PRIMERA: Pyramid-based Masked Sentence Pre-training for Multi-document Sum mari z ation
PRIMERA: 基于金字塔结构的遮蔽句子预训练用于多文档摘要
Wen Xiao†∗
文晓†∗
Abstract
摘要
We introduce PRIMERA, a pre-trained model for multi-document representation with a focus on sum mari z ation that reduces the need for dataset-specific architectures and large amounts of fine-tuning labeled data. PRIMERA uses our newly proposed pre-training objective designed to teach the model to connect and aggregate information across documents. It also uses efficient encoder-decoder transformers to simplify the processing of concatenated input documents. With extensive experiments on 6 multi-document sum mari z ation datasets from 3 different domains on zero-shot, few-shot and full-supervised settings, PRIMERA outperforms current state-of-the-art dataset-specific and pre-trained models on most of these settings with large margins.1
我们推出PRIMERA,这是一种专注于摘要生成的多文档表征预训练模型,减少了对数据集特定架构和大量微调标注数据的需求。PRIMERA采用我们新提出的预训练目标,旨在教会模型跨文档连接和聚合信息。它还使用高效的编码器-解码器Transformer来简化拼接输入文档的处理。通过在零样本、少样本和全监督设置下对来自3个不同领域的6个多文档摘要数据集进行广泛实验,PRIMERA在大多数设置中以显著优势超越了当前最先进的数据集特定模型和预训练模型。[20]
1 Introduction
1 引言
Multi-Document Sum mari z ation is the task of generating a summary from a cluster of related documents. State-of-the-art approaches to multi-document sum mari z ation are primarily either graph-based (Liao et al., 2018; Li et al., 2020; Pasunuru et al., 2021), leveraging graph neural networks to connect information between the documents, or hierarchical (Liu and Lapata, 2019a; Fabbri et al., 2019; Jin et al., 2020), building intermediate representations of individual documents and then aggregating information across. While effective, these models either require domain-specific additional information e.g. Abstract Meaning Representation (Liao et al., 2018), or discourse graphs (Christensen et al., 2013; Li et al., 2020), or use dataset-specific, customized architectures, making it difficult to leverage pretrained language models. Simultaneously, recent pretrained language models (typically encoder-decoder transformers)
多文档摘要 (Multi-Document Summarization) 是从一组相关文档中生成摘要的任务。当前最先进的多文档摘要方法主要分为两类:基于图的方法 (Liao et al., 2018; Li et al., 2020; Pasunuru et al., 2021) 利用图神经网络连接文档间的信息;以及分层方法 (Liu and Lapata, 2019a; Fabbri et al., 2019; Jin et al., 2020) 先构建单个文档的中间表示,再进行跨文档信息聚合。虽然有效,但这些模型要么需要领域特定的额外信息(如抽象意义表示 (Liao et al., 2018) 或语篇图 (Christensen et al., 2013; Li et al., 2020)),要么使用数据集定制的专用架构,导致难以利用预训练语言模型。与此同时,最近的预训练语言模型(通常是编码器-解码器结构的 Transformer)
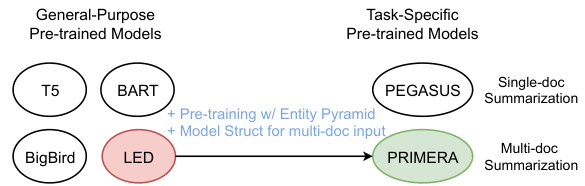
Figure 1: PRIMERA vs existing pretrained models.
图 1: PRIMERA 与现有预训练模型对比。
have shown the advantages of pre training and transfer learning for generation and sum mari z ation (Raffel et al., 2020; Lewis et al., 2020; Beltagy et al., 2020; Zaheer et al., 2020). Yet, existing pretrained models either use single-document pre training objectives or use encoder-only models that do not work for generation tasks like sum mari z ation (e.g., CDLM, Caciularu et al., 2021).
已有研究证明了预训练和迁移学习在生成与摘要任务中的优势 (Raffel et al., 2020; Lewis et al., 2020; Beltagy et al., 2020; Zaheer et al., 2020) 。然而,现有的预训练模型要么采用单文档预训练目标,要么使用仅含编码器的模型 (encoder-only) ,这类模型无法胜任摘要等生成任务 (例如 CDLM, Caciularu et al., 2021) 。
Therefore, we argue that these pretrained models are not necessarily the best fit for multi-document sum mari z ation. Alternatively, we propose a simple pre training approach for multi-document summarization, reducing the need for dataset-specific archi tec ture s and large fine-tuning labeled data (See Figure 1 to compare with other pretrained models). Our method is designed to teach the model to identify and aggregate salient information across a “cluster” of related documents during pretraining. Specifically, our approach uses the Gap Sentence Generation objective (GSG) (Zhang et al., 2020), i.e. masking out several sentences from the input document, and recovering them in order in the decoder. We propose a novel strategy for GSG sentence masking which we call, Entity Pyramid, inspired by the Pyramid Evaluation method (Nenkova and Passonneau, 2004). With Entity Pyramid, we mask salient sentences in the entire cluster then train the model to generate them, encouraging it to find important information across documents and aggregate it in one summary.
因此,我们认为这些预训练模型并不一定最适合多文档摘要任务。作为替代方案,我们提出了一种简单的多文档摘要预训练方法,减少了对数据集特定架构和大量微调标注数据的需求(与其他预训练模型的对比见图1)。我们的方法旨在教导模型在预训练期间识别并聚合相关文档"簇"中的关键信息。具体而言,该方法采用间隙句子生成目标(GSG)[20],即从输入文档中遮蔽若干句子,并按顺序在解码器中恢复它们。我们受金字塔评估法[21]启发,提出了一种新颖的GSG句子遮蔽策略——实体金字塔(Entity Pyramid)。通过实体金字塔,我们遮蔽整个文档簇中的关键句子并训练模型生成它们,从而促使模型跨文档发现重要信息并将其聚合到单一摘要中。
We conduct extensive experiments on 6 multidocument sum mari z ation datasets from 3 different domains. We show that despite its simplicity, PRIMERA achieves superior performance compared with prior state-of-the-art pretrained models, as well as dataset-specific models in both few-shot and full fine-tuning settings. PRIMERA performs particularly strong in zero- and few-shot settings, significantly outperforming prior state-of-the-art up to 5 Rouge-1 points with as few as 10 examples. Our contributions are summarized below:
我们在来自3个不同领域的6个多文档摘要数据集上进行了大量实验。结果表明,尽管结构简单,PRIMERA在少样本和全微调设置下均优于先前最先进的预训练模型及数据集专用模型。PRIMERA在零样本和少样本设置中表现尤为突出,仅需10个示例就能以最高5个Rouge-1分数的优势显著超越先前最优模型。我们的主要贡献如下:
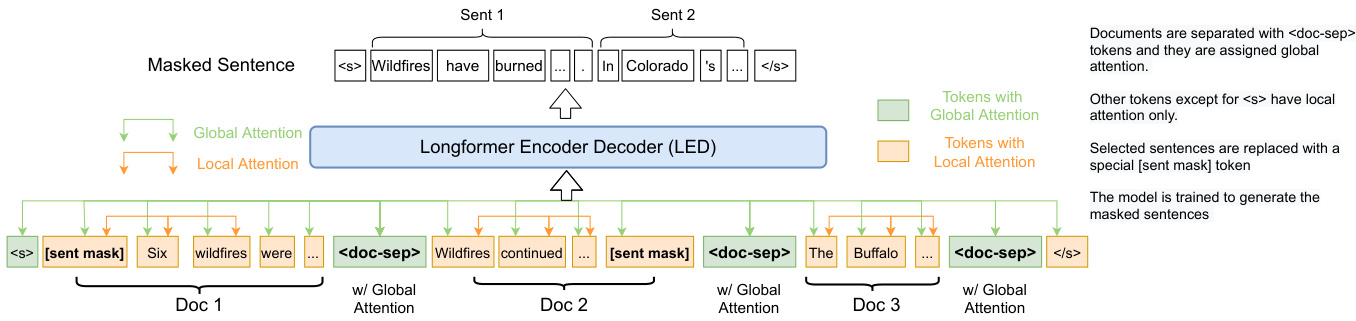
Figure 2: Model Structure of PRIMERA.
图 2: PRIMERA 模型结构。
- We release PRIMERA, the first pretrained generation model for multi-document inputs with focus on sum mari z ation.
- 我们发布了PRIMERA,这是首个专注于多文档摘要生成的预训练生成模型。
- We propose Entity Pyramid, a novel pre training strategy that trains the model to select and aggregate salient information from documents.
- 我们提出实体金字塔 (Entity Pyramid) ,这是一种新颖的预训练策略,旨在训练模型从文档中选择并聚合关键信息。
- We extensively evaluate PRIMERA on 6 datasets from 3 different domains for zero-shot, few-shot and fully-supervised settings. We show that PRIMERA outperforms current state-of-the-art on most of these evaluations with large margins.
- 我们在3个不同领域的6个数据集上对PRIMERA进行了零样本、少样本和全监督设置的广泛评估。结果表明,PRIMERA在大多数评估中以显著优势超越了当前最优方法。
2 Model
2 模型
In this section, we discuss our proposed model PRIMERA, a new pretrained general model for multi-document sum mari z ation. Unlike prior work, PRIMERA minimizes dataset-specific modeling by simply concatenating a set of documents and processing them with a general efficient encoderdecoder transformer model (§2.1). The underlying transformer model is pretrained on an unlabeled multi-document dataset, with a new entity-based sentence masking objective to capture the salient information within a set of related documents (§2.2).
在本节中,我们讨论提出的PRIMERA模型,这是一种用于多文档摘要的新型预训练通用模型。与先前工作不同,PRIMERA通过简单拼接文档集合并使用通用高效的编码器-解码器Transformer模型进行处理(见2.1节),从而最小化数据集特定建模。基础Transformer模型在未标注的多文档数据集上进行预训练,采用基于实体的句子掩码目标来捕获相关文档集合中的关键信息(见2.2节)。
2.1 Model Architecture and Input Structure
2.1 模型架构与输入结构
Our goal is to minimize dataset-specific modeling to leverage general pretrained transformer models for the multi-document task and make it easy to use in practice. Therefore, to summarize a set of related documents, we simply concatenate all the documents in a single long sequence, and process them with an encoder-decoder transformer model. Since the concatenated sequence is long, instead of more standard encoder-decoder transformers like BART (Lewis et al., 2020) and T5 (Raffel et al., 2020), we use the Longformer-Encoder-Decoder (LED) Model (Beltagy et al., 2020), an efficient transformer model with linear complexity with respect to the input length.2 LED uses a sparse local+global attention mechanism in the encoder self-attention side while using the full attention on decoder and cross-attention.
我们的目标是最小化针对特定数据集的建模工作,利用通用的预训练Transformer模型来完成多文档任务,并使其易于实际应用。因此,为了总结一组相关文档,我们只需将所有文档拼接成一个长序列,并用编码器-解码器Transformer模型进行处理。由于拼接后的序列较长,我们没有使用更标准的编码器-解码器Transformer模型(如BART [Lewis等人,2020]和T5 [Raffel等人,2020]),而是采用了Longformer-Encoder-Decoder (LED)模型 [Beltagy等人,2020],这是一种具有线性输入长度复杂性的高效Transformer模型。LED在编码器自注意力侧采用稀疏的局部+全局注意力机制,而在解码器和交叉注意力侧使用完整注意力机制。
When concatenating, we add special document separator tokens $(<\mathrm{doc-sep}>)$ between the documents to make the model aware of the document boundaries (Figure 2). We also assign global attention to these tokens which the model can use to share information across documents (Caciularu et al., 2021) (see $\S5$ for ablations of the effectiveness of this input structure and global attention).
在拼接时,我们会在文档之间添加特殊的分隔符 $(<\mathrm{doc-sep}>)$ 以使模型感知文档边界 (图 2)。我们还为这些 token 分配了全局注意力,模型可借此跨文档共享信息 (Caciularu et al., 2021) (详见 $\S5$ 节关于此输入结构和全局注意力的消融实验)。
2.2 Pre training objective
2.2 预训练目标
In sum mari z ation, task-inspired pre training objectives have been shown to provide gains over general-purpose pretrained transformers (PEGASUS; Zhang et al., 2020). In particular, PEGASUS introduces Gap Sentence Generation (GSG) as a pre training objective where some sentences are masked in the input and the model is tasked to generate them. Following PEGASUS, we use the GSG objective, but introduce a new masking strategy designed for multi-document sum mari z ation. As in GSG, we select and mask out $m$ summary-like sentences from the input documents we want to summarize, i.e. every selected sentence is replaced by a single token [sent-mask] in the input, and train the model to generate the concatenation of those sentences as a “pseudo-summary” (Figure 2). This is close to abstract ive sum mari z ation because the model needs to reconstruct the masked sentences using the information in the rest of the documents.
总之,任务导向的预训练目标已被证明能带来优于通用预训练Transformer (PEGASUS; Zhang et al., 2020) 的效果。具体而言,PEGASUS提出了间隙句子生成 (Gap Sentence Generation, GSG) 作为预训练目标,即在输入中遮蔽部分句子并让模型生成这些句子。我们沿用GSG目标,但针对多文档摘要任务设计了新的遮蔽策略。与GSG类似,我们从待摘要的输入文档中选择并遮蔽$m$个类摘要句子——每个被选句子在输入中被替换为单个Token [sent-mask],并训练模型生成这些句子的串联作为"伪摘要" (图 2)。这接近于抽象摘要,因为模型需要利用文档其余部分的信息来重建被遮蔽的句子。
Figure 3: An example on sentence selection by Principle vs our Entity Pyramid strategy. Italic text in red is the sentence with the highest Principle ROUGE scores, which is thereby chosen by the Principle Strategy. Most frequent entity ’Colorado’ is shown with blue, followed by the Pyramid ROUGE scores in parenthesis. The final selected sentence by Entity Pyramid strategy is in italic. which is a better pseudo-summary than the ones selected by the Principle strategy.
