Combining Efficient Net and Vision Transformers for Video Deepfake Detection
结合 EfficientNet 和 Vision Transformer 进行视频深度伪造检测
Abstract. Deepfakes are the result of digital manipulation to forge realistic yet fake imagery. With the astonishing advances in deep generative models, fake images or videos are nowadays obtained using variation al auto encoders (VAEs) or Generative Adversarial Networks (GANs). These technologies are becoming more accessible and accurate, resulting in fake videos that are very difficult to be detected. Traditionally, Convolutional Neural Networks (CNNs) have been used to perform video deepfake detection, with the best results obtained using methods based on Efficient Net B7. In this study, we focus on video deep fake detection on faces, given that most methods are becoming extremely accurate in the generation of realistic human faces. Specifically, we combine various types of Vision Transformers with a convolutional Efficient Net B0 used as a feature extractor, obtaining comparable results with some very recent methods that use Vision Transformers. Differently from the state-of-the-art approaches, we use neither distillation nor ensemble methods. Furthermore, we present a straightforward inference procedure based on a simple voting scheme for handling multiple faces in the same video shot. The best model achieved an AUC of 0.951 and an F1 score of $88.0%$ , very close to the state-of-the-art on the DeepFake Detection Challenge (DFDC). The code for reproducing our results is publicly available here: https://github.com/davide-coccomini/
摘要。深度伪造(Deepfakes)是通过数字处理技术生成逼真虚假图像的结果。随着深度生成模型的惊人进步,如今可以使用变分自编码器(VAEs)或生成对抗网络(GANs)来获取伪造图像或视频。这些技术正变得越来越易用且精确,导致生成的伪造视频极难被检测。传统上,卷积神经网络(CNNs)被用于视频深度伪造检测,其中基于EfficientNet B7的方法取得了最佳效果。本研究聚焦于人脸视频深度伪造检测,鉴于大多数方法在生成逼真人脸方面已变得极为精确。具体而言,我们将多种视觉Transformer与作为特征提取器的卷积EfficientNet B0相结合,获得了与近期使用视觉Transformer方法相当的结果。与现有技术方法不同,我们既未使用蒸馏也未采用集成方法。此外,我们提出了一种基于简单投票方案的直接推理流程,用于处理同一视频镜头中的多张人脸。最佳模型取得了0.951的AUC值和88.0%的F1分数,非常接近深度伪造检测挑战赛(DFDC)的最先进水平。重现我们结果的代码已公开在此处:https://github.com/davide-coccomini/
Combining-Efficient Net-and-Vision-Transformers-for-Video-Deepfake-Detection.
结合EfficientNet与Vision Transformer的视频深度伪造检测
Keywords: Deep Fake Detection $\cdot$ Transformer Networks $\cdot$ Deep Learning
关键词:深度伪造检测 (Deep Fake Detection) $\cdot$ Transformer 网络 $\cdot$ 深度学习
1 Introduction
1 引言
With the recent advances in generative deep learning techniques, it is nowadays possible to forge highly-realistic and credible misleading videos. These methods have generated numerous fake news or revenge porn videos, becoming a severe problem in modern society [6]. These fake videos are known as deepfakes. Given the astonishing realism obtained by recent models in the generation of human faces, deepfakes are mainly obtained by transposing one person’s face onto another’s. The results are so realistic that it is almost like the person being replaced is actually present in the video, and the replaced actors are rigged to say things they never actually said [38].
随着生成式深度学习 (Generative Deep Learning) 技术的最新进展,如今人们可以伪造高度逼真且可信的误导性视频。这些方法已经催生了大量假新闻或复仇色情视频,成为现代社会的一个严重问题 [6]。这些虚假视频被称为深度伪造 (deepfakes)。鉴于近期模型在生成人脸方面取得的惊人逼真效果,深度伪造主要通过将一个人的面部移植到另一个人的面部来实现。其结果逼真到几乎就像被替换的人真的出现在视频中一样,而被替换的演员会被操纵说出他们从未真正说过的话 [38]。
The evolution of deepfakes generation techniques and their increasing accessibility forces the research community to find effective methods to distinguish a manipulated video from a real one. At the same time, more and more models based on Transformers are gaining ground in the field of Computer Vision, showing excellent results in image processing [21,17], document retrieval [27], and efficient visual-textual matching [30,32], mainly for use in large-scale multi-modal retrieval systems [1,31].
