Swap Path Network for Robust Person Search Pre-training
鲁棒行人搜索预训练的交换路径网络
Abstract
摘要
In person search, we detect and rank matches to a query person image within a set of gallery scenes. Most person search models make use of a feature extraction backbone, followed by separate heads for detection and reidentification. While pre-training methods for vision backbones are well-established, pre-training additional modules for the person search task has not been previously examined. In this work, we present the first framework for end-toend person search pre-training. Our framework splits person search into object-centric and query-centric methodologies, and we show that the query-centric framing is robust to label noise, and trainable using only weakly-labeled person bounding boxes. Further, we provide a novel model dubbed Swap Path Net (SPNet) which implements both query-centric and object-centric training objectives, and can swap between the two while using the same weights. Using SPNet, we show that query-centric pre-training, followed by object-centric fine-tuning, achieves state-of-theart results on the standard PRW and CUHK-SYSU person search benchmarks, with $96.4%$ mAP on CUHK-SYSU and $6l.2%$ mAP on PRW. In addition, we show that our method is more effective, efficient, and robust for person search pre-training than recent backbone-only pre-training alternatives.
在行人搜索任务中,我们通过检测和排序图库场景中与查询人物图像的匹配项来实现目标。大多数行人搜索模型采用特征提取主干网络,后接独立的检测和重识别头部模块。尽管视觉主干网络的预训练方法已较为成熟,但针对行人搜索任务额外模块的预训练此前尚未得到研究。本文提出了首个端到端行人搜索预训练框架,将方法分为以目标为中心和以查询为中心两种范式,并证明以查询为中心的框架对标签噪声具有鲁棒性,仅需弱标注的人物边界框即可训练。此外,我们提出名为交换路径网络 (SPNet) 的新型模型,该模型同时实现以查询为中心和以目标为中心的训练目标,并能保持权重不变的情况下切换两种模式。实验表明:SPNet采用以查询为中心的预训练后接以目标为中心的微调策略,在PRW和CUHK-SYSU基准测试中分别取得61.2%和96.4%的mAP值,达到当前最优水平。相比近期仅针对主干网络的预训练方案,我们的方法在行人搜索预训练中展现出更高效率、更强效果及更优鲁棒性。
1. Introduction
1. 引言
Person search is the combined formulation of two subproblems: detection of all person bounding boxes in a set of gallery scenes, and $r e$ -identification (re-id) of all detected boxes with respect to a query person box. Recent person search models are mainly end-to-end, and have a feature extraction backbone, followed by separate heads for detection and re-identification. It is typical to initialize this feature backbone using weights pre-trained for classification on the ImageNet $I k$ dataset [38]. Only recently have approaches emerged considering pre-training backbones for person search on annotated person data [8, 24], even then only considering cropped bounding boxes from the LUPerson [13] or Market [51] datasets.
人员搜索是两个子问题的组合形式:在一组图库场景中检测所有人物边界框,以及将所有检测到的边界框与查询人物框进行重新识别 (re-id)。近期的人员搜索模型主要是端到端的,具有一个特征提取主干网络,后接独立的检测和重新识别头部。通常使用在ImageNet $I k$ 数据集[38]上预训练的分类权重来初始化这个特征主干网络。直到最近才出现考虑在标注人物数据上预训练主干网络用于人员搜索的方法[8,24],即便如此也仅考虑了从LUPerson[13]或Market[51]数据集中裁剪的边界框。
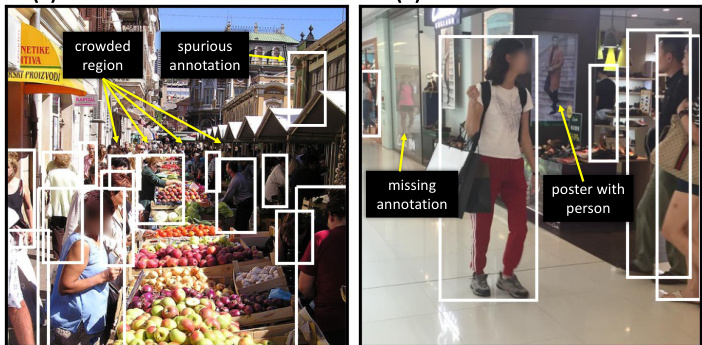
(a) Label Noise in Coco Persons (b) Label Noise in CUHK-SYSU Figure 1. Examples of label noise and annotation challenges in real annotated scenes, with white boxes used for annotations.
图 1: 真实标注场景中的标签噪声和标注挑战示例 (a) Coco Persons数据集中的标签噪声 (b) CUHK-SYSU数据集中的标签噪声,其中白色方框用于标注。
For the detection portion of person search, annotations and predictions typically take the form of rectangular bounding boxes. In datasets annotated for person detection, label noise is unavoidable, shown in Fig. 1. For example, how small does a person have to be before they become part of a crowd, shown in Fig. 1a? How does a model handle the presence of missing annotations or images of people in the scene, shown in Fig. 1b? What if a person is behind a window in a building, visible in a monitor screen, or reflected in a mirror? If a detector is used to automatically label people in a scene, how does a model handle spurious extra annotations? These problems are compounded by pre-training, because annotation biases in the pre-training dataset may not reflect those in the target fine-tuning dataset.
在人员搜索的检测部分,标注和预测通常采用矩形边界框的形式。在针对人员检测标注的数据集中,标签噪声不可避免,如图1所示。例如,一个人需要多小才会被视为人群的一部分(如图1a所示)?模型如何处理场景中缺失标注或人员图像的情况(如图1b所示)?如果一个人位于建筑物窗户后方、显示器屏幕中或镜子反射里,又该如何处理?若使用检测器自动标注场景中的人员,模型如何处理虚假的额外标注?这些问题在预训练过程中会被放大,因为预训练数据集中的标注偏差可能与目标微调数据集不一致。
This leaves three key issues unresolved in the pursuit of effective pre-training for person search: 1) current backbone pre-training is done using a pretext task unrelated to the person search task, 2) all parameters beyond the backbone are randomly initialized, and 3) current pre-training approaches do not consider robustness to label noise and annotation biases present in person data. Therefore, a model is needed which can simultaneously pre-train for detection and re-id, while achieving domain transfer from a pretraining dataset of heterogeneous imagery that contains label noise and bias.
在追求有效的人物搜索预训练过程中,仍有三个关键问题未解决:1) 当前主干网络的预训练使用与人物搜索任务无关的代理任务完成,2) 主干网络之外的所有参数均为随机初始化,3) 现有预训练方法未考虑对人物数据中存在的标签噪声和标注偏见的鲁棒性。因此,需要一种能同时预训练检测与重识别任务,并能实现从包含标签噪声和偏见的异构图像预训练数据集进行领域迁移的模型。
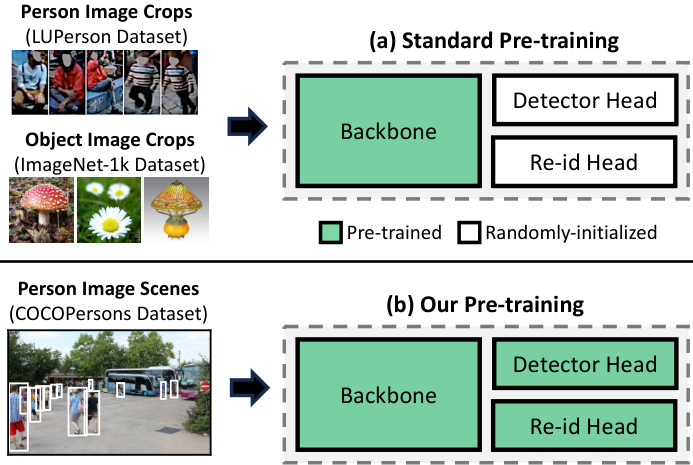
Figure 2. The standard person search model pre-training approach (shown top) pre-trains only backbone weights using either ImageNet-1k classification or person image crops from e.g., LUPerson. Our approach (shown bottom) initializes all model weights using full person scenes with multiple annotated persons. (LUPerson images from paper [13])
图 2: 标准行人搜索模型预训练方法 (上图所示) 仅使用 ImageNet-1k 分类或来自 LUPerson 等数据集的裁剪行人图像预训练骨干网络权重。我们的方法 (下图所示) 使用包含多个标注行人的完整场景图像初始化全部模型权重。(LUPerson 图像来自论文 [13])
In this paper, we develop a novel model which addresses these challenges by pre-training using the query-centric detection pretext task. In query-centric detection, we detect matches to a query object in a gallery scene, vs. standard object-centric detection, where we detect a pre-determined set of objects in a scene. The model is named Swap Path Net (SPNet) because it can swap between query-centric and object-centric pathways, while using the same weights. The two pathways are needed because the query-centric mode is robust to label noise and learns more general iz able features, making it ideal for pre-training, while the object-centric mode performs better at person search and is much more efficient during inference, making it preferable for fine-tuning on person search. In addition, SPNet is capable of pretraining using weakly-labeled person bounding boxes, i.e. identity correspondence between scenes is not known. We visualize our pre-training approach vs. typical backboneonly pre-training in Fig. 2.
