LION: Linear Group RNN for 3D Object Detection in Point Clouds
LION: 用于点云3D物体检测的线性分组循环神经网络
Abstract
摘要
The benefit of transformers in large-scale 3D point cloud perception tasks, such as 3D object detection, is limited by their quadratic computation cost when modeling long-range relationships. In contrast, linear RNNs have low computational complexity and are suitable for long-range modeling. Toward this goal, we propose a simple and effective window-based framework built on LInear grOup RNN (i.e., perform linear RNN for grouped features) for accurate 3D object detection, called LION. The key property is to allow sufficient feature interaction in a much larger group than transformer-based methods. However, effectively applying linear group RNN to 3D object detection in highly sparse point clouds is not trivial due to its limitation in handling spatial modeling. To tackle this problem, we simply introduce a 3D spatial feature descriptor and integrate it into the linear group RNN operators to enhance their spatial features rather than blindly increasing the number of scanning orders for voxel features. To further address the challenge in highly sparse point clouds, we propose a 3D voxel generation strategy to densify foreground features thanks to linear group RNN as a natural property of auto-regressive models. Extensive experiments verify the effectiveness of the proposed components and the generalization of our LION on different linear group RNN operators including Mamba, RWKV, and RetNet. Furthermore, it is worth mentioning that our LIONMamba achieves state-of-the-art on Waymo, nuScenes, Argoverse V2, and ONCE datasets. Last but not least, our method supports kinds of advanced linear RNN operators (e.g., RetNet, RWKV, Mamba, xLSTM and TTT) on small but popular KITTI dataset for a quick experience with our linear RNN-based framework.
在大规模3D点云感知任务(如3D目标检测)中,Transformer因建模长距离关系时存在二次计算成本,其优势受到限制。相比之下,线性RNN具有较低计算复杂度,更适合长距离建模。为此,我们提出了一种基于线性分组RNN(即对分组特征执行线性RNN)的简单高效窗口化框架LION,用于精准3D目标检测。其核心特性是允许在比基于Transformer的方法更大的组内实现充分特征交互。然而,由于线性分组RNN在空间建模方面的局限性,将其有效应用于高度稀疏点云的3D目标检测并非易事。为此,我们创新性地引入3D空间特征描述符,将其集成到线性分组RNN算子中以增强空间特征,而非盲目增加体素特征的扫描顺序数量。针对高度稀疏点云的挑战,我们提出3D体素生成策略,利用线性分组RNN作为自回归模型的天然特性来增强前景特征密度。大量实验验证了所提组件的有效性,以及LION对不同线性分组RNN算子(包括Mamba、RWKV和RetNet)的泛化能力。值得注意的是,LIONMamba在Waymo、nuScenes、Argoverse V2和ONCE数据集上实现了最先进性能。最后,我们的方法支持在小而流行的KITTI数据集上使用多种先进线性RNN算子(如RetNet、RWKV、Mamba、xLSTM和TTT),便于快速体验基于线性RNN的框架。
1 Introduction
1 引言
3D object detection serves as a fundamental technique in 3D perception and is widely used in navigation robots and self-driving cars. Recently, transformer-based [53] feature extractors have made significant progress in general tasks of Natural Language Processing (NLP) and 2D vision by flexibly modeling long-range relationships. To this end, some researchers have made great efforts to transfer the success of transformers to 3D object detection. Specifically, to reduce the computation costs, SST [15] and SWFormer [50] divide point clouds into pillars and implement window attention for pillar feature interaction in a local 2D window. Considering some potential information loss of the pillar-based manners along the height dimension, DSVT-Voxel [57] further adopts voxel-based formats and implements set attention for voxel feature interaction in a limited group size.
3D物体检测是3D感知的基础技术,广泛应用于导航机器人和自动驾驶汽车中。近年来,基于Transformer [53]的特征提取器通过灵活建模长距离关系,在自然语言处理(NLP)和2D视觉的通用任务中取得了显著进展。为此,一些研究者致力于将Transformer的成功经验迁移到3D物体检测领域。具体而言,为降低计算成本,SST [15]和SWFormer [50]将点云划分为柱体(pillar),并在局部2D窗口中实现柱体特征交互的窗口注意力机制。考虑到基于柱体的方法在高度维度可能存在信息损失,DSVT-Voxel [57]进一步采用基于体素(voxel)的格式,在有限分组大小内实现体素特征交互的集合注意力机制。
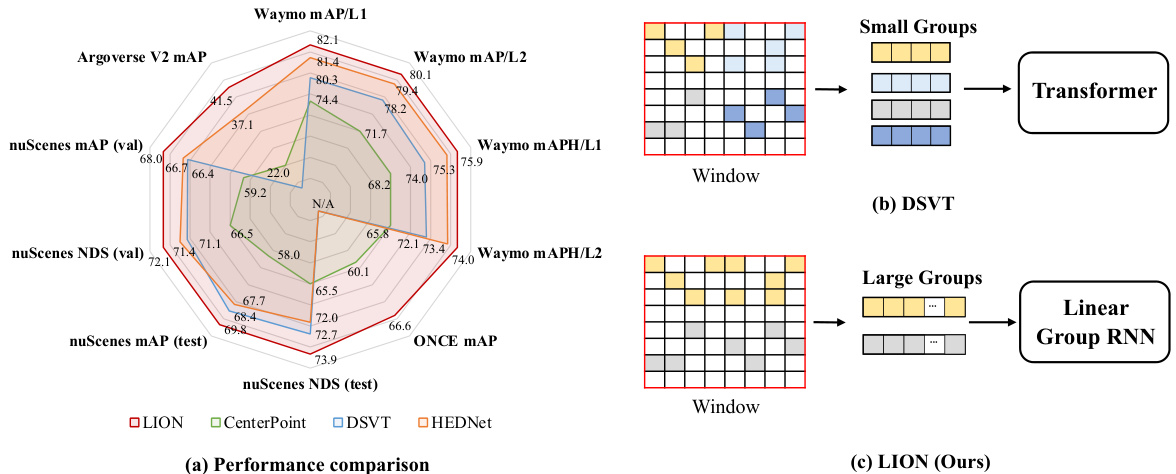
Figure 1: (a) Comparison of different 3D backbones in terms of detection performance on Waymo [49], nuScenes [4], Argoverse V2 [59] and ONCE [34] datasets. Here, we adopt Mamba [22] as the default operator of our LION. Besides, we present the simplified schematic of DSVT (b) [57] and our LION (c) for implementing feature interaction in 3D backbones.
图 1: (a) 不同3D主干网络在Waymo [49]、nuScenes [4]、Argoverse V2 [59]和ONCE [34]数据集上的检测性能对比。此处我们采用Mamba [22]作为LION的默认算子。同时展示了DSVT (b) [57]和我们LION (c) 在3D主干网络中实现特征交互的简化示意图。
Although the above methods have achieved some success in 3D detection, they perform self-attention for pillar or voxel feature interaction with only a small group size due to computational limitations, locking the potential of transformers for modeling long-range relationships. Moreover, it is worth noting that modeling long-range relationships can benefit from large datasets, which will be important for achieving foundational models in 3D perception tasks in the future. Fortunately, in the field of large language models (LLM) and 2D perception tasks, some representative linear RNN operators such as Mamba [22] and RWKV [37] with linear computational complexity have achieved competitive performance with transformers, especially for long sequences. Therefore, a question naturally arises: can we perform long-range feature interaction in larger groups at a lower computation cost based on linear RNNs in 3D object detection?
尽管上述方法在3D检测中取得了一定成果,但由于计算限制,它们仅在小规模组内对柱体或体素特征进行自注意力交互,这限制了Transformer建模长距离关系的潜力。值得注意的是,长距离关系建模能够受益于大规模数据集,这对未来实现3D感知任务的基础模型至关重要。幸运的是,在大语言模型和2D感知任务领域,一些具有线性计算复杂度的代表性线性RNN算子(如Mamba [22]和RWKV [37])已展现出与Transformer相当的性能,尤其在长序列处理方面。因此,一个自然产生的问题是:在3D目标检测中,我们能否基于线性RNN以更低计算成本实现更大规模组内的长距离特征交互?
To this end, we propose a window-based framework based on LInear grOup RNN (i.e., perform linear RNN for grouped features in a window-based framework) termed LION for accurate 3D object detection in point clouds. Different from the existing method DSVT (b) in Figure 1, our LION (c) could support thousands of voxel features to interact with each other in a large group for establishing the long-range relationship. Nevertheless, effectively adopting linear group RNN to construct a proper 3D detector in highly sparse point cloud scenes remains challenging for capturing the spatial information of objects. Concretely, linear group RNN requires sequential features as inputs. However, converting voxel features into sequential features may result in the loss of spatial information (e.g., two features that are close in 3D spatial position might be very far in this 1D sequence). Therefore, we propose a simple 3D spatial feature descriptor and decorate the linear group RNN operators with it, thus compensating for the limitations of linear group RNN in 3D local spatial modeling.
为此,我们提出了一种基于LInear grOup RNN(即在窗口化框架中对分组特征执行线性RNN)的窗口化框架LION,用于点云中的精确3D目标检测。与图1中现有方法DSVT (b)不同,我们的LION (c)能够支持数千个体素特征在大组内相互交互,从而建立长程关系。然而,在高度稀疏的点云场景中,如何有效采用线性分组RNN构建合适的3D检测器以捕获物体空间信息仍具挑战性。具体而言,线性分组RNN需要序列特征作为输入,但将体素特征转换为序列特征可能导致空间信息丢失(例如,3D空间位置上相邻的两个特征可能在一维序列中相距甚远)。为此,我们提出了一种简单的3D空间特征描述符,并用其修饰线性分组RNN算子,从而弥补线性分组RNN在3D局部空间建模中的局限性。
Furthermore, to enhance feature representation in highly sparse point clouds, we present a new 3D voxel generation strategy based on linear group RNN to densify foreground features. A common manner of addressing this is to add an extra branch to distinguish the foregrounds, as seen in previous methods [50, 17, 67]. However, this solution is relatively complex and rarely used in 3D backbone due to its lack of structural elegance. Instead, we simply choose the high response of the feature map in the 3D backbone as the areas for voxel generation. Subsequently, the auto-regressive property of linear group RNN can be effectively employed to generate voxel features.
此外,为增强高度稀疏点云中的特征表征能力,我们提出了一种基于线性组RNN的新型3D体素生成策略以增强前景特征密度。常见解决方案是像先前方法[50, 17, 67]那样添加额外分支区分前景,但该方案相对复杂且因结构不够优雅而罕见于3D主干网络。我们转而直接选择3D主干网络中特征图的高响应区域作为体素生成区域,随后可有效利用线性组RNN的自回归特性生成体素特征。
Finally, as shown in Figure 1 (a), we compare LION with the existing representative methods. We can clearly observe that our LION achieves state-of-the-art on a board autonomous datasets in terms of detection performance. To summarize, our contributions are as follows: 1) We propose a simple and effective window-based 3D backbone based on the linear group RNN named LION to allow long-range feature interaction. 2) We introduce a simple 3D spatial feature descriptor and integrate it with the linear group RNN, compensating for the lack of capturing 3D local spatial information. 3) We provide a new 3D voxel generation strategy to densify foreground features, producing a more disc rim i native feature representation in highly sparse point clouds. 4) We verify the generalization of our LION with different linear group RNN mechanisms (e.g., Mamba, RWKV, RetNet). In particular, our LION-Mamba achieves state-of-the-art on challenging Waymo [49], nuScenes [4], Argoverse V2 [59], and ONCE [34] dataset, which further illustrates the superiority of LION.
最后,如图1(a)所示,我们将LION与现有代表性方法进行对比。可以清晰观察到,在检测性能方面,我们的LION在多个自动驾驶数据集上达到了最先进水平。总结而言,我们的贡献如下:1) 我们提出了一种基于线性组RNN、名为LION的简单有效窗口化3D骨干网络,可实现长程特征交互;2) 我们引入了一个简单的3D空间特征描述符,并将其与线性组RNN集成,弥补了3D局部空间信息捕获的不足;3) 我们提供了新的3D体素生成策略来增强前景特征密度,在高度稀疏的点云中生成更具判别性的特征表示;4) 我们通过不同线性组RNN机制(如Mamba、RWKV、RetNet)验证了LION的泛化能力。特别地,我们的LION-Mamba在Waymo [49]、nuScenes [4]、Argoverse V2 [59]和ONCE [34]等具有挑战性的数据集上达到了最先进水平,进一步证明了LION的优越性。

Figure 2: The illustration of LION, which mainly consists of several LION blocks, each paired with a voxel generation for feature enhancement and a voxel merging for down-sampling features along the height dimension. $(H,W,D)$ indicates the shape of the 3D feature map, where $H$ , $W$ , and $D$ are the length, width, and height of the 3D feature map along the X-axis, Y-axis, and $\mathrm{_{Z}}$ -axis. $N$ is the number of LION blocks. In LION, we first convert point clouds to voxels and partition these voxels into a series of equal-size groups. Then, we feed these grouped features into LION 3D backbone to enhance their feature representation. Finally, these enhanced features are fed into a BEV backbone and a detection head for final 3D detection.
