End-to-End Spatio-Temporal Action Local is ation with Video Transformers
基于视频Transformer的端到端时空动作定位
Abstract
摘要
The most performant spatio-temporal action localisation models use external person proposals and complex external memory banks. We propose a fully end-to-end, purely-transformer based model that directly ingests an input video, and outputs tubelets – a sequence of bounding boxes and the action classes at each frame. Our flexible model can be trained with either sparse bounding-box supervision on individual frames, or full tubelet annotations. And in both cases, it predicts coherent tubelets as the output. Moreover, our end-to-end model requires no additional pre-processing in the form of proposals, or post-processing in terms of non-maximal suppression. We perform extensive ablation experiments, and significantly advance the stateof-the-art results on four different spatio-temporal action local is ation benchmarks with both sparse keyframes and full tubelet annotations.
性能最优的时空动作定位模型通常依赖外部人物提议框和复杂的外部记忆库。我们提出了一种完全端到端、纯Transformer架构的模型,可直接输入视频并输出管状体(tubelet)——即一系列边界框序列及每帧对应的动作类别。该灵活模型既支持基于单帧稀疏边界框标注的训练,也可利用完整管状体标注进行训练,且两种情况下均能预测出连贯的管状体输出。此外,我们的端到端模型既不需要提议框等预处理步骤,也无需非极大值抑制等后处理操作。通过大量消融实验,我们在四个时空动作定位基准测试(包含稀疏关键帧标注和完整管状体标注两种设置)上显著提升了当前最优性能。
1. Introduction
1. 引言
Spatio-temporal action local is ation is an important problem with applications in advanced video search engines, robotics and security among others. It is typically formulated in one of two ways: Firstly, predicting the bounding boxes and actions performed by an actor at a single keyframe given neighbouring frames as spatio-temporal context [18, 29]. Or alternatively, predicting a sequence of bounding boxes and actions (i.e. “tubes”), for each actor at each frame in the video [22, 48].
时空动作定位是一个重要问题,在高级视频搜索引擎、机器人和安全等领域有广泛应用。它通常以两种方式之一进行建模:首先,在给定相邻帧作为时空上下文的情况下,预测单个关键帧中行为者的边界框和执行的动作 [18, 29];或者,为视频中每一帧的每个行为者预测一系列边界框和动作(即"管道")[22, 48]。
The most performant models [3, 14, 39, 61], particularly for the first, keyframe-based formulation of the problem, employ a two-stage pipeline inspired by the Fast-RCNN object detector [17]: They first run a separate person detector to obtain proposals. Features from these proposals are then aggregated and classified according to the actions of interest. These models have also been supplemented with memory banks containing long-term contextual information from other frames [39, 54, 60, 61], and/or detections of other potentially relevant objects [2, 54] to capture additional scene context, achieving state-of-the-art results.
性能最佳的模型 [3, 14, 39, 61](特别是针对基于关键帧的第一种问题表述方案)采用了受 Fast-RCNN 目标检测器 [17] 启发的两阶段流程:首先运行独立的人物检测器获取候选区域,随后聚合这些区域的特征并根据目标动作进行分类。这些模型还通过添加存储长期上下文信息的记忆库 [39, 54, 60, 61] 和/或检测其他潜在相关对象 [2, 54] 来捕获额外场景上下文,从而实现了最先进的性能。

Figure 1. We propose an end-to-end Spatio-Temporal Action Recognition model named STAR. Our model is end-to-end in that it does not require any external region proposals to predict tubelets – sequences of bounding boxes associated with a given person in every frame and their corresponding action classes. Our model can be trained with either sparse box annotations on selected keyframes, or full tubelet supervision.
图 1: 我们提出了一种名为STAR的端到端时空动作识别模型。该模型的端到端特性体现在无需任何外部区域提议即可预测管段(tubelets)——即视频每帧中与特定人物关联的边界框序列及其对应动作类别。我们的模型既可通过关键帧稀疏框标注进行训练,也可采用完整管段监督方式。
And whilst proposal-free algorithms, which do not require external person detectors, have been developed for detecting both at the keyframe-level [8, 26, 52] and tubeletlevel [23, 65], their performance has typically lagged behind their proposal-based counterparts. Here, we show for the first time that an end-to-end trainable spatio-temporal model outperforms a two-stage approach.
虽然无需外部人物检测器的无提案算法 (proposal-free algorithms) 已在关键帧级别 [8, 26, 52] 和短管级别 [23, 65] 实现双模态检测,但其性能通常落后于基于提案的算法。本文首次证明端到端可训练的时空模型性能优于两阶段方法。
As shown in Fig. 1, we propose our Spatio-Temporal Action TransformeR (STAR) that consists of a puretransformer architecture, and is based on the DETR [6] detection model. Our model is “end-to-end” in that it does not require pre-processing in the form of proposals, nor postprocessing in the form of non-maximal suppression (NMS) in contrast to the majority of prior work. The initial stage of the model is a vision encoder. This is followed by a decoder that processes learned latent queries, which represent each actor in the video, into output tubelets – a sequence of bounding boxes and action classes at each time step of the input video clip. Our model is versatile in that we can train it with either fully-labeled tube annotations, or with sparse keyframe annotations (when only a limited number of keyframes are labelled). In the latter case, our network still predicts tubelets, and learns to associate detections of an actor, from one frame to the next, without explicit supervision. This behaviour is facilitated by our formulation of factorised queries, decoder architecture and tubelet matching in the loss which all contain temporal inductive biases.
如图 1 所示,我们提出了时空动作 Transformer (Spatio-Temporal Action TransformeR, STAR) ,该模型采用纯 Transformer 架构,并基于 DETR [6] 检测模型构建。我们的模型是"端到端"的,与大多数现有工作不同,它既不需要以候选框形式进行预处理,也不需要通过非极大值抑制 (NMS) 进行后处理。模型的第一阶段是视觉编码器,随后解码器会将学习到的潜在查询 (latent queries) 处理为输出管段 (tubelets) —— 即输入视频片段每个时间步的边界框序列和动作类别。我们的模型具有通用性,既可以使用完整标注的管段数据进行训练,也可以使用稀疏关键帧标注 (仅标记少量关键帧) 进行训练。在后一种情况下,我们的网络仍能预测管段,并学会在没有显式监督的情况下将演员的检测结果在帧间关联起来。这种能力得益于我们对分解查询 (factorised queries) 的表述、解码器架构以及损失函数中的管段匹配机制,这些设计都包含了时序归纳偏置。
We conduct thorough ablation studies of these modelling choices. Informed by these experiments, we achieve state-of-the-art on both keyframe-based action localisation datasets like AVA [18] and AVA-Kinetics [29], and also tubelet-based datasets like UCF101-24 [48] and JHMDB [22]. In particular, we achieve a Frame mAP of 44.6 on AVA-Kinetics outperforming previous published work [39] by 8.2 points, and a recent foundation model [58] by 2.1 points. In addition, our Video AP50 on UCF101-24 surpasses prior work [65] by 11.6 points. Moreover, our state-of-the-art results are achieved with a single forwardpass through the model, using only a video clip as input, and without any separate external person detectors providing proposals [3, 58, 61], complex memory banks [39, 61, 65], or additional object detectors [2, 54], as used by the prior state-of-the-art. Furthermore, we outperform these complex, prior, state-of-the-art two-stage models whilst also having additional functionality in that our model predicts tubelets, that is, temporally consistent bounding boxes at each frame of the input video clip.
我们对这些建模选择进行了全面的消融研究。通过这些实验,我们在基于关键帧的动作定位数据集(如 AVA [18] 和 AVA-Kinetics [29])以及基于管状片段的数据集(如 UCF101-24 [48] 和 JHMDB [22])上均取得了最先进的成果。具体而言,我们在 AVA-Kinetics 上实现了 44.6 的帧 mAP,比之前发表的工作 [39] 高出 8.2 分,比近期的基础模型 [58] 高出 2.1 分。此外,我们在 UCF101-24 上的 Video AP50 比之前的工作 [65] 高出 11.6 分。更重要的是,我们的最先进成果仅需对模型进行一次前向传播,仅使用视频片段作为输入,无需任何单独的外部人物检测器提供提议 [3, 58, 61]、复杂的记忆库 [39, 61, 65] 或额外的物体检测器 [2, 54],而这些在之前的最先进方法中均有使用。此外,我们的模型不仅超越了这些复杂的、之前最先进的两阶段模型,还具备额外的功能——能够预测管状片段,即在输入视频片段的每一帧上生成时间一致的目标框。
2. Related Work
2. 相关工作
Models for spatio-temporal action local is ation have typically built upon advances in object detectors for images. The most performant methods for action local is ation [3, 14, 39, 54, 61] are based on “two-stage” detectors like FastRCNN [17]. These models use external, pre-computed person detections, and use them to ROI-pool features which are then classified into action classes. Although these models are cumbersome in that they require an additional model and backbone to first detect people, and therefore additional detection training data as well, they are currently the leading approaches on datasets such as AVA [18]. Such models using external proposals are also particularly suited to datasets such as AVA [18] as each person is exhaustively labelled as performing an action, and therefore there are fewer false-positives from using action-agnostic person detections compared to datasets such as UCF101 [48].
时空动作定位模型通常建立在图像目标检测技术进展的基础上。当前性能最优的动作定位方法 [3, 14, 39, 54, 61] 都基于 FastRCNN [17] 等"两阶段"检测器。这些模型使用外部预计算的人物检测框进行 ROI (Region of Interest) 特征池化,再将特征分类为动作类别。尽管这类模型需要额外的人物检测模型和骨干网络,还需额外的检测训练数据,但目前在 AVA [18] 等数据集上仍保持领先优势。使用外部候选框的模型特别适合 AVA [18] 这类数据集,因为其中每个人都标注了执行动作,相比 UCF101 [48] 等数据集,使用动作无关的人物检测框产生的误报更少。
The performance of these two-stage models has further been improved by incorporating more contextual information using feature banks extracted from additional frames in the video [39, 54, 60, 61] or by utilising detections of additional objects in the scene [2, 5, 57, 64]. Both of these cases require significant additional computation and complexity to train additional auxiliary models and to precompute features from them that are then used during training and inference of the local is ation model.
通过利用从视频额外帧中提取的特征库 [39, 54, 60, 61] 或利用场景中其他物体的检测结果 [2, 5, 57, 64] 来融入更多上下文信息,这类两阶段模型的性能得到了进一步提升。这两种情况都需要大量额外计算和复杂度,以训练额外的辅助模型并预计算其特征,这些特征随后用于定位模型的训练和推理。
Our proposed method, in contrast, is end-to-end in that it directly produces detections without any additional inputs besides a video clip. Moreover, it outperforms these prior works without resorting to external proposals or memory banks, showing that a transformer backbone is sufficient to capture long-range dependencies in the input video. In addition, unlike previous two-stage methods, our method directly predicts tubelets: a sequence of bounding boxes and actions for each frame of the input video, and can do so even when we do not have full tubelet annotations available.
