ABSTRACT
摘要
As various databases of facial expressions have been made accessible over the last few decades, the Facial Expression Recognition (FER) task has gotten a lot of interest. The multiple sources of the available databases raised several challenges for facial recognition task. These challenges are usually addressed by Convolution Neural Network (CNN) architectures. Different from CNN models, a Transformer model based on attention mechanism has been presented recently to address vision tasks. One of the major issue with Transformers is the need of a large data for training, while most FER databases are limited compared to other vision applications. Therefore, we propose in this paper to learn a vision Transformer jointly with a Squeeze and Excitation (SE) block for FER task. The proposed method is evaluated on different publicly available FER databases including $\mathrm{CK}+$ , JAFFE, RAF-DB and SFEW. Experiments demonstrate that our model outperforms state-of-the-art methods on $\mathrm{CK}+$ and SFEW and achieves competitive results on JAFFE and RAF-DB.
随着过去几十年面部表情数据库的日益开放,面部表情识别(Facial Expression Recognition, FER)任务受到了广泛关注。不同来源的可用数据库给面部识别任务带来了诸多挑战,这些挑战通常由卷积神经网络(Convolution Neural Network, CNN)架构来解决。与CNN模型不同,最近提出了一种基于注意力机制的Transformer模型来处理视觉任务。Transformer的主要问题之一是需要大量数据进行训练,而与其他视觉应用相比,大多数FER数据库规模有限。因此,本文提出将视觉Transformer与挤压激励(Squeeze and Excitation, SE)模块联合学习用于FER任务。所提方法在多个公开可用的FER数据库上进行了评估,包括$\mathrm{CK}+$、JAFFE、RAF-DB和SFEW。实验表明,我们的模型在$\mathrm{CK}+$和SFEW上优于现有最优方法,在JAFFE和RAF-DB上取得了具有竞争力的结果。
Keywords ViT $\cdot$ Squeeze and Excitation $\cdot$ Facial Expressions Recognition
关键词 ViT $\cdot$ 压缩激励 $\cdot$ 面部表情识别
1 Introduction
1 引言
Year after year, human life is increasingly intertwined with Artificial Intelligence (AI)-based systems. As a result, there is a growing attention in technologies that can understand and interact with humans, or that can provide improved contact between humans. To that end, more researchers are involved in developing automated FER methods that can be summarised in three categories including Handcrafted, Deep Learning and Hybrid. Main handcrafted solutions [1, 2, 3] are based on techniques like local binary pattern (LBP), Histogram of Oriented Gradients (HOG) and Optical Flow (OF). They present good results on lab-made databases $\mathrm{CK}+$ [4] and JAFFE [5]), in contrast, they perform modestly on wild databases (SFEW [6] and RAF-DB [7]). Some researchers [8, 9, 10] have taken advantage of advancements in deep learning techniques, especially in CNN architectures, to outperform previous hand-crafted solutions. Others [11, 12] propose solutions that mix the handcrafted techniques with deep learning techniques to address specific challenges in FER.
年复一年,人类生活与基于人工智能 (AI) 的系统日益紧密交织。因此,能够理解并与人类互动、或改善人际交互的技术正受到越来越多的关注。为此,更多研究者致力于开发自动化的面部表情识别 (FER) 方法,这些方法可归纳为三类:手工设计方法、深度学习方法和混合方法。主要的手工设计方案 [1, 2, 3] 基于局部二值模式 (LBP)、方向梯度直方图 (HOG) 和光流 (OF) 等技术。它们在实验室构建的数据库 ($\mathrm{CK}+$ [4] 和 JAFFE [5]) 上表现良好,但在自然场景数据库 (SFEW [6] 和 RAF-DB [7]) 上表现一般。部分研究者 [8, 9, 10] 利用深度学习技术(尤其是 CNN 架构)的进展,超越了传统手工方案。另一些研究 [11, 12] 提出将手工技术与深度学习相结合的方案,以应对 FER 中的特定挑战。
Impressive results [13, 14, 15] from Transformer models on Natural Language Processing (NLP) tasks have motivated vision community to study the application of Transformers to computer vision problems. The idea is to represent an image as a sequence of patches in analogy of a sequence of words in a sentence in NLP domain. Transformers are made to learn parallel relation between sequence inputs through an attention mechanism which makes them theoretically suitable for both tasks NLP and image processing. The Transformer was firstly introduced by Vaswani et al. [13] as a machine translation model, and then multiple variants [13, 14, 15] were proposed to increase the model accuracy and overcome various NLP challenges. Recently, a Vision Transformer (ViT) is presented for different computer vision tasks from image classification [16], object detection [17] to image data generation [18]. The Transformer proves its capability and overcomes state-of-the-art performance in different NLP applications as well as in vision applications. However, these attention-based architectures are computationally more demanding than CNNs and training data hunger.
Transformer模型在自然语言处理(NLP)任务中取得的显著成果[13,14,15],推动了视觉领域研究其在计算机视觉问题中的应用。其核心思想是将图像表示为一系列图像块(patch)的序列,类似于NLP领域中句子由单词序列组成。Transformer通过注意力机制学习序列输入间的并行关系,理论上同时适用于NLP和图像处理任务。该模型最初由Vaswani等人[13]提出用于机器翻译,随后衍生出多种变体[13,14,15]以提升精度并解决各类NLP难题。近期提出的Vision Transformer(ViT)已成功应用于图像分类[16]、目标检测[17]和图像生成[18]等视觉任务。Transformer不仅在NLP领域展现出超越现有技术的性能,在视觉应用中也证明了其强大能力。然而,这些基于注意力的架构相比CNN需要更多计算资源,且对训练数据量要求更高。
In this paper, we propose to alleviate the problem, that ViT has, caused by the lack of training data for FER with a block of SE. We also provide an internal representations analysis of the ViT on facial expressions. The contribution of this paper can be summarized in four-folds:
本文提出通过引入SE模块缓解ViT因面部表情识别(FER)训练数据不足导致的问题,并对ViT在面部表情任务中的内部表征进行了分析。主要贡献包含四个方面:
The remaining of this paper is organized as follows. Section 2 reviews the related work. Section 3 firstly gives an overview of the proposed method and then describes the details of the ViT and the SE block. Section 4 presents the experimental results. Finally, Section 5 concludes the paper.
