Multimodal Differential Network for Visual Question Generation
多模态差分网络在视觉问题生成中的应用
Abstract
摘要
Generating natural questions from an image is a semantic task that requires using visual and language modality to learn multimodal represent at ions. Images can have multiple visual and language contexts that are relevant for generating questions namely places, captions, and tags. In this paper, we propose the use of exemplars for obtaining the relevant context. We obtain this by using a Multimodal Differential Network to produce natural and engaging questions. The generated questions show a remarkable similarity to the natural questions as validated by a human study. Further, we observe that the proposed approach substantially improves over state-of-the-art benchmarks on the quantitative metrics (BLEU, METEOR, ROUGE, and CIDEr).
从图像生成自然问题是一项需要结合视觉与语言模态来学习多模态表征的语义任务。图像可能包含与问题生成相关的多重视觉和语言上下文,例如场景、描述文字和标签。本文提出利用示例样本获取相关上下文,通过多模态差分网络生成自然且引人入胜的问题。人工评估表明,生成的问题与自然问题具有显著相似性。此外,定量指标(BLEU、METEOR、ROUGE和CIDEr)显示,该方法较现有最优基准有显著提升。
1 Introduction
1 引言
To understand the progress towards multimedia vision and language understanding, a visual Turing test was proposed by (Geman et al., 2015) that was aimed at visual question answering (Antol et al., 2015). Visual Dialog (Das et al., 2017) is a natural extension for VQA. Current dialog systems as evaluated in (Chat top adh yay et al., 2017) show that when trained between bots, AI-AI dialog systems show improvement, but that does not translate to actual improvement for Human-AI dialog. This is because, the questions generated by bots are not natural (human-like) and therefore does not translate to improved human dialog. There- fore it is imperative that improvement in the quality of questions will enable dialog agents to perform well in human interactions. Further, (Ganju et al., 2017) show that unanswered questions can be used for improving VQA, Image captioning and Object Classification.
为了解多媒体视觉与语言理解领域的进展,(Geman et al., 2015) 提出了针对视觉问答 (Antol et al., 2015) 的视觉图灵测试。视觉对话 (Das et al., 2017) 是视觉问答的自然延伸。(Chat top adh yay et al., 2017) 的评估显示,当前AI-AI对话系统在机器间训练时表现提升,但这种进步并未转化为人机对话的实际改进。这是因为机器生成的问题缺乏自然性(类人性),因此无法提升人类对话质量。因此,提高问题质量对实现对话智能体在人类交互中的优异表现至关重要。此外,(Ganju et al., 2017) 研究表明未回答问题可用于改进视觉问答、图像描述和物体分类任务。
An interesting line of work in this respect is the work of (Most af azad eh et al., 2016). Here the authors have proposed the challenging task of generating natural questions for an image. One aspect that is central to a question is the context that is relevant to generate it. However, this context changes for every image. As can be seen in Figure 1, an image with a person on a skateboard would result in questions related to the event. Whereas for a little girl, the questions could be related to age rather than the action. How can one have widely varying context provided for generating questions? To solve this problem, we use the context obtained by considering exemplars, specifically we use the difference between relevant and irrelevant exemplars. We consider different contexts in the form of Location, Caption, and Part of Speech tags.
在这方面,一个有趣的研究方向是 (Mostafazadeh et al., 2016) 的工作。作者提出了为图像生成自然问题这一具有挑战性的任务。问题的核心在于生成问题所需的相关上下文,然而这种上下文会因图像而异。如图 1 所示,一张有人在滑滑板的图像会产生与该事件相关的问题,而对一个小女孩的提问则可能涉及年龄而非动作。如何为问题生成提供差异巨大的上下文?为解决这个问题,我们利用通过考虑示例获得的上下文,具体而言,我们使用相关示例与不相关示例之间的差异。我们以位置 (Location)、标题 (Caption) 和词性标签 (Part of Speech tags) 的形式考虑不同的上下文。

Figure 1: Can you guess which among the given questions is human annotated and which is machine generated? 0
图 1: 你能猜出给定的问题中哪些是人类标注的,哪些是机器生成的吗? 0
Our method implicitly uses a differential context obtained through supporting and contrasting exemplars to obtain a differentiable embedding. This embedding is used by a question decoder to decode the appropriate question. As discussed further, we observe this implicit differential context to perform better than an explicit keyword based context. The difference between the two approaches is illustrated in Figure 2. This also allows for better optimization as we can backpropagate through the whole network. We provide detailed empirical evidence to support our hypothesis. As seen in Figure 1 our method generates natural questions and improves over the state-ofthe-art techniques for this problem.
我们的方法隐式地利用通过支持性和对比性示例获得的差异上下文来获取可微分嵌入。问题解码器使用该嵌入来解码相应问题。如后续讨论所示,我们发现这种隐式差异上下文的表现优于基于显式关键词的上下文。这两种方法的区别如图 2 所示。这也使得优化效果更佳,因为我们可以对整个网络进行反向传播。我们提供了详细的实证证据来支持这一假设。如图 1 所示,我们的方法能生成自然问题,并针对该问题改进了现有最先进技术。
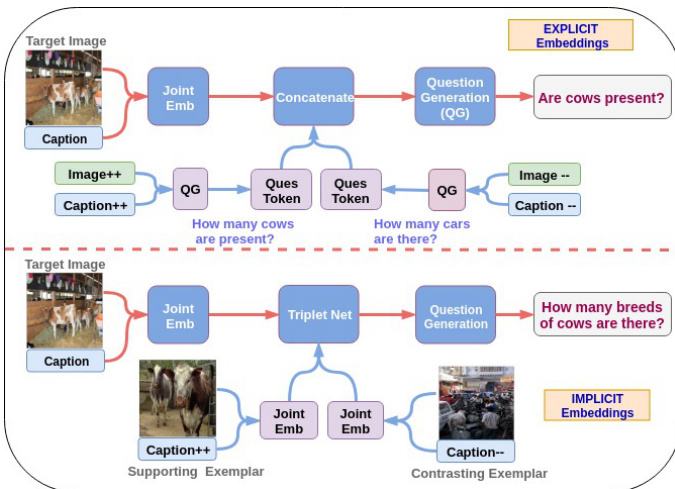
Figure 2: Here we provide intuition for using implicit embeddings instead of explicit ones. As explained in section 1, the question obtained by the implicit embeddings are natural and holistic than the explicit ones.
图 2: 这里我们展示了使用隐式嵌入(implicit embeddings)而非显式嵌入(explicit embeddings)的直观优势。如第1节所述,通过隐式嵌入获得的问题比显式嵌入更自然且更全面。
To summarize, we propose a multimodal differential network to solve the task of visual question generation. Our contributions are: (1) A method to incorporate exemplars to learn differential embeddings that captures the subtle differences between supporting and contrasting examples and aid in generating natural questions. (2) We provide Multimodal differential embeddings, as image or text alone does not capture the whole context and we show that these embeddings outperform the ablations which incorporate cues such as only image, or tags or place information. (3) We provide a thorough comparison of the proposed network against state-of-the-art benchmarks along with a user study and statistical significance test.
总结来说,我们提出了一种多模态差分网络来解决视觉问题生成任务。我们的贡献包括:(1) 一种利用示例学习差分嵌入的方法,能够捕捉支持样本与对比样本之间的细微差异,从而辅助生成自然问题。(2) 我们提供了多模态差分嵌入,因为仅靠图像或文本无法捕捉完整上下文,并且我们证明这些嵌入在性能上优于仅包含图像、标签或位置信息等线索的消融实验。(3) 我们对所提出的网络与最先进的基准进行了全面比较,并辅以用户研究和统计显著性检验。
2 Related Work
2 相关工作
Generating a natural and engaging question is an interesting and challenging task for a smart robot (like chat-bot). It is a step towards having a natural visual dialog instead of the widely prevalent visual question answering bots. Further, having the ability to ask natural questions based on different contexts is also useful for artificial agents that can interact with visually impaired people. While the task of generating question automatically is well studied in NLP community, it has been relatively less studied for image-related natural questions. This is still a difficult task (Most af azad eh et al., 2016) that has gained recent interest in the community.
生成自然且引人入胜的问题对于智能机器人(如聊天机器人)而言是一项有趣且具有挑战性的任务。这是实现自然视觉对话的重要一步,而非目前广泛流行的视觉问答机器人。此外,基于不同情境提出自然问题的能力,对于能与视障人士交互的人工智能体也很有价值。虽然自动生成问题在自然语言处理领域已有深入研究,但与图像相关的自然问题生成研究相对较少。这仍是一项困难任务[20],近期正逐渐获得学界关注。
Recently there have been many deep learning based approaches as well for solving the textbased question generation task such as (Du et al., 2017). Further, (Serban et al., 2016) have proposed a method to generate a factoid based question based on triplet set subject, relation and object} to capture the structural representation of text and the corresponding generated question.
近年来,基于深度学习的方法在解决基于文本的问答生成任务方面也取得了许多进展,例如 (Du et al., 2017)。此外,(Serban et al., 2016) 提出了一种基于三元组(主语、关系、宾语)生成事实性问题的技术,以捕捉文本的结构化表征及其对应生成的问题。
These methods, however, were limited to textbased question generation. There has been extensive work done in the Vision and Language domain for solving image captioning, paragraph generation, Visual Question Answering (VQA) and Visual Dialog. (Barnard et al., 2003; Farhadi et al., 2010; Kulkarni et al., 2011) proposed conventional machine learning methods for image description. (Socher et al., 2014; Vinyals et al., 2015; Karpathy and Fei-Fei, 2015; Xu et al., 2015; Fang et al., 2015; Chen and Lawrence Zitnick, 2015; Johnson et al., 2016; Yan et al., 2016) have generated descriptive sentences from images with the help of Deep Networks. There have been many works for solving Visual Dialog (Chappell et al., 2004; Das et al., 2016, 2017; De Vries et al., 2017; Strub et al., 2017). A variety of methods have been proposed by (Malinowski and Fritz, 2014; Lin et al., 2014; Antol et al., 2015; Ren et al., 2015; Ma et al., 2016; Noh et al., 2016) for solving VQA task including attention-based methods (Zhu et al., 2016; Fukui et al., 2016; Gao et al., 2015; Xu and Saenko, 2016; Lu et al., 2016; Shih et al., 2016; Patro and Namboodiri, 2018). However, Visual Question Generation (VQG) is a separate task which is of interest in its own right and has not been so well explored (Most af azad eh et al., 2016). This is a vision based novel task aimed at generating natural and engaging question for an image. (Yang et al., 2015) proposed a method for continuously generating questions from an image and subsequently answering those questions. The works closely related to ours are that of (Most af azad eh et al., 2016) and (Jain et al., 2017). In the former work, the authors used an encoder-decoder based framework whereas in the latter work, the authors extend it by using a variational auto encoder based sequential routine to obtain natural questions by performing sampling of the latent variable.
