MixNet: Toward Accurate Detection of Challenging Scene Text in the Wild
MixNet:面向野外复杂场景文本的精准检测
Abstract
摘要
Detecting small scene text instances in the wild is particularly challenging, where the influence of irregular positions and nonideal lighting often leads to detection errors. We present MixNet, a hybrid architecture that combines the strengths of CNNs and Transformers, capable of accurately detecting small text from challenging natural scenes, regardless of the orientations, styles, and lighting conditions. MixNet incorporates two key modules: (1) the Feature Shuffle Network (FSNet) to serve as the backbone and (2) the Central Transformer Block (CTBlock) to exploit the 1D manifold constraint of the scene text. We first introduce a novel feature shuffling strategy in FSNet to facilitate the exchange of features across multiple scales, generating high-resolution features superior to popular ResNet and HRNet. The FSNet backbone has achieved significant improvements over many existing text detection methods, including PAN, DB, and FAST. Then we design a complementary CTBlock to leverage center line based features similar to the medial axis of text regions and show that it can outperform contour-based approaches in challenging cases when small scene texts appear closely. Extensive experimental results show that MixNet, which mixes FSNet with CTBlock, achieves state-of-the-art results on multiple scene text detection datasets.
在自然场景中检测小型文本实例尤为困难,不规则位置和非理想光照的影响常导致检测错误。我们提出混合架构MixNet,结合CNN与Transformer的优势,能精准检测复杂自然场景中的任意方向、风格和光照条件的小型文本。该网络包含两个核心模块:(1) 作为主干网络的特征混洗网络(FSNet);(2) 利用场景文本一维流形约束的中心Transformer模块(CTBlock)。我们首先在FSNet中引入创新的特征混洗策略,促进多尺度特征交换,生成优于ResNet和HRNet的高分辨率特征。该主干网络在PAN、DB、FAST等现有文本检测方法基础上实现显著提升。随后设计互补的CTBlock模块,利用类似文本区域中轴线的中心线特征,证明其在密集小文本场景中优于基于轮廓的方法。大量实验表明,融合FSNet与CTBlock的MixNet在多个场景文本检测数据集上达到最先进水平。
Introduction
引言
Scene text detection is a common task in computer vision with various practical applications in scene understanding, autonomous driving, real-time translation, and optical character recognition. Deep learning-based methods continuously set new performance records on scene text detection benchmarks. In natural scenes, text boxes can appear in arbitrary orientations and non-rectangular shapes. Segmentation-based methods are widely used to handle texts of arbitrary shapes. Unlike object detection methods that rely on bounding boxes, segmentation-based methods predict pixel-level masks to identify texts in each area. However, these methods often rely on Convolutional Neural Networks (CNNs), which tend to ignore the global geometric distribution of the overall text boundary layout, leading to the following two problems. First, CNN focuses on local spatial features and thus is sensitive to noise in text regions. Second, commonly used CNN backbones, such as ResNet (He et al. 2016) and VGG (Simonyan and Zisserman 2014), provide rough high-resolution features, which are useful for large text detection but not conducive to the detection of small text instances.
场景文本检测是计算机视觉中的常见任务,在场景理解、自动驾驶、实时翻译和光学字符识别等领域具有多种实际应用。基于深度学习的方法不断刷新场景文本检测基准的性能记录。在自然场景中,文本框可能以任意方向和非矩形形状出现。基于分割的方法被广泛用于处理任意形状的文本。与依赖边界框的目标检测方法不同,基于分割的方法通过预测像素级掩码来识别每个区域的文本。然而,这些方法通常依赖于卷积神经网络 (CNN),其往往会忽略整体文本边界布局的全局几何分布,从而导致以下两个问题:首先,CNN 关注局部空间特征,因此对文本区域的噪声敏感;其次,常用的 CNN 主干网络 (如 ResNet [He et al. 2016] 和 VGG [Simonyan and Zisserman 2014]) 提供的高分辨率特征较为粗糙,这对大文本检测有用,但不利于小文本实例的检测。
Transformer (Vaswani et al. 2017) has gained remarkable success in multiple fields and provides an alternative method to extract features. Unlike CNN, which focuses on local features of adjacent regions, Transformer emphasizes the global spatial relationships between text regions. Along with extensive research on Transformer, several contour-based methods have recently been developed that directly detect text contours and achieve state-of-the-art performance. For example, TESTR (Zhang et al. 2022) used the Transformer encoder to extract a larger range of text features and send the Region of Interest (ROI) to the decoder to generate a text box based on the box-to-polygon flow. DPText-DETR (Ye et al. 2022) performed point sampling in text ROI to obtain better location information. These contour-based methods can generate text contours directly from input images, thus eliminating the need for post-processing in segmentation-based methods.
Transformer (Vaswani et al. 2017) 在多个领域取得了显著成功,并提供了一种提取特征的替代方法。与专注于相邻区域局部特征的 CNN 不同,Transformer 强调文本区域之间的全局空间关系。随着对 Transformer 的广泛研究,最近开发了几种基于轮廓的方法,这些方法直接检测文本轮廓并实现了最先进的性能。例如,TESTR (Zhang et al. 2022) 使用 Transformer 编码器提取更大范围的文本特征,并将感兴趣区域 (ROI) 发送到解码器,以基于从框到多边形的流程生成文本框。DPText-DETR (Ye et al. 2022) 在文本 ROI 中进行点采样以获得更好的位置信息。这些基于轮廓的方法可以直接从输入图像生成文本轮廓,从而消除了基于分割方法的后处理需求。
In this paper, we propose a hybrid architecture named MixNet to combine the strengths of CNNs and Transformers (see Fig. 1). We hypothesize that changing the backbone architecture is necessary to provide powerful high-resolution features and reduce the interferences e.g., noise contamination and illumination variation that hinders accurate detection, especially in the presence of small and curved texts. We have empirically observed that low-resolution features are less affected by noise. Therefore, it is desirable to develop a scale-invariant backbone for feature extraction. We propose a novel Feature Shuffle Network (FSNet) to exchange features between low-resolution and high-resolution layers during feature extraction, which deepens the extraction layer of high-resolution features. FSNet allows the backbone to generate better features than other popular backbones such as ResNet and HRNet (Wang et al. 2020).
本文提出了一种名为MixNet的混合架构,旨在结合CNN与Transformer的优势(见图1)。我们假设改变主干网络架构对于提供强大的高分辨率特征、减少噪声污染和光照变化等干扰至关重要,这些干扰会阻碍检测精度,尤其在小尺寸和弯曲文本场景下。实验观察表明,低分辨率特征受噪声影响较小。因此,开发具有尺度不变性的特征提取主干网络具有重要价值。我们提出新型特征混洗网络(FSNet),通过在特征提取过程中交换高低分辨率层特征,从而深化高分辨率特征的提取层级。相比ResNet、HRNet等主流主干网络(Wang et al. 2020),FSNet能使主干网络生成更优特征。
After extracting features, we propose a new Central Transformer Block (CTBlock) to further enhance the global geometric distribution of the text regions. Specifically, the heatmap generated by the image features is postprocessed to obtain a rough contour of the text. Based on this rough text contour, we sample image features that represent positional information and features of the text contour. These sampled features are then used as input for the Transformer module to learn the geometric distribution of text boundaries and generate the center lines of text contours. Traditional contour-based methods cannot detect two adjacent text lines well if they are too close, which makes their contours on the heatmap interfere with each other. However, their center lines are still separated. Thus, we sample the feature points along their respective center lines and merge the contour feature together so that the above occlusion problem can be well addressed. The merged features are fed into the next Transformer module to calculate the vertex offset for each point. A precise text contour is then generated by applying the vertex offsets to the initial contour of the text.