本文的剩余部分结构如下。第2节回顾了相关工作。第3节首先概述了所提出的方法,然后详细描述了ViT (Vision Transformer) 和SE (Squeeze-and-Excitation) 模块。第4节展示了实验结果。最后,第5节对全文进行了总结。
2 Related Works
2 相关工作
In this section, we briefly review some related works on ViT and facial expression recognition solutions.
本节简要回顾了ViT (Vision Transformer) 和面部表情识别解决方案的相关工作。
2.1 Vision Transformer (ViT)
2.1 Vision Transformer (ViT)
The ViT is first proposed by Do sov it ski y et al. [16] for image classification. The main part of the model is the encoder part of the Transformer as first introduced for machine translation by Vaswani et al. [13]. To transform the images into a sequence of patches they use a linear projection, and for the classification, they use only the token class vector. The model achieves state-of-the-art performance on ImageNet [20] classification using fine-tuning on JFT-300M [21]. From that and the fact that this model contains much more parameters (about 100M) than CNNs, we can say that ViT are data-hungry models. To address this heavily relying on large-scale databases, Touvron et al. [22] proposed DEIT model. It’s a ViT with two classification tokens. The first one is fed to an Multiple Layer Perceptron (MLP) head for the classification and the other one is used on the distillation process with a CNN teacher model pretrained on ImageNet [20]. The DEIT was only trained on ImageNet and outperforms both the ViT model and the teacher model. Yuan et al. [23] overcome the same limitation of ViT using novel token iz ation process. The proposed T2T-ViT [23] model has two modules: 1) the T2T token iz ation module that consists in two steps: re-struct uri z ation and soft split, to model the local information and reduce the length of tokens progressively, and 2) the Transformer encoder module. It achieves state-of-the-art performance on ImageNet [20] classification without a pre training on JFT-300M [21].
ViT (Vision Transformer) 最初由Dosovitskiy等人[16]提出用于图像分类。该模型的核心部分是Vaswani等人[13]首次为机器翻译引入的Transformer编码器结构。为了将图像转换为补丁序列,他们采用了线性投影方法,而分类任务仅使用类别token向量。通过在JFT-300M[21]上进行微调,该模型在ImageNet[20]分类任务上达到了最先进的性能。鉴于该模型参数量(约1亿)远超CNN,可以说ViT是数据饥渴型模型。
针对这种对大尺度数据库的重度依赖问题,Touvron等人[22]提出了DEIT模型。这是一种包含两个分类token的ViT变体:第一个token输入多层感知机(MLP)头部进行分类,第二个token用于与ImageNet[20]预训练的CNN教师模型进行蒸馏训练。DEIT仅使用ImageNet数据训练,其性能就超越了原始ViT模型和教师模型。
Yuan等人[23]通过创新的token化流程解决了ViT的相同局限。他们提出的T2T-ViT[23]模型包含两个模块:1) T2T token化模块(通过重构和软分割两步操作建模局部信息并逐步缩减token长度),2) Transformer编码器模块。该模型无需在JFT-300M[21]上预训练,就在ImageNet[20]分类任务中实现了最先进的性能。
2.2 Facial Expression Recognition
2.2 面部表情识别
The FER task has progressed from handcrafted [1, 2, 3] solutions to deep learning [8, 24, 10, 25] and Hybrid [11, 12, 26] solutions. In 2014, Turan et al. [2] proposed a region-based handcrafted system for FER. They extracted features from the eye and mouth regions using Local Phase Quantization (LPQ) and Pyramid of Histogram of Oriented Gradients (PHOG). A Principal Component Analysis (PCA) is used as a tool for features selection. They fused the two groups of features with a Canonical Correlation Analysis (CCA) and finally, a Support Vector Machine (SVM) is applied as a classifier. More recent work [3], proposed an automatic FER system based on LBP and HOG as features extractor. A local linear embedding technique is used to reduce features dimensionality and a SVM for the classification part. They reached state-of-the-art performance for handcrafted solutions on JAFFE [5], KDEF [27] and RafD [28]. Recently, more challenging and rich data have been made publicly available and with the progress of deep learning architectures, many deep learning solutions based on CNN models are revealed. Otberdout et al. [24] proposed to use Symmetric
FER任务的发展经历了从手工设计[1,2,3]到深度学习[8,24,10,25]再到混合方法[11,12,26]的演进。2014年,Turan等人[2]提出了一种基于区域的手工FER系统,采用局部相位量化(LPQ)和梯度方向金字塔直方图(PHOG)从眼部与嘴部区域提取特征,并运用主成分分析(PCA)进行特征选择。通过典型相关分析(CCA)融合两组特征后,最终使用支持向量机(SVM)进行分类。最新研究[3]提出基于LBP和HOG特征提取器的自动FER系统,采用局部线性嵌入技术降维并搭配SVM分类器,在JAFFE[5]、KDEF[27]和RafD[28]数据集上取得了手工方法的最高性能。近年来随着更具挑战性的丰富数据公开和深度学习架构进步,涌现出许多基于CNN模型的解决方案。Otberdout等人[24]提出采用对称...
Positive Definite (SPC) to replace the fully connected layer in CNN architecture for facial expression classification. Wang et al. [25] proposed a region-based solution with a CNN model with two blocks of attention. They perform different crop of the same image and apply a CNN on each patch. A self-attention module is then applied followed by a relation attention module. On the self-attention block, they use a loss function in a way that one of the cropped image may have a weight larger than the weight given to the input image. More recently, Farzaneh et al. [10] have integrated an attention block to estimate the weights of features with a sparse center loss to achieve intra-class compactness and inter-class separation. Deep learning based solutions have widely outperformed handcrafted solutions especially on wild databases like RAF-DB [7], SFEW[6], AffectNet [29] and others.
