MetaFormer : A Unified Meta Framework for Fine-Grained Recognition
MetaFormer: 面向细粒度识别的统一元框架
Abstract
摘要
Fine-Grained Visual Classification (FGVC) is the task that requires recognizing the objects belonging to multiple subordinate categories of a super-category. Recent state-of-the-art methods usually design sophisticated learning pipelines to tackle this task. However, visual information alone is often not sufficient to accurately differentiate between fine-grained visual categories. Nowadays, the meta-information (e.g., spatio-temporal prior, attribute, and text description) usually appears along with the images. This inspires us to ask the question: Is it possible to use a unified and simple framework to utilize various meta-information to assist in fine-grained identification? To answer this problem, we explore a unified and strong meta-framework (MetaFormer) for fine-grained visual classification. In practice, MetaFormer provides a simple yet effective approach to address the joint learning of vision and various meta-information. Moreover, MetaFormer also provides a strong baseline for FGVC without bells and whistles. Extensive experiments demonstrate that MetaFormer can effectively use various metainformation to improve the performance of fine-grained recognition. In a fair comparison, MetaFormer can outperform the current SotA approaches with only vision information on the i Naturalist 2017 and i Naturalist 2018 datasets. Adding meta-information, MetaFormer can exceed the current SotA approaches by $5.9%$ and $5.3%$ , respectively. Moreover, MetaFormer can achieve $92.3%$ and $92.7%$ on CUB-200-2011 and NABirds, which significantly outperforms the SotA approaches. The source code and pretrained models are released at https://github.com/ dqshuai/MetaFormer.
细粒度视觉分类 (Fine-Grained Visual Classification, FGVC) 是一项需要识别属于超类别下多个子类别对象的任务。当前最先进的方法通常设计复杂的学习流程来解决该任务。然而,仅凭视觉信息往往不足以准确区分细粒度视觉类别。如今,元信息 (如时空先验、属性和文本描述) 通常会与图像一起出现。这启发我们提出一个问题:是否可以使用一个统一且简单的框架来利用各种元信息辅助细粒度识别?为回答该问题,我们探索了一种用于细粒度视觉分类的统一强大元框架 (MetaFormer)。实践中,MetaFormer 提供了一种简单而有效的方法来解决视觉与各种元信息的联合学习问题。此外,MetaFormer 还为 FGVC 提供了一个无需复杂修饰的强大基线。大量实验证明,MetaFormer 能有效利用各类元信息提升细粒度识别性能。在公平比较中,仅使用视觉信息时,MetaFormer 在 iNaturalist 2017 和 iNaturalist 2018 数据集上已能超越当前 SotA 方法。添加元信息后,MetaFormer 分别以 $5.9%$ 和 $5.3%$ 的优势超越当前 SotA 方法。此外,MetaFormer 在 CUB-200-2011 和 NABirds 上分别达到 $92.3%$ 和 $92.7%$ 的准确率,显著优于 SotA 方法。源代码和预训练模型发布于 https://github.com/dqshuai/MetaFormer。
1. Introduction
1. 引言
In contrast to generic object classification, fine-grained visual classification aims to correctly classify objects belonging to the same basic category (birds, cars, etc.) into subcategories. FGVC has long been considered a challenging task due to the small inter-class variations and large intra-class variations.
与通用物体分类不同,细粒度视觉分类 (fine-grained visual classification) 旨在将属于同一基本类别(鸟类、汽车等)的对象正确分类为子类别。由于类间差异小、类内差异大,FGVC 长期以来被认为是一项具有挑战性的任务。
To the best of our knowledge, predominant approaches for FGVC are mainly concerned about how to make the network focus on the most disc rim i native regions, such as partbased model [12,16,25] and attention-based model [15,53]. Intuitively, such methods introduce inductive bias of localization to neural networks with elaborate structure, inspired by human observation behavior. In addition, human experts often use information besides vision to assist them in classifying when some species are visually in distinguishable. Note that the data of fine-grained recognition is multisource heterogeneous in the era of information explosion. Therefore, it is unreasonable that the neural network completes fine-grained classification tasks only with visual information. In practice, fine-grained classification, which is more difficult to distinguish visually, requires the help of orthogonal signals more than coarse-grained classification. Previous work [6,20,28] utilize additional information, such as spatio-temporal prior and text description, to assist finegrained classification. However, the design of these works for additional information only targets specific information, which is not universal. This inspires us to design a unified yet effective method to utilize various meta-information flexibly.
据我们所知,当前细粒度视觉分类 (FGVC) 的主流方法主要关注如何使网络聚焦于最具判别性的区域,例如基于部件的模型 [12,16,25] 和基于注意力的模型 [15,53]。直观上,这些方法通过精心设计的结构,将定位的归纳偏置引入神经网络,其灵感源于人类观察行为。此外,当某些物种在视觉上难以区分时,人类专家常借助视觉以外的信息辅助分类。值得注意的是,在信息爆炸时代,细粒度识别数据具有多源异构特性。因此,神经网络仅依靠视觉信息完成细粒度分类任务是不合理的。实践中,视觉上更难以区分的细粒度分类比粗粒度分类更需要正交信号的辅助。先前工作 [6,20,28] 利用时空先验、文本描述等附加信息辅助细粒度分类,但这些设计仅针对特定信息,缺乏普适性。这启发我们设计一种统一且高效的方法来灵活利用各类元信息。
Vision Transformer (ViT) shows pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. Intuitively, it is feasible to simultaneously take vision token and meta token as the input of the transformer for FGVC. However, it is still unclear whether the different modalities impair the model’s performance when interfering with each other. To answer this problem, we propose MetaFormer which uses a transformer to fuse vision and meta-information. As shown in Figure 1, MetaFormer can effectively improve the accuracy of FGVC with the assistance of meta-information. In practice, MetaFormer can also be seen as a hybrid structure backbone where the convolution can downsample the image and introduce the inductive bias of the convolution, and the transformer can fuse visual and meta-information. In this manner, MetaFormer also provides a strong baseline for FGVC without bells and whistles.
Vision Transformer (ViT) 表明,将纯 Transformer 直接应用于图像块序列可以在图像分类任务中表现优异。直观上,同时将视觉 token 和元 token 作为 Transformer 的输入用于细粒度视觉分类 (FGVC) 是可行的。然而,当不同模态相互干扰时,是否会损害模型性能尚不明确。为解决这一问题,我们提出了 MetaFormer,它使用 Transformer 融合视觉和元信息。如图 1 所示,MetaFormer 在元信息的辅助下能有效提升 FGVC 的准确率。实际应用中,MetaFormer 也可视为一种混合结构主干网络:卷积层能对图像进行下采样并引入卷积的归纳偏置,而 Transformer 能融合视觉与元信息。通过这种方式,MetaFormer 还为 FGVC 提供了一个无需复杂修饰的强基线。
Recent advances in image classification [18, 33] demonstrate large-scale pre-training could effectively improve the accuracy of both coarse-grained classification and finegrained classification. However, most of the current methods for FGVC are based on ImageNet-1k for pre-training, which hinders further exploration of fine-grained recognition. Thanks to the simplicity of MetaFormer, we further explore the influence of the pre-trained model in detail, which can provide references to researchers regarding the pre-trained model. As shown in Figure 1, large-scale pretrained models can significantly improve the accuracy of fine-grained recognition. Surprisingly, without introducing any priors for fine-grained tasks, MetaFormer can achieve the SotA performance on multiple datasets using the largescale pre-trained model.
图像分类的最新进展 [18, 33] 表明,大规模预训练能有效提升粗粒度分类和细粒度分类的准确率。然而当前多数细粒度视觉分类 (FGVC) 方法仍基于 ImageNet-1k 进行预训练,这限制了细粒度识别能力的进一步探索。得益于 MetaFormer 的简洁性,我们详细探究了预训练模型的影响机制,可为研究者提供预训练模型选择的参考依据。如图 1 所示,大规模预训练模型能显著提升细粒度识别准确率。令人惊讶的是,在未引入任何细粒度任务先验知识的情况下,MetaFormer 仅通过大规模预训练模型就能在多个数据集上实现当前最优 (SotA) 性能。
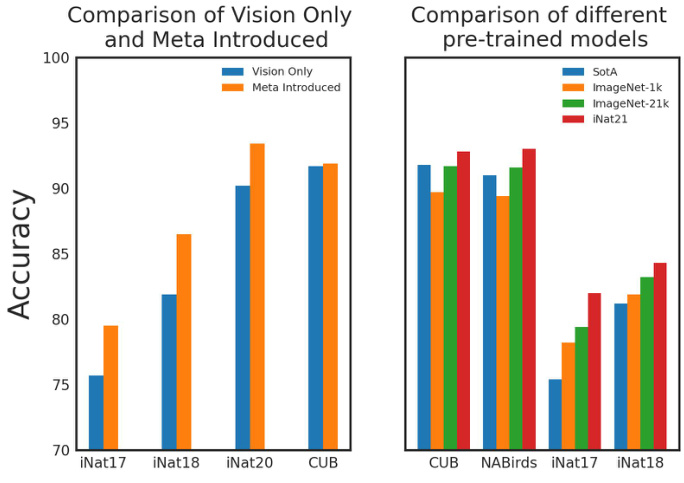
Figure 1. An overview of performance comparison of MetaFormer which using various meta-information and large-scale pre-trained model with state-of-the-art methods.
