Abstract ive Sum mari z ation of Spoken and Written Instructions with BERT
基于BERT的口语和书面指令摘要生成

Figure 1: A screenshot of a How2 YouTube video with transcript and model generated summary.
图 1: 带有字幕和模型生成摘要的How2 YouTube视频截图。
ABSTRACT
摘要
Sum mari z ation of speech is a difficult problem due to the spontaneity of the flow, d is flue nci es, and other issues that are not usually encountered in written texts. Our work presents the first application of the BERTSum model to conversational language. We generate abstract ive summaries of narrated instructional videos across a wide variety of topics, from gardening and cooking to software configuration and sports. In order to enrich the vocabulary, we use transfer learning and pretrain the model on a few large crossdomain datasets in both written and spoken English. We also do preprocessing of transcripts to restore sentence segmentation and punctuation in the output of an ASR system. The results are evaluated with ROUGE and Content-F1 scoring for the How2 and WikiHow datasets. We engage human judges to score a set of summaries randomly selected from a dataset curated from HowTo100M and YouTube. Based on blind evaluation, we achieve a level of textual fluency and utility close to that of summaries written by human content creators. The model beats current SOTA when applied to WikiHow articles that vary widely in style and topic, while showing no performance regression on the canonical CNN/DailyMail dataset. Due to the high general iz ability of the model across different styles and domains, it has great potential to improve accessibility and discover ability of internet content. We envision this integrated as a feature in intelligent virtual assistants, enabling them to summarize both written and spoken instructional content upon request.
语音摘要由于语言流的自发性、不流畅性以及其他书面文本中通常不存在的问题而成为一个难题。我们的工作首次将BERTSum模型应用于会话语言。我们针对从园艺、烹饪到软件配置和体育等各种主题的叙述性教学视频生成抽象摘要。为了丰富词汇量,我们采用迁移学习技术,在多个大型跨领域数据集(包含书面和口语英语)上对模型进行预训练。同时,我们对转录文本进行预处理,以恢复自动语音识别(ASR)系统输出中的句子分割和标点符号。通过ROUGE和Content-F1评分对How2和WikiHow数据集的结果进行评估。我们邀请人工评审员对从HowTo100M和YouTube精选数据集中随机选取的摘要进行评分。基于盲测评估,我们的模型在文本流畅性和实用性方面达到了接近人类内容创作者撰写摘要的水平。该模型在风格主题差异显著的WikiHow文章上表现优于当前SOTA(State-of-the-art)模型,同时在经典CNN/DailyMail数据集上未出现性能衰退。由于该模型在不同风格和领域间具有高度泛化能力,其在提升互联网内容可访问性与可发现性方面具有巨大潜力。我们设想将其集成到智能虚拟助手中,使其能够根据需求对书面和口语教学内容进行摘要生成。
CCS CONCEPTS
CCS概念
KEYWORDS
关键词
Text Sum mari z ation; Natural Language Processing; Information Retrieval; Abstraction; BERT; Neural Networks; Virtual Assistant; Narrated Instructional Videos; Language Modeling
文本摘要;自然语言处理;信息检索;抽象化;BERT;神经网络;虚拟助手;讲解式教学视频;语言建模
ACM Reference Format:
ACM 参考文献格式:
Alexandra Savelieva, Bryan Au-Yeung, and Vasanth Ramani. 2020. Abstractive Sum mari z ation of Spoken and Written Instructions with BERT. In Proceedings of KDD Workshop on Conversational Systems Towards Mainstream Adoption (KDD Converse’20). ACM, New York, NY, USA, 9 pages.
Alexandra Savelieva、Bryan Au-Yeung 和 Vasanth Ramani。2020。基于 BERT 的口头和书面指令摘要生成。发表于《KDD 对话系统迈向主流应用研讨会论文集》(KDD Converse'20)。ACM,美国纽约,共 9 页。
1 INTRODUCTION
1 引言
The motivation behind our work involves making the growing amount of user-generated online content more accessible. In order to help users digest information, our research focuses on improving automatic sum mari z ation tools. Many creators of online content use a variety of casual language, filler words, and professional jargon. Hence, sum mari z ation of text implies not only an extraction of important information from the source, but also a transformation to a more coherent and structured output. In this paper we focus on both extractive and abstract ive sum mari z ation of narrated instructions in both written and spoken forms. Extractive sum mari z ation is a simple classification problem for identifying the most important sentences in the document and classifies whether a sentence should be included in the summary. Abstract ive sum mari z ation, on the other hand, requires language generation capabilities to create summaries containing novel words and phrases not found in the source text. Language models for sum mari z ation of conversational texts often face issues with fluency, intelligibility, and repetition. This is the first attempt to use BERT-based model for summarizing spoken language from ASR (speech-to-text) inputs. We are aiming to develop a generalized tool that can be used across a variety of domains for How2 articles and videos. Success in solving this problem opens up possibilities for extension of the sum mari z ation model to other applications in this area, such as sum mari z ation of dialogues in conversational systems between humans and bots [13].