采用对称正定(SPC)替代CNN架构中的全连接层进行面部表情分类。Wang等人[25]提出了一种基于区域的解决方案,采用带双注意力模块的CNN模型。他们对同一图像进行不同裁剪,并在每个图像块上应用CNN。随后依次应用自注意力模块和关系注意力模块。在自注意力模块中,他们采用了一种特殊的损失函数,使得某个裁剪图像的权重可能超过输入图像的权重。最近,Farzaneh等人[10]通过集成注意力模块来估计特征权重,并结合稀疏中心损失函数,实现了类内紧凑性和类间分离性。基于深度学习的解决方案已显著超越手工设计方法,尤其在RAF-DB[7]、SFEW[6]、AffectNet[29]等非约束场景数据库上表现突出。
Other researchers have though about combining deep learning techniques with handcrafted techniques into a hybrid system. Levi et al. [11] proposed to apply CNN on the image, its LBP and the mapped LBP to a 3D space using Multi Dimensional Scaling (MDS). Xu et al. [12] proposed to fuse CNN features with LBP features and they used PCA as features selector. Newly, many Transformer models have been introduced for different computer vision tasks and in that context Ma et al. [26] proposed a convolutional vision Transformer. They extract features from the input image as well as form its LBP using a ResNet18. Then, they fuse the extracted features with an attention al selective fusion module and fed the output to a Transformer encoder with a MLP head to perform the classification. To our knowledge, [26] is considered as the first solution based on Transformer architecture for FER. However, our proposed solution differs in applying the Transformer encoder directly on the image and not on the extracted features which may reduce the complexity of the proposed system and aid to study and analyse the application of ViT on FER problem as one of the interesting vision tasks.
其他研究者也考虑过将深度学习技术与手工技术结合成混合系统。Levi等人[11]提出在图像、其LBP(局部二值模式)及通过多维缩放(MDS)映射到3D空间的LBP上应用CNN。Xu等人[12]建议融合CNN特征与LBP特征,并采用PCA作为特征选择器。近年来,许多Transformer模型被引入不同计算机视觉任务,在此背景下Ma等人[26]提出了一种卷积视觉Transformer。他们使用ResNet18从输入图像及其LBP中提取特征,随后通过注意力选择融合模块整合特征,并将输出送入带MLP头的Transformer编码器进行分类。据我们所知,[26]被认为是首个基于Transformer架构的FER解决方案。然而,我们提出的方案不同之处在于直接将Transformer编码器应用于图像而非提取特征,这有助于降低系统复杂度,并为研究分析ViT在FER这一有趣视觉任务中的应用提供支持。
Table 8 (presented in the Supplementary Material) summarizes some state-of-the-art approaches with details on the used architecture and databases. We can notice that different databases are used to address different issues and challenges. From these databases we selected 4 of them to study our proposed solution and compare it with state-of-the-art works. The selected databases are described in the experiments and comparison Section 4. In the next section we will describe our proposed solution.
表8 (见补充材料) 总结了部分前沿方法,详细列出了所用架构和数据库。我们可以注意到,不同数据库用于解决不同问题和挑战。从中我们选取了4个数据库来研究提出的解决方案,并与前沿工作进行对比。所选数据库将在实验与对比章节4中描述。下一节将详细介绍我们提出的解决方案。
3 Proposed Method
3 提出的方法
In this section, we introduce the proposed solution in three separate paragraphs: an overview, then some details of the ViT architecture and the attention mechanism, and finally the SE block.
在本节中,我们将通过三个独立段落介绍提出的解决方案:概述、ViT架构与注意力机制的部分细节,以及最后的SE模块。
3.1 Architecture overview
3.1 架构概述
The proposed solution contains two main parts, a vision Transformer to extract local attention features and a SE block to extract global relation from the extracted features which may optimize the learning process on small facial expressions databases.
所提出的解决方案包含两个主要部分:一个用于提取局部注意力特征的视觉Transformer,以及一个SE模块(Squeeze-and-Excitation block)用于从提取的特征中获取全局关系,这可以优化在小规模面部表情数据库上的学习过程。
3.2 Vision Transformer
3.2 Vision Transformer
The vision Transformer consists of two steps: the token iz ation and the Transformer encoder. In the token iz ation step, the image is cropped onto $L$ equal $(h\times h)$ dimension patches and then flattened to a vector. An extra learnable vector is added as a token for classification called "cls_tkn". Each vector is marked with a position value. To summarize, the input of the Transformer encoder is $L+1$ vectors of length $h^{2}+1$ .
视觉Transformer由两个步骤组成:Token化和Transformer编码器。在Token化步骤中,图像被裁剪为$L$个尺寸相同$(h\times h)$的补丁,然后展平为向量。额外添加一个可学习的向量作为分类Token,称为"cls_tkn"。每个向量都标有位置值。总结来说,Transformer编码器的输入是$L+1$个长度为$h^{2}+1$的向量。
As shown in Figure 1, the Transformer encoder is a sequence of $N$ blocks of the attention module. The main part of the attention block is the Multi-Head Attention (MHA). The MHA is build with $z$ heads of self-Attention, also called intra-attention. According to [13], the idea of the self-attention is to relate different positions of a single sequence in order to compute a representation of the sequence. For a given sequence, 3 layers are used: Q-layer, K-layer and V-layer and the self-attention function will be a mapping of a query (Q or Q-layer) and a set of key-value (K or K-layer; $\mathrm{v}$ or V-layer) pairs to an output. The self-attention function is summarized by Equation (1):
如图 1 所示,Transformer 编码器由 $N$ 个注意力模块块组成。注意力块的主要部分是多头注意力 (Multi-Head Attention, MHA)。MHA 由 $z$ 个自注意力 (self-Attention) 头构建而成,也称为内部注意力 (intra-attention)。根据 [13],自注意力的思想是将单个序列的不同位置关联起来以计算序列的表示。对于给定序列,使用了 3 个层:Q 层、K 层和 V 层,自注意力函数将是查询 (Q 或 Q 层) 与一组键值对 (K 或 K 层;$\mathrm{v}$ 或 V 层) 到输出的映射。自注意力函数由公式 (1) 总结:
And so the MHA Equation (2) will be:
因此,MHA 方程 (2) 将表示为:
$$
A t t e n t i o n(Q,K,V)=s o f t m a x(\frac{Q K^{T}}{\sqrt{d_{k}}})V.
