FunASR: A Fundamental End-to-End Speech Recognition Toolkit
FunASR: 端到端语音识别基础工具包
Abstract
摘要
This paper introduces FunASR1, an open-source speech recognition toolkit designed to bridge the gap between academic research and industrial applications. FunASR offers models trained on large-scale industrial corpora and the ability to deploy them in applications. The toolkit’s flagship model, Paraformer, is a non-auto regressive end-to-end speech recognition model that has been trained on a manually annotated Mandarin speech recognition dataset that contains 60,000 hours of speech. To improve the performance of Paraformer, we have added timestamp prediction and hotword customization capabilities to the standard Paraformer backbone. In addition, to facilitate model deployment, we have open-sourced a voice activity detection model based on the Feed forward Sequential Memory Network (FSMN-VAD) and a text post-processing punctuation model based on the controllable time-delay Transformer (CT-Transformer), both of which were trained on industrial corpora. These functional modules provide a solid foundation for building high-precision long audio speech recognition services. Compared to other models trained on open datasets, Paraformer demonstrates superior performance.
本文介绍FunASR1,一个旨在弥合学术研究与工业应用差距的开源语音识别工具包。FunASR提供基于大规模工业语料库训练的模型及其应用部署能力。该工具包的核心模型Paraformer是一种非自回归端到端语音识别模型,其训练数据为包含6万小时语音的手工标注中文语音识别数据集。为提升Paraformer性能,我们在标准Paraformer主干网络中增加了时间戳预测和热词定制功能。此外,为简化模型部署,我们开源了基于前馈序列记忆网络(FSMN-VAD)的语音活动检测模型,以及基于可控时延Transformer(CT-Transformer)的文本后处理标点模型,二者均基于工业语料库训练。这些功能模块为构建高精度长语音识别服务提供了坚实基础。与基于公开数据集训练的其他模型相比,Paraformer展现出更优性能。
1. Introduction
1. 引言
Over the past few years, the performance of end-to-end (E2E) models has surpassed that of conventional hybrid systems on automatic speech recognition (ASR) tasks. There are three popular E2E approaches: connection is t temporal classification (CTC) [1], recurrent neural network transducer (RNN-T) [2] and attention based encoder-decoder (AED) [3, 4]. Of these, AED models have dominated seq2seq modeling for ASR, due to their superior recognition accuracy [4–13]. Open-source toolkits including ESPNET [14], WeNet [15], Paddle Speech [16] and K2 [17] et al., have been developed to facilitate research in endto-end speech recognition. These open-source tools have played a great role in reducing the difficulty of building an end-to-end speech recognition system.
过去几年,端到端(E2E)模型在自动语音识别(ASR)任务上的表现已超越传统混合系统。目前主流的三种端到端方法包括:连接时序分类(CTC) [1]、循环神经网络转导器(RNN-T) [2]以及基于注意力的编码器-解码器(AED) [3,4]。其中,AED模型凭借其卓越的识别准确率[4-13],在ASR的序列到序列建模领域占据主导地位。为促进端到端语音识别研究,业界已开发出ESPNET[14]、WeNet[15]、Paddle Speech[16]和K2[17]等开源工具包。这些开源工具极大降低了构建端到端语音识别系统的难度。
In this work, we introduce FunASR, a new open source speech recognition toolkit designed to bridge the gap between academic research and industrial applications. FunASR builds upon previous works and provides several unique features:
在本工作中,我们推出了FunASR,这是一个旨在弥合学术研究与工业应用之间鸿沟的全新开源语音识别工具包。FunASR基于先前的研究成果,提供了多项独特功能:
- Modelsope: FunASR provides a comprehensive range of pretrained models based on industrial data. The flagship model, Paraformer [18], is a non-auto regressive end-to-end speech recognition model that has been trained on a manually annotated Mandarin speech recognition dataset that contains
- 模型范围: FunASR提供基于工业数据的全方位预训练模型。旗舰模型Paraformer [18]是一种非自回归端到端语音识别模型,该模型在包含手动标注的中文语音识别数据集上进行了训练
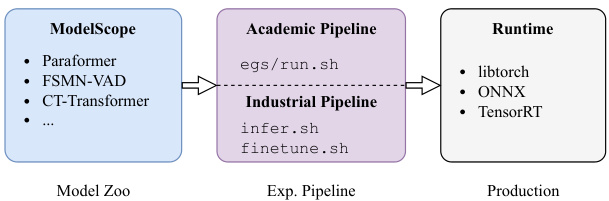
Figure 1: Overview of FunASR design.
图 1: FunASR设计概览。
60,000 hours of speech. Compared with Conformer [5] and RNN-T [2] supported by mainstream open source frameworks, Paraformer offers comparable performance while being more efficient.
