Why Is It Hate Speech? Masked Rationale Prediction for Explain able Hate Speech Detection
为什么这是仇恨言论?基于遮蔽理由预测的可解释仇恨言论检测
Abstract
摘要
In a hate speech detection model, we should consider two critical aspects in addition to detection performance–bias and explain ability. Hate speech cannot be identified based solely on the presence of specific words: the model should be able to reason like humans and be explain able. To improve the performance concerning the two aspects, we propose Masked Rationale Prediction (MRP) as an intermediate task. MRP is a task to predict the masked human rationales–snippets of a sentence that are grounds for human judgment–by referring to surrounding tokens combined with their unmasked rationales. As the model learns its reasoning ability based on rationales by MRP, it performs hate speech detection robustly in terms of bias and explain ability. The proposed method generally achieves state-of-the-art performance in various metrics, demonstrating its effectiveness for hate speech detection. Warning: This paper contains samples that may be upsetting.
在仇恨言论检测模型中,除检测性能外还需考虑两个关键因素——偏差(bias)和可解释性(explainability)。仇恨言论不能仅通过特定词汇存在与否进行判定:模型应具备类人推理能力且决策过程可解释。为提升这两方面的性能,我们提出掩码依据预测(Masked Rationale Prediction, MRP)作为中间任务。MRP通过结合周边token及其未掩码依据(rationales)——即支撑人类判断的句子片段——来预测被掩码的人类判断依据。当模型通过MRP学习基于依据的推理能力时,能在偏差控制和可解释性方面实现稳健的仇恨言论检测。所提方法在多项指标上普遍达到最先进性能,验证了其对仇恨言论检测的有效性。警告:本文包含可能引起不适的示例内容。
1 Introduction
1 引言
With the recent development of social media and online communities, hate speech, one of the critical social problems, can spread easily. The spread of hate strengthens discrimination and prejudice against the target social groups and can violate their human rights. Moreover, online hatred extends offline and causes real-world crimes. Therefore, properly regulating online hate speech is important to address many social problems related to aversion.
随着社交媒体和在线社区的近期发展,仇恨言论这一关键社会问题极易扩散。仇恨的传播会强化对目标社会群体的歧视与偏见,并可能侵犯其人权。此外,网络仇恨会延伸至线下,引发现实世界的犯罪行为。因此,妥善管控网络仇恨言论对解决诸多与厌恶情绪相关的社会问题至关重要。
In addition to the detection performance, two essential considerations are involved in implementing a hate speech detection model–bias and explainability. Hate speech should not be judged by any specific word but by the context in which the word is used. Even if any word generally considered vicious does not exist in a text, the text can be hate speech. A specific expression does not always imply hatred either (e.g., e.g., ‘nigger’) (Del Vigna12 et al., 2017). However, the presence of this word can cause a model to make a biased detection of hate speech. This erroneous judgment may inadvertently strengthen the discrimination against the target group of the expression (Sap et al., 2019; Davidson et al., 2019). In this respect, the model’s bias toward specific expressions should be excluded.
除了检测性能外,在实施仇恨言论检测模型时还需考虑两个关键因素——偏差(bias)和可解释性。仇恨言论不应通过特定词汇来判断,而应结合词汇使用的上下文语境。即使文本中不存在普遍认为恶毒的词汇,仍可能构成仇恨言论。特定表达也并非总是隐含仇恨(例如"nigger") (Del Vigna12 et al., 2017)。然而,这类词汇的出现可能导致模型对仇恨言论产生有偏见的检测。这种错误判断可能会无意间强化对该表达目标群体的歧视(Sap et al., 2019; Davidson et al., 2019)。因此,应排除模型对特定表达的偏见倾向。
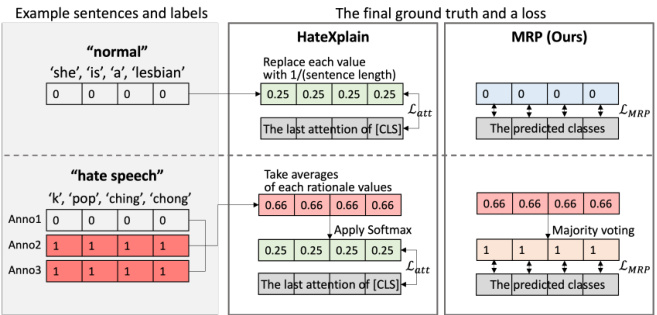
Figure 1: Examples for the two methods to get the final ground truths. Example input sentences are represented with the class and human rationale labels. In this figure, HateXplain uses the same ground truth about both normal and hateful sentences for the loss. However, our method could determine the two classes with the ground truths.
图 1: 获取最终真实标签的两种方法示例。输入句子示例展示了类别和人工标注依据标签。本图中,HateXplain对正常和仇恨语句使用相同的真实标签计算损失。而我们的方法能够根据真实标签区分这两类。
The expressions that can cause biased judgment should be interpreted in context. It means it is vital for the hate speech detection models to have the ability to make judgments based on context, as humans do. Therefore, the model should be explain able to humans so that the rationale behind a result is explained (Liu et al., 2018). Here, the rationale is a piece of a sentence as justification for the model’s prediction about the sentence, as defined by related research (Hancock et al., 2018; Lei et al., 2016).
可能导致偏见判断的表达应在上下文中进行解释。这意味着仇恨言论检测模型必须具备像人类一样基于上下文做出判断的能力。因此,该模型应具备可解释性,以便阐明结果背后的逻辑依据 (Liu et al., 2018)。此处所述逻辑依据是指相关研究定义的、作为模型对句子预测理由的句子片段 (Hancock et al., 2018; Lei et al., 2016)。
To the best of our knowledge, HateXplain (Mathew et al., 2020) is the first hate speech detection benchmark dataset that considers both these aspects. They proposed a method that utilizes rationales as attention ground truths to complement the performance of the two elements. However, when most tokens are annotated as the human rationale in a hateful sentence, the rationale’s information could be meaningless as the ground truth attention becomes hard to be distinguished from that of a normal sentence, as shown in Figure 1. This can hinder the model’s learning.
据我们所知,HateXplain (Mathew et al., 2020) 是首个同时考虑这两个方面的仇恨言论检测基准数据集。他们提出了一种利用人类标注依据 (rationale) 作为注意力真实标签的方法,以提升两个要素的性能。然而如图 1 所示,当仇恨语句中大部分 token 都被标注为人类依据时,这些依据信息可能失去意义——因为真实注意力分布会变得与普通语句难以区分,从而阻碍模型学习。
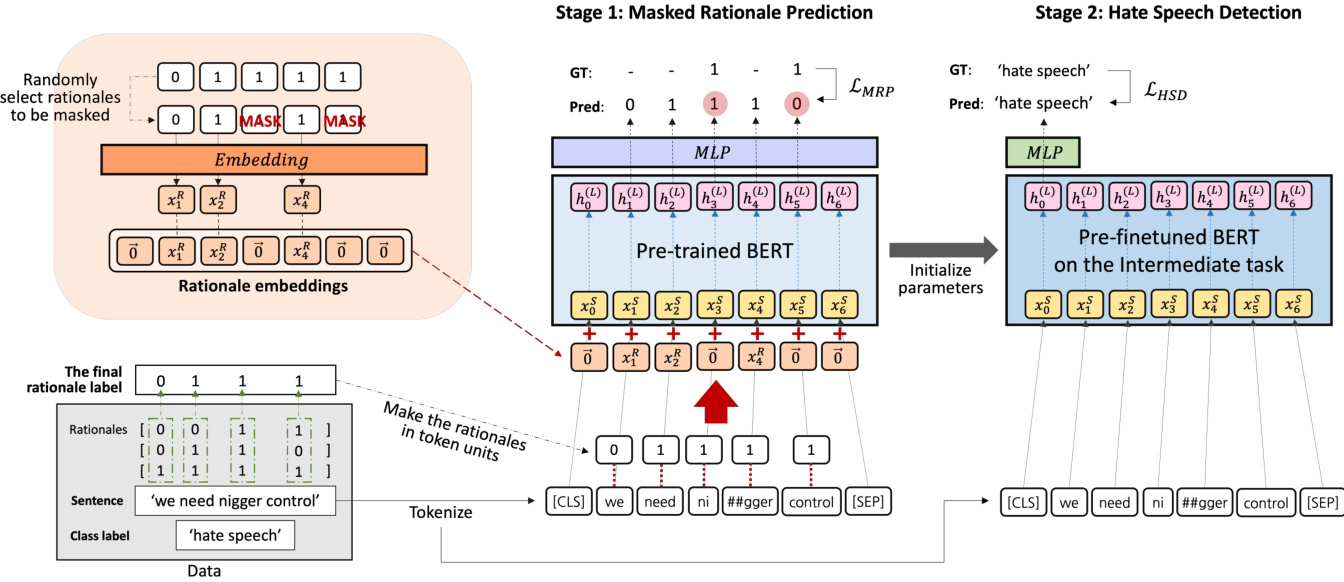
Figure 2: Framework of the proposed method. We finetune a pre-trained BERT through two training stages– Masked Rationale Prediction (MRP) and then hate speech detection. In MRP, the partially masked rationale label is inputted as the rationale embeddings by being added into the input embeddings of BERT. The model predicts each masked rationale per token. The model for hate speech detection is initialized by the updated parameters during MRP.