$$
$$
A t t e n t i o n(Q,K,V)=s o f t m a x(\frac{Q K^{T}}{\sqrt{d_{k}}})V.
$$
$$
\begin{array}{r l}&{M H A(Q,K,V)=C o n c a t(h e a d_{0},...,h e a d_{z})W^{O},}\ &{~h e a d_{i}=A t t e n t i o n(Q W_{i}^{Q},K W_{i}^{K},V W_{i}^{V}).}\end{array}
$$
$$
\begin{array}{r l}&{M H A(Q,K,V)=C o n c a t(h e a d_{0},...,h e a d_{z})W^{O},}\ &{~h e a d_{i}=A t t e n t i o n(Q W_{i}^{Q},K W_{i}^{K},V W_{i}^{V}).}\end{array}
$$
where the projections $W^{O},W_{i}^{Q},W_{i}^{K}$ and $W_{i}^{V}$ are parameters’ matrices.
其中投影矩阵 $W^{O},W_{i}^{Q},W_{i}^{K}$ 和 $W_{i}^{V}$ 为参数矩阵。
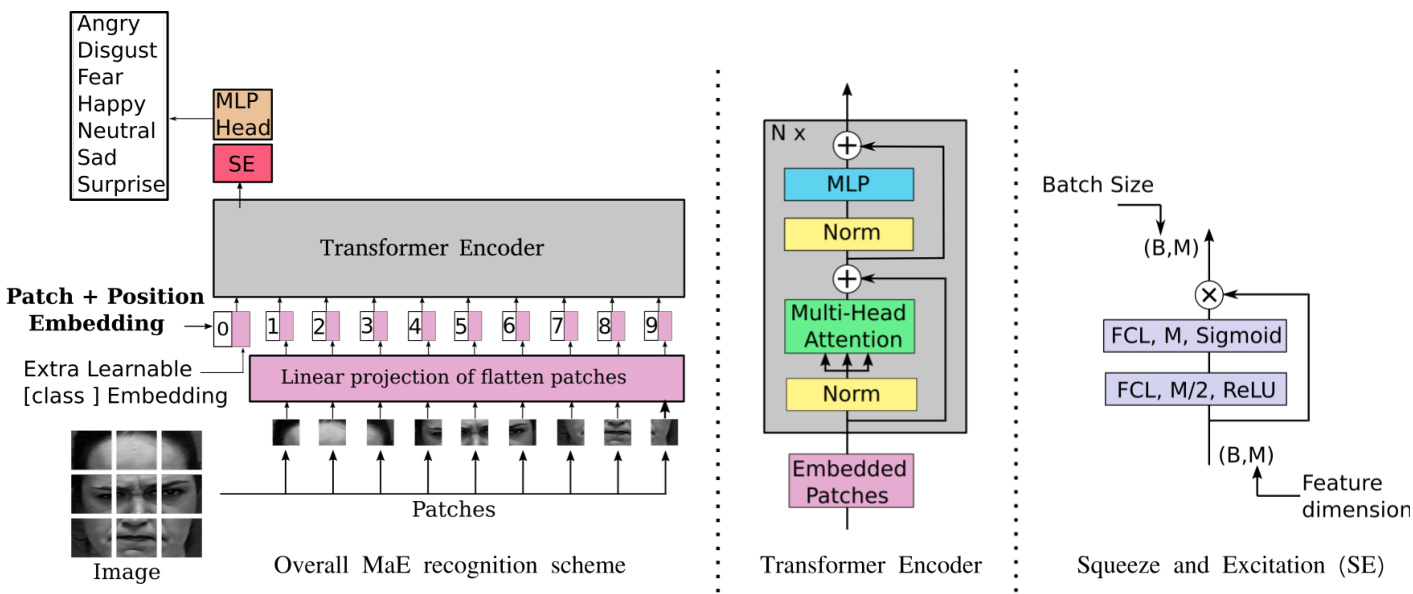
Figure 1: Overview of the proposed solution. The used ViT is the base version with 14 layers of Transformer encoder and patch dimension of $(16\times16)$ . The ViT is already trained on JFT-300M [21] database and fine-tuned to ImageNet-1K [20] database.
图 1: 所提方案概述。使用的ViT为基础版本,包含14层Transformer编码器,分块尺寸为$(16\times16)$。该ViT已在JFT-300M [21] 数据库上完成预训练,并针对ImageNet-1K [20] 数据库进行了微调。
3.3 Squeeze and Excitation (SE)
3.3 压缩和激励 (SE)
The Squeeze and Excitation block, shown on the right of the Figure 1, is also an attention mechanism. It contains widely fewer parameters than self-attention block as shown by Equation (3) where two fully connected layers are used with only one operation of pointwise multiplication. It is firstly introduced in [30] to optimize CNN architecture as a channel-wise attention module, concretely we use only the excitation part since the squeeze part is a pooling layer build to reduce the dimension of the 2d-CNN layers.