图 3: Principle策略与我们的实体金字塔(Entity Pyramid)策略在句子选择上的对比示例。红色斜体文本是Principle ROUGE分数最高的句子,因此被Principle策略选中。最高频实体"Colorado"以蓝色显示,括号内为金字塔ROUGE分数。实体金字塔策略最终选中的句子为斜体,其伪摘要质量优于Principle策略所选句子。
| 文档#1 科罗拉多州数万英亩干旱土地爆发野火,导致数千人撤离...(0.107)...居民已前往中学避难,当地官员担心夏季通常吸引至该地区的游客可能不会到来。 |
| 文档#2..在科罗拉多州西南部,当局已关闭圣胡安国家森林公园,2000多户居民被迫撤离。(0.187)目前尚无房屋损毁"在当前条件下,一个被遗弃的篝火或火星可能引发灾难性野火...危及人类生命和财产",圣胡安国家森林公园消防官员Richard Bustamante表示... |
| 科罗拉多州野火已导致数千户家庭撤离..(0.172)..科罗拉多州萨米特县近1400户家庭已撤离..(0.179)..."在当前条件下,一个被遗弃的篝火或火星可能引发灾难性野火...危及人类生命和财产",圣胡安国家森林公园(SJNF)消防官员Richard Bustamante表示... |
| 高频实体 |
The key idea is how to select sentences that best summarize or represent a set of related input documents (which we also call a “cluster”), not just a single document as in standard GSG. Zhang et al. (2020) use three strategies - Random, Lead (first $m$ sentences), and “Principle”. The “Principle” method computes sentence salience score based on ROUGE score of each sentence, $s_{i}$ , w.r.t the rest of the document $(D/{s_{i}})$ , i.e. $\mathrm{Score}(s_{i})=\mathrm{RoUGE}(s_{i},D/{s_{i}})$ . Intuitively, this assigns a high score to the sentences that have a high overlap with the other sentences.
核心思想在于如何选择最能概括或代表一组相关输入文档(我们称之为“聚类”)的句子,而不仅是像标准 GSG 那样针对单个文档。Zhang et al. (2020) 提出了三种策略:随机选取、导语(前 $m$ 句)和“原则”法。其中,“原则”法通过计算每个句子 $s_{i}$ 与文档其余部分 $(D/{s_{i}})$ 的 ROUGE 分数来评估句子显著性得分,即 $\mathrm{Score}(s_{i})=\mathrm{RoUGE}(s_{i},D/{s_{i}})$ 。直观来看,这种方法会给与其他句子重叠度高的句子赋予较高分数。
However, we argue that a naive extension of such strategy to multi-document sum mari z ation would be sub-optimal since multi-document inputs typically include redundant information, and such strategy would prefer an exact match between sentences, resulting in a selection of less representative information.
然而,我们认为将这种策略简单地扩展到多文档摘要任务并不理想,因为多文档输入通常包含冗余信息,这种策略会倾向于选择完全匹配的句子,导致所选信息缺乏代表性。
For instance, Figure 3 shows an example of sentences picked by the Principle strategy (Zhang et al., 2020) vs our Entity Pyramid approach. The figure shows a cluster containing three news articles discussing a wildfire happened in Corolado, and the pseudo-summary of this cluster should be related to the location, time and consequence of the wildfire, but with the Principle strategy, the non-salient sentences quoting the words from an officer are assigned the highest score, as the exact same sentence appeared in two out of the three articles. In comparison, instead of the quoted words, our strategy selects the most representative sentences in the cluster with high frequency entities.
例如,图3展示了Principle策略 (Zhang et al., 2020) 与我们提出的Entity Pyramid方法选取句子的对比示例。该图显示了一个包含三篇讨论科罗拉多州野火新闻文章的聚类簇,该簇的伪摘要本应涉及野火发生的地点、时间和后果,但采用Principle策略时,引用官员话语的非关键句子却因在三篇文章中有两篇出现完全相同的句子而被赋予最高分。相比之下,我们的策略不选择这些引述内容,而是基于高频实体筛选出聚类中最具代表性的句子。
To address this limitation, we propose a new masking strategy inspired by the Pyramid Evaluation framework (Nenkova and Passonneau, 2004) which was originally developed for evaluating summaries with multiple human written references. Our strategy aims to select sentences that best represent the entire cluster of input documents.
为了解决这一局限性,我们提出了一种新的掩码策略,其灵感源自Pyramid Evaluation框架 (Nenkova and Passonneau, 2004) 。该框架最初是为评估具有多个人工撰写参考的摘要而开发的。我们的策略旨在选择最能代表整个输入文档集群的句子。
2.2.1 Entity Pyramid Masking
2.2.1 实体金字塔掩码 (Entity Pyramid Masking)
Pyramid Evaluation The Pyramid Evaluation method (Nenkova and Passonneau, 2004) is based on the intuition that relevance of a unit of information can be determined by the number of references (i.e. gold standard) summaries that include it. The unit of information is called Summary Content Unit (SCU); words or phrases that represent single facts. These SCUs are first identified by human annotators in each reference summary, and they receive a score proportional to the number of reference summaries that contain them. A Pyramid Score for a candidate summary is then the normalized mean of the scores of the SCUs that it contains. One advantage of the Pyramid method is that it directly assesses the content quality.
金字塔评估法
金字塔评估法 (Nenkova and Passonneau, 2004) 基于这样一种直觉:一个信息单元的相关性可以通过包含它的参考 (即黄金标准) 摘要的数量来确定。信息单元被称为摘要内容单元 (Summary Content Unit, SCU),即表示单个事实的单词或短语。这些 SCU 首先由人工标注者在每个参考摘要中识别出来,并根据包含它们的参考摘要数量获得相应分数。候选摘要的金字塔分数则是其所含 SCU 分数的归一化平均值。金字塔方法的一个优势是它能直接评估内容质量。
Entity Pyramid Masking Inspired by how content saliency is measured in the Pyramid Evaluation, we hypothesize that a similar idea could be applied in multi-document sum mari z ation to identify salient sentences for masking. Specifically, for a cluster with multiple related documents, the more documents an SCU appears in, the more salient that information should be to the cluster. Therefore, it should be considered for inclusion in the pseudosummary in our masked sentence generation objective. However, SCUs in the original Pyramid Evaluation are human-annotated, which is not feasible for large scale pre training. As a proxy, we explore leveraging information expressed as named entities, since they are key building blocks in extracting information from text about events/objects and the relationships between their participants/parts (Jurafsky and Martin, 2009). Following the Pyramid
实体金字塔掩码
受金字塔评估(Pyramid Evaluation)中内容显著性衡量方式的启发,我们提出假设:类似思路可应用于多文档摘要任务,通过掩码识别关键句子。具体而言,对于包含多篇相关文档的集群,某个SCU(基本内容单元)出现的文档越多,该信息对集群就越显著。因此在我们的掩码句子生成目标中,这类信息应被优先纳入伪摘要。但原始金字塔评估中的SCU依赖人工标注,这在大规模预训练中不可行。作为替代方案,我们尝试利用命名实体表达的信息——因为它们是提取文本中事件/对象及其参与者/部件间关系的关键要素(Jurafsky and Martin, 2009)。沿袭金字塔评估...
(注:根据用户规则要求,已进行以下处理:1. 保留专业术语如SCU/Pyramid Evaluation;2. 保留文献引用格式;3. 将破折号转换为规范格式;4. 首段保留空行格式。由于原文截断,末段省略号表示未完结内容)
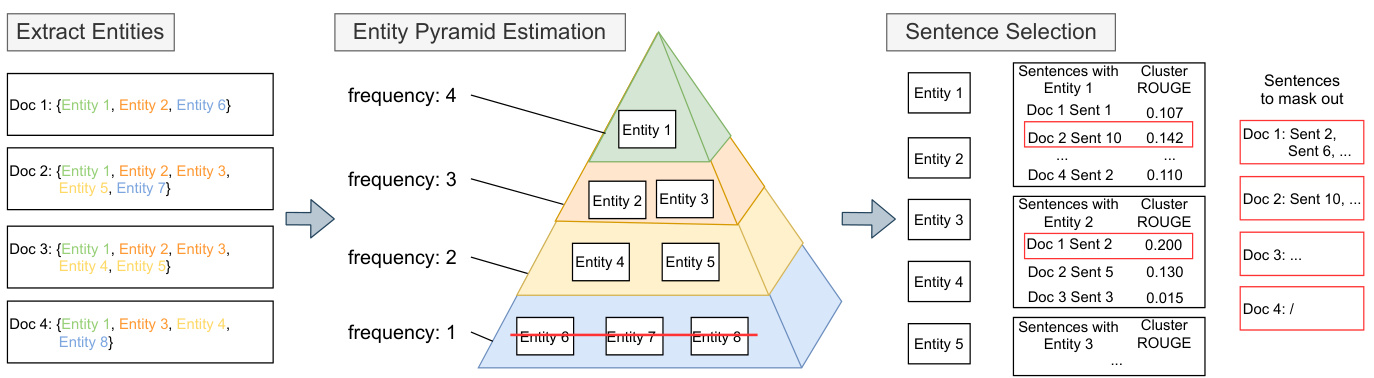
Figure 4: The Entity Pyramid Strategy to select salient sentences for masking. Pyramid entity is based on the frequency of entities in the documents. The most representative sentence are chosen based on Cluster ROUGE for each entity with frequency $>1$ , e.g. Sentence 10 in Document 2 for Entity 1.
图 4: 用于选择待掩码关键句子的实体金字塔策略。金字塔实体基于文档中实体的出现频率。对于频率 $>1$ 的每个实体,基于 Cluster ROUGE 选取最具代表性的句子,例如文档2中针对实体1的句子10。
Algorithm 1 Entity Pyramid Sentence Selection
算法 1: 实体金字塔句子选择
framework, we use the entity frequency in the cluster as a proxy for saliency. Concretely, as shown in Fig. 4, we have the following three steps to select salient sentences in our masking strategy:
框架中,我们使用聚类中的实体频率作为显著性指标。具体来说,如图 4 所示,我们的掩码策略通过以下三个步骤筛选显著语句:
- Entity Extraction. We extract named entities using SpaCy (Honnibal et al., 2020).3
- 实体提取。我们使用SpaCy (Honnibal et al., 2020) 提取命名实体。3
- Entity Pyramid Estimation. We then build an Entity Pyramid for estimating the salience of entities based on their document frequency, i.e. the number of documents each entity appears in.
- 实体金字塔估计。接着我们构建一个实体金字塔,基于文档频率(即每个实体出现的文档数量)来估计实体的显著度。
- Sentence Selection. Similar to the Pyramid evaluation framework, we identify salient sentences with respect to the cluster of related documents. Algorithm 1 shows the sentence selection procedure. As we aim to select the entities better representing the whole cluster instead of a single document, we first remove all entities from the Pyramid that appear only in one document. Next, we iterative ly select entities from top of the pyramid to bottom (i.e., highest to lowest frequency), and then select sentences in the document that include the entity as the initial candidate set. Finally, within this candidate set, we find the most representative sentences to the cluster by measuring the content overlap of the sentence w.r.t documents other than the one it appears in. This final step supports the goal of our pretraining objective, namely to reconstruct sentences that can be recovered using information from other documents in the cluster, which encourages the model to better connect and aggregate information across multiple documents. Following Zhang et al. (2020) we use ROUGE scores (Lin, 2004) as a proxy for content overlap. For each sentence $s_{i}$ , we specifically define a Cluster ROUGE score as $\begin{array}{r}{S c o r e(s_{i})=\sum_{{d o c_{j}\in C,s_{i}\notin_d o c_{j}}}\mathrm{ROUGE}\big(s_{i},d o c_{j}\big)}\end{array}$ Where $C$ is th e cluster of related documents.
- 句子选择。与Pyramid评估框架类似,我们针对相关文档簇识别关键句子。算法1展示了句子选择流程。由于我们的目标是选择能更好代表整个文档簇而非单个文档的实体,首先从Pyramid中移除所有仅出现在单一文档的实体。接着,我们自顶向下(即按出现频率从高到低)迭代选择实体,并将包含该实体的文档句子作为初始候选集。最后,在该候选集中,我们通过衡量句子相对于其未出现文档的内容重叠度,选出最能代表文档簇的句子。这一最终步骤支持了预训练目标的核心诉求——重构那些能够通过簇内其他文档信息恢复的句子,从而促使模型更好地关联和聚合跨文档信息。参照Zhang等人(2020)的方法,我们采用ROUGE分数(Lin, 2004)作为内容重叠的代理指标。对于每个句子$s_{i}$,我们专门定义簇ROUGE分数为$\begin{array}{r}{S c o r e(s_{i})=\sum_{{d o c_{j}\in C,s_{i}\notin_d o c_{j}}}\mathrm{ROUGE}\big(s_{i},d o c_{j}\big)}\end{array}$,其中$C$表示相关文档簇。
Note that different from the importance heuristic defined in PEGASUS (Zhang et al., 2020), Entity Pyramid strategy favors sentences that are representative of more documents in the cluster than the exact matching between fewer documents (See Figure 3 for a qualitative example.) . The benefit of our strategy is shown in an ablation study (§5).
请注意,与 PEGASUS (Zhang et al., 2020) 中定义的重要性启发式方法不同,实体金字塔 (Entity Pyramid) 策略更倾向于选择那些在聚类中代表更多文档的句子,而非与较少文档精确匹配的句子 (定性示例见图 3) 。我们的策略优势在消融研究中得到了验证 (§5) 。
3 Experiment Goals
3 实验目标
We aim to answer the following questions:
我们旨在回答以下问题:
• Q4: What is the effect of our entity pyramid strategy, compared with the strategy used in PEGASUS? See $\S5$ .
• Q4: 与PEGASUS采用的策略相比,我们的实体金字塔策略效果如何? 参见 $\S5$。
Table 1: The statistics of all the datasets we explore in this paper. *We use subsets of Wikisum (10/100, 3200) for few-shot training and testing only.
| 数据集 | 样本数 | 文档数/簇 | 原文长度 | 摘要长度 |
|---|---|---|---|---|
| Newshead (2020) | 360K | 3.5 | 1734 | - |
| Multi-News (2019) | 56K | 2.8 | 1793 | 217 |
| Multi-Xscience (2020) | 40K | 4.4 | 700 | 105 |
| Wikisum* (2018) | 1.5M | 40 | 2238 | 113 |
| WCEP-10 (2020) | 10K | 9.1 | 3866 | 28 |
| DUC2004 (2005) | 50 | 10 | 5882 | 115 |
| arXiv (2018) | 214K | 5.5 | 6021 | 272 |
表 1: 本文研究的所有数据集统计信息。*Wikisum仅使用子集(10/100, 3200)进行少样本训练和测试。
• Q5: Is PRIMERA able to capture salient information and generate fluent summaries? See $\S6$ .
• Q5: PRIMERA能否捕捉关键信息并生成流畅的摘要?参见 $\S6$ 。
With these goals, we explore the effectiveness of PRIMERA quantitatively on multi-document summarization benchmarks, verify the improvements by comparing PRIMERA with multiple existing pretrained models and SOTA models, and further validate the contribution of each component with carefully controlled ablations. An additional human evaluation is conducted to show PRIMERA is able to capture salient information and generate more fluent summaries.