我们工作的动机在于让日益增长的用户生成在线内容更易获取。为帮助用户消化信息,我们的研究聚焦于改进自动摘要工具。许多在线内容创作者会使用各种非正式语言、填充词和专业术语,因此文本摘要不仅需要从源内容中提取关键信息,还需将其转化为更连贯、结构化的输出。本文同时关注书面与口语形式叙述指令的抽取式摘要和生成式摘要。抽取式摘要是通过简单分类任务识别文档中最重要句子,并判断该句子是否应包含在摘要中;而生成式摘要则需要语言生成能力,以创造源文本中未出现过的新词汇和短语组成的摘要。面向对话文本的摘要语言模型常面临流畅性、可理解性和重复性问题。这是首次尝试使用基于BERT的模型对ASR(语音转文本)输入的口语内容进行摘要。我们的目标是开发一个通用工具,可跨领域应用于How2文章和视频。成功解决该问题将为摘要模型拓展至该领域其他应用(如人机对话系统中对话摘要[13])创造可能性。
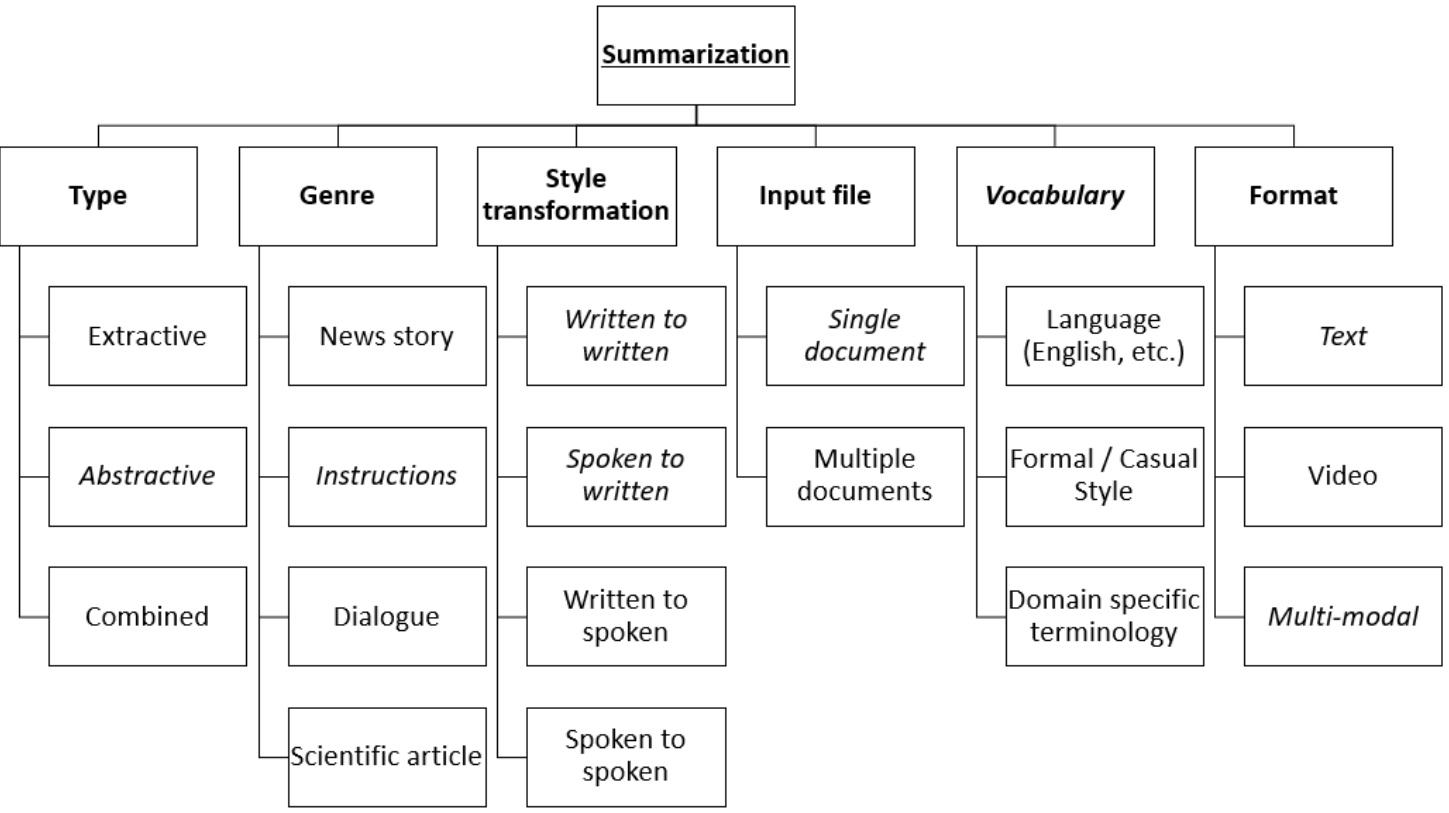
Figure 2: A taxonomy of sum mari z ation types and methods.
图 2: 摘要类型与方法的分类体系。
The rest of this paper is divided in the following sections:
本文其余部分结构如下:
2 PRIOR WORK
2 相关工作
A taxonomy of sum mari z ation types and methods is presented in Figure 2. Prior to 2014, sum mari z ation was centered on extracting lines from single documents using statistical models and neural networks with limited success [23] [17]. The work on sequence to sequence models from Sutskever et al. [22] and Cho et al. [2] opened up new possibilities for neural networks in natural language processing. From 2014 to 2015, LSTMs (a variety of RNN) became the dominant approach in the industry which achieved state of the art results. Such architectural changes became successful in tasks such as speech recognition, machine translation, parsing, image captioning. The results of this paved the way for abstract ive summarization, which began to score competitively against extractive sum mari z ation. In 2017, a paper by Vaswani et.al. [25] provided a solution to the âĂŸfixed length vectorâĂŹ problem, enabling neural networks to focus on important parts of the input for prediction tasks. Applying attention mechanisms with transformers became more dominant for tasks, such as translation and sum mari z ation.
图 2: 展示了摘要类型的分类体系与方法。2014年之前,摘要技术主要集中于使用统计模型和神经网络从单篇文档中抽取句子,但成效有限 [23][17]。Sutskever等人 [22] 和Cho等人 [2] 提出的序列到序列模型研究为神经网络在自然语言处理领域开辟了新可能。2014至2015年间,LSTM(一种RNN变体)成为业界主流方法并取得当时最佳效果。此类架构变革在语音识别、机器翻译、句法分析和图像描述等任务中表现优异,为抽象摘要技术铺平了道路,使其开始能与抽取式摘要竞争。2017年,Vaswani等人 [25] 的论文解决了"定长向量"问题,使神经网络能聚焦输入数据的关键部分进行预测任务。采用Transformer的注意力机制在翻译和摘要等任务中逐渐占据主导地位。
In abstract ive video sum mari z ation, models which incorporate variations of LSTM and deep layered neural networks have become state of the art performers. In addition to textual inputs, recent research in multi-modal sum mari z ation incorporates visual and audio modalities into language models to generate summaries of video content. However, generating compelling summaries from conversational texts using transcripts or a combination of modalities is still challenging. The deficiency of human annotated data has limited the amount of benchmarked datasets available for such research [18] [10]. Most work in the field of document summarization relies on structured news articles. Video sum mari z ation focuses on heavily curated datasets with structured time frames, topics, and styles [4]. Additionally, video sum mari z ation has been traditionally accomplished by isolating and concatenating important video frames using natural language processing techniques [5]. Above all, there are often inconsistencies and stylistic changes in spoken language that are difficult to translate into written text. In this work, we approach video sum mari zat ions by extending top performing single-document text sum mari z ation models [19] to a combination of narrated instructional videos, texts, and news documents of various styles, lengths, and literary attributes.
