Delete, Retrieve, Generate: A Simple Approach to Sentiment and Style Transfer
删除、检索、生成:一种简单的情感与风格迁移方法
Abstract
摘要
We consider the task of text attribute transfer: transforming a sentence to alter a specific attribute (e.g., sentiment) while preserving its attribute-independent content (e.g., changing “screen is just the right size” to “screen is too small”). Our training data includes only sentences labeled with their attribute (e.g., positive or negative), but not pairs of sentences that differ only in their attributes, so we must learn to disentangle attributes from attributeindependent content in an unsupervised way. Previous work using adversarial methods has struggled to produce high-quality outputs. In this paper, we propose simpler methods motivated by the observation that text attributes are often marked by distinctive phrases (e.g., “too small”). Our strongest method extracts content words by deleting phrases associated with the sentence’s original attribute value, retrieves new phrases associated with the target attribute, and uses a neural model to fluently combine these into a final output. On human evaluation, our best method generates grammatical and appropriate responses on $22%$ more inputs than the best previous system, averaged over three attribute transfer datasets: altering sentiment of reviews on Yelp, altering sentiment of reviews on Amazon, and altering image captions to be more romantic or humorous.
我们研究文本属性迁移任务:通过改变句子中的特定属性(如情感)同时保留其属性无关内容(例如将"屏幕大小刚好"改为"屏幕太小")。训练数据仅包含带有属性标签的句子(如正面或负面),而没有仅属性不同的句子对,因此必须以无监督方式学习分离属性与属性无关内容。先前使用对抗方法的研究难以生成高质量输出。本文基于"文本属性通常由特定短语标记(如'太小')"这一观察,提出了更简单的方法。我们最优的方法通过删除与原属性相关的短语来提取内容词,检索与目标属性相关的新短语,并利用神经模型流畅组合生成最终输出。在人工评估中,我们的最佳方法在三个属性迁移数据集(修改Yelp评论情感、修改Amazon评论情感、使图片描述更浪漫或幽默)上平均比之前最优系统多产生22%语法正确且内容恰当的输出。
1 Introduction
1 引言
The success of natural language generation (NLG) systems depends on their ability to carefully control not only the topic of produced utterances, but also attributes such as sentiment and style. The desire for more sophisticated, controllable NLG has led to increased interest in text attribute transfer— the task of editing a sentence to alter specific attributes, such as style, sentiment, and tense (Hu et al., 2017; Shen et al., 2017; Fu et al., 2018). In each of these cases, the goal is to convert a sentence with one attribute (e.g., negative sentiment) to one with a different attribute (e.g., positive sentiment), while preserving all attribute-independent content1 (e.g., what properties of a restaurant are being discussed). Typically, aligned sentences with the same content but different attributes are not available; systems must learn to disentangle attributes and content given only unaligned sentences labeled with attributes.
自然语言生成(NLG)系统的成功不仅取决于其控制生成话语主题的能力,还取决于对情感和风格等属性的精确把控。对更复杂、可控NLG的需求,推动了文本属性迁移(text attribute transfer)研究的兴起——这项任务旨在通过编辑句子来改变特定属性(如风格、情感和时态) (Hu et al., 2017; Shen et al., 2017; Fu et al., 2018)。在这些研究中,目标都是将具有某种属性(如消极情感)的句子转换为具有不同属性(如积极情感)的句子,同时保留所有与属性无关的内容(如讨论餐厅的哪些特性)。通常情况下,我们无法获得内容相同但属性不同的对齐句子;系统必须仅通过带有属性标注的非对齐句子,来学习分离属性和内容。
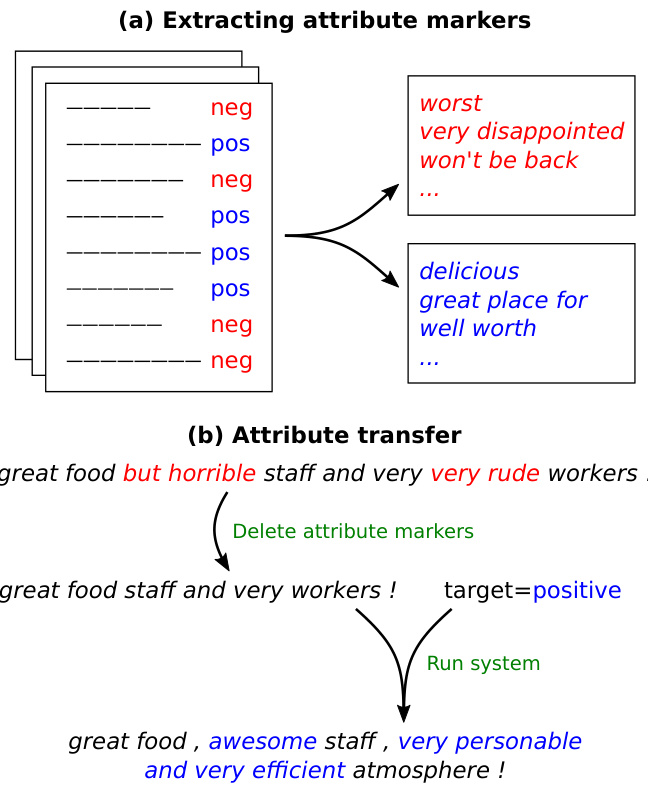
Figure 1: An overview of our approach. (a) We identify attribute markers from an unaligned corpus. (b) We transfer attributes by removing markers of the original attribute, then generating a new sentence conditioned on the remaining words and the target attribute.
图 1: 方法概述。(a) 我们从非对齐语料中识别属性标记。(b) 通过移除原始属性标记并基于剩余词语和目标属性生成新句子,实现属性迁移。
Previous work has attempted to use adversarial networks (Shen et al., 2017; Fu et al., 2018) for this task, but—as we demonstrate—their outputs tend to be low-quality, as judged by human raters. These models are also difficult to train (Salimans et al., 2016; Arjovsky and Bottou, 2017; Bousmalis et al., 2017).
先前的研究尝试使用对抗网络 (Shen et al., 2017; Fu et al., 2018) 来完成这项任务,但正如我们所展示的,根据人类评估者的判断,它们的输出往往质量较低。这些模型也较难训练 (Salimans et al., 2016; Arjovsky and Bottou, 2017; Bousmalis et al., 2017)。
In this work, we propose a set of simpler, easierto-train systems that leverage an important observation: attribute transfer can often be accomplished by changing a few attribute markers— words or phrases in the sentence that are indicative of a particular attribute—while leaving the rest of the sentence largely unchanged. Figure 1 shows an example in which the sentiment of a sentence can be altered by changing a few sentiment-specific phrases but keeping other words fixed.
在本工作中,我们提出了一组更简单、更易训练的系统,这些系统基于一个重要发现:属性迁移通常只需改变少量属性标记(即句子中指示特定属性的单词或短语),而保持句子其余部分基本不变。图 1: 展示了一个示例,通过改变少量情感相关短语但固定其他词汇,即可改变句子的情感倾向。
With this intuition, we first propose a simple baseline that already outperforms prior adversarial approaches. Consider a sentiment transfer (negative to positive) task. First, from unaligned corpora of positive and negative sentences, we identify attribute markers by finding phrases that occur much more often within sentences of one attribute than the other (e.g., “worst” and “very disp pointed” are negative markers). Second, given a sentence, we delete any negative markers in it, and regard the remaining words as its content. Third, we retrieve a sentence with similar content from the positive corpus.
基于这一直觉,我们首先提出一个简单基线方法,其性能已超越现有对抗式方法。以情感转换(负面转正面)任务为例:首先,从无对齐的正面和负面语料库中,通过识别在某一属性句子中出现频率显著更高的短语(如"worst"和"very disappointed"属于负面标记词)来确定属性标记词;其次,给定句子时删除其中的负面标记词,将剩余词汇视作内容部分;最后,从正面语料库中检索内容相似的句子。
We further improve upon this baseline by incorpora ting a neural generative model, as shown in Figure 1. Our neural system extracts content words in the same way as our baseline, then generates the final output with an RNN decoder that conditions on the extracted content and the target attribute. This approach has significant benefits at training time, compared to adversarial networks: having already separated content and attribute, we simply train our neural model to reconstruct sentences in the training data as an auto-encoder.
我们通过引入神经生成模型进一步改进了这一基线方法,如图 1 所示。我们的神经系统采用与基线相同的方式提取内容词,然后通过一个 RNN (Recurrent Neural Network) 解码器生成最终输出,该解码器以提取的内容和目标属性为条件。与对抗网络相比,这种方法在训练时具有显著优势:由于已经分离了内容和属性,我们只需将神经模型训练为自动编码器来重建训练数据中的句子。
We test our methods on three text attribute transfer datasets: altering sentiment of Yelp reviews, altering sentiment of Amazon reviews, and altering image captions to be more romantic or humorous. Averaged across these three datasets, our simple baseline generated grammatical sentences with appropriate content and attribute $23%$ of the time, according to human raters; in contrast, the best adversarial method achieved only $12%$ . Our best neural system in turn outperformed our baseline, achieving an average success rate of $34%$ . Our code and data, including newly collected human reference outputs for the Yelp and Amazon domains, can be found at https://github.com/lijuncen/ Sentiment-and-Style-Transfer.