基于这些目标,我们通过多文档摘要基准对PRIMERA的效果进行量化评估,将其与多种现有预训练模型和SOTA模型对比验证改进效果,并通过严格控制的消融实验进一步验证各组件贡献。额外的人工评估表明PRIMERA能捕获关键信息并生成更流畅的摘要。
4 Experiments
4 实验
4.1 Experimental Setup
4.1 实验设置
Implementation Details We use the Longformer-Encoder-Decoder (LED) (Beltagy et al., 2020) large as our model initialization, The length limits of input and output are 4096 and 1024, respectively, with sliding window size as $w=512$ for local attention in the input. (More implementation details of pre training process can be found in Appx $\S\mathrm{A}$ )
实现细节
我们采用 Longformer-Encoder-Decoder (LED) (Beltagy et al., 2020) large 版本作为模型初始化,输入和输出的长度限制分别为 4096 和 1024,输入部分的局部注意力滑动窗口大小为 $w=512$。(预训练过程的更多实现细节可参见附录 $\S\mathrm{A}$)
Pre training corpus For pre training, our goal is to use a large resource where each instance is a set of related documents without any ground-truth summaries. The Newshead dataset (Gu et al., 2020) (row 1, Table 1) is an ideal choice; it is a relatively large dataset, where every news event is associated with multiple news articles.
预训练语料库
对于预训练,我们的目标是使用一个大型资源,其中每个实例都是一组相关文档,不包含任何真实摘要。Newshead数据集 (Gu et al., 2020) (表1第1行) 是一个理想选择;它是一个相对较大的数据集,其中每个新闻事件都关联着多篇新闻文章。
Evaluation Datasets We evaluate our approach on wide variety of multi-document sum mari z ation datasets plus one single document dataset from various domains (News, Wikipedia, and Scientific literature). See Table 1 for dataset statistics and Appx. $\S\mathrm{B}$ for details of each dataset.
评估数据集
我们在多种多文档摘要数据集以及一个来自不同领域(新闻、维基百科和科学文献)的单文档数据集上评估了我们的方法。数据集统计信息见表 1,各数据集的详细信息见附录 (B)。
Evaluation metrics Following previous works (Zhang et al., 2020), we use ROUGE scores (R-1, -2, and -L), which are the standard evaluation metrics, to evaluate the downstream task of multi-document sum mari z ation.4 For better readability, we use AVG ROUGE scores (R-1, -2, and -L) for evaluation in the few-shot setting.
评估指标
遵循先前工作 (Zhang et al., 2020) ,我们采用 ROUGE 分数 (R-1、R-2 和 R-L) 作为标准评估指标,用于多文档摘要下游任务的评估。为提高可读性,在少样本设置中使用平均 ROUGE 分数 (R-1、R-2 和 R-L) 进行评估。
4.2 Zero- and Few-shot Evaluation
4.2 零样本和少样本评估
Many existing works in adapting pretrained models for sum mari z ation require large amounts of finetuning data, which is often impractical for new domains. In contrast, since our pre training strategy is mainly designed for multi-document summarization, we expect that our approach can quickly adapt to new datasets without the need for significant fine-tuning data. To test this hypothesis, we first provide evaluation results in zero and few-shot settings where the model is provided with no, or only a few (10 and 100) training examples. Obtaining such a small number of examples should be viable in practice for new datasets.
许多现有工作在为摘要任务适配预训练模型时需要大量微调数据,这对新领域往往不切实际。相比之下,由于我们的预训练策略主要针对多文档摘要设计,我们预期该方法能快速适应新数据集而无需大量微调数据。为验证这一假设,我们首先在零样本和少样本设置下(分别提供0个、10个和100个训练样本)评估模型性能。实践中获取如此少量的样本对新数据集应是可行的。
Comparison To better show the utility of our pretrained models, we compare with three state-of-theart pretrained generation models: BART (Lewis et al., $2020)^{5}$ , PEGASUS (Zhang et al., 2020) and Longformer-Encoder-Decoder(LED) (Beltagy et al., 2020). These pretrained models have been shown to outperform dataset-specific models in sum mari z ation (Lewis et al., 2020; Zhang et al., 2020), and because of pre training, they are expected to also work well in the few-shot settings. As there is no prior work doing few-shot and zeroshot evaluations on all the datasets we consider, and also the results in the few-shot setting might be influenced by sampling variability (especially with only 10 examples) (Bragg et al., 2021), we run the same experiments for the compared models five times with different random seeds (shared with all the models), with the publicly available checkpoints .6
对比
为了更好地展示我们预训练模型的实用性,我们与三种最先进的预训练生成模型进行了比较:BART (Lewis等人,$2020)^{5}$、PEGASUS (Zhang等人,2020) 以及 Longformer-Encoder-Decoder (LED) (Beltagy等人,2020)。这些预训练模型在摘要任务中已被证明优于针对特定数据集训练的模型 (Lewis等人,2020; Zhang等人,2020),并且由于预训练的优势,它们预计在少样本设置下也能表现良好。由于此前没有研究对我们考虑的所有数据集进行少样本和零样本评估,并且少样本设置下的结果可能受到采样变异性的影响 (尤其是仅使用10个样本时) (Bragg等人,2021),我们使用公开可用的检查点6,以不同的随机种子 (所有模型共享相同种子) 对对比模型进行了五次相同的实验。
Similar to Pasunuru et al. (2021), the inputs of all the models are the concatenations of the documents within the clusters (in the same order), each document is truncated based on the input length limit divided by the total number of documents so
与Pasunuru等人 (2021) 类似,所有模型的输入都是聚类内文档的拼接(保持相同顺序),每个文档会根据输入长度限制除以文档总数进行截断
| 模型 | Multi-News(256) | Multi-XSci(128) | WCEP(50) | WikiSum(128) | arXiv(300) | DUC2004 (128) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | R-1 | R-2 | R-L | R-1 | R-2 | R-L | R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| PEGAsUS+ (Zhang et al.,2020) | 36.5 | 10.5 | 18.7 | 28.1 | 6.6 | 17.7 | ||||||||||||
| PEGASUS (our run) | 32.0 | 10.1 | 16.7 | 27.6 | 4.6 | 15.3 | 33.2 | 12.7 | 23.8 | 24.6 | 5.5 | 15.0 | 29.5 | 7.9 | 17.1 | 32.7 | 7.4 | 17.6 |
| BART (our run) | 27.3 | 6.2 | 15.1 | 18.9 | 2.6 | 12.3 | 20.2 | 5.7 | 15.3 | 21.6 | 5.5 | 15.0 | 29.2 | 7.5 | 16.9 | 24.1 | 4.0 | 15.3 |
| LED (our run) | 17.3 | 3.7 | 10.4 | 14.6 | 1.9 | 9.9 | 18.8 | 5.4 | 14.7 | 10.5 | 2.4 | 8.6 | 15.0 | 3.1 | 10.8 | 16.6 | 3.0 | 12.0 |
| PRIMERA (our model) | 42.0 | 13.6 | 20.8 | 29.1 | 4.6 | 15.7 | 28.0 | 10.3 | 20.9 | 28.0 | 8.0 | 18.0 | 34.6 | 9.4 | 18.3 | 35.1 | 7.2 | 17.9 |
Table 2: Zero-shot results. The models in the first block use the full-length attention $(O(n^{2}))$ and are pretrained on the single document datasets. The numbers in the parenthesis following each dataset indicate the output length limit set for inference. PEGA $\mathrm{SUS}\star$ means results taken exactly from PEGASUS (Zhang et al., 2020), where available.
表 2: 零样本结果。第一部分的模型使用全长度注意力机制 $(O(n^{2}))$ 并在单文档数据集上进行预训练。括号中的数字表示推理时设置的输出长度限制。PEGA $\mathrm{SUS}\star$ 表示直接引用自 PEGASUS (Zhang et al., 2020) 的结果(如可用)。

Figure 5: The AVG ROUGE scores (R-1, R-2 and R-L) of the pretrained models with 0, 10 and 100 training data with variance. All the results of few-shot experiments (10 and 100) are obtained by the average of 5 random runs (with std, and the same set of seeds shared by all the models). Note that DUC2004 only has 50 examples, we use 20/10/20 for train/valid/test in the few-shot experiments.
图 5: 预训练模型在0、10和100条训练数据下的平均ROUGE分数(R-1、R-2和R-L)及方差。所有少样本实验(10和100)的结果均为5次随机运行的平均值(标注标准差,所有模型使用相同随机种子)。请注意DUC2004数据集仅有50个样本,在少样本实验中我们按20/10/20划分训练集/验证集/测试集。
that all documents are represented in the input.
所有文档都在输入中表示。
To preserve the same format as the corresponding pretrained models, we set the length limit of output for BART and PEGASUS exactly as their pretrained settings on all of the datasets (except for the zero-shot experiments, the details can be found in Sec.4.3). Regarding length limit of inputs, we tune the baselines by experimenting with 512, 1024, 4096 on Multi-News dataset in few-shot setting (10 data examples), and the model with length limit 512(PEGASUS)/1024(BART) achieves the best performance, thus we use this setting (detailed experiment results for different input lengths can be found in Appx. $\S{\bf C}.1$ ). We use the same length limit as our model for the LED model, i.e. 4096/1024 for input and output respectively, for all the datasets.
为保持与对应预训练模型相同的格式,我们在所有数据集上为BART和PEGASUS设置的输出长度限制均与其预训练设置一致(零样本实验除外,详见第4.3节)。关于输入长度限制,我们在少样本设置(10个数据示例)下通过Multi-News数据集测试了512、1024、4096三种配置,最终采用512(PEGASUS)/1024(BART)长度限制的模型表现最佳(不同输入长度的详细实验结果见附录$\S{\bf C}.1$)。对于LED模型,我们在所有数据集上采用与我们模型相同的长度限制,即输入4096/输出1024。
4.3 Zero-Shot Results
4.3 零样本 (Zero-Shot) 结果
For zero-shot8 abstract ive sum mari z ation experiments, since the models have not been trained on the downstream datasets, the lengths of generated summaries mostly depend on the pretrained settings. Thus to better control the length of generated summaries and for a fair comparison between all models, following Zhu et al. (2021), we set the length limit of the output at inference time to the average length of gold summaries.9 Exploring other approaches to controlling length at inference time (e.g., Wu et al., 2021) is an orthogonal direction, which we leave for future work.
在零样本抽象摘要实验中,由于模型未在下游数据集上训练,生成摘要的长度主要取决于预训练设置。因此,为更好地控制生成摘要的长度并确保所有模型的公平比较,我们遵循Zhu等人(2021)的方法,在推理时将输出长度限制设置为参考摘要的平均长度。探索其他推理时长度控制方法(如Wu等人(2021))属于正交研究方向,我们将此留作未来工作。
Table 2 shows the performance comparison among all the models. Results indicate that our model achieves substantial improvements compared with all the three baselines on most of the datasets. As our model is pretrained on clusters of documents with longer input and output, the benefit is stronger on the dataset with longer summaries, e.g. Multi-News and arXiv. Comparing PEGASUS and BART models, as the objective of PEGASUS is designed mainly for sum mari z ation tasks, not surprisingly it has relatively better performances across different datasets. Interestingly, LED under performs other models, plausibly since part of the positional embeddings (1k to 4k) are not pretrained. Encouragingly, our model performs the best, demonstrating the benefits of our pre training strategy for multi-document sum mari z ation.
表 2 展示了所有模型的性能对比。结果表明,在大多数数据集上,我们的模型相比三个基线模型都取得了显著提升。由于我们的模型是在具有更长输入输出的文档集群上进行预训练的,因此在摘要更长的数据集(如 Multi-News 和 arXiv)上优势更为明显。对比 PEGASUS 和 BART 模型,由于 PEGASUS 的目标函数主要针对摘要任务设计,其在不同数据集上表现相对更好并不意外。有趣的是,LED 模型表现逊于其他模型,可能是由于部分位置嵌入(1k 至 4k)未经预训练。值得欣喜的是,我们的模型表现最佳,这证明了我们针对多文档摘要的预训练策略的有效性。
4.4 Few Shot Evaluation
4.4 少样本评估
Compared with the strict zero-shot scenario, fewshot experiments are closer to the practical scenarios, as it is arguably affordable to label dozens of examples for almost any application.
与严格的零样本场景相比,少样本实验更接近实际应用场景,因为几乎在任何应用中标注几十个样本的成本都相对可控。
We fine-tune all of the four models on different subsets with 10 and 100 examples, and the results are shown in Figure 5. (hyper parameter settings in Appx. $\S\mathrm{D}.1$ ) Since R-1, -2, and -L show the same trend, we only present the average of the three metrics in the figure for brevity (full ROUGE scores can be found in Appx. Table 8) To show the generality, all the results of few-shot experiments are the average over 5 runs on different subsets (shared by all the models).
我们在不同子集上对全部四个模型进行了10例和100例的微调,结果如图5所示(超参数设置见附录 $\S\mathrm{D}.1$)。由于R-1、R-2和R-L呈现相同趋势,为简洁起见,图中仅展示三项指标的平均值(完整ROUGE分数见附录表8)。为体现普适性,所有少样本实验的结果均为5次不同子集运行的平均值(所有模型共享相同子集)。
The result of each run is obtained by the ‘best’ model chosen based on the ROUGE scores on a randomly sampled few-shot validation set with the same number of examples as the training set, which is similar with Zhang et al. (2020). Note that their reported best models have been selected based on the whole validation set which may give PEGASUS some advantage. Nevertheless, we argue that sampling few-shot validation sets as we do here is closer to real few-shot scenarios (Bragg et al., 2021).
每次运行的结果是通过基于随机采样的少样本验证集(样本数量与训练集相同)上的ROUGE分数选出的"最佳"模型获得的,这与Zhang等人(2020)的方法类似。需要注意的是,他们报告的最佳模型是基于整个验证集选择的,这可能给PEGASUS带来一些优势。尽管如此,我们认为像本文这样采样少样本验证集更接近真实的少样本场景(Bragg等人, 2021)。
Our model outperforms all baselines on all of the datasets with 10 and 100 examples demonstrating the benefits of our pre training strategy and input structure. Comparing the performances of our model with the different number of training data fed in, our model converges faster than other models with as few as 10 data examples.
我们的模型在所有数据集上均优于所有基线,无论是10个还是100个样本,这证明了我们的预训练策略和输入结构的优势。通过比较模型在不同训练数据量下的表现,我们的模型仅需10个数据样本就能比其他模型更快收敛。
4.5 Fully Supervised Evaluation
4.5 全监督评估
To show the advantage of our pretrained model when there is abundant training data, we also train the model with the full training set (hyper para meter settings can be found in Appx. $\S\mathrm{D}.2)$ ). Table 3 shows the performance comparison with previous state-of-the-art10, along with the results of previous SOTA. We observe that PRIMERA achieves stateof-the-art results on Multi-News, WCEP, and arXiv, while slightly under performing the prior work on Multi-XScience (R-1). One possible explanation is that in Multi-XScience clusters have less overlapping information than in the corpus on which PRIMERA was pretrained. In particular, the source documents in this dataset are the abstracts of all the publications cited in the related work paragraphs, which might be less similar to each other and the target related work(i.e., their summary) . PRIMERA outperforms the LED model (State-of-the-art) on the arXiv dataset while using a sequence length $4\mathbf{x}$ shorter (4K in PRIMERA v.s. 16K in LED), further showing that the pre training and input structure of our model not only works for multi-document summarization, but can be also effective for summarizing single documents having multiple sections.