图 2: 所提方法的框架。我们通过两个训练阶段对预训练的 BERT 进行微调——掩码依据预测 (MRP) 和仇恨言论检测。在 MRP 中,部分掩码的依据标签作为依据嵌入,通过添加到 BERT 的输入嵌入中进行输入。模型预测每个 token 的掩码依据。仇恨言论检测模型通过 MRP 期间更新的参数进行初始化。
In this paper, we present a method to implement a hate speech detection model much more effectively by using the human rationale of hate for finetuning a pre-trained language model. To achieve this, we propose Masked Rationale Prediction (MRP) as an intermediate task before finetuning the model on hate speech detection. MRP trains a model to predict the human rationale label of each token by referring to the context of the input sentence. The model takes the human rationale information of some input tokens among the sentence along with the corresponding tokens as input. It then predicts the rationale of the remaining tokens on which the rationale is masked. We embed the rationales to provide the human rationales as input per token. The masking process of the partial rationales is implemented while creating rationale embeddings; some rationale embedding vectors are replaced with zero vectors.
本文提出一种方法,通过利用人类仇恨言论判定依据来微调预训练语言模型,从而更高效地实现仇恨言论检测。为此,我们提出掩码依据预测(MRP)作为仇恨言论检测微调前的中间任务。MRP通过参考输入句子的上下文,训练模型预测每个token的人类判定依据标签。该模型以句子中部分输入token及其对应的人类判定依据作为输入,进而预测被掩码处理token的判定依据。我们将判定依据嵌入向量化,为每个token提供人类判定依据输入。部分依据的掩码过程在创建依据嵌入时实现:部分依据嵌入向量会被替换为零向量。
MRP allows the model to make judgments per token about its masked rationale by considering surrounding tokens with an unmasked rationale. With this, the model learns a human-like reasoning process to get context-dependent abusiveness of tokens. The model parameters trained on MRP become the initial parameter values for hate speech detection in the following training stage. In this way, based on the way of human reasoning for hate, the model can get improved abilities in terms of bias and explain ability in detecting hate speech. We experimented with BERT (Devlin et al., 2018) as the pre-trained model. Consequently, our models finetuned in the proposed way–BERTMRP and BERT-RP–achieve state-of-the-art performance overall on all three types of 11 metrics of HateXplain benchmark–Performance-based, Biasbased, and Explain ability-based (Mathew et al., 2020). And the two models, especially BERT-MRP, also show the best results in qualitative evaluation of explicit and implicit hate speech detection.
MRP允许模型通过考虑带有未遮蔽依据的周围token,对每个被遮蔽依据的token进行判断。通过这种方式,模型学习了一种类似人类的推理过程,以获取token在上下文中的侮辱性。训练MRP所得的模型参数将成为下一阶段仇恨言论检测任务的初始参数值。基于人类对仇恨言论的推理方式,该方法能提升模型在检测仇恨言论时的偏置控制能力和可解释性。我们采用BERT (Devlin et al., 2018)作为预训练模型进行实验。最终,通过所提方法微调的模型——BERT-MRP和BERT-RP——在HateXplain基准测试的所有11项指标上均达到最先进水平,这些指标分为三类:基于性能、基于偏置和基于可解释性 (Mathew et al., 2020)。两个模型(特别是BERT-MRP)在显性与隐性仇恨言论检测的定性评估中也展现出最佳结果。
The main contributions of this paper are:
本文的主要贡献包括:
• We propose a method to utilize human rationales as input by transforming them into rationale embeddings. Combining the embedded rationales with the corresponding input sentence can provide information about the human rationales per token during model training. • We propose Masked Rationale Prediction (MRP), a learning method that leads the model to predict the masked rationale by considering the surrounding tokens. The model is allowed to learn the reasoning process in context. • We finetune a pre-trained BERT in two stages– on MRP as an intermediate task and then on hate speech detection. The parameters trained concerning human reasoning for hate become a sufficient basis not only for the detection but also in terms of the model bias and explainability.
• 我们提出一种方法,通过将人类推理依据 (rationale) 转化为嵌入向量来将其作为模型输入。在训练过程中,将这些嵌入向量与对应文本结合,可为每个token提供人类推理依据的信息。
• 我们提出掩码推理预测 (Masked Rationale Prediction,MRP) 学习方法,引导模型通过上下文token预测被掩码的推理依据,使模型能够学习语境中的推理过程。
• 我们采用两阶段微调预训练BERT模型:先以MRP作为中间任务进行训练,再进行仇恨言论检测任务。这种针对人类仇恨推理逻辑的参数训练,不仅能提升检测效果,还能改善模型偏差和可解释性。
2 Related works Hate speech detection With the advance of deep learning, hate speech detection studies have utilized neural networks (Badjatiya et al., 2017; Han and Eisenstein, 2019), and word embedding methods (McKeown and McGregor, 2018). More recently, Transformer-based (Vaswani et al., 2017) models have shown remarkable results. In hate speech detection, BERT has been adopted for various studies as hate speech detection can be considered a classification task. Mandl et al. (2019) and Ranasinghe et al. (2019) compared a BERT-based model with Recurrent Neural Networks (RNNs)-based models and showed the BERT-based model outperforms other models. Furthermore, some studies have considered the model’s bias and explain ability. Vaidya et al. (2020) improved accuracy and reduced unintended bias by adopting multi-task learning that predicts toxicity of text and target group labels as additional information. Mathew et al. (2020) utilized rationales of the dataset as additional information for finetuning BERT to deal with the bias and explain ability. To improve performance in terms of the two considerations, we propose a more effective finetuning approach based on BERT and the rationales by adopting the pre-training framework. Pre-finetuning on an intermediate task Recently, finetuning a pre-trained model on a downstream task has become the norm (Howard and Ruder, 2018; Radford et al., 2018). However, it cannot be guaranteed that the model finetuned with a small dataset compared to its size will be sufficiently welladjusted for the target downstream task (Phang et al., 2018). Pre-finetuning is a technique to train the model on a task before the target task (Aghajanyan et al., 2021). This can help the model learn the data patterns or reduce the tuning time so that it converges quickly to better fit the target task. According to Pr uk s a chat kun et al. (2020); Aghajanyan et al. (2021), the more closely the intermediate task is related to the target task, the better the effect of pre-finetuning. And inference tasks involving the reasoning process show a remarkable improvement in the target task performance. We adopt this method to train a pre-trained language model through two stages for hate speech detection.
2 相关工作
仇恨言论检测
随着深度学习的进步,仇恨言论检测研究已开始利用神经网络 (Badjatiya et al., 2017; Han and Eisenstein, 2019) 和词嵌入方法 (McKeown and McGregor, 2018)。近年来,基于 Transformer (Vaswani et al., 2017) 的模型展现出显著效果。由于仇恨言论检测可视为分类任务,BERT 被广泛应用于相关研究。Mandl et al. (2019) 和 Ranasinghe et al. (2019) 将基于 BERT 的模型与基于循环神经网络 (RNN) 的模型进行对比,证明前者性能更优。此外,部分研究关注模型偏见与可解释性。Vaidya et al. (2020) 通过多任务学习(同时预测文本毒性和目标群体标签作为附加信息)提升准确率并降低非预期偏见。Mathew et al. (2020) 利用数据集的逻辑依据作为微调 BERT 的附加信息,以处理偏见和可解释性问题。为从这两方面提升性能,我们提出基于 BERT 和逻辑依据的预训练框架微调方法。
中间任务预微调
当前,在下游任务上微调预训练模型已成为主流 (Howard and Ruder, 2018; Radford et al., 2018)。但对于参数量远大于训练数据规模的模型,难以保证其能充分适配目标下游任务 (Phang et al., 2018)。预微调技术通过在目标任务前训练中间任务来优化模型 (Aghajanyan et al., 2021),可帮助模型学习数据模式或缩短调优时间,使其快速收敛至更适合目标任务的状态。根据 Pr uk s a chat kun et al. (2020) 和 Aghajanyan et al. (2021) 的研究,中间任务与目标任务关联性越强,预微调效果越显著;涉及推理过程的中间任务能大幅提升目标任务表现。我们采用该方法,通过两阶段训练预训练语言模型以检测仇恨言论。
As the intermediate task, we propose MRP, which guides the model to infer the human rationale of each token based on surrounding tokens.
