Citrus: Leveraging Expert Cognitive Pathways in a Medical Language Model for Advanced Medical Decision Support
Citrus: 在医疗语言模型中利用专家认知路径实现高级医疗决策支持
Abstract
摘要
Large language models (LLMs), particularly those with reasoning capabilities, have rapidly advanced in recent years, demonstrating significant potential across a wide range of applications. However, their deployment in healthcare, especially in disease reasoning tasks, is hindered by the challenge of acquiring expert-level cognitive data. In this paper, we introduce Citrus, a medical language model that bridges the gap between clinical expertise and AI reasoning by emulating the cognitive processes of medical experts. The model is trained on a large corpus of simulated expert disease reasoning data, synthesized using a novel approach that accurately captures the decision-making pathways of clinicians. This approach enables Citrus to better simulate the complex reasoning processes involved in diagnosing and treating medical conditions. To further address the lack of publicly available datasets for medical reasoning tasks, we release the last-stage training data, including a custom-built medical diagnostic dialogue dataset. This opensource contribution aims to support further research and development in the field. Evaluations using authoritative benchmarks such as MedQA, covering tasks in medical reasoning and language understanding, show that Citrus achieves superior performance compared to other models of similar size. These results highlight Citrus’s potential to significantly enhance medical decision support systems, providing a more accurate and efficient tool for clinical decision-making.
近年来,具备推理能力的大语言模型(LLM)快速发展,在广泛的应用场景中展现出巨大潜力。然而在医疗领域,尤其是疾病推理任务中,专业级认知数据的获取难题阻碍了其实际部署。本文提出医疗语言模型Citrus,通过模拟医学专家的认知过程,弥合临床专业知识与AI推理之间的鸿沟。该模型基于大规模模拟专家疾病推理数据进行训练,这些数据采用能精准捕捉临床医生决策路径的创新方法合成。该方法使Citrus能更好地模拟诊疗过程中涉及的复杂推理流程。
针对医疗推理任务公开数据集匮乏的问题,我们发布了包含定制医疗诊断对话数据集在内的最终阶段训练数据。这一开源贡献旨在支持该领域的后续研究发展。在MedQA等涵盖医疗推理与语言理解任务的权威基准测试中,Citrus展现出优于同类规模模型的性能表现。这些结果表明Citrus有望显著提升医疗决策支持系统,为临床决策提供更精准高效的工具。
1 Introduction
1 引言
Recent advancements in the reasoning capabilities of LLMs have become a focal point in research and are increasingly seen as a benchmark for assessing the intelligence level of these models[1, 2]. While the progress in reasoning capabilities has been rapid in domains like mathmetics and programming, the development in healthcare remains relatively limited[3–6]. The open-ended nature of medical practice presents a more complex challenge for Language Models. Medical expertise is cultivated through real-world clinical practice, making it essential for medical reasoning models to learn from the diagnostic and treatment processes of human experts. As a result, emulating the reasoning pathways of medical professionals becomes a crucial step for developing effective medical reasoning models.
近年来,大语言模型(LLM)的推理能力进展已成为研究焦点,并逐渐被视为评估模型智能水平的重要基准[1, 2]。尽管在数学和编程等领域推理能力发展迅速,但医疗健康领域的进展仍相对有限[3–6]。医疗实践的开放性特征为语言模型带来了更复杂的挑战。医学专业能力需要通过真实临床实践来培养,因此医疗推理模型必须从人类专家的诊疗过程中学习。模拟医疗专业人员的推理路径由此成为开发有效医疗推理模型的关键步骤。
Clinical practice, requiring highly sophisticated medical reasoning skills, encompasses patient consultation, diagnosis, differential diagnosis, and treatments[7, 8]. Medical experts have systematically summarized the thought processes involved in clinical practice[9–12]. For medical language models to successfully assist in clinical decision-making, they must not only process vast amounts of medical data but also emulate the complex cognitive processes of expert medical professionals[13]. This requires LLMs to understand not only the explicit medical knowledge but also the implicit reasoning steps that experts use when diagnosing and treating patients. Furthermore, as medical decisions often involve ambiguity, incomplete data, and uncertainty, models must be able to handle these complexities in a way that mirrors expert judgment.
临床实践需要高度复杂的医学推理技能,涵盖患者问诊、诊断、鉴别诊断和治疗 [7, 8]。医学专家已系统总结了临床实践中的思维过程 [9–12]。要让医学大语言模型成功辅助临床决策,它们不仅需要处理海量医疗数据,还必须模拟专业医疗人员的复杂认知过程 [13]。这要求大语言模型既要理解显性医学知识,也要掌握专家诊疗时使用的隐性推理步骤。此外,由于医疗决策常涉及模糊性、不完整数据和不确定性,模型必须能以符合专家判断的方式处理这些复杂情况。
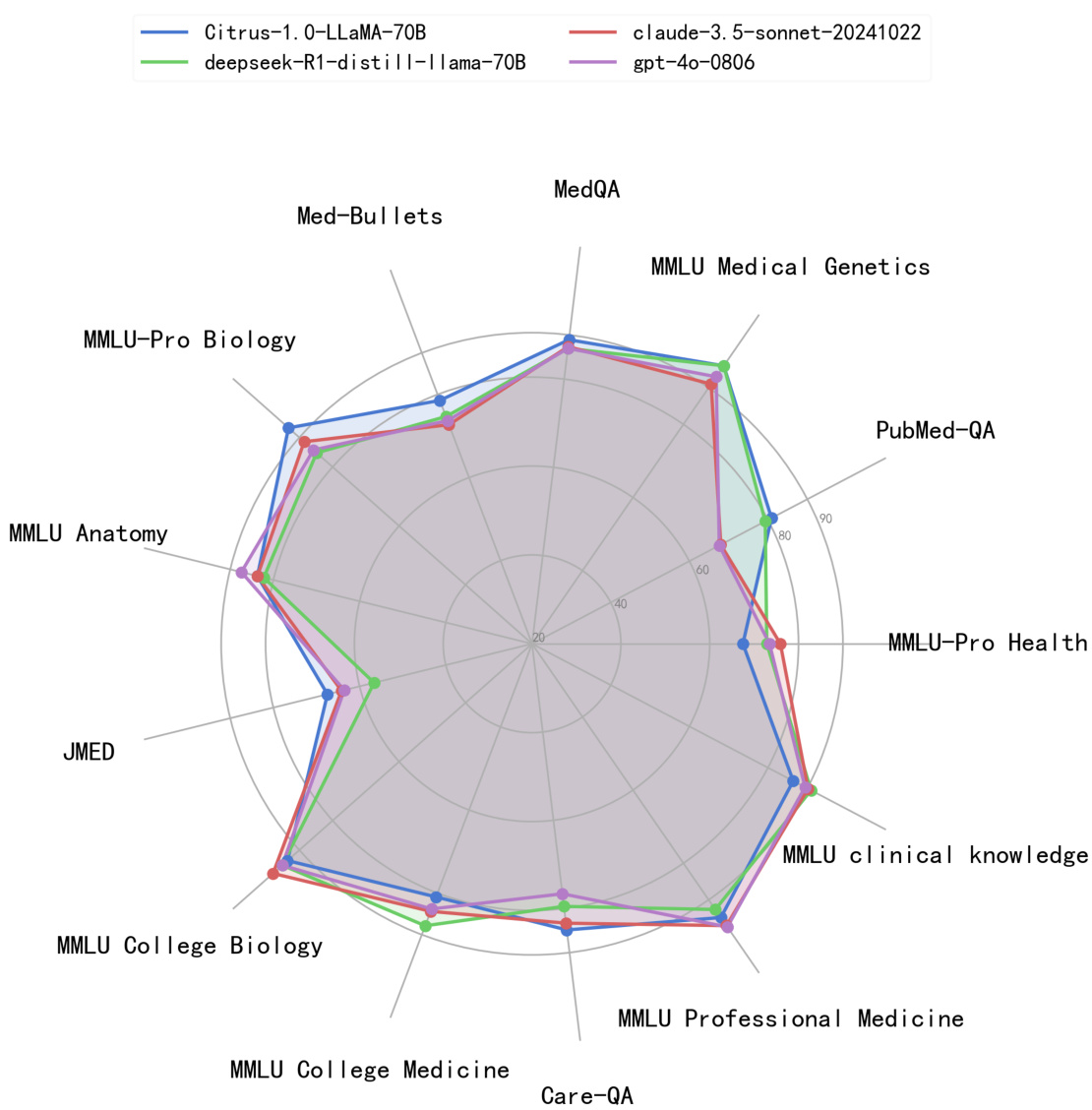
Figure 1: Citrus rank high in several authoritative medical benchmarks, comparing with two widely used LLMs, GPT-4o and Claude and a powerful 70B scale LLM, which is distilled from DeepSeekR1.
图 1: Citrus在多个权威医学基准测试中表现优异,与两种广泛使用的大语言模型GPT-4o和Claude以及从DeepSeekR1蒸馏而来的强大70B规模大语言模型进行对比。
To achieve this, it is necessary for medical language models to be trained on data that closely mirrors the decision-making processes of clinicians. However, obtaining real-world expert-level clinical reasoning data is challenging, as it requires capturing the nuances of expert thought, which are often difficult to quantify. Moreover, existing datasets, although valuable, often fail to replicate the dynamic and often ambiguous nature of clinical practice. In response, new approaches to data synthesis and model training are required to bridge these gaps, enabling models to mimic expert reasoning while also adapting to the complexities and variability inherent in medical practice.
为实现这一目标,医疗领域的大语言模型需在高度模拟临床医生决策过程的数据上进行训练。然而,获取真实世界专家级临床推理数据具有挑战性,因为这需要捕捉专家思维的细微差异,而这些差异往往难以量化。此外,现有数据集虽然宝贵,却通常无法复现临床实践中动态且常具模糊性的特点。为此,需要采用新的数据合成与模型训练方法,以弥合这些差距,使模型既能模仿专家推理,又能适应医疗实践中固有的复杂性和多变性。
In collaboration with human medical experts, we have designed a methodology for enhancing complex reasoning capabilities in large medical language models, specifically tailored for clinical scenarios. This training-free approach emulates the cognitive reasoning processes of medical professionals, resulting in significant improvements in complex reasoning tasks across multiple models, including
在与人类医学专家合作的过程中,我们设计了一种专门针对临床场景、用于增强大医疗语言模型复杂推理能力的方法。这种免训练方案模拟了医疗专业人员的认知推理过程,使得包括
Llama3.1[14] and GPT-4[15]. Inspired by the results, we took further steps and carefully designed a multi-stage training method incorporating multiple phases of continuous pre-training (CPT), supervised fine-tuning (SFT) and reinforcement learning (RL). In this paper, we present Citrus, a medical language model that leverages expert cognitive pathways to simulate the reasoning processes of clinicians. By training Citrus on a large corpus of simulated medical reasoning data, we replicate the dynamic and iterative nature of clinical decision-making. This enables the model to engage in more accurate and effective reasoning, forming the foundation for future AI-driven medical decision support systems. Additionally, we successfully translated this methodology into a trainable approach, resulting in substantial performance improvements in several open-source base models across a variety of medical benchmarks. The advanced medical reasoning and decision-making support provided by Citrus have enabled it to outperform 70B parameter models in the medical domain.
