System Combination via Quality Estimation for Grammatical Error Correction
基于质量评估的系统组合在语法错误纠正中的应用
Abstract
摘要
Quality estimation models have been developed to assess the corrections made by grammatical error correction (GEC) models when the reference or gold-standard corrections are not available. An ideal quality estimator can be utilized to combine the outputs of multiple GEC systems by choosing the best subset of edits from the union of all edits proposed by the GEC base systems. However, we found that existing GEC quality estimation models are not good enough in differentiating good corrections from bad ones, resulting in a low $F_{0.5}$ score when used for system combination. In this paper, we propose GRECO1, a new state-of-the-art quality estimation model that gives a better estimate of the quality of a corrected sentence, as indicated by having a higher correlation to the $F_{0.5}$ score of a corrected sentence. It results in a combined GEC system with a higher $F_{0.5}$ score. We also propose three methods for utilizing GEC quality estimation models for system combination with varying generality: modelagnostic, model-agnostic with voting bias, and model-dependent method. The combined GEC system outperforms the state of the art on the CoNLL-2014 test set and the BEA-2019 test set, achieving the highest $F_{0.5}$ scores published to date.
质量评估模型旨在当参考或黄金标准修正不可用时,评估语法错误修正(GEC)模型所做的修改。理想的质量评估器可通过从GEC基础系统提出的所有修正集合中选择最佳子集,来整合多个GEC系统的输出。然而,我们发现现有的GEC质量评估模型在区分优质修正与劣质修正方面表现欠佳,导致用于系统组合时$F_{0.5}$分数较低。本文提出GRECO1——一种新的最先进质量评估模型,能更准确地评估修正句的质量,表现为与修正句$F_{0.5}$分数具有更高相关性。该模型使组合GEC系统获得了更高的$F_{0.5}$分数。我们还提出三种利用GEC质量评估模型进行系统组合的方法,其通用性依次递增:模型无关法、带投票偏置的模型无关法以及模型依赖法。组合GEC系统在CoNLL-2014测试集和BEA-2019测试集上均超越现有技术水平,取得了迄今公布的最高$F_{0.5}$分数。
1 Introduction
1 引言
Grammatical error correction (GEC) is the task of automatically detecting and correcting errors in text, including but not limited to grammatical errors, misspellings, orthographic errors, and semantic errors (Cho l lamp at t et al., 2016; Cho l lamp at t and $\mathrm{Ng}$ , 2018a; Qorib et al., 2022; Bryant et al., 2023). A GEC model is evaluated by calculating the $F$ -score (van Rijsbergen, 1979) from compar- ing the edits proposed by the GEC model against gold (human-annotated) reference edits. GEC edits are a set of insertion, deletion, or substitution operations that are applied to the original (source) sentence to make it free from errors. An edit is represented by three values: start index, end index, and correction string (Table 1). Since CoNLL-2014 $\mathbf{Ng}$ et al., 2014), $F_{0.5}$ has become the standard metric for GEC. Gr und kiew i cz et al. (2015) and Cho l lamp at t and $\mathrm{Ng}$ (2018c) reported that the $F_{0.5}$ score correlates better with human judgment than other GEC metrics.
语法错误纠正 (GEC) 是自动检测并纠正文本中错误的任务,包括但不限于语法错误、拼写错误、正字法错误和语义错误 (Cho l lamp at t et al., 2016; Cho l lamp at t and $\mathrm{Ng}$, 2018a; Qorib et al., 2022; Bryant et al., 2023)。GEC 模型通过计算 $F$ 值 (van Rijsbergen, 1979) 来评估,该值通过比较 GEC 模型提出的编辑与人工标注的参考编辑得出。GEC 编辑是一组插入、删除或替换操作,应用于原始 (源) 句子以消除错误。一个编辑由三个值表示:起始索引、结束索引和纠正字符串 (表 1)。自 CoNLL-2014 $\mathbf{Ng}$ et al., 2014) 以来,$F_{0.5}$ 已成为 GEC 的标准指标。Gr und kiew i cz et al. (2015) 和 Cho l lamp at t and $\mathrm{Ng}$ (2018c) 报告称,$F_{0.5}$ 分数比其他 GEC 指标更能反映人类判断。
Qorib and $\mathrm{Ng}$ (2022) reported that GEC models have outperformed humans when measured by the $F_{0.5}$ metric, but still make occasional mistakes in simple cases. Thus, we need a way to evaluate the corrections proposed by a GEC model before accepting their corrections as a replacement for our original sentences. In real-world use cases where the gold reference is not available, we can use a GEC quality estimation model to assess the quality of the correction made by a GEC model.
Qorib和$\mathrm{Ng}$ (2022) 报告称,当以$F_{0.5}$指标衡量时,GEC模型的表现已超过人类,但在简单案例中仍会偶尔出错。因此,我们需要一种方法来评估GEC模型提出的修正建议,然后才能接受其修正作为原始句子的替代。在现实应用场景中无法获得黄金参考时,可以使用GEC质量评估模型来衡量GEC模型所做修正的质量。
GEC quality estimation model accepts a source sentence and its correction and produces a quality score. The quality score characterizes the accuracy and appropriateness of a correction with respect to the source sentence. The higher the score, the more accurate and appropriate the correction is. A quality estimation model is typically used as a filtering method to accept or reject a correction made by a GEC model (Cho l lamp at t and $\mathrm{Ng}$ , 2018b). It can also be used for choosing the best correction from the top $k$ outputs of a GEC system (Liu et al., 2021).
GEC质量评估模型接收源句子及其修正结果,并生成质量分数。该分数表征修正结果相对于源句子的准确性和恰当性。分数越高,修正越准确恰当。质量评估模型通常用作过滤方法,以接受或拒绝GEC模型生成的修正 (Cho et al., 2018b) ,也可用于从GEC系统输出的前$k$个结果中选择最佳修正 (Liu et al., 2021)。
In this paper, we propose to extend that use case further. Instead of choosing the best correction (hypothesis) from GEC models, we can use a GEC quality estimation model to produce a new and more accurate correction, based on the edits that appear in the hypotheses. We generate all possible hypotheses from the edit combinations and score them using a quality estimation model. The highest-scoring hypothesis is then deemed as the most appropriate correction of the source sentence.
在本文中,我们提议进一步扩展该用例。不同于从GEC模型中选择最佳修正(假设),我们可以利用GEC质量评估模型,基于假设中出现的编辑操作生成全新且更准确的修正。我们通过编辑组合生成所有可能的假设,并使用质量评估模型对其进行评分,最终将得分最高的假设视为源句最合适的修正。
Table 1: Example GEC edits.
表 1: GEC编辑示例
| 源修正 | To sum it up I still consider having their own car is way more safe and convinient . To sum up , I still consider having your own car way more safe and convenient . |
|---|---|
| 差异编辑 | Tosum {it}up {,} I still consider having {their→ your} own car {is}v waymore safe and{convinient→ convenient}. (2,3,"), (4,4,‘,), (8,9,“your'), (11,12,“"), (16,17,‘convenient') |
We discuss this in more detail in Section 3. The main contributions of this paper are:
我们将在第3节详细讨论这一点。本文的主要贡献包括:
• We present novel methods for utilizing GEC quality estimation models for system combination. • We reveal and highlight the low performance of existing GEC quality estimation models when used for system combination. • We present a new state-of-the-art GEC quality estimation model that has better correlation to the $F_{0.5}$ score and produces higher $F_{0.5}$ scores when used for system combination. • We report new state-of-the-art scores on the CoNLL-2014 and BEA-2019 test sets.
