An Efficient Gloss-Free Sign Language Translation Using Spatial Configurations and Motion Dynamics with LLMs
基于大语言模型利用空间构型与运动动态的高效无注释手语翻译
Abstract
摘要
Gloss-free Sign Language Translation (SLT) converts sign videos into spoken language sentences without relying on glosses, which are the written representations of signs. Recently, Large Language Models (LLMs) have shown remarkable translation performance in glossfree methods by harnessing their powerful natural language generation capabilities. However, these methods often rely on domain-specific fine-tuning of visual encoders to achieve optimal results. By contrast, we emphasize the importance of capturing the spatial configurations and motion dynamics in sign language. With this in mind, we introduce Spatial and Motionbased Sign Language Translation (SpaMo), a novel LLM-based SLT framework. The core idea of SpaMo is simple yet effective: instead of domain-specific tuning, we use offthe-shelf visual encoders to extract spatial and motion features, which are then input into an LLM along with a language prompt. Additionally, we employ a visual-text alignment process as a lightweight warm-up step before applying SLT supervision. Our experiments demonstrate that SpaMo achieves state-of-theart performance on three popular datasets— PHOENIX14T, CSL-Daily, and How2Sign— without visual fine-tuning 1.
无注释手语翻译 (SLT) 将手语视频直接转换为口语语句,无需依赖手语注释(即手语的书面表示形式)。近期,大语言模型 (LLM) 凭借其强大的自然语言生成能力,在无注释方法中展现出卓越的翻译性能。然而,这些方法通常需要对视觉编码器进行领域特定微调才能获得最佳效果。相比之下,我们强调捕捉手语空间构型和运动动态的重要性。基于此,我们提出了基于空间与运动的手语翻译框架 (SpaMo) ,这是一种新型基于大语言模型的 SLT 框架。SpaMo 的核心思想简单而高效:我们使用现成的视觉编码器提取空间和运动特征,而非领域特定微调,随后将这些特征与语言提示共同输入大语言模型。此外,在应用 SLT 监督前,我们采用视觉-文本对齐流程作为轻量级预热步骤。实验表明,SpaMo 在 PHOENIX14T、CSL-Daily 和 How2Sign 三个主流数据集上均实现了最先进性能,且无需视觉微调 [1]。
1 Introduction
1 引言
Sign language is a visual means of communication primarily used by Deaf communities, relying on physical movements rather than spoken words. In this paper, we tackle Sign Language Translation (SLT), focusing on converting sign videos into spoken language sentences. Early SLT methods (Camgoz et al., 2020; Zhou et al., 2021a; Chen et al., 2022a,b; Zhang et al., 2023b) have primarily relied on glosses—written representations of signs using corresponding words. Glosses provide a structured form of sign language, which helps identify semantic boundaries within continuous sign sequences. This, in turn, allows the models to better comprehend the overall content of the sign videos (Yin et al., 2023; Wei and Chen, 2023). However, annotating glosses is a labor-intensive and time-consuming process that requires expertise in sign language. This significantly hinders the expansion of sign language datasets and limits the development of SLT methods (Li et al., 2020b; Shi et al., 2022; Lin et al., 2023).
手语是一种主要由聋人群体使用的视觉交流方式,依赖肢体动作而非口语表达。本文研究手语翻译(SLT)任务,重点将手语视频转换为口语语句。早期SLT方法(Camgoz等人,2020;Zhou等人,2021a;Chen等人,2022a,b;Zhang等人,2023b)主要依赖glosses(用手语对应词汇书写的符号表征)。Glosses提供了结构化的手语形式,有助于识别连续手语序列中的语义边界,从而使模型能更好地理解手语视频的整体内容(Yin等人,2023;Wei和Chen,2023)。然而,标注glosses是项需要手语专业知识的劳动密集型工作,这严重阻碍了手语数据集的扩展,限制了SLT方法的发展(Li等人,2020b;Shi等人,2022;Lin等人,2023)。

Figure 1: Visual examples of spatial configurations and motion dynamics in sign language. The images are sourced from WLASL (Li et al., 2020a).
图 1: 手语空间构型与运动动态的视觉示例。图像来源于WLASL (Li et al., 2020a)。
To address these limitations, there has been a shift towards gloss-free methods that rely solely on the sign videos and corresponding translations. While these methods still under perform compared to the gloss-based methods, efforts have been made to reduce the performance gap by focusing on temporal semantic structures (Li et al., 2020b) and aligning visual and textual modalities (Zhao et al., 2021; Yin et al., 2023; Zhou et al., 2023; Zhao et al., 2024). Recently, LLMs have demonstrated remarkable translation performance in a gloss-free setting by harnessing their powerful language generation capabilities. However, the modality gap between the continuous sign videos and discrete text poses a challenge for the LLMs in effectively understanding the sign videos. To address this, many methods fine-tune their visual encoders to be more domainspecific to sign language (Wong et al., 2024; Chen et al., 2024; Rust et al., 2024; Gong et al., 2024).
为解决这些局限性,研究趋势已转向仅依赖手语视频和对应翻译的无注释方法。虽然这些方法性能仍不及基于注释的方法,但通过关注时序语义结构 (Li et al., 2020b) 以及对齐视觉与文本模态 (Zhao et al., 2021; Yin et al., 2023; Zhou et al., 2023; Zhao et al., 2024),研究者们正努力缩小性能差距。近期,大语言模型凭借其强大的语言生成能力,在无注释场景下展现出卓越的翻译性能。然而,连续手语视频与离散文本之间的模态差异,对大语言模型有效理解手语视频构成了挑战。为此,许多方法通过微调视觉编码器使其更适配手语领域 (Wong et al., 2024; Chen et al., 2024; Rust et al., 2024; Gong et al., 2024)。
That said, fine-tuning visual encoders can be resource-heavy and time-consuming, making it impractical for real-world applications, especially when considering the diversity of sign languages. This leads to an important question: Is domainspecific tuning of visual encoders necessary to achieve optimal performance in LLM-based SLT? We argue that focusing on the inherent characteristics of sign language could reduce the need for such extensive fine-tuning. First, visual encoders trained on general domains (Radford et al., 2021; Oquab et al., 2023) have already proven highly effective in downstream tasks such as action recognition (Huang et al., 2024; Tang et al., 2024) and video captioning (Yang et al., 2023; Zhou et al., 2024). Moreover, LLMs are capable of retaining rich visual information from these general encoders in their latent space (Zhang et al., 2024c). Rather than emphasizing fine-tuning, we shift our attention to the crucial roles of spatial configurations and motion dynamics in sign language.
然而,微调视觉编码器可能耗费大量资源且耗时,这使得它在实际应用中不太可行,尤其是在考虑到手语的多样性时。这就引出了一个重要问题:在基于大语言模型的SLT中,是否必须对视觉编码器进行领域特定调优才能达到最佳性能?我们认为,关注手语的固有特性可以减少对这种大规模微调的需求。首先,在通用领域训练的视觉编码器 (Radford et al., 2021; Oquab et al., 2023) 已被证明在下游任务中非常有效,例如动作识别 (Huang et al., 2024; Tang et al., 2024) 和视频字幕生成 (Yang et al., 2023; Zhou et al., 2024)。此外,大语言模型能够在潜在空间中保留来自这些通用编码器的丰富视觉信息 (Zhang et al., 2024c)。与其强调微调,我们将注意力转向手语中空间配置和运动动态的关键作用。
Spatial configurations include the arranging and positioning of signs within the signing space, including hand shapes, facial expressions, and body postures. These components work together to distinguish different signs and convey their intended meanings (Emmorey and Casey, 1995). As shown in Figure 1a, the signs for “cold” and “winter” both use the same handshape, with a shivering motion of the fists. The primary difference lies in the facial expressions: “cold” is typically accompanied by a tense or grimaced expression, while “winter” may feature a more neutral expression. Motion dynamics, on the other hand, involve the path, speed, and rhythm of hand movements, illustrating how movements alter the meanings of signs over time (Bosworth et al., 2019). As shown in Figure 1b, the signs for “chair” and “sit” both use the same “H” handshape and involve the interaction of both hands. However, the motion differentiates these signs: “chair” involves a repetitive tapping motion, while “sit” involves a single, smooth motion. These examples highlight the importance of the spatial configurations and motion dynamics in conveying accurate messages in sign language.
空间配置包括在手语空间中排列和定位符号,包括手形、面部表情和身体姿势。这些组成部分共同作用以区分不同的符号并传达其预期含义 (Emmorey and Casey, 1995)。如图 1a 所示,"冷"和"冬天"的手势都使用相同的手形,即拳头颤抖的动作。主要区别在于面部表情:"冷"通常伴随紧张或扭曲的表情,而"冬天"可能呈现更中性的表情。另一方面,运动动态涉及手部移动的路径、速度和节奏,说明动作如何随时间改变符号的含义 (Bosworth et al., 2019)。如图 1b 所示,"椅子"和"坐"的手势都使用相同的"H"手形,并涉及双手的交互。然而,动作区分了这些符号:"椅子"涉及重复的轻敲动作,而"坐"涉及单一流畅的动作。这些例子突显了空间配置和运动动态在手语中传达准确信息的重要性。
To this end, we introduce a novel gloss-free framework, Spatial and Motion-based Sign Language Translation (SpaMo). SpaMo is designed to fully exploit the spatial configurations and motion dynamics in the sign videos using off-the-shelf visual encoders, all without the need for domainspecific fine-tuning. As shown in Figure 2, the core idea is simple: We extract spatial features (spatial configurations) and motion features (motion dynamics) using two different visual encoders, and feed these into an LLM with a language prompt. Specifically, we use a pre-trained image encoder (e.g., ViT) as Spatial Encoder (SE) to individually encode each frame for its spatial features. To further refine the spatial features, we apply $S^{2}$ scaling (Shi et al., 2024), which processes a sign image at multiple scales. Additionally, we use a video encoder (e.g., VideoMAE) as Motion Encoder (ME) to encode sign clips (groups of sign frames) into the motion features. To capture finer motion dynamics, we apply a sliding window approach, which results in implicit gloss-level representations (Cheng et al., 2023; Hwang et al., 2024). Next, Sign Adapter (SA), comprising Multi-Layer Perceptron (MLP) layers, transfers these features to the LLM. To further bridge the modality gap, we propose VisualText Alignment (VT-Align), a training strategy that aligns the visual features with the LLM’s embedding space, promoting more efficient training and improved translation performance.
为此,我们提出了一种新颖的无注释框架——基于空间与运动的手语翻译系统(SpaMo)。如图2所示,该框架的核心思想简单明了:通过两种不同的视觉编码器提取空间特征(空间构型)和运动特征(运动动态),并配合语言提示将其输入大语言模型。具体而言,我们使用预训练图像编码器(如ViT)作为空间编码器(SE)逐帧提取空间特征。为进一步优化空间特征,我们采用$S^{2}$缩放技术(Shi et al., 2024)对标志图像进行多尺度处理。同时,采用视频编码器(如VideoMAE)作为运动编码器(ME)将手语片段(帧组)编码为运动特征。为捕捉更精细的运动动态,我们应用滑动窗口方法实现隐式的注释级表征(Cheng et al., 2023; Hwang et al., 2024)。随后,由多层感知机(MLP)构成的符号适配器(SA)将这些特征转换至大语言模型。为弥合模态差异,我们提出视觉文本对齐(VT-Align)训练策略,通过将视觉特征与大语言模型的嵌入空间对齐,实现更高效的训练和更优的翻译性能。
2 Related Work
2 相关工作
2.1 Gloss-free Sign Language Translation
2.1 无注释手语翻译
Gloss-free SLT directly converts sign videos into spoken language sentences without relying on glosses. These methods, however, often underperform compared to gloss-based methods (Camgoz et al., 2020; Zhou et al., 2021b,a; Yin et al., 2021; Chen et al., 2022a,b; Zhang et al., 2023b; Jing et al., 2024). To address the performance gap, recent work has focused on several key areas: enhancing the temporal semantic structure (Li et al., 2020b), improving the alignment between visual and textual modalities (Zhao et al., 2021; Lin et al., 2023; Fu et al., 2023), leveraging LLMs (Wong et al., 2024; Gong et al., 2024; Chen et al., 2024), and scaling efforts by utilizing larger sign language datasets (Uthus et al., 2024; Rust et al., 2024). De- spite these advancements, most gloss-free methods depend on fine-tuning visual encoders using the glosses (Li et al., 2020b; Yin et al., 2023; Fu et al., 2023), target translations (Zhou et al., 2023; Wong et al., 2024), or self-supervised learning (Gong et al., 2024; Rust et al., 2024). In particular, fine- tuning with the glosses helps the visual encoders to offer more domain-specific training on continuous or isolated Sign Language Recognition (SLR) datasets, such as WLASL (Li et al., 2020a) and PHOENIX14T (Camgoz et al., 2018).
无标注手语翻译 (gloss-free SLT) 直接将手语视频转换为口语语句,无需依赖标注文本。然而,这些方法的性能通常低于基于标注的方法 (Camgoz et al., 2020; Zhou et al., 2021b,a; Yin et al., 2021; Chen et al., 2022a,b; Zhang et al., 2023b; Jing et al., 2024)。为解决性能差距,近期研究聚焦于几个关键方向:增强时序语义结构 (Li et al., 2020b)、改进视觉与文本模态的对齐 (Zhao et al., 2021; Lin et al., 2023; Fu et al., 2023)、利用大语言模型 (Wong et al., 2024; Gong et al., 2024; Chen et al., 2024),以及通过更大规模手语数据集进行扩展 (Uthus et al., 2024; Rust et al., 2024)。尽管取得进展,大多数无标注方法仍依赖于使用标注文本 (Li et al., 2020b; Yin et al., 2023; Fu et al., 2023)、目标翻译文本 (Zhou et al., 2023; Wong et al., 2024) 或自监督学习 (Gong et al., 2024; Rust et al., 2024) 对视觉编码器进行微调。特别地,使用标注文本微调有助于视觉编码器在连续或孤立手语识别 (SLR) 数据集(如 WLASL (Li et al., 2020a) 和 PHOENIX14T (Camgoz et al., 2018))上获得更具领域针对性的训练。
Consequently, we classify these methods as weakly gloss-free due to the implicit involvement of the glosses, as further elaborated in Section 4.2. On the other hand, the rest of the fine-tuning methods eliminate reliance on these annotations. However, they often require substantial resources. As a results, it can be difficult to achieve robust visual representations and improve translation performance without access to a sufficiently large dataset. To address this limitation, our approach diverges from this norm by focusing on capturing the spatial configurations and motion dynamics through offthe-shelf visual encoders. This allows us to bypass the need for resource-intensive fine-tuning.
因此,我们将这些方法归类为弱无注释 (weakly gloss-free) ,因为注释的隐式参与(详见第4.2节)。另一方面,其余微调方法完全摒弃了对这些标注的依赖,但通常需要大量资源。因此,在缺乏足够大规模数据集的情况下,难以获得鲁棒的视觉表征并提升翻译性能。为解决这一局限,我们的方法通过现成视觉编码器捕捉空间构型与运动动态,从而规避资源密集型的微调需求。
2.2 Scaling Language Models in SLT
2.2 手语翻译中的语言模型扩展
The scaling laws in language models (Kaplan et al., 2020) have been pivotal in the rise of Large Language Models (LLMs) (Touvron et al., 2023; Chiang et al., 2023; Chung et al., 2024). Leveraging their strong generation capabilities, LLMs have been applied across diverse domains: multilingual translation (Zhu et al., 2023; Zhang et al., $2023\mathrm{a}$ ; Gao et al., 2024), pose generation (Feng et al., 2024; Zhang et al., 2024b), and visual question answering (Li et al., 2023; Liu et al., 2024a,b), extending their impact beyond Natural Language Processing. LLMs have also demonstrated impressive translation performance in the SLT domain. SLT methods using the LLMs focus on aligning high-dimensional visual features with inputs comprehensible to LLMs. These methods involve fine-tuning visual encoders to produce languagelike tokens (Gong et al., 2024), using pseudoglosses (Wong et al., 2024), or performing videogrounded text generation tasks (Chen et al., 2024).