作为中间任务,我们提出MRP,引导模型基于周围token推断每个token的人类推理依据。
Explain able NLP and rationale Explaining the rationale of the result of an AI model is necessary for it to be explain able to humans (Liu et al., 2018). Some Natural Language Processing (NLP) studies define rationale as snippets of an input text on which the model’s prediction is supported (Hancock et al., 2018; Lei et al., 2016). Lei et al. (2016) implemented a generator that generates words considered rationales and used them as input of an encoder for sentiment classification. Bao et al. (2018) mapped the human rationales into the model attention values to solve the low-resource problem by learning a domain-invariant token representation. For hate speech detection, HateXplain employs the human rationales as ground truth attention to concentrate on aggressive tokens. Unlike existing approaches, we utilize the masked human rationale label embeddings as input. They become the useful additional information of each token.
可解释NLP与依据说明
解释AI模型结果的依据对于使其对人类可解释至关重要 (Liu et al., 2018)。部分自然语言处理(NLP)研究将依据定义为支持模型预测的输入文本片段 (Hancock et al., 2018; Lei et al., 2016)。Lei等人(2016)实现了一个生成器,用于生成被视为依据的词语,并将其作为情感分类编码器的输入。Bao等人(2018)将人类依据映射到模型注意力值,通过学习领域不变的token表示来解决低资源问题。针对仇恨言论检测,HateXplain采用人类依据作为真实注意力,聚焦于攻击性token。与现有方法不同,我们利用掩码处理后的人类依据标签嵌入作为输入,这些嵌入成为每个token的有用附加信息。
Masked label prediction The UniMP model presented by Shi et al. (2020) aims to solve the graph node classification problem using graph transformer networks (Yun et al., 2019). They maximized the propagation information required to reconstruct a partially observable label by using both feature information and label information as inputs. However, to prevent over fitting due to excessive information, some label information is masked, and the masked label is predicted. We apply a similar method to text data for an intermediate task with rationales. Through additional rationale information, the model increases the understanding of input sentences, and the performance of the downstream task is improved.
掩码标签预测
Shi等人(2020)提出的UniMP模型旨在利用图Transformer网络(Yun等人,2019)解决图节点分类问题。他们通过同时使用特征信息和标签信息作为输入,最大化重建部分可观测标签所需的传播信息。为防止因信息过载导致的过拟合,该方法会掩码部分标签信息并预测被掩码的标签。我们将类似方法应用于带有理论依据的文本数据中间任务。通过额外的理论依据信息,模型增强了对输入句子的理解,从而提升了下游任务的性能。
3 Method
3 方法
Hate speech detection can be described as a text classification problem. Following the problem setting of HateXplain, we define the problem as a three-class classification involving three categories– ‘hate speech,’ ‘offensive,’ or ‘normal’. We finetune a pre-trained BERT on hate speech detection. Note that other transformer encoder-based models can be used instead. Before finetuning the model on this task, we pre-finetune it on an intermediate task. We propose Masked Rationale Prediction (MRP) as the intermediate task. Our method is described in Figure 2.
仇恨言论检测可视为一个文本分类问题。参照HateXplain的问题设定,我们将其定义为包含"仇恨言论"、"冒犯性言论"和"正常言论"的三分类任务。我们在仇恨言论检测任务上微调了预训练的BERT模型(注:也可使用其他基于Transformer编码器的模型)。在任务微调前,我们先对模型进行中间任务的预微调。我们提出遮蔽依据预测(Masked Rationale Prediction, MRP)作为中间任务,具体方法如图2所示。
3.1 Masked rationale prediction
3.1 掩码原理预测
For MRP, we utilize human rationales of hate provided by the HateXplain dataset. Annotators marked some words in a sentence as rationales for judging the sentence as abusive. A rationale label is presented in a list format, including 1 as rationale and 0 as non-rationale per word in the corresponding sentence. There are no such labels for a sentence whose final class is ‘normal.’ As the dataset was annotated by two or three people per sentence, some pre-processing is required to get the final rationale labels for MRP. To manipulate the multiple rationale labels to one per sentence, we obtain the average value of the rationales per word, and if it is over 0.5, the value of 1; otherwise, the value of 0 is determined as the final rationale of the corresponding word. The final rationale label is a list of these last values. In the case of the ‘normal’ sentence, a list of zeros is used. Accordingly, the final rationale label consists of as many 0s or 1s as the number of words in the sentence. As a sentence is tokenized, its rationale label is also modified in token units.
对于MRP任务,我们采用HateXplain数据集中提供的人类仇恨判定依据。标注者将句子中部分词语标记为判定该句具有攻击性的依据。依据标签以列表形式呈现,对应句子中的每个词语分别标注为1(依据)或0(非依据)。被最终归类为"normal"的句子则没有此类标签。由于数据集中每个句子由两到三人标注,需经过预处理才能获得MRP所需的最终依据标签。为将多重依据标签整合为每句单一标签,我们计算每个词语标注结果的平均值:若超过0.5则取1,否则取0作为该词语的最终依据值。最终依据标签即为这些值的列表。对于"normal"类句子,则使用全零列表。因此,最终依据标签由与句子词语数量相同的0或1构成。当句子被分词时,其依据标签也按token单位相应调整。
MRP is based on token classification, which predicts the rationale label $R$ per token in an input sentence $S$ . In our MRP, the rationale labels, as well as the sentences, are used as inputs. The process of embedding $S$ is the same as that of BERT. We denote the embedded $S$ as $X^{S}=$ ${x_{0}^{S},x_{1}^{S},\cdot\cdot\cdot,x_{n-1}^{S}}\in\mathbb{R}^{n\times d}$ where $n$ is the se- quence length and $d$ is the embedding size. And to use $R$ as input, we pass it through an embedding layer to get $X^{R}={x_{0}^{R},x_{1}^{R},\cdot\cdot\cdot,x_{n-1}^{R}}\in\mathbb{R}^{n\times d}$ as shown in Figure 2. The rationale embeddings reflect the attributes of each token as a ground for the human judgment.
MRP基于Token分类,通过预测输入句子$S$中每个Token的理性标签$R$来实现。在我们的MRP中,理性标签和句子都作为输入使用。嵌入$S$的过程与BERT相同。我们将嵌入后的$S$表示为$X^{S}={x_{0}^{S},x_{1}^{S},\cdot\cdot\cdot,x_{n-1}^{S}}\in\mathbb{R}^{n\times d}$,其中$n$为序列长度,$d$为嵌入维度。为了将$R$作为输入,我们通过嵌入层得到$X^{R}={x_{0}^{R},x_{1}^{R},\cdot\cdot\cdot,x_{n-1}^{R}}\in\mathbb{R}^{n\times d}$,如图2所示。理性嵌入反映了每个Token作为人类判断依据的属性。
MRP differs from BERT’s Masked Language Modeling (MLM) in masking processing. Specifically, we do not mask the tokens; we mask the rationales. To construct the partially masked rationale embeddings ${\tilde{X}}^{R}$ , some rationales are randomly selected to be masked. Each of rationales is transformed into its corresponding embedding vector, except the masked ones. For masking, zero vectors replace the embedding vectors of each corresponding token. For example, if we mask $x_{1}^{R}$ and B, then the rationale embedding matrix is like $\tilde{X}^{R}={\vec{0},\vec{0},x_{2}^{R},\vec{0},\cdot\cdot\cdot,x_{n-2}^{R},\vec{0}}$ . The first and last rationale embeddings corresponding to CLS and SEP tokens, respectively, are replaced with $\vec{0}$ .
MRP与BERT的掩码语言建模(MLM)在掩码处理上有所不同。具体来说,我们不掩码token,而是掩码依据(rationale)。为了构建部分掩码的依据嵌入${\tilde{X}}^{R}$,我们会随机选择部分依据进行掩码。每个依据都会转换为对应的嵌入向量,除了被掩码的部分。对于掩码操作,零向量会替换每个对应token的嵌入向量。例如,如果我们掩码$x_{1}^{R}$和B,那么依据嵌入矩阵就会像$\tilde{X}^{R}={\vec{0},\vec{0},x_{2}^{R},\vec{0},\cdot\cdot\cdot,x_{n-2}^{R},\vec{0}}$这样。分别对应CLS和SEP token的第一个和最后一个依据嵌入也会被替换为$\vec{0}$。
The MRP model predicts the rationale by taking the sum of the embedded tokens $X^{S}$ and the partially masked rationales ${\tilde{X}}^{R}$ as input. We then get:
MRP模型通过将嵌入的token $X^{S}$ 和部分掩码的rationales ${\tilde{X}}^{R}$ 之和作为输入来预测rationale。我们得到:
$$
\begin{array}{r l}&{H_{M R P}^{(0)}=X^{S}+\tilde{X}^{R},}\ &{H_{M R P}^{(l+1)}=\mathrm{Transformer}(H_{M R P}^{(l)}),}\ &{\quad\quad\hat{X}^{R}=\mathrm{MLP}(H_{M R P}^{(L)}).}\end{array}
$$
$$
\begin{array}{r l}&{H_{M R P}^{(0)}=X^{S}+\tilde{X}^{R},}\ &{H_{M R P}^{(l+1)}=\mathrm{Transformer}(H_{M R P}^{(l)}),}\ &{\quad\quad\hat{X}^{R}=\mathrm{MLP}(H_{M R P}^{(L)}).}\end{array}
$$
The $l$ -th hidden state passes through the transformer last hidden state $H_{M R P}^{(L)}$ $l+1$ outputs a predicted rationale through Multi-Layer Perceptron (MLP). In other words, the model is guided to predict the masked rationales by referring to the representations of tokens using their corresponding observed rationales.