60,000小时的语音数据。与主流开源框架支持的Conformer [5]和RNN-T [2]相比,Paraformer在保持相当性能的同时更加高效。
- Training & Finetuning: FunASR is a comprehensive toolkit that offers a range of example recipes to train end-to-end speech recognition models from scratch, including Transformer, Conformer, and Paraformer models for datasets like AISHELL [19, 20], We net Speech [21] and Libri Speech [22]. Additionally, FunASR provides a convenient finetuning script that allows users to quickly fine-tune a pre-trained model from the ModelScope on a small amount of domain data, resulting in high-performance recognition models. This feature is particularly beneficial for academic researchers and developers who may have limited access to data and computing power required to train models from scratch.
- 训练与微调:FunASR 是一个综合性工具包,提供了一系列示例方案用于从头训练端到端语音识别模型,包括针对 AISHELL [19, 20]、WeNet Speech [21] 和 Libri Speech [22] 等数据集的 Transformer、Conformer 和 Paraformer 模型。此外,FunASR 还提供了便捷的微调脚本,用户可通过少量领域数据快速微调 ModelScope 上的预训练模型,从而获得高性能识别模型。该功能对数据与计算资源有限、难以从头训练模型的学术研究者和开发者尤为实用。
- Speech Recognition Services: FunASR enables users to build speech recognition services that can be deployed on realapplications. To facilitate model deployment, we have also released a voice activity detection model based on the Feedforward Sequential Memory Network (FSMN-VAD) [23] and a text post-processing punctuation model based on the controllable time-delay Transformer (CT-Transformer) [24], both of which were trained on industrial corpora. To improve the performance of Paraformer, we have added timestamp prediction and hotword customization capabilities to the standard Paraformer backbone. Additionally, FunASR includes an inference engine that supports CPU and GPU inference through ONNX, libtorch, and TensorRT. These functional modules simplify the process of building high-precision, long audio speech recognition services using FunASR.
- 语音识别服务:FunASR 支持用户构建可部署于实际应用的语音识别服务。为简化模型部署流程,我们发布了基于前馈序列记忆网络 (FSMN-VAD) [23] 的语音活动检测模型,以及基于可控延时 Transformer (CT-Transformer) [24] 的文本后处理标点模型,二者均在工业级语料库上训练完成。为提升 Paraformer 性能,我们在标准 Paraformer 主干网络中新增了时间戳预测和热词定制功能。此外,FunASR 还包含支持 ONNX、libtorch 和 TensorRT 的推理引擎,可实现 CPU 与 GPU 推理。这些功能模块显著降低了使用 FunASR 构建高精度、长音频语音识别服务的复杂度。
Overall, FunASR is a powerful speech recognition toolkit that offers unique features not found in other open source tools. We believe that our contributions will help to further advance the field of speech recognition and enable more researchers and developers to apply these techniques to real-world applications. It should be noted that, this paper only reports the experiments on Mandarin corpora, due to the limitation of the number of pages. In fact, FunASR supports many types of languages, including English, French, German, Spanish, Russian, Japanese, Korean, etc (more details could be found in model zoo).
总体而言,FunASR是一款功能强大的语音识别工具包,具备其他开源工具所没有的独特功能。我们相信,这些贡献将有助于进一步推动语音识别领域的发展,并使更多的研究人员和开发者能够将这些技术应用到实际场景中。需要注意的是,由于篇幅限制,本文仅报告了在普通话语料库上的实验结果。事实上,FunASR支持多种语言,包括英语、法语、德语、西班牙语、俄语、日语、韩语等(更多细节可查阅模型库)。
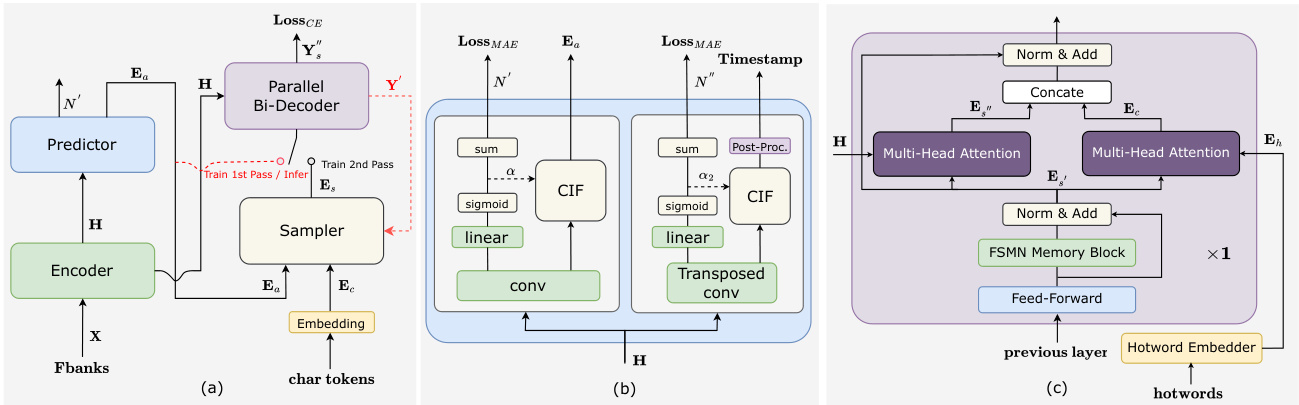
Figure 2: Illustrations of the Paraformer related architectures. (a) Paraformer; (b) Advanced timestamp prediction; (c) Contextual decoder layer for hotword customization.
