A PREVIEW OF XIYAN-SQL: A MULTI-GENERATOR ENSEMBLE FRAMEWORK FOR TEXT-TO-SQL
XIYAN-SQL 预览:一个用于文本到 SQL 的多生成器集成框架
ABSTRACT
摘要
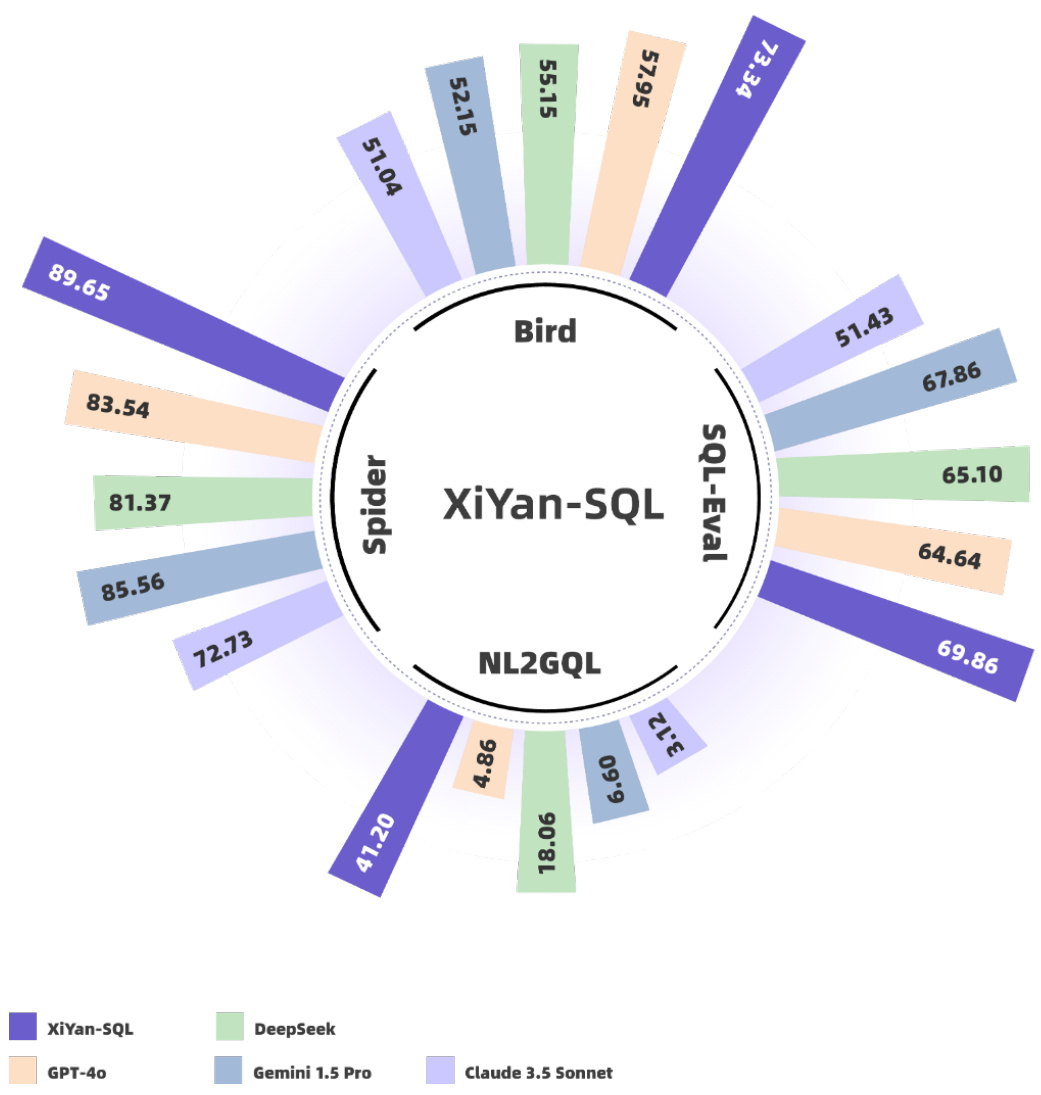
To tackle the challenges of large language model performance in natural language to SQL tasks, we introduce XiYan-SQL, an innovative framework that employs a multi-generator ensemble strategy to improve candidate generation. We introduce M-Schema, a semi-structured schema representation method designed to enhance the understanding of database structures. To enhance the quality and diversity of generated candidate SQL queries, XiYan-SQL integrates the significant potential of in-context learning (ICL) with the precise control of supervised fine-tuning. On one hand, we propose a series of training strategies to fine-tune models to generate high-quality candidates with diverse preferences. On the other hand, we implement the ICL approach with an example selection method based on named entity recognition to prevent over emphasis on entities. The refiner optimizes each candidate by correcting logical or syntactical errors. To address the challenge of identifying the best candidate, we fine-tune a selection model to distinguish nuances of candidate SQL queries. The experimental results on multiple dialect datasets demonstrate the robustness of XiYan-SQL in addressing challenges across different scenarios. Overall, our proposed XiYan-SQL achieves the state-of-the-art execution accuracy of $75.63%$ on Bird benchmark, $89.65%$ on the Spider test set, $69.86%$ on SQL-Eval, $41.20%$ on NL2GQL. The proposed framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods.
为解决大语言模型在自然语言转SQL任务中的性能挑战,我们提出了XiYan-SQL创新框架,该框架采用多生成器集成策略来改进候选生成。我们设计了M-Schema这种半结构化模式表示方法,旨在增强对数据库结构的理解。为提升生成候选SQL查询的质量和多样性,XiYan-SQL将上下文学习(ICL)的重要潜力与监督微调的精确控制相结合。一方面,我们提出一系列训练策略来微调模型,使其生成具有不同偏好的高质量候选查询;另一方面,我们采用基于命名实体识别的示例选择方法实现ICL,避免对实体的过度关注。优化器通过修正逻辑或语法错误来改进每个候选查询。针对最佳候选查询的识别难题,我们微调了选择模型以区分候选SQL查询的细微差异。在多方言数据集上的实验结果证明了XiYan-SQL在不同场景中应对挑战的鲁棒性。总体而言,我们提出的XiYan-SQL在Bird基准测试中达到75.63%的最优执行准确率,在Spider测试集上达89.65%,在SQL-Eval上为69.86%,在NL2GQL上达41.20%。该框架不仅提升了SQL查询的质量和多样性,其性能也超越了先前的方法。
Keywords LLM, Text-to-SQL, NL2SQL
关键词 大语言模型 (LLM), 文本转SQL (Text-to-SQL), 自然语言转SQL (NL2SQL)
1 Introduction
1 引言
The ability to convert natural language queries into structured query language (SQL) through natural language to SQL (NL2SQL) technology represents a significant advancement in making complex datasets more accessible. It greatly facilitates both non-expert and advanced users in extracting valuable insights from extensive data repositories [2, 15, 24, 27, 6, 10, 13, 29, 20, 19, 23, 22]. Recent advancements in large language models (LLMs) have significantly enhanced the efficacy and accuracy of NL2SQL applications.