图 1: 采用不同元信息和大规模预训练模型的 MetaFormer 与最先进方法的性能对比概览。
The contribution of this study are summarized as follows:
本研究的贡献总结如下:
• We propose a unified and extremely effective metaframework for FGVC to unify the visual appearance and various meta-information. This urges us to reflect on the development of FGVC from a brand fresh perspective. • We provide a strong baseline for FGVC by only using the global feature. Meanwhile, we explored the impact of the pre-trained model on fine-grained classification in detail. Code and pre-trained models are available to assist researchers in further exploration. • Without any inductive bias of fine-grained visual classification task, MetaFormer can achieve $92.3%$ and $92.7%$ on CUB-200-2011 and NABirds, outperforming the SotA approaches. Using only vision information, MetaFormer can also achieve SotA performance ( $78.2%$ and $81.9%$ ) on i Naturalist 2017 and i Naturalist 2018 in a fair comparison.
• 我们提出了一种统一且极为有效的细粒度视觉分类 (FGVC) 元框架,用于统一视觉外观和各种元信息。这促使我们从全新的角度反思 FGVC 的发展。
• 我们仅使用全局特征为 FGVC 提供了一个强大的基线。同时,我们详细探讨了预训练模型对细粒度分类的影响。代码和预训练模型已开源,以帮助研究人员进一步探索。
• 在没有任何细粒度视觉分类任务归纳偏置的情况下,MetaFormer 在 CUB-200-2011 和 NABirds 数据集上分别达到了 $92.3%$ 和 $92.7%$ 的准确率,超越了当前最优方法。仅使用视觉信息时,MetaFormer 在公平比较下也能在 iNaturalist 2017 和 iNaturalist 2018 数据集上达到当前最优性能 ($78.2%$ 和 $81.9%$)。
2. Related Work
2. 相关工作
In this section, we briefly review existing works on finegrained visual classification and transformer.
本节简要回顾细粒度视觉分类与Transformer的现有研究工作。
2.1. Fine-Grained Visual classification
2.1. 细粒度视觉分类
The existing fine-grained classification methods can be divided into vision only and multi-modality. The former relies entirely on visual information to tackle the problem of fine-grained classification, while the latter tries to take multi-modality data to establish joint representations for incorporating multi-modality information, facilitating finegrained recognition.
现有的细粒度分类方法可分为仅视觉和多模态两类。前者完全依赖视觉信息来解决细粒度分类问题,后者则尝试利用多模态数据建立联合表征以融合多模态信息,从而提升细粒度识别能力。
Vision Only. Fine-grained classification methods that only rely on vision can be roughly classified into two categories: localization methods [16, 25, 55] and featureencoding methods [52, 54, 57]. Early work [27, 48] used part annotations as supervision to make the network pay attention to the subtle discrepancy between some species and suffers from its expensive annotations. RA-CNN [15] was proposed to zoom in subtle regions, which recursively learns disc rim i native region attention and region-based feature representation at multiple scales in a mutually reinforced way. MA-CNN [53] designed a multi-attention module where part generation and feature learning can reinforce each other. NTSNet [51] proposed a self-supervision mechanism to localize informative regions without part annotations effectively. Feature-encoding methods are devoted to enriching feature expression capabilities to improve the performance of fine-grained classification. Bilinear CNN [24] was proposed to extract higher-order features, where two feature maps are multiplied using the outer product. HBP [52] further designed a hierarchical framework to do crosslayer bilinear pooling. DBTNet [54] proposed deep bilinear transformation, which takes advantage of semantic information and can obtain bilinear features efficiently. CAP [2] designed context-aware attention al pooling to captures subtle changes in image. TransFG [18] proposed a Part Selection Module to select disc rim i native image patches applying vision transformer. Compared with localization methods, feature-encoding methods are difficult to tell us the discriminative regions between different species explicitly.
仅视觉方法。仅依赖视觉的细粒度分类方法大致可分为两类:定位方法 [16, 25, 55] 和特征编码方法 [52, 54, 57]。早期工作 [27, 48] 使用部件标注作为监督信号,迫使网络关注物种间的细微差异,但面临标注成本高昂的问题。RA-CNN [15] 通过递归学习区域注意力与多尺度特征表示,以相互强化的方式放大细微区域。MA-CNN [53] 设计了多注意力模块,使部件生成与特征学习相互促进。NTSNet [51] 提出自监督机制,无需部件标注即可有效定位信息区域。特征编码方法致力于增强特征表达能力以提升细粒度分类性能。双线性CNN [24] 通过外积运算提取高阶特征。HBP [52] 进一步设计了跨层双线性池化的分层框架。DBTNet [54] 提出深度双线性变换,利用语义信息高效获取双线性特征。CAP [2] 采用上下文感知注意力池化捕捉图像的细微变化。TransFG [18] 基于视觉Transformer (Vision Transformer) 设计部件选择模块来筛选判别性图像块。相比定位方法,特征编码方法难以直观展示物种间的差异区域。
Multi Modality. In order to differentiate between these challenging visual categories, it is helpful to take advantage of additional information, i.e., geo location, attributes, and text description. Geo-Aware [6] introduced geographic information prior to fine-grained classification and systematically examined a variety of methods using geographic information prior, including post-processing, white listing, and feature modulation. Presence-Only [28] also introduced spatio-temporal prior into the network, proving that it can effectively improve the final classification performance. KERL [4] combined rich additional information and deep neural network architecture, which organized rich visual concepts in the form of a knowledge graph. Meanwhile, KERL [4] used a gated graph neural network to propagate node messages through the graph to generate knowledge representation. CVL [20] proposed a two-branch network where one branch learns visual features, one branch learns text features, and finally combines the two parts to obtain the final latent semantic representations. The methods mentioned above are all designed for specific prior information and cannot flexibly adapt to different auxiliary information.
多模态。为了区分这些具有挑战性的视觉类别,利用额外信息(即地理位置、属性和文本描述)会很有帮助。Geo-Aware [6] 在细粒度分类前引入了地理信息,并系统性地研究了多种利用地理先验信息的方法,包括后处理、白名单和特征调制。Presence-Only [28] 也将时空先验引入网络,证明其能有效提升最终分类性能。KERL [4] 结合了丰富的附加信息与深度神经网络架构,以知识图谱的形式组织丰富的视觉概念,同时使用门控图神经网络通过图谱传播节点信息以生成知识表示。CVL [20] 提出了一种双分支网络,其中一个分支学习视觉特征,另一个分支学习文本特征,最终结合两部分获得潜在的语义表示。上述方法均针对特定先验信息设计,无法灵活适应不同的辅助信息。
2.2. Vision Transformer
2.2. Vision Transformer
Transformer was first proposed for machine translation by [44] and has since been become a general method in natural language processing. Inspired by this, transformer models are further extended to other popular computer vision tasks such as object detection [3, 35], segmentation [56], object tracking [30, 34], video instance segmentation [47, 50]. Lately, Vision Transformer (ViT) [13] directly applied pure transformer to the image patch for classification and achieved impressive performance. Compared with CNN, Vision Transformer has much less image-specific inductive bias. As a result, ViT requires large-scale training datasets (i.e., JFT-300M), intense data augmentation, and regular iz ation strategies to perform well. Following ViT, [9, 26] tried to introduce some inductive bias, i.e., convolutional inductive biases, and locality into the vision transformer.
Transformer 最初由 [44] 提出用于机器翻译,随后成为自然语言处理的通用方法。受此启发,Transformer 模型进一步扩展到其他流行的计算机视觉任务,例如目标检测 [3, 35]、分割 [56]、目标跟踪 [30, 34]、视频实例分割 [47, 50]。最近,Vision Transformer (ViT) [13] 直接将纯 Transformer 应用于图像块进行分类,并取得了令人印象深刻的性能。与 CNN 相比,Vision Transformer 的图像特定归纳偏置要少得多。因此,ViT 需要大规模训练数据集 (例如 JFT-300M)、强力的数据增强和正则化策略才能表现良好。继 ViT 之后,[9, 26] 尝试在视觉 Transformer 中引入一些归纳偏置,例如卷积归纳偏置和局部性。
3. Method
3. 方法
We introduce the hybrid framework that combines convolution and vision transformer in section 3.1. Then, section 3.2 elaborates on how to add meta-information to im- prove the performance of fine-grained classification.
我们在第3.1节介绍了结合卷积与视觉Transformer (Vision Transformer) 的混合框架。随后,第3.2节详细阐述了如何通过添加元信息来提升细粒度分类性能。
3.1. Hybrid Framework
3.1. 混合框架
The overall framework of MetaFormer is shown in Fig 2. In practice, MetaFormer is a hybrid framework where convolution is used to encode vision information, and the transformer layer is used to fuse vision and meta information. Following canonical ConvNet, we construct a network of 5 stages (S0, S1, S2, S3&S4). At the beginning of each stage, the input size decreases to realize the layout of different scales. The first stage S0 is a simple 3-layer convolutional stem. In addition, S1 and S2 are MBConv blocks with squeeze-excitation. We employ Transformer blocks with relative position bias in S3 and S4. Starting from S0 to S4, we always reduce the input size by $2\times$ and increase the number of channels. The down sampling of s3 and s4 is convolution with stride 2, also known as Overlapping Patch
MetaFormer的整体框架如图2所示。实际上,MetaFormer是一个混合框架,其中卷积用于编码视觉信息,而Transformer层用于融合视觉和元信息。遵循经典ConvNet结构,我们构建了一个包含5个阶段(S0、S1、S2、S3&S4)的网络。每个阶段开始时,输入尺寸会减小以实现不同尺度的布局。第一阶段S0是一个简单的3层卷积茎。此外,S1和S2是带有压缩激励(squeeze-excitation)的MBConv模块。我们在S3和S4中采用了带有相对位置偏置的Transformer模块。从S0到S4,我们始终将输入尺寸缩小$2\times$并增加通道数。S3和S4的下采样采用步长为2的卷积,也称为重叠补丁(Overlapping Patch)。
Embedding. Following [8], details of MetaFormer series as summarized in Table 1.