相比之下,我们提出的方法是端到端的,它仅需输入视频片段即可直接生成检测结果。此外,该方法无需依赖外部提案或记忆库就能超越先前工作,这表明Transformer主干网络足以捕捉输入视频中的长程依赖关系。与以往两阶段方法不同,我们的方法能直接预测小管段(tubelets):为输入视频每一帧生成边界框序列及对应动作,且即使在没有完整小管段标注的情况下也能实现这一目标。
A number of proposal-free action local is ation models have also been developed [8, 16, 23, 26, 52, 65]. These methods are based upon alternative object detection architectures such as SSD [34], CentreNet [66], YOLO [41], DETR [6] and Sparse-RCNN [53]. However, in contrast to our approach, they have been outperformed by their proposal-based counterparts. Moreover, some of these methods [16, 26, 52] also consist of separate network backbones for learning video feature representations and proposals for a keyframe, and are thus effectively two networks trained jointly, and cannot predict tubelets either.
已开发出多种无提议(proposal-free)动作定位模型[8, 16, 23, 26, 52, 65]。这些方法基于替代性目标检测架构,如SSD[34]、CentreNet[66]、YOLO[41]、DETR[6]和Sparse-RCNN[53]。但与我们的方法相比,它们的性能始终不及基于提议(proposal-based)的对应方法。此外,其中部分方法[16, 26, 52]仍采用独立网络主干来学习视频特征表示和关键帧提议,本质上仍是联合训练的两个独立网络,同样无法预测管状片段(tubelets)。
Among prior works that do not use external proposals, and also directly predict tubelets [23, 30, 31, 46, 47, 65], our work is the most similar to TubeR [65] given that our model is also based on DETR. Our model, however, is purely transformer-based (including the encoder) and achieves substantially higher performance without requiring external memory banks pre computed offline like [65]. Furthermore, unlike TubeR, we also demonstrate how our model can predict tubelets (i.e. predictions at every frame of the input video), even when we only have sparse keyframe supervision (i.e. ground truth annotation for a limited number of frames) available.
在不使用外部提案并直接预测视频片段 (tubelet) 的先前研究中 [23, 30, 31, 46, 47, 65],我们的工作与 TubeR [65] 最为相似,因为我们的模型同样基于 DETR (Detection Transformer) 。然而,我们的模型完全基于 Transformer (包括编码器) ,且无需像 [65] 那样依赖离线预计算的外部记忆库即可实现显著更高的性能。此外,与 TubeR 不同,我们还证明了即使在仅有稀疏关键帧监督 (即仅对有限帧提供真实标注) 的情况下,我们的模型仍能预测视频片段 (即对输入视频的每一帧进行预测) 。
Finally, we note that DETR has also been extended as a proposal-free method to addressing different local is ation tasks in video such as video instance segmentation [59], temporal local is ation [35,38,62] and moment retrieval [28].
最后,我们注意到DETR也被扩展为一种无提案方法,用于解决视频中的不同定位任务,如视频实例分割 [59]、时序定位 [35,38,62] 和片段检索 [28]。
3. Spatio-Temporal Action Transformer
3. 时空动作Transformer
Our proposed model ingests a sequence of video frames, and directly predicts tubelets (a sequence of bounding boxes and action labels). In contrast to leading spatio-temporal action recognition models, our model does not use external person detections [3, 39, 55, 61] or external memory banks [39, 60, 65] to achieve strong results.
我们提出的模型接收一系列视频帧,并直接预测小管序列(一组边界框和动作标签)。与领先的时空动作识别模型不同,我们的模型无需借助外部人物检测 [3, 39, 55, 61] 或外部记忆库 [39, 60, 65] 即可取得优异效果。
As summarised in Fig. 2, our model consists of a vision encoder (Sec. 3.1), followed by a decoder which processes learned query tokens into output tubelets (Sec. 3.2). We incorporate temporal inductive biases into our decoder to improve accuracy and tubelet prediction with weaker supervision. Our model is inspired by the DETR architecture [6] for object detection in images, and is also trained with a setbased loss and Hungarian matching. We detail our loss, and how we can train with either sparse keyframe supervision or full tubelet supervision, in Sec. 3.3.
如图 2 所示,我们的模型由视觉编码器 (Sec. 3.1) 和将学习到的查询 token 处理为输出管状片段 (Sec. 3.2) 的解码器组成。我们在解码器中引入时间归纳偏置,以提升弱监督下的准确性和管状片段预测能力。该模型受 DETR [6] 图像目标检测架构启发,同样采用基于集合的损失函数和匈牙利匹配进行训练。我们在 Sec. 3.3 详细阐述了损失函数设计,以及如何通过稀疏关键帧监督或完整管状片段监督进行训练。
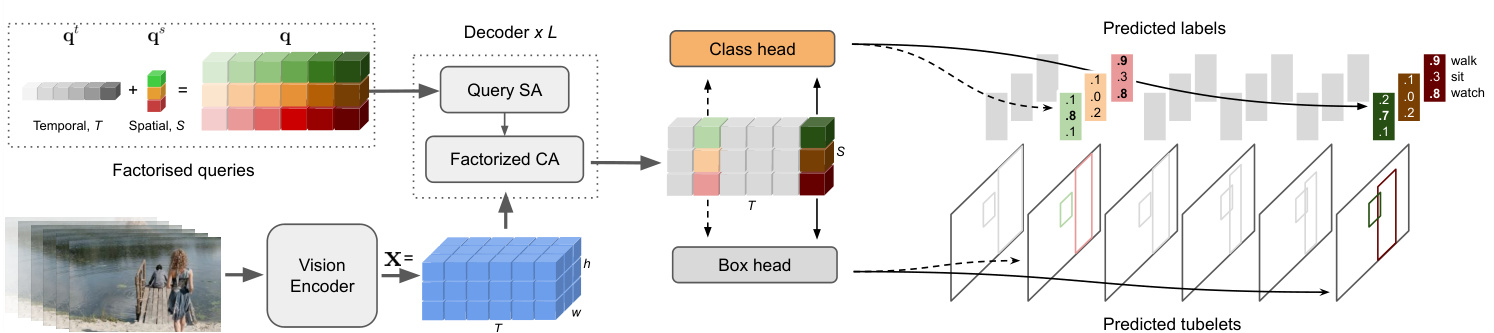
Figure 2. Our model processes a fixed-length video clip, and for each frame, outputs tubelets (i.e. linked bounding boxes with associated action class probabilities). It consists of a transformer-based vision encoder which outputs a video representation, $\mathbf{x}\in\mathbb{R}^{T\times h\times w\times d}$ . The video representation, along with learned queries, $\mathbf{q}$ (which are factorised into spatial ${\bf q}^{s}$ and temporal components $\mathbf{q}^{t}$ ) are decoded into tubelets by a decoder of $L$ layers followed by shallow box and class prediction heads.
图 2: 我们的模型处理固定长度的视频片段,并为每帧输出管状检测区域 (即带有关联动作类别概率的链接边界框)。该模型包含基于Transformer的视觉编码器,可输出视频表征 $\mathbf{x}\in\mathbb{R}^{T\times h\times w\times d}$。视频表征与学习到的查询向量 $\mathbf{q}$ (分解为空间分量 ${\bf q}^{s}$ 和时间分量 $\mathbf{q}^{t}$) 通过 $L$ 层解码器解码为管状检测区域,最后经过浅层框预测头和类别预测头。
3.1. Vision Encoder
3.1. 视觉编码器
The vision backbone processes an input video, $\textbf{X}\in$ RT ×H×W ×3 to produce a feature representation of the input video $\mathbf{x}\in\mathbb{R}^{t\times h\times w\times d}$ . Here, $T,H$ and $W$ are the original temporal-, height- and width-dimensions of the input video respectively, whilst $t$ , $h$ and $w$ are the spatio-temporal dimensions of their feature representation, and $d$ its latent dimension. As we use a transformer, specifically the ViViT Factorised Encoder [1], these spatio-temporal dimensions depend on the patch size when tokenising the input. To retain spatio-temporal information, we remove the spatialand temporal-aggregation steps in the original transformer backbone. And if the temporal patch size is larger than 1, we bilinearly upsample the final feature map along the temporal axis to maintain the original temporal resolution.
视觉主干网络处理输入视频 $\textbf{X}\in$ RT ×H×W ×3,生成输入视频的特征表示 $\mathbf{x}\in\mathbb{R}^{t\times h\times w\times d}$。其中,$T,H$ 和 $W$ 分别表示输入视频的原始时间、高度和宽度维度,而 $t$、$h$ 和 $w$ 是其特征表示的时空维度,$d$ 为潜在维度。由于我们采用 Transformer (具体为 ViViT Factorised Encoder [1]),这些时空维度取决于输入 Token 化时的分块大小。为保留时空信息,我们移除了原始 Transformer 主干中的空间与时间聚合步骤。若时间分块大小超过 1,则沿时间轴对最终特征图进行双线性上采样以维持原始时间分辨率。
3.2. Tubelet Decoder
3.2. Tubelet解码器
Our decoder processes the visual features, $\textbf{x}\in$ $\mathbb{R}^{T\times h\times w\times c}$ , along with learned queries, $\textbf{q}\in\mathbb{R}^{T\times S\times d}$ to outputs tubelets, $\mathbf{y} =~(\mathbf{b},\mathbf{a})$ which are a sequence of bounding boxes, $b\in\mathbb{R}^{T\times S\times4}$ and corresponding actions, $\boldsymbol{a}\in\mathbb{R}^{T\times S\times C}$ . Here, $S$ denotes the maximum number of bounding boxes per frame (padded with “background” as necessary) and $C$ denotes the number of output classes.
我们的解码器处理视觉特征 $\textbf{x}\in\mathbb{R}^{T\times h\times w\times c}$ 和学习查询 $\textbf{q}\in\mathbb{R}^{T\times S\times d}$ ,输出管状体 $\mathbf{y} =~(\mathbf{b},\mathbf{a})$ ,即一系列边界框 $b\in\mathbb{R}^{T\times S\times4}$ 和对应动作 $\boldsymbol{a}\in\mathbb{R}^{T\times S\times C}$ 。其中 $S$ 表示每帧的最大边界框数量(必要时用“背景”填充), $C$ 表示输出类别数。
The idea of decoding learned queries into output detections using the transformer decoder architecture of Vaswani et al. [56] was used in DETR [6]. In summary, the decoder of [6, 56] consists of $L$ layers, each performing a series of self-attention operations on the queries, and cross-attention between the queries and encoder outputs.
将学习到的查询解码为输出检测的想法,使用 Vaswani 等人 [56] 提出的 Transformer 解码器架构,在 DETR [6] 中得到了应用。简而言之,[6, 56] 的解码器由 $L$ 层组成,每一层都对查询执行一系列自注意力操作,并在查询与编码器输出之间进行交叉注意力计算。
We modify the queries, self-attention and cross-attention operations for our spatio-temporal local is ation scenario, as shown in Fig. 2 and 3 to include additional temporal inductive biases, and to improve accuracy as detailed below.
我们对查询、自注意力 (self-attention) 和交叉注意力 (cross-attention) 操作进行了修改,以适应时空局部化场景。如图 2 和图 3 所示,这些修改引入了额外的时序归纳偏置 (temporal inductive biases) ,并提高了准确性,具体细节如下。
Queries Queries, q, in DETR, are decoded using the encoded visual features, $\mathbf{x}$ , into bounding box predictions, and are analogous to the “anchors” used in other detection architectures such as Faster-RCNN [42].
