UniHCP: A Unified Model for Human-Centric Perceptions
UniHCP: 以人为本的感知统一模型
Abstract
摘要
Human-centric perceptions (e.g., pose estimation, human parsing, pedestrian detection, person re-identification, etc.) play a key role in industrial applications of visual models. While specific human-centric tasks have their own relevant semantic aspect to focus on, they also share the same underlying semantic structure of the human body. However, few works have attempted to exploit such homogeneity and design a general-propose model for human-centric tasks. In this work, we revisit a broad range of human-centric tasks and unify them in a minimalist manner. We propose UniHCP, a Unified Model for Human-Centric Perceptions, which unifies a wide range of human-centric tasks in a simplified end-to-end manner with the plain vision transformer architecture. With large-scale joint training on 33 humancentric datasets, UniHCP can outperform strong baselines on several in-domain and downstream tasks by direct evaluation. When adapted to a specific task, UniHCP achieves new SOTAs on a wide range of human-centric tasks, e.g., 69.8 mIoU on CIHP for human parsing, 86.18 mA on PA100K for attribute prediction, 90.3 mAP on Market1501 for ReID, and 85.8 JI on CrowdHuman for pedestrian detection, performing better than specialized models tailored for each task. The code and pretrained model are available at https://github.com/OpenGVLab/UniHCP.
以人为本的感知任务(如姿态估计、人体解析、行人检测、行人重识别等)在视觉模型的工业应用中扮演着关键角色。虽然特定的人本任务各有其关注的语义层面,但它们都共享相同的人体底层语义结构。然而,很少有研究尝试利用这种同质性来设计通用的人本任务模型。本文重新审视了广泛的人本任务,并以极简方式将其统一。我们提出UniHCP(人本感知统一模型),通过朴素的视觉Transformer架构,以简化的端到端方式统一了多种人本任务。通过在33个人本数据集上进行大规模联合训练,UniHCP在直接评估时能超越多个领域内和下游任务的强基线。当适配特定任务时,UniHCP在广泛的人本任务中刷新了SOTA纪录:人体解析任务在CIHP上达到69.8 mIoU,属性预测在PA100K上达到86.18 mA,行人重识别在Market1501上达到90.3 mAP,行人检测在CrowdHuman上达到85.8 JI,表现均优于为各任务专门设计的模型。代码与预训练模型已开源:https://github.com/OpenGVLab/UniHCP。
1. Introduction
1. 引言
Research on human-centric perceptions has come a long way with tremendous advancements in recent years. Many methods have been developed to enhance the performance of pose estimation [67], human parsing [52], pedestrian detection [6], and many other human-centered tasks. These significant progress play a key role in advancing the applications of visual models in numerous fields, such as sports analysis [12], autonomous driving [105], and electronic retailing [31].
以人为中心的感知研究近年来取得了长足进步。在姿态估计[67]、人体解析[52]、行人检测[6]等众多人本任务领域,研究者们开发了大量提升性能的方法。这些重要进展对推动视觉模型在体育分析[12]、自动驾驶[105]、电子零售[31]等领域的应用起到了关键作用。
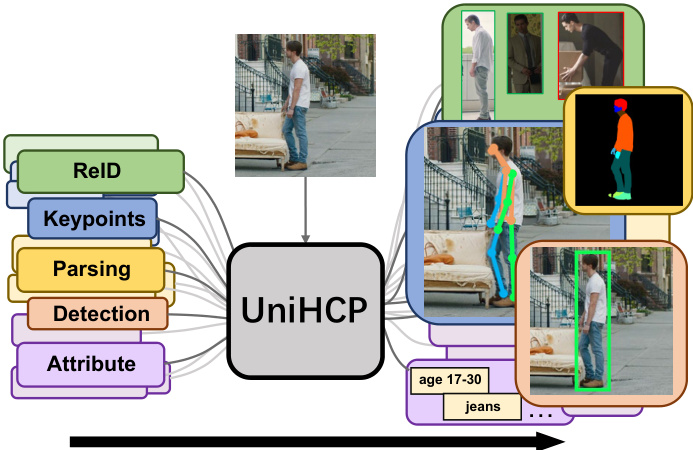
Figure 1. UniHCP unifies 5 human-centric tasks under one model and is trained on a massive collection of human-centric datasets.
图 1: UniHCP 将5种以人为中心的任务统一在一个模型下,并在海量以人为中心的数据集上进行训练。
Although different human-centric perception tasks have their own relevant semantic information to focus on, those semantics all rely on the same basic structure of the human body and the attributes of each body part [69, 89]. In light of this, there have been some attempts trying to exploit such homogeneity and train a shared neural network jointly with distinct human-centric tasks [32, 33, 52, 54, 68, 77, 83, 95, 106]. For instance, human parsing has been trained in conjunction with human keypoint detection [52,68,106], pedestrian attribute recognition [95], pedestrian detection [54] or person re-identification [32] (ReID). The experimental results of these works empirically validate that some humancentric tasks may benefit each other when trained together. Motivated by these works, a natural expectation is that a more versatile all-in-one model could be a feasible solution for general human-centric perceptions, which can utilize the homogeneity of human-centric tasks for improving performance, enable fast adaption to new tasks, and decrease the burden of memory cost in large-scale multitask system deployment compared with specific models to specific tasks.
尽管不同的人体中心感知任务各自关注相关的语义信息,但这些语义都依赖于相同的人体基本结构和各部位属性 [69, 89]。基于此,已有研究尝试利用这种同质性,通过不同人体中心任务联合训练共享神经网络 [32, 33, 52, 54, 68, 77, 83, 95, 106]。例如,人体解析曾与人体关键点检测 [52,68,106]、行人属性识别 [95]、行人检测 [54] 或行人重识别 [32] (ReID) 联合训练。这些工作的实验结果实证表明,某些人体中心任务在联合训练时可能相互促进。受此启发,我们自然期待一个更通用的全能模型可能成为通用人体中心感知的可行解决方案——它既能利用任务同质性提升性能,又可快速适应新任务,相比针对单一任务的专用模型还能降低多任务系统部署时的内存开销。
However, unifying distinct human-centric tasks into a general model is challenging considering the data diversity and output structures. From the data’s perspective, images in different human-centric tasks and different datasets have different resolutions and characteristics (e.g., day and night, indoor and outdoor), which calls for a robust representative network with the capability to accommodate them. From the perspective of output, the annotations and expected outputs of different human-centric tasks have distinct structures and granular i ties. Although this challenge can be bypassed via deploying separate output heads for each task/dataset, it is not scalable when the number of tasks and datasets is large.
然而,考虑到数据的多样性和输出结构,将不同的人本任务统一到一个通用模型中具有挑战性。从数据角度来看,不同人本任务和不同数据集中的图像具有不同的分辨率和特征(例如白天与夜晚、室内与室外),这需要一个具备适应能力的鲁棒性表征网络。从输出来看,不同人本任务的标注和预期输出具有不同的结构和粒度。虽然可以通过为每个任务/数据集部署独立的输出头来绕过这一挑战,但当任务和数据集数量庞大时,这种方法缺乏可扩展性。
In this work, we aim to explore a simple, scalable formulation for unified human-centric system and, for the first time, propose a Unified model for Human-Centric Perceptions (UniHCP). As shown in Figure.1, UniHCP unifies and simultaneously handles five distinct human-centric tasks, namely, pose estimation, semantic part segmentation, pedestrian detection, ReID, and person attribute recognition. Motivated by the extraordinary capacity and flexibility of the vision transformers [49, 101], a simple yet unified encoder-decoder architecture with the plain vision transformer is employed to handle the input diversity, which works in a simple feed forward and end-to-end manner, and can be shared across all human-centric tasks and datasets to extract general human-centric knowledge. To generate the output for different tasks with the unified model, UniHCP defines Task-specific Queries, which are shared among all datasets with the same task definition and interpreted into different output units through a Task-guided Interpreter shared across different datasets and tasks. With task-specific queries and the versatile interpreter, UniHCP avoids the widely used task-specific output heads, which minimizes task-specific parameters for knowledge sharing and make backbone-encoded features reusable across tasks.
在本工作中,我们旨在探索一种简单、可扩展的统一以人为中心的系统框架,并首次提出了统一的人体感知模型(UniHCP)。如图1所示,UniHCP统一并同时处理五项以人为中心的任务:姿态估计、语义部位分割、行人检测、ReID(行人重识别)和人物属性识别。受视觉Transformer[49, 101]卓越能力和灵活性的启发,我们采用基于纯视觉Transformer的简单统一编码器-解码器架构来处理输入多样性,该架构以简单的前馈和端到端方式工作,并可在所有以人为中心的任务和数据集间共享,以提取通用的人体中心知识。为了用统一模型生成不同任务的输出,UniHCP定义了任务特定查询(Task-specific Queries),这些查询在具有相同任务定义的所有数据集间共享,并通过跨数据集和任务共享的任务引导解释器(Task-guided Interpreter)转换为不同的输出单元。借助任务特定查询和多功能解释器,UniHCP避免了广泛使用的任务特定输出头,最大限度地减少了知识共享所需的任务特定参数,并使骨干编码特征可跨任务复用。
Own to these designs, UniHCP is suitable and easy to perform multitask pre training at scale. To this end, we pretrained an UniHCP model on a massive collection of 33 labeled human-centric datasets. By harnessing the abundant supervision signals of each task, we show such a model can simultaneously handle these in-pretrain tasks well with competitive performance compared to strong baselines relying on specialized architectures. When adapted to a specific task, both in-domain and downstream, our model achieves new SOTAs on several human-centric task benchmarks. In summary, the proposed model has the following properties:
得益于这些设计,UniHCP 适合并易于进行大规模多任务预训练。为此,我们在包含 33 个标注以人为中心数据集的庞大数据集上预训练了 UniHCP 模型。通过利用每个任务的丰富监督信号,我们展示了该模型能够同时很好地处理这些预训练任务,其性能与依赖专用架构的强基线模型相当。当适应特定任务时,无论是在领域内还是下游任务,我们的模型在多个以人为中心的基准测试中均实现了新的 SOTA (State-of-the-Art)。总之,所提出的模型具有以下特性:
with a task-guided interpreter. ■ Trainable at scale and demonstrates competitive performance compared to task-specialized models.
配备任务导向型解释器。■ 可规模化训练,与专用任务模型相比展现出竞争力性能。
The following sections are organized as follows: Section 2 reviews the related works with focuses on HumanCentric perception and unified models. Section 3 describes the proposed model. Section 4 provides implementation details together with empirical results and ablation studies. Finally, we conclude the paper in Section 5.
以下章节安排如下:第2节回顾相关工作,重点介绍以人为中心的感知 (HumanCentric perception) 和统一模型 (unified models) 。第3节描述提出的模型。第4节提供实现细节、实证结果和消融研究。最后,第5节对全文进行总结。
2. Related Works
2. 相关工作
2.1. Human-Centric Perceptions
2.1. 以人为本的感知
Human-centric perceptions are essential for substantial real-world applications. Depending on the targeted visual concept, the way of decoding output from image features varies across tasks. Specifically, pose estimation and pedestrian detection are both localization tasks that can be solved by either regression-based methods [41, 103] or heatmapbased methods [37, 38, 93]. Human parsing, as a finegrained segmentation problem, is usually solved by perpixel classification. While contour-based methods [70, 94] can also obtain segmentation masks, it requires instancelevel mask annotations, which are not always available. PAR is treated as a multi-label classification task [116], and ReID is treated as a feature learning task [81].
以人为中心的感知对于实际应用至关重要。根据目标视觉概念的不同,从图像特征解码输出的方式因任务而异。具体而言,姿态估计和行人检测都属于定位任务,可通过基于回归的方法 [41, 103] 或基于热图的方法 [37, 38, 93] 解决。人体解析作为细粒度分割问题,通常采用逐像素分类方法处理。虽然基于轮廓的方法 [70, 94] 也能获得分割掩码,但需要实例级掩码标注,而这些标注并不总是可用。PAR (物理活动识别) 被视为多标签分类任务 [116],而 ReID (行人重识别) 则被视为特征学习任务 [81]。
Recently, several transformer-based solutions have been proposed for these human-centric tasks, with attention block designs on both backbone [23, 96, 100] and decoding network [46, 50, 60, 66, 95, 110]. However, these methods involve different task-specific designs and thus cannot be integrated into one model seamlessly. Built upon the general success of these works, we take a further step and unify human-centric tasks under the same architecture based on plain vision transformer.
近期,多项基于Transformer的解决方案被提出用于这些以人为中心的任务,其注意力模块设计同时涵盖主干网络[23, 96, 100]和解码网络[46, 50, 60, 66, 95, 110]。然而,这些方法采用了不同的任务专用设计,因此无法无缝集成到单一模型中。基于这些工作的普遍成功,我们进一步推进,在纯视觉Transformer架构下统一了以人为中心的任务。
2.2. Unified Models
2.2. 统一模型
A general-purpose model that can handle different tasks in a unified manner has long been a coveted alternative to models specifically tailored for different tasks. Pioneering works regarding Natural Language Processing (NLP) [71], vision-language [65], and basic vision tasks [34, 73] have shown the effectiveness of such kind of unified cross-task models. ExT5 [3] and OFA [88] further provide a degree of promise for the performance benefits of large-scale multitask co-training. Among models supporting visual tasks, UniHead [51] and UViM [35] propose a unified architecture for several vision tasks. However, they are only trained and evaluated in a single-task manner.
