HOISDF: Constraining 3D Hand-Object Pose Estimation with Global Signed Distance Fields
HOISDF: 基于全局符号距离场约束的3D手-物体姿态估计
Abstract
摘要
Human hands are highly articulated and versatile at handling objects. Jointly estimating the 3D poses of a hand and the object it manipulates from a monocular camera is challenging due to frequent occlusions. Thus, existing methods often rely on intermediate 3D shape representations to increase performance. These representations are typically explicit, such as 3D point clouds or meshes, and thus provide information in the direct surroundings of the intermediate hand pose estimate. To address this, we introduce HOISDF, a Signed Distance Field (SDF) guided hand-object pose estimation network, which jointly exploits hand and object SDFs to provide a global, implicit representation over the complete reconstruction volume. Specifically, the role of the SDFs is threefold: equip the visual encoder with implicit shape information, help to encode hand-object interactions, and guide the hand and object pose regression via SDF-based sampling and by augmenting the feature representations. We show that HOISDF achieves state-of-the-art results on hand-object pose estimation benchmarks (DexYCB and HO3Dv2). Code is available at https://github.com/amathislab/HOISDF.
人手具有高度灵活性和多变性,能够灵巧操控物体。由于频繁遮挡,从单目摄像头联合估计手部及其操控物体的三维姿态极具挑战性。因此,现有方法通常依赖中间三维形状表征来提升性能。这些表征多为显式形式(如三维点云或网格),仅能提供手部姿态估计局部邻域的信息。为此,我们提出HOISDF——一种基于符号距离场(SDF)引导的手-物姿态估计网络,通过联合利用手部和物体的SDF,在整个重建空间内提供全局隐式表征。具体而言,SDF发挥三重作用:为视觉编码器提供隐式形状信息、辅助编码手-物交互关系、通过基于SDF的采样和特征增强来引导姿态回归。实验表明,HOISDF在手-物姿态估计基准测试(DexYCB和HO3Dv2)中达到最先进水平。代码详见https://github.com/amathislab/HOISDF。
1. Introduction
1. 引言
Pose estimation during hand-object interaction from a single monocular view can contribute to widespread applications, e.g., in augmented reality [10], robotics [2, 15], human-computer interaction [42], and neuroscience [36]. Many excellent 3D hand [32, 45, 51, 58] and object [8, 25, 41] pose estimation algorithms have been developed. However, due to severe occlusion, they can easily fail during hand-object interactions. This has led to the emergence of dedicated hand-object interaction datasets [7, 18, 20, 35], and subsequently joint hand-object pose estimation has drawn increasing attention. Despite much progress, most methods still struggle when the hand or object is heavily occluded [11, 19, 22, 30, 39, 47, 49]. We argue that this limitation is rooted in the way 3D shape information is embedded in these algorithms.
单手单目视角下的手物交互姿态估计可广泛应用于增强现实 [10]、机器人学 [2, 15]、人机交互 [42] 和神经科学 [36] 等领域。目前已开发出许多优秀的3D手部 [32, 45, 51, 58] 和物体 [8, 25, 41] 姿态估计算法。然而由于严重遮挡,这些算法在手物交互时容易失效。这促使了专用手物交互数据集 [7, 18, 20, 35] 的出现,进而使联合手物姿态估计日益受到关注。尽管取得诸多进展,大多数方法在手部或物体被严重遮挡时仍表现不佳 [11, 19, 22, 30, 39, 47, 49]。我们认为这一局限源于3D形状信息在这些算法中的嵌入方式。
In essence, existing methods can be classified into two approaches: Direct lifting and coarse-to-fine methods (see Figure 1). Direct lifting methods first filter 2D image features according to the pixel positions of the hand and object and then use the remaining features to make predictions [11, 19, 30, 33, 39]. These methods do not utilize explicit 3D intermediate representations and rely entirely on the network to learn the mapping from 2D image to 3D pose. Coarse-to-fine techniques make an initial prediction from the 2D image and improve upon it with a refinement network [12, 13, 22, 47, 49]. The intermediate represent at ions can either be hand joints [12, 13] or hand vertices [22, 47, 49], which can be interpreted as explicit shape representations. Although these representations can incorporate 3D shape information, we argue that implicit shape representations in the form of signed distance fields (SDFs) offer more effective 3D shape information for subsequent computations.
本质上,现有方法可分为两类:直接提升法 (direct lifting) 和由粗到精法 (参见图 1)。直接提升法首先根据手部和物体的像素位置过滤2D图像特征,然后利用剩余特征进行预测 [11, 19, 30, 33, 39]。这些方法不使用显式的3D中间表示,完全依赖网络学习从2D图像到3D姿态的映射。由粗到精技术则从2D图像生成初始预测,并通过细化网络进行改进 [12, 13, 22, 47, 49]。中间表示可以是手部关节点 [12, 13] 或手部顶点 [22, 47, 49],这些可视为显式形状表示。虽然这些表示能融合3D形状信息,但我们认为带符号距离场 (SDFs) 形式的隐式形状表示为后续计算提供了更有效的3D形状信息。
To achieve this, we introduce HOISDF (a Hand-Object Interaction pose estimation network with Signed-Distance Fields), which uses SDFs to guide the 3D hand-object pose estimation in a global manner (Figure 1). HOISDF consists of two sequential components: a module learning to predict the signed distance field, and a module that performs pose regression that is field-guided (Figure 2). The signed distance field learning module regresses the hand and object signed distance fields based on the image features. The module is encouraged to focus on capturing global information (e.g., rough hand/object shape, global rotation and translation) by regressing signed distances in the original camera space, since we believe global plausibility is more important in the intermediate stage, while fine-grained details can be recovered in the later stages. To effectively leverage the dense field information, our field-guided pose regression module effectively uses the learned field information to (i) sample informative query points, (ii) augment the image features for those points, (iii) gather cross-target (i.e., hand-to-object or object-to-hand) cues to reduce the influence of mutual occlusion, and (iv) combine the point features together to estimate the hand and object poses.
为此,我们提出了HOISDF(基于符号距离场的手-物交互姿态估计网络),该方法通过符号距离场(SDF)以全局方式引导三维手-物姿态估计(图1)。HOISDF包含两个顺序组件:学习预测符号距离场的模块,以及执行场引导姿态回归的模块(图2)。符号距离场学习模块基于图像特征回归手部和物体的符号距离场。该模块通过在原始相机空间回归符号距离,被鼓励专注于捕捉全局信息(例如粗略的手/物体形状、全局旋转和平移),因为我们认为在中间阶段全局合理性更为重要,而细粒度细节可以在后续阶段恢复。为了有效利用密集场信息,我们的场引导姿态回归模块充分利用学习到的场信息来:(i)采样信息丰富的查询点,(ii)为这些点增强图像特征,(iii)收集跨目标(即手到物或物到手)线索以减少相互遮挡的影响,(iv)将点特征组合起来估计手部和物体的姿态。
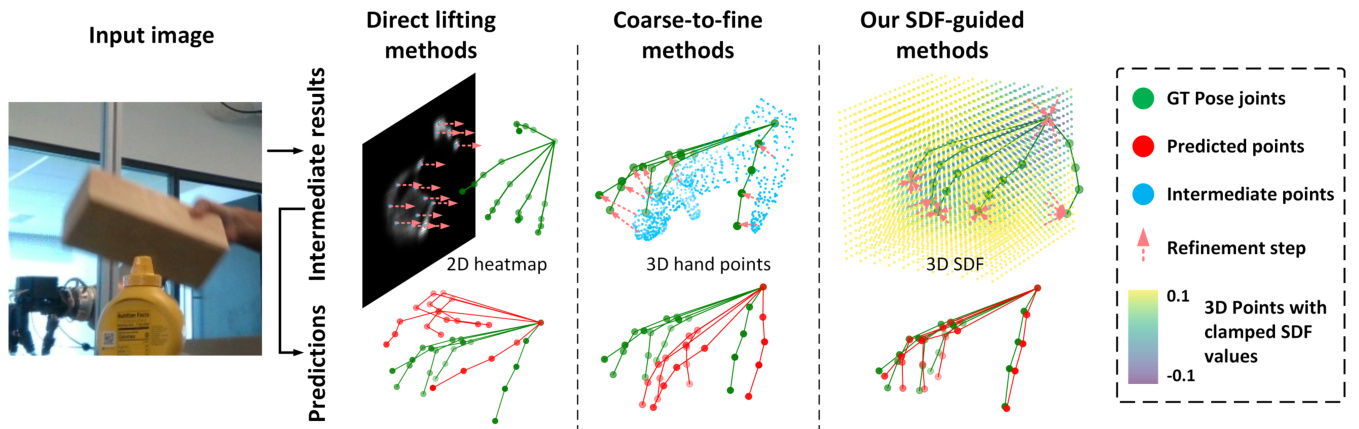
Figure 1. Conceptual advantage of the SDF-guided model over existing approaches. Our model utilizes Signed Distance Fields (SDF) to provide global and dense constraints for hand-object pose estimation. In contrast to direct lifting and coarse-to-fine methods, which struggle to refine poor initial predictions, the distance field yields global cues not limited to areas near an initial prediction.
