SkeletonX: Data-Efficient Skeleton-based Action Recognition via Cross-sample Feature Aggregation
SkeletonX: 基于跨样本特征聚合的高效骨骼动作识别
Abstract—While current skeleton action recognition models demonstrate impressive performance on large-scale datasets, their adaptation to new application scenarios remains challenging. These challenges are particularly pronounced when facing new action categories, diverse performers, and varied skeleton layouts, leading to significant performance degeneration. Additionally, the high cost and difficulty of collecting skeleton data make large-scale data collection impractical. This paper studies one-shot and limited-scale learning settings to enable efficient adaptation with minimal data. Existing approaches often overlook the rich mutual information between labeled samples, resulting in sub-optimal performance in low-data scenarios. To boost the utility of labeled data, we identify the variability among performers and the common ali ty within each action as two key attributes. We present SkeletonX, a lightweight training pipeline that integrates seamlessly with existing GCNbased skeleton action recognizer s, promoting effective training under limited labeled data. First, we propose a tailored sample pair construction strategy on two key attributes to form and aggregate sample pairs. Next, we develop a concise and effective feature aggregation module to process these pairs. Extensive experiments are conducted on NTU $\mathbf{RGB}{+}\mathbf{D}$ , NTU $\mathbf{RGB}{+}\mathbf{D}$ 120, and PKU-MMD with various GCN backbones, demonstrating that the pipeline effectively improves performance when trained from scratch with limited data. Moreover, it surpasses previous state-of-the-art methods in the one-shot setting, with only 1/10 of the parameters and much fewer FLOPs. The code and data are available at: https://github.com/zzysteve/SkeletonX
摘要——尽管当前基于骨架的动作识别模型在大规模数据集上展现出优异性能,但其在新应用场景中的适应性仍面临挑战。这些挑战在面对新动作类别、多样化执行者及不同骨架布局时尤为突出,导致性能显著下降。此外,骨架数据采集的高成本与高难度使得大规模数据收集难以实现。本文研究一次性学习和有限规模学习设定,以实现最小数据量的高效适配。现有方法往往忽视标注样本间丰富的互信息,导致低数据场景下的性能欠佳。为提升标注数据利用率,我们识别出执行者间的差异性和动作内部的共性作为两个关键属性,并提出SkeletonX——一个能与现有基于GCN的骨架动作识别器无缝集成的轻量级训练流程,促进有限标注数据下的有效训练。首先,我们针对两个关键属性设计定制化的样本对构建策略以形成并聚合样本对;其次,开发简洁高效的特征聚合模块处理这些样本对。在NTU $\mathbf{RGB}{+}\mathbf{D}$、NTU $\mathbf{RGB}{+}\mathbf{D}$ 120和PKU-MMD数据集上采用多种GCN骨干网络进行大量实验表明:该流程在有限数据从头训练时能有效提升性能,且在一次性学习设定中以仅1/10参数量和更少FLOPs超越先前最优方法。代码与数据详见:https://github.com/zzysteve/SkeletonX
Index Terms—Action Recognition, Data-Efficient, SkeletonBased Method.
索引术语—动作识别 (Action Recognition)、数据高效 (Data-Efficient)、基于骨架的方法 (Skeleton-Based Method)。
I. INTRODUCTION
I. 引言
H fUielMdA iNn arc etc ie on nt rye eca or gsn itainodn chaans bbeee na pap lifeadst -tdoe v he luo m pian ngmachine interaction, virtual reality, video understanding, etc. Different from RGB videos, skeleton sequences exclusively capture the coordinates of key joints, which are robust against variations in camera viewpoints, background, and appearance. With the development of depth sensor and human pose estimation methods [1]–[4], several large-scale skeleton-based datasets [5]–[7] are proposed. Graph Convolutional Networks (GCNs) have gained significant attention in skeleton-based action recognition, as human skeletons are naturally graphstructured data. Numerous methods [8]–[17] have been proposed for skeleton-based action recognition, achieving impressive performance.
骨架动作识别在增强人机交互、虚拟现实、视频理解等领域具有广泛应用前景。与RGB视频不同,骨骼序列仅记录关键关节坐标,对摄像机视角、背景和外观变化具有较强鲁棒性。随着深度传感器和人体姿态估计方法[1]-[4]的发展,多个大规模骨架数据集[5]-[7]相继提出。由于人体骨架本质上是图结构数据,图卷积网络(GCNs)在骨架动作识别领域获得广泛关注。目前已有大量方法[8]-[17]被提出用于骨架动作识别,并取得了显著性能。
Despite these advancements, most existing approaches rely heavily on large-scale, high-quality labeled datasets, which hinders adaptability in novel application scenarios. Creating such datasets requires advanced depth sensors and extensive human effort [6], [18], making the process costly and impractical. To mitigate these challenges, recent studies have shifted toward one-shot skeleton-based action recognition [19]–[21], where the novel actions are classified with only one reference per class. This paradigm follows a pretrain-and-match protocol: models are first pretrained on base action categories with abundant samples and then classify novel categories by matching features against the reference samples, as illustrated in Fig. 1(a). One-shot recognition significantly reduces data requirements during inference, making it particularly suitable for real-world applications with limited annotated data.
尽管取得了这些进展,但现有方法大多严重依赖大规模、高质量的标注数据集,这限制了其在新应用场景中的适应性。创建此类数据集需要先进的深度传感器和大量人工投入 [6], [18],导致过程成本高昂且不切实际。为缓解这些挑战,近期研究转向了基于骨架的单样本动作识别 [19]–[21],其中每个新动作类别仅需一个参考样本即可完成分类。该范式遵循预训练-匹配协议:模型先在具有丰富样本的基础动作类别上进行预训练,然后通过将特征与参考样本进行匹配来分类新类别,如图 1(a) 所示。单样本识别显著降低了推理时的数据需求,使其特别适用于标注数据有限的现实应用场景。
However, deploying these one-shot models in real-world scenarios presents additional challenges, as illustrated in Fig. 1. Human actions, represented in skeleton modality, are closely tied to skeleton modeling methods, including the number of joints and the skeletal layout. Different motion capture systems and human pose estimation methods [5], [22] often generate skeletons with varying layouts and numbers of joints [6], [23], leading to mismatches between the base actions in the pre training phase and the novel actions in the inference phase. This discrepancy presents a significant limitation for GCN models, whose structures are inherently tied to the predefined skeleton topology. Consequently, models pretrained on large-scale datasets cannot be directly applied to new skeleton layouts. Moreover, performance may further degrade in domains with substantial distribution al shifts, such as medical applications [24].
然而,将这些单次模型部署到现实场景中会面临更多挑战,如图 1 所示。以骨骼模态表示的人类动作与骨骼建模方法密切相关,包括关节数量和骨骼布局。不同的动作捕捉系统和人体姿态估计方法 [5], [22] 通常会生成具有不同布局和关节数量的骨骼 [6], [23],导致预训练阶段的基础动作与推理阶段的新动作之间出现不匹配。这种差异对 GCN (Graph Convolutional Network) 模型构成了显著限制,因为其结构本质上与预定义的骨骼拓扑相关联。因此,在大规模数据集上预训练的模型无法直接应用于新的骨骼布局。此外,在存在显著分布偏移的领域(如医疗应用 [24]),性能可能会进一步下降。
Therefore, we explore a novel and challenging limited-scale setting that addresses aspects that one-shot learning cannot fully resolve. Instead of adapting models through matching, the limited-scale paradigm aims to effectively train models from scratch using limited training samples, as illustrated in Fig. 1(c). In this paradigm, the model is trained on a few samples collected from minimum subjects and camera setups collected specific to the target scenarios. Limited-scale training harnesses the performance benefits of continuous data collection while avoiding extra computational costs during inference, which are often associated with matching-based few-shot learning methods. As illustrated in Fig. 2, our method can achieve better performance by collecting 20 samples per class for novel actions and continues to improve as more data are collected. This setting also bridges the gap between oneshot/few-shot learning and large-scale training, where the former typically relies on no more than five samples per category, while the latter requires hundreds of annotated examples.
因此,我们探索了一种新颖且具有挑战性的有限规模场景,该场景解决了一次性学习无法完全解决的问题。不同于通过匹配来适配模型,有限规模范式旨在利用有限的训练样本从头开始有效训练模型,如图1(c)所示。在这一范式中,模型通过从目标场景中收集的少量受试者和相机设置样本进行训练。有限规模训练既保持了持续数据收集带来的性能优势,又避免了推理过程中额外的计算成本,这些成本通常与基于匹配的少样本学习方法相关。如图2所示,我们的方法通过为每个新动作类别收集20个样本即可实现更优性能,并且随着数据量的增加持续提升。这一设定也弥合了一次性/少样本学习与大规模训练之间的差距:前者通常每类仅依赖不超过五个样本,而后者则需要数百个标注样本。
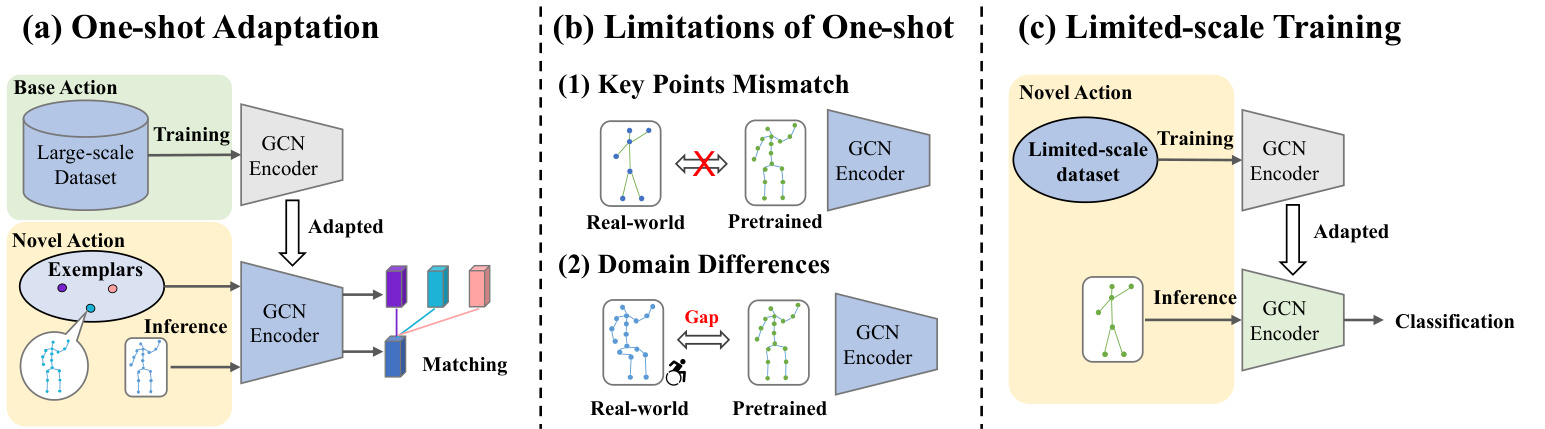
Fig. 1. Illustration of two adaptation paradigms. (a) In the one-shot setting, feature encoders are first pretrained on large-scale datasets. When adapting to the inference phase, novel samples are recognized by matching them with features extracted by the pre-trained encoder. (b) However, this pretrain-and-matching paradigm fails when the number of key points differs from the pre training phase. Even if the joint layouts are the same, domain gaps can occur, which degrade the model’s performance. (c) To address this, we propose a limited-scale setting where the model is trained effectively from scratch with minimal newly collected data. This approach adapts the model directly to the inference phase without matching.
图 1: 两种适应范式的示意图。(a) 在单样本设置中,特征编码器首先在大规模数据集上进行预训练。当适应推理阶段时,通过将新样本与预训练编码器提取的特征进行匹配来识别它们。(b) 然而,当关键点数量与预训练阶段不同时,这种预训练加匹配的范式就会失效。即使关节布局相同,也可能出现领域差距,从而降低模型性能。(c) 为解决这个问题,我们提出了一种有限规模设置,该设置通过最少量的新收集数据从头开始有效训练模型。这种方法无需匹配即可直接将模型适应到推理阶段。
A key challenge in limited-scale settings arises from the inherent variability in actions performed by different individuals. Variations in body shapes, motion styles, and personal habits introduce significant diversity to action sequences, complicating recognition. As samples of novel action categories are scarce, the network struggles to learn diverse action representations from limited subjects, leading to degenerated feature extraction capabilities. Existing methods are designed for large-scale datasets, enhancing sample diversity through random rotation [19], [25] and mixup [26]–[28], while the rich mutual information among different action sequences is overlooked.