深度伪造(Deepfake)生成技术的演进及其日益普及的趋势,迫使研究界必须寻找有效方法来区分篡改视频与真实视频。与此同时,越来越多基于Transformer的模型正在计算机视觉领域崭露头角,在图像处理[21,17]、文档检索[27]以及高效的视觉-文本匹配[30,32]方面展现出卓越性能,这些技术主要应用于大规模多模态检索系统[1,31]。
In this paper, we analyze different solutions based on combinations of convolutional networks, particularly the Efficient Net B0, with different types of Vision Transformers and compare the results with the current state-of-the-art. Unlike Vision Transformers, CNNs still maintain an important architectural prior, the spatial locality, which is very important for discovering image patch abnormalities and maintaining good data efficiency. CNNs, in fact, have a long-established success on many tasks, ranging from image classification [13,40] and object detection [35,2,8] to abstract visual reasoning [28,29].
在本文中,我们分析了基于卷积网络(特别是Efficient Net B0)与不同类型Vision Transformer组合的多种解决方案,并将结果与当前最先进技术进行对比。与Vision Transformer不同,CNN仍保留着关键的空间局部性先验结构,这对发现图像块异常和保持良好数据效率至关重要。事实上,CNN在图像分类[13,40]、目标检测[35,2,8]乃至抽象视觉推理[28,29]等众多任务中早已取得长期成功。
In this paper, we also propose a simple yet effective voting mechanism to perform inference on videos. We show that this methodology could lead to better and more stable results.
本文还提出了一种简单而有效的投票机制用于视频推理。研究表明该方法能够获得更好且更稳定的结果。
2 Related Works
2 相关工作
2.1 Deepfake Generation
2.1 Deepfake生成
There are mainly two generative approaches to obtain realistic faces: Generative Adversarial Networks (GANs) [15] and Variation al Auto Encoders (VAEs) [23].
获取逼真人脸图像主要有两种生成方法:生成对抗网络 (GANs) [15] 和变分自编码器 (VAEs) [23]。
GANs employ two distinct networks. The disc rim in at or, the one that must be able to identify when a video is fake or not, and the generator, the network that actually modifies the video in a sufficiently credible way to deceive its counterpart. With GANs, very credible and realistic results have been obtained, and over time, numerous approaches have been introduced such as StarGAN [7] and DiscoGAN [22]; the best results in this field have been obtained with StyleGAN-V2 [20].
GANs采用两种不同的网络。判别器 (discriminator) 必须能够识别视频真伪,而生成器 (generator) 则负责对视频进行逼真修改以欺骗判别器。通过GANs技术,研究者已取得高度逼真的成果,并陆续提出了StarGAN [7]、DiscoGAN [22] 等多种改进方案。目前该领域的最佳成果由StyleGAN-V2 [20] 实现。
VAE-based solutions, instead, make use of a system consisting of two encoderdecoder pairs, each of which is trained to deconstruct and reconstruct one of the two faces to be exchanged. Subsequently, the decoding part is switched, and this allows the reconstruction of the target person’s face. The best-known uses of this technique were Deep Face Lab [34], DFaker1, and Deep Fake t f 2.
基于VAE的解决方案则采用了一个由两个编码器-解码器对组成的系统,每对都经过训练以解构并重建待交换的两张人脸之一。随后,交换解码部分即可重建目标人物的面部。该技术最著名的应用包括Deep Face Lab [34]、DFaker1和Deep Fake t f 2。
2.2 Deepfake Detection
2.2 Deepfake检测
The problem of deepfake detection has a widespread interest not only in the visual domain. For example, the recent work in [12] analyzes deepfakes in tweets for finding and defeating false content in social networks.
深度伪造检测问题不仅在视觉领域引起广泛关注。例如,近期研究[12]通过分析推文中的深度伪造内容,旨在发现并打击社交网络中的虚假信息。
In an attempt to address the problem of deepfakes detection in videos, numerous datasets have been produced over the years. These datasets are grouped into three generations, the first generation consisting of DF-TIMIT [24], UADFC [41] and Face Forensics++ [36], the second generation datasets such as Google Deepfake Detection Dataset [11], Celeb-DF [25], and finally the third generation datasets, with the DFDC dataset [9] and Deep Forensics [19]. The further the generations go, the larger these datasets are, and the more frames they contain.
