PAtt-Lite: Lightweight Patch and Attention MobileNet for Challenging Facial Expression Recognition
PAtt-Lite: 轻量级补丁与注意力MobileNet用于挑战性面部表情识别
This research is supported by Telekom Malaysia Research & Development under grant number RDTC/231084 and Deanship of Scientific Research, King Khalid University, Saudi Arabia, under Grant number RGP2/332/44.
本研究由马来西亚电信研发部 (Telekom Malaysia Research & Development) 资助 (项目编号: RDTC/231084) 以及沙特阿拉伯哈立德国王大学科研部 (Deanship of Scientific Research, King Khalid University) 资助 (项目编号: RGP2/332/44)。
ABSTRACT Facial Expression Recognition (FER) is a machine learning problem that deals with recognizing human facial expressions. While existing work has achieved performance improvements in recent years, FER in the wild and under challenging conditions remains a challenge. In this paper, a lightweight patch and attention network based on Mobile Ne tV 1, referred to as PAtt-Lite, is proposed to improve FER performance under challenging conditions. A truncated ImageNet-pre-trained Mobile Ne tV 1 is utilized as the backbone feature extractor of the proposed method. In place of the truncated layers is a patch extraction block that is proposed for extracting significant local facial features to enhance the representation from Mobile Ne tV 1, especially under challenging conditions. An attention classifier is also proposed to improve the learning of these patched feature maps from the extremely lightweight feature extractor. The experimental results on public benchmark databases proved the effectiveness of the proposed method. PAttLite achieved state-of-the-art results on $\mathrm{CK}+$ , RAF-DB, FER2013, FERPlus, and the challenging conditions subsets for RAF-DB and FERPlus.
摘要 面部表情识别(FER)是一项通过机器学习识别人类面部表情的技术。尽管现有研究近年来取得了性能提升,但在复杂环境和挑战性条件下的FER仍存在困难。本文提出了一种基于MobileNetV1的轻量级局部特征与注意力网络(PAtt-Lite),用于提升挑战性条件下的FER性能。该方法采用截断的ImageNet预训练MobileNetV1作为主干特征提取器,并在截断层位置设计了局部特征提取模块,用于捕获关键的面部局部特征以增强MobileNetV1的表征能力,特别是在挑战性条件下。同时提出了注意力分类器来优化从极轻量级特征提取器获得的局部特征图学习。在公开基准数据集上的实验结果验证了该方法的有效性,PAtt-Lite在$\mathrm{CK}+$、RAF-DB、FER2013、FERPlus等数据集,以及RAF-DB和FERPlus的挑战性子集上均取得了最先进的性能。
INDEX TERMS Facial Expression Recognition, Mobile Ne tV 1, Patch Extraction, Self-Attention.
索引术语 面部表情识别 (Facial Expression Recognition), Mobile Ne tV 1, 区块提取 (Patch Extraction), 自注意力机制 (Self-Attention)。
I. INTRODUCTION
I. 引言
F pAeCcIt AofL neo x np vre ers bsi alo nh uism aan c coo mm pml eux n iacantdi ofna stchiant aitinnvgol vaess- a range of facial muscle movements. These changes can convey a wide range of emotions and mental states, including happiness, sadness, anger, surprise, fear, and disgust. Given the importance of facial expressions in communication, it is not surprising that there has been a growing interest in automated facial expression recognition (FER) technology. FER has the potential to revolutionize a wide range of fields, from education to healthcare. For example, FER could be used in educational settings to measure the effectiveness and quality of teaching [1], [2], or in healthcare settings to assist in the analysis of the psychological condition of a patient [3], [4]. Along with the advances made in GPU technology, the enormous potential for downstream applications of FER also contributed to its increasing popularity.
面部表情是人类非语言交流的重要组成部分,涉及一系列面部肌肉运动。这些变化能传递丰富的情感和心理状态,包括快乐、悲伤、愤怒、惊讶、恐惧和厌恶。鉴于面部表情在沟通中的重要性,人们对自动化面部表情识别(FER)技术日益增长的兴趣也就不足为奇了。FER技术具有革新多个领域的潜力,从教育到医疗保健均有应用场景。例如,在教育领域可用于衡量教学效果与质量[1][2],在医疗场景中则能辅助分析患者心理状况[3][4]。随着GPU技术的进步,FER在下游应用中的巨大潜力也推动了其日益普及。
The main challenges that FER poses differently from other image classification tasks are the inter-class similarities and intra-class differences in human facial expressions. Interclass similarities refer to the subtle differences between facial expressions, which makes it difficult to highlight the small differences between facial expressions and recognize them correctly. On the other hand, intra-class differences, also known as subject variability, refer to the characteristic of FER databases that images from an expression class are made up of different subjects with different facial structures, gender, age, and race. This variability can hinder the learning performance of a solution, as the model may struggle to generalize across different subjects, leading to reduced accuracy and reliability. For example, the differences between an angry face and a disgusted face may be minimal, whereas the differences between two different individuals within the same expression class can be quite significant.
面部表情识别 (FER) 与其他图像分类任务的主要区别在于人类面部表情的类间相似性和类内差异性。类间相似性指不同表情之间的细微差别,这使得模型难以突出面部表情的微小差异并正确识别。另一方面,类内差异(又称主体变异性)指 FER 数据库中同一表情类别的图像由不同主体组成,这些主体具有不同的面部结构、性别、年龄和种族。这种变异性会阻碍模型的学习性能,因为模型可能难以泛化到不同主体,导致准确性和可靠性下降。例如,愤怒表情和厌恶表情之间的差异可能微乎其微,而同一表情类别下两个不同个体之间的差异却可能十分显著。
In addition, existing work has exposed other FER challenges on in-the-wild databases, namely the recognition of negative expressions, FER under challenging conditions, and reliance on large neural networks. The scarcity of negative expression images on the Internet has made it difficult to collect a representative database that can reflect real-world scenarios. Therefore, it can result in a class imbalance in the in-the-wild FER databases, which can cause the recognition rate of negative expressions to be lower than that of positive expressions. FER under challenging conditions refers to the recognition of facial expressions when the subjects are posed at certain angles or when the subject faces are partially occluded by other objects. The accurate recognition of these samples is important, especially since the challenging conditions are likely conditions identical to the downstream applications. Meanwhile, in the pursuit of classification performance, existing work is also slowly leaning towards large neural networks to achieve these performance improvements. However, considering the computing resources of downstream applications, FER methods should be readily available for these applications without requiring powerful resources.
此外,现有研究揭示了野外数据库上面临的其他FER(面部表情识别)挑战,包括负面表情识别、挑战性条件下的FER以及对大型神经网络的依赖。互联网上负面表情图像的稀缺性导致难以收集能反映真实场景的代表性数据库,这可能造成野外FER数据库中类别不平衡,使得负面表情的识别率低于正面表情。挑战性条件下的FER指的是当受试者以特定角度摆姿势或面部被其他物体部分遮挡时的表情识别。这些样本的准确识别至关重要,特别是因为挑战性条件很可能与下游应用场景完全一致。与此同时,为追求分类性能,现有研究也逐渐倾向于采用大型神经网络来实现性能提升。但考虑到下游应用的计算资源,FER方法应能在无需强大资源的情况下适用于这些应用场景。
In this paper, PAtt-Lite, a lightweight patch and attention network is proposed to improve the FER performance under challenging conditions. First, a truncated Mobile Ne tV 1 is employed as the backbone model. A patch extraction block is proposed for the truncated backbone model to enforce the model to extract significant local facial features to classify facial expressions under challenging conditions accurately. It is designed to be lightweight while responsible for splitting the Mobile Ne tV 1 feature maps into 4 non-overlapping regions. A self-attention classifier is proposed for the backbone model to improve the learning of the output feature maps. With a dot product self-attention layer sandwiched between two fully connected layers, the attention classifier is able to learn the patched feature maps better than a vanilla classifier, hence enhancing the performance of the proposed PAtt-Lite under challenging conditions. Finally, to evaluate the performance of the proposed method, one lab-controlled database, i.e., $\mathrm{CK}+$ , and three in-the-wild databases, i.e., RAF-DB, FER2013, and FERPlus are employed as the benchmark databases of this research. Extensive experiments to determine the performance of the proposed method under challenging conditions such as occlusion and posed subjects using the challenging condition subsets introduced by [5] are also conducted.
本文提出了一种轻量级的补丁与注意力网络PAtt-Lite,用于提升挑战性条件下的面部表情识别(FER)性能。首先,采用截断的MobileNetV1作为骨干模型。针对截断后的骨干模型提出了补丁提取模块,强制模型提取显著的面部局部特征,从而在挑战性条件下准确分类面部表情。该模块采用轻量化设计,负责将MobileNetV1特征图划分为4个非重叠区域。为骨干模型设计了自注意力分类器以改善输出特征图的学习效果。通过在两个全连接层之间嵌入点积自注意力层,该注意力分类器能比传统分类器更好地学习补丁特征图,从而提升PAtt-Lite在挑战性条件下的性能表现。最后,采用一个实验室控制数据库($\mathrm{CK}+$)和三个真实场景数据库(RAF-DB、FER2013和FERPlus)作为基准测试集。通过[5]提出的挑战性条件子集,还进行了大量实验来评估该方法在遮挡、摆拍等挑战性条件下的性能表现。
The main contributions of this work are as follows:
本工作的主要贡献如下:
The remaining of this paper is organized as follows. Section 2 reviews related work with a focus on the application of the patch extraction block and the attention mechanism. Section 3 provides an overview of the architecture of the proposed PAtt-Lite, followed by detailed explanations of each module in the proposed solutions. Section 4 introduces the benchmark databases and details the experimental setting of the proposed method, along with an ablation analysis of the modules presented in the solutions, and a comparison of the proposed method with the state-of-the-art. Finally, the conclusion for this paper is included in Section 5.
本文的剩余部分组织如下。第2节回顾了相关工作,重点介绍了补丁提取块 (patch extraction block) 和注意力机制 (attention mechanism) 的应用。第3节概述了所提出的PAtt-Lite架构,随后详细解释了解决方案中各个模块的设计。第4节介绍了基准数据库,详细说明了所提方法的实验设置,并对解决方案中的模块进行了消融分析,同时将所提方法与最先进技术进行了比较。最后,第5节总结了本文内容。
II. RELATED WORK
II. 相关工作
A. CONVOLUTIONAL NEURAL NETWORK
A. 卷积神经网络 (Convolutional Neural Network)
Convolutional Neural Network (CNN) is a class of deep learning models designed to process grid-like data such as images. It employs convolutional layers to automatically detect patterns or features through spatial hierarchies, enabling the network to learn progressively complex information, and pooling layers to reduce dimensionality and computational complexity while maintaining important features. These networks have achieved significant results in computer vision tasks such as image classification, image segmentation, and object detection. The main advantage of CNNs is their ability to learn complex features automatically without the need for manual feature engineering. Besides, CNNs are also highly adaptable to different input sizes while being able to handle complex patterns and data variations.