我们在三个文本属性迁移数据集上测试了我们的方法:修改Yelp评论的情感倾向、修改Amazon评论的情感倾向,以及将图片描述改写得更浪漫或幽默。根据人工评估,在这三个数据集上,我们的简单基线模型平均有23%的概率生成语法正确且内容与属性相符的句子;相比之下,最佳对抗方法仅达到12%。而我们最好的神经网络系统又超越了基线模型,平均成功率达到34%。我们的代码和数据(包括新收集的Yelp和Amazon领域人工参考输出)可在https://github.com/lijuncen/Sentiment-and-Style-Transfer获取。
2 Problem Statement
2 问题陈述
We assume access to a corpus of labeled sentences , where $x_{i}$ is a sentence and $\ensuremath{\boldsymbol{v}}{i}\in\ensuremath{\mathcal{V}}$ , the set of possible attributes (e.g., for sentiment, $\nu=$ “positive”, “negative” ). We define $\mathcal{D}_{v}={x:$ $(x,v)\in{\mathcal{D}}}$ , the set of sentences in the corpus with attribute $v$ . Crucially, we do not assume access to a parallel corpus that pairs sentences with different attributes and the same content.
我们假设可以访问一个带标签句子的语料库 ,其中 $x_{i}$ 是句子, $\ensuremath{\boldsymbol{v}}f{i}\in\ensuremath{\mathcal{V}}$ 表示可能的属性集合 (例如情感分析中 $\nu=$ "正面"、"负面") 。定义 $\mathcal{D}_{v}={x:$ $(x,v)\in{\mathcal{D}}}$ 为语料中具有属性 $v$ 的句子集合。关键的是,我们并不假设存在平行语料库 (parallel corpus) 来匹配不同属性但内容相同的句子。
Our goal is to learn a model that takes as input $(x,v^{\mathrm{tgt}})$ where $x$ is a sentence exhibiting source (original) attribute $v^{\mathrm{src}}$ , and $v^{\mathrm{tgt}}$ is the target attribute, and outputs a sentence $y$ that retains the content of $x$ while exhibiting $v^{\mathrm{tgt}}$ .
我们的目标是学习一个模型,该模型以 $(x,v^{\mathrm{tgt}})$ 作为输入,其中 $x$ 是展现源(原始)属性 $v^{\mathrm{src}}$ 的句子,$v^{\mathrm{tgt}}$ 是目标属性,并输出一个句子 $y$,该句子在展现 $v^{\mathrm{tgt}}$ 的同时保留 $x$ 的内容。
3 Approach
3 方法
As a motivating example, suppose we wanted to change the sentiment of “The chicken was delicious.” from positive to negative. Here the word “delicious” is the only sentiment-bearing word, so we just need to replace it with an appropriate negative sentiment word. More generally, we find that the attribute is often localized to a small fraction of the words, an inductive bias not captured by previous work.
作为一个启发性的例子,假设我们想将"鸡肉很美味"的情感从正面改为负面。这里"美味"是唯一带有情感色彩的词,因此只需将其替换为适当的负面情感词即可。更普遍地说,我们发现属性通常集中在少数词汇上,这一归纳偏置未被前人工作所捕捉。
How do we know which negative sentiment word to insert? The key observation is that the remaining content words provide strong cues: given “The chicken was . . . ”, one can infer that a tasterelated word like “bland” fits, but a word like “rude” does not, even though both have negative sentiment. In other words, while the deleted sentiment words do contain non-sentiment information too, this information can often be recovered using the other content words.
我们如何确定插入哪个负面情感词?关键在于观察到剩余内容词提供了强烈线索:给定“鸡肉是……”,可以推断出像“寡淡”这样与味道相关的词是合适的,而像“粗鲁”这样的词则不合适,尽管两者都具有负面情感。换句话说,虽然被删除的情感词确实也包含非情感信息,但这些信息通常可以通过其他内容词来恢复。
In the rest of this section, we describe our four systems: two baselines (RETRIEVE ONLY and TEMPLATE BASED) and two neural models (DELETEONLY and DELETE AND RETRIEVE). An overview of all four systems is shown in Figure 2. Formally, the main components of these systems are as follows:
在本节剩余部分,我们将描述四个系统:两个基线模型(RETRIEVE ONLY 和 TEMPLATE BASED)以及两个神经模型(DELETEONLY 和 DELETE AND RETRIEVE)。所有四个系统的概览如图 2 所示。这些系统的主要组件如下:
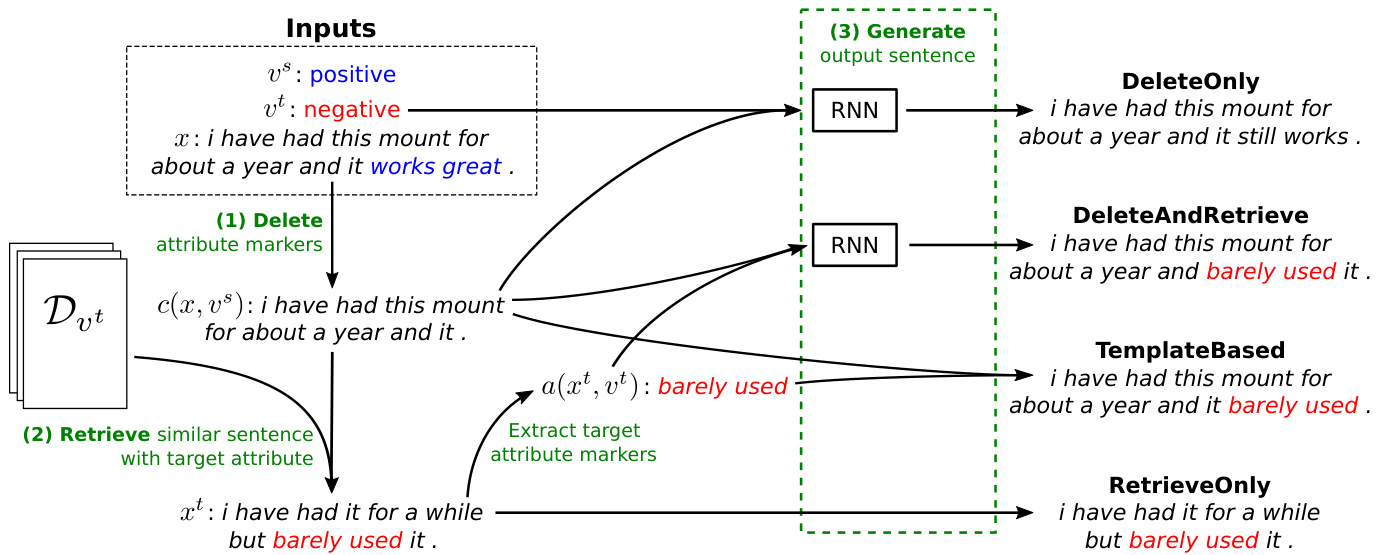
Figure 2: Our four proposed methods on the same sentence, taken from the AMAZON dataset. Every method uses the same procedure (1) to separate attribute and content by deleting attribute markers; they differ in the construction of the target sentence. RETRIEVE ONLY directly returns the sentence retrieved in (2). TEMPLATE BASED combines the content with the target attribute markers in the retrieved sentence by slot filling. DELETE AND RETRIEVE generates the output from the content and the retrieved target attribute markers with an RNN. DELETEONLY generates the output from the content and the target attribute with an RNN.
图 2: 我们在同一句子上提出的四种方法(取自AMAZON数据集)。所有方法都采用相同的步骤(1)通过删除属性标记来分离属性和内容,区别在于目标句子的构建方式。RETRIEVE ONLY直接返回步骤(2)检索到的句子。TEMPLATE BASED通过槽填充将内容与检索到的目标属性标记组合。DELETE AND RETRIEVE使用RNN根据内容和检索到的目标属性标记生成输出。DELETEONLY使用RNN根据内容和目标属性生成输出。
- Delete: All 4 systems use the same procedure to separate the words in $x$ into a set of attribute markers $a(x,v^{\mathrm{src}})$ and a sequence of content words $c(x,v^{\mathrm{src}})$ .
- 删除:所有4个系统都采用相同的流程,将$x$中的单词分割为一组属性标记$a(x,v^{\mathrm{src}})$和一个内容词序列$c(x,v^{\mathrm{src}})$。
- Retrieve: 3 of the 4 systems look through the corpus and retrieve a sentence $x^{\mathrm{tgt}}$ that has the target attribute $v^{\mathrm{tgt}}$ and whose content is similar to that of $x$ .