本文提出了一种新颖模型,通过以查询为中心(query-centric)的检测预训练任务解决这些挑战。与传统以物体为中心(object-centric)的检测不同(后者检测场景中预定义的对象集合),我们的查询中心检测任务旨在从图库场景中检测与查询对象匹配的实例。该模型被命名为交换路径网络(SPNet),因其能在共享权重的前提下,在查询中心与物体中心两种路径模式间切换。双路径设计的必要性在于:查询中心模式对标签噪声具有鲁棒性,能学习更具泛化性的特征,是理想的预训练方案;而物体中心模式在行人搜索任务中表现更优且推理效率更高,更适合用于行人搜索的微调阶段。此外,SPNet支持使用弱标注行人边界框(即无需知晓跨场景的身份对应关系)进行预训练。图2展示了本预训练方法与典型骨干网络预训练的对比可视化结果。
We show that when SPNet is pre-trained in the querycentric mode, and fine-tuned in the object-centric mode, it achieves state-of-the-art performance on the benchmark CUHK-SYSU [46] and Person Re-identification in the Wild (PRW) [52] person search datasets. We demonstrate that weakly-supervised pre-training on the COCO Persons dataset [29,39] using our method is more effective, efficient, and robust than recent backbone-only pre-training alternatives for unsupervised person re-id [8, 15, 53].
我们证明,当SPNet在以查询为中心的模式下进行预训练,并在以对象为中心的模式下进行微调时,它在基准数据集CUHK-SYSU [46]和野外行人重识别(PRW) [52]上实现了最先进的性能。我们展示了使用我们的方法在COCO Persons数据集[29,39]上进行弱监督预训练,比最近仅针对无监督行人重识别[8, 15, 53]的主干网络预训练替代方案更有效、高效且鲁棒。
Our contributions are as follows:
我们的贡献如下:
• The Swap Path Network: an efficient end-to-end model of person search which can operate in query-centric or object-centric modes. • A query-centric pre-training algorithm unique to the Swap Path Network that results in SOTA performance
• Swap Path Network:一种高效端到端的人员搜索模型,支持以查询为中心或以对象为中心的运行模式。
• 该网络独有的以查询为中心的预训练算法,实现了当前最优(SOTA)性能
and is robust to label noise.
并且对标签噪声具有鲁棒性。
We support these claims with extensive experiments demonstrating the efficiency of the SPNet model and the efficacy of the pre-training approach. Further, we ensure reprod uci bil it y by providing the code and installation instructions required to repeat all experiments, which are included in the corresponding GitHub repository .
我们通过大量实验验证了SPNet模型的高效性和预训练方法的有效性,从而支持这些观点。此外,为确保可复现性,我们提供了重复所有实验所需的代码和安装说明,这些内容已包含在相应的GitHub仓库中。
2. Related Work
2. 相关工作
2.1. Person Search
2.1. 人物搜索
Weakly-Supervised. In the context of person search, weak supervision (WS) refers to training on person bounding boxes without identity-level labels. Several methods [16,17,24,42,44,47] have emerged in recent years to tackle this problem by using weakly-supervised objectives directly on the target dataset. These methods focus on clustering visual features and applying contextual information to determine pseudo-labels used for a contrastive re-id loss. In contrast, our method is orthogonal to the problem of determining pseudo-labels, focusing on the query-centric vs. objectcentric training distinction. In addition, we apply weak supervision only during pre-training on a source dataset, then perform fully-supervised fine-tuning on the target dataset. We note that other methods assume the underlying data has multiple images per identity, and exploit this to form pseudo-labels based on common features, while we do not. Therefore, other methods may perform better for the WS scenario on PRW, CUHK-SYSU, but are not suitable for pre-training on large unlabeled person datasets where there are few or only one image per person like COCO Persons.
弱监督。在行人搜索领域,弱监督(WS)指仅使用不带身份标签的行人边界框进行训练。近年来涌现了若干方法[16,17,24,42,44,47],通过在目标数据集上直接应用弱监督目标来解决该问题。这些方法聚焦于聚类视觉特征并利用上下文信息生成用于对比重识别损失的伪标签。与之不同,我们的方法不涉及伪标签生成问题,而是关注以查询为中心和以目标为中心的训练范式差异。此外,我们仅在源数据集预训练阶段采用弱监督,之后在目标数据集上进行全监督微调。需要指出的是,其他方法假设基础数据中每个身份包含多张图像,并据此提取共性特征生成伪标签,而我们的方法无此假设。因此,其他方法可能在PRW、CUHK-SYSU等数据集的弱监督场景表现更优,但不适用于COCO Persons这类每人仅含少量甚至单张图像的大规模无标注行人数据集预训练。
Query-Centric vs. Object-Centric. Most person search models implement an object-centric (OC) approach [3, 12, 25, 27, 48, 50], in which we detect persons independent of any query, then afterwards compare queries to detected persons. By contrast, query-centric (QC) person search models [11,34,35,43] use query person images during the detection process, producing proposals tailored to each query, but significantly increasing time complexity of inference computation.
以查询为中心 vs. 以对象为中心。多数人物搜索模型采用以对象为中心 (OC) 的方法 [3, 12, 25, 27, 48, 50],即先独立于查询检测人物,再将查询与检测到的人物进行比对。相比之下,以查询为中心 (QC) 的人物搜索模型 [11,34,35,43] 在检测过程中利用查询人物图像,生成针对每个查询的候选框,但会显著增加推理计算的时间复杂度。
Despite the greater time complexity of query-centric person search, multiple successful approaches have emerged. QEEPS [34] and QGN [35] use query information both during detection and computation of re-id embeddings by combining query features with backbone features using squeeze-and-excitation layers [21]. IGPN [11] and TCTS [43] are two-step models which extract person embeddings from a separate network, and combine these embeddings with features from the detector network. In our approach, we consider query-centric (QC) learning as a pretraining objective, while fine-tuning in the object-centric (OC) mode, though our framework supports query-centric evaluation as well. This allows us to learn more robust features in the QC mode, while retaining efficient evaluation in the OC mode.
尽管以查询为中心的行人搜索具有更高的时间复杂度,但已涌现出多种成功方法。QEEPS [34] 和 QGN [35] 在检测和重识别嵌入计算阶段均利用查询信息,通过挤压激励层 [21] 将查询特征与骨干网络特征融合。IGPN [11] 与 TCTS [43] 采用两阶段模型架构,先从独立网络提取行人嵌入,再将其与检测器网络特征结合。本方法将查询中心 (QC) 学习作为预训练目标,但在物体中心 (OC) 模式下进行微调,同时框架也支持查询中心评估。这种设计使我们在 QC 模式下学习更具鲁棒性的特征,同时保留 OC 模式下的高效评估优势。
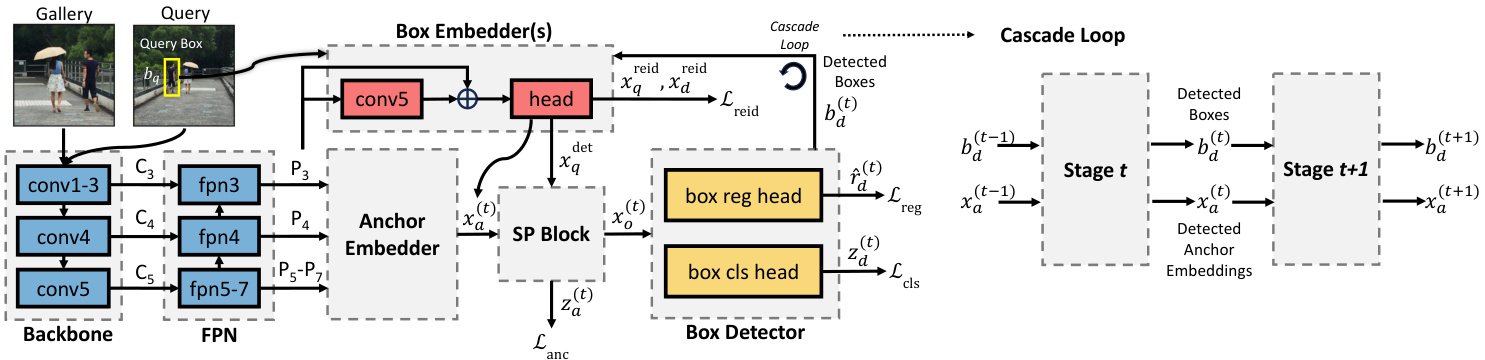
Figure 3. Full SPNet architecture is shown on the left, with details about the Cascade Loop shown on the right. The subscripts $q,d,a$ stand for “query”, “detection”, and “anchor” respectively. The superscript “reid” means the embedding or loss is used for re-id, and the superscript “det” means the embedding is used for detection.
图 3: 左侧展示了完整的SPNet架构,右侧详细说明了级联循环(Cascade Loop)结构。下标$q,d,a$分别代表"query"、"detection"和"anchor"。上标"reid"表示该嵌入或损失函数用于重识别(re-id),上标"det"表示该嵌入用于检测任务。
Pre-training. Person search models typically use backbone weights initialized from standard ImageNet-1k classifier training, while other model weights are initialized randomly. To our knowledge, the only other work to date to explore another backbone initialization strategy is SOLIDER [8]. The SOLIDER framework trains on unlabeled person crops from the LUPerson dataset [13] by optimizing backbone features using cluster pseudo-labels based on tokens learned with DINO [5]. Unlike our proposed method, SOLIDER initializes only the backbone, and not the rest of the model. In addition, SOLIDER trains only on person crops, while we train on full person scenes, containing potentially many persons. While SOLIDER is the only prior pre-training method which measures fine-tuning for the person search task, there is a rich body of work on similar unsupervised person re-id methods [9,14,15,33,49,53], which also train only on cropped person images.