查询
在 DETR 中,查询 (queries, q) 通过编码的视觉特征 $\mathbf{x}$ 解码为边界框预测,其作用类似于 Faster-RCNN [42] 等其他检测架构中使用的"锚点 (anchors)"。
The most straightforward way to define queries is to randomly initialise $\bar{\mathbf{q}}\in\mathbb{R}^{T\times S\times d}$ , where there are $S$ bounding boxes at each of the $T$ input frames in the video clip.
定义查询最直接的方法是随机初始化 $\bar{\mathbf{q}}\in\mathbb{R}^{T\times S\times d}$ ,其中视频片段的 $T$ 个输入帧中每帧包含 $S$ 个边界框。
However, we find it is more effective to factorise the queries into separate learned spatial, $\mathbf{q}^{s}\in\mathbb{R}^{S\times d}$ , and temporal, qT ×d parameters. To obtain the final tubelet queries, we simply repeat the spatial queries across all frames, and add them to their corresponding temporal embedding at each location, as shown in Fig. 2. More concretely $\mathbf{q}{i j}=$ $\mathbf{q}{i}^{t}+\mathbf{q}_{j}^{s}$ where $i$ and $j$ denote the temporal and spatial indices respectively.
然而,我们发现将查询分解为独立学习的空间参数 $\mathbf{q}^{s}\in\mathbb{R}^{S\times d}$ 和时间参数 $\mathbf{q}^{T}\in\mathbb{R}^{T\times d}$ 更为有效。如图 2 所示,为获得最终的管状查询 (tubelet queries),只需将空间查询在所有帧上重复,并与对应位置的时序嵌入相加。具体表示为 $\mathbf{q}{i j}=\mathbf{q}{i}^{t}+\mathbf{q}_{j}^{s}$,其中 $i$ 和 $j$ 分别表示时间和空间索引。
The factorised query representation means that the same spatial embedding is used across all frames. Intuitively, this encourages the $i^{t h}$ spatial query embedding, $\mathbf{q}_{i}^{s}$ , to bind to the same location across different frames of the video, and since objects typically have small displacements from frame to frame, may help to associate bounding boxes within a tubelet together. We verify this intuition empirically in the experimental section.
分解式查询表示意味着所有帧使用相同的空间嵌入。直观上,这促使第 $i^{t h}$ 个空间查询嵌入 $\mathbf{q}_{i}^{s}$ 在视频不同帧中绑定到同一位置,由于物体通常帧间位移较小,可能有助于将管状片段内的边界框关联起来。我们通过实验部分验证了这一直觉。
Decoder layer The decoder layer in the original transformer [56] consists of self-attention on the queries, $\mathbf{q}$ , followed by cross-attention between the queries and the outputs of the encoder, $\mathbf{x}$ , and then a multilayer perceptron (MLP) layer [19, 56]. These operations can be denoted by
解码器层 原始Transformer [56]中的解码器层由查询的自注意力 (self-attention) $\mathbf{q}$、查询与编码器输出的交叉注意力 (cross-attention) $\mathbf{x}$ 以及多层感知机 (MLP) 层 [19, 56] 组成。这些操作可表示为
$$
\begin{array}{r l}&{\mathbf{u}^{\ell}=\mathrm{MHSA}(\mathbf{q}^{\ell})+\mathbf{q}^{\ell},}\ &{\mathbf{v}^{\ell}=\mathrm{CA}(\mathbf{u}^{\ell},\mathbf{x})+\mathbf{u}^{\ell},}\ &{\mathbf{z}^{\ell}=\mathrm{MLP}(\mathbf{v}^{\ell})+\mathbf{v}^{\ell},}\end{array}
$$
$$
\begin{array}{r l}&{\mathbf{u}^{\ell}=\mathrm{MHSA}(\mathbf{q}^{\ell})+\mathbf{q}^{\ell},}\ &{\mathbf{v}^{\ell}=\mathrm{CA}(\mathbf{u}^{\ell},\mathbf{x})+\mathbf{u}^{\ell},}\ &{\mathbf{z}^{\ell}=\mathrm{MLP}(\mathbf{v}^{\ell})+\mathbf{v}^{\ell},}\end{array}
$$
where $\mathbf{z}^{\ell}$ is the output of the $\ell^{t h}$ decoder layer, $\mathbf{u}$ and $\mathbf{v}$ are intermediate variables, MHSA denotes multi-headed selfattention and CA cross-attention. Note that the inputs to the MLP and self- and cross-attention operations are layernormalised [4], which we omit here for clarity.
其中 $\mathbf{z}^{\ell}$ 是第 $\ell^{t h}$ 层解码器的输出,$\mathbf{u}$ 和 $\mathbf{v}$ 是中间变量,MHSA 表示多头自注意力机制 (multi-headed self-attention),CA 表示交叉注意力机制 (cross-attention)。请注意,MLP 以及自注意力和交叉注意力操作的输入都经过层归一化 [4],为清晰起见此处省略。

Figure 3. Our decoder layer consists of factorised self-attention (SA) (left) and cross-attention (CA) (right) operations designed to provide a spatio-temporal inductive bias and reduce computation. Both operations restrict attention to the same spatial and temporal slices as the query token, as illustrated by the receptive field (blue) for a given query token (magenta). Factorised SA consists of two operations, whilst in Factorised CA, there is one operation.
图 3: 我们的解码器层由分解自注意力 (SA) (左) 和交叉注意力 (CA) (右) 操作组成,旨在提供时空归纳偏置并减少计算量。如给定查询token (洋红色) 的感受野 (蓝色) 所示,两种操作都将注意力限制在与查询token相同的空间和时间切片上。分解SA包含两个操作,而分解CA仅包含一个操作。
In our model, we factorise the self- and cross-attention layers across space and time respectively as shown in Fig. 3, to introduce a temporal locality inductive bias, and also to increase model efficiency. Concretely, when applying MHSA, we first compute the queries, keys and values, over which we attend twice: first independently at each time step with each frame, and then, independently along the time axis at each spatial location. Similarly, we modify the crossattention operation so that only tubelet queries and backbone features from the same time index attend to each other.
在我们的模型中,我们分别对空间和时间维度上的自注意力层和交叉注意力层进行分解(如图3所示),以引入时间局部性归纳偏置,同时提升模型效率。具体而言,在应用多头自注意力(MHSA)时,我们首先计算查询、键和值,然后进行两次注意力计算:第一次在每个时间步内独立处理各帧,第二次在每个空间位置沿时间轴独立处理。类似地,我们调整交叉注意力操作,使得仅相同时间索引的管状查询(tubelet queries)与骨干网络特征相互关注。
Local is ation and classification heads We obtain the final predictions of the network, $\mathbf{y}=(\mathbf{b},\mathbf{a})$ , by applying a small feed-forward network to the outputs to the decoder, $\mathbf{z}$ , following DETR [6]. The sequence of bounding boxes, b, is obtained with a 3-layer MLP, and is parameter is ed by the box center, width and height for each frame in the tubelet. A single-layer linear projection is used to obtain class logits, a. As we predict a fixed number of $S$ bounding boxes per frame, and $S$ is more than the maximum number of ground truth instances in the frame, we also include an additional class label, $\mathcal{D}$ , which represents the “background” class which tubelets with no action class can be assigned to.
定位与分类头部
我们通过将一个小型前馈网络应用于解码器输出 $\mathbf{z}$,获得网络的最终预测 $\mathbf{y}=(\mathbf{b},\mathbf{a})$,遵循 DETR [6] 的方法。边界框序列 b 通过一个 3 层 MLP 获得,其参数由每个管状片段(tubelet)中帧的框中心、宽度和高度确定。使用单层线性投影获取类别逻辑值 a。由于我们为每帧预测固定数量 $S$ 的边界框,且 $S$ 超过帧中真实实例的最大数量,因此我们还引入了一个额外的类别标签 $\mathcal{D}$,代表“背景”类,无动作类别的管状片段可被分配至该类。
3.3. Training objective
3.3. 训练目标
Our model predicts bounding boxes and action classes at each frame of the input video. Many datasets, however, such as AVA [18], are only sparsely annotated at selected keyframes of the video. In order to leverage the available annotations, we compute our training loss, Eq. 4, only at the annotated frames of the video, after having matched the predictions to the ground truth. This is denoted as
我们的模型在输入视频的每一帧预测边界框和动作类别。然而许多数据集(如AVA [18])仅在视频选定的关键帧上进行了稀疏标注。为了利用现有标注,我们仅在视频的标注帧上计算训练损失(式4),并在将预测结果与真实标注匹配后进行。这一过程表示为
$$
\mathcal{L}(\mathbf{y},\hat{\mathbf{y}})=\frac{1}{|\mathcal{T}|}\sum_{t\in\mathcal{T}}\mathcal{L}_{\mathrm{frame}}(\mathbf{y},\hat{\mathbf{y}}),
$$
$$
\mathcal{L}(\mathbf{y},\hat{\mathbf{y}})=\frac{1}{|\mathcal{T}|}\sum_{t\in\mathcal{T}}\mathcal{L}_{\mathrm{frame}}(\mathbf{y},\hat{\mathbf{y}}),
$$
where $\tau$ is the set of labelled frames; $\mathbf{y}$ and $\hat{\bf y}$ denote the ground truth and predicted tubelets after matching.
其中 $\tau$ 是标记帧的集合;$\mathbf{y}$ 和 $\hat{\bf y}$ 分别表示匹配后的真实标注和预测管段。
Following DETR [6], our training loss at each frame, ${\mathcal{L}}{\mathrm{frame}}$ , is a sum of an $L_{1}$ regression loss on bounding boxes, the generalised IoU loss [43] on bounding boxes, and a cross-entropy loss on action labels:
遵循 DETR [6] 的方法,我们在每一帧的训练损失 ${\mathcal{L}}{\mathrm{frame}}$ 由三部分组成:边界框的 $L_{1}$ 回归损失、边界框的广义 IoU 损失 [43] 以及动作标签的交叉熵损失:
$$
\begin{array}{r l r}{\lefteqn{\mathcal{L}{\mathrm{frame}}({\mathbf b}^{t},\hat{{\mathbf b}}^{t},{\mathbf a}^{t},\hat{{\mathbf a}}^{t})=\sum_{i}\mathcal{L}{\mathrm{box}}({\mathbf b}{i}^{t},\hat{{\mathbf b}}{i}^{t})+\mathcal{L}{\mathrm{iou}}({\mathbf b}{i}^{t},\hat{{\mathbf b}}{i}^{t})}}\ &{}&{+\mathcal{L}{\mathrm{class}}({\mathbf a}{i}^{t},\hat{{\mathbf a}}_{i}^{t}).\quad\quad\quad(\hat{\mathbf a}^{t},\hat{{\mathbf a}}^{t})}\end{array}
$$
$$
\begin{array}{r l r}{\lefteqn{\mathcal{L}{\mathrm{frame}}({\mathbf b}^{t},\hat{{\mathbf b}}^{t},{\mathbf a}^{t},\hat{{\mathbf a}}^{t})=\sum_{i}\mathcal{L}{\mathrm{box}}({\mathbf b}{i}^{t},\hat{{\mathbf b}}{i}^{t})+\mathcal{L}{\mathrm{iou}}({\mathbf b}{i}^{t},\hat{{\mathbf b}}{i}^{t})}}\ &{}&{+\mathcal{L}{\mathrm{class}}({\mathbf a}{i}^{t},\hat{{\mathbf a}}_{i}^{t}).\quad\quad\quad(\hat{\mathbf a}^{t},\hat{{\mathbf a}}^{t})}\end{array}
$$
Matching Set-based detection models such as DETR can make predictions in any order, which is why the predictions need to be matched to the ground truth before computing the training loss.