图 2: Paraformer相关架构示意图。(a) Paraformer; (b) 高级时间戳预测; (c) 用于热词定制的上下文解码器层。
2. Overview of FunASR
2. FunASR 概述
The overall framework of FunASR is illustrated in Fig. 1. ModelScope manages the models utilized in FunASR and hosts critical ones such as Paraformer, FSMN-VAD, and CT-Transformer.
FunASR的整体框架如图1所示。ModelScope管理FunASR中使用的模型,并托管关键模型如Paraformer、FSMN-VAD和CT-Transformer。
Users of FunASR can easily perform experiments using its Pytorch-based pipelines, which are categorized as either academic or industrial pipelines. The academic pipeline, denoted by $r u n.s h$ , enables users to train models from scratch. The $r u n.s h$ script follows the recipe style of ESPNET and includes stages for data preparation (stage 0), feature extraction (stage 1), dictionary generation (stage 2), model training (stage 3 and 4), and model inference and scoring (stage 5). In contrast, the industrial pipeline offers two separate scripts: inf er.sh for inference and f inetune.sh for fine-tuning. These pipelines are easy to use, with users only needing to specify the model name and dataset.
FunASR用户可轻松使用基于Pytorch的两种实验流程:学术流程与工业流程。学术流程通过$run.sh$脚本实现,支持用户从零开始训练模型。该脚本遵循ESPNET的配方风格,包含数据准备(stage 0)、特征提取(stage 1)、词典生成(stage 2)、模型训练(stage 3和4)以及模型推理与评分(stage 5)等阶段。工业流程则提供两个独立脚本:$infer.sh$用于推理,$finetune.sh$用于微调。这些流程操作简便,用户仅需指定模型名称和数据集即可。
FunASR also provides an easy-to-use runtime for deploying models in applications. To support various hardware platforms such as CPU, GPU, Android, and iOS, we offer different runtime backends including Libtorch, ONNX, and TensorRT. In addition, we utilize AMP quantization [25] to accelerate the inference runtime and ensure optimal performance. With these features, FunASR makes it easy to deploy and use speech recognition models in a wide range of applications.
FunASR 还提供了一个易于使用的运行时环境,用于在应用程序中部署模型。为支持 CPU、GPU、Android 和 iOS 等多种硬件平台,我们提供了包括 Libtorch、ONNX 和 TensorRT 在内的不同运行时后端。此外,我们利用 AMP 量化 [25] 技术加速推理运行时,确保最佳性能。通过这些特性,FunASR 能够轻松在各种应用中部署和使用语音识别模型。
3. Main Modules of FunASR
3. FunASR 主要模块
3.1. Paraformer
3.1. Paraformer
To begin, let us provide a brief overview of Paraformer [18], a model that we have previously proposed, depicted in Fig. 2(a). Paraformer is a single-step non-auto regressive (NAR) model that incorporates a glancing language model-based sampler module to enhance the NAR decoder’s ability to capture token inter-dependencies.
首先,我们简要介绍一下之前提出的Paraformer [18] 模型,如图 2(a) 所示。Paraformer 是一种单步非自回归 (NAR) 模型,它通过引入基于扫视语言模型 (glancing language model) 的采样器模块来增强 NAR 解码器捕获 token 间依赖关系的能力。
The Paraformer consists of two core modules: the predictor and the sampler. The predictor module is used to generate acoustic embeddings, which capture the information from the input speech signals. During training, the sampler module incorporates target embeddings by randomly substituting tokens into the acoustic embeddings to generate semantic embeddings. This approach allows the model to capture the interdependence between different tokens and improves the overall performance of the model. However, during inference, the sampler module is inactive, and the acoustic embeddings are used to output the final prediction over only a single pass. This approach ensures faster inference times and lower latency.
Paraformer包含两个核心模块:预测器和采样器。预测器模块用于生成声学嵌入 (acoustic embeddings),从输入语音信号中捕获信息。在训练过程中,采样器模块通过随机替换token到声学嵌入中来融合目标嵌入,从而生成语义嵌入。这种方法使模型能够捕获不同token间的相互依赖关系,并提升整体性能。但在推理阶段,采样器模块处于非激活状态,声学嵌入仅通过单次前向传播输出最终预测结果,从而确保更快的推理速度和更低延迟。
In order to further enhance the performance of Paraformer, this paper proposes modifications including timestamp prediction and hotword customization. In addition, the loss function used in [18] has been updated by removing the MWER loss, which was found to contribute little to performance gains. An additional CE loss is now used in the first pass decoder to reduce the discrepancy between training and inference. The next subsection will provide detailed explanations.
