A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers
基于研究论文的信息检索问答数据集
Abstract
摘要
Readers of academic research papers often read with the goal of answering specific questions. Question Answering systems that can answer those questions can make consumption of the content much more efficient. However, building such tools requires data that reflect the difficulty of the task arising from complex reasoning about claims made in multiple parts of a paper. In contrast, existing informationseeking question answering datasets usually contain questions about generic factoid-type information. We therefore present QASPER, a dataset of 5,049 questions over 1,585 Natural Language Processing papers. Each question is written by an NLP practitioner who read only the title and abstract of the corresponding paper, and the question seeks information present in the full text. The questions are then answered by a separate set of NLP practitioners who also provide supporting evidence to answers. We find that existing models that do well on other QA tasks do not per- form well on answering these questions, under performing humans by at least $27F_{1}$ points when answering them from entire papers, motivating further research in document-grounded, information-seeking QA, which our dataset is designed to facilitate.
学术论文的读者通常以回答特定问题为目标进行阅读。能够解答这些问题的问答系统可以大幅提升内容消化效率。然而构建此类工具需要能反映任务难度的数据,这种难度源于对论文多个部分主张的复杂推理。相比之下,现有信息检索型问答数据集通常只包含关于通用事实型信息的问题。为此我们推出QASPER数据集,包含针对1,585篇自然语言处理论文提出的5,049个问题。每个问题均由仅阅读过对应论文标题和摘要的NLP从业者撰写,且答案需从全文获取。随后由另一组NLP从业者回答问题并提供答案依据。研究发现,在其他QA任务表现优异的现有模型在此类问题上表现欠佳,从整篇论文回答时$27F_{1}$分低于人类水平,这推动了我们数据集旨在促进的文档 grounded 信息检索型QA领域的进一步研究。
1 Introduction
1 引言
Machines built to assist humans who engage with texts to seek information ought to be designed with an awareness of the information need. Abstractly, the human’s need should define the lens through which the system views the text in order to find desired information. Existing information-seeking machine reading datasets (e.g., Kwiatkowski et al., 2019; Clark et al., 2020) have led to significant progress in reading at scale (e.g., Asai et al., 2020; Guu et al., 2020; Liu et al., 2020). However, most of those benchmarks focus on an “open domain” setting where the questions are not anchored in any particular user context. The result is an emphasis on generic factoid questions, rather than the full range of information needs people have.
为辅助人类通过文本获取信息而设计的机器,应当以理解信息需求为核心进行构建。从抽象层面看,系统的文本处理视角应由用户需求定义,从而精准定位目标信息。现有信息检索型机器阅读数据集(如Kwiatkowski等人,2019;Clark等人,2020)已推动大规模阅读技术取得显著进展(如Asai等人,2020;Guu等人,2020;Liu等人,2020)。但多数基准测试聚焦"开放域"场景,其问题脱离具体用户语境,导致模型更侧重通用事实型问答,而非覆盖人类真实信息需求的完整光谱。

Figure 1: An example instance taken from QASPER. A question about the paper is written after reading only the title and the abstract. To arrive at the answer, one finds relevant evidence, which can be spread across multiple paragraphs. In this example, to answer the question about “baselines”, the reader must realize from evidence from Sections 3 and 4 that “context documents” come pre-ranked in the dataset and the paper’s “baselines” select from these “context documents.”
图 1: 取自QASPER的示例实例。仅阅读标题和摘要后撰写的论文相关问题。为得出答案,需寻找可能分散在多个段落中的相关证据。本例中,要回答关于"baselines"的问题,读者必须从第3节和第4节的证据中意识到"context documents"在数据集中已预先排序,而论文的"baselines"从这些"context documents"中进行选择。
We present QASPER,1 an information-seeking question answering (QA) dataset over academic research papers. Each question is written as a followup to the title and abstract of a particular paper, and the answer, if present, is identified in the rest of the paper, along with evidence required to arrive at it. This setup results in questions requiring more complex document-level reasoning than prior datasets, because $(i)$ abstracts provide rich prompts for questions that can be asked as follow-up and (ii) academic research papers naturally trigger questions by their target readers that require supporting or refuting claims. This evidence may be spread across the paper, including tables and figures, often resulting in complex entailment problems. The example in Figure 1 illustrates one such case where we need to retrieve information from paragraphs in three different sections to answer the question.
我们提出了QASPER[1],这是一个面向学术研究论文的信息检索式问答(QA)数据集。每个问题都是针对特定论文标题和摘要的后续提问,答案(如果存在)则需从论文正文中定位,并附带得出该答案所需的证据。这种设置使得问题需要比现有数据集更复杂的文档级推理能力,因为:(i) 摘要为可提出的后续问题提供了丰富提示;(ii) 学术论文会自然地引发目标读者需要证实或反驳观点的问题。这些证据可能分散在全文各处(包括表格和图表),往往形成复杂的蕴涵问题。图1中的示例展示了这种情况:我们需要从三个不同章节的段落中检索信息来回答问题。
QASPER contains 5,049 questions over 1,585 natural language processing (NLP) papers, asked by regular readers of NLP papers, and answered by a separate set of NLP practitioners. Each paper has an average of 3.2 questions, up to a maximum of 12 questions for a single paper. In addition to providing answers when the questions are answerable, the annotators were asked to select text, tables, or figures as evidence required for answering the questions. $55.5%$ of the questions require evidence from multiple paragraphs in the paper and $13%$ require tables or figures. To the best of our knowledge, QASPER is the first QA dataset in the academic research domain focusing on entire papers, and not just abstracts.
QASPER包含5,049个关于1,585篇自然语言处理(NLP)论文的问题,这些问题由NLP论文的普通读者提出,并由另一组NLP从业者回答。每篇论文平均有3.2个问题,单篇论文最多有12个问题。除了在问题可回答时提供答案外,标注者还被要求选择文本、表格或图表作为回答问题所需的证据。55.5%的问题需要从论文的多个段落中寻找证据,13%的问题需要表格或图表。据我们所知,QASPER是学术研究领域首个关注整篇论文而不仅仅是摘要的问答数据集。
To quantify the difficulty of the tasks in QASPER, we apply state-of-the-art document-level Transformer (Vaswani et al., 2017) models to the tasks of selecting evidence and generating answers, and show that the best model performance lags behind humans by $27~F_{1}$ points at answering questions from entire papers, and 32 $F_{1}$ points at selecting the paragraphs that provide evidence to answer the questions, indicating that these are both unsolved problems. Additionally, we experiment with oracles that answer questions from gold evidence and find that better pre training and domain-adaptation might be helpful.
为了量化QASPER中任务的难度,我们采用最先进的文档级Transformer (Vaswani et al., 2017)模型进行证据选择和答案生成任务。结果显示,在整篇论文问答任务上,最佳模型性能落后人类27 $F_{1}$ 分;在选取问题证据段落的环节上,差距达32 $F_{1}$ 分,这表明这两个问题尚未得到解决。此外,我们通过黄金证据问答实验发现,更好的预训练和领域适应可能带来提升。
2 Building the QASPER Dataset
2 构建QASPER数据集
We now describe our process for constructing the dataset. We began with a set of open-access NLP papers, recruited NLP practitioners who are regular readers of research papers, and designed two different data collection interfaces: one for collecting follow-up questions given titles and abstracts, and another for obtaining evidence and answers to those questions.
我们现在描述构建数据集的过程。首先选取一组开放获取的NLP论文,招募了经常阅读研究论文的NLP从业者,并设计了两种不同的数据收集界面:一种用于根据标题和摘要收集后续问题,另一种用于获取这些问题的证据和答案。
2.1 Papers
2.1 论文
We filtered S2ORC (Lo et al., 2020),2 a collection of machine-readable full text for open-access papers, to $(i)$ those from arXiv with an associated LaTeX source file,3 and $(i i)$ are in the computa- tional linguistics domain.4 We limited our domain to computational linguistics to ensure high quality as we have access to realistic users through our research network; broader domain collection is left to future work and should be enabled by the proof-of-concept of our protocols given in this paper. We used the S2ORC parser (which normalizes multi-file LaTeX sources and resolves comments and macros) to convert LaTeX markup to full text while preserving section and paragraph breaks and math equations. We supplemented the paper text with extracted images of figures and tables associated with their captions; these were crawled from Semantic Scholar.5 The result of this process was a collection of 18K full text papers for annotation.
我们筛选了S2ORC (Lo et al., 2020) —— 一个机器可读的开放获取论文全文数据集,具体条件为:$(i)$ 来自arXiv且附带LaTeX源文件的论文,以及$(ii)$ 属于计算语言学领域的论文。我们将领域限定为计算语言学,以便通过研究网络接触真实用户来确保数据质量;更广泛领域的收集工作留待未来完成,并应通过本文提出的协议验证其可行性。使用S2ORC解析器(可规范化多文件LaTeX源码并处理注释与宏命令)将LaTeX标记转换为完整文本,同时保留章节段落划分和数学公式。我们还从Semantic Scholar爬取了论文中的图表及其标题作为补充。最终获得18,000篇待标注的全文论文集合。
2.2 Decoupled Data Collection
2.2 解耦数据收集
To ensure that our questions are realistic, we decoupled the question-writing and question-answering phases. For both tasks we recruited graduate students studying NLP and freelancers practicing NLP through professional networks and Upwork6. All the workers were regular readers of NLP papers, and were paid $\mathrm{US}\$25$ per hour on average ( $\mathbb{S}20–\mathbb{S}40$ based on experience). We paid them on a per-hour basis and not a per-question basis to prioritize data quality over quantity. A total of 25 workers wrote questions while 51 answered them.
