Extended Few-Shot Learning: Exploiting Existing Resources for Novel Tasks
扩展少样本学习:利用现有资源应对新任务
Abstract
摘要
In many practical few-shot learning problems, even though labeled examples are scarce, there are abundant auxiliary datasets that potentially contain useful information. We propose the problem of extended few-shot learning to study these scenarios. We then introduce a framework to address the challenges of efficiently selecting and effectively using auxiliary data in few-shot image classification. Given a large auxiliary dataset and a notion of semantic similarity among classes, we automatically select pseudo shots, which are labeled examples from other classes related to the target task. We show that naive approaches, such as (1) modeling these additional examples the same as the target task examples or (2) using them to learn features via transfer learning, only increase accuracy by a modest amount. Instead, we propose a masking module that adjusts the features of auxiliary data to be more similar to those of the target classes. We show that this masking module performs better than naively modeling the support examples and transfer learning by 4.68 and 6.03 percentage points, respectively. Code is available at: https://github.com/Bats Research/efsl.
在许多实际的少样本学习问题中,尽管标注样本稀缺,但存在大量可能包含有用信息的辅助数据集。我们提出扩展少样本学习问题来研究这些场景,并引入一个框架以解决少样本图像分类中高效选择和有效使用辅助数据的挑战。给定大型辅助数据集及类别间语义相似性度量,我们自动选择伪样本(pseudo shots)——即来自与目标任务相关其他类别的标注样本。研究表明,简单方法(如:(1) 将这些额外样本与目标任务样本同等建模,或 (2) 通过迁移学习利用它们学习特征)仅能小幅提升准确率。为此,我们提出掩码模块来调整辅助数据的特征,使其更接近目标类别特征。实验表明,该掩码模块性能分别比简单建模支持样本和迁移学习高出4.68和6.03个百分点。代码详见:https://github.com/Bats Research/efsl。
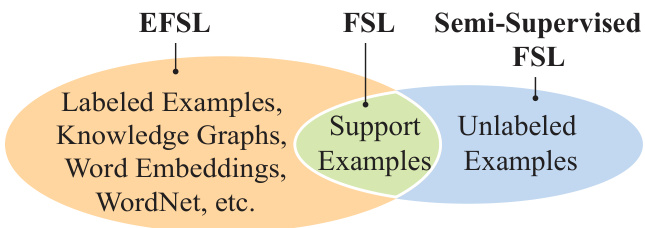
Figure 1: The extended few-shot learning (EFSL) setting in relation to traditional few-shot learning (FSL) and semisupervised FSL. All settings use support examples of the target classes. Semi-supervised FSL adds unlabeled examples. In contrast, EFSL uses external labeled data, disjoint from support classes, to harness the link between non-visual sources and labels.
图 1: 扩展少样本学习 (EFSL) 与传统少样本学习 (FSL) 及半监督 FSL 的关系。所有设定都使用目标类的支持样本。半监督 FSL 增加了未标注样本。相比之下,EFSL 利用与支持类不相交的外部标注数据,以建立非视觉源与标签之间的关联。
traditional FSL setting is an important test of generalization from limited resources, we argue that it fails to cap- ture many other realistic scenarios found in practice. Although the number of base classes is small (hundreds), the size and breadth of labeled datasets publicly accessible and internally available to organizations are great. In scenarios where parts of those massive datasets are semantically related to novel tasks, the challenge is not limited labeled data per se, but a lack of labeled examples of the novel classes.
传统的小样本学习 (FSL) 设置虽然能有效测试有限资源下的泛化能力,但我们认为其未能涵盖实践中的许多现实场景。尽管基类数量较少(数百个),但公开可获取及组织内部可用的标记数据集规模庞大且覆盖广泛。当这些海量数据集的部分内容与新任务存在语义关联时,真正的挑战并非标记数据本身的稀缺性,而是缺乏新类别的标记样本。
1. Introduction
1. 引言
Large labeled datasets for novel machine learning tasks are costly and time-consuming to gather, so there is a great demand for methods that can learn new tasks with limited labeling. One such area of work is few-shot learning (FSL). In FSL, the model must predict the labels of query images given only one or a few labeled examples of each target class, called the support set. Recent FSL works limit the available training resources to the support set and a labeled set of base classes [7, 18, 23, 31, 33, 39]. While the
针对新型机器学习任务的大规模标注数据集收集成本高且耗时,因此亟需能够通过有限标注学习新任务的方法。少样本学习 (FSL) 是该领域的重要研究方向。在少样本学习中,模型仅能通过每个目标类别的少量标注示例(称为支持集)来预测查询图像的标签。当前主流少样本学习方法将训练资源严格限制为支持集和已标注的基础类别集合 [7, 18, 23, 31, 33, 39]。
Now, practitioners face new questions. Given a novel few-shot task, which labeled data should be used as additional information? How should these related examples be incorporated into the model? For example, consider an online advertising platform that needs to identify images of a recently introduced shoe. In the typical FSL setup, the company has to train a model with just a few available images of that specific shoe. The typical approach ignores the company’s database of previous models, as well as their semantic knowledge about the properties of this new shoe (e.g., available colors, style, target customers, etc.). There are numerous other similar situations in industry, government, and research, where proprietary datasets and knowledge bases, public ones, or combinations of both are available when trying to solve new FSL tasks. From another perspective, humans use a significant amount of prior knowledge and data to solve novel tasks. Therefore, it is important to thoroughly investigate how machine learning models can use these resources in low-label regimes like FSL.
现在,从业者面临新的问题。给定一个新的少样本任务,应该使用哪些标注数据作为额外信息?如何将这些相关示例整合到模型中?例如,考虑一个在线广告平台需要识别一款新推出鞋子的图片。在典型的少样本学习设置中,公司只能用该特定鞋款的少量可用图片训练模型。传统方法会忽略公司以往模型的数据库,以及关于这款新鞋语义属性的知识(例如可选颜色、款式、目标客户等)。工业界、政府和研究领域存在大量类似场景,在解决新的少样本任务时,可能拥有专有数据集和知识库、公共资源或两者的组合。从另一个角度看,人类会利用大量先验知识和数据来解决新任务。因此,深入研究机器学习模型如何在少样本等低标注场景中利用这些资源至关重要。
We introduce Extended Few-Shot Learning (EFSL) as a formulation of this problem. In EFSL, models can take advantage of other available resources outside of labeled examples of the target classes, in addition to the support set. As illustrated in Figure 1, EFSL harnesses a wider range of available resources compared to similar problems.
我们提出了扩展少样本学习 (Extended Few-Shot Learning, EFSL) 作为该问题的形式化定义。在EFSL中,除了支持集外,模型还能利用目标类别标注样本之外的其他可用资源。如图 1 所示,与类似问题相比,EFSL利用了更广泛的可用资源。
We contribute benchmarks for this new problem, which are designed to evaluate EFSL models with auxiliary data of different semantic distances to the target task. We organize a large auxiliary dataset such as Image Net 22 k [3] in a hierarchy and consider different scenarios in which the target classes, some number of ancestors, and all their descendants are removed from the auxiliary data. These benchmarks provide a fair evaluation of future work on EFSL by controlling the contribution of auxiliary data.
我们为这一新问题贡献了基准测试,旨在评估具有不同语义距离辅助数据的目标任务的EFSL模型。我们将Image Net 22k [3]等大型辅助数据集按层次结构组织,并考虑从辅助数据中移除目标类别、若干祖先类别及其所有后代类别的不同场景。这些基准通过控制辅助数据的贡献,为未来EFSL研究提供了公平的评估标准。
The EFSL task introduces several new challenges, which we address with a novel framework. First, it is essential to intelligently select a subset of auxiliary data that is related to the target task. We propose using common sense knowledge graphs (e.g., ConceptNet [34]) for selecting the most related auxiliary classes to target classes. We call this related subset of auxiliary examples pseudo shots. Our method takes advantage of the direct relation between semantic and visual similarity of images [4]. Second, it is necessary to design an adaptable mechanism to effectively incorporate pseudo shots into existing FSL models. Pseudo shots often contain noisy and irrelevant information, because they are examples of classes distinct from the target classes. We find that naively using FSL methods on pseudo shots fails to fully exploit the potential of auxiliary data, especially as the pseudo shots’ semantic distance increases from the target classes. To address this issue, we design a masking module that identifies the more helpful information. We train the masking module in a meta-learning fashion through numerous EFSL episodes to identify the most helpful similarities between auxiliary data and the target task. We also show that this framework is compatible with many traditional FSL class if i ers including nearest centroid classifiers [2, 12, 25, 33, 37, 40], relation networks [35], and embedding adaptation methods [41], demonstrating the versatility of auxiliary data in the FSL setting.
EFSL任务引入了若干新挑战,我们通过创新框架予以解决。首先,需智能筛选与目标任务相关的辅助数据子集。我们提出利用常识知识图谱(如ConceptNet [34])选取与目标类别最相关的辅助类别,称这类相关辅助样本为伪样本(pseudo shots)。该方法利用了图像语义与视觉相似度的直接关联特性 [4]。其次,需设计自适应机制将伪样本有效整合至现有FSL模型中。由于伪样本来自与目标类别不同的类目,常包含噪声及无关信息。我们发现直接对伪样本应用FSL方法无法充分释放辅助数据潜力,尤其当伪样本与目标类别的语义距离增大时。为此,我们开发了能识别有效信息的掩码模块,通过大量EFSL场景的元学习训练来捕捉辅助数据与目标任务间最具价值的相似特征。该框架可兼容多种传统FSL分类器,包括最近质心分类器 [2, 12, 25, 33, 37, 40]、关系网络 [35] 及嵌入自适应方法 [41],证明了辅助数据在FSL场景中的通用性。
Finally, we conduct extensive experiments to study various aspects of the EFSL problem. We find that the magnitude of improvement for image classification crucially depends on the modeling choices made, especially when the auxiliary data is semantically distant from the target classes. When auxiliary data is used only to train a better image embedding function, average accuracy increases by 5.86 percentage points.
最后,我们进行了大量实验来研究EFSL问题的各个方面。我们发现,图像分类性能提升的幅度很大程度上取决于建模选择,尤其是当辅助数据在语义上与目标类别相距较远时。当辅助数据仅用于训练更好的图像嵌入函数时,平均准确率提高了5.86个百分点。
Further using auxiliary data to naively update target class prototypes reduces the average gain to 4.13 percentage points. In contrast, using our proposed masking module increases average accuracy by a total of 8.81 percentage points relative to the baseline without any auxiliary data.
进一步使用辅助数据直接更新目标类原型,平均增益降至4.13个百分点。相比之下,采用我们提出的掩码模块后,相较于完全不使用辅助数据的基线,平均准确率总共提升了8.81个百分点。
The improvement provided by the masking module over basic feature embeddings increases from 4.68 to 12.85 points as the semantic difference between the auxiliary data and target classes grows. Our findings indicate that employing auxiliary data is a challenging problem requiring specific models designed to address the questions specific to this new problem.