图 1: SDF引导模型相对于现有方法的概念优势。我们的模型利用有向距离场 (Signed Distance Fields, SDF) 为手-物体姿态估计提供全局且密集的约束。与直接提升和由粗到细的方法相比(这些方法难以优化较差的初始预测),距离场提供的全局线索不受限于初始预测附近的区域。
Overall, HOISDF can be trained in an end-to-end manner. We achieve state-of-the-art results on the DexYCB and $\mathrm{HO}3\mathrm{Dv}2$ datasets, corroborating the benefits of using SDFs as global constraints for hand-object pose estimation and the effectiveness of our approach to exploiting the field information. Altogether, our main contributions are:
总体而言,HOISDF可以进行端到端训练。我们在DexYCB和$\mathrm{HO}3\mathrm{Dv}2$数据集上取得了最先进的结果,证实了使用SDF (Signed Distance Field) 作为手-物体姿态估计全局约束的优势,以及我们利用场信息方法的有效性。我们的主要贡献包括:
2. Related Work
2. 相关工作
2.1. 3D Hand-Object Pose Estimation
2.1. 3D 手-物姿态估计
Recently, joint hand-object pose estimation has drawn increasing research interest [29], and many hand and object interaction datasets have been developed [7, 18, 20, 35]. The current methods can be divided into direct lifting techniques and coarse-to-fine strategies. Among the former, Chen et al. [11] fused hand and object features with sequential LSTM models. Hampali et al. [19] extracted 2D keypoints and sent them to a transformer architecture to find the correlation with the 3D poses. Li et al. [30] proposed a data synthesis pipeline that can leverage the training feedback to enhance hand object pose learning. Lin et al. [33] proposed to learn harmonious features by avoiding handobject competition in middle-layer feature learning. For the coarse-to-fine methods, Hasson et al. [22] obtained initial hand and object meshes and optimized them with interaction constraints. Tse et al. [47] used an attention-guided graph convolution to iterative ly extract features from the previous hand-object estimates. Wang et al. [49] designed a dense mutual attention module to explore the relations from the initial hand-object predictions. We build on those methods but, in contrast, focus on implicit 3D shape information by learning SDFs, which provide global, dense constraints to guide the pose predictions.
近年来,联合手-物体姿态估计研究日益受到关注[29],并已开发出多个人手与物体交互数据集[7, 18, 20, 35]。现有方法可分为直接提升技术和由粗到精策略两大类。在直接提升技术中,Chen等人[11]通过序列LSTM模型融合手部与物体特征;Hampali等人[19]提取2D关键点后输入Transformer架构以建立与3D姿态的关联;Li等人[30]提出能利用训练反馈增强手部物体姿态学习的数据合成流程;Lin等人[33]则通过避免中间层特征学习中手-物体竞争来学习协调特征。在由粗到精方法中,Hasson等人[22]先获取初始手部和物体网格,再通过交互约束进行优化;Tse等人[47]采用注意力引导的图卷积从先前手-物体估计中迭代提取特征;Wang等人[49]设计了密集互注意力模块来挖掘初始手-物体预测间的关系。我们在这些方法基础上,创新性地聚焦于通过学习SDF(有符号距离场)获取隐式3D形状信息,从而为姿态预测提供全局密集约束。
2.2. Distance Fields in Hand-Object Interactions
2.2. 手物交互中的距离场
Unlike explicit representations such as point clouds and meshes, neural distance fields provide a continuous and differentiable implicit representation that encodes the 3D shape information into the network parameters. Given a 3D query point, a neural distance field outputs the signed or unsigned distance from this point to the object surface. Neural distance fields have been widely used in 3D shape reconstruction and representation [1, 16, 38, 40, 55]. Recently, SDFs have also been exploited in the context of hand-object interaction. In particular, Karun rat an a kul et al. [26] proposed to jointly model the hand, the object, and contact areas using an SDF. Ye et al. [54] used an SDF and the predicted hand to infer the shape of a hand-held object. Chen et al. [12] pre-aligned the 3D space with hand-object global poses to support the SDF prediction. Chen et al. [13] further used entire kinematic chains of local pose transformations to obtain finer-grained alignment. However, those methods mainly use SDF as the endpoint of the model to directly reconstruct 3D meshes instead of using SDF as an intermediate representation. Here we explore how SDFs as an intermediate representations can guide subsequent pose estimation. Our experiments clearly demonstrate the benefits of our approach.
与点云和网格等显式表示不同,神经距离场 (neural distance field) 提供了一种连续且可微的隐式表示,将3D形状信息编码到网络参数中。给定一个3D查询点,神经距离场会输出该点到物体表面的有符号或无符号距离。神经距离场已广泛应用于3D形状重建和表示 [1, 16, 38, 40, 55]。最近,SDF (Signed Distance Field) 也被应用于手-物交互领域。Karunratanakul等人 [26] 提出使用SDF联合建模手部、物体和接触区域。Ye等人 [54] 利用SDF和预测的手部来推断手持物体的形状。Chen等人 [12] 通过预对齐3D空间与手-物全局位姿来支持SDF预测。Chen等人 [13] 进一步利用局部位姿变换的完整运动链来获得更精细的对齐效果。然而这些方法主要将SDF作为模型的终点直接重建3D网格,而非将其作为中间表示。本文探索了如何将SDF作为中间表示来指导后续位姿估计,实验结果表明了该方法的优势。
2.3. Attention-based Methods
2.3. 基于注意力机制的方法
Attention mechanisms [48] have been wildly successful in machine learning [4, 6, 14, 17, 24] due to their effectiveness at exploiting long-range correlation. In the context of modeling hand-object relationships, Hampali et al. [19] propose modeling correlations between 2D keypoints and 3D hand and object poses using cross attention. Tze et al. [47] design an attention-guided graph convolution network to capture hand and object mesh information dynamically. Wang et al. [49] propose to exploit mutual attention between hand and object vertices to learn interaction dependencies. By contrast, our HOISDF applies attention across field-guided query points to mine the global 3D shape consistency context and cross-attend between hand and object.
注意力机制 [48] 因其在利用长程相关性方面的有效性,在机器学习领域取得了巨大成功 [4, 6, 14, 17, 24]。在手-物关系建模方面,Hampali 等人 [19] 提出使用交叉注意力 (cross attention) 建模 2D 关键点与 3D 手部和物体姿态之间的相关性。Tze 等人 [47] 设计了一种注意力引导的图卷积网络,动态捕捉手部和物体的网格信息。Wang 等人 [49] 提出利用手部和物体顶点间的相互注意力来学习交互依赖关系。相比之下,我们的 HOISDF 在场引导的查询点间应用注意力机制,挖掘全局 3D 形状一致性上下文,并在手部和物体间进行交叉注意力计算。
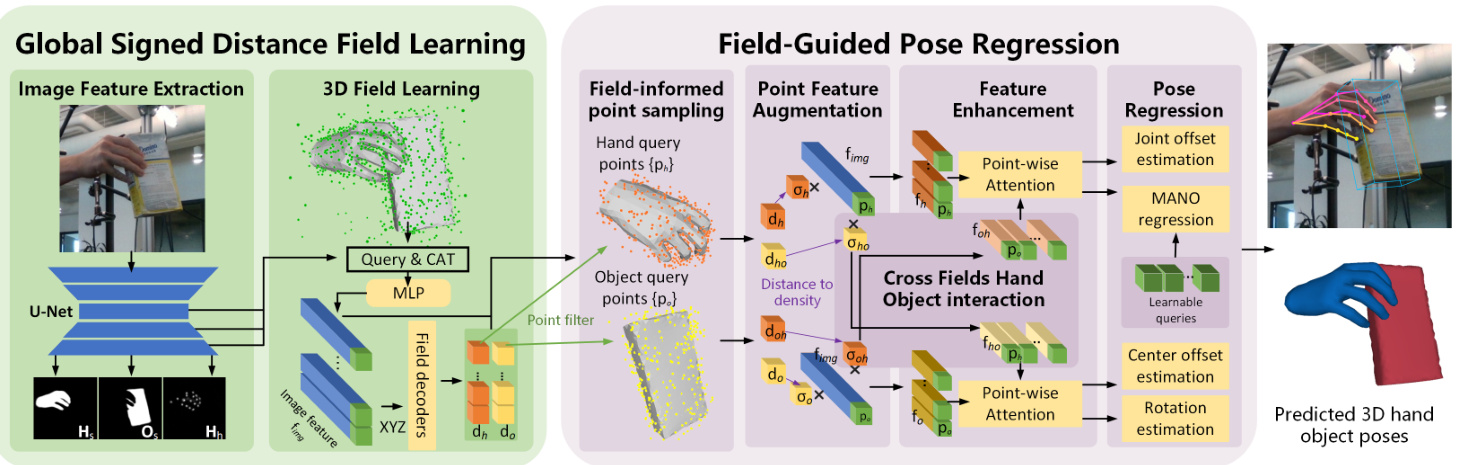
Figure 2. Overall pipeline of HOISDF. HOISDF has two parts: A global signed distance field learning module and a field-guided pose regression module. The global signed distance field learning module regresses the hand object signed distances as the intermediate representation and encodes the 3D shape information into the image backbone through implicit field learning. The field-guided pose regression module uses global field information to filter and augment the point features as well as guiding hand-object interaction. Those enhanced point features are then sent to regress hand and object poses using point-wise attention.
图 2: HOISDF的整体流程。HOISDF包含两个部分:全局符号距离场学习模块和场引导姿态回归模块。全局符号距离场学习模块通过隐式场学习将手-物符号距离回归为中间表示,并将3D形状信息编码到图像主干中。场引导姿态回归模块利用全局场信息过滤增强点特征,并指导手物交互。这些增强后的点特征随后通过逐点注意力机制回归手部和物体姿态。
3. HOISDF
3. HOISDF
We propose Hand-object Pose Estimation with Global Signed Distance Fields (HOISDF), a joint hand-object pose estimation model that leverages global shape constraints from a signed distance field. HOISDF comprises two components: A global signed distance field learning module and a field-guided pose regression module (Figure 2). Both components benefit from the robust 3D shape information modeled with the SDF and the whole architecture is trained end-to-end.