嵌入 (Embedding)。根据 [8],MetaFormer 系列的详细信息总结如表 1。
Table 1. Detail setting of MetaFormer series. L denotes the number of blocks, and D represents the hidden dimension (channels).
| Stages | MetaFormer-0 | MetaFormer-1 | MetaFormer-2 |
| S0 | L=3 D=64 | L=3 D=64 | L=3 D=128 |
| S1 | L=2 D=96 | L=2 D=96 | L=2 D=128 |
| S2 | L=3 D=192 | L=6 D=192 | L=6 D=256 |
| S3 S4 | L=5 D=384 L=2 D=768 | L=14 D=384 L=2 D=768 | L=14 D=512 L=2 D=1024 |
表 1: MetaFormer系列详细配置。L表示块数量,D代表隐藏维度(通道数)。
| Stages | MetaFormer-0 | MetaFormer-1 | MetaFormer-2 |
|---|---|---|---|
| S0 | L=3 D=64 | L=3 D=64 | L=3 D=128 |
| S1 | L=2 D=96 | L=2 D=96 | L=2 D=128 |
| S2 | L=3 D=192 | L=6 D=192 | L=6 D=256 |
| S3 S4 | L=5 D=384 L=2 D=768 | L=14 D=384 L=2 D=768 | L=14 D=512 L=2 D=1024 |
Relative Transformer Layer. The self-attention operation in Transformer is permutation-invariant, which cannot leverage the order of the tokens in an input sequence. To mitigate this problem, following [1, 31], we introduce a relative position bias $B\in\mathbb{R}^{(M^{2}+N)\times(M^{2}+N)}$ to each position in computing similarity as follows:
相对Transformer层。Transformer中的自注意力操作是排列不变的,无法利用输入序列中token的顺序。为了缓解这个问题,我们遵循[1, 31]的方法,在计算相似度时为每个位置引入一个相对位置偏置$B\in\mathbb{R}^{(M^{2}+N)\times(M^{2}+N)}$,具体如下:
$$
A t t e n t i o n(Q,K,V)=S o f t M a x(Q K^{T}/\sqrt{d}+B)V
$$
$$
A t t e n t i o n(Q,K,V)=S o f t M a x(Q K^{T}/\sqrt{d}+B)V
$$
where $Q,K,V\in\mathbb{R}^{(M^{2}+N)\times d}$ are query, key and value matrices. $M^{2}$ is the number of patches of the image. $N$ is the number of extra tokens, including class token and meta tokens. $d$ is the query/key dimension. Follow [26], we parameterize a matrix $\hat{B}\in\mathbb{R}^{(2M-1)\times(2M-1)+1}$ , since the relative position of the image block varies from $-M-1$ to $M+1$ and a special relative position bias is needed to indicate the relative position of the extra token and the vision token. There is no spatial position relationship between each extra token and other tokens, so all extra tokens only share the same relative position bias. The relative transformer block (Eq. 2) contains multihead self-attention with relative position bias (MSA), multi-layer perceptron (MLP) blocks and Layernorm (LN). $\mathbf{z}{\mathrm{0}}$ in Eq. 2 represents the token sequence including classification token $(\mathbf{x}{c l a s s})$ , meta token $(\mathbf{x}{m e t a}^{i})$ and visual token $(\mathbf{x}_{v i s i o n}^{i})$ .
其中 $Q,K,V\in\mathbb{R}^{(M^{2}+N)\times d}$ 是查询(query)、键(key)和值(value)矩阵。$M^{2}$ 表示图像分块数量,$N$ 是额外token数量(包括类别token和元token)。$d$ 为查询/键的维度。参照[26],我们参数化矩阵 $\hat{B}\in\mathbb{R}^{(2M-1)\times(2M-1)+1}$,因为图像块的相对位置范围在 $-M-1$ 到 $M+1$ 之间,且需要特殊相对位置偏置来表示额外token与视觉token的相对位置。各额外token之间不存在空间位置关系,因此所有额外token共享相同的相对位置偏置。相对Transformer块(公式2)包含带相对位置偏置的多头自注意力(MSA)、多层感知机(MLP)模块和层归一化(LN)。公式2中的 $\mathbf{z}{\mathrm{0}}$ 表示包含分类token $(\mathbf{x}{c l a s s})$、元token $(\mathbf{x}{m e t a}^{i})$ 和视觉token $(\mathbf{x}_{v i s i o n}^{i})$ 的token序列。
$$
\begin{array}{r l}{\mathbf{z}{0}=[\mathbf{x}{c l a s s};\mathbf{x}{m e t a}^{1},\cdot\cdot\cdot,\mathbf{x}{m e t a}^{n-1};\mathbf{x}{v i s i o n}^{1},\cdot\cdot\cdot,\mathbf{x}{v i s i o n}^{m}]}\ {\mathbf{z}{i}^{'}=M S A(L N(\mathbf{z}{i-1}))+\mathbf{z}{i}}\ {\mathbf{z}{i}=M L P(L N(\mathbf{z}{i}^{'}))+\mathbf{z}{i}^{'}\quad\mathbf{z}_{i}\in\mathbb{R}^{(M^{2}+N)\times d}}\end{array}
$$
$$
\begin{array}{r l}{\mathbf{z}{0}=[\mathbf{x}{c l a s s};\mathbf{x}{m e t a}^{1},\cdot\cdot\cdot,\mathbf{x}{m e t a}^{n-1};\mathbf{x}{v i s i o n}^{1},\cdot\cdot\cdot,\mathbf{x}{v i s i o n}^{m}]}\ {\mathbf{z}{i}^{'}=M S A(L N(\mathbf{z}{i-1}))+\mathbf{z}{i}}\ {\mathbf{z}{i}=M L P(L N(\mathbf{z}{i}^{'}))+\mathbf{z}{i}^{'}\quad\mathbf{z}_{i}\in\mathbb{R}^{(M^{2}+N)\times d}}\end{array}
$$
$\mathbf{z}{c l a s s}^{1}$ and $\mathbf{z}{c l a s s}^{2}$ at the end, respectively, which represent that the dimension of $\mathbf{z}{c l a s s}^{1}$ and $\mathbf{z}{c l a s s}^{2}$ zclass are different, hence zc1la ss is expanded by MLP. Next, zc1lass and z2 $\mathbf{z}_{c l a s s}^{2}$ are aggregated by Aggregate Layer which is as follows:
$\mathbf{z}{c l a s s}^{1}$ 和 $\mathbf{z}{c l a s s}^{2}$ 分别位于末端,表示 $\mathbf{z}{c l a s s}^{1}$ 和 $\mathbf{z}{c l a s s}^{2}$ 的维度不同,因此 zc1lass 通过 MLP 进行扩展。接着,zc1lass 和 z2 $\mathbf{z}_{c l a s s}^{2}$ 通过聚合层 (Aggregate Layer) 进行聚合,具体如下:
$$
\begin{array}{r l}{\hat{\mathbf{z}}{c l a s s}^{1}=M L P(L N(\mathbf{z}{c l a s s}^{1}))}\ {\mathbf{z}{c l a s s}=C o n v1d(C o n c a t(\hat{\mathbf{z}}{c l a s s}^{1},\mathbf{z}{c l a s s}^{2}))}\ {\mathbf{y}=L N(\mathbf{z}_{c l a s s})}\end{array}
$$
$$
\begin{array}{r l}{\hat{\mathbf{z}}{c l a s s}^{1}=M L P(L N(\mathbf{z}{c l a s s}^{1}))}\ {\mathbf{z}{c l a s s}=C o n v1d(C o n c a t(\hat{\mathbf{z}}{c l a s s}^{1},\mathbf{z}{c l a s s}^{2}))}\ {\mathbf{y}=L N(\mathbf{z}_{c l a s s})}\end{array}
$$
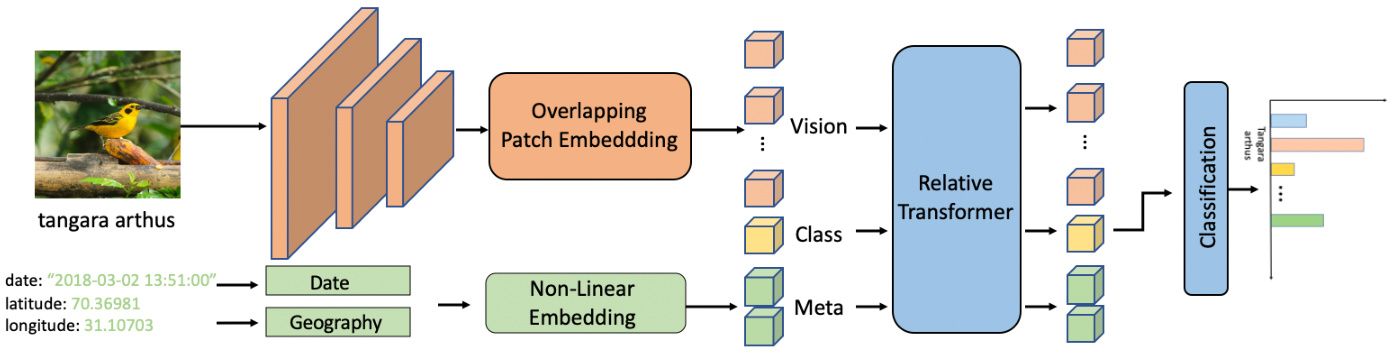
Figure 2. The overall framework of MetaFormer with meta-information. MetaFormer can also be seen as a pure backbone for FGVC except Non-Linear Embedding. The meta-information is encoded by non-linear embedding. Vision token, Meta token and Class token are used for information fusion through the Relative Transformer Layer. Finally, the class token is used for the category prediction.