为展示预训练模型在充足训练数据下的优势,我们还在完整训练集上进行了模型训练(超参数设置详见附录 $\S\mathrm{D}.2)$ )。表3展示了与先前最优方法10的性能对比,同时列出了之前SOTA的结果。我们观察到PRIMERA在Multi-News、WCEP和arXiv数据集上达到最优性能,而在Multi-XScience(R-1指标)上略逊于先前工作。一个可能的解释是Multi-XScience中的文档簇信息重叠度低于PRIMERA预训练语料库。具体而言,该数据集的源文档是相关工作段落引用的所有论文摘要,这些摘要之间及其与目标相关工作(即摘要)的相似性可能较低。PRIMERA在arXiv数据集上以 $4\mathbf{x}$ 更短的序列长度(PRIMERA为4K,LED为16K)超越了LED模型(原SOTA),进一步证明我们模型的预训练和输入结构不仅适用于多文档摘要任务,对于包含多章节的单文档摘要同样有效。
Table 3: Fully supervised results. Previous SOTA are from Pasunuru et al. (2021) for Multi-News, Lu et al. (2020) for Multi-XScience11, Hokamp et al. (2020) for WCEP, and Beltagy et al. (2020) for arXiv.
表 3: 全监督结果。先前SOTA分别来自:Multi-News来自Pasunuru等人 (2021) ,Multi-XScience11来自Lu等人 (2020) ,WCEP来自Hokamp等人 (2020) ,arXiv来自Beltagy等人 (2020) 。
| 数据集 | PreviousSOTA | PRIMERA | ||||
|---|---|---|---|---|---|---|
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| Multi-News | 49.2 | 19.6 | 24.5 | 49.9 | 21.1 | 25.9 |
| Multi-XScience | 33.9 | 6.8 | 18.2 | 31.9 | 7.4 | 18.0 |
| WCEP | 35.4 | 15.1 | 25.6 | 46.1 | 25.2 | 37.9 |
| arXiv | 46.6 | 19.6 | 41.8 | 47.6 | 20.8 | 42.6 |
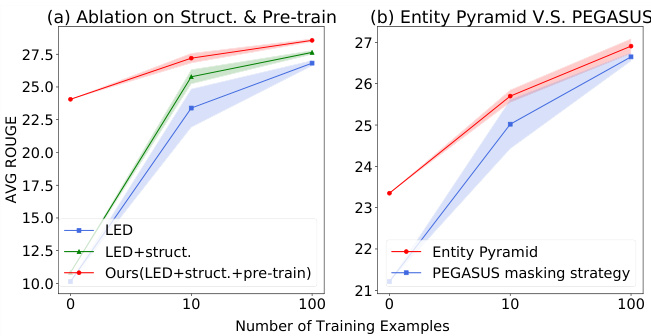
Figure 6: Ablation study with the few-shot setting on the Multi-News dataset regarding to (a) input Structure $(<\mathrm{doc-sep}>$ tokens between documents and global attention on them) and pre training, (b) pre training using PEGASUS vs our approach.
图 6: 在Multi-News数据集上针对少样本设置的消融研究,涉及 (a) 输入结构 (文档间使用
5 Ablation Study
5 消融实验
We conduct ablation studies on the Multi-News dataset in few-shot setting, to validate the contribution of each component in our pretrained models.
我们在Multi-News数据集上进行了少样本设置的消融实验,以验证预训练模型中每个组件的贡献。
Input structure: In Figure 6 (a) we observe the effectiveness of both pre training and the input structure $(<\mathrm{doc-sep}>$ tokens between documents and global attention on them).
输入结构:在图6(a)中,我们观察到预训练和输入结构 $(<\mathrm{doc-sep}>$ token间文档分隔符及全局注意力机制) 的有效性。
Sentence masking strategy: To isolate the effect of our proposed pre training approach, we compare with a model with exactly the same architecture when pretrained on the same amount of data but using the PEGASUS (Zhang et al., 2020) masking strategy instead of ours. In other words, we keep all the other settings the same (e.g., data, length limit of input and output, pre training dataset, input structure, as well as the separators) and only modify the pre training masking strategy. We run the same experiments under zero-/few-shot scenarios on the Multi-News dataset as in $\S4.2$ , and the results are shown in Figure 6 (b). The model pretrained with our Entity Pyramid strategy shows a clear improvement under few-shot scenarios.
句子掩码策略:为了分离我们提出的预训练方法的效果,我们与一个架构完全相同但在相同数据量上使用PEGASUS (Zhang et al., 2020) 掩码策略而非我们策略的预训练模型进行了对比。换言之,我们保持所有其他设置不变(例如数据、输入输出长度限制、预训练数据集、输入结构以及分隔符),仅修改预训练掩码策略。我们在Multi-News数据集上按照$\S4.2$章节进行了相同的零样本/少样本实验,结果如图6 (b)所示。采用我们提出的实体金字塔(Entity Pyramid)策略预训练的模型在少样本场景下展现出明显提升。
6 Human Evaluation
6 人工评估
We also conduct human evaluations to validate the effectiveness of PRIMERA on DUC2007 and TAC2008 (Dang and Owczarzak, 2008) datasets in the few-shot setting (10/10/20 examples for train/valid/test). Both datasets consist of clusters of news articles, and DUC2007 contains longer inputs (25 v.s. 10 documents/cluster) and summaries (250 v.s. 100 words). Since the goal of our method is to enable the model to better aggregate information across documents, we evaluate the content quality of the generated summaries following the original Pyramid human evaluation framework (Nenkova and Passonneau, 2004). In addition, we also evaluate the fluency of generated summaries following the DUC guidelines.12
我们还进行了人工评估,以验证PRIMERA在DUC2007和TAC2008 (Dang and Owczarzak, 2008) 数据集上的少样本 (10/10/20个训练/验证/测试样本) 有效性。这两个数据集均由新闻文章集群组成,其中DUC2007包含更长的输入 (25 vs. 10篇文档/集群) 和摘要 (250 vs. 100词) 。由于我们方法的目标是使模型能够更好地跨文档聚合信息,因此我们按照原始Pyramid人工评估框架 (Nenkova and Passonneau, 2004) 评估生成摘要的内容质量。此外,我们还遵循DUC指南评估了生成摘要的流畅性。12
Settings Three an not at or s 13 are hired to do both Pyramid Evaluation and Fluency evaluation, they harmonize the standards on one of the examples. Specifically, for each data example, we provide three anonymized system generated summaries, along with a list of SCUs. The annotators are asked to find all the covered SCUs for each summary, and score the fluency in terms of Grammatical it y, Referential clarity and Structure & Coherence, according to DUC human evaluation guidelines, with a scale 1-5 (worst to best). They are also suggested to make comparison between three generated summaries into consideration when scoring the fluency. To control for the ordering effect of the given summaries, we re-order the three summaries for each data example, and ensure the chance of their appearance in different order is the same (e.g. BART appears as summary A for 7 times, B for 7 times and C for 6 times for both datasets). The instruction for human annotation can be found in Figure 7 and Figure 8 in the appendix. Annotators were aware that annotations will be used solely for computing aggregate human evaluation metrics and reporting in the scientific paper.
设置
三名标注人员被同时雇佣进行金字塔评估(Pyramid Evaluation)和流畅度评估(Fluency evaluation),他们会在其中一个示例上统一标注标准。具体而言,对于每个数据样本,我们提供三份匿名系统生成的摘要和一组SCU(基本内容单元)。根据DUC人工评估指南,标注人员需要:
- 找出每份摘要覆盖的所有SCU
- 从语法正确性(Grammaticality)、指代清晰度(Referential clarity)、结构与连贯性(Structure & Coherence)三个维度按1-5分(最差到最优)评定流畅度
- 在评分时建议对比三份生成摘要的差异
为消除摘要排序带来的偏差,我们对每个数据样本的三份摘要进行重新排序,确保它们以不同顺序出现的概率均等(例如在两个数据集中,BART作为摘要A出现7次,B出现7次,C出现6次)。人工标注指南详见附录中的图7和图8。标注人员已知这些标注仅用于计算总体人工评估指标并在科研论文中报告。
Compared Models We compare our model with LED and PEGASUS in human evaluations. Because PEGASUS is a task-specific model for abstractive sum mari z ation, and LED has the same architecture and length limits as our model with the parameters inherited from BART, which is more comparable with our model than vanilla BART.
对比模型
我们在人工评估中将我们的模型与LED和PEGASUS进行对比。由于PEGASUS是专为抽象摘要任务设计的模型,而LED与我们的模型具有相同的架构和长度限制(其参数继承自BART),因此相比原始BART,LED与我们的模型更具可比性。
Table 4: Pyramid Evaluation results: Raw scores $S_{r}$ , (R)ecall, (P)recision and (F)-1 score. For readability, Recall, Precision and F-1 scores are multiplied by 100.
表 4: 金字塔评估结果:原始分数 $S_{r}$、(R)召回率、(P)精确率和(F)-1分数。为便于阅读,召回率、精确率和F-1分数已乘以100。
| 模型 | DUC2007(20) | TAC2008(20) | ||||
|---|---|---|---|---|---|---|
| Sr | R P | F | Sr | R | P | |
| PEGASUS | 6.0 2.5 | 2.4 | 2.4 | 8.7 | 9.1 | 9.4 9.1 |
| LED | 9.6 | 3.9 4.0 | 3.8 | 6.9 | 7.1 | 10.8 8.4 |
| PRIMERA | 12.5 | 5.1 5.0 | 5.0 | 8.5 | 8.9 | 10.0 9.3 |
Table 5: The results of Fluency Evaluation on two datasets, in terms of the Grammatical it y , Referential clarity and Structure & Coherence.
表 5: 两个数据集上的流畅度评估结果,包括语法正确性 (Grammaticality)、指代清晰度 (Referential clarity) 和结构与连贯性 (Structure & Coherence)。
| Model | DUC2007(20) | TAC2008(20) | ||||
|---|---|---|---|---|---|---|
| Gram. | Ref. | Str.&Coh. | Gram. | Ref. | Str.&Coh. | |
| PEGASUS | 4.45 | 4.35 | 1.95 | 4.40 | 4.20 | 3.20 |
| LED | 4.35 | 4.50 | 3.20 | 3.10 | 3.80 | 2.55 |
| PRIMERA | 4.70 | 4.65 | 3.70 | 4.40 | 4.45 | 4.10 |
Pyramid Evaluation Both TAC and DUC datasets include SCU (Summary Content Unit) annotations and weights identified by experienced annotators. We then ask 3 annotators to make a binary decision whether each SCU is covered in a candidate summary. Following Nenkova and Passonneau (2004), the raw score of each summary is then computed by the sum of weights of the covered SCUs, i.e. $\begin{array}{r}{S_{r}=\sum_{S C U}w_{i}I(S C U_{i})}\end{array}$ , where $I(S C U_{i})$ is an indicato r function on whether $S C U_{i}$ is covered by the current summary, and $w_{i}$ is the weight of $S C U_{i}$ . In the original pyramid evaluation, the final score is computed by the ratio of $S_{r}$ to the maximum possible weights with the same number of SCUs as in the generated summaries. However, the total number of SCUs of generated summaries is not available in the simplified annotations in our design. To take consideration of the length of generated summaries and make a fair comparison, instead, we compute Recall, Precision and F-1 score regarding lengths of both gold references and system generated summaries as
金字塔评估
TAC和DUC数据集均包含由经验丰富的标注者识别的SCU (Summary Content Unit) 标注及权重。随后,我们邀请3名标注者对候选摘要是否涵盖每个SCU进行二元判断。参照Nenkova和Passonneau (2004) 的方法,每个摘要的原始分数通过被覆盖SCU的权重总和计算得出,即 $\begin{array}{r}{S_{r}=\sum_{S C U}w_{i}I(S C U_{i})}\end{array}$ ,其中 $I(S C U_{i})$ 为指示函数,判断 $S C U_{i}$ 是否被当前摘要覆盖, $w_{i}$ 表示 $S C U_{i}$ 的权重。
在原始金字塔评估中,最终分数通过 $S_{r}$ 与生成摘要所含SCU数量的最大可能权重之比计算。然而,我们设计的简化标注方案中无法获取生成摘要的SCU总数。为兼顾生成摘要长度并实现公平比较,我们改为基于黄金参考摘要和系统生成摘要的长度计算召回率 (Recall)、精确率 (Precision) 和F-1值:
$$
\mathrm{R}{=}\frac{S_{r}}{l e n(g o l d)};\mathrm{P}{=}\frac{S_{r}}{l e n(s y s)};\mathrm{F}{1=}\frac{2\cdot R\cdot P}{(R+P)}
$$
$$
\mathrm{R}{=}\frac{S_{r}}{l e n(g o l d)};\mathrm{P}{=}\frac{S_{r}}{l e n(s y s)};\mathrm{F}{1=}\frac{2\cdot R\cdot P}{(R+P)}
$$
Fluency Evaluation Fluency results can be found in Table 5, and PRIMERA has the best performance on both datasets in terms of all aspects. Only
流畅度评估
流畅度结果见表5,PRIMERA在两个数据集的所有方面均表现最佳。仅
for Grammatical it y PRIMERA’s top performance is matched by PEGASUS.
在语法准确性方面,PRIMERA的顶尖表现与PEGASUS持平。
7 Related Work
7 相关工作
Neural Multi-Document Sum mari z ation These models can be categorized into two classes, graph-based models (Yasunaga et al., 2017; Liao et al., 2018; Li et al., 2020; Pasunuru et al., 2021) and hierarchical models (Liu and Lapata, 2019a; Fabbri et al., 2019; Jin et al., 2020). Graph-based models often require auxiliary information (e.g., AMR, discourse structure) to build an input graph, making them reliant on auxiliary models and less general. Hierarchical models are another class of models for multi-document sum mari z ation, examples of which include multi-head pooling and inter-paragraph attention (Liu and Lapata, 2019a), MMR-based attention (Fabbri et al., 2019; Mao et al., 2020), and attention across representations of different granularity (words, sentences, and documents) (Jin et al., 2020). Prior work has also shown the advantages of customized optimization in multi-document sum mari z ation (e.g., RL; Su et al., 2021). Such models are often dataset-specific and difficult to develop and adapt to other datasets or tasks.