我们提出了基于全局有向距离场的手-物姿态估计方法(HOISDF),这是一种利用有向距离场全局形状约束的联合手-物姿态估计模型。HOISDF包含两个组件:全局有向距离场学习模块和场引导姿态回归模块 (图 2)。这两个组件都受益于用SDF建模的鲁棒3D形状信息,整个架构采用端到端训练方式。
3.1. Global Signed Distance Field Learning
3.1. 全局符号距离场学习
We simultaneously learn hand and object signed distance fields (SDFs) with the following rationale: i) An SDF implicitly represents 3D shape with the model parameters; the implicit learning procedure can thus propagate 3D shape information to the feature extraction module. ii) Jointly learning hand and object fields allows the model to encode their mutual constraints. Meanwhile, since we predict hand and object signed distances in the initial stage as intermediate representations, we encourage our SDF learning module to focus more on global plausibility rather than local fine-grained details. Below, we describe the image feature extraction and the SDF learning in detail.
我们同时学习手部和物体的有符号距离场 (SDF),其基本原理如下:i) SDF 通过模型参数隐式表示三维形状,因此隐式学习过程可以将三维形状信息传播到特征提取模块。ii) 联合学习手部和物体场使模型能够编码它们的相互约束。同时,由于我们在初始阶段预测手部和物体的有符号距离作为中间表示,我们鼓励 SDF 学习模块更关注全局合理性而非局部细粒度细节。下面,我们将详细描述图像特征提取和 SDF 学习过程。
Image Feature Extraction. For extracting hierarchical features F, we use a standard encoder-decoder architecture, specifically a U-Net [19, 23, 46]. Following standard practice [19, 33, 49], we regress 2D predictions (a single channel heatmap [19] and hand/object segmentation masks with loss $\mathcal{L}_{i m g}$ , see Supp. Mat. A for details) to enable the model to represent hand-object interaction at the 2D image level.
图像特征提取。为了提取层次化特征F,我们采用标准的编码器-解码器架构,具体为U-Net [19, 23, 46]。遵循常规做法 [19, 33, 49],我们回归二维预测(单通道热力图 [19] 和手部/物体分割掩码,损失函数为$\mathcal{L}_{img}$,详见补充材料A部分),使模型能够在二维图像层面表征手-物交互。
3D Signed Distance Field Learning. With the extracted image features, the SDF module learns the continuous mapping from a 3D query point $\mathbf{p}\in\mathbb{R}^{3}$ to the shortest signed distances between $\mathbf{p}$ and the hand/object surfaces. Compared to [12, 13], we directly learn SDFs in the original space without rotating to canonical spaces using pose predictions. Our SDF module will consequently focus on the global information (e.g., general shape, location and global rotation) of the hand and object.
3D 有符号距离场 (Signed Distance Field) 学习。通过提取的图像特征,SDF模块学习从3D查询点$\mathbf{p}\in\mathbb{R}^{3}$到$\mathbf{p}$与手部/物体表面之间最短有符号距离的连续映射。与[12, 13]相比,我们直接在原始空间中学习SDF,而无需使用姿态预测旋转到规范空间。因此,我们的SDF模块将专注于手部和物体的全局信息(例如整体形状、位置和全局旋转)。
Specifically, given a 3D query point $\mathbf{p}\in\mathbb{R}^{3}$ , we project it to the 2D image space to compute the pixel-aligned image features [13, 19, 49, 50] extracted by the U-Net decoder ${{\bf F}_{d e c}^{i}}$ , where $i\in\mathcal X$ indexes over the hierarchical decoder levels of the U-Net. We then concatenate the queried image features and pass them to a Multilayer Perceptron (MLP) to obtain a feature vector
具体来说,给定一个3D查询点$\mathbf{p}\in\mathbb{R}^{3}$,我们将其投影到2D图像空间,计算由U-Net解码器${{\bf F}_{d e c}^{i}}$提取的像素对齐图像特征[13, 19, 49, 50],其中$i\in\mathcal X$索引U-Net的分层解码器级别。然后我们将查询到的图像特征拼接起来,并传递给多层感知机(MLP)以获得特征向量
$$
{\bf f}{i m g}=\mathrm{\bfMLP}(\oplus_{i\in\mathcal{X}}{\bf F}{d e c}^{i}(\pi_{3D\to2D})),
$$
$$
{\bf f}{i m g}=\mathrm{\bfMLP}(\oplus_{i\in\mathcal{X}}{\bf F}{d e c}^{i}(\pi_{3D\to2D})),
$$
where $\pi_{3D\rightarrow2D}$ represents the projection and interpolation operation, $\bigoplus$ indicates the concatenation of all the hierarchical pixel-aligned image features, and $\mathcal{X}$ is the set of hierarchical features.
其中 $\pi_{3D\rightarrow2D}$ 表示投影和插值操作,$\bigoplus$ 表示所有分层像素对齐图像特征的拼接,$\mathcal{X}$ 是分层特征集合。
To emphasize the importance of $\mathbf{p}$ , we expand the coordinate representation by a Fourier Positional Encoding [37] into a vector $\mathbf{f}{p o s}$ . We then concatenate the triplet $\mathbf{p}$ , $\mathbf{f}{p o s}$ and $\mathbf{f}{i m g}$ together and pass them to the hand SDF decoder $\mathbb{S D F}{h}$ and the object SDF decoder $\mathbb{S D F}_{o}$ . This can be ex
为了强调 $\mathbf{p}$ 的重要性,我们通过傅里叶位置编码 [37] 将坐标表示扩展为向量 $\mathbf{f}{pos}$。然后将三元组 $\mathbf{p}$、$\mathbf{f}{pos}$ 和 $\mathbf{f}{img}$ 拼接在一起,并传递给手部 SDF 解码器 $\mathbb{SDF}{h}$ 和物体 SDF 解码器 $\mathbb{SDF}_{o}$。这可以
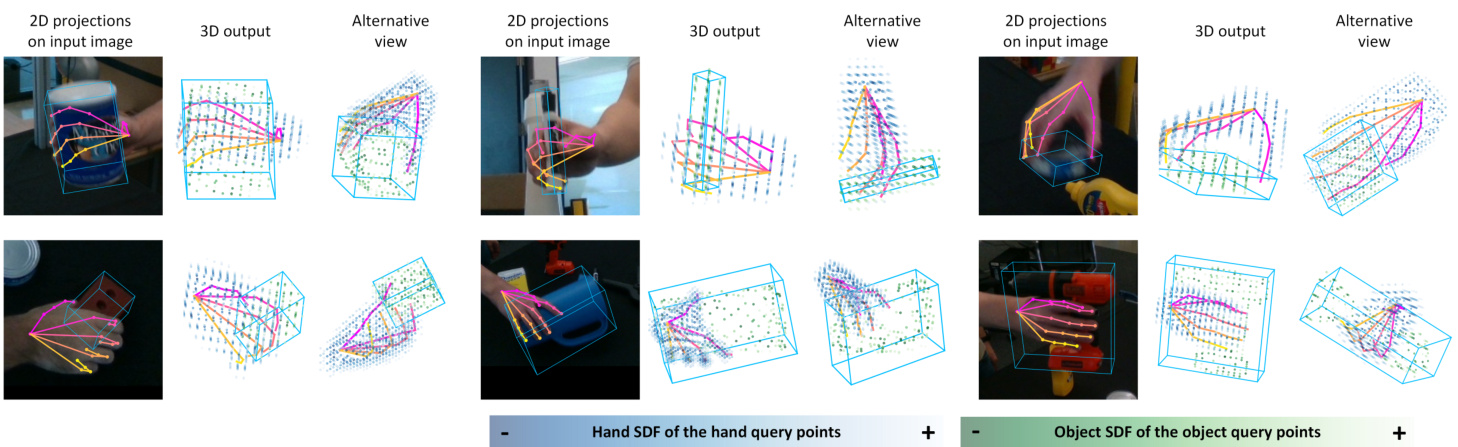
Figure 3. Visualization of the intermediate query points on DexYCB testset. The darkness of the query points reflects the predicted distance from the query point to the hand (in blue) and object (in green) surfaces. The intermediate SDF representations can capture the GT 3D hand and object shapes. HOISDF effectively uses the robust global clues from SDFs to deal well with various objects and hand movements as well as their mutual occlusions.
图 3: DexYCB测试集上中间查询点的可视化效果。查询点的深浅反映了预测距离(蓝色为手部表面,绿色为物体表面)。中间SDF表征能够捕捉真实的三维手部和物体形状。HOISDF有效利用SDF提供的全局鲁棒线索,成功处理各类物体、手部运动及其相互遮挡情况。
pressed as
表达为
$$
\begin{array}{r l}&{\mathbf{f}{s d f}=\mathbf{p}\oplus\mathbf{f}{p o s}\oplus\mathbf{f}{i m g},}\ &{\quad d_{h}=\mathbb{S}\mathbb{D}\mathbb{F}{h}(\mathbf{f}{s d f}),}\ &{\quad d_{o}=\mathbb{S}\mathbb{D}\mathbb{F}{o}(\mathbf{f}_{s d f}).}\end{array}
$$
$$
\begin{array}{r l}&{\mathbf{f}{s d f}=\mathbf{p}\oplus\mathbf{f}{p o s}\oplus\mathbf{f}{i m g},}\ &{\quad d_{h}=\mathbb{S}\mathbb{D}\mathbb{F}{h}(\mathbf{f}{s d f}),}\ &{\quad d_{o}=\mathbb{S}\mathbb{D}\mathbb{F}{o}(\mathbf{f}_{s d f}).}\end{array}
$$
Here, $d_{h}$ is the shortest distance from $\mathbf{p}$ to the hand mesh surface, and $d_{o}$ is the shortest distance from $\mathbf{p}$ to the object mesh surface; $d_{h}$ and $d_{o}$ will be positive if they are outside the surface and negative otherwise. The field decoders $\mathbb{S D F}{h}$ , and $\mathbb{S D F}_{o}$ are all 3-layer MLPs with tanh activation in the last layer [26].