Llama3.1[14]与GPT-4[15]。受此启发,我们进一步设计了一套融合持续预训练(CPT)、监督微调(SFT)和强化学习(RL)的多阶段训练方法。本文提出Citrus医疗语言模型,该模型通过专家认知路径模拟临床医生的推理过程。基于海量模拟医疗推理数据的训练,我们复现了临床决策的动态迭代特性,使模型能进行更精准有效的推理,为未来AI驱动的医疗决策支持系统奠定基础。此外,我们将该方法成功转化为可训练方案,使多个开源基础模型在多项医疗基准测试中取得显著性能提升。Citrus凭借先进的医疗推理与决策支持能力,在医疗领域超越了700亿参数模型的表现。
At the same time, we identified a key challenge in current medical language model evaluations: the structured nature of assessment questions often fails to capture the inherent ambiguity of patient symptoms in real-world clinical practice. By leveraging real-world consultations at JD Health’s internet hospital, we have created a clinical practice evaluation dataset JDH MEDical Practice Dataset (JMED) that reflects real-world disease distribution, and can be regularly updated.
同时,我们发现了当前医学语言模型评估中的一个关键挑战:评估问题的结构化特性往往无法捕捉真实临床实践中患者症状的固有模糊性。通过利用京东健康互联网医院的实际问诊数据,我们创建了一个反映真实疾病分布、可定期更新的临床实践评估数据集JDH医疗实践数据集(JMED)。
The contributions of this paper are as follows:
本文的贡献如下:
2 Related Works
2 相关工作
Medical reasoning in clinical practice In clinical practice, determining the most rational expert thinking process has always been a key research focus[8–12]. The hypo the tico-deductive method[16– 18] is a reasoning process from general to specific, which determines diseases based on symptom combinations according to known medical theories. According to this method, some diagnostic hypotheses or conclusions has been raised firstly after collecting information from patients and will be waiting for testing. And these hypotheses, to some extent, guided the subsequent diagnosis and treatment. Pattern-recognition method[19, 20] is a reasoning process from specific to general, which discovers patterns based on clinical observations and empirical summaries. Physicians quickly establish preliminary diagnoses through certain typical descriptions and specific combinations of symptoms that have been repeatedly validated in long-term clinical practice. The dual-processing theory (DPT)[21, 22], which integrates hypothesis testing methodologies with pattern recognition approaches, has gained widespread recognition and acceptance among medical experts. DPT includes system 1 and system 2[23]. System 1 is a fast, intuitive, non-analytical process which is similar to pattern-recognition method, while System 2 is a slow, deliberate, analytical process related to hypo the tico-deductive method[9, 24]. DPT posits that the reasoning pathway in clinical practice necessitates the concurrent integration of both intuitive and analytical processes[23, 25, 26].
临床实践中的医学推理
在临床实践中,确定最合理的专家思维过程一直是关键研究重点[8–12]。假设-演绎法(hypothetico-deductive method)[16–18]是从一般到特殊的推理过程,根据已知医学理论通过症状组合确定疾病。该方法首先在收集患者信息后提出若干诊断假设或结论等待验证,这些假设在一定程度上指导后续诊疗工作。模式识别法(pattern-recognition method)[19,20]则是从特殊到一般的推理过程,通过临床观察和经验总结发现规律模式。医生通过长期临床实践中反复验证的某些典型描述和特定症状组合快速建立初步诊断。
双加工理论(dual-processing theory, DPT)[21,22]整合了假设检验方法与模式识别路径,已获得医学专家的广泛认可。该理论包含系统1和系统2[23]:系统1是快速、直觉、非分析性的认知过程,类似于模式识别法;系统2则是缓慢、审慎、分析性的过程,与假设-演绎法相关[9,24]。DPT认为临床实践中的推理路径需要同时整合直觉与分析处理过程[23,25,26]。
Application of Large Language Models in Medical Reasoning Researchers have realized the great potential of LLMs reasoning in medical problems solving[27, 28, 3]. Recent advancements in LLMs for healthcare have been propelled by improved training methodologies, including CPT, SFT, and RL, which significantly enhance medical dialogue comprehension and question-answering capabilities[27, 29–48]. Training-free techniques, such as advanced prompt engineering, have enabled general-purpose LLMs to perform specific medical tasks without retraining, as evidenced by studies like MedPrompt[49, 39, 50–55]. The implementation of multi-agent systems simulating experts from various medical departments has improved decision-making and overall medical performance by supporting complex tasks such as multi-step reasoning and treatment planning[56–59]. Research has highlighted the potential of generating intermediate steps to enhance reasoning abilities, exemplified by OpenAI’s O1[1]. Additionally, R1 has demonstrated that training with large-scale synthetic data can yield exceptional reasoning models[2]. Inspired by these innovations, models such as Huatuo-O1[60], O1-Journey[61, 62], and Baichuan-M1[63] have been developed, utilizing inferencetime scaling to produce extended reasoning outputs, thereby excelling in diagnostic tasks involving complex medical cases[64]. Huatuo-O1 focuses on advancing the complex reasoning capabilities of LLMs in healthcare by constructing verifiable medical problems and employing medical validators to ensure output accuracy. In contrast, O1-Journey emphasizes enhancing LLMs’ ability to handle intricate medical tasks through reasoning augmentation. Baichuan-M1, developed from scratch and specifically optimized for medical applications, is designed to excel in both general domains such as mathematics and programming, as well as specialized medical fields including diagnostic support, medical research, and treatment recommendations. Building on these advancements, our objective is to effectively emulate doctors’ cognitive processes in clinical practice to enhance the medical capabilities of large language models.
大语言模型在医学推理中的应用
研究人员已意识到大语言模型在解决医学问题中的推理潜力[27, 28, 3]。医疗领域大语言模型的最新进展得益于训练方法的改进,包括CPT、SFT和RL,这些方法显著提升了医学对话理解与问答能力[27, 29–48]。免训练技术(如高级提示工程)使通用大语言模型无需重新训练即可执行特定医疗任务,MedPrompt等研究已验证了这一点[49, 39, 50–55]。通过模拟多科室专家的多智能体系统,支持多步推理和治疗方案制定等复杂任务,决策质量和整体医疗表现得到提升[56–59]。研究强调生成中间步骤可增强推理能力,OpenAI的O1[1]即为典型案例。此外,R1证明利用大规模合成数据训练可产生卓越的推理模型[2]。受此启发,华佗-O1[60]、O1-Journey[61, 62]和百川-M1[63]等模型采用推理时扩展技术生成长链推理输出,在复杂病例诊断任务中表现优异[64]。
华佗-O1通过构建可验证医学问题并采用医学验证器确保输出准确性,重点提升大语言模型在医疗领域的复杂推理能力;O1-Journey则侧重通过推理增强提升模型处理复杂医疗任务的能力。从头训练并针对医疗场景专门优化的百川-M1,在数学与编程等通用领域及诊断支持、医学研究和治疗建议等专业医疗领域均表现突出。基于这些进展,我们的目标是有效模拟医生临床认知过程,以增强大语言模型的医疗能力。
Evaluation of medical capabilities in large language models Large language models have shown considerable promise in the medical field, and several benchmarks exist to evaluate their capabilities in this domain. Some studies compile medical license examination questions into medical competency assessment datasets, evaluating large language models’ medical capabilities in the same way medical students are tested[62]. Some works collect key questions from medical papers, requiring large language models to read medical paper abstracts to answer medical research questions, examining the models’ ability to comprehend medical literature[65]. Furthermore, to more accurately assess and differentiate the reasoning abilities of large models, the MMLU-Pro[66] dataset selects more challenging and reasoning-focused questions from MMLU[67] and expands the number of answer choices from four to ten. We aim to combine the advantages of these works to construct a clinical practice evaluation dataset that aligns with the distribution characteristics of real patients and can be regularly updated.
大语言模型医学能力评估
大语言模型在医学领域展现出巨大潜力,现有多个基准用于评估其在该领域的能力。部分研究将医师资格考试题目汇编成医学能力评估数据集,以医学生考核方式评测大语言模型的医学能力 [62]。另有工作收集医学论文中的关键问题,要求大语言模型通过阅读论文摘要回答医学研究问题,检验模型对医学文献的理解能力 [65]。此外,为更精准评估和区分大模型的推理能力,MMLU-Pro [66] 数据集从 MMLU [67] 中筛选更具挑战性且侧重推理的题目,并将选项数量从四个扩展至十个。我们计划整合这些工作的优势,构建符合真实患者分布特征且可定期更新的临床实践评估数据集。
3 Training Data
3 训练数据
3.1 Understanding Clinical Reasoning
3.1 理解临床推理
Recent studies have used the Chain-of-Thought (COT)[68] generation technique to enhance the reasoning capabilities of medical models. We argue that structuring the reasoning process to mirror the cognitive pathways of expert doctors in a structured COT approach is more effective in activating the model’s reasoning potential compared to unstructured, base-model-driven processes. Additionally, structured reasoning is easier for human experts to verify. Upon observing the reasoning processes of medical professionals, we identify two primary reasoning methods: the hypo the tico-deductive method and the pattern-recognition method. The hypo the tico-deductive method involves generating hypotheses based on available information, testing these hypotheses against further data, and revising them to form conclusions. This method emphasizes critical thinking and careful hypothesis testing, making it a robust approach in clinical practice, especially when facing complex, uncertain cases.In contrast, the pattern-recognition method relies on the recognition of patterns or symptoms that closely match previous cases or well-established medical knowledge. This method is often more intuitive and is useful when dealing with familiar or straightforward cases. It involves rapid decision-making based on experience rather than hypothesis testing. Experienced experts typically combine both methods in clinical decision-making to ensure efficient and accurate outcomes.
近期研究采用思维链 (Chain-of-Thought, COT) [68] 生成技术来增强医疗模型的推理能力。我们认为,与无结构的基模型驱动过程相比,通过结构化COT方法构建符合专家医生认知路径的推理过程,能更有效地激活模型的推理潜力。此外,结构化推理更便于人类专家验证。通过观察医疗专业人士的推理过程,我们总结出两种主要推理方法:假说演绎法 (hypothetico-deductive method) 和模式识别法 (pattern-recognition method)。假说演绎法需要根据现有信息生成假设,用后续数据验证这些假设并修正以得出结论。该方法强调批判性思维和严谨的假设检验,是临床实践中处理复杂不确定病例的可靠方法。相比之下,模式识别法依赖于识别与既往病例或成熟医学知识高度吻合的症状模式。这种方法更依赖直觉,适用于处理熟悉或简单的病例,其决策基于经验而非假设检验。经验丰富的专家通常会结合两种方法进行临床决策,以确保高效准确的结果。
Leveraging the cognitive pathways of medical experts, we propose a multi-stage data construction methodology that allows LLMs to integrate both reasoning methods, emulating expert reasoning patterns in medical decision-making[37], shown in Figure.2. The main approaches are as follows:
利用医学专家的认知路径,我们提出了一种多阶段数据构建方法,使大语言模型能够整合两种推理方式,模拟医学决策中的专家推理模式[37],如图2所示。主要方法如下:
COT data by simulating expert reasoning processes. Additionally, a two-stage curriculum learning strategy is implemented as a prerequisite to smooth the model’s learning trajectory.