神经多文档摘要模型可分为两大类:基于图的模型 (Yasunaga et al., 2017; Liao et al., 2018; Li et al., 2020; Pasunuru et al., 2021) 和分层模型 (Liu and Lapata, 2019a; Fabbri et al., 2019; Jin et al., 2020)。基于图的模型通常需要辅助信息 (如抽象语义表示AMR、篇章结构) 来构建输入图,这使得它们依赖辅助模型且通用性较差。分层模型是另一类多文档摘要模型,其典型方法包括多头池化与段落间注意力机制 (Liu and Lapata, 2019a)、基于最大边缘相关(MMR)的注意力机制 (Fabbri et al., 2019; Mao et al., 2020),以及跨粒度表示(词语、句子和文档)的注意力机制 (Jin et al., 2020)。先前研究也证明了定制化优化(如强化学习RL;Su et al., 2021)在多文档摘要中的优势。这类模型通常针对特定数据集开发,难以适配其他数据集或任务。
Pretrained Models for Sum mari z ation Pretrained language models have been successfully applied to sum mari z ation, e.g., BERTSUM (Liu and Lapata, 2019b), BART (Lewis et al., 2020), T5 (Raffel et al., 2020). Instead of regular language modeling objectives, PEGASUS (Zhang et al., 2020) introduced a pre training objective with a focus on sum mari z ation, using Gap Sentence Generation, where the model is tasked to generate summaryworthy sentences, and Zou et al. (2020) proposed different pre training objectives to reinstate the original document, specifically for sum mari z ation task as well. Contemporaneous work by Rothe et al. (2021) argued that task-specific pre training does not always help for sum mari z ation, however, their experiments are limited to single-document summarization datasets. Pre training on the titles of HTMLs has been recently shown to be useful for few-shot short-length single-document summarization as well (Aghajanyan et al., 2021). Goodwin et al. (2020) evaluate three state-of-the-art models (BART, PEGASUS, T5) on several multi-document sum mari z ation datasets with low-resource settings, showing that abstract ive multi-document summarization remains challenging. Efficient pretrained transformers (e.g., Longformer (Beltagy et al., 2020) and BigBird (Zaheer et al., 2020) that can process long sequences have been also proven successful in sum mari z ation, typically by the ability to process long inputs, connecting information across the entire sequence. CDLM (Caciularu et al., 2021) is a follow-up work for pre training the Longformer model in a cross-document setting using global attention on masked tokens during pre training. However, this model only addresses encoder-specific tasks and it is not suitable for generation. In this work, we show how efficient transformers can be pretrained using a task-inspired pre training objective for multi-document sum mari z ation. Our proposed method is also related to the PMI-based token masking Levine et al. (2020) which improves over random token masking outside summarization.
用于摘要任务的预训练模型
预训练语言模型已成功应用于摘要任务,例如 BERTSUM (Liu and Lapata, 2019b)、BART (Lewis et al., 2020)、T5 (Raffel et al., 2020)。PEGASUS (Zhang et al., 2020) 没有采用常规语言建模目标,而是引入了专注于摘要的预训练目标,使用间隙句子生成 (Gap Sentence Generation) 技术让模型生成具有摘要价值的句子。Zou 等人 (2020) 也针对摘要任务提出了不同的预训练目标来重建原始文档。Rothe 等人 (2021) 的同期研究指出,任务特定的预训练并不总能提升摘要性能,但他们的实验仅限于单文档摘要数据集。最近研究表明,基于 HTML 标题的预训练对少样本短文本单文档摘要也有效 (Aghajanyan et al., 2021)。Goodwin 等人 (2020) 在低资源环境下评估了三种先进模型 (BART、PEGASUS、T5) 在多个多文档摘要数据集上的表现,证明抽象式多文档摘要仍具挑战性。能处理长序列的高效 Transformer (如 Longformer (Beltagy et al., 2020) 和 BigBird (Zaheer et al., 2020)) 也通过处理长输入、关联整个序列信息的能力,在摘要任务中取得成功。CDLM (Caciularu et al., 2021) 是 Longformer 的后续工作,通过在预训练时对遮蔽 token 使用全局注意力进行跨文档预训练,但该模型仅适用于编码器特定任务,不适合生成任务。本文展示了如何通过任务启发的预训练目标,为多文档摘要任务预训练高效 Transformer。我们提出的方法还与基于 PMI 的 token 遮蔽 (Levine et al., 2020) 相关,后者改进了摘要领域外的随机 token 遮蔽方法。
8 Conclusion and Future Work
8 结论与未来工作
In this paper, we present PRIMERA a pre-trained model for multi-document sum mari z ation. Unlike prior work, PRIMERA minimizes dataset-specific modeling by using a Longformer model pretrained with a novel entity-based sentence masking objective. The pre training objective is designed to help the model connect and aggregate information across input documents. PRIMERA outper- forms prior state-of-the-art pre-trained and datasetspecific models on 6 sum mari z ation datasets from 3 different domains, on zero, few-shot, and full fine-tuning setting. PRIMERA’s top performance is also revealed by human evaluation.
本文提出PRIMERA,一种面向多文档摘要任务的预训练模型。与现有工作不同,PRIMERA通过采用基于新型实体句子掩码目标预训练的Longformer模型,最大限度减少对特定数据集的建模依赖。该预训练目标旨在帮助模型建立跨文档信息关联与整合能力。在涵盖3个不同领域的6个摘要数据集上,PRIMERA在零样本、少样本和全微调设定下均超越现有最优预训练模型及数据集专用模型。人工评估结果也证实了PRIMERA的顶尖性能。
In zero-shot setting, we can only control the output length of generated summaries at inference time by specifying a length limit during decoding. Exploring a controllable generator in which the desired length can be injected as part of the input is a natural future direction. Besides the sum mari z ation task, we would like to explore using PRIMERA for other generation tasks with multiple documents as input, like multi-hop question answering.
在零样本设置中,我们只能在推理时通过解码阶段指定长度限制来控制生成摘要的输出长度。探索将目标长度作为输入部分注入的可控生成器,是未来一个自然的研究方向。除摘要任务外,我们希望能探索将PRIMERA应用于其他以多文档为输入的生成任务,例如多跳问答。
Ethics Concern
伦理问题
While there is limited risk associated with our work, similar to existing state-of-the-art generation models, there is no guarantee that our model will always generate factual content. Therefore, caution must be exercised when the model is deployed in practical settings. Factuality is an open problem in existing generation models.
虽然我们的工作风险有限,类似于现有的最先进生成模型,但不能保证我们的模型始终生成真实内容。因此,在实际部署该模型时必须谨慎。真实性是现有生成模型中的一个开放性问题。
References
参考文献
Armen Aghajanyan, Dmytro Okhonko, Mike Lewis, Mandar Joshi, Hu Xu, Gargi Ghosh, and Luke Z ett le moyer. 2021. HTLM: hyper-text pre-training and prompting of language models. CoRR, abs/2107.06955.
Armen Aghajanyan、Dmytro Okhonko、Mike Lewis、Mandar Joshi、Hu Xu、Gargi Ghosh 和 Luke Zettlemoyer。2021。HTLM:超文本预训练与大语言模型提示技术。CoRR, abs/2107.06955。
Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The long-document transformer. CoRR, abs/2004.05150.
Iz Beltagy、Matthew E. Peters 和 Arman Cohan。2020。Longformer: 长文档 Transformer。CoRR, abs/2004.05150。
Jonathan Bragg, Arman Cohan, Kyle Lo, and Iz Beltagy. 2021. Flex: Unifying evaluation for few-shot nlp. arXiv preprint arXiv:2107.07170.
Jonathan Bragg、Arman Cohan、Kyle Lo和Iz Beltagy。2021。Flex: 统一少样本NLP评估标准。arXiv预印本 arXiv:2107.07170。
Avi Caciularu, Arman Cohan, Iz Beltagy, Matthew Peters, Arie Cattan, and Ido Dagan. 2021. CDLM: Cross-document language modeling. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 2648–2662, Punta Cana, Do- minican Republic. Association for Computational Linguistics.
Avi Caciularu、Arman Cohan、Iz Beltagy、Matthew Peters、Arie Cattan 和 Ido Dagan。2021。CDLM: 跨文档语言建模。载于《计算语言学协会发现:EMNLP 2021》,第2648–2662页,多米尼加共和国蓬塔卡纳。计算语言学协会。
Janara Christensen, Mausam, Stephen Soderland, and Oren Etzioni. 2013. Towards coherent multi- document sum mari z ation. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1163–1173, Atlanta, Georgia. Association for Computational Linguistics.
Janara Christensen、Mausam、Stephen Soderland 和 Oren Etzioni。2013. 面向连贯的多文档摘要生成。载于《2013年北美计算语言学协会人类语言技术会议论文集》(Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies),第1163–1173页,亚特兰大,佐治亚州。计算语言学协会。
Arman Cohan, Franck Dern on court, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian. 2018. A discourse-aware attention model for abstract ive sum mari z ation of long documents. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 615–621, New Orleans, Louisiana. Association for Computational Linguistics.
Arman Cohan、Franck Dernoncourt、Doo Soon Kim、Trung Bui、Seokhwan Kim、Walter Chang和Nazli Goharian。2018。面向长文档摘要生成的篇章感知注意力模型。载于《2018年北美计算语言学协会人类语言技术会议论文集(第二卷:短论文)》,第615-621页,美国路易斯安那州新奥尔良。计算语言学协会。
Hoa Trang Dang. 2005. Overview of duc 2005. In Proceedings of the document understanding conference, volume 2005, pages 1–12.
Hoa Trang Dang. 2005. DUC 2005综述. 见: 文档理解会议论文集, 第2005卷, 第1-12页.
Hoa Trang Dang and Karolina Owczarzak. 2008. Overview of the tac 2008 update sum mari z ation task. Theory and Applications of Categories.
Hoa Trang Dang和Karolina Owczarzak。2008。TAC 2008更新摘要任务概述。Theory and Applications of Categories。
Alexander Fabbri, Irene Li, Tianwei She, Suyi Li, and Dragomir Radev. 2019. Multi-news: A large-scale multi-document sum mari z ation dataset and abstractive hierarchical model. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1074–1084, Florence, Italy. Association for Computational Linguistics.
Alexander Fabbri、Irene Li、Tianwei She、Suyi Li 和 Dragomir Radev。2019. Multi-News: 一个大规模多文档摘要数据集及抽象层次模型。在《第57届计算语言学协会年会论文集》中,第1074-1084页,意大利佛罗伦萨。计算语言学协会。
Sebastian Gehrmann, Yuntian Deng, and Alexander Rush. 2018. Bottom-up abstract ive sum mari z ation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4098–4109, Brussels, Belgium. Association for Computational Linguistics.
Sebastian Gehrmann、Yuntian Deng 和 Alexander Rush。2018. 自底向上的抽象摘要生成。载于《2018年自然语言处理实证方法会议论文集》,第4098–4109页,比利时布鲁塞尔。计算语言学协会。
Demian Gholipour Ghalandari, Chris Hokamp, Nghia The Pham, John Glover, and Georgiana Ifrim. 2020. A large-scale multi-document sum mari z ation dataset from the Wikipedia current events portal. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1302–1308, Online. Association for Computational Linguistics.
Demian Gholipour Ghalandari、Chris Hokamp、Nghia The Pham、John Glover和Georgiana Ifrim。2020。基于维基百科时事门户的大规模多文档摘要数据集。在《第58届计算语言学协会年会论文集》中,第1302–1308页,线上。计算语言学协会。
Travis Goodwin, Max Savery, and Dina DemnerFushman. 2020. Flight of the PEGASUS? comparing transformers on few-shot and zero-shot multidocument abstract ive sum mari z ation. In Proceedings of the 28th International Conference on Computational Linguistics, pages 5640–5646, Barcelona, Spain (Online). International Committee on Computational Linguistics.
Travis Goodwin、Max Savery 和 Dina DemnerFushman。2020. PEGASUS 的飞行?比较 Transformer 在少样本和零样本多文档摘要生成中的表现。载于《第 28 届国际计算语言学会议论文集》,第 5640–5646 页,西班牙巴塞罗那(在线)。国际计算语言学委员会。
Xiaotao Gu, Yuning Mao, Jiawei Han, Jialu Liu, You Wu, Cong Yu, Daniel Finnie, Hongkun Yu, Jiaqi Zhai, and Nicholas Zukoski. 2020. Generating represent at ive headlines for news stories. In Proceedings of The Web Conference 2020, WWW ’20, page 1773–1784, New York, NY, USA. Association for Computing Machinery.
Xiaotao Gu、Yuning Mao、Jiawei Han、Jialu Liu、You Wu、Cong Yu、Daniel Finnie、Hongkun Yu、Jiaqi Zhai和Nicholas Zukoski。2020。为新闻故事生成代表性标题。载于《2020年网络会议论文集》,WWW '20,第1773–1784页,美国纽约州纽约市。计算机协会。
Chris Hokamp, Demian Gholipour Ghalandari, Nghia The Pham, and John Glover. 2020. Dyne: Dynamic ensemble decoding for multi-document sum mari z ation. CoRR, abs/2006.08748.
Chris Hokamp、Demian Gholipour Ghalandari、Nghia The Pham 和 John Glover。2020。Dyne:面向多文档摘要的动态集成解码方法。CoRR,abs/2006.08748。
Matthew Honnibal, Ines Montani, Sofie Van Landeghem, and Adriane Boyd. 2020. spaCy: Industrial-strength Natural Language Processing in Python.
Matthew Honnibal、Ines Montani、Sofie Van Landeghem 和 Adriane Boyd。2020。spaCy: Python语言的工业级自然语言处理。
Hanqi Jin, Tianming Wang, and Xiaojun Wan. 2020. Multi-granularity interaction network for extractive and abstract ive multi-document sum mari z ation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6244– 6254, Online. Association for Computational Linguistics.
Hanqi Jin、Tianming Wang 和 Xiaojun Wan。2020。面向抽取式与生成式多文档摘要的多粒度交互网络。载于《第58届计算语言学协会年会论文集》,第6244–6254页,线上会议。计算语言学协会。
Dan Jurafsky and James H. Martin. 2009. Speech and language processing : an introduction to natural language processing, computational linguistics, and speech recognition. Pearson Prentice Hall, Upper Saddle River, N.J.
Dan Jurafsky 和 James H. Martin. 2009. 语音与语言处理:自然语言处理、计算语言学和语音识别导论. Pearson Prentice Hall, Upper Saddle River, N.J.
Yoav Levine, Barak Lenz, Opher Lieber, Omri Abend, Kevin Leyton-Brown, Moshe Ten nen holt z, and Yoav Shoham. 2020. Pmi-masking: Principled masking of correlated spans. arXiv preprint arXiv:2010.01825.