语言模型的缩放定律 (Kaplan et al., 2020) 对大语言模型 (LLM) 的崛起起到了关键作用 (Touvron et al., 2023; Chiang et al., 2023; Chung et al., 2024)。凭借其强大的生成能力,大语言模型已被应用于多个领域:多语言翻译 (Zhu et al., 2023; Zhang et al., $2023\mathrm{a}$; Gao et al., 2024)、姿态生成 (Feng et al., 2024; Zhang et al., 2024b) 和视觉问答 (Li et al., 2023; Liu et al., 2024a,b),其影响力已超越自然语言处理范畴。在符号语言翻译 (SLT) 领域,大语言模型也展现出卓越的翻译性能。基于大语言模型的 SLT 方法主要关注如何将高维视觉特征与模型可理解的输入对齐,具体包括:微调视觉编码器以生成类语言 token (Gong et al., 2024)、使用伪注释 (Wong et al., 2024) 或执行视频文本生成任务 (Chen et al., 2024)。
In this work, we take a different approach by focusing on spatial configurations and motion dynamics. We extract spatial and motion features and pass them to LLMs with a light warm-up process. This method is simple yet effective, demonstrating that an extensive pre-training for the visual encoders is unnecessary to achieve peak performance.
在这项工作中,我们采用了一种不同的方法,重点关注空间配置和运动动力学。我们提取空间和运动特征,并通过轻量级预热过程将其传递给大语言模型。这种方法简单却有效,表明无需对视觉编码器进行大量预训练即可达到峰值性能。
3 Method
3 方法
We first give an overview of our framework in Section 3.1. We then explain SE and ME in Sections 3.2 and 3.3, respectively. Next, we discuss SA in Section 3.4 and VT-Align in Section 3.5. Finally, we explain the training details in Section 3.6.
我们首先在第3.1节概述框架结构,随后分别在第3.2节和第3.3节解释SE和ME。接着在第3.4节讨论SA,并在第3.5节介绍VT-Align。最后在第3.6节说明训练细节。
3.1 Framework Overview
3.1 框架概述
Given a sign video $X={x_{i}}{i=1}^{T}$ , where each frame $x_{i}\in{\overset{\cdot}{\mathbb{R}}}^{H\times W}$ represents a frame with height $H$ and width $W$ , the objective of SLT is to generate a corresponding spoken language sentence $Y={y_{j}}_{j=1}^{U}$ , composed of $U$ words. Previous gloss-free methods (Zhou et al., 2023; Wong et al., 2024; Gong et al., 2024; Chen et al., 2024) have involved fine-tuning visual encoders using sign language data to make them more domain-specific, leading to improvements in translation accuracy. However, while this fine-tuning introduces more domain knowledge at the feature extraction level, it is unnecessary, especially with LLMs, which already maintain rich visual information from the visual encoder in their latent space (Zhang et al., 2024c). Although there may be a trade-off, we argue that utilizing the spatial configurations and motion dynamics with proper alignment and training, offers a more efficient and effective solution.
给定一个手语视频 $X={x_{i}}{i=1}^{T}$ ,其中每帧 $x_{i}\in{\overset{\cdot}{\mathbb{R}}}^{H\times W}$ 表示高度为 $H$ 、宽度为 $W$ 的画面,手语翻译 (SLT) 的目标是生成对应的口语语句 $Y={y_{j}}_{j=1}^{U}$ ,该语句由 $U$ 个单词组成。现有无注释方法 (Zhou et al., 2023; Wong et al., 2024; Gong et al., 2024; Chen et al., 2024) 通过用手语数据微调视觉编码器使其更具领域特异性,从而提升翻译准确率。然而,尽管这种微调在特征提取层面引入了更多领域知识,但其必要性存疑——尤其是使用大语言模型时,其潜空间已保有视觉编码器提供的丰富视觉信息 (Zhang et al., 2024c)。虽然存在权衡,但我们认为通过适当的对齐训练利用空间构型与运动动力学特征,能提供更高效优质的解决方案。
As shown in Figure 2, Spatial Encoder (SE) and Motion Encoders (ME) extract two distinct features from the sign video $X$ : Spatial features $Z_{s}$ capture the spatial configurations (Emmorey and Casey, 1995), and motion features $Z_{m}$ represent the motion dynamics (Bosworth et al., 2019). These fea- tures are then integrated into a combined sign feature $Z_{s m}$ via Sign Adapter (SA). The combined feature is then fed to an LLM with a language prompt, guiding the LLM to generate the translation in the desired language. Additionally, we perform VisualText Alignment (VT-Align) to minimize the gap between the visual and textual modalities before and during training under SLT supervision. In the following sections, we provide a detailed explanation of SE, ME, SA, and VT-Align.
如图 2 所示,空间编码器 (Spatial Encoder, SE) 和运动编码器 (Motion Encoder, ME) 从手语视频 $X$ 中提取两种不同的特征:空间特征 $Z_{s}$ 捕捉空间配置 (Emmorey and Casey, 1995),运动特征 $Z_{m}$ 表示运动动态 (Bosworth et al., 2019)。这些特征通过手语适配器 (Sign Adapter, SA) 整合为联合手语特征 $Z_{s m}$。随后,联合特征与语言提示一起输入大语言模型,引导其生成目标语言的翻译结果。此外,我们在手语翻译监督训练前后执行视觉-文本对齐 (VisualText Alignment, VT-Align) 以缩小视觉与文本模态间的差异。下文将详细阐述 SE、ME、SA 和 VT-Align 的实现机制。
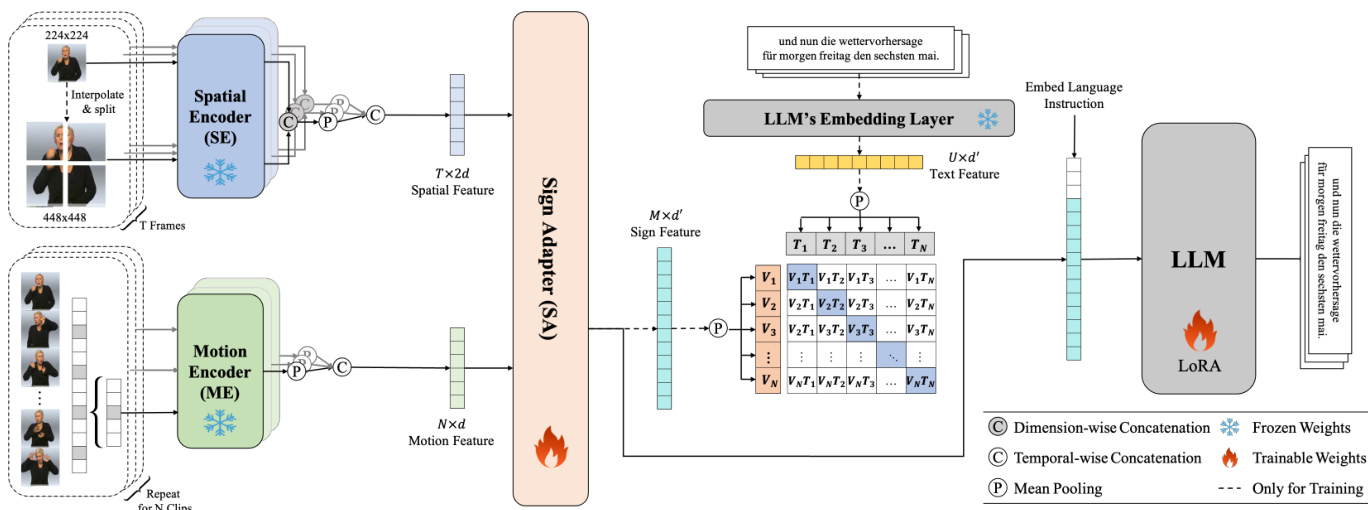
Figure 2: An overview of the SpaMo framework, which consists of three parts: (i) Sign Feature Extraction: Spatial and motion features are extracted using SE and ME, using the $S^{2}$ and sliding window approaches to capture detailed spatial configurations and motion dynamics. (ii) VT-Align: The extracted features are combined within SA to form a unified sign feature. During training, a warm-up process is employed to ensure that SA has well-initialized weights, effectively bridging the modality gap between the sign video and text. (iii) LLM: the LLM processes the sign feature along with a language-instructive prompt and is trained using LoRA.
图 2: SpaMo框架概览,包含三个部分:(i) 手语特征提取:使用SE和ME提取空间与运动特征,采用$S^{2}$和滑动窗口方法捕捉精细的空间构型与运动动态。(ii) VT-Align:在SA中融合提取的特征形成统一的手语特征。训练时采用预热过程确保SA权重良好初始化,有效弥合手语视频与文本的模态差异。(iii) 大语言模型:大语言模型处理手语特征及语言指令提示,并使用LoRA进行训练。
3.2 Spatial Encoder
3.2 空间编码器
SE extracts spatial features $Z_{s}$ from the sign video $X$ . We utilize a pre-trained image encoder (e.g., ViT), which is kept frozen, and enhances its capability to capture finer spatial information by applying Scaling on Scales $(S^{2})$ (Shi et al., 2024). $S^{2}$ is parameter-free and enables the extraction of multi-scale features without altering the original pre-trained encoder. By processing sign images at multiple resolutions, $S^{2}$ provides a more comprehensive spatial understanding, ensuring that SE captures both fine-grained and broad spatial details for accurate sign language interpretation. The resulting spatial features can be represented as Zs ∈ RT ×2d, where $T$ is the number of frames, and $2d$ is the increased embedding dimension, reflecting the integration of multi-scale features.
SE从手语视频$X$中提取空间特征$Z_{s}$。我们采用预训练的图像编码器(如ViT),保持其参数冻结,并通过应用尺度缩放$(S^{2})$ (Shi et al., 2024)增强其捕捉细粒度空间信息的能力。$S^{2}$无需参数且能在不改变原始预训练编码器的情况下提取多尺度特征。通过处理多分辨率手语图像,$S^{2}$提供了更全面的空间理解,确保SE能同时捕获细粒度和宏观空间细节以实现准确的手语识别。最终空间特征可表示为Zs ∈ RT ×2d,其中$T$为帧数,$2d$为增加的嵌入维度,反映了多尺度特征的融合。
3.3 Motion Encoder
3.3 运动编码器
ME derives motion features from the sign video $X$ . Similar to SE, we employ a pre-trained video encoder (e.g., VideoMAE), which remains frozen, to process sign clips segmented from the video. However, accurately segmenting the sign video into distinct gloss-level clips is challenging without the support of pre-trained Continuous Sign Language Recognition (CSLR) models (Wei and Chen, 2023). To address this limitation, we use a sliding window approach to capture implicit gloss-level representations (Cheng et al., 2023; Hwang et al., 2024). Specifically, we divide the sign video into short, overlapping clips, then feed each clip into ME to extract the implicit gloss-level motion features $Z_{m}\in~\mathbb{R}^{N\times d}$ , where $N$ is the number of segments. The number of segments $N$ is calculated as $\begin{array}{r}{N=\left\lfloor\frac{T-w}{s}\right\rfloor+1}\end{array}$ , where $T$ is the total number of frames, and $w$ and $s$ are the window size and stride, respectively. Since $Z_{m}$ is generated by processing $N$ short clips, it can also be interpreted as a sequence of $N$ clip-wise features.
ME从手语视频$X$中提取运动特征。与SE类似,我们采用预训练的视频编码器(如VideoMAE)来处理从视频中分割出的手语片段,该编码器保持冻结状态。然而,在没有预训练连续手语识别(CSLR)模型支持的情况下(Wei and Chen, 2023),准确地将手语视频分割为不同的词条级片段具有挑战性。为解决这一限制,我们采用滑动窗口方法来捕捉隐式词条级表征(Cheng et al., 2023; Hwang et al., 2024)。具体而言,我们将手语视频划分为短小且重叠的片段,然后将每个片段输入ME以提取隐式词条级运动特征$Z_{m}\in~\mathbb{R}^{N\times d}$,其中$N$为片段数量。片段数量$N$的计算公式为$\begin{array}{r}{N=\left\lfloor\frac{T-w}{s}\right\rfloor+1}\end{array}$,其中$T$为总帧数,$w$和$s$分别为窗口大小和步长。由于$Z_{m}$是通过处理$N$个短片段生成的,它也可以被解释为$N$个片段级特征的序列。
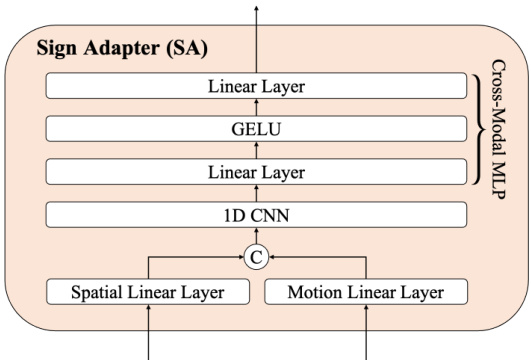
Figure 3: An overview of Sign Adapter.
图 3: Sign Adapter 概览图
3.4 Sign Adapter
3.4 Sign Adapter
In the previous sections, we extracted two distinct visual features: the spatial features $Z_{s}$ and the motion features $Z_{m}$ . These features differ in both their dimensions and representation, as depicted in Figure 2. To effectively integrate these features, we introduce an additional module called Sign Adaptor (SA). As shown in Figure 3, SA includes linear projection layers, a 1D CNN, and a Multi-Layer Perceptron (MLP). These components work together to integrate the spatial and motion features into a unified sign representation, denoted as $Z_{s m}$ . First, the spatial and motion features are passed through linear projection layers to transform them into features with matching dimensions. Next, the 1D CNN is applied for short-term modeling of the combined features. Finally, a cross-modal MLP (Liu et al., 2024a) is employed to bridge the visual and textual modalities. The resulting outputs are represented as $Z_{s m}\in\mathbb{R}^{M\times d^{\prime}}$ , where $M$ represents the reduced number of frames after convolution, and $d^{\prime}$ is the dimension aligned with that of the LLM. Although SA aids in bridging the modality gap between visual and textual features during training under the SLT supervision, the gap remains. To tackle this issue, we introduce VT-Align, which will be detailed in the next section.
在前面的章节中,我们提取了两种不同的视觉特征:空间特征 $Z_{s}$ 和运动特征 $Z_{m}$。这些特征在维度和表示上都有所不同,如图 2 所示。为了有效整合这些特征,我们引入了一个名为 Sign Adaptor (SA) 的附加模块。如图 3 所示,SA 包括线性投影层、1D CNN 和多层感知机 (MLP)。这些组件共同作用,将空间和运动特征整合为一个统一的手语表示,记为 $Z_{s m}$。首先,空间和运动特征通过线性投影层转换为具有匹配维度的特征。接着,应用 1D CNN 对组合特征进行短期建模。最后,采用跨模态 MLP (Liu et al., 2024a) 来桥接视觉和文本模态。最终输出表示为 $Z_{s m}\in\mathbb{R}^{M\times d^{\prime}}$,其中 $M$ 表示卷积后减少的帧数,$d^{\prime}$ 是与大语言模型对齐的维度。尽管 SA 在 SLT 监督下的训练过程中有助于缩小视觉和文本特征之间的模态差距,但这种差距仍然存在。为了解决这个问题,我们引入了 VT-Align,这将在下一节中详细介绍。
3.5 Visual-Text Alignment
3.5 视觉-文本对齐
VT-Align is a warm-up and go process designed to provide the SA module with well-initialized weights before the SLT supervision begins. This initial alignment is crucial, as it helps the model more effectively bridge the modality gap during training. To achieve this alignment, we employ a widely-used softmax-based contrastive learning approach (Radford et al., 2021; Jia et al., 2021).
VT-Align是一种预热启动流程,旨在SLT监督开始前为SA模块提供良好初始化的权重。这种初始对齐至关重要,因为它能帮助模型在训练过程中更有效地弥合模态差距。为实现这种对齐,我们采用了基于softmax的对比学习方法 (Radford et al., 2021; Jia et al., 2021)。
Specifically, given a mini-batch $\boldsymbol{\mathcal{B}}\quad=\quad$ ${(S_{1},Y_{1}),(S_{2},Y_{2}),\ldots}$ of sign-text pairs, the contrastive learning objective encourages the embeddings of matching pairs $(S_{i},Y_{i})$ to align closely while pushing apart the embeddings of mismatched pairs $(S_{i},Y_{j\neq i})$ . Text features $Z_{t}$ are extracted from the target translation $Y_{i}$ using the LLM’s embedding layer $E_{l l m}(\cdot)$ . Note that only the SA module $f_{s a}(\cdot)$ is updated during this process, while $E_{l l m}(\cdot)$ remains fixed to preserve the LLM’s language capabilities.