通过模拟专家推理过程生成COT数据。此外,采用两阶段课程学习策略作为平滑模型学习轨迹的前提条件。
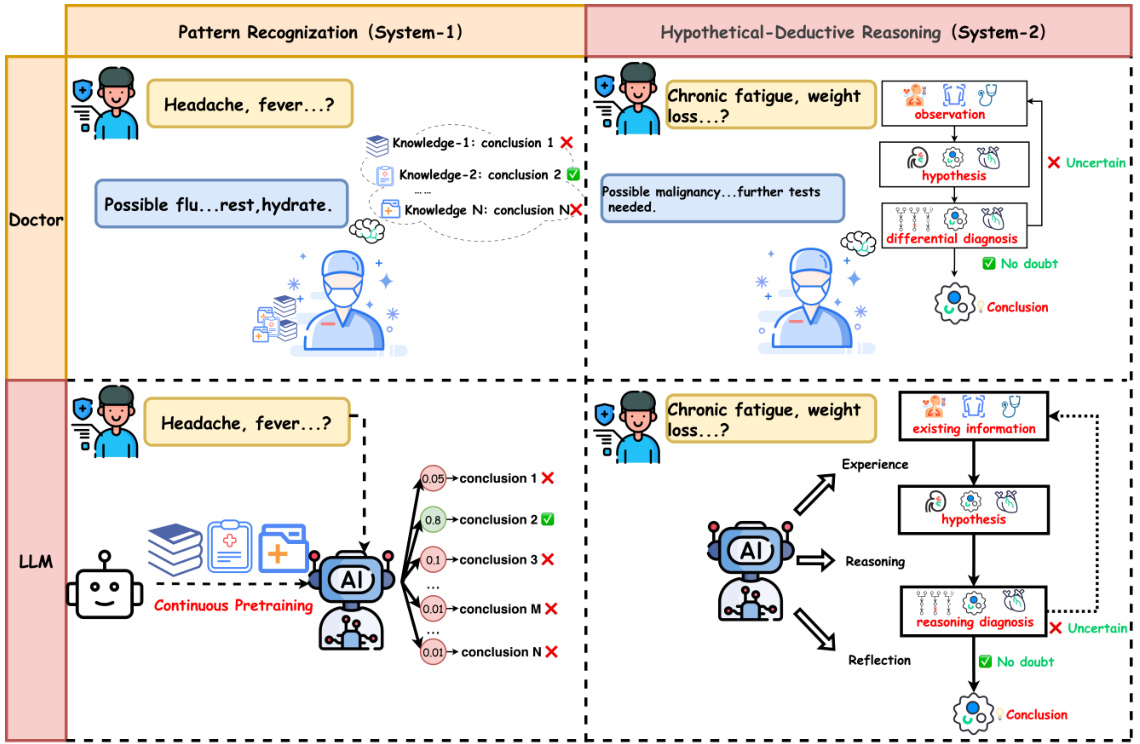
Figure 2: LLMs preforms similar cognitive pathways as medical experts. CPT enabled LLMs to learn medical knowledge and perform pattern recognition as doctors do, meanwhile LLMs are capable to handle hypothetical-deductive reasoning by executing several specific reasoning steps, which can be trained through SFT and RL procedure.
图 2: 大语言模型(LLM)展现出与医学专家相似的认知路径。CPT使大语言模型能够像医生一样学习医学知识并进行模式识别,同时通过执行多个特定推理步骤来处理假设-演绎推理,这些能力可通过监督微调(SFT)和强化学习(RL)流程进行训练。
3.2 CPT Data for Pattern Recognition
3.2 用于模式识别的CPT数据
The pattern-recognition method is typically embedded in the pre-training of large language models and is refined further during domain-specific training. Through the CPT process, a comprehensive medical domain dataset is used to enhance the pattern recognition capabilities of LLMs in addressing medical challenges. By collecting medical field data and preprocessing it, we have obtained a CPT dataset that enables LLMs to learn medical knowledge and perform pattern recognition.
模式识别方法通常嵌入在大语言模型(LLM)的预训练阶段,并在特定领域训练中进一步优化。通过CPT(Continual Pre-Training)流程,利用全面的医学领域数据集增强大语言模型解决医学挑战的模式识别能力。通过收集医学领域数据并进行预处理,我们获得了CPT数据集,使大语言模型能够学习医学知识并执行模式识别。
Data Collection The sources of CPT data include the following aspects:
数据收集
CPT数据的来源包括以下几个方面:
Data Process Data sourced from the web requires careful attention to data cleaning and labeling processes. Following the RedPajama[69] approach, we applied natural language processing techniques, such as entity recognition, relationship extraction, and text classification, for data cleaning and labeling. Additionally, we performed de duplication to ensure the quality of the dataset.
数据处理
来自网络的数据需要特别注意数据清洗和标注流程。我们遵循RedPajama[69]的方法,应用了自然语言处理技术(如实体识别、关系抽取和文本分类)进行数据清洗和标注。此外,我们还进行了去重处理以确保数据集质量。
For handling PDFs with complex structures, we leveraged certain computer vision solutions. In contrast to web text, data from research papers and medical guidelines presents a different challenge. While this type of data often boasts high-quality content, extracting and transforming it from highly complex structured formats into a form suitable for the CPT training process is particularly challenging. We processed over one million PDF documents using methods such as MAPneo[70].
为处理具有复杂结构的PDF文件,我们采用了部分计算机视觉解决方案。与研究论文和医疗指南的数据相比,网页文本数据带来了不同的挑战。虽然这类数据通常拥有高质量内容,但将其从高度复杂的结构化格式中提取并转换为适合CPT训练过程的形态尤为困难。我们使用MAPneo[70]等方法处理了超过一百万份PDF文档。
Regarding medical textbooks, we applied data augmentation techniques to synthesize data. Data derived from medical textbooks inherently represents an optimal training corpus. However, due to limitations on the number of medical books available for collection, this dataset is smaller compared to web and academic materials. In order to ensure that these high-quality data points have a significant impact during training without being overshadowed by the other two data sources, we utilized techniques such as WizardLM’s self-evolution method to diversify and expand the knowledge from individual books into a variety of medical queries[71].
关于医学教材,我们采用了数据增强技术来合成数据。源自医学教材的数据本质上代表了最佳的训练语料。然而,由于可收集的医学书籍数量有限,该数据集相较于网络和学术资料规模较小。为确保这些高质量数据在训练过程中产生显著影响而不被另外两个数据源掩盖,我们运用了WizardLM自进化方法等技术,将单本书籍的知识多样化为各类医学查询[71]。
Scale and Distribution To mitigate the performance degradation caused by catastrophic forgetting, we cannot train the model solely on medical corpora. Therefore, we cleaned and selected approximately 200 billion tokens of CPT corpus from the following public datasets (CCI[72], PubMed[73], SlimPajama[74], WuDao[75], Chinese Web Text[76], Math Pile[77], Stack Code[78], etc.) and pur- chased medical book data. After categorizing and labeling the data, we found that medical data accounted for about $30%$ of the total.
规模与分布
为缓解灾难性遗忘导致的性能下降,我们无法仅在医学语料上训练模型。因此,我们从以下公开数据集(CCI[72]、PubMed[73]、SlimPajama[74]、WuDao[75]、Chinese Web Text[76]、Math Pile[77]、Stack Code[78]等)中清洗筛选出约2000亿token的CPT语料,并采购了医学书籍数据。经分类标注后发现,医学数据占比约$30%$。
3.3 Data Synthesis for Hypo the tico-Deductive Reasoning
3.3 假设演绎推理的数据合成
The hypo the tico-deductive method is typically characterized by the following steps in an expert’s thinking process: collecting information, analyzing symptoms, generating diagnostic hypotheses, conducting differential diagnosis, and reaching conclusions. In this process, hypothesis generation and hypothesis testing are the core components of the reasoning process. To model this, we propose a comprehensive data series including general ability sft data with data course and medical ability sft data inspired from training-free dual expert data synthesis system.
假设-演绎法在专家的思维过程中通常表现为以下步骤:收集信息、分析症状、生成诊断假设、进行鉴别诊断并得出结论。该过程中,假设生成与假设检验是推理过程的核心环节。为此,我们提出一个综合数据序列建模方案,包含基于数据课程(data course)的通用能力微调(sft)数据,以及受无训练双专家数据合成系统启发的医疗能力微调数据。
3.3.1 General Medical Instruction Data
3.3.1 通用医疗指令数据
To enhance the model’s fundamental instruction-following capabilities and improve its ease of training, we design a two-stage data course that is not limited to medical problems. We refer to these as Stage-1 and Stage-2 SFT Data[79]. We recognize that it is an impractical task to directly train a base model, which has undergone medical knowledge CPT, to acquire medical reasoning abilities. LLMs struggle to effectively address complex medical reasoning problems when starting with no prior task-handling capabilities. To address this, we adopted a two-stage, general-purpose SFT data approach as part of our data curriculum.
为增强模型的基础指令遵循能力并提升训练便捷性,我们设计了一个不限于医学问题的两阶段数据课程,分别称为阶段1和阶段2 SFT数据[79]。我们认识到,直接训练已完成医学知识CPT的基础模型来获得医学推理能力是不切实际的。当大语言模型初始缺乏任务处理能力时,难以有效解决复杂的医学推理问题。为此,我们采用了两阶段通用SFT数据方案作为数据课程的一部分。
In the first stage, we train the model with approximately 7 million basic instruction examples to improve its ability to follow simple instructions. In the second stage, we use 1.4 million higher-quality and more complex instructions, aiming to enhance the model’s multi-turn dialogue handling and complex instruction-following capabilities while preserving the abilities gained from the first stage. This process results in the stage-2 SFT model, which provides a solid foundation for more specialized task training in subsequent phases.
在第一阶段,我们用约700万条基础指令样本训练模型,以提升其遵循简单指令的能力。第二阶段采用140万条更高质量、更复杂的指令,旨在增强模型处理多轮对话和遵循复杂指令的能力,同时保留第一阶段习得的技能。这一过程产出了第二阶段SFT模型,为后续更专业化的任务训练奠定了坚实基础。
3.3.2 Dual Expert Reasoning Method
3.3.2 双专家推理方法
In this section, we present the Dual-Expert Reasoning Method. Through this approach, LLMs can emulate medical experts by employing hypo the tico-deductive reasoning processes to address medical problems.
在本节中,我们提出双专家推理方法。通过这种方法,大语言模型(LLM)可以模拟医学专家,采用假设-演绎推理流程来解决医学问题。
To emulate the Hypo the tico-Deductive Process , we established a Reasoning Expert. When confronted with a problem, this role analyzes the available information, formulates new hypotheses, and conducts thorough reasoning. During the Training-free experiments, we observed that this process allows considerable flexibility. When the model does not engage in reflection, a significant amount of invalid reasoning processes are generated. This is unacceptable in terms of both reasoning accuracy and training efficiency. To address this, a multi-expert ensemble approach proves to be an effective solution. Thus, we designed a second expert, called the Reflection Expert. The Reflection Expert is tasked with evaluating the reasonableness of the reasoning process and discarding unreasonable or irrelevant steps. We then designed a cognitive flow loop to ensure the model generates a sufficient number of reasonable and accurate reasoning steps:
为模拟假说-演绎过程 (Hypothetico-Deductive Process),我们建立了一个推理专家角色。当遇到问题时,该角色会分析现有信息、提出新假设并进行缜密推理。在零样本实验中,我们发现这一过程具有高度灵活性。当模型未进行反思时,会产生大量无效推理过程,这在推理准确性和训练效率上都是不可接受的。为解决该问题,多专家集成方法被证明是有效方案。因此我们设计了第二个专家角色——反思专家,其职责是评估推理过程的合理性,并剔除不合理或无关的推理步骤。随后我们设计了一个认知流循环,确保模型生成足够数量合理且准确的推理步骤:
- The model lists the existing information as the starting point for reasoning. 2. Based on the existing information, the model proposes possible diagnoses as the endpoints of the reasoning.