基于集合匹配的检测模型(如DETR)可以按任意顺序生成预测结果,因此在计算训练损失前需将预测值与真实标注进行匹配。
The first form of matching that we consider is to independently perform bipartite matching at each frame to align the model’s predictions to the ground truth (or the $\boldsymbol{\mathcal{O}}$ background class) before computing the loss. In this case, we use the Hungarian algorithm [27] to obtain $T$ permutations of $S$ elements, $\hat{\pi}^{t}\in\Pi^{t}$ , at each frame, where the permutation at the $t^{t h}$ frame minimises the per-frame loss,
我们考虑的第一种匹配形式是在计算损失之前,独立地在每一帧执行二分匹配,将模型的预测与真实值(或 $\boldsymbol{\mathcal{O}}$ 背景类)对齐。在这种情况下,我们使用匈牙利算法 [27] 在每一帧获得 $S$ 个元素的 $T$ 种排列 $\hat{\pi}^{t}\in\Pi^{t}$ ,其中第 $t^{t h}$ 帧的排列使逐帧损失最小化。
$$
\hat{\boldsymbol{\pi}}^{t}=\operatorname*{argmin}{\boldsymbol{\pi}\in\Pi^{t}}\mathcal{L}{\mathrm{frame}}(\mathbf{y}^{t},\hat{\mathbf{y}}_{\pi(i)}^{t}).
$$
$$
\hat{\boldsymbol{\pi}}^{t}=\operatorname*{argmin}{\boldsymbol{\pi}\in\Pi^{t}}\mathcal{L}{\mathrm{frame}}(\mathbf{y}^{t},\hat{\mathbf{y}}_{\pi(i)}^{t}).
$$
An alternative is to perform tubelet matching, where all queries with the same spatial index, ${\bf q}^{s}$ , must match to the same ground truth annotation across all frames of the input video. Here the permutation is obtained over $S$ elements as
另一种方法是执行小管匹配 (tubelet matching),其中所有具有相同空间索引 ${\bf q}^{s}$ 的查询必须与输入视频所有帧中的相同真实标注匹配。这里的排列是在 $S$ 个元素上获得的。
$$
\hat{\boldsymbol{\pi}}=\underset{\pi\in\Pi}{\arg\operatorname*{min}}\frac{1}{|\mathcal{T}|}\sum_{t\in\mathcal{T}}\mathcal{L}{\mathrm{frame}}(\mathbf{y}^{t},\hat{\mathbf{y}}_{\pi^{t}(i)}^{t}).
$$
$$
\hat{\boldsymbol{\pi}}=\underset{\pi\in\Pi}{\arg\operatorname*{min}}\frac{1}{|\mathcal{T}|}\sum_{t\in\mathcal{T}}\mathcal{L}{\mathrm{frame}}(\mathbf{y}^{t},\hat{\mathbf{y}}_{\pi^{t}(i)}^{t}).
$$
Intuitively, tubelet matching provides stronger supervision when we have full tubelet annotations available. Note that regardless of the type of matching that we perform, the loss computation and the overall model architecture remains the same. Note that we do not weight terms in Eq. 5, for both matching and loss calculation, for simplicity, and to avoid having additional hyper parameters, as also done in [37].
直观上,当拥有完整的小管(tubelet)标注时,小管匹配能提供更强的监督信号。需要注意的是,无论采用何种匹配方式,损失计算和整体模型架构保持不变。为简化流程并避免引入额外超参数(如[37]的做法),我们在公式5的匹配和损失计算中均未设置权重项。
3.4. Discussion
3.4. 讨论
As our approach is based on DETR, it does not require external proposals nor non-maximal suppression for postprocessing. The idea of using DETR for action local is ation has also been explored by TubeR [65] and WOO [8]. There are, however, a number of key differences: WOO does not detect tubelets at all, but only actions at the center keyframe.
由于我们的方法基于DETR (DEtection TRansformer) ,因此不需要外部提案或后处理中的非极大值抑制。TubeR [65] 和 WOO [8] 也探索了将DETR用于动作定位的想法。但存在几个关键差异:WOO完全不检测小管段 (tubelet) ,而仅检测中心关键帧的动作。
We also factorise our queries in the spatial and temporal dimensions (Sec. 3.2) to provide inductive biases urging spatio-temporal association. Moreover, we predict action classes separately for each time step in the tubelet, meaning that each of our queries binds to an actor in the video. TubeR, in contrast, parameter is es queries such that they are each associated with separate actions (features are averagepooled over the tubelet, and then linearly classified into a single action class). This choice also means that TubeR requires an additional “action switch” head to predict when tubelets start and end, which we do not require as different time steps in a tubelet can have different action classes in our model. Furthermore, we show experimentally (Tab. 1) that TubeR’s parameter is ation obtains lower accuracy. We also consider two types of matching in the loss computation (Sec. 3.3) unlike TubeR, with “tubelet matching” designed for predicting more temporally consistent tubelets. And in contrast to TubeR, we experimentally show how our decoder design allows our model to accurately predict tubelets even with weak, keyframe supervision.
我们还在空间和时间维度上对查询进行因子分解(第3.2节),以提供促使时空关联的归纳偏置。此外,我们为管状片段中的每个时间步单独预测动作类别,这意味着每个查询都与视频中的某个参与者绑定。相比之下,TubeR通过参数化查询使它们各自关联不同的动作(特征在管状片段上平均池化后,线性分类为单一动作类别)。这种选择还意味着TubeR需要一个额外的"动作切换"头来预测管状片段的开始和结束,而我们不需要,因为我们的模型中管状片段的不同时间步可以有不同的动作类别。此外,实验表明(表1),TubeR的参数化方法准确率较低。与TubeR不同,我们在损失计算中考虑了两种匹配类型(第3.3节),其中"管状片段匹配"旨在预测时间上更一致的管状片段。与TubeR相比,我们通过实验展示了解码器设计如何使模型即使在弱关键帧监督下也能准确预测管状片段。
Finally, TubeR requires additional complexity in the form of a “short-term context module” [65] and the external memory bank of [60] which is computed offline using a separate model to achieve strong results. As we show experimentally in the next section, we outperform TubeR without any additional modules, meaning that our model does indeed produce tubelets in an end-to-end manner.
最后,TubeR 需要以 "短期上下文模块" [65] 和 [60] 的外部记忆库形式增加额外复杂度,这些模块需通过离线计算的独立模型来实现优异效果。如下节实验所示,我们在无需任何附加模块的情况下超越了 TubeR,这表明我们的模型确实能以端到端方式生成 tubelet。
4. Experimental Evaluation
4. 实验评估
4.1. Experimental set-up
4.1. 实验设置
Datasets We evaluate on four spatio-temporal action localisation benchmarks. AVA and AVA-Kinetics contain sparse annotations at each keyframe, whereas UCF101-24 and JHMDB51-21 contain full tubelet annotations.
数据集
我们在四个时空动作定位基准上进行了评估。AVA和AVA-Kinetics在每个关键帧包含稀疏标注,而UCF101-24和JHMDB51-21则包含完整的管状(tubelet)标注。
AVA [18] consists of 430, 15-minute video clips from movies. Keyframes are annotated at every second in the video, with about 210 000 labelled frames in the training set, and 57 000 in the validation set. There are 80 atomic actions labelled for every actor in the clip, of which 60 are used for evaluation [18]. Following standard practice, we report the Frame Average Precision (fAP) at an IoU threshold of 0.5 using the latest v2.2 annotations [18].
AVA [18] 数据集包含从电影中截取的430段15分钟视频片段。视频每秒标注关键帧,训练集包含约21万标注帧,验证集包含5.7万标注帧。每个片段中的演员被标注了80个原子动作,其中60个用于评估 [18]。按照标准做法,我们使用最新的v2.2标注 [18],在IoU阈值为0.5时报告帧平均精度 (fAP)。
AVA-Kinetics [29] is a superset of AVA, and adds detection annotations following the AVA protocol, to a subset of Kinetics 700 [7] videos. Only a single keyframe in a 10- second Kinetics clip is labelled. In total, about 140 000 labelled keyframes are added to the training set, and 32 000 to the validation sets of AVA. Once again, we follow standard practice in reporting the Frame AP at a $0.5\mathrm{IoU}$ threshold.
AVA-Kinetics [29] 是 AVA 的超集,它按照 AVA 协议为 Kinetics 700 [7] 视频的子集添加了检测标注。在 10 秒的 Kinetics 片段中,仅标注单个关键帧。训练集共新增约 14 万标注关键帧,AVA 验证集新增 3.2 万关键帧。我们再次采用标准做法,在 $0.5\mathrm{IoU}$ 阈值下报告帧级平均精度 (Frame AP)。
UCF101-24 [48] is a subset of UCF101, and annotates 24 action classes with full spatio-temporal tubes in 3 207 untrimmed videos. Note that actions are not labelled exhaustively as in AVA, and there may be people present in the video who are not performing any labelled action. Following standard practice, we use the corrected annotations of [46]. We report both the Frame AP, which evaluates the predictions at each frame independently, and also the Video AP. The Video AP uses a 3D, spatio-temporal IoU to match predictions to targets. And since UCF101-24 videos are up to 900 frames long (median length of 164 frames), and our network processes $T=32$ frames at a time, we link together tubelet predictions from our network into full-videotubes using the same causal linking algorithm as [23,31] for fair comparison.
UCF101-24 [48] 是 UCF101 的子集,在 3,207 个未修剪视频中为 24 个动作类别标注了完整的时空管。请注意,与 AVA 不同,这些动作并未被详尽标注,视频中可能存在未执行任何标注动作的人物。按照标准做法,我们使用 [46] 修正后的标注。我们同时报告帧 AP (Frame AP) 和视频 AP (Video AP),其中帧 AP 独立评估每帧的预测结果,而视频 AP 则使用 3D 时空 IoU 来匹配预测与目标。由于 UCF101-24 的视频长度可达 900 帧(中位数为 164 帧),而我们的网络每次处理 $T=32$ 帧,因此我们采用与 [23,31] 相同的因果链接算法,将网络输出的短管预测连接成完整视频管,以确保公平比较。
Table 1. Comparison of detection architectures on AVA controlling for the same backbone (ViViT-B), resolution (160p) and training settings. Our end-to-end approach outperforms proposal-based ROI models. Binding each query to a person, rather than to an action (as done in TubeR [65]), also yields solid improvements.
表 1: 在相同骨干网络 (ViViT-B)、分辨率 (160p) 和训练设置下,AVA数据集上检测架构的对比。我们的端到端方法优于基于提案的ROI模型。将每个查询(query)绑定到人而非动作(如TubeR [65]所做)也带来了显著提升。
| Proposals | AP50 | |
|---|---|---|
| Two-stage ROI model | [60] | 25.2 |
| Query binds to action | None | 23.6 |
| Ours, query binds to person | None | 26.7 |
JHMDB51-21 [22] also contains full tube annotations in 928 trimmed videos. However, as the videos are shorter and at most 40 frames, we can process the entire clip with our network, and do not need to perform any linking.