预训练。人物搜索模型通常使用基于标准ImageNet-1k分类器训练初始化的骨干网络权重,而其他模型权重则随机初始化。据我们所知,目前唯一探索其他骨干初始化策略的工作是SOLIDER [8]。该框架通过在LUPerson数据集[13]的无标注人物裁剪图上训练,利用DINO [5]学习到的token生成聚类伪标签来优化骨干特征。与我们提出的方法不同,SOLIDER仅初始化骨干网络而非整个模型。此外,SOLIDER仅在人物裁剪图上训练,而我们的训练数据是包含多人的完整场景图像。虽然SOLIDER是唯一评估人物搜索任务微调效果的预训练方法,但存在大量类似的无监督行人重识别方法[9,14,15,33,49,53],这些方法也仅在裁剪后的人物图像上进行训练。
2.2. Unsupervised Detector Pre-training
2.2. 无监督检测器预训练
In UP-DETR [10], a DETR detector model [4] is pretrained with the random query patch detection pretext task, and fine-tuned for object detection. This model is the closest current model to ours in function, as it supports query-centric detection pre-training with random patches, and object-centric fine-tuning without layer modifications. By comparison, our model implements search instead of only detection, and optimizes much faster due to the explicit spatial inductive bias of anchor-based models vs. DETR. In DETReg [1], a DETR model is trained with pseudolabel boxes generated by selective search [41]. While this approach has the potential to transfer well if the selective search object distribution resembles that of the downstream task, this is unlikely in practice, and the model will have to “unlearn” bad pseudo-boxes during fine-tuning, an issue which is avoided with our query-centric approach.
在UP-DETR [10]中,研究者通过随机查询图像块检测的预训练任务对DETR检测器模型 [4] 进行预训练,并针对目标检测任务进行微调。该模型是目前功能上最接近我们工作的模型,因为它支持基于随机图像块的查询中心式检测预训练,以及无需修改网络层的目标中心式微调。相比之下,我们的模型实现了搜索功能而非单纯检测,并且由于基于锚点的模型相较于DETR具有显式空间归纳偏置,使得优化速度大幅提升。在DETReg [1]中,研究者使用选择性搜索 [41] 生成的伪标签框来训练DETR模型。虽然当选择性搜索的目标分布与下游任务相似时,这种方法可能具有较好的迁移性能,但实践中这种情况较难出现,且模型在微调过程中需要"遗忘"不良伪标注框——这个问题通过我们的查询中心式方法得以规避。
3. Methods
3. 方法
3.1. SPNet Description
3.1. SPNet 描述
A diagram detailing components of SPNet and the Cascade Loop sub component is shown in Fig. 3. SPNet takes Gallery images as input, and outputs detected boxes $b_{d}$ with corresponding class logits $z_{d}$ and re-id embeddings $x_{d}^{\mathrm{reid}}$ . SPNet also takes a Query scene as input with a corresponding ground truth person box $b_{q}$ , and outputs the re-id embedding for that box $x_{q}^{\mathrm{reid}}$ . The query re-id embedding $x_{q}^{\mathrm{reid}}$ is compared to gallery re-id embeddings $x_{d}^{\mathrm{reid}}$ via cosine similarity to produce re-id scores, which are used to rank predictions for retrieval. Image features $\left(\mathbf{C}{3}{-}\mathbf{C}{5}\right)$ are learned by the backbone and refined by the FPN $(\mathrm{{P}{3}{-}\mathrm{{C}{7})}}$ , and then fed to the Box Embedder, with either query boxes $b_{q}$ or detected boxes $b_{d}$ , to learn re-id embeddings $x^{\mathrm{reid}},x^{\mathrm{det}}$ . FPN features are also fed to the Anchor Embedder to learn initial anchor embeddings ${\boldsymbol{{x}}}_{a}^{0}$ .
图 3 展示了 SPNet 及其子组件 Cascade Loop 的详细结构图。SPNet 以图库图像 (Gallery images) 作为输入,输出检测框 $b_{d}$ 及其对应的类别逻辑值 $z_{d}$ 与重识别嵌入特征 $x_{d}^{\mathrm{reid}}$。同时,SPNet 接收查询场景 (Query scene) 输入及对应的人员真实框 $b_{q}$,输出该框的重识别嵌入特征 $x_{q}^{\mathrm{reid}}$。通过余弦相似度计算查询重识别嵌入 $x_{q}^{\mathrm{reid}}$ 与图库重识别嵌入 $x_{d}^{\mathrm{reid}}$ 的匹配度,生成用于检索排序的重识别分数。骨干网络提取的图像特征 $\left(\mathbf{C}{3}{-}\mathbf{C}{5}\right)$ 经 FPN $(\mathrm{{P}{3}{-}\mathrm{{C}{7})}}$ 细化后,输入至框嵌入器 (Box Embedder):当输入为查询框 $b_{q}$ 时生成 $x^{\mathrm{reid}}$,输入检测框 $b_{d}$ 时生成 $x^{\mathrm{det}}$。FPN 特征同时输入锚点嵌入器 (Anchor Embedder) 以生成初始锚点嵌入 ${\boldsymbol{{x}}}_{a}^{0}$。
The Box Embedder can be optionally duplicated to pro $\boldsymbol{x}{q}^{\mathrm{det}}$ ,e osre psa hra arte e dq iu.ee.r $x_{q}^{\mathrm{reid}}=x_{q}^{\mathrm{det}}$ g, ss fhoorr trhe-aind $\boldsymbol{x}{\boldsymbol{q}}^{\mathrm{reid}}$ sa $x_{q}$ .d eU te sic nti go na shared Box Embedder has a regularizing effect by pushing $x_{q}$ to comply with both re-id and detection losses, while duplicating the Box Embedder gives more capacity for each task, which can lead to over fitting. Embeddings $x_{a}$ , and $x_{q}$ for QC, then enter the SP Block, where they may pass through either the QC or OC pathway, depicted in Fig. 4.
Box Embedder 可选择性地复制以生成 $\boldsymbol{x}{q}^{\mathrm{det}}$ ,或直接共享 $\boldsymbol{x}{q}^{\mathrm{reid}}=x_{q}^{\mathrm{det}}$ 。使用共享的 Box Embedder 会通过迫使 $x_{q}$ 同时满足重识别 (re-id) 和检测 (detection) 损失来产生正则化效果,而复制 Box Embedder 则为每个任务提供更多容量,但可能导致过拟合。嵌入向量 $x_{a}$ 和 $x_{q}$ 进入 SP Block 后,可能通过 QC 或 OC 路径处理,如图 4 所示。
QC Pathway. In the QC pathway, shown in Fig. 4a, we compute offset embeddings $x_{o}$ from the Offset Layer, by simply subtracting each anchor embedding from the query embedding: $x_{o}=x_{q}-x_{a}$ . Offset embeddings $x_{o}$ are passed to a Logits Layer, explained in Sec. 3.3, to produce classifier predictions $z_{a}$ for each anchor box, which predict whether a given anchor matches the query $q$ . These $z_{a}$ are used similarly to classifier logits in a standard Faster R-CNN Regional Proposal Network (RPN) [36]: they filter a large number of anchors, typically more than 100, 000 down to less than $1,000$ , which are then refined to produce
QC路径。在QC路径中(如图4a所示),我们通过简单地从查询嵌入中减去每个锚点嵌入来计算来自偏移层(Offset Layer)的偏移嵌入 $x_{o}$ : $x_{o}=x_{q}-x_{a}$ 。偏移嵌入 $x_{o}$ 被传递到对数层(Logits Layer)(详见第3.3节),为每个锚框生成分类器预测 $z_{a}$ ,这些预测用于判断给定锚点是否与查询 $q$ 匹配。这些 $z_{a}$ 的使用方式类似于标准Faster R-CNN区域提议网络(RPN)[36]中的分类器对数:它们将大量锚点(通常超过100,000个)筛选至少于 $1,000$ 个,随后进行细化以生成

Figure 4. Query-centric (a) and object-centric (b) pathways of the SP Block. Note that the query-centric pathway takes as input a query embedding $x_{q}$ extracted from a person image, while the object-centric pathway predicts the query embedding $\hat{x}{q}$ directly from a matching anchor embedding $x_{a}$ using the Bridge Layer $g_{\phi}$ .
图 4: SP模块的查询中心路径(a)和对象中心路径(b)。注意,查询中心路径的输入是从人物图像中提取的查询嵌入 $x_{q}$ ,而对象中心路径则通过桥接层 $g_{\phi}$ 直接从匹配的锚点嵌入 $x_{a}$ 预测查询嵌入 $\hat{x}_{q}$ 。
more accurate boxes.
更精确的边界框。
OC Pathway. In the OC pathway, shown in Fig. 4b, we do not have knowledge of any query embedding $x_{q}$ , so we instead compute a pseudo-query embedding $\hat{x}{q}$ using the Bridge Layer, by default a single affine layer $g_{\phi}(x_{a})= $ $W x_{a}+b$ with learnable parameters $\phi={W,b}$ . By mimicking the QC pathway instead of predicting localization offsets and logits directly from $x_{a}$ , we improve transfer performance between the two pathways. Crucially, the layer $g_{\phi}$ is the only difference between the QC and OC models, meaning that all SPNet weights, aside from $\phi$ , can be trained in one mode, and ported to the other, or vice versa.