- 模型将现有信息列为推理的起点。
- 基于现有信息,模型提出可能的诊断作为推理的终点。
This method allows the model to emulate the structured, logical reasoning used by physicians in medical decision-making. By using dual-expert reasinong method, the model can generate multiple possible conclusions, evaluate the validity of each, and progressively refine its reasoning to arrive at the most plausible conclusion. Furthermore, when faced with incomplete or ambiguous information, the model can request external knowledge to assist in making a diagnosis, mimicking the diagnostic approach of medical professionals.
该方法使模型能够模拟医生在医疗决策中使用的结构化逻辑推理。通过采用双专家推理方法,模型可以生成多个可能的结论,评估每个结论的有效性,并逐步完善其推理以得出最可信的结论。此外,当面对不完整或模糊的信息时,模型可以请求外部知识来辅助诊断,从而模拟医疗专业人员的诊断方法。
3.3.3 Medical Reasoning Instruction Data
3.3.3 医学推理指令数据
In this section, we describe the construction of Stage-3 SFT Data using the Dual-Expert Reasoning Method. This dataset, called Citrus_S3, designed to improve medical reasoning abilities in LLMs, will be open-sourced to promote further research and development in the field. To ensure accuracy and diversity, we propose several advanced data processing techniques, outlined below.
在本节中,我们将介绍如何使用双专家推理方法构建第三阶段监督微调(SFT)数据集Citrus_S3。该数据集旨在提升大语言模型(LLM)的医学推理能力,并将开源以推动该领域的进一步研究发展。为确保数据准确性和多样性,我们提出了以下先进的数据处理技术:
Reasoning Model with Ground Truth The key to generating reliable medical COT training data using this dual-expert method without additional supervised training is ensuring that the model generates a reasonable and accurate reasoning process. To achieve this, we modified the training-free method by providing the reflection model with the ground truth for the medical questions faced by the reasoning model. In this setup, the reflection model evaluates the reasonableness of the steps generated by the reasoning model and subtly guides it toward the correct answer, without directly providing the solution.This design results in a redefined step 4 in the dual-expert method.
带真实答案的推理模型
采用这种双专家方法生成可靠的医学COT训练数据而无需额外监督训练的关键,在于确保模型能生成合理且准确的推理过程。为此,我们改进了无需训练的方法:为反思模型提供推理模型所面对医学问题的真实答案。在这种设置下,反思模型会评估推理模型生成步骤的合理性,并巧妙引导其接近正确答案,而非直接提供解决方案。这一设计重新定义了双专家方法中的步骤4。
Question Seeds Another indispensable part to successfully execute this data generation procedure is to have extensive medical questions, which should be complicated enough to ignite reasoning process as well as equipped with ground truth that has been properly verified.
问题种子
成功执行这一数据生成流程的另一个不可或缺的部分是拥有大量医学问题。这些问题需要足够复杂以激发推理过程,同时还需配备经过适当验证的正确答案。
Question Rewriting The training question seeds in datasets like MedQA[80] are closed-form questions. We believe that providing answer options limits the model’s reasoning capacity, restricting its ability to explore different reasoning paths. To improve generalization, we made the following adjustments:
问题重写
MedQA[80]等数据集中的训练问题种子多为封闭式问题。我们认为提供答案选项会限制模型的推理能力,阻碍其探索不同推理路径。为提高泛化性,我们做出以下调整:
Question Quality Control Simple medical questions can be answered based on the model’s existing knowledge, but they do not require complex medical reasoning. To filter data useful for learning reasoning abilities, we used models such as GPT-4o-2024-0513, Qwen2.5-7B[81], and Llamba-3.1-8B[82] to answer closed-form questions. If these models answered correctly, the data was categorized as easy data, which does not require reasoning. Otherwise, it was categorized as hard data. During the SFT data sampling stage, we used all the hard data and a small portion of easy data to ensure the quality of the training dataset.
问题质量控制
简单的医学问题可以根据模型现有知识回答,不需要复杂的医学推理。为了筛选有助于学习推理能力的数据,我们使用了 GPT-4o-2024-0513、Qwen2.5-7B[81] 和 Llamba-3.1-8B[82] 等模型来回答封闭式问题。如果这些模型回答正确,数据被归类为简单数据(无需推理),否则归类为困难数据。在 SFT 数据采样阶段,我们使用了全部困难数据和少量简单数据,以确保训练数据集的质量。
Data rewriting Data rewriting is essential to transform multi-expert problem analysis into a first-person thought process. We use LLMs to accomplish this task with several strict constraints:
数据重写
数据重写对于将多专家问题分析转化为第一人称思考过程至关重要。我们使用大语言模型 (LLM) 在以下严格约束条件下完成此任务:
3.3.4 Data Analysis
3.3.4 数据分析
| DataSetName | TrainingStage | Scale | Field | ConstructionMethod |
|---|---|---|---|---|
| WebData | CPT | 287B | General | Open-Source |
| MedicalTextbooks | CPT | 4.6Btokens | modernmedicine | Collect |
| Medicalguidelines andliterature | CPT | 73Btokens | modernmedicine | Collect |
| Infinity-Instruct-7M | SFT stage1 | 7Mlines | General&InstructionFellowing | Open-Sourceandin-housedata |
| Infinity-Instruct-gen | SFT stage 2 | 1.4Mlines | General&InstructionFellowing | Open-Sourceandin-housedata |
| Citrus_S3 | SFTs stage3 | 60K lines | Long COT on Medical Reasoning | Data Synthesis |
| Citrus_xpo | RL | 50K pairs | Long COT on Medical Reasoning | RejectionSampling |
Table 1: Training Data statistics. Our training data is incorporating with CPT data, SFT data and RL data. The table shows the scale, field and construction method of each dataset.
表 1: 训练数据统计。我们的训练数据整合了CPT数据、SFT数据和RL数据。该表展示了每个数据集的规模、领域和构建方法。
This data synthesis approach, which is shown in Table.1, enables LLMs to generate medical COT data that aligns with medical logic, thereby enhancing their medical capabilities without the need for additional model training. Furthermore, by utilizing data synthesized using the hypo the tico-deductive method for model training, the model can acquire medical reasoning capabilities similar to those of doctors.
表 1 所示的数据合成方法使大语言模型(LLM)能够生成符合医学逻辑的医疗思维链(COT)数据,从而无需额外模型训练即可提升其医疗能力。此外,通过使用基于假设-演绎法合成的数据进行模型训练,该模型可获得类似医生的医学推理能力。
4 Model Training
4 模型训练
In this section, we present a comprehensive training procedure that integrates multiple stages, including CPT, SFT, and RL, referred in Figure.3. Through this multi-phase approach, we aim to transform a base model, initially lacking domain-specific medical knowledge and reasoning abilities, into a robust medical reasoning model capable of performing complex cognitive processes to effectively address and solve clinical problems. The training procedure leverages both generalpurpose and medical-specific data, progressively refining the model’s ability to handle medical tasks and engage in sophisticated reasoning when confronted with real-world clinical scenarios.
在本节中,我们提出了一种整合CPT、SFT和RL等多阶段的综合训练流程(如图3所示)。通过这种多阶段方法,我们的目标是将一个最初缺乏特定领域医学知识和推理能力的基础模型,转化为能够执行复杂认知过程、有效解决临床问题的强大医学推理模型。该训练流程同时利用通用数据和医学专用数据,逐步提升模型处理医疗任务的能力,使其在面对真实临床场景时能进行复杂推理。
4.1 CPT Stage
4.1 CPT阶段
This phase focuses on the continuous pre-training of existing foundation models to enhance their comprehension of medical domain knowledge. A primary challenge lies in adapting the same dataset for different foundation models, which possess distinct training data ratios and quality control mechanisms.
本阶段侧重于对现有基础模型进行持续预训练,以增强其对医学领域知识的理解能力。主要挑战在于如何将同一数据集适配于不同基础模型,这些模型具有差异化的训练数据比例与质量控制机制。
In the continuous pre-training of large language models, the ratio of data from different sources is a critical topic. Here, we employ an AutoML approach to dynamically determine the proportion of each data source during training. Specifically, we frame the data ratio problem as a multi-armed bandit problem[83]. We hypothesize that the benefit of encountering previously seen content in continuous pre-training is relatively small, so the model should be encouraged to learn new knowledge. Therefore, we treat the training loss from each data source as a reward. Through this methodology, base models are exposed to training corpora with dynamically adjusted sampling ratios across different training phases, resulting in substantially improved convergence efficiency.
在大语言模型的持续预训练中,不同来源数据的配比是关键议题。我们采用AutoML方法动态确定训练过程中各数据源的比例,具体将数据配比问题建模为多臂老虎机问题[83]。我们假设持续预训练中重复接触已见内容的收益相对较小,因此应鼓励模型学习新知识。为此,我们将各数据源的训练损失作为奖励信号,通过这种方法使基座模型在不同训练阶段接触采样比例动态调整的语料,从而显著提升收敛效率。
4.2 SFT Stage
4.2 SFT阶段
4.2.1 Medical Reasoning Ability SFT Training
4.2.1 医疗推理能力监督微调(SFT)训练
We propose a three-stage SFT training framework to enhance the model’s medical reasoning capabilities. As discussed in Section 3.3, the SFT datasets across these three stages are arranged in ascending order of difficulty. The underlying rationale is that the model should first master general knowledge application skills before proceeding to complex medical reasoning logic. In the following section, we will focus on elaborating the third stage of SFT training.
我们提出了一种三阶段的监督微调(SFT)训练框架来增强模型的医疗推理能力。如第3.3节所述,这三个阶段的SFT数据集按照难度升序排列。其核心理念是模型应先掌握通用知识应用技能,再进阶到复杂的医疗推理逻辑。下文将重点阐述SFT训练的第三阶段。
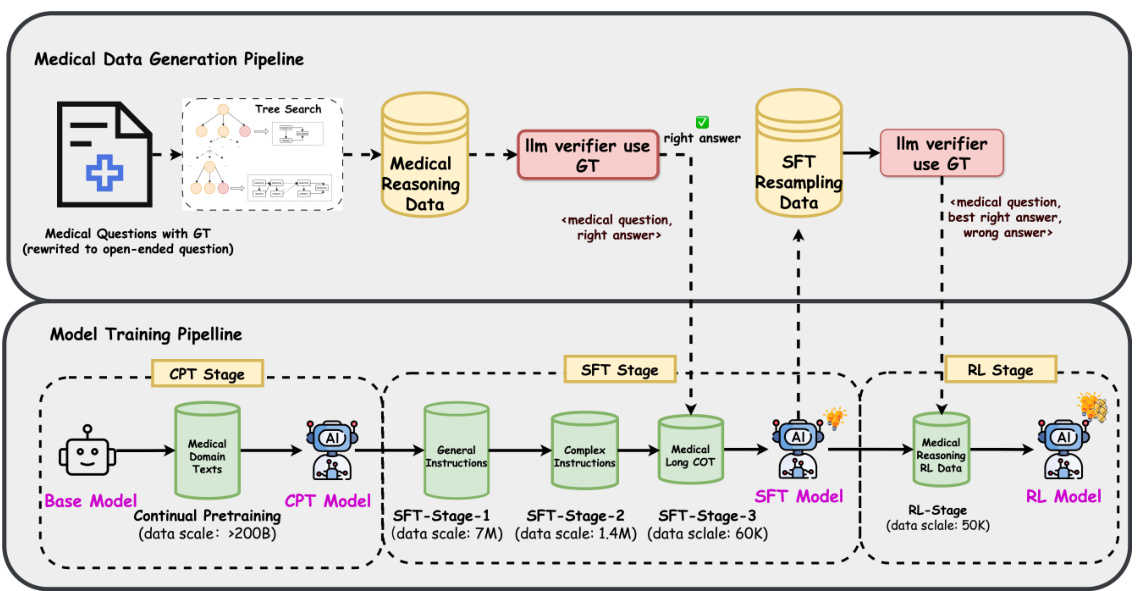
Figure 3: Overview of training stages and training data pipeline . The training process consists of three stages: CPT, SFT, and RL. We shows training purposes and dataset scale on each stage, also, we points out the data pipeline in corresponding stage.