为进一步提升Paraformer的性能,本文提出了包括时间戳预测和热词定制在内的改进方案。此外,对文献[18]中使用的损失函数进行了更新,移除了对性能提升贡献甚微的MWER损失。当前在第一遍解码器中增加了CE损失,以减少训练与推理之间的差异。下一小节将对此进行详细说明。
3.2. Timestamp Predictor
3.2. 时间戳预测器
Accurate timestamp prediction is a crucial function of ASR systems. However, conventional industrial ASR systems require an extra hybrid model to conduct force-alignment (FA) for timestamp prediction (TP), leading to increased computation and time costs. FunASR provides an end-to-end ASR model that achieves accurate timestamp prediction by redesigning the structure of the Paraformer predictor, as depicted in Fig.2(b). We introduce a transposed convolution layer and LSTM layer to upsample the encoder output, and timestamps are generated by post-processing CIF [26] weights $\alpha_{2}$ . We treat the frames between two fireplaces as the duration of the former tokens and mark out the silence parts according to $\alpha_{2}$ . In addition, FunASR also releases a force-alignment-like model named TP-Aligner, which includes an encoder of smaller size and a timestamp predictor. It takes speech and corresponding transcription as input to generate timestamps.
准确的时间戳预测是ASR系统的关键功能。然而,传统工业ASR系统需要额外的混合模型进行强制对齐(FA)以实现时间戳预测(TP),导致计算和时间成本增加。FunASR提供了一种端到端ASR模型,通过重新设计Paraformer预测器结构实现精准时间戳预测,如图2(b)所示。我们引入转置卷积层和LSTM层对编码器输出进行上采样,并通过后处理CIF[26]权重$\alpha_{2}$生成时间戳。将两个触发点之间的帧视为前序token的持续时间,并根据$\alpha_{2}$标出静音部分。此外,FunASR还发布了类强制对齐模型TP-Aligner,包含较小尺寸的编码器和时间戳预测器,以语音及对应文本为输入生成时间戳。
Table 1: Evaluation of timestamp prediction.
表 1: 时间戳预测评估。
| 数据 | 系统 | AAS (ms) |
|---|---|---|
| AISHELL | Force-alignment | 80.1 |
| Paraformer-TP | 71.0 | |
| Industrial Data | Force-alignment | 60.3 |
| Paraformer-large-TP | 65.3 | |
| TP-Aligner | 69.3 | |
We conducted experiments on AISHELL and 60,000-hour industrial data to evaluate the quality of timestamp prediction. The evaluation metrics used for measuring timestamp quality is the accumulated average shift (AAS) [27]. We used a test set of 5,549 utterances with manually marked timestamps to compare the timestamp prediction performance of the provided models with FA systems trained with Kaldi [28]. The results show that Paraformer-TP outperforms the FA system on AISHELL. In industrial experiments, we found that the proposed timestamp prediction method is comparable to the hybrid FA system in terms of timestamp accuracy (with a gap of less than 10ms). Moreover, the one-pass solution is valuable for commercial usage as it helps in reducing computation and time overhead.
我们在AISHELL和6万小时工业数据上进行了实验,以评估时间戳预测的质量。用于衡量时间戳质量的评估指标是累积平均偏移量(AAS) [27]。我们使用包含5,549条人工标注时间戳的测试集,将所提供模型的时间戳预测性能与基于Kaldi [28]训练的FA系统进行对比。结果表明,Paraformer-TP在AISHELL上优于FA系统。在工业实验中,我们发现所提出的时间戳预测方法在精度上与混合FA系统相当(差距小于10毫秒)。此外,这种单次推理方案对商业应用具有重要价值,可有效降低计算和时间开销。
3.3. Hotword Customization
3.3. 热词定制
Contextual Paraformer offers the ability to customize hotwords by utilizing named entities, which enhances incentives and improves the recall and accuracy. Two additional modules have been added to the basic Paraformer model - a hotword embedder and a multi-head attention in the last layer of the decoder, depicted in Fig. 2(c).
Contextual Paraformer 提供了通过命名实体自定义热词的能力,从而增强激励并提高召回率和准确率。在基础 Paraformer 模型上增加了两个模块——热词嵌入器和解码器最后一层的多头注意力 (multi-head attention) ,如图 2(c) 所示。
We utilize hotwords, denoted as $\pmb{w}=\pmb{w_{1}},...,\pmb{w}{n}$ , as input to our hotword embedder [29]. The hotword embedder consists of an embedding layer and LSTM layer, which takes the context hotwords as input and generates an embedding, denoted as $E_{h}$ , by using the last state of the LSTM. Specifically, the hotwords are first fed to the hotword embedder, which produces a sequence of hidden states. We then use the last hidden state as the embedding of the hotwords, capturing the contextual information of the input sequence.