掩码模块相较于基础特征嵌入的提升效果,随着辅助数据与目标类别间语义差异的扩大,从4.68分提升至12.85分。研究表明,利用辅助数据是一个具有挑战性的问题,需要设计特定模型来解决这一新问题特有的难题。
We summarize our main contributions:
我们总结主要贡献如下:
2. Background
2. 背景
In traditional FSL, the model is trained and evaluated on a set of base classes $C^{t r a i n}$ and testing classes $C^{t e s t}$ , respectively. Note that base classes and testing classes are disjoint, i.e., $C^{t r a i n}\cap C^{t e s t}=\emptyset$ . Traditional FSL follows an episodic scheme [7, 18, 23, 31, 33, 39]. To create a K- shot N-way episode, we randomly select a set of $\mathbf{N}$ classes as support, i.e. target, classes $C$ . Based on the few-shot assumption, there are only $K$ labeled images available per support class, where $K$ is an small number. Thus, we randomly select $K$ images from each of the $N$ classes. This set of $N\times K$ examples is known as the support set, $S$ . We take another $q$ samples from each of the $N$ classes as our query set, $Q$ . The model is aware of the support set labels and is expected to predict the query set labels. Testing and training episodes are created in a similar way, but, the support classes are selected from $C^{t e s t}$ and $C^{t r a i n}$ , respectively.
在传统的少样本学习 (FSL) 中,模型分别在基础类 $C^{train}$ 和测试类 $C^{test}$ 上进行训练和评估。需要注意的是,基础类和测试类是互斥的,即 $C^{train}\cap C^{test}=\emptyset$。传统的少样本学习遵循情景式训练方案 [7, 18, 23, 31, 33, 39]。要创建一个 K-shot N-way 情景,我们随机选择 $\mathbf{N}$ 个类作为支撑类(即目标类)$C$。根据少样本假设,每个支撑类只有 $K$ 个带标签的图像可用,其中 $K$ 是一个很小的数字。因此,我们从这 $N$ 个类中每个类随机选择 $K$ 张图像。这组 $N\times K$ 个样本被称为支撑集 $S$。我们再从这 $N$ 个类中各取 $q$ 个样本作为查询集 $Q$。模型已知支撑集的标签,并需要预测查询集的标签。测试和训练情景的创建方式类似,但支撑类分别选自 $C^{test}$ 和 $C^{train}$。
3. Extended Few-Shot Learning (EFSL)
3. 扩展少样本学习 (EFSL)
Extended few-shot learning has a similar goal to traditional FSL, i.e., predicting the query labels given a small support set. However, in EFSL, the input is extended beyond the support set and includes other labeled datasets and non-visual, semantic knowledge sources. Examples of such datasets are public benchmark data and proprietary datasets belonging to organizations. External labeled datasets are constrained to exclude all examples of the support classes, but there is no constraint on the non-visual resources. Importantly, EFSL preserves the few-shot assumption in traditional FSL, defined in $\S2$ , because there are no examples of support classes in auxiliary resources.
扩展少样本学习 (EFSL) 与传统少样本学习 (FSL) 的目标相似,即在给定少量支持集的情况下预测查询标签。然而在 EFSL 中,输入内容不仅限于支持集,还包含其他标注数据集和非视觉语义知识来源。这类数据集的例子包括公共基准数据和机构专属数据集。外部标注数据集需排除所有支持类别的样本,但对非视觉资源没有限制。值得注意的是,EFSL 仍遵循传统 FSL(定义见 $\S2$ )的少样本假设,因为辅助资源中不包含支持类别的样本。
Given the immense size and variety of available auxiliary datasets, one of EFSL’s goals is to find a subset of useful and informative examples. EFSL extends the traditional episodes by an auxiliary support set $S_{c}^{\prime}$ which consists of the $K^{\prime}$ most informative auxiliary examples for each class $c$ . Formally, the extended episodes are as following
考虑到可用辅助数据集的庞大规模和多样性,EFSL的目标之一是找到有用且信息丰富的示例子集。EFSL通过引入辅助支持集 $S_{c}^{\prime}$ 来扩展传统的情节 (episode) ,该集合包含每个类别 $c$ 中最具信息量的 $K^{\prime}$ 个辅助示例。形式上,扩展后的情节如下所示
$$
\mathcal{E}{c}^{\prime}=\mathcal{E}{c}\cup{S_{c}^{\prime}}={S_{c},S_{c}^{\prime},Q_{c}}\quad\forall c\in C.
$$
$$
\mathcal{E}{c}^{\prime}=\mathcal{E}{c}\cup{S_{c}^{\prime}}={S_{c},S_{c}^{\prime},Q_{c}}\quad\forall c\in C.
$$
3.1. EFSL Benchmarks
3.1. EFSL 基准测试
Here, we introduce benchmarks to evaluate EFSL models. We intend to evaluate scenarios with varying degrees of similarity between the auxiliary data and target task. Ideally, an algorithm would do well even with distantly related data, and, if that is not possible, degrade gracefully. To create auxiliary datasets of increasing semantic distance from the target tasks, we use the hierarchical relationships among words in WordNet [6] to prune data. In WordNet, organiz- ing words with respect to the hyponym (subtype) relation creates a directed tree in which child classes are subtypes of their parents. In all scenarios, we eliminate class $c$ and all of its descendants, and use the remaining classes as the set of allowed auxiliary classes with respect to $c$ . As we select data of increasing semantic distance, we move up the tree and prune ancestors of the class $c$ and their descendants. We refer to each such dataset as a level from 0 (pruning class $c$ and its descendants) to 3 (pruning the great-grandparents of class $c$ and all its descendants).
在此,我们引入基准来评估EFSL模型。我们旨在评估辅助数据与目标任务之间相似度不同的场景。理想情况下,算法即使在数据关联性较低时也能表现良好,若无法实现,则性能应平稳下降。为创建与目标任务语义距离逐渐增加的辅助数据集,我们利用WordNet [6]中词语的层级关系来筛选数据。在WordNet中,通过下位词(子类型)关系组织词语会形成有向树结构,其中子类是其父类的子类型。在所有场景中,我们剔除类别$c$及其所有后代,并将剩余类别作为相对于$c$的允许辅助类别集合。随着选择语义距离逐渐增大的数据,我们沿树结构上移,依次剔除类别$c$的祖先节点及其后代。我们将每个此类数据集称为一个层级,从0级(剔除类别$c$及其后代)到3级(剔除类别$c$的曾祖父节点及其所有后代)。
Formally, let $p_{l}^{c}$ be the $l^{t h}$ ancestor of class $c$ such that $p_{0}^{c}=c$ and $\boldsymbol{p}_{n}^{c}$ is the root of the WordNet tree where $n$ is the depth of class $c$ in the tree. Also, let $d^{c}$ be the set of all the descendants of class $c$ . Given a set of classes, $\mathbb{C}$ , we constrain the auxiliary classes at level $l$ and use $C^{A}$ as the set of available auxiliary classes with respect to $\mathbb{C}$
形式上,设 $p_{l}^{c}$ 为类别 $c$ 的第 $l^{t h}$ 个祖先,其中 $p_{0}^{c}=c$,且 $\boldsymbol{p}_{n}^{c}$ 是 WordNet 树的根节点,其中 $n$ 为类别 $c$ 在树中的深度。同时,设 $d^{c}$ 为类别 $c$ 的所有后代集合。给定类别集合 $\mathbb{C}$,我们在层级 $l$ 约束辅助类别,并使用 $C^{A}$ 表示相对于 $\mathbb{C}$ 的可用辅助类别集合。
$$
C^{A}=C^{T}\setminus\bigcup_{c\in\mathbb{C}}d^{p_{l}^{c}},
$$
$$
C^{A}=C^{T}\setminus\bigcup_{c\in\mathbb{C}}d^{p_{l}^{c}},
$$
where $C^{T}$ is the set of all the classes in the auxiliary data source. In our experiments, we use this technique to extend several FSL benchmarks.
其中 $C^{T}$ 是辅助数据源中所有类别的集合。在我们的实验中,我们使用该技术扩展了多个少样本学习基准。
4. Learning with Auxiliary Data
4. 利用辅助数据学习
Here, we address the main challenges of EFSL. Figure 2 shows the block diagram of our framework. In $\S4.1$ , we tackle auxiliary data selection using a common sense knowledge graph (Figure 2a). Next, taking in the support and auxiliary sets, we first try a simple approach for designing a feature embedding module in $\S4.2$ (Figure 2b). However, the performance of these basic embeddings is mediocre, with performance often being harmed by semantically distant auxiliary data $\S5$ and $\S6$ ). We address this deficiency in $\S4.3$ with our masking module, which filters the irrelevant information in auxiliary data (Figure 2c). The resulting masked embeddings are compatible with a wide range of existing FSL classification techniques, demonstrating the extensive applicability of exploiting auxiliary data. In $\S~4.4$ , we use three popular methods for standard FSL to classify the embeddings: nearest centroid classifier [2, 33, 35, 36], relation networks [35], and embedding adaptation [41] (Figure 2d). We demonstrate that all three methods significantly benefit from the higher quality masked embeddings.
在此,我们探讨了EFSL面临的主要挑战。图2展示了我们框架的模块示意图。在$\S4.1$中,我们利用常识知识图谱解决辅助数据选择问题(图2a)。接着,基于支持集和辅助集,我们在$\S4.2$中首先尝试了一种简单的特征嵌入模块设计方法(图2b)。然而,这些基础嵌入的表现平平,其性能常受语义差距较大的辅助数据影响($\S5$和$\S6$)。我们在$\S4.3$中通过掩码模块解决了这一缺陷,该模块能过滤辅助数据中的无关信息(图2c)。生成的掩码嵌入与多种现有FSL分类技术兼容,展现了利用辅助数据的广泛适用性。在$\S~4.4$中,我们采用三种主流的标准FSL方法对嵌入进行分类:最近质心分类器[2,33,35,36]、关系网络[35]以及嵌入自适应[41](图2d)。实验表明,这三种方法都能显著受益于更高质量的掩码嵌入。
4.1. Auxiliary Data Selection
4.1. 辅助数据选择
Our selection method intends to maximize the semantic and visual similarities between the support classes and selected auxiliary examples. We can view these distantly related auxiliary examples as low quality instances of the support classes. Thus, we call such examples pseudo shots. In $\S6$ , we show that not only does our selection of auxiliary data contain more useful information than random examples, but also that random examples usually lead to poor performance.
我们的选择方法旨在最大化支持类与所选辅助样本之间的语义和视觉相似性。我们可以将这些远距离相关的辅助样本视为支持类的低质量实例。因此,我们将此类样本称为伪样本 (pseudo shots)。在 $\S6$ 中,我们不仅展示了所选辅助数据比随机样本包含更多有用信息,还证明了随机样本通常会导致性能不佳。
We propose using a notion of semantic similarity between two classes to select a subset of auxiliary examples. Semantic similarity has a broader applicability and is comput ation ally more efficient than visual similarity. Visual similarity requires pair-wise image comparisons with high computational cost. Because semantic and visual similarity between two categories are directly related [4], we can avoid expensive pair-wise image comparisons by using semantic similarity as a computationally efficient proxy for visual similarity. This setup can potentially discover a wider visual range of auxiliary data that pertains to each support class.