为了解决视频深度伪造检测的问题,多年来已产生了众多数据集。这些数据集分为三代:第一代包括 DF-TIMIT [24]、UADFC [41] 和 Face Forensics++ [36];第二代数据集如 Google Deepfake Detection Dataset [11] 和 Celeb-DF [25];最后是第三代数据集,包括 DFDC 数据集 [9] 和 Deep Forensics [19]。随着代际演进,这些数据集的规模不断扩大,包含的帧数也越来越多。
In particular, on the DFDC dataset, which is the largest and most complete, multiple experiments were carried out trying to obtain an effective method for deepfake detection. Very good results were obtained with Efficient Net B7 ensemble technique in [37]. Other noteworthy methods include those conducted in [33], who attempted to identify spatio-temporal anomalies by combining an Efficient Net with a Gated Recurrent Unit (GRU). Some efforts to capture spatiotemporal inconsistencies were made in [26] using 3DCNN networks and in [3], which presented a method that exploits optical flow to detect video glitches. Some more classical methods have also been proposed to perform deepfake detection. In particular, the authors in [16] proposed a method based on K-nearest neighbors, while the work in [41] exploited SVMs. Of note is the very recent work of Giudice et al. [14] in which they presented an innovative method for identifying so-called GAN Specific Frequencies (GSF) that represent a unique fingerprint of different generative architectures. By exploiting the Discrete Cosine Transform (DCT) they manage to identify anomalous frequencies.
特别是在最大且最完整的DFDC数据集上,进行了多项实验以寻求有效的深度伪造(deepfake)检测方法。[37]中采用Efficient Net B7集成技术取得了优异成果。其他值得关注的方法包括[33]提出的结合Efficient Net与门控循环单元(GRU)的时空异常检测,以及[26]使用3DCNN网络和[3]利用光流检测视频异常的时空不一致性研究。部分传统方法也被应用于深度伪造检测,如[16]提出的K近邻算法和[41]采用的SVM方法。值得注意的是Giudice等人在[14]中的最新工作,他们通过离散余弦变换(DCT)识别生成对抗网络特有频率(GSF),为不同生成架构提供了独特指纹特征。
More recently, methods based on Vision Transformers have been proposed. Notably, the method presented in [39] obtained good results by combining Transformers with a convolutional network, used to extract patches from faces detected in videos.
最近,基于视觉Transformer的方法被提出。值得注意的是,[39]中提出的方法通过将Transformer与卷积网络相结合取得了良好效果,该网络用于从视频检测到的人脸中提取图像块。
State of the art was then recently improved by performing distillation from the Efficient Net B7 pre-trained on the DFDC dataset to a Vision Transformer [18]. In this case, the Vision Transformer patches are combined with patches extracted from the Efficient Net B7 pre-trained via global pooling and then passed to the Transformer Encoder. A distillation token is then added to the Transformer network to transfer the knowledge acquired by the Efficient Net B7.
当前最先进的方法是通过在DFDC数据集上预训练的Efficient Net B7向Vision Transformer [18]进行知识蒸馏来实现的。在此方法中,Vision Transformer的patch与通过全局池化从预训练的Efficient Net B7中提取的patch相结合,然后输入到Transformer编码器中。随后,在Transformer网络中增加了一个蒸馏token (distillation token) 以传递Efficient Net B7所习得的知识。
3 Method
3 方法
The proposed methods analyze the faces extracted from the source video to determine whenever they have been manipulated. For this reason, faces are preextracted using a state-of-the-art face detector, MTCNN [42]. We propose two mixed convolutional-transformer architectures that take as input a pre-extracted face and output the probability that the face has been manipulated. The two presented architectures are trained in a supervised way to discern real from fake examples. For this reason, we solve the detection task by framing it as a binary classification problem. Specifically, we propose the Efficient ViT and the Convolutional Cross ViT, better explained in the following paragraphs.
所提出的方法通过分析从源视频中提取的人脸来判断其是否被篡改。为此,我们采用当前最先进的人脸检测器MTCNN [42]对人脸进行预提取。本文提出了两种混合卷积-Transformer架构,以预提取的人脸作为输入,输出该人脸被篡改的概率。这两种架构通过监督学习训练,用于区分真实样本与伪造样本。因此,我们将检测任务构建为一个二分类问题。具体而言,我们提出了Efficient ViT和Convolutional Cross ViT两种架构,下文将详细阐述。
The proposed models are trained on a face basis, and then they are used at inference time to draw a conclusion on the whole video shot by aggregating the inferred output both in time and across multiple faces, as explained in Section 4.3.