图 2: LION结构示意图,主要由多个LION块组成,每个块包含用于特征增强的体素生成模块和沿高度维度下采样特征的体素合并模块。$(H,W,D)$表示3D特征图的形状,其中$H$、$W$和$D$分别代表3D特征图沿X轴、Y轴和$\mathrm{_{Z}}$轴的长度、宽度和高度。$N$为LION块的数量。在LION中,我们首先将点云转换为体素,并将这些体素划分为一系列等大小的组。随后,将这些分组特征输入LION 3D骨干网络以增强其特征表示。最后,这些增强后的特征被输入BEV骨干网络和检测头,以完成最终的3D检测。
2 Related Work
2 相关工作
3D Object Detection in Point Clouds. 3D object detectors in point clouds can be roughly divided into point-based and voxel-based. For point-based methods [6, 65, 39, 10, 30, 36, 24, 47, 69, 64, 40, 62, 5], they usually sample point clouds and adopt point encoder [41, 42] to directly extract point features. However, the point sampling and grouping utilized by point-based methods is time-consuming. To avoid these problems, voxel-based methods [13, 12, 31, 45, 46, 48, 23, 56, 60, 66, 61, 67] convert the input irregular point clouds into regular 3D voxels and then extract 3D features by 3D sparse convolution. Although these methods achieve promising performance, they are still limited by the local receptive field of 3D convolution. Therefore, some methods [8, 33] adopt the large kernel to enlarge the receptive field and achieve better performance.
点云中的3D目标检测。点云中的3D目标检测器大致可分为基于点(point-based)和基于体素(voxel-based)两类。基于点的方法[6, 65, 39, 10, 30, 36, 24, 47, 69, 64, 40, 62, 5]通常对点云进行采样,并采用点编码器(point encoder)[41, 42]直接提取点特征,但其点采样与分组操作耗时严重。为解决这些问题,基于体素的方法[13, 12, 31, 45, 46, 48, 23, 56, 60, 66, 61, 67]将不规则点云转换为规则的3D体素,再通过3D稀疏卷积提取特征。虽然这些方法取得了良好性能,但仍受限于3D卷积的局部感受野。为此,部分研究[8, 33]采用大卷积核来扩大感受野以获得更优性能。
Linear RNN. Recurrent Neural Networks (RNNs) are initially developed to address problems in Natural Language Processing (NLP), such as time series prediction and speech recognition, by effectively capturing temporal dependencies in sequential data. Recently, to overcome the quadratic computational complexity of transformers, significant advancements have been made in time-parallel iz able data-dependent RNNs (called linear RNNs in this paper) [43, 35, 37, 38, 52, 11, 63, 22, 51, 3]. These models retain linear complexity while offering efficient parallel training capabilities, allowing their performance to match or even surpass that of transformers. Due to their s cal ability and efficiency, linear RNNs are poised to play an increasingly important role in various fields and some works [14, 1, 28] have applied linear RNNs to 2D/3D vision filed. In this paper, we aim to further extend linear RNNs to 3D object detection tasks thanks to their long-range relationship modeling capabilities.
线性RNN。循环神经网络(RNN)最初是为解决自然语言处理(NLP)中的时间序列预测和语音识别等问题而开发的,它能有效捕捉序列数据中的时间依赖性。近年来,为克服Transformer的二次计算复杂度,时间并行化数据依赖型RNN(本文称为线性RNN)领域取得了重大进展[43,35,37,38,52,11,63,22,51,3]。这些模型在保持线性复杂度的同时提供高效的并行训练能力,使其性能可与Transformer匹敌甚至超越。凭借其可扩展性和高效性,线性RNN正日益成为各领域的重要工具,已有研究[14,1,28]将其应用于2D/3D视觉领域。本文旨在利用其长程关系建模能力,进一步将线性RNN扩展至3D目标检测任务。
Transformers in 3D Object Detection. Transformer [53] has achieved great success in many tasks, motivating numerous works to adopt attention mechanisms in 3D object detection to achieve better performance. However, the application of transformers is non-trivial in large-scale point clouds. Many works [16, 50, 32, 57] apply transformers to extract features by partitioning pillars or voxels into several groups based on local windows. Although these approaches achieve promising performance, they usually adopt small groups for feature interaction due to the quadratic computational complexity of transformers, hindering them from capturing long-range dependencies in 3D space. In contrast, we propose a simple and effective framework based on linear RNNs named LION to achieve long-range feature interaction for accurate 3D object detection thanks to their linear computational complexity.
3D目标检测中的Transformer。Transformer [53] 在许多任务中取得了巨大成功,这促使众多工作将注意力机制应用于3D目标检测以提升性能。然而,在大规模点云中应用Transformer并非易事。许多研究 [16, 50, 32, 57] 通过将点云划分为局部窗口的支柱(pillar)或体素(voxel)组来应用Transformer提取特征。虽然这些方法取得了良好性能,但由于Transformer二次方的计算复杂度,它们通常采用小规模分组进行特征交互,这阻碍了其在3D空间中捕获长距离依赖关系。相比之下,我们提出了一种基于线性RNN的简单高效框架LION,借助其线性计算复杂度,实现了长距离特征交互以进行精确的3D目标检测。
3 Method
3 方法
Due to computational limitations, some transformer-based methods [15, 57, 32] usually convert features into pillars or group small size of voxel features to interact with each other within small groups, limiting the advantages of transformers in long-range modeling. More recently, some linear RNN operators [22, 37, 52] that maintain linear complexity with the length of the input sequence are proposed to model long-range feature interaction. More importantly, the linear RNN operators such as Mamba [22] and RWKV [37] have even shown comparable performance with transformers in LLM thanks to their low computation cost in long-range feature interaction. This further motivates us to adopt linear RNNs to construct a 3D detector for long-range modeling, which might be meaningful for the unified multi-modal large model in 3D perception in the near future. However, effectively applying linear group RNN to 3D object detection is challenging and rarely explored due to the lack of strong spatial modeling in highly sparse point cloud scenes. Next, we will introduce our solution.
由于计算限制,一些基于Transformer的方法[15, 57, 32]通常将特征转换为柱状结构或将小规模体素特征分组交互,限制了Transformer在长程建模中的优势。最近,一些能保持输入序列长度线性复杂度的线性RNN算子[22, 37, 52]被提出用于建模长程特征交互。更重要的是,像Mamba[22]和RWKV[37]这样的线性RNN算子,凭借其在长程特征交互中的低计算成本,甚至在大语言模型中展现出与Transformer相当的性能。这进一步激励我们采用线性RNN构建用于长程建模的3D检测器,这对未来统一的多模态大模型在3D感知中的应用可能具有重要意义。然而,由于在高度稀疏的点云场景中缺乏强大的空间建模能力,如何有效将线性分组RNN应用于3D目标检测仍具挑战性且鲜有研究。接下来,我们将介绍我们的解决方案。
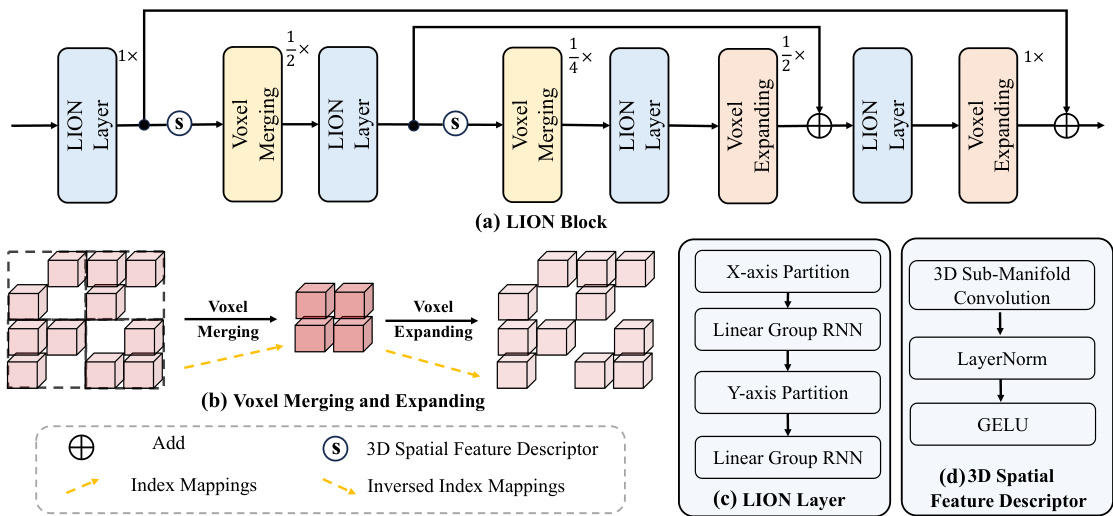
Figure 3: (a) shows the structure of LION block, which involves four LION layers, two voxel merging operations, two voxel expanding operations, and two 3D spatial feature descriptors. Here, $1\times,{\frac{1}{\mathrm{ \times~}}}\times,$ , and $\frac{1}{4}\times$ indicate the resolution of 3D feature map as $(H,W,D)$ , $(H/2,W/\bar{2},D/2)$ and $(H/4,W/4,D^{\overline{{*}}}/4)$ , respectively. (b) is the process of voxel merging for voxel down-sampling and voxel expanding for voxel up-sampling. (c) presents the structure of LION layer. (d) shows the details of the 3D spatial feature descriptor.
图 3: (a) 展示了 LION 块的结构,包含四个 LION 层、两次体素合并操作、两次体素扩展操作以及两个 3D 空间特征描述符。其中 $1\times,{\frac{1}{\mathrm{ \times~}}}\times,$ 和 $\frac{1}{4}\times$ 分别表示 3D 特征图的分辨率为 $(H,W,D)$ 、 $(H/2,W/\bar{2},D/2)$ 和 $(H/4,W/4,D^{\overline{{*}}}/4)$ 。(b) 是体素下采样时的体素合并过程与体素上采样时的体素扩展过程。(c) 呈现了 LION 层的结构。(d) 展示了 3D 空间特征描述符的细节。
3.1 Overview
3.1 概述
In this paper, we propose a simple and effective window-based framework based on LInear grOup RNN (i.e., perform linear RNN for grouped features in a window-based framework) named LION, which can group thousands of voxels (dozens of times more than the number of previous methods [15, 57, 32]) for feature interaction. The pipeline of our LION is presented in Figure 2. LION consists of a 3D backbone, a BEV backbone, and a detection head, maintaining a consistent pipeline with most voxel-based 3D detectors [60, 57, 66]. In this paper, our contribution lies in the design of the 3D backbone based on linear group RNN. In the following, we will present the details of our proposed 3D backbone, which includes $N$ LION blocks for long-range feature interaction, $N$ voxel generation operations for enhancing feature representation in sparse point clouds, and $N$ voxel merging operations for gradually down-sampling features in height.
本文提出了一种基于线性分组循环神经网络 (LInear grOup RNN) 的简单高效窗口化框架 LION (即在窗口化框架中对分组特征执行线性 RNN),该框架能够将数千个体素 (比现有方法 [15, 57, 32] 多出数十倍) 分组进行特征交互。图 2 展示了 LION 的流程架构。LION 由 3D 骨干网络、BEV 骨干网络和检测头组成,与大多数基于体素的 3D 检测器 [60, 57, 66] 保持一致的流程。本文的创新点在于基于线性分组 RNN 的 3D 骨干网络设计。下文将详细阐述我们提出的 3D 骨干网络,该网络包含:$N$ 个用于长程特征交互的 LION 模块、$N$ 个用于增强稀疏点云特征表示的体素生成操作,以及 $N$ 个沿高度方向逐步降采样特征的体素合并操作。
3D Sparse Window Partition. Our LION is a window-based 3D detector. Thus, before feeding voxel features into our LION block, we need to implement a 3D sparse window partition to group them for feature interaction. Specifically, we first convert point clouds into voxels with the total number of $L$ . Then, we divide these voxels into non-overlapping 3D windows with the shape of $(T_{x},T_{y},T_{z})$ , where $T_{x}$ , $T_{y}$ and $T_{z}$ denote the length, width, and height of the window along the $\boldsymbol{\mathrm X}$ -axis, Y-axis, and $Z$ -axis. Next, we sort voxels along the $\boldsymbol{\mathrm X}$ -axis for the X-axis window partition and along the Y-axis for the Y-axis window partition, respectively. Finally, to save computation cost, we adopt the equal-size grouping manner in FlatFormer [32] instead of the classic equal-window grouping manner in SST [15]. That is, we partition sorted voxels into groups with equal size $K$ rather than windows of equal shapes for feature interaction. Due to the quadratic computational complexity of transformers, previous transformer-based methods [15, 57, 32] only achieve feature interaction using a small group size. In contrast, we adopt a much larger group size $K$ to obtain long-range feature interaction thanks to the linear computational complexity of the linear group RNN operators.