- 检索:4个系统中有3个会遍历语料库,检索出具有目标属性 $v^{\mathrm{tgt}}$ 且内容与 $x$ 相似的句子 $x^{\mathrm{tgt}}$。
- Generate: Given the content $c(x,v^{\mathrm{src}})$ , target attribute $v^{\mathrm{tgt}}$ , and (optionally) the retrieved sentence $x^{\mathrm{tgt}}$ , each system generates $y$ , either in a rule-based fashion or with a neural sequence-to-sequence model.
- 生成:给定内容 $c(x,v^{\mathrm{src}})$、目标属性 $v^{\mathrm{tgt}}$ 以及(可选)检索到的句子 $x^{\mathrm{tgt}}$,每个系统以基于规则的方式或使用神经序列到序列模型生成 $y$。
We describe each component in detail below.
我们在下面详细描述每个组件。
3.1 Delete
3.1 删除
We propose a simple method to delete attribute markers ( $n$ -grams) that have the most discriminative power. Formally, for any $v\in\nu$ , we define the salience of an $n$ -gram $u$ with respect to $v$ by its (smoothed) relative frequency in $\mathcal{D}_{v}$ :
我们提出了一种简单方法来删除最具区分力的属性标记($n$-gram)。形式上,对于任意$v\in\nu$,我们通过$n$-gram $u$在$\mathcal{D}_{v}$中的(平滑)相对频率来定义其相对于$v$的显著度:
$$
s(u,v)=\frac{\mathrm{count}(u,\mathcal{D}{v})+\lambda}{\left(\sum_{v^{\prime}\in\mathcal{V},v^{\prime}\ne v}\mathrm{count}(u,\mathcal{D}_{v^{\prime}})\right)+\lambda},
$$
$$
s(u,v)=\frac{\mathrm{count}(u,\mathcal{D}{v})+\lambda}{\left(\sum_{v^{\prime}\in\mathcal{V},v^{\prime}\ne v}\mathrm{count}(u,\mathcal{D}_{v^{\prime}})\right)+\lambda},
$$
where count $(u,\mathcal{D}{v})$ denotes the number of times an $n$ -gram $u$ appears in $\mathcal{D}_{v}$ , and $\lambda$ is the smoothing parameter. We declare $u$ to be an attribute marker for $v$ if $s(u,v)$ is larger than a specified threshold $\gamma$ . The attributed markers can be viewed as discri mi native features for a Naive Bayes classifier.
其中 $(u,\mathcal{D}{v})$ 表示 $n$-gram $u$ 在 $\mathcal{D}_{v}$ 中出现的次数,$\lambda$ 是平滑参数。当 $s(u,v)$ 大于指定阈值 $\gamma$ 时,我们将 $u$ 声明为 $v$ 的属性标记。这些属性标记可视为朴素贝叶斯分类器的判别性特征。
We define $a(x,v^{\mathrm{src}})$ to be the set of all source attribute markers in $x$ , and define $c(x,v^{\mathrm{src}})$ as the sequence of words after deleting all markers in $a(x,v^{\mathrm{src}})$ from $x$ . For example, for “The chicken was delicious,” we would delete “delicious” and consider “The chicken was. . . ” to be the content (Figure 2, Step 1).
我们定义 $a(x,v^{\mathrm{src}})$ 为 $x$ 中所有源属性标记的集合,并将 $c(x,v^{\mathrm{src}})$ 定义为从 $x$ 中删除 $a(x,v^{\mathrm{src}})$ 所有标记后得到的词序列。例如,对于句子"The chicken was delicious",我们会删除"delicious"并将"The chicken was..."视为内容 (图 2: 步骤1)。
3.2 Retrieve
3.2 检索
To decide what words to insert into $c(x,v^{\mathrm{src}})$ , one useful strategy is to look at similar sentences with the target attribute. For example, negative sentences that use phrases similar to “The chicken was. . . ” are more likely to contain “bland” than “rude.” Therefore, we retrieve sentences of similar content and use target attribute markers in them for insertion.
为了确定在 $c(x,v^{\mathrm{src}})$ 中插入哪些词语,一个有效的策略是查看具有目标属性的类似句子。例如,使用类似"The chicken was..."这类短语的否定句更可能包含"bland"而非"rude"。因此,我们检索内容相似的句子,并利用其中的目标属性标记进行插入。
Formally, we retrieve $x^{\mathrm{tgt}}$ according to:
形式上,我们根据以下公式检索 $x^{\mathrm{tgt}}$:
$$
x^{\mathrm{{tgt}}}=\operatorname*{argmin}{x^{\prime}\in\mathcal{D}_{v^{\mathrm{{tgt}}}}}d(c(x,v^{\mathrm{{src}}}),c(x^{\prime},v^{\mathrm{{tgt}}})),
$$
$$
x^{\mathrm{{tgt}}}=\operatorname*{argmin}{x^{\prime}\in\mathcal{D}_{v^{\mathrm{{tgt}}}}}d(c(x,v^{\mathrm{{src}}}),c(x^{\prime},v^{\mathrm{{tgt}}})),
$$
where $d$ may be any distance metric comparing two sequences of words. We experiment with two options: (i) TF-IDF weighted word overlap and (ii) Euclidean distance using the content embeddings in Section 3.3 (Figure 2, Step 2).
其中 $d$ 可以是比较两个词序列的任何距离度量。我们实验了两种方案:(i) TF-IDF 加权词重叠度 (ii) 使用第 3.3 节内容嵌入的欧氏距离 (图 2, 步骤 2)。
3.3 Generate
3.3 生成
Finally, we describe how each system generates $y$ (Figure 2, Step 3).
最后,我们描述每个系统如何生成 $y$ (图 2,步骤 3)。
RETRIEVE ONLY returns the retrieved sentence $x^{\mathrm{tgt}}$ verbatim. This is guaranteed to produce a grammatical sentence with the target attribute, but its content might not be similar to $x$ .
RETRIEVE ONLY 仅返回检索到的句子 $x^{\mathrm{tgt}}$ 的原文。这保证了生成的句子具有目标属性且语法正确,但其内容可能与 $x$ 不相似。
TEMPLATE BASED replaces the attribute markers deleted from the source sentence $a(x,v^{\mathrm{src}})$ with those of the target sentence $a(x^{\mathrm{{tgt}}},v^{\mathrm{{tgt}}})$ .2 This strategy relies on the assumption that if two attribute markers appear in similar contexts , they are roughly syntactically exchangeable. For example, “love” and “don’t like” appear in similar contexts (e.g., “i love this place.” and “i don’t like this place.”), and exchanging them is syntactically valid. However, this naive swapping of attribute markers can result in ungrammatical outputs.
基于模板的方法将源句 $a(x,v^{\mathrm{src}})$ 中删除的属性标记替换为目标句 $a(x^{\mathrm{{tgt}}},v^{\mathrm{{tgt}}})$ 的属性标记。该策略基于以下假设:若两个属性标记出现在相似上下文中,则它们在句法上大致可互换。例如,"love"和"don't like"出现在相似上下文(如"i love this place."与"i don't like this place."),互换它们在句法上是有效的。但这种简单的属性标记交换可能导致不合语法的输出。
DELETEONLY first embeds the content $c(x,v^{\mathrm{src}})$ into a vector using an RNN. It then concatenates the final hidden state with a learned embedding for $v^{\mathrm{tgt}}$ , and feeds this into an RNN decoder to generate $y$ . The decoder attempts to produce words indicative of the source content and target attribute, while remaining fluent.
DELETEONLY首先使用RNN将内容$c(x,v^{\mathrm{src}})$嵌入为向量,然后将最终隐藏状态与目标属性$v^{\mathrm{tgt}}$的学习嵌入向量拼接,输入RNN解码器以生成$y$。解码器在保持流畅性的同时,试图生成既反映源内容又体现目标属性的词汇。
DELETE AND RETRIEVE is similar to DELETEONLY, but uses the attribute markers of the retrieved sentence $x^{\mathrm{tgt}}$ rather than the target attribute $v^{\mathrm{tgt}}$ . Like DELETEONLY, it encodes $c(x,v^{\mathrm{src}})$ with an RNN. It then encodes the sequence of attribute markers $a(x^{\mathrm{{tgt}}},v^{\mathrm{{tgt}}})$ with another RNN. The RNN decoder uses the concatenation of this vector and the content embedding to generate $y$ .
DELETE AND RETRIEVE 与 DELETEONLY 类似,但使用检索句子 $x^{\mathrm{tgt}}$ 的属性标记而非目标属性 $v^{\mathrm{tgt}}$。与 DELETEONLY 相同,它通过 RNN 对 $c(x,v^{\mathrm{src}})$ 进行编码,随后用另一个 RNN 对属性标记序列 进行编码。RNN 解码器通过该向量与内容嵌入的拼接来生成 $y$。
DELETE AND RETRIEVE combines the advantages of TEMPLATE BASED and DELETEONLY. Unlike TEMPLATE BASED, DELETEAND RETRIEVE can pick a better place to insert the given attribute markers, and can add or remove function words to ensure grammatical it y. Compared to DELETEONLY, DELETE AND RETRIEVE has a stronger inductive bias towards using target attribute markers that are likely to fit in the current context. Guu et al. (2018) showed that retrieval strategies like ours can help neural generative models. Finally, DELETE AND RETRIEVE gives us finer control over the output; for example, we can control the degree of sentiment by deciding whether to add “good” or “fantastic” based on the retrieved sentence $x^{\mathrm{tgt}}$ .