有限规模场景下的一个关键挑战源于不同个体执行动作时固有的差异性。体型差异、运动风格和个人习惯等因素导致动作序列存在显著多样性,使识别任务复杂化。由于新动作类别的样本稀缺,网络难以从有限受试者中学习多样化的动作表征,导致特征提取能力退化。现有方法专为大规模数据集设计,通过随机旋转[19][25]和混合增强[26][28]来提升样本多样性,却忽视了不同动作序列间丰富的互信息。
To address these challenges, we propose a novel crosssample aggregation framework, SkeletonX. Our approach targets two key attributes in skeleton-based action recognition: the variability among performers and common ali ty within each action. To leverage these attributes, we introduce a tailored sample-pair construction strategy that forms pair batches for the original input batch. Each sample is first encoded and processed through a disentanglement module. The disentangled features are aggregated by our proposed cross-sample feature aggregation module, effectively introducing diversity into the training process despite the limited availability of labeled samples. Additionally, we propose an action-aware aggregation loss to further enhance the learning process, which encourages the model to learn disc rim i native feature representation, while ensuring end-to-end training for the pipeline. SkeletonX is designed to be practical and flexible, allowing seamless integration into various GCN architectures. We also provide an analysis based on Information Bottleneck Theory [29], [30] to better understand the mechanism behind performance gain through cross-sample feature aggregation. Extensive experiments conducted on limited-scale and one-shot settings with three datasets and multiple backbones demonstrate the effectiveness and general iz ability of our method.
为了解决这些挑战,我们提出了一种新颖的跨样本聚合框架SkeletonX。该方法聚焦于基于骨架的动作识别中的两个关键属性:执行者间的差异性和动作内部的共性。为利用这些属性,我们引入了一种定制化的样本对构建策略,为原始输入批次生成配对批次。每个样本首先经过编码并通过解耦模块处理,随后解耦的特征由我们提出的跨样本特征聚合模块进行整合,从而在标注样本有限的情况下有效提升训练过程的多样性。此外,我们提出了一种动作感知聚合损失函数,通过鼓励模型学习判别性特征表示来增强学习过程,同时确保整个流程的端到端训练。SkeletonX设计兼具实用性与灵活性,可无缝集成到各类GCN架构中。基于信息瓶颈理论[29][30],我们还提供了性能提升机制的分析。通过在三个数据集和多种骨干网络上的小样本及单样本设定实验,充分验证了方法的有效性和泛化能力。
Our contributions can be summarized as follows.
我们的贡献可总结如下。
II. RELATED WORK
II. 相关工作
A. Skeleton-based Action Recognition
A. 基于骨架的动作识别
Action recognition using skeleton data has attracted increasing attention for its inherent robustness and compact nature. Early studies [31]–[34] framed the task as a sequential modeling problem, employing Recurrent Neural Networks (RNNs) to solve it. However, RNNs suffer from gradient vanishing and long training time, which hinder the model from achieving better performance.
基于骨骼数据的动作识别因其固有的鲁棒性和紧凑性而受到越来越多的关注。早期研究[31]–[34]将该任务视为序列建模问题,采用循环神经网络(RNNs)进行解决。然而,RNNs存在梯度消失和训练时间长的缺陷,阻碍了模型获得更好的性能。
As human skeletons are naturally graph-structured data, Graph Convolutional Networks (GCNs) have gained significant attention in skeleton-based action recognition. Yan et al. [8] pioneered a GCN-based approach for skeleton-based action recognition, incorporating partitioning strategies for skeletons and integrating spatial and temporal convolution to model skeleton sequences effectively. Given the significance of topology information in skeleton sequences, many scholars have focused on topology modeling through dynamic topology modeling [9], [12], [13], [16], [35], [36], hierarchical modeling [15] and spatial-temporal channel aggregation [10], [11], [14], [17], [36]. Although previous GCN models are inherently capable of processing spatial and temporal information, we propose enhancing their performance through a cross-sample aggregation training paradigm.
由于人体骨骼天然具有图结构数据特性,图卷积网络 (GCN) 在基于骨骼的动作识别领域受到广泛关注。Yan等人 [8] 率先提出基于GCN的骨骼动作识别方法,通过骨骼分区策略并结合空间与时序卷积来有效建模骨骼序列。鉴于拓扑信息在骨骼序列中的重要性,许多学者通过动态拓扑建模 [9]、[12]、[13]、[16]、[35]、[36]、分层建模 [15] 以及时空通道聚合 [10]、[11]、[14]、[17]、[36] 等方式聚焦于拓扑建模。虽然现有GCN模型本身具备处理时空信息的能力,但我们提出通过跨样本聚合训练范式来进一步提升其性能。
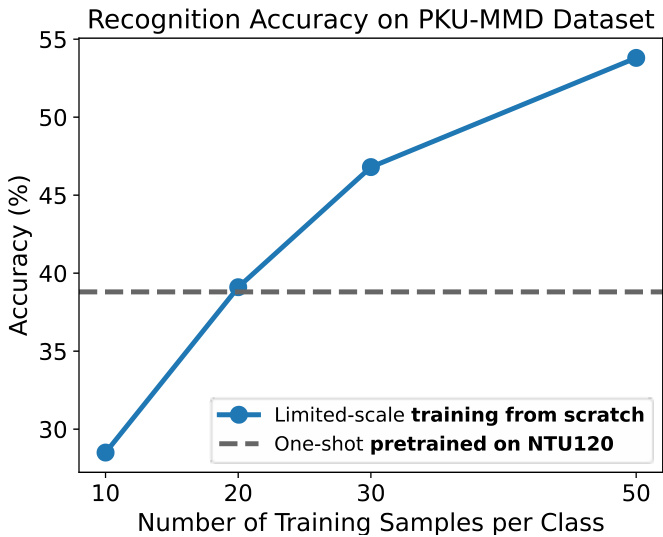
Fig. 2. Illustration of the performance degeneration when transferring oneshot pretrained models on NTU $\mathrm{RGB+D}~120$ dataset to PKU-MMD datasets. The gray dashed line indicates the performance of the one-shot setting. The blue line demonstrates the limited-scale setting, which requires collecting only a handful of samples and training the model from scratch. By collecting 20 samples per class for novel actions, the model achieves better performance than the one-shot pretrained one, and still benefits from continuous data accumulation.
图 2: 展示了在将NTU $\mathrm{RGB+D}~120$ 数据集上单次预训练模型迁移至PKU-MMD数据集时的性能退化情况。灰色虚线表示单次设置下的性能表现。蓝线展示了有限规模设置(仅需收集少量样本并从头训练模型)的效果。通过为每个新动作类别收集20个样本,模型表现优于单次预训练模型,并仍能持续受益于数据积累。
B. One-shot Skeleton-based Action Recognition
B. 基于单样本骨架的动作识别
Motivated by the human ability to recognize new concepts with one example, one-shot skeleton action recognition has attracted increasing attention in recent years. Liu et al. [6] presented a large-scale dataset with one-shot skeleton-based action recognition benchmarks, and introduced an APSR frame- work to emphasize the body parts relevant to the novel actions as a solution. Sabater et al. [24] proposed a motion encoder based on geometric information, which is robust to various movement kinematics. Wang et al. [20] introduced JEANIE, a method that aligns the joint of temporal blocks and simulates viewpoints during meta-learning. M emme she i mer et al. [19] introduced an image-based skeleton representation and trained an embedder to project the images into an embedding vector. Zhu et al. [37] proposed a novel matrix-based distance metric to determine the spatial and temporal similarity between two skeleton sequences. Penget al. [38] studied occluded skeleton recognition scenarios and proposed Trans4SOAR to fusion diverse inputs. Yang et al. [21] proposed a multi-spatial and multi-temporal skeleton feature representation, and a matching technique that handles scale-wise and cross-scale features.
受人类通过单一示例识别新概念的能力启发,单次骨架动作识别近年来受到越来越多的关注。Liu等人[6]提出了一个包含单次骨架动作识别基准的大规模数据集,并引入了APSR框架作为解决方案,强调与新颖动作相关的身体部位。Sabater等人[24]提出了一种基于几何信息的运动编码器,对各种运动学变化具有鲁棒性。Wang等人[20]提出了JEANIE方法,该方法在元学习过程中对齐时序块的关节并模拟视角变化。Memmesheimer等人[19]引入了一种基于图像的骨架表示方法,并训练嵌入器将图像投影为嵌入向量。Zhu等人[37]提出了一种新颖的基于矩阵的距离度量方法,用于确定两个骨架序列之间的空间和时间相似性。Peng等人[38]研究了遮挡骨架识别场景,提出了Trans4SOAR来融合多样化输入。Yang等人[21]提出了一种多空间多时间的骨架特征表示方法,以及处理跨尺度和尺度内特征的匹配技术。
formation for enhancing representation learning. Additionally, these methods are designed under meta-learning paradigms, limiting the applications in other cases. Distinct from previous methods, we introduce a novel approach involving a sample pair selection strategy and aggregation method to fuse pair samples. Our method can be further expanded to more scenarios while maintaining compatibility with established methods.
为增强表征学习而融合信息。此外,这些方法基于元学习范式设计,限制了其他场景的应用。与现有方法不同,我们提出了一种创新的样本对选择策略和聚合方法来实现样本对融合。该方法可进一步扩展至更多场景,同时保持与现有方法的兼容性。
C. Limited-scale settings
C. 小规模设置
Previous research mainly focuses on matching strategies, distance metrics, or improving model structure to achieve better feature representation. We propose that the inherent correlations among the limited labeled samples hold rich in
以往研究主要关注匹配策略、距离度量或改进模型结构以获得更好的特征表示。我们提出有限标注样本间的内在关联蕴含着丰富的
Some work has conducted experiments on randomly resampled data with few-shot [39], [40] or fully-supervised [41] settings. However, we note that random sampling is not realistic for applications. The full dataset includes diverse action performers and camera setups. Several samples are likely obtained from nearly every performer and setup through random sampling, while each performer or setup contributes only a few samples. When training samples are collected for specific applications, it would be more practical to recruit a few volunteers with some camera setups and collect more samples. Therefore, we propose a new simulation of the scenarios with a new limited-scale sampling strategy.
一些研究在少样本 [39][40] 或全监督 [41] 设置下对随机重采样数据进行了实验。但我们注意到,随机采样在实际应用中并不现实。完整数据集包含多样化的动作执行者和摄像机配置。通过随机采样,很可能从几乎每个执行者和配置中获得多个样本,而每个执行者或配置仅贡献少量样本。当为特定应用收集训练样本时,更实际的做法是招募少量志愿者并使用部分摄像机配置来采集更多样本。因此,我们提出了一种新的有限规模采样策略来模拟此类场景。
III. METHOD
III. 方法
In this section, we first formulate the problem settings. An overview of our method is provided in Fig. 3. The remainder of this section introduces the sample pairs selection strategy, cross-sample feature aggregation, and action-aware loss function within our proposed pipeline.
在本节中,我们首先阐述问题设定。图 3 展示了方法概览,其余部分将依次介绍样本对选择策略、跨样本特征聚合方法,以及我们提出流程中的动作感知损失函数。
A. Preliminary and Problem Definition
A. 初步研究与问题定义
Skeleton-based Action Sequence. A human skeleton can be defined with a set of vertices ${\cal S}=(x_{1},x_{2},\dots,x_{V})$ , where $V$ is the number of joints provided by the dataset, and each vertex $x_{i}$ is denoted with 3-dimensional coordinate. One action sequence $X_{i} =~(S_{1},S_{2},...,S_{T})$ consists of $T$ frames of human skeleton sequence, therefore $X_{i}\in\mathbb{R}^{T\times V\times3}$ . The label of the skeleton sequence is denoted as one-hot label $y\in\mathbb{R}^{K}$ , where $K$ is the number of action categories.
基于骨架的动作序列。人体骨架可以定义为一组顶点 ${\cal S}=(x_{1},x_{2},\dots,x_{V})$ ,其中 $V$ 是数据集提供的关节数量,每个顶点 $x_{i}$ 用三维坐标表示。一个动作序列 $X_{i} =~(S_{1},S_{2},...,S_{T})$ 由 $T$ 帧人体骨架序列组成,因此 $X_{i}\in\mathbb{R}^{T\times V\times3}$ 。骨架序列的标签表示为独热编码标签 $y\in\mathbb{R}^{K}$ ,其中 $K$ 是动作类别数量。
One-shot Action Recognition aims to identify the novel action with only one exemplar per category. Training set is denoted as $D_{b}$ , which contains $B$ base classes $C_{b} =~$ ${c_{1},c_{2},\ldots,c_{B}}$ . Testing set contains $N$ novel classes $C_{n}=$ ${c_{1},c_{2},\ldots,c_{N}}$ . The training set shares no common class with the testing set, i.e. $C_{b}\cap C_{n}=\emptyset$ . The models are first trained with $C_{b}$ , and act as feature extractors during inference. For most of the one-shot methods, the final prediction is made by measuring the distances between test samples and exemplars in feature space.