3D稀疏窗口划分。我们的LION是一种基于窗口的3D检测器。因此,在将体素特征输入LION模块前,需要实施3D稀疏窗口划分来分组特征以进行交互。具体而言,我们首先将点云转换为总数为$L$的体素,然后将这些体素划分为形状为$(T_{x},T_{y},T_{z})$的非重叠3D窗口,其中$T_{x}$、$T_{y}$和$T_{z}$分别表示窗口沿$\boldsymbol{\mathrm X}$轴、Y轴和$Z$轴的长度、宽度和高度。接着,我们对体素分别沿$\boldsymbol{\mathrm X}$轴进行X轴窗口划分和沿Y轴进行Y轴窗口划分排序。最后,为节省计算成本,我们采用FlatFormer [32]中的等尺寸分组方式,而非SST [15]传统的等窗口分组方式。即,我们将排序后的体素划分为大小为$K$的等尺寸组而非等形状窗口进行特征交互。由于Transformer的二次计算复杂度,先前基于Transformer的方法[15,57,32]仅能使用小分组尺寸实现特征交互。相比之下,得益于线性分组RNN算子的线性计算复杂度,我们采用更大的分组尺寸$K$以获得长程特征交互。
3.2 LION Block
3.2 LION 模块
The LION block is the core component of our approach, which involves LION layer for long-range feature interaction, 3D spatial feature descriptor for capturing local 3D spatial information, voxel merging for feature down-sampling and voxel expanding for feature up-sampling, as shown in Figure 3 (a). Besides, LION block is a hierarchical structure to better extract multi-scale features due to the gap of different 3D objects in size. Next, we introduce each part of LION block.
LION块是我们方法的核心组件,包含用于长距离特征交互的LION层、捕获局部3D空间信息的3D空间特征描述符 (3D spatial feature descriptor) 、用于特征下采样的体素合并 (voxel merging) 以及用于特征上采样的体素扩展 (voxel expanding) ,如图 3 (a) 所示。此外,由于不同3D物体在尺寸上的差异,LION块采用分层结构以更好地提取多尺度特征。接下来我们将介绍LION块的各个组成部分。
LION Layer. In LION block, we apply LION layer to model a long-range relationship among grouped features with the help of the linear group RNN operator. Specifically, as shown in Figure 3 (c), we provide the structure of LION layer, which is composed of two linear group RNN operators. The first one is used to perform long-range feature interaction based on the X-axis window partition and the second one can extract long-range feature information based on the Y-axis window partition. Taking advantage of two different window partitions, LION layer can obtain more sufficient feature interaction, producing more disc rim i native feature representation.
LION层。在LION块中,我们借助线性组RNN算子,应用LION层来建模分组特征之间的长程关系。具体来说,如图3(c)所示,我们展示了LION层的结构,它由两个线性组RNN算子组成。第一个算子用于基于X轴窗口划分执行长程特征交互,第二个算子可以基于Y轴窗口划分提取长程特征信息。利用两种不同的窗口划分,LION层可以获得更充分的特征交互,生成更具判别性的特征表示。
3D Spatial Feature Descriptor. Although linear RNNs have the advantages of long-range modeling with low computation cost, it is not ignorable that the spatial information might be lost when input voxel features are flattened into 1D sequential features. For example, as shown in Figure 4, there are two adjacent features (i.e., indexed as 01 and 34) in 3D space. However, after they are flattened into 1D sequential features, the distance between them in 1D space is very far. We regard this phenomenon as a loss of 3D spatial information. To tackle this problem, an available manner is to increase the number of scan orders for voxel features such as VMamba [29]. However, the order of scanning is too hand-designed. Besides, as the scanning orders increase, the corresponding computation cost also increases significantly. Therefore, it is not appropriate in large-scale sparse 3D point clouds to adopt this manner. As shown in Figure 3 (d), we introduce a 3D spatial feature descriptor, which consists of a 3D submanifold convolution, a LayerNorm layer, and a GELU activation function. Naturally, we can leverage the 3D spatial feature descriptor to provide rich 3D local position-aware information for the LION layer. Besides, we place the 3D spatial feature descriptor before the voxel merging to reduce spatial information loss in the process of voxel merging. We provide the corresponding experiment in our appendix.
3D空间特征描述符。虽然线性RNN具有长程建模和低计算成本的优势,但不可忽视的是,当输入体素特征被展平为一维序列特征时,空间信息可能会丢失。例如,如图4所示,在3D空间中有两个相邻特征(即索引为01和34)。然而,当它们被展平为一维序列特征后,在一维空间中的距离变得非常远。我们将这种现象视为3D空间信息的丢失。为解决这一问题,一种可行的方法是增加体素特征的扫描顺序数量,如VMamba [29]。然而,扫描顺序过于依赖人工设计。此外,随着扫描顺序的增加,相应的计算成本也会显著上升。因此,在大规模稀疏3D点云中采用这种方式并不合适。如图3(d)所示,我们引入了一个3D空间特征描述符,它由3D子流形卷积、LayerNorm层和GELU激活函数组成。自然地,我们可以利用3D空间特征描述符为LION层提供丰富的3D局部位置感知信息。此外,我们将3D空间特征描述符放置在体素合并之前,以减少体素合并过程中的空间信息丢失。我们在附录中提供了相应的实验。
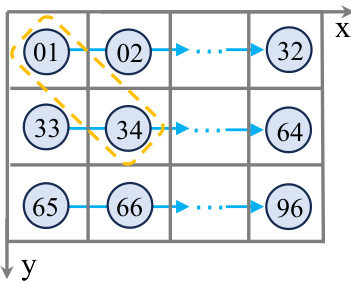
Figure 4: The illustration of spatial information loss when flattening into 1D sequences. For example, there are two adjacent voxels in spatial position (indexed as 01 and 34) but are far in the 1D sequences along the X order.
图 4: 展平为一维序列时的空间信息丢失示意图。例如,两个空间位置相邻的体素(索引为01和34)在按X顺序排列的一维序列中相距甚远。
Voxel Merging and Voxel Expanding. To enable the network to obtain multi-scale features, our LION adopts a hierarchical feature extraction structure. To achieve this, we need to perform feature down-sampling and up-sampling operations in highly sparse point clouds. However, it is worth mentioning that we cannot simply apply max or average pooling or up-sampling operations as in 2D images since 3D point clouds possess irregular data formats. Therefore, as shown in Figure 3 (b), we adopt voxel merging for feature down-sampling and voxel expanding for feature up-sampling in highly sparse point clouds. Specifically, for voxel merging, we calculate the down-sampled index mappings to merge voxels. In voxel expanding, we up-sample the down-sampled voxels by the corresponding inversed index mappings.
体素合并与体素扩展。为了让网络能够获取多尺度特征,我们的LION采用了分层特征提取结构。为实现这一点,我们需要在高度稀疏的点云中进行特征下采样和上采样操作。但值得注意的是,由于3D点云具有不规则的数据格式,我们不能简单地像处理2D图像那样直接应用最大池化、平均池化或上采样操作。如图3(b)所示,我们在高度稀疏点云中采用体素合并实现特征下采样,通过体素扩展实现特征上采样。具体而言,对于体素合并操作,我们通过计算下采样索引映射来合并体素;在体素扩展时,则通过对应的逆向索引映射对下采样体素进行上采样。
3.3 Voxel Generation
3.3 体素生成
Considering the challenge of feature representation in highly sparse point clouds and the potential information loss of implementing voxel merging in Figure 2, we propose a voxel generation strategy to address these issues with the help of the auto-regressive capacity of the linear group RNN.
考虑到高度稀疏点云中特征表示的挑战以及图 2 中实施体素合并可能导致的信息丢失问题,我们提出了一种体素生成策略,借助线性组 RNN 的自回归能力来解决这些问题。
Distinguishing Foreground Voxels without Supervision. In voxel generation, the first challenge is identifying which regions of voxel features need to be generated. Different from previous methods [50, 17, 67] that employ some supervised information based on well-learned BEV features to obtain the foreground region for feature diffusion. However, these approaches may be unsuitable for a 3D backbone and may even compromise its elegance. Interestingly, we notice that the corresponding high values of feature responses along the channel dimension in the 3D backbone (Refer to the visualization in Figure 6 in our appendix) are usually the foregrounds. Therefore, we compute the feature response $F_{i}^{*}$ for the output feature $F_{i}$ of the $i^{\dot{t}h}$ LION block, where $i=1,2,...,N$ indicates the index of LION block in the 3D backbone. Thus, this above process can be formulated as:
无监督区分前景体素。在体素生成中,首个挑战是确定需要生成哪些体素特征区域。不同于先前方法[50, 17, 67]基于学习良好的BEV特征采用监督信息来获取特征扩散的前景区域,这些方法可能不适用于3D骨干网络,甚至可能损害其简洁性。有趣的是,我们注意到3D骨干网络中沿通道维度特征响应的高值(参见附录图6的可视化)通常对应前景。因此,我们计算第i个LION块输出特征$F_{i}$的特征响应$F_{i}^{*}$,其中$i=1,2,...,N$表示3D骨干网络中LION块的索引。该过程可表述为:
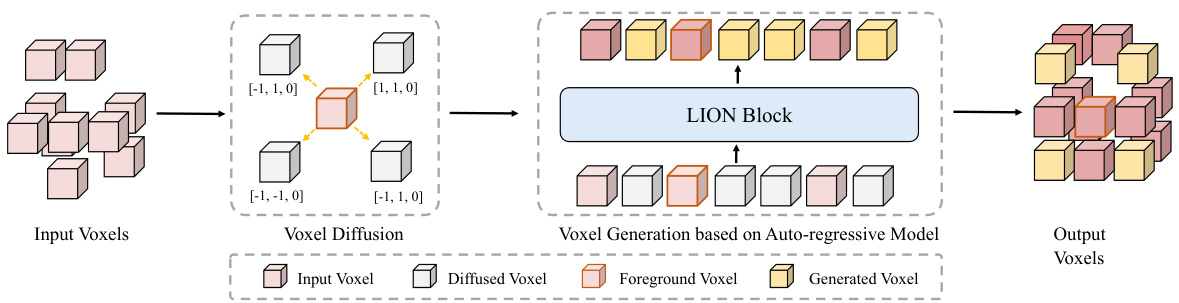
Figure 5: The details of voxel generation. For input voxels, we first select the foreground voxels and diffuse them along different directions. Then, we initialize the corresponding features of the diffused voxels as zeros and utilize the auto-regressive ability of the following LION block to generate diffused features. Note that we do not present the voxel merging here for simplicity.
图 5: 体素生成细节。对于输入体素,我们首先选择前景体素并沿不同方向扩散它们。然后,我们将扩散体素的对应特征初始化为零,并利用后续 LION 模块的自回归能力生成扩散特征。为简化说明,此处未展示体素合并过程。
$$
F_{i}^{*}=\frac{1}{C}\sum_{j=0}^{C}F_{i}^{j},
$$
$$
F_{i}^{*}=\frac{1}{C}\sum_{j=0}^{C}F_{i}^{j},
$$
where $C$ is the channel dimension of $F_{i}$ . Next, we sort the feature responses $F_{i}^{}$ in descending order and select the corresponding Top $m$ voxels as the foregrounds from the total number $L$ of non-empty voxels, where $m=r*L$ and $r$ is the ratio of foregrounds. This process can be computed as:
其中 $C$ 是 $F_{i}$ 的通道维度。接着,我们将特征响应 $F_{i}^{}$ 按降序排序,并从非空体素总数 $L$ 中选取对应的 Top $m$ 个体素作为前景,其中 $m=r*L$,$r$ 为前景比例。该过程可表示为:
$$
F_{m}=\mathrm{Top}{m}(F_{i}^{*}),
$$
$$
F_{m}=\mathrm{Top}{m}(F_{i}^{*}),
$$
where $\mathrm{Top}{m}(F_{i}^{})$ means selecting Top $\cdot m$ voxel features from $F_{i}^{*}.F_{m}$ are the selected foreground features, which will serve for the subsequent voxel generation.
