Hyper spectral MAE: The Hyper spectral Imagery Classification Model using Fourier-Encoded Dual-Branch Masked Auto encoder
高光谱MAE:基于傅里叶编码双分支掩码自编码器的高光谱图像分类模型
Abstract—Hyper spectral imagery provides rich spectral detail but poses unique challenges due to its high dimensionality in both spatial and spectral domains. Therefore, we propose Hyper spectral MAE, a transformer-based foundation model for hyper spectral data featuring a dual-masking strategy that randomly occludes $50%$ of the spatial patches and $50%$ of the spectral bands during pre-training. This forces the model to learn meaningful representations by reconstructing missing information across both dimensions. A positional embedding with spectral wavelength based on learnable harmonic Fourier components is introduced to encode the identity of each spectral band, ensuring that the model is sensitive to spectral order and spacing. The reconstruction objective employs a composite loss combining mean-squared error (MSE) and spectral angle mapper (SAM) to balance pixel-level accuracy and spectral-shape fidelity.
摘要—高光谱图像提供了丰富的光谱细节,但由于其在空间和光谱维度上的高复杂性,也带来了独特的挑战。为此,我们提出了高光谱MAE (Hyper spectral MAE),这是一种基于Transformer的高光谱数据基础模型,其特点是在预训练过程中采用双重掩码策略,随机遮挡50%的空间块和50%的光谱波段。这迫使模型通过重建两个维度上缺失的信息来学习有意义的表征。我们引入了一种基于可学习谐波傅里叶分量的光谱波长位置嵌入,以编码每个光谱波段的身份,确保模型对光谱顺序和间距敏感。重建目标采用了均方误差(MSE)和光谱角制图(SAM)相结合的复合损失,以平衡像素级精度和光谱形状保真度。
The resulting model is of foundation scale $\left(\approx\bf{0.18~B}\right.$ parameters, 768-dimensional embeddings), indicating a high-capacity architecture suitable for transfer learning. We evaluated Hyper spectral MAE on two large-scale hyper spectral corpora—NASA EO-1 Hyperion (1,600 scenes, about 300 billion pixel spectra) and DLR EnMAP Level-0 (1,300 scenes, about 300 billion pixel spectra)—and fine-tuned it for land-cover classification on the Indian Pines benchmark. Transfer-learning results on Indian Pines demonstrate state-of-the-art performance, confirming that our masked pre-training yields robust spectral–spatial representations. The proposed approach highlights how dual masking and spectral embeddings can advance hyperspectral image reconstruction.
最终得到的模型具有基础规模(约 0.18 B 参数,768 维嵌入),表明其适合迁移学习的高容量架构。我们在两个大规模高光谱数据集——NASA EO-1 Hyperion(1,600 个场景,约 3000 亿像素光谱)和 DLR EnMAP Level-0(1,300 个场景,约 3000 亿像素光谱)上评估了 Hyper spectral MAE,并在 Indian Pines 基准测试上对其进行了土地覆盖分类的微调。Indian Pines 的迁移学习结果展示了最先进的性能,证实了我们的掩码预训练能够产生稳健的光谱-空间表征。所提出的方法凸显了双重掩码和光谱嵌入如何推动高光谱图像重建的进步。
• Dual-Masking Strategy: We simultaneously mask spatial patches and spectral bands, forcing the model to capture cross-dimensional dependencies [4]. • Fourier-Based Spectral Encoding: Spectral wavelength embeddings are introduced via harmonic Fourier components, encouraging the model to learn spectral locality and periodicity [5]. • Spectral–Spatial Reconstruction Loss: A composite loss combining mean-squared error (MSE) and spectral angle mapper (SAM) [6] ensures both numerical accuracy and high-fidelity spectral profiles [7]. Foundation-Scale Model: Our transformer architecture scales to hundreds of millions of parameters, setting a new size benchmark for hyper spectral foundation models.
- 双重掩码策略:同时掩码空间区块和光谱波段,迫使模型捕捉跨维度依赖性 [4]。
- 基于傅里叶的光谱编码:通过谐波傅里叶分量引入光谱波长嵌入,促使模型学习光谱局部性与周期性 [5]。
- 光谱-空间重建损失:结合均方误差 (MSE) 和光谱角制图 (SAM) [6] 的复合损失函数,确保数值精度与高保真光谱特征 [7]。
- 基础规模模型:我们的Transformer架构可扩展至数亿参数,为高光谱基础模型设定了新的规模基准。
A. Masked Auto encoders (MAE)
A. 掩码自编码器 (Masked Autoencoders, MAE)
B. Organization
B. 组织架构
The remainder of the paper is organized as follows. Section II reviews related work on masked auto encoders and hyper spectral representation learning. Section III details the proposed model and training methodology. Section IV describes the experimental setup and datasets. Section V presents empirical results, and Section VI concludes the paper.
本文的剩余部分结构如下。第 II 节回顾了掩码自编码器 (masked auto encoders) 和高光谱表示学习的相关工作。第 III 节详细介绍了所提出的模型和训练方法。第 IV 节描述了实验设置和数据集。第 V 节展示了实证结果,第 VI 节对全文进行了总结。
II. RELATED WORK
II. 相关工作
I. INTRODUCTION
I. 引言
H dYrPedEsR SofP Eco Cn TtiR gAu oL u ism sapgeecst r(aHl SbIas)n dcsa pptuerr e pdioxzele,n se ntoa bhliunng- fine-grained material discrimination in fields such as remote sensing, agriculture, and mineral exploration. However, this wealth of spectral information leads to high dimensionality and large data volume, making representation learning for HSIs challenging [1], [2].