在提取特征后,我们提出了一种新的中央Transformer模块(CTBlock)来进一步增强文本区域的全局几何分布。具体而言,通过对图像特征生成的热图进行后处理,获得文本的粗略轮廓。基于这一粗略文本轮廓,我们采样代表位置信息和文本轮廓特征的图像特征。这些采样特征随后作为Transformer模块的输入,用于学习文本边界的几何分布并生成文本轮廓的中心线。传统基于轮廓的方法在检测两条相邻文本行时,若它们过于接近,会导致它们在热图上的轮廓相互干扰。然而,它们的中心线仍然是分离的。因此,我们沿着各自中心线采样特征点,并将轮廓特征合并,从而有效解决上述遮挡问题。合并后的特征被输入到下一个Transformer模块中,计算每个点的顶点偏移量。通过将顶点偏移量应用于文本的初始轮廓,最终生成精确的文本轮廓。
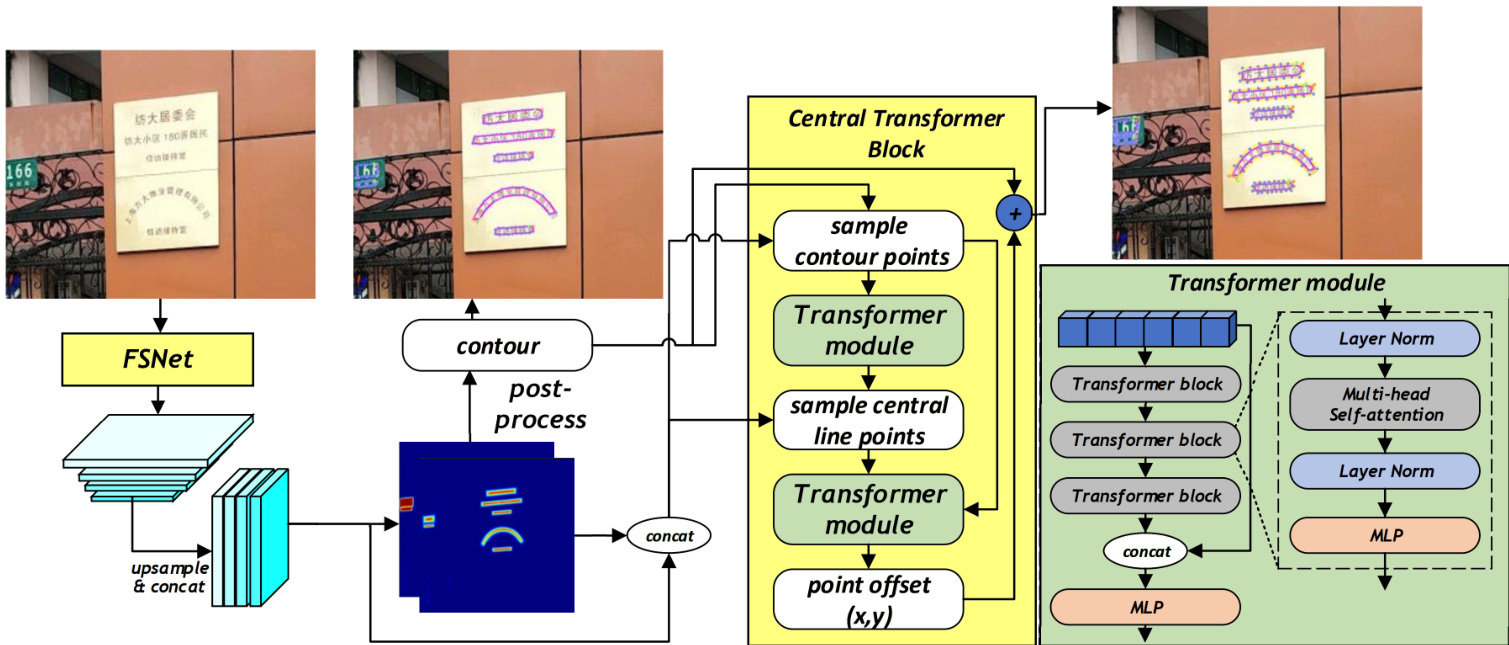
Figure 1: MixNet is a hybrid architecture for scene text detection that includes two novel components: (1) the Feature Shuffling Network (FSNet) for generating high-resolution features and (2) the Central Transformer Block (CTBlock) for detecting the medial axis of text regions (called “center line” in this paper). MixNet (FSNet+CTBlock) is particularly effective in detecting small and curved text in natural scenes, e.g., fine prints on the plaque.
图 1: MixNet是一种用于场景文本检测的混合架构,包含两个新颖组件:(1) 用于生成高分辨率特征的特征混洗网络(FSNet);(2) 用于检测文本区域中轴线(本文称为"中心线")的中心Transformer模块(CTBlock)。MixNet(FSNet+CTBlock)在检测自然场景中的小尺寸和弯曲文本(如牌匾上的细密文字)时表现尤为出色。
The contribution of this paper includes:
本文的贡献包括:
Related works
相关工作
Segmentation-based Scene Text Detection
基于分割的场景文本检测
Segmentation-based scene text detection model generates a heatmap indicating the likelihood of each image pixel being a text instance. The heatmap is then processed to produce several text contours. This approach faces a major challenge: if the predicted heatmap connects multiple text instances, the post-processing algorithms cannot separate them correctly. To address this issue, most segmentation-based methods predict the text kernel rather than the text instance, reducing the likelihood of text instances being connected by reducing their size. DB (Liao et al. 2020) proposes an additional method of predicting the threshold map to require higher confidence values for the border of the text instance to deal with the problem of connecting text instances. On the other hand, PAN (Wang et al. 2019) predicts the embedding value of each pixel, with each text instance having a different embedding value. Pixel aggregation post-processing is used to connect pixels with the same embedding value. By differentiating the embedding value, multiple text instances can be separated into multiple text contours by post-processing, even if they are connected.
基于分割的场景文本检测模型会生成一个热图(heatmap),用于指示每个图像像素作为文本实例的概率。随后对该热图进行处理以生成若干文本轮廓。这种方法面临一个主要挑战:如果预测的热图连接了多个文本实例,后处理算法将无法正确分离它们。为解决该问题,大多数基于分割的方法会预测文本内核(text kernel)而非文本实例,通过缩小范围来降低文本实例相互连接的概率。DB (Liao et al. 2020) 提出了一种预测阈值图的附加方法,要求文本实例边界具有更高置信度值以处理文本实例连接问题。另一方面,PAN (Wang et al. 2019) 预测每个像素的嵌入值(embedding value),每个文本实例具有不同的嵌入值。通过像素聚合后处理将具有相同嵌入值的像素连接起来。通过区分嵌入值,即使多个文本实例相连,后处理也能将其分离为多个文本轮廓。
Segmentation-based methods has a speed issue when running the post-processing algorithm on CPU to convert the predicted heatmap into text contours. Therefore, methods such as DB and PAN use a lightweight backbone to achieve real-time scene text detection. FAST (Chen et al. 2021) proposes a lightweight network constructed by Neural Architecture Search (NAS) with a post-processing algorithm that uses the GPU to perform part of the steps. The inference time of FAST is much faster due to the lightweight architecture and optimized post-processing. However, their capability of handing small or curved texts remains questionable.
基于分割的方法在CPU上运行后处理算法将预测的热力图转换为文本轮廓时存在速度问题。因此,DB和PAN等方法采用轻量级骨干网络以实现实时场景文本检测。FAST (Chen et al. 2021) 提出了一种通过神经架构搜索 (Neural Architecture Search, NAS) 构建的轻量级网络,其后处理算法利用GPU执行部分步骤。得益于轻量级架构和优化的后处理,FAST的推理速度显著提升,但其处理小文本或弯曲文本的能力仍存疑。
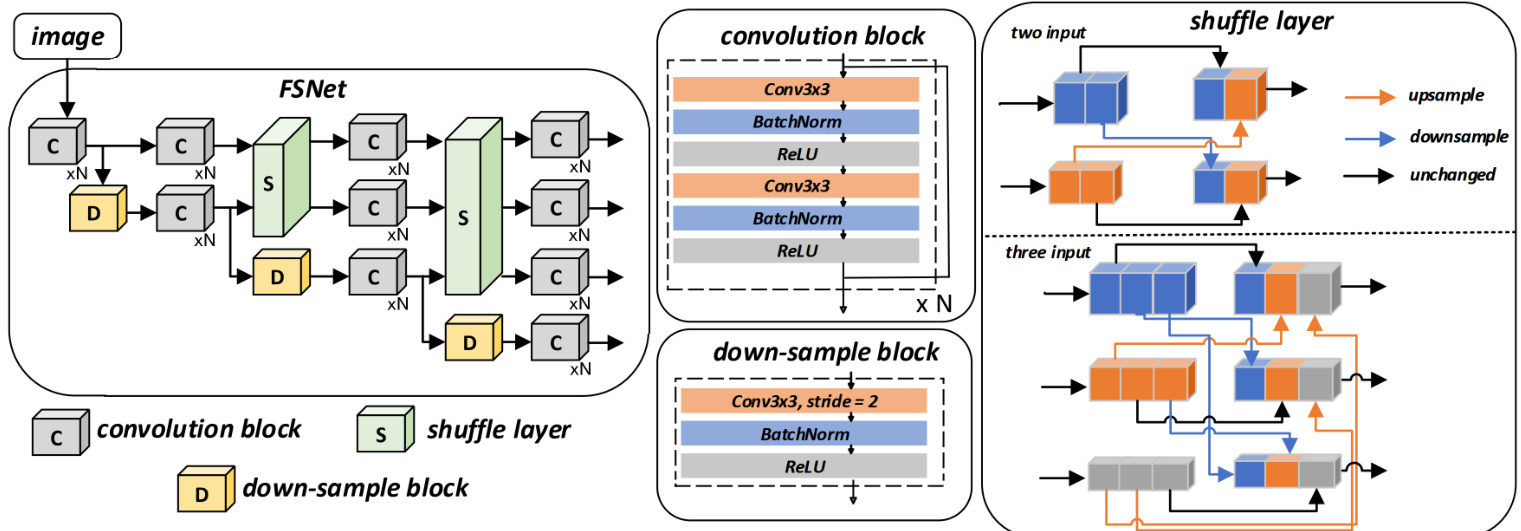
Figure 2: Detailed architecture of FSNet: feature shuffle is implemented by two shuffle layers. Detailed implementations of the three modules (C, D, S) are shown on the right. Note that FSNet contains two shuffle layers. The first shuffle layer has two-resolution feature inputs (top-right) and the second shuffle layer has three-resolution feature inputs (bottom-right).
图 2: FSNet详细架构:特征混洗通过两个混洗层实现。右侧展示了三个模块(C、D、S)的具体实现。注意FSNet包含两个混洗层,第一个混洗层接收双分辨率特征输入(右上),第二个混洗层接收三分辨率特征输入(右下)。
Contour-based Scene Text Detection
基于轮廓的场景文本检测
Contour-based scene text detection methods utilize mathematical curves to fit the text of arbitrary shapes. The model predicts the parameters of the curve that fit the text. As the text shape becomes more complex, the model requires more parameters, and the fitting becomes more prone to failure. However, contour-based methods have an end-to-end structure for generating text boxes, directly outputting the control points of the curve to represent the text outline. This eliminates the need for post-processing required by segmentationbased methods. Additionally, contour-based methods can generate overlapping text boxes, which cannot be achieved by segmentation-based methods.