卷积神经网络 (Convolutional Neural Network, CNN) 是一类专为处理图像等网格化数据而设计的深度学习模型。它通过卷积层自动检测空间层级中的模式或特征,使网络能够逐步学习复杂信息,并利用池化层在保留重要特征的同时降低维度和计算复杂度。这类网络在图像分类、图像分割和目标检测等计算机视觉任务中取得了显著成果。CNN 的主要优势在于无需人工特征工程即可自动学习复杂特征。此外,CNN 能高度适应不同输入尺寸,同时处理复杂模式和数据变化。
With the advancement in GPU technology and the availability of mature deep learning libraries, existing work for FER has focused more on deep learning solutions recently. These solutions often outperform the handcrafted methods, especially in in-the-wild databases. Most of the CNN-based methods, such as [5]–[11], attempt to improve the FER performance by exploiting local information in different ways with their additional modules.
随着GPU技术的进步和成熟深度学习库的出现,现有的FER研究近期更侧重于深度学习解决方案。这些方案通常优于手工设计的方法,尤其是在非受控环境数据库中。大多数基于CNN的方法,例如[5]–[11],都试图通过各自的附加模块以不同方式利用局部信息来提升FER性能。
The development of CNN architectures has brought forward many innovations, including residual connections [12], bottleneck design [12], [13], batch normalization [14] and its alternatives [15], [16], depthwise separable convolutions [17], and many more. However, the architectures that integrate some of these innovations are complex and have a higher number of training parameters, which in turn require larger databases and longer training time. By contrast, the architecture of Mobile Ne tV 1 [17] is simpler and lighter than most of the well-known CNN architectures by comparison. Thus, the ImageNet-pre-trained Mobile Ne tV 1 is selected as the baseline architecture for this research, due to its high performance despite its lightweight and simple architecture. This simple architecture also has provided an easy finetuning process since over fitting and under fitting on the benchmark databases are easy to control with this architecture.
CNN架构的发展带来了许多创新,包括残差连接 [12]、瓶颈设计 [12][13]、批量归一化 (batch normalization) [14] 及其替代方案 [15][16]、深度可分离卷积 (depthwise separable convolutions) [17] 等。然而,整合了部分这些创新的架构往往较为复杂,训练参数量更大,因此需要更大的数据库和更长的训练时间。相比之下,MobileNetV1 [17] 的架构比大多数知名CNN架构更为简洁轻量。由于其在保持轻量简洁架构的同时仍具备高性能,本研究选择ImageNet预训练的MobileNetV1作为基线架构。该简单架构还便于微调,因其能有效控制在基准数据库上的过拟合与欠拟合问题。
The base feature extractor is paired with the proposed patch extraction block as our attempt to improve FER performance under challenging conditions. The patch extraction block is designed to solely extract local features. This distinguishes it from the methods used in [6], [8], [10], which employed patch attention mechanisms. Specifically, the proposed patch extraction is inspired by that of the vision transformer architecture but remains different from its inspiration in terms of implementation details, which will be explained in the next subsection.
基础特征提取器与所提出的补丁提取块相结合,旨在提升在挑战性条件下的面部表情识别(FER)性能。该补丁提取块专为提取局部特征而设计,这与[6]、[8]、[10]中采用补丁注意力机制的方法形成区别。具体而言,所提出的补丁提取方法受视觉Transformer架构启发,但在实现细节上与其灵感来源存在差异,这将在下一小节详细说明。
B. VISION TRANSFORMERS
B. VISION TRANSFORMERS
In recent years, the Transformer architecture has gained increasing attention in various deep learning tasks, particularly natural language processing. It is a type of neural network introduced by [18] that was designed for sequenceto-sequence tasks. The architecture consists of a stacked encoder and/or decoder layers that allow for efficient and scalable processing of large input data while learning even more complex patterns in the data. The vision transformer (ViT) architecture introduced by [19] is a novel approach that adapts the Transformer architecture to computer vision tasks. It divides images into smaller, non-overlapping patches and reshapes them into 1D sequences before processing them as a sequence using a Transformer model. The success of this architecture has also attracted researchers’ attention for the development of ViT alternatives such as DeiT [20] and Swin Transformer [21], [22]. Overall, ViT and its alternatives have achieved state-of-the-art performance on various tasks, including image classification, thus demonstrating the versatility and effectiveness of the Transformer architecture beyond natural language processing.
近年来,Transformer架构在各种深度学习任务中受到越来越多的关注,尤其是在自然语言处理领域。这是一种由[18]提出的神经网络类型,专为序列到序列任务设计。该架构由堆叠的编码器和/或解码器层组成,能够高效且可扩展地处理大规模输入数据,同时学习数据中更复杂的模式。[19]提出的视觉Transformer (ViT) 架构是一种创新方法,将Transformer架构适配到计算机视觉任务中。它将图像划分为较小的、不重叠的图块,并将其重塑为一维序列,然后使用Transformer模型作为序列进行处理。该架构的成功也吸引了研究者们对ViT替代方案的关注,例如DeiT [20]和Swin Transformer [21]、[22]。总体而言,ViT及其替代方案在图像分类等多种任务上实现了最先进的性能,从而证明了Transformer架构在自然语言处理之外的通用性和有效性。
Hence, researchers also have begun to introduce the Transformer or the ViT architecture for FER in recent years [23]–[29], motivated by their performance achieved across different tasks. Based on the results posted in existing work, the application of vision transformers in FER is proven to be useful with $\mathrm{ViT}{+}\mathrm{SE}$ [23] posting the state-of-the-art performance of $99.80%$ mean accuracy across 10 folds on the $\mathrm{CK}+$ database, $\mathrm{POSTER{++}}$ [27] being the best-performing method on the RAF-DB database with $92.21%$ accuracy, and POSTER [25] being the second best-performing method on the FERPlus database by achieving $91.62%$ accuracy. However, this performance often comes with large architectures with significantly more parameters than CNN-based methods. Nevertheless, the raw performance of the ViT architecture also attracted our attention to draw some inspiration for integrating into the Mobile Ne tV 1 backbone for better FER performance.
因此,近年来研究人员也开始将Transformer或ViT架构引入FER领域[23]–[29],这主要得益于它们在不同任务中展现出的优异性能。现有工作表明,视觉Transformer在FER中的应用已被证明是有效的:$\mathrm{ViT}{+}\mathrm{SE}$[23]在$\mathrm{CK}+$数据库上以10折交叉验证取得了99.80%的平均准确率,达到当前最优性能;$\mathrm{POSTER{++}}$[27]以92.21%的准确率成为RAF-DB数据库上表现最佳的方法;POSTER[25]则以91.62%的准确率成为FERPlus数据库上第二优的方法。不过,这些高性能往往伴随着庞大的架构,其参数量远超基于CNN的方法。尽管如此,ViT架构的原始性能仍吸引了我们的注意,我们从中汲取灵感,将其整合到MobileNetV1主干网络中,以期获得更好的FER性能。
Although the patch extraction block is ultimately inspired by ViT, there exist some differences in terms of the imple ment ation details. The first difference is the design and placement of the patch extraction block. The patch extraction mechanism in ViT is a single-layer convolution that is placed at the beginning of the architecture, whereas the patch extraction block in the proposed PAtt-Lite is a multi-layer convo- lution that is placed within the architecture. This placement allows the proposed method to fully utilize the pretrained weights of the backbone Mobile Ne tV 1, which were trained on ImageNet samples of size $224\times224$ . Secondly, ViT splits the input image of size $224\times224$ into 196 non-overlapping patches of size $16\times16$ , whereas PAtt-Lite splits the output feature maps from Mobile Ne tV 1 of size $14\times14$ into 4 non-overlapping patches of size $1\times1$ . The larger receptive regions of the proposed patch extraction block also help the proposed PAtt-Lite in extracting significant and high-level facial features.
尽管补丁提取模块最终受到ViT的启发,但在实现细节上存在一些差异。第一个差异在于补丁提取模块的设计和位置。ViT中的补丁提取机制是位于架构开头的单层卷积,而所提出的PAtt-Lite中的补丁提取模块是位于架构内部的多层卷积。这种布局使得所提出的方法能够充分利用骨干网络MobileNetV1在ImageNet样本(尺寸为$224\times224$)上预训练的权重。其次,ViT将尺寸为$224\times224$的输入图像分割为196个不重叠的$16\times16$补丁,而PAtt-Lite则将MobileNetV1输出的$14\times14$特征图分割为4个不重叠的$1\times1$补丁。所提出的补丁提取模块具有更大的感受野,这也有助于PAtt-Lite提取显著且高层次的面部特征。
The attention mechanism is intended to model the human attention mechanism, by highlighting parts of the input feature while ignoring the others, which enables better learning of the correlation between two input sequences. There are many variations of the attention mechanisms which sport different score functions, like additive attention [30] and dot-product attention [31]. The key component of the Transformer architecture is its self-attention, which is an attention mechanism that relates different positions of the same sequence. In this paper, an attention classifier inspired by the Transformer architecture is proposed to further improve the learning of output feature maps from the modified lightweight feature extractor. Specifically, the proposed attention classifier attempts to replicate the performance of vision transformers without requiring its series of selfattention blocks. Instead, a dot-product self-attention operation is integrated between the fully connected layers of the classifier. Through this design decision, the model can be kept lightweight while retaining high feature extractive and classification performance for FER.
注意力机制旨在模拟人类的注意力机制,通过突出输入特征的部分内容而忽略其他部分,从而更好地学习两个输入序列之间的相关性。注意力机制有多种变体,采用不同的评分函数,如加法注意力 [30] 和点积注意力 [31]。Transformer 架构的核心组件是自注意力 (self-attention),它是一种将同一序列的不同位置关联起来的注意力机制。本文提出了一种受 Transformer 架构启发的注意力分类器,以进一步改进从改进的轻量级特征提取器中学习输出特征图。具体而言,所提出的注意力分类器试图在不使用一系列自注意力块的情况下复现视觉 Transformer 的性能,而是在分类器的全连接层之间集成了一个点积自注意力操作。通过这种设计决策,模型可以保持轻量级,同时为 FER 保留高特征提取和分类性能。
III. METHODOLOGY
III. 方法论
A. OVERVIEW
A. 概述
Fig. 1 illustrates the overall architecture of the proposed PAttLite. The proposed PAtt-Lite is built upon a truncated pretrained Mobile Ne tV 1, combined with the proposed patch extraction block and attention classifier. Specifically, layers after the depthwise convolution of block 9 are truncated. The proposed patch extraction block and attention classifier are added to the truncated backbone model.
图 1 展示了所提出的 PAttLite 整体架构。该方案基于截断的预训练 MobileNetV1 构建,结合了提出的补丁提取模块和注意力分类器。具体而言,在 block 9 的深度卷积层之后截断网络,并将提出的补丁提取模块和注意力分类器添加到截断后的骨干模型中。
Given an image sample, the input will first go into the truncated Mobile Ne tV 1 to leverage the feature-extracting capability of the pre-trained model on the lower-level details of the image. The output feature maps are then used as input for our patch extraction block, where meaningful local features are extracted. The output feature maps from the patch extraction block are in the dimensions of $2\times2\times D$ , where $D$ represents the depth of the feature maps. The attention classifier takes the feature maps that have been global average pooled as input, and outputs the probabilities of the facial expressions.