我们提出利用两个类别之间的语义相似度概念来筛选辅助样本子集。语义相似度具有更广泛的适用性,且计算效率高于视觉相似度。视觉相似度需要进行计算成本高昂的成对图像比较。由于两个类别间的语义相似度与视觉相似度直接相关 [4],我们可以通过语义相似度这一计算高效的代理指标,避免昂贵的成对图像比较。该方法有望为每个支持类发现更广视觉范围的关联辅助数据。
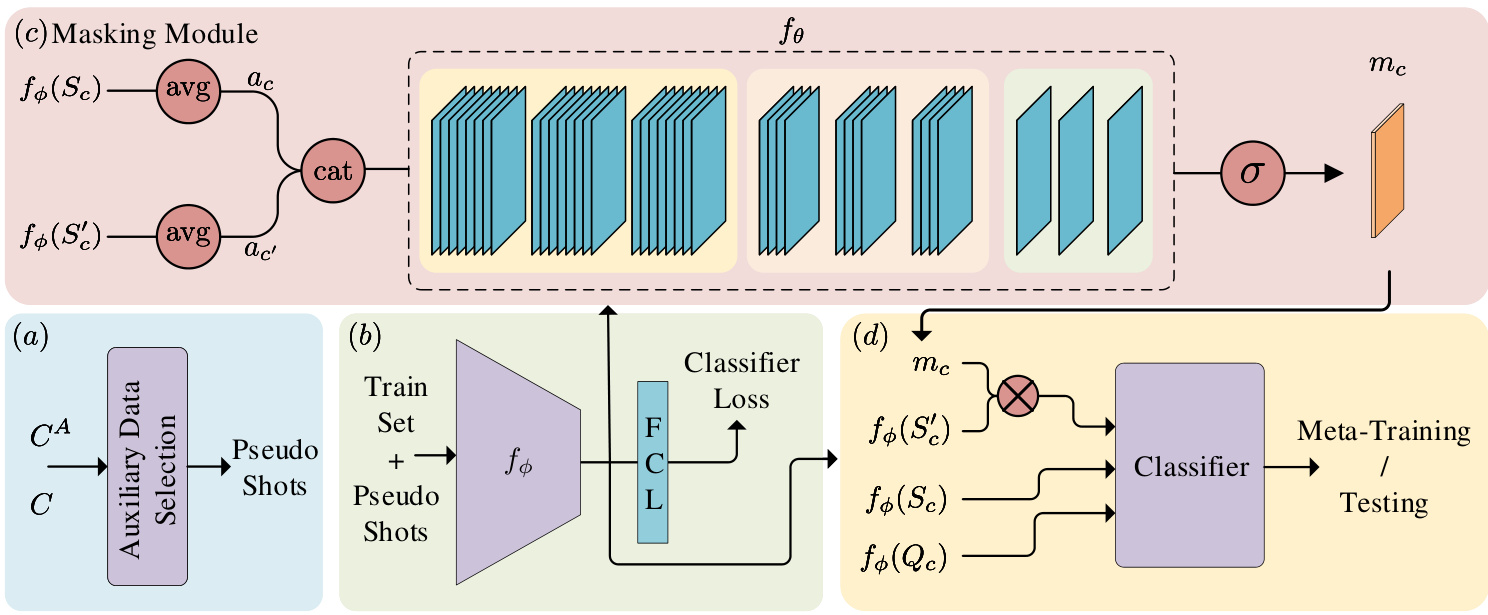
Figure 2: The proposed framework for EFSL. a) We use common sense knowledge graphs to select a subset of auxiliary examples. b) We use the base classes and the corresponding pseudo shots to train the feature embedding module. c) The masking module takes the support set and pseudo shot embeddings and generates a mask $m_{c}$ to filter the irrelevant information in pseudo shots. d) We feed the query, support set, and masked pseudo shot embeddings to a classifier and generate the logits for meta-training/testing.
图 2: EFSL 提出的框架。a) 我们使用常识知识图谱选择辅助样本的子集。b) 我们使用基类和对应的伪样本训练特征嵌入模块。c) 掩码模块接收支持集和伪样本嵌入,生成掩码 $m_{c}$ 以过滤伪样本中的无关信息。d) 我们将查询、支持集和掩码后的伪样本嵌入输入分类器,生成元训练/测试的对数几率。
To estimate the semantic similarity between two classes, we employ common sense knowledge graphs, graph structures modeling natural concepts and their relations. We focus on the ConceptNet graph [34], given its wide domain coverage of concepts, multiple relationship types, and useful Euclidean word embeddings to capture semantic similarity. These embeddings combine the relational knowledge in ConceptNet with distribution al semantics from Word2Vec [22] and GloVe [26] embeddings using a generalized retrofitting method [5]. This hybrid semantic space is highly useful in word relatedness evaluations, with nodes having a smaller distance not just to those with names that often co-occur in text, but also those that are related in other ways, such as having similar functions, properties, appearing in similar contexts or physical locations, etc.
为了估计两个类别之间的语义相似度,我们采用常识知识图谱(graph structures modeling natural concepts and their relations)。我们重点关注ConceptNet图谱[34],因其具有广泛的概念领域覆盖、多重关系类型,以及能有效捕捉语义相似度的欧几里得词嵌入(word embeddings)。这些嵌入通过广义重构方法[5],将ConceptNet中的关系知识与来自Word2Vec[22]和GloVe[26]嵌入的分布语义相结合。这种混合语义空间在词汇相关性评估中非常实用,节点之间的距离不仅与文本中常共现的名称更近,还与通过其他方式相关联的节点更近,例如具有相似功能、属性、出现在相似语境或物理位置等。
We use a metric of cosine similarity between two classes’ corresponding node vectors in ConceptNet. For class $c$ , we select the $N^{\prime}$ most similar auxiliary classes $C_{c}^{\prime}$ , and randomly choose $K^{\prime}$ samples from them as the auxiliary support set $S_{c}^{\prime}$ :
我们使用ConceptNet中两个类别对应节点向量的余弦相似度作为度量。对于类别 $c$,我们选择 $N^{\prime}$ 个最相似的辅助类别 $C_{c}^{\prime}$,并从中随机选取 $K^{\prime}$ 个样本作为辅助支持集 $S_{c}^{\prime}$:
$$
C_{c}^{\prime}=\mathrm{argmax}{{c_{1},...,c_{N^{\prime}}}\subseteq C^{A}}\sum_{c_{i}}\langle E_{c},E_{c_{i}}\rangle,
$$
$$
C_{c}^{\prime}=\mathrm{argmax}{{c_{1},...,c_{N^{\prime}}}\subseteq C^{A}}\sum_{c_{i}}\langle E_{c},E_{c_{i}}\rangle,
$$
where $C^{A}$ is the set of available auxiliary classes, $E$ is the corresponding word vector, and $\langle\cdot\rangle$ is cosine similarity.
其中 $C^{A}$ 是可用辅助类别的集合, $E$ 是对应的词向量, $\langle\cdot\rangle$ 表示余弦相似度。
4.2. Feature Embedding
4.2. 特征嵌入
We use an embedding function $f_{\phi}$ to represent images as lower-dimensional feature vectors. We train a ResNet12 on the union of base classes and pseudo shots, selected by following $\S4.1$ . Following previous works [2, 36], we use a typical cross entropy loss. After training, we drop the fully connected output layer and use the remaining model as our embedding function $f_{\phi}$ . We freeze the parameters of $f_{\phi}$ after this. We refer to the features generated by $f_{\phi}$ as basic embeddings.
我们使用嵌入函数 $f_{\phi}$ 将图像表示为低维特征向量。在基础类和伪样本的并集上训练一个ResNet12,其选择方法遵循 $\S4.1$。按照先前工作[2,36]的做法,我们采用标准的交叉熵损失。训练完成后,移除全连接输出层,将剩余模型作为嵌入函数 $f_{\phi}$ 使用,并在此后冻结其参数。由 $f_{\phi}$ 生成的特征称为基础嵌入(basic embeddings)。
4.3. Masking Module
4.3. 掩码模块
Although basic embeddings improve the accuracy, as shown by our experiments in $\S_{\lambda}5.2$ , their performance is mediocre, especially when the pseudo shots and auxiliary classes are semantically distant. To maximize our gain, we design a masking module that compares the features of the support set and pseudo shots, and learns to filter the irrelevant information in pseudo shots.
虽然基础嵌入(embedding)提高了准确性(如我们在$\S_{\lambda}5.2$中的实验所示),但其表现仍显平庸,尤其在伪样本(pseudo shots)与辅助类(auxiliary classes)语义距离较远时。为最大化收益,我们设计了一个掩码模块(masking module),通过比较支持集(support set)与伪样本的特征,学习过滤伪样本中的无关信息。
To avoid computationally expensive pairwise comparisons between support set and pseudo shots, we compare the prototype of each support class with the prototype of the corresponding pseudo shots. For each support class $c$ , we use a mean aggregator over basic embeddings to calculate the prototypes. Let basic embeddings, the output of $f_{\phi}$ , be of shape $(C^{},W,H)$ where $C^{},W$ , and $H$ are the number of channels, width, and height of the embeddings, respectively.1 In each episode, the mean aggregator transforms the dimensions as
为避免支持集与伪样本间计算成本高昂的成对比较,我们将每个支持类别的原型与对应伪样本的原型进行比较。对于每个支持类别$c$,我们使用基础嵌入的均值聚合器计算原型。设基础嵌入(即$f_{\phi}$的输出)形状为$(C^{},W,H)$,其中$C^{},W$和$H$分别表示嵌入的通道数、宽度和高度。在每个训练片段中,均值聚合器对维度进行如下变换:

Figure 3: Support images, pseudo shots, and masked pseudo shots for three different classes are shown in columns (a), (b), and (c), respectively. Warmer colors represent higher mask values. The masking module successfully learns to identify the most similar region to support images in pseudo shots.
图 3: 三组不同类别的支持图像、伪样本及掩膜伪样本分别展示在(a)、(b)、(c)三列中。暖色调表示更高的掩膜值。掩膜模块成功学会了识别伪样本中与支持图像最相似的区域。
$$
\mathrm{mean:}\left(N,K^{},C^{},W,H\right)\rightarrow\left(N,C^{*},W,H\right),
$$
$$
\mathrm{mean:}\left(N,K^{},C^{},W,H\right)\rightarrow\left(N,C^{*},W,H\right),
$$
where $K^{*}$ equals $K$ and $K^{\prime}$ for support images and pseudo shots, respectively.
其中 $K^{*}$ 分别等于支持图像的 $K$ 和伪样本的 $K^{\prime}$。
We define a function $f_{\theta}$ that takes two sets of feature embeddings as input, and outputs a 2D matrix with similar dimensions to feature maps. Then, we use the sigmoid function to calculate matrix $m$ with values in [0, 1]. Ideally, $m$ assigns 1 to the regions where both input embeddings contain identical information and 0 to regions with totally dissimilar information and a number between 0 and 1 for other regions with varying degree of similarity.
