer-based model, BertSumAbs, fails to perform well because of the smaller amount of text data available to fine-tune the model.
从纯文本(Text Only)模型的得分可以看出,文本模态包含与最终摘要最相关的信息量,其次是视频和音频模态。结合音频-文本和视频-文本模态获得的分数也表明了这一点。基于Transformer的模型BertSumAbs由于可用于微调模型的文本数据量较少而表现不佳。
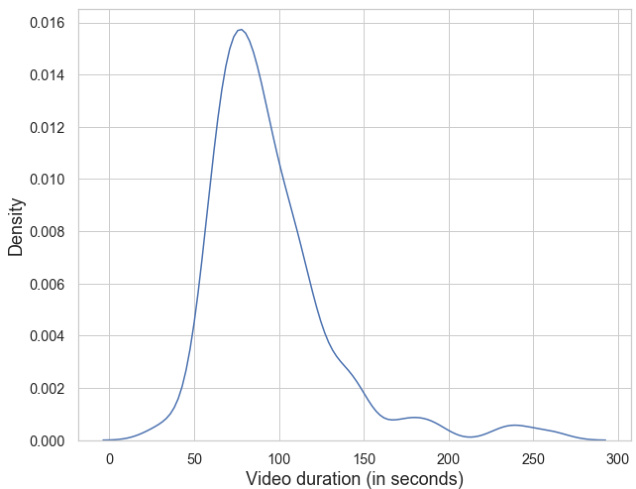
Figure 2: Distribution of the duration of videos (in seconds) in the test set.
图 2: 测试集中视频时长(以秒为单位)的分布情况。
We also observe that combining the text and audio modalities leads to a lower ROUGE score than the Text Only model, which indicates that the plain hierarchical attention model fails to learn well over the audio modality by itself. This observation is in line with the result obtained by the TrimodalH2 model, where we simply extend the hierarchical attention approach to three modalities.
我们还发现,结合文本和音频模态的ROUGE分数低于纯文本模型(Text Only),这表明基础的层次化注意力模型本身难以有效学习音频模态。这一观察结果与TrimodalH2模型的结论一致——当我们简单地将层次化注意力方法扩展到三模态时也出现了类似现象。
4.2.1 Usefulness of audio modality
4.2.1 音频模态的有用性
The MAST and the TrimodalH2 models achieve a higher Content F1 score than the Video-Text baseline, indicating that the model learns to extract more useful content by utilizing information from the audio modality corresponding to the characteristics of speech, in line with our initial hypothesis as illustrated in Table 1
MAST和TrimodalH2模型的内容F1分数高于视频-文本基线,表明该模型通过利用与语音特征对应的音频模态信息,学会了提取更有用的内容,这与我们在表1中展示的初始假设一致。
However, the TrimodalH2 model, which simply adds the audio modality in the second level of hierarchical attention, fails to outperform the VideoText baseline in terms of ROUGE scores. Our architecture lets the MAST model choose between paying attention to a different combination of modali- ties with the text modality. This forces the model to pay more attention to the text modality, thereby overcoming the shortcoming of the TrimodalH2 model and achieving better ROUGE scores, while maintaining a similar Content F1 score when compared to TrimodalH2.
然而,简单在分层注意力第二级加入音频模态的TrimodalH2模型,其ROUGE分数未能超越VideoText基线。我们的MAST架构允许模型自主选择将文本模态与不同模态组合进行注意力交互。这种设计强制模型更关注文本模态,从而克服了TrimodalH2模型的缺陷,在保持与TrimodalH2相近的Content F1分数同时,获得了更优的ROUGE分数。
4.2.2 Attention distribution across modalities
4.2.2 跨模态注意力分布
To understand the importance of individual modalities and their combinations, we plot their attention distribution at different levels of attention hi- erarchy across the decoder timesteps. Figure 4a corresponds to attention weights as calculated in equation 14 while figures 4b and $_{4\mathtt{C}}$ correspond to the product of attention weights between equations 11, 8 and corresponding weight in equation 14 for each decoder timestep. The final attention within each individual modality at each decoder timestep is calculated by multiplying the corresponding cumulative attention weights obtained at level 2 of attention hierarchy with the attention weights obtained in equation 2 (figures 4d to 4f). The attention weights assigned to the audio modality have been added across input timesteps (group size of 30) in order to obtain a more interpret able visualization.