• 我们提出了利用语法错误修正 (GEC) 质量评估模型进行系统组合的新方法。
• 我们揭示并强调了现有 GEC 质量评估模型在用于系统组合时的低性能问题。
• 我们提出了一种新的最先进 GEC 质量评估模型,该模型与 $F_{0.5}$ 分数具有更好的相关性,并在用于系统组合时产生更高的 $F_{0.5}$ 分数。
• 我们在 CoNLL-2014 和 BEA-2019 测试集上报告了新的最先进分数。
2 Related Work
2 相关工作
2.1 GEC Quality Estimation Models
2.1 GEC质量评估模型
In this section, we briefly discuss existing neural GEC quality estimation models, including a neural reference-less GEC metric.
在本节中,我们简要讨论现有的神经语法错误修正(GEC)质量评估模型,包括一种无参考的神经GEC度量方法。
2.1.1 NeuQE
2.1.1 NeuQE
NeuQE (Cho l lamp at t and Ng, 2018b) is the first neural quality estimation model for GEC. NeuQE uses the predictor-estimator framework (Kim et al., 2017) which trains a word prediction task on the predictor network and trains the quality score on the estimator network. The estimator is trained using knowledge from the predictor. NeuQE has two types of model, one for $F_{0.5}$ score estimation and the other for post-editing effort estimation. NeuQE is trained on the NUCLE (Dahlmeier et al., 2013) and FCE (Yann a kou dak is et al., 2011) corpora.
NeuQE (Cho等人, 2018b) 是首个用于语法纠错(GEC)的神经质量评估模型。该模型采用预测器-估计器框架 (Kim等人, 2017),通过在预测器网络上训练词语预测任务,并在估计器网络上训练质量评分。估计器的训练利用了来自预测器的知识。NeuQE包含两种模型:一种用于估计$F_{0.5}$分数,另一种用于评估后期编辑工作量。该模型基于NUCLE (Dahlmeier等人, 2013) 和FCE (Yannakoudakis等人, 2011) 语料库进行训练。
2.1.2 VERNet
2.1.2 VERNet
VERNet (Liu et al., 2021) estimates the quality of a GEC model from the top $k$ outputs of beam search decoding of the GEC model. VERNet uses BERT-like architecture to get the representation of each token. It then constructs a fully-connected graph between pairs of (source, hypothesis) for each beam search output to learn the interaction between hypotheses, then summarizes and aggregates the information of the hypotheses’ interaction using two custom attention mechanisms. VERNet trains the model using the top-5 outputs of the Riken&Tohoku (Kiyono et al., 2019) model on the FCE, NUCLE, and W&I+LOCNESS (Bryant et al., 2019; Granger, 1998) datasets.
VERNet (Liu等人,2021) 通过束搜索解码(beam search)生成的前$k$个输出来评估语法纠错(GEC)模型的质量。该模型采用类BERT架构获取每个Token的表示,并为每个束搜索输出构建(源句,假设句)对的完全连接图以学习假设间的交互关系,随后通过两种定制注意力机制汇总并聚合假设交互信息。VERNet使用Riken&Tohoku模型(Kiyono等人,2019)在FCE、NUCLE及W&I+LOCNESS数据集(Bryant等人,2019; Granger, 1998)上生成的前5个输出进行训练。
2.1.3 SOME
2.1.3 SOME
SOME (Yoshimura et al., 2020) is a reference-less GEC metric that scores a GEC correction based on three scoring aspects: grammatical it y, fluency, and meaning preservation. SOME consists of three BERT models, one for each scoring aspect. Different from the aforementioned GEC quality estimation models, SOME does not aim to estimate the $F_{0.5}$ score. Instead, it estimates the aspect scores directly. The authors created a new dataset to train the BERT models by annotating outputs of various GEC systems on the CoNLL-2013 test set with the three scoring aspects. The authors argue that reference-less metrics are better than $F_{0.5}$ score because it is difficult to cover all possible corrections in the gold reference.
SOME (Yoshimura et al., 2020) 是一种无参考的语法纠错(GEC)评估指标,它基于三个评分维度对纠错结果进行打分:语法正确性、流畅性和意义保持性。SOME由三个BERT模型组成,每个模型对应一个评分维度。与之前提到的GEC质量评估模型不同,SOME并不旨在估计$F_{0.5}$分数,而是直接评估各维度的得分。作者通过在CoNLL-2013测试集上对多个GEC系统输出的三个维度进行标注,创建了一个新的数据集来训练这些BERT模型。作者认为无参考指标优于$F_{0.5}$分数,因为在黄金参考中很难涵盖所有可能的修正。
2.2 GEC System Combination Methods
2.2 GEC系统组合方法
In this section, we briefly discuss state-of-the-art GEC system combination methods.
在本节中,我们简要讨论最先进的语法纠错 (GEC) 系统组合方法。
2.2.1 ESC
2.2.1 ESC
ESC (Qorib et al., 2022) is a system combination method that takes the union of all edits from the base systems, scores each edit to decide whether the edit should be kept or discarded, and generates the final corrections using the selected edits. ESC uses logistic regression to score each edit based on the edit type and inclusion in the base systems, and filters the overlapping edit based on a threshold and a greedy selection method. ESC is trained on the BEA-2019 development set.
ESC (Qorib等人,2022) 是一种系统组合方法,它汇集基础系统的所有编辑内容,对每个编辑进行评分以决定保留或舍弃,并利用选定的编辑生成最终修正。该方法通过逻辑回归基于编辑类型和基础系统包含情况对编辑评分,并采用阈值和贪心选择算法过滤重叠编辑。ESC在BEA-2019开发集上完成训练。

Figure 1: Beam search with beam size $(b)=2$ . The blue arrow denotes generation of a new hypothesis, and the orange circle denotes the hypotheses with the highest scores. At each step, new hypotheses are generated by applying edit $e_{i}$ to the top $b$ hypotheses of step $i-1$ .
图 1: 束搜索 (beam search) 的束宽 $(b)=2$ 。蓝色箭头表示生成新假设,橙色圆圈表示得分最高的假设。在每一步中,通过将编辑操作 $e_{i}$ 应用于步骤 $i-1$ 的前 $b$ 个假设来生成新假设。
2.2.2 MEMT
2.2.2 MEMT
MEMT (Heafield and Lavie, 2010) is a system combination method that combines models’ outputs by generating candidate hypotheses through token alignments and scoring each candidate according to its textual features, which include n-gram language model score, n-gram similarity to each base model’s output, and sentence length. MEMT was originally designed for machine translation system combination, but Susanto et al. (2014) successfully adapted it for use in GEC.