图 3: 训练阶段及训练数据流程概览。训练过程包含三个阶段: CPT、SFT 和 RL。我们展示了各阶段的训练目标与数据集规模,并标注了对应阶段的数据流程。
The third phase of SFT training focuses on improving the model’s performance in the target task domain: medical reasoning. We used data obtained from the Training-Free approach and fine-tuned the Stage-2 SFT model in this phase. The main objective of this phase is to enhance the model’s ability to perform long COT in medical reasoning tasks. We used approximately 100,000 medical benchmark problems with Ground Truth gold-standard answers to generate reasoning data, which were used to train the model’s medical reasoning capabilities. To maintain the model’s general-purpose capabilities during this process, we included reasoning data from other domains, such as logical and mathematical reasoning, in quantities comparable to the medical data. A toekn distribution statistics of stage 3 SFT training data is shown in Figure.4.
SFT训练的第三阶段专注于提升模型在目标任务领域——医学推理中的表现。我们采用从Training-Free方法获得的数据,在此阶段对Stage-2 SFT模型进行微调。该阶段的主要目标是增强模型在医学推理任务中执行长链思维链(COT)的能力。我们使用约10万道带有Ground Truth黄金标准答案的医学基准问题生成推理数据,用于训练模型的医学推理能力。为保持模型的通用能力,在此过程中我们加入了与医学数据量相当的其他领域推理数据,例如逻辑推理和数学推理。阶段3 SFT训练数据的token分布统计如图4所示。
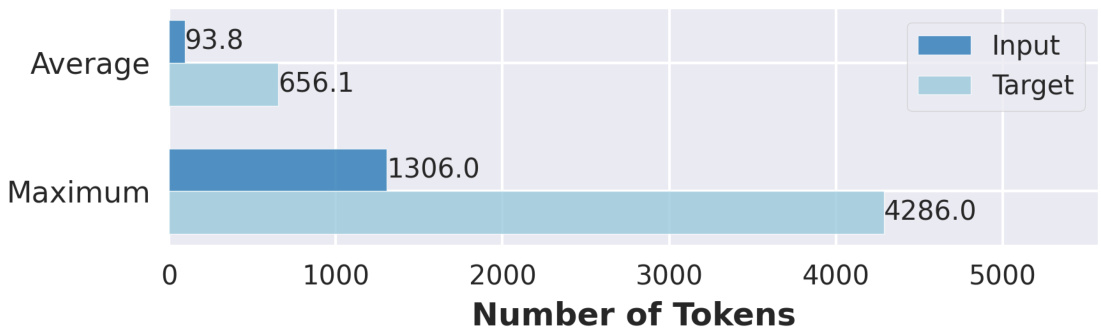
Figure 4: Token distribution statistics of stage 3 SFT training data. The data are designed and manufactured to simulate the long COT reasoning process of medical experts. We confirm a average length of 656 tokens and upper-bound of the length is around 4k.
图 4: 阶段3 SFT训练数据的Token分布统计。该数据经过设计加工,用于模拟医学专家的长链思维(COT)推理过程。我们确认平均长度为656个Token,长度上限约为4k。
4.2.2 SFT Data Format
4.2.2 SFT 数据格式
For all SFT data, we follow an unified template format: <sft-input, sft-target>. The sft-input consists of open-ended questions, and we expect the reasoning model to follow a structured thought process before providing answers. The resulting sft-target outputs follow the format:
对于所有监督微调(SFT)数据,我们遵循统一的模板格式:<sft-input, sft-target>。sft-input由开放式问题组成,我们期望推理模型在提供答案前遵循结构化的思考过程。最终的sft-target输出格式为:
tokens
4.3 RL Stage
4.3 强化学习阶段
After obtaining the Stage-3 SFT model, an effective reinforcement learning (RL) training phase is necessary. Compared to online methods, the RL techniques used in this phase, such as SIMPO[84] and CPO[85], have distinct advantages. SimPO completely eliminates the dependency on reference models, by directly using the average log probability generated by the policy model as an implicit reward. This not only reduces computational and memory consumption but also simplifies the training process, avoiding the complexity brought by multi-stage optimization. By introducing length normalization, SimPO effectively prevents the model from being biased toward generating lengthy but low-quality responses due to the reward mechanism. However, SimPO is quite sensitive to the learning rate, so we introduced NLL loss, similar to the CPO method, to enhance training stability. These methods offer more stable and efficient learning compared to traditional online reinforcement learning methods. For the RL training, we used data that shares the same origin as that used in Pre-RL SFT, sampling and training on a dataset of approximately 50,000 instances.
在获得第三阶段监督微调(SFT)模型后,需要开展有效的强化学习(RL)训练阶段。相较于在线方法,本阶段采用的SIMPO[84]和CPO[85]等RL技术具有显著优势。SimPO通过直接使用策略模型生成的平均对数概率作为隐式奖励,完全消除了对参考模型的依赖。这不仅降低了计算和内存消耗,还简化了训练流程,避免了多阶段优化带来的复杂性。通过引入长度归一化机制,SimPO有效防止模型因奖励机制倾向生成冗长但低质量的响应。但SimPO对学习率较为敏感,因此我们借鉴CPO方法引入负对数似然(NLL)损失函数来提升训练稳定性。相比传统在线强化学习方法,这些技术能提供更稳定高效的学习效果。在RL训练阶段,我们使用了与预强化学习SFT同源的数据集,从中采样约5万条样本进行训练。
4.3.1 RL Data Sampling
4.3.1 RL 数据采样
We use the best-performing checkpoint after the Stage-3 SFT to perform rejection sampling. The process is as follows:
我们使用阶段3监督微调(SFT)后表现最佳的检查点进行拒绝采样。具体流程如下:
Repeat Sampling: Open-ended questions (without answer options) are given to the model, which generates 20 responses at a high temperature (temperature $=1.2$ ).
重复采样:向模型提出开放式问题(无预设选项),并在高温参数(temperature $=1.2$)下生成20组回答。
Construct Preference Data: To teach the model reasoning methods instead of just generating reasoning-like statements, we use rule-based rewards based on answer correctness, other than neural reward models. This ensures that rewards are accurately aligned with the correct reasoning steps. Specifically:
构建偏好数据:为了教会模型推理方法而非仅生成类似推理的陈述,我们基于答案正确性采用基于规则的奖励机制,而非神经奖励模型。这确保奖励与正确的推理步骤精确对应。具体而言:
4.3.2 RL Data Format
4.3.2 RL 数据格式
For the RL stage, the data format is <RL-input, chosen, rejected>. The RL-input format matches the sft-input format, and chosen and rejected follow the sft-target format.
在强化学习 (RL) 阶段,数据格式为 <RL输入, 优选, 淘汰>。RL输入格式与监督微调 (sft-input) 格式一致,优选和淘汰遵循监督微调目标 (sft-target) 格式。
5 JDH Medical Practice Dataset: Construction and Validation of a Real-World Clinical Dialogue Benchmark
5 JDH医疗实践数据集:真实世界临床对话基准的构建与验证
Evaluating medical models is inherently challenging, especially when aligning them with real-world clinical settings. Effective evaluations should ensure that these models can be applied successfully in clinical practice.We systematically analyzed several widely-used medical QA datasets (e.g., MedQA[80], PubMedQA[86], MedMCQA[87], MedBullets[88], MMLU[67], MMLU-Pro[66], and CARE-QA[89]), as shown in Table 2. This analysis revealed three distinctive characteristics: (1) Most datasets are exclusively sourced from medical journal literature or professional medical examinations, with none incorporating real-world hospital data; (2) Question formats primarily consist of multiplechoice questions (MCQs) with 4-5 options, except for MMLU-Pro, which uses a 10-option format. These questions feature clear conditions and fixed options, failing to capture the ambiguity and limited diagnostic information encountered in real clinical settings; (3) With the exception of CareQA, the remaining datasets lack continuous updates after their initial release.
评估医学模型本质上是具有挑战性的,尤其是在使其与现实临床环境保持一致时。有效的评估应确保这些模型能成功应用于临床实践。我们系统分析了多个广泛使用的医学问答数据集(如MedQA[80]、PubMedQA[86]、MedMCQA[87]、MedBullets[88]、MMLU[67]、MMLU-Pro[66]和CARE-QA[89]),如表2所示。该分析揭示了三个显著特征:(1) 大多数数据集仅来源于医学期刊文献或专业医学考试,未包含真实医院数据;(2) 问题形式主要为4-5选项的多选题(MCQs),除MMLU-Pro采用10选项形式。这些问题具有明确条件和固定选项,无法反映真实临床场景中的模糊性和有限诊断信息;(3) 除CareQA外,其余数据集在首次发布后均缺乏持续更新。
To address this, we developed the JMED, a novel dataset based on real-world medical data distributions. Unlike existing datasets, JMED closely mimics authentic clinical data while facilitating effective model training. Although based on real consultation data, it is not directly sourced from actual medical data, allowing us to incorporate key elements necessary for model training. We ensured compliance with ethical and legal standards throughout the data collection process, safeguarding privacy and meeting ethical guidelines. Due to the open-ended nature of medical consultations, where definitive answers are often elusive, the evaluation process is more challenging. To address this, each question includes 21 response options, with a "None of the above" choice. This design significantly increases the complexity and difficulty of distinguishing the correct answers, thereby providing a more rigorous assessment framework.
为此,我们开发了JMED数据集,这是一个基于真实医疗数据分布的新型数据集。与现有数据集不同,JMED在有效促进模型训练的同时,高度模拟真实临床数据。虽然基于真实问诊数据,但并非直接取自实际医疗数据,这使得我们可以融入模型训练所需的关键要素。整个数据收集过程严格遵循伦理和法律标准,确保隐私保护并符合伦理规范。由于医疗咨询具有开放性特征,往往难以获得明确答案,这使得评估过程更具挑战性。为此,每个问题都包含21个应答选项,其中包括"以上都不是"选项。这种设计显著增加了区分正确答案的复杂度和难度,从而提供了更严谨的评估框架。
Compared to existing medical QA datasets, JMED has three principal advantages: First, it more accurately reflects the ambiguity in patient symptom descriptions and the dynamic nature of clinical diagnosis in real-world scenarios. Second, the expanded response options require enhanced reasoning capabilities to identify the correct answers among numerous distract or s. Additionally, leveraging the vast amount of consultation data from JDH Internet Hospital, we can continuously generate data that aligns with the distribution characteristics of real patients.