图 2: 带有元信息的MetaFormer整体框架。除非线性嵌入外,MetaFormer也可视为细粒度视觉分类(FGVC)的纯主干网络。元信息通过非线性嵌入进行编码。视觉Token、元Token和类别Token通过相对Transformer层进行信息融合。最终,类别Token用于类别预测。
where $\mathbf{y}$ is the output that combines multi-scale vision and meta information.
其中 $\mathbf{y}$ 是融合多尺度视觉和元信息的输出。
Overlapping Patch Embedding. We use overlapping patch embedding to tokenize the feature map and implement down sampling to reduce computational consumption. Following [46], we use convolution with zero padding to implement overlapping patch embedding as well.
重叠块嵌入 (Overlapping Patch Embedding)。我们采用重叠块嵌入对特征图进行Token化处理,并通过下采样降低计算消耗。参照 [46] 的方法,我们同样使用带零填充的卷积来实现重叠块嵌入。
3.2. Meta Information
3.2. 元信息
Relying on appearance information alone is often not sufficient to accurately distinguish some fine-grained species. When an image of species is given, human experts also make full use of additional information to assist in making the final decision. Recent advances in Vision Transformer show that it is feasible to encode images into sequence tokens in computer vision. This also provides a simple and effective solution for adding meta-information using the transformer layer.
仅依靠外观信息通常不足以准确区分某些细粒度物种。当给定物种图像时,人类专家也会充分利用附加信息来辅助最终决策。Vision Transformer的最新进展表明,将图像编码为序列token (Token)在计算机视觉中是可行的。这为使用transformer层添加元信息提供了一种简单有效的解决方案。
Intuitively, species distribution presents a trend of clustering geographically, and the living habits of different species are different so that spatio-temporal information can assist the fine-grained task of species classification. When conditioned on latitude and longitude, we firstly want geographical coordinates to wrap around the earth. To achieve this, We converted the geographic coordinate system to a rectangular coordinate system, i.e., $[l a t,l o n]\rightarrow$ $[x,y,z]$ . Similarly, the distance between December and January is closer than the distance from October. And, 23:00 should result in a similar embedding with 00:00. Therefore, we perform the mapping $[m o n t h,h o u r]~\rightarrow$ $\begin{array}{r}{\big[s i n\big(\frac{2\pi m o n t h}{12}\big),\Bar{c o s}\big(\frac{2\pi m o n t h}{12}\big),s i n\big(\frac{2\Bar{\pi}h\Bar{o u r}}{24}\big),c o s\big(\frac{2\pi h\Bar{o u r}}{24}\big)\big]}\end{array}$ .
直观上,物种分布呈现出地理上的聚类趋势,且不同物种的生活习性各异,因此时空信息有助于辅助细粒度的物种分类任务。在给定经纬度条件下,我们首先希望地理坐标能环绕地球。为此,我们将地理坐标系转换为直角坐标系,即 $[lat,lon]\rightarrow$ $[x,y,z]$。同理,12月与1月之间的距离应比10月更近,且23:00的嵌入表示应与00:00相似。因此,我们执行映射 $[month,hour]~\rightarrow$ $\begin{array}{r}{\big[sin\big(\frac{2\pi month}{12}\big),\overline{cos}\big(\frac{2\pi month}{12}\big),sin\big(\frac{2\overline{\pi}h\overline{our}}{24}\big),cos\big(\frac{2\pi h\overline{our}}{24}\big)\big]}\end{array}$。
When using attribute as meta-information, we initialize the attribute list as a vector. For example, there are 312 attributes on the CUB-200-2011 dataset; thus, a vector with a dimension of 312 can be generated. For meta-information in text form, we obtain the embedding of each word by BERT [11]. In particular, when each image has multiple sentences as meta-information, we randomly select one sentence for training each time, and the maximum length of each sentence is 32.
当使用属性作为元信息时,我们将属性列表初始化为向量。例如,CUB-200-2011 数据集中有 312 个属性,因此可以生成一个维度为 312 的向量。对于文本形式的元信息,我们通过 BERT [11] 获取每个单词的嵌入表示。特别地,当每张图像有多个句子作为元信息时,我们每次随机选择一个句子进行训练,且每个句子的最大长度为 32。
Further, as shown in Fig 2, non-linear embedding $(f:$ $R^{n}\to R^{d}$ ) is a multi-layered fully-connected neural network that maps meta-information to embedding vector. Vision information and meta-information are different semantic levels. Thus, it is more difficult to learn visual information than auxiliary information. If a large amount of auxil- iary information is fed to the network in the early stage of training, the visual ability of the network will be impaired. We mask part of the meta-information in a linearly decreasing ratio during the training to alleviate this problem.
此外,如图 2 所示,非线性嵌入 $(f:$ $R^{n}\to R^{d}$ ) 是一个多层全连接神经网络,将元信息映射为嵌入向量。视觉信息和元信息属于不同语义层级,因此学习视觉信息比辅助信息更困难。若在训练初期向网络输入大量辅助信息,会损害其视觉能力。为此,我们在训练过程中以线性递减的比例掩码部分元信息来缓解该问题。
4. Experiments
4. 实验
Datasets. We conduct experiments on ImageNet [10] image classification while it provides pre-trained models for fine-grained classification. We verify the effectiveness of our framework for adding meta-information on i Naturalist 2017 [43], iNaturalist 2018 [42], iNaturalist 2021 [17], and CUB-200-2011 [45]. We also evaluate our proposed framework on several widely used fine-grained benchmarks, i.e., Stanford Cars [23], Aircraft [29], and NABirds [41]. In addition, we do not use any bounding box/part annotation. The details of benchmarks widely used for fine-grained classification are summarized in Table 2.
数据集。我们在ImageNet [10]图像分类上进行实验,同时它提供了用于细粒度分类的预训练模型。我们在iNaturalist 2017 [43]、iNaturalist 2018 [42]、iNaturalist 2021 [17]和CUB-200-2011 [45]上验证了添加元信息的框架有效性。我们还在几个广泛使用的细粒度基准测试上评估了提出的框架,即Stanford Cars [23]、Aircraft [29]和NABirds [41]。此外,我们没有使用任何边界框/部件标注。表2总结了广泛用于细粒度分类的基准测试的详细信息。
Implementation details. First, we resize input images to $384^{*}384$ . AdamW [22] optimizer is employed with using a cosine decay learning rate scheduler. The learning rate is initialized as $5e^{-5}$ except $5e^{-3}$ for the Stanford Cars dataset and $5e^{-4}$ for the Aircraft dataset. The weight decay is 0.05. We include most of the augmentation and regu lari z ation strategies of [26] in training. We fine-tune the model for 300 epochs and perform 5 epochs of warm-up. An increasing degree of stochastic depth augmentation is employed for MetaFormer-0, MetaFormer-1, MetaFormer
实现细节。首先,我们将输入图像调整为 $384^{*}384$ 的尺寸。采用 AdamW [22] 优化器,并使用余弦衰减学习率调度器。除 Stanford Cars 数据集的学习率初始化为 $5e^{-3}$ 和 Aircraft 数据集为 $5e^{-4}$ 外,其余学习率初始化为 $5e^{-5}$。权重衰减为 0.05。我们在训练中包含了 [26] 提出的大多数数据增强和正则化策略。模型微调 300 个周期,并进行 5 个周期的预热。对于 MetaFormer-0、MetaFormer-1 和 MetaFormer,采用逐步增加的随机深度增强策略。
Table 2. Dataset statistics. Meta represents whether there is auxiliary information that can be used to improve the accuracy of finegrained recognition.
表 2: 数据集统计信息。Meta表示是否存在可用于提升细粒度识别准确率的辅助信息。
| 数据集 | 类别数量 | Meta | 训练样本数 | 测试样本数 |
|---|---|---|---|---|
| iNaturalist2017 | 5,089 | √ | 579,184 | 95,986 |
| iNaturalist2018 | 8,142 | √ | 437,513 | 24,426 |
| iNaturalist2021 | 10,000 | √ | 2,686,843 | 100,000 |
| CUB-200-2011 | 200 | 人 | 5,994 | 5,794 |
| StanfordCars | 196 | × | 8,144 | 8,041 |
| Aircraft | 100 | 6,667 | 3,333 | |
| NABirds | 555 | × | 23,929 | 24,633 |
2 with the maximum rate of 0.1, 0.2, 0.3, respectively.
最大速率分别为0.1、0.2、0.3。
4.1. Comparison with CoAtNet on ImageNet-1k
4.1. 与CoAtNet在ImageNet-1k上的对比
Table 3. Comparison with CoAtNet on ImageNet-1k. The results show that MetaFormer outperforms CoAtNet on ImageNet1k. More comparisons with other SotA backbones could be found in appendix.
表 3: ImageNet-1k 上与 CoAtNet 的对比。结果显示 MetaFormer 在 ImageNet1k 上优于 CoAtNet。与其他 SotA 骨干网络的更多对比可参见附录。
| Method | image size | #Param. | #FLOPS | ImageNet top-1 acc |
|---|---|---|---|---|
| CoAtNet-O [8] | 2242 | 25M | 4.2G | 81.6 |
| CoAtNet-1 [8] | 2242 | 42M | 8.G | 83.3 |
| CoAtNet-2 18 | 2242 | - | - | 84.1 |
| MetaFormer-0 | 2242 | 75M | 15.7G | 82.9 |
| MetaFormer-1 | 2242 | 28M | 4.6G | 83.9 |
| MetaFormer-2 | 2242 | 45M | 8.5G | 84.1 |
| MetaFormer-2 (复现) | 2242 | 81M | 16.9G | - |
Table 3 shows the accuracy of ImageNet-1k. Our network architecture outperforms CoAtNet. When we implement this architecture, CoAtNet is our template. The obvious difference between MetaFormer and CoAtNet is that MetaFormer retains the class token in the ViT to obtain the final output, while CoAtNet uses pooling. Especially, we additionally designed an aggregate layer to integrate class tokens obtained at different stages. Finally, Using regular ImageNet-1k training, MetaFormer can achieve performance that exceeds CoAtNet: $+2.3%$ for MetaFormer0 over CoAtNet-0, and $+0.6%$ for MetaFormer-1 over CoAtNet-1, respectively.