MEMT (Heafield and Lavie, 2010) 是一种系统组合方法,它通过token对齐生成候选假设,并根据文本特征对每个候选进行评分,这些特征包括n-gram语言模型得分、与每个基础模型输出的n-gram相似度以及句子长度。MEMT最初是为机器翻译系统组合设计的,但Susanto等人 (2014) 成功将其应用于语法错误纠正 (GEC) 领域。
2.2.3 EditScorer
2.2.3 EditScorer
EditScorer (Sorokin, 2022) is a model that scores each edit based on its textual features to generate a better correction. The model can be used to rerank edits from a single model or combine edits from multiple models. It has a similar principle to ESC but uses the textual features of the edit and its surrounding context instead of the edit type. The textual feature is acquired from RoBERTa-large’s (Liu et al., 2019) token representation of the candidate sentence. The model is trained with more than 2.4M sentence pairs from cLang8 (Rothe et al., 2021) and the BEA-2019 training set.
EditScorer (Sorokin, 2022) 是一种基于文本特征对每次编辑进行评分以生成更好修正的模型。该模型可用于对单一模型的编辑结果进行重排序,或整合多个模型的编辑结果。其原理与ESC类似,但使用的是编辑内容及其上下文环境的文本特征,而非编辑类型。文本特征通过RoBERTa-large (Liu et al., 2019) 对候选句子的token表征获取。该模型使用来自cLang8 (Rothe et al., 2021) 和BEA-2019训练集的240万组句子对进行训练。
3 GEC System Combination via Quality Estimation
3 基于质量评估的GEC系统组合
To be able to use a GEC quality estimation model for system combination, we assume an ideal quality estimation model that can discern good hypotheses from bad ones and produce appropriate quality scores. Even though a perfect quality estimation model does not exist yet, quality estimation that behaves closely to our assumption will be good enough to be useful for combining GEC systems.
为了将GEC质量评估模型用于系统组合,我们假设存在一个理想的质量评估模型,能够区分优劣假设并生成适当的质量分数。尽管目前尚不存在完美的质量评估模型,但行为接近我们假设的质量评估模型已经足够用于组合GEC系统。
3.1 Problem Formulation
3.1 问题表述
For a source sentence $s~={s_{1},s_{2},...,s_{l}}$ with length $l$ and a hypothesis $\boldsymbol{h}~=~{h_{1},h_{2},...,h_{m}}$ with length $m$ , a quality estimation model produces a quality score $Q(s,h)$ to assess how good $h$ is as a correction to $s$ . When combining GEC systems, we have multiple hypotheses from different base GEC systems. From these hypotheses, we can extract all the edits. Let $\mathbb{E}$ denote the union of all edits.
对于一个长度为 $l$ 的源句子 $s~={s_{1},s_{2},...,s_{l}}$ 和一个长度为 $m$ 的假设 $\boldsymbol{h}~=~{h_{1},h_{2},...,h_{m}}$ ,质量评估模型会生成一个质量分数 $Q(s,h)$ 来评估 $h$ 作为 $s$ 的修正有多好。在组合多个语法纠错 (GEC) 系统时,我们会得到来自不同基础 GEC 系统的多个假设。从这些假设中,我们可以提取出所有的编辑操作。设 $\mathbb{E}$ 表示所有编辑操作的并集。
A new hypothesis can be generated by applying an edit $e_{i}\in\mathbb{E}$ to the source sentence $s$ . If it is a correct edit $(e_{i}^{+})$ , the quality score of the resulting hypothesis should be higher than when the edit is not applied or when a wrong edit $(e_{i}^{-})$ is applied. Let $h\oplus e$ denote the operation of applying edit $e$ to sentence $h$ . For any hypothesis $h$ (including the case of $h=s$ ), an ideal quality estimation model should have the following property:
通过对源句 $s$ 应用编辑 $e_{i}\in\mathbb{E}$ 可以生成一个新假设。若该编辑为正确编辑 $(e_{i}^{+})$ ,生成假设的质量分数应高于未应用编辑或应用错误编辑 $(e_{i}^{-})$ 的情况。用 $h\oplus e$ 表示对句子 $h$ 应用编辑 $e$ 的操作。对于任意假设 $h$ (包括 $h=s$ 的情况),理想的质量评估模型应具备以下特性:
$$
Q(s,h\oplus e^{+})>Q(s,h)>Q(s,h\oplus e^{-})
$$
$$
Q(s,h\oplus e^{+})>Q(s,h)>Q(s,h\oplus e^{-})
$$
3.2 Beam Search
3.2 束搜索 (Beam Search)
From an edit union of size $\lvert\mathbb{E}\rvert$ , we can get $2^{|\mathbb{E}|}$ possible hypotheses. However, scoring all possible hypotheses is too costly, so we use beam search with size $b$ to generate the potential candidates in a reasonable time. We apply each edit in $\mathbb{E}$ one by one to the hypotheses in the current beam to generate new candidates, with time complexity $O(b\times|\mathbb{E}|)$ .
从大小为 $\lvert\mathbb{E}\rvert$ 的编辑联合中,我们可以得到 $2^{|\mathbb{E}|}$ 种可能的假设。然而,对所有可能的假设进行评分成本过高,因此我们使用大小为 $b$ 的束搜索 (beam search) 在合理时间内生成潜在候选。我们将 $\mathbb{E}$ 中的每个编辑依次应用于当前束中的假设以生成新候选,时间复杂度为 $O(b\times|\mathbb{E}|)$。
Initially, the beam contains the source sentence and all edits in $\mathbb{E}$ are sorted from left to right, i.e., edits with smaller start and end indices are processed earlier. In each step, we generate new candidates by applying the current edit to all candidate sentences in the beam if it does not create a conflict with previously added edits. We use the edit conflict definition of Qorib et al. (2022). Next, we compute the quality scores for the new candidates and add them to the beam. At the end of each step, we trim the beam by only keeping the top $b$ candidates with the highest quality scores. After we finish processing all edits, the candidate with the highest quality score becomes the final correction. We illustrate this process in Figure 1.
初始时,光束包含源句子和 $\mathbb{E}$ 中的所有编辑,这些编辑按从左到右排序(即起始和结束索引较小的编辑优先处理)。在每一步中,若当前编辑与已添加编辑无冲突(采用 Qorib 等人 (2022) 的编辑冲突定义),则将其应用于光束中的所有候选句子以生成新候选。随后计算新候选的质量分数并将其加入光束。每步结束时,仅保留质量分数最高的前 $b$ 个候选以修剪光束。处理完所有编辑后,质量分数最高的候选即为最终修正结果。该过程如图 1 所示。
4 Quality Estimation Method
4 质量评估方法
A correction produced by a GEC model can be wrong in three aspects: keeping wrong words or phrases from the source sentence, changing the words or phrases into the wrong ones, or missing some words or phrases. In other words, a quality estimation model needs to know which words are correct and which are wrong, as well as determine whether the gaps between words are correct or wrong (in which case a word or phrase needs to be inserted).
语法纠错(GEC)模型的修正可能在三个方面出错:保留源句中的错误单词或短语、将单词或短语改为错误的表达,或遗漏某些单词或短语。换言之,质量评估模型需要识别哪些单词是正确的、哪些是错误的,同时判断单词间的空缺是否正确(若错误则需插入单词或短语)。
A GEC quality estimation model should also produce the quality scores proportionately. A better correction of the same source sentence should get a higher score than a worse one. That is, a quality estimation model should be able to rank hypotheses by their quality scores correctly.
