High-Order Structure Based Middle-Feature Learning for Visible-Infrared Person Re-Identification
基于高阶结构的中层特征学习在可见光-红外行人重识别中的应用
Abstract
摘要
Visible-infrared person re-identification (VI-ReID) aims to retrieve images of the same persons captured by visible (VIS) and infrared (IR) cameras. Existing VI-ReID methods ignore high-order structure information of features while being relatively difficult to learn a reasonable common feature space due to the large modality discrepancy between VIS and IR images. To address the above problems, we propose a novel high-order structure based middle-feature learning network (HOS-Net) for effective VI-ReID. Specifically, we first leverage a short- and long-range feature extraction (SLE) module to effectively exploit both short-range and long-range features. Then, we propose a high-order structure learning (HSL) module to successfully model the high-order relationship across different local features of each person image based on a whitened hypergraph network. This greatly alleviates model collapse and enhances feature representations. Finally, we develop a common feature space learning (CFL) module to learn a disc rim i native and reasonable common feature space based on middle features generated by aligning features from different modalities and ranges. In particular, a modality-range identity-center contrastive (MRIC) loss is proposed to reduce the distances between the VIS, IR, and middle features, smoothing the training process. Extensive experiments on the SYSU-MM01, RegDB, and LLCM datasets show that our HOS-Net achieves superior state-ofthe-art performance. Our code is available at https://github. com/J aula u coen g/HOS-Net.
可见光-红外行人重识别(VI-ReID)旨在检索由可见光(VIS)和红外(IR)摄像头捕获的同一行人图像。现有VI-ReID方法忽略了特征的高阶结构信息,同时由于VIS和IR图像之间存在较大模态差异,较难学习到合理的共同特征空间。针对上述问题,我们提出了一种基于高阶结构的中间特征学习网络(HOS-Net)。具体而言,我们首先利用短长程特征提取(SLE)模块有效获取短程和长程特征。接着提出高阶结构学习(HSL)模块,基于白化超图网络成功建模每张行人图像不同局部特征间的高阶关系,极大缓解了模型坍塌问题并增强了特征表示能力。最后开发了共同特征空间学习(CFL)模块,通过对齐不同模态和范围的特征生成中间特征,进而学习判别性强且合理的共同特征空间。特别提出模态-范围身份中心对比(MRIC)损失函数,缩小VIS、IR与中间特征之间的距离,使训练过程更加平滑。在SYSU-MM01、RegDB和LLCM数据集上的大量实验表明,我们的HOS-Net取得了最先进的性能。代码已开源在https://github.com/Julaucong/HOS-Net。
Introduction
引言
Over the past few years, person re-identification (ReID) has attracted increasing attention due to its significant importance in surveillance and security applications. A large number of single-modality person ReID methods have been proposed based on visible (VIS) cameras. However, these methods may fail under low-light conditions. Unlike VIS cameras, infrared (IR) cameras are less affected by illumination changes. Recently, visible-infrared person re-identification (VI-ReID), which leverages both VIS and IR cameras, has been developed to match cross-modality person images, mitigating the limitations of single-modality person ReID.
近年来,行人重识别(ReID)因其在监控安防应用中的重要意义而受到越来越多的关注。基于可见光(VIS)摄像头的单模态行人ReID方法已被大量提出。然而,这些方法在低光照条件下可能失效。与可见光摄像头不同,红外(IR)摄像头受光照变化的影响较小。近期,可见光-红外行人重识别(VI-ReID)通过联合使用VIS和IR摄像头来匹配跨模态行人图像,从而缓解单模态行人ReID的局限性。
A major challenge of VI-ReID is the large modality discrepancy between VIS and IR images. To reduce the modality discrepancy, existing VI-ReID methods can be divided into image-level and feature-level methods. The image-level methods (Dai et al. 2018; Wang et al. 2020; Wei et al. 2022), generate middle-modality or new modality images based on generative adversarial networks (GAN). However, the GANbased methods easily suffer from the problems of color inconsistency or loss of image details. Hence, the generated images may not be reliable for subsequent classification.
可见光-红外跨模态行人重识别(VI-ReID)的主要挑战在于可见光(VIS)与红外(IR)图像间存在显著模态差异。为减小模态差异,现有方法可分为图像级和特征级两类。图像级方法(Dai et al. 2018; Wang et al. 2020; Wei et al. 2022)基于生成对抗网络(GAN)生成中间模态或新模态图像,但这类方法易出现色彩失真或图像细节丢失问题,导致生成图像可能不适用于后续分类任务。
The feature-level methods (Ye et al. 2021b; Lu, Zou, and Zhang 2023; Zhang et al. 2022) follow a two-step learning pipeline (i.e., they first extract features for VIS and IR images, and then map these features into a common feature space). Generally, these methods have two issues. On the one hand, they often ignore high-order structure information of features (i.e., the different levels of dependence across local features), which can be important for matching crossmodality images. On the other hand, they usually directly minimize the distances between VIS and IR features in the common feature space. However, such a manner increases the difficulty of learning a reasonable common feature space due to the large modality discrepancy.
特征级方法 (Ye et al. 2021b; Lu, Zou, and Zhang 2023; Zhang et al. 2022) 遵循两步学习流程 (即先提取可见光-红外(VIS-IR)图像特征,再将特征映射到公共特征空间)。这类方法通常存在两个问题:一方面,它们往往忽略特征的高阶结构信息 (即局部特征间不同层级的依赖关系),而这些信息对跨模态图像匹配至关重要;另一方面,它们通常直接在公共特征空间中最小化VIS与IR特征的距离。然而,由于模态差异较大,这种方式会增加学习合理公共特征空间的难度。
To address the above issues, in this paper, we propose a novel high-order structure based middle-feature learning network (HOS-Net), which consists of a backbone, a shortand long-range feature extraction (SLE) module, a highorder structure learning (HSL) module, and a common feature space learning (CFL) module, for VI-ReID. The key novelty of our method lies in the novel formulation of exploiting high-order structure information and middle features to learn a disc rim i native and reasonable common feature space, greatly alleviating the modality discrepancy.
为了解决上述问题,本文提出了一种基于高阶结构的中层特征学习网络(HOS-Net),该网络由主干网络、短长期特征提取(SLE)模块、高阶结构学习(HSL)模块和公共特征空间学习(CFL)模块组成,用于VI-ReID。我们方法的关键创新在于利用高阶结构信息和中层特征来学习一个判别性强且合理的公共特征空间,从而显著缓解模态差异。
Specifically, given a VIS-IR image pair, the SLE module (consisting of a convolutional branch and a Transformer branch) extracts short-range and long-range features. Then, the HSL module models the dependence on short-range and long-range features based on a whitened hypergraph. Finally, the CFL module learns a common feature space by generating and leveraging middle features. In the CFL module, instead of directly adding or concatenating features from different modalities and ranges, we leverage graph attention to properly align these features, obtaining middle features. Based on it, a modality-range identity-center contrastive (MRIC) loss is developed to reduce the distances between the VIS, IR, and middle features, smoothing the process of learning the common feature space.
具体来说,给定一个可见光-红外(VIS-IR)图像对,短长程特征提取(SLE)模块(由卷积分支和Transformer分支组成)会提取短程和长程特征。随后,基于白化超图的异质短长程(HSL)模块会建模对短程和长程特征的依赖关系。最后,通过生成并利用中间特征,共融特征学习(CFL)模块学习到一个共同特征空间。在CFL模块中,我们没有直接相加或拼接来自不同模态和范围的特征,而是利用图注意力机制来适当对齐这些特征,从而获得中间特征。基于此,我们开发了模态-范围身份中心对比(MRIC)损失函数,以减小可见光、红外和中间特征之间的距离,从而平滑共同特征空间的学习过程。
The contributions of our work are twofold:
我们工作的贡献有两方面:
• First, we introduce an HSL module to learn high-order structure information of both short-range and long-range features. Such an innovative way effectively models high-order relationship across different local features of a person image without suffering from model collapse, greatly enhancing feature representations. • Second, we design a CFL module to learn a discriminative and reasonable common feature space by taking advantage of middle features. In particular, a novel MRIC loss is developed to minimize the distances between VIS, IR, and middle features. This is beneficial for the extraction of disc rim i native modality-irrelevant ReID features.
• 首先,我们引入HSL模块来学习短程和长程特征的高阶结构信息。这种创新方法有效建模了行人图像不同局部特征间的高阶关系,避免了模型坍塌,显著增强了特征表示能力。
• 其次,我们设计了CFL模块,通过利用中间特征来学习具有判别力的合理公共特征空间。特别地,开发了新型MRIC损失函数来最小化可见光(VIS)、红外(IR)与中间特征之间的距离,这有利于提取判别性的模态无关ReID特征。
Extensive experiments on the SYSU-MM01, RegDB, and LLCM datasets demonstrate that our proposed HOS-Net obtains excellent performance in comparison with several state-of-the-art VI-ReID methods.
在SYSU-MM01、RegDB和LLCM数据集上的大量实验表明,与多种先进的可见光-红外行人重识别(VI-ReID)方法相比,我们提出的HOS-Net取得了优异的性能。
Related Work
相关工作
Single-Modality Person Re-Identification (ReID). A variety of single-modality person ReID methods have been developed and achieved promising performance in the cases of occlusion, cloth-changing, and pose changes. Yan et al. (Yan et al. 2021) propose an occlusion-based data augmentation strategy and a bounded exponential distance loss for oc- cluded person ReID. Jin et al. (Jin et al. 2022) introduce an additional gait recognition task to learn cloth-agnostic features. Note that these methods are based on VIS cameras and thus they perform poorly in low-light conditions.
单模态行人重识别(ReID)。针对遮挡、换装和姿态变化等情况,研究者们开发了多种单模态行人重识别方法并取得了良好性能。Yan等人(Yan et al. 2021)提出了一种基于遮挡的数据增强策略和有界指数距离损失函数来处理遮挡情况下的行人重识别。Jin等人(Jin et al. 2022)则通过引入额外的步态识别任务来学习与服装无关的特征。需要注意的是,这些方法都基于可见光(VIS)摄像头,因此在低光照条件下表现不佳。
Visible-Infrared Person Re-Identification (VI-ReID). The image-level methods (Dai et al. 2018; Wang et al. 2020; Wei et al. 2022) often reduce the modality discrepancy by generating middle-modality images or new modality images. Wei et al. (Wei et al. 2022) propose a bidirectional image translation subnetwork to generate middle-modality images from VIS and IR modalities. Li et al. (Li et al. 2020) and Zhang et al. (Zhang et al. 2021) introduce light-weight middle-modality image generators to mitigate the modality discrepancy. Instead of generating middle-modality images, we align the features from different modalities and ranges with graph attention, generating reliable middle features. Moreover, we design an MRIC loss to optimize the distances between VIS, IR, and middle features, benefiting the extraction of disc rim i native ReID features.