给定一个图像样本,输入首先会进入截断的MobileNetV1,以利用预训练模型在图像底层细节上的特征提取能力。输出的特征图随后作为我们补丁提取模块的输入,从中提取有意义的局部特征。补丁提取模块输出的特征图维度为$2\times2\times D$,其中$D$表示特征图的深度。注意力分类器将经过全局平均池化的特征图作为输入,输出面部表情的概率。
B. MOBILE NE TV 1
B. MOBILE NE TV 1
CNNs have been used in various computer vision tasks, such as object detection, image classification, and semantic segmentation, with state-of-the-art performance. However, CNNs can be computationally intensive and require large memory footprints, which makes them impractical for deployment on mobile or edge devices. Mobile Ne tV 1 [17] is a family of lightweight CNN architectures designed to be used on mobile and embedded devices. By leveraging depthwise separable convolutions, Mobile Ne tV 1 achieves a significant reduction in the number of model parameters and the number of multiplication and addition operations required for inference (Mult-Adds).
CNN 已被广泛应用于各种计算机视觉任务,如目标检测、图像分类和语义分割,并取得了最先进的性能。然而,CNN 计算密集且需要较大的内存占用,这使得它们难以部署在移动或边缘设备上。MobileNetV1 [17] 是一系列专为移动和嵌入式设备设计的轻量级 CNN 架构。通过利用深度可分离卷积 (depthwise separable convolutions),MobileNetV1 显著减少了模型参数数量以及推理所需的乘加运算量 (Mult-Adds)。

FIGURE 1. Architecture of the proposed PAtt-Lite. The image sample will first go through the truncated Mobile Ne tV 1 for feature extraction, in which the output feature maps will be padded and used as input for the proposed patch extraction block. The output feature maps of dimensions $2\times2\times256$ from the patch extraction block will then be global average pooled before being taken by the attention classifier.
图 1: 提出的 PAtt-Lite 架构。图像样本首先通过截断的 MobileNetV1 进行特征提取,输出的特征图会被填充并作为提出的补丁提取模块的输入。从补丁提取模块输出的 $2\times2\times256$ 维度特征图将经过全局平均池化后,再由注意力分类器处理。
Depthwise separable convolution is a departure from the standard convolutional operation, as they split a standard convolution into two separate operations by performing depthwise convolutions followed by pointwise convolutions. Depthwise convolution is different from conventional convolution in that depthwise convolution applies a single convolutional filter for each input channel, whereas conventional convolution has filters that are as deep as its input. Meanwhile, pointwise convolution can be achieved using the standard convolutional operation by setting the kernel size to 1. Effectively, pointwise convolutions enable the mixing of input channels as conventional convolutions do.
深度可分离卷积 (depthwise separable convolution) 是对标准卷积操作的改进,它将标准卷积拆分为两个独立操作:先进行深度卷积 (depthwise convolution),再进行逐点卷积 (pointwise convolution)。深度卷积与传统卷积的区别在于,前者对每个输入通道单独应用一个卷积核,而后者卷积核的深度与输入通道数相同。逐点卷积可通过将标准卷积核尺寸设为1来实现,其作用与传统卷积类似,能够实现输入通道的混合。
The architecture of Mobile Ne tV 1 is simpler than most of the well-known CNN architectures by comparison. Other than being a lightweight architecture, the absence of complex designs like residual connections and bottleneck layers also contributed to the easiness of finetuning the pre-trained weights on our benchmark databases optimally. Mathematically, the feature extractive process from the truncated MobileNetV1 is formulated as follows:
MobileNetV1 的架构相比大多数知名 CNN 架构更为简单。除了作为轻量级架构外,其未采用残差连接 (residual connections) 和瓶颈层 (bottleneck layers) 等复杂设计,这也使得我们能够更轻松地在基准数据库上对预训练权重进行最优微调。从数学角度,截断版 MobileNetV1 的特征提取过程可表述如下:
$$
X_{F E}=\mathrm{MobileNetV1}(X)
$$
$$
X_{F E}=\mathrm{MobileNetV1}(X)
$$
where $X$ is the original sample image and $X_{F E}$ is the output feature maps from the backbone feature extractor.
其中 $X$ 是原始样本图像,$X_{F E}$ 是主干特征提取器输出的特征图。
C. PATCH EXTRACTION
C. 补丁提取
The key advantage of using a pre-trained CNN for transfer learning is that earlier layers have learned generic features of the training samples, such as the edges, whereas the later layers have learned specific features of training samples. In the context of PAtt-Lite, layers after the depthwise convolution of block 9 are skipped. The patch extraction block is added to better adapt to the FER databases than simply fine-tuning the final layers. This modification to the feature extractor also results in a shorter training period, as a higher learning rate can be used as opposed to when the pre-trained weights are being finetuned.
使用预训练 CNN (Convolutional Neural Network) 进行迁移学习的关键优势在于:浅层网络已学习训练样本的通用特征(如边缘),而深层网络则掌握了样本的特定特征。在 PAtt-Lite 架构中,跳过了第 9 个模块深度卷积后的所有层。相比仅微调最终层,新增的 patch 提取模块能更好地适配 FER (Facial Expression Recognition) 数据库。这种特征提取器的改进还缩短了训练周期——由于无需微调预训练权重,可采用更高的学习率。
Our proposed patch extraction block consists of three different convolutional layers, the first two being depthwise separable convolutional layers and the last being a pointwise convolutional layer. Operating on feature maps from the Mobile Ne tV 1 that are padded to the dimension of $16\times16$ , the first separable convolutional layer is responsible for splitting the feature maps into four patches while learning higher-level features from its input. Subsequently, the second separable convolutional layer and the pointwise convolutional layer are responsible for learning the higher-level features from the patched feature maps, resulting in output with a dimension of $2\times2$ . Instead of the standard convolutional layer used in conventional CNNs, the depthwise separable convolutional layer is selected for PAtt-Lite. This design decision improves the classification performance of the proposed method on challenging subsets while reducing the number of model parameters.
我们提出的补丁提取块由三个不同的卷积层组成,前两层是深度可分离卷积层,最后一层是逐点卷积层。该模块处理来自MobileNetV1、填充至$16×16$维度的特征图,其中第一层可分离卷积负责将特征图分割为四个补丁,同时从输入中学习更高层次特征。随后,第二层可分离卷积与逐点卷积层负责从分块后的特征图中学习高级特征,最终输出$2×2$维度的结果。PAtt-Lite选用深度可分离卷积层替代传统CNN的标准卷积层,这一设计在降低模型参数量的同时,提升了该方法在复杂子集上的分类性能。
The design process of the patch extraction block started with a grid search for the optimum Mobile Ne tV 1 output layer with the number of patches for the patch extraction block. The baseline block consisted of a convolutional layer and a pointwise convolutional layer, which is retained in the final design. Our grid search has experimented with five convolutional kernel sizes, which are 3, 4, 5, 7, 8, and all layers of Mobile Ne tV 1 with the feature map size of $2\times2\times D$ . The summary of these experiments is included in Table 5.
块提取模块的设计过程始于对最佳Mobile Ne tV 1输出层与块提取模块中块数量的网格搜索。基础模块包含一个卷积层和一个逐点卷积层,这一结构在最终设计中得以保留。我们尝试了五种卷积核尺寸(3、4、5、7、8)以及Mobile Ne tV 1所有特征图尺寸为$2\times2\times D$的层级进行网格搜索。相关实验总结见表5。
The baseline patch extraction block is then redesigned based on the optimum patch size and output layer. With the pointwise convolutional layer kept as is, the first convolutional layer was swapped out for a separable convolutional layer, which has a significantly smaller number of parameters while still providing the same spatial and channel convolution. Meanwhile, another separable convolutional layer was added to the patch extraction block to keep the number of patches constant while removing the need for a larger convolutional kernel. Thus, we arrived at our final design for the patch extraction block.
随后基于最佳补丁大小和输出层重新设计了基准补丁提取块。在保持逐点卷积层不变的情况下,将第一个卷积层替换为可分离卷积层,该层的参数量显著减少,同时仍提供相同的空间和通道卷积。此外,还在补丁提取块中添加了另一个可分离卷积层,以保持补丁数量恒定,同时无需使用更大的卷积核。由此,我们得出了补丁提取块的最终设计方案。
D. GLOBAL AVERAGE POOLING
D. 全局平均池化 (Global Average Pooling)
Global average pooling (GAP) is a technique that was first introduced in [32] to address the problem of over fitting in CNNs. GAP is a type of pooling operation that computes a single value for each feature map by taking the average of all the values in that map. Unlike conventional pooling operations, which reduce the spatial resolution of feature maps, GAP is normally applied at the end of a CNN architecture.
全局平均池化 (GAP) 是一种首次在 [32] 中提出的技术,用于解决 CNN 中的过拟合问题。GAP 是一种池化操作,通过计算特征图中所有值的平均值来为每个特征图生成单一值。与降低特征图空间分辨率的传统池化操作不同,GAP 通常应用于 CNN 架构的末端。
The application of GAP can result in a much smaller output volume, with the output value also acting as a confidence map for each category that CNN is trained to recognize.
GAP的应用可以显著减小输出体积,其输出值同时作为CNN训练识别每个类别的置信度图。
GAP in the proposed PAtt-Lite is responsible for averaging the patch representation from our patch extraction block, which removes the need of flattening the feature maps and feeding them into fully connected layers, hence resulting in a slight reduction in the number of parameters while further minimizing the possibility of over fitting.
所提出的PAtt-Lite中的GAP负责对来自补丁提取块的补丁表示进行平均处理,这样无需将特征图展平并输入全连接层,从而在略微减少参数数量的同时进一步降低了过拟合的可能性。
Let $X_{P E}$ be the output feature maps from the patch extraction block and $\bar{X}_{P E}$ be the output from the GAP operation, this operation can be represented with the equation as follows:
设 $X_{P E}$ 为补丁提取模块输出的特征图,$\bar{X}_{P E}$ 为全局平均池化 (GAP) 操作后的输出,该操作可用以下等式表示:
$$
\bar{X}{P E}=\mathbf{G}\mathbf{A}\mathbf{P}(X_{P E})
$$
$$
\bar{X}{P E}=\mathbf{G}\mathbf{A}\mathbf{P}(X_{P E})
$$
E. ATTENTION CLASSIFIER
E. 注意力分类器
An attention classifier is introduced in the proposed method for better learning of representation from the backbone MobileNetV1 and the patch extraction block. The attention classifier comprises a dot-product [31] self-attention [33] layer placed between two fully connected layers of the newly added classifier.
所提方法引入了注意力分类器,以更好地从主干网络MobileNetV1和块提取模块中学习表征。该注意力分类器由点积[31]自注意力[33]层构成,置于新增分类器的两个全连接层之间。
Dot product attention is a specific type of self-attention mechanism where the attention weights are computed as a dot product between the query vector and the key vector, divided by the square root of the dimension of the key vectors. Selfattention, also known as intra-attention in [33], is a mechanism that allows a neural network to focus on specific parts of its input during computation selectively. The idea behind self-attention is to allow the network to learn a set of attention weights that indicate how important each input element is to the output of the network. It has become a popular technique in natural language processing and computer vision tasks as it can help improve performance by selectively attending to the most relevant parts of the input.