其中 $\mathrm{Top}{m}(F_{i}^{})$ 表示从 $F_{i}^{*}$ 中选取 Top $\cdot m$ 个体素特征。$F_{m}$ 是选中的前景特征,将用于后续体素生成。
Voxel Generation with Auto-regressive Property. The previous method [50] adopts a K-NN manner to obtain generated voxel features based on their K-NN features, which might be sub-optimal to enhance feature representation due to the redundant features and the limited receptive field. Fortunately, the linear RNN is well-suited for auto-regressive tasks in addition to its advantage of handling long sequences. Therefore, we leverage the auto-regressive property of linear RNN to effectively generate the new voxel features by performing sufficient feature interaction with other voxel features in a large group. Specifically, for convenience, we define the corresponding coordinates of selected foreground voxel features $F_{m}$ as $P_{m}$ . As shown in Figure 5, we first obtain diffused voxels by diffusing $P_{m}$ with four different offsets (i.e., [-1,-1, 0], [1,1, 0], [1,-1, 0], and [-1,1, 0]) along the $\boldsymbol{\mathrm X}$ -axis, Y-axis, and $\boldsymbol{Z}$ -axis, respectively. Then, we initialize the corresponding features of diffused voxels by all zeros. Next, we concatenate the output feature $F_{i}$ of the $i^{t h}$ LION block with the initialized voxel features, and feed them into the subsequent $(i+1)^{t h}$ LION block. Finally, thanks to the auto-regressive ability of the LION block, the diffused voxel features can be effectively generated based on other voxel features in large groups. This process can be formulated as:
具有自回归特性的体素生成。先前的方法[50]采用K近邻(K-NN)方式基于邻近特征生成体素特征,但由于冗余特征和有限感受野,这种特征表示可能不够理想。幸运的是,线性RNN除了擅长处理长序列外,还非常适合自回归任务。因此,我们利用线性RNN的自回归特性,通过与大组内其他体素特征充分交互来有效生成新体素特征。具体而言,为方便起见,我们将选定前景体素特征$F_{m}$的对应坐标定义为$P_{m}$。如图5所示,我们首先通过沿$\boldsymbol{\mathrm X}$轴、Y轴和$\boldsymbol{Z}$轴分别施加四种偏移量(即[-1,-1,0]、[1,1,0]、[1,-1,0]和[-1,1,0])对$P_{m}$进行扩散获得扩散体素。然后,我们将扩散体素的对应特征初始化为全零。接着,将第$i^{th}$个LION块的输出特征$F_{i}$与初始化的体素特征拼接,并输入到后续$(i+1)^{th}$个LION块中。最终,得益于LION块的自回归能力,扩散体素特征可以基于大组内其他体素特征被有效生成。该过程可表述为:
$$
F_{p}=F_{i}\oplus F_{[-1,-1,0]}\oplus F_{[1,1,0]}\oplus F_{[1,-1,0]}\oplus F_{[-1,1,0]},
$$
$$
F_{p}=F_{i}\oplus F_{[-1,-1,0]}\oplus F_{[1,1,0]}\oplus F_{[1,-1,0]}\oplus F_{[-1,1,0]},
$$
$$
F_{p}^{'}=\mathrm{Block}(F_{p}),
$$
$$
F_{p}^{'}=\mathrm{Block}(F_{p}),
$$
where $F_{[x,y,z]}$ denotes the initialized voxel features with diffused offsets of $\mathbf{X}$ , y, and $\mathbf{Z}$ along the X-axis, $\mathrm{Y}$ -axis, and $\mathrm{\bfZ}$ -axis. The $\bigoplus$ and Block denote the concatenation and LION block respectively.
其中 $F_{[x,y,z]}$ 表示沿X轴、Y轴和Z轴扩散偏移量 $\mathbf{X}$、y和 $\mathbf{Z}$ 初始化的体素特征,$\bigoplus$ 和 Block 分别表示拼接操作和 LION 模块。
4 Experiments
4 实验
4.1 Datasets and Evaluation Metrics
4.1 数据集与评估指标
Waymo Open Dataset. Waymo Open dataset (WOD) [49] is a well-known benchmark for large-scale outdoor 3D perception, comprising 1150 scenes which are divided into 798 scenes for training, 202 scenes for validation, and 150 scenes for testing. Each scene includes about 200 frames, covering a perception range of $150m\times150m$ . For evaluation metrics, WOD employs 3D mean Average Precision (mAP) and mAP weighted by heading accuracy (mAPH), each divided into two difficulty levels: L1 is for objects detected with more than five points and L2 is for those at least one point.
Waymo Open数据集。Waymo Open数据集 (WOD) [49] 是大规模户外3D感知领域的知名基准,包含1150个场景,划分为798个训练场景、202个验证场景和150个测试场景。每个场景包含约200帧数据,感知范围覆盖 $150m\times150m$ 。评估指标采用3D平均精度均值 (mAP) 和航向精度加权mAP (mAPH),各分为两个难度等级:L1对应检测到5个以上点云的目标,L2对应至少检测到1个点云的目标。
nuScenes Dataset. nuScenes [4] is a popular outdoor 3D perception benchmark with a perception range of up to 50 meters. Each frame in the scene is annotated with 2Hz. The dataset includes 1000 scenes, which is divided into 750 scenes for training, 150 scenes for validation, and 150 scenes for testing. nuScenes adopts mean Average Precision (mAP) and the NuScenes Detection Score (NDS) as evaluation metrics.
nuScenes数据集。nuScenes [4] 是一个流行的户外3D感知基准测试,感知范围可达50米。场景中的每一帧以2Hz频率进行标注。该数据集包含1000个场景,分为750个训练场景、150个验证场景和150个测试场景。nuScenes采用平均精度均值 (mAP) 和NuScenes检测分数 (NDS) 作为评估指标。
Argoverse V2 Dataset. Argoverse V2 [59] is a popular outdoor 3D perception benchmark with a long-range perception of up to 200 meters. It contains 1000 sequences in total, 700 for training, 150 for validation, and 150 for testing. Each frame in the scene is annotated with $10\mathrm{Hz}$ . For the evaluation metric, Argoverse v2 adopts a similar mean Average Precision (mAP) metric with nuScenes [4].
Argoverse V2数据集。Argoverse V2 [59] 是一个流行的户外3D感知基准,感知范围可达200米。它总共包含1000个序列,其中700个用于训练,150个用于验证,150个用于测试。场景中的每一帧都以 $10\mathrm{Hz}$ 的频率进行标注。在评估指标方面,Argoverse V2采用了与nuScenes [4] 类似的平均精度均值 (mAP) 指标。
ONCE Dataset. ONCE [34] is another representative autonomous driving dataset, which consists of 5000, 3000, and 8000 frames for training, validation, and testing set, respectively. Each frame is annotated with 5 classes (Car, Bus, Truck, Pedestrian, and Cyclist). Besides, ONCE merges the car, bus, and truck class into a super-class called vehicle following WOD [49]. For the detection metric, ONCE extends [19] by taking the object orientations into special consideration and evaluating the final performance by mAP for three classes.
ONCE数据集。ONCE [34] 是另一个具有代表性的自动驾驶数据集,分别包含5000、3000和8000帧用于训练、验证和测试集。每帧标注了5个类别(汽车(Car)、巴士(Bus)、卡车(Truck)、行人(Pedestrian)和骑行者(Cyclist))。此外,ONCE遵循WOD [49] 的做法,将汽车、巴士和卡车类别合并为一个称为车辆(vehicle)的超类。在检测指标方面,ONCE扩展了[19]的方法,特别考虑物体朝向,并通过三类别的mAP评估最终性能。
4.2 Implementation Details
4.2 实现细节
Network Architecture. In our LION, we provide three representative linear RNN operators (i.e., Mamba [22], RWKV [37], and RetNet [52]). Each of operator adopts a bi-directional structure to better capture 3D geometric information inspired by [21]. On WOD, we keep the same channel dimension $C=64$ for all LION blocks in LION-Mamba, LION-RWKV, and LION-RetNet. For the large version of LION-Mamba-L, we set $C=128$ . We follow DSVT-Voxel [57] to set the grid size as $(0.32\mathrm{m},0.32\mathrm{m},0.1875\mathrm{m})$ . The number of LION blocks $N$ is set to 4. For these four LION blocks, the window sizes $(T_{x},T_{y},T_{z})$ are set to (13, 13, 32), (13, 13, 16), (13, 13, 8), and (13, 13, 4), and the corresponding group sizes $K$ are 4096, 2048, 1024, 512, respectively. Besides, we adopt the same center-based detection head and loss function as DSVT [57] for fair comparison. In the voxel generation, we set the ratio $r=0.2$ to balance the performance and computation cost. For the nuScenes dataset, we replace DSVT [57] 3D backbone with our LION 3D backbone except for changing the grid size to $(0.32m,0.32m,0.15m)$ . For the Argoverse V2 dataset, we replace the 3D backbones of VoxelNext [9] or SAFDNet [67] with our LION 3D backbone except for setting the grid size to $(0.4m,0.4m,0.25m)$ . Moreover, it is noted that we only add three extra LION layers to further enhance the 3D backbone features, rather than applying the BEV backbone to obtain the dense BEV features. For the ONCE dataset, we replace SECOND [60] 3D backbone with our LION 3D backbone except for adopting the grid size as $(0.4m,0.4m,0.25m)$ .
网络架构。在我们的LION中,我们提供了三种代表性的线性RNN算子(即Mamba [22]、RWKV [37]和RetNet [52])。每个算子都采用双向结构,以更好地捕捉3D几何信息,灵感来源于[21]。在WOD上,我们为LION-Mamba、LION-RWKV和LION-RetNet中的所有LION块保持相同的通道维度$C=64$。对于大型版本的LION-Mamba-L,我们设置$C=128$。我们遵循DSVT-Voxel [57]将网格大小设置为$(0.32\mathrm{m},0.32\mathrm{m},0.1875\mathrm{m})$。LION块的数量$N$设置为4。对于这四个LION块,窗口大小$(T_{x},T_{y},T_{z})$分别设置为(13, 13, 32)、(13, 13, 16)、(13, 13, 8)和(13, 13, 4),对应的组大小$K$分别为4096、2048、1024和512。此外,为了公平比较,我们采用与DSVT [57]相同的基于中心的检测头和损失函数。在体素生成中,我们设置比率$r=0.2$以平衡性能和计算成本。对于nuScenes数据集,我们将DSVT [57]的3D主干替换为我们的LION 3D主干,仅将网格大小改为$(0.32m,0.32m,0.15m)$。对于Argoverse V2数据集,我们将VoxelNext [9]或SAFDNet [67]的3D主干替换为我们的LION 3D主干,仅将网格大小设置为$(0.4m,0.4m,0.25m)$。此外,需要注意的是,我们仅添加了三个额外的LION层以进一步增强3D主干特征,而不是应用BEV主干来获取密集的BEV特征。对于ONCE数据集,我们将SECOND [60]的3D主干替换为我们的LION 3D主干,仅将网格大小设置为$(0.4m,0.4m,0.25m)$。
Training Process. On the WOD, we adopt the same point cloud range, data augmentations, learning rate, and optimizer as the previous method [57]. We train our model 24 epochs with a batch size of 16 on 8 NVIDIA Tesla V100 GPUs. Besides, we utilize the fade strategy [55] to achieve better performance in the last epoch. For the nuScenes dataset, we adopt the same point cloud range, data augmentations, and optimizer as previous method [2]. Moreover, we find that LION converges faster than previous methods on nuScenes dataset. Therefore, we only train our model for 36 epochs without CBGS [73]. The learning rate and batch size are set to 0.003 and 16, respectively. It is worth noting that the CBGS strategy extends training iterations about 4.5 times, which means that our training iterations are much fewer than previous methods [2] (i.e., 20 epochs with CBGS). For the Argoverse V2 dataset and the ONCE dataset, we adopt the same training process with SAFDNet [67] and SECOND [60], respectively.
训练过程。在WOD数据集上,我们采用与先前方法[57]相同的点云范围、数据增强策略、学习率和优化器。使用8块NVIDIA Tesla V100 GPU以16的批次大小训练24个周期,并采用fade策略[55]在最终周期实现更优性能。对于nuScenes数据集,我们沿用先前方法[2]的点云范围、数据增强和优化器设置。实验发现LION在该数据集上收敛速度优于先前方法,因此仅训练36个周期且未使用CBGS[73]策略,学习率和批次大小分别设为0.003和16。值得注意的是,CBGS策略会使训练迭代次数增加约4.5倍,这意味着我们的训练迭代量远少于采用CBGS的先前方法[2](即20个周期)。针对Argoverse V2和ONCE数据集,我们分别采用与SAFDNet[67]和SECOND[60]相同的训练流程。
4.3 Main Results
4.3 主要结果
In this section, we provide a board comparison of our LION with existing methods on WOD, nuScenes, Argoverse V2 and ONCE datasets for 3D object detection. Furthermore, in the section A.1 of our appendix, we present more types of linear RNN operators (e.g., RetNet, RWKV, Mamba, xLSTM, and TTT) based on our LION framework for 3D detection on a small but popular dataset KITTI [20] for a quick experience.
在本节中,我们针对3D目标检测任务,在WOD、nuScenes、Argoverse V2和ONCE数据集上对LION与现有方法进行了全面对比。此外,在附录A.1章节中,我们基于LION框架展示了更多类型的线性RNN算子(如RetNet、RWKV、Mamba、xLSTM和TTT),并在小型但广受欢迎的KITTI数据集[20]上进行了3D检测的快速验证。
Results on WOD. To illustrate the superiority of our LION, we provide the comparison with existing representative methods on the WOD in Table 1. Here, we also conduct the experiments on our LION with different linear group RNN operators, including LION-Mamba, LION-RWKV and LION-RetNet.
WOD上的结果。为了展示我们LION的优越性,我们在表1中提供了与WOD上现有代表性方法的对比。此外,我们还对不同线性组RNN算子(包括LION-Mamba、LION-RWKV和LION-RetNet)的LION进行了实验。
Table 1: Performances on the Waymo Open Dataset validation set (train with $100%$ training data). $\ddagger$ denotes the two-stage method. Bold denotes the best performance of all methods. “-L" means we double the dimension of channels in LION 3D backbone. RNN denotes the linear RNN operator. All results are presented with single-frame input, no test-time augmentation, and no model ensembling.