基于轮廓的场景文本检测方法利用数学曲线来拟合任意形状的文本。模型通过预测拟合文本的曲线参数实现检测。当文本形状越复杂时,模型需要更多参数,拟合过程也更容易失败。但这类方法具有端到端的文本框生成结构,能直接输出表征文本轮廓的曲线控制点,无需像基于分割的方法那样进行后处理。此外,基于轮廓的方法可以生成重叠文本框,这是基于分割的方法无法实现的。
ABCNet (Liu et al. 2020) is the first architecture to predict control points of Bezier curves that fit the text of arbitrary shapes. TextBPN (Zhang et al. 2021) uses dilated convolution to generate rough boundary and offset information and then iterative ly deforms the boundary to generate more accurate text boundaries. FCENet (Zhu et al. 2021) enhances the ability to predict highly curved texts by introducing Fourier contour embedding. Recently, inspired by Transformer, FSG (Tang et al. 2022) has used a Transformer encoder to predict more accurate curve parameters. TESTR designs a box-to-polygon process that uses anchor box proposals from the Transformer encoder to generate positional queries, which facilitates polygon detection. However, such a bounding-box representation might lack precision. DPText-DETR (Ye et al. 2022) conducts point sampling directly in the text bounding box to address this issue of TESTR. In our study, we use heatmaps to extract both contours and center lines (approximating the medial axis of text regions) from each text instance.
ABCNet (Liu et al. 2020) 是首个预测贝塞尔曲线控制点以拟合任意形状文本的架构。TextBPN (Zhang et al. 2021) 使用扩张卷积生成粗略边界和偏移信息,随后通过迭代变形边界得到更精确的文本轮廓。FCENet (Zhu et al. 2021) 通过引入傅里叶轮廓嵌入增强了对高弯曲文本的预测能力。近期受Transformer启发,FSG (Tang et al. 2022) 采用Transformer编码器预测更精确的曲线参数。TESTR设计了从框到多边形的流程,利用Transformer编码器的锚框提议生成位置查询,从而优化多边形检测。但此类边界框表示可能精度不足。DPText-DETR (Ye et al. 2022) 直接在文本边界框内进行点采样以解决TESTR的问题。本研究中,我们通过热力图从每个文本实例中同时提取轮廓线和中轴线(近似文本区域的骨架)。
The Proposed Method Overview of MixNet
方法概述 MixNet
Fig. 1 illustrates the overall architecture of MixNet. FSNet is used as the backbone network to extract text features and generate pixel-level classification, distance field, orientation field, and embedding values. This information is then used to generate a rough text contour. The $P$ points sampled from the rough text contour are taken as input to the CTBlock. Specifically, the $P$ sample points and their corresponding image features are entered into the CTBlock as a sequence. Then, the first Transformer module predicts $x$ and $y$ offsets of the sample points and uses them to generate the center line of a text contour. In the same way, the center line is sampled and combined with the feature sequence of the rough contour and sent to the second Transformer module to correct the rough text contour and produce a finer text contour. In this section, we first explain in detail the backbone of FSNet and then the process of predicting point offsets using the CTBlock.
图 1: 展示了MixNet的整体架构。FSNet作为主干网络用于提取文本特征并生成像素级分类、距离场、方向场和嵌入值。这些信息随后被用来生成粗略的文本轮廓。从粗略文本轮廓中采样的$P$个点作为CTBlock的输入。具体来说,$P$个采样点及其对应的图像特征以序列形式输入CTBlock。接着,第一个Transformer模块预测采样点的$x$和$y$偏移量,并用它们生成文本轮廓的中心线。以同样的方式,对中心线进行采样,并将其与粗略轮廓的特征序列结合,送入第二个Transformer模块以修正粗略文本轮廓,生成更精细的文本轮廓。本节首先详细解释FSNet的主干结构,然后介绍使用CTBlock预测点偏移量的过程。
Feature Shuffle Network (FSNet)
特征混洗网络 (FSNet)
CNN-based backbones can be sensitive to noise during feature extraction. Popular backbones such as ResNet and VGG often produce rough high-resolution features that are not well suited to detect small text instances. To address these challenges, we propose FSNet, which incorporates a network that can better extract high-resolution features. Additionally, we empirically observed that low-resolution features have better ability against noise and perturbations. Thus, FSNet is designed to exchange both low- and highresolution features during feature extraction, making the extracted high-resolution features less vulnerable to noise. These two characteristics improve the FSNet backbone’s capability for detecting small-sized texts. The architecture of FSNet is similar to HRNet (Wang et al. 2020), but with a key difference in the way FSNet shuffles features. While HRNet mixes features between layers by adding them, FSNet equally divides the channels of each resolution and shuffles the divided features. After shuffling, the cut features of each resolution are up-sampled and down-sampled to the same size and concatenated into new features.
基于CNN的骨干网络在特征提取时可能对噪声敏感。ResNet和VGG等流行骨干网络生成的高分辨率特征往往较为粗糙,不适用于检测小文本实例。为解决这些问题,我们提出FSNet,该网络能更好地提取高分辨率特征。此外,我们通过实验观察到低分辨率特征具有更强的抗噪声和干扰能力。因此,FSNet在特征提取过程中设计了高低分辨率特征交换机制,使提取的高分辨率特征不易受噪声影响。这两个特性提升了FSNet骨干网络检测小尺寸文本的能力。FSNet架构与HRNet (Wang et al. 2020) 类似,但关键区别在于特征混洗方式:HRNet通过相加实现跨层特征混合,而FSNet将各分辨率的通道均等分割后混洗分割特征,最后将各分辨率切割特征上采样/下采样至相同尺寸并拼接为新特征。
FSNet contains three main modules, namely the convolution block, down-sample block, and shuffle layer, as shown in Fig. 2. Convolution blocks are stacked in large numbers to extract features. The down-sample block uses a $3\times3$ convolution with a stride of two for down-sampling. Note that the stacking amount of each convolution block is different. FSNet contains two shuffle layers (green in Fig. 2). The first shuffle layer has two-resolution feature inputs and the second shuffle layer has three-resolution feature inputs. The shuffle layer divides the channels of the features of each resolution into the number of inputs $N$ . The input feature $F^{i}$ is divided into $N$ cut features $\backslash_{1}^{i},...,F_{n}^{i},...,F_{N}^{i}$ , where $F_{n}^{i}$ denotes the $n{-}t h$ input at the $i$ -th scale. The cropped features are up-sampled or down-sampled to the corresponding size according to the index and then concatenated to form new features. The shuffling operation can facilitate the exchange of features across multiple scales, generating more disc rim i native features superior to the popular ResNet and HRNet (Wang et al. 2020). Since the shuffle layer has no learnable parameters, it is more efficient than HRNet. At the final layer of FSNet, the results of all four scales are concatenated into a single feature map.
FSNet包含三个主要模块,分别是卷积块(convolution block)、下采样块(down-sample block)和混洗层(shuffle layer),如图2所示。卷积块被大量堆叠以提取特征。下采样块使用步长为2的$3\times3$卷积进行下采样。注意每个卷积块的堆叠数量不同。FSNet包含两个混洗层(图2中绿色部分)。第一个混洗层具有双分辨率特征输入,第二个混洗层具有三分辨率特征输入。混洗层将每个分辨率特征的通道数划分为输入数量$N$。输入特征$F^{i}$被划分为$N$个切割特征$\backslash_{1}^{i},...,F_{n}^{i},...,F_{N}^{i}$,其中$F_{n}^{i}$表示第$i$个尺度下的第$n{-}t h$个输入。裁剪后的特征根据索引进行上采样或下采样至对应尺寸,然后拼接形成新特征。这种混洗操作可以促进跨多尺度的特征交换,生成比主流ResNet和HRNet更具判别性的特征(Wang et al. 2020)。由于混洗层没有可学习参数,其效率高于HRNet。在FSNet的最后一层,所有四个尺度的结果被拼接为单一特征图。
Central Transformer Block (CTBlock)
Central Transformer Block (CTBlock)
In prior work, sampling points were located primarily in the peripheral vicinity of text instances. For example, points were sampled along the bounding box of each text region in DPText-DETR (Ye et al. 2022). However, such peripheral sampled features often encompass numerous background attributes, which prevents focusing on just the text. To overcome this challenge, we present Central Transformer Block (CTBlock), an innovative design that integrates the center line with the corresponding features to represent each text region. The Transformer module within CTBlock adopts an encoder-decoder structure. As shown in Fig. 1 right, a three-layer transformer block is included as the encoder. Each transformer block contains a multihead self-attention block and a Multi-Layer Perceptron (MLP) network. The decoder consists of a simple MLP.