我们定义了一个函数 $f_{\theta}$,它接收两组特征嵌入作为输入,并输出一个与特征图尺寸相似的二维矩阵。然后,我们使用 sigmoid 函数计算值域在 [0, 1] 之间的矩阵 $m$。理想情况下,$m$ 会在输入嵌入包含完全相同信息的区域赋值为 1,在信息完全不同的区域赋值为 0,而在其他具有不同相似程度的区域赋值为 0 到 1 之间的数值。
We use $f_{\theta}$ to identify the similarities between support set and pseudo shot prototypes. For each class $c$ , we concatenate the support set prototype $a_{c}$ and pseudo shot prototype $a_{c}^{\prime}$ calculated by Eq. (4). Let $m_{c}$ be the mask for class $c$
我们使用 $f_{\theta}$ 来识别支持集和伪样本原型之间的相似性。对于每个类别 $c$,我们将支持集原型 $a_{c}$ 和由式 (4) 计算得到的伪样本原型 $a_{c}^{\prime}$ 进行拼接。设 $m_{c}$ 为类别 $c$ 的掩码。
$$
\begin{array}{c}{{m_{c}=\sigma(f_{\theta}(\cot(a_{c},a_{c^{\prime}})))}}\ {{\sigma(f_{\theta}(.)):(N,2C^{*},W,H)\rightarrow(N,1,W,H).}}\end{array}
$$
$$
\begin{array}{c}{{m_{c}=\sigma(f_{\theta}(\cot(a_{c},a_{c^{\prime}})))}}\ {{\sigma(f_{\theta}(.)):(N,2C^{*},W,H)\rightarrow(N,1,W,H).}}\end{array}
$$
To exploit the inherent spatial correlation of images, we calculate a spatial mask for the $(H,W)$ plane rather than having a single scalar mask value per $(H,W)$ plane. We update pseudo shot embeddings by element-wise multiplication of $m_{c}$ with each of the $C^{*}$ feature maps. We refer to these updated features maps as masked embeddings.
为了利用图像固有的空间相关性,我们为$(H,W)$平面计算空间掩码,而不是为每个$(H,W)$平面分配单一标量掩码值。我们通过将$m_{c}$与$C^{*}$个特征图逐元素相乘来更新伪镜头嵌入,并将这些更新后的特征图称为掩码嵌入。
Figure 3 shows images of support classes, their corresponding pseudo shot, and the generated mask. The masking module successfully identifies the similarities between images and filters less useful information.
图 3: 展示了支持类别的图像、其对应的伪样本以及生成的掩码。掩码模块成功识别了图像间的相似性,并过滤了效用较低的信息。
4.4. Classifier
4.4. 分类器
After filtering extraneous information, we can view masked pseudo shots as weaker examples of the support classes. Thus, we merge the pseudo shots and support set features
在过滤无关信息后,我们可以将掩码伪样本视为支撑类的弱化示例。因此,我们将伪样本与支撑集特征进行合并
$$
S_{c}^{f}={f_{\phi}(x);\forall x\in S_{c}}\cup{f_{\phi}(x)\odot m_{c};\forall x\in S_{c}^{\prime}},
$$
$$
S_{c}^{f}={f_{\phi}(x);\forall x\in S_{c}}\cup{f_{\phi}(x)\odot m_{c};\forall x\in S_{c}^{\prime}},
$$
where $\odot$ is the Hadamard product and $S_{c}^{f}$ is the merged support set for class $c$ . The structure of the merged episode is similar to a regular FSL task, allowing us to use a wide range of regular FSL class if i ers for prediction. We evaluate the merged task with three popular FSL class if i ers: nearest centroid classifier, relation module, and embedding adaptation. See the appendix for more details on class if i ers and architecture of the masking module.
其中 $\odot$ 表示哈达玛积 (Hadamard product),$S_{c}^{f}$ 是类别 $c$ 的合并支持集。合并后的情节结构与常规小样本学习任务类似,使我们能够使用多种常规小样本分类器进行预测。我们使用三种流行的小样本分类器评估合并任务:最近质心分类器、关系模块和嵌入自适应。关于分类器和掩码模块架构的更多细节,请参阅附录。
Nearest centroid classifier (NCC). NCC is the most popular classifier in FSL literature [2, 12, 25, 33, 37, 40]. For each class $c$ , the centroid $h_{c}$ is the average over the merged support set $S_{c}^{f}$ . For a query example $x$ , Eq. (6) calculates a probability distribution over support classes
最近邻质心分类器 (NCC)。NCC 是少样本学习文献中最常用的分类器 [2, 12, 25, 33, 37, 40]。对于每个类别 $c$,其质心 $h_{c}$ 是合并支持集 $S_{c}^{f}$ 的平均值。对于一个查询样本 $x$,公式 (6) 计算了支持类别的概率分布
$$
p(y=c|x)=\frac{\exp(\langle f_{\phi}(x),h_{c}\rangle)}{\sum_{c^{\prime}\in C}\exp(\langle f_{\phi}(x),h_{c^{\prime}}\rangle)}\quad\forall c\in C,
$$
where $\langle\cdot\rangle$ is cosine similarity. The query example is labeled with the highest probability class.
其中 $\langle\cdot\rangle$ 表示余弦相似度。查询示例被标记为概率最高的类别。
Relation Module (RM). Relation networks consist of a feature embedding module and a relation module for classification [35]. The relation module generates a relation score for each pair of class centroid and query example features. For each query example, we calculate the relation score for all classes and select the class with highest relation score.
关系模块 (RM)。关系网络由特征嵌入模块和用于分类的关系模块组成 [35]。该关系模块为每个类别质心与查询样本特征对生成一个关系分数。对于每个查询样本,我们计算其与所有类别的关系分数,并选择关系分数最高的类别。
Embedding adaptation (EA). FSL models usually use the same embedding function for all tasks. Several works have proposed adapting the feature embeddings for each FSL task to be more disc rim i native [14, 19, 41]. Similar to Ye et al. [41], we calculate the centroids for all support classes, then use a Transformer function [38] to modify the centroids for the current episode. With the updated class centroids, we use Eq. (6) to calculate the probability distribution for support classes and choose the most likely class.
嵌入自适应 (Embedding Adaptation, EA)。少样本学习模型通常对所有任务使用相同的嵌入函数。一些研究提出针对每个少样本学习任务调整特征嵌入以增强判别性 [14, 19, 41]。与 Ye 等人 [41] 的方法类似,我们计算所有支持类的质心,然后使用 Transformer 函数 [38] 调整当前情景的质心。通过更新后的类质心,我们使用公式 (6) 计算支持类的概率分布并选择最可能的类别。
Training. We train our pipeline increment ally. First, we train the feature embedding function and freeze its parameters. We then train the masking module with the nearest centroid classifier through numerous episodes. Next, we replace NCC with another classifier, freeze the parameters of both feature embedding and masking module and repeat the same episodic training.
训练。我们采用增量方式训练整个流程。首先训练特征嵌入函数并冻结其参数。随后通过大量训练片段训练带有最近质心分类器的掩码模块。接着用另一个分类器替换NCC,冻结特征嵌入和掩码模块的参数,并重复相同的片段式训练。
Table 1: EFSL results on mini Image Net and tiered Image Net with level 0 pruning of the auxiliary data. Results are for three classifier types: nearest-centroid classifier (NCC), relation module (RM), and embedding adaptation (EA). Each section shows results for the baseline without any auxiliary data, the baseline with basic embeddings of auxiliary data, and the proposed method using masked embeddings. Each entry is mean accuracy over 800 episodes with $95%$ confidence intervals.
表 1: 在miniImageNet和tieredImageNet上使用辅助数据0级剪枝的EFSL结果。结果针对三种分类器类型:最近质心分类器(NCC)、关系模块(RM)和嵌入自适应(EA)。每个部分展示了不使用任何辅助数据的基线、使用辅助数据基础嵌入的基线以及使用掩码嵌入的提出方法的结果。每个条目为800次实验的平均准确率,置信区间为95%。
| 模型 | miniImageNet 1-shot | miniImageNet 5-shot | tieredImageNet 1-shot | tieredImageNet 5-shot |
|---|---|---|---|---|
| NCC Baseline | 56.7 ± 0.71 | 75.93 ± 0.53 | 64.46 ± 0.83 | 82.21 ± 0.62 |
| NCC+BasicPS | 69.93 ± 0.76 | 76.70 ± 0.64 | 76.09 ± 0.81 | 82.38 ± 0.67 |
| NCC+Masked PS | 75.82 ± 0.62 | 85.93 ± 0.42 | 80.66 ± 0.68 | 87.83 ± 0.51 |
| RM Baseline | 58.42 ± 0.77 | 74.42 ± 0.55 | 62.58 ± 0.85 | 78.65 ± 0.69 |
| RM + Basic PS | 66.67 ± 0.78 | 72.39 ± 0.65 | 64.39 ± 0.88 | 72.62 ± 0.81 |
| RM+Masked PS | 67.48 ± 0.72 | 78.67 ± 0.53 | 67.51 ± 0.85 | 78.70 ± 0.69 |
| EA Baseline | 61.69 ± 0.74 | 77.24 ± 0.52 | 67.92 ± 0.84 | 82.90 ± 0.59 |
| EA+Basic PS | 72.42 ±0.72 | 80.58 ± 0.58 | 75.52 ± 0.80 | 81.94 ± 0.69 |
| EA+MaskedPS | 76.88 ±0.67 | 86.28 ± 0.41 | 80.54 ± 0.69 | 87.53 ± 0.53 |
5. Experimental Evaluation
5. 实验评估
In this section, we evaluate the proposed framework for the EFSL problem. As expected, adding auxiliary resources to the input improves the performance. More importantly, we find that addressing challenges like auxiliary data selection and designing specific models for EFSL have a significant impact on performance. Our masking module improves the accuracy by 4.68 points compared to naively using basic auxiliary embeddings. Later, in $\S~6$ , we find that not addressing these challenges can even cause failure resulting in accuracy lower than standard FSL.
在本节中,我们评估了针对EFSL问题提出的框架。正如预期的那样,向输入中添加辅助资源可以提高性能。更重要的是,我们发现解决辅助数据选择和为EFSL设计特定模型等挑战对性能有显著影响。与简单地使用基本辅助嵌入相比,我们的掩码模块将准确率提高了4.68个百分点。随后,在$\S~6$中,我们发现如果不解决这些挑战,甚至可能导致失败,使得准确率低于标准FSL。
5.1. Datasets
5.1. 数据集
We extend four popular FSL datasets and create benchmarks for EFSL using the procedure from $\S\enspace3.1$ . mini Image Net and tiered Image Net are both subsets of the ILSVRC-12 dataset [29]. mini Image Net [39] consists of 100 classes with 600 images per class. Classes are split into 64, 20, and 16 classes for training, testing, and validation, respectively. tiered Image Net [28] contains 608 classes, of which 351 classes are for training, 160 for testing, and 97 for validation. Both mini Image Net and tiered Image Net contain $84\times84$ RGB images. CIFAR-FS and FC-100 are both variants of the CIFAR-100 dataset for FSL. CIFARFS [18] splits CIFAR-100 into 64, 20, and 16 classes, and FC-100 [25] splits CIFAR-100 into 60, 20, and 20 classes for training, testing, and validation, respectively. Both datasets contain $32\times32$ RGB images.