可见光-红外行人重识别 (VI-ReID)。图像级方法 (Dai et al. 2018; Wang et al. 2020; Wei et al. 2022) 通常通过生成中间模态图像或新模态图像来减少模态差异。Wei等人 (Wei et al. 2022) 提出双向图像转换子网络,从可见光(VIS)和红外(IR)模态生成中间模态图像。Li等人 (Li et al. 2020) 和 Zhang等人 (Zhang et al. 2021) 引入轻量级中间模态图像生成器以缓解模态差异。不同于生成中间模态图像,我们通过图注意力对齐来自不同模态和范围的特征,生成可靠的中间特征。此外,我们设计了MRIC损失函数来优化可见光、红外和中间特征之间的距离,有助于提取具有判别力的重识别特征。
The feature-level methods map the features of different modalities into a common feature space to reduce the modality discrepancy. A few methods (Ye et al. 2021b; Yang, Chen, and Ye 2023; Lu, Zou, and Zhang 2023) leverage CNN or ViT as the backbone to extract features. Some methods (Chen et al. 2022a; Wan et al. 2023) adopt off-the-shelf key point extractors to generate key point labels of person images and learn modality-irrelevant features. But the key point extractor may introduce noisy labels, deteriorating the disc rim inability of final ReID features. Many VI-ReID methods (Liu, Tan, and Zhou 2020; Huang et al. 2022, 2023)
特征级方法将不同模态的特征映射到共同的特征空间以减少模态差异。部分方法 (Ye et al. 2021b; Yang, Chen and Ye 2023; Lu, Zou and Zhang 2023) 采用CNN或ViT作为骨干网络提取特征。另有方法 (Chen et al. 2022a; Wan et al. 2023) 使用现成的关键点提取器生成行人图像关键点标签,学习模态无关特征。但关键点提取器可能引入噪声标签,降低最终ReID特征的判别能力。许多VI-ReID方法 (Liu, Tan and Zhou 2020; Huang et al. 2022, 2023)
employ the contrastive-based loss, which directly minimizes the distances between VIS and IR features, to obtain a common feature space. However, it is not a trivial task to learn a reasonable common feature space due to the large modality discrepancy between modalities.
采用基于对比的损失函数,直接最小化可见光(VIS)与红外(IR)特征间的距离,以获得共同特征空间。然而,由于模态间存在较大差异,学习合理的共同特征空间并非易事。
Our method belongs to feature-level methods. However, conventional feature-level methods mainly consider firstorder structure information of features (i.e., the pairwise relation across features). Moreover, they directly reduce the distances between VIS and IR features. Different from these methods, our method not only captures high-order structure information of features but also generates middle features, greatly facilitating our model to learn an effective common feature space.
我们的方法属于特征级方法。然而,传统的特征级方法主要考虑特征的一阶结构信息(即特征间的成对关系)。此外,它们直接减小可见光(VIS)与红外(IR)特征之间的距离。与这些方法不同,我们的方法不仅捕捉特征的高阶结构信息,还生成中间特征,极大地促进了模型学习有效的共同特征空间。
Graph Neural Networks in Person Re-Identification. Graph neural network (GNN) is a class of neural networks that is designed to operate on graph-structured data. Li et al. (Li et al. 2021) propose a pose and similarity basedGNN to reduce the problem of pose misalignment for singlemodality person ReID. Wan et al. (Wan et al. 2023) develop a geometry guided dual-alignment strategy to align VIS and IR features, improving the consistency of multi-modality node representations. Different from pairwise connections in the vanilla graph models, Feng et al. (Feng et al. 2019) propose a hypergraph neural network (HGNN) to encode highorder feature correlations in a hypergraph structure. Lu et al. (Lu et al. 2023) model high-order spatio-temporal correlations based on HGNN (which relies on high-quality skeleton labels) for video person ReID.
图神经网络在行人重识别中的应用。图神经网络 (GNN) 是一类专为处理图结构数据而设计的神经网络。Li 等人 (Li et al. 2021) 提出了一种基于姿态和相似性的 GNN 方法,以缓解单模态行人重识别中的姿态错位问题。Wan 等人 (Wan et al. 2023) 开发了几何引导的双对齐策略来对齐可见光 (VIS) 和红外 (IR) 特征,从而提升多模态节点表征的一致性。与传统图模型中的成对连接不同,Feng 等人 (Feng et al. 2019) 提出超图神经网络 (HGNN) 来编码超图结构中的高阶特征关联。Lu 等人 (Lu et al. 2023) 基于 HGNN (该方法依赖高质量骨骼标注) 对视频行人重识别中的高阶时空关联进行建模。
However, the above HGNN-based methods may easily suffer from the model collapse problem (i.e., high-order correlations collapse to a single correlation) since a hyperedge can connect an arbitrary number of nodes. Unlike the above methods, we leverage the whitening operation, which plays the role of “scattering” on the nodes of the hypergraph, to significantly alleviate model collapse.
然而,上述基于HGNN的方法容易因超边可连接任意数量节点而遭遇模型坍塌问题(即高阶相关性坍缩为单一相关性)。与这些方法不同,我们利用白化操作对超图节点进行"散射"式处理,从而显著缓解模型坍塌。
Proposed Method
提出的方法
Overview
概述
The overview of our proposed HOS-Net is given in Figure 1. HOS-Net consists of a backbone, an SLE module, an HSL module, and a CFL module. In this paper, we adopt a two-stream AGW (Ye et al. 2021b) as the backbone. Given a VIS-IR image pair with the same identity, we first pass it through the backbone to obtain paired VIS-IR features. Then, these features are fed into the SLE module to learn short-range and long-range features for each modality. Next, the HSL module exploits high-order structure information of short-range and long-range features based on a whitened hypergraph network. Finally, the CFL module learns a discri mi native common feature space based on middle features that are obtained by aligning VIS and IR features through graph attention. In the CFL module, we develop an MRIC loss to reduce the distances between the VIS, IR, and middle features, greatly smoothing the process of learning the common feature space.
图 1: 展示了我们提出的HOS-Net整体架构。HOS-Net由主干网络、SLE模块、HSL模块和CFL模块组成。本文采用双流AGW (Ye et al. 2021b)作为主干网络。给定同一身份的红外-可见光图像对,首先通过主干网络提取成对的可见光-红外特征。随后,这些特征被输入SLE模块,学习每种模态的短程和长程特征。接着,HSL模块基于白化超图网络利用短程和长程特征的高阶结构信息。最后,CFL模块通过学习中间特征构建判别性公共特征空间,这些中间特征通过图注意力机制对齐可见光和红外特征获得。在CFL模块中,我们设计了MRIC损失函数来缩小可见光、红外及中间特征之间的距离,显著平滑了公共特征空间的学习过程。
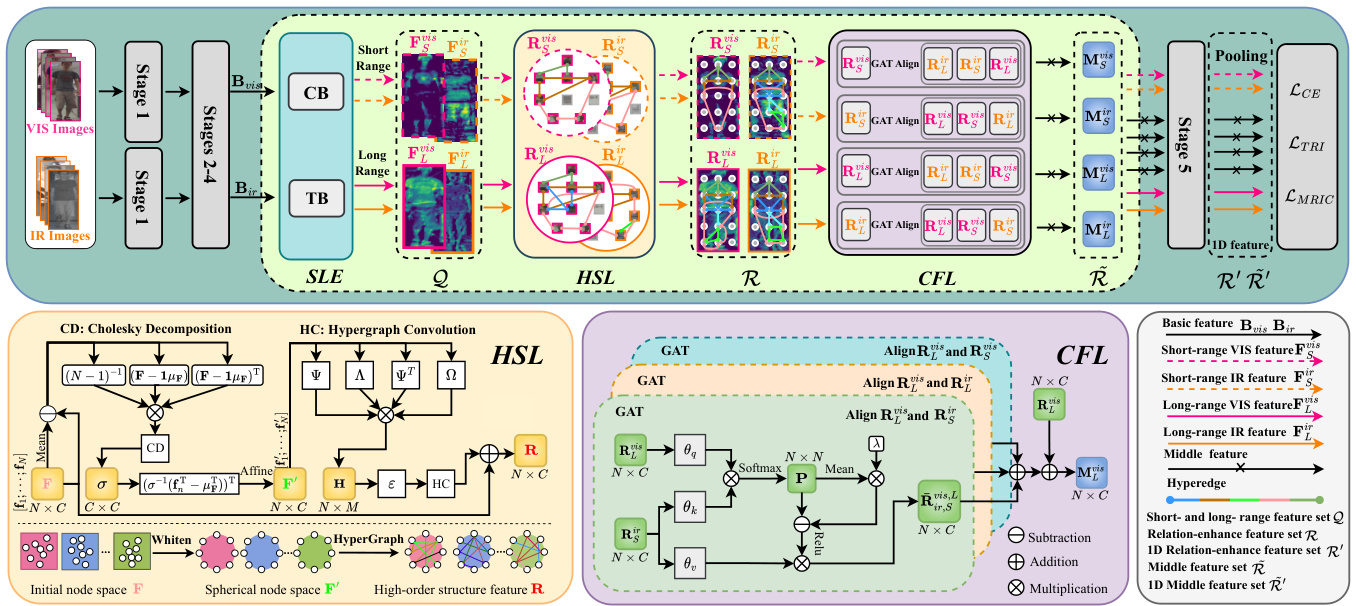
Figure 1: Overview of the proposed HOS-Net, including a backbone, a short- and long-range feature extraction (SLE) module, a high-order structure learning (HSL) module, and a common feature space learning (CFL) module. The HOS-Net is jointly optimized by $\mathcal{L}{C E}$ , $\mathcal{L}{T R I}$ , and $\mathcal{L}_{M R I C}$ .
