Tracking Anything with Decoupled Video Segmentation
基于解耦视频分割的通用目标追踪

Figure 1. Visualization of our semi-online video segmentation results. Top: our algorithm (DEVA) extends Segment Anything (SAM) [30] to video for open-world video segmentation with no user input required. Bottom: DEVA performs text-prompted video segmentation for novel objects (with prompt “beyblade”, a type of spinning-top toy) by integrating Grounding-DINO [38] and SAM [30].
图 1: 我们的半在线视频分割结果可视化。顶部:我们的算法 (DEVA) 将 Segment Anything (SAM) [30] 扩展到视频领域,实现无需用户输入的开开放世界视频分割。底部:DEVA 通过整合 Grounding-DINO [38] 和 SAM [30],对新颖物体 (提示词为 "beyblade",一种陀螺玩具) 执行文本提示视频分割。
Abstract
摘要
Training data for video segmentation are expensive to annotate. This impedes extensions of end-to-end algorithms to new video segmentation tasks, especially in large-vocabulary settings. To ‘track anything’ without training on video data for every individual task, we develop a decoupled video segmentation approach (DEVA), composed of task-specific image-level segmentation and class/task-agnostic bi-directional temporal propagation. Due to this design, we only need an image-level model for the target task (which is cheaper to train) and a universal temporal propagation model which is trained once and generalizes across tasks. To effectively combine these two modules, we use bi-directional propagation for (semi-)online fusion of segmentation hypotheses from different frames to generate a coherent segmentation. We show that this decoupled formulation compares favorably to end-to-end approaches in several data-scarce tasks including large-vocabulary video panoptic segmentation, open-world video segmentation, referring video segmentation, and unsupervised video object segmentation. Code is available at: hkchengrex.github.io/ Tracking-Anything-with-DEVA.
视频分割的训练数据标注成本高昂,这阻碍了端到端算法在新视频分割任务中的扩展,尤其是在大词汇量场景下。为了实现"追踪万物"而无需针对每项任务单独训练视频数据,我们开发了一种解耦视频分割方法(DEVA),该方法由任务专用的图像级分割和类别/任务无关的双向时序传播组成。得益于这一设计,我们仅需为目标任务训练一个图像级模型(训练成本更低)和一个通用时序传播模型(只需训练一次即可跨任务泛化)。为有效整合这两个模块,我们采用双向传播技术对不同帧的分割假设进行(半)在线融合,从而生成连贯的分割结果。实验表明,在包括大词汇量视频全景分割、开放世界视频分割、指代视频分割和无监督视频目标分割等多个数据稀缺任务中,这种解耦方案优于端到端方法。代码已开源:hkchengrex.github.io/Tracking-Anything-with-DEVA。
1. Introduction
1. 引言
Video segmentation aims to segment and associate objects in a video. It is a fundamental task in computer vision and is crucial for many video understanding applications.
视频分割旨在对视频中的物体进行分割与关联。这是计算机视觉领域的一项基础任务,对众多视频理解应用至关重要。
Most existing video segmentation approaches train endto-end video-level networks on annotated video datasets. They have made significant strides on common benchmarks like YouTube-VIS [69] and Cityscape-VPS [27]. However, these datasets have small vocabularies: YouTube-VIS contains 40 object categories, and Cityscape-VPS only has 19. It is questionable whether recent end-to-end paradigms are scalable to large-vocabulary, or even open-world video data. A recent larger vocabulary (124 classes) video segmentation dataset, VIPSeg [45], has been shown to be more difficult – using the same backbone, a recent method [34] achieves only 26.1 VPQ compared with 57.8 VPQ on CityscapeVPS. To the best of our knowledge, recent video segmentation methods [2, 39] developed for the open-world setting (e.g., BURST [2]) are not end-to-end and are based on tracking of per-frame segmentation – further highlighting the difficulty of end-to-end training on large-vocabulary datasets. As the number of classes and scenarios in the dataset increases, it becomes more challenging to train and develop end-to-end video models to jointly solve segmentation and association, especially if annotations are scarce.
现有的大多数视频分割方法都是在标注视频数据集上训练端到端的视频级网络。它们在YouTube-VIS [69]和Cityscape-VPS [27]等常见基准测试中取得了显著进展。然而,这些数据集的词汇量较小:YouTube-VOS包含40个物体类别,而Cityscape-VPS仅有19类。近期端到端范式是否能扩展到大规模词汇库甚至开放世界视频数据仍存疑。最新发布的大词汇量(124类)视频分割数据集VIPSeg [45]已被证明更具挑战性——使用相同骨干网络时,最新方法[34]在Cityscape-VPS上获得57.8 VPQ,而在VIPSeg上仅达到26.1 VPQ。据我们所知,针对开放世界设置开发的近期视频分割方法[2,39](如BURST [2])并非端到端方案,而是基于逐帧分割跟踪——这进一步凸显了在大词汇量数据集上进行端到端训练的困难。随着数据集中类别和场景数量的增加,训练和开发端到端视频模型来联合解决分割与关联问题变得更具挑战性,特别是在标注稀缺的情况下。
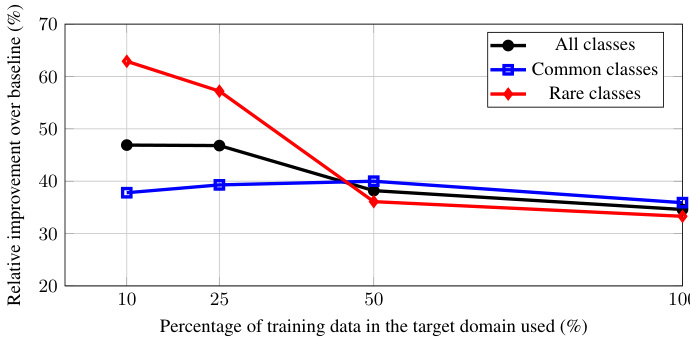
Figure 2. We plot relative $\overline{{\mathrm{VPQ}}}$ increase of our decoupled approach over the end-to-end baseline when we vary the training data in the target domain (VIPSeg [45]). Common/rare classes are the top/bottom $50%$ most annotated object category in the training set. Our improvement is most significant $(>60%)$ in rare classes when there is a small amount of training data. This is because our decoupling allows the use of external class-agnostic temporal propagation data – data that cannot be used by existing end-to-end baselines. Details in Section 4.5.1.
图 2: 当我们在目标域(VIPSeg [45])中改变训练数据时,绘制了我们的解耦方法相对于端到端基线的相对提升。常见/稀有类别是训练集中标注数量最多/最少的$50%$物体类别。当训练数据量较少时,我们在稀有类别上的改进最为显著$(>60%)$。这是因为我们的解耦方法可以利用外部与类别无关的时间传播数据——这些数据无法被现有端到端基线使用。详见第4.5.1节。
In this work, we aim to reduce reliance on the amount of target training data by leveraging external data outside of the target domain. For this, we propose to study decoupled video segmentation, which combines task-specific imagelevel segmentation and task-agnostic temporal propagation. Due to this design, we only need an image-level model for the target task (which is cheaper) and a universal temporal propagation model which is trained once and generalizes across tasks. Universal promptable image segmentation models like ‘segment anything’ (SAM) [30] and others [76, 32, 24, 73, 74] have recently become available and serve as excellent candidates for the image-level model in a ‘track anything’ pipeline – Figure 1 shows some promising results of our integration with these methods.
在本工作中,我们旨在通过利用目标领域之外的外部数据来减少对目标训练数据量的依赖。为此,我们提出研究解耦视频分割 (decoupled video segmentation) ,该方法结合了任务特定的图像级分割和任务无关的时间传播。由于这种设计,我们只需要为目标任务准备一个图像级模型(成本更低)和一个通用时间传播模型,后者只需训练一次即可跨任务泛化。最近出现的通用可提示图像分割模型,如 "segment anything" (SAM) [30] 和其他模型 [76, 32, 24, 73, 74] ,非常适合作为 "track anything" 流程中的图像级模型——图 1 展示了我们与这些方法集成的一些有前景的结果。
Researchers have studied decoupled formulations before, as ‘tracking-by-detection’ [26, 58, 3]. However, these approaches often consider image-level detections immutable, while the temporal model only associates detected objects. This formulation depends heavily on the quality of per-image detections and is sensitive to image-level errors.
研究人员此前研究过解耦式方案,即"检测跟踪法"[26, 58, 3]。但这些方法通常将图像级检测视为不可变,而时序模型仅关联检测到的物体。该方案高度依赖单帧图像检测质量,并对图像级错误十分敏感。
In contrast, we develop a (semi-)online bi-directional propagation algorithm to 1) denoise image-level segmentation with in-clip consensus (Section 3.2.1), and 2) combine results from temporal propagation and in-clip consensus gracefully (Section 3.2.2). This bi-directional propaga- tion allows temporally more coherent and potentially better results than those of an image-level model (see Figure 2).