高光谱图像 (HSI) 能够捕获连续光谱信息,在遥感、农业和矿产勘探等领域实现细粒度物质判别。然而,丰富的光谱信息导致高维度和海量数据,使得高光谱图像的表征学习极具挑战性 [1] [2]。
Self-supervised foundation models—especially masked autoencoders (MAE)—have recently shown promise in learning robust representations from unlabeled data in computer vision [3]. In the hyper spectral domain, such models offer the potential to exploit rich spectral–spatial redundancies, yet existing work remains limited to small-scale tasks. Therefore, we propose Hyper spectral MAE, a dedicated masked-modeling framework that scales MAE principles to foundation-model size for hyper spectral imagery.
自监督基础模型——尤其是掩码自编码器 (MAE) ——近期在计算机视觉领域展现了从未标注数据中学习鲁棒表征的潜力 [3]。在高光谱领域,此类模型有望利用丰富的光谱-空间冗余特性,但现有研究仍局限于小规模任务。为此,我们提出高光谱MAE框架,将MAE原理扩展至高光谱图像的基础模型规模。
A. Motivation and Contributions
A. 动机与贡献
Our main contributions are:
我们的主要贡献是:
* Corresponding author. Email: ds.kim@gnewsoft.com
- 通讯作者。邮箱:ds.kim@gnewsoft.com
Masked image modeling has gained popularity after the success of Vision MAE by He et al. [3], which showed that reconstructing masked patches is an effective pretext task for learning image representations. The original MAE applies random masking to input image patches and uses a ViT [8] encoder to encode visible patches and a lightweight decoder to reconstruct the missing patches. This approach has been extended to various domains.
掩码图像建模 (Masked Image Modeling) 在何恺明等人提出的Vision MAE [3] 取得成功后广受欢迎,该研究证明重建掩码图像块是学习图像表征的有效预训练任务。原始MAE对输入图像块进行随机掩码,使用ViT [8] 编码器处理可见图像块,并通过轻量级解码器重建缺失块。该方法已被扩展至多个领域。
In hyper spectral imaging, a straightforward application is to mask spatial patches of the HSI cube and reconstruct them. Zhuang et al. [9] applied an MAE-like augmentation network for target detection in HSI, using a 1-D positional encoding for spectra because 2-D positional encoding was deemed unsuitable for spectral data. Similarly, Lin et al. [10] introduced SS-MAE, a spatial–spectral masked auto encoder with two branches: one masks and reconstructs random spatial patches, while the other masks and reconstructs random spectral bands. Their results confirm that incorporating spectral masking in addition to spatial masking leads to better feature learning. Our dual-masking strategy is inspired by this idea, but we integrate both aspects within a single unified architecture and additionally introduce cross-branch interactions.
在高光谱成像中,一种直接的应用是对HSI立方体的空间块进行掩膜并重建。Zhuang等人[9]采用类似MAE的增强网络进行HSI目标检测,由于二维位置编码被认为不适合光谱数据,因此对光谱使用了一维位置编码。类似地,Lin等人[10]提出了SS-MAE,这是一种具有双分支的空间-光谱掩膜自编码器:一个分支对随机空间块进行掩膜和重建,另一个分支对随机光谱波段进行掩膜和重建。他们的结果证实,在空间掩膜基础上加入光谱掩膜能带来更好的特征学习。我们的双掩膜策略受此启发,但我们在单一统一架构中整合了这两个方面,并额外引入了跨分支交互。
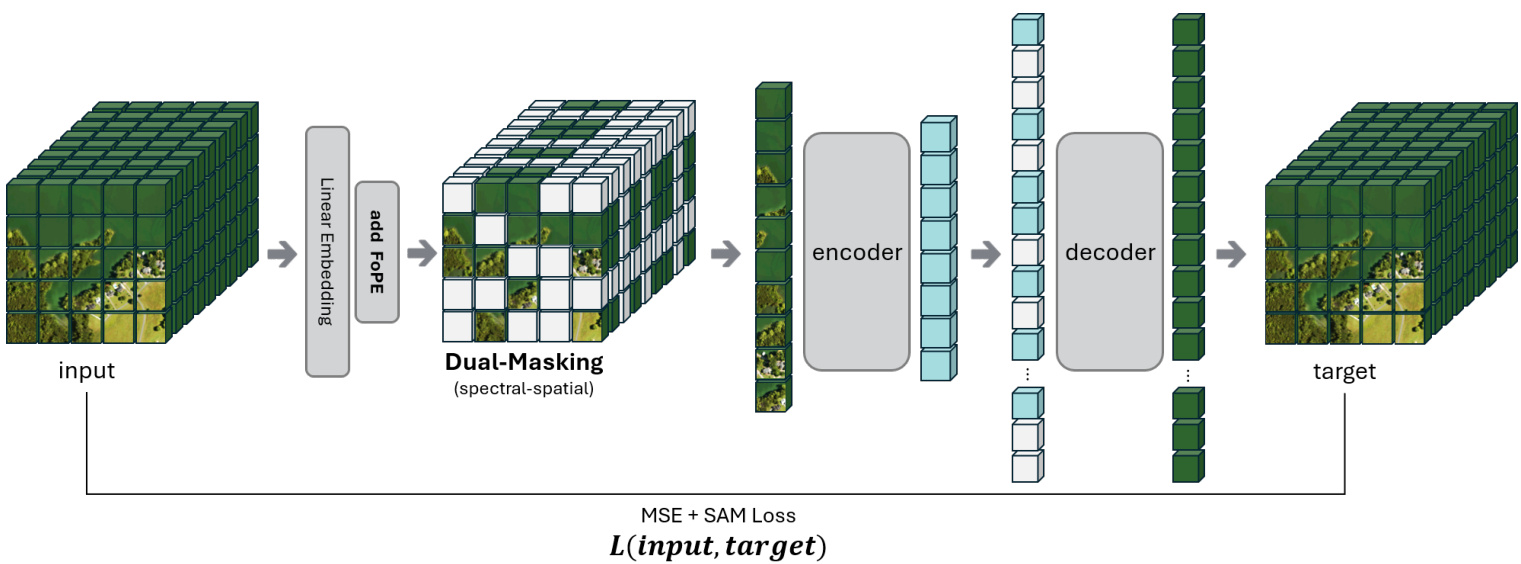
Fig. 1. Hyper spectral MAE overall pipeline.