GEC质量评估模型还应按比例生成质量分数。同一源句的更好修正应比更差的修正获得更高的分数。也就是说,质量评估模型应能根据质量分数正确对假设进行排序。
In this section, we describe our approach to build a quality estimation model with the aforementioned qualities, which we call GRECO (Gamma tica lit yscorer for re-ranking corrections).
在本节中,我们将介绍如何构建一个具备上述特性的质量评估模型,该模型称为GRECO (Gamma tica lit yscorer for re-ranking corrections)。
4.1 Architecture
4.1 架构
Our model uses a BERT-like pre-trained language model as its core architecture (Figure 2). We draw inspiration from quality estimation for machine translation models (Kim et al., 2019; Lee, 2020; Wang et al., 2020). The input to the model is the concatenation of the source sentence and a hypothesis, with the source sentence and the hypothesis prefixed with [CLS] $\left(s_{0}\right)$ and [SEP] $(h_{0})$ pseudotokens respectively.
我们的模型采用类似BERT的预训练语言模型作为核心架构 (图 2)。我们借鉴了机器翻译模型质量评估的研究思路 (Kim et al., 2019; Lee, 2020; Wang et al., 2020)。模型输入是源语句与假设语句的拼接组合,源语句和假设语句分别以[CLS] $\left(s_{0}\right)$ 和[SEP] $(h_{0})$ 伪标记作为前缀。
For every word in the hypothesis, the model learns to predict its word label $w_{i}$ and gap label $g_{i}$ . The word label denotes whether the current word is correct. $w_{i}$ is 1 when the word is correct and 0 otherwise. The gap label denotes whether there should be a word or phrase inserted right after the current word and before the next word. $g_{i}$ is 1 when the gap is correct (i.e., there should be no words inserted) and 0 otherwise. The gold word labels and gap labels are computed by extracting the differences between the hypothesis and the gold reference sentence using ERRANT (Bryant et al., 2017). The word label $w_{i}$ and gap label $g_{i}$ are computed from the projection of the embeddings learned by the pre-trained language model to a value in [0,1] using a two-layered neural network with tanh activation $(\phi)$ . We formally describe them in Equation (2) and (3), where LM denotes the pre-trained language model, $\sigma$ denotes the sigmoid function, $\mathbf{\delta}{\mathbf{}}A_{w}$ , ${\bf}{\bf}{{\bf}{\bf}{\bf}}^{}$ , $b_{w}$ , and $b_{w}$ denote the weights and biases for the weight label projector, and $A_{g},a_{g},b_{g}$ , and $b_{g}$ denote the weights and biases for the gap label projector. The size of $\mathbf{}A_{w}$ and $A_{g}$ is $d_{L M}\times d_{L M}$ , while the size of ${\bf}{\bf}{w}$ , ${\pmb a}{g}$ , $b_{w}$ , and $b_{g}$ is $d_{L M}\times1$ , with $d_{L M}$ being the language model dimension.
对于假设中的每个词,模型学习预测其词标签 $w_{i}$ 和间隙标签 $g_{i}$。词标签表示当前词是否正确。当词正确时 $w_{i}$ 为1,否则为0。间隙标签表示在当前词与下一个词之间是否应插入词或短语。当间隙正确(即无需插入词)时 $g_{i}$ 为1,否则为0。通过使用ERRANT (Bryant et al., 2017)提取假设与黄金参考句之间的差异来计算黄金词标签和间隙标签。词标签 $w_{i}$ 和间隙标签 $g_{i}$ 是通过将预训练语言模型学习的嵌入投影到[0,1]范围内的值来计算的,使用具有tanh激活 $(\phi)$ 的双层神经网络。我们在公式(2)和(3)中正式描述它们,其中LM表示预训练语言模型,$\sigma$ 表示sigmoid函数,$\mathbf{\delta}{\mathbf{}}A_{w}$、${\bf}{\bf}{{\bf}{\bf}{\bf}}^{}$、$b_{w}$ 和 $b_{w}$ 表示权重标签投影器的权重和偏置,$A_{g},a_{g},b_{g}$ 和 $b_{g}$ 表示间隙标签投影器的权重和偏置。$\mathbf{}A_{w}$ 和 $A_{g}$ 的大小为 $d_{L M}\times d_{L M}$,而 ${\bf}{\bf}{w}$、${\pmb a}{g}$、$b_{w}$ 和 $b_{g}$ 的大小为 $d_{L M}\times1$,其中 $d_{L M}$ 是语言模型的维度。
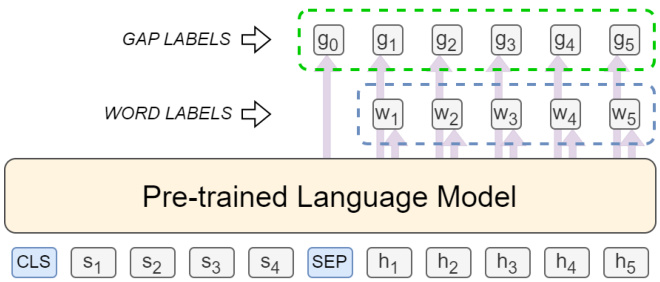
Figure 2: Model architecture
图 2: 模型架构
$$
\begin{array}{r l}&{V=\mathrm{LM}(s;h)}\ &{\quad=\mathrm{LM}(s_{0},s_{1},\ldots,s_{l},h_{0},h_{1},\ldots,h_{m})}\ &{\quad={v_{0}^{s},v_{1}^{s},\ldots,v_{l}^{s},v_{0}^{h},v_{1}^{h},\ldots,v_{m}^{h}}}\ &{w_{i}=\sigma(a_{w}^{T}\phi(A_{w}v_{i}^{h}+b_{w})+b_{w})}\ &{g_{i}=\sigma(a_{g}^{T}\phi(A_{g}v_{i}^{h}+b_{g})+b_{g})}\end{array}
$$
$$
\begin{array}{r l}&{V=\mathrm{LM}(s;h)}\ &{\quad=\mathrm{LM}(s_{0},s_{1},\ldots,s_{l},h_{0},h_{1},\ldots,h_{m})}\ &{\quad={v_{0}^{s},v_{1}^{s},\ldots,v_{l}^{s},v_{0}^{h},v_{1}^{h},\ldots,v_{m}^{h}}}\ &{w_{i}=\sigma(a_{w}^{T}\phi(A_{w}v_{i}^{h}+b_{w})+b_{w})}\ &{g_{i}=\sigma(a_{g}^{T}\phi(A_{g}v_{i}^{h}+b_{g})+b_{g})}\end{array}
$$
The length of the word label vector $\mathbf{\nabla}_{\mathbf{\overrightarrow{\mathbf{\vert~\mathbf{\nabla~}~}}}}$ is the same as the hypothesis $(m)$ , while the length of the gap label vector $\pmb{g}$ is $m+1$ . The gap vector length is one more than the hypothesis’ length to account for the potentially missing words at the start of the hypothesis. If the pre-trained language model uses sub-word token iz ation, tokens that are not the beginning of a word are masked. The quality score $Q\left(s,h\right)$ is calculated from the normalized product of the word label and gap label probabilities from all words in the hypothesis.