相比之下,我们开发了一种(半)在线双向传播算法,用于:1) 通过片段内一致性对图像级分割进行去噪(第3.2.1节),以及2) 优雅地结合时序传播和片段内一致性的结果(第3.2.2节)。这种双向传播能比图像级模型产生时间一致性更高、效果可能更好的结果(见图2)。
We do not aim to replace end-to-end video approaches. Indeed, we emphasize that specialized frameworks on video tasks with sufficient video-level training data (e.g., YouTubeVIS [69]) outperform the developed method. Instead, we show that our decoupled approach acts as a strong baseline when an image model is available but video data is scarce. This is in spirit similar to pre training of large language models [52]: a task-agnostic understanding of natural language is available before being finetuned on specific tasks – in our case, we learn propagation of segmentation s of class-agnostic objects in videos via a temporal propagation module and make technical strides in applying this knowledge to specific tasks. The proposed decoupled approach transfers well to large-scale or open-world datasets, and achieves state-of-the-art results in large-scale video panoptic segmentation (VIPSeg [45]) and open-world video segmentation (BURST [2]). It also performs competitively on referring video segmentation (Ref-YouTubeVOS [55], Ref-DAVIS [25]) and unsupervised video object segmentation (DAVIS-16/17[5]) without end-to-end training.
我们并不旨在取代端到端的视频方法。事实上,我们强调,在拥有足够视频级训练数据(如YouTubeVIS [69])的视频任务上,专用框架的表现优于所开发的方法。相反,我们展示了当图像模型可用但视频数据稀缺时,我们的解耦方法可以作为一个强大的基线。这与大语言模型 [52] 的预训练理念相似:在对特定任务进行微调之前,先获得对自然语言的任务无关理解——在我们的案例中,我们通过时序传播模块学习视频中类别无关对象的分割传播,并在将这一知识应用于特定任务时取得技术进展。所提出的解耦方法能够很好地迁移到大规模或开放世界数据集,并在大规模视频全景分割(VIPSeg [45])和开放世界视频分割(BURST [2])中取得了最先进的结果。同时,在没有端到端训练的情况下,它在参考视频分割(Ref-YouTubeVOS [55]、Ref-DAVIS [25])和无监督视频对象分割(DAVIS-16/17 [5])任务上也表现出了竞争力。
To summarize:
总结:
• We propose using decoupled video segmentation that leverages external data, which allows it to generalize better to target tasks with limited annotations than end-to-end video approaches and allows us to seamlessly incorporate existing universal image segmentation models like SAM [30]. • We develop bi-directional propagation that denoises image segmentation s and merges image segmentation s with temporally propagated segmentation s gracefully. • We empirically show that our approach achieves favorable results in several important tasks including largescale video panoptic segmentation, open-world video segmentation, referring video segmentation, and unsupervised video object segmentation.
• 我们提出利用外部数据的解耦视频分割方法,相比端到端视频方案能更好地泛化到标注有限的目标任务,并可无缝集成SAM [30]等通用图像分割模型。
• 我们开发了双向传播机制,能有效降噪图像分割结果,并优雅地融合图像分割与时序传播的分割结果。
• 实验表明,我们的方法在视频全景分割、开放世界视频分割、指代视频分割和无监督视频目标分割等多个重要任务中取得优异效果。
2. Related Works
2. 相关工作
End-to-End Video Segmentation. Recent end-to-end video segmentation approaches [50, 23, 62, 4, 6, 14, 13] have made significant progress in tasks like Video Instance Segmentation (VIS) and Video Panoptic Segmentation (VPS), especially in closed and small vocabulary datasets like YouTube-VIS [69] and Cityscape-VPS [27].
端到端视频分割。近期端到端视频分割方法 [50, 23, 62, 4, 6, 14, 13] 在视频实例分割 (VIS) 和视频全景分割 (VPS) 等任务中取得显著进展,尤其在 YouTube-VIS [69] 和 Cityscape-VPS [27] 这类封闭小词汇量数据集上表现突出。
However, these methods require end-to-end training and their s cal ability to larger vocabularies, where video data and annotations are expensive, is questionable. MaskProp [4] uses mask propagation to provide temporal information, but still needs to be trained end-to-end on the target task. This is because their mask propagation is not class-agnostic. We circumvent this training requirement and instead decouple the task into image segmentation and temporal propagation, each of which is easier to train with image-only data and readily available class-agnostic mask propagation data respectively.
然而,这些方法需要端到端训练,在词汇量较大(视频数据和标注成本高昂)的场景下,其可扩展性存疑。MaskProp [4] 通过掩模传播提供时序信息,但仍需针对目标任务进行端到端训练,因其掩模传播不具备类别无关性。我们规避了这种训练需求,将任务解耦为图像分割和时序传播两部分,分别利用仅含图像的数据和现成的类别无关掩模传播数据即可高效训练。
Open-World Video Segmentation. Recently, an openworld video segmentation dataset BURST [2] has been proposed. It contains 482 object classes in diverse scenarios and evaluates open-world performance by computing metrics for the common classes (78, overlap with COCO [37]) and uncommon classes (404) separately. The baseline in BURST [2] predicts a set of object proposals using an image instance segmentation model trained on COCO [37] and associates the proposals frame-by-frame using either box IoU or STCN [11]. OWTB [39] additionally associates proposals using optical flow and pre-trained Re-ID features. Dif- ferently, we use bi-directional propagation that generates segmentation s instead of simply associating existing segmentations – this reduces sensitivity to image segmentation errors. UVO [18] is another open-world video segmentation dataset and focuses on human actions. We mainly evaluate on BURST [2] as it is much more diverse and allows separate evaluation for common/uncommon classes.
开放世界视频分割。近期,研究者提出了开放世界视频分割数据集BURST [2],该数据集包含482个多样场景下的物体类别,并通过分别计算常见类别(78个,与COCO [37] 重叠)和非常见类别(404个)的指标来评估开放世界性能。BURST [2] 的基线方法使用基于COCO [37] 训练的图像实例分割模型预测一组物体候选框,并采用框交并比(box IoU)或STCN [11] 进行逐帧关联。OWTB [39] 进一步结合光流和预训练Re-ID特征进行候选框关联。与之不同,我们采用双向传播技术直接生成分割结果而非简单关联现有分割——这降低了对图像分割错误的敏感性。UVO [18] 是另一个开放世界视频分割数据集,其关注点在于人类行为。我们主要在BURST [2] 上进行评估,因其场景多样性更高且支持常见/非常见类别的独立评测。
Decoupled Video Segmentation. ‘Tracking-bydetection’ approaches [26, 58, 3] often consider image-level detections immutable and use a short-term temporal tracking model to associate detected objects. This formulation depends heavily on the quality of per-image detections and is sensitive to image-level errors. Related long-term temporal propagation works exist [20, 19], but they consider a single task and do not filter the image-level segmentation. We instead propose a general framework, with a bi-directional propagation mechanism that denoises the image segmentation s and allows our result to potentially perform better than the image-level model.
解耦视频分割。基于检测的跟踪方法 [26, 58, 3] 通常将图像级检测视为不可变,并使用短期时序跟踪模型关联检测到的对象。这种方案高度依赖单帧检测质量,并对图像级误差敏感。相关长期时序传播研究 [20, 19] 虽存在,但仅针对单一任务且未过滤图像级分割结果。我们提出了一种通用框架,采用双向传播机制对图像分割结果 s 进行去噪,使最终效果可能超越图像级模型。
Video Object Segmentation. Semi-supervised Video Object Segmentation (VOS) aims to propagate an initial ground-truth segmentation through a video [47, 46, 70, 9]. However, it does not account for any errors in the initial segmentation, and cannot incorporate new segmentation given by the image model at later frames. SAM-PT [53] combines point tracking with SAM [12] to create a video object segmentation pipeline, while our method tracks masks directly. We find a recent VOS algorithm [9] works well for our temporal propagation model. Our proposed bi-directional propagation is essential for bringing image segmentation models and propagation models together as a unified video segmentation framework.
视频目标分割。半监督视频目标分割 (VOS) 旨在通过视频传播初始真实分割 [47, 46, 70, 9]。然而,它没有考虑初始分割中的任何错误,也无法在后续帧中整合图像模型给出的新分割。SAM-PT [53] 将点跟踪与 SAM [12] 结合创建了一个视频目标分割流程,而我们的方法直接跟踪掩码。我们发现最近的 VOS 算法 [9] 非常适合我们的时序传播模型。我们提出的双向传播对于将图像分割模型和传播模型整合为统一的视频分割框架至关重要。
Unified Video Segmentation. Recent Video-K-Net [34] uses a unified framework for multiple video tasks but requires separate end-to-end training for each task. Unicorn [66], TarViS [1], and UNINEXT [67] share model parameters for different tasks, and train on all the target tasks end-to-end. They report lower tracking accuracy for objects that are not in the target tasks during training compared with class-agnostic VOS approaches, which might be caused by joint learning with class-specific features. In contrast, we only train an image segmentation model for the target task, while the temporal propagation model is always fully classagnostic for generalization across tasks.
统一视频分割。近期提出的Video-K-Net [34]采用统一框架处理多视频任务,但需为每个任务单独进行端到端训练。Unicorn [66]、TarViS [1]和UNINEXT [67]通过共享模型参数支持多任务,并采用全目标任务的端到端训练。与类别无关的视频目标分割(VOS)方法相比,这些方法对训练目标外物体的跟踪精度较低,可能是由于与类别特定特征的联合学习导致。相比之下,我们仅针对目标任务训练图像分割模型,而时序传播模型始终保持完全类别无关性以实现跨任务泛化。
Segmenting/Tracking Anything. Concurrent to our work, Segment Anything (SAM) [30] demonstrates the effectiveness and general iz ability of large-scale training for universal image segmentation, serving as an important foundation for open-world segmentation. Follow-up works [68, 12] extend SAM to video data by propagating the masks generated by SAM with video object segmentation algorithms. However, they rely on single-frame segmentation and lack the denoising capability of our proposed in-clip consensus approach.