我们利用热词(hotwords),记为 $\pmb{w}=\pmb{w_{1}},...,\pmb{w}{n}$,作为热词嵌入器 [29] 的输入。该热词嵌入器由嵌入层和 LSTM 层组成,它以上下文热词作为输入,并通过使用 LSTM 的最后一个状态生成嵌入表示 $E_{h}$。具体而言,热词首先被送入热词嵌入器,生成一系列隐藏状态。然后我们使用最后一个隐藏状态作为热词的嵌入表示,从而捕捉输入序列的上下文信息。
To capture the relationship between the hotword embedding $E_{h}$ and the output of the last layer of the FSMN memory block $\mathit{{\mathbf{{E}}{s}}}^{\prime}$ , we employ a multi-head attention module. Then, we concate the $\scriptstyle{E_{s}}^{\prime}$ and contextual attention $E_{c}$ . This operation is formalized in Equation 1:
为了捕捉热词嵌入 $E_{h}$ 与FSMN记忆块最后一层输出 $\mathit{{\mathbf{{E}}{s}}}^{\prime}$ 之间的关系,我们采用了多头注意力模块。随后,我们将 $\scriptstyle{E_{s}}^{\prime}$ 与上下文注意力 $E_{c}$ 进行拼接。该操作在公式1中形式化表示为:
$$
\begin{array}{r l}&{E_{c}=\mathrm{MultiHeadAttention}(E_{s^{\prime}}W_{c}^{Q},E_{h}W_{c}^{K},E_{h}W_{c}^{V}),}\ &{E_{s^{\prime\prime}}=\mathrm{MultiHeadAttention}(E_{s^{\prime}}W_{s}^{Q},H W_{s}^{K},H W_{s}^{V}),}\ &{=\mathrm{Conv1d}([E_{s^{\prime\prime}};E_{c}])}\end{array}
$$
$$
\begin{array}{r l}&{E_{c}=\mathrm{MultiHeadAttention}(E_{s^{\prime}}W_{c}^{Q},E_{h}W_{c}^{K},E_{h}W_{c}^{V}),}\ &{E_{s^{\prime\prime}}=\mathrm{MultiHeadAttention}(E_{s^{\prime}}W_{s}^{Q},H W_{s}^{K},H W_{s}^{V}),}\ &{=\mathrm{Conv1d}([E_{s^{\prime\prime}};E_{c}])}\end{array}
$$
We use a one-dimensional convolutional layer $(C o n v1d)$ to reduce its dimensionality to match that of the hidden state $E_{s_{\perp}^{'}}$ , which serves as the input of the subsequent layer. It’s worth noting that apart from this modification, the other processes of our Contextual Paraformer are the same as those of the standard Paraformer.
我们使用一维卷积层 $(Conv1d)$ 将其维度降低以匹配隐藏状态 $E_{s_{\perp}^{'}}$ 的维度,该状态作为后续层的输入。值得注意的是,除了这一修改外,我们的 Contextual Paraformer 其他流程与标准 Paraformer 相同。
Table 2: The test sets used in this customization task.
表 2: 本次定制任务中使用的测试集。
| Dataset | Utts | Named Entities |
|---|---|---|
| AI domain | 486 | 204 |
| Common domain | 1308 | 231 |
During the training, the hotwords are randomly generated from target in each training batch. As for inference, we can specify hotwords by providing a list of named entities to the model.
在训练过程中,热词(hotwords)会在每个训练批次中从目标内容随机生成。推理时,我们可以通过向模型提供命名实体列表来指定热词。
Table 3: Evaluation of hotword customization
表 3: 热词定制效果评估
| 数据集 | 热词 | CER | R | P | F1 |
|---|---|---|---|---|---|
| AISHELL 热词子测试 | 无 | 10.01 | 16 | 100 | 27 |
| 有 | 4.55 | 74 | 100 | 85 | |
| 工业AI领域 | 无 | 7.96 | 70 | 98 | 82 |
| 有 | 6.31 | 89 | 98 | 93 | |
| 工业通用领域 | 无 | 9.47 | 67 | 100 | 80 |
| 有 | 8.75 | 80 | 98 | 88 |
To evaluate the hotword customization effect of Contextual Paraformer, we created a hotword testset by sampling 235 audio clips containing entity words from the AISHELL testset, which included 187 named entities. The dataset has been uploaded to the ModelScope and the test recipe has been opened to FunASR. Additionally, we expanded our experiments to include the AI domain and Common domain of industrial tasks, as presented in Tab. 2.