所提出的模型以人脸为单位进行训练,在推理阶段则通过聚合时间维度和多张人脸的推断输出(如第4.3节所述)来对整个视频片段做出综合判定。
The Efficient ViT The Efficient ViT is composed of two blocks, a convolutional module for working as a feature extractor and a Transformer Encoder, in a setup very similar to the Vision Transformer (ViT) [10]. Considering the promising results of the Efficient Net, we use an Efficient Net B0, the smallest of the EfficientNet networks, as a convolutional extractor for processing the input faces. Specifically, the Efficient Net produces a visual feature for each chunk from the input face. Each chunk is $7\times7$ pixels. After a linear projection, every feature from each spatial location is further processed by a Vision Transformer. The CLS token is used for producing the binary classification score. The architecture is illustrated in Figure 1a. The Efficient Net B0 feature extractor is initialized with the pre-trained weights and fine-tuned to allow the last layers of the network to perform a more consistent and suitable extraction for this specific downstream task. The features extracted from the Efficient Net B0 convolutional network simplify the training of the Vision Transformer, as the CNN features already embed important low-level and localized information from the image.
高效ViT
高效ViT由两个模块组成:一个作为特征提取器的卷积模块和一个Transformer编码器,其结构与Vision Transformer (ViT) [10] 非常相似。考虑到EfficientNet的优异表现,我们采用EfficientNet网络中最小的EfficientNet B0作为卷积提取器来处理输入的人脸图像。具体而言,EfficientNet为输入人脸的每个图像块生成视觉特征,每个图像块大小为$7\times7$像素。经过线性投影后,每个空间位置的特征会由Vision Transformer进一步处理。CLS token用于生成二分类分数。该架构如图1a所示。EfficientNet B0特征提取器使用预训练权重初始化,并通过微调使网络最后一层能针对这一特定下游任务进行更一致且合适的特征提取。从EfficientNet B0卷积网络提取的特征简化了Vision Transformer的训练,因为CNN特征已嵌入了图像中重要的低层次局部信息。
The Convolutional Cross ViT Limiting the architecture to the use only small patches as in the Efficient ViT may not be the ideal choice, as artifacts introduced by deepfakes generation methods may arise both locally and globally. For this reason, we also introduce the Convolutional Cross ViT architecture. The Convolutional Cross ViT builds upon both the Efficient ViT and the multi-scale Transformer architecture by [5]. More in detail, the Convolutional Cross ViT uses two distinct branches: the S-branch, which deals with smaller patches, and the L-branch, which works on larger patches for having a wider receptive field. The visual tokens output by the Transformer Encoders from the two branches are combined through cross attention, allowing direct interaction between the two paths. Finally, the CLS tokens corresponding to the outputs from the two branches are used to produce two separate logits. These logits are summed, and a final sigmoid produces the final probabilities. A detailed overview of this architecture is shown in Fig. 1b. For the Convolutional Cross ViT, we use two different CNN backbones. The former is the Efficient Net B0, which processes $7\times7$ image patches for the S-branch and $54\times54$ for the L-branch. The latter is the CNN by Wodajo et al. [39], which handles $7\times7$ image patches for the S-branch and $64\times64$ for the L-branch.