为确保问题设置的真实性,我们将问题编写与回答环节分离。两项任务均通过专业社交平台和Upwork招募了自然语言处理(NLP)方向的研究生及从业自由职业者。所有参与者均为NLP论文的常规读者,平均时薪为25美元(根据资历浮动于20-40美元区间)。采用计时付费而非计件付费机制,以确保数据质量优先于数量。最终25名工作者负责问题编写,51名工作者参与问题回答。
Questions To ensure that annotators were actually interested in the paper they are reading, we provided them with a lightweight search interface to search papers from the aforementioned collection to focus on their papers of interest. The interface supports entering manual queries and examples of the queries annotators used include general (e.g., “computer vision”) or specific (e.g., “question answering”, “information extraction”) areas of study, specific tasks (e.g., “language identification”), entities (e.g., “bert”, “transformers”) or concepts (e.g., “commonsense”, “interpret ability”), or domain specifications (e.g., “medical”, “wikipedia”). Annotators also had the option to not enter any search queries; in this case, they were shown random papers. Annotators were displayed only the title and abstracts of relevant papers and asked to write any number of questions they had about the paper. Annotators were instructed to only write questions that are not answerable from the title and abstract but expected to be answered somewhere in the paper. Annotators also provided basic information about their expertise in NLP and how familiar they already were with the paper for which they asked questions. Most workers (about $70%$ ) had some experience in NLP, with $20%$ having more than five years of experience. A vast majority $(94%)$ of the abstracts were seen by the questionwriters for the first time.
问题
为确保标注者真正对他们正在阅读的论文感兴趣,我们提供了一个轻量级搜索界面,让他们能够从上述论文集中搜索自己感兴趣的论文。该界面支持手动输入查询,标注者使用的查询示例包括研究领域(如“计算机视觉”)、具体方向(如“问答”“信息抽取”)、特定任务(如“语言识别”)、实体(如“BERT”“Transformer”)或概念(如“常识”“可解释性”),以及领域限定(如“医学”“维基百科”)。标注者也可以选择不输入任何查询,此时系统会随机展示论文。界面仅显示相关论文的标题和摘要,并要求标注者提出关于论文的任何问题。标注者被要求只提出无法通过标题和摘要回答、但预期能在论文中找到答案的问题。此外,标注者还需提供他们在NLP领域的专业背景信息,以及对所提问论文的熟悉程度。大多数标注者(约70%)具备NLP相关经验,其中20%拥有超过五年经验。绝大多数(94%)摘要对提问者而言是首次阅读。
Answers Annotators were randomly assigned papers with all the corresponding questions written for that paper. They were shown the paper title, abstract, question, full text, and all associated figures and tables to answer the questions. After reading these, annotators were were asked to:
答案标注者被随机分配论文,并需回答针对该论文撰写的所有对应问题。他们可查看论文标题、摘要、问题、全文及所有相关图表来回答问题。阅读完毕后,标注者需完成以下步骤:
• Make a binary decision as to whether the question is answerable given the paper.
• 根据论文内容对问题是否可回答做出二元判断。
• If the question is answerable, select the minimal set of evidence snippets that contains the answer to the question. This could be (possibly d is contiguous) paragraphs from the text and/or figures or tables. Annotators were asked to prioritize text over figures and tables, unless the information required was present only in figures or tables. When multiple paragraphs could serve as evidence, annotators were asked to first prioritize evidence that adequately answered the question, and then paragraphs that occurred earlier in the text.
• 如果问题可回答,选择包含答案的最小证据片段集。这些可能是文本中的(可能不连续的)段落和/或图表。标注人员被要求优先选择文本而非图表,除非所需信息仅存在于图表中。当多个段落可作为证据时,标注人员需首先选择能充分回答问题的段落,其次优先选择文中出现较早的段落。
• If the question is answerable, also provide a concise answer to the question. Annotators were also asked to also indicate whether their concise answer was $(i)$ extracted from the evidence, (ii) “yes” or “no”, or (iii) abstract iv ely written.
• 如果问题可回答,还需提供一个简洁的答案。标注者还需指明其简洁答案属于:(i) 从证据中提取的,(ii) "是"或"否",或(iii) 抽象概括的。
Annotators were allowed to skip any questions they did not feel comfortable answering. Since the answering task is significantly more complex than the question-writing task, we designed interactive tutorials and qualification exams for the workers for this task using CrowdAQ (Ning et al., 2020). Workers who scored well were invited to work on the task. If the test performance indicated that the workers did not have sufficient NLP knowledge, or were not used to reading papers we did not let them work on the task. In cases where the workers misunderstood the task, but had sufficient background knowledge, we provided additional training before letting them work on the task.
标注者可以跳过任何他们不愿回答的问题。由于回答任务比提问任务复杂得多,我们使用CrowdAQ (Ning et al., 2020) 为工作人员设计了交互式教程和资格测试。表现优异的工作人员会被邀请参与任务。若测试结果显示工作人员缺乏足够的自然语言处理 (NLP) 知识或不习惯阅读论文,则不允许其参与任务。对于误解任务但具备足够背景知识的工作人员,我们会提供额外培训后再允许其参与。
3 QASPER Analysis
3 QASPER分析
Table 1 provides representative examples from QASPER categorized by question, answer, and evidence types, which we describe here in greater detail.
表 1: 按问题、答案和证据类型分类的 QASPER 代表性示例,我们将在此进行更详细的说明。
Question types We first analyze whether our annotation setup results in questions that are anchored in the context of the papers. To answer this question, we manually7 categorized a set of 200 ques- tions as being applicable to most papers in the domain (general) vs. being applicable only to the paper that the question is written about (specific). Table 1 shows that most of the questions $(67%)$ are specific to the papers they are written about. This result indicates the advantage of viewing the QASPER task as a question answering problem, instead of an information extraction problem since a fixed schema would not be able to handle the long tail of paper-specific information needs.
问题类型
我们首先分析我们的标注设置是否会产生基于论文上下文的问题。为了回答这个问题,我们手动将200个问题分类为适用于该领域大多数论文的通用问题,或仅适用于问题所针对的论文的特定问题。表1显示,大多数问题$(67%)$是针对其所写论文的特定问题。这一结果表明,将QASPER任务视为问答问题而非信息抽取问题的优势,因为固定模式无法处理针对论文特定信息需求的长尾情况。
Answer types As shown in Table 1, most of the answers in the dataset are extractive. The average length of the extractive answers is 14.4 words (including all spans), and that of abstract ive spans is 15.6 words.
回答类型
如表 1 所示,数据集中大部分答案属于抽取式 (extractive)。抽取式答案的平均长度为 14.4 词 (包含所有片段),抽象式 (abstractive) 片段的平均长度为 15.6 词。
Evidence types Evidence can include one or more paragraphs from the paper, a figure, or a table, or a combination of these. Table 1 shows the distribution of these types. Among the answerable questions with text-only evidence, $55.5%$ of the answers have multi-paragraph evidence (Figure 1 is one example). Unanswerable questions do not have any evidence. Among the answerable ones, $(3.0%)$ have no evidence when the answer is $N o$ , and the evidence is the lack of a mention of something specific. The last question in Table 4 is one example of such a case.
证据类型
证据可以包含论文中的一个或多个段落、一张图、一张表或这些的组合。表 1 展示了这些类型的分布情况。在仅含文本证据的可回答问题中,$55.5%$ 的答案具有多段落证据 (图 1 是一个例子)。不可回答的问题没有任何证据。在可回答的问题中,$(3.0%)$ 当答案为 $No$ 时没有证据,此时证据是对特定内容缺乏提及。表 4 的最后一个问题就是这种情况的一个例子。
Distribution of evidence paragraphs We perform an analysis to identify the main sections of a paper that contain textual evidence. We assign each evidence paragraph to its containing top-level8 section, and perform some section name normalization. We find that among the frequently used section names such as “Experiments” and “Introduction,” there was not a single section name that contained a majority of evidence spans, indicating that the distribution of evidence over section in the paper was more or less uniform.
证据段落的分布
我们通过分析来确定论文中包含文本证据的主要部分。将每个证据段落归类到其所属的顶级8章节,并对部分章节名称进行标准化处理。研究发现,在"实验"和"引言"等常用章节名称中,没有任何一个章节包含多数证据片段,这表明证据在论文各章节的分布大体上是均匀的。
Table 1: Examples of questions (top), answers (middle), and evidence (bottom) sampled from QASPER. $%$ are relative frequencies of the corresponding type over all examples in QASPER. The percentages for evidence types sum over $100%$ due to double-counting of 446 answers with both Table/Figure and Text evidence.