我们按照 $\S\enspace3.1$ 的流程扩展了四个流行的少样本学习(FSL)数据集,并创建了EFSL基准。mini ImageNet和tiered ImageNet都是ILSVRC-12数据集[29]的子集。mini ImageNet[39]包含100个类别,每类600张图像,按64、20、16类分别划分训练集、测试集和验证集。tiered ImageNet[28]包含608个类别,其中351类用于训练,160类用于测试,97类用于验证。这两个数据集均为 $84\times84$ 分辨率的RGB图像。CIFAR-FS和FC-100都是CIFAR-100数据集的少样本学习变体:CIFAR-FS[18]将CIFAR-100划分为64、20、16类,FC-100[25]则划分为60、20、20类,分别用于训练、测试和验证。这两个数据集均包含 $32\times32$ 分辨率的RGB图像。
For auxiliary data, we choose classes with more than 500 samples as the set of auxiliary classes $C^{T}$ from ImageNet22k [3]. For each test episode, we use support classes $C$ for $\mathbb{C}$ in Eq. (2) to get the allowed classes $C^{A}$ for level $l$ auxiliary data. For training, we use all of the test classes $C^{t e s t}$ for $\mathbb{C}$ in Eq. (2) to prune $C^{T}$ and enforce the desired semantic distance with all test classes.
对于辅助数据,我们从ImageNet22k [3]中选取样本量超过500的类别作为辅助类别集$C^{T}$。在每个测试片段中,我们使用支持类别$C$作为式(2)中的$\mathbb{C}$,以获取层级$l$辅助数据的允许类别集$C^{A}$。训练阶段,我们将所有测试类别$C^{test}$作为式(2)中的$\mathbb{C}$来剪枝$C^{T}$,并确保与所有测试类别保持预期的语义距离。
5.2. Results
5.2. 结果
We evaluate using both basic and masked embeddings to create centroids, and consider all three classification methods from $\S4.4$ on the four benchmarks with level 0 auxiliary data. We emphasize the results at level 0, which is still a challenging setting because the auxiliary data contains no samples of the test classes nor any subtypes of the test classes. For context, we also report the accuracy of the class if i ers for traditional FSL. These baselines help better understand the benefits of different approaches to EFSL and underscore the different effects of auxiliary data at different levels of semantic distance.
我们评估了使用基础嵌入和掩码嵌入来创建质心的效果,并在四个具有0级辅助数据的基准测试上考虑了来自$\S4.4$的三种分类方法。我们重点关注0级的结果,这仍然是一个具有挑战性的设定,因为辅助数据既不包含测试类的样本,也不包含测试类的任何子类型。作为背景,我们还报告了传统少样本学习分类器的准确率。这些基线有助于更好地理解不同EFSL方法的优势,并凸显辅助数据在不同语义距离层级上的不同影响。
ImageNet. Table 1 reports the accuracy for the three class if i ers on ImageNet derivatives. Adding pseudo shots with basic embeddings improves the accuracy for all combinations of the models, tasks, and datasets, with a greater impact for 1-shot tasks. This consistent improvement shows the value of auxiliary resources in low-shot regimes. Using masked pseudo shot embeddings further improves the performance of basic embeddings across all experiments. On average, the masking module boosts the accuracy of the basic embeddings by 3.98 and 6.39 points for 1- and 5-shot tasks, respectively with the maximum improvement of 9.23 points. Compared to traditional FSL, these existing resources improve the average accuracy by a total of 12.85 and 5.60 points for 1- and 5-shot tasks, respectively.
ImageNet。表 1 报告了三种分类器在ImageNet衍生数据集上的准确率。使用基础嵌入添加伪样本能够提升所有模型、任务和数据组合的准确率,其中对1样本任务的提升效果更为显著。这一持续性改进证明了辅助资源在低样本场景中的价值。在所有实验中,使用掩码伪样本嵌入进一步提升了基础嵌入的性能。平均而言,掩码模块将1样本和5样本任务中基础嵌入的准确率分别提高了3.98和6.39个百分点,最大提升幅度达9.23个百分点。与传统少样本学习相比,这些现有资源将1样本和5样本任务的平均准确率分别累计提升了12.85和5.60个百分点。
Table 2: EFSL results on CIFAR-FS and FC-100 with level 0 pruning of the auxiliary data. Results are for three classifier types: nearest-centroid classifier (NCC), relation module (RM), and embedding adaptation (EA). Each section shows results for the baseline without any auxiliary data, the baseline with basic embeddings of auxiliary data, and the proposed method using masked embeddings. Each entry is mean accuracy over 800 episodes with $95%$ confidence intervals.
表 2: 辅助数据经过 0 级剪枝后在 CIFAR-FS 和 FC-100 上的 EFSL 结果。结果针对三种分类器类型:最近质心分类器 (NCC)、关系模块 (RM) 和嵌入自适应 (EA)。每个部分展示了不使用任何辅助数据的基线、使用辅助数据基础嵌入的基线以及使用掩码嵌入的提出方法的结果。每个条目为 800 次实验的平均准确率,置信区间为 95%。
| 模型 | CIFAR-FS 1-shot | CIFAR-FS 5-shot | FC-100 1-shot | FC-100 5-shot |
|---|---|---|---|---|
| NCC Baseline | 66.56 ± 0.71 | 84.43 ± 0.56 | 40.28 ± 0.59 | 56.25 ± 0.59 |
| NCC+BasicPS | 75.78 ± 0.79 | 85.79 ± 0.54 | 49.51 ± 0.67 | 57.51 ± 0.66 |
| NCC + Masked PS | 82.00 ± 0.65 | 90.49 ± 0.49 | 53.72 ± 0.67 | 65.52 ± 0.62 |
| RM Baseline | 67.81 ± 0.80 | 82.26 ± 0.64 | 37.51 ± 0.62 | 50.28 ± 0.60 |
| RM + Basic PS | 73.32 ± 0.84 | 81.68 ± 0.64 | 43.22 ± 0.65 | 49.18 ± 0.66 |
| RM + Masked PS | 74.17 ± 0.80 | 86.21 ± 0.57 | 42.04 ± 0.65 | 52.02 ± 0.63 |
| EA Baseline | 69.86 ± 0.74 | 85.32 ± 0.57 | 41.52 ± 0.62 | 57.46 ± 0.64 |
| EA + Basic PS | 77.74 ± 0.77 | 87.08 ± 0.53 | 51.23 ± 0.65 | 58.13 ± 0.65 |
| EA+MaskedPS | 83.02 ± 0.62 | 90.84 ± 0.48 | 54.59 ± 0.66 | 65.64 ± 0.63 |
CIFAR-100. In Table 2, we present the accuracy of the class if i ers on variants of CIFAR-100. As expected, adding auxiliary data with basic embeddings improves the performance for almost all tasks. Consistent with previous results, using masked embeddings further improves the accuracy of basic embeddings. On average, the masking module improves the accuracy of the basic embeddings by 3.12 and 5.23 points for 1- and 5-shot tasks, respectively. The masking module increases the accuracy of basic embeddings by up to 8.01 points. The masking module boosts the average accuracy of the traditional FSL by 11 and 5.79 points for 1- and 5-shot tasks, respectively.
CIFAR-100。在表2中,我们展示了分类器在CIFAR-100变体上的准确率。与预期一致,添加带有基础嵌入(embeddings)的辅助数据能提升几乎所有任务的性能。与此前结果一致,使用掩码嵌入(masked embeddings)能进一步提升基础嵌入的准确率。平均而言,掩码模块将基础嵌入在1样本和5样本任务中的准确率分别提高了3.12和5.23个百分点。掩码模块最高可将基础嵌入的准确率提升8.01个百分点。对于传统少样本学习(FSL),掩码模块将1样本和5样本任务的平均准确率分别提升了11和5.79个百分点。
6. Analysis
6. 分析
Here, we further study the auxiliary data with basic and masked embeddings and the impact of semantic distance on performance. We compare EFSL with transfer learning and semi-supervised FSL, and discuss their differences.
在此,我们进一步研究了带有基础嵌入和掩码嵌入的辅助数据,以及语义距离对性能的影响。我们将EFSL与迁移学习和半监督FSL进行比较,并讨论它们之间的差异。
Auxiliary Data Benchmarks. Table 3 reports the performance of the embedding adaptation classifier with different levels of auxiliary data. We clearly see the value of auxiliary data as masked embeddings improve over the traditional FSL accuracy by 4.71 points even with level 3 auxiliary data–which contains no WordNet great-grandparents of the test classes nor their subtypes.
辅助数据基准测试。表3报告了嵌入适应分类器在不同级别辅助数据下的性能表现。我们清晰地看到辅助数据的价值——即便使用不含测试类WordNet曾祖节点及其子类型的3级辅助数据,掩码嵌入仍比传统少样本学习准确率高出4.71个百分点。
The accuracy of the masked embeddings degrades more gracefully than basic embeddings with more semantically distant auxiliary examples, by 5.66 and 9.78 points, respectively. As shown in Figure 4, the improvement of masked embeddings over basic embeddings increases for higher levels of auxiliary data. The masking module thus provides a solution to the real world problem when auxiliary data similar to the target classes are not easily obtainable.
掩码嵌入 (masked embeddings) 的准确度下降比基础嵌入 (basic embeddings) 更为平缓,在语义距离更远的辅助样本下分别仅降低5.66和9.78分。如图4所示,随着辅助数据层级的提升,掩码嵌入相较基础嵌入的改进幅度逐步增大。因此,当难以获取与目标类别相似的辅助数据时,掩码模块为解决这一现实问题提供了方案。
Proposed Framework vs. Transfer Learning. Transfer learning aims to reuse pre-trained representations for new tasks. Models can use pre-trained parameters as-is or fine tune on new tasks. We use our pre-trained embedding function to evaluate the pre-training performance. We also fine-tune our pre-trained embedding function with test pseudo shots to compare an alternative approach. As shown in Table 4, pre-training improves the traditional FSL accuracy. Fine-tuning on test pseudo shots improves the 1-shot task but harms the 5-shot compared to only pre-training. Our masking method surpasses pre-training and fine-tuning accuracy by 6.03 and 7.15 points, respectively. Evaluating 800 episodes with our masking method is much faster than fine-tuning, 5 minutes vs. 15 hours. We also show that our method gains benefit from using auxiliary data at test time even without pre-training benefits. See appendix for details.
所提框架与迁移学习的对比。迁移学习旨在为新任务重用预训练的表征。模型可以直接使用预训练参数,或针对新任务进行微调。我们使用预训练的嵌入函数来评估预训练性能,同时用测试伪样本对预训练嵌入函数进行微调以对比替代方案。如表4所示,预训练提升了传统少样本学习的准确率。相比仅进行预训练,测试伪样本微调在1样本任务上有所改进,但在5样本任务上表现更差。我们的掩码方法分别以6.03和7.15个百分点的优势超越了预训练和微调的准确率。使用掩码方法评估800个任务片段的速度远快于微调(5分钟 vs. 15小时)。我们还证明,即使没有预训练优势,我们的方法也能通过测试时使用辅助数据获得收益。详见附录。
Table 3: Embedding adaptation classifier results on mini Image Net and tiered Image Net with level 0–3 auxiliary data. Results are for the baseline without any auxiliary data, the baseline with basic embeddings of auxiliary data, and the proposed method using masked embeddings. Each entry is mean accuracy over 800 episodes.