能够以统一方式处理不同任务的通用模型,长期以来都是针对特定任务定制模型的理想替代方案。在自然语言处理(NLP) [71]、视觉语言[65]和基础视觉任务[34, 73]领域的开创性工作已证明了这类统一跨任务模型的有效性。ExT5 [3]和OFA [88]进一步证明了大规模多任务协同训练带来的性能优势。在支持视觉任务的模型中,UniHead [51]和UViM [35]提出了适用于多种视觉任务的统一架构,但它们仅以单任务方式进行训练和评估。
For methods supporting multitask co-training, UniPerceiver [118] focuses on tasks in which the desired output is inherently language or labels, which does not fit humancentric tasks. While UniT [25], OFA [88], Unified-IO [64], and Pix2Seq v2 [8] further extend the support for detection, keypoint detection, segmentation, and many other visual tasks, they rely on independent decoder heads [25, 88] or auto regressive modeling [8, 64]. These works do not focus on human-centric vision tasks. Differently, our work introduces a shared decoder head (task-guided interpreter) in a parallelly feed forward manner for human-centric vision tasks, which is simple yet maximizes the parameter sharing among different tasks.
对于支持多任务协同训练的方法,UniPerceiver [118] 主要关注输出本质上是语言或标签的任务,这不适用于以人为中心的任务。而UniT [25]、OFA [88]、Unified-IO [64] 和 Pix2Seq v2 [8] 进一步扩展了对检测、关键点检测、分割及其他多种视觉任务的支持,但它们依赖于独立的解码头 [25, 88] 或自回归建模 [8, 64]。这些工作并未聚焦以人为中心的视觉任务。不同的是,我们的工作针对以人为中心的视觉任务,以并行前馈方式引入了一个共享解码头(任务引导解释器),这种方式简单且能最大化不同任务间的参数共享。
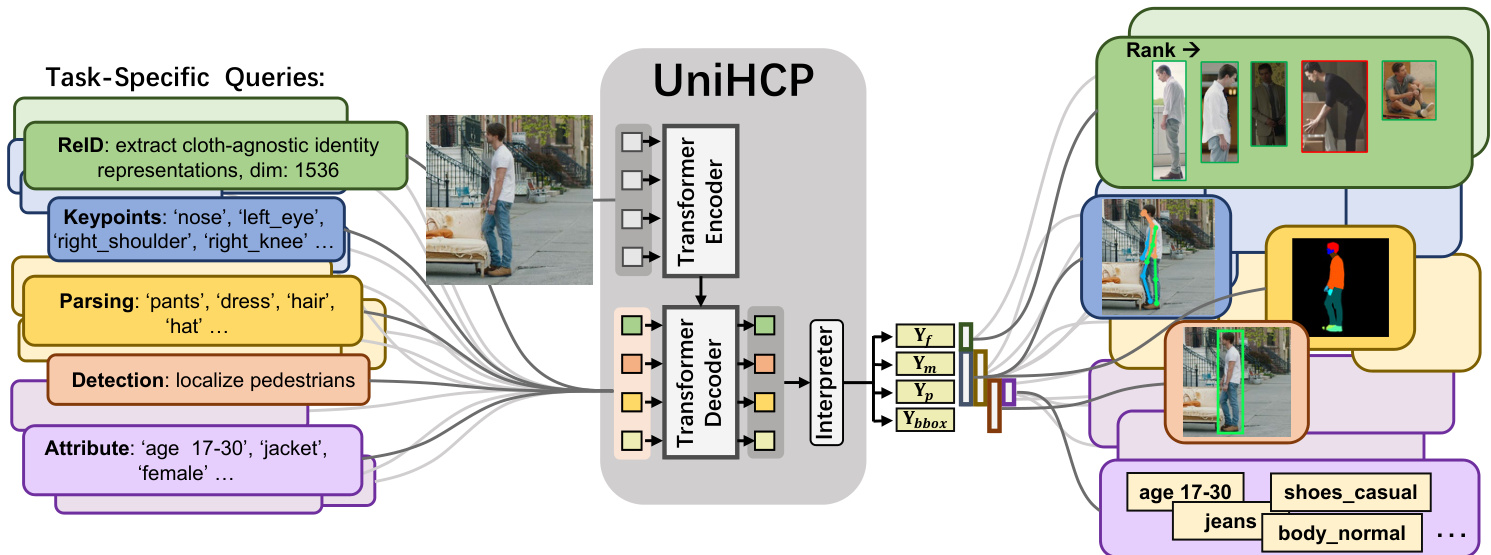
Figure 2. UniHCP handles a massive collection of human-centric tasks uniformly by task-specific queries and a task-guided interpreter, all predictions are yielded in parallel through a simple encoder-decoder transformer architecture.
图 2: UniHCP通过任务特定查询(task-specific queries)和任务引导解释器(task-guided interpreter)统一处理海量以人为中心的任务,所有预测结果均通过简单的编码器-解码器Transformer架构并行生成。
Table 1. Network details of UniHCP
表 1. UniHCP 网络详情
| 层数 | 维度 | 参数量 | |
|---|---|---|---|
| 编码器 (Encoder) | 12 | 768 | 91.1M |
| 解码器 (Decoder) | 9 | 256 | 14.5M |
| 任务引导解释器 (Task-guided Interpreter) | - | - | 3.5M |
| 任务特定查询 (Task-specific queries) | - | 256 | <0.03M |
| 总计 | - | - | 109.1M |
| 任务无关参数量/总参数量 | - | - | 99.97% |
In the case of human-centric tasks, many works have shown great success by co-training a pair of human-centric tasks [32, 33, 52, 54, 68, 77, 83, 95, 106]. However, there is no work exploring a general unified model that can handle all representative human-centric tasks. Our work is the first attempt at designing, training, and evaluating a unified human-centric model with a large-scale multitask setting.
在以人为中心的任务方面,已有许多研究通过联合训练成对的人本任务取得了显著成功 [32, 33, 52, 54, 68, 77, 83, 95, 106]。然而,目前尚未有研究探索能够处理所有代表性人本任务的通用统一模型。我们的工作是首次尝试在大规模多任务设置下设计、训练和评估统一的人本模型。
3. UniHCP
3. UniHCP
To share the most knowledge among various humancentric tasks, we attempt to maximize weight sharing among all tasks in UniHCP. Specifically, our UniHCP, as shown in Figure 2, consists of three components: (1) A taskagnostic transformer encoder $E$ to extract image features. (2) A transformer decoder $D$ that attends to task-specific information according to task-specific queries ${\mathbf{Q}^{t}}$ , where $t$ denotes a specific task. (3) A task-guided interpreter $\mathcal{T}$ produces output units, in which we decompose the output of multiple human-centric perception tasks into sharable units of diverse granular i ties, i.e., feature representation, local probability map, global probability, bounding box coordinates. Since only the queries to the decoders are not shared among tasks, we can learn human-centric knowledge across different granular i ties by the designed interpreters and achieve maximum parameter sharing among all tasks, i.e., $99.97%$ shared parameters, as shown in Table 1. The pipeline for our UniHCP is described as follows.
为了在各种以人为中心的任务间共享最多的知识,我们尝试在UniHCP中最大化所有任务间的权重共享。具体而言,如图2所示,我们的UniHCP包含三个组件:(1) 一个任务无关的Transformer编码器 $E$ 用于提取图像特征;(2) 一个根据任务特定查询 ${\mathbf{Q}^{t}}$ 关注任务特定信息的Transformer解码器 $D$ ,其中 $t$ 表示特定任务;(3) 一个任务引导的解释器 $\mathcal{T}$ 生成输出单元,我们将多个以人为中心的感知任务输出分解为不同粒度的可共享单元,即特征表示、局部概率图、全局概率、边界框坐标。由于只有解码器的查询在任务间不共享,我们可以通过设计的解释器学习不同粒度的人类中心知识,并实现所有任务间的最大参数共享(如表1所示,共享参数达99.97%)。UniHCP的流程如下所述。
Step 1: Given an image $\mathbf{X}$ sampled from the dataset in task $t$ , extract encoded features $\mathbf{F}$ by the task-agnostic transformer encoder $E$ (Sec. 3.1).
步骤1:给定从任务$t$的数据集中采样的图像$\mathbf{X}$,通过任务无关的Transformer编码器$E$提取编码特征$\mathbf{F}$(见第3.1节)。
Step $2:\mathrm{~A }$ transformer decoder $D$ with task-specific queries $\mathbf{Q}^{t}$ extracts task-specific features from encoded features $\mathbf{F}$ (Sec. 3.2).
步骤 $2:\mathrm{~A }$ Transformer解码器 $D$ 通过任务特定查询 $\mathbf{Q}^{t}$ 从编码特征 $\mathbf{F}$ 中提取任务特定特征 (第3.2节)。
Step 3: Generate output units according to the queried task, i.e., attended features $\mathbf{Y}{f}$ , local probability map ${\bf Y}{m}$ , global probability $\mathbf{Y}{p}$ and bounding box coordinates $\mathbf{Y}{b b o x}$ by a task-guided interpreter $\mathcal{T}$ (Sec. 3.3). For example, for human parsing, two units: local probability map ${\bf Y}{m}$ (for semantic part segmentation) and global probability $\mathbf{Y}_{p}$ (for existence of body part in the image), are generated.
步骤3:根据查询任务生成输出单元,即通过任务引导解释器 $\mathcal{T}$(第3.3节)生成关注特征 $\mathbf{Y}{f}$、局部概率图 ${\bf Y}{m}$、全局概率 $\mathbf{Y}{p}$ 和边界框坐标 $\mathbf{Y}{b b o x}$。例如,对于人体解析任务,会生成两个单元:局部概率图 ${\bf Y}{m}$(用于语义部位分割)和全局概率 $\mathbf{Y}_{p}$(用于判断图像中是否存在该身体部位)。
Step 4: Calculate the loss of the corresponding task for optimizing the encoder $E$ , the decoder $D$ , the task-specific queries $\mathbf{Q}^{t}$ and task-guided interpreter $\mathcal{T}$ by backward prop- agation (Sec. 3.4).
步骤4:通过反向传播计算对应任务的损失,用于优化编码器 $E$、解码器 $D$、任务特定查询 $\mathbf{Q}^{t}$ 和任务引导解释器 $\mathcal{T}$(见第3.4节)。
3.1. Task-agnostic Transformer Encoder
3.1. 任务无关的Transformer编码器
UniHCP uses a plain Vision Tr as n former [15] (ViT) as the encoder. To handle input images of different resolutions, we use a shared learnable positional embedding with the size of $84\times84$ and interpolate it based on the spatial size of the input image after patch projection. The encoded feature $\mathbf{F}$ can be mathematically calculated as
UniHCP 采用普通的 Vision Transformer [15] (ViT) 作为编码器。为处理不同分辨率的输入图像,我们使用尺寸为 $84\times84$ 的可学习共享位置嵌入,并在图像块投影后根据输入图像的空间尺寸进行插值。编码特征 $\mathbf{F}$ 可通过数学公式计算为
$$
\mathbf{F}=E(\mathbf{X},\mathbf{P}_{E}),
$$
$$
\mathbf{F}=E(\mathbf{X},\mathbf{P}_{E}),
$$
where $\mathbf{P}_{E}$ is the positional embedding after interpolation and $E$ denotes the task-agnostic transformer encoder.
其中 $\mathbf{P}_{E}$ 是插值后的位置嵌入 (positional embedding),$E$ 表示任务无关的 Transformer 编码器。
3.2. Decoder with Task-specific Queries
3.2. 带任务特定查询的解码器
To obtain the most disc rim i native feature for each task while maximizing knowledge sharing, we design taskspecific queries to guide the transformer decoder only attending to task-relevant information.
为了在最大化知识共享的同时为每个任务获取最具区分性的特征,我们设计了任务特定查询来引导Transformer解码器仅关注任务相关信息。
Task-specific Queries. Task queries for task $t$ are denoted as
任务特定查询。任务 $t$ 的查询表示为
$$
\mathbf{Q}^{t}=[\mathbf{q}{1}^{t},\mathbf{q}{2}^{t},...,\mathbf{q}_{N^{t}}^{t}],
$$
$$
\mathbf{Q}^{t}=[\mathbf{q}{1}^{t},\mathbf{q}{2}^{t},...,\mathbf{q}_{N^{t}}^{t}],
$$
where $N^{t}$ denotes the number of queries representing $N^{t}$ different semantic meanings in task $t$ . For pedestrian attribute recognition, pose estimation, human parsing, and ReID, the number of queries respectively equals to the number of attributes, the number of pose joints, the number of semantic parsing classes, and the length of desired ReID features. For pedestrian detection, we follow the implementation in [90], with details provided in the supplementary material. We randomly initialize the task-specific query $\mathbf{Q}^{t}$ as learnable embeddings $\mathbf{Q}_{0}^{t}$ and refine it with the following decoder blocks.