具体来说,给定一个小批量 $\boldsymbol{\mathcal{B}}\quad=\quad$ ${(S_{1},Y_{1}),(S_{2},Y_{2}),\ldots}$ 的手语-文本对,对比学习目标鼓励匹配对 $(S_{i},Y_{i})$ 的嵌入紧密对齐,同时推开不匹配对 $(S_{i},Y_{j\neq i})$ 的嵌入。文本特征 $Z_{t}$ 通过大语言模型的嵌入层 $E_{l l m}(\cdot)$ 从目标翻译 $Y_{i}$ 中提取。注意在此过程中仅更新SA模块 $f_{s a}(\cdot)$,而 $E_{l l m}(\cdot)$ 保持固定以保留大语言模型的语言能力。
where $\begin{array}{r}{Z_{s m}^{(i)}=\frac{f_{s a}(S_{i})}{|f_{s a}(S_{i})|{2}}}\end{array}$ $\begin{array}{r}{Z_{t}^{(i)}=\frac{E_{l l m}(T_{i})}{\lVert E_{l l m}(T_{i})\rVert_{2}}}\end{array}$ ∥Ellllmm(Tii)∥2 , and
其中 $\begin{array}{r}{Z_{s m}^{(i)}=\frac{f_{s a}(S_{i})}{|f_{s a}(S_{i})|{2}}}\end{array}$ $\begin{array}{r}{Z_{t}^{(i)}=\frac{E_{l l m}(T_{i})}{\lVert E_{l l m}(T_{i})\rVert_{2}}}\end{array}$ ∥Ellllmm(Tii)∥2 ,以及
$\tau$ denotes a learnable temperature parameter used to scale the logits.
$\tau$ 表示一个可学习的温度参数,用于缩放 logits。
3.6 Training Details
3.6 训练细节
Our framework is optimized in two phases: an initial warm-up phase followed by training with the SLT supervision. In the warm-up phase, we begin with a training phase the SA module using VT-Align for a designated number of steps (e.g., 4K steps). After completing the warm-up phase, we proceed to the joint training for both SA and the LLM. For fine-tuning the LLM, we utilize LoRA (Hu et al., 2021), a lightweight and efficient method specifically designed for this purpose. Overall, our method is trained with a combined loss function:
我们的框架优化分为两个阶段:初始预热阶段和随后的SLT监督训练阶段。在预热阶段,我们首先使用VT-Align对SA模块进行指定步数(例如4K步)的训练。完成预热后,我们开始对SA和大语言模型进行联合训练。针对大语言模型的微调,我们采用专为此目的设计的轻量高效方法LoRA (Hu et al., 2021)。整体训练采用组合损失函数:
$$
\mathcal{L}{S p a M o}=\mathcal{L}{c e}+\mathcal{L}_{v t},
$$
$$
\mathcal{L}{S p a M o}=\mathcal{L}{c e}+\mathcal{L}_{v t},
$$
where $\mathcal{L}{c e}$ represents cross-entropy loss, and $\mathcal{L}_{v t}$ continuously manages the alignment.
其中 $\mathcal{L}{c e}$ 表示交叉熵损失 (cross-entropy loss),而 $\mathcal{L}_{v t}$ 持续管理对齐。
4 Experiments
4 实验
4.1 Implementation Details
4.1 实现细节
For SE and ME, we use CLIP ViT-L/14 (Radford et al., 2021) and VideoMAE-L/16 (Tong et al., 2022), respectively. To extract the spatial features, the sign images are interpolated to multiple scales, such as $224\times224$ and $448\times448$ . For each scale, larger images are split into sub-images of regular size $(224\times224)$ and processed individually. These features from the sub-images are then pooled and concatenated with features from the original representation. For the motion features, each clip consists of 16 frames, based on the findings from (Wilbur, 2009), which suggests that this frame interval captures a single sign. We set the stride $s$ between consecutive clips to 8. We use FlanT5-XL (Chung et al., 2024) as the LLM for PHOENIX14T and How2Sign, while mT0- XL (Mu en nigh off et al., 2022) is used for the CSLDaily. During the warm-up phase with VT-Align, we use 4K steps on PHOENIX14T and CSL-Daily, and 15K steps on How2Sign. Additional implementation details can be found in Appendix A.
对于SE和ME,我们分别采用CLIP ViT-L/14 (Radford et al., 2021)和VideoMAE-L/16 (Tong et al., 2022)。为提取空间特征,手语图像会被插值到多尺度(如$224\times224$和$448\times448$)。每个尺度的较大图像会被分割为固定尺寸$(224\times224)$的子图像单独处理,这些子图像特征经池化后与原始表征特征拼接。运动特征方面,根据(Wilbur, 2009)的研究,每个片段包含16帧以捕捉单个手语动作,连续片段间步长$s$设为8。PHOENIX14T和How2Sign采用FlanT5-XL (Chung et al., 2024)作为大语言模型,CSLDaily则使用mT0-XL (Mu en nigh off et al., 2022)。VT-Align预热阶段在PHOENIX14T和CSL-Daily上训练4K步,How2Sign训练15K步。更多实现细节见附录A。
4.2 Experimental Settings
4.2 实验设置
Datasets. We evaluated our method on three sign language datasets: PHOENIX14T (Camgoz et al., 2018), CSL-Daily (Zhou et al., 2021a), and How2Sign (Duarte et al., 2021). PHOENIX14T is a German Sign Language dataset comprising
数据集。我们在三个手语数据集上评估了我们的方法:PHOENIX14T (Camgoz et al., 2018)、CSL-Daily (Zhou et al., 2021a) 和 How2Sign (Duarte et al., 2021)。PHOENIX14T 是一个德国手语数据集,包含
Table 1: Performance comparison on the PHOENIX14T and CSL-Daily datasets. “Vis. Ft.” denotes the visually fine-tuned on sign language datasets. $^\ddag$ denotes results reproduced by Yin et al. for CSL-Daily. The best results are highlighted as bold, and the second-best are underlined.
表 1: PHOENIX14T 和 CSL-Daily 数据集上的性能对比。"Vis. Ft." 表示在手语数据集上进行了视觉微调。$^\ddag$ 表示 Yin 等人复现的 CSL-Daily 结果。最佳结果以粗体标出,次优结果以下划线标出。
| 设置 | 方法 | Vis.Ft. | B1 | B2 | B3 | RG | B1 | B2 | B3 | B4 | RG |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 基于词注释 | SLRT (Camgoz et al., 2020) | √ | 46.61 | 33.73 | 26.19 | 21.32 | 37.38 | 24.36 | 16.55 | 11.79 | 36.74 |
| BN-TIN-Transf.+SignBT (Zhou et al., 2021a) | x | 50.80 | 37.75 | 29.72 | 24.32 | 49.54 | 51.42 | 37.26 | 27.76 | 21.34 | |
| MMTLB (Chen et al., 2022a) | 53.97 | 41.75 | 33.84 | 28.39 | 52.65 | 53.31 | 40.41 | 30.87 | 23.92 | ||
| TS-SLT (Chen et al., 2022b) | 54.90 | 42.43 | 34.46 | 28.95 | 53.48 | 55.44 | 42.59 | 32.87 | 25.79 | ||
| SLTUNET (Zhang et al., 2023b) | 52.92 | 41.76 | 33.99 | 28.47 | 52.11 | 54.98 | 41.44 | 31.84 | 25.01 | ||
| TSPNet (Li et al., 2020b) | 36.10 | 23.12 | 16.88 | 13.41 | 34.96 | 17.09 | 8.98 | 5.07 | 2.97 | ||
| 弱无词注释 | GASLT (Yin et al., 2023) | 39.07 | 26.74 | 21.86 | 15.74 | 39.86 | 19.90 | 9.94 | 5.98 | 4.07 | |
| ConSLT (Fu et al., 2023) | √ | - | 21.59 | 47.69 | - | - | - | 1 | |||
| CSGCR (Zhao et al., 2021) | x | 36.71 | 25.40 | 18.86 | 15.18 | 38.85 | |||||
| GFSLT-VLP (Zhou et al., 2023) | 43.71 | 33.18 | 26.11 | 21.44 | 42.29 | 39.37 | 24.93 | 16.26 | 11.00 | ||
| 无词注释 | FLa-LLM (Chen et al., 2024) | 46.29 | 35.33 | 28.03 | 23.09 | 45.27 | 37.13 | 25.12 | 18.38 | 14.20 | |
| Sign2GPT (Wong et al., 2024) | 49.54 | 35.96 | 28.83 | 22.52 | 48.90 | 41.75 | 28.73 | 20.60 | 15.40 | ||
| SignLLM (Gong et al., 2024) | 45.21 | 34.78 | 28.05 | 23.40 | 44.49 | 39.55 | 28.13 | 20.07 | 15.75 | ||
| SpaMo (Ours) | 49.80 | 37.32 | 29.50 | 24.32 | 46.57 | 48.90 | 36.90 | 26.78 | 20.55 |
| 设置 | 方法 | 模态 | 视觉特征 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | ROUGE | BLEURT |
|---|---|---|---|---|---|---|---|---|---|
| 弱无注释 | GloFE-VN (Lin et al., 2023) | 地标 | 14.94 | 7.27 | 3.93 | 2.24 | 12.61 | 31.65 | |
| 弱无注释 | OpenSLT (Tarres et al., 2023) | RGB | 34.01 | 19.30 | 12.18 | 8.03 | |||
| 无注释 | YT-ASL-SLT (Uthus et al., 2024) | 地标 | 14.96 | 5.11 | 2.26 | 1.22 | 29.98 | ||
| 无注释 | SSVP-SLT (Rust et al., 2024)↑ | RGB | 30.20 | 16.70 | 10.50 | 7.00 | 25.70 | 39.30 | |
| 无注释 | FLa-LLM (Chen et al., 2024) | RGB | 29.81 | 18.99 | 13.27 | 9.66 | 27.81 | ||
| 无注释 | SpaMo (Ours) | RGB | 33.41 | 20.28 | 13.96 | 10.11 | 30.56 | 42.23 |
Table 2: Performance comparison of translation results on the How2Sign dataset. YT-ASL-SLT and SSVP-SLT (marked with †) are reported without dataset scaling to ensure a fair comparison.
表 2: How2Sign数据集上翻译结果的性能对比。为确保公平比较,YT-ASL-SLT和SSVP-SLT (标记为†) 未进行数据集缩放处理。
8,257 samples and a vocabulary of 2,887 German words. CSL-Daily is a Chinese Sign Language dataset with 20,654 samples and a 2,343 Chinese characters. How2Sign focuses on American Sign Language and includes 35,191 samples with a vocabulary of 16K English words. Detailed dataset statistics are provided in Appendix B.
8,257个样本和2,887个德语单词的词汇表。CSL-Daily是一个中文手语数据集,包含20,654个样本和2,343个汉字。How2Sign专注于美国手语,包含35,191个样本和16K英语单词的词汇表。详细数据集统计信息见附录B。
Evaluation Metrics. We report BLEU via SacreBLEU (Papineni et al., 2002; Post, 2018)2 and ROUGE-L (Lin and Och, 2004). BLEU-n assesses translation precision by evaluating n-grams. ROUGE-L measures text similarity by calculating the F1 score based on the longest common subsequences between predicted and reference texts. We also report BLEURT (Sellam et al., 2020) from the BLEURT-20 checkpoint 3, which has been shown to correlate well with human judgments.
评估指标。我们通过 SacreBLEU (Papineni et al., 2002; Post, 2018) 报告 BLEU 值以及 ROUGE-L (Lin and Och, 2004)。BLEU-n 通过评估 n-gram 来衡量翻译精确度。ROUGE-L 通过计算预测文本与参考文本间最长公共子序列的 F1 分数来评估文本相似性。我们还报告了基于 BLEURT-20 检查点的 BLEURT (Sellam et al., 2020),该指标已被证明与人工判断具有良好相关性。
A Taxonomy of SLT. In Section 2, we explored gloss-free methods, including those that incorporate gloss-supervised visual encoders. Although these approaches have traditionally been categorized as gloss-free, we argue that they should more accurately be described as weakly gloss-free due to their dependence on gloss-annotated data. This classification is detailed in Table 1. Specifically, methods such as TSPNet (Li et al., 2020b), GASLT (Yin et al., 2023), ConSLT (Fu et al., 2023),
手语翻译分类体系。在第2节中,我们探讨了无注释词方法,包括那些采用注释词监督视觉编码器的方案。虽然这些方法传统上被归类为无注释词技术,但我们认为由于其对注释词标注数据的依赖,更准确的说法应是弱无注释词方法。该分类详见表1。具体而言,TSPNet (Li et al., 2020b)、GASLT (Yin et al., 2023)、ConSLT (Fu et al., 2023)等方法...
GloFE-VN (Lin et al., 2023), and OpenSLT (Tarrés et al., 2023) rely on sign features extracted by visual encoders trained on continuous or isolated sign language recognition (SLR) datasets.
GloFE-VN (Lin等人, 2023) 和 OpenSLT (Tarrés等人, 2023) 依赖于通过视觉编码器提取的手语特征, 这些编码器是在连续或孤立手语识别 (SLR) 数据集上训练的。
4.3 Comparison with State-of-the-Art
4.3 与最先进技术的对比
Results on PHOENIX14T and CSL-Daily. We first compared our method with both gloss-based and gloss-free methods on PHOENIX14T. As shown in Table 1, most previous methods rely on the domain-specific fine-tuning of their visual encoders. By contrast, our method demonstrates consistent improvements across all reported metrics on PHOENIX14T without such fine-tuning. The only exception is ROUGE, where we achieved the second-best result. Specifically, the improvement on BLEU-4 is by a margin of 0.92, representing a $3.93%$ increase over SignLLM (Gong et al., 2024). On CSL-Daily, which covers a broader range of topics than PHOENIX14T, the performance gains are even more pronounced. Our method achieved a margin increase of 4.8 in BLEU-4, reflecting a $30.41%$ improvement over SignLLM.
PHOENIX14T 和 CSL-Daily 上的结果。我们首先在 PHOENIX14T 上将我们的方法与基于手语注释 (gloss-based) 和无手语注释 (gloss-free) 的方法进行了比较。如表 1 所示,大多数先前的方法依赖于其视觉编码器的领域特定微调。相比之下,我们的方法在 PHOENIX14T 上所有报告的指标上都表现出一致的改进,而无需进行此类微调。唯一的例外是 ROUGE,我们取得了第二好的结果。具体来说,BLEU-4 的改进幅度为 0.92,比 SignLLM (Gong et al., 2024) 提高了 $3.93%$。在涵盖比 PHOENIX14T 更广泛主题的 CSL-Daily 上,性能提升更为明显。我们的方法在 BLEU-4 上实现了 4.8 的增幅,比 SignLLM 提高了 $30.41%$。
Results on How2Sign. Next, we evaluated our method on How2Sign, which poses greater challenges than PHOENIX14T due to its broader opendomain nature, longer sign videos, and larger vocabulary. As shown in Table 2, our method outperformed previous methods across all reported metrics. Specifically, we achieved a 0.45 margin in BLEU-4 which represents a $4.66%$ improvement over Fla-LLM (Chen et al., 2024). We see a performance gain in BLEURT, reaching 2.93, which is $7.46%$ higher than SSVP-SLT (Rust et al., 2024) under the non-scaled dataset setting.
How2Sign 上的结果。接下来,我们在 How2Sign 上评估了我们的方法,由于其更广泛的开放领域特性、更长的符号视频和更大的词汇量,该数据集比 PHOENIX14T 带来了更大的挑战。如表 2 所示,我们的方法在所有报告的指标上都优于之前的方法。具体而言,我们在 BLEU-4 上取得了 0.45 的领先优势,比 Fla-LLM (Chen et al., 2024) 提高了 $4.66%$。在 BLEURT 上我们实现了 2.93 的性能提升,比非缩放数据集设置下的 SSVP-SLT (Rust et al., 2024) 高出 $7.46%$。
Table 3: Ablation study of the main component.
表 3: 主要组件的消融研究
| SE | ME | VT-Align | B1 | B2 | B3 | RG | |
|---|---|---|---|---|---|---|---|
| √ | 46.44 | 33.79 | 26.07 | 21.11 | 42.15 | ||
| √ | 29.71 | 16.23 | 10.99 | 8.36 | 22.44 | ||
| √ | √ | 47.59 | 35.05 | 27.34 | 22.26 | 43.92 | |
| √ | √ | 48.12 | 35.19 | 27.42 | 22.49 | 44.19 | |
| 49.80 | 37.32 | 29.50 | 24.32 | 46.57 |
Table 4: Ablation study of the impact of LLM.