表 3: ImageNet-1k 的准确率。我们的网络架构优于 CoAtNet。在实现该架构时,我们以 CoAtNet 为模板。MetaFormer 与 CoAtNet 的显著区别在于:MetaFormer 保留了 ViT 中的 class token 以获取最终输出,而 CoAtNet 采用池化操作。特别地,我们还额外设计了一个聚合层来整合不同阶段获得的 class token。最终,使用常规 ImageNet-1k 训练时,MetaFormer 能实现超越 CoAtNet 的性能:MetaFormer0 相比 CoAtNet-0 提升 $+2.3%$,MetaFormer-1 相比 CoAtNet-1 提升 $+0.6%$。
4.2. The Power of Meta Information
4.2. 元信息的力量
The table 4 shows the results of a series of i Naturalist datasets with spatio-temporal prior. Geo-Aware [6] systematically examined various ways of incorporating geolocation information into fine-grained image classification, such as white listing, post-processing, and feature modulation. Presence-Only [28] use spatio-temporal information as the prior to improve the accuracy of fine-grained recognition. Limited by the network architecture, previous advances on geographical priors were only carried out on the poor baseline.
表 4 展示了带有时空先验的一系列 iNaturalist 数据集的结果。Geo-Aware [6] 系统地研究了将地理位置信息融入细粒度图像分类的各种方法,例如白名单 (white listing)、后处理 (post-processing) 和特征调制 (feature modulation)。Presence-Only [28] 使用时空信息作为先验来提高细粒度识别的准确性。受限于网络架构,先前关于地理先验的研究仅在较差的基线上进行。
In this paper, we provide a series of strong baselines with spatio-temporal information. Moreover, we employ the transformer layer in the backbone to utilize additional information without any special head. In the case of different input sizes and different model sizes, adding spatio-temporal information in our way can achieve a consistent improvement of $3%.6%$ . On the one hand, it shows the power of meta-information, and on the other hand, it shows the rationality of the way that MetaFormer adds meta-information.
本文提出了一系列融合时空信息的强基线方法。通过在大语言模型 (LLM) 骨干网络中使用Transformer层,我们无需特殊模块即可有效利用附加信息。实验表明,在不同输入尺寸和模型规模下,采用本文提出的时空信息融合方式能稳定提升模型性能 $3%.6%$ 。这一方面验证了元信息 (meta-information) 的强大作用,另一方面也证明了MetaFormer融合元信息方式的合理性。
Moreover, when a larger model is used, the visual ability can be improved reasonably. For example, compared to MetaFormer-0, MetaFormer-2 increases the accuracy of the i Naturalist 2017 from $75.7%$ to $79.0%$ with model pretrained on ImageNet-1k. A stronger pre-training model can also bring performance improvements. For example, when adopting MetaFormer-2, the accuracy of i Naturalist 2017 can be increased from $79.0%$ to $80.4%$ using a model pretrained on ImageNet-21k. We have observed that the visual ability is improved while the gain brought by metainformation has not been greatly attenuated when using a larger model and stronger pre-training. This shows that part of the samples in the test set must be effectively identified with the aid of meta-information. In addition, MetaFormer achieved $83.4%$ , $88.7%$ and $93.6%$ accuracy on iNaturalist 2017, i Naturalist 2018 and i Naturalist 2021, respectively. This provides benchmark results for the i Naturalist series of large-scale datasets.
此外,当使用更大规模的模型时,视觉能力可以得到合理提升。例如,与 MetaFormer-0 相比,基于 ImageNet-1k 预训练的 MetaFormer-2 将 iNaturalist 2017 的准确率从 $75.7%$ 提升至 $79.0%$。更强的预训练模型也能带来性能改进:当采用 MetaFormer-2 时,使用 ImageNet-21k 预训练的模型可将 iNaturalist 2017 准确率从 $79.0%$ 提升至 $80.4%$。我们观察到,在使用更大模型和更强预训练时,视觉能力提升的同时元信息带来的增益并未显著衰减,这表明测试集中部分样本必须借助元信息才能有效识别。此外,MetaFormer 在 iNaturalist 2017、iNaturalist 2018 和 iNaturalist 2021 上分别实现了 $83.4%$、$88.7%$ 和 $93.6%$ 的准确率,这为 iNaturalist 系列大规模数据集提供了基准结果。
In order to verify that our model can adapt to various forms of additional information, we conducted experiments on the CUB-200-2011 with text description as well as attribute. The results in the table 5 show that the accuracy can be increased from $91.7%$ to $91.9%$ when using image and text description as input in testing. A similar result can be observed when using attributes as meta-information. To effectively ensure the validity of meta-information, we use a model pre-trained on Imagenet-21k to initialize the parameters of MetaFormer-1. In the case of a strong baseline, meta-information can still bring gain, which shows that our method indeed leverages meta-information to assist finegrained recognition.
为了验证我们的模型能适应各种形式的附加信息,我们在CUB-200-2011数据集上分别进行了文本描述和属性特征的实验。表5结果显示:当测试阶段使用图像和文本描述作为输入时,准确率能从$91.7%$提升至$91.9%$;使用属性作为元信息时也能观察到类似效果。为确保元信息的有效性,我们采用在Imagenet-21k预训练的模型来初始化MetaFormer-1的参数。即使在强基线条件下,元信息仍能带来性能提升,这表明我们的方法确实能利用元信息辅助细粒度识别。
CVL [20] designed complex vision stream and language stream to leverage text descriptions to improve the accuracy of fine-grained recognition. KERL [4] integrates the knowledge graph into the feature learning to promote finegrained image recognition, thereby using attribute information to supervise the learning. Compared with these methods that require complex modules, our method is straightforward and can adapt to different meta-information. Note that these methods are verified based on the poor baseline. In addition, CAP [2] achieved the SotA performance on the CUB-200-2011. Our method can achieve comparable per
CVL [20] 设计了复杂的视觉流和语言流,利用文本描述提升细粒度识别的准确性。KERL [4] 将知识图谱融入特征学习以促进细粒度图像识别,从而利用属性信息监督学习过程。相比这些需要复杂模块的方法,我们的方案简洁直观,能适配不同元信息。需注意的是,这些方法均基于较弱基线进行验证。此外,CAP [2] 在CUB-200-2011数据集上取得了SotA (state-of-the-art) 性能。我们的方法能够实现可比的表现
Table 4. Results in i Naturalist 2019, i Naturalist 2018, and i Naturalist 2021 with meta-information. The green numbers represent the improvement brought by adding meta-information compared to only using images as input. It is worth noting that with the improvement of visual ability, the improvement brought by meta-information has not been greatly attenuated, which demonstrates the necessity of meta-information.
表 4. iNaturalist 2019、iNaturalist 2018 和 iNaturalist 2021 的元信息实验结果。绿色数字表示添加元信息相比仅使用图像输入带来的提升。值得注意的是,随着视觉能力的提升,元信息带来的改进并未大幅衰减,这证明了元信息的必要性。
| 方法 | 主干网络 | 预训练 | 图像尺寸 | 元信息方法 | iNat17 | iNat18 | iNat21 |
|---|---|---|---|---|---|---|---|
| Geo-Aware [6] | Inception V3 | ImageNet-1k | 299 | 仅图像 | 70.1 | ||
| 白名单 | 72.6 | ||||||
| 后处理 | 79.0 | ||||||
| Presence-Only [28] | Inception V3 | ImageNet-1k | 299 | 特征修改 | 78.2 | 60.2 | |
| 仅图像 | 63.27 | ||||||
| 先验 | 69.6 | 72.7 | |||||
| ImageNet-1k | 520 384 | 仅图像先验 | 66.2 77.5 | ||||
| 75.7 | 79.5 | 88.4 | |||||
| MetaFormer-0 | ImageNet-1k | 384 | 仅图像Transformer | 79.8(+4.1) | 85.4(+5.9) | 92.6(+4.2) | |
| 仅图像 | 78.2 | 81.9 | 90.2 | ||||
| MetaFormer-1 | ImageNet-1k | 384 | Transformer | 81.3(+3.1) | 86.5(+4.6) | 93.4(+3.2) | |
| 仅图像 | 79.0 | 82.6 | 89.8 | ||||
| MetaFormer-2 | ImageNet-21k | 384 | Transformer | 82.0(+3.0) | 86.8(+4.2) | 93.2(+3.4) | |
| 仅图像 | 80.4 | 84.3 | 90.3 | ||||
| Transformer | 83.4(+3.0) | 88.7(+4.4) | 93.6(+3.3) |
Table 5. Result on CUB-200-2011 with meta-information. ImageOnly represents using image only as input in training. Image+Attribute and Image $^+$ Text represent adding attribute and text description on the basis of the image as input in training. Input in Testing represents the format of the input information used in the testing. We observe that the addition of meta-information can not only improve the final performance of fine-grained recognition, but also improve the visual ability of the model on the CUB-200- 2011.