单样本动作识别旨在每个类别仅有一个示例的情况下识别新动作。训练集记为 $D_{b}$,包含 $B$ 个基类 $C_{b} =~$ ${c_{1},c_{2},\ldots,c_{B}}$。测试集包含 $N$ 个新类 $C_{n}=$ ${c_{1},c_{2},\ldots,c_{N}}$。训练集与测试集无共同类别,即 $C_{b}\cap C_{n}=\emptyset$。模型首先用 $C_{b}$ 训练,在推理时作为特征提取器。多数单样本方法通过测量特征空间中测试样本与示例的距离来生成最终预测。
Limited-scale Setting aims to train the network from scratch with a limited number of samples collected from the target scenario in a fully supervised manner. When dealing with varying numbers of joints or significant domain gaps, the existing one-shot learning paradigm may not directly apply to real-world scenarios. We propose the limited-scale setting, which collects a handful of samples for each action category. Formally, the limited-scale dataset is denoted as $D_{L S}= $ ${X_{1}^{1},\ldots,X_{1}^{N},X_{2}^{1},\ldots,X_{2}^{N},\ldots,X_{C}^{1},\ldots,X_{C}^{N}}$ , where $X_{i}^{j}$ is the $j$ -th skeleton sequence drawn from action class $i$ . $N$ is the number of samples drawn for each class, and $C$ represents the number of classes.
有限规模设置 (Limited-scale Setting) 旨在通过从目标场景中收集有限数量的样本,以全监督方式从头训练网络。当处理不同关节数量或显著领域差距时,现有的单样本学习范式可能无法直接应用于现实场景。我们提出有限规模设置,该设置会为每个动作类别收集少量样本。形式上,有限规模数据集表示为 $D_{L S}= $ ${X_{1}^{1},\ldots,X_{1}^{N},X_{2}^{1},\ldots,X_{2}^{N},\ldots,X_{C}^{1},\ldots,X_{C}^{N}}$ ,其中 $X_{i}^{j}$ 是从动作类别 $i$ 中提取的第 $j$ 个骨骼序列。 $N$ 是每个类别抽取的样本数量, $C$ 表示类别总数。
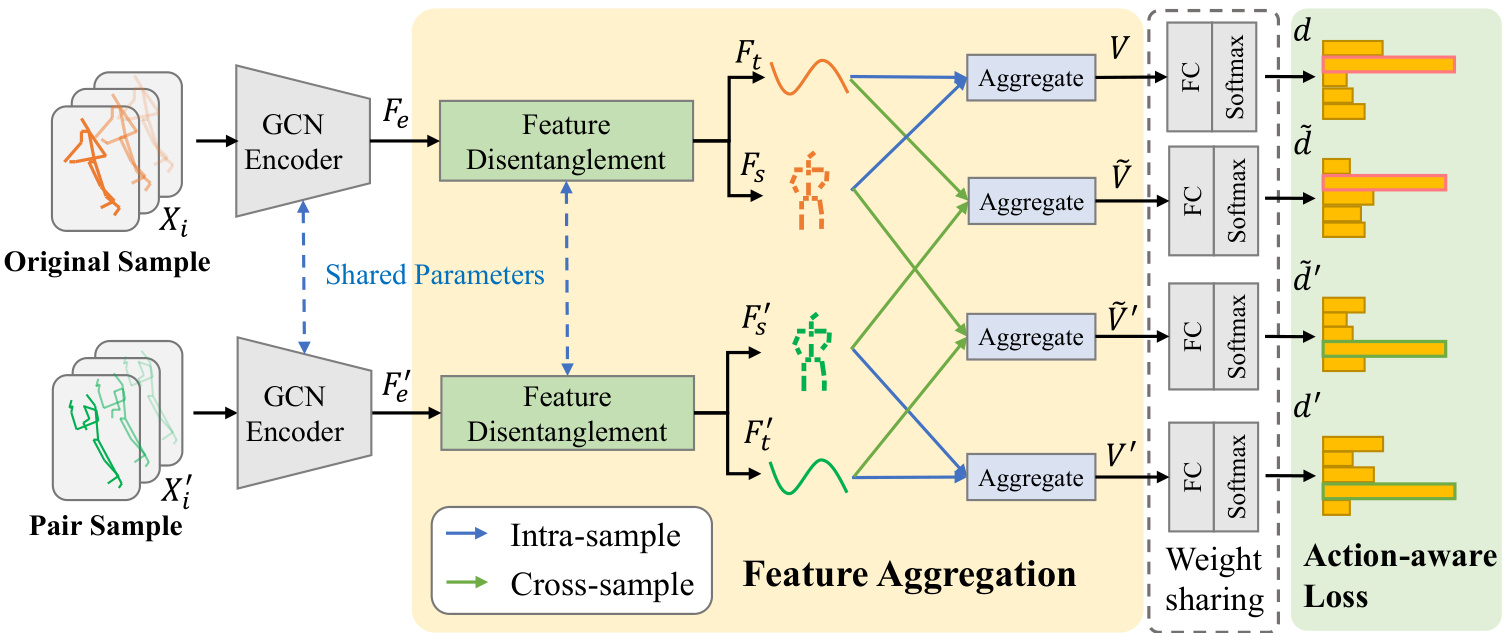
Fig. 3. Overview of SkeletonX. In the training phase, an original sample $(X)$ and its pair sample $(X^{'})$ are first encoded using a GCN backbone to features $F_{e}$ and $F_{e}^{\prime}$ , followed by disentanglement into spatial features $(\check{F}{s},F_{s}^{'})$ and temporal features $(\dot{F_{t}},\dot{F_{t}^{'}})$ . These features are processed through a feature aggregation module, where $V$ and $V^{\prime}$ result from intra-sample aggregation, and $\widetilde{V}$ and $\widetilde{V}^{\prime}$ from cross-sample aggregation. The aggregated features are then passed through a fully connected layer and softmax function to produce the p reedicted e probability distribution $\overline{{d}},\widetilde{d},\widetilde{d^{\prime}}$ , and $d^{\prime}$ . The model is finally optimized with our proposed action-aware loss.
图 3: SkeletonX 概览。在训练阶段,原始样本 $(X)$ 及其配对样本 $(X^{'})$ 首先通过 GCN 骨干网络编码为特征 $F_{e}$ 和 $F_{e}^{\prime}$,随后解耦为空间特征 $(\check{F}{s},F{s}^{'})$ 和时间特征 $(\dot{F_{t}},\dot{F_{t}^{'}})$。这些特征经过特征聚合模块处理,其中 $V$ 和 $V^{\prime}$ 来自样本内聚合,$\widetilde{V}$ 和 $\widetilde{V}^{\prime}$ 来自跨样本聚合。聚合后的特征通过全连接层和 softmax 函数生成预测概率分布 $\overline{{d}},\widetilde{d},\widetilde{d^{\prime}}$ 和 $d^{\prime}$。模型最终通过我们提出的动作感知损失函数进行优化。
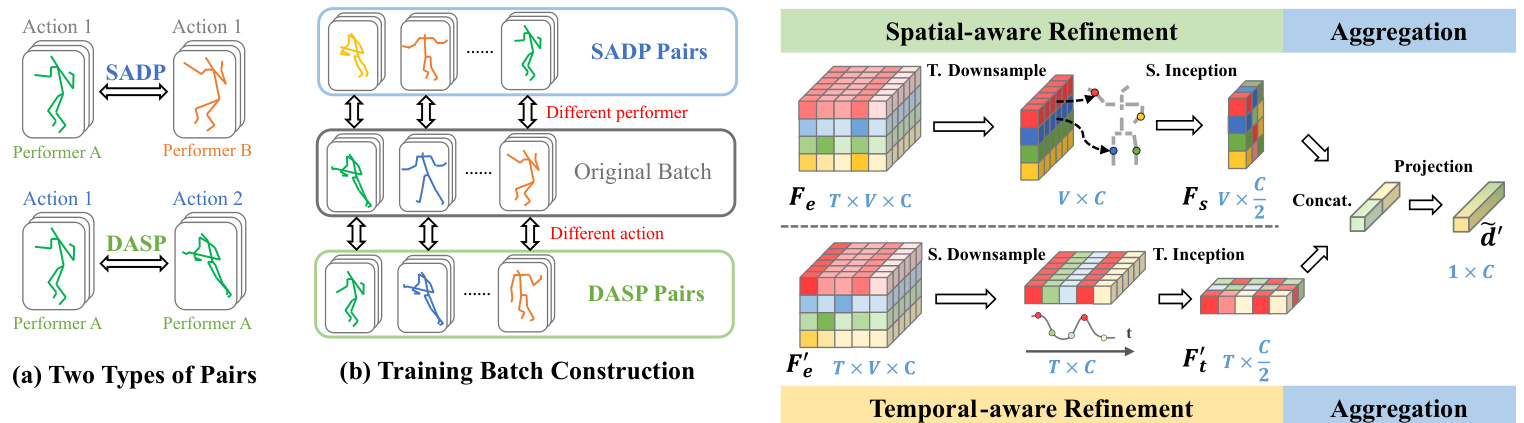
Fig. 4. Illustration for (a) two types of sample pairs: DASP (Different Action, Same Performer) and SADP (Same Action, Different Performer). (b) Trainingtime batch construction. For each sample within the original batch, its DASP sample and SADP sample form two batches, which are used in the aggregation step of our proposed pipeline.
图 4: (a) 两种样本对的图示: DASP (不同动作, 相同表演者) 和 SADP (相同动作, 不同表演者)。 (b) 训练时批次构建。对于原始批次中的每个样本, 其 DASP 样本和 SADP 样本形成两个批次, 用于我们提出的流程的聚合步骤。
Fig. 5. Illustration for cross-sample aggregation. Features of the original sample $F_{e}$ and its pair sample $F_{e}^{\prime}$ are refined by two branches respectively and then aggregated to produce the final prediction d′.
图 5: 跨样本聚合示意图。原始样本特征 $F_{e}$ 及其配对样本特征 $F_{e}^{\prime}$ 分别通过两个分支进行精炼,随后聚合生成最终预测结果 d′。
In contrast to prior work [39]–[41] which randomly selects samples from the training set, this setting controls the number of subjects and camera perspectives to minimize costs. To simulate this challenging scenario, we resample the training data while keeping the testing data fixed in cross-subject fully supervised learning. Further details are provided in Section IV-B.
与先前工作[39]–[41]从训练集中随机选取样本的做法不同,本方案通过控制受试者数量和摄像机视角来最小化成本。为模拟这一挑战性场景,我们在跨被试全监督学习中保持测试数据不变的情况下对训练数据进行重采样。更多细节详见第IV-B节。
B. Sample Pairs Selection Strategy
B. 样本对选择策略
We define two types of sample pairs based on two key attributes of skeleton-based action recognition: performer and action, as illustrated in Fig. 4(a). For example, consider a sample that depicts Action 1, performed by Performer A. The corresponding DASP partner would be another skeleton sequence representing action 2, also performed by Performer A. Conversely, the SADP partner would be the same action category but performed by a different individual, Performer B. By fixing one attribute, the model can focus on the other during the subsequent cross-sample aggregation process.
我们基于基于骨架的动作识别的两个关键属性——执行者和动作,定义了两种样本对类型,如图 4(a) 所示。例如,假设有一个样本展示的是执行者A完成的动作1,其对应的DASP伙伴就是另一个由执行者A完成动作2的骨架序列;而SADP伙伴则是同一动作类别但由不同执行者B完成的样本。通过固定其中一个属性,模型就能在后续跨样本聚合过程中专注于另一个属性。
During each training step, a batch is constructed by randomly selecting skeleton sequences, as illustrated in Fig. 4(b). For every sequence within the batch, one sample from each pair type is drawn to form two batches for aggregation. The strategy enables us to disentangle and aggregate samples. It is worth noting that this procedure can be performed dynamically by a modified data loader during training, or statically through data pre-processing to reduce the overhead of sample selection.
在每个训练步骤中,会通过随机选择骨架序列来构建一个批次,如图 4(b) 所示。对于批次中的每个序列,从每对类型中抽取一个样本,形成两个用于聚合的批次。该策略使我们能够解耦并聚合样本。值得注意的是,这一过程可以通过训练时修改数据加载器动态执行,也可以通过数据预处理静态完成以减少样本选择的开销。
C. Cross-sample Feature Aggregation
C. 跨样本特征聚合
Most of the GCN-based methods [8], [9], [13], [14] focus on designing GCN building blocks while adhering to the overall structure proposed by [8]. In the general structure, the skeleton sequence is encoded to features using a GCN encoder. These encoded features are then processed through a simple Global Average Pooling (GAP) layer, producing sequencelevel feature vectors for final prediction.