其中 $N^{t}$ 表示任务 $t$ 中代表 $N^{t}$ 种不同语义含义的查询数量。对于行人属性识别、姿态估计、人体解析和ReID任务,查询数量分别等于属性数量、姿态关节点数量、语义解析类别数和目标ReID特征长度。对于行人检测任务,我们遵循[90]中的实现方式,具体细节见补充材料。我们随机初始化任务特定查询 $\mathbf{Q}^{t}$ 作为可学习嵌入 $\mathbf{Q}_{0}^{t}$,并通过后续解码器块对其进行优化。
Following the common practice as in [10, 84, 90], all $\mathbf{Q}^{t}$ are also associated with a positional embedding $\mathbf{Q}{p}^{t}$ , which has the same dimension as $\mathbf{Q}^{t}$ and is not shared across tasks. Different from $\mathbf{Q}^{t}$ that will be progressively refined in the decoder blocks, $\mathbf{Q}{p}^{t}$ is shared across decoder blocks. For tasks other than pedestrian detection, $\mathbf{Q}_{p}^{t}$ is simply a learnable positional embedding that is randomly initialized. For pedestrian detection, we have
遵循[10, 84, 90]的通用做法,所有$\mathbf{Q}^{t}$还关联一个位置嵌入$\mathbf{Q}{p}^{t}$,其维度与$\mathbf{Q}^{t}$相同且不跨任务共享。与会在解码器块中逐步优化的$\mathbf{Q}^{t}$不同,$\mathbf{Q}{p}^{t}$在解码器块间共享。对于行人检测之外的任务,$\mathbf{Q}_{p}^{t}$仅是随机初始化的可学习位置嵌入。对于行人检测任务,我们有
$$
\mathbf{Q}{p}^{t}=p r o j({\mathcal{A}}_{\mathbf{Q}}),
$$
$$
\mathbf{Q}{p}^{t}=p r o j({\mathcal{A}}_{\mathbf{Q}}),
$$
where $\mathcal{A}_{\mathbf{Q}}\in\mathbb{R}^{N^{t}\times2}$ refers to $N^{t}$ learnable anchor points that are initialized with a uniform distribution following [90], and proj is a projection from coordinates to positional embeddings (more details about the projector are elaborated in the supplementary materials).
其中 $\mathcal{A}_{\mathbf{Q}}\in\mathbb{R}^{N^{t}\times2}$ 表示 $N^{t}$ 个可学习的锚点,这些锚点按照 [90] 的方法采用均匀分布进行初始化,proj 表示从坐标到位置嵌入的投影 (关于投影器的更多细节详见补充材料)。
Decoder. The transformer decoder aims to attend to taskspecific features according to the task queries. We follow the standard design of transformer decoders [84]. In the decoder, each transformer block $D_{l}$ for $l=1,2,...,L$ consists of a cross-attention module, a self-attention module, and a feed-forward module (FFN), where $L$ denotes the number of transformer blocks. We place cross-attention before selfattention as adopted by [10, 40]. For each block $D_{l}$ , we attend to task-specific information from the encoded feature by task queries, which can be formulated as
解码器。Transformer解码器旨在根据任务查询关注任务特定特征。我们遵循Transformer解码器的标准设计[84]。在解码器中,每个Transformer块$D_{l}$($l=1,2,...,L$)由交叉注意力模块、自注意力模块和前馈模块(FFN)组成,其中$L$表示Transformer块的数量。我们采用[10, 40]的方案,将交叉注意力置于自注意力之前。对于每个块$D_{l}$,我们通过任务查询从编码特征中提取任务特定信息,其公式可表示为
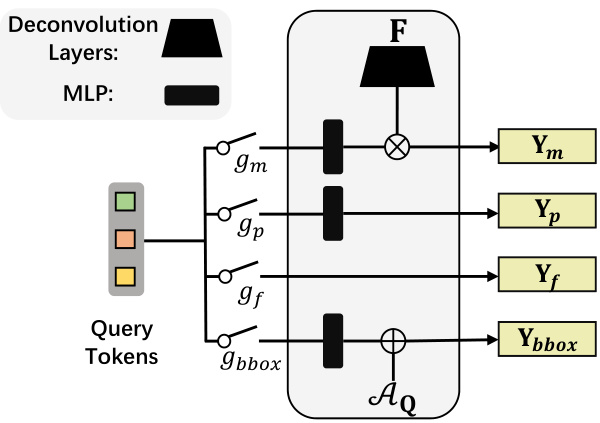
Figure 3. Task-guided interpreter. $\otimes$ denotes a dynamic convolution module [9] that takes the projected query feature as the kernel and takes the tokens $\mathbf{F}$ from the encoder as the feature map, where $\mathbf{F}$ is upscaled to the desired resolution $H^{\prime}\times W^{\prime}$ , $\bigoplus$ denotes addition, for which the inputs are the projected query feature in the format of $[\nabla c x,\nabla c x,h,w]$ and $\mathcal{A}_{\mathbf{Q}}$ , which contains the anchor point $[c x,c y]$ (see supplementary materials for details).
图 3: 任务引导解释器。$\otimes$ 表示动态卷积模块 [9],它以投影后的查询特征作为卷积核,并将编码器输出的 tokens $\mathbf{F}$ 作为特征图,其中 $\mathbf{F}$ 被上采样至目标分辨率 $H^{\prime}\times W^{\prime}$。$\bigoplus$ 表示加法运算,其输入为格式为 $[\nabla c x,\nabla c x,h,w]$ 的投影查询特征和包含锚点 $[c x,c y]$ 的 $\mathcal{A}_{\mathbf{Q}}$ (详见补充材料)。
$$
\mathbf{Q}{l}^{t}=D_{l}(\mathbf{Q}{l-1}^{t},\mathbf{Q}{p}^{t},\mathbf{F},\mathbf{F}_{p}),
$$
$$
\mathbf{Q}{l}^{t}=D_{l}(\mathbf{Q}{l-1}^{t},\mathbf{Q}{p}^{t},\mathbf{F},\mathbf{F}_{p}),
$$
$$
\mathbf{F}{p}=p r o j(\mathcal{A}_{\mathbf{F}}),
$$
$$
\mathbf{F}{p}=p r o j(\mathcal{A}_{\mathbf{F}}),
$$
$\mathcal{A}{\mathbf{F}}\in\mathbb{R}^{H_{\mathbf{F}}W_{\mathbf{F}}\times2}$ is the coordinates with respect to the original image for all feature tokens in $\mathbf{F} \in~\dot{R}^{H_{\mathbf{F}}\times W_{\mathbf{F}}}$ . For the cross-attention in the decoder $D_{l}$ , the query is $\hat{\mathbf{Q}}{l}^{t}=$ $\mathbf{Q}{l-1}^{t}+\mathbf{Q}{p}^{t}$ , the key is $\hat{\textbf{K}}=\textbf{F}^{\prime}+\textbf{F}{p}$ , and the value is $\hat{\mathbf{V}}=\mathbf{F}^{\prime}$ , where $\mathbf{F}^{\prime}$ is linearly projected from the features of the encoder $\mathbf{F}$ to align channel dimensions. The result of cross-attention is then passed for self-attention in $D_{l}$ .
$\mathcal{A}{\mathbf{F}}\in\mathbb{R}^{H_{\mathbf{F}}W_{\mathbf{F}}\times2}$ 是特征图 $\mathbf{F} \in~\dot{R}^{H_{\mathbf{F}}\times W_{\mathbf{F}}}$ 中所有特征token相对于原始图像的坐标。对于解码器 $D_{l}$ 中的交叉注意力机制,查询向量为 $\hat{\mathbf{Q}}{l}^{t}=$ $\mathbf{Q}{l-1}^{t}+\mathbf{Q}{p}^{t}$,键向量为 $\hat{\textbf{K}}=\textbf{F}^{\prime}+\textbf{F}{p}$,值向量为 $\hat{\mathbf{V}}=\mathbf{F}^{\prime}$,其中 $\mathbf{F}^{\prime}$ 是通过对编码器特征 $\mathbf{F}$ 进行线性投影以对齐通道维度得到的。交叉注意力的结果随后会传递到 $D_{l}$ 的自注意力机制中。
3.3. Task-guided Interpreter
3.3. 任务导向型解释器
Task-guided interpreter $\mathcal{T}$ interprets query tokens $\mathbf{Q}^{t}$ into four output units subject to the request of a specific task. As shown in Figure 3, these four output units are as follows:
任务引导解释器 $\mathcal{T}$ 根据特定任务需求,将查询 token $\mathbf{Q}^{t}$ 解析为四个输出单元。如图 3 所示,这四个输出单元如下:
$$
\begin{array}{r l}&{\mathrm{feature vector unit:}{\mathbf Y}{f}\in{\mathbb R}^{N^{t}\times C}}\ &{\mathrm{globalprobabilityunit:}{\mathbf Y}{p}\in{\mathbb R}^{N^{t}\times1}}\ &{\mathrm{local probability map unit:}{\mathbf Y}{m}\in{\mathbb R}^{N^{t}\times H^{\prime}\times W^{\prime}}}\ &{\mathrm{bounding box~unit:}{\mathbf Y}_{b b o x}\in{\mathbb R}^{N^{t}\times4},}\end{array}
$$
$$
\begin{array}{r l}&{\mathrm{特征向量单元:}{\mathbf Y}{f}\in{\mathbb R}^{N^{t}\times C}}\ &{\mathrm{全局概率单元:}{\mathbf Y}{p}\in{\mathbb R}^{N^{t}\times1}}\ &{\mathrm{局部概率图单元:}{\mathbf Y}{m}\in{\mathbb R}^{N^{t}\times H^{\prime}\times W^{\prime}}}\ &{\mathrm{边界框单元:}{\mathbf Y}_{b b o x}\in{\mathbb R}^{N^{t}\times4},}\end{array}
$$
where $C$ is the output dimension of the decoder, $H^{\prime}\times W^{\prime}$ denotes the desired resolution for the local probability map.
其中 $C$ 是解码器的输出维度,$H^{\prime}\times W^{\prime}$ 表示局部概率图的期望分辨率。
Given task $t$ and output interpreter $\mathcal{T}$ , the output of the UniHCP is defined as follows:
给定任务 $t$ 和输出解释器 $\mathcal{T}$,UniHCP 的输出定义如下:
$$
{\mathbf{Y}{u}|g_{u}^{\mathbf{t}{t}}=1,u\in{f,p,m,b b o x}}=\mathcal{T}(\mathbf{Q}^{t},\mathbf{g}^{\mathbf{t}_{t}}),
$$
$$
{\mathbf{Y}{u}|g_{u}^{\mathbf{t}{t}}=1,u\in{f,p,m,b b o x}}=\mathcal{T}(\mathbf{Q}^{t},\mathbf{g}^{\mathbf{t}_{t}}),
$$
where $\mathbf{t}{t}\in{r e i d,\ldots,p o s e}$ denotes the task type of task $t$ , $\mathbf{g}^{\mathbf{t}}={g_{u}^{\mathbf{t}}}$ is a set of task-specific binary gates $(g\in{0,1})$ that represents the desired output units for task type t.
其中 $\mathbf{t}{t}\in{r e i d,\ldots,p o s e}$ 表示任务 $t$ 的类型,$\mathbf{g}^{\mathbf{t}}={g_{u}^{\mathbf{t}}}$ 是一组任务特定的二元门 $(g\in{0,1})$,代表任务类型 t 所需的输出单元。
Guidance from tasks to output units. For human parsing, local probability map (for semantic part segmentation) and global probability (for existence of body part in the image) are activated, corresponding to $g_{m}^{s e g}=1$ and $g_{p}^{s e g}=1$ respectively. For person ReID, feature vectors are used, corresponding to $g_{f}^{r e i d}=1$ . For pose estimation, $g_{m}^{p o s e}=1$ (for localizing key points) and $g_{p}^{p o s e}=1$ (for existence of keypoints in the image). For detection, $g_{b b o x}^{d e t}=1$ (for bounding box prediction) and gpde $g_{p}^{d e t}=1$ (for existence of object). For pedestrian attribute prediction, $g_{p}^{p a r}=1$ (for existence of attributes in the image). Therefore, the output unit of global probabilities is shared among pose estimation, human parsing, pedestrian detection, and attribute recognition. The output unit of local probability maps is shared among pose estimation and human parsing.