图 1: 高光谱MAE整体流程。
B. Transformers for HSI
B. 高光谱成像的Transformer
Vision Transformers (ViT) [8] have been applied to hyper spectral images in recent studies. A naïve approach treats each hyper spectral patch (with all bands) as a token sequence and applies ViT for classification. While ViTs can model long-range spatial relationships, early attempts often ignored the explicit spectral structure. For example, some works reduced HSI to RGB (three bands) to apply pretrained ViTs, losing most spectral information. Others processed each pixel’s spectrum with a spectral transformer, treating each pixel’s spectral vector as a sequence of tokens.
视觉Transformer (ViT) [8] 近年来被应用于高光谱图像研究。一种简单的方法是将每个高光谱图像块(包含所有波段)视为一个token序列,并应用ViT进行分类。虽然ViT能够建模长距离空间关系,但早期尝试往往忽略了显式的光谱结构。例如,部分研究将高光谱图像降维至RGB(三个波段)以应用预训练ViT,导致大部分光谱信息丢失。另一些研究则使用光谱Transformer处理每个像素的光谱,将每个像素的光谱向量视为token序列。
Sche i ben re if et al. [11] proposed a Spectral Transformer that attends to bands for each pixel, significantly improving accuracy by leveraging full spectral information. They further introduced a factorized Spatial–Spectral Transformer (SST), which applies self-attention sequentially along spatial and spectral dimensions to handle the large token count in HSI. Factorizing attention in this way proved efficient and boosted performance. Our dual-branch transformer shares a similar motivation of decoupling spectral and spatial attention, but instead of sequential factorization, we employ parallel branches with cross-attention fusion to jointly learn spectral–spatial features.
Sche i ben re if等[11]提出了一种关注每个像素波段的Spectral Transformer (光谱Transformer),通过利用完整光谱信息显著提高了准确性。他们进一步引入了分解式空间-光谱Transformer (SST),沿空间和光谱维度顺序应用自注意力机制来处理HSI中的大量Token。这种注意力分解方式被证明是高效的,并提升了性能。我们的双分支Transformer具有类似的光谱与空间注意力解耦动机,但不同于顺序分解,我们采用具有交叉注意力融合的并行分支来联合学习光谱-空间特征。
C. HSI-Specific Networks
C. 高光谱成像专用网络
Recently, various specialized networks have been designed explicitly for hyper spectral image (HSI) classification tasks. Traditionally, methods such as 3-D convolutional neural networks (3-D CNNs) and hybrid spectral-spatial CNNs have been widely adopted due to their ability to directly extract spatial-spectral features from HSI cubes via volumetric convolutions.
近年来,针对高光谱图像(HSI)分类任务已设计出多种专用网络。传统方法如三维卷积神经网络(3-D CNNs)和混合光谱-空间CNN因其能通过立体卷积直接从HSI立方体中提取空间-光谱特征而被广泛采用。
Emerging advancements have focused on incorporating transformer architectures into HSI-specific contexts to leverage self-attention mechanisms for improved representation learning. For example, Zhu et al. [1] developed Spectral MAE, a spectral-focused masked auto encoder explicitly designed for reconstructing spectral bands from partially masked inputs. Spectral MAE employs a specialized positional encoding tailored to spectral data, achieving superior reconstruction quality for various band combinations.
新兴进展主要集中在将Transformer架构融入高光谱成像(HSI)特定场景,利用自注意力机制提升表征学习效果。例如Zhu等学者[1]提出了Spectral MAE,这是一种专为从部分掩码输入重建光谱波段而设计的谱向掩码自编码器。该模型采用针对光谱数据特制的定位编码方案,在不同波段组合下都能实现卓越的重建质量。
Similarly, Wang et al. [4] introduced HSI-MAE, which utilizes separate spatial and spectral encoders with fusion layers. HSI-MAE explicitly learns spatial context and spectral correlation via two encoder branches, somewhat similar to our dual-branch design.
同样地,Wang等人[4]提出的HSI-MAE采用了带有融合层的独立空间与光谱编码器。该模型通过双编码器分支显式学习空间上下文与光谱相关性,这与我们的双分支设计有一定相似性。
Our work, Hyper spectral MAE goes further by introducing learnable Fourier-based positional features and a cross-attention-based embedding mechanism with MSE $^+$ SAM Loss function.
我们的工作 Hyper spectral MAE 更进一步,引入了基于可学习傅里叶的位置特征和采用 MSE $^+$ SAM 损失函数的跨注意力嵌入机制。
In summary, whereas previous works have addressed spectral–spatial feature learning in parts (e.g., 1-D positional embeddings or dual-branch encoders), our work combines and extends these ideas in a unified framework with foundation model scale. We next describe the components of HyperspectralMAE in detail.
