Packed Levitated Marker for Entity and Relation Extraction
用于实体和关系提取的Packed Levitated Marker
Abstract
摘要
Recent entity and relation extraction works focus on investigating how to obtain a better span representation from the pre-trained encoder. However, a major limitation of existing works is that they ignore the inter relation between spans (pairs). In this work, we propose a novel span representation approach, named Packed Levitated Mark- ers (PL-Marker), to consider the interrelation between the spans (pairs) by strategically packing the markers in the encoder. In particular, we propose a neighborhood-oriented packing strategy, which considers the neighbor spans integrally to better model the entity boundary information. Furthermore, for those more complicated span pair classification tasks, we design a subject-oriented pack- ing strategy, which packs each subject and all its objects to model the interrelation between the same-subject span pairs. The experimental results show that, with the enhanced marker feature, our model advances baselines on six NER benchmarks, and obtains a $4.1%{-}4.3%$ strict relation F1 improvement with higher speed over previous state-of-the-art models on ACE04 and ACE05. Our code and models are publicly available at https://github.com/ thunlp/PL-Marker.
近期实体与关系抽取研究主要关注如何从预训练编码器中获取更优的跨度表示。然而现有工作的核心局限在于忽视了跨度(配对)间的相互关系。本文提出名为Packed Levitated Markers (PL-Marker) 的新型跨度表示方法,通过在编码器中策略性地打包标记(markers)来建模跨度(配对)间的关联。具体而言,我们提出邻域导向打包策略,通过整体考虑相邻跨度来更好地建模实体边界信息。针对更复杂的跨度对分类任务,我们设计了主体导向打包策略,将每个主体与其所有客体打包以建模同主体跨度对间的相互作用。实验表明,增强的标记特征使我们的模型在六个NER基准测试中超越基线,并在ACE04和ACE05数据集上以更高速度实现了4.1%-4.3%的严格关系F1值提升。代码与模型已开源:https://github.com/thunlp/PL-Marker。
1 Introduction
1 引言
Recently, pre-trained language models (PLMs) (Devlin et al., 2019; Liu et al., 2019) have achieved significant improvements in Named Entity Recognition (NER, Luo et al. (2020); Fu et al. (2021)) and Relation Extraction (RE, Wadden et al. (2019); Zhou and Chen (2021)), two key sub-tasks of information extraction. Recent works (Wang et al., 2021c; Zhong and Chen, 2021) regard these two tasks as span classification or span pair classification, and thus focus on extracting better span representations from the PLMs.
近期,预训练语言模型 (PLM) (Devlin et al., 2019; Liu et al., 2019) 在信息抽取的两项关键子任务——命名实体识别 (NER, Luo et al. (2020); Fu et al. (2021)) 和关系抽取 (RE, Wadden et al. (2019); Zhou and Chen (2021)) 中取得了显著进展。最新研究 (Wang et al., 2021c; Zhong and Chen, 2021) 将这两项任务视为跨度分类或跨度对分类问题,因此专注于从预训练语言模型中提取更优质的跨度表示。
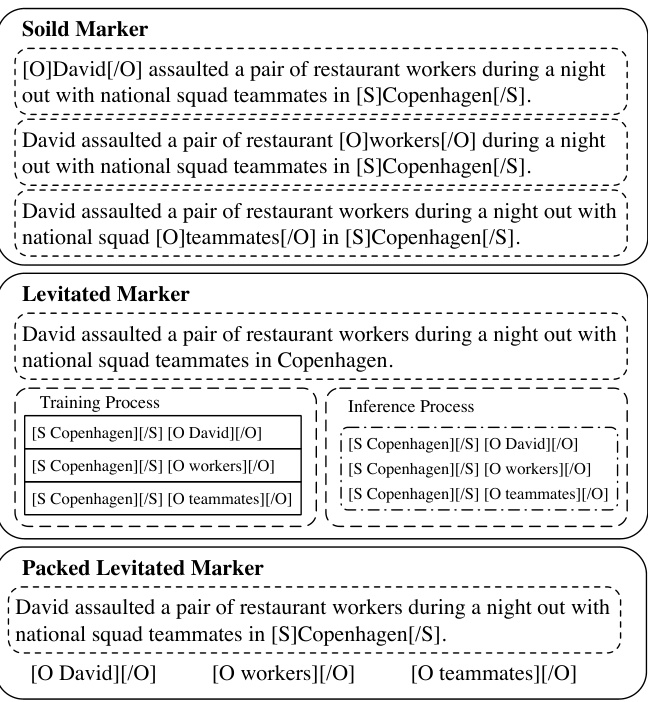
Figure 1: An example in the RE task. Solid Marker separately processes three pairs of spans with different insertions of markers. Levitated Marker processes the span pairs independently during training and processes them in batches during inference. Our proposed Packed Levitated Marker packs three objects for the same subject into an instance to process.
图 1: RE任务中的示例。Solid Marker分别处理三对带有不同标记插入的跨度。Levitated Marker在训练期间独立处理跨度对,在推理期间批量处理它们。我们提出的Packed Levitated Marker将同一主题的三个对象打包成一个实例进行处理。
Three span representation extraction methods are widely used: (1) T-Concat (Lee et al., 2017; Jiang et al., 2020) concatenates the representation of the span’s boundary (start and end) tokens to obtain the span representation. It collects information at the token level but ignores the connection between boundary tokens of a span when they pass through the network; (2) Solid Marker (Soares et al., 2019; Xiao et al., 2020) explicitly insert two solid markers before and after the span to highlight the span in the input text. And it inserts two pair of markers to locate the subject and object of a span pair. However, the method cannot handle multiple span pairs at the same time because of its weakness in specifying the solid markers of a span pair from more than two pairs of markers in the sequence. (3)
三种广泛使用的跨度表示提取方法:(1) T-Concat (Lee et al., 2017; Jiang et al., 2020) 通过拼接跨度边界(起始和结束)token的表示来获取跨度表示。该方法在token级别收集信息,但忽略了跨度边界token在网络中传递时的关联性;(2) Solid Marker (Soares et al., 2019; Xiao et al., 2020) 在输入文本中显式地插入两个固定标记来突出显示跨度,并使用两对标记来定位跨度对中的主体和客体。但由于无法从序列中多对标记中准确指定特定跨度对的固定标记,该方法无法同时处理多个跨度对;(3)
Levitated Marker (Zhong and Chen, 2021) first sets a pair of levitated markers to share the same position with the span’s boundary tokens and then ties a pair of markers by a directional attention. To be specific, the markers within a pair are set to be visible to each other in the attention mask matrix, but not to the text token and other pairs of markers. Existing work (Zhong and Chen, 2021) simply replaces solid markers with levitated markers for an efficient batch computation, but sacrifices the model performance.
悬浮标记 (Levitated Marker) (Zhong and Chen, 2021) 首先将一对悬浮标记设置为与文本跨度的边界token共享相同位置,然后通过定向注意力机制绑定这对标记。具体而言,在注意力掩码矩阵中,同一对标记相互可见,但对文本token和其他标记对不可见。现有工作 (Zhong and Chen, 2021) 为了高效批量计算,直接用悬浮标记替换实体标记,但牺牲了模型性能。
As the RE example shown in Figure 1, to correctly identify that David, workers and teammates are located_in Copenhagen, it is important to separate out that David attacked the restaurant workers and he had social relation with his teammates. However, prior works with markers (Zhong and Chen, 2021) independently processes the span pairs with different insertions of markers in the training phrase, and thus ignore interrelation between spans (pairs) (Sorokin and Gurevych, 2017; Luan et al., 2019; Wadden et al., 2019).
如图 1 所示的 RE 示例,要正确识别 David、workers 和 teammates 位于 Copenhagen,关键在于区分 David 袭击了餐厅员工与他同队友之间存在社会关系这两个事实。然而,先前采用标记方法的研究 (Zhong and Chen, 2021) 在训练阶段独立处理带有不同标记插入的跨度对,因而忽略了跨度(对)之间的相互关系 (Sorokin and Gurevych, 2017; Luan et al., 2019; Wadden et al., 2019)。
In this work, we introduce Packed Levitated Marker (PL-Marker), to model the interrelation between spans (pairs) by strategically packing levitated markers in the encoding phase. A key challenge of packing levitated markers together for span classification tasks is that the increasing number of inserted levitated markers would exacerbate the complexity of PLMs quadratically (Ye et al., 2021). Thus, we have to divide spans into several groups to control the length of each input sequence for a higher speed and feasibility. In this case, it is necessary to consider the neighbor spans integrally, which could help the model compare neighbor spans, e.g. the span with the same start token, to acquire a more precise entity boundary. Hence, we propose a neighborhood-oriented packing strategy, which packs the spans with the same start token into a training instance as much as possible to better distinguish the entity boundary.