然而,这些方法仅限于基于文本的问题生成。在视觉与语言领域已有大量工作致力于解决图像描述生成、段落生成、视觉问答 (VQA) 和视觉对话任务。(Barnard et al., 2003; Farhadi et al., 2010; Kulkarni et al., 2011) 提出了基于传统机器学习的图像描述方法。(Socher et al., 2014; Vinyals et al., 2015; Karpathy and Fei-Fei, 2015; Xu et al., 2015; Fang et al., 2015; Chen and Lawrence Zitnick, 2015; Johnson et al., 2016; Yan et al., 2016) 则借助深度网络从图像生成描述性语句。针对视觉对话任务的研究 (Chappell et al., 2004; Das et al., 2016, 2017; De Vries et al., 2017; Strub et al., 2017) 也层出不穷。(Malinowski and Fritz, 2014; Lin et al., 2014; Antol et al., 2015; Ren et al., 2015; Ma et al., 2016; Noh et al., 2016) 提出了多种解决VQA任务的方法,包括基于注意力机制的方法 (Zhu et al., 2016; Fukui et al., 2016; Gao et al., 2015; Xu and Saenko, 2016; Lu et al., 2016; Shih et al., 2016; Patro and Namboodiri, 2018)。但视觉问题生成 (VQG) 作为一个独立任务,其研究价值尚未得到充分探索 (Mostafazadeh et al., 2016)。这项基于视觉的新颖任务旨在为图像生成自然且引人入胜的问题。(Yang et al., 2015) 提出了从图像持续生成问题并自动回答的方法。与本研究最相关的是 (Mostafazadeh et al., 2016) 和 (Jain et al., 2017) 的工作:前者采用基于编码器-解码器的框架,后者则通过基于变分自编码器的序列化流程对隐变量进行采样,从而扩展生成了更自然的问题。
3 Approach
3 方法
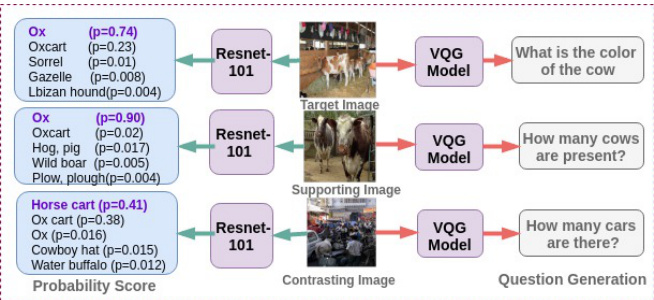
Figure 3: An illustrative example shows the validity of our obtained exemplars with the help of an object classification network, RESNET-101. We see that the probability scores of target and supporting exemplar image are similar. That is not the case with the contrasting exemplar. The corresponding generated questions when considering the individual images are also shown.
图 3: 示例展示了通过目标分类网络 RESNET-101 验证所获样本的有效性。可见目标图像与支持样本图像的概率分数相近,而对比样本则不然。同时展示了基于各图像生成的对应问题。
In this section, we clarify the basis for our approach of using exemplars for question generation. To use exemplars for our method, we need to ensure that our exemplars can provide context and that our method generates valid exemplars.
在本节中,我们阐明了使用示例进行问题生成方法的基础。为了将示例应用于我们的方法,需要确保示例能够提供上下文,并且我们的方法能生成有效的示例。
We first analyze whether the exemplars are valid or not. We illustrate this in figure 3. We used a pre-trained RESNET-101 (He et al., 2016) ob- ject classification network on the target, supporting and contrasting images. We observed that the supporting image and target image have quite similar probability scores. The contrasting exemplar image, on the other hand, has completely different probability scores.
我们首先分析示例是否有效。如图 3 所示, 我们使用预训练的 RESNET-101 (He et al., 2016) 目标分类网络对目标图像、支持图像和对比图像进行处理。观察到支持图像与目标图像具有非常相似的概率分数, 而对比示例图像则呈现完全不同的概率分数分布。
Exemplars aim to provide appropriate context. To better understand the context, we experimented by analysing the questions generated through an exemplar. We observed that indeed a supporting exemplar could identify relevant tags (cows in Figure 3) for generating questions. We improve use of exemplars by using a triplet network. This network ensures that the joint image-caption embedding for the supporting exemplar are closer to that of the target image-caption and vice-versa. We empirically evaluated whether an explicit approach that uses the differential set of tags as a one-hot encoding improves the question generation, or the implicit embedding obtained based on the triplet network. We observed that the implicit multimodal differential network empirically provided better context for generating questions. Our understanding of this phenomenon is that both target and supporting exemplars generate similar questions whereas contrasting exemplars generate very different questions from the target question. The triplet network that enhances the joint embedding thus aids to improve the generation of target question. These are observed to be better than the explicitly obtained context tags as can be seen in Figure 2. We now explain our method in detail.
范例旨在提供合适的上下文。为了更好地理解上下文,我们通过分析范例生成的问题进行了实验。我们发现支持性范例确实能识别出生成问题所需的相关标签(如图3中的奶牛)。我们通过使用三元组网络改进了范例的利用方式,该网络确保支持性范例的联合图像-标题嵌入更接近目标图像-标题的嵌入,反之亦然。我们通过实验评估了两种方法:一种是显式地使用差异标签集作为独热编码来改进问题生成,另一种是基于三元组网络获得的隐式嵌入。结果表明,隐式多模态差异网络在实验上为问题生成提供了更好的上下文。对此现象的理解是:目标和支持性范例会生成相似的问题,而对比范例则会产生与目标问题截然不同的问题。因此,增强联合嵌入的三元组网络有助于改进目标问题的生成。如图2所示,这些方法优于显式获取的上下文标签。接下来我们将详细阐述我们的方法。
4 Method
4 方法
The task in visual question generation (VQG) is to generate a natural language question $\hat{Q}$ , for an image $I$ . We consider a set of pre-generated context $C$ from image $I$ . We maximize the conditional probability of generated question given image and context as follows:
视觉问题生成 (VQG) 的任务是为图像 $I$ 生成自然语言问题 $\hat{Q}$。我们考虑从图像 $I$ 中预先生成的一组上下文 $C$,通过最大化给定图像和上下文条件下生成问题的条件概率来实现这一目标:
$$
\hat{\theta}=\arg\operatorname*{max}{\theta}\sum_{(I,C,Q)}\log P(Q|I,C,\theta)
$$
$$
\hat{\theta}=\arg\operatorname*{max}{\theta}\sum_{(I,C,Q)}\log P(Q|I,C,\theta)
$$
where $\theta$ is a vector for all possible parameters of our model. $Q$ is the ground truth question. The log probability for the question is calculated by using joint probability over ${q_{0},q_{1},.....,q_{N}}$ with the help of chain rule. For a particular question, the above term is obtained as:
其中 $\theta$ 是我们模型所有可能参数的向量,$Q$ 是真实问题。问题的对数概率通过链式法则对 ${q_{0},q_{1},.....,q_{N}}$ 联合概率计算得出。对于特定问题,上述项可表示为:
$$
\log P(\hat{Q}|I,C)=\sum_{t=0}^{N}\log P(q_{t}|I,C,q_{0},..,q_{t-1})
$$
$$
\log P(\hat{Q}|I,C)=\sum_{t=0}^{N}\log P(q_{t}|I,C,q_{0},..,q_{t-1})
$$
where $N$ is length of the sequence, and $q_{t}$ is the $t^{t h}$ word of the question. We have removed $\theta$ for simplicity.
其中 $N$ 是序列长度,$q_{t}$ 是问题的第 $t^{t h}$ 个词。为简化表达,我们省略了 $\theta$。
Our method is based on a sequence to sequence network (Sutskever et al., 2014; Vinyals et al., 2015; Bahdanau et al., 2014). The sequence to se- quence network has a text sequence as input and output. In our method, we take an image as input and generate a natural question as output. The architecture for our model is shown in Figure 4. Our model contains three main modules, (a) Representation Module that extracts multimodal features (b) Mixture Module that fuses the multimodal represent ation and (c) Decoder that generates question using an LSTM-based language model.
我们的方法基于序列到序列网络 (Sutskever et al., 2014; Vinyals et al., 2015; Bahdanau et al., 2014)。该网络以文本序列作为输入和输出。在我们的方法中,我们将图像作为输入并生成自然问题作为输出。模型架构如图 4 所示。我们的模型包含三个主要模块:(a) 表征模块 (Representation Module),用于提取多模态特征;(b) 混合模块 (Mixture Module),用于融合多模态表征;(c) 解码器 (Decoder),使用基于 LSTM 的语言模型生成问题。
During inference, we sample a question word $q_{i}$ from the softmax distribution and continue sampling until the end token or maximum length for the question is reached. We experimented with both sampling and argmax and found out that argmax works better. This result is provided in the supplementary material.
在推理过程中,我们从softmax分布中采样一个疑问词$q_{i}$,并持续采样直到遇到结束token或达到问题的最大长度。我们尝试了采样和argmax两种方法,发现argmax效果更优。该结果详见补充材料。
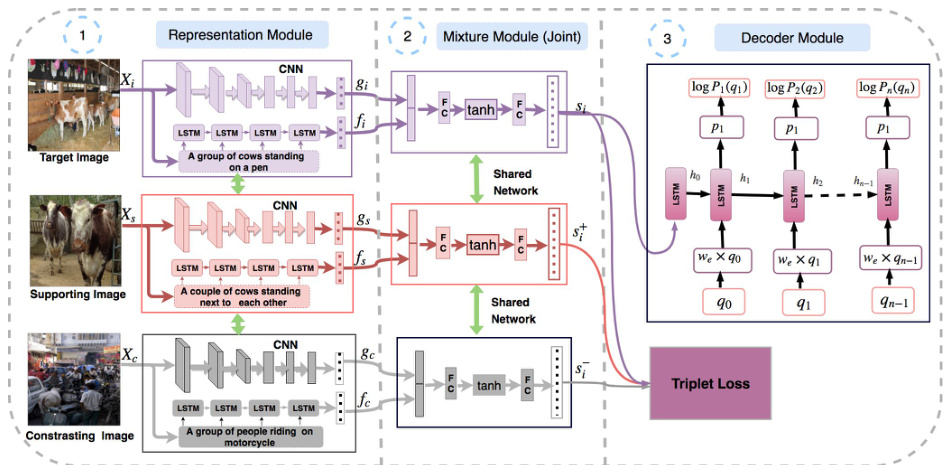
Figure 4: This is an overview of our Multimodal Differential Network for Visual Question Generation. It consists of a Representation Module which extracts multimodal features, a Mixture Module that fuses the multimodal representation and a Decoder that generates question using an LSTM based language model. In this figure, we have shown the Joint Mixture Module. We train our network with a Cross-Entropy and Triplet Loss.
图 4: 这是我们用于视觉问题生成的多模态差分网络概览。它包含一个提取多模态特征的表征模块 (Representation Module)、一个融合多模态表征的混合模块 (Mixture Module),以及一个基于LSTM语言模型生成问题的解码器 (Decoder)。图中展示的是联合混合模块 (Joint Mixture Module)。我们使用交叉熵损失和三重态损失 (Cross-Entropy and Triplet Loss) 来训练该网络。
4.1 Multimodal Differential Network
4.1 多模态差分网络
The proposed Multimodal Differential Network (MDN) consists of a representation module and a joint mixture module.
提出的多模态差分网络(MDN)由表示模块和联合混合模块组成。
4.1.1 Finding Exemplars
4.1.1 寻找范例
We used an efficient KNN-based approach (k-d tree) with Euclidean metric to obtain the exemplars. This is obtained through a coarse quantization of nearest neighbors of the training examples into 50 clusters, and selecting the nearest as supporting and farthest as the contrasting exemplars. We experimented with ITML based metric learning (Davis et al., 2007) for image features. Surprisingly, the KNN-based approach outperforms the latter one. We also tried random exemplars and different number of exemplars and found that $k=5$ works best. We provide these results in the supplementary material.
我们采用了一种高效的基于KNN (k-d树) 的方法,并使用欧几里得度量来获取样本。具体做法是将训练样本的最近邻粗略量化为50个簇,并选择最近的作为支持样本,最远的作为对比样本。我们还尝试了基于ITML (Davis等人,2007) 的度量学习方法用于图像特征。令人惊讶的是,基于KNN的方法表现优于后者。我们还尝试了随机样本和不同数量的样本,发现$k=5$时效果最佳。这些结果详见补充材料。
4.1.2 Representation Module
4.1.2 表征模块
We use a triplet network (Frome et al., 2007; Hoffer and Ailon, 2015) in our representation module. We refereed a similar kind of work done in (Patro and Namboodiri, 2018) for building our triplet network. The triplet network consists of three sub-parts: target, supporting, and contrasting networks. All three networks share the same parameters. Given an image $x_{i}$ we obtain an embedding $g_{i}$ using a CNN parameterized by a function $G(x_{i},W_{c})$ where $W_{c}$ are the weights for the CNN. The caption $C_{i}$ results in a caption embedding $f_{i}$ through an LSTM parameterized by a function $F(C_{i},W_{l})$ where $W_{l}$ are the weights for the LSTM. This is shown in part 1 of Figure 4.