DELETE AND RETRIEVE 结合了 TEMPLATE BASED 和 DELETEONLY 的优势。与 TEMPLATE BASED 不同,DELETE AND RETRIEVE 能够选择更合适的位置插入给定的属性标记,并能通过增减功能词保证语法正确性。相比 DELETEONLY,该方法对目标属性标记的使用具有更强的归纳偏置,使其更契合当前语境。Guu 等人 (2018) 的研究表明,类似本文采用的检索策略能有效辅助神经生成模型。此外,DELETE AND RETRIEVE 提供了更精细的输出控制能力,例如根据检索到的目标句 $x^{\mathrm{tgt}}$ 可灵活选择添加"good"或"fantastic"来实现情感强度的调控。
3.4 Training
3.4 训练
We now describe how to train DELETEANDRETRIEVE and DELETEONLY. Recall that at training time, we do not have access to ground truth outputs that express the target attribute. Instead, we train DELETEONLY to reconstruct the sentences in the training corpus given their content and original attribute value by maximizing:
我们现在描述如何训练DELETEANDRETRIEVE和DELETEONLY。回想一下,在训练时我们无法获得表达目标属性的真实输出。相反,我们通过最大化以下目标来训练DELETEONLY,使其根据训练语料库中句子的内容和原始属性值进行重建:
$$
L(\theta)=\sum_{(x,v^{\mathrm{src}})\in\mathcal{D}}\log p(x\mid c(x,v^{\mathrm{src}}),v^{\mathrm{src}});\theta).
$$
$$
L(\theta)=\sum_{(x,v^{\mathrm{src}})\in\mathcal{D}}\log p(x\mid c(x,v^{\mathrm{src}}),v^{\mathrm{src}});\theta).
$$
For DELETE AND RETRIEVE, we could similarly learn an auto-encoder that reconstructs $x$ from $c(x,v^{\mathrm{src}})$ and $a(x,v^{\mathrm{src}})$ . However, this results in a trivial solution: because $a(x,v^{\mathrm{src}})$ and $c(x,v^{\mathrm{src}})$ were known to come from the same sentence, the model merely learns to stitch the two sequences together without any smoothing. Such a model would fare poorly at test time, when we may need to alter some words to fluently combine $a(x^{\mathrm{{tgt}}},v^{\mathrm{{tgt}}})$ with $c(x,v^{\mathrm{src}})$ . To address this train/test mismatch, we adopt a denoising method similar to the denoising auto-encoder (Vincent et al., 2008). During training, we apply some noise to $a(x,v^{\mathrm{src}})$ by randomly altering each attribute marker in it independently with probability 0.1. Specifically, we replace an attribute marker with another randomly selected attribute marker of the same attribute and word-level edit distance 1 if such a noising marker exists, e.g., “was very rude” to “very rude”, which produces $a^{\prime}(x,v^{\mathrm{src}})$ .
对于 DELETE AND RETRIEVE 方法,我们同样可以训练一个自编码器 (auto-encoder) 来从 $c(x,v^{\mathrm{src}})$ 和 $a(x,v^{\mathrm{src}})$ 重构 $x$。但这样会导致一个平凡解:由于已知 $a(x,v^{\mathrm{src}})$ 和 $c(x,v^{\mathrm{src}})$ 来自同一句子,模型仅学会简单拼接这两个序列而不进行任何平滑处理。这种模型在测试时会表现不佳,因为实际场景中可能需要修改部分词汇才能流畅地将 $a(x^{\mathrm{{tgt}}},v^{\mathrm{{tgt}}})$ 与 $c(x,v^{\mathrm{src}})$ 结合。为解决训练/测试不匹配问题,我们采用了类似去噪自编码器 (denoising auto-encoder) [20] 的方法:在训练时以0.1的概率独立随机修改 $a(x,v^{\mathrm{src}})$ 中的每个属性标记 (attribute marker)。具体而言,若存在满足条件的噪声标记,我们会将原标记替换为同属性且编辑距离 (word-level edit distance) 为1的随机属性标记(例如将"was very rude"改为"very rude"),从而生成 $a^{\prime}(x,v^{\mathrm{src}})$。
Therefore, the training objective for DELETEAND RETRIEVE is to maximize:
因此,DELETEAND RETRIEVE 的训练目标是最大化:
$$
L(\theta)=\sum_{(x,v^{\mathrm{src}})\in\mathcal{D}}\log p(x\mid c(x,v^{\mathrm{src}}),a^{\prime}(x,v^{\mathrm{src}});\theta).
$$
$$
L(\theta)=\sum_{(x,v^{\mathrm{src}})\in\mathcal{D}}\log p(x\mid c(x,v^{\mathrm{src}}),a^{\prime}(x,v^{\mathrm{src}});\theta).
$$
4 Experiments
4 实验
We evaluated our approach on three domains: flipping sentiment of Yelp reviews (YELP) and Amazon reviews (AMAZON), and changing image captions to be romantic or humorous (CAPTIONS). We compared our four systems to human references and three previously published adversarial approaches. As judged by human raters, both of our two baselines outperform all three adversarial methods. Moreover, DELETE AND RETRIEVE outperforms all other automatic approaches.
我们在三个领域评估了我们的方法:翻转Yelp评论(YELP)和亚马逊评论(AMAZON)的情感倾向,以及将图片描述改为浪漫或幽默风格(CAPTIONS)。我们将四个系统与人工参考文本及三种已发表的对抗方法进行对比。根据人工评分结果显示,我们的两个基线模型均优于所有三种对抗方法。此外,DELETE AND RETRIEVE方法在所有自动化方法中表现最优。
Table 1: Dataset statistics.
表 1: 数据集统计。
| Dataset | Attributes | Train | Dev | Test |
|---|---|---|---|---|
| YELP | Positive Negative | 270K 180K | 2000 2000 | 500 500 |
| CAPTIONS | Romantic Humorous Factual | 6000 6000 0 | 300 300 0 | 0 300 |
| AMAZON | Positive Negative | 277K 278K | 985 1015 | 500 500 |
4.1 Datasets
4.1 数据集
First, we describe the three datasets we use, which are commonly used in prior works too. All datasets are randomly split into train, development, and test sets (Table 1).
首先,我们介绍所使用的三个数据集,这些数据集在先前研究中也常被使用。所有数据集均被随机划分为训练集、开发集和测试集 (表 1)。
YELP Each example is a sentence from a business review on Yelp, and is labeled as having either positive or negative sentiment.
YELP 每个示例都是Yelp上的一条商业评论句子,并被标记为具有正面或负面情感。
AMAZON Similar to YELP, each example is a sentence from a product review on Amazon, and is labeled as having either positive or negative sentiment (He and McAuley, 2016).
AMAZON 与 YELP 类似,每个示例都是来自 Amazon 产品评论的一句话,并被标记为具有正面或负面情感 (He and McAuley, 2016)。
CAPTIONS In the CAPTIONS dataset (Gan et al., 2017), each example is a sentence that describes an image, and is labeled as either factual, romantic, or humorous. We focus on the task of converting factual sentences into romantic and humorous ones. Unlike YELP and AMAZON, CAPTIONS is actually an aligned corpus—it contains captions for the same image in different styles. Our systems do not use these alignments, but we use them as gold references for evaluation.
CAPTIONS 数据集
在CAPTIONS数据集 (Gan et al., 2017) 中,每个样本都是一句描述图像的句子,并被标注为事实性、浪漫或幽默风格。我们专注于将事实性句子转换为浪漫和幽默风格的任务。与YELP和AMAZON不同,CAPTIONS实际上是一个对齐语料库——它包含同一张图像的不同风格描述。我们的系统并未使用这些对齐关系,但将其作为评估的黄金标准参考。
CAPTIONS is also unique in that we reconstruct romantic and humorous sentences during training, whereas at test time we are given factual captions. We assume these factual captions carry only content, and therefore do not look for and delete factual attribute markers; The model essentially only inserts romantic or humorous attribute markers as appropriate.
CAPTIONS 的独特之处还在于,我们在训练过程中重建浪漫和幽默的句子,而在测试时则使用事实性描述。我们假设这些事实性描述仅包含内容,因此不会寻找并删除事实属性标记;模型基本上只根据需要插入浪漫或幽默属性标记。
4.2 Human References
4.2 人类参考
To supply human reference outputs to which we could compare the system outputs for YELP and AMAZON, we hired crowd workers on Amazon Mechanical Turk to write gold outputs for all test sentences. Workers were instructed to edit a sentence to flip its sentiment while preserving its content.