表 5: 在 CUB-200-2011 上使用元信息的结果。ImageOnly 表示训练时仅使用图像作为输入。Image+Attribute 和 Image$^+$Text 表示在图像输入基础上分别添加属性和文本描述作为训练输入。Input in Testing 表示测试时使用的输入信息格式。我们观察到,添加元信息不仅能提升细粒度识别的最终性能,还能增强模型在 CUB-200-2011 上的视觉能力。
| 方法 | 主干网络 | 测试输入 CUB |
|---|---|---|
| ResNet-50[19] | ResNet-50 | 图像 84.5 |
| CVL [20] | VGG-16 | 图像+文本 85.6 |
| KERL [4] | VGG-16 | 图像+属性 87.0 |
| S3N [12] StackedLSTM [16] | ResNet-50 | 图像 89.6 |
| CAP [2] | GoogleNet Xception | 图像 90.4 91.8 |
| 纯图像 | MetaFormer-1 | 图像 91.4 |
| 图像+文本 | MetaFormer-1 | 图像 91.7(+0.3) |
| 图像+属性 | MetaFormer-1 | 图像+文本 91.9(+0.2) 图像 91.5(+0.1) |
formance to CAP without meta-information.
性能表现不包含元信息的CAP。
Using images as input in training, MetaFormer-1 achieves $91.4%$ accuracy on CUB-200-2011. Under the same training settings, when image and text description are used as input in training and the only image is used as input in testing, the accuracy rate becomes $91.7%$ . This shows that meta-information can not only improve the final recognition performance, but also promote the improvement of the model’s visual ability.
在训练中使用图像作为输入时,MetaFormer-1 在 CUB-200-2011 上达到了 91.4% 的准确率。在相同的训练设置下,当训练时使用图像和文本描述作为输入而测试时仅使用图像作为输入时,准确率提升至 91.7%。这表明元信息不仅能提高最终识别性能,还能促进模型视觉能力的提升。
4.3. The Visualization of Meta Information
4.3. 元信息可视化
To have an intuitive understanding of meta-information, following [28], we firstly generate spatial predictions for several different species from i Naturalist 2021. In Fig. 3, each image is generated by querying each location on the surface of the earth to generate a prediction of the category of interest. The scattered points represent the true geographical distribution of the current species. In practice, we evaluate $1000\times2000$ spatial locations and mask out the predictions over the ocean for visualization. It can be seen from the visualization that the model can learn the geographic distribution of species and thus use the prior of this geographic distribution to assist fine-grained classification.
为了直观理解元信息,我们遵循[28]的方法,首先从iNaturalist 2021数据集中为多个不同物种生成空间预测。图3中,每张图像均通过查询地球表面各位置生成目标类别的预测结果,散点表示该物种真实的实际地理分布。实际操作中,我们评估了$1000×2000$个空间位置,并屏蔽了海洋区域的预测以便可视化。从可视化结果可见,模型能够学习物种的地理分布特征,进而利用这种地理分布先验来辅助细粒度分类任务。
In order to verify whether the model uses the text information to assist fine-grained recognition, in Fig. 4, we visualize the top-5 of the similarity between the vision token and class token and the top-3 between the word token and class token, respectively. The class token is finally used to predict the species category. From the visualization, it can be seen that the class token has a high similarity with some tokens representing the species’ attributes. Moreover, visual tokens and word tokens with high similarity often show a complementary relationship. Meanwhile, in Fig. 5, we visualize the visual attention map corresponding to the word token, in which the words representing the attributes of the species usually have a high similarity with the corresponding vision token.
为了验证模型是否利用文本信息辅助细粒度识别,在图4中,我们分别可视化了视觉token与类别token之间的前5相似度,以及单词token与类别token之间的前3相似度。类别token最终用于预测物种类别。从可视化结果可以看出,类别token与某些代表物种属性的token具有较高相似性。此外,高相似度的视觉token和单词token往往呈现出互补关系。同时,在图5中,我们可视化了单词token对应的视觉注意力图,其中代表物种属性的单词通常与对应的视觉token具有较高相似性。
4.4. The Importance of Pre-trained Model
4.4. 预训练模型的重要性
Pre-trained models are essential for fine-grained classification, but, to the best of our knowledge, no research has given a baseline for fine-grained classification under different pre-training. So in this paper, we study in detail the impact of varying pre-training on fine-grained classification and achieved SotA performance on several datasets.
预训练模型对于细粒度分类至关重要,但据我们所知,尚无研究针对不同预训练条件下的细粒度分类给出基准。因此,本文详细研究了不同预训练对细粒度分类的影响,并在多个数据集上实现了SotA(当前最优)性能。
The experiment results on CUB-200-2011 and NABirds are shown in Table 6. Compared to Imagenet-1k, when we transfer networks trained on Imagenet-21k, MetaFormer1 achieved $2.0%$ and $2.2%$ improvements on CUB-200- 2011 and NABirds. The accuracy of CUB-200-2011 and NABirds is $92.3%$ and $92.7%$ , respectively, which outperforms the SotA approaches $(91.8%$ and $91.0%$ on CAP [2]) by a clear margin, using i Naturalist 2021 for pre-training. i Naturalist 2021 with fewer data can perform better than Imagenet-21k since the domain similarity between iNaturalist 2021 and downstream datasets is higher. Using the MetaFormer-0 with fewer parameters and models pretrained on i Naturalist, we also achieve performance $(91.8%$ and $91.2%$ ) equivalent to the SotA approaches.
CUB-200-2011和NABirds上的实验结果如表6所示。与Imagenet-1k相比,当我们迁移在Imagenet-21k上训练的网络时,MetaFormer1在CUB-200-2011和NABirds上分别实现了$2.0%$和$2.2%$的提升。CUB-200-2011和NABirds的准确率分别为$92.3%$和$92.7%$,明显优于当前最优方法(CAP[2]的$91.8%$和$91.0%$),且使用了iNaturalist 2021进行预训练。数据量较少的iNaturalist 2021性能优于Imagenet-21k,因为iNaturalist 2021与下游数据集的领域相似性更高。使用参数更少的MetaFormer-0和在iNaturalist上预训练的模型,我们也取得了与当前最优方法相当的性能($91.8%$和$91.2%$)。
Existing methods are designed with complex multi-stage strategies (CPM [16]), multi-branch structures (Cross-X [27], API-Net [57]) or elaborate attention modules (CAL [32], CAP [2]), resulting in difficulty in implementing. DSTL [7]studies transfer learning by fine-tuning from large-scale datasets to small-scale datasets and carefully selects the data used for pre-training. Our experiments show that when the amount of data used for pre-training is higher and there are more categories, better performance can be achieved without selecting data. However, we did not deliberately select data during pre-training. FixSENet154 [40] designed a complex image resolution strategy for training and testing, and we use a scientific image resolution strategy. When ImageNet-21k is also used to pretrain the model, our method achieves the same performance as TransFG [18] without any additional structure, and our model has fewer parameters and higher throughput. Our experimental results show that the SotA performance can still be achieved on the CUB-200-2011 and NABirds datasets without any inductive bias of fine-grained recognition tasks. This can provide researchers with a simple and effective baseline model and facilitate actual implementation.
现有方法采用复杂的多阶段策略 (CPM [16]) 、多分支结构 (Cross-X [27], API-Net [57]) 或精心设计的注意力模块 (CAL [32], CAP [2]) ,导致实现困难。DSTL [7] 通过从大规模数据集微调到小规模数据集来研究迁移学习,并精心选择预训练数据。我们的实验表明,当预训练数据量更大且类别更多时,无需筛选数据即可获得更好性能。但我们在预训练阶段并未刻意选择数据。FixSENet154 [40] 为训练和测试设计了复杂的图像分辨率策略,而我们采用科学的图像分辨率策略。当同样使用 ImageNet-21k 预训练模型时,我们的方法在没有任何额外结构的情况下达到与 TransFG [18] 相同的性能,且模型参数量更少、吞吐量更高。实验结果表明,在 CUB-200-2011 和 NABirds 数据集上,即使不引入细粒度识别任务的归纳偏置,仍能实现 SotA 性能。这可为研究者提供简单有效的基线模型,并促进实际应用落地。
i Naturalist 2017 and i Naturalist 2018 are large-scale datasets for fine-grained recognition. In Table 7, we show the SotA results on i Naturalist 2017 and i Naturalist 2018, using MetaFormer-1. We observe that there is currently no reference performance for both i Naturalist 2017 and iNaturalist 2018. For example, when the model parameters trained by ImageNet-1k are used to initialize the model, FixSENet [40] achieves an accuracy of $75.4%$ on iNaturalist 2017 and Grafit [39] achieves an accuracy of $81.2%$ on i Naturalist 2018. However, our experiment found that the accuracy of i Naturalist 2017 and i Naturalist 2018 should be $78.2%$ and $81.9%$ , respectively, without any special design, using the model pre-trained on ImageNet-1k. The transfer learning performance by fine-tuning MetaFormer-1 on finegrained datasets is also presented in Table 7. More results can be found in the appendix.
i Naturalist 2017 和 i Naturalist 2018 是用于细粒度识别的大规模数据集。在表 7 中,我们展示了使用 MetaFormer-1 在 i Naturalist 2017 和 i Naturalist 2018 上的 SotA (state-of-the-art) 结果。我们观察到目前 i Naturalist 2017 和 iNaturalist 2018 均无参考性能指标。例如,当使用 ImageNet-1k 训练的模型参数初始化模型时,FixSENet [40] 在 iNaturalist 2017 上达到了 $75.4%$ 的准确率,而 Grafit [39] 在 i Naturalist 2018 上达到了 $81.2%$ 的准确率。然而,我们的实验发现,在没有任何特殊设计的情况下,使用 ImageNet-1k 预训练的模型,i Naturalist 2017 和 i Naturalist 2018 的准确率应分别为 $78.2%$ 和 $81.9%$。表 7 还展示了通过在细粒度数据集上微调 MetaFormer-1 得到的迁移学习性能。更多结果可在附录中找到。
Table 6. Results on CUB-200-2011 and NABirds with different pre-trained models.