表 1: Waymo Open Dataset 验证集上的性能 (使用 $100%$ 训练数据)。 $\ddagger$ 表示两阶段方法。粗体表示所有方法中的最佳性能。"-L"表示我们将 LION 3D 骨干网络的通道维度加倍。RNN 表示线性 RNN 算子。所有结果均为单帧输入,无测试时增强,无模型集成。
| 方法 | 发表会议 | 算子 | Vehicle3DAP/APH L1 | Vehicle3DAP/APH L2 | Pedestrian3DAP/APH L1 | Pedestrian3DAP/APH L2 | Cyclist3DAP/APH L1 | Cyclist3DAP/APH L2 | mAP/mAPH L2 |
|---|---|---|---|---|---|---|---|---|---|
| SECOND[60] | Sensors 18 CVPR 19 CVPR21 | Conv | 72.3/71.7 | 63.9/63.3 | 68.7/58.2 | 60.7/51.3 | 60.6/59.3 | 58.3/57.0 | 61.0/57.2 |
| PointPillars [26] | - | Conv | 72.1/71.5 74.2/73.6 | 63.6/63.1 66.2/65.7 | 70.6/56.7 76.6/70.5 | 62.8/50.3 68.8/63.2 | 64.4/62.3 72.3/71.1 | 61.9/59.9 69.7/68.5 | 62.8/57.8 |
| CenterPoint[66] PV-RCNN[45] | - | Conv | 78.0/77.5 | - | 79.2/73.0 | 70.4/64.7 | 71.5/70.3 | - | 68.2/65.8 69.6/67.2 |
| PillarNet-34 [44] | CVPR 20 ECCV22 | Conv | 79.1/78.6 | 69.4/69.0 70.9/70.5 | 80.6/74.0 | 72.3/66.2 | 72.3/71.2 | 69.0/67.8 69.7/68.7 | 71.0/68.5 |
| FSD# [17] | NeurIPS 22 | Conv | 79.2/78.8 | 70.5/70.1 | 82.6/77.3 | 73.9/69.1 | 77.1/76.0 | 74.4/73.3 | 72.9/70.8 |
| AFDetV2[25] | AAAI 22 | Conv | 77.6/77.1 | 69.7/69.2 | 80.2/74.6 | 72.2/67.0 | 73.7/72.7 | 71.0/70.1 | - |
| PillarNeXt [27] | CVPR 23 | Conv | 78.4/77.9 | 70.3/69.8 | 82.5/77.1 | 74.9/69.8 | 73.2/72.2 | 70.6/69.6 | 71.0/68.8 71.9/69.7 |
| VoxelNext[9] | CVPR 23 | Conv | 78.2/77.7 | 69.9/69.4 | 81.5/76.3 | 73.5/68.6 | 76.1/74.9 | 73.3/72.2 | 72.2/70.1 |
| CenterFormer[72] | ECCV22 | Conv | 75.0/74.4 | 69.9/69.4 | 78.6/73.0 | 73.6/68.3 | 72.3/71.3 | 69.8/68.8 | 71.1/68.9 |
| PV-RCNN++[46] | IJCV22 | - | 79.3/78.8 | 70.6/70.2 | 81.3/76.3 | 73.2/68.0 | 73.7/72.7 | 71.2/70.2 | 71.7/69.5 |
| TransFusion [2] | CVPR22 | - | -/- | /65.1 | -/- | /63.7 | /- | /65.9 | /64.9 |
| ConQueR[74] | CVPR 23 | - | 76.1/75.6 | 68.7/68.2 | 79.0/72.3 | 70.9/64.7 | 73.9/72.5 | 71.4/70.1 | 70.3/67.7 |
| FocalFormer3D [7] | ICCV23 | -/- 81.1/80.6 | - | 68.1/67.6 | -/- | 72.7/66.8 | -/- | 73.7/72.6 | 71.5/69.0 |
| HEDNet [68] | NeurIPS 23 | - | - | 73.2/72.7 | 84.4/80.0 | 76.8/72.6 | 78.7/77.7 | 75.8/74.9 | 75.3/73.4 |
| SST_TS#[15] | CVPR22 | - | 76.2/75.8 | 68.0/67.6 | 81.4/74.0 | 72.8/65.9 | - | - | - |
| SWFormer[50] | ECCV22 | Transformer | 77.8/77.3 | 69.2/68.8 | 80.9/72.7 | 72.5/64.9 | - | -/- | /- -/- |
| OcTr [70] | CVPR 23 | - | 78.1/77.6 | 69.8/69.3 | 80.8/74.4 | 72.5/66.5 | - | 72.6/71.5 | 69.9/68.9 |
| DSVT-Pillar [57] | CVPR 23 | - | 79.3/78.8 | 70.9/70.5 | 82.8/77.0 | 75.2/69.8 | - | 76.4/75.4 | 73.6/72.7 |
| DSVT-Voxel [57] | CVPR 23 | - | 79.7/79.3 | 71.4/71.0 | 83.7/78.9 | 76.1/71.5 | - | 77.5/76.5 | 74.6/73.7 |
| LION-RetNet (Ours) | - | - | 79.0/78.5 | 70.6/70.2 | 84.6/80.0 | - | 77.2/72.8 | 79.0/78.0 | 76.1/75.1 |
| LION-RWKV (Ours) | - | RNN | - | - | - | 84.6/80.0 | 77.1/72.7 | 78.7/77.7 | 75.8/74.8 |
| LION-Mamba (Ours) | - | - | 79.7/79.3 | 71.3/71.0 | 84.9/80.4 | - | 77.5/73.2 | 79.7/78.7 | 76.7/75.8 |
| LION-Mamba-L (Ours) | - | - | 79.5/79.1 80.3/79.9 | 71.1/70.7 72.0/71.6 | 85.8/81.4 | - | 78.5/74.3 | 80.1/79.0 | 77.2/76.2 |
Table 2: Performances on the nuScenes validation and test set. ‘T.L.’, ‘C.V.’, ‘Ped.’, ‘M.T.’, ‘T.C.’, and ’B.R.’ are short for trailer, construction vehicle, pedestrian, motor, traffic cone, and barrier, respectively. All results are reported without any test-time augmentation and model ensembling.
表 2: nuScenes 验证集和测试集上的性能表现。'T.L.'、'C.V.'、'Ped.'、'M.T.'、'T.C.' 和 'B.R.' 分别是 trailer (挂车)、construction vehicle (工程车)、pedestrian (行人)、motor (摩托车)、traffic cone (交通锥) 和 barrier (护栏) 的缩写。所有结果均未使用测试时数据增强和模型集成。
| 方法 | 发表会议 | NDS | mAP | Car | Truck | Bus | T.L. | C.V. | Ped. | M.T. | Bike | T.C. B.R. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CenterPoint[66] | CVPR 21 | 66.5 | 59.2 | 84.9 | 57.4 | 70.7 | 38.1 | 16.9 | 85.1 59.0 | 42.0 | 69.8 | 68.3 |
| VoxelNeXt[9] | CVPR23 | 66.7 | 60.5 | 83.9 | 55.5 | 70.5 38.1 | 21.1 | 84.6 | 62.8 | 50.0 | 69.4 | 69.4 |
| Uni3DETR[58] | NeurIPS 23 | 68.5 | 61.7 | — | — | — | — | — | — | — | — | — |
| TransFusion-LiDAR[2] | CVPR22 | 70.1 | 65.5 | 86.9 | 60.8 | 73.1 43.4 | 25.2 | 87.5 | 72.9 | 57.3 | 77.2 | 70.3 |
| DSVT [57] | CVPR23 | 71.1 | 66.4 | 87.4 | 62.6 | 75.9 42.1 | 25.3 | 88.2 | 74.8 | 58.7 | 77.9 | 71.0 |
| HEDNet[68] | NeurIPS 23 | 71.4 | 66.7 | 87.7 | 60.6 | 77.8 | 50.7 28.9 | 87.1 | 74.3 | 56.8 | 76.3 | 66.9 |
| LION-RetNet (Ours) | — | 71.9 | 67.3 | 87.9 | 64.3 | 78.7 | 44.6 27.6 | 88.9 | 73.5 | 56.6 | 79.2 | 72.1 |
| LION-RWKV (Ours) | — | 71.7 | 66.8 | 88.1 | 59.0 | 77.6 46.6 | 28.0 | 89.7 | 74.3 | 56.2 | 80.1 | 68.3 |
| LION-Mamba (Ours) | — | 72.1 | 68.0 | 87.9 | 64.9 | 77.6 44.4 | 28.5 | 89.6 | 75.6 | 59.4 | 80.8 | 71.6 |
| 方法 | 发表会议 | NDS | mAP | Car | Truck | Bus | T.L. | C.V. | Ped. | M.T. | Bike | T.C. B.R. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TransFusion-LiDAR[2] | CVPR22 | 70.2 | 65.5 | 86.2 | 56.7 | 66.3 58.8 | 28.2 | 86.1 | 68.3 | 44.2 | 82.0 | 78.2 |
| DSVT [57] | CVPR23 | 72.7 | 68.4 | 86.8 | 58.4 | 67.3 63.1 | 37.1 | 88.0 | 73.0 | 47.2 | 84.9 | 78.4 |
| HEDNet [68] | NeurIPS 23 | 72.0 | 67.7 | 87.1 | 56.5 | 70.4 | 63.5 33.6 | 87.9 | 70.4 | 44.8 | 85.1 | 78.1 |
| LION-Mamba (Ours) | — | 73.9 | 69.8 | 87.2 | 61.1 | 68.9 | 65.0 | 36.3 90.0 | 74.0 | 49.2 | 87.3 | 79.5 |
Compared with the transformer-based methods [15, 50, 57], our LION with different linear group RNN operators outperforms the previous state-of-the-art (SOTA) transformer-based 3D backbone DSVT-Voxel [57], illustrating the generalization of our proposed framework. To further scale up our LION, we present the performance of LION-Mamba-L by doubling the channel dimension of LION-Mamba. It can be observed that LION-Mamba-L significantly outperforms DSVT-Voxel with 1.9 mAPH/L2, leading to a new SOTA performance. The above promising results effectively demonstrate the superiority of our proposed LION.
与基于Transformer的方法[15, 50, 57]相比,我们采用不同线性组RNN算子的LION超越了此前最先进的(SOTA)基于Transformer的3D骨干网络DSVT-Voxel[57],这证明了我们提出框架的泛化能力。为了进一步扩展LION规模,我们通过将LION-Mamba的通道维度加倍展示了LION-Mamba-L的性能。可以观察到,LION-Mamba-L以1.9 mAPH/L2的显著优势超越DSVT-Voxel,创造了新的SOTA性能。上述优异结果有效证明了我们提出的LION的优越性。
Results on nuScenes. We also evaluate our LION on nuScenes validation and test set [4] further to verify the effectiveness of our LION. As shown in Table 2, on nuScenes validation set, our LION-RetNet, LION-RWKV, and LION-Mamba achieves 71.9, 71.7, and 72.1 NDS, respectively, which outperforms the previous advanced methods DSVT [57] and HEDNet [68]. Besides, our LION-Mamba even brings a new SOTA on nuScenes test benchmark, which beats the previous advanced method DSVT with 1.2 NDS and $1.4\mathrm{mAP},$ effectively illustrating the superiority of our LION. Note that all results of our LION are conducted without any test-time augmentation and model ensembling.
nuScenes上的结果。我们进一步在nuScenes验证集和测试集[4]上评估LION以验证其有效性。如表2所示,在nuScenes验证集上,我们的LION-RetNet、LION-RWKV和LION-Mamba分别达到71.9、71.7和72.1 NDS,优于此前先进方法DSVT[57]和HEDNet[68]。此外,LION-Mamba在nuScenes测试基准上创造了新SOTA,以1.2 NDS和$1.4\mathrm{mAP}$的优势超越先前先进方法DSVT,有效证明了LION的优越性。需注意,所有LION结果均未使用测试时数据增强和模型集成技术。
Table 3: Comparison with prior methods on Argoverse V2 validation set. ‘Vehicle’, ‘C-Barrel’, ‘MPC-Sign’, ‘A-Bus’, ‘C-Cone’, ‘V-Trailer’, ‘MBT’, ‘W-Device’ and ‘W-Rider’ are short for regular vehicle, construction barrel, mobile pedestrian crossing sign, articulated bus, construction cone, vehicular trailer, message board trailer, wheeled device, and wheeled rider.