OC 路径。在 OC 路径中(如图 4b 所示),我们无法获知任何查询嵌入 $x_{q}$,因此转而使用桥接层(Bridge Layer)计算伪查询嵌入 $\hat{x}{q}$。默认情况下,桥接层是一个单仿射层 $g_{\phi}(x_{a})= $ $W x_{a}+b$,其可学习参数为 $\phi={W,b}$。通过模拟 QC 路径而非直接从 $x_{a}$ 预测定位偏移量和逻辑值,我们提升了两个路径间的迁移性能。关键的是,层 $g_{\phi}$ 是 QC 和 OC 模型间的唯一区别,这意味着除 $\phi$ 外,所有 SPNet 权重都可以在一种模式下训练,并迁移到另一种模式,反之亦然。
Box Prediction. Both pathways output offset embeddings $x_{o}$ that are passed to a separate Box Detector module, shown in Fig. 3, which performs the box refinement. The box reg head is a 4-layer MLP with input $x_{o}$ which predicts offsets $\hat{r}{d}$ between anchor boxes and matching ground truth boxes. The box cls head uses the same Logits Layer as the SP Block to produce class logits $z_{d}$ . Predicted boxes $b_{d}$ are fed back to the Box Embedder, the same as that used to produce $\boldsymbol{x}{q}^{\mathrm{reid}}$ , to produce predicted reid embeddings $x_{d}^{\mathrm{reid}}$ . The $x_{q}^{\mathrm{reid}}$ from queries are compared to xrdeid from gallery images for ranking.
框预测。两条路径均输出偏移嵌入 $x_{o}$,传递给独立的框检测器模块(如图 3 所示)进行框细化处理。框回归头是一个4层MLP,以 $x_{o}$ 为输入,预测锚框与匹配真实框之间的偏移量 $\hat{r}{d}$。框分类头使用与SP块相同的Logits Layer生成类别logits $z_{d}$。预测框 $b_{d}$ 被反馈至框嵌入器(与生成 $\boldsymbol{x}{q}^{\mathrm{reid}}$ 的模块相同),生成预测的reid嵌入 $x_{d}^{\mathrm{reid}}$。查询的 $x_{q}^{\mathrm{reid}}$ 将与图库图像的xrdeid进行比对以完成排序。
Cascade Loop. We can iterative ly refine box accuracy and scores by repeating the same basic prediction structure in a loop, referred to as the Cascade Loop in Fig. 3, originating from the Cascade R-CNN detector [2], and also done in the SeqNet [27] and SeqNeXt [23] person search models. In the Cascade Loop, predicted boxes b(dt) from stage $t$ are fed back into the Box Embedder to produce anchor embeddings x(at) for the next step t + 1. The outputs z(at ), x(ot ), z(dt ), and $\hat{r}{d}^{(t)}$ are also updated during each Cascade Loop step. The detector re-id embeddings $x_{d}^{\mathrm{reid}}$ are computed from the detected boxes coming out of the final Cascade Loop stage. The SP Block, Box Detector, and Box Embedder are all duplicated for each round, meaning that we use modules with the same architecture, but do not share weights of the same module between rounds.
级联循环 (Cascade Loop)。我们可以通过循环重复相同的基础预测结构来迭代优化边界框精度和分数,如图 3 所示的级联循环,该结构源自 Cascade R-CNN 检测器 [2],并在 SeqNet [27] 和 SeqNeXt [23] 行人搜索模型中也有应用。在级联循环中,阶段 $t$ 预测的边界框 $b_{d}^{(t)}$ 会反馈给边界框嵌入器 (Box Embedder),为下一步 $t+1$ 生成锚点嵌入 $x_{a}^{(t)}$。输出 $z_{a}^{(t)}$、$x_{o}^{(t)}$、$z_{d}^{(t)}$ 和 $\hat{r}{d}^{(t)}$ 也会在每次级联循环步骤中更新。检测器重识别嵌入 $x_{d}^{\mathrm{reid}}$ 由最终级联循环阶段输出的检测边界框计算得出。SP 模块 (SP Block)、边界框检测器 (Box Detector) 和边界框嵌入器 (Box Embedder) 在每轮循环中都会复制,这意味着我们使用相同架构的模块,但不同轮次间不共享同一模块的权重。
3.2. Pretext Task
3.2. 前置任务
The goal of our pre-training pretext task is to initialize nearly all model weights to optimize for transfer to the downstream person search task. In Fig. 5, we show the QC detection pretext task compared to standard OC detection. In OC detection, the goal is to regress each anchor class probability $p$ to 1 if the anchor matches a ground truth box $b_{g}$ e.g., $b_{a}^{(1)}$ , or 0 if it does not e.g., $b_{a}^{(2)}$ . The overlap threshold for matching boxes is $0.5~\mathrm{IoU}$ . For matching anchors, we also regress box offsets $\hat{r}^{(1)}$ to targets $r^{(1)}$ . In QC detection, the regression targets are the same, but predictions for each anchor are computed only relative to a query, explained by the QC vs. OC pathways in the previous section. QC detection results in more robust optimization, because it can better handle label noise like the missing annotation in Fig. 5 or examples in Fig. 1. Intuitively, QC detection allows us to learn salient features for transfer to person search without rigidly defining positive and negative detections.
我们预训练代理任务的目标是初始化几乎所有模型权重,以优化向下游人员搜索任务的迁移。在图5中,我们展示了QC检测代理任务与标准OC检测的对比。在OC检测中,若锚框匹配真实框$b_{g}$(例如$b_{a}^{(1)}$),则目标是将每个锚框类别概率$p$回归至1;若不匹配(例如$b_{a}^{(2)}$)则回归至0。匹配框的重叠阈值为$0.5~\mathrm{IoU}$。对于匹配锚框,我们还将框偏移量$\hat{r}^{(1)}$回归至目标$r^{(1)}$。在QC检测中,回归目标相同,但每个锚框的预测仅相对于查询计算(由前文QC与OC路径解释)。QC检测能实现更鲁棒的优化,因为它能更好处理标签噪声(如图5中的漏标或图1的示例)。直观而言,QC检测让我们能学习迁移至人员搜索任务的显著特征,而无需严格定义正负检测。
Our pre-training experiments utilize weakly-labeled person boxes. Since identities are not tracked between images for weakly-labeled data, we generate correspondence between images using data augmentation: we know that a box in an image corresponds to the same box in an augmented version of that image, with potentially different coordinates, visualized in Fig. 5. Augmentations consist of scaling, cropping, and horizontal flipping.
我们的预训练实验使用了弱标注的人体检测框。由于弱标注数据在图像间未进行身份追踪,我们通过数据增强生成图像间的对应关系:已知某图像中的检测框与其增强版本中的对应框代表同一目标(坐标可能不同),如图 5 所示。增强操作包括缩放、裁剪和水平翻转。
For QC detection on weakly-labeled data, each image in a batch is augmented $k$ times, where $k=2$ for all experiments, with each augmented image taking a turn as both query and gallery. Annotated boxes in the query image are compared against the corresponding box in the gallery image, and assigned to anchors with overlap $\geq0.5$ IoU. Self comparisons are allowed as well, in which the query and gallery are the same image.
对于弱标注数据的质量控制检测,每批次图像会进行$k$次增强(实验中$k=2$),每次增强后的图像轮流作为查询图像和检索图像。查询图像中的标注框会与检索图像中对应框进行比较,并与交并比(IoU)$\geq0.5$的锚框匹配。允许自比较情况,即查询图像和检索图像为同一图像。
For all cases, OC optimization treats annotated boxes as true objects with the same anchor matching criterion as QC, and pushes anchor scores to 0 or 1 as shown in Fig. 5. We also augment batch images $k$ times for the OC case to fairly compare with QC, though it is not necessary.
在所有情况下,OC优化将标注框视为真实物体,采用与QC相同的锚框匹配准则,并将锚框分数推至0或1,如图5所示。为了与QC进行公平比较,我们还对OC情况下的批次图像进行了$k$次增强,尽管这不是必需的。

Figure 5. Visual comparison of object-centric (OC) and query-centric (QC) detection tasks between two augmentations of the same base image (Query, Gallery). One person box is annotated (ground truth $b_{q},b_{g})$ , while the other is not (missing annotation). Note that anchor box1 $b_{a}^{(1)}$ overlaps ground truth box $b_{g}$ while anchor box2 $b_{a}^{(2)}$ does not. Anchor embeddings $x_{a}$ are used to compute box offsets $\hat{r}$ and anchor probabilities $p$ either directly (OC) or relatively using $x_{o}=x_{q}-x_{a}$ (QC). We do not compute box offsets $\hat{r}$ for ba because it does not match any ground truth.
图 5: 以物体为中心 (OC) 和以查询为中心 (QC) 检测任务在同一基础图像 (Query, Gallery) 两种增强版本上的视觉对比。标注了一个人物框 (真实标注 $b_{q},b_{g}$),另一个未标注 (漏标)。注意锚框1 $b_{a}^{(1)}$ 与真实标注框 $b_{g}$ 重叠,而锚框2 $b_{a}^{(2)}$ 未重叠。锚嵌入 $x_{a}$ 用于直接计算框偏移量 $\hat{r}$ 和锚概率 $p$ (OC),或通过 $x_{o}=x_{q}-x_{a}$ 进行相对计算 (QC)。我们不为 ba 计算框偏移量 $\hat{r}$,因其未匹配任何真实标注。
3.3. Losses
3.3. 损失函数
Classifier Losses. For the offset embeddings $x_{o}$ shown in Fig. 3, it is critical to define a loss function which enforces a consistent relationship between query embeddings $x_{q}$ and anchor embeddings $x_{a}$ , while performing the classification regression. The goal is to regress query-anchor matches to 1 and non-matches to 0, shown in Fig. 5. For this task, we model the anchor loss after the Norm-Aware Embedding concept from [6], and the Focal Loss from [28].