通过自然语言转SQL(NL2SQL)技术将自然语言查询转换为结构化查询语言(SQL)的能力,标志着复杂数据集更易访问的重大进步。该技术极大便利了非专业用户和高级用户从海量数据存储库中提取有价值洞见[2, 15, 24, 27, 6, 10, 13, 29, 20, 19, 23, 22]。大语言模型(LLM)的最新进展显著提升了NL2SQL应用的效能与准确性。
There are generally two approaches for NL2SQL solutions based on LLMs: prompt engineering [3, 5, 17, 18], and supervised fine-tuning (SFT) [9]. Prompt engineering leverages the intrinsic capabilities of the model by optimizing prompts to generate diverse SQL queries. Prompt engineering has demonstrated promising results in NL2SQL using zero-shot [3] or few-shot prompting [28, 5, 18]. This type of approach typically employs closed-source models with enormous parameters, such as GPT-4 [1] and Gemini 1.5 [26], which present significant potential and powerful generalization capability. However, most methods rely on multi-path generation and selecting the best option utilizing self-consistency, resulting in significant inference overheads. Approaches based on SFT seek to fine-tune models with much smaller parameter sizes on the NL2SQL task to produce more controllable SQL queries, such as CodeS [9]. Nevertheless, due to their limited parameters, these methods struggle to perform complex NL2SQL reasoning and transfer to databases within a new domain.
基于大语言模型的NL2SQL解决方案通常有两种方法:提示工程(prompt engineering)[3,5,17,18]和监督微调(supervised fine-tuning,SFT)[9]。提示工程通过优化提示来激发模型的内在能力,从而生成多样化的SQL查询。采用零样本[3]或少样本提示[28,5,18]的提示工程方法在NL2SQL任务中已展现出优异效果。这类方法通常使用闭源的大参数模型(如GPT-4[1]和Gemini 1.5[26]),这些模型具有显著潜力和强大的泛化能力。但多数方法依赖多路径生成和基于自一致性的最优选择策略,导致较高的推理开销。基于SFT的方法则尝试在NL2SQL任务上微调小参数规模的模型(如CodeS[9])以生成更可控的SQL查询。然而受限于参数量,这类方法难以完成复杂的NL2SQL推理,也难以迁移到新领域的数据库。
In this technical report, we propose XiYan-SQL, a novel NL2SQL framework that employs a multi-generator ensemble strategy to enhance candidate generation. XiYan-SQL combines prompt engineering and the SFT method to generate candidate SQL queries with high quality and diversity. To enhance high quality, we take advantage of the high control l ability of SFT and utilize a range of training strategies to specifically fine-tune models to generate candidates with different preferences. We introduce a two-stage multi-task training approach, which first activates the model’s fundamental SQL generation capabilities, and subsequently transitions to a model with enhanced semantic understanding and diverse stylistic preferences. To enhance diversity of generated candidates and capability of generating complex SQL queries, we utilize in-context learning to prompt LLMs. We propose to extract the skeleton of the questions by masking the named entities with common special tokens and using skeleton similarity to select and organize useful examples. Then, each generator is followed by a refiner to correct logical or syntactical error based on execution results or error information. Finally, a selection agent is required to select the best option. Most existing works use self-consistency, but the most consistent result is not always the correct case. So we propose to fine-tune a model to understand and identify the subtle differences among candidates and pick the final response.
在本技术报告中,我们提出了XiYan-SQL——一种采用多生成器集成策略来增强候选生成的新型NL2SQL框架。XiYan-SQL结合提示工程和SFT方法,生成具有高质量与多样性的候选SQL查询。为提升质量,我们利用SFT的高可控性,通过多种训练策略专门微调模型以生成不同偏好的候选查询。我们引入两阶段多任务训练方法:先激活模型的基础SQL生成能力,再转向具备增强语义理解与多样化风格偏好的模型。为增强候选查询的多样性及复杂SQL生成能力,我们采用上下文学习来提示大语言模型。提出通过通用特殊符号掩码命名实体提取问题骨架,并基于骨架相似度筛选组织有效示例。随后每个生成器配备修正器,根据执行结果或错误信息修正逻辑或语法错误。最终由选择智能体筛选最佳方案。现有工作多采用自一致性方法,但最一致的结果未必正确。因此我们提出微调模型来理解识别候选间的细微差异,从而选定最终响应。
Additionally, to enhance LLMs for better understanding of the database schema, we propose a new schema representation method named M-Schema. Inspired by MAC-SQL Schema [28], M-Schema presents the hierarchical structure between databases, tables, and columns in a semi-structured form. We revised MAC-SQL Schema by adding data types and resulting in a more compact and clear format. We conduct experiments to compare the impact of different schema representations on NL2SQL performance. In comparison to DDL Schema and MAC-SQL Schema, LLMs using M-Schema demonstrate superior performance.
此外,为提升大语言模型(LLM)对数据库模式(schema)的理解能力,我们提出了一种名为M-Schema的新模式表示方法。受MAC-SQL Schema [28]启发,M-Schema以半结构化形式呈现数据库、表和列之间的层级关系。我们在MAC-SQL Schema基础上添加数据类型,形成更紧凑清晰的格式。通过实验对比不同模式表示对NL2SQL性能的影响,发现采用M-Schema的大语言模型表现优于DDL Schema和MAC-SQL Schema。
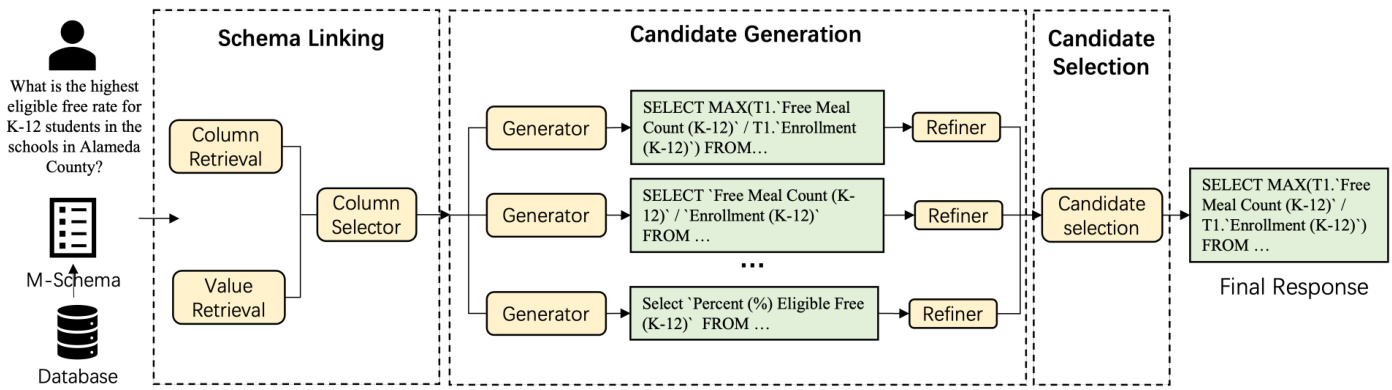
Figure 1: Overview of the proposed XiYan-SQL workflow, which consists of three agents: 1) Schema Linking, which retrieves and selects the most database schema; 2) Candidate Generation: which generates high-quality candidate SQL queries using ICL and SFT generators; 3) Candidate Selection, which picks the final response among the generated candidates. M-Schema is served as schema representation and provided to LLMs.