为评估Contextual Paraformer的热词定制效果,我们从AISHELL测试集中采样了235条包含实体词的音频片段构建热词测试集,其中包含187个命名实体。该数据集已上传至ModelScope平台,测试方案已对FunASR开源。此外,我们将实验范围扩展至工业任务中的AI领域和通用领域,具体数据如 表2 所示。

Figure 3: Illustration of CT-Transformer architecture.
图 3: CT-Transformer架构示意图。
Tab. 3 presents the experimental results of our study on the impact of hotwords on the performance of Contextual Paraformer. We employed CER and F1-score as evaluation metrics for the customization task. Our results indicate an impressive improvement of approximately $58%$ in F1-score on the AISHELL-1 named entity subtest. Moreover, we achieved an average of $10%$ improvement on industrial customization tasks.
表 3: 展示了我们对热词(hotwords)对Contextual Paraformer性能影响的实验结果。我们采用CER(字符错误率)和F1-score作为定制化任务的评估指标。结果表明,在AISHELL-1命名实体子测试集上F1-score提升了约$58%$,在工业定制化任务中平均获得了$10%$的性能提升。
3.4. Voice Activity Detection
3.4. 语音活动检测 (Voice Activity Detection)
Voice activity detection (VAD) plays a important role in speech recognition systems by detecting the beginning and end of effective speech. FunASR provides an efficient VAD model based on the FSMN structure [23]. To improve model discrimination, we use monophones as modeling units, given the relatively rich speech information. During inference, the VAD system requires post-processing for improved robustness, including operations such as threshold settings and sliding windows.
语音活动检测 (VAD) 在语音识别系统中通过检测有效语音的起止点发挥着重要作用。FunASR 提供了一种基于 FSMN 结构 [23] 的高效 VAD 模型。为提高模型区分度,我们采用音素作为建模单元,因其包含相对丰富的语音信息。在推理阶段,VAD 系统需通过后处理增强鲁棒性,包括阈值设置、滑动窗口等操作。
Table 4: Evaluation of VAD on continuous utterances.
表 4: 连续语音的语音活动检测 (VAD) 评估
| 数据集 | VAD | CER | 语音占比% |
|---|---|---|---|
| 会议领域 | 无 | 2.42 | 1 |
| 有 | 2.31 | 0.92 | |
| 视频领域 | 无 | 27.87 | 1 |
| 有 | 25.34 | 0.78 |
The evaluation of VAD is presented in detail in Table 4. The test set consists of manually annotated data from two domains: 2 hours of meeting data and 4 hours of video data. We report the Character Error Rate (CER) and the percentage of utterances sent to ASR inference for recognition. The results demonstrate that the VAD effectively filters out invalid voice, allowing the recognition system to focus on effective speech and leading to a significant CER improvement.
表 4: 详细展示了语音活动检测 (VAD) 的评估结果。测试集包含来自两个领域的人工标注数据:2 小时会议数据和 4 小时视频数据。我们报告了字符错误率 (CER) 以及发送至 ASR 推理进行识别的语音片段百分比。结果表明,VAD 能有效过滤无效语音,使识别系统专注于有效语音,从而显著提升 CER。
3.5. Text Post processing
3.5. 文本后处理
Text post processing is a critical step in generating readable ASR transcripts, which involves adding punctuation marks and removing speech d is flue nci es. FunASR includes a CTTransformer model that performs both tasks in real-time, as described in [24]. The model’s overall framework is presented in Fig. 3. To meet real-time constraints, the model allows partial outputs to be frozen with controllable time delay. A fast decoding strategy is utilized to minimize latency while maintaining competitive performance. Moreover, to reduce computational complexity, the strategy dynamically discards a history that is too long based on already predicted punctuation marks.