总之,以往的研究仅部分解决了光谱-空间特征学习问题(例如一维位置嵌入或双分支编码器),而我们的工作将这些思想结合并扩展到一个具有基础模型规模的统一框架中。接下来我们将详细阐述HyperspectralMAE的各个组件。
III. METHODOLOGY
III. 方法论
We begin by outlining the encoder–decoder Transformer architecture of Hyper spectral MAE, which employs specialized embedding modules and dual masking operations. The encoder receives a partially masked hyper spectral image and produces latent representations, while the decoder reconstructs the full HSI from these latents. During pre-training, a fraction of the input is masked both spatially and spectrally, forcing the encoder to infer missing information from the unmasked context along both dimensions. To this end, several key modules are introduced and detailed below.
我们首先概述Hyper spectral MAE的编码器-解码器Transformer架构,该架构采用专用嵌入模块和双重掩码操作。编码器接收部分掩码的高光谱图像并生成潜在表征,而解码器则从这些潜在表征中重建完整HSI。在预训练期间,输入数据会在空间和光谱维度上进行部分掩码,迫使编码器从两个维度的未掩码上下文中推断缺失信息。为此,我们引入并详细说明以下关键模块:
A. Overview of Hyper spectral MAE Architecture
A. 高光谱 MAE 架构概述
Figure 1 shows Hyper spectral MAE’s overall pipeline. Let some of X RH×W ×B,
图 1: 展示了高光谱MAE的整体流程。设X RH×W ×B的部分数据,
$$
\mathbf{X}={x_{i,j,b}\in\mathbb{R}\mid i=1,\ldots,H;j=1,\ldots,W;b=1,\ldots,B}
$$
$$
\mathbf{X}={x_{i,j,b}\in\mathbb{R}\mid i=1,\ldots,H;j=1,\ldots,W;b=1,\ldots,B}
$$
be an input hyper spectral image with spatial height $H$ , width $W$ , and $B$ spectral bands. We partition X into non-overlapping spatial-spectral patches: each spatial patch covers a $9\times9$ pixel window and each spectral patch spans a block of 8 consecutive bands. Formally, for spatial indices $p=1,\ldots,\lfloor H/9\rfloor$ and $q=$ $1,\dots,\lfloor W/9\rfloor$ , and spectral-group index $k=1,\ldots,\lfloor B/8\rfloor$ , a patch is defined as
设输入高光谱图像的空间高度为 $H$,宽度为 $W$,具有 $B$ 个光谱波段。我们将 X 划分为不重叠的空谱联合块:每个空间块覆盖 $9\times9$ 像素窗口,每个光谱块跨越连续的8个波段。形式上,对于空间索引 $p=1,\ldots,\lfloor H/9\rfloor$ 和 $q=1,\dots,\lfloor W/9\rfloor$,以及光谱组索引 $k=1,\ldots,\lfloor B/8\rfloor$,每个块定义为
as HSI-MAE [4] did. This yields tokens that represent local spatial–spectral regions. Each token is augmented with learned positional encodings—2-D spatial encodings (as in ViT) and our proposed spectral wavelength encodings for the band-group index. The encoder, a ViT-like Transformer, operates on visible unmasked tokens to produce latent features; a lightweight decoder then combines these latents with learned mask tokens to reconstruct the original hyper spectral image.
如HSI-MAE [4]所做的那样。这会生成代表局部空间-光谱区域的token。每个token都通过学习的定位编码进行增强——包括二维空间编码(与ViT相同)和我们提出的针对波段组索引的光谱波长编码。编码器采用类似ViT的Transformer架构,对可见的未遮蔽token进行处理以生成潜在特征;随后一个轻量级解码器将这些潜在特征与学习的遮蔽token相结合,重建原始高光谱图像。
B. Dual Spatial–Spectral Masking
B. 双重空间-光谱掩蔽
Inspired by HSI-MAE [4], For spatial masking, we randomly sample $50%$ of spatial grid coordinates $(p,q)$ and mask all tokens whose spatial index equals any of the selected $(p,q)$ pairs-i.e., every spectral-group slice at those positions is hidden. and for spectral masking from the remaining tokens after spatial masking, we randomly sample $50%$ of spectralgroup indices $k$ (equivalently, band groups $b$ ) and mask every token whose spectral index belongs to this set, regardless of its spatial location.
受HSI-MAE [4]启发,在空间掩码方面,我们随机采样50%的空间网格坐标$(p,q)$,并掩码所有空间索引等于任一选定$(p,q)$对的token(即这些位置上的每个光谱组切片都被隐藏)。对于光谱掩码,在空间掩码后的剩余token中,我们随机采样50%的光谱组索引$k$(等效于波段组$b$),并掩码所有光谱索引属于该集合的token,无论其空间位置如何。
C. Spectral Wavelength Positional Encoding
C. 光谱波长位置编码
In Hyper spectral MAE, we introduce a spectral wavelength positional embedding to capture global spectral dependencies. For each spectral patch $k$ (eight consecutive bands) we first compute its representative wavelength as the arithmetic mean of the centre-wavelengths of those bands:
在高光谱MAE中,我们引入了光谱波长位置嵌入(spectral wavelength positional embedding)来捕获全局光谱依赖性。对于每个光谱块$k$(八个连续波段),我们首先计算其代表波长作为这些波段中心波长的算术平均值:
$$
\lambda_{k}=\frac{1}{8}\sum_{m=1}^{8}\lambda_{b_{k}^{(m)}},
$$
$$
\lambda_{k}=\frac{1}{8}\sum_{m=1}^{8}\lambda_{b_{k}^{(m)}},
$$
Can be corresponding angulaer frequency is
对应角频率为
$$
\omega_{k}={\frac{2\pi}{\lambda_{k}}}.