表 6. 不同预训练模型在 CUB-200-2011 和 NABirds 数据集上的结果
| Method | Backbone | Pretain | CUBNABirds |
|---|---|---|---|
| CPM [16] CAL [32] TransFG [18] CAP [2] Cross-X [27] DSTL [7] API-Net [57] DenseNet-161 | GoogleNet ResNet101 ViT-B_16 Xception ResNet50 Inception-v3 | ImageNet-1k ImagNet-1k ImageNet-21k ImageNet-1k ImageNet-1k iNat17 | 90.4 90.6 91.7 90.8 91.8 91.0 87.7 86.2 89.3 87.9 90.0 88.1 |
| FixSENet [40] MetaFormer | SENet-154 MetaFormer-0 MetaFormer-1 ImageNet-21k | ImageNet-1k iNat21 ImageNet-1k iNat21 92.3 | 88.7 89.2 91.8 91.2 89.7 89.4 91.3 91.6 92.7 |
Table 7. Results on i Naturalist 2017 and i Naturalist 2018 with different pre-trained models.
表 7: 不同预训练模型在 iNaturalist 2017 和 iNaturalist 2018 上的结果
| 方法 | 主干网络 | 预训练数据 | iNat17/iNat18 |
|---|---|---|---|
| TransFG [18] FixSENet [40] DeiT-B [38] Grafit [39] | ViT-B_16 SENet-154 ViT-B_16 RegNet-8GF | ImageNet-21k ImageNet-1k ImageNet-21k ImageNet-1k | 70.9 75.4 80.1 81.2 |
| MetaFormer | MetaFormer-1ImageNet-21k | ImageNet-1k iNat21 | 78.2 81.9 79.4 83.2 82.0 87.5 |
Table 8. Results on Stanford Cars and Aircraft with different pretrained models.
表 8. 不同预训练模型在Stanford Cars和Aircraft数据集上的结果。
| 方法 | 主干网络 | 预训练数据 | Cars/Aircraft |
|---|---|---|---|
| GPipe [21] DCL [5] S3N [12] PMG [14] API-Net[57] CAP [2] | AmoebaNet-B ResNet-50 ResNet-50 ResNet-50 DenseNet-161 Xception | ImageNet-1k ImageNet-1k ImageNet-1k ImageNet-1k ImageNet-1k | 94.6 92.7 94.5 93.0 94.7 92.8 95.1 93.4 95.3 93.9 95.7 94.1 |
| MetaFormer MetaFormer-1 | ImageNet-1k ImageNet-1k iNat21 | 94.9 92.8 95.0 94.2 95.0 94.3 |

Figure 3. Spatial predictions. Predicted distributions for several object categories using a model trained on i Naturalist 2021. Darker color indicates that the current location is more responsive to the category of interest. Scattered points represent the true geographic distribution of the current species.
图 3: 空间预测。使用在iNaturalist 2021上训练的模型对多个物体类别的预测分布。颜色越深表示当前位置对目标类别的响应越强。散点表示当前物种的真实地理分布。

Figure 4. Top-k of similarity between class token with other tokens including vision token and word token. The orange squares in the image represent the five visual tokens that are most similar to the class token. In addition, the orange background in the text represents the three word tokens that are most similar to the class token.
图 4: 类别token与视觉token及单词token之间相似度的Top-k结果。图中橙色方块代表与类别token最相似的五个视觉token。此外,文本中的橙色背景标注了与类别token最相似的三个单词token。
Table 8 shows the results of our model on Stanford Cars and Aircraft. On Stanford Cars and Aircraft, most of the previous methods used ImageNet-1k for pre-training. We offer the different transfer learning performances by finetuning MetaFormer-1 on these two fine-grained datasets. Experiments show that on Stanford Cars, a more potent pretraining model does not bring further performance improvement. We argue that more simple pictures in the Stanford Cars dataset require less work on pre-trained models. On the Aircraft dataset, the model pre-trained with i Naturalist 2021 is worse than that trained with ImageNet-21k because it has a more extensive domain gap with the downstream domain.
表 8 展示了我们的模型在 Stanford Cars 和 Aircraft 数据集上的结果。在 Stanford Cars 和 Aircraft 上,大多数先前的方法使用 ImageNet-1k 进行预训练。我们通过在两个细粒度数据集上微调 MetaFormer-1 来展示不同的迁移学习性能。实验表明,在 Stanford Cars 上,更强的预训练模型并未带来进一步的性能提升。我们认为 Stanford Cars 数据集中更简单的图片对预训练模型的要求较低。而在 Aircraft 数据集上,使用 i Naturalist 2021 预训练的模型表现不如使用 ImageNet-21k 训练的模型,因为前者与下游领域的域差距更大。
Figure 5. Self-attention map of word token. The warmer the color, the higher the similarity between the token of the current position and the word token.
图 5: 单词token的自注意力热力图。颜色越暖表示当前位置token与单词token的相似度越高。
5. Conclusion
5. 结论
In this work, we propose a unified meta-framework for fine-grained visual classification. MetaFormer uses the transformer to fuse visual information and various meta-information, not introducing any additional structure. Meanwhile, MetaFormer also provides a simple yet effective baseline for FGVC. In addition, we systematically examined the impact of different pre-training models on finegrained tasks. MetaFormer achieves SotA performance on the i Naturalist series, CUB-200-2011, and NABirds datasets. Meanwhile, we believe that meta-information is essential for fine-grained recognition tasks in the future. And, MetaFormer can provide a way to utilize various auxiliary information.
在本工作中,我们提出了一个用于细粒度视觉分类的统一元框架。MetaFormer采用Transformer融合视觉信息与多种元信息,无需引入额外结构。同时,该框架为细粒度视觉分类(FGVC)提供了简单有效的基线方案。此外,我们系统研究了不同预训练模型对细粒度任务的影响。MetaFormer在iNaturalist系列、CUB-200-2011和NABirds数据集上实现了最先进(SotA)性能。我们认为元信息对未来细粒度识别任务至关重要,而MetaFormer为利用各类辅助信息提供了可行路径。
MetaFormer : A Unified Meta Framework for Fine-Grained Recognition
MetaFormer:面向细粒度识别的统一元框架
Supplementary Material
补充材料
A. The detailed information of MetaFormer
A. MetaFormer 的详细信息
Detailed experimental setting for ImageNet-1k and ImageNet-21k. When training from the scratch on ImageNet-1k, the input image size is $224^{2}$ . we adopt AdamW [22] optimizer and train for 300 epochs and 20 epochs of linear warm-up with batchsize of 1024. The learning rate is initialized as $1e^{-3}$ and weight decay is 0.05. Most of the augmentation and regular iz ation strategies of [26] are included in training. Note that an increasing degree of stochastic depth augmentation is employed for larger models, i.e. 0.1, 0.2, 0.3 for MetaFormer-0, MetaFormer1, and MetaFormer-2, respectively. For resolutions of $384^{2}$ , we fine-tune the models trained at $224^{2}$ resolution using an initial learning rate of $1e^{-4}$ for 30 epochs and 2 epochs of warm-up, instead of training from scratch. For ImageNet21k, we train for 90 epochs and 5 epochs of warm-up with the input image resolution of $224^{2}$ and fine-tune a model for 10 epochs with the input image resolution of $384^{2}$ .
ImageNet-1k和ImageNet-21k的详细实验设置。在ImageNet-1k上从头训练时,输入图像尺寸为$224^{2}$。我们采用AdamW [22]优化器,训练300个epoch,其中包含20个epoch的线性预热(warm-up),批量大小为1024。学习率初始化为$1e^{-3}$,权重衰减为0.05。训练中包含了[26]提出的大部分数据增强和正则化策略。需要注意的是,对于更大的模型会采用递增的随机深度增强(stochastic depth augmentation)强度,即MetaFormer-0、MetaFormer-1和MetaFormer-2分别对应0.1、0.2和0.3。对于$384^{2}$分辨率,我们使用$224^{2}$分辨率预训练的模型进行微调,初始学习率为$1e^{-4}$,微调30个epoch并包含2个epoch的预热,而非从头训练。对于ImageNet-21k,我们以$224^{2}$的输入图像分辨率训练90个epoch(包含5个epoch预热),然后以$384^{2}$的输入图像分辨率微调10个epoch。
Detailed architecture of MetaFormer. The MetaFormer consists of the convolutional layer and the transformer layer. The first three stages mainly adopt MBConv blocks, and the latter two stages adopt the Relative transformer blocks. We mimic the canonical convolutional network, adpot the convolution layer with stride of 2 in stage 0 and stage 1 for down sampling, and adopt max-pooling for down sampling in stage 2. In stage 3 and stage 4, overlapping patch embedding is employed for down sampling. The class tokens of stage 3 and stage 4 are integrated through the aggregate layer. Among them, the class token of stage3 will be dimensionally expanded by MLP. For all Transformer blocks, the size of each attention head is 8. The expansion rate for the inverted bottleneck is always 4, and the expansion (shrink) rate for the Squeeze-and-Excitation is always 0.25.
MetaFormer的详细架构。MetaFormer由卷积层和Transformer层组成。前三个阶段主要采用MBConv模块,后两个阶段采用相对Transformer模块。我们模仿经典卷积网络,在阶段0和阶段1使用步长为2的卷积层进行下采样,阶段2采用最大池化下采样。阶段3和阶段4采用重叠补丁嵌入进行下采样。阶段3和阶段4的类别Token通过聚合层整合。其中,阶段3的类别Token将通过MLP进行维度扩展。所有Transformer模块中,每个注意力头的大小为8。逆瓶颈的扩展率始终为4,挤压激励模块的扩展(收缩)率始终为0.25。
Performance comparison with SotA backbone. Parameters, flops and throughput of MetaFormer are shown in the table 10. Meanwhile, it shows the comparison result on ImageNet-1k with the state-of-the-art backbone.