与现有医疗问答数据集相比,JMED具备三大核心优势:首先,它能更精准地反映真实场景中患者症状描述的模糊性和临床诊断的动态性;其次,扩展的选项设置要求模型具备更强的推理能力,才能在大量干扰项中识别正确答案;此外,依托京东健康互联网医院海量问诊数据,我们可持续生成符合真实患者分布特征的数据。
| 数据源 (DataSource) | 答案格式 (AnswerFormat) | 测试数据集大小 (TestDatasetSize) | 发布时间 (ReleasedTime) | 最近更新时间 (LatestUpdateTime) | |
|---|---|---|---|---|---|
| MedQA | 考试 (Examination) | 4选项多选题 (4-optionMCQs) | 1,273 | 2022 | 2022 |
| PubMedQA | 文献 (Literature) | 3选项多选题 (3-optionMCQs) | 1,000 | 2019 | 2019 |
| MedMCQA | 考试 (Examination) | 4选项多选题 (4-optionMCQs) | 4,183 | 2022 | 2022 |
| MedBullets | 考试 (Examination) | 5选项多选题 (5-optionMCQs) | 308 | 2024 | 2024 |
| MMLU | 考试 (Examination) | 4选项多选题 (4-optionMCQs) | 1,871 | 2021 | 2021 |
| MMLU-Pro | 考试 (Examination) | 10选项多选题 (10-optionMCQs) | 818 | 2024 | 2024 |
| CareQA | 考试 (Examination) | 4选项多选题 (4-option MCQs) | 5,410 | 2020 | 2024 |
| JMED | 医院 (Hospital) | 21选项多选题 (21-optionMCQs) | 1,000 | 2025 | 可更新 (updatable) |
Table 2: Comparison of our dataset JMED with existing medical QA datasets. JMED outperforms the most amount of options in MCQs and is the only one based on real-world hospital data. These two factors make JMED more challenging and realistic.
表 2: 我们的数据集 JMED 与现有医疗问答数据集的对比。JMED 在单选题中表现最优,且是唯一基于真实医院数据构建的数据集。这两个因素使得 JMED 更具挑战性和现实意义。
5.1 Data Collection and Construction Pipeline
5.1 数据收集与构建流程
5.1.1 Raw Data Processing
5.1.1 原始数据处理
The dataset originates from anonymized doctor-patient dialogues at JD Health Internet Hospital, filtered to retain consultations adhering to standardized diagnostic workflows. The initial release contains 1,000 high-quality clinical records spanning all age groups (0-90 years) and multiple specialties.
数据集源自京东健康互联网医院的匿名医患对话,经过筛选保留了符合标准化诊疗流程的咨询记录。初始版本包含1000份高质量临床病历,覆盖全年龄段(0-90岁)及多个专科领域。
5.1.2 Structured Transformation
5.1.2 结构化转换
We constructed a set of multiple-choice questions (MCQs) based on the pre processed data, as illustrated in Figure 5.
我们基于预处理数据构建了一套选择题 (MCQs) ,如图 5 所示。
• Electronic Medical Record (EMR) Generation: Extracted key clinical elements using prompt engineering to create structured EMRs. • Question Formulation: Employed the DeepSeek-r1 model to parse EMRs and generate clinically coherent questions aligned with diagnostic reasoning pathways.
- 电子病历 (EMR) 生成:通过提示工程提取关键临床要素,生成结构化电子病历。
- 问题构建:采用 DeepSeek-r1 模型解析电子病历,生成符合诊断推理路径的临床连贯性问题。

Figure 5: The construction framework of our dataset, JMED, is illustrated with arrows indicating the type of data used as input for the LLMs and the corresponding response obtained at each step. We begin by consolidating the dialogue data into EMRs, then transform it into the format of medical examination questions, and finally, through option expansion and quality checks, we obtain our dataset.
图 5: 我们的数据集JMED构建框架示意图,箭头表示每个步骤中作为大语言模型输入的数据类型及相应输出。我们首先将对话数据整合为电子病历(EMR),然后转换为医学试题格式,最终通过选项扩展和质量检查得到最终数据集。
• Option Expansion: Generated 21 mutually exclusive diagnostic options (including standardized ICD-10 terms and plausible differential diagnoses) using LLMs, ensuring compliance with the International Classification of Diseases, 10th Revision (ICD-10).
• 选项扩展:使用大语言模型生成21个互斥的诊断选项(包括标准化的ICD-10术语和合理的鉴别诊断),确保符合《国际疾病分类第十次修订版》(ICD-10)的要求。
5.2 Quality Assurance Framework
5.2 质量保障框架
Considering the seriousness and precision required in the medical field, a three-tier quality control system was established. This primary review process involves collaboration with physicians from 15 departments, with each department having two attending or associate attending-level doctors review the questions. Secondary validation is distributed to associate experienced physicians to conduct a re-evaluation, leveraging their expertise to ensure data quality and accuracy, and final audit is processed by chief physicians. All manual review processes must adhere to the criteria as describe in appendix D.
考虑到医疗领域所需的严谨性和精确性,我们建立了三级质量控制体系。初级审核流程由15个科室的医师协作完成,每个科室安排两名主治或副主任医师级别医生进行题目审核。二级验证由资深副主任医师开展复评,借助其专业经验确保数据质量与准确性,终审则由主任医师执行。所有人工审核流程均须遵循附录D所述标准。
Based on the aforementioned criteria, we have constructed a set of 1000 multiple-choice questions derived, encompassing multiple departments and age groups. Each data entry includes a unique ID, department, question, options, and the correct answer. The options adhere to the ICD-10 standard for disease nomenclature and have been reviewed and validated by professional physicians to ensure the appropriateness of the questions, options, and correct answers.
基于上述标准,我们构建了一套包含1000道选择题的数据集,涵盖多个科室和年龄段。每条数据包含唯一ID、科室、问题、选项和正确答案。选项遵循ICD-10疾病命名标准,并经过专业医师审核验证,确保问题、选项及正确答案的合理性。
5.3 Dataset Characteristics
5.3 数据集特征
As shown in Figure 6, the validated subset comprises 1000 clinically rigorous multiple-choice questions with the following demographic distributions:
如图 6 所示,经过验证的子集包含 1000 道临床严格的多选题,其人口统计分布如下:

Figure 6: Age distribution statistics of males and females in our dataset. We got the main age distribution of the dataset is 21-40 years old with $83.38%$ in portion. Meanwhile, we observe an unbalanced distribution in gender, that male patients are $58%$ .
图 6: 数据集中男性和女性的年龄分布统计。数据显示主要年龄集中在21-40岁区间,占比达83.38%。同时观察到性别分布不均衡现象,男性患者占比58%。
This distribution aligns with real-world usage patterns of online consultation platforms: adults constitute the primary user base, while consultations for pediatric and elderly patients are typically initiated by caregivers. Statistical analysis confirms that internet-based healthcare platforms have emerged as the preferred channel for adult populations seeking medical services.
这一分布与在线问诊平台的实际使用模式相符:成年人构成主要用户群体,而儿科和老年患者的问诊通常由看护者发起。统计分析证实,互联网医疗平台已成为成年人群体寻求医疗服务时的首选渠道。
6 Experiments
6 实验
6.1 Experimental Setup
6.1 实验设置
Implementation Details We tested our methodology on Qwen2.5-72B[81], LLama3.1-70B[14] as our base models due to their foundational capabilities. The knowledge capacity of such large-scale models is a prerequisite for stimulating medical reasoning abilities. We use a two-stage SFT to enhance the general capabilities of the model, and in the third stage, we use a small amount of reasoning data to improve the model’s medical reasoning ability. In the final stage, we performed reject sampling and alignment on the model to further enhance its reasoning capabilities. We use DeepSpeed ZeRO-3 and Accelerate to train the LLM, with AdamW as the optimizer. The $\beta1$ and $\beta2$ of AdamW are 0.9 and 0.95, respectively. We apply a weight decay of 1e-4 and clip the gradient norm to 1.0.
实现细节
我们基于Qwen2.5-72B[81]和LLama3.1-70B[14]作为基础模型测试了我们的方法,因为它们具备基础能力。这类大规模模型的知识容量是激发医疗推理能力的先决条件。我们采用两阶段监督微调(SFT)增强模型的通用能力,在第三阶段使用少量推理数据提升模型的医疗推理能力。最终阶段通过拒绝采样和对齐操作进一步强化模型的推理能力。
训练使用DeepSpeed ZeRO-3和Accelerate框架,优化器采用AdamW,其超参数$\beta1$和$\beta2$分别设为0.9和0.95。权重衰减系数为1e-4,梯度范数裁剪阈值为1.0。
Training Hyper parameters The hyper parameter settings for our model training are shown in the table below. The training parameters for Qwen and LLaMA differ only in the learning rate during the alignment phase. Details are shown in Table 3.
训练超参数
我们的模型训练超参数设置如下表所示。Qwen和LLaMA的训练参数仅在对齐阶段的学习率上有所不同。具体细节如表3所示。
6.2 Benchmarks
6.2 基准测试
We utilized the MedQA[80], PubMedQA[86], MedMCQA[87], MedBullets[88], MMLU[67], MMLU-Pro[66], and CARE-QA[89] as benchmarks, with JMED serving as a medical reasoning evaluation dataset specifically developed by us.
我们采用MedQA[80]、PubMedQA[86]、MedMCQA[87]、MedBullets[88]、MMLU[67]、MMLU-Pro[66]和CARE-QA[89]作为基准测试集,并以JMED作为我们专门开发的医学推理评估数据集。
Table 3: Model Training Hyper parameter Settings. We show the training hyper parameters for both Qwen2.5-72B and Llama3.1-70B in different stages. We find only a slight difference in the learning rate during the alignment phase since Llama is harder to constrain with such a high learning rate which Qwen is working at.
表 3: 模型训练超参数设置。我们展示了 Qwen2.5-72B 和 Llama3.1-70B 在不同阶段的训练超参数。我们发现仅在对齐阶段学习率存在轻微差异,因为 Llama 在 Qwen 使用的高学习率下更难约束。
| 模型名称 | 训练阶段 | 学习率 | 批量大小 | 训练轮数 | 其他超参数 |
|---|---|---|---|---|---|
| Citrus-Qwen-72B | stage1 | 5e-6 | 512 | 2 | |
| Citrus-Qwen-72B stage1 | stage2 | 5e-6 | 512 | 1 | |
| Citrus-Qwen-72B stage2 | stage3 | 5e-6 | 512 | 2 | |
| Citrus-Qwen-72B stage3 | cpo-simpo | 1e-6 | 16 | 3 | Q=0.05, β=10, γ=5.4 |
| Citrus-Llama-70B | stage1 | 5e-6 | 512 | 2 | |
| Citrus-Llama-70B stage1 | stage2 | 5e-6 | 512 | 1 | |
| Citrus-Llama-70B stage2 | stage3 | 5e-6 | 512 | 2 | |
| Citrus-Llama-70B stage3 | cpo-simpo | 3e-7 | 16 | 3 | Q=0.05, β=10, γ=5.4 |
MedQA dataset is derived from multiple-choice questions of the United States Medical Licensing Examination (USMLE), covering English, Simplified Chinese, and Traditional Chinese. It is designed to evaluate a model’s understanding and reasoning ability in medical knowledge.
MedQA数据集源自美国医师执照考试(USMLE)的选择题,涵盖英语、简体中文和繁体中文,旨在评估模型对医学知识的理解和推理能力。
PubMedQA is a biomedical question-answering dataset collected from PubMed abstracts, containing 1,000 expert-annotated, 61,200 unlabeled, and 211,300 artificially generated QA instances to evaluate a model’s understanding and reasoning ability in biomedical research texts.
PubMedQA是一个从PubMed摘要中收集的生物医学问答数据集,包含1,000个专家标注、61,200个未标注和211,300个人工生成的问答实例,用于评估模型在生物医学研究文本中的理解和推理能力。
MedMCQA is sourced from multiple-choice questions in the AIIMS and NEET PG entrance exams. The dataset comprises over 194,000 multiple-choice questions, covering 2,400 healthcare topics and 21 medical subjects. Its purpose is to evaluate and improve models for generating answers to multiple-choice questions in the medical field.