图 1: 提出的XiYan-SQL工作流程概览,包含三个AI智能体:1) 模式链接(Schema Linking),负责检索并选择最相关的数据库模式;2) 候选生成(Candidate Generation),通过上下文学习(ICL)和监督微调(SFT)生成高质量SQL查询候选;3) 候选选择(Candidate Selection),从生成的候选中挑选最终响应。其中M-Schema作为模式表示提供给大语言模型使用。
We present comprehensive evaluations on both relational and non-relational databases, specifically focusing on prominent systems such as SQLite, PostgreSQL, and nGQL. XiYan-SQL demonstrates remarkable performance across a range of benchmarks, achieving the state-of-the-art performance on the Spider [32], SQL-Eval, and NL2GQL [33] datasets with $89.65%$ , $69.86%$ , and $41.20%$ execution accuracy, respectively. In the context of the more challenging Bird [10] benchmark, XiYan-SQL also reaches the top accuracy of $75.63%$ . The impressive results achieved on various challenging NL2SQL benchmarks not only validate the effectiveness of our approach but also demonstrate its significant potential for broader applications in NL2SQL translation tasks. XiYan-SQL can be accessed from https://bailian.console.aliyun.com/xiyan. We also release the source code for connecting to the database and building M-Schema at https://github.com/X Generation Lab/M-Schema.
我们对关系型和非关系型数据库进行了全面评估,重点研究了SQLite、PostgreSQL和nGQL等主流系统。XiYan-SQL在一系列基准测试中表现卓越,在Spider [32]、SQL-Eval和NL2GQL [33]数据集上分别达到89.65%、69.86%和41.20%的执行准确率,实现了最先进的性能。在更具挑战性的Bird [10]基准测试中,XiYan-SQL也以75.63%的准确率位居榜首。这些在各种高难度NL2SQL基准测试中取得的优异成果,不仅验证了我们方法的有效性,更展现了其在NL2SQL翻译任务中更广泛应用的巨大潜力。XiYan-SQL可通过https://bailian.console.aliyun.com/xiyan访问,数据库连接与M-Schema构建的源代码已发布于https://github.com/X Generation Lab/M-Schema。
2 Overall Framework
2 总体框架
This section outlines the proposed XiYan-SQL framework, which consists of three primary components: 1) Schema Linking; 2) Candidate Generation; 3) Candidate Selection. Schema Linking is used to select relevant columns and retrieve values from a large database schema, helping to minimize irrelevant information and focus on related data. This contextual information is then organized into M-Schema and fed into Candidate Generation module to generate potential candidate SQL queries. These candidates are refined using a self-refinement process. Ultimately, a Candidate Selection agent compares all the candidates to determine the final SQL query . This pipeline is illustrated in Figure 1.
本节概述提出的XiYan-SQL框架,该框架包含三个主要组件:1) 模式链接(Schema Linking);2) 候选生成(Candidate Generation);3) 候选选择(Candidate Selection)。模式链接用于从大型数据库模式中选择相关列并检索值,帮助最小化无关信息并聚焦相关数据。随后将这些上下文信息组织成M-Schema并输入候选生成模块,以生成潜在的候选SQL查询。这些候选查询通过自优化过程进行精炼。最终,候选选择智能体比较所有候选查询以确定最终的SQL查询。该流程如图1所示。
3 M-Schema
3 M-Schema
The database schema needs to be provided in the prompt so that LLM understands the database structure. We propose a novel representation named M-Schema. M-Schema illustrates the hierarchical relationships between the database, tables, and columns in a semi-structured format and employs specifical tokens for identification: "【DB_ID】" marks the database, "# Table" signifies tables, and "【Foreign Keys】" indicates foreign keys. For each table, we present table name and description, where table description can be omitted. The information from a table is converted into a list, where each item is a tuple representing the details of a column. Each column includes the column name, data type, column description, primary key identifier, and example values. Additionally, foreign keys need to be listed due to their importance.
数据库模式(schema)需要包含在提示词中,以便大语言模型理解数据库结构。我们提出了一种名为M-Schema的新型表示方法。M-Schema以半结构化格式展示数据库、表和列之间的层级关系,并使用特定token进行标识:"【DB_ID】"标记数据库,"# Table"表示表,"【Foreign Keys】"标识外键。对于每个表,我们提供表名和描述(表描述可省略)。表信息被转换为列表形式,其中每个条目都是表示列详情的元组。每列包含列名、数据类型、列描述、主键标识符和示例值。此外,由于外键的重要性,需要单独列出外键关系。
Figure 2 shows examples of representing a database in DDL Schema, MAC-SQL [28] Schema and M-Schema. The Data Definition Language (DDL) schema is the most commonly used representation. However, it lacks essential table and column descriptions, as well as example values. Consequently, LLMs struggle to differentiate between similar columns. Derived from MAC-SQL Schema, M-Schema is a more compact representation. It differs from MAC-SQL Schema mainly in column representation, detailed as follows:
图 2: 展示了用DDL Schema、MAC-SQL [28] Schema和M-Schema表示数据库的示例。数据定义语言(DDL) schema是最常用的表示形式,但它缺乏关键的表和列描述以及示例值,导致大语言模型难以区分相似列。M-Schema源自MAC-SQL Schema,是一种更紧凑的表示形式,它与MAC-SQL Schema的主要区别在于列的表示方式,具体如下:
• Data type. Data type ensures that the data is correctly structured and manipulated. MAC-SQL Schema lacks data type specifications, which may result in incorrect outcomes when generated SQL queries are executed. • Primary key marking. We include primary key marking to maintain relationships between tables in a relational database.
• 数据类型 (Data type)。数据类型确保数据被正确结构化和操作。MAC-SQL Schema 缺少数据类型规范,可能导致生成的 SQL 查询执行时出现错误结果。
• 主键标记 (Primary key marking)。我们引入主键标记以维护关系型数据库中表间的关系。
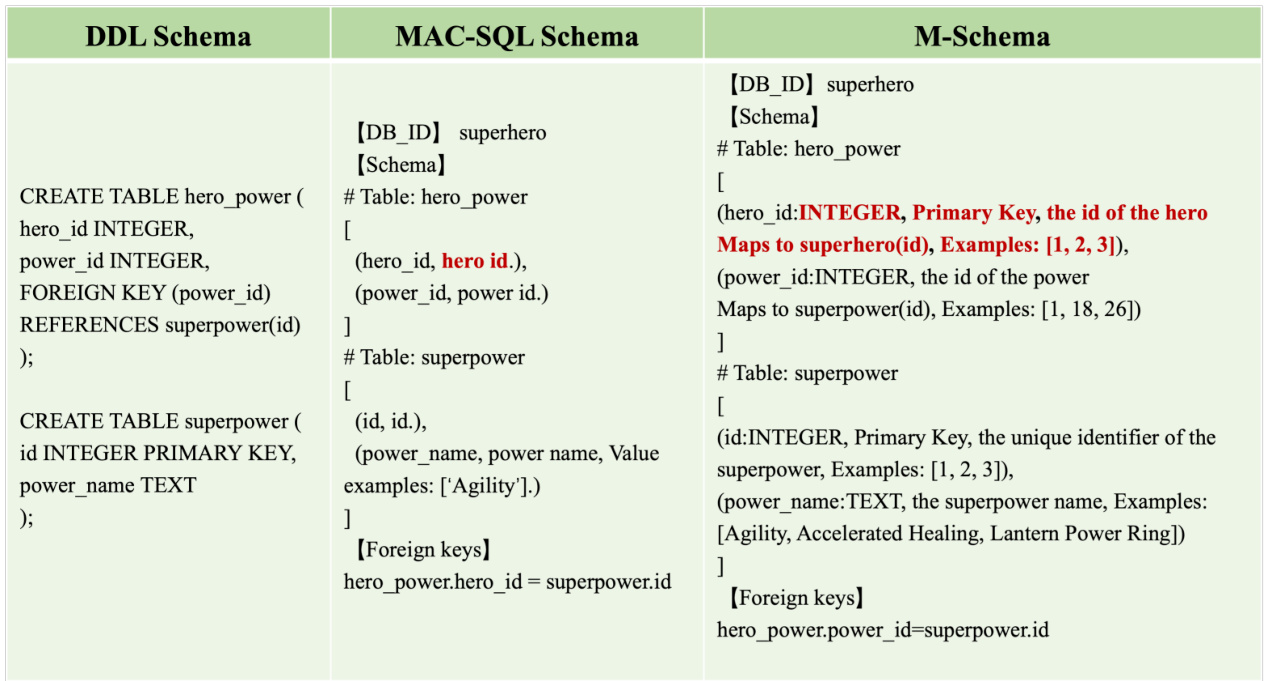
Figure 2: Examples of representing a database schema in DDL Schema, MAC-SQL Schema and M-Schema. The red text highlights the differences between M-Schema and MAC-SQL Schema. M-Schema adds data types, primary key markings, and changes the rules for displaying sample values.