表 4: 大语言模型影响的消融研究
| Models | #TrainableParams | #TotalParams | B4 |
|---|---|---|---|
| w/oLLM | 60.5M | 60.5M | 6.35 |
| mBART-L (Liu et al., 2020) | 680M | 680M | 10.94 |
| mT0-XL (Muennighoff et al., 2022) | 23.5M | 3.5B | 24.23 |
| Llama-2 (Touvron et al., 2023) | 32.4M | 7B | 13.86 |
| Flan-T5-XL (Chung et al., 2024) | 22.7M | 3B | 24.32 |
Kernel Density Estimation. To assess the quality of sign representations, following Ye et al. (2023), we employed the Kernel Density Estimation (KDE) to estimate the probability density func- tions of embeddings from GFSLT-VLP and our method on PHOENIX14T. Note that we reproduced GFSLT-VLP using the official code4. As shown in Table 5, our method produced more compact and confident representations than GFSLTVLP. More details on the KDE process are provided in Appendix A.4.
核密度估计 (Kernel Density Estimation)。为了评估手语表征的质量,我们遵循 Ye 等人 (2023) 的方法,采用核密度估计 (KDE) 来估算 PHOENIX14T 数据集中 GFSLT-VLP 与我们方法的嵌入概率密度函数。需要说明的是,我们使用官方代码4复现了 GFSLT-VLP。如表 5 所示,我们的方法比 GFSLT-VLP 产生了更紧凑且置信度更高的表征。关于 KDE 过程的更多细节详见附录 A.4。
4.4 Ablation Study
4.4 消融实验
To further evaluate our method, we conducted extensive ablation experiments on PHOENIX14T, the most widely used sign language dataset. Additional results can be found in Appendix C.
为了进一步评估我们的方法,我们在最广泛使用的手语数据集PHOENIX14T上进行了大量消融实验。更多结果详见附录C。
Effect of Main Components. We begin by evaluating the impact of the key components in our framework: SE, ME, and VT-Align. As shown in Table 3, using SE or ME individually results in lower performance, with ME performing the worst in terms of BLEU-4. However, combining SE and ME leads to an overall improvement. Notably, when VT-Align is integrated with SE, the performance rises, nearly matching Sign2GPT (22.52 vs. 22.49). The best results are achieved when all components (SE, ME, and VT-Align) are used together, yielding the highest scores across all metrics. This highlights the importance of each component in enhancing overall performance of SpaMo.
主要组件的影响。我们首先评估框架中关键组件的影响:SE、ME和VT-Align。如表3所示,单独使用SE或ME会导致性能下降,其中ME在BLEU-4指标上表现最差。然而,结合SE和ME会带来整体提升。值得注意的是,当VT-Align与SE结合时,性能上升,几乎与Sign2GPT持平(22.52 vs. 22.49)。当所有组件(SE、ME和VT-Align)一起使用时,取得了最佳结果,在所有指标上都获得了最高分。这凸显了每个组件对提升SpaMo整体性能的重要性。
Table 5: Comparison of KDE entropy values across different embeddings. Lower entropy values indicate more confident and distinct representations.
表 5: 不同嵌入方法下的KDE熵值对比。熵值越低表示表征越自信且独特。
| 方法 | KDEs熵值 √ |
|---|---|
| GFSLT-VLP (Zhou et al.,2023) | 0.32 |
| SPaMo (Ours) | 0.12 |
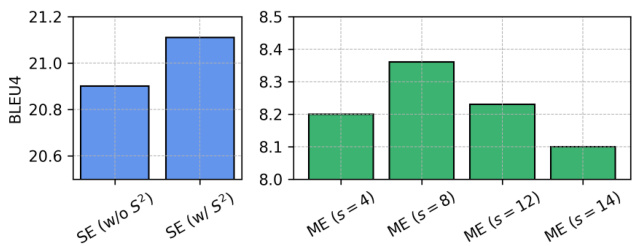
Figure 4: Ablation study for SE and ME. $S^{2}$ represents Scaling on Scales, and $s$ denotes stride size. Note that the presented results do not include VT-Align.
图 4: SE和ME的消融研究。$S^{2}$表示尺度缩放(Scaling on Scales),$s$表示步长大小。请注意,展示的结果不包含VT-Align。
Effect of LLM. Next, we explored the impact of different types of LLMs by replacing our model, as shown in Table 4. We compared five models, each with a different number of parameters: our method without pre-trained weights, mBART-L, mT0-XL, Flan-T5-XL, and Llama-2. Among these, Flan-T5- XL achieves the best performance, though it nearly ties with $\mathrm{mT0-XL}$ . Interestingly, despite its larger parameter count, Llama-2, which is also employed in SignLLM, does not outperform the others. This finding aligns with the observations of Zhang et al., suggesting that scaling up LMs does not always lead to better performance.
大语言模型的影响。接下来,我们通过替换模型探究了不同类型大语言模型的影响,如表 4 所示。我们比较了五个参数量不同的模型:未使用预训练权重的本方法、mBART-L、mT0-XL、Flan-T5-XL 和 Llama-2。其中 Flan-T5-XL 取得了最佳性能,但其表现与 $\mathrm{mT0-XL}$ 几乎持平。值得注意的是,尽管参数量更大,SignLLM 采用的 Llama-2 并未优于其他模型。这一发现与 Zhang 等人的研究 [20] 一致,表明扩大语言模型规模并不总能带来性能提升。
Effect of $S^{2}$ and Neighboring Gap. Finally, we evaluated the effect of $S^{2}$ and the gap between neighboring clips on SE and ME, respectively. As shown in Figure 4, $S^{2}$ substantially improves translation performance, highlighting its effectiveness in helping SE capture more spatial details. Additionally, our analysis reveals that a stride size of 8 between neighboring clips yields the best results, suggesting that this stride size optimally aids ME in extracting the motion dynamics.
$S^{2}$ 与相邻间隔的影响。最后,我们分别评估了 $S^{2}$ 和相邻片段间隔对SE(空间编码器)和ME(运动编码器)的影响。如图4所示,$S^{2}$ 显著提升了翻译性能,凸显了其在帮助SE捕获更多空间细节方面的有效性。此外,分析表明相邻片段间隔为8时效果最佳,说明该间隔能最优辅助ME提取运动动态。
4.5 Qualitative Analysis
4.5 定性分析
Translation Results. Table 6 presents two example translations on PHOENIX14T, comparing our method with GFSLT-VLP, the only other publicly available baseline. In the first example (top), our method provides an accurate translation, whereas GFSLT-VLP fails to capture the correct semantic meaning. In the second example (bottom), our method again produces a precise translation, while GFSLT-VLP introduces errors, resulting in incorrect information. These examples demonstrate the superior accuracy of our method in generating reliable translations. More translation examples are shown in Appendix C.4.
表6展示了在PHOENIX14T数据集上的两个翻译示例,将我们的方法与目前唯一公开的基线方法GFSLT-VLP进行对比。第一个示例(上方)中,我们的方法提供了准确翻译,而GFSLT-VLP未能捕捉正确语义。第二个示例(下方)中,我们的方法再次生成精确译文,GFSLT-VLP则出现错误导致信息失真。这些案例证明我们的方法在生成可靠翻译时具有更优的准确性。更多翻译示例见附录C.4。
Table 6: Translation results on the test set compared to GFSLT-VLP on PHOENIX14T. Correctly translated 1-grams are highlighted in blue, while incorrect translations are marked in red.
表 6: 在PHOENIX14T测试集上与GFSLT-VLP的翻译结果对比。正确翻译的1-gram用蓝色高亮显示,错误翻译用红色标记。
| Ref: | dieneuewochebeginntnochwechselhaftundetwaskihler. (thenewweekbeginsstillchangeableandsomewhatcooler) ammontagwiederwechselhaftundkihler. |
| GFSLT-VLP: | (onMondayagainchangeableandcooler) die neue wochebeginnt wechselhaft undwiederkihler. |
| Ours: | (thenewweekbeginschangeableandagaincooler) |
| Ref: | otherwise,alotofsunshine. im ibrigen land viel sonne. |
| GFSLT-VLP: | intherestofthecountry,alotofsun. |
| Ours: | sonstvielsonnenschein otherwise,alotofsunshine. |
Table 7: Comparison between visual tokens (Vis. Token) and their corresponding glosses. Words highlighted in green are exact matches, those in pink are semantic matches, and words in blue are absent in the gloss but appear in the translation.
表 7: 视觉token (Vis. Token) 与其对应注释的比较。绿色高亮的单词是完全匹配,粉色是语义匹配,蓝色的单词在注释中未出现但出现在翻译中。
| Vis.Token: | NORDWEST SONST | FREUNDLICH STURDY (NORTHWESTOTHERWISEFRIENDLYSTURDY) |
| Gloss: | NORDWEST (NORTHWESTFRIENDLY) richtungnordenundwestenist esrechtfreundlich. | FREUNDLICH |
| Translation: | (Towardsthenorthandwestitisquitepleasant.) | |
| Vis. Token: | BLEIBT WIND WINTER (REMAINSWINDWINTER) | |
| Gloss: | BLEIBEN WIND (REMAINWIND) es bleibt windig. | |
| Translation: | (it remainswindy.) | |
| Vis.Token: | LIEBE GUTEN (DEARGOODEVENINGBEAUTIFUL) | ABEND SCHONEN |
| Gloss: | GUT ABEND (GOODEVENINGGREETINGS) | BEGRUESSEN |
| Translation: | guten abend liebe zuschauer. (goodeveningdearviewers.) | |
Visual Token Analysis. We performed an additional analysis to explore how the LLM interprets the sign videos. For each visual feature, we identified the word with the shortest distance in the LLM’s embedding space, representing the closest match. Further details can be found in Appendix A.5. Figure 5 shows the t-SNE visualization of each sign feature mapped to the corresponding word. We observed that certain visual features align closely with specific words, which likely represents the semantic concepts that the LLM associates with these features. In other words, these words represent the LLM’s interpretation or labeling of the visual content. We refer to these mapped words as “visual tokens”. We further compared these visual tokens with the ground-truth glosses as shown in Table 7. To ensure a clearer and more accurate semantic comparison, repetitive words were removed from the visual tokens. Surprisingly, the LLM’s interpretation of the sign videos is similar to the glosses, though not perfectly aligned. This suggests that the LLM has learned to link particular video patterns with specific textual concepts, explaining why those words cluster near the visual features in the embedding space. Additionally, we found that the visual tokens capture words that are present in the translation but not in the glosses. This finding suggests that visual tokens may provide a more comprehensive representation than current glosses, potentially broadening their scope beyond what has been traditionally documented.
视觉Token分析。我们进行了额外分析以探究大语言模型如何解读手语视频。针对每个视觉特征,我们在模型的嵌入空间中找到距离最近的对应词汇作为最佳匹配(详见附录A.5)。图5展示了各手语特征映射到对应词汇的t-SNE可视化结果。研究发现某些视觉特征与特定词汇高度关联,这些词汇很可能代表了大语言模型对这些特征所关联的语义概念。换言之,这些词汇反映了模型对视觉内容的"解读"或"标注",我们将其定义为"视觉Token"。我们进一步将这些视觉Token与真实注释词汇进行对比(如表7所示),为确保语义对比更清晰准确,已剔除视觉Token中的重复词汇。值得注意的是,大语言模型对手语视频的解读虽未完全匹配但接近人工注释,这表明模型已学会将特定视频模式与文本概念相关联,这解释了为何这些词汇会在嵌入空间中靠近视觉特征聚集。此外,我们发现视觉Token能捕捉到翻译文本中存在但未出现在注释中的词汇,这一发现表明视觉Token可能比现有注释提供更全面的表征,有望突破传统标注的范畴。
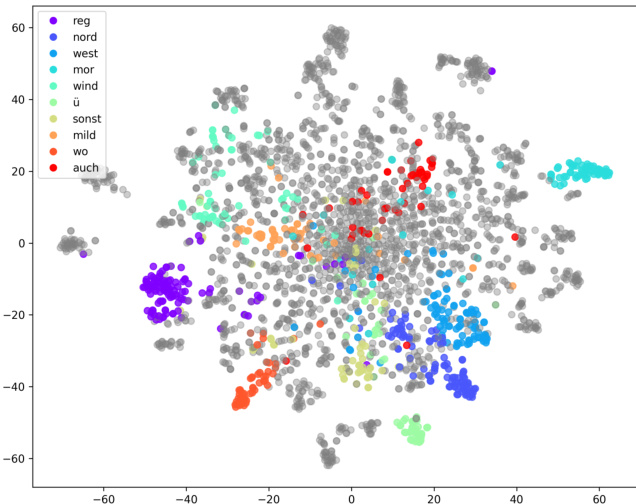
Figure 5: The t-SNE visualization of sign features. Different colors represent features with distinct semantics, while gray points are other categories not listed.
图 5: 手语特征的 t-SNE 可视化。不同颜色代表具有不同语义的特征,灰色点表示未列出的其他类别。
5 Conclusion
5 结论
In this paper, we introduced SpaMo, a novel glossfree SLT framework based on LLMs. Apart from the previous methods that rely on domain-specific fine-tuning of their visual encoders, SpaMo focuses on capturing the spatial configurations and motion dynamics, eliminating the need for resource- intensive fine-tuning. We also proposed VT-Align, a training strategy that effectively aligns and narrows the modality gap between the sign videos and target texts, enabling the transformation of the sign videos into inputs interpret able by the LLM. Our approach achieved state-of-the-art results on three popular datasets. Furthermore, we provided the first comprehensive analysis of how the LLM interprets the sign videos within its embedding space and translates them into corresponding text.
本文介绍了SpaMo,一种基于大语言模型 (LLM) 的新型无注释手语翻译 (SLT) 框架。与以往依赖视觉编码器领域特定微调的方法不同,SpaMo专注于捕捉空间构型和运动动态,从而避免了资源密集型的微调过程。我们还提出了VT-Align训练策略,该策略能有效对齐并缩小手语视频与目标文本之间的模态差异,使手语视频转化为大语言模型可解释的输入。我们的方法在三个主流数据集上取得了最先进的性能。此外,我们首次全面分析了大语言模型如何在其嵌入空间中解析手语视频并将其转化为对应文本。
Limitations
局限性
Recently, scaling datasets (Uthus et al., 2024; Rust et al., 2024) has consistently led to performance improvements, as seen with larger sign language datasets, such as Youtube-ASL (Uthus et al., 2024) and BOBSL (Albanie et al., 2021). While dataset scaling could also enhance our method, in this work, we focus on a constrained setting. Specifically, we use limited sign language datasets to evaluate and compare results, demonstrating the effectiveness of our method in resource-limited scenarios. Future work will involve expanding the dataset size to explore the full potential of our method and to assess its s cal ability and performance across more extensive and diverse datasets.
最近,扩大数据集规模 (Uthus et al., 2024; Rust et al., 2024) 持续带来性能提升,这在更大规模的手语数据集 (如 Youtube-ASL (Uthus et al., 2024) 和 BOBSL (Albanie et al., 2021)) 中已得到验证。虽然扩大数据集也能提升我们的方法性能,但本工作聚焦于资源受限的场景。具体而言,我们使用有限规模的手语数据集进行评估和结果对比,以证明该方法在资源受限场景下的有效性。未来工作将扩展数据集规模,以探索该方法的全部潜力,并评估其在更广泛、更多样化数据集上的可扩展性和性能表现。
In this paper, we highlight that domain-specific fine-tuning of visual encoders is not essential for our method. However, this implies that our method relies on visual encoders pre-trained on general tasks such as action recognition and image captioning. To bridge this gap, we introduce a prealignment process and apply LoRA fine-tuning to the LLM. While this might appear to be a compromise, it significantly reduces the resource requirements compared to fine-tuning both the visual encoders and the LLM. Additionally, as we discussed in the previous paragraph, this limitation can be addressed as more data becomes available, allowing for improved s cal ability and performance over time.
本文指出,领域特定的视觉编码器微调对我们的方法并非必需。但这也意味着我们的方法依赖于在动作识别、图像描述等通用任务上预训练的视觉编码器。为弥补这一差距,我们引入了预对齐(prealignment)流程,并对大语言模型应用了LoRA微调。虽然这看似是一种折中方案,但与同时微调视觉编码器和大语言模型相比,该方法显著降低了资源需求。此外,正如前文所述,随着数据量的增加,这一限制将得到解决,从而持续提升方法的扩展性和性能。
Ethics Statement
伦理声明
Our work focuses on developing a practical framework for SLT with the goal of overcoming communication barriers faced by the Deaf and hardof-hearing communities. Although our approach utilizes off-the-shelf visual encoders and LLMs, there is a possibility that the framework could produce unexpected or biased outputs due to the inherent limitations in the pre-trained models. However, we are optimistic that future advancements in LLMs will help mitigate these issues. We rely on open datasets such as PHOENIX14T (Camgoz et al., 2018), CSL-Daily (Zhou et al., 2021a), and How2Sign (Duarte et al., 2021), which, while containing potentially identifiable information, present minimal concerns regarding personal privacy. Additionally, our method has been validated only on German, Chinese, and American sign languages, limiting its applicability to other sign languages. We call for future research in SLT to expand on a broader range of sign languages, promoting greater equity for the Deaf community.