图 1: 右侧所示的Squeeze and Excitation模块同样是一种注意力机制。如公式(3)所示,它仅通过两次全连接层和一次点乘运算实现,因此参数量远低于自注意力模块。该模块最初由[30]提出,用于优化CNN架构作为通道注意力模块。具体实现中,我们仅采用其激励(excitation)部分,因为压缩(squeeze)部分是为降低2D-CNN层维度而设计的池化层。
$$
\begin{array}{r}{S E(c l s_t k n)=c l s_t k n\odot E x c i t a i o n(c l s_t k n),\qquad}\ {E x c i t a i o n(c l s_t k n)=S i g m o i d(F C L_{\gamma}(R e L U(F C L_{\gamma/4}(c l s_t k n)))).}\end{array}
$$
$$
\begin{array}{r}{S E(c l s_t k n)=c l s_t k n\odot E x c i t a i o n(c l s_t k n),\qquad}\ {E x c i t a i o n(c l s_t k n)=S i g m o i d(F C L_{\gamma}(R e L U(F C L_{\gamma/4}(c l s_t k n)))).}\end{array}
$$
where $F C L_{\gamma}$ and $F C L_{\gamma/4}$ are fully connected layers with respectively $\gamma$ neurons and $\gamma/4$ neurons, $\gamma$ is the length of the cls_tkn which is the classification token vector and $\odot$ is a pointwise multiplication. The idea of using SE in our architecture is to optimize the learning of the ViT by learning more global attention relations between extracted local attention features. Thus, the SE is introduced on top of the Transformer encoder more precisely on the classification token vector. Different from the self-attention block where it is used inside the Transformer encoder to encode the input sequence and extract features through cls_tkn, the SE is applied to re calibrate the feature responses by explicitly modelling inter-dependencies among cls_tkn channels.
其中 $F C L_{\gamma}$ 和 $F C L_{\gamma/4}$ 分别是具有 $\gamma$ 个神经元和 $\gamma/4$ 个神经元的全连接层,$\gamma$ 是分类标记向量 cls_tkn 的长度,$\odot$ 表示逐点乘法。在我们的架构中使用 SE (Squeeze-and-Excitation) 的目的是通过学习提取的局部注意力特征之间更全局的注意力关系,来优化 ViT (Vision Transformer) 的学习。因此,SE 被引入到 Transformer 编码器之上,更准确地说是在分类标记向量上应用。与自注意力块不同(自注意力块在 Transformer 编码器内部用于编码输入序列并通过 cls_tkn 提取特征),SE 的作用是通过显式建模 cls_tkn 通道间的相互依赖关系来重新校准特征响应。
4 Experiments and Comparison
4 实验与对比
In this section, we first describe the used databases, and then provide an ablation study for different contributions with other details on the proposed solution and an analysis of additional visualisation for in-depth understanding of the ViT applied on FER task. Finally, we present a comparison with state-of-the-art works.
在本节中,我们首先介绍所使用的数据库,然后针对不同贡献进行消融研究,并提供所提出解决方案的其他细节,同时通过额外可视化分析深入理解应用于FER(面部表情识别)任务的ViT (Vision Transformer) 。最后,我们与当前最先进的工作进行对比。
4.1 FER Databases
4.1 FER 数据库
$\mathbf{CK}+$ [4] : published on 2010, and it is an extended version of Cohne-Kanade (CK) database. It contains 593 sequences taken in lab environment with two data formats $(640\times490)$ and $(640\times480)$ . It encompasses the 7 basic expressions which are : Angry, Disgust, Fear, Happy, Neutral, sad and Surprise, plus the Contempt expression. In our case, we only worked on the 7 basic expressions to have a fair study with other databases and with most state-of-the-art solutions. JAFFE [5]: The Japanese Female Facial Expression (JAFFE) database is a 213 gray scale images of acted Japanese female facial expressions. All the images are resized onto $(256\times256)$ . It contains the 7 basic expressions. FER-2013 [19]: The FER-2013 database, or sometimes referred as FERPlus, is almost 35k facial expressions database on 7 basic expressions. Published in 2013 in a challenge on Kaggle plate-form1. The images are collected from the web converted to gray scale model and resized to $(48\times48)$ . Theoretically, this database could suffer from mis labeling since a $68%\pm5%$ human accuracy is reported. However, since it is a large spontaneous databases of facial expressions we used it as a pre-training data for our model.
$\mathbf{CK}+$ [4]:发布于2010年,是Cohne-Kanade (CK)数据库的扩展版本。它包含593个在实验室环境下采集的序列,具有两种数据格式$(640\times490)$和$(640\times480)$。涵盖了7种基本表情:愤怒、厌恶、恐惧、快乐、中性、悲伤和惊讶,外加轻蔑表情。在我们的研究中,仅使用7种基本表情以与其他数据库及主流解决方案进行公平对比。
JAFFE [5]:日本女性面部表情(JAFFE)数据库包含213张日本女性表演性面部表情的灰度图像。所有图像均调整为$(256\times256)$尺寸,包含7种基本表情。
FER-2013 [19]:FER-2013数据库(或称FERPlus)包含约3.5万张7种基本表情的面部图像。该数据库于2013年通过Kaggle平台竞赛发布,图像采集自网络并转换为灰度模型,尺寸调整为$(48\times48)$。理论上该数据库可能存在标签错误(据报告人类标注准确率为$68%\pm5%$),但由于其作为大规模自然表情数据库,我们将其用作模型的预训练数据。
SFEW [6]: The Static Facial Expression in the Wild (SFEW) is a very challenging databases with images captured from different movies. It contains 1,766 RGB images with size of ( $720\times576)$ . It is also labeled with the 7 basic expressions.
SFEW [6]: Static Facial Expression in the Wild (SFEW) 是一个极具挑战性的数据库,其图像采集自不同电影。它包含1,766张尺寸为 ( $720\times576$ ) 的RGB图像,并标注了7种基本表情。
RAF-DB [7]: The Real-world Affective Faces Database (RAF-DB) is a recent database with nearly 30K of mixed RGB and gray scale images collected from different internet websites. This database contains two separate sub-data: one with 7 basic expressions and the other with 12 compound facial expressions. In the experiments, we used the 7 basic expressions version.
RAF-DB [7]: Real-world Affective Faces Database (RAF-DB) 是一个包含近3万张从不同网站收集的混合RGB与灰度图像的最新数据库。该数据库包含两个独立子集: 一个包含7种基本表情, 另一个包含12种复合面部表情。实验中我们采用了7种基本表情版本。
Table 7 (presented in the Supplementary Material) summarizes previous presented databases with reference to the year and the publication conference and some other details. For FER task there are other publicly available databases that address different issues, but we restrained our choices on these databases because they are in the center of interest of major state-of-the-art solutions.