与SotA骨干网络的性能对比。表10展示了MetaFormer的参数、浮点运算量和吞吐量,同时呈现了在ImageNet-1k数据集上与最先进骨干网络的对比结果。
Performance comparison of CLT and GAP. We ultimately design a simple and effective framework, which can integrate a variety of meta information. Therefore, we retain the class token as a bridge between visual information and additional prior information. The class token can pass through S3 and S4 in serial $(C L T_{s e r i a l})$ , or in parallel $(C L T_{p a r a l l e l})$ . Specifically, the parallel means that S3 and S4 obtain two class tokens, respectively, and then they are combined through the aggregate layer. The ablation study is shown in the table 9. In table 9, $G A P$ represents the global average pooling operation, and $C L T_{f i n a l}$ represents only the S4 class token is used for class prediction. Experiments show that the result of $C L T_{p a r a l l e l}$ using a aggregate layer is better than $C L T_{f i n a l}$ and $C L T_{s e r i a l}$ . Moreover, using GAP is not better than using class token on ImageNet-1k.
CLT与GAP的性能对比。我们最终设计了一个简单有效的框架,可以整合多种元信息。因此,我们保留类别token (class token)作为视觉信息与额外先验信息之间的桥梁。类别token可以串行通过S3和S4 $(CLT_{serial})$,也可以并行通过 $(CLT_{parallel})$。具体而言,并行方式是指S3和S4分别获得两个类别token,然后通过聚合层(aggregate layer)进行组合。消融实验如 表9 所示。在 表9 中,$GAP$ 表示全局平均池化(global average pooling)操作,$CLT_{final}$ 表示仅使用S4的类别token进行分类预测。实验表明,使用聚合层的 $CLT_{parallel}$ 结果优于 $CLT_{final}$ 和 $CLT_{serial}$。此外,在ImageNet-1k数据集上使用GAP的效果不如使用类别token。
Table 9. Accuracy of MetaFormer using different methods for class prediction. GAP represents performing global average pooling to obtain the feature vector for classification prediction. CLT means leveraging the class token to classify.
表 9: 采用不同类别预测方法的MetaFormer准确率。GAP表示通过全局平均池化获取分类预测的特征向量,CLT表示利用类别token进行分类。
| Backbone | ImageNet top-1 acc | |
|---|---|---|
| GAP | MetaFormer-0 | 82.9 |
| CLTfinal | MetaFormer-0 | 82.6 |
| CLTserial | MetaFormer-0 | 82.8 |
| CLTparallel | MetaFormer-0 | 82.9 |
B. Performance on fine-grained datasets with different pre-trained model. Large-scale pre-training can effectively improve the performance of fine-grained recognition.
B. 不同预训练模型在细粒度数据集上的性能表现。大规模预训练能有效提升细粒度识别的性能。
The table 11 shows the transfer performance of 6 fine-grained datasets(CUB-200-2011, NABirds, i Naturalist 2017, i Naturalist 2018, Stanford Cars, and Aircraft) under different pre-trained models.
表 11 展示了 6 个细粒度数据集 (CUB-200-2011, NABirds, i Naturalist 2017, i Naturalist 2018, Stanford Cars 和 Aircraft) 在不同预训练模型下的迁移性能。
References
参考文献

Figure 6. Overview of MetaFormer. The first three stages use convolution to downsample, and the next two stages use a relative transformer layer to fuse the image and meta information. The class tokens obtained in the two stages are fused through the aggregation layer.
图 6: MetaFormer 架构概览。前三个阶段使用卷积进行下采样,后两个阶段采用相对位置Transformer层融合图像与元信息。两个阶段获得的类别Token通过聚合层进行融合。
Table 10. The result of MetaFormer and comparison of other backbones on ImageNet-1k. Throughput is measured using the GitHub repository of [49] with V100 GPU
表 10. MetaFormer 的结果及与其他主干网络在 ImageNet-1k 上的对比。吞吐量使用 [49] 的 GitHub 仓库在 V100 GPU 上测得
| 方法 | 图像尺寸 | 参数量 | 计算量 (FLOPs) | 吞吐量 (图像/秒) | ImageNet top-1 准确率 | |
|---|---|---|---|---|---|---|
| 纯卷积 | EfficientNet-B4 [36] | 380² | 19M | 4.2G | 349.4 | 82.9 |
| EfficientNet-B5 [36] | 456² | 30M | 9.9G | 169.1 | 83.6 | |
| EfficientNet-B6 [36] | 528² | 43M | 19.0G | 96.9 | 84.0 | |
| EfficientNet-B7 [36] | 600² | 66M | 37.0G | 55.1 | 84.3 | |
| EfficientNetV2-S [37] | 128² - 300² | 24M | 8.8G | 666.7 | 83.9 | |
| EfficientNetV2-M [37] | 128² - 380² | 55M | 24G | 280.7 | 85.1 | |
| 纯ViT | ViT-B/16 [13] | 384² | 86M | 55.4G | 85.9 | 77.9 |
| DeiT-S [38] | 224² | 22M | 4.6G | 940.4 | 79.8 | |
| DeiT-B [38] | 224² | 86M | 17.5G | 292.3 | 81.8 | |
| DeiT-B [38] | 384² | 86M | 55.4G | 85.9 | 83.1 | |
| 局部MSA | Swin-T [26] | 224² | 29M | 4.5G | 755.2 | 81.3 |
| Swin-S [26] | 224² | 50M | 8.7G | 436.9 | 83.0 | |
| CoAtNet-0 [8] | 224² | 88M | 15.4G | 278.1 | 83.3 | |
| 卷积+MSA | 224² | 25M | 4.2G | 81.6 | ||
| CoAtNet-1 [8] | 224² | 42M | 8.4G | 83.3 | ||
| CoAtNet-2 [8] | 224² | 75M | 15.7G | - | 84.1 | |
| CoAtNet-0 [8] | 384² | 25M | 13.4G | 83.9 | ||
| CoAtNet-1 [8] | 384² | 42M | 27.4G | 85.1 | ||
| CoAtNet-2 [8] | 384² | 75M | 49.8G | 85.7 | ||
| 卷积+MSA | MetaFormer-0 | 224² | 28M | 4.6G | 840.1 | 82.9 |
| MetaFormer-1 | 224² | 45M | 8.5G | 444.8 | 83.9 | |
| MetaFormer-2 | 224² | 81M | 16.9G | 438.9 | 84.1 | |
| MetaFormer-0 | 384² | 28M | 13.4G | 349.4 | 84.2 | |
| MetaFormer-1 | 384² | 45M | 24.7G | 165.3 | 84.4 | |
| MetaFormer-2 | 384² | 81M | 49.7G | 132.7 | 84.6 |
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5157–5166, 2019. 7 [6] Grace Chu, Brian Potetz, Weijun Wang, Andrew Howard, Yang Song, Fernando Brucher, Thomas Leung, and Hartwig Adam. Geo-aware networks for fine-grained recognition. In Proceedings of the IEEE/CVF International Conference on
在IEEE/CVF计算机视觉与模式识别会议论文集,第5157-5166页,2019年。7
[6] Grace Chu、Brian Potetz、Weijun Wang、Andrew Howard、Yang Song、Fernando Brucher、Thomas Leung和Hartwig Adam。面向细粒度识别的地理感知网络。收录于IEEE/CVF国际会议论文集
Computer Vision Workshops, pages 0–0, 2019. 1, 2, 5, 6
计算机视觉研讨会,第0–0页,2019年。1, 2, 5, 6
[7] Yin Cui, Yang Song, Chen Sun, Andrew Howard, and Serge Belongie. Large scale fine-grained categorization and domain-specific transfer learning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4109–4118, 2018. 7
[7] Yin Cui, Yang Song, Chen Sun, Andrew Howard, 和 Serge Belongie. 大规模细粒度分类与领域特定迁移学习. 见: IEEE计算机视觉与模式识别会议论文集, 第4109-4118页, 2018. 7
Table 11. Result on fine-grained datasets with different pre-trained model
表 11. 不同预训练模型在细粒度数据集上的结果
| Backbone | Pretrain | CUB | NABirds | iNaturalist2017 | iNaturalist2018 | Cars | Aircraft |
|---|---|---|---|---|---|---|---|
| MetaFormer-0 | ImageNet-1k | 89.6 | 89.1 | 75.7 | 79.5 | 95.0 | 91.2 |
| ImageNet-21k | 89.7 | 89.5 | 75.8 | 79.9 | 94.6 | 91.2 | |
| iNaturalist2021 | 91.8 | 91.5 | 78.3 | 82.9 | 95.1 | 87.4 | |
| MetaFormer-1 | ImageNet-1k | 89.7 | 89.4 | 78.2 | 81.9 | 94.9 | 90.8 |
| ImageNet-21k | 91.3 | 91.6 | 79.4 | 83.2 | 95.0 | 92.6 | |
| iNaturalist2021 | 92.3 | 92.7 | 82.0 | 87.5 | 95.0 | 92.5 | |
| MetaFormer-2 | ImageNet-1k | 89.7 | 89.7 | 79.0 | 82.6 | 95.0 | 92.4 |
| ImageNet-21k | 91.8 | 92.2 | 80.4 | 84.3 | 95.1 | 92.9 | |
| iNaturalist2021 | 92.9 | 93.0 | 82.8 | 87.7 | 95.4 | 92.8 |