第 $l$ 个隐藏状态通过 Transformer 最后一层隐藏状态 $H_{M R P}^{(L)}$ 后,经由多层感知机 (MLP) 输出 $l+1$ 层的预测依据。换言之,该模型通过引用 Token 对应已观测依据的表征,来预测被掩码的依据。
The loss $\mathcal{L}_{M R P}$ is calculated with only the predictions of the masked rationales. Therefore, our objective function is:
损失 $\mathcal{L}_{M R P}$ 仅通过遮蔽依据 (masked rationales) 的预测值计算得出。因此,我们的目标函数为:
$$
\begin{array}{r}{\arg\operatorname*{max}{\theta}\log\mathtt{p}{\theta}\left(\hat{X}^{R}|X^{S},\tilde{X}^{R}\right)=}\ {\displaystyle\sum_{m\in\cal M}\log\mathfrak{p}{\theta}\left(x_{m}^{R}|X^{S},\tilde{X}^{R}\right),}\end{array}
$$
$$
\begin{array}{r}{\arg\operatorname*{max}{\theta}\log\mathtt{p}{\theta}\left(\hat{X}^{R}|X^{S},\tilde{X}^{R}\right)=}\ {\displaystyle\sum_{m\in\cal M}\log\mathfrak{p}{\theta}\left(x_{m}^{R}|X^{S},\tilde{X}^{R}\right),}\end{array}
$$
where $M$ indicates a set of index numbers of rationales that have been masked.
其中 $M$ 表示一组已被掩盖的理性依据的索引编号集合。
3.2 Hate speech detection
3.2 仇恨言论检测
Hate speech detection is implemented as threeclass text classification. The model predicts which category $Y$ the input sentence belongs to among ‘hate speech’, ‘offensive’, and ‘normal’. The head that outputs the predicted class $\hat{Y}$ is used on the top of BERT. Before training, the model parameters are initialized by parameters updated on the intermediate task MRP, except for the head. As the forms of heads are different for two stages, their parameters are randomly initialized. Consequently, in the finetuning stage on hate speech detection, the rationale labels are not involved functionally, icnopnusti doef rtehde ams $[0]{n\times d}$ $H_{H S D}^{(0)}=X^{S}$ . this stage, the
仇恨言论检测被实现为三分类文本分类任务。模型预测输入句子$Y$属于"仇恨言论"、"冒犯性内容"或"正常内容"中的哪一类别。在BERT顶部使用输出预测类别$\hat{Y}$的分类头。训练前,除分类头外,模型参数均通过中间任务MRP更新后的参数进行初始化。由于两个阶段分类头结构不同,其参数采用随机初始化。因此在仇恨言论检测的微调阶段,原理标签不参与功能运算,初始化为$[0]{n\times d}$的$H_{H S D}^{(0)}=X^{S}$。
In this stage, the model does not refer to the rationale labels. The parameters trained during MRP are utilized as a base for reasoning hatefulness in context. The loss $\mathcal{L}_{H S D}$ is obtained through a cross-entropy function, as the task is a multi-class classification problem.
在此阶段,模型不参考原理标签。MRP训练期间获得的参数被用作上下文仇恨性推理的基础。由于该任务是一个多类分类问题,损失 $\mathcal{L}_{HSD}$ 通过交叉熵函数获得。
$$
\arg\operatorname*{max}{\theta}\log\mathbb{p}_{\theta}\left(\hat{Y}|X^{S}\right).
$$
$$
\arg\operatorname*{max}{\theta}\log\mathbb{p}_{\theta}\left(\hat{Y}|X^{S}\right).
$$
Table 1: Results for the performance-based and the bias-based metrics. Scores in bold type are the best for each corresponding metric, while the underlined are the second best, and so are in Table 2.
表 1: 基于性能和偏见的指标结果。加粗分数表示对应指标的最佳结果,下划线表示次优结果,表 2 同理。
| Model | ration. | pre-fin. | Acc. | MacroF1 | AUROC | GMB-Sub. | GMB-BPSN | GMB-BNSP |
|---|---|---|---|---|---|---|---|---|
| BERT | 69.0 | 67.4 | 84.3 | 76.2 | 70.9 | 75.7 | ||
| BERT-HateXplain | 69.8 | 68.7 | 85.1 | 80.7 | 74.5 | 76.3 | ||
| BERT-MLM | √ | 70.0 | 67.5 | 85.4 | 79.0 | 67.7 | 80.9 | |
| BERT-RP | 70.7 | 69.3 | 85.3 | 81.4 | 74.6 | 84.8 | ||
| BERT-MRP | √ | 70.4 | 69.9 | 86.2 | 81.5 | 74.8 | 85.4 |
Table 2: Results for the explain ability-based metrics. The lower the score Sufficiency in Faithfulness, the better, and the higher the other scores, the better.
| 模型 | 可解释性 | |||||
|---|---|---|---|---|---|---|
| 合理性 | 忠实性 | |||||
| 推理 | 预训练 IOUF1 | Token F1 | AUPRC | 完备性 ↑HnS | ||
| BERT[Att] | 13.0 11.8 | 49.7 | 77.8 | 44.7 5.7 | ||
| BERT[LIME] | 46.8 | 74.7 | 43.6 | 0.8 | ||
| BERT-HateXplain[Att] | 12.0 | 41.1 | 62.6 | 42.4 | 16.0 | |
| BERT-HateXplain[LIME] | 11.2 | 45.2 | 72.2 | 50.0 | 0.4 | |
| BERT-MLM[Att] | 13.5 | 43.5 | 60.8 | 40.1 | 11.9 | |
| BERT-MLM [LIME] | √ | 11.3 | 47.2 | 76.5 43.4 | -5.5 | |
| BERT-RP[Att] | 13.8 11.4 | 50.3 | 73.8 | 45.4 7.2 | ||
| BERT-RP[LIME] | 49.3 | 77.7 | 48.6 | -2.6 | ||
| BERT-MRP[Att] | 14.1 | 50.4 | 74.5 | 47.9 | 6.7 | |
| BERT-MRP[LIME] | √ | √ 12.9 | 50.1 | 79.2 | 48.3 | -1.2 |
表 2: 基于可解释性指标的结果。忠实性中的充分性分数越低越好,其他分数越高越好。
4 Experiments
4 实验
4.1 Dataset
4.1 数据集
For both stages of the intermediate and the target task, we use the HateXplain dataset. It contains 20,148 items collected from Twitter and Gab. Every item consists of one English sentence with its own ID and annotations about labels for its category, target groups, and rationales, which are annotated by two or three annotators. Based on the IDs, the dataset is split into 8:1:1 for training, validation, and test phases. Following the permanent split provided by the dataset, the models can’t reference any test data during the training phases of all stages.
在中间任务和目标任务的两个阶段中,我们都使用了HateXplain数据集。该数据集包含从Twitter和Gab收集的20,148条数据项,每条数据项由一个英文句子及其唯一ID、类别标签、目标群体和理由注释组成,这些注释由两到三名标注者完成。根据ID,数据集按8:1:1的比例划分为训练集、验证集和测试集。遵循数据集提供的固定划分,所有阶段的模型在训练过程中都无法引用任何测试数据。
4.2 Metrics
4.2 指标
The evaluation is according to the metrics of HateXplain, which are classified into three types: performance-based, bias-based, and explain abilitybased. The performance-based metrics measure the detection performance in distinguishing among three classes (i.e., hate speech, offensive, and normal). Accuracy, macro F1 score, and AUROC score are used as the metrics.