在本工作中,我们引入了打包悬浮标记(PL-Marker),通过在编码阶段策略性地打包悬浮标记来建模片段(对)间的相互关系。为跨度分类任务打包悬浮标记的一个关键挑战在于,插入的悬浮标记数量增加会以平方级加剧预训练语言模型(PLM)的计算复杂度(Ye et al., 2021)。因此,我们必须将跨度划分为若干组以控制每个输入序列的长度,从而提升处理速度和可行性。这种情况下,需要整体考虑相邻跨度,这有助于模型比较相邻跨度(例如具有相同起始token的跨度)以获得更精确的实体边界。为此,我们提出了一种面向邻域的打包策略,该策略尽可能将具有相同起始token的跨度打包至同一训练实例,以更好地区分实体边界。
For the more complicated span pair classification tasks, an ideal packing scheme is to pack all the span pairs together with multiple pairs of levitated markers, to model all the span pairs integrally. However, since each pair of levitated markers is already tied by directional attention, if we continue to apply directional attention to bind two pairs of markers, the levitated marker will not be able to identify its partner marker of the same span. Hence, we adopt a fusion of solid markers and levitated markers, and use a subject-oriented packing strategy to model the subject with all its related objects integrally. To be specific, we emphasize the subject span with solid markers and pack all its candidate object spans with levitated markers. Moreover, we apply an object-oriented packing strategy for an intact bidirectional modeling (Wu et al., 2020).
对于更复杂的跨度对分类任务,理想的打包方案是用多对悬浮标记将所有跨度对打包在一起,以整体建模所有跨度对。然而,由于每对悬浮标记已通过定向注意力绑定,若继续应用定向注意力来关联两对标记,悬浮标记将无法识别同一跨度的伴侣标记。因此,我们采用实心标记与悬浮标记的融合方案,并使用面向主体的打包策略来整体建模主体及其相关客体。具体而言,我们用实心标记强调主体跨度,并用悬浮标记打包其所有候选客体跨度。此外,我们采用面向客体的打包策略以实现完整的双向建模 (Wu et al., 2020)。
We examine the effect of PL-Marker on two typical span (pair) classification tasks, NER and endto-end RE. The experimental results indicate that PL-Marker with neighborhood-oriented packing scheme performs much better than the model with random packing scheme on NER, which shows the necessity of considering the neighbor spans integrally. And our model also advances the TConcat model on six NER benchmarks, which demonstrates the effectiveness of the feature obtained by span marker. Moreover, compared with the previous state-of-the-art RE model, our model gains a $4.1%{-}4.3%$ strict relation F1 improvement with higher speed on ACE04 and ACE05 and also achieves better performance on SciERC, which shows the importance of considering the interrelation between the subject-oriented span pairs.
我们研究了PL-Marker在两个典型跨度(配对)分类任务——命名实体识别(NER)和端到端关系抽取(RE)上的效果。实验结果表明,采用邻域导向打包方案的PL-Marker在NER任务上表现显著优于随机打包方案模型,这证明了将相邻跨度作为整体考虑的必要性。我们的模型还在六个NER基准测试中超越了TConcat模型,验证了跨度标记器所获特征的有效性。此外,相较于之前最先进的RE模型,我们的模型在ACE04和ACE05数据集上实现了$4.1%{-}4.3%$的严格关系F1值提升(且速度更快),在SciERC数据集上也取得了更优表现,这凸显了考虑主语导向跨度对之间相互关系的重要性。
2 Related Work
2 相关工作
In recent years, span representation has attracted great attention from academia, which facilitates various NLP applications, such as named entity recognition (Ouchi et al., 2020), relation and event extraction (Luan et al., 2019), co reference resolution (Lee et al., 2017), semantic role labeling (He et al., 2018) and question answering (Lee et al., 2016). Existing methods to enhance span representation can be roughly grouped into three categories:
近年来,跨度表示 (span representation) 引起了学术界的广泛关注,它促进了多种自然语言处理应用的发展,例如命名实体识别 (Ouchi et al., 2020)、关系与事件抽取 (Luan et al., 2019)、共指消解 (Lee et al., 2017)、语义角色标注 (He et al., 2018) 以及问答系统 (Lee et al., 2016)。现有增强跨度表示的方法大致可分为三类:
Span Pre-training The span pre-training approaches enhance the span representation for PLMs via span-level pre-training tasks. Sun et al. (2019); Lewis et al. (2020); Raffel et al. (2020) mask and learn to recover random contiguous spans rather than random tokens. Joshi et al. (2020) further learns to store the span information in its boundary tokens for downstream tasks.
跨度预训练
跨度预训练方法通过跨度级别的预训练任务增强预训练语言模型(PLM)的跨度表示能力。Sun等人(2019); Lewis等人(2020); Raffel等人(2020)采用遮蔽并学习恢复随机连续跨度而非随机token的方法。Joshi等人(2020)进一步学习将跨度信息存储在其边界token中以供下游任务使用。
Knowledge Infusion This series of methods focuses on infusing external knowledge into their models. Zhang et al. (2019); Peters et al. (2019); Wang et al. (2021a) learn to use the external entity embedding from the knowledge graph or the synonym net to acquire knowledge. Soares et al. (2019); Xiong et al. (2020); Wang et al. (2021b);
知识注入
这一系列方法专注于将外部知识注入到模型中。Zhang et al. (2019); Peters et al. (2019); Wang et al. (2021a) 研究如何利用知识图谱或同义词网络中的外部实体嵌入来获取知识。Soares et al. (2019); Xiong et al. (2020); Wang et al. (2021b);
Yamada et al. (2020) conduct specific entity-related pre-training to incorporate knowledge into their models with the help of Wikipeidia anchor texts.
Yamada等人 (2020) 通过维基百科锚文本辅助,进行特定实体相关的预训练以将知识融入模型。
Structural Extension The structural extension methods add reasoning modules to the existing models, such as biaffine attention (Wang et al., 2021d), graph propagation (Wadden et al., 2019) and memory flow (Shen et al., 2021). With the support of modern pre-training encoders (e.g. BERT), the simple model with solid markers could achieve state-of-art results in RE (Zhou and Chen, 2021; Zhong and Chen, 2021). However, it is hard to specify the solid markers of a span pair from more than two pairs of markers in the sequence. Hence, previous work (Zhong and Chen, 2021) has to process span pairs independently, which is time-consuming and ignores the interrelation between the span pairs. In this work, we introduce the neighborhoodoriented and the subject-oriented packing strategies to take advantage of the levitated markers to provide an integral modeling on spans (pairs).
结构扩展
结构扩展方法为现有模型添加推理模块,例如双仿射注意力(Wang et al., 2021d)、图传播(Wadden et al., 2019)和记忆流(Shen et al., 2021)。在现代预训练编码器(如BERT)的支持下,带有固定标记的简单模型能在关系抽取(RE)中取得最先进的结果(Zhou and Chen, 2021; Zhong and Chen, 2021)。然而,当序列中存在超过两对标记时,很难为跨度对指定固定标记。因此,先前工作(Zhong and Chen, 2021)不得不独立处理各跨度对,这种方式效率低下且忽略了跨度对之间的关联。本文提出面向邻域和面向主题的打包策略,利用悬浮标记实现对跨度(对)的整体建模。
To our best knowledge, we are the first to apply the levitated markers on the NER. On the RE, the closest work to ours is the PURE (Approx.) (Zhong and Chen, 2021), which independently encodes each span pair with two pairs of levitated markers in the training phase and batches multiple pairs of markers to accelerate the inference process. Compared to their work, our model adopts a fusion subject-oriented packing scheme and thus handle multiple span pairs well in both the training and inference process. We detail the differences between our work and PURE in Section 4.4.2 and explain why our model performs better.