图 1: 提出的HOS-Net概述,包括一个主干网络、短程和长程特征提取(SLE)模块、高阶结构学习(HSL)模块以及公共特征空间学习(CFL)模块。HOS-Net通过$\mathcal{L}{CE}$、$\mathcal{L}{TRI}$和$\mathcal{L}_{MRIC}$联合优化。
Short- and Long-Range Feature Extraction (SLE) Module
短程与长程特征提取 (SLE) 模块
Conventional VI-ReID methods (Ye et al. 2021b; Yang, Chen, and Ye 2023) often leverage CNN or ViT for feature extraction. CNN excels at capturing short-range features, while ViT is good at obtaining long-range features (Zhang, Hu, and Wang 2022; Chen et al. 2022b). In this paper, we adopt an SLE module to exploit short-range and long-range features by taking advantage of both CNN and ViT. The SLE module contains a convolutional branch (CB) and a Transformer branch (TB). CB contains 3 convolutional blocks and TB contains 2 Transformer blocks with 4 heads. Assume that we have a VIS-IR image pair ${\mathbf{I}^{v i s},\mathbf{I}^{i r}}$ with the same identity. We denote the VIS and IR features obtained from the backbone as ${\bf B}^{v i s}$ and $\mathbf{B}^{i r}$ , respectively.
传统VI-ReID方法 (Ye et al. 2021b; Yang, Chen和Ye 2023) 通常利用CNN或ViT进行特征提取。CNN擅长捕捉短程特征,而ViT善于获取长程特征 (Zhang, Hu和Wang 2022; Chen et al. 2022b)。本文采用SLE模块,通过结合CNN和ViT的优势来利用短程和长程特征。SLE模块包含一个卷积分支(CB)和一个Transformer分支(TB)。CB包含3个卷积块,TB包含2个具有4个头的Transformer块。假设我们有一个具有相同身份的VIS-IR图像对${\mathbf{I}^{v i s},\mathbf{I}^{i r}}$。我们将从主干网络获得的VIS和IR特征分别表示为${\bf B}^{v i s}$和$\mathbf{B}^{i r}$。
Then, ${\bf B}^{v i s}$ and $\mathbf{B}^{i r}$ are fed into the SLE module to obtain short-range and long-range features for each modality, i.e.,
然后,${\bf B}^{v i s}$ 和 $\mathbf{B}^{i r}$ 被输入到 SLE 模块中,以获取每种模态的短程和长程特征,即
$$
\begin{array}{r l}&{{\bf F}{S}^{v i s}=\mathrm{CB}({\bf B}^{v i s}),\quad{\bf F}{L}^{v i s}=\mathrm{TB}({\bf B}^{v i s}),}\ &{{\bf F}{S}^{i r}=\mathrm{CB}({\bf B}^{i r}),\quad{\bf F}_{L}^{i r}=\mathrm{TB}({\bf B}^{i r}),}\end{array}
$$
$$
\begin{array}{r l}&{{\bf F}{S}^{v i s}=\mathrm{CB}({\bf B}^{v i s}),\quad{\bf F}{L}^{v i s}=\mathrm{TB}({\bf B}^{v i s}),}\ &{{\bf F}{S}^{i r}=\mathrm{CB}({\bf B}^{i r}),\quad{\bf F}_{L}^{i r}=\mathrm{TB}({\bf B}^{i r}),}\end{array}
$$
where $\mathrm{CB}(\cdot)$ and $\mathrm{TB}(\cdot)$ represent the convolutional branch and the Transformer branch, respectively; $\mathbf{F}{S}^{v i s}\in\mathbb{R}^{H\times W\times C}$ and $\mathbf{F}{S}^{i r}~ \in~\mathbb{R}^{H\times W\times C}$ denote the short-range features for the VIS and IR images, respectively; $\mathbf{F}{L}^{v i s}\in\mathbb{R}^{H\times W\times C}$ and $\mathbf{F}{L}^{i r}\in\mathbb{R}^{H\times W\times C}$ denote the long-range features for the VIS and IR images, respectively; $H,W$ , and $C$ denote the height, width, and channel number of the feature, respectively. Thus, for a VIS-IR image pair, we can obtain the feature set $\mathcal{Q}={{\bf F}{L}^{v i s},{\bf F}{S}^{v i s},{\bf F}{L}^{i\bar{r}},\bar{\bf F}_{S}^{i r}}$ , which is used as the input of the HSL module.
其中 $\mathrm{CB}(\cdot)$ 和 $\mathrm{TB}(\cdot)$ 分别表示卷积分支和 Transformer 分支;$\mathbf{F}{S}^{v i s}\in\mathbb{R}^{H\times W\times C}$ 和 $\mathbf{F}{S}^{i r}\in~\mathbb{R}^{H\times W\times C}$ 分别表示可见光(VIS)和红外(IR)图像的短程特征;$\mathbf{F}{L}^{v i s}\in\mathbb{R}^{H\times W\times C}$ 和 $\mathbf{F}{L}^{i r}\in\mathbb{R}^{H\times W\times C}$ 分别表示可见光和红外图像的长程特征;$H,W$ 和 $C$ 分别表示特征的高度、宽度和通道数。因此,对于可见光-红外图像对,我们可以获得特征集 $\mathcal{Q}={{\bf F}{L}^{v i s},{\bf F}{S}^{v i s},{\bf F}{L}^{i\bar{r}},\bar{\bf F}_{S}^{i r}}$,该集合将作为 HSL 模块的输入。
High-Order Structure Learning (HSL) Module
高阶结构学习 (HSL) 模块
The features extracted from the SLE module only encode pixel-wise and region-wise dependencies in the person images. However, the high-order structure information, which indicates different levels of relation in the features (e.g., head, torso, upper arm, and lower arm belongs to the upper part of the body while head, torso, arm, and leg belong to the whole body), is not well exploited. Therefore, inspired by HGNN (Feng et al. 2019), we introduce the HSL module to capture high-order correlations across different local features, enhancing feature representations. Note that the conventional HGNN tends to suffer from the problem of model collapse. To alleviate this problem, we take advantage of the whitening operation and apply it to the hypergraph network, as shown in Figure 1.
从SLE模块提取的特征仅编码了人物图像中像素级和区域级的依赖关系。然而,高阶结构信息(例如头部、躯干、上臂和下臂属于身体上半部分,而头部、躯干、手臂和腿属于整个身体)所表示的特征间多层次关系尚未得到充分利用。因此,受HGNN (Feng et al. 2019) 启发,我们引入HSL模块来捕捉不同局部特征间的高阶相关性,从而增强特征表示。需要注意的是,传统HGNN容易陷入模型坍塌问题。为缓解该问题,我们利用白化操作并将其应用于超图网络,如图 1 所示。
Different from pairwise connections in the vanilla graph models, a hypergraph can connect an arbitrary number of nodes to exploit high-order structure information. We construct a whitened hypergraph for each feature in $\mathcal{Q}$ . The hypergraph is defined as $\bar{\mathcal{G}}~=(\mathcal{V},\mathcal{E},\mathbf{W})$ , where $\nu=$ ${v_{1},\cdots,v_{N}}$ denotes the node set, $\mathcal{E}={e_{1},\cdots,e_{M}}$ denotes the hyperedge set, and W represents the weight matrix of the hyperedge set. Here, $N=H W$ and $M$ are the numbers of nodes and hyperedges, respectively. In this paper, we consider each $1\times1\times C$ grid of each feature in $\mathcal{Q}$ as a node. We represent the $n$ -th node by $\mathbf{f}{n}\in\mathbb{R}^{1\times C}$ and thus all nodes are represented by $\mathbf{F}=[\mathbf{f}{1};\cdot\cdot\cdot;\mathbf{f}_{N}]\in\mathbb{R}^{N\times C}$ .
与传统图模型中的成对连接不同,超图 (hypergraph) 可以连接任意数量的节点以利用高阶结构信息。我们为 $\mathcal{Q}$ 中的每个特征构建一个白化超图,该超图定义为 $\bar{\mathcal{G}} =~(\mathcal{V},\mathcal{E},\mathbf{W})$ ,其中 $\nu=$ ${v_{1},\cdots,v_{N}}$ 表示节点集, $\mathcal{E}={e_{1},\cdots,e_{M}}$ 表示超边集,W 表示超边集的权重矩阵。这里 $N=H W$ 和 $M$ 分别是节点和超边的数量。在本文中,我们将 $\mathcal{Q}$ 中每个特征的 $1\times1\times C$ 网格视为一个节点,并用 $\mathbf{f}{n}\in\mathbb{R}^{1\times C}$ 表示第 $n$ 个节点,因此所有节点可表示为 $\mathbf{F}=[\mathbf{f}{1};\cdot\cdot\cdot;\mathbf{f}_{N}]\in\mathbb{R}^{N\times C}$ 。
The traditional hypergraph network allows for unrestricted connections among nodes to capture high-order structure information. Hence, it easily suffers from model collapse (i.e., the nodes connected by different hyperedges are the same) during hypergraph learning. To mitigate this problem, we introduce a whitening operation to project the nodes into a spherical distribution. In fact, the whitening operation plays the role of “scattering” on the nodes, thereby avoiding the collapse of diverse high-order connections to a single connection. This enables us to explore various highorder relationships across these features effectively.