大多数基于GCN的方法 [8], [9], [13], [14] 都专注于设计GCN构建模块,同时遵循 [8] 提出的整体结构。在该通用结构中,骨骼序列通过GCN编码器编码为特征,这些编码后的特征随后经过简单的全局平均池化 (GAP) 层处理,生成用于最终预测的序列级特征向量。
As previous methods have proposed sophisticated designs on spatial and temporal modeling within GCN encoders, the design philosophy of our aggregation module is to enhance the capabilities of existing modules instead of replacing them. Therefore, we propose a concise feature aggregation module on the output of the GCN encoders to replace the GAP layer. As shown in Fig. 5, it includes two refinement modules focusing on spatial and temporal information respectively, which provide fine-grained decoupled features for aggregation.
由于先前的方法已在GCN编码器中提出了复杂的时空建模设计,我们聚合模块的设计理念是增强现有模块的能力而非替代它们。因此,我们在GCN编码器输出端提出了一个简洁的特征聚合模块来替代GAP层。如图5所示,该模块包含分别专注于空间和时间信息的两个细化模块,为聚合提供细粒度解耦特征。
We take the cross-sample aggregation process of V ′ shown in Fig. 3 as an example. Given the encoded fea tuere $F_{e}~\in$ $\mathbb{R}^{T\times\bar{V}\times C}$ , the spatial-aware refinement is defined as:
我们以图 3 中 V′ 的跨样本聚合过程为例。给定编码特征 $F_{e}~\in$ $\mathbb{R}^{T\times\bar{V}\times C}$ ,空间感知精炼定义为:
$$
F_{s}=\mathbf{ReLU}(\mathbf{BN}(W_{s}^{c}\cdot\mathbf{AP}{t}(F_{e})+b_{s}^{c}))
$$
$$
F_{s}=\mathbf{ReLU}(\mathbf{BN}(W_{s}^{c}\cdot\mathbf{AP}{t}(F_{e})+b_{s}^{c}))
$$
where $W_{s}^{c}$ and $b_{s}^{c}$ are channel-wise learnable weights that aggregate information of each joint, enabling the network to capture spatial patterns. $\mathbf{AP}_{t}$ indicate Average Pooling along the temporal axis, it down-samples the feature on the temporal axis, allowing the module to focus on spatial information of joints. BN represents batch normalization, and ReLU is the activation function.
其中 $W_{s}^{c}$ 和 $b_{s}^{c}$ 是通道级可学习权重,用于聚合每个关节的信息,使网络能够捕捉空间模式。$\mathbf{AP}_{t}$ 表示沿时间轴的平均池化 (Average Pooling),它对时间轴上的特征进行下采样,使模块能够专注于关节的空间信息。BN 代表批归一化 (batch normalization),ReLU 是激活函数。
Temporal-aware refinement branch uses $\mathbf{AP}{s}$ along spatial axis and its own parameters $W_{t}^{c},~b_{t}^{c}$ , defined as:
时序感知细化分支沿空间轴使用 $\mathbf{AP}{s}$ 及其自身参数 $W_{t}^{c},~b_{t}^{c}$,定义为:
$$
F_{t}^{'}=\mathbf{ReLU}(\mathbf{BN}(W_{t}^{c}\cdot\mathbf{AP}{s}(F_{e}^{'})+b_{t}^{c}))
$$
$$
F_{t}^{'}=\mathbf{ReLU}(\mathbf{BN}(W_{t}^{c}\cdot\mathbf{AP}{s}(F_{e}^{'})+b_{t}^{c}))
$$
By disentangling the feature, the spatial feature carries the performer’s properties (i.e., performer-related), while the temporal feature captures the action momentum along the timeline (i.e., action-related). As the gradients flow forward, the module also encourages the GCN encoder to distinguish the two aspects of actions better.
通过分离特征,空间特征承载了表演者的属性(即与表演者相关),而时间特征则捕捉了沿时间线的动作动量(即与动作相关)。随着梯度向前传播,该模块还鼓励GCN编码器更好地区分动作的两个方面。
Aggregation of two decoupled features is done through concatenation and projection layer, defined as:
两个解耦特征的聚合通过拼接和投影层完成,定义为:
$$
\widetilde{d}^{\prime}=W_{p}\cdot\mathbf{Concat}(\mathbf{AP}{s}(F_{s}),\mathbf{AP}{t}(F_{t}^{'}))+b_{p}
$$
$$
\widetilde{d}^{\prime}=W_{p}\cdot\mathbf{Concat}(\mathbf{AP}{s}(F_{s}),\mathbf{AP}{t}(F_{t}^{'}))+b_{p}
$$
where the average pooling (AP) summarizes the performerrelated and action-related feature, and a learnable projection layer with parameters $W_{p}$ and $b_{p}$ to further fuse the feature. Concat indicates concatenation along the feature dimension. We discover that concatenation is surprisingly effective by the ablation studies. This effectiveness may be attributed to our training strategy, which guides the sophisticated designed modules in GCN encoders to focus on different aspects, thus enhancing performance.
其中平均池化 (AP) 汇总了表演者相关和动作相关的特征,并通过可学习的投影层(参数为 $W_{p}$ 和 $b_{p}$)进一步融合特征。Concat 表示沿特征维度进行拼接。通过消融实验,我们发现拼接操作的效果出奇地好。这种有效性可能归因于我们的训练策略,它引导 GCN 编码器中精心设计的模块专注于不同方面,从而提升性能。
D. Loss Function
D. 损失函数
Based on the design of our proposed module, we present an action-aware loss function to encourage the model to learn different representations related to actions among various subjects. As shown in Fig. 3, the aggregated features are fed into a fully connected (FC) layer followed by a SoftMax layer to produce the final predictions. After feature aggregation, two source samples produce predictions based on four aggregated features. We employ Cross-Entropy (CE) as the loss function based on action-aware labels to train the network, where the label of the aggregated feature is determined by the source of the action-related feature.
基于我们提出的模块设计,我们提出了一种动作感知损失函数,以鼓励模型学习不同主体间与动作相关的不同表征。如图 3 所示,聚合特征被输入到一个全连接 (FC) 层,随后通过 SoftMax 层生成最终预测。特征聚合后,两个源样本基于四个聚合特征产生预测。我们采用交叉熵 (CE) 作为基于动作感知标签的损失函数来训练网络,其中聚合特征的标签由动作相关特征的来源决定。
Based on two aggregated samples, we present two types of loss functions: inter-sample loss and intra-sample loss.
基于两个聚合样本,我们提出了两种类型的损失函数:样本间损失和样本内损失。
$\widetilde{V}$ has the same label as original sample $y$ , while V ′ is labeeled according to the paired sample $y^{'}$ . The loss is d eefined as Equation 4, where $\tilde{d}$ and $\widetilde{d}^{\prime}$ represent the probabilities of the two aggregated sa meples ile lust rated in Fig. 3.
$\widetilde{V}$ 与原样本 $y$ 具有相同标签,而 V′ 根据配对样本 $y^{'}$ 进行标注。损失函数定义为公式 4,其中 $\tilde{d}$ 和 $\widetilde{d}^{\prime}$ 表示两个聚合样本的概率,如图 3 所示。
$$
{L}_{D A S P}={\bf C E}(\widetilde{d},y)+{\bf C E}(\widetilde{d}^{'},y^{'})
$$
$$
{L}_{D A S P}={\bf C E}(\widetilde{d},y)+{\bf C E}(\widetilde{d}^{'},y^{'})
$$
The aggregation is similarly performed for the SADP pair. Since “SA” stands for “Same Action”, the paired sample label $y^{'}$ is the same as the original sample $y$ . The SADP loss is formulated as:
同样对SADP对进行聚合。由于"SA"代表"相同动作",配对样本标签$y^{'}$与原样本$y$相同。SADP损失函数公式为:
$$
L_{S A D P}=\mathbf{CE}(\widetilde{d},y)+\mathbf{CE}(\widetilde{d}^{\prime},y)
$$
$$
L_{S A D P}=\mathbf{CE}(\widetilde{d},y)+\mathbf{CE}(\widetilde{d}^{\prime},y)
$$
The features of the original sample and two paired samples are also aggregated, as indicated by the blue arrows in Fig. 3. The loss of intra-sample aggregation is formulated as:
原始样本与两个配对样本的特征也进行了聚合,如图 3 中的蓝色箭头所示。样本内聚合的损失公式为:
$$
{\cal L}{I n t r a}={\bf C E}(d,y)+{\bf C E}(d^{'},y)+{\bf C E}(d_{*}^{'},y^{'})
$$
$$
{\cal L}{I n t r a}={\bf C E}(d,y)+{\bf C E}(d^{'},y)+{\bf C E}(d_{*}^{'},y^{'})
$$
where $d^{'}$ indicates the SADP pair, and $d_{*}^{'}$ indicates the DASP pair.
其中 $d^{'}$ 表示 SADP 对,$d_{*}^{'}$ 表示 DASP 对。
Finally, CE losses from different training objectives are combined to form the final learning objective function:
最终,将不同训练目标的交叉熵损失组合起来,形成最终的学习目标函数:
$$
L=L_{I n t r a}+w_{x}\left(L_{D A S P}+L_{S A D P}\right)
$$
$$
L=L_{I n t r a}+w_{x}\left(L_{D A S P}+L_{S A D P}\right)
$$
where $w_{x}$ is the balance hyper-parameter for cross-sample aggregation.
其中 $w_{x}$ 是跨样本聚合的平衡超参数。
$E$ . Theoretical Analysis
$E$ . 理论分析
In this section, we analyze the feature aggregation technique through Information Bottleneck (IB) theory [29], [30], and propose that it provides more information for the model under limited training data. Previous research on skeleton-based action recognition [42] has demonstrated the correlation between mutual information and improved performance. Unlike the prior approach, which focused on designing the network structure, we enhance mutual information via sample aggregation, thus boosting performance. Additionally, we validate our theory through experiments in Section IV-J.
在本节中,我们通过信息瓶颈 (Information Bottleneck, IB) 理论 [29][30] 分析特征聚合技术,并提出该方法能在有限训练数据下为模型提供更多信息。基于骨架的动作识别研究 [42] 已证明互信息与性能提升之间的相关性。与先前专注于设计网络结构的方法不同,我们通过样本聚合增强互信息,从而提升性能。此外,我们在第 IV-J 节通过实验验证了该理论。
In the following analysis, we focus on cross-sample aggregation for DASP. Nevertheless, the subsequent formulation also applies to the alternative case. As described in the previous section, the skeleton sequence $X_{i}$ and its paired sample $X_{i}^{\prime}$ are first encoded by encoder $f_{\theta}$ to features $F_{i}$ and $F_{i}^{\prime}$ . To simplify the notation, we omit subscripts and superscripts in the formulas, representing the samples as $X$ and $X^{\prime}$ , and the corresponding features as $F$ and $F^{\prime}$ .
在以下分析中,我们重点讨论DASP的跨样本聚合。尽管如此,后续公式同样适用于替代情况。如前一节所述,骨架序列$X_{i}$及其配对样本$X_{i}^{\prime}$首先通过编码器$f_{\theta}$编码为特征$F_{i}$和$F_{i}^{\prime}$。为简化表示,我们省略公式中的下标和上标,将样本表示为$X$和$X^{\prime}$,对应特征表示为$F$和$F^{\prime}$。
$$
F=f_{\theta}(X)F^{\prime}=f_{\theta}(X^{\prime})
$$
$$
F=f_{\theta}(X)F^{\prime}=f_{\theta}(X^{\prime})
$$
The aggregation module $A$ takes two features as input, with the first feature encoding action information and the second encoding performer information. The aggregated features are denoted as $\widetilde{V}$ and $\widetilde{V}^{\prime}$ following Fig. 3.
聚合模块 $A$ 以两个特征作为输入,第一个特征编码动作信息,第二个编码执行者信息。聚合后的特征记为 $\widetilde{V}$ 和 $\widetilde{V}^{\prime}$,如图 3 所示。
$$
\widetilde V=A(F,F^{\prime})\qquad\widetilde V^{\prime}=A(F^{\prime},F)
$$
$$
\widetilde V=A(F,F^{\prime})\qquad\widetilde V^{\prime}=A(F^{\prime},F)
$$
We analyze the first aggregated feature $\widetilde{V}$ , denoted as $V$ for simplicity. The label of $X$ is denoted as $Y$ . eFollowing previous work [29], [30], the information bottleneck objective function can be formulated as
我们分析第一个聚合特征 $\widetilde{V}$ (为简化记为 $V$)。$X$ 的标签记为 $Y$。根据先前工作 [29]、[30],信息瓶颈目标函数可表述为
$$
R_{I B}=I(D;Y)-\beta I(D;X)
$$
$$
R_{I B}=I(D;Y)-\beta I(D;X)
$$
where $I(\cdot;\cdot)$ denotes the mutual information between two random variables, $\beta$ is the Lagrange multiplier, and $D$ represents the intermediate feature. According to IB theory, the model improves by learning a concise representation while retains good predictive capability, achieved by maximizing the objective function $R_{I B}$ .