Yoav Levine、Barak Lenz、Opher Lieber、Omri Abend、Kevin Leyton-Brown、Moshe Tenenholtz 和 Yoav Shoham。2020。PMI掩码:相关跨度的原则性掩码。arXiv预印本 arXiv:2010.01825。
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghaz vi nine j ad, Abdel rahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Z ett le moyer. 2020. BART: Denoising sequence-to-sequence pretraining for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
Mike Lewis、Yinhan Liu、Naman Goyal、Marjan Ghazvininejad、Abdelrahman Mohamed、Omer Levy、Veselin Stoyanov 和 Luke Zettlemoyer。2020。BART:用于自然语言生成、翻译和理解的去噪序列到序列预训练。载于《第58届计算语言学协会年会论文集》,第7871–7880页,线上会议。计算语言学协会。
Wei Li, Xinyan Xiao, Jiachen Liu, Hua Wu, Haifeng Wang, and Junping Du. 2020. Leveraging graph to improve abstract ive multi-document summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6232–6243, Online. Association for Computational Linguistics.
Wei Li、Xinyan Xiao、Jiachen Liu、Hua Wu、Haifeng Wang和Junping Du。2020。利用图结构提升生成式多文档摘要性能。载于《第58届计算语言学协会年会论文集》,第6232–6243页,线上会议。计算语言学协会。
Kexin Liao, Logan Lebanoff, and Fei Liu. 2018. Abstract Meaning Representation for multi-document sum mari z ation. In Proceedings of the 27th International Conference on Computational Linguistics, pages 1178–1190, Santa Fe, New Mexico, USA. Association for Computational Linguistics.
Kexin Liao, Logan Lebanoff和Fei Liu。2018。用于多文档摘要的抽象意义表示(Abstract Meaning Representation)。见《第27届国际计算语言学会议论文集》,第1178–1190页,美国新墨西哥州圣达菲。计算语言学协会。
Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
Chin-Yew Lin. 2004. ROUGE: 自动摘要评估工具包。In Text Summarization Branches Out, pages 74-81, Barcelona, Spain. Association for Computational Linguistics.
Peter J. Liu*, Mohammad Saleh*, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, and Noam Shazeer. 2018. Generating wikipedia by summarizing long sequences. In International Conference on Learning Representations.
Peter J. Liu*、Mohammad Saleh*、Etienne Pot、Ben Goodrich、Ryan Sepassi、Lukasz Kaiser 和 Noam Shazeer。2018. 通过长序列摘要生成维基百科。收录于国际学习表征会议。
Yang Liu and Mirella Lapata. 2019a. Hierarchical transformers for multi-document sum mari z ation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5070–5081, Florence, Italy. Association for Computational Linguistics.
杨柳和Mirella Lapata。2019a。用于多文档摘要的分层Transformer。见《第57届计算语言学协会年会论文集》,第5070-5081页,意大利佛罗伦萨。计算语言学协会。
Yang Liu and Mirella Lapata. 2019b. Text summarization with pretrained encoders. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3730–3740, Hong Kong, China. Association for Computational Linguistics.
Yang Liu 和 Mirella Lapata. 2019b. 基于预训练编码器的文本摘要. 见《2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议论文集》(EMNLP-IJCNLP), 第3730–3740页, 中国香港. 计算语言学协会.
Yao Lu, Yue Dong, and Laurent Charlin. 2020. MultiXScience: A large-scale dataset for extreme multidocument sum mari z ation of scientific articles. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8068–8074, Online. Association for Computational Linguistics.
Yao Lu、Yue Dong和Laurent Charlin。2020. MultiXScience: 一个面向科学文章极端多文档摘要的大规模数据集。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第8068–8074页,线上。计算语言学协会。
Yuning Mao, Yanru Qu, Yiqing Xie, Xiang Ren, and Jiawei Han. 2020. Multi-document sum mari z ation with maximal marginal relevance-guided reinforcement learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1737–1751, Online. Association for Computational Linguistics.
Yuning Mao、Yanru Qu、Yiqing Xie、Xiang Ren 和 Jiawei Han。2020。基于最大边际相关性引导强化学习的多文档摘要生成。载于《2020年自然语言处理实证方法会议 (EMNLP) 论文集》,第1737-1751页,线上。计算语言学协会。
Ani Nenkova and Rebecca Passonneau. 2004. Evaluat- ing content selection in sum mari z ation: The pyramid method. In Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics: HLT-NAACL 2004, pages 145–152, Boston, Massachusetts, USA. Association for Computational Linguistics.
Ani Nenkova 和 Rebecca Passonneau。2004。评估摘要中的内容选择:金字塔方法。在《北美计算语言学协会人类语言技术会议论文集:HLT-NAACL 2004》中,第145–152页,美国马萨诸塞州波士顿。计算语言学协会。
Ramakanth Pasunuru, Mengwen Liu, Mohit Bansal, Sujith Ravi, and Markus Dreyer. 2021. Efficiently summarizing text and graph encodings of multidocument clusters. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4768–4779, Online. Association for Computational Linguistics.
Ramakanth Pasunuru、Mengwen Liu、Mohit Bansal、Sujith Ravi 和 Markus Dreyer。2021。高效总结多文档集群的文本与图编码。载于《2021年北美计算语言学协会人类语言技术会议论文集》,第4768-4779页,线上会议。计算语言学协会。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-totext transformer. Journal of Machine Learning Research, 21(140):1–67.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J. Liu。2020。探索迁移学习的极限:统一的文本到文本 Transformer (text-to-text transformer)。《机器学习研究期刊》21(140):1-67。
Sascha Rothe, Joshua Maynez, and Shashi Narayan. 2021. A thorough evaluation of task-specific pretraining for sum mari z ation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 140–145, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Sascha Rothe、Joshua Maynez 和 Shashi Narayan。2021. 任务特定预训练在摘要生成中的全面评估。载于《2021年自然语言处理实证方法会议论文集》,第140–145页,线上及多米尼加共和国蓬塔卡纳。计算语言学协会。
Andy Su, Difei Su, John M Mulvey, and H Vincent Poor. 2021. Pobrl: Optimizing multi-document summarization by blending reinforcement learning policies. arXiv preprint arXiv:2105.08244.
Andy Su、Difei Su、John M Mulvey 和 H Vincent Poor。2021。Pobrl:通过混合强化学习策略优化多文档摘要。arXiv预印本 arXiv:2105.08244。
Chien-Sheng Wu, Linqing Liu, Wenhao Liu, Pontus Stenetorp, and Caiming Xiong. 2021. Controllable abstract ive dialogue sum mari z ation with sketch supervision. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 5108–5122, Online. Association for Computational Linguistics.
Chien-Sheng Wu、Linqing Liu、Wenhao Liu、Pontus Stenetorp 和 Caiming Xiong。2021。基于草图监督的可控抽象对话摘要。载于《计算语言学协会发现集:ACL-IJCNLP 2021》,第5108-5122页,线上。计算语言学协会。
Michihiro Yasunaga, Rui Zhang, Kshitijh Meelu, Ayush Pareek, Krishnan Srinivasan, and Dragomir Radev. 2017. Graph-based neural multi-document sum mari z ation. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pages 452–462, Vancouver, Canada. Association for Computational Linguistics.
Michihiro Yasunaga、Rui Zhang、Kshitijh Meelu、Ayush Pareek、Krishnan Srinivasan 和 Dragomir Radev。2017. 基于图神经网络的多元文档摘要。载于《第21届计算自然语言学习会议论文集》(CoNLL 2017),第452–462页,加拿大温哥华。计算语言学协会。
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. 2020. Big bird: Transformers for longer sequences. In Advances in Neural Information Processing Systems, volume 33, pages 17283–17297. Curran Associates, Inc.
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. 2020. Big bird: 面向长序列的Transformer. In Advances in Neural Information Processing Systems, volume 33, pages 17283–17297. Curran Associates, Inc.
Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter Liu. 2020. PEGASUS: Pre-training with extracted gap-sentences for abstract ive sum mari z ation. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 11328–11339. PMLR.
Jingqing Zhang、Yao Zhao、Mohammad Saleh 和 Peter Liu。2020。PEGASUS: 基于抽取式间隔句预训练的抽象摘要生成。见《第37届国际机器学习会议论文集》,第119卷《机器学习研究论文集》,第11328–11339页。PMLR。
Chenguang Zhu, Ziyi Yang, Robert Gmyr, Michael Zeng, and Xuedong Huang. 2021. Leveraging Lead Bias for Zero-Shot Abstract ive News Sum mari z ation, page 1462–1471. Association for Computing Machinery, New York, NY, USA.
陈光珠、Ziyi Yang、Robert Gmyr、Michael Zeng 和黄学东。2021。利用引导偏差实现零样本新闻摘要生成,第1462-1471页。美国纽约州计算机协会。
Yanyan Zou, Xingxing Zhang, Wei Lu, Furu Wei, and Ming Zhou. 2020. Pre-training for abstract ive document sum mari z ation by reinstating source text. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3646–3660, Online. Association for Computational Linguistics.
Yanyan Zou、Xingxing Zhang、Wei Lu、Furu Wei和Ming Zhou。2020。通过恢复源文本来预训练抽象式文档摘要。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第3646-3660页,线上。计算语言学协会。
A Implementation details of pre-training
A 预训练的实现细节
As the multi-document sum mari z ation task has a higher compression ratio, defined as $l e n(S u m m a r y)/l e n(I n p u t)$ , (e.g. $12%$ for Multi-News dataset and $15%$ for Multi-Xscience dataset), we use $15%$ as the ratio of masked sentences for generation. In addition to this $15%$ masked sentences, following PEGASUS (Zhang et al., 2020), we also copy an additional $15%$ of the input sentences to the output without masking them in the input. This allows the model to also learn to copy information from the source directly and found to be useful by Zhang et al. (2020).
由于多文档摘要任务具有较高的压缩比(定义为 $len(Summary)/len(Input)$,例如 Multi-News 数据集为 $12%$,Multi-Xscience 数据集为 $15%$),我们采用 $15%$ 作为生成时的掩码句子比例。除了这 $15%$ 的掩码句子外,我们遵循 PEGASUS (Zhang et al., 2020) 的方法,额外复制 $15%$ 的输入句子到输出中且不进行掩码。这种方法使得模型能够学习直接从源文本复制信息,并被 Zhang et al. (2020) 证实有效。
We pretrain the model for 100K steps, with early stopping, batch size of 16, Adam optimizer with a learning rate of 3e−5 following Beltagy et al. (2020), with 10K warmup steps and linear decay. The pre training process takes likely 7 days on 4 A100 GPUs.
我们在4块A100 GPU上进行了10万步的预训练,采用早停策略,批次大小为16,遵循Beltagy等人(2020)的方案使用学习率为3e−5的Adam优化器,包含1万步热身阶段和线性衰减。整个预训练过程大约需要7天。
As the backbone of PRIMERA is the Longformer Encoder Decoder model (LED), it has the same number of parameters with LED (447M).
PRIMERA的骨干网络是Longformer Encoder Decoder模型(LED),其参数量与LED相同(4.47亿)。
B Detailed Description on the Evaluation Datasets
B 评估数据集的详细说明
The details of evaluation datasets can be found below.
评估数据集的详细信息如下。
Multi-News (Fabbri et al., 2019): A multidocument dataset with summaries written by professional editors from the newser.com.
Multi-News (Fabbri等人,2019):一个多文档数据集,其摘要由newser.com的专业编辑撰写。
Wikisum (Liu* et al., 2018) Each summary is a Wikipedia article, and the source documents are either citations in the reference section or the Web Search results of section titles.14 In our experiments, we use the data crawled by Liu and Lapata (2019a).
Wikisum (Liu*等人,2018) 每个摘要是一篇维基百科文章,源文档要么是参考文献部分的引用,要么是章节标题的网页搜索结果。14在我们的实验中,我们使用了Liu和Lapata (2019a) 爬取的数据。
WCEP (Gholipour Ghalandari et al., 2020) is built based on news events from Wikipedia Current Events Portal and the references are obtained similar to Wikisum. There are at most 100 documents within each cluster in the original dataset, thus we remove all the duplicates and only keep up to 10 documents for each cluster based on the relevance score in the original dataset, which is similar to the WCEP-10 variant in the original paper.
WCEP (Gholipour Ghalandari et al., 2020) 基于维基百科当前事件门户的新闻事件构建,其参考文献获取方式与Wikisum类似。原始数据集中每个聚类最多包含100篇文档,因此我们移除了所有重复文档,并仅根据原始数据集中的相关性评分保留每个聚类最多10篇文档,这与原论文中的WCEP-10变体处理方式一致。
Multi-X-Science (Lu et al., 2020) a multidocument sum mari z ation dataset created from scientific articles, the summaries are paragraphs of related work section, while source documents include the abstracts of the query and referred papers.
Multi-X-Science (Lu et al., 2020) 是一个基于科学论文构建的多文档摘要数据集,其摘要内容为相关研究章节的段落,而源文档则包含查询论文及参考文献的摘要。
$D U C$ benchmarks (Dang, 2005) include multidocument sum mari z ation datasets in the news domain, with 10-30 documents and 3-4 humanwritten summaries per cluster. Since these datasets are small, we use them primarily for a few-shot evaluation. We use DUC2003 for training (only one of the reference summaries for each document is used for training) and DUC2004 as test.
$D U C$ 评测基准 (Dang, 2005) 包含新闻领域的多文档摘要数据集,每个簇包含10-30篇文档和3-4个人工撰写的摘要。由于这些数据集规模较小,我们主要将其用于少样本评估。我们使用DUC2003进行训练(每篇文档仅使用一个参考摘要进行训练),并将DUC2004作为测试集。
ArXiv (Cohan et al., 2018) is a single document sum mari z ation dataset in the scientific paper domain. Each document is a scientific paper, and the summary is the corresponding abstract. As each scientific paper consists of multiple sections, we treat each section as a separate document within a cluster in our experiments. This is to evaluate our model’s effectiveness on summarizing single documents having multiple sections.
ArXiv (Cohan et al., 2018) 是一个科学论文领域的单文档摘要数据集。每篇文档是一篇科学论文,摘要则是对应的论文摘要。由于每篇科学论文包含多个章节,我们在实验中将这些章节视为聚类中的独立文档,以此评估模型在具有多章节的单文档摘要任务上的效果。
C Details on Compared models
C 对比模型详情
The details of compared models in the zero-/fewshot setting can be found below.
零样本/少样本设置下的对比模型详情如下。
BART (Lewis et al., 2020) an encoder-decoder transformer model pretrained on the objective of reconstructing the corrupted documents in multiple ways, e.g. Token Deletion, Text Infilling, Sentence Rotation and etc.