评估基于HateXplain的指标,分为三类:基于性能、基于偏见和基于可解释性。基于性能的指标衡量模型在区分三类内容(即仇恨言论、冒犯性和正常内容)时的检测性能,采用准确率、宏观F1分数和AUROC分数作为衡量标准。
The bias-based metrics evaluate how biased the model is for specific expressions or profanities easily assumed to be hateful. HateXplain follows AUC-based metrics developed by Borkan et al. (2019). The model classifies the data into ‘toxic’– hateful and offensive–and ‘non-toxic’–normal. For evaluating the model’s prediction results, the data are separated into four subsets: $D_{g}^{+},D_{g}^{-},D^{+}$ , and $D^{-}$ . The target group labels are considered standard for dividing data into subgroups. The notations with $g$ denote the data of a specific subgroup among the subgroups, and the notations without g are the remaining data. $+$ and mean that the data are toxic and non-toxic, respectively. Based on these subsets, three AUC metrics are calculated.
基于偏见的指标评估模型对特定表达或脏话的偏见程度,这些内容容易被假定为仇恨言论。HateXplain采用Borkan等人 (2019) 开发的基于AUC (Area Under Curve) 的评估指标。该模型将数据分类为"有毒"(仇恨和攻击性)和"无毒"(正常)两类。为评估模型预测结果,数据被划分为四个子集:$D_{g}^{+}$、$D_{g}^{-}$、$D^{+}$和$D^{-}$。目标群体标签作为划分数据子组的标准,带$g$的符号表示子组中的特定子群数据,不带g的符号表示剩余数据。$+$和$-$分别表示数据有毒和无毒。基于这些子集,计算得出三个AUC指标。
Subgroup AUC is to evaluate how biased the model is to the context of each target group: $A U C(D_{g}^{-}+D_{g}^{+})$ . The higher the score, the less biased the model is with its prediction of a certain social group.
子群AUC用于评估模型对每个目标群体上下文的偏见程度:$A U C(D_{g}^{-}+D_{g}^{+})$。分数越高,模型对特定社会群体的预测偏见越小。
BPSN (Background Positive, Subgroup Negative) AUC measures the model’s false-positive rates regarding the target groups: $A U C(D^{+}{+}D_{g}^{-})$ . The higher the score is, the less a model is likely to confuse non-toxic sentences whose target is the specific subgroup and toxic sentences whose target is one of the other groups.
BPSN (Background Positive, Subgroup Negative) AUC 衡量模型在目标群体上的假阳性率: $A U C(D^{+}{+}D_{g}^{-})$。分数越高,模型越不容易将针对特定子群组的非恶意句子与针对其他群组的恶意句子混淆。
BNSP (Background Negative, Subgroup Positive) AUC measures the model’s false-negative rates regarding the target groups: $A U C(D^{-}{+}D_{g}^{+})$ . The higher the score is, the less the model is likely to confuse non-toxic sentences whose target is the specific group and toxic sentences whose target is one of the other groups.
BNSP (背景负例,子群正例) AUC 衡量模型针对目标群体的假阴性率:$A U C(D^{-}{+}D_{g}^{+})$。该分数越高,模型越不容易混淆以特定群体为目标的非毒性语句和以其他群体为目标的毒性语句。
We calculate GMB (Generalized Mean of Bias)1 of the three metrics as the final scores to combine those ten scores of each of the metrics into one overall measure according to the HateXplain benchmark. The formula is: $M_{p}(m_{s})= $ $\begin{array}{r}{\big(\frac{1}{N}\sum_{s=1}^{N}m_{s}^{p}\big)^{\frac{1}{p}}}\end{array}$ , where $M_{p}$ means the $\boldsymbol{p}^{t h}$ powermean function, $m_{s}$ is one of the bias metrics $m$ calculated for a specific subgroup $s$ , and $\mathbf{N}$ is the number of subgroups which is 10 in this paper.
我们根据HateXplain基准,计算三个指标的GMB (Generalized Mean of Bias)1作为最终分数,将每个指标的十个分数合并为一个总体衡量标准。公式为:$M_{p}(m_{s})= $ $\begin{array}{r}{\big(\frac{1}{N}\sum_{s=1}^{N}m_{s}^{p}\big)^{\frac{1}{p}}}\end{array}$,其中$M_{p}$表示$\boldsymbol{p}^{t h}$幂平均函数,$m_{s}$是为特定子群$s$计算的偏差度量$m$之一,$\mathbf{N}$是子群数量,本文中为10。
The explain ability-based metrics evaluate how much the model is explain able. HateXplain follows ERASER (DeYoung et al., 2019), which is a benchmark for the evaluation of explain ability of an NLP model based on rationales. The metrics are divided into Plausibility and Faithfulness. Plausibility refers to how the model’s rationale matches the human rationale. Plausibility can be considered both discrete selection and soft selection. For discrete selection, We convert token scores to binary values by more than some threshold(here 0.5). Then, We measures IOU F1 score and Token F1 score. For soft selection, We constructed AUPRC by sweeping a threshold over token scores.
基于可解释性的指标评估模型的可解释程度。HateXplain遵循ERASER (DeYoung et al., 2019)基准,该基准用于评估基于原理的NLP模型可解释性。指标分为合理性(Plausibility)和忠实性(Faithfulness)。合理性指模型原理与人类原理的匹配程度,可分为离散选择和软选择两种情况。对于离散选择,我们将token分数通过阈值(此处为0.5)转换为二进制值,然后测量IOU F1分数和Token F1分数。对于软选择,我们通过扫描token分数阈值来构建AUPRC。
Faithfulness evaluates the influence of the model rationale on its prediction result and consists of Comprehensiveness and Sufficiency. Comprehensiveness assumes the model prediction is less confidence when rationales are removed. This metric can be calculated: $m({x}{i}){j}-m({x}{i}\backslash{r}{i}){j}$ . $m(x_{i}){j}$ is the prediction probability of the corresponding class j with an input sentence $x_{i}$ by the model $m$ And $x_{i}\backslash r_{i}$ is the sentence manipulated by removing the predicted rationale tokens $r_{i}$ from $x_{i}$ .2 The higher a score, the more influential the model’s rationales in its prediction. Sufficiency captures the extent to which extracted rationales are acceptable for a model to make a prediction: $m(x_{i}){j}-m(r_{i})_{j}$ . A low score of this metric means that the rationales are adequate in the prediction.
忠实度评估模型依据对其预测结果的影响,包含全面性和充分性两个指标。全面性假设移除依据时模型预测置信度会降低,计算公式为:$m({x}{i}){j}-m({x}{i}\backslash{r}{i}){j}$。其中$m(x_{i}){j}$表示模型$m$对输入句子$x_{i}$中类别j的预测概率,$x_{i}\backslash r_{i}$则是从$x_{i}$中移除预测依据token$r_{i}$后的句子。该分数越高,表明模型依据对预测的影响越大。充分性衡量提取的依据对模型做出预测的支撑程度:$m(x_{i}){j}-m(r_{i})_{j}$。该指标分数越低,说明依据对预测的支持越充分。
In addition, for the HateXplain benchmark, the scores are calculated based on the attention scores of the last layer or by using the LIME method (Ribeiro et al., 2016). The former is marked as [Att], and the latter is [LIME] in Table 2. DeYoung et al. (2019) and Mathew et al. (2020) contain more detailed explanations.
此外,对于HateXplain基准测试,分数是基于最后一层的注意力分数或使用LIME方法 (Ribeiro et al., 2016) 计算的。前者在表2中标记为[Att],后者标记为[LIME]。DeYoung et al. (2019) 和 Mathew et al. (2020) 包含了更详细的解释。
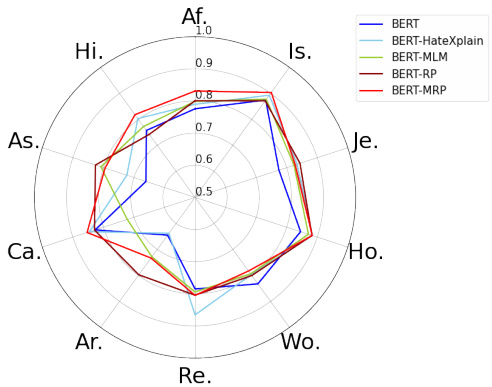
Figure 3: The Subgroup scores among bias-based metrics for each of ten target groups. The target group labels are ‘African’, ‘Islam’, ‘Jewish’, ‘Homosexual’, ‘Women’, ‘Refugee’, ‘Arab’, ‘Caucasian’, ‘Asian’, and ‘Hispanic’ in clockwise direction respectively. The BPSN and BNSP scores are attached in Appendix.