在先前的工作中,采样点主要位于文本实例的外围区域。例如,DPText-DETR (Ye et al. 2022) 沿着每个文本区域的边界框进行采样。然而,这种外围采样特征通常包含大量背景属性,导致难以聚焦文本本身。为解决这一问题,我们提出了中心Transformer模块 (CTBlock),该创新设计通过整合中心线及其对应特征来表征每个文本区域。CTBlock中的Transformer模块采用编码器-解码器结构:如图1右所示,编码器由三层Transformer模块构成,每个模块包含多头自注意力块和多层感知机 (MLP) 网络;解码器则由简单MLP组成。
The key advantage of the proposed transformer module is that the combination of peripheral and center line features can produce a more precise text contour. When two text instances are positioned closely, the contour features of the neighboring regions might lead to deformation or even interference. The center line effectively maintains the separation of these two text instances in such scenarios. In practice, a rough contour of each text instance is extracted based on the heatmap generated by the backbone network. Then we select $N$ points along each contour to represent the text contour. The length of each contour, denoted $C_{i}$ , is $L_{i}$ , where $i$ is the index of each text instance. We divide $L_{i}$ into $N$ equal parts of length $T$ . A point is sampled every time $T$ and passed from the starting point. After repeating this process $N$ times, we obtain $N$ points along the text contour. We empirically observed a slight performance improvement with $N\geq20$ . To maintain a balance between inference time and performance, we set $N=20$ in our experiments. The corresponding image features and heatmaps are extracted to form a sequence of features. Next, it passes through the first transformer module, which generates points that represent
所提出的Transformer模块的关键优势在于,外围与中心线特征的结合能生成更精确的文本轮廓。当两个文本实例位置相邻时,相邻区域的轮廓特征可能导致形变甚至相互干扰。中心线在此类场景中能有效保持两个文本实例的分离。实际应用中,我们基于主干网络生成的热力图提取每个文本实例的粗略轮廓,随后沿轮廓选取$N$个点来表征文本轮廓。每个轮廓$C_{i}$的长度记为$L_{i}$($i$为文本实例索引),将$L_{i}$等分为$N$段,每段长度$T$。从起点开始每隔$T$距离采样一个点,重复$N$次后即可获得轮廓上的$N$个点。实验表明当$N\geq20$时性能略有提升,为平衡推理时间与性能,实验中设定$N=20$。提取对应的图像特征与热力图形成特征序列后,通过首个Transformer模块生成表征点。

Figure 3: The sample point of a center line is shown as a red dot. We assume that scene text is positioned along either a straight line or a smooth curve in natural scenes (i.e., a 1D manifold embedded into the 2D Euclidean space).
图 3: 中心线的采样点显示为红点。我们假设自然场景中的文本沿着直线或平滑曲线排列 (即嵌入二维欧几里得空间的一维流形)。
the center line.
中心线
Fig. 3 illustrates some examples of such center line based scene text detection. During training, the center line points are supervised, and the ground truth for these points is obtained from the upper and lower contours of the text contour ground truth. As the number of ground truth points in each dataset may vary, we use the aforementioned sampling method to obtain a fixed number $C$ of center line points and $C{=}10$ in this paper. Similarly, after obtaining the center line points, we cropped the corresponding image features and heatmaps to form another feature sequence. Finally, by combining the feature sequence of text contour and the feature sequence of center line, the second Transformer module outputs the vertex offset for each point of the initial contour, resulting in a more precise and refined contour.
图 3 展示了一些基于中心线的场景文本检测示例。在训练过程中,中心线点会受到监督,这些点的真实标签 (ground truth) 来源于文本轮廓真实标签的上下轮廓线。由于每个数据集的真实标签点数可能不同,我们采用上述采样方法获取固定数量 $C$ 的中心线点 (本文中 $C{=}10$)。同样地,在获得中心线点后,我们裁剪对应的图像特征和热力图 (heatmap) 以形成另一组特征序列。最终,通过结合文本轮廓特征序列和中心线特征序列,第二个 Transformer 模块输出初始轮廓各点的顶点偏移量,从而得到更精确细致的轮廓。
Experiments
实验
Datasets
数据集
We use Total-Text (Ch’ng and Chan 2017) and ICDARArT (Chng et al. 2019), to evaluate the challenging cases, where the scene texts come with arbitrary shapes. Additionally, we employ MSRA-TD500 (Yao et al. 2012) as a validation dataset for multi-directional scene texts.
我们使用Total-Text (Ch'ng and Chan 2017)和ICDARArT (Chng et al. 2019)来评估具有任意形状的场景文本这一挑战性案例。此外,我们采用MSRA-TD500 (Yao et al. 2012)作为多方向场景文本的验证数据集。
Total-Text is a challenging scene text detection benchmark dataset containing arbitrarily shaped text, horizontal, multidirectional, and curved text lines. The dataset comprises 1,555 images, with 1,255 images allocated for training and 300 images for testing. All text instances are annotated with word-level granularity.
Total-Text是一个具有挑战性的场景文本检测基准数据集,包含任意形状文本、水平、多方向和弯曲文本行。该数据集包含1,555张图像,其中1,255张用于训练,300张用于测试。所有文本实例均以单词级粒度进行标注。
ICDAR-ArT is a large curved text dataset containing 5,603 training images and 4,563 testing images. It includes numerous text instances that are horizontal, multi-directional, or curved. We employ both the Total-Text and ArT datasets to assess the detection capability of MixNet on curved texts.
ICDAR-ArT是一个大型弯曲文本数据集,包含5,603张训练图像和4,563张测试图像。它包括大量水平、多方向或弯曲的文本实例。我们采用Total-Text和ArT数据集来评估MixNet在弯曲文本上的检测能力。
MSRA-TD500 comprises 500 training images and 200 test images, featuring multilingual, multi-oriented long texts (curved texts are not included). We use this dataset to evaluate the detection ability on multi-oriented texts. We include an additional 400 images from HUST-TR400 (Yao, Bai, and Liu 2014) for training in this evaluation.
MSRA-TD500包含500张训练图像和200张测试图像,包含多语言、多方向的长文本(不包括弯曲文本)。我们使用该数据集评估多方向文本的检测能力。在本评估中,我们还加入了来自HUST-TR400 (Yao, Bai, and Liu 2014) 的400张额外图像用于训练。
SynthText (Gupta, Vedaldi, and Zisserman 2016) is a synthetic dataset containing 800K text images. All images are generated from 8K background images and 8 million synthetic word instances with word-level and character-level annotations. This dataset is used to pre-train our model.
SynthText (Gupta, Vedaldi, and Zisserman 2016) 是一个包含80万张文本图像的合成数据集。所有图像均基于8000张背景图和800万个合成单词实例生成,具备单词级和字符级标注。该数据集用于预训练我们的模型。
Table 1: Performance evaluation on both noise-free and noisy datasets. Note how FSNet demonstrates better noise-resistant performance over ResNet50.
表 1: 在无噪声和有噪声数据集上的性能评估。请注意 FSNet 相比 ResNet50 展现出更好的抗噪声性能。
| Backbone | Impulse noise | Prec.(%) | Recall(%) | F1(%) | Small(%) | Medium(%) | Large(%) |
|---|---|---|---|---|---|---|---|
| ResNet50 FSNet | 0% | 91.8 92.1 | 84.0 87.7 | 87.7 89.8 (+2.1) | 53.0 68.8 | 88.0 92.4 | 94.5 97.6 |
| ResNet50 FSNet | 5% | 85.0 90.4 | 68.3 72.1 | 75.8 80.3 (+4.5) | 26.9 42.3 | 68.3 75.3 | 89.2 92.0 |
| ResNet50 FSNet | 10% | 83.4 88.6 | 58.9 65.2 | 69.1 75.1 (+6.0) | 16.5 30.7 | 57.2 63.8 | 84.9 88.0 |
Table 2: Performance evaluation on Total-Text dataset for three scene text detection methods with and w/o FSNet. FSNet unanimously improves precision, recall, and F1 scores for all three methods.
表 2: 在Total-Text数据集上三种场景文本检测方法使用与不使用FSNet的性能评估。FSNet一致提升了所有三种方法的精确率、召回率和F1分数。
| 方法 | FSNet | 精确率(%) | 召回率(%) | F1分数(%) |
|---|---|---|---|---|
| PAN | × | 89.3 | 81.0 | 85.0 |
| PAN | √ | 89.5 | 83.8 | 86.5 |
| DB | × | 87.1 | 82.5 | 84.7 |
| DB | √ | 89.2 | 83.5 | 86.2 |
| FAST | × | 89.9 | 83.2 | 86.4 |
| FAST | √ | 92.8 | 84.0 | 88.2 |
Table 3: Performance evaluation on different versions of FSNet on Total-Text. Best scores are highlighted in bold.
表 3: Total-Text数据集上不同版本FSNet的性能评估。最佳得分以粗体标出。
| 版本 | 参数量(M) | 精确率(%) | 召回率(%) | F1值(%) | 帧率(FPS) |
|---|---|---|---|---|---|
| Ver.1 | 29.3 | 93.1 | 87.0 | 89.9 | 15.2 |
| Ver.2 | 15.1 | 90.3 | 85.5 | 87.9 | 21.0 |
| Ver.3 | 27.2 | 92.4 | 86.1 | 89.2 | 21.1 |
| Ver.4 | 28.6 | 93.6 | 84.6 | 88.9 | 16.7 |
Implementation Details
实现细节
We used FSNet as the backbone and pre-trained it for five epochs on SynthText in our experiments. During pretraining, we utilized Adam optimizer and fixed the learning rate at 0.001. In the fine-tuning stage, we trained the model for 600 epochs on Total-Text, ArT, and other datasets, with an initial learning rate of 0.001 that decayed to 0.9 after every 50 epochs. The input image size was set to $640\times640$ , and we employed data augmentation techniques such as random rotation $(-30^{o}\sim30^{o})$ , random cropping, random flipping, and color jittering. The code was implemented using Python 3 and the PyTorch 1.10.2 framework. The training was carried out on an RTX-3090 GPU with 24G memory.
实验中,我们以FSNet为骨干网络,在SynthText数据集上进行了5个epoch的预训练。预训练阶段采用Adam优化器,学习率固定为0.001。在微调阶段,模型在Total-Text、ArT等数据集上训练了600个epoch,初始学习率为0.001,每50个epoch衰减至0.9倍。输入图像尺寸设为$640\times640$,并采用了随机旋转$(-30^{o}\sim30^{o})$、随机裁剪、随机翻转和色彩抖动等数据增强技术。代码基于Python 3和PyTorch 1.10.2框架实现,训练在24G显存的RTX-3090 GPU上进行。
Accuracy Improvement of FSNet
FSNet的准确率提升
Table 1 provides empirical validation of the advancements achieved by the integration of high-resolution features in detecting small texts. In this table, text instances are categorized based on their sizes (Small, Medium, Large), and the detection performance is evaluated using Precision (Prec.), Recall, and F1-score. As evident in Table 1, FSNet greatly improves the success rates for detecting small and medium texts within the noise-free dataset. We next report experiments assessing FSNet’s noise resistance capabilities. We used impulse noise to simulate noise and used ResNet50 as the control group. Initially, ResNet50 and FSNet models were individually trained using a noise-free training dataset.