据我们所知,我们是首个将悬浮标记 (levitated markers) 应用于命名实体识别 (NER) 的研究。在关系抽取 (RE) 领域,最接近的工作是 PURE (Approx.) (Zhong and Chen, 2021) ,该研究在训练阶段使用两对悬浮标记独立编码每个跨度对,并通过批量处理多对标记来加速推理过程。相比之下,我们的模型采用了一种融合主体导向的打包方案,从而在训练和推理过程中都能很好地处理多个跨度对。我们将在第4.4.2节详细说明我们的工作与 PURE 的区别,并解释为何我们的模型表现更优。
3 Method
3 方法
In this section, we first introduce the architecture of the levitated marker. Then, we present how we pack the levitated marker to obtain the span representation and span pair representation.
在本节中,我们首先介绍悬浮标记 (levitated marker) 的架构,然后阐述如何通过打包悬浮标记来获取跨度表示 (span representation) 和跨度对表示 (span pair representation)。
3.1 Background: Levitated Marker
3.1 背景: 悬浮标记 (Levitated Marker)
Levitated marker is used as an approximation of solid markers, which allows models to classify multiple pairs of entities simultaneously to accelerate the inference process (Zhong and Chen, 2021). A pair of levitated markers, associated with a span, consists of a start token marker and an end token marker. These two markers share the same position embedding with the start and end tokens of the corresponding span, while keeping the position id of original text tokens unchanged. In order to specify multiple pairs of levitated markers in parallel, a directional attention mask matrix is applied. Specifically, each levitated marker is visible to its partner marker within pair in the attention mask matrix, but not to the text tokens and other levitated markers. In the meantime, the levitated markers are able to attend to the text tokens to aggregate information for their associated spans.
悬浮标记 (levitated marker) 作为实体标记的近似表示,使模型能够同时分类多组实体以加速推理过程 (Zhong and Chen, 2021)。与文本片段关联的一对悬浮标记包含起始token标记和结束token标记,这两个标记与对应文本片段的起止token共享相同的位置嵌入 (position embedding),同时保持原始文本token的位置ID不变。
为并行指定多组悬浮标记,需采用定向注意力掩码矩阵 (directional attention mask matrix)。具体而言,在注意力掩码矩阵中,每组悬浮标记仅对组内配对标记可见,而对文本token及其他悬浮标记不可见。同时,悬浮标记可关注文本token以聚合其关联文本片段的信息。
3.2 Neighborhood-oriented Packing for Span
3.2 面向邻域的Span打包策略
Benefiting from the parallelism of levitated markers, we can flexibly pack a series of related spans into a training instance. In practice, we append multiple associated levitated markers to an input sequence to conduct a comprehensive modeling on each span.
得益于悬浮标记的并行性,我们可以灵活地将一系列相关跨度打包到一个训练实例中。在实际应用中,我们会向输入序列追加多个关联的悬浮标记,从而对每个跨度进行综合建模。
However, even though the entity length is restricted, some of the span classification tasks still contain a large number of candidate spans. Hence, we have to group the markers into several batches to equip the model with higher speed and feasibility in practice. To better model the connection between spans with the same start tokens, we adopt a neighborhood-oriented packing scheme. As shown in Figure 2, we first sort the pairs of levitated markers by taking the position of start marker as the first keyword and the position of end marker as the second keyword. After that, we split them into groups of size up to $K$ and thus gather adjacent spans into the same group. We packs each groups of markers and dispersed ly process them in multiple runs.
然而,尽管实体长度受到限制,部分跨度分类任务仍包含大量候选跨度。因此,我们需将标记分组为若干批次,以提升模型的实际运行速度与可行性。为更好地建模具有相同起始token的跨度间关联,我们采用邻域导向的分组方案。如图2所示,我们首先以起始标记位置为第一关键词、结束标记位置为第二关键词对悬浮标记对进行排序,随后将其拆分为最多包含$K$个元素的组,从而将相邻跨度归入同一组。每组标记被集中打包后,通过多轮分散处理。
Formally, given a sequence of $N$ text tokens, $X={x_{1},\ldots,x_{N}}$ and a maximum span length $L$ , we define the candidate spans set as $S(X)=$ ${(1,1),..,(1,L),...,(N,N-L),..,(N,N))}$ . We first divide $S(X)$ into multiple groups up to the size of $K$ in order. For example, we cluster $K$ spans, $\begin{array}{r}{{(1,1),(1,2),...,(\lceil\frac{K}{L}\rceil,K-\lfloor\frac{K-1}{L}\rfloor*L)}}\end{array}$ , into a group $S_{1}$ . We associate a pair of levitated markers to each span in $S_{1}$ . Then, we provide the combined sequence of the text token and the inserted levitated markers to the PLM (e.g. BERT) to obtain the contextual i zed representations of the start token marker H(s) = {hi(s)} and that of the end token marker $H^{(e)}={h_{i}^{(e)}}$ . Here, $h_{a}^{(s)}$ and $h_{b}^{(e)}$ are associated with the span $s_{i}=\left(a,b\right)$ , for which we obtain the span representations:
形式上,给定一个由$N$个文本Token组成的序列$X={x_{1},\ldots,x_{N}}$和最大跨度长度$L$,我们将候选跨度集定义为$S(X)=$${(1,1),..,(1,L),...,(N,N-L),..,(N,N))}$。首先将$S(X)$按顺序划分为多个大小不超过$K$的组。例如,我们将$K$个跨度$\begin{array}{r}{{(1,1),(1,2),...,(\lceil\frac{K}{L}\rceil,K-\lfloor\frac{K-1}{L}\rfloor*L)}}\end{array}$聚类为组$S_{1}$,并为$S_{1}$中的每个跨度关联一对悬浮标记。接着,将文本Token与插入的悬浮标记组合序列输入PLM(如BERT),获得起始Token标记的上下文表示H(s) = {hi(s)}和结束Token标记的上下文表示$H^{(e)}={h_{i}^{(e)}}$。其中,$h_{a}^{(s)}$和$h_{b}^{(e)}$与跨度$s_{i}=\left(a,b\right)$相关联,由此得到跨度表示:
$$
\psi(s_{i})=[h_{a}^{(s)};h_{b}^{(e)}]
$$
$$
\psi(s_{i})=[h_{a}^{(s)};h_{b}^{(e)}]
$$
where $[A;B]$ denotes the concatenation operation
其中 $[A;B]$ 表示连接操作
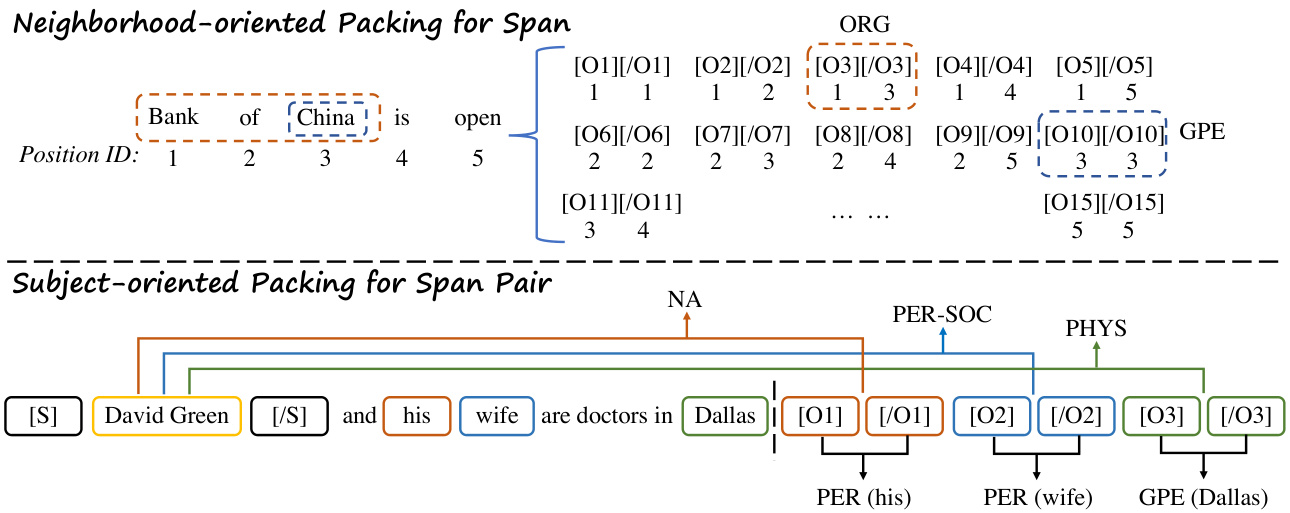
Figure 2: An overview of our neighborhood-oriented packing and subject-oriented packing strategies. [S][/S] are solid markers. [O][/O] are levitated markers. With a maximum group size, the neighborhood-oriented packing strategy clusters the neighbor spans, e.g. {(1,1),(1,2),...,(1,5)}, in the same group. The subject-oriented packing strategy encloses the subject span, David Green, with solid markers, applies levitated markers on its candidate object spans, his, wife and Dallas, and packs them into an instance.