分类器损失。对于图 3 中所示的偏移嵌入 $x_{o}$,关键在于定义一个损失函数,在执行分类回归时强制保持查询嵌入 $x_{q}$ 和锚点嵌入 $x_{a}$ 之间的一致性关系。目标是将查询-锚点匹配回归为 1,非匹配回归为 0,如图 5 所示。为此任务,我们基于 [6] 的 Norm-Aware Embedding 概念和 [28] 的 Focal Loss 对锚点损失进行建模。
Recall the offset embedding is defined as the difference between query and anchor embeddings: $x_{o}=x_{q}-x_{a}$ with $x_{o}\in\mathbb{R}^{d}$ . Assign $w=|x_{o}|$ . In the Norm-Aware Embedding work [6], classification logits are computed from embedding norms using a Batch Norm layer [22].To avoid use of unstable batch statistics, we instead compute a fixed rescaling by modeling $x_{o}\sim\mathcal{N}(0,I_{d})$ , which implies $w\sim\operatorname{Chi}(d)$ . Then we can standardize $w$ using the mean and standard deviation of the Chi distribution, with class logits given by $z=-(w-\mu_{\mathrm{Chi}})/s_{\mathrm{Chi}}$ . Finally, we compute class probabilities with the logistic sigmoid $p=\sigma(z)$ .
回想偏移嵌入(offset embedding)被定义为查询(query)与锚点(anchor)嵌入之间的差异:$x_{o}=x_{q}-x_{a}$,其中$x_{o}\in\mathbb{R}^{d}$。设$w=|x_{o}|$。在Norm-Aware Embedding工作[6]中,分类逻辑值(logits)是通过使用批归一化(Batch Norm)层[22]从嵌入范数计算得出的。为了避免使用不稳定的批次统计量,我们改为通过对$x_{o}\sim\mathcal{N}(0,I_{d})$建模来计算固定重缩放,这意味着$w\sim\operatorname{Chi}(d)$。然后我们可以使用卡方分布(Chi distribution)的均值和标准差来标准化$w$,类别逻辑值由$z=-(w-\mu_{\mathrm{Chi}})/s_{\mathrm{Chi}}$给出。最后,我们使用逻辑S型函数(logistic sigmoid)$p=\sigma(z)$计算类别概率。
For anchor logits $z_{a}$ , we compute a loss averaged across all anchors $\mathcal{L}{\mathrm{anc}}$ , applying the Focal Loss defined in [28], with hyper parameters $\alpha_{\mathrm{{FL}}}=0.5,\gamma_{\mathrm{{FL}}}=1$ . For cascade layer class logits $z_{d}$ , we compute a loss $\mathcal{L}_{\mathrm{cls}}$ averaged across predicted boxes using the unweighted Cross Entropy Loss.
对于锚点对数 $z_{a}$,我们计算所有锚点的平均损失 $\mathcal{L}{\mathrm{anc}}$,采用 [28] 中定义的 Focal Loss (焦点损失),超参数设为 $\alpha_{\mathrm{{FL}}}=0.5,\gamma_{\mathrm{{FL}}}=1$。对于级联层分类对数 $z_{d}$,我们使用未加权的交叉熵损失计算预测框的平均损失 $\mathcal{L}_{\mathrm{cls}}$。
Additional justification is given in Supplementary Sec. 9.2, where we compare our FixedNorm logits formulation vs. the standard BatchNorm, and describe other intuitive benefits of our formulation.
补充说明见补充材料第9.2节,其中我们比较了FixedNorm logits公式与标准BatchNorm的差异,并描述了该公式的其他直观优势。
Box Regression Loss. For bounding box offset regression, we use the generalized IoU (GIoU) loss [37], shown as $\mathcal{L}{\mathrm{reg}}$ . This loss has a beneficial interaction with the classifier loss: for matching query and anchor boxes (high IoU/GIoU), the target box regression offsets should be small, corresponding to $\Vert x_{o}\Vert$ small. This allows the model to learn that the magnitude of $\Vert x_{o}\Vert$ correlates directly to the size of predicted box offsets.
边界框回归损失。对于边界框偏移回归,我们使用广义IoU (GIoU)损失[37],表示为$\mathcal{L}{\mathrm{reg}}$。该损失与分类器损失存在有益交互:对于匹配查询框和锚框(高IoU/GIoU)的情况,目标框回归偏移量应较小,对应$\Vert x_{o}\Vert$较小。这使得模型能够学习到$\Vert x_{o}\Vert$的幅值直接关联预测框偏移量的大小。
Re-id Losses. For our re-id losses, we use two variations of the normalized temperature-scaled cross-entropy loss [7,
Re-id损失函数。对于我们的re-id损失函数,我们使用了归一化温度缩放交叉熵损失[7]的两种变体。
40]. We use the terms positive pair and negative pair to refer to two embeddings with the same label or different labels respectively.
我们使用正样本对 (positive pair) 和负样本对 (negative pair) 来分别指代具有相同标签或不同标签的两个嵌入向量 [40]。
We define the probability for positive pair $(x,x^{+})$ under the contrastive objective as
我们将正样本对 $(x,x^{+})$ 在对比目标下的概率定义为
$$
p(x,x^{+})=\frac{s_{\tau}(x,x^{+})}{s_{\tau}(x,x^{+})+\sum_{x^{-}\in\chi_{x}^{-}}s_{\tau}(x,x^{-})}
$$
$$
p(x,x^{+})=\frac{s_{\tau}(x,x^{+})}{s_{\tau}(x,x^{+})+\sum_{x^{-}\in\chi_{x}^{-}}s_{\tau}(x,x^{-})}
$$
With the full contrastive loss expressed as
完整对比损失表示为
$$
\mathcal{L}{\mathrm{reid}}=-\log\sum_{x\in\mathcal{X}}\sum_{x^{+}\in\mathcal{X}_{x}^{+}}p(x,x^{+})
$$
$$
\mathcal{L}{\mathrm{reid}}=-\log\sum_{x\in\mathcal{X}}\sum_{x^{+}\in\mathcal{X}_{x}^{+}}p(x,x^{+})
$$
using $s_{\tau}(u,v)\triangleq\exp\left(\sin(u,v)/\tau\right)$ and $\sin(u,v)\triangleq u.$ · $v/|u||v|,u,v\in\mathbb{R}^{d}$ . $\chi$ denotes the set of all $x$ , ${\chi}{x}^{+}$ the set of all positive samples for $x$ , and $\chi_{x}^{-}$ the set of all negative samples for $x$ . To produce variations of this loss, we vary compositions of the sets ${\chi}{x}^{+}$ and $\chi_{x}^{-}$ .
使用 $s_{\tau}(u,v)\triangleq\exp\left(\sin(u,v)/\tau\right)$ 和 $\sin(u,v)\triangleq u.$ · $v/|u||v|,u,v\in\mathbb{R}^{d}$。$\chi$ 表示所有 $x$ 的集合,${\chi}{x}^{+}$ 表示 $x$ 的所有正样本集合,$\chi_{x}^{-}$ 表示 $x$ 的所有负样本集合。为了产生这种损失的变化,我们改变集合 ${\chi}{x}^{+}$ 和 $\chi_{x}^{-}$ 的组合。
Fine-Tuning Re-id Loss. During fine-tuning, we use the standard online instance matching (OIM) loss from [46].
微调Re-id损失。在微调阶段,我们采用[46]提出的标准在线实例匹配(OIM)损失函数。
Pre-Training Re-id Loss. During pre-training, we use a variation of the momentum contrast loss (MoCo) from [18]. Like in MoCo, we define an encoder network which is updated via gradient descent, and a momentum network, which is updated as a moving average of the encoder. We call embeddings from the encoder network $x_{e}$ and embeddings from the momentum network $x_{m}$ . Define $\bar{x}{m}$ as the mean of all predicted box embeddings with corresponding box having $\mathrm{IoU}\geq0.7$ with a given ground truth box. We store embeddings $\bar{x}{m}$ in a queue during training. Then, we form positive pairs ${\boldsymbol{\chi}}{{\boldsymbol{x}}{e}}^{+}$ with all embeddings $(x_{e},\bar{x}{m}^{+})$ and negative pairs $\chi_{x_{e}}^{-}$ with all embeddings $(x_{e},\bar{x}_{m}^{-})$ .