表 1: 通过整合高分辨率特征在小文本检测方面取得的进展提供了实证验证。该表根据文本实例的尺寸(小、中、大)进行分类,并使用精确率(Prec.)、召回率和F1分数评估检测性能。如表 1 所示,FSNet 在无噪声数据集中显著提高了检测中小文本的成功率。接下来我们报告评估FSNet抗噪能力的实验,使用脉冲噪声模拟噪声,并以ResNet50作为对照组。初始阶段,ResNet50和FSNet模型均使用无噪声训练数据集单独训练。
Table 4: Ablation study of MixNet on Total-Text.
表 4: MixNet在Total-Text上的消融研究
| Pretrain | FSNet | Centerline | Prec.(%) | Recall(%) | F1(%) | FPS |
|---|---|---|---|---|---|---|
| X | × | X | 91.4 | 80.5 | 85.7 | 21.7 |
| X | √ | × | 91.1 | 83.7 | 87.3 | 15.7 |
| × | V | √ | 92.0 | 84.1 | 87.8 | 15.2 |
| √ | × | × | 91.8 | 84.0 | 87.7 | 21.7 |
| √ | √ | × | 93.1 | 87.0 | 89.9 | 15.7 |
| √ | √ | 93.0 | 88.0 | 90.5 | 15.2 |
Table 5: Ablations study on the effects of using other backbones on Total-Text.
表 5: 不同骨干网络在Total-Text数据集上的消融研究
| Backbone | Paras(M) | Prec.(%) | Recall(%) | F1(%) | FPS |
|---|---|---|---|---|---|
| ResNet50 | 25.5 | 88.2 | 82.9 | 85.5 | 21.7 |
| ResNet101 | 44.5 | 91.3 | 82.0 | 86.4 | 17.8 |
| HRNet_w18 | 9.6 | 87.9 | 74.5 | 80.7 | 14.5 |
| HRNet_w32 | 28.5 | 90.9 | 82.3 | 86.4 | 13.7 |
| HRNet_w48 | 65.8 | 91.3 | 82.7 | 86.8 | 12.9 |
| FSNet_S | 27.2 | 91.9 | 84.2 | 87.9 | 21.1 |
| FSNetM | 29.3 | - | - | - | - |
Subsequently, noise points were introduced to the test data with probabilities of $5%$ and $10%$ , generating two noiseaffected datasets. Finally, the trained models were used to detect text instances on the test data without noise, with $5%$ noise, and with $10%$ noise. As in Table 1, within the noisefree dataset, FSNet exhibited a $2.1%$ increase in F1-score compared to ResNet50. This improvement is further in the presence of noise, with enhancements of $4.5%$ and $6.0%$ for the two noise ratios, respectively. Although both models experienced a significant decline in performance with increasing noise levels, FSNet demonstrated superior noise resis- tance in noisy environments. This robustness is attributed to FSNet’s architectural exchange of low-resolution and highresolution features, which mitigates noise impact as features undergo convolution and pooling operations.
随后,在测试数据中以 $5%$ 和 $10%$ 的概率引入噪声点,生成两个受噪声影响的数据集。最后,使用训练好的模型分别在无噪声、含 $5%$ 噪声和含 $10%$ 噪声的测试数据上检测文本实例。如表 1 所示,在无噪声数据集中,FSNet 的 F1 分数比 ResNet50 提高了 $2.1%$。这一优势在存在噪声时进一步扩大,两种噪声比例下分别提升了 $4.5%$ 和 $6.0%$。尽管随着噪声水平增加,两种模型的性能都出现显著下降,但 FSNet 在噪声环境中表现出更强的抗噪能力。这种鲁棒性源于 FSNet 架构中低分辨率与高分辨率特征的交换机制,该机制通过卷积和池化操作有效缓解了噪声影响。
We next evaluate FSNet’s capabilities by replacing the backbones and FPN architectures of existing models such as differentiable b inari z ation (DB) (Liao et al. 2020), pixel aggregation network (PAN) (Wang et al. 2019), and Faster Arbitrarily-Shaped Text (FAST) Detector (Chen et al. 2021) with FSNet. We fixed the output channel of FSNet to be 256 for each scale, to generate image features across four scales. We apply $1\times1$ convolution to match the channel numbers with those of the original architecture. The training details adhered to the original methods protocol. As shown in Table 2, this replacement yielded a $1.5%$ increase in F1-score for both the DB and PAN architectures and a substantial
接下来,我们通过将现有模型(如可微分二值化 (DB) (Liao et al. 2020)、像素聚合网络 (PAN) (Wang et al. 2019) 和 Faster Arbitrarily-Shaped Text (FAST) Detector (Chen et al. 2021) 的主干网络和 FPN 架构替换为 FSNet,来评估 FSNet 的能力。我们将 FSNet 每个尺度的输出通道固定为 256,以生成四个尺度的图像特征。我们应用 $1\times1$ 卷积来匹配原始架构的通道数。训练细节遵循原始方法的协议。如表 2 所示,这种替换使 DB 和 PAN 架构的 F1 分数提高了 $1.5%$,并且显著
Table 6: Comparison between MixNet and other methods on the MSRA-TD500 dataset. Best scores are highlighted in bold.
表 6: MixNet 与其他方法在 MSRA-TD500 数据集上的对比。最佳分数以粗体标出。
| 方法 | Backbone | 精确率 (%) | 召回率 (%) | F1 (%) |
|---|---|---|---|---|
| CRAFT (Baek et al. 2019) PAN (Wang et al. 2019) DB (Lia0 et al. 2020) | ResNet50 | 88.2 | 78.2 | 82.9 |
| ResNet18 | 84.4 | 83.8 | 84.1 | |
| ResNet50-DCN | 91.5 91.5 | 79.2 | 84.9 | |
| ResNet50-DCN NAS-based | 92.1 | 83.3 83.0 | 87.2 87.3 | |
| FAST (Chen et al. 2021) MixNet (Ours) | FSNet_S | 92.3 | 84.6 | 88.3 |
| MixNet (Ours) | FSNet_M | 90.7 | 88.1 | 89.4 |
Table 7: Comparison between MixNet and other methods on the Total-Text dataset. Best scores are highlighted in bold.
表 7: MixNet与其他方法在Total-Text数据集上的对比。最佳分数以粗体标出。
| 方法 | Backbone | 精确率(%) | 召回率(%) | F1(%) | FPS |
|---|---|---|---|---|---|
| DB (Lia0 et al. 2020) | ResNet50-DCN | 87.1 | 82.5 | 84.7 | 32.0 |
| PAN (Wang et al. 2019) | ResNet18 | 89.3 | 81.0 | 85.0 | 39.6 |
| CRAFT (Baek et al.2019) | ResNet50 | 87.6 | 79.9 | 83.6 | 8.6 |
| I3CL (Du et al.2022) | ResNet50 | 89.8 | 84.2 | 86.9 | 7.6 |
| FSG (Tang et al. 2022) | ResNet50 | 90.7 | 85.7 | 88.1 | 13.1 |
| TextFuseNet (Ye et al.2020) | ResNet101 | 89.0 | 85.8 | 87.5 | 3.7 |
| TESTR (Zhanget al.2022) | ResNet50 | 92.8 | 83.7 | 88.0 | 5.3 |
| TextBPN++ (Zhang et al.2023) | ResNet50 | 91.8 | 85.3 | 88.5 | 13.1 |
| DPText-DETR(Yeetal.2022) | ResNet50 | 91.8 | 86.4 | 89.0 | 17.0 |
| MixNet (Ours) | FSNet_S | 92.4 | 86.1 | 89.2 | 21.1 |
| MixNet (Ours) | FSNet_M | 93.0 | 88.1 | 90.5 | 15.2 |
Table 8: Performance comparisons between MixNet and others on ICDAR-ArT. Best scores are highlighted in bold.
表 8: MixNet与其他方法在ICDAR-ArT上的性能对比。最佳分数以粗体标出。
| 方法 | 骨干网络 | 精确率(%) | 召回率(%) F1值(%) |
|---|---|---|---|
| CRAFT | ResNet50 | 77.2 | 68.9 72.9 |
| TextBPN++ | ResNet50 | 81.1 | 71.1 75.8 |
| I3CL | ResNet50 | 80.6 | 75.4 77.9 |
| DPText-DETR | ResNet50 | 83.0 | 73.3 78.1 |
| TextFuseNet | ResNet101 | 85.4 | 72.8 78.6 |
| MixNet (Ours) | FSNet_S | 82.3 | 75.0 78.5 |
| MixNet (Ours) | FSNet_M | 83.0 | 76.7 79.7 |
$1.8%$ increase for FAST. This result shows that FSNet can successfully improve multiple existing methods.