词标签向量$\mathbf{\nabla}_{\mathbf{\overrightarrow{\mathbf{\vert~\mathbf{\nabla~}~}}}}$ 的长度与假设 $(m)$ 相同,而间隔标签向量 $\pmb{g}$ 的长度为 $m+1$。间隔向量的长度比假设长度多1,是为了考虑假设开头可能缺失的单词。如果预训练语言模型使用子词 token 化,非词首的 token 会被掩码。质量分数 $Q\left(s,h\right)$ 由假设中所有单词的词标签概率和间隔标签概率的归一化乘积计算得出。
$$
Q\left(s,h\right)=\sqrt[2m+1]{\prod_{i=1}^{m}w_{i}\cdot\prod_{i=0}^{m}g_{i}}
$$
$$
Q\left(s,h\right)=\sqrt[2m+1]{\prod_{i=1}^{m}w_{i}\cdot\prod_{i=0}^{m}g_{i}}
$$
4.2 Loss Function
4.2 损失函数
The model is trained on two objectives: predicting the word label and gap label, and ranking the hypotheses correctly with the quality score, i.e., hypotheses with higher $F_{0.5}$ scores should have higher quality scores than hypotheses with lower $F_{0.5}$ scores. This translates into three loss functions: word label loss $(\mathcal{L}{w})$ , gap label loss $(\mathcal{L}{g})$ , and rank loss $(\mathcal{L}_{r})$ . The first two losses are based on binary cross-entropy loss and the rank loss is based on RankNet (Burges et al., 2005; Burges, 2010) with a slight modification to amplify the power term with a multiplier $\mu$ .
该模型基于两个目标进行训练:预测单词标签和间隔标签,以及根据质量分数正确排序假设,即具有较高 $F_{0.5}$ 分数的假设应比 $F_{0.5}$ 分数较低的假设获得更高的质量分数。这转化为三个损失函数:单词标签损失 $(\mathcal{L}{w})$、间隔标签损失 $(\mathcal{L}{g})$ 和排序损失 $(\mathcal{L}_{r})$。前两个损失基于二元交叉熵损失,而排序损失基于RankNet (Burges et al., 2005; Burges, 2010),并稍作修改以通过乘数 $\mu$ 放大幂项。
$$
\begin{array}{l}{{\displaystyle{\mathcal{L}}=\frac{1}{n}\sum_{j=1}^{n}{\mathcal{L}}{w(j)}+\frac{1}{n}\sum_{j=1}^{n}{\mathcal{L}}{g(j)}+\gamma\cdot{\mathcal{L}}{r}}}\ {{\displaystyle{\mathcal{L}}{w}=-\frac{1}{m}\sum_{i=1}^{m}(y^{u}\cdot\log w_{i}+}}\ {{\displaystyle(1-y_{u}^{u})\cdot\log(1-w_{i}))}}\ {{\displaystyle{\mathcal{L}}{g}=-\frac{1}{m+1}\sum_{i=0}^{m}(y_{i}^{g}\cdot\log g_{i}+}}\ {{\displaystyle(1-y_{i}^{u})\cdot\log(1-g_{i}))}}\ {{\displaystyle{\mathcal{L}}_{r}=\sum_{u\ge v\nearrow s}\log\left(1+{e^{-\sigma(g_{v}-Q_{u})_{i}}}\right)}}\end{array}
$$
$$
\begin{array}{l}{{\displaystyle{\mathcal{L}}=\frac{1}{n}\sum_{j=1}^{n}{\mathcal{L}}{w(j)}+\frac{1}{n}\sum_{j=1}^{n}{\mathcal{L}}{g(j)}+\gamma\cdot{\mathcal{L}}{r}}}\ {{\displaystyle{\mathcal{L}}{w}=-\frac{1}{m}\sum_{i=1}^{m}(y^{u}\cdot\log w_{i}+}}\ {{\displaystyle(1-y_{u}^{u})\cdot\log(1-w_{i}))}}\ {{\displaystyle{\mathcal{L}}{g}=-\frac{1}{m+1}\sum_{i=0}^{m}(y_{i}^{g}\cdot\log g_{i}+}}\ {{\displaystyle(1-y_{i}^{u})\cdot\log(1-g_{i}))}}\ {{\displaystyle{\mathcal{L}}_{r}=\sum_{u\ge v\nearrow s}\log\left(1+{e^{-\sigma(g_{v}-Q_{u})_{i}}}\right)}}\end{array}
$$
We formalize the loss functions in Equation (5) to (8), where $n$ is the number of training instances, $y^{w}$ and $y^{g}$ are the correct labels for the word label and gap label respectively, $y_{v}^{r}$ and $Q_{v}$ are the $F_{0.5}$ score and quality score of hypothesis $v$ respectively, and $\gamma$ is a hyper-parameter.
我们将方程(5)至(8)中的损失函数形式化定义如下:其中$n$表示训练实例数量,$y^{w}$和$y^{g}$分别代表词标签和间隔标签的正确标注,$y_{v}^{r}$与$Q_{v}$分别表示假设$v$的$F_{0.5}$分数和质量评分,$\gamma$为超参数。
4.3 System Combination Biases
4.3 系统组合偏差
The $Q$ score from quality estimation models is model-agnostic as it fully depends on the source sentence and the hypothesis sentence, independent of the system that proposes the hypothesis. With a perfect quality estimation model, it should be enough to get the best hypothesis. If we use an imperfect quality estimation model, some valuable information in the system combination task can be useful to get a better hypothesis, such as how many systems propose an edit and which systems propose it. We incorporate the former through a voting bias and the latter through edit scores from an editbased system combination method. In this section, we discuss how we replace the quality score $Q$ in the beam search with a biased hypothesis score $Q^{\prime}$ .
质量评估模型中的$Q$分数是与模型无关的,因为它完全依赖于源句和假设句,而与提出假设的系统无关。如果使用一个完美的质量评估模型,那么获得最佳假设就足够了。但如果我们使用一个不完美的质量评估模型,系统组合任务中的一些有价值信息可能有助于获得更好的假设,例如有多少系统提出了某个编辑以及是哪些系统提出的。我们通过投票偏差(voting bias)来整合前者,并通过基于编辑的系统组合方法中的编辑分数(edit scores)来整合后者。本节将讨论如何在束搜索(beam search)中用带有偏置的假设分数$Q^{\prime}$替代质量分数$Q$。
4.3.1 Voting Bias
4.3.1 投票偏差
Model voting is a common ensemble method that chooses a prediction label based on how many base systems predict that label. The rationale behind it is straightforward: the more systems propose a label, the more likely for it to be correct. In GEC, voting ensemble has also been used to combine edit labels from multiple GEC sequence-tagging models (Tarnavskyi et al., 2022).