预训练Re-id损失。在预训练阶段,我们采用[18]中动量对比损失(MoCo)的变体。与MoCo类似,我们定义了一个通过梯度下降更新的编码器网络,以及一个作为编码器移动平均更新的动量网络。我们将编码器网络生成的嵌入表示为$x_{e}$,动量网络生成的嵌入表示为$x_{m}$。定义$\bar{x}{m}$为所有预测框嵌入的均值,这些预测框与给定真实框的交并比(IoU)满足$\mathrm{IoU}\geq0.7$。训练过程中,我们将嵌入$\bar{x}{m}$存储在队列中。随后,我们为所有嵌入$(x_{e},\bar{x}{m}^{+})$构建正样本对${\boldsymbol{\chi}}{{\boldsymbol{x}}{e}}^{+}$,为所有嵌入$(x_{e},\bar{x}{m}^{-})$构建负样本对$\chi_{x_{e}}^{-}$。
We are effectively comparing current embeddings to moving average cluster centroids [24], in the limit where the cluster consists of only one person image. In absence of cluster pseudo-labels similar to those used in [24] and other weakly-supervised methods, it is critical to have a representative embedding to compare against aside from the image itself. As in [12], we found it useful to utilize proposals with $\mathrm{IoU}\geq0.7\$ , but did not find it beneficial to weight them by IoU in the re-id loss, as in that work.
我们实际上是将当前嵌入(embeddings)与移动平均聚类中心[24]进行比较,在聚类仅包含单个人物图像的极限情况下。由于缺乏类似[24]和其他弱监督方法中使用的聚类伪标签,除了图像本身外,拥有一个具有代表性的嵌入进行比较至关重要。如[12]所示,我们发现使用交并比(IoU)≥0.7的提议(proposals)是有益的,但并未发现像该研究那样在重识别(re-id)损失中按IoU加权能带来额外优势。
Final Loss. The final loss for both pre-training and finetuning is simply the unweighted sum of all described losses: $\begin{array}{r}{\mathcal{L}=\bar{\mathcal{L}}{\mathrm{reid}}+\bar{\mathcal{L}}{\mathrm{anc}}+\sum_{t=1}^{T+1}\bar{\mathcal{L}}{\mathrm{reg}}^{(t)}+\mathcal{L}_{\mathrm{cls}}^{(t)}}\end{array}$ Lc(lts) , where T is the number of cascade stages.
最终损失。预训练和微调的最终损失仅为所有描述损失的未加权总和:$\begin{array}{r}{\mathcal{L}=\bar{\mathcal{L}}{\mathrm{reid}}+\bar{\mathcal{L}}{\mathrm{anc}}+\sum_{t=1}^{T+1}\bar{\mathcal{L}}{\mathrm{reg}}^{(t)}+\mathcal{L}_{\mathrm{cls}}^{(t)}}\end{array}$ Lc(lts) ,其中T为级联阶段数。
4. Experiments
4. 实验
4.1. Datasets and Evaluation
4.1. 数据集与评估
Datasets. We perform weakly-supervised pre-training on the train partition of the COCO Persons dataset [39], which contains 64k scenes with $257\mathrm{k}$ person box annotations. COCOPersons is the subset of MS-COCO2017 [29] images containing at least one person annotation; non-person annotations are ignored. We fine-tune models on the two standard person search benchmark datasets: CUHK-SYSU [46] and PRW [52]. Other metadata about the datasets are presented in Supplementary Sec. 7.
数据集。我们在COCO Persons数据集[39]的训练集上进行弱监督预训练,该数据集包含64k个场景和$257\mathrm{k}$个人体框标注。COCOPersons是MS-COCO2017[29]中包含至少一个人体标注的图像子集,非人体标注被忽略。我们在两个标准人物搜索基准数据集上微调模型:CUHK-SYSU[46]和PRW[52]。其他数据集元数据见补充材料第7节。
Evaluation. We evaluate all models by measuring finetuning performance once on the standard retrieval test scenario for CUHK-SYSU or PRW, described in Supplementary Sec. 7. While we compare QC vs. OC pre-training, fine-tuning is always done in the OC mode. In Supplementary Sec. 9.1, we show that QC fine-tuning is less effective than OC fine-tuning.
评估。我们通过分别在CUHK-SYSU或PRW的标准检索测试场景下测量微调性能来评估所有模型(详见补充材料第7节)。在比较QC(Query-Centric)与OC(Object-Centric)预训练时,微调始终采用OC模式。补充材料第9.1节表明,QC微调效果逊于OC微调。
To measure performance, we use standard detection performance metrics of recall $\ @0.5$ IoU and average precision $\ @0.5$ $(\mathrm{AP}@0.5)$ IoU, indicating predictions with an overlap of $>0.5$ IoU with a ground truth box are considered matches. For person search evaluation, we use the standard metrics of mean average precision (mAP) and top-1 accuracy (top-1).
为了衡量性能,我们使用标准检测性能指标:召回率 $\ @0.5$ IoU 和平均精度 $\ @0.5$ $(\mathrm{AP}@0.5)$ IoU,表示与真实标注框重叠度 $>0.5$ IoU 的预测视为匹配。对于人员搜索评估,我们采用标准指标平均精度均值 (mAP) 和 top-1 准确率 (top-1)。
4.2. Implementation Details
4.2. 实现细节
We describe the most important implementation details, with additional information given in Supplementary Sec. 8. Model Configurations. We perform experiments with two variants of the SPNet model: SPNet-S(mall) and SPNetL(arge), with differences shown in Tab. 2. Unless otherwise stated, SPNet-S uses a ConvNeXt-T [30] backbone, and SPNet-L uses a ConvNeXt-B backbone.
我们描述了最重要的实现细节,补充信息见补充材料第8节"模型配置"。我们使用SPNet模型的两个变体进行实验:SPNet-S(小)和SPNet-L(大),具体差异如Tab. 2所示。除非另有说明,SPNet-S使用ConvNeXt-T [30]骨干网络,SPNet-L使用ConvNeXt-B骨干网络。
Optimization. For all experiments, we pre-train and finetune for 30 epochs each, using the AdamW optimizer [32], a cosine-annealed schedule, and linear warmup following [31, 32].
优化。对于所有实验,我们使用AdamW优化器[32]、余弦退火调度和线性预热[31, 32],分别进行30轮预训练和微调。
Pre-training Optimization. For experiments pre-training SPNet with our method, the backbone is initialized using ImageNet-1k classifier weights unless otherwise stated. For the pre-training re-id loss, we use the MoCo objective described in Sec. 3.3 with a queue length of 65, 536, momentum of 0.9999, and temperature $\tau=0.1$ . We use the Pretrain config from Tab. 2 for learning rate and weight decay settings. We also experiment with four variations of layer freezing and learning rates for the backbone and postbackbone modules, with results shown in Supplementary Sec. 9.1 Fig. 7. We note that QC outperforms OC pretraining for nearly all configurations.
预训练优化。在使用我们的方法预训练SPNet的实验中,除非另有说明,否则主干网络均使用ImageNet-1k分类器权重进行初始化。对于预训练的行人重识别损失,我们采用第3.3节描述的MoCo目标函数,队列长度为65,536,动量系数为0.9999,温度参数$\tau=0.1$。学习率和权重衰减设置采用表2中的Pretrain配置。我们还针对主干网络和后主干网络模块尝试了四种层冻结与学习率组合方案,具体结果见补充材料第9.1节图7。值得注意的是,在几乎所有配置中,QC预训练方法都优于OC预训练。
Fine-tuning Optimization. For the fine-tuning re-id loss, we use the OIM objective described in Sec. 3.3 with temperature $1/30$ , momentum 0.5, and queue length 5, 000 for CUHK and 500 for PRW, which are the standard settings. We use the Fine-tune config from Tab. 2, with image size $512\times512$ used for SPNet-S, and image size $1024\times1024$ used for SPNet-L.
微调优化。对于微调的行人重识别损失,我们使用第3.3节描述的OIM目标函数,温度参数设为$1/30$,动量参数为0.5,队列长度在CUHK数据集设为5,000,PRW数据集设为500,这些均为标准设置。我们采用表2中的微调配置,其中SPNet-S使用$512\times512$的图像尺寸,SPNet-L使用$1024\times1024$的图像尺寸。
Training and Inference Speed. All models were trained using a single A100 GPU with 82GB VRAM. Pre-training and fine-tuning times are shown in Supplementary Sec. 8, with the QC pre-training taking 30 hours for SPNet-S and 46.5 hours for SPNet-L. While the SOLIDER [8] authors do not give precise training times, they train for 110 epochs on 8 V100 GPUs, and reported the training took several days. A related approach from the LUPerson paper [15] trains for 200 epochs on 8 V100 GPUs. Another crop-only approach callled PASS [53] pre-trains for 100 epochs on 8 A100 GPUs, which takes 60-120 hours depending on the backbone. In addition, LUPerson, PASS, and SOLIDER each pre-train on the much larger LUPerson dataset with 4.18M images vs. our 64k images in the COCO Persons dataset. Given the results comparison in Tab. 3, this shows our method achieves much greater pre-training efficiency for person search. Further, we show in Tab. 1 that SPNet-L achieves comparable metrics to other top models when using a ResNet50 backbone [19], with inference speed more than 5 FPS greater than the next fastest SeqNeXt model at 27.6 vs. 22.3 FPS.