点积注意力 (dot product attention) 是一种特定的自注意力机制,其注意力权重通过查询向量与键向量的点积除以键向量维度的平方根计算得出。自注意力 (self-attention) 在文献 [33] 中也被称为内部注意力 (intra-attention),该机制使神经网络能够在计算过程中选择性地聚焦于输入的特定部分。其核心思想是让网络学习一组注意力权重,用以表征每个输入元素对网络输出的重要程度。作为自然语言处理与计算机视觉任务中的常用技术,它通过选择性地关注输入中最相关的部分来提升模型性能。
Let $Q,K$ , and $V$ be the query, key, and value vectors, respectively, and $d_{q}::=::d_{k}$ . The dot-product self-attention score can be computed as follows:
设 $Q$、$K$ 和 $V$ 分别为查询 (query)、键 (key) 和值 (value) 向量,且 $d_{q}::=::d_{k}$。点积自注意力 (dot-product self-attention) 分数可按如下方式计算:
$$
{\mathrm{Attention}}(Q,K,V)=\operatorname{softmax}({\frac{Q K^{T}}{\sqrt{d_{q}}}})V
$$
$$
{\mathrm{Attention}}(Q,K,V)=\operatorname{softmax}({\frac{Q K^{T}}{\sqrt{d_{q}}}})V
$$
where $d_{k}$ is the dimensionality of the key vectors. The softmax function is applied to the dot-product similarity scores to obtain a set of attention weights that sum up to 1. These weights are used to compute a weighted sum of the value vectors, resulting in the final attention output. Hence, together with the fully connected layers, the attention classifier can be represented with the following equations:
其中 $d_{k}$ 是键向量的维度。对点积相似度分数应用 softmax 函数得到一组总和为 1 的注意力权重,这些权重用于计算值向量的加权和,最终得到注意力输出。因此,结合全连接层,注意力分类器可用以下方程表示:
$$
X_{R}=\mathrm{ReLU}(\bar{X}_{P E})
$$
$$
X_{R}=\mathrm{ReLU}(\bar{X}_{P E})
$$
Let $Q,K$ , and $V$ be the query, key, and value vectors computed from the input vector $X_{R}$ , the final attention output, $X_{A}$ can be computed as follows:
设 $Q$、$K$ 和 $V$ 为由输入向量 $X_{R}$ 计算得到的查询(query)、键(key)和值(value)向量,最终注意力输出 $X_{A}$ 可按如下方式计算:
$$
\begin{array}{c}{{X_{A}=\mathrm{Attention}(Q,K,V)}}\ {{\phantom{X_{A}=}}}\ {{Y=\mathrm{softmax}(X_{A})}}\end{array}
$$
$$
\begin{array}{c}{{X_{A}=\mathrm{Attention}(Q,K,V)}}\ {{\phantom{X_{A}=}}}\ {{Y=\mathrm{softmax}(X_{A})}}\end{array}
$$
where $\bar{X}{P E}$ is the output values from GAP, $X_{R}$ is the output values from the first fully connected layer with ReLU activation function, and $Y$ represents the predicted target label as output from the final fully connected layer with softmax activation function.
其中 $\bar{X}{P E}$ 是全局平均池化 (GAP) 的输出值,$X_{R}$ 是带 ReLU 激活函数的第一全连接层的输出值,$Y$ 表示带 softmax 激活函数的最终全连接层输出的预测目标标签。
IV. EXPERIMENTS AND COMPARISON
IV. 实验与对比
A. DATABASES
A. 数据库
Both laboratory-controlled and in-the-wild databases are used to evaluate the proposed PAtt-Lite, namely $\mathrm{CK}+$ , RAFDB, FER2013, and FERPlus. Summaries of the class data distribution for in-the-wild databases and their challenging subsets are presented in Table 1 and Table 2. A summary of the training distribution for in-the-wild databases is also shown in Table 3.
为评估提出的PAtt-Lite模型,我们使用了实验室控制环境和真实场景下的数据库,包括$\mathrm{CK}+$、RAFDB、FER2013和FERPlus。表1和表2分别呈现了真实场景数据库及其挑战性子集的类别数据分布概况,表3则展示了真实场景数据库的训练数据分布摘要。
$\mathbf{CK}+$ [34] is a well-known laboratory-controlled database extended from the CK database. The database consists of 593 image sequences from 123 subjects, of which 327 are labeled with one of the 7 discrete emotions: Anger, Disgust, Fear, Happy, Sadness, Surprise, and Contempt, with the first images in the sequence being the neutral expression. This research evaluates the 7 emotions $\mathrm{CK}+$ with 10-fold subjectindependent cross-validation to have a fair comparison with most existing work.
$\mathbf{CK}+$ [34] 是一个由CK数据库扩展而来的知名实验室控制数据库。该数据库包含来自123名受试者的593个图像序列,其中327个被标记为7种离散情绪之一:愤怒、厌恶、恐惧、快乐、悲伤、惊讶和轻蔑,序列中的第一张图像为中性表情。本研究采用10折受试者独立交叉验证对这7种情绪进行评估,以便与大多数现有工作进行公平比较。
RAF-DB [35] is another widely used database in recent years. The database contains great variation in terms of gender, age, race, and pose of the subjects. Nearly 30,000 sample images are included in the database with crowd sourced annotations from 40 taggers. This research evaluates the basic expression subset of the database, which contains 12,271 training images and 3,068 testing images. The challenging condition test subsets of the RAF-DB database introduced by [5] are also evaluated in this research.
RAF-DB [35] 是近年来另一个广泛使用的数据库。该数据库在受试者的性别、年龄、种族和姿态方面具有很大差异。数据库中包含近30,000张样本图像,并由40名标注者进行了众包标注。本研究评估了该数据库的基本表情子集,其中包含12,271张训练图像和3,068张测试图像。本文还评估了由[5]提出的RAF-DB数据库中的挑战性条件测试子集。
FER2013 [36] is introduced during the FER challenge hosted on Kaggle. It is a database collected through the Google image search API, with nearly 36,000 sample images included. The sample images are annotated with 7 basic expression labels, i.e., Angry, Disgust, Fear, Happy, Neutral, Sad, and Surprise, by 1 tagger. Compared to RAF-DB, this is a relatively more challenging database, as some of the samples are incorrectly labeled and some are without a face.
FER2013 [36] 是在Kaggle平台上举办的面部表情识别(FER)挑战赛中推出的数据集。该数据库通过Google图片搜索API采集,包含近36,000张样本图像。所有样本由1名标注者标记了7种基本表情标签:愤怒(Angry)、厌恶(Disgust)、恐惧(Fear)、快乐(Happy)、平静(Neutral)、悲伤(Sad)和惊讶(Surprise)。与RAF-DB相比,该数据库更具挑战性,因为部分样本存在错误标注或无人脸的情况。
FERPlus [37] is extended from FER2013 by relabeling the original database through crowd sourcing from 10 taggers. The sample images are annotated with 8 basic expression labels, through the addition of the Contempt label. This process has corrected incorrectly labelled samples and has removed faceless samples, resulting in 35,710 sample images in the database. The challenging condition test subsets of the FERPlus database introduced by [5] are also evaluated in this research.
FERPlus [37] 是对FER2013的扩展,通过10名标注者的众包方式对原始数据库进行重新标注。样本图像标注了8种基本表情标签,新增了轻蔑(Contempt)标签。这一过程修正了错误标注的样本并移除了无面部样本,最终数据库包含35,710张样本图像。本研究还评估了文献[5]提出的FERPlus数据库中具有挑战性的测试子集。
B. IMPLEMENTATION DETAILS
B. 实现细节
The proposed method is implemented with the TensorFlow library on an NVIDIA TESLA P100 GPU from the Kaggle platform. A resizing operation is added to ensure that all sample images are resized to $224\times224$ . Random horizontal flip and random contrast are performed for data augmentation.
所提出的方法使用TensorFlow库在Kaggle平台的NVIDIA TESLA P100 GPU上实现。添加了调整大小操作以确保所有样本图像尺寸统一为$224\times224$。通过随机水平翻转和随机对比度进行数据增强。
TABLE 1. Summary of class data distribution for in-the-wild databases.
表 1: 真实场景数据库的类别数据分布概览
| 数据库 | 愤怒 | 厌恶 | 恐惧 | 快乐 | 中性 | 悲伤 | 惊讶 | 轻蔑 |
|---|---|---|---|---|---|---|---|---|
| RAF-DB | 867 | 877 | 355 | 5957 | 3204 | 2460 | 1619 | |
| FER2013 | 4953 | 547 | 5121 | 8989 | 6198 | 6077 | 4002 | |
| FERPlus | 3123 | 253 | 825 | 9367 | 13014 | 4414 | 4493 | 221 |
TABLE 2. Summary of class data distribution for challenging subsets of RAF-DB and FERPlu
表 2: RAF-DB和FERPlus挑战性子集的类别数据分布摘要
| 子集 | 愤怒 | 厌恶 | 恐惧 | 快乐 | 中性 | 悲伤 | 惊讶 | 轻蔑 |
|---|---|---|---|---|---|---|---|---|
| RAF-DB | ||||||||
| 遮挡 | 31 | 47 | 35 | 236 | 191 | 122 | 72 | |
| 姿态30 | 75 | 78 | 38 | 446 | 282 | 179 | 149 | |
| 姿态45 | 37 | 36 | 20 | 164 | 129 | 90 | 82 | |
| FERPlus | ||||||||
| 遮挡 | 23 | 3 | 33 | 122 | 162 | 125 | 135 | 2 |
| 姿态30 | 102 | 5 | 28 | 286 | 466 | 151 | 127 | 5 |
| 姿态45 | 52 | 1 | 16 | 141 | 271 | 89 | 59 | 4 |
TABLE 3. Summary of training distribution for in-the-wild databases.
表 3: 真实场景数据库的训练分布总结
| 数据库 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| RAF-DB | 12271 | 3068 | |
| FER2013 | 28659 | 3584 | 3582 |
| FERPlus | 28558 | 3579 | 3573 |
A two-stage training-finetuning process from [38] is employed for the training process. The pre-trained weights are frozen to solely adapt the new components to the output from Mobile Ne tV 1 during the training stage. For the finetuning process, several layers were unfrozen for finetuning the feature extractor to the benchmark databases. To extract the best feature extractive performance from the backbone Mobile Ne tV 1, 40 layers, 59 layers, 46 layers, and 49 layers were unfrozen for $\mathrm{CK}+$ , RAF-DB, FER2013, and FERPlus, respectively.
训练过程采用了[38]提出的两阶段训练-微调方法。在训练阶段,预训练权重被冻结,仅调整新组件以适应MobileNetV1的输出。微调阶段则解冻了若干层,使特征提取器能适配基准数据库。为充分发挥MobileNetV1骨干网络的特征提取能力,针对CK+、RAF-DB、FER2013和FERPlus数据集分别解冻了40层、59层、46层和49层。
We use sparse categorical cross entropy as the loss function, Adam as the optimizer, and a batch size of 8 for all experiments. For better stability of the proposed method, global gradient norm clipping is also added to the experiments. The initial learning rate is set to $1\times10^{-3}$ for the initial training process. The learning rate is scheduled by decreasing it when the model accuracy is not improving for longer than the number of epochs that were set as patience. For the finetuning process, the learning rate is scheduled based on the inverse time decay schedule with the initial learning rate of $1\times10^{-5}$ . The number of epochs for both the initial training and finetuning process is determined by the early stopping callback with restoration to the best weights when the training process is terminated.