模型投票是一种常见的集成方法,它根据有多少个基础系统预测该标签来选择预测标签。其背后的原理很简单:提出某个标签的系统越多,该标签正确的可能性就越大。在语法错误纠正(GEC)中,投票集成也被用于结合多个GEC序列标注模型的编辑标签(Tarnavskyi等人,2022)。
$$
h=s\oplus\mathbb{E}_{h}
$$
$$
h=s\oplus\mathbb{E}_{h}
$$
$$
Q^{\prime}(s,h)=Q(s,h)\cdot V(\mathbb{E}_{h})^{\alpha}
$$
$$
Q^{\prime}(s,h)=Q(s,h)\cdot V(\mathbb{E}_{h})^{\alpha}
$$
$$
V(\mathbb{E}{h})={\frac{1}{|\mathbb{E}{h}|}}\sum_{e\in\mathbb{E}_{h}}{\frac{c o u n t(e)}{c}}
$$
$$
V(\mathbb{E}{h})={\frac{1}{|\mathbb{E}{h}|}}\sum_{e\in\mathbb{E}_{h}}{\frac{c o u n t(e)}{c}}
$$
We incorporate voting bias into beam search by multiplying the quality score with a voting score $V$ (Eq. 10). The voting score is calculated by the average number of base systems that propose an edit $(c o u n t(e))$ for all edits in the hypothesis $(\mathbb{E}_{h})$ , normalized by the number of base systems $c$ The effect of voting bias is governed by a hyperparameter $\alpha$ , $0\leq\alpha\leq1$ . If $\alpha=0$ , voting bias is not used.
我们通过将质量分数与投票分数$V$(公式10)相乘,将投票偏差引入集束搜索。投票分数由所有基础系统对假设$(\mathbb{E}_{h})$中每个编辑$(count(e))$提出的平均编辑次数计算得出,并通过基础系统数量$c$进行归一化。投票偏差的影响由超参数$\alpha$控制,$0\leq\alpha\leq1$。若$\alpha=0$,则不使用投票偏差。
4.3.2 Edit Score
4.3.2 编辑得分
Qorib et al. (2022) reported that the best hypothesis is the one that maximizes the strengths of the base systems. Edit-based GEC system combination methods approximate the strengths of GEC models through their performance on each edit type and learn the best combination from the edit type feature. If we have edit scores that reflect the base GEC models’ strength, we can incorporate them into the hypothesis scoring function.
Qorib等人 (2022) 指出最佳假设是能够最大化基础系统优势的方案。基于编辑的GEC系统组合方法通过各编辑类型的性能来评估GEC模型优势,并从编辑类型特征中学习最优组合。若获得能反映基础GEC模型优势的编辑分数,便可将其纳入假设评分函数。
One way to incorporate the edit scores is by multiplying the hypothesis score with the edit scores. However, if we only multiply the scores of the edits that are applied to the hypothesis, we will reward hypotheses with fewer edits, even if we normalize the edit score2. Instead, we want to reward hypotheses that contain good edits and penalize hypotheses that miss good edits. Thus, we design the edit score to be the product of all edits in the edit union $\mathbb{E}$ .
一种整合编辑分数的方法是将假设分数与编辑分数相乘。然而,如果仅乘以应用于假设的编辑分数(即使对编辑分数进行归一化处理),会导致编辑较少的假设获得更高评分。相反,我们需要奖励包含优质编辑的假设,并惩罚遗漏优质编辑的假设。因此,我们将编辑分数设计为编辑集合 $\mathbb{E}$ 中所有编辑的乘积。
$$
Q^{\prime}(s,h)=Q(s,h)^{1-\beta}\cdot V(\mathbb{E}{h})^{\alpha}\cdot E S(\mathbb{E}_{h},\mathbb{E})^{\beta}
$$
$$
Q^{\prime}(s,h)=Q(s,h)^{1-\beta}\cdot V(\mathbb{E}{h})^{\alpha}\cdot E S(\mathbb{E}_{h},\mathbb{E})^{\beta}
$$
Table 2: Quality estimation and re-ranking results on the CoNLL-2014 test set. $\rho$ denotes Spearman’s rank correlation coefficient.
表 2: CoNLL-2014 测试集上的质量评估与重排序结果。$\rho$ 表示斯皮尔曼等级相关系数。
| 模型 | 单系统评估 | 多系统评估 | ||||||
|---|---|---|---|---|---|---|---|---|
| p | P | R | F0.5 | p | P | R | F0.5 | |
| NeuQE | -0.003 | 52.53 | 12.83 | 32.45 | 0.212 | 38.30 | 10.84 | 25.43 |
| VERNet | 0.199 | 72.13 | 35.93 | 60.04 | 0.354 | 65.06 | 22.41 | 47.12 |
| SOME | 0.002 | 53.02 | 51.06 | 52.62 | 0.392 | 47.30 | 34.62 | 44.07 |
| GPT-2 | 0.088 | 54.09 | 50.98 | 53.43 | 0.116 | 46.67 | 33.32 | 43.21 |
| GRECO | 0.445 | 71.23 | 47.72 | 64.84 | 0.415 | 67.39 | 30.71 | 54.40 |
We formulate the hypothesis score with voting bias and edit score $E S$ in Equation (12) – (14), where $p_{E S}$ denotes the probability of each edit. The effect of edit score is governed by the hyper-parameter $\beta$ , $0\leq\beta<1$ . If $\beta=0$ , the edit score is not used.
我们通过投票偏差和编辑分数 $E S$ 在公式 (12) - (14) 中构建假设评分,其中 $p_{E S}$ 表示每次编辑的概率。编辑分数的影响由超参数 $\beta$ ($0\leq\beta<1$) 控制。若 $\beta=0$,则不使用编辑分数。
5 Experiments
5 实验
5.1 Model Training
5.1 模型训练
We use DeBERTA-V3-Large (He et al., 2023) as the pre-trained language model. We train the quality estimation model using the unique corrections of nine GEC systems, which are BARTGEC (Katsumata and Komachi, 2020), GECToR RoBERTa (Ome lian ch uk et al., 2020), GECToR XLNet, GECToR BERT, Kakao&Brain ensemble (Choe et al., 2019), Kakao&Brain Transformerbase, Riken&Tohoku ensemble (Kiyono et al., 2019), T5-Large (Rothe et al., 2021), and UEDINMS ensemble (Gr und kiew i cz et al., 2019), on the W&I+LOCNESS training set.
我们使用DeBERTA-V3-Large (He et al., 2023)作为预训练语言模型。在W&I+LOCNESS训练集上,我们利用九个语法纠错(GEC)系统的独特修正来训练质量评估模型,这些系统包括:BARTGEC (Katsumata and Komachi, 2020)、GECToR RoBERTa (Omelianchuk et al., 2020)、GECToR XLNet、GECToR BERT、Kakao&Brain ensemble (Choe et al., 2019)、Kakao&Brain Transformer-base、Riken&Tohoku ensemble (Kiyono et al., 2019)、T5-Large (Rothe et al., 2021)以及UEDINMS ensemble (Grundkiewicz et al., 2019)。
The training data are grouped into small groups of size $n$ , with corrections of the same source sentence grouped together as much as possible, and each group must contain at least $\frac{n}{2}$ corrections from the same source sentence. This way, the rank loss (Eq. 8) computes more comparisons of hypotheses from the same source. Corrections with no edits are filtered out so that the model can focus more on predicting the labels on edit words. Perfect corrections are also filtered out to maintain the label distribution balance. W&I+LOCNESS has 34,308 sentences and the resulting training data, obtained after filtering the unique corrections of the nine GEC systems above, has 65,824 hypotheses. During training, word labels and gap labels associated with tokens not present in the source sentence are given a higher weight $z$ than other word and gap labels in the calculation of $\mathcal{L}{w}$ and $\mathcal{L}_{g}$ . We choose the hyper-parameters based on the model’s performance on the BEA-2019 development set (Bryant et al., 2019) and the CoNLL-2013 test set ( $\mathrm{Ng}$ et al., 2013). We list the hyper-parameters and explain our hyper-parameter search in Appendix B.