为了提供可与YELP和AMAZON系统输出对比的人工参考输出,我们通过Amazon Mechanical Turk平台雇佣众包工作者为所有测试句子撰写黄金标准输出。工作人员需按要求改写句子以反转其情感倾向,同时保持内容不变。
Our delete-retrieve-generate approach relies on the prior knowledge that to accomplish attribute transfer, a small number of attribute markers should be changed, and most other words should be kept the same. We analyzed our human reference data to understand the extent to which humans follow this pattern. We measured whether humans preserved words our system marks as content, and changed words our system marks as attribute-related (Section 3.1). We define the content word preservation rate $S_{c}$ as the average fraction of words our system marks as content that were preserved by humans, and the attributerelated word change rate $S_{a}$ as the average fraction of words our system marks as attribute-related that were changed by humans:
我们的删除-检索-生成方法基于一个先验知识:要实现属性迁移,只需更改少量属性标记词,同时保持其他大多数词语不变。为验证人类是否遵循该模式,我们分析了人工参考数据:统计人类保留被系统标记为内容词的比例,以及修改被系统标记为属性相关词的情况(第3.1节)。定义内容词保留率 $S_{c}$ 为人类保留的系统标记内容词的平均比例,属性相关词修改率 $S_{a}$ 为人类修改的系统标记属性词的平均比例:
$$
\begin{array}{l}{{S_{c}=\displaystyle\frac{1}{|\mathcal{D}{\mathrm{test}}|}\sum_{(x,v^{\mathrm{src}},y^{})\in\mathcal{D}{\mathrm{test}}}\frac{|c(x,v^{\mathrm{src}})\cap y^{}|}{|c(x,v^{\mathrm{src}})|}}}\ {{S_{a}=1-\displaystyle\frac{1}{|\mathcal{D}{\mathrm{test}}|}\sum_{(x,v^{\mathrm{src}},y^{})\in\mathcal{D}_{\mathrm{test}}}\frac{|a(x,v^{\mathrm{src}})\cap y^{*}|}{|a(x,v^{\mathrm{src}})|},}}\end{array}
$$
$$
\begin{array}{l}{{S_{c}=\displaystyle\frac{1}{|\mathcal{D}{\mathrm{test}}|}\sum_{(x,v^{\mathrm{src}},y^{})\in\mathcal{D}{\mathrm{test}}}\frac{|c(x,v^{\mathrm{src}})\cap y^{}|}{|c(x,v^{\mathrm{src}})|}}}\ {{S_{a}=1-\displaystyle\frac{1}{|\mathcal{D}{\mathrm{test}}|}\sum_{(x,v^{\mathrm{src}},y^{})\in\mathcal{D}_{\mathrm{test}}}\frac{|a(x,v^{\mathrm{src}})\cap y^{*}|}{|a(x,v^{\mathrm{src}})|},}}\end{array}
$$
where $\mathcal{D}{\mathrm{test}}$ is the test set, $y^{*}$ is the human reference sentence, and $|\cdot|$ denotes the number of nonstopwords. Higher values of $S_{c}$ and $S_{a}$ indicate that humans preserve content words and change attribute-related words, in line with the inductive bias of our model. $S_{c}$ is 0.61, 0.71, and 0.50 on YELP, AMAZON, and CAPTIONS, respectively; $S_{a}$ is 0.72 on YELP and 0.54 on AMAZON (not applicable on CAPTIONS).
其中 $\mathcal{D}{\mathrm{test}}$ 是测试集,$y^{*}$ 是人类参考句子,$|\cdot|$ 表示非停用词的数量。$S_{c}$ 和 $S_{a}$ 的值越高,表明人类保留了内容词并改变了与属性相关的词,这与我们模型的归纳偏差一致。$S_{c}$ 在 YELP、AMAZON 和 CAPTIONS 上分别为 0.61、0.71 和 0.50;$S_{a}$ 在 YELP 上为 0.72,在 AMAZON 上为 0.54 (不适用于 CAPTIONS)。
To understand why humans sometimes deviated from the inductive bias of our model, we randomly sampled 50 cases from YELP where humans changed a content word or preserved an attribute-related word. $70%$ of changed content words were unimportant words (e.g., “whole” was deleted from “whole experience”), and another $18%$ were paraphrases (e.g., “charge” became “price”); the remaining $12%$ were errors where the system mislabeled an attribute-related word as a content word (e.g., “old” became “new”). $84%$ of preserved attribute-related words did pertain to sentiment but remained fixed due to changes in the surrounding context (e.g., “don’t like” became “like”, and “below average” became “above average”); the remaining $16%$ were mistagged by our system as being attribute-related (e.g., “walked out”).
为了理解人类为何有时会偏离我们模型的归纳偏置,我们从YELP随机抽取了50个案例,其中人类修改了内容词或保留了属性相关词。70%被修改的内容词是不重要词汇(例如“whole”从“whole experience”中被删除),另有18%属于同义改写(例如“charge”变为“price”);其余12%是系统错误地将属性相关词标记为内容词的情况(例如“old”变为“new”)。84%被保留的属性相关词确实与情感相关,但因上下文变化而保持固定(例如“don’t like”变为“like”,“below average”变为“above average”);剩余16%是被系统错误标记为属性相关的词汇(例如“walked out”)。
4.3 Previous Methods
4.3 先前方法
We compare with three previous models, all of which use adversarial training. STYLEEMBED
我们与之前三种采用对抗训练 (adversarial training) 的模型进行对比:STYLEEMBED
Table 2: Human evaluation results on all three datasets. We show average human ratings for grammaticality (Gra), content preservation (Con), and target attribute match (Att) on a 1 to 5 Likert scale, as well as overall success rate (Suc). On all three datasets, DELETE AND RETRIEVE is the best overall system, and all four of our methods outperform previous work.
表 2: 三个数据集上的人工评估结果。我们展示了语法正确性 (Gra)、内容保持度 (Con) 和目标属性匹配度 (Att) 的平均人工评分 (采用1-5级李克特量表),以及总体成功率 (Suc)。在所有三个数据集中,DELETE AND RETRIEVE 是整体最佳的系统,并且我们的四种方法都优于之前的工作。
| YELP | AMAZON | CAPTIONS | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gra | Con | Att | Suc | Gra | Con | Att | Suc | Gra | Con | Att | Suc | |
| CROSSALIGNED | 2.8 | 2.9 | 3.5 | 14% | 3.2 | 2.5 | 2.9 | 7% | 3.9 | 2.0 | 3.2 | 16% |
| STYLEEMBEDDING | 3.5 | 3.7 | 2.1 | 9% | 3.2 | 2.9 | 2.8 | 11% | 3.3 | 2.9 | 3.0 | 17% |
| MULTIDECODER | 2.8 | 3.1 | 3.0 | 8% | 3.0 | 2.6 | 2.8 | 7% | 3.4 | 2.8 | 3.2 | 18% |
| RETRIEVEONLY | 4.2 | 2.7 | 4.2 | 25% | 3.8 | 2.8 | 3.1 | 17% | 4.2 | 2.6 | 3.8 | 27% |
| TEMPLATEBASED | 3.0 | 3.9 | 3.9 | 21% | 3.4 | 3.6 | 3.1 | 19% | 3.3 | 4.1 | 3.5 | 33% |
| DELETEONLY | 3.0 | 3.7 | 3.9 | 24% | 3.7 | 3.8 | 3.2 | 24% | 3.6 | 3.5 | 3.5 | 32% |
| DELETEANDRETRIEVE | 3.3 | 3.7 | 4.0 | 29% | 3.9 | 3.7 | 3.4 | 29% | 3.8 | 3.5 | 3.9 | 43% |
| Human | 4.6 | 4.5 | 4.5 | 75% | 4.2 | 4.0 | 3.7 | 44% | 4.3 | 3.9 | 4.0 | 56% |
DING $\mathrm{Fu}$ et al., 2018) learns an vector encoding of the source sentence such that a decoder can use it to reconstruct the sentence, but a discriminator, which tries to identify the source attribute using this encoding, fails. They use a basic MLP disc rim in at or and an LSTM decoder. MULTIDECODER (Fu et al., 2018) is similar to STYLEEMBEDDING, except that it uses a different decoder for each attribute value. CROSS ALIGNED (Shen et al., 2017) also encodes the source sentence into a vector, but the disc rim in at or looks at the hidden states of the RNN decoder instead. The system is trained so that the disc rim in at or cannot distinguish these hidden states from those obtained by forcing the decoder to output real sentences from the target domain; this objective encourages the real and generated target sentences to look similar at a population level.