这里,$d_{h}$ 是 $\mathbf{p}$ 到手部网格表面的最短距离,$d_{o}$ 是 $\mathbf{p}$ 到物体网格表面的最短距离;如果 $d_{h}$ 和 $d_{o}$ 位于表面外侧则为正值,反之为负值。场解码器 $\mathbb{S D F}{h}$ 和 $\mathbb{S D F}_{o}$ 均为3层MLP (多层感知机) ,最后一层使用tanh激活函数 [26]。
During training, we sample $N_{s}$ 3D query points, ensuring that most points are sampled near the hand and object mesh surfaces. We pre-compute the ground-truth distances from the query point to the hand and object surfaces and use the smooth-L1 loss [43] to supervise the learning of $d_{h}$ and $d_{o}$ . We sum the losses together and refer to the resulting loss as Lsdf .
在训练过程中,我们采样 $N_{s}$ 个3D查询点,确保大多数点采样在手部和物体网格表面附近。我们预先计算查询点到手部和物体表面的真实距离,并使用平滑L1损失 [43] 来监督 $d_{h}$ 和 $d_{o}$ 的学习。我们将这些损失相加,并将最终损失称为Lsdf。
3.2. Integrating Field Information: Field-guided Pose Regression
3.2. 整合场信息:场引导的姿态回归
After the field learning module, we aim to use the learned fields to predict the hand and object poses. However, effectively using the field information is non-trivial: i) The field information is implicitly encoded in the model parameters; we can only read the field information at a specific location by sending a query point into the network; ii) The resulting signed distance at a certain query point is just a scalar distance, which on its own provides only a weak link with the pose prediction; iii) How to explicitly model the hand-object interaction using SDF is unclear. To address these challenges, we hence introduce the field-guided pose regression module described below.
在场学习模块之后,我们的目标是利用学习到的场来预测手部和物体姿态。然而,有效利用场信息并非易事:i) 场信息隐式编码在模型参数中,我们只能通过向网络发送查询点来读取特定位置的场信息;ii) 某个查询点输出的带符号距离仅是一个标量值,其本身与姿态预测的关联性较弱;iii) 如何利用SDF显式建模手-物体交互尚不明确。为解决这些挑战,我们引入了下文描述的场引导姿态回归模块。
3.2.1 Field-informed Point Sampling
3.2.1 基于场信息的点采样
To address the first problem, we propose a point-sampling strategy that aims to extract the most helpful field information while querying only a few points. It builds on the assumption that the query points near the ground-truth surface are the most informative ones. As such, during inference, we voxelize the 3D space with $N_{v}$ bins, which gives us $N_{v}^{3}$ query points. We first use the hand and object bounding boxes to filter the points in 2D space. Then, we send the remaining points into $\mathbb{S D F}{h}$ and $\mathbb{S D F}{o}$ and sort them according to the obtained hand and object signed distances separately. We sample $N_{v}^{2}/n_{h}$ hand query points and $N_{v}^{2}/n_{o}$ object query points with the lowest absolute hand distance and object distance, respectively. Here, $n_{h}$ and $n_{o}$ are two positive hyper parameters controlling the number of samples. Since we can access the ground-truth mesh during training, we directly sample $N_{h}$ hand query points near the hand mesh and $N_{o}$ object query points near the object mesh (with an absolute distance smaller than $4\mathrm{cm}$ ) for speed and memory optimization (2x faster). Towards the end of training, we also sample points with the same strategy as during testing to learn the point distribution. We will show the effec ti ve ness of our proposed sampling strategy in Sec. 4.4.
为解决第一个问题,我们提出了一种点采样策略,旨在仅查询少量点的同时提取最有用的场信息。该策略基于一个假设:靠近真实表面的查询点信息量最大。因此,在推理阶段,我们使用$N_{v}$个网格单元对3D空间进行体素化,得到$N_{v}^{3}$个查询点。首先利用手部和物体边界框在2D空间筛选点集,随后将剩余点输入$\mathbb{S D F}{h}$和$\mathbb{S D F}{o}$,并分别根据获得的手部/物体有向距离进行排序。我们采样$N_{v}^{2}/n_{h}$个绝对手部距离最小的手部查询点,以及$N_{v}^{2}/n_{o}$个绝对物体距离最小的物体查询点。其中$n_{h}$和$n_{o}$是控制采样数量的两个正超参数。由于训练阶段可获取真实网格,为优化速度和内存(提速2倍),我们直接在距手部网格$4\mathrm{cm}$范围内采样$N_{h}$个手部查询点,在距物体网格相同距离内采样$N_{o}$个物体查询点。训练后期,我们也采用与测试阶段相同的采样策略来学习点分布规律。该采样策略的有效性将在第4.4节展示。
3.2.2 Field-based Point Feature Augmentation
3.2.2 基于场(Field-based)的点特征增强
To address the second problem, given a sampled hand query point $\mathbf{p}{h}$ , we convert $d_{h}$ to the volume density $\sigma_{h}=~\alpha^{-1}s i g m o i d(-d_{h}/\alpha)$ , where $\alpha$ is a learnable pa- rameter to control the tightness of the density around the surface boundary. This is motivated by the strategy used in StyleSDF [38] for image rendering, but here we use it for the purpose of feature augmentation. We then multiply $\sigma_{h}$ with $\mathbf{f}{i m g}$ . The field information will thus influence the whole feature representation. $\mathbf{p}{h}$ and its positional encoding $\mathbf{f}{p o s}$ discussed in Sec. 3.1 are also concatenated to further augment the point feature. The final hand query point feature $\mathbf{f}_{h}$ is obtained as
为了解决第二个问题,给定一个采样的手部查询点 $\mathbf{p}{h}$,我们将 $d_{h}$ 转换为体积密度 $\sigma_{h}=~\alpha^{-1}s i g m o i d(-d_{h}/\alpha)$,其中 $\alpha$ 是一个可学习参数,用于控制表面边界周围密度的紧密度。这一策略受到 StyleSDF [38] 在图像渲染中所用方法的启发,但在此我们将其用于特征增强的目的。接着,我们将 $\sigma_{h}$ 与 $\mathbf{f}{i m g}$ 相乘。这样,场信息将影响整个特征表示。$\mathbf{p}{h}$ 及其在 3.1 节中讨论的位置编码 $\mathbf{f}{p o s}$ 也会被拼接进来,以进一步增强点的特征。最终的手部查询点特征 $\mathbf{f}_{h}$ 表示为
$$
\mathbf{f}{h}=\mathbf{p}{h}\oplus\mathbf{f}{p o s}\oplus(\mathbf{f}{i m g}\cdot\boldsymbol{\sigma}_{h}).
$$
$$
\mathbf{f}{h}=\mathbf{p}{h}\oplus\mathbf{f}{p o s}\oplus(\mathbf{f}{i m g}\cdot\boldsymbol{\sigma}_{h}).
$$
For a sampled object query point ${\bf p}{o}$ , the object query point feature ${\bf f}{o}$ is obtained in an analogous way (i.e., augmenting the feature by the volume density $\sigma_{o}$ based on object SDF $d_{o}$ ).
对于采样的物体查询点 ${\bf p}{o}$,物体查询点特征 ${\bf f}{o}$ 以类似方式获取(即基于物体SDF $d_{o}$ 通过体积密度 $\sigma_{o}$ 增强特征)。
3.2.3 Cross Fields Hand-Object Interaction
3.2.3 跨领域手-物交互
Since we use the shared image backbone to learn the handobject SDFs jointly, hand-object relations can be implicitly modeled during implicit field learning. Here, we aim to model the hand-object interaction explicitly to better deal with the mutual occlusions. Intuitively, the hand-object contact areas are highly informative about the object/hand pose. Therefore, we augment the hand/object query points with the object/hand SDFs, respectively, to serve as interaction cues (Fig. 2). Specifically, for a sampled object query point ${\bf p}{o}$ , we send it to the hand SDF decoder $\mathbb{S D F}{h}$ to obtain the cross-hand signed distance $d_{o h}$ . $d_{o h}$ is then converted to the volume density $\sigma_{o h}$ and used to augment the queried image feature $\mathbf{f}{i m g}$ similarly to Sec. 3.2.2. The final cross-hand query point feature $\mathbf{f}_{o h}$ is obtained as
由于我们使用共享的图像主干网络联合学习手部-物体SDF (Signed Distance Field),在隐式场学习过程中可以隐式建模手部-物体关系。本文旨在显式建模手部-物体交互,以更好地处理相互遮挡问题。直观而言,手部-物体接触区域对物体/手部姿态具有高度信息量。因此,我们分别用物体/手部SDF来增强手部/物体查询点,作为交互线索 (图 2)。具体来说,对于采样的物体查询点 ${\bf p}{o}$,我们将其输入手部SDF解码器 $\mathbb{S D F}{h}$ 以获取跨手部有符号距离 $d_{o h}$。随后将 $d_{o h}$ 转换为体积密度 $\sigma_{o h}$,并按照第3.2.2节类似方式增强查询图像特征 $\mathbf{f}{i m g}$。最终获得的跨手部查询点特征 $\mathbf{f}_{o h}$ 表示为:
$$
\mathbf{f}{o h}=\mathbf{p}{o}\oplus\mathbf{f}{p o s}\oplus(\mathbf{f}{i m g}\cdot\boldsymbol{\sigma}_{o h}).
$$
$$
\mathbf{f}{o h}=\mathbf{p}{o}\oplus\mathbf{f}{p o s}\oplus(\mathbf{f}{i m g}\cdot\boldsymbol{\sigma}_{o h}).
$$
$\mathbf{f}{o h}$ will serve as object cues for hand pose estimation. A ${\bf p}{o}$ with smaller $d_{o h}$ will play a bigger role in helping the hand pose estimation. Similarly, a hand query point $\mathbf{p}{h}$ is also sent to object SDF decoder $\mathbb{S D F}{o}$ and used to generate a cross-object query point feature $\mathbf{f}_{h o}$ .