我们的工作聚焦于开发一套实用的手语翻译(SLT)框架,旨在克服聋哑及听力障碍群体面临的沟通壁垒。虽然该方法采用了现成的视觉编码器和大语言模型(LLM),但由于预训练模型固有的局限性,框架仍可能产生意外或有偏见的输出。我们相信未来大语言模型的发展将有助于缓解这些问题。研究使用了PHOENIX14T (Camgoz et al., 2018)、CSL-Daily (Zhou et al., 2021a)和How2Sign (Duarte et al., 2021)等公开数据集,这些数据虽可能包含可识别信息,但个人隐私风险极低。当前方法仅在德语、汉语和美国手语上得到验证,限制了其对其他手语体系的适用性。我们呼吁未来研究应拓展更多手语类型,以促进聋哑群体的公平权益。
Acknowledgment
致谢
This work was supported by the Institute for Information and communications Technology Promotion (IITP) grant funded by the Korea government (MSIT) (No. 2022-0-00010, Development of Korean sign language translation service technology for the deaf in medical environment).
本研究由韩国政府(MSIT)资助的信息通信技术促进院(IITP)项目支持 (编号2022-0-00010, 医疗环境下聋哑人士韩语手语翻译服务技术开发)。
References
参考文献
tion. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5120–5130.
在IEEE/CVF计算机视觉与模式识别会议论文集第5120–5130页。
Yutong Chen, Ronglai Zuo, Fangyun Wei, Yu Wu, Shu- jie Liu, and Brian Mak. 2022b. Two-stream network for sign language recognition and translation. Advances in Neural Information Processing Systems, 35:17043–17056.
Yutong Chen、Ronglai Zuo、Fangyun Wei、Yu Wu、Shujie Liu 和 Brian Mak。2022b。手语识别与翻译的双流网络。神经信息处理系统进展,35:17043–17056。
Zhigang Chen, Benjia Zhou, Jun Li, Jun Wan, Zhen Lei, Ning Jiang, Quan Lu, and Guoqing Zhao. 2024. Factorized learning assisted with large language model for gloss-free sign language translation. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 7071– 7081. ELRA and ICCL.
Zhigang Chen, Benjia Zhou, Jun Li, Jun Wan, Zhen Lei, Ning Jiang, Quan Lu, and Guoqing Zhao. 2024. 基于大语言模型的无手语词典因式分解学习翻译方法. 载于《2024年计算语言学、语言资源与评估联合国际会议论文集》(LREC-COLING 2024), 第7071–7081页. ELRA与ICCL出版.
Yiting Cheng, Fangyun Wei, Jianmin Bao, Dong Chen, and Wenqiang Zhang. 2023. Cico: Domain-aware sign language retrieval via cross-lingual contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19016–19026.
Yiting Cheng、Fangyun Wei、Jianmin Bao、Dong Chen 和 Wenqiang Zhang。2023。Cico: 基于跨语言对比学习的领域感知手语检索。见《IEEE/CVF计算机视觉与模式识别会议论文集》,第19016–19026页。
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. 2024. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476.
Zesen Cheng、Sicong Leng、Hang Zhang、Yifei Xin、Xin Li、Guanzheng Chen、Yongxin Zhu、Wenqi Zhang、Ziyang Luo、Deli Zhao 等。2024。VideoLlama 2:视频大语言模型中时空建模与音频理解的进展。arXiv预印本 arXiv:2406.07476。
Pengzhi Gao, Zhongjun He, Hua Wu, and Haifeng Wang. 2024. Towards boosting many-to-many multilingual machine translation with large language models. arXiv preprint arXiv:2401.05861.
彭志高、何忠俊、吴华、王海峰。2024。利用大语言模型提升多对多多语言机器翻译性能。arXiv预印本 arXiv:2401.05861。
Jia Gong, Lin Geng Foo, Yixuan He, Hossein Rahmani, and Jun Liu. 2024. Llms are good sign language translators. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18362–18372.
贾功、林耿富、何逸轩、Hossein Rahmani和刘军。2024。大语言模型是优秀的手语翻译者。发表于IEEE/CVF计算机视觉与模式识别会议论文集,页码18362–18372。
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
Edward J Hu、Yelong Shen、Phillip Wallis、Zeyuan Allen-Zhu、Yuanzhi Li、Shean Wang、Lu Wang 和 Weizhu Chen。2021。LoRA:大语言模型的低秩自适应。arXiv预印本 arXiv:2106.09685。
Lianyu Hu, Liqing Gao, Zekang Liu, and Wei Feng. 2023. Continuous sign language recognition with correlation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2529–2539.
胡连宇, 高丽清, 刘泽康, 冯伟. 2023. 基于相关性网络的连续手语识别. 见: IEEE/CVF计算机视觉与模式识别会议论文集, 第2529–2539页.
Xiaohu Huang, Hao Zhou, Kun Yao, and Kai Han. 2024. FROSTER: frozen CLIP is A strong teacher for openvocabulary action recognition. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net.
Xiaohu Huang、Hao Zhou、Kun Yao和Kai Han。2024。FROSTER:冻结CLIP模型是开放词汇动作识别的强力教师。收录于第十二届国际学习表征会议(ICLR 2024),2024年5月7-11日,奥地利维也纳。OpenReview.net。
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. 2023. Vicuna: An open-source chatbot impressing gpt-4 with $90%*$ chatgpt quality. 2(3):6.
Wei-Lin Chiang、Zhuohan Li、Zi Lin、Ying Sheng、Zhanghao Wu、Hao Zhang、Lianmin Zheng、Siyuan Zhuang、Yonghao Zhuang、Joseph E Gonzalez等。2023。Vicuna: 一款以90% ChatGPT质量惊艳GPT-4的开源聊天机器人。2(3):6。
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2024. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1–53.
Hyung Won Chung、Le Hou、Shayne Longpre、Barret Zoph、Yi Tay、William Fedus、Yunxuan Li、Xuezhi Wang、Mostafa Dehghani、Siddhartha Brahma 等. 2024. 规模化指令微调语言模型. 《机器学习研究期刊》, 25(70):1–53.
Amanda Duarte, Shruti Palaskar, Lucas Ventura, Deepti Ghadiyaram, Kenneth DeHaan, Florian Metze, Jordi Torres, and Xavier Giro-i Nieto. 2021. How2sign: a large-scale multimodal dataset for continuous american sign language. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2735–2744.
Amanda Duarte, Shruti Palaskar, Lucas Ventura, Deepti Ghadiyaram, Kenneth DeHaan, Florian Metze, Jordi Torres, and Xavier Giro-i Nieto. 2021. How2sign: 面向连续美式手语的大规模多模态数据集. 见: IEEE/CVF计算机视觉与模式识别会议论文集, 第2735–2744页.
Karen Emmorey and Shannon Casey. 1995. A comparison of spatial language in english & american sign language. Sign Language Studies, 88(1):255–288.
Karen Emmorey 和 Shannon Casey. 1995. 英语与美国手语空间语言的比较研究. Sign Language Studies, 88(1):255–288.
Yao Feng, Jing Lin, Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, and Michael J Black. 2024. Chatpose: Chatting about 3d human pose. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2093–2103.
Yao Feng、Jing Lin、Sai Kumar Dwivedi、Yu Sun、Priyanka Patel和Michael J Black。2024。Chatpose:关于3D人体姿态的对话。载于IEEE/CVF计算机视觉与模式识别会议论文集,第2093–2103页。
Biao Fu, Peigen Ye, Liang Zhang, Pei Yu, Cong Hu, Xiaodong Shi, and Yidong Chen. 2023. A token-level contrastive framework for sign language translation. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE.
Biao Fu, Peigen Ye, Liang Zhang, Pei Yu, Cong Hu, Xiaodong Shi, and Yidong Chen. 2023. 基于Token级别对比框架的手语翻译研究. In ICASSP 2023-2023 IEEE国际声学、语音与信号处理会议 (ICASSP), pages 1–5. IEEE.
Eui Jun Hwang, Sukmin Cho, Huije Lee, Youngwoo Yoon, and Jong C Park. 2024. Universal gloss-level representation for gloss-free sign language translation and production. arXiv preprint arXiv:2407.02854.
Eui Jun Hwang、Sukmin Cho、Huije Lee、Youngwoo Yoon 和 Jong C Park。2024。用于无注释手语翻译与生成的通用注释级表征。arXiv预印本 arXiv:2407.02854。
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. 2021. Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pages 4904–4916. PMLR.
Chao Jia、Yinfei Yang、Ye Xia、Yi-Ting Chen、Zarana Parekh、Hieu Pham、Quoc Le、Yun-Hsuan Sung、Zhen Li和Tom Duerig。2021。利用噪声文本监督扩展视觉与视觉-语言表征学习。见《国际机器学习会议》,第4904-4916页。PMLR。
Liqiang Jing, Xuemeng Song, Xinxing Zu, Na Zheng, Zhongzhou Zhao, and Liqiang Nie. 2024. Vk-g2t: Vision and context knowledge enhanced gloss2text. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7860–7864. IEEE.
Liqiang Jing, Xuemeng Song, Xinxing Zu, Na Zheng, Zhongzhou Zhao, and Liqiang Nie. 2024. Vk-g2t: 视觉与上下文知识增强的gloss2text. 收录于ICASSP 2024-2024 IEEE声学、语音与信号处理国际会议(ICASSP), 页码7860–7864. IEEE.
Tianjie Ju, Yubin Zheng, Hanyi Wang, Haodong Zhao, and Gongshen Liu. 2023. Is continuous prompt a combination of discrete prompts? towards a novel view for interpreting continuous prompts. In Findings of the Association for Computational Linguistics: ACL 2023, pages 7804–7819.
Tianjie Ju、Yubin Zheng、Hanyi Wang、Haodong Zhao和Gongshen Liu。2023。连续提示是离散提示的组合吗?一种解释连续提示的新视角。载于《计算语言学协会发现:ACL 2023》,第7804–7819页。
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeff Wu, and Dario Amodei. 2020. Scaling laws for neural language models. ArXiv, abs/2001.08361.
Jared Kaplan、Sam McCandlish、Tom Henighan、Tom B. Brown、Benjamin Chess、Rewon Child、Scott Gray、Alec Radford、Jeff Wu 和 Dario Amodei。2020。神经网络语言模型的缩放定律。ArXiv,abs/2001.08361。
Dongxu Li, Cristian Rodriguez, Xin Yu, and Hongdong Li. 2020a. Word-level deep sign language recognition from video: A new large-scale dataset and meth- ods comparison. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1459–1469.
Dongxu Li、Cristian Rodriguez、Xin Yu和Hongdong Li。2020a。基于视频的单词级深度手语识别:新的大规模数据集与方法比较。载于《IEEE/CVF冬季计算机视觉应用会议论文集》,第1459-1469页。
Dongxu Li, Chenchen Xu, Xin Yu, Kaihao Zhang, Benjamin Swift, Hanna Suominen, and Hongdong Li. 2020b. Tspnet: Hierarchical feature learning via temporal semantic pyramid for sign language translation. Advances in Neural Information Processing Systems, 33:12034–12045.
Dongxu Li、Chenchen Xu、Xin Yu、Kaihao Zhang、Benjamin Swift、Hanna Suominen 和 Hongdong Li。2020b。TSPNet: 基于时序语义金字塔的手语翻译分层特征学习方法。《神经信息处理系统进展》33:12034–12045。
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Boots trapping language-image pretraining with frozen image encoders and large language models. In International conference on machine learning, pages 19730–19742. PMLR.
Junnan Li、Dongxu Li、Silvio Savarese 和 Steven Hoi。2023。BLIP-2:基于冻结图像编码器与大语言模型的语言-图像预训练引导方法。见国际机器学习会议,第19730–19742页。PMLR。
Chin-Yew Lin and Franz Josef Och. 2004. Automatic evaluation of machine translation quality using longest common sub sequence and skip-bigram statistics. In Proceedings of the 42nd annual meeting of the association for computational linguistics (ACL04), pages 605–612.
Chin-Yew Lin和Franz Josef Och。2004。基于最长公共子序列和跳跃二元组统计的机器翻译质量自动评估。在第42届计算语言学协会年会论文集(ACL04)中,第605–612页。
Kezhou Lin, Xiaohan Wang, Linchao Zhu, Ke Sun, Bang Zhang, and Yi Yang. 2023. Gloss-free endto-end sign language translation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics.
Kezhou Lin、Xiaohan Wang、Linchao Zhu、Ke Sun、Bang Zhang 和 Yi Yang。2023。无注释端到端手语翻译。见《第61届计算语言学协会年会论文集》。
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024a. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 26296–26306.
Haotian Liu、Chunyuan Li、Yuheng Li和Yong Jae Lee。2024a。基于视觉指令调优的改进基线方法。载于IEEE/CVF计算机视觉与模式识别会议论文集,第26296–26306页。
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2024b. Visual instruction tuning. Advances in neural information processing systems, 36.
Haotian Liu、Chunyuan Li、Qingyang Wu 和 Yong Jae Lee。2024b。视觉指令调优。神经信息处理系统进展,36。
Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghaz vi nine j ad, Mike Lewis, and Luke Z ett le moyer. 2020. Multilingual denoising pretraining for neural machine translation. Trans. Assoc. Comput. Linguistics, 8:726–742.
Yinhan Liu、Jiatao Gu、Naman Goyal、Xian Li、Sergey Edunov、Marjan Ghazvininejad、Mike Lewis 和 Luke Zettlemoyer。2020。神经机器翻译的多语言去噪预训练。Trans. Assoc. Comput. Linguistics,8:726–742。
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regular iz ation. arXiv preprint arXiv:1711.05101.
Ilya Loshchilov 和 Frank Hutter. 2017. 解耦权重衰减正则化 (Decoupled weight decay regularization). arXiv preprint arXiv:1711.05101.
Niklas Mu en nigh off, Thomas Wang, Lintang Sutawika, Adam Roberts, Stella Biderman, Teven Le Scao, M Saiful Bari, Sheng Shen, Zheng-Xin Yong, Hailey Schoelkopf, et al. 2022. Cross lingual generalization through multitask finetuning. In Annual Meeting of the Association for Computational Linguistics, pages 15991–16111.
Niklas Muennighoff、Thomas Wang、Lintang Sutawika、Adam Roberts、Stella Biderman、Teven Le Scao、M Saiful Bari、Sheng Shen、Zheng-Xin Yong、Hailey Schoelkopf等。2022。通过多任务微调实现跨语言泛化。载于《计算语言学协会年会》,第15991–16111页。
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. 2023. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193.
Maxime Oquab、Timothée Darcet、Théo Moutakanni、Huy Vo、Marc Szafraniec、Vasil Khalidov、Pierre Fernandez、Daniel Haziza、Francisco Massa、Alaaeldin El-Nouby 等. 2023. Dinov2: 无监督学习鲁棒视觉特征. arXiv 预印本 arXiv:2304.07193.
Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
Kishore Papineni、Salim Roukos、Todd Ward和WeiJing Zhu。2002。BLEU:一种机器翻译自动评估方法。载于《第40届计算语言学协会年会论文集》,第311-318页。
Matt Post. 2018. A call for clarity in reporting bleu scores. In Proceedings of the Third Conference on Machine Translation: Research Papers.
Matt Post. 2018. 关于BLEU分数报告清晰化的倡议。见《第三届机器翻译研究论文会议论文集》。
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR.
Alec Radford、Jong Wook Kim、Chris Hallacy、Aditya Ramesh、Gabriel Goh、Sandhini Agarwal、Girish Sastry、Amanda Askell、Pamela Mishkin、Jack Clark 等. 2021. 从自然语言监督中学习可迁移的视觉模型. 见: 国际机器学习会议, 第8748–8763页. PMLR.
Nils Reimers and Iryna Gurevych. 2019. SentenceBERT: Sentence embeddings using Siamese BERTnetworks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, Hong Kong, China. Association for Computational Linguistics.
Nils Reimers 和 Iryna Gurevych. 2019. SentenceBERT: 基于孪生 BERT 网络的句子嵌入方法. 见《2019年自然语言处理经验方法会议暨第九届国际自然语言处理联合会议论文集》(EMNLP-IJCNLP), 第3982–3992页, 中国香港. 计算语言学协会.