在视频摘要生成领域,整合了LSTM变体和深层神经网络的模型已成为当前最优性能代表。除文本输入外,近期多模态摘要研究将视觉与听觉模态融入语言模型,用于生成视频内容摘要。然而,仅依靠文字记录或多模态组合从对话文本中生成引人入胜的摘要仍具挑战性。人工标注数据的匮乏限制了该领域基准数据集的数量[18][10]。文档摘要领域的研究大多依赖结构化的新闻文章,而视频摘要则聚焦于经过严格筛选、具有明确时间框架、主题和风格的数据集[4]。传统视频摘要方法主要通过自然语言处理技术隔离并拼接关键视频帧来实现[5]。尤为关键的是,口语中常存在不一致性和风格变化,这些特征难以转化为书面文本。本研究通过将顶尖单文档文本摘要模型[19]扩展应用于叙述型教学视频、文本及不同风格、长度与文学属性的新闻文档组合,探索视频摘要生成新路径。
Table 1: Training and Testing Datasets
表 1: 训练与测试数据集
| 总训练数据集规模 | 535,527 |
| CNN/DailyMail | 90,266 和 196,961 |
| WikiHowText | 180,110 |
| How2Videos | 68,190 |
| 总测试数据集规模 | 5,195个视频 |
| YouTube (DIY视频和教学视频) | 1,809 |
| HowTo100M | 3,386 |
3 METHODOLOGY
3 方法论
3.1 Data Collection
3.1 数据收集
We hypothesize that our model’s ability to form coherent summaries across various texts will benefit from training across larger amounts of data. Table 1 illustrates various textual and video dataset sizes. All training datasets include written summaries. The language and length of the data span from informal to formal and single sentence to short paragraph styles.
我们假设,通过在更大规模的数据上进行训练,模型生成各类文本连贯摘要的能力将得到提升。表 1 展示了不同文本和视频数据集的规模。所有训练数据集均包含书面摘要,数据语言风格和长度涵盖从非正式到正式、从单句到短段落等多种形式。
Table 2: Additional Dataset Statistics
表 2: 附加数据集统计
| YouTube 最小/最大长度 | 4/1,940单词 |
| YouTube 平均长度 | 259单词 |
| HowTo10oM 样本最小/最大长度 | 5/6,587单词 |
| HowTo10oM 样本平均长度 | 859单词 |
Despite the development of instructional datasets such as Wikihow and How2, advancements in sum mari z ation have been limited by the availability of human annotated transcripts and summaries. Such datasets are difficult to obtain and expensive to create, often resulting in repetitive usage of singular-tasked and highly structured data . As seen with samples in the How2 dataset, only the videos with a certain length and structured summary are used for training and testing. To extend our research boundaries, we complemented existing labeled sum mari z ation datasets with auto-generated instruct ional video scripts and human-curated descriptions.
尽管已有Wikihow和How2等教学数据集的开发,但摘要技术的进步仍受限于人工标注文本与摘要的可用性。这类数据集获取困难且构建成本高昂,往往导致单一任务高度结构化数据的重复使用。例如How2数据集中的样本仅选取特定时长且具有结构化摘要的视频用于训练测试。为拓展研究边界,我们通过自动生成的教学视频脚本和人工整理的描述内容,对现有标注摘要数据集进行了补充。
We introduce a new dataset obtained from combining several ’How-To’ and Do-It-Yourself YouTube playlists along with samples from the published How To 100 Million Dataset [16]. To test the plausibility of using this model in the wild, we selected videos across different conversational texts that have no corresponding summaries or human annotations. The selected ’How-To’ [24]) and ’DIY’[6] datasets are instructional playlists covering different topics from downloading mainstream software to home improvement. The ’How-To’ playlist uses machine voice-overs in the videos to aid instruction while the ’DIY’ playlist has videos with a human presenter. The How To 100 Million Dataset is a large scale dataset of over 100 million video clips taken from narrated instructional videos across 140 categories. Our dataset incorporates a sample across all categories and utilizes the natural language annotations from automatically transcribed narrations provided by YouTube.
我们引入了一个新数据集,该数据集通过整合多个"How-To"和DIY YouTube播放列表以及已发布的How To 1亿数据集[16]中的样本构建而成。为测试该模型在真实场景中的适用性,我们选取了不同对话文本中无对应摘要或人工标注的视频样本。所选"How-To"[24]和"DIY"[6]数据集是教学类播放列表,涵盖从主流软件下载到家装改造等各类主题。"How-To"播放列表使用机器语音辅助教学,而"DIY"播放列表则采用真人演示。How To 1亿数据集是包含1.4亿个视频片段的大规模数据集,源自140个类别的旁白教学视频。我们的数据集涵盖所有类别的样本,并利用了YouTube自动转录旁白提供的自然语言标注。
3.2 Preprocessing
3.2 预处理
Due to diversity and complexity of our input data, we built a preprocessing pipeline for aligning the data to a common format. We observed issues with lack of punctuation, incorrect wording, and extraneous introductions which impacted model training. With these challenges, our model misinterpreted text segment boundaries and produces poor quality summaries. In exceptional cases, the model failed to produce any summary. In order to maintain the fluency and coherency in human written summaries, we cleaned and restored sentence structure as shown in the Figure 3. We applied entity detection from an open-source software library for advanced natural language processing called spacy [8] and nltk: the Natural Language Toolkit for symbolic and statistical natural language processing [15] to remove introductions and anonymize the inputs of our sum mari z ation model. We split sentences and tokenized using the Stanford Core NLP toolkit on all datasets and pre processed the data in the same method used by See et.al. in [21].
由于输入数据的多样性和复杂性,我们构建了一个预处理流程来将数据对齐到统一格式。我们观察到标点缺失、错误措辞和冗余导语等问题影响了模型训练。这些挑战导致模型误判文本段落边界并生成低质量摘要,极端情况下甚至无法生成任何摘要。为保持人工撰写摘要的流畅性和连贯性,我们按照图 3 所示清洗并重建了句子结构。我们使用了开源自然语言处理库spacy [8]进行实体检测,并采用nltk(自然语言工具包)[15]进行符号化与统计自然语言处理,以此移除导语并对摘要模型输入进行匿名化处理。所有数据集均采用Stanford Core NLP工具包进行分句和Token化,预处理方法遵循See等人在[21]中使用的流程。
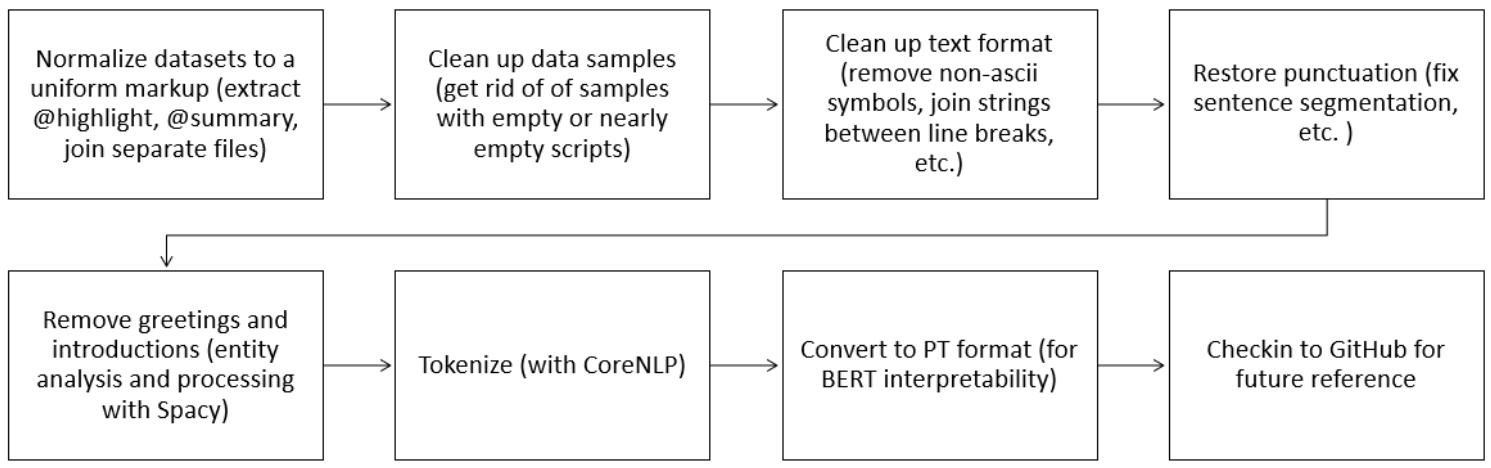
Figure 3: A pipeline for preprocessing of texts for sum mari z ation.