从任务到输出单元的指导。对于人体解析,激活局部概率图(用于语义部位分割)和全局概率(用于判断图像中是否存在身体部位),分别对应 $g_{m}^{s e g}=1$ 和 $g_{p}^{s e g}=1$。对于行人重识别(ReID),使用特征向量,对应 $g_{f}^{r e i d}=1$。对于姿态估计,$g_{m}^{p o s e}=1$(用于定位关键点)和 $g_{p}^{p o s e}=1$(用于判断图像中是否存在关键点)。对于检测任务,$g_{b b o x}^{d e t}=1$(用于边界框预测)和 $g_{p}^{d e t}=1$(用于判断目标存在性)。对于行人属性预测,$g_{p}^{p a r}=1$(用于判断图像中是否存在属性)。因此,全局概率输出单元在姿态估计、人体解析、行人检测和属性识别任务间共享,局部概率图输出单元则在姿态估计和人体解析任务间共享。
Discussion. The task-guided interpreter interprets each query token independently. Previous works focused on auto regressive decoding with token iz ation [8, 64] or taskspecific heads [25, 99] to handle different output units required by specific tasks. In contrast, the task-guided interpreter can handle tasks involving a varying number of classes, yield all results in parallel, and do not require taskspecific heads. This is achieved by two designs in our UniHCP framework: 1) Class/instance information is selfcontained in queries. As mentioned in Section 3.2, a query represents a particular semantic class in pose estimation, attribute prediction, human parsing, and pedestrian detection. We only need to retrieve a scalar probability value from a query to obtain the confidence information for a particular class/human instance. 2) Outputs of the same modality share the same output unit. For example, the heatmap for a particular joint in pose estimation and the heatmap for a particular body part in human parsing have the same dimension. Although these outputs have different meanings, experimental results in Section 4.3 show that it is suitable to obtain them through the same output unit and fully let the task-specific queries handle the differences in preferred information to be represented.
讨论。任务引导型解释器独立解释每个查询token。先前的研究主要关注采用自回归解码配合token化处理[8,64]或任务特定头[25,99]来应对不同任务所需的输出单元。相比之下,任务引导型解释器能处理涉及可变类别数量的任务,并行生成所有结果,且无需任务特定头。这得益于我们UniHCP框架的两项设计:1)类别/实例信息内置于查询中。如第3.2节所述,在姿态估计、属性预测、人体解析和行人检测任务中,每个查询代表特定语义类别。我们只需从查询中提取标量概率值即可获得特定类别/人体实例的置信度信息;2)相同模态的输出共享相同单元。例如姿态估计中特定关节的热力图与人体解析中特定身体部位的热力图具有相同维度。虽然这些输出含义不同,但第4.3节的实验表明,通过相同输出单元获取这些结果并完全由任务特定查询处理待表征信息的差异是可行的。
3.4. Objective Functions
3.4. 目标函数
In this section, we will introduce the objective functions for training diverse human-centric tasks together and illustrate how these objectives are related to the output units defined in Eq. 6. Unless otherwise specified, we omit the GT inputs in loss functions for brevity.
在本节中,我们将介绍训练多样化以人为中心任务的联合目标函数,并阐述这些目标如何与公式6定义的输出单元相关联。除非另有说明,为简洁起见,损失函数中的GT输入均被省略。
Overall Objective Function. Given a collection of datasets $\mathbb{D}={\mathcal{D}|\mathbf{t}{\mathcal{D}}\in{r e i d,\dots,p o s e}}$ , where $\mathbf{t}{\mathcal{D}}$ denotes the task type of dataset $\mathcal{D}$ , we also note $t_{\mathcal{D}}$ as the task of dataset $\mathcal{D}$ , we have the overall loss defined as:
总体目标函数。给定数据集集合 $\mathbb{D}={\mathcal{D}|\mathbf{t}{\mathcal{D}}\in{r e i d,\dots,p o s e}}$,其中 $\mathbf{t}{\mathcal{D}}$ 表示数据集 $\mathcal{D}$ 的任务类型,我们也将 $t_{\mathcal{D}}$ 记作数据集 $\mathcal{D}$ 的任务,总体损失定义为:
$$
\mathcal{L}=\sum_{\mathcal{D}\in\mathbb{D}}w_{\mathcal{D}}\mathcal{L}{\mathbf{t}{\mathcal{D}}}(\mathcal{I}(\mathbf{Q}^{t_{\mathcal{D}}},\mathbf{g}^{\mathbf{t}_{\mathcal{D}}})),
$$
$$
\mathcal{L}=\sum_{\mathcal{D}\in\mathbb{D}}w_{\mathcal{D}}\mathcal{L}{\mathbf{t}{\mathcal{D}}}(\mathcal{I}(\mathbf{Q}^{t_{\mathcal{D}}},\mathbf{g}^{\mathbf{t}_{\mathcal{D}}})),
$$
where $w_{T}$ is the loss weight for dataset $\mathcal{D}$ , which is calculated based on the task type and batch size (calculations are elaborated in supplementary materials).
其中 $w_{T}$ 是数据集 $\mathcal{D}$ 的损失权重,其值根据任务类型和批次大小计算得出(具体计算方式详见补充材料)。
ReID. Person ReID is a feature learning task for extracting identification information. Therefore, we directly supervised the features after the decoder by identity annotations. Specifically, for ReID task, the extracted feature is a simple concatenation of all feature vectors $\mathbf{Y}{f}=~[y_{f}^{1};\dots;y_{f}^{\hat{N}^{t}}]$ , where $N^{t}=6$ by default. The loss function is a combination of ID loss [114] and triplet loss [58] written as follows:
ReID。行人重识别 (ReID) 是一项用于提取身份信息的特征学习任务。因此,我们直接通过身份标注对解码器后的特征进行监督。具体而言,对于ReID任务,提取的特征是所有特征向量 $\mathbf{Y}{f}=~[y_{f}^{1};\dots;y_{f}^{\hat{N}^{t}}]$ 的简单拼接,其中默认 $N^{t}=6$。损失函数由ID损失 [114] 和三元组损失 [58] 组合而成,公式如下:
$$
\mathcal{L}{r e i d}=\mathcal{L}{I D}(\mathbf{Y}{f})+\mathcal{L}{t r i p l e t}(\mathbf{Y}_{f}).
$$
$$
\mathcal{L}{r e i d}=\mathcal{L}{I D}(\mathbf{Y}{f})+\mathcal{L}{t r i p l e t}(\mathbf{Y}_{f}).
$$
PAR. Pedestrian attribute recognition only predicts whether an attribute exists in the global image. Therefore, we only supervise the output unit of global probabilities $\mathbf{Y}{p}$ from the task-guided interpreter. Specifically, following the common practice [46, 82], we adopt the weighted binary cross-entropy loss. Given the probability predictions $\mathbf{Y}_{p}$ associated with $N^{t}$ attributes, we have:
PAR. 行人属性识别仅预测全局图像中是否存在某个属性。因此,我们仅对任务引导解释器输出的全局概率单元 $\mathbf{Y}{p}$ 进行监督。具体而言,遵循常见做法 [46, 82],我们采用加权二元交叉熵损失。给定与 $N^{t}$ 个属性相关联的概率预测 $\mathbf{Y}_{p}$,我们有:
$$
\begin{array}{r l r}{{\mathcal{L}{p a r}=\displaystyle\sum_{n=1}^{N_{t}}w_{n}(y_{n}\log(y_{p}^{n})+(1-y_{n})\log(1-y_{p}^{n})),}}\ &{}&{w_{n}=y_{n}e^{1-\gamma_{n}}+(1-y_{n})e^{\gamma_{n}},}\end{array}
$$
$$
\begin{array}{r l r}{{\mathcal{L}{p a r}=\displaystyle\sum_{n=1}^{N_{t}}w_{n}(y_{n}\log(y_{p}^{n})+(1-y_{n})\log(1-y_{p}^{n})),}}\ &{}&{w_{n}=y_{n}e^{1-\gamma_{n}}+(1-y_{n})e^{\gamma_{n}},}\end{array}
$$
where $y_{n}$ denotes the annotation of $n$ -th attribute and $\gamma_{n}$ denotes the positive example ratio of $n$ -th attribute.
其中 $y_{n}$ 表示第 $n$ 个属性的标注,$\gamma_{n}$ 表示第 $n$ 个属性的正例比例。
Human Parsing. Human parsing can be considered as semantic segmentation of human part. We view the presence of semantic classes as predictable attributes since the semantic classes are not always present in an image. Therefore, the global probability $\mathbf{Y}{p}$ and local probability map ${\bf Y}{m}$ are selected from the output units to describe whether a semantic part exists on the image level (global) and pixel level (local), respectively. Given a query $\mathbf{q}{l}$ defined in Eq. 2 which corresponds to a semantic class in human parsing, we adopt the binary cross entropy loss as $\mathcal{L}{p a r}$ in pedestrian attribute recognition to constrain the global probability $\mathbf{Y}{p}$ , and a combination of binary cross-entropy loss and dice loss [10] to supervised local probability map ${\bf Y}_{m}$ as follows:
人体解析。人体解析可视为人体部位的语义分割。由于语义类别并非始终存在于图像中,我们将语义类别的存在视为可预测属性。因此,从输出单元中选取全局概率$\mathbf{Y}{p}$和局部概率图${\bf Y}{m}$,分别描述语义部位在图像层面(全局)和像素层面(局部)是否存在。给定式2中定义的对应人体解析语义类别的查询$\mathbf{q}{l}$,我们采用行人属性识别中的二元交叉熵损失作为$\mathcal{L}{p a r}$来约束全局概率$\mathbf{Y}{p}$,并组合二元交叉熵损失和dice损失[10]来监督局部概率图${\bf Y}_{m}$如下:
$\begin{array}{r}{\mathcal{L}{s e g}=\lambda_{p a r}\mathcal{L}{p a r}(\mathbf{Y}{p})+\mathcal{L}{b c e}(\mathbf{Y}{m})+\mathcal{L}{d i c e}(\mathbf{Y}{m}),}\end{array}$ where $\lambda_{p a r}$ denotes the loss weight for $\mathcal{L}{p a r}(\mathbf{Y}_{p})$ .
$\begin{array}{r}{\mathcal{L}{s e g}=\lambda_{p a r}\mathcal{L}{p a r}(\mathbf{Y}{p})+\mathcal{L}{b c e}(\mathbf{Y}{m})+\mathcal{L}{d i c e}(\mathbf{Y}{m}),}\end{array}$ 其中 $\lambda_{p a r}$ 表示 $\mathcal{L}{p a r}(\mathbf{Y}_{p})$ 的损失权重。
Pose Estimation. We follow the common top-down setting for pose estimation, i.e., predicting keypoints based on the cropped human instances. We predict the heatmap w.r.t. the keypoints via mean-squared error. Similar to human parsing formulation, we also select the global probability $\mathbf{Y}{p}$ and local probability map ${\bf Y}_{m}$ to predict whether a keypoint exists in the image level and pixel level, respectively. Mathematically, we have:
姿态估计。我们采用常见的自上而下(top-down)姿态估计方法,即基于裁剪后的人体实例预测关键点。通过均方误差预测关键点对应的热力图。与人体解析公式类似,我们也选择全局概率$\mathbf{Y}{p}$和局部概率图${\bf Y}_{m}$,分别预测图像级别和像素级别是否存在关键点。数学表达式为:
$$
\mathcal{L}{p o s e}=\lambda_{p a r}\mathcal{L}{p a r}(\mathbf{Y}{p})+\mathcal{L}{m s e}(\mathbf{Y}_{m}).
$$
$$
\mathcal{L}{p o s e}=\lambda_{p a r}\mathcal{L}{p a r}(\mathbf{Y}{p})+\mathcal{L}{m s e}(\mathbf{Y}_{m}).
$$
Pedestrian Detection. Pedestrian Detection is a local prediction task but in a sparse manner. Following the widely adopted designs in end-to-end transformer-based detection [7, 110], ground-truth for $N^{t}$ query features in $\mathbf{Q}{l}$ are determined by optimal bipartite matching between all $N^{t}$ predictions and GT boxes. Given output units $\mathbf{Y}{p}$ and $\mathbf{Y}_{b b o x}$ , we adopt the identical cost formulation and loss as in [110],
行人检测。行人检测是一种局部预测任务,但采用稀疏方式进行。遵循端到端基于Transformer的检测中广泛采用的设计[7, 110],$\mathbf{Q}{l}$中$N^{t}$个查询特征的真值通过所有$N^{t}$个预测与GT框之间的最优二分匹配确定。给定输出单元$\mathbf{Y}{p}$和$\mathbf{Y}_{b b o x}$,我们采用与[110]相同的成本公式和损失函数。
$$
\begin{array}{r}{\mathcal{L}{p e d d e t}=\lambda_{c l s}\mathcal{L}{c l s}(\mathbf{Y}{p})+\lambda_{i o u}\mathcal{L}{i o u}(\mathbf{Y}{b b o x})+}\ {\lambda_{L1}\mathcal{L}{L1}(\mathbf{Y}_{b b o x}).\qquad}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}{p e d d e t}=\lambda_{c l s}\mathcal{L}{c l s}(\mathbf{Y}{p})+\lambda_{i o u}\mathcal{L}{i o u}(\mathbf{Y}{b b o x})+}\ {\lambda_{L1}\mathcal{L}{L1}(\mathbf{Y}_{b b o x}).\qquad}\end{array}
$$
where $\mathcal{L}{c l s},\mathcal{L}{i o u}$ and $\mathcal{L}_{L1}$ are focal loss [56], GIoU loss [72], and $L1$ loss, respectively. Their corresponding loss weights $\lambda$ are also identically set as in [110].