卷积交叉ViT
将架构限制为仅使用小尺寸图像块(如Efficient ViT)可能并非理想选择,因为深度伪造生成方法引入的伪影可能在局部和全局同时出现。为此,我们提出了卷积交叉ViT架构。该架构基于Efficient ViT和[5]提出的多尺度Transformer架构,具体采用双分支设计:S分支处理较小图像块,L分支处理较大图像块以获得更广的感受野。两个分支的Transformer编码器输出的视觉Token通过交叉注意力机制交互融合,最终将两个分支的CLS Token生成的对数几率相加,经Sigmoid函数输出最终概率。架构细节如图1b所示。
卷积交叉ViT采用两种CNN骨干网络:Efficient Net B0处理S分支的7×7图像块和L分支的54×54图像块;Wodajo等人[39]提出的CNN网络则处理S分支的7×7图像块和L分支的64×64图像块。
4 Experiments
4 实验
We probed the presented architectures against some state-of-the-art methods on two widely-used datasets. In particular, we considered Convolutional ViT [39], ViT with distillation [18], and Selim Efficient Net B7 [37], the winner of the Deep
我们对所提出的架构在两个广泛使用的数据集上与一些先进方法进行了对比测试。具体而言,我们考虑了Convolutional ViT [39]、带蒸馏的ViT [18]以及Deep竞赛冠军Selim Efficient Net B7 [37]。
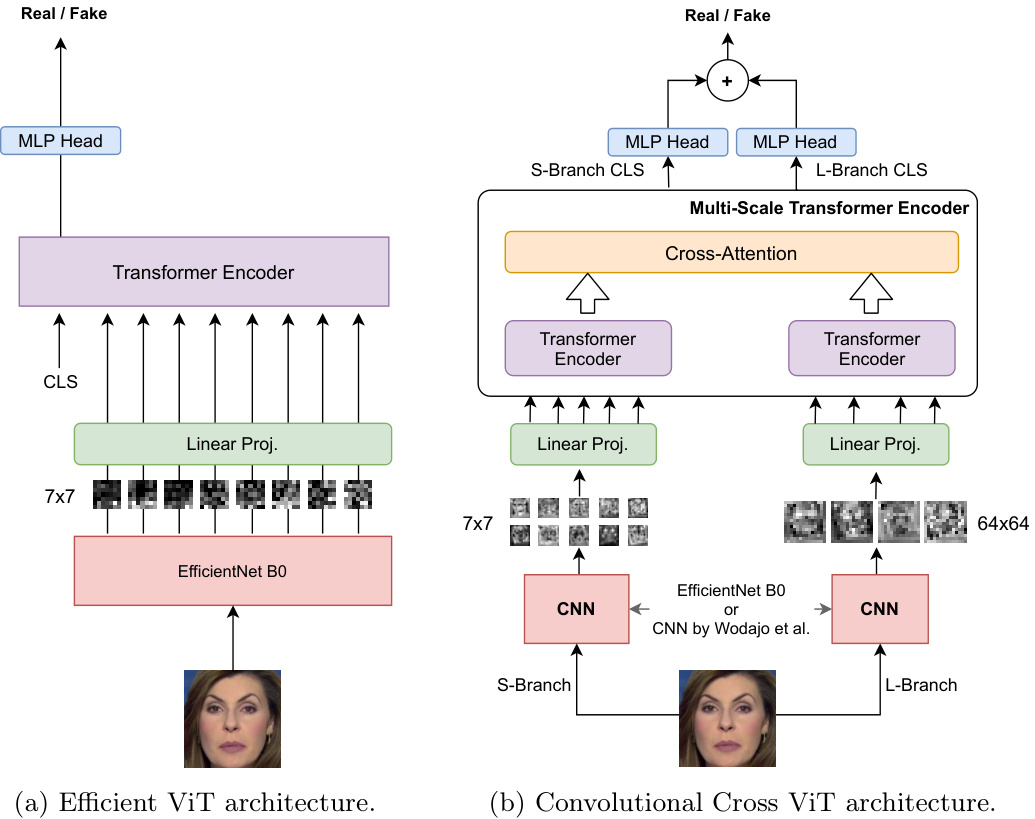
Fig. 1: The proposed architectures. Notice that for the Convolutional Cross ViT in (b), we experimented both with Efficient Net B0 and with the convolutional architecture by [39] as feature extractors.
图 1: 提出的架构。注意在(b)中的卷积交叉ViT (Convolutional Cross ViT)中,我们尝试了Efficient Net B0和[39]提出的卷积架构作为特征提取器。
Fake Detection Challenge (DFDC). Notice that the results for Convolutional ViT [39] are not reported in the original paper, but they are obtained executing the test code on DFDC test set using the available pre-trained model released by the authors.