为了理解各模态及其组合的重要性,我们绘制了它们在解码器时间步上不同注意力层级的注意力分布。图4a对应公式14计算的注意力权重,而图4b和图4c则对应每个解码器时间步上公式11、8与公式14中相应权重的乘积结果。每个解码器时间步上各模态的最终注意力,是通过将注意力层级第二级获得的累积注意力权重与公式2中的注意力权重相乘计算得出(图4d至图4f)。为获得更直观的可视化效果,音频模态的注意力权重已按输入时间步(每组30个)进行跨步求和。

Figure 3: Distribution of Rouge-L scores of summaries produced for different video durations (in seconds) for MAST and Video-Text baseline. The videos are binned into groups of 25 seconds by duration and the distribution of Rouge-L scores within each group is shown us- ing density plots. The dotted lines inside each group show the quartile distribution.
图 3: MAST 和视频-文本基线模型针对不同视频时长(以秒为单位)生成摘要的Rouge-L分数分布。视频按时长以25秒为间隔分组,每组内的Rouge-L分数分布通过密度图展示。每组内部的虚线表示四分位分布。
Through these visualization s, we observe that the text modality dominates the generation of the output summary while giving lesser attention to the audio and video modalities (the latter being more important). These findings support the extra importance being given to the text modality in the MAST model during its interaction with the other modalities. Figures 4b and 4d highlight the modest gains through the audio modality and the challenge in its appropriate usage.
通过这些可视化分析,我们观察到文本模态主导了输出摘要的生成,而对音频和视频模态的关注较少(后者更为重要)。这些发现支持了MAST模型在与其他模态交互时对文本模态的额外重视。图4b和图4d突显了通过音频模态获得的有限收益及其在适当使用方面面临的挑战。
4.2.3 Performance across video durations
4.2.3 不同视频时长下的性能表现
We also look at how our model performs for different video durations in our test set. Figure 3 shows the variation in the Rouge-L scores across different videos for MAST and the Video-Text baseline. The figure shows videos binned into seven groups of 25 seconds by duration. We can observe from the quartile distribution that MAST outperforms the baseline in five out of the seven groups, gives similar performance for videos with a duration between 75-100 seconds, and under performs for videos with a duration between 150-175 seconds. However, overall, by looking at the distribution of the duration of videos in our test set (Figure 2), we can observe that MAST outperforms the baseline for a vast majority of videos across durations.
我们还研究了模型在测试集中针对不同视频时长的表现。图3展示了MAST和视频-文本基线在不同视频上的Rouge-L分数变化情况。图中将视频按时长分为7组,每组间隔25秒。从四分位分布可以看出,MAST在其中5组表现优于基线,在75-100秒时长视频上表现相当,而在150-175秒时长视频上表现稍逊。但总体而言,通过观察测试集中视频时长的分布情况(图2),我们可以发现MAST在绝大多数时长范围的视频上都优于基线。
5 Related Work
5 相关工作
5.1 Abstract ive text sum mari z ation
5.1 抽象文本摘要
Abstract ive sum mari z ation of documents was traditionally achieved by paraphrasing and fusing multiple sentences along with their grammatical rewriting (Woodsend and Lapata, 2012). This was later improved by taking inspiration from human comprehension capabilities when Fang and Teufel (2014) implemented the model of human comprehension and sum mari z ation proposed by Kintsch and Van Dijk (1978). They did this by identifying these concepts in text through the application of co-reference resolution, named entity recognition and semantic similarity detection, implemented as a two-step competition.
摘要
文档的抽象摘要传统上通过改写、融合多个句子及其语法重写来实现 (Woodsend and Lapata, 2012)。Fang和Teufel (2014) 受人类理解能力启发改进了这一方法,他们实现了Kintsch和Van Dijk (1978) 提出的人类理解与摘要模型。该模型通过共指消解、命名实体识别和语义相似度检测来识别文本中的概念,并以两步竞争机制实现。
The real stimulus to the field of abstract ive summarization was provided by the application of neural encoder-decoder architectures. Rush et al. (2015) were among the first to achieve state-of-theart results on Gigaword (Graff et al., 2003) and the DUC-2004 (Over et al., 2007) datasets and estab- lished the importance of end-to-end deep learning models for abstract ive sum mari z ation. Their work was later improved upon by See et al. (2017) where they used copying from the source text to remove the problem of incorrect generation of facts in the summary, as well as a coverage mechanism to curb the problem of repetition of words in the generated summary.