其中 $\mathcal{L}{c l s},\mathcal{L}{i o u}$ 和 $\mathcal{L}_{L1}$ 分别为焦点损失 (focal loss) [56]、GIoU损失 [72] 和 $L1$ 损失。其对应的损失权重 $\lambda$ 也参照 [110] 进行了相同设置。
4. Experiments
4. 实验
4.1. Implementation details
4.1. 实现细节
Datasets. To enable general human-centric perceptions, we pretrain the proposed UniHCP at scale on a massive and diverse collection of human-centric datasets. Specifically, the training splits of 33 publically available datasets are gathered to form the training set for UniHCP, including nine datasets for pose estimation and six datasets for ReID, Human Parsing, Attribute Prediction, Pedestrain Detection, sera prat ely. For ReID, there are two different subtasks: general ReID and cloth-changing ReID, where the difference is whether cloth-change is considered for person ReID. We empirically found it is best to view them as different tasks and solve them with different task queries. Hence, we treat these two sub-tasks as different tasks and give them separate queries.
数据集。为了实现通用的人本感知能力,我们在海量多样化的人本数据集集合上对提出的UniHCP模型进行了大规模预训练。具体而言,我们收集了33个公开数据集的训练集划分来构建UniHCP的训练集,其中包括9个姿态估计数据集、6个行人重识别(ReID)数据集,以及人体解析、属性预测、行人检测等任务数据集。对于行人重识别任务,存在两个不同子任务:常规ReID和换装ReID,区别在于是否考虑衣着变化对行人重识别的影响。实证研究表明,最佳实践是将它们视为不同任务并使用独立的任务查询(token)进行处理,因此我们对这两个子任务分配了独立查询。
We carefully follow the de-duplication practices as introduced in [102] to remove the samples that could appear in the evaluation datasets. We also remove images whose ground truth labels are not given, leading to $2.3\mathbf{M}$ distinct training samples in total. For evaluation, apart from the available validation or test splits of the 33 training sets, we also included several out-of-pretrain downstream datasets for each type of human-centric task. More details about dataset setups can be found in supplementary materials.
我们严格按照[102]中介绍的去重方法,移除了可能出现在评估数据集中的样本。同时剔除了未提供真实标签的图像,最终得到总计230万( $2.3\mathbf{M}$ )个独立训练样本。在评估环节,除了33个训练集自带的验证集/测试集划分外,我们还为每类以人为中心的任务添加了多个预训练范围外的下游数据集。更多数据集配置细节可在补充材料中查阅。
Table 2. Representative datasets used in multitask co-training.
表 2: 多任务协同训练中使用的代表性数据集。
| 任务类型 | 数据集 | 样本数量 |
|---|---|---|
| 行人重识别 (ReID, 6个数据集) | CUHK03 [47] DGMarket [113] PRCC [97] | 268,002 |
| 姿态估计 (9个数据集) | COCO-Pose [57] AI Challenger [92] PoseTrack [1] | 1,261,749 |
| 人体解析 (6个数据集) | LIP [20] CIHP [19] DeepFashion2 [18] | 384,085 |
| 属性预测 (6个数据集) | PA-100K [62] RAPv2 [39] UAV-Human [45] | 242,880 |
| 行人检测 (6个数据集) | COCO-Person [57] CrowdHuman [74] WiderPedestrian [63] | 170,687 |
Training. We use the standard ViT-B [15] as the encoder network and initialize it with the MAE pretrained [22] weights following [49, 96]. For the main results, we use a batch size of 4324 in total, with the dataset-specific batch size being proportional to the size of each dataset. Unless otherwise specified, the image resolution used in pretraining is $256\times192$ for pose estimation and attribute prediction, $256\times128$ for ReID, $480\times480$ for human parsing, and a maximum height/width of 1333 for pedestrian detection.
训练。我们采用标准ViT-B[15]作为编码器网络,并按照[49, 96]的方法使用MAE预训练[22]权重进行初始化。在主实验结果中,总批次大小设为4324,各数据集的批次大小与其规模成比例。除非另有说明,预训练使用的图像分辨率如下:姿态估计和属性预测为$256\times192$,ReID为$256\times128$,人体解析为$480\times480$,行人检测的最大高度/宽度为1333。
For computational efficiency, each GPU only runs one specific task, and each task can be evenly distributed to multiple GPUs whereas a single GPU is not capable of handling its workloads. To further save the GPU memory during the training time, we adopt the gradient check pointing [4] in the encoder forward pass among all tasks and additionally use accumulative gradients for detection tasks. Due to the high GPU-memory demand of detection datasets, the batch size for the detection task is timed by 0.6.
出于计算效率考虑,每块GPU仅运行单一任务,每个任务可均匀分配至多块GPU(单块GPU无法独立处理其工作负载)。为在训练期间进一步节省GPU内存,我们在所有任务的编码器前向传播中采用了梯度检查点技术(gradient check pointing) [4],并针对检测任务额外使用了梯度累积。由于检测数据集对GPU内存的高需求,检测任务的批次大小按0.6倍率进行缩放。
We use Adafactor [75] optimizer and follow the recommended modifications [101] for adopting it to ViT, we set $\beta_{1}=0.9$ , $\beta_{2}$ clipped at 0.999, disables the parameter scal- ing and decoupled weight decay to 0.05. We linearly warm up the learning rate for the first 1500 iterations to 1e-3, after which the learning rate is decayed to 0 following a cosine decay scheduler. We also use a drop-path rate of 0.2 and layer-wise learning rate decay [49, 96] of 0.75 in the ViT-B encoder. For the main results, the whole training process takes 105k iterations which are approximately 130 epochs for detection datasets and 200 epochs for other datasets. The whole training takes 120 hours in total on 88 NVIDIA V100 GPUs.
我们使用Adafactor [75]优化器,并遵循针对ViT的推荐调整[101],设置$\beta_{1}=0.9$,$\beta_{2}$上限为0.999,关闭参数缩放功能,解耦权重衰减率为0.05。前1500次迭代中学习率线性预热至1e-3,之后按余弦衰减调度器降至0。ViT-B编码器中采用0.2的随机路径丢弃率和0.75的分层学习率衰减[49,96]。主实验结果显示,完整训练流程进行105k次迭代(检测数据集约130个epoch,其他数据集约200个epoch),在8块NVIDIA V100 GPU上总耗时120小时。
Table 3. Person ReID evaluation on Market1501, MSMT, CUHK03 with mAP. †indicates using additional camera IDs.
表 3. 在Market1501、MSMT17和CUHK03数据集上基于mAP的人员重识别评估。†表示使用了额外的摄像头ID。
| 方法 | Market1501 | MSMT17 | CUHK03 |
|---|---|---|---|
| HOReID [87] | 84.9 | ||
| MNE [44] | 77.7 | ||
| SAN [30] | 88.0 | 55.7 | 76.4 |
| TransReID [23] | 86.8 | 61.0 | |
| TransReID [23] | 88.9 | 67.4 | |
| UniHCP (directeval) | 80.7 | 55.2 | 68.6 |
| UniHCP (finetune) | 90.3 | 67.3 | 83.1 |
Table 6. Pedestrian detection evaluation on CrowdHuman val set. Compared with the SOTA, UniHCP achieves comparable mAP and better JI.
表 6: CrowdHuman验证集行人检测评估。与SOTA相比,UniHCP实现了相当的mAP和更高的JI。
| 方法 | mAP | MR-2(↓) | JI |
|---|---|---|---|
| DETR [7] | 75.9 | 73.2 | 74.4 |
| PEDR [55] | 91.6 | 43.7 | 83.3 |
| Deformable-DETR[117] | 91.5 | 43.7 | 83.1 |
| Sparse-RCNN[80] | 91.3 | 44.8 | 81.3 |
| Iter-Deformable-DETR[110] | 92.1 | 41.5 | 84.0 |
| Iter-Sparse-RCNN[110] | 92.5 | 41.6 | 83.3 |
| UniHCP(directeval) | 90.0 | 46.6 | 82.2 |
| UniHCP(finetune) | 92.5 | 41.6 | 85.8 |
4.2. Main Results
4.2. 主要结果
To demonstrate the capability of UniHCP as a unified model for human-centric perceptions, we first evaluate our UniHCP on thirteen datasets that appear in the pre training stage (in Section 4.2.1), e.g., CIHP. Furthermore, we employ five datasets whose training splits are not included in the pre training stage to evaluate the cross-datasets transferability of UniHCP (in Section 4.2.2). We also demonstrate that UniHCP has the potential to efficiently transfer to new datasets that do not appear in pre training with only a few images (in Section 4.2.3). For detailed evaluation configuration, please refer to the supplementary.
为展示UniHCP作为以人为中心的统一感知模型的能力,我们首先在预训练阶段涉及的13个数据集(如CIHP)上评估UniHCP(见第4.2.1节)。此外,我们采用5个训练集未包含在预训练阶段的数据集来评估UniHCP的跨数据集可迁移性(见第4.2.2节)。我们还证明UniHCP只需少量图像即可高效迁移到预训练未见过的新数据集(见第4.2.3节)。具体评估配置请参阅补充材料。
Table 4. Pedestrian attribute recognition evaluation on PA-100K and RAPv2 test sets with mA.
表 4: 基于mA指标的PA-100K和RAPv2测试集行人属性识别评估
| 方法 | PA-100K | RAPv2 |
|---|---|---|
| SSC [28] | 81.87 | |
| C-Tran [36] | 81.53 | |
| Q2L [60] | 80.72 | |
| L2L [46] | 82.37 | |
| DAFL [29] | 83.54 | 81.04 |
| UniHCP(directeval) | 79.32 | 77.20 |
| UniHCP(finetune) | 86.18 | 82.34 |
4.2.1 In-pretrain Dataset Results
4.2.1 预训练数据集内结果
Table 5. Human parsing evaluation on Human3.6M, LIP and CIHP val sets with mIoU.
表 5: 基于mIoU指标在Human3.6M、LIP和CIHP验证集上的人体解析评估
| 方法 | H3.6M | LIP | CIHP |
|---|---|---|---|
| HCM0CO[24] | 62.50 | ||
| SNT[27] | 54.73 | 60.87 | |
| PCNet[108] | 57.03 | 61.05 | |
| SCHP[43] | 59.36 | ||
| CDGNet[59] | 60.30 | 65.56 | |
| UniHCP(directeval) | 65.90 | 63.80 | 68.60 |
| UniHCP(finetune) | 65.95 | 63.86 | 69.80 |
We conduct extensive evaluations on thirteen in-pretrain datasets to demonstrate the effectiveness of our UniHCP. Table 3-7 summarize the evaluation results of UniHCP on five representative human-centric tasks, i.e., person ReID, pedestrian attribute recognition, human parsing, pedestrian detection, and pose estimation. We report two kinds of evaluation results of our UniHCP: (1) direct evaluation, where the pre-trained model with cross-task shared encoder-decoder weights and task-specific queries are directly used for evaluation on the target dataset, and (2) finetuning, where the pretrained UniHCP are first finetuned with the train split of the target dataset and then evaluated.
我们对13个预训练数据集进行了广泛评估,以证明UniHCP的有效性。表3-7汇总了UniHCP在五个代表性人物中心任务上的评估结果,包括行人重识别 (person ReID)、行人属性识别、人体解析、行人检测和姿态估计。我们报告了UniHCP的两种评估结果:(1) 直接评估,即使用跨任务共享编码器-解码器权重和任务特定查询的预训练模型直接在目标数据集上进行评估;(2) 微调,即先用目标数据集的训练集对预训练的UniHCP进行微调,再进行评估。
Table 7. Pose estimation evaluation on COCO, Human3.6M, AI Challenge and OCHuman. Following [96], we report the results on COCO val set, Human3.6M, AI Challenge val set, and OCHuman test set. †denotes the results reported by MMPose [11]. ‡denotes the results achieved using multi-dataset training.
表 7: COCO、Human3.6M、AI Challenge 和 OCHuman 上的姿态估计评估。根据 [96],我们报告了 COCO val 集、Human3.6M、AI Challenge val 集和 OCHuman 测试集上的结果。†表示 MMPose [11] 报告的结果。‡表示使用多数据集训练获得的结果。
| 方法 | COCO/mAP | H3.6M/EPE(↓) | AIC/mAP | OCHuman/mAP |
|---|---|---|---|---|
| HRNet-w32+[79] | 74.4 | 9.4 | ||
| HRNet-w48+[79] | 75.1 | 7.4 | ||
| TokenPose-L/D24[50] | 75.9 | |||
| HRFormer-B [100] | 75.6 | |||
| ViTPose-B[96] | 75.8 | |||
| ViTPose-B[96] | 77.1 | 32.0 | 87.3 | |
| UniHCP(directeval) | 76.1 | 6.9 | 32.5 | 87.4 |
| UniHCP(finetune) | 76.5 | 6.6 | 33.6 | N/A |
As observed, the direct evaluation results of UniHCP show promising performance on most human-centric tasks, especially on human parsing and pose estimation tasks, which show better or on-par performance with the StateOf-The-Art (SOTA). The exception is the person ReID task, which observes noticeable performance gaps with the SOTA. We suggest this is due to its huge disparity from other tasks and can be remedied with quick finetuning.