分割/追踪任意物体。与我们的工作同期,Segment Anything (SAM) [30] 展示了大规模训练在通用图像分割中的有效性和泛化能力,为开放世界分割奠定了重要基础。后续研究 [68, 12] 通过视频目标分割算法传播 SAM 生成的掩码,将其扩展至视频数据。但这些方法依赖单帧分割,缺乏我们提出的片段内共识去噪能力。
3. Decoupled Video Segmentation
3. 解耦视频分割
3.1. Formulation
3.1. 公式化
Decoupled Video Segmentation. Our decoupled video segmentation approach is driven by an image segmentation model and a universal temporal propagation model. The image model, trained specifically on the target task, provides task-specific image-level segmentation hypotheses. The temporal propagation model, trained on class-agnostic mask propagation datasets, associates and propagates these hypotheses to segment the whole video. This design separates the learning of task-specific segmentation and the learning of general video object segmentation, leading to a robust framework even when data in the target domain is scarce and insufficient for end-to-end learning.
解耦视频分割。我们的解耦视频分割方法由一个图像分割模型和一个通用时序传播模型驱动。图像模型针对目标任务专门训练,提供任务特定的图像级分割假设。时序传播模型在类别无关的掩码传播数据集上训练,将这些假设关联并传播以分割整个视频。该设计将任务特定分割学习与通用视频对象分割学习分离,即使在目标领域数据稀缺且不足以进行端到端学习时,也能形成稳健的框架。
Notation. Using $t$ as the time index, we refer to the corresponding frame and its final segmentation as $I_{t}$ and $\mathbf{M}{t}$ respectively. In this paper, we represent a segmentation as a set of non-overlapping per-object binary segments, i.e., $\mathbf{M}{t}={m_{i},0<i\leq|\mathbf{M}{t}|}$ , where $m_{i}\cap m_{j}=\emptyset$ if $i\neq j$ .
符号说明。以 $t$ 作为时间索引,我们将对应的帧及其最终分割结果分别记为 $I_{t}$ 和 $\mathbf{M}{t}$。本文中将分割结果表示为一系列互不重叠的逐对象二值分割区域,即 $\mathbf{M}{t}={m_{i},0<i\leq|\mathbf{M}{t}|}$,其中当 $i\neq j$ 时满足 $m_{i}\cap m_{j}=\emptyset$。
The image segmentation model ${\mathrm{Seg}}(I)$ takes an image $I$ as input and outputs a segmentation. We denote its output segmentation at time $t$ as $\mathrm{Seg}(I_{t})=\mathrm{Seg}{t}={s_{i},0<$ $i\leq|\mathrm{Seg}_{t}|}$ , which is also a set of non-overlapping binary segments. This segmentation model can be swapped for different target tasks, and users can be in the loop to correct the segmentation as we do not limit its internal architecture.
图像分割模型 ${\mathrm{Seg}}(I)$ 以图像 $I$ 作为输入并输出分割结果。我们将时间 $t$ 的输出分割表示为 $\mathrm{Seg}(I_{t})=\mathrm{Seg}{t}={s_{i},0<$ $i\leq|\mathrm{Seg}_{t}|}$,它也是一组非重叠的二进制分割片段。该分割模型可根据不同目标任务进行替换,且用户可参与循环以修正分割结果,因为我们未限制其内部架构。
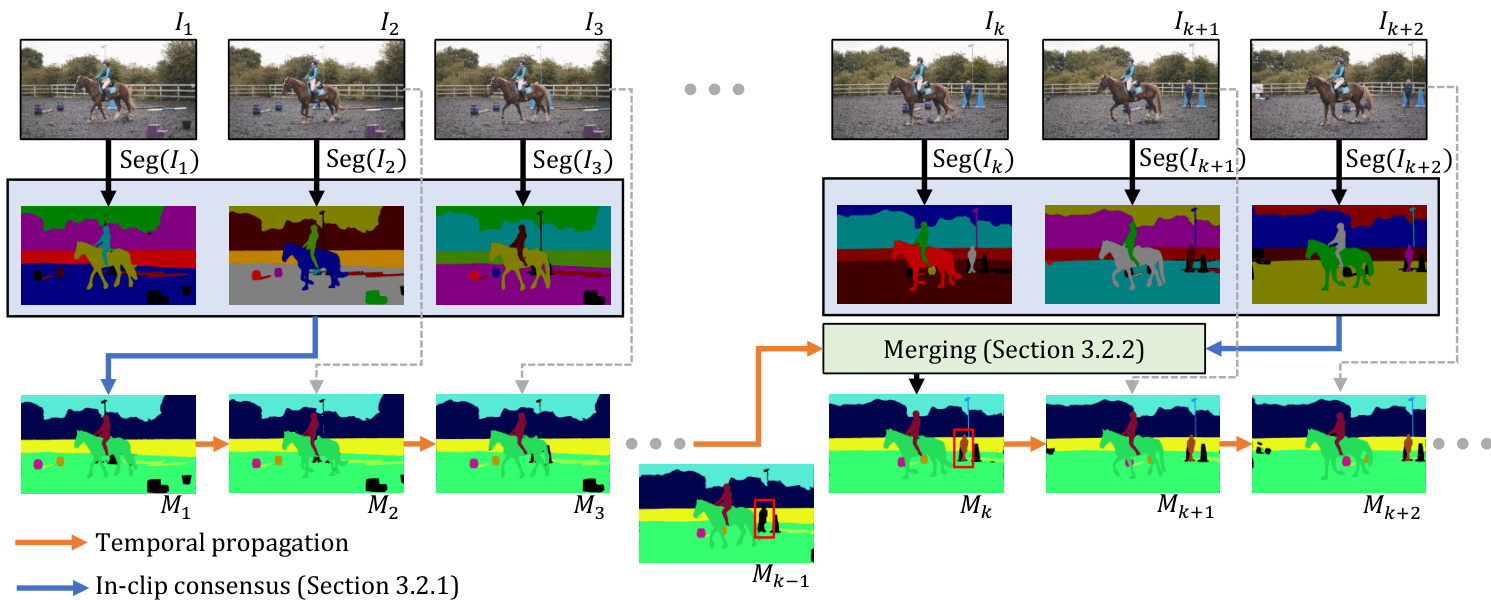
Figure 3. Overview of our framework. We first filter image-level segmentation s with in-clip consensus (Section 3.2.1) and temporally propagate this result forward. To incorporate a new image segmentation at a later time step (for previously unseen objects, e.g., red box), we merge the propagated results with in-clip consensus as described in Section 3.2.2. Specifics of temporal propagation are in the appendix.
图 3: 我们的框架概览。首先通过片段内共识 (Section 3.2.1) 筛选图像级分割结果,并将该结果在时间维度向前传播。当后续时间步出现新图像分割时 (例如红框标注的未见物体),我们按照 Section 3.2.2 所述将传播结果与片段内共识进行融合。时间传播的具体实现详见附录。
The temporal propagation model $\mathrm{Prop}(\mathbf{H},I)$ takes a collection of segmented frames (memory) $\mathbf{H}$ and a query image $I$ as input and segments the query frame with the objects in the memory. For instance, Prop $({I_{1},\mathbf{M}{1}},I_{2})$ propagates the segmentation ${{\bf{M}}{1}}$ from the first frame $I_{1}$ to the second frame $I_{2}$ . Unless mentioned explicitly, the memory $\mathbf{H}$ contains all past segmented frames.
时序传播模型 $\mathrm{Prop}(\mathbf{H},I)$ 以分割帧集合(记忆)$\mathbf{H}$ 和查询图像 $I$ 作为输入,将记忆中的对象分割结果传播到查询帧。例如,Prop $({I_{1},\mathbf{M}{1}},I_{2})$ 会将第一帧 $I_{1}$ 的分割结果 ${{\bf{M}}{1}}$ 传播至第二帧 $I_{2}$。若无特别说明,记忆 $\mathbf{H}$ 包含所有历史分割帧。
Overview. Figure 3 illustrates the overall pipeline. At a high level, we aim to propagate segmentation s discovered by the image segmentation model to the full video with temporal propagation. We mainly focus on the (semi-)online setting. Starting from the first frame, we use the image segmentation model for initialization. To denoise errors from single-frame segmentation, we look at a small clip of a few frames in the near future (in the online setting, we only look at the current frame) and reach an in-clip consensus (Section 3.2.1) as the output segmentation. Afterward, we use the temporal propagation model to propagate the segmentation to subsequent frames. We modify an off-the-shelf state-of-the-art video object segmentation XMem [9] as our temporal propagation model, with details given in the appendix. The propagation model itself cannot segment new objects that appear in the scene. Therefore, we periodically incorporate new image segmentation results using the same in-clip consensus as before and merge the consensus with the propagated result (Section 3.2.2). This pipeline combines the strong temporal consistency from the propagation model (past) and the new semantics from the image segmentation model (future), hence the name bi-directional propagation. Next, we will discuss the bi-directional propagation pipeline in detail.