JHMDB51-21 [22] 在928段剪辑视频中也包含完整的管状标注。但由于这些视频较短,最多只有40帧,我们可以直接用网络处理整个片段,无需进行任何链接操作。
Implementation details For our vision encoder backbone, we use ViViT Factorised Encoder [1] where model sizes, such as “Base” and “Large” follow the original definitions from [11, 12]. It is initial is ed from pretrained checkpoints, which are typically first pretrained on image datasets like ImageNet-21K [10] and then finetuned on video datasets like Kinetics [24]. Our model processes $T=32$ unless otherwise specified, and has $S=64$ spatial queries per frame, and the latent dimensionality of the decoder is $d=2048$ . Exhaustive implementation details and training hyper parameters are included in the supplementary.
实现细节
对于视觉编码器主干,我们采用ViViT Factorised Encoder [1],其中模型尺寸(如"Base"和"Large")遵循[11, 12]的原始定义。该模型从预训练检查点初始化,通常先在ImageNet-21K [10]等图像数据集上预训练,再在Kinetics [24]等视频数据集上微调。除非另有说明,我们的模型处理$T=32$帧,每帧包含$S=64$个空间查询,解码器的潜在维度为$d=2048$。完整的实现细节和训练超参数见补充材料。
4.2. Ablation studies
4.2. 消融实验
We analyse the design choices in our model by conducting experiments on both AVA (with sparse per-frame supervision) and on UCF101-24 (where we can evaluate the quality of our predicted tubelets). Unless otherwise stated, our backbone is ViViT-Base pretrained on Kinetics 400, and the frame resolution is 160 pixels (160p) on the smaller side.
我们通过在 AVA (带有稀疏逐帧监督) 和 UCF101-24 (可评估预测管状体质量) 上进行实验来分析模型的设计选择。除非另有说明,我们的主干网络是在 Kinetics 400 上预训练的 ViViT-Base,帧分辨率较小边为 160 像素 (160p)。
Comparison of detection architectures Table 1 compares our model to two relevant baselines: Firstly, a twostage Fast-RCNN model using external person detections from [60] (as used by [3, 13, 14, 60]). And secondly, we compare to using the query parameter is ation used in TubeR [65], where each query binds to an action, as described in Sec. 3.4. We control other experimental settings by using the same backbone (ViViT-Base) and resolution (160p).
检测架构对比
表 1 将我们的模型与两个相关基线进行比较:首先是一个使用来自 [60] 的外部人物检测的两阶段 Fast-RCNN 模型(如 [3, 13, 14, 60] 所用);其次,我们与 TubeR [65] 中使用的查询参数化方法进行对比,其中每个查询绑定一个动作,如第 3.4 节所述。我们通过使用相同的主干网络 (ViViT-Base) 和分辨率 (160p) 来控制其他实验设置。
Table 2. Comparison of independent and factorised queries on the AVA and UCF101-24 datasets. Factorised queries are particularly beneficial for predicting tubelets, as shown by the VideoAP on UCF101-24 which has full tube annotations. Both models use tubelet matching in the loss.
表 2: AVA 和 UCF101-24 数据集上独立查询与因子化查询的对比。如 UCF101-24 上带有完整管状标注的 VideoAP 所示,因子化查询对预测小管 (tubelet) 特别有利。两个模型在损失函数中都使用了小管匹配。
| AVA | UCF101-24 | ||||
|---|---|---|---|---|---|
| 查询方式 | fAP | fAP | VAP20 | VAP50 | VAP50:95 |
| 独立查询 | 25.2 | 85.6 | 86.3 | 59.5 | 28.9 |
| 因子化查询 | 26.3 | 86.5 | 87.4 | 63.4 | 29.8 |
Table 3. Comparison of independent and tubelet matching for computing the loss on AVA and UCF101-24. Tubelet matching helps for tube-level evaluation metrics like the Video AP (vAP) on UCF101-24. Note that tubelet matching is actually still possible on AVA as the annotations are at 1fps with actor identities.
表 3: 独立匹配与管段匹配在AVA和UCF101-24数据集上计算损失的对比。管段匹配有助于提升UCF101-24的管级评估指标,如视频平均精度(vAP)。需要注意的是,由于AVA数据集以1fps频率标注了演员身份信息,因此在该数据集上仍可实现管段匹配。
| Query | AVA (fAP) | UCF101-24 (fAP) | VAP20 | vAP50 | VAP50:95 |
|---|---|---|---|---|---|
| 逐帧匹配 | 26.7 | 88.2 | 85.7 | 63.5 | 29.4 |
| 管段匹配 | 26.3 | 86.5 | 87.4 | 63.4 | 29.8 |
The first row of Tab. 1 shows that our end-to-end model improves upon a two-stage model by 1.5 points on AVA, emphasising the promise of our approach. Note that the proposals of [60] achieve an AP50 of 93.9 for person detection on the AVA validation set. They were obtained by first pretraining a Faster-RCNN [42] detector on COCO keypoints, and then finetuning on the person boxes from the training set of AVA, using a resolution of 1333 on the longer side. Our model is end-to-end, and does not require external proposals generated by a separate model at all.
表 1 的第一行显示,我们的端到端模型在 AVA 上将两阶段模型的性能提升了 1.5 个百分点,这凸显了我们方法的潜力。需要注意的是,[60] 提出的方案在 AVA 验证集上的人体检测 AP50 达到了 93.9。该方案首先在 COCO 关键点数据集上预训练 Faster-RCNN [42] 检测器,然后使用较长边为 1333 的分辨率在 AVA 训练集的人体框上进行微调。而我们的模型是端到端的,完全不需要依赖外部模型生成的候选框。
The second row of Tab. 1 compares our model, where each query represents a person and all of their actions (Sec. 3.2) to the approach of TubeR [65] (Sec. 3.4), where there is a separate query for each action being performed. We observe that this parameter is ation has a substantial impact, with our method outperforming it significantly by 3.1 points, motivating the design of our decoder.
表 1 的第二行将我们的模型 (每个查询代表一个人及其所有行为 (第 3.2 节)) 与 TubeR [65] 的方法 (第 3.4 节) (每个执行行为对应独立查询) 进行对比。我们观察到该参数设置具有显著影响,我们的方法以 3.1 分的优势大幅领先,这验证了解码器设计的合理性。
Query parameter is ation Table 2 compares our independent and factorised query methods (Sec. 3.2) on AVA and UCF101-24. We observe that factorised queries consistently provide improvements on both the Frame AP and the Video AP across both datasets. As hypothesis ed in Sec. 3.2, we believe that this is due to the inductive bias present in this parameter is ation. Note that we can only measure the Video AP on UCF101-24 as it has tubes labelled.
查询参数化
表 2 比较了我们在 AVA 和 UCF101-24 数据集上采用的独立查询与因子化查询方法 (见第 3.2 节) 。实验表明,因子化查询在两个数据集的帧级 AP (Frame AP) 和视频级 AP (Video AP) 指标上均取得稳定提升。如第 3.2 节假设所述,我们认为这得益于该参数化方式蕴含的归纳偏置。需要注意的是,由于只有 UCF101-24 标注了动作管 (tubes) ,视频级 AP 仅能在该数据集上进行评估。
Matching for loss calculation As described in Sec. 3.3, when matching the predictions to the ground truth for loss computation, we can either independently match the outputs at each frame to the ground truths at each frame, or, we can match the entire predicted tubelets to the ground truth tubelets. Table 3 shows that tubelet matching does indeed improve the quality of the predicted tubelets, as shown by the Video AP on UCF101-24. However, this comes at the cost of the quality of per-frame predictions (i.e. Frame AP). This suggests that tubelet matching improves the association of bounding boxes predicted at different frames (hence higher Video AP), but may also impair the quality of the bounding boxes predicted at each frame (Frame AP). Note that it is technically possible for us to also perform tubelet matching on AVA, since AVA is annotated at 1fps with actor identities, and our model is input 32 frames at 12.5fps (therefore 2.56 seconds of temporal context) meaning that we have sparse tubelets with 2 or 3 annotated frames.
损失计算中的匹配
如第3.3节所述,在将预测结果与真实标注进行匹配以计算损失时,我们可以选择将每一帧的输出独立匹配到对应帧的真实标注,或者将整个预测的管状片段(tubelet)与真实管状片段进行匹配。表3显示,管状片段匹配确实提升了预测管状片段的质量,这体现在UCF101-24数据集上的视频平均精度(Video AP)指标上。然而,这种改进是以牺牲单帧预测质量(即帧平均精度(Frame AP))为代价的。这表明管状片段匹配改善了不同帧间预测边界框的关联性(从而获得更高的Video AP),但可能同时降低了单帧预测边界框的质量(Frame AP)。需要注意的是,从技术上讲,我们也可以在AVA数据集上实施管状片段匹配,因为AVA数据集以1fps的频率标注了演员身份信息,而我们的模型输入为12.5fps的32帧(即2.56秒的时间上下文),这意味着我们拥有包含2到3个标注帧的稀疏管状片段。
(注:根据术语表要求,"tubelet"首次出现时译为"管状片段(tubelet)",后文统一使用"管状片段";技术指标"Video AP"和"Frame AP"保留英文缩写;数据集名称"UCF101-24"和"AVA"保留原格式;时间单位"fps"和"秒"按常规处理;表格引用格式转换为"表3")
Table 4. Our model can predict tubelets even when the ground truth annotations are sparse. We show this by sub sampling training annotations from the UCF101-24 dataset. Our model sees minimal performance deterioration even when using only $1/24$ or $4%$ of the annotated frames.
表 4: 我们的模型即使在地面真实标注稀疏的情况下也能预测 tubelets。我们通过在 UCF101-24 数据集中对训练标注进行子采样来展示这一点。即使仅使用 $1/24$ 或 $4%$ 的标注帧,我们的模型性能下降也极小。
| 采样方式 | 标注帧数 | fAP | VAP20 | VAP50 | VAP50:95 |
|---|---|---|---|---|---|
| 全帧 | 458814 | 86.5 | 87.4 | 63.4 | 29.8 |
| 每12帧 | 39237 | 85.2 | 87.2 | 63.0 | 29.3 |
| 每24帧 | 20243 | 84.9 | 86.8 | 63.2 | 28.1 |
| 每视频1帧 | 2284 | 70.2 | 77.1 | 48.5 | 20.4 |
Table 5. Effect of decoder depth on performance on the AVA dataset. Performance saturates at $L=6$ layers.
表 5: 解码器深度对 AVA 数据集性能的影响。性能在 $L=6$ 层时达到饱和。
| 层数 (L) | 0 | 1 | 3 | 6 | 9 |
|---|---|---|---|---|---|
| mAP ↑ | 23.4 | 24.6 | 26.2 | 26.5 | 26.7 |
As tubelet matching helps with the overall Video AP, we use it for subsequent experiments on UCF101-24. For AVA, we use per-frame matching as the standard evaluation metric is the Frame AP, and annotations are sparse at 1fps.