表 7 (见补充材料) 总结了之前介绍的数据库,包括年份、发表会议和其他一些细节。对于 FER (Facial Expression Recognition) 任务,还有其他公开可用的数据库涉及不同问题,但我们选择这些数据库是因为它们是当前最先进解决方案的核心关注点。
4.2 Architecture and training parameters
4.2 架构与训练参数
In all experiments, we use a pretrained ViT-B16-224 (weights ), the base version of the ViT with $(16\times16)$ patch size and $(224\times224)$ input image size. Since ViT training needs large data to reach good performance we used the following list of data augmentation: Random Horizontal flip, Random GrayScale conversion, different values of brightness, contrast and saturation. All images are converted to 3 channels, resized to $(224\times224)$ and normalized. The regular is ation methods we used in this work are Cutout [31] and Mixup [32]. The training is performed with categorical cross entropy as a loss function and AdamW [33] as an optimizer. The learning rate is fixed to $1.6\times10^{-4}$ with a batch size of 16. When training on FER-2013 database, the number of epochs is fixed to 8 and for the rest of databases it is fixed to 10. The training process is carried-out on a Tesla K80 TPU with 8 cores using Pytorch1.7.
在所有实验中,我们使用预训练的ViT-B16-224(权重),这是ViT的基础版本,具有$(16\times16)$的补丁大小和$(224\times224)$的输入图像尺寸。由于ViT训练需要大量数据才能达到良好性能,我们采用了以下数据增强方法:随机水平翻转、随机灰度转换、不同的亮度、对比度和饱和度值。所有图像均转换为3通道,调整大小为$(224\times224)$并进行归一化处理。本工作中使用的正则化方法包括Cutout [31]和Mixup [32]。训练采用分类交叉熵作为损失函数,AdamW [33]作为优化器。学习率固定为$1.6\times10^{-4}$,批量大小为16。在FER-2013数据库上训练时,epoch数固定为8,其他数据库固定为10。训练过程在8核Tesla K80 TPU上使用Pytorch1.7完成。
4.3 Ablation Study
4.3 消融实验
In the ablation study, we assess the performance of the ViT architecture, the added SE block and the use of FER2013 [19] as a pre-training data. Table 1 shows the result of different experiments on $\mathrm{CK}+$ , JAFFE, RAF-DB and SFEW. From first line, we can notice that ViT can reach state-of-the-art performance on lab-made databases like $\mathrm{CK}+$ [4] and JAFFE [5], however on SFEW [6] the Transformer is less effective. In all cases, we can notice that there is a benefit of using SE and the pre-training phase on FER-2013 [19]. The two contributions may not be complementary on lab-made data ( $\mathrm{CK}{+}{+}$ [4] and JAFFE [5]). For example, on $\mathrm{CK}{+}{+}$ [4] we can notice that the pre-training improves the performance only when combined with the SE. On JAFFE [5], the best solution is the one that relies on pre-training without the SE. Although, on wild databases (RAF-DB [7] and SFEW [6]) the added value of both contributions is more noticeable, specially on SFEW [6] we can obtain a $16%$ gain on accuracy compared to the ViT without a SE neither a pre-training on FER-2013 [19].
在消融研究中,我们评估了ViT架构、新增的SE模块以及使用FER2013[19]作为预训练数据的性能表现。表1展示了在$\mathrm{CK}+$、JAFFE、RAF-DB和SFEW数据集上的不同实验结果。从第一行可以看出,ViT在实验室构建的数据库如$\mathrm{CK}+$[4]和JAFFE[5]上能达到最先进性能,但在SFEW[6]数据集上Transformer效果欠佳。所有实验表明,使用SE模块和FER-2013[19]预训练阶段均有收益。这两种改进在实验室数据($\mathrm{CK}{+}{+}$[4]和JAFFE[5])上可能不具备互补性。例如在$\mathrm{CK}{+}{+}$[4]中,预训练仅在与SE模块结合时才能提升性能;而在JAFFE[5]上,最佳方案是不使用SE模块的预训练模型。但在真实场景数据库(RAF-DB[7]和SFEW[6])中,两种改进的协同价值更为显著,特别是在SFEW[6]上,相比未使用SE模块且未进行FER-2013[19]预训练的ViT模型,准确率可获得$16%$的提升。
Table 1: Ablation Study
* The used ViT model is already trained on ImageNet [20].
表 1: 消融实验
| 模型 | 预训练 | CK+ [4] | JAFFE [5] | RAF-DB [7] | SFEW [6] |
|---|---|---|---|---|---|
| ViT | X* | 0.9857 | 0.8823 | 0.8595 | 0.3828 |
| ViT+SE | X* | 0.9949 | 0.9061 | 0.8618 | 0.4084 |
| ViT | FER-2013[19]* | 0.9817 | 0.9483 | 0.8703 | 0.5035 |
| ViT+SE | FER-2013[19]* | 0.9980 | 0.9292 | 0.8722 | 0.5429 |
- 使用的ViT模型已在ImageNet [20]上预训练。
The confusion matrices of the proposed $\mathrm{ViT}{+}\mathrm{SE}$ pre-trained on FER-2013 are reported in Figure 2, the left plot is for the validation set of RAF-DB [7] and the right plot is for the validation set of SFEW [6]. The Happy and Neutral expressions are the best recognized on the SFEW [6] database with respectively an accuracy of $69%$ and $57%$ . For RAF-DB [7], the Happy expression has the best accuracy with $93%$ followed by the Sad expression with $89%$ accuracy.