观察到,UniHCP的直接评估结果在多数以人为中心的任务上表现出色,尤其在人体解析 (human parsing) 和姿态估计 (pose estimation) 任务中,其性能优于或持平当前最先进技术 (StateOfTheArt/SOTA)。例外的是行人重识别 (person ReID) 任务,其表现与SOTA存在明显差距。我们认为这是由于该任务与其他任务差异过大所致,可通过快速微调 (finetuning) 弥补。
With finetuning, our UniHCP achieves new SOTAs on nine out of the total twelve datasets and on par performance on the rest three datasets, even without task-specific design in architecture or task-specific priors, showing that UniHCP extracts complementary knowledge among humancentric tasks. Concretely, Table 4 shows that in the human attribute recognition task, UniHCP significantly surpasses previous SOTA DAFL [29] by $+3.79%$ mA on PA-100K and $+1.20%$ mA on RAPv2 datasets, respectively, which indicates that UniHCP well extracts the shared attribute information among using the output unit of global probabilities in the interpreter. Second, UniHCP also pushes the performance of another important human task, i.e., human parsing, to a new level. Specifically, $+3.45%$ mIoU, $+3.56%$ mIoU, and $+4.24%$ mIoU performance gains are observed on Human3.6M, LIP, and CIHP datasets, respectively. We suggest the newly-added global supervision $\mathcal{L}_{p a r}$ will help UniHCP to suppress the false prediction on not appeared semantic parts. UniHCP also shows superior performance to previous methods on pose estimation. On person ReID, UniHCP outperforms TransReid [23] on Market1501 and MNE [44] on CUHK03 without the help of any additional camera information and training images during evaluation. For pedestrian detection, our UniHCP achieves $+1.8%$ JI performance gain compared with Iter-Deformable-DETR [110] and on-par performance with the Iter-Sparse-RCNN [110] on mAP. These strong performances on diverse datasets across five tasks demonstrate the feasibility and powerful ness of the unified human-centric model and large-scale pre training.
通过微调,我们的UniHCP在全部12个数据集中有9个实现了新的SOTA(state-of-the-art),其余3个数据集也达到同等性能,且无需针对特定任务设计架构或先验知识,这表明UniHCP能够提取以人为中心任务间的互补知识。具体而言,表4显示:在人体属性识别任务中,UniHCP显著超越之前SOTA方法DAFL [29],在PA-100K和RAPv2数据集上分别提升$+3.79%$ mA和$+1.20%$ mA,这证明UniHCP能有效利用解释器中全局概率输出单元提取共享属性信息。其次,UniHCP将另一重要任务——人体解析的性能推向新高度,在Human3.6M、LIP和CIHP数据集上分别实现$+3.45%$ mIoU、$+3.56%$ mIoU和$+4.24%$ mIoU提升。我们认为新增的全局监督$\mathcal{L}_{p a r}$有助于抑制对未出现语义部分的错误预测。在姿态估计任务中,UniHCP同样优于先前方法。行人重识别方面,UniHCP在无需额外摄像头信息和评估阶段训练图像的情况下,超越Market1501上的TransReid [23]和CUHK03上的MNE [44]。对于行人检测任务,相比Iter-Deformable-DETR [110]实现$+1.8%$ JI提升,与Iter-Sparse-RCNN [110]的mAP性能持平。这五项任务跨多样数据集的强劲表现,验证了统一以人为中心模型与大规规模预训练的可行性和强大能力。
Table 8. Transfer performance on ATR [53], SenseReID [109], Caltech [14], MPII [2] and PETA [13]. Results with †are achieved by using additional data. DE - direct evaluation. FT - finetuning.
表 8. 在ATR [53]、SenseReID [109]、Caltech [14]、MPII [2]和PETA [13]上的迁移性能。带†的结果是通过使用额外数据实现的。DE - 直接评估。FT - 微调。
| 方法 | 解析 | ReID | 检测 | 姿态 | 属性 |
|---|---|---|---|---|---|
| ATR | SenseReID | Caltech(↓) | MPII | PETA | |
| SOTA | 97.39 [59] | 34.6 [109] | 46.6 [21] | 92.3 [98] | 87.07 [29] |
| SOTA↑ | 28.8 [21] | 93.3 [96] | |||
| UniHCP(DE) | 46.0 | 37.8 | |||
| UniHCP(FT) | 97.74 | N/A | 27.2 | 93.2 | 88.78 |
Table 9. One-shot human parsing and human pose estimation transfer results under different tuning settings. Every method uses only 1 image per class to transfer. We repeat each experiment for 10 times and report the mean and standard deviation.
表 9: 不同调参设置下的单样本人体解析和人体姿态估计迁移结果。每种方法每类仅使用1张图像进行迁移。每个实验重复10次并报告均值和标准差。
| 方法 | 可学习参数比例 | 解析 (ATR/pACC) | 姿态 (MPII/PCKh) |
|---|---|---|---|
| 单样本微调 | 100% | 90.49±1.22 | 70.6±7.53 |
| 单样本提示调参 | %I> | 93.65±0.77 | 83.8±5.08 |
| 全数据微调 | 100% | 97.74 | 93.2 |
4.2.2 Cross-datasets Transfer Results
4.2.2 跨数据集迁移结果
As the task-guided interpreter formulates all the requests of human-centric tasks into four output units, human-centric knowledge learned behind these units can be easily transferred to unseen datasets. We conduct evaluations on another five datasets which do not appear during pre training to evaluate the transfer ability of UniHCP. UniHCP is finetuned to adapt to new datasets except for SenseReID, on which the performance is tested by direct evaluation. As shown in Table 8, UniHCP outperforms existing SOTAs in 4 out of 5 datasets. Specifically, UniHCP achieves $+0.35%$ pACC, $+11.4%$ top-1, $-1.6%$ heavy occluded $\mathbf{M}\mathbf{R}^{-2}({\downarrow})$ , $+0.1%$ PCKh, and $+1.71%$ mA on ATR, SenseReID, Cal- tech, MPII, and PETA, respectively. On MPII, UniHCP achieves on-par performance with multi-datasets trained SOTA while improving single-dataset trained SOTA by $+0.9%$ PCKh. Notably, even without finetuning, UniHCP achieves a heavy occluded $\mathbf{M}\mathbf{R}^{-2}({\downarrow})$ performance gain on single-dataset trained SOTA. Consistent improvements on transfer tasks provide strong support to the decent transfer ability of UniHCP.
由于任务引导解释器将所有以人为中心的任务请求表述为四个输出单元,这些单元背后学习到的以人为本知识可以轻松迁移到未见数据集上。我们在预训练阶段未出现的另外五个数据集上评估UniHCP的迁移能力。除SenseReID采用直接评估外,UniHCP通过微调适配新数据集。如表8所示,UniHCP在五分之四的数据集上超越现有SOTA方法:在ATR、SenseReID、Cal-tech、MPII和PETA上分别取得$+0.35%$ pACC、$+11.4%$ top-1、$-1.6%$ heavy occluded $\mathbf{M}\mathbf{R}^{-2}({\downarrow})$、$+0.1%$ PCKh和$+1.71%$ mA的提升。在MPII数据集上,UniHCP与多数据集训练的SOTA性能持平,同时将单数据集训练的SOTA提升了$+0.9%$ PCKh。值得注意的是,即使不进行微调,UniHCP在单数据集训练的SOTA基础上仍实现了 heavy occluded $\mathbf{M}\mathbf{R}^{-2}({\downarrow})$的性能增益。迁移任务中一致的性能提升有力证明了UniHCP出色的迁移能力。
| 方法 | 总参数量 | 共享参数量 | 共享模块 | 平均分 | ||
|---|---|---|---|---|---|---|
| 编码器 (Encoder) | 解码器 (Decoder) | 任务引导解释器 (Task-guided Interpreter) | ||||
| Baseline | 109.32M | 109.08M | √ | √ | √ | 67.4 |
| (a) | 156.17M | 105.60M | 67.4 | |||
| (b) | 489.67M | 91.07M | 60.6 | |||
| (c) | 170.83M | 109.08M | √ | bytt | bytt | 65.0 |
4.2.3 Data-Efficient Transferring
4.2.3 数据高效迁移
As UniHCP achieves SOTAs on full-data finetuning setting, we further evaluate its potential for transferring to new datasets with extremely scarce training images, e.g., only one image per class for training. As summarized in Table 9, by conducting prompt tuning with one image per class, UniHCL achieves $93.65%$ pACC on ATR for parsing and $83.8%$ PCKh on MPII for pose estimation, respec- tively. For prompt tuning on ATR, we follow [61]. For prompt tuning on MPII, we only update queries and their associate position embeddings. The prompt tuning results are close to that of the full-data finetuning setting and suppress the results of finetuning the whole model with one image per class for a large margin. Moreover, UniHCP with prompt tuning shows much lower standard deviations than one-shot finetuning on human parsing and pose estimation tasks, verifying that UniHCP learns generic human-centric representation which is beneficial for data-efficient transferring with low computation cost.
由于UniHCP在全数据微调(finetuning)设置下实现了SOTA性能,我们进一步评估其在训练图像极度稀缺的新数据集上的迁移潜力,例如每类仅用一张图像进行训练。如表9所示,通过每类仅用一张图像进行提示调优(prompt tuning),UniHCL在ATR数据集上达到93.65%的解析pACC,在MPII数据集上达到83.8%的姿态估计PCKh。对于ATR的提示调优,我们遵循[61]的方法;对于MPII的提示调优,我们仅更新查询(queries)及其关联的位置嵌入(position embeddings)。提示调优的结果接近全数据微调设置,且大幅优于每类仅用一张图像进行全模型微调的结果。此外,采用提示调优的UniHCP在人体解析和姿态估计任务上表现出比单样本微调(one-shot finetuning)低得多的标准差,验证了UniHCP学习到的通用人体中心表征(generic human-centric representation)有利于以低计算成本实现高效数据迁移。
4.3. Ablation Study on Weight Sharing
4.3. 权重共享消融研究
As UniHCP achieves desirable performance on various human-centric tasks while sharing most parameters among different tasks, one problem remains whether more taskspecific parameters benefit learning. To answer the question, we ablate three weight sharing variants of UniHCP during pre training using a 60k-iteration training schedule with 1k batch size. Results in Table 10(b) show that compared to the original UniHCP i.e., the Baseline), unifying task-guided interpreters among all tasks resulted in an average performance on par with using specific heads while reducing about $30%$ of the parameters. We also note that using task-specific or task-type-specific decoders and interpreters leads to an obvious ( $-6.8%$ and $-2.4%$ , respectively) performance drop on average when compared to the original UniHCP (see results in Table 10(b) and (c)). We speculate that in these ablation settings, complementary humancentric knowledge can not be properly shared among tasks, which leads to performance drops on most tasks.
由于UniHCP在共享多数参数的同时,在各类人本任务中均取得优异性能,我们进一步探究任务专属参数是否有助于学习。为此,我们在预训练阶段对UniHCP进行了三种权重共享变体的消融实验,采用6万次迭代、批量大小为1k的训练方案。表10(b)结果显示:与原始UniHCP(即基线模型)相比,统一所有任务的任务引导解释器在参数量减少约30%的情况下,平均性能与使用专用头结构相当。我们还发现,采用任务专属或任务类型专属的解码器及解释器时,相较原始UniHCP模型会分别导致平均性能显著下降(-6.8%和-2.4%,参见表10(b)(c)结果)。推测这些消融设定阻碍了人本知识的跨任务互补性共享,因而导致多数任务性能下滑。
5. Conclusions
5. 结论
In this work, we present a Unified Model for HumanCentric Perceptions (UniHCP). Based on a simple querybased task formulation, UniHCP can easily handle multiple distinctly defined human-centric tasks simultaneously. Extensive experiments on diverse datasets demonstrate that UniHCP pretrained on a massive collection of humancentric datasets delivers a competitive performance compared with task-specific models. When adapted to specific tasks, UniHCP obtains a series of SOTA performances over a wide spectrum of human-centric benchmarks. Further analysis also demonstrate the capability of UniHCP on parameter and data-efficient transfer and the benefit of weight sharing designs. We hope our work can motivate more future works on developing general human-centric models.
在本工作中,我们提出了一个以人为中心的统一感知模型(UniHCP)。基于简单的基于查询的任务表述,UniHCP可以轻松同时处理多个明确定义的以人为中心的任务。在多种数据集上的大量实验表明,与特定任务模型相比,在以人为中心的大规模数据集上预训练的UniHCP表现出了有竞争力的性能。当适应特定任务时,UniHCP在广泛的以人为中心基准测试中获得了一系列SOTA性能。进一步的分析还展示了UniHCP在参数和数据高效迁移方面的能力以及权重共享设计的优势。我们希望我们的工作能够激励更多未来关于开发通用以人为中心模型的研究。
Acknowledgement. This paper was supported by the Australian Research Council Grant DP 200103223, Australian Medical Research Future Fund MR FAI 000085, CRC-P Smart Material Recovery Facility (SMRF) – Curby Soft Plastics, and CRC-P ARIA - Bionic Visual-Spatial Prosthesis for the Blind.
致谢。本文由澳大利亚研究理事会资助项目DP 200103223、澳大利亚医学研究未来基金MR FAI 000085、CRC-P智能材料回收设施(SMRF)-Curby软塑料以及CRC-P ARIA-盲人仿生视觉空间假体项目支持。
A. One-shot Transfer Results
A. 单次迁移结果
In this section, we provide details and full results for oneshot fine-tuning and prompt tuning on human parsing and pose estimation. For each experiment, we sample ten sets of images with different random seeds; we also grid search on both iterations and learning rates until performance converges. The reported results are based on the best config found for each setting.