FAST 提升 1.8%。这一结果表明 FSNet 能有效改进多种现有方法。
Ablation Study
消融实验
The stacking depth of each convolution block within FSNet was initially set to 4, denoted as Version 1. Despite delivering commendable performance, the computation load stemming from multi-layer convolutions on high-resolution features placed a strain on inference time. Consequently, we made adjustments to the convolution count within each block. Illustrated in Fig. 4, we devised four iterations of FSNet, each featuring a distinct convolution count. In Version 2, we streamlined the stacking depth of each convolution block to 2, resulting in a significant boost in computational speed and a reduction in parameter count. However, this modification led to a noticeable decrease in performance on the dataset. Consequently, we opt to discard this version. In Versions 3 and 4, we implemented a reduction in the number of high-resolution convolutional layers, balanced by an increase in low-resolution convolutional layers to compensate. Scores and derivation speeds for all versions are itemized in Table 3. Clearly, the reduction of high-resolution convolutional layers triggers a marked increase in inference time. In our pursuit of striking a balance between performance and inference speed, we designated the convolution count of Ver. 3 as the blueprint for a lighter FSNet version, denoted as FSNet S. Additionally, for optimal results, the convolution count of Ver. 1 was retained as the foundational configuration for FSNet, named FSNet M.
FSNet中每个卷积块的初始堆叠深度设为4,称为版本1。虽然表现出色,但高分辨率特征上的多层卷积计算负荷影响了推理速度。为此,我们调整了各块内的卷积层数。如图4所示,我们设计了四个FSNet迭代版本,各具不同卷积层数。在版本2中,将各卷积块的堆叠深度精简为2,显著提升了计算速度并减少了参数量,但导致数据集性能明显下降,因此弃用该版本。版本3和4通过减少高分辨率卷积层、增加低分辨率卷积层进行补偿。各版本的得分与推导速度详见表3。显然,减少高分辨率卷积层会显著增加推理时间。为平衡性能与推理速度,我们采用版本3的卷积层数作为轻量版FSNet S的设计基准;同时保留版本1的配置作为基础版FSNet M,以获得最优效果。

Figure 4: The stacking numbers of each convolution block in four different versions of FSNet (note that the numbers within each square box denoting the stacking depth varies).
图 4: FSNet四种不同版本中每个卷积块的堆叠数量(注意每个方框内的数字表示堆叠深度各不相同)。
Next, we validate the benefits of our newly proposed designs. We use the baseline using ResNet50 backbone which incorporates only contour-sampled points in the Transformer module. Table 4 shows the results. In comparison, the use of FSNet backbone improves the scene text detection F1-score by $2.1%$ , and the incorporation of center line features in CTBlock further improves the F1-score by $0.5%$ .
接下来,我们验证新提出设计带来的优势。使用仅包含轮廓采样点的Transformer模块、以ResNet50为骨干网络的基线模型。表4展示了实验结果。相比之下,采用FSNet骨干网络使场景文本检测的F1值提升了$2.1%$,而在CTBlock中引入中心线特征进一步将F1值提高了$0.5%$。
Comparison with Other Backbone
与其他骨干网络的对比
Since the architecture of FSNet is similar to that of HRNet, we compared the parameters of the two architectures and their performance on Total-Text. Furthermore, since ResNet is the architecture most commonly used in text detection methods, we also compared ResNet in the table. As Table 5 shows, FSNet has a clear performance gap. However, despite having similar parameters to ResNet50, the highresolution convolution operation and the up-sampling and down-sampling of the shuffle layer lead to a decrease in calculation time.
由于FSNet的架构与HRNet相似,我们比较了两种架构的参数及其在Total-Text数据集上的性能。此外,由于ResNet是文本检测方法中最常用的架构,我们也在表中对比了ResNet。如表5所示,FSNet存在明显的性能差距。但尽管其参数量与ResNet50相近,高分辨率卷积操作以及混洗层的上采样和下采样会导致计算时间增加。

Figure 5: MixNet is capable of detecting small text from the scene, regardless of its orientation, shapes, and positions
图 5: MixNet能够检测场景中的小文本,无论其方向、形状和位置如何
Multi-oriented Scene Text Detection Result
多方向场景文本检测结果
We use the MSRA-TD500 dataset to test the detection ability of MixNet on multi-oriented text detection. Consistent with other methods (Liao et al. 2020, 2022), we also use 400 training images from HUST-TR400 dataset. Table 6 shows the performance comparisons between our method and other methods. Our architecture achieves an F-measure of $89.4%$ on MSRA-TD500 dataset. Compared to other methods, our architecture improves the F measure by $2.1%$ . This experiment proves that our architecture outperforms other methods on multi-oriented and multi-language text.
我们使用MSRA-TD500数据集测试MixNet在多方向文本检测上的能力。与其他方法 (Liao et al. 2020, 2022) 一致,我们也采用了HUST-TR400数据集的400张训练图像。表6展示了本方法与其他方法的性能对比。我们的架构在MSRA-TD500数据集上实现了89.4%的F值,相较其他方法提升了2.1%。该实验证明我们的架构在多方向多语言文本检测任务中具有优势。
Arbitrary-shaped Scene Text Detection Results
任意形状场景文本检测结果
As mentioned previously, the Total-Text dataset and ArT dataset hold significant importance in the realm of arbitraryshaped text detection. These datasets encompass a wide range of text orientations, including horizontal, multidirectional, and curved text lines. Hence, we employ these two datasets to validate the capabilities of our architecture in detecting arbitrary-shaped text. Our results in the TotalText dataset are presented in the last column of Table 7. Our architecture attains a remarkable F1-score of $90.5%$ , thereby establishing a new state-of-the-art in performance. Compared to the prevailing methods, our F1-measure shows an improvement of $1.5%$ , while the recall increases by $1.7%$ . Moving to the ArT dataset, our architecture achieves an Fmeasure of $79.7%$ . The comparative analysis between our approach and other methods is presented in Table 8. Compared to Text F useNet, our method improves the F1 score by $1.1%$ and recall by $3.9%$ . These experimental results underscore the fact that our architecture attains cuttingedge performance in arbitrary-shaped text detection. Despite the varying orientations of the text instances, our method demonstrates a consistent ability to effectively detect them. Fig. 5 provides examples of text detection achieved by our method on diverse datasets. It becomes evident that MixNet excels at detecting straight lines, curves, and even densely arranged lengthy texts.
如前所述,Total-Text数据集和ArT数据集在任意形状文本检测领域具有重要意义。这些数据集涵盖了多种文本方向,包括水平、多方向和弯曲文本行。因此,我们采用这两个数据集来验证我们架构在任意形状文本检测方面的能力。我们在TotalText数据集上的结果展示在表7的最后一列。我们的架构取得了90.5%的显著F1分数,从而建立了新的性能标杆。与主流方法相比,我们的F1值提高了1.5%,召回率提升了1.7%。在ArT数据集上,我们的架构实现了79.7%的F值。我们方法与其他方法的对比分析展示在表8中。与TextFuseNet相比,我们的方法将F1分数提高了1.1%,召回率提升了3.9%。这些实验结果突显了我们架构在任意形状文本检测方面达到了尖端性能。尽管文本实例方向各异,我们的方法始终展现出有效检测的能力。图5展示了我们方法在不同数据集上实现的文本检测示例。显然,MixNet擅长检测直线、曲线甚至密集排列的长文本。
Conclusion
结论
In this paper, we introduce MixNet, an architecture consisting of FSNet and the Central Transformer Block. FSNet enhances image features and minimizes noise interference in high-resolution data by shuffling features between low-resolution and high-resolution layers. Moreover, the Central Transformer Block incorporates a point sampling on contours and center lines. This design helps the model learn and optimize text boundaries, leading to more precise text contours. Our experimental results underscore the efficacy of MixNet, as it achieves state-of-the-art performance on benchmarks for arbitrarily shaped scene text detection. Looking ahead, our future research involves exploring more effective methods for conveying low- and high-resolution features and delving into streamlined but highly representative point sampling approaches.
本文介绍了MixNet架构,该架构由FSNet和中央Transformer模块(Central Transformer Block)组成。FSNet通过在低分辨率与高分辨率层之间进行特征混洗,增强了图像特征并减少了高分辨率数据中的噪声干扰。此外,中央Transformer模块采用了轮廓与中心线的点采样(point sampling)设计,帮助模型学习并优化文本边界,从而获得更精确的文本轮廓。实验结果表明MixNet在任意形状场景文本检测基准上达到了最先进性能。展望未来,我们将探索更有效的低/高分辨率特征传递方法,并研究精简但高表征力的点采样方案。
References Baek, Y.; Lee, B.; Han, D.; Yun, S.; and Lee, H. 2019. Character region awareness for text detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 9365–9374. Chen, Z.; Wang, J.; Wang, W.; Chen, G.; Xie, E.; Luo, P.; andLu, T. 2021. FAST: Faster Arbitrarily-Shaped Text Detec- tor with Minimalist Kernel Representation. arXiv preprint arXiv:2111.02394. Ch’ng, C. K.; and Chan, C. S. 2017. Total-text: A comprehensive dataset for scene text detection and recognition. In 2017 14th IAPR international conference on document analysis and recognition (ICDAR), volume 1, 935–942. IEEE. Chng, C. K.; Liu, Y.; Sun, Y.; Ng, C. C.; Luo, C.; Ni, Z.; Fang, C.; Zhang, S.; Han, J.; Ding, E.; et al. 2019. Icdar2019robust reading challenge on arbitrary-shaped text-rrc-art. In 2019 International Conference on Document Analysis and Recognition (ICDAR), 1571–1576. IEEE. Du, B.; Ye, J.; Zhang, J.; Liu, J.; and Tao, D. 2022. I3cl: Intra-and inter-instance collaborative learning for arbitraryshaped scene text detection. International Journal of Computer Vision, 130(8): 1961–1977. Gupta, A.; Vedaldi, A.; and Zisserman, A. 2016. Synthetic data for text local is ation in natural images. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2315–2324. He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778. Liao, M.; Wan, Z.; Yao, C.; Chen, K.; and Bai, X. 2020. Real-time scene text detection with differentiable binarization. In Proceedings of the AAAI conference on artificial intelligence, volume 34, 11474–11481. Liao, M.; Zou, Z.; Wan, Z.; Yao, C.; and Bai, X. 2022. Realtime scene text detection with differentiable b inari z ation and adaptive scale fusion. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1): 919–931. Liu, Y.; Chen, H.; Shen, C.; He, T.; Jin, L.; and Wang, L. 2020. Abcnet: Real-time scene text spotting with adaptive bezier-curve network. In proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 9809– 9818. Simonyan, K.; and Zisserman, A. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556. Tang, J.; Zhang, W.; Liu, H.; Yang, M.; Jiang, B.; Hu, G.; and Bai, X. 2022. Few could be better than all: Feature sampling and grouping for scene text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4563–4572. Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. Advances in neural information processing systems, 30.