图 2: 我们的邻域导向打包和主体导向打包策略概览。[S][/S]为实体标记,[O][/O]为悬浮标记。在设定最大组大小的情况下,邻域导向打包策略会将相邻片段(如{(1,1),(1,2),...,(1,5)})聚类到同一组。主体导向打包策略则用实体标记包裹主体片段David Green,对其候选对象片段his、wife和Dallas施加悬浮标记,并将它们打包为一个实例。
on the vector $A$ and $B$ .
在向量 $A$ 和 $B$ 上。
For instance, we apply the levitated marker to a typical overlapping span classification task, NER, which aims to assign an entity type or a non-entity type to each possible span in a sentence. We obtain the span representation from the PLM via the packed levitated markers and then combine the features of PL-Marker and T-Concat to better predict the entity type of the cadidate span.
例如,我们将悬浮标记应用于典型的重叠跨度分类任务——命名实体识别(NER),该任务旨在为句子中每个可能的跨度分配一个实体类型或非实体类型。我们通过打包的悬浮标记从预训练语言模型(PLM)中获取跨度表示,然后结合PL-Marker和T-Concat的特征来更好地预测候选跨度的实体类型。
3.3 Subject-oriented Packing for Span Pair
3.3 面向主题的跨度对打包
To obtain a span pair representation, a feasible method is to adopt levitated markers to emphasize a series of the subject and object spans simultaneously. Commonly, each pair of levitated markers is tied by the directional attention. But if we continue to apply directional attention to bind two pairs of markers, the levitated marker will not be able to identify its partner marker of the same span. Hence, as shown in Figure 2, our span pair model adopts a fusion subject-oriented packing scheme to offer an integral modeling for the same-subject spans.
为获取跨度对表示,一种可行方法是采用悬浮标记(levitated markers)同时强调一系列主客体跨度。通常,每对悬浮标记通过定向注意力(directional attention)绑定。但若继续应用定向注意力绑定两对标记,悬浮标记将无法识别同属一个跨度的伙伴标记。因此,如图2所示,我们的跨度对模型采用融合主体导向打包方案(fusion subject-oriented packing scheme),为同主体跨度提供整体建模。
Formally, given an input sequence $X$ , a subject span, $s_{i}=(a,b)$ and its candidate object spans $(c_{1},d_{1}),(c_{2},d_{2}),...(c_{m},d_{m})$ , We insert a pair of solid markers [S] and [/S] before and after the subject span. Then, we apply levitated markers [O] and $[/\mathrm{O}]$ to all candidate object spans, and pack them into an instance. Let $\hat{X}$ denotes this modified sequence with inserted markers:
形式上,给定输入序列 $X$、主体跨度 $s_{i}=(a,b)$ 及其候选对象跨度 $(c_{1},d_{1}),(c_{2},d_{2}),...(c_{m},d_{m})$,我们在主体跨度前后插入一对实心标记 [S] 和 [/S]。然后,对所有候选对象跨度应用悬浮标记 [O] 和 $[/\mathrm{O}]$,并将它们打包成一个实例。设 $\hat{X}$ 表示插入标记后的修改序列:
$$
\begin{array}{r l}&{\hat{X}=...[\mathsf{S}],x_{a},...,x_{b},[/\mathsf{S}],...,x_{c_{1}}\cup[01],...,}\ &{\quad x_{d_{1}}\cup[/01],...,x_{c_{2}}\cup[02],...,x_{d_{2}}\cup[/02]...,}\end{array}
$$
$$
\begin{array}{r l}&{\hat{X}=...[\mathsf{S}],x_{a},...,x_{b},[/\mathsf{S}],...,x_{c_{1}}\cup[01],...,}\ &{\quad x_{d_{1}}\cup[/01],...,x_{c_{2}}\cup[02],...,x_{d_{2}}\cup[/02]...,}\end{array}
$$
where the tokens jointed by the symbol share the same position embedding. We apply a pretrained encoder on $\hat{X}$ and finally obtain the span pair representation for $s_{i}=(a,b)$ and $s_{j}=(c,d)$ :
其中由符号连接的token共享相同的位置嵌入。我们对$\hat{X}$应用预训练编码器,最终得到跨度对$s_{i}=(a,b)$和$s_{j}=(c,d)$的表示:
$$
\phi(s_{i},s_{j})=[h_{a-1};h_{b+1};h_{c}^{(s)};h_{d}^{(e)}]
$$
$$
\phi(s_{i},s_{j})=[h_{a-1};h_{b+1};h_{c}^{(s)};h_{d}^{(e)}]
$$
where $\left[;\right]$ denotes the concatenation operation. $h_{a-1}$ and $h_{b+1}$ denote the contextual i zed representation of the inserted solid markers for $s_{i}$ ; $h_{c}^{\bar{(s)}}$ and $h_{d}^{(e)}$ are the contextual i zed representation of the inserted levitated markers for $s_{j}$ .
其中 $\left[;\right]$ 表示拼接操作。$h_{a-1}$ 和 $h_{b+1}$ 表示 $s_{i}$ 插入的固定标记的上下文表示;$h_{c}^{\bar{(s)}}$ 和 $h_{d}^{(e)}$ 表示 $s_{j}$ 插入的悬浮标记的上下文表示。
Compared to the method that applies two pairs of solid markers on the subject and object respectively (Zhong and Chen, 2021), our fusion marker scheme replaces the solid markers with the levitated markers for the object span, which would impair the emphasis on the object span to some extent. To provide the supplemental information, we introduce an inverse relation from the object to the subject for a bidirectional prediction (Wu et al., 2020).
与在主语和宾语上分别应用两对固定标记的方法 (Zhong and Chen, 2021) 相比,我们的融合标记方案将宾语跨度的固定标记替换为悬浮标记,这会在一定程度上削弱对宾语跨度的强调。为了提供补充信息,我们引入了从宾语到主语的反向关系以实现双向预测 (Wu et al., 2020)。
For instance, we evaluate our model on a typical span pair classification task, end-to-end RE, which concentrates on identifying whether all span pairs are related and their relation types. Following Zhong and Chen (2021), we first use a NER model to filter candidate entity spans, and then acquire the span pair representation of the filtered entity span pairs to predict the relation between them. Moreover, to build the connection between entity type and relation type, we add an auxiliary loss for predicting the type of object entity (Zhou and Chen, 2021; Han et al., 2021).
例如,我们在一个典型的跨度对分类任务(端到端关系抽取)上评估模型性能,该任务专注于判断所有跨度对是否相关及其关系类型。遵循Zhong和Chen (2021)的方法,我们首先使用命名实体识别(NER)模型筛选候选实体跨度,然后获取过滤后实体跨度对的表征来预测其间关系。此外,为建立实体类型与关系类型的关联,我们增加了预测目标实体类型的辅助损失项 (Zhou and Chen, 2021; Han et al., 2021)。
3.4 Complexity Analysis
3.4 复杂度分析
Dominated by the large feed-forward network, the computation of PLM rises almost linearly with the increase in small sequence length (Dai et al., 2020; Ye et al., 2021). Gradually, as the sequence length continues to grow, the computation dilates quadratically due to the Self-Attention module (Vaswani et al., 2017). Obviously, the insertion of levitated markers extends the length of input sequence. For the span pair classification tasks, the number of candidate spans is relatively small , thus the increased computation is limited. For the span classification tasks, we group the markers into several batches, which can control the sequence length within the interval in which the complexity increases nearly linearly. For the NER, we enumerate candidate spans in a small-length sentence and then use its context words to expand the sentence to 512 tokens, for which the number of candidate spans in a sentence is usually less than the context length in practice. Hence, with a small number of packing groups, the complexity of PL-Marker is still near-linearly to the complexity of previous models.