我们在表征模块中使用了三元组网络 (Frome et al., 2007; Hoffer and Ailon, 2015)。我们参考了 (Patro and Namboodiri, 2018) 中类似的工来构建三元组网络。该网络包含三个子部分:目标网络、支持网络和对比网络,三者共享相同参数。给定图像 $x_{i}$,我们通过参数为 $G(x_{i},W_{c})$ 的 CNN 获得嵌入向量 $g_{i}$,其中 $W_{c}$ 是 CNN 的权重。描述文字 $C_{i}$ 通过参数为 $F(C_{i},W_{l})$ 的 LSTM 生成描述嵌入 $f_{i}$,其中 $W_{l}$ 是 LSTM 的权重。该过程如图 4 第一部分所示。
Similarly we obtain image embeddings and caption embeddings $f_{s}$ & $f_{c}$ .
同样地,我们得到图像嵌入 和标题嵌入 $f_{s}$ & $f_{c}$。
$$
\begin{array}{l l}{{g_{i}=G(x_{i},W_{c})=C N N(x_{i})}}\ {{f_{i}=F(C_{i},W_{l})=L S T M(C_{i})}}\end{array}
$$
$$
\begin{array}{l l}{{g_{i}=G(x_{i},W_{c})=C N N(x_{i})}}\ {{f_{i}=F(C_{i},W_{l})=L S T M(C_{i})}}\end{array}
$$
4.1.3 Mixture Module
4.1.3 混合模块
The Mixture module brings the image and caption embeddings to a joint feature embedding space. The input to the module is the embeddings obtained from the representation module. We have evaluated four different approaches for fusion viz., joint, element-wise addition, hadamard and attention method. Each of these variants receives im- age features $g_{i}$ & the caption embedding $f_{i}$ , and outputs a fixed dimensional feature vector $s_{i}$ . The Joint method concatenates $g_{i}$ & $f_{i}$ and maps them to a fixed length feature vector $s_{i}$ as follows:
混合模块 (Mixture module) 将图像和标题嵌入映射到联合特征嵌入空间。该模块的输入是来自表征模块的嵌入向量。我们评估了四种不同的融合方法:联合 (joint) 、逐元素相加 (element-wise addition) 、哈达玛积 (hadamard) 和注意力机制 (attention method) 。每种变体接收图像特征 $g_{i}$ 和标题嵌入 $f_{i}$ ,并输出固定维度的特征向量 $s_{i}$ 。联合方法将 $g_{i}$ 和 $f_{i}$ 拼接后映射为固定长度的特征向量 $s_{i}$ ,具体实现如下:
$$
s_{i}=W_{j}^{T}*\operatorname{tanh}(W_{i j}g_{i}\frown(W_{c j}f_{i}+b_{j}))
$$
$$
s_{i}=W_{j}^{T}*\operatorname{tanh}(W_{i j}g_{i}\frown(W_{c j}f_{i}+b_{j}))
$$
where $g_{i}$ is the 4096-dimensional convolutional feature from the FC7 layer of pretrained VGG-19 Net (Simonyan and Zisserman, 2014). $W_{i j},W_{c j},W_{j}$ are the weights and $b_{j}$ is the bias for different layers. ⌢ is the concatenation operator.
其中 $g_{i}$ 是预训练 VGG-19 网络 (Simonyan and Zisserman, 2014) FC7 层提取的 4096 维卷积特征。$W_{i j},W_{c j},W_{j}$ 为各层权重,$b_{j}$ 为偏置项。⌢ 表示拼接运算符。
Similarly, We obtain context vectors $s_{i}^{+}$ & $s_{i}^{-}$ for the supporting and contrasting exemplars. Details for other fusion methods are present in supplementary.The aim of the triplet network (Schroff et al., 2015) is to obtain context vectors that bring the supporting exemplar embeddings closer to the target embedding and vice-versa. This is obtained as follows:
同样地,我们获取支持样本和对比样本的上下文向量 $s_{i}^{+}$ 和 $s_{i}^{-}$。其他融合方法的细节见补充材料。三元组网络 (Schroff et al., 2015) 的目标是获取使支持样本嵌入更接近目标嵌入的上下文向量,反之亦然。具体实现如下:
$$
\begin{array}{r l}&{D(t(s_{i}),t(s_{i}^{+}))+\alpha<D(t(s_{i}),t(s_{i}^{-}))}\ &{\forall(t(s_{i}),t(s_{i}^{+}),t(s_{i}^{-}))\in M,}\end{array}
$$
$$
\begin{array}{r l}&{D(t(s_{i}),t(s_{i}^{+}))+\alpha<D(t(s_{i}),t(s_{i}^{-}))}\ &{\forall(t(s_{i}),t(s_{i}^{+}),t(s_{i}^{-}))\in M,}\end{array}
$$
where $D(t(s_{i}),t(s_{j}))=||t(s_{i})-t(s_{j})||{2}^{2}$ is the euclidean distance between two embeddings $t(s_{i})$ and $t(s_{j})$ . M is the training dataset that contains all set of possible triplets. $T(s_{i},s_{i}^{+},s_{i}^{-})$ is the triplet loss function. This is decomposed into two terms, one that brings the supporting sample closer and one that pushes the contrasting sample further. This is given by
其中 $D(t(s_{i}),t(s_{j}))=||t(s_{i})-t(s_{j})||{2}^{2}$ 表示两个嵌入向量 $t(s_{i})$ 和 $t(s_{j})$ 之间的欧氏距离。M 是包含所有可能三元组的训练数据集。$T(s_{i},s_{i}^{+},s_{i}^{-})$ 是三元组损失函数,可分解为两项:一项使支持样本更接近,另一项使对比样本更远离。其表达式为
$$
T(s_{i},s_{i}^{+},s_{i}^{-})=\mathtt{m a x}(0,D^{+}+\alpha-D^{-})
$$
$$
T(s_{i},s_{i}^{+},s_{i}^{-})=\mathtt{m a x}(0,D^{+}+\alpha-D^{-})
$$
Here $D^{+},D^{-}$ represent the euclidean distance between the target and supporting sample, and target and opposing sample respectively. The parameter $\alpha(=0.2)$ controls the separation margin between these and is obtained through validation data.
这里 $D^{+},D^{-}$ 分别表示目标样本与支持样本、目标样本与对抗样本之间的欧氏距离。参数 $\alpha(=0.2)$ 控制它们之间的分离边界,并通过验证数据获得。
4.2 Decoder: Question Generator
4.2 解码器:问题生成器
The role of decoder is to predict the probability for a question, given $s_{i}$ . RNN provides a nice way to perform conditioning on previous state value using a fixed length hidden vector. The conditional probability of a question token at particular time step $q_{t}$ is modeled using an LSTM as used in machine translation (Sutskever et al., 2014). At time step $t$ , the conditional probability is denoted by $P(q_{t}|I,C,q_{0},...q_{t-1})=P(q_{t}|I,C,h_{t})$ , where $h_{t}$ is the hidden state of the LSTM cell at time step $t$ , which is conditioned on all the previously generated words ${q_{0},q_{1},...q_{N-1}}$ . The word with maximum probability in the probability distribution of the LSTM cell at step $k$ is fed as an input to the LSTM cell at step $k+1$ as shown in part 3 of Figure 4. At $t=-1$ , we are feeding the output of the mixture module to LSTM. $\hat{Q}={\hat{q_{0}},\hat{q_{1}},...q\hat{\cal N}-1}$ are the predicted question tokens for the input image $I$ . Here, we are using $\hat{q_{0}}$ and $q\hat{N_{-1}}$ as the special token START and STOP respectively. The softmax probability for the predicted question token at different time steps is given by the following equations where LSTM refers to the standard LSTM cell equations:
解码器的作用是在给定 $s_{i}$ 的情况下预测问题的概率。RNN 提供了一种利用固定长度隐藏向量对先前状态值进行条件处理的优雅方式。特定时间步 $q_{t}$ 的问题 token 的条件概率通过 LSTM (长短期记忆网络) 建模,该方法借鉴自机器翻译领域 (Sutskever et al., 2014)。在时间步 $t$ 时,条件概率表示为 $P(q_{t}|I,C,q_{0},...q_{t-1})=P(q_{t}|I,C,h_{t})$ ,其中 $h_{t}$ 是 LSTM 单元在时间步 $t$ 的隐藏状态,其条件依赖于所有先前生成的词汇 ${q_{0},q_{1},...q_{N-1}}$ 。如 图 4 第 3 部分所示,在步骤 $k$ 时,LSTM 单元概率分布中概率最大的词汇将作为输入馈送到步骤 $k+1$ 的 LSTM 单元。当 $t=-1$ 时,我们将混合模块的输出馈送至 LSTM。$\hat{Q}={\hat{q_{0}},\hat{q_{1}},...q\hat{\cal N}-1}$ 是针对输入图像 $I$ 预测的问题 token。此处,我们分别使用 $\hat{q_{0}}$ 和 $q\hat{N_{-1}}$ 作为特殊 token START 和 STOP。不同时间步预测问题 token 的 softmax 概率由以下公式给出,其中 LSTM 指代标准 LSTM 单元方程:
$$
\begin{array}{r l}&{x_{-1}=S_{i}=\mathrm{Mixture~Module}(g_{i},f_{i})}\ &{h_{0}=\mathrm{LSTM}(x_{-1})}\ &{x_{t}=W_{e}*q_{t},\forall t\in{0,1,2,\ldots N-1}}\ &{h_{t+1}=\mathrm{LSTM}(x_{t},h_{t}),\forall t\in{0,1,2,\ldots N-1}}\ &{o_{t+1}=W_{o}*h_{t+1}}\ &{\hat{y}{t+1}=P(q_{t+1}|I,C,h_{t})=\mathrm{Softmax}(o_{t+1})}\ &{L o s s_{t+1}=l o s s(\hat{y}{t+1},y_{t+1})}\end{array}
$$
$$
\begin{array}{r l}&{x_{-1}=S_{i}=\mathrm{Mixture~Module}(g_{i},f_{i})}\ &{h_{0}=\mathrm{LSTM}(x_{-1})}\ &{x_{t}=W_{e}*q_{t},\forall t\in{0,1,2,\ldots N-1}}\ &{h_{t+1}=\mathrm{LSTM}(x_{t},h_{t}),\forall t\in{0,1,2,\ldots N-1}}\ &{o_{t+1}=W_{o}*h_{t+1}}\ &{\hat{y}{t+1}=P(q_{t+1}|I,C,h_{t})=\mathrm{Softmax}(o_{t+1})}\ &{L o s s_{t+1}=l o s s(\hat{y}{t+1},y_{t+1})}\end{array}
$$
Where $\hat{y}_{t+1}$ is the probability distribution over all question tokens. loss is cross entropy loss.
其中 $\hat{y}_{t+1}$ 是所有问题token的概率分布,损失函数采用交叉熵损失。
4.3 Cost function
4.3 成本函数
Our objective is to minimize the total loss, that is the sum of cross entropy loss and triplet loss over all training examples. The total loss is:
我们的目标是最小化总损失,即所有训练样本的交叉熵损失和三元组损失之和。总损失为:
$$
L=\frac{1}{M}\sum_{i=1}^{M}(L_{c r o s s}+\gamma L_{t r i p l e t})
$$
$$
L=\frac{1}{M}\sum_{i=1}^{M}(L_{c r o s s}+\gamma L_{t r i p l e t})
$$
where $M$ is the total number of samples, $\gamma$ is a constant, which controls both the loss. $L_{t r i p l e t}$ is the triplet loss function 5. $L_{c r o s s}$ is the cross entropy loss between the predicted and ground truth questions and is given by:
其中 $M$ 为样本总数,$\gamma$ 为控制两项损失的常数。$L_{triplet}$ 为三元组损失函数 [5],$L_{cross}$ 表示预测问题与真实问题之间的交叉熵损失,其表达式为:
$$
L_{c r o s s}=\frac{-1}{N}\sum_{t=1}^{N}y_{t}\mathrm{log}P(\hat{q}{t}|I_{i},C_{i},\hat{q_{0}},..q\hat{\phantom{-}}_{-1})
$$
$$
L_{c r o s s}=\frac{-1}{N}\sum_{t=1}^{N}y_{t}\mathrm{log}P(\hat{q}{t}|I_{i},C_{i},\hat{q_{0}},..q\hat{\phantom{-}}_{-1})
$$
where, $N$ is the total number of question tokens, $y_{t}$ is the ground truth label. The code for MDN-VQG model is provided 1.