其中 $I(\cdot;\cdot)$ 表示两个随机变量之间的互信息,$\beta$ 是拉格朗日乘数,$D$ 代表中间特征。根据信息瓶颈 (Information Bottleneck, IB) 理论,模型通过学习简洁表示同时保持良好预测能力来提升性能,这是通过最大化目标函数 $R_{I B}$ 实现的。
In our work, the aggregated feature $V$ replaces the feature $D$ of the baseline method through sample aggregation. Given the data processing inequality,
在我们的工作中,聚合特征 $V$ 通过样本聚合替代了基线方法的特征 $D$。根据数据处理不等式,
$$
I(V;Y)\leq I(F,F^{\prime};Y)
$$
$$
I(V;Y)\leq I(F,F^{\prime};Y)
$$
where $I(F,F^{\prime};Y)$ represents the mutual information between features of the pair samples and the corresponding label $Y$ . If the aggregation method encodes the information efficiently, $I(V;Y)$ will approach its upper bound $I(F,F^{\prime};Y)$ . The mutual information of $V$ and $Y$ can be expressed as
其中 $I(F,F^{\prime};Y)$ 表示成对样本特征与对应标签 $Y$ 之间的互信息。若聚合方法能高效编码信息,则 $I(V;Y)$ 将趋近其上界 $I(F,F^{\prime};Y)$。变量 $V$ 与 $Y$ 的互信息可表示为
$$
\begin{array}{l}{{\displaystyle{\cal I}(V;Y)=E_{V,Y}[{\bf l o g}\frac{p(Y|V)}{p(Y)}]} }\ {{\displaystyle~=E_{V,Y}[{\bf l o g}(p(Y|V))]+H(Y)}}\end{array}
$$
$$
\begin{array}{l}{{\displaystyle{\cal I}(V;Y)=E_{V,Y}[{\bf l o g}\frac{p(Y|V)}{p(Y)}]} }\ {{\displaystyle~=E_{V,Y}[{\bf l o g}(p(Y|V))]+H(Y)}}\end{array}
$$
where $E$ denotes the mathematical expectation, $p$ denotes the probability distribution, and $q$ is the variation al estimate of $p.H$ indicates the entropy function. According to [30],
其中 $E$ 表示数学期望,$p$ 表示概率分布,$q$ 是 $p$ 的变分估计。$H$ 表示熵函数。根据 [30],
$$
\begin{array}{r}{I(V;Y)=E_{V,Y}[\mathbf{log}(p(Y|V))]+H(Y)}\ {\geq E_{V,Y}[\mathbf{log}(q(Y|V))]+H(Y)}\end{array}
$$
$$
\begin{array}{r}{I(V;Y)=E_{V,Y}[\mathbf{log}(p(Y|V))]+H(Y)}\ {\geq E_{V,Y}[\mathbf{log}(q(Y|V))]+H(Y)}\end{array}
$$
From equations (10) and (15), we obtain
根据方程 (10) 和 (15), 我们得出
$$
I(F,F^{\prime};Y)\ge I(V;Y)\ge E_{V,Y}[\log(q(Y|V))]+H(Y)
$$
$$
I(F,F^{\prime};Y)\ge I(V;Y)\ge E_{V,Y}[\log(q(Y|V))]+H(Y)
$$
In our action-aware loss, the model is optimized using crossentropy loss, which is equivalent to
在我们的动作感知损失中,模型使用交叉熵损失 (crossentropy loss) 进行优化,这相当于
$$
E_{V,Y}[\mathbf{log}(q(Y|V))]
$$
$$
E_{V,Y}[\mathbf{log}(q(Y|V))]
$$
By maximizing the lower bound of mutual information $I(V;Y)$ , we optimize the first term of the information bottleneck theory, which improves the predictive capability of the model.
通过最大化互信息 $I(V;Y)$ 的下界,我们优化了信息瓶颈理论的第一项,从而提升了模型的预测能力。
TABLE I ABLATION ON MAJOR COMPONENTS IN LIMITED-SCALE SETTING AND ONE-SHOT SETTING (O.S.). TOP-1 ACCURACY $(%)$ IS DISPLAYED. Pair INDICATES SAMPLE PAIRS SELECTION, Disent. INDICATES FEATURE DISENTANGLEMENT, $X$ -Aggr. INDICATES CROSS-SAMPLE AGGREGATION.
表 1: 有限规模设置和单样本设置 (O.S.) 下主要组件的消融实验。Top-1 准确率 $(%)$ 已显示。Pair 表示样本对选择,Disent. 表示特征解耦,$X$-Aggr. 表示跨样本聚合。
| 方法 | NTU | NTU120 | PKU | NTU120(O.S.) |
|---|---|---|---|---|
| Baseline | 41.5 | 19.7 | 28.5 | 39.0 |
| + Pair | 46.4 | 23.6 | 31.4 | 43.1 |
| + Disent. | 47.2 | 24.4 | 36.0 | 47.4 |
| + X-Aggr. | 52.3 | 27.0 | 37.0 | 48.2 |
TABLE II ABLATION ON BALANCE HYPER-PARAMETER IN NTU $\mathrm{RGB}{+}\mathrm{D}$ LIMITED-SCALE SETTING. RESULTS ARE SHOWN IN TOP-1 ACCURACY $(%)$ .
表 2: NTU RGB+D 有限规模设置中平衡超参数的消融研究。结果以 Top-1 准确率 (%) 展示。
| 每类样本数 | |
|---|---|
| 10 | |
| 0.1 | 52.3 |
| 0.2 | 51.4 |
| 0.5 | 52.1 |
| 1.0 | 51.2 |
IV. EXPERIMENT
IV. 实验
A. Datasets
A. 数据集
We select three widely adopted datasets that provide subject (performer) attributes of each action sequence to implement and evaluate our proposed method.
我们选择了三个广泛采用的数据集来实施和评估所提出的方法,这些数据集提供了每个动作序列的主体(执行者)属性。
NTU-RGB $\mathbf{+D}$ (NTU) [5] dataset consists of 56,880 video samples captured using Microsoft Kinect v2, which is one of the most widely used dataset in skeleton-based action recognition. Depth cameras with 3 different horizontal angle settings provide precise 3D coordinates of joints. Actions in this dataset are performed by 40 human subjects and are categorized into 60 classes. The dataset provides two benchmarks: Cross Subject (CSub) and Cross View (CView). CSub setting divides the dataset according to the subjects. The training set includes 20 subjects, and the testing set includes the other 20 subjects. CView setting splits the dataset by the camera views, while the subjects are the same in the training and testing phase.
NTU-RGB $\mathbf{+D}$ (NTU) [5] 数据集包含56,880个使用Microsoft Kinect v2捕捉的视频样本,是基于骨架的动作识别领域应用最广泛的数据集之一。通过3种不同水平角度设置的深度相机,该数据集提供了精确的关节3D坐标。40名受试者执行了60类动作。数据集提供两个基准:跨受试者(CSub)和跨视角(CView)。CSub按受试者划分数据集,训练集包含20人,测试集包含另外20人。CView则按相机视角划分数据,训练与测试阶段的受试者完全一致。
NTU-RGB $\mathbf{+D}$ 120 (NTU-120) [6] dataset extends NTU- $\mathrm{RGB}{+}\mathrm{D}$ [5] to 113,945 human skeleton sequences to 120 action categories performed by 106 subjects, and 32 different views that vary in camera setup and background. It also provides an additional benchmark: One-shot learning, where 20 classes are assigned as novel categories with one exemplar sample per class.
NTU-RGB $\mathbf{+D}$ 120 (NTU-120) [6] 数据集将 NTU- $\mathrm{RGB}{+}\mathrm{D}$ [5] 扩展到 113,945 个人体骨骼动作序列,涵盖 106 名受试者执行的 120 种动作类别,以及摄像机设置和背景各异的 32 种不同视角。该数据集还提供了一个额外基准:单样本学习 (One-shot learning) ,其中 20 个类别被指定为新增类别,每个类别仅包含一个示例样本。
PKU-MMD [7] dataset is a large-scale multi-modality benchmark for 3D skeleton action recognition. It contains around 28,000 action instances and comprises two subsets under different settings: Part I and Part II. We employ part II in this paper, primarily because it provides sequence-wise subject label. Part II contains around 6,900 action instances with 41 action classes, performed by 13 subjects. Part II is also more challenging than Part I due to short action intervals, concurrent actions, and heavy occlusion.
PKU-MMD [7] 数据集是一个用于3D骨骼动作识别的大规模多模态基准。它包含约28,000个动作实例,由两部分不同设置下的子集组成:第一部分和第二部分。本文采用第二部分,主要因其提供了序列级的主体标签。第二部分包含约6,900个动作实例,涵盖41个动作类别,由13名主体完成。由于动作间隔短、并发动作多以及严重遮挡,第二部分比第一部分更具挑战性。
TABLE III ABLATION STUDY ON FEATURE DISENTANGLEMENT BY SETTING PART OF THE DISENTANGLED FEATURE TO ZERO IN LIMITED-SCALE SETTING (10 SAMPLES PER CLASS) ON NTU-RGB $+\mathrm{D}$ DATASET. TOP-1 ACCURACY $(%)$ IS SHOWN IN THE TABLE. w/o Action Feat. INDICATES MASK ACTION FEATURE, AND w/o Performer Feat. INDICATES MASKING THE PERFORMER FEATURE.
表 III: 在NTU-RGB $+\mathrm{D}$ 数据集上通过将部分解耦特征置零进行的特征解耦消融研究 (每类10个样本的有限规模设置)。表中显示的是Top-1准确率 $(%)$。w/o Action Feat. 表示屏蔽动作特征,w/o Performer Feat. 表示屏蔽执行者特征。
| Method | CTR-GCN | ST-GCN | TCA-GCN |
|---|---|---|---|
| Baseline | 41.5 | 35.4 | 42.1 |
| Ours | 52.3 | 47.9 | 50.9 |
| w/o Action Feat. | 11.5 | 11.2 | 13.0 |
| w/o Performer Feat. | 49.9 | 36.0 | 48.1 |
TABLE IV ACCURACY $(%)$ COMPARISON ON ONE-SHOT SETTING WITH DIFFERENT NUMBERS OF TRAINING CLASSES ON NTU $\mathbf{RGB}{+}\mathbf{D}$ 120 DATASET. THE BEST RESULTS ARE SHOWN IN BOLD, AND THE SECOND BEST RESULTS ARE SHOWN WITH UNDERLINE.
表 4: NTU RGB+D 120 数据集上不同训练类别数量下一次性设置的准确率 (%) 对比。最佳结果以粗体显示,次佳结果以下划线显示。
| 训练类别 | 20 | 40 | 60 | 80 | 100 |
|---|---|---|---|---|---|
| APSR [6] | 29.1 | 34.8 | 39.2 | 42.8 | 45.3 |
| SL-DML [43] | 36.7 | 42.4 | 49.0 | 46.4 | 50.9 |
| Skeleton-DML[19] | 28.6 | 37.5 | 48.6 | 48.0 | 54.2 |
| uDTW [44] | 32.2 | 39.0 | 41.2 | 45.3 | 49.0 |
| JEANIE [20] | 38.5 | 44.1 | 50.3 | 51.2 | 57.0 |
| SMAM [45] | 35.8 | 46.2 | 51.7 | 52.2 | 56.4 |
| ALCA-GCN [37] | 38.7 | 46.6 | 51.0 | 53.7 | 57.6 |
| STA-MLN [46] | 42.5 | 48.8 | 53.1 | 54.3 | 59.9 |
| M&C-scale [21] | 44.1 | 55.3 | 60.3 | 64.2 | 68.7 |
| SkeletonX(本方法) | 48.2 | 54.9 | 61.6 | 65.6 | 69.1 |
B. Evaluation Protocols
B. 评估协议
To validate the data efficiency of our proposed method, we conduct experiments in two settings: the one-shot setting and the limited-scale setting.
为验证所提方法的数据效率,我们在两种设置下进行实验:单样本设置和小规模设置。
One-shot Learning. We follow the one-shot evaluation protocol proposed in [6], which selects 100 base classes and 20 novel classes with one fixed exemplar. Samples from base classes are used for training, and samples other than the exemplars in the novel classes are used for testing. For NTU $\mathrm{RGB}{+}\mathrm{D}$ and PKU-MMD datasets, we follow previous work [21], [38], [47] to assign 10 novel classes with one fixed exemplar.