表 3: 在mini ImageNet和tiered ImageNet上使用0-3级辅助数据的嵌入适应分类器结果。结果包括无任何辅助数据的基线、使用辅助数据基础嵌入的基线以及使用掩码嵌入的提出方法。每个条目为800次测试的平均准确率。
| 模型 | 级别 | miniImageNet | tieredImageNet |
|---|---|---|---|
| 1-shot 5-shot | 1-shot 5-shot | ||
| Baseline | 61.69 77.24 | 67.92 82.90 | |
| 0 | 72.42 80.58 | 75.52 81.94 | |
| Basic | 1 | 70.58 | 76.98 71.74 |
| 2 | 66.67 | 75.74 65.99 | |
| 3 | 60.02 71.81 | 63.67 75.84 | |
| Masked | 0 | 76.88 86.28 | 80.54 87.53 |
| 1 | 75.43 83.98 | 80.54 87.53 | |
| 2 | 73.79 83.84 | 73.29 86.36 | |
| 3 | 68.73 80.36 | 73.27 86.24 |
Table 4: EFSL results on mini Image Net and tiered Image Net with level 0 auxiliary data. Results are for the nearest centroid classifier, with various ablations and alternative setups. Accuracies are over 800 episodes.
表 4: 基于mini ImageNet和tiered ImageNet的EFSL结果(使用0级辅助数据)。结果采用最近质心分类器,包含多种消融实验和替代方案。准确率基于800次测试。
| 模型 | miniImageNet | tieredImageNet | ||
|---|---|---|---|---|
| 1-shot | 5-shot | 1-shot | 5-shot | |
| TraditionalFSL | 56.7 | 75.93 | 64.46 | 82.21 |
| Pre-training | 59.81 | 82.38 | 72.07 | 87.19 |
| Fine Tuning | 62.71 | 77.29 | 72.51 | 82.64 |
| NCC + Masked PS | 75.82 | 85.93 | 80.66 | 87.83 |
EFSL vs. Semi-Supervised FSL. Semi-supervised FSL (SSFSL) is the closest problem to EFSL, but still has significant differences. Compared to traditional FSL, SSFSL models can use unlabeled examples both during training and testing. Labeled data encodes valuable knowledge from human annotators, but SSFSL misses this source of knowledge. Without labels, it is not possible to link visual data and semantic knowledge sources. Restricted to unlabeled data, SSFSL cannot access the large sources of rich knowledge (e.g., knowledge graphs, knowledge bases, word embeddings, to name a few). In general, EFSL can use the auxiliary examples more effectively with the extra metadata that is available. We try to use SSFSL methods for solving EFSL, but we find that the performance of SSFSL methods is sub-optimal and we need models designed specifically for EFSL. Experimental results are provided in the appendix.
EFSL与半监督FSL对比。半监督FSL(SSFSL)是与EFSL最接近的问题,但仍存在显著差异。与传统FSL相比,SSFSL模型在训练和测试阶段都能使用未标注样本。标注数据承载着人类标注者的宝贵知识,但SSFSL缺失了这一知识来源。由于缺乏标签,SSFSL无法建立视觉数据与语义知识源之间的关联。受限于未标注数据,SSFSL无法利用丰富的知识源(如知识图谱、知识库、词嵌入等)。总体而言,EFSL能通过额外的元数据更有效地利用辅助样本。我们尝试用SSFSL方法解决EFSL问题,但发现其性能欠佳,需要专门为EFSL设计的模型。实验结果详见附录。
Random Auxiliary Data. We compare the performance of our selection method, $\S4.1$ , with random sampling. We find that random sampling fails catastrophically with basic embeddings. Using masked embeddings improves the accuracy but it is still far behind our proposed selection method. Results are reported in the appendix.
随机辅助数据。我们将第4.1节中的选择方法与随机采样进行性能对比。发现随机采样在基础嵌入 (basic embeddings) 上表现极差,使用掩码嵌入 (masked embeddings) 虽能提升准确率,但仍远落后于我们提出的选择方法。完整结果见附录。
7. Related Work
7. 相关工作
Meta-learning is the dominant approach for solving FSL problems. Meta-learning tries to learn transferable knowledge based on the training classes and use this learned knowledge during test time. This transferable knowledge can be a discriminating metric space [17, 25, 33, 35, 39], or a fast converging algorithm or initial state [7, 18, 24, 27, 30]. All of these methods rely solely on the support set.
元学习 (Meta-learning) 是解决少样本学习 (FSL) 问题的主流方法。元学习旨在基于训练类别学习可迁移知识,并在测试阶段应用这些知识。这种可迁移知识可以是判别性度量空间 [17, 25, 33, 35, 39]、快速收敛算法或初始状态 [7, 18, 24, 27, 30]。这些方法都完全依赖于支持集 (support set)。
Trans duct ive models have recently gained attention for FSL. These models use the query set as unlabeled data in each episode [16, 21]. EGNN [16] uses a graph convolutional edge labeling network to propagate the support set labels to query samples. TPN [21] propagates the labels of the support set to unlabeled (query) samples by learning to construct a graph structure. There are a number of other trans duct ive FSL solutions that rely on the query set as well as the support set in each episode [8, 15].
转导式模型 (Transductive models) 近期在少样本学习 (FSL) 领域受到关注。这类模型将查询集 (query set) 作为每轮任务中的未标注数据使用 [16, 21]。EGNN [16] 采用图卷积边标记网络,将支持集 (support set) 的标签传播到查询样本。TPN [21] 通过学习构建图结构,将支持集的标签传播至未标注(查询)样本。还存在其他多种转导式少样本学习方法,它们同样依赖每轮任务中的查询集和支持集 [8, 15]。

Figure 4: The improvement of masked over basic embeddings for level 0 to 3 auxiliary data, ordered left to right.
图 4: 从左到右依次展示了基础嵌入 (basic embeddings) 在添加 0 至 3 级辅助数据时,经过掩码处理 (masked) 后的改进效果。
Semi-supervised FSL methods are similar to transductive methods, but their unlabeled set is not the same as the query set [11, 20, 28, 32, 42]. Ren et al. [28] include unla- beled samples in each episode and propose a masking mechanism to control the effect of unrelated unlabeled samples. As the source of unlabeled samples, they use a mix of samples from random and support classes with a 1:1 ratio. Several other works [20, 21, 32] use the same unlabeled set as Ren et al. [28]. TransMatch [42] draws unlabeled samples from support classes in each episode and measures robustness against distract or s, but does not try to exploit them. Gidaris et al. [11] use tiered Image Net as the source of unlabeled data for self-supervised learning for mini Image Net.
半监督FSL方法与转导方法类似,但其未标注集与查询集并不相同 [11, 20, 28, 32, 42]。Ren等人 [28] 在每个训练周期中加入未标注样本,并提出掩码机制来控制无关未标注样本的影响。他们采用随机类别与支持类别样本1:1混合的方式作为未标注样本来源。其他多项研究 [20, 21, 32] 使用了与Ren等人 [28] 相同的未标注集。TransMatch [42] 从每个周期的支持类中抽取未标注样本并测量抗干扰鲁棒性,但未尝试利用这些样本。Gidaris等人 [11] 使用分层ImageNet作为mini ImageNet自监督学习的未标注数据源。
Some recent studies aim for more disc rim i native features and propose related masking methods that further refine the embedded features [14, 19]. CTM [19] looks at all the support samples together and generates a mask that indicates the most disc rim i native features for the current task. CAN [14] calculates a cross attention map for each pair of class centroid features and query features. The cross attention map improves the disc rim i native power of features by localizing the target object. Our masking module differs from these works by comparing support sets and pseudo shots to import information from the pseudo shots.
一些近期研究致力于获取更具判别性的特征,并提出了进一步优化嵌入特征的相关掩码方法 [14, 19]。CTM [19] 同时考察所有支持样本,生成指示当前任务最具判别性特征的掩码。CAN [14] 为每对类中心特征与查询特征计算交叉注意力图,通过定位目标对象来提升特征的判别能力。我们的掩码模块与这些工作的不同之处在于:通过比较支持集与伪样本 (pseudo shots) 来引入伪样本中的信息。
Other related work includes Xing et al. [40], which uses word vectors directly to update class prototypes, whereas we use word vectors as a tool to select auxiliary samples. Ge and Yu [9] use visual similarity and Zhang et al. [43] use meta-learning to select auxiliary data for fine-grained image classification. Finally, concurrent work [1] considers trans duct ive FSL for multi-domain problems.
其他相关工作包括Xing等人[40]的研究,他们直接使用词向量更新类别原型,而我们则将其作为筛选辅助样本的工具。Ge和Yu[9]利用视觉相似性,Zhang等人[43]采用元学习方法为细粒度图像分类选择辅助数据。此外,同期研究[1]探讨了多领域问题中的转导式少样本学习(FSL)。
8. Conclusion
8. 结论
In this work, we introduced the EFSL problem and associated benchmarks to capture the many practical scenarios in which auxiliary resources can aid in novel few-shot tasks. We proposed a framework for EFSL that uses semantic knowledge to aid the selection of auxiliary data and a masking module to select the useful parts of that data. It is compatible with a wide range of existing methods for FSL. We showed that it outperforms naive solutions and is robust as the available auxiliary data grows semantically distant from the test classes. We believe that the problem of exploiting auxiliary data for new tasks will be increasingly important as shared datasets continue to multiply.
在本工作中,我们提出了EFSL问题及相关基准,以涵盖众多可通过辅助资源助力新少样本任务的现实场景。我们设计了一个EFSL框架,利用语义知识辅助选择辅助数据,并通过掩码模块筛选数据中有用的部分。该框架兼容现有多种少样本学习方法,实验表明其性能优于简单解决方案,且在辅助数据与测试类语义距离增大时仍保持稳健。我们相信,随着共享数据集持续增长,利用辅助数据解决新任务的问题将愈发重要。
Acknowledgements
致谢
This material is based on research sponsored by Defense Advanced Research Projects Agency (DARPA) and Air Force Research Laboratory (AFRL) under agreement number FA8750-19-2-1006, and by the National Science Foundation (NSF) under award IIS-1813444. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of Defense Advanced Research Projects Agency (DARPA) and Air Force Research Laboratory (AFRL) or the U.S. Government. We gratefully acknowledge support from Google and Cisco. Disclosure: Stephen Bach is an advisor to Snorkel AI, a company that provides software and services for weakly supervised machine learning.
本材料基于美国国防高级研究计划局 (DARPA) 和空军研究实验室 (AFRL) 根据协议编号 FA8750-19-2-1006 以及美国国家科学基金会 (NSF) 根据奖项 IIS-1813444 资助的研究。美国政府有权为政府目的复制和分发重印本,无论其上是否有版权标记。本文所载观点和结论仅为作者个人观点,不应被解释为代表美国国防高级研究计划局 (DARPA)、空军研究实验室 (AFRL) 或美国政府的官方政策或认可,无论是明示还是暗示。我们衷心感谢谷歌和思科的支持。披露声明:Stephen Bach 是 Snorkel AI 的顾问,该公司为弱监督机器学习提供软件和服务。
References
参考文献
A. Further Analysis
A. 进一步分析
Proposed Framework without Pre-training. To study the benefits of using pseudo shots at test time, we train the embedding function using only base classes and repeat our main experiments. As shown in Table 5, using pseudo shots at test time improves the performance of the traditional FSL even without pre-training. This indicates that the combination of our selection method and masking module adds useful information at test time, supporting our claim that benefits of pseudo shots are beyond simple pre-training.