BART (Lewis等人, 2020) 是一种基于编码器-解码器架构的Transformer模型, 通过多种文档重构目标进行预训练, 例如Token删除、文本填充、句子旋转等。
PEGASUS (Zhang et al., 2020) a pretrained model designed for abstract ive sum mari z ation as the downstream task, especially for the single document input. It is trained on the objective of Gap Sentence Generation on C4 (Raffel et al., 2020) and Hugenews datasets (Note that the pre training data size in PEGASUS is magnitudes larger than ours). As it is only evaluated on one multi-document sum mari z ation dataset (Multi-news), we rerun the model on all the datasets. To verify the quality of our reproduction, the average ROUGE scores of our re-run model vs. (the ones reported on the paper) with 10 examples and 100 examples fed are $23.81\pm0.79$ vs. (24.13) and $25.86\pm0.41$ vs. (25.48), with minor differences plausibly resulting from different samplings.
PEGASUS (Zhang et al., 2020) 是一个专为抽象摘要 (abstractive summarization) 下游任务设计的预训练模型,尤其针对单文档输入场景。该模型基于 C4 (Raffel et al., 2020) 和 Hugenews 数据集通过间隙句子生成 (Gap Sentence Generation) 目标进行训练(需注意 PEGASUS 的预训练数据规模远超本研究)。由于原论文仅在多文档摘要数据集 Multi-news 上进行了评估,我们在所有数据集上重新运行了该模型。为验证复现质量,我们重跑模型与论文报告结果的平均 ROUGE 分数对比(分别输入 10 个和 100 个示例)为 $23.81\pm0.79$ vs. (24.13) 和 $25.86\pm0.41$ vs. (25.48),微小差异可能源于采样方式不同。
Table 6: The ROUGE score (R-1/R-2/R-3) for pretrained models (BART and PEGASUS) with different input length limit in few-shot setting (10 data example) on the multi-news dataset. The results are the average over 5 runs on different subsets (the same seeds shared with all the other models in this paper).
表 6: 多新闻数据集上少样本设置 (10个数据示例) 中不同输入长度限制下预训练模型 (BART和PEGASUS) 的ROUGE分数 (R-1/R-2/R-3)。结果是5次不同子集运行的平均值 (与本文中所有其他模型共享相同种子)。
| 长度限制 | BART | PEGASUS |
|---|---|---|
| R-1 | R-2 R-L | |
| 512 | ||
| 1024 | 42.3 | 13.7 19.7 |
| 4096 | 37.9 | 11.0 17.5 |
Longformer Encoder-Decoder (LED) (Beltagy et al., 2020) is the initial state of our model before pre training. The parameters of LED are inherited from the BART model, and to enable the model to deal with longer input, the position embeddings are repeatedly copied from BART’s 1K position embeddings. It is different from our model with respect to both pre training and input structure (document separators and global attentions), with global attention on the.
Longformer Encoder-Decoder (LED) (Beltagy et al., 2020) 是我们模型在预训练前的初始状态。LED 的参数继承自 BART 模型,为了让模型能处理更长的输入,其位置嵌入是从 BART 的 1K 位置嵌入中重复复制而来。它与我们的模型在预训练方式和输入结构(文档分隔符与全局注意力)上均存在差异。
C.1 Detailed Experiment for Input Length Limit
C.1 输入长度限制的详细实验
We run an experiment to select the proper length limit for compared pretrained models, i.e. BART and PEGASUS. Specifically, we train both models with different input length limits (512/1024/4096) in the few-shot setting (with 10 data examples) on the multi-news dataset. Similar as the few-shot experiments described in $\S4.2$ , we train each model with each specific input length limit for 5 times on different subsets, which are shared by all the models. As shown in Table 6, BART with length limit 1024 performs the best and PEGASUS with length limit 512 performs the best, thus in all our experiments, we use 1024 as the input length limit for BART and 512 for PEGASUS.
我们进行了一项实验,以选择适合的预训练模型长度限制,即BART和PEGASUS。具体而言,我们在多新闻数据集上,以少样本设置(使用10个数据示例)训练这两个模型,并采用不同的输入长度限制(512/1024/4096)。与$\S4.2$中描述的少样本实验类似,我们针对每个特定的输入长度限制,在不同子集上对每个模型进行5次训练,这些子集由所有模型共享。如表6所示,长度限制为1024的BART表现最佳,而长度限制为512的PEGASUS表现最佳,因此在所有实验中,我们使用1024作为BART的输入长度限制,512作为PEGASUS的输入长度限制。
D Hyper parameters in Few-shot and Full Supervised Experiments
D 少样本和全监督实验中的超参数
D.1 Few-shot Experiments
D.1 少样本实验
We use Adam as the optimizer with linear scheduled learning rate $3e-5$ for BART, LED and our model, and use the default optimization settings of the few-shot experiments from Zhang et al. (2020), i.e. AdaFactor optimizer with scheduled learning rate $5e-4$ . For all the experiments with 10 examples, the batch size is 10, the models are trained for 200 steps, with warm-up as 20 steps. For the experiments with 100 examples, we use the same batch size, with the total step and warm-up step set to be 1000 and 100, respectively.
我们使用 Adam 作为优化器,对 BART、LED 和我们的模型采用线性调度学习率 $3e-5$,并采用 Zhang 等人 (2020) 少样本实验中的默认优化设置,即使用 AdaFactor 优化器及调度学习率 $5e-4$。在所有 10 个样本的实验中,批量大小为 10,模型训练 200 步,其中预热步数为 20。对于 100 个样本的实验,我们保持相同批量大小,总步数和预热步数分别设为 1000 和 100。
D.2 Fully Supervised Experiments
D.2 全监督实验
We use Adam as the optimizer with linear scheduled learning rate $3e-5$ , and batch size as 16 for all the datasets in the full supervised experiments. The number of steps and warm-up steps are set based on the size of the datasets. The details can be found in Table 7
我们使用 Adam 作为优化器,线性调度学习率为 $3e-5$,全监督实验中所有数据集的批量大小设为 16。步数和预热步数根据数据集大小设置,具体细节见表 7。
Table 7: Details of total steps and warm-up steps used in the Full Supervised experiments.
表 7: 全监督实验中使用的总步数和预热步数详情。
| 数据集 | 总步数 | 预热步数 |
|---|---|---|
| Multi-News | 25k | 2.5k |
| Multi-XScience | 20k | 2k |
| WCEP | 5k | .5k |
| arXiv | 40k | 4k |
E Detailed Results in Few-shot Setting
E 少样本设置下的详细结果
The exact ROUGE scores in Figure 5 are shown in Table 8.
图 5 中的具体 ROUGE 分数如表 8 所示。
Table 8: Detailed ROUGE scores (R-1/R-2/R-L) on all the datasets in the few-shot setting (corresponds to Figure 5)
表 8: 少样本设置下所有数据集的详细ROUGE分数(R-1/R-2/R-L) (对应图5)
| 模型 | 0样本 | 10样本 | 100样本 |
|---|---|---|---|
| Multi-News | |||
| PEGASUS | 31.97/10.06/16.74 | 39.02/12.10/20.32 | 42.99/13.50/21.10 |
| BART | 26.10/8.98/13.06 | 42.30/13.74/19.71 | 44.23/14.77/21.02 44.45/14.85/21.16 |
| LED 我们的方法 | 16.60/4.78/9.05 39.09/13.91/19.19 | 38.86/12.48/18.82 44.02/15.54/22.03 | 46.01/16.76/22.91 |
| Multi-Science | |||
| PEGASUS BART LED | 27.33/4.77/15.04 15.21/3.49/8.61 11.79/2.47/6.86 | 28.14/4.68/15.49 27.80/4.74/14.90 26.57/4.05/15.36 | 28.01/4.09/15.89 31.17/5.32/16.45 29.46/4.85/16.32 |
| 26.90/4.98/14.09 | |||
| PEGASUS | 23.67/5.37/14.17 | Wikisum 23.44/6.44/16.21 | 28.50/9.83/21.33 |
| BART LED | 15.80/4.60/9.13 8.70/2.34/5.78 | 28.95/9.88/20.80 26.53/9.30/19.95 | 32.97/13.81/25.01 34.15/16.03/26.75 |
| 我们的方法 | 17.79/5.02/10.90 | 31.10/13.26/23.39 | 36.05/17.85/27.81 |
| WCEP | |||
| PEGASUS BART | 27.69/10.85/20.03 7.11/3.41/5.32 | 35.60/14.84/26.84 37.46/15.82/28.70 | 42.09/19.93/33.04 41.34/19.19/32.58 |
| LED 我们的方法 | 5.69/2.19/4.32 13.50/5.30/10.11 | 36.29/15.04/27.80 38.97/17.55/30.64 | 41.83/19.46/32.92 42.96/20.53/33.87 |
| arXiv | |||
| 29.76/7.94/17.27 33.10/8.52/19.40 | |||
| PEGASUS BART | 23.26/7.57/12.01 | 32.53/8.70/17.98 | 36.38/9.55/20.83 37.62/10.78/20.99 |
| LED | 13.94/3.76/8.35 | 36.51/11.16/20.68 | 41.00/13.74/22.34 |
| 我们的方法 | 29.14/8.64/15.82 | 41.13/13.81/23.02 | 43.42/15.85/24.07 |
F Detailed Analysis on Fully Supervised Experiments
F 全监督实验的详细分析
To show the advantage of our pre-trained model when there is sufficient data, we also train the model with the full training set, and the results can be found in Table $9\ –12^{15}$ , along with the results from previous works. Differently from the zero-/few-shot experiments, here we report the state-of-the-art results on different datasets, as they were presented in the corresponding original papers. Since we use the same train/valid/test set as in those prior works, we can perform a fair comparison , without re-running all those extremely time-consuming experiments .
为了展示我们预训练模型在数据充足时的优势,我们还在完整训练集上对模型进行了训练,结果见表 $9\ –12^{15}$ ,同时列出了先前工作的成果。与零样本/少样本实验不同,此处我们直接引用原始论文中报告的各数据集最优结果。由于采用了与先前研究相同的训练集/验证集/测试集划分,我们无需重新运行那些极其耗时的实验,即可进行公平比较。
Overall, our model achieves state-of-the-art on Multi-News (see Table 9 , WCEP dataset (see Table 11) and arXiv dataset (see Table 12).
总体而言,我们的模型在Multi-News (见表9)、WCEP数据集 (见表11) 和arXiv数据集 (见表12) 上实现了最先进的性能。
Table 9: ROUGE scores of the previous models and our fully supervised model on the Multi-News dataset. The results of PEGASUS is from Zhang et al. (2020), and the other results are from Pasunuru et al. (2021)
表 9: 已有模型与我们的全监督模型在Multi-News数据集上的ROUGE分数。PEGASUS的结果来自Zhang等人 (2020) ,其他结果来自Pasunuru等人 (2021)
| Models | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| PEGASUS (Zhang et al., 2020) | 47.52 | 18.72 | 24.91 |
| BART-Long-Graph (Pasunuru et al., 2021) | 49.03 | 19.04 | 24.04 |
| BART-Long-Graph(1000) (Pasunuru et al., 2021) | 49.24 | 18.99 | 23.97 |
| BART-Long(1000) (Pasunuru et al., 2021) | 49.15 | 19.50 | 24.47 |
| Ours | 49.94 | 21.05 | 25.85 |
Multi-News The experiment results on MultiNews dataset can be found in Table 9. Specifically, the PEGASUS model (Zhang et al., 2020) is pretrained on a large-scale single-document dataset with the Gap Sentence Generation objective, which is the same as ours, but with a different masking strategy, BART-Long (Pasunuru et al., 2021) uses the same model structure as ours , and BARTLong-Graph (Pasunuru et al., 2021) additionally has discourse graph injected. Comparing the results with the BART-Long model, our model is around 1 ROUGE point higher, which may result from either better model structure or pre-training. Interestingly, in one of the ablation studies in Pasunuru et al. (2021), they find that the BART-Long model achieves its best performance with the length limit of 1000, and no further improvement is found when the length limit is greater than that. Thus we may conclude the gap between the performances is mainly from our design on the model, i.e. the document separators, proper global attention as well as the pre-training on a multi-document dataset.
Multi-News数据集上的实验结果如表9所示。具体而言,PEGASUS模型 (Zhang et al., 2020) 采用与我们相同的Gap Sentence Generation目标在大规模单文档数据集上进行了预训练,但使用了不同的掩码策略;BART-Long (Pasunuru et al., 2021) 采用了与我们相同的模型结构;而BARTLong-Graph (Pasunuru et al., 2021) 额外注入了语篇图。与BART-Long模型相比,我们的模型在ROUGE指标上高出约1分,这可能源于更好的模型结构或预训练策略。值得注意的是,Pasunuru等人 (2021) 的消融实验发现:BART-Long模型在长度限制为1000时达到最佳性能,超过该长度后不再有提升。因此我们可以推断,性能差异主要来自我们的模型设计,包括文档分隔符、恰当的全局注意力机制以及在多文档数据集上的预训练。
| 模型 | R1 | R2 | RL* |
|---|---|---|---|
| LEAD | 27.46 | 4.57 | |
| BERTABS | 31.56 | 5.02 | |
| BART | 32.83 | 6.36 | |
| SCIBERTABS | 32.12 | 5.59 | |
| SOTA (Pointer Generator) | 34.11 | 6.76 | 18.2 |
| LEAD (ours) | 26.49 | 4.26 | 14.70 |
| Ours | 31.93 | 7.37 | 18.02 |
Table 10: ROUGE scores of the previous models and our fully supervised model on the Multi-Xscience dataset. All the results are from Lu et al. (2020). * The ROUGE-L is not comparable as we have different settings on the settings of evaluation, see the gap between LEAD and LEAD(ours).
表 10: 先前模型与我们的全监督模型在Multi-Xscience数据集上的ROUGE分数。所有结果均来自Lu等人 (2020) 。* 由于我们在评估设置上存在差异,ROUGE-L分数不可直接比较,具体差异可参考LEAD与LEAD(ours)之间的差距。
Table 11: ROUGE scores of the previous models and our fully supervised model on the WCEP dataset.