Phillip Rust, Bowen Shi, Skyler Wang, Necati Cihan Camgöz, and Jean Maillard. 2024. Towards privacyaware sign language translation at scale. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).
Phillip Rust、Bowen Shi、Skyler Wang、Necati Cihan Camgöz 和 Jean Maillard。2024。迈向大规模隐私保护手语翻译。载于《第62届计算语言学协会年会论文集(第一卷:长论文)》。
Thibault Sellam, Dipanjan Das, and Ankur P Parikh. 2020. Bleurt: Learning robust metrics for text generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7881–7892.
Thibault Sellam、Dipanjan Das 和 Ankur P Parikh. 2020. Bleurt: 学习文本生成的鲁棒性指标. 见《第58届计算语言学协会年会论文集》, 页7881–7892.
Baifeng Shi, Ziyang Wu, Maolin Mao, Xin Wang, and Trevor Darrell. 2024. When do we not need larger vision models? arXiv preprint arXiv:2403.13043.
Baifeng Shi、Ziyang Wu、Maolin Mao、Xin Wang 和 Trevor Darrell。2024。何时我们不需要更大的视觉模型?arXiv预印本 arXiv:2403.13043。
Bowen Shi, Diane Brentari, Greg S hak hn aro vich, and Karen Livescu. 2022. Open-domain sign language translation learned from online video. In Proceedings of the Conference on Empirical Methods in Natural Language Processing.
Bowen Shi、Diane Brentari、Greg Shakhnarovich 和 Karen Livescu。2022。基于在线视频学习的开放领域手语翻译。载于《自然语言处理实证方法会议论文集》。
Zixuan Tang, Youjun Zhao, Yuhang Wen, and Mengyuan Liu. 2024. A survey on backbones for deep video action recognition. arXiv preprint arXiv:2405.05584.
Zixuan Tang, Youjun Zhao, Yuhang Wen, and Mengyuan Liu. 2024. 深度视频动作识别骨干网络综述. arXiv preprint arXiv:2405.05584.
Laia Tarrés, Gerard I Gállego, Amanda Duarte, Jordi Torres, and Xavier Giró-i Nieto. 2023. Sign language translation from instructional videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 5625–5635.
Laia Tarrés, Gerard I Gállego, Amanda Duarte, Jordi Torres, and Xavier Giró-i Nieto. 2023. 教学视频中的手语翻译. 收录于IEEE/CVF计算机视觉与模式识别会议(CVPR)研讨会论文集, 第5625–5635页.
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. 2022. Videomae: Masked auto encoders are data-efficient learners for self-supervised video pretraining. Advances in neural information processing systems, 35:10078–10093.
张彤、宋一兵、王珏和王立民。2022。VideoMAE:掩码自编码器是自监督视频预训练的数据高效学习器。神经信息处理系统进展,35:10078–10093。
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
Hugo Touvron、Louis Martin、Kevin Stone、Peter Albert、Amjad Almahairi、Yasmine Babaei、Nikolay Bashlykov、Soumya Batra、Prajjwal Bhargava、Shruti Bhosale 等. 2023. Llama 2: 开放基础与微调对话模型. arXiv 预印本 arXiv:2307.09288.
Biao Zhang, Garrett Tanzer, and Orhan Firat. 2024a. Scaling sign language translation. Advances in neural information processing systems.
Biao Zhang、Garrett Tanzer 和 Orhan Firat. 2024a. 手语翻译规模化. 神经信息处理系统进展.
Appendix
附录
In this Appendix, we first provide additional implementation details in Section A. Then, Section B provides more details about the sign language dataset used in this study, including its statistics. In Section C, we present further experimental results. Fi- nally, in Section D, we discuss the feasibility of existing Vision-Language Models (VLMs) in the SLT domain.
在本附录中,我们首先在A节提供额外的实现细节。接着,B节详细介绍了本研究中使用的 sign language (手语) 数据集及其统计信息。C节展示了更多实验结果。最后,D节探讨了现有视觉-语言模型 (Vision-Language Models, VLMs) 在手语翻译 (SLT) 领域的可行性。
A More Implementation Details
更多实现细节
A.1 Components of SpaMo.
A.1 SpaMo的组成部分
In the SA module, we utilize two distinct linear projection layers tailored for the output feature of ME and SE. For short-term modeling, we employ a 1D CNN configured with a specific sequence of layers: ${K5,P2,K5,P2}$ , where $K_{\sigma}$ represents a kernel size of $\sigma$ , and $P_{\sigma}$ indicates a pooling layer with a kernel size of $\sigma$ (Hu et al., 2023). To integrate features into the LLM’s embedding space, we leverage an MLP cross-modal connector (Liu et al., 2024a), projecting the features into a 2048- dimensional space.
在SA模块中,我们为ME和SE的输出特征分别定制了两个不同的线性投影层。针对短期建模,我们采用了由特定层序列 ${K5,P2,K5,P2}$ 配置的1D CNN,其中 $K_{\sigma}$ 表示核尺寸为 $\sigma$ 的卷积层, $P_{\sigma}$ 代表核尺寸为 $\sigma$ 的池化层 (Hu et al., 2023)。为了将特征整合到大语言模型的嵌入空间,我们利用MLP跨模态连接器 (Liu et al., 2024a) 将特征投影至2048维空间。
A.2 Prompt Template.
A.2 提示模板
To focus the LLM on the SLT task, we employ a specific prompting strategy. Our prompt includes a clear instructive prompt: “Translate the given sentence into German.” Following this, we incorporate multilingual translations via a translation engine such as Google Translate5, which are sampled from the training set. These translations are included to facilitate In-Context Learning (ICL) (Brown et al., 2020). The prompt is structured as follows: “Translate the given sentence into German. $\mathrm{[SRC]=}$ [TRG].” Here, the source input (e.g., a sentence in French) serves as the foreign language example, and the corresponding response is the translation into the target language (e.g., German, as used in PHOENIX14T). An example of this prompt struc- ture is provided in Table 8. To ensure that the LLM does not directly access the target translations during training, we shuffle the translation samples so that they do not match the target translation. At test time, we select a translation pair from the training set to use as a reference.
为了让大语言模型专注于手语翻译(SLT)任务,我们采用了特定的提示策略。提示内容包含明确的指令:"将给定句子翻译成德语"。随后,我们通过谷歌翻译等翻译引擎引入多语言译文(这些译文均采样自训练集),以促进上下文学习(ICL) [20]。提示模板结构如下:"将给定句子翻译成德语。$\mathrm{[SRC]=}$ [TRG]"。其中源语言输入(如法语例句)作为外语示例,对应响应则是目标语言(如PHOENIX14T数据集使用的德语)的译文。表8展示了该提示结构的应用示例。为确保训练时大语言模型不会直接接触目标译文,我们对翻译样本进行随机打乱处理以避免与目标译文匹配。测试阶段则从训练集中选取翻译对作为参考样本。
A.3 Training.
A.3 训练
For training, we use the AdamW optimizer (Loshchilov and Hutter, 2017), with $\beta_{1}~=0.9$ , $\beta_{2}=~0.98$ , and a weight decay of 0.01. The learning rate schedule includes a cosine decay with a peak learning rate of 1e-4 and a linear warmup of over 10K steps, with a minimum learning rate of 5e-5. We train our model for 40 epochs, using a single NVIDIA A100 GPU, completing the entire process within 24 hours.
训练时,我们采用 AdamW 优化器 (Loshchilov and Hutter, 2017),设置 $\beta_{1}~=0.9$、$\beta_{2}=~0.98$,权重衰减为 0.01。学习率调度采用余弦衰减策略,峰值学习率为 1e-4,配合 10K 步的线性预热,最低学习率为 5e-5。模型在单块 NVIDIA A100 GPU 上训练 40 个周期,全程耗时不超过 24 小时。
Table 8: An example of prompt used in this paper.
| SignVideoInput: | [ExtractedSignFeature] |
| 一—一一一— | Instruction:Translate the given sentence into German. Soil frost is possible there and in the southern lowmountainranges.=dort sowiein densidlichen |
| InContextExamplars | La helada del suelo es posible alliy en las cadenas montaniosas delsur.=dort sowieinden siidlichen |
| mittelgebirgen istbodenfrost moglich. Le gel du sol est possible la-bas et dans les chaines de montagnes basses du sud.=dort sowie in den sidlichen |
表 8: 本文使用的提示词示例。
| SignVideoInput: | [ExtractedSignFeature] |
|---|---|
| Instruction: | 将给定句子翻译成德语。Soil frost is possible there and in the southern lowmountainranges.=dort sowiein densidlichen |
| InContextExamplars | La helada del suelo es posible alliy en las cadenas montaniosas delsur.=dort sowieinden siidlichen |
| mittelgebirgen istbodenfrost moglich. Le gel du sol est possible la-bas et dans les chaines de montagnes basses du sud.=dort sowie in den sidlichen |
Table 9: Ablation study on various combinations of visual encoders. The results are with VT-Align.
| Visual Encoders (SE+ME) | B1 | B2 | B3 | RG | |
| DINOv2+V-JEPA | 45.67 | 32.94 | 25.27 | 20.35 | 41.32 |
| DINOv2+VideoMAE | 47.31 | 34.60 | 26.90 | 21.86 | 42.50 |
| CLIP+V-JEPA | 47.82 | 34.71 | 26.76 | 21.66 | 43.68 |
| CLIP+VideoMAE | 49.80 | 37.32 | 29.50 | 24.32 | 46.57 |
表 9: 不同视觉编码器组合的消融研究。结果基于 VT-Align。
| 视觉编码器 (SE+ME) | B1 | B2 | B3 | RG | |
|---|---|---|---|---|---|
| DINOv2+V-JEPA | 45.67 | 32.94 | 25.27 | 20.35 | 41.32 |
| DINOv2+VideoMAE | 47.31 | 34.60 | 26.90 | 21.86 | 42.50 |
| CLIP+V-JEPA | 47.82 | 34.71 | 26.76 | 21.66 | 43.68 |
| CLIP+VideoMAE | 49.80 | 37.32 | 29.50 | 24.32 | 46.57 |
Table 10: Ablation on our method with and without LoRA.
| Methods | B1 | B2 | B3 | RG | |
| Ours s(w/oLoRA) | 46.11 | 32.65 | 24.69 | 19.67 | 42.91 |
| Ours (w/ LoRA) | 49.80 | 37.32 | 29.50 | 24.32 | 46.57 |
表 10: 使用和不使用 LoRA 的消融实验结果。
| 方法 | B1 | B2 | B3 | RG | |
|---|---|---|---|---|---|
| 我们的方法 (不带LoRA) | 46.11 | 32.65 | 24.69 | 19.67 | 42.91 |
| 我们的方法 (带LoRA) | 49.80 | 37.32 | 29.50 | 24.32 | 46.57 |
A.4 Evaluating Process with KDEs.
A.4 基于核密度估计 (KDE) 的评估流程
To evaluate the quality of the learned representations, we utilize Kernel Density Estimation (KDE) to estimate the probability density functions of the embeddings from GFSLT-VLP and ours. Due to different dimensionality between these methods (1,024 vs. 2,048), we run Principal Component Analysis (PCA) to reduce the number of dimensions while retaining the most significant variance components. This dimensionality reduction facilitates more efficient and stable KDE fitting. KDE can be expressed as:
为了评估学习到的表征质量,我们采用核密度估计(Kernel Density Estimation, KDE)来估算GFSLT-VLP与本文方法的嵌入概率密度函数。由于这些方法的维度存在差异(1,024维 vs. 2,048维),我们通过主成分分析(Principal Component Analysis, PCA)降维并保留最重要的方差成分。这种降维处理有助于实现更高效稳定的KDE拟合。KDE可表示为:
$$
f_{\mathrm{kde}}(\mathbf{z})=\frac{1}{n h^{d}}\sum_{i=1}^{n}K\left(\frac{\mathbf{z}-\mathbf{z_{i}}}{h}\right),
$$
$$
f_{\mathrm{kde}}(\mathbf{z})=\frac{1}{n h^{d}}\sum_{i=1}^{n}K\left(\frac{\mathbf{z}-\mathbf{z_{i}}}{h}\right),
$$
where $\mathbf{z_{i}}$ denotes the representation points, $K$ denotes the kernel function, $h$ is the bandwidth parameter, $d$ is the dimensionality of the data, and $n$ is the number of data points.
其中 $\mathbf{z_{i}}$ 表示表示点,$K$ 表示核函数,$h$ 是带宽参数,$d$ 是数据的维度,$n$ 是数据点的数量。
| Dataset | Language | #Vocab | Train/Valid/Test | Avg.No.Frame | Gloss | Domain |
| PHOENIX14T(Camgoz et al.,2018) | DGS | 3K | 7,096/519/642 | 116 | WeatherForecast | |
| CSL-Daily (Zhou et al.,2021a) | CSL | 2K | 18,401/1,077/1,176 | 119 | Daily-life | |
| How2Sign (Duarte et al.,2021) | ASL | 16K | 31,128/1,741/2,322 | 173 | X | Instructional |
| 数据集 | 语言 | 词汇量 | 训练/验证/测试 | 平均帧数 | 手语注释 | 领域 |
|---|---|---|---|---|---|---|
| PHOENIX14T (Camgoz et al., 2018) | DGS | 3K | 7,096/519/642 | 116 | 天气预报 | |
| CSL-Daily (Zhou et al., 2021a) | CSL | 2K | 18,401/1,077/1,176 | 119 | 日常生活 | |
| How2Sign (Duarte et al., 2021) | ASL | 16K | 31,128/1,741/2,322 | 173 | X | 教学指导 |
Table 11: Statistics of three sign language datasets used in this work. DGS: German Sign Language; CSL: Chinese Sign Language; ASL: American Sign Language; Avg. No. Frame: average number of video frames.
表 11: 本工作使用的三个手语数据集统计信息。DGS: 德国手语;CSL: 中国手语;ASL: 美国手语;Avg. No. Frame: 平均视频帧数。
The entropy of KDE is then calculated as:
KDE的熵计算公式为:
$$
H=-\sum_{i=1}^{n}f_{\mathrm{kde}}(\mathbf{z_{i}})\log f_{\mathrm{kde}}(\mathbf{z_{i}}),
$$
$$
H=-\sum_{i=1}^{n}f_{\mathrm{kde}}(\mathbf{z_{i}})\log f_{\mathrm{kde}}(\mathbf{z_{i}}),
$$
where $H$ represents the entropy, and $f(\mathbf{z_{i}})$ are the estimated density values at the representation points.
其中 $H$ 表示熵,$f(\mathbf{z_{i}})$ 为表征点处的估计密度值。
A.5 Generating Visual Tokens
A.5 生成视觉Token
Inspired by the reverse engineering (Ju et al., 2023), we first compute the Euclidean distance between the sign feature $Z_{s m}$ and the LLM’s embedding table $E_{l l m}\in\mathbb{R}^{V\times d^{\prime}}$ , where $V$ represents the vocabulary size. Each sign feature is then mapped to the word associated with the shortest distance in this space. This process can be expressed as $\mathrm{dist}(Z_{s m},E_{l l m})\leq\Delta$ , where $\mathrm{dist}(\cdot)$ denotes the Euclidean distance function, and $\Delta$ represents the shortest distance to $E_{l l m}$ across all sign features.
受逆向工程 (Ju et al., 2023) 启发,我们首先计算符号特征 $Z_{sm}$ 与大语言模型嵌入表 $E_{llm}\in\mathbb{R}^{V\times d^{\prime}}$ 之间的欧氏距离,其中 $V$ 表示词汇表大小。然后将每个符号特征映射到该空间中距离最短的关联单词。这一过程可表示为 $\mathrm{dist}(Z_{sm},E_{llm})\leq\Delta$,其中 $\mathrm{dist}(\cdot)$ 表示欧氏距离函数,$\Delta$ 代表所有符号特征到 $E_{llm}$ 的最短距离。
B Statistics of Sign Language Datasets
B 手语数据集统计
Table 11 presents a comparative overview of three popular sign language datasets: PHOENIX14T, CSL-Daily, and How2Sign, each with distinct statistics and domain.
表 11: 三种主流手语数据集(PHOENIX14T、CSL-Daily和How2Sign)的对比概览,各具不同的统计特征和应用领域。
PHOENIX14T focuses on German Sign Language (DGS) within the specific domain of weather forecasting, featuring a relatively small vocabulary of 3K words and a concise average video length of 116 frames. It includes 7,096 training samples, 519 validation samples, and 642 test samples, with gloss annotations available. This dataset is tailored for domain-specific tasks, offering clear and repetitive patterns ideal for translation and recognition within weather-related contexts.