其中,$N$ 是问题 token 的总数,$y_{t}$ 是真实标签。MDN-VQG 模型的代码已提供 [1]。
4.4 Variations of Proposed Method
4.4 所提方法的变体
While, we advocate the use of multimodal differential network for generating embeddings that can be used by the decoder for generating questions, we also evaluate several variants of this architecture. These are as follows:
虽然我们提倡使用多模态差分网络来生成嵌入,以供解码器生成问题,但我们也评估了该架构的几种变体,具体如下:
Tag Net: In this variant, we consider extracting the part-of-speech (POS) tags for the words present in the caption and obtaining a Tag embedding by considering different methods of combining the one-hot vectors. Further details and experimental results are present in the supplementary. This Tag embedding is then combined with the image embedding and provided to the decoder network.
Tag Net:在该变体中,我们考虑提取字幕中单词的词性 (POS) 标签,并通过不同方法组合独热向量来获取标签嵌入。补充材料中提供了更多细节和实验结果。随后将该标签嵌入与图像嵌入结合,并输入解码器网络。
Place Net: In this variant we explore obtaining embeddings based on the visual scene understanding. This is obtained using a pre-trained PlaceCNN (Zhou et al., 2017) that is trained to classify 365 different types of scene categories. We then combine the activation map for the input image and the VGG-19 based place embedding to obtain the joint embedding used by the decoder.
Place Net: 在该变体中,我们探索基于视觉场景理解获取嵌入表示。具体通过预训练的PlaceCNN (Zhou et al., 2017) 实现,该网络经过训练可分类365种不同场景类别。随后我们将输入图像的激活图与基于VGG-19的场景嵌入相结合,生成解码器使用的联合嵌入表示。
Differential Image Network: Instead of using multimodal differential network for generating embeddings, we also evaluate differential image network for the same. In this case, the embedding does not include the caption but is based only on the image feature. We also experimented with using multiple exemplars and random exemplars. Further details, pseudocode and results regarding these are present in the supplementary material.
差分图像网络:与使用多模态差分网络生成嵌入不同,我们也评估了差分图像网络的性能。在这种情况下,嵌入不包含标题,仅基于图像特征。我们还尝试了使用多个范例和随机范例的方法。更多细节、伪代码和结果详见补充材料。

Figure 5: These are some examples from the VQG-COCO dataset which provide a comparison between our generated questions and human annotated questions. (a) is the human annotated question for all the images. More qualitative results are present in the supplementary material.
图 5: 这些是来自VQG-COCO数据集的示例,展示了我们生成的问题与人工标注问题的对比。(a) 是所有图像对应的人工标注问题。更多定性分析结果详见补充材料。
4.5 Dataset
4.5 数据集
We conduct our experiments on Visual Question Generation (VQG) dataset (Most af azad eh et al., 2016), which contains human annotated questions based on images of MS-COCO dataset. This dataset was developed for generating natural and engaging questions based on common sense reasoning. We use VQG-COCO dataset for our experiments which contains a total of 2500 training images, 1250 validation images, and 1250 testing images. Each image in the dataset contains five natural questions and five ground truth captions. It is worth noting that the work of (Jain et al., 2017) also used the questions from VQA dataset (Antol et al., 2015) for training purpose, whereas the work by (Most af azad eh et al., 2016) uses only the VQG-COCO dataset. VQA-1.0 dataset is also built on images from MS-COCO dataset. It contains a total of 82783 images for training, 40504 for validation and 81434 for testing. Each image is associated with 3 questions. We used pretrained caption generation model (Karpathy and Fei-Fei, 2015) to extract captions for VQA dataset as the human annotated captions are not there in the dataset. We also get good results on the VQA dataset (as shown in Table 2) which shows that our method doesn’t necessitate the presence of ground truth captions. We train our model separately for VQG-COCO and VQA dataset.
我们在视觉问题生成(VQG)数据集(Mostafazadeh et al., 2016)上进行了实验,该数据集包含基于MS-COCO数据集图像的人工标注问题。该数据集旨在通过常识推理生成自然且引人入胜的问题。我们使用包含2500张训练图像、1250张验证图像和1250张测试图像的VQG-COCO数据集进行实验。数据集中每张图像包含五个自然问题和五个真实描述。值得注意的是,(Jain et al., 2017)的研究还使用了VQA数据集(Antol et al., 2015)的问题进行训练,而(Mostafazadeh et al., 2016)的研究仅使用VQG-COCO数据集。VQA-1.0数据集同样基于MS-COCO图像构建,包含82783张训练图像、40504张验证图像和81434张测试图像,每张图像关联3个问题。由于VQA数据集中缺少人工标注描述,我们使用预训练的标题生成模型(Karpathy and Fei-Fei, 2015)为其提取描述。如表2所示,我们在VQA数据集上也取得了良好效果,这表明我们的方法无需依赖真实描述。我们分别针对VQG-COCO和VQA数据集训练了模型。
4.6 Inference
4.6 推理
We made use of the 1250 validation images to tune the hyper parameters and are providing the results on test set of VQG-COCO dataset. During inference, We use the Representation module to find the embeddings for the image and ground truth caption without using the supporting and contrasting exemplars. The mixture module provides the joint representation of the target image and ground truth caption. Finally, the decoder takes in the joint features and generates the question. We also experimented with the captions generated by an Image-Captioning network (Karpathy and Fei-Fei, 2015) for VQG-COCO dataset and the result for that and training details are present in the supplementary material.
我们利用1250张验证图像调整超参数,并在VQG-COCO数据集的测试集上提供了结果。在推理过程中,我们使用表征模块(Representation module)直接获取图像和真实描述的嵌入向量,无需借助支持性和对比性示例。混合模块(mixture module)则生成目标图像与真实描述的联合表征。最终,解码器接收这些联合特征并生成问题。我们还尝试使用图像描述生成网络(Image-Captioning network)[Karpathy and Fei-Fei, 2015]为VQG-COCO数据集生成描述,相关实验结果及训练细节详见补充材料。
5 Experiments
5 实验
We evaluate our proposed MDN method in the following ways: First, we evaluate it against other variants described in section 4.4 and 4.1.3. Second, we further compare our network with stateof-the-art methods for VQA 1.0 and VQG-COCO dataset. We perform a user study to gauge human opinion on naturalness of the generated question and analyze the word statistics in Figure 6. This is an important test as humans are the best deciders of naturalness. We further consider the statistical significance for the various ablations as well as the state-of-the-art models. The quantitative evaluation is conducted using standard metrics like BLEU (Papineni et al., 2002), METEOR (Banerjee and Lavie, 2005), ROUGE (Lin, 2004), CIDEr (Vedantam et al., 2015). Although these metrics have not been shown to correlate with ‘naturalness’ of the question these still provide a reasonable quantitative measure for comparison. Here we only provide the BLEU1 scores, but the remaining BLEU-n metric scores are present in the supplementary. We observe that the proposed MDN provides improved embeddings to the decoder. We believe that these embeddings capture instance specific differential information that helps in guiding the question generation. Details regarding the metrics are given in the supplementary material.
我们通过以下方式评估提出的MDN方法:首先,在4.4节和4.1.3节描述的变体上进行对比测试。其次,将我们的网络与VQA 1.0和VQG-COCO数据集上的前沿方法进行比较。通过用户调研评估生成问题的自然度,并在图6中分析词汇统计特征——由于人类是自然度的最佳评判者,这项测试至关重要。我们还对各消融实验模型及前沿方法进行了统计显著性分析。
定量评估采用BLEU (Papineni et al., 2002)、METEOR (Banerjee and Lavie, 2005)、ROUGE (Lin, 2004)、CIDEr (Vedantam et al., 2015)等标准指标。虽然这些指标与问题的"自然度"相关性尚未被证实,但仍可为比较提供合理的量化依据。本文仅展示BLEU1分数,其余BLEU-n分数详见补充材料。实验表明,MDN能为解码器提供更优的嵌入表示,我们相信这些嵌入捕获了实例特定的差异信息,有助于指导问题生成。具体指标说明详见补充材料。
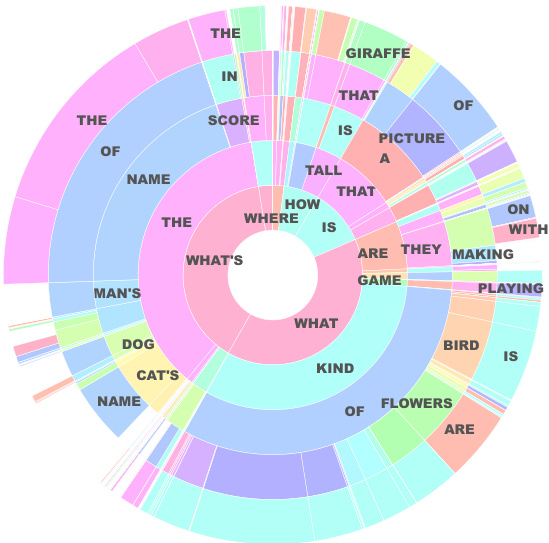
Figure 6: Sunburst plot for VQG-COCO: The $i^{t h}$ ring captures the frequency distribution over words for the $i^{t h}$ word of the generated question. The angle subtended at the center is proportional to the frequency of the word. While some words have high frequency, the outer rings illustrate a fine blend of words. We have restricted the plot to 5 rings for easy readability. Best viewed in color.
图 6: VQG-COCO的旭日图:第$i^{t h}$环表示生成问题中第$i^{t h}$个单词的词频分布。中心张角与单词频率成正比。虽然某些单词出现频率较高,但外层环显示出词汇的精细混合。为便于阅读,图中仅展示5层环。建议彩色查看。
5.1 Ablation Analysis
5.1 消融分析
We considered different variations of our method mentioned in section 4.4 and the various ways to obtain the joint multimodal embedding as described in section 4.1.3. The results for the VQGCOCO test set are given in table 1. In this table, every block provides the results for one of the variations of obtaining the embeddings and different ways of combining them. We observe that the
我们考虑了第4.4节提到的不同方法变体,以及第4.1.3节描述的各种获取联合多模态嵌入的方式。表1展示了VQGCOCO测试集的结果,其中每个区块对应一种嵌入获取变体与不同组合方式。实验表明
Joint Method (JM) of combining the embeddings works the best in all cases except the Tag Embeddings. Among the ablations, the proposed MDN method works way better than the other variants in terms of BLEU, METEOR and ROUGE metrics by achieving an improvement of $6%$ , $12%$ and $18%$ in the scores respectively over the best other variant.
联合方法 (JM) 在所有情况下都表现最佳,除了标签嵌入 (Tag Embeddings)。在消融实验中,所提出的 MDN 方法在 BLEU、METEOR 和 ROUGE 指标上远超其他变体,分别比最佳变体提升了 $6%$、$12%$ 和 $18%$。
| Emb. | Method | BLEU1 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|
| Tag Tag | AtM HM | 22.4 24.4 | 8.6 10.8 | 22.5 24.3 | 20.8 55.0 |
| Tag Tag PlaceCNN | AM JM | 24.4 22.2 | 10.6 10.5 | 23.9 22.8 | 49.4 50.1 |
| PlaceCNN PlaceCNN | AtM HM AM | 24.4 24.0 24.1 | 10.3 10.4 10.6 | 24.0 24.3 24.3 | 51.8 49.8 51.5 |
| PlaceCNN Diff.Img | JM AtM | 25.7 20.5 | 10.8 8.5 | 24.5 24.4 | 56.1 19.2 |
| Diff.Img | HM | 23.6 | 8.6 | ||
| AM | 22.3 | 22.0 | |||
| Diff.Img | |||||
| 20.6 | 8.5 | 24.4 | 19.2 | ||
| Diff.Img | JM | 30.4 | 11.7 | 22.3 | |
| MDN | AtM | 22.4 | 22.8 | ||
| MDN | 8.8 | 24.6 | 22.4 | ||
| HM | 26.6 | 12.8 | 30.1 | 31.4 | |
| MDN | AM | 29.6 | 15.4 | 32.8 | 41.6 |
| MDN (Ours) | JM | 36.0 | 23.4 | 41.8 | 50.7 |
Table 1: Analysis of variants of our proposed method on VQG-COCO Dataset as mentioned in section 4.4 and different ways of getting a joint embedding (Attention (AtM), Hadamard (HM), Addition (AM) and Joint (JM) method as given in section 4.1.3) for each method. Refer section 5.1 for more details.