我们采用稀疏分类交叉熵作为损失函数,使用Adam优化器,所有实验的批次大小均为8。为提升所提方法的稳定性,实验中还加入了全局梯度范数裁剪。初始训练阶段的学习率设为$1\times10^{-3}$,当模型准确率在设定耐心周期数内未提升时,学习率会按计划下降。在微调阶段,学习率采用逆时间衰减调度,初始学习率为$1\times10^{-5}$。初始训练和微调过程的周期数均通过早停回调机制确定,训练终止时会恢复最佳权重。
C. ABLATION STUDY
C. 消融实验
For the ablation study, the effectiveness of the patch extraction block and the attention classifier are evaluated by comparing them to the baseline performance of the finetuned Mobile Ne tV 1. Experiments are conducted on all benchmark databases for a proper evaluation on the effect of the proposed modules. The summary of the experimental results for our grid search on the optimum output layer and number of patches is also included in Table 5. Additionally, experimental results for the comparison between patch extraction and patch attention on in-the-wild databases are also included to justify the proposed patch extraction instead of conventional patch attention. The experimental results for this study are presented in Table 4 and Table 6.
为了进行消融研究,我们通过对比微调MobileNetV1的基线性能,评估了补丁提取模块和注意力分类器的有效性。实验在所有基准数据库上进行,以正确评估所提出模块的效果。表5还包含了我们对最佳输出层和补丁数量进行网格搜索的实验结果总结。此外,还包含了在真实场景数据库中补丁提取与传统补丁注意力的对比实验结果,以证明采用补丁提取而非传统补丁注意力的合理性。本研究的实验结果展示在表4和表6中。
1) Effectiveness of proposed modules
1) 所提出模块的有效性
As shown in Table 4, the proposed patch extraction block is observed to have a slight decrease in performance compared to the Mobile Ne tV 1 baseline in in-the-wild databases. The performance drops in in-the-wild databases are mainly due to the difference in the number of trainable parameters between the original layers and the layers from the patch extraction block, which the newly initialized layers also resulted in the absence of pre-trained weights from the final layers. On the other hand, the Mobile Ne tV 1 baseline struggled to get a $100.00%$ mean accuracy on $\mathrm{CK}+$ based on our experiments. However, with the small scale of $\mathrm{CK}+$ , this performance is immediately achievable with the addition of the patch extraction block, hence validating its effectiveness.
如表 4 所示,与 MobileNetV1 基线相比,所提出的补丁提取块在真实场景数据库中性能略有下降。真实场景数据库中的性能下降主要是由于原始层与补丁提取块的层之间可训练参数数量的差异,新初始化的层也导致最终层缺少预训练权重。另一方面,根据我们的实验,MobileNetV1 基线在 $\mathrm{CK}+$ 上难以达到 $100.00%$ 的平均准确率。然而,由于 $\mathrm{CK}+$ 规模较小,通过添加补丁提取块即可立即实现这一性能,从而验证了其有效性。
For the effectiveness of the proposed attention classifier, it improved the classification accuracy compared to the baseline. Moreover, the attention classifier has also significantly improved the classification accuracy on in-the-wild databases, achieving near-state-of-the-art performance on all in-the-wild databases that we benchmarked on. Specifically, the attention classifier provided an improvement of $5.83%$ for RAF-DB, $14.46%$ for FER2013, and $7.83%$ for FERPlus.
所提出的注意力分类器在效果上相比基线模型提升了分类准确率。此外,该注意力分类器在真实场景数据库上的分类准确率也有显著提升,在我们测试的所有真实场景数据库上都达到了接近最先进的性能。具体而言,注意力分类器在RAF-DB上提升了5.83%,在FER2013上提升了14.46%,在FERPlus上提升了7.83%。
While the results show that the performance dropped with the patch extraction block alone, further performance improvement is achieved with both modules combined. This improvement is believed to stem from the self-attention layer between the fully connected layers, enabling the classifier to better adapt to the representations from the patch extraction block. The performance of the attention classifier is further boosted with the introduction of the newly initialized patch extraction block, which allowed these two modules to be trained at a higher learning rate, as opposed to the small learning rate normally used in finetuning over the pre-trained weights. Overall, the proposed patch extraction block provides a further improvement of $3.92%$ accuracy on RAFDB, $2.37%$ on FER2013, and $4.84%$ on FERPlus over the Mobile Ne tV 1 with attention classifier.
结果显示,仅使用补丁提取模块时性能有所下降,但结合两个模块后性能得到进一步提升。这一改进被认为源于全连接层之间的自注意力层,使分类器能更好地适应补丁提取模块的表征。通过引入新初始化的补丁提取模块,注意力分类器的性能得到进一步增强,这使得两个模块能以更高的学习率进行训练,而非通常微调预训练权重时使用的较小学习率。总体而言,所提出的补丁提取模块在RAFDB上准确率提升了3.92%,在FER2013上提升2.37%,在FERPlus上提升4.84%,均优于带注意力分类器的MobileNetV1。
TABLE 4. Ablation study for the proposed method on all benchmark databases. The best result is highlighted in bold.
表 4: 所提方法在所有基准数据库上的消融研究。最佳结果以粗体标出。
| AttentionClassifier | PatchExtraction | CK+ | RAF-DB | FER2013 | FERPlus |
|---|---|---|---|---|---|
| × | × | 99.90 | 85.17 | 68.54 | 82.88 |
| 100.00 | 81.10 | 61.52 | 77.72 | ||
| 100.00 | 91.00 | 83.00 | 90.71 | ||
| √ | 100.00 | 95.05 | 92.50 | 95.55 |
TABLE 5. Summary of classification accuracy for different output layers and different kernel sizes on RAF-DB. The best accuracy is highlighted in bold.
表 5: RAF-DB数据集上不同输出层和不同核尺寸的分类准确率汇总。最佳准确率以粗体标出。
| 层数 | 核类型 | 最佳准确率 (%) |
|---|---|---|
| 17 | NP7 | 90.03 |
| 17 | OP3 | 89.96 |
| 17 | OP5 | 89.80 |
| 17 | P4 | 89.11 |
| 17 | P8 | 88.92 |
| 23 | NP7 | 93.71 |
| 23 | P8 | 93.45 |
| 23 | OP5 | 91.69 |
| 23 | OP3 | 91.17 |
| 23 | P4 | 89.93 |
| 29 | NP7 | 94.78 |
| 29 | OP3 | 93.84 |
| 29 | P8 | 93.64 |
| 29 | P4 | 89.41 |
| 29 | OP5 | 80.22 |
| 35 | P8 | 94.56 |
| 35 | NP7 | 93.64 |
| 35 | P4 | 90.51 |
| 35 | OP5 | 85.43 |
| 35 | OP3 | 82.95 |
| 41 | P8 | 94.39 |
| 41 | NP7 | 93.09 |
| 41 | OP5 | 92.86 |
| 41 | P4 | 89.50 |
| 41 | OP3 | 82.66 |
| 47 | P8 | 87.84 |
| 47 | NP7 | 86.38 |
| 47 | OP5 | 84.03 |
| 47 | OP3 | 79.04 |
| 47 | P4 | 78.13 |
2) Patch Extraction Block
2) 图像块提取模块 (Patch Extraction Block)
TABLE 6. Comparison between patch extraction and patch attention on in-the-wild databases. The best result is highlighted in bold.
表 6: 真实场景数据库中局部提取与局部注意力的对比。最佳结果以粗体标出。
| RAF-DB | FER2013 | FERPlus | |
|---|---|---|---|
| PatchAttention | 94.17 | 89.86 | 92.72 |
| Patch Extraction | 95.05 | 92.50 | 95.55 |
Based on the experimental results in Table 5, output feature maps from activated depthwise convolutional layers are the optimum layers for our patch extraction block, whereby patch sizes of 7 and 8 (with padding around the feature maps) generally yield the best results. Hence, this means splitting the feature maps into four patches is more optimal for our implementations.
根据表5中的实验结果,激活的深度可分离卷积层输出的特征图是我们的补丁提取模块的最佳层级,其中补丁大小为7和8(在特征图周围填充)通常能产生最佳结果。因此,这意味着在我们的实现中,将特征图分割为四个补丁更为理想。
However, as the kernel size for the convolution operation gets bigger, so does its number of parameters, which contradicts with our idea of designing a small and lightweight model for facial expression recognition. Hence, we derived the design of the patch extraction block by experimenting with the replacement of the convolutional layer with a large kernel for the depthwise separable convolutional layer with a smaller kernel. In theory, this should still retain the performance of the original design as the separable convolutional layer is still performing the spatial and channel convolution that a conventional convolutional layer has. We also intend to keep the number of patches constant while trying to use a smaller kernel. Thus, the padding to the output feature maps from Mobile Ne tV 1 was kept, and a patch size of 4 was used for the first separable convolutional layer, and a patch size of 2 was used for the second separable convolutional layer. From our experimental results, the replacement proved to be successful with the tradeoff of a minor performance drop for a significant reduction in the number of parameters.
然而,随着卷积操作的核尺寸增大,其参数量也随之增加,这与我们设计轻量化面部表情识别模型的初衷相悖。为此,我们通过实验将大核卷积层替换为小核深度可分离卷积层,从而推导出块提取模块的设计方案。理论上,由于可分离卷积层仍执行传统卷积层的空间与通道卷积操作,该设计应能保持原始架构的性能。在尝试使用更小卷积核的同时,我们还需保持块(patch)数量恒定。因此,MobileNetV1输出特征图的填充(padding)得以保留:第一层可分离卷积采用4×4块尺寸,第二层采用2×2块尺寸。实验结果表明,这种替换方案以轻微性能下降为代价,实现了参数量的大幅削减。
- Comparison between patch extraction and patch attention As shown in Table 6, the conventional patch attention mechanism does not bring any performance gain when compared to the proposed patch extraction block. Instead, experimental results have demonstrated that the proposed patch extraction block performed better in the proposed method than the patch attention across all in-the-wild databases.
- 块提取与块注意力机制对比
如表 6 所示,传统块注意力机制相比提出的块提取模块未带来任何性能提升。实验结果表明,在所有真实场景数据库中,提出的块提取模块在本文方法中的表现均优于块注意力机制。
Whereas the purpose of integrating a patch attention mechanism is often to highlight significant local facial regions and hence improve the classification performance under challenging conditions, the confusion matrices depicted in Fig. 2 - 5 have shown that the patch attention is identical to the patch extraction in terms of performance under challenging conditions. Specifically, the classification accuracy and perclass performance under challenging conditions are similar between these two designs. Both performed similarly well overall and in most classes except the Contempt class and the Disgust class, where both struggled to perform well.
而整合补丁注意力 (patch attention) 机制的目的通常是为了突出重要的局部面部区域,从而提升在挑战性条件下的分类性能。但图 2-5 所示的混淆矩阵表明,在挑战性条件下,补丁注意力与补丁提取 (patch extraction) 的性能表现相同。具体而言,这两种设计在挑战性条件下的分类准确率和各类别表现相似。除了 Contempt 类和 Disgust 类表现欠佳外,两者在整体和大多数类别上的表现都较为接近。
D. METHOD ANALYSIS
D. 方法分析
In this section, PAtt-Lite is analyzed using Grad-CAM visu aliz at ions in Fig. 6 and Fig. 7. It can be observed that PAtt-Lite can recognize the facial expression of the subjects through or around the occlusion and under a variety of pose angles, besides some that have weird ratios.