$\mathbf{f}{o h}$ 将作为手部姿态估计的对象线索。${\bf p}{o}$ 的 $d_{o h}$ 越小,对手部姿态估计的帮助作用越大。类似地,手部查询点 $\mathbf{p}{h}$ 也会被送入物体 SDF 解码器 $\mathbb{S D F}{o}$,用于生成跨物体查询点特征 $\mathbf{f}_{h o}$。
3.2.4 Feature Enhancement with Point-wise Attention
3.2.4 基于逐点注意力 (Point-wise Attention) 的特征增强
As the pixel-aligned feature $\mathbf{f}{i m g}$ mainly contains local information, the local query point features $\mathbf{f}{h}$ and ${\bf f}{o}$ could be misled and thus make wrong predictions in the presence of severe occlusion. To address this problem, we propose to use an attention mechanism [27, 48] to exploit reliable dependencies in the global context. In contrast to existing approaches that either perform attention over 2D features [19] or over 3D mesh vertex features [47, 49], our point-wise attention explores the global field information and the local image information with the aim of finding global 3D shape consistency between the sampled query points. Specifically, the extracted $N_{h}$ hand query point features ${\mathbf{f}{h}^{i}}{i\in(0,N_{h})}$ are sent into a hand attention module, which consists of six Multi-Head Self-Attention (MHSA) layers [27, 48].
由于像素对齐特征 $\mathbf{f}{i m g}$ 主要包含局部信息,在严重遮挡情况下,局部查询点特征 $\mathbf{f}{h}$ 和 ${\bf f}{o}$ 可能会被误导从而导致错误预测。为解决该问题,我们提出使用注意力机制 [27, 48] 来挖掘全局上下文中的可靠依赖关系。与现有方法(仅在2D特征 [19] 或3D网格顶点特征 [47, 49] 上执行注意力)不同,我们的逐点注意力同时探索全局场信息和局部图像信息,旨在发现采样查询点之间的全局3D形状一致性。具体而言,提取的 $N_{h}$ 个手部查询点特征 ${\mathbf{f}{h}^{i}}{i\in(0,N_{h})}$ 会被送入包含六层多头自注意力 (MHSA) 模块 [27, 48] 的手部注意力模块。
Meanwhile, to leverage object cues inside the crosshand query point features ${\mathbf{f}{o h}^{i}}{i\in(0,N_{o})}$ , we also send them to the MHSA layers SA to conduct cross attention with ${\mathbf{f}{h}^{i}}{i\in(0,N_{h})}$ . The resulting enhanced hand point features are computed as
同时,为了利用交叉手部查询点特征 ${\mathbf{f}{o h}^{i}}{i\in(0,N_{o})}$ 中的物体线索,我们还将它们送入MHSA层的SA模块,与 ${\mathbf{f}{h}^{i}}{i\in(0,N_{h})}$ 进行交叉注意力计算。最终增强的手部点特征通过以下方式得到:
$$
({\mathbf{f}{e h}^{i}}{i\in(0,N_{h})},*)=\mathbb{S}\mathbb{A}\big({\mathbf{f}{h}^{i}}{i\in(0,N_{h})},{\mathbf{f}{o h}^{i}}{i\in(0,N_{o})}\big),
$$
$$
({\mathbf{f}{e h}^{i}}{i\in(0,N_{h})},*)=\mathbb{S}\mathbb{A}\big({\mathbf{f}{h}^{i}}{i\in(0,N_{h})},{\mathbf{f}{o h}^{i}}{i\in(0,N_{o})}\big),
$$
where $^*$ denotes that we ignore the output from the $N_{o}$ cross-hand query tokens. Analogously, the enhanced object point features ${\mathbf{f}{e o}^{i}}{i\in(0,N_{o})}$ can be obtained by processing object query point features ${\mathbf{f}{o}^{i}}{i\in(0,N_{o})}$ and cross-object query point features ${\mathbf{f}{h o}^{i}}{i\in(0,N_{h})}$ with an object attention module.
其中 $^*$ 表示我们忽略了来自 $N_{o}$ 个交叉手部查询 token 的输出。类似地,增强后的物体点特征 ${\mathbf{f}{e o}^{i}}{i\in(0,N_{o})}$ 可以通过物体注意力模块处理物体查询点特征 ${\mathbf{f}{o}^{i}}{i\in(0,N_{o})}$ 和交叉物体查询点特征 ${\mathbf{f}{h o}^{i}}{i\in(0,N_{h})}$ 获得。
3.2.5 Point-wise Pose Regression
3.2.5 逐点位姿回归
With attention, we incorporate globally consistent information and cross-target cues into the hand point features ${\mathbf{f}{e h}^{i}}$ and object point features ${{\bf f}{e o}^{i}}$ . Those points thus have enough global-local shape context information to regress hand-object poses. We apply asymmetric designs for hand and object pose estimation. Since the hand is non-rigid, flexible, and typically occluded when grasping an object, regressing the hand pose requires gathering richer information inside the ${{\bf f}_{e h}^{i}}$ . We hence follow [19] to use Cross- Attention layers $\mathbb{C A}$ with the learned hand pose queries ${\mathbf{q}^{i}}$ . We supervise the learning of hand pose queries with MANO parameters [44] to obtain both hand joints and a hand mesh. Sixteen hand pose queries regress 3-D MANO joint angles, and one more hand pose query regresses the 10-D mano shape parameters $\beta$ . This can be expressed as
通过注意力机制,我们将全局一致信息和跨目标线索融入手部点特征${\mathbf{f}{e h}^{i}}$和物体点特征${{\bf f}{e o}^{i}}$中。这些点因此具备足够的全局-局部形状上下文信息,可用于回归手-物姿态。我们对手部和物体姿态估计采用非对称设计:由于手部具有非刚性、高灵活性且抓握时通常被遮挡的特性,回归手部姿态需要从${{\bf f}_{e h}^{i}}$中聚合更丰富的信息。为此,我们沿用[19]的方法,采用交叉注意力层$\mathbb{C A}$与学习得到的手部姿态查询${\mathbf{q}^{i}}$。通过MANO参数[44]监督手部姿态查询的学习,同时获取手部关节和手部网格。其中16个手部姿态查询回归3D MANO关节角度,另1个手部姿态查询回归10维MANO形状参数$\beta$。该过程可表示为
$$
\begin{array}{r}{({\pmb{\theta}^{i}\in\mathbb{R}^{3}}{i\in(0,16)},\beta)=\qquad}\ {\mathbb{C}\mathbb{A}({\mathbf{f}{e h}^{i}}{i\in(0,N_{h})},({\mathbf{q}^{i}}_{i\in(0,16)},\mathbf{q}^{16})).}\end{array}
$$
$$
\begin{array}{r}{({\pmb{\theta}^{i}\in\mathbb{R}^{3}}{i\in(0,16)},\beta)=\qquad}\ {\mathbb{C}\mathbb{A}({\mathbf{f}{e h}^{i}}{i\in(0,N_{h})},({\mathbf{q}^{i}}_{i\in(0,16)},\mathbf{q}^{16})).}\end{array}
$$
We use a smooth-L1 loss [43] to supervise the learning of the MANO parameters, referred to as $\mathcal{L}{\mathrm{mano}}$ . Similarly to [19], we also regress the intermediate hand pose objective to guide the final predictions. However, since our ${{\bf f}{e h}^{i}}$ already contains rich 3D information, we directly regress 3D hand joints instead of 2D joints as in [19]. We use ${{\bf f}{e h}^{i}}$ as dense local regressors [31, 51] to predict the offsets ${\mathbf{o}{h}^{i j}}$ from each hand query point $\mathbf{p}{h}^{i}$ to every pose joint as well as the prediction confidence. The corresponding loss is denoted as $\mathcal{L}_{\mathrm{off}}$ . Note that the design of the hand pose regressor is not identical. Our field-guided query points already include rich global-local shape context information and yield satisfactory pose estimation results with various regressors (see Sec. 4.5 and Fig. F1).
我们采用平滑L1损失 [43] 来监督MANO参数的学习,记为$\mathcal{L}{\mathrm{mano}}$。与[19]类似,我们也回归中间手部姿态目标以指导最终预测。但由于我们的${{\bf f}{e h}^{i}}$已包含丰富3D信息,我们直接回归3D手部关节点而非如[19]中的2D关节点。我们将${{\bf f}{e h}^{i}}$作为密集局部回归器[31, 51]来预测从每个手部查询点$\mathbf{p}{h}^{i}$到各姿态关节的偏移量${\mathbf{o}{h}^{i j}}$及预测置信度,对应损失记为$\mathcal{L}_{\mathrm{off}}$。需注意手部姿态回归器的设计并不相同——我们的场引导查询点已包含丰富的全局-局部形状上下文信息,配合不同回归器均可获得令人满意的姿态估计结果(参见第4.5节和图F1)。
Compared with the hand, the object is more rigid. Therefore, we simply regress rotation vectors ${\mathbf{r}^{i}}$ and translation vectors ${\mathbf{t}^{i}}$ with all the enhanced object point features ${{\bf f}{e o}^{i}}$ and use a smooth-L1 loss [43] $\mathcal{L}_{\mathrm{obj}}$ to supervise them. During inference, we average the predictions from all the object points to obtain the final object translation and orientation.