训练数据被分成大小为$n$的小组,尽可能将同一源句的修正归为一组,且每组必须包含至少$\frac{n}{2}$条来自同一源句的修正。这样,排序损失(公式8)能计算更多来自同一源句的假设比较。未编辑的修正会被过滤,使模型更专注于预测编辑词的标签。完美修正同样被过滤以维持标签分布平衡。W&I+LOCNESS数据集包含34,308个句子,经上述九个GEC系统去重过滤后,最终训练数据包含65,824条假设。训练过程中,在计算$\mathcal{L}{w}$和$\mathcal{L}_{g}$时,对源句中不存在的token关联的词标签和间隙标签赋予更高权重$z$。超参数选择基于模型在BEA-2019开发集(Bryant等,2019)和CoNLL-2013测试集(Ng等,2013)的表现,具体超参数及搜索策略详见附录B。
5.2 Evaluation
5.2 评估
We evaluate our model on quality estimation, reranking, and system combination tasks. We compare our models to other GEC quality estimation models (NeuQE, VERNet, SOME) and a language model baseline, GPT-2 Large (Radford et al., 2019), which has been reported to perform relatively well on unsupervised GEC task (Ali kani otis and Raheja, 2019). We use the RC variant of NeuQE and the ELECTRA variant of VERNet which produce the highest scores on the CoNLL-2014 test set $\mathbf{\mathrm{(Ng}}$ et al., 2014). For the system combination task, we compare our model to state-of-the-art GEC system combination methods in Section 2.2.
我们在质量评估、重排序和系统组合任务上评估了我们的模型。我们将模型与其他GEC(语法错误纠正)质量评估模型(NeuQE、VERNet、SOME)以及一个语言模型基线GPT-2 Large (Radford et al., 2019) 进行了比较,后者在无监督GEC任务中表现相对较好 (Ali kani otis and Raheja, 2019)。我们使用了NeuQE的RC变体和VERNet的ELECTRA变体,这些变体在CoNLL-2014测试集上取得了最高分 $\mathbf{\mathrm{(Ng}}$ et al., 2014)。对于系统组合任务,我们在第2.2节中将我们的模型与最先进的GEC系统组合方法进行了比较。
For the quality estimation and re-ranking tasks, we perform experiments in two scenarios: single system and multi-system evaluation. For single system evaluation, we follow Liu et al. (2021) on evaluating the models on the top-5 outputs of Riken&Tohoku (Kiyono et al., 2019) on the CoNLL-2014 test set. For multi-system evaluation, we evaluate the models on the outputs of 12 participating teams of the CoNLL-2014 shared task.
在质量评估和重排序任务中,我们在两种场景下进行实验:单系统评估和多系统评估。对于单系统评估,我们遵循 Liu 等人 (2021) 的方法,在 CoNLL-2014 测试集上对 Riken&Tohoku (Kiyono 等人,2019) 的前 5 个输出进行模型评估。对于多系统评估,我们在 CoNLL-2014 共享任务 12 个参赛团队的输出上评估模型。
For the quality estimation task, we follow Chollampatt and $\mathrm{Ng}$ (2018b) in comparing the correlation coefficient of the quality score to the sentence- level $F_{0.5}$ score. We use Spearman’s rank correlation coefficient (Spearman, 1904), which is the primary metric of the WMT-2022 shared task on quality estimation (Zerva et al., 2022).
在质量评估任务中,我们遵循 Chollampatt 和 $\mathrm{Ng}$ (2018b) 的方法,将质量分数与句子级 $F_{0.5}$ 分数的相关系数进行比较。我们采用 Spearman 等级相关系数 (Spearman, 1904),这是 WMT-2022 质量评估共享任务的主要指标 (Zerva et al., 2022)。
For the re-ranking task, we pick one hypothesis with the highest quality score for each source sentence, and then compute the corpus-level $F_{0.5}$ score for the chosen hypotheses of all source sentences. We also add the source sentence as one of the hypotheses so that a model has the option to not make any corrections if the hypotheses are bad. We use the $\mathbf{M}^{2}$ Scorer (Dahlmeier and $\mathrm{Ng}$ , 2012) to compute the $F_{0.5}$ score.
在重排序任务中,我们为每个源句选取质量得分最高的一个假设,然后计算所有源句所选假设的语料库级 $F_{0.5}$ 分数。我们还将源句本身作为假设之一加入,以便模型在假设质量不佳时可以选择不作任何修正。使用 $\mathbf{M}^{2}$ Scorer (Dahlmeier 和 $\mathrm{Ng}$, 2012) 计算 $F_{0.5}$ 分数。
Table 3: System combination results. The first group of rows shows the base GEC systems that are combined, while the second and the third group of rows show the combination results of existing quality estimation models and system combination methods respectively. We do not show Kakao&Brain’s score on CoNLL-2014 as it is not used in the CoNLL-2014 combination. ESC and MEMT results are taken from (Qorib et al., 2022). $\mathrm{GRECO}{\nu o t i n g}$ refers to our model with voting bias, and $\mathrm{GRECO}_{\nu o t i n g+\mathrm{ESC}}$ refers to our model with voting bias and edit scores from ESC.
表 3: 系统组合结果。第一组行显示被组合的基础GEC系统,第二组和第三组行分别展示现有质量估计模型和系统组合方法的结果。由于Kakao&Brain未参与CoNLL-2014组合,其得分未显示。ESC和MEMT结果引自(Qorib et al., 2022)。$\mathrm{GRECO}{\nu o t i n g}$指带投票偏置的模型,$\mathrm{GRECO}_{\nu o t i n g+\mathrm{ESC}}$指结合投票偏置与ESC编辑得分的模型。
| 模型 | BEA-2019 Dev (F0.5) | BEA-2019 Test P R | F0.5 | CoNLL-2014 Test | R F0.5 |
|---|---|---|---|---|---|
| 1. T5-Large 2.GECToR XLNet | 56.21 | 74.30 66.75 | 72.66 | 69.66 51.50 | 65.07 |
| 3.GECToR RoBERTa | 55.62 54.18 | 79.20 53.90 77.20 55.10 | 72.40 71.50 | 77.49 40.15 73.91 | 65.34 |
| 4. Riken&Tohoku | 53.95 | 74.7 56.7 | 70.2 | 41.66 73.26 44.17 | 64.00 64.74 |
| 5. UEDIN-MS | 53.00 | 72.28 60.12 | 69.47 | 75.15 41.21 | 64.52 |
| 6. Kakao&Brain | 53.27 | 75.19 51.91 | 69.00 | - | - |
| NeuQE | 29.30 | 68.48 20.19 | 46.32 | 66.48 15.87 | 40.59 |
| VERNet | 54.80 | 73.19 58.42 | 69.67 | 74.08 39.12 | 62.85 |
| SOME | 52.23 | 66.40 67.83 | 66.68 | 68.39 54.23 | 65.00 |
| GPT-2 | 52.00 | 67.20 68.08 | 67.38 | 68.30 52.65 | 64.47 |
| ESC | 63.09 | 86.65 60.91 | 79.90 | 81.48 43.78 | 69.51 |
| MEMT | 60.72 | 82.20 63.00 | 77.48 | 76.44 48.06 | 68.37 |
| EditScorer | 61.66 | 88.05 58.71 | 80.05 | 74.32 51.44 | 68.25 |
| GRECO | 60.74 | 80.03 66.22 | 76.83 | 76.39 50.35 | 69.23 |
| GRECOvoting | 62.22 | 82.86 65.10 | 78.58 | 79.36 48.69 | 70.48 |
| GRECOvoting+ESC | 63.40 | 86.45 63.13 | 80.50 | 79.36 48.69 | 70.48 |
For the system combination task, we combine the base systems given in Table 3 using ESC, MEMT, and EditScorer. We also combine the same base systems using beam search via quality estimation for the different quality estimation methods NeuQE, VERNet, SOME, GPT-2, GRECO, $\mathrm{GRECO}{\nu o t i n g}$ , and $\mathrm{GRECO}{\nu o t i n g+\mathrm{ESC}}$ . We report the $F_{0.5}$ scores on the BEA-2019 test set and CoNLL2014 test set.