传统超图网络允许节点之间无限制连接以捕获高阶结构信息。因此,在超图学习过程中容易发生模型坍塌(即不同超边连接的节点完全相同)。为解决该问题,我们引入白化操作将节点投影至球面分布。实际上,白化操作对节点起到"分散"作用,从而避免多样高阶连接坍缩为单一连接,使我们能有效探索这些特征间的各类高阶关系。
The whitened node $\mathbf{f}_{n}^{\prime}$ can be obtained as
白化节点 $\mathbf{f}_{n}^{\prime}$ 可通过以下方式获得
$$
\mathbf{f}{n}^{\prime}=\gamma_{n}\big(\sigma^{-1}(\mathbf{f}{n}^{\mathrm{T}}-\mu_{\mathbf{F}}^{\mathrm{T}})\big)^{\mathrm{T}}+\beta_{n,}
$$
$$
\mathbf{f}{n}^{\prime}=\gamma_{n}\big(\sigma^{-1}(\mathbf{f}{n}^{\mathrm{T}}-\mu_{\mathbf{F}}^{\mathrm{T}})\big)^{\mathrm{T}}+\beta_{n,}
$$
where $\sigma_{\mathrm{ \scriptsize~\in~\mathbb{R}^{C\times C} }}$ denotes the lower triangular matrix, which is obtained by the Cholesky decomposition $\sigma\sigma^{\mathrm{{T}}}=$ N1 1 (F − 1µF)T(F − 1µF); µF ∈ R1×C denotes the mean vector of $\mathbf{F}$ ; $\mathbf{1} \in~\mathbb{R}^{N\times1}$ is a column vector of all ones; $\gamma_{n} \in~\mathbb{R}^{1\times1}$ and $\beta_{n} \in~\mathbb{R}^{1\times C}$ are the affine parameters learned from the network. In this way, all the whitened nodes can be represented by $\mathbf{F}^{\prime}=[\mathbf{f}{1}^{\prime};\cdot\cdot\cdot;\mathbf{\dot{f}}_{N}^{\prime}]\in\mathbb{R}^{N\times C}$ .
其中 $\sigma_{\mathrm{ \scriptsize~\in~\mathbb{R}^{C\times C} }}$ 表示通过Cholesky分解 $\sigma\sigma^{\mathrm{{T}}}=$ N1 1 (F − 1µF)T(F − 1µF) 得到的下三角矩阵;$\mu_F \in \mathbb{R}^{1\times C}$ 表示 $\mathbf{F}$ 的均值向量;$\mathbf{1} \in~\mathbb{R}^{N\times1}$ 是全1列向量;$\gamma_{n} \in\mathbb{R}^{1\times1}$ 和 $\beta_{n} \in~\mathbb{R}^{1\times C}$ 是从网络中学到的仿射参数。这样,所有白化节点可以表示为 $\mathbf{F}^{\prime}=[\mathbf{f}{1}^{\prime};\cdot\cdot\cdot;\mathbf{\dot{f}}_{N}^{\prime}]\in\mathbb{R}^{N\times C}$。
Similar to (Higham and de Kergorlay 2022), we use crosscorrelation to learn the incidence matrix $\mathbf{H}\in\mathbb{R}^{N\times M}$ , i.e.,
类似于 (Higham 和 de Kergorlay 2022),我们使用互相关学习关联矩阵 $\mathbf{H}\in\mathbb{R}^{N\times M}$,即
$$
\mathbf{H}=\varepsilon(\Psi(\mathbf{F}^{\prime})\Lambda(\mathbf{F}^{\prime})\Psi(\mathbf{F}^{\prime})^{\mathrm{T}}\boldsymbol{\Omega}(\mathbf{F}^{\prime})),
$$
$$
\mathbf{H}=\varepsilon(\Psi(\mathbf{F}^{\prime})\Lambda(\mathbf{F}^{\prime})\Psi(\mathbf{F}^{\prime})^{\mathrm{T}}\boldsymbol{\Omega}(\mathbf{F}^{\prime})),
$$
where $\Psi(\cdot)$ represents the linear transformation; $\Lambda(\cdot)$ and $\Omega(\cdot)$ are responsible for learning a distance metric by a diagonal operation and determining the contribution of the node to the corresponding hyperedges through the learnable parameters, respectively; $\varepsilon(\cdot)$ is the step function.
其中 $\Psi(\cdot)$ 表示线性变换;$\Lambda(\cdot)$ 和 $\Omega(\cdot)$ 分别负责通过对角操作学习距离度量,以及通过可学习参数确定节点对相应超边的贡献;$\varepsilon(\cdot)$ 是阶跃函数。
Based on the learned $\mathbf{H}$ , we adopt a hypergraph convolutional operation to aggregate high-order structure information and then enhance feature representations. The relation enhanced feature $\mathbf{R}\in\mathbb{R}^{N\times C}$ can be obtained as
基于学习到的$\mathbf{H}$,我们采用超图卷积操作来聚合高阶结构信息,进而增强特征表示。关系增强特征$\mathbf{R}\in\mathbb{R}^{N\times C}$可通过以下方式获得:
$$
\mathbf{R}=(\mathbf{I}-\mathbf{D}^{1/2}\mathbf{H}\mathbf{W}\mathbf{B}^{-1}\mathbf{H}^{\mathrm{T}}\mathbf{D}^{-1/2})\mathbf{F}^{\prime}\boldsymbol{\Theta}+\mathbf{F},
$$
$$
\mathbf{R}=(\mathbf{I}-\mathbf{D}^{1/2}\mathbf{H}\mathbf{W}\mathbf{B}^{-1}\mathbf{H}^{\mathrm{T}}\mathbf{D}^{-1/2})\mathbf{F}^{\prime}\boldsymbol{\Theta}+\mathbf{F},
$$
where $\mathbf{I}\in\mathbb{R}^{N\times N}$ is the identity matrix; $\mathbf{W_{\lambda}}\in\mathbb{R}^{M\times M}$ denotes the weight matrix; ${\bf D}\in\dot{\mathbb{R}}^{N\times N}$ and $\mathbf{B}\in\mathbb{R}^{M\times M}$ represent the node degree matrix and the hyperedge degree matrix obtained by the broadcast operation, respectively; Θ ∈ RC×C denotes the learnable parameters.
其中 $\mathbf{I}\in\mathbb{R}^{N\times N}$ 是单位矩阵;$\mathbf{W_{\lambda}}\in\mathbb{R}^{M\times M}$ 表示权重矩阵;${\bf D}\in\dot{\mathbb{R}}^{N\times N}$ 和 $\mathbf{B}\in\mathbb{R}^{M\times M}$ 分别表示通过广播操作获得的节点度矩阵和超边度矩阵;Θ ∈ RC×C 表示可学习参数。
Following the above process, we pass features in $\mathcal{Q}$ through the HSL module and obtain a relation-enhanced feature set $\mathcal{R}={{\bf R}{L}^{v i s},{\bf R}{S}^{v i s},{\bf R} {L}^{i r},{\bf R}_{S}^{i r}}$ , where each feature in $\mathcal{R}$ is obtained by Eq. (4).
按照上述流程,我们将特征集 $\mathcal{Q}$ 通过HSL模块处理,得到关系增强的特征集 $\mathcal{R}={{\bf R}{L}^{v i s},{\bf R}{S}^{v i s},{\bf R}{L}^{i r},{\bf R}_{S}^{i r}}$ ,其中 $\mathcal{R}$ 中的每个特征均由公式(4)计算获得。
Common Feature Space Learning (CFL) Module
通用特征空间学习 (CFL) 模块
Conventional feature-level VI-ReID methods usually learn a common feature space based on a contrastive-based loss, which directly minimizes the distances between VIS and IR features. However, such a manner cannot achieve a reasonable common feature space because of the large modality discrepancy. To address the above problem, it is desirable to learn the middle features from VIS and IR features, enabling us to obtain a reasonable common feature space.
传统的基于特征级别的可见光-红外行人重识别(VI-ReID)方法通常通过对比损失(contrastive-based loss)学习一个共同特征空间,直接最小化可见光(VIS)与红外(IR)特征之间的距离。然而,由于模态差异较大,这种方式难以获得合理的共同特征空间。为解决该问题,需要从可见光与红外特征中学习中间特征,从而构建合理的共同特征空间。
A straightforward way to obtain a middle feature is to add or concatenate the VIS or IR features from different ranges. However, the above way cannot generate reliable middle features due to feature misalignment and loss of semantic information. Therefore, we propose a CFL module, which aligns the features from different modalities and ranges by graph attention (GAT) (Guo et al. 2021) and generates reliable middle features, as shown in Figure 1.
获取中间特征的一种直接方法是对不同范围下的可见光(VIS)或红外(IR)特征进行相加或拼接。然而,由于特征错位和语义信息丢失,上述方法无法生成可靠的中间特征。因此,我们提出了CFL模块,该模块通过图注意力网络(GAT) (Guo et al. 2021) 对齐来自不同模态和范围的特征,并生成可靠的中间特征,如图 1 所示。
Specifically, we align each feature in $\mathcal{R}$ with the other three features in $\mathcal{R}$ and generate a middle feature, which involves the information from different modalities and ranges. We take the alignment between two features ${\bf R}{L}^{v i s}$ and $\mathbf{R}{S}^{i r}$ as an example. First, we establish the similarity between ${\bf R}{L}^{v i s}$ and $\mathbf{R}_{S}^{i r}$ by using the inner product and the softmax function. This process can be formulated as
具体来说,我们将 $\mathcal{R}$ 中的每个特征与其他三个特征对齐,并生成一个中间特征,该特征包含来自不同模态和范围的信息。以两个特征 ${\bf R}{L}^{v i s}$ 和 $\mathbf{R}{S}^{i r}$ 的对齐为例。首先,我们通过内积和 softmax 函数建立 ${\bf R}{L}^{v i s}$ 和 $\mathbf{R}_{S}^{i r}$ 之间的相似性。这一过程可以表述为
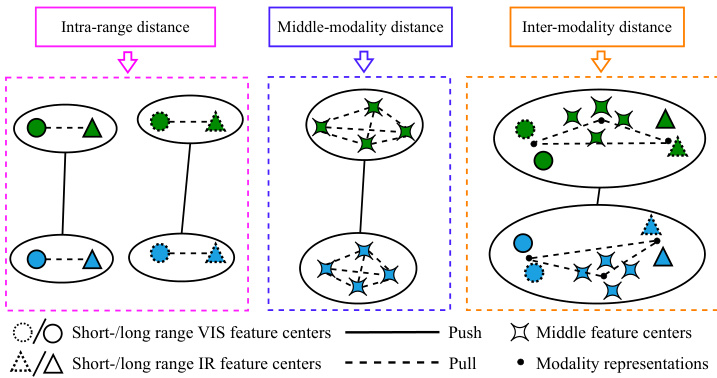
Figure 2: Illustration of the proposed MRIC loss. Different colors represent different identities.