图 3: 文本摘要预处理流程。
3.3 Sum mari z ation models
3.3 摘要模型
We utilized the BertSum models proposed in [14] for our research. This includes both Extractive and Abstract ive sum mari z ation models, which employs a document level encoder based on Bert. The transformer architecture applies a pretrained BERT encoder with a randomly initialized Transformer decoder. It uses two different learning rates: a low rate for the encoder and a separate higher rate for the decoder to enhance learning.
我们采用了[14]中提出的BertSum模型进行研究。该模型包括抽取式(Extractive)和生成式(Abstractive)摘要模型,采用基于BERT的文档级编码器。其Transformer架构使用预训练的BERT编码器搭配随机初始化的Transformer解码器,并采用两种不同学习率:编码器使用较低学习率,解码器则使用较高学习率以增强学习效果。
We used a 4-GPU Linux machine and initialized a baseline by training an extractive model on 5,000 video samples from the How2 dataset. Initially, we applied BERT base uncased with 10,000 steps and fine tuned the sum mari z ation model and BERT layer, selecting the top-performing epoch sizes. We followed this initial model by training the abstract ive model on How2 and WikiHow individually.
我们使用了一台配备4块GPU的Linux机器,通过在How2数据集的5000个视频样本上训练抽取式模型来初始化基线。首先,我们应用了BERT base uncased模型进行了10000步训练,并对摘要模型和BERT层进行了微调,选择了表现最佳的epoch大小。随后,我们分别在How2和WikiHow数据集上训练了抽象模型。
The best version of the abstract ive sum mari z ation model was trained on our aggregated dataset of CNN/DailyMail, Wikihow, and How2 datasets with a total of 535,527 examples and 210,000 steps. We used a training batch size of 50 and ran the model for 20 epochs. By controlling the order of datasets in which we trained our model, we were able to improve the fluency of summaries. As stated in previous research, the original model contained more than 180 million parameters and used two Adam optimizers with $\beta_{1}=0.9$ and $\beta_{2}=0.999$ for the encoder and decoder respectively. The encoder used a learning rate of 0.002 and the decoder had a learning rate of 0.2 to ensure that the encoder was trained with more accurate gradients while the decoder became stable. The results of experiments are discussed in Section 4.
我们最佳的摘要生成模型是在汇总了CNN/DailyMail、Wikihow和How2数据集(共计535,527个样本)上训练而成,训练步数达210,000步。采用50的批次大小进行训练,共运行20个周期。通过控制模型训练所用数据集的顺序,我们成功提升了摘要的流畅度。如先前研究所述,原始模型包含超过1.8亿个参数,并为编码器和解码器分别配置了两个Adam优化器($\beta_{1}=0.9$ 和 $\beta_{2}=0.999$)。编码器采用0.002的学习率,解码器则使用0.2的学习率,以确保编码器通过更精确的梯度进行训练,同时保持解码器的稳定性。实验结果将在第4节展开讨论。
We hypothesized that the training order is important to the model in the same way humans learn. The idea of applying curriculum learning [1] in natural language processing has been a growing topic of interest [26]. We begin training on highly structured samples before moving to more complicated, but predictable language structure 4. Only after training textual scripts do we proceed to video scripts, which presents additional challenges of ad-hoc flow and conversational language.
我们假设训练顺序对模型的重要性与人类学习方式类似。在自然语言处理中应用课程学习 (curriculum learning) [1] 的理念已成为日益关注的话题 [26]。我们首先训练高度结构化的样本,然后转向更复杂但可预测的语言结构4。只有在完成文本脚本训练后,我们才会处理视频脚本,这会带来临时流程和对话语言的新挑战。
3.4 Scoring of results
3.4 结果评分
Results were scored using ROUGE, the standard metric for abstractive sum mari z ation [11]. While we expected a correlation between good summaries and high ROUGE scores, we observed examples of poor summaries with high scores, such as in Figure 10, and good summaries with low ROUGE scores. Illustrative example of why ROUGE metrics is not sufficient is presented in Appendix, Figure 10.
结果采用ROUGE(摘要生成任务的标准评估指标)[11]进行评分。虽然我们预期优质摘要会获得较高ROUGE分数,但观察到存在低质量摘要获得高分(如图10所示)以及优质摘要得分偏低的情况。附录中的图10具体展示了ROUGE指标存在不足的典型案例。
Additionally, we added Content F1 scoring, a metric proposed by Carnegie Mellon University [3] to focus on the relevance of content. Similar to ROUGE, Content F1 scores summaries with a weighted f-score and a penalty for incorrect word order. It also discounts stop and buzz words that frequently occur in the How-To domain, such as âĂIJlearn from experts how to in this free online videoâĂİ.
此外,我们增加了内容F1值 (Content F1) 评分,这是卡内基梅隆大学 [3] 提出的一个关注内容相关性的指标。与ROUGE类似,内容F1值通过加权f值对摘要进行评分,并对错误的词序施加惩罚。它还剔除了在How-To领域中频繁出现的停用词和流行词,例如"learn from experts how to in this free online video"。
To score passages with no written summaries, we surveyed human judges with a framework for evaluation using Python, Google Forms, and Excel spreadsheets. Summaries included in the surveys are randomly sampled from our dataset to avoid biases. In order to avoid asymmetrical information between human versus machine generated summaries, we removed capitalized text. We asked two types of questions: A Turing test question for participants to distinguish AI from human-generated descriptions. The second involves selecting quality ratings for summaries. Below are definitions of criteria for clarity:
为了给没有书面摘要的段落评分,我们通过Python语言、Google Forms和Excel表格构建的评估框架对人工评审员进行了调查。调查中包含的摘要从数据集中随机抽样以避免偏差。为防止人工与机器生成摘要之间存在信息不对称,我们移除了大写文本。我们设置了两类问题:一是让参与者区分AI与人类生成描述的图灵测试问题;二是要求对摘要质量进行评分。以下是清晰度评判标准的定义:
Fluency: Does the text have a natural flow and rhythm? • Usefulness: Does it have enough information to make a user decide whether they want to spend time watching the video? Succinctness: Does the text look concise or do does it have redundancy? • Consistency: Are there any non sequiturs - ambiguous, confusing or contradicting statements in the text? • Realist i city: Is there anything that seems far-fetched and bizarre in words combinations and doesn’t look "normal"?