受大型前馈网络主导,预训练语言模型(PLM)的计算量随较短序列长度的增加呈近线性增长 (Dai et al., 2020; Ye et al., 2021)。随着序列长度持续增加,由于自注意力(Self-Attention)模块的作用 (Vaswani et al., 2017),计算量会呈现二次方膨胀。显然,悬浮标记的插入会延长输入序列长度。对于跨度对分类任务,候选跨度数量相对较少,因此增加的计算量有限。对于跨度分类任务,我们将标记分组为若干批次,从而将序列长度控制在复杂度呈近线性增长的区间内。针对命名实体识别(NER)任务,我们首先在短句内枚举候选跨度,然后使用上下文词汇将句子扩展至512个token——实践中单个句子的候选跨度数量通常小于上下文长度。因此,通过少量分组打包,PL-Marker的复杂度仍与基线模型保持近线性关系。
Moreover, to further alleviate the inference cost, we adopt PL-Marker as a post-processing module of a two-stage model, in which it is used to identify entities from a small number of candidate entities proposed by a simpler and faster model.
此外,为进一步降低推理成本,我们采用PL-Marker作为两阶段模型的后处理模块,用于从更简单快速的模型生成的少量候选实体中识别目标实体。
4 Experiment
4 实验
4.1 Experimental Setup
4.1 实验设置
4.1.1 Dataset
4.1.1 数据集
For the NER task, we conduct experiments on both flat and nested benchmarks. Firstly, on the flat NER, we adopt CoNLL03 (Sang and Meulder, 2003), OntoNotes 5.0 (Pradhan et al., 2013) and Few-NERD (Ding et al., 2021). Then, on the nested NER, we use ACE04 (Doddington et al., 2004), ACE05 (Walker et al., 2006) and SciERC (Luan et al., 2018). The three nested NER datasets are also used to evaluate the end-to-end RE. We follow Luan et al. (2019) to split ACE04 into 5 folds and split ACE05 into train, development, and test
在NER(命名实体识别)任务中,我们在平面和嵌套两种基准测试上都进行了实验。首先,针对平面NER,我们采用了CoNLL03 (Sang和Meulder,2003)、OntoNotes 5.0 (Pradhan等,2013)和Few-NERD (Ding等,2021)。然后,对于嵌套NER,我们使用了ACE04 (Doddington等,2004)、ACE05 (Walker等,2006)和SciERC (Luan等,2018)。这三个嵌套NER数据集也被用于评估端到端关系抽取(RE)任务。我们遵循Luan等(2019)的方法,将ACE04划分为5折,并将ACE05划分为训练集、开发集和测试集。
Table 1: The statistics of the adopted datasets.
表 1: 采用数据集的统计信息。
| Dataset | #Sents | #Ents (#Types) | #Rels (#Types) |
|---|---|---|---|
| CoNLL03 | 22.1k | 35.1k (4) | |
| OntoNotes5.0 | 103.8k | 161.8k (18) | |
| Few-NERD | 188.2k | 491.7k (66) | 一 |
| ACE05 | 14.5k | 38.3k (7) | 7.1k (6) |
| ACE04 | 8.7k | 22.7k (7) | 4.1k (6) |
| SciERC | 2.7k | 8.1k (6) | 4.6k (7) |
4.1.2 Evaluation Metrics
4.1.2 评估指标
For NER task, we follow a span-level evaluation setting, where the entity boundary and entity type are required to correctly predicted. For the endto-end RE, we report two evaluation metrics: (1) Boundaries evaluation (Rel) requires the model to correctly predict the boundaries of the subject entity and the object entity, and the entity relation; (2) Strict evaluation $(\mathrm{Rel}+)$ further requires the model to predict the entity types on the basis of the requirement of the boundary prediction. Moreover, following Wang et al. (2021d), we regard each symmetric relational instance as two directed relational instances.
在NER(命名实体识别)任务中,我们采用span-level(跨度级)评估设置,要求正确预测实体边界和实体类型。对于端到端RE(关系抽取),我们报告两项评估指标:(1) 边界评估(Rel)要求模型正确预测主语实体和宾语实体的边界以及实体关系;(2) 严格评估(Rel+)在边界预测要求的基础上,进一步要求模型预测实体类型。此外,遵循Wang等人(2021d)的做法,我们将每个对称关系实例视为两个有向关系实例。
4.1.3 Implementation Details
4.1.3 实现细节
We adopt bert-base-uncased (Devlin et al., 2019) and albert-xxlarge-v1 (Lan et al., 2020) encoders for ACE04 and ACE05. For SciERC, we use the indomain scibert-scivocab-uncased (Beltagy et al., 2019) encoder. For flat NER, we adopt roberta- large encoder. We also leverage the cross-sentence information (Luan et al., 2019; Luoma and Pyysalo, 2020), which extends each sentence by its context and ensures that the original sentence is located in the middle of the expanded sentence as much as possible. As discussed in Section 4.4.1, for the packing scheme on NER, we set the group size to 256 to improve efficiency. We run all experiments with 5 different seeds and report the average score. See the appendix for the standard deviations and the detailed training configuration.
我们采用bert-base-uncased (Devlin等人,2019)和albert-xxlarge-v1 (Lan等人,2020)编码器处理ACE04和ACE05数据集。对于SciERC数据集,我们使用领域专用的scibert-scivocab-uncased (Beltagy等人,2019)编码器。在平面NER任务中,我们采用roberta-large编码器。同时利用跨句信息(Luan等人,2019; Luoma和Pyysalo,2020),通过上下文扩展每个句子,并确保原始句子尽可能位于扩展句的中间位置。如第4.4.1节所述,针对NER任务的打包方案,我们将组大小设置为256以提高效率。所有实验均使用5个不同随机种子运行,并报告平均得分。标准差和详细训练配置参见附录。
4.2 Named Entity Recognition
4.2 命名实体识别
4.2.1 Baselines
4.2.1 基线方法
Our packing scheme allows the model to apply the levitated markers to process massive span pairs and to our best knowledge, we are the first to apply the levitated markers on the NER task. We compare our neighborhood-oriented packing scheme with the Random Packing, which randomly packs the candidate spans into groups. We adopt two common NER models: (1) SeqTagger (Devlin et al., 2019) regards NER as a sequence tagging task and applies a token-level classifier to distinguish the IOB2 tags for each word (Sang and Veenstra, 1999). (2) T-Concat (Jiang et al., 2020; Zhong and Chen, 2021) assigns an entity type or a non-entity type to each span based on its T-Concat span representation. Note that solid markers cannot deal with the overlapping spans simultaneously, thus it is too inefficient to apply solid markers independently on the NER task.