图 2 展示了在 FER-2013 上预训练的 $\mathrm{ViT}{+}\mathrm{SE}$ 混淆矩阵,左图为 RAF-DB [7] 的验证集结果,右图为 SFEW [6] 的验证集结果。在 SFEW [6] 数据库中,Happy (快乐) 和 Neutral (中性) 表情的识别效果最佳,准确率分别为 $69%$ 和 $57%$。对于 RAF-DB [7],Happy (快乐) 表情以 $93%$ 的准确率表现最优,其次是 Sad (悲伤) 表情,准确率为 $89%$。

Figure 2: Confusion matrices of $\mathrm{ViT}{+}S\mathrm{E}$ on the validation set of RAF-DB (left) and the validation set of SFEW (right).
图 2: $\mathrm{ViT}{+}S\mathrm{E}$ 在 RAF-DB 验证集(左)和 SFEW 验证集(右)上的混淆矩阵。

Figure 3: t-SNE plots corresponding to the 768-dimensional features from the ViT, $\mathrm{ViT}{+}\mathrm{SE}$ before and after the SE block and the 512-dimensional features from the ResNet50. The features correspond to the RAF-DB images. The accuracy of ResNet50, ViT and $\mathrm{ViT}{+}\mathrm{SE}$ on RAF-DB are respectively: 0.8061, 0.8595 and 0.8618.
图 3: 来自ViT的768维特征、SE模块前后的$\mathrm{ViT}{+}\mathrm{SE}$特征以及ResNet50的512维特征对应的t-SNE图。这些特征对应于RAF-DB数据集中的图像。ResNet50、ViT和$\mathrm{ViT}{+}\mathrm{SE}$在RAF-DB上的准确率分别为:0.8061、0.8595和0.8618。
On the two confusion matrices, we can notice that our model confront difficulties in recognizing the Fear expression, and that may be due to the less amount of data provided for that expression compared to the rest of expressions.
从这两个混淆矩阵中可以看出,我们的模型在识别恐惧表情时存在困难,这可能是由于该表情的训练数据量比其他表情少所致。
4.4 Transformer visualisation and analysis
4.4 Transformer可视化与分析
In this section, we have conducted a various set of experiments in RAF-DB database. Specially, we evaluate the classification outputs of the model through t-SNE and we provide a visual analysis of the ViT model performance with the SE in comparison with CNN.
在本节中,我们在RAF-DB数据库上进行了多组实验。特别地,我们通过t-SNE评估了模型的分类输出,并对比CNN提供了带有SE(Squeeze-and-Excitation)的ViT模型性能的可视化分析。
Figure 3 shows the t-SNE of the extracted features form the ViT model without SE, the features of the $\mathrm{ViT}+\mathrm{SE}$ after the SE block and before SE, and compared with t-SNE of ResNet50 [34] features trained also on RAF-DB. Based on t-SNE, the ViT architectures enable better separation of classes compared to CNN base-line architecture (ResNet50).
图 3: 展示了从无SE模块的ViT模型中提取的特征、经过SE模块前后的$\mathrm{ViT}+\mathrm{SE}$特征,以及与同样在RAF-DB上训练的ResNet50 [34]特征的t-SNE对比。根据t-SNE分析,相比基于CNN的基线架构(ResNet50),ViT架构能实现更好的类别分离。

Figure 4: GRAD-CAM, Score-CAM, Eigen-CAM maps of the last layer before the classification block for the Happy expression (image from the validation set of RAF-DB [7]).
图 4: 快乐表情分类块前最后一层的 GRAD-CAM、Score-CAM 和 Eigen-CAM 热力图 (图片来自 RAF-DB [7] 验证集)。
In addition, the SE block enhances ViT model robustness, as the intra-distances between clusters are maximized. Interestingly, the features before the SE form a more compact clusters with inter-distance lower than the features after the SE, which may interpret the features before SE are more robust than those after the SE. However, we tried to use the before SE features directly in the classification task and no performance gain has been reported. Figure 4 shows different maps of attention of the ViT, the $\mathrm{ViT}{+}\mathrm{SE}$ and the ResNet50, using Grad-Cam [35], Score-Cam [36] and Eigen-Cam [37] tools. This visualisation shows that ViT architectures succeed to focus more locally which confirm the interest of using the self-attention blocks for computer vision tasks. Once again, we can notice the gain of using the SE block with different tools but mostly using Eigen-CAM [37].
此外,SE模块(Squeeze-and-Excitation)增强了ViT模型的鲁棒性,因为其最大化簇间距离。有趣的是,SE模块前的特征会形成更紧密的簇,且簇间距离小于SE模块后的特征,这可能表明SE前的特征比SE后的更具鲁棒性。然而,我们尝试直接在分类任务中使用SE前的特征,并未观察到性能提升。图4展示了ViT、ViT+SE和ResNet50通过Grad-CAM [35]、Score-CAM [36]和Eigen-CAM [37]工具生成的注意力热图对比。可视化结果表明,ViT架构能更聚焦局部区域,印证了自注意力模块在计算机视觉任务中的价值。值得注意的是,使用SE模块后,各类可视化工具(尤其是Eigen-CAM [37])均显示出性能提升。
Other investigations of the ViT architecture are presented in the Supplementary Material (Figure 5) that shows the evolution of the attention form first attention block to a deeper attention blocks and we can notice that the focus of the ViT goes from global attention to more local attention. This particular behaviour of the ViT on FER task is the motivation of using SE block on top of it to build a calibrated relation between different local focuses. In Figure 6 (Supplementary Material), we show the focus of the ViT compared to the $\mathrm{ViT}+\mathrm{SE}$ for different facial expressions and it shows how the SE can rectify the local attention feature extracted with the ViT, by searching for a global attention relations.