与手部相比,物体具有更高的刚性。因此,我们直接通过所有增强后的物体点特征 ${{\bf f}{e o}^{i}}$ 回归旋转向量 ${\mathbf{r}^{i}}$ 和平移向量 ${\mathbf{t}^{i}}$,并使用平滑L1损失 [43] $\mathcal{L}_{\mathrm{obj}}$ 进行监督。在推理阶段,我们对所有物体点的预测结果取平均,从而获得最终的物体平移和朝向。
4. Experiments
4. 实验
We first introduce the hand-object interaction benchmarks, describe implementation details and compare HOISDF with state-of-the-art (SOTA) methods. We finally detail ablation results.
我们首先介绍手-物体交互基准测试,描述实现细节,并将HOISDF与最先进(SOTA)方法进行比较。最后详细分析消融实验结果。
4.1. Datasets and Evaluation Metrics
4.1. 数据集和评估指标
We evaluate HOISDF on hand-object benchmarks: DexYCB [7] and HO3Dv2 [18] containing, respectively, 582K and 77K images of human interacting with YCB objects [5].
我们在手-物交互基准测试 DexYCB [7] 和 HO3Dv2 [18] 上评估 HOISDF,这两个数据集分别包含 58.2 万张和 7.7 万张人类与 YCB 物体 [5] 交互的图像。
DexYCB Dataset. We use the default S0 train-test split defined by DexYCB [7]. Some methods [33, 34] use the full DexYCB dataset by flipping the left-hand images (denoted as DexYCB Full), while other methods [12, 13, 20, 22, 47, 49, 53] select input frames in which the right hand and the object are in close interaction to ensure the physical contact (denoted as DexYCB). In general when we refer to DexYCB we mean this latter split. To broadly compare, we train HOISDF on both settings. Since most of the methods use the data only with the right hand, we conduct our ablations under the DexYCB split.
DexYCB数据集。我们采用DexYCB [7]定义的默认S0训练-测试划分。部分方法[33, 34]通过镜像左手图像使用完整DexYCB数据集(记为DexYCB Full),而其他方法[12, 13, 20, 22, 47, 49, 53]筛选右手与物体紧密交互的输入帧以确保物理接触(记为DexYCB)。通常情况下我们提及DexYCB时指代后者划分。为全面对比,我们在两种设置下训练HOISDF。由于多数方法仅使用右手数据,我们在DexYCB划分下进行消融实验。
For hand pose estimation, we report Mean Joint Error (MJE) and Procrustes Aligned Mean Joint Error (PAMJE) [57]. We also report Mean Mesh Error (MME), area under the curve of the percentage of correct vertices (VAUC) the F-scores $\mathrm{F@5mm}$ and $\mathrm{F@15mm},$ ), and corresponding Procrustes Aligned version following [52] to measure hand mesh reconstruction performance. For object 6D pose estimation, we report Object Center Error (OCE) following [12, 13], Mean Corner error (MCE) following [49], and standard pose estimation average closest point distance (ADD-S) following [20, 22, 49] to measure performance in center, corner, and vertex levels.
对于手部姿态估计,我们报告平均关节误差 (MJE) 和普氏对齐平均关节误差 (PAMJE) [57]。同时报告平均网格误差 (MME)、正确顶点百分比曲线下面积 (VAUC)、F分数 (F@5mm 和 F@15mm),以及参照 [52] 的普氏对齐版本以衡量手部网格重建性能。对于物体6D姿态估计,参照 [12, 13] 报告物体中心误差 (OCE),参照 [49] 报告平均角点误差 (MCE),并采用标准姿态估计平均最近点距离 (ADD-S) [20, 22, 49] 来评估中心、角点和顶点层级的性能。
HO3Dv2 Dataset. We use the standard train-test splitting protocol and submit the test results to the official website to report performance. Since the HO3Dv2 is relatively small-scale, some methods [49, 53] render synthetic hand object images to enhance learning. Therefore, apart from training the model only with the original data in the HO3Dv2 training set, we also train another model (denoted with ‘*‘ in Table 4) by including synthetic images. We follow the render pipeline of Wang et al. [49].
HO3Dv2数据集。我们采用标准的训练-测试分割协议,并将测试结果提交至官方网站以报告性能。由于HO3Dv2规模相对较小,部分方法[49,53]通过渲染合成的手部物体图像来增强学习效果。因此,除了仅使用HO3Dv2训练集中的原始数据训练模型外,我们还通过加入合成图像训练了另一个模型(表4中用“*”标注)。我们遵循Wang等人[49]的渲染流程。
For hand pose estimation, we use the HO3Dv2 evaluation metrics to measure the performance: Mean Joint Error (MJE), Scale-Translation aligned Mean Joint Error (STMJE) [58], and Procrustes aligned Mean Joint Error (P-MJE) [57]. For object 6D pose estimation, we report mean Object Mesh Error (OME) and standard pose estimation average closest point distance (ADD-S) following [20, 22, 49].
对于手部姿态估计,我们采用HO3Dv2评估指标衡量性能:平均关节误差 (MJE)、尺度-平移对齐平均关节误差 (STMJE) [58] 以及普氏对齐平均关节误差 (P-MJE) [57]。对于物体6D姿态估计,我们按照[20, 22, 49]报告平均物体网格误差 (OME) 和标准姿态估计最近点距离均值 (ADD-S)。
Table 1. Quantitative comparison on the DexYCB dataset. Trained and tested on the DexYCB Full split. HOISDF reaches lower hand and object pose estimation errors. The metrics are represented in millimeters. The last column indicates whether a method performs the object 6D pose estimation.
表 1: DexYCB数据集上的定量比较。在DexYCB Full分割上进行训练和测试。HOISDF实现了更低的手部和物体姿态估计误差。指标单位为毫米(mm)。最后一列表示方法是否执行物体6D姿态估计。
| 指标[mm] | MJE | PAMJE | OCE | MCE | ADD-S | 物体 |
|---|---|---|---|---|---|---|
| Lin等[32] | 15.2 | 6.99 | 否 | |||
| Spurr等[44] | 17.3 | 6.83 | 否 | |||
| Liu等[34] | 15.2 | 6.58 | 是 | |||
| Park等[39] | 14.0 | 5.80 | 否 | |||
| Chen等[9] | 14.2 | 6.40 | 否 | |||
| Xu等[52] | 14.0 | 5.70 | 否 | |||
| Lin等[33] | 12.6 | 5.47 | 42.7 | 48.0 | 33.8 | 是 |
| HOISDF (本文) | 10.1 | 5.13 | 27.6 | 35.8 | 18.6 | 是 |
Table 2. Same as Table 1, but for DexYCB split, see Sec. 4.1.
| 指标[mm] | MJE | PAMJE | OCE | MCE | ADD-S | 物体 |
|---|---|---|---|---|---|---|
| Hasson等[20] | 17.6 | 是 | ||||
| Hasson等[22] | 18.8 | 52.5 | 是 | |||
| Tze等[47] | 15.3 | 是 | ||||
| Li等[53] | 12.8 | 是 | ||||
| Chen等[12] | 19.0 | 27.0 | 是 | |||
| Chen等[13] | 14.4 | 19.1 | 是 | |||
| Wang等[49] | 12.7 | 6.86 | 27.3 | 32.6 | 15.9 | 是 |
| Lin等[33] | 11.9 | 5.81 | 39.8 | 45.7 | 31.9 | 是 |
| HOISDF (本文) | 10.1 | 5.31 | 18.4 | 27.4 | 13.3 | 是 |
表 2: 同表 1,但针对DexYCB分割,参见第4.1节。
4.2. Implementation and Training Details
4.2. 实现与训练细节
We adopt ResNet-50 as the U-Net backbone [23, 46]. All the point features: the image $\mathbf{f}{i m g}$ , the hand $\mathbf{f}{e h}$ , and object $\mathbf{f}_{e o}$ are of size 256. We employ a transformer [48] encoder as our point-wise attention module and a transformer decoder as our MANO regressor [44]. We follow the standard practice [19, 33, 49] to train a unified model for all the objects in the dataset. The overall loss is a weighted sum of all individual loss functions,
我们采用 ResNet-50 作为 U-Net 的主干网络 [23, 46]。所有点特征:图像 $\mathbf{f}{i m g}$、手部 $\mathbf{f}{e h}$ 和物体 $\mathbf{f}_{e o}$ 的尺寸均为 256。我们使用 Transformer [48] 编码器作为逐点注意力模块,并使用 Transformer 解码器作为 MANO 回归器 [44]。我们遵循标准实践 [19, 33, 49],为数据集中的所有物体训练一个统一模型。总体损失是所有单独损失函数的加权和。
$$
\begin{array}{r}{\mathcal{L}=\lambda_{1}\mathcal{L}{i m g}+\lambda_{2}\mathcal{L}{s d f}+\lambda_{3}\mathcal{L}{\mathrm{mano}}+\qquad}\ {\lambda_{4}\mathcal{L}{\mathrm{off}}+\lambda_{5}\mathcal{L}_{\mathrm{obj}},}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}=\lambda_{1}\mathcal{L}{i m g}+\lambda_{2}\mathcal{L}{s d f}+\lambda_{3}\mathcal{L}{\mathrm{mano}}+\qquad}\ {\lambda_{4}\mathcal{L}{\mathrm{off}}+\lambda_{5}\mathcal{L}_{\mathrm{obj}},}\end{array}
$$
where $\lambda_{1}$ to $\lambda_{5}$ are used to balance all the loss terms to the same scale. During training, the network parameters are optimized with Adam [28] with a mini-batch size of 32. The initial learning rate is 1e-4 and decays by 0.7 every 5 epochs. HOISDF typically converges to a satisfying result after about 40 epochs.
其中 $\lambda_{1}$ 到 $\lambda_{5}$ 用于平衡所有损失项至相同量级。训练时采用 Adam [28] 优化器,最小批次 (mini-batch) 大小为 32,初始学习率为 1e-4 并每 5 个周期衰减 0.7 倍。HOISDF 通常在大约 40 个周期后收敛至理想结果。
For query points sampling, during training, we sample $N_{s}=1000$ query points for 3D field learning. During inference, we empirically found that with a disc ret iz ation size of $N_{v}=64$ , sampling $N_{v}^{2}/n_{h}=600$ hand query points and $N_{v}^{2}/n_{o}=200$ object query points was enough for good performance.