表 1: 第4.4节提到的VQG-COCO数据集上我们提出方法的变体分析,以及第4.1.3节给出的每种方法获取联合嵌入的不同方式(注意力机制 (AtM)、哈达玛积 (HM)、加法 (AM) 和联合方法 (JM))。更多细节请参考第5.1节。
5.2 Baseline and State-of-the-Art
5.2 基线方法和当前最优技术
The comparison of our method with various baselines and state-of-the-art methods is provided in table 2 for VQA 1.0 and table 3 for VQG-COCO dataset. The comparable baselines for our method are the image based and caption based models in which we use either only the image or the caption embedding and generate the question. In both the tables, the first block consists of the current stateof-the-art methods on that dataset and the second contains the baselines. We observe that for the VQA dataset we achieve an improvement of $8%$ in BLEU and $7%$ in METEOR metric scores over the baselines, whereas for VQG-COCO dataset this is $15%$ for both the metrics. We improve over the previous state-of-the-art (Yang et al., 2015) for VQA dataset by around $6%$ in BLEU score and $10%$ in METEOR score. In the VQG-COCO dataset, we improve over (Most af azad eh et al., 2016) by $3.7%$ and (Jain et al., 2017) by $3.5%$ in terms of METEOR scores.
我们的方法与各种基线方法和最先进方法的比较结果如表2(针对VQA 1.0数据集)和表3(针对VQG-COCO数据集)所示。我们方法的可比基线是基于图像和基于标题的模型,其中我们仅使用图像或标题嵌入来生成问题。在这两个表格中,第一部分包含该数据集当前最先进的方法,第二部分包含基线方法。我们观察到,在VQA数据集上,我们的方法在BLEU指标上比基线提高了8%,在METEOR指标上提高了7%;而在VQG-COCO数据集上,这两个指标均提高了15%。我们在VQA数据集上的BLEU分数比之前的最先进方法(Yang等人,2015)提高了约6%,METEOR分数提高了10%。在VQG-COCO数据集上,我们的METEOR分数比(Mostafazadeh等人,2016)提高了3.7%,比(Jain等人,2017)提高了3.5%。
5.3 Statistical Significance Analysis
5.3 统计显著性分析
We have analysed Statistical Significance (Demsar, 2006) of our MDN model for VQG for different variations of the mixture module mentioned in section 4.1.3 and also against the state-of-the-art methods. The Critical Difference (CD) for Nemenyi (Fiser et al., 2016) test depends upon the given $\alpha$ (confidence level, which is 0.05 in our case) for average ranks and N (number of tested datasets). If the difference in the rank of the two methods lies within CD, then they are not significantly different and vice-versa. Figure 7 visualizes the post-hoc analysis using the CD diagram. From the figure, it is clear that MDN-Joint works best and is statistically significantly different from the state-of-the-art methods.
我们分析了MDN模型在视觉问题生成(VQG)任务中的统计显著性(Demsar, 2006),针对4.1.3节提到的混合模块不同变体以及当前最优方法进行了对比。Nemenyi检验(Fiser et al., 2016)的关键差异值(CD)取决于给定的$\alpha$(置信水平,本研究取0.05)、平均排名和N(测试数据集数量)。若两种方法的排名差异在CD范围内,则说明它们没有显著差异,反之亦然。图7通过CD图展示了事后分析结果,从中可以明显看出MDN-Joint表现最佳,且与当前最优方法存在统计显著性差异。
Table 2: State-of-the-Art comparison on VQA-1.0 Dataset. The first block consists of the state-of-the-art results, second block refers to the baselines mentioned in section 5.2, third block provides the results for the variants of mixture module present in section 4.1.3.
表 2: VQA-1.0数据集上的最新技术对比。第一区块为当前最优结果,第二区块对应5.2节提到的基线方法,第三区块展示了4.1.3节混合模块变体的实验结果。
| 方法 | BLEU1 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|
| Sample(Yang,2015) | 38.8 | 12.7 | 34.2 | 13.3 |
| Max(Yang,2015) Image Only | 59.4 56.6 | 17.8 | 49.3 | 33.1 |
| CaptionOnly | 57.1 | 15.1 15.5 | 40.0 36.6 | 31.0 30.5 |
| MDN-Attention | 60.7 | 16.7 | 49.8 | 33.6 |
| MDN-Hadamard | 61.7 | 16.7 | 50.1 | 29.3 |
| MDN-Addition | 61.7 | 18.3 | 50.4 | 42.6 |
| MDN-Joint(Ours) | 65.1 | 22.7 | 52.0 | 33.1 |
Table 3: State-of-the-Art (SOTA) comparison on VQGCOCO Dataset. The first block consists of the SOTA results, second block refers to the baselines mentioned in section 5.2, third block shows the results for the best method for different ablations mentioned in table 1.
表 3: VQGCOCO数据集上的最新技术 (SOTA) 对比。第一块为SOTA结果,第二块为5.2节提到的基线方法,第三块展示了表1中不同消融实验的最佳方法结果。
| Context | BLEU1 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|
| Natural2016 | 19.2 | 19.7 | ||
| Creative2017 Image Only | 35.6 20.8 | 19.9 | - | - |
| CaptionOnly | 21.1 | 8.6 8.5 | 22.6 25.9 | 18.8 22.3 |
| Tag-Hadamard | 24.4 | 10.8 | 24.3 | 55.0 |
| PlaceCNN-Joint | 25.7 | 10.8 | 24.5 | 56.1 |
| Diff.Image-Joint | 30.4 | 11.7 | 26.3 | 38.8 |
| MDN-Joint(Ours) | ||||
| Humans2016 | 36.0 86.0 | 23.4 60.8 | 41.8 | 50.7 |
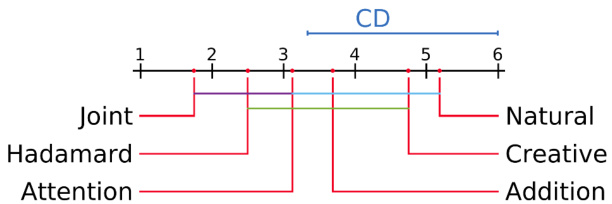
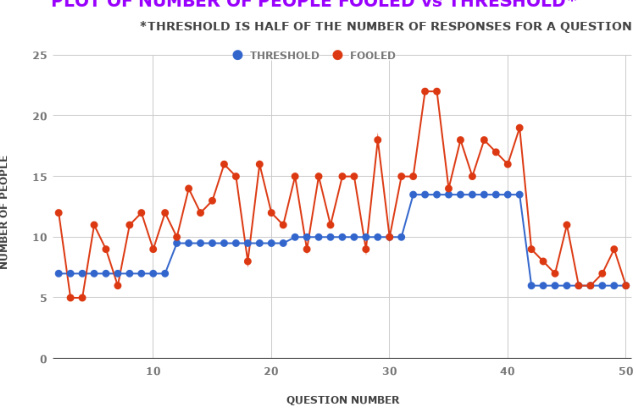
Figure 7: The mean rank of all the models on the basis of METEOR score are plotted on the $\mathbf{X}$ -axis. Here Joint refers to our MDN-Joint model and others are the different variations described in section 4.1.3 and Natural (Most af azad eh et al., 2016), Creative (Jain et al., 2017). The colored lines between the two models represents that these models are not significantly different from each other. Figure 8: Perceptual Realism Plot for human survey. Here every question has different number of responses and hence the threshold which is the half of total responses for each question is varying. This plot is only for 50 of the 100 questions involved in the survey. See section 5.4 for more details.
图 7: 基于 METEOR 分数的所有模型平均排名绘制在 $\mathbf{X}$ 轴上。其中 Joint 指代我们的 MDN-Joint 模型,其他则为 4.1.3 节所述的不同变体及 Natural (Mostafazadeh et al., 2016)、Creative (Jain et al., 2017)。模型间的彩色连线表示这些模型彼此无显著差异。
图 8: 人类调查的感知真实性曲线。每个问题获得不同数量的响应,因此各问题的阈值(即总响应数的一半)存在差异。该曲线仅展示调查中 100 个问题中的 50 个,详见 5.4 节。
PLOT OF NUMBER OF PEOPLE FOOLED VS THRESHOLD*
图 1: 被欺骗人数与阈值的关系图*
5.4 Perceptual Realism
5.4 感知真实性
A human is the best judge of naturalness of any question, We evaluated our proposed MDN method using a ‘Naturalness’ Turing test (Zhang et al., 2016) on 175 people. People were shown an image with 2 questions just as in figure 1 and were asked to rate the naturalness of both the questions on a scale of 1 to 5 where 1 means ‘Least Natural’ and 5 is the ‘Most Natural’. We provided 175 people with 100 such images from the VQGCOCO validation dataset which has 1250 images. Figure 8 indicates the number of people who were fooled (rated the generated question more or equal to the ground truth question). For the 100 images, on an average $59.7%$ people were fooled in this experiment and this shows that our model is able to generate natural questions.
人类是判断问题自然程度的最佳裁判。我们采用Zhang等人(2016)提出的"自然度"图灵测试方法,对175名受试者评估了提出的MDN方法。如图1所示,受试者会看到一张图片和两个问题,并被要求以1-5分评估这两个问题的自然程度(1分表示"最不自然",5分表示"最自然")。我们从包含1250张图片的VQGCOCO验证数据集中选取100张图片进行测试。图8显示了被"欺骗"的受试者人数(即给生成问题打分高于或等于真实问题的受试者)。在这100张图片的测试中,平均有59.7%的受试者被"欺骗",这表明我们的模型能够生成自然的问题。
6 Conclusion
6 结论
In this paper we have proposed a novel method for generating natural questions for an image. The approach relies on obtaining multimodal differential embeddings from image and its caption. We also provide ablation analysis and a detailed comparison with state-of-the-art methods, perform a user study to evaluate the naturalness of our generated questions and also ensure that the results are statistically significant. In future, we would like to analyse means of obtaining composite embeddings. We also aim to consider the generalisation of this approach to other vision and language tasks.
本文提出了一种为图像生成自然问题的新方法。该方法依赖于从图像及其标题中获取多模态差分嵌入 (multimodal differential embeddings) 。我们还提供了消融分析 (ablation analysis) 并与最先进方法进行了详细对比,通过用户研究评估生成问题的自然度,并确保结果具有统计显著性。未来我们将探索获取复合嵌入 (composite embeddings) 的方法,并致力于将该方法推广至其他视觉与语言任务。
A Supplementary Material
A 补充材料
Section B will provide details about training configuration for MDN, Section C will explain the various Proposed Methods and we also provide a discussion in section D regarding some important questions related to our method. We report BLEU1, BLEU2, BLEU3, BLEU4, METEOR, ROUGE and CIDER metric scores for VQGCOCO dataset. We present different experiments with Tag Net in which we explore the performance of various tags (Noun, Verb, and Question tags) and different ways of combining them to get the context vectors.
B部分将详细介绍MDN的训练配置,C部分将阐述各种提出的方法,D部分则针对我们方法相关的重要问题展开讨论。我们在VQGCOCO数据集上报告了BLEU1、BLEU2、BLEU3、BLEU4、METEOR、ROUGE和CIDER指标分数。通过Tag Net进行了多组实验,探究了不同标签(名词、动词和疑问词标签)的性能表现,以及组合这些标签获取上下文向量的多种方式。
Algorithm 1 Multimodal Differential Network
算法 1 多模态差分网络

Figure 9: These are some more examples from the VQG-COCO dataset which provide a comparison between the questions generated by our model and human annotated questions. (b) is the human annotated question for the first row-fourth column, & fifth column image and (a) for the rest of images.