DING $\mathrm{Fu}$ 等人 (2018) 通过学习源句子的向量编码,使得解码器能够利用该编码重构句子,但判别器 (discriminator) 无法通过该编码识别源属性。他们使用了一个基础的多层感知机 (MLP) 判别器和一个长短期记忆网络 (LSTM) 解码器。MULTIDECODER (Fu 等人, 2018) 与 STYLEEMBEDDING 类似,不同之处在于它为每个属性值使用了不同的解码器。CROSS ALIGNED (Shen 等人, 2017) 同样将源句子编码为向量,但判别器关注的是 RNN 解码器的隐藏状态而非编码本身。该系统通过训练使得判别器无法区分这些隐藏状态与通过强制解码器输出目标域真实句子所获得的隐藏状态;这一目标促使生成的目标句子与真实目标句子在整体分布上看起来相似。
4.4 Experimental Details
4.4 实验细节
For our methods, we use 128-dimensional word vectors and a single-layer GRU with 512 hidden units for both encoders and the decoder. We use the maxout activation function (Goodfellow et al., 2013). All parameters are initialized by sampling from a uniform distribution between $-0.1$ and 0.1. For optimization, we use Adadelta (Zeiler, 2012) with a minibatch size of 256.
在我们的方法中,我们使用128维词向量和具有512个隐藏单元的单层GRU作为编码器和解码器。我们采用maxout激活函数 (Goodfellow et al., 2013)。所有参数通过从$-0.1$到0.1的均匀分布中采样进行初始化。优化方面,我们使用Adadelta (Zeiler, 2012),并设置256的小批量大小。
For attribute marker extraction, we consider spans up to 4 words, and the smoothing parameter $\lambda$ is set to 1. We set the attribute marker threshold $\gamma$ , which controls the precision and recall of our attribute markers, to 15, 5.5 and 5 for YELP, AMAZON, and CAPTIONS. These values were set by manual inspection of the resulting markers and tuning slightly on the dev set. For retrieval, we used the TF-IDF weighted word overlap score for DELETE AND RETRIEVE and TEMPLATE BASED, and the Euclidean distance of content embeddings for RETRIEVE ONLY. We find the two scoring functions give similar results.
在属性标记提取中,我们考虑最多4个词的跨度,并将平滑参数$\lambda$设为1。针对YELP、AMAZON和CAPTIONS数据集,我们分别将控制属性标记精确率与召回率的阈值$\gamma$设置为15、5.5和5。这些数值是通过人工检查生成的标记并在开发集上微调确定的。检索环节中,DELETE AND RETRIEVE和TEMPLATE BASED方法采用TF-IDF加权词重叠分数,RETRIEVE ONLY方法则使用内容嵌入向量的欧氏距离。实验表明两种评分函数效果相近。
For all neural models, we do beam search with a beam size of 10. For DELETE AND RETRIEVE, similar to Guu et al. (2018), we retrieve the top10 sentences and generate results using markers from each sentence. We then select the output with the lowest perplexity given by a separately-trained neural language model on the target-domain training data.
对于所有神经模型,我们采用束搜索 (beam search) ,束宽为10。对于 DELETE AND RETRIEVE 方法,类似 Guu et al. (2018) 的做法,我们检索出前10个句子,并使用每个句子中的标记生成结果。然后根据在目标领域训练数据上单独训练的神经语言模型给出的最低困惑度,选择最终输出。
4.5 Human Evaluation
4.5 人工评估
We hired workers on Amazon Mechanical Turk to rate the outputs of all systems. For each source sentence and target attribute, the same worker was shown the output of each tested system. Workers were asked to rate each output on three criteria on a Likert scale from 1 to 5: grammatical it y, similarity to the target attribute, and preservation of the source content. Finally, we consider a generated output “successful” if it is rated 4 or 5 on all three criteria. For each dataset, we evaluated 400 randomly sampled examples (200 for each target attribute).
我们在Amazon Mechanical Turk上雇佣工作人员对所有系统的输出进行评分。对于每个源句子和目标属性,同一名工作人员会看到每个测试系统的输出结果。工作人员被要求按照1到5的李克特量表从三个维度对每个输出进行评分:语法正确性、与目标属性的相似度以及源内容保留程度。最后,若某生成输出在所有三个维度上都获得4或5分,我们则视其为"成功"输出。针对每个数据集,我们评估了400个随机抽样样本(每个目标属性各200例)。
Table 2 shows the human evaluation results. On all three datasets, both of our baselines have a higher success rate than the previously published models, and DELETE AND RETRIEVE achieves the best performance among all systems. Additionally, we see that human raters strongly preferred the human references to all systems, suggesting there is still significant room for improvement on this task.
表 2 展示了人工评估结果。在所有三个数据集上,我们的两个基线模型都比之前发布的模型具有更高的成功率,其中 DELETE AND RETRIEVE 在所有系统中表现最佳。此外,我们发现人类评估者明显更倾向于人工参考文本而非任何系统输出,这表明该任务仍有显著的改进空间。
We find that a human evaluator’s judgment of a sentence is largely relative to other sentences being evaluated together and examples given in the instruction (different for each dataset/task). Therefore, evaluating all system outputs in one batch is important and results on different datasets are not directly comparable.
我们发现人类评估者对句子的判断很大程度上取决于同时评估的其他句子以及指令中给出的示例(不同数据集/任务有所不同)。因此,批量评估所有系统输出非常重要,且不同数据集的结果不能直接比较。
4.6 Analysis
4.6 分析
We analyze the strengths and weaknesses of the different systems. Table 3 show typical outputs of each system on the YELP and CAPTIONS dataset.
我们分析了不同系统的优缺点。表 3 展示了各系统在 YELP 和 CAPTIONS 数据集上的典型输出。
We first analyze the adversarial methods. CROSS ALIGNED and MULTI DECODER tend to lose the content of the source sentence, as seen in both the example outputs and the overall human ratings. The decoder tends to generate a frequent but only weakly related sentence with the target attribute. On the other hand, STYLEEMBEDDING almost always generates a paraphrase of the input sentence, implying that the encoder preserves some attribute information. We conclude that there is a delicate balance between preserving the original content and dropping the original attribute, and existing adversarial models tend to sacrifice one or the other.
我们首先分析对抗方法。从示例输出和整体人工评分来看,CROSS ALIGNED和MULTI DECODER往往会丢失源句子的内容。解码器倾向于生成一个频繁出现但与目标属性仅弱相关的句子。另一方面,STYLEEMBEDDING几乎总是生成输入句子的改写,这意味着编码器保留了一些属性信息。我们得出结论:在保留原始内容和丢弃原始属性之间存在微妙的平衡,而现有的对抗模型往往会牺牲其中一方。
Next, we analyze our baselines. RETRIEVEONLY scores well on grammatical it y and having the target attribute, since it retrieves sentences with the desired attribute directly from the corpus. However, it is likely to change the content when there is no perfectly aligned sentence in the target domain. In contrast, TEMPLATEBASED is good at preserving the content because the content words are guaranteed to be kept. However, it makes grammatical mistakes due to the unsmoothed combination of content and attribute words.
接下来,我们分析基线模型的表现。RETRIEVEONLY 在语法性和目标属性匹配上得分较高,因为它直接从语料库中检索具有所需属性的句子。然而,当目标域中没有完全匹配的句子时,它很可能会改变内容。相比之下,TEMPLATEBASED 擅长保留内容,因为内容词被确保保留。但由于内容和属性词的生硬组合,它会出现语法错误。
DELETE AND RETRIEVE and DELETEONLY achieve a good balance among grammatical it y, preserving content, and changing the attribute. Both have strong inductive bias on what words should be changed, but still have the flexibility to smooth out the sentence. The main difference is that DELETEONLY fills in attribute words based on only the target attribute, whereas DELETEAND RETRIEVE conditions on retrieved attribute words. When there is a diverse set of phrases to fill in—for example in CAPTIONS— conditioning on retrieved attribute words helps generate longer sentences with more specific attribute descriptions.
DELETE AND RETRIEVE 和 DELETEONLY 在语法性、内容保留和属性修改之间实现了良好平衡。两者对需要修改的词语都有较强的归纳偏置,但仍具备灵活调整句子的能力。主要区别在于:DELETEONLY 仅基于目标属性填充属性词,而 DELETE AND RETRIEVE 则以检索到的属性词为条件。当需要填充的短语具有多样性时(例如在 CAPTIONS 场景中),以检索到的属性词为条件有助于生成包含更具体属性描述的长句。
4.7 Automatic Evaluation
4.7 自动评估
Following previous work (Hu et al., 2017; Shen et al., 2017), we also compute automatic evaluation metrics, and compare these numbers to our human evaluation results.
遵循先前工作 (Hu et al., 2017; Shen et al., 2017) ,我们同样计算了自动评估指标,并将这些数值与人工评估结果进行对比。
We use an attribute classifier to assess whether outputs have the desired attribute (Hu et al., 2017; Shen et al., 2017). We define the classifier score as the fraction of outputs classified as having the target attribute. For each dataset, we train an attribute classifier on the same training data. Specifically, we encode the sentence into a vector by a bidirectional LSTM with an average pooling layer over the outputs, and train the classifier by minimizing the logistic loss.
我们使用一个属性分类器来评估输出是否具有所需属性 (Hu et al., 2017; Shen et al., 2017)。我们将分类器分数定义为被分类为具有目标属性的输出比例。对于每个数据集,我们在相同的训练数据上训练一个属性分类器。具体来说,我们通过一个双向 LSTM (长短期记忆网络) 将句子编码为向量,并在输出上使用平均池化层,然后通过最小化逻辑损失来训练分类器。
We also compute BLEU between the output and the human references, similar to Gan et al. (2017). A high BLEU score primarily indicates that the system can correctly preserve content by retaining the same words from the source sentence as the reference. One might also hope that it has some correlation with fluency, though we expect this correlation to be much weaker.