表 3: Argoverse V2 验证集上与现有方法的对比。其中 'Vehicle'、'C-Barrel'、'MPC-Sign'、'A-Bus'、'C-Cone'、'V-Trailer'、'MBT'、'W-Device' 和 'W-Rider' 分别是普通车辆、施工桶、移动人行横道标志、铰接式公交车、施工锥、车辆拖车、信息板拖车、轮式设备和轮式骑手的缩写。
| Method | mAP | Pedest | do1s | Truck XO | Bollard B | Motorcyclist | MP | ycle Motorcyo cle | B | School | Cab Cone Truck | V-Trailer | ehicle | Stroller | Wheelchair | Device |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CenterPoint[66] | 22.0 | 67.6 38.9 | 46.5 | 16.9 | 37.4 | 40.1 | 32.2 | 28.6 | 27.4 | 33.4 | 24.5 | 8.7 | 25.8 | 22.6 | 29.5 | 22.4 |
| HEDNet [68] | 37.1 | 78.2 47.7 | 67.6 | 46.4 | 45.9 | 56.9 | 67.0 | 48.7 | 46.5 | 58.2 | 47.5 | 23.3 | 40.9 | 27.5 | 46.8 | 27.9 |
| VoxelNeXt[9] | 30.7 28.2 | 72.7 38.8 68.1 40.9 | 63.2 59.0 | 40.2 29.0 | 40.1 38.5 | 53.9 41.8 | 64.9 42.6 | 44.7 39.7 | 39.4 26.2 | 42.4 49.0 | 40.6 38.6 | 20.1 20.4 | 25.2 30.5 | 19.9 14.8 | 44.9 41.2 | 20.9 26.9 |
| FSDv1 [17] FSDv2 [18] | 37.6 | 77.0 47.6 | 70.5 | 43.6 | 41.5 | 53.9 | 58.5 | 56.8 | 39.0 | 60.7 | 49.4 | 28.4 | 41.9 | 30.2 | 44.9 | 33.4 |
| SAFDNet[67] | 39.7 | 78.5 49.4 | 70.7 | 51.5 | 44.7 | 65.7 | 72.3 | 54.3 | 49.7 | 60.8 | 50.0 | 31.3 | 44.9 | 24.7 | 55.4 | 31.4 |
| LION-RetNet | 40.7 | 74.7 41.0 | 72.7 | 47.5 | 44.2 | 66.9 | 77.0 | 57.1 | 48.3 | 63.7 | 55.1 | 27.0 | 42.5 | 25.2 | 57.9 | 29.7 |
| LION-RWKV | 41.1 | 76.3 44.6 | 74.0 | 52.1 | 46.0 | 68.1 | 75.8 | 55.8 | 49.4 | 62.8 | 55.3 | 27.1 | 42.9 | 25.9 | 60.1 | 30.9 |
| LION-Mamba | 41.5 | 75.1 43.6 | 73.9 | 53.9 | 45.1 | 66.4 | 74.7 | 61.3 | 48.7 | 65.1 | 56.2 | 21.7 | 42.7 | 25.3 | 58.4 | 28.9 |
Table 4: Comparison with previous methods on ONCE validation set. We use the center head of Center Point for a fair comparison.
表 4: ONCE验证集上与先前方法的对比。为公平比较,我们使用Center Point的中心头。
| 方法 | 车辆整体 | 0-30m | 30-50m | 50m-inf | 行人整体 | 0-30m | 30-50m | 50m-inf | 骑行者整体 | 0-30m | 30-50m | 50m-inf | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointRCNN[47] | 52.1 | 74.5 | 40.9 | 16.8 | 4.3 | 6.2 | 2.4 | 0.9 | 29.8 | 46.0 | 20.9 | 5.5 | 28.7 |
| PointPillars[26] | 68.6 | 80.9 | 62.1 | 47.0 | 17.6 | 19.7 | 15.2 | 10.2 | 46.8 | 58.3 | 40.3 | 25.9 | 44.3 |
| SECOND[60] | 71.2 | 84.0 | 63.0 | 47.3 | 26.4 | 29.3 | 24.1 | 18.1 | 58.0 | 70.0 | 52.4 | 34.6 | 51.9 |
| PV-RCNN[45] | 77.8 | 89.4 | 72.6 | 58.6 | 23.5 | 25.6 | 22.8 | 17.3 | 59.4 | 71.7 | 52.6 | 36.2 | 53.6 |
| CenterPoint[66] | 66.8 | 80.1 | 59.6 | 43.4 | 49.9 | 56.2 | 42.6 | 26.3 | 63.5 | 74.3 | 57.9 | 41.5 | 60.1 |
| PointPainting[54] | 66.2 | 80.3 | 59.8 | 42.3 | 44.8 | 52.6 | 36.6 | 22.5 | 62.3 | 73.6 | 57.2 | 40.4 | 57.8 |
| LION-RetNet | 78.1 | 88.7 | 72.4 | 58.5 | 52.4 | 60.5 | 43.6 | 26.3 | 68.3 | 79.4 | 62.9 | 46.1 | 66.3 |
| LION-RWKV | 78.3 | 89.2 | 72.6 | 56.7 | 50.6 | 60.0 | 40.4 | 24.2 | 68.4 | 79.4 | 63.2 | 45.7 | 65.8 |
| LION-Mamba | 78.2 | 89.1 | 72.6 | 57.5 | 53.2 | 62.4 | 44.0 | 24.5 | 68.5 | 79.2 | 63.2 | 47.1 | 66.6 |
Table 5: Ablation study for each component in LION. Here, the large group size means that we set it as (4096, 2048, 1024, 512) for four blocks (also refer to the section of our implementation details), otherwise, we set a small group size as (256, 256, 256, 256).
表 5: LION 中各组件的消融研究。此处,大组大小意味着我们为四个块设置为 (4096, 2048, 1024, 512) (也可参考实现细节部分),否则,我们设置为小组大小 (256, 256, 256, 256)。
| Large GroupSize | 3DSpatialFeatureDescriptor | VoxelGeneration | Vehicle | Pedestrian | Cyclist | mAP/mAPH (L2) |
|---|---|---|---|---|---|---|
| 65.6/65.2 | 72.3/65.0 | 68.3/67.2 | 68.8/65.8 | |||
| √ | 一 | 一 | 66.2/65.7 | 73.7/67.2 | 68.7/67.6 | 69.5/66.9 |
| √ | 一 | 66.5/66.1 | 74.8/69.6 | 70.9/70.0 | 70.8/68.6 | |
| 一 | √ | 66.4/66.0 | 73.5/67.4 | 70.4/69.3 | 70.1/67.6 | |
| √ | √ | 67.0/66.6 | 75.4/70.2 | 71.9/71.0 | 71.4/69.3 |
Results on Argoverse V2. To further verify the effectiveness of our LION on the long-range perception, we evaluate the experiments on Argoverse V2 validation set. For a fair comparison, we adopt the same detection head [66] with VoxelNext [9] and SAFDNet [67] for long-range perception. As shown in Table 3, our LION-RetNet, LION-RWKV, and LION-Mamba achieve the detection performance with $40.7\mathrm{mAP}{\mathrm{mA}}$ $41.1~\mathrm{mAP}$ and $41.5~\mathrm{mAP}_{}$ all three of which have outperformed the previous SOTA method SAFDNet [67], leading to new SOTA results. These superior results clearly illustrate the effectiveness of our LION.
Argoverse V2 上的结果。为了进一步验证我们的 LION 在远距离感知上的有效性,我们在 Argoverse V2 验证集上进行了实验评估。为了公平比较,我们采用了与 VoxelNext [9] 和 SAFDNet [67] 相同的检测头 [66] 进行远距离感知。如表 3 所示,我们的 LION-RetNet、LION-RWKV 和 LION-Mamba 分别实现了 $40.7\mathrm{mAP}{\mathrm{mA}}$、$41.1~\mathrm{mAP}$ 和 $41.5~\mathrm{mAP}_{}$ 的检测性能,三者均超越了之前的 SOTA 方法 SAFDNet [67],创造了新的 SOTA 结果。这些优异结果清晰地证明了我们 LION 的有效性。
Results on ONCE. We also evaluated our LION on ONCE validation set to further verify the effectiveness of our LION. As shown in Table 4, our LION-RetNet, LION-RWKV, and LION-Mamba produces advanced detection performance with 66.3 mAP, $65.8\mathrm{mAP}.$ , and $66.6\mathrm{mAP},$ respectively. It is worth mentioning that our LION-Mamba outperforms the previous SOTA method Center Point [66] with $6.5~\mathrm{mAP}_{\mathrm{ i c~}}$ , leading to a new SOTA result. These experiments illustrate the superiority of our LION.
ONCE数据集上的结果。我们还在ONCE验证集上评估了LION,以进一步验证其有效性。如表4所示,我们的LION-RetNet、LION-RWKV和LION-Mamba分别取得了66.3 mAP、$65.8\mathrm{mAP}$和$66.6\mathrm{mAP}$的先进检测性能。值得注意的是,LION-Mamba以$6.5~\mathrm{mAP}_{\mathrm{ i c~}}$的优势超越了之前的SOTA方法Center Point [66],创造了新的SOTA记录。这些实验证明了LION的优越性。
4.4 Ablation Study
4.4 消融实验
In this section, we conduct ablation studies of LION on the WOD validation set with $20%$ training data. If not specified, we adopt LION-Mamba as our default model and train our model with 12 epochs in the following ablation studies. For more experiments, please refer to our appendix.
在本节中,我们在WOD验证集上使用20%的训练数据对LION进行消融研究。若无特殊说明,后续消融实验默认采用LION-Mamba模型,训练周期为12轮。更多实验请参阅附录。
Ablation Study of LION. To illustrate the effectiveness of our proposed LION, we conduct the ablation study for each component, including the design of large group size, 3D spatial feature descriptor, and voxel generation in Table 5. Here, our baseline is proposed LION that removes the design of large group size, 3D spatial feature descriptor, and voxel generation. In Table 5, we observe that the design of large group size even brings 1.1 mAPH/L2 performance improvement, which illustrates the benefits of performing long-range feature interaction with the help of linear RNN. Then, we integrate the 3D spatial feature descriptor, which further produces an obvious performance improvement with 1.7 mAPH/L2. This demonstrates the superiority of the 3D spatial feature descriptor in compensating for the lack of capturing spatial information of linear RNNs. Furthermore, we notice that the 3D spatial feature descriptor is very helpful to small objects (e.g., Pedestrians) thanks to its capability of extracting the local information of 3D objects. To address the challenge of feature representation in highly sparse point clouds, we adopt voxel generation to enhance the features of foregrounds, which brings a promising gain of 0.7 mAPH/L2 (67.6 vs. 66.9). By combining all components, our LION achieves a superior performance of 69.3 mAPH/L2, which outperforms the baseline of 3.5 mAPH/L2.
LION的消融研究。为了说明我们提出的LION的有效性,我们对每个组件进行了消融研究,包括大组大小设计、3D空间特征描述符和体素生成,如表5所示。这里的基线是移除了大组大小设计、3D空间特征描述符和体素生成的LION。在表5中,我们观察到,大组大小设计甚至带来了1.1 mAPH/L2的性能提升,这说明了借助线性RNN进行长距离特征交互的好处。然后,我们集成了3D空间特征描述符,进一步带来了1.7 mAPH/L2的明显性能提升。这证明了3D空间特征描述符在弥补线性RNN捕获空间信息不足方面的优越性。此外,我们注意到,3D空间特征描述符由于能够提取3D物体的局部信息,对小物体(如行人)非常有帮助。为了解决高度稀疏点云中特征表示的挑战,我们采用体素生成来增强前景特征,这带来了0.7 mAPH/L2的显著增益(67.6 vs. 66.9)。通过结合所有组件,我们的LION实现了69.3 mAPH/L2的卓越性能,优于基线的3.5 mAPH/L2。
Table 6: Ablation study for 3D Spatial Feature Descriptor (3D SFD) in LION.
表 6: LION 中 3D 空间特征描述符 (3D SFD) 的消融研究
| 方法 | 车辆 | 行人 | 骑行者 | 平均 AP/APH (L2) |
|---|---|---|---|---|
| Baseline | 66.4/66.0 | 73.5/67.4 | 70.4/69.3 | 70.1/67.6 |
| MLP | 66.6/66.2 | 74.1/68.1 | 70.0/69.0 | 70.2/67.7 |
| Linear Group RNN | 66.4/66.0 | 74.0/68.2 | 70.5/69.5 | 70.3/67.9 |
| 3D SFD (Ours) | 67.0/66.6 | 75.4/70.2 | 71.9/71.0 | 71.4/69.3 |
Table 7: Ablation study for voxel generation in LION. “Baseline” indicates no voxel generation. “Zero Feats” and “K-NN Feats” indicate initializing features to all zeros and K-NN features, respectively. “Auto-Regressive” uses the LION block based on linear group RNN for its auto-regressive property. “Sparse-Conv” maintains the same structure as the LION block but replaces the linear group RNN with 3D sub-manifold convolution.
表 7: LION中体素生成的消融研究。"Baseline"表示不生成体素。"Zero Feats"和"K-NN Feats"分别表示将特征初始化为全零和K-NN特征。"Auto-Regressive"使用基于线性组RNN的LION块以实现自回归特性。"Sparse-Conv"保持与LION块相同的结构,但将线性组RNN替换为3D子流形卷积。
| 序号 | 方法 | 车辆 | 行人 | 骑行者 | 平均AP/APH(L2) |
|---|---|---|---|---|---|
| I | Baseline | 66.5/66.1 | 74.8/69.6 | 70.9/70.0 | 70.8/68.6 |
| II | ZeroFeats+Sparse-Conv | 64.6/64.2 | 72.8/67.4 | 69.3/68.3 | 68.9/66.6 |
| III | K-NN Feats+Auto-Regressive | 66.5/66.1 | 74.0/68.7 | 71.1/70.1 | 70.5/68.3 |
| IV | Zero Feats+Auto-Regressive (Ours) | 67.0/66.6 | 75.4/70.2 | 71.9/71.0 | 71.4/69.3 |
Superiority of 3D Spatial Feature Descriptor. To further verify the necessity of 3D spatial feature descriptor, we provide the comparison with two available manners including the MLP and linear RNN to replace our descriptor in Table 6. Here, we set our LION without 3D spatial feature descriptor as the baseline in this part. We observe that MLP even does not bring promising performance improvement in terms of mAPH/L2 since MLP lacks the ability to capture local 3D spatial information. Furthermore, considering the limited receptive field of MLP, we adopt a linear group RNN operator to replace MLP. We find that there is only slight performance improvement with 0.3 mAPH/L2, which indicates that the linear group RNN might not be good at modeling local spatial relationships although it has the strong capability to establish long-range relationships. In contrast, our 3D spatial feature descriptor brings obvious performance improvement, which boosts the baseline of 1.7 mAPH/L2. This effectively illustrates the superiority of the 3D spatial feature descriptor in compensating for the lack of local 3D spatial-aware modeling in the linear group RNN.