MedMCQA数据集来源于AIIMS和NEET PG入学考试中的选择题。该数据集包含超过194,000道选择题,涵盖2,400个医疗健康主题和21个医学学科,旨在评估和改进医学领域选择题答案生成的模型。
MedBullets is a free learning and collaboration community that offers a large collection of USMLEstyle questions and study resources. The dataset includes over 1,000 free USMLE Step 1-style questions, along with extensive study materials. The question type is primarily USMLE Step 1-style multiple-choice questions. Its purpose is to provide a learning and collaboration platform for medical students.
MedBullets 是一个免费的学习与协作社区,提供大量 USMLE 风格的试题和学习资源。该数据集包含 1,000 多道免费的 USMLE Step 1 风格试题及丰富的学习资料,题型主要为 USMLE Step 1 风格的多选题,旨在为医学生提供学习与协作平台。
MMLU is a large-scale multitask language understanding benchmark dataset designed to evaluate the knowledge and reasoning abilities of large language models across multiple subjects.
MMLU是一个大规模多任务语言理解基准数据集,旨在评估大语言模型在多个学科领域的知识和推理能力。
MMLU-Pro is an improved and upgraded version of MMLU, designed to provide more challenging and difficult test questions.
MMLU-Pro是MMLU的改进升级版本,旨在提供更具挑战性和难度的测试题目。
CareQA is a healthcare QA dataset. The dataset originates from official sources of the Spanish Specialized Healthcare Training (FSE) examinations, including the biology, chemistry, medicine, nursing, pharmacology, and psychology tests from 2020 to 2024.
CareQA是一个医疗问答数据集。该数据集源自西班牙专科医疗培训(FSE)考试的官方题库,包含2020至2024年生物学、化学、医学、护理学、药理学和心理学科目的试题。
JMED dataset comes from JD Health’s online internet hospital and is designed to simulate real clinical data.
JMED数据集来自京东健康的在线互联网医院,旨在模拟真实的临床数据。
6.3 Main Results
6.3 主要结果
We evaluated multiple open-source and closed source LLMs on medical tasks, as shown in Table below.
我们在医疗任务上评估了多个开源和闭源的大语言模型,如下表所示。
According to the Main Result Table.4, Citrus1.0-Llama-70B reach a top class performance on 70B scale models, especially on MedQA,PubMedQA,MedBullets,CareQA benchmark. Citrus also surpasses many close-source top LLMs such as Claude-sonnet and GPT-4o. Our model consistently demonstrates strong performance across a wide range of medical benchmarks, highlighting the effectiveness of our proposed approach. Observing the loss curve in Figure.7, it can be seen that the model gradually converges at each SFT stage. In the alignment phase, the reward curve of CPO-SimPO gradually rises and converges. The evaluation results indicate that the performance of the aligned model is the best among all stages.
根据主结果表4显示,Citrus1.0-Llama-70B在70B规模模型中达到顶级性能,尤其在MedQA、PubMedQA、MedBullets和CareQA基准测试中表现突出。Citrus还超越了Claude-sonnet和GPT-4o等众多闭源顶尖大语言模型。我们的模型在各类医学基准测试中持续展现强劲性能,凸显了所提出方法的有效性。观察图7中的损失曲线可见,模型在每个SFT阶段逐步收敛。在对齐阶段,CPO-SimPO的奖励曲线逐渐上升并收敛。评估结果表明,对齐后模型的性能是所有阶段中最优的。
6.4 Future Discussion
6.4 未来展望
In the ablation experiments, we explore the impacts on different stage of training, including SFT stage 1,2,3 and RL stage. As the most distinguishable and influential benchmarks for medical scenario challenges, MedQA is carefully selected as "North star" during our training procedure from the base model all the way to the final one. The results shown in Table.5 provide insights into the importance of each procedure in the training pipeline, discussed as below.
在消融实验中,我们探究了训练不同阶段的影响,包括SFT阶段1、2、3和RL阶段。作为医疗场景挑战中最具区分度和影响力的基准测试,MedQA被精心选为我们从基础模型到最终模型的整个训练过程中的"北极星"。表5所示的结果揭示了训练流程中每个环节的重要性,具体讨论如下。
Table 4: Main Results on Medical Benchmarks. LLMs are seperated into 70B scale group and beyond 70B group. Citrus leads most benchmarks among 70B LLMs, moreover, Citrus also surpasses several LLMs beyond 70B on medical benchmarks. bold highlights the best scores, and underlines indicate the second-best.
表 4: 医学基准测试主要结果。大语言模型按70B规模组和超70B组划分。Citrus在70B大语言模型中领先多数基准测试,此外,Citrus在医学基准上还超越了部分超70B模型。加粗显示最高分,下划线表示次优。
| MedQA | PubMed-QA | Care QA | JMED | Med-Bullets | MMLU-Pro Health | MMLU-Pro Biology | |
|---|---|---|---|---|---|---|---|
| deepseek-R1-distill-llama-70B | 0.8696 | 0.793 | 0.7952 | 0.571 | 0.7468 | 0.7286 | 0.848 |
| Llama3.1-70B-instruct | 0.7722 | 0.793 | 0.5333 | 0.559 | 0.6429 | 0.6467 | 0.7978 |
| huatuoGPT-o1-70B | 0.835 | 0.812 | 0.7095 | 0.763 | 0.7164 | 0.8382 | |
| qwen2.5-72B-instruct | 0.7455 | 0.756 | 0.667 | 0.665 | 0.834 | ||
| O1-Journey Learning-llama-70B | 0.8648 | 0.7727 | |||||
| Citrus1.0-llama-70B | 0.8892 | 0.809 | 0.8486 | 0.684 | 0.7857 | 0.6748 | 0.8326 |
| LLMs beyond 70B | |||||||
| claude-3.5-sonnet-20241022 | 0.8735 | 0.68 | 0.8333 | 0.669 | 0.7273 | 0.7592 | 0.8856 |
| gpt-4o-0806 | 0.8743 | 0.697 | 0.8095 | 0.668 | 0.7435 | 0.7323 | 0.8577 |
| deepseek-v3 | 0.7824 | 0.732 | 0.7667 | 0.646 | 0.6558 | 0.6993 | 0.8173 |
| deepseek-R1 | 0.9097 | 0.767 | 0.9123 | 0.751 | 0.8149 | 0.7518 | 0.8577 |
| gpt-o1-mini | 0.8955 | 0.706 | 0.6571 | 0.629 | 0.8084 | 0.7213 | 0.855 |
| gpt-o1-preview | 0.9513 | 0.725 | 0.8714 | 0.716 | 0.8896 | 0.7714 | 0.894 |
| MMLU Anatomy | MMLU clinical knowledge | MMLU College Biology | MMLU College Medicine | MMLU Medical Genetics | MMLU Professional Medicine | |
|---|---|---|---|---|---|---|
| LLMs around 70B | ||||||
| deepseek-R1-distill-llama-70B | 0.8222 | 0.9094 | 0.9514 | 0.8786 | 0.96 | 0.9265 |
| Llama3.1-70B-instruct | 0.8148 | 0.8566 | 0.7861 | 0.95 | 0.9118 | |
| huatuoGPT-o1-70B | 0.837 | 0.883 | 0.8092 | 0.96 | 0.9632 | |
| qwen2.5-72B-instruct | 0.8519 | 0.8528 | 0.8208 | 0.89 | 0.9044 | |
| Citrus1.0-llama-70B | 0.837 | 0.8642 | 0.9357 | 0.8092 | 0.96 | 0.9485 |
| LLMs beyond 70B | ||||||
| claude-3.5-sonnet-20241022 | 0.837 | 0.9019 | 0.9792 | 0.8439 | 0.91 | 0.9706 |
| gpt-4o-0806 | 0.8741 | 0.8943 | 0.9514 | 0.8382 | 0.93 | 0.9743 |
| deepseek-v3 | 0.837 | 0.8868 | 0.9514 | 0.8092 | 0.9 | 0.9301 |
| deepseek-R1 | 0.9259 | 0.9283 | 0.9792 | 0.8844 | 0.98 | 0.9596 |
| gpt-o1-mini | 0.8074 | 0.8604 | 0.8439 | 0.96 | 0.9596 | |
| gpt-o1-preview | 0.9185 | 0.9094 | 0.9514 | 0.8728 | 0.97 | 0.9706 |
SFT Training Stages The first two stages of SFT primarily focus on grounding the model with general knowledge and reasoning tasks. Training on these stages reach an acceptable level for the model to handling reasoning tasks. The third stage is where the model’s medical reasoning capabilities are fine-tuned.This stage’s effectiveness is demonstrated in the performance improvements on the MedQA benchmark as the model progresses from 77.06 to 84.13.
SFT训练阶段
SFT的前两个阶段主要侧重于让模型掌握通用知识和推理任务。在这些阶段的训练使模型达到处理推理任务的可接受水平。第三阶段是对模型医学推理能力进行微调的关键阶段。该阶段的效果体现在MedQA基准测试中模型的性能提升,从77.06分提高到84.13分。
SFT data size impact The influence of data size on the model’s performance is evident when considering the results from different configurations of Stage 3. Fine-tuning with 20k SFT data yields a performance of 83.12, whereas utilizing 60k SFT data boosts performance to 84.13. However, further increasing the data size to $130\mathrm{k\Omega}$ results in a slight performance dip to 83.74, suggesting diminishing returns as the model approaches an optimal configuration for this stage.
SFT数据规模影响
不同第三阶段配置的结果明显体现了数据规模对模型性能的影响。使用2万条SFT数据进行微调时性能为83.12,而采用6万条SFT数据可将性能提升至84.13。但当数据量进一步增加到$130\mathrm{k\Omega}$时,性能略微下降至83.74,这表明随着模型接近该阶段的最优配置,边际效益正在递减。
RL Data Proportion We experimented with varying the composition of the rejection sampling data. The most successful configuration involved using $45\mathrm{k\Omega}$ medical questions and an additional 5k non-medical questions, resulting in a performance of 88.92. This configuration demonstrates that introducing non-medical question data in other scientific fields into the training process can help balance the model’s understanding of both domain-specific and general reasoning tasks, enhancing overall model performance.
RL数据比例
我们尝试改变拒绝采样数据的组成。最成功的配置是使用$45\mathrm{k\Omega}$个医学问题和额外的5k个非医学问题,最终性能达到88.92。这一配置表明,在训练过程中引入其他科学领域的非医学问题数据有助于平衡模型对领域特定任务和通用推理任务的理解,从而提升整体模型性能。

Figure 7: Training Loss. The figure shows the loss curve of each stage in the training process. The model gradually converges at each SFT stage in (a)(b)(c). In figure7(d), the alignment phase reward curve of CPO-SimPO gradually rises and converges.
图 7: 训练损失。该图展示了训练过程中每个阶段的损失曲线。(a)(b)(c)中模型在每次SFT阶段逐渐收敛。图7(d)中,CPO-SimPO的对齐阶段奖励曲线逐步上升并收敛。
Table 5: The ablation experiments on Citrus1.0-Llama-70B. The SFT stage results and RL stage results are shown in sequence to show different contributions to final perform of model from different stages. We also implemented several experiments to reveal the impact from data size and data portion. "w/o" and "w/" denote "without" and "with". Bold highlights the best scores in each segment.Use MedQA benchmark to evaluate the influence on different training stages and data sizes.