假脸检测挑战赛 (DFDC)。需要注意的是,卷积ViT [39]的结果并未在原论文中报告,而是通过使用作者发布的预训练模型在DFDC测试集上执行测试代码获得的。
4.1 Datasets and Face Extraction
4.1 数据集与人脸提取
We initially conducted some tests on Face Forensics++. The dataset is composed of original and fake videos generated through different deepfake generation techniques. For evaluating, we considered the videos generated in the Deepfakes, Face2Face, Face Shifter, FaceSwap and Neural Textures sub-datasets. We also used the DFDC test set containing 5000 videos. The model trained on the entire training set, which includes fake videos of all considered methods of Face Forensics $^{++}$ and the training videos of DFDC dataset, was used to calculate the accuracy measures of the model, reported separately. In order to compare our methods also on the DFDC test set, we tested the Convolutional Vision
我们最初在Face Forensics++数据集上进行了一些测试。该数据集由原始视频和通过不同深度伪造(deepfake)生成技术制作的伪造视频组成。评估时,我们选取了Deepfakes、Face2Face、Face Shifter、FaceSwap和Neural Textures子数据集生成的视频。同时使用了包含5000段视频的DFDC测试集。通过在完整训练集(包含Face Forensics++所有伪造方法生成的假视频及DFDC数据集的训练视频)上训练的模型,我们分别计算了模型的准确率指标。为了在DFDC测试集上对比我们的方法,我们还测试了卷积视觉(Convolutional Vision)
Transformer [39] on these videos obtaining the necessary AUC and F1-score values for comparison.
Transformer [39] 在这些视频上获得了用于比较的必要 AUC 和 F1-score 值。
During training, we extracted the faces from the videos using an MTCNN, and we performed data augmentation like in [37]. Differently from them, we extracted the faces so that they were always squared and without padding. The images obtained are used during the training, thus ignoring the remaining part of the frames. We used the Albumen tat ions library [4], and we applied common transformations such as the introduction of blur, Gaussian noise, transposition, rotation, and various isotropic resizes during training.
训练过程中,我们使用MTCNN从视频中提取人脸,并按照[37]的方法进行数据增强。与之不同的是,我们提取的人脸始终保持正方形且无填充。获得的图像用于训练,因此忽略了帧的其余部分。我们使用了Albumentations库[4],并在训练过程中应用了常见的变换,如引入模糊、高斯噪声、转置、旋转和各种各向同性缩放。
4.2 Training
4.2 训练
We trained the networks on 220,444 faces extracted from the videos of DFDC training set and Face Forensics $^{++}$ training videos, and we used 8070 faces for validation from DFDC dataset. The training set was constructed trying to maintain a good balance between the real class composed of 116,950 images and fakes with 103,494 images.
我们在DFDC训练集和Face Forensics++训练视频中提取的220,444张人脸图像上训练网络,并从DFDC数据集中使用8,070张人脸进行验证。训练集的构建力求在由116,950张真实图像和103,494张伪造图像组成的类别之间保持良好平衡。
We used pre-trained Efficient Net B0 and Wodajo CNN feature extractors. However, we observed better results when fine-tuning them, so we did not freeze the extraction layers. We used the standard binary cross-entropy loss as our objective during training. We optimized our network end-to-end, using an SGD optimizer with a learning rate of 0.01.
我们使用了预训练的 Efficient Net B0 和 Wodajo CNN 特征提取器。但在微调时观察到更好的效果,因此没有冻结提取层。训练过程中采用标准二元交叉熵损失作为目标函数,使用学习率为 0.01 的 SGD 优化器进行端到端网络优化。
4.3 Inference
4.3 推理
At inference time, we set a real/fake threshold at 0.55 as done in [18]. However, we proposed a slightly more elaborated voting procedure instead of averaging all ratings on individual faces indistinctly within the video. Specifically, we merged the scores, grouping them by the identifier of the actors. The face identifier is available as an output from the employed MTCNN face detector. The scores from different actors are averaged over time to produce a probability of the face being fake. Then, the per-actor scores are merged using hard voting. In particular, if there is at least one actor face passing the threshold, the whole video is classified as fake. The procedure is graphically explained in Fig. 2a. We claim that this approach is helpful to handle better videos in which only one of the actors’ faces has been manipulated.
在推理阶段,我们按照[18]的做法将真假阈值设为0.55。但我们提出了一种更为精细的投票机制,而非简单平均视频中所有人脸的评分。具体而言,我们根据演员标识符对分数进行分组合并(该标识符来自所用MTCNN人脸检测器的输出)。将不同演员的面部评分按时间平均后,得出该人脸为伪造的概率。随后采用硬投票机制合并各演员分数:只要存在一个演员面部超过阈值,整个视频即被判定为伪造。该流程如图2a所示。我们主张这种方法能有效处理仅单个演员面部被篡改的视频场景。
In addition, it is interesting to evaluate how the performance changes when a varying number of faces are considered at inference time. To ensure that the tests are as light yet effective as possible, we experimented on one of our networks to see how the F1-score varies with the number of faces considered at testing time (Fig. 2b). We notice that a plateau is reached when no more than 30 faces are used, so employing more than this number of faces seems statistically useless at inference time.