概述。图 3 展示了整体流程框架。从高层次看,我们的目标是通过时序传播将图像分割模型发现的分割结果(s)扩展到完整视频。我们主要关注(半)在线场景:从首帧开始,使用图像分割模型进行初始化。为消除单帧分割的噪声误差,我们会观察未来几帧的短片段(在线场景下仅观察当前帧),通过片段内共识机制(章节 3.2.1)输出最终分割结果。随后使用时序传播模型将分割结果传递至后续帧。我们基于现成的先进视频目标分割模型 XMem [9] 改造了时序传播模块,具体细节见附录。传播模型本身无法分割场景中新出现的物体,因此需要定期通过相同的片段内共识机制整合新的图像分割结果,并将共识结果与传播结果融合(章节 3.2.2)。该流程结合了传播模型(历史帧)的强时序一致性和图像分割模型(未来帧)的新语义特征,故命名为双向传播。下文将详细解析双向传播流程。
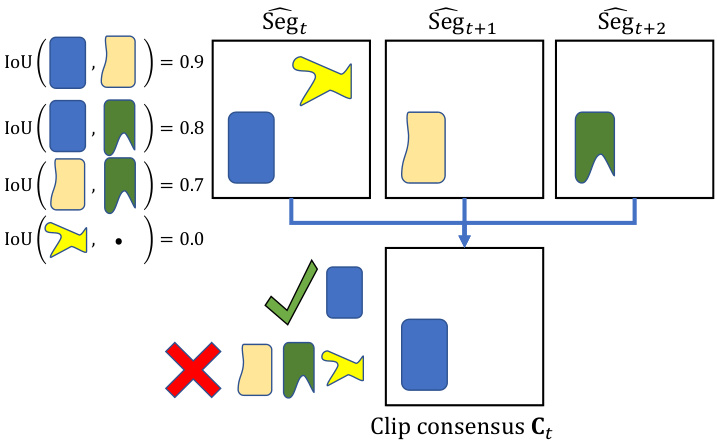
Figure 4. A simple illustration of in-clip consensus. The top three squares represent object proposals from three different frames aligned to time $t$ . The blue shape is the most supported by other object proposals and is selected as output. The yellow shape is not supported by any and is ruled out as noise. The remaining are not used due to significant overlap with the selected (blue) shape.
图 4: 片段内共识的简单示意图。顶部三个方块代表对齐到时间 $t$ 的三帧不同图像中的物体候选框。蓝色形状获得最多其他物体候选框的支持,因此被选为输出结果。黄色形状未获得任何支持,被视为噪声剔除。其余候选框因与选定(蓝色)形状存在显著重叠而未予采用。
3.2. Bi-Directional Propagation
3.2. 双向传播
3.2.1 In-clip Consensus
3.2.1 片段内共识
Formulation. In-clip consensus operates on the image segmentation s of a small future clip of $n$ frames $(\mathrm{Seg}{t}$ , $\mathrm{Seg}{t+1}$ , ..., $\mathrm{Seg}{t+n-1})$ and outputs a denoised consensus $\mathbf{C}{t}$ for the current frame. In the online setting, $n=1$ and $\mathbf{C}{t}=\mathrm{Seg}_{t}$ . In the subsequent discussion, we focus on the semi-online setting, as consensus computation in the online setting is straightforward. As an overview, we first obtain a set of object proposals on the target frame $t$ via spatial alignment, merge the object proposals into a combined represent ation in a second step, and optimize for an indicator variable to choose a subset of proposals as the output in an integer program. Figure 4 illustrates this in-clip consensus computation in a stylized way and we provide details regarding each of the three aforementioned steps (spatial alignment, representation, and integer programming) next.
公式化。片段内共识机制作用于未来一小段 $n$ 帧的图像分割结果 $(\mathrm{Seg}{t}$ , $\mathrm{Seg}{t+1}$ , ..., $\mathrm{Seg}{t+n-1})$ ,并为当前帧输出去噪后的共识结果 $\mathbf{C}{t}$ 。在线设置中,$n=1$ 且 $\mathbf{C}{t}=\mathrm{Seg}_{t}$ 。后续讨论将聚焦半在线设置,因为在线设置下的共识计算较为直接。总体流程分为三步:首先通过空间对齐在目标帧 $t$ 上获取物体候选集;第二步将这些候选集合并为统一表征;最后通过整数规划优化指示变量以选取候选子集作为输出。图4以风格化方式展示了片段内共识计算流程,下文将详细阐述空间对齐、表征构建和整数规划这三个关键步骤。
Spatial Alignment. As the segmentation s $(\mathrm{Seg}{t}$ , $\mathrm{Seg}{t+1}$ , ..., $\mathrm{Seg}{t+n-1})$ correspond to different time steps, they might be spatially misaligned. This misalignment complicates the computation of correspondences between segments. To align segmentation s $\mathrm{Seg}{{\mathrm{}}{t+i}}$ with frame $t$ , techniques like optical flow warping are applicable. In this paper, we simply re-use the temporal propagation model to find the aligned segmentation $\widehat{\mathbf{Seg}}{t+i}$ (note ${\widehat{\mathbf{Seg}}}{t}=\mathbf{Seg}_{t},$ ) via
空间对齐。由于分割结果 $(\mathrm{Seg}{t}$ , $\mathrm{Seg}{t+1}$ , ..., $\mathrm{Seg}{t+n-1})$ 对应不同时间步,它们可能存在空间错位问题。这种错位会加大分段间对应关系的计算难度。为了将分割结果 与第 $t$ 帧对齐,可采用光流扭曲等技术。本文直接复用时序传播模型,通过计算得到对齐后的分割结果 $\widehat{\mathbf{Seg}}{t+i}$ (注意 ${\widehat{\mathbf{Seg}}}{t}=\mathbf{Seg}_{t},$ )。
Note, the propagation model here only uses one frame as memory at a time and this temporary memory ${I_{t+i},\mathrm{Seg}_{t+i}}$ is discarded immediately after alignment. It does not interact with the global memory $\mathbf{H}$ .
注意,这里的传播模型每次仅使用一帧作为记忆,并且在完成对齐后立即丢弃这个临时记忆 ${I_{t+i},\mathrm{Seg}_{t+i}}$ 。它不会与全局记忆 $\mathbf{H}$ 产生交互。
Representation. Recall that we represent a segmentation as a set of non-overlapping per-object binary segments. After aligning all the segmentation s to frame $t$ , each segment is an object proposal for frame $I_{t}$ . We refer to the union of all these proposals via $\mathbf{P}$ (time index omitted for clarity):
表示。回想一下,我们将分割表示为一组互不重叠的每对象二值分割段。将所有分割对齐到帧$t$后,每个分割段都是帧$I_{t}$的一个对象提议。我们通过$\mathbf{P}$(为清晰起见省略时间索引)来指代所有这些提议的并集:
$$
\mathbf{P}=\bigcup_{i=0}^{n-1}\widehat{\mathrm{Seg}}{t+i}={p_{i},0<i\leq|\mathbf{P}|}.
$$
$$
\mathbf{P}=\bigcup_{i=0}^{n-1}\widehat{\mathrm{Seg}}{t+i}={p_{i},0<i\leq|\mathbf{P}|}.
$$
The output of consensus voting is represented by an indicator variable $v^{*}\in{0,1}^{|\mathbf{P}|}$ that combines segments into the consensus output $\mathbf{C}_{t}$ :
共识投票的输出由一个指示变量 $v^{*}\in{0,1}^{|\mathbf{P}|}$ 表示,该变量将分段合并为共识输出 $\mathbf{C}_{t}$:
$$
\mathbf{C}{t}={p_{i}|v_{i}^{*}=1}={c_{i},0<i\leq|\mathbf{C}|}.
$$
$$
\mathbf{C}{t}={p_{i}|v_{i}^{*}=1}={c_{i},0<i\leq|\mathbf{C}|}.
$$
We resolve overlapping segments $c_{i}$ in $\mathbf{C}{t}$ by prioritizing smaller segments as they are more vulnerable to being majorly displaced by overlaps. This priority is implemented by sequentially rendering the segments $c_{i}$ on an image in descending order of area. We optimize for $v$ based on two simple criteria:
我们通过优先处理较小片段 $c_{i}$ 来解决 $\mathbf{C}{t}$ 中的重叠问题,因为较小片段更容易因重叠而大幅错位。具体实现方式是按照面积降序依次渲染图像上的片段 $c_{i}$。针对 $v$ 的优化基于两个简单标准:
We combine these criteria in an integer programming problem which we describe next.
我们接下来将这些标准结合到一个整数规划问题中进行描述。
Integer Programming. We aim to optimize the indicator variable $v$ to achieve the above two objectives, by addressing the following integer programming problem:
整数规划。我们旨在通过解决以下整数规划问题来优化指标变量 $v$,以实现上述两个目标:
$$
v^{*}=\mathrm{argmax}{\boldsymbol{v}}\sum_{i}\left(\mathrm{Supp}{i}+\mathrm{Penal}{i}\right)\mathrm{s.t.}\sum_{i,j}\mathrm{Overlap}_{i j}=0.
$$
$$
v^{*}=\mathrm{argmax}{\boldsymbol{v}}\sum_{i}\left(\mathrm{Supp}{i}+\mathrm{Penal}{i}\right)\mathrm{s.t.}\sum_{i,j}\mathrm{Overlap}_{i j}=0.
$$
Next, we discuss each of the terms in the program in detail.