我们的打包方案允许模型应用悬浮标记 (levitated markers) 处理大量跨度对,据我们所知,这是首次将悬浮标记应用于命名实体识别 (NER) 任务。我们将邻域导向打包方案与随机打包 (Random Packing) 进行对比,后者随机将候选跨度分组打包。实验采用两种常见 NER 模型:(1) SeqTagger (Devlin et al., 2019) 将 NER 视为序列标注任务,通过 token 级分类器为每个单词分配 IOB2 标签 (Sang and Veenstra, 1999);(2) T-Concat (Jiang et al., 2020; Zhong and Chen, 2021) 基于跨度拼接表示 (T-Concat span representation) 为每个跨度分配实体类型或非实体类型。需注意,固定标记 (solid markers) 无法同时处理重叠跨度,因此在 NER 任务中独立使用固定标记效率极低。
Table 2: Micro F1 on the test set for the flat NER. OntoN5: OntoNotes 5.0; F-NERD: Few-NERD.
| 模型 | CoNLL03 | OntoN5 | F-NERD |
|---|---|---|---|
| Ma and Hovy (2016) | 91.0 | 86.3 | |
| Devlin et al.(2019) | 92.8 | 89.2 | 68.9 |
| Li et al. (2020) | 93.0 | 91.1 | |
| Yu et al. (2020) | 93.5 | 91.3 | |
| Yan et al.(2021) | 93.2 | 90.4 | |
| SeqTagger (Our impl.) | 93.6 | 91.2 | 69.0 |
| T-Concat (Our impl.) | 93.0 | 91.7 | 70.6 |
| Random Packing | 93.9 | 91.8 | |
| PL-Marker (Our model) | 94.0 | 91.9 | 61.5 70.9 |
表 2: 平面命名实体识别测试集的 Micro F1 分数。OntoN5: OntoNotes 5.0; F-NERD: Few-NERD。
4.2.2 Results
4.2.2 结果
We show the flat NER results in the Table 2 and the nested NER results in the Ent column of Table 3, where PURE (Zhong and Chen, 2021) ap- plies the T-Concat feature on its NER module. As follow, some observations are summarized from the experimental results: (1) The model with our neighborhood-oriented packing strategy outperforms the model with random packing strategy on all three flat NER datsets, especially obtaining a $9.4%$ improvement on Few-NERD. Few-NERD contains longer sentences and thus includes 325 candidate spans on average, while CoNLL03 and OntoNotes 5.0 only contain 90 and 174 respectively. It shows that the neighborhood-oriented packing strategy can well handle the dataset with longer sentences and more groups of markers, to better model the interrelation among neighbor spans. (2) With the same large pre-trained encoder, PL-Marker achieves an absolute F1 improvement of $+0.1%$ - $1.1%$ over T-Concat on all six NER benchmarks, which shows the advantage of levitated markers in aggregating span-wise representation for the entity type prediction; (3) PL-Marker outperforms SeqTagger by an absolute F1 of $+0.4%$ , $+0.7%$ , $+1.9%$ in CoNLL03, OntoNote 5.0 and Few-NERD respectively, where CoNLL03, OntoNote 5.0 and Few-NERD contain 4, 18 and 66 entity types respectively. Such improvements prove the effectiveness of PL-Marker in handling diverse interrelation between entities of diverse types.
我们在表2中展示了平面命名实体识别(NER)的结果,在表3的Ent列展示了嵌套命名实体识别的结果,其中PURE (Zhong和Chen, 2021)在其NER模块上应用了T-Concat特征。根据实验结果,我们总结出以下观察:(1) 采用我们面向邻域的打包策略的模型在所有三个平面NER数据集上都优于随机打包策略的模型,特别是在Few-NERD上获得了9.4%的提升。Few-NERD包含更长的句子,因此平均有325个候选跨度,而CoNLL03和OntoNotes 5.0分别只有90和174个。这表明面向邻域的打包策略能很好地处理包含较长句子和更多标记组的数据集,从而更好地建模相邻跨度之间的相互关系。(2) 在相同的大型预训练编码器下,PL-Marker在所有六个NER基准测试中相比T-Concat实现了绝对F1值提升0.1%至1.1%,这显示了悬浮标记在聚合跨度的表示以预测实体类型方面的优势;(3) PL-Marker在CoNLL03、OntoNote 5.0和Few-NERD上分别比SeqTagger的绝对F1值高出0.4%、0.7%和1.9%,其中CoNLL03、OntoNote 5.0和Few-NERD分别包含4、18和66种实体类型。这些改进证明了PL-Marker在处理不同类型实体间多样相互关系方面的有效性。
4.3 Relation Extraction
4.3 关系抽取
4.3.1 Baselines
4.3.1 基线方法
For the end-to-end RE, we compare our model, PL-Marker, with a series of state-of-the-art models. Here, we introduce two of the most representative works with T-Concat and Solid Markers span represent ation: (1) ${\bf D y G I E++}$ (Wadden et al., 2019) first acquires the T-Concat span representation, and then iterative ly propagates co reference and relation type confidences through a span graph to refine the representation; (2) PURE (Zhong and Chen, 2021) adopts independent NER and RE models, where the RE model processes each possible entity pair in one pass. In their work, PURE (Full) adopts two pairs of solid markers to emphasize a span pair and the PURE (Approx) employs two pairs of levitated markers to underline the span pair.
在端到端关系抽取(RE)任务中,我们将PL-Marker模型与一系列前沿模型进行对比。此处重点介绍两种采用T-Concat和Solid Markers跨度表示的最具代表性工作:(1) ${\bf DyGI E++}$ (Wadden et al., 2019) 首先生成T-Concat跨度表示,然后通过跨度图迭代传播共指和关系类型置信度来优化表示;(2) PURE (Zhong and Chen, 2021) 采用独立的命名实体识别(NER)和关系抽取模型,其中RE模型单次处理所有可能的实体对。该研究中,PURE (Full)使用两对solid markers强化跨度对表示,而PURE (Approx)则采用两对levitated markers标注跨度对。
4.3.2 Results
4.3.2 结果
As shown in Table 3, with the same $\mathrm{BERT_{BASE}}$ encoder, our approach outperforms previous methods by strict F1 of $+1.7%$ on ACE05 and $+2.5%$ on ACE04. With the SciBERT encoder, our approach also achieves the best performance on SciERC. Using a larger encoder, ALBERT XX LARGE, both of our NER and RE models are further improved. Compared to the previous state-of-the-art model, PURE (Full), our model gains a substantially $+4.1%$ and $+4.3%$ strict relation F1 improvement on ACE05 and ACE04 respectively. Such improvements over PURE indicate the effectiveness of modeling the interrelation between the same-subject or the sameobject entity pairs in the training process.
如表 3 所示,在相同的 $\mathrm{BERT_{BASE}}$ 编码器下,我们的方法在 ACE05 和 ACE04 上分别以严格 F1 值 $+1.7%$ 和 $+2.5%$ 的优势超越了先前的方法。使用 SciBERT 编码器时,我们的方法在 SciERC 上也取得了最佳性能。采用更大的 ALBERT XX LARGE 编码器后,我们的 NER 和 RE 模型均得到进一步提升。与之前的最先进模型 PURE (Full) 相比,我们的模型在 ACE05 和 ACE04 上的严格关系 F1 值分别显著提升了 $+4.1%$ 和 $+4.3%$。这些相对于 PURE 的改进表明,在训练过程中对同主体或同客体实体对之间的相互关系进行建模是有效的。
4.4 Inference Speed
4.4 推理速度
In this section, we compare the models’ inference speed on an A100 GPU with a batch size of 32. We use the BASE size encoder for ACE05 and SciERC in the experiments and the LARGE size encoder for flat NER models.
在本节中,我们比较了模型在A100 GPU上以32批次大小的推理速度。实验中,ACE05和SciERC使用BASE尺寸编码器,平面NER模型使用LARGE尺寸编码器。
4.4.1 Speed of Span Model
4.4.1 Span模型的速度
We evaluate the inference speed of PL-Marker with different group size $K$ on CoNLL03 and FewNERD. We also evaluate a cascade Two-stage model, which uses a fast BASE-size T-Concat model to filter candidate spans for our model. As shown in Table 4, PL-Marker achieves a 0.4 F1 improvement on CoNLL03 but sacrifices $60%$ speed compared to the SeqTagger model. And we observe that our proposed Two-stage model achieves similar performance to PL-Marker with $3.1\mathbf{X}$ speedup on Few-NERD, which shows it is more efficient to use PL-Marker as a post-processing module to elaborate the coarse prediction from a simple model. In addition, when the group size grows to 512, PLMarker slows down due to the increased complexity of the Transformer. Hence, we choose a group size of 256 in practice.