表 1: QASPER 中采样的问题(顶部)、答案(中部)和证据(底部)示例。百分比表示该类型在 QASPER 所有示例中的相对频率。由于 446 个答案同时包含表格/图和文本证据,证据类型的百分比总和超过 100%。
| 问题 | 类型 | % | 论文 |
|---|---|---|---|
| 他们使用了哪些数据集?数据库中还包含哪些其他政治事件? | 通用 特定 | 33.3% 66.7% | 1;2;3 1706.01875 |
| 问题 答案 | 类型 | % | 论文 |
| 分析了哪五个对话属性?他们使用哪种神经网络架构作为注意力冲突机制的基础? | 抽取式 | 51.8% | 1705.00571 |
| 模型;置信度;连续性;查询相关性;重复性;特异性 基于 GRU 的编码器、交互块和由堆叠全连接层组成的分类器 | 抽象式 | 24.2% | 1906.08593 |
| 他们是否确保添加匈牙利层后架构在所有地方都可微?字幕使用什么语言? | 是/否 | 13.9% | 1712.02555 |
| 不适用 | 无法回答 | 10.2% | 1909.09070 |
| 问题 他们使用哪些新任务来展示共享元知识的迁移能力? | 证据 为了测试我们学习的 Meta-LSTM 的可迁移性,我们还设计了一个实验,其中我们轮流选择 15 个任务来训练我们的多任务学习模型,然后将学习到的 Meta-LSTM 迁移到 | 类型 文本 | % 81.6% |
| 根据基准框架微调某些模型的最低成本是多少? | 剩余的一个任务。迁移的 Meta-LSTM 的参数,即公式 (33) 中的 0,是固定的,不能在新任务上更新。表 1 | 表格/图 11.6% | |
| 他们建议将前提和假设一起翻译吗? | 不适用 | 无 | 12.8% |
Inter-annotator agreement $44%$ of the questions in QASPER have multiple annotated answers. On average, each question is answered by 1.6 annotators (up to a maximum of 6 annotators for the same question). Using these multiple annotations, we compute some measures of agreement between annotators. First, we found that there is a high level of agreement $(90%)$ regarding answerability of questions. Second, we find that annotators agreed on the type of the evidence (text vs. figure) in $84.0%$ of the cases. Papers often provide the same information both in tables and text, and agreement over the evidence types could be a consequence of our clear annotation guidelines regarding
标注者间一致性
QASPER中44%的问题有多个标注答案。平均每个问题由1.6位标注者回答(同一问题最多有6位标注者)。利用这些多重标注,我们计算了标注者间的一致性指标。首先,我们发现关于问题可答性的一致性水平很高(90%)。其次,标注者在84.0%的情况下对证据类型(文本 vs. 图表)达成一致。论文常在表格和文本中提供相同信息,这种证据类型的一致性可能源于我们明确的标注指南
selecting evidence.
选择证据。
Correctness To estimate the correctness of the answer annotations in QASPER, we manually analyzed 100 randomly sampled questions with multiple answer annotations (averaging 2.73 answers per question). We found that 207 $(75.8%)$ of the answers were correct. $98%$ of the questions had at least one correct answer, and $77%$ had most of the answers correct.
正确性 为了评估QASPER中答案标注的正确性,我们手动分析了100个随机抽样的多答案标注问题(平均每个问题有2.73个答案)。我们发现207个(75.8%)答案是正确的。98%的问题至少有一个正确答案,77%的问题大部分答案是正确的。
4 Modeling QASPER
4 QASPER建模
This section explains the task, evaluation metrics, and a model addressing QASPER tasks.
本节阐述任务内容、评估指标以及解决QASPER任务的模型。
4.1 Task Setup
4.1 任务设置
We formally define the QASPER tasks as follows: Given a paper, and a question about it, the primary task is to determine if the question is answerable, and output a predicted answer, that is one or more spans in the full-text of the paper, yes, no or other free-form text. A system built for this will be evaluated based on the correctness of the predicted answer measured against the reference answers. Since QASPER also provides labeled evidence for all questions, the system may also use auxiliary supervision provided by the evidence.
我们正式定义 QASPER 任务如下:给定一篇论文和与之相关的问题,主要任务是确定该问题是否可回答,并输出预测答案,即论文全文中的一个或多个片段、是/否或其他自由文本。针对此任务构建的系统将根据预测答案与参考答案的正确性进行评估。由于 QASPER 还为所有问题提供了标注证据,系统也可以利用证据提供的辅助监督信息。
One such auxiliary task is to predict the evidence required for the question. The inputs are the same as that of the primary task, but the outputs are expected to be one or more paragraphs in the fulltext, figures, or tables, and they will be evaluated against labeled evidence spans.
其中一个辅助任务是预测问题所需的证据。输入与主任务相同,但输出预期为全文中的一个或多个段落、图表或表格,并将根据标注的证据范围进行评估。
Evaluation metrics As an automatic proxy for the measure of correctness of all types of answers, we use the span-level $F_{1}$ measure proposed by Rajpurkar et al. (2016). We convert answers that are multiple selected spans into single commaseparated strings. For questions with multiple reference answers, we compute the max span $F_{1}$ of the predictions over all the references. We evaluate the performance of a system over the auxiliary task by computing a $F_{1}$ score over the set of paragraphs, figures, and tables chosen by the system against the reference evidence, considering a max when there are multiple references. We refer to these metrics as Answer $F_{1}$ and Evidence $F_{1}$ , respectively.
评估指标
作为对所有类型答案正确性衡量的自动代理,我们采用 Rajpurkar 等人 (2016) 提出的 span-level $F_{1}$ 度量。我们将多选 span 的答案转换为逗号分隔的单一字符串。对于具有多个参考答案的问题,我们计算预测结果在所有参考上的最大 span $F_{1}$。我们通过计算系统所选段落、图 (figure) 和表 (table) 与参考证据之间的 $F_{1}$ 分数来评估系统在辅助任务上的表现,当存在多个参考时取最大值。我们将这些指标分别称为答案 $F_{1}$ (Answer $F_{1}$) 和证据 $F_{1}$ (Evidence $F_{1}$)。
Data splits We split the dataset into train, validation, and test sets, so that each paper appears in only one of them. Our analysis of correctness of annotations presented in Section 3 indicates a high likelihood $(98%)$ of evaluating against a correct reference when evaluation is aggregated over multiple references. Hence we ensure that most of the questions in validation and test sets have multiple references $98%$ in test, and $74%$ in validation). This resulted in 2,593, 1,005, and 1,451 questions in the three sets, respectively.
数据划分
我们将数据集划分为训练集、验证集和测试集,确保每篇论文仅出现在其中一个集合中。第3节对标注正确性的分析表明,当评估基于多个参考时,正确参考的评估概率较高(98%)。因此我们确保验证集和测试集中大多数问题具有多个参考(测试集98%,验证集74%)。最终三个集合分别包含2,593、1,005和1,451个问题。
Estimating human performance To estimate an upper bound on model performance given our data splits and metrics, we assess the performance of the workers when evaluated against each other using the same metrics on a sample of the test set. Since model performance is evaluated by aggregating over multiple references, we consider a subset of the test set containing questions with at least three references ( $40%$ of the test set), evaluate each reference against the remaining, and compute an average over all such combinations. This procedure estimates the human performance to be 60.9 Answer $\cdot F_{1}$ , and 71.6 Evidence $\cdot F_{1}$ . Note that given the disagreements among the workers estimated in Section 3, this is a lower bound on human performance for two reasons: first, because only two annotations are used to compute the metric, while systems are evaluated against all three; and second, because the annotators are NLP practitioners, not expert researchers, and it is likely that an expert would score higher. Hence we report these numbers, along with a breakdown over answer types in Table 2 and Table 3 as human performance lower bounds.
估计人类表现
为了在给定数据划分和指标的情况下估计模型性能的上限,我们通过让工作人员在测试集样本上使用相同指标相互评估来衡量其表现。由于模型性能是通过聚合多个参考结果来评估的,我们选取测试集中至少包含三个参考的问题子集(占测试集的40%),将每个参考与其他参考进行对比评估,并计算所有此类组合的平均值。该流程测得的人类表现为60.9(答案$\cdot F_{1}$)和71.6(证据$\cdot F_{1}$)。需要注意的是,根据第3节估计的工作人员间分歧情况,这是人类表现的下界,原因有二:首先,计算指标时仅使用两个标注,而系统评估会对照全部三个标注;其次,标注者为自然语言处理从业者而非专家研究员,专家很可能获得更高分数。因此我们将这些数值(连同表2和表3中按答案类型细分的表现)报告为人类表现下界。
4.2 QASPER Model
4.2 QASPER 模型
We base our model on pretrained Transformer (Vaswani et al., 2017) models which currently produce state-of-the-art results on a majority of QA tasks.9 Recall that QASPER introduces two main modeling challenges – different answer types and long input documents.
我们的模型基于预训练的Transformer (Vaswani等人,2017) ,该模型目前在大多数问答任务中都能取得最先进的结果。需要注意的是,QASPER带来了两大建模挑战——不同的答案类型和长输入文档。
First, QASPER includes a variety of answer types, including extractive, abstract ive, yes/no, and unanswerable questions, which means a typical spanselection BERT-based QA model (Devlin et al., 2019) is not sufficient to support all these answer types. We address this by converting all answer types into a single task: generating answer text (Raffel et al., 2020; Khashabi et al., 2020).10 This is a sequence-to-sequence formulation that requires an encoder-decoder Transformer model where the encoder reads the question and the document and the decoder generates the answer text.