训练与推理速度。所有模型均在配备82GB显存的单个A100 GPU上进行训练。预训练与微调时长见补充材料第8节,其中SPNet-S的QC预训练耗时30小时,SPNet-L耗时46.5小时。虽然SOLIDER [8]作者未提供精确训练时长,但其使用8块V100 GPU训练110个周期,报告称训练耗时数天。LUPerson论文[15]提出的相关方法使用8块V100 GPU训练200个周期。另一种仅使用裁剪的PASS方法[53]在8块A100 GPU上预训练100个周期,根据骨干网络不同耗时60-120小时。此外,LUPerson、PASS和SOLIDER均在包含418万图像的LUPerson数据集上预训练,而我们的COCO Persons数据集仅含6.4万图像。结合表3的结果对比,这表明我们的方法在行人搜索任务中实现了更高的预训练效率。表1进一步显示,当采用ResNet50骨干网络[19]时,SPNet-L的指标与其他顶级模型相当,且推理速度达到27.6 FPS,比次快的SeqNeXt模型(22.3 FPS)高出5 FPS以上。
| Model | Backbone | CUHK-SYSU mAP | CUHK-SYSU top-1 | PRW mAP | PRW top-1 | FPS |
|---|---|---|---|---|---|---|
| SeqNet [27] | ResNet50 | 93.8 | 94.6 | 46.7 | 83.4 | 12.2 |
| SeqNeXt[23] | ResNet50 | 93.8 | 94.3 | 51.1 | 85.8 | 22.3 |
| SPNet-L | ResNet50 | 93.8 | 94.5 | 51.2 | 86.9 | 27.6 |
| COAT [50] | ResNet50 | 94.2 | 94.7 | 53.3 | 87.4 | 11.1 |
Table 1. Person search metrics and inference speed for models with ResNet50 backbone with ImageNet-1k classifier initialization. Inference speed in frames per second (FPS) measured on PRW with a single A100 GPU.
表 1: 基于 ResNet50 骨干网络及 ImageNet-1k 分类器初始化的模型在行人搜索任务中的指标与推理速度。推理速度以每秒帧数 (FPS) 为单位,在 PRW 数据集上使用单块 A100 GPU 测得。
4.3. Comparison with State-of-the-art
4.3. 与最先进技术的对比
In Tab. 3 (top), we compare performance of SPNet with recent state-of-the-art person search models. To show cases where more than one pre-training step is used, we indicate the first step with Pre-training (1) and the second with Pretraining (2). If no pre-training is used, indicated by “-”, all weights are randomly initialized. We show that SPNetL, with QC pre-training on COCO Persons, matches or exceeds other models in most metrics for the CUHK-SYSU and PRW datasets e.g., improving mAP by $+1.7%$ on PRW over previous SOTA LEAPS [12].
在表3 (上) 中,我们将SPNet与当前最先进的人员搜索模型进行性能对比。为展示使用多步预训练的情况,我们用"预训练(1)"表示第一步,"预训练(2)"表示第二步。若未使用预训练(标记为"-"),则所有权重均为随机初始化。实验表明,采用COCO Persons数据集进行QC预训练的SPNetL模型,在CUHK-SYSU和PRW数据集的大部分指标上达到或超越了其他模型性能,例如在PRW数据集上将mAP指标较先前SOTA方法LEAPS [12]提升了+1.7%。
Table 2. SPNet architecture (top) and layer optimization (bottom) hyper parameter configurations. LR $=$ Learning Rate, WD $=$ Weight Decay.
表 2: SPNet架构(上)和层优化(下)的超参数配置。LR $=$ 学习率(Learning Rate), WD $=$ 权重衰减(Weight Decay)。
| Config.Name | CascadeSteps | SharedHeads | Re-id Dim |
|---|---|---|---|
| SPNet-S | 0 | √ | 128 |
| SPNet-L | 2 | 2048 |
| Config.Name | Backbone LR | WD | LR | Post-Backbone WD | Image Size |
|---|---|---|---|---|---|
| Pre-train | 1e-5 | 0 | 1e-4 | 1e-3 | 512 |
| Fine-tune | 1e-4 | 5e-4 | 1e-4 | 5e-4 | 512 or 1024 |
In addition, we show that the QC pre-training itself on SPNet-L adds $0.5%$ mAP for CUHK-SYSU and $2.3%$ mAP for PRW. This shows that the benefit from query-centric pre-training extends to the high-end of the model size / performance spectrum, even when performance statistics are nearly saturated, as on CUHK-SYSU and PRW. In contrast, we note that OC pre-training slightly degraded performance on CUHK, demonstrating the need for SPNet and the QC pre-training approach, i.e. that performance cannot be trivally improved for any person search model by simply incorporating OC pre-training.
此外,我们发现SPNet-L上的QC(以查询为中心)预训练本身为CUHK-SYSU带来了0.5%的mAP提升,为PRW带来了2.3%的mAP提升。这表明,即使像CUHK-SYSU和PRW这样性能指标接近饱和的情况下,以查询为中心的预训练优势仍能延伸到模型规模/性能范围的高端。相比之下,我们注意到OC(以目标为中心)预训练在CUHK上略微降低了性能,这印证了SPNet和QC预训练方法的必要性——即不能简单地通过引入OC预训练来轻易提升任意人员搜索模型的性能。
4.4. Comparison with Pre-training Alternatives
4.4. 与预训练替代方案的对比
In Tab. 3 (bottom), we compare our pre-training approach to the backbone-only SOLIDER pre-training approach [8] vs. random initialization or standard ImageNet1k classifier initialization. To do a fair experimental comparison, we use models with the Swin-B backbone variant from the SOLIDER codebase for all trials. In addition, we isolate for the effect of the pre-training dataset by rerunning SOLIDER on person crops from the COCO Persons dataset. We report results from our SPNet-L model and the original SeqNet model used by SOLIDER.
在表3 (底部),我们将预训练方法与仅使用骨干网络的SOLIDER预训练方法[8]进行了对比,同时对比了随机初始化或标准ImageNet1k分类器初始化。为确保实验公平性,所有试验均采用SOLIDER代码库中Swin-B骨干变体的模型。此外,我们通过在COCO Persons数据集的人物裁剪图上重新运行SOLIDER,来隔离预训练数据集的影响。结果报告了我们的SPNet-L模型和SOLIDER原版使用的SeqNet模型的表现。
For SPNet-L, we find that our QC pre-training approach outperforms all alternative initialization strategies, in some cases by wide margins e.g., $+4.5%$ on PRW over ImageNet1k initialization alone. While SOLIDER pre-training on LUPerson is significantly better than random initialization, shown in the first two rows, it is less effective than simple ImageNet-1k classifier pre-training, and far less effective than our QC pre-training approach. In addition, when we apply additional pre-training to SOLIDER on the COCOPersons dataset, there is no improvement to fine-tuning performance, and even degradation in the case of ImageNet-1k classifier initialization. This shows that the COCO Persons crops alone are not nearly as effective for crop-only pretraining as the LUPerson dataset, which is over $16\times$ larger. Further, it shows these crops add no additional information beyond either LUPerson or ImageNet-1k. This means that any benefits provided by our pre-training approach, which utilizes full scenes and not just crops, come from scene context and the pre-training method itself.
对于SPNet-L,我们发现我们的QC预训练方法在所有替代初始化策略中表现最优,某些情况下优势显著,例如在PRW数据集上比仅使用ImageNet1k初始化高出+4.5%。虽然LUPerson上的SOLIDER预训练明显优于随机初始化(如开头两行所示),但其效果仍不及简单的ImageNet-1k分类器预训练,更远逊于我们的QC预训练方法。此外,当我们在COCOPersons数据集上对SOLIDER进行额外预训练时,微调性能并未提升,甚至在ImageNet-1k分类器初始化的情况下出现下降。这表明仅使用COCO Persons裁剪图像进行预训练的效果远不如规模超过16倍的LUPerson数据集。进一步说明这些裁剪图像未能提供超越LUPerson或ImageNet-1k的额外信息。这意味着我们采用完整场景(而非仅裁剪区域)的预训练方法所带来的优势,完全源于场景上下文和预训练方法本身。
Further, we show that our QC approach exceeds our OC approach when both are initialized from ImageNet-1k classifier pre-training, with both the ConvNeXt-B backbone shown in Tab. 3 (top), and the Swin-B backbone shown in Tab. 3 (bottom). This validates our reasoning that QC pretraining learns more robust features than OC pre-training.
此外,我们发现当两种方法都基于ImageNet-1k分类器预训练初始化时,我们的QC方法优于OC方法。这一结论在表3(上)所示的ConvNeXt-B骨干网络和表3(下)所示的Swin-B骨干网络中均得到验证,从而证实了我们的推断:QC预训练比OC预训练能学习到更具鲁棒性的特征。
Finally, we show that although ImageNet-1k classifier pre-training outperforms LUPerson SOLIDER pre-training for SPNet-L, SOLIDER is significantly better for the SeqNet model, as reported in the SOLIDER paper. Differing performance for SPNet is likely due to a mismatch of the SOLIDER pre-training objective in creating effective features for the feature pyramid network in SPNet, caused by exacerbating scale misalignment of features [48]. In contrast, ImageNet-1k features are more general, and pair better with the feature pyramid network out-of-the-box.
最后,我们发现虽然 ImageNet-1k 分类器预训练在 SPNet-L 上优于 LUPerson SOLIDER 预训练,但如 SOLIDER 论文所述,SOLIDER 在 SeqNet 模型上表现显著更优。SPNet 的性能差异可能源于 SOLIDER 预训练目标与 SPNet 特征金字塔网络的有效特征创建不匹配,这是由于特征尺度错位加剧所致 [48]。相比之下,ImageNet-1k 特征更具通用性,能更好地与特征金字塔网络开箱即用。
4.5. Pre-training with Noisy Labels
4.5. 带噪声标签的预训练
In this section, we show that QC pre-training results in better fine-tuning performance than OC pre-training in the weakly-labeled scenario with noisy labels. We model two noisy labels use cases: 1) ground truth annotations which should be present are missing and 2) there are additional spurious annotations. This has applications both for manual labeling, in which persons may be missed, not all persons are annotated by design, or there is inherent labeling ambiguity as shown in Fig. 1. It is also relevant for auto-labeling, in which a detector is used to label imagery, but may have low recall, creating missing annotations, or high recall but also high false positive rate, creating spurious annotations.