接下来,我们将详细讨论程序中的每一项内容。
First, we define the pairwise Intersection-over-Union (IoU) between the $i$ -th proposal and the $j$ -th proposal as:
首先,我们将第 $i$ 个提案(proposal)与第 $j$ 个提案之间的交并比(Intersection-over-Union,IoU)定义为:
$$
\mathrm{IoU}{i j}=\mathrm{IoU}{j i}=\frac{\left|p_{i}\cap p_{j}\right|}{\left|p_{i}\cup p_{j}\right|},0\leq\mathrm{IoU}_{i j}\leq1.
$$
$$
\mathrm{IoU}{i j}=\mathrm{IoU}{j i}=\frac{\left|p_{i}\cap p_{j}\right|}{\left|p_{i}\cup p_{j}\right|},0\leq\mathrm{IoU}_{i j}\leq1.
$$
Lastly, we introduce a penalty for selecting any segment for 1) tie-breaking when a segment has no support, and 2) excluding noisy segments, with weight $\alpha$ :
最后,我们引入一个惩罚项用于选择任何片段,其作用为:1) 在片段无支持时进行平局决胜,2) 排除噪声片段,权重为 $\alpha$:
$$
{\mathrm{Penal}}{i}=-\alpha v_{i}.
$$
$$
{\mathrm{Penal}}{i}=-\alpha v_{i}.
$$
We set the tie-breaking weight $\alpha=0.5$ . For all but the first frame, we merge $\mathbf{C}{t}$ with the propagated segmentation $\mathrm{Prop}(\mathbf{H},I_{t})$ into the final output $\mathbf{M}_{t}$ as described next.
我们将断点权重设为 $\alpha=0.5$。除第一帧外,按照下述方法将 $\mathbf{C}{t}$ 与传播分割结果 $\mathrm{Prop}(\mathbf{H},I_{t})$ 合并为最终输出 $\mathbf{M}_{t}$。
3.2.2 Merging Propagation and Consensus
3.2.2 合并传播与共识
Formulation. Here, we seek to merge the propagated segmentation $\mathrm{Prop}(\mathbf{H},I_{t})=\mathbf{R}{t}={r_{i},0<i\leq|\mathbf{R}|}$ (from the past) with the consensus $\mathbf{C}{t}={c_{j},0<j\leq|\mathbf{C}|}$ (from the near future) into a single segmentation $\mathbf{M}{t}$ . We associate segments from these two segmentation s and denote the association with an indicator $a_{i j}$ which is 1 if $r_{i}$ associates with $c_{j}$ , and 0 otherwise. Different from the inclip consensus, these two segmentation s contain fundamentally different information. Thus, we do not eliminate any segments and instead fuse all pairs of associated segments while letting the un associated segments pass through to the output. Formally, we obtain the final segmentation via
公式化。在此,我们的目标是将传播的分割 $\mathrm{Prop}(\mathbf{H},I_{t})=\mathbf{R}{t}={r_{i},0<i\leq|\mathbf{R}|}$ (来自过去)与共识 $\mathbf{C}{t}={c_{j},0<j\leq|\mathbf{C}|}$ (来自近未来)合并为一个单一分割 $\mathbf{M}{t}$。我们将这两个分割中的片段关联起来,并用指示符 $a_{i j}$ 表示关联关系,若 $r_{i}$ 与 $c_{j}$ 关联,则 $a_{i j}$ 为1,否则为0。与片段内共识不同,这两个分割包含根本不同的信息。因此,我们不会消除任何片段,而是融合所有关联的片段对,同时让未关联的片段直接传递到输出。形式上,我们通过以下方式获得最终分割:
$$
\mathbf{M}{t}={r_{i}\cup c_{j}|a_{i j}=1}\cup{r_{i}|\forall_{j}a_{i j}=0}\cup{c_{j}|\forall_{i}a_{i j}=0},
$$
$$
\mathbf{M}{t}={r_{i}\cup c_{j}|a_{i j}=1}\cup{r_{i}|\forall_{j}a_{i j}=0}\cup{c_{j}|\forall_{i}a_{i j}=0},
$$
where overlapping segments are resolved by prioritizing the smaller segments as discussed in Section 3.2.1.
在重叠段落的处理中,优先采用较小段落,如第3.2.1节所述。
Requiring any matched pairs from two non-overlapping segmentation s to have IoU $>0.5$ leads to a unique matching, as shown in [29]. Therefore, a greedy solution of setting $a_{i j}=1$ if $e_{i j}>0$ and 0 otherwise suffices to obtain an optimal result.
要求来自两个非重叠分割区域的任何匹配对必须具有IoU $>0.5$ ,从而形成唯一匹配,如[29]所示。因此,采用贪心解法,当 $e_{ij}>0$ 时设 $a_{ij}=1$ ,否则设为0,即可获得最优结果。
Segment Deletion. As an implementation detail, we delete inactive segments from the memory to reduce computational costs. We consider a segment $r_{i}$ inactive when it fails to associate with any segments $c_{j}$ from the consensus for consecutive $L$ times. Such objects might have gone out of view or were a mis detection. Concretely, we associate a counter $\mathrm{cnt}{i}$ with each propagated segment $r_{i}$ , initialized as 0. When $r_{i}$ is not associated with any segments $c_{j}$ from the consensus, i.e., $\forall_{j}a_{i j}=0$ , we increment $\mathrm{cnt}{i}$ by 1 and reset $\mathrm{cnt}{i}$ to 0 otherwise. When $\mathrm{cnt}{i}$ reaches the pre-defined threshold $L$ , the segment $r_{i}$ is deleted from the memory. We set L = 5 in all our experiments.
片段删除。作为实现细节,我们会从内存中删除非活跃片段以降低计算成本。当某个片段 $r_{i}$ 连续 $L$ 次未能与共识中的任何片段 $c_{j}$ 建立关联时,即视为非活跃状态。这类对象可能已离开视野或属于误检测。具体而言,我们为每个传播片段 $r_{i}$ 关联一个计数器 $\mathrm{cnt}{i}$(初始值为0)。若 $r_{i}$ 未与共识中的任何片段 $c_{j}$ 关联(即 $\forall_{j}a_{i j}=0$),则将 $\mathrm{cnt}{i}$ 加1;否则重置为0。当 $\mathrm{cnt}{i}$ 达到预设阈值 $L$ 时,该片段 $r_{i}$ 将从内存中删除。所有实验中均设定 L = 5。
4. Experiments
4. 实验
We first present our main results using a large-scale video panoptic segmentation dataset (VIPSeg [45]) and an open-world video segmentation dataset (BRUST [2]). Next, we show that our method also works well for referring video object segmentation and unsupervised video object segmentation. We present additional results on the smaller-scale YouTubeVIS dataset in the appendix, but un surprisingly recent end-to-end specialized approaches perform better because a sufficient amount of data is available in this case. Figure 1 visualizes some results of the integration of our approach with universal image segmentation models like SAM [30] or Grounding-Segment-Anything [38, 30]. By default, we merge in-clip consensus with temporal propagation every 5 frames with a clip size of $n=3$ in the semionline setting, and $n=1$ in the online setting. We evaluate all our results using either official evaluation codebases or official servers. We use image models trained with standard training data for each task (using open-sourced models whenever available) and a universal temporal propagation module for all tasks unless otherwise specified.
我们首先在一个大规模视频全景分割数据集(VIPSeg [45])和一个开放世界视频分割数据集(BRUST [2])上展示主要结果。接着,我们证明该方法在指代视频目标分割和无监督视频目标分割任务中同样表现优异。附录中提供了小规模YouTubeVIS数据集上的额外结果,但不出所料,由于该场景下数据量充足,近期端到端的专用方法表现更优。图1: 可视化展示了我们的方法与通用图像分割模型(如SAM [30]或Grounding-Segment-Anything [38, 30])结合的若干效果。默认情况下,在半在线设置中我们每5帧以$n=3$的片段尺寸进行片段内共识与时序传播的融合,在线设置中则采用$n=1$。所有实验结果均通过官方评估代码库或服务器进行验证。除非特别说明,我们为每个任务使用标准训练数据训练的图像模型(优先采用开源模型),并为所有任务配置统一的时序传播模块。
The temporal propagation model is based on XMem [9], and is trained in a class-agnostic fashion with image segmentation datasets [56, 60, 72, 33, 8] and video object segmentation datasets [65, 47, 48]. With the long-term memory of XMem [9], our model can handle long videos with ease.
时序传播模型基于XMem [9],采用与类别无关的方式训练,使用了图像分割数据集 [56, 60, 72, 33, 8] 和视频目标分割数据集 [65, 47, 48]。借助XMem [9]的长期记忆机制,我们的模型能够轻松处理长视频。
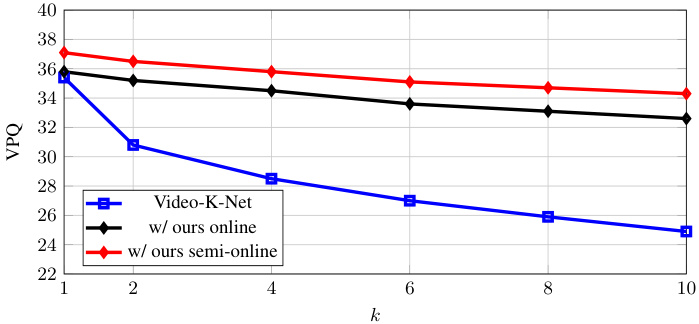
Figure 5. Performance trend comparison of Video-K-Net [34] and our decoupled approach with the same base model. Ours decreases slower with larger $k$ , indicating that the proposed decoupled method has a better long-term propagation.
图 5: Video-K-Net [34] 与我们解耦方法在相同基础模型上的性能趋势对比。随着 $k$ 增大,我们的方法下降更缓慢,表明所提出的解耦方法具有更好的长期传播能力。
We use top $\mathbf{\nabla\cdot}\mathbf{k}$ filtering [10] with $k=30$ following [9]. The performance of our modified propagation model on common video object segmentation benchmarks (DAVIS [47], YouTubeVOS [65], and MOSE [16]) are listed in the appendix.