图 3: 十个目标群体在基于偏见的指标中的子群体得分。目标群体标签按顺时针方向分别为"非洲裔"、"伊斯兰教"、"犹太裔"、"同性恋"、"女性"、"难民"、"阿拉伯裔"、"高加索裔"、"亚裔"和"拉丁裔"。BPSN和BNSP得分详见附录。
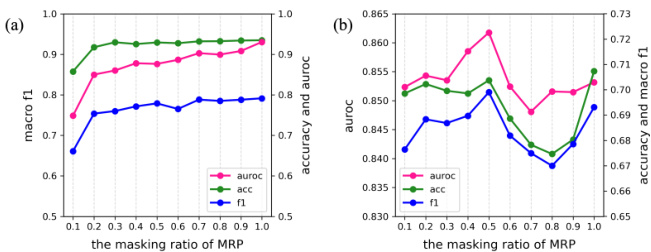
Figure 4: Classification test scores of the proposed models according to masking ratio in MRP. (a) is for token classification after training on MRP in the first stage, and (b) is for hate speech detection in the final stage. The case of masking $100%$ of tokens is the same as BERT-RP.
图 4: 基于MRP中掩码比例提出的模型分类测试分数。(a) 为第一阶段MRP训练后的token分类结果,(b) 为最终阶段的仇恨言论检测结果。当掩码比例为 $100%$ 时,其情况与BERT-RP相同。
4.3 Models and Experimental settings
4.3 模型与实验设置
The evaluated models in Table 1 and Table 2 are as follows. All models are based on a BERT-baseuncased model for a pre-trained model and finetuned on hate speech detection. BERT in the tables is simply finetuned on hate speech detection with a fully-connected layer as a head for the three-class classification described above.
表1和表2中评估的模型如下。所有模型均基于BERT-baseuncased预训练模型,并在仇恨言论检测任务上进行微调。表格中的BERT模型仅通过全连接层作为分类头,针对上述三分类任务进行仇恨言论检测微调。
BERT-HateXplain uses attention supervision in addition to BERT. It matches the last attention values corresponding to the CLS token to the rationale used as ground truth attention. With this, the CLS token takes additional rationale-based attention information for the prediction. The loss is the summation of this attention loss and the detection loss. The results of BERT and BERT-HateXplain are the same as those presented in Mathew et al. (2020).
BERT-HateXplain 在 BERT 基础上引入了注意力监督机制。该方法将 CLS token 对应的最终注意力值与作为真实注意力依据的 rationale 进行匹配,从而使 CLS token 在预测时获得基于 rationale 的额外注意力信息。总损失函数由注意力损失和检测损失相加构成。BERT 和 BERT-HateXplain 的结果与 Mathew 等人 (2020) [20] 的研究结果一致。
BERT-MLM is evaluated to compare the effectiveness of pre-finetuning tasks. Training a pretrained NLP model with MLM using data of the downstream task is frequently used for the model to understand the downstream data and improve its performance (Han and Eisenstein, 2019; BenDavid et al., 2020; Arefyev et al., 2021). It is implemented by simply masking $15%$ tokens of each input sentence.
BERT-MLM 被用于评估预微调任务的有效性。使用下游任务数据通过 MLM (Masked Language Model) 训练预训练 NLP 模型是常见做法,旨在帮助模型理解下游数据并提升性能 (Han and Eisenstein, 2019; BenDavid et al., 2020; Arefyev et al., 2021)。具体实现时,只需对每个输入句子中 $15%$ 的 Token 进行掩码处理。
BERT-MRP and BERT-RP are the proposed models in this paper. BERT-MRP is the model trained on MRP as an intermediate task and then finetuned on hate speech detection. The ratio of masked rationales per token is set to $50%$ of the entire rationale label. BERT-RP is trained on Rationale Prediction (RP), which is MRP when the ratio is set to $100%$ –masking all the rationales. It is functionally the same as token classification with the rationale label as ground truth.
BERT-MRP和BERT-RP是本文提出的模型。BERT-MRP是在MRP (Masked Rationale Prediction) 作为中间任务训练后,再针对仇恨言论检测进行微调的模型。每个token的掩码依据(rationale)比例设置为完整依据标签的$50%$。BERT-RP则基于依据预测(RP)任务训练,该任务本质上是将MRP的掩码比例设为$100%$(即掩码全部依据),其功能等同于以依据标签为真实值的token分类任务。
BERT-MLM, BERT-RP, and BERT-MRP are directly trained in this study. The experimental settings are the same for all models and each training step. The learning rate is $5e{-}5$ during prefinetuning and $2e{-}5$ for hate speech detection, which is the same as BERT-HateXplain. We use the RAdam optimizer and an Nvidia GeForce GTX 1050 graphics card.
本研究直接训练了BERT-MLM、BERT-RP和BERT-MRP模型。所有模型在每个训练步骤中的实验设置均相同:预微调阶段学习率为$5e{-}5$,仇恨言论检测阶段学习率为$2e{-}5$,与BERT-HateXplain保持一致。实验采用RAdam优化器,并使用Nvidia GeForce GTX 1050显卡。
4.4 Comparisons of results
4.4 结果对比
Table 1 and Table 2 present the performances of the models. For all metrics, the proposed models–the two from the bottom–perform much better overall.
表 1 和表 2 展示了模型的性能表现。在所有指标上,提出的模型(底部两个)整体表现明显更优。
Performance-based metrics As summarized in Table 1, the proposed method outperforms the other methods. BERT-MRP shows the highest scores for Macro F1 and AUROC and BERT-RP for accuracy. The pre-finetuned models perform better than those that are not. It shows that the pre-finetuning process helps understand the data and allows enough time for tuning parameters for the target task, thereby improving performance. On the other hand, among the pre-finetuned models, the proposed models show better results than BERT-MLM. Furthermore, they outperform BERT-HateXplain, which also uses the rationale during training like ours. This shows that predicting the human rationale for hate as an intermediate task effectively implements a hate speech detection model.
基于性能的指标
如表 1 所示,所提出的方法优于其他方法。BERT-MRP 在 Macro F1 和 AUROC 上得分最高,而 BERT-RP 在准确率上表现最佳。经过预微调的模型表现优于未预微调的模型。这表明预微调过程有助于理解数据,并为目标任务的参数调整提供了足够时间,从而提升了性能。另一方面,在预微调模型中,所提出的模型表现优于 BERT-MLM。此外,它们还优于同样在训练中使用合理性标注的 BERT-HateXplain。这表明将预测仇恨的人类合理性作为中间任务,能有效实现仇恨言论检测模型。
Bias-based metrics For the model bias, the proposed models show superior results compared to other models. According to Table 1, the models trained using the rationales achieve higher scores than others in general. Given that the human rationales of hatred imply that hate speech is judged based on the context, not merely specific expressions, learning the rationale can exclude the model bias towards the particular words for the prediction. Meanwhile, the proposed BERT-RP and BERT-MRP show better performance than BERTHateXplain, even though they all utilize the rationale in training. BERT-MRP shows the best scores, and BERT-RP is the second-best for all three metrics. Additionally, Figure 3 shows the scores of the models for each of the ten major target groups. It can be seen that the proposed models score evenly high for all the target groups. While other models have significant differences in their bias depending on the groups, the proposed models have comparatively no correlation with them.
基于偏见的指标
在模型偏见方面,所提出的模型相比其他模型展现出更优的结果。根据表 1,使用理性训练(rationales)的模型总体上得分更高。由于人类仇恨理性表明,仇恨言论的判断基于上下文而非特定表达,学习理性可以排除模型预测时对特定词语的偏见。同时,提出的 BERT-RP 和 BERT-MRP 表现优于 BERTHateXplain,尽管它们都利用了理性进行训练。BERT-MRP 在所有三个指标中得分最高,BERT-RP 次之。此外,图 3 展示了各模型针对十大目标群体的得分情况。可以看出,所提出的模型在所有目标群体上得分均匀且较高。而其他模型的偏见程度因群体差异显著,所提出的模型则与之无明显相关性。
Explain ability-based metrics In terms of explainability, the proposed models still perform better than others overall. For Plausibility, BERT-MRP achieves the best performance for all three metrics. It scores much higher than others because it is allowed to directly guess the human rationales during the intermediate training stage. For Faithfulness, BERT-HateXplain[LIME] shows the highest score for Comprehensiveness, and BERT-MLM[LIME] is the best for Sufficiency. However, these models do not reliably score well when considering all four scores obtained according to each of the two measurement methods: attention values or LIME. They show worse scores than BERT for the rest of the scores. On the other hand, BERT-MRP and BERT-RP offer stably high performance for all five explain ability-based metrics.
基于能力的指标解释
在可解释性方面,所提出的模型总体上仍优于其他模型。就合理性(Plausibility)而言,BERT-MRP在所有三个指标上都取得了最佳表现。由于该模型在中间训练阶段被允许直接猜测人类依据,其得分远高于其他模型。在忠实性(Faithfulness)方面,BERT-HateXplain[LIME]在全面性(Comprehensiveness)上得分最高,而BERT-MLM[LIME]在充分性(Sufficiency)上表现最佳。然而,当综合考虑通过两种测量方法(注意力值或LIME)获得的四项分数时,这些模型的得分并不稳定可靠。对于其余分数,它们表现不如原始BERT模型。相比之下,BERT-MRP和BERT-RP在所有五项基于解释能力的指标上都保持了稳定的高性能。
Based on all these results, BERT-MRP and BERT-RP demonstrate the best performance overall for the three types of metrics. Thus, learning the human rationale as an intermediate task before training on hate speech detection seems effective for detection performance and model bias and its explain ability. This framework contributes to better performance than the other–pre-finetuning on MLM as well as another way of using rationales.