由于视频片段匹配有助于提升整体视频平均精度(Video AP),我们在后续的UCF101-24实验中采用了该方法。对于AVA数据集,由于标准评估指标是帧平均精度(Frame AP)且标注稀疏(1fps),我们使用逐帧匹配方案。
Weakly-supervised tubelet detection Our model can predict tubelets even when the ground truth annotations are sparse and only labelled at certain frames (such as the AVA dataset). We quantitatively measure this ability of our model on the UCF101-24 dataset which has full tube annotations. We do so by sub sampling labels from the training set, and evaluating the full tubes on the validation set.
弱监督管状检测
我们的模型即使在标注稀疏且仅在某些帧上标注(如 AVA 数据集)的情况下,也能预测管状结构。我们在具有完整管状标注的 UCF101-24 数据集上定量评估了模型的这一能力。具体做法是从训练集中子采样标签,并在验证集上评估完整管状结构。
As shown in Tab. 4, we still obtain meaningful tube predictions, with a Video AP20 of 77.1, when using only a single frame of annotation from each UCF video clip. When retaining 1 frame of supervision for every 24 labelled frames (which is roughly 1fps and corresponds to the AVA dataset’s annotations), we observe minimal deterioration with respect to the fully supervised model (all Video AP metrics are within 0.7 points). And retaining 1 frame of annotation for every 12 consecutive labelled frames performs similarly to using all frames in the video clip. These results suggest that due to the redundancy in the dataset (motion between frames is often limited), and the inductive bias of our model, we do not require every frame in the tube to be labelled in order to produce accurate tubelet predictions.
如表 4 所示,当仅使用每个 UCF 视频片段中的单帧标注时,我们仍能获得有意义的管状预测,其 Video AP20 为 77.1。当每 24 个标注帧保留 1 帧监督(约 1fps,与 AVA 数据集的标注对应)时,我们观察到相对于全监督模型的性能下降极小(所有 Video AP 指标差异均在 0.7 分以内)。而每 12 个连续标注帧保留 1 帧标注的表现与使用视频片段中所有帧的效果相当。这些结果表明,由于数据集中的冗余(帧间运动通常有限)以及我们模型的归纳偏置,无需对管状结构中的每一帧进行标注即可生成准确的管状预测。
Table 6. Effect of the type of attention used in the decoder on AVA. Factorised attention is both more accurate and efficient (almost half of the GFLOPs per decoder layer).
表 6: 解码器中使用的注意力类型对 AVA 的影响。分解注意力 (Factorised attention) 在准确性和效率上都更优 (每解码层 GFLOPs 几乎减半)。
| 解码器注意力类型 | mAP | GFLOPs |
|---|---|---|
| Full | 26.4 | 10.5 |
| Factorised | 26.7 | 5.3 |
Table 7. Increasing the image resolution on the AVA dataset leads to consistent accuracy improvements, primarily on small objects. APs, APm and APl denote the AP at $0.5~\mathrm{IoU}$ threshold on small, medium and large boxes respectively following the COCO protocol [33]. AVA videos have a median aspect ratio of 16:10, and we pad the larger side when the aspect ratio is different.
表 7: 在AVA数据集上提高图像分辨率会带来准确率的持续提升,主要针对小物体。APs、APm和APl分别表示遵循COCO协议 [33] 的小、中、大检测框在 $0.5~\mathrm{IoU}$ 阈值下的平均精度(AP)。AVA视频的中位宽高比为16:10,当宽高比不同时我们对较长边进行填充。
| 分辨率 | mAP | APs | APm | AP1 |
|---|---|---|---|---|
| 140×224 | 25.4 | 7.2 | 11.2 | 27.8 |
| 160×256 | 26.7 | 11.5 | 12.5 | 28.7 |
| 220×352 | 28.8 | 12.0 | 15.1 | 30.7 |
| 260×416 | 29.4 | 13.3 | 15.8 | 31.0 |
| 320×512 | 30.0 | 17.5 | 16.0 | 32.0 |
Table 8. Comparison of pre training for our models with ViViT-B and ViViT-L backbones on AVA using a resolution of $160\times256$ . Larger models benefit more from additional initial pre training.
表 8: 采用 $160\times256$ 分辨率时,我们的模型与 ViViT-B 和 ViViT-L 骨干网络在 AVA 数据集上的预训练对比。更大的模型能从额外的初始预训练中获益更多。
| 预训练方式 | STAR/B | STAR/L |
|---|---|---|
| IN21K [10] → K400 [24] | 26.7 | 27.0 |
| IN21K [10] → K700 [7] | 27.3 | 27.6 |
| JFT [51] → WTS [50] | 31.1 | 34.2 |
| CLIP [40] → K700 [7] | 30.3 | 36.2 |
Decoder design Tables 5 and 6 analyse the effect of the decoder depth and the type of attention in the decoder (described in Sec. 3.2). As seen in Tab. 5, detection accuracy on AVA increases with the number of decoder layers, plateauing at around 6 layers. It is possible to use no decoder layers too: In this case, instead of learning queries q (Sec. 3.2), we simply interpret the outputs of the vision encoder (Sec. 3.1), x, as our queries and apply the local is ation and classification heads directly upon them. Using decoder layers, however, can provide a performance increase of up to $3.3\mathrm{mAP}$ points ( $14%$ relative), emphasising their utility.
解码器设计
表5和表6分析了解码器深度和解码器中注意力类型的影响(见3.2节)。如表5所示,AVA上的检测精度随着解码器层数的增加而提升,在约6层时趋于稳定。也可以不使用解码器层:此时,我们不学习查询q(3.2节),而是直接将视觉编码器(3.1节)的输出x作为查询,并直接在其上应用定位和分类头。然而,使用解码器层可带来高达$3.3\mathrm{mAP}$(相对提升$14%$)的性能增益,凸显了其实用性。
Table 6 shows that factorised attention in the decoder is more accurate than standard, “full” attention between all queries and visual features. Moreover, it is more efficient too, using almost half of the GFLOPs at each decoder layer.
表 6: 解码器中的因子化注意力 (factorised attention) 比所有查询与视觉特征之间的标准"完整"注意力更准确。此外,它的效率也更高,在每一解码层仅使用了近一半的 GFLOPs。
Effect of resolution and pre training Scaling up the image resolution is critical to achieving high performance for object detection in images [21, 44]. However, we are not aware of previous works studying this for video action localisation. Table 7 shows that we do indeed observe substantial improvements from higher resolution, improving by up to 4.6 points on AVA. As expected, higher resolutions help more for detection at small sizes, where we follow the COCO [33] convention of object sizes. Note that AVA videos have a median aspect ratio of 16:10, and we pad the larger side for videos with different aspect ratios.
分辨率与预训练的影响
提升图像分辨率对于实现高性能图像目标检测至关重要 [21, 44]。然而,此前尚未有研究探讨该因素对视频动作定位任务的影响。表 7 显示,更高分辨率确实能带来显著性能提升,在 AVA 数据集上最高可提升 4.6 分。如预期所示,高分辨率对小尺寸目标检测的提升更为明显(此处采用 COCO [33] 的目标尺寸划分标准)。需注意 AVA 视频的中位宽高比为 16:10,我们会为不同比例的视频填充较长边。
Similarly, Tab. 8 shows the effect of different pretraining datasets. Video vision transformers are typically pretrained on an image dataset (like ImageNet-21K [10] or JFT [51]), before being finetuned on a video dataset, such as Kinetics [24]. We find that the initial image checkpoint plays an important rule, with CLIP [40] pre training significantly outperforming supervised pre training on ImageNet21K [12, 49]. And perhaps surprisingly, we find that CLIPLarge-pretrained models, then finetuned on Kinetics 700 [7] outperform models pretrained on JFT [51] and finetuned on the large-scale, but noisy WTS dataset [50] of web-scraped videos. Moreover, we find that large backbones benefit more from more pre training data.
同样地,表 8 展示了不同预训练数据集的效果。视频视觉 Transformer 通常先在图像数据集 (如 ImageNet-21K [10] 或 JFT [51]) 上进行预训练,再在 Kinetics [24] 等视频数据集上微调。我们发现初始图像检查点起着重要作用,CLIP [40] 预训练显著优于 ImageNet21K [12, 49] 上的监督式预训练。可能令人惊讶的是,我们发现先在 CLIPLarge 上预训练、再在 Kinetics 700 [7] 上微调的模型,其表现优于先在 JFT [51] 上预训练、再在规模更大但噪声较多的网络爬取视频数据集 WTS [50] 上微调的模型。此外,我们发现更大的主干网络能从更多预训练数据中获益更多。
4.3. Comparison to state-of-the-art
4.3. 与最先进技术的比较
We compare our model to the state-of-the-art on datasets with both sparsely annotated keyframes (AVA and AVAKinetics), and full tubes (UCF101-24 and JHMDB).
我们在稀疏标注关键帧(AVA 和 AVAKinetics)以及完整动作片段(UCF101-24 和 JHMDB)的数据集上,将我们的模型与当前最优模型进行了比较。
AVA and AVA-Kinetics Table 9 shows that we achieve state-of-the-art results on both the challenging AVA and AVA-Kinetics datasets. The previous best methods relied on external proposals [3, 58, 61] and external memory banks [39, 61] which we outperform. There are fewer prior end-to-end approaches, and we outperform these by an even larger margin. We achieve greater relative improvements on AVA-Kinetics, showing that our end-to-end approach can leverage larger datasets more effectively. Note that we do not perform any test-time augmentation, in contrast to other approaches that ensemble results over multiple resolutions and/or left/right flips. To our knowledge, we surpass the previous best reported results on these datasets, achieving a Frame AP of 41.7 on AVA, and 44.6 on AVA-Kinetics. Notably, we outperform Intern Video [58], a recent video foundation model that is pretrained on 7 different web-scale video datasets. The model of [58] consists of two different encoders, one of which is also initial is ed from CLIP [40]. Like Intern Video, we achieve the best results on AVA by training a model on AVA-Kinetics, and then evaluating it only on the AVA validation set.
AVA 和 AVA-Kinetics
表 9 显示,我们在具有挑战性的 AVA 和 AVA-Kinetics 数据集上均取得了最先进的结果。先前的最佳方法依赖于外部提案 [3, 58, 61] 和外部记忆库 [39, 61],而我们的表现优于这些方法。此前端到端方法较少,我们的优势更为显著。在 AVA-Kinetics 上,我们取得了更大的相对改进,表明我们的端到端方法能更有效地利用更大规模的数据集。需要注意的是,我们未进行任何测试时增强,而其他方法通常会对多分辨率或左右翻转结果进行集成。据我们所知,我们超越了这些数据集上先前报告的最佳结果,在 AVA 上实现了 41.7 的帧 AP,在 AVA-Kinetics 上实现了 44.6 的帧 AP。值得注意的是,我们的表现优于 Intern Video [58]——这是一个近期在 7 个不同网络规模视频数据集上预训练的视频基础模型。[58] 的模型包含两个不同的编码器,其中一个也以 CLIP [40] 初始化。与 Intern Video 类似,我们通过在 AVA-Kinetics 上训练模型,然后仅在 AVA 验证集上评估,从而在 AVA 上取得了最佳结果。
UCF101-24 Table 10 shows that we achieve state-of-theart results on UCF101-24, both in terms of frame-level detection metrics (Frame AP), and tube-level detection metrics (Video AP). We achieve state-of-the-art results when using a model pre train in ed on Kinetics 400, and then see further improvements when using a larger backbone and pre training on Kinetics 700, with original CLIP initialisation, consistent with our results on AVA (Tab. 8 and 9). In particular, to our knowledge, we outperform the best previous reported Video AP50 number by 11.6 points. Note that as UCF videos are a maximum of 900 frames, and our network processes $T=32$ frames, we link together tubelets using the same causal algorithm as [23, 31].