在本节中,我们通过图6和图7中的Grad-CAM可视化分析PAtt-Lite。可以观察到,除了部分比例异常的情况外,PAtt-Lite能够通过遮挡物或围绕遮挡物识别受试者的面部表情,并在多种姿态角度下保持识别能力。
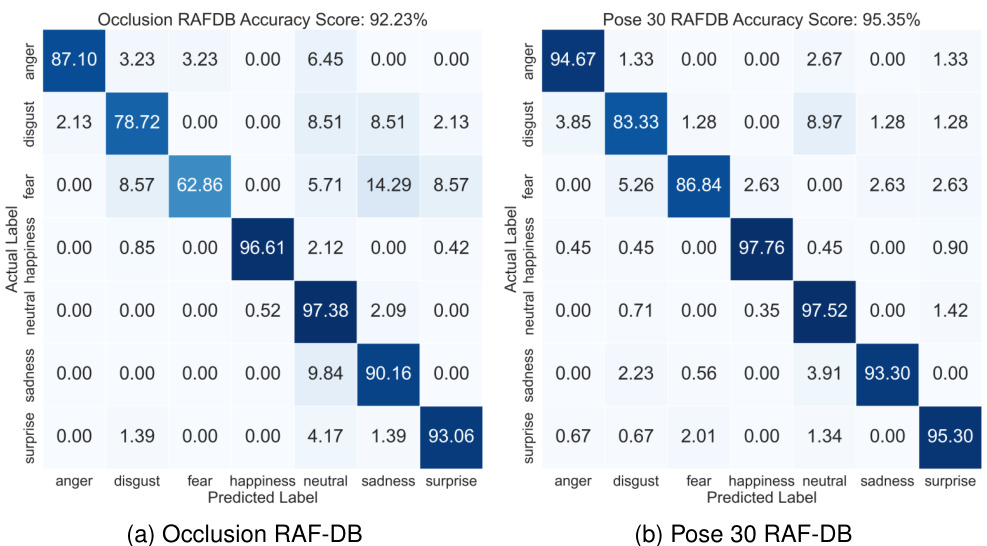
FIGURE 2. Confusion matrices of patch extraction on challenging subsets of RAF-DB.
图 2: RAF-DB 挑战性子集上补丁提取的混淆矩阵

FIGURE 3. Confusion matrices of patch attention on challenging subsets of RAF-DB.
图 3: RAF-DB 挑战性子集上 patch attention 的混淆矩阵

FIGURE 4. Confusion matrices of patch extraction on challenging subsets of FERPlus.
图 4: FERPlus 挑战性子集上 patch 提取的混淆矩阵



FIGURE 5. Confusion matrices of patch attention on challenging subsets of FERPlus.
图 5: 基于FERPlus挑战性子集的局部注意力混淆矩阵



FIGURE 6. Grad-CAM of PAtt-Lite on all seven classes of RAF-DB. The first row is the sample images from the testing set whereas the second row is the Grad-CAM visualization s for each sample from the row above.
图 6: RAF-DB数据集七种类别上PAtt-Lite的Grad-CAM可视化。第一行为测试集样本图像,第二行为对应上方样本的Grad-CAM热力图。
As highlighted in [39], we believe expression annotations are the limiting factor of today’s FER methods. Upon close inspection of the Grad-CAM from Fig. 7, it can be observed that some predictions, such as the fifth sample on the third row and the second sample on the fourth row, appear to be more closely represented by predictions from PAtt-Lite rather than the ground truths. These bad annotations are not limited to the test set but are available in the training set as well, which we believe contributed to PAtt-Lite’s over fitting to the databases, as can be observed in Fig. 7, where some samples, such as the sixth samples on the second row, may seem ambiguous or incorrectly predicted.
如[39]所述,我们认为表情标注是当前FER (Facial Expression Recognition) 方法的主要瓶颈。通过仔细观察图7中的Grad-CAM可视化结果,可以发现某些预测结果(例如第三行第五个样本和第四行第二个样本)与PAtt-Lite的预测更为接近,而非真实标注。这些错误标注不仅存在于测试集,训练集中同样存在。我们认为这导致了PAtt-Lite对数据库的过拟合现象,如图7所示——部分样本(例如第二行第六个样本)的预测结果存在歧义或明显错误。
Besides the annotation, we also noticed that PAtt-Lite generally performed better on faces that are well-posed instead of faces that have a weird ratio, messy, or require context information. This is also illustrated in the visualization s in Fig. 7, such as the first sample on the third row and the fourth sample on the fourth row, where the backbone extractor randomly highlights the feature maps instead of focusing on the facial features.
除了标注之外,我们还注意到 PAtt-Lite 通常在姿态端正的人脸上表现更好,而不是那些比例奇怪、杂乱或需要上下文信息的人脸。这一点在图 7 的可视化结果中也有所体现,例如第三行的第一个样本和第四行的第四个样本,其中主干提取器随机高亮了特征图,而不是专注于面部特征。
On the other hand, the lower class accuracy in smaller classes can be explained by referring to Table 1, Table 2, and the confusion matrices, which most pointed that our method generally performed worse in the smaller classes. When the percentages are converted into the number of samples, it can be clearly observed that PAtt-Lite made a similar number of false predictions across all classes.
另一方面,小类别中较低的准确率可以参考表 1、表 2 和混淆矩阵来解释,这些数据大多表明我们的方法在较小类别中表现普遍较差。当百分比转换为样本数量时,可以清楚地观察到 PAtt-Lite 在所有类别中做出了相似数量的错误预测。
E. METHOD COMPARISON
E. 方法比较
In this section, PAtt-Lite is compared with state-of-the-art methods on the benchmark databases. The performance comparisons are shown in Table 7 - 11. In addition, the confusion matrices of the proposed PAtt-Lite on RAF-DB, FER2013, and FERPlus are depicted in Fig. 8.
在本节中,我们将PAtt-Lite与基准数据库上的最先进方法进行比较。性能对比结果如表7至表11所示。此外,图8展示了所提出的PAtt-Lite在RAF-DB、FER2013和FERPlus数据集上的混淆矩阵。
1) Results on $\mathsf+$
1) $\mathsf+$ 上的结果
The performance comparison of the proposed method with the state-of-the-art methods for $\mathrm{CK}+$ is presented in Table 7. The proposed PAtt-Lite outperformed all CNN-based existing work [8], [9], [40], [41] and transformer-based existing work [23] in terms of cross-validation mean accuracy for $\mathrm{CK}+$ by achieving $100.00%$ mean accuracy across 10-fold cross-validation. To the best of our knowledge, FER-VT [42] is the only other method that reported the same performance with a transformer-based method.
所提方法与最先进方法在 $\mathrm{CK}+$ 数据集上的性能对比见表 7。在 10 折交叉验证中,提出的 PAtt-Lite 以 $100.00%$ 的平均准确率超越了所有基于 CNN 的现有工作 [8], [9], [40], [41] 和基于 Transformer 的现有工作 [23]。据我们所知,FER-VT [42] 是另一种同样达到该性能的基于 Transformer 的方法。

IGURE 7. Examples of true and false predictions on RAF-DB and their activation maps. The ground truths of the samples are labeled in black whereas the true and false predictions are labeled in green and red, respectively.
图 7: RAF-DB数据集上正确与错误预测示例及其激活热力图。样本的真实标签以黑色标注,正确预测和错误预测分别用绿色和红色标注。

FIGURE 8. Confusion matrices of PAtt-Lite on in-the-wild databases.
图 8: PAtt-Lite 在真实场景数据库上的混淆矩阵
TABLE 7. Comparison of the state-of-the-art results on $\mathsf{C K}_{+}$ . The best result is highlighted in bold.
表 7: $\mathsf{C K}_{+}$ 数据集上的最新结果对比。最佳结果以粗体标出。
| 方法 | 准确率 |
|---|---|
| gACNN [8] | 96.40 |
| pACNN [8] | 97.03 |
| SCAN-CCI [9] | 97.31 |
| IF-GAN [40] | 97.52 |
| FDRL [41] | 99.54 |
| ViT+SE [23] | 99.80 |
| FER-VT [42] | 100.00 |
| PAtt-Lite | 100.00 |
2) Results on RAF-DB.
2) RAF-DB 数据集上的结果
The performance comparison of the proposed PAtt-Lite with state-of-the-art methods on RAF-DB is shown in Table 8. An accuracy and parameter comparison between the proposed method and state-of-the-art methods is also presented in Fig. 9. VTFF [28], TransFER [24], Facial Chirality [45], APViT [26], POSTER [25], $\mathrm{POSTER{++}}$ [27], and ARBEx [47] are transformer-based architecture, whereas RAN [5], SCANCCI [9], ARM [44], EAC [43], and DDAMFN [46] are CNN
所提出的PAtt-Lite与最先进方法在RAF-DB上的性能对比见表8。图9还展示了所提方法与最先进方法的准确率和参数量对比。VTFF [28]、TransFER [24]、Facial Chirality [45]、APViT [26]、POSTER [25]、$\mathrm{POSTER{++}}$[27]和ARBEx [47]采用基于Transformer的架构,而RAN [5]、SCANCCI [9]、ARM [44]、EAC [43]和DDAMFN [46]采用CNN架构。
TABLE 8. Comparison of the state-of-the-art results on RAF-DB and FERPlus. The best result is highlighted in bold.
表 8: RAF-DB和FERPlus数据集上的最新结果对比。最佳结果以粗体标出。
| 方法 | 参数量 | RAF-DB | FERPlus |
|---|---|---|---|
| VTFF[28] | 80.1M | 88.81 | |
| RAN [5] | 11.2M | 86.90 | 89.16 |
| VTFF[28] | 51.8M | 88.14 | |
| SCAN-CCI[9] | 70M | 89.02 | 89.42 |
| EAC [43] | 11.2M | 89.99 | 89.64 |
| ARM [44] | 11.2M | 90.42 | |
| TransFER[24] | 65.2M | 90.91 | 90.83 |
| FacialChirality[45] | 46.2M | 91.20 | |
| DDAMFN[46] | 4.11M | 91.35 | 90.74 |
| APViT [26] | 65.2M | 91.98 | 90.86 |
| POSTER[25] | 71.8M | 92.05 | 91.62 |
| POSTER++[27] | 43.7M | 92.21 | |
| ARBEx[47] | 92.47 | 93.09 | |
| CIAO [48] | 17.9M | 94.50 | |
| PAtt-Lite | 1.10M | 95.05 | 95.55 |
based architecture.
基于架构。
Based on the comparison, the transformer-based methods are generally outperforming and have a greater number of parameters than the CNN-based methods, with SCAN-CCI [9] being the exception as it has 70M parameters despite having a CNN-based architecture. Our proposed PAtt-Lite achieved better performance with a CNN backbone than all transformer-based state-of-the-art. Specifically, PAtt-Lite has $2.58%$ over transformer-based ARBEx [47], a modified version of the lightest transformer-based method, $\mathrm{POSTER{++}}$ [27], recorded the best result for RAF-DB. For comparison with CNN-based methods, PAtt-Lite achieved an improvement of $4.63%$ overall accuracy over ARM [44]. In terms of performance comparison with lightweight methods, our proposed method also outperformed RAN [5], EAC [43], ARM [44], and DDAMFN [46] by $8.15%$ , $5.06%$ , $4.63%$ , and $3.70%$ respectively, while having significantly lesser parameters.