$$
$$
\omega_{k}={\frac{2\pi}{\lambda_{k}}}.
$$
Where original [12] positional encoding(PE) is
原始[12]位置编码(PE)是
$$
\begin{array}{r l r}&{}&{\mathrm{PE}(\mathrm{pos},2i)=\mathrm{sin}\left(\frac{\mathrm{pos}}{10000^{2i/d_{\mathrm{model}}}}\right),}\ &{}&{\mathrm{PE}(\mathrm{pos},2i+1)=\mathrm{cos}\left(\frac{\mathrm{pos}}{10000^{2i/d_{\mathrm{model}}}}\right),}\end{array}
$$
$$
\begin{array}{r l r}&{}&{\mathrm{PE}(\mathrm{pos},2i)=\mathrm{sin}\left(\frac{\mathrm{pos}}{10000^{2i/d_{\mathrm{model}}}}\right),}\ &{}&{\mathrm{PE}(\mathrm{pos},2i+1)=\mathrm{cos}\left(\frac{\mathrm{pos}}{10000^{2i/d_{\mathrm{model}}}}\right),}\end{array}
$$
where $i$ indexes the dimension and $d_{m o d e l}$ is the embedding dimention. We can analogously define a multi-frequency spectral encoding that injects the wavelength $\lambda_{k}$ at multiple scales. Let $d_{s p e c}$ be our desired embedding dimension. For $i=0,1,\ldots,\frac{d_{\mathrm{spec}}}{2}-1$ , we define:
其中 $i$ 表示维度索引,$d_{model}$ 为嵌入维度。我们可以类似地定义一个多频光谱编码,将波长 $\lambda_{k}$ 以多尺度形式注入。设 $d_{spec}$ 为目标嵌入维度,对于 $i=0,1,\ldots,\frac{d_{\mathrm{spec}}}{2}-1$,定义如下:
$$
\begin{array}{r l r}&{}&{\mathrm{SpecEnc}\left(\lambda_{k},2i\right)=\mathrm{sin}\left(\frac{\omega_{k}}{10000^{\frac{2i}{d_{\mathrm{spec}}}}}\right),}\ &{}&{\mathrm{SpecEnc}\left(\lambda_{k},2i+1\right)=\mathrm{cos}\left(\frac{\omega_{k}}{10000^{\frac{2i}{d_{\mathrm{pec}}}}}\right),}\end{array}
$$
$$
\begin{array}{r l r}&{}&{\mathrm{SpecEnc}\left(\lambda_{k},2i\right)=\mathrm{sin}\left(\frac{\omega_{k}}{10000^{\frac{2i}{d_{\mathrm{spec}}}}}\right),}\ &{}&{\mathrm{SpecEnc}\left(\lambda_{k},2i+1\right)=\mathrm{cos}\left(\frac{\omega_{k}}{10000^{\frac{2i}{d_{\mathrm{pec}}}}}\right),}\end{array}
$$
Hence, the spectral embedding vector for band $\mathbf{b}$ is
因此,波段 $\mathbf{b}$ 的光谱嵌入向量为
$$
\begin{array}{r}{\mathbf{v}{\mathrm{spec}}(\lambda_{k})=\left[\sin\left(\frac{\omega_{k}}{10000^{0}}\right),\cos\left(\frac{\omega_{k}}{10000^{0}}\right),\right.\qquad}\ {\left.\sin\left(\frac{\omega_{k}}{10000^{2/d_{\mathrm{spec}}}}\right),\cos\left(\frac{\omega_{k}}{10000^{2/d_{\mathrm{spec}}}}\right),\dots\right].}\end{array}
$$
$$
\begin{array}{r}{\mathbf{v}{\mathrm{spec}}(\lambda_{k})=\left[\sin\left(\frac{\omega_{k}}{10000^{0}}\right),\cos\left(\frac{\omega_{k}}{10000^{0}}\right),\right.\qquad}\ {\left.\sin\left(\frac{\omega_{k}}{10000^{2/d_{\mathrm{spec}}}}\right),\cos\left(\frac{\omega_{k}}{10000^{2/d_{\mathrm{spec}}}}\right),\dots\right].}\end{array}
$$
cycling over all $i$ .
遍历所有 $i$。
$D$ . Training Objective: MSE with SAM
$D$。训练目标:带SAM的均方误差 (MSE)
Let some of Y RH×W ×B,
令部分 Y RH×W ×B,
$$
\mathbf{Y}={y_{i,j,b}\in\mathbb{R}\mid1\leq i\leq H,1\leq j\leq W,1\leq b\leq B}
$$
$$
\mathbf{Y}={y_{i,j,b}\in\mathbb{R}\mid1\leq i\leq H,1\leq j\leq W,1\leq b\leq B}
$$
denote the ground-truth hyper spectral data cube, where $H$ and $W$ are the spatial dimensions and $B$ is the number of spectral bands.