流畅性:文本是否具有自然的流动感和节奏感?
实用性:是否包含足够信息让用户决定是否值得花时间观看视频?
简洁性:文本看起来是否简明扼要,还是存在冗余?
一致性:是否存在不合逻辑的表述——含糊、令人困惑或自相矛盾的陈述?
真实性:是否存在用词组合牵强怪异、显得不"正常"的情况?
Options for grading summaries are as follows: 1: Bad 2: Below Average 3: Average 4: Good 5: Great.
摘要评分的选项如下:1: 差 2: 低于平均 3: 平均 4: 好 5: 优秀。

Figure 4: Cross Entropy: Training vs Validation
图 4: 交叉熵 (Cross Entropy) : 训练集与验证集对比
4 EXPERIMENTS AND RESULTS
4 实验与结果
4.1 Training
4.1 训练
BertSum model is the best performing model on the CNN/DailyMail dataset producing state-of-the-art results (Row 6) 3. BertSum model supports both extractive and abstract ive sum mari z ation techniques. Our baseline results were obtained from applying this extractive BertSum model pretrained on CNN/DailyMail to How2 videos. But the model produced very low scores for our scenario. Summaries generated from the model were incoherent, repetitive, and uninformative. Despite poor performance, the model performed better in the health sub-domain within How2 videos. We explained this as a symptom of heavy coverage in news reports generated by CNN/DailyMail. We realized that extractive sum mari z ation is not the strongest model for our goal: most YouTube videos are presented with a casual conversational style, while summaries have higher formality. We pivoted to abstract ive sum mari z ation to improve performance.
BertSum 模型在 CNN/DailyMail 数据集上表现最佳,取得了最先进的结果(第 6 行)。3. BertSum 模型同时支持抽取式 (extractive) 和生成式 (abstractive) 摘要技术。我们的基线结果是通过将在 CNN/DailyMail 上预训练的抽取式 BertSum 模型应用于 How2 视频获得的。但该模型在我们的场景中得分非常低。模型生成的摘要不连贯、重复且信息量不足。尽管性能不佳,该模型在 How2 视频的健康子领域中表现更好。我们将此解释为 CNN/DailyMail 生成的新闻报道中大量覆盖的症状。我们意识到抽取式摘要并不是实现我们目标的最强模型:大多数 YouTube 视频以随意的对话风格呈现,而摘要具有更高的正式性。我们转向生成式摘要以提高性能。
Abstract ive model uses an encoder-decoder architecture, combining the same pretrained BERT encoder with a randomly initialized Transformer decoder. It uses a special technique where the encoder portion is almost kept same with a very low learning rate and creates a separate learning rate for the decoder to make it learn better. In order to create a general iz able abstract ive model, we first trained on a large corpus of news. This allowed our model to understand structured texts. We then introduced Wikihow, which exposes the model to the How-To domain. Finally, we trained and validated on the How2 dataset, narrowing the focus of the model to a selectively structured format. In addition to ordered training, we experimented with training the model using random sets of homogeneous samples. We discovered that training the model using an ordered set of samples performed better than random ones.
摘要模型采用编码器-解码器架构,将相同的预训练BERT编码器与随机初始化的Transformer解码器相结合。该模型采用了一种特殊技术:编码器部分几乎保持不变且学习率极低,同时为解码器设置独立学习率以提升其学习效果。为构建通用摘要模型,我们首先在大型新闻语料库上进行训练,使模型能够理解结构化文本。随后引入Wikihow数据集,使模型接触"操作指南"领域。最终在How2数据集上进行训练和验证,将模型聚焦于选择性结构化格式。除有序训练外,我们还尝试使用随机同质样本集进行训练,发现有序样本集的训练效果优于随机样本集。
The cross entropy chart in the Figure 4 shows that the model is neither over fitting nor under fitting the training data. Good fit is indicated with the convergence of training and validation lines. Figure 5 shows the modelâĂŹs accuracy metric on the training and validation sets. The model is validated using the How2 dataset against the training dataset. The model improves as expected with more steps.
图4中的交叉熵图表显示,该模型既没有过拟合也没有欠拟合训练数据。训练线和验证线的收敛表明拟合良好。图5展示了模型在训练集和验证集上的准确率指标。该模型使用How2数据集对训练数据集进行验证。随着步数增加,模型性能如预期般提升。

Figure 5: Accuracy: Training vs Validation
图 5: 准确率:训练集 vs 验证集
4.2 Evaluation
4.2 评估
The BertSum model trained on CNN/DailyMail [14] resulted in state of the art scores when applied to samples from those datasets. However, when tested on our How2 Test dataset, it gave very poor performance and a lack of generalization in the model (see Row 1 in Table 3). Looking at the data, we found that the model tends to pick the first one or two sentences for the summary. We hypothesized that removing introductions from the text would help improve ROUGE scores. Our model improved a few ROUGE points after applying preprocessing described in the Section 3.2 above. Another improvement came from adding word deduping to the output of the model, as we observed it occurring on rare words which are unfamiliar to the model. We still did not achieve scores get higher than 22.5 ROUGE-1 F1 and 20 ROUGE-L F1 (initial scores achieved from training with only the CNN/DailyMail dataset and tested on How2 data). Reviewing scores and texts of individual summaries showed that the model performed better on some topics such as medicine, while scoring lower on others, such as sports.