图 2: 提出的MRIC损失示意图。不同颜色代表不同身份。
$$
\mathbf{P}=\mathrm{Softmax}((\theta_{q}\mathbf{R}{L}^{v i s})(\theta_{k}\mathbf{R}_{S}^{i r})^{\mathrm{T}}),
$$
$$
\mathbf{P}=\mathrm{Softmax}((\theta_{q}\mathbf{R}{L}^{v i s})(\theta_{k}\mathbf{R}_{S}^{i r})^{\mathrm{T}}),
$$
where $\theta_{q}$ and $\theta_{k}$ are linear transformations; $\mathbf{P}\in\mathbb{R}^{N\times N}$ denotes the similarity matrix; and $\operatorname{Softmax}(\cdot)$ denotes the softmax function.
其中 $\theta_{q}$ 和 $\theta_{k}$ 是线性变换;$\mathbf{P}\in\mathbb{R}^{N\times N}$ 表示相似度矩阵;$\operatorname{Softmax}(\cdot)$ 表示 softmax 函数。
Then, we adopt graph attention to perform alignment between ${\bf R}{L}^{v i s}$ and $\mathbf{R}{S}^{i r}$ according to the similarity matrix. Therefore, the aggregated node $\bar{\mathbf{R}}_{i r,S}^{v i s,L}\in\mathbb{R}^{N\times C}$ is
然后,我们采用图注意力机制根据相似度矩阵对 ${\bf R}{L}^{v i s}$ 和 $\mathbf{R}{S}^{i r}$ 进行对齐。因此,聚合节点 $\bar{\mathbf{R}}_{i r,S}^{v i s,L}\in\mathbb{R}^{N\times C}$ 为
$$
\begin{array}{r}{\bar{\mathbf{R}}{i r,S}^{v i s,L}=\mathrm{GAT}(\mathbf{R}{L}^{v i s},\mathbf{R}{S}^{i r})\quad\quad}\ {=\mathrm{ReLU}(\mathbf{P}-\lambda\mathrm{Mean}(\mathbf{P})\mathbf{11}^{\mathrm{T}})(\theta_{v}\mathbf{R}_{S}^{i r}),}\end{array}
$$
$$
\begin{array}{r}{\bar{\mathbf{R}}{i r,S}^{v i s,L}=\mathrm{GAT}(\mathbf{R}{L}^{v i s},\mathbf{R}{S}^{i r})\quad\quad}\ {=\mathrm{ReLU}(\mathbf{P}-\lambda\mathrm{Mean}(\mathbf{P})\mathbf{11}^{\mathrm{T}})(\theta_{v}\mathbf{R}_{S}^{i r}),}\end{array}
$$
where $\mathrm{GAT}(\cdot)$ denotes the graph attention operation; $\theta_{v}$ is the linear transformation; $\lambda$ is the balancing parameter that reduces nodes with low similarity; $\mathbf{11}^{\mathrm{T}}\in\mathbb{R}^{\ln^{\mathrm{\sum}}N^{\mathrm{\sum}}N}$ is a matrix of all ones; and $\mathrm{ReLU}(\cdot)$ and $\mathrm{Mean}(\cdot)$ represent the ReLU activation function and the mean operation, respectively.
其中 $\mathrm{GAT}(\cdot)$ 表示图注意力操作;$\theta_{v}$ 为线性变换;$\lambda$ 是降低低相似度节点影响的平衡参数;$\mathbf{11}^{\mathrm{T}}\in\mathbb{R}^{\ln^{\mathrm{\sum}}N^{\mathrm{\sum}}N}$ 为全1矩阵;$\mathrm{ReLU}(\cdot)$ 和 $\mathrm{Mean}(\cdot)$ 分别代表ReLU激活函数与均值运算。
Based on the above, a middle feature $\mathbf{M}{L}^{v i s}\in\mathbb{R}^{N\times C}$ is obtained by aligning ${\bf R}{L}^{v i s}$ with $\mathbf{R}{S}^{i r},\mathbf{R}{L}^{i r}$ , and ${\bf R}_{S}^{v i s}$ , that is,
基于上述方法,通过将 ${\bf R}{L}^{v i s}$ 与 $\mathbf{R}{S}^{i r}$、$\mathbf{R}{L}^{i r}$ 以及 ${\bf R}{S}^{v i s}$ 对齐,得到一个中间特征 $\mathbf{M}_{L}^{v i s}\in\mathbb{R}^{N\times C}$,即
$$
\begin{array}{r}{{\bf M}{L}^{v i s}=\mathrm{GAT}({\bf R}{L}^{v i s},{\bf R}{S}^{i r})+\mathrm{GAT}({\bf R}{L}^{v i s},{\bf R}{L}^{i r})+}\ {\mathrm{GAT}({\bf R}{L}^{v i s},{\bf R}{S}^{v i s})+{\bf R}_{L}^{v i s}.\qquad}\end{array}
$$
$$
\begin{array}{r}{{\bf M}{L}^{v i s}=\mathrm{GAT}({\bf R}{L}^{v i s},{\bf R}{S}^{i r})+\mathrm{GAT}({\bf R}{L}^{v i s},{\bf R}{L}^{i r})+}\ {\mathrm{GAT}({\bf R}{L}^{v i s},{\bf R}{S}^{v i s})+{\bf R}_{L}^{v i s}.\qquad}\end{array}
$$
To mitigate the intra-class difference and inter-class discrepancy, we propose the MRIC loss to improve feature representations and reduce the distances between the VIS, IR, and middle features. The MRIC loss consists of three items: an intra-range loss, a middle feature loss, and an intermodality loss based on the identity centers. The illustration of the MRIC loss is shown in Figure 2.
为缓解类内差异和类间差异,我们提出MRIC损失函数来改进特征表示并缩小可见光(VIS)、红外(IR)与中间特征之间的距离。MRIC损失包含三个组成部分:类内距离损失、中间特征损失以及基于身份中心的跨模态损失。该损失函数示意图如图2所示。
Technically, we first obtain identity centers, which are robust to pedestrian appearance changes, by the weighted average of the features of each person at one modality and a specific range. For instance, the center of the relation-enhanced features for the person with the identity $i$ at the VIS modality and long-range can be obtained as
技术上,我们首先通过单模态特定范围内各行人特征的加权平均,获得对行人外观变化具有鲁棒性的身份中心。例如,身份 $i$ 在可见光(VIS)模态和长距离下的关系增强特征中心可表示为
$$
\mathbf{c}{L,i}^{v i s}=\sum_{j=1}^{K}\frac{\exp({\sum_{k=1}^{K}\mathbf{r}{L,i,j}^{v i s}\mathbf{r}{L,i,k}^{v i s}}^{\mathrm{T}})}{\sum_{j=1}^{K}\exp({\sum_{k=1}^{K}\mathbf{r}{L,i,j}^{v i s}\mathbf{r}{L,i,k}^{v i s}}^{\mathrm{T}})}\mathbf{r}_{L,i,j}^{v i s},
$$
$$
\mathbf{c}{L,i}^{v i s}=\sum_{j=1}^{K}\frac{\exp({\sum_{k=1}^{K}\mathbf{r}{L,i,j}^{v i s}\mathbf{r}{L,i,k}^{v i s}}^{\mathrm{T}})}{\sum_{j=1}^{K}\exp({\sum_{k=1}^{K}\mathbf{r}{L,i,j}^{v i s}\mathbf{r}{L,i,k}^{v i s}}^{\mathrm{T}})}\mathbf{r}_{L,i,j}^{v i s},
$$
where $K$ is the number of VIS features of each person; $\mathbf{r}_{L,i,k}^{v i s}\in\mathbb{R}^{1\times C^{\prime}}$ denotes the $k$ -th 1D relation-enhanced longrange VIS feature defined in $\mathcal{R}^{\prime}$ with the identity $i$ .
其中 $K$ 表示每个人的 VIS (Visual Identity-Sensitive) 特征数量;$\mathbf{r}_{L,i,k}^{v i s}\in\mathbb{R}^{1\times C^{\prime}}$ 表示在 $\mathcal{R}^{\prime}$ 中定义的、身份标识为 $i$ 的第 $k$ 个一维关系增强长程 VIS 特征。
Accordingly, we can obtain the identity center sets $\mathcal{C}{L}^{v i s}$ $({\mathbf{c}{L,i}^{v i\check{s}}}{i=1}^{P})$ , $\mathcal{C}{S}^{v i s}$ $({\mathbf{c}{S,i}^{v i s}}{i=1}^{P})$ , $\mathcal{C}{L}^{i r}$ $({\mathbf{c}{L,i}^{i r}}{i=1}^{P})$ , $\mathcal{C}{S}^{i r}$ ${\mathbf{c}{S,i}^{i r}}{i=1}^{P})$ , $\tilde{\mathcal{C}}{L}^{v i s}$ $({\tilde{\mathbf{c}}{L,i}^{v i s}}{i=1}^{P})$ , $\tilde{\mathcal{C}}{S}^{v i s}$ $({\tilde{\mathbf{c}}{S,i}^{v i s}}{i=1}^{P})$ , $\tilde{\mathcal{C}}{L}^{i r}$ $({\tilde{\mathbf{c}}{L,i}^{i r}}{i=1,}^{P}),\tilde{\mathcal{C}}{S}^{i r}({\tilde{\mathbf{c}}{S,i}^{i r}}_{i=1}^{P}).$ , where $\mathcal{C}$ and $\tilde{\mathcal{C}}$ represent the center set for the enhanced features and the middle features at a specific range and modality, respectively; $P$ is the number of person identities in the training set.