无预训练的提议框架。为研究测试时使用伪样本 (pseudo shots) 的优势,我们仅使用基类训练嵌入函数并重复主要实验。如表 5 所示,即使没有预训练,测试时使用伪样本也能提升传统少样本学习 (FSL) 的性能。这表明我们的选择方法与掩码模块的组合在测试时提供了有效信息,验证了伪样本的优势不仅源于简单的预训练这一观点。
Semi-Supervised FSL methods for EFSL. Semisupervised FSL methods use unlabeled examples as auxiliary data. We study the performance of SSFSL methods on EFSL tasks. We select the masking soft K-means method of Ren et al. [28] (MS K-Means). We choose this spe- cific semi-supervised method because it has a distinct masking module that we can integrate in our framework. It is a soft masking mechanism for updating class centroids. This mechanism masks entire images based on the assumption that the unlabeled data is a mix of target classes and distractors. In contrast, our proposed masking module masks individual feature patches of images based on the assumption that the auxiliary data contains related images, but no actual samples of the target class. To have a fair comparison, we implement MS K-Means with our (higher capacity) embedding function trained on the same data. We freeze the embedding function and apply their masking mechanism on the resulting embeddings. With this implementation, MS KMeans is identical to our pipeline other than their masking module.
面向EFSL的半监督FSL方法。半监督FSL方法使用未标注样本作为辅助数据。我们研究了SSFSL方法在EFSL任务上的表现,选取了Ren等人[28]提出的掩码软K均值方法(MS K-Means)。选择该特定半监督方法的原因是它具有可集成到我们框架中的独立掩码模块。该机制通过软掩码方式更新类中心点,其核心假设是未标注数据由目标类和干扰物混合组成,因此对整幅图像进行掩码处理。而我们的掩码模块基于不同前提——辅助数据仅含相关图像但不包含目标类真实样本,故对图像特征块进行局部掩码。为保证公平对比,我们采用相同数据训练的高容量嵌入函数实现MS K-Means,冻结嵌入函数后在其输出嵌入上应用原论文的掩码机制。此实现下,除掩码模块外MS K-Means与我们的流程完全一致。
The performance of MS K-Means with level 0 auxiliary data is reported in Table 6. We select the auxiliary data following $\S4.1$ . The proposed masking module performs significantly better than MS K-Means for both 1-shot tasks, where the limited label problem is severe. Our masking method also performs better for 5-shot tasks, especially on
表 6 报告了使用 0 级辅助数据的 MS K-Means 性能表现。我们按照 $\S4.1$ 的方法选择辅助数据。在标签有限问题严重的 1-shot 任务中,我们提出的掩码模块表现显著优于 MS K-Means。我们的掩码方法在 5-shot 任务中也表现更好,特别是在...
| 模型 | miniImageNet | tieredImageNet |
|---|---|---|
| 1-shot | 5-shot | |
| 传统少样本学习 (Traditional FSL) | 56.7 | 75.93 |
| 基础PS无预训练 (Basic PS w/o PT) | 64.48 | 71.41 |
| MaskedPS无预训练 (MaskedPSw/oPT) | 67.37 | 78.05 |
| 基础PS (Basic PS) | 69.93 | 76.70 |
| MaskedPS | 75.82 | 85.93 |
Table 5: EFSL results on mini Image Net and tiered Image Net with level 0 auxiliary data. Results are for the nearest centroid classifier, with various ablations and alternative setups. PT stands for pre-training in section two. Accuracies are averaged over 800 episodes.
表 5: 基于mini Image Net和tiered Image Net的EFSL (level 0辅助数据) 结果。所有结果均采用最近质心分类器,包含多种消融实验和替代方案。PT代表第2节中的预训练 (pre-training) 。准确率为800次实验的平均值。
Table 6: EFSL results on mini Image Net and tiered Image Net with level 0 auxiliary data. Other than MS K-Means, the results are for the nearest centroid classifier. Accuracies are averaged over 800 episodes.
| 模型 | miniImageNet | tieredImageNet |
|---|---|---|
| 1-shot | 5-shot | |
| TraditionalFSL | 56.7 | 75.93 |
| MS K-Means [28] | 63.73 | 83.97 |
| BasicRndPS | 27.58 | 52.33 |
| Masked Rnd PS | 48.87 | 80.31 |
| Masked PS | 75.82 | 85.93 |
表 6: 使用0级辅助数据在mini ImageNet和tiered ImageNet上的EFSL结果。除MS K-Means外,其他结果均基于最近质心分类器。准确率为800次实验的平均值。
the smaller mini Image Net. It emphasizes the need for designing models to specifically address EFSL challenges.
较小的mini Image Net。它强调需要设计专门应对EFSL挑战的模型。
Random Auxiliary Data. We ablate the proposed selection method in $\S4.1$ and use random sampling to measure its impact in our framework. As shown in Table 6, random sampling fails catastrophically with basic embeddings. As expected, the masking module removes a significant amount of the irrelevant information and increases the accuracy. But, even with masking, random sampling performs poorly on 1-shot tasks and is far behind the proposed selection method on 5-shot tasks.
随机辅助数据。我们在$\S4.1$中消融了提出的选择方法,并使用随机抽样来衡量其在我们框架中的影响。如表6所示,随机抽样在基本嵌入上完全失败。正如预期的那样,掩码模块去除了大量无关信息并提高了准确性。但是,即使使用掩码,随机抽样在1样本任务上表现不佳,在5样本任务上也远落后于提出的选择方法。
Auxiliary Data Benchmarks. We evaluate the performance of all three class if i ers with level 0–3 auxiliary data. Table 7 reports the mean accuracy on mini Image Net and tiered Image Net. The mean accuracy on CIFAR-FS and FC100 is presented in Table 8. As the semantic distance between target classes and pseudo shots increases, the accuracy decreases. Models with masked embeddings degrade more gracefully than models with basic embeddings. The masking module extracts useful information even from level 3 auxiliary data. It consistently improves the performance of traditional FSL for mini Image Net and tiered Image Net with level 3 auxiliary data. For CIFAR-FS and FC-100, the performance of masked pseudo shots is comparable to traditional FSL. The masking module fails to extract useful information for CIFAR-100 derivatives from small $32\times32$ images at level 3 auxiliary data. It is likely that the limited spatial information in smaller images reduces the benefits of a spatial mask.
辅助数据基准测试。我们评估了所有三个分类器在0-3级辅助数据下的性能表现。表7展示了在mini ImageNet和tiered ImageNet上的平均准确率,表8则呈现了CIFAR-FS和FC100的结果。随着目标类与伪样本间语义距离增大,准确率逐渐下降。采用掩码嵌入的模型比基础嵌入模型性能下降更为平缓,其掩码模块甚至能从3级辅助数据中提取有效信息。对于mini ImageNet和tiered ImageNet,该模块持续提升了传统少样本学习在3级辅助数据下的表现。而在CIFAR-FS和FC-100数据集上,掩码伪样本的表现与传统方法相当。值得注意的是,对于源自CIFAR-100的小尺寸 ($32\times32$) 图像,掩码模块在3级辅助数据下未能提取有效信息,这可能是较小图像有限的空间信息降低了空间掩码的效用。
B. Architecture
B. 架构
Embedding Function. In all cases, we use ResNet12 [13] as our embedding function with DropBlock [10] for regularization. We use (640, 320, 160, 64) filters instead of the original (512, 256, 128, 64) filters in ResNet12. With this modification, our embedding function is similar to that of Tian et al. [36].
嵌入函数 (Embedding Function)。在所有实验中,我们采用 ResNet12 [13] 作为嵌入函数,并使用 DropBlock [10] 进行正则化。我们将 ResNet12 原有的滤波器数量 (512, 256, 128, 64) 调整为 (640, 320, 160, 64)。经过这一调整后,我们的嵌入函数与 Tian 等人 [36] 的方案相似。
Table 7: EFSL results on mini Image Net and tiered Image Net with level 0–3 auxiliary data. Results are for three classifier types: nearest-centroid classifier (NCC), relation module (RM), and embedding adaptation (EA). Each entry is mean accuracy over 800 episodes with $95%$ confidence intervals.
| 嵌入方式 | 模型 | 层级 | miniImageNet (1-shot) | miniImageNet (5-shot) | tieredImageNet (1-shot) | tieredImageNet (5-shot) |
|---|---|---|---|---|---|---|
| 基础PS | NCC | - | 69.93 ± 0.76 | 76.70 ± 0.64 | 76.09 ± 0.81 | 82.38 ± 0.67 |
| RM | 0 | 66.67 ± 0.78 | 72.39 ± 0.65 | 64.39 ± 0.88 | 72.62 ± 0.81 | |
| EA | - | 72.42 ± 0.72 | 80.58 ± 0.58 | 75.52 ± 0.80 | 81.94 ± 0.69 | |
| NCC | 1 | 68.82 ± 0.74 | 74.98 ± 0.64 | 72.17 ± 0.93 | 80.37 ± 0.78 | |
| RM | - | 66.32 ± 0.78 | 71.30 ± 0.74 | 62.50 ± 0.86 | 70.47 ± 0.80 | |
| EA | - | 70.58 ± 0.72 | 76.98 ± 0.67 | 71.74 ± 0.87 | 80.51 ± 0.76 | |
| NCC | - | 65.24 ± 0.71 | 72.49 ± 0.63 | 67.68 ± 0.94 | 77.35 ± 0.73 | |
| RM | 2 | 62.30 ± 0.76 | 69.01 ± 0.67 | 51.80 ± 0.81 | 60.94 ± 0.88 | |
| EA | - | 66.67 ± 0.72 | 75.74 ± 0.65 | 65.99 ± 0.92 | 76.22 ± 0.77 | |
| NCC | - | 59.28 ± 0.78 | 69.25 ± 0.68 | 64.43 ± 0.87 | 76.03 ± 0.73 | |
| RM | 3 | 48.66 ± 0.73 | 59.43 ± 0.70 | 46.80 ± 0.86 | 61.44 ± 0.84 | |
| EA | - | 60.02 ± 0.90 | 71.81 ± 0.73 | 63.67 ± 0.87 | 75.84 ± 0.73 | |
| 掩码PS | NCC | - | 75.82 ± 0.62 | - | - | - |
| - | 0 | - | 85.93 ± 0.42 | 80.66 ± 0.68 | 87.83 ± 0.51 | |
| RM EA | - | 67.48 ± 0.72 | 78.67 ± 0.53 | 67.51 ± 0.85 | 78.70 ± 0.69 | |
| - | - | 76.88 ± 0.67 | 86.28 ± 0.41 | 80.54 ± 0.69 | 87.53 ± 0.53 | |
| NCC | 1 | 74.24 ± 0.68 | 82.87 ± 0.53 | 79.09 ± 0.78 | 87.74 ± 0.53 | |
| RM | - | 68.81 ± 0.76 | 76.55 ± 0.66 | 67.14 ± 0.79 | 79.61 ± 0.68 | |
| EA | - | 75.43 ± 0.69 | 83.98 ± 0.51 | 80.54 ± 0.69 | 87.53 ± 0.53 | |
| NCC | 2 | 71.60 ± 0.64 | 82.49 ± 0.47 | 73.82 ± 0.74 | 86.75 ± 0.51 | |
| RM | - | 65.76 ± 0.69 | 77.28 ± 0.57 | 62.02 ± 0.88 | 77.12 ± 0.75 | |
| EA | - | 73.79 ± 0.66 | 83.84 ± 0.49 | 73.29 ± 0.76 | 86.36 ± 0.53 | |
| NCC | - | 67.15 ± 0.67 | 79.48 ± 0.55 | 73.78 ± 0.74 | 86.94 ± 0.54 | |
| RM | 3 | 61.98 ± 0.71 | 73.76 ± 0.62 | 63.83 ± 0.81 | 77.57 ± 0.68 | |
| EA | - | 68.73 ± 0.71 | 80.36 ± 0.55 | 73.27 ± 0.75 | 86.24 ± 0.58 |
表 7: miniImageNet 和 tieredImageNet 上使用 0-3 级辅助数据的 EFSL 结果。结果包含三种分类器类型: 最近质心分类器 (NCC)、关系模块 (RM) 和嵌入自适应 (EA)。每个条目为 800 次实验的平均准确率,置信区间为 95%。
Masking Module. We achieve the spatial mask introduced in $\S4.3$ with several ResBlocks [13] arranged in a pyramid structure for $f_{\theta}$ . Specifically, it consists of three ResBlocks with $(2C^{},C^{},1)$ filters. In our implementation, the three ResBlocks have (640, 320, 1) filters.