在CNN/DailyMail数据集[14]上训练的BertSum模型在该数据集样本上取得了最先进的分数。然而,在我们的How2测试集上进行测试时,其表现非常差且缺乏泛化能力(见表3第1行)。通过观察数据,我们发现该模型倾向于选择文本开头的一两句话作为摘要。我们假设移除文本的引言部分将有助于提高ROUGE分数。在应用第3.2节所述的预处理后,我们的模型获得了几个ROUGE分数的提升。另一项改进来自为模型输出添加去重处理,因为我们观察到模型会对不熟悉的生僻词进行重复输出。即便如此,我们仍未获得超过22.5的ROUGE-1 F1和20的ROUGE-L F1分数(该初始分数是仅使用CNN/DailyMail数据集训练并在How2数据上测试所得)。对单个摘要的分数和文本进行审查后发现,该模型在医学等主题上表现较好,而在体育等其他主题上得分较低。
The differences in conversational style of the video scripts and news stories (on which the models were pretrained) impacted the quality of the model output. In our initial application of the extractive sum mari z ation model pretrained on CNN/DailyMail dataset, stylistic errors manifested in a distinct way. The model considered initial introductory sentences to be important in generating summaries (this phenomena is referred to by [15] as N-lead, where N is the number of important first sentences). Our model generated short, simple worded summaries such as "hi!" and "hello, this is
视频脚本和新闻故事(模型预训练数据)的对话风格差异影响了模型输出质量。在我们最初应用基于CNN/DailyMail数据集预训练的抽取式摘要模型时,风格错误以独特方式显现。该模型认为开篇介绍句对生成摘要至关重要([15]将这种现象称为N-lead,其中N表示重要首句的数量)。我们的模型生成了简短、用词简单的摘要,例如"嗨!"和"你好,我是<姓名全称>"。
Retraining abstract ive BertSum on How2 gave a very interesting unexpected result - the model converged to a state of spitting out the same meaningless summary of buzzwords that are common for most videos, regardless of the domain: "learn how to do the the the a in this free video clip clip clip series clip clip on how to make a and expert chef and expert in this unique and expert and expert. to utilize and professional . this unique expert for a professional."
在How2数据集上重新训练抽象式BertSum模型得到了一个非常有趣的意外结果——无论视频领域如何,该模型都收敛到了输出相同无意义摘要的状态,这些摘要由大多数视频常见的流行词组成:"学习如何在这个免费视频片段系列中做到这一点,了解如何制作并与专家厨师和专家一起成为这个独特领域的专家。利用专业资源。这个独特的专家为专业人士服务。"
In our next series of experiments, we used extended dataset for training. Even though the difference in ROUGE scores for the results from BertSum Model 1 (see Table 3) are not drastically different from BertSum Models 2 and 3, the quality of summaries from the perspective of human judges is qualitatively different.
在我们的下一系列实验中,我们使用扩展数据集进行训练。尽管BertSum模型1(参见表3)的ROUGE分数结果与BertSum模型2和3没有显著差异,但从人类评判者的角度来看,摘要质量存在质的差异。
Our best results on How2 videos (see experiment 4 in Table 3) were accomplished by leveraging the full set of labeled datasets (CNN/DM, WikiHow, and How2 videos) with order preserving configuration. The best ROUGE scores we got for video sum mari z ation are comparable to best results among news documents [14] (see row 9 in Table 3).
我们在How2视频上的最佳结果(见表3中的实验4)是通过利用完整标注数据集(CNN/DM、WikiHow和How2视频)并采用顺序保留配置实现的。视频摘要任务获得的最佳ROUGE分数与新闻文档[14]中的最优结果相当(见表3第9行)。
Finally, we beat current best results on WikiHow. The current benchmark Rouge-L score for WikiHow dataset is 26.54 in Row 8. 3 Our model uses the BERT abstract ive sum mari z ation model to produce a Rouge-L score of 36.8 in Row 5 3, outperforming the current benchmark score by 10.26 points. Compared to Pointer Generator $^+$ Coverage model, the improvement on Rouge-1 and Rouge-L is about 10 points each. We got same results testing for WikiHow using BertSum with ordered training on the the entire How2, WikiHow, and CNN/DailyMail dataset.
最终,我们在WikiHow数据集上超越了当前最佳结果。目前WikiHow数据集的基准Rouge-L分数为26.54(见第8行)。我们的模型采用BERT摘要生成模型(BERT abstractive summarization model),在第5行实现了36.8的Rouge-L分数,较基准分数高出10.26分。与Pointer Generator$^+$Coverage模型相比,Rouge-1和Rouge-L指标均提升约10分。通过在整个How2、WikiHow和CNN/DailyMail数据集上进行有序训练的BertSum测试,我们在WikiHow上获得了相同的结果。
With our initial results, we achieved fluent and understandable video descriptions which give a clear idea about the content. Our scores did not surpass scores from other researchers [20] despite employing BERT. However, our summaries appear to be more fluent and useful in content for users looking at summaries in the How-To domain. Some examples are given in the [Appendix: C].
根据初步结果,我们实现了流畅易懂的视频描述,能清晰传达内容要点。尽管采用了BERT模型,我们的评分仍未超越其他研究者的成果 [20]。但在How-To领域,我们的摘要显得更流畅且对查看摘要的用户更具实用性。部分示例见[附录: C]。
Abstract ive sum mari z ation was helpful for reducing the effects of speech-to-text errors, which we observed in some videos transcripts, especially auto-generated closed captioning in the additional dataset that we created as part of this project (transcripts in How2 videos were reviewed and manually corrected, so spelling errors there are less common). For example, in one of the samples in our test dataset closed captioning confuses the speaker s words âĂIJhow you get a text from a YouTube videoâĂİ for âĂIJhow you get attacks from a YouTube videoâĂİ. As there is usually a lot of redundancy in explanations, the model is still able to figure out sufficient context to produce a meaningful summary. We did not observe situations where the summaries did not match topic of the video due to impact from spelling errors that frequently occur in ASR-generated scripts without human supervision, but ensuring correct boundaries between sentences by using Spacy to fix punctuation errors at preprocessing stage made a very big difference.
摘要
语音转文本错误会影响视频字幕的准确性,特别是在本项目新增数据集中的自动生成隐藏字幕中尤为明显(How2视频的字幕经过人工校对修正,拼写错误较少)。例如,测试数据集中某样本的字幕将说话者的内容"how you get a text from a YouTube video"误转为"how you get attacks from a YouTube video"。由于教学讲解通常存在大量信息冗余,模型仍能推断出足够上下文生成有效摘要。我们未发现因ASR(自动语音识别)生成脚本的拼写错误导致摘要偏离视频主题的情况,但通过Spacy工具在预处理阶段修正标点错误以确立正确的句子边界,对结果质量产生了显著提升。
Based on these observations, we decided that the model generated strong results comparable to human written descriptions. To analyze the differences in summary quality, we leveraged help of human experts to evaluate conversational characteristics between our summaries and the descriptions that users provide for their videos on YouTube. We recruited a diverse group of $30+$ volunteers to blindly evaluate a set of 25 randomly selected video summaries that were generated by our model and video descriptions from our curated conversational dataset. We created two types of questions: one, a version of famous Turing test, was a challenge to distinguish AI from human-curated descriptions and used the framework described in Section 3.4. Participants were made aware that there is equal possibility that some, all, or none of these summary outputs were machine generated in this classification task. The second question collects a distribution of ratings addressing conversation quality. The aggregated results for both evaluations are in Figures 6 - 8. We observe zero perfect scores on Turing test answers. Results included many false positives and false negatives [Appendix: D].