图 2: 用DDL Schema、MAC-SQL Schema和M-Schema表示数据库模式的示例。红色文字标明了M-Schema与MAC-SQL Schema的区别。M-Schema增加了数据类型、主键标记,并修改了样本值的显示规则。
• Column description. In MAC-SQL schema, the column description is derived from the column name, whereas M-Schema connects to the database to obtain more detailed descriptions. • Value examples: We simplify "Value examples" marking into "Examples" to reduce redundancy. We also establish new display rules for values, such as string length and the number of examples.
• 列描述。在MAC-SQL模式中,列描述是从列名派生的,而M-Schema则连接到数据库以获取更详细的描述。
• 值示例:我们将"Value examples"标记简化为"Examples"以减少冗余。同时为值建立了新的显示规则,例如字符串长度和示例数量。
Besides, the leading spaces in each column representation are removed from MAC-SQL Schema. We release how to connect to the database engine and build the M-Schema representation at https://github.com/X Generation Lab/ M-Schema and support commonly used databases such as MySQL and PostgreSQL.
此外,MAC-SQL Schema 移除了各列表示中的前导空格。我们发布了如何连接数据库引擎并构建 M-Schema 表示的方法,详见 https://github.com/X Generation Lab/M-Schema,并支持 MySQL 和 PostgreSQL 等常用数据库。
4 Schema Linking
4 Schema Linking
Schema linking connects references in natural language queries to elements within a database schema, including table, columns and values. Our schema linking pipeline consists of a retrieval module and a column selector.
模式链接将自然语言查询中的引用与数据库模式中的元素(包括表、列和值)关联起来。我们的模式链接流程由检索模块和列选择器组成。
Retrieval Module In order to search for similar values and columns in the database, similar to the approach in [17], we first prompt the model with few-shot examples to identify keywords and entities in the question. We then use a column retriever to retrieve relevant columns. Based on the semantic similarity between the keywords and the column descriptions, we retrieve the top $\boldsymbol{\cdot}\mathbf{k}$ columns for each keyword. To enhance efficiency, value retriever employs a two-phase retrieval strategy based on Locality Sensitive Hashing (LSH) and semantic similarity to identify similar values in the database. The final selected schema is the union set of column retriever and value retriever.
检索模块
为了在数据库中搜索相似的值和列,类似于[17]中的方法,我们首先使用少样本示例提示模型以识别问题中的关键词和实体。然后使用列检索器获取相关列。根据关键词与列描述之间的语义相似度,我们为每个关键词检索出前$\boldsymbol{\cdot}\mathbf{k}$列。为提高效率,值检索器采用基于局部敏感哈希(LSH)和语义相似度的两阶段检索策略,以识别数据库中的相似值。最终选定的模式是列检索器和值检索器的并集。
Column Selector Column Selector aims to reduce the tables and columns to minimally sufficient schema for SQL generation. The retrieved schema from the previous step is organized as M-Schema and presented with LLMs. We then employ a few-shot manner to prompt the language model to evaluating the relevance of each column to the user’s query, selecting only those necessary.
列选择器
列选择器的目标是将表和列精简为生成SQL所需的最小化模式。从上一步骤检索到的模式被组织为M-Schema并呈现给大语言模型。随后,我们采用少样本方式提示语言模型评估每列与用户查询的相关性,仅选择必要的列。
5 Candidate Generation
5 候选生成
For candidate generation, we employ various generators to generate high-quality and diverse SQL candidates. On one hand, we utilize a range of training strategies to specifically fine-tune the generation models, aiming to generate high-precision SQL candidates with diverse syntactic styles. On the other hand, we also incorporate the ICL approach to enhance the diversity of the SQL candidates. Our Refiner further improves the generated SQL queries. In the following sections, we provide a brief overview of each part.
在候选生成阶段,我们采用多种生成器来产生高质量且多样化的SQL候选语句。一方面,我们运用多种训练策略对生成模型进行针对性微调,旨在生成具有多样化语法风格的高精度SQL候选。另一方面,我们还结合了ICL (In-Context Learning) 方法来提升SQL候选的多样性。我们的优化器(Refiner)会进一步改进生成的SQL查询语句。以下章节将简要概述每个部分。
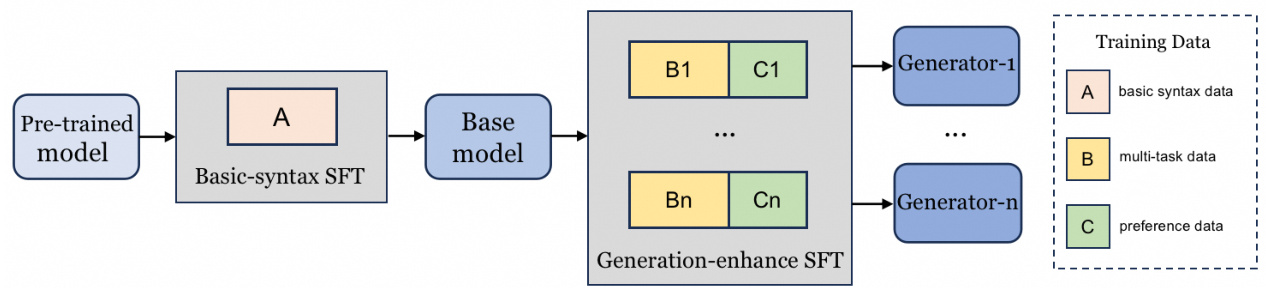
Figure 3: The two-stage and multi-task training pipeline for Fine-tuned SQL generators.
图 3: 微调SQL生成器的两阶段多任务训练流程。
5.1 Fine-tuned SQL Generator
5.1 微调SQL生成器
The core purpose is to generate high-precision and diverse SQL candidates. To this end, we take advantage of the high control l ability of fine-tuning models on specific tasks to build a series of high-precision models with different preferences. As shown in Figure 3, we employ a two-stage and multi-task training approach to fine-tune the model, including basic-syntax training and generation-enhance training. Through this training approach, the intermediate and final results of our pipeline are a set of models with distinct advantages.
核心目标是生成高精度且多样化的SQL候选方案。为此,我们利用微调模型在特定任务上的高可控性优势,构建了一系列具有不同偏好的高精度模型。如图3所示,我们采用两阶段多任务训练方法对模型进行微调,包括基础语法训练和生成增强训练。通过这种训练方式,我们流程的中间结果和最终成果是一组具备差异化优势的模型。
Basic-syntax training Basic-syntax training focuses on fine-tuning the pre-trained model with the basic and single SQL patterns and syntax. In this stage, the data used for training is SQL dialect-agnostic, covering basic syntax very comprehensively, with a total of tens of thousands of samples. The training objective is to develop a base model that activates SQL generation capabilities and can serve as a transition to different specialized SQL tasks.