我们采用顶部$\mathbf{\nabla\cdot}\mathbf{k}$滤波[10],并按照[9]的方法设置$k=30$。改进后的传播模型在常见视频目标分割基准(DAVIS [47]、YouTubeVOS [65]和MOSE [16])上的性能指标详见附录。
4.1. Large-Scale Video Panoptic Segmentation
4.1. 大规模视频全景分割 (Large-Scale Video Panoptic Segmentation)
We are interested in addressing the large vocabulary setting. To our best knowledge, VIPSeg [45] is currently the largest scale in-the-wild panoptic segmentation dataset, with 58 things classes and 66 stuff classes in 3,536 videos of 232 different scenes.
我们致力于解决大词汇量场景下的问题。据我们所知,VIPSeg [45] 是目前规模最大的开放场景全景分割数据集,包含232个不同场景的3,536段视频,涵盖58个物品类别和66个背景类别。
Metrics. To evaluate the quality of the result, we adopt the commonly used VPQ (Video Panoptic Quality) [27] and STQ (Segmentation and Tracking Quality) [63] metrics. VPQ extends image-based PQ (Panoptic Quality) [29] to video data by matching objects in sliding windows of $k$ frames (denoted ${\mathrm{VPQ}}^{k}$ ). When $k=1$ , $\mathrm{VPQ}=\mathrm{PQ}$ and associations of segments between frames are ignored. Correct long-range associations, which are crucial for object tracking and video editing tasks, are only evaluated with a large value of $k$ . For a more complete evaluation of VPS, we evaluate $k\in{1,2,4,6,8,10,\infty}$ . Note, $\mathrm{VPQ}^{\infty}$ considers the entire video as a tube and requires global association. We additionally report $\overline{{\mathrm{VPQ}}}$ , which is the average of $\mathrm{VPQ}^{\infty}$ and the arithmetic mean of $\mathrm{VPQ}^{{1,2,4,6,8,10}}$ . This weights $\mathrm{VPQ}^{\infty}$ higher as it represents video-level performance, while the other metrics only assess frame-level or clip-level results. STQ is proposed in STEP [63] and is the geometric mean of AQ (Association Quality) and SQ (Segmentation Quality). It evaluates pixel-level associations and semantic segmentation quality respectively. We refer readers to [27] and [63] for more details on VPQ and STQ.
指标。为评估结果质量,我们采用常用的VPQ(Video Panoptic Quality)[27]和STQ(Segmentation and Tracking Quality)[63]指标。VPQ通过匹配$k$帧滑动窗口中的对象(记为${\mathrm{VPQ}}^{k}$),将基于图像的PQ(Panoptic Quality)[29]扩展到视频数据。当$k=1$时,$\mathrm{VPQ}=\mathrm{PQ}$且忽略帧间片段关联。对于物体追踪和视频编辑任务至关重要的长程关联,仅通过较大的$k$值进行评估。为更全面评估VPS,我们测试$k\in{1,2,4,6,8,10,\infty}$。需注意,$\mathrm{VPQ}^{\infty}$将整个视频视为一个管状结构并要求全局关联。我们还报告$\overline{{\mathrm{VPQ}}}$,即$\mathrm{VPQ}^{\infty}$与$\mathrm{VPQ}^{{1,2,4,6,8,10}}$算术平均值的均值。该指标赋予$\mathrm{VPQ}^{\infty}$更高权重,因其表征视频级性能,而其他指标仅评估帧级或片段级结果。STQ由STEP[63]提出,是AQ(Association Quality)与SQ(Segmentation Quality)的几何平均数,分别评估像素级关联和语义分割质量。关于VPQ和STQ的更多细节,请参阅[27]和[63]。
Main Results. Table 1 summarizes our findings. To assess generality, we study three models as image segmentation input (PanoFCN [35], Mask 2 Former [7], and Video- K-Net [34]) to our decoupled approach. The weights of these image models are initialized by pre-training on the COCO panoptic dataset [37] and subsequently fine-tuned on VIPSeg [45]. Our method outperforms both baseline Clip-PanoFCN [45] and state-of-the-art Video-K-Net [34] with the same backbone, especially if $k$ is large, i.e., when long-term associations are more important. Figure 5 shows the performance trend with respect to $k$ . The gains for large values of $k$ highlight the use of a decoupled formulation over end-to-end training: the latter struggles with associations eventually, as training sequences aren’t arbitrarily long. Without any changes to our generalized mask propagation module, using a better image backbone (e.g., SwinB [40]) leads to noticeable improvements. Our method can likely be coupled with future advanced methods in image segmentation for even better performance.
主要结果。表1总结了我们的发现。为评估泛化性,我们研究了三种图像分割模型(PanoFCN [35]、Mask2Former [7] 和 Video-K-Net [34])作为我们解耦方法的输入。这些图像模型的权重通过在COCO全景数据集[37]上进行预训练初始化,随后在VIPSeg[45]上微调。我们的方法在相同骨干网络下均优于基线Clip-PanoFCN[45]和最先进的Video-K-Net[34],尤其当$k$值较大时(即长期关联更重要时)。图5展示了性能随$k$值的变化趋势。大$k$值下的性能提升凸显了解耦公式相对于端到端训练的优势:后者最终难以处理关联问题,因为训练序列长度有限。在未对通用掩码传播模块做任何改动的情况下,使用更强的图像骨干网络(如SwinB[40])可带来显著提升。我们的方法未来有望与更先进的图像分割方法结合以获得更优性能。
Table 1. Comparisons of end-to-end approaches (e.g., state-of-the-art Video-K-Net [34]) with our decoupled approach on the large-scale video panoptic segmentation dataset VIPSeg [45]. Our method scales with better image models and performs especially well with large $k$ where long-term associations are considered. All baselines are reproduced using official codebases.
表 1: 在大规模视频全景分割数据集 VIPSeg [45] 上,端到端方法 (如当前最优的 Video-K-Net [34]) 与我们解耦方法的对比。我们的方法随着更好的图像模型扩展,在考虑长期关联的大 $k$ 值时表现尤为突出。所有基线均使用官方代码库复现。
| Backbone | 方法 | 模式 | VPQ1 | VPQ² | VPQ4 | VPQ6 | VPQ8 | VPQ10 | VPQ∞ | VPQ | STQ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Clip-PanoFCN | end-to-end [45] | semi-online | 27.3 | 26.0 | 24.2 | 22.9 | 22.1 | 21.5 | 18.1 | 21.1 | 28.3 | |
| Clip-PanoFCN | decoupled (ours) | online | 29.5 | 28.9 | 28.1 | 27.2 | 26.7 | 26.1 | 25.0 | 26.4 | 35.7 | |
| Clip-PanoFCN | decoupled (ours) | semi-online | 31.3 | 30.8 | 30.1 | 29.4 | 28.8 | 28.3 | 27.1 | 28.4 | 35.8 | |
| Video-K-Net | R50 | end-to-end [34] | online | 35.4 | 30.8 | 28.5 | 27.0 | 25.9 | 24.9 | 21.7 | 25.2 | 33.7 |
| Video-K-Net | R50 | decoupled (ours) | online | 35.8 | 35.2 | 34.5 | 33.6 | 33.1 | 32.6 | 30.5 | 32.3 | 38.4 |
| Video-K-Net | R50 | decoupled (ours) | semi-online | 37.1 | 36.5 | 35.8 | 35.1 | 34.7 | 34.3 | 32.3 | 33.9 | 38.6 |
| Mask2Former | R50 | decoupled (ours) | online | 41.0 | 40.2 | 39.3 | 38.4 | 37.9 | 37.3 | 33.8 | 36.4 | 41.1 |
| Mask2Former | R50 | decoupled (ours) | semi-online | 42.1 | 41.5 | 40.8 | 40.1 | 39.7 | 39.3 | 36.1 | 38.3 | 41.5 |
| Video-K-Net | Swin-B | end-to-end [34] | online | 49.8 | 45.2 | 42.4 | 40.5 | 39.1 | 37.9 | 32.6 | 37.5 | 45.2 |
| Video-K-Net | Swin-B | decoupled (ours) | online | 48.2 | 47.4 | 46.5 | 45.6 | 45.1 | 44.5 | 42.0 | 44.1 | 48.6 |
| Video-K-Net | Swin-B | decoupled (ours) | semi-online | 50.0 | 49.3 | 48.5 | 47.7 | 47.3 | 46.8 | 44.5 | 46.4 | 48.9 |
| Mask2Former | Swin-B | decoupled (ours) | online | 55.3 | 54.6 | 53.8 | 52.8 | 52.3 | 51.9 | 49.0 | 51.2 | 52.4 |
| Mask2Former | Swin-B | decoupled (ours) | semi-online | 56.0 | 55.4 | 54.6 | 53.9 | 53.5 | 53.1 | 50.0 | 52.2 | 52.2 |
Table 2. Comparison to baselines in the open-world video segmentation dataset BURST [2]. ‘com’ stands for ‘common classes’ and ‘unc’ stands for ‘uncommon classes’. Our method performs better in both – in the common classes with Mask 2 Former [7] image backbone, and in the uncommon classes with EntitySeg [49]. The agility to switch image backbones is one of the main advantages of our decoupled formulation. Baseline performances are transcribed from [2].