图 9: 这些是来自VQG-COCO数据集的更多示例,展示了我们模型生成的问题与人工标注问题之间的对比。(b) 是第一行第四列和第五列图像的人工标注问题,(a) 是其余图像的问题。
| 上下文 | 方法 | BLEU-1 | Meteor | Rouge | CIDer |
|---|---|---|---|---|---|
| 图像 | 23.2 | 8.6 | 25.6 | 18.8 | |
| 标题 | 23.5 | 8.6 | 25.9 | 24.3 | |
| Tag-n | JM | 22.2 | 10.5 | 22.8 | 50.1 |
| Tag-n | AtM | 22.4 | 8.6 | 22.5 | 20.8 |
| Tag-n | HM | 24.8 | 10.6 | 24.4 | 53.2 |
| Tag-n | AM | 24.4 | 10.6 | 23.9 | 49.4 |
| Tag-V | JM | 23.9 | 10.5 | 24.1 | 52.9 |
| Tag-V | AtM | 22.2 | 8.6 | 22.4 | 20.9 |
| Tag-V | HM | 24.5 | 10.7 | 24.2 | 52.3 |
| Tag-V | AM | 24.6 | 10.6 | 24.1 | 49.0 |
| Tag-wh | JM | 22.4 | 10.5 | 22.5 | 48.6 |
| Tag-wh | AtM | 22.2 | 8.6 | 22.4 | 20.9 |
| Tag-wh | HM | 24.6 | 10.8 | 24.3 | 55.0 |
| Tag-wh | AM | 24.0 | 10.4 | 23.7 | 47.8 |
B Dataset and Training Details
B 数据集与训练细节
B.1 Dataset
B.1 数据集
We conduct our experiments on two types of dataset: VQA dataset (Antol et al., 2015), which contains human annotated questions based on images on MS-COCO dataset. Second one is VQG-COCO dataset based on natural question (Most af azad eh et al., 2016).
我们在两类数据集上进行实验:VQA数据集 (Antol et al., 2015) ,包含基于MS-COCO数据集图像的人工标注问题;其次是基于自然问题的VQG-COCO数据集 (Most af azad eh et al., 2016) 。
B.1.1 VQA dataset
B.1.1 VQA (Visual Question Answering) 数据集
VQA dataset(Antol et al., 2015) is built on complex images from MS-COCO dataset. It contains a total of 204721 images, out of which 82783 are for training, 40504 for validation and 81434 for testing. Each image in the MS-COCO dataset is associated with 3 questions and each question has 10 possible answers. So there are 248349 QA pair for training, 121512 QA pairs for validating and 244302 QA pairs for testing. We used pre-trained caption generation model (Karpathy et al., 2014) to extract captions for VQA dataset.
VQA数据集 (Antol et al., 2015) 基于MS-COCO数据集中的复杂图像构建。该数据集共包含204721张图像,其中82783张用于训练,40504张用于验证,81434张用于测试。MS-COCO数据集中的每张图像关联3个问题,每个问题有10个可能的答案。因此训练集包含248349个问答对,验证集包含121512个问答对,测试集包含244302个问答对。我们使用预训练的标题生成模型 (Karpathy et al., 2014) 为VQA数据集提取描述文本。
Table 4: Analysis of different Tags for VQG-COCOdataset. We analyse noun tag (Tag-n), verb tag (Tag-v) and question tag (Tag-wh) for different fusion methods namely joint, attention, Hadamard and addition based fusion. Table 5: Combination of 3 tags of each category for hadamard mixture model namely addition, concatenation, multiplication and 1d-convolution
表 4: VQG-COCO数据集不同标签分析。我们针对联合(joint)、注意力(attention)、哈达玛(Hadamard)和加法(addition)四种融合方法,分别分析了名词标签(Tag-n)、动词标签(Tag-v)和疑问词标签(Tag-wh)。表 5: 哈达玛混合模型中三类标签的组合方式对比,包括加法、拼接、乘法和一维卷积
| 上下文 | BLEU-1 | Meteor | Rouge | CIDer |
|---|---|---|---|---|
| Tag-n3-add | 22.4 | 9.1 | 22.2 | 26.7 |
| Tag-n3-con | 24.8 | 10.6 | 24.4 | 53.2 |
| Tag-n3-joint | 22.1 | 8.9 | 21.7 | 24.6 |
| Tag-n3-conv | 24.1 | 10.3 | 24.0 | 47.9 |
| Tag-v3-add | 24.1 | 10.2 | 23.9 | 46.7 |
| Tag-v3-con | 24.5 | 10.7 | 24.2 | 52.3 |
| Tag-v3-joint | 22.5 | 9.1 | 22.1 | 25.6 |
| Tag-v3-conv | 23.2 | 9.0 | 24.2 | 38.0 |
| Tag-q3-add | 24.5 | 10.5 | 24.4 | 51.4 |
| Tag-q3-con | 24.6 | 10.8 | 24.3 | 55.0 |
| Tag-q3-joint | 22.1 | 9.0 | 22.0 | 25.9 |
| Tag-q3-conv | 24.3 | 10.4 | 24.0 | 48.6 |
B.1.2 VQG dataset
B.1.2 VQG 数据集
The VQG-COCO dataset(Most af azad eh et al., 2016), is developed for generating natural and engaging questions that are based on common sense reasoning. This dataset contains a total of 2500 training images, 1250 validation images and 1250
VQG-COCO数据集 (Most af azad eh et al., 2016) 旨在生成基于常识推理的自然且引人入胜的问题。该数据集共包含2500张训练图像、1250张验证图像和1250张
| 方法 | 示例 | BLEU-1 | Meteor | Rouge | CIDer |
|---|---|---|---|---|---|
| AM AM | IE(K=1) | 21.8 | 7.6 | 22.8 | 22.0 |
| AM | IE(K=2) IE(K=3) | 22.4 22.1 | 8.3 8.8 | 23.4 24.7 | 16.0 |
| AM | IE(K=4) | 23.7 | 9.5 | 24.1 | |
| AM | IE(K=5) | 24.4 | 11.7 | 25.9 | 25.2 |
| AM | IE(K=R) | 18.8 | 6.4 | 25.0 20.0 | 27.8 20.1 |
| HM | IE(K=1) | 23.6 | 7.2 | 25.3 | 21.0 |
| HM | IE(K=2) | 23.2 | 8.9 | 27.8 | 22.1 |
| HM | IE(K=3) | 24.8 | 9.8 | 27.9 | |
| HM | IE(K=4) | 27.7 | 9.4 | 28.5 | |
| HM | IE(K=5) | 28.3 | 10.2 | 26.1 | 33.8 |
| HM | IE(K=R) | 20.1 | 7.7 | 26.6 | 31.5 |
| JM | IE(K=1) | 20.1 | 20.1 | 20.5 | |
| IE(K=2) | 7.9 | 21.8 | 20.9 | ||
| JM | IE(K=3) | 22.6 | 8.5 | 22.4 | 28.2 |
| JM | 24.0 | 9.2 | 24.4 | 29.5 | |
| JM | IE(K=4) | 28.7 | 10.2 | 24.4 | 32.8 |
| JM | IE(K=5) | 30.4 | 11.7 | 26.3 | 38.8 |
| JM | IE(K=R) | 21.8 | 7.4 | 22.1 | 22.5 |
Table 6: VQG-COCO-dataset, Analysis of different number of Exemplars for addition model, hadamard model and joint model, R is random exemplar. All these experiment are for the differential image network. $_{\mathrm{k}=5}$ performs the best and hence we use this value for the results in main paper.
表 6: VQG-COCO数据集,针对加法模型、Hadamard模型和联合模型的不同示例数量分析,R表示随机示例。所有实验均针对差分图像网络进行。$_{\mathrm{k}=5}$表现最佳,因此在主论文中采用此值。

Figure 10: The mean rank of all the models on the basis of BLEU score are plotted on the $\mathbf{X}$ -axis. Here Joint refers to our MDN-Joint model and others are the different variations of our model and Natural(Most af azad eh et al., 2016), Creative-(Jain et al., 2017). Also the colored lines between two models represent that those models are not significantly different from each other.
图 10: 基于BLEU分数的所有模型平均排名绘制在$\mathbf{X}$轴上。其中Joint指代我们的MDN-Joint模型,其他为我们模型的不同变体以及Natural (Mostafazadeh et al., 2016)、Creative (Jain et al., 2017)。两模型间的彩色连线表示这些模型彼此间无显著差异。
testing images. Each image in the dataset contains 5 natural questions.
测试图像。数据集中的每张图像包含5个自然问题。
B.2 Training Configuration
B.2 训练配置
We have used RMSPROP optimizer to update the model parameter and configured hyperparameter values to be as follows: learning rate $=$ 0.0004, batch size $=200,\alpha=0.99,\epsilon=1e-$ 8 to train the classification network . In order to train a triplet model, we have used RMSPROP to optimize the triplet model model parameter and configure hyper-parameter values to be: learning rate $=0.001$ , batch s $\mathrm{ize}=200,\alpha=$ $0.9,\epsilon=1e-8$ . We also used learning rate decay to decrease the learning rate on every epoch by a
我们使用RMSPROP优化器更新模型参数,并设置超参数如下:学习率$=0.0004$,批量大小$=200$,$\alpha=0.99$,$\epsilon=1e-8$来训练分类网络。为训练三元组模型,我们采用RMSPROP优化三元组模型参数,配置超参数为:学习率$=0.001$,批量大小$\mathrm{ize}=200$,$\alpha=0.9$,$\epsilon=1e-8$。同时采用学习率衰减策略,在每个训练周期降低学习率。
factor given by:
因子由下式给出:
$$
D e c a y\l_{-}f a c t o r=e x p\left(\frac{l o g(0.1)}{a*b}\right)
$$
$$
D e c a y\l_{-}f a c t o r=e x p\left(\frac{l o g(0.1)}{a*b}\right)
$$
where values of $\scriptstyle{\mathrm{a=1}}500$ and $\mathrm{b}{=}1250$ are set empirically.
其中经验性地设定了 $\scriptstyle{\mathrm{a=1}}500$ 和 $\mathrm{b}{=}1250$ 的值。
C Ablation Analysis of Model
C 模型消融分析
While, we advocate the use of multimodal differential network (MDN) for generating embeddings that can be used by the decoder for generating questions, we also evaluate several variants of this architecture namely (a) Differential Image Network, (b) Tag net and (c) Place net. These are described in detail as follows:
虽然我们提倡使用多模态差分网络 (MDN) 生成嵌入供解码器生成问题,但我们也评估了该架构的几种变体,即 (a) 差分图像网络 (Differential Image Network) 、(b) 标签网络 (Tag net) 和 (c) 地点网络 (Place net)。具体描述如下:
C.1 Differential Image Network
C.1 差分图像网络
For obtaining the exemplar image based context embedding, we propose a triplet network consist of three network, one is target net, supporting net and opposing net. All these three networks designed with convolution neural network and shared the same parameters.
为获取基于范例图像的上下文嵌入,我们提出了一种由三个网络组成的三元组网络架构,包括目标网络、支持网络和对抗网络。这三个网络均采用卷积神经网络(CNN)设计并共享相同参数。
The weights of this network are learnt through end-to-end learning using a triplet loss. The aim is to obtain latent weight vectors that bring the supporting exemplar close to the target image and enhances the difference between opposing examples. More formally, given an image $x_{i}$ we obtain an embedding $g_{i}$ using a CNN that we parameterize through a function $G(x_{i},W_{c})$ where $W_{c}$ are the weights of the CNN. This is illustrated in figure 11.
该网络的权重通过使用三元组损失进行端到端学习获得。其目标是学习到能将支持样本拉近目标图像、同时增大对抗样本差异的潜在权重向量。更正式地说,给定图像$x_{i}$,我们通过参数化为函数$G(x_{i},W_{c})$的CNN(其中$W_{c}$为CNN权重)获得嵌入表示$g_{i}$,如图11所示。

Figure 11: Differential Image Network
图 11: 差分图像网络
Table 7: Full State-of-the-Art comparison on VQG-COCO Dataset. The first block consists of the state-of-the-art results, second block refers to the baselines mentioned in State-of-the-art section of main paper and the third block provides the results for the best method for different ablations of our method.