3D空间特征描述符的优越性。为进一步验证3D空间特征描述符的必要性,我们在表6中提供了与两种现有方法(MLP和线性RNN)的对比,这两种方法被用来替代我们的描述符。此处,我们将未使用3D空间特征描述符的LION设为本部分基线。我们观察到,由于MLP缺乏捕捉局部3D空间信息的能力,其甚至未在mAPH/L2指标上带来显著性能提升。此外,考虑到MLP有限的感受野,我们采用线性分组RNN算子替代MLP。发现性能仅微幅提升0.3 mAPH/L2,这表明线性分组RNN虽擅长建立长程关系,却可能不擅长建模局部空间关系。相比之下,我们的3D空间特征描述符带来1.7 mAPH/L2的显著性能提升,有效证明了其在弥补线性分组RNN局部3D空间感知建模不足方面的优越性。
Effectiveness of Voxel Generation. Voxel generation is applied to enhance the feature representation of objects in highly sparse point clouds for accurate 3D object detection. Therefore, to explore the effectiveness of our proposed voxel generation, we present the comparison with several available manners in Table 7. First, we compare our results of IV with II by only replacing the operator of linear group RNN in LION block with 3D sub-manifold convolution to generate the diffused features. We find that the manner of IV (69.3 vs. 66.6) significantly outperforms the performance of II in terms of mAPH/L2. This benefits from the linear group RNN’s ability to model long-range feature interactions, generating a more reliable feature representation through its auto-regressive capacity, demonstrating the superiority of voxel generation with the linear group RNN. To further illustrate that the effectiveness of voxel generation is from its auto-regressive property of LION block rather than a strong feature extractor, we initialize the diffused features of the foreground voxels by K-NN operation (III) instead of the manner of all-zeros features (IV) and then feed them to the same following LION block for voxel generation. In Table 7, we find that the manner of III is inferior to IV by 1.0 mAPH/L2. This clearly illustrates that our voxel generation is benefiting from its auto-regressive property of LION block. Finally, compared with the baseline (I), our voxel generation (IV) can obtain a promising performance improvement, which verifies its effectiveness.
体素生成的有效性。体素生成用于增强高度稀疏点云中物体的特征表示,以实现精确的3D物体检测。因此,为探究所提体素生成方法的有效性,我们在表7中对比了多种可行方案。首先,我们通过仅将LION模块中的线性组RNN算子替换为3D子流形卷积来生成扩散特征,对比方案IV与II的结果。发现IV方案(69.3 vs. 66.6)在mAPH/L2指标上显著优于II方案。这得益于线性组RNN建模长程特征交互的能力,通过其自回归特性生成更可靠的特征表示,证明了采用线性组RNN进行体素生成的优越性。为进一步说明体素生成的有效性源于LION模块的自回归特性而非强特征提取器,我们采用K近邻操作(III)替代全零特征初始化(IV)来初始化前景体素的扩散特征,再输入相同结构的LION模块进行体素生成。表7显示III方案比IV方案低1.0 mAPH/L2,这清晰表明我们的体素生成受益于LION模块的自回归特性。最终,与基线方案(I)相比,我们的体素生成方案(IV)可获得显著性能提升,验证了其有效性。
5 Conclusion
5 结论
In this paper, we have presented a simple and effective window-based framework termed LION, which can capture the long-range relationship by adopting linear RNN for large groups. Specifically, LION incorporates a proposed LION block to unlock the great potential of linear RNNs in modeling a long-range relationship and a voxel generation strategy to obtain more disc rim i native feature representation in sparse point clouds. Extensive ablation studies demonstrate the effectiveness of our proposed components. Additionally, the generalization of our LION is verified by performing different linear group RNN operators. Benefiting from our well-designed framework and the proposed superior components, our LION-Mamba achieves state-of-the-art performance on the challenging Waymo and nuScenes datasets.
本文提出了一种简单高效的基于窗口的框架LION,该框架通过在线性RNN大组中采用线性循环神经网络来捕捉长程依赖关系。具体而言,LION整合了提出的LION模块以释放线性RNN在建模长程关系方面的巨大潜力,并采用体素生成策略在稀疏点云中获得更具判别性的特征表示。大量消融实验证明了我们提出组件的有效性。此外,通过实施不同的线性组RNN算子验证了LION的泛化能力。得益于精心设计的框架和提出的卓越组件,我们的LION-Mamba在极具挑战性的Waymo和nuScenes数据集上实现了最先进的性能。
Limitations. Although our LION based on the linear group RNN can perform long-range feature interaction with linear complexity, the corresponding running speed still needs further improvement since linear RNNs are not as efficient as transformers in parallel computing.
局限性。尽管我们基于线性组RNN的LION能以线性复杂度进行长程特征交互,但由于线性RNN在并行计算中的效率不如Transformer,其运行速度仍需进一步提升。
References
参考文献
A Appendix
A 附录
The appendix is organized as follows. First, in section A.1, we provide more types of linear RNN operators (e.g., RetNet, RWKV, Mamba, xLSTM, and TTT) based on our LION framework for 3D detection on a small but popular dataset KITTI for a quick experience. Second, we present extra experiments on the WOD [49] validation set in section A.2, including the placement of the 3D spatial feature descriptor, the impact of different window sizes and different group sizes in inference, and the ratio $r$ in voxel generation. Third, we provide the comparison of computation cost and parameter size in section A.3, and detailed information of LION structure in section A.4. Forth, in section A.5, we visualize the feature maps of different LION blocks to illustrate the rationality of distinguishing foreground voxels based on feature response. Finally, we provide the comparison of qualitative results with DSVT [57] and qualitative results of LION to demonstrate the superiority of our LION in section A.6 and section A.7. Besides, we discuss the broader impacts in section A.8.
附录结构如下。首先,在A.1节中,我们基于LION框架提供了更多类型的线性RNN算子(如RetNet、RWKV、Mamba、xLSTM和TTT),在小型但流行的KITTI数据集上进行3D检测的快速体验。其次,在A.2节中展示了WOD [49]验证集上的额外实验,包括3D空间特征描述符的放置、不同窗口大小和不同组大小在推理中的影响,以及体素生成中的比例$r$。第三,在A.3节中提供了计算成本和参数大小的比较,在A.4节中详细介绍了LION结构。第四,在A.5节中,我们可视化了不同LION块的特征图,以说明基于特征响应区分前景体素的合理性。最后,在A.6节和A.7节中,我们提供了与DSVT [57]的定性结果比较以及LION的定性结果,以展示LION的优越性。此外,在A.8节中讨论了更广泛的影响。
A.1 Experiments on KITTI dataset
A.1 在KITTI数据集上的实验
Table 8: Effectiveness on the KITTI validation set for Car, Pedestrian, and Cyclist. * represents our reproduced results by keeping the same configures except for their 3D backbones for a fair comparison. Our LION supports different representative linear RNN operators (TTT, xLSTM, RetNet, RWKV, and Mamba). mAP is calculated by all categories and all difficulties with recall 11.
表 8: KITTI验证集上对汽车、行人和骑行者的检测效果。*表示我们在保持相同配置(仅替换3D主干网络)情况下复现的结果,以确保公平比较。我们的LION支持不同代表性线性RNN算子(TTT、xLSTM、RetNet、RWKV和Mamba)。mAP通过所有类别和所有难度(召回率11)计算得出。
| 方法 | 汽车Easy | 汽车Moderate | 汽车peH | 行人Easy | 行人Moderate | 行人peH | 骑行者Easy | 骑行者Moderate | 骑行者peH | mAP |
|---|---|---|---|---|---|---|---|---|---|---|
| VoxelNet [71] | 77.5 | 65.1 | 57.7 | 39.5 | 33.7 | 31.5 | 61.2 | 48.4 | 44.4 | 51.0 |
| SECOND [60] | 83.1 | 73.7 | 66.2 | 51.1 | 42.6 | 37.3 | 70.5 | 53.9 | 46.9 | 58.4 |
| PointPillars [26] | 79.1 | 75.0 | 68.3 | 52.1 | 43.5 | 41.5 | 75.8 | 59.1 | 52.9 | 60.8 |
| PointRCNN [47] | 85.9 | 75.8 | 68.3 | 49.4 | 41.8 | 38.6 | 73.9 | 59.6 | 53.6 | 60.8 |
| TANet [31] | 83.8 | 75.4 | 67.7 | 54.9 | 46.7 | 42.4 | 73.8 | 59.9 | 53.5 | 62.0 |
| DSVT-Pillar* [57] | 87.3 | 77.4 | 76.2 | 61.4 | 56.8 | 51.8 | 82.3 | 67.1 | 63.7 | 69.3 |
| DSVT-Voxel* [57] | 87.8 | 77.8 | 76.8 | 66.1 | 59.7 | 55.2 | 83.5 | 66.7 | 63.2 | 70.8 |
| LION-TTT | 87.9 | 78.0 | 76.7 | 63.4 | 58.6 | 53.7 | 84.0 | 69.6 | 64.5 | 70.7 |
| LION-xLSTM | 87.7 | 77.9 | 76.8 | 66.6 | 59.3 | 54.0 | 82.4 | 67.4 | 63.4 | 70.6 |
| LION-RetNet | 88.0 | 77.9 | 76.7 | 67.4 | 60.2 | 55.8 | 83.6 | 69.6 | 64.6 | 71.5 |
| LION-Mamba | 88.6 | 78.3 | 77.2 | 67.2 | 60.2 | 55.6 | 83.0 | 68.6 | 63.9 | 71.4 |
| LION-RWKV | 88.5 | 78.3 | 77.1 | 68.9 | 62.2 | 58.1 | 89.6 | 71.2 | 66.9 | 73.4 |
KITTI Dataset. KITTI [20] is a popular benchmark dataset for autonomous driving, which consists of 7481 training frames and 7518 test frames for 3D object detection. We follow the dataset splitting protocol in [40] and further split the 7481 training frames into 3712 frames for training set and 3769 frames for validation set. For the 3D detection task, KITTI dataset mainly detects Car, Pedestrian, and Cyclist for three difficulty levels, i.e., Easy, Moderate, and Hard. And the mean Average Precision (mAP) using 11 recall positions is adopted as the evaluation metric.
KITTI数据集。KITTI [20] 是自动驾驶领域广泛使用的基准数据集,包含7481帧训练图像和7518帧测试图像用于3D目标检测。我们遵循[40]中的数据集划分方案,将7481帧训练图像进一步划分为3712帧训练集和3769帧验证集。针对3D检测任务,该数据集主要检测车辆(Car)、行人(Pedestrian)和骑行者(Cyclist)三类目标,并按检测难度分为简单(Easy)、中等(Moderate)和困难(Hard)三个等级。评估指标采用基于11个召回率点的平均精度均值(mAP)。
Results on KITTI. We conduct experiments on the KITTI validation set to illustrate the generalization of LION for different linear RNN operators. We select some representative linear RNN operators (TTT [51], xLSTM [3], RetNet [52], Mamba [22], and RWKV [37]) for LION. We adopt the same training parameters (i.e., number of epochs, learning rate, optimizer) with SECOND [60]. Besides, we use the same BEV backbone and the detection head with SECOND [60]. For a fair comparison, we keep the same configure of DSVT [57] and all our LION methods except 3D backbones. As shown in Table 8, LION-RetNet, LION-Mamba, and LION-RWKV outperforms DSVT-Voxel by 0.7 mAP, $0.6\mathrm{mAP}.$ , and 2.6 mAP. These experiments demonstrate the generalization and effectiveness of our linear RNN-based framework LION.
KITTI实验结果。我们在KITTI验证集上进行了实验,以展示LION框架对不同线性RNN算子(TTT [51]、xLSTM [3]、RetNet [52]、Mamba [22]和RWKV [37])的泛化能力。实验采用与SECOND [60]相同的训练参数(包括训练周期、学习率和优化器),并沿用了SECOND [60]的BEV主干网络和检测头。为确保公平性,除3D主干网络外,DSVT [57]与所有LION变体均保持相同配置。如表8所示,LION-RetNet、LION-Mamba和LION-RWKV分别以0.7 mAP、$0.6\mathrm{mAP}$和2.6 mAP的优势超越DSVT-Voxel。这些实验验证了基于线性RNN的LION框架的泛化性和有效性。
A.2 Extra Experiments
A.2 额外实验
The Placement of 3D Spatial Feature Descriptor. We conduct experiments about the placement of the 3D spatial feature descriptor, as shown in Table 9. We regard the manner that does not adopt the 3D SFD of our LION as the baseline. Here, we provide two available manners: Placement 1 and Placement 2. For Placement 1, we place the 3D SFD after voxel merging. For Placement 2, we place 3D SFD before the voxel merging. Compared to the baseline, Placement 1 brings 1.0 mAPH/L2 improvement, which demonstrates the effectiveness of 3D SFD in compensating for the lack of local 3D spatial-aware modeling in linear RNNs. Moreover, Placement 2 further brings $0.7\mathrm{mAPH}/\mathrm{L}2$ improvement over Placement 1, which demonstrates the effectiveness of 3D SFD for reducing spatial information loss in the process of voxel merging.