首先,QASPER 包含多种答案类型,包括抽取式、摘要式、是非题和无法回答的问题,这意味着典型的基于 BERT 的跨度选择问答模型 (Devlin et al., 2019) 不足以支持所有这些答案类型。我们通过将所有答案类型转换为单一任务来解决这个问题:生成答案文本 (Raffel et al., 2020; Khashabi et al., 2020)。这是一种序列到序列的表述,需要一个编码器-解码器 Transformer 模型,其中编码器读取问题和文档,解码器生成答案文本。
Second, research papers are much longer than the typical 512 or 1024 token limit of most BERTlike models, so we need a Transformer model that can process long inputs. We use the LongformerEncoder-Decoder (LED; Beltagy et al., 2020), an encoder-decoder Transformer model that can efficiently process input sequences thousands of tokens long. With LED’s support for input sequence length of 16K tokens, we can encode $99%$ of the paper full texts in the QASPER dataset without truncation.
其次,研究论文的长度远超大多数类BERT模型的512或1024 token限制,因此我们需要能处理长输入的Transformer模型。我们采用LongformerEncoder-Decoder (LED; Beltagy等人,2020)——一种可高效处理数千token长输入序列的编码器-解码器Transformer模型。借助LED对16K token输入序列长度的支持,我们能在不截断的情况下编码QASPER数据集中99%的论文全文。
Longformer-Encoder-Decoder (LED) LED (Beltagy et al., 2020) is a variant of the original Transformer encoder-decoder model that replaces the Transformer’s full self-attention in the encoder with the efficient local+global attention pattern of Longformer. This allows each token to attend to only its local window and a pre-specified set of global locations of interest, thereby scaling self-attention computation linearly with the input size (as opposed to quadratically with full context self-attention). LED has a similar architecture to BART (Lewis et al., 2020) in terms of number of layers and hidden state sizes, with the distinction that it has a larger position embeddings matrix, allowing it to process inputs of up to 16K tokens long (up from 1K tokens in the original BART model). In practice, LED’s parameters are initialized from a pretrained BART model, and LED copies BART’s position embeddings 16 times to fill the entire 16K position embeddings matrix. For all experiments we use the LED-base sized model, which uses BART-base weights.
Longformer-Encoder-Decoder (LED)
LED (Beltagy等人,2020) 是原始Transformer编码器-解码器模型的变体,它将编码器中的完整自注意力机制替换为Longformer高效的局部+全局注意力模式。这使得每个Token仅关注其局部窗口和预定义的全局关键位置,从而将自注意力计算复杂度降至与输入规模线性相关(而非完整上下文自注意力所需的平方级)。LED在层数和隐藏状态维度上与BART (Lewis等人,2020) 架构相似,区别在于其位置嵌入矩阵更大,可处理长达16K Token的输入(原BART模型仅支持1K Token)。实际应用中,LED参数从预训练的BART模型初始化,并通过16次复制BART位置嵌入来构建完整的16K位置嵌入矩阵。所有实验均采用基于BART-base权重的LED-base规模模型。
Input and Output Encoding For the input, we follow the Longformer QA models (Beltagy et al., 2020) and encode the question and context in one concatenated string with “global attention” over all the question tokens. For the output, all answer types are encoded as single strings. The string is the text of the abstract ive answer, a comma separated concatenation of the extractive spans, “Yes”, “No”, or “Unanswerable”.
输入与输出编码
对于输入部分,我们遵循Longformer QA模型 (Beltagy et al., 2020) 的做法,将问题和上下文编码为一个拼接字符串,并对所有问题token启用"全局注意力"。输出部分将所有答案类型编码为单个字符串:该字符串可以是摘要式答案文本、抽取式片段逗号分隔拼接结果、"Yes"、"No"或"Unanswerable"。
Evidence extraction To support extracting evidence paragraphs, we prepend each paragraph with a $</\operatorname{S}>$ token and add a classification head over these tokens on LED’s encoder side. We also add Longformer’s global attention over these tokens to facilitate direct information flow across the paragraphs. We then train LED using both loss functions (teacher-forced text generation and paragraph classification) in a multi-task training setup. For the answer generation, we use a cross-entropy loss function over the vocabulary. For the evidence paragraph extraction, we use a cross-entropy loss function with binary 0 or 1 gold labels for evidence/non- evidence paragraph. To account for class imbalance, we use loss scaling with weights proportional to the ratio of positive to negative gold paragraphs in the batch, which we found to be crucial for the model to train. One benefit of multi-task training of evidence extraction along with answer selection is that tasks can benefit each other (see Section 5.2).
证据提取
为支持提取证据段落,我们在每个段落前添加一个 $</\operatorname{S}>$ token,并在LED编码器端为这些token添加分类头。我们还为这些token添加了Longformer的全局注意力机制,以促进跨段落的直接信息流动。随后,我们在多任务训练设置中使用两种损失函数(教师强制文本生成和段落分类)来训练LED。对于答案生成,我们在词汇表上使用交叉熵损失函数。对于证据段落提取,我们使用带有二元0或1黄金标签(证据/非证据段落)的交叉熵损失函数。为解决类别不平衡问题,我们采用按批次中正负黄金段落比例加权的损失缩放方法,发现这对模型训练至关重要。证据提取与答案选择的多任务训练的一个优势是任务可以相互促进(见第5.2节)。
5 Experiments
5 实验
We evaluate model performance on question answering and evidence selection tasks, and compare them to estimated lower bounds on human performance. These human performance estimates are calculated by comparing the answers of questions for which we have multiple human annotations. For each question, we choose one annotation as if it were a prediction, and evaluate it against the rest of the annotations, and consider as human performance the average over all annotations chosen as predictions. We restrict our experiments to the subset of questions in QASPER that can be answered from text in the paper, ignoring those that require figures or tables as evidence ( $13%$ of the dataset; see Section 3) to avoid having to deal with multimodal inputs. We leave multimodal question answering to future work.
我们在问答和证据选择任务上评估模型性能,并将其与人类表现的估计下限进行比较。这些人类表现估计值是通过对比我们拥有多份人工标注的问题答案计算得出的。对于每个问题,我们选择一份标注视为预测结果,将其与其他标注进行比对,并将所有被选为预测的标注平均值视为人类表现。我们将实验限制在QASPER数据集中仅需论文文本即可回答的问题子集(占数据集的13%,参见第3节),排除了需要图表作为证据的问题,以避免处理多模态输入。多模态问答任务将留待未来研究。
5.1 Training Details
5.1 训练细节
We train all models using the Adam optimizer (Kingma and Ba, 2014) and a triangular learning rate scheduler (Howard and Ruder, 2018) with $10%$ warmup. To determine number of epochs, peak learning rate, and batch size, we performed manual hyper parameter search on a subset of the training data. We searched over {1, 3, 5} epochs with learning rates ${1e^{-5},3e^{-5},5e^{-5},9e^{-5}}$ , and found that smaller batch sizes generally work better than larger ones. Our final configuration was 10 epochs, peak learning rate of $5e^{-5}$ , and batch size of 2, which we used for all reported experimental settings. When handling full text, we use gradient check pointing (Chen et al., 2016) to reduce memory consumption. We run our experiments on a single RTX 8000 GPU, and each experiment takes 30–60 minutes per epoch.
我们使用Adam优化器 (Kingma and Ba, 2014) 和三角学习率调度器 (Howard and Ruder, 2018) 训练所有模型,其中预热阶段占比10%。为确定训练周期数、峰值学习率和批量大小,我们在训练数据子集上进行了手动超参数搜索。搜索范围包括{1, 3, 5}个周期,学习率从${1e^{-5},3e^{-5},5e^{-5},9e^{-5}}$中选取,发现较小批量通常优于大批量。最终配置为10个周期、$5e^{-5}$峰值学习率和批量大小2,该配置用于所有报告的实验设置。处理全文时,我们采用梯度检查点技术 (Chen et al., 2016) 降低内存消耗。实验在单块RTX 8000 GPU上运行,每个周期耗时30-60分钟。
5.2 Results
5.2 结果
Question answering Table 2 shows the overall performance of the LED-base model11 on question answering, as well as the performance breakdown on the different answer types. The table also compares LED-base variants when the input is heuristically limited to smaller parts of the paper (i.e., no context, abstract, introduction). We generally observe that, by using more context, the performance improves. Specifically, as we observe in row 5 encoding the entire context results in significant overall performance improvement ( $\Delta=+9.5)$ over the best heuristic (“introduction”). This signifies the importance of encoding the entire paper. Comparing rows 4 and 5, we observe that using the evidence prediction as a multi-task scaffolding objective helps, improving the results by $\Delta=+0.8$ points.