我们在CoNLL03和FewNERD数据集上评估了PL-Marker在不同分组大小$K$下的推理速度。同时评估了一种级联两阶段模型,该模型使用快速的BASE尺寸T-Concat模型为我们的模型筛选候选跨度。如表4所示,PL-Marker在CoNLL03上实现了0.4的F1提升,但与SeqTagger模型相比牺牲了$60%$的速度。我们观察到,提出的两阶段模型在Few-NERD上实现了与PL-Marker相近的性能,同时获得了$3.1\mathbf{X}$的加速比,这表明将PL-Marker作为后处理模块来优化简单模型的粗预测更为高效。此外,当分组大小增至512时,由于Transformer复杂度增加,PL-Marker速度下降。因此实际应用中我们选择256的分组大小。
Table 3: Overall entity and relation F1 scores on the test sets of ACE04, ACE05 and SciERC. The encoders used in different models: $\mathrm{BERT}{\mathrm{B}}=\mathrm{BERT}{\mathrm{BASE}}$ , $\mathrm{BERT_{L}=B E R T_{L A R G E}}$ , $\mathrm{ALB}{\mathrm{XXL}}=\mathrm{ALBERT}{\mathrm{XXLARGE}}$ . Specially, TriMF, UniRE, PURE and PL-Marker apply $\mathrm{BERT}_{\mathrm{BASE}}$ on ACE04/05 and apply the SciBERT on SciERC. 3 denotes that the model leverages the cross-sentence information. Representation Type: T–T-Concat; S–Solid Marker; $L-$ Levitated Marker. Model name abbreviation: PURE-F: PURE (Full); PURE-A: PURE (Approx.).
表 3: ACE04、ACE05 和 SciERC 测试集上的整体实体和关系 F1 分数。不同模型使用的编码器: $\mathrm{BERT}{\mathrm{B}}=\mathrm{BERT}{\mathrm{BASE}}$ , $\mathrm{BERT_{L}=B E R T_{L A R G E}}$ , $\mathrm{ALB}{\mathrm{XXL}}=\mathrm{ALBERT}{\mathrm{XXLARGE}}$ 。特别地,TriMF、UniRE、PURE 和 PL-Marker 在 ACE04/05 上使用 $\mathrm{BERT}_{\mathrm{BASE}}$ ,在 SciERC 上使用 SciBERT。3 表示模型利用了跨句子信息。表示类型: T–T-Concat; S–Solid Marker; $L-$ Levitated Marker。模型名称缩写: PURE-F: PURE (Full); PURE-A: PURE (Approx.)。
| Encoder | Rep Type | ACE05 | ACE04 | SciERC | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Ent | Rel | Rel+ | Ent | Rel | Rel+ | Ent | Rel | Rel+ | |||
| Li and Ji (2014) | 80.8 | 52.1 | 49.5 | 79.7 | 48.3 | 45.3 | |||||
| SPtree (Miwa and Bansal, 2016) DYGIE (Luan et al., 2019) | LSTM | T | 83.4 | 55.6 | 81.8 | 48.4 | |||||
| ELMo | T | 88.4 63.2 | 87.4 | 59.7 | 65.2 | 41.6 | |||||
| Multi-turn QA (Li et al.,2019) OneIE (Lin et al., 2020) | BERTL | T | 84.8 88.8 | 60.2 | 83.6 | 49.4 | |||||
| DYGIE++ (Wadden et al., 2019) | BERTg/ | T | 67.5 | ||||||||
| TriMF (Shen et al., 2021) | T | 88.6 | 63.4 | = | |||||||
| 87.6 | 66.5 | 62.8 | 70.2 | 52.4 | |||||||
| UniRE (Wang et al., 2021d) | T | 88.8 | 64.3 | 87.7 | 60.0 | 68.4 | 36.9 | ||||
| PURE-F (Zhong and Chen, 2021) SciBERT | S | 90.1 | 67.7 | 64.8 | 89.2 | 63.9 | 60.1 | 68.9 50.1 | 36.8 | ||
| PURE-A (Zhong and Chen, 2021) PL-Marker (Our Model) | L S&L | 一 | 66.5 | 48.1 | |||||||
| 89.8 | 69.0 | 66.5 | 88.8 | 66.7 | 62.6 | 69.9 | 53.2 | 41.6 | |||
| TableSeq (Wang and Lu, 2020) | ALBxXL | T | 89.5 | 67.6 | 64.3 | 88.6 | 63.3 | 59.6 | |||
| UniRE (Wang et al., 2021d) | T | 90.2 | 66.0 | 89.5 | - | 63.0 | |||||
| PURE-F (Zhong and Chen, 2021) | S | 90.9 | 69.4 | 67.0 | 90.3 | 66.1 | 62.2 | ||||
| PL-Marker (Our Model) | S&L | 91.1 | 73.0 | 71.1 | 90.4 | 69.7 | 66.5 |
Table 4: Micro F1 and efficiency on NER benchmarks with respect to the model and different packing group size $K$ . We adopt a maximum span length of 8 for CoNLL03 and 16 for Few-NERD.
表 4: 不同模型及打包组大小 $K$ 在NER基准测试中的Micro F1和效率。CoNLL03采用最大跨度长度8,Few-NERD采用16。
| 模型 | K | CoNLL03 Ent (F1) | CoNLL03 Speed (sent/s) | Few-NERD Ent (F1) | Few-NERD Speed (sent/s) |
|---|---|---|---|---|---|
| SeqTagger | - | 93.6 | 138.7 | 69.0 | 142.0 |
| T-Concat | - | 93.0 | 137.2 | 70.6 | 126.8 |
| T-Concat | 128 | 94.0 | 54.8 | 70.9 | 23.8 |
| PL-Marker | 256 | - | 39.6 | - | 25.8 |
| PL-Marker | 512 | - | 22.9 | - | 18.3 |
| Two-stage | 16 | 93.7 | 87.1 | 70.8 | 80.6 |
| Two-stage | 32 | 94.0 | 83.3 | 70.9 | 79.8 |
Table 5: Comparison of our RE model and PURE in relation F1 (boundaries) and speed. We report the result with BASE encoders. All models adopt the same entity input from the entity model of PURE.
表 5: 我们的关系抽取 (RE) 模型与 PURE 在关系 F1 (边界) 和速度上的对比。所有结果均基于 BASE 编码器报告。所有模型均采用 PURE 实体模型的相同实体输入。
| 模型 | ACE05 | SciERC | ||
|---|---|---|---|---|
| Rel (F1) | Speed (sent/s) | Rel (F1) | Speed (sent/s) | |
| PURE (Full) | 67.7 | 76.5 | 50.1 | 88.3 |
| PURE (Approx.) | 66.5 | 593.7 | 48.8 | 424.2 |
| PL-Marker | 69.3 | 211.7 | 52.8 | 190.9 |
4.4.2 Speed of Span Pair Model
4.4.2 跨度对模型的速度
We apply the subject-oriented and the objectoriented packing strategies on levitated markers for RE. Here, we compare our model with the other two marker-based models. Firstly, PURE $(\mathbf{Full})$ (Zhong and Chen, 2021) applies solid markers to process each entity pair independently. Secondly, PURE (Approx.) packs the levitated markers of all entity pairs into an instance for batch computation. Since the performance and the running time of the above methods rely on the quality and the number of predicted entities, for a fair comparison, we adopt the same entity input from the entity model of PURE on all the RE models. Table 5 shows the relation F1 scores and the inference speed of the above three methods. On both datasets, our RE model, PL-Marker, achieves the best performance and PURE (Approx.) has highest efficiency
我们在关系抽取(RE)任务中对悬浮标记采用了面向主体和面向客体的打包策略。在此,我们将本模型与其他两种基于标记的模型进行对比:首先,PURE $(\mathbf{Full})$ (Zhong and Chen, 2021)采用固定标记独立处理每个实体对;其次,PURE (Approx.)将所有实体对的悬浮标记打包至单个实例进行批量计算。由于上述方法的性能和运行时间依赖于预测实体的质量与数量,为确保公平比较,我们在所有RE模型中均采用PURE实体模型的相同实体输入。表5展示了三种方法的关系F1分数和推理速度。在两个数据集上,我们的RE模型PL-Marker均取得最佳性能,而PURE (Approx.)具有最高效率。
Relation Extraction
关系抽取
Text: Liana drove 10 hours from Pennsylvania to attend the rally in Manhattan with her parents PURE: (Liana, located in, Manhattan) Our: (Liana, located in, Manhattan), (her parents, located in, Manhattan)
文本:Liana从宾夕法尼亚州驱车10小时,与父母一同参加曼哈顿的集会
PURE:(Liana, 位于, 曼哈顿)
Our:(Liana, 位于, 曼哈顿), (她的父母, 位于, 曼哈顿)
Table 6: Case study of our NER and RE model.