在本节中,我们证明在带有噪声标签的弱标注场景下,QC(质量控制)预训练比OC(开放类别)预训练能带来更好的微调性能。我们建模了两种噪声标签用例:1) 本应存在的地面真实标注缺失;2) 存在额外的伪标注。这种情况既适用于人工标注(可能出现漏标、设计上未标注全部目标,或存在如图1所示的固有标注歧义),也适用于自动标注(使用检测器标注图像时可能出现低召回率导致标注缺失,或高召回率伴随高误报率产生伪标注)。
To model missing labels, we create successive partitions of COCO Persons with increments of $40%$ of annotations removed, with each smaller partition being a subset of all larger partitions. To model spurious labels, we add increments of $40%$ of the total labels in the original set, drawing from the existing distribution of bounding box shapes in the dataset. The results are shown in Fig. 6, where we compare how QC and OC pre-training are affected by quantity of missing or spurious labels, as measured by fine-tuning performance on CUHK-SYSU. Results are compared to the baseline ImageNet-1k classifier backbone initialization, shown by the black dashed line. For all plots, we show that QC pre-training exceeds OC pre-training in all sample regimes for full fine-tuning. Even when only $20%$ of samples are used, QC pre-training offers a small benefit to finetuning for person search, shown by mAP in Fig. 6a, where OC pre-training actually harms fine-tuning performance by forcing the model to learn that most ground truth person boxes are background. This trend is reflected for detection performance as well, shown in plot Fig. 6b.
为模拟缺失标签的情况,我们对COCO Persons数据集进行连续分区,每次移除40%的标注,确保每个较小分区都是较大分区的子集。为模拟虚假标签,我们在原始标签集基础上按40%的增量添加标签,这些新增标签的边界框形状分布与数据集现有分布一致。结果如图6所示,我们通过CUHK-SYSU上的微调性能对比了QC和OC预训练对缺失或虚假标签数量的敏感性。所有结果均以黑色虚线表示的ImageNet-1k分类器主干网络初始化作为基线。各曲线图显示,在全微调场景下,QC预训练在所有样本区间均优于OC预训练。即使仅使用20%样本时(见图6a的mAP指标),QC预训练仍对人物搜索微调有小幅提升,而OC预训练由于强制模型将多数真实人物框识别为背景,反而损害了微调性能。该趋势在检测性能中同样存在(见图6b)。
4.6. Ablation Studies
4.6. 消融研究
Query-Centric vs. Object-Centric. Additional ablations comparing QC vs. OC pre-training and fine-tuning are given in Supplementary Sec. 9.1. These results show that QC pre-training outperforms OC pre-training across a range of settings, including variations in the pre-training loss and variations in learning rates and weight freezing. We also break down performance for the detection and re-id subtasks, showing that QC pre-training helps both tasks, with differences in magnitude depending on the dataset.
以查询为中心 vs. 以对象为中心。补充实验对比了QC与OC在预训练和微调中的表现,详见补充材料第9.1节。结果表明,在不同预训练损失函数、学习率及权重冻结方案下,QC预训练均优于OC预训练。我们还分别分析了检测与重识别子任务的性能,显示QC预训练对两项任务均有提升,提升幅度因数据集而异。
| 人物搜索模型 | 主干网络 | 预训练(1) 方法/数据集 | 预训练(2) 方法/数据集 | CUHK-SYSU mAP | top-1 | PRW mAP | top-1 |
|---|---|---|---|---|---|---|---|
| SOTA模型对比 | |||||||
| SeqNet [27] COAT [50] | ResNet50 ResNet50 | 分类器/IN1k 分类器/IN1k | 93.8 94.2 | 94.6 94.7 | 46.7 53.3 | 83.4 87.4 | |
| PSTR [3] SeqNeXt [23] | PVTv2-B2 [45] ConvNeXt-B | 分类器/IN1k 分类器/IN1k | 95.2 | 96.2 | 56.5 | 89.7 | |
| LEAPS [12] | PVTv2-B2 | 分类器/IN1k | 96.1 | 96.5 | 57.6 | 89.5 | |
| 96.4 | 96.9 | 59.5 | 89.7 | ||||
| SPNet-L | ConvNeXt-B | 分类器/IN1k | 95.9 | 96.6 | 58.9 | 89.7 | |
| SPNet-L | ConvNeXt-B | 分类器/IN1k | Ours-OC/COCO | 95.8 | 96.4 | 60.7 | 90.2 |
| SPNet-L | ConvNeXt-B | 分类器/IN1k | Ours-QC/COCO | 96.4 | 97.0 | 61.2 | 90.9 |
| 预训练对比 | |||||||
| SPNet-L | Swin-B | 69.8 | 71.8 | 20.3 | 68.7 | ||
| SPNet-L | Swin-B | SOLIDER/LUP | 88.0 | 89.4 | 38.1 | 81.3 | |
| SPNet-L | Swin-B | SOLIDER/LUP | SOLIDER/COCO | 88.0 | 89.4 | 38.1 | 81.3 |
| SPNet-L | Swin-B | 分类器/IN1k | 94.2 | 95.0 | 49.7 | 85.8 | |
| SPNet-L | Swin-B | 分类器/IN1k | SOLIDER/COCO | 94.0 | 94.8 | 49.7 | 86.1 |
| SPNet-L | Swin-B | 分类器/IN1k | Ours-OC/COCO | 94.4 | 95.2 | 52.6 | 88.7 |
| SPNet-L | Swin-B | SOLIDER/LUP | Ours-QC/COCO | 95.1 | 95.8 | 53.0 | 88.3 |
| SPNet-L | Swin-B | 分类器/IN1k | Ours-QC/COCO | 95.8 | 96.3 | 54.2 | 89.0 |
| Swin-B | |||||||
| SeqNet | Swin-B | 58.5 | 59.1 | 13.8 | 55.9 | ||
| SeqNet SeqNet | Swin-B | 分类器/IN1k SOLIDER/LUP | 88.8 94.9 | 89.6 95.5 | 45.1 59.7 | 82.5 86.8 |
Table 3. (Top) Comparison of SOTA models. (Bottom) Comparison of performance gained from pre-training SPNet using our method vs. SOLIDER and other initialization strategies. ImageNet-1k is abbreviated as IN1k, LUPerson as LUP, and COCO Persons as COCO. When both Pre-training columns have “-”, no pre-training is used and all weights are randomly initialized.
表 3: (上) SOTA模型对比。(下) 使用我们的方法预训练SPNet与SOLIDER及其他初始化策略的性能增益对比。ImageNet-1k缩写为IN1k,LUPerson缩写为LUP,COCO Persons缩写为COCO。若两个预训练列均为“-”,则表示未使用预训练且所有权重均为随机初始化。

Figure 6. Plots of retrieval (a) and detector (b) stats for fine-tuning on the CUHK-SYSU dataset for QC and OC models pre-trained on COCO Persons with noisy labels vs. the classifier baseline.
图 6: 在CUHK-SYSU数据集上微调的检索(a)和检测器(b)统计图,对比了基于COCO Persons噪声标签预训练的QC/OC模型与分类器基线。
Architecture Ablations. In Supplementary Sec. 9.2, we show that the baseline model with FixedNorm logits achieves greater performance for all metrics over the model with BatchNorm logits. We also consider the impact of model hyper parameters, including embedding dimension, number of cascade stages, shared vs. separate embedding heads, and backbone choice. Notably, we find that all model variants benefit from QC pre-training.
架构消融实验。补充材料第9.2节显示,采用FixedNorm对数输出的基线模型在所有指标上均优于BatchNorm对数输出模型。我们还研究了模型超参数的影响,包括嵌入维度、级联阶段数量、共享/独立嵌入头设计以及主干网络选择。值得注意的是,所有模型变体都能从QC预训练中获益。
5. Conclusion
5. 结论
We propose and validate Swap Path Net (SPNet), an end-to-end model for person search, which supports querycentric (QC) and object-centric (OC) modes of operation. We show that the model benefits from QC pre-training and OC fine-tuning, and that pre-training can be done using only weakly-labeled person bounding boxes. We show that 1) pre-training provides a significant boost to performance for all model variants, 2) QC pre-training benefits fine-tuning more than OC pre-training and is more robust to label noise, and 3) the model with QC pre-training achieves SOTA finetuning performance on CUHK-SYSU and PRW. Finally, we show that our end-to-end person search pre-training method is more effective and efficient than backbone-only pre-training alternatives.
我们提出并验证了Swap Path Net (SPNet),这是一种支持以查询为中心(QC)和以对象为中心(OC)两种操作模式的端到端人物搜索模型。研究表明:1) 预训练能显著提升所有模型变体的性能;2) QC预训练比OC预训练更有利于微调,且对标签噪声更具鲁棒性;3) 采用QC预训练的模型在CUHK-SYSU和PRW数据集上实现了当前最优(SOTA)的微调性能。最后证明,我们的端到端人物搜索预训练方法比仅预训练骨干网络更高效有效。