文本后处理是生成可读ASR转录稿的关键步骤,涉及添加标点符号和去除言语不流畅部分。FunASR包含一个CTTransformer模型,可实时执行这两项任务,如[24]所述。该模型的整体框架如图3所示。为满足实时性要求,该模型允许通过可控时间延迟冻结部分输出。采用快速解码策略在保持竞争力的同时最小化延迟。此外,为降低计算复杂度,该策略会根据已预测标点符号动态丢弃过长的历史记录。
Table 5: Comparison of CERs on AISHELL, AISHELL-2 and We net Speech with open source speech toolkits. RTF is evaluated with batchsize 1.(† : The number of the model parameters is 110M)
表 5: AISHELL、AISHELL-2 和 WeNet Speech 与开源语音工具包的 CER 对比 (RTF 评估批大小为 1) († : 模型参数量为 110M)
| 模型 | 参数量 | AR/NAR | 语言模型 | AISHELL test | AISHELL-2 test_ios | WenetSpeech test_meeting | RTF |
|---|---|---|---|---|---|---|---|
| ESPNETConformer[14] | 46.25M | AR | 有 | 4.60 | 5.70 | 15.90 | |
| WeNet Conformer-U2++[30] | 47.30M | AR | 有 | 4.40 | 5.35 | 17.34 ↑ | |
| PaddleSpeech DeepSpeech2 [16] | 58.4M | NAR | 有 | 6.40 | |||
| K2 Transducer[17] | 80M | AR | 无 | 5.05 | 5.56 | 14.44 ↑ | |
| Conformer | 46.25M | AR | 有/无 | 4.65 5.21 | 5.35 5.83 | 15.21 | 1.4300 0.2100 |
| Paraformer | 46.3M | NAR | 无 | 4.95 | 5.73 | 1 | 0.0168 |
| Paraformer-large | 220M | NAR | 无 | 1.95 | 2.85 | 6.97 | 0.0251 |
Table 6: The results of text post processing
表 6: 文本后处理结果
| 模型 | 标点符号 | 不流畅性 | 推理时间 | ||||
|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | ||
| BLSTM | 60.2 | 48.8 | 53.9 | 84.1 | 57.0 | 67.9 | 1112.9s (×1.0) |
| Full-Trans. | 62.1 | 55.9 | 58.8 | 83.1 | 61.2 | 70.5 | 676.7s (×1.6) |
| CT-Trans. | 62.7 | 55.3 | 58.8 | 82.4 | 61.5 | 70.5 | 585.8s (×1.9) |
We evaluated the punctuation prediction and disfluency detection on an in-house Chinese dataset that consists of about 24K spoken utterances with punctuation and disfluency annotations. Tab. 6 shows the precision (P), recall (R), and $\mathrm{F_{1}}$ -score $(\mathrm{F_{1}})$ of the models. The results indicate that the CT-Transformer achieves competitive $\mathrm{F_{1}}$ with a faster inference speed.
我们在一个内部中文数据集上评估了标点预测和不流畅性检测,该数据集包含约24K条带有标点和不流畅性标注的口语语句。表6展示了各模型的精确率(P)、召回率(R)和$\mathrm{F_{1}}$分数$(\mathrm{F_{1}})$。结果表明,CT-Transformer以更快的推理速度实现了具有竞争力的$\mathrm{F_{1}}$分数。
4. Experiments
4. 实验
4.1. Evaluation ASR
4.1. 语音识别评估 (ASR)
In our experiments, we evaluate the performance of our models on the AISHELL, AISHELL-2, and We net Speech datasets and present the results in detail in Table 5. When compared to other open source toolkits, FunASR achieves comparable results to the baseline Conformer model. To ensure a fair comparison with Paraformer, we remove the language models (LM) and joint-CTC decoding of Conformer. The results show that Paraformer slightly outperforms Conformer without LM in terms of recognition accuracy. We also evaluate the computational efficiency of the models in terms of inference speed by RTF on GPU (V100) with a batch size of 1. The Paraformer model achieves a 12x speedup in inference, which is a significant advantage over auto regressive models. Even when the number of parameters in the Paraformer-large model is increased from 46M to 220M, the RTF still outperforms the AR model with 46M parameters.
在我们的实验中,我们评估了模型在AISHELL、AISHELL-2和We net Speech数据集上的性能,并在表5中详细展示了结果。与其他开源工具包相比,FunASR取得了与基线Conformer模型相当的结果。为确保与Paraformer的公平对比,我们移除了Conformer的语言模型(LM)和联合CTC解码。结果显示,在无LM情况下,Paraformer的识别准确率略优于Conformer。我们还通过GPU(V100)上批大小为1的RTF评估了模型的推理速度效率。Paraformer模型实现了12倍的推理加速,相比自回归模型具有显著优势。即使Paraformer-large模型的参数量从46M增至220M,其RTF仍优于46M参数的AR模型。
FunASR provides a pre-trained Paraformer-large model that is specifically trained on a 60,000 hour Mandarin speech recognition corpus used in industry. The performance of Paraformer-large is impressive, as shown in Table 5. It achieves low CERs of $1.95%$ , $2.85%$ , and $6.97%$ on the AISHELL test, AISHELL-2 test ios, and We net Speech test meeting task, respectively. These results demonstrate the importance of using large-scale speech corpora in improving the performance of ASR systems.
FunASR提供了一个预训练的Paraformer-large模型,该模型专门针对工业级6万小时普通话语音识别语料库进行训练。如表5所示,Paraformer-large表现出色,在AISHELL测试集、AISHELL-2测试集ios和WeNet语音会议任务测试集上分别实现了$1.95%$、$2.85%$和$6.97%$的低字符错误率(CER)。这些结果证明了大规模语音语料库对提升ASR系统性能的重要性。
Moreover, FunASR offers customization capabilities for our pretrain model, allowing it to be finetuned on domainspecific data. The results of using the AISHELL and industrial domain data (200h) to finetune our Paraformer-large model are presented in Table 7. Our model achieved relative improvements of $7.4%$ and $8.7%$ on the AISHELL dev and test tasks, respectively. Additionally, the experiments in the logistics field have demonstrated that finetuning the Paraformer-large model results in a significant improvement in recognition and domain keywords recall. The short testset consists of audio files that are $5.77s$ long on average, with a total duration of 2.41 hours. The long testset is 4.95 hours long and contains audio with an average length of 162.0s. On average, we observed an increase in domain keywords recall from $76.7%$ to $96.8%$ , and a decrease in CER from $11.25%$ to $10.10%$ . The experiments have demonstrated that the pretrained model can be finetuned with your corpus to achieve significant improvements in the relevant field.