神经编码器-解码器架构的应用为抽象摘要领域提供了真正的推动力。Rush等人(2015)率先在Gigaword(Graff等人,2003)和DUC-2004(Over等人,2007)数据集上取得了最先进的结果,并确立了端到端深度学习模型对抽象摘要的重要性。See等人(2017)后来改进了他们的工作,通过从源文本复制来消除摘要中事实生成错误的问题,并使用覆盖机制来抑制生成摘要中单词重复的问题。
5.2 Pretrained language models
5.2 预训练语言模型
Another breakthrough for the field of natural language processing came with the use of pre-trained language models for carrying out various language downstream tasks. Pre-trained language models like BERT (Devlin et al., 2018) introduced masked language modelling, which allowed models to learn interactions between left and right context words. These models have significantly changed the way word embeddings are generated by training contextual embeddings rather than static embeddings. Liu and Lapata (2019) presented how BERT could be used for text sum mari z ation and proposed a new fine-tuning schedule for abstract ive summarization which adopted different optimizers for the encoder and the decoder to alleviate the mismatch between the two. BERT models typically require large amounts of annotated data to produce state-ofthe-art results. Recent works, like GAN-BERT by Croce et al. (2020) focus on solving this problem.
自然语言处理领域的另一项突破是利用预训练语言模型执行各种下游语言任务。BERT (Devlin et al., 2018) 等预训练模型引入了掩码语言建模技术,使模型能够学习左右上下文词汇间的交互关系。这些模型通过训练上下文嵌入而非静态嵌入,彻底改变了词向量的生成方式。Liu和Lapata (2019) 展示了如何将BERT应用于文本摘要任务,并提出了一种新的抽象摘要微调方案:采用不同优化器分别处理编码器和解码器,以缓解两者间的失配问题。BERT模型通常需要大量标注数据才能达到最优性能,Croce等人 (2020) 提出的GAN-BERT等近期研究正着力解决这一难题。
5.3 Advancements in speech recognition and computer vision
5.3 语音识别与计算机视觉的进展
Parallel advancements in the field of speech recognition and computer vision have been able to give us successful methods to extract useful features of speech and images. Peddinti et al. (2015) built a robust acoustic model for speech recognition using a time-delay neural network. They were able to achieve state-of-the-art results in the IARPA ASpIRE Challenge. Similarly, with the advancements of convolutional neural networks, the field of computer vision has progressed significantly. He et al. (2016) demonstrated the strength of deep residual networks which learned residual functions with reference to the layers and were able to achieve stateof-the art results on the ImageNet dataset. Hara et al. (2018) showed that simple 3D Convolutional Neural Network (CNN) architectures outperform complex 2D architectures and trained a ResNeXt101 3D CNN to recognize 400 different human actions on the Kinetics dataset (Kay et al., 2017).
语音识别和计算机视觉领域的并行发展为我们提供了提取语音和图像有用特征的成功方法。Peddinti等人(2015) 使用延时神经网络构建了一个鲁棒的语音识别声学模型,在IARPA ASpIRE挑战赛中取得了最先进的成果。同样地,随着卷积神经网络的进步,计算机视觉领域也取得了显著进展。He等人(2016) 展示了深度残差网络通过学习层间残差函数的强大能力,在ImageNet数据集上实现了最先进的性能。Hara等人(2018) 证明简单的3D卷积神经网络(CNN)架构优于复杂的2D架构,并在Kinetics数据集(Kay等人, 2017) 上训练了一个ResNeXt101 3D CNN来识别400种不同的人类动作。
5.4 Sum mari z ation beyond text
5.4 超越文本的摘要生成
The advancements in these fields have in turn also facilitated text sum mari z ation. Rott and Cerva (2016) used only the input audio to generate textual summaries while Sah et al. (2017) were among the first to show the possibility of summarizing long videos and then annotating the summarized video to obtain a textual summary. These models, however, were not able to capture the information of other modalities to obtain the output textual summary and hence their limitations led to the increasing use of multimodal data. A major hindrance in the field of multimodal text summarization was the lack of datasets. Li et al. (2017) created an asynchronous benchmark dataset with humanannotated summaries for 500 videos. Sanabria et al. (2018) then released a large-scale dataset for instruct ional videos. JN et al. (2020) and Zhu et al. (2018) presented multimodal text sum mari z ation models using textual and visual modalities as input and multimodal outputs of summarized text and video. Palaskar et al. (2019) used How2 dataset to present an abstract ive summary of open-domain videos. These models, however, are not completely multimodal since they do not utilise the audio information. A major focus of our work is to highlight the importance of using audio data as input and incorporate it in a truly multimodal manner.