单样本学习。我们遵循[6]提出的单样本评估协议,该协议选择100个基类和20个新类,每个新类固定一个示例。基类样本用于训练,新类中除示例外的样本用于测试。对于NTU $\mathrm{RGB}{+}\mathrm{D}$和PKU-MMD数据集,我们沿用先前工作[21]、[38]、[47]的设置,分配10个新类并固定一个示例。
Limited-Scale Training. We sample from the original cross-subject training set to simulate datasets with different scales and explore the potential of performance improvement with continuous data collection. Specifically, we draw 10, 20, 30, and 50 samples per class for the training set. Instead of randomly drawn samples from the training set [39], we limit the number of subjects and setups to reduce the cost of finding volunteers and setting up different camera views. As illustrated in Alg. 1, we select $P$ performers with the least setups when sampling from each action category based on cross-subject setting. Specifically, we first create a table $T$ with columns ‘performer’, ‘setup’, and ‘skeleton filename’. Each row corresponds to a sample in the training set, initially sorted alphabetically by ‘skeleton filename’. The testing set is kept intact to ensure adequate evaluation.
有限规模训练。我们从原始跨主体训练集中采样,模拟不同规模的数据集,探索持续数据收集带来的性能提升潜力。具体而言,我们为训练集每类抽取10、20、30和50个样本。不同于从训练集中随机抽取样本[39],我们通过限制主体数量和拍摄配置来降低寻找志愿者和架设多视角摄像机的成本。如算法1所示,基于跨主体设置从每个动作类别采样时,我们优先选择拍摄配置最少的$P$个表演者。具体流程为:首先创建包含"表演者"、"配置"和"骨骼文件名"三列的表格$T$,每行对应训练集的一个样本,初始按"骨骼文件名"字母序排列。测试集保持完整以确保评估充分性。
Algorithm 1 Limited-scale Sample Selection Algorithm
算法 1: 有限规模样本选择算法
Input: Table $T$ with columns: performer ID, setup, and action ID
表 $T$ 包含列:表演者 ID、设置和动作 ID
Parameter: Number of samples per class $N$ , Number of action categories $C$ , Number of performer $P$
参数:每类样本数 $N$,动作类别数 $C$,表演者数 $P$
Output: Trimmed Table $T^{\prime}$
输出:修剪后的表 $T^{\prime}$
C. Implementation Details
C. 实现细节
Experiments are conducted using two Nvidia RTX 2080 Ti GPUs for the CTR-GCN [13], ST-GCN [8] and BlockGCN [16] encoders. Two Nvidia V100 GPUs are used for experiments on TCA-GCN [14] and Skate Former [48] due to their excessive parameters. We follow the data pre-processing procedures described in [13], which remove empty frames and resize each video clip to 64 frames. For all GCN-based backbones, we apply the SGD optimizer with a momentum of 0.9 and a weight decay of 0.0004 to train the model. For the transformer-based model Skate Former, we follow the training protocol as the original paper [48]. The balance parameter $w_{x}=0.1$ is set for two settings based on the ablation studies. All experiments are conducted in the joint modality.
实验使用两块Nvidia RTX 2080 Ti GPU运行CTR-GCN [13]、ST-GCN [8]和BlockGCN [16]编码器。由于TCA-GCN [14]和Skate Former [48]参数量过大,改用两块Nvidia V100 GPU进行实验。我们遵循[13]描述的数据预处理流程:删除空帧并将每个视频片段调整为64帧。所有基于GCN的骨干网络均采用动量0.9、权重衰减0.0004的SGD优化器进行训练。对于基于Transformer的Skate Former模型,我们沿用原论文[48]的训练方案。根据消融实验,两种设置下的平衡参数$w_{x}=0.1$。所有实验均在关节模态下进行。
During the inference phase, the feature disentanglement module and aggregate module are retained with the trained parameters and only perform intra-sample aggregation. The output of the SoftMax layer indicates the probability of each action category.
在推理阶段,特征解耦模块和聚合模块保留训练后的参数,仅执行样本内聚合。SoftMax层的输出表示每个动作类别的概率。
Limited-Scale Training. The model is trained for 65 epochs with an initial learning rate of 0.1. The learning rate decays by a factor of 0.1 at epoch 35 and 55. To stabilize the training process, a warm-up strategy is employed during the first 5 epochs. Following [13], the batch size is set at 64 for NTU $\mathrm{RGB}{+}\mathrm{D}$ , NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 120 and PKU-MMD in baseline methods. To accommodate the additional samples introduced by our method, the batch size is reduced to 32 when training with our approach.
有限规模训练。模型训练65个周期,初始学习率为0.1,在第35和55周期时学习率衰减为原来的0.1倍。为稳定训练过程,前5个周期采用预热策略。参照[13],基线方法在NTU $\mathrm{RGB}{+}\mathrm{D}$、NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 120和PKU-MMD数据集上的批次大小设为64。为适应本方法引入的额外样本,采用本方法训练时将批次大小降至32。
One-shot Learning. We adopt [13] as the GCN encoder for one-shot learning. The model is trained for 25 epochs for better performance. The initial learning rate is set at 0.1 with a warm-up in the first 5 epochs. The learning rate decays by 0.1 at epoch 10 and 15. The model is trained on base categories in a fully-supervised setting. During inference, the FC layer and SoftMax layer are removed to generate features for action sequences. Protonet [49] is used as the metric learning method for feature matching.
单样本学习 (One-shot Learning)。我们采用[13]作为单样本学习的GCN编码器。该模型训练25个周期以获得更优性能,初始学习率设为0.1并在前5个周期进行预热,学习率在第10和15个周期衰减0.1倍。模型在完全监督设置下基于基础类别进行训练,推理阶段移除FC层和SoftMax层以生成动作序列特征,采用Protonet[49]作为特征匹配的度量学习方法。
D. Ablation Studies
D. 消融实验
Ablation on Major Components. Ablation studies are conducted under two low-data conditions: limited-scale setting with 10 samples per class and one-shot learning setting with 20 training classes to demonstrate the efficacy of each component under extreme conditions. The results are shown in Table I. The sample pairs selection strategy along improves performance by encouraging the model to learn correlations. Subsequently, integrating the feature disentanglement module into the model results in a more substantial performance boost. By further introducing cross-sample aggregation, the model explicitly learns from the mixture of different samples, thereby increasing diversity and improving the performance. Each component contributes to the overall performance gains, demonstrating the effectiveness of our proposed method.
主要组件消融实验。消融研究在两种低数据条件下进行:每类10个样本的有限规模设置和20个训练类别的单样本学习设置,以验证各组件在极端条件下的有效性。结果如表1所示。样本对选择策略通过鼓励模型学习相关性来提升性能。随后,将特征解耦模块整合到模型中会带来更显著的性能提升。通过进一步引入跨样本聚合,模型能够显式地从不同样本的混合中学习,从而增加多样性并提高性能。每个组件都对整体性能提升有所贡献,证明了我们提出方法的有效性。
TABLE V ABLATION ON FEATURE AGGREGATION METHODS IN LIMITED-SCALE SETTING. TOP-1 ACCURACY $(%)$ IS DISPLAYED.
表 5: 有限规模设置下特征聚合方法的消融实验。展示的是 TOP-1 准确率 $(%)$ 。
| 方法 | NTURGB+D120 | NTURGB+D | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 20 | 30 | 50 | Average | 10 | 20 | 30 | 50 | Average | |
| Concat | 27.0 | 32.6 | 38.1 | 43.5 | 35.3 | 52.3 | 62.6 | 67.9 | 73.4 | 64.1 |
| MatMul | 24.3 | 31.4 | 36.2 | 41.1 | 33.3 | 52.8 | 61.0 | 67.0 | 72.4 | 63.3 |
| Cross-attn | 26.0 | 30.2 | 36.4 | 43.0 | 33.9 | 52.6 | 62.7 | 67.0 | 73.5 | 64.0 |
TABLE VI ACCURACY $(%)$ IN THE ONE-SHOT SETTING. NTU AND NTU-120 REFER TO NTU-RGB $+\mathrm{D}$ AND NTU-120 RESPECTIVELY. Param. INDICATES NUMBEROF PARAMETERS. FLOPS OF THE BACKBONE MODEL ARE PRESENTED IN PARENTHESES (IF APPLICABLE). THE BEST RESULTS ARE HIGHLIGHTED IN BOLD.
† Reported in paper [38].
表 6: 单样本设置下的准确率 $(%)$。NTU 和 NTU-120 分别指 NTU-RGB $+\mathrm{D}$ 和 NTU-120。Param. 表示参数量。主干模型的浮点运算次数 (FLOPS) 在括号中给出 (如适用)。最佳结果以粗体标出。
| 方法 | NTU | NTU120 | PKU-MMD(II) | Param.(M) | GFLOPs |
|---|---|---|---|---|---|
| 元学习方法 | |||||
| ProtoNet [49] | 75.0 | 66.0 | 37.0 | 1.46 | 1.79 (1.79) |
| FEAT [50] | 80.5 | 65.1 | 32.3 | 1.70 | 1.80 (1.79) |
| 其他方法 | |||||
| CATFormer [51] | 73.2 | 57.2 | 31.8 | 4.17 | 18.35 |
| FR-Head [52] | 78.1 | 65.4 | 34.3 | 1.99 | 1.79 |
| 基于匹配的方法 | |||||
| SL-DML [43] | 50.9 | 11.2 | 23.8 | ||
| Skeleton-DML [19] | 54.2 | 11.2t | 23.8t | ||
| SL-DML (CTR-GCN [13]) | 43.9t | 1.60 (1.46) | 9.2 (1.79) | ||
| Trans4SOAR (Small)[38] | 56.3 | 23.1 | 34.1 | ||
| Trans4SOAR (Base)[38] | 57.1 | 43.8 | 47.9 | ||
| Koopman [53] | 68.1 | 1.46 | 1.96 (1.79) | ||
| S-scale [21] | 77.4 | 63.2 | 3.78 | 30.4 (3.99) | |
| M-scale [21] | 81.6 | 67.6 | 15.12 | 79.6 (12.85) | |
| M&C-scale [21] | 82.7 | 68.7 | 15.12 | 79.9 (12.85) | |
| 我们的方法 | 83.2 | 69.1 | 38.3 | 1.53 (1.46) | 1.80 (1.79) |
† 数据来自论文 [38]。
Ablation on Hyper-parameters. We analyze the balance parameter $w_{x}$ in the sample aggregation loss, with result shown in Table II. We find that $w_{x}~=~0.1$ yields better performance across all settings in limited-scale training. Nevertheless, the sample aggregation is still useful. As shown in Table I, the $^{\circ\circ}+$ Disent.” column equivalent to setting this hyperparameter to 0, reveals a notable performance deterioration to $47.2%$ .
超参数消融实验。我们分析了样本聚合损失中的平衡参数 $w_{x}$ ,结果如表 II 所示。发现在有限规模训练中, $w_{x}~=~0.1$ 能在所有设置下取得更优性能。尽管如此,样本聚合仍具有实用价值。如表 I 所示,将超参数设为 0 的 $^{\circ\circ}+$ Disent." 列显示性能显著下降至 $47.2%$ 。
Effectiveness of Feature Disentanglement. To evaluate the contribution of the disentangled features to the final prediction, and demonstrate that the action feature and the performer feature are decoupled, we manually mask the action feature or performer feature by setting it to zero before aggregation. Results shown in Table III show a significant performance decline without the action feature. The absence of the performer feature impairs the performance but still surpasses the baseline. This indicates that the action-related feature predominantly drives the classification, yet still requires the performer feature for optimal performance. The performer-related feature appears to enhance action diversity, thus contributing to more accurate inference.
特征解耦的有效性。为评估解耦特征对最终预测的贡献,并验证动作特征与执行者特征确实解耦,我们在聚合前手动将动作特征或执行者特征置零进行掩码。表 III 结果显示,缺失动作特征会导致性能显著下降,而缺失执行者特征虽会损害性能但仍超越基线。这表明动作相关特征主导分类过程,但仍需执行者特征来实现最优性能。执行者相关特征似乎能增强动作多样性,从而提升推理准确性。
Training Classes in One-shot Setting. One important question in one-shot action recognition is how many training classes are sufficient for learning effective action representations. Following previous studies on NTU $\mathrm{RGB}{+}\mathrm{D}$ 120 dataset, we train our model on different numbers of training classes. The result shown in Table IV illustrates the competitive performance of our method, especially when training data is scarce.
单样本设置中的训练类别。单样本动作识别中的一个重要问题是,多少训练类别足以学习有效的动作表征。根据先前关于NTU $\mathrm{RGB}{+}\mathrm{D}$ 120数据集的研究,我们在不同数量的训练类别上训练模型。表IV所示的结果表明,我们的方法具有竞争优势,尤其是在训练数据稀缺时。
Ablation on Aggregation Strategy. To examine the impact of different designs on feature aggregation. We conduct ablation studies on different feature aggregation strategies in the limited-scale setting, presented in Table V with the following setups:
特征聚合策略消融实验。为了探究不同设计对特征聚合的影响,我们在有限规模设置下对不同特征聚合策略进行了消融研究,具体设置如表 V 所示:
(1) Concatenation: where disentangled features are first processed through an average pooling layer and then concate
(1) 串联:首先通过平均池化层处理解耦特征,然后进行拼接
TABLE VII TOP-1 ACCURACY $(%)$ WHEN COMBINING OUR PROPOSED METHOD TO MULTIPLE SKELETON-BASED ACTION RECOGNITION GCN BACKBONES IN LIMITED-SCALE SETTING. THE BEST TOP-1 ACCURACY IS IN BOLD. R.R. INDICATES RANDOM ROTATION.