表 7: VQG-COCO数据集上的完整技术现状对比。第一区块为当前最优结果,第二区块对应主论文技术现状章节提到的基线方法,第三区块展示了我们方法在不同消融实验中的最佳表现。
| Context | BLEU1 | BLEU2 | BLEU3 | BLEU4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| Natural2016 | 19.2 | 19.7 | |||||
| Creative2017 | 35.6 | - | - | - | 19.9 | - | |
| Image Only Caption Only | 20.8 | 14.1 | 8.5 | 5.2 | 8.6 | 22.6 | 18.8 |
| Tag-Hadamard | 21.1 | 14.2 | 8.6 | 5.4 | 8.5 | 25.9 | 22.3 |
| PlaceCNN-Joint | 15.1 | 9.5 | 6.3 | 10.8 | 24.3 | 55.0 | |
| Diff.Image-Joint | 25.7 | 15.7 | 9.9 | 6.5 | 10.8 | 24.5 | 56.1 |
| 30.4 | 20.1 | 14.3 | 8.3 | 11.7 | 26.3 | 38.8 | |
| MDN-Joint (Ours) | 36.0 | 24.9 | 16.8 | 10.4 | 23.4 | 41.8 | 50.7 |
| Humans 2016 | 86.0 | - | 60.8 |
C.2 Tag net
C.2 标签网络
The tag net consists of two parts Context Extractor & Tag Embedding Net. This is illustrated in figure 12.
标签网络由两部分组成:上下文提取器 (Context Extractor) 和标签嵌入网络 (Tag Embedding Net)。如图 12 所示。
Extract Context: The first step is to extract the caption of the image using Neural Talk 2 (Karpathy et al., 2014) model. We find the part-ofspeech(POS) tag present in the caption. POS taggers have been developed for two well known corpuses, the Brown Corpus and the Penn Treebanks. For our work, we are using the Brown Corpus tags. The tags are clustered into three category namely Noun tag, Verb tag and Question tags (What, Where, . . . ). Noun tag consists of all the noun & pronouns present in the caption sentence and similarly, verb tag consists of verb & adverbs present in the caption sentence. The question tags consists of the 7-well know question words i.e., why, how, what, when, where, who and which. Each tag token is represented as a one-hot vector of the dimension of vocabulary size. For generalization, we have considered 5 tokens from each category of the Tags.
提取上下文:第一步是使用Neural Talk 2 (Karpathy等人,2014)模型提取图像的标题。我们识别标题中存在的词性(POS)标签。POS标注器已针对两个著名语料库开发,分别是Brown Corpus和Penn Treebanks。在我们的工作中,我们使用Brown Corpus标签。这些标签被聚类为三类:名词标签、动词标签和疑问标签(What、Where等)。名词标签包含标题句子中的所有名词和代词,动词标签包含标题句子中的动词和副词,疑问标签包含7个常见疑问词(why、how、what、when、where、who和which)。每个标签token被表示为词汇表大小维度的一热向量。为了泛化,我们从每类标签中考虑了5个token。
Tag Embedding Net: The embedding network consists of word embedding followed by temporal convolutions neural network followed by maxpooling network. In the first step, sparse high dimensional one-hot vector is transformed to dense low dimension vector using word embedding. After this, we apply temporal convolution on the word embedding vector. The uni-gram, bi-gram and tri-gram feature are computed by applying convolution filter of size 1, 2 and 3 respect a bility. Finally, we applied max-pooling on this to get a vector representation of the tags as shown figure 12. We concatenated all the tag words followed by fully connected layer to get feature dimension of 512. We also explored joint networks based on concatenation of all the tags, on elementwise addition and element-wise multiplication of the tag vectors. However, we observed that convolution over max pooling and joint concatenation gives better performance based on CIDer score.
标签嵌入网络 (Tag Embedding Net):该嵌入网络由词嵌入层、时序卷积神经网络和最大池化网络组成。首先,通过词嵌入将稀疏的高维one-hot向量转换为稠密的低维向量。随后,在词嵌入向量上应用时序卷积,分别使用尺寸为1、2和3的卷积核计算单字词、双字词和三字词特征。最后通过最大池化操作得到如图12所示的标签向量表示。我们将所有标签词向量拼接后接入全连接层,最终得到512维特征。我们还探索了基于标签拼接、逐元素相加和逐元素相乘的联合网络结构,但根据CIDer评分,最大池化卷积与联合拼接方案表现更优。
$$
F_{C}=\mathrm{Tag.CNN}(C_{t})
$$
$$
F_{C}=\mathrm{Tag.CNN}(C_{t})
$$
Where, T CNN is Temporally Convolution Neural Network applied on word embedding vector with kernel size three.
其中,T CNN是应用于词嵌入向量的时间卷积神经网络 (Temporally Convolution Neural Network),卷积核大小为3。

Figure 12: Illustration of Tag Net
图 12: Tag Net示意图
C.3 Place net
C.3 Place net
Visual object and scene recognition plays a crucial role in the image. Here, places in the image are labeled with scene semantic categories(Zhou et al., 2017), comprise of large and diverse type of environment in the world, such as (amusement park, tower, swimming pool, shoe shop, cafeteria, rain-forest, conference center, fish pond, etc.). So we have used different type of scene semantic categories present in the image as a place based context to generate natural question. A place365 is a convolution neural network is modeled to classify 365 types of scene categories, which is trained on the place2 dataset consist of $1.8\mathrm{mil}.$ - lion of scene images. We have used a pre-trained VGG16-places365 network to obtain place based context embedding feature for various type scene categories present in the image. The context feature $F_{C}$ is obtained by:
视觉对象和场景识别在图像中起着至关重要的作用。这里,图像中的地点被标注了场景语义类别 (Zhou et al., 2017),涵盖了世界上各种多样化的环境类型,例如(游乐园、塔楼、游泳池、鞋店、自助餐厅、雨林、会议中心、鱼塘等)。因此,我们利用图像中存在的不同类型场景语义类别作为基于地点的上下文来生成自然问题。Place365是一个卷积神经网络,用于分类365种场景类别,该网络在包含180万张场景图像的Place2数据集上训练。我们使用预训练的VGG16-places365网络来获取图像中各种场景类别的基于地点的上下文嵌入特征。上下文特征$F_{C}$通过以下方式获得:
$$
F_{C}=w*\mathsf{p}_{-}\mathrm{conv}(I)+b
$$
$$
F_{C}=w*\mathsf{p}_{-}\mathrm{conv}(I)+b
$$
Where, p conv is Place365 CNN. We have extracted conv5 features of dimension 14x14x512 for attention model and FC8 features of dimension 365 for joint, addition and hadamard model of places365. Finally, we use a linear transformation to obtain a 512 dimensional vector.
其中,p conv 是 Place365 CNN。我们提取了维度为 14x14x512 的 conv5 特征用于注意力模型,以及维度为 365 的 FC8 特征用于 Place365 的联合、加法和哈达玛积模型。最后,我们使用线性变换得到一个 512 维的向量。
We explored using the CONV5 having feature dimension 14x14 512, FC7 having 4096 and FC8 having feature dimension of 365 of places365.
我们探索了使用特征维度为14x14x512的CONV5层、4096维的FC7层以及Places365数据集中365维的FC8层。
D Ablation Analysis
D 消融分析
D.1 Sampling Exemplar: KNN vs ITML
D.1 采样示例:KNN 与 ITML
Our method is aimed at using efficient exemplarbased retrieval techniques. We have experimented with various exemplar methods, such as ITML (Davis et al., 2007) based metric learning for image features and KNN based approaches. We observed KNN based approach (K-D tree) with Euclidean metric is a efficient method for finding exemplars. Also we observed that ITML is computationally expensive and also depends on the training procedure. The table provides the experimental result for Differential Image Network variant with $\mathrm{k\Omega}$ (number of exemplars) $=2$ and Hadamard method:
我们的方法旨在使用高效的基于样本检索技术。我们尝试了多种样本方法,例如基于ITML (Davis et al., 2007) 的图像特征度量学习和基于KNN的方法。我们发现采用欧氏度量的KNN方法 (K-D树) 是一种高效的样本查找方法。同时我们也注意到ITML计算成本较高,且依赖于训练过程。下表展示了采用 $\mathrm{k\Omega}$ (样本数量) $=2$ 和Hadamard方法的Differential Image Network变体实验结果:
Table 8: VQG-COCO-dataset, Analysis of different methods of finding Exemplars for hadamard model. ITML vs KNN based methods. We see that both give more or less similar results but since ITML is computationally expensive and the dataset size is also small, it is not that efficient for our use. All these experiment are for the differential image network for $\mathrm{K}{=}2$ only.
表 8: VQG-COCO数据集,分析为Hadamard模型寻找示例的不同方法。ITML与基于KNN的方法对比。可以看出两者结果大致相似,但由于ITML计算成本高且数据集规模较小,对我们的用途效率不高。所有实验仅针对差分图像网络的 $\mathrm{K}{=}2$ 情况。
D.2 Question Generation approaches: Sampling vs Argmax
D.2 问题生成方法:采样 (Sampling) 与最大概率 (Argmax)
Table 9: VQG-COCO-dataset, Analysis of question generation approaches:sampling vs Argmax in MDNJoint model for ${\mathrm{K}}{=}5$ only. We see that Argmax clearly outperforms the sampling method.
| Meth | Exemplar | BLEU-1 | Meteor | Rouge | CIDer |
| KNN | IE(K=2) | 23.2 | 8.9 | 27.8 | 22.1 |
| ITML | IE(K=2) | 22.7 | 9.3 | 24.5 | 22.1 |
表 9: VQG-COCO数据集,问题生成方法分析:仅针对 ${\mathrm{K}}{=}5$ 的MDNJoint模型中的采样(sampling)与Argmax方法对比。可见Argmax明显优于采样方法。
| Meth | Exemplar | BLEU-1 | Meteor | Rouge | CIDer |
|---|---|---|---|---|---|
| KNN | IE(K=2) | 23.2 | 8.9 | 27.8 | 22.1 |
| ITML | IE(K=2) | 22.7 | 9.3 | 24.5 | 22.1 |
We obtained the decoding using standard practice followed in the literature (Sutskever et al., 2014). This method selects the argmax sentence. Also, we evaluated our method by sampling from the probability distributions and provide the results for
我们按照文献中的标准做法 (Sutskever et al., 2014) 获取解码结果。该方法选择 argmax 句子。此外,我们还通过从概率分布中采样来评估我们的方法,并提供相关结果。
our proposed MDN-Joint method for VQG dataset as follows:
| Meth | BLEU-1 | Meteor | Rouge | CIDer |
| Sampling | 17.9 | 11.5 | 20.6 | 22.1 |
| Argmax | 36.0 | 23.4 | 41.8 | 50.7 |
我们提出的 MDN-Joint 方法在 VQG 数据集上的表现如下:
| Meth | BLEU-1 | Meteor | Rouge | CIDer |
|---|---|---|---|---|
| Sampling | 17.9 | 11.5 | 20.6 | 22.1 |
| Argmax | 36.0 | 23.4 | 41.8 | 50.7 |
D.3 How are exemplars improving Embedding
D.3 示例如何改进嵌入
In Multimodel differential network, we use exemplars and train them using a triplet loss. It is known that using a triplet network, we can learn a representation that accentuates how the image is closer to a supporting exemplar as against the opposing exemplar (Hoffer and Ailon, 2015; Frome et al., 2007). The Joint embedding is obtained between the image and language representations. Therefore the improved representation helps in obtaining an improved context vector. Further we show that this also results in improving VQG.
在多模态差分网络中,我们使用样本并通过三元组损失进行训练。已知采用三元组网络可以学习到一种表征,该表征能突出显示图像与支持样本的接近程度相对于对立样本的差异 (Hoffer and Ailon, 2015; Frome et al., 2007)。图像与语言表征之间会生成联合嵌入,因此改进后的表征有助于获得更优的上下文向量。我们进一步证明该方法还能提升视觉问答生成 (VQG) 性能。
D.4 Are exemplars required?
D.4 是否需要范例?
We had similar concerns and validated this point by using random exemplars for the nearest neighbor for MDN. ( $\operatorname{k=R}$ in table 6) In this case the method is similar to the baseline. This suggests that with random exemplar, the model learns to ignore the cue.
我们对这一点也有类似的担忧,并通过为MDN的最近邻使用随机示例进行了验证 (k=R 见表6) 。在这种情况下,该方法与基线类似。这表明,使用随机示例时,模型学会了忽略提示。
D.5 Are captions necessary for our method?