这些领域的进步反过来也促进了文本摘要技术的发展。Rott和Cerva (2016) 仅使用输入音频生成文本摘要,而Sah等人 (2017) 率先展示了通过总结长视频并标注摘要视频来获取文本摘要的可能性。然而,这些模型无法捕捉其他模态的信息来生成输出文本摘要,因此其局限性促使多模态数据的使用日益增多。多模态文本摘要领域的主要障碍是缺乏数据集。Li等人 (2017) 创建了一个包含500个视频人工标注摘要的异步基准数据集。Sanabria等人 (2018) 随后发布了一个大规模教学视频数据集。JN等人 (2020) 和Zhu等人 (2018) 提出了使用文本和视觉模态作为输入、并生成摘要文本和视频多模态输出的多模态文本摘要模型。Palaskar等人 (2019) 利用How2数据集呈现了开放域视频的抽象摘要。然而,这些模型并非完全多模态,因为它们未利用音频信息。我们工作的一个重要重点是强调使用音频数据作为输入并以真正多模态方式整合其价值。

Figure 4: Visualization of attention weights in the Trimodal Hierarchical Attention layer for a sample video in the test set. Figures 4a to $_{4\mathrm{c}}$ show the varying attention distribution on different combinations of modalities across the decoder timesteps. Figures 4d to 4f show the attention distribution on the encoder timesteps for each modality across the decoder timesteps. This shows the usefulness of each modality for the generation of the summary.
图 4: 测试集样本视频在三模态分层注意力层中的注意力权重可视化。图4a至$_{4\mathrm{c}}$展示了解码器时间步上不同模态组合的注意力分布变化。图4d至4f显示了各模态在解码器时间步上对编码器时间步的注意力分布。这体现了各模态对摘要生成的有效性。
6 Conclusion
6 结论
In this work2, we presented MAST, a state of the art sequence to sequence based model that uses information from all three modalities – audio, text and video – to generate abstract ive multimodal text summaries. It uses a Trimodal Hierarchical Attention layer to utilize information from all modalities. We explored the role played by adding the audio modality and compared MAST with several baseline models, demonstrating the effectiveness of our approach.
在本研究中[2],我们提出了MAST,这是一种基于序列到序列(state of the art)的先进模型,利用音频、文本和视频三种模态的信息生成抽象的多模态文本摘要。该模型采用三模态分层注意力(Trimodal Hierarchical Attention)层来整合所有模态的信息。我们探究了添加音频模态的作用,并将MAST与多个基线模型进行对比,验证了该方法的有效性。
In the future, we would like to extend this work by looking at alternate audio modality representations including using neural networks for audio feature extraction, and also explore the use of transformers for an end to end attention based learning. We also aim to explore the application of MAST to other multimodal tasks like translation.
未来,我们希望通过研究其他音频模态表示(包括使用神经网络进行音频特征提取)来扩展这项工作,并探索使用Transformer实现端到端的基于注意力的学习。我们还计划探索将MAST应用于翻译等其他多模态任务。
References
参考文献
Automatic metric for reliable optimization and evaluation of machine translation systems. In Proceedings of the sixth workshop on statistical machine translation, pages 85–91.
机器翻译系统可靠优化与评估的自动指标。见第六届统计机器翻译研讨会论文集,第85-91页。
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2018。BERT:面向语言理解的深度双向Transformer预训练。arXiv预印本 arXiv:1810.04805。
Yimai Fang and Simone Teufel. 2014. A summariser based on human memory limitations and lexical competition. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, pages 732–741.
方一麦和Simone Teufel。2014。基于人类记忆限制与词汇竞争的摘要生成器。载于《第14届欧洲计算语言学会会议论文集》,第732–741页。
Orhan Firat and Kyunghyn Cho. 2016. Con- ditional gated recurrent unit with attention mechanism. https://github.com/nyu-dl/dl4mttutorial/blob/master/docs/cgru.pdf.