PHOENIX14T专注于天气预报特定领域内的德国手语(DGS),词汇量相对较小,为3K词,平均视频长度较短,仅116帧。该数据集包含7,096个训练样本、519个验证样本和642个测试样本,并提供手势注释。该数据集专为领域特定任务设计,其清晰且重复的模式非常适合天气相关场景下的翻译和识别任务。
In comparison, CLS-Daily, a dataset for Chinese Sign Language (CSL), covers a broader range of topics than PHOENIX14T, spanning areas such as family life, medical care, school, banking, shopping, and social interactions. It features a vocabulary of 2K words and an average video length of 119 frames. The dataset includes 18,401 training samples, 1,077 validation samples, and 1,176 test samples, also with gloss annotations.
相比之下,中文手语数据集 CLS-Daily 涵盖的主题范围比 PHOENIX14T 更广,涉及家庭生活、医疗保健、学校、银行、购物和社交互动等领域。该数据集包含 2K 词汇量,视频平均长度为 119 帧,包含 18,401 个训练样本、1,077 个验证样本和 1,176 个测试样本,同样带有手势注释。
| Methods | Vis.Ft. | #TrainableParams | #TotalParams | B4 |
| GFSLT-VLP(Zhouetal.,2023) | 215.6M | 215.6M | 21.44 | |
| Sign2GPT(Wongetal.,2024) | 16M | 1.8B | 22.52 | |
| Fla-LLM (Chen et al., 2024) | >705.6M* | >705.6M* | 23.09 | |
| SignLLM (Gong et al.,2024) | >7B* | 23.40 | ||
| SpaMo(Ours) | X | 22.7M | 3.5B | 24.32 |
| 方法 | 视觉特征 | 可训练参数量 | 总参数量 | B4 |
|---|---|---|---|---|
| GFSLT-VLP (Zhou et al., 2023) | 215.6M | 215.6M | 21.44 | |
| Sign2GPT (Wong et al., 2024) | 16M | 1.8B | 22.52 | |
| Fla-LLM (Chen et al., 2024) | >705.6M* | >705.6M* | 23.09 | |
| SignLLM (Gong et al., 2024) | >7B* | 23.40 | ||
| SpaMo (Ours) | X | 22.7M | 3.5B | 24.32 |
Table 12: Model parameter comparison. * denotes an estimated value due to the un availability of public code. “Vis. Ft.” denotes to the visually fine-tuned on sign language datasets.
表 12: 模型参数对比。* 表示由于缺乏公开代码而估算的数值。"Vis. Ft." 表示在手语数据集上进行了视觉微调。
On the other hand, How2Sign focuses on American Sign Language (ASL) in the instructional domain. It offers a significantly larger and more diverse dataset, with a vocabulary of 16K words and an average video length of 173 frames. The dataset consists of 31,128 training samples, 1,741 validation samples, and 2,322 test samples, but lacks gloss annotations. The diversity and complexity of How2Sign make it particularly suitable for general sign language related tasks, especially those that involve understanding varied and intricate sign sequences.
另一方面,How2Sign专注于教学领域的美式手语(ASL)。它提供了规模更大、多样性更丰富的数据集,包含16K单词的词汇量,视频平均长度为173帧。该数据集由31,128个训练样本、1,741个验证样本和2,322个测试样本组成,但缺少手势注释(gloss annotations)。How2Sign的多样性和复杂性使其特别适合通用手语相关任务,尤其是涉及理解多变且复杂手语序列的任务。
C More Experiments
C 更多实验
C.1 Effect of Visual Encoders.
C.1 视觉编码器的影响
We assess the effect of various combinations of visual encoders (SE & ME). Table 9 shows four different encoders: DINOv2 (Oquab et al., 2023), CLIP (Radford et al., 2021), V-JEPA (Bardes et al., 2024), and VideoMAE (Tong et al., 2022). The results demonstrate that the combination of CLIP and VideoMAE delivers the highest performance, suggesting potential for further improvement as visual encoders continue to advance.
我们评估了不同视觉编码器 (SE & ME) 组合的效果。表 9 展示了四种不同的编码器:DINOv2 (Oquab et al., 2023)、CLIP (Radford et al., 2021)、V-JEPA (Bardes et al., 2024) 和 VideoMAE (Tong et al., 2022)。结果表明,CLIP 与 VideoMAE 的组合能提供最佳性能,这表明随着视觉编码器的持续发展还有进一步提升的潜力。
C.2 Effect of LoRA.
C.2 LoRA 的效果
We evaluate the effect of LoRA on the LLM. As illustrated in Table 10, the LLM with LoRA demonstrates superior performance.
我们评估了LoRA对大语言模型的影响。如表 10 所示,采用LoRA的大语言模型展现出更优的性能。
C.3 Parameter Comparisons
C.3 参数对比
We present a comparison of various SLT methods, focusing on the presence of visual fine-tuning ("Vis. Ft."), the number of trainable and total parameters, and their performance as measured by the BLEU-4 score. As shown in Table 12, our method, SpaMo, achieves the highest BLEU-4 score of 24.32 without the need for the visual fine-tuning. SpaMo requires 22.7M trainable parameters, which is relatively efficient compared to other methods such as GFSLT-VLP (215.6M), Sign2GPT (16M), and FlaLLM $(>705.6\mathrm{M})$ . This demonstrates that SpaMo effectively balances model complexity and training efficiency to achieve superior performance without the additional step of the visual fine-tuning.
我们对各种SLT方法进行了比较,重点关注视觉微调 ("Vis. Ft.") 的使用、可训练参数和总参数数量以及BLEU-4分数衡量的性能。如表 12 所示,我们的方法 SpaMo 在无需视觉微调的情况下取得了最高的BLEU-4分数24.32。SpaMo仅需22.7M可训练参数,相比GFSLT-VLP (215.6M)、Sign2GPT (16M)和FlaLLM $(>705.6\mathrm{M})$ 等方法更为高效。这表明SpaMo在模型复杂度和训练效率之间取得了良好平衡,无需额外视觉微调步骤即可实现卓越性能。
Table 13: Cosine similarity between the visual tokens and the glosses.
| Pairs | CosineSimilarity |
| Glosses&Target Translations | 0.8400 |
| Visual Tokens & Target Translations | 0.6781 |
| VisualTokens&Glosses | 0.6779 |
表 13: 视觉 token 与注释词之间的余弦相似度。
| 配对项 | 余弦相似度 |
|---|---|
| 注释词与目标翻译 | 0.8400 |
| 视觉 token 与目标翻译 | 0.6781 |
| 视觉 token 与注释词 | 0.6779 |
C.4 More Qualitative Results
C.4 更多定性结果
We provide additional translation examples for PHOENIX14T, CSL-Daily, and How2Sign. As shown in Table 14, in PHOENIX14T, our method consistently delivers accurate translations, while GFSLT-VLP struggles to capture the correct semantic meaning.
我们为PHOENIX14T、CSL-Daily和How2Sign提供了额外的翻译示例。如表14所示,在PHOENIX14T中,我们的方法始终能提供准确的翻译,而GFSLT-VLP则难以捕捉正确的语义。
In CSL-Daily, we present a comparison between glosses and visual tokens, as well as between reference translations and generated translations. As shown in Table 15, most visual tokens are matched to the glosses, though they are not perfectly aligned. Notably, in the last three examples, the visual tokens include words that are missing from the glosses but appear in the reference translations.
在CSL-Daily中,我们比较了注释词与视觉token (visual tokens) 以及参考译文与生成译文之间的差异。如表15所示,大多数视觉token能与注释词匹配,但并非完全对应。值得注意的是,最后三个示例中的视觉token包含了注释词缺失但出现在参考译文中的词汇。
For How2Sign, Table 16 presents translation results along with their corresponding visual tokens. Since How2Sign lacks gloss annotations, we include actual sign frames for qualitative comparison. Similar to the results on PHOENIX14T and CSLDaily, many visual tokens in How2Sign are closely aligned with the translations. Note that although OpenSLT (Tarrés et al., 2023) is the only publicly available baseline6, we were unable to reproduce their results due to a broken link to the fine-tuned I3D features at the time of drafting.
关于How2Sign,表16展示了翻译结果及其对应的视觉token。由于How2Sign缺少手语注释标注,我们加入了实际手语帧画面进行定性对比。与PHOENIX14T和CSLDaily的结果类似,How2Sign中许多视觉token与翻译内容高度吻合。需要注意的是,虽然OpenSLT (Tarrés et al., 2023) 是当前唯一公开的基线模型[6],但在本文撰写时因其微调版I3D特征链接失效,我们未能复现其实验结果。
C.5 Cosine Similarity Between Visual Tokens and Glosses
C.5 视觉Token与词义标注间的余弦相似度
We use Sentence-BERT (Reimers and Gurevych, 2019) to evaluate the similarity between the generated visual tokens and the ground-truth glosses from PHOENIX14T, using cosine similarity. Additionally, we assess the similarity between the visual tokens and the target translation, as well as the alignment between the glosses and the translation, which highlights varying degrees of correspondence.
我们使用 Sentence-BERT (Reimers and Gurevych, 2019) 通过余弦相似度评估生成的视觉 token 与 PHOENIX14T 真实手语注释之间的相似性。此外,我们还评估了视觉 token 与目标翻译之间的相似度,以及手语注释与翻译之间的对齐情况,这些分析揭示了不同程度的对应关系。

Figure 6: Performance curves across epochs.
图 6: 各训练轮次性能曲线。
As shown in Table 13, and as we expected, the highest similarity occurs between glosses and target translations, indicating a strong semantic correspondence. By contrast, the visual tokens show lower similarity to both target translations and glosses, suggesting that they are not random. The reason for the score not being higher is likely the inclusion of unrelated words in the visual tokens compared to the actual glosses, as illustrated in Table 7.
如表 13 所示,正如我们所预期的,注释 (glosses) 和目标翻译之间的相似度最高,表明二者存在很强的语义对应关系。相比之下,视觉 token 与目标翻译和注释的相似度都较低,这表明它们并非随机生成。得分没有更高的原因可能是视觉 token 中包含了与实际注释无关的词语,如表 7 所示。
C.6 Performance Curve Across Epochs
C.6 跨训练周期的性能曲线
Figure 6 shows the performance curves of SpaMo using BLEU-4 and ROUGE over 40 training epochs on the PHOENIX14T dataset. For comparison, we note that other models such as SignLLM, Sign2GPT, and Fla-LLM are trained for 20, 100, and 75 epochs, respectively. These results highlight the progressive improvements in SpaMo’s performance as training advances, offering a detailed look at its efficiency relative to other models.
图 6: 展示了 SpaMo 在 PHOENIX14T 数据集上使用 BLEU-4 和 ROUGE 指标经过 40 个训练周期的性能曲线。作为对比,我们注意到其他模型如 SignLLM、Sign2GPT 和 Fla-LLM 分别训练了 20、100 和 75 个周期。这些结果突显了 SpaMo 性能随训练进程的逐步提升,并提供了其相对于其他模型效率的详细观察。
D Feasibility of Existing VLMs in SLT
D 现有视觉语言模型在手语翻译中的可行性
Recent advancements in Vision-Language Models (VLMs) (Alayrac et al., 2022; Li et al., 2023; Liu et al., 2024b; Cheng et al., 2024) have enabled LLMs to comprehend various modalities including images and videos, beyond just text. However, in the SLT domain, current VLM designs are not well-suited for processing long sequences of sign videos. As shown in Table 11, the average sign video length exceeds 116 frames, which is significantly longer than typical action recognition or video-text datasets, where sample lengths are often under 16 frames. For example, Flamingo (Alayrac et al., 2022), a widely recognized vision-language model, uses 8 frames during training and only 32 frames during inference—far fewer than what is required for SLT. Similarly, Video Llama 2 (Cheng et al., 2024) employs 8 frames for training. Moreover, recent LLM-based SLT methods (Wong et al., 2024; Gong et al., 2024), including our method, can be classified within the VLM family but are specialized to process and capture long sign video sequences.
视觉语言模型 (Vision-Language Models, VLMs) 的最新进展 (Alayrac et al., 2022; Li et al., 2023; Liu et al., 2024b; Cheng et al., 2024) 使得大语言模型能够理解包括图像和视频在内的多种模态,而不仅仅是文本。然而,在手语翻译 (Sign Language Translation, SLT) 领域,当前的 VLM 设计并不适合处理长序列的手语视频。如表 11 所示,手语视频的平均长度超过 116 帧,远长于典型的动作识别或视频-文本数据集(样本长度通常少于 16 帧)。例如,广泛认可的视觉语言模型 Flamingo (Alayrac et al., 2022) 在训练时仅使用 8 帧,推理时也仅用 32 帧——远低于 SLT 所需的数量。类似地,Video Llama 2 (Cheng et al., 2024) 在训练时也仅采用 8 帧。此外,近期基于大语言模型的 SLT 方法 (Wong et al., 2024; Gong et al., 2024)(包括我们的方法)虽可归类为 VLM 家族,但专门用于处理和捕捉长序列手语视频。
Table 14: Translation results on the test set compared to GFSLT-VLP on PHOENIX14T. Correctly translated 1-grams are highlighted in blue, while incorrect translations are marked in red.