D.5 我们的方法是否需要字幕?
This is not actually necessary. In our method, we have used an existing image captioning method (Karpathy and Fei-Fei, 2015) to generate captions for images that did not have them. For VQG dataset, captions were available and we have used that, but, for VQA dataset captions were not available and we have generated captions while training. We provide detailed evidence with respect to caption-question pairs to ensure that we are generating novel questions. While the caption generates scene description, our proposed method generates semantically meaningful and novel questions. Examples for Figure 1 of main paper: First Image:- Caption- A young man skateboarding around little cones. Our QuestionIs this a skateboard competition? Second Image:- Caption- A small child is standing on a pair of skis. Our Question:- How old is that little girl?
这实际上并非必要。在我们的方法中,我们使用了现有的图像描述生成方法 (Karpathy and Fei-Fei, 2015) 为没有描述的图像生成描述。对于VQG数据集,已有现成描述可供使用;而对于VQA数据集,我们在训练过程中生成了相应描述。我们提供了详尽的描述-问题配对证据,以确保生成的是新颖问题。描述生成的是场景说明,而我们提出的方法生成的是具有语义意义且新颖的问题。主论文图1的示例:第一张图:描述-一个年轻男子绕着小锥筒滑滑板。我们的问题:这是一场滑板比赛吗?第二张图:描述-一个小孩子站在一副滑雪板上。我们的问题:那个小女孩多大了?
D.6 Intuition behind Triplet Network:
D.6 Triplet Network 背后的直觉:
The intuition behind use of triplet networks is clear through this paper(Frome et al., 2007) that first advocated its use. The main idea is that when we learn distance functions that are close for similar and far from dissimilar representations, it is not clear that close and far are with respect to what measure. By incorporating a triplet we learn distance functions that learn that A is more similar to B as compared to C. Learning such measures allows us to bring target image-caption joint embeddings that are closer to supporting exemplars as compared to contrasting exemplars.
本文(Frome et al., 2007)首次提出使用三元组网络的动机很明确:当我们学习使相似表示距离近、不相似表示距离远的度量函数时,"近"和"远"的具体衡量标准并不清晰。通过引入三元组结构,我们可以学习到A与B的相似度高于A与C的度量函数。这种度量方式使我们能够将目标图像-标题联合嵌入向支持样本靠近,同时远离对比样本。
E Analysis of Network
E 网络分析
E.1 Analysis of Tag Context
E.1 标签上下文分析
Tag is language based context. These tags are extracted from caption, except question-tags which is fixed as the 7 ’Wh words’ (What, Why, Where, Who, When, Which and How). We have experimented with Noun tag, Verb tag and ’Wh-word’ tag as shown in tables. Also, we have experimented in each tag by varying the number of tags from 1 to 7. We combined different tags using 1Dconvolution, concatenation, and addition of all the tags and observed that the concatenation mechanism gives better results.
标签是基于语言的上下文。这些标签从标题中提取,除了固定为7个“Wh疑问词”(What、Why、Where、Who、When、Which和How)的问题标签。我们尝试了名词标签、动词标签和“Wh疑问词”标签,如表中所示。此外,我们还通过将标签数量从1到7变化来测试每个标签。我们使用一维卷积、拼接以及所有标签相加的方式组合不同标签,并观察到拼接机制能带来更好的结果。
As we can see in the table 4 that taking Nouns, Verbs and Wh-Words as context, we achieve significant improvement in the BLEU, METEOR and CIDEr scores from the basic models which only takes the image and the caption respectively. Taking Nouns generated from the captions and questions of the corresponding training example as context, we achieve an increase of $1.6%$ in Bleu Score and $2%$ in METEOR and $34.4%$ in CIDEr Score from the basic Image model. Similarly taking Verbs as context gives us an increase of $1.3%$ in Bleu Score and $2.1%$ in METEOR and $33.5%$ in CIDEr Score from the basic Image model. And the best result comes when we take 3 Wh-Words as context and apply the Hadamard Model with concatenating the 3 WH-words.
从表4可以看出,以名词、动词和疑问词作为上下文时,我们相比仅使用图像或字幕的基础模型,在BLEU、METEOR和CIDEr分数上均取得显著提升。使用训练样本对应字幕和问题生成的名词作为上下文时,基础图像模型的BLEU分数提升1.6%、METEOR提升2%、CIDEr提升34.4%。类似地,以动词为上下文使基础图像模型的BLEU提升1.3%、METEOR提升2.1%、CIDEr提升33.5%。最佳结果出现在采用3个疑问词作为上下文,并通过Hadamard模型进行拼接时。
Also in Table 5 we have shown the results when we take more than one words as context. Here we show that for 3 words i.e 3 nouns, 3 verbs and 3 Wh-words, the Concatenation model performs the best. In this table the conv model is using 1D convolution to combine the tags and the joint model combine all the tags.
同样在表5中,我们展示了采用多词作为上下文时的结果。此处证明对于3个词(即3个名词、3个动词和3个Wh-词)的情况,Concatenation模型表现最佳。该表中conv模型使用一维卷积(1D convolution)来组合标签,而joint模型则整合所有标签。
E.2 Analysis of Context: Exemplars
E.2 上下文分析:范例
In Multimodel Differential Network and Differential Image Network, we use exemplar images(target, supporting and opposing image) to obtain the differential context. We have performed the experiment based on the single exemplar $(\mathrm{K}{=}1)$ ), which is one supporting and one opposing image along with target image, based on two exemplar $\scriptstyle\mathrm{K}=2,$ , i.e. two supporting and two opposing image along with single target image. similarly we have performed experiment for ${\mathrm{K}}{=}3$ and ${\bf K}{=}4$ as shown in table- 6.
在多模态差分网络和差分图像网络中,我们使用示例图像(目标图像、支持图像和对抗图像)来获取差分上下文。我们基于单示例 $(\mathrm{K}{=}1)$ (即一张支持图像和一张对抗图像配合目标图像)进行了实验,同时也基于双示例 $\scriptstyle\mathrm{K}=2$ (即两张支持图像和两张对抗图像配合单张目标图像)进行了实验。类似地,我们还对 ${\mathrm{K}}{=}3$ 和 ${\bf K}{=}4$ 的情况进行了实验,如表6所示。
E.3 Mixture Module: Other Variations
E.3 混合模块:其他变体
Hadamard method uses element-wise multiplication whereas Addition method uses element-wise addition in place of the concatenation operator of the Joint method. The Hadamard method finds a correlation between image feature and caption feature vector while the Addition method learns a resultant vector. In the attention method, the output $S_{i}$ is the weighted average of attention probability vector $P_{a t t}$ and convolutional features $G_{i m g}$ . The attention probability vector weights the contribution of each convolutional feature based on the caption vector. This attention method is similar to work stack attention method (Yang et al., 2016). The attention mechanism is given by:
Hadamard方法采用元素级乘法,而Addition方法则使用元素级加法替代Joint方法的拼接操作。Hadamard方法寻找图像特征与标题特征向量之间的相关性,Addition方法则学习一个合成向量。在注意力方法中,输出$S_{i}$是注意力概率向量$P_{att}$与卷积特征$G_{img}$的加权平均。该注意力概率向量根据标题向量对每个卷积特征的贡献进行加权。此注意力方法类似于堆叠注意力方法 (Yang et al., 2016) 的工作,其机制由以下公式给出:
$$
\begin{array}{r l}&{h_{a t t}=\operatorname{tanh}(W_{I}G_{i m g}\oplus(W_{C}F_{c a p}+b_{c}))}\ &{P_{a t t}=\operatorname{Softmax}(W_{P}^{T}h_{a t t}+b_{P})}\ &{V_{a t t}=\displaystyle\sum_{i}P_{a t t}(i)G_{i m g}(i)}\ &{A_{a t t}=V_{a t t}+f_{i}}\ &{s_{i}=\operatorname{tanh}(W_{A}A_{a t t}+b_{A})}\end{array}
$$
$$
\begin{array}{r l}&{h_{a t t}=\operatorname{tanh}(W_{I}G_{i m g}\oplus(W_{C}F_{c a p}+b_{c}))}\ &{P_{a t t}=\operatorname{Softmax}(W_{P}^{T}h_{a t t}+b_{P})}\ &{V_{a t t}=\displaystyle\sum_{i}P_{a t t}(i)G_{i m g}(i)}\ &{A_{a t t}=V_{a t t}+f_{i}}\ &{s_{i}=\operatorname{tanh}(W_{A}A_{a t t}+b_{A})}\end{array}
$$
where $G_{i m g}$ is the 14x14x512-dimensional convo- lution feature map from the fifth convolution layer of VGG-19 Net of image $X_{i}$ and $f_{i}$ is the caption context vector. The attention probability vec- tor $P_{a t t}$ is a 196-dimensional vector. $W_{I},W_{C},W_{P}$ are the weights and $b_{c},b_{A},b_{c}$ is the bias for different layers. We evaluate the different approaches and provide results for the same. Here $\bigoplus$ represents element-wise addition.
其中 $G_{img}$ 是从图像 $X_i$ 的 VGG-19 网络第五卷积层提取的 14x14x512 维卷积特征图,$f_i$ 是描述文本的上下文向量。注意力概率向量 $P_{att}$ 是一个 196 维向量。$W_I$、$W_C$、$W_P$ 是权重,$b_c$、$b_A$、$b_c$ 是不同层的偏置项。我们评估了不同方法并提供了相应结果。此处 $\bigoplus$ 表示逐元素相加。
E.4 Evaluation Metrics
E.4 评估指标
Our task is similar to encoder -decoder framework of machine translation. we have used same evaluation metric is used in machine translation. BLEU(Papineni et al., 2002) is the first metric to find the correlation between generated question with ground truth question. BLEU score is used to measure the precision value, i.e That is how much words in the predicted question is appeared in reference question. BLEU-n score measures the n-gram precision for counting cooccurrence on reference sentences. we have evaluated BLEU score from n is 1 to 4. The mechanism of ROUGE-n(Lin, 2004) score is similar to BLEU-n,where as, it measures recall value instead of precision value in BLEU. That is how much words in the reference question is appeared in predicted question.Another version ROUGE metric is ROUGE-L, which measures longest common sub-sequence present in the generated question. METEOR(Banerjee and Lavie, 2005) score is another useful evaluation metric to calculate the similarity between generated question with reference one by considering synonyms, stemming and paraphrases. the output of the METEOR score measure the word matches between predicted question and reference question. In VQG, it compute the word match score between predicted question with five reference question. CIDer(Vedantam et al., 2015) score is a consensus based evaluation metric. It measure human-likeness, that is the sentence is written by human or not. The consensus is measured, how often n-grams in the predicted question are appeared in the reference question. If the $\mathbf{n}$ -grams in the predicted question sentence is appeared more frequently in reference question then question is less informative and have low CIDer score. We provide our results using all these metrics and compare it with existing baselines.
我们的任务类似于机器翻译中的编码器-解码器框架。我们采用了与机器翻译相同的评估指标。BLEU (Papineni et al., 2002) 是首个用于衡量生成问题与真实问题相关性的指标,通过计算预测问题中出现在参考问题中的词汇比例来评估精确度。BLEU-n 分数通过统计参考句中n-gram共现情况来衡量n-gram精确度,我们评估了n取1至4时的BLEU分数。ROUGE-n (Lin, 2004) 的机制与BLEU-n类似,但侧重召回率而非精确率,即统计参考问题中出现在预测问题中的词汇比例。其变体ROUGE-L则通过检测生成问题中最长公共子序列来评估。METEOR (Banerjee and Lavie, 2005) 是另一重要指标,通过考虑同义词、词干和释义来计算生成问题与参考问题的相似度,其输出结果反映预测问题与参考问题间的词汇匹配度。在视觉问题生成(VQG)任务中,该指标会计算预测问题与五个参考问题间的词汇匹配分数。CIDer (Vedantam et al., 2015) 是基于共识的评估指标,通过衡量预测问题中n-gram在参考问题中的出现频率来判断语句的拟人化程度:若预测句中的 $\mathbf{n}$ -gram在参考句中频繁出现,则该问题信息量较低且CIDer分数偏低。我们使用全部上述指标呈现实验结果,并与现有基线进行对比。