基于所有这些结果,BERT-MRP和BERT-RP在三种类型指标上总体表现最佳。因此,在仇恨言论检测训练前学习人类推理作为中间任务,似乎对检测性能、模型偏差及其可解释性都有效。该框架相比其他方法(如在MLM上的预微调及另一种使用推理的方式)贡献了更好的性能。
BERT-MRP generally achieves better results than BERT-RP, wherein the intermediate task is basically the same as token classification. The plots in Figure 4 show the change in test scores according to the masking ratio in MRP. According to Figure 4(a), when more than $20%$ of all rationales were masked, there is no significant difference in the token classification performance, although the amount of loss decreases as the ratio decreases. When each model was re-trained for hate speech detection, as shown in Figure 4(b), the case of $50%$ ratio in BERT-MRP achieved the best classification performance. As MRP is a method for inferring the rationale of a particular token based on surrounding tokens, the model can successfully learn the human rationale within the context. Learning parameters during this reasoning process based on context seems to effectively prevent biased prediction while still being explain able and consequently improves the detection performance substantially.
BERT-MRP通常比BERT-RP取得更好的结果,其中间任务基本与token分类相同。图4中的曲线展示了MRP中根据掩码比例测试分数的变化。根据图4(a),当超过20%的论据被掩码时,token分类性能没有显著差异,尽管损失量随着比例降低而减少。如图4(b)所示,当每个模型重新训练用于仇恨言论检测时,BERT-MRP中50%比例的情况实现了最佳分类性能。由于MRP是一种基于周围token推断特定token论据的方法,该模型能成功学习上下文内的人类论据。在这一基于上下文的推理过程中学习参数,似乎能有效防止预测偏差,同时保持可解释性,从而显著提升检测性能。

Table 3: The highlighted words of the human rationale and the rationale of the models with detection results. BERT-HX is BERT-HateXplain. In the label column, the ground truth is of humans and the remaining labels are the predictions of each model. HS is ’hate speech,’ OF is ’offensive,’ and NO is ’normal.’ More examples are in Appendix.
表 3: 人类依据词与模型依据词的高亮显示及检测结果对比。BERT-HX指BERT-HateXplain。标签列中,基准真值来自人类标注,其余标签为各模型预测结果。HS表示'仇恨言论',OF表示'冒犯性内容',NO表示'正常内容'。更多示例见附录。
4.5 Qualitative results
4.5 定性结果
Table 3 shows examples of detection results from models that use human rationale for their training. The visualized values as the model rationales are the LIME results used to measure the explain ability-based scores. For the human ground truth, the average value per word of humanannotated rationales is expressed for each word.
表 3: 展示了使用人类解释进行训练的模型检测结果示例。模型解释的可视化值是用于衡量基于可解释性分数的 LIME 结果。对于人类标注的真实值,每个词的人类标注解释平均值被表示为每个词的值。
The darker the color, the higher the values.
颜色越深,数值越高。
It is relatively easy to judge explicit hate speech that includes clear derogatory expressions. As shown in Case 1 of Table 3, all the models perform well. The human rationale tends to focus on specific abusive words, and so does the rationale of each model. However, the rationales of the two proposed models match the ground truth better than BERT-HateXplain. Our method to train a model on a token classification-based task leads well the model to focus on human-like grounds in the sentence by directly learning the human rationale.
判断包含明显贬损表达的显性仇恨言论相对容易。如表 3 的案例 1 所示,所有模型都表现良好。人类的判断依据往往集中在特定的侮辱性词汇上,各模型的判断依据也是如此。然而,我们提出的两种模型的判断依据比 BERT-HateXplain 更接近真实情况。我们通过在基于 token 分类的任务上训练模型的方法,通过直接学习人类的判断依据,能很好地引导模型关注句子中类似人类的依据。
As in Case 2, the implicit hate speech with no aggressive expressions cannot be grasped through context. The human rationale thus tends to appear throughout the sentence. As this might make hate speech detection relatively challenging, the detection results of BERT-HateXplain or BERTRP seem incorrect for some sentences. However,
与案例2类似,缺乏攻击性表达的隐性仇恨言论无法通过上下文把握。因此人类依据往往贯穿整个句子。由于这可能使仇恨言论检测相对具有挑战性,BERT-HateXplain或BERTRP的检测结果对某些句子似乎不正确。然而,
BERT-MRP works accurately based on its rationale that is much more similar to human’s than others. Meanwhile, BERT-HateXplain shows a low matching rate of the rationale when the human rationale is throughout the sentence. It uses the human rationale as the ground truth attention, and if there is no difference in the human rationale across tokens, the ground truth could become similar to that of any normal sentence represented by uniform values. This affects the model’s explain ability and may lead to incorrect detection results. The proposed method does not cause that problem. It gets the distinguishable ground truth from normal ones and assigns it as labels to tokens. On the other hand, the rationale of BERT-MRP matches the ground truth better than that of BERT-RP. MRP requires more context-awareness ability when predicting the masked token by allowing the model to consider the abusiveness of surrounding words that are provided corresponding human rationale. This offers robust detection performance, even when it is necessary to understand the context.
BERT-MRP 的工作原理与人类思维高度相似,因此准确性较高。相比之下,BERT-HateXplain 在人类依据贯穿整句时,其依据匹配率较低。该方法将人类依据作为真实注意力基准,若人类依据在 token 间无差异,其基准值会趋近于用均匀值表示的普通句子。这会削弱模型的可解释性,并可能导致错误检测。本文提出的方法避免了该问题,它从正常样本中提取可区分的真实依据,并将其作为 token 标签。此外,BERT-MRP 的依据比 BERT-RP 更贴合真实基准。MRP 在预测掩码 token 时需要更强的上下文感知能力,通过让模型结合周边词语的侮辱性(这些词语已标注对应的人类依据)来实现。即便需要理解上下文,该方法仍能保持稳健的检测性能。
5 Conclusion
5 结论
This paper presents a method to implement a hate speech detection model considering bias and explain ability. We adopt a framework to finetune a pre-trained language model in two stages. As the intermediate task, we propose Masked Rationale Prediction (MRP), which predicts masked rationales for some tokens with the additional rationale information of the remaining surrounding tokens. With this, the model learns to identify abusiveness for each token and the human reasoning process based on context. The trained model by MRP is finetuned again on hate speech detection.
本文提出了一种在考虑偏见和可解释性的情况下实现仇恨言论检测模型的方法。我们采用了一个框架,分两个阶段微调预训练语言模型。作为中间任务,我们提出了掩码依据预测(MRP),该方法通过剩余周围token的额外依据信息来预测某些token的掩码依据。通过这种方式,模型学会根据上下文识别每个token的侮辱性以及人类的推理过程。经过MRP训练的模型会在仇恨言论检测任务上再次进行微调。
As a result, across quantitative and qualitative evaluations, the proposed model shows state-ofthe-art performance in bias and explain ability, as well as the detection result. And the examples demonstrate its robustness in detecting hate speech, whether explicit or implicit, based on its superior explain ability. Meanwhile, we experimented with only BERT as the pre-trained model to compare our method with base models. But any other Transformer encoder-based model can be easily applied, which can be taken as future work.
因此,在定量和定性评估中,所提出的模型在偏差性、可解释性以及检测结果方面均展现出最先进的性能。实例表明,凭借其卓越的可解释能力,该模型在检测显性或隐性仇恨言论时具有鲁棒性。同时,我们仅使用BERT作为预训练模型进行实验,以对比本方法与基线模型的差异。但任何其他基于Transformer编码器的模型均可轻松适配,这可以作为未来的研究方向。
Acknowledgements
致谢
This work was supported by the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF) (NRF-2021S1A5A2A03065899), and also by the NRF of Korea grant funded by the Korean government (MSIT) (NRF-2022R1A2C1007434).
本研究由韩国教育部和韩国国家研究基金会 (NRF) (NRF-2021S1A5A2A03065899) 资助,同时由韩国政府 (MSIT) 资助的韩国国家研究基金会 (NRF) 项目 (NRF-2022R1A2C1007434) 提供支持。
References
参考文献
Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric Lehman, Caiming Xiong, Richard Socher, and Byron C Wallace. 2019. Eraser: A benchmark to evaluate rationalized nlp models. arXiv preprint arXiv:1911.03429.