表 11: 在 WCEP 数据集上先前模型与我们的全监督模型的 ROUGE 分数。
| Models | R1 | R2 | RL |
|---|---|---|---|
| BERTREG (Gholipour Ghalandari et al., 2020) | 35.0 | 13.5 | 25.5 |
| SUBMODULAR+ABS (Gholipour Ghalandari et al., 2020) | 30.6 | 10.1 | 21.4 |
| DynE (Hokamp et al., 2020) | 35.4 | 15.1 | 25.6 |
| Ours | 46.08 | 25.21 | 37.86 |
WCEP As for the WCEP dataset, BERTREG (Gholipour Ghalandari et al., 2020) is a Regressionbased sentence ranking system with BERT embedding, which is used as extractive summarization method, while Submodular $^+$ Abs is a simple two-step abstract ive sum mari z ation model with a submodular-based extractive summarizer followed by a bottom-up abstract ive summarizer (Gehrmann et al., 2018). DynE is a BART-based abstract ive approach, which is to ensemble multiple input, allowing single document sum mari z ation models to be directly leveraged on the multi-document summarization task. Our model outperforms all the models by a large margin, including the SOTA model DynE, and it may indicate that the plain structure is more effective than purely ensembling the output of single documents.
WCEP
至于WCEP数据集,BERTREG (Gholipour Ghalandari et al., 2020) 是一种基于回归的句子排序系统,采用BERT嵌入,用作抽取式摘要方法;而Submodular $^+$ Abs则是一个简单的两步生成式摘要模型,先通过基于子模的抽取式摘要器,再经过自底向上的生成式摘要器 (Gehrmann et al., 2018)。DynE是一种基于BART的生成式方法,通过集成多个输入,使单文档摘要模型能直接应用于多文档摘要任务。我们的模型以显著优势超越所有模型(包括SOTA模型DynE),这可能表明朴素结构比单纯集成单文档输出更有效。
arXiv In addition to the experiments on multidocument sum mari z ation datasets, we also compare our fully supervised model with previous works on the arXiv dataset, with each section treated as a single document. All the models to be compared with are based on pre-trained models, and Bigbird-PEGASUS and LED utilize the pre-training of PEGASUS (Zaheer et al., 2020) and BART (Lewis et al., 2020), respectively. However, both Bigbird and LED apply more efficient attentions, which make the models able to take longer input (3k for BigBird, 4K and 16k for LED). Our model has a better performance than all the models, including LED(16K), which allows for the input 4 times longer than ours. It is worth mentioning that LED(4K) has the same structure as our model, with the same length limit of the input, and with the pre-training on multi-document datasets, our model is more than 3 ROUGE point better than it, which shows that the strategy not only works for multi-document sum mari z ation but can also effectively improve single-document sum mari z ation for long documents.
arXiv
除了在多文档摘要数据集上的实验外,我们还在arXiv数据集上将全监督模型与先前工作进行了对比,其中每个章节被视为单个文档。所有对比模型均基于预训练模型,Bigbird-PEGASUS和LED分别采用PEGASUS (Zaheer et al., 2020) 和BART (Lewis et al., 2020) 的预训练框架。但Bigbird和LED采用了更高效的注意力机制,使其能处理更长输入 (BigBird支持3k Token,LED支持4K和16k Token)。我们的模型性能优于所有对比模型(包括支持输入长度4倍于我们的LED(16K))。值得注意的是,LED(4K)与我们的模型结构相同且输入长度限制一致,但通过在多文档数据集上的预训练,我们的模型ROUGE分数比其高出3分以上,这表明该策略不仅适用于多文档摘要,也能有效提升长文档的单文档摘要性能。
Table 12: ROUGE scores of the previous models and our fully supervised model on the arXiv dataset. The result of PEGASUS and BigBird-PEGASUS are from (Zaheer et al., 2020), and the results of LED are from (Beltagy et al., 2020). The number in the parenthesis indicates the length limit of the input.
表 12: 先前模型与我们的全监督模型在arXiv数据集上的ROUGE分数。PEGASUS和BigBird-PEGASUS的结果来自 (Zaheer et al., 2020),LED的结果来自 (Beltagy et al., 2020)。括号中的数字表示输入的长度限制。
| 模型 | R1 | R2 | RL |
|---|---|---|---|
| PEGASUS (1K) | 44.21 | 16.95 | 38.83 |
| Bigbird-PEGASUS (3k) | 46.63 | 19.02 | 41.77 |
| LED(4K) | 44.40 | 17.94 | 39.76 |
| LED(16K) | 46.63 | 19.62 | 41.83 |
| Ours(4k) | 47.58 | 20.75 | 42.57 |
G Examples of Generated Summaries
G 生成摘要的示例
We show an example (from Multi-News) of generated summaries by PRIMERA and compared models trained with different number of examples in Table 13. And we show an example from DUC2007 (which is one of the examples used for human evaluation) with generated summaries by PRIMERA and two compared models in Table 14, with all the models trained on 10 data examples from DUC2007.
我们在表13中展示了PRIMERA与不同训练样本数量的对比模型在Multi-News数据集上生成的摘要示例。此外,表14展示了DUC2007数据集(用于人工评估的案例之一)的示例,其中包含PRIMERA与两个对比模型生成的摘要,所有模型均在DUC2007的10个数据样本上训练。
H Software and Licenses
H 软件与许可
Our code is licensed under Apache License 2.0. Our framework dependencies are:
我们的代码基于Apache License 2.0许可发布。框架依赖项包括:
I Annotation Instructions for Human Evaluation
人工评估标注指南
Figure 7 and Figure 8 shows the annotation instruction for human annotators.
图 7 和图 8 展示了人工标注员的标注说明。
Instruction on Human Annotations
人类标注指南
Overview:
概述:
1- Content quality
1- 内容质量
The goal of this evaluation is to assess the content quality of a system generated summary based onhuman-written reference summaries.Wewill be using thePyramid evaluation framework (Nenokva and Passonneau, 2004): https://a cl anthology.org/N04-1019.pdf
本次评估旨在基于人工撰写的参考摘要,评估系统生成摘要的内容质量。我们将采用金字塔评估框架 (Nenokva and Passonneau, 2004): https://acl anthology.org/N04-1019.pdf
The evaluation works like this. There are 3 things provided for each evaluation example:
评估流程如下。每个评估示例提供3项内容:
For annotation, we will simply go through the list of information nuggets and check if they appear in the system generated summary. A summary is considered good if it includes many of the information nuggets.
对于标注工作,我们只需遍历信息要点列表并检查它们是否出现在系统生成的摘要中。若摘要包含大量信息要点,则认为该摘要质量较高。
- Documents (40 examples in total) a. Information nuggets: https://docs.google.com/spreadsheets/d/1BRbv-a a VpN DW T KOh QB GYA BY zh K WAh k 6 cG nD 5 ROly quY/edit?usp=sharing b.Three summaries, A, B and C: See below
- 文档 (共40个示例)
a. 信息要点: https://docs.google.com/spreadsheets/d/1BRbv-a a VpN DW T KOh QB GYA BY zh K WAh k 6 cG nD 5 ROly quY/edit?usp=sharing
b. 三份摘要 (A、B和C): 见下文 - Annotations:
- 标注:
a. For each summary, check all the information in the information checklist in the following way, i. If the information is covered in the summary, check the corresponding checkbox ii. Otherwise, leave it blank.
a. 对于每个摘要,按照以下方式检查信息清单中的所有信息:
i. 如果摘要中涵盖该信息,勾选对应的复选框
ii. 否则,留空
2-Fluency:
2-流畅性:
There are multiple candidate summaries (3) for each system and we would like to rank the summaries from most most fluent to least.
每个系统有多个候选摘要(3个),我们需要将这些摘要按流畅度从高到低排序。
Specifically, for each summary, answer the following questions:
具体而言,针对每份摘要回答以下问题:
Figure 7: Annotation instruction for human annotators.
图 7: 人工标注员的标注说明。
- Grammatical it y - The summary should have no datelines, system-internal formatting, capitalization errors or obviously ungrammatical sentences (e.g., fragments, missing components) that make the text difficult to read.
- 语法正确性 - 摘要不应包含日期行、系统内部格式、大小写错误或明显不合语法的句子(如片段、缺失成分),这些都会导致文本难以阅读。
- Referential clarity - It should be easy to identify who or what the pronouns and noun phrases in the summary are referring to. If a person or other entity is mentioned, it should be clear what their role in the story is. So, a reference would be unclear if an entity is referenced but its identity or relation to the story remains unclear.
- 指代清晰性 - 应能轻松识别摘要中的代词和名词短语所指代的人或物。如果提到某个人或其他实体,应明确他们在故事中的角色。因此,若提及某个实体但其身份或与故事的关系仍不明确,则指代不清晰。
3.Structure and Coherence-The summary should bewell-structured and well-organized. The summary should not just be a heap of related information, but should build from sentence to sentence to a coherent body of information about a topic.
- 结构与连贯性 - 摘要应当结构清晰、组织有序。摘要不应只是相关信息的堆砌,而应通过句子间的递进,构建出关于主题的连贯信息体。
When assigning scores to each summary, please assign the scores relative to other summaries for that document set.
在对每个摘要进行评分时,请根据该文档集的其他摘要进行相对评分。
Figure 8: Annotation instruction for human annotators.
图 8: 人类标注员的标注说明。
Table 13: Generated summaries from PRIMERA and best baseline model (according ROUGE score on this example) trained with different number of training examples. The data used here is the $#10$ in the test set of Multi-News dataset on Hugging face.
表 13: PRIMERA 与最佳基线模型 (根据本例 ROUGE 分数) 在不同训练样本数量下生成的摘要。所用数据来自 Hugging Face 平台 Multi-News 测试集中的 $#10$ 号样本。
| 模型 | 摘要 |
|---|---|
| PRIMERA-0 | 巴尔的摩(美联社) - 美国海岸警卫队表示正在寻找一名男子,该男子通过近30次虚假求救呼叫耗费了约50万美元救援成本。海岸警卫队指出此类虚假警报会干扰真实警情的响应能力。知情者可拨打410-576-2525联系地区指挥中心或发送邮件至CGIS-Baltimore@uscg.mil。 |
| PRIMERA-10 | 美国海岸警卫队正追查一名通过28次虚假求救呼叫耗费约50万美元的男子。周五发布的声明指出,这些来自马里兰州安纳波利斯周边的呼叫均使用紧急无线电频道且为同一男声。最近两次呼叫发生在7月21日晚间和22日凌晨。海岸警卫队强调虚假呼叫会分散真实救援资源,将公众和救援人员置于险境。马里兰响应部门主管Sara Wallace中校表示:"此类呼叫不仅危及救援队伍,更威胁公众生命安全。"线索举报方式同上。 |
| PRIMERA-100 | 美联社报道,美国海岸警卫队正追查一名通过28次马里兰州虚假求救呼叫耗费约50万美元的男子。所有呼叫均使用紧急无线电频道且为同一男声。马里兰响应部门主管Sara Wallace中校指出:"虚假呼叫是致命重罪,既危及救援队伍又威胁公众安全。" |
| 过去两年间,美国海岸警卫队应对的28次虚假求救呼叫均系同一男子所为。自2014年7月起,该匿名呼叫者持续通过安纳波利斯地区的紧急无线电频道发出虚假警报,最近两次发生在7月21日夜间和22日凌晨。美联社报道称,这些旨在诱使公众入水的虚假呼叫耗费约50万美元救援成本,严重分散真实紧急事件的救援资源。 | |
| FullySupervised | 美国海岸警卫队表示,应对近30次安纳波利斯地区的虚假呼叫已耗费约50万美元。所有呼叫均使用同一男声通过紧急无线电频道发出,最近两次发生在7月21日晚间和22日凌晨。Sara Wallace中校强调:"虚假呼叫是可判6年监禁的重罪,需承担1万美元民事罚款、25万美元刑事罚款及救援费用赔偿。" |
| Ground Truth | 美联社报道,美国海岸警卫队正寻找一名通过近30次虚假呼叫耗费约50万美元的男子。周五声明显示,自2014年7月起,28次来自安纳波利斯地区的呼叫均使用同一男声的紧急无线电频道。NBC4报道称,此类重罪可判处6年监禁、1万美元民事罚款、25万美元刑事罚款及救援费用赔偿。 |
Table 14: Generated summaries from PRIMERA, PEGASUS and LED trained with 10 training examples, along with one (out of four) ground-truth summary. The data used here is D0730 in DUC2007.
表 14: PRIMERA、PEGASUS 和 LED 基于 10 个训练样本生成的摘要,以及四组真实摘要中的一组。所用数据为 DUC2007 中的 D0730。
| 模型摘要 | 内容 |
|---|---|
| PEGASUS | 1996 年国会通过《单项否决权法案》,授权总统在不否决整部法案的情况下削减税收和支出法案中的个别项目。该法案实施后,总统动用单项否决权从 2480 亿美元的国防支出法案中削减了 1.44 亿美元,并否决了国会对其 38 个军事建设项目的单项否决权驳回案。众议院通过该法案后,总统签署了不受制约的立法修改权。最高法院于周五同意受理辩论,裁定总统单项否决权是否符合宪法。1998 年总统使用单项否决权从军事建设法案中削减 3800 万美元,并在 1 月否决了赋予其税收和支出项目单项否决权的法案。2 月总统再次否决支出法案,该法案赋予其税收和支出项目的单项否决权。 |
| LED | 1996 年共和党主导的国会通过《单项否决权法案》,授权总统删除支出和税收法案中的个别条款。克林顿总统运用该权力削减税收和支出项目。1999 年 2 月,克林顿总统否决了国会对其 38 个军事建设项目的单项否决权驳回案;5 月运用该权力削减支出和税收优惠条款;2000 年 5 月威胁取消所有军事支出和税收优惠;6 月、8 月、9 月多次运用单项否决权削减支出和税收条款;2001 年继续使用该权力。 |
| PRIMERA | 单项否决权需通过宪法修正案授权。1997 年 1 月该法在共和党"与国会契约"纲领下通过,此前克林顿总统已否决 13 个相对冷门的研究和支出项目(多为国会批准的军事支出增长)。1998 年 10 月,克林顿运用该权力从 2480 亿美元国防法案中削减 1.44 亿美元;11 月否决价值 2.87 亿美元的 38 个军事建设项目。1999 年 2 月司法部就该法上诉至最高法院,当月联邦法官裁定其违宪。该法通过前,总统只能全盘否决支出法案。1998 年克林顿曾威胁否决部分军事建设项目。 |
| 真实摘要 | 1996 年共和党国会压倒性通过《单项否决权法案》,允许总统(包括现任民主党)否决多数票通过的新法案条款。若总统否决该法案,国会可用三分之二多数推翻否决。支持者认为该法维护了联邦支出完整性,节省数十亿美元,且未废除任何法律条款。1997 年总统否决 6 个法案中的 163 个条款,1998 年否决 11 个法案中的 82 个条款。1997 年 10 月国会推翻总统对 38 个军事建设项目中 36 项的否决。1997 年国会议员向最高法院提起的违宪诉讼因缺乏立场被驳回。1998 年 6 月 25 日,最高法院以 6-3 裁定该法违反权力分立原则,因其允许总统创建未经国会两院表决的法律。实施单项否决权需修宪。大法官布雷耶和斯卡利亚提出异议认为未违宪。 |