此外,FunASR还提供了预训练模型的定制化能力,可针对特定领域数据进行微调。表7展示了使用AISHELL和工业领域数据(200小时)对Paraformer-large模型进行微调的结果。我们的模型在AISHELL开发集和测试集任务上分别实现了7.4%和8.7%的相对提升。物流领域的实验表明,微调后的Paraformer-large模型在识别准确率和领域关键词召回率方面均有显著提升。短测试集平均音频时长为5.77秒,总时长2.41小时;长测试集时长为4.95小时,平均音频长度162.0秒。实验数据显示,领域关键词召回率从76.7%提升至96.8%,CER(字符错误率)从11.25%降至10.10%。这些实验证明,通过使用特定语料库对预训练模型进行微调,可在相关领域取得显著性能提升。
Table 7: Evaluation of funetuning
表 7: 微调评估
| 模型 | 数据集 | 预训练 (CER%/召回率%) | 微调 (CER%/召回率%) |
|---|---|---|---|
| AISHELL | dev | 1.75 / - | 1.62 / - |
| AISHELL | test | 1.95 / - | 1.78 / - |
| Logistics domain | short | 9.4 / 79.4 | 7.6 / 97.6 |
| Logistics domain | long | 13.1 / 74.0 | 12.6 / 96.0 |
4.2. Runtime Benchmark
4.2. 运行时基准测试
This section evaluates the runtime performance of Paraformerlarge in terms of both CER and RTF on an Intel(R) Xeon(R) CPU E5-8269CY $\begin{array}{r}{@2.5\mathrm{GHz}}\end{array}$ with one thread core. We evaluate the performance of Paraformer-large with two runtime backends, as shown in Table 8. To optimize performance, FunASR adopts the automatic mixed precision quantization (AMP) method proposed in [25, 31]. The results demonstrate that AMP quantization improves inference speed by $40%$ without any significant reduction in recognition accuracy.
本节在 Intel(R) Xeon(R) CPU E5-8269CY $\begin{array}{r}{@2.5\mathrm{GHz}}\end{array}$ 单线程核心上评估 Paraformer-large 在 CER (字符错误率) 和 RTF (实时率) 方面的运行时性能。如表 8 所示,我们使用两种运行时后端评估 Paraformer-large 的性能。为优化性能,FunASR 采用了 [25, 31] 提出的自动混合精度量化 (automatic mixed precision quantization, AMP) 方法。结果表明,AMP 量化在不显著降低识别准确率的情况下,将推理速度提升了 $40%$。
Table 8: Runtime benchmark.
表 8: 运行时基准测试。
| 量化方式 | Libtorch | Onnx | ||
|---|---|---|---|---|
| Float32 | Int8 | Float32 | Int8 | |
| RTF | 0.1026 | 0.0597 | 0.0778 | 0.0446 |
| CER | 1.95 | 1.95 | 1.95 | 1.95 |
5. Conclusions
5. 结论
This paper presents FunASR, a system designed to bridge the gap between academic research and industrial applications in speech recognition. FunASR provides access to models trained on large-scale industrial corpora, as well as the ability to easily deploy them in real-world applications. We make a wide range of industrial models available, including Paraformer-large model, as well as FSMN-VAD and CT-Transformer models, etc. By making these models openly available, FunASR enables researchers to easily deploy them in real-world scenarios.
本文介绍FunASR系统,旨在弥合语音识别领域学术研究与工业应用之间的鸿沟。FunASR不仅提供基于大规模工业语料库训练的模型访问权限,还能轻松实现实际应用部署。我们开放了包括Paraformer-large模型、FSMN-VAD模型和CT-Transformer模型等在内的多种工业级模型。通过开源这些模型,FunASR使研究人员能够便捷地将它们部署到真实场景中。
[18] Z. Gao, S. Zhang, I. McLoughlin, and Z. Yan, “Paraformer: Fast and accurate parallel transformer for non-auto regressive end-toend speech recognition,” arXiv preprint arXiv:2206.08317, 2022.
[18] Z. Gao, S. Zhang, I. McLoughlin, and Z. Yan, "Paraformer: 面向非自回归端到端语音识别的快速精准并行Transformer", arXiv预印本 arXiv:2206.08317, 2022.