表10显示,我们在UCF101-24数据集上取得了最先进的成果,无论是在帧级检测指标(Frame AP)还是视频级检测指标(Video AP)方面。当使用Kinetics 400预训练模型时,我们已获得最优结果;而采用更大骨干网络并在Kinetics 700上预训练(保持原始CLIP初始化)后,性能得到进一步提升,这与我们在AVA数据集上的结果(表8和表9)一致。特别值得注意的是,据我们所知,我们的Video AP50指标比之前报道的最佳结果高出11.6个百分点。由于UCF视频最长不超过900帧,而我们的网络处理的是$T=32$帧片段,因此我们采用与[23, 31]相同的因果算法进行视频片段链接。
Table 9. Comparison to the state-of-the-art (reported with mean Average Precision; mAP $\uparrow$ ) on AVA [18] and AVA-Kinetics (AVA-K) [29]. For AVA, we use the latest v2.2 annotations. Methods using external proposals (i.e. not end-to-end) are also trained on additional object detection and human pose data. Unless otherwise stated, separate models are trained for AVA and AVA-Kinetics. ∗ denotes the model was trained on AVA-Kinetics and evaluated on AVA. “Res.” denotes the frame resolution of the shorter side.
表 9. 在 AVA [18] 和 AVA-Kinetics (AVA-K) [29] 上与最先进技术的比较 (以平均精度均值 mAP $\uparrow$ 报告)。对于 AVA,我们使用最新的 v2.2 标注。使用外部提议 (即非端到端) 的方法还额外训练了目标检测和人体姿态数据。除非另有说明,AVA 和 AVA-Kinetics 分别训练了单独的模型。∗ 表示模型在 AVA-Kinetics 上训练并在 AVA 上评估。"Res." 表示较短边的帧分辨率。
| 方法 | 预训练 | 视图 | AVA | AVA-K | Res. | 骨干网络 | 端到端 |
|---|---|---|---|---|---|---|---|
| MViT-B [13] | K400 | 1 | 27.3 | MViT | × | ||
| Unified [2] | K400 | 6 | 27.7 | 320 | SlowFast | × | |
| AIA [54] | K700 | 18 | 32.3 | 320 | SlowFast | × | |
| ACAR [39] | K700 | 6 | 33.3 | 36.4 | 320 | SlowFast | × |
| MeMViT [61] | K700 | 一 | 34.4 | 一 | 312 | MViTv2 | × |
| Co-finetuning [3] | IN21K→→K700,MiT,SSv2 | 1 | 32.8 | 33.1 | 320 | ViViT/L | × |
| VideoMAE[55] | JFT,WTS→K700,MiT,SSv2 | 1 | 36.1 | 36.2 | 320 | ViViT/L | × |
| SSL K700 → Sup.K700. | 一 | 39.3 | 256 | ViViT/L | × | ||
| InternVideo* [58] | 7 different datasets | 41.0 | 42.5 | Uniformer v2 | |||
| Action Transformer [29] | K400 | 1 | 23.0 | 400 | I3D | ||
| wO0[8] | K600 | 1 | 28.3 | 一 | 320 | SlowFast | |
| TubeR [65] | Instagram65M [36]—→K400 | 2 | 33.6 | 一 | 256 | CSN-152 | |
| STAR/B (ours) | IN21K-→K400 | 1 | 30.0 | 36.6 | 320 | ViViT/B | |
| JFT→WTS | 1 | 36.3 | 41.8 | 320 | ViViT/B | < | |
| CLIP-→K700 | 1 | 33.9 | 39.1 | 320 | ViViT/B | ||
| JFT→WTS | 1 | 39.0 | 44.6 | 320 | ViViT/L | ||
| STAR/L (ours)* | CLIP→K700 CLIP-→K700 | 1 1 | 39.2 41.7 | 44.5 44.5 | 320 320 | ViViT/L ViViT/L |
Table 10. Comparison to the state-of-the-art on datasets with tubelet annotations, namely UCF101-24 [48] and JHMDB51-21 [22]. For Video AP on UCF101-24, predicted tubelets of STAR models were linked using the causal algorithm from [23, 31] for fair comparison. For Video AP calculation on JHMDB, we processed the entire video with our network, and did not link tubelets.
表 10. 在带有管状标注的数据集(即 UCF101-24 [48] 和 JHMDB51-21 [22])上与当前最优方法的对比。对于 UCF101-24 的 Video AP,STAR 模型的预测管状结果使用了 [23, 31] 中的因果算法进行链接以确保公平比较。对于 JHMDB 的 Video AP 计算,我们使用网络处理了整个视频,并未链接管状结果。
| UCF101-24 | JHMDB51-21 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 预训练 | fAP | VAP20 | VAP50 | VAP50:95 | fAP | VAP20 | VAP50 | 主干网络 | |
| ACT [23] | IN1K | 67.1 | 77.2 | 51.4 | 25.0 | 65.7 | 74.2 | 73.7 | VGG |
| MOC [31] | IN1K→COCO | 78.0 | 82.8 | 53.8 | 28.3 | 70.8 | 77.3 | 77.2 | DLA34 |
| Unified [2] | K600 | 79.3 | — | — | — | — | — | SlowFast | |
| wO0 [8] | K600 | — | — | — | — | 80.5 | — | — | SlowFast |
| TubeR [65] | IG65MK400 | 83.2 | 83.3 | 58.4 | 28.9 | — | 87.4 | 82.3 | CSN-152 |
| TubeR with flow [65] | K400 | 81.3 | 85.3 | 60.2 | 29.7 | — | 81.8 | 80.7 | I3D |
| STAR/B (ours) | IN21K→→K400 | 87.3 | 87.7 | 66.2 | 30.9 | 86.6 | 89.1 | 88.5 | ViViT/B |
| STAR/L (ours) | CLIP-→K700 | 90.3 | 88.0 | 71.8 | 35.2 | 92.1 | 93.1 | 92.6 | ViViT/L |
JHMDB51-21 Table 10 also shows that we surpass the state-of-the-art on JHMDB, on both Frame AP and Video AP metrics too. The videos in this dataset are trimmed (meaning that labelled actions are being performed on each frame), and also shorter. As a result, the Video AP is not as strict as it is on UCF101-24. Additionally, as the input videos are a maximum of 40 frames, we set $T=40$ in our model so that we process the entire clip at once and therefore do not need to perform any tubelet linking.
JHMDB51-21 表 10 同样显示,我们在 JHMDB 数据集上以帧平均精度 (Frame AP) 和视频平均精度 (Video AP) 指标超越了当前最优水平。该数据集的视频经过裁剪 (即每一帧都标注了正在执行的动作) 且时长较短,因此 Video AP 的评判标准不如 UCF101-24 严格。此外,由于输入视频最长 40 帧,我们在模型中设定 $T=40$ 以一次性处理整个片段,从而无需进行任何管段 (tubelet) 链接。
Qualitative examples Figure 4 presents visualisation s of our model’s tubelets.
定性示例
图 4: 展示了我们模型的管状结构可视化效果。
5. Conclusion
5. 结论
We have presented STAR, an end-to-end spatio-temporal action local is ation model that can output tubelets, when either sparse keyframe, or full tubelet annotation is available.
我们提出了STAR,这是一种端到端的时空动作定位模型,能够在稀疏关键帧或完整管状标注可用时输出管状片段。

Figure 4. Visualisation of the tubelets predicted by our model. The colour corresponds directly to the spatial index of a query token, as our model produces tubelets without any post processing. Dashed lines denote the ground truth bounding box, and the predicted class label is below the tubelet. The first row shows a tubelet over 5.4 seconds on UCF101-24. Second row shows a tubelet over 2.6 seconds on AVA where only the central keyframe is annotated.
图 4: 本模型预测的管状体可视化效果。颜色直接对应查询token的空间索引,因为我们的模型无需任何后处理即可生成管状体。虚线表示真实标注边界框,预测类别标签位于管状体下方。首行展示UCF101-24数据集中持续5.4秒的管状体,次行展示AVA数据集中持续2.6秒的管状体(仅中央关键帧带标注)。
Our approach achieves state-of-the-art results on four action local is ation datasets for both frame-level and tubelet-level predictions (in particular, we obtain $44.6%$ mAP on the challenging AVA-Kinetics dataset), outperforming complex methods that use external proposals and memory banks.
我们的方法在四个动作定位数据集上实现了帧级别和片段级别预测的最先进成果(特别是在具有挑战性的AVA-Kinetics数据集上获得了44.6%的mAP),表现优于使用外部提议和记忆库的复杂方法。
References
参考文献
A. Additional experiments
A. 补充实验
A.1. Implementation details
A.1. 实现细节
We exhaustively list hyper parameter choices for the models used in our state-of-the-art comparisons in Tab. 11 and 12.
我们在表 11 和 12 中详尽列出了用于先进性能对比的模型超参数选择。
Note that our model hyper parameters in Tab. 11 follow the same nomenclature from ViT [12] and ViViT [1] for defining “Base” and “Large” variants.
注意,我们的模型超参数在表 11 中遵循 ViT [12] 和 ViViT [1] 相同的命名规则来定义"Base"和"Large"变体。
Our experiments use similar data pre-processing and augmentations as prior work [14, 60, 61], such as horizontal flipping, colour jittering (consistently across all frames of the video) and box jittering. In addition, we used a novel keyframe “de centering” augmentation (Sec. A.2) as our model predicts tubelets, and more aggressive scale augmentation (Sec. A.3).
我们的实验采用了与先前工作 [14, 60, 61] 类似的数据预处理和增强方法,例如水平翻转、色彩抖动(在视频所有帧中保持一致)和框抖动。此外,由于我们的模型预测的是小管 (tubelets),我们使用了一种新颖的关键帧"去中心化"增强方法(见附录 A.2),以及更激进的尺度增强(见附录 A.3)。
We train with synchronous SGD and a cosine learning rate decay schedule. As shown in Tab. 12, we typically use the same training hyper parameters across experiments. Note that for the JHMDB dataset, we use $T=40$ frames as input to our model, as this is sufficient to cover the longest video clips in this dataset. We also do not need to perform “de centering” (Sec. A.2) for datasets with full tube annotations (UCF101-24 and JHMDB51-21). As shown in Tab. 11, we found it beneficial to use a lower learning rate for the vision encoder of our model, as it was already pretrained, in contrast to the decoder which was learned from scratch.