在本节中,我们将详细介绍人体解析和姿态估计任务中一次性微调 (oneshot fine-tuning) 与提示调优 (prompt tuning) 的完整实验结果。针对每项实验,我们采用不同随机种子采样十组图像数据,并通过网格搜索 (grid search) 迭代次数和学习率直至性能收敛。最终报告结果为各设置下最优配置的评估数据。
Data sampling. In one-shot transfer experiments, only one image per class is used for a task [17]. Table 11 shows the number of sampled images on one-shot transfer tasks. Note that in UniHCP, classification tasks are multi-label classification for human parsing, pose estimation, and attribute recognition, where each query performs binary classification via the global probability unit. Therefore, we also make sure the presence of cases where a class is absent is covered in our samples. Such handling avoids the query simply learning to output 1 when the corresponding class always presents within the sampled images. On the other hand, when a class does appear in most of the images, e.g., all keypoint joints in pose estimation or the background class in human parsing, we are able to achieve reasonably good results without such handling, thus we do not intentionally sample “not present” case for keypoint joints and background class in our experiments.
数据采样。在单样本迁移实验中,每个类别仅使用一张图像完成任务 [17]。表11展示了单样本迁移任务中的采样图像数量。需要注意的是,UniHCP中的分类任务针对人体解析、姿态估计和属性识别采用多标签分类,每个查询通过全局概率单元进行二元分类。因此,我们确保样本中涵盖类别缺失的情况。这种处理方式避免了当对应类别始终存在于采样图像中时,查询简单地学习输出1的情况。另一方面,当某个类别出现在大多数图像中时(例如姿态估计中的所有关键点关节或人体解析中的背景类别),即使不进行此类处理也能获得合理良好的结果,因此在实验中我们未对关键点关节和背景类别刻意采样"不存在"的情况。
Table 11. Number of sampled images on one-shot transfer tasks. As we can easily find pose samples with all keypoint joints present in the image and do not have to consider the case where a joint is absent as explained above, we only need one sample to perform one-shot transfer on pose estimation.
表 11: 单样本迁移任务中的采样图像数量。由于我们可以轻松找到包含所有关键点关节的姿势样本,且无需考虑上述关节缺失的情况,因此在姿态估计任务中只需一个样本即可执行单样本迁移。
| 解析/ATR [53] | 姿态/MPII [2] | |
|---|---|---|
| 采样图像数量 | 3~4 | 1 |
Number of tunable parameters. For fine-tuning settings, all parameters are tuned. For prompt tuning on human parsing, we follow [61, 118] and add learnable prompt tokens in decoder layers. We update queries, additional prompt tokes, and layer normalization weights. For prompt tuning on pose estimation, we only update queries and their associate position embeddings. Table. 12 shows the number of parameters of each learnable component in prompt tuning.
可调参数数量。在微调设置中,所有参数均被调整。对于人体解析的提示调优 (prompt tuning),我们遵循[61, 118]并在解码器层添加可学习的提示token (prompt tokens),更新查询 (queries)、额外提示token及层归一化权重。对于姿态估计的提示调优,仅更新查询及其关联的位置嵌入 (position embeddings)。表12展示了提示调优中各可学习组件的参数量。
Table 12. Number of tunable parameters for prompt tuning on human parsing, pose estimation, and pedestrian attribute recognition.
表 12. 人体解析、姿态估计和行人属性识别任务中提示调优的可调参数量
| 解析/ATR | 姿态/MPII | 属性/PETA | |
|---|---|---|---|
| Query | 9216 | 8704 | 35840 |
| Deep prompt [61,118] | 32256 | - | 1 |
| LN [118] | 16128 | - | 1 |
| 可学习参数占比 | 0.053% | 0.008% | 0.033% |
A.1. Human Parsing
A.1. 人体解析
Table 13 shows the full one-shot results for fine-tuning and prompt tuning on human parsing.
表 13: 展示了针对人体解析任务进行微调 (fine-tuning) 和提示调优 (prompt tuning) 的完整单样本 (one-shot) 结果。
Table 13. One-shot human parsing results on ATR, evaluated by pACC. FT - finetuning, PT - prompt tuning.
表 13. ATR数据集上单样本人体解析结果 (以pACC指标评估)。FT - 微调, PT - 提示调优。
| 1 | 乙 | 3 | 4 | 6 | 7 | 6 | 10 | avg. | std. | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FT | 91.28 | 91.21 | 90.75 | 87.90 | 91.48 | 92.14 | 89.67 | 89.36 | 90.67 | 90.48 | 90.49 | 1.22 |
| PT | 93.31 | 92.99 | 93.41 | 92.31 | 93.89 | 95.16 | 93.41 | 93.81 | 94.01 | 94.23 | 93.65 | 0.77 |
A.2. Pose Estimation
A.2. 姿态估计
Table 14 shows the full one-shot results for fine-tuning and prompt tuning on pose estimation.
表 14: 展示了姿态估计任务中微调 (fine-tuning) 和提示调优 (prompt tuning) 的完整单样本 (one-shot) 结果。
Table 14. One-shot pose estimation results on MPII, evaluated by mAP. FT - finetuning, PT - prompt tuning.
表 14. MPII数据集上的单样本姿态估计结果 (mAP评估指标)。FT - 微调, PT - 提示调优。
| 一 | 乙 | 3 | 4 | 6 | 7 | 00 | 6 | 10 | avg. | std. | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FT | 64.18 | 78.68 | 78.18 | 60.52 | 73.71 | 67.80 | 70.44 | 57.20 | 79.26 | 76.07 | 70.60 | 7.53 |
| PT | 87.32 | 86.13 | 87.33 | 77.44 | 85.91 | 81.16 | 88.29 | 71.97 | 87.45 | 85.29 | 83.83 | 5.08 |
B. Few-shot Transfer Results for Pedestrian Attribute Recognition
B. 行人属性识别的少样本迁移结果
In this section, we provide the few-shot transfer results for finetuning and prompt tuning on pedestrian attribute recognition. Different from human parsing and pose estimation datasets, the targeted downstream pedestrian attribute recognition dataset PETA [13] contains images from ten different domains. Randomly sampling only one image per class may mislead the queries to extract domain-biased representation, and we found the one-shot result is poor for both finetuning and prompt tuning under this setting. Therefore, we loosen the data constraint to few-shot setting to evaluate the data-efficient transfer performance on pedestrian attribute recognition. Similar to one-shot experiments, we conduct the experiment on ten different sets of images, grid search on hyper parameters, and report results based on the best config for each setting.
在本节中,我们提供了行人属性识别任务中微调 (finetuning) 和提示调优 (prompt tuning) 的少样本迁移结果。与人体解析和姿态估计数据集不同,目标下游数据集 PETA [13] 包含来自十个不同领域的图像。若每类仅随机采样一张图像,可能导致查询提取出具有领域偏差的表征。我们发现,在此设定下,单样本的微调和提示调优结果均不理想。因此,我们放宽数据限制至少样本设定,以评估行人属性识别任务的数据高效迁移性能。与单样本实验类似,我们在十组不同图像集上进行实验,对超参数进行网格搜索,并基于每组设定的最佳配置报告结果。
Data sampling. PETA has ten different domains and 35 different attributes. For each domain, we sample images until both “present” and “not present” cases appeared at least once for each attribute; we sample multiple times and take the one with the least samples as a few-shot dataset. It takes samples to satisfy this constraint in our experiments.
数据采样。PETA包含10个不同领域和35种不同属性。针对每个领域,我们对图像进行采样,直到每个属性的"存在"和"不存在"情况都至少出现一次;我们进行多次采样,并选择样本量最少的一次作为少样本数据集。实验中满足此约束条件需要 个样本。
Number of tunable parameters. All parameters are tuned for finetuning. For prompt tuning, we only update queries and their associate position embeddings. The number of tunable parameters in prompt tuning is shown in Table 12. Results. Table 15 shows the full few-shot results for pedestrian attribute recognition; prompt tuning achieves better performance with a smaller standard deviation.
可调参数数量。所有参数均用于微调(finetuning)。在提示调优(prompt tuning)中,我们仅更新查询(query)及其关联的位置嵌入(position embeddings)。提示调优的可调参数数量如表12所示。
结果。表15展示了行人属性识别(pedestrian attribute recognition)的完整少样本(few-shot)结果:提示调优以更小的标准差实现了更优性能。
Table 15. Few-shot pedestrian attribute recognition results on PETA, evaluated by mA. FT - finetuning, PT - prompt tuning.
表 15: PETA数据集上少样本行人属性识别结果 (以mA为评估指标)。FT - 微调 (finetuning), PT - 提示调优 (prompt tuning)。
| 1 | 2 | 4 | 6 | 7 | 8 | 6 | 10 | avg. | std. | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FT | 59.41 | 61.03 | 59.17 | 61.73 | 59.11 | 61.30 | 59.31 | 60.46 | 60.30 | 61.38 | 60.32 | 0.96 |
| PT | 61.71 | 61.53 | 62.41 | 62.52 | 61.19 | 63.29 | 61.58 | 61.66 | 62.94 | 63.12 | 62.20 | 0.72 |
C. Full Ablation Results on Weight Sharing
C. 权重共享的完整消融实验结果
In Table 16, we provide full results for the ablation study in Section 4.3. UniHCP achieves comparable performance with using task-specific interpreters while sharing most of the parameters among different human-centric tasks.
在表16中,我们提供了第4.3节消融研究的完整结果。UniHCP在共享不同人本任务间大部分参数的同时,实现了与使用任务特定解释器相当的性能。
D. Additional Architecture Details
D. 附加架构细节
D.1. Task-guided Interpreter
D.1. 任务导向型解释器
Since the task-guided interpreter decodes each query token independently, we formulate the interpreter design by describing the generation of each output unit element $y\in\mathbf{Y}$ from query token $q\in Q^{t}$ .
由于任务引导的解释器独立解码每个查询token,我们通过描述从查询token $q\in Q^{t}$ 生成每个输出单元元素 $y\in\mathbf{Y}$ 来构建解释器设计。
Feature vector unit $\mathbf{Y}{f}$ : as the query token is already in a feature space, we do not add any additional post processing. we have $\boldsymbol{y}{f}=\boldsymbol{q},\boldsymbol{y}_{f}\in\mathbb{R}^{C}$ , where $C$ is the output dimension of the decoder.
特征向量单元 $\mathbf{Y}{f}$:由于查询Token已处于特征空间,我们不进行任何额外的后处理。设 $\boldsymbol{y}{f}=\boldsymbol{q},\boldsymbol{y}_{f}\in\mathbb{R}^{C}$,其中 $C$ 为解码器的输出维度。
Global probability unit $\mathbf{Y}{p}$ : we apply a 1-lyr MLP (i.e. linear projector) followed by a sigmoid function $\sigma$ , on top of query token $q$ to yield global probability $y_{p}\in\mathbb{R}^{1}$ .
全局概率单元 $\mathbf{Y}{p}$:我们在查询token $q$ 上应用一个单层MLP(即线性投影器)和sigmoid函数 $\sigma$,以生成全局概率 $y_{p}\in\mathbb{R}^{1}$。
D.2. Positional Embedding for Encoder
D.2. 编码器的位置嵌入 (Positional Embedding)
The positional embedding for the encoder is shared across tasks and is interpolated according to the spatial size of the patch projected input image. The maximum image resolution during training is $1333\times800$ (or $800\times1333$ ), which will then be padded to $1344\times800$ before patch projection (rounded up to be divisible by patch size 16). Thus, the maximum H/W dimension for images after patch projection is 84. Accordingly, we set the number of tokens for learnable positional embedding to $84\times84=7056$ .
编码器的位置嵌入在不同任务间共享,并根据经过块投影的输入图像空间尺寸进行插值。训练期间的最大图像分辨率为 $1333\times800$(或 $800\times1333$),在块投影前会填充至 $1344\times800$(向上取整为块大小16的倍数)。因此,块投影后图像的最大高/宽维度为84。相应地,我们将可学习位置嵌入的token数量设为 $84\times84=7056$。
D.3. Decoder Positional Embedding Projector
D.3. 解码器位置嵌入投影器
The positional embedding projector proj follows the design in [90]. The coordinate is first encoded by sine-cosine position encoding function [84] and then projected by a simple 2-Layer MLP.
位置嵌入投影器 proj 遵循 [90] 中的设计。坐标首先通过正弦-余弦位置编码函数 [84] 进行编码,然后通过一个简单的 2 层 MLP 进行投影。
D.4. Auxiliary Loss:
D.4. 辅助损失:
Apart from the loss for $Q_{L}^{t}$ after $L$ -th decoder block, we also add auxiliary losses to intermediate queries for pose estimation, human parsing, and pedestrian detection following the best practices in [7,10,110]. For pose estimation and human parsing, the auxiliary loss is calculated on $Q_{l}^{t}$ for $l\in{0,...,L-1}$ following [10]. For pedestrian detection, the auxiliary loss is calculated on $Q_{l}^{t}$ for $l\in{1,...,L-1}$ following [7, 110].