此外,评估在推理时考虑不同数量人脸对性能的影响也很有趣。为确保测试尽可能轻量且有效,我们在一个网络上进行了实验,观察测试时考虑的人脸数量如何影响F1分数 (图 2b)。我们发现当使用不超过30张人脸时性能趋于稳定,因此在推理时使用超过该数量的人脸在统计上似乎没有意义。

Fig. 2: Inference.
图 2: 推理
same video. tracted faces.
同一视频中的提取人脸。
Table 1: Results on DFDC test dataset
† Uses an ensemble of 6 networks.
表 1: DFDC测试数据集结果
| 模型 | AUC | F1分数 | 参数量 |
|---|---|---|---|
| 带蒸馏的ViT [18] | 0.978 | 91.9% | 373M |
| Selim EfficientNet B7 [37]† | 0.972 | 90.6% | 462M |
| 卷积ViT [39] | 0.843 | 77.0% | 89M |
| Efficient ViT (本工作) | 0.919 | 83.8% | 109M |
| Conv. Cross ViT Wodajo CNN (本工作) | 0.925 | 84.5% | 142M |
| Conv.Cross ViT 1 Eff.Net B0 - Avg (本工作) | 0.947 | 85.6% | 101M |
| Conv. Cross ViT Eff.Net BO - Voting (本工作) | 0.951 | 88.0% | 101M |
† 使用了6个网络的集成。
4.4 Results
4.4 结果
Table 1 shows that all models developed with Efficient Net achieve considerably higher AUC and F1-scores than the Convolutional ViT presented in [39], providing initial evidence that this specific network structure may be more suitable for this type of task. It can also be noticed that the models based on Cross Vision Transformer obtain the best results, confirming the theory that joined local and global image processing brings to better anomaly identification.
表 1 显示,所有基于 Efficient Net 开发的模型都比 [39] 中提出的 Convolutional ViT 获得了显著更高的 AUC 和 F1 分数,初步证明这种特定网络结构可能更适合此类任务。还可以注意到,基于 Cross Vision Transformer 的模型取得了最佳结果,印证了局部与全局图像处理相结合能带来更好异常识别的理论。
The models with Cross Vision Transformer show a particularly marked improvement when using the Efficient Net B0 as a patch extractor. Although the AUC and F1-score remain slightly below other state-of-the-art methods (in the first two rows of Table 1), these results were obtained using neither distillation nor ensemble techniques that complicate both training and inference. In fact, we can notice how the Cross Vision Transformer with the Efficient Net extractor can reach a competitive performance using less than $1/3$ of the parameters of the top methods.
采用交叉视觉Transformer (Cross Vision Transformer) 的模型在使用EfficientNet B0作为补丁提取器时表现出显著提升。尽管AUC和F1分数仍略低于其他前沿方法 (见表1前两行),但这些结果是在未使用蒸馏或集成技术的情况下取得的,这些技术会使训练和推理过程复杂化。实际上,我们可以观察到,配备EfficientNet提取器的交叉视觉Transformer仅需不到顶级方法$1/3$的参数量即可达到具有竞争力的性能。
Furthermore, in the last two rows of Table 1 we can notice how our voting procedure used at inference time can slightly improve the results with respect to a plain average of the scores from all the faces indistinctly, as done by the other methods. In Fig. 3 we report a detailed ROC plot for the architectures on the DFDC dataset.
此外,在表1的最后两行中,我们可以注意到,与其他方法不加区分地对所有面部评分进行简单平均相比,我们在推理时采用的投票程序能略微提升结果。在图3中,我们展示了DFDC数据集上各架构的详细ROC曲线图。
Table 2: Models accuracy on Face Forensics $^{++}$
表 2: 各模型在 Face Forensics$^{++}$ 上的准确率
| 模型 | Mean | FaceSwap | DeepFakes | FaceShifter | NeuralTextures |
|---|---|---|---|---|---|
| ConvolutionalViT [39] | 67% | 69% | 93% | 46% | 60% |
| EfficientViT (our) | 76% | 78% | 83% | 76% | 68% |
| Conv.CrossViT Wodajo CNN (our) | 76% | 81% | 83% | 73% | 67% |
| Conv.Cross ViT EfficientNet BO(our) | 80% | 84% | 87% | 80% | 69% |

Fig. 3: ROC Curves comparison between our best model and others on DFDC test set.