3D空间特征描述符的放置。我们进行了关于3D空间特征描述符放置的实验,如表9所示。我们将不采用LION中3D SFD的方式作为基线。这里提供了两种可选方式:放置1和放置2。对于放置1,我们在体素合并后放置3D SFD;对于放置2,则在体素合并前放置3D SFD。与基线相比,放置1带来了1.0 mAPH/L2的性能提升,证明了3D SFD在弥补线性RNN局部3D空间感知建模不足方面的有效性。此外,放置2相比放置1进一步带来$0.7\mathrm{mAPH}/\mathrm{L}2$的提升,表明3D SFD能有效减少体素合并过程中的空间信息损失。
Table 9: The Placement of 3D Spatial Feature Descriptor.
表 9: 3D空间特征描述符的放置方式
| 方法 | 车辆 | 行人 | 骑行者 | 平均精度/mAPH (L2) |
|---|---|---|---|---|
| Baseline | 66.4/66.0 | 73.5/67.4 | 70.4/69.3 | 70.1/67.6 |
| Placement1 | 66.5/66.1 | 74.8/69.1 | 71.1/70.2 | 70.1/68.6 |
| Placement 2 (Ours) | 67.0/66.6 | 75.4/70.2 | 71.9/71.0 | 71.4/69.3 |
Table 10: The ratio $r$ in voxel gene n ration.
表 10: 体素生成比率中的 $r$ 值
| Ratio | 3D AP/APH (L2) | mAP/mAPH (L2) | ||
|---|---|---|---|---|
| Vehicle | Pedestrian | Cyclist | ||
| 0 | 66.5/66.1 | 74.8/69.6 | 70.9/70.0 | 70.8/68.6 |
| 0.2 (Ours) | 67.0/66.6 | 75.4/70.2 | 71.9/71.0 | 71.4/69.3 |
| 0.5 | 67.2/66.8 | 75.3/70.0 | 72.1/71.1 | 71.5/69.3 |
The Ratio in Voxel Generation. We conduct the ablation study for foreground selection ratio $r$ in voxel generation. As shown in Table 10, compared with baseline $(r=0)$ ), the manner of setting $r=0.2$ brings $0.7\mathrm{mAPH}/\mathrm{L}2$ performance improvement. When we set a larger ratio $r=0.5$ , the performance is improved slightly. Therefore, we set $r=0.2$ to balance the performance and computation cost.
体素生成中的比例选择。我们对体素生成中的前景选择比例 $r$ 进行了消融实验。如表 10 所示,与基线 $(r=0)$ 相比,设置 $r=0.2$ 的方式带来了 $0.7\mathrm{mAPH}/\mathrm{L}2$ 的性能提升。当设置更大比例 $r=0.5$ 时,性能仅有小幅提升。因此,我们最终选择 $r=0.2$ 以平衡性能与计算成本。
Different Window Sizes and Group Sizes in Inference. To analyze the impact of window size and group size in the inference process, we evaluate the results under the cases of different window sizes and group sizes with the same trained model of LION-Mamba (i.e., window size={(13, 13, 32), (13, 13, 16), (13, 13, 8), and $(13,13,4)}$ and group $\mathsf{s i z e}{=}{4096,2048,1024,512}$ ) on WOD $100%$ training data. As shown in Table 11, surprisingly, we find that using different window sizes or group sizes during inference still does not significantly affect performance. This indicates that LION might decrease the strong dependence on hand-crafted priors and have good extrapolation ability.
推理中不同窗口大小和分组大小的影响。为分析窗口大小和分组大小在推理过程中的影响,我们使用同一训练好的LION-Mamba模型(即窗口大小={(13,13,32)、(13,13,16)、(13,13,8)、$(13,13,4)}$,分组大小$\mathsf{size}{=}{4096,2048,1024,512}$)在WOD $100%$训练数据上评估不同配置下的结果。如表11所示,令人惊讶的是,我们发现推理时使用不同的窗口大小或分组大小仍不会显著影响性能。这表明LION可能降低了对人工设计先验的强依赖性,并具有良好的外推能力。
A.3 Comparison of Computation Cost and Parameter Size
A.3 计算成本与参数量对比
We compare different 3D backbones on the WOD validation set. As shown in Table 12, LION with RWKV [38], RetNet [52], and Mamba [22], achieve 72.8, 72.7, and 73.2 mAPH/L2, respectively. Compared with other sparse convolution and transformer-based backbones, LION achieves superior accuracy while maintaining a satisfactory computation cost and parameter size.
我们在 WOD 验证集上比较了不同的 3D 骨干网络。如表 12 所示,采用 RWKV [38]、RetNet [52] 和 Mamba [22] 的 LION 分别实现了 72.8、72.7 和 73.2 mAPH/L2。与其他基于稀疏卷积和 Transformer 的骨干网络相比,LION 在保持令人满意的计算成本和参数规模的同时,实现了更高的准确率。
Table 11: Comparison of different window and group sizes in inference on WOD validation set (train with $100%$ training data). Bold denotes the result of LION with the default settings in the main paper.
表 11: WOD验证集上不同窗口和组大小的推理对比 (使用 $100%$ 训练数据训练)。粗体表示主论文中LION默认设置的结果。
| WindowSize | GroupSize | mAP/mAPH(L2) | |
|---|---|---|---|
| [7,7,32],[7,7,16],[7,7,8],[7,7,4] | [4096,2048,1024,512] | 73.24 | |
| [13,13,32],[13,13,16],[13,13,8],[13,13,4] | [4096,2048,1024,512] | 73.24 | |
| [25,25,32],[25,25,16],[25,25,8],[25,25,4] | [4096,2048,1024,512] | 73.25 | |
| [13,13,32],[13,13,16],[13,13,8],[13,13,4] | [2048,1024,512,256] | 73.18 | |
| [13,13,32],[13,13,16],[13,13,8],[13,13,4] | [4096,2048,1024,512] | 73.24 | |
| [13,13,32],[13,13,16],[13,13,8],[13,13,4] | [8192,4096,2048,1024] | 73.02 |
Table 12: Comparison of computation cost and parameter size of different 3D backbones on the WOD validation set.
表 12: WOD验证集上不同3D主干网络的计算成本和参数量对比。
| Backbone | Operator | mAP/mAPH (L2) | FLOPs (G) | Params (M) |
|---|---|---|---|---|
| ResBackbone8× [66] | Sparse Conv | 68.2/65.8 | 48.2 | 2.7 |
| SST [15] | Transformer | 67.8/64.6 | 86.2 | 1.6 |
| FlatFormer [32] | Transformer | 69.7/67.2 | 48.3 | 1.1 |
| DSVT-Pillar[57] | Transformer | 73.2/71.0 | 88.2 | 2.7 |
| DSVT-Voxel[57] | Transformer | 74.0/72.1 | 100.8 | 2.7 |
| LION (Ours) | RWKV | 74.7/72.8 | 79.4 | 3.0 |
| LION (Ours) | RetNet | 74.6/72.7 | 51.3 | 2.0 |
| LION (Ours) | Mamba | 75.1/73.2 | 58.5 | 1.4 |
Table 13: Detailed architecture specifications on Waymo Open dataset.
表 13: Waymo Open 数据集上的详细架构规格。
| LION-RWKV | LION-RetNet | LION-Mamba | LION-Mamba-L | |
|---|---|---|---|---|
| Block | Window Shape Dim, Group Size | Window Shape Dim, Group Size | Window Shape Dim, Group Size | Window Shape Dim, Group Size |
| Block 1 | [13, 13, 32] 64, 4096 | [13, 13, 32] 64, 4096 | [13, 13, 32] 64, 4096 | [13, 13, 32] 128, 4096 |
| Block 2 | [13, 13, 16] 64, 2048 | [13, 13, 16] 64, 2048 | [13, 13, 16] 64, 2048 | [13, 13, 16] 128, 2048 |
| Block 3 | [13, 13, 8] 64, 1024 | [13, 13, 8] 64, 1024 | [13, 13, 8] 64, 1024 | [13, 13, 8] 128, 1024 |
| Block 4 | [13, 13, 4] 64, 512 | [13, 13, 4] 64, 512 | [13, 13, 4] 64, 512 | [13, 13, 4] 128, 512 |
A.4 Architecture Specifications
A.4 架构规范
As shown in Table 13, the architecture specifications of the LION models (LION-RWKV, LIONRetNet, LION-Mamba, and LION-Mamba-L) on Waymo Open dataset are detailed in terms of window shape, dimension, and group size. For LION-Mamba-L, we set the dimension to 128 to double the channel of LION.
如表 13 所示,Waymo Open 数据集上 LION 模型 (LION-RWKV、LIONRetNet、LION-Mamba 和 LION-Mamba-L) 的架构规格详细列出了窗口形状、维度和组大小。对于 LION-Mamba-L,我们将维度设置为 128,使 LION 的通道数翻倍。
A.5 Visualization for Feature Map
A.5 特征图可视化
As shown in Figure 6, we visualize feature maps of different LION blocks. We can observe that as the features pass through more blocks, the magnitude of the foreground’s feature response becomes larger, demonstrating the rationality of distinguishing foreground voxels by feature response. Besides, we find that the foreground features become more dense and more distinguished, which also demonstrates the effectiveness of the voxel generation operation.
如图 6 所示,我们可视化了不同 LION 模块的特征图。可以观察到,随着特征通过更多模块,前景特征响应的幅度变得更大,这证明了通过特征响应区分前景体素的合理性。此外,我们发现前景特征变得更加密集和显著,这也证明了体素生成操作的有效性。
A.6 Comparison of Qualitative Results with DSVT
A.6 与 DSVT 的定性结果对比
To illustrate the superiority of LION, we present the visualization of the qualitative results of DSVT [57] (a) and LION (b) on the WOD [49] validation set, as shown in Figure 7. Specifically, in the first and third columns, our LION can reduce more false positives compared with DSVT. In the second column, our LION even detects some hard objects at a distance. In the last column, our LION can achieve more accurate localization. These qualitative results demonstrate the superior performance of our LION.
为展示LION的优越性,我们在WOD [49]验证集上呈现了DSVT [57] (a) 和LION (b) 的定性结果可视化,如图7所示。具体而言,在第一和第三列中,与DSVT相比,我们的LION能减少更多误检。在第二列中,LION甚至能检测到远处的困难目标。最后一列显示,LION可实现更精准的定位。这些定性结果证明了LION的卓越性能。

Figure 6: Visualization of feature map of different blocks. We highlight the foreground annotated by red GT boxes. The color map represents the magnitude of the feature response.
图 6: 不同区块特征图的可视化。我们用红色GT标注框突出显示前景部分。颜色映射代表特征响应的强度。

Figure 7: Comparison of DSVT and LION on the WOD validation set from the BEV perspective. Blue and green boxes are the prediction and ground truth boxes. It can be seen that LION can achieve better results compared to DSVT, demonstrating the superiority of LION.
图 7: DSVT与LION在WOD验证集上从BEV视角的对比。蓝色和绿色框分别为预测框与真实框。可以看出LION相比DSVT能取得更好的效果,展现了LION的优越性。
A.7 Qualitative Results
A.7 定性结果
As shown in Figure 8, we visualize the qualitative results of LION on the WOD validation set. As shown in the first column, LION can still achieve satisfactory results even in crowded 3D scenes. However, as shown in the second and third columns, LION misses some objects at a distance with sparse point clouds. Therefore, we will further improve the performance of distant objects by fusing the image features in the future.
如图 8 所示,我们在 WOD 验证集上可视化了 LION 的定性结果。如第一列所示,即使在拥挤的 3D 场景中,LION 仍能取得令人满意的结果。然而,如第二列和第三列所示,LION 会遗漏一些点云稀疏的远处物体。因此,我们未来将通过融合图像特征来进一步提升远距离物体的检测性能。
A.8 Broader Impacts
A.8 更广泛的影响
LION achieves promising performance for 3D object detection, enhancing the safety of autonomous driving. However, LION has relatively high requirements on computing resources to achieve faster running speed, which puts forward higher requirements for the hardware of autonomous driving.
LION 在 3D 物体检测方面表现出色,提升了自动驾驶的安全性。然而,为了实现更快的运行速度,LION 对计算资源的要求相对较高,这对自动驾驶硬件提出了更高的要求。

Figure 8: Qualitative results of LION on the WOD validation set. Green and blue boxes denote ground truth and predicted bounding boxes, respectively.
图 8: LION 在 WOD 验证集上的定性结果。绿色和蓝色框分别表示真实标注框和预测边界框。
Future research could focus on optimizing LION to improve bottlenecks in running speed while maintaining high detection accuracy, making it more accessible and practical for autonomous driving.
未来研究可着重优化LION,在保持高检测精度的同时提升运行速度的瓶颈,使其更易于应用于自动驾驶并更具实用性。