在查询点采样方面,训练阶段我们采样 $N_{s}=1000$ 个查询点用于3D场学习。推理阶段通过实验发现,当离散化尺寸为 $N_{v}=64$ 时,采样 $N_{v}^{2}/n_{h}=600$ 个手部查询点和 $N_{v}^{2}/n_{o}=200$ 个物体查询点即可获得良好性能。
4.3. Comparisons with State-of-the-Art Methods
4.3. 与最先进方法的对比
Quantitative comparisons on DexYCB. We evaluate HOISDF on the DexYCB test sets (Tables 1, 2, and Table T1 for per object results) and compare it with (SOTA)
在DexYCB上的定量比较。我们在DexYCB测试集上评估HOISDF(表1、表2及表T1为各物体结果)并与当前最优方法(SOTA)进行对比。
Table 3. Quantitative comparison with hand mesh metrics on the DexYCB Full testset. MME and PAMME are in millimeters.
| 指标 | MME↓ | VAUC↑ | F@5个 | F@15个 | PAMME↓ | PAV AUC↑ | PAF@5个 | PAF@15↑ | 物体 |
|---|---|---|---|---|---|---|---|---|---|
| Park 等人 [39] | 13.1 | 76.6 | 51.5 | 92.4 | 5.5 | 89.0 | 78.0 | 99.0 | 否 |
| Chen 等人 [9] | 13.1 | 76.1 | 50.8 | 92.1 | 5.6 | 88.9 | 78.5 | 98.8 | 否 |
| Xu 等人 [52] | 13.0 | 76.2 | 51.3 | 92.1 | 5.5 | 89.1 | 80.1 | 99.0 | 否 |
| Lin 等人 [33] | 11.6 | 77.6 | 53.0 | 93.3 | 5.2 | 89.6 | 79.8 | 99.2 | 是 |
| HOISDF (ours) | 9.9 | 80.5 | 60.1 | 94.9 | 4.9 | 90.2 | 81.8 | 99.3 | 是 |
表 3: 在 DexYCB Full 测试集上与手部网格指标的定量对比。MME 和 PAMME 单位为毫米。
methods. Among the best models, [49] is best at object estimation while [33] is best at hand pose estimation. However, HOISDF outperforms prior methods by a substantial margin for both hand and object metrics. Liu et al.[34] and Lin et al.[33] trained on the S0-DexYCB split. We train and test our HOISDF using the same split and observe a consistent improvement over them (Table 2). It is also worth mentioning that HOISDF beats the methods that perform just hand pose estimation (e.g.,[32, 39, 44, 52]). Furthermore, we also compare HOISDF with SDF-based hand object interaction methods [12, 13]. As mentioned in Sec. 3.1, both of them use SDFs to regress the (output) hand meshes, while we use SDFs as intermediate representations and for field-guided inference. HOISDF significantly outperforms these methods.
在众多优秀模型中,[49]在物体姿态估计方面表现最佳,而[33]在手部姿态估计上最为出色。但HOISDF在手部和物体指标上都大幅超越了现有方法。Liu等人[34]和Lin等人[33]使用S0-DexYCB数据集划分进行训练。我们采用相同划分训练并测试HOISDF模型,观察到对其性能的持续提升(表2)。值得注意的是,HOISDF甚至超越了仅专注于手部姿态估计的方法(如[32, 39, 44, 52])。此外,我们还比较了HOISDF与基于SDF的手物交互方法[12, 13]。如第3.1节所述,这些方法都使用SDF来回归(输出)手部网格,而我们将其作为中间表征并用于场引导推理。HOISDF显著优于这些方法。
As HOISDF also predicts a MANO mesh, we compare it with the SOTA methods for hand mesh reconstruction performance on the DexYCB Full test set (Table 3). We observe consistent improvements with HOISDF.
由于HOISDF也能预测MANO网格,我们将其与手部网格重建的SOTA方法在DexYCB Full测试集上进行比较(表3)。我们观察到HOISDF带来了持续的性能提升。
Quantitative comparisons on HO3Dv2. As further evidence of the effectiveness of HOISDF, we also evaluate it on the HO3Dv2 dataset. Again, HOISDF consistently beats the current SOTA methods on almost all the hand and object metrics both with and without synthetic data (Table 4, Table T2 for per object results). Lin et al. [33] obtains slightly better performance with regard to PAMJE, but performs very poorly in the other metrics, while HOISDF is more balanced.
HO3Dv2上的定量比较。为了进一步证明HOISDF的有效性,我们还在HO3Dv2数据集上对其进行了评估。无论是使用还是未使用合成数据,HOISDF在几乎所有手部和物体指标上都持续超越当前SOTA方法 (表4、表T2展示了各物体结果) 。Lin等人 [33] 在PAMJE指标上略优,但在其他指标上表现较差,而HOISDF则更为均衡。
On both datasets, especially HO3Dv2 with fewer data, HOISDF yields a larger improvement on the metrics that exploit more global information (MJE, STMJE and object metrics). We attribute this advantage to the fact that SDFs, as intermediate representations, capture global information effectively to guide the subsequent pose estimations. We will first visualize query points (Fig. 3) and then validate our design choices.
在两个数据集上,尤其是数据量较少的HO3Dv2上,HOISDF在利用更多全局信息的指标(MJE、STMJE和物体指标)上取得了更大提升。我们将这一优势归因于SDF作为中间表征能有效捕捉全局信息来指导后续姿态估计。我们将首先可视化查询点(图 3: ),然后验证我们的设计选择。
Visualization of the learned SDFs. We visualize the pose predictions and the intermediate hand-object query points on the DexYCB testset (Fig. 3). We can see that the remaining query points after the field-informed point sampling already reveal the general hand object shape (see Sec. 3.2.1).
学习到的SDF可视化。我们在DexYCB测试集上展示了姿态预测和中间手部-物体查询点 (图 3)。可以看到经过场感知点采样后剩余的查询点已经能反映出整体手部-物体形状 (参见第3.2.1节)。

Figure 4. Qualitative comparisons between HOISDF and [33, 49] on DexYCB testset. HOISDF effectively uses robust global clues near the hand and object to deal well with various objects and severe occlusions.
图 4: HOISDF 与 [33, 49] 在 DexYCB 测试集上的定性对比。HOISDF 有效利用手部和物体附近的鲁棒全局线索,能够妥善处理各种物体及严重遮挡情况。
Table 4. Quantitative comparison on the HO3Dv2 dataset. The metrics are represented in millimeters.‘*‘ denotes models that were co-trained with synthetic data.
表 4: HO3Dv2数据集上的量化对比。度量单位为毫米。'*'表示使用合成数据联合训练的模型。
| 度量单位[mm] | MJE | STMJE | PAMJE | OME | ADD-S |
|---|---|---|---|---|---|
| Hasson et al. [20] | 31.8 | 11.0 | |||
| Hasson et al. [21] | 36.9 | 11.4 | 67.0 | 22.0 | |
| Hasson et al. [22] | 26.8 | 12.0 | 80.0 | 40.0 | |
| Liu et al. [34] | 31.7 | 10.1 | |||
| Hampali et al. [19] | 25.5 | 25.7 | 10.8 | 68.0 | 21.4 |
| Lin et al. [33] | 28.9 | 28.4 | 8.9 | 64.3 | 32.4 |
| HOISDF(ours) | 23.6 | 22.8 | 9.6 | 48.5 | 17.8 |
| Li et al.* [53] | 26.3 | 25.3 | 11.4 | ||
| Wang et al.* [49] | 22.2 | 23.8 | 10.1 | 45.5 | 20.8 |
| HOISDF*(ours) | 19.0 | 18.3 | 9.2 | 35.5 | 14.4 |
Qualitative comparisons. Next, we compared HOISDF qualitatively with two SOTA hand object pose estimation methods on the DexYCB test set (Fig. 4) and the HO3Dv2 test set (Fig. F4). We can see HOISDF outperforms [33, 49] under various objects and different types of hand-object interactions.
定性比较。接下来,我们在DexYCB测试集(图4)和HO3Dv2测试集(图F4)上,将HOISDF与两种SOTA手物姿态估计方法进行了定性对比。可以看出HOISDF在不同物体及多种手物交互类型下均优于[33, 49]。
4.4. Ablation for Intermediate Representations
4.4. 中间表征消融实验
Since using SDF as a global intermediate representation is the key component of HOISDF, we analyze the role of the SDF here, comparing it with other intermediate representations, and analyzing the query points.
由于使用SDF作为全局中间表示是HOISDF的关键组成部分,我们在此分析SDF的作用,将其与其他中间表示进行比较,并分析查询点。
Table 5. Comparison between different intermediate representations on DexYCB testset. The SDF-based intermediate representation outperforms other representations because it encodes 3D shape information, is direct to regress, and has less joint cumulative error.
表 5: 不同中间表示在DexYCB测试集上的对比。基于SDF的中间表示优于其他表示,因为它编码了3D形状信息,更易于直接回归,并且具有更少的关节累积误差。
| 指标 [mm] | MJE | PAMJE | OCE | MCE | ADD-S |
|---|---|---|---|---|---|
| 2D关键点 | 14.9 | 7.13 | 34.2 | 45.3 | 22.9 |
| 2D分割 | 14.1 | 6.88 | 31.3 | 43.1 | 21.0 |
| 3D顶点 | 12.7 | 6.57 | 24.1 | 35.3 | 16.5 |
| 3D SDF (ours) | 10.1 | 5.31 | 18.4 | 27.4 | 13.3 |
| 指标 [mm] | 均值 | MCP | PIP | DIP | 指尖 |
|---|---|---|---|---|---|
| Wang et al. [49] | 7.67 | 7.63 | 6.36 | 6.29 | 10.4 |
| HOISDF (本方法) | 6.16 | 6.02 | 5.27 | 5.40 | 7.95 |
Table 6. Sampled point distributions. Using SDF as global guidance for point sampling gathers intermediate query points closer to the GT pose joints. MCP, PIP, DIP, and Tip are different finger parts.