因此,我们可以得到身份中心集 $\mathcal{C}{L}^{v i s}$ $({\mathbf{c}{L,i}^{v i\check{s}}}{i=1}^{P})$、$\mathcal{C}{S}^{v i s}$ $({\mathbf{c}{S,i}^{v i s}}{i=1}^{P})$、$\mathcal{C}{L}^{i r}$ $({\mathbf{c}{L,i}^{i r}}{i=1}^{P})$、$\mathcal{C}{S}^{i r}$ ${\mathbf{c}{S,i}^{i r}}{i=1}^{P})$、$\tilde{\mathcal{C}}{L}^{v i s}$ $({\tilde{\mathbf{c}}{L,i}^{v i s}}{i=1}^{P})$、$\tilde{\mathcal{C}}{S}^{v i s}$ $({\tilde{\mathbf{c}}{S,i}^{v i s}}{i=1}^{P})$、$\tilde{\mathcal{C}}{L}^{i r}$ $({\tilde{\mathbf{c}}{L,i}^{i r}}{i=1,}^{P})$、$\tilde{\mathcal{C}}{S}^{i r}({\tilde{\mathbf{c}}{S,i}^{i r}}_{i=1}^{P})$。其中,$\mathcal{C}$ 和 $\tilde{\mathcal{C}}$ 分别表示特定范围和模态下增强特征和中间特征的中心集;$P$ 为训练集中人员身份的数量。
The intra-range loss LSMLR IC is to reduce the distances between the same-range VIS and IR features from the same persons while enlarging the distances between the samerange VIS and IR features from different persons, that is,
域内损失LSMLR IC旨在缩小同一人物可见光(VIS)与红外(IR)特征间的距离,同时扩大不同人物同域VIS与IR特征之间的距离。
$$
\mathcal{L}{M R I C}^{S L}=\mathcal{L}{M R I C}^{\mathcal{C}{S}^{v i s},\mathcal{C}{S}^{i r}}+\mathcal{L}{M R I C}^{\mathcal{C}{L}^{v i s},\mathcal{C}_{L}^{i r}},
$$
$$
\mathcal{L}{M R I C}^{S L}=\mathcal{L}{M R I C}^{\mathcal{C}{S}^{v i s},\mathcal{C}{S}^{i r}}+\mathcal{L}{M R I C}^{\mathcal{C}{L}^{v i s},\mathcal{C}_{L}^{i r}},
$$
where
哪里
$$
\begin{array}{r l}&{\mathcal{L}{M R I C}^{A,B}=-\displaystyle\sum_{i=1}^{P}\log\frac{\exp(\mathbf{S}{i,i}^{A,B})}{\sum_{z=1}^{P}\exp(\mathbf{S}{i,z}^{A,B})}}\ &{-\displaystyle\sum_{i=1}^{P}\log\frac{\exp(\mathbf{S}{i,i}^{A,B})}{\sum_{z=1}^{P}\exp(\mathbf{S}{z,i}^{A,B})}+\displaystyle\sum_{i=1}^{P}\mathcal{L}{1}(\mathbf{a}{i}-\mathbf{b}_{i}).}\end{array}
$$
$$
\begin{array}{r l}&{\mathcal{L}{M R I C}^{A,B}=-\displaystyle\sum_{i=1}^{P}\log\frac{\exp(\mathbf{S}{i,i}^{A,B})}{\sum_{z=1}^{P}\exp(\mathbf{S}{i,z}^{A,B})}}\ &{-\displaystyle\sum_{i=1}^{P}\log\frac{\exp(\mathbf{S}{i,i}^{A,B})}{\sum_{z=1}^{P}\exp(\mathbf{S}{z,i}^{A,B})}+\displaystyle\sum_{i=1}^{P}\mathcal{L}{1}(\mathbf{a}{i}-\mathbf{b}_{i}).}\end{array}
$$
betTwheee nm idd if df leer-efenta tumried ldoles s $\mathcal{L}_{M R I C}^{M I D}$ tihs atto i rs,educe the distances
betTwheee nm idd if df leer-efenta tumried ldoles s $\mathcal{L}_{M R I C}^{M I D}$ tihs atto i rs,educe the distances
$$
\begin{array}{r}{\mathcal{L}{M R I C}^{M I D}=\mathcal{L}{M R I C}^{\tilde{C}{S}^{v i s},\tilde{C}{L}^{v i s}}+\mathcal{L}{M R I C}^{\tilde{C}{S}^{v i s},\tilde{C}{S}^{i r}}+\mathcal{L}{M R I C}^{\tilde{C}{S}^{v i s},\tilde{C}{L}^{i r}}+}\ {\mathcal{L}{M R I C}^{\tilde{C}{L}^{v i s},\tilde{C}{S}^{i r}}+\mathcal{L}{M R I C}^{\tilde{C}{L}^{v i s},\tilde{C}{L}^{i r}}+\mathcal{L}{M R I C}^{\tilde{C}{S}^{i r},\tilde{C}_{L}^{i r}}.}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}{M R I C}^{M I D}=\mathcal{L}{M R I C}^{\tilde{C}{S}^{v i s},\tilde{C}{L}^{v i s}}+\mathcal{L}{M R I C}^{\tilde{C}{S}^{v i s},\tilde{C}{S}^{i r}}+\mathcal{L}{M R I C}^{\tilde{C}{S}^{v i s},\tilde{C}{L}^{i r}}+}\ {\mathcal{L}{M R I C}^{\tilde{C}{L}^{v i s},\tilde{C}{S}^{i r}}+\mathcal{L}{M R I C}^{\tilde{C}{L}^{v i s},\tilde{C}{L}^{i r}}+\mathcal{L}{M R I C}^{\tilde{C}{S}^{i r},\tilde{C}_{L}^{i r}}.}\end{array}
$$
The inter-modality loss LVM IRMIC is to reduce the intraclass distances and enlarge the inter-class distances between VIS, IR, and middle features, which is expressed as
跨模态损失 LVM IRMIC 旨在减小可见光(VIS)、红外(IR)和中间特征之间的类内距离,同时增大类间距离,其表达式为
$$
\mathcal{L}{M R I C}^{V I M}=\mathcal{L}{M R I C}^{\mathcal{C}^{v i s},\boldsymbol{C}^{i r}}+\mathcal{L}{M R I C}^{\mathcal{C}^{v i s},\boldsymbol{C}^{m i d}}+\mathcal{L}_{M R I C}^{\boldsymbol{C}^{i r},\boldsymbol{C}^{m i d}},
$$
$$
\mathcal{L}{M R I C}^{V I M}=\mathcal{L}{M R I C}^{\mathcal{C}^{v i s},\boldsymbol{C}^{i r}}+\mathcal{L}{M R I C}^{\mathcal{C}^{v i s},\boldsymbol{C}^{m i d}}+\mathcal{L}_{M R I C}^{\boldsymbol{C}^{i r},\boldsymbol{C}^{m i d}},
$$
where $\mathcal{C}^{v i s},\mathcal{C}^{i r}$ , and $\mathcal{C}^{m i d}$ denote the identity center sets corresponding to VIS, IR, and middle features, respectively;
其中 $\mathcal{C}^{v i s}$、$\mathcal{C}^{i r}$ 和 $\mathcal{C}^{m i d}$ 分别表示对应于可见光 (VIS)、红外 (IR) 和中间特征的身份中心集;
$\mathcal{C}^{v i s}$ and $\mathcal{C}^{\mathit{i r}}$ are obtained by averaging all the features from the same modality for each person; $\mathcal{C}^{\breve{m}i d}$ is obtained by averaging all the middle features for each person.
$\mathcal{C}^{v i s}$ 和 $\mathcal{C}^{\mathit{i r}}$ 是通过对每个人的同一模态特征取平均得到的;$\mathcal{C}^{\breve{m}i d}$ 是通过对每个人的所有中间特征取平均得到的。
Therefore, the MRIC loss is
因此,MRIC损失为
$$
\mathcal{L}{M R I C}=\mathcal{L}{M R I C}^{S L}+\mathcal{L}{M R I C}^{M I D}+\mathcal{L}_{M R I C}^{V I M}.
$$
$$
\mathcal{L}{M R I C}=\mathcal{L}{M R I C}^{S L}+\mathcal{L}{M R I C}^{M I D}+\mathcal{L}_{M R I C}^{V I M}.
$$
Joint Loss
联合损失 (Joint Loss)
The joint loss is defined as
联合损失 (joint loss) 定义为
$$
\mathcal{L}=\mathcal{L}{C E}+\mathcal{L}{T R I}+\mathcal{L}_{M R I C},
$$
$$
\mathcal{L}=\mathcal{L}{C E}+\mathcal{L}{T R I}+\mathcal{L}_{M R I C},
$$
where $\mathcal{L}{C E}$ represents the cross-entropy loss and $\mathcal{L}_{T R I}$ denotes the triplet loss (Hermans, Beyer, and Leibe 2017).
其中 $\mathcal{L}{C E}$ 表示交叉熵损失 (cross-entropy loss),$\mathcal{L}_{T R I}$ 表示三元组损失 (triplet loss) (Hermans, Beyer, and Leibe 2017)。
The training of HOS-Net is given in Supplement $A$ .
HOS-Net的训练过程详见补充材料$A$。
Experiments Experimental Settings
实验 实验设置
Datasets. The SYSU-MM01 dataset (Wu et al. 2020) contains a total of 30,071 VIS images and 15,792 IR images from 491 different identities. The RegDB dataset (Nguyen et al. 2017) consists of 412 identities, where each identity has $10~\mathrm{VIS}$ images and $10~\mathrm{IR}$ images captured by two overlapping cameras. The LLCM dataset (Zhang and Wang 2023) is captured in low-light environments. The training set contains 713 identities (with 16,946 VIS images and 13,975 IR images) while the test set contains 351 identities (with 8,680 VIS images and 7,166 IR images).
数据集。SYSU-MM01数据集 (Wu et al. 2020) 包含来自491个不同身份的30,071张可见光(VIS)图像和15,792张红外(IR)图像。RegDB数据集 (Nguyen et al. 2017) 包含412个身份,每个身份有$10~\mathrm{VIS}$图像和$10~\mathrm{IR}$图像,由两个重叠的摄像头拍摄。LLCM数据集 (Zhang and Wang 2023) 是在低光照环境下采集的,训练集包含713个身份(16,946张VIS图像和13,975张IR图像),测试集包含351个身份(8,680张VIS图像和7,166张IR图像)。
Implementation Details. All the images are resized to $256\times128$ with horizontal flip, random erasing, and channel augmentation for data augmentation (Ye et al. 2021a) during the training phase. For each mini-batch, we randomly choose 8 identities, where 4 VIS images and $4\mathrm{IR}$ images of each identity are selected. We adopt AGW (Ye et al. 2021b) as our backbone. We use the warm-up strategy to update the learning rate from 0.01 to 0.1 at the first 10 epochs. At the 20 and 50 epochs, the learning rates are set to 0.01 and 0.001, respectively. We use SGD as the optimizer and the momentum parameter is set to 0.9. The total number of training epochs is set to 120. Our proposed HOS-Net is implemented with the PyTorch on an NVIDIA RTX3090 GPU. The number of hyperedges $M$ is set to 256. $\lambda$ in Eq. (6) is set to 1.3.