基础语法训练
基础语法训练专注于用基础和单一SQL模式及语法对预训练模型进行微调。在此阶段,训练数据与SQL方言无关,全面覆盖基础语法,总计包含数万个样本。训练目标是开发一个具备SQL生成能力的基础模型,可作为过渡到不同专业SQL任务的桥梁。
Generation-enhance training After the first stage of training, we turn to generation-enhance training, aimed at enhancing the model’s semantic understanding and stylistic preference in syntax. In this stage, we can combine various multi-task data and syntactic preference data to obtain an enhanced model. The model can benefit from multi-task data to better understand the mapping relationship between questions and SQL queries. Specifically, in addition to the standard task of converting questions to SQL queries, we further design the task of converting SQL to questions, which aims to infer potential questions based on the provided contextual information and SQL query. We have defined the task from SQL to evidence, which is intended to select the most relevant evidence from a set of candidates based on the context and SQL. Moreover, we also introduce the SQL discrimination and regeneration tasks, aimed at performing SQL optimization based on execution feedback, along with other related tasks. This series of specialized tasks effectively enhances the linking between SQL and contextual information, thereby improving overall generation capabilities. The model can benefit from various styles of patterns and syntactic features to better generate a wider diversity of SQL candidates. We utilize different LLMs to rephrase the original query in multiple ways without altering its original meaning. This approach effectively expands the sample data into different syntactic styles, thereby teaching the model to learn from this data form during the training phase.
生成增强训练
在第一阶段训练完成后,我们转向生成增强训练,旨在提升模型在语法层面的语义理解与风格偏好。此阶段可结合多种多任务数据和句法偏好数据,获得增强后的模型。
通过多任务数据,模型能更深入理解问题与SQL查询间的映射关系。具体而言,除了标准的问题转SQL任务外,我们还设计了SQL转问题的逆向任务,旨在根据提供的上下文信息和SQL推断潜在问题。我们定义了从SQL到证据的任务,用于依据上下文和SQL从候选集中筛选最相关证据。此外还引入了SQL判别与重构任务,基于执行反馈进行SQL优化,以及其他关联任务。这一系列专项任务有效强化了SQL与上下文信息的关联,从而提升整体生成能力。
模型还能从多样化的模式风格和句法特征中受益,生成更具多样性的SQL候选方案。我们利用不同大语言模型对原始查询进行多形式改写(保持原意不变),将样本数据有效扩展至不同句法风格,使模型在训练阶段学会从这类数据形式中学习。
Due to multiple dialects in SQL queries, we can process each dialect separately during this stage, following this defined pipeline. Subsequently, we may opt to either train an individual model for each dialect or jointly train a multi-dialect model. In practical applications, we can fine-tune a target model by selecting subsets of multi-task and preference data according to our needs, enabling the generation of high-quality SQL candidates.
由于SQL查询存在多种方言,我们可以在此阶段按照既定流程分别处理每种方言。随后,可以选择为每种方言单独训练模型,或联合训练一个多方言模型。在实际应用中,通过按需选择多任务和偏好数据的子集对目标模型进行微调,从而生成高质量的SQL候选方案。
5.2 ICL SQL Generator
5.2 ICL SQL 生成器
The performance of ICL-based NL2SQL generation depends not only on the inherent abilities of the model but also on the examples provided. Several methods have been proposed to retrieve useful examples, such as masked question similarity and query similarity [5]. Although masked question similarity excludes the influence of table and column names, it is still sensitive to the entities. Query similarity based method requires a preliminary model to generate an approximation SQL, so the capabilities of the preliminary model directly affect the final result.
基于ICL的NL2SQL生成性能不仅取决于模型的内在能力,还与提供的示例有关。目前已提出多种检索有效示例的方法,例如掩码问题相似度和查询相似度[5]。虽然掩码问题相似度排除了表和列名的影响,但仍对实体敏感。基于查询相似度的方法需要预训练模型生成近似SQL,因此预训练模型的能力直接影响最终结果。
XiYan-SQL employs an example selection strategy based on the skeleton similarity between the user question and the question from the training set. All named entities in the question are first identified using NLTK’s tool, then the named entities of the same type are replaced with a special token. For example, "China" and "America" are both identified as countries, so both of them are replaced by "
XiYan-SQL采用基于用户问题与训练集中问题骨架相似度的示例选择策略。首先使用NLTK工具识别问题中的所有命名实体,然后将同类命名实体替换为特殊token。例如"China"和"America"均被识别为国家,因此都被替换为"
Table 1: Details of dataset used in our experiments.
表 1: 实验中使用的数据集详情。
| Dataset | Dialect | # Questions | #DBs |
|---|---|---|---|
| Spider | SQLite | 1981 | 39 |
| Bird | SQLite | 1534 | 11 |
| SQL-Eval | PostgresQL | 304 | 11 |
| NL2GQL | nGQL | 288 | 3 |
Additionally, we noticed that SQL examples, which only manipulate one table, are of limited help for SQL generation involving multiple tables. When selecting SQL examples, for questions that two or more tables are selected through schema linking, we only choose SQL queries that involve operations on multiple tables. Based on the number of tables and the similarity threshold, a maximum of 5 examples are used for each question.
此外,我们发现仅操作单表的SQL示例对涉及多表的SQL生成帮助有限。在选择SQL示例时,对于通过模式链接(schema linking)选中两个及以上表的问题,我们仅选用涉及多表操作的SQL查询。根据表数量和相似度阈值,每个问题最多使用5个示例。
For benchmarks such as Bird and Spider, the databases of the training and test sets are not repeated, so presenting the schema of the examples in the prompt helps the model better understand the relationship between the schema and the SQL query. In order to reduce token consumption and the interference of redundant columns, only the minimal set of columns is provided for each selected SQL example.
对于Bird和Spider等基准测试,训练集和测试集的数据库并不重复,因此在提示中展示示例的数据库模式(schema)有助于模型更好地理解模式与SQL查询之间的关系。为减少token消耗和冗余列的干扰,每个选定的SQL示例仅提供最小化的列集合。
5.3 SQL Refiner
5.3 SQL优化器
The generated candidate SQL queries inevitably contain logical or syntactical errors [17, 25]. By utilizing clues from these SQL query deficiencies, we can undertake corrections to some extent. To this end, we employ a SQL Refiner to optimize the generated SQL. In practice, based on schema-related context, the generated SQL queries, and execution results (including potential error information), we enable the model to perform a second round of corrective generation. The original SQL and the regenerated SQL can further be subjected to a selection model (as discussed in Section 6) for optimal choice, and this process can be executed iterative ly.
生成的候选SQL查询不可避免地包含逻辑或语法错误[17, 25]。通过利用这些SQL查询缺陷中的线索,我们可以在一定程度上进行修正。为此,我们采用SQL Refiner来优化生成的SQL。在实际操作中,基于模式相关的上下文、生成的SQL查询以及执行结果(包括可能的错误信息),我们使模型能够进行第二轮纠正性生成。原始SQL和重新生成的SQL可以进一步通过选择模型(如第6节所述)进行最优选择,并且该过程可以迭代执行。
6 Candidate Selection
6 候选选择
Based on the schema linking and various candidate generators, we can generate a set of candidate queries for the given question. The challenge of selecting the correct and reasonable SQL query from the pool of candidates remains to be addressed. Most methods [7, 25] employ self-consistency [30] to select the SQL query that appears most consistently across multiple candidate samples. However, this approach has limitations: it cannot handle situations where none of the queries are consistent, and even the most consistent result is not always the correct case.