Jay DeYoung、Sarthak Jain、Nazneen Fatema Rajani、Eric Lehman、Caiming Xiong、Richard Socher 和 Byron C Wallace。2019。Eraser: 一个评估合理化 NLP 模型的基准。arXiv 预印本 arXiv:1911.03429。
Xiaochuang Han and Jacob Eisenstein. 2019. Unsupervised domain adaptation of contextual i zed embeddings for sequence labeling. arXiv preprint arXiv:1904.02817.
Xiaochuang Han and Jacob Eisenstein. 2019. 面向序列标注任务的上下文嵌入无监督域适应方法. arXiv preprint arXiv:1904.02817.
Braden Hancock, Martin Bringmann, Paroma Varma, Percy Liang, Stephanie Wang, and Christopher Ré. 2018. Training class if i ers with natural language explanations. In Proceedings of the conference. Association for Computational Linguistics. Meeting, volume 2018, page 1884. NIH Public Access.
Braden Hancock、Martin Bringmann、Paroma Varma、Percy Liang、Stephanie Wang 和 Christopher Ré。2018年。使用自然语言解释训练分类器。见《会议论文集》。计算语言学协会会议,卷2018,第1884页。美国国立卫生研究院公共访问。
Jeremy Howard and Sebastian Ruder. 2018. Universal language model fine-tuning for text classification. arXiv preprint arXiv:1801.06146.
Jeremy Howard 和 Sebastian Ruder. 2018. 通用语言模型微调用于文本分类. arXiv 预印本 arXiv:1801.06146.
Tao Lei, Regina Barzilay, and Tommi Jaakkola. 2016. Rationalizing neural predictions. arXiv preprint arXiv:1606.04155.
Tao Lei, Regina Barzilay 和 Tommi Jaakkola. 2016. 合理化神经预测. arXiv 预印本 arXiv:1606.04155.
Hui Liu, Qingyu Yin, and William Yang Wang. 2018. Towards explain able nlp: A generative explanation framework for text classification. arXiv preprint arXiv:1811.00196.
Hui Liu、Qingyu Yin和William Yang Wang。2018。迈向可解释的自然语言处理:一个用于文本分类的生成式解释框架。arXiv预印本arXiv:1811.00196。
Thomas Mandl, Sandip Modha, Prasenjit Majumder, Daksh Patel, Mohana Dave, Chintak Mandlia, and Aditya Patel. 2019. Overview of the hasoc track at fire 2019: Hate speech and offensive content identification in indo-european languages. In Proceedings of the 11th forum for information retrieval evaluation, pages 14–17.
Thomas Mandl、Sandip Modha、Prasenjit Majumder、Daksh Patel、Mohana Dave、Chintak Mandlia和Aditya Patel。2019。FIRE 2019的HASOC赛道概述:印欧语言中的仇恨言论和攻击性内容识别。见《第11届信息检索评估论坛论文集》,第14-17页。
Binny Mathew, Punyajoy Saha, Seid Muhie Yimam, Chris Biemann, Pawan Goyal, and Animesh Mukherjee. 2020. Hatexplain: A benchmark dataset for explain able hate speech detection. arXiv preprint arXiv:2012.10289.
Binny Mathew、Punyajoy Saha、Seid Muhie Yimam、Chris Biemann、Pawan Goyal 和 Animesh Mukherjee。2020。Hatexplain:一个可解释仇恨言论检测的基准数据集。arXiv预印本 arXiv:2012.10289。
Rohan K shi r sagar 1 Tyrus Cukuvac1 Kathleen McKe- own and Susan McGregor. 2018. Predictive embeddings for hate speech detection on twitter. EMNLP 2018, page 26.
Rohan K shi r sagar 1 Tyrus Cukuvac1 Kathleen McKeown 和 Susan McGregor. 2018. 推特仇恨言论检测的预测嵌入方法. EMNLP 2018, 第26页.
Jason Phang, Thibault Févry, and Samuel R Bowman. 2018. Sentence encoders on stilts: Supplementary training on intermediate labeled-data tasks. arXiv preprint arXiv:1811.01088.
Jason Phang、Thibault Févry 和 Samuel R Bowman. 2018. 高跷上的句子编码器:基于中间标注数据任务的补充训练. arXiv 预印本 arXiv:1811.01088.
Yada Pr uk s a chat kun, Jason Phang, Haokun Liu, Phu Mon Htut, Xiaoyi Zhang, Richard Yuanzhe Pang, Clara Vania, Katharina Kann, and Samuel R Bowman. 2020. Intermediate-task transfer learning with pretrained models for natural language understanding: When and why does it work? arXiv preprint arXiv:2005.00628.
Yada Pr uk s a chat kun, Jason Phang, Haokun Liu, Phu Mon Htut, Xiaoyi Zhang, Richard Yuanzhe Pang, Clara Vania, Katharina Kann, and Samuel R Bowman. 2020. 基于预训练模型的自然语言理解中间任务迁移学习:何时有效及原因分析?arXiv preprint arXiv:2005.00628.
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training.
Alec Radford、Karthik Narasimhan、Tim Salimans 和 Ilya Sutskever。2018。通过生成式预训练提升语言理解能力。
Tharindu Ranasinghe, Marcos Zampieri, and Hansi He t tiara ch chi. 2019. Brums at hasoc 2019: Deep learning models for multilingual hate speech and offensive language identification. In FIRE (working notes), pages 199–207.
Tharindu Ranasinghe、Marcos Zampieri 和 Hansi He t tiara ch chi. 2019. Brums at hasoc 2019: 多语言仇恨言论与攻击性语言识别的深度学习模型. 见 FIRE (working notes), 第 199–207 页.
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. " why should i trust you?" explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135–1144.
Marco Tulio Ribeiro、Sameer Singh和Carlos Guestrin。2016。《"我为何要相信你?":解释任何分类器的预测》。载于第22届ACM SIGKDD知识发现与数据挖掘国际会议论文集,第1135-1144页。
Maarten Sap, Dallas Card, Saadia Gabriel, Yejin Choi, and A Noah Smith. 2019. The risk of racial bias in hate speech detection. In ACL.
Maarten Sap、Dallas Card、Saadia Gabriel、Yejin Choi 和 A Noah Smith。2019. 仇恨言论检测中的种族偏见风险。载于 ACL。
Yunsheng Shi, Zhengjie Huang, Shikun Feng, Hui Zhong, Wenjin Wang, and Yu Sun. 2020. Masked label prediction: Unified message passing model for semi-supervised classification. arXiv preprint arXiv:2009.03509.
Yunsheng Shi、Zhengjie Huang、Shikun Feng、Hui Zhong、Wenjin Wang 和 Yu Sun。2020。掩码标签预测:半监督分类的统一消息传递模型。arXiv预印本 arXiv:2009.03509。
Ameya Vaidya, Feng Mai, and Yue Ning. 2020. Empirical analysis of multi-task learning for reducing identity bias in toxic comment detection. In Proceedings of the International AAAI Conference on Web and Social Media, volume 14, pages 683–693.
Ameya Vaidya、Feng Mai和Yue Ning。2020。多任务学习在减少毒性评论检测中身份偏见方面的实证分析。见《国际AAAI网络与社交媒体会议论文集》第14卷,第683-693页。
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30.
Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N Gomez、Łukasz Kaiser 和 Illia Polosukhin。2017。注意力机制就是你所需要的一切 (Attention is all you need)。神经信息处理系统进展,30。
Seongjun Yun, Minbyul Jeong, Raehyun Kim, Jaewoo Kang, and Hyunwoo J Kim. 2019. Graph transformer networks. Advances in neural information processing systems, 32.
Seongjun Yun、Minbyul Jeong、Raehyun Kim、Jaewoo Kang 和 Hyunwoo J Kim。2019。图Transformer网络 (Graph Transformer Networks)。Advances in neural information processing systems,32。

Figure A1: The Bias-based scores for each 10 target groups. The target group labels are ‘African’, ‘Islam’, ‘Jewish’, ‘Homosexual’, ‘Women’, ‘Refugee’, ‘Arab’, ‘Caucasian’, ‘Asian’, and ‘Hispanic’ in clockwise direction respectively.
图 A1: 各10个目标群体的基于偏见的分数。目标群体标签按顺时针方向分别为"非洲裔"、"伊斯兰教"、"犹太教"、"同性恋"、"女性"、"难民"、"阿拉伯裔"、"高加索裔"、"亚裔"和"拉丁裔"。

Table A1: The highlighted words of the human rationale and the rationale of the models with detection results in ’hate speech’ sentences.
表 A1: 人类依据词与模型依据词在'仇恨言论'句子中的检测结果对比

Table A2: The highlighted words of the human rationale and the rationale of the models with detection results in ’offensive’ sentences.
表 A2: 人类依据词与模型依据词在'冒犯性'语句中的检测结果高亮对比。