实现细节。所有图像在训练阶段被调整为$256\times128$大小,并采用水平翻转、随机擦除和通道增强进行数据增强 (Ye et al. 2021a)。每个小批量随机选择8个身份,其中每个身份选取4张可见光(VIS)图像和$4\mathrm{红外}$(IR)图像。我们采用AGW (Ye et al. 2021b)作为主干网络,使用热身策略在前10个周期将学习率从0.01逐步提升至0.1。在第20和50个周期时,学习率分别设置为0.01和0.001。优化器选用SGD,动量参数设为0.9,总训练周期数为120。提出的HOS-Net基于PyTorch框架在NVIDIA RTX3090 GPU上实现,超边数量$M$设为256,公式(6)中的$\lambda$设为1.3。
Cumulative Matching characteristics (CMC) and mean Average Precision (mAP) are used as our evaluation metrics. CMC measures the matching probability of the ground-truth person occurring in the top $k$ retrieved results (Rank $k$ accuracy). Besides, we randomly divide the RegDB dataset for training and testing. The above process is repeated ten times and we report the average performance. We also randomly split the gallery set of the SYSU-MM01 and LLCM datasets ten times to report the average performance.
我们采用累积匹配特性 (CMC) 和平均精度均值 (mAP) 作为评估指标。CMC 衡量真实身份出现在检索结果前 $k$ 位 (Rank $k$ 准确率) 的匹配概率。此外,我们对 RegDB 数据集进行随机划分用于训练和测试,重复该过程十次并报告平均性能。对于 SYSU-MM01 和 LLCM 数据集,我们同样对图库集进行十次随机划分以报告平均性能。
Comparison with State-of-the-Art Methods
与现有最优方法的对比
The comparison results are given in Table 1. More results are shown in Supplement B.
对比结果如表 1 所示。更多结果见补充材料 B。
SYSU-MM01. As shown in Table 1, our proposed HOSNet obtains the best or comparable performance among all the competing methods. Specifically, HOS-Net gives about $13.0%$ and $15.2%$ improvements in terms of mAP over some image-level methods (such as JSIA-ReID and TSME) for both all and indoor search modes, respectively. Compared with the CNN-based method (DDAG) and Transformerbased method (PMT), HOS-Net surpasses them by at least $8.1%$ in Rank-1 and $9.2%$ in mAP for the all search mode. Moreover, for the indoor search mode, HOS-Net outperforms the second-best method DEEN by $3.9%$ in Rank-1 and $3.4%$ in mAP. DEEN ignores the importance of high-order structure information, leading to inferior performance.
表1显示,我们提出的HOSNet在所有竞争方法中取得了最佳或相当的性能表现。具体而言,在全场景和室内搜索模式下,HOSNet相较于部分图像级方法(如JSIA-ReID和TSME)的mAP指标分别提升了约13.0%和15.2%。与基于CNN的方法(DDAG)和基于Transformer的方法(PMT)相比,HOSNet在全场景搜索模式的Rank-1和mAP指标上分别至少领先8.1%和9.2%。此外,在室内搜索模式下,HOSNet的Rank-1和mAP指标较第二优方法DEEN分别高出3.9%和3.4%。DEEN由于忽略了高阶结构信息的重要性,导致性能表现欠佳。
Table 1: Comparisons with state-of-the-art methods on the SYSU-MM01, RegDB and LLCM datasets. The bold font and the underline denote the best and second-best performance, respectively.
| 方法 | SYSU-MM01 | RegDB | LLCM | |||
|---|---|---|---|---|---|---|
| All search | Indoor search | VIS to IR | IR to VIS | VIS to IR | IR to VIS | |
| R-1/mAP | R-1/mAP | R-1/mAP | R-1/mAP | R-1/mAP | R-1/mAP | |
| D"RL (Wang et al. 2019) | 28.9/29.2 | - / - | 43.4/44.1 | - / - | - / - | - / - |
| Hi-CMD (Choi et al. 2020) | 34.9/35.9 | - / - | 70.9/66.0 | - / - | - / - | - / - |
| JSIA-ReID (Wang et al. 2020) | 38.1/36.9 | 43.8/52.9 | 48.1/48.9 | 48.5/49.3 | - / - | - / - |
| X-Modality (Li et al. 2020) | 49.9/50.7 | - / - | 62.2/60.2 | - / - | - / - | - / - |
| DDAG (Ye et al. 2020) | 54.8/53.0 | 61.0/68.0 | 69.3/63.5 | 68.1/61.8 | 48.0/52.3 | 40.3/48.4 |
| LbA (Park et al. 2021) | 55.4/54.1 | 58.5/66.3 | 74.2/67.6 | 67.5/72.4 | 50.8/55.6 | 43.8/53.1 |
| G²DA (Wan et al. 2023) | 63.9/60.7 | 71.0/76.0 | 74.0/65.5 | 69.7/62.0 | - / - | - / - |
| TSME (Liu et al. 2022b) | 64.2/61.2 | 64.8/71.5 | 87.4/76.9 | 86.4/75.7 | - / - | - / - |
| SPOT (Chen et al. 2022a) | 65.3/62.3 | 69.4/74.6 | 80.4/72.5 | 79.4/72.3 | - / - | - / - |
| PMT (Lu, Zou, and Zhang 2023) | 67.5/65.0 | 71.7/76.5 | 84.8/76.6 | 84.2/75.1 | - / - | - / - |
| CAJ (Ye et al. 2021a) | 69.9/66.9 | 76.3/80.4 | 85.0/79.1 | 84.8/77.8 | 56.5/59.8 | 48.8/56.6 |
| MMN (Zhang et al. 2021) | 70.6/66.9 | 76.2/79.6 | 91.6/84.1 | 87.5/80.5 | 59.9/62.7 | 52.5/58.9 |
| MAUM (Liu et al. 2022a) | 71.7/68.8 | 77.0/81.9 | 87.9/85.1 | 87.0/84.3 | - / - | - / - |
| DEEN (Zhang and Wang 2023) | 74.7/71.8 | 80.3/83.3 | 91.1/85.1 | 89.5/83.4 | 62.5/65.8 | 54.9/62.9 |
| HOS-Net (Ours) | 75.6/74.2 | 84.2/86.7 | 94.7/90.4 | 93.3/89.2 | 64.9/67.9 | 56.4/63.2 |
表 1: 在 SYSU-MM01、RegDB 和 LLCM 数据集上与最先进方法的比较。加粗和下划线分别表示最佳和次佳性能。
RegDB. From Table 1, we can also observe that our proposed HOS-Net achieves the best performance for two search modes. For two search modes, our HOS-Net outperforms MMN by $3.1%/6.3%$ and $5.8%/8.7%$ in Rank- $1/\mathrm{mAP},$ respectively. Moreover, compared with $\mathrm{G^{2}D A}$ and SPOT, which rely on high-quality person structure labels to obtain modality-shared features, HOS-Net improves the Rank1 and mAP by at least $13.9%$ and $16.9%$ , respectively, for the IR to VIS search mode. This further indicates the superiority of our high-order structure-based network for VI-ReID.
从表1中我们还可以观察到,所提出的HOS-Net在两种搜索模式下均取得最佳性能。在两种搜索模式中,HOS-Net在Rank-1/mAP指标上分别以3.1%/6.3%和5.8%/8.7%的优势超越MMN。此外,与依赖高质量人体结构标签获取模态共享特征的G²DA和SPOT相比,在IR到VIS搜索模式下,HOS-Net将Rank1和mAP分别提升了至少13.9%和16.9%。这进一步证明了我们基于高阶结构的网络在VI-ReID任务中的优越性。
LLCM. We also report the comparison results on the LLCM dataset in Table 1. For the IR to VIS search mode, our HOS-Net outperforms MMN by $3.9%$ and $4.3%$ in terms of Rank-1 and mAP, respectively. Moreover, HOS-Net performs significantly better than the second-best DEEN for the VIS to IR search mode, achieving the best results with $64.9%/67.9%$ in Rank $1/\mathrm{mAP}.$ . Therefore, HOS-Net can learn a disc rim i native and reasonable common feature space to reduce the modality discrepancy.
LLCM。我们在表1中也报告了LLCM数据集的对比结果。在IR到VIS搜索模式下,我们的HOS-Net在Rank-1和mAP指标上分别比MMN高出$3.9%$和$4.3%$。此外,在VIS到IR搜索模式下,HOS-Net显著优于第二名的DEEN,以$64.9%/67.9%$的Rank-1/mAP取得了最佳结果。因此,HOS-Net能够学习到一个判别性强且合理的共同特征空间,从而减少模态差异。
Ablation Studies
消融实验
Effectiveness of Key Components. We conduct ablation studies to validate the effectiveness of each key component of the proposed HOS-Net (including SLE, HSL, CFL, and the MRIC loss). The results are shown in Table 2, where Method 1 represents the baseline AGW method.
关键组件的有效性。我们通过消融实验验证了所提出的HOS-Net各关键组件(包括SLE、HSL、CFL和MRIC损失)的有效性。结果如表2所示,其中方法1代表基线AGW方法。
SLE: By introducing SLE, Method 2 achieves about $2.5%$ and $5.7%$ higher mAP than Method 1 on the SYSU-MM01 and RegDB datasets, respectively. This shows the effectiveness of our SLE, which explores different ranges of person features by taking advantage of both CNN and Transformer. HSL: By incorporating HSL into Method 2, Method 3 achieves $1.6%/3.0%$ and $2.4%/2.3%$ improvements in Rank $1/\mathrm{mAP}$ on two datasets, respectively. This validates the importance of HSL, which adopts the whitened hypergraph network to model the high-order relationship across different local features of each person image and avoid model collapse. CFL: Method 5 introduces CFL to Method 3 and it obtains higher accuracy $0.7%/0.7%$ improvements in Rank $1/\mathrm{mAP}$ on the RegDB dataset) than Method 3. This demonstrates that learning reliable middle features can effectively reduce the modality discrepancy. The MRIC loss: Compared with Method 5, Method 7 achieves $1.6%/1.3%$ and $2.0%/2.6%$ improvements in Rank $1/\mathrm{mAP}$ on two datasets, respectively. The MRIC loss can improve feature representations and reduce discrepancies between the VIS and IR modalities, achieving a reasonable common feature space.