基于模式链接(schema linking)和各种候选生成器,我们可以为给定问题生成一组候选查询。如何从候选池中选择正确合理的SQL查询仍是一个待解决的问题。大多数方法[7,25]采用自洽性(self-consistency)[30]来选择在多个候选样本中出现最一致的SQL查询。但这种方法存在局限性:无法处理所有查询都不一致的情况,且即使最一致的结果也不总是正确答案。
For this purpose, we employ a selection model to make judgments. We measure the consistency of SQL execution results to group them, allowing us to identify inconsistent samples from each group to form a candidate set. Then, we utilize the selection model to select the most reasonable candidate based on the provided contextual information and the candidate set. Instead of employing a prompt-based approach with LLM, we specifically fine-tune a model as a selection model to better distinguish nuances of candidate SQL queries. To align with the varying syntactic preferences of the SQL candidates, we also deliberately perform paraphrasing on the training data of the selection model.
为此,我们采用选择模型进行判断。通过衡量SQL执行结果的一致性进行分组,从而从每组中识别出不一致的样本构成候选集。随后,利用选择模型结合上下文信息和候选集筛选出最合理的候选方案。与基于提示的大语言模型方法不同,我们专门微调了一个选择模型以更好区分候选SQL查询的细微差异。为匹配不同SQL候选的语法偏好,我们还特意对选择模型的训练数据进行了改写。
7 Experiments
7 实验
7.1 Experimental Setup
7.1 实验设置
To assess the general iz ability of the proposed XiYan-SQL framework, we evaluate it in an end-to-end way on both relational and non-relational graph databases. Spider [32] and Bird [10] are widely-recognized cross-domain datasets that use SQLite. Since the test set of the BIRD benchmark is not available, we conduct experiments and performance evaluations on the development set. SQL-Eval 3 is an open-source PostgreSQL evaluation dataset released by Defog, constructed based on Spider. NL2GQL [33] built on graph databases is also involved in our experiments. The detailed information of datasets is shown in Table 1. We use Execution Accuracy (EX) to access the effectiveness of the generated SQL queries. EX compares the results of a predicted SQL query and a reference SQL query executed on a specific database instance.
为了评估所提出的XiYan-SQL框架的泛化能力,我们在关系型和非关系型图数据库上以端到端方式进行了评估。Spider [32] 和 Bird [10] 是广泛认可的跨领域数据集,均使用SQLite。由于BIRD基准测试集未公开,我们在开发集上进行了实验和性能评估。SQL-Eval 3是Defog发布的基于Spider构建的PostgreSQL开源评估数据集。我们还实验了基于图数据库构建的NL2GQL [33]。数据集详细信息如表1所示。我们采用执行准确率(EX)来衡量生成SQL查询的有效性,该方法通过比较预测SQL查询与参考SQL查询在特定数据库实例上的执行结果来实现。
Table 2: Performance comparison of different NL2SQL methods on Bird benchmark.
表 2: 不同NL2SQL方法在Bird基准测试中的性能对比
| 方法 | EX(开发集) | EX(测试集) |
|---|---|---|
| CHASE-SQL + Gemini [17] | 74.46 | 74.79 |
| DSAIR + GPT-40 | 74.32 | 74.12 |
| ExSL + granite-34b-code | 72.43 | 73.17 |
| AskData + GPT-4o | 72.03 | 72.39 |
| OpenSearch-SQL,v2 + GPT-40 | 69.30 | 72.28 |
| Distillery + GPT-4o [16] | 67.21 | 71.83 |
| CHESS [25] | 68.31 | 71.10 |
| Insights AI | 72.16 | 70.26 |
| PURPLE+RED+GPT-40 | 68.12 | 70.21 |
| MCS-SQL [25] | 63.36 | 65.45 |
| SuperSQL [8] | 58.50 | 62.66 |
| SFT CodeS-15B [9] | 58.47 | 60.37 |
| GPT-40 | 57.95 | - |
| TA-SQL + GPT-4[21] | 56.19 | 59.14 |
| DAIL-SQL [5] | 54.76 | 57.41 |
| XiYan-SQL | 73.34 | 75.63 |
Table 3: Performance comparison of different NL2SQL methods on Spider test benchmark.
表 3: 不同NL2SQL方法在Spider测试基准上的性能对比
| 方法 | EX(%) |
|---|---|
| MCS-SQL + GPT-4 [7] CHASE-SQL + Gemini 1.5 [17] PET-SQL[11] SuperSQL [8] DAIL-SQL+ GPT-4[5] | 89.6 87.6 87.6 87.0 |
| DPG-SQL + GPT-4 Tool-SQL+ GPT-4[31] | 86.6 85.6 85.6 |
| DIN-SQL+ GPT-4 [18] GPT-40 | 85.3 83.54 |
| C3 + ChatGPT + 零样本 [3] XiYan-SQL | 82.3 89.65 |
Table 4: Performance comparison of different methods on SQL-Eval benchamrrk.
表 4: 不同方法在 SQL-Eval 基准测试中的性能对比
| 方法 | EX(%) |
|---|---|
| SQL-Coder-8B DeepSeek | 60.20 65.36 |
| GPT-40 Claude3.5Sonnet | 64.64 51.43 |
| Gemini1.5Pro XiYan-SQL | 67.86 69.86 |
Table 5: Performance comparison of different methods on NL2GQL benchmark.
表 5: NL2GQL基准测试上不同方法的性能对比。
| 方法 | EX(%) |
|---|---|
| DeepSeek GPT-40 | 18.06 ±4.86 |
| Claude3.5Sonnet Gemini 1.5 Pro | 3.12 ±6.60 |
| XiYan-SQL | 41.20 |
7.2 Bird Results
7.2 鸟类结果
We compare the performance of different NL2SQL methods on Bird benchmark in Table 2. XiYan-SQL reaches the top of Bird leader board with an accuracy of $75.63%$ , outperforming the second place of $0.84%$ . CHASE-SQL [17] framework employs multiple chain-of-thought prompting techniques to generate candidates, and subsequently implements a binary voting mechanism among 21 candidates, achieving an accuracy of $74.70%$ . XiYan-SQL yields a competitive performance by voting among only 5 candidates.
我们在表2中比较了不同NL2SQL方法在Bird基准测试上的性能。XiYan-SQL以75.63%的准确率位居Bird排行榜首位,领先第二名0.84%。CHASE-SQL [17]框架采用多轮思维链提示技术生成候选SQL,随后在21个候选方案中实施二元投票机制,最终达到74.70%的准确率。而XiYan-SQL仅需对5个候选方案进行投票即可获得具有竞争力的表现。
We also observe that a significant number of the leading methods on the bird lear der bora d are based on prompt engineering techniques. It suggests the immense potential of large-scale models and the importance of carefully designed prompts in optimizing model performance. The SFT based method, $\mathrm{ExSL+}$ Granite-34B-Code, secures the fourth position with an accuracy of $73.17%$ . This notable performance indicates that, smaller-sized models are indeed capable of generating complex SQL queries effectively through advanced training techniques. XiYan-SQL integrates the methodologies of SFT and ICL to balance the test time and the overall performance of the system.