参考文献
Baek, Y.; Lee, B.; Han, D.; Yun, S.; and Lee, H. 2019. 基于字符区域感知的文本检测。见《IEEE/CVF计算机视觉与模式识别会议论文集》,9365–9374。
Chen, Z.; Wang, J.; Wang, W.; Chen, G.; Xie, E.; Luo, P.; and Lu, T. 2021. FAST:基于极简核表示的快速任意形状文本检测器。arXiv预印本 arXiv:2111.02394。
Ch’ng, C. K.; and Chan, C. S. 2017. Total-text:场景文本检测与识别的综合数据集。见《2017年第14届IAPR国际文档分析与识别会议(ICDAR)》第1卷,935–942。IEEE。
Chng, C. K.; Liu, Y.; Sun, Y.; Ng, C. C.; Luo, C.; Ni, Z.; Fang, C.; Zhang, S.; Han, J.; Ding, E.; 等. 2019. ICDAR2019任意形状文本鲁棒阅读挑战赛-RRC-ART。见《2019年国际文档分析与识别会议(ICDAR)》,1571–1576。IEEE。
Du, B.; Ye, J.; Zhang, J.; Liu, J.; and Tao, D. 2022. I3CL:面向任意形状场景文本检测的实例内与实例间协同学习。《国际计算机视觉杂志》,130(8): 1961–1977。
Gupta, A.; Vedaldi, A.; and Zisserman, A. 2016. 自然图像文本定位的合成数据。见《IEEE计算机视觉与模式识别会议论文集》,2315–2324。
He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. 图像识别的深度残差学习。见《IEEE计算机视觉与模式识别会议论文集》,770–778。
Liao, M.; Wan, Z.; Yao, C.; Chen, K.; and Bai, X. 2020. 基于可微分二值化的实时场景文本检测。见《AAAI人工智能会议论文集》第34卷,11474–11481。
Liao, M.; Zou, Z.; Wan, Z.; Yao, C.; and Bai, X. 2022. 基于可微分二值化与自适应尺度融合的实时场景文本检测。《IEEE模式分析与机器智能汇刊》,45(1): 919–931。
Liu, Y.; Chen, H.; Shen, C.; He, T.; Jin, L.; and Wang, L. 2020. ABCNet:基于自适应贝塞尔曲线网络的实时场景文本定位。见《IEEE/CVF计算机视觉与模式识别会议论文集》,9809–9818。
Simonyan, K.; and Zisserman, A. 2014. 超深卷积网络的大规模图像识别。arXiv预印本 arXiv:1409.1556。
Tang, J.; Zhang, W.; Liu, H.; Yang, M.; Jiang, B.; Hu, G.; and Bai, X. 2022. 少样本可能优于全样本:场景文本检测的特征采样与分组。见《IEEE/CVF计算机视觉与模式识别会议论文集》,4563–4572。
Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. 注意力机制就是一切。《神经信息处理系统进展》,30。
MixNet: Toward Accurate Detection of Challenging Scene Text in the Wild — Supplementary Material
MixNet:面向野外复杂场景文本的精准检测——补充材料
Anonymous submission
匿名投稿
Introduction
引言
In the supplementary material, we introduce a series of additional experiments aimed at providing additional evidence of the efficacy of our method.
在补充材料中,我们引入了一系列额外实验,旨在为方法的有效性提供更多证据。
The first experiment in this study is related to the impact of the point sampling parameter $N$ , which is consistently set to 20 in all the primary experiments in this paper. Through this experiment, we systematically evaluated the effect of varying the values of $N$ on the detection performance.
本研究的第一项实验涉及点采样参数$N$的影响,该参数在本文所有主要实验中均设为20。通过本实验,我们系统评估了改变$N$值对检测性能的影响。
The second experiment includes HRNet as an additional benchmark to extend the comparison between FSNet and ResNet in both noise-free and noisy scenarios presented in the main paper. Notably, both FSNet and HRNet maintain high-resolution features in this experiment. Through this setup, we validate that our feature shuffle strategy yields more substantial improvements compared to HRNet’s feature fusion approach. By showcasing the superiority of our proposed feature shuffle strategy in enhancing performance, even in comparison to established techniques like HRNet’s feature fusion, we contribute to the broader understanding of effective feature handling in text detection methodologies.
第二次实验将HRNet作为额外基准,扩展了主论文中FSNet与ResNet在无噪声和含噪声场景下的对比。值得注意的是,本实验中FSNet和HRNet均保持了高分辨率特征。通过该实验设计,我们验证了相比HRNet的特征融合方法,我们的特征混洗策略能带来更显著的性能提升。通过展示所提特征混洗策略在性能增强方面的优越性(即使与HRNet特征融合等成熟技术相比),我们为文本检测方法中高效特征处理的深入研究提供了新见解。
The third experiment delves into the influence of the presence of the shuffle layer on the detection ability, elucidating the enhancements brought about by our feature shuffle approach. Collectively, these supplementary experiments contribute to a comprehensive understanding of our method’s effectiveness and provide deeper insights into the specific facets of our proposed approach.
第三次实验深入探讨了混洗层(shuffle layer)的存在对检测能力的影响,阐明了我们提出的特征混洗方法带来的提升效果。综合来看,这些补充实验有助于全面理解我们方法的有效性,并为我们提出的方案的具体层面提供了更深入的见解。
Number of Point Samples
点采样数量
In the context of our paper, each text instance is encoded utilizing $N=20$ sampling points and subsequently refined through the Central Transformer Block. In general, a larger number of sampling points contributes to a more precise representation of the contour fit. Nevertheless, an escalated number of sampling points results in a heightened computational burden on the Central Transformer Block, thereby impacting the frame-per-second (FPS) performance. As a consequence, a judicious selection of the sampling number $N$ becomes imperative, striking an optimal equilibrium between detection accuracy and inference speed.
在我们的论文中,每个文本实例使用$N=20$个采样点进行编码,随后通过中央Transformer块(Central Transformer Block)进行优化。一般而言,更多的采样点有助于更精确地表示轮廓拟合。然而,采样点数量的增加会导致中央Transformer块的计算负担加重,从而影响每秒帧数(FPS)性能。因此,需要明智地选择采样数$N$,在检测精度和推理速度之间取得最佳平衡。
The experiment is performed to explore the impact of varying the number of sampling points $(N)$ on both detection performance and FPS. The results are summarized in
实验旨在探究不同采样点数量 $(N)$ 对检测性能和FPS的影响,结果总结如下:
Table 1: Performance evaluation on different point sample number N.
表 1: 不同点采样数 N 的性能评估
| N | Prec.(%) | Recall(%) | F1(%) FPS |
|---|---|---|---|
| 12 | 90.2 | 83.4 | 86.6 15.9 |
| 16 | 90.6 | 83.1 | 86.6 15.5 |
| 20 | 91.1 | 83.7 | 87.3 15.2 |
| 24 | 91.0 | 84.0 | 87.4 15.0 |
| 28 | 91.3 | 84.1 | 87.5 14.8 |
Table 1 for the $N$ values of 12, 16, 20, 24, and 28. Notably, due to the inherent complexity of representing curved text contours, the experiment starts from a minimum of $N=12$ . As indicated in the table, as $N$ increases, the FPS gradually decreases. However, the performance of MixNet remains stable when $N\geq20$ . To achieve an optimal balance be- tween detection accuracy and inference speed, we adopted $N=20$ for all of our experiments.
表 1: 展示了 $N$ 取值为 12、16、20、24 和 28 时的实验结果。值得注意的是,由于表示弯曲文本轮廓的固有复杂性,实验从最小值 $N=12$ 开始。如表所示,随着 $N$ 的增加,FPS 逐渐下降。然而,当 $N\geq20$ 时,MixNet 的性能保持稳定。为了在检测精度和推理速度之间取得最佳平衡,我们在所有实验中采用了 $N=20$。
Further Comparison with HRNet in Noisy Environment
与HRNet在噪声环境下的进一步对比
We conducted a performance comparison between FSNet and ResNet50 under conditions of both non-noise and noisy environments. We adopt HRNet, which shares architectural similarities with FSNet, as an additional benchmark for evaluation. In particular, it is important to note that both HRNet and FSNet effectively retain high-resolution features. As illustrated in Table 2, in the context of a quiet environment, both HRNet and FSNet exhibit an edge over ResNet50 in the detection of small text instances. Therefore, in terms of FSNet’s performance with the shuffle layer, it achieves a $1.8%$ higher F1-score than HRNet.
我们在无噪声和含噪声环境下对FSNet与ResNet50进行了性能对比。采用与FSNet具有架构相似性的HRNet作为额外评估基准,需特别指出的是HRNet和FSNet均能有效保留高分辨率特征。如表2所示,在安静环境中,HRNet和FSNet对小文本实例的检测均优于ResNet50。具体到带shuffle层的FSNet表现,其F1分数比HRNet高出$1.8%$。
Subsequently, when noise is introduced at levels of $5%$ and $10%$ , it becomes clear that HRNet experiences a notable decline in its ability to detect small text instances. Additionally, the performance gap between HRNet and FSNet also widens in the presence of noise. This observation underscores the robustness of FSNet’s architecture in handling noisy environments, particularly in contrast to HRNet and ResNet50. Our feature shuffling mechanism can bring semantic features from deep layer to shallow layer, resulting in this robustness improvement.