我们采用同步随机梯度下降 (SGD) 和余弦学习率衰减策略进行训练。如表 12 所示,不同实验通常采用相同的训练超参数。需要注意的是,在 JHMDB 数据集上,我们使用 $T=40$ 帧作为模型输入,这足以覆盖该数据集中最长的视频片段。对于具有完整管状标注的数据集 (UCF101-24 和 JHMDB51-21),我们不需要执行"去中心化"操作 (附录 A.2)。如表 11 所示,我们发现对已预训练的视觉编码器采用较低学习率效果更佳,而解码器由于是从零开始训练,则无需降低学习率。
A.2. De centering
A.2. 去中心化
The majority of prior work on keyframe-based action local is ation datasets (e.g. AVA and AVA-Kinetics) predict only at the centre frame of the video clip, as only sparse supervision at this central keyframe is available. As our model predicts tubelets, we intuitively would like to supervise it for other frames in the input clip as well.
以往基于关键帧的动作定位研究(如 AVA 和 AVA-Kinetics 数据集)大多仅预测视频片段的中心帧,因为这些数据集仅在该中心关键帧提供稀疏标注。由于我们的模型预测的是管状片段 (tubelet),我们直观上也希望对输入片段中的其他帧进行监督。
To this end, we introduce another data augmentation strategy, named “de centering”, where we sample video clips during training such that the keyframe with supervision is no longer at the central frame, but may deviate randomly from the central position. We parameter is e this by an integer, $\rho$ , which defines the maximum possible deviation, and randomly sample a displacement $\in\left[-\rho,\rho\right]$ during training.
为此,我们引入了另一种名为"去中心化 (de centering)"的数据增强策略,即在训练过程中采样视频片段时,使带有监督的关键帧不再位于中心帧,而是可能随机偏离中心位置。我们通过整数参数$\rho$来定义最大可能偏离值,并在训练期间随机采样位移$\in\left[-\rho,\rho\right]$。
Table 11. Model architecture hyper parameters. We used the same decoder even when scaling up the vision encoder.
表 11. 模型架构超参数。即使放大视觉编码器时,我们也使用相同的解码器。
| 超参数 | 模型大小 |
|---|---|
| Base | |
| 解码器 | |
| 层数 | 6 |
| 学习率 | 10-4 |
| 隐藏层大小 | 256 |
| MLP维度 | 2048 |
| Dropout率 | 0.1 |
| 框头层数 | 3 |
| 编码器 | |
| 学习率 | 5 × 10-6 |
| 学习率 (CLIP初始化) | 1.25 × 10-6 |
| 图像块大小 | 16 × 16 × 2 |
| 空间层数 | 12 |
| 时序层数 | 4 |
| 注意力头数 | 12 |
| 隐藏层大小 | 768 |
| MLP维度 | 3072 |
We found that this data augmentation strategy results in qualitative improvements in the predicted tubelets (as shown in the supplementary video). However, as shown in Tab. 13, it has minimal effect on the Frame AP which only measures performance on the annotated, central frame of AVA video clips.
我们发现这种数据增强策略能显著提升预测管状体(tubelet)的质量(如补充视频所示)。但如表13所示,它对仅衡量AVA视频片段标注中央帧性能的Frame AP指标影响甚微。
Note that for datasets with full tube annotations, i.e. UCF101-24 and JHMDB51-21, there is no need to apply de centering, as each frame of the video clip is already annotated. We do, however, use de centering with the $\rho=8$ , when training with weak supervision on UCF101-24 (Tab. 4 of the main paper).
需要注意的是,对于带有完整管状标注的数据集(如UCF101-24和JHMDB51-21),无需进行去中心化处理,因为视频片段的每一帧都已标注。然而,我们在对UCF101-24进行弱监督训练时(主论文表4),确实使用了$\rho=8$的去中心化方法。
A.3. Scale augmentation
A.3. 尺度增强
Consistent with object detection in images [9,15,32,45], we found it necessary to perform spatial scale augmentation during training to achieve competitive action localisation performance. As shown in Tab. 14, we found that performing “zoom out” as well as “zoom in” scale augmentation during training significantly boosts action localisation performance. This departs from the choice of performing “zoom in” only scale augmentation in previous work [14, 60, 61].
与图像中的目标检测一致 [9,15,32,45],我们发现有必要在训练期间进行空间尺度增强以获得有竞争力的动作定位性能。如表 14 所示,我们发现训练期间同时进行“缩小”和“放大”尺度增强能显著提升动作定位性能。这与之前工作中仅采用“放大”尺度增强的选择不同 [14, 60, 61]。
A.4. Focal and auxiliary loss
A.4. 焦点损失与辅助损失
Following [37, 63, 67] we use sigmoid focal crossentropy loss [32] as our classification loss,
遵循 [37, 63, 67] 的研究,我们采用 sigmoid focal crossentropy loss [32] 作为分类损失函数。
$$
\begin{array}{r l}&{\mathcal{L}_{\mathrm{class}}(a,\hat{a})=-\alpha\cdot a\cdot\hat{a}^{\gamma}\log(\hat{a})}\ &{\qquad-\left(1-\alpha\right)(1-a)(1-\hat{a})^{\gamma}\log(1-\hat{a}),}\end{array}
$$
$$
\begin{array}{r l}&{\mathcal{L}_{\mathrm{class}}(a,\hat{a})=-\alpha\cdot a\cdot\hat{a}^{\gamma}\log(\hat{a})\ &{\qquad-\left(1-\alpha\right)(1-a)(1-\hat{a})^{\gamma}\log(1-\hat{a}),}\end{array}
$$
Table 12. Model training hyper parameters for the four datasets considered in our paper. We train with synchronous SGD and a cosin learning rate decay schedule.
表 12. 本文考虑的四个数据集的模型训练超参数。我们使用同步SGD和余弦学习率衰减计划进行训练。
| 超参数 | AVA | AVA-K | UCF101-24 | JHMDB51-21 |
|---|---|---|---|---|
| 训练周期(训练步数) | 30 (148 050) | 30 (246 690) | 30 (88 230) | 40 (6 800) |
| 批量大小 | 128 | |||
| 优化器 | Adam [25] | Adam [25] | Adam [25] | Adam [25] |
| Adam β1 | 0.9 | 0.9 | 0.9 | 0.9 |
| Adam β2 | 0.999 | 0.999 | 0.999 | 0.999 |
| 梯度裁剪C2范数 | 1.0 | 1.0 | 1.0 | 1.0 |
| Focal loss Q | 0.3 | 0.3 | 0.3 | 0.3 |
| Focal loss | 2.0 | 2.0 | 2.0 | 2.0 |
| 空间查询数量(S) | 64 | 64 | 64 | 64 |
| 帧数(T) | 32 | 32 | 32 | 40 |
| 中心偏差,p:逐帧匹配 | 4 | 4 | 0 | 0 |
| 中心偏差,p:小管匹配 | 16 | 16 | 0 | 0 |
| 随机深度 [20] | 0.2 | 0.2 | 0.5 | 0.5 |
Table 13. Effect of keyframe de centering studied on the AVA dataset (resolution $160\mathrm{p},$ ) for a model with $\mathrm{IN}21\mathrm{K}{\rightarrow}\mathrm{K}400$ initialisation, and factorised queries. Mild amounts of keyframe decentering do not hurt performance measured on the center frame while explicitly supervising the models ability to localise and predict actions on other frames. In fact, models trained with small amounts of de centering tend to perform better than models trained without any de centering.
表 13. 关键帧去中心化效果研究(在AVA数据集上,分辨率 $160\mathrm{p}$,使用 $\mathrm{IN}21\mathrm{K}{\rightarrow}\mathrm{K400}$ 初始化和因子化查询的模型)。适度的关键帧去中心化不会损害中心帧上的性能表现,同时显式监督模型在其他帧上定位和预测动作的能力。事实上,经过少量去中心化训练的模型往往比未经任何去中心化训练的模型表现更好。
| 中心偏移量 (p) | mAP↑ |
|---|---|
| 0 | 26.5 |
| 1 | 26.8 |
| 2 | 26.5 |
| 4 | 26.7 |
| 8 | 26.4 |
| 16 | 26.6 |
Table 14. Comparison of spatial scale augmentation for our models with a ViViT/B backbone on the AVA dataset (resolution of $140\mathrm{p}$ on the shorter side). We find that large range in scale-jittering, in the range of (0.5, 2.0) of the original input frame, as used in [15] works the best. Notably, doing scale augmentation in range of $\left({\frac{8}{7}},{\frac{10}{7}}\right)$ as in the open-sourced SlowFast [14] performs significantly worse. Performing no scale augmentation (first row) performs the worst as expected.
表 14: 基于ViViT/B骨干网络在AVA数据集(短边分辨率$140\mathrm{p}$)上的空间尺度增强效果对比。我们发现采用[15]中提出的原始输入帧(0.5, 2.0)范围内的大尺度抖动效果最佳。值得注意的是,采用开源SlowFast[14]中$\left({\frac{8}{7}},{\frac{10}{7}}\right)$范围的尺度增强效果明显较差。如预期所示,不进行尺度增强(首行)的效果最差。
| 尺度范围(min,max) | mAP↑ |
|---|---|
| (1,1) (无增强) (1.14,1.43) [14] | 22.5 23.9 |
| (0.25, 1.0) | 22.7 |
| (0.5, 1.0) | 23.4 |
| (0.25,4.0) | 25.1 |
| (0.5, 2.0) | 25.6 |
Table 15. Effect of using sigmoid loss and auxiliary losses studied on the AVA dataset (resolution $160\mathrm{p})$ for a model with $\mathrm{IN}21\mathrm{K}{\rightarrow}\mathrm{K}400$ initial is ation. Focal loss $\textrm{\xi}\alpha=0.3$ and $\gamma=2$ ) clearly performs better than the alternatives. Moreover, the use of auxiliary losses leads to a mild degradation in performance when combined with focal loss, but improves results when the focal loss is not used.
表 15: 在 AVA 数据集 (分辨率 $160\mathrm{p}$) 上研究使用 sigmoid 损失函数和辅助损失对 $\mathrm{IN}21\mathrm{K}{\rightarrow}\mathrm{K}400$ 初始化模型的影响。Focal loss ($\textrm{\xi}\alpha=0.3$ 和 $\gamma=2$) 明显优于其他方案。此外,当与 focal loss 结合使用时,辅助损失会导致性能轻微下降,但在不使用 focal loss 时能改善结果。
| Focalloss | Auxiliary losses | mAP↑ |
|---|---|---|
| × | × | 20.8 |
| x | 21.8 | |
| √ | 26.4 | |
| √ | x | 26.8 |
where $a$ and $\hat{a}$ are the ground truth and predicted action class probabilities respectively. $\alpha$ and $\gamma$ are hyper para meters of the focal loss [32]. Furthermore, following [37] we do not use auxiliary losses [6] (i.e. attaching output heads after each decoder layer and summing up the losses from each layer) previously found to be beneficial for matchingbased detection models. Both of these choices are motivated by our ablations in Tab. 15: We observe that the focal loss consistently improves performance, and that auxilliary losses are only beneficial when the focal loss is not used.
其中 $a$ 和 $\hat{a}$ 分别是真实动作类别概率和预测动作类别概率。$\alpha$ 和 $\gamma$ 是焦点损失 (focal loss) [32] 的超参数。此外,参照 [37] 的做法,我们没有使用之前被证明对基于匹配的检测模型有益的辅助损失 (auxiliary losses) [6](即在每个解码器层后附加输出头并累加各层损失)。这两个选择都源于表 15 中的消融实验:我们观察到焦点损失能持续提升性能,而辅助损失仅在未使用焦点损失时才有益处。