Orhan Firat 和 Kyunghyn Cho. 2016. 带注意力机制的条件门控循环单元。https://github.com/nyu-dl/dl4mttutorial/blob/master/docs/cgru.pdf。
David Graff, Junbo Kong, Ke Chen, and Kazuaki Maeda. 2003. English gigaword. Linguistic Data Consortium, Philadelphia, 4(1):34.
David Graff、Junbo Kong、Ke Chen和Kazuaki Maeda。2003。English gigaword。Linguistic Data Consortium,费城,4(1):34。
Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. 2018. Can s patio temporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 6546–6555.
Kensho Hara, Hirokatsu Kataoka, 和 Yutaka Satoh. 2018. 时空3D CNN能否重演2D CNN与ImageNet的历史? 在《IEEE计算机视觉与模式识别会议论文集》中, 页码6546–6555。
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770– 778.
Kaiming He、Xiangyu Zhang、Shaoqing Ren 和 Jian Sun。2016。深度残差学习在图像识别中的应用。载于《IEEE计算机视觉与模式识别会议论文集》,第770-778页。
Sepp Hochreiter and Juirgen Schmid huber. 1997. Long short-term memory. Neural computation, 9(8):1735–1780.
Sepp Hochreiter 和 Juirgen Schmidhuber. 1997. 长短期记忆 (Long Short-Term Memory). Neural computation, 9(8):1735–1780.
Zhu JN, Zhang JJ, Li HR, Zong CQ, et al. 2020. Multimodal sum mari z ation with guidance of multimodal reference. Association for Computational Linguistics.
朱建南、张佳佳、李浩然、宗长青等。2020。基于多模态参考指导的多模态摘要生成。计算语言学协会。
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. 2017. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950.
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, 等. 2017. Kinetics人类动作视频数据集. arXiv预印本 arXiv:1705.06950.
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Diederik P Kingma 和 Jimmy Ba. 2014. Adam: 一种随机优化方法. arXiv preprint arXiv:1412.6980.
Walter Kintsch and Teun A Van Dijk. 1978. Toward a model of text comprehension and production. Psychological review, 85(5):363.
Walter Kintsch 和 Teun A Van Dijk. 1978. 文本理解与生成的模型探索. Psychological review, 85(5):363.
Haoran Li, Junnan Zhu, Cong Ma, Jiajun Zhang, Chengqing Zong, et al. 2017. Multi-modal summarization for asynchronous collection of text, image, audio and video.
Haoran Li, Junnan Zhu, Cong Ma, Jiajun Zhang, Chengqing Zong等. 2017. 面向异步采集文本、图像、音频和视频的多模态摘要生成.
Jindrich Libovicky and Jindrich Helcl. 2017. Attention strategies for multi-source sequence-to-sequence learning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 196–202.
Jindrich Libovicky 和 Jindrich Helcl。2017。多源序列到序列学习的注意力策略。见《第55届计算语言学协会年会论文集(第二卷:短文)》,第196–202页。
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text sum mari z ation branches out, pages 74–81.
Chin-Yew Lin. 2004. ROUGE: 自动摘要评估工具包。In Text summarization branches out, pages 74–81.
Yang Liu and Mirella Lapata. 2019. Text summarization with pretrained encoders. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3721–3731.
Yang Liu 和 Mirella Lapata. 2019. 基于预训练编码器的文本摘要. 见《2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议论文集》(EMNLP-IJCNLP), 第3721–3731页.
Kristian Woodsend and Mirella Lapata. 2012. Multiple aspect sum mari z ation using integer linear programming. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pages 233–243. Association for Computational Linguistics.
Kristian Woodsend和Mirella Lapata。2012。基于整数线性规划的多角度摘要生成。载于《2012年自然语言处理经验方法会议与计算自然语言学习联合会议论文集》,第233–243页。计算语言学协会。
Junnan Zhu, Haoran Li, Tianshang Liu, Yu Zhou, Jiajun Zhang, Chengqing Zong, et al. 2018. Msmo: multimodal sum mari z ation with multimodal output.
Junnan Zhu、Haoran Li、Tianshang Liu、Yu Zhou、Jiajun Zhang、Chengqing Zong 等。2018. Msmo: 多模态摘要生成与多模态输出。