对于系统组合任务,我们使用ESC、MEMT和EditScorer对表3中给出的基础系统进行组合。同时,我们还通过质量估计的波束搜索方法(采用NeuQE、VERNet、SOME、GPT-2、GRECO、$\mathrm{GRECO}{\nu o t i n g}$和$\mathrm{GRECO}{\nu o t i n g+\mathrm{ESC}}$等不同质量估计方法)对相同的基础系统进行组合。实验结果报告了BEA-2019测试集和CoNLL2014测试集上的$F_{0.5}$分数。
We use William’s test (Williams, 1959) to measure the statistical significance of the correlation coefficients. We use bootstrap resampling on 100 samples for the statistical significance of the $F_{0.5}$ scores in the re-ranking and system combination tasks.
我们使用William检验 (Williams, 1959) 来衡量相关系数的统计显著性。在重排序和系统组合任务中,我们对100个样本进行自助重采样以评估 $F_{0.5}$ 分数的统计显著性。
6 Results
6 结果
6.1 Quality Estimation and Re-Ranking
6.1 质量评估与重排序
We report the results of quality estimation and reranking evaluation in Table 2. Our model significantly outperforms all other quality estimation models on the correlation score and $F_{0.5}$ score in both experimental settings $(p<0.001)$ . Our re-ranking result has higher precision, recall, and $F_{0.5}$ score compared to the top-1 output of Riken&Tohoku, which has a precision, recall, and $F_{0.5}$ score of 68.59, 44.87, and 62.03 respectively3.
我们在表2中报告了质量评估和重排序的结果。我们的模型在两种实验设置下 $(p<0.001)$ 的相关系数和 $F_{0.5}$ 分数上均显著优于其他所有质量评估模型。与Riken&Tohoku的top-1输出(其精确率、召回率和 $F_{0.5}$ 分数分别为68.59、44.87和62.03)相比,我们的重排序结果具有更高的精确率、召回率和 $F_{0.5}$ 分数。
6.2 System Combination
6.2 系统组合
We report the results of the system combination experiments in Table 3. Existing GEC quality estimation models fail to produce better corrections. More surprisingly, all of them produce combination scores that are lower than the fourth best base system on the BEA-2019 experiment and the second best base system on the CoNLL-2014 experiment. Our model without any additional biases (GRECO) successfully produces better corrections with 4.17 points and 3.89 points higher than the best base system on the BEA-2019 (T5-Large) and CoNLL2014 (GECToR XLNet) test sets respectively.
我们在表3中报告了系统组合实验的结果。现有的语法错误修正(GEC)质量评估模型未能生成更好的修正结果。更令人惊讶的是,在BEA-2019实验中,所有组合系统的得分都低于第四好的基线系统;在CoNLL-2014实验中,则低于第二好的基线系统。而我们的无偏置模型(GRECO)成功生成了更优的修正结果:在BEA-2019测试集(T5-Large)和CoNLL2014测试集(GECToR XLNet)上,分别比最佳基线系统高出4.17分和3.89分。
By adding the voting bias, our model outperforms MEMT on both datasets and ESC and EditScorer on the CoNLL-2014 test set. Our model when augmented with voting bias and edit scores from ESC outperforms ESC and EditScorer on the BEA-2019 test set by 0.6 and 0.45 points respectively. Note that EditScorer is trained with 70 times more data than GRECO. Using edit scores from ESC on the CoNLL-2014 test set does not change the result since the optimal edit weight $(\beta)$ is zero. In other experiments, we found that combining with ESC can also improve the $F_{0.5}$ score on the CoNLL-2014 test set (Appendix Table 11). Our final model has significantly higher scores than all other methods $\phantom{0}p<0.005\phantom{0}$ .
通过引入投票偏差,我们的模型在两个数据集上均优于MEMT,并在CoNLL-2014测试集上超越了ESC和EditScorer。当结合投票偏差与ESC的编辑分数时,我们的模型在BEA-2019测试集上分别以0.6分和0.45分的优势超过ESC和EditScorer。需注意EditScorer的训练数据量是GRECO的70倍。在CoNLL-2014测试集上使用ESC的编辑分数未改变结果,因为最优编辑权重$(\beta)$为零。其他实验表明,结合ESC还能提升CoNLL-2014测试集的$F_{0.5}$分数(附录表11)。我们的最终模型得分显著高于所有其他方法$\phantom{0}p<0.005\phantom{0}$。
Table 4: Combination of the same base systems in Table 3, but with model [1] replaced by T5-XL and model [3] replaced by GECToR-Large RoBERTa.
表 4: 表 3 中相同基础系统的组合,但将模型 [1] 替换为 T5-XL,模型 [3] 替换为 GECToR-Large RoBERTa。
| 模型 | BEA-2019测试 P R | F0.5 |
|---|---|---|
| 1.T5-XL | 76.85 80.70 | 67.26 74.72 53.39 73.21 |
| 3. GECToR-Large + 模型 1 [2], [4], [5], [6] | 来自表 3 | |
| ESC | 86.64 | 61.54 80.10 |
| GRECO | 80.46 | 66.59 77.24 |
| GRECOvoting | 83.24 | 65.12 78.85 |
| GRECOvoting+ESC | 86.66 | 63.72 80.84 |
We also evaluate our model on the combination of stronger GEC models. We replace T5-Large by T5-XL and GECToR RoBERTa by GECToR-Large RoBERTa (Tarnavskyi et al., 2022) from the base systems and achieve the highest BEA-2019 test score, 80.84, reported to date. (Table 4).
我们还在更强GEC模型的组合上评估了我们的模型。我们将基础系统中的T5-Large替换为T5-XL,并将GECToR RoBERTa替换为GECToR-Large RoBERTa (Tarnavskyi等人, 2022),从而取得了迄今为止报道的最高BEA-2019测试分数80.84 (表4)。