| Ref: | und nun die wettervorhersage fiur morgen sonntag den zwolften juli. (andnow theweatherforecastfortomorrowSunday thetwelfthof July.) |
| GFSLT-VLP: | und nun die wettervorhersage fuir morgen sonntag den zwolften juni. (andnowtheweatherforecastfortomorrow,Sunday,thetwelfthofJune.) |
| Ours: | (andnow theweatherforecastfortomorrowSunday thetwelfthofJuly.) |
| Ref: | in der nacht muss vor allem in der nordwesthalfte mit schauern und gewittern gerechnet werden die heftig ausfallen konnen. (During thenight,showers and thunderstorms are expected,especially in thenorthwest half,whichcouldbeheavy.) |
| GFSLT-VLP: | heute nacht gibt es im norden teilweise kraftige schauer und gewitter die ortlich unwetterartig sein konnen. |
| Ours: | (At night,showers and thunderstorms canbe expected,especially in thenorthwest half,which cansometimesbestrong.) in der nacht muss vor allem in der nordwesthalfte mit schauern und gewittern gerechnet werden die mitunter kraftig sein konnen. |
| (Duringthenight,showers andthunderstorms areexpected,particularly inthenorthwesthalf,whichmaybeheavy.) und nun die wettervorhersage fir morgen donnerstag den siebenundzwanzigsten august. | |
| Ref: GFSLT-VLP: | (and now theweatherforecastfortomorrow,Thursday thetwenty-seventhof August.) und nun die wettervorhersage fir morgen donnerstag den sechsundzwanzigsten august. |
| Ours: | (andnow theweatherforecastfortomorrow,Thursday thetwenty-sixthof August.) und nun die wettervorhersage fuir morgen donnerstag den siebenundzwanzigsten august. (and now theweatherforecastfortomorrow,Thursday the twenty-seventhofAugust.) |
| Ref: | am tag ist es im westen freundlich sonst sonne und dichtere wolken im wechsel hier und da fallen einzelne schauer. |
| GFSLT-VLP: | (Duringthedayitisfriendlyinthewest,otherwise sunand denserclouds alternate,withoccasional showershere and there) am tag wechseln sonne und wolken einander ab im westen fallen mitunter gewittrige schauer. (Duringthedaysunandcloudsalternate,inthewest,occasional stormy showersmayocur) |
| Ours: | am tag ist es im westen freundlich mit sonne und dichteren wolken hier und da fallen schauer. (During the day it isfriendlyin thewestwith sun anddenser clouds,with occasionalshowershere and there) |
| Ref: | abseits der gewittern weht der wind schwach bis maBig an der kiste frisch. (Away from thethunderstorms,thewind blows weakto moderate,fresh at the coast.) |
| GFSLT-VLP: | abgesehen von gewitterboen schwacher bis maBiger an den kisten auch frischer wind (Apar fromthunderstormgusts,weaktomoderate,alsofreshwindat thecoasts.) |
| Ours: | abseits der gewittern weht der wind schwach bis maBig an den kisten auch frisch. (Awayfrom thethunderstorms,thewindblows weakto moderate,alsofresh atthecoasts.) |
| Ref: | am sonntag im norden und an den alpen mal sonne mal wolken und ab und an schauer sonst ist es recht freundlich. |
| GFSLT-VLP: | (OnSunday in thenorth andin theAlps sometimes sun sometimes clouds andoccasional showers otherwiseit isquitepleasant.) am sonntag im norden an den alpen einige schauer sonst ist es recht freundlich. (OnSunday in thenorthin the Alps some showers otherwiseit is quite pleasant.) |
| Ours: | am sonntag im norden und an den alpen mal sonne mal wolken und nur einzelne schauer sonst meist freundlich. (OnSundayinthenorthandintheAlps sometimes sunsometimes clouds and onlyafewshowers otherwisemostlypleasant.) |
| am mittwoch eine mischung aus sonne wolken und nebelfeldern im nordwesten hier und da schauer sonst ist es trocken. | |
| Ref: | (OnWednesday a mix of sun,clouds,and fogpatches in thenorthwest;here and there showers,otherwise it is dry.) am mittwoch gibt es viele wolken hier und da schauer vor allem im nordwesten bleibt es meist trocken. |
| GFSLT-VLP: | (OnWednesday therewill bemany clouds;here and there showers,especially in thenorthwest,it remainsmostly dry.) am mittwoch eine mischung aus sonne wolken und nebel im nordwesten einige schauer sonst bleibt es meist trocken. |
| Ours: | (OnWednesday a mix of sun,clouds,andfoginthenorthwest;some showers,otherwiseitremainsmostly dry.) am tag scheint verbreitet die sonne im siden und westen bilden sich spaiter gebietsweise quellwolken. |
| Ref: | (During theday,thesun shineswidely inthe south,andlater,isolatedcumulus cloudsform inthewest.) am tag scheint in der sidhalfte haufig die sonne hier und da ein par wolken. |
| GFSLT-VLP: Ours: | (Duringthe day,thesun often shinesinthe southernhalf,hereand thereafewclouds.) am tag scheint verbreitet die sonne im siden und im auBersten westen tauchen hier und da ein paar quellwolken auf. |
| (Duringtheday,thesunshineswidely inthesouth,andinthefarwest,hereandthere,afewcumulus clouds appear.) der wind weht maBig bis frisch mit starken bis stirmischen boen im bergland teilweise schwere sturmboen im sidosten mitunter nur schwacher wind. | |
| Ref: | Thewindblowsmderatelytofreshlywithstrongtostomygustsnhoutanouregionsparlyseverestormustsintheoutheastoccasionallyonlyweakwind der wind weht maBig bis frisch bei schauern sowie im sidosten schwere sturmboen im bergland starker bis stirmboen. |
| GFSLT-VLP: Ours: | (Thewind blows moderately tofreshlywithshowers,as wellas severestorm gusts in the southeast,in themountainous regions strong to stormy gusts.) der wind weht maBig bis frisch mit starken bis stirmischen boen auf den bergen schwere sturmboen im siden sonst schwacher wind. |
| (Thewind blows moderatelytofreshlywithstrongtostormy gusts onthemountains,severe stormgusts inthe south,otherwiseweakwind.) am montag iberall wechselhaft und deutlich kihler. | |
| Ref: GFSLT-VLP: | (OnMonday,everywhereis changeable andsignificantly cooler.) am montag wird es wieder wechselhafter kihler. |
| Ours: | (OnMonday,it will be changeable and cooleragain.) am montag iberall wechselhaft und deutlich kihler. |
| (OnMonday,everywhereischangeableandsignificantlycooler.) sonst ein wechsel aus sonne und wolken. | |
| Ref: GFSLT-VLP: | (Otherwisea mix of sun and clouds.) ansonsten wechseln sich teilweise dichte wolken und sonne ab. |
| Ours: | (Otherwisepartially denseclouds andsun alternate.) sonst ein wechsel aus sonne und wolken. |
| (Otherwise a mix of sun and clouds.) und nun die wettervorhersage fur morgen samstag den sechsundzwanzigsten januar. | |
| Ref: | Andnowtheweatherforecastfortomorrow,Saturday,thetwenty-sixthofJanuary. und nun die wettervorhersage fir morgen samstag den sechsundzwanzigsten dezember. |
| GFSLT-VLP: | Andnowtheweatherforecastfortomorrow,Saturday,thetwenty-sixthofDecember und nun die wettervorhersage fir morgen samstag den sechsundzwanzigsten januar. |
| Ours: | Andnowtheweatherforecastfortomorrow,Saturday,thetwenty-sixthofJanuary. |
| sonst ist es recht freundlich. | |
| Ref: | Otherwiseit isquite pleasant. sonst iberwiegend freundlich. GFSLT-VLP: Otherwisemostly pleasant. |
表 14: 在 PHOENIX14T 测试集上与 GFSLT-VLP 的翻译结果对比。正确翻译的 1-gram 用蓝色高亮显示,错误翻译用红色标记。
| Ref: | und nun die wettervorhersage fiur morgen sonntag den zwolften juli. (andnow theweatherforecastfortomorrowSunday thetwelfthof July.) |
| GFSLT-VLP: | und nun die wettervorhersage fuir morgen sonntag den zwolften juni. (andnowtheweatherforecastfortomorrow,Sunday,thetwelfthofJune.) |
| Ours: | (andnow theweatherforecastfortomorrowSunday thetwelfthofJuly.) |
| Ref: | in der nacht muss vor allem in der nordwesthalfte mit schauern und gewittern gerechnet werden die heftig ausfallen konnen. (During thenight,showers and thunderstorms are expected,especially in thenorthwest half,whichcouldbeheavy.) |
| GFSLT-VLP: | heute nacht gibt es im norden teilweise kraftige schauer und gewitter die ortlich unwetterartig sein konnen. |
| Ours: | (At night,showers and thunderstorms canbe expected,especially in thenorthwest half,which cansometimesbestrong.) in der nacht muss vor allem in der nordwesthalfte mit schauern und gewittern gerechnet werden die mitunter kraftig sein konnen. |
| | (Duringthenight,showers andthunderstorms areexpected,particularly inthenorthwesthalf,whichmaybeheavy.) und nun die wettervorhersage fir morgen donnerstag den siebenundzwanzigsten august. |
| Ref: GFSLT-VLP: | (and now theweatherforecastfortomorrow,Thursday thetwenty-seventhof August.) und nun die wettervorhersage fir morgen donnerstag den sechsundzwanzigsten august. |
| Ours: | (andnow theweatherforecastfortomorrow,Thursday thetwenty-sixthof August.) und nun die wettervorhersage fuir morgen donnerstag den siebenundzwanzigsten august. (and now theweatherforecastfortomorrow,Thursday the twenty-seventhofAugust.) |
| Ref: | am tag ist es im westen freundlich sonst sonne und dichtere wolken im wechsel hier und da fallen einzelne schauer. |
| GFSLT-VLP: | (Duringthedayitisfriendlyinthewest,otherwise sunand denserclouds alternate,withoccasional showershere and there) am tag wechseln sonne und wolken einander ab im westen fallen mitunter gewittrige schauer. (Duringthedaysunandcloudsalternate,inthewest,occasional stormy showersmayocur) |
| Ours: | am tag ist es im westen freundlich mit sonne und dichteren wolken hier und da fallen schauer. (During the day it isfriendlyin thewestwith sun anddenser clouds,with occasionalshowershere and there) |
| Ref: | abseits der gewittern weht der wind schwach bis maBig an der kiste frisch. (Away from thethunderstorms,thewind blows weakto moderate,fresh at the coast.) |
| GFSLT-VLP: | abgesehen von gewitterboen schwacher bis maBiger an den kisten auch frischer wind (Apar fromthunderstormgusts,weaktomoderate,alsofreshwindat thecoasts.) |
| Ours: | abseits der gewittern weht der wind schwach bis maBig an den kisten auch frisch. (Awayfrom thethunderstorms,thewindblows weakto moderate,alsofresh atthecoasts.) |
| Ref: | am sonntag im norden und an den alpen mal sonne mal wolken und ab und an schauer sonst ist es recht freundlich. |
| GFSLT-VLP: | (OnSunday in thenorth andin theAlps sometimes sun sometimes clouds andoccasional showers otherwiseit isquitepleasant.) am sonntag im norden an den alpen einige schauer sonst ist es recht freundlich. (OnSunday in thenorthin the Alps some showers otherwiseit is quite pleasant.) |
| Ours: | am sonntag im norden und an den alpen mal sonne mal wolken und nur einzelne schauer sonst meist freundlich. (OnSundayinthenorthandintheAlps sometimes sunsometimes clouds and onlyafewshowers otherwisemostlypleasant.) |
| | am mittwoch eine mischung aus sonne wolken und nebelfeldern im nordwesten hier und da schauer sonst ist es trocken. |
| Ref: | (OnWednesday a mix of sun,clouds,and fogpatches in thenorthwest;here and there showers,otherwise it is dry.) am mittwoch gibt es viele wolken hier und da schauer vor allem im nordwesten bleibt es meist trocken. |
| GFSLT-VLP: | (OnWednesday therewill bemany clouds;here and there showers,especially in thenorthwest,it remainsmostly dry.) am mittwoch eine mischung aus sonne wolken und nebel im nordwesten einige schauer sonst bleibt es meist trocken. |
| Ours: | (OnWednesday a mix of sun,clouds,andfoginthenorthwest;some showers,otherwiseitremainsmostly dry.) am tag scheint verbreitet die sonne im siden und westen bilden sich spaiter gebietsweise quellwolken. |
| Ref: | (During theday,thesun shineswidely inthe south,andlater,isolatedcumulus cloudsform inthewest.) am tag scheint in der sidhalfte haufig die sonne hier und da ein par wolken. |
| GFSLT-VLP: Ours: | (Duringthe day,thesun often shinesinthe southernhalf,hereand thereafewclouds.) am tag scheint verbreitet die sonne im siden und im auBersten westen tauchen hier und da ein paar quellwolken auf. |
| | (Duringtheday,thesunshineswidely inthesouth,andinthefarwest,hereandthere,afewcumulus clouds appear.) der wind weht maBig bis frisch mit starken bis stirmischen boen im bergland teilweise schwere sturmboen im sidosten mitunter nur schwacher wind. |
| Ref: | Thewindblowsmderatelytofreshlywithstrongtostomygustsnhoutanouregionsparlyseverestormustsintheoutheastoccasionallyonlyweakwind der wind weht maBig bis frisch bei schauern sowie im sidosten schwere sturmboen im bergland starker bis stirmboen. |
| GFSLT-VLP: Ours: | (Thewind blows moderately tofreshlywithshowers,as wellas severestorm gusts in the southeast,in themountainous regions strong to stormy gusts.) der wind weht maBig bis frisch mit starken bis stirmischen boen auf den bergen schwere sturmboen im siden sonst schwacher wind. |
| | (Thewind blows moderatelytofreshlywithstrongtostormy gusts onthemountains,severe stormgusts inthe south,otherwiseweakwind.) am montag iberall wechselhaft und deutlich kihler. |
| Ref: GFSLT-VLP: | (OnMonday,everywhereis changeable andsignificantly cooler.) am montag wird es wieder wechselhafter kihler. |
| Ours: | (OnMonday,it will be changeable and cooleragain.) am montag iberall wechselhaft und deutlich kihler. |
| | (OnMonday,everywhereischangeableandsignificantlycooler.) sonst ein wechsel aus sonne und wolken. |
| Ref: GFSLT-VLP: | (Otherwisea mix of sun and clouds.) ansonsten wechseln sich teilweise dichte wolken und sonne ab. |
| Ours: | (Otherwisepartially denseclouds andsun alternate.) sonst ein wechsel aus sonne und wolken. |
| | (Otherwise a mix of sun and clouds.) und nun die wettervorhersage fur morgen samstag den sechsundzwanzigsten januar. |
| Ref: | Andnowtheweatherforecastfortomorrow,Saturday,thetwenty-sixthofJanuary. und nun die wettervorhersage fir morgen samstag den sechsundzwanzigsten dezember. |
| GFSLT-VLP: | Andnowtheweatherforecastfortomorrow,Saturday,thetwenty-sixthofDecember und nun die wettervorhersage fir morgen samstag den sechsundzwanzigsten januar. |
| Ours: | Andnowtheweatherforecastfortomorrow,Saturday,thetwenty-sixthofJanuary. |
| | sonst ist es recht freundlich. |
| Ref: | Otherwiseit isquite pleasant. sonst iberwiegend freundlich. |
| GFSLT-VLP: | Otherwisemostly pleasant. |
| Gloss: | 你小张什么时间认识 |
| Vis. Token: | 你 小 三 张三机场哪里 什么 时候 桌 认识 |
| Ref: Ours: | 你和小张什么时候认识的? 你和小张什么时候认识 的? |
| Gloss: | 椅子他们想什么 时间 去 买 |
| Vis. Token: Ref: | 椅子时候什么你们他们他 想 每天 什么 时候 旅游去 |
| Ours: | 他们想什么时候去买椅子? 他们想什么 时候 去买椅子? |
| Gloss: Vis. Token: | 不是他 去 见面 同学 |
| Ref: | 不是为什么一个他去 看见他人看 同学 桌? |
| Ours: | 不是,他是去见他同学。 |
| 不是,他是去看同学。 | |
| Gloss: | 这衣服红怎么样这是新 |
| Vis. Token: | 孩子北京 衣服 红色喜欢我他怎么样 认识跑身体跑 这 |
| Ref: | 这件 红色的衣服怎么样?这是新的。 |
| Ours: | 这件 红色 的衣服怎么样?是今年 的。 |
| Gloss: | 中午吃好了要多吃水果 |
| Vis. Token: | 饮料吃饭吃 了冷了完 了老板安全 要 粥早 多 喜欢饮料吃饭 |
| Ref: | 吃完午饭要多吃点水果。 |
| Ours: | 吃完午饭我要多吃点水果。 |
| Gloss: | 你们吃什么我请客 |
| Vis. Token: | 看你们大家来 吃 饭什么他怕我 请 十分钟 |
| Ref: | |
| Ours: | 你们吃点什么,我请客。 你们吃饭什么?我请你们吃饭。 |
| Gloss: | 超市我要买椅子你去 |
| Vis. Token: | 超市 买事茶怕我 要 我买 椅子 时候什么 你 |
| Ref: | 他来去 我要去超市买椅子,你去吗? |
| Ours: | 我要去超市买椅子,你去吗? |
| Gloss: | 我驾驶 高铁站接儿子 |
| Vis. Token: | 天■气大憾冷 怕我 我们 去 下雨大学今天 |
| Ref: | 天气太冷了,我们去打篮球吧, |
| Ours: | 天气太冷了,我们去打篮球吧。 |
| Gloss: | 穿暖没有我想不买 |
| Vis. Token: | |
| 衣服 饱热情急没有怕我想 觉得想 不 不是买 不是 | |
| Ref: | |
| 这件衣服不保暖,我不想买。 | |
| Ours: | |
| 这件衣服不保暖,我不想买。 |
| 原文 | 视觉 Token | 参考译文 | 我们的译文 |
|---|---|---|---|
| 你小张什么时间认识 | 你 小 三 张三机场哪里 什么 时候 桌 认识 | 你和小张什么时候认识的? | 你和小张什么时候认识的? 你和小张什么时候认识的? |
| 椅子他们想什么 时间 去 买 | 椅子时候什么你们他们他 想 每天 什么 时候 旅游去 | 他们想什么时候去买椅子? 他们想什么时候去买椅子? | |
| 不是他 去 见面 同学 | 不是为什么一个他去 看见他人看 同学 桌? | 不是,他是去见他同学。 不是,他是去看同学。 | |
| 这衣服红怎么样这是新 | 孩子北京 衣服 红色喜欢我他怎么样 认识跑身体跑 这 | 这件红色的衣服怎么样?这是新的。 | 这件红色的衣服怎么样?是今年的。 |
| 中午吃好了要多吃水果 | 饮料吃饭吃 了冷了完 了老板安全 要 粥早 多 喜欢饮料吃饭 | 吃完午饭要多吃点水果。 | 吃完午饭我要多吃点水果。 |
| 你们吃什么我请客 | 看你们大家来 吃 饭什么他怕我 请 十分钟 | 你们吃点什么,我请客。 你们吃饭什么?我请你们吃饭。 | |
| 超市我要买椅子你去 | 超市 买事茶怕我 要 我买 椅子 时候什么 你 | 我要去超市买椅子,你去吗? | 我要去超市买椅子,你去吗? |
| 我驾驶 高铁站接儿子 | 天■气大憾冷 怕我 我们 去 下雨大学今天 | 天气太冷了,我们去打篮球吧, | 天气太冷了,我们去打篮球吧。 |
| 穿暖没有我想不买 | 衣服 饱热情急没有怕我想 觉得想 不 不是买 不是 | 这件衣服不保暖,我不想买。 | 这件衣服不保暖,我不想买。 |