问题回答
表 2: 展示了基于 LED 的模型11在问题回答上的整体表现,以及不同答案类型的性能细分。该表还比较了当输入被启发式限制在论文较小部分(即无上下文、摘要、引言)时 LED-base 的变体表现。我们普遍观察到,通过使用更多上下文,性能会有所提升。具体而言,如第 5 行所示,编码整个上下文相比最佳启发式方法(“引言”)带来了显著的总体性能提升($\Delta=+9.5$),这凸显了编码整篇论文的重要性。比较第 4 行和第 5 行,我们发现将证据预测作为多任务支架目标有助于提升结果,提高了 $\Delta=+0.8$ 分。
Table 2: LED-base and lower-bound human performance on answering questions in QASPER, measured in Answer $F_{!}$ . The top three rows are heuristic baselines that try to predict answers without encoding entire papers. w/ scaff. refers to the inclusion of the evidence selection scaffold during training.
表 2: LED-base 和人类在 QASPER 上回答问题的下限性能,以 Answer $F_{!}$ 衡量。前三行是启发式基线,试图在不编码整篇论文的情况下预测答案。w/ scaff. 指训练时包含证据选择支架。
| 输入 | 抽取式 | 生成式 | 是/否 | 不可回答 | 总体 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 开发集 | 测试集 | 开发集 | 测试集 | 开发集 | 测试集 | 开发集 | 测试集 | 开发集 | 测试集 | |
| 仅问题 | 4.60 | 5.91 | 6.06 | 7.38 | 69.05 | 66.36 | 58.43 | 66.67 | 17.81 | 22.48 |
| 问题+摘要 | 6.69 | 7.97 | 7.50 | 8.25 | 69.05 | 63.43 | 51.14 | 62.50 | 18.60 | 22.30 |
| 问题+引言 | 4.40 | 6.60 | 2.52 | 3.16 | 65.87 | 67.28 | 71.00 | 78.07 | 18.30 | 24.08 |
| 问题+全文 | 26.07 | 30.96 | 16.59 | 15.76 | 67.48 | 70.33 | 28.57 | 26.21 | 29.05 | 32.80 |
| 问题+全文(w/ scaff.) | 24.62 | 29.97 | 13.86 | 15.02 | 63.64 | 68.90 | 38.89 | 44.97 | 28.01 | 33.63 |
| 人类(下限) | 58.92 | 39.71 | 78.98 | 69.44 | 60.92 |
Evidence selection Table 3 illustrates the evidence selection performance of the LED-large and LED-base models compared with simpler baselines. We observe that LED variants outperform the simple TF-IDF baseline but there still remains a large gap to human performance.
证据选择
表 3: 展示了 LED-large 和 LED-base 模型与简单基线相比的证据选择性能。我们观察到 LED 变体优于简单的 TF-IDF 基线,但与人类表现仍存在较大差距。
Varying amounts of training Figure 2 shows the learning curve that measures the validation Answer- $\cdot F_{1}$ and Evidence- $F_{1}$ of the LED-base vari- ants based on training data size. The learning curve suggests that performance has not reached a plateau, and future data collection could be useful.
不同训练量的效果
图 2: 展示了基于训练数据规模的 LED-base 变体在验证集上的 Answer-$\cdot F_{1}$ 和 Evidence-$F_{1}$ 学习曲线。该曲线表明模型性能尚未达到稳定阶段,未来数据收集可能仍有提升空间。
Answer prediction from gold evidence To better isolate the question answering (as opposed to evidence selection) task performance, we perform oracle experiments where models are given the gold evidence. For these experiments, we are able to use larger (T5-large; Raffel et al., 2020) or better task-adapted pretrained models (UnifiedQA-large; Khashabi et al., 2020), which perform significantly better in the oracle setting. We did not use them in the non-oracle setting, however, as Longformer versions of these models are not available, and LED’s ability to handle the full document without the need for a pipelined retrieval system was more important. These experiments show that (1) the human lower bound is in fact a lower bound, as large models exceed it for span answers in this setting; (2) the majority of the large headroom in the non-oracle setting can be closed with better evidence selection; and (3) research into making large pretrained models able to better scale to long documents would be beneficial.
基于黄金证据的答案预测
为了更好地区分问答任务(而非证据选择任务)的性能表现,我们进行了理想实验,为模型提供黄金证据。在这些实验中,我们能够使用更大规模的模型(T5-large;Raffel等人,2020)或更适合任务的预训练模型(UnifiedQA-large;Khashabi等人,2020),这些模型在理想设定下表现显著更优。但未在非理想设定中使用它们,因为这些模型的Longformer版本不可用,且LED无需流水线检索系统即可处理完整文档的能力更为重要。实验表明:(1) 人类表现下限确实是下限,因为在此设定下大模型在片段答案上超越了该界限;(2) 非理想设定中的大部分性能差距可通过改进证据选择来缩小;(3) 研究如何使大型预训练模型更好地适应长文档将大有裨益。
Table 3: Model and lower-bound human performance on selecting evidence for questions in QASPER
表 3: QASPER 问题证据选择任务中模型与人类表现下限对比
| 模型 | 证据 F值 Dev. | 证据 F值 Test |
|---|---|---|
| LED-base | 23.94 | 29.85 |
| LED-large | 31.25 | 39.37 |
| TF-IDF | 10.68 | 9.20 |
| Random paragraph | 2.09 | 1.30 |
| First paragraph | 0.71 | 0.34 |
| Human (lower bound) | 71.62 |
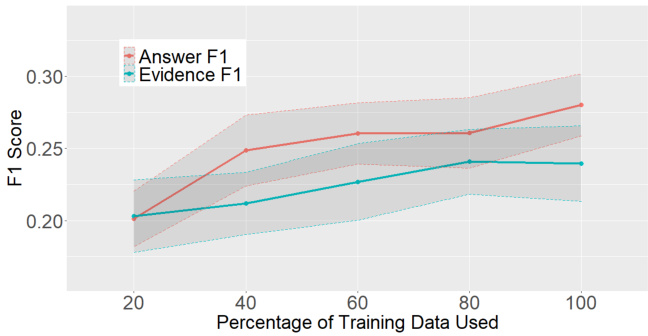
Figure 2: Learning curves showing Answer ${\bf\nabla}\cdot F_{1}$ and Evidence $\cdot F_{1}$ on the dev. set while varying training data size.
图 2: 学习曲线展示了在不同训练数据规模下开发集上的答案 ${\bf\nabla}\cdot F_{1}$ 和证据 $\cdot F_{1}$ 表现。
Error analysis To gain insight into the model’s errors, we sample 67 test questions with predicted Answer $\cdot F_{1}$ scores below 0.10 from the LED model trained with evidence prediction scaffolding. We remove four cases in which the predicted answers are actually correct. Examining gold answers of the remaining 63, we find 31 are extractive, 24 are abstract ive, 3 are “yes”, 3 are “no,” and 2 are unanswerable. We observe that LED often predicts shorter spans than the gold answers (9.5 words shorter than gold counterparts, on average). Focusing only on the 55 questions with either extractive or abstract ive gold answers, we manually categorize error types in Table 5.
错误分析
为了深入理解模型的错误,我们从经过证据预测支架训练的LED模型中抽样了67个预测答案$\cdot F_{1}$得分低于0.10的测试问题。排除了4个预测答案实际正确的案例后,对其余63个问题的参考答案进行分析,发现31个为抽取式答案,24个为生成式答案,3个为"是",3个为"否",2个为无答案。我们观察到LED预测的文本跨度通常比参考答案更短(平均比参考答案少9.5个词)。针对55个具有抽取式或生成式参考答案的问题,我们在表5中手动分类了错误类型。
表5:
Table 4: Model performance on the QASPER test set on answering questions given gold evidence. We do not show performance on Yes/No and Unanswerable types because they can be trivially predicted to a large extent from the absence of gold evidence.
表 4: 在给定黄金证据条件下,各模型在 QASPER 测试集上回答问题的性能表现。由于 Yes/No 和 Unanswerable 类型问题在很大程度上可通过黄金证据缺失直接预测,故未展示其性能数据。
| 模型 | Answer F1 |
|---|---|
| Span | |
| LED-base | 54.20 |
| T5-large | 65.59 |
| UnifiedQA-large | 67.23 |
6 Related Work
6 相关工作
Information-Verifying QA A large body of work on question answering follows the information-verifying paradigm where the writer of the question already knows its answer, and the questions are written solely for evaluating the knowledge or understanding capabilities of machines. Some examples include SQuAD (Rajpurkar et al., 2016), TriviaQA (Joshi et al., 2017), Narrative QA (Kocisky et al., 2018),WikiHop (Welbl et al., 2018), HotpotQA (Yang et al., 2018), CoQA (Reddy et al., 2019), DROP (Dua et al., 2019), QUOREF (Dasigi et al., 2019). Most datasets for QA on academic research papers also fall within the information-verifying paradigm as they automatically construct QA examples using extracted entities and relations and structured knowledge resources, like DrugBank. Some examples include emrQA (Pampari et al., 2018), BioRead (Pappas et al., 2018), BioMRC (Pappas et al., 2020), MedHop (Welbl et al., 2018). While these datasets enabled significant progress in machine comprehension, they include biases in questions that may not reflect real-world settings (Kwiatkowski et al., 2019).