表示真实的高光谱数据立方体,其中$H$和$W$为空间维度,$B$为光谱波段数。
The network produces a reconstruction
网络生成重建结果
$$
\hat{\mathbf{Y}}={\hat{y}_{i,j,b}}\in\mathbb{R}^{H\times W\times B}
$$
$$
\hat{\mathbf{Y}}={\hat{y}_{i,j,b}}\in\mathbb{R}^{H\times W\times B}
$$
During pre-training, a two-stage masking procedure (Sect. C) selects a subset
在预训练阶段,一个两阶段掩码处理流程(见附录C)会选取一个子集
$$
\mathcal{M}\subseteq{1,\dots,H}\times{1,\dots,W}\times{1,\dots,B}
$$
$$
\mathcal{M}\subseteq{1,\dots,H}\times{1,\dots,W}\times{1,\dots,B}
$$
of spatial-spectral indices to be hidden from the encoder. For convenience, the complete set of spatial coordinates is written as
空间光谱索引的隐藏编码。为方便起见,完整空间坐标集记为
$$
\Omega={1,\dots,H}\times{1,\dots,W}
$$
$$
\Omega={1,\dots,H}\times{1,\dots,W}
$$
The first component of the loss is the mean squared reconstruction error evaluated only at masked voxels:
损失函数的第一个组成部分是仅在掩码体素处评估的均方重建误差:
$$
\mathcal{L}{\mathrm{MSE}}=\frac{1}{\left|\mathcal{M}\right|}\sum_{(i,j,b)\in\mathcal{M}}\left(y_{i,j,b}-\hat{y}_{i,j,b}\right)^{2}
$$
$$
\mathcal{L}{\mathrm{MSE}}=\frac{1}{\left|\mathcal{M}\right|}\sum_{(i,j,b)\in\mathcal{M}}\left(y_{i,j,b}-\hat{y}_{i,j,b}\right)^{2}
$$
By confining the error computation to $\mathcal{M}$ , the encoderdecoder is forced to infer radiance values that were never observed at input time. 3) Spectral-angle mapper over all pixels
通过将误差计算限制在 $\mathcal{M}$ 内,编码器-解码器被迫推断输入时从未观测到的辐射值。3) 全像素光谱角制图器
For each pixel $(i,j)\in\Omega$ , define the ground-truth and reconstructed spectra
对于每个像素 $(i,j)\in\Omega$,定义真实光谱和重建光谱
$$
\begin{array}{r}{\mathbf{y}{i,j}=[y_{i,j,1},\dots,y_{i,j,B}]^{\top},\quad\hat{\mathbf{y}}{i,j}=[\hat{y}{i,j,1},\dots,\hat{y}_{i,j,B}]^{\top}.}\end{array}
$$
$$
\begin{array}{r}{\mathbf{y}{i,j}=[y_{i,j,1},\dots,y_{i,j,B}]^{\top},\quad\hat{\mathbf{y}}{i,j}=[\hat{y}{i,j,1},\dots,\hat{y}_{i,j,B}]^{\top}.}\end{array}
$$
Their spectral angle is
它们的谱角是
$$
\mathrm{SAM}(i,j)=\operatorname{arccos}\left(\frac{\mathbf{y}{i,j}^{\top}\hat{\mathbf{y}}{i,j}}{\left|\mathbf{y}{i,j}\right|{2}\left|\hat{\mathbf{y}}{i,j}\right|_{2}}\right)
$$
$$
\mathrm{SAM}(i,j)=\operatorname{arccos}\left(\frac{\mathbf{y}{i,j}^{\top}\hat{\mathbf{y}}{i,j}}{\left|\mathbf{y}{i,j}\right|{2}\left|\hat{\mathbf{y}}{i,j}\right|_{2}}\right)
$$
Averaging over all spatial locations produces the SAM loss
对所有空间位置取平均得到SAM损失
$$
\mathcal{L}{\mathrm{SAM}}=\frac{1}{|\Omega|}\sum_{(i,j)\in\Omega}\mathrm{SAM}(i,j)
$$
$$
\mathcal{L}{\mathrm{SAM}}=\frac{1}{|\Omega|}\sum_{(i,j)\in\Omega}\mathrm{SAM}(i,j)
$$
This term promotes spectral-shape fidelity throughout the entire image rather than only at the masked positions, a property shown to benefit downstream analytical tasks. The final training objective is a convex combination of the two criteria:
该术语提升了整个图像而非仅限于掩膜位置的光谱形状保真度,这一特性已被证明有利于下游分析任务。最终训练目标是这两个标准的凸组合:
$$
\mathcal{L}{\mathrm{rec}}=\alpha\mathcal{L}{\mathrm{MSE}}+(1-\alpha)\mathcal{L}_{\mathrm{SAM}}
$$
$$
\mathcal{L}{\mathrm{rec}}=\alpha\mathcal{L}{\mathrm{MSE}}+(1-\alpha)\mathcal{L}_{\mathrm{SAM}}
$$
where the weighting factor $\alpha\in[0,1]$ determines the tradeoff between radiometric accuracy and spectral-shape preservation. In all experiments we set $\alpha=0.5$ . Gradients originat- ing from ${\mathcal{L}}{\mathrm{MSE}}$ are back-propagated exclusively through the masked voxels, whereas $\mathcal{L}_{\mathrm{SAM}}$ distributes its gradients across the full data cube. This asymmetric propagation compels the network to reconstruct unseen spatial-spectral regions with high numerical precision while maintaining globally coherent spectral signatures-yielding latent representations that are well-suited for subsequent hyper spectral classification task.