除了第 $L$ 个解码器块后 $Q_{L}^{t}$ 的损失外,我们还按照 [7,10,110] 的最佳实践,为姿态估计、人体解析和行人检测的中间查询添加了辅助损失。对于姿态估计和人体解析,辅助损失按照 [10] 在 $Q_{l}^{t}$ 上计算,其中 $l\in{0,...,L-1}$。对于行人检测,辅助损失按照 [7,110] 在 $Q_{l}^{t}$ 上计算,其中 $l\in{1,...,L-1}$。
D.5. Pose Estimation
D.5. 姿态估计
For pose estimation, we set $\lambda_{p a r}=0.001$ . During the inference time, when the metric requires a confidence score for keypoint filtering and NMS (e.g. mAP), we additionally multiply the global probability prediction $y_{p}$ to the confidence score and lower the visibility threshold to 0.05 accordingly.
在姿态估计中,我们设定 $\lambda_{p a r}=0.001$。推理阶段,当指标需要关键点过滤和非极大值抑制(NMS)的置信度分数时(如mAP),我们会额外将全局概率预测 $y_{p}$ 乘到置信度分数上,并将可见性阈值相应降至0.05。
E. Additional Training Details
E. 额外训练细节
Loss Weight $w_{T}$ : for dataset ${\mathcal{D}^{\prime}}$ , its loss weight $w_{T}$ is calculated as follows:
损失权重 $w_{T}$ : 对于数据集 ${\mathcal{D}^{\prime}}$,其损失权重 $w_{T}$ 的计算方式如下:
$$
w_{\mathscr D^{\prime}}=\frac{b_{\mathscr D^{\prime}}w_{\mathbf t_{\mathscr D^{\prime}}}}{\sum_{\mathscr D\in\mathbb D}b_{\mathscr D}w_{\mathbf t_{\mathscr D}}},
$$
$$
w_{\mathscr D^{\prime}}=\frac{b_{\mathscr D^{\prime}}w_{\mathbf t_{\mathscr D^{\prime}}}}{\sum_{\mathscr D\in\mathbb D}b_{\mathscr D}w_{\mathbf t_{\mathscr D}}},
$$
where $b_{\mathcal{D}}$ denotes the batch size allocated to dataset $\mathcal{D}$ and $w_{\mathbf{t}{\mathcal{D}}}$ denotes the sample weight for task type $\mathbf{t}{\mathcal{D}}$ . The loss weight is normalized so that it only controls the relative weight for each dataset. Samples belonging to the same task type are treated with equal importance. Since different task types have different loss functions, image input resolution, number of samples, and convergence pattern, their loss weight should be set differently. For a reasonable loss weight trade-off between tasks, we gradually add task types one at a time in a small 10k iteration joint training setup and sweep sample weights for the newly added task type. After the hyper parameter search, we set $w_{r e i d}=10,w_{p a r}=$ $1\times10^{-\dot{2}},w_{s e g}=5,w_{p o s e}=2\times10^{3},w_{p e d d e t}=2.$ .
其中 $b_{\mathcal{D}}$ 表示分配给数据集 $\mathcal{D}$ 的批次大小,$w_{\mathbf{t}{\mathcal{D}}}$ 表示任务类型 $\mathbf{t}{\mathcal{D}}$ 的样本权重。损失权重经过归一化处理,仅控制各数据集的相对权重。属于同一任务类型的样本具有同等重要性。由于不同任务类型具有不同的损失函数、图像输入分辨率、样本数量和收敛模式,其损失权重应分别设置。为了在任务间实现合理的损失权重权衡,我们在一个10k次迭代的小型联合训练设置中逐步添加任务类型,并扫描新添加任务类型的样本权重。经过超参数搜索后,我们设定 $w_{reid}=10$,$w_{par}=1\times10^{-2}$,$w_{seg}=5$,$w_{pose}=2\times10^{3}$,$w_{peddet}=2$。
Dataset-wise Configurations: we provide detailed datasetwise training configurations in Table 17. In addition to these training datasets, downstream datasets are ATR [53], SenseReID [109], Caltech [14], MPII [2] and PETA [13].
数据集配置:我们在表17中提供了详细的各数据集训练配置。除这些训练数据集外,下游数据集还包括ATR [53]、SenseReID [109]、Caltech [14]、MPII [2]和PETA [13]。
Table 17. UniHCP joint training setup. †the batch size for pedestrian detection is reduced due to high GPU consumption.
表 17. UniHCP联合训练设置。†由于GPU消耗较高,行人检测的批次大小有所减少。
| 方法 | 共享模块 | 解析/mIoU | ReID/mAP | 检测/mAP | 属性/mA | 平均 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 编码器 | 解码器 | 任务头 | H3.6 | LIP | CIHP | Market1501 | MSMT17 | CUHK03 | CrowdHuman | COCO | AIC | OCHuman | PA-100K | RAPv2 | ||
| Baseline | 64.6 | 61.9 | 64.4 | 82.1 | 59.0 | 59.9 | 80.5 | 73.5 | 29.0 | 77.0 | 81.0 | 75.3 | ||||
| (a) | 65.4 | 61.6 | 64.1 | 82.7 | 59.9 | 62.1 | 82.2 | 73.5 | 27.9 | 74.9 | 81.3 | 73.0 | ||||
| (b) | 64.2 | 59.8 | 61.1 | 76.9 | 51.3 | 51.0 | 36.2 68.4 | 71.3 | 25.6 | 69.0 | 81.9 | 78.7 | ||||
| (c) | bytt | bytt | 64.1 | 61.6 | 63.0 | 79.4 | 54.4 | 56.3 | 72.7 | 26.8 | 71.3 | 82.1 | 79.8 |
Table 16. Detailed results for different parameter-sharing methods.
表 16: 不同参数共享方法的详细结果
| 任务类型 | 数据集 D | 批次大小 bD | 每GPU批次大小 | 数据集周期 | bDWtD | GPU数量 | 样本数量 | 样本权重 wtp |
|---|---|---|---|---|---|---|---|---|
| 行人检测 | CrowdHuman [74] EuroCity Persons [5] CityPersons [104] WiderPerson [105] WiderPedestrian [63] COCO-Person [57] | 212t | 4 | 130.19t | 424 | 53 | 170,687 | 2 |
| 行人重识别 | Market-1501 [111] CUHK03 [47] MSMT17 [91] | 96 | 96 | 199.06 | 960 | 1 | 50,549 | 10 |
| 行人重识别 | DGMarket [113] PRCC [97] | 415 | 415 | 200.04 | 4150 | 1 | 217,453 | 10 |
| 姿态估计 | LaST [76] | |||||||
| 姿态估计 | COCO-Pose [57] AI Challenger [92] | 286 720 | 286 | 200.1 199.46 | 572000 | 1 | 149,813 | 2000 |
| 姿态估计 | 240 | 1440000 | 3 | 378,352 | 2000 | |||
| 姿态估计 | PoseTrack [1] | 185 | 185 | 199.55 | 3710000 | 1 | 97,174 | 2000 |
| 姿态估计 | MHP [42] | 77 | 77 | 199.59 | 154000 | 1 | 40,437 | 2000 |
| 姿态估计 | 3DPW [86] | 131 | 131 | 199.98 | 262000 | 1 | 68,663 | 2000 |
| 姿态估计 | UpennAction [107] | 66 | 66 | 200.66 200.03 | 132000 | 1 | 34,475 | 2000 |
| 姿态估计 | JRDB-Pose[85] Halpe [16] | 266 79 | 266 79 | 200.69 | 532000 158000 | 1 1 | 139,385 41,263 | 2000 |
| 人体 | Human3.6M (姿态) [26] | 596 | 298 | 200.11 | 1192000 | 2 | 312,187 | 2000 2000 |
| 人体 | LIP [20] | 58 | 58 | 199.57 | 290 | 1 | 30,462 | 5 |
| 人体 | CIHP [19] | 54 | 54 | 200.14 | 270 | 1 | 28,280 | 5 |
| 人体 | Deep fashion [18] | 364 | 52 | 198.75 | 1820 | 7 | 191,961 | 5 |
| 人体 | VIP [115] | 35 | 35 | 198.63 | 175 | 1 | 18,469 | 5 |
| 行人属性识别 | ModaNet [112] | 100 | 50 | 200.62 | 500 | 2 | 52,245 | 5 |
| 行人属性识别 | Human3.6M (解析)[26] | 120 | 40 | 200.71 | 600 | 3 | 62,668 | 5 |
| 行人属性识别 | PA-100K [62] | 172 | 172 | 200.32 | 1.72 | 1 | 90,000 | 0.01 |
| 行人属性识别 | RAPv2 [39] | 130 | 130 54 | 200.55 199.75 | 1.3 0.54 | 1 1 | 67,943 | 0.01 |
| 行人属性识别 | HARDHC [48] | 54 31 | 31 | 200.78 | 0.31 | 1 | 28,336 16,183 | 0.01 |
| 行人属性识别 | UAV-Human [45] Parse27k [78] | 52 | 52 | 198.33 | 0.52 | 1 | 27,482 | 0.01 0.01 |
| Market-1501 (属性) [111] | 25 | 25 | 202.57 | 0.25 | 1 | 12,936 | 0.01 | |
| 汇总 | / | 总计: 4324 | / | 平均: 200.00 (不含检测) | / | 总计: 88 | 总计: 2,327,403 | / |
F. Additional Finetuning Details
F. 额外微调细节
We provide major finetuning configurations in Table 18; other settings are identical to the training config.
我们在表 18 中提供了主要的微调配置,其他设置与训练配置相同。
G. Ethics
G. 伦理
In this work, we proposed a model to unify multiple human-centric tasks and trained the model on a huge collection of public and widely used human-centric datasets. We acknowledge that the resulting model demonstrates good performance on public ReID benchmarks and thus may be associated with potential identity information leaking without consent if misused. Therefore, the pretrained model will be released only on a case-by-case basis, and the requester must sign an agreement limiting the usage to research purposes only. In addition, the pretrained query tokens for ReID tasks will be excluded from the model release.
在本工作中,我们提出了一个统一多个人类中心任务的模型,并在大量公开且广泛使用的人类中心数据集上进行了训练。我们承认,该模型在公开的行人重识别(ReID)基准测试中表现出良好性能,因此若被滥用,可能导致未经同意的潜在身份信息泄露。因此,预训练模型将仅限个案发布,且申请者必须签署协议,限定仅用于研究目的。此外,针对ReID任务的预训练查询Token将不会包含在发布的模型中。
Table 18. Detailed finetuning configs for human-centric tasks.
表 18: 以人为中心任务的详细微调配置
| 任务类型 | 数据集 | 学习率 | 批量大小 | 迭代次数 | 骨干网络学习率乘数 | DropPath率 | 层衰减率 | 权重衰减 |
|---|---|---|---|---|---|---|---|---|
| 行人检测 | CrowdHuman [74] | 2.00E-04 | 32 | 160k | 1.0 | 0.2 | 0.75 | 0.05 |
| 行人检测 | Caltech [14] | 1.00E-05 | 32 | 30k | 0.1 | 0.2 | 0.75 | 0.05 |
| 行人重识别 | Market-1501 [111] | 1.00E-04 | 64 | 40k | 0.4 | 0.05 | 0.75 | 0.5 |
| 行人重识别 | CUHK03 [47] | 5.00E-05 | 64 | 20k | 0.9 | 0.1 | 0.95 | 0.5 |
| 行人重识别 | MSMT17 [91] | 1.00E-04 | 64 | 40k | 0.9 | 0.05 | 0.75 | 0.5 |
| 姿态估计 | COCO-Pose [57] | 1.00E-04 | 512 | 20k | 0.9 | 0.25 | 0.75 | 0.05 |
| 姿态估计 | AI Challenger [92] | 1.00E-03 | 512 | 10k | 0.9 | 0.2 | 0.75 | 0.05 |
| 姿态估计 | Human3.6M (Pose) [26] | 5.00E-06 | 512 | 10k | 0.9 | 0.3 | 0.75 | 0.05 |
| 姿态估计 | MPII [2] | 7.00E-05 | 512 | 7.5k | 0.9 | 0.3 | 0.75 | 0.05 |
| 姿态估计 | LIP [20] | 5.00E-05 | 64 | 30k | 1.0 | 0.3 | 0.75 | 0.05 |
| 人体解析 | CIHP [19] | 1.00E-04 | 64 | 35k | 1.4 | 0.3 | 0.65 | 0.05 |
| 人体解析 | Human3.6M (parse) [26] | 1.00E-05 | 64 | 25k | 1.3 | 0.3 | 0.85 | 0.05 |
| 人体解析 | ATR [53] | 1.00E-04 | 64 | 15k | 0.7 | 0.3 | 0.85 | 0.05 |
| 行人属性识别 | PA-100K [62] | 3.00E-03 | 128 | 10k | 0.05 | 0.2 | 0.85 | 0.05 |
| 行人属性识别 | RAPv2 [39] | 5.00E-04 | 128 | 4k | 0.5 | 0.3 | 0.75 | 0.05 |
| 行人属性识别 | PETA [13] | 1.00E-03 | 128 | 20k | 0.2 | 0.3 | 0.75 | 0.05 |