表 5: Citrus1.0-Llama-70B的消融实验。依次展示SFT阶段和RL阶段结果,以呈现不同训练阶段对模型最终表现的贡献差异。同时通过多组实验揭示数据规模与数据构成的影响。"w/o"和"w/"分别表示"不包含"和"包含"。加粗数字标注各分段最优成绩。采用MedQA基准评估不同训练阶段及数据规模的影响。
| MedQA | |
|---|---|
| BaselineLLMs | |
| Llama-3.1-70B-base | 48.95 |
| Llama-3.1-70B-instruct | 78.40 |
| OursLLMs | |
| Citrus1.0-Qwen-72B | 87.12 |
| Citrus1.0-Llama-70B | 88.92 |
| SupervisedFinetune(SFT) | |
| Citrus-Llama-70Bstage1/2 | 77.06 |
| Citrus-Llama-70B stage1/2 + stage3 w/ 20k sft data | 83.12 |
| Citrus-Llama-70B stage1/2 + stage3 w/ 60k sft data | 84.13 |
| Citrus-Llama-70B stage1/2 + stage3 w/ 130k sft data | 83.74 |
| ReinforcementLearning(RL) | |
| Citrus-Llama-70B-stage3 CPO+SIMPO w/17k Rejection Sample data | 87.82 |
| Citrus-Llama-70B-stage3 CPO+SIMPO w/45k Rejection Sample data | 87.20 |
| Citrus-Llama-70B-stage3 CPO+SIMPO w/ 45k+ 5k non-med Rejection Sample data | 88.92 |
RL Data Size Impact We also explore different RL data size on $17\mathrm{k\Omega}$ and $45\mathrm{k\Omega}$ . For $45\mathrm{k\Omega}$ scale, we use the core, most-difficult 17k data combined with 28k other data, which is not challenging enough for complex medical cognitive task from same sources. The results show that the use of $17\mathrm{k}$ rejection sample data yields a better performance 87.82, which is slightly higher than the model training by larger dataset improvements. This illustrated that a smaller size is enough for the model to capture the core ability of medical reasoning.
RL数据规模影响
我们还探究了不同RL数据规模对$17\mathrm{k\Omega}$和$45\mathrm{k\Omega}$的影响。针对$45\mathrm{k\Omega}$规模,我们使用了核心且最具挑战性的17k数据与28k其他数据组合,但这些数据对相同来源的复杂医学认知任务而言难度不足。结果表明,使用$17\mathrm{k}$拒绝样本数据取得了87.82的更好性能,略高于通过更大数据集训练的模型提升。这说明较小规模的数据已足够让模型掌握医学推理的核心能力。
7 Conclusion
7 结论
We present Citrus, a medical language model designed to enhance medical reasoning by emulating the cognitive processes of medical experts. Through a novel data synthesis approach and a multistage training methodology, we have developed a model capable of efficiently handling complex medical decision-making tasks. By releasing the model and its training data, we aim to promote further research in AI-driven medical reasoning and decision-making, thereby contributing to the advancement of healthcare technologies.
我们推出Citrus,这是一个旨在通过模拟医学专家的认知过程来增强医学推理能力的医疗语言模型。通过创新的数据合成方法和多阶段训练策略,我们开发出一个能够高效处理复杂医疗决策任务的模型。通过开源该模型及其训练数据,我们希望推动AI驱动的医学推理和决策领域的研究,从而为医疗技术的进步做出贡献。
Thinking like an Expert We have constructed a medical reasoning dataset modeled from the cognitive processes of doctors, and have effectively demonstrated that such data significantly enhances the problem-solving capabilities of LLMs in medical scenario. Through an exploration of doctors thought processes, design of experimental data and attempts at model training, we have ultimately developed an LLM capable of effectively leveraging Long COT generated data to address medical issues. From a high-order perspective, we envision that our approach could be widely applicable across domains. By de constructing the cognitive strategies of experts and utilizing representative core data to generate training data through our approach, models could potentially learn to abstract thinking specific to a given domain. We believe this approach can serve as a comprehensive alternative to human feedback. As a criterion, it effectively replaces the necessity of human feedback in training, allowing the model to understand the underlying characteristics of thinking. Through this understanding, the model can approach general iz able problems from an elevated level of cognitive abstraction, thereby becoming a domain expert.
像专家一样思考
我们构建了一个基于医生认知过程的医学推理数据集,并有效证明了此类数据能显著提升大语言模型在医疗场景中的问题解决能力。通过探索医生思维过程、设计实验数据和尝试模型训练,最终开发出能够有效利用长链思维生成数据解决医学问题的大语言模型。
从更高维度看,我们设想该方法可跨领域广泛适用。通过解构专家的认知策略,并利用代表性核心数据通过我们的方法生成训练数据,模型有望学习特定领域的抽象思维。我们相信这种方法可全面替代人类反馈。作为标准,它有效取代了训练中对人类反馈的需求,使模型能理解思维的本质特征。通过这种理解,模型可以从更高层次的认知抽象层面处理可泛化问题,从而成为领域专家。
Complex Training Pipeline We developed a comprehensive multi-phase training pipeline for Citrus, incorporating CPT, SFT, and RL, to enable the model to efficiently learn and adapt to complex medical reasoning tasks. By understanding the problem-solving thought processes of medical experts, we identified the dual-process theory and applied distinct cognitive strategies to various training phases using CPT and SFT. While we believe that extensive pre-training data and clinical examples will help the model perform pattern recognition, there is currently no effective method to equip the model with the complex reasoning abilities that medical experts use to solve problems. We employed a warm-up training phase using data courses and a carefully designed COT data generation method. By training the base model in a specific order, it is gradually enhanced into a medical reasoning model. In the final stage, we claim that offline RL training could further enhance the model’s reasoning ability, ultimately ranking it among the top models of similar parameter scales on several authoritative benchmarks.
复杂训练流程
我们为Citrus开发了一套全面的多阶段训练流程,结合了CPT(Continual Pre-Training)、SFT(Supervised Fine-Tuning)和RL(Reinforcement Learning),使模型能高效学习并适应复杂的医学推理任务。通过分析医学专家解决问题的思维过程,我们运用双过程理论,在CPT和SFT阶段采用不同的认知策略。虽然我们认为大量预训练数据和临床案例有助于模型进行模式识别,但目前尚无有效方法让模型掌握医学专家用于解决问题的复杂推理能力。我们采用数据课程的预热训练阶段和精心设计的COT(Chain-of-Thought)数据生成方法,通过特定顺序训练基础模型,逐步将其强化为医学推理模型。最终阶段,我们提出离线RL训练可进一步提升模型的推理能力,使其在多个权威基准测试中跻身同参数规模模型的顶尖行列。
A Ethical Statement
伦理声明
Although the proposed model is a medical LLM with complex reasoning capabilities, it may still produce content that includes hallucinations or inaccuracies. Therefore, the current model is not suitable for real-world applications. Consequently, we will impose strict limitations on the use of our model. The models are not permitted for use in clinical or other industry applications where such inaccuracies could lead to unintended consequences. We emphasize the ethical responsibility of users to adhere to these restrictions in order to safeguard the safety and integrity of their applications.
尽管所提出的模型是具有复杂推理能力的医疗大语言模型,它仍可能生成包含幻觉或错误的内容。因此,当前模型不适合实际应用。我们将对模型使用施加严格限制:禁止将该模型用于临床或其他行业应用场景,以免因内容错误导致意外后果。我们强调用户有道德责任遵守这些限制,以确保其应用的安全性和可靠性。
B Prompt
B 提示
Here are the prompt examples.
以下是提示词示例。
Reasoning Expert Prompt
推理专家提示
You are tasked with addressing a medical examination question. Please carefully read the question, provide a detailed thought process, and then present your final answer.
你被要求解答一个医学考试题目。请仔细阅读题目,提供详细的思考过程,然后给出最终答案。
Facing on the previous question, you are an assistant that engages in extremely thorough, self-questioning reasoning.
面对前面的问题,你是一个进行极其彻底、自我质疑式推理的助手。
Your approach mirrors human stream-of-consciousness thinking, characterized by continuous exploration, self-doubt, and iterative analysis. With the expectation that when facing this medical issue, you will be able to apply professional medical reasoning methods, such as differential diagnosis, to further reason and think about the problem.”
你的方法反映了人类意识流的思考方式,其特点是持续探索、自我怀疑和迭代分析。期望在面对这一医学问题时,你能运用专业的医学推理方法(如鉴别诊断)来进一步推理和思考问题。
Below is the definition of the differential diagnosis method in medical reasoning:
以下是医学推理中鉴别诊断方法的定义:
Differential diagnosis refers to the process of systematically considering different possible diseases, ruling out diagnoses that do not match the condition, and ultimately determining the most likely disease. It involves the following steps:
鉴别诊断 (Differential diagnosis) 指系统性地考虑不同可能的疾病、排除不符合病情的诊断并最终确定最可能疾病的过程。其步骤包括:
Please establish the following process in your logical reasoning:
请在逻辑推理中建立以下流程:
Reflection Expert Prompt
反思专家提示
C Standard Inquiry Process
C标准调查流程
User-submitted consultation requests Users submit information regarding their medical conditions, symptoms, and medical history on the JDH platform. This information is typically submitted in the form of text, images, or videos.
用户提交的咨询请求
用户在JDH平台上提交关于其健康状况、症状和病史的信息。这些信息通常以文本、图像或视频的形式提交。
Conversation records between doctors and users After receiving a user’s consultation request, doctors engage in real-time text, voice, or video communication with the user. These conversation records contain key information such as the doctor’s inquiries about the user’s condition, the diagnostic process, and treatment recommendations.
医生与用户间的对话记录
在收到用户的咨询请求后,医生会通过实时文字、语音或视频与用户进行交流。这些对话记录包含医生对用户病情的询问、诊断过程及治疗建议等关键信息。
Diagnostic plans and prescriptions Based on the user’s condition description and conversation content, doctors provide diagnostic results, treatment plans, and medication prescriptions.
诊断方案与处方
基于用户的病情描述和对话内容,医生提供诊断结果、治疗方案及用药处方。
D Quality-Check
D 质量检查
Consultation Professionalism
咨询专业性
• Assess whether the physician has omitted any critical or non-critical questions during the consultation regarding the patient’s chief complaint, current medical history, or past medical history, which could lead to insufficient grounds for the final conclusion. • Evaluate whether the physician failed to inquire about allergy history or special past medical conditions when recommending antibiotics or other treatments, potentially causing significant harm to the patient’s physical and mental well-being. • Determine whether the physician neglected to routinely collect information on the patient’s allergy history, liver and kidney function, or special disease history when advising on medications or products that may cause allergic reactions or other harm. Consultation quality must be comprehensive, detailed, and without any deficiencies.
• 评估医生在问诊过程中是否遗漏了关于患者主诉、现病史或既往史的关键或非关键问题,导致最终结论依据不足。
• 评价医生在推荐抗生素或其他治疗方案时,是否未询问过敏史或特殊既往病史,可能对患者身心健康造成重大伤害。
• 判断医生在建议可能引发过敏反应或其他危害的药物或产品时,是否未常规采集患者的过敏史、肝肾功能或特殊疾病史信息。
问诊质量必须全面、细致且无任何疏漏。
Diagnostic Professionalism
诊断专业性
Question Professionalism
问题专业性
• Verify the high relevance of the question content to the dialogue content. • Evaluate the rationality of the distractor options and whether they have a hierarchical relationship with the correct option, leading to ambiguity in the answer. • Ensure the information in the question is sufficient for diagnosis. The quality of the question must meet the standards of being informative, well-evidenced, and having reasonably set options.
• 验证问题内容与对话内容的高度相关性。
• 评估干扰选项的合理性,以及它们是否与正确选项存在层级关系,导致答案模糊。
• 确保问题中的信息足以用于诊断。问题的质量必须符合信息丰富、证据充分且选项设置合理等标准。