表 VII: 在有限规模设置下将我们提出的方法结合到多个基于骨架的动作识别GCN骨干网络时的TOP-1准确率 $(%)$。最佳TOP-1准确率以粗体显示。R.R.表示随机旋转。
| 方法 | PKU-MMD (II) 10 | 20 | 30 | 50 | NTU 10 | 20 | 30 | 50 | NTU-120 10 | 20 | 30 | 50 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ST-GCN [8] | 22.3 | 34.8 | 43.5 | 51.6 | 34.9 | 51.7 | 57.4 | 66.0 | 18.9 | 21.2 | 25.7 | 35.4 |
| w/ Mixup | 25.9 | 36.3 | 42.6 | 51.9 | 37.3 | 53.1 | 59.7 | 67.0 | 19.4 | 23.1 | 30.4 | 41.3 |
| w/ R.R. | 25.6 | 34.4 | 46.8 | 52.2 | 41.0 | 55.4 | 62.1 | 70.0 | 21.0 | 24.9 | 27.0 | 40.9 |
| w/ Ours | 33.3 | 43.5 | 49.4 | 54.4 | 49.0 | 60.0 | 64.7 | 71.5 | 24.1 | 27.3 | 33.5 | 43.0 |
| △ | +11.0 | +8.7 | +5.9 | +2.8 | +14.1 | +8.3 | +7.3 | +5.5 | +5.2 | +6.1 | +7.8 | +7.6 |
| TCA-GCN [14] | 29.8 | 39.6 | 46.1 | 52.7 | 40.9 | 52.9 | 59.8 | 67.3 | 20.9 | 24.7 | 27.1 | 33.8 |
| w/ Mixup | 33.0 | 42.0 | 46.9 | 52.5 | 45.8 | 57.6 | 62.5 | 68.8 | 23.6 | 27.2 | 29.3 | 42.1 |
| w/ R.R. | 27.9 | 41.7 | 47.4 | 53.4 | 46.0 | 57.4 | 63.5 | 70.7 | 24.8 | 29.6 | 32.0 | 37.9 |
| w/ Ours | 35.4 | 42.8 | 49.5 | 54.8 | 51.3 | 61.7 | 67.3 | 73.1 | 26.1 | 30.0 | 35.4 | 43.7 |
| △ | +5.6 | +3.2 | +3.4 | +2.1 | +10.4 | +8.8 | +7.5 | +5.8 | +5.2 | +5.3 | +8.3 | +9.9 |
| BlockGCN [16] | 25.5 | 33.8 | 38.2 | 47.9 | 34.8 | 48.1 | 53.7 | 61.0 | 18.3 | 24.3 | 28.2 | 39.5 |
| w/ Mixup | 28.3 | 34.8 | 41.6 | 47.7 | 38.5 | 53.4 | 58.2 | 66.5 | 20.4 | 28.7 | 34.2 | 44.2 |
| w/ R.R. | 27.5 | 31.4 | 40.2 | 46.5 | 37.3 | 51.1 | 56.0 | 64.0 | 19.8 | 29.1 | 34.2 | 41.2 |
| w/ Ours | 30.4 | 37.2 | 43.8 | 49.5 | 45.2 | 56.8 | 63.1 | 68.7 | 25.0 | 34.0 | 39.4 | 47.4 |
| △ | +4.9 | +3.4 | +5.6 | +1.6 | +10.4 | +8.7 | +9.4 | +7.7 | +6.7 | +9.7 | +11.2 | +7.9 |
| CTR-GCN [13] | 29.2 | 40.1 | 46.7 | 53.2 | 41.5 | 53.9 | 60.0 | 67.5 | 21.3 | 25.5 | 29.8 | 38.6 |
| w/ Mixup | 34.2 | 42.7 | 48.0 | 54.2 | 45.4 | 57.3 | 64.0 | 69.9 | 24.7 | 28.3 | 34.4 | 42.7 |
| w/ R.R. | 31.6 | 41.2 | 47.7 | 53.7 | 46.4 | 58.5 | 64.4 | 70.8 | 24.8 | 30.5 | 34.0 | 42.4 |
| w/ Ours | 36.9 | 42.6 | 49.0 | 54.5 | 52.2 | 61.7 | 67.0 | 73.0 | 26.1 | 32.3 | 36.8 | 43.6 |
| △ | +7.7 | +2.5 | +2.3 | +1.3 | +10.7 | +7.8 | +7.0 | +5.5 | +4.8 | +6.8 | +7.0 | +5.0 |
nated.
已终止。
(2) Matrix Multiplication: which involves element-wise multiplication along the channel dimension, followed by a $1\times1$ convolution and global average pooling across the temporal and spatial dimensions.
(2) 矩阵乘法 (Matrix Multiplication):沿通道维度进行逐元素相乘,随后执行 $1\times1$ 卷积,并在时间和空间维度上进行全局平均池化 (global average pooling)。
(3) Cross Attention: where the temporal feature serves as the query, and the spatial features act as key and value.
(3) 交叉注意力 (Cross Attention): 其中时序特征作为查询 (query), 空间特征作为键 (key) 和值 (value)。
While other strategies slightly outperform concatenation in some settings on the NTU $\mathrm{RGB}{+}\mathrm{D}$ dataset, the concatenation method consistently delivers more stable performance across different datasets. Furthermore, concatenation introduces no extra parameters and avoids heavy computation overhead. These findings suggest that cross-sample feature aggregation may enhance spatial and temporal modeling within GCN encoders, thus improving feature representation. Additionally, in limited-scale settings where the number of samples is small, aggregation methods like the attention mechanism may focus on noise, which could impair the robustness of the model on full-scale testing data. Since the main goal of our method is to learn better representations from scarce data, we adopt a simpler aggregation strategy, following Occam’s Razor, to prevent over-complicating the model.
在其他策略于NTU $\mathrm{RGB}{+}\mathrm{D}$ 数据集某些场景中表现略优的情况下,拼接方法在不同数据集间始终展现出更稳定的性能。此外,拼接方式无需引入额外参数,且避免了繁重的计算开销。这些发现表明跨样本特征聚合可能增强GCN编码器中的时空建模能力,从而提升特征表征质量。值得注意的是,在样本数量有限的场景中,注意力机制等聚合方法可能聚焦于噪声,进而影响模型在全量测试数据上的鲁棒性。由于本方法的核心目标是从稀缺数据中学习更优表征,我们遵循奥卡姆剃刀原则,采用更简单的聚合策略以避免模型过度复杂化。
E. Model Efficiency Comparison
E. 模型效率对比
To illustrate the efficiency of our design, we compare it with two competitive methods. Since there is no official implementation code available for these methods, we obtain the code for their backbone models and calculate the number of parameters and FLOPs by running a single sample in inference mode. Then we calculate the additional parameters and FLOPs introduced by each method according to their papers and combine them with the baseline ones to get the final results. Due to the lightweight and universal module design of our method, the number of parameters only increases by approximately 0.07M. As presented in Table VI, our lightweight design achieves competitive results with state-ofthe-art methods [21] with 1/10 parameters and 1/40 FLOPs.
为了说明我们设计的高效性,我们将其与两种竞争方法进行了比较。由于这些方法没有官方实现代码,我们获取了其主干模型的代码,并通过在推理模式下运行单个样本来计算参数数量和FLOPs。然后根据各自论文计算每种方法引入的额外参数和FLOPs,再与基线值结合得出最终结果。得益于我们方法的轻量级通用模块设计,参数数量仅增加约0.07M。如表VI所示,我们的轻量级设计仅用1/10参数和1/40 FLOPs就达到了与最先进方法[21]相当的竞争力。
TABLE VIII ACCURACY $(%)$ COMPARISON ON ONE-SHOT SKELETON ACTION RECOGNITION ON NTU $\mathrm{RGB+D}$ AND NTU $\mathrm{RGB}{+}\mathrm{D}$ 120 DATASETS.
表 VIII NTU RGB+D 和 NTU RGB+D 120 数据集上单次骨架动作识别的准确率 (%) 对比
| 方法 | 会议/期刊 | NTU | NTU-120 |
|---|---|---|---|
| Meta Learning | |||
| ProtoNet [49] | NIPS 2017 | 75.0 | 66.0 |
| FEAT [50] | CVPR 2020 | 80.5 | 65.1 |
| Base GCN Models | |||
| ST-GCN [8] | AAAI 2018 | 71.7 | 63.3 |
| CTR-GCN [13] | CVPR 2021 | 76.6 | 64.6 |
| TCA-GCN [14] | Arxiv 2022 | 71.0 | 66.3 |
| One-shot Methods | |||
| APSR [6] | TPAMI 2020 | 45.3 | |
| TCN [24] | CVPR 2021 | 46.5 | |
| SL-DML [43] | ICPR 2021 | 50.9 | |
| Skeleton-DML [19] | WACV2022 | 54.2 | |
| uDTW [44] | ECCV2022 | 72.4 | 49.0 |
| JEANIE [20] | ACCV2022 | 80.0 | 57.0 |
| ALCA-GCN [37] | WACV2023 | 57.6 | |
| Koopman [53] | CVPR 2023 | 68.1 | |
| SMAM [45] | TIP 2023 | 73.6 | 56.4 |
| Trans4SOAR [38] | TMM 2023 | 74.2 | 57.1 |
| STA-MLN [46] | SPL 2024 | 59.9 | |
| CrossGLG [47] | ECCV 2024 | 75.6 | 62.6 |
| M&C-scale [21] | TPAMI 2024 | 82.7 | 68.7 |
| SkeletonX (Ours) | 83.2 | 69.1 |
TABLE IX ACCURACY $(%$ COMPARISON ON ONE-SHOT SKELETON ACTION RECOGNITION METHODS ON PKU-MMD (II) DATASET.
表 IX PKU-MMD (II) 数据集上单样本骨架动作识别方法的准确率 $(%$ 对比
| 方法 | 会议 | PKU-MMD (II) |
|---|---|---|
| MetaLearning | ||
| ProtoNet [49] | NIPS 2017 | 37.0 |
| FEAT [50] | CVPR2020 | 32.3 |
| BaseGCNmodels | ||
| ST-GCN[8] | AAAI2018 | 31.6 |
| CTR-GCN [13] | CVPR2022 | 32.5 |
| TCA-GCN [14] | Arxiv2023 | 28.8 |
| SkeletonX (Ours) | 38.3 |

Fig. 6. Visualization of feature space using t-SNE for samples from NTU $\scriptstyle\mathrm{RGB+D}$ dataset. Each row represents a different GCN backbone. The first column presents the results from the original backbones, while the second column displays the results from our proposed method.
图 6: 使用t-SNE对NTU $\scriptstyle\mathrm{RGB+D}$ 数据集样本进行特征空间可视化的结果。每行代表不同的GCN主干网络,第一列展示原始主干网络的结果,第二列展示我们提出方法的结果。
F. Visualization on Action Feature
F. 动作特征可视化
To gain insight into the feature space distribution, we randomly select several categories from the NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ dataset and visualize their distributions using t-SNE, as shown in Fig. 6. Specifically, we extract the output feature before the FC layer for the original backbones, and the output actionrelated feature from the feature disentanglement module for our proposed method. Each column represents one GCN backbone. The upper row is from the original backbones, and the bottom row is from our proposed method. It can be observed that our method achieves a more disc rim i native feature representation, characterized by clearer boundaries and more compact clusters.
为了深入理解特征空间的分布情况,我们从 NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 数据集中随机选取了几个类别,并使用 t-SNE 可视化它们的分布,如图 6 所示。具体而言,对于原始骨干网络,我们提取了全连接层前的输出特征;而对于我们提出的方法,则从特征解耦模块中提取了与动作相关的输出特征。每一列代表一种 GCN 骨干网络,上排为原始骨干网络的结果,下排为我们提出的方法。可以观察到,我们的方法实现了更具判别性的特征表示,表现为更清晰的边界和更紧凑的聚类。
G. Combine with Base Models
G. 与基础模型结合
To demonstrate the universality of our approach across different GCN architectures, we implement our method on various GCN models. For fair comparison, we re-implement the baseline methods and test them on multiple datasets under the limited-scale setting. The results are presented in Table VII. Compared to other augmentation methods in skeletonbased action recognition, our proposed method improves the performance the most across various backbones. The maximum improvement is $14.1%$ in 10 samples per class setting, highlighting its effectiveness, particularly when training data are scarce.