掩码模块 (Masking Module) 。我们通过将多个 ResBlock [13] 以金字塔结构排列来实现 $\S4.3$ 中介绍的空间掩码功能,作为 $f_{\theta}$ 的具体实现。具体而言,该模块包含三个滤波器配置为 $(2C^{},C^{},1)$ 的 ResBlock。在我们的实现中,这三个 ResBlock 分别采用 (640, 320, 1) 的滤波器配置。
C. Optimizer
C. 优化器
We use stochastic gradient descent (SGD) as optimizer with initial learning rate of 0.05, momentum of 0.9, weight decay of 5.e-4, and learning rate decay of 0.1. We train the embedding function for 100 epochs and decay the learning rate at epochs 60 and 80. We use the parameters at the last epoch as $f_{\phi}$ . We train the masking module and class if i ers for 150 epochs and decay the learning rate at epoch 70. We use the parameters at the epoch with highest validation accuracy for the masking module and the class if i ers.
我们使用随机梯度下降 (SGD) 作为优化器,初始学习率为 0.05,动量为 0.9,权重衰减为 5.e-4,学习率衰减为 0.1。我们训练嵌入函数 100 个周期,并在第 60 和 80 个周期时衰减学习率。我们使用最后一个周期的参数作为 $f_{\phi}$。我们训练掩码模块和分类器 150 个周期,并在第 70 个周期时衰减学习率。对于掩码模块和分类器,我们使用验证准确率最高的周期参数。
D. Dataset Alignment.
D. 数据集对齐
ImageNet classes are WordNet IDs. Thus, it is straightforward to map classes to WordNet nodes. To map the classes to ConceptNet nodes, we use the corresponding noun in WordNet database for each class. CIFAR-100 classes are nouns. We use all the corresponding WordNet IDs to the selected support classes as $\mathbb{C}$ in Eq. (2). We directly use nouns for mapping CIFAR-100 classes to ConceptNet nodes.
ImageNet类别对应WordNet的ID。因此,可以直接将类别映射到WordNet节点。为了将类别映射到ConceptNet节点,我们使用WordNet数据库中每个类别对应的名词。CIFAR-100类别均为名词。我们将所有与选定支持类别对应的WordNet ID作为式(2)中的$\mathbb{C}$。对于CIFAR-100类别到ConceptNet节点的映射,我们直接使用名词。
E. Class if i ers
E. 分类器
Relation Module. As explained in $\S~4.4$ , relation network consists of two major modules: a feature embedding module and a relation module [35]. The relation module $f_{\beta}$ is parameterized with convolutional layers followed by several linear layers. The relation module takes the concatenated embeddings of the query example and class centroid and outputs a single scalar. Using a sigmoid non-linearity, the relation module outputs a relation score in [0, 1]. The query example is labeled with the class with highest relation score. Let $h_{c}$ be the centroid of class $c$ calculated as
关系模块。如 $\S~4.4$ 所述,关系网络由两个主要模块组成:特征嵌入模块和关系模块 [35]。关系模块 $f_{\beta}$ 通过卷积层和若干线性层进行参数化。该模块接收查询样本与类别质心的拼接嵌入向量,输出单个标量值。通过sigmoid非线性变换,关系模块输出[0, 1]区间的关系分数。查询样本最终被标注为具有最高关系分数的类别。设 $h_{c}$ 为类别 $c$ 的质心,其计算公式为
Table 8: EFSL results on CIFAR-FS and FC-100 with level 0–3 auxiliary data. Results are for three classifier types: nearestcentroid classifier (NCC), relation module (RM), and embedding adaptation (EA). Each entry is mean accuracy over 800 episodes with $95%$ confidence intervals.
表 8: CIFAR-FS 和 FC-100 上使用 0-3 级辅助数据的 EFSL 结果。结果针对三种分类器类型:最近质心分类器 (NCC)、关系模块 (RM) 和嵌入自适应 (EA)。每个条目为 800 次实验的平均准确率,置信区间为 $95%$。
| 嵌入方式 | 模型 | 级别 | CIFAR-FS (1-shot) | CIFAR-FS (5-shot) | FC-100 (1-shot) | FC-100 (5-shot) |
|---|---|---|---|---|---|---|
| Basic PS | NCC | - | 75.78 ± 0.79 | - | 49.51 ± 0.67 | - |
| RM | 0 | 73.32 ± 0.84 | 85.79 ± 0.54 | 43.22 ± 0.65 | 57.51 ± 0.66 | |
| EA | 0 | 77.74 ± 0.77 | 87.08 ± 0.53 | 51.23 ± 0.65 | 58.13 ± 0.65 | |
| NCC | - | 67.39 ± 0.98 | 81.46 ± 0.69 | 43.55 ± 0.76 | 52.68 ± 0.71 | |
| RM | 1 | 63.96 ± 0.95 | 77.41 ± 0.71 | 38.49 ± 0.75 | 45.68 ± 0.69 | |
| EA | 1 | 70.78 ± 0.88 | 82.70 ± 0.68 | 46.71 ± 0.77 | 55.44 ± 0.70 | |
| NCC | - | 56.66 ± 1.06 | 75.55 ± 0.69 | 36.04 ± 0.75 | 48.85 ± 0.72 | |
| RM | 2 | 41.33 ± 0.90 | 65.64 ± 0.98 | 31.95 ± 0.62 | 40.07 ± 0.69 | |
| EA | 2 | 56.16 ± 0.95 | 75.75 ± 0.66 | 37.64 ± 0.78 | 50.40 ± 0.70 | |
| NCC | - | 47.56 ± 1.00 | 73.71 ± 0.73 | 30.00 ± 0.63 | 43.12 ± 0.64 | |
| RM | 3 | 44.40 ± 0.88 | 66.80 ± 0.94 | 26.63 ± 0.62 | 35.86 ± 0.64 | |
| EA | 3 | 49.32 ± 0.94 | 74.48 ± 0.72 | 30.58 ± 0.64 | 43.47 ± 0.62 | |
| Masked PS | NCC | - | 82.00 ± 0.65 | 90.49 ± 0.49 | 53.72 ± 0.67 | 65.52 ± 0.62 |
| RM | 0 | 74.17 ± 0.80 | 86.21 ± 0.57 | 42.04 ± 0.65 | - | |
| EA | 0 | - | - | - | 52.02 ± 0.63 | |
| NCC | 1 | 83.02 ± 0.62 | 90.84 ± 0.48 | 54.59 ± 0.66 | 65.64 ± 0.63 | |
| RM | 1 | 78.98 ± 0.69 | 88.88 ± 0.53 | 49.69 ± 0.74 | 63.75 ± 0.63 | |
| EA | 1 | 74.55 ± 0.79 | 82.96 ± 0.66 | 40.47 ± 0.68 | 51.82 ± 0.65 | |
| NCC | 2 | 69.90 ± 0.80 | 84.69 ± 0.54 | 49.12 ± 0.70 | 64.12 ± 0.67 | |
| RM | 2 | 68.45 ± 0.89 | 81.42 ± 0.58 | 37.54 ± 0.64 | 52.03 ± 0.59 | |
| EA | 2 | 70.07 ± 0.79 | 84.59 ± 0.56 | 49.32 ± 0.70 | 63.94 ± 0.68 | |
| NCC | 3 | 68.53 ± 0.72 | 84.68 ± 0.55 | 41.72 ± 0.60 | 57.72 ± 0.59 | |
| RM | 3 | 67.12 ± 0.77 | 81.26 ± 0.55 | 35.03 ± 0.59 | 49.11 ± 0.57 | |
| EA | 3 | 69.26 ± 0.70 | 84.65 ± 0.54 | 41.53 ± 0.58 | 57.26 ± 0.61 |
$$
h_{c}=\frac{\sum_{x\in S_{c}^{f}}x}{|S_{c}^{f}|}\quad\forall c\in C.
$$
$$
h_{c}=\frac{\sum_{x\in S_{c}^{f}}x}{|S_{c}^{f}|}\quad\forall c\in C.
$$
For query example $x$
对于查询示例 $x$
$$
r_{c}=\sigma(f_{\beta}(\mathrm{cat}(h_{c},f_{\phi}(x))))\forall c\in{\cal C},
$$
$$
r_{c}=\sigma(f_{\beta}(\mathrm{cat}(h_{c},f_{\phi}(x))))\forall c\in{\cal C},
$$
where $r_{c}$ is the relation score.
其中 $r_{c}$ 为关系得分。
Embedding Adaptation. Most FSL methods train one embedding function with base classes. After training the embedding function, all tasks use the same parameters, i.e., the embedding function is task agnostic. Embedding adaptation models customize the feature embeddings for each task such that they are more disc rim i native [14, 19, 41]. Here, we use the FEAT (Few-shot Embedding Adaptation with Transformer) model from [41]. Let $T$ be a set-to-set function that takes the set of support class centroids as input. Then, $T$ returns an adapted set of cluster centroids, that are more disc rim i native for the current task. Formally, $H^{T}=T(H)$ where $H$ is the set of support class centroids, $H={h_{c}:c\in C}$ . For a query example $x$ , we use $H^{T}$ in Eq. (6) to calculate the probability distribution over support classes.
嵌入自适应。大多数少样本学习方法使用基类训练一个嵌入函数。训练完成后,所有任务共享相同参数,即嵌入函数与任务无关。嵌入自适应模型会为每个任务定制特征嵌入,使其更具判别性 [14, 19, 41]。本文采用 [41] 提出的 FEAT (基于Transformer的少样本嵌入自适应) 模型。设 $T$ 为集合到集合的函数,以支持类质心集合为输入,输出适应后的聚类质心集合,这些质心对当前任务更具判别性。形式化表示为 $H^{T}=T(H)$ ,其中 $H$ 是支持类质心集合 $H={h_{c}:c\in C}$ 。对于查询样本 $x$ ,我们使用公式(6)中的 $H^{T}$ 来计算支持类上的概率分布。