信息验证式问答
大量关于问答的研究遵循信息验证范式,即问题的提出者已知答案,编写问题仅用于评估机器的知识或理解能力。例如SQuAD (Rajpurkar et al., 2016)、TriviaQA (Joshi et al., 2017)、Narrative QA (Kocisky et al., 2018)、WikiHop (Welbl et al., 2018)、HotpotQA (Yang et al., 2018)、CoQA (Reddy et al., 2019)、DROP (Dua et al., 2019)、QUOREF (Dasigi et al., 2019)。学术论文问答的大多数数据集也属于信息验证范式,它们通过提取实体关系或结构化知识资源(如DrugBank)自动构建问答样本,例如emrQA (Pampari et al., 2018)、BioRead (Pappas et al., 2018)、BioMRC (Pappas et al., 2020)、MedHop (Welbl et al., 2018)。尽管这些数据集推动了机器理解的重大进展,但其问题存在可能偏离真实场景的偏差 (Kwiatkowski et al., 2019)。
Information-Seeking QA in General Domain
通用领域的信息检索问答
Recognizing this challenge, others have followed an information-seeking paradigm where the writer of questions is genuinely interested in finding the answer to the question, or at least does not have access to the answer. Examples of such datasets include WikiQA (Yang et al., 2015), NewsQA (Trischler et al., 2017), MsMarco (Campos et al., 2016), QuAC (Choi et al., 2018), Natural Questions (Kwiatkowski et al., 2019), TyDiQA (Clark et al., 2020), and IIRC (Ferguson et al., 2020). Un- like QASPER, Natural Questions and TyDiQA12 questions are not grounded in any contexts, and the associated documents are linked to the questions after they are written. In contrast, QASPER’s questions are real follow-up questions about a paper that a reader of appropriate domain expertise would have after reading the title and the abstract. The priming lets the readers ask detailed questions that are specific to the papers in context, those that require a deeper understanding of the contexts, like those shown in Figure 1 and Table 1. QuAC used similar data collection method but with focus on entities, which QASPER does not impose.
认识到这一挑战后,其他研究采用了信息寻求范式,即问题提出者确实希望找到问题答案,或至少无法直接获取答案。这类数据集包括 WikiQA (Yang et al., 2015) 、NewsQA (Trischler et al., 2017) 、MsMarco (Campos et al., 2016) 、QuAC (Choi et al., 2018) 、Natural Questions (Kwiatkowski et al., 2019) 、TyDiQA (Clark et al., 2020) 和 IIRC (Ferguson et al., 2020) 。与 QASPER 不同,Natural Questions 和 TyDiQA 的问题不基于任何上下文,相关文档是在问题编写后才关联的。而 QASPER 的问题是关于论文的真实后续问题,具有相应领域专业知识的读者在阅读标题和摘要后会产生这些问题。这种引导使读者能够提出针对论文上下文的详细问题,这些问题需要更深入理解上下文,如图 1 和表 1 所示。QuAC 采用了类似的数据收集方法,但侧重于实体,而 QASPER 没有这一限制。
Domain-Specific Information-seeking QA Some work has been done on information-seeking QA on academic research papers. PubmedQA (Jin et al., 2019) derives Yes/No/Maybe questions from PubMed paper titles answered from the conclusion sections of the corresponding abstracts. BioAsq benchmarks (Balikas et al., 2013; Nentidis et al., 2018; Krallinger et al., 2020) focus on open-domain QA over PubMed abstracts. Like QASPER, BioAsq answers can take different forms (e.g., yes/no, extracted span(s)). QASPER differs from BioAsq in that questions are grounded in a single paper of interest. Furthermore, QASPER uses the paper full text, not just the abstract. To the best of our knowledge, QASPER is the first information-seeking QA dataset in a computer science domain, while most prior work using academic research papers has been in bio medicine. Furthermore, with over 5K annotated questions, QASPER is also larger than other comparable human-annotated QA datasets – PubmedQA and BioAsq contain 1K and 3.2K questions, respectively. Finally, QASPER poses a challenging full document-level task while other related datasets are abstract-level. Beyond the domain of academic research, realistic QA datasets have also been built in the privacy policy domain (Ravi chan der et al., 2019; Ahmad et al., 2020). These tasks are similar to our evidence selection task.
领域特定信息检索问答
部分工作已针对学术研究论文的信息检索问答展开。PubmedQA (Jin et al., 2019) 从PubMed论文标题中提取是/否/可能问题,并通过对应摘要的结论部分回答。BioAsq基准测试 (Balikas et al., 2013; Nentidis et al., 2018; Krallinger et al., 2020) 专注于PubMed摘要的开放域问答。与QASPER类似,BioAsq的答案可采用不同形式 (如是/否、提取片段)。QASPER与BioAsq的不同之处在于问题均基于单篇目标论文,且使用全文而非仅摘要。据我们所知,QASPER是计算机科学领域首个信息检索问答数据集,而此前多数基于学术论文的研究集中在生物医学领域。此外,QASPER拥有超5K标注问题,规模大于其他同类人工标注问答数据集——PubmedQA和BioAsq分别包含1K和3.2K问题。最后,QASPER提出具有挑战性的全文级任务,而其他相关数据集均为摘要级。
除学术研究领域外,隐私政策领域也构建了现实场景问答数据集 (Ravichander et al., 2019; Ahmad et al., 2020),这些任务与我们的证据选择任务相似。
7 Conclusion
7 结论
We presented QASPER, an information-seeking QA dataset over NLP research papers. With natural questions asked as follow-up to titles and abstracts, the task presented by QASPER requires evidence from multiple paragraphs and/or figures and tables within the full text of the papers. Our empirical results show plenty of room for improvement when compared to the estimated human performance, and suggest that QASPER could serve as a test-bed for evaluating document-grounded QA research.
我们提出了QASPER,这是一个基于NLP研究论文的信息检索问答数据集。该任务通过针对论文标题和摘要提出的自然后续问题,要求从论文全文的多个段落和/或图表中寻找证据。实证结果表明,与预估的人类表现相比,当前模型仍有很大提升空间,这表明QASPER可作为评估文档问答研究的测试平台。
Table 5: Error analysis of our best model (LED from row 5 from Table 2) on 55 test examples with low $F_{1}$ score (excluding those with “yes,” “no,” or “unanswerable” gold answers). “Quotations” denote extractive gold answers. We note Lacks domain knowledge errors are not always solved by better entity type resolution (see $\dagger.$ ).
表 5: 我们最佳模型 (表 2 第 5 行的 LED) 在 55 个低 $F_{1}$ 分数测试样本上的错误分析 (排除含"是"、"否"或"不可回答"标准答案的样本)。"引用"表示抽取式标准答案。需注意缺乏领域知识的错误并不总能通过更好的实体类型解析解决 (见 $\dagger.$ )。
| 错误类型 | 占比 | 示例问题 | 标准答案 | 预测答案 |
|---|---|---|---|---|
| 错误预测为不可回答 | 34.5% | 文本如何进行分割? | "在处理前将文档分块" | 不可回答 |
| 缺乏领域知识 | 23.6% | 偏差缓解方法还能应用于哪些场景? | "情感分析,其他身份问题如种族" | GRU |
| 神经关系抽取器与哪些基线进行比较? | Berant et al.(2013), Yao and Van Durme (2014), Xu et al. (2014), Berant and Liang (2014),... | Freebase, MCCNN | ||
| 使用了哪些手工特征? | "句子位置、句子长度、时态、限定形容词、元话语特征" | 最小词数为40,并行线程数为4,上下文 | ||
| 信息不足 | 20.0% | 他们所说的学习表征空间的内在几何是什么意思? | "推断的嵌入空间创建了本体论的全局一致结构化预测,而非局部关系预测" | 窗口为10内在几何 |
| 不全面 | 提出的训练框架如何缓解偏差模式? | 通过平衡或,通过为每个类别分配特定权重来平滑不同类别间的伪影 | 通过最小化偏差的影响 | |
| 考虑了哪些指标? | "ter, bleu, rouge, nist, lepor, cider, meteor, 语义相似度(sim)" | 数据集上的模式基于语法的指标(GBMs) | ||
| 是否征求了双相情感障碍患者使用这些数据的许可? | 可读性和语法性"对于Twitter和Reddit用户,假定其公开推文为默示同意。博客用户需联系获取使用其文本的许可" | 否 | ||
| 缺乏特异性 | 7.3% | 性能指标有哪些? | "Rouge-1, Rouge-2和" | Rouge分数 |
| 他们使用了哪些监督机器学习模型? | "ZeroR, 朴素贝叶斯, J48, 和" | Weka分类器 | ||
| ENE标签集包含多少标签? | "200个细粒度类别" | 1 | ||
| 缺乏数值理解 | 7.3% |
systems built on QASPER would not be expected to work well on non-English language research papers.
基于QASPER构建的系统预计无法在非英语研究论文上良好运行。
Ethical Considerations
伦理考量
We present a new dataset that uses papers authored by other researchers. To adhere to copyright, we have restricted ourselves to arXiv papers released under a CC-BY-* license, as identified via Unpaywall, which was used in the S2ORC (Lo et al., 2020) dataset construction. Due to our choice to use arXiv as the source of papers, QASPER is almost entirely an English-language dataset, and QA
我们提出一个新数据集,其采用了其他研究者撰写的论文。为遵守版权规定,我们仅限使用通过Unpaywall识别、采用CC-BY-*许可发布的arXiv论文,该方法曾用于S2ORC (Lo et al., 2020) 数据集构建。由于选择arXiv作为论文来源,QASPER几乎完全是一个英语语料数据集,且QA
We have determined the amount we paid the annotators to be well-above the minimum wage in our local area. While we do collect information about annotator background in NLP and familiarity with the papers they are annotating, we have not collected personal identifiable information without their permission except for payment purposes, and do not include any such information in the released dataset.