表 2: 开放世界视频分割数据集 BURST [2] 的基线对比。"com"代表"常见类别","unc"代表"罕见类别"。我们的方法在两类中都表现更优——使用 Mask2Former [7] 图像主干时在常见类别表现更好,使用 EntitySeg [49] 时在罕见类别表现更优。可灵活切换图像主干是我们解耦式框架的主要优势之一。基线性能数据转录自 [2]。
| 方法 | 验证集 | 测试集 | |||||
|---|---|---|---|---|---|---|---|
| OWTAall | OWTAcom | OWTAunc | OWTAall | OWTAcom | OWTAunc | ||
| Mask2Former | w/ Box tracker [2] | 60.9 | 66.9 | 24.0 | 55.9 | 61.0 | 24.6 |
| Mask2Former | w/ STCN tracker [2] | 64.6 | 71.0 | 25.0 | 57.5 | 62.9 | 23.9 |
| OWTB [39] | 55.8 | 59.8 | 38.8 | 56.0 | 59.9 | 38.3 | |
| Mask2Former | w/oursonline | 69.5 | 74.6 | 42.3 | 70.1 | 75.0 | 44.1 |
| Mask2Former | w/ourssemi-online | 69.9 | 75.2 | 41.5 | 70.5 | 75.4 | 44.1 |
| EntitySeg | w/oursonline | 68.8 | 72.7 | 49.6 | 69.5 | 72.9 | 53.0 |
| EntitySeg | w/ ours semi-online | 69.5 | 73.3 | 50.5 | 69.8 | 73.1 | 53.3 |
4.2. Open-World Video Segmentation
4.2. 开放世界视频分割 (Open-World Video Segmentation)
Open-world video segmentation addresses the difficult problem of discovering, segmenting, and tracking objects in the wild. BURST [2] is a recently proposed dataset that evaluates open-world video segmentation. It contains diverse scenarios and 2,414 videos in its validation/test sets. There are a total of 482 object categories, 78 of which are ‘common’ classes while the rest are ‘uncommon’.
开放世界视频分割致力于解决在自然场景中发现、分割和跟踪物体的难题。BURST [2] 是近期提出的评估开放世界视频分割的数据集,其验证/测试集包含多样化场景和2,414段视频,共涵盖482个物体类别(其中78个为"常见"类,其余为"罕见"类)。
Metrics. Following [2], we assess Open World Tracking Accuracy (OWTA), computed separately for ‘all’, ‘common’, and ‘uncommon’ classes. False positive tracks are not directly penalized in the metrics as the ground-truth annotations are not exhaustive for all objects in the scene, but indirectly penalized by requiring the output mask to be mutually exclusive. We refer readers to [2, 42] for details.
指标。参照 [2],我们评估开放世界跟踪准确率 (Open World Tracking Accuracy, OWTA),分别计算"全部"、"常见"和"罕见"类别的结果。由于真实标注未涵盖场景中所有对象,误报轨迹不会直接在指标中惩罚,但通过要求输出掩码互斥来间接惩罚。详情请参阅 [2, 42]。
Main Results. Table 2 summarizes our findings. We study two image segmentation models: Mask 2 Former [7], and EntitySeg [49], both of which are pretrained on the COCO [37] dataset. The Mask 2 Former weight is trained for the instance segmentation task, while EntitySeg is trained for ‘entity segmentation’, that is to segment all visual entities without predicting class labels. We find EntitySeg works better for novel objects, as it is specifically trained to do so. Being able to plug and play the latest development of open-world image segmentation models without any finetuning is one of the major advantages of our formulation.
主要结果。表2总结了我们的发现。我们研究了两种图像分割模型:Mask 2 Former [7]和EntitySeg [49],两者均在COCO [37]数据集上进行了预训练。Mask 2 Former权重针对实例分割任务进行训练,而EntitySeg则针对"实体分割"进行训练,即分割所有视觉实体而不预测类别标签。我们发现EntitySeg在新物体上表现更好,因为它专门为此进行了训练。能够即插即用最新的开放世界图像分割模型而无需任何微调,是我们方法的主要优势之一。

Figure 6. An in-the-wild result in the BURST [2] dataset. Note, we can even track the small skateboarder (pink mask on the road).
图 6: BURST [2] 数据集中的真实场景结果。注意,我们甚至能追踪到小型滑板手(路面上的粉色掩膜)。
Our approach outperforms the baselines, which all follow the ‘tracking-by-detection’ paradigm. In these baselines, segmentation s are detected every frame, and a shortterm temporal module is used to associate these segmentations between frames. This paradigm is sensitive to misdetections in the image segmentation model. ‘Box tracker’ uses per-frame object IoU; ‘STCN tracker’ uses a pretrained STCN [11] mask propagation network; and OWTB [39] uses a combination of IoU, optical flow, and Re-ID features. We also make use of mask propagation, but we go beyond the setting of simply associating existing segmentations – our bi-directional propagation allows us to improve upon the image segmentation s and enable long-term tracking. Figure 6 compares our results on one of the videos in BURST to OWTB [39].
我们的方法优于所有遵循"检测跟踪"(tracking-by-detection)范式的基线方案。在这些基线中,每帧都会检测分割结果,并使用短期时序模块来关联帧间的分割。该范式对图像分割模型中的误检非常敏感。"Box tracker"使用逐帧目标IoU;"STCN tracker"采用预训练的STCN[11]掩码传播网络;OWTB[39]则结合了IoU、光流和Re-ID特征。我们也使用了掩码传播,但超越了简单关联现有分割的设置——我们的双向传播能够改进图像分割结果并实现长期跟踪。图6展示了我们在BURST数据集某视频上与OWTB[39]的对比结果。
4.3. Referring Video Segmentation
4.3. 参考视频分割 (Referring Video Segmentation)
Referring video segmentation takes a text description of an object as input and segments the target ob- ject. We experiment on Ref-DAVIS17 [25] and RefYouTubeVOS [55] which augments existing video object segmentation datasets [47, 65] with language expressions. Following [64], we assess which is the average of Jaccard index $(\mathcal{T})$ , and boundary F1-score $(\mathcal{F})$ .
参考视频分割以对象的文本描述作为输入,并分割目标对象。我们在Ref-DAVIS17 [25] 和 RefYouTubeVOS [55] 上进行了实验,这两个数据集通过语言表达增强了现有的视频对象分割数据集 [47, 65]。遵循 [64] 的方法,我们评估了 ,即 Jaccard 指数 $(\mathcal{T})$ 和边界 F1 分数 $(\mathcal{F})$ 的平均值。
Table 3 tabulates our results. We use an image-level Refer Former [64] as the image segmentation model. We find that the quality of referring segmentation has a high variance across the video (e.g., the target object might be too small at the beginning of the video). As in all competing approaches [55, 64, 17], we opt for an offline setting to reduce this variance. Concretely, we perform the initial inclip consensus by selecting 10 uniformly spaced frames in the video and using the frame with the highest confidence given by the image model as a ‘key frame’ for aligning the other frames. We then forward- and backward-propagate from the key frame without incorporating additional image segmentation s. We give more details in the appendix. Our method outperforms other approaches.
表 3: 展示了我们的实验结果。我们采用图像级 Refer Former [64] 作为图像分割模型。研究发现,参照分割质量在视频中存在较大波动 (例如目标物体在视频开头可能过小)。与所有竞争方法 [55, 64, 17] 相同,我们选择离线设置来降低这种波动。具体而言,我们通过选取视频中均匀间隔的 10 帧,并使用图像模型给出最高置信度的帧作为"关键帧"来对齐其他帧,从而完成初始 inclip 共识。随后我们仅从关键帧进行前向和后向传播,不引入额外的图像分割。更多细节见附录。我们的方法优于其他方案。
Table 3. comparisons on two referring video segmentation datasets. Ref-YTVOS stands for Ref-YouTubeVOS [55].
表 3. 在两个参考视频分割数据集上的对比。Ref-YTVOS 代表 Ref-YouTubeVOS [55]。
| 方法 | Ref-DAVIS [25] | Ref-YTVOS [55] |
|---|---|---|
| URVOS [55] | 51.6 | 47.2 |
| ReferFormer [64] | 60.5 | 62.4 |
| VLT [17] | 61.6 | 63.8 |
| Ours | 66.3 | 66.0 |
4.4. Unsupervised Video Object Segmentation
4.4. 无监督视频目标分割
Unsupervised video object segmentation aims to find and segment salient target object(s) in a video. We evaluate on DAVIS-16 [47] (single-object) and DAVIS-17 [5] (multi-object). In the single-object setting, we use the image saliency model DIS [51] as the image model and employ an offline setting as in Section 4.3. In the multi-object setting, since the image saliency model only segments one object, we instead use EntitySeg [49] and follow our semionline protocol on open-world video segmentation in Section 4.2. Table 4 summarizes our findings. Please refer to the appendix for details.
无监督视频目标分割旨在视频中寻找并分割显著目标物体。我们在DAVIS-16 [47](单目标)和DAVIS-17 [5](多目标)数据集上进行评估。单目标场景下,使用图像显著性模型DIS [51]作为图像模型,并采用第4.3节的离线设置。多目标场景中,由于图像显著性模型仅能分割单个目标,我们改用EntitySeg [49]模型,并遵循第4.2节开放世界视频分割的半在线协议。表4总结了实验结果,详见附录。
Table 4. comparisons on three unsupervised video object segmentation datasets: DAVIS16 validation (D16-val), DAVIS17 validation (D17-val), and DAVIS17 test-dev (D17-td). Missing entries mean that the method did not report results on that dataset.