通过比较发现,基于Transformer的方法通常表现更优且参数量大于基于CNN的方法,其中SCAN-CCI [9]是例外——尽管采用CNN架构却拥有7000万参数。我们提出的PAtt-Lite在使用CNN主干网络时,其性能超越了所有基于Transformer的先进方法。具体而言,PAtt-Lite在RAF-DB数据集上以2.58%的优势超过基于Transformer的ARBEx [47](最轻量级Transformer方法POSTER++ [27]的改进版)。与基于CNN的方法相比,PAtt-Lite整体准确率比ARM [44]高出4.63%。在轻量化方法性能对比中,我们的方法同样以8.15%、5.06%、4.63%和3.70%的优势分别超越RAN [5]、EAC [43]、ARM [44]和DDAMFN [46],同时参数量显著更少。
Furthermore, following [25]–[28], a per-class performance comparison is added in Table 9 to compare the performance of PAtt-Lite on different classes of the database. For [9], [10], [24], [29], [44], which did not specifically report their perclass accuracy, their results from the confusion matrices are taken for comparison. Overall, a similar trend for the perclass performance is observed when PAtt-Lite is compared with existing work, where the per-class accuracy for the Disgust class and the Fear class is lacking behind the other classes. However, our method managed to slightly improve the per-class accuracy for the Disgust class over APViT [26] and perform on par with it for the Fear class while having 59 times fewer parameters. Overall, small improvements can be observed across all expression classes except class Anger and class Neutral, where significant improvement is recorded for the former and a small performance drop is noted for the latter. Noticeably, the proposed method managed to record a $6.79%$ improvement over all other state-of-the-art methods for class Anger, while recording a $1.87%$ performance drop over ARM [44]. Although the per-class accuracy for the Disgust class and the Fear class can be further improved,
此外,根据[25]–[28]的研究,表9中添加了每类性能比较,以评估PAtt-Lite在数据库不同类别上的表现。对于未明确报告每类准确率的[9]、[10]、[24]、[29]、[44],我们从混淆矩阵中提取其结果进行对比。总体而言,PAtt-Lite与现有工作相比呈现出相似的每类性能趋势,其中厌恶(Disgust)和恐惧(Fear)类别的准确率仍落后于其他类别。但我们的方法在参数减少59倍的情况下,将厌恶类准确率较APViT[26]略有提升,恐惧类表现则与之持平。除愤怒(Anger)和中性(Neutral)类外,其他表情类别均观察到小幅改进——前者记录到显著提升,后者出现轻微下降。值得注意的是,本方法在愤怒类上较所有其他先进方法实现了$6.79%$的提升,但对ARM[44]存在$1.87%$的性能回落。尽管厌恶类和恐惧类的每类准确率仍有提升空间,

FIGURE 9. Accuracy and parameter comparison on RAF-DB.
图 9: RAF-DB 上的准确率和参数量对比
PAtt-Lite demonstrated consistently strong performance by managing to achieve about $93%$ per-class accuracy or greater in the remaining classes, resulting in an average accuracy of $90.38%$ . This corresponds to an improvement in the average accuracy of $4.02%$ over APViT [26], which previously reported the best average accuracy. Moreover, when compared to Im ponderous Net [10], which has the nearest number of parameters as our proposed method, PAtt-Lite achieved an improvement of $12.81%$ in terms of average accuracy, while performing stronger and more consistent on all expression classes.
PAtt-Lite 在剩余类别中始终保持强劲性能,每个类别的准确率均达到约 93% 或更高,平均准确率为 90.38%。相较于此前报告最佳平均准确率的 APViT [26],这一结果实现了 4.02% 的平均准确率提升。此外,与参数量最接近我们方法的 Imponderous Net [10] 相比,PAtt-Lite 平均准确率提升了 12.81%,且在所有表情类别上表现更强劲、更稳定。
3) Results on FER2013
3) FER2013 上的结果
The comparison of the proposed method with the stateof-the-art methods on FER2013 is depicted in Table 10. FER2013 has been a database that existing work struggled to perform well on until recently when FLEPNet [55] and NECM-PECM Ensemble [56] were proposed. Compared to the existing work, PAtt-Lite recorded a classification performance of $92.50%$ , which equates to an improvement of $4.5%$ over NECM-PECM Ensemble [56].
表 10 展示了所提方法与 FER2013 数据集上现有最优方法的对比结果。FER2013 一直是现有方法难以取得理想性能的数据库,直到最近 FLEPNet [55] 和 NECM-PECM Ensemble [56] 的提出。与现有工作相比,PAtt-Lite 实现了 $92.50%$ 的分类准确率,相比 NECM-PECM Ensemble [56] 提升了 $4.5%$。
From the confusion matrix in Fig 8b, the per-class performance of our proposed method on FER2013 is observed to have a similar trend to RAF-DB and existing work [50], [55], where generally strong per-class accuracy can be achieved for all expression classes except the Disgust class and the Fear class, which are relatively weaker compared to the remaining classes. However, PAtt-Lite has managed to achieve significantly better performance across all expression classes. Specifically, the proposed method improves the per-class accuracy of all expressions except Disgust and Fear to more than $90%$ accuracy. This is unlike most existing work, which has struggled to achieve such performance on all expressions except the Happy class.
从图8b的混淆矩阵中可以看出,我们提出的方法在FER2013数据集上的各类别性能与RAF-DB及现有工作[50][55]呈现相似趋势:除厌恶(Disgust)和恐惧(Fear)类别外,其他表情类别普遍能达到较高准确率,这两个类别的表现相对较弱。然而PAtt-Lite在所有表情类别上都实现了显著提升。具体而言,该方法将除厌恶和恐惧外所有表情的类别准确率提升至90%以上,这与大多数现有研究形成鲜明对比——后者通常仅能在快乐(Happy)类别上达到类似性能水平。
TABLE 9. Per-class performance comparison of the state-of-the-art results on RAF-DB. The best result is highlighted in bold.
表 9: RAF-DB数据集上各类别性能的先进结果对比。最佳结果以粗体标出。
| 方法 | #参数量 | 愤怒 | 厌恶 | 恐惧 | 快乐 | 中性 | 悲伤 | 惊讶 | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| ImponderousNet[10] | 1.45M | 78.00 | 54.00 | 57.00 | 96.00 | 88.00 | 85.00 | 85.00 | 77.57 |
| MViT [29] | 33M | 78.40 | 63.75 | 60.81 | 95.61 | 89.12 | 87.45 | 87.54 | 80.38 |
| VTFF [28] | 51.8M | 85.80 | 68.12 | 64.86 | 94.09 | 87.50 | 87.24 | 85.41 | 81.86 |
| SCAN-CCI[9] | 70M | 81.00 | 70.00 | 66.00 | 96.00 | 89.00 | 86.00 | 88.00 | 82.29 |
| ARM [44] | 11.2M | 77.20 | 64.40 | 70.30 | 95.40 | 97.90 | 83.90 | 90.30 | 82.77 |
| TransFER[24] | 65.2M | 88.89 | 79.37 | 68.92 | 95.95 | 90.15 | 88.70 | 89.06 | 85.86 |
| POSTER++[27] | 43.7M | 88.27 | 71.88 | 68.92 | 97.22 | 92.06 | 92.89 | 90.58 | 85.97 |
| POSTER [25] | 71.8M | 88.89 | 75.00 | 67.57 | 96.96 | 92.35 | 91.21 | 90.27 | 86.04 |
| APViT[26] | 65.2M | 86.42 | 73.75 | 72.97 | 97.30 | 92.06 | 88.70 | 93.31 | 86.36 |
| PAtt-Lite | 1.10M | 95.68 | 80.00 | 72.97 | 97.97 | 96.03 | 93.93 | 96.05 | 90.38 |
TABLE 10. Comparison of the state-of-the-art results on FER2013. The best result is highlighted in bold.
表 10: FER2013数据集上的最新结果对比。最佳结果以粗体标出。
| 方法 | 准确率 |
|---|---|
| KDL [49] | 71.28 |
| MAFER [50] | 73.45 |
| PASM [51] | 73.59 |
| LHC-Net [52] | 74.42 |
| EmoNeXt-XLarge [53] | 76.12 |
| MoVE-CNNs [54] | 77.70 |
| FLEPNet [55] | 80.72 |
| NECM-PECMEnsemble [56] | 88.00 |
| PAtt-Lite | 92.50 |
4) Results on FERPlus
4) FERPlus 上的结果
FERPlus has an additional Contempt expression than the other in-the-wild databases in this research. The classification performance of our proposed method is compared with the state-of-the-art methods in the last column of Table 8. The accuracy and parameter of the proposed PAtt-Lite are also compared with state-of-the-art methods in Fig. 10. Like RAF-DB, transformer-based methods generally have better results than CNN-based methods, except for CIAO [48], which reported the best accuracy for FERPlus with a CNN backbone.
FERPlus比本研究中其他野外数据库多了一种轻蔑(Contempt)表情。表8最后一列将我们提出的方法与最先进方法的分类性能进行了比较。图10中还对比了所提出的PAtt-Lite与最先进方法在准确率和参数量上的表现。与RAF-DB类似,基于Transformer的方法通常比基于CNN的方法效果更好,但采用CNN骨干网络的CIAO [48]在FERPlus上报告了最佳准确率。
The proposed PAtt-Lite has achieved slight improvement on FERPlus when compared to the state-of-the-art methods. Specifically, PAtt-Lite achieved a classification accuracy of $95.55%$ , which corresponds to a performance improvement of $1.05%$ over CIAO [48], while having 16 times lesser parameters than CIAO [48]. When compared to transformerbased methods, our method achieved a $3.93%$ improvement in classification accuracy over POSTER [25] with 65 times lesser parameters, and a $2.46%$ improvement over ARBEx [47], a modified $\mathrm{POSTER{++}}$ [27]. For comparison with lighter state-of-the-art methods, PAtt-Lite with significantly lesser parameters also outperformed RAN [5], EAC [43], and DDAMFN [46] by $6.39%$ , $5.91%$ , and $4.81%$ , respectively, in terms of overall accuracy.
提出的PAtt-Lite相较于现有最优方法在FERPlus上取得了小幅提升。具体而言,PAtt-Lite实现了95.55%的分类准确率,比CIAO[48]高出1.05%,同时参数量仅为后者的1/16。与基于Transformer的方法相比,我们的方法以65倍更少的参数量,在分类准确率上比POSTER[25]提升3.93%,比改进版POSTER++[27]的ARBEx[47]提升2.46%。在与轻量级最优方法的对比中,参数量显著更少的PAtt-Lite在整体准确率上分别以6.39%、5.91%和4.81%的优势超越RAN[5]、EAC[43]和DDAMFN[46]。
It is visible that our proposed method is still struggling with the Contempt class upon inspecting the confusion matrix in Fig. 8c, with the Disgust class and the Fear class following a general trend from RAF-DB and FER2013. However, this performance drop is expected due to the severe class imbalance between these classes and the larger class. Similar performance drops on some of these negative expression classes are also reported in existing work [9], [25], [26]. Despite this, our proposed method still achieved significant improvements in all other expression classes, with around or higher than $95%$ performance across these 5 classes.