其中权重因子 $\alpha\in[0,1]$ 决定了辐射精度与光谱形状保留之间的权衡。在所有实验中我们设定 $\alpha=0.5$。源自 ${\mathcal{L}}{\mathrm{MSE}}$ 的梯度仅通过掩膜体素反向传播,而 $\mathcal{L}_{\mathrm{SAM}}$ 将其梯度分布在整个数据立方体上。这种非对称传播迫使网络以高数值精度重建未见过的空间-光谱区域,同时保持全局一致的光谱特征,从而产生非常适合后续高光谱分类任务的潜在表征。
IV. EXPERIMENTS
IV. 实验
A. Pre-Training Data
A. 预训练数据
We assembled a large corpus of hyper spectral imagery to pre-train Hyper spectral MAE in a self-supervised manner. This corpus includes NASA EO-1 Hyperion [13] and DLR EnMAP Level-0 [14], among others, totaling on the order of 600 billion raw pixels. These datasets span a variety of scenes and sensor characteristics, providing a diverse spectral–spatial training signal. We did not use any class labels during pre-training; the model learned purely by reconstructing masked portions of the input data. We apply standard data augmentations such as random flipping and mild spectral jitter to increase robustness. The model was trained with an AdamW optimizer for several epochs until convergence of the reconstruction loss.
我们构建了一个大型高光谱影像数据集,以自监督方式预训练高光谱MAE (Masked Autoencoder)。该数据集包含NASA EO-1 Hyperion [13]、DLR EnMAP Level-0 [14]等,总计约6000亿原始像素。这些数据涵盖多种场景和传感器特性,提供了丰富的光谱-空间训练信号。预训练过程中未使用任何类别标签,模型仅通过重建输入数据的掩码部分进行学习。我们采用随机翻转和轻微光谱抖动等标准数据增强方法来提升鲁棒性。模型使用AdamW优化器训练多个周期,直至重建损失收敛。
NASA EO-1 Hyperion (1,600 scenes, ${\sim}300$ billion pixel spectra) Each Hyperion scene covers a $7.7~\mathrm{km}$ (cross-track) $\times 42~\mathrm{km}$ (along-track) swath at $30\textrm{m}$ spatial sampling $(\sim256\times1,400$ pixels) over 220 contiguous spectral bands (0.357–2.576 $\mu\mathrm{m}$ , $10\mathrm{nm}$ sampling), totaling roughly 300 billion pixels.
NASA EO-1 Hyperion (1,600景数据,约3,000亿像素光谱) 每景Hyperion数据覆盖7.7公里(跨轨方向)×42公里(沿轨方向)条带,空间采样率为30米(约256×1,400像素),包含220个连续光谱波段(0.357–2.576μm,10nm采样),总像素量约达3,000亿。
DLR EnMAP Level-0 (1,300 scenes, ${\sim}300$ billion pixel spectra) Each EnMAP scene covers a $30~\mathrm{km}\times30~\mathrm{km}$ area at $30\mathrm{m~}$ ground sampling $(1,000~\times 1,000$ pixels) across 246 spectral bands $^{\prime}430{-}2{,}450\mathrm{nm}$ ; $6.5{-}10~\mathrm{nm}$ sampling), for a similar total of about 300 billion pixels.
DLR EnMAP Level-0 (1,300景,约3,000亿像素光谱) 每景EnMAP数据覆盖30 km×30 km区域,地面采样分辨率30米 (1,000×1,000像素),包含246个光谱波段 (430-2,450nm;6.5-10 nm采样),总像素量同样约为3,000亿。
B. Model Scale and Implementation
B. 模型规模与实现
The Hyper spectral MAE encoder is a multi-layer Transformer with 768-dimensional embeddings and multi-head self-attention. A shallower decoder reconstructs the full HSI. The model totals about $1.8\times10^{8}$ parameters, enabled by large-scale unlabeled data and mixed-precision training.
高光谱MAE编码器是一个具有768维嵌入和多头自注意力机制的多层Transformer。较浅的解码器负责重建完整的高光谱图像(HSI)。该模型总参数量约为$1.8\times10^{8}$,得益于大规模无标签数据和混合精度训练的支持。
C. Fine-Tuning on Classification
C. 分类任务微调
After pre-training, we evaluate the learned representations on downstream HSI classification tasks. We evaluate on the Indian Pines dataset—a classic hyper spectral scene of an agricultural area captured by the AVIRIS sensor, with 224 spectral bands and 16 ground-truth land-cover categories (after masking unused classes). Indian Pines is particularly challenging due to its limited size (only 10,249 labeled pixels) and high intra-class spectral variability.
预训练完成后,我们在下游高光谱图像(HSI)分类任务上评估学习到的表征。测试数据采用Indian Pines数据集——这是一个由AVIRIS传感器拍摄的经典农业区高光谱场景,包含224个光谱波段和16种真实地表覆盖类别(经过掩膜处理去除无效类别)。由于样本量有限(仅10,249个标注像素)且存在较高的类内光谱变异性,Indian Pines数据集具有显著挑战性。
D. Evaluation Metrics
D. 评估指标
We evaluate on the standard Indian Pines dataset $(145\times145$ pixels, 16 classes) following exactly the same train–test split and settings used by Hong et al. [15] for Spectral Former—a protocol subsequently adopted by HyLITE [16]—to enable direct comparison. All models are assessed with three common HSI metrics: Overall Accuracy (OA), Average Accuracy (AA), and Cohen’s Kappa coefficient $(\kappa)$ , which measure overall pixel correctness, mean per-class accuracy, and chance-corrected agreement with ground truth, respectively. By mirroring the prior evaluation protocol, we ensure that results for Hyper spectral MAE are directly comparable to existing methods under identical conditions.