表 6: 我们的NER和RE模型案例研究
in the inference process. Compared to the PURE (Full), our model obtains a $2.2\mathrm{x}{-}2.8\mathrm{x}$ speedup and better performance on ACE05 and SciERC. Compared to PURE (Approx.), our model achieves a $2.8%-4.0%$ relation F1 (boundaries) improvement on ACE05 and SciERC, which again demonstrates the effectiveness of our fusion markers and packing strategy. Overall, our model, with a novel subjectoriented packing strategy for markers, has been proven effective in practice, with satisfactory accuracy and affordable cost.
在推理过程中。与PURE (Full)相比,我们的模型在ACE05和SciERC上实现了2.2倍至2.8倍的速度提升和更优性能。相较于PURE (Approx.),我们的模型在ACE05和SciERC上关系F1值(边界)提升了2.8%-4.0%,再次验证了融合标记(marker)与打包策略的有效性。总体而言,采用面向实体的新型标记打包策略后,我们的模型在实践中展现出显著效果,兼具理想精度与可控成本。
4.5 Case Study
4.5 案例研究
Table 7: The relation F1 (boundaries) on the test set of ACE05 and SciERC with different input features for the ablation study. gold: use the gold entities; e2e: use the entities predicted by our entity model. w/o.: without. w.: with.
表 7: ACE05 和 SciERC 测试集上关系 F1 (边界) 在不同输入特征下的消融研究结果。gold: 使用标注实体;e2e: 使用我们实体模型预测的实体。w/o.: 不包含。w.: 包含。
| 命名实体识别 |
|---|
| 文本: 这是央视国际频道的《海峡两岸》节目...大陆赠台大熊猫候选名单可能 |
| 增加。T-Concat: : (Cross Strait, WORK OF ART), (CCTV Inter- |
| national Channel,ORG),(Taiwan,GPE) Our: (Cross Strait, ORG),(CCTV International Channel, ORG),(Taiwan,GPE) |
We show several cases to compare our span model with T-Concat and to compare our span pair model with PURE (Full). As shown in Table 6, our span model could collect contextual information, such as Taiwan and mainland, for underlined span, Cross Strait, assisting in predicting its type as organization rather than work of art. Our span model learns to integrally consider the interrelation between the same-object relational facts in training phase, so as to successfully obtain the fact that both Liana and her parents are located in Manhattan.
我们展示几个案例来比较我们的span模型与T-Concat,以及比较我们的span pair模型与PURE (Full)。如表6所示,我们的span模型能够为下划线span"Cross Strait"收集上下文信息(例如台湾和大陆),从而帮助将其类型预测为组织而非艺术品。我们的span模型学会在训练阶段整体考虑相同对象关系事实之间的相互关联,因此成功获取了Liana和她父母都位于曼哈顿的事实。
4.6 Ablation Study
4.6 消融实验
In this section, we conduct ablation studies to investigate the contribution of different components to our RE model, where we apply BASE size encoder in the experiments.
在本节中,我们通过消融实验研究不同组件对RE模型的贡献,实验中采用BASE尺寸编码器。
Two pairs of Levitated Markers We evaluate the w/o solid marker baseline, which applies two pairs of levitated markers on the subject and object respectively and packs all the span pairs into an instance. As shown in Table 7, compared to PL
两对悬浮标记
我们评估了无实体标记基线,该基线分别在主语和宾语上应用两对悬浮标记,并将所有跨度对打包成一个实例。如表 7 所示,与 PL 相比
| 模型 | ACE05 (gold) | ACE05 (e2e) | SciERC (gold) | SciERC (e2e) |
|---|---|---|---|---|
| PL-Marker | 74.0 | 69.0 | 72.5 | 53.2 |
| w/o.solidmarker | 72.0 | 67.3 | 68.7 | 50.6 |
| w/o.inverserelation | 72.9 | 68.1 | 71.6 | 52.7 |
| w/o. entity type loss | 73.4 | 68.4 | 72.3 | 53.2 |
| w.type marker | 74.0 | 68.3 | 72.1 | 53.0 |
Marker, the model without solid markers drops a huge $2.0%-3.8%$ F1 on ACE05 and SciERC when the golden entities are given. The result demonstrates that it is sub-optimal to continue to apply directional attention to bind two pairs of levitated markers, since a pair of levitated marker is already tied by the directional attention.
Marker模型在没有固定标记的情况下,当给定黄金实体时,在ACE05和SciERC上的F1分数大幅下降了2.0%-3.8%。结果表明,继续应用定向注意力来绑定两对悬浮标记并不是最优选择,因为一对悬浮标记已经通过定向注意力联系在一起。
Inverse Relation We establish an inverse relation for each asymmetric relation for a bidirectional prediction. We evaluate the model without inverse relation, which replaces the constructed inverse relation with a non-relation type and adopts a unidirectional prediction. As shown in Table 7, the model without inverse relation drops $0.9%{-1.1%}$ F1 on both datasets with the gold entities given, indicating the significance of modeling the information from the object entity to the subject entity in our asymmetric framework.
逆向关系
我们为双向预测中的每个非对称关系建立了逆向关系。我们评估了不含逆向关系的模型,该模型用非关系类型替代构建的逆向关系,并采用单向预测。如表7所示,在给定黄金实体的两个数据集上,不含逆向关系的模型F1值下降了$0.9%{-1.1%}$,这表明在我们的非对称框架中,从对象实体到主体实体的信息建模具有重要意义。
Entity Type We add an auxiliary entity type loss to RE model to introduce the entity type information. As shown in Table 7, when the gold enti- ties are given, the model without entity type loss drops $0.4%{-}0.7%$ F1 on both datasets, which shows the importance of entity type information in RE. Moreover, we try to apply the type markers (Zhong and Chen, 2021), such as $/S u b j e c t{:}P E R J$ and $\it{1}O b\cdot$ - $_{j e c t:G P E J}$ , to inject entity type information predicted by the NER model into the RE model. We find the RE model with type marker performs slightly worse than the model with entity type loss in the end-to-end setting. It shows that the entity type prediction error from the NER model may be propagated to the RE model if we adopt the type markers as input features. Finally, we discuss when to use the entity type prediction from the RE model to refine the NER prediction in the Appendix and we finally refine entity type for ACE04 and ACE05 except SciERC according to their dataset statistic.
实体类型
我们向关系抽取(RE)模型添加了辅助实体类型损失以引入实体类型信息。如表7所示,当给定黄金实体时,不使用实体类型损失的模型在两个数据集上的F1值均下降$0.4%{-}0.7%$,这表明实体类型信息在关系抽取中的重要性。此外,我们尝试应用类型标记(Zhong and Chen, 2021),例如$/S u b j e c t{:}P E R J$和$\it{1}O b\cdot$ - $_{j e c t:G P E J}$,将NER模型预测的实体类型信息注入到RE模型中。我们发现,在端到端设置中,使用类型标记的RE模型性能略低于使用实体类型损失的模型。这表明如果我们采用类型标记作为输入特征,NER模型的实体类型预测错误可能会传播到RE模型。最后,我们在附录中讨论了何时使用RE模型的实体类型预测来优化NER预测,并最终根据数据集统计情况优化了除SciERC外的ACE04和ACE05的实体类型。
5 Conclusion
5 结论
In this work, we present a novel packed levitated markers, with a neighborhood-oriented packing strategy and a subject-oriented packing strategy, to obtain the span (pair) representation. Considering the interrelation between spans and span pairs, our model achieves the state-of-the-art F1 scores and a promising efficiency on both NER and RE tasks across six standard benchmarks. In future, we will further investigate how to generalize the markerbased span representation to more NLP tasks.
在本研究中,我们提出了一种新颖的悬浮标记打包方法,通过邻域导向打包策略和主体导向打包策略来获取跨度(配对)表示。考虑到跨度和跨度对之间的相互关系,我们的模型在六个标准基准测试中,无论是命名实体识别(NER)还是关系抽取(RE)任务,均取得了最先进的F1分数和令人满意的效率。未来,我们将进一步研究如何将基于标记的跨度表示推广到更多的自然语言处理任务中。