我们还观察到,Bird lear der bora d榜单上许多领先方法都基于提示工程(prompt engineering)技术。这表明大规模模型具有巨大潜力,同时也说明精心设计的提示词对于优化模型性能至关重要。基于监督微调(SFT)的方法$\mathrm{ExSL+}$ Granite-34B-Code以73.17%的准确率位列第四,这一显著成绩表明:通过先进训练技术,较小规模的模型确实能有效生成复杂SQL查询。XiYan-SQL综合运用监督微调和上下文学习(ICL)方法,在系统测试时间与整体性能之间取得了平衡。
7.3 Spider Results
7.3 Spider 结果
To demonstrate the general iz ability of our approach, we also evaluate XiYan-SQL on the Spider dataset. As demonstrated in Table 3, improvements in the underlying backbone model capabilities have contributed to notable improvements in performance metrics. Specifically, GPT-4o has achieved a remarkable accuracy of $83.54%$ . Moreover, XiYan-SQL refreshes the state-of-the-art execution accuracy of $89.65%$ , with a marginal advantage of merely $0.05%$ over previous leading models.
为了验证我们方法的泛化能力,我们还在Spider数据集上评估了XiYan-SQL。如表3所示,底层主干模型能力的提升显著改善了性能指标。具体而言,GPT-4o实现了 $83.54%$ 的出色准确率。此外,XiYan-SQL以 $89.65%$ 的执行准确率刷新了当前最优水平,仅比之前的领先模型高出 $0.05%$ 的微弱优势。
Table 6: Ablation studies on different schema representations.
表 6: 不同模式表示法的消融研究。
| Model | EX(DDL Schema, %) | EX(MAC-SQL Schema, %) | EX(M-Schema, %) |
|---|---|---|---|
| GPT-40 | 55.67 | 57.30 | 57.95 |
| DeepSeek | 53.52 | 55.28 | 55.15 |
| Claude3.5Sonnet | 49.74 | 50.26 | 51.04 |
| Gemini 1.5 Pro | 49.22 | 52.41 | 52.15 |
7.4 SQL-Eval Results
7.4 SQL-Eval 评测结果
Table 4 presents the results on SQL-Eval dataset. SQL-Eval provides multiple reference SQL queries and we choose the first option as ground truth for metric computation. XiYan-SQL reports the highest score of $69.86%$ on SQL-Eval. We outperform SQL-Coder-8B 4 fine-tuned on LLaMA-3 [4] by a large margin of $8.59%$ and closed-source backbone models by $2{\sim}5$ percent. It demonstrates the general iz ability of XiYan-SQL on SQL generation for PostgreSQL.
表 4: SQL-Eval数据集上的结果。SQL-Eval提供了多个参考SQL查询,我们选择第一个选项作为指标计算的基准真值。XiYan-SQL在SQL-Eval上取得了最高分 $69.86%$ ,大幅领先基于LLaMA-3 [4]微调的SQL-Coder-8B 4达 $8.59%$ ,并比闭源骨干模型高出 $2{\sim}5$ 个百分点。这证明了XiYan-SQL在PostgreSQL SQL生成任务上的泛化能力。
7.5 NL2GQL Results
7.5 NL2GQL 结果
To assess the effectiveness of XiYan-SQL on non-relational graph datasets, we sample a total of 288 examples from the NL2GQL [33] dataset, which were previously utilized in MoMQ [12]. As shown in Table 5, GPT-4o, DeepSeek, Gemini $1.5\mathrm{Pro}$ and Claude 3.5 Sonnet show a limited overall execution accuracy on NL2GQL dataset. XiYan-SQL achieves $41.20%$ execution accuracy, outperforming them by a large margin and demonstrating the best performance overall.
为评估XiYan-SQL在非关系型图数据集上的表现,我们从NL2GQL[33]数据集中抽取了288个样本(该数据集曾被MoMQ[12]采用)。如表5所示,GPT-4o、DeepSeek、Gemini $1.5\mathrm{Pro}$ 和Claude 3.5 Sonnet在NL2GQL数据集上的整体执行准确率较低。XiYan-SQL以 $41.20%$ 的执行准确率显著超越这些模型,展现出最佳综合性能。
7.6 Ablation Studies
7.6 消融实验
To further investigate the effectiveness of each component in our framework, we conduct ablation studies on the Bird development benchmark because of its challenging nature and more reflective of the real-world scenarios.
为了进一步研究框架中各组件的有效性,我们在Bird开发基准上进行了消融实验,因其具有挑战性且更能反映真实场景。
7.6.1 M-Schema
7.6.1 M-Schema
We conduct ablation study on the Bird development benchmark to present the impact of different schema representations on end-to-end SQL generation performance. To demonstrate the generalization ability of our proposed M-Schema, we use four powerful LLMs as NL2SQL generators, DeepSeek [14], Claude 3.5 Sonnet 5, Gemini $1.5\mathrm{Pro}$ and GPT-4o [1]. As shown in Table 6, all four models have performance improvements using M-Schema as the representation of database schema compared to DDL Schema, with an average increase of $2.03%$ . Although M-schema is similar to MAC-SQL Schema in structure, GPT-4o and Claude 3.5 Sonnet show $0.65%$ and $0.78%$ improvements, respectively. While DeepSeek and Gemini 1.5 have slight accuracy decreases of $0.13%$ and $0.26%$ . The experimental results indicate that M-Schema is a better representation than DDL Schema and MAC-SQL Schema and demonstrates powerful general iz ability.
我们在Bird开发基准上进行了消融实验,以展示不同模式表示对端到端SQL生成性能的影响。为验证提出的M-Schema的泛化能力,我们采用四种强大LLM作为自然语言转SQL生成器:DeepSeek[14]、Claude 3.5 Sonnet、Gemini $1.5\mathrm{Pro}$ 和GPT-4o[1]。如表6所示,与DDL Schema相比,使用M-Schema作为数据库模式表示时,四个模型的性能均有提升,平均提高 $2.03%$ 。尽管M-Schema在结构上与MAC-SQL Schema相似,但GPT-4o和Claude 3.5 Sonnet分别实现了 $0.65%$ 和 $0.78%$ 的精度提升,而DeepSeek和Gemini 1.5则出现 $0.13%$ 和 $0.26%$ 的轻微下降。实验结果表明,M-Schema是优于DDL Schema和MAC-SQL Schema的表示方法,并展现出强大的泛化能力。
7.6.2 Schema Linking
7.6.2 模式链接
We conduct ablation study to evaluate the effectiveness of schema linking. We utilize recall and precision metrics to evaluate the correctness of the selected columns based on the corrected SQL query, which serves as the ground truth. We use GPT-4o as the NL2SQL generator to analyze the impact of schema linking on end-to-end EX metrics. The results are show in Table 7. Without schema linking, we provide all tables, columns and random sampled example values to LLM. It shows a precision of $10.14%$ and EX of $57.95%$ . The schema linking method in this report achieves a high precision of $74.74%$ while only slightly decreasing the recall. By providing the most relevant information to the model, the execution accuracy is improved by $2.15%$ , demonstrating the effectiveness of schema linking.
我们通过消融实验评估模式链接(schema linking)的有效性。采用召回率和精确率指标,基于修正后的SQL查询(作为基准真值)评估所选列的正确性。使用GPT-4o作为自然语言转SQL生成器,分析模式链接对端到端EX指标的影响。结果如表7所示:未使用模式链接时,我们向大语言模型提供所有表、列及随机采样的示例值,其精确率为$10.14%$,EX值为$57.95%$。本报告采用的模式链接方法实现了$74.74%$的高精确率,同时仅略微降低召回率。通过向模型提供最相关信息,执行准确率提升了$2.15%$,验证了模式链接的有效性。
表7:
7.6.3 Candidate Generation and Selection
7.6.3 候选生成与选择
To evaluate the effectiveness and impact of candidate generation and selection, we conduct various ablation studies on XiYan-SQL. Table 8 presents the performance of XiYan-SQL when certain components are dropped, highlighting their significance in achieving high-quality performance. The "XiYan-SQL All" method achieves an accuracy of
为了评估候选生成与选择的有效性和影响,我们对XiYan-SQL进行了多项消融实验。表8展示了当移除某些组件时XiYan-SQL的性能表现,凸显了这些组件对实现高质量性能的重要性。"XiYan-SQL All"方法的准确率达到
Table 7: Ablation studies on schema linking.