表 4: 三个无监督视频目标分割数据集上的 对比:DAVIS16验证集 (D16-val)、DAVIS17验证集 (D17-val) 和 DAVIS17测试开发集 (D17-td)。缺失条目表示该方法未报告该数据集的结果。
| 方法 | D16-val | D17-val | D17-td |
|---|---|---|---|
| RTNet [54] | 85.2 | ||
| PMN [31] | 85.9 | ||
| UnOVOST [43] | 67.9 | 58.0 | |
| Propose-Reduce [36] | - | 70.4 | |
| Ours | 88.9 | 73.4 | 62.1 |
4.5. Ablation Studies
4.5. 消融研究
4.5.1 Varying Training Data
4.5.1 训练数据的变化
Here, we vary the amount of training data in the target domain (VIPSeg [45]) to measure the sensitivity of endto-end approaches vs. our decoupled approach. We subsample different percentages of videos from the training set to train Video-K-Net-R50 [34] (all networks are still pretrained with COCO-panoptic [37]). We then compare endto-end performances with our (semi-online) decoupled performances (the temporal propagation model is unchanged as it does not use any data from the target domain). Figure 1 plots our findings – our model has a much higher relative VPQ improvement over the baseline Video-K-Net for rare classes if little training data is available.
在此,我们通过改变目标领域(VIPSeg [45])的训练数据量,来测量端到端方法与我们解耦方法的敏感性。我们从训练集中抽取不同比例的视频子集来训练Video-K-Net-R50 [34](所有网络仍使用COCO-panoptic [37]进行预训练)。随后将端到端性能与我们(半在线)解耦方法的性能进行对比(时序传播模型保持不变,因其未使用目标领域的任何数据)。图1展示了我们的发现——当可用训练数据较少时,我们的模型在稀有类别上相比基线Video-K-Net具有更高的相对VPQ提升。
Table 5. Performances of our method on VIPSeg [45] with different hyper parameters and design choices. By default, we use a clip size of $n=3$ and a merge frequency of every 5 frames with spatial alignment for a balance between performance and speed.
表 5. 我们的方法在VIPSeg [45]数据集上采用不同超参数和设计选择时的性能表现。默认情况下,我们使用$n=3$的片段长度和每5帧进行一次空间对齐的合并频率,以平衡性能与速度。
| 变化片段长度 | VPQ1 VPQ10 | VPQ | STQ | FPS |
|---|---|---|---|---|
| n=1 | 41.0 37.3 | 36.4 | 41.1 | 10.3 |
| n=2 | 40.4 | 37.2 36.3 | 39.0 | 9.8 |
| n=3 | 42.1 39.3 | 38.3 | 41.5 | 7.8 |
| n=4 | 42.1 | 38.5 | 42.3 | 6.6 |
| n=5 | 41.7 | 38.9 38.3 | 42.8 | 5.6 |
| 变化合并频率 | VPQ1 VPQ10 | VPQ | STQ | FPS |
|---|---|---|---|---|
| 每3帧 | 42.2 | 39.2 | 38.4 | 42.6 5.2 |
| 每5帧 | 42.1 | 39.3 | 38.3 41.5 | 7.8 |
| 每7帧 | 41.5 | 39.0 | 35.7 | 40.5 8.4 |
| 空间对齐? | VPQ1 | VPQ10 | VPQ | STQ FPS |
|---|---|---|---|---|
| 是 | 42.1 | 39.3 | 38.3 | 41.5 |
| 否 | 36.7 | 33.9 | 32.8 | 7.8 33.7 9.2 |
4.5.2 In-Clip Consensus
4.5.2 片段内共识
Here we explore hyper parameters and design choices in inclip consensus. Table 5 tabulates our performances with different clip sizes, different frequencies of merging in-clip consensus with temporal propagation, and whether to use spatial alignment during in-clip consensus. Mask 2 FormerR50 is used as the backbone in all entries. For clip size $n=2$ , tie-breaking is ambiguous. A large clip is more comput ation ally demanding and potentially leads to inaccurate spatial alignment as the appearance gap between frames in the clip increases. A high merging frequency reduces the delay between the appearance of a new object and its detection in our framework but requires more computation. By default, we use a clip size $n=3$ , merge consensus with temporal propagation every 5 frames, and enable spatial alignment for a balance between performance and speed.
我们在此探讨inclip共识中的超参数与设计选择。表5列出了采用不同片段大小、不同时间传播融合频率以及是否在片段共识中使用空间对齐时的性能表现。所有实验均以Mask 2 FormerR50为骨干网络。当片段大小$n=2$时,平局情况存在歧义。较大片段会提高计算需求,且随着帧间外观差异增大可能导致空间对齐不准。高频融合能缩短新物体出现到被检测到的延迟,但会增加计算量。默认配置采用$n=3$的片段大小、每5帧执行一次时间传播融合,并启用空间对齐以平衡性能与速度。
4.5.3 Using Temporal Propagation
4.5.3 使用时间传播 (Temporal Propagation)
Here, we compare different approaches for using temporal propagation in a decoupled setting. Tracking-by-detection approaches [26, 58, 3] typically detect segmentation at every frame and use temporal propagation to associate these per-frame segmentation s. We test these short-term association approaches using 1) mask IoU between adjacent frames, 2) mask IoU of adjacent frames warped by optical flow from RAFT [59], and 3) query association [22] of query-based segmentation [7] between adjacent frames. We additionally compare with variants of our temporal propagation method: 4) ‘ShortTrack’, where we consider only short-term tracking by re-initializing the memory H every frame, and 5) ‘Trust ImageS eg’, where we explicitly trust the consensus given by the image segmentation s over temporal propagation by discarding segments that are not associated with a segment in the consensus (i.e., dropping the middle term in Eq. (9)). Table 6 tabulates our findings. For all entries, we use Mask 2 Former-R50 [7] in the online setting on VIPSeg [45] for fair comparisons.
在此,我们比较了在解耦设置下使用时间传播的不同方法。基于检测的跟踪方法 [26, 58, 3] 通常会在每一帧检测分割结果,并利用时间传播将这些逐帧分割结果关联起来。我们测试了以下短期关联方法:1) 相邻帧之间的掩码交并比 (mask IoU),2) 通过 RAFT [59] 光流扭曲后的相邻帧掩码交并比,以及 3) 基于查询的分割方法 [7] 在相邻帧之间的查询关联 [22]。我们还对比了本时间传播方法的变体:4) 'ShortTrack'(每帧重新初始化记忆 H 以实现短期跟踪),以及 5) 'Trust ImageSeg'(通过丢弃未与共识分割结果关联的片段,显式信任图像分割给出的共识而非时间传播,即舍弃公式 (9) 中的中间项)。表 6 汇总了实验结果。所有测试均采用在线设置的 Mask2Former-R50 [7] 在 VIPSeg [45] 数据集上进行公平比较。
Table 6. Performances of different temporal schema on VIPSeg [45]. Our bi-directional propagation scheme is necessary for the final high performance.
表 6: 不同时序方案在VIPSeg [45]上的性能表现。我们的双向传播方案对最终高性能至关重要。
| 时序方案 | VPQ | VPQ | VPQ10 VPQ | STQ |
|---|---|---|---|---|
| MaskIoU | 39.9 | 32.7 | 27.7 27.6 | 34.5 |
| MaskIoU+flow | 40.2 | 33.7 | 28.8 28.6 | 37.0 |
| Query assoc. | 40.4 | 33.1 | 28.1 28.0 | 35.8 |
| ShortTrack | 40.6 | 33.3 | 28.3 28.2 | 37.2 |
| 'TrustImageSeg' | 40.3 | 37.5 | 33.7 33.2 | 37.9 |
| Ours,bi-direction | 41.0 | 39.3 | 37.3 36.4 | 41.1 |
4.6. Limitations
4.6. 局限性
As the temporal propagation model is task-agnostic, it cannot detect new objects by itself. As shown by the red boxes in Figure 3, the new object in the scene is missing from $\mathbf{M}{k-1}$ and can only be detected in ${\bf M}_{k}$ – this results in delayed detections relating to the frequency of merging with in-clip consensus. Secondly, we note that end-to-end approaches still work better when training data is sufficient, i.e., in smaller vocabulary settings like YouTubeVIS [69] as shown in the appendix. But we think decoupled methods are more promising in large-vocabulary/open-world settings.
由于时间传播模型是任务无关的,它无法自行检测新对象。如图3中的红框所示,场景中的新对象在$\mathbf{M}{k-1}$中缺失,只能在${\bf M}_{k}$中被检测到——这会导致检测延迟,其程度与片段内共识合并的频率相关。其次,我们注意到当训练数据充足时(例如附录中展示的YouTubeVIS [69]这类小词汇量场景),端到端方法仍表现更优。但我们认为解耦方法在大词汇量/开放世界设定中更具前景。
5. Conclusion
5. 结论
We present DEVA, a decoupled video segmentation approach for ‘tracking anything’. It uses a bi-directional propagation technique that effectively scales image segmentation methods to video data. Our approach critically lever- ages external task-agnostic data to reduce reliance on the target task, thus generalizing better to tasks with scarce data than end-to-end approaches. Combined with universal image segmentation models, our decoupled paradigm demonstrates state-of-the-art performance as a first step towards open-world large-vocabulary video segmentation.
我们提出DEVA,一种用于"追踪万物"的解耦视频分割方法。该方法采用双向传播技术,将图像分割方法高效扩展到视频数据。我们的方法关键性地利用了与任务无关的外部数据,降低对目标任务的依赖,相比端到端方法能更好地泛化到数据稀缺的任务。结合通用图像分割模型,这一解耦范式展现了最先进的性能,成为迈向开放世界大词汇量视频分割的第一步。