我们在标准Indian Pines数据集$(145\times145$像素,16个类别)上进行评估,严格遵循Hong等人[15]为Spectral Former设计的训练-测试划分方案和参数设置(该方案后来被HyLITE[16]沿用),以确保结果可直接比较。所有模型均采用三种高光谱图像(HSI)常用指标进行评估:总体准确率(OA)、平均准确率(AA)和Cohen's Kappa系数$(\kappa)$,这些指标分别衡量整体像素正确率、各类别平均准确率以及与真实标注的校正后一致性。通过复现先前的评估方案,我们确保超光谱MAE(Hyper spectral MAE)的结果能够在相同条件下与现有方法直接对比。
V. RESULTS AND DISCUSSION
V. 结果与讨论
A. Reconstruction Performance
A. 重建性能
During self-supervised pre-training, Hyper spectral MAE demonstrated the ability to accurately reconstruct masked portions of the input. These indicate that the model learns a high-fidelity internal representation of HSI data.
在高光谱MAE的自监督预训练过程中,该模型展现出精确重建输入掩码部分的能力。这表明模型学习到了高保真度的高光谱数据内部表征。
B. Transfer Learning to Indian Pines
B. 迁移学习应用于Indian Pines
The Indian Pines results highlight the effectiveness of Hyper spectral MA $E$ as a foundation model for HSI. With only small training pixels the fine-tuned model achieved an Overall Accuracy (OA) of $92.37%$ , surpassing previous state-of-the-art methods. Compared with the best conventional CNN baseline (2-D CNN [17], $75.89%$ OA) and the transformer-based Spectral Former [15] $78.97%$ OA), Hyper spectral MAE shows gains of roughly 13 percentage points in OA and 10 points in AA, establishing a new benchmark for this dataset. The result shown at Table I.
Indian Pines数据集的结果凸显了Hyper spectral MAE (E)作为高光谱成像(HSI)基础模型的有效性。仅用少量训练像素微调后,模型就达到了92.37%的总体准确率(OA),超越了之前最先进的方法。与最佳传统CNN基线(2-D CNN [17],75.89% OA)和基于Transformer的Spectral Former [15](78.97% OA)相比,Hyper spectral MAE在OA上提升了约13个百分点,在AA上提升了10个点,为该数据集建立了新基准。结果如 表1 所示。
These substantial gains emphasize the strength of our pre-training and fine-tuning strategy, particularly when training data are limited.
这些显著收益凸显了我们预训练和微调策略的优势,尤其是在训练数据有限的情况下。
TABLE I CLASSIFICATION RESULTS ON THE INDIAN PINES DATASET
表 1: INDIAN PINES 数据集分类结果
| 方法 | OA (%) | AA (%) | Kappa |
|---|---|---|---|
| kNN [18] | 59.17 | 63.90 | 0.54 |
| RF [19] | 69.80 | 76.78 | 0.65 |
| SVM [20] | 72.36 | 83.16 | 0.68 |
| 1-D CNN [17] | 70.43 | 79.60 | 0.66 |
| 2-D CNN [17] | 75.89 | 86.64 | 0.72 |
| RNN [21] | 70.66 | 76.37 | 0.66 |
| miniGCN [22] | 75.11 | 78.03 | 0.71 |
| ViT [8] | 71.86 | 78.97 | 0.68 |
| SpectralFormer [15] | 78.97 | 85.39 | 0.76 |
| HyLITE [16] | 89.80 | 94.69 | 0.88 |
| Ours (HyperspectralMAE) | 92.37 | 95.80 | 0.91 |
VI. CONCLUSIONS
VI. 结论
We introduced Hyper spectral MAE, a transformer-based masked auto encoder that learns rich spectral–spatial represent at ions from hyper spectral imagery. The proposed dual-masking strategy—simultaneously hiding $50%$ of spatial patches and $50%$ of spectral bands—forces the network to reason jointly across both dimensions. A wavelength-aware spectral positional embedding further equips the model with an explicit notion of spectral frequency, while a composite $\mathrm{MSE}+\mathrm{SAM}$ reconstruction loss balances pixel-level accuracy and spectral-shape fidelity. Scaled to about $0.18\mathrm{B}$ parameters, Hyper spectral MAE attains state-of-the-art results on Indian Pines, even when fine-tuned with only few labeled pixels.
我们提出了Hyper spectral MAE (高光谱掩码自编码器),这是一种基于Transformer的掩码自编码器,能够从高光谱图像中学习丰富的谱间-空间表征。该模型采用双重掩码策略——同时遮蔽50%的空间区块和50%的光谱波段——迫使网络在双重维度上进行联合推理。波长感知的光谱位置嵌入进一步赋予模型明确的光谱频率概念,而复合的MSE+SAM重建损失函数则平衡了像素级精度与光谱形态保真度。当参数量扩展至约0.18B时,Hyper spectral MAE在Indian Pines数据集上实现了最先进的性能,即使在仅用少量标注像素进行微调的情况下依然表现优异。
These findings underscore the promise of large-scale self-supervised learning for hyper spectral data, a domain often constrained by scarce annotations. The model’s strong transfer performance on limited supervision suggests practical value for real-world applications such as precision agriculture, environmental monitoring, and mineral exploration.
这些发现凸显了大规模自监督学习在高光谱数据领域的潜力,该领域常受限于稀缺的标注数据。模型在有限监督下表现出的强大迁移能力,预示着其在精准农业、环境监测和矿物勘探等实际应用中的实用价值。
Future work will explore scaling Hyper spectral MAE to even larger model sizes and extending the framework to additional tasks, including anomaly detection, spectral unmixing, and retrieval. We believe this study represents a step toward general-purpose foundation models for hyper spectral sensing, bridging the gap between rich spectral data and modern representation learning.
未来工作将探索将高光谱MAE扩展到更大模型规模,并将该框架扩展到更多任务,包括异常检测、光谱解混和检索。我们相信这项研究为高光谱传感的通用基础模型迈进了一步,弥合了丰富光谱数据与现代表征学习之间的差距。