我们确定支付给标注者的报酬远高于当地最低工资标准。虽然我们会收集标注者在自然语言处理(NLP)领域的背景信息及其对所标注论文的熟悉程度,但除支付用途外,我们未经许可不会收集任何个人身份信息,且发布的数据集中不包含此类信息。
References
参考文献
Wasi Ahmad, Jianfeng Chi, Yuan Tian, and Kai-Wei Chang. 2020. PolicyQA: A reading comprehension dataset for privacy policies. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 743–749, Online. Association for Computational Linguistics.
Wasi Ahmad、Jianfeng Chi、Yuan Tian和Kai-Wei Chang。2020。PolicyQA:隐私政策阅读理解数据集。载于《计算语言学协会发现:EMNLP 2020》,第743–749页,线上。计算语言学协会。
Akari Asai, Kazuma Hashimoto, Hannaneh Hajishirzi, Richard Socher, and Caiming Xiong. 2020. Learning to retrieve reasoning paths over wikipedia graph for question answering. In International Conference on Learning Representations.
Akari Asai、Kazuma Hashimoto、Hannaneh Hajishirzi、Richard Socher 和 Caiming Xiong。2020。学习检索维基百科图谱中的推理路径以进行问答。发表于国际学习表征会议。
Georgios Balikas, Ioannis Partalas, Aris K osmo poul os, Sergios Petridis, Prodromos Malak as i otis, Ioannis Pav lo poul os, Ion And rout so poul os, Nicolas Baskiotis, Eric Gaussier, Thierry Artieres, et al. 2013. Evaluation framework specifications. Project deliverable D, 4.
Georgios Balikas、Ioannis Partalas、Aris Kosmopoulos、Sergios Petridis、Prodromos Malakasiotis、Ioannis Pavlopoulos、Ion Androutsopoulos、Nicolas Baskiotis、Eric Gaussier、Thierry Artieres等。2013。评估框架规范。项目交付成果D, 4。
Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The long-document transformer. ArXiv, abs/2004.05150.
Iz Beltagy、Matthew E. Peters 和 Arman Cohan。2020。Longformer:长文档 Transformer。ArXiv,abs/2004.05150。
Daniel Fernando Campos, T. Nguyen, M. Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, L. Deng, and Bhaskar Mitra. 2016. Ms marco: A human generated machine reading comprehension dataset. ArXiv, abs/1611.09268.
Daniel Fernando Campos、T. Nguyen、M. Rosenberg、Xia Song、Jianfeng Gao、Saurabh Tiwary、Rangan Majumder、L. Deng 和 Bhaskar Mitra。2016。MS MARCO: 人工生成的机器阅读理解数据集。ArXiv, abs/1611.09268。
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. 2016. Training deep nets with sublinear memory cost. ArXiv, abs/1604.06174.
Tianqi Chen、Bing Xu、Chiyuan Zhang 和 Carlos Guestrin。2016。以次线性内存成本训练深度网络。ArXiv,abs/1604.06174。
Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wentau Yih, Yejin Choi, Percy Liang, and Luke Zettlemoyer. 2018. QuAC: Question answering in context. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2174–2184, Brussels, Belgium. Association for Computational Linguistics.
Eunsol Choi、He He、Mohit Iyyer、Mark Yatskar、Wentau Yih、Yejin Choi、Percy Liang 和 Luke Zettlemoyer。2018. QuAC: 上下文问答。载于《2018年自然语言处理实证方法会议论文集》,第2174-2184页,比利时布鲁塞尔。计算语言学协会。
Jonathan H. Clark, Eunsol Choi, Michael Collins, Dan Garrette, Tom Kwiatkowski, Vitaly Nikolaev, and Jennimaria Palomaki. 2020. TyDi QA: A bench- mark for information-seeking question answering in typo logically diverse languages. Transactions of the Association for Computational Linguistics, 8:454– 470.
Jonathan H. Clark、Eunsol Choi、Michael Collins、Dan Garrette、Tom Kwiatkowski、Vitaly Nikolaev 和 Jennimaria Palomaki。2020。TyDi QA:一个面向类型多样语言的信息寻求问答基准。计算语言学协会汇刊,8:454–470。
Pradeep Dasigi, Nelson F. Liu, Ana Marasovic, Noah A. Smith, and Matt Gardner. 2019. Quoref: A reading comprehension dataset with questions requiring co referential reasoning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5925–5932, Hong Kong, China. Association for Computational Linguistics.
Pradeep Dasigi、Nelson F. Liu、Ana Marasovic、Noah A. Smith 和 Matt Gardner。2019. Quoref: 一个需要共指推理的阅读理解数据集。载于《2019年自然语言处理实证方法会议暨第九届自然语言处理国际联合会议论文集》(EMNLP-IJCNLP),第5925–5932页,中国香港。计算语言学协会。
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2019. BERT: 面向语言理解的深度双向Transformer预训练。载于《2019年北美计算语言学协会人类语言技术会议论文集》(长文与短文),第1卷,第4171–4186页,明尼苏达州明尼阿波利斯市。计算语言学协会。
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. 2019. DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2368–2378, Minneapolis, Minnesota. Association for Computational Linguistics.
Dheeru Dua、Yizhong Wang、Pradeep Dasigi、Gabriel Stanovsky、Sameer Singh和Matt Gardner。2019。DROP:需要段落离散推理的阅读理解基准。载于《2019年北美计算语言学协会会议论文集:人类语言技术(长文与短文)》第1卷,第2368–2378页,明尼苏达州明尼阿波利斯市。计算语言学协会。
James Ferguson, Matt Gardner, Hannaneh Hajishirzi, Tushar Khot, and Pradeep Dasigi. 2020. IIRC: A dataset of incomplete information reading comprehension questions. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1137–1147, Online. Association for Computational Linguistics.
James Ferguson、Matt Gardner、Hannaneh Hajishirzi、Tushar Khot 和 Pradeep Dasigi。2020. IIRC: 一个不完整信息阅读理解问题的数据集。载于《2020年自然语言处理经验方法会议论文集》(EMNLP),第1137–1147页,线上。计算语言学协会。
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. 2020. Realm: Retrievalaugmented language model pre-training. ArXiv, abs/2002.08909.
Kelvin Guu、Kenton Lee、Zora Tung、Panupong Pasupat 和 Ming-Wei Chang。2020. REALM:检索增强的语言模型预训练。arXiv,abs/2002.08909。
Jeremy Howard and Sebastian Ruder. 2018. Universal language model fine-tuning for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 328–339, Melbourne, Australia. Association for Computational Linguistics.
Jeremy Howard 和 Sebastian Ruder。2018。通用语言模型微调在文本分类中的应用。载于《第56届计算语言学协会年会论文集(第一卷:长论文)》,第328-339页,澳大利亚墨尔本。计算语言学协会。
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. 2019. PubMedQA: A dataset for biomedical research question answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2567– 2577, Hong Kong, China. Association for Computational Linguistics.
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen 和 Xinghua Lu. 2019. PubMedQA: 一个用于生物医学研究问答的数据集. 见《2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议论文集》(EMNLP-IJCNLP), 第2567–2577页, 中国香港. 计算语言学协会.
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Z ett le moyer. 2017. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, Vancouver, Canada. Association for Computational Linguistics.
Mandar Joshi、Eunsol Choi、Daniel Weld 和 Luke Zettlemoyer。2017. TriviaQA: 一个大规模远程监督的阅读理解挑战数据集。载于《第55届计算语言学协会年会论文集(第一卷:长论文)》,第1601–1611页,加拿大温哥华。计算语言学协会。
Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabharwal, Oyvind Tafjord, Peter Clark, and Hannaneh Hajishirzi. 2020. UNIFIEDQA: Crossing for- mat boundaries with a single QA system. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1896–1907, Online. Association for Computational Linguistics.
Daniel Khashabi、Sewon Min、Tushar Khot、Ashish Sabharwal、Oyvind Tafjord、Peter Clark 和 Hannaneh Hajishirzi。2020。UNIFIEDQA:跨格式边界的统一问答系统。载于《计算语言学协会发现:EMNLP 2020》,第1896-1907页,线上。计算语言学协会。
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. ArXiv, abs/1412.6980.
Diederik P Kingma 和 Jimmy Ba. 2014. Adam: 一种随机优化方法. ArXiv, abs/1412.6980.
Tomas Kocisky, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis, and Edward Gre fens te tte. 2018. The Narrative QA reading comprehension challenge. Transactions of the Association for Computational Linguistics, 6:317– 328.
Tomas Kocisky、Jonathan Schwarz、Phil Blunsom、Chris Dyer、Karl Moritz Hermann、Gábor Melis 和 Edward Grefenstette。2018. Narrative QA 阅读理解挑战赛。计算语言学协会汇刊,6:317–328。
Martin Krallinger, Anastasia Krithara, A. Nentidis, G. Paliouras, and Marta Villegas. 2020. Bioasq at clef2020: Large-scale biomedical semantic indexing and question answering. Advances in Information Retrieval, 12036:550 – 556.