从图 8c 的混淆矩阵可以看出,我们提出的方法在 Contempt 类别上仍然存在困难,Disgust 和 Fear 类别则延续了 RAF-DB 和 FER2013 的总体趋势。这种性能下降是预料之中的,因为这些类别与较大类别之间存在严重的类别不平衡问题。现有研究 [9], [25], [26] 也报告了部分负面表情类别存在类似的性能下降。尽管如此,我们提出的方法在其他所有表情类别上仍取得了显著提升,这5个类别的性能均达到或超过 $95%$。

FIGURE 10. Accuracy and parameter comparison on FERPlus.
图 10: FERPlus 上的准确率和参数量对比
5) Results on challenging subsets
5) 具有挑战性的子集结果
The proposed method has shown great results in classifying samples under challenging conditions. Table 11 shows the difference in the performance of the proposed method compared to recent work on challenging subsets for RAF-DB and FERPlus. Specifically, PAtt-Lite achieved an improvement of more than $3%$ across all three challenging subsets for RAFDB, outperforming Facial Chirality [45] which reported the best results on these subsets with $46.2\mathbf{M}$ parameters. Meanwhile, to our best knowledge, our proposed method is the first to achieve more than $90%$ accuracy for all challenging subsets for FERPlus. A performance improvement of around $4%$ to $7%$ is achieved across the three subsets compared to SCAN-CCI [9], which previously reported the best performance with 70M parameters. From the comparison with the best results on these subsets, the proposed PAtt-Lite achieved state-of-the-art performance across all subsets with significantly lesser parameters. Meanwhile, when compared with the lighter methods such as RAN [5] and Im ponderous
所提方法在具有挑战性的条件下对样本进行分类表现出色。表 11 展示了该方法在 RAF-DB 和 FERPlus 挑战性子集上与近期工作的性能差异。具体而言,PAtt-Lite 在 RAFDB 的三个挑战性子集上均实现了超过 $3%$ 的提升,优于参数量为 $46.2\mathbf{M}$ 的 Facial Chirality [45](这些子集上此前的最佳结果)。同时,据我们所知,我们的方法是首个在 FERPlus 所有挑战性子集上准确率超过 $90%$ 的方案。与参数量为 70M 的 SCAN-CCI [9](此前最佳性能)相比,三个子集上实现了约 $4%$ 至 $7%$ 的性能提升。通过与这些子集上最佳结果的对比可见,所提出的 PAtt-Lite 以显著更少的参数在所有子集上实现了最先进的性能。此外,与 RAN [5] 和 Im ponderous 等轻量方法相比...
TABLE 11. Comparison of the state-of-the-art results on challenging subsets for RAF-DB and FERPlus. The best result is highlighted in bold.
表 11: RAF-DB和FERPlus挑战性子集的当前最佳结果对比。最佳结果以粗体标出。
| 方法 | 参数量 | RAF-DB | FERPlus | ||||
|---|---|---|---|---|---|---|---|
| 遮挡 (Occlusion) | 姿态>30 (Pose>30) | 姿态>45 (Pose>45) | 遮挡 (Occlusion) | 姿态>30 (Pose>30) | 姿态>45 (Pose>45) | ||
| RAN [5] | 11.2M | 82.72 | 86.74 | 85.20 | 83.63 | 82.23 | 80.40 |
| Imponderous Net [10] | 1.45M | 83.40 | 86.12 | 84.41 | 83.47 | 86.84 | 84.83 |
| VTFF[28] | 51.8M | 83.95 | 87.97 | 88.35 | - | - | - |
| VTFF[28] | 80.1M | - | - | - | 84.79 | 88.29 | 87.20 |
| OADN [11] | - | - | - | - | 84.57 | 88.52 | 87.50 |
| SCAN-CCI[9] | 70M | 85.03 | 89.82 | 89.07 | 86.12 | 88.89 | 88.15 |
| MViT [29] | 33M | 85.17 | 87.99 | 88.40 | - | - | - |
| FacialChirality[45] | 46.2M | 88.16 | 91.50 | 90.86 | - | - | - |
| PAtt-Lite | 1.10M | 92.23 | 95.35 | 94.44 | 93.22 | 96.07 | 92.58 |
Net [10] on subsets of RAF-DB, PAtt-Lite managed to outperform these methods by around $9%$ . The proposed method also managed to outperform the lighter methods by more than $9%$ on the first two subsets and by $7.75%$ on the Pose 45 subset of FERPlus.
在RAF-DB的子集上,PAtt-Lite以约9%的优势超越了Net [10]等方法。该方法在前两个子集上以超过9%的优势领先轻量级方法,在FERPlus的Pose 45子集上优势达7.75%。
V. CONCLUSION
V. 结论
This work presents PAtt-Lite, a Mobile Ne tV 1-based solution, to improve the classification accuracy of FER under challenging conditions. The proposed PAtt-Lite achieves state-of-theart performance in all benchmark databases and their subsets while being significantly lighter than other state-of-the-art methods at just 1.10M parameters. Specifically, the proposed patch extraction block improves the FER performance of PAtt-Lite under challenging conditions by enforcing the model to extract significant local facial features. On the other hand, the attention classifier is proposed to learn the patched representation better and improve the overall performance of the proposed lightweight method.
本研究提出了PAtt-Lite,一种基于MobileNetV1的解决方案,旨在提升挑战性条件下面部表情识别(FER)的分类准确率。该方案仅需1.10M参数量,显著轻于其他先进方法,并在所有基准数据库及其子集上实现了最先进的性能。具体而言,所提出的局部特征提取模块通过强制模型提取显著的面部局部特征,有效提升了PAtt-Lite在挑战性条件下的FER性能。同时,注意力分类器的引入能更好地学习局部特征表示,从而提升这一轻量级方法的整体性能。
This work provides valuable insight into potential future directions by highlighting the advantages and possible improvements of our proposed method. One such direction is robustness improvement to PAtt-Lite, especially towards low-resource expressions, which can be done by further refining the patch extraction blocks or experimenting with a feature extractor backbone that has more performance or is more robust. Besides, as highlighted in the previous section, while large FER databases are available, good annotations are required to further advance the field of FER. Hence, we also suggest that there could be an effort for the development of a FER database with more reliable annotations. Existing FER methods have advanced to a point where they can potentially discover patterns that are difficult for human annotators to detect. Therefore, a crowd sourced database that incorporates insights from state-of-the-art FER methods could be a valuable resource for further research in this field.
本研究通过强调所提出方法的优势与潜在改进方向,为未来研究提供了宝贵洞见。一个重要方向是提升PAtt-Lite模型对低资源表情的鲁棒性,可通过优化补丁提取模块或采用性能更强、鲁棒性更好的特征提取主干网络实现。如前一节所述,尽管现有大型面部表情识别(FER)数据库众多,但该领域发展仍需更优质的标注数据。我们建议开发具有更高标注可靠性的FER数据库,现有FER方法已能识别人类标注者难以察觉的微妙模式,因此融合前沿FER方法洞察力的众包数据库将成为推动该领域研究的重要资源。
Overall, this work has shown the potential to use MobileNetV1 as a baseline feature extractor in FER. The need for continued research and development is also highlighted to further improve the accuracy and reliability of automated facial expression recognition, especially under challenging conditions and low-resource expressions.
总体而言,这项工作展示了使用 MobileNetV1 作为面部表情识别 (FER) 基准特征提取器的潜力。研究同时强调需要持续开展研发工作,以进一步提升自动化面部表情识别的准确性和可靠性,特别是在挑战性条件和低资源表情场景下。
REFERENCES
参考文献

JIA LE NGWE received the bachelor’s degree in Artificial Intelligence (AI) from the Multimedia University, Malaysia, in 2022. He is currently pursuing his Ph.D. degree in the field of AI at Multimedia University. His research interest includes generative modelling, affective computing, and edge AI.
JIA LE NGWE 于2022年获得马来西亚多媒体大学人工智能 (AI) 学士学位,目前正在该校攻读人工智能领域的博士学位。他的研究方向包括生成建模 (generative modelling)、情感计算 (affective computing) 和边缘人工智能 (edge AI)。

ALI ALQAHTANI received the Ph.D. degree in computer science from Swansea University, Swansea, U.K., in 2021. He is currently an Assistant Professor with the Department of Computer Science, King Khalid University, Abha, Saudi Arabia. He has published several refereed conference and journal publications. His research interests include various aspects of pattern recognition, deep learning, and machine intelligence and their applications to real-world problems.
ALI ALQAHTANI于2021年获得英国斯旺西大学计算机科学博士学位,现任沙特阿拉伯艾卜哈哈立德国王大学计算机科学系助理教授。他已发表多篇经同行评审的会议和期刊论文,研究兴趣涵盖模式识别、深度学习、机器智能的多个方面及其在现实问题中的应用。

KIAN MING LIM received B.IT (Hons) in Information Systems Engineering, Master of Engineering Science (MEngSc) and Ph.D. (I.T.) degrees from Multimedia University. He is currently a Lecturer with the Faculty of Information Science and Technology, Multimedia University. His research and teaching interests includes machine learning, deep learning, and computer vision and pattern recognition.
KIAN MING LIM 获多媒体大学信息系统工程荣誉学士学位、工程科学硕士学位(MEngSc)及信息技术博士学位(Ph.D.)。现任多媒体大学信息科技学院讲师,研究方向与教学领域涵盖机器学习、深度学习、计算机视觉及模式识别。

CHIN POO LEE is a Senior Lecturer in the Faculty of Information Science and Technology at Multimedia University, Malaysia. She completed her Masters of Science and Ph.D. in Information Technology in the area of abnormal behaviour detection and gait recognition. She is a certified Professional Technologist since 2018, a member of International Association of Engineers since 2020 as well as Outcome-Based Education Consultant and Trainer. Her research interests include action recognition, computer vision, gait recognition, natural language processing and deep learning.
CHIN POO LEE是马来西亚多媒体大学信息科学与技术学院的高级讲师。她完成了信息技术领域的理学硕士和博士学位,研究方向为异常行为检测与步态识别。自2018年起成为认证专业技术人员,2020年加入国际工程师协会,同时担任成果导向教育顾问和培训师。她的研究兴趣包括动作识别、计算机视觉、步态识别、自然语言处理和深度学习。

THIAN SONG ONG received the M.Sc. degree from the University of Sunderland, U.K., in 2001, and the Ph.D. degree from Multimedia University, Malaysia, in 2008. He works with the Faculty of Information Sciences and Technology (FIST), Multimedia University. He has more than 70 publications from conferences and international refereed journals published. His research interests include biometric security and machine learning. From 2013 to 2015, he served on the Editorial
THIAN SONG ONG 于2001年获得英国桑德兰大学硕士学位,2008年获得马来西亚多媒体大学博士学位。现任教于多媒体大学信息科学与技术学院 (FIST)。他在国际会议和期刊上发表论文70余篇,研究方向涵盖生物特征识别安全与机器学习。2013至2015年期间担任期刊编委。
Board of the IEEE BIOMETRICS COUNCIL NEWSLETTER
IEEE生物识别理事会通讯委员会
VOLUME 4, 2016
第4卷,2016