随后,当引入 $5%$ 和 $10%$ 级别的噪声时,可以明显看出 HRNet 检测小文本实例的能力显著下降。此外,在存在噪声的情况下,HRNet 和 FSNet 之间的性能差距也进一步扩大。这一观察结果凸显了 FSNet 架构在处理噪声环境中的鲁棒性,尤其是与 HRNet 和 ResNet50 相比。我们的特征混洗机制能够将深层语义特征传递到浅层,从而实现了这种鲁棒性提升。
Table 2: Performance evaluation on both noise-free and noisy datasets. Note how FSNet demonstrates better noise-resistant performance over ResNet50 and HRNet.
表 2: 在无噪声和有噪声数据集上的性能评估。注意 FSNet 相比 ResNet50 和 HRNet 展现出更好的抗噪声性能。
| Backbone | Impulse noise | Prec.(%) | Recall(%) | F1(%) | Small(%) | Medium(%) | Large(%) |
|---|---|---|---|---|---|---|---|
| HRNet_w32 ResNet50 | 0% | 91.6 | 84.8 | 88.0 | 62.5 | 88.7 | 95.5 |
| 91.8 | 84.0 | 87.7 | 53.0 | 88.0 | 94.5 | ||
| FSNet HRNet_w32 ResNet50 | 5% | 92.1 90.3 | 87.7 64.6 | 89.8 (+1.8) 75.3 | 68.8 | 92.4 | 97.6 |
| 85.0 | 68.3 | 75.8 | 32.0 26.9 | 66.0 | 85.8 89.2 | ||
| FSNet HRNet_w32 | 90.4 | 72.1 | 80.3 (+4.5) | 42.3 | 68.3 75.3 | 92.0 | |
| 86.3 | 53.8 | 66.3 | 15.3 | 53.0 | 79.0 | ||
| ResNet50 FSNet | 10% | 83.4 | 58.9 | 69.1 | 16.5 | 57.2 | 84.9 |
| 88.6 | 65.2 | 75.1 (+6.0) | 30.7 | 63.8 | 88.0 |
| Backbone | shufflelayer | Prec.(%) | Recall(%) | F1(%) | Small(%) | Medium(%) | Large(%) |
|---|---|---|---|---|---|---|---|
| FSNet | × | 90.2 | 85.6 | 87.8 | 58.7 | 92.1 | 95.2 |
| FSNet | 92.1 | 87.7 | 89.8 | 68.8 | 92.4 | 97.6 |
Table 4: Performance comparisons between MixNet and others on CTW-1500
表 4: MixNet 与其他方法在 CTW-1500 上的性能对比
| 方法 | 主干网络 | 精确率(%) | 召回率(%) | F1(%) |
|---|---|---|---|---|
| PAN | ResNet18 | 86.4 | 81.2 | 83.7 |
| TextFuseNet | ResNet50 | 85.8 | 85.0 | 85.4 |
| TextBPN++ | ResNet50 | 87.3 | 83.8 | 85.5 |
| I3CL | ResNet50 | 87.4 | 84.5 | 85.9 |
| MixNet (Ours) | FSNet_S | 89.2 | 82.9 | 86.0 |
| MixNet (Ours) | FSNet_M | 90.3 | 84.8 | 87.5 |
Table 3: ablation study of shuffle layer Table 5: Performance comparison between MixNet and DPText-DETR on CTW-1500 when using DPText-DETR’s score program
表 3: 混洗层消融实验
表 5: MixNet与DPText-DETR在CTW-1500数据集上使用DPText-DETR评分程序的性能对比
| 方法 | 骨干网络 | 精确率(%) | 召回率(%) | F1分数(%) |
|---|---|---|---|---|
| DPText-DETR | ResNet50 | 91.7 | 86.2 | 88.8 |
| MixNet (Ours) | FSNet_S | 89.5 | 87.0 | 88.2 |
| MixNet (Ours) | FSNet_M | 91.4 | 88.3 | 89.8 |
Ablation Study of Shuffle Layer in FSNet
FSNet中Shuffle层的消融研究
The aim here is to delve into the analysis of the shuffle layer within FSNet. We establish a baseline by removing the shuffle layer from FSNet, forming the basis of our experimental comparison. As depicted in Table 3, the inclusion of the shuffle layer leads to an impressive increase in F1-score by $2.0%$ . Moreover, this augmentation notably enhances the detection performance for both small- and medium-text instances, especially in small ones. Our feature shuffling mechanism can not only improve robustness to noise by bringing semantic features from the deep layer to the shallow layer, but also improve accuracy in small-sized text detection by bringing detailed spatial features from the shall layer to the deep layer. The experimental results show the importance of the shuffle layer in our method.
此处旨在深入分析FSNet中的混洗层(shuffle layer)。我们通过移除FSNet的混洗层建立基线,作为实验对比基础。如表3所示,引入混洗层使F1分数显著提升$2.0%$。该增强机制对小尺寸和中尺寸文本实例的检测性能提升尤为明显,特别是小文本。我们的特征混洗机制不仅能够通过将深层语义特征传递至浅层来增强噪声鲁棒性,还能通过将浅层细节空间特征传递至深层来提高小文本检测精度。实验结果验证了混洗层在本方法中的重要性。
Evaluation Performance on CTW1500 dataset
CTW1500 数据集上的评估表现
Our results in the CTW1500 dataset are presented in the last column of Table 4. Our architecture achieves an F1 score of
我们在CTW1500数据集上的结果呈现在表4的最后一列。我们的架构取得了F1分数为
$87.5%$ , establishing a new state-of-the-art in terms of performance. Compared to other methods, our F1-score improves by $1.6%$ . On the other hand, we found that the score program of DPText-DETR is different from the official one. For comparison with DPText-DETR, in Table 5 we show the results using the same score program as DPText-DETR. As can be seen in the last column of Table 5, our F1-socre has increased by $1.0%$ , and the recall has increased by $2.1%$ .
$87.5%$,在性能方面确立了新的最先进水平。与其他方法相比,我们的F1分数提高了$1.6%$。另一方面,我们发现DPText-DETR的评分程序与官方版本不同。为了与DPText-DETR进行对比,在表5中我们展示了使用相同评分程序的结果。如表5最后一列所示,我们的F1分数提升了$1.0%$,召回率提升了$2.1%$。
Visualization Results and Case Studies
可视化结果与案例研究
In this section, we present a collection of visualization results to offer a more comprehensive understanding. Figure 1 showcases the detection outcomes across various text scenarios. Notably, MixNet exhibits proficient performance in scenarios involving (a) curved text, (b) small-sized text, (c) noisy backgrounds, and (d) variations in lighting and shad- ows.
在本节中,我们展示了一系列可视化结果以提供更全面的理解。图 1: 呈现了不同文本场景下的检测效果。值得注意的是,MixNet 在以下场景中表现出色:(a) 弯曲文本,(b) 小尺寸文本,(c) 噪声背景,以及 (d) 光照和阴影变化。
Furthermore, Figure 2 illustrates instances where MixNet scene text detections are not $100%$ correct. Progressing from left to right, three distinct issues are highlighted: (1) detection of extremely small text, (2) detection of single charac- ters, and (3) incorrect segmentation. In the depiction, (a) represents the detection result produced by MixNet, while (b) illustrates the corresponding ground-truth. In the mentioned cases, although MixNet demonstrates satisfactory detection rates for small characters, consistent detection of extremely diminutive characters remains a challenge. Moreover, individual characters occasionally risk being overlooked, likely due to the bias in the training data towards instances with multiple characters, leading to an imbalance in feature represent ation for single characters and background elements. Lastly, the example at the right showcases a situation where the white space between text elements mirrors the background feature, causing MixNet to rely heavily on adjacent text features to identify key regions. Substantial white spaces exceeding a certain threshold can disrupt the connection of text features, potentially leading to erroneous detections.
此外,图 2 展示了 MixNet 场景文本检测未达到 $100%$ 准确率的案例。从左至右依次呈现三个典型问题:(1) 极小文本检测,(2) 单字符检测,(3) 错误分割。图示中 (a) 为 MixNet 的检测结果,(b) 为对应真实标注。尽管 MixNet 对小字符检测率表现尚可,但对极端微小字符的稳定检测仍是挑战。此外,单个字符偶尔存在漏检风险,这可能是训练数据偏向多字符实例导致的单字符与背景特征表征失衡所致。最右侧案例显示,当文本元素间留白与背景特征相似时,MixNet 会过度依赖相邻文本特征识别关键区域。超过阈值的留白可能破坏文本特征连续性,从而引发误检。

Figure 1: Visualization results for various scene text detection examples. (a) corresponds to curved text, (b) depicts small-sized text, (c) illustrates a noisy background, and (d) showcases variations in lighting and shadows.
图 1: 各类场景文本检测结果的可视化示例。(a) 对应弯曲文本,(b) 展示小尺寸文本,(c) 呈现噪声背景,(d) 体现光照与阴影变化。

Figure 2: Visualization results for a few cases where some scene texts are not $100%$ detected. (a) corresponds the prediction of MixNet, (b) represent the ground-truth of images.
图 2: 部分场景文本未被 100% 检测到的案例可视化结果。(a) 对应 MixNet 的预测结果,(b) 代表图像的真实标注。