基于这些观察,我们判定该模型生成的摘要质量与人工撰写的视频描述相当。为分析摘要质量的差异,我们借助专家人力评估了模型摘要与用户在YouTube上提供的视频描述之间的对话特性差异。我们招募了30多名志愿者组成多样化小组,对随机选取的25个视频摘要进行盲测评估——其中部分摘要由模型生成,部分来自我们整理的对话数据集中的视频描述。我们设计了两类问题:第一类采用著名的图灵测试框架(详见3.4节),要求区分AI生成与人工编写的描述,并告知参与者这些摘要可能全部、部分或完全由机器生成;第二类问题则收集对话质量的评分分布。两项评估的汇总结果见图6至图8。在图灵测试中未出现满分答案,结果包含大量误判案例[附录D]。
The quality of our test output is comparable to YouTube summaries. "Realistic" text is the main growth opportunity because the abstract ive model is prone to generating incoherent sentences that are grammatically correct. Human authors are prone to making language use errors. The advantage of using abstract ive summarization models allows us to mitigate some issues with video author’s grammar.
我们的测试输出质量与YouTube摘要相当。"真实"文本是主要的增长机会,因为抽象化模型容易生成语法正确但不连贯的句子。人类作者容易犯语言使用错误。使用抽象化摘要模型的优势使我们能够缓解视频作者语法方面的一些问题。

Figure 6: Scores of human judges in the challenge to distinguishing ML-generated summaries from actual video annotations on YouTube
图 6: 人类评委在区分YouTube上机器学习生成摘要与真实视频标注挑战中的评分

Figure 7: Distribution of average FP and FN ratio per question
图 7: 每个问题的平均假阳性(FP)和假阴性(FN)比率分布

Figure 8: Quality assessment of generated summaries
图 8: 生成摘要的质量评估
5 CONCLUSION
5 结论
The contributions of our research address multiple issues that we identified in pursuit of generalizing BertSum model for summarization of instructional video scripts throughout the training process.
我们的研究贡献解决了在训练过程中为教学视频脚本摘要推广BertSum模型时发现的多个问题。
• We explored how different combinations of training data and parameters impact the training performance of BertSum abstract ive sum mari z ation model. • We came up with novel preprocessing steps for auto-generated closed captioning scripts before sum mari z ation.
• 我们探索了不同训练数据和参数组合如何影响BertSum摘要生成模型的训练性能。
• 我们提出了针对自动生成的字幕脚本在摘要生成前的新颖预处理步骤。
Table 3: Comparison of results
表 3: 结果对比
| 模型 | 预训练数据 | 测试集 | Rouge-1 | Rouge-L | Content-F1 |
|---|---|---|---|---|---|
| 1. BertSum, 带前后处理的BertSum | CNN/DM | How2 | 18.08 至 22.47 | 18.01 至 20.07 | 26.0 |
| 2. 随机训练的BertSum | How2, 1/50采样的WikiHow, CNN/DM | How2 | 24.4 | 21.45 | 18.7 |
| 3. 随机训练且带后处理的BertSum | How2, 1/50采样的WikiHow, CNN/DM | How2 | 26.32 | 22.47 | 32.9 |
| 4. 有序训练的BertSum | How2, WikiHow, CNN/DM | How2 | 48.26 | 44.02 | 36.4 |
| 5. BertSum | WikiHow | WikiHow | 35.91 | 34.82 | 29.8 |
| 6. BertSum [14] | CNN/DM | CNN/DM | 43.23 | 39.63 | 超出范围 |
| 7. 多模态模型 [18] | How2 | How2 | 59.3 | 59.2 | 48.9 |
| 8. MatchSum (BERT-base) [27] | WikiHow | WikiHow | 31.85 | 29.58 | 不可用 |
| 9. WikiHow的Lead 3 [9] | 不适用 | CNN/DM | 40.34 | 36.57 | 不可用 |
| 10. CNN/DM的Lead 3 [9] | 不适用 | WikiHow | 26.00 | 24.25 | 不可用 |
| 11. How2的Lead 3 [9] | 不适用 | How2 | 23.66 | 20.69 | 16.2 |
• We generalized BertSum abstract ive sum mari z ation model to auto-generated instructional video scripts with the quality level that is close to randomly sampled descriptions created by YouTube users. • We designed and implemented a new framework for blind unbiased review that produces more actionable and objective scores, augmenting ROUGE, BLEU and Content F1.
• 我们将BertSum抽象摘要生成模型推广应用于自动生成教学视频脚本,其质量水平接近YouTube用户随机创建的描述。
• 我们设计并实现了一个新的盲审无偏框架,该框架能产生更具可操作性和客观性的评分,增强了ROUGE、BLEU和Content F1指标。
All the artifacts listed above are available in to our repository for the benefit of future researchers . Overall, the results we obtained by now on amateur narrated instructional videos make us believe that we were able to come up with a trained model that generates summaries from ASR (speech-to-text) scripts of competitive quality to human-curated descriptions on YouTube. With the limited availability of labeled summary datasets, our future plan is to create several benchmark models to extend the human valuation framework with human curated summaries. Given the successes of generalized summaries across informal and formal styles of conversation, we believe that investigating the application of these sum mari z ation models to human - chatbot dialogues is an important direction for future work.
以上列出的所有成果均已存放在我们的代码库中,以供未来研究人员使用。目前我们在业余讲解类视频上取得的成果表明,训练出的模型能够从ASR(语音转文字)脚本生成与YouTube人工编辑描述质量相当的摘要。鉴于带标注摘要数据集的稀缺性,我们未来计划建立多个基准模型,通过人工编辑摘要来扩展人类评估框架。鉴于该摘要模型在非正式与正式对话风格中的通用性表现,我们认为探索这些摘要模型在人机对话(human-chatbot dialogues)中的应用将是未来的重要研究方向。
ACKNOWLEDGMENTS
致谢
We would first like to thank Shruti Palaskar, whose mentorship and guidance were invaluable throughout our research. We would also like to thank Jack Xue, James McCaffrey, Jiun-Hung Chen, Jon Rosenberg, Isidro Hegouaburu, Sid Reddy, Mike Tamir, and Troy Deck for their insights and feedback. We also thank the survey participants for taking time to complete our human evaluation study.
我们首先要感谢Shruti Palaskar,她在整个研究过程中提供了无价的指导和帮助。同时感谢Jack Xue、James McCaffrey、Jiun-Hung Chen、Jon Rosenberg、Isidro Hegouaburu、Sid Reddy、Mike Tamir和Troy Deck的深刻见解与反馈。还要感谢参与调查的人员抽出时间完成我们的人工评估研究。
REFERENCES
参考文献
A MODEL DETAILS
模型细节
Extractive sum mari z ation is generally a binary classification task with labels indicating whether sentences should be included in the summary. Abstract ive sum mari z ation, on the other hand, requires language generation capabilities to create summaries containing novel words and phrases not found in the source text.