表 7: 模式链接消融研究
| 方法 | 精确率(%) | 召回率(%) | EX(%) |
|---|---|---|---|
| Baseline | 10.14 | 100.00 | 57.95 |
| + Schema Linking | 74.74 | 95.47 | 60.10 |
Table 8: Ablation studies of candidate generation and selection on the performance of XiYan-SQL on the Bird development benchmark.
表 8: 候选生成与选择对XiYan-SQL在Bird开发基准上性能的消融研究。
| 方法 | EX(%) | △EX(%) |
|---|---|---|
| XiYan-SQL All | 71.58 | |
| XiYan-SQL w/o Fine-tuned generator | 68.67 | -2.91 |
| XiYan-SQL w/o ICL generator | 70.27 | -1.31 |
| XiYan-SQL w/o Refiner | 71.03 | -0.55 |
| XiYan-SQL w/o Selection model | 68.84 | -2.74 |
| XiYan-SQL All (five candidates) | 73.34 |
$71.51%$ by utilizing three candidates, of which two are generated from two distinct fine-tuned SQL generators (as described in Section 5.1), while one is produced by the ICL SQL generator with GPT-4o (as presented in Section 5.2). For the candidate generator, there is a significant decrease in the performance of XiYan-SQL when the fine-tuned candidate generators are removed, further indicating that our generator is capable of generating high-quality and diverse candidate SQL queries. Similarly, the removal of the ICL generator and Refiner also leads to a decline in performance. Additionally, concerning candidate selection, we observe that when the selection model is not employed, relying solely on self-consistency for candidate selection, XiYan-SQL’s performance decreases by approximately three percentage points. This finding underscores the effectiveness of our proposed method. Finally, when the number of SQL candidates is increased to five, the accuracy of XiYan-SQL can further reach $73.34%$ .
通过使用三个候选SQL查询(其中两个由两个不同的微调SQL生成器生成,如第5.1节所述,另一个由基于GPT-4o的ICL SQL生成器生成,如第5.2节所述),准确率达到$71.51%$。当移除微调的候选生成器时,XiYan-SQL性能显著下降,进一步表明我们的生成器能够产生高质量且多样化的候选SQL查询。同样,移除ICL生成器和优化器也会导致性能降低。此外,在候选选择方面,我们发现若不采用选择模型而仅依赖自一致性进行选择,XiYan-SQL的性能会下降约三个百分点,这一结果凸显了所提方法的有效性。最后,当SQL候选数量增至五个时,XiYan-SQL的准确率可进一步提升至$73.34%$。
8 Conclusion
8 结论
In this technical report, we present a multi-generator ensemble framework for NL2SQL, named XiYan-SQL, which harnesses the benefits of the SFT approach to achieve enhanced control l ability while also integrating the ICL approach to maximize the generation of high-quality and diverse SQL candidates. We propose a two-stage and multi-task training method to train a series of models with different preferences, along with a candidate selection strategy to select the most reasonable candidate. Xiyan-SQL demonstrates state-of-the-art performance on publicly available relational databases, including Spider and SQL-Eval, as well as on non-relational database NL2GQL. This highlights the significant potential of XiYan-SQL for high-quality NL2SQL generation on unseen samples coming from different distributions.
在本技术报告中,我们提出了一种名为XiYan-SQL的多生成器集成框架,用于自然语言转SQL(NL2SQL)任务。该框架结合监督微调(SFT)方法的优势以实现更强的控制能力,同时整合上下文学习(ICL)方法来最大化生成高质量且多样化的SQL候选方案。我们提出了一种两阶段多任务训练方法,用于训练具有不同偏好的系列模型,并设计了候选选择策略来筛选最合理的SQL语句。XiYan-SQL在Spider、SQL-Eval等公开关系型数据库及非关系型数据库NL2GQL任务上均展现出最先进的性能,这凸显了该框架在面对不同分布未见样本时生成高质量NL2SQL的巨大潜力。
References
参考文献
A SQLite Example
SQLite 示例
In this section, we provide an example of natural language to SQLite.
在本节中,我们提供一个自然语言转SQLite的示例。

Figure 4: An example of natural language to SQLite.
图 4: 自然语言转 SQLite 的示例。
B PostgreSQL Example
B PostgreSQL 示例
In this section, we provide an example of natural language to PostgreSQL.
在本节中,我们提供一个从自然语言到PostgreSQL的示例。

Figure 5: An example of natural language to PostgreSQL.
图 5: 自然语言转PostgreSQL的示例。
C NL2GQL Example
C NL2GQL 示例
In this section, we provide an NL2GQL example. We extended M-Schema to represent graph databases as illustrated in Figure 6.
在本节中,我们提供一个NL2GQL示例。我们扩展了M-Schema来表示图数据库,如图 6: 所示。
| DATABASE SCHEMA | Question Generated | nGQL | GT nGQL |
|---|---|---|---|
| 【DB_ID】 nba 【Schema】 Node properties: - player | -tag_name -team -`vid |
||
| - 'name': STRING | |||
| -`age':INTEGER | |||
| - bachelor -`vid' -'name': STRING | |||
Relationship properties: _like - vid' -^name': STRING - speciality': STRING _serve |
D ICL Generator Prompt
D ICL Generator Prompt
In this section, we provide an example of our ICL generator prompt. An one-shot example is presented in Figure 7.
在本节中,我们提供了一个ICL生成器提示的示例。图7展示了一个单样本示例。

Figure 7: An example of ICL generator prompt.
图 7: ICL生成器提示示例。
E Candidate Selection Prompt
E 候选选择提示
F Refiner Prompt
F Refiner Prompt
In this section, we provide an example prompt of Refiner used to fix syntax or logical errors.
在本节中,我们提供了一个用于修复语法或逻辑错误的Refiner提示示例。
You are a SQLite expert. There is a SQL query generated based on the following Database Schema description and the potential Evidence to respond to the Question. However, executing this SQL has resulted in an eror, and you need to fix it based on the error message. Utilize your knowledge ofSQLite to ge nerate the correct SQL.
你是一位SQLite专家。根据以下数据库架构描述和相关证据生成的SQL查询在执行时出现错误,需要根据错误信息进行修正。请运用你的SQLite知识生成正确的SQL语句。
【Database Schema】{DATABASE SCHEMA} 【Evidence】{evidence}
数据库模式 (Database Schema)
证据 (Evidence)
【Question】
【问题】
If there are any, what are the websites address of the schools with a free meal count of 1,900- 2,000 to students aged 5-17? Include the name of the school.
有哪些学校为5-17岁学生提供1900-2000份免费餐食?请列出学校名称及官网地址。
【SQL】
【SQL】
SELECT T2.Website, T2.School FROM frpm AS T1 INNER JOIN schools AS T2 ON T1.CDSCode $=$ T2.CDSC ode WHERE T1. Free Meal Count (Ages 5-17) BETWEEN 1900 AND 2000
SELECT T2.Website, T2.School FROM frpm AS T1 INNER JOIN schools AS T2 ON T1.CDSCode $=$ T2.CDSCode WHERE T1. Free Meal Count (Ages 5-17) BETWEEN 1900 AND 2000