Martin Krallinger、Anastasia Krithara、A. Nentidis、G. Paliouras和Marta Villegas。2020。BioASQ在CLEF2020:大规模生物医学语义索引与问答系统。《信息检索进展》,12036:550-556。
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red- field, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466.
Tom Kwiatkowski、Jennimaria Palomaki、Olivia Redfield、Michael Collins、Ankur Parikh、Chris Alberti、Danielle Epstein、Illia Polosukhin、Jacob Devlin、Kenton Lee、Kristina Toutanova、Llion Jones、Matthew Kelcey、Ming-Wei Chang、Andrew M. Dai、Jakob Uszkoreit、Quoc Le 和 Slav Petrov。2019。Natural Questions:问答研究基准。《计算语言学协会汇刊》7:453–466。
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghaz vi nine j ad, Abdel rahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Z ett le moyer. 2020. BART: Denoising sequence-to-sequence pretraining for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
Mike Lewis、Yinhan Liu、Naman Goyal、Marjan Ghazvininejad、Abdelrahman Mohamed、Omer Levy、Veselin Stoyanov 和 Luke Zettlemoyer。2020。BART:用于自然语言生成、翻译和理解的去噪序列到序列预训练。载于《第58届计算语言学协会年会论文集》,第7871–7880页,线上会议。计算语言学协会。
Dayiheng Liu, Yeyun Gong, Jie Fu, Yu Yan, Jiusheng Chen, Daxin Jiang, Jiancheng Lv, and Nan Duan. 2020. RikiNet: Reading Wikipedia pages for natural question answering. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6762–6771, Online. Asso- ciation for Computational Linguistics.
Dayiheng Liu、Yeyun Gong、Jie Fu、Yu Yan、Jiusheng Chen、Daxin Jiang、Jiancheng Lv 和 Nan Duan。2020. RikiNet:通过阅读维基百科页面实现自然问题解答。载于《第58届计算语言学协会年会论文集》,第6762–6771页,线上会议。计算语言学协会。
Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel Weld. 2020. S2ORC: The semantic scholar open research corpus. In Proceedings of the Association for Computational Linguistics (ACL).
Kyle Lo、Lucy Lu Wang、Mark Neumann、Rodney Kinney和Daniel Weld。2020。S2ORC:语义学者开放研究语料库。载于《计算语言学协会会议论文集》(ACL)。
Anastasios Nentidis, Anastasia Krithara, Konstantinos Bou gia ti otis, Georgios Paliouras, and Ioannis Kakadiaris. 2018. Results of the sixth edition of the BioASQ challenge. In Proceedings of the 6th BioASQ Workshop A challenge on large-scale biomedical semantic indexing and question answering, pages 1–10, Brussels, Belgium. Association for Computational Linguistics.
Anastasios Nentidis、Anastasia Krithara、Konstantinos Bougiatiotis、Georgios Paliouras 和 Ioannis Kakadiaris。2018。第六届 BioASQ 挑战赛结果。见《第六届 BioASQ 研讨会论文集:大规模生物医学语义索引与问答挑战》,第 1-10 页,比利时布鲁塞尔。计算语言学协会。
Qiang Ning, Hao Wu, Pradeep Dasigi, Dheeru Dua, Matt Gardner, Robert L. Logan IV, Ana Marasovic, and Zhen Nie. 2020. Easy, reproducible and quality-controlled data collection with CROWDAQ.
钱宁、吴昊、Pradeep Dasigi、Dheeru Dua、Matt Gardner、Robert L. Logan IV、Ana Marasovic和聂震。2020。使用CROWDAQ实现简易、可复现且质量可控的数据收集。
In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 127–134, Online. Association for Computational Linguistics.
2020年自然语言处理实证方法会议系统演示论文集,第127-134页,在线。计算语言学协会。
Anusri Pampari, Preethi Raghavan, Jennifer Liang, and Jian Peng. 2018. emrQA: A large corpus for question answering on electronic medical records. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2357–2368, Brussels, Belgium. Association for Computational Linguistics.
Anusri Pampari、Preethi Raghavan、Jennifer Liang和Jian Peng。2018. emrQA: 一个用于电子病历问答的大型语料库。载于《2018年自然语言处理实证方法会议论文集》,第2357–2368页,比利时布鲁塞尔。计算语言学协会。
Dimitris Pappas, Ion And rout so poul os, and Haris Papageorgiou. 2018. BioRead: A new dataset for biomedical reading comprehension. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan. European Language Resources Association (ELRA).
Dimitris Pappas、Ion Androutsopoulos和Haris Papageorgiou。2018. BioRead:生物医学阅读理解新数据集。载于《第十一届国际语言资源与评估会议论文集》(LREC 2018),日本宫崎市。欧洲语言资源协会(ELRA)。
Dimitris Pappas, Petros Stavro poul os, Ion Androutsopoulos, and Ryan McDonald. 2020. BioMRC: A dataset for biomedical machine reading comprehension. In Proceedings of the 19th SIGBioMed Workshop on Biomedical Language Processing, pages 140–149, Online. Association for Computational Linguistics.
Dimitris Pappas、Petros Stavropoulos、Ion Androutsopoulos 和 Ryan McDonald。2020. BioMRC:生物医学机器阅读理解数据集。载于第19届SIGBioMed生物医学语言处理研讨会论文集,第140-149页,线上。计算语言学协会。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-totext transformer. Journal of Machine Learning Research, 21(140):1–67.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J. Liu。2020。探索迁移学习的极限:基于统一文本到文本Transformer的研究。《机器学习研究期刊》,21(140):1–67。
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: $100{,}000+$ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392, Austin, Texas. Association for Computational Linguistics.
Pranav Rajpurkar、Jian Zhang、Konstantin Lopyrev 和 Percy Liang。2016. SQuAD:面向机器理解文本的 $100{,}000+$ 问题。载于《2016年自然语言处理实证方法会议论文集》,第2383–2392页,得克萨斯州奥斯汀。计算语言学协会。
Abhilasha Ravi chan der, Alan W Black, Shomir Wilson, Thomas Norton, and Norman Sadeh. 2019. Question answering for privacy policies: Combining com- putational and legal perspectives. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4947–4958, Hong Kong, China. Association for Computational Linguistics.
Abhilasha Ravichander, Alan W Black, Shomir Wilson, Thomas Norton 和 Norman Sadeh. 2019. 隐私政策问答: 结合计算与法律视角. 见《2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议论文集》(EMNLP-IJCNLP), 第4947–4958页, 中国香港. 计算语言学协会.
Siva Reddy, Danqi Chen, and Christopher D. Manning. 2019. CoQA: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7:249–266.
Siva Reddy、Danqi Chen 和 Christopher D. Manning。2019。CoQA:对话式问答挑战。计算语言学协会汇刊,7:249–266。
Adam Trischler, Tong Wang, Xingdi Yuan, Justin Har- ris, Alessandro Sordoni, Philip Bachman, and Kaheer Suleman. 2017. NewsQA: A machine compre- hension dataset. In Proceedings of the 2nd Workshop on Representation Learning for NLP, pages 191–200, Vancouver, Canada. Association for Computational Linguistics.
Adam Trischler、Tong Wang、Xingdi Yuan、Justin Harris、Alessandro Sordoni、Philip Bachman 和 Kaheer Suleman。2017. NewsQA:一个机器阅读理解数据集。载于《第2届自然语言处理表征学习研讨会论文集》,第191-200页,加拿大温哥华。计算语言学协会。
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N Gomez、Łukasz Kaiser 和 Illia Polosukhin。2017. Attention is all you need。载于《神经信息处理系统进展》第30卷。Curran Associates公司。
Johannes Welbl, Pontus Stenetorp, and Sebastian Riedel. 2018. Constructing datasets for multi-hop reading comprehension across documents. Transactions of the Association for Computational Linguis- tics, 6:287–302.
Johannes Welbl、Pontus Stenetorp和Sebastian Riedel。2018。跨文档多跳阅读理解数据集的构建。计算语言学协会汇刊,6:287–302。
Yi Yang, Wen-tau Yih, and Christopher Meek. 2015. WikiQA: A challenge dataset for open-domain question answering. In Proceedings of the 2015 Con- ference on Empirical Methods in Natural Language Processing, pages 2013–2018, Lisbon, Portugal. Association for Computational Linguistics.
Yi Yang、Wen-tau Yih和Christopher Meek。2015。WikiQA: 开放域问答挑战数据集。2015年自然语言处理实证方法会议论文集,第2013–2018页,葡萄牙里斯本。计算语言学协会。
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salak hut dino v, and Christopher D. Manning. 2018. HotpotQA: A dataset for diverse, explain able multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium. Association for Computational Linguistics.
Zhilin Yang、Peng Qi、Saizheng Zhang、Yoshua Bengio、William Cohen、Ruslan Salakhutdinov 和 Christopher D. Manning。2018. HotpotQA:一个支持多样化、可解释多跳问答的数据集。载于《2018年自然语言处理实证方法会议论文集》,第2369–2380页,比利时布鲁塞尔。计算语言学协会。