图 3: 我们的最佳模型与其他模型在DFDC测试集上的ROC曲线对比。
In order to compare the developed models also on another dataset, we carried out some tests also on Face Forensics $^{++}$ . As shown in Table 2, our models outperform the original Convolutional ViT [39] on all sub-datasets of FaceForensics $^{++}$ , excluding DeepFakes. This is probably because the network could better generalize on very specific types of deepfakes. It is worth noting how the results obtained in terms of accuracy on the various sub-datasets confirm the assumption already made in [39]: some deepfakes techniques such as Neural Textures produce videos that are more difficult to find, thus resulting in lower accuracy values than other sub-datasets. However, the average of all our three models is higher than the average obtained by the Convolutional ViT. The Convolutional Cross ViT achieves the best result with the Efficient Net B0 backbone, obtaining a mean accuracy of 80%.
为了在另一个数据集上比较开发的模型,我们还在 Face Forensics$^{++}$ 上进行了一些测试。如表 2 所示,我们的模型在 FaceForensics$^{++}$ 的所有子数据集上(除 DeepFakes 外)均优于原始 Convolutional ViT [39]。这可能是因为网络能够更好地泛化到特定类型的深度伪造内容。值得注意的是,各子数据集在准确率方面的结果验证了 [39] 中已有的假设:像 Neural Textures 这样的深度伪造技术生成的视频更难检测,因此其准确率值低于其他子数据集。然而,我们三个模型的平均准确率仍高于 Convolutional ViT 的平均值。其中 Convolutional Cross ViT 以 Efficient Net B0 为骨干网络取得了最佳结果,平均准确率达到 80%。
5 Conclusions
5 结论
In this research, we demonstrated the effectiveness of mixed convolutionaltransformer networks in the Deepfake detection task. Specifically, we used pretrained convolutional networks, such as the widely used Efficient Net B0, to extract visual features, and we relied on Vision Transformers to obtain an informative global description for the downstream task. We showed that it is possible to obtain state-of-the-art results without necessarily resorting to distillation techniques from models based on convolutional or ensemble networks. The use of a patch extractor based on Efficient Net proved to be particularly effective even by simply using the smallest network in this category. Efficient Net also led to better results than the generic convolutional network trained from scratch used in Wodajo et al [39]. We then proposed a mixed architecture, the Convolutional Cross ViT, that works at two different scales to capture local and global details. The tests carried out with these models demonstrated the importance of multi-scale analysis for determining the manipulation of an image.
在本研究中,我们证明了混合卷积Transformer网络在Deepfake检测任务中的有效性。具体而言,我们使用预训练的卷积网络(如广泛使用的Efficient Net B0)提取视觉特征,并依赖Vision Transformer为下游任务获取信息丰富的全局描述。研究表明,无需借助基于卷积或集成网络的蒸馏技术,也能获得最先进的结果。即使仅使用该类别中最小的网络,基于Efficient Net的补丁提取器也被证明特别有效。与Wodajo等人[39]中从头训练的通用卷积网络相比,Efficient Net也带来了更好的结果。我们随后提出了一种混合架构——卷积交叉ViT(Convolutional Cross ViT),该架构通过两种不同尺度来捕捉局部和全局细节。使用这些模型进行的测试证明了多尺度分析对于确定图像篡改的重要性。
We also paid particular attention to the inference phase. In particular, we presented a simple yet effective voting scheme for explicitly dealing with multiple faces in a video. The scores from multiple actor faces are first averaged over time, and only then hard voting is used to decide if at least one face was manipulated. This inference mechanism yielded slightly better and stable results than the global average pooling of the scores performed by previous methods.
我们还特别关注了推理阶段。具体来说,我们提出了一种简单而有效的投票方案,用于显式处理视频中的多张人脸。首先对多个演员人脸得分进行时间维度上的平均,随后仅通过硬投票判定是否存在至少一张人脸被篡改。该推理机制相比先前方法的全局平均池化得分操作,取得了略优且更稳定的结果。