SLE: 通过引入SLE,方法2在SYSU-MM01和RegDB数据集上的mAP分别比方法1提高了约2.5%和5.7%。这表明我们的SLE通过结合CNN和Transformer的优势探索不同范围的人物特征具有显著效果。
HSL: 将HSL整合到方法2后,方法3在两个数据集上的Rank 1/mAP分别提升了1.6%/3.0%和2.4%/2.3%。这验证了HSL采用白化超图网络建模人物图像局部特征间高阶关系并避免模型坍塌的重要性。
CFL: 方法5在方法3基础上引入CFL,在RegDB数据集上获得了更高的准确率(Rank 1/mAP提升0.7%/0.7%),表明学习可靠的中间特征能有效减小模态差异。
MRIC损失: 与方法5相比,方法7在两个数据集上的Rank 1/mAP分别提升了1.6%/1.3%和2.0%/2.6%。MRIC损失能优化特征表示并减小可见光(VIS)与红外(IR)模态间的差异,构建合理的共同特征空间。
Table 2: The influence of key components of HOS-Net on the performance on the SYSU-MM01 and RegDB datasets.
表 2: HOS-Net关键组件在SYSU-MM01和RegDB数据集上的性能影响
| # | 方法 | SYSU-MM01 (R-1/mAP) | RegDB (R-1/mAP) |
|---|---|---|---|
| 1 | Baseline | 69.9/66.9 | 85.0/79.1 |
| 2 | Baseline+SLE | 71.7/69.4 | 89.6/84.8 |
| 3 | +HSL | 73.3/72.4 | 92.0/87.1 |
| 4 | +CFL | 72.1/70.2 | 91.6/86.5 |
| 5 | +HSL+CFL | 74.0/72.9 | 92.7/87.8 |
| 6 | +CFL +LM RIC | 74.5/72.7 | 93.2/88.4 |
| 7 | +HSL+CFL+LMRIC | 75.6/74.2 | 94.7/90.4 |
Effectiveness of the Hypergraph and the Whitening Operation. HSL is based on a whitened hypergraph network to discover the high-order relationship of person features and avoid model collapse. As shown in Table 3, by modeling the high-order structure with the hypergraph, the model brings about $0.8%/0.9%$ gains in Rank $1/\mathrm{mAP}$ on SYSUMM01. Note that the original hypergraph network allows unrestricted connections among nodes to capture high-order structure information, suffering from model collapse during hypergraph learning. By adding the whitening operation into the hypergraph learning, the performance is improved by $0.8%/2.1%$ and $0.9%/0.8%$ in Rank $1/\mathrm{mAP}$ on two datasets, respectively. Hence, the whitening operation is beneficial to alleviate mode collapse and improve the final performance.
超图与白化操作的有效性。HSL基于白化超图网络来发现人物特征的高阶关系并避免模型坍塌。如表3所示,通过超图建模高阶结构,该模型在SYSUMM01数据集上使Rank1/mAP指标分别提升$0.8%/0.9%$。原始超图网络允许节点间无限制连接以捕获高阶结构信息,但会在超图学习过程中出现模型坍塌现象。通过在超图学习中引入白化操作,两个数据集的Rank1/mAP指标分别提升$0.8%/2.1%$和$0.9%/0.8%$。因此,白化操作有助于缓解模式坍塌并提升最终性能。
Table 3: The influence of the hypergraph and the whitening operation on the SYSU-MM01 and $\mathrm{RegDB}$ datasets.
表 3: 超图和白化操作对 SYSU-MM01 和 $\mathrm{RegDB}$ 数据集的影响。
| Settings | SYSU-MM01 | RegDB |
|---|---|---|
| Hypergraph | Whitening | R-1/mAP |
| - | 71.7/69.4 | |
| √ | 72.5/70.3 | |
| 人 | 73.3/72.4 |
Table 4: The influence of generating middle features from different modality and range features on SYSU-MM01.
表 4: 从不同模态和范围特征生成中间特征对 SYSU-MM01 的影响
| Settings | Modalities | Ranges | SYSU-MM01 (R-1/mAP) |
|---|---|---|---|
| Addition | 72.0/71.1 | ||
| √ | 71.8/70.9 | ||
| √ | 71.4/70.4 | ||
| Concatenation | 71.9/70.8 | ||
| √ | 72.3/71.1 | ||
| 72.5/71.2 | |||
| GAT | 73.4/72.3 | ||
| 73.6/72.4 | |||
| 74.0/72.9 |
Influence of Different Middle Features. The CFL module leverages graph attention to align features from different modalities and ranges to generate reliable middle features. In this subsection, we evaluate the influence of different middle features on the performance. The results are given in Table 4. Compared with the methods that generate middle features by adding or concatenating the VIS or IR features, our method with GAT improves mAP on the SYSU-MM01 datasets, respectively. This clearly indicates the effectiveness of the middle features generated by GAT.
不同中间特征的影响。CFL模块利用图注意力机制对齐来自不同模态和范围的特征,以生成可靠的中间特征。本节评估不同中间特征对性能的影响,结果如表4所示。与通过相加或拼接可见光(VIS)或红外(IR)特征生成中间特征的方法相比,采用GAT的我们的方法在SYSU-MM01数据集上分别提升了mAP值,这清楚表明了GAT生成中间特征的有效性。
Influence of Each Term in the MRIC Loss. The MRIC loss is proposed to improve feature representations and reduce the distances between the VIS, IR, and middle features. As shown in Table 5, when all the terms in the MRIC loss are used to jointly train the network, Rank $1/\mathrm{mAP}$ is improved by $1.6%/1.3%$ and $2.0%/2.6%$ in comparison with HOS-Net trained without the MRIC loss on two datasets, respectively. This indicates that HOS-Net trained with the MRIC loss can achieve a reasonable common feature space.
MRIC损失各项的影响。提出MRIC损失是为了改进特征表示并减小可见光(VIS)、红外(IR)与中间特征之间的距离。如表5所示,当使用MRIC损失的所有项联合训练网络时,与未使用MRIC损失的HOS-Net相比,在两个数据集上的Rank $1/\mathrm{mAP}$ 分别提升了 $1.6%/1.3%$ 和 $2.0%/2.6%$ 。这表明采用MRIC损失训练的HOS-Net能够获得合理的公共特征空间。
Feature Distribution Visualization. We randomly sample a total of 40,000 positive and negative matching pairs from the test set and visualize the cosine similarity distribution on the SYSU-MM01 dataset, as shown in Figure 3(a-c). The cosine similarity of positive matching pairs is increased while the similarity differences between positive and negative matching pairs are enlarged.
特征分布可视化。我们从测试集中随机抽取共40,000个正负匹配对,并在SYSU-MM01数据集上可视化余弦相似度分布,如图3(a-c)所示。正匹配对的余弦相似度得到提升,同时正负匹配对之间的相似度差异被放大。
Table 5: The influence of each term in the MRIC loss.
表 5: MRIC损失函数中各项目的影响
| Settings | SYSU-MM01 (R-1/mAP) | RegDB (R-1/mAP) |
|---|---|---|
| 74.0/72.9 | 92.7/87.8 | |
| 74.3/73.3 | 93.4/88.6 | |
| MRIC MID | ||
| +L MRIC SL MID | 74.4/73.2 | 93.3/88.3 |
| +C MRIC+C MRIC | 75.0/73.8 | 93.8/89.2 |
| +C SL MID VIM MRIC+L MRIC+L MRIC | 75.6/74.2 | 94.7/90.4 |

Figure 3: (a-c) give the distributions of the intra-class and inter-class similarities of VIS and IR modality features on the SYSU-MM01 dataset. (d-f) visualize the distribution of person features from VIS and IR modalities in the 2D feature space on the SYSU-MM01 dataset. Circles and crosses represent features from VIS and IR modalities, respectively.
图 3: (a-c) 展示了 SYSU-MM01 数据集中可见光(VIS)和红外(IR)模态特征的类内及类间相似度分布。(d-f) 在二维特征空间中可视化 SYSU-MM01 数据集上可见光与红外模态行人特征的分布情况,其中圆圈和十字分别代表可见光与红外模态的特征。
This shows that the proposed HOS-Net can effectively reduce the modality gap between VIS and IR modalities. Then, we adopt t-SNE (Van der Maaten and Hinton 2008) to illustrate feature distributions obtained by different methods on the SYSU-MM01 dataset, as shown in Figure 3(d-f). Compared with the Baseline, our HOS-Net can reduce intra-class differences and enlarge inter-class discrepancies in different modalities. More ablation studies and visualization results can refer to Supplement C and $D$ .
这表明所提出的HOS-Net能有效减小可见光(VIS)与红外(IR)模态间的差异。接着,我们采用t-SNE (Van der Maaten and Hinton 2008) 可视化SYSU-MM01数据集上不同方法获得的特征分布,如图3(d-f) 所示。与基线方法相比,我们的HOS-Net能在不同模态间减小类内差异并增大类间差异。更多消融实验与可视化结果可参考附录C和 $D$ 。
CONCLUSION
结论
In this paper, we propose a novel HOS-Net consisting of the backbone, SLE, HSL, and CFL modules for VI-ReID. The SLE module is first designed to learn short-range and long-range features by taking advantage of both CNN and Transformer. Then, the HSL module exploits diverse highorder structure information of features without suffering from model collapse based on a whitened hypergraph. Finally, the CFL module generates reliable middle features and obtains a reasonable common feature space. Extensive experiments on three VI-ReID benchmarks verify the effectiveness of HOS-Net in comparison with several state-ofthe-art methods. Currently, the training complexity of our method is still high (see Supplement $C$ for more details). We plan to explore new ways to reduce the training complexity.
本文提出了一种新颖的HOS-Net网络,由主干网络、SLE模块、HSL模块和CFL模块组成,用于可见光-红外行人重识别(VI-ReID)。首先,SLE模块通过结合CNN和Transformer的优势,设计用于学习短程和长程特征。其次,HSL模块基于白化超图利用特征的多样化高阶结构信息,同时避免模型坍塌。最后,CFL模块生成可靠的中层特征,并获得合理的共同特征空间。在三个VI-ReID基准数据集上的大量实验表明,HOS-Net相比多种先进方法具有显著优势。目前,我们方法的训练复杂度仍然较高(详见补充材料 $C$ )。我们计划探索降低训练复杂度的新方法。