为验证我们方法在不同图卷积网络(GCN)架构中的普适性,我们在多种GCN模型上实现了该方法。为保证公平比较,我们重新实现了基线方法,并在有限规模设置下测试了多个数据集。结果如表VII所示。与其他基于骨架动作识别的数据增强方法相比,我们提出的方法在各类骨干网络中实现了最大性能提升。在每类10样本的设置下最高提升达$14.1%$,这尤其凸显了该方法在训练数据稀缺时的有效性。
When applied to transformer-based models, our method also shows performance gains with some settings, as illustrated in Table X. Skate Former includes multiple data augmentation methods, we keep all of them as the baseline and implement our method. We observe that performance improvements are less significant compared to those achieved with GCN-based backbones. This discrepancy could be attributed to the inherent differences between the global attention mechanism of the Transformer and the topology-based approach of GCNs. The attention mechanism in Transformers may not perform as effectively in settings with fewer data, as it may focus on less relevant parts of the data.
当应用于基于Transformer的模型时,我们的方法在某些设置下也展现出性能提升,如表X所示。Skate Former包含多种数据增强方法,我们将其全部保留作为基线并实施我们的方法。观察到性能改进相比基于GCN的主干网络所取得的提升较为有限。这种差异可能源于Transformer的全局注意力机制与GCN基于拓扑结构的方法之间存在固有差异。在数据较少的设置中,Transformer的注意力机制可能无法有效聚焦数据相关部分。
H. Applying to Other Modality
H. 应用于其他模态
To validate the effectiveness of our method on other modalities, we have extended our experiments to the bone modality, which is also widely used in skeleton-based action recognition [6], [13], [52]. The results, as shown in Table XI, demonstrate that our method performs well in this modality, with a significant performance increase of up to $15.0%$ on the NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ dataset with 10 samples per category.
为了验证我们方法在其他模态上的有效性,我们将实验扩展到了骨骼模态(该模态也广泛应用于基于骨架的动作识别领域)[6], [13], [52]。如表11所示,结果表明我们的方法在该模态上表现良好,在NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 数据集(每类别10个样本)上实现了高达$15.0%$的性能提升。
Our approach consistently outperforms the baseline methods across different datasets, including PKU-MMD (II), NTU, and NTU-120. This highlights the versatility and robustness of our method in adapting to different input modalities and the limited-scale setting.
我们的方法在不同数据集上始终优于基线方法,包括PKU-MMD (II)、NTU和NTU-120。这凸显了我们方法在适应不同输入模态和有限规模设置时的多功能性和鲁棒性。
I. Comparison With State-of-the-Art Methods
I. 与现有最优方法的对比
To validate the effectiveness of our method with increasing pre training data, we conduct a comprehensive comparison with state-of-the-art one-shot methods. We also re-implement several meta-learning methods compatible with GCNs for comparison. Results of NTU $\mathrm{RGB}{+}\mathrm{D}$ and NTU $\mathrm{RGB}{+}\mathrm{D}$ 120 are shown in Table VIII and PKU-MMD (II) in Table IX, demonstrating that our method achieves state-of-the-art performance on multiple datasets. Our method achieves competitive results to advanced matching-based approaches [21], [53] while maintaining a concise and lightweight design.
为验证我们方法在预训练数据增加情况下的有效性,我们与当前最先进的单样本方法进行了全面对比。同时重新实现了多种兼容图卷积网络 (GCN) 的元学习方法进行对照实验。NTU $\mathrm{RGB}{+}\mathrm{D}$ 和 NTU $\mathrm{RGB}{+}\mathrm{D}$ 120数据集的结果展示在表 VIII 中,PKU-MMD (II) 数据集结果见 表 IX。实验表明,我们的方法在多个数据集上都达到了最先进性能。在保持简洁轻量设计的同时,本方法与先进的基于匹配的方法 [21], [53] 取得了具有竞争力的结果。
J. Mutual Information Estimation
J. 互信息估计
To validate the hypothesis that cross-sample feature aggregation improves Mutual Information (MI), we compare two MI values: the baseline MI, $I(F;Y)$ , calculated using the original feature $F=f_{\theta}(X)$ , and the MI, $I(V;Y)$ , computed using the aggregated feature $V=A(F,F^{\prime})$ in our proposed method. Since it is difficult to directly compute MI between variables of different dimensions, we estimate MI through MINE method [54].
为验证跨样本特征聚合能提升互信息 (Mutual Information, MI) 的假设,我们比较了两个 MI 值:基准 MI ($I(F;Y)$) 使用原始特征 $F=f_{\theta}(X)$ 计算,而 MI ($I(V;Y)$) 则采用我们提出的聚合特征 $V=A(F,F^{\prime})$ 计算。由于难以直接计算不同维度变量间的 MI,我们通过 MINE 方法 [54] 进行估计。
TABLE X TOP-1 ACCURACY $(%)$ WHEN COMBINING OUR PROPOSED METHOD TO TRANSFORMER-BASED METHOD SKATE FORMER [48] IN LIMITED-SCALE SETTING. THE BEST TOP-1 ACCURACY IS IN BOLD.
表 X: 在有限规模设置下将我们提出的方法与基于Transformer的方法SkateFormer[48]结合时的TOP-1准确率$(%)$。最佳TOP-1准确率以粗体显示。
| 方法 | PKU-MMD (II) | NTU | NTU-120 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 20 | 30 | 50 | 10 | 20 | 30 | 50 | 10 | 20 | 30 | 50 | |
| SkateFormer[48] | 26.1 | 33.5 | 40.0 | 47.9 | 39.8 | 51.9 | 60.6 | 70.2 | 14.0 | 21.4 | 23.6 | 27.2 |
| w/ Ours | 28.2 | 38.2 | 46.8 | 55.7 | 44.4 | 58.9 | 66.2 | 72.8 | 16.4 | 20.9 | 22.2 | 29.7 |
| △ | +2.1 | +4.7 | +6.8 | +7.8 | +4.6 | +7.0 | +5.6 | +2.6 | +2.4 | -0.5 | -1.4 | +2.5 |
TABLE XI EXTENDING OUR PROPOSED METHOD TO BONE MODALITY IN LIMITED-SCALE SETTING. THE BEST TOP-1 ACCURACY $(%)$ IS IN BOLD.
表 XI 将我们提出的方法扩展到有限规模设置下的骨骼模态。最佳 Top-1 准确率 $(%)$ 以粗体显示。
| 方法 | PKU-MMD (II) | NTU | NTU-120 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 20 | 30 | 50 | 10 | 20 | 30 | 50 | 10 | 20 | 30 | 50 | |
| ST-GCN | 23.8 | 29.4 | 35.5 | 46.6 | 28.7 | 41.1 | 48.1 | 58.7 | 12.7 | 18.9 | 23.1 | 34.1 |
| w/ R.R. | 24.2 | 34.5 | 40.1 | 49.8 | 38.4 | 48.3 | 55.8 | 65.8 | 14.9 | 21.0 | 27.2 | 37.4 |
| w/ Ours | 26.7 | 38.8 | 41.5 | 49.7 | 41.0 | 52.8 | 62.2 | 69.5 | 20.3 | 25.4 | 32.9 | 42.9 |
| △ | +2.9 | +9.4 | +6.0 | +3.1 | +12.3 | +11.7 | +14.1 | +10.8 | +7.6 | +6.5 | +9.8 | +8.8 |
| TCA-GCN | 25.5 | 32.5 | 41.4 | 49.3 | 32.2 | 45.5 | 52.9 | 63.4 | 13.1 | 19.4 | 24.6 | 38.0 |
| w/ R.R. | 24.8 | 35.5 | 42.2 | 51.9 | 40.8 | 54.4 | 60.1 | 69.0 | 16.0 | 20.7 | 27.9 | 41.8 |
| w/ Ours | 31.5 | 40.7 | 47.2 | 54.7 | 46.5 | 58.6 | 65.3 | 72.3 | 20.5 | 28.3 | 37.0 | 45.1 |
| △ | +6.0 | +8.2 | +5.8 | +5.4 | +14.3 | +13.1 | +12.4 | +8.9 | +7.4 | +9.1 | +12.4 | +7.1 |
| CTR-GCN | 26.0 | 33.7 | 41.4 | 48.6 | 30.9 | 46.4 | 54.4 | 65.1 | 15.8 | 21.9 | 25.7 | 37.8 |
| w/ R.R. | 25.6 | 37.4 | 44.5 | 51.9 | 40.4 | 54.4 | 61.3 | 69.6 | 17.6 | 25.0 | 31.6 | 40.4 |
| w/Ours | 29.4 | 39.8 | 46.7 | 54.1 | 45.9 | 58.0 | 65.5 | 72.0 | 22.9 | 30.6 | 36.9 | 45.2 |
| △ | +3.4 | +6.1 | +5.3 | +5.5 | +15.0 | +11.6 | +11.1 | +6.9 | +7.1 | +8.7 | +11.2 | +7.4 |

Fig. 7. Comparison on estimated Mutual Information (MI). The estimated MI converges to a stable value as the estimator is trained. Our method improves the mutual information compared to the baseline.
图 7: 互信息 (Mutual Information, MI) 估计对比。随着估计器的训练,估计的互信息值逐渐收敛至稳定状态。相较于基线方法,我们的方案显著提升了互信息量。
Specifically, we use ST-GCN [8] as the baseline model and train the MI estimator for 4500 steps (500 epochs) on 10 samples per category from the NTU $\mathrm{RGB}{+}\mathrm{D}$ dataset with a batch size of 64. As the MI estimator is trained, it gradually converges to a stable value. The relative size of this value allows us to compare the differences in mutual information between the baseline and our method. The results, shown in Figure 7, indicate that our method improves the MI from 3.02 to 5.69, outperforming the baseline. This verifies the assumption in Section III-E
具体而言,我们采用ST-GCN [8]作为基线模型,在NTU $\mathrm{RGB}{+}\mathrm{D}$ 数据集的每个类别10个样本上训练互信息(MI)估计器4500步(500轮次),批量大小为64。随着互信息估计器的训练,其值逐渐收敛至稳定状态。该值的相对大小使我们能够比较基线方法与我们方法之间的互信息差异。如图7所示,我们的方法将互信息从3.02提升至5.69,优于基线结果。这验证了第III-E节的假设。
V. CONCLUSION
V. 结论
In this paper, we investigate two low-data scenarios for skeleton-based action recognition and propose a novel crosssample aggregation method for action recognition under limited training data. First, it selects two types of sample pairs for each sample within a batch, then disentangles the sample and its pair to performer-related and action-related features. The decoupled features of the paired samples are crossed over and subsequently reassembled through an aggregation module. We also provide an analysis based on IB theory for a better understanding of the underlying mechanism of our proposed method. Our method can be easily integrated with multiple GCN backbones, demonstrating effectiveness and compatibility, and achieves competitive performance with fewer parameters and FLOPs.
本文研究了基于骨架的动作识别中的两种低数据场景,并提出了一种适用于有限训练数据的跨样本聚合新方法。该方法首先为批次内的每个样本选择两类样本对,随后将样本及其配对样本解耦为执行者相关特征和动作相关特征。通过聚合模块对配对样本的解耦特征进行交叉重组。我们还基于信息瓶颈(IB)理论进行了分析,以更好理解所提方法的内在机制。本方法可轻松集成多种图卷积网络(GCN)骨干,在参数量和FLOPs较少的情况下展现出优异性能与兼容性。
Discussion: 1) While our method demonstrates strong performance on GCN-based models, the performance gains on transformer architectures remain unstable. Currently, our method is tailored for GCN models. We plan to further explore the two key attributes in transformer-based architectures, focusing on optimizing the aggregation process to improve stability and performance. 2) We have been able to provide formal proofs for optimizing one term in the IB theory, however, the second term remains unproven due to the complex nature of deep learning models and the limitations of multi-variable mutual information estimation techniques. The black-box nature of deep learning models further complicates the derivation of a comprehensive theoretical justification. We believe that with a more systematic and formalized proof, coupled with corresponding experiments, the cross-sample aggregation method can be extended beyond the current application to a broader range of fields.
讨论:
- 虽然我们的方法在基于GCN的模型上表现出色,但在Transformer架构上的性能提升仍不稳定。目前该方法专为GCN模型设计。我们计划进一步探索基于Transformer架构的两个关键属性,重点优化聚合过程以提升稳定性和性能。
- 我们已能为信息瓶颈(IB)理论中的一个项提供形式化证明,但由于深度学习模型的复杂性、多变量互信息估计技术的局限性,第二个项仍缺乏证明。深度学习模型的黑箱特性进一步增加了构建完整理论依据的难度。我们相信,通过更系统化、形式化的证明配合相应实验,跨样本聚合方法可突破当前应用范围,拓展至更广泛的领域。
In conclusion, we hope that our work contributes to the advancement of data-efficient and computationally efficient skeleton-based action recognition, and inspires applications in other domains.
总之,我们希望这项工作能推动数据高效和计算高效的基于骨架的动作识别研究发展,并激励其他领域的应用。