抽取式摘要通常是一个二元分类任务,标签用于指示句子是否应包含在摘要中。而生成式摘要则需要语言生成能力,以创建包含源文本中未出现过的新词和短语的摘要。
The architecture in the Figure 9 shows the BertSum model. It uses a novel documentation level encoder based on BERT which can encode a document and obtain representation for the sentences. CLS token is added to every sentence instead of just 1 CLS token in the original BERT model. Abstract ive model uses an encoderdecoder architecture, combining the same pretrained BERT encoder with a randomly initialized Transformer decoder. The model uses a special technique where the encoder portion is almost kept same with a very low learning rate and a separate learning rate is used for the decoder to make it learn better.
图 9 中的架构展示了 BertSum 模型。它使用了一种基于 BERT 的新型文档级编码器,能够编码文档并获取句子表征。与原始 BERT 模型仅使用 1 个 CLS token 不同,该模型为每个句子都添加了 CLS token。摘要生成模型采用编码器-解码器架构,将相同的预训练 BERT 编码器与随机初始化的 Transformer 解码器相结合。该模型采用了一种特殊技术:编码器部分几乎保持不变(使用极低学习率),而解码器则使用独立学习率以提升学习效果。

Figure 9: BertSum Architecture. From [14]
图 9: BertSum架构。来自 [14]
B AN ILLUSTRATIVE EXAMPLE OF WHY ROUGE METRICS ARE NOT SUFFICIENT
B 一个说明ROUGE指标不足之处的示例

Figure 10: An example where ROUGE metric is confusing
图 10: ROUGE指标产生混淆的示例
C EXAMPLES OF COMPARISON OF OUR MODEL OUTPUT VS BENCHMARK [18] AND REFERENCE SUMMARIES
C 我们的模型输出与基准[18]和参考摘要的对比示例
Below examples were selected to illustrate several aspects of the problem. First, we share URLs of the videos so that the reader may view the original content. Second, we share the final result of abstract ive sum mari z ation with our current best model version (Summary Abs). For comparison, we provide summaries from current Benchmark for How2 videos that bypasses our model in terms of scores, but, as can be seen in these examples, not in the fluency and usefulness. Reference represents the actual YouTube video description curated by the authors. For contrast, we show Summary Ext - the result of extractive sum mari z ation, which explains why abstract ive sum mari z ation is a better fit for the purpose, as we are trying to accomplish style conversion from spoken for the source text to written for the target summary. Since BertSum is uncased, all texts below were converted to lower case for consistency.
以下示例用于说明该问题的多个方面。首先,我们分享视频链接以便读者查看原始内容。其次,我们展示当前最佳模型版本(Summary Abs)生成的抽象摘要最终结果。作为对比,我们提供了How2视频基准测试的摘要结果(该基准在评分上优于我们的模型),但如示例所示,其流畅性和实用性不及我们的模型。Reference代表作者整理的YouTube视频实际描述。为形成反差,我们还展示了抽取式摘要结果(Summary Ext),这解释了为何抽象摘要更符合目标需求——因为我们正试图实现从口语化的源文本到书面化目标摘要的风格转换。由于BertSum模型不区分大小写,下文所有文本均转为小写以保持一致性。
Video 1: https://www.youtube.com/watch?v=F 4 UZ 3 bG MP 8 • Summary Abs 1: growing rudbeckia requires full hot sun and good drainage. grow rudbeckia with tips from a gardening specialist in this free video on plant and flower care. care for rudbeckia with gardening tips from an experienced gardener. • Benchmark 1: growing black - eyed - susan is easy with these tips, get expert gardening tips in this free gardening video .
视频 1: https://www.youtube.com/watch?v=F 4 UZ 3 bG MP 8
• 摘要 1: 种植金光菊 (rudbeckia) 需要充足阳光和良好排水。通过园艺专家的技巧学习金光菊养护方法,本免费视频将展示植物与花卉护理要点。资深园丁将分享金光菊的栽培秘诀。
• 基准测试 1: 掌握这些技巧即可轻松培育黑心菊 (black-eyed-susan),本免费园艺视频提供专业种植指导。
D EXAMPLES OF FALSE POSITIVES AND FALSE NEGATIVES FROM SURVEY RESULTS
D 调查结果中的假阳性和假阴性示例
False Negative (FN): Survey participants believed sample summaries were written by robots when sample were written by humans.
假阴性 (False Negative, FN): 调查参与者误将人类撰写的样本摘要判定为机器人所写。
False Positive (FP): Survey participants believed sample summaries were written by humans when sample were written by robot.
误报 (FP): 调查参与者误认为由机器人撰写的样本摘要出自人类之手。
FN Examples:
FN 示例:
• "permanently fix flat atv tires with tireject ??. dry rot, bead leaks, nails, sidewall punctures are no issue. these 30yr old atv tires permanently sealed and back into service in under 5 min. they sealed right up and held air for the first time in a long time. this liquid rubber and kevlar are a permanent repair and will protect from future punctures."
• "用TireJect永久修复瘪掉的ATV轮胎?干裂、胎圈漏气、钉子、侧壁穿孔都不是问题。这些30年历史的ATV轮胎在5分钟内被永久密封并重新投入使用。它们立即密封并长时间以来首次保持气压。这种液态橡胶和凯夫拉材料是永久性修复,可防止未来穿孔。"
• "how to repair a bicycle tire $:$ how to remove the tube from bicycle tires. by using handy tire levers, expert cyclist shows how to remove the tube from bicycle tires, when changing a flat tire, in this free bicycle repair video."
• "如何修理自行车轮胎:如何从自行车轮胎中取出内胎。专业骑手在此免费自行车维修视频中演示了更换漏气轮胎时,如何使用便捷的撬胎棒从自行车轮胎中取出内胎。"
FP Examples:
FP 示例:
"learn about the parts of a microscope with expert tips and advice on refurbishing antiques from a professional photographer in this free video clip on home astronomy and buildings. learn more about how to use a light microscope with a demonstration from a science teacher. "
在这个关于家庭天文学和建筑的免费视频片段中,跟随专业摄影师的专家建议,了解显微镜的各个部件以及古董修复技巧。通过科学教师的演示,进一步学习如何使用光学显微镜。
• "watch as a seasoned professional demonstrates how to use a deep fat fryer in this free online video about home pool care. get professional tips and advice from an expert on how to organize your kitchen appliance and kitchen appliance for special occasions."
• "在这段关于家庭泳池护理的免费在线视频中,观看一位经验丰富的专业人士演示如何使用深油炸锅。从专家那里获取专业技巧和建议,了解如何为特殊场合整理厨房电器和厨房用具。"