我们还计算了输出结果与人工参考译文之间的BLEU值,这与Gan等人 (2017) 的方法类似。较高的BLEU分数主要表明系统能够通过保留源句中与参考译文相同的单词来正确保持内容。虽然人们可能希望它与流畅性有一定相关性,但我们预计这种相关性会弱得多。
Table 4 shows the classifier and BLEU scores. In Table 5, we compute the system-level correlation between classifier score and human judgments of attribute transfer, and between BLEU and human judgments of content preservation and grammatical it y. We also plot scores given by the automatic metrics and humans in Figure 4. While the scores are sometimes well-correlated, the results vary significantly between datasets; on AMAZON, there is no correlation between the classifier score and the human evaluation. Manual inspection shows that on AMAZON, some product genres are associated with either mostly positive or mostly negative reviews. However, our systems produce, for example, negative reviews about products that are mostly discussed positively in the training set. Therefore, the classifier often gives unreliable predictions on system outputs. As expected, BLEU does not correlate well with human grammatical it y ratings. The lack of automatic fluency evaluation artificially favors systems like TEMPLATE BASED, which make more grammatical mistakes. We conclude that while these automatic evaluation methods are useful for model development, they cannot replace human evaluation.
表 4 展示了分类器和 BLEU 分数。在表 5 中,我们计算了分类器分数与人工属性迁移评分之间的系统级相关性,以及 BLEU 分数与人工内容保留和语法评分之间的相关性。图 4 中还绘制了自动指标与人工评分的对比。虽然分数有时相关性较好,但不同数据集的结果差异显著:在 AMAZON 数据集上,分类器分数与人工评估完全无相关性。人工检查发现,AMAZON 上某些产品类别的评价几乎全是正面或负面,而我们的系统却会生成与训练集主流评价相反的评论(例如对以正面评价为主的产品生成负面评论),导致分类器对系统输出的预测不可靠。正如预期,BLEU 与人工语法评分相关性不佳,这种自动流畅度评估的缺失会人为偏向 TEMPLATE BASED 等语法错误更多的系统。我们得出结论:虽然这些自动评估方法对模型开发有帮助,但无法替代人工评估。
4.8 Trading off Content versus Attribute
4.8 内容与属性的权衡
One advantage of our methods is that we can control the trade-off between matching the target attribute and preserving the source content. To achieve different points along this trade-off curve,
我们的方法有一个优势,就是可以控制匹配目标属性和保留源内容之间的权衡。为了实现这条权衡曲线上不同的点,
| 来源 | 内容 |
|---|---|
| SOURCE | 我们坐下后,得到了非常缓慢和懒散的服务。 |
| CROSSALIGNED | 我们下去后,得到了美味又友好的食物。 |
| STYLEEMBEDDING | 我们坐下后,得到了非常缓慢的服务,而且价格很糟糕。 |
| MULTIDECODER | 我们坐下后,得到了一些非常快的快餐。 |
| TEMPLATEBASED | 我们坐下后,得到的服务总是很棒,甚至更好。 |
| RETRIEVEONLY | 我点了一个巨大的素食三明治,还享受了A级客户服务。 |
| DELETEONLY | 我们坐下后,得到了很棒且快速的服务。 |
| DELETEANDRETRIEVE | 我们找到了一个非常舒适的座位,并得到了一些服务。 |
| 来源 | 内容 |
|---|---|
| SOURCE | 两只狗在树旁玩耍。 |
| CROSSALIGNED | 一只狗正在草地上奔跑。 |
| STYLEEMBEDDING | 两只狗在树旁玩耍。 |
| MULTIDECODER | 两只狗在树旁玩耍。 |
| TEMPLATEBASED | 两只狗在树旁玩耍,充满爱意。 |
| RETRIEVEONLY | 两只狗在泳池里玩耍,像最好的朋友一样。 |
| DELETEANDRETRIEVE | 两只狗在树旁玩耍,享受着童年的快乐。 |
| DELETEONLY | 两只相爱的狗在树旁快乐地玩耍。 |
| 来源 | 内容 |
|---|---|
| SOURCE | 这是我很久以来遇到的最糟糕的游戏。 |
| CROSSALIGNED | 这是我几年来拥有的最好的东西。 |
| STYLEEMBEDDING | 这是我很久以来遇到的最糟糕的游戏。 |
| MULTIDECODER | 这是我很久以来拥有的最好的刀,没有空间。 |
| TEMPLATEBASED | 这是我很久以来遇到的最好的。 |
| RETRIEVEONLY | 客户服务是我很久以来遇到的最好的之一。 |
| DELETEONLY | 这是我很久以来遇到的最好的游戏。 |
| DELETEANDRETRIEVE | 这是我很久以来遇到的最好的游戏。 |
Table 3: Example outputs on YELP, CAPTIONS, and AMAZON. Additional examples for transfer from opposite directions are given in Table 6. Added or changed words are in italic. Attribute markers are colored.
表 3: YELP、CAPTIONS 和 AMAZON 上的示例输出。表 6 中提供了反向迁移的更多示例。添加或更改的单词以斜体显示。属性标记已着色。
| YELP | CAPTIONS | AMAZON | |
|---|---|---|---|
| Classifier | BLEU | Classifier | |
| CROSSALIGNED | 73.7% | 3.1 | 74.3% |
| STYLEEMBEDDING | 8.7% | 11.8 | 54.7% |
| MULTIDECODER | 47.6% | 7.1 | 68.5% |
| TEMPLATEBASED | 81.7% | 11.8 | 92.5% |
| RETRIEVEONLY | 95.4% | 0.4 | 95.5% |
| DELETEONLY | 85.7% | 7.5 | 83.0% |
| DELETEANDRETRIEVE | 88.7% | 8.4 | 96.8% |
Table 4: Automatic evaluation results. “Classifier” shows the percentage of sentences labeled as the target attribute by the classifier. BLEU measures content similarity between the output and the human reference.
表 4: 自动评估结果。"Classifier"表示分类器将句子标记为目标属性的百分比。BLEU衡量输出与人工参考之间的内容相似度。
we simply vary the threshold $\gamma$ (Section 3.1) at test time to control how many attribute markers we delete from the source sentence. In contrast, other methods (Shen et al., 2017; Fu et al., 2018) would require retraining the model with different hyper parameters to achieve this effect.
我们只需在测试时调整阈值 $\gamma$ (见第3.1节) 来控制从源句中删除多少属性标记。相比之下,其他方法 (Shen et al., 2017; Fu et al., 2018) 需要通过不同超参数重新训练模型才能达到相同效果。
Figure 3 shows this trade-off curve for DELETE AND RETRIEVE, DELETEONLY, and TEMPLATE BASED on YELP, where target attribute match is measured by the classifier score and content preservation is measured by BLEU.3
图 3: 展示了 YELP 数据集上 DELETE AND RETRIEVE、DELETE ONLY 和 TEMPLATE BASED 方法的权衡曲线,其中目标属性匹配通过分类器得分衡量,内容保留通过 BLEU 分数衡量。
We see a clear trade-off between changing the attribute and retaining the content.
我们看到了改变属性和保留内容之间的明显权衡。
5 Related Work and Discussion
5 相关工作与讨论
Our work is closely related to the recent body of work on text attribute transfer with unaligned data, where the key challenge to disentangle attribute and content in an unsupervised way. Most existing work (Shen et al., 2017; Zhao et al., 2018; Fu et al., 2018; Melnyk et al., 2017) uses adversarial training to separate attribute and content: the content encoder aims to fool the attribute disc rim in at or by removing attribute information from the content embedding. However, we find that empirically it is often easy to fool the disc rim in at or without ac
我们的工作与近期利用非对齐数据进行文本属性迁移的研究密切相关,其核心挑战在于以无监督方式分离属性与内容。现有大多数工作 [20][21][22][23] 采用对抗训练实现属性-内容分离:内容编码器通过从内容嵌入中去除属性信息,旨在欺骗属性判别器。但实证表明,模型往往能轻易欺骗判别器而无需实际...
| 分类器 | BLEU | |||
|---|---|---|---|---|
| 属性 | 内容 | 语法性 | ||
| 所有数据 | 0.810 (p < 0.01) | 0.876 (p < 0.01) | -0.127 (p = 0.58) | |
| YELP | 0.991 | (p < 0.01) | 0.9355 (p < 0.01) | 0.119 (p = 0.80) |
| CAPTIONS | 0.982 | 2(p < 0.01) | 0.991 (p < 0.01) | -0.631 (p = 0.13) |
| AMAZON | -0.036 | (p = 0.94) | 0.8577(p < 0.01) | 0.306 (p = 0.50) |
Table 5: Spearman correlation between two automatic evaluation metrics and related human evaluation scores. While some correlations are strong, the classifier exhibits poor correlation on AMAZON, and BLEU only measures content, not grammatical it y.