补充材料(图5)展示了ViT架构的其他研究结果,呈现了注意力机制从首个注意力块到深层注意力块的演变过程。我们可以观察到ViT的关注点从全局注意力逐渐转向更局部的注意力。ViT在面部表情识别(FER)任务中的这一特殊表现,正是我们在其基础上引入SE模块的动机——旨在不同局部关注点之间建立校准关系。在补充材料图6中,我们对比了ViT与$\mathrm{ViT}+\mathrm{SE}$对不同面部表情的关注模式,结果表明SE模块能通过寻找全局注意力关系,有效修正ViT提取的局部注意力特征。
4.5 Comparison with state-of-the-art
4.5 与最先进技术的比较
In this paper, we compare our proposed model $\mathrm{ViT}{+}\mathrm{SE}$ pre-trained on FER-2013 [19] database with state-of-the-art solution on 2 lab-made databases $\mathrm{CK}+$ [4] and JAFFE [5]) and 2 wild databases (RAF-DB [7] and SFEW [6]). Table 2 shows that we have the highest accuracy on $\mathrm{CK}+$ [4] with a $99.80%$ using a 10-fold cross-validation protocol. Table 5 shows that we set the new state-of-the-art performance for single models on SFEW [6] with $54.29%$ accuracy, however a higher accuracy $(56.4%)$ is reported in [25] using ensemble models. Furthermore, in Table 3 the proposed solution have a good 10-fold cross validation accuracy on JAFFE [5] with $92.92%$ . To our knowledge, it is the highest performance with a deep learning based solution but still less by almost $3%$ than the highest obtained accuracy with newly handcrafted proposed solution [3]. Table 4 shows that our solution has a good result on RAF-DB [7] with an accuracy of $87.22%$ , to position as the third best solution among state-of-the-art on this database, less than the best record by nearly $3%$ .
本文中,我们将提出的 $\mathrm{ViT}{+}\mathrm{SE}$ 模型(基于FER-2013 [19]数据库预训练)与最先进解决方案在2个实验室自制数据库($\mathrm{CK}+$ [4]和JAFFE [5])及2个真实场景数据库(RAF-DB [7]和SFEW [6])上进行比较。表2显示,采用10折交叉验证协议时,我们在$\mathrm{CK}+$ [4]上以$99.80%$的准确率取得最高结果。表5表明,我们以$54.29%$的准确率在SFEW [6]上为单模型设立了新标杆,但文献[25]通过集成模型报告了更高准确率$(56.4%)$。此外,表3显示所提方案在JAFFE [5]上获得$92.92%$的优秀10折交叉验证准确率。据我们所知,这是基于深度学习的解决方案中的最佳表现,但仍比采用新型手工设计方案的文献[3]最高准确率低约$3%$。表4显示我们的方案在RAF-DB [7]上取得$87.22%$的良好结果,位列该数据库现有方案第三名,与最佳记录相差近$3%$。
Table 2: Comparison on $\mathbf{CK}+$ [4] with 10-fold cross validation.
表 2: 在 $\mathbf{CK}+$ [4] 数据集上采用 10 折交叉验证的性能对比。
| 参考文献 | 模型类型 | 准确率 |
|---|---|---|
| [2] 2014 | 手工特征 | 0.9503 |
| [9]2020 [38]2021 | 深度学习 深度学习 | 0.9759 0.9800 |
| ViT + SE | 深度学习 | 0.9980 |
Table 3: Comparison on JAFFE [5] with 10-fold cross validation.
表 3: JAFFE [5] 数据集上的 10 折交叉验证对比结果。
| 参考文献 | 模型类型 | 准确率 |
|---|---|---|
| [39]2015 | 手工特征 (Handcrafted) | 0.9180 |
| [3]2020 [38]2021 | 手工特征/深度学习 (Handcrafted/Deep Learning) | 0.9600/0.9280 |
| ViT+SE | 深度学习 (Deep Learning) | 0.9292 |
Table 4: Comparison on the validation set of RAFDB [7]
表 4: RAFDB [7] 验证集上的对比
| Ref. | Model Type | Accuracy |
|---|---|---|
| [25]2020 [26]2021 | 深度学习混合模型 (Deep Learning Hybrid) | 0.8690 0.8814 |
| [40]2021 | 深度学习 (Deep Learning) | 0.9055 |
| ViT + SE | 深度学习 (Deep Learning) | 0.8722 |
Table 5: Comparison on the validation set of SFEW [6]
表 5: SFEW [6] 验证集上的对比
| Ref. | Model Type | Accuracy |
|---|---|---|
| [24]2018 41]2018 [25]2020 | 深度学习 深度学习 深度学习 | 0.4918 0.5252 0.5419 |
| ViT+SE | 深度学习 | 0.5429 |
5 Conclusion
5 结论
In this work, we introduced the $\mathrm{ViT}{+}\mathrm{SE}$ , a simple scheme that optimize the learning of the ViT by an attention block called Squeeze and Excitation. It performs impressively well for improving the performance of ViT in FER task. Furthermore, it also improves the robustness of the model as shown in the t-SNE representation of the extracted features and in the attention maps. We have presented the classification performance on lab-made databases $\mathrm{CK}+$ and JAFFE) and wild databases (RAF-DB and SFEW) to evaluate the gain of the SE block and the use of FER-2013 as a pre-training database. By comparing to different state-of-the-art solutions, we have shown that our proposed solution achieves the highest performance with a single model on $\mathrm{CK}+$ and SFEW, and competitive results on JAFFE and RAF-DB. As future work, we aim to extend the ViT architecture to address the temporal aspect for a more competitive task like micro-expressions recognition.
在本工作中,我们提出了 $\mathrm{ViT}{+}\mathrm{SE}$ 方案,这是一种通过名为Squeeze and Excitation的注意力模块来优化ViT学习的简单方法。该方法在提升ViT于面部表情识别(FER)任务中的表现方面效果显著。此外,如提取特征的t-SNE表征和注意力图所示,它还增强了模型的鲁棒性。我们通过在实验室构建的数据库( $\mathrm{CK}+$ 和JAFFE)及自然场景数据库(RAF-DB和SFEW)上展示分类性能,评估了SE模块的增益以及使用FER-2013作为预训练数据库的效果。通过与不同前沿方案的对比,我们证明了所提方案在 $\mathrm{CK}+$ 和SFEW上以单一模型取得了最高性能,在JAFFE和RAF-DB上也获得了具有竞争力的结果。作为未来工作,我们计划扩展ViT架构以处理时序特征,从而应对微表情识别等更具挑战性的任务。