表 6: 采样点分布。使用 SDF (Signed Distance Field) 作为全局引导进行点采样,可使中间查询点更接近 GT (Ground Truth) 姿态关节点。MCP、PIP、DIP 和 Tip 分别代表手指的不同部位。
Comparison of different intermediate representations.
不同中间表示方法的比较。
Here, to elucidate the role of the SDF, we build several baselines that use different intermediate representations while trying to keep the remaining model components (e.g., image backbones, feature dimensions, pose regressors, etc.) the same as in our model. We replace the 3D field learning module (Sec. 3.1) with 2D keypoint learning, 2D segmentation learning, and 3D mesh learning (see Supp. Mat. B.1). We found that utilizing intermediate 2D representations is much worse, and that 3D vertices are also significantly less powerful than SDFs (Table 5). Next, we provide further evidence for the effectiveness of using SDF as an intermediate representation by analyzing the sampled query points during inference.
为阐明SDF的作用,我们构建了多个基线模型,这些模型采用不同的中间表示形式,同时尽量保持其余组件(如图像主干网络、特征维度、姿态回归器等)与本模型一致。我们将3D场学习模块(第3.1节)替换为2D关键点学习、2D分割学习和3D网格学习(参见补充材料B.1节)。实验发现:使用2D中间表示的效果明显较差,而3D顶点表示的性能也显著低于SDF(表5)。接下来,我们通过分析推理过程中采样的查询点,进一步验证SDF作为中间表示的有效性。
Analysis of the sampled points. We argued that the SDF representation better captures global shape information across the capture volume (Figure 1). We analyze the point distributions of HOISDF’s hand query points sampled using our proposed point sampling strategy and the intermediate hand mesh vertices extracted by the initial stage of Wang et al. [49]. Indeed, our model samples closer points to the hand joints, particularly for the most challenging finger joints like the finger tips (Table 6).
对采样点的分析。我们认为SDF(Signed Distance Field)表示能更好地捕捉整个捕获空间内的全局形状信息(图1)。我们分析了HOISDF使用我们提出的点采样策略采样的手部查询点分布,以及Wang等人[49]初始阶段提取的中间手部网格顶点分布。实际上,我们的模型采样点更接近手部关节,尤其是最具挑战性的手指关节(如指尖)(表6)。
4.5. Ablations for the Field-Guided Pose Regression Module
4.5. 场引导位姿回归模块的消融实验
The field-guided pose regression module is the other key component to let HOISDF effectively leverage the SDF information. To verify that, we conduct ablations for different parts. Firstly, we showed that our field-guided sampling method is efficient and robust by comparing it with other sampling ways (Table 7). Secondly, we assessed the role of the point feature augmentation method by comparing it with different variations; altering various parts gracefully
场引导姿态回归模块是HOISDF有效利用SDF信息的另一关键组件。为验证这一点,我们对不同部分进行了消融实验。首先,通过与其他采样方式对比(表7),证明我们的场引导采样方法高效且鲁棒。其次,通过对比不同变体评估了点特征增强方法的作用:优雅地修改各个部件
Table 7. Comparison between different sampling strategies on DexYCB testset. Our field-informed point sampling can achieve the best performance. See Supp. Mat. B.3 for details on the alternative sampling strategies.
表 7: 不同采样策略在DexYCB测试集上的对比。我们提出的场感知点采样方法能取得最佳性能。关于替代采样策略的详细信息,请参阅补充材料B.3。
| 指标 [mm] | MJE | PAMJE | OCE | MCE | ADD-S |
|---|---|---|---|---|---|
| 随机采样 | 25.8 | 13.5 | 48.4 | 53.7 | 29.6 |
| 符号距离 | 13.3 | 6.58 | 19.7 | 30.7 | 15.9 |
| 场梯度 | 10.1 | 5.29 | 18.5 | 27.7 | 13.5 |
| 绝对距离 (本文方法) | 10.1 | 5.31 | 18.4 | 27.4 | 13.3 |
| 指标 [mm] | MJE | PAMJE | OCE | MCE | ADD-S |
|---|---|---|---|---|---|
| 无SDF增强 | 11.5 | 6.05 | 23.6 | 31.2 | 15.7 |
| 带密度拼接 | 11.0 | 5.71 | 22.7 | 30.5 | 15.3 |
| 带距离拼接 | 11.5 | 6.07 | 23.3 | 30.9 | 15.6 |
| 带SDF增强 | 10.8 | 5.68 | 22.2 | 30.0 | 15.1 |
Table 8. Effects of field-based point feature augmentation on the DexYCB test set. Our SDF feature augmentation best enhances features for the subsequent pose estimations. See Supp. Mat. B.3 for details on the alternative augmentations.
表 8: 基于场点特征增强在 DexYCB 测试集上的效果。我们的 SDF (Signed Distance Field) 特征增强能最优提升后续姿态估计的特征性能。详见补充材料 B.3 节对其他增强方式的说明。
Table 9. Effects of hand-object feature enhancement on the DexYCB testset. HOISDF’s cross feature enhancement gave the best results. See Supp. Mat. B.3 for details on the alternative feature computations.
表 9: 手部-物体特征增强在DexYCB测试集上的效果。HOISDF的跨特征增强取得了最佳结果。替代特征计算的详细信息请参见补充材料B.3。
| 指标 [mm] | MJE | PAMJE | OCE | MCE | ADD-S |
|---|---|---|---|---|---|
| 无跨特征增强 | 10.8 | 5.68 | 22.2 | 30.0 | 15.1 |
| 跨图像特征 | 11.1 | 5.74 | 20.2 | 28.6 | 14.2 |
| 跨目标特征 | 11.3 | 5.81 | 23.7 | 31.8 | 15.9 |
| 跨特征增强 (本文方法) | 10.1 | 5.31 | 18.4 | 27.4 | 13.3 |
Table 10. Robustness to different pose regressors on the DexYCB testset. Benefiting from the rich global-local context information inside the enhanced features, HOISDF can obtain great per- formance even with simple pose regression targets. See Supp. Mat. B.3 for details on the alternative regression targets.
表 10: DexYCB测试集上对不同位姿回归器的鲁棒性。得益于增强特征中丰富的全局-局部上下文信息,HOISDF即使使用简单的位姿回归目标也能获得出色性能。替代回归目标的详细信息参见补充材料B.3节。
| 指标 [mm] | MJE | PAMJE |
|---|---|---|
| 无中间关节回归 | 10.4 | 5.49 |
| 无MANO回归 | 10.5 | 5.65 |
| 带MANO形状&逆运动学 | 10.0 | 5.35 |
| MANO回归 (Ours) | 10.1 | 5.31 |
reduced the performance (Table 8). Next, the mutual handobject feature enhancement method proposed in Sec.3.2.3 is also proven to be effective by removing the cross attention or replacing with other non-augmented features (Table 9). Finally, we show that HOISDF is robust to changes in regression targets (Table 10) since our hand/object query points already capture enough global-local context with our field-guided module. Overall, these ablations validate our design choices.
降低了性能 (表 8)。其次,3.2.3节提出的手物互增强特征方法通过移除交叉注意力或替换为其他非增强特征也验证了有效性 (表 9)。最后,实验表明HOISDF对回归目标变化具有鲁棒性 (表 10),因为我们的手部/物体查询点已通过场引导模块捕获了足够的全局-局部上下文。总体而言,这些消融实验验证了我们的设计选择。
5. Conclusion
5. 结论
We proposed a novel 3D hand-object pose estimation algorithm that takes advantage of jointly learned signed distance fields. It achieves strong results and inference is fast (see Sup. Mat. C) We believe this paradigm could also be applied to other pose estimation problems, e.g., [2, 10, 15, 36, 42].
我们提出了一种新颖的3D手部-物体姿态估计算法,该算法利用了联合学习的符号距离场(Signed Distance Fields)技术。该方法取得了优异的结果且推理速度快(详见补充材料C)。我们认为该范式也可应用于其他姿态估计问题,例如 [2, 10, 15, 36, 42]。
Acknowledgments
致谢
The work was funded by EPFL and Microsoft Swiss Joint Research Center (H.Q., A.M.). H.Q. acknowledges support from a Boehringer Ingelheim Fonds PhD stipend. We are grateful to the members of the Mathis Group and in particular Niels Poulsen for comments on an earlier version of this manuscript. We also sincerely thank Rong Wang, Wei Mao and Hongdong Li for sharing the hand-object rendering pipeline [49].
该研究由EPFL和微软瑞士联合研究中心资助 (H.Q., A.M.)。H.Q.获得了勃林格殷格翰基金会博士奖学金的资助。我们感谢Mathis Group成员,特别是Niels Poulsen对本手稿早期版本的评论。我们也衷心感谢Rong Wang、Wei Mao和Hongdong Li分享了手-物体渲染管线 [49]。
Supplementary materials
补充材料
We first provide additional details on the architecture design of HOISDF with respect to the image feature extraction and hand pose regression. Then, we provide additional details for the ablation experiments. Finally, we conduct additional experiments to assess the effectiveness of HOISDF.
我们首先补充HOISDF在图像特征提取和手部姿态回归方面的架构设计细节。接着,补充说明消融实验的具体设置。最后,通过额外实验验证HOISDF的有效性。