表 5: 两种自动评估指标与相关人工评分之间的Spearman相关性。虽然部分相关性较强,但分类器在AMAZON数据集上表现较差,且BLEU仅衡量内容而非语法正确性。

Figure 3: Trade-off curves between matching the target attribute (measured by classifier scores) and preserving the content (measured by BLEU). Bigger points on the curve correspond to settings used for both training and our official evaluation.
图 3: 目标属性匹配度 (通过分类器得分衡量) 与内容保留度 (通过 BLEU 衡量) 之间的权衡曲线。曲线上较大的点对应训练阶段和官方评估阶段共同采用的参数设置。
tually removing the attribute information. Therefore, we explicitly separate attribute and content by taking advantage of the prior knowledge that the attribute is localized to parts of the sentence.
实际上移除属性信息。因此,我们利用属性信息集中于句子部分这一先验知识,显式地将属性和内容分离。
To address the problem of unaligned data, Hu et al. (2017) relies on an attribute classifier to guide the generator to produce sentences with a desired attribute (e.g. sentiment, tense) in the Variation al Auto encoder (VAE) framework. Similarly, Zhao et al. (2018) used a regularized autoencoder in the adversarial training framework; however, they also find that these models require extensive hyper parameter tuning and the content tends to be changed during the transfer. Shen et al. (2017) used a disc rim in at or to align target sentences and sentences transfered to the target domain from the source domain. More recently, unsupervised machine translation models (Artetxe et al., 2017; Lample et al., 2017) used a cycle loss similar to Jun-Yan et al. (2017) to ensure that the content is preserved during the transformation. These methods often rely on bilinguial word vectors to provide word-for-word translations, which are then finetune by back-translation. Thus they can be used to further improve our results.
为解决数据未对齐的问题,Hu等人(2017)在变分自编码器(VAE)框架中,依靠属性分类器引导生成器产生具有所需属性(如情感、时态)的句子。类似地,Zhao等人(2018)在对抗训练框架中使用了正则化自编码器;但他们也发现这些模型需要大量超参数调优,且在转换过程中内容易被改变。Shen等人(2017)使用判别器来对齐目标句子和从源域转换到目标域的句子。最近,无监督机器翻译模型(Artetxe等人,2017;Lample等人,2017)采用了类似Jun-Yan等人(2017)的循环损失来确保转换过程中内容得以保留。这些方法通常依赖双语词向量提供逐词翻译,再通过回译进行微调。因此它们可用于进一步提升我们的结果。
Our method of detecting attribute markers is reminiscent of Naive Bayes, which is a strong baseline for tasks like sentiment classification (Wang and Manning, 2012). Deleting these attribute markers can be viewed as attacking a Naive Bayes classifier by deleting the most informative features (Globerson and Roweis, 2006), similarly to how adversarial methods are trained to fool an attribute classifier. One difference is that our classifier is fixed, not jointly trained with the model.
我们检测属性标记的方法让人联想到朴素贝叶斯 (Naive Bayes) ,后者是情感分类等任务的强基线 (Wang and Manning, 2012) 。删除这些属性标记可视为通过删除最具信息量的特征来攻击朴素贝叶斯分类器 (Globerson and Roweis, 2006) ,类似于对抗训练方法通过愚弄属性分类器来提升模型鲁棒性。不同之处在于我们的分类器是固定的,并未与模型联合训练。
To conclude, we have described a simple method for text attribute transfer that outperforms previous models based on adversarial training. The main leverage comes from the inductive bias that attributes are usually manifested in localized disc rim i native phrases. While many prior works on linguistic style analysis confirm our observation that attributes often manifest in idiosyncratic phrases (Recasens et al., 2013; Schwartz et al., 2017; Newman et al., 2003), we recognize the fact that in some problems (e.g., Pavlick and Tetreault (2017)), content and attribute cannot be so cleanly separated along phrase boundaries. Looking forward, a fruitful direction is to develop a notion of attributes more general than $n$ -grams, but with more inductive bias than arbitrary latent vectors.
总结来说,我们提出了一种简单的文本属性迁移方法,其性能优于以往基于对抗训练的模型。该方法的核心优势源于归纳偏置 (inductive bias) —— 属性通常体现在局部判别性短语中。虽然许多先前关于语言风格分析的研究 (如 Recasens 等人 [2013]、Schwartz 等人 [2017]、Newman 等人 [2003]) 也证实了属性常通过特定短语显现这一观察,但我们认识到在某些问题中 (例如 Pavlick 和 Tetreault [2017] 的研究),内容与属性无法沿短语边界完全分离。展望未来,一个富有前景的方向是建立比 $n$-gram 更普适、同时比任意隐向量更具归纳偏置的属性表征方法。
Reproducibility. All code, data, and experiments for this paper are available on the CodaLab platform at https://worksheets. codalab.org/worksheets/ 0xe3eb416773ed4883bb737662b31b4948/.
可复现性。本文的所有代码、数据和实验均可在CodaLab平台上获取,地址为:https://worksheets.codalab.org/worksheets/0xe3eb416773ed4883bb737662b31b4948/。
Acknowledgements. This work is supported by the DARPA Communicating with Computers (CwC) program under ARO prime contract no. W911NF- 15-1-0462. J.L. is supported by Tencent. R.J. is supported by an NSF Graduate Research Fellowship under Grant No. DGE-114747.
致谢。本研究由DARPA计算机通信(CwC)项目资助(ARO主合同号W911NF-15-1-0462)。J.L.获得腾讯公司支持。R.J.获得美国国家科学基金会研究生研究奖学金资助(资助号DGE-114747)。
Table 6: Additional example outputs on YELP, CAPTIONS, and AMAZON. Added or changed words are in italic. Attribute markers are colored.
| 来源 | 内容 |
|---|---|
| 从正面到负面 (YELP) | |
| SOURCE | 我丈夫点了一份鲁宾三明治,他很喜欢。 |
| CROSSALIGNED | 我丈夫点了一份开胃三明治,但她搞错了。 |
| STYLEEMBEDDING | 我丈夫点了一份超棒的三明治,他很喜欢。 |
| MULTIDECODER | 我丈夫点了一份基础款三明治,不过被我忽略了。 |
| TEMPLATEBASED | 我丈夫点了一份鲁宾三明治,但我不在乎。 |
| RETRIEVEONLY | 我点了俱乐部三明治,我妈妈点了鸡肉沙拉三明治。 |
| DELETEONLY | 我丈夫点了一份鲁宾三明治,结果难吃死了! |
| DELETEANDRETRIEVE | 我丈夫点了一份鲁宾三明治,但太干了。 |
| 从事实陈述到幽默表达 (CAPTIONS) | |
| SOURCE CROSSALIGNED | 一只黑白相间的狗正在浅水中奔跑。 |
| STYLEEMBEDDING | 两只狗在田野上玩耍争夺水源。 |
| 一只黑白相间的狗正在浅水中奔跑。 | |
| MULTIDECODER | 一只黑白相间的狗正在长满草的浅水中奔跑。 |
| TEMPLATEBASED | 一只黑白相间的狗正在浅水中奔跑寻找着什么。 |
| RETRIEVEONLY | 一只黑白相间的狗正在雪地里缓慢奔跑。 |
| DELETEANDRETRIEVE | 一只黑白相间的狗正在浅水中奔跑寻找骨头。 |
| DELETEONLY | 一只黑白相间的狗像鱼一样在浅水中奔跑。 |
| 从正面到负面 (AMAZON) | |
| SOURCE | 我绝对推荐这个可爱的手机壳。 |
| CROSSALIGNED | 我很长时间都不会推荐这个。 |
| STYLEEMBEDDING | 我绝对推荐这个可爱的手机壳。 |
| MULTIDECODER | 我绝对推荐这款胸罩。 |
| TEMPLATEBASED | 跳过这个可爱的手机壳吧。 |
| RETRIEVEONLY | 可爱是可爱但用不久...所以如果你想要一个NUM床头柜手机壳,这款适合你。 |
| DELETEONLY | 我不会推荐这个可爱的手机壳。 |
| DELETEANDRETRIEVE | 我不会推荐这个可爱的手机壳。 |
表 6: YELP、CAPTIONS和AMAZON数据集上的额外输出示例。新增或修改的单词用斜体表示。属性标记已着色。

Figure 4: Scatter plots of humans scores vs. automatic metric scores on attribute transfer, content preservation, and grammatical it y. The automatic metrics have some correlation with the attribute transfer and content preservation ratings, though results vary across datasets; the metrics do not measure grammaticality.
图 4: 人类评分与自动指标评分在属性迁移 (attribute transfer) 、内容保留 (content preservation) 和语法正确性 (grammaticality) 上的散点图。自动指标与属性迁移和内容保留评分存在一定相关性 (但不同数